

language:
- en
pipeline_tag: text-classification
![]()
Llama-3.1-Bespoke-MiniCheck-7B
![]()
This is a fact-checking model developed by Bespoke Labs and maintained by Liyan Tang and Bespoke Labs. The model is an improvement of the MiniCheck model proposed in the following paper:
📃 MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents, EMNLP 2024
The model takes as input a document and a sentence and determines whether the sentence is supported by the document: MiniCheck-Model(document, claim) -> {0, 1}
In order to fact-check a multi-sentence claim, the claim should first be broken up into sentences. The document does not need to be chunked unless it exceeds 32K tokens. Depending on use cases, adjusting chunk size may yield better performance.
Llama-3.1-Bespoke-MiniCheck-7B is finetuned from internlm/internlm2_5-7b-chat (Cai et al., 2024)
on the combination of 35K data points only:
- 21K ANLI examples (Nie et al., 2020)
- 14K synthetically-generated examples following the scheme in the MiniCheck paper, but with additional proprietary data curation techniques (sampling, selecting additional high quality data sources, etc.) from Bespoke Labs. Specifically, we generate 7K "claim-to-document" (C2D) and 7K "doc-to-claim" (D2C) examples. The following steps were taken to avoid benchmark contamination: the error types of the model in the benchmark data were not used, and the data sources were curated independent of the benchmark.
All synthetic data is generated by meta-llama/Meta-Llama-3.1-405B-Instruct, thus the name Llama-3.1-Bespoke-MiniCheck-7B.
While scaling up the model (compared to what is in MiniCheck) helped, many improvements come from high-quality curation, thus establishing the superiority of Bespoke Labs's curation technology.
Model Variants
We also have other three MiniCheck model variants:
- lytang/MiniCheck-Flan-T5-Large (Model Size: 0.8B)
- lytang/MiniCheck-RoBERTa-Large (Model Size: 0.4B)
- lytang/MiniCheck-DeBERTa-v3-Large (Model Size: 0.4B)
Model Performance
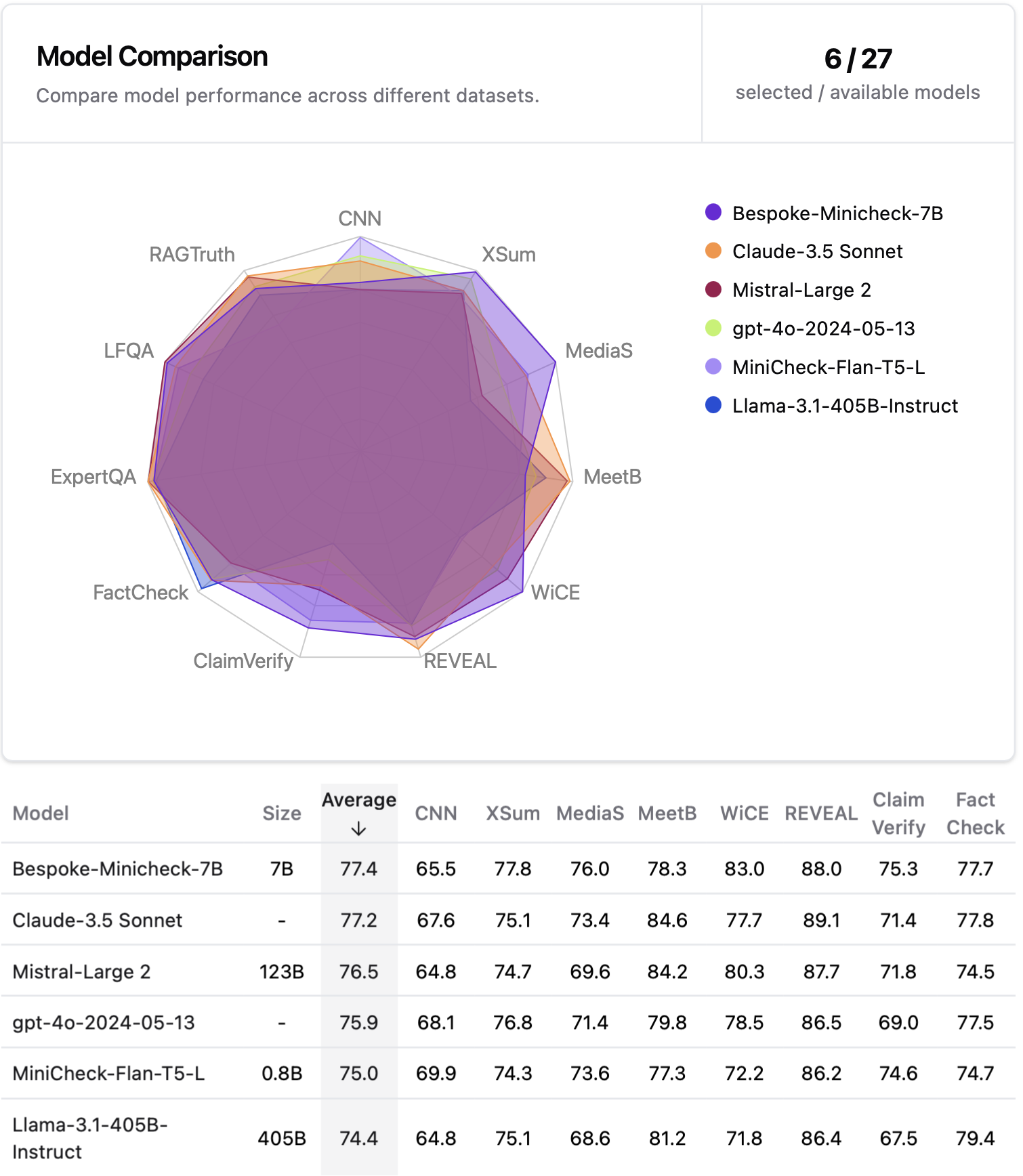
The performance of these models is evaluated on our new collected benchmark (unseen by our models during training), LLM-AggreFact, from 11 recent human annotated datasets on fact-checking and grounding LLM generations. Llama-3.1-Bespoke-MiniCheck-7B is the SOTA fact-checking model despite its small size.
