
A question about lora_r and lora_alpha configuration

Thanks for your excellent work @ehartford
Last week I read an article on fine-tuning: Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experim, In it:
"As a rule of thumb, it’s usually common to choose an alpha that is twice as large as the rank when finetuning LLMs (note that this is different when working with diffusion models). Let’s try this out and see what happens when we increase alpha two-fold"
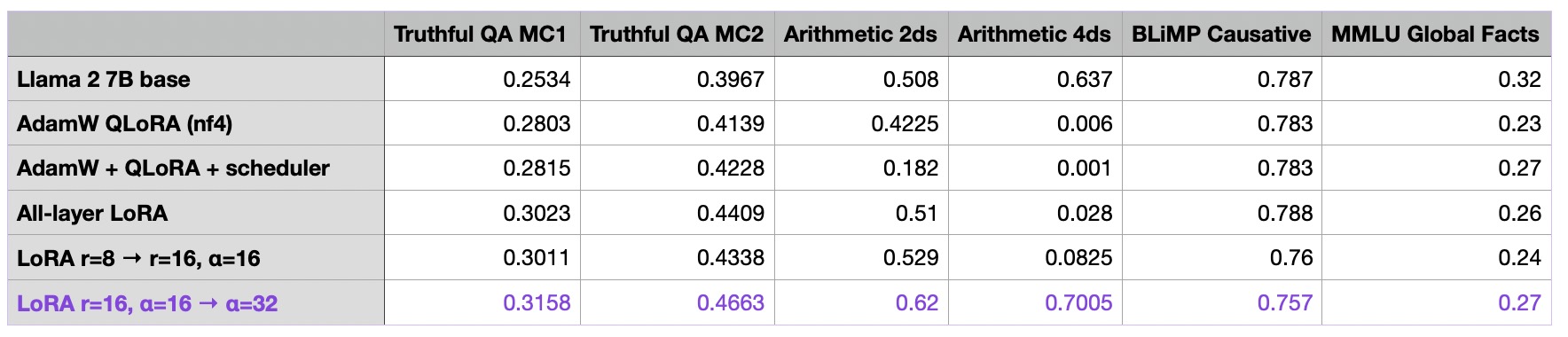
I noticed you set the lora_r=32 and lora_alpha=16 in the axolotl yml file, which didn't comply with the common rule. May I know the reason behind it? I'm just curious about it.
Thanks and have a nice day!

I actually don't know!
I could train it again with another setting if you think it would give better results.
I saw the llama2 example in Axolotl has the same settings.
The article I mentioned compares two settings: "lora_r=32, lora_alpha=64" with "lora_r=32, lora_alpha=1". The result of the first one is better than previous one.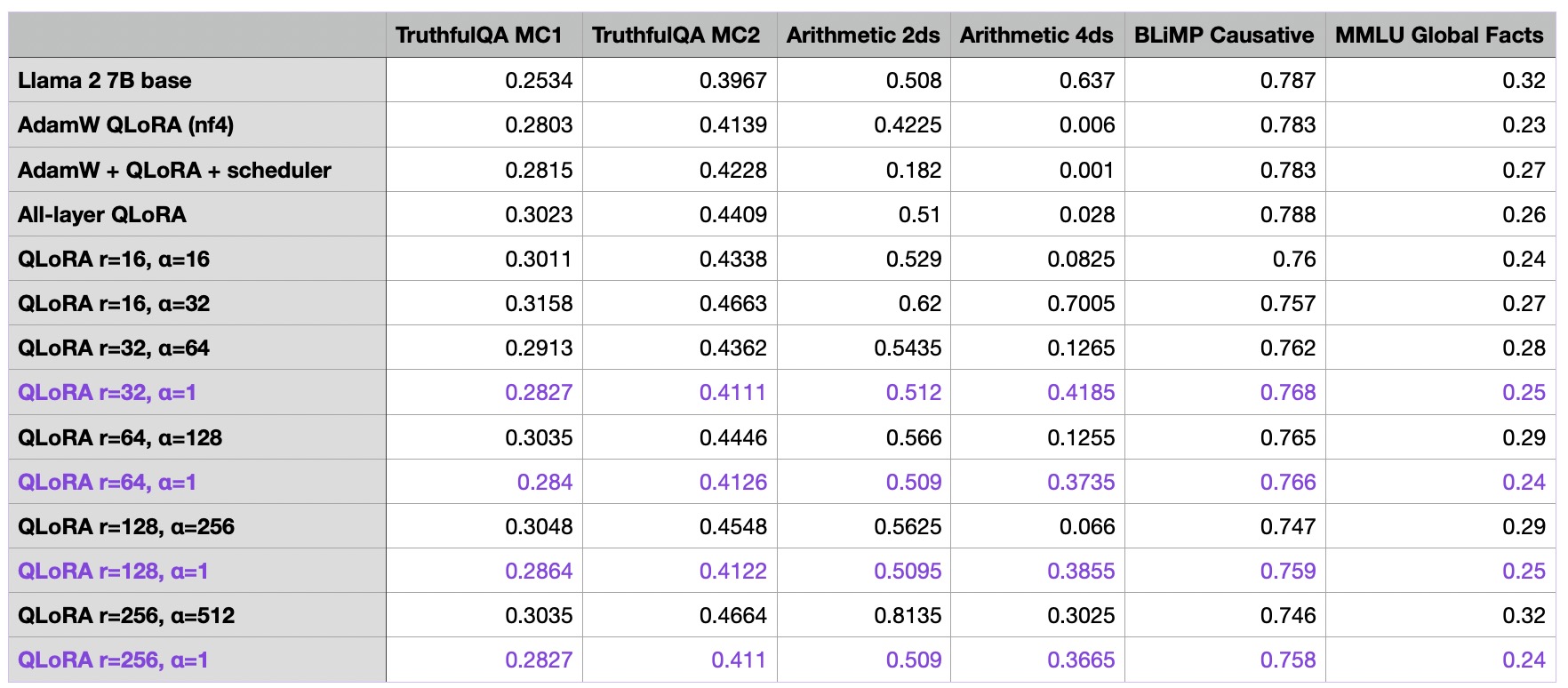
But the article didn't mention detail procedures among tests, it's hard to say the results are statistically significant.
I tested smaller models under 7B, the results are not significant. However, since the models themself are weak, it can not prove if those settings are useful.
I didn't have enough resources to test them on 34B or bigger ones. If you have time and resources, it's appreciated if you can test the "lora_r=32, lora_alpha=64" on new trainings to check if they can get better scores on leaderboard.
Thanks and have a nice day!