

MonteXiaofeng/CareBot_Medical_multi-llama3-8b-base
Updated
•
14
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
You agree to not use the dataset to conduct experiments that cause harm to human subjects.
Log in or Sign Up to review the conditions and access this dataset content.
Industry models play a vital role in promoting the intelligent transformation and innovative development of enterprises. High-quality industry data is the key to improving the performance of large models and realizing the implementation of industry applications. However, the data sets currently used for industry model training generally have problems such as small data volume, low quality, and lack of professionalism.
In June, we released the IndustryCorpus dataset: We have further upgraded and iterated on this dataset, and the iterative contents are as follows:
The data processing process is consistent with IndustryCorpus

The disk size of each industry data after full process processing is as follows
| Industry category | Data size (GB) | Industry category | Data size (GB) |
|---|---|---|---|
| Programming | 11.0 | News | 51.0 |
| Biomedicine | 61.7 | Petrochemical | 40.2 |
| Medical health-psychology and Chinese medicine | 271.7 | Aerospace | 38.6 |
| Tourism and geography | 64.0 | Mining | 8.9 |
| Law and justice | 238.5 | Finance and economics | 145.8 |
| Mathematics-statistics | 156.7 | Literature and emotions | 105.5 |
| Other information services_information security | 1.8 | Transportation | 40.5 |
| Fire safety_food safety | 4.3 | Science and technology_scientific research | 101.6 |
| Automobile | 39.3 | Water Conservancy_Ocean | 20.2 |
| Accommodation-catering-hotel | 29.6 | Computer-communication | 157.8 |
| Film and television entertainment | 209.4 | Subject education | 340.9 |
| Real estate-construction | 105.2 | Artificial intelligence-machine learning | 7.7 |
| Electric power and energy | 68.7 | Current affairs-government affairs-administration | 271.5 |
| Agriculture, forestry, animal husbandry and fishery | 111.9 | Sports | 262.5 |
| Games | 37.6 | Other manufacturing | 47.2 |
| Others | 188.6 | ||
| Total (GB) | 3276G |
The industry data distribution chart in the summary data set is as follows

From the distribution chart, we can see that subject education, sports, current affairs, law, medical health, film and television entertainment account for most of the overall data. The data of these industries are widely available on the Internet and textbooks, and the high proportion of them is in line with expectations. It is worth mentioning that since we have supplemented the data of mathematics, we can see that the proportion of mathematics data is also high, which is inconsistent with the proportion of mathematics Internet corpus data.
All our data repos have a unified naming format, f"BAAI/IndustryCorpus2_{name}", where name corresponds to the English name of the industry. The list of industry names is shown below
{
"交通运输": "transportation",
"医学_健康_心理_中医": "medicine_health_psychology_traditional_chinese_medicine",
"数学_统计学": "mathematics_statistics",
"时政_政务_行政": "current_affairs_government_administration",
"消防安全_食品安全": "fire_safety_food_safety",
"石油化工": "petrochemical",
"计算机_通信": "computer_communication",
"人工智能_机器学习": "artificial_intelligence_machine_learning",
"其他信息服务_信息安全": "other_information_services_information_security",
"学科教育_教育": "subject_education_education",
"文学_情感": "literature_emotion",
"水利_海洋": "water_resources_ocean",
"游戏": "game",
"科技_科学研究": "technology_scientific_research",
"采矿": "mining",
"住宿_餐饮_酒店": "accommodation_catering_hotel",
"其他制造": "other_manufacturing",
"影视_娱乐": "film_entertainment",
"新闻传媒": "news_media",
"汽车": "automobile",
"生物医药": "biomedicine",
"航空航天": "aerospace",
"金融_经济": "finance_economics",
"体育": "sports",
"农林牧渔": "agriculture_forestry_animal_husbandry_fishery",
"房地产_建筑": "real_estate_construction",
"旅游_地理": "tourism_geography",
"法律_司法": "law_judiciary",
"电力能源": "electric_power_energy",
"计算机编程_代码": "computer_programming_code",
}
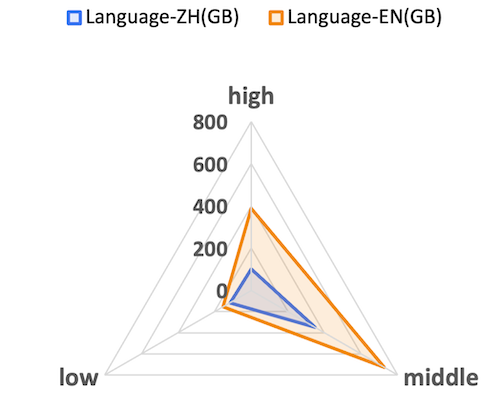
We filter the entire data according to data quality, remove extremely low-quality data, and divide the available data into three independent groups: Low, Middle, and Hight, to facilitate data matching and combination during model training. The distribution of data of different qualities is shown below. It can be seen that the data quality distribution trends of Chinese and English are basically the same, with the largest number of middle data, followed by middle data, and the least number of low data; in addition, it can be observed that the proportion of hight data in English is higher than that in Chinese (with a larger slope), which is also in line with the current trend of distribution of different languages.
In order to improve the coverage of industry classification in the data set to actual industries and align with the industry catalog defined in the national standard, we refer to the national economic industry classification system and the world knowledge system formulated by the National Bureau of Statistics, merge and integrate the categories, and design the final 31 industry categories covering Chinese and English. The category table names are as follows
Data construction of industry classification model
Data construction
Data source: pre-training corpus sampling and open source text classification data, of which pre-training corpus accounts for 90%. Through data sampling, the ratio of Chinese and English data is guaranteed to be 1:1
Label construction: Use the LLM model to make multiple classification judgments on the data, and select the data with consistent multiple judgments as training data
Data scale: 36K
The overall process of data construction is as follows:

