

metadata
language:
- ja
- en
license: apache-2.0
datasets:
- augmxnt/ultra-orca-boros-en-ja-v1
model-index:
- name: shisa-gamma-7b-v1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 53.16
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=augmxnt/shisa-gamma-7b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 77.3
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=augmxnt/shisa-gamma-7b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 55.23
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=augmxnt/shisa-gamma-7b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 50.73
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=augmxnt/shisa-gamma-7b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 73.88
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=augmxnt/shisa-gamma-7b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 22.74
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=augmxnt/shisa-gamma-7b-v1
name: Open LLM Leaderboard
shisa-gamma-7b-v1
For more information see our main Shisa 7B model
We applied a version of our fine-tune data set onto Japanese Stable LM Base Gamma 7B and it performed pretty well, just sharing since it might be of interest.
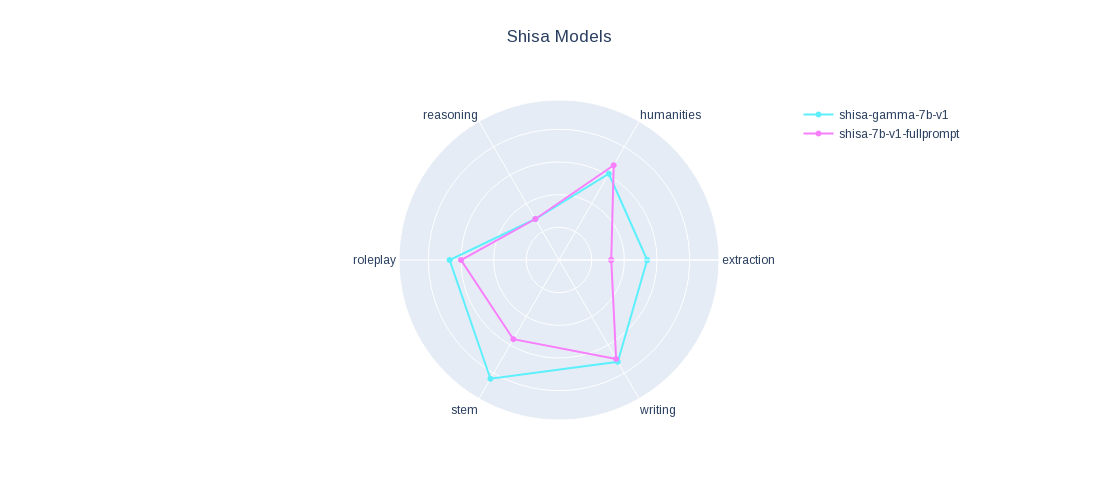
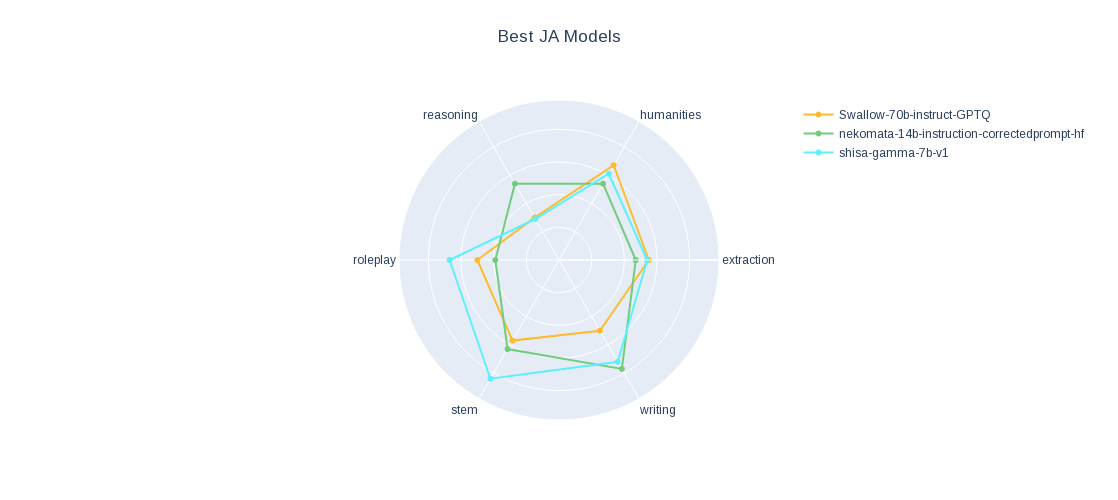
Check out our JA MT-Bench results.
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 55.50 |
| AI2 Reasoning Challenge (25-Shot) | 53.16 |
| HellaSwag (10-Shot) | 77.30 |
| MMLU (5-Shot) | 55.23 |
| TruthfulQA (0-shot) | 50.73 |
| Winogrande (5-shot) | 73.88 |
| GSM8k (5-shot) | 22.74 |