
status
stringclasses 1
value | repo_name
stringclasses 31
values | repo_url
stringclasses 31
values | issue_id
int64 1
104k
| title
stringlengths 4
233
| body
stringlengths 0
186k
⌀ | issue_url
stringlengths 38
56
| pull_url
stringlengths 37
54
| before_fix_sha
stringlengths 40
40
| after_fix_sha
stringlengths 40
40
| report_datetime
unknown | language
stringclasses 5
values | commit_datetime
unknown | updated_file
stringlengths 7
188
| chunk_content
stringlengths 1
1.03M
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Apple"
data[1].metadata["company"]="Miscrosoft"
data[2].metadata["company"]="Tesla"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
metadatas = []
for text in texts:
metadatas.append({
"company": text.metadata["company"]
})
Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name, metadatas=metadatas)
```
I want to build a Q&A system, so that I will mention a company name in my query and pinecon should look for the documents having company `A` in the metadata. Here what I have:
```
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
index_name = "index"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pinecone.from_existing_index(index_name=index_name, embedding=embeddings)
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the total revenue of Apple?"
docs = docsearch.similarity_search(query, include_metadata=True)
res = chain.run(input_documents=docs, question=query)
print(res)
```
However, there are still document chunks from non-Apple documents in the output of `docs`. What am I doing wrong here and how do I utilize the information in metadata both on doc_search and chat-gpt query (If possible)? Thanks | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | "2023-03-21T01:32:20Z" | python | "2023-03-27T22:04:53Z" | langchain/vectorstores/chroma.py | self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Run similarity search with Chroma.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Document]: List of documents most simmilar to the query text.
"""
docs_and_scores = self.similarity_search_with_score(query, k, where=filter)
return [doc for doc, _ in docs_and_scores]
def similarity_search_by_vector( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Apple"
data[1].metadata["company"]="Miscrosoft"
data[2].metadata["company"]="Tesla"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
metadatas = []
for text in texts:
metadatas.append({
"company": text.metadata["company"]
})
Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name, metadatas=metadatas)
```
I want to build a Q&A system, so that I will mention a company name in my query and pinecon should look for the documents having company `A` in the metadata. Here what I have:
```
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
index_name = "index"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pinecone.from_existing_index(index_name=index_name, embedding=embeddings)
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the total revenue of Apple?"
docs = docsearch.similarity_search(query, include_metadata=True)
res = chain.run(input_documents=docs, question=query)
print(res)
```
However, there are still document chunks from non-Apple documents in the output of `docs`. What am I doing wrong here and how do I utilize the information in metadata both on doc_search and chat-gpt query (If possible)? Thanks | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | "2023-03-21T01:32:20Z" | python | "2023-03-27T22:04:53Z" | langchain/vectorstores/chroma.py | self,
embedding: List[float],
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs most similar to embedding vector.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query vector.
"""
results = self._collection.query(
query_embeddings=embedding, n_results=k, where=filter
)
return _results_to_docs(results)
def similarity_search_with_score( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Apple"
data[1].metadata["company"]="Miscrosoft"
data[2].metadata["company"]="Tesla"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
metadatas = []
for text in texts:
metadatas.append({
"company": text.metadata["company"]
})
Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name, metadatas=metadatas)
```
I want to build a Q&A system, so that I will mention a company name in my query and pinecon should look for the documents having company `A` in the metadata. Here what I have:
```
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
index_name = "index"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pinecone.from_existing_index(index_name=index_name, embedding=embeddings)
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the total revenue of Apple?"
docs = docsearch.similarity_search(query, include_metadata=True)
res = chain.run(input_documents=docs, question=query)
print(res)
```
However, there are still document chunks from non-Apple documents in the output of `docs`. What am I doing wrong here and how do I utilize the information in metadata both on doc_search and chat-gpt query (If possible)? Thanks | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | "2023-03-21T01:32:20Z" | python | "2023-03-27T22:04:53Z" | langchain/vectorstores/chroma.py | self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Tuple[Document, float]]:
"""Run similarity search with Chroma with distance.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Tuple[Document, float]]: List of documents most similar to the query
text with distance in float.
"""
if self._embedding_function is None:
results = self._collection.query(
query_texts=[query], n_results=k, where=filter
)
else:
query_embedding = self._embedding_function.embed_query(query)
results = self._collection.query(
query_embeddings=[query_embedding], n_results=k, where=filter
)
return _results_to_docs_and_scores(results)
def delete_collection(self) -> None: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Apple"
data[1].metadata["company"]="Miscrosoft"
data[2].metadata["company"]="Tesla"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
metadatas = []
for text in texts:
metadatas.append({
"company": text.metadata["company"]
})
Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name, metadatas=metadatas)
```
I want to build a Q&A system, so that I will mention a company name in my query and pinecon should look for the documents having company `A` in the metadata. Here what I have:
```
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
index_name = "index"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pinecone.from_existing_index(index_name=index_name, embedding=embeddings)
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the total revenue of Apple?"
docs = docsearch.similarity_search(query, include_metadata=True)
res = chain.run(input_documents=docs, question=query)
print(res)
```
However, there are still document chunks from non-Apple documents in the output of `docs`. What am I doing wrong here and how do I utilize the information in metadata both on doc_search and chat-gpt query (If possible)? Thanks | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | "2023-03-21T01:32:20Z" | python | "2023-03-27T22:04:53Z" | langchain/vectorstores/chroma.py | """Delete the collection."""
self._client.delete_collection(self._collection.name)
def persist(self) -> None:
"""Persist the collection.
This can be used to explicitly persist the data to disk.
It will also be called automatically when the object is destroyed.
"""
if self._persist_directory is None:
raise ValueError(
"You must specify a persist_directory on"
"creation to persist the collection."
)
self._client.persist()
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Optional[Embeddings] = None,
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None, |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Apple"
data[1].metadata["company"]="Miscrosoft"
data[2].metadata["company"]="Tesla"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
metadatas = []
for text in texts:
metadatas.append({
"company": text.metadata["company"]
})
Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name, metadatas=metadatas)
```
I want to build a Q&A system, so that I will mention a company name in my query and pinecon should look for the documents having company `A` in the metadata. Here what I have:
```
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
index_name = "index"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pinecone.from_existing_index(index_name=index_name, embedding=embeddings)
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the total revenue of Apple?"
docs = docsearch.similarity_search(query, include_metadata=True)
res = chain.run(input_documents=docs, question=query)
print(res)
```
However, there are still document chunks from non-Apple documents in the output of `docs`. What am I doing wrong here and how do I utilize the information in metadata both on doc_search and chat-gpt query (If possible)? Thanks | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | "2023-03-21T01:32:20Z" | python | "2023-03-27T22:04:53Z" | langchain/vectorstores/chroma.py | **kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a raw documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
texts (List[str]): List of texts to add to the collection.
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
metadatas (Optional[List[dict]]): List of metadatas. Defaults to None.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
chroma_collection = cls(
collection_name=collection_name,
embedding_function=embedding,
persist_directory=persist_directory,
client_settings=client_settings,
)
chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
return chroma_collection
@classmethod
def from_documents(
cls,
documents: List[Document],
embedding: Optional[Embeddings] = None,
ids: Optional[List[str]] = None, |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Apple"
data[1].metadata["company"]="Miscrosoft"
data[2].metadata["company"]="Tesla"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
metadatas = []
for text in texts:
metadatas.append({
"company": text.metadata["company"]
})
Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name, metadatas=metadatas)
```
I want to build a Q&A system, so that I will mention a company name in my query and pinecon should look for the documents having company `A` in the metadata. Here what I have:
```
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
index_name = "index"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pinecone.from_existing_index(index_name=index_name, embedding=embeddings)
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the total revenue of Apple?"
docs = docsearch.similarity_search(query, include_metadata=True)
res = chain.run(input_documents=docs, question=query)
print(res)
```
However, there are still document chunks from non-Apple documents in the output of `docs`. What am I doing wrong here and how do I utilize the information in metadata both on doc_search and chat-gpt query (If possible)? Thanks | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | "2023-03-21T01:32:20Z" | python | "2023-03-27T22:04:53Z" | langchain/vectorstores/chroma.py | collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
**kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a list of documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
documents (List[Document]): List of documents to add to the vectorstore.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
texts = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
return cls.from_texts(
texts=texts,
embedding=embedding,
metadatas=metadatas,
ids=ids,
collection_name=collection_name,
persist_directory=persist_directory,
client_settings=client_settings,
) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b65/langchain/chains/qa_with_sources/base.py#L119-L120
it appears, the parsing rule might be too strict for extract the list of sources. Often, when the agent is fetching information from the vectorstore, the `VectorStoreQAWithSourcesTool` output is something like `....SOURCES:\n<source1>\n<source2>...` instead of `...SOURCES: <source1>,<source2>...`.
Due to this, the `VectorStoreQAWithSourcesTool` output is broken and the agent response is impacted.
P.S. I used `Chroma` as the vectorstore db and `OpenAI(temperature=0)` as the LLM. | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | "2023-03-16T15:47:53Z" | python | "2023-03-28T22:28:20Z" | langchain/chains/qa_with_sources/base.py | """Question answering with sources over documents."""
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, Extra, root_validator
from langchain.chains.base import Chain
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
from langchain.chains.combine_documents.map_reduce import MapReduceDocumentsChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.chains.qa_with_sources.loading import load_qa_with_sources_chain
from langchain.chains.qa_with_sources.map_reduce_prompt import (
COMBINE_PROMPT,
EXAMPLE_PROMPT,
QUESTION_PROMPT,
)
from langchain.docstore.document import Document
from langchain.prompts.base import BasePromptTemplate
from langchain.schema import BaseLanguageModel
class BaseQAWithSourcesChain(Chain, BaseModel, ABC): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b65/langchain/chains/qa_with_sources/base.py#L119-L120
it appears, the parsing rule might be too strict for extract the list of sources. Often, when the agent is fetching information from the vectorstore, the `VectorStoreQAWithSourcesTool` output is something like `....SOURCES:\n<source1>\n<source2>...` instead of `...SOURCES: <source1>,<source2>...`.
Due to this, the `VectorStoreQAWithSourcesTool` output is broken and the agent response is impacted.
P.S. I used `Chroma` as the vectorstore db and `OpenAI(temperature=0)` as the LLM. | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | "2023-03-16T15:47:53Z" | python | "2023-03-28T22:28:20Z" | langchain/chains/qa_with_sources/base.py | """Question answering with sources over documents."""
combine_documents_chain: BaseCombineDocumentsChain
"""Chain to use to combine documents."""
question_key: str = "question"
input_docs_key: str = "docs"
answer_key: str = "answer"
sources_answer_key: str = "sources"
return_source_documents: bool = False
"""Return the source documents."""
@classmethod
def from_llm( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b65/langchain/chains/qa_with_sources/base.py#L119-L120
it appears, the parsing rule might be too strict for extract the list of sources. Often, when the agent is fetching information from the vectorstore, the `VectorStoreQAWithSourcesTool` output is something like `....SOURCES:\n<source1>\n<source2>...` instead of `...SOURCES: <source1>,<source2>...`.
Due to this, the `VectorStoreQAWithSourcesTool` output is broken and the agent response is impacted.
