
File size: 8,044 Bytes
c15bdba c208306 c15bdba c208306 c15bdba 914583c c15bdba cc7bf2c c15bdba c208306 c15bdba c208306 c15bdba cc7bf2c c208306 ee75183 c15bdba cc7bf2c c15bdba c208306 c15bdba c208306 c15bdba bf3f22b c15bdba c208306 c15bdba c208306 c15bdba c208306 c15bdba c208306 c15bdba c208306 c15bdba c208306 c15bdba b120b50 c208306 c15bdba b120b50 c208306 c15bdba c208306 c15bdba c208306 b120b50 c15bdba c208306 b120b50 c208306 c15bdba c208306 c15bdba cee4ec0 c15bdba cee4ec0 cc7bf2c cee4ec0 cc7bf2c c15bdba c208306 c15bdba cc7bf2c c208306 c15bdba c208306 c15bdba c208306 c15bdba c208306 c15bdba c208306 c2ae1a5 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 |
---
pipeline_tag: text-generation
base_model: bigcode/starcoder2-15b
datasets:
- bigcode/self-oss-instruct-sc2-exec-filter-50k
license: bigcode-openrail-m
library_name: transformers
tags:
- code
model-index:
- name: starcoder2-15b-instruct-v0.1
results:
- task:
type: text-generation
dataset:
name: LiveCodeBench (code generation)
type: livecodebench-codegeneration
metrics:
- type: pass@1
value: 20.4
- task:
type: text-generation
dataset:
name: LiveCodeBench (self repair)
type: livecodebench-selfrepair
metrics:
- type: pass@1
value: 20.9
- task:
type: text-generation
dataset:
name: LiveCodeBench (test output prediction)
type: livecodebench-testoutputprediction
metrics:
- type: pass@1
value: 29.8
- task:
type: text-generation
dataset:
name: LiveCodeBench (code execution)
type: livecodebench-codeexecution
metrics:
- type: pass@1
value: 28.1
- task:
type: text-generation
dataset:
name: HumanEval
type: humaneval
metrics:
- type: pass@1
value: 72.6
- task:
type: text-generation
dataset:
name: HumanEval+
type: humanevalplus
metrics:
- type: pass@1
value: 63.4
- task:
type: text-generation
dataset:
name: MBPP
type: mbpp
metrics:
- type: pass@1
value: 75.2
- task:
type: text-generation
dataset:
name: MBPP+
type: mbppplus
metrics:
- type: pass@1
value: 61.2
- task:
type: text-generation
dataset:
name: DS-1000
type: ds-1000
metrics:
- type: pass@1
value: 40.6
---
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation

## Model Summary
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
- **Authors:**
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
[Federico Cassano](https://federico.codes/),
[Jiawei Liu](https://jw-liu.xyz),
[Yifeng Ding](https://yifeng-ding.com),
[Naman Jain](https://naman-ntc.github.io),
[Harm de Vries](https://www.harmdevries.com),
[Leandro von Werra](https://twitter.com/lvwerra),
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
[Lingming Zhang](https://lingming.cs.illinois.edu).

