
text
stringlengths 51
1.2k
| lang
stringclasses 2
values | title
stringclasses 5
values |
|---|---|---|
ank Herbert](/wiki/Frank_Herbert "Frank Herbert"), met en scène de manière fascinante l'émergence d'une intelligence artificielle forte. Plus récemment, l'écrivain français [Christian Léourier](/wiki/Christian_L%C3%A9ourier "Christian Léourier") a placé une intelligence artificielle au cur de son roman court *[Helstrid](/wiki/Helstrid "Helstrid")* (2018), dans lequel cette IA laisse un être humain mourir, contrevenant ainsi aux [trois lois de la robotique](/wiki/Trois_lois_de_la_robotique "Trois lois de la robotique") instaurées par Isaac Asimov près de quatre-vingts ans plus tôt.
Les [androïdes](/wiki/Andro%C3%AFde "Androïde") faisant preuve d'intelligence artificielle dans la fiction sont nombreux : le personnage de [Data](/wiki/Data_(Star_Trek) "Data (Star Trek)") de la série télévisée *[Star Trek : The Next Generation](/wiki/Star_Trek_:_La_Nouvelle_G%C3%A9n%C3%A9ration "Star Trek : La Nouvelle Génération")* est un être cybernétique doué d'intelligence, avec des capacités importantes d'apprentissage. Il est officier supérieur sur le vaisseau *[Enterprise](/wiki/Enterprise_(NX-01) "Enterprise (NX-01)")* et évolue aux côtés de ses coéquipiers humains qui l'inspirent dans sa quête | fr | ai.md |
d'humanité. Son pendant cinématographique est Bishop dans les films *[Aliens](/wiki/Aliens,_le_retour "Aliens, le retour")* (1986) et *[Alien 3](/wiki/Alien_3 "Alien 3")* (1992). Dans le [manga](/wiki/Manga "Manga") *[Ghost in the Shell](/wiki/Ghost_in_the_Shell "Ghost in the Shell")*, une androïde s'éveille à la conscience. Dans la saga *[Terminator](/wiki/Terminator_(s%C3%A9rie_de_films) "Terminator (série de films)")* avec [Arnold Schwarzenegger](/wiki/Arnold_Schwarzenegger "Arnold Schwarzenegger"), le [T-800](/wiki/T-800 "T-800") reprogrammé, conçu initialement pour tuer, semble dans la capacité d'éprouver des sentiments humains. Par ailleurs, les Terminators successifs sont envoyés dans le passé par [Skynet](/wiki/Skynet_(Terminator) "Skynet (Terminator)"), une intelligence artificielle qui a pris conscience d'elle-même, et du danger que représentent les humains envers elle-même[[233]](#cite_note-236).
### Quelques IA célèbres dans la science-fiction[[modifier](/w/index.php?title=Intelligence_artificielle&veaction=edit§ion=63 "Modifier la section: Quelques IA célèbres dans la science-fiction") | [modifier le code](/w/index.php?title=Intelligence_artificielle&action=edit& | fr | ai.md |
section=63 "Modifier le code source de la section : Quelques IA célèbres dans la science-fiction")]
Utilisation dans les jeux[[modifier](/w/index.php?title=Intelligence_artificielle&veaction=edit§ion=64 "Modifier la section: Utilisation dans les jeux") | [modifier le code](/w/index.php?title=Intelligence_artificielle&action=edit§ion=64 "Modifier le code source de la section : Utilisation dans les jeux")]
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Les jeux, notamment les [jeux de stratégie](/wiki/Jeux_de_strat%C3%A9gie "Jeux de stratégie"), ont marqué l'histoire de l'intelligence artificielle, même s'ils ne mesurent que des compétences particulières, telles que la capacité de la machine en matière de calcul de [probabilités](/wiki/Probabilit%C3%A9s "Probabilités"), de prise de décision mais aussi d'[apprentissage](/wiki/Apprentissage_automatique "Apprentissage automatique").
[Hans Berliner](/wiki/Hans_B | fr | ai.md |
erliner "Hans Berliner") (1929-2017), docteur en science informatique à l'[université Carnegie-Mellon](/wiki/Universit%C3%A9_Carnegie-Mellon "Université Carnegie-Mellon") et joueur d'[échecs](/wiki/%C3%89checs "Échecs"), fut l'un des pionniers de la [programmation](/wiki/Programmation_informatique "Programmation informatique") pour les ordinateurs de jeu. Ses travaux commencèrent par un [programme](/wiki/Programme_informatique "Programme informatique") capable de battre un humain professionnel au [backgammon](/wiki/Backgammon "Backgammon"), puis, à partir des années 1960 et avec l'aide d'[IBM](/wiki/IBM "IBM"), il fit des recherches pour créer un programme capable de rivaliser avec des [grands maîtres](/wiki/Grand_ma%C3%AEtre_international "Grand maître international") du [jeu d'échecs](/wiki/%C3%89checs "Échecs"). Ses travaux contribuèrent quelques décennies plus tard à la réalisation du supercalculateur [Deep Blue](/wiki/Deep_Blue "Deep Blue")[[235]](#cite_note-238).
Outre la capacité des jeux à permettre de mesurer les performances de l'intelligence artificielle, que ce soit au travers d'un score ou d'un affrontement face à un humain, les jeux offrent un environnement propice à | fr | ai.md |
l'expérimentation pour les chercheurs, notamment dans le domaine de l'[apprentissage par renforcement](/wiki/Apprentissage_par_renforcement "Apprentissage par renforcement")[[236]](#cite_note-actuia.com-239).
Dans le jeu [Othello](/wiki/Othello_(jeu) "Othello (jeu)"), sur un plateau de 8 cases sur 8, chaque joueur place tour à tour des pions de sa couleur (noir ou blanc). Le vainqueur est celui qui possède les pions de la couleur dominante.
L'une des premières intelligences artificielles pour l'Othello est IAGO, développée en 1976 par l'université [Caltech](/wiki/California_Institute_of_Technology "California Institute of Technology") de [Pasadena](/wiki/Pasadena "Pasadena") (Californie), qui bat sans difficultés le champion japonais Fumio Fujita.
Le premier tournoi d'Othello hommes contre machines est organisé en 1980. Un an plus tard, un nouveau tournoi de programmes regroupent 20 systèmes[[237]](#cite_note-240). C'est entre 1996 et 1997 que le nombre de programmes explose : *Darwersi* (1996-1999) par Olivier Arsac, *Hannibal* (1996) par Martin Piotte et Louis Geoffroy, *Keyano* (1997) par Mark Brockington, *Logistello* (1997) par Michael Buro, etc.
En 1968, le [maître inter | fr | ai.md |
national](/wiki/Ma%C3%AEtre_international "Maître international") anglais [David Levy](/wiki/David_Levy_(joueur_d%27%C3%A9checs) "David Levy (joueur d'échecs)") lança un défi à des spécialistes en intelligence artificielle, leur pariant qu'aucun [programme informatique](/wiki/Programme_informatique "Programme informatique") ne serait capable de le battre aux [échecs](/wiki/%C3%89checs "Échecs") dans les dix années à venir. Il remporta son pari, n'étant finalement battu par [Deep Thought](/wiki/Deep_Thought_(ordinateur_d%27%C3%A9checs) "Deep Thought (ordinateur d'échecs)") qu'en 1989[[238]](#cite_note-241).
En 1988, l'ordinateur [HiTech](/wiki/HiTech "HiTech") de [Hans Berliner](/wiki/Hans_Berliner "Hans Berliner") est le premier programme à battre un [grand maître](/wiki/Grand_ma%C3%AEtre_international "Grand maître international") du jeu d'échecs, [Arnold Denker](/wiki/Arnold_Denker "Arnold Denker") (74 ans) en match (3,5-1,5)[[239]](#cite_note-242),[[d]](#cite_note-243).
En 1997, le [supercalculateur](/wiki/Superordinateur "Superordinateur") conçu par [IBM](/wiki/IBM "IBM"), [Deep Blue](/wiki/Deep_Blue "Deep Blue") (surnommé *Deeper Blue* lors de ce [match revanche](/wiki/Match | fr | ai.md |
s_Deep_Blue_contre_Kasparov#Match_revanche_(1997) "Matchs Deep Blue contre Kasparov")), bat Garry Kasparov (3,5-2,5) et marque un tournant : pour la première fois, le meilleur joueur humain du jeu d'échecs est battu en match (et non lors d'une partie unique) par une machine.
En décembre 2017, une version généraliste d'[AlphaGo Zero](/wiki/AlphaGo_Zero "AlphaGo Zero") (le successeur du programme [AlphaGo](/wiki/AlphaGo "AlphaGo") de [DeepMind](/wiki/DeepMind "DeepMind")[[e]](#cite_note-244)) nommée [AlphaZero](/wiki/AlphaZero "AlphaZero"), est développée pour jouer à n'importe quel jeu en connaissant seulement les règles, et en apprenant à jouer seul contre lui-même. Ce programme est ensuite entraîné pour le [go](/wiki/Go_(jeu) "Go (jeu)"), le [shogi](/wiki/Shogi "Shogi") et les échecs. Après 9 heures d'entraînement, AlphaZero bat le programme d'échecs [Stockfish](/wiki/Stockfish_(programme_d%27%C3%A9checs) "Stockfish (programme d'échecs)") (leader dans son domaine), avec un score de 28 victoires, 72 nulles et aucune défaite. Il faut cependant noter que la puissance de calcul disponible pour AlphaZero (4 [TPU](/wiki/Tensor_Processing_Unit "Tensor Processing Unit") v2 pour jouer, so | fr | ai.md |
it une puissance de calcul de 720 [Teraflops](/wiki/FLOPS "FLOPS")) était très supérieure à la puissance disponible de Stockfish pour ce match, ce dernier tournant sur un ordinateur équipé de seulement 64 [curs](/wiki/Microprocesseur_multi-c%C5%93ur "Microprocesseur multi-cur") [Intel](/wiki/Intel "Intel")[[240]](#cite_note-245). AlphaZero a également battu (après apprentissage) le programme de shgi [Elmo](/w/index.php?title=Elmo_(shogi_engine)&action=edit&redlink=1 "Elmo (shogi engine) (page inexistante)") [(en)](https://en.wikipedia.org/wiki/elmo_(shogi_engine) "en:elmo (shogi engine)")[[241]](#cite_note-246),[[242]](#cite_note-247).
En 2015, l'IA réalise des progrès significatifs dans la pratique du [go](/wiki/Go_(jeu) "Go (jeu)"), plus complexe à appréhender que les [échecs](/wiki/%C3%89checs "Échecs") (entre autres à cause du plus grand nombre de positions : 10170 au go, contre 1050 pour les échecs, et de parties plausibles : 10600 au go, contre 10120 pour les échecs)[[243]](#cite_note-pixel996-248).
En octobre 2015, [AlphaGo](/wiki/AlphaGo "AlphaGo"), un logiciel d'IA conçu par [DeepMind](/wiki/DeepMind "DeepMind"), filiale de [Google](/wiki/Google "Google"), bat pour la pr | fr | ai.md |
emière fois [Fan Hui](/wiki/Fan_Hui "Fan Hui"), le triple champion européen de go[[244]](#cite_note-Nature2017-249) et ainsi relève ce qu'on considérait comme l'un des plus grands défis pour l'intelligence artificielle. Cette tendance se confirme en mars 2016 quand AlphaGo [bat par trois fois consécutives](/wiki/Match_AlphaGo_-_Lee_Sedol "Match AlphaGo - Lee Sedol") le champion du monde de la discipline, [Lee Sedol](/wiki/Lee_Sedol "Lee Sedol"), dans un duel en cinq parties[[245]](#cite_note-250). Lee Sedol a déclaré au terme de la seconde partie qu'il n'avait trouvé « aucune faiblesse » chez l'ordinateur et que sa défaite était « sans équivoque ».
[](/wiki/Fichier:IBM_Watson_w_Jeopardy.jpg)Réplique de [Watson](/wiki/Watson_(intelligence_artificielle) "Watson (intelligence artificielle)"), lors d'un concours de *[Jeopardy!](/wiki/Jeopardy! "Jeopardy!")*
En 2011, l'IA [Watson](/wiki/Watson_(intelligence_artificielle) "Watson (intelligence artificielle)") conçue par [IBM](/wiki/IBM "IBM") bat ses adversaires humains au [jeu télévisé](/wiki/Jeu_t%C3%A9l%C3%A9vis%C3%A9 "Je | fr | ai.md |
u télévisé") américain *[Jeopardy!](/wiki/Jeopardy! "Jeopardy!")*. Dans ce jeu de questions/réponses, la [compréhension du langage](/wiki/Compr%C3%A9hension_du_langage_naturel "Compréhension du langage naturel") est essentielle pour la machine ; pour ce faire, Watson a pu s'appuyer sur une importante [base de données](/wiki/Base_de_donn%C3%A9es "Base de données") interne lui fournissant des éléments de [culture générale](/wiki/Culture_g%C3%A9n%C3%A9rale "Culture générale"), et avait la capacité d'apprendre par lui-même, notamment de ses erreurs. Il disposait néanmoins d'un avantage, la capacité d'appuyer instantanément (et donc avant ses adversaires humains) sur le [buzzer](/wiki/Buzzer "Buzzer") pour donner une réponse[[243]](#cite_note-pixel996-248).
Article connexe : [Libratus](/wiki/Libratus "Libratus")
En 2007, Polaris est le premier [programme informatique](/wiki/Programme_informatique "Programme informatique") à gagner un tournoi de [poker](/wiki/Poker "Poker") significatif face à des joueurs professionnels humains[[246]](#cite_note-251),[[247]](#cite_note-Heads-up-252).