P.S. I used `Chroma` as the vectorstore db and `OpenAI(temperature=0)` as the LLM. | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | "2023-03-16T15:47:53Z" | python | "2023-03-28T22:28:20Z" | langchain/chains/qa_with_sources/base.py | cls,
llm: BaseLanguageModel,
document_prompt: BasePromptTemplate = EXAMPLE_PROMPT,
question_prompt: BasePromptTemplate = QUESTION_PROMPT,
combine_prompt: BasePromptTemplate = COMBINE_PROMPT,
**kwargs: Any,
) -> BaseQAWithSourcesChain:
"""Construct the chain from an LLM."""
llm_question_chain = LLMChain(llm=llm, prompt=question_prompt)
llm_combine_chain = LLMChain(llm=llm, prompt=combine_prompt)
combine_results_chain = StuffDocumentsChain(
llm_chain=llm_combine_chain,
document_prompt=document_prompt,
document_variable_name="summaries",
)
combine_document_chain = MapReduceDocumentsChain(
llm_chain=llm_question_chain,
combine_document_chain=combine_results_chain,
document_variable_name="context",
)
return cls(
combine_documents_chain=combine_document_chain,
**kwargs,
)
@classmethod
def from_chain_type( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b65/langchain/chains/qa_with_sources/base.py#L119-L120
it appears, the parsing rule might be too strict for extract the list of sources. Often, when the agent is fetching information from the vectorstore, the `VectorStoreQAWithSourcesTool` output is something like `....SOURCES:\n<source1>\n<source2>...` instead of `...SOURCES: <source1>,<source2>...`.
Due to this, the `VectorStoreQAWithSourcesTool` output is broken and the agent response is impacted.
P.S. I used `Chroma` as the vectorstore db and `OpenAI(temperature=0)` as the LLM. | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | "2023-03-16T15:47:53Z" | python | "2023-03-28T22:28:20Z" | langchain/chains/qa_with_sources/base.py | cls,
llm: BaseLanguageModel,
chain_type: str = "stuff",
chain_type_kwargs: Optional[dict] = None,
**kwargs: Any,
) -> BaseQAWithSourcesChain:
"""Load chain from chain type."""
_chain_kwargs = chain_type_kwargs or {}
combine_document_chain = load_qa_with_sources_chain(
llm, chain_type=chain_type, **_chain_kwargs
)
return cls(combine_documents_chain=combine_document_chain, **kwargs)
class Config: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b65/langchain/chains/qa_with_sources/base.py#L119-L120
it appears, the parsing rule might be too strict for extract the list of sources. Often, when the agent is fetching information from the vectorstore, the `VectorStoreQAWithSourcesTool` output is something like `....SOURCES:\n<source1>\n<source2>...` instead of `...SOURCES: <source1>,<source2>...`.
Due to this, the `VectorStoreQAWithSourcesTool` output is broken and the agent response is impacted.
P.S. I used `Chroma` as the vectorstore db and `OpenAI(temperature=0)` as the LLM. | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | "2023-03-16T15:47:53Z" | python | "2023-03-28T22:28:20Z" | langchain/chains/qa_with_sources/base.py | """Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.question_key]
@property
def output_keys(self) -> List[str]:
"""Return output key.
:meta private:
"""
_output_keys = [self.answer_key, self.sources_answer_key]
if self.return_source_documents:
_output_keys = _output_keys + ["source_documents"]
return _output_keys
@root_validator(pre=True)
def validate_naming(cls, values: Dict) -> Dict:
"""Fix backwards compatability in naming."""
if "combine_document_chain" in values:
values["combine_documents_chain"] = values.pop("combine_document_chain")
return values
@abstractmethod
def _get_docs(self, inputs: Dict[str, Any]) -> List[Document]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b65/langchain/chains/qa_with_sources/base.py#L119-L120
it appears, the parsing rule might be too strict for extract the list of sources. Often, when the agent is fetching information from the vectorstore, the `VectorStoreQAWithSourcesTool` output is something like `....SOURCES:\n<source1>\n<source2>...` instead of `...SOURCES: <source1>,<source2>...`.
Due to this, the `VectorStoreQAWithSourcesTool` output is broken and the agent response is impacted.
P.S. I used `Chroma` as the vectorstore db and `OpenAI(temperature=0)` as the LLM. | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | "2023-03-16T15:47:53Z" | python | "2023-03-28T22:28:20Z" | langchain/chains/qa_with_sources/base.py | """Get docs to run questioning over."""
def _call(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
docs = self._get_docs(inputs)
answer, _ = self.combine_documents_chain.combine_docs(docs, **inputs)
if "SOURCES: " in answer:
answer, sources = answer.split("SOURCES: ")
else:
sources = ""
result: Dict[str, Any] = {
self.answer_key: answer,
self.sources_answer_key: sources,
}
if self.return_source_documents:
result["source_documents"] = docs
return result
class QAWithSourcesChain(BaseQAWithSourcesChain, BaseModel):
"""Question answering with sources over documents."""
input_docs_key: str = "docs"
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.input_docs_key, self.question_key]
def _get_docs(self, inputs: Dict[str, Any]) -> List[Document]:
return inputs.pop(self.input_docs_key)
@property
def _chain_type(self) -> str:
return "qa_with_sources_chain" |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,834 | LLMMathChain to allow ChatOpenAI as an llm | 1. Cannot initialize match chain with ChatOpenAI LLM
llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In[33], line 1
----> 1 llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
File ~/anaconda3/envs/gpt_index/lib/python3.8/site-packages/pydantic/main.py:341, in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for LLMMathChain
llm
Can't instantiate abstract class BaseLLM with abstract methods _agenerate, _generate, _llm_type (type=type_error)
2. Works ok with OpenAI LLM
llm_math = LLMMathChain(llm=OpenAI(temperature=0))
| https://github.com/langchain-ai/langchain/issues/1834 | https://github.com/langchain-ai/langchain/pull/2183 | 3207a7482915a658cf8f473ae0a81ba9998c8531 | fd1fcb5a7d48cbe18b480b1493b66540e4709745 | "2023-03-20T23:12:24Z" | python | "2023-03-30T14:52:58Z" | langchain/chains/llm_math/base.py | """Chain that interprets a prompt and executes python code to do math."""
from typing import Dict, List
from pydantic import BaseModel, Extra
from langchain.chains.base import Chain
from langchain.chains.llm import LLMChain
from langchain.chains.llm_math.prompt import PROMPT
from langchain.llms.base import BaseLLM
from langchain.prompts.base import BasePromptTemplate
from langchain.python import PythonREPL
class LLMMathChain(Chain, BaseModel):
"""Chain that interprets a prompt and executes python code to do math.
Example:
.. code-block:: python
from langchain import LLMMathChain, OpenAI
llm_math = LLMMathChain(llm=OpenAI())
"""
llm: BaseLLM
"""LLM wrapper to use."""
prompt: BasePromptTemplate = PROMPT
"""Prompt to use to translate to python if neccessary."""
input_key: str = "question"
output_key: str = "answer"
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def input_keys(self) -> List[str]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,834 | LLMMathChain to allow ChatOpenAI as an llm | 1. Cannot initialize match chain with ChatOpenAI LLM
llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In[33], line 1
----> 1 llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
File ~/anaconda3/envs/gpt_index/lib/python3.8/site-packages/pydantic/main.py:341, in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for LLMMathChain
llm
Can't instantiate abstract class BaseLLM with abstract methods _agenerate, _generate, _llm_type (type=type_error)
2. Works ok with OpenAI LLM
llm_math = LLMMathChain(llm=OpenAI(temperature=0))
| https://github.com/langchain-ai/langchain/issues/1834 | https://github.com/langchain-ai/langchain/pull/2183 | 3207a7482915a658cf8f473ae0a81ba9998c8531 | fd1fcb5a7d48cbe18b480b1493b66540e4709745 | "2023-03-20T23:12:24Z" | python | "2023-03-30T14:52:58Z" | langchain/chains/llm_math/base.py | """Expect input key.
:meta private:
"""
return [self.input_key]
@property
def output_keys(self) -> List[str]:
"""Expect output key.
:meta private:
"""
return [self.output_key]
def _process_llm_result(self, t: str) -> Dict[str, str]:
python_executor = PythonREPL()
self.callback_manager.on_text(t, color="green", verbose=self.verbose)
t = t.strip()
if t.startswith("```python"):
code = t[9:-4]
output = python_executor.run(code)
self.callback_manager.on_text("\nAnswer: ", verbose=self.verbose)
self.callback_manager.on_text(output, color="yellow", verbose=self.verbose)
answer = "Answer: " + output
elif t.startswith("Answer:"):
answer = t
elif "Answer:" in t:
answer = "Answer: " + t.split("Answer:")[-1]
else:
raise ValueError(f"unknown format from LLM: {t}")
return {self.output_key: answer}
def _call(self, inputs: Dict[str, str]) -> Dict[str, str]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,834 | LLMMathChain to allow ChatOpenAI as an llm | 1. Cannot initialize match chain with ChatOpenAI LLM
llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In[33], line 1
----> 1 llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
File ~/anaconda3/envs/gpt_index/lib/python3.8/site-packages/pydantic/main.py:341, in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for LLMMathChain
llm
Can't instantiate abstract class BaseLLM with abstract methods _agenerate, _generate, _llm_type (type=type_error)
2. Works ok with OpenAI LLM
llm_math = LLMMathChain(llm=OpenAI(temperature=0))
| https://github.com/langchain-ai/langchain/issues/1834 | https://github.com/langchain-ai/langchain/pull/2183 | 3207a7482915a658cf8f473ae0a81ba9998c8531 | fd1fcb5a7d48cbe18b480b1493b66540e4709745 | "2023-03-20T23:12:24Z" | python | "2023-03-30T14:52:58Z" | langchain/chains/llm_math/base.py | llm_executor = LLMChain(
prompt=self.prompt, llm=self.llm, callback_manager=self.callback_manager
)
self.callback_manager.on_text(inputs[self.input_key], verbose=self.verbose)
t = llm_executor.predict(question=inputs[self.input_key], stop=["```output"])
return self._process_llm_result(t)
async def _acall(self, inputs: Dict[str, str]) -> Dict[str, str]:
llm_executor = LLMChain(
prompt=self.prompt, llm=self.llm, callback_manager=self.callback_manager
)
self.callback_manager.on_text(inputs[self.input_key], verbose=self.verbose)
t = await llm_executor.apredict(
question=inputs[self.input_key], stop=["```output"]
)
return self._process_llm_result(t)
@property
def _chain_type(self) -> str:
return "llm_math_chain" |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,174 | failed tests on Windows platform | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_files
If it is because these tests should run only on Linux, we can add
>if not sys.platform.startswith("win"):
pytest.skip("skipping windows-only tests", allow_module_level=True)
to the `test_bash.py`
and
>@pytest.mark.skipif(sys.platform.startswith("win", reason="skipping windows-only tests")
to `test_llm_bash/test_simple_question`
regarding [this](https://docs.pytest.org/en/7.1.x/how-to/skipping.html).