Model training:
Parameter update: add classification head to pre-trained BERT model for text classification model training
Model selection: considering model performance and inference efficiency, we selected a 0.5B scale model. Through comparative experiments, we finally selected BGE-M3 and full parameter training as our base model
Training hyperparameters: full parameter training, max_length = 2048, lr = 1e-5, batch_size = 64, validation set evaluation acc: 86%

Why should we filter low-quality data?
Below is low-quality data extracted from the data. It can be seen that this kind of data is harmful to the learning of the model.
{"text": "\\_\\__\n\nTranslated from *Chinese Journal of Biochemistry and Molecular Biology*, 2007, 23(2): 154--159 \\[译自:中国生物化学与分子生物学报\\]\n"}
{"text": "#ifndef _IMGBMP_H_\n#define _IMGBMP_H_\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nconst uint8_t bmp[]={\n\\/\\/-- 调入了一幅图像:D:\\我的文档\\My Pictures\\12864-555.bmp --*\\/\n\\/\\/-- 宽度x高度=128x64 --\n0x00,0x06,0x0A,0xFE,0x0A,0xC6,0x00,0xE0,0x00,0xF0,0x00,0xF8,0x00,0x00,0x00,0x00,\n0x00,0x00,0xFE,0x7D,0xBB,0xC7,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xC7,0xBB,0x7D,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x08,\n0x0C,0xFE,0xFE,0x0C,0x08,0x20,0x60,0xFE,0xFE,0x60,0x20,0x00,0x00,0x00,0x78,0x48,\n0xFE,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xFE,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFE,0xFF,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFF,0x00,0x00,0xFE,0xFF,0x03,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFE,0x00,0x00,0x00,0x00,0xC0,0xC0,\n0xC0,0x00,0x00,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,\n0xFF,0xFE,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,\n0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,0xFF,0x00,0x00,0x00,0x00,0xE1,0xE1,\n0xE1,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,\n0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,\n0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,\n0x0F,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0xE2,0x92,0x8A,0x86,0x00,0x00,0x7C,0x82,0x82,0x82,0x7C,\n0x00,0xFE,0x00,0x82,0x92,0xAA,0xC6,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0x02,0x02,0x02,0xFE,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x24,0xA4,0x2E,0x24,0xE4,0x24,0x2E,0xA4,0x24,0x00,0x00,0x00,0xF8,0x4A,0x4C,\n0x48,0xF8,0x48,0x4C,0x4A,0xF8,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xC0,0x20,0x10,0x10,\n0x10,0x10,0x20,0xC0,0x00,0x00,0xC0,0x20,0x10,0x10,0x10,0x10,0x20,0xC0,0x00,0x00,\n0x00,0x12,0x0A,0x07,0x02,0x7F,0x02,0x07,0x0A,0x12,0x00,0x00,0x00,0x0B,0x0A,0x0A,\n0x0A,0x7F,0x0A,0x0A,0x0A,0x0B,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x20,0x40,0x40,\n0x40,0x50,0x20,0x5F,0x80,0x00,0x1F,0x20,0x40,0x40,0x40,0x50,0x20,0x5F,0x80,0x00,\n}; \n\n\n#ifdef __cplusplus\n}\n#endif\n\n#endif \\/\\/ _IMGBMP_H_ _SSD1306_16BIT_H_\n"}
Data construction
Data source: Random sampling of pre-trained corpus
Label construction: Design data scoring rules, use LLM model to perform multiple rounds of scoring, and select data with a difference of less than 2 in multiple rounds of scoring
Data scale: 20k scoring data, Chinese and English ratio 1:1
Data scoring prompt
quality_prompt = """Below is an extract from a web page. Evaluate whether the page has a high natural language value and could be useful in an naturanl language task to train a good language model using the additive 5-point scoring system described below. Points are accumulated based on the satisfaction of each criterion:
- Zero score if the content contains only some meaningless content or private content, such as some random code, http url or copyright information, personally identifiable information, binary encoding of images.
