
source
stringclasses 1
value | text
stringlengths 152
659k
| filtering_features
stringlengths 402
437
| source_other
stringlengths 440
819k
|
|---|---|---|---|
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add hooks sufficient to build task-local data
username_0: As currently proposed, futures-core 0.3 will not build in task-local data. The idea is to instead address needs here through external libraries via scoped thread-local storage.
For any robust task-local data, however, we want the ability to hook into the task spawning process, so that data inheritance schemes can be set up.
This issue tracks the design of such hooks.
<issue_comment>username_1: If https://github.com/rust-lang-nursery/wg-net/issues/56 proceeds and spawning is removed from task::Context, I expect the value of having a good story around task-local data to increase. In general, I don't really want to stash a `Box<Executor>` in all the places that need spawning.
Things task-local data would be helpful for:
0. Default spawn (https://github.com/rust-lang-nursery/wg-net/issues/56)
1. Storing trace info (https://github.com/tokio-rs/tokio/issues/561)
2. Storing request-local data like user credentials
<issue_comment>username_2: I think most places that need spawning are application code, which can just reference an appropriate executor via globals or handles or whatever it likes directly, as they do today in futures 0.1.
<issue_comment>username_1: Yes, that's certainly true. I've updated my comment to clarify I'm talking about executor-generic framework code.
<issue_comment>username_1: Prior discussion: https://github.com/rust-lang-nursery/futures-rs/issues/937
<issue_comment>username_3: For task-local storage, what is needed is to run code before each top-level future poll (and potentially, if using scoped-tls, code after too).
One solution is to add a hook that allows wrapping every future that comes in the executor into some wrapper future type: this way the wrapper future would be able to execute code around the wrapped future.
Actually, this could even be done by consuming the executor and returning a wrapping executor that first wraps the future with the task-local-wrapper, and then forwards the wrapped future to the wrapped executor.
However, I'm not sure this “consuming the executor and returning it” would actually work: what I actually want is `tokio::spawn` to use the wrapping executor -- which, AFAIU, wouldn't happen with the consume-and-wrap design.
<issue_comment>username_1: I messed around with @mitsuhiko's [execution-context](https://crates.io/crates/execution-context) crate yesterday. It's futures-agnostic and works via TLS, and I made it work with futures exactly as @username_3 said: a wrapper future:
```rust
/// Returns a future that executes within the scope of the current [ExecutionContext].
pub fn context_propagating<F: Future>(future: F) -> impl Future<Output = F::Output> {
ContextFuture {
future,
context: ExecutionContext::capture(),
}
}
/// A future that executes within a specific [ExecutionContext].
struct ContextFuture<F> {
future: F,
context: ExecutionContext,
}
impl<F> Future for ContextFuture<F>
where
F: Future,
{
type Output = F::Output;
fn poll(self: PinMut<Self>, cx: &mut task::Context) -> Poll<F::Output> {
let me = unsafe { PinMut::get_mut_unchecked(self) };
let future = unsafe { PinMut::new_unchecked(&mut me.future) };
me.context.run(|| future.poll(cx))
}
}
```
This works quite well! Like @username_3, I definitely see the value in hooking into the spawn mechanism, because wrapping every future in `context_propagating` before spawning is error-prone. Empirically, I've seen context propagation issues in production servers more times than I can count. Such a hook would have to be opt-in, because not every application needs or can use task-local data via TLS.
<issue_comment>username_2: A portable mechanism for wrapping all top-level `poll` calls might have broader applications as well: for example, task-level profiling, or just logging warnings when a poll call blocks for unreasonably long, would call for something similar.
<issue_comment>username_3: I guess the first design decision is: do we want to add hooks to modify top-level `poll` calls into an existing `Executor`, or do we want to wrap `Executor`s into other, different-top-level-poll-call-behaviour `Executor`s?
I lean for the first option, because it'd work nicely with eg. `tokio::spawn`, while wrapping `Executor`s into other `Executor`s would mean the top-level executor would need to be changed.
<issue_comment>username_0: @username_1 @username_3 A question regarding these executor-level hooks: it seems like if you ever use a library that creates its own executor internally, you would have no way to instrument it with hooks. And of course you could forget to do so on your own executor. Both of which would lead to propagation failures.
Or were you thinking of providing a *global* hook mechanism of some kind?
<issue_comment>username_1: @username_0 I hadn't considered the multi-executor scenario at all. Do you have any thoughts on a global hook mechanism?
<issue_comment>username_3: Actually, the more I think about this, would it be for `task_local` or for handling time (`timeout` shouldn't require forcing the executor, it's generic enough), the more I think that futures should look like this (written in the github comment box, please forgive shallowness of reflexion):
```rust
trait Executor {
type Context: BasicContext;
}
trait BasicContext {
type Waker: BasicWaker;
fn get_waker(&mut Self) -> Self::Waker;
}
trait BasicWaker {
// ...
}
trait Future<Exec: Executor> {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut <Exec as Executor>::Context) -> Poll<Self::Output>;
}
```
This could be expanded with:
```rust
trait TaskLocalExecutor: Executor
where <Self as Executor>::Context: TaskLocalContext,
{ }
trait TaskLocalContext {
fn get_task_local(ctx: &mut <Self as Executor>::Context) -> &mut TaskLocalMap;
}
// some magic using TaskLocalMap to make it available as a task-local through some macro
```
And
```rust
trait TimeoutExecutor: Executor
where <Self as Executor>::Context: TimeoutContext,
{
type TimeoutFuture: Future<Output = ()>;
fn timeout_future(ctx: &mut <Self as Executor>::Context, d: Duration) -> TimeoutFuture;
}
// Some macro to make it easily usable from async/await
```
and [etc.] (actually, even `Waker` could be moved to specific executors, not all futures require that the executor is able to wake them and some executors may not support waking but just run each future in a round-robin fashion… though that'd maybe be over-doing it)
A `Future` would then be written like:
```rust
impl<E: Executor + TimeoutExecutor> Future for MyFuture {
type Output = /* ... */;
fn poll(self: Pin<&mut Self>, cx: &mut <Exec as Executor>::Context) -> Poll<Self::Output> {
// ...
}
}
```
And a future combinator function would look like:
```rust
fn run_after_10s<E: Executor + TimeoutExecutor, F: Future<E>>(f: F) -> impl Future<E> {
E::timeout_future(Duration::from_millis(10000)).and_then(|_| f)
}
```
Assuming that `async/await` is able to infer the bounds to set to its `Executor` depending on its contents, this sounds like a minor inconvenience when writing futures manually (a bit more boilerplate) for much more flexibility and portability (task locals, timeouts, and likely other things that will be implemented by lots of executors and that we've not yet thought about)
I guess this has already been discussed somewhere… could someone point me to where, so I understand the discussion around it?
<issue_comment>username_3: Oh, forgot to mention: it would also allow experimenting with cross-executor task_locals / timeouts outside of `std`, given that `std` would only need to provide the `Executor` trait, and libraries could define `TaskLocalExecutor`, `TimeoutExecutor`, etc.
<issue_comment>username_4: @username_3 https://github.com/rust-lang-nursery/futures-rs/issues/1196 has some similar prior discussion. The place where I've always thought this would become far too tedious is in propagating the bounds everywhere it's needed (i.e. when you have a function generic over `F: Future` you now need to have `E: Executor, F: Future<E>` and `f: impl Future` becomes `f: impl Future<impl Executor>`). Maybe that just won't be a common enough issue to really matter.
<issue_comment>username_3: @username_4 Thank you for the pointer! I'll continue discussion there :)
<issue_comment>username_2: It's worth noting that tokio constructs its executor(s) lazily, so there is adequate opportunity to hook into them during startup without forcing ugly global state into standard APIs.<issue_closed> | {'fraction_non_alphanumeric': 0.08020536223616657, 'fraction_numerical': 0.005818596691386195, 'mean_word_length': 4.345121951219512, 'pattern_counts': {'":': 0, '<': 44, '<?xml version=': 0, '>': 52, 'https://': 6, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '1158655', 'n_tokens_mistral': 2448, 'n_tokens_neox': 2337, 'n_words': 1124} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Updating the server to allow optional policy_path values
username_0: This change updates the server, updating how it processes config values and allowing it to handle optional or ommitted policy_path values. This fixes a bug where users could not leave the policy_path config file unset, in addition to a bug that forced users to use '/etc/pykmip/policies' as their policy directory.
Fixes #210 | {'fraction_non_alphanumeric': 0.037037037037037035, 'fraction_numerical': 0.009259259259259259, 'mean_word_length': 5.185714285714286, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15383225', 'n_tokens_mistral': 107, 'n_tokens_neox': 104, 'n_words': 62} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: privatelink.vault.azure.net is maybe missing
username_0: Hi,
I think that the private dns zone privatelink.vault.azure.net is missing for Keyvault.
Regards
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: a88af182-32aa-a8f3-359d-b92ae1cfb8c7
* Version Independent ID: 01ce07fc-4bc2-def5-9ecd-a80330ad9488
* Content: [Azure Private Endpoint DNS configuration](https://docs.microsoft.com/en-us/azure/private-link/private-endpoint-dns)
* Content Source: [articles/private-link/private-endpoint-dns.md](https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/private-link/private-endpoint-dns.md)
* Service: **private-link**
* GitHub Login: @asudbring
* Microsoft Alias: **allensu**
<issue_comment>username_1: @username_0, from portal configuration it looks like there is only one private dns ("privatelink.vaultcore.azure.net") is available. I did test it locally and can see only **keyvault-name.privatelink.vaultcore.azure.net** getting populated on creating new private endpoint connection to Azure key vault.

<issue_comment>username_0: This is strange: I created a keyvault and the DNS configuration of the private endpoint is the following:
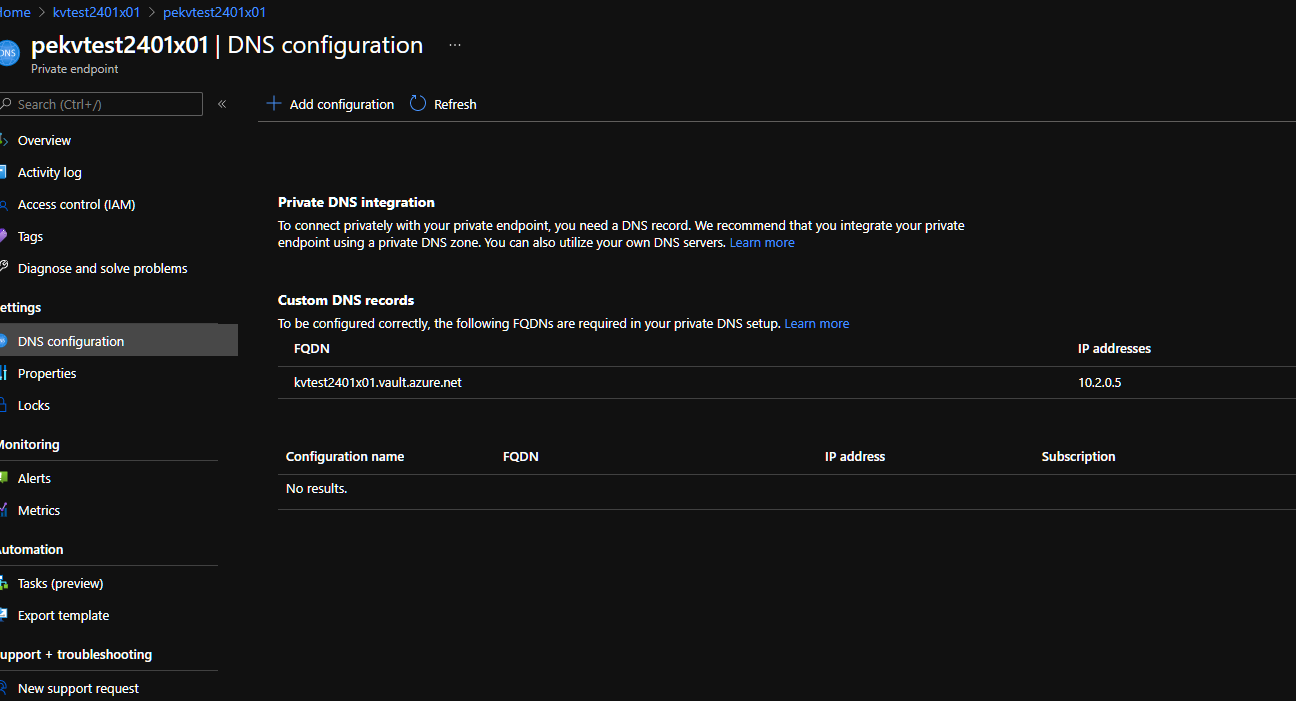
<issue_comment>username_0: Ok I see, there is not parity like other services; vault.azure.net is translated in privatelink.vaultcore.azure.net ?
<issue_comment>username_1: @username_0 , you should be able to see the private DNS zone you have created in their respective category,

<issue_comment>username_0: Thanks for you help. I didn't find it first because I had to create the DNS zone before and I thought that there is a consistent pattern like blob table...<issue_closed> | {'fraction_non_alphanumeric': 0.10285714285714286, 'fraction_numerical': 0.07142857142857142, 'mean_word_length': 5.1976401179941005, 'pattern_counts': {'":': 0, '<': 8, '<?xml version=': 0, '>': 8, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18195959', 'n_tokens_mistral': 772, 'n_tokens_neox': 686, 'n_words': 187} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: CI: pin setuptool<0.60 in Azure template
username_0: Azure pipelines are failing. Ex: https://dev.azure.com/scipy-org/SciPy/_build/results?buildId=17282&view=logs&jobId=7902a2c1-7b88-5b2d-6408-84b88759c642&j=7902a2c1-7b88-5b2d-6408-84b88759c642&t=893309fc-8329-5d49-356d-625e41704eb4
<details>
<summary>Details</summary>
```
`numpy.distutils` is deprecated since NumPy 1.23.0, as a result
of the deprecation of `distutils` itself. It will be removed for
Python >= 3.12. For older Python versions it will remain present.
It is recommended to use `setuptools < 60.0` for those Python versions.
For more details, see:
https://numpy.org/devdocs/reference/distutils_status_migration.html
from numpy.distutils.core import setup
Running from SciPy source directory.
/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/setuptools/config/pyprojecttoml.py:100: _ExperimentalProjectMetadata: Support for project metadata in `pyproject.toml` is still experimental and may be removed (or change) in future releases.
warnings.warn(msg, _ExperimentalProjectMetadata)
Traceback (most recent call last):
File "setup.py", line 532, in <module>
setup_package()
File "setup.py", line 528, in setup_package
```
</details>
<issue_comment>username_0: Another issue which I think is not related is with our pyproject.toml
```
distutils.errors.DistutilsOptionError: Impossible to expand dynamic value of 'description'. No configuration found for `tool.setuptools.dynamic.description`
```
<issue_comment>username_0: `refguide_asv_check` failure is not related. Jinja got an update yesterday cc @rossbar
<issue_comment>username_0: Cool, GH actions is in maintenance now...
<issue_comment>username_0: We don't see it yet due to the maintenance but logs are here https://dev.azure.com/scipy-org/SciPy/_build/results?buildId=17289&view=results
Seems like we can merge. | {'fraction_non_alphanumeric': 0.09744897959183674, 'fraction_numerical': 0.061224489795918366, 'mean_word_length': 4.717201166180758, 'pattern_counts': {'":': 0, '<': 13, '<?xml version=': 0, '>': 12, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19006590', 'n_tokens_mistral': 717, 'n_tokens_neox': 629, 'n_words': 179} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Insurance price/payout issue
username_0: Insurance payouts much higher than price.
<issue_comment>username_0: ROF table was not being properly imported by insurance class when using imported ROF tables. Now that it is, insurance price is higher than it should be by some ~50% on average when using imported tables, although I believe this is a theoretical and not a code problem -- maybe an amplification of the errors of the imported tables. | {'fraction_non_alphanumeric': 0.039832285115303984, 'fraction_numerical': 0.008385744234800839, 'mean_word_length': 5.207792207792208, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '28126376', 'n_tokens_mistral': 110, 'n_tokens_neox': 107, 'n_words': 70} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: send login data as JSON
username_0: Set the content-type to `application/json` and send the login data as stringified JSON.
Per @skiqh's [work-around](https://github.com/username_2/pouchdb-authentication/issues/111#issuecomment-242810853) in #111
For anyone else with the issue in the meantime, you can use his fork:
`npm i --save https://github.com/skiqh/pouchdb-authentication.git\#patch-1`
<issue_comment>username_1: @username_2 I also like to have this PR. Can also release a version for you.
<issue_comment>username_2: This passes the test suite, so I'm perfectly fine with this. Will do a release today. Thanks!
<issue_comment>username_2: published in 0.5.4
<issue_comment>username_1: Thanks! | {'fraction_non_alphanumeric': 0.09421265141318977, 'fraction_numerical': 0.034993270524899055, 'mean_word_length': 5.048780487804878, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5643489', 'n_tokens_mistral': 245, 'n_tokens_neox': 227, 'n_words': 83} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Incorrect mapping of sourcemaps using node-sass@1.1.4
username_0: @dlmanning I decided to update gulp-sass to 1.2.2. today and noticed that all my css classes mapped to incorrect scss sourcefiles and/or line numbers. Figured it had to be something that changed. I'm no JS wizzkid but I checked your dependencies and noticed you're using the relaxt ^ instead of ~ for node-sass. dependency.They recently bumped from 1.0.3 to 1.1.4 and with ^1.0 it would require the new 1.1.4 version. If I use the 1.0.3 version the problem is resolved.
<issue_comment>username_1: As this is an upstream bug, I'm going to close this issue.<issue_closed> | {'fraction_non_alphanumeric': 0.06706408345752608, 'fraction_numerical': 0.03278688524590164, 'mean_word_length': 4.291338582677166, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30960125', 'n_tokens_mistral': 207, 'n_tokens_neox': 197, 'n_words': 99} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Scenarios are not running: ConnectionClose, ConnectionClose, DbFortunesDapper, DbFortunesEf, DbFortunesRaw ...
username_0: Some scenarios have stopped running:
| Scenario | Environment | Last Run |
| -------- | ----------- | -------- |
| ConnectionClose | Linux, Physical, http, KestrelSockets | 9/16/19 12:45:21 AM +00:00 |
| ConnectionClose | Linux, Physical, https, KestrelSockets | 9/16/19 12:45:39 AM +00:00 |
| DbFortunesDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:39:58 AM +00:00 |
| DbFortunesEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:40:40 AM +00:00 |
| DbFortunesRaw | Linux, Physical, http, KestrelSockets | 9/16/19 12:39:15 AM +00:00 |
| DbMultiQueryDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:31:39 AM +00:00 |
| DbMultiQueryEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:32:20 AM +00:00 |
| DbMultiQueryRaw | Linux, Physical, http, KestrelSockets | 9/16/19 12:30:56 AM +00:00 |
| DbMultiUpdateDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:35:49 AM +00:00 |
| DbMultiUpdateEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:36:30 AM +00:00 |
| DbMultiUpdateRaw | Linux, Physical, http, KestrelSockets | 9/16/19 12:35:06 AM +00:00 |
| DbSingleQueryDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:27:24 AM +00:00 |
| DbSingleQueryEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:28:07 AM +00:00 |
| DbSingleQueryRaw | Linux, Physical, http, KestrelSockets | 9/16/19 12:26:43 AM +00:00 |
| HttpClient | Linux, Physical, http, KestrelSockets | 9/16/19 12:43:35 AM +00:00 |
| HttpClientFactory | Linux, Physical, http, KestrelSockets | 9/16/19 12:45:02 AM +00:00 |
| HttpClientParallel | Linux, Physical, http, KestrelSockets | 9/16/19 12:44:16 AM +00:00 |
| Json | Linux, Physical, h2, KestrelSockets | 9/16/19 12:21:11 AM +00:00 |
| Json | Linux, Physical, h2c, KestrelSockets | 9/16/19 12:21:51 AM +00:00 |
| MemoryCachePlaintext | Linux, Physical, http, KestrelSockets | 9/16/19 12:22:34 AM +00:00 |
| MemoryCachePlaintextSetRemove | Linux, Physical, http, KestrelSockets | 9/16/19 12:23:16 AM +00:00 |
| MvcDbFortunesDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:42:04 AM +00:00 |
| MvcDbFortunesEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:42:47 AM +00:00 |
| MvcDbFortunesRaw | Linux, Physical, http, KestrelSockets | 9/16/19 12:41:22 AM +00:00 |
| MvcDbMultiQueryDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:33:44 AM +00:00 |
| MvcDbMultiQueryEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:34:25 AM +00:00 |
| MvcDbMultiQueryRaw | Linux, Physical, http, KestrelSockets | 9/16/19 12:33:01 AM +00:00 |
| MvcDbMultiUpdateDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:37:53 AM +00:00 |
| MvcDbMultiUpdateEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:38:34 AM +00:00 |
| MvcDbSingleQueryDapper | Linux, Physical, http, KestrelSockets | 9/16/19 12:29:30 AM +00:00 |
| MvcDbSingleQueryEf | Linux, Physical, http, KestrelSockets | 9/16/19 12:30:12 AM +00:00 |
| MvcDbSingleQueryRaw | Linux, Physical, http, KestrelSockets | 9/16/19 12:28:48 AM +00:00 |
| PlaintextNonPipelined | Linux, Physical, https, KestrelSockets | 9/16/19 12:19:07 AM +00:00 |
| PlaintextNonPipelined | Linux, Physical, h2, KestrelSockets | 9/16/19 12:19:49 AM +00:00 |
| PlaintextNonPipelined | Linux, Physical, h2c, KestrelSockets | 9/16/19 12:20:29 AM +00:00 |
| PlaintextNonPipelinedLogging | Linux, Physical, http, KestrelSockets | 9/16/19 12:47:34 AM +00:00 |
| PlaintextNonPipelinedLoggingNoScopes | Linux, Physical, http, KestrelSockets | 9/16/19 12:48:17 AM +00:00 |
| ResponseCachingPlaintextCached | Linux, Physical, http, KestrelSockets | 9/16/19 12:23:58 AM +00:00 |
| ResponseCachingPlaintextRequestNoCache | Linux, Physical, http, KestrelSockets | 9/16/19 12:25:20 AM +00:00 |
| ResponseCachingPlaintextResponseNoCache | Linux, Physical, http, KestrelSockets | 9/16/19 12:24:39 AM +00:00 |
| ResponseCachingPlaintextVaryByCached | Linux, Physical, http, KestrelSockets | 9/16/19 12:26:02 AM +00:00 |
[Logs](https://aka.ms/aspnet/benchmarks/jenkins)<issue_closed>
<issue_comment>username_1: Fixed | {'fraction_non_alphanumeric': 0.14285714285714285, 'fraction_numerical': 0.14810398282852372, 'mean_word_length': 5.09593023255814, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25447637', 'n_tokens_mistral': 2031, 'n_tokens_neox': 1624, 'n_words': 392} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Is PM reciever muted
username_0: ## Issue
When PlayerA sends a PM to PlayerB, while PlayerB is muted PlayerA does not get any information about this.
## Suggested behaviour
1. PlayerA is not an admin.
2. PlayerA gets a message "PlayerB is muted for another X minutes".
3. PlayerB does not recieve any PM.<issue_closed> | {'fraction_non_alphanumeric': 0.06077348066298342, 'fraction_numerical': 0.011049723756906077, 'mean_word_length': 4.112676056338028, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '21258582', 'n_tokens_mistral': 111, 'n_tokens_neox': 108, 'n_words': 53} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: property value is truncated to 40 characters
username_0: Hello,
I tried using the properties dataformat, and in my test I find that the mapped property value is truncated to 40 characters.
Example:
foo.bar: Loremipsumdolorsitametconsecteturadipiscingelit
This is be mapped to a String in my POJO with value "Loremipsumdolorsitametconsecteturadip...".
Is this an issue with my test or with the mapper?
Thanks.
<issue_comment>username_1: What dataformat? With which Jackson version? With what code?
Please include a reproduction showing how truncation occurs: there are no known problems like this reported.<issue_closed> | {'fraction_non_alphanumeric': 0.044977511244377814, 'fraction_numerical': 0.008995502248875561, 'mean_word_length': 5.242990654205608, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13608112', 'n_tokens_mistral': 193, 'n_tokens_neox': 182, 'n_words': 86} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Issues reading Yubikey 5
username_0: Hello,
I recently installed LineageOS 16 on my oneplus 3. I am trying to read my one time passwords with the Yubico Authenticator app but unfortunately I only manage to get a "Error in yubikey communication error!". I am not really sure what causes the issue but found a clue in the logcat I made.
```
06-28 08:32:30.897 4518 4546 E yubioath: Error using OathClient
06-28 08:32:30.897 4518 4546 E yubioath: java.io.IOException: Transceive length exceeds supported maximum
06-28 08:32:30.897 4518 4546 E yubioath: at android.nfc.TransceiveResult.getResponseOrThrow(TransceiveResult.java:50)
06-28 08:32:30.897 4518 4546 E yubioath: at android.nfc.tech.BasicTagTechnology.transceive(BasicTagTechnology.java:151)
06-28 08:32:30.897 4518 4546 E yubioath: at android.nfc.tech.IsoDep.transceive(IsoDep.java:172)
06-28 08:32:30.897 4518 4546 E yubioath: at nordpol.android.AndroidCard.transceive(:1)
06-28 08:32:30.897 4518 4546 E yubioath: at c.c.a.f.c.a(:1)
06-28 08:32:30.897 4518 4546 E yubioath: at c.c.a.d.e.a(:22)
06-28 08:32:30.897 4518 4546 E yubioath: at c.c.a.d.e.a(:18)
06-28 08:32:30.897 4518 4546 E yubioath: at c.c.a.d.e.<init>(:3)
06-28 08:32:30.897 4518 4546 E yubioath: at c.c.a.a.d.<init>(:2)
06-28 08:32:30.897 4518 4546 E yubioath: at c.c.a.g.e.a(:18)
06-28 08:32:30.897 4518 4546 E yubioath: at c.c.a.g.f.a(:8)
06-28 08:32:30.897 4518 4546 E yubioath: at d.c.a.b.a.a.c(:2)
06-28 08:32:30.897 4518 4546 E yubioath: at e.a.a.X$a.a(:11)
06-28 08:32:30.897 4518 4546 E yubioath: at e.a.a.V.run(:1)
06-28 08:32:30.897 4518 4546 E yubioath: at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)
06-28 08:32:30.897 4518 4546 E yubioath: at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
06-28 08:32:30.897 4518 4546 E yubioath: at java.lang.Thread.run(Thread.java:764)
```
The full logcat is available [here](https://pastebin.com/25x3UkXx).