If you want you can assign this issue to me :)
UPDATE:
Probably` tests/unit_test/utilities/test_loading/[test_success, test_failed_request]` (tests with correspondent `_teardown`) are also failing because of the Windows environment. | https://github.com/langchain-ai/langchain/issues/2174 | https://github.com/langchain-ai/langchain/pull/2238 | 609b14a57004b4679341a05729577ec5dbcaff7d | 579ad85785a4011bdcb9fc316d2c1bcddfb9d427 | "2023-03-30T03:43:17Z" | python | "2023-04-01T19:52:21Z" | tests/unit_tests/chains/test_llm_bash.py | """Test LLM Bash functionality."""
import pytest
from langchain.chains.llm_bash.base import LLMBashChain
from langchain.chains.llm_bash.prompt import _PROMPT_TEMPLATE
from tests.unit_tests.llms.fake_llm import FakeLLM
@pytest.fixture
def fake_llm_bash_chain() -> LLMBashChain:
"""Fake LLM Bash chain for testing."""
question = "Please write a bash script that prints 'Hello World' to the console."
prompt = _PROMPT_TEMPLATE.format(question=question)
queries = {prompt: "```bash\nexpr 1 + 1\n```"}
fake_llm = FakeLLM(queries=queries)
return LLMBashChain(llm=fake_llm, input_key="q", output_key="a")
def test_simple_question(fake_llm_bash_chain: LLMBashChain) -> None:
"""Test simple question that should not need python."""
question = "Please write a bash script that prints 'Hello World' to the console."
output = fake_llm_bash_chain.run(question)
assert output == "2\n" |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,174 | failed tests on Windows platform | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_files
If it is because these tests should run only on Linux, we can add
>if not sys.platform.startswith("win"):
pytest.skip("skipping windows-only tests", allow_module_level=True)
to the `test_bash.py`
and
>@pytest.mark.skipif(sys.platform.startswith("win", reason="skipping windows-only tests")
to `test_llm_bash/test_simple_question`
regarding [this](https://docs.pytest.org/en/7.1.x/how-to/skipping.html).
If you want you can assign this issue to me :)
UPDATE:
Probably` tests/unit_test/utilities/test_loading/[test_success, test_failed_request]` (tests with correspondent `_teardown`) are also failing because of the Windows environment. | https://github.com/langchain-ai/langchain/issues/2174 | https://github.com/langchain-ai/langchain/pull/2238 | 609b14a57004b4679341a05729577ec5dbcaff7d | 579ad85785a4011bdcb9fc316d2c1bcddfb9d427 | "2023-03-30T03:43:17Z" | python | "2023-04-01T19:52:21Z" | tests/unit_tests/test_bash.py | """Test the bash utility."""
import re
import subprocess
from pathlib import Path
from langchain.utilities.bash import BashProcess
def test_pwd_command() -> None:
"""Test correct functionality."""
session = BashProcess()
commands = ["pwd"]
output = session.run(commands)
assert output == subprocess.check_output("pwd", shell=True).decode()
def test_incorrect_command() -> None: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,174 | failed tests on Windows platform | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_files
If it is because these tests should run only on Linux, we can add
>if not sys.platform.startswith("win"):
pytest.skip("skipping windows-only tests", allow_module_level=True)
to the `test_bash.py`
and
>@pytest.mark.skipif(sys.platform.startswith("win", reason="skipping windows-only tests")
to `test_llm_bash/test_simple_question`
regarding [this](https://docs.pytest.org/en/7.1.x/how-to/skipping.html).
If you want you can assign this issue to me :)
UPDATE:
Probably` tests/unit_test/utilities/test_loading/[test_success, test_failed_request]` (tests with correspondent `_teardown`) are also failing because of the Windows environment. | https://github.com/langchain-ai/langchain/issues/2174 | https://github.com/langchain-ai/langchain/pull/2238 | 609b14a57004b4679341a05729577ec5dbcaff7d | 579ad85785a4011bdcb9fc316d2c1bcddfb9d427 | "2023-03-30T03:43:17Z" | python | "2023-04-01T19:52:21Z" | tests/unit_tests/test_bash.py | """Test handling of incorrect command."""
session = BashProcess()
output = session.run(["invalid_command"])
assert output == "Command 'invalid_command' returned non-zero exit status 127."
def test_incorrect_command_return_err_output() -> None:
"""Test optional returning of shell output on incorrect command."""
session = BashProcess(return_err_output=True)
output = session.run(["invalid_command"])
assert re.match(r"^/bin/sh:.*invalid_command.*not found.*$", output)
def test_create_directory_and_files(tmp_path: Path) -> None:
"""Test creation of a directory and files in a temporary directory."""
session = BashProcess(strip_newlines=True)
temp_dir = tmp_path / "test_dir"
temp_dir.mkdir()
commands = [
f"touch {temp_dir}/file1.txt",
f"touch {temp_dir}/file2.txt",
f"echo 'hello world' > {temp_dir}/file2.txt",
f"cat {temp_dir}/file2.txt",
]
output = session.run(commands)
assert output == "hello world"
output = session.run([f"ls {temp_dir}"])
assert output == "file1.txt\nfile2.txt" |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | """Wrapper around OpenSearch vector database."""
from __future__ import annotations
import uuid
from typing import Any, Dict, Iterable, List, Optional
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_from_dict_or_env
from langchain.vectorstores.base import VectorStore
IMPORT_OPENSEARCH_PY_ERROR = (
"Could not import OpenSearch. Please install it with `pip install opensearch-py`."
)
SCRIPT_SCORING_SEARCH = "script_scoring"
PAINLESS_SCRIPTING_SEARCH = "painless_scripting"
MATCH_ALL_QUERY = {"match_all": {}}
def _import_opensearch() -> Any:
"""Import OpenSearch if available, otherwise raise error."""
try:
from opensearchpy import OpenSearch
except ImportError:
raise ValueError(IMPORT_OPENSEARCH_PY_ERROR)
return OpenSearch
def _import_bulk() -> Any: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | """Import bulk if available, otherwise raise error."""
try:
from opensearchpy.helpers import bulk
except ImportError:
raise ValueError(IMPORT_OPENSEARCH_PY_ERROR)
return bulk
def _get_opensearch_client(opensearch_url: str, **kwargs: Any) -> Any:
"""Get OpenSearch client from the opensearch_url, otherwise raise error."""
try:
opensearch = _import_opensearch()
client = opensearch(opensearch_url, **kwargs)
except ValueError as e:
raise ValueError(
f"OpenSearch client string provided is not in proper format. "
f"Got error: {e} "
)
return client
def _validate_embeddings_and_bulk_size(embeddings_length: int, bulk_size: int) -> None:
"""Validate Embeddings Length and Bulk Size."""
if embeddings_length == 0:
raise RuntimeError("Embeddings size is zero")
if bulk_size < embeddings_length:
raise RuntimeError(
f"The embeddings count, {embeddings_length} is more than the "
f"[bulk_size], {bulk_size}. Increase the value of [bulk_size]."
)
def _bulk_ingest_embeddings( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | client: Any,
index_name: str,
embeddings: List[List[float]],
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
) -> List[str]:
"""Bulk Ingest Embeddings into given index."""
bulk = _import_bulk()
requests = []
ids = []
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
_id = str(uuid.uuid4())
request = {
"_op_type": "index",
"_index": index_name,
"vector_field": embeddings[i],
"text": text,
"metadata": metadata,
"_id": _id,
}
requests.append(request)
ids.append(_id)
bulk(client, requests)
client.indices.refresh(index=index_name)
return ids
def _default_scripting_text_mapping(dim: int) -> Dict: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | """For Painless Scripting or Script Scoring,the default mapping to create index."""
return {
"mappings": {
"properties": {
"vector_field": {"type": "knn_vector", "dimension": dim},
}
}
}
def _default_text_mapping( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | dim: int,
engine: str = "nmslib",
space_type: str = "l2",
ef_search: int = 512,
ef_construction: int = 512,
m: int = 16,
) -> Dict:
"""For Approximate k-NN Search, this is the default mapping to create index."""
return {
"settings": {"index": {"knn": True, "knn.algo_param.ef_search": ef_search}},
"mappings": {
"properties": {
"vector_field": {
"type": "knn_vector",
"dimension": dim,
"method": {
"name": "hnsw",
"space_type": space_type,
"engine": engine,
"parameters": {"ef_construction": ef_construction, "m": m},
},
}
}
},
}
def _default_approximate_search_query( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | query_vector: List[float], size: int = 4, k: int = 4
) -> Dict:
"""For Approximate k-NN Search, this is the default query."""
return {
"size": size,
"query": {"knn": {"vector_field": {"vector": query_vector, "k": k}}},
}
def _default_script_query(
query_vector: List[float],
space_type: str = "l2",
pre_filter: Dict = MATCH_ALL_QUERY,
) -> Dict:
"""For Script Scoring Search, this is the default query."""
return {
"query": {
"script_score": {
"query": pre_filter,
"script": {
"source": "knn_score",
"lang": "knn",
"params": {
"field": "vector_field",
"query_value": query_vector,
"space_type": space_type,
},
},
}
}
}
def __get_painless_scripting_source(space_type: str, query_vector: List[float]) -> str: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | """For Painless Scripting, it returns the script source based on space type."""
source_value = (
"(1.0 + " + space_type + "(" + str(query_vector) + ", doc['vector_field']))"
)
if space_type == "cosineSimilarity":
return source_value
else:
return "1/" + source_value
def _default_painless_scripting_query(
query_vector: List[float],
space_type: str = "l2Squared",
pre_filter: Dict = MATCH_ALL_QUERY,
) -> Dict:
"""For Painless Scripting Search, this is the default query."""
source = __get_painless_scripting_source(space_type, query_vector)
return {
"query": {
"script_score": {
"query": pre_filter,
"script": {
"source": source,
"params": {
"field": "vector_field",
"query_value": query_vector,
},
},
}
}
}
def _get_kwargs_value(kwargs: Any, key: str, default_value: Any) -> Any: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | """Get the value of the key if present. Else get the default_value."""
if key in kwargs:
return kwargs.get(key)
return default_value
class OpenSearchVectorSearch(VectorStore):
"""Wrapper around OpenSearch as a vector database.
Example:
.. code-block:: python
from langchain import OpenSearchVectorSearch
opensearch_vector_search = OpenSearchVectorSearch(
"http://localhost:9200",
"embeddings",
embedding_function
)
"""
def __init__(
self,
opensearch_url: str,
index_name: str,
embedding_function: Embeddings,
**kwargs: Any,
):
"""Initialize with necessary components."""
self.embedding_function = embedding_function
self.index_name = index_name
self.client = _get_opensearch_client(opensearch_url, **kwargs)
def add_texts( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
bulk_size: int = 500,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
bulk_size: Bulk API request count; Default: 500
Returns:
List of ids from adding the texts into the vectorstore.
"""
embeddings = [
self.embedding_function.embed_documents([text])[0] for text in texts
]
_validate_embeddings_and_bulk_size(len(embeddings), bulk_size)
return _bulk_ingest_embeddings(
self.client, self.index_name, embeddings, texts, metadatas
)
def similarity_search( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
By default supports Approximate Search.
Also supports Script Scoring and Painless Scripting.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.