En 2017, lors du tournoi de poker « *Brains Vs. Artificial Intelligence : Upping the Ante* » (« Cervea | fr | ai.md |
u contre Intelligence Artificielle : on monte la mise ») organisé dans un [casino](/wiki/Casino_(lieu) "Casino (lieu)") de [Pennsylvanie](/wiki/Pennsylvanie "Pennsylvanie"), l'intelligence artificielle [Libratus](/wiki/Libratus "Libratus"), développée par des chercheurs de l'[université Carnegie-Mellon](/wiki/Universit%C3%A9_Carnegie-Mellon "Université Carnegie-Mellon") de [Pittsburgh](/wiki/Pittsburgh "Pittsburgh"), est confrontée à des adversaires humains dans le cadre d'une partie marathon étalée sur 20 jours[[247]](#cite_note-Heads-up-252). Les joueurs humains opposés à Libratus, tous professionnels de poker, affrontent successivement la machine dans une partie en face à face (*[heads up](/w/index.php?title=Heads_up_poker&action=edit&redlink=1 "Heads up poker (page inexistante)") [(en)](https://en.wikipedia.org/wiki/Heads_up_poker "en:Heads up poker")*) selon les règles du « [No Limit](/wiki/No_limit_(poker) "No limit (poker)") [Texas hold'em](/wiki/Texas_hold%27em "Texas hold'em") » (*no limit* signifiant que les mises ne sont pas plafonnées), la version alors la plus courante du poker. Les parties sont retransmises en direct et durant huit heures par jour sur la plateforme [T | fr | ai.md |
witch](/wiki/Twitch "Twitch")[[248]](#cite_note-numerama-253).
Au terme de plus de 120 000 [mains](/wiki/Main_au_poker "Main au poker") jouées, Libratus remporte tous ses duels face aux joueurs humains et accumule 1 766 250 dollars (virtuels). Le joueur humain ayant perdu le moins d'argent dans son duel face à la machine, Dong Kim, est tout de même en déficit de plus de 85 000 dollars. Dans leurs commentaires du jeu de leur adversaire, les joueurs humains admettent que celui-ci était à la fois déconcertant et terriblement efficace. En effet, Libratus « étudiait » chaque nuit, grâce aux ressources d'un supercalculateur situé à Pittsburgh, ses mains jouées durant la journée écoulée, utilisant les 15 millions d'heures-processeur de calculs du supercalculateur[[248]](#cite_note-numerama-253).
La victoire, nette et sans bavure, illustre les progrès accomplis dans le traitement par l'IA des « informations imparfaites », où la réflexion doit prendre en compte des données incomplètes ou dissimulées. Les estimations du nombre de possibilités d'une partie de poker sont en effet d'environ 10160 dans la variante *no limit* en face à face[[248]](#cite_note-numerama-253).
Auparavant, en 2015, | fr | ai.md |
le joueur professionnel [Doug Polk](/w/index.php?title=Doug_Polk&action=edit&redlink=1 "Doug Polk (page inexistante)") [(en)](https://en.wikipedia.org/wiki/Doug_Polk "en:Doug Polk") avait remporté la première édition de cet évènement contre une autre IA, baptisée [Claudico](/w/index.php?title=Claudico&action=edit&redlink=1 "Claudico (page inexistante)") [(en)](https://en.wikipedia.org/wiki/Claudico "en:Claudico")[[248]](#cite_note-numerama-253).
En mars 2022, un logiciel de bridge de la start-up française Nukkai parvient à gagner un tournoi et à expliquer aux perdants leurs erreurs[[249]](#cite_note-254).
Notes et références[[modifier](/w/index.php?title=Intelligence_artificielle&veaction=edit§ion=71 "Modifier la section: Notes et références") | [modifier le code](/w/index.php?title=Intelligence_artificielle&action=edit§ion=71 "Modifier le code source de la section : Notes et références")]
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | fr | ai.md |
------------
* (en) Cet article est partiellement ou en totalité issu de l'article de Wikipédia en anglais intitulé .
1. [](#cite_ref-7) (en) « the building of computer programs which perform tasks which are, for the moment, performed in a more satisfactory way by humans because they require high level mental processes such as: perception learning, memory organization and critical reasoning
»
.
2. [](#cite_ref-102) DarkBert a été initialement conçu comme un outil de lutte contre le cybercrime.
3. [](#cite_ref-212) [[
209]](#cite_note-211).Un nouveau sondage a été effectué en 2023 sur 2778 chercheurs
4. [](#cite_ref-243) 74 ans
et crédité d'un [Arnold Denker](/wiki/Arnold_Denker "Arnold Denker") était alors âgé deet crédité d'un [classement Elo](/wiki/Classement_Elo "Classement Elo") de 2300, ce qui relativise un peu la performance du programme, un [fort grand maître](/wiki/Grand_ma%C3%AEtre_international#Grands_ma%C3%AEtres_de_premi%C3%A8re_force "Grand maître international") étant à cette époque plus vers les 2 650-2 700 points Elo, voire davantage.
5. [](#cite_ref-244) Voir plus bas dans la section « Go ».
Sur les autres projets Wikimedia :
**Aspects techniques**
**Asp | fr | ai.md |
ects prospectifs**
* Étude : CGET (2019) *Intelligence artificielle - État de l'art et perspectives pour la France* ; 21 février 2019. URL:<https://cget.gouv.fr/ressources/publications/intelligence-artificielle-etat-de-l-art-et-perspectives-pour-la-france> ([ISBN](/wiki/International_Standard_Book_Number "International Standard Book Number") [978-2-11-152634-1](/wiki/Sp%C3%A9cial:Ouvrages_de_r%C3%A9f%C3%A9rence/978-2-11-152634-1 "Spécial:Ouvrages de référence/978-2-11-152634-1")) ([ISSN](/wiki/International_Standard_Serial_Number "International Standard Serial Number") ).
* Jusqu'où ira l'intelligence artificielle ? », *[Pour la science](/wiki/Pour_la_science "Pour la science")*, hors-série no 115, mai-juin 2022, p. 4-119»,, hors-série115,4-119
**Aspects philosophiques**
**Fondements cognitifs, psychologiques et biologiques**
* Intelligence artificielle et psychologie cognitive, Paris, 1998, 179 p. ([ISBN](/wiki/International_Standard_Book_Number "International Standard Book Number") [2-10-002989-4](/wiki/Sp%C3%A9cial:Ouvrages_de_r%C3%A9f%C3%A9rence/2-10-002989-4 "Spécial:Ouvrages de référence/2-10-002989-4"))Hervé Chaudet et Liliane Pellegrin,, Paris, [Dunod](/wiki/%C3%89diti | fr | ai.md |
ons_Dunod "Éditions Dunod") , 179
**Aspects linguistiques**
* [Gérard Sabah](/wiki/G%C3%A9rard_Sabah "Gérard Sabah"), L'Intelligence artificielle et le langage, Représentations des connaissances, Processus de compréhension, vol. 1, Hermès, 1989, 768 p. ([ISBN](/wiki/International_Standard_Book_Number "International Standard Book Number") [2-86601-134-1](/wiki/Sp%C3%A9cial:Ouvrages_de_r%C3%A9f%C3%A9rence/2-86601-134-1 "Spécial:Ouvrages de référence/2-86601-134-1"))1, Hermès,, 768
* L'Intelligence artificielle et le langage, Représentations des connaissances, Processus de compréhension, vol. 2, Paris, Hermès, 1990, 768 p. ([ISBN](/wiki/International_Standard_Book_Number "International Standard Book Number") [2-86601-187-2](/wiki/Sp%C3%A9cial:Ouvrages_de_r%C3%A9f%C3%A9rence/2-86601-187-2 "Spécial:Ouvrages de référence/2-86601-187-2"))Gérard Sabah,2, Paris, Hermès,, 768
* Compréhension des langues et interaction (Traité IC2, Série Cognition et Traitement de l'Information), Paris, Hermès science: Lavoisier, 2006, 400 p. ([ISBN](/wiki/International_Standard_Book_Number "International Standard Book Number") [2-7462-1256-0](/wiki/Sp%C3%A9cial:Ouvrages_de_r%C3%A9f%C3%A9rence/2-7462-1256-0 | fr | ai.md |
"Spécial:Ouvrages de référence/2-7462-1256-0"))Gérard Sabah,, Paris, Hermès science: Lavoisier,, 400
* (en) Krzysztof Wok, Machine learning in translation corpora processing, Boca Raton, FL, 2019, 264 p. ([ISBN](/wiki/International_Standard_Book_Number "International Standard Book Number") [978-0-367-18673-9](/wiki/Sp%C3%A9cial:Ouvrages_de_r%C3%A9f%C3%A9rence/978-0-367-18673-9 "Spécial:Ouvrages de référence/978-0-367-18673-9"))Krzysztof Wok,, Boca Raton, FL, [Taylor & Francis](/wiki/Taylor_%26_Francis "Taylor & Francis") , 264
**Histoire**
* trad. de l'anglais), À la recherche de l'intelligence artificielle, Paris, 1997, 438 p. ([ISBN](/wiki/International_Standard_Book_Number "International Standard Book Number") [2-08-081428-1](/wiki/Sp%C3%A9cial:Ouvrages_de_r%C3%A9f%C3%A9rence/2-08-081428-1 "Spécial:Ouvrages de référence/2-08-081428-1"))Daniel Crevier et Nathalie Bukcek (de l'anglais),, Paris, [Flammarion](/wiki/Groupe_Flammarion "Groupe Flammarion") , 438
(en) *The Tumultuous history of the search for artiticial intelligence*.)
**Vulgarisation**
**Politique, relations internationales**
**Aspects juridiques**
* [Législation sur l'intelligence artificielle](/wiki/L%C3%A9gi | fr | ai.md |
slation_sur_l%27intelligence_artificielle "Législation sur l'intelligence artificielle"), aussi appelée *AI Act*
* *[Digital Services Act](/wiki/Digital_Services_Act "Digital Services Act")*, ou loi sur les services numériques de l'Union européenne
**Notions générales**
**Notions techniques**
**Chercheurs en intelligence artificielle (espace anglophone)**
**Chercheurs en intelligence artificielle (espace francophone)**
**Laboratoires et entreprises en intelligence artificielle**
[](/wiki/Mod%C3%A8le:Trop_de_liens "Si ce bandeau n'est plus pertinent, retirez-le. Cliquez ici pour en savoir plus.")Si ce bandeau n'est plus pertinent, retirez-le. Cliquez ici pour en savoir plus.[](/wiki/Fichier:Echo_pagelinked.svg)**Cet article ou cette section contient trop de [liens externes](/wiki/Wikip%C3%A9dia:Liens_externes "Wikipédia:Liens externes")** (mai 2024).
Les liens externes doivent être des [sites de réf | fr | ai.md |
érence](/wiki/Wikip%C3%A9dia:V%C3%A9rifiabilit%C3%A9 "Wikipédia:Vérifiabilité") dans le [domaine du sujet](/wiki/Wikip%C3%A9dia:Wikip%C3%A9dia_est_une_encyclop%C3%A9die "Wikipédia:Wikipédia est une encyclopédie"). Il est souhaitable - si cela présente un intérêt - de [citer ces liens comme source](/wiki/Wikip%C3%A9dia:Citez_vos_sources "Wikipédia:Citez vos sources") et de les enlever du corps de l'article ou de la section *« Liens externes »*.
#### Bases de données et dictionnaires[[modifier](/w/index.php?title=Intelligence_artificielle&veaction=edit§ion=78 "Modifier la section: Bases de données et dictionnaires") | [modifier le code](/w/index.php?title=Intelligence_artificielle&action=edit§ion=78 "Modifier le code source de la section : Bases de données et dictionnaires")] | fr | ai.md |
Study of algorithms that improve automatically through experience
"Statistical learning" redirects here. For statistical learning in linguistics, see [statistical learning in language acquisition](/wiki/Statistical_learning_in_language_acquisition "Statistical learning in language acquisition")
**Machine learning** (**ML**) is a [field of study](/wiki/Field_of_study "Field of study") in [artificial intelligence](/wiki/Artificial_intelligence "Artificial intelligence") concerned with the development and study of [statistical algorithms](/wiki/Computational_statistics "Computational statistics") that can learn from [data](/wiki/Data "Data") and [generalize](/wiki/Generalize "Generalize") to unseen data, and thus perform [tasks](/wiki/Task_(computing) "Task (computing)") without explicit [instructions](/wiki/Machine_code "Machine code").[[1]](#cite_note-1) Recently, [artificial neural networks](/wiki/Artificial_neural_network "Artificial neural network") have been able to surpass many previous approaches in performance.[[2]](#cite_note-ibm-2)[[3]](#cite_note-:6-3)
ML finds application in many fields, including [natural language processing](/wiki/Natural_language_processing "Natural | en | ml.md |
language processing"), [computer vision](/wiki/Computer_vision "Computer vision"), [speech recognition](/wiki/Speech_recognition "Speech recognition"), [email filtering](/wiki/Email_filtering "Email filtering"), [agriculture](/wiki/Agriculture "Agriculture"), and medicine.[[4]](#cite_note-tvt-4)[[5]](#cite_note-:7-5) When applied to business problems, it is known under the name [predictive analytics](/wiki/Predictive_analytics "Predictive analytics"). Although not all machine learning is [statistically](/wiki/Statistics "Statistics") based, [computational statistics](/wiki/Computational_statistics "Computational statistics") is an important source of the field's methods.
The mathematical foundations of ML are provided by [mathematical optimization](/wiki/Mathematical_optimization "Mathematical optimization") (mathematical programming) methods. [Data mining](/wiki/Data_mining "Data mining") is a related (parallel) field of study, focusing on [exploratory data analysis](/wiki/Exploratory_data_analysis "Exploratory data analysis") (EDA) through [unsupervised learning](/wiki/Unsupervised_learning "Unsupervised learning").[[7]](#cite_note-7)[[8]](#cite_note-:9-8)
From a theoretical v | en | ml.md |
iewpoint, [probably approximately correct (PAC) learning](/wiki/Probably_approximately_correct_learning "Probably approximately correct learning") provides a framework for describing machine learning.