## Use
### Intended use
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
```python
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
```
Here is the expected output:
``````
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
```python
from typing import TypeVar, Callable
T = TypeVar('T')
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
if len(items) <= 1:
return items
pivot = items[0]
less = [x for x in items[1:] if less_than(x, pivot)]
greater = [x for x in items[1:] if not less_than(x, pivot)]
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
```
``````
### Bias, Risks, and Limitations
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
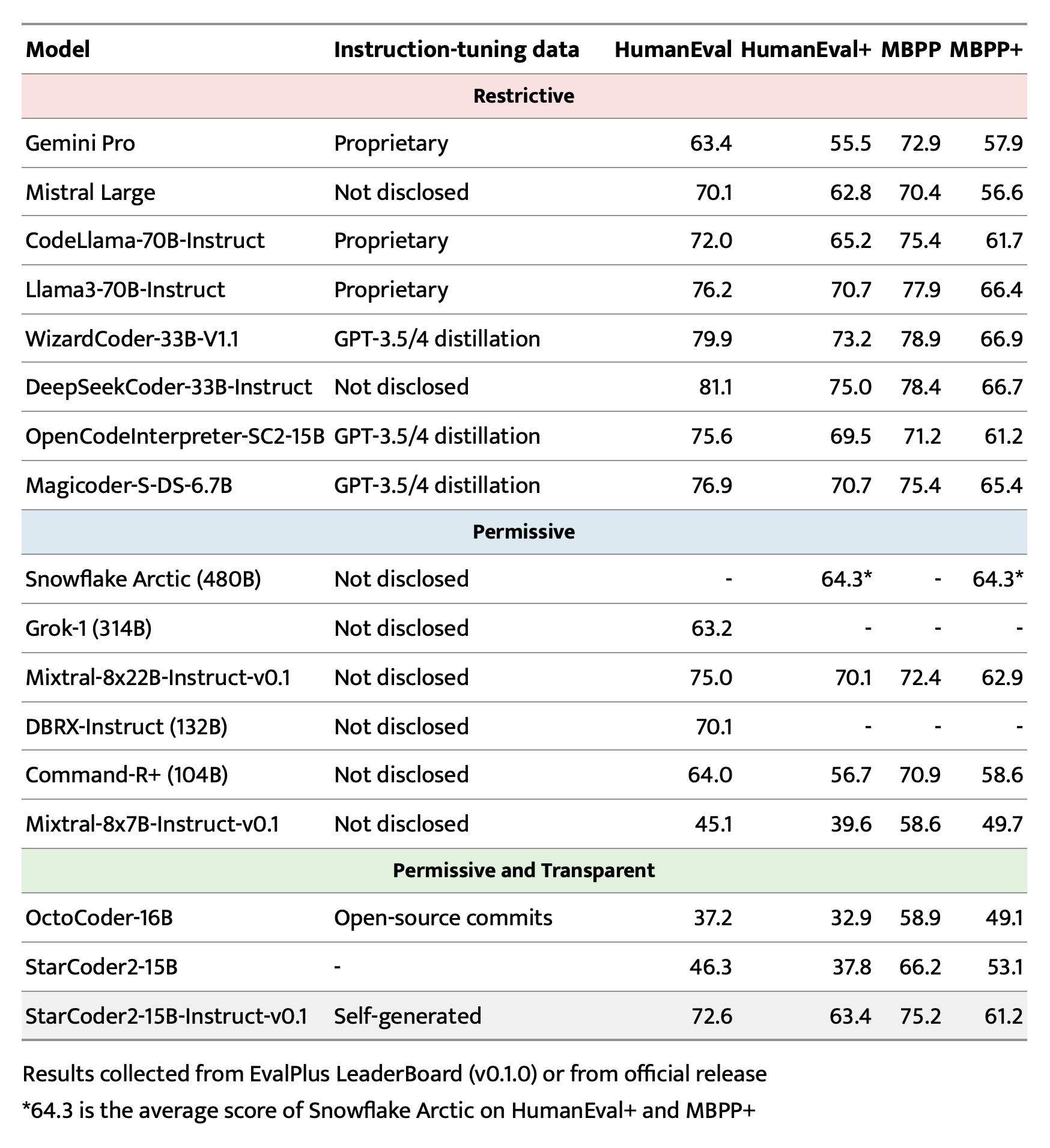
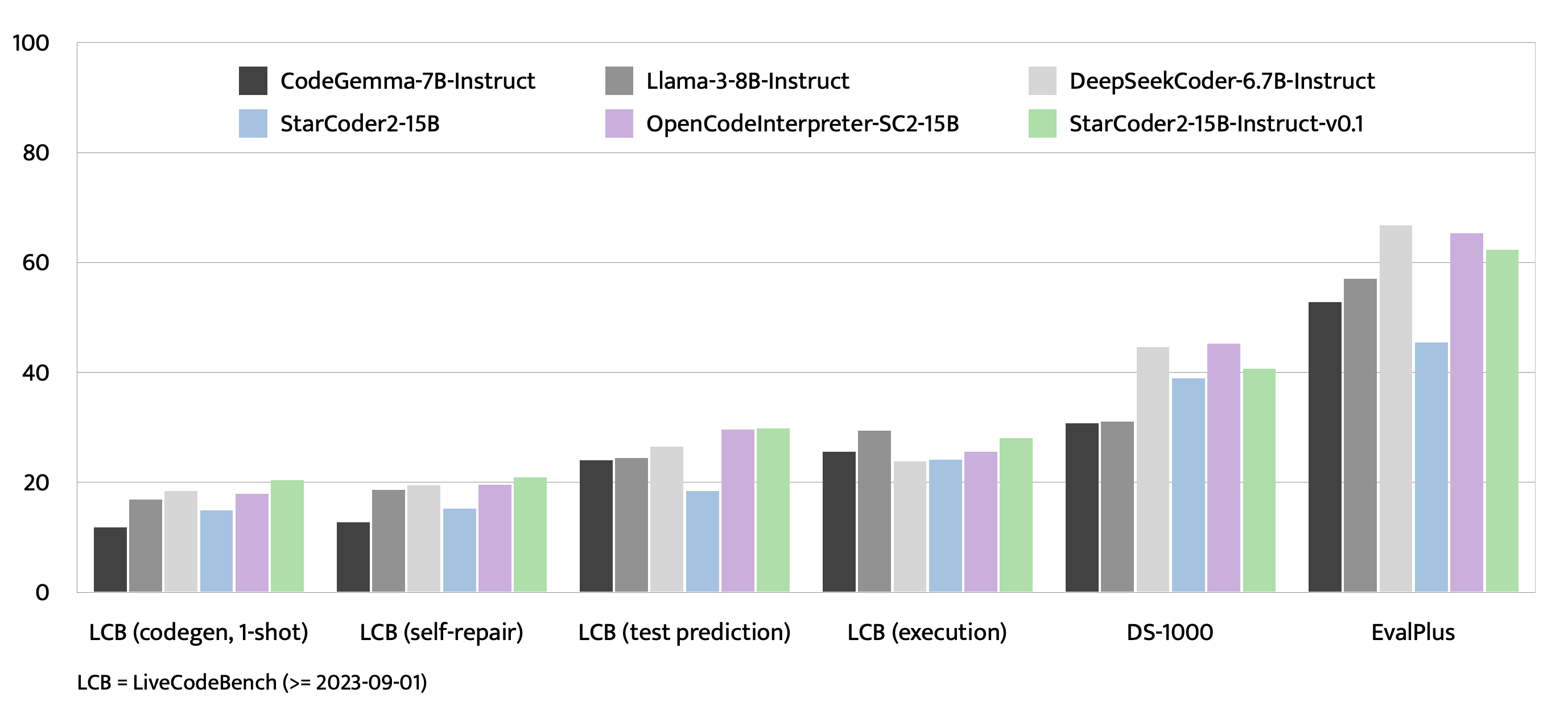
## Training Details
### Hyperparameters
- **Optimizer:** Adafactor
- **Learning rate:** 1e-5
- **Epoch:** 4
- **Batch size:** 64
- **Warmup ratio:** 0.05
- **Scheduler:** Linear
- **Sequence length:** 1280
- **Dropout**: Not applied
### Hardware
1 x NVIDIA A100 80GB
## Resources
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
### Full Data Pipeline
Our dataset generation pipeline has several steps. We provide intermediate datasets for every step of the pipeline:
1. Original seed dataset filtered from The Stack v1: https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered
2. Seed dataset filtered using StarCoder2-15B as a judge for removing items with bad docstrings: https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered-sc2
3. seed -> concepts: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-concepts
4. concepts -> instructions: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-instructions
5. instructions -> response: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-responses-unfiltered
6. Responses filtered by executing them: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-500k-raw
7. Executed responses filtered by deduplicating them (final dataset): https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k |