Optional Args for Approximate Search:
search_type: "approximate_search"; default: "approximate_search"
size: number of results the query actually returns; default: 4
Optional Args for Script Scoring Search:
search_type: "script_scoring"; default: "approximate_search"
space_type: "l2", "l1", "linf", "cosinesimil", "innerproduct",
"hammingbit"; default: "l2"
pre_filter: script_score query to pre-filter documents before identifying
nearest neighbors; default: {"match_all": {}}
Optional Args for Painless Scripting Search:
search_type: "painless_scripting"; default: "approximate_search"
space_type: "l2Squared", "l1Norm", "cosineSimilarity"; default: "l2Squared" |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | pre_filter: script_score query to pre-filter documents before identifying
nearest neighbors; default: {"match_all": {}}
"""
embedding = self.embedding_function.embed_query(query)
search_type = _get_kwargs_value(kwargs, "search_type", "approximate_search")
if search_type == "approximate_search":
size = _get_kwargs_value(kwargs, "size", 4)
search_query = _default_approximate_search_query(embedding, size, k)
elif search_type == SCRIPT_SCORING_SEARCH:
space_type = _get_kwargs_value(kwargs, "space_type", "l2")
pre_filter = _get_kwargs_value(kwargs, "pre_filter", MATCH_ALL_QUERY)
search_query = _default_script_query(embedding, space_type, pre_filter)
elif search_type == PAINLESS_SCRIPTING_SEARCH:
space_type = _get_kwargs_value(kwargs, "space_type", "l2Squared")
pre_filter = _get_kwargs_value(kwargs, "pre_filter", MATCH_ALL_QUERY)
search_query = _default_painless_scripting_query(
embedding, space_type, pre_filter
)
else:
raise ValueError("Invalid `search_type` provided as an argument")
response = self.client.search(index=self.index_name, body=search_query)
hits = [hit["_source"] for hit in response["hits"]["hits"][:k]]
documents = [
Document(page_content=hit["text"], metadata=hit["metadata"]) for hit in hits
]
return documents
@classmethod
def from_texts(
cls,
texts: List[str], |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
bulk_size: int = 500,
**kwargs: Any,
) -> OpenSearchVectorSearch:
"""Construct OpenSearchVectorSearch wrapper from raw documents.
Example:
.. code-block:: python
from langchain import OpenSearchVectorSearch
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
opensearch_vector_search = OpenSearchVectorSearch.from_texts(
texts,
embeddings,
opensearch_url="http://localhost:9200"
)
OpenSearch by default supports Approximate Search powered by nmslib, faiss
and lucene engines recommended for large datasets. Also supports brute force
search through Script Scoring and Painless Scripting.
Optional Keyword Args for Approximate Search:
engine: "nmslib", "faiss", "hnsw"; default: "nmslib"
space_type: "l2", "l1", "cosinesimil", "linf", "innerproduct"; default: "l2"
ef_search: Size of the dynamic list used during k-NN searches. Higher values
lead to more accurate but slower searches; default: 512
ef_construction: Size of the dynamic list used during k-NN graph creation.
Higher values lead to more accurate graph but slower indexing speed;
default: 512
m: Number of bidirectional links created for each new element. Large impact
on memory consumption. Between 2 and 100; default: 16
Keyword Args for Script Scoring or Painless Scripting: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | is_appx_search: False
"""
opensearch_url = get_from_dict_or_env(
kwargs, "opensearch_url", "OPENSEARCH_URL"
)
client = _get_opensearch_client(opensearch_url)
embeddings = embedding.embed_documents(texts)
_validate_embeddings_and_bulk_size(len(embeddings), bulk_size)
dim = len(embeddings[0])
index_name = get_from_dict_or_env(
kwargs, "index_name", "OPENSEARCH_INDEX_NAME", default=uuid.uuid4().hex
)
is_appx_search = _get_kwargs_value(kwargs, "is_appx_search", True)
if is_appx_search:
engine = _get_kwargs_value(kwargs, "engine", "nmslib")
space_type = _get_kwargs_value(kwargs, "space_type", "l2")
ef_search = _get_kwargs_value(kwargs, "ef_search", 512)
ef_construction = _get_kwargs_value(kwargs, "ef_construction", 512)
m = _get_kwargs_value(kwargs, "m", 16)
mapping = _default_text_mapping(
dim, engine, space_type, ef_search, ef_construction, m
)
else:
mapping = _default_scripting_text_mapping(dim)
client.indices.create(index=index_name, body=mapping)
_bulk_ingest_embeddings(client, index_name, embeddings, texts, metadatas)
return cls(opensearch_url, index_name, embedding) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Loader that loads data from Google Drive."""
from pathlib import Path
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, root_validator, validator
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
SCOPES = ["https://www.googleapis.com/auth/drive.readonly"]
class GoogleDriveLoader(BaseLoader, BaseModel): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Loader that loads Google Docs from Google Drive."""
service_account_key: Path = Path.home() / ".credentials" / "keys.json"
credentials_path: Path = Path.home() / ".credentials" / "credentials.json"
token_path: Path = Path.home() / ".credentials" / "token.json"
folder_id: Optional[str] = None
document_ids: Optional[List[str]] = None
file_ids: Optional[List[str]] = None
@root_validator
def validate_folder_id_or_document_ids(
cls, values: Dict[str, Any]
) -> Dict[str, Any]:
"""Validate that either folder_id or document_ids is set, but not both."""
if values.get("folder_id") and (
values.get("document_ids") or values.get("file_ids")
):
raise ValueError(
"Cannot specify both folder_id and document_ids nor "
"folder_id and file_ids"
)
if (
not values.get("folder_id")
and not values.get("document_ids")
and not values.get("file_ids")
):
raise ValueError("Must specify either folder_id, document_ids, or file_ids")
return values
@validator("credentials_path")
def validate_credentials_path(cls, v: Any, **kwargs: Any) -> Any: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Validate that credentials_path exists."""
if not v.exists():
raise ValueError(f"credentials_path {v} does not exist")
return v
def _load_credentials(self) -> Any:
"""Load credentials."""
try:
from google.auth.transport.requests import Request
from google.oauth2 import service_account
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
except ImportError: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | raise ImportError(
"You must run"
"`pip install --upgrade "
"google-api-python-client google-auth-httplib2 "
"google-auth-oauthlib`"
"to use the Google Drive loader."
)
creds = None
if self.service_account_key.exists():
return service_account.Credentials.from_service_account_file(
str(self.service_account_key), scopes=SCOPES
)
if self.token_path.exists():
creds = Credentials.from_authorized_user_file(str(self.token_path), SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
str(self.credentials_path), SCOPES
)
creds = flow.run_local_server(port=0)
with open(self.token_path, "w") as token:
token.write(creds.to_json())
return creds
def _load_sheet_from_id(self, id: str) -> List[Document]:
"""Load a sheet and all tabs from an ID."""
from googleapiclient.discovery import build
creds = self._load_credentials()
sheets_service = build("sheets", "v4", credentials=creds) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | spreadsheet = sheets_service.spreadsheets().get(spreadsheetId=id).execute()
sheets = spreadsheet.get("sheets", [])
documents = []
for sheet in sheets:
sheet_name = sheet["properties"]["title"]
result = (
sheets_service.spreadsheets()
.values()
.get(spreadsheetId=id, range=sheet_name)
.execute()
)
values = result.get("values", [])
header = values[0]
for i, row in enumerate(values[1:], start=1):
metadata = {
"source": (
f"https://docs.google.com/spreadsheets/d/{id}/"
f"edit?gid={sheet['properties']['sheetId']}"
),
"title": f"{spreadsheet['properties']['title']} - {sheet_name}",
"row": i,
}
content = []
for j, v in enumerate(row):
title = header[j].strip() if len(header) > j else ""
content.append(f"{title}: {v.strip()}")
page_content = "\n".join(content)
documents.append(Document(page_content=page_content, metadata=metadata))
return documents
def _load_document_from_id(self, id: str) -> Document: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Load a document from an ID."""
from io import BytesIO
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from googleapiclient.http import MediaIoBaseDownload
creds = self._load_credentials()
service = build("drive", "v3", credentials=creds)
file = service.files().get(fileId=id).execute()
request = service.files().export_media(fileId=id, mimeType="text/plain")
fh = BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
try:
while done is False:
status, done = downloader.next_chunk()
except HttpError as e:
if e.resp.status == 404:
print("File not found: {}".format(id))
else:
print("An error occurred: {}".format(e))
text = fh.getvalue().decode("utf-8")
metadata = {
"source": f"https://docs.google.com/document/d/{id}/edit",
"title": f"{file.get('name')}",
}
return Document(page_content=text, metadata=metadata)
def _load_documents_from_folder(self) -> List[Document]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Load documents from a folder."""
from googleapiclient.discovery import build
creds = self._load_credentials()
service = build("drive", "v3", credentials=creds)
results = (
service.files()
.list(
q=f"'{self.folder_id}' in parents",
pageSize=1000,
fields="nextPageToken, files(id, name, mimeType)",
)
.execute()
)
items = results.get("files", [])
returns = []
for item in items:
if item["mimeType"] == "application/vnd.google-apps.document":
returns.append(self._load_document_from_id(item["id"]))
elif item["mimeType"] == "application/vnd.google-apps.spreadsheet":
returns.extend(self._load_sheet_from_id(item["id"]))
elif item["mimeType"] == "application/pdf":
returns.extend(self._load_file_from_id(item["id"]))
else:
pass
return returns
def _load_documents_from_ids(self) -> List[Document]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Load documents from a list of IDs."""
if not self.document_ids:
raise ValueError("document_ids must be set")
return [self._load_document_from_id(doc_id) for doc_id in self.document_ids]
def _load_file_from_id(self, id: str) -> List[Document]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Load a file from an ID."""
from io import BytesIO
from googleapiclient.discovery import build
from googleapiclient.http import MediaIoBaseDownload
creds = self._load_credentials()
service = build("drive", "v3", credentials=creds)
file = service.files().get(fileId=id).execute()
request = service.files().get_media(fileId=id)
fh = BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
content = fh.getvalue()
from PyPDF2 import PdfReader
pdf_reader = PdfReader(BytesIO(content))
return [
Document(
page_content=page.extract_text(),
metadata={
"source": f"https://drive.google.com/file/d/{id}/view",
"title": f"{file.get('name')}",
"page": i,
},
)
for i, page in enumerate(pdf_reader.pages)
]
def _load_file_from_ids(self) -> List[Document]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Load files from a list of IDs."""
if not self.file_ids:
raise ValueError("file_ids must be set")
docs = []
for file_id in self.file_ids:
docs.extend(self._load_file_from_id(file_id))
return docs
def load(self) -> List[Document]:
"""Load documents."""
if self.folder_id:
return self._load_documents_from_folder()
elif self.document_ids:
return self._load_documents_from_ids()
else:
return self._load_file_from_ids() |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | """OpenAI chat wrapper."""
from __future__ import annotations
import logging
import sys
from typing import Any, Callable, Dict, List, Mapping, Optional, Tuple
from pydantic import Extra, Field, root_validator
from tenacity import (
before_sleep_log,
retry,
retry_if_exception_type,
stop_after_attempt,
wait_exponential,
)
from langchain.chat_models.base import BaseChatModel
from langchain.schema import (
AIMessage,
BaseMessage,
ChatGeneration,
ChatMessage,
ChatResult,
HumanMessage,
SystemMessage,
)
from langchain.utils import get_from_dict_or_env
logger = logging.getLogger(__file__)
def _create_retry_decorator(llm: ChatOpenAI) -> Callable[[Any], Any]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | import openai
min_seconds = 4
max_seconds = 10
return retry(
reraise=True,
stop=stop_after_attempt(llm.max_retries),
wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds),
retry=(
retry_if_exception_type(openai.error.Timeout)
| retry_if_exception_type(openai.error.APIError)
| retry_if_exception_type(openai.error.APIConnectionError)
| retry_if_exception_type(openai.error.RateLimitError)
| retry_if_exception_type(openai.error.ServiceUnavailableError)
),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
async def acompletion_with_retry(llm: ChatOpenAI, **kwargs: Any) -> Any:
"""Use tenacity to retry the async completion call."""
retry_decorator = _create_retry_decorator(llm)
@retry_decorator
async def _completion_with_retry(**kwargs: Any) -> Any: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | return await llm.client.acreate(**kwargs)
return await _completion_with_retry(**kwargs)
def _convert_dict_to_message(_dict: dict) -> BaseMessage:
role = _dict["role"]
if role == "user":
return HumanMessage(content=_dict["content"])
elif role == "assistant":
return AIMessage(content=_dict["content"])
elif role == "system":
return SystemMessage(content=_dict["content"])
else:
return ChatMessage(content=_dict["content"], role=role)
def _convert_message_to_dict(message: BaseMessage) -> dict:
if isinstance(message, ChatMessage):
message_dict = {"role": message.role, "content": message.content}
elif isinstance(message, HumanMessage):
message_dict = {"role": "user", "content": message.content}
elif isinstance(message, AIMessage):
message_dict = {"role": "assistant", "content": message.content}
elif isinstance(message, SystemMessage):
message_dict = {"role": "system", "content": message.content}
else:
raise ValueError(f"Got unknown type {message}")
if "name" in message.additional_kwargs:
message_dict["name"] = message.additional_kwargs["name"]
return message_dict
class ChatOpenAI(BaseChatModel): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | """Wrapper around OpenAI Chat large language models.