I am trying to figure out if the issue is caused by the Yubico app or by LineageOS but unfortunately I am not to familiar with android logcat files so I would be more than happy if you guys could point me in the right direction here.
<issue_comment>username_1: Might be related to #95, you might want to check that for clues. Although it looks like you're getting a different error message. What version of the app are you using?
<issue_comment>username_0: I am using version v2.1.0 of the Yubico Authenticator app. I also posted my issue on the [XDA forums](https://forum.xda-developers.com/showpost.php?p=79810033&postcount=2650) and nvertigo67 on XDA told me to try adding `ISO_DEP_MAX_TRANSCEIVE=0xFEFF` in my `libnfc-nxp.conf`. I'll try looking into that aswell.
<issue_comment>username_1: One other thing you can try is installing the latest 2.2.0 beta, you can get it from the Play Store by opting in to the beta channel for the app.
<issue_comment>username_0: The fix provided by nvertigo67 worked, I am going to try and get this fix inside the installer image for LineageOS :D<issue_closed> | {'fraction_non_alphanumeric': 0.10097822656989587, 'fraction_numerical': 0.14799621331650362, 'mean_word_length': 4.007898894154819, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '7264963', 'n_tokens_mistral': 1512, 'n_tokens_neox': 1250, 'n_words': 396} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Why mapEventToState have currentState?
username_0: Hello
Why do you use `currentState` in `mapEventToState` if `currentState` is a property of `bloc` and can be access with the same way without be a parameter of `mapEventToState`
Thanks.
```dart
@override
Stream<int> mapEventToState(int currentState, CounterEvent event) async* {
yield currentState +1;
}
```
the same as this
```dart
@override
Stream<int> mapEventToState( CounterEvent event) async* {
yield currentState +1;
}
```
<issue_comment>username_1: @username_0 thanks for bringing this up! Originally, blocs didn't have a currentState property so the `mapEventToState` signature needed it. Now that `currentState` is a property in all Blocs it is no longer needed. #162 will address this change.
Thanks again for bringing this up! I totally forgot to make this simplification after adding `currentState`.
<issue_comment>username_1: published [bloc v0.11.0](https://pub.dartlang.org/packages/bloc) 🎉<issue_closed> | {'fraction_non_alphanumeric': 0.08484270734032412, 'fraction_numerical': 0.012392755004766444, 'mean_word_length': 4.769230769230769, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '22037342', 'n_tokens_mistral': 326, 'n_tokens_neox': 305, 'n_words': 121} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Alter title and heading on world_location_news pages
username_0: title change to 'UK and COUNTRY', and heading change to 'COUNTRY and the
UK'
<issue_comment>username_1: Hi @username_0 👋 Could you post the link to the trello card that this PR relates to (in the PR description)?
<issue_comment>username_0: Hi @username_1, the link is - https://trello.com/c/aQPSDsVW/74-change-page-title-and-description-for-world-location-news-pages
<issue_comment>username_1: @username_0 when you add the Trello card to the PR description (at the top), it will automatically pop a link to the PR into the Trello card, which is quite useful! | {'fraction_non_alphanumeric': 0.07738998482549317, 'fraction_numerical': 0.013657056145675266, 'mean_word_length': 5.407766990291262, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '27615956', 'n_tokens_mistral': 208, 'n_tokens_neox': 197, 'n_words': 84} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: OeMiddleware - does support POST / PATCH / DELETE ?
username_0: I have tried to create a new entity with Dynamic Data from connection string -
app.UseOdataToEntityMiddleware<OePageMiddleware>("/odata3", edmModel);
and shows data as it was a GET , not a POST .
Apparently, from the code in
`public class OeMiddleware
public async Task Invoke(HttpContext httpContext)
private async Task InvokeApi(HttpContext httpContext)`
it calls always GET , not POST.
There is a
parser.ExecutePostAsync
but it is not called. And , when I try to call POST , verifies if it is batch or OperationImportSegment , then it call anyway the ExecuteQueryAsync
OeMiddleware - support POST / PATCH / DELETE ?
<issue_comment>username_1: [Test](https://github.com/username_1/OdataToEntity/blob/master/test/OdataToEntity.Test/Common/BatchTest.cs)
[Test data](https://github.com/username_1/OdataToEntity/tree/master/test/OdataToEntity.Test/Batches)
<issue_comment>username_0: I have tried - with no luck. Working example:
I have http://netcoreblockly.herokuapp.com/odata/$metadata
You can see the classRooms at
http://netcoreblockly.herokuapp.com/odata/ClassRoom
I tried to POST ( with PostMan) to the endpoint:
http://netcoreblockly.herokuapp.com/odata/ClassRoom
The following:
{
"Name": "Classdasds1",
"idClassRoom": 10
}
It answers as the GET .
it is necessary , for the POST to work, to have a schema ?
(my code is: edmModel = DynamicMiddlewareHelper.CreateEdmModel(providerSchema, informationSchemaMapping: null); )
<issue_comment>username_1: I will try to implement this on the weekend<issue_closed>
<issue_comment>username_1: 
<issue_comment>username_0: Thanks! Could you deploy on NuGet also ?
<issue_comment>username_1: Hi @username_0
[2.5.0.2](https://www.nuget.org/packages/OdataToEntity.EfCore.DynamicDataContext/)
<issue_comment>username_0: I have a problem with DELETE
It does not Delete ( verb: delete) Could you please verify?
Thanks again
<issue_comment>username_0: As an example:
GET - http://netcoreblockly.herokuapp.com/odatadb/ClassRoom(23)
works
PATCH- http://netcoreblockly.herokuapp.com/odatadb/ClassRoom(23)
BODY:
{
"Name":"testAndrei
}
works
DELETE- http://netcoreblockly.herokuapp.com/odatadb/ClassRoom(23)
does NOT work
<issue_comment>username_1: will fix it on the weekend
<issue_comment>username_1: I have tried to create a new entity with Dynamic Data from connection string -
app.UseOdataToEntityMiddleware<OePageMiddleware>("/odata", edmModel);
and shows data as it was a GET , not a POST .
Apparently, from the code in
`public class OeMiddleware
public async Task Invoke(HttpContext httpContext)
private async Task InvokeApi(HttpContext httpContext)`
it calls always GET , not POST.
There is a
parser.ExecutePostAsync
but it is not called. And , when I try to call POST , verifies if it is batch or OperationImportSegment , then it call anyway the ExecuteQueryAsync
OeMiddleware - support POST / PATCH / DELETE ?<issue_closed>
<issue_comment>username_0: Please deploy on nuget
<issue_comment>username_1: [OdataToEntity.AspNetCore 2.5.0.3](https://www.nuget.org/packages/OdataToEntity.AspNetCore/)
<issue_comment>username_0: This package depends on
https://www.nuget.org/packages/OdataToEntity/
version 2.5.0.3 that was not deployed.
So I cannot update reference.
Please deploy also OdataToEntity
<issue_comment>username_0: It works!
Thanks!
( With your software , we can now edit any SqlServer / MySql / PostGres ) if provided a connection string. - and I will put on Blockly) | {'fraction_non_alphanumeric': 0.08666843360720912, 'fraction_numerical': 0.020938245428041347, 'mean_word_length': 4.3760683760683765, 'pattern_counts': {'":': 3, '<': 20, '<?xml version=': 0, '>': 20, 'https://': 6, 'lorem ipsum': 0, 'www.': 3, 'xml': 0}, 'pii_count': 3, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '10828552', 'n_tokens_mistral': 1254, 'n_tokens_neox': 1195, 'n_words': 366} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Crash on file copy using redirected drive
username_0: **Describe the bug**
Copying a large file (200M) between a Debian 10 box and a Windows 10 VM, I received a crash at 93%. Reconnected, started transfer again and it worked the second time with no problems. On the Win10 VM, I was copying the file from a redirected folder on my Debian 10 box.
**To Reproduce**
Could not reproduce.
**Expected behavior**
File copy with no errors - second time worked
**Screenshots**
N/A - provided dump file.
**Application details**
* FreeRDP Version
This is FreeRDP version 2.0.0-dev5 (dc89923f4
* Command line used
$ /opt/freerdp-nightly/bin/xfreerdp +old-license /log-level:info /u:Administrator /p:Password /size:1600x800 +clipboard /drive:Temp,/home/user/Temp /admin /sec:nla /cert-ignore /v:192.168.0.XX
* output of `/buildconfig`
$ /opt/freerdp-nightly/bin/xfreerdp /buildconfig
This is FreeRDP version 2.0.0-dev5 (dc89923f4)
Build configuration: BUILD_TESTING=OFF BUILTIN_CHANNELS=ON HAVE_AIO_H=1 HAVE_EXECINFO_H=1 HAVE_FCNTL_H=1 HAVE_INTTYPES_H=1 HAVE_MATH_C99_LONG_DOUBLE=1 HAVE_POLL_H=1 HAVE_PTHREAD_MUTEX_TIMEDLOCK=ON HAVE_PTHREAD_MUTEX_TIMEDLOCK_LIB=1 HAVE_PTHREAD_MUTEX_TIMEDLOCK_SYMBOL= HAVE_SYSLOG_H=1 HAVE_SYS_EVENTFD_H=1 HAVE_SYS_FILIO_H= HAVE_SYS_MODEM_H= HAVE_SYS_SELECT_H=1 HAVE_SYS_SOCKIO_H= HAVE_SYS_STRTIO_H= HAVE_SYS_TIMERFD_H=1 HAVE_TM_GMTOFF=1 HAVE_UNISTD_H=1 HAVE_XI_TOUCH_CLASS=1 WITH_ALSA=ON WITH_CAIRO=ON WITH_CCACHE=ON WITH_CHANNELS=ON WITH_CLANG_FORMAT=ON WITH_CLIENT=ON WITH_CLIENT_AVAILABLE=1 WITH_CLIENT_CHANNELS=ON WITH_CLIENT_CHANNELS_AVAILABLE=1 WITH_CLIENT_COMMON=ON WITH_CLIENT_INTERFACE=OFF WITH_CUPS=ON WITH_DEBUG_ALL=OFF WITH_DEBUG_CAPABILITIES=OFF WITH_DEBUG_CERTIFICATE=OFF WITH_DEBUG_CHANNELS=OFF WITH_DEBUG_CLIPRDR=OFF WITH_DEBUG_DVC=OFF WITH_DEBUG_KBD=OFF WITH_DEBUG_LICENSE=OFF WITH_DEBUG_MUTEX=OFF WITH_DEBUG_NEGO=OFF WITH_DEBUG_NLA=OFF WITH_DEBUG_NTLM=OFF WITH_DEBUG_RAIL=OFF WITH_DEBUG_RDP=OFF WITH_DEBUG_RDPDR=OFF WITH_DEBUG_RDPEI=OFF WITH_DEBUG_RDPGFX=OFF WITH_DEBUG_REDIR=OFF WITH_DEBUG_RFX=OFF WITH_DEBUG_RINGBUFFER=OFF WITH_DEBUG_SCARD=OFF WITH_DEBUG_SND=OFF WITH_DEBUG_SVC=OFF WITH_DEBUG_SYMBOLS=OFF WITH_DEBUG_THREADS=OFF WITH_DEBUG_TIMEZONE=OFF WITH_DEBUG_TRANSPORT=OFF WITH_DEBUG_TSG=OFF WITH_DEBUG_TSMF=OFF WITH_DEBUG_WND=OFF WITH_DEBUG_X11=OFF WITH_DEBUG_X11_CLIPRDR=OFF WITH_DEBUG_X11_LOCAL_MOVESIZE=OFF WITH_DEBUG_XV=OFF WITH_DSP_EXPERIMENTAL=OFF WITH_DSP_FFMPEG=ON WITH_EVENTFD_READ_WRITE=1 WITH_FAAC=OFF WITH_FAAD2=OFF WITH_FFMPEG=TRUE WITH_FFMPEG=TRUE WITH_GFX_H264=ON WITH_GPROF=OFF WITH_GSM=OFF WITH_GSSAPI=OFF WITH_GSTREAMER_0_10=ON WITH_GSTREAMER_1_0=ON WITH_ICU=OFF WITH_IPP=OFF WITH_JPEG=OFF WITH_LAME=OFF WITH_LIBRARY_VERSIONING=ON WITH_LIBSYSTEMD=OFF WITH_MACAUDIO=OFF WITH_MACAUDIO=OFF WITH_MACAUDIO_AVAILABLE=0 WITH_MANPAGES=ON WITH_MBEDTLS=OFF WITH_OPENCL=OFF WITH_OPENH264=OFF WITH_OPENSLES=OFF WITH_OPENSSL=ON WITH_OSS=ON WITH_PAM=ON WITH_PCSC=ON WITH_PROFILER=OFF WITH_PROXY_MODULES=OFF WITH_PULSE=ON WITH_SAMPLE=OFF WITH_SANITIZE_ADDRESS=ON WITH_SANITIZE_ADDRESS_AVAILABLE=1 WITH_SANITIZE_MEMORY=OFF WITH_SANITIZE_MEMORY=OFF WITH_SANITIZE_MEMORY_AVAILABLE=0 WITH_SANITIZE_THREAD=OFF WITH_SANITIZE_THREAD=OFF WITH_SANITIZE_THREAD_AVAILABLE=0 WITH_SERVER=ON WITH_SERVER_CHANNELS=ON WITH_SERVER_INTERFACE=ON WITH_SMARTCARD_INSPECT=OFF WITH_SOXR=OFF WITH_SSE2=ON WITH_SWSCALE=OFF WITH_THIRD_PARTY=OFF WITH_VAAPI=OFF WITH_VALGRIND_MEMCHECK=OFF WITH_VALGRIND_MEMCHECK=OFF WITH_VALGRIND_MEMCHECK_AVAILABLE=0 WITH_WAYLAND=OFF WITH_WINPR_TOOLS=ON WITH_X11=ON WITH_X264=OFF WITH_XCURSOR=ON WITH_XDAMAGE=ON WITH_XEXT=ON WITH_XFIXES=ON WITH_XI=ON WITH_XINERAMA=ON WITH_XKBFILE=ON WITH_XRANDR=ON WITH_XRENDER=ON WITH_XSHM=ON WITH_XTEST=ON WITH_XV=ON WITH_ZLIB=ON
Build type: Debug
CFLAGS: -g -O2 -fdebug-prefix-map=/build/freerdp-nightly-2.0.0+0~20200222024833.771~1.gbpdc8992=. -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2 -fPIC -Wall -Wno-unused-result -Wno-unused-but-set-variable -Wno-deprecated-declarations -fvisibility=hidden -Wimplicit-function-declaration -Wredundant-decls -g -fsanitize=address -fsanitize-address-use-after-scope -fno-omit-frame-pointer -DWINPR_DLL
Compiler: GNU, 8.3.0
Target architecture: x64
* OS version connecting to
Windows 10 VM latest updates Version 1903
* If available the log output from a run with `/log-level:trace`
[15:47:07:309] [12332:12333] [INFO][com.freerdp.core] - freerdp_connect:freerdp_set_last_error_ex resetting error state
[15:47:07:309] [12332:12333] [INFO][com.freerdp.client.common.cmdline] - loading channelEx rdpdr
[15:47:07:309] [12332:12333] [INFO][com.freerdp.client.common.cmdline] - loading channelEx rdpsnd
[15:47:07:309] [12332:12333] [INFO][com.freerdp.client.common.cmdline] - loading channelEx cliprdr
[15:47:07:644] [12332:12333] [INFO][com.freerdp.primitives] - primitives autodetect, using optimized
[15:47:07:649] [12332:12333] [INFO][com.freerdp.core] - freerdp_tcp_is_hostname_resolvable:freerdp_set_last_error_ex resetting error state
[15:47:07:649] [12332:12333] [INFO][com.freerdp.core] - freerdp_tcp_connect:freerdp_set_last_error_ex resetting error state
[15:47:09:204] [12332:12333] [INFO][com.freerdp.gdi] - Local framebuffer format PIXEL_FORMAT_BGRX32
[15:47:09:204] [12332:12333] [INFO][com.freerdp.gdi] - Remote framebuffer format PIXEL_FORMAT_RGB16
[15:47:09:239] [12332:12333] [INFO][com.winpr.clipboard] - initialized POSIX local file subsystem
[15:47:09:240] [12332:12333] [INFO][com.freerdp.channels.rdpsnd.client] - Loaded fake backend for rdpsnd
[15:47:09:240] [12332:12338] [INFO][com.freerdp.channels.rdpdr.client] - Loading device service drive [Temp] (static)
[15:47:10:468] [12332:12333] [INFO][com.freerdp.client.x11] - Logon Error Info LOGON_WARNING [LOGON_MSG_SESSION_CONTINUE]
[15:47:10:610] [12332:12338] [INFO][com.freerdp.channels.rdpdr.client] - registered device #1: Temp (type=8 id=1)
[15:47:10:791] [12332:12339] [WARN][com.freerdp.channels.cliprdr.common] - [cliprdr_packet_format_list_new] called with invalid type 00000000
=================================================================
==12332==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x6020000085f0 at pc 0x55e569a789a2 bp 0x7f9924decac0 sp 0x7f9924decab8
READ of size 4 at 0x6020000085f0 thread T1
#0 0x55e569a789a1 (/opt/freerdp-nightly/bin/xfreerdp+0x3e9a1)
#1 0x55e569a69320 (/opt/freerdp-nightly/bin/xfreerdp+0x2f320)
#2 0x55e569a992f5 (/opt/freerdp-nightly/bin/xfreerdp+0x5f2f5)
#3 0x55e569a99a5c (/opt/freerdp-nightly/bin/xfreerdp+0x5fa5c)
#4 0x7f9932d8688b (/opt/freerdp-nightly/bin/../lib/libwinpr2.so.2+0x16488b)
#5 0x7f9932a42fa2 in start_thread (/lib/x86_64-linux-gnu/libpthread.so.0+0x7fa2)
#6 0x7f9932b5a4ce in clone (/lib/x86_64-linux-gnu/libc.so.6+0xf94ce)
0x6020000085f1 is located 0 bytes to the right of 1-byte region [0x6020000085f0,0x6020000085f1)
allocated by thread T1 here:
#0 0x7f99345a8330 in __interceptor_malloc (/lib/x86_64-linux-gnu/libasan.so.5+0xe9330)
#1 0x7f99343a8144 in XGetWindowProperty (/lib/x86_64-linux-gnu/libX11.so.6+0x2a144)
Thread T1 created by T0 here:
#0 0x7f993450fdb0 in __interceptor_pthread_create (/lib/x86_64-linux-gnu/libasan.so.5+0x50db0)
#1 0x7f9932d863eb (/opt/freerdp-nightly/bin/../lib/libwinpr2.so.2+0x1643eb)
#2 0x7f9932d86c9a in CreateThread (/opt/freerdp-nightly/bin/../lib/libwinpr2.so.2+0x164c9a)
#3 0x55e569a8f2ff (/opt/freerdp-nightly/bin/xfreerdp+0x552ff)
#4 0x55e569a4dba6 (/opt/freerdp-nightly/bin/xfreerdp+0x13ba6)
#5 0x7f9932a8509a in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2409a)
SUMMARY: AddressSanitizer: heap-buffer-overflow (/opt/freerdp-nightly/bin/xfreerdp+0x3e9a1)
Shadow bytes around the buggy address:
0x0c047fff9060: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff9070: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff9080: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff9090: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff90a0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
=>0x0c047fff90b0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa[01]fa
0x0c047fff90c0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
[Truncated]
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==12332==ABORTING
**Desktop (please complete the following information):**
- OS: [e.g. iOS] Debian 10
- Browser [e.g. chrome, safari] N/A
- Version [e.g. 22] N/A
**Additional context**
I'm not sure if this problem happened because of FreeRDP or some other external issue (network, VPN, etc) but I wanted to bring it to your attention in case you can see something in the trace/dump. HTH
<issue_comment>username_1: Thank you for the report, that one I was not aware of.
Could you reproduce with the -dbg package installed?
<issue_comment>username_1: One thing that can be said is it looks like this has nothing to do with drive redirection, `XGetWindowProperty` where the memory is allocated allows to determine that.
<issue_comment>username_0: @username_1, here is another crash log after installing the -dbg package from last night:
/opt/freerdp-nightly/bin/xfreerdp +old-license /log-level:info /u:Administrator /p:Password /size:1600x800 +clipboard /drive:Temp,/home/user/Temp /admin /sec:nla /cert-ignore /v:192.168.0.XX
[13:23:40:146] [4191:4192] [INFO][com.freerdp.core] - freerdp_connect:freerdp_set_last_error_ex resetting error state
[13:23:40:146] [4191:4192] [INFO][com.freerdp.client.common.cmdline] - loading channelEx rdpdr
[13:23:40:146] [4191:4192] [INFO][com.freerdp.client.common.cmdline] - loading channelEx rdpsnd
[13:23:40:147] [4191:4192] [INFO][com.freerdp.client.common.cmdline] - loading channelEx cliprdr
[13:23:40:484] [4191:4192] [INFO][com.freerdp.primitives] - primitives autodetect, using optimized
[13:23:40:489] [4191:4192] [INFO][com.freerdp.core] - freerdp_tcp_is_hostname_resolvable:freerdp_set_last_error_ex resetting error state
[13:23:40:489] [4191:4192] [INFO][com.freerdp.core] - freerdp_tcp_connect:freerdp_set_last_error_ex resetting error state
[13:23:42:097] [4191:4192] [INFO][com.freerdp.gdi] - Local framebuffer format PIXEL_FORMAT_BGRX32
[13:23:42:097] [4191:4192] [INFO][com.freerdp.gdi] - Remote framebuffer format PIXEL_FORMAT_RGB16
[13:23:42:138] [4191:4192] [INFO][com.winpr.clipboard] - initialized POSIX local file subsystem
[13:23:42:138] [4191:4192] [INFO][com.freerdp.channels.rdpsnd.client] - Loaded fake backend for rdpsnd
[13:23:42:139] [4191:4197] [INFO][com.freerdp.channels.rdpdr.client] - Loading device service drive [Temp] (static)
[13:23:43:809] [4191:4192] [INFO][com.freerdp.client.x11] - Logon Error Info LOGON_FAILED_OTHER [LOGON_MSG_SESSION_CONTINUE]
[13:23:43:887] [4191:4197] [INFO][com.freerdp.channels.rdpdr.client] - registered device #1: Temp (type=8 id=1)
[13:23:43:892] [4191:4198] [WARN][com.freerdp.channels.cliprdr.common] - [cliprdr_packet_format_list_new] called with invalid type 00000000
=================================================================
==4191==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x602000013f70 at pc 0x55e0964ea9a2 bp 0x7f83106ecac0 sp 0x7f83106ecab8
READ of size 4 at 0x602000013f70 thread T1
#0 0x55e0964ea9a1 in xf_cliprdr_process_selection_request client/X11/xf_cliprdr.c:894
#1 0x55e0964ea9a1 in xf_cliprdr_handle_xevent client/X11/xf_cliprdr.c:1020
#2 0x55e0964db320 in xf_event_process client/X11/xf_event.c:1062
#3 0x55e09650b2f5 in xf_process_x_events client/X11/xf_client.c:503
#4 0x55e09650b2f5 in handle_window_events client/X11/xf_client.c:1468
#5 0x55e09650ba5c in xf_client_thread client/X11/xf_client.c:1635
#6 0x7f831e68888b in thread_launcher winpr/libwinpr/thread/thread.c:327
#7 0x7f831e344fa2 in start_thread (/lib/x86_64-linux-gnu/libpthread.so.0+0x7fa2)
#8 0x7f831e45c4ce in clone (/lib/x86_64-linux-gnu/libc.so.6+0xf94ce)
0x602000013f71 is located 0 bytes to the right of 1-byte region [0x602000013f70,0x602000013f71)
allocated by thread T1 here:
#0 0x7f831fee8330 in __interceptor_malloc (/lib/x86_64-linux-gnu/libasan.so.5+0xe9330)
#1 0x7f831fce8144 in XGetWindowProperty (/lib/x86_64-linux-gnu/libX11.so.6+0x2a144)
Thread T1 created by T0 here:
#0 0x7f831fe4fdb0 in __interceptor_pthread_create (/lib/x86_64-linux-gnu/libasan.so.5+0x50db0)
#1 0x7f831e6883eb in winpr_StartThread winpr/libwinpr/thread/thread.c:356
#2 0x7f831e688c9a in CreateThread winpr/libwinpr/thread/thread.c:469
#3 0x55e0965012ff in xfreerdp_client_start client/X11/xf_client.c:1768
#4 0x55e0964bfba6 in main client/X11/cli/xfreerdp.c:74
#5 0x7f831e38709a in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2409a)
SUMMARY: AddressSanitizer: heap-buffer-overflow client/X11/xf_cliprdr.c:894 in xf_cliprdr_process_selection_request
Shadow bytes around the buggy address:
0x0c047fffa790: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fffa7a0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fffa7b0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fffa7c0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fffa7d0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa 00 07
=>0x0c047fffa7e0: fa fa 00 07 fa fa fa fa fa fa fa fa fa fa[01]fa
0x0c047fffa7f0: fa fa fd fd fa fa fd fd fa fa fd fd fa fa fd fd
0x0c047fffa800: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fffa810: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fffa820: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fffa830: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==4191==ABORTING
HTH
<issue_comment>username_1: @username_0 thank you, that was exactly what I was looking for.<issue_closed> | {'fraction_non_alphanumeric': 0.09868155522669178, 'fraction_numerical': 0.11226960850262344, 'mean_word_length': 4.932561851556265, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 9, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 2, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29965654', 'n_tokens_mistral': 6958, 'n_tokens_neox': 5978, 'n_words': 1367} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Can't add functions to the JSON object
username_0: <!--
IF YOU DON'T FILL OUT THE FOLLOWING INFORMATION YOUR ISSUE MIGHT BE CLOSED WITHOUT INVESTIGATING
-->
I'm trying to add [Crockford's Cycle.js](https://github.com/douglascrockford/JSON-js/blob/master/cycle.js) to my app.
### Bug Report or Feature Request (mark with an `x`)
```
- [x] bug report -> please search issues before submitting
- [ ] feature request
```
### Versions.
<!--
Output from: `ng --version`.
If nothing, output from: `node --version` and `npm --version`.