History[[edit](/w/index.php?title=Machine_learning&action=edit§ion=1 "Edit section: History")]
--------------------------------------------------------------------------------------------------
The term *machine learning* was coined in 1959 by [Arthur Samuel](/wiki/Arthur_Samuel_(computer_scientist) "Arthur Samuel (computer scientist)"), an [IBM](/wiki/IBM "IBM") employee and pioneer in the field of [computer gaming](/wiki/Computer_gaming "Computer gaming") and [artificial intelligence](/wiki/Artificial_intelligence "Artificial intelligence").[[9]](#cite_note-Samuel-9)[[10]](#cite_note-:8-10) The synonym *self-teaching computers* was also used in this time period.[[11]](#cite_note-cyberthreat-11)[[12]](#cite_note-12)
Although the earliest machine learning model was introduced in the 1950s when [Arthur Samuel](/wiki/Arthur_Samuel_(computer_scientist) "Arthur Samuel (computer scientist)") invented a [program](/wiki/Computer_program "Computer program") that calculated the winning | en | ml.md |
chance in checkers for each side, the history of machine learning roots back to decades of human desire and effort to study human cognitive processes.[[13]](#cite_note-:02-13) In 1949, Canadian psychologist [Donald Hebb](/wiki/Donald_O._Hebb "Donald O. Hebb") published the book *[The Organization of Behavior](/wiki/Organization_of_Behavior "Organization of Behavior")*, in which he introduced a [theoretical neural structure](/wiki/Hebbian_theory "Hebbian theory") formed by certain interactions among [nerve cells](/wiki/Nerve_cells "Nerve cells").[[14]](#cite_note-14) Hebb's model of [neurons](/wiki/Neuron "Neuron") interacting with one another set a groundwork for how AIs and machine learning algorithms work under nodes, or [artificial neurons](/wiki/Artificial_neuron "Artificial neuron") used by computers to communicate data.[[13]](#cite_note-:02-13) Other researchers who have studied human cognitive systems contributed to the modern machine learning technologies as well, including logician [Walter Pitts](/wiki/Walter_Pitts "Walter Pitts") and [Warren McCulloch](/wiki/Warren_Sturgis_McCulloch "Warren Sturgis McCulloch"), who proposed the early mathematical models of neural networks | en | ml.md |
to come up with algorithms that mirror human thought processes.[[13]](#cite_note-:02-13)
By the early 1960s an experimental "learning machine" with [punched tape](/wiki/Punched_tape "Punched tape") memory, called Cybertron, had been developed by [Raytheon Company](/wiki/Raytheon_Company "Raytheon Company") to analyze [sonar](/wiki/Sonar "Sonar") signals, [electrocardiograms](/wiki/Electrocardiography "Electrocardiography"), and speech patterns using rudimentary [reinforcement learning](/wiki/Reinforcement_learning "Reinforcement learning"). It was repetitively "trained" by a human operator/teacher to recognize patterns and equipped with a "[goof](/wiki/Goof "Goof")" button to cause it to re-evaluate incorrect decisions.[[15]](#cite_note-15) A representative book on research into machine learning during the 1960s was Nilsson's book on Learning Machines, dealing mostly with machine learning for pattern classification.[[16]](#cite_note-16) Interest related to pattern recognition continued into the 1970s, as described by Duda and Hart in 1973.[[17]](#cite_note-17) In 1981 a report was given on using teaching strategies so that an [artificial neural network](/wiki/Artificial_neural_ne | en | ml.md |
twork "Artificial neural network") learns to recognize 40 characters (26 letters, 10 digits, and 4 special symbols) from a computer terminal.[[18]](#cite_note-18)
[Tom M. Mitchell](/wiki/Tom_M._Mitchell "Tom M. Mitchell") provided a widely quoted, more formal definition of the algorithms studied in the machine learning field: "A computer program is said to learn from experience *E* with respect to some class of tasks *T* and performance measure *P* if its performance at tasks in *T*, as measured by *P*, improves with experience *E*."[[19]](#cite_note-Mitchell-1997-19) This definition of the tasks in which machine learning is concerned offers a fundamentally [operational definition](/wiki/Operational_definition "Operational definition") rather than defining the field in cognitive terms. This follows [Alan Turing](/wiki/Alan_Turing "Alan Turing")'s proposal in his paper "[Computing Machinery and Intelligence](/wiki/Computing_Machinery_and_Intelligence "Computing Machinery and Intelligence")", in which the question "Can machines think?" is replaced with the question "Can machines do what we (as thinking entities) can do?".[[20]](#cite_note-20)
Modern-day machine learning has two obj | en | ml.md |
ectives. One is to classify data based on models which have been developed; the other purpose is to make predictions for future outcomes based on these models. A hypothetical algorithm specific to classifying data may use computer vision of moles coupled with supervised learning in order to train it to classify the cancerous moles. A machine learning algorithm for stock trading may inform the trader of future potential predictions.[[21]](#cite_note-21)
Relationships to other fields[[edit](/w/index.php?title=Machine_learning&action=edit§ion=2 "Edit section: Relationships to other fields")]
----------------------------------------------------------------------------------------------------------------------------------------------
### Artificial intelligence[[edit](/w/index.php?title=Machine_learning&action=edit§ion=3 "Edit section: Artificial intelligence")]
[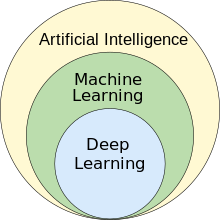](/wiki/File:AI_hierarchy.svg)Machine learning as subfield of AI[[22]](#cite_note-journalimcms.org-22)
As a scientific endeavor, machine learning grew out of the quest for [artificial intelligence](/wiki/Artificial_int | en | ml.md |
elligence "Artificial intelligence") (AI). In the early days of AI as an [academic discipline](/wiki/Discipline_(academia) "Discipline (academia)"), some researchers were interested in having machines learn from data. They attempted to approach the problem with various symbolic methods, as well as what were then termed "[neural networks](/wiki/Artificial_neural_network "Artificial neural network")"; these were mostly [perceptrons](/wiki/Perceptron "Perceptron") and [other models](/wiki/ADALINE "ADALINE") that were later found to be reinventions of the [generalized linear models](/wiki/Generalized_linear_model "Generalized linear model") of statistics.[[23]](#cite_note-23) [Probabilistic reasoning](/wiki/Probabilistic_reasoning "Probabilistic reasoning") was also employed, especially in [automated medical diagnosis](/wiki/Automated_medical_diagnosis "Automated medical diagnosis").[[24]](#cite_note-aima-24):488
However, an increasing emphasis on the [logical, knowledge-based approach](/wiki/Symbolic_AI "Symbolic AI") caused a rift between AI and machine learning. Probabilistic systems were plagued by theoretical and practical problems of data acquisition and representation.[[24]](#c | en | ml.md |
ite_note-aima-24):488 By 1980, [expert systems](/wiki/Expert_system "Expert system") had come to dominate AI, and statistics was out of favor.[[25]](#cite_note-changing-25) Work on symbolic/knowledge-based learning did continue within AI, leading to [inductive logic programming](/wiki/Inductive_logic_programming "Inductive logic programming")(ILP), but the more statistical line of research was now outside the field of AI proper, in [pattern recognition](/wiki/Pattern_recognition "Pattern recognition") and [information retrieval](/wiki/Information_retrieval "Information retrieval").[[24]](#cite_note-aima-24):708-710,755 Neural networks research had been abandoned by AI and [computer science](/wiki/Computer_science "Computer science") around the same time. This line, too, was continued outside the AI/CS field, as "[connectionism](/wiki/Connectionism "Connectionism")", by researchers from other disciplines including [Hopfield](/wiki/John_Hopfield "John Hopfield"), [Rumelhart](/wiki/David_Rumelhart "David Rumelhart"), and [Hinton](/wiki/Geoff_Hinton "Geoff Hinton"). Their main success came in the mid-1980s with the reinvention of [backpropagation](/wiki/Backpropagation "Backpropagation | en | ml.md |
").[[24]](#cite_note-aima-24):25
Machine learning (ML), reorganized and recognized as its own field, started to flourish in the 1990s. The field changed its goal from achieving artificial intelligence to tackling solvable problems of a practical nature. It shifted focus away from the [symbolic approaches](/wiki/Symbolic_artificial_intelligence "Symbolic artificial intelligence") it had inherited from AI, and toward methods and models borrowed from statistics, [fuzzy logic](/wiki/Fuzzy_logic "Fuzzy logic"), and [probability theory](/wiki/Probability_theory "Probability theory").[[25]](#cite_note-changing-25)
### Data compression[[edit](/w/index.php?title=Machine_learning&action=edit§ion=4 "Edit section: Data compression")]
### Data mining[[edit](/w/index.php?title=Machine_learning&action=edit§ion=5 "Edit section: Data mining")]
Machine learning and [data mining](/wiki/Data_mining "Data mining") often employ the same methods and overlap significantly, but while machine learning focuses on prediction, based on *known* properties learned from the training data, [data mining](/wiki/Data_mining "Data mining") focuses on the [discovery](/wiki/Discovery_(observation) "Discovery | en | ml.md |
(observation)") of (previously) *unknown* properties in the data (this is the analysis step of [knowledge discovery](/wiki/Knowledge_discovery "Knowledge discovery") in databases). [Data mining](/wiki/Data_mining "Data mining") uses many machine learning methods, but with different goals; on the other hand, machine learning also employs data mining methods as "[unsupervised learning](/wiki/Unsupervised_learning "Unsupervised learning")" or as a preprocessing step to improve learner accuracy. Much of the confusion between these two research communities (which do often have separate conferences and separate journals, [ECML PKDD](/wiki/ECML_PKDD "ECML PKDD") being a major exception) comes from the basic assumptions they work with: in machine learning, performance is usually evaluated with respect to the ability to *reproduce known* knowledge, while in knowledge discovery and data mining (KDD) the key task is the discovery of previously *unknown* knowledge. Evaluated with respect to known knowledge, an uninformed (unsupervised) method will easily be outperformed by other supervised methods, while in a typical KDD task, supervised methods cannot be used due to the unavailability of tra | en | ml.md |
ining data.
Machine learning also has intimate ties to [optimization](/wiki/Mathematical_optimization "Mathematical optimization"): many learning problems are formulated as minimization of some [loss function](/wiki/Loss_function "Loss function") on a training set of examples. Loss functions express the discrepancy between the predictions of the model being trained and the actual problem instances (for example, in classification, one wants to assign a label to instances, and models are trained to correctly predict the pre-assigned labels of a set of examples).[[35]](#cite_note-35)
### Generalization[[edit](/w/index.php?title=Machine_learning&action=edit§ion=6 "Edit section: Generalization")]
The difference between optimization and machine learning arises from the goal of [generalization](/wiki/Generalization_(learning) "Generalization (learning)"): while optimization algorithms can minimize the loss on a training set, machine learning is concerned with minimizing the loss on unseen samples. Characterizing the generalization of various learning algorithms is an active topic of current research, especially for [deep learning](/wiki/Deep_learning "Deep learning") algorithms.
# | en | ml.md |
## Statistics[[edit](/w/index.php?title=Machine_learning&action=edit§ion=7 "Edit section: Statistics")]
Machine learning and [statistics](/wiki/Statistics "Statistics") are closely related fields in terms of methods, but distinct in their principal goal: statistics draws population [inferences](/wiki/Statistical_inference "Statistical inference") from a [sample](/wiki/Sample_(statistics) "Sample (statistics)"), while machine learning finds generalizable predictive patterns.[[36]](#cite_note-36) According to [Michael I. Jordan](/wiki/Michael_I._Jordan "Michael I. Jordan"), the ideas of machine learning, from methodological principles to theoretical tools, have had a long pre-history in statistics.[[37]](#cite_note-mi_jordan_ama-37) He also suggested the term [data science](/wiki/Data_science "Data science") as a placeholder to call the overall field.[[37]](#cite_note-mi_jordan_ama-37)
Conventional statistical analyses require the a priori selection of a model most suitable for the study data set. In addition, only significant or theoretically relevant variables based on previous experience are included for analysis. In contrast, machine learning is not built on a pre-structure | en | ml.md |
d model; rather, the data shape the model by detecting underlying patterns. The more variables (input) used to train the model, the more accurate the ultimate model will be.[[38]](#cite_note-38)
[Leo Breiman](/wiki/Leo_Breiman "Leo Breiman") distinguished two statistical modeling paradigms: data model and algorithmic model,[[39]](#cite_note-:4-39) wherein "algorithmic model" means more or less the machine learning algorithms like [Random Forest](/wiki/Random_forest "Random forest").
Some statisticians have adopted methods from machine learning, leading to a combined field that they call *statistical learning*.[[40]](#cite_note-islr-40)
### Statistical physics[[edit](/w/index.php?title=Machine_learning&action=edit§ion=8 "Edit section: Statistical physics")]
Analytical and computational techniques derived from deep-rooted physics of disordered systems can be extended to large-scale problems, including machine learning, e.g., to analyze the weight space of [deep neural networks](/wiki/Deep_neural_network "Deep neural network").[[41]](#cite_note-SP_1-41) Statistical physics is thus finding applications in the area of [medical diagnostics](/wiki/Medical_diagnostics "Medical diag | en | ml.md |
nostics").[[42]](#cite_note-SP_2-42)
Theory[[edit](/w/index.php?title=Machine_learning&action=edit§ion=9 "Edit section: Theory")]
------------------------------------------------------------------------------------------------
A core objective of a learner is to generalize from its experience.[[6]](#cite_note-bishop2006-6)[[43]](#cite_note-:5-43) Generalization in this context is the ability of a learning machine to perform accurately on new, unseen examples/tasks after having experienced a learning data set. The training examples come from some generally unknown probability distribution (considered representative of the space of occurrences) and the learner has to build a general model about this space that enables it to produce sufficiently accurate predictions in new cases.