To use, you should have the ``openai`` python package installed, and the
environment variable ``OPENAI_API_KEY`` set with your API key.
Any parameters that are valid to be passed to the openai.create call can be passed
in, even if not explicitly saved on this class.
Example:
.. code-block:: python
from langchain.chat_models import ChatOpenAI
openai = ChatOpenAI(model_name="gpt-3.5-turbo")
"""
client: Any
model_name: str = "gpt-3.5-turbo"
"""Model name to use."""
temperature: float = 0.7
"""What sampling temperature to use."""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Holds any model parameters valid for `create` call not explicitly specified."""
openai_api_key: Optional[str] = None
openai_organization: Optional[str] = None
request_timeout: int = 60
"""Timeout in seconds for the OpenAPI request."""
max_retries: int = 6
"""Maximum number of retries to make when generating."""
streaming: bool = False
"""Whether to stream the results or not."""
n: int = 1
"""Number of chat completions to generate for each prompt."""
max_tokens: Optional[int] = None
"""Maximum number of tokens to generate."""
class Config: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | """Configuration for this pydantic object."""
extra = Extra.ignore
@root_validator(pre=True)
def build_extra(cls, values: Dict[str, Any]) -> Dict[str, Any]:
"""Build extra kwargs from additional params that were passed in."""
all_required_field_names = {field.alias for field in cls.__fields__.values()}
extra = values.get("model_kwargs", {})
for field_name in list(values):
if field_name not in all_required_field_names:
if field_name in extra:
raise ValueError(f"Found {field_name} supplied twice.")
extra[field_name] = values.pop(field_name)
values["model_kwargs"] = extra
return values
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that api key and python package exists in environment."""
openai_api_key = get_from_dict_or_env(
values, "openai_api_key", "OPENAI_API_KEY"
)
openai_organization = get_from_dict_or_env( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | values,
"openai_organization",
"OPENAI_ORGANIZATION",
default="",
)
try:
import openai
openai.api_key = openai_api_key
if openai_organization:
openai.organization = openai_organization
except ImportError:
raise ValueError(
"Could not import openai python package. "
"Please it install it with `pip install openai`."
)
try:
values["client"] = openai.ChatCompletion
except AttributeError:
raise ValueError(
"`openai` has no `ChatCompletion` attribute, this is likely "
"due to an old version of the openai package. Try upgrading it "
"with `pip install --upgrade openai`."
)
if values["n"] < 1:
raise ValueError("n must be at least 1.")
if values["n"] > 1 and values["streaming"]:
raise ValueError("n must be 1 when streaming.")
return values
@property
def _default_params(self) -> Dict[str, Any]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | """Get the default parameters for calling OpenAI API."""
return {
"model": self.model_name,
"request_timeout": self.request_timeout,
"max_tokens": self.max_tokens,
"stream": self.streaming,
"n": self.n,
"temperature": self.temperature,
**self.model_kwargs,
}
def _create_retry_decorator(self) -> Callable[[Any], Any]:
import openai
min_seconds = 4
max_seconds = 10
return retry(
reraise=True,
stop=stop_after_attempt(self.max_retries),
wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds),
retry=(
retry_if_exception_type(openai.error.Timeout)
| retry_if_exception_type(openai.error.APIError)
| retry_if_exception_type(openai.error.APIConnectionError)
| retry_if_exception_type(openai.error.RateLimitError)
| retry_if_exception_type(openai.error.ServiceUnavailableError)
),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
def completion_with_retry(self, **kwargs: Any) -> Any: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | """Use tenacity to retry the completion call."""
retry_decorator = self._create_retry_decorator()
@retry_decorator
def _completion_with_retry(**kwargs: Any) -> Any:
return self.client.create(**kwargs)
return _completion_with_retry(**kwargs)
def _combine_llm_outputs(self, llm_outputs: List[Optional[dict]]) -> dict:
overall_token_usage: dict = {}
for output in llm_outputs:
if output is None:
continue
token_usage = output["token_usage"]
for k, v in token_usage.items():
if k in overall_token_usage:
overall_token_usage[k] += v
else:
overall_token_usage[k] = v
return {"token_usage": overall_token_usage, "model_name": self.model_name}
def _generate( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
message_dicts, params = self._create_message_dicts(messages, stop)
if self.streaming:
inner_completion = ""
role = "assistant"
params["stream"] = True
for stream_resp in self.completion_with_retry(
messages=message_dicts, **params
):
role = stream_resp["choices"][0]["delta"].get("role", role)
token = stream_resp["choices"][0]["delta"].get("content", "")
inner_completion += token
self.callback_manager.on_llm_new_token(
token,
verbose=self.verbose,
)
message = _convert_dict_to_message(
{"content": inner_completion, "role": role}
)
return ChatResult(generations=[ChatGeneration(message=message)])
response = self.completion_with_retry(messages=message_dicts, **params)
return self._create_chat_result(response)
def _create_message_dicts( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | self, messages: List[BaseMessage], stop: Optional[List[str]]
) -> Tuple[List[Dict[str, Any]], Dict[str, Any]]:
params: Dict[str, Any] = {**{"model": self.model_name}, **self._default_params}
if stop is not None:
if "stop" in params:
raise ValueError("`stop` found in both the input and default params.")
params["stop"] = stop
message_dicts = [_convert_message_to_dict(m) for m in messages]
return message_dicts, params
def _create_chat_result(self, response: Mapping[str, Any]) -> ChatResult:
generations = []
for res in response["choices"]:
message = _convert_dict_to_message(res["message"])
gen = ChatGeneration(message=message)
generations.append(gen)
llm_output = {"token_usage": response["usage"], "model_name": self.model_name}
return ChatResult(generations=generations, llm_output=llm_output)
async def _agenerate( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
message_dicts, params = self._create_message_dicts(messages, stop)
if self.streaming:
inner_completion = ""
role = "assistant"
params["stream"] = True
async for stream_resp in await acompletion_with_retry(
self, messages=message_dicts, **params
):
role = stream_resp["choices"][0]["delta"].get("role", role)
token = stream_resp["choices"][0]["delta"].get("content", "")
inner_completion += token
if self.callback_manager.is_async:
await self.callback_manager.on_llm_new_token(
token,
verbose=self.verbose,
)
else:
self.callback_manager.on_llm_new_token(
token,
verbose=self.verbose,
)
message = _convert_dict_to_message(
{"content": inner_completion, "role": role}
) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | return ChatResult(generations=[ChatGeneration(message=message)])
else:
response = await acompletion_with_retry(
self, messages=message_dicts, **params
)
return self._create_chat_result(response)
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model_name": self.model_name}, **self._default_params}
def get_num_tokens(self, text: str) -> int:
"""Calculate num tokens with tiktoken package."""
if sys.version_info[1] <= 8:
return super().get_num_tokens(text)
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please it install it with `pip install tiktoken`."
)
enc = tiktoken.encoding_for_model(self.model_name)
tokenized_text = enc.encode(text)
return len(tokenized_text)
def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | """Calculate num tokens for gpt-3.5-turbo and gpt-4 with tiktoken package.
Official documentation: https://github.com/openai/openai-cookbook/blob/
main/examples/How_to_format_inputs_to_ChatGPT_models.ipynb"""
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please it install it with `pip install tiktoken`."
)
model = self.model_name
if model == "gpt-3.5-turbo":
model = "gpt-3.5-turbo-0301"
elif model == "gpt-4":
model = "gpt-4-0314"
try:
encoding = tiktoken.encoding_for_model(model) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | except KeyError:
logger.warning("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301":
tokens_per_message = 4
tokens_per_name = -1
elif model == "gpt-4-0314":
tokens_per_message = 3
tokens_per_name = 1
else:
raise NotImplementedError(
f"get_num_tokens_from_messages() is not presently implemented "
f"for model {model}."
"See https://github.com/openai/openai-python/blob/main/chatml.md for "
"information on how messages are converted to tokens."
)
num_tokens = 0
messages_dict = [_convert_message_to_dict(m) for m in messages]
for message in messages_dict:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3
return num_tokens |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121
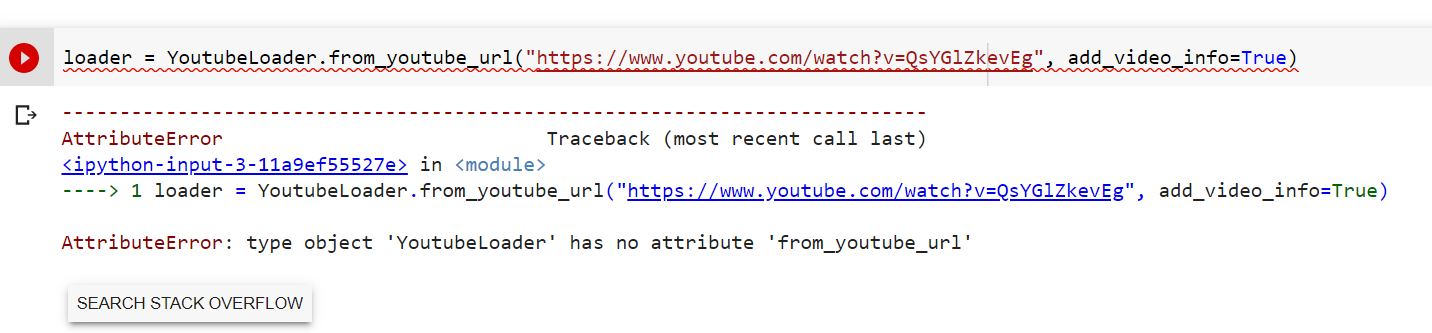
| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | """Loader that loads YouTube transcript."""
from __future__ import annotations
from pathlib import Path
from typing import Any, Dict, List, Optional
from pydantic import root_validator
from pydantic.dataclasses import dataclass
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
SCOPES = ["https://www.googleapis.com/auth/drive.readonly"]
@dataclass
class GoogleApiClient:
"""A Generic Google Api Client.
To use, you should have the ``google_auth_oauthlib,youtube_transcript_api,google``
python package installed.