Windows (7/8/10). Linux (incl. distribution). macOS (El Capitan? Sierra?)
-->
@angular/cli: 1.1.2
node: 7.10.0
os: linux x64
@angular/animations: 4.3.4
@angular/common: 4.3.4
@angular/compiler: 4.3.4
@angular/core: 4.3.4
@angular/forms: 4.3.4
@angular/http: 4.3.4
@angular/platform-browser: 4.3.4
@angular/platform-browser-dynamic: 4.3.4
@angular/router: 4.3.4
@angular/cli: 1.1.2
@angular/compiler-cli: 4.3.4
@angular/language-service: 4.3.4
### Repro steps.
<!--
Simple steps to reproduce this bug.
Please include: commands run, packages added, related code changes.
A link to a sample repo would help too.
-->
1. Generate new CLI project with `ng new test`
2. Append to `head` of `index.html`
```
<script type="text/javascript">
// Copy paste Crockford's raw script. This basically begins like:
// if (typeof JSON.decycle !== "function") {
// JSON.decycle = function decycle(object, replacer) {
// ...
// }
// }
</script>
```
3. Run `ng serve`
4. From dev console, `console.log(JSON.decycle)` prints `undefined`.
### The log given by the failure.
<!-- Normally this include a stack trace and some more information. -->
No errors are logged.
### Desired functionality.
<!--
What would like to see implemented?
What is the usecase?
-->
I should be able to use `JSON.decycle` and `JSON.retrocycle`. Running `console.log(JSON)` shows that these methods do not exist on the JSON object.
### Mention any other details that might be useful.
<!-- Please include a link to the repo if this is related to an OSS project. -->
If I insert a `console.log(JSON.decycle)` inside the setup script tag, right after the declaration of `JSON.decycle`, I see that `decycle` is indeed a method on the JSON object. However, when I attempt the same thing outside of that script tag (in code, or in the dev console), `console.log(JSON.decycle)` prints `undefined`.
Also, just dropping that entire script into the dev console successfully adds the methods to the JSON object.
It seems like modifications to the JSON object aren't being preserved.
<issue_comment>username_1: For support requests, you can use gitter or take a look at StackOverflow for more information. If I've misunderstood the problem, please open a new issue, thanks!<issue_closed> | {'fraction_non_alphanumeric': 0.11895161290322581, 'fraction_numerical': 0.018481182795698926, 'mean_word_length': 3.0284167794316645, 'pattern_counts': {'":': 0, '<': 12, '<?xml version=': 0, '>': 13, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15808294', 'n_tokens_mistral': 965, 'n_tokens_neox': 915, 'n_words': 362} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Use font icons in hierarchy toggle, prettify default theme
username_0: <!-- Reviewable:start -->
This change is [<img src="https://reviewable.io/review_button.svg" height="34" align="absmiddle" alt="Reviewable"/>](https://reviewable.io/reviews/vaadin/vaadin-grid/1074)
<!-- Reviewable:end -->
<issue_comment>username_1: Hierarchy toggle icons are so simple, we could just use CCS triangles instead https://css-tricks.com/snippets/css/css-triangle/
---
*Comments from [Reviewable](https://reviewable.io:443/reviews/vaadin/vaadin-grid/1074)*
<!-- Sent from Reviewable.io -->
<issue_comment>username_0: Review status: 0 of 2 files reviewed at latest revision, 1 unresolved discussion, some commit checks failed.
---
*[vaadin-grid-hierarchy-toggle.html, line 11 at r1](https://reviewable.io:443/reviews/vaadin/vaadin-grid/1074#-Kxw8DpSrkl1s9P_u42V:-KxwPZn13nmxYJ9_ysK2:b-ycrqjc) ([raw file](https://github.com/vaadin/vaadin-grid/blob/0260cb20679510fd3a652cf482ad60a19fd73f1d/vaadin-grid-hierarchy-toggle.html#L11)):*
<details><summary><i>Previously, username_1 (<NAME>) wrote…</i></summary><blockquote>
Hierarchy toggle icons are so simple, we could just use CCS triangles instead https://css-tricks.com/snippets/css/css-triangle/
</blockquote></details>
Font icons don’t require alignment with text, and also provide out-of-the-box support for changing color, font size and line height.
Apart from that, if we do CSS triangles manually here, we would have to decide the sizes, position, angle values, and so on. I could put decisions to my taste here, but nobody trusts my design taste. :-(
---
*Comments from [Reviewable](https://reviewable.io:443/reviews/vaadin/vaadin-grid/1074)*
<!-- Sent from Reviewable.io -->
<issue_comment>username_2: <img class="emoji" title=":lgtm:" alt=":lgtm:" align="absmiddle" src="https://reviewable.io/lgtm.png" height="20" width="61"/>
---
Reviewed 2 of 2 files at r1.
Review status: all files reviewed at latest revision, 1 unresolved discussion, some commit checks failed.
---
*Comments from [Reviewable](https://reviewable.io:443/reviews/vaadin/vaadin-grid/1074#-:-KxwePMmpkEJyLZ_vd_m:bnfp4nl)*
<!-- Sent from Reviewable.io -->
<issue_comment>username_1: <img class="emoji" title=":lgtm:" alt=":lgtm:" align="absmiddle" src="https://reviewable.io/lgtm.png" height="20" width="61"/>
---
Reviewed 2 of 2 files at r1.
Review status: all files reviewed at latest revision, all discussions resolved, some commit checks failed.
---
*Comments from [Reviewable](https://reviewable.io:443/reviews/vaadin/vaadin-grid/1074#-:-KxwefO5tv9zaouJUWov:bnfp4nl)*
<!-- Sent from Reviewable.io --> | {'fraction_non_alphanumeric': 0.14724615961034096, 'fraction_numerical': 0.04083926564256276, 'mean_word_length': 5.082004555808656, 'pattern_counts': {'":': 4, '<': 24, '<?xml version=': 0, '>': 24, 'https://': 12, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '21316347', 'n_tokens_mistral': 993, 'n_tokens_neox': 887, 'n_words': 223} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Handle arrays as the root object.
username_0: Hi there! We're using this for JSON serialization/deserialization. Thanks for the project.
We noticed that although the library handles nested arrays well, if you give it an array as an initial value, you get the mapObj back. So, this PR just casts the mapObj it back to an array if the input was one.
<issue_comment>username_1: Hi ben thanks for taking the time todo the PR, I've had a look from what I understand you're saying. ```camelCaseKeys([])``` returns a mapobj not an array?
I've looked at the tests and the test 'Should return an array' checks for this.
If this is not the problem you are suggesting would you be able to add a test to demonstrate the problem?
Thanks
<issue_comment>username_1: see latest release - https://github.com/username_1/camelcase-keys-recursive/releases/tag/v0.8.0 | {'fraction_non_alphanumeric': 0.06361607142857142, 'fraction_numerical': 0.0078125, 'mean_word_length': 4.3076923076923075, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '14280049', 'n_tokens_mistral': 253, 'n_tokens_neox': 240, 'n_words': 132} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Move instead of copy.
username_0: [Place](https://github.com/altmp/cpp-sdk/blob/d52d98b8a239499c6caef85cd637fbebe1a23814/types/Array.h#L128)
There will be a deep copying of the object, and here just moving it is enough. Change to:
`newData[i] = std::move(data[i]);`
<issue_comment>username_1: Can you describe why this is needed.
<issue_comment>username_0: You won't believe it, but moving an object is much faster and more efficient than copying it. Can you imagine? Shock.
<issue_comment>username_1: Thats depending on the type of the array.
<issue_comment>username_1: Doesn't that makes the data invalid when its setted to the array and then invalidated inside the resize method but also used outside the array.
<issue_comment>username_0: The memory you move from is deleted in the next line. Accordingly, you need to MOVE from it, not copy it.
<issue_comment>username_1: The next line only deletes the arrays, but doesn't the elements inside it.
<issue_comment>username_0: Learn the basics.<issue_closed> | {'fraction_non_alphanumeric': 0.07545367717287488, 'fraction_numerical': 0.03247373447946514, 'mean_word_length': 5.591194968553459, 'pattern_counts': {'":': 0, '<': 10, '<?xml version=': 0, '>': 10, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18505327', 'n_tokens_mistral': 332, 'n_tokens_neox': 308, 'n_words': 132} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Nested table style not being applied correctly to cells (uses parent table cell)
username_0: Nested style on InnerTable td (with text-align:center) is not being applied; the text-align:left from the containing OuterTable td is being applied.
Please see example HTML:
https://gist.github.com/username_0/5fe6ced6b180c9122907
<issue_comment>username_1: I can confirm this issue.
```html
<style>
table.outerclass td {
color: red;
}
table.innerclass td {
color: green;
}
</style>
<table class="outerclass">
<tr>
<td>
<table class="innerclass">
<tr>
<td>
this should be green
</td>
</tr>
</table>
</td>
</tr>
</table>
```
renders to
```html
<table class="outerclass">
<tbody><tr>
<td style="color: red">
<table class="innerclass">
<tbody><tr>
<td style="color: red">
this should be green
</td>
</tr>
</tbody></table>
</td>
</tr>
</tbody></table>
```<issue_closed> | {'fraction_non_alphanumeric': 0.11629746835443038, 'fraction_numerical': 0.012658227848101266, 'mean_word_length': 1.5, 'pattern_counts': {'":': 0, '<': 34, '<?xml version=': 0, '>': 34, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '26909526', 'n_tokens_mistral': 381, 'n_tokens_neox': 353, 'n_words': 102} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: The improved issue template is confusing
username_0: ### New Issue Checklist
- [ ] The title is short and descriptive
- [ ] The issue contains an:
- [ ] Idea (new feature, user story, etc)
- [ ] Problem
- [ ] You have explained the:
- [ ] Context
- [ ] Problem or idea
- [ ] Solution or next step
### Context
I was creating new issues this morning. As I was filling things out, I found the new template jarring.
### Problem or idea
The context seems like it should come before the problem. Also, the checklist that is supposed to be used to make sure the issue is reasonably complete is commented out.
### Solution or next step
I'd propose that we revert the portions of https://github.com/AlexsLemonade/refinebio/pull/137 that change the checklist.
<issue_comment>username_1: I agree
<issue_comment>username_2: I don't like having to read everybody else's checklist for every new ticket. It's up to you to do file a proper ticket, it's not up to people who actually work on tickets to have to read somebody else's checklist of things that should be done anyway every time.

<issue_comment>username_0: There were two changes.
* One puts `context` before `problem`.
* The other is the commenting out of the checklist.
As someone who files tickets, we'll get better ones if the template works for people. Asking for context before asking for the problem seems like the natural ordering.
Also, giving people a checklist can be a handy way to go about getting better tickets. It also helps to quickly triage bad tickets. Someone who didn't fill out the checklist probably also didn't do the other things that make a ticket useful.
<issue_comment>username_0: Yea - the GitHub -> ToDo is suboptimal there. I think our checklist that is not a checklist can be converted to a checklist that is a checklist. 😄
<issue_comment>username_3: I think that will remind people about the things we care about. Also I'm not sure I agree that the checklist makes it easier to triage bad tickets. I think we can just as easily visibly check that each of the sections has something in it as we can check that the corresponding checkboxes have been filled out.
There's a few things I find annoying about the checklist, but this is one that hasn't been brought up yet:
<issue_comment>username_0: On my plate. Will aim to do it today.<issue_closed> | {'fraction_non_alphanumeric': 0.06381381381381382, 'fraction_numerical': 0.027402402402402402, 'mean_word_length': 4.018832391713747, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 10, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24561113', 'n_tokens_mistral': 804, 'n_tokens_neox': 720, 'n_words': 372} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Checks from policy not automatically applying
username_0: I have some checks set up as a policy and have the policy applied. However they do not show up until I create a check manually and then delete the check from a device. Then the policy checks show up for only that device.
<issue_comment>username_1: this is a known bug see the discussion in https://github.com/username_1/tacticalrmm/issues/6<issue_closed>
<issue_comment>username_1: I have some checks set up as a policy and have the policy applied. However they do not show up until I create a check manually and then delete the check from a device. Then the policy checks show up for only that device.
<issue_comment>username_1: gonna re-open this for visibility and tracking
<issue_comment>username_2: @username_0 Can you see if your issue is resolved with the latest updates?
<issue_comment>username_0: It is working now!<issue_closed>
<issue_comment>username_2: @username_0 I am doing some rework on the policy checks and we look at this. Thanks for testing!
<issue_comment>username_2: @username_0 I think this is due to policies not applying to newly installed agents. I will make a fix shortly.<issue_closed>
<issue_comment>username_2: #78 Should fix this issue. Once it is merged, let me know if you have any issues. Thanks! | {'fraction_non_alphanumeric': 0.04909365558912387, 'fraction_numerical': 0.012084592145015106, 'mean_word_length': 5.220657276995305, 'pattern_counts': {'":': 0, '<': 13, '<?xml version=': 0, '>': 13, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '20199903', 'n_tokens_mistral': 344, 'n_tokens_neox': 342, 'n_words': 195} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Only lets me login 1 time per account?
username_0: ### Expected Behavior
To be able to start the Bot in terminal, then stop it, then be able to start it again whenever I choose.
### Actual Behavior
I can only run the bot one time per account. After that, I have to change my account information in the config file for it to work.
### Steps to Reproduce
Just running the bot
### Other Information
This is the error that shows Traceback (most recent call last):
File "pokecli.py", line 220, in <module>
main()
File "pokecli.py", line 206, in main
bot.start()
File "/Users/userstuff/PokemonGo-Bot/pokemongo_bot/__init__.py", line 31, in start
self._setup_api()
File "/Users/userstuff/PokemonGo-Bot/pokemongo_bot/__init__.py", line 159, in _setup_api
balls_stock = self.pokeball_inventory()
File "/Users/userstuff/PokemonGo-Bot/pokemongo_bot/__init__.py", line 234, in pokeball_inventory
inventory_dict = inventory_req['responses']['GET_INVENTORY'][
KeyError: 'GET_INVENTORY'
OS:
Git Commit: commit 4182e93f9bfbe471d07b74e95c55cdfbacda127b
Python Version: Python 2.7.10
<issue_comment>username_1: your error has nothing to do with what you are describing
<issue_comment>username_0: Could you please explain how to fix both issues? The error I show only
appears when I use Control C in terminal to stop the bot, then try to
restart the bot with the same account logged in. For example, if I tried to
use the bot with <EMAIL>, it would work fine for the first use. But
if I stopped the bot in terminal, then tried to start it again (still using
the account <EMAIL>) the error I pasted in my issue would appear.
However, the error disappears after I try using a new account with the bot.
Any help would be greatly appreciated.
Cheers
<issue_comment>username_2: I get that Get_Inventory error often, usually first time starting the bot. I just attempt to start it again immediately afterwards and it works.<issue_closed> | {'fraction_non_alphanumeric': 0.06666666666666667, 'fraction_numerical': 0.021890547263681594, 'mean_word_length': 4.2643979057591626, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '10839786', 'n_tokens_mistral': 640, 'n_tokens_neox': 590, 'n_words': 275} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: v1.3 Volunteer management
username_0: **Volunteer Management:**
Things to consider/To-do:
* Do we want to show m and f to users?
* Should date of birth be displayed in numbers format? Perhaps a human-friendly way to display it would be something like 3 Jan 1998.
* Also need to touch up on the right panel
* Documentation<issue_closed> | {'fraction_non_alphanumeric': 0.08979591836734693, 'fraction_numerical': 0.08571428571428572, 'mean_word_length': 4.776470588235294, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '8443785', 'n_tokens_mistral': 182, 'n_tokens_neox': 157, 'n_words': 54} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: http post with esp32
username_0: Hello
i want to communicate with esp32 over the wifi using dart language.
i want to send a message from flutter that should receive by esp 32 and vice versa
<issue_comment>username_1: I will just paste your [SO question](https://stackoverflow.com/questions/58153426/how-to-communicate-with-esp-32-wifi-module) here in case somebody will help there earlier.
<issue_comment>username_0: no sir no one helped me over there
<issue_comment>username_2: Please ask questions like this on stackoverflow as we can't give individual support here.
<issue_comment>username_0: This is a flutter related issue
<issue_comment>username_2: Hi,
no this is not a Flutter related problem but standard network programming with the Dart HttpClient, http package or dio package.
This place is for reporting bugs and suggest new features | {'fraction_non_alphanumeric': 0.05174353205849269, 'fraction_numerical': 0.024746906636670417, 'mean_word_length': 5.267605633802817, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '16832476', 'n_tokens_mistral': 248, 'n_tokens_neox': 232, 'n_words': 116} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: New Crowdin translations
username_0:
<issue_comment>username_0: :tada: This PR is included in version 1.4.23 :tada:
The release is available on:
- [npm package (@latest dist-tag)](https://www.npmjs.com/package/warframe-worldstate-data/v/1.4.23)
- [GitHub release](https://github.com/WFCD/warframe-worldstate-data/releases/tag/v1.4.23)
Your **[semantic-release](https://github.com/semantic-release/semantic-release)** bot :package::rocket: | {'fraction_non_alphanumeric': 0.16176470588235295, 'fraction_numerical': 0.029411764705882353, 'mean_word_length': 5.625, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 3, 'lorem ipsum': 0, 'www.': 1, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30147252', 'n_tokens_mistral': 177, 'n_tokens_neox': 162, 'n_words': 30} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Tidy up CSS link formatting
username_0: - no need for `type/css` in HTML5 documents
- having `rel="stylesheet"` first can improve readability/scannability of the code and as it's more consistent aids with gZip compression.
- no need for closing `/` in HTML5 documents
<issue_comment>username_1: But is makes it more readable and is a style preference. Let's leave it in.
<issue_comment>username_0: Then it should be consistent I guess? Should I edit the PR to add the closing slash to the other stylesheets in the head?
<issue_comment>username_1: Yes please. Thank you.
Also, the test failures we're see here are not related to this change, but are being addressed in #1782. | {'fraction_non_alphanumeric': 0.06162464985994398, 'fraction_numerical': 0.014005602240896359, 'mean_word_length': 4.72, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19343137', 'n_tokens_mistral': 203, 'n_tokens_neox': 190, 'n_words': 104} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Does grunt-contrib-requirejs add semicolons to the end of sourcemaps references that do not have a newline?
username_0: I was using grunt-contrib-requirejs and ran it with the uglify: none on RactiveJS 0.6.1, which has sourcemap comments like this
//# sourceMappingURL=ractive.js.map
In one case, the sourcemap does not break into a new line. After the task completes, there is a semicolon at the end.
//# sourceMappingURL=ractive.js.map;
This causes the browser to generate an error saying the sourcemap cannot be found.
I've already heard back from r.js (jburke), who stated that r.js doesn't cause this after running r.js on the command line via node. See https://github.com/jrburke/r.js/issues/799
Is there something in this Grunt task that might be doing this?<issue_closed> | {'fraction_non_alphanumeric': 0.06420927467300833, 'fraction_numerical': 0.008323424494649227, 'mean_word_length': 3.895348837209302, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '1391216', 'n_tokens_mistral': 257, 'n_tokens_neox': 238, 'n_words': 115} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Secretless FAQ answers the "dynamic secrets" comparison
username_0: Our FAQ should speak to the dynamic secrets approach and say why the secretless solution is better.
We can say things like “other approaches to solving this problem propose creating secrets on-demand and expiring them aggressively. We believe that approach won’t be manageable at scale, nor does it truly get to the heart of the issue: applications shouldn’t have secrets in the first place.”<issue_closed>
<issue_comment>username_1: This issue was moved to cyberark/secretless-docs#85 | {'fraction_non_alphanumeric': 0.044142614601018676, 'fraction_numerical': 0.006791171477079796, 'mean_word_length': 5.781609195402299, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '27928573', 'n_tokens_mistral': 142, 'n_tokens_neox': 135, 'n_words': 80} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Reset* vars in user don't get nullified when password is changed
username_0: Set these vars to null in case a reset password was asked.
Scenario:
user (one with short memory) requests a
reset-token and then does nothing => asks the
administrator to reset his password.
User would have a new password but still anyone with the
reset-token would be able to change the password.<issue_closed> | {'fraction_non_alphanumeric': 0.038910505836575876, 'fraction_numerical': 0.0019455252918287938, 'mean_word_length': 2.21875, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19078849', 'n_tokens_mistral': 118, 'n_tokens_neox': 110, 'n_words': 64} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: StreamingFileUpload with throthling and javascript events
username_0: In Micronaut `1.2.0.RC1`.
I have a simple upload method using `StreamingFileUpload`. The final receiver of the data can be simplified to this code:
```java
protected Single<String> upload(@Nonnull StreamingFileUpload file) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
return Single.create(emitter -> {
Flowable
.fromPublisher(file)
.doOnComplete(() -> {
out.close();
emitter.onSuccess("OK");
System.out.println("GOT ALL BYTES");
})
.forEach(it -> {
byte[] bytes = it.getBytes();
out.write(bytes);
System.out.println("GOT BYTES: " + bytes.length);
});
});
}
```
Now, on the client side I upload files to this methods from Angular client. The client listens to progress events (the same as [in this article](https://www.techiediaries.com/angular-file-upload-progress-bar/), or [the same in pure JS](http://christopher5106.github.io/web/2015/12/13/HTML5-file-image-upload-and-resizing-javascript-with-progress-bar.html)).
1. Scenario 1 - I just upload the files - it works.
1. Scenario 2 - because in Scenario 1 I upload to localhost, in this scenario I enable network throttle in Chrome to "Fast 3G", so that the network is slow and I can truly see the progress. It works.
1. Scenario 3 - in this scenario I'm applying throttle on the server side using `Thread.sleep()`, what reflects my real usage scenario (on the server side the data is consumed slower than can arrive through the link):
```java
protected Single<String> upload(@Nonnull StreamingFileUpload file) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
return Single.create(emitter -> {
Flowable
.fromPublisher(file)
.doOnComplete(() -> {
out.close();
emitter.onSuccess("OK");
System.out.println("GOT ALL BYTES");
})
.forEach(it -> {
byte[] bytes = it.getBytes();
out.write(bytes);
System.out.println("GOT BYTES: " + bytes.length);
Thread.sleep(100);
});
});
}
```
So in scenario 3 I consume data slower, what can be seen in the logs, but the progress events indicate 100% of upload almost immediately, like the whole file was received immediately and buffered in-memory by Micronaut. I recorded some video showing all scenarios [here](https://youtu.be/CeDs1RH4LXQ).
The question is why those events indicate 100% immediately, is this a bug, I'm doing something wrong, or the file is buffered? Because if the file is buffered in-memory it somehow kills the streaming upload concept for me completely.
<issue_comment>username_1: The reason is because as you thought the data is being buffered in memory. The reason it is being buffered in memory is because you have requested `Long.MAX_VALUE` demand.
The `forEach` method executes the following:
```
public final Disposable subscribe(Consumer<? super T> onNext) {
return subscribe(onNext, Functions.ON_ERROR_MISSING,
Functions.EMPTY_ACTION, FlowableInternalHelper.RequestMax.INSTANCE);
}
```
As you can see the `FlowableInternalHelper.RequestMax.INSTANCE` is being used. If you want to control the flow of demand, you shouldn't do that.<issue_closed>
<issue_comment>username_0: OK, I see, thanks. But for this implementation the behavior is the same:
```java
protected Single<String> upload(@Nonnull StreamingFileUpload file) {
ByteArrayOutputStream out = new ByteArrayOutputStream((int) entry.size);
return Single.create(emitter -> {
file.subscribe(new Subscriber<>() {
protected Subscription s;
@Override
public void onSubscribe(Subscription s) {
this.s = s;
s.request(1);
}
@Override
public void onNext(PartData it) {
try {
byte[] bytes = it.getBytes();
out.write(bytes);
Utils.sleep(100);
System.out.println("GOT BYTES: "+bytes.length);
s.request(1);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void onError(Throwable t) {
emitter.onError(t);
}
@Override
public void onComplete() {
try {
out.close();
System.out.println("GOT ALL BYTES");
emitter.onSuccess("OK");
} catch (IOException e) {
e.printStackTrace();
}
}
});
});
}
```
<issue_comment>username_1: @username_0 Do you have an example I can look at?
<issue_comment>username_0: I've never delved deeper into javascript upload events, but I think they report upload stream progress, how it is visible on the sending (client) side.
I extracted some code from my example and found [this stuff](https://stackoverflow.com/questions/7057342/how-to-get-a-progress-bar-for-a-file-upload-with-apache-httpclient-4) about reporting progress using Apache HTTP Client. I'm not 100% if this is an equivalent of uploading with ajax, but it looks likewise.
Please look at the repo [here](https://github.com/username_0/micronaut-1905).
<issue_comment>username_0: Just a work of explanation. CLIENT PROGRESS shows how the client sees the packages consumed by the server. It immediately uploads everything and just after that SERVER PROGRESS log lines shows when they appear on the server side. It looks first it's uploaded to the sever, cached somewhere in the server, and then my consumer is fed with this data.
In the example from the repo I upload 512KB.
<issue_comment>username_0: That's interesting, I've checked a little more. Go to [large](https://github.com/username_0/micronaut-1905/tree/large), I reduced the output a little, so that it reports only some of progress, not on each received/sent packet. Now the original log of uploading 512KB looks the following:
```
14:42:47.087 INFO micronaut.upload.UploadTest - 4 kB
14:42:47.135 INFO micronaut.upload.UploadTest - 512 kB
14:42:47.136 INFO micronaut.upload.UploadController - 839 B
14:42:53.745 INFO micronaut.upload.UploadController - 512 kB
14:42:53.803 INFO micronaut.upload.UploadTest - 512 kB
```
`UploadTest` (the client) started with uploading 4KB, then it finished with uploading 512KB, then `UploadController` (the server) received first 839B, then after 6 secs it received the whole 512KB, and the client request has finished with 512KB reported as uploaded.
This is the same as for `master` branch, but with a different approach to logging packages.
