
Hugging Face's logo
tags:
- object-detection
- vision library_name: faster_rcnn datasets:
- coco
Faster R-CNN
Model desription
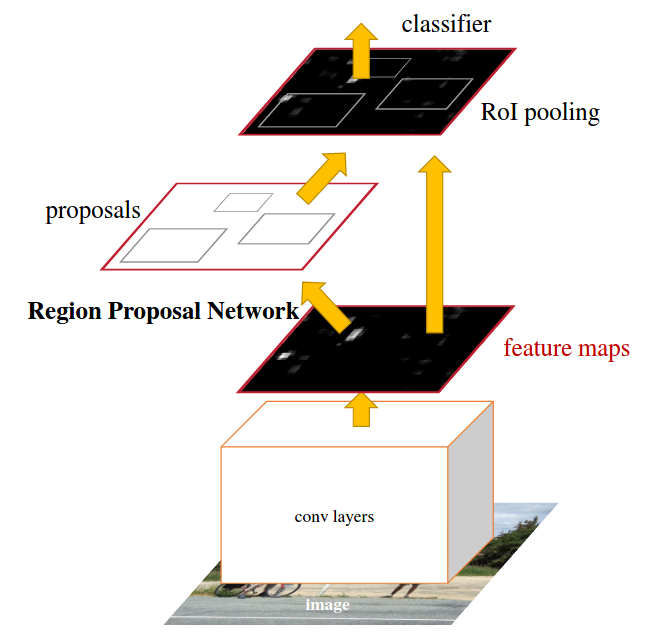
This model is an enhanced version of the Fast R-CNN model. Due to the computation bottleneck posed by Fast-RCNN that saw the innovation of Region of Pooling. Faster-RCNN introduces the Region of Proposal Network(RPN) and reuses the same CNN results for the same proposal instead of running a selective search algorithm. The RPN is trained end-to-end to generate high-quality region proposals, which Fast R-CNN uses for detection. The model merges RPN and Fast R-CNN into a single network by sharing their convolutional features. With 'attention' mechanisms, the RPN component tells the unified network where to look. This state-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations.
This Model is based on the Pretrained model from OpenMMlab
More information on the Model, Dataset, Training and Results:
The model
By implementing a CNN-based region proposal network, the Faster R-CNN addresses the bottleneck issue that the Fast R-CNN raised during the proposal stage. Additionally, it uses the concept of various size anchor boxes, which accelerates the object detection model. Convolution layers receive input from images and generate a feature map. We obtain the region of proposals by adding a layer of convolution to the extracted feature map.
To output the box and class information, the convolution layer traverses across the feature map at each position using a 3X3 window to create box proposals. At each output, a K number of boxes are generated at relative coordinates position from the pre-defined anchor boxes. The final box output is the probability of whether the box contains the object.
Datasets
Training
Please read the paper for more information on training, or check OpenMMLab repository
In four stages, the model training is done:
The RPN is trained on the COCO object detection datasets in the first stage to produce the region of proposals. The trained RPN from stage one is then used to train the Fast R-CNN. Following this training, a detector network is used to initialize the RPN's training with fixed shared convolution layers, and the network's unique layers are adjusted. Finally, the last step is fine-tuning unique layers of Fast R-CNN, forming a unified network.
Results Summary
- The RPN model achieves better results than the one that uses selective search.
- Pascal VOC 2007 & 2012 are used for the test sets
- The selective search model takes more time(ms) than the RPN model.
Intended uses & limitations
Due to the efficiency in learning, the training dataset is superior to ordinary CNN algorithms. Faster R-CNN has the disadvantage that the RPN is trained with all of the size 256 mini-batch anchors being taken from a single image. The network may take a long time to attain convergence because all samples from one image may be correlated.