
Core ML Stable Diffusion
Collection
16 items
•
Updated
•
18
This model was generated by Hugging Face using Apple’s repository which has ASCL. This version contains 6-bit palettized Core ML weights for iOS 17 or macOS 14. To use weights without quantization, please visit this model instead.
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
This stable-diffusion-2-1-base model fine-tunes stable-diffusion-2-base (512-base-ema.ckpt) with 220k extra steps taken, with punsafe=0.98 on the same dataset.
These weights here have been converted to Core ML for use on Apple Silicon hardware.
There are 4 variants of the Core ML weights:
coreml-stable-diffusion-2-1-base
├── original
│ ├── compiled # Swift inference, "original" attention
│ └── packages # Python inference, "original" attention
└── split_einsum
├── compiled # Swift inference, "split_einsum" attention
└── packages # Python inference, "split_einsum" attention
There are also two zip archives suitable for use in the Hugging Face demo app and other third party tools:
coreml-stable-diffusion-2-1-base-palettized_original_compiled.zip contains the compiled, 6-bit model with ORIGINAL attention implementation.coreml-stable-diffusion-2-1-base-palettized_split_einsum_v2_compiled.zip contains the compiled, 6-bit model with SPLIT_EINSUM_V2 attention implementation.Please, refer to https://huggingface.co/blog/diffusers-coreml for details.
diffusersstablediffusion repository: download the v2-1_512-ema-pruned.ckpt here.Developed by: Robin Rombach, Patrick Esser
Model type: Diffusion-based text-to-image generation model
Language(s): English
License: CreativeML Open RAIL++-M License
Model Description: This is a model that can be used to generate and modify images based on text prompts. It is a Latent Diffusion Model that uses a fixed, pretrained text encoder (OpenCLIP-ViT/H).
Resources for more information: GitHub Repository.
Cite as:
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
The model is intended for research purposes only. Possible research areas and tasks include
Excluded uses are described below.
Note: This section is originally taken from the DALLE-MINI model card, was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. Stable Diffusion vw was primarily trained on subsets of LAION-2B(en), which consists of images that are limited to English descriptions. Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for. This affects the overall output of the model, as white and western cultures are often set as the default. Further, the ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts. Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
Training Data The model developers used the following dataset for training the model:
Training Procedure Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
We currently provide the following checkpoints, for various versions:
512-base-ema.ckpt: Fine-tuned on 512-base-ema.ckpt 2.0 with 220k extra steps taken, with punsafe=0.98 on the same dataset.768-v-ema.ckpt: Resumed from 768-v-ema.ckpt 2.0 with an additional 55k steps on the same dataset (punsafe=0.1), and then fine-tuned for another 155k extra steps with punsafe=0.98.512-base-ema.ckpt: 550k steps at resolution 256x256 on a subset of LAION-5B filtered for explicit pornographic material, using the LAION-NSFW classifier with punsafe=0.1 and an aesthetic score >= 4.5.
850k steps at resolution 512x512 on the same dataset with resolution >= 512x512.
768-v-ema.ckpt: Resumed from 512-base-ema.ckpt and trained for 150k steps using a v-objective on the same dataset. Resumed for another 140k steps on a 768x768 subset of our dataset.
512-depth-ema.ckpt: Resumed from 512-base-ema.ckpt and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by MiDaS (dpt_hybrid) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
512-inpainting-ema.ckpt: Resumed from 512-base-ema.ckpt and trained for another 200k steps. Follows the mask-generation strategy presented in LAMA which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the 1.5-inpainting checkpoint.
x4-upscaling-ema.ckpt: Trained for 1.25M steps on a 10M subset of LAION containing images >2048x2048. The model was trained on crops of size 512x512 and is a text-guided latent upscaling diffusion model.
In addition to the textual input, it receives a noise_level as an input parameter, which can be used to add noise to the low-resolution input according to a predefined diffusion schedule.
Hardware: 32 x 8 x A100 GPUs
Optimizer: AdamW
Gradient Accumulations: 1
Batch: 32 x 8 x 2 x 4 = 2048
Learning rate: warmup to 0.0001 for 10,000 steps and then kept constant
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
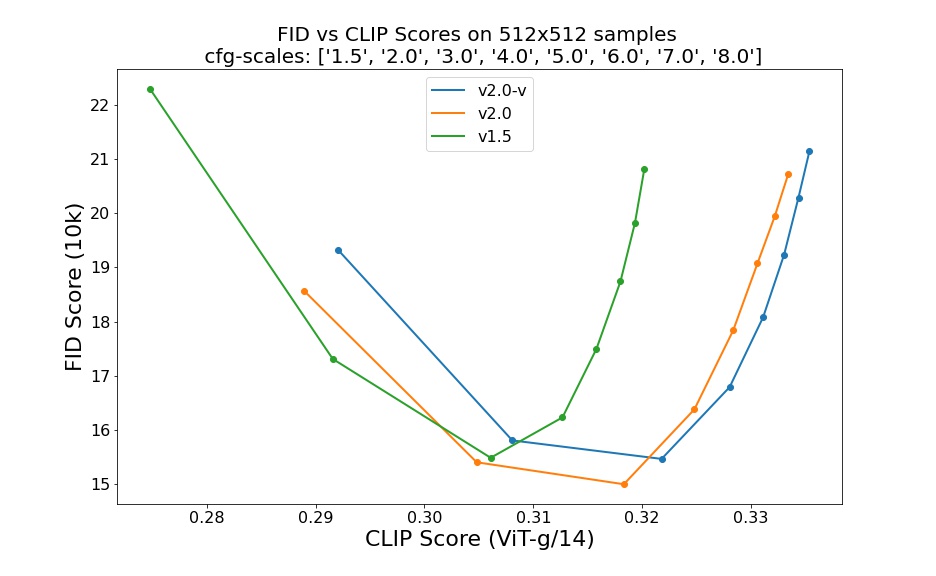
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
Stable Diffusion v1 Estimated Emissions Based on that information, we estimate the following CO2 emissions using the Machine Learning Impact calculator presented in Lacoste et al. (2019). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
This model card was adapted by Pedro Cuenca from the original written by: Robin Rombach, Patrick Esser and David Ha and is based on the Stable Diffusion v1 and DALL-E Mini model card.