As the google api expects credentials you need to set up a google account and
register your Service. "https://developers.google.com/docs/api/quickstart/python"
Example:
.. code-block:: python
from langchain.document_loaders import GoogleApiClient
google_api_client = GoogleApiClient(
service_account_path=Path("path_to_your_sec_file.json")
)
"""
credentials_path: Path = Path.home() / ".credentials" / "credentials.json"
service_account_path: Path = Path.home() / ".credentials" / "credentials.json"
token_path: Path = Path.home() / ".credentials" / "token.json"
def __post_init__(self) -> None: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | self.creds = self._load_credentials()
@root_validator
def validate_channel_or_videoIds_is_set(
cls, values: Dict[str, Any]
) -> Dict[str, Any]:
"""Validate that either folder_id or document_ids is set, but not both."""
if not values.get("credentials_path") and not values.get(
"service_account_path"
):
raise ValueError("Must specify either channel_name or video_ids")
return values
def _load_credentials(self) -> Any:
"""Load credentials."""
try:
from google.auth.transport.requests import Request
from google.oauth2 import service_account
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from youtube_transcript_api import YouTubeTranscriptApi
except ImportError:
raise ImportError(
"You must run"
"`pip install --upgrade "
"google-api-python-client google-auth-httplib2 "
"google-auth-oauthlib"
"youtube-transcript-api`"
"to use the Google Drive loader" |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | )
creds = None
if self.service_account_path.exists():
return service_account.Credentials.from_service_account_file(
str(self.service_account_path)
)
if self.token_path.exists():
creds = Credentials.from_authorized_user_file(str(self.token_path), SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
str(self.credentials_path), SCOPES
)
creds = flow.run_local_server(port=0)
with open(self.token_path, "w") as token:
token.write(creds.to_json())
return creds
class YoutubeLoader(BaseLoader):
"""Loader that loads Youtube transcripts."""
def __init__(
self, video_id: str, add_video_info: bool = False, language: str = "en"
):
"""Initialize with YouTube video ID."""
self.video_id = video_id
self.add_video_info = add_video_info
self.language = language
@classmethod
def from_youtube_channel(cls, youtube_url: str, **kwargs: Any) -> YoutubeLoader: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | """Given a channel name, load all videos."""
video_id = youtube_url.split("youtube.com/watch?v=")[-1]
return cls(video_id, **kwargs)
def load(self) -> List[Document]:
"""Load documents."""
try:
from youtube_transcript_api import NoTranscriptFound, YouTubeTranscriptApi
except ImportError:
raise ImportError(
"Could not import youtube_transcript_api python package. "
"Please install it with `pip install youtube-transcript-api`."
)
metadata = {"source": self.video_id}
if self.add_video_info:
video_info = self._get_video_info()
metadata.update(video_info)
transcript_list = YouTubeTranscriptApi.list_transcripts(self.video_id)
try:
transcript = transcript_list.find_transcript([self.language])
except NoTranscriptFound:
en_transcript = transcript_list.find_transcript(["en"])
transcript = en_transcript.translate(self.language)
transcript_pieces = transcript.fetch()
transcript = " ".join([t["text"].strip(" ") for t in transcript_pieces])
return [Document(page_content=transcript, metadata=metadata)]
def _get_video_info(self) -> dict: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | """Get important video information.
Components are:
- title
- description
- thumbnail url,
- publish_date
- channel_author
- and more.
"""
try:
from pytube import YouTube
except ImportError:
raise ImportError(
"Could not import pytube python package. "
"Please install it with `pip install pytube`."
)
yt = YouTube(f"https://www.youtube.com/watch?v={self.video_id}")
video_info = {
"title": yt.title,
"description": yt.description,
"view_count": yt.views,
"thumbnail_url": yt.thumbnail_url,
"publish_date": yt.publish_date,
"length": yt.length,
"author": yt.author,
}
return video_info
@dataclass
class GoogleApiYoutubeLoader(BaseLoader): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | """Loader that loads all Videos from a Channel
To use, you should have the ``googleapiclient,youtube_transcript_api``
python package installed.
As the service needs a google_api_client, you first have to initialize
the GoogleApiClient.
Additionally you have to either provide a channel name or a list of videoids
"https://developers.google.com/docs/api/quickstart/python"
Example:
.. code-block:: python
from langchain.document_loaders import GoogleApiClient
from langchain.document_loaders import GoogleApiYoutubeLoader
google_api_client = GoogleApiClient(
service_account_path=Path("path_to_your_sec_file.json")
)
loader = GoogleApiYoutubeLoader(
google_api_client=google_api_client,
channel_name = "CodeAesthetic"
)
load.load()
"""
google_api_client: GoogleApiClient
channel_name: Optional[str] = None
video_ids: Optional[List[str]] = None
add_video_info: bool = True
captions_language: str = "en"
def __post_init__(self) -> None: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | self.youtube_client = self._build_youtube_client(self.google_api_client.creds)
def _build_youtube_client(self, creds: Any) -> Any:
try:
from googleapiclient.discovery import build
from youtube_transcript_api import YouTubeTranscriptApi
except ImportError:
raise ImportError(
"You must run"
"`pip install --upgrade "
"google-api-python-client google-auth-httplib2 "
"google-auth-oauthlib"
"youtube-transcript-api`"
"to use the Google Drive loader"
)
return build("youtube", "v3", credentials=creds)
@root_validator
def validate_channel_or_videoIds_is_set( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | cls, values: Dict[str, Any]
) -> Dict[str, Any]:
"""Validate that either folder_id or document_ids is set, but not both."""
if not values.get("channel_name") and not values.get("video_ids"):
raise ValueError("Must specify either channel_name or video_ids")
return values
def _get_transcripe_for_video_id(self, video_id: str) -> str:
from youtube_transcript_api import NoTranscriptFound, YouTubeTranscriptApi
transcript_list = YouTubeTranscriptApi.list_transcripts(self.video_ids)
try:
transcript = transcript_list.find_transcript([self.captions_language])
except NoTranscriptFound:
en_transcript = transcript_list.find_transcript(["en"])
transcript = en_transcript.translate(self.captions_language)
transcript_pieces = transcript.fetch()
return " ".join([t["text"].strip(" ") for t in transcript_pieces])
def _get_document_for_video_id(self, video_id: str, **kwargs: Any) -> Document: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | captions = self._get_transcripe_for_video_id(video_id)
video_response = (
self.youtube_client.videos()
.list(
part="id,snippet",
id=video_id,
)
.execute()
)
return Document(
page_content=captions,
metadata=video_response.get("items")[0],
)
def _get_channel_id(self, channel_name: str) -> str:
request = self.youtube_client.search().list(
part="id",
q=channel_name,
type="channel",
maxResults=1,
)
response = request.execute()
channel_id = response["items"][0]["id"]["channelId"]
return channel_id
def _get_document_for_channel(self, channel: str, **kwargs: Any) -> List[Document]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | channel_id = self._get_channel_id(channel)
request = self.youtube_client.search().list(
part="id,snippet",
channelId=channel_id,
maxResults=50,
)
video_ids = []
while request is not None:
response = request.execute()
for item in response["items"]:
if not item["id"].get("videoId"):
continue
meta_data = {"videoId": item["id"]["videoId"]}
if self.add_video_info:
item["snippet"].pop("thumbnails")
meta_data.update(item["snippet"])
video_ids.append(
Document(
page_content=self._get_transcripe_for_video_id(
item["id"]["videoId"]
),
metadata=meta_data,
)
)
request = self.youtube_client.search().list_next(request, response)
return video_ids
def load(self) -> List[Document]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121

| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | """Load documents."""
document_list = []
if self.channel_name:
document_list.extend(self._get_document_for_channel(self.channel_name))
elif self.video_ids:
document_list.extend(
[
self._get_document_for_video_id(video_id)
for video_id in self.video_ids
]
)
else:
raise ValueError("Must specify either channel_name or video_ids")
return document_list |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/fix.py | from __future__ import annotations
from typing import Any
from langchain.chains.llm import LLMChain
from langchain.output_parsers.prompts import NAIVE_FIX_PROMPT
from langchain.prompts.base import BasePromptTemplate
from langchain.schema import BaseLanguageModel, BaseOutputParser, OutputParserException
class OutputFixingParser(BaseOutputParser): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/fix.py | """Wraps a parser and tries to fix parsing errors."""
parser: BaseOutputParser
retry_chain: LLMChain
@classmethod
def from_llm(
cls,
llm: BaseLanguageModel,
parser: BaseOutputParser,
prompt: BasePromptTemplate = NAIVE_FIX_PROMPT,
) -> OutputFixingParser:
chain = LLMChain(llm=llm, prompt=prompt)
return cls(parser=parser, retry_chain=chain)
def parse(self, completion: str) -> Any:
try:
parsed_completion = self.parser.parse(completion)
except OutputParserException as e:
new_completion = self.retry_chain.run(
instructions=self.parser.get_format_instructions(),
completion=completion,
error=repr(e),
)
parsed_completion = self.parser.parse(new_completion)
return parsed_completion
def get_format_instructions(self) -> str:
return self.parser.get_format_instructions() |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/pydantic.py | import json
import re
from typing import Any
from pydantic import BaseModel, ValidationError
from langchain.output_parsers.format_instructions import PYDANTIC_FORMAT_INSTRUCTIONS
from langchain.schema import BaseOutputParser, OutputParserException
class PydanticOutputParser(BaseOutputParser): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/pydantic.py | pydantic_object: Any
def parse(self, text: str) -> BaseModel:
try:
match = re.search(
"\{.*\}", text.strip(), re.MULTILINE | re.IGNORECASE | re.DOTALL
)
json_str = ""
if match:
json_str = match.group()
json_object = json.loads(json_str)
return self.pydantic_object.parse_obj(json_object)
except (json.JSONDecodeError, ValidationError) as e:
name = self.pydantic_object.__name__
msg = f"Failed to parse {name} from completion {text}. Got: {e}"
raise OutputParserException(msg)
def get_format_instructions(self) -> str:
schema = self.pydantic_object.schema()
reduced_schema = schema
if "title" in reduced_schema:
del reduced_schema["title"]
if "type" in reduced_schema:
del reduced_schema["type"]
schema = json.dumps(reduced_schema)
return PYDANTIC_FORMAT_INSTRUCTIONS.format(schema=schema) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/retry.py | from __future__ import annotations
from typing import Any
from langchain.chains.llm import LLMChain
from langchain.prompts.base import BasePromptTemplate
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import (
BaseLanguageModel,
BaseOutputParser,
OutputParserException,
PromptValue,
)
NAIVE_COMPLETION_RETRY = """Prompt:
{prompt}
Completion:
{completion}
Above, the Completion did not satisfy the constraints given in the Prompt.
Please try again:"""
NAIVE_COMPLETION_RETRY_WITH_ERROR = """Prompt:
{prompt}
Completion:
{completion}
Above, the Completion did not satisfy the constraints given in the Prompt.
Details: {error}
Please try again:"""
NAIVE_RETRY_PROMPT = PromptTemplate.from_template(NAIVE_COMPLETION_RETRY)
NAIVE_RETRY_WITH_ERROR_PROMPT = PromptTemplate.from_template(
NAIVE_COMPLETION_RETRY_WITH_ERROR
)
class RetryOutputParser(BaseOutputParser): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/retry.py | """Wraps a parser and tries to fix parsing errors.
Does this by passing the original prompt and the completion to another
LLM, and telling it the completion did not satisfy criteria in the prompt.