Now on `large` branch we can increase uploaded file size from 512KB to 10MB in the following way:
```bash
$ dd if=/dev/zero of=./test/file.txt count=1024 bs=10240
```
And the result is the following:
```
14:47:51.251 INFO micronaut.upload.UploadTest - 4 kB
14:47:51.313 INFO micronaut.upload.UploadTest - 4,2 MB
14:47:51.313 INFO micronaut.upload.UploadController - 847 B
14:47:52.438 INFO micronaut.upload.UploadController - 80,8 kB
14:47:52.438 INFO micronaut.upload.UploadTest - 4,2 MB
14:47:52.439 INFO micronaut.upload.UploadTest - 4,2 MB
14:47:52.439 INFO micronaut.upload.UploadController - 88,8 kB
14:47:52.439 INFO micronaut.upload.UploadController - 88,8 kB
14:47:52.440 INFO micronaut.upload.UploadTest - 4,2 MB
14:47:52.541 INFO micronaut.upload.UploadTest - 7,6 MB
14:47:52.542 INFO micronaut.upload.UploadController - 96,8 kB
14:47:55.717 INFO micronaut.upload.UploadController - 344,8 kB
14:47:55.718 INFO micronaut.upload.UploadTest - 7,6 MB
14:47:55.782 INFO micronaut.upload.UploadTest - 9 MB
14:47:55.782 INFO micronaut.upload.UploadController - 352,8 kB
14:48:15.098 INFO micronaut.upload.UploadController - 1,8 MB
14:48:15.099 INFO micronaut.upload.UploadTest - 9 MB
14:48:15.099 INFO micronaut.upload.UploadTest - 9 MB
14:48:15.099 INFO micronaut.upload.UploadController - 1,8 MB
14:48:15.100 INFO micronaut.upload.UploadController - 1,8 MB
14:48:15.100 INFO micronaut.upload.UploadTest - 9 MB
14:48:15.201 INFO micronaut.upload.UploadTest - 10 MB
14:48:15.201 INFO micronaut.upload.UploadController - 1,8 MB
14:50:00.460 INFO micronaut.upload.UploadTest - 10 MB
```
So again, it pushes the whole 10MB in first second on the client side, and the it's consumed a little less than two minutes by the server.
<issue_comment>username_1: @username_0 I can't reproduce that
```
09:13:26.631 INFO micronaut.upload.UploadTest - 4 kB
09:13:33.560 INFO micronaut.upload.UploadTest - 544 kB
09:13:33.561 INFO micronaut.upload.UploadController - 844 B
09:13:37.235 INFO micronaut.upload.UploadController - 280.8 kB
09:13:37.235 INFO micronaut.upload.UploadTest - 548 kB
09:13:37.307 INFO micronaut.upload.UploadTest - 548 kB
09:13:37.308 INFO micronaut.upload.UploadController - 288.8 kB
09:13:42.255 INFO micronaut.upload.UploadController - 402.6 kB
09:13:42.255 INFO micronaut.upload.UploadTest - 552 kB
09:13:42.256 INFO micronaut.upload.UploadTest - 556 kB
09:13:42.256 INFO micronaut.upload.UploadController - 410.6 kB
09:13:42.356 INFO micronaut.upload.UploadController - 410.6 kB
09:13:42.356 INFO micronaut.upload.UploadTest - 560 kB
09:13:42.359 INFO micronaut.upload.UploadTest - 1 MB
09:13:42.359 INFO micronaut.upload.UploadController - 411.1 kB
09:13:42.361 INFO micronaut.upload.UploadController - 411.1 kB
09:13:42.361 INFO micronaut.upload.UploadTest - 1 MB
09:13:42.461 INFO micronaut.upload.UploadTest - 1 MB
09:13:42.462 INFO micronaut.upload.UploadController - 419.1 kB
09:13:43.706 INFO micronaut.upload.UploadController - 507.1 kB
09:13:43.706 INFO micronaut.upload.UploadTest - 1 MB
09:13:43.706 INFO micronaut.upload.UploadTest - 1 MB
09:13:43.706 INFO micronaut.upload.UploadController - 515.1 kB
09:13:43.706 INFO micronaut.upload.UploadController - 515.1 kB
09:13:43.706 INFO micronaut.upload.UploadTest - 1 MB
09:13:43.811 INFO micronaut.upload.UploadTest - 1.3 MB
09:13:43.811 INFO micronaut.upload.UploadController - 523.1 kB
09:13:47.022 INFO micronaut.upload.UploadController - 763.1 kB
09:13:47.023 INFO micronaut.upload.UploadTest - 1.3 MB
09:13:47.023 INFO micronaut.upload.UploadTest - 1.3 MB
09:13:47.023 INFO micronaut.upload.UploadController - 771.1 kB
09:13:47.023 INFO micronaut.upload.UploadController - 771.1 kB
09:13:47.023 INFO micronaut.upload.UploadTest - 1.3 MB
09:13:47.127 INFO micronaut.upload.UploadTest - 1.6 MB
09:13:47.127 INFO micronaut.upload.UploadController - 779.1 kB
09:13:50.338 INFO micronaut.upload.UploadController - 1,019.1 kB
09:13:50.339 INFO micronaut.upload.UploadTest - 1.6 MB
09:13:50.339 INFO micronaut.upload.UploadTest - 1.6 MB
09:13:50.339 INFO micronaut.upload.UploadController - 1 MB
09:13:50.339 INFO micronaut.upload.UploadController - 1 MB
09:13:50.340 INFO micronaut.upload.UploadTest - 1.6 MB
09:13:50.443 INFO micronaut.upload.UploadTest - 1.9 MB
09:13:50.443 INFO micronaut.upload.UploadController - 1 MB
09:13:53.656 INFO micronaut.upload.UploadController - 1.2 MB
09:13:53.656 INFO micronaut.upload.UploadTest - 1.9 MB
09:13:53.656 INFO micronaut.upload.UploadTest - 1.9 MB
09:13:53.656 INFO micronaut.upload.UploadController - 1.3 MB
09:13:53.656 INFO micronaut.upload.UploadController - 1.3 MB
09:13:53.656 INFO micronaut.upload.UploadTest - 1.9 MB
09:13:53.762 INFO micronaut.upload.UploadTest - 2.2 MB
09:13:53.762 INFO micronaut.upload.UploadController - 1.3 MB
09:13:56.956 INFO micronaut.upload.UploadController - 1.5 MB
09:13:56.956 INFO micronaut.upload.UploadTest - 2.2 MB
09:13:56.956 INFO micronaut.upload.UploadTest - 2.2 MB
09:13:56.957 INFO micronaut.upload.UploadController - 1.5 MB
09:13:56.957 INFO micronaut.upload.UploadController - 1.5 MB
09:13:56.957 INFO micronaut.upload.UploadTest - 2.2 MB
09:13:57.063 INFO micronaut.upload.UploadTest - 2.5 MB
09:13:57.063 INFO micronaut.upload.UploadController - 1.5 MB
09:14:00.255 INFO micronaut.upload.UploadController - 1.7 MB
09:14:00.256 INFO micronaut.upload.UploadTest - 2.5 MB
09:14:00.256 INFO micronaut.upload.UploadTest - 2.5 MB
09:14:00.256 INFO micronaut.upload.UploadController - 1.8 MB
09:14:00.256 INFO micronaut.upload.UploadController - 1.8 MB
09:14:00.256 INFO micronaut.upload.UploadTest - 2.5 MB
09:14:00.360 INFO micronaut.upload.UploadTest - 2.7 MB
09:14:00.360 INFO micronaut.upload.UploadController - 1.8 MB
09:14:03.557 INFO micronaut.upload.UploadController - 2 MB
09:14:03.557 INFO micronaut.upload.UploadTest - 2.7 MB
09:14:03.558 INFO micronaut.upload.UploadTest - 3 MB
09:14:03.558 INFO micronaut.upload.UploadController - 2 MB
09:14:06.877 INFO micronaut.upload.UploadController - 2.2 MB
09:14:06.878 INFO micronaut.upload.UploadTest - 3 MB
09:14:06.878 INFO micronaut.upload.UploadTest - 3 MB
09:14:06.878 INFO micronaut.upload.UploadController - 2.3 MB
09:14:06.878 INFO micronaut.upload.UploadController - 2.3 MB
09:14:06.878 INFO micronaut.upload.UploadTest - 3 MB
[Truncated]
09:15:26.422 INFO micronaut.upload.UploadTest - 9.2 MB
09:15:26.422 INFO micronaut.upload.UploadController - 8.3 MB
09:15:29.625 INFO micronaut.upload.UploadController - 8.5 MB
09:15:29.625 INFO micronaut.upload.UploadTest - 9.2 MB
09:15:29.730 INFO micronaut.upload.UploadTest - 9.5 MB
09:15:29.730 INFO micronaut.upload.UploadController - 8.5 MB
09:15:32.929 INFO micronaut.upload.UploadController - 8.8 MB
09:15:32.929 INFO micronaut.upload.UploadTest - 9.5 MB
09:15:33.029 INFO micronaut.upload.UploadTest - 9.7 MB
09:15:33.029 INFO micronaut.upload.UploadController - 8.8 MB
09:15:36.248 INFO micronaut.upload.UploadController - 9 MB
09:15:36.248 INFO micronaut.upload.UploadTest - 9.7 MB
09:15:36.352 INFO micronaut.upload.UploadTest - 10 MB
09:15:36.352 INFO micronaut.upload.UploadController - 9 MB
09:15:39.543 INFO micronaut.upload.UploadController - 9.3 MB
09:15:39.543 INFO micronaut.upload.UploadTest - 10 MB
09:15:39.647 INFO micronaut.upload.UploadTest - 10 MB
09:15:39.648 INFO micronaut.upload.UploadController - 9.3 MB
09:15:49.607 INFO micronaut.upload.UploadTest - 10 MB
```
<issue_comment>username_1: You can debug into the `.getBytes()` and you'll see it releases the data from memory entirely
<issue_comment>username_0: Hmm, interesting :) Are you on linux?
<issue_comment>username_1: macOS 10.14.5
JDK 1.8.0_212
<issue_comment>username_0: I'm on
```
Linux 4.4.0-97-generic #120-Ubuntu SMP Tue Sep 19 17:28:18 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
```
<issue_comment>username_0: I've modified a little `Dockefile` in `large` branch and added `run-test-in-docker.sh` which can be used to run test in docker container (at least on Linux - on Mac maybe you'll need to change something). The OS is apparently alpine. My results:
```
micronaut.upload.UploadTest > testWithApacheHttpClient() STANDARD_OUT
13:37:43.605 INFO micronaut.upload.UploadTest - 4 kB
13:37:43.669 INFO micronaut.upload.UploadTest - 4.2 MB
13:37:43.669 INFO micronaut.upload.UploadController - 847 B
13:37:44.814 INFO micronaut.upload.UploadController - 80.8 kB
13:37:44.815 INFO micronaut.upload.UploadTest - 4.2 MB
13:37:44.816 INFO micronaut.upload.UploadTest - 4.2 MB
13:37:44.816 INFO micronaut.upload.UploadController - 88.8 kB
13:37:44.817 INFO micronaut.upload.UploadController - 88.8 kB
13:37:44.817 INFO micronaut.upload.UploadTest - 4.2 MB
13:37:44.919 INFO micronaut.upload.UploadTest - 7 MB
13:37:44.920 INFO micronaut.upload.UploadController - 96.8 kB
13:37:45.634 INFO micronaut.upload.UploadController - 144.8 kB
13:37:45.635 INFO micronaut.upload.UploadTest - 7 MB
13:37:45.636 INFO micronaut.upload.UploadTest - 7 MB
13:37:45.637 INFO micronaut.upload.UploadController - 152.8 kB
13:37:45.639 INFO micronaut.upload.UploadController - 152.8 kB
13:37:45.639 INFO micronaut.upload.UploadTest - 7 MB
13:37:45.740 INFO micronaut.upload.UploadTest - 8.4 MB
13:37:45.742 INFO micronaut.upload.UploadController - 160.8 kB
13:37:57.901 INFO micronaut.upload.UploadController - 1.1 MB
13:37:57.902 INFO micronaut.upload.UploadTest - 8.4 MB
13:37:57.967 INFO micronaut.upload.UploadTest - 9.8 MB
13:37:57.969 INFO micronaut.upload.UploadController - 1.1 MB
13:38:17.352 INFO micronaut.upload.UploadController - 2.6 MB
13:38:17.352 INFO micronaut.upload.UploadTest - 9.8 MB
13:38:17.352 INFO micronaut.upload.UploadTest - 9.8 MB
13:38:17.353 INFO micronaut.upload.UploadController - 2.6 MB
13:38:17.353 INFO micronaut.upload.UploadController - 2.6 MB
13:38:17.353 INFO micronaut.upload.UploadTest - 9.8 MB
13:38:17.453 INFO micronaut.upload.UploadTest - 10 MB
13:38:17.454 INFO micronaut.upload.UploadController - 2.6 MB
13:39:53.446 INFO micronaut.upload.UploadTest - 10 MB
```
For example, the client reaches 9.8MB in 14 secs, while the server consumed only 2.6MB.
<issue_comment>username_1: You can put a breakpoint here https://github.com/micronaut-projects/micronaut-core/blob/e0337cc98c7988b75cad43b20251fa6d33db04b2/http-server-netty/src/main/java/io/micronaut/http/server/netty/HttpDataReference.java#L216
and here https://github.com/micronaut-projects/micronaut-core/blob/e0337cc98c7988b75cad43b20251fa6d33db04b2/http-server-netty/src/main/java/io/micronaut/http/server/netty/HttpDataReference.java#L225 to see what data is being buffered in memory
<issue_comment>username_1: This sounds like either an issue with the client or Netty
<issue_comment>username_0: I doubt about the client, because in the same way behaves chrome upload.
About your breakpoints, the first one is never touched, but at the second one I was able to add following log line in Idea: `"HOOK2: " + data.length()`. I'm putting the results into the attachment.
[hook2.log](https://github.com/micronaut-projects/micronaut-core/files/3422421/hook2.log)
What are your results from docker?
<issue_comment>username_0: It reports always 8192, the same size as in original example from my master branch.
However, in Linux (or in Docker) the data needs to be cached somewhere. As you said, maybe it's the netty issue.
<issue_comment>username_1: If its always 8192 then that is all we have access to and there isn't anything that can be done on our end
<issue_comment>username_0: OK | {'fraction_non_alphanumeric': 0.10156845659514215, 'fraction_numerical': 0.10941073957085284, 'mean_word_length': 3.6880265509318355, 'pattern_counts': {'":': 0, '<': 26, '<?xml version=': 0, '>': 34, 'https://': 8, 'lorem ipsum': 0, 'www.': 1, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '7099607', 'n_tokens_mistral': 7776, 'n_tokens_neox': 6263, 'n_words': 1783} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: TFBertForSequenceClassification: Non-deterministic when training on GPU, even with TF_DETERMINISTIC_OPS="1"
username_0: **System information**
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04.3 LTS
- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: -
- TensorFlow installed from (source or binary): used on Google Colab
- TensorFlow version (use command below): 2.2.0
- Python version: 3.6.9
- Bazel version (if compiling from source): -
- GCC/Compiler version (if compiling from source): -
- CUDA/cuDNN version: 10.1
- GPU model and memory: Tesla K80
**Describe the current behavior**
[Colab Link with a minimal example](https://colab.research.google.com/drive/1VSU8lYFD0E1HKZrIL1MvyIRwAktlSF_t#scrollTo=9NM47IRsy_v4)
Training a [transformers](huggingface/transformers/) `TFBertForSequenceClassification` model ([model code direkt link](https://github.com/huggingface/transformers/blob/3d495c61efbd2ca8a17827ff3103f7c820f0e9da/src/transformers/modeling_tf_bert.py#L910)) with keras/tf2.2.0 on the GPU is non-deterministic, even when setting all relevant random seeds and following the best practice guide in [these gputechconf slides](https://developer.download.nvidia.com/video/gputechconf/gtc/2019/presentation/s9911-determinism-in-deep-learning.pdf).
As clearly documented in [this table](https://github.com/NVIDIA/tensorflow-determinism#confirmed-current-gpu-specific-sources-of-non-determinism-with-solutions), training on the GPU can be expected to be deterministic for TF 2.2.0 when setting environment variable `TF_DETERMINISTIC_OPS` to `"1"`.
In spite of me setting this variable in my code (prior to importing tensorflow), this is not the case in my example.
Having seen previous issues (#38185) documented for `CrossEntropyLoss`, I also used the [suggested workaround for those](https://github.com/tensorflow/tensorflow/issues/38185#issuecomment-643014439).
Nonetheless, my code remains non-deterministic on the GPU.
**Describe the expected behavior**
For TF 2.2.0, training on the GPU is expected to be deterministic when fixing random seeds and using:
```python
os.environ["TF_DETERMINISTIC_OPS"] = "1"
```
Thus, my expectation is that the example code provided in my colab notebook should be deterministic on the colab GPU runtime as well.
**Standalone code to reproduce the issue**
Colab Link, reproducible on CPU runtime, non-deterministic on GPU runtime: https://colab.research.google.com/drive/1VSU8lYFD0E1HKZrIL1MvyIRwAktlSF_t#scrollTo=9NM47IRsy_v4
**Other info / logs** Include any logs or source code that would be helpful to
diagnose the problem. If including tracebacks, please include the full
traceback. Large logs and files should be attached.
<issue_comment>username_1: I have tried reproducing issue in TF2.2 -[CPU ](https://colab.research.google.com/gist/username_1/baaff5ec5a89755b7bb210925995d0b7/untitled34.ipynb) and [GPU](https://colab.research.google.com/gist/username_1/644e4ada0911e91dba7072ca7844c592/untitled33.ipynb).Is this the expected behavior?.Thanks!
<issue_comment>username_2: Note that this issue is being addressed as an [issue in the tensorflow-determinism repo](https://github.com/NVIDIA/tensorflow-determinism/issues/19). | {'fraction_non_alphanumeric': 0.09016632623285672, 'fraction_numerical': 0.04610446454625036, 'mean_word_length': 5.187725631768953, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 9, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 1, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6639258', 'n_tokens_mistral': 1192, 'n_tokens_neox': 1057, 'n_words': 340} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Get btc price with websocket
username_0: Instead of fetching the btc price only when calls are made we open at the launch of the application a websocket that will run in a thread and regularly update the btc and satoshis price per usd(t) in a global variable so that we gain some response time. Unfortunately coingecko and coinmarketcap doesn't offer websocket solution so I used the binance one but it only refer prices with stablecoins which are mostly usd stablecoins and no other currencies.
Fixes #19
<issue_comment>username_1: Thank you for this nice feature. What do you think to have the "old" solution switchable in the config? I would test this PR the next day's.
<issue_comment>username_2: I think this is a really very interesting option!
I tested that. Unfortunately this didn't work with the old image "2019-04-08-raspbian-stretch-lightningatm.gz". Running the command `pip3 install -r requirements.txt` does not find the required "websocket-client==1.2.3". It was only when I used a recent image that he was able to install the actual websocket client.
I discovered an error in app.py line 231:
`config.BTCPRICE = config.btc_price`
But that leads to an error. It should be:
`config.BTCPRICE = utils.get_btc_price(config.conf["atm"]["cur"])`
Then it works!
<issue_comment>username_2: I think the image from 2019 with the "strech" os (V.9) is quite old and we should make a cut for the ATM and go to the latest version "bullseye" (V.11). When that's done we can also adjust the `requirements.txt` for this PR.
<issue_comment>username_2: The program is therefore executable and we only have the problem that it is not downward compatible due to the requirements of `websocket-client==1.2.3` in requirements.txt. The OS with Debian Version 9 (Stretch) only know the `websocket-client` up to version 0.59.0. Unfortunately, it then makes a module import error when it starts. I haven't found a way to change it later. Only with the new version 11 (Bullseye) does it run smoothly.
We should consider how we can get a clean cut where we can also add future new features
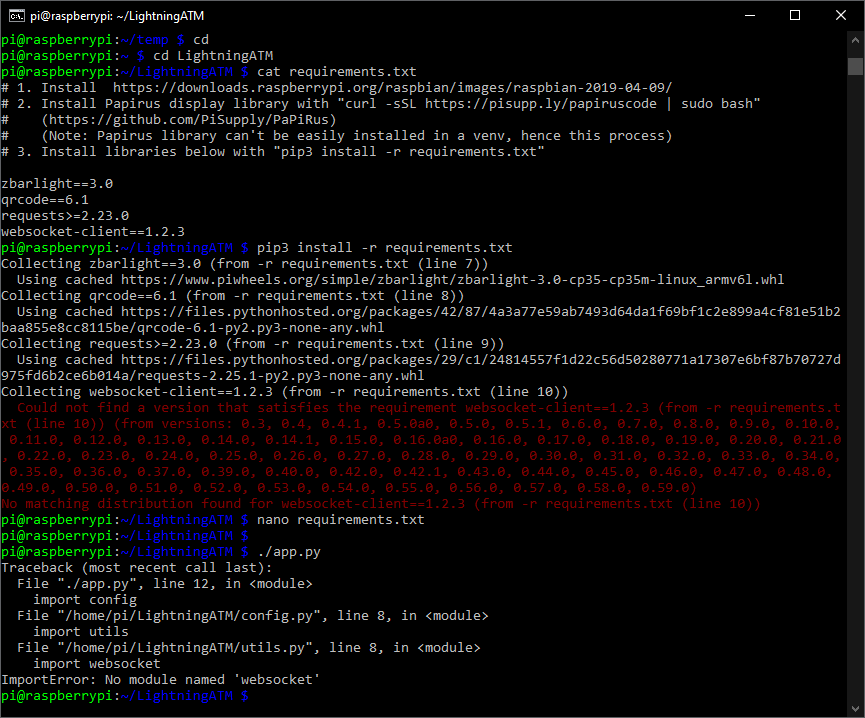
. | {'fraction_non_alphanumeric': 0.06347826086956522, 'fraction_numerical': 0.041304347826086954, 'mean_word_length': 4.439716312056738, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '22425834', 'n_tokens_mistral': 733, 'n_tokens_neox': 652, 'n_words': 330} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Hooks not deregistering after component is destroyed
username_0: Im using `angular 1.6.6` and `@ui-router/angularjs 1.0.3`. I'm registering `onStart` hooks in the constructor on the controller of one of my components. When ever I leave and reenter the component the hook registers itself again. I verify this by logging `$transitions.getHooks('onStart')`
Is this behaviour the expected one? I understood that hooks died after the component died as well.<issue_closed>
<issue_comment>username_0: Wrong repo. I apologize | {'fraction_non_alphanumeric': 0.07014388489208633, 'fraction_numerical': 0.014388489208633094, 'mean_word_length': 5.402298850574713, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24068131', 'n_tokens_mistral': 154, 'n_tokens_neox': 144, 'n_words': 72} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Update CountryFinderButton.jsx
username_0: Updating the copy as requested by the content team: https://uktrade.atlassian.net/browse/GP2-2540
This updates the copy so that users are clearer about what is about to happen when they change country.
### Workflow
- [X ] Ticket exists in Jira https://uktrade.atlassian.net/browse/GP2-2540
- [X ] Jira ticket has the correct status.
### Merging
- [x] This PR can be merged by reviewers. (If unticked, please leave for the author to merge) | {'fraction_non_alphanumeric': 0.08442776735459662, 'fraction_numerical': 0.020637898686679174, 'mean_word_length': 3.8545454545454545, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '1101930', 'n_tokens_mistral': 177, 'n_tokens_neox': 160, 'n_words': 65} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: A Way to Toggle Font Size
username_0: The font size can be a little small and kearning close together, for people with bad eyes a larger font could help. Maybe could put a font size toggle near the dark mode toggle.
<issue_comment>username_1: This is a v2 feature that needs to be run by our designer @shea-fitz first. | {'fraction_non_alphanumeric': 0.042492917847025496, 'fraction_numerical': 0.0084985835694051, 'mean_word_length': 4.709677419354839, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18921002', 'n_tokens_mistral': 94, 'n_tokens_neox': 93, 'n_words': 58} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: HELP: Clientside not working, no data-val-requiredif attributes
username_0: I'm having some difficulty with getting the clientside validation to work on a .net core mvc app. It's hitting my required-if annotation rule server-side. I've started through the debugging suggestions, and I never get to the breakpoint on "computeRequiredIf" I believe because no data-val-requiredif* attributes are getting added to the generated html elements. With the .net core, there's no more global.asax and Application_start to add the ExpressiveAnnotationModelValidatorProvider, but it is working serverside, so maybe that's not the issue. Any thoughts on what I did to cause the omission of attributes?
I'm just using the stock EditorFor helper, and here's the model property definition:
`[MaxLength(50)]`
`[Display(Name = "Name")]`
`[RequiredIf("shortAnswer3 == 'Yes'", ErrorMessage = "Required if you would like a response.")]`
`public string shortAnswer4 { get; set; }`
<issue_comment>username_1: ASP.NET Core is not yet supported.
<issue_comment>username_0: I see. Thank you for the quick reply. Well, it looks like a wonderful library and I hope to use it in the future. Cheers!<issue_closed> | {'fraction_non_alphanumeric': 0.07380373073803731, 'fraction_numerical': 0.0056772100567721, 'mean_word_length': 5.108910891089109, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '9357840', 'n_tokens_mistral': 337, 'n_tokens_neox': 318, 'n_words': 163} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: reddit_tifu dataset: Checksums didn't match for dataset source files
username_0: ## Describe the bug
When loading the reddit_tifu dataset, it throws the exception "Checksums didn't match for dataset source files"
## Steps to reproduce the bug
```python
import datasets
from datasets import load_dataset
print(datasets.__version__)
# load_dataset('billsum')
load_dataset('reddit_tifu', 'short')
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: mac os
- Python version: Python 3.7.6
- PyArrow version: 3.0.0
<issue_comment>username_1: Hi @username_0,
We have already fixed this. You should update `datasets` version to at least 1.18.4:
```shel
pip install -U datasets
```
Duplicate of:
- #3773<issue_closed>
<issue_comment>username_0: thanks @username_1 . by upgrading to 1.18.4 and using `load_dataset("...", download_mode="force_redownload")` fixed
the bug.
using the following as you suggested in another thread can also fixed the bug
```
pip install git+https://github.com/huggingface/datasets#egg=datasets
```
<issue_comment>username_1: The latter solution (installing from GitHub) was proposed because the fix was not released yet. But last week we made the 1.18.4 release (with the patch), so no longer necessary to install from GitHub.
