
Document Processing
Collection
Any model or dataset dealing with documentary-type objects (layout detection, VQA, OCR, etc.)
•
9 items
•
Updated
•
3
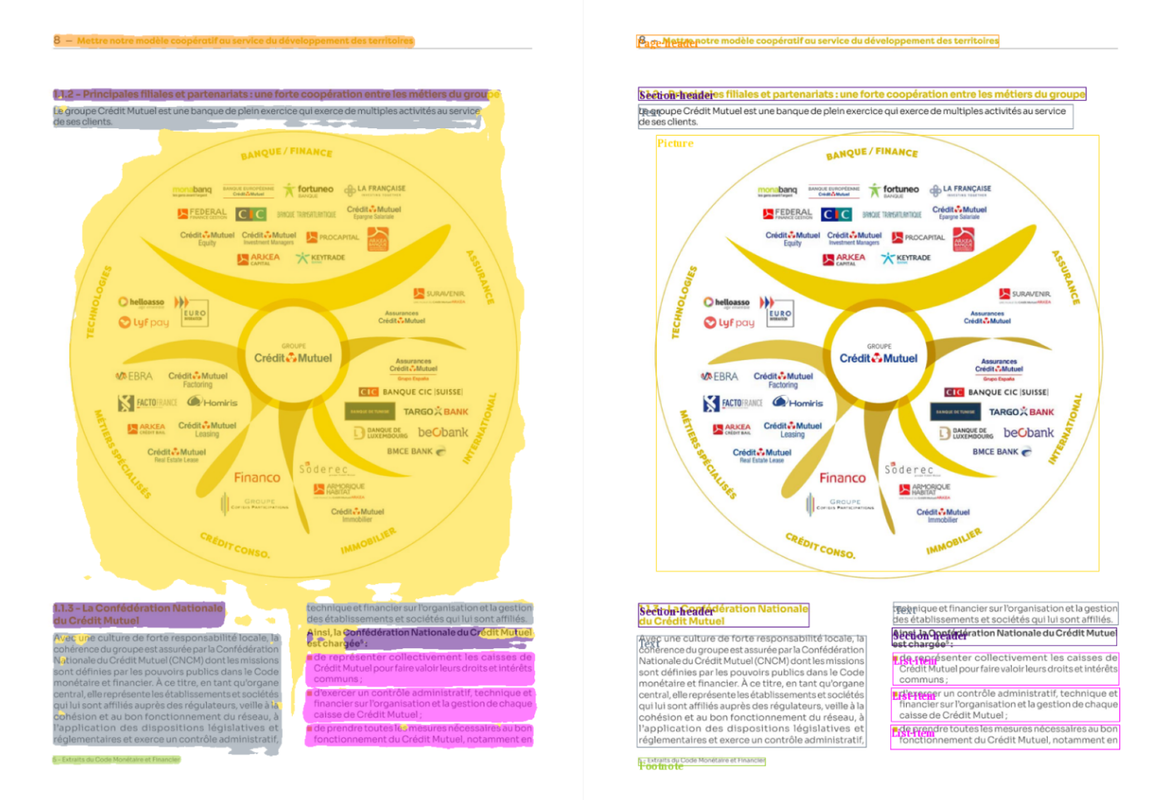
We present the model cmarkea/detr-layout-detection, which allows extracting different layouts (Text, Picture, Caption, Footnote, etc.) from an image of a document. This is a fine-tuning of the model detr-resnet-50 on the DocLayNet dataset. This model can jointly predict masks and bounding boxes for documentary objects. It is ideal for processing documentary corpora to be ingested into an ODQA system.
This model allows extracting 11 entities, which are: Caption, Footnote, Formula, List-item, Page-footer, Page-header, Picture, Section-header, Table, Text, and Title.
In this section, we will assess the model's performance by separately considering semantic segmentation and object detection. In both cases, no post-processing was applied after estimation.
For semantic segmentation, we will use the F1-score to evaluate the classification of each pixel. For object detection, we will assess performance based on the Generalized Intersection over Union (GIoU) and the accuracy of the predicted bounding box class. The evaluation is conducted on 500 pages from the PDF evaluation dataset of DocLayNet.
| Class | f1-score (x100) | GIoU (x100) | accuracy (x100) |
|---|---|---|---|
| Background | 95.82 | NA | NA |
| Caption | 82.68 | 74.71 | 69.05 |
| Footnote | 78.19 | 74.71 | 74.19 |
| Formula | 87.25 | 76.31 | 97.79 |
| List-item | 81.43 | 77.0 | 90.62 |
| Page-footer | 82.01 | 69.86 | 96.64 |
| Page-header | 68.32 | 77.68 | 88.3 |
| Picture | 81.04 | 81.84 | 90.88 |
| Section-header | 73.52 | 73.46 | 85.96 |
| Table | 78.59 | 85.45 | 90.58 |
| Text | 91.93 | 83.16 | 91.8 |
| Title | 70.38 | 74.13 | 63.33 |
Now, let's compare the performance of this model with other models.
| Model | f1-score (x100) | GIoU (x100) | accuracy (x100) |
|---|---|---|---|
| cmarkea/detr-layout-detection | 91.27 | 80.66 | 90.46 |
| cmarkea/dit-base-layout-detection | 90.77 | 56.29 | 85.26 |
from transformers import AutoImageProcessor
from transformers.models.detr import DetrForSegmentation
img_proc = AutoImageProcessor.from_pretrained(
"cmarkea/detr-layout-detection"
)
model = DetrForSegmentation.from_pretrained(
"cmarkea/detr-layout-detection"
)
img: PIL.Image
with torch.inference_mode():
input_ids = img_proc(img, return_tensors='pt')
output = model(**input_ids)
threshold=0.4
segmentation_mask = img_proc.post_process_segmentation(
output,
threshold=threshold,
target_sizes=[img.size[::-1]]
)
bbox_pred = img_proc.post_process_object_detection(
output,
threshold=threshold,
target_sizes=[img.size[::-1]]
)
@online{DeDetrLay,
AUTHOR = {Cyrile Delestre},
URL = {https://huggingface.co/cmarkea/detr-layout-detection},
YEAR = {2024},
KEYWORDS = {Image Processing ; Transformers ; Layout},
}