"""
parser: BaseOutputParser
retry_chain: LLMChain
@classmethod
def from_llm(
cls,
llm: BaseLanguageModel,
parser: BaseOutputParser,
prompt: BasePromptTemplate = NAIVE_RETRY_PROMPT,
) -> RetryOutputParser:
chain = LLMChain(llm=llm, prompt=prompt)
return cls(parser=parser, retry_chain=chain)
def parse_with_prompt(self, completion: str, prompt_value: PromptValue) -> Any: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/retry.py | try:
parsed_completion = self.parser.parse(completion)
except OutputParserException:
new_completion = self.retry_chain.run(
prompt=prompt_value.to_string(), completion=completion
)
parsed_completion = self.parser.parse(new_completion)
return parsed_completion
def parse(self, completion: str) -> Any:
raise NotImplementedError(
"This OutputParser can only be called by the `parse_with_prompt` method."
)
def get_format_instructions(self) -> str:
return self.parser.get_format_instructions()
class RetryWithErrorOutputParser(BaseOutputParser):
"""Wraps a parser and tries to fix parsing errors.
Does this by passing the original prompt, the completion, AND the error
that was raised to another language and telling it that the completion
did not work, and raised the given error. Differs from RetryOutputParser
in that this implementation provides the error that was raised back to the
LLM, which in theory should give it more information on how to fix it.
"""
parser: BaseOutputParser
retry_chain: LLMChain
@classmethod
def from_llm( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/retry.py | cls,
llm: BaseLanguageModel,
parser: BaseOutputParser,
prompt: BasePromptTemplate = NAIVE_RETRY_WITH_ERROR_PROMPT,
) -> RetryWithErrorOutputParser:
chain = LLMChain(llm=llm, prompt=prompt)
return cls(parser=parser, retry_chain=chain)
def parse_with_prompt(self, completion: str, prompt_value: PromptValue) -> Any:
try:
parsed_completion = self.parser.parse(completion)
except OutputParserException as e:
new_completion = self.retry_chain.run(
prompt=prompt_value.to_string(), completion=completion, error=repr(e)
)
parsed_completion = self.parser.parse(new_completion)
return parsed_completion
def parse(self, completion: str) -> Any:
raise NotImplementedError(
"This OutputParser can only be called by the `parse_with_prompt` method."
)
def get_format_instructions(self) -> str:
return self.parser.get_format_instructions() |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/structured.py | from __future__ import annotations
import json
from typing import List
from pydantic import BaseModel
from langchain.output_parsers.format_instructions import STRUCTURED_FORMAT_INSTRUCTIONS
from langchain.schema import BaseOutputParser, OutputParserException
line_template = '\t"{name}": {type} // {description}'
class ResponseSchema(BaseModel):
name: str
description: str
def _get_sub_string(schema: ResponseSchema) -> str:
return line_template.format(
name=schema.name, description=schema.description, type="string"
)
class StructuredOutputParser(BaseOutputParser): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/structured.py | response_schemas: List[ResponseSchema]
@classmethod
def from_response_schemas(
cls, response_schemas: List[ResponseSchema]
) -> StructuredOutputParser:
return cls(response_schemas=response_schemas)
def get_format_instructions(self) -> str:
schema_str = "\n".join(
[_get_sub_string(schema) for schema in self.response_schemas]
)
return STRUCTURED_FORMAT_INSTRUCTIONS.format(format=schema_str)
def parse(self, text: str) -> BaseModel:
json_string = text.split("```json")[1].strip().strip("```").strip()
try:
json_obj = json.loads(json_string)
except json.JSONDecodeError as e:
raise OutputParserException(f"Got invalid JSON object. Error: {e}")
for schema in self.response_schemas:
if schema.name not in json_obj:
raise OutputParserException(
f"Got invalid return object. Expected key `{schema.name}` "
f"to be present, but got {json_obj}"
)
return json_obj |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Common schema objects."""
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Dict, List, NamedTuple, Optional
from pydantic import BaseModel, Extra, Field, root_validator
def get_buffer_string(
messages: List[BaseMessage], human_prefix: str = "Human", ai_prefix: str = "AI"
) -> str:
"""Get buffer string of messages."""
string_messages = []
for m in messages:
if isinstance(m, HumanMessage):
role = human_prefix
elif isinstance(m, AIMessage):
role = ai_prefix
elif isinstance(m, SystemMessage):
role = "System"
elif isinstance(m, ChatMessage):
role = m.role
else:
raise ValueError(f"Got unsupported message type: {m}")
string_messages.append(f"{role}: {m.content}")
return "\n".join(string_messages)
class AgentAction(NamedTuple): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Agent's action to take."""
tool: str
tool_input: str
log: str
class AgentFinish(NamedTuple):
"""Agent's return value."""
return_values: dict
log: str
class Generation(BaseModel):
"""Output of a single generation."""
text: str
"""Generated text output."""
generation_info: Optional[Dict[str, Any]] = None
"""Raw generation info response from the provider"""
"""May include things like reason for finishing (e.g. in OpenAI)"""
class BaseMessage(BaseModel): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Message object."""
content: str
additional_kwargs: dict = Field(default_factory=dict)
@property
@abstractmethod
def type(self) -> str:
"""Type of the message, used for serialization."""
class HumanMessage(BaseMessage):
"""Type of message that is spoken by the human."""
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "human"
class AIMessage(BaseMessage):
"""Type of message that is spoken by the AI."""
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "ai"
class SystemMessage(BaseMessage):
"""Type of message that is a system message."""
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "system"
class ChatMessage(BaseMessage): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Type of message with arbitrary speaker."""
role: str
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "chat"
def _message_to_dict(message: BaseMessage) -> dict:
return {"type": message.type, "data": message.dict()}
def messages_to_dict(messages: List[BaseMessage]) -> List[dict]:
return [_message_to_dict(m) for m in messages]
def _message_from_dict(message: dict) -> BaseMessage:
_type = message["type"]
if _type == "human":
return HumanMessage(**message["data"])
elif _type == "ai":
return AIMessage(**message["data"])
elif _type == "system":
return SystemMessage(**message["data"])
elif _type == "chat":
return ChatMessage(**message["data"])
else:
raise ValueError(f"Got unexpected type: {_type}")
def messages_from_dict(messages: List[dict]) -> List[BaseMessage]:
return [_message_from_dict(m) for m in messages]
class ChatGeneration(Generation): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Output of a single generation."""
text = ""
message: BaseMessage
@root_validator
def set_text(cls, values: Dict[str, Any]) -> Dict[str, Any]:
values["text"] = values["message"].content
return values
class ChatResult(BaseModel):
"""Class that contains all relevant information for a Chat Result."""
generations: List[ChatGeneration]
"""List of the things generated."""
llm_output: Optional[dict] = None
"""For arbitrary LLM provider specific output."""
class LLMResult(BaseModel):
"""Class that contains all relevant information for an LLM Result."""
generations: List[List[Generation]]
"""List of the things generated. This is List[List[]] because
each input could have multiple generations."""
llm_output: Optional[dict] = None
"""For arbitrary LLM provider specific output."""
class PromptValue(BaseModel, ABC):
@abstractmethod
def to_string(self) -> str:
"""Return prompt as string."""
@abstractmethod
def to_messages(self) -> List[BaseMessage]:
"""Return prompt as messages."""
class BaseLanguageModel(BaseModel, ABC): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | @abstractmethod
def generate_prompt(
self, prompts: List[PromptValue], stop: Optional[List[str]] = None
) -> LLMResult:
"""Take in a list of prompt values and return an LLMResult."""
@abstractmethod
async def agenerate_prompt(
self, prompts: List[PromptValue], stop: Optional[List[str]] = None
) -> LLMResult:
"""Take in a list of prompt values and return an LLMResult."""
def get_num_tokens(self, text: str) -> int:
"""Get the number of tokens present in the text."""
try:
from transformers import GPT2TokenizerFast
except ImportError:
raise ValueError(
"Could not import transformers python package. "
"This is needed in order to calculate get_num_tokens. "
"Please install it with `pip install transformers`."
)
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
tokenized_text = tokenizer.tokenize(text)
return len(tokenized_text)
def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Get the number of tokens in the message."""
return sum([self.get_num_tokens(get_buffer_string([m])) for m in messages])
class BaseMemory(BaseModel, ABC):
"""Base interface for memory in chains."""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
@abstractmethod
def memory_variables(self) -> List[str]:
"""Input keys this memory class will load dynamically."""
@abstractmethod
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return key-value pairs given the text input to the chain.
If None, return all memories
"""
@abstractmethod
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save the context of this model run to memory."""
@abstractmethod
def clear(self) -> None:
"""Clear memory contents."""
class BaseChatMessageHistory(ABC):
"""Base interface for chat message history
See `ChatMessageHistory` for default implementation.
"""
"""
Example: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | .. code-block:: python
class FileChatMessageHistory(BaseChatMessageHistory):
storage_path: str
session_id: str
@property
def messages(self):
with open(os.path.join(storage_path, session_id), 'r:utf-8') as f:
messages = json.loads(f.read())
return messages_from_dict(messages)
def add_user_message(self, message: str):
message_ = HumanMessage(content=message)
messages = self.messages.append(_message_to_dict(_message))
with open(os.path.join(storage_path, session_id), 'w') as f:
json.dump(f, messages)
def add_ai_message(self, message: str):
message_ = AIMessage(content=message)
messages = self.messages.append(_message_to_dict(_message))
with open(os.path.join(storage_path, session_id), 'w') as f:
json.dump(f, messages)
def clear(self):
with open(os.path.join(storage_path, session_id), 'w') as f:
f.write("[]")
"""
messages: List[BaseMessage]
@abstractmethod
def add_user_message(self, message: str) -> None: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Add a user message to the store"""
@abstractmethod
def add_ai_message(self, message: str) -> None:
"""Add an AI message to the store"""
@abstractmethod
def clear(self) -> None:
"""Remove all messages from the store"""
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
class BaseRetriever(ABC):
@abstractmethod
def get_relevant_documents(self, query: str) -> List[Document]:
"""Get documents relevant for a query.
Args:
query: string to find relevant documents for
Returns:
List of relevant documents
"""
@abstractmethod
async def aget_relevant_documents(self, query: str) -> List[Document]:
"""Get documents relevant for a query.
Args:
query: string to find relevant documents for
Returns:
List of relevant documents
"""
Memory = BaseMemory
class BaseOutputParser(BaseModel, ABC): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Class to parse the output of an LLM call.
Output parsers help structure language model responses.
"""
@abstractmethod
def parse(self, text: str) -> Any:
"""Parse the output of an LLM call.
A method which takes in a string (assumed output of language model )
and parses it into some structure.
Args:
text: output of language model
Returns:
structured output
"""
def parse_with_prompt(self, completion: str, prompt: PromptValue) -> Any:
"""Optional method to parse the output of an LLM call with a prompt.
The prompt is largely provided in the event the OutputParser wants
to retry or fix the output in some way, and needs information from
the prompt to do so.
Args:
completion: output of language model
prompt: prompt value
Returns:
structured output
"""
return self.parse(completion)
def get_format_instructions(self) -> str: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Instructions on how the LLM output should be formatted."""
raise NotImplementedError
@property
def _type(self) -> str:
"""Return the type key."""
raise NotImplementedError
def dict(self, **kwargs: Any) -> Dict:
"""Return dictionary representation of output parser."""
output_parser_dict = super().dict()
output_parser_dict["_type"] = self._type
return output_parser_dict
class OutputParserException(Exception):
"""Exception that output parsers should raise to signify a parsing error.