You can now install from PyPI, as usual:
```shell
pip install -U datasets
``` | {'fraction_non_alphanumeric': 0.0977542932628798, 'fraction_numerical': 0.021136063408190225, 'mean_word_length': 4.224137931034483, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 2, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '17909443', 'n_tokens_mistral': 501, 'n_tokens_neox': 456, 'n_words': 177} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Travis: Add Jobs With Enabled `BUILD_FULL` & Disabled `BUILD_SHARED`
username_0: # Description
This pull request is a slightly extended version of PR #2275. I mainly added workarounds for problems that occur, if we enable `BUILD_FULL` and disable `BUILD_SHARED`. One puzzling problem is that compiling the unit test of the Base64 plugin works in macOS, but fails on Linux reporting [linker errors](https://travis-ci.org/username_0/elektra/jobs/445799127#L2225-L2229):
```
src/plugins_tests/CMakeFiles/testmod_base64.dir/base64/testmod_base64.c.o: In function `test_base64_encoding':
src/plugins/base64/testmod_base64.c:74: undefined reference to `base64Encode'
src/plugins_tests/CMakeFiles/testmod_base64.dir/base64/testmod_base64.c.o: In function `test_base64_decoding':
src/plugins/base64/testmod_base64.c:98: undefined reference to `base64Decode'
src/plugins/base64/testmod_base64.c:112: undefined reference to `base64Decode'
```
. Maybe someone else has an idea why that is the case…
<issue_comment>username_1: @username_0 maybe the order of linker flags is wrong (the linker on Linux might be more pedantic about that).
@petermax2 Or do you have an idea?
<issue_comment>username_0: Commit 601171e should [solve the issue](https://travis-ci.org/ElektraInitiative/libelektra/jobs/446798802#L2933). I do not know if the fix does introduce other problems though. | {'fraction_non_alphanumeric': 0.08615819209039548, 'fraction_numerical': 0.06285310734463277, 'mean_word_length': 5.621495327102804, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '8686524', 'n_tokens_mistral': 509, 'n_tokens_neox': 451, 'n_words': 140} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: update to beta5
username_0: com.android.tools.build:gradle:2.0.0-beta5
Also added CoordinatorLayout.java and AppBarLayout.java
I think it may better better to pull this into a new branch so I created cheese.
Anyhow this was done because I had an issue with the shadow layer not updating on scroll changes...
Thanks for your work and I hope that this pull request helps save you some of your time. Great Library project!
https://androidreclib.wordpress.com/2015/12/23/lets-port-design-support-library-to-carbon/#more-225
<issue_comment>username_0: might want to know this was done with a strong focus on API 19 and no care for other API levels
<issue_comment>username_1: Thank you for your kind words, I really appreciate that and all help I get from my users!
AppBarLayout and other Design Support Library widgets are available in carbon.beta package. Did you try them? If there's something wrong with them, feel free to open an issue.
<issue_comment>username_0: had not even started to look into the beta source yet...but it functions well in your demo and I am not finding flaws or errors...
I looked at some of your "open issues" and mostly they do not seem like they are actual issues.
Though I guess I can add to that issueless issue list...
https://github.com/username_1/Carbon/issues/196
<issue_comment>username_1: This pull request seems to be outdated. | {'fraction_non_alphanumeric': 0.056842105263157895, 'fraction_numerical': 0.018947368421052633, 'mean_word_length': 4.074733096085409, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '23507255', 'n_tokens_mistral': 409, 'n_tokens_neox': 373, 'n_words': 202} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Code block breaks formatting in Markdown preview in Insider build
username_0: Issue Type: <b>Bug</b>
This issue occurs only on the insiders build. Version 1.25.0 works as expected.
Steps to reproduce: Create a new file, set the language to Markdown and insert the following snippet:
``````
Normal text
```text
Code block
```
Everything is broken
``````
Now preview the file with `Cmd-K V` or `Ctrl-K V`. The text after the code block is not styled correctly. On the dark theme it's displayed in a yellow monospace font as seen in screenshot.
Insider version:
Normal version:
<img width="757" alt="screen shot 2018-07-11 at 15 50 58" src="https://user-images.githubusercontent.com/839351/42572599-71b120f8-8522-11e8-900e-22ba9b805d66.png">
VS Code version: Code - Insiders 1.25.0-insider (28d5806f24f99c2c6ad633e4e08ed5ea00169c83, 2018-06-11T05:11:22.150Z)
OS version: Darwin x64 17.5.0
<details>
<summary>System Info</summary>
|Item|Value|
|---|---|
|CPUs|Intel(R) Core(TM) i7-4770HQ CPU @ 2.20GHz (8 x 2200)|
|GPU Status|2d_canvas: enabled<br>checker_imaging: disabled_off<br>flash_3d: enabled<br>flash_stage3d: enabled<br>flash_stage3d_baseline: enabled<br>gpu_compositing: enabled<br>multiple_raster_threads: enabled_on<br>native_gpu_memory_buffers: enabled<br>rasterization: enabled<br>video_decode: enabled<br>video_encode: enabled<br>webgl: enabled<br>webgl2: enabled|
|Load (avg)|2, 2, 2|
|Memory (System)|16.00GB (0.11GB free)|
|Process Argv|/private/var/folders/9_/jkrpz3px2658swfrw0qg9zwr0000gp/T/AppTranslocation/4D8D7D57-5580-426F-ADA7-140AEEB99958/d/Visual Studio Code - Insiders.app/Contents/MacOS/Electron|
|Screen Reader|no|
|VM|0%|
</details>Extensions: none
<!-- generated by issue reporter -->
<issue_comment>username_0: I realized that I don't have the newest version of insider, it seems to work properly on the 5a4eab812bd485942061f71af39f3eabc52a1035 commit on Windows. I'll test tomorrow on OS X too.<issue_closed>
<issue_comment>username_0: Works fine on the newest insider build on OS X too. | {'fraction_non_alphanumeric': 0.11334225792057118, 'fraction_numerical': 0.11244979919678715, 'mean_word_length': 5.227777777777778, 'pattern_counts': {'":': 0, '<': 25, '<?xml version=': 0, '>': 25, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5116146', 'n_tokens_mistral': 976, 'n_tokens_neox': 809, 'n_words': 213} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Direct self-reference leading to cycle
username_0: use 0.69.0 agent
getting a reproducer is challenging as it goes through many internal libraries.
Can you help with resolving this?
Even a temporary fix to solve if for now works.
```
com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Direct self-reference leading to cycle (through reference chain: io.reactivex.internal.operators.observable.ObservableFlatMap["__datadogContext$io$reactivex$Observable"]->datadog.trace.agent.core.DDSpan["localRootSpan"]->datadog.trace.agent.core.DDSpan["localRootSpan"])
at com.fasterxml.jackson.databind.exc.InvalidDefinitionException.from(InvalidDefinitionException.java:77)
at com.fasterxml.jackson.databind.SerializerProvider.reportBadDefinition(SerializerProvider.java:1191)
at com.fasterxml.jackson.databind.ser.BeanPropertyWriter._handleSelfReference(BeanPropertyWriter.java:944)
at com.fasterxml.jackson.databind.ser.BeanPropertyWriter.serializeAsField(BeanPropertyWriter.java:721)
at com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:719)
at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:155)
at com.fasterxml.jackson.databind.ser.BeanPropertyWriter.serializeAsField(BeanPropertyWriter.java:727)
at com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:719)
at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:155)
at com.fasterxml.jackson.databind.ser.BeanPropertyWriter.serializeAsField(BeanPropertyWriter.java:727)
at com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:719)
at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:155)
at com.fasterxml.jackson.databind.ser.DefaultSerializerProvider._serialize(DefaultSerializerProvider.java:480)
at com.fasterxml.jackson.databind.ser.DefaultSerializerProvider.serializeValue(DefaultSerializerProvider.java:319)
at com.fasterxml.jackson.databind.ObjectMapper._configAndWriteValue(ObjectMapper.java:3905)
at com.fasterxml.jackson.databind.ObjectMapper.writeValueAsString(ObjectMapper.java:3219)
at com.dream11.api.route.AbstractRoute.getString(AbstractRoute.java:157)
at com.dream11.api.route.AbstractRoute.prepareResponse(AbstractRoute.java:75)
at com.dream11.api.route.AbstractRoute.lambda$handle$0(AbstractRoute.java:67)
at io.reactivex.internal.observers.LambdaObserver.onNext(LambdaObserver.java:63)
at datadog.trace.instrumentation.rxjava2.TracingObserver.onNext(TracingObserver.java:28)
at io.reactivex.internal.operators.observable.ObservableObserveOn$ObserveOnObserver.drainNormal(ObservableObserveOn.java:200)
at io.reactivex.internal.operators.observable.ObservableObserveOn$ObserveOnObserver.run(ObservableObserveOn.java:252)
at io.reactivex.internal.schedulers.ScheduledRunnable.run(ScheduledRunnable.java:66)
at io.reactivex.internal.schedulers.ScheduledRunnable.call(ScheduledRunnable.java:57)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
<issue_comment>username_1: The issue here is that Jackson is attempting to serialize a transient field which is injected by the tracer to help track context. The tracer uses a field for this association to avoid the memory overhead of using a separate (weak) map.
The injected field is deliberately marked as transient so it won't get serialized but it appears that Jackson is ignoring this flag because it also has an associated getter. (This behaviour is different to JDK serialization which just looks at the transient flag.)
According to https://github.com/fasterxml/jackson-databind/issues/296 you can tell Jackson to handle the transient flag just like `@JsonIgnore` (ie. overriding the fact that it has a getter) by enabling `MapperFeature.PROPAGATE_TRANSIENT_MARKER` in your mapper.
You could also turn off field-injection, but this is not really recommended because of the increase in memory needed for tracing (especially when asynchronous flows are involved) so if possible I would recommend using that mapper feature.
There are also some things we could look at doing in the tracer to help avoid this situation, but those would require code changes.
Note that 0.67.0 is not affected because it didn't have rxJava 2 instrumentation and therefore didn't use any field-injection.
<issue_comment>username_1: I've made a change in the tracer to help avoid this in the future: #2229 - it will be available in the next tracer release (0.71.0) | {'fraction_non_alphanumeric': 0.0815651158263578, 'fraction_numerical': 0.02413860229706054, 'mean_word_length': 6.578171091445427, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 19}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '11116555', 'n_tokens_mistral': 1606, 'n_tokens_neox': 1396, 'n_words': 333} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Octant plugin prebuilt binary in releases
username_0: cc @ImJasonH please include a prebuilt static bin of octant tekton plugin to be used from sidecar containers (dockerfiles with "RUN wget linux-x86-64 files"...)
<issue_comment>username_0: I have done this in my tekton sidecar for including the tekton plugin in the sidecar container along with octant binary.
https://github.com/username_0/che-sidecar-tekton/blob/1767abbf5dda590106498c84e2aa3f83a431ef22/Dockerfile#L15 | {'fraction_non_alphanumeric': 0.06274509803921569, 'fraction_numerical': 0.06666666666666667, 'mean_word_length': 5.905405405405405, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '27542621', 'n_tokens_mistral': 175, 'n_tokens_neox': 155, 'n_words': 55} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Remove outdated Troubleshooting section
username_0: Hi.
I found out that the troubleshooting section in the README.md missed '.' at the end of the sentence.
So, I just added it.
Thank you for your time. Hope you could merge it!
<issue_comment>username_1: Thanks. Actually I deleted the whole section because it is woefully outdated, and had nothing to do with troubleshooting React itself. | {'fraction_non_alphanumeric': 0.05104408352668213, 'fraction_numerical': 0.004640371229698376, 'mean_word_length': 4.6103896103896105, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29645600', 'n_tokens_mistral': 121, 'n_tokens_neox': 114, 'n_words': 61} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Show catalogue before logging in
username_0: # Definition of Done / Review checklist
## Reviewability
- (https://github.com/CSCfi/rems/issues/2120)[ https://github.com/CSCfi/rems/issues/2120] link to issue
<img width="636" alt="Screenshot 2020-05-06 at 11 23 56" src="https://user-images.githubusercontent.com/7344718/81154088-3bd17e80-8f8c-11ea-830c-6b47c5a3fb92.png">
<issue_comment>username_0: After looking at it together with @Macroz we figures something funky is going on with "/catalogue" path, @Macroz has promised to take a look at it and then we can continue, currently I am contonuing with the dev config file
<issue_comment>username_0: Can it be finally merged? @Macroz @username_1 ?
<issue_comment>username_1: The tests failed because master is broken :/ you should re-merge master once #2195 is merged.
I'd like you to fix the comments for test_api.clj, after that this can be merged.
<issue_comment>username_1: #2195 is in now
<issue_comment>username_0: @username_1 @Macroz is master still broken?
<issue_comment>username_1: @username_0 no, see my message above yours :)
but sync with @Macroz before pushing, he was going to fix this branch | {'fraction_non_alphanumeric': 0.0884070058381985, 'fraction_numerical': 0.06422018348623854, 'mean_word_length': 5.217616580310881, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '20570116', 'n_tokens_mistral': 418, 'n_tokens_neox': 373, 'n_words': 140} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Azure NPM update/rolling restart
username_0: We have an outage that was reported internally as the AAW network was crippled caused by an update made to our NPM nodes.
This update/change caused all azure-npm node to perform a rolling restart and churn out network policies. Which makes it impossible for them to respond to request until their queue has been cleared.
Outage was reported to the CNS team @sylus & @zachomedia and also communicated to our #general support channel in Slack.<issue_closed>
<issue_comment>username_0: Services are now responding | {'fraction_non_alphanumeric': 0.037037037037037035, 'fraction_numerical': 0.003367003367003367, 'mean_word_length': 5.134020618556701, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '3432603', 'n_tokens_mistral': 150, 'n_tokens_neox': 143, 'n_words': 85} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Missing coma in inputs traits definition of FSL FNIRT
username_0: ### Summary
Definition of [`FNIRT.inputs.intensity_mapping_model`](https://github.com/nipy/nipype/blob/0b3a116997eda4c364fea2b0e4e3dc902b1ede4e/nipype/interfaces/fsl/preprocess.py#L880) is missing a coma between 'global_non_linear' and 'local_linear' and thus both options are unusable.
### Actual behavior
### Expected behavior
### How to replicate the behavior
### Script/Workflow details
[`FNIRT.inputs.intensity_mapping_model`](https://github.com/nipy/nipype/blob/0b3a116997eda4c364fea2b0e4e3dc902b1ede4e/nipype/interfaces/fsl/preprocess.py#L880)
### Platform details:
{'sys_platform': 'darwin', 'scipy_version': '0.19.1', 'networkx_version': '1.11', 'commit_source': '(none found)', 'commit_hash': '<not found>', 'sys_version': '3.5.3 | packaged by conda-forge | (default, May 12 2017, 15:35:12) \n[GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)]', 'nipype_version': '1.0.0-dev', 'sys_executable': '/Users/miguel/anaconda/bin/python', 'numpy_version': '1.12.1', 'traits_version': '4.6.0', 'pkg_path': '/Users/miguel/anaconda/lib/python3.5/site-packages/nipype', 'nibabel_version': '2.1.0'}
1.0.0-dev
### Execution environment
Choose one
- Container [Tag: ???]
- My python environment inside container [Base Tag: ???]
- My python environment outside container<issue_closed>
<issue_comment>username_1: closed in #2125 | {'fraction_non_alphanumeric': 0.15595075239398085, 'fraction_numerical': 0.07250341997264022, 'mean_word_length': 5.4449339207048455, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '10235277', 'n_tokens_mistral': 611, 'n_tokens_neox': 535, 'n_words': 107} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Project Not Compiling
username_0: when i try to compile using
python vsum_train.py --dataset datasets/eccv16_dataset_tvsum_google_pool5.h5 --max-epochs 60 --hidden-dim 256
It gives following error
python vsum_train.py --dataset datasets/eccv16_dataset_tvsum_google_pool5.h5 --max-epochs 60 --hidden-dim 256
WARNING (theano.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
[29/06/2018 08:46:03] model options: {'disp_freq': 1, 'optimizer': 'adam', 'regularizer': 'L2', 'U_init': 'normal', 'base_lr': 1e-05, 'train_dataset_path': 'datasets/eccv16_dataset_tvsum_google_pool5.h5', 'alpha': 0.01, 'max_epochs': 60, 'W_init': 'normal', 'weight_decay': 1e-05, 'distant_sim_thre': 20, 'ignore_distant_sim': False, 'decay_stepsize': -1, 'model_file': None, 'decay_rate': 0.1, 'hidden_dim': 256, 'input_dim': 1024, 'n_episodes': 5}
[29/06/2018 08:46:03] initializing net model
Traceback (most recent call last):
File "vsum_train.py", line 158, in <module>
train_dataset_path=args.dataset)
File "vsum_train.py", line 56, in train
net = reinforceRNN(model_options)
File "/home/ssong/campTest1/vsumm-reinforce/model_reinforceRNN.py", line 40, in __init__
init_state=None, init_memory=None, go_backwards=False
File "/home/ssong/campTest1/vsumm-reinforce/theano_nets.py", line 342, in __init__
self.output = self.step(self.state_below)
File "/home/ssong/campTest1/vsumm-reinforce/theano_nets.py", line 396, in step
go_backwards=self.go_backwards
File "/home/ssong/.local/lib/python2.7/site-packages/theano/scan_module/scan.py", line 1077, in scan
scan_outs = local_op(*scan_inputs)
File "/home/ssong/.local/lib/python2.7/site-packages/theano/gof/op.py", line 615, in __call__
node = self.make_node(*inputs, **kwargs)
File "/home/ssong/.local/lib/python2.7/site-packages/theano/scan_module/scan_op.py", line 546, in make_node
inner_sitsot_out.type.dtype))
ValueError: When compiling the inner function of scan the following error has been encountered: The initial state (`outputs_info` in scan nomenclature) of variable IncSubtensor{Set;:int64:}.0 (argument number 1) has dtype float32, while the result of the inner function (`fn`) has dtype float64. This can happen if the inner function of scan results in an upcast or downcast.
using following python version
Python 2.7.12
<issue_comment>username_1: It says the dtype is supposed to be float32 but found float64. You need to change the global config to `floatX = float32`.
<issue_comment>username_0: python vsum_train.py --dataset datasets/eccv16_dataset_tvsum_google_pool5.h5 --max-epochs 60 --hidden-dim 256
WARNING (theano.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
[29/06/2018 02:57:38] model options: {'disp_freq': 1, 'optimizer': 'adam', 'regularizer': 'L2', 'U_init': 'normal', 'base_lr': 1e-05, 'train_dataset_path': 'datasets/eccv16_dataset_tvsum_google_pool5.h5', 'alpha': 0.01, 'max_epochs': 60, 'W_init': 'normal', 'weight_decay': 1e-05, 'distant_sim_thre': 20, 'ignore_distant_sim': False, 'decay_stepsize': -1, 'model_file': None, 'decay_rate': 0.1, 'hidden_dim': 256, 'input_dim': 1024, 'n_episodes': 5}
[29/06/2018 02:57:38] initializing net model
Traceback (most recent call last):
File "vsum_train.py", line 158, in <module>
train_dataset_path=args.dataset)
File "vsum_train.py", line 56, in train
net = reinforceRNN(model_options)
File "/home/ssong/campTest1/vsumm-reinforce/model_reinforceRNN.py", line 110, in __init__
grads = [T.grad(cost=cost, wrt=p) for p in self.params]
File "/home/ssong/.local/lib/python2.7/site-packages/theano/gradient.py", line 611, in grad
rval[i].type.why_null)
theano.gradient.NullTypeGradError: tensor.grad encountered a NaN. This variable is Null because the grad method for input 0 (Reshape{2}.0) of the UndefinedGrad op is mathematically undefined.
<issue_comment>username_1: you need to use theano 0.9.
i suggest using the pytorch version, which requires less efforts in configuration.
<issue_comment>username_0: Hi ,
Can u add some config details in readme about the packages u have used and version that can help me and other users to configure this project easily .
( it may be obvious for some users but for someone like me would be very helpful) .
<issue_comment>username_0: Hi , Its bit of a silly question but can u elaborate **path_to/video_frames** this command
python summary2video.py -p log-test/result.h5 -d **path_to/video_frames** -i 0 --fps 30 --save-dir log --save-name summary.mp4
where do they reside , or do i need to extract them from raw dataset.
<issue_comment>username_2: Hi!
I met the same problem, have you solved it?
using following version:
python: 2.7.12
theano:0.9.0 | {'fraction_non_alphanumeric': 0.11634176690170053, 'fraction_numerical': 0.04811281625881377, 'mean_word_length': 4.674117647058823, 'pattern_counts': {'":': 0, '<': 10, '<?xml version=': 0, '>': 10, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '10886787', 'n_tokens_mistral': 1827, 'n_tokens_neox': 1645, 'n_words': 492} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: RAML
username_0: What do you think of using [RAML](http://raml.org/) to describe a typical CRUD app according to RAPIS ?
<issue_comment>username_1: Hello !
I have personally never used RAML, but it looks great!
However, this specification is intended to define how to design a rest API, regardless of the language, format or libraries.
<issue_comment>username_0: Indeed, RAML is great, it generates html api documentation and mock server. The other rest api description languages are *swagger* and *apiary* but RAML is my preferred one. | {'fraction_non_alphanumeric': 0.06457242582897033, 'fraction_numerical': 0.005235602094240838, 'mean_word_length': 5.3076923076923075, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29523468', 'n_tokens_mistral': 154, 'n_tokens_neox': 151, 'n_words': 80} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Compatibility issue with Advanced Rocketry
username_0: Here's a snip from the crashlog
net.minecraftforge.fml.common.LoaderExceptionModCrash: Caught exception from WrapUp (wrapup)
Caused by: java.lang.NoClassDefFoundError: zmaster587/advancedRocketry/block/BlockSmallPlatePress
at thelm.jaopca.modules.ModuleAdvancedRocketry.addPresserRecipe(ModuleAdvancedRocketry.java:52)
at thelm.jaopca.modules.ModulePlate.init(ModulePlate.java:94)
at thelm.jaopca.registry.RegistryCore.registerInit(RegistryCore.java:407)
at thelm.jaopca.registry.RegistryCore.init(RegistryCore.java:83)
at thelm.jaopca.utils.JAOPCAEventHandler.onInitWrapUp(JAOPCAEventHandler.java:38)
at net.minecraftforge.fml.common.eventhandler.ASMEventHandler_1395_JAOPCAEventHandler_onInitWrapUp_Event2.invoke(.dynamic)
at net.minecraftforge.fml.common.eventhandler.ASMEventHandler.invoke(ASMEventHandler.java:90)
at net.minecraftforge.fml.common.eventhandler.EventBus$1.invoke(EventBus.java:144)
at net.minecraftforge.fml.common.eventhandler.EventBus.post(EventBus.java:182)
at thelm.wrapup.WrapUp.secondMovement(WrapUp.java:63)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at net.minecraftforge.fml.common.FMLModContainer.handleModStateEvent(FMLModContainer.java:637)
at sun.reflect.GeneratedMethodAccessor4.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at com.google.common.eventbus.Subscriber.invokeSubscriberMethod(Subscriber.java:91)
at com.google.common.eventbus.Subscriber$SynchronizedSubscriber.invokeSubscriberMethod(Subscriber.java:150)
at com.google.common.eventbus.Subscriber$1.run(Subscriber.java:76)
at com.google.common.util.concurrent.MoreExecutors$DirectExecutor.execute(MoreExecutors.java:399)
at com.google.common.eventbus.Subscriber.dispatchEvent(Subscriber.java:71)
at com.google.common.eventbus.Dispatcher$PerThreadQueuedDispatcher.dispatch(Dispatcher.java:116)
at com.google.common.eventbus.EventBus.post(EventBus.java:217)
at net.minecraftforge.fml.common.LoadController.sendEventToModContainer(LoadController.java:219)
at net.minecraftforge.fml.common.LoadController.propogateStateMessage(LoadController.java:197)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at com.google.common.eventbus.Subscriber.invokeSubscriberMethod(Subscriber.java:91)
at com.google.common.eventbus.Subscriber$SynchronizedSubscriber.invokeSubscriberMethod(Subscriber.java:150)
at com.google.common.eventbus.Subscriber$1.run(Subscriber.java:76)
at com.google.common.util.concurrent.MoreExecutors$DirectExecutor.execute(MoreExecutors.java:399)
at com.google.common.eventbus.Subscriber.dispatchEvent(Subscriber.java:71)
at com.google.common.eventbus.Dispatcher$PerThreadQueuedDispatcher.dispatch(Dispatcher.java:116)
at com.google.common.eventbus.EventBus.post(EventBus.java:217)
at net.minecraftforge.fml.common.LoadController.distributeStateMessage(LoadController.java:136)
at net.minecraftforge.fml.common.Loader.initializeMods(Loader.java:749)
at net.minecraftforge.fml.client.FMLClientHandler.finishMinecraftLoading(FMLClientHandler.java:336)
at net.minecraft.client.Minecraft.init(Minecraft.java:535)
at net.minecraft.client.Minecraft.run(Minecraft.java:4431)
at net.minecraft.client.main.Main.main(SourceFile:123)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at net.minecraft.launchwrapper.Launch.launch(Launch.java:135)
at net.minecraft.launchwrapper.Launch.main(Launch.java:28)
Caused by: java.lang.ClassNotFoundException: zmaster587.advancedRocketry.block.BlockSmallPlatePress
at net.minecraft.launchwrapper.LaunchClassLoader.findClass(LaunchClassLoader.java:191)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 50 more
Caused by: java.lang.NullPointerException<issue_closed>
<issue_comment>username_0: Issue is only with release version of Advanced Rocketry, issue in not applicable to latest beta version. As such I'm closing issue. | {'fraction_non_alphanumeric': 0.09619597689703246, 'fraction_numerical': 0.029277036446922925, 'mean_word_length': 5.777327935222672, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6012381', 'n_tokens_mistral': 1659, 'n_tokens_neox': 1560, 'n_words': 165} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Reduce number of user load from DB
username_0: We have request scoped object `org.gluu.model.security.Identity`. This object lives during processing request only. Hence oxAuth can store in it person entry after first load. And other parts of the code can use it.