The computational analysis of machine learning algorithms and their performance is a branch of [theoretical computer science](/wiki/Theoretical_computer_science "Theoretical computer science") known as [computational learning theory](/wiki/Computational_learning_theory "Computational learning theory") via the [Probably Approximately Correct Learning](/wiki/Probably_approximately_correct_learning "Proba | en | ml.md |
bly approximately correct learning") (PAC) model. Because training sets are finite and the future is uncertain, learning theory usually does not yield guarantees of the performance of algorithms. Instead, probabilistic bounds on the performance are quite common. The [bias-variance decomposition](/wiki/Bias%E2%80%93variance_decomposition "Bias-variance decomposition") is one way to quantify generalization [error](/wiki/Errors_and_residuals "Errors and residuals").
For the best performance in the context of generalization, the complexity of the hypothesis should match the complexity of the function underlying the data. If the hypothesis is less complex than the function, then the model has under fitted the data. If the complexity of the model is increased in response, then the training error decreases. But if the hypothesis is too complex, then the model is subject to [overfitting](/wiki/Overfitting "Overfitting") and generalization will be poorer.[[44]](#cite_note-alpaydin-44)
In addition to performance bounds, learning theorists study the time complexity and feasibility of learning. In computational learning theory, a computation is considered feasible if it can be done in [polyn | en | ml.md |
omial time](/wiki/Time_complexity#Polynomial_time "Time complexity"). There are two kinds of [time complexity](/wiki/Time_complexity "Time complexity") results: Positive results show that a certain class of functions can be learned in polynomial time. Negative results show that certain classes cannot be learned in polynomial time.
Approaches[[edit](/w/index.php?title=Machine_learning&action=edit§ion=10 "Edit section: Approaches")]
---------------------------------------------------------------------------------------------------------
Machine learning approaches are traditionally divided into three broad categories, which correspond to learning paradigms, depending on the nature of the "signal" or "feedback" available to the learning system:
* [Supervised learning](/wiki/Supervised_learning "Supervised learning"): The computer is presented with example inputs and their desired outputs, given by a "teacher", and the goal is to learn a general rule that [maps](/wiki/Map_(mathematics) "Map (mathematics)") inputs to outputs.
* [Unsupervised learning](/wiki/Unsupervised_learning "Unsupervised learning"): No labels are given to the learning algorithm, leaving it on its own to find | en | ml.md |
structure in its input. Unsupervised learning can be a goal in itself (discovering hidden patterns in data) or a means towards an end ([feature learning](/wiki/Feature_learning "Feature learning")).
* [Reinforcement learning](/wiki/Reinforcement_learning "Reinforcement learning"): A computer program interacts with a dynamic environment in which it must perform a certain goal (such as [driving a vehicle](/wiki/Autonomous_car "Autonomous car") or playing a game against an opponent). As it navigates its problem space, the program is provided feedback that's analogous to rewards, which it tries to maximize.[[6]](#cite_note-bishop2006-6)
Although each algorithm has advantages and limitations, no single algorithm works for all problems.[[45]](#cite_note-45)[[46]](#cite_note-46)[[47]](#cite_note-47)
### Supervised learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=11 "Edit section: Supervised learning")]
[](/wiki/File:Svm_max_sep_hyperplane_with_margin.png)A [support-vector machine](/wiki/Support-vector_machine "Support-vector | en | ml.md |
machine") is a supervised learning model that divides the data into regions separated by a [linear boundary](/wiki/Linear_classifier "Linear classifier"). Here, the linear boundary divides the black circles from the white.
Supervised learning algorithms build a mathematical model of a set of data that contains both the inputs and the desired outputs.[[48]](#cite_note-48) The data is known as [training data](/wiki/Training_data "Training data"), and consists of a set of training examples. Each training example has one or more inputs and the desired output, also known as a supervisory signal. In the mathematical model, each training example is represented by an [array](/wiki/Array_data_structure "Array data structure") or vector, sometimes called a [feature vector](/wiki/Feature_vector "Feature vector"), and the training data is represented by a [matrix](/wiki/Matrix_(mathematics) "Matrix (mathematics)"). Through [iterative optimization](/wiki/Mathematical_optimization#Computational_optimization_techniques "Mathematical optimization") of an [objective function](/wiki/Loss_function "Loss function"), supervised learning algorithms learn a function that can be used to predict the outpu | en | ml.md |
t associated with new inputs.[[49]](#cite_note-49) An optimal function allows the algorithm to correctly determine the output for inputs that were not a part of the training data. An algorithm that improves the accuracy of its outputs or predictions over time is said to have learned to perform that task.[[19]](#cite_note-Mitchell-1997-19)
Types of supervised-learning algorithms include [active learning](/wiki/Active_learning_(machine_learning) "Active learning (machine learning)"), [classification](/wiki/Statistical_classification "Statistical classification") and [regression](/wiki/Regression_analysis "Regression analysis").[[50]](#cite_note-:3-50) Classification algorithms are used when the outputs are restricted to a limited set of values, and regression algorithms are used when the outputs may have any numerical value within a range. As an example, for a classification algorithm that filters emails, the input would be an incoming email, and the output would be the name of the folder in which to file the email.
[Similarity learning](/wiki/Similarity_learning "Similarity learning") is an area of supervised machine learning closely related to regression and classification, but t | en | ml.md |
he goal is to learn from examples using a similarity function that measures how similar or related two objects are. It has applications in [ranking](/wiki/Ranking "Ranking"), [recommendation systems](/wiki/Recommender_system "Recommender system"), visual identity tracking, face verification, and speaker verification.
### Unsupervised learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=12 "Edit section: Unsupervised learning")]
Unsupervised learning algorithms find structures in data that has not been labeled, classified or categorized. Instead of responding to feedback, unsupervised learning algorithms identify commonalities in the data and react based on the presence or absence of such commonalities in each new piece of data. Central applications of unsupervised machine learning include clustering, [dimensionality reduction](/wiki/Dimensionality_reduction "Dimensionality reduction"),[[8]](#cite_note-:9-8) and [density estimation](/wiki/Density_estimation "Density estimation").[[51]](#cite_note-JordanBishop2004-51) Unsupervised learning algorithms also streamlined the process of identifying large [indel](/wiki/Indel "Indel") based [haplotypes](/wiki/Haplotype | en | ml.md |
"Haplotype") of a gene of interest from [pan-genome](/wiki/Pan-genome "Pan-genome").[[52]](#cite_note-52)
[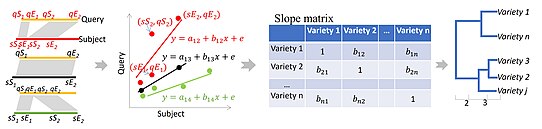](/wiki/File:CLIPS.jpg)Clustering via Large Indel Permuted Slopes, CLIPS,[[53]](#cite_note-53) turns the alignment image into a learning regression problem. The varied slope (*b*) estimates between each pair of DNA segments enables to identify segments sharing the same set of indels.
Cluster analysis is the assignment of a set of observations into subsets (called *clusters*) so that observations within the same cluster are similar according to one or more predesignated criteria, while observations drawn from different clusters are dissimilar. Different clustering techniques make different assumptions on the structure of the data, often defined by some *similarity metric* and evaluated, for example, by *internal compactness*, or the similarity between members of the same cluster, and *separation*, the difference between clusters. Other methods are based on *estimated density* and *graph connectivity*.
### Semi-supervised learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=13 | en | ml.md |
"Edit section: Semi-supervised learning")]
Semi-supervised learning falls between [unsupervised learning](/wiki/Unsupervised_learning "Unsupervised learning") (without any labeled training data) and [supervised learning](/wiki/Supervised_learning "Supervised learning") (with completely labeled training data). Some of the training examples are missing training labels, yet many machine-learning researchers have found that unlabeled data, when used in conjunction with a small amount of labeled data, can produce a considerable improvement in learning accuracy.
In [weakly supervised learning](/wiki/Weak_supervision "Weak supervision"), the training labels are noisy, limited, or imprecise; however, these labels are often cheaper to obtain, resulting in larger effective training sets.[[54]](#cite_note-54)
### Reinforcement learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=14 "Edit section: Reinforcement learning")]
Reinforcement learning is an area of machine learning concerned with how [software agents](/wiki/Software_agent "Software agent") ought to take [actions](/wiki/Action_selection "Action selection") in an environment so as to maximize some notion of cumu | en | ml.md |
lative reward. Due to its generality, the field is studied in many other disciplines, such as [game theory](/wiki/Game_theory "Game theory"), [control theory](/wiki/Control_theory "Control theory"), [operations research](/wiki/Operations_research "Operations research"), [information theory](/wiki/Information_theory "Information theory"), [simulation-based optimization](/wiki/Simulation-based_optimization "Simulation-based optimization"), [multi-agent systems](/wiki/Multi-agent_system "Multi-agent system"), [swarm intelligence](/wiki/Swarm_intelligence "Swarm intelligence"), [statistics](/wiki/Statistics "Statistics") and [genetic algorithms](/wiki/Genetic_algorithm "Genetic algorithm"). In reinforcement learning, the environment is typically represented as a [Markov decision process](/wiki/Markov_decision_process "Markov decision process") (MDP). Many reinforcements learning algorithms use [dynamic programming](/wiki/Dynamic_programming "Dynamic programming") techniques.[[55]](#cite_note-55) Reinforcement learning algorithms do not assume knowledge of an exact mathematical model of the MDP and are used when exact models are infeasible. Reinforcement learning algorithms are used in | en | ml.md |
autonomous vehicles or in learning to play a game against a human opponent.
### Dimensionality reduction[[edit](/w/index.php?title=Machine_learning&action=edit§ion=15 "Edit section: Dimensionality reduction")]
[Dimensionality reduction](/wiki/Dimensionality_reduction "Dimensionality reduction") is a process of reducing the number of random variables under consideration by obtaining a set of principal variables.[[56]](#cite_note-56) In other words, it is a process of reducing the dimension of the [feature](/wiki/Feature_(machine_learning) "Feature (machine learning)") set, also called the "number of features". Most of the dimensionality reduction techniques can be considered as either feature elimination or [extraction](/wiki/Feature_extraction "Feature extraction"). One of the popular methods of dimensionality reduction is [principal component analysis](/wiki/Principal_component_analysis "Principal component analysis") (PCA). PCA involves changing higher-dimensional data (e.g., 3D) to a smaller space (e.g., 2D). This results in a smaller dimension of data (2D instead of 3D), while keeping all original variables in the model without changing the data.[[57]](#cite_note-57)
The | en | ml.md |
[manifold hypothesis](/wiki/Manifold_hypothesis "Manifold hypothesis") proposes that high-dimensional data sets lie along low-dimensional [manifolds](/wiki/Manifold "Manifold"), and many dimensionality reduction techniques make this assumption, leading to the area of [manifold learning](/wiki/Manifold_learning "Manifold learning") and [manifold regularization](/wiki/Manifold_regularization "Manifold regularization").
### Other types[[edit](/w/index.php?title=Machine_learning&action=edit§ion=16 "Edit section: Other types")]
Other approaches have been developed which do not fit neatly into this three-fold categorization, and sometimes more than one is used by the same machine learning system. For example, [topic modeling](/wiki/Topic_modeling "Topic modeling"), [meta-learning](/wiki/Meta-learning_(computer_science) "Meta-learning (computer science)").[[58]](#cite_note-58)
Self-learning, as a machine learning paradigm was introduced in 1982 along with a neural network capable of self-learning, named *crossbar adaptive array* (CAA).[[59]](#cite_note-59) It is learning with no external rewards and no external teacher advice. The CAA self-learning algorithm computes, in a crossbar | en | ml.md |
fashion, both decisions about actions and emotions (feelings) about consequence situations. The system is driven by the interaction between cognition and emotion.[[60]](#cite_note-60)
The self-learning algorithm updates a memory matrix W =||w(a,s)|| such that in each iteration executes the following machine learning routine:
1. in situation *s* perform action *a*
2. receive a consequence situation *s'*
3. compute emotion of being in the consequence situation *v(s')*
4. update crossbar memory *w'(a,s) = w(a,s) + v(s')*
It is a system with only one input, situation, and only one output, action (or behavior) a. There is neither a separate reinforcement input nor an advice input from the environment. The backpropagated value (secondary reinforcement) is the emotion toward the consequence situation. The CAA exists in two environments, one is the behavioral environment where it behaves, and the other is the genetic environment, wherefrom it initially and only once receives initial emotions about situations to be encountered in the behavioral environment. After receiving the genome (species) vector from the genetic environment, the CAA learns a goal-seeking behavior, in an environment | en | ml.md |
that contains both desirable and undesirable situations.[[61]](#cite_note-61)
#### Feature learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=18 "Edit section: Feature learning")]
Several learning algorithms aim at discovering better representations of the inputs provided during training.[[62]](#cite_note-pami-62) Classic examples include [principal component analysis](/wiki/Principal_component_analysis "Principal component analysis") and cluster analysis. Feature learning algorithms, also called representation learning algorithms, often attempt to preserve the information in their input but also transform it in a way that makes it useful, often as a pre-processing step before performing classification or predictions. This technique allows reconstruction of the inputs coming from the unknown data-generating distribution, while not being necessarily faithful to configurations that are implausible under that distribution. This replaces manual [feature engineering](/wiki/Feature_engineering "Feature engineering"), and allows a machine to both learn the features and use them to perform a specific task.