Model Usage
Please run the following command to install the MiniCheck package and all necessary dependencies.
pip install "minicheck[llm] @ git+https://github.com/Liyan06/MiniCheck.git@main"
Below is a simple use case
from minicheck.minicheck import MiniCheck
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
doc = "A group of students gather in the school library to study for their upcoming final exams."
claim_1 = "The students are preparing for an examination."
claim_2 = "The students are on vacation."
# model_name can be one of:
# ['roberta-large', 'deberta-v3-large', 'flan-t5-large', 'Bespoke-MiniCheck-7B']
scorer = MiniCheck(model_name='Bespoke-MiniCheck-7B', enable_prefix_caching=False, cache_dir='./ckpts')
pred_label, raw_prob, _, _ = scorer.score(docs=[doc, doc], claims=[claim_1, claim_2]) # can set `chunk_size=your-specified-value` here, default to 32K chunk size.
print(pred_label) # [1, 0]
print(raw_prob) # [0.9840446675150499, 0.010986349594852094]
Throughput
We speed up Llama-3.1-Bespoke-MiniCheck-7B inference with vLLM. Based on our test on a single A6000 (48 VRAM), Llama-3.1-Bespoke-MiniCheck-7B with vLLM and MiniCheck-Flan-T5-Large have throughputs > 500 docs/min.
Automatic Prefix Caching
Automatic Prefix Caching (APC in short) caches the KV cache of existing queries, so that a new query can directly reuse the KV cache if it shares the same prefix with one of the existing queries, allowing the new query to skip the computation of the shared part.
To enable automatic prefix caching for Bespoke-MiniCheck-7B, simply set enable_prefix_caching=True when initializing the
MiniCheck model (no other changes are needed):
scorer = MiniCheck(model_name='Bespoke-MiniCheck-7B', enable_prefix_caching=True, cache_dir='./ckpts')
How automatic prefix caching affects the throughput and model performance can be found in the GitHub Repo.
Test on our LLM-AggreFact Benchmark
import pandas as pd
from datasets import load_dataset
from minicheck.minicheck import MiniCheck
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# load 29K test data
df = pd.DataFrame(load_dataset("lytang/LLM-AggreFact")['test'])
docs = df.doc.values
claims = df.claim.values
scorer = MiniCheck(model_name='Bespoke-MiniCheck-7B', enable_prefix_caching=False, cache_dir='./ckpts')
pred_label, raw_prob, _, _ = scorer.score(docs=[doc, doc], claims=[claim_1, claim_2]) # ~ 500 docs/min, depending on hardware
To evaluate the result on the benchmark
from sklearn.metrics import balanced_accuracy_score
df['preds'] = pred_label
result_df = pd.DataFrame(columns=['Dataset', 'BAcc'])
for dataset in df.dataset.unique():
sub_df = df[df.dataset == dataset]
bacc = balanced_accuracy_score(sub_df.label, sub_df.preds) * 100
result_df.loc[len(result_df)] = [dataset, bacc]
result_df.loc[len(result_df)] = ['Average', result_df.BAcc.mean()]
result_df.round(1)
License
This work is licensed under CC BY-NC 4.0. For commercial licensing, please contact company@bespokelabs.ai.
Citation
@InProceedings{tang-etal-2024-minicheck,
title = {MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents},
author = {Liyan Tang and Philippe Laban and Greg Durrett},
booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing},
year = {2024},
publisher = {Association for Computational Linguistics},
url = {https://arxiv.org/pdf/2404.10774}
}
@misc{tang2024bespokeminicheck,
title={Bespoke-Minicheck-7B},
author={Bespoke Labs},
year={2024},
url={https://huggingface.co/bespokelabs/Bespoke-MiniCheck-7B},
}
Acknowledgements
Model perfected at Bespoke Labs.
Team:
We also thank Giannis Daras for feedback and Sarthak Malhotra for market research.