Datasets:

image
imagewidth (px) 700
700
| label
class label 2
classes |
|---|---|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
0boxes
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
|
1images
|
OCR GENERATED Machine-Readable Zone (MRZ) Text Detection
The dataset includes a collection of GENERATED photos containing Machine Readable Zones (MRZ) commonly found on identification documents such as passports, visas, and ID cards. Each photo in the dataset is accompanied by text detection and Optical Character Recognition (OCR) results.
💴 For Commercial Usage: To discuss your requirements, learn about the price and buy the dataset, leave a request on TrainingData to buy the dataset
This dataset is useful for developing applications related to document verification, identity authentication, or automated data extraction from identification documents.
The dataset is solely for informational or educational purposes and should not be used for any fraudulent or deceptive activities.

Dataset structure
- images - contains of original images of documents
- boxes - includes bounding box labeling for the original images
- annotations.xml - contains coordinates of the bounding boxes and detected text, created for the original photo
Data Format
Each image from images folder is accompanied by an XML-annotation in the annotations.xml file indicating the coordinates of the bounding boxes and detected text . For each point, the x and y coordinates are provided.
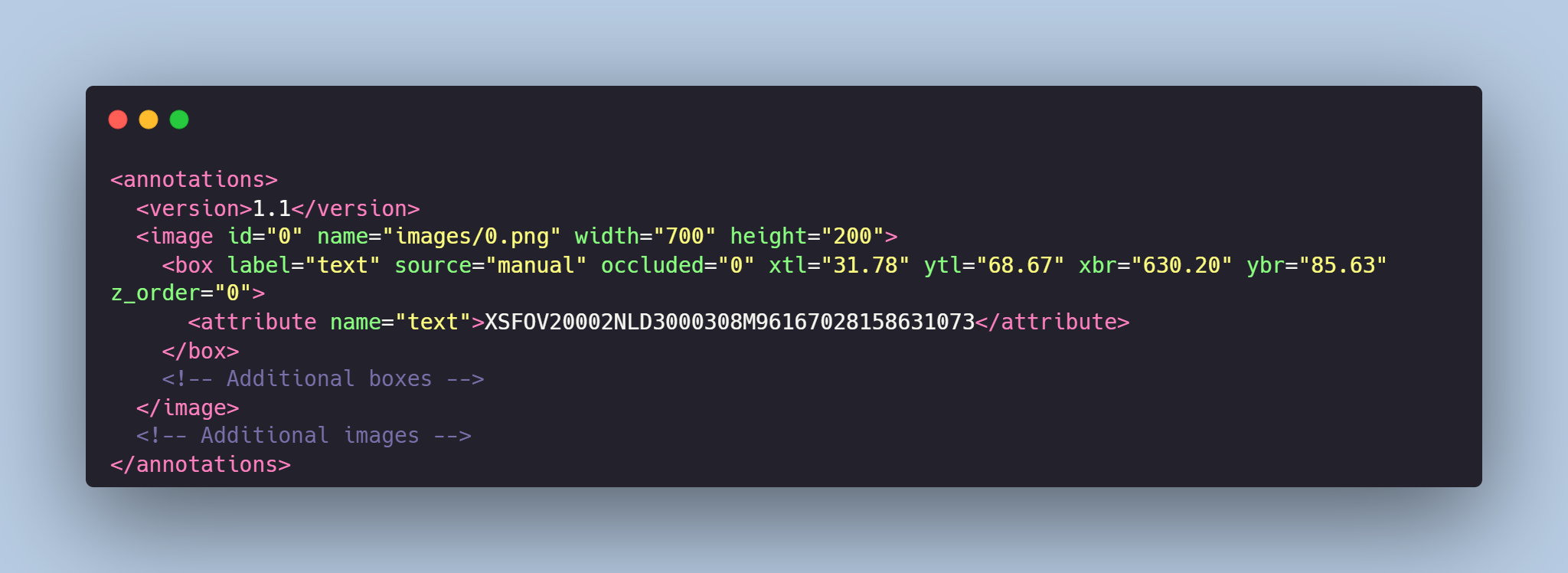
Text Detection in the Documents might be made in accordance with your requirements.
💴 Buy the Dataset: This is just an example of the data. Leave a request on https://trainingdata.pro/datasets to discuss your requirements, learn about the price and buy the dataset
TrainingData provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: https://www.kaggle.com/trainingdatapro/datasets
TrainingData's GitHub: https://github.com/Trainingdata-datamarket/TrainingData_All_datasets
keywords: text detection, text recognition, optical character recognition, document text recognition, document text detection, detecting text-lines, object detection, deep-text-recognition, text area detection, text extraction, images dataset, image-to-text, generated data, passports, passport designs, machine-readable zone, mrz, mrz recognition, mrz code, synthetic data, synthetic data generation, synthetic dataset , gdpr synthetic data, object detection, computer vision, documents, document security, cybersecurity, information security systems, passport data extraction
- Downloads last month
- 138