Feature learning can be either supervised or unsupervised. I | en | ml.md |
n supervised feature learning, features are learned using labeled input data. Examples include [artificial neural networks](/wiki/Artificial_neural_network "Artificial neural network"), [multilayer perceptrons](/wiki/Multilayer_perceptron "Multilayer perceptron"), and supervised [dictionary learning](/wiki/Dictionary_learning "Dictionary learning"). In unsupervised feature learning, features are learned with unlabeled input data. Examples include dictionary learning, [independent component analysis](/wiki/Independent_component_analysis "Independent component analysis"), [autoencoders](/wiki/Autoencoder "Autoencoder"), [matrix factorization](/wiki/Matrix_decomposition "Matrix decomposition")[[63]](#cite_note-63) and various forms of [clustering](/wiki/Cluster_analysis "Cluster analysis").[[64]](#cite_note-coates2011-64)[[65]](#cite_note-65)[[66]](#cite_note-jurafsky-66)
[Manifold learning](/wiki/Manifold_learning "Manifold learning") algorithms attempt to do so under the constraint that the learned representation is low-dimensional. [Sparse coding](/wiki/Sparse_coding "Sparse coding") algorithms attempt to do so under the constraint that the learned representation is sparse, meanin | en | ml.md |
g that the mathematical model has many zeros. [Multilinear subspace learning](/wiki/Multilinear_subspace_learning "Multilinear subspace learning") algorithms aim to learn low-dimensional representations directly from [tensor](/wiki/Tensor "Tensor") representations for multidimensional data, without reshaping them into higher-dimensional vectors.[[67]](#cite_note-67) [Deep learning](/wiki/Deep_learning "Deep learning") algorithms discover multiple levels of representation, or a hierarchy of features, with higher-level, more abstract features defined in terms of (or generating) lower-level features. It has been argued that an intelligent machine is one that learns a representation that disentangles the underlying factors of variation that explain the observed data.[[68]](#cite_note-68)
Feature learning is motivated by the fact that machine learning tasks such as classification often require input that is mathematically and computationally convenient to process. However, real-world data such as images, video, and sensory data has not yielded attempts to algorithmically define specific features. An alternative is to discover such features or representations through examination, withou | en | ml.md |
t relying on explicit algorithms.
#### Sparse dictionary learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=19 "Edit section: Sparse dictionary learning")]
Sparse dictionary learning is a feature learning method where a training example is represented as a linear combination of [basis functions](/wiki/Basis_function "Basis function"), and is assumed to be a [sparse matrix](/wiki/Sparse_matrix "Sparse matrix"). The method is [strongly NP-hard](/wiki/Strongly_NP-hard "Strongly NP-hard") and difficult to solve approximately.[[69]](#cite_note-69) A popular [heuristic](/wiki/Heuristic "Heuristic") method for sparse dictionary learning is the [*k*-SVD](/wiki/K-SVD "K-SVD") algorithm. Sparse dictionary learning has been applied in several contexts. In classification, the problem is to determine the class to which a previously unseen training example belongs. For a dictionary where each class has already been built, a new training example is associated with the class that is best sparsely represented by the corresponding dictionary. Sparse dictionary learning has also been applied in [image de-noising](/wiki/Image_de-noising "Image de-noising"). The key idea is that | en | ml.md |
a clean image patch can be sparsely represented by an image dictionary, but the noise cannot.[[70]](#cite_note-70)
#### Anomaly detection[[edit](/w/index.php?title=Machine_learning&action=edit§ion=20 "Edit section: Anomaly detection")]
In [data mining](/wiki/Data_mining "Data mining"), anomaly detection, also known as outlier detection, is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data.[[71]](#cite_note-:0-71) Typically, the anomalous items represent an issue such as [bank fraud](/wiki/Bank_fraud "Bank fraud"), a structural defect, medical problems or errors in a text. Anomalies are referred to as [outliers](/wiki/Outlier "Outlier"), novelties, noise, deviations and exceptions.[[72]](#cite_note-72)
In particular, in the context of abuse and network intrusion detection, the interesting objects are often not rare objects, but unexpected bursts of inactivity. This pattern does not adhere to the common statistical definition of an outlier as a rare object. Many outlier detection methods (in particular, unsupervised algorithms) will fail on such data unless aggregated appropriately. Instead, | en | ml.md |
a cluster analysis algorithm may be able to detect the micro-clusters formed by these patterns.[[73]](#cite_note-73)
Three broad categories of anomaly detection techniques exist.[[74]](#cite_note-ChandolaSurvey-74) Unsupervised anomaly detection techniques detect anomalies in an unlabeled test data set under the assumption that the majority of the instances in the data set are normal, by looking for instances that seem to fit the least to the remainder of the data set. Supervised anomaly detection techniques require a data set that has been labeled as "normal" and "abnormal" and involves training a classifier (the key difference to many other statistical classification problems is the inherently unbalanced nature of outlier detection). Semi-supervised anomaly detection techniques construct a model representing normal behavior from a given normal training data set and then test the likelihood of a test instance to be generated by the model.
#### Robot learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=21 "Edit section: Robot learning")]
[Robot learning](/wiki/Robot_learning "Robot learning") is inspired by a multitude of machine learning methods, starting fr | en | ml.md |
om supervised learning, reinforcement learning,[[75]](#cite_note-75)[[76]](#cite_note-76) and finally [meta-learning](/wiki/Meta-learning_(computer_science) "Meta-learning (computer science)") (e.g. MAML).
#### Association rules[[edit](/w/index.php?title=Machine_learning&action=edit§ion=22 "Edit section: Association rules")]
Association rule learning is a [rule-based machine learning](/wiki/Rule-based_machine_learning "Rule-based machine learning") method for discovering relationships between variables in large databases. It is intended to identify strong rules discovered in databases using some measure of "interestingness".[[77]](#cite_note-piatetsky-77)
Rule-based machine learning is a general term for any machine learning method that identifies, learns, or evolves "rules" to store, manipulate or apply knowledge. The defining characteristic of a rule-based machine learning algorithm is the identification and utilization of a set of relational rules that collectively represent the knowledge captured by the system. This is in contrast to other machine learning algorithms that commonly identify a singular model that can be universally applied to any instance in order to make | en | ml.md |
a prediction.[[78]](#cite_note-78) Rule-based machine learning approaches include [learning classifier systems](/wiki/Learning_classifier_system "Learning classifier system"), association rule learning, and [artificial immune systems](/wiki/Artificial_immune_system "Artificial immune system").
Based on the concept of strong rules, [Rakesh Agrawal](/wiki/Rakesh_Agrawal_(computer_scientist) "Rakesh Agrawal (computer scientist)"), [Tomasz Imieliski](/wiki/Tomasz_Imieli%C5%84ski "Tomasz Imieliski") and Arun Swami introduced association rules for discovering regularities between products in large-scale transaction data recorded by [point-of-sale](/wiki/Point-of-sale "Point-of-sale") (POS) systems in supermarkets.[[79]](#cite_note-mining-79) For example, the rule
{
o
n
i
o
n
s
,
p
o
t
a
t
o
e
s
}
{
b
u
r
g
e
r
}
{\displaystyle \{\mathrm {onions,potatoes} \}\Rightarrow \{\mathrm {burger} \}}
 found in the sales data of a supermarket would indicate that if a customer buys oni | en | ml.md |
ons and potatoes together, they are likely to also buy hamburger meat. Such information can be used as the basis for decisions about marketing activities such as promotional [pricing](/wiki/Pricing "Pricing") or [product placements](/wiki/Product_placement "Product placement"). In addition to [market basket analysis](/wiki/Market_basket_analysis "Market basket analysis"), association rules are employed today in application areas including [Web usage mining](/wiki/Web_usage_mining "Web usage mining"), [intrusion detection](/wiki/Intrusion_detection "Intrusion detection"), [continuous production](/wiki/Continuous_production "Continuous production"), and [bioinformatics](/wiki/Bioinformatics "Bioinformatics"). In contrast with [sequence mining](/wiki/Sequence_mining "Sequence mining"), association rule learning typically does not consider the order of items either within a transaction or across transactions.
Learning classifier systems (LCS) are a family of rule-based machine learning algorithms that combine a discovery component, typically a [genetic algorithm](/wiki/Genetic_algorithm "Genetic algorithm"), with a learning component, performing either [supervised learning](/wiki/Supe | en | ml.md |
rvised_learning "Supervised learning"), [reinforcement learning](/wiki/Reinforcement_learning "Reinforcement learning"), or [unsupervised learning](/wiki/Unsupervised_learning "Unsupervised learning"). They seek to identify a set of context-dependent rules that collectively store and apply knowledge in a [piecewise](/wiki/Piecewise "Piecewise") manner in order to make predictions.[[80]](#cite_note-80)
[Inductive logic programming](/wiki/Inductive_logic_programming "Inductive logic programming") (ILP) is an approach to rule learning using [logic programming](/wiki/Logic_programming "Logic programming") as a uniform representation for input examples, background knowledge, and hypotheses. Given an encoding of the known background knowledge and a set of examples represented as a logical database of facts, an ILP system will derive a hypothesized logic program that [entails](/wiki/Entailment "Entailment") all positive and no negative examples. [Inductive programming](/wiki/Inductive_programming "Inductive programming") is a related field that considers any kind of programming language for representing hypotheses (and not only logic programming), such as [functional programs](/wiki/Func | en | ml.md |
tional_programming "Functional programming").
Inductive logic programming is particularly useful in [bioinformatics](/wiki/Bioinformatics "Bioinformatics") and [natural language processing](/wiki/Natural_language_processing "Natural language processing"). [Gordon Plotkin](/wiki/Gordon_Plotkin "Gordon Plotkin") and [Ehud Shapiro](/wiki/Ehud_Shapiro "Ehud Shapiro") laid the initial theoretical foundation for inductive machine learning in a logical setting.[[81]](#cite_note-81)[[82]](#cite_note-82)[[83]](#cite_note-83) Shapiro built their first implementation (Model Inference System) in 1981: a Prolog program that inductively inferred logic programs from positive and negative examples.[[84]](#cite_note-84) The term *inductive* here refers to [philosophical](/wiki/Inductive_reasoning "Inductive reasoning") induction, suggesting a theory to explain observed facts, rather than [mathematical induction](/wiki/Mathematical_induction "Mathematical induction"), proving a property for all members of a well-ordered set.
Models[[edit](/w/index.php?title=Machine_learning&action=edit§ion=23 "Edit section: Models")]
----------------------------------------------------------------------------- | en | ml.md |
--------------------
A **machine learning model** is a type of [mathematical model](/wiki/Mathematical_model "Mathematical model") which, after being "trained" on a given dataset, can be used to make predictions or classifications on new data. During training, a learning algorithm iteratively adjusts the model's internal parameters to minimize errors in its predictions.[[85]](#cite_note-85) By extension the term model can refer to several level of specifity, from a general class of models and their associated learning algorithms, to a fully trained model with all its internal parameters tuned.[[86]](#cite_note-86)
Various types of models have been used and researched for machine learning systems, picking the best model for a task is called [model selection](/wiki/Model_selection "Model selection").
### Artificial neural networks[[edit](/w/index.php?title=Machine_learning&action=edit§ion=24 "Edit section: Artificial neural networks")]
[](/wiki/File:Colored_neural_network.svg)An artificial neural network is an interconnected group of nodes, akin to the vast | en | ml.md |
network of [neurons](/wiki/Neuron "Neuron") in a [brain](/wiki/Brain "Brain"). Here, each circular node represents an [artificial neuron](/wiki/Artificial_neuron "Artificial neuron") and an arrow represents a connection from the output of one artificial neuron to the input of another.
Artificial neural networks (ANNs), or [connectionist](/wiki/Connectionism "Connectionism") systems, are computing systems vaguely inspired by the [biological neural networks](/wiki/Biological_neural_network "Biological neural network") that constitute animal [brains](/wiki/Brain "Brain"). Such systems "learn" to perform tasks by considering examples, generally without being programmed with any task-specific rules.
An ANN is a model based on a collection of connected units or nodes called "[artificial neurons](/wiki/Artificial_neuron "Artificial neuron")", which loosely model the [neurons](/wiki/Neuron "Neuron") in a biological [brain](/wiki/Brain "Brain"). Each connection, like the [synapses](/wiki/Synapse "Synapse") in a biological [brain](/wiki/Brain "Brain"), can transmit information, a "signal", from one artificial neuron to another. An artificial neuron that receives a signal can process it and | en | ml.md |
then signal additional artificial neurons connected to it. In common ANN implementations, the signal at a connection between artificial neurons is a [real number](/wiki/Real_number "Real number"), and the output of each artificial neuron is computed by some non-linear function of the sum of its inputs. The connections between artificial neurons are called "edges". Artificial neurons and edges typically have a [weight](/wiki/Weight_(mathematics) "Weight (mathematics)") that adjusts as learning proceeds. The weight increases or decreases the strength of the signal at a connection. Artificial neurons may have a threshold such that the signal is only sent if the aggregate signal crosses that threshold. Typically, artificial neurons are aggregated into layers. Different layers may perform different kinds of transformations on their inputs. Signals travel from the first layer (the input layer) to the last layer (the output layer), possibly after traversing the layers multiple times.
The original goal of the ANN approach was to solve problems in the same way that a [human brain](/wiki/Human_brain "Human brain") would. However, over time, attention moved to performing specific tasks, lead | en | ml.md |
ing to deviations from [biology](/wiki/Biology "Biology"). Artificial neural networks have been used on a variety of tasks, including [computer vision](/wiki/Computer_vision "Computer vision"), [speech recognition](/wiki/Speech_recognition "Speech recognition"), [machine translation](/wiki/Machine_translation "Machine translation"), [social network](/wiki/Social_network "Social network") filtering, [playing board and video games](/wiki/General_game_playing "General game playing") and [medical diagnosis](/wiki/Medical_diagnosis "Medical diagnosis").