This exists to differentiate parsing errors from other code or execution errors
that also may arise inside the output parser. OutputParserExceptions will be
available to catch and handle in ways to fix the parsing error, while other
errors will be raised.
"""
pass |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | tests/unit_tests/output_parsers/test_pydantic_parser.py | """Test PydanticOutputParser"""
from enum import Enum
from typing import Optional
from pydantic import BaseModel, Field
from langchain.output_parsers.pydantic import PydanticOutputParser
from langchain.schema import OutputParserException
class Actions(Enum): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | tests/unit_tests/output_parsers/test_pydantic_parser.py | SEARCH = "Search"
CREATE = "Create"
UPDATE = "Update"
DELETE = "Delete"
class TestModel(BaseModel):
action: Actions = Field(description="Action to be performed")
action_input: str = Field(description="Input to be used in the action")
additional_fields: Optional[str] = Field(
description="Additional fields", default=None
)
DEF_RESULT = """{
"action": "Update",
"action_input": "The PydanticOutputParser class is powerful",
"additional_fields": null
}"""
DEF_RESULT_FAIL = """{
"action": "update",
"action_input": "The PydanticOutputParser class is powerful",
"additional_fields": null
}"""
DEF_EXPECTED_RESULT = TestModel(
action=Actions.UPDATE,
action_input="The PydanticOutputParser class is powerful",
additional_fields=None,
)
def test_pydantic_output_parser() -> None: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | tests/unit_tests/output_parsers/test_pydantic_parser.py | """Test PydanticOutputParser."""
pydantic_parser = PydanticOutputParser(pydantic_object=TestModel)
result = pydantic_parser.parse(DEF_RESULT)
print("parse_result:", result)
assert DEF_EXPECTED_RESULT == result
def test_pydantic_output_parser_fail() -> None:
"""Test PydanticOutputParser where completion result fails schema validation."""
pydantic_parser = PydanticOutputParser(pydantic_object=TestModel)
try:
pydantic_parser.parse(DEF_RESULT_FAIL)
except OutputParserException as e:
print("parse_result:", e)
assert "Failed to parse TestModel from completion" in str(e)
else:
assert False, "Expected OutputParserException" |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,905 | Ignore files from `.gitignore` in Git loader | those files may be `node_modules` or `.pycache` files or sensitive env files, all of which should be ignored by default | https://github.com/langchain-ai/langchain/issues/2905 | https://github.com/langchain-ai/langchain/pull/2909 | 7ee87eb0c8df10315b45ebbddcad36a72b7fe7b9 | 66bef1d7ed17f00e7b554ca5413e336970489253 | "2023-04-14T17:08:38Z" | python | "2023-04-14T22:02:21Z" | langchain/document_loaders/git.py | import os
from typing import Callable, List, Optional
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
class GitLoader(BaseLoader):
"""Loads files from a Git repository into a list of documents.
Repository can be local on disk available at `repo_path`,
or remote at `clone_url` that will be cloned to `repo_path`.
Currently supports only text files.
Each document represents one file in the repository. The `path` points to
the local Git repository, and the `branch` specifies the branch to load
files from. By default, it loads from the `main` branch.
"""
def __init__( |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,905 | Ignore files from `.gitignore` in Git loader | those files may be `node_modules` or `.pycache` files or sensitive env files, all of which should be ignored by default | https://github.com/langchain-ai/langchain/issues/2905 | https://github.com/langchain-ai/langchain/pull/2909 | 7ee87eb0c8df10315b45ebbddcad36a72b7fe7b9 | 66bef1d7ed17f00e7b554ca5413e336970489253 | "2023-04-14T17:08:38Z" | python | "2023-04-14T22:02:21Z" | langchain/document_loaders/git.py | self,
repo_path: str,
clone_url: Optional[str] = None,
branch: Optional[str] = "main",
file_filter: Optional[Callable[[str], bool]] = None,
):
self.repo_path = repo_path
self.clone_url = clone_url
self.branch = branch
self.file_filter = file_filter
def load(self) -> List[Document]:
try:
from git import Blob, Repo
except ImportError as ex:
raise ImportError(
"Could not import git python package. "
"Please install it with `pip install GitPython`."
) from ex
if not os.path.exists(self.repo_path) and self.clone_url is None:
raise ValueError(f"Path {self.repo_path} does not exist")
elif self.clone_url:
repo = Repo.clone_from(self.clone_url, self.repo_path)
repo.git.checkout(self.branch)
else:
repo = Repo(self.repo_path) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,905 | Ignore files from `.gitignore` in Git loader | those files may be `node_modules` or `.pycache` files or sensitive env files, all of which should be ignored by default | https://github.com/langchain-ai/langchain/issues/2905 | https://github.com/langchain-ai/langchain/pull/2909 | 7ee87eb0c8df10315b45ebbddcad36a72b7fe7b9 | 66bef1d7ed17f00e7b554ca5413e336970489253 | "2023-04-14T17:08:38Z" | python | "2023-04-14T22:02:21Z" | langchain/document_loaders/git.py | repo.git.checkout(self.branch)
docs: List[Document] = []
for item in repo.tree().traverse():
if not isinstance(item, Blob):
continue
file_path = os.path.join(self.repo_path, item.path)
if self.file_filter and not self.file_filter(file_path):
continue
rel_file_path = os.path.relpath(file_path, self.repo_path)
try:
with open(file_path, "rb") as f:
content = f.read()
file_type = os.path.splitext(item.name)[1]
try:
text_content = content.decode("utf-8")
except UnicodeDecodeError:
continue
metadata = {
"file_path": rel_file_path,
"file_name": item.name,
"file_type": file_type,
}
doc = Document(page_content=text_content, metadata=metadata)
docs.append(doc)
except Exception as e:
print(f"Error reading file {file_path}: {e}")
return docs |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | "2023-04-13T17:10:45Z" | python | "2023-04-16T20:44:04Z" | langchain/vectorstores/__init__.py | """Wrappers on top of vector stores."""
from langchain.vectorstores.atlas import AtlasDB
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.chroma import Chroma
from langchain.vectorstores.deeplake import DeepLake
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores.faiss import FAISS
from langchain.vectorstores.milvus import Milvus
from langchain.vectorstores.opensearch_vector_search import OpenSearchVectorSearch
from langchain.vectorstores.pinecone import Pinecone
from langchain.vectorstores.qdrant import Qdrant
from langchain.vectorstores.weaviate import Weaviate
__all__ = [
"ElasticVectorSearch",
"FAISS",
"VectorStore",
"Pinecone",
"Weaviate",
"Qdrant",
"Milvus",
"Chroma",
"OpenSearchVectorSearch",
"AtlasDB",
"DeepLake",
] |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/base.py | """Base interface for chains combining documents."""
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple
from pydantic import Field
from langchain.chains.base import Chain
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter, TextSplitter
class BaseCombineDocumentsChain(Chain, ABC):
"""Base interface for chains combining documents."""
input_key: str = "input_documents"
output_key: str = "output_text"
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.input_key]
@property
def output_keys(self) -> List[str]:
"""Return output key.
:meta private:
"""
return [self.output_key]
def prompt_length(self, docs: List[Document], **kwargs: Any) -> Optional[int]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/base.py | """Return the prompt length given the documents passed in.
Returns None if the method does not depend on the prompt length.
"""
return None
@abstractmethod
def combine_docs(self, docs: List[Document], **kwargs: Any) -> Tuple[str, dict]:
"""Combine documents into a single string."""
@abstractmethod
async def acombine_docs(
self, docs: List[Document], **kwargs: Any
) -> Tuple[str, dict]:
"""Combine documents into a single string asynchronously."""
def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
docs = inputs[self.input_key]
other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
output, extra_return_dict = self.combine_docs(docs, **other_keys)
extra_return_dict[self.output_key] = output
return extra_return_dict
async def _acall(self, inputs: Dict[str, Any]) -> Dict[str, str]:
docs = inputs[self.input_key]
other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
output, extra_return_dict = await self.acombine_docs(docs, **other_keys)
extra_return_dict[self.output_key] = output
return extra_return_dict
class AnalyzeDocumentChain(Chain): |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/base.py | """Chain that splits documents, then analyzes it in pieces."""
input_key: str = "input_document"
output_key: str = "output_text"
text_splitter: TextSplitter = Field(default_factory=RecursiveCharacterTextSplitter)
combine_docs_chain: BaseCombineDocumentsChain
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.input_key]
@property
def output_keys(self) -> List[str]:
"""Return output key.
:meta private:
"""
return [self.output_key]
def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
document = inputs[self.input_key]
docs = self.text_splitter.create_documents([document])
other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
other_keys[self.combine_docs_chain.input_key] = docs
return self.combine_docs_chain(other_keys, return_only_outputs=True) |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/refine.py | """Combining documents by doing a first pass and then refining on more documents."""
from __future__ import annotations
from typing import Any, Dict, List, Tuple
from pydantic import Extra, Field, root_validator
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.docstore.document import Document
from langchain.prompts.base import BasePromptTemplate
from langchain.prompts.prompt import PromptTemplate
def _get_default_document_prompt() -> PromptTemplate:
return PromptTemplate(input_variables=["page_content"], template="{page_content}")
class RefineDocumentsChain(BaseCombineDocumentsChain):
"""Combine documents by doing a first pass and then refining on more documents."""
initial_llm_chain: LLMChain
"""LLM chain to use on initial document."""
refine_llm_chain: LLMChain
"""LLM chain to use when refining."""
document_variable_name: str
"""The variable name in the initial_llm_chain to put the documents in.
If only one variable in the initial_llm_chain, this need not be provided."""
initial_response_name: str
"""The variable name to format the initial response in when refining."""
document_prompt: BasePromptTemplate = Field(
default_factory=_get_default_document_prompt
)
"""Prompt to use to format each document."""
return_intermediate_steps: bool = False
"""Return the results of the refine steps in the output."""
@property
def output_keys(self) -> List[str]: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/refine.py | """Expect input key.
:meta private:
"""
_output_keys = super().output_keys
if self.return_intermediate_steps:
_output_keys = _output_keys + ["intermediate_steps"]
return _output_keys
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@root_validator(pre=True)
def get_return_intermediate_steps(cls, values: Dict) -> Dict: |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/refine.py | """For backwards compatibility."""
if "return_refine_steps" in values:
values["return_intermediate_steps"] = values["return_refine_steps"]
del values["return_refine_steps"]
return values
@root_validator(pre=True)
def get_default_document_variable_name(cls, values: Dict) -> Dict:
"""Get default document variable name, if not provided."""
if "document_variable_name" not in values:
llm_chain_variables = values["initial_llm_chain"].prompt.input_variables
if len(llm_chain_variables) == 1:
values["document_variable_name"] = llm_chain_variables[0]
else:
raise ValueError(
"document_variable_name must be provided if there are "
"multiple llm_chain input_variables"
)
else:
llm_chain_variables = values["initial_llm_chain"].prompt.input_variables
if values["document_variable_name"] not in llm_chain_variables:
raise ValueError(
f"document_variable_name {values['document_variable_name']} was "
f"not found in llm_chain input_variables: {llm_chain_variables}"
)
return values
def combine_docs(self, docs: List[Document], **kwargs: Any) -> Tuple[str, dict]: |