<issue_comment>username_1: Implemented in 4.0. During single authorization code flow we had 6 queries to fetch user object. Now we have 1.<issue_closed> | {'fraction_non_alphanumeric': 0.05555555555555555, 'fraction_numerical': 0.013333333333333334, 'mean_word_length': 5.013333333333334, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '27998052', 'n_tokens_mistral': 118, 'n_tokens_neox': 113, 'n_words': 63} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: ⚠️ GitLab Server has degraded performance
username_0: In [`7727827`](https://github.com/username_0/upptime/commit/77278279c5a211c31341f3006b89facabf1692d3
), GitLab Server (https://gitlab01.its-telekom.eu) experienced **degraded performance**:
- HTTP code: 200
- Response time: 6611 ms
<issue_comment>username_0: **Resolved:** GitLab Server performance has improved in [`4851e8d`](https://github.com/username_0/upptime/commit/4851e8dbb5371c1e5c9026dd83cbd8c27f6cb8bb
).<issue_closed> | {'fraction_non_alphanumeric': 0.12548262548262548, 'fraction_numerical': 0.14478764478764478, 'mean_word_length': 7.948275862068965, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '8931862', 'n_tokens_mistral': 229, 'n_tokens_neox': 189, 'n_words': 33} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: pytest.config has removed, but how can I push cmdline value to testclass
username_0: ### problem
when upgrade to 5.0 version, pytest.config has removed, I canot push cmdline value to testclass
My test arch only uses one testclass with only one testcase which is extended by parametrize testcase yml file, but I want use cmdline value for testcase yml file.
my code is following
conftest.py file
```
import pytest
def pytest_addoption(parser):
parser.addoption("--bed", action="store", default="__testbed.yml",
help="testbed file")
```
testxx.py file
```
class TestTotal():
bed_file = pytest.config.getoption("--bed")
casedir = bed.casedir
@pytest.mark.parametrize("serial, desc, ops, expect, resetops, judgetype", yml_read.ptest_read_yml(casedir, template))
def test_cases(self, serial, desc, ops, expect, resetops, judgetype):
.........................................
```
### trying
I try request.config, buf failed for ```bed``` will be used before testcase and fixture is useless
I try pytest_generate_tests to set cls var ```bed_file```, also failed for cls var cannot be seen in TestTotal and only be seen in test function
I only hope varaibles to hold cmdline argument
who can help me, thanks very much!
<issue_comment>username_1: Hello @username_0,
`pytest.config` was deprecated in version 4 and has been removed in version 5.
You can use [`pytest.request`](https://docs.pytest.org/en/latest/reference.html#request) to achieve the similar (same) result.
If you need more information about why it was deprecated and examples with pytest.request, please look at the original issue #3050 .
If you don't have any other question, you can close this ticket :)
<issue_comment>username_0: Thanks @username_1
using pytest_generate_tests and metafunc.parametrize will solve this probelm
conftest.py file
```
import os
import pytest
import yml_read
def pytest_addoption(parser):
parser.addoption("--bed", action="store", default="__testbed.yml",
help="testbed file")
def pytest_generate_tests(metafunc):
bed_file = metafunc.config.getoption("--bed")
...................
metafunc.parametrize("serial, desc, ops, expect, resetops, judgetype", yml_read.ptest_read_yml(bed_file))
```<issue_closed> | {'fraction_non_alphanumeric': 0.11483654652137469, 'fraction_numerical': 0.005448449287510477, 'mean_word_length': 3.495291902071563, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '10866506', 'n_tokens_mistral': 745, 'n_tokens_neox': 718, 'n_words': 253} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Running grunt setup fails, git submodule doesnt exist?
username_0: Running `grunt setup` failed on getting the fonts. Is this a public repo?
````
Submodule 'app/assets/stylesheets/fonts' (<EMAIL>:lonelyplanet/lp-fonts.git) registered for path 'app/assets/stylesheets/fonts'
Cloning into 'app/assets/stylesheets/fonts'...
ERROR: Repository not found.
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
Clone of '<EMAIL>:lonelyplanet/lp-fonts.git' into submodule path 'app/assets/stylesheets/fonts' failed
````<issue_closed>
<issue_comment>username_0: Nevermind i'm blind :) says in the realm. | {'fraction_non_alphanumeric': 0.10224089635854341, 'fraction_numerical': 0.0028011204481792717, 'mean_word_length': 5.163793103448276, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4613929', 'n_tokens_mistral': 227, 'n_tokens_neox': 210, 'n_words': 74} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Advanced searching
username_0: Let users search by multiple data fields. Another useful feature to add, should be easy..
Example:
Genome = C. trachomatis 434/Bu
Cellular component = inclusion membrane protein
Host-pathogen interaction = true (has an entry)
Very powerful and useful if we can do that.<issue_closed>
<issue_comment>username_0: This is the same as
<issue_comment>username_0: Let users search by multiple data fields. Another useful feature to add, should be easy..
Example:
Genome = C. trachomatis 434/Bu
Cellular component = inclusion membrane protein
Host-pathogen interaction = true (has an entry)
Very powerful and useful if we can do that.
<issue_comment>username_0: Oops, this issue already exists as #16
<issue_comment>username_1: Here is what I have for UI:


Currently will have options for any of the 3 go classes, HP, uniprot and entrez
<issue_comment>username_1: Latest Update

<issue_comment>username_1: @andrewsu @username_0 Live on chlambase dev. https://dev.chlambase.org/keyword/test
<issue_comment>username_1: TODO: Add autocomplete for go term fields
<issue_comment>username_1: TODO: Add mutant (after refactoring) and EC Number search fields
<issue_comment>username_1: All done, but leaving open until we move to production
<issue_comment>username_0: 2 small suggestions:
1. Can you add an advanced search link to the header bar of all gene pages?
2. (not a small one) Give thought to adding an option for ortholog filtering. I'll think about this as well... but an example use case: filter all Cmur genes for those with no orthologs in CT-D and CT-L2. No bright idea how to implement this in a simple way.<issue_closed> | {'fraction_non_alphanumeric': 0.07568359375, 'fraction_numerical': 0.06396484375, 'mean_word_length': 5.246951219512195, 'pattern_counts': {'":': 0, '<': 14, '<?xml version=': 0, '>': 14, 'https://': 4, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '23298140', 'n_tokens_mistral': 717, 'n_tokens_neox': 654, 'n_words': 235} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Peatio Express installation (cheap) less then 2 hour
username_0: Chennai india based IT guy offering cheap and fast installation of peatio (rubykube) cryptocurrency exchange :) ping me for availability :)
Need following details for express installation
1, Domain,
2, hosting with best configuration,
3, SSL,
4, SSH details,
Chat with me in telegram
https://t.me/poseidon27<issue_closed> | {'fraction_non_alphanumeric': 0.0675990675990676, 'fraction_numerical': 0.018648018648018648, 'mean_word_length': 5.417910447761194, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '22391385', 'n_tokens_mistral': 122, 'n_tokens_neox': 117, 'n_words': 53} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Problem with the Usage commend for downloading data.
username_0: I am not sure if it is different to use this command on Mac or Windows, but the command you write there does now work for me.
`python src/download_data.py --url="http://www.csc-scc.gc.ca/005/opendata-donneesouvertes/Open%20Data%20File%2020170409%20v3%20(English).csv" --file_path="../data/raw/offender_profile.csv".csv" --file_path="./data/raw/offender_profile.csv"
`
It seems you have two `file_path` argument?
I modified the command as the following and it works for me:
`python src/download_data.py --url="http://www.csc-scc.gc.ca/005/opendata-donneesouvertes/Open%20Data%20File%2020170409%20v3%20(English).csv" --file_path="data/raw/offender_profile.csv"`
Any idea?
<issue_comment>username_0: One more problem, we need to change the `sample-docopt.r` to `clean_offender_profile_raw_data.r` for this command:
`Rscript src/sample-docopt.r --raw_data_path="./data/raw/offender_profile.csv" --processed_dir_path="./data/processed"`
<issue_comment>username_1: Agreed, changes have been incorporated.
<issue_comment>username_0: Solved.<issue_closed> | {'fraction_non_alphanumeric': 0.12694300518134716, 'fraction_numerical': 0.04145077720207254, 'mean_word_length': 5.4748603351955305, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 0, 'lorem ipsum': 0, 'www.': 2, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 3, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13506797', 'n_tokens_mistral': 425, 'n_tokens_neox': 395, 'n_words': 94} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: [System.Net.WebClient] does not contain a method with the name "new"
username_0: Set-ExecutionPolicy Bypass -Scope Process -Force;iex "$(([System.Net.WebClient]::new()).Download
String('http://install.username_2framework.com'));Install-Xpand -Assets @('Assemblies','Nuget','VSIX','Source') #-Version '
19.1.402.0' -SkipGac -InstallationPath 'C:\Xpand'"
An error occurred while calling the method, because [System.Net.WebClient] does not contain a method with the name "new".
Windows 7
<issue_comment>username_1: whats your powershell version?
<issue_comment>username_0: 2.0
<issue_comment>username_1: to be safe i guess u need to upgrade to 5
<issue_comment>username_2: Closing issue for age. Feel free to reopen it at any time.
.Thank you for your contribution.<issue_closed> | {'fraction_non_alphanumeric': 0.12014563106796117, 'fraction_numerical': 0.02063106796116505, 'mean_word_length': 5.5476190476190474, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 1, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19101365', 'n_tokens_mistral': 270, 'n_tokens_neox': 254, 'n_words': 83} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Cargo Nightly(3568be9 2016-11-26) failes to update the registry: SSL certificate is invalid
username_0: Cargo nightly `cargo 0.16.0-nightly (3568be9 2016-11-26)` fails to update the registry when running `cargo update`.
After trying ~10 times, I ran `rustup run stable cargo update` and it worked(on stable).
Here is the log on another Rust application:
```
RUST_LOG=debug cargo update --verbose 9:23:43
DEBUG:cargo::update: executing; cmd=cargo-update; args=["/home/lilian/.multirust/toolchains/nightly-x86_64-unknown-linux-gnu/bin/cargo", "update", "--verbose"]
DEBUG:cargo::core::workspace: find_root - trying /home/lilian/Git/Cargo.toml
DEBUG:cargo::core::workspace: find_root - trying /home/lilian/Cargo.toml
DEBUG:cargo::core::workspace: find_root - trying /home/Cargo.toml
DEBUG:cargo::core::workspace: find_root - trying /Cargo.toml
DEBUG:cargo::core::workspace: find_members - only me as a member
DEBUG:cargo::core::registry: load/missing file:///home/lilian/Git/imgui-rs
DEBUG:cargo::sources::config: loading: file:///home/lilian/Git/imgui-rs
DEBUG:cargo::core::resolver: initial activation: imgui v0.1.0-pre (file:///home/lilian/Git/imgui-rs)
DEBUG:cargo::core::registry: load/missing registry https://github.com/rust-lang/crates.io-index
DEBUG:cargo::sources::config: loading: registry https://github.com/rust-lang/crates.io-index
Updating registry `https://github.com/rust-lang/crates.io-index`
DEBUG:cargo::sources::registry::remote: attempting github fast path for https://github.com/rust-lang/crates.io-index
DEBUG:cargo::sources::registry::remote: fast path failed, falling back to a git fetch
DEBUG:cargo: handle_error; err=CliError { error: Some(ChainedError { error: failed to load source for a dependency on `glium`, cause: ChainedError { error: Unable to update registry https://github.com/rust-lang/crates.io-index, cause: ChainedError { error: failed to fetch `https://github.com/rust-lang/crates.io-index`, cause: Error { code: -17, klass: 16, message: "The SSL certificate is invalid" } } } }), unknown: false, exit_code: 101 }
error: failed to load source for a dependency on `glium`
Caused by:
Unable to update registry https://github.com/rust-lang/crates.io-index
Caused by:
failed to fetch `https://github.com/rust-lang/crates.io-index`
Caused by:
[16/-17] The SSL certificate is invalid
```
<issue_comment>username_1: Thanks for the report! I believe this is https://github.com/rust-lang/cargo/issues/3340 which is now being tracked for rustup at https://github.com/rust-lang-nursery/rustup.rs/issues/844<issue_closed> | {'fraction_non_alphanumeric': 0.13415545590433484, 'fraction_numerical': 0.02391629297458894, 'mean_word_length': 4.496919917864476, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 10, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 2, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24695742', 'n_tokens_mistral': 932, 'n_tokens_neox': 863, 'n_words': 222} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Is compatible with protobufjs?
username_0: I was wondering if it is compatible with the generated sources by protobufjs package.
I am looking for a solution to generate both server interfaces and client stubs in typescript. Sadly i could not find any official workaround yet however protobufjs seems to be a doable way.
Do you have any other recommendation?
<issue_comment>username_1: Hello, can you elaborate more on the issue as I am not sure I understand completely. Mali uses the official [grpc module](https://www.npmjs.com/package/grpc), which in turn [uses protobufjs](https://github.com/grpc/grpc-node/blob/grpc%401.19.0/packages/grpc-native-core/package.json#L36). I do not really use TypeScript so not sure how that factors into this.
<issue_comment>username_0: Sorry,
It is my fault. Figured it finally. :)<issue_closed> | {'fraction_non_alphanumeric': 0.07208237986270023, 'fraction_numerical': 0.012585812356979404, 'mean_word_length': 4.87248322147651, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 2, 'lorem ipsum': 0, 'www.': 1, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24894200', 'n_tokens_mistral': 244, 'n_tokens_neox': 238, 'n_words': 111} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: [ERROR] Not yet supported by the V8 runtime
username_0: Can anybody explain to me what's wrong with it, and how to fix?
<issue_comment>username_1: same problem
<issue_comment>username_2: I've recently upgrade the server side to latest `frida`. Can you show me the version of your frida on iOS device?
<issue_comment>username_0: Here is the version on my iPhone:
`~ root# frida-server --version`
`12.6.7`
And here is the version on my MacBook:
`frida --version`
`12.6.7`
<issue_comment>username_3: Same problem here, running this version of frida:
`root# frida-server --version
12.6.8
`
Error with passionfruit:
`Rejection: Error: GDBus.Error:re.frida.Error.InvalidArgument: not yet supported by the V8 runtime`<issue_closed>
<issue_comment>username_2: Sorry, forgot to update package.json.
Should be fixed now
<issue_comment>username_4: Still not working on 0.5.1. Same error, `frida-server` 12.6.8.
<issue_comment>username_5: Same Issue here
<issue_comment>username_2: Can anybody explain to me what's wrong with it, and how to fix?
<issue_comment>username_6: Same Issue here.
<issue_comment>username_7: same error
<issue_comment>username_8: I was able to resolve this issue by building it from current master branch.
```$ git clone https://github.com/chaitin/passionfruit.git
$ npm install
$ npm run dev```
<issue_comment>username_9: Same issue here,all packages are latest version.
<issue_comment>username_9: thanks,it worked for me.
<issue_comment>username_10: I am getting the same issue - "Rejection: Error: GDBus.Error:re.frida.Error.InvalidArgument: not yet supported by the V8 runtime"
<issue_comment>username_2: Sorry. The root cause is that from v0.5.1 I have moved to v8 engine, which doesn't support bytecode. It should be gone after v0.5.3.<issue_closed> | {'fraction_non_alphanumeric': 0.09041095890410959, 'fraction_numerical': 0.025205479452054796, 'mean_word_length': 5.12751677852349, 'pattern_counts': {'":': 0, '<': 19, '<?xml version=': 0, '>': 19, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '22868169', 'n_tokens_mistral': 591, 'n_tokens_neox': 571, 'n_words': 220} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Publish to NPM :)
username_0: angular-chart.js is great! Have you considered publishing it to NPM? A lot of people use npm instead of bower for package management.
<issue_comment>username_1: Yes it is already...<issue_closed>
<issue_comment>username_0: That it is :P. Sorry. You may want to update the keywords so that it's [searchable](https://www.npmjs.com/search?q=angular-chart). | {'fraction_non_alphanumeric': 0.10047846889952153, 'fraction_numerical': 0.007177033492822967, 'mean_word_length': 5.446153846153846, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 1, 'lorem ipsum': 0, 'www.': 1, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '21708849', 'n_tokens_mistral': 126, 'n_tokens_neox': 122, 'n_words': 49} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: [Suggestion] extended info about Blade extends and sections
username_0: A colleague of mine recently asked about some Blade section and I noticed I didn't fully understand how these are working as well.
I'm wondering about these in particular:
1. To end a section: `@show` VS `@endsection` VS `@stop` VS `@apply`
2. In [the example in the docs](https://laravel.com/docs/5.6/blade#template-inheritance), a sidebar is extended. What if one would like to remove or replace this sidebar completely in one view?
-> Remove the `@parent`, but this would still cause the full sidebar to be rendered first. (and thus causing trouble if data is missing) If I understood correctly, using `@endsection` in the layout instead of `@show` might stop this. However, will all child views now be required to use an `@show` to render the sidebar?
I'd be very grateful if anyone sees a way of improving the docs on this one. Also willing to write myself when someone provides a bit of explanation first.
<issue_comment>username_1: @username_0 - please feel free to go ahead and submit the PR for this, and Taylor will be able to look at it and deicde.<issue_closed>
<issue_comment>username_0: Sure, will do! | {'fraction_non_alphanumeric': 0.06726094003241491, 'fraction_numerical': 0.006482982171799027, 'mean_word_length': 4.563063063063063, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '11226386', 'n_tokens_mistral': 338, 'n_tokens_neox': 319, 'n_words': 189} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: add wikipedia biography dataset
username_0: My first PR containing the Wikipedia biographies dataset. I have followed all the steps in the [guide](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). It passes all the tests.
<issue_comment>username_0: Does anyone know why am I getting this "Some checks were not successful" message? For the _code_quality_ one, I have successfully run the flake8 command.
<issue_comment>username_0: Ok, I need to update the README.md, but don't know if that will fix the errors
<issue_comment>username_1: Hi @username_0 , thanks for adding the dataset!
It looks like `black` is throwing the code quality error: you need to run `make style` with the latest version of `black` (`black --version` should return 20.8b1)
We also added a requirement to specify encodings when using the python `open` function (line 163 in the current version of your script)
Finally, you will need to add the tags and field descriptions to the README as described here https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#tag-the-dataset-and-write-the-dataset-card
Let us know if you have any further questions!
<issue_comment>username_1: Also, please leave the full template of the readme with the `[More Information Needed]` paragraphs: you don't have to fill them out now but it will make it easier for us to go back to later :)
<issue_comment>username_0: Thank you for your help, @username_1! I have updated everything (finally run the _make style_, added the tags, the ecoding to the _open_ function and put back the empty fields in the README). Hope it works now! :)
<issue_comment>username_1: LGTM!
<issue_comment>username_2: merging since the CI is fixed on master | {'fraction_non_alphanumeric': 0.06500847936687394, 'fraction_numerical': 0.010175240248728096, 'mean_word_length': 5.061643835616438, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6300152', 'n_tokens_mistral': 501, 'n_tokens_neox': 480, 'n_words': 242} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Goal : Partner
username_0: I prefer to not have girlfriend than having someone that I'm not compatible with.
2020, I tried the app Tinder. But is not for me. I'm searching a serious relationship not a 1 date night.
May 2021, I found an App called [Hinge](https://hinge.co) that seams more aligned with what I'm searching for. Now, my biggest concern is myself :joy:. | {'fraction_non_alphanumeric': 0.07125307125307126, 'fraction_numerical': 0.02457002457002457, 'mean_word_length': 4.1645569620253164, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '3786354', 'n_tokens_mistral': 123, 'n_tokens_neox': 108, 'n_words': 63} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Can't access any sites including 192.168.33.10 after npm run watch
username_0: Hi guys,
Bit of a wierd one here...I use webpack to develop my sites with scotchbox...works fine everywhere except for my desktop pc (i also use a laptop and a mac at work and both are fine)
The laptop and desktop are using linux.
The laptop is using mint and the desktop is using ubuntu...ubuntu is pretty much a fresh install.
So when I vagrant up everything works fine but then when I run npm run watch is when it dies for some reason? I can't access any of my websites or the default 192.168.33.10
I have developed sites in wordpress and processwire cms and both have the same issue so its nothing to do with that.
I have multiple sites running by adding them (in vagrant ssh) to /etc/apache2/sites-available.
The super wierd thing is that if i run vagrant up and then wait about 15 minutes its fine but if i run it straight away it kills it all.
It has also randomly just died on me in the middle of working.
The only thing that fixes it is restarting the operating system.
Vagrant reload does not give any errors and im not really sure where to look for errors for this.
Any help would be appreciated.
Below is my webpack.config.js if it helps although like i said it works fine on other computers...just is a wierdo on this one.
`var webpack = require('webpack'),
path = require('path'),
glob = require('glob-all'),
ExtractTextPlugin = require("extract-text-webpack-plugin"),
PurifyCSSPlugin = require('purifycss-webpack'),
CleanWebpackPlugin = require('clean-webpack-plugin'),
BuildManifestPlugin = require('./build/plugins/BuildManifestPlugin'),
CopyWebpackPlugin = require('copy-webpack-plugin'),
BrowserSyncPlugin = require('browser-sync-webpack-plugin'),
inProduction = (process.env.NODE_ENV === 'production');
//glob = require('glob-all');
module.exports = {
entry:{
app:'./ui-theme/js/app.js',
vendor:[ //Add any JS libraries here by calling the parent folder name in node_modules.
'jquery',
'bootstrap-sass'
]
},
output:{
path: path.resolve(__dirname, './site/templates'),
filename:'./scripts/[name].js'
},
module:{
rules:[
{
test: /\.(woff|woff2|eot|ttf|svg)$/,
use:{
loader: 'url-loader',
options:{
limit:8192,
name:'./fonts/[name].[ext]'
}
}
},
{
test: /\.scss$/,
use:ExtractTextPlugin.extract({
use: ['css-loader','sass-loader'],
fallback:'style-loader'
})
},
{
test: /\.js$/,
exclude: /node_modules/,
loader: "babel-loader"
}
]
},
watchOptions:{
ignored: /node_modules/
},
plugins:[
[Truncated]
'site/templates/**/*.php',
'site/templates/*.php',
'ui-theme/scss/*.scss',
'ui-theme/js/*.js'
]
}),
// This outputs the name of the files into a manifest.json file
// Need to figure out the best way of re-writing header / footer files with these values.
// See build/plugins for code.
// new BuildManifestPlugin()
]
};
if(inProduction){
module.exports.plugins.push(
new webpack.optimize.UglifyJsPlugin()
);
}
`
<issue_comment>username_1: Maybe you are running out of memory. I would consider doing one Vagrantfile
per project
<issue_comment>username_0: I highly doubt it although I have plenty of memory in my computer...how do I assign more to scotchbox?
Also as previously stated its a fresh install of ubuntu and until an hour ago I only had one project on there anyway.
My laptop has half the memory that my desktop does and has four or five previous projects running in the same scotchbox vagrant with no issues whatsoever. At work on my mac I have about 20 different projects running on that thing with no issues (its the same set up I have at home) and there is only 8gb of ram on that thing.
<issue_comment>username_1: Maybe the VM is running out of memory?
TBH I'm not sure what the answer is here. Maybe someone can figure out what's going on?
<issue_comment>username_0: Yeah I understood what you were saying...which is why i asked how I give it more? I assume its got a default setting of a certain amount that I can hopefully change?
<issue_comment>username_1: ```
config.vm.provider "virtualbox" do |v|
v.memory = 4096
v.cpus = 4
end
```
Maybe something like this?<issue_closed>
<issue_comment>username_0: Well the problem hasn't been solved but I figured out what it is....apache randomly keeps stopping and I don't know why. So if it does i have to vagrant ssh and do a sudo service apache2 start. I have no idea why this is happening but at least I found a quicker fix than having to restart every time.
<issue_comment>username_2: Hi I am having same problem. but this apache restart did not worked for me, any other solution please? | {'fraction_non_alphanumeric': 0.08187569780424266, 'fraction_numerical': 0.008373650911797544, 'mean_word_length': 2.2955242182709994, 'pattern_counts': {'":': 0, '<': 10, '<?xml version=': 0, '>': 10, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 2, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25982106', 'n_tokens_mistral': 1532, 'n_tokens_neox': 1387, 'n_words': 634} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Coordinates in CSV file no limited to four decimal places
username_0: The coordinates in the result should be rounded to reasonable accuracy, too, as we do it for the input:
```python
#
# rounding coordinates to reasonable accuracy
#
# see https://gis.stackexchange.com/a/208739
#
lat_lo = round(lat_lo, 4)
lat_hi = round(lat_hi, 4)
lon_hi = round(lon_hi, 4)
lon_lo = round(lon_lo, 4)
```
Go to [Code](https://github.com/52North/MariDataHarvest/blob/main/EnvDataServer/app.py#L324-L332).
Requesting the following data, the resulting coordinates have up to 16 decimal places.
```csv
Time range: 2019-06-02 00:44:00 to 2019-06-02 12:55:00,,,
Longitude extent: 1.61 to 6.18,,,
Latitude extent: 53.00 to 55.16,,,
Spatial Resolution 0.083deg x 0.083deg,,,
Temporal Resolution 3-hours interval,,,
Credit (Wave-Wind-Physical): E.U. Copernicus Marine Service Information (CMEMS),,,
Credit (GFS): National Centers for Environmental Prediction/National Weather Service/NOAA,,,
Accessed on 2022-02-01 10:57:24,,,
Error(s): ,,,
latitude,longitude,time,VHM0_WW
52.997,1.607,2019-06-02 00:44:00,0.4354017150281338
52.997,1.607,2019-06-02 03:44:00,0.48501256607868165
52.997,1.607,2019-06-02 06:44:00,0.5505601363923266
52.997,1.607,2019-06-02 09:44:00,0.6087635072508395
52.997,1.69,2019-06-02 00:44:00,0.46592905816830743
52.997,1.69,2019-06-02 03:44:00,0.5236179489900831
52.997,1.69,2019-06-02 06:44:00,0.5939488696490431
52.997,1.69,2019-06-02 09:44:00,0.6639426764193687
52.997,1.773,2019-06-02 00:44:00,0.48650004597974444
52.997,1.773,2019-06-02 03:44:00,0.5541489307372638
52.997,1.773,2019-06-02 06:44:00,0.6337261238057263
52.997,1.773,2019-06-02 09:44:00,0.7121875631269267
52.997,1.8559999999999999,2019-06-02 00:44:00,0.49679391377512677
52.997,1.8559999999999999,2019-06-02 03:44:00,0.5737379222314644
[...]
``` | {'fraction_non_alphanumeric': 0.1466321243523316, 'fraction_numerical': 0.3487046632124352, 'mean_word_length': 4.470254957507082, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 2, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '14868501', 'n_tokens_mistral': 1245, 'n_tokens_neox': 823, 'n_words': 145} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: JDBC store implementation
username_0: Still a draft, but passes all integration tests.
The implementation supports multiple dialects to support different databases. At the moment, only hsqldb, postgreslql and cockroachdb are implemented. hsqldb is used as the default database to run the tests, running the tests via other databases works.
The code in this PR is based on #700 and definitely not ready for a review, more a dirty proof-of-concept.
All values end in a single row (no relations in the database schema). Databases must support the SQL arrays (or a similar mechanism).
Trees (aka the `children` or an `L1` and `Ref`) are mapped as 43 distinct columns to allow rather simple SQL conditions and updates.
