
Image generated by https://ideogram.ai/
We introduce Vision-Flan, the largest human-annotated visual instruction tuning dataset that consists of 200+ diverse vision-language tasks derived from 101 open-source computer vision datasets. Each task is equipped with an expert written instruction and carefully designed templates for the inputs and outputs. The dataset encompasses a wide range of tasks such as image captioning, visual question-answering, and visual understanding. Vision-Flan is built to support various researches and applications in vision-language models, pushing the boundaries of understanding and interaction between these two modalities. Researchers and practitioners can leverage this dataset to advance the state of the art vision-language models and develop innovative algorithms in a wide range of domains.
This dataset includes:
- 1,664,261 instances sourced from academic datasets
- 187 diverse tasks
Usage
from datasets import load_dataset
# save the dataset to disk
dataset = load_dataset("Vision-Flan/vision-flan")
dataset.save_to_disk("test.hf")
Run the script to unzip all data that is zipped
unzip.sh
Dataset Details
Dataset columns
| conversations | id | task_name | image |
|---|---|---|---|
| LIST(DICT) | STRING | STRING | STRING |


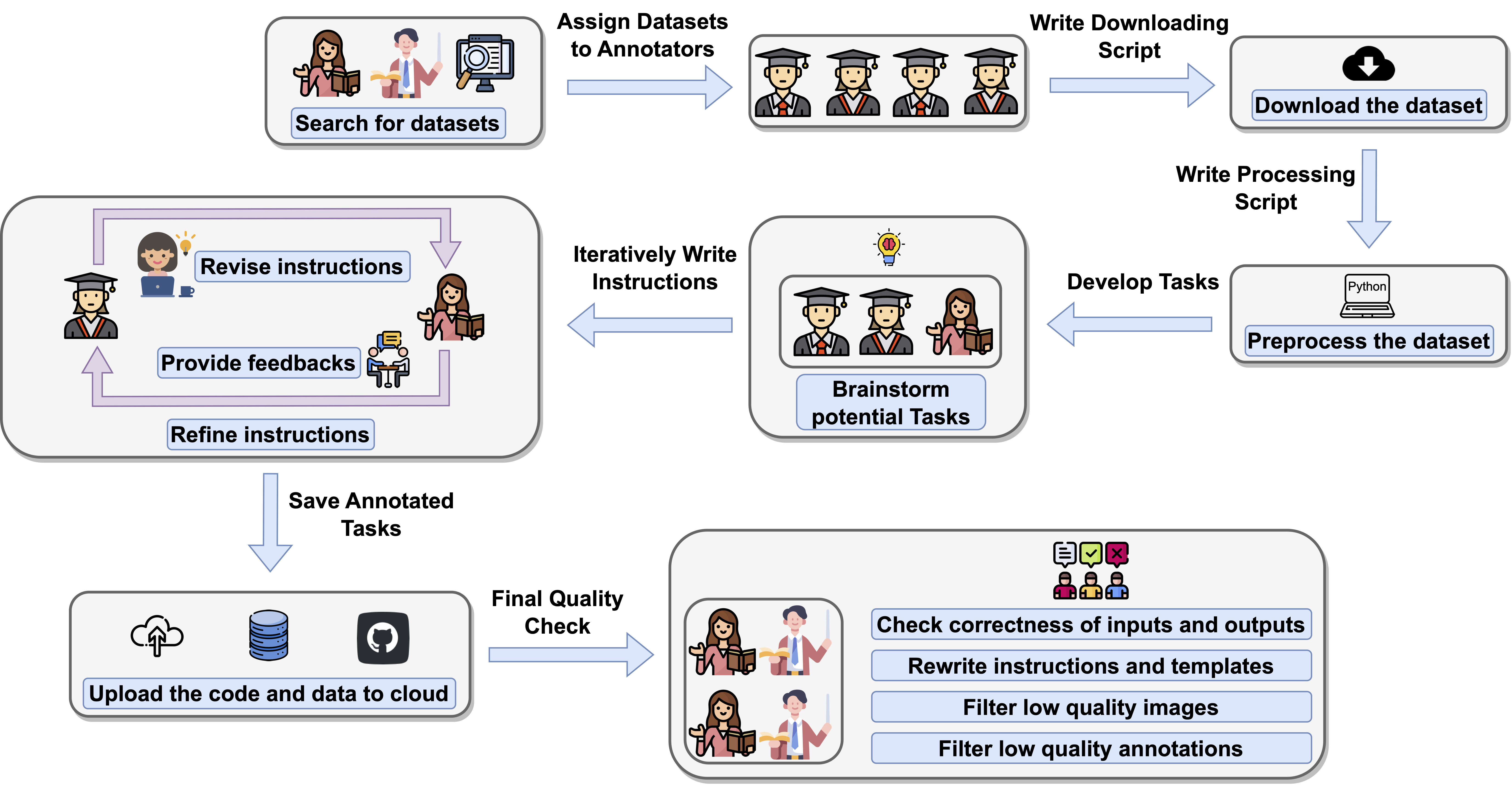
Collection and Annotation
Examples