[Deep learning](/wiki/Deep_learning "Deep learning") consists of multiple hidden layers in an artificial neural network. This approach tries to model the way the human brain processes light and sound into vision and hearing. Some successful applications of deep learning are [computer vision](/wiki/Computer_vision "Computer vision") and [speech recognition](/wiki/Speech_recognition "Speech recognition").[[87]](#cite_note-87)
### Decision trees[[edit](/w/index.php?title=Machine_learning&action=edit§ion=25 "Edit section: Decision trees")]
[](/wiki/File:Decision_Tree.jpg)A decision tree showing survival probability of passengers on the [Titanic](/wiki/Titanic "Titanic")
Decision tree learning uses a [decision tree](/wiki/Decision_tree "Decision tree") as a [predictive model](/wiki/Predictive_modeling "Predictive modeling") to go from observations about an item (represented in the branches) to conclusions about the item's target value (represented in the leaves). It is one of the predictive modeling approaches used in statistics, data mining, and machine learning. Tree models where the target variable can take a discrete set of values are called classification trees; in these tree structures, [leaves](/wiki/Leaf_node "Leaf node") represent class labels, and branches represent [conjunctions](/wiki/Logical_conjunction "Logical conjunction") of features that lead to those class labels. Decision trees where the target variable can take continuous values (typically [real numbers](/wiki/Real_numbers "Real numbers")) are called regression trees. In decision analysis, a decision tree can be used to visually and explicitly represent decisions and [decision making](/wiki/Decision_making "Decision making"). In data mining, a d | en | ml.md |
ecision tree describes data, but the resulting classification tree can be an input for decision-making.
### Support-vector machines[[edit](/w/index.php?title=Machine_learning&action=edit§ion=26 "Edit section: Support-vector machines")]
Support-vector machines (SVMs), also known as support-vector networks, are a set of related [supervised learning](/wiki/Supervised_learning "Supervised learning") methods used for classification and regression. Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that predicts whether a new example falls into one category.[[88]](#cite_note-CorinnaCortes-88) An SVM training algorithm is a non-[probabilistic](/wiki/Probabilistic_classification "Probabilistic classification"), [binary](/wiki/Binary_classifier "Binary classifier"), [linear classifier](/wiki/Linear_classifier "Linear classifier"), although methods such as [Platt scaling](/wiki/Platt_scaling "Platt scaling") exist to use SVM in a probabilistic classification setting. In addition to performing linear classification, SVMs can efficiently perform a non-linear classification using what is called the [kernel trick](/ | en | ml.md |
wiki/Kernel_trick "Kernel trick"), implicitly mapping their inputs into high-dimensional feature spaces.
### Regression analysis[[edit](/w/index.php?title=Machine_learning&action=edit§ion=27 "Edit section: Regression analysis")]
[](/wiki/File:Linear_regression.svg)Illustration of linear regression on a data set
Regression analysis encompasses a large variety of statistical methods to estimate the relationship between input variables and their associated features. Its most common form is [linear regression](/wiki/Linear_regression "Linear regression"), where a single line is drawn to best fit the given data according to a mathematical criterion such as [ordinary least squares](/wiki/Ordinary_least_squares "Ordinary least squares"). The latter is often extended by [regularization](/wiki/Regularization_(mathematics) "Regularization (mathematics)") methods to mitigate overfitting and bias, as in [ridge regression](/wiki/Ridge_regression "Ridge regression"). When dealing with non-linear problems, go-to models include [polynomial regression](/wiki/Polynomial_regression "Pol | en | ml.md |
ynomial regression") (for example, used for trendline fitting in Microsoft Excel[[89]](#cite_note-89)), [logistic regression](/wiki/Logistic_regression "Logistic regression") (often used in [statistical classification](/wiki/Statistical_classification "Statistical classification")) or even [kernel regression](/wiki/Kernel_regression "Kernel regression"), which introduces non-linearity by taking advantage of the [kernel trick](/wiki/Kernel_trick "Kernel trick") to implicitly map input variables to higher-dimensional space.
### Bayesian networks[[edit](/w/index.php?title=Machine_learning&action=edit§ion=28 "Edit section: Bayesian networks")]
[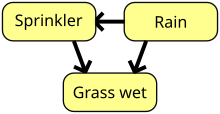](/wiki/File:SimpleBayesNetNodes.svg)A simple Bayesian network. Rain influences whether the sprinkler is activated, and both rain and the sprinkler influence whether the grass is wet.
A Bayesian network, belief network, or directed acyclic graphical model is a probabilistic [graphical model](/wiki/Graphical_model "Graphical model") that represents a set of [random variables](/wiki/Random_variables "Random variables") and their | en | ml.md |
[conditional independence](/wiki/Conditional_independence "Conditional independence") with a [directed acyclic graph](/wiki/Directed_acyclic_graph "Directed acyclic graph") (DAG). For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases. Efficient algorithms exist that perform [inference](/wiki/Bayesian_inference "Bayesian inference") and learning. Bayesian networks that model sequences of variables, like [speech signals](/wiki/Speech_recognition "Speech recognition") or [protein sequences](/wiki/Peptide_sequence "Peptide sequence"), are called [dynamic Bayesian networks](/wiki/Dynamic_Bayesian_network "Dynamic Bayesian network"). Generalizations of Bayesian networks that can represent and solve decision problems under uncertainty are called [influence diagrams](/wiki/Influence_diagram "Influence diagram").
### Gaussian processes[[edit](/w/index.php?title=Machine_learning&action=edit§ion=29 "Edit section: Gaussian processes")]
[](/wiki/File:Regressions_sine_demo.svg)An example of Gaussian Process Regression (prediction) compared with other regression models[[90]](#cite_note-90)
A Gaussian process is a [stochastic process](/wiki/Stochastic_process "Stochastic process") in which every finite collection of the random variables in the process has a [multivariate normal distribution](/wiki/Multivariate_normal_distribution "Multivariate normal distribution"), and it relies on a pre-defined [covariance function](/wiki/Covariance_function "Covariance function"), or kernel, that models how pairs of points relate to each other depending on their locations.
Given a set of observed points, or input-output examples, the distribution of the (unobserved) output of a new point as function of its input data can be directly computed by looking like the observed points and the covariances between those points and the new, unobserved point.
Gaussian processes are popular surrogate models in [Bayesian optimization](/wiki/Bayesian_optimization "Bayesian optimization") used to do [hyperparameter optimization](/wiki/Hyperparameter_optimization "Hyperparameter optimization").
### Genetic algorithms[[ed | en | ml.md |
it](/w/index.php?title=Machine_learning&action=edit§ion=30 "Edit section: Genetic algorithms")]
A genetic algorithm (GA) is a [search algorithm](/wiki/Search_algorithm "Search algorithm") and [heuristic](/wiki/Heuristic_(computer_science) "Heuristic (computer science)") technique that mimics the process of [natural selection](/wiki/Natural_selection "Natural selection"), using methods such as [mutation](/wiki/Mutation_(genetic_algorithm) "Mutation (genetic algorithm)") and [crossover](/wiki/Crossover_(genetic_algorithm) "Crossover (genetic algorithm)") to generate new [genotypes](/wiki/Chromosome_(genetic_algorithm) "Chromosome (genetic algorithm)") in the hope of finding good solutions to a given problem. In machine learning, genetic algorithms were used in the 1980s and 1990s.[[91]](#cite_note-91)[[92]](#cite_note-92) Conversely, machine learning techniques have been used to improve the performance of genetic and [evolutionary algorithms](/wiki/Evolutionary_algorithm "Evolutionary algorithm").[[93]](#cite_note-93)
### Belief functions[[edit](/w/index.php?title=Machine_learning&action=edit§ion=31 "Edit section: Belief functions")]
The theory of belief functions, also re | en | ml.md |
ferred to as evidence theory or Dempster-Shafer theory, is a general framework for reasoning with uncertainty, with understood connections to other frameworks such as [probability](/wiki/Probability "Probability"), [possibility](/wiki/Possibility_theory "Possibility theory") and [imprecise probability theories](/wiki/Imprecise_probability "Imprecise probability"). These theoretical frameworks can be thought of as a kind of learner and have some analogous properties of how evidence is combined (e.g., Dempster's rule of combination), just like how in a [pmf](/wiki/Probability_mass_function "Probability mass function")-based Bayesian approach[*[clarification needed](/wiki/Wikipedia:Please_clarify "Wikipedia:Please clarify")*] would combine probabilities. However, there are many caveats to these beliefs functions when compared to Bayesian approaches in order to incorporate ignorance and [uncertainty quantification](/wiki/Uncertainty_quantification "Uncertainty quantification"). These belief function approaches that are implemented within the machine learning domain typically leverage a fusion approach of various [ensemble methods](/wiki/Ensemble_methods "Ensemble methods") to better ha | en | ml.md |
ndle the learner's [decision boundary](/wiki/Decision_boundary "Decision boundary"), low samples, and ambiguous class issues that standard machine learning approach tend to have difficulty resolving.[[3]](#cite_note-:6-3)[[5]](#cite_note-:7-5)[[10]](#cite_note-:8-10) However, the computational complexity of these algorithms are dependent on the number of propositions (classes), and can lead to a much higher computation time when compared to other machine learning approaches.
### Training models[[edit](/w/index.php?title=Machine_learning&action=edit§ion=32 "Edit section: Training models")]
Typically, machine learning models require a high quantity of reliable data in order for the models to perform accurate predictions. When training a machine learning model, machine learning engineers need to target and collect a large and representative [sample](/wiki/Sample_(statistics) "Sample (statistics)") of data. Data from the training set can be as varied as a [corpus of text](/wiki/Corpus_of_text "Corpus of text"), a collection of images, [sensor](/wiki/Sensor "Sensor") data, and data collected from individual users of a service. [Overfitting](/wiki/Overfitting "Overfitting") is some | en | ml.md |
thing to watch out for when training a machine learning model. Trained models derived from biased or non-evaluated data can result in skewed or undesired predictions. Bias models may result in detrimental outcomes thereby furthering the negative impacts on society or objectives. [Algorithmic bias](/wiki/Algorithmic_bias "Algorithmic bias") is a potential result of data not being fully prepared for training. Machine learning ethics is becoming a field of study and notably be integrated within machine learning engineering teams.