Branch-commits in `Ref` work for up to 15 elements. No explicit overflow-protection implemented, it would probably just throw a lot of exceptions, if that limit is exceeded.
<!-- Reviewable:start -->
---
This change is [<img src="https://reviewable.io/review_button.svg" height="34" align="absmiddle" alt="Reviewable"/>](https://reviewable.io/reviews/projectnessie/nessie/718)
<!-- Reviewable:end -->
<issue_comment>username_0: Converted the PR back to "draft". There are two reasons for that:
* I've been lazy with rebasing this PR
* The limitation of 15 commits per branch can likely be exceeded, so it's likely that a Nessie server returns a bunch errors back to the client, without a "guard" that protects the store implementation from that many commits per branch.
<issue_comment>username_0: Closing in favor of #1638 | {'fraction_non_alphanumeric': 0.07160804020100503, 'fraction_numerical': 0.013819095477386936, 'mean_word_length': 4.550522648083624, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25970878', 'n_tokens_mistral': 435, 'n_tokens_neox': 408, 'n_words': 219} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Access keys is under Security + networking tab now
username_0: Access keys is under **Security + networking** tab now

---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 247d9900-c024-7ed5-3ea2-6541606c7712
* Version Independent ID: ce928556-d603-1722-79bb-67fbaf81da37
* Content: [Register and scan Azure Data Lake Storage (ADLS) Gen2 - Azure Purview](https://docs.microsoft.com/en-us/azure/purview/register-scan-adls-gen2)
* Content Source: [articles/purview/register-scan-adls-gen2.md](https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/purview/register-scan-adls-gen2.md)
* Service: **purview**
* Sub-service: **purview-data-catalog**
* GitHub Login: @shsandeep123
* Microsoft Alias: **sandeepshah**<issue_closed>
<issue_comment>username_1: @username_0 Thanks for pointing out the issue, I've addressed this issue in PR: [https://github.com/MicrosoftDocs/azure-docs-pr/pull/162570](https://github.com/MicrosoftDocs/azure-docs-pr/pull/162570)
The changes should be live EOD or tomorrow. In future, if you see any minor bug fixes in the doc, feel free to click on the edit button and submit a PR to update. we love to take community contributions. | {'fraction_non_alphanumeric': 0.12091038406827881, 'fraction_numerical': 0.07112375533428165, 'mean_word_length': 4.742857142857143, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29952299', 'n_tokens_mistral': 530, 'n_tokens_neox': 469, 'n_words': 122} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: can not get tags, hs-tags: user error
username_0: Hello. I am having troubles generating tags in the agda repo.
When running the following command
```bash
find src/full/ -name "*.*hs" | xargs \
hs-tags --cabal Agda.cabal \
-i .stack-work/dist/x86_64-linux-tinfo6/Cabal-3.4.0.0/build/autogen/cabal_macros.h -e
```
I invariably get the following error:
```bash
hs-tags: user error (Pattern match failure in do expression at Main.hs:216:13-19)
```
I am using hs-tags 0.1.5. I compiled Agda from source using stack, and this project config file:
```bash
stack-9.0.1.yaml
```
Maybe am I just misusing hs-tags? If that's it, please excuse the inconvenience.
<issue_comment>username_1: The error is raised here: https://github.com/agda/hs-tags/blob/5e5fca935ce5cc689623c88bed55324527c50728/Main.hs#L216
Here, `ghc` is invoked in the following way:
```
$ ghc --print-libdir
/usr/local/lib/ghc-9.0.1
```
This may fail if you have no `ghc` in the `PATH`.
Maybe you can work around this by (1) installing `ghc-9.0.1` so that it is in the `PATH` as `ghc`, and then (2) install with something like `stack install --stack-yaml=stack-9.0.1 --system-ghc`. Step (2) might not even be necessary.
<issue_comment>username_1: So maybe we should do that...
<issue_comment>username_0: Meanwhile the `stack exec` workaround worked for me, thank you very much.
<issue_comment>username_1: I pushed 791b1b8 implementing https://github.com/agda/hs-tags/issues/3#issuecomment-901807519.
@username_0 : Would you help me out, installing `hs-tags` from the latest `master` and testing whether it makes a difference for you?
<issue_comment>username_0: Certainly. Will do that as soon as I get access to my machine.
<issue_comment>username_0: It works:) For the record here is what I did
1. delete old hs-tags binary
2. install hs-tags master
`hs-tags --help` gives me `hs-tags version 0.1.6`.
3. run this command in agda repo (in the agda/ directory)
```bash
find src/full/ -name "*.*hs" | xargs \
-- hs-tags --cabal Agda.cabal \
-i .stack-work/dist/x86_64-linux-tinfo6/Cabal-3.4.0.0/build/autogen/cabal_macros.h \
--etags=./src/full/TAGS
```
Thanks<issue_closed> | {'fraction_non_alphanumeric': 0.12352406902815623, 'fraction_numerical': 0.04632152588555858, 'mean_word_length': 3.7787418655097613, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 2, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18846972', 'n_tokens_mistral': 850, 'n_tokens_neox': 791, 'n_words': 265} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: proposal: add small api to support byte/string views
username_0: Please answer these questions before submitting your issue. Thanks!
1. What version of Go are you using (`go version`)?
go version go1.6 linux/amd64
(rest doesn't apply, since I don't report a bug here)
It would be nice to make it easier to define, shareable, read-only views of data from which many consumable readers can be derived.
I did expect something like https://godoc.org/github.com/username_0/views/bytes
and https://godoc.org/github.com/username_0/views/strings in the respective bytes and strings packages of the stdlib.
These are useful in interfaces like https://godoc.org/github.com/username_0/views
<issue_comment>username_1: Can't you just use bytes.Reader and strings.Reader ? If they lack the
ReaderAt behaviour, maybe we could add that instead.
<issue_comment>username_0: @username_1 The problem with bytes.Reader and strings.Reader is, that they cannot be shared. The are consumables. I want something to share and create many consumables with known size from.
<issue_comment>username_1: Why does this need to go in the standard library?
<issue_comment>username_0: @username_1 the reason would be to encourage that pattern of sharing.
It probably makes more sense when including https://godoc.org/github.com/username_0/views#SizeReaderAt as well in io.
This has been duplicated in various places already (e.g. https://godoc.org/google.golang.org/api/googleapi#SizeReaderAt and https://godoc.org/go4.org/readerutil#SizeReaderAt), which define interfaces types incompatible to each other when put in a function signature.
<issue_comment>username_1: But why does it need to go in the standard library to achieve that? The
stdlib shouldn't just be a dumping ground of good ideas waiting for a rainy
day, that's how we got python 2.
<issue_comment>username_2: If this bug is about adding `SizeReaderAt` to the `io` package, I could support that. I meant to add `SizeReaderAt` ages ago and I still think it's a good idea.
If this bug is about e.g. #5376, then this can be closed as a dup.
<issue_comment>username_0: @username_2 the goal was also to add the matching support for bytes/strings. But if this is too much API for these, then I would live with adding those in lots of *_test.go files as I do now...
<issue_comment>username_0: @username_1 e.g. Static asset serving in net/http could be improved based on that.
<issue_comment>username_2: What is "the matching support"? Can you concretely explain what this bug is about? `*strings.Reader` and `*bytes.Reader` are both already implement `SizeReaderAt`.
<issue_comment>username_0: @username_2 This issue is about immutable in-memory assets originally based on `string` or `[]byte`, but handled in the same way by API on top of it. Its a different approach to your old idea of a "byte view". `*strings.Reader` and `*bytes.Reader` are both not shareable, because they implement to many other interfaces besides SizeReaderAt.
<issue_comment>username_2: @username_0, you can share a `*strings.Reader` or *bytes.Reader` as a `SizeReaderAt`.
<issue_comment>username_0: OK, looks like I have a bit trouble getting my point across. Let's close it and focus on more important stuff.<issue_closed> | {'fraction_non_alphanumeric': 0.06990881458966565, 'fraction_numerical': 0.01033434650455927, 'mean_word_length': 4.713541666666667, 'pattern_counts': {'":': 0, '<': 15, '<?xml version=': 0, '>': 15, 'https://': 6, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '21891076', 'n_tokens_mistral': 922, 'n_tokens_neox': 883, 'n_words': 450} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Getting TypeError: Cannot read property 'config' of undefined [middleware/auth/index.js:11:26]
username_0: I am getting this error running my own `peerjs-server`:
```
TypeError: Cannot read property 'config' of undefined
at handle (/srv/node/peerjs-server/dist/src/api/middleware/auth/index.js:11:26)
at Layer.handle [as handle_request] (/srv/node/peerjs-server/node_modules/express/lib/router/layer.js:95:5)
at trim_prefix (/srv/node/peerjs-server/node_modules/express/lib/router/index.js:317:13)
at /srv/node/peerjs-server/node_modules/express/lib/router/index.js:284:7
at param (/srv/node/peerjs-server/node_modules/express/lib/router/index.js:354:14)
at param (/srv/node/peerjs-server/node_modules/express/lib/router/index.js:365:14)
at param (/srv/node/peerjs-server/node_modules/express/lib/router/index.js:365:14)
at param (/srv/node/peerjs-server/node_modules/express/lib/router/index.js:365:14)
at Function.process_params (/srv/node/peerjs-server/node_modules/express/lib/router/index.js:410:3)
at next (/srv/node/peerjs-server/node_modules/express/lib/router/index.js:275:10)
```
On the browser console log I get:
```
Failed to load resource: the server responded with a status of 500 (Internal Server Error)
https://my.domain.com:9000/peerjs/peerjs/2fe858b9-d3cf-431a-ba61-b39e11e77e80/vlsv2lkgce/id?i=0
```
<issue_comment>username_0: Error was due to using old version of `PeerJS`<issue_closed> | {'fraction_non_alphanumeric': 0.13687707641196012, 'fraction_numerical': 0.05249169435215947, 'mean_word_length': 4.397849462365591, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24698947', 'n_tokens_mistral': 601, 'n_tokens_neox': 538, 'n_words': 93} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Windows build errors in filament_framegraph_test.
username_0: **Describe the bug**
Attempting to build filament on Windows with tests enabled, gets build errors:
`..\filament\test\filament_framegraph_test.cpp(237): error C2059: syntax error: 'template'
D:\dev\filament\filament\src\fg2/FrameGraphPass.h(69): note: see reference to function template instantiation 'auto FrameGraphTest_WriteWrite_Test::TestBody::<lambda_2>::operator ()<Data>(const filament::FrameGraphResources &,const _T1 &,filament::backend::DriverApi &) const' being compiled
with
[
Data=FrameGraphTest_WriteWrite_Test::TestBody::PassData,
_T1=FrameGraphTest_WriteWrite_Test::TestBody::PassData
]`
and
`..\filament\test\filament_framegraph_test.cpp(238): error C2181: illegal else without matching if
..\filament\test\filament_framegraph_test.cpp(237): error C2065: 'gtest_ar': undeclared identifier
..\filament\test\filament_framegraph_test.cpp(237): error C2440: '<function-style-cast>': cannot convert from 'initializer list' to 'testing::internal::AssertHelper'`
**To Reproduce**
Steps to reproduce the behavior:
1.In a Windows VS2019 powershell terminal, with git, python, cmake, ninja in the PATH
2. run commands:
`git clone https://github.com/google/filament.git
cd .\filament\
mkdir build-dest
cd .\build-dest\
cmake -GNinja ..
ninja`
Observer build failure
**Expected behavior**
Build should succeed.
**Desktop (please complete the following information):**
- OS: Windows 10
- GPU: AMD RX5800
**Additional context**
Python 3.7.0
Microsoft (R) C/C++ Optimizing Compiler Version 19.28.29913 for x64
Microsoft (R) Incremental Linker Version 14.28.29913.0
ninja 1.10.1
cmake version 3.19.6<issue_closed> | {'fraction_non_alphanumeric': 0.11117226197028068, 'fraction_numerical': 0.043478260869565216, 'mean_word_length': 4.4431137724550895, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '2568649', 'n_tokens_mistral': 647, 'n_tokens_neox': 561, 'n_words': 156} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Make '[SNIP]' length configurable in the config file and have an environment variable override
username_0:
<issue_comment>username_1: @username_0 , I've just done some work on trace_printf_str and a configurable length should be easy once the configuration api is ready. The only change will be to use the heap or alloca to get a working buffer.
<issue_comment>username_0: Great! | {'fraction_non_alphanumeric': 0.05301204819277108, 'fraction_numerical': 0.00963855421686747, 'mean_word_length': 5.933333333333334, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '20544160', 'n_tokens_mistral': 110, 'n_tokens_neox': 107, 'n_words': 56} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Output IGA results to new VTK cell: Bezier
username_0: and was wondering whether MFEM writes Bezier elements? The latest version of ParaView (v5.8) supports Bezier elements as specified in the below VTK merge request and attached PDF.
https://gitlab.kitware.com/vtk/vtk/-/merge_requests/6055
https://gitlab.kitware.com/vtk/vtk/uploads/99926ecad9ce008bcc7e2b1b7ca57784/vtk_bezier_cells_v2.pdf
<issue_comment>username_1: Currently, Bezier output in the ParaView format is not supported. Right now, ParaView output of a NURBS mesh in MFEM will use Lagrange elements.
This could be an interesting feature to add. It would be helpful to have some example files and more complete format documentation (I guess that will come with time, since this feature is brand new in ParaView...)
<issue_comment>username_2: I haven't looked carefully yet -- is this more about supporting NURBS meshes, see e.g. the [MFEM NURBS mesh format](https://mfem.org/mesh-formats/#nurbs-meshes), or is it about representing the mesh nodes in the [positive Bernstein basis](https://github.com/mfem/mfem/blob/d9c4909da3766e49e66187ee063b8504e9d5138b/fem/fe.hpp#L35)?
<issue_comment>username_1: My understanding was that this is about supporting NURBS meshes.
<issue_comment>username_0: @username_2 I believe the new addition to VTK / ParaView requires a NURBS result to have its (non)rational Bezier components extracted and each Bezier cell described via Bernstein basis.
In general my question was related to the support of high-order MFEM IGA results in ParaView. Whether they were supported at all (which it sounds like they do, via approximation as Lagrange elements), and whether it would make sense to use the new Bezier cell definition to represent the results.<issue_closed>
<issue_comment>username_2: Discussion continued offline | {'fraction_non_alphanumeric': 0.06024744486282948, 'fraction_numerical': 0.03335126412049489, 'mean_word_length': 5.158940397350993, 'pattern_counts': {'":': 0, '<': 8, '<?xml version=': 0, '>': 8, 'https://': 4, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4989635', 'n_tokens_mistral': 565, 'n_tokens_neox': 518, 'n_words': 229} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Filter from the DB
username_0: Rather than load all the listings from the DB (probably thousands) then filter the returned collection, this PR runs filters against the database and only return the required results
<issue_comment>username_1: Nice addition! Thanks!
<issue_comment>username_0: Thanks for your amazing work @username_1 | {'fraction_non_alphanumeric': 0.04918032786885246, 'fraction_numerical': 0.01092896174863388, 'mean_word_length': 6.978260869565218, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '26923556', 'n_tokens_mistral': 89, 'n_tokens_neox': 86, 'n_words': 46} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Version Note
username_0: Hi Arvind -
Great work on adding the Cities to the gem. Looks great. I might do a few pull requests in the future to clean up a few things that I noticed, but it looks really great overall.
I was wondering if we need to create a git tag for version 3.0. I see that versioning stops at 2.0.0 in git. Rubygems appears to use the git tags to show releases.
If we want to follow Semantic versioning, which I think is a good idea, we should follow this guide:
http://semver.org/
That would put the gem at version 3.0.x because we have completely changed the public changing interface. We should also change the version file in the gem itselt each time we cut a new release.
I think we should probably update the version to be like 3.0.x and do a git tag to reflect it.
Thoughts?
Thanks,
<NAME>.<issue_closed>
<issue_comment>username_1: Hi <NAME>
I have also found the same you mention , in this week we are going to release 3.0.0 , with tag as you suggested , also before that need to check all the functionality which I am doing , Also I have added couple of ticket like one demo app and wikki updation once it will done then I think we can go with new release. Thanks for share your thought.
Thanks
Arvind | {'fraction_non_alphanumeric': 0.039907904834996163, 'fraction_numerical': 0.010744435917114352, 'mean_word_length': 3.3905723905723906, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25239474', 'n_tokens_mistral': 367, 'n_tokens_neox': 351, 'n_words': 225} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Overhaul manual pages for the web
username_0: Commands that have subcommands now list those subcommands in their docs:
<img width="1120" alt="" src="https://user-images.githubusercontent.com/887/140167175-bb068e7d-3c04-4a13-8e24-6a3b71f19b37.png">
<img width="1074" alt="" src="https://user-images.githubusercontent.com/887/140167204-769b79eb-78dc-45f1-a358-c0ca4c904cd5.png">
Command flags are now rendered as a definition list in HTML rather than as plaintext table and they now appear above the "Examples" section:
<img width="566" alt="" src="https://user-images.githubusercontent.com/887/140167927-77ffab0b-5afa-4d04-ae52-983f4cd97b6b.png">
"Examples" sections are now syntax-highlighted and exempt from processing Go template `{{ ... }}` tags [as if they were Liquid tags](https://github.com/cli/cli/issues/4322) for Jekyll sites:
<img width="735" alt="" src="https://user-images.githubusercontent.com/887/140167480-94a8c43f-a7f0-4fd4-8b74-1d48544eb37b.png">
Also:
- Usage synopsis for runnable commands is now rendered near the start of the manual page, rather than in the middle
- The `--help` flag is no longer repetitively documented in every manual page as an inherited flag
- Every command man page now links to its parent command, making it easier to navigate "upwards"
- Group `gh secret` among Actions commands
- Consistently capitalize "GitHub Actions"
- Make sure displayed URLs are rendered as hyperlinks
- Fix rendering of [`gh codespace cp` docs](https://cli.github.com/manual/gh_codespace_cp)
<issue_comment>username_1: On a whim after stumbling across it I took a crack at adding the code formatting before checking to see if any of the active PR's or issues addressed it. Was literally the first go I've ever written and it was prematurely superseded by a PR approved yesterday. 🤷
<issue_comment>username_0: @username_1 This happens to me all the time. I hope you had fun fixing the bug on your own and learning Go. Don't let this discourage you from contributing to our or any other project 👍 | {'fraction_non_alphanumeric': 0.08841902931283037, 'fraction_numerical': 0.07015857760691975, 'mean_word_length': 4.6730245231607626, 'pattern_counts': {'":': 0, '<': 8, '<?xml version=': 0, '>': 8, 'https://': 6, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29196444', 'n_tokens_mistral': 725, 'n_tokens_neox': 631, 'n_words': 245} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Enable logging via MPI's file I/O tools
username_0: MPI has tools to write to files from separate processes. For tracking down errors in intermediate calculations, it would be convenient to have a logging tool that lets you choose certain checkpoints to print out to a log file.
Example of mpi4py being used for file i/o, from their tutorials:
```
amode = MPI.MODE_WRONLY|MPI.MODE_CREATE
comm = MPI.COMM_WORLD
fh = MPI.File.Open(comm, "./datafile.contig", amode)
buffer = np.empty(10, dtype=np.int)
buffer[:] = comm.Get_rank()
offset = comm.Get_rank()*buffer.nbytes
fh.Write_at_all(offset, buffer)
fh.Close()
``` | {'fraction_non_alphanumeric': 0.09730538922155689, 'fraction_numerical': 0.005988023952095809, 'mean_word_length': 4.352, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '7581495', 'n_tokens_mistral': 226, 'n_tokens_neox': 208, 'n_words': 77} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: bug in blender export
username_0: Just fixed a horrible bug in blender export. Seriously, I almost cried...
Essentially the problem was this:
- "save" generated a list where the id/name of one particular sceneobject was "Cube", which corresponded to it's object name in blender
- "generate_geometries" generated a json string of meshes, where the corresponding scene object was not named "Cube", but "Cube.012" - the name of the only mesh in the scene object "Cube"
it was not a problem of choosing the name from the scene object or the data object
- object.name vs. object.data.name
- in both cases object.data.name was chosen
rather the problem was that in the "save" function
- object.data.name was "Cube"
while in the "generate_geometries" function
- object.data.name was "Cube.012"
i resolved this problem by commenting out
'------- generate_mesh_string
for mesh, object in anim_meshes:
bpy.data.meshes.remove(mesh)
'-------
'------- generate_mesh_string
for mesh, object in meshes:
bpy.data.meshes.remove(mesh)
'------
I didn't understand why this would be necessary. But if it is, a solution should be found.<issue_closed> | {'fraction_non_alphanumeric': 0.08130699088145897, 'fraction_numerical': 0.005319148936170213, 'mean_word_length': 2.474934036939314, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 4, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '21564872', 'n_tokens_mistral': 365, 'n_tokens_neox': 342, 'n_words': 157} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Should the result for textDocument/hover be markdown or plaintext?
username_0: There are a few python docstyles out in the wild. See: https://stackoverflow.com/a/24385103. Most notably, none of these are markdown.
The return type from pyls for a textDocument/hover request is a `MarkedString[]`. Usually this returns a list of 2 marked strings. The first `MarkedString` has the form `{"language": "python", "value": "some content"}`. The second `MarkedString` is a string.
The LSP spec [states that](https://microsoft.github.io/language-server-protocol/specification#textDocument_hover) clients should interpret `MarkedString` strings as markdown. This results in the docblocks being rendered odd for different requests. Here are some examples:
textDocument/hover rendering *markdown*:
https://cdn.discordapp.com/attachments/645268178397560865/738774901837660210/Snipaste_2020-07-31_23-05-05.png
textDocument/signatureHelp rendering *plaintext*:
https://cdn.discordapp.com/attachments/645268178397560865/738774912193265785/Snipaste_2020-07-31_23-03-44.png
textDocument/complete rendering *plaintext*:
https://cdn.discordapp.com/attachments/645268178397560865/738774915062169621/Snipaste_2020-07-31_23-06-57.png
The solution is to update textDocument/hover by making it return *plaintext* instead of *markdown*. Since Python has diverse doc-styles it's somewhat hard to translate docs to markdown, so let's just do plaintext for now.
<issue_comment>username_1: Agreed. Please submit a pull request for that. Thanks!
<issue_comment>username_2: FYI: https://github.com/username_2/docstring-to-markdown (now used on my fork and by jedi-language-server). | {'fraction_non_alphanumeric': 0.09032258064516129, 'fraction_numerical': 0.09560117302052785, 'mean_word_length': 5.437735849056604, 'pattern_counts': {'":': 2, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 6, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25001636', 'n_tokens_mistral': 614, 'n_tokens_neox': 500, 'n_words': 162} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: No examples in C++
username_0: Readme says it can be used in C++, but there are no learning materials how for example do RL in c++
<issue_comment>username_1: Please excuse the late answer. You can find many c++ examples under /examples/study.cases. However most of them are current research projects, so the needed model is in a private repository. We non-the-less hope that it can help you to understand how to build a Korali-app in c++. | {'fraction_non_alphanumeric': 0.06553911205073996, 'fraction_numerical': 0.004228329809725159, 'mean_word_length': 4.576470588235294, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24368726', 'n_tokens_mistral': 126, 'n_tokens_neox': 122, 'n_words': 75} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: add ReadOnlyEventStore interface
username_0: resolves: https://github.com/prooph/event-store/issues/250
<issue_comment>username_1: easy pick ;)
<issue_comment>username_1: @username_0 when you write:
Closes #250
<issue_comment>username_0: Ah good to know, thx
<issue_comment>username_1: the cool thing is, that github adds a note to the linked issue that it was closed by ...
<issue_comment>username_1: hehe resolves also work: https://help.github.com/articles/closing-issues-via-commit-messages/
but without double point ;) | {'fraction_non_alphanumeric': 0.099644128113879, 'fraction_numerical': 0.023131672597864767, 'mean_word_length': 5.950617283950617, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5772536', 'n_tokens_mistral': 180, 'n_tokens_neox': 169, 'n_words': 52} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Open port error
username_0: I get error on open port.
Exception thrown: 'System.IO.IOException' in RJCP.SerialPortStream.dll
Additional information: Unknown error 0x79: COM7
Sometimes also Unknown error 0x490: COM7
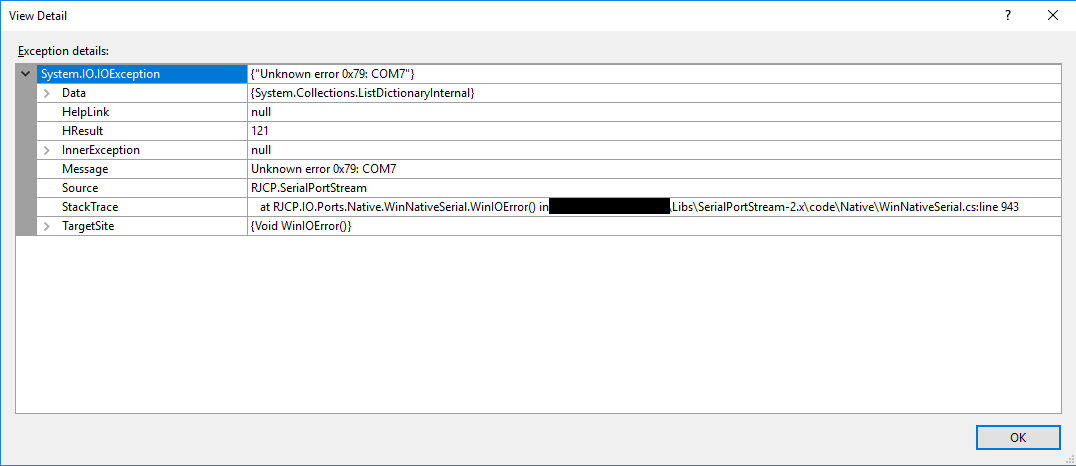
It helps only if i resrtart bluetooth. Can this be fixed somehow ?
<issue_comment>username_1: I've heard of a similar issue before with bluetooth. This is being returned by the Windows itself and there is no known workaround that I know of.
Have you tried with other terminal software? Do you notice if the Bluetooth device is connected or not?
