

metadata
base_model: black-forest-labs/FLUX.1-dev
library_name: diffusers
license: other
widget:
- text: >-
a bustling manga street, devoid of vehicles, detailed with vibrant colors
and dynamic line work, characters in the background adding life and
movement, under a soft golden hour light, with rich textures and a lively
atmosphere, high resolution, sharp focus
output:
url: images/example_v9pjueoq1.png
- text: >-
Grainy shot of a robot cooking in the kitchen, with soft shadows and
nostalgic film texture.
output:
url: images/example_7rny6lj4p.png
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- flux
- flux-diffusers
- template:sd-lora
Flux DreamBooth LoRA - davidberenstein1957/image-preferences-flux-dev-lora

- Prompt
- a bustling manga street, devoid of vehicles, detailed with vibrant colors and dynamic line work, characters in the background adding life and movement, under a soft golden hour light, with rich textures and a lively atmosphere, high resolution, sharp focus

- Prompt
- a boat in the canals of Venice, painted in gouache with soft, flowing brushstrokes and vibrant, translucent colors, capturing the serene reflection on the water under a misty ambiance, with rich textures and a dynamic perspective

- Prompt
- A vibrant orange poppy flower, enclosed in an ornate golden frame, against a black backdrop, rendered in anime style with bold outlines, exaggerated details, and a dramatic chiaroscuro lighting.
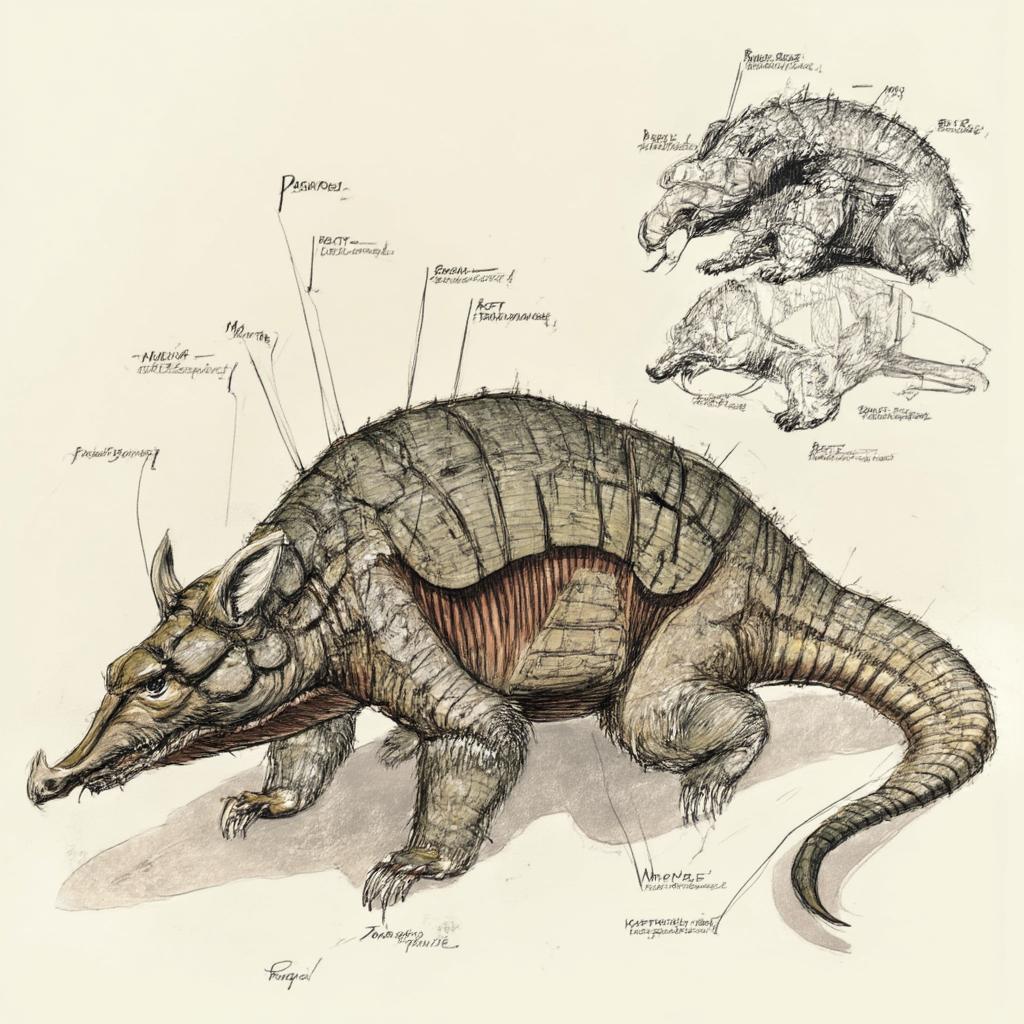
- Prompt
- Armored armadillo, detailed anatomy, precise shading, labeled diagram, cross-section, high resolution.

- Prompt
- A photographic photo of a hedgehog in a forest 4k

- Prompt
- Grainy shot of a robot cooking in the kitchen, with soft shadows and nostalgic film texture.
Model description
These are davidberenstein1957/image-preferences-flux-schnell-lora DreamBooth LoRA weights for black-forest-labs/FLUX.1-schnell.
The weights were trained using DreamBooth with the Flux diffusers trainer.
Was LoRA for the text encoder enabled? False.
Trigger words
You should use `` to trigger the image generation.
Download model
Download the *.safetensors LoRA in the Files & versions tab.
Use it with the 🧨 diffusers library
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16).to('cuda')
pipeline.load_lora_weights('davidberenstein1957/image-preferences-flux-dev-lora', weight_name='pytorch_lora_weights.safetensors')
image = pipeline('').images[0]
For more details, including weighting, merging and fusing LoRAs, check the documentation on loading LoRAs in diffusers
License
Please adhere to the licensing terms as described here.
Intended uses & limitations
How to use
# TODO: add an example code snippet for running this diffusion pipeline
Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
Training details
[TODO: describe the data used to train the model]