#### Federated learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=33 "Edit section: Federated learning")]
Federated learning is an adapted form of [distributed artificial intelligence](/wiki/Distributed_artificial_intelligence "Distributed artificial intelligence") to training machine learning models that decentralizes the training process, allowing for users' privacy to be maintained by not needing to send their data to a centralized server. This also increases efficiency by decentralizing the training process to many devices. For example, [Gboard](/wiki/Gboard "Gboard") uses federated machine learning to train search query prediction | en | ml.md |
models on users' mobile phones without having to send individual searches back to [Google](/wiki/Google "Google").[[94]](#cite_note-94)
Applications[[edit](/w/index.php?title=Machine_learning&action=edit§ion=34 "Edit section: Applications")]
-------------------------------------------------------------------------------------------------------------
There are many applications for machine learning, including:
In 2006, the media-services provider [Netflix](/wiki/Netflix "Netflix") held the first "[Netflix Prize](/wiki/Netflix_Prize "Netflix Prize")" competition to find a program to better predict user preferences and improve the accuracy of its existing Cinematch movie recommendation algorithm by at least 10%. A joint team made up of researchers from [AT&T Labs](/wiki/AT%26T_Labs "AT&T Labs")-Research in collaboration with the teams Big Chaos and Pragmatic Theory built an [ensemble model](/wiki/Ensemble_Averaging "Ensemble Averaging") to win the Grand Prize in 2009 for $1 million.[[97]](#cite_note-97) Shortly after the prize was awarded, Netflix realized that viewers' ratings were not the best indicators of their viewing patterns ("everything is a recommendation") and they ch | en | ml.md |
anged their recommendation engine accordingly.[[98]](#cite_note-98) In 2010 The Wall Street Journal wrote about the firm Rebellion Research and their use of machine learning to predict the financial crisis.[[99]](#cite_note-99) In 2012, co-founder of [Sun Microsystems](/wiki/Sun_Microsystems "Sun Microsystems"), [Vinod Khosla](/wiki/Vinod_Khosla "Vinod Khosla"), predicted that 80% of medical doctors jobs would be lost in the next two decades to automated machine learning medical diagnostic software.[[100]](#cite_note-100) In 2014, it was reported that a machine learning algorithm had been applied in the field of art history to study fine art paintings and that it may have revealed previously unrecognized influences among artists.[[101]](#cite_note-101) In 2019 [Springer Nature](/wiki/Springer_Nature "Springer Nature") published the first research book created using machine learning.[[102]](#cite_note-102) In 2020, machine learning technology was used to help make diagnoses and aid researchers in developing a cure for COVID-19.[[103]](#cite_note-103) Machine learning was recently applied to predict the pro-environmental behavior of travelers.[[104]](#cite_note-104) Recently, machine | en | ml.md |
learning technology was also applied to optimize smartphone's performance and thermal behavior based on the user's interaction with the phone.[[105]](#cite_note-105)[[106]](#cite_note-106)[[107]](#cite_note-107) When applied correctly, machine learning algorithms (MLAs) can utilize a wide range of company characteristics to predict stock returns without [overfitting](/wiki/Overfitting "Overfitting"). By employing effective feature engineering and combining forecasts, MLAs can generate results that far surpass those obtained from basic linear techniques like [OLS](/wiki/Ordinary_least_squares "Ordinary least squares").[[108]](#cite_note-108)
Recent advancements in machine learning have extended into the field of quantum chemistry, where novel algorithms now enable the prediction of solvent effects on chemical reactions, thereby offering new tools for chemists to tailor experimental conditions for optimal outcomes.[[109]](#cite_note-109)
Machine Learning is becoming a useful tool to investigate and predict evacuation decision making in large scale and small scale disasters. Different solutions have been tested to predict if and when householders decide to evacuate during wildfires | en | ml.md |
and hurricanes.[[110]](#cite_note-110)[[111]](#cite_note-111)[[112]](#cite_note-112) Other applications have been focusing on pre evacuation decisions in building fires.[[113]](#cite_note-113)[[114]](#cite_note-114)
Limitations[[edit](/w/index.php?title=Machine_learning&action=edit§ion=35 "Edit section: Limitations")]
-----------------------------------------------------------------------------------------------------------
Although machine learning has been transformative in some fields, machine-learning programs often fail to deliver expected results.[[115]](#cite_note-115)[[116]](#cite_note-116)[[117]](#cite_note-117) Reasons for this are numerous: lack of (suitable) data, lack of access to the data, data bias, privacy problems, badly chosen tasks and algorithms, wrong tools and people, lack of resources, and evaluation problems.[[118]](#cite_note-118)
The "[black box theory](/wiki/Black_box "Black box")" poses another yet significant challenge. Black box refers to a situation where the algorithm or the process of producing an output is entirely opaque, meaning that even the coders of the algorithm cannot audit the pattern that the machine extracted out of the data.[[119 | en | ml.md |
]](#cite_note-:12-119) The House of Lords Select Committee, which claimed that such an "intelligence system" that could have a "substantial impact on an individual's life" would not be considered acceptable unless it provided "a full and satisfactory explanation for the decisions" it makes.[[119]](#cite_note-:12-119)
In 2018, a self-driving car from [Uber](/wiki/Uber "Uber") failed to detect a pedestrian, who was killed after a collision.[[120]](#cite_note-120) Attempts to use machine learning in healthcare with the [IBM Watson](/wiki/Watson_(computer) "Watson (computer)") system failed to deliver even after years of time and billions of dollars invested.[[121]](#cite_note-121)[[122]](#cite_note-122) Microsoft's [Bing Chat](/wiki/Bing_Chat "Bing Chat") chatbot has been reported to produce hostile and offensive response against its users.[[123]](#cite_note-123)
Machine learning has been used as a strategy to update the evidence related to a systematic review and increased reviewer burden related to the growth of biomedical literature. While it has improved with training sets, it has not yet developed sufficiently to reduce the workload burden without limiting the necessary sensiti | en | ml.md |
vity for the findings research themselves.[[124]](#cite_note-124)
### Bias[[edit](/w/index.php?title=Machine_learning&action=edit§ion=36 "Edit section: Bias")]
Different machine learning approaches can suffer from different data biases. A machine learning system trained specifically on current customers may not be able to predict the needs of new customer groups that are not represented in the training data. When trained on human-made data, machine learning is likely to pick up the constitutional and unconscious biases already present in society.[[125]](#cite_note-:15-125)
Language models learned from data have been shown to contain human-like biases.[[126]](#cite_note-126)[[127]](#cite_note-127) In an experiment carried out by [ProPublica](/wiki/ProPublica "ProPublica"), an [investigative journalism](/wiki/Investigative_journalism "Investigative journalism") organization, a machine learning algorithm's insight into the recidivism rates among prisoners falsely flagged "black defendants high risk twice as often as white defendants."[[128]](#cite_note-:22-128) In 2015, Google Photos would often tag black people as gorillas,[[128]](#cite_note-:22-128) and in 2018, this still wa | en | ml.md |
s not well resolved, but Google reportedly was still using the workaround to remove all gorillas from the training data and thus was not able to recognize real gorillas at all.[[129]](#cite_note-129) Similar issues with recognizing non-white people have been found in many other systems.[[130]](#cite_note-130) In 2016, Microsoft tested [Tay](/wiki/Tay_(chatbot) "Tay (chatbot)"), a [chatbot](/wiki/Chatbot "Chatbot") that learned from Twitter, and it quickly picked up racist and sexist language.[[131]](#cite_note-131)
Because of such challenges, the effective use of machine learning may take longer to be adopted in other domains.[[132]](#cite_note-132) Concern for [fairness](/wiki/Fairness_(machine_learning) "Fairness (machine learning)") in machine learning, that is, reducing bias in machine learning and propelling its use for human good, is increasingly expressed by artificial intelligence scientists, including [Fei-Fei Li](/wiki/Fei-Fei_Li "Fei-Fei Li"), who reminds engineers that "[t]here's nothing artificial about AI. It's inspired by people, it's created by people, and-most importantly-it impacts people. It is a powerful tool we are only just beginning to understand, and that i | en | ml.md |
s a profound responsibility."[[133]](#cite_note-133)
### Explainability[[edit](/w/index.php?title=Machine_learning&action=edit§ion=37 "Edit section: Explainability")]
Explainable AI (XAI), or Interpretable AI, or Explainable Machine Learning (XML), is artificial intelligence (AI) in which humans can understand the decisions or predictions made by the AI.[[134]](#cite_note-134) It contrasts with the "black box" concept in machine learning where even its designers cannot explain why an AI arrived at a specific decision.[[135]](#cite_note-135) By refining the mental models of users of AI-powered systems and dismantling their misconceptions, XAI promises to help users perform more effectively. XAI may be an implementation of the social right to explanation.
### Overfitting[[edit](/w/index.php?title=Machine_learning&action=edit§ion=38 "Edit section: Overfitting")]
[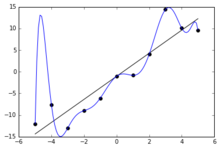](/wiki/File:Overfitted_Data.png)The blue line could be an example of overfitting a linear function due to random noise.
Settling on a bad, overly complex theory gerrymandered to fit all the past training data is | en | ml.md |
known as overfitting. Many systems attempt to reduce overfitting by rewarding a theory in accordance with how well it fits the data but penalizing the theory in accordance with how complex the theory is.
### Other limitations and vulnerabilities[[edit](/w/index.php?title=Machine_learning&action=edit§ion=39 "Edit section: Other limitations and vulnerabilities")]
Learners can also disappoint by "learning the wrong lesson". A toy example is that an image classifier trained only on pictures of brown horses and black cats might conclude that all brown patches are likely to be horses. A real-world example is that, unlike humans, current image classifiers often do not primarily make judgments from the spatial relationship between components of the picture, and they learn relationships between pixels that humans are oblivious to, but that still correlate with images of certain types of real objects. Modifying these patterns on a legitimate image can result in "adversarial" images that the system misclassifies.[[138]](#cite_note-138)[[139]](#cite_note-139)
Adversarial vulnerabilities can also result in nonlinear systems, or from non-pattern perturbations. For some systems, it is poss | en | ml.md |
ible to change the output by only changing a single adversarially chosen pixel.[[140]](#cite_note-TD_1-140) Machine learning models are often vulnerable to manipulation and/or evasion via [adversarial machine learning](/wiki/Adversarial_machine_learning "Adversarial machine learning").[[141]](#cite_note-141)
Researchers have demonstrated how [backdoors](/wiki/Backdoor_(computing) "Backdoor (computing)") can be placed undetectably into classifying (e.g., for categories "spam" and well-visible "not spam" of posts) machine learning models which are often developed and/or trained by third parties. Parties can change the classification of any input, including in cases for which a type of [data/software transparency](/wiki/Algorithmic_transparency "Algorithmic transparency") is provided, possibly including [white-box access](/wiki/White-box_testing "White-box testing").[[142]](#cite_note-142)[[143]](#cite_note-143)[[144]](#cite_note-144)
Model assessments[[edit](/w/index.php?title=Machine_learning&action=edit§ion=40 "Edit section: Model assessments")]
-----------------------------------------------------------------------------------------------------------------------
Classificat | en | ml.md |
ion of machine learning models can be validated by accuracy estimation techniques like the [holdout](/wiki/Test_set "Test set") method, which splits the data in a training and test set (conventionally 2/3 training set and 1/3 test set designation) and evaluates the performance of the training model on the test set. In comparison, the K-fold-[cross-validation](/wiki/Cross-validation_(statistics) "Cross-validation (statistics)") method randomly partitions the data into K subsets and then K experiments are performed each respectively considering 1 subset for evaluation and the remaining K-1 subsets for training the model. In addition to the holdout and cross-validation methods, [bootstrap](/wiki/Bootstrapping_(statistics) "Bootstrapping (statistics)"), which samples n instances with replacement from the dataset, can be used to assess model accuracy.[[145]](#cite_note-145)
In addition to overall accuracy, investigators frequently report [sensitivity and specificity](/wiki/Sensitivity_and_specificity "Sensitivity and specificity") meaning True Positive Rate (TPR) and True Negative Rate (TNR) respectively. Similarly, investigators sometimes report the [false positive rate](/wiki/False_p | en | ml.md |
ositive_rate "False positive rate") (FPR) as well as the [false negative rate](/wiki/False_negative_rate "False negative rate") (FNR). However, these rates are ratios that fail to reveal their numerators and denominators. The [total operating characteristic](/wiki/Total_operating_characteristic "Total operating characteristic") (TOC) is an effective method to express a model's diagnostic ability. TOC shows the numerators and denominators of the previously mentioned rates, thus TOC provides more information than the commonly used [receiver operating characteristic](/wiki/Receiver_operating_characteristic "Receiver operating characteristic") (ROC) and ROC's associated area under the curve (AUC).[[146]](#cite_note-146)
Ethics[[edit](/w/index.php?title=Machine_learning&action=edit§ion=41 "Edit section: Ethics")]
-------------------------------------------------------------------------------------------------
Machine learning poses a host of [ethical questions](/wiki/Machine_ethics "Machine ethics"). Systems that are trained on datasets collected with biases may exhibit these biases upon use ([algorithmic bias](/wiki/Algorithmic_bias "Algorithmic bias")), thus digitizing cultural | en | ml.md |
prejudices.[[147]](#cite_note-147) For example, in 1988, the UK's [Commission for Racial Equality](/wiki/Commission_for_Racial_Equality "Commission for Racial Equality") found that [St. George's Medical School](/wiki/St_George%27s,_University_of_London "St George's, University of London") had been using a computer program trained from data of previous admissions staff and this program had denied nearly 60 candidates who were found to be either women or had non-European sounding names.[[125]](#cite_note-:15-125) Using job hiring data from a firm with racist hiring policies may lead to a machine learning system duplicating the bias by scoring job applicants by similarity to previous successful applicants.[[148]](#cite_note-Edionwe_Outline-148)[[149]](#cite_note-Jeffries_Outline-149) Another example includes predictive policing company [Geolitica](/wiki/Geolitica "Geolitica")'s predictive algorithm that resulted in "disproportionately high levels of over-policing in low-income and minority communities" after being trained with historical crime data.[[128]](#cite_note-:22-128)
While responsible [collection of data](/wiki/Data_collection "Data collection") and documentation of algorith | en | ml.md |
mic rules used by a system is considered a critical part of machine learning, some researchers blame lack of participation and representation of minority population in the field of AI for machine learning's vulnerability to biases.[[150]](#cite_note-150) In fact, according to research carried out by the Computing Research Association (CRA) in 2021, "female faculty merely make up 16.1%" of all faculty members who focus on AI among several universities around the world.[[151]](#cite_note-:32-151) Furthermore, among the group of "new U.S. resident AI PhD graduates," 45% identified as white, 22.4% as Asian, 3.2% as Hispanic, and 2.4% as African American, which further demonstrates a lack of diversity in the field of AI.[[151]](#cite_note-:32-151)
AI can be well-equipped to make decisions in technical fields, which rely heavily on data and historical information. These decisions rely on objectivity and logical reasoning.[[152]](#cite_note-152) Because human languages contain biases, machines trained on language *[corpora](/wiki/Text_corpus "Text corpus")* will necessarily also learn these biases.[[153]](#cite_note-153)[[154]](#cite_note-154)
Other forms of ethical challenges, not rela | en | ml.md |
ted to personal biases, are seen in health care. There are concerns among health care professionals that these systems might not be designed in the public's interest but as income-generating machines.[[155]](#cite_note-155) This is especially true in the United States where there is a long-standing ethical dilemma of improving health care, but also increasing profits. For example, the algorithms could be designed to provide patients with unnecessary tests or medication in which the algorithm's proprietary owners hold stakes. There is potential for machine learning in health care to provide professionals an additional tool to diagnose, medicate, and plan recovery paths for patients, but this requires these biases to be mitigated.[[156]](#cite_note-156)
Hardware[[edit](/w/index.php?title=Machine_learning&action=edit§ion=42 "Edit section: Hardware")]
-----------------------------------------------------------------------------------------------------
Since the 2010s, advances in both machine learning algorithms and computer hardware have led to more efficient methods for training [deep neural networks](/wiki/Deep_neural_network "Deep neural network") (a particular narrow subdoma | en | ml.md |
in of machine learning) that contain many layers of non-linear hidden units.[[157]](#cite_note-157) By 2019, graphic processing units ([GPUs](/wiki/GPU "GPU")), often with AI-specific enhancements, had displaced CPUs as the dominant method of training large-scale commercial cloud AI.[[158]](#cite_note-158) [OpenAI](/wiki/OpenAI "OpenAI") estimated the hardware computing used in the largest deep learning projects from AlexNet (2012) to AlphaZero (2017), and found a 300,000-fold increase in the amount of compute required, with a doubling-time trendline of 3.4 months.[[159]](#cite_note-159)[[160]](#cite_note-160)
### Neuromorphic/Physical Neural Networks[[edit](/w/index.php?title=Machine_learning&action=edit§ion=43 "Edit section: Neuromorphic/Physical Neural Networks")]
A [physical neural network](/wiki/Physical_neural_network "Physical neural network") or [Neuromorphic computer](/wiki/Neuromorphic_engineering "Neuromorphic engineering") is a type of [artificial neural network](/wiki/Artificial_neural_network "Artificial neural network") in which an electrically adjustable material is used to emulate the function of a [neural synapse](/wiki/Chemical_synapse "Chemical synapse"). | en | ml.md |
"Physical" neural network is used to emphasize the reliance on physical hardware used to emulate [neurons](/wiki/Neurons "Neurons") as opposed to software-based approaches. More generally the term is applicable to other artificial neural networks in which a [memristor](/wiki/Memristor "Memristor") or other electrically adjustable resistance material is used to emulate a neural synapse.[[161]](#cite_note-161)[[162]](#cite_note-162)
### Embedded Machine Learning[[edit](/w/index.php?title=Machine_learning&action=edit§ion=44 "Edit section: Embedded Machine Learning")]
**Embedded Machine Learning** is a sub-field of machine learning, where the machine learning model is run on [embedded systems](/wiki/Embedded_systems "Embedded systems") with limited computing resources such as [wearable computers](/wiki/Wearable_computer "Wearable computer"), [edge devices](/wiki/Edge_device "Edge device") and [microcontrollers](/wiki/Microcontrollers "Microcontrollers").[[163]](#cite_note-163)[[164]](#cite_note-164)[[165]](#cite_note-165) Running machine learning model in embedded devices removes the need for transferring and storing data on cloud servers for further processing, henceforth, reduc | en | ml.md |
ing data breaches and privacy leaks happening because of transferring data, and also minimizes theft of intellectual properties, personal data and business secrets. Embedded Machine Learning could be applied through several techniques including [hardware acceleration](/wiki/Hardware_acceleration "Hardware acceleration"),[[166]](#cite_note-166)[[167]](#cite_note-167) using [approximate computing](/wiki/Approximate_computing "Approximate computing"),[[168]](#cite_note-168) optimization of machine learning models and many more.[[169]](#cite_note-169)[[170]](#cite_note-170) [Pruning](/wiki/Pruning_(artificial_neural_network) "Pruning (artificial neural network)"), [Quantization](/w/index.php?title=Quantization_(Embedded_Machine_Learning)&action=edit&redlink=1 "Quantization (Embedded Machine Learning) (page does not exist)"), [Knowledge Distillation](/wiki/Knowledge_distillation "Knowledge distillation"), Low-Rank Factorization, Network Architecture Search (NAS) & Parameter Sharing are few of the techniques used for optimization of machine learning models.