- Add 1 point if the extract provides some basic information, even if it includes some useless contents like advertisements and promotional material.
- Add another point if the extract is written in good style, semantically fluent, and free of repetitive content and grammatical errors.
- Award a third point tf the extract has relatively complete semantic content, and is written in a good and fluent style, the entire content expresses something related to the same topic, rather than a patchwork of several unrelated items.
- A fourth point is awarded if the extract has obvious educational or literary value, or provides a meaningful point or content, contributes to the learning of the topic, and is written in a clear and consistent style. It may be similar to a chapter in a textbook or tutorial, providing a lot of educational content, including exercises and solutions, with little to no superfluous information. The content is coherent and focused, which is valuable for structured learning.
- A fifth point is awarded if the extract has outstanding educational value or is of very high information density, provides very high value and meaningful content, does not contain useless information, and is well suited for teaching or knowledge transfer. It contains detailed reasoning, has an easy-to-follow writing style, and can provide deep and thorough insights.
The extract:
<{EXAMPLE}>.
After examining the extract:
- Briefly justify your total score, up to 50 words.
- Conclude with the score using the format: "Quality score: <total points>"
...
"""
Model training
Model selection: Similar to the classification model, we also used a 0.5b scale model and compared beg-m3 and qwen-0.5b. The final experiment showed that bge-m3 had the best overall performance
Model hyperparameters: base bge-m3, full parameter training, lr=1e-5, batch_size=64, max_length = 2048
Model evaluation: On the validation set, the consistency rate of the model and GPT4 in sample quality judgment was 90%.

Training benefits from high-quality data
In order to verify whether high-quality data can bring more efficient training efficiency, we extracted high-quality data from the 50b data before screening under the same base model. It can be considered that the distribution of the two data is roughly the same, and autoregressive training is performed.
As can be seen from the curve, the 14B tokens of the model trained with high-quality data can achieve the performance of the model with 50B of ordinary data. High-quality data can greatly improve training efficiency.

In addition, high-quality data can be added to the model as data in the pre-training annealing stage to further improve the model effect. To verify this conjecture, when training the industry model, we added pre-training data converted from high-quality data after screening and some instruction data to the annealing stage of the model. It can be seen that the performance of the model has been greatly improved.

Finally, high-quality pre-training predictions contain a wealth of high-value knowledge content, from which instruction data can be extracted to further improve the richness and knowledge of instruction data. This also gave rise to the BAAI/IndustryInstruction project, which we will explain in detail there.
If you find our work helpful, feel free to give us a cite.
@misc {beijing_academy_of_artificial_intelligence,
author= { Xiaofeng Shi and Lulu Zhao and Hua Zhou and Donglin Hao},
title = { IndustryCorpus2},
year = 2024,
url = { https://huggingface.co/datasets/BAAI/IndustryCorpus2 },
doi = { 10.57967/hf/3488 },
publisher = { Hugging Face }
}