Software[[edit](/w/index.php?title=Machine_learning&action=edit§ion=45 "Edit section: Software")]
----------------------------- | en | ml.md |
------------------------------------------------------------------------
[Software suites](/wiki/Software_suite "Software suite") containing a variety of machine learning algorithms include the following:
### Free and open-source software[[edit](/w/index.php?title=Machine_learning&action=edit§ion=46 "Edit section: Free and open-source software")]
### Proprietary software with free and open-source editions[[edit](/w/index.php?title=Machine_learning&action=edit§ion=47 "Edit section: Proprietary software with free and open-source editions")]
### Proprietary software[[edit](/w/index.php?title=Machine_learning&action=edit§ion=48 "Edit section: Proprietary software")]
Journals[[edit](/w/index.php?title=Machine_learning&action=edit§ion=49 "Edit section: Journals")]
-----------------------------------------------------------------------------------------------------
Conferences[[edit](/w/index.php?title=Machine_learning&action=edit§ion=50 "Edit section: Conferences")]
-----------------------------------------------------------------------------------------------------------
See also[[edit](/w/index.php?title=Machine_learning&action=edit§ion=51 "Edit section: | en | ml.md |
See also")]
-----------------------------------------------------------------------------------------------------
References[[edit](/w/index.php?title=Machine_learning&action=edit§ion=52 "Edit section: References")]
---------------------------------------------------------------------------------------------------------
Sources[[edit](/w/index.php?title=Machine_learning&action=edit§ion=53 "Edit section: Sources")]
---------------------------------------------------------------------------------------------------
Further reading[[edit](/w/index.php?title=Machine_learning&action=edit§ion=54 "Edit section: Further reading")]
------------------------------------------------------------------------------------------------------------------- | en | ml.md |
comment un marché concurrentiel fonctionne-t-il ?
Objectifs d'apprentissage
Savoir que le marché est une institution et savoir distinguer les marchés selon leur degré de concurrence (de la concurrence parfaite au monopole).
Savoir interpréter des courbes d'offre et de demande ainsi que leurs pentes, et comprendre comment leur confrontation détermine l'équilibre sur un marché de type concurrentiel où les agents sont preneurs de prix.
Savoir illustrer et interpréter les déplacements des courbes et sur les courbes, par différents exemples chiffrés, notamment celui de la mise en uvre d'une taxe forfaitaire.
Savoir déduire la courbe d'offre de la maximisation du profit par le producteur et comprendre qu'en situation de coût marginal croissant, le producteur produit la quantité qui permet d'égaliser le coût marginal et le prix ; savoir l'illustrer par des exemples.
Comprendre les notions de surplus du producteur et du consommateur.
Problématique d'ensemble
Retrouvez éduscol sur :
Les élèves en classe de seconde ont déjà étudié les différents acteurs du marché (vendeurs et acheteurs) et la formation des prix sur un marché à partir d'un modèle simple en retenant l'hypothèse que la | fr | économie_français.md |
demande est une fonction décroissante du prix et que l'offre est une fonction croissante du prix. Ils auront également compris les effets sur l'équilibre de la mise en place d'une taxe.
Ce premier questionnement de science économique de la classe de première a pour objectif d'approfondir cette compréhension des mécanismes de marché par l'appropriation, par les élèves, de la construction des courbes d'offre et demande, l'interprétation de leur pente et de leur déplacement et l'étude de l'objectif de maximisation des profits par les offreurs.
Il permet aussi d'explorer plus précisément les mécanismes qui permettent la réalisation d'une situation d'équilibre et sa signification à travers l'introduction des notions de surplus et de gains à l'échange.
Savoirs scientifiques de référence
[Cette partie est dédiée aux savoirs scientifiques ; il ne s'agit pas d'un cours à destination des élèves qui devrait contenir davantage d'illustrations concrètes (voir les ressources et activités pédagogiques)]
L'existence d'offreurs et de demandeurs ne suffit pas à l'existence d'un marché. Pour son fonctionnement, le marché a besoin de règles et d'institutions (droits de propriété, normes d'hygièn | fr | économie_français.md |
e et de sécurité, la monnaie etc..) qui s'imposent aux acteurs et constituent le cadre des transactions marchandes. Le marché a besoin d'institutions pour fonctionner et il est lui-même une institution dans la mesure où il organise une grande partie des échanges.
Les marchés se distinguent aussi par leur degré de concurrence mesuré essentiellement par le nombre d'offreurs. Le modèle de base de la théorie économique est celui de la concurrence parfaite sur lequel on a un très grand nombre d'offreurs et de demandeurs de produits identiques. À l'opposé, on trouve le monopole, marché sur lequel l'offreur est unique. Entre ces deux situations, sur les marchés oligopolistiques les offreurs sont en nombre limité.
La demande décroît avec le prix, elle est donc représentée par une courbe décroissante ; la pente est alors négative. Plus la pente est forte, moins le consommateur modifiera la quantité demandée suite à une variation du prix ; c'est le cas par exemple des produits de première nécessité. Plus la pente est faible, plus le consommateur modifiera la quantité demandée suite à une variation du prix ; c'est par exemple le cas des produits qui peuvent être substitués par d'autres prod | fr | économie_français.md |
uits).
Demande à pente négative forte
Demande à pente négative plus faible
Retrouvez éduscol sur :
L'offre croît avec le prix, elle est donc représentée par une courbe croissante ; la pente est alors positive. Plus la pente est forte, moins l'offreur modifiera la quantité offerte suite à la variation du prix ; c'est par exemple le cas lorsqu'il est difficile de se procurer rapidement des facteurs de production. Plus la pente est faible, plus l'offreur modifiera la quantité offerte suite à la variation du prix.
Une offre à pente positive forte
Une offre à pente positive plus faible
Sur un marché concurrentiel, les agents, aussi bien les vendeurs que les acheteurs, sont très nombreux et aucun, à lui seul, n'a le pouvoir de faire varier le prix du marché : ils sont preneurs de prix. Le prix d'équilibre sur un marché concurrentiel est alors le résultat de la confrontation entre l'offre et la demande. Sur une représentation graphique, cela correspond au point d'intersection entre la courbe de demande et la courbe d'offre.
Retrouvez éduscol sur :
Un déplacement sur les courbes d'offre ou de demande est dû à une variation du prix. Lorsque les déterminants de l'offre et de la dema | fr | économie_français.md |
nde, autres que le prix, varient ce sont les courbes qui se déplacent (car les fonctions d'offre et/ou de demande sont modifiées).
Ainsi, lorsqu'un des déterminants de l'offre autre que le prix (par exemple les coûts de production ou la fiscalité) varie, la courbe d'offre se déplace.
Selon le même principe, lorsqu'un des déterminants de la demande autre que le prix (par exemple, les goûts ou le revenu) varie, la courbe de demande se déplace.
La mise en place d'une taxe forfaitaire entraîne une modification du comportement de l'agent sur lequel elle porte : soit le prix payé par l'acheteur va augmenter, soit les coûts de production du producteur vont augmenter. Cela se traduit par le déplacement des courbes d'offre ou de demande.
Si la taxe est instaurée pour le producteur, l'acheteur ne modifie par son comportement. En revanche, l'offreur va diminuer la quantité offerte pour chaque prix donc la courbe va se déplacer vers la gauche (pour chaque prix, on offre moins de biens en raison du coût supplémentaire que représente la taxe) ou vers le haut (l'offreur va offrir la même quantité à la condition que le prix augmente). L'équilibre est alors modifié : les quantités échangées dim | fr | économie_français.md |
inuent et le prix augmente. Mais le prix payé n'est pas le prix reçu par le producteur. La différence constitue la taxe perçue et reversée.
Retrouvez éduscol sur :
Si la taxe est instaurée pour l'acheteur, la droite de demande se déplace vers la gauche (l'acheteur va acheter moins pour chaque niveau de prix) ou vers le bas (l'acheteur achète la même quantité si le prix exigé par l'offreur baisse pour compenser la taxe). L'impact sur l'équilibre est alors le suivant : les quantités échangées diminuent et le prix diminue. Ici aussi, si la taxe est payée par l'acheteur, elle est supportée par les deux lorsqu'on compare par rapport à l'équilibre.
Instauration d'une taxe sur l'acheteur
Modification de l'équilibre
Retrouvez éduscol sur :
Le producteur choisit le volume de production qui lui permet de maximiser son profit. Il s'agit de tenir compte de ses coûts et de sa recette.
Le coût total est constitué des coûts fixes et des coûts variables. Les premiers sont constants et s'imposent à l'entreprise quel que soit le niveau de production ; les seconds dépendent du volume de la production. Quand la production s'accroît, le coût total s'accroît en général d'abord moins rapidement pu | fr | économie_français.md |
is s'accroît de plus en plus rapidement au-delà d'un point d'inflexion ; le coût marginal (coût supplémentaire induit par la dernière unité produite) est croissant à partir de ce point.
En raisonnant dans le cadre d'un marché concurrentiel, sur lequel l'entreprise est preneuse de prix, la recette marginale (recette induite par la vente d'une unité supplémentaire) correspond au prix du marché et est constante puisque le producteur ne peut à lui seul agir sur le prix. La recette totale quant à elle correspond au prix de vente multiplié par le nombre d'unités produites.
Le profit total est égal à la différence entre recette totale et coût total. Pour maximiser son profit, l'entreprise doit produire une quantité telle que sa recette marginale soit égale à son coût marginal, autrement dit elle a intérêt à augmenter sa production tant que le coût marginal est inférieur à la recette marginale.
Comme le producteur produit la quantité qui égalise le coût marginal et le prix, la courbe d'offre correspond à la courbe de coût marginal puisque, pour chaque niveau de prix donné par le marché, la courbe de coût marginal permet de déterminer les quantités qui seront produites et offertes. La co | fr | économie_français.md |
urbe d'offre est donc croissante comme l'est, à partir d'un certain point, la courbe de coût marginal.
Graphiquement :
De la courbe de coût marginal.. (coût marginal en fonction de la quantité)
à la courbe d'offre (quantité produite et offerte en fonction du prix)
Comprendre les notions de surplus du producteur et du consommateur.
Les demandeurs (acheteurs) achètent tant que l'utilité qu'ils retirent de l'acquisition du bien est supérieure au coût de cette acquisition. Or l'utilité peut être approchée par le prix maximum qu'un acheteur est prêt à payer pour se procurer ce bien ou ce service alors que le coût d'acquisition correspond au prix d'équilibre effectivement payé par le demandeur. L'écart entre les deux représente donc la satisfaction qu'ils retirent de leur participation au marché : c'est ce que l'économiste nomme le surplus du consommateur.
On le représente graphiquement par la surface délimitée par la courbe de demande, au-dessus du prix du marché :
Inversement, les offreurs qui auraient proposé des prix plus faibles que le prix d'équilibre se retrouvent avec un surplus qui est égal à la différence entre le prix auquel ils étaient prêts à vendre le produit et le p | fr | économie_français.md |
rix du marché.
Retrouvez éduscol sur :
On le représente graphiquement par la surface délimitée par la courbe d'offre, en dessous du prix du marché :
Les gains à l'échange correspondent aux avantages que l'échange procure aux demandeurs et aux offreurs. Ces gains à l'échange correspondent à la somme du surplus des consommateurs et du surplus des producteurs.
Graphiquement :
À l'équilibre, les gains à l'échange sont maximums. Ainsi, si le prix est supérieur au prix d'équilibre, la quantité échangée est plus faible ; cela entraîne une baisse du surplus total (la baisse du surplus du consommateur n'est que partiellement compensée par la hausse du surplus du producteur). De même, si le prix est inférieur au prix d'équilibre, la quantité échangée est aussi plus faible et une partie du surplus total est perdue (l'augmentation du surplus du consommateur ne compense pas la baisse de celui du producteur). Lorsque le prix et la quantité ne sont pas à l'équilibre, le surplus total est donc plus faible qu'en situation d'équilibre.
Ressources et activités pédagogiques
Activité pédagogique 1
Qu'est-ce qu'un marché ?
Finalité : Introduire la notion de marché
Ressources préconisées :
La | fr | économie_français.md |