The error that you observe is raised immediately after trying to open. So if Windows won't open it, I don't know what else can be done other than your application check for any Bluetooth specific features that might be needed prior:
```
m_ComPortHandle = UnsafeNativeMethods.CreateFile(@"\\.\" + PortName,
NativeMethods.FileAccess.GENERIC_READ | NativeMethods.FileAccess.GENERIC_WRITE,
NativeMethods.FileShare.FILE_SHARE_NONE,
IntPtr.Zero,
NativeMethods.CreationDisposition.OPEN_EXISTING,
NativeMethods.FileAttributes.FILE_FLAG_OVERLAPPED,
IntPtr.Zero);
if (m_ComPortHandle.IsInvalid) WinIOError();
```<issue_closed>
<issue_comment>username_0: If i look under windows bluetooth device i see state "familiar". (but this does not change until open is actualy made)
If i close bluetooth connection on windows it does not help.
If i close bluetooth connection on the device (antena) it helps. SerialPortStream is able to open port than.
It is possible to reset/restart bluetooth device some how to workaround ?
<issue_comment>username_1: Hi username_0,
Nothing that the SerialPortStream can do. It sounds like a state of the bluetooth driver or remote device that is waiting for a connection to be closed. Is there a command that your device requires before closing the port locally? Any forums on the web that state a similar issue with your chipset/device?
<issue_comment>username_0: I hope this can help
First one works always, no need to restart
Device BTHENUM\Dev_00126F357E35\7&1ebe74a&0&BluetoothDevice_00126F357E35
Device BTHENUM\Dev_00126FD20503\7&1ebe74a&0&BluetoothDevice_00126FD20503
Device BTHENUM\Dev_00126FD20972\7&1ebe74a&0&BluetoothDevice_00126FD20972
<issue_comment>username_1: Sorry - I don't quite understand what you mean. Is that a COM port? Can you explain?
In any case, it would be outside of the scope of the SerialPortStream to handle Bluetooth devices explicitly, as it's also outside of the scope of the MS implementation of SerialPort.
<issue_comment>username_0: Those were bluetooth device names, i tryed 3 of them.
What is the corect way to close port in i close application ? So it can be open again when i start app ?
<issue_comment>username_1: To close the SerialPortStream, you should Dispose() of it, or Close() it. Closing the port with Close() will close the device, but any buffers read can still be read, but writing is obviously no longer possible. Disposing will also close the serial port, but also discards any open buffers. | {'fraction_non_alphanumeric': 0.05250596658711217, 'fraction_numerical': 0.03967780429594272, 'mean_word_length': 4.111280487804878, 'pattern_counts': {'":': 0, '<': 10, '<?xml version=': 0, '>': 10, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4282399', 'n_tokens_mistral': 1007, 'n_tokens_neox': 905, 'n_words': 411} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: `Sposify` working on iOS 13.3
username_0: ```
{
"packageId": "com.spos",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "com.spos",
"deviceId": "iPhone10,6",
"url": "http://cydia.saurik.com/package/com.spos/",
"packageName": "Sposify",
"packageVersionIndexed": true,
"iOSVersion": "13.3",
"category": "Tweaks",
"repository": "aesthyrica",
"name": "Sposify",
"installed": "8.5.49",
"packageInstalled": true,
"packageStatusExplaination": "This package version has been marked as Working based on feedback from users in the community. The current positive rating is 100% with 2 working reports.",
"id": "com.spos",
"commercial": false,
"packageIndexed": true,
"tweakCompatVersion": "tweakcompatible-zebra-1.1.5",
"shortDescription": "Sposify is a tweak which adds various enhancements to the Spotify application on iOS.",
"latest": "8.5.49",
"author": "aesthyrica",
"packageStatus": "Working"
},
"base64": "eyJhcmNoMzIiOmZhbHNlLCJwYWNrYWdlSWQiOiJjb20uc3BvcyIsImRldmljZUlkIjoiaVBob25lMTAsNiIsInVybCI6Imh0dHA6XC9cL2N5ZGlhLnNhdXJpay5jb21cL3BhY2thZ2VcL2NvbS5zcG9zXC8iLCJwYWNrYWdlTmFtZSI6IlNwb3NpZnkiLCJwYWNrYWdlVmVyc2lvbkluZGV4ZWQiOnRydWUsImlPU1ZlcnNpb24iOiIxMy4zIiwiY2F0ZWdvcnkiOiJUd2Vha3MiLCJyZXBvc2l0b3J5IjoiYWVzdGh5cmljYSIsIm5hbWUiOiJTcG9zaWZ5IiwiaW5zdGFsbGVkIjoiOC41LjQ5IiwicGFja2FnZUluc3RhbGxlZCI6dHJ1ZSwicGFja2FnZVN0YXR1c0V4cGxhaW5hdGlvbiI6IlRoaXMgcGFja2FnZSB2ZXJzaW9uIGhhcyBiZWVuIG1hcmtlZCBhcyBXb3JraW5nIGJhc2VkIG9uIGZlZWRiYWNrIGZyb20gdXNlcnMgaW4gdGhlIGNvbW11bml0eS4gVGhlIGN1cnJlbnQgcG9zaXRpdmUgcmF0aW5nIGlzIDEwMCUgd2l0aCAyIHdvcmtpbmcgcmVwb3J0cy4iLCJpZCI6ImNvbS5zcG9zIiwiY29tbWVyY2lhbCI6ZmFsc2UsInBhY2thZ2VJbmRleGVkIjp0cnVlLCJ0d2Vha0NvbXBhdFZlcnNpb24iOiJ0d2Vha2NvbXBhdGlibGUtemVicmEtMS4xLjUiLCJzaG9ydERlc2NyaXB0aW9uIjoiU3Bvc2lmeSBpcyBhIHR3ZWFrIHdoaWNoIGFkZHMgdmFyaW91cyBlbmhhbmNlbWVudHMgdG8gdGhlIFNwb3RpZnkgYXBwbGljYXRpb24gb24gaU9TLiIsImxhdGVzdCI6IjguNS40OSIsImF1dGhvciI6ImFlc3RoeXJpY2EiLCJwYWNrYWdlU3RhdHVzIjoiV29ya2luZyJ9",
"chosenStatus": "working",
"notes": ""
}
```<issue_closed> | {'fraction_non_alphanumeric': 0.08998615597600369, 'fraction_numerical': 0.07245039224734656, 'mean_word_length': 7.43579766536965, 'pattern_counts': {'":': 27, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19275960', 'n_tokens_mistral': 1192, 'n_tokens_neox': 1105, 'n_words': 98} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: 12/02/2022 - External security review testing - Review required
username_0: :page_facing_up: Title - External security review testing
:calendar: Expires - 12/02/2022
:family: Team - Product Marketing Review Team
:package: Product - Other
:link: [GitHub Link](https://github.com/UKCloud/documentation/tree/master/articles/other/other-ref-external-security-review-testing.md)
:link: [Knowledge Centre Link](https://docs.ukcloud.com/articles/other/other-ref-external-security-review-testing.html)
**Before making any changes, make sure you're familiar with our [guidelines](https://docs.ukcloud.com/articles/other/other-ref-knowledge-guidelines.html) for contributing to Knowledge Centre articles.**
<issue_comment>username_0: Email sent to SME | {'fraction_non_alphanumeric': 0.11862244897959184, 'fraction_numerical': 0.02295918367346939, 'mean_word_length': 5.487603305785124, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30543275', 'n_tokens_mistral': 245, 'n_tokens_neox': 222, 'n_words': 56} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: uupload.ir wrong filter
username_0: This filter `||uupload.ir/files/*.gif` from your list blocks non-ads images.

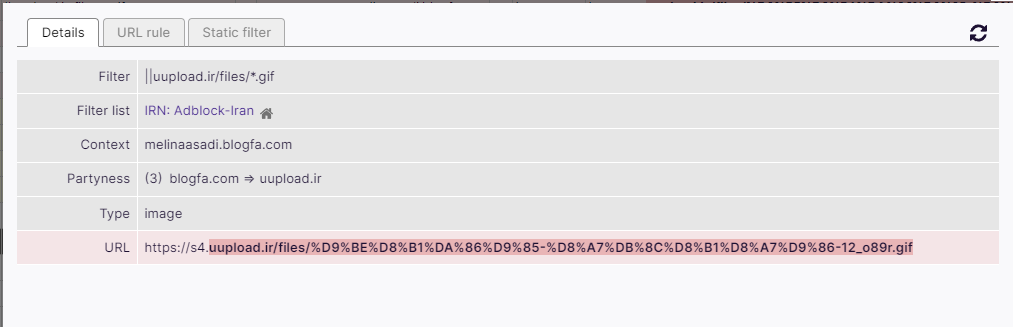
* Are these ads?


<issue_closed> | {'fraction_non_alphanumeric': 0.1907051282051282, 'fraction_numerical': 0.16506410256410256, 'mean_word_length': 5.868131868131868, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '20633017', 'n_tokens_mistral': 333, 'n_tokens_neox': 287, 'n_words': 22} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add socket_connect_timeout option.
username_0: This allows you to specify the connection timeout for the stream; note that once the stream is connected the existing code performs `stream.setTimeout(0)` thereby preventing this patch triggering an idle timeout on an established connection. (This is also why I called it `socket_connect_timeout` rather than simply `socket_timeout`.)
I added `this.stream.setTimeout` to `install_stream_listeners` as it seemed the DRY-est place to put it since it is called for all streams just after they're created. If this is not the right place, please let me know.
<issue_comment>username_1: @username_2 LGTM would you please rebase and add some tests?
<issue_comment>username_2: by @username_2 you mean @username_0 right? :smile:
<issue_comment>username_1: @username_2 ups sorry for bringing you up :D
And yes, I meant @username_0
<issue_comment>username_0: :laughing: thanks @username_2 :)
@username_1 I'm not sure how I'd write a test for this
<issue_comment>username_0: Rebased :)
<issue_comment>username_1: @username_0 shouldn't it be enough if you just manipulate the socket timeout with the parameter? What you want to reach is to have a individual timeout instead of the system one, so everything else should stay the same?
And a test could be written by checking the system timeout (use a before, create a client that can't connect and check for the timeout and safe that value). Now you can increase or decrease that value as you want and do the same again and check that the timeout triggered at another time.
<issue_comment>username_0: What endpoint should I use that it times out connecting to? I think a closed port won't do because it'll just drop the connection immediately (no chance for a timeout) so it'd need to be one that drops the packets. Adding an `iptables` filter would make the test platform dependent; is there a cross-platform `/dev/null` equivalent for TCP?
<issue_comment>username_0: (`debug()` change implemented)
<issue_comment>username_1: You could mock the stream :)
Google just gave me this: https://gist.github.com/mjackson/1201196
<issue_comment>username_1: @username_0 I used your work to use the connection_timeout as socket timeout if explicitly provided and mentioned you in the changelog. That way we do not have to add another option and most people thought the connection timeout would also set a socket timeout.
Thx a lot for your help!
<issue_comment>username_0: Thanks @username_1; sorry I didn't get around to writing the tests yet but your solution's probably better anyway! :smile:
<issue_comment>username_0: Hey @username_1; I think your fix serves a different purpose to my PR - I want the connection attempt to fail, be closed, and then attempt again in a much tighter loop than the OS default (like every 30 seconds rather than 180); whereas `connect_timeout` stops attempting to reconnect meaning we remain disconnected forever. There may still be value in this PR
<issue_comment>username_3: This should really be reopened
<issue_comment>username_1: @username_0 thanks for pointing this out and sorry for not understanding your original issue properly right away.
There seems to be a new PR to do the same: https://github.com/NodeRedis/node_redis/pull/1430
<issue_comment>username_0: No problem :) | {'fraction_non_alphanumeric': 0.052615844544095666, 'fraction_numerical': 0.013452914798206279, 'mean_word_length': 5.242537313432836, 'pattern_counts': {'":': 0, '<': 17, '<?xml version=': 0, '>': 17, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25745591', 'n_tokens_mistral': 882, 'n_tokens_neox': 839, 'n_words': 478} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Dart VM: It is a compile-time error if the compilation unit found at the specified URI is not a library declaration
username_0: co19/Language/14_Libraries_and_Scripts/2_Exports_A05_t01<issue_closed>
<issue_comment>username_1: This report is missing a lot of information. I'm closing it as "Invalid", but if this report is for a bug that still exists, feel free to re-open with repro instructions, etc.. | {'fraction_non_alphanumeric': 0.05922551252847381, 'fraction_numerical': 0.025056947608200455, 'mean_word_length': 5.567164179104478, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '11745298', 'n_tokens_mistral': 131, 'n_tokens_neox': 123, 'n_words': 57} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: No access to docker.sdelements.com
username_0: Hi. I have been trying to use your repository to set up a moodle container.
Using
docker-compose --file docker-compose.yml up --force-recreate --no-deps --detach
I get
Pulling nginx-php-moodle (docker.sdelements.com:443/moodle/nginx-php-moodle:7.2-3.5.1)...
ERROR: Get https://docker.sdelements.com:443/v2/moodle/nginx-php-moodle/manifests/7.2-3.5.1: no basic auth credentials
If the repo is meant to be private, I do apologize. I would suggest stating that in the repo description.
<issue_comment>username_1: @username_0
Apologies for the late reply, I completely missed this note.
- Do you still use this container? If so, I can try to find some time to publish a version on Docker hub
- Where do you suggest putting the note? I don't see any existing reference to our docker registry except in the CI configuration
<issue_comment>username_0: Hey! No problem. I'm using the one from bitnami or moodle directly I think, so no need to stress about it :)
<issue_comment>username_1: Thanks for the update!
I'll close this for now.<issue_closed> | {'fraction_non_alphanumeric': 0.08079930495221546, 'fraction_numerical': 0.019113814074717638, 'mean_word_length': 3.944206008583691, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '2467320', 'n_tokens_mistral': 388, 'n_tokens_neox': 352, 'n_words': 149} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Can't build publishable lib which depends on other libs
username_0: Similar to [#3518 ](https://github.com/nrwl/nx/issues/3518)
I have been trying to export a CLI app that depends on other internal libs but I am not sure how to replace the dependencies in the created package.json.
libs/cli:
- depends on: libs/sdk
`libs/sdk` is publishable.
`libs/cli/package.json`:
```
{
"name": "cli",
"version": "0.0.1",
"bin": "src/index.js",
"main": "src/index.js"
}
```
- I compile `libs/cli` with:
```
nx build cli --with-deps
```
In my `dist/libs/cli` it generates the dependencies for package.json with:
```
{
"name": "cli",
"version": "0.0.1",
"bin": "src/index.js",
"main": "src/index.js",
"typings": "./src/index.d.ts",
"dependencies": {
"yargs": "^17.3.1",
...
"@fm/sdk": "0.0.1",
},
"peerDependencies": {}
}
```
The issue is that my `@fm/sdk` isn't published to npm and needs to be accessed in `@fm/cli`.
I tried to configure my package.json with _moduleAliases:
```
"_moduleAliases": {
"@fm/sdk" : "../sdk"
}
```
It still doesn't work. and I get:
```
Error: Cannot find module '@fm/sdk'
Require stack:...
code: 'MODULE_NOT_FOUND',
requireStack: [...
```
Any help would be much appreciated :)
<issue_comment>username_1: Hi @username_0,
You mentioned `libs/sdk` is publishable but did you publish it to npm? Or are you saying you don't want `libs/sdk` to be published but still can be access from `@fm/cli`
<issue_comment>username_2: Hi @username_0, If `@fm/cli` is publishable and depends on `@fm/sdk`, then `@fm/sdk` should be publishable as well. We don't currently have an easy way to rollup multiple projects into a single package.<issue_closed> | {'fraction_non_alphanumeric': 0.1546162402669633, 'fraction_numerical': 0.014460511679644048, 'mean_word_length': 3.223004694835681, 'pattern_counts': {'":': 14, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '11942368', 'n_tokens_mistral': 657, 'n_tokens_neox': 621, 'n_words': 212} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Adding Tabular Transformers to model zoo, and adding unsupervised pretraining funcitonality
username_0: *Description of changes:*
1) adding Transformer for Tabular data to supervised learning model zoo, module name is tab_transformer.
2) adding unsupervised pretraining functionality using Transformer. Change to API is minimal for the user. One simply needs to call task.fit with and extra argument for unlabeled data. Specifically:
predictor = task.fit(train_data=train_data, label=label_column, unlabeled_data=unlabeled_data)
where unlabeled_data is a dataframe with the same column values as train_data except that the label column missing.
Sample benchmark results for few-shot learning using unsupervised pretraining followed by finetuning compared with supervised learning on the labeled data alone (see binary classification task from test_semi_supervised.py script in unittests):
############ Illustrative benchmark results ############
Number of unlabeled examples 50,000.
Number of labeled examples=20:
Supervised accuracy: 56.2%
Pretrain-finetune accuracy: 75.6%
Number of labeled examples=50:
Supervised accuracy: 75.2%
Pretrain-finetune accuracy: 77.2%
(supervised accuracies averaged over 5 repeats due to noise)
################################################
I didn't do extensive benchmarking on supervised tasks, but anecdotally found little improvement from using the Transformer as part of the ensemble for purely supervised learning alone.
Changes primarily involved adding new scripts for the Transformer and its training, and therefore shouldn't affect the core code base much. However, there was one aspect of the core platform I had to change: in order to allow the unlabeled_data argument to be passed to task.fit I threaded this argument through tabular_prediction.py and default_learner.py. I also had to modify the general_data_preprocessing function to handle the unlabeled data together with labeled data.
A short list of known limitation and additional features to add is included at the bottom of the following script:
autogluon/utils/tabular/ml/models/tab_transformer/TabTransformer_model.py
Best,
Josh
--------------
By submitting this pull request, I confirm that you can use, modify, copy, and redistribute this contribution, under the terms of your choice.
<issue_comment>username_1: Hi Josh,
Thanks for making a pull request! I notice that you still have this PR tagged as 'draft'. Are you interested in code reviews at this time?
Best,
Nick
<issue_comment>username_0: Hi Nick, I am still going to make a few small tweaks. I will "officially" submit the request soon.
Best,
Josh
<issue_comment>username_1: Just to confirm with you, are you asking for reviews now that the PR is not a draft?
<issue_comment>username_0: Thanks for the thoughts Dave, I'll take a pass through and do a bit of cleaning up.
<issue_comment>username_2: Job PR-626-6 is done.
Docs are uploaded to http://autogluon-staging.s3-website-us-west-2.amazonaws.com/PR-626/6/index.html
<issue_comment>username_0: Hi Nick,
Many thanks for the detailed review. You raise many valid points, which I will go through as soon as possible.
Josh
<issue_comment>username_3: Minor issue: when I run TabTransformer in supervised learning mode, I see warning message:
.../scikit_learn-0.22.2.post1-py3.7-macosx-10.9-x86_64.egg/sklearn/preprocessing/_discretization.py:197: UserWarning: Bins whose width are too small (i.e., <= 1e-8) in feature 0 are removed. Consider decreasing the number of bins.
<issue_comment>username_3: User specified hyperparameter don't appear to work. See the following example I tried:
```
predictor = task.fit(train_data=train_data, label=label_column, output_directory=savedir, hyperparameters={'Transf':{'p_dropout': 0.5}})
tf_model = predictor._trainer.load_model('TabTransformerModelClassifier')
print(tf_model.model)
```
prints model-architecture with dropout-layers that look like this: `(do): Dropout(p=0.1, inplace=False)`
This indicates my user-specified hyperparameter didn't override the default `p_dropout=0.1`
<issue_comment>username_3: Thanks for the PR and sorry for delay reviewing!
Here are some of my major comments:
Could you provide some example code snippets here that you've been using to test out your TabTransformer (will help us better see what the user-experience is actually like)?
It seems there's unused code in the PR (perhaps from before you), so it would be awesome if you could try to cut out as much of the unnecessary code as you can. Also can you resolve a lot of the code being duplicated?
The printing statements should all be replaced by logging with levels corresponding to how critical each print statement is (which level of output user sees is then automatically controlled by `verbosity` argument in AutoGluon). This is critical to make the output less cluttered as TabTransformer will be trained alongside tons of other models.
<issue_comment>username_1: While making changes in this PR, please rebase with mainline so that CI can build, this will be very useful in detecting issues and debugging. | {'fraction_non_alphanumeric': 0.06627284474801551, 'fraction_numerical': 0.013106885730108916, 'mean_word_length': 3.9209809264305178, 'pattern_counts': {'":': 0, '<': 13, '<?xml version=': 0, '>': 12, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 8, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '16856118', 'n_tokens_mistral': 1452, 'n_tokens_neox': 1327, 'n_words': 665} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Save/Share button UI bug
username_0: Save/Share buttons on search results work only if pressen exactly on text area (green block), if outside of text - no action. "Button" area to be extended to whole width.
<issue_comment>username_0: Deleted since duplicates #177
<issue_comment>username_0: 
<issue_comment>username_0: Duplication of similar issue with styling.<issue_closed> | {'fraction_non_alphanumeric': 0.10551181102362205, 'fraction_numerical': 0.12440944881889764, 'mean_word_length': 6.395348837209302, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15711209', 'n_tokens_mistral': 256, 'n_tokens_neox': 212, 'n_words': 50} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add notes on how to upgrade from v0.4
username_0: README should have section on how to upgrade.
So far: #9 -- changed matcher and directory names.
Specific upgrade instructions might depend on whether the 1.0 release includes the new flags mentioned in #16 | {'fraction_non_alphanumeric': 0.050335570469798654, 'fraction_numerical': 0.026845637583892617, 'mean_word_length': 4.245614035087719, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '11035908', 'n_tokens_mistral': 81, 'n_tokens_neox': 75, 'n_words': 43} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Remove EMSA1_BSI (no longer recommended by BSI)
username_0: I've asked someone at the BSI and the BSI variant of EMSA1 is no longer needed. They now recommend the version that is implemented in the `emsa1` module.
<issue_comment>username_1: CVC (Card Verifiable Certificates) also depends on EMSA1_BSI; this padding scheme was originally added as part of the CVC patch. I wonder if this should be taken as a sign to just call it a day on the (already bitrotting and probably broken) CVC suppport.
<issue_comment>username_0: Talked to one at the BSI and they are also fine with removing it. | {'fraction_non_alphanumeric': 0.04326923076923077, 'fraction_numerical': 0.011217948717948718, 'mean_word_length': 5.067961165048544, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '26320711', 'n_tokens_mistral': 178, 'n_tokens_neox': 172, 'n_words': 98} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: llvm: Update LLVM to include fix for pathologic case in its LiveDebugValues pass.
username_0: See #36926.
r? @username_1
<issue_comment>username_0: Oh, wait, I remembered I need to update something in order not to break the build bots, right? Give me a sec...
<issue_comment>username_1: Ah yeah we'll want to modify `src/rustllvm/llvm-auto-clean-trigger`
<issue_comment>username_1: r=me though
<issue_comment>username_2: :pushpin: Commit 7fcc124 has been approved by `username_1`
<!-- @username_2 r=username_1 7fcc1246c6b98d5715f9bc4a961751ea4e032822 -->
<issue_comment>username_0: @username_2 r=username_1
<issue_comment>username_1: @username_2: p=1
<issue_comment>username_2: :hourglass: Testing commit 7fcc124 with merge f6409e0...
<issue_comment>username_2: :broken_heart: Test failed - [auto-linux-32-opt](https://buildbot.rust-lang.org/builders/auto-linux-32-opt/builds/10764)
<issue_comment>username_3: Don't you also want to incorporate the fix to #36924 here?
<issue_comment>username_0: @username_3 Yes, that seems like a good idea. I'll take care of it.
<issue_comment>username_0: I'm currently running `make check` locally on a branch also containing the SimplifyCFG fix. If that passes, I'll make another PR against the LLVM repo and update this one.
Btw, I have no clue what that test failure above is about. It seems unrelated to changes in LLVM debuginfo generation.
<issue_comment>username_0: @username_2 r=username_1
@username_1 I'm assuming, since you merged @username_3's PR to the LLVM repo, that you are in favor of including that patch with this update...
<issue_comment>username_2: :pushpin: Commit 7d03bad has been approved by `username_1`
<!-- @username_2 r=username_1 7d03badb2ad9c018faa65a088b37ff5cf3dc6fa4 -->
<issue_comment>username_0: @username_2 p=1
<issue_comment>username_1: 👍
<issue_comment>username_1: @username_2: retry force clean
<issue_comment>username_2: :hourglass: Testing commit 7d03bad with merge a3bc191...
<issue_comment>username_2: :sunny: Test successful - [auto-linux-32-nopt-t](https://buildbot.rust-lang.org/builders/auto-linux-32-nopt-t/builds/10722), [auto-linux-32-opt](https://buildbot.rust-lang.org/builders/auto-linux-32-opt/builds/10777), [auto-linux-64-cargotest](https://buildbot.rust-lang.org/builders/auto-linux-64-cargotest/builds/2011), [auto-linux-64-cross-freebsd](https://buildbot.rust-lang.org/builders/auto-linux-64-cross-freebsd/builds/1836), [auto-linux-64-debug-opt](https://buildbot.rust-lang.org/builders/auto-linux-64-debug-opt/builds/3995), [auto-linux-64-nopt-t](https://buildbot.rust-lang.org/builders/auto-linux-64-nopt-t/builds/10720), [auto-linux-64-opt](https://buildbot.rust-lang.org/builders/auto-linux-64-opt/builds/10677), [auto-linux-64-opt-rustbuild](https://buildbot.rust-lang.org/builders/auto-linux-64-opt-rustbuild/builds/2650), [auto-linux-64-x-android-t](https://buildbot.rust-lang.org/builders/auto-linux-64-x-android-t/builds/10653), [auto-linux-cross-opt](https://buildbot.rust-lang.org/builders/auto-linux-cross-opt/builds/3877), [auto-linux-musl-64-opt](https://buildbot.rust-lang.org/builders/auto-linux-musl-64-opt/builds/5827), [auto-mac-32-opt](https://buildbot.rust-lang.org/builders/auto-mac-32-opt/builds/10759), [auto-mac-64-opt](https://buildbot.rust-lang.org/builders/auto-mac-64-opt/builds/10733), [auto-mac-64-opt-rustbuild](https://buildbot.rust-lang.org/builders/auto-mac-64-opt-rustbuild/builds/2677), [auto-mac-cross-ios-opt](https://buildbot.rust-lang.org/builders/auto-mac-cross-ios-opt/builds/1857), [auto-win-gnu-32-opt](https://buildbot.rust-lang.org/builders/auto-win-gnu-32-opt/builds/5854), [auto-win-gnu-32-opt-rustbuild](https://buildbot.rust-lang.org/builders/auto-win-gnu-32-opt-rustbuild/builds/2710), [auto-win-gnu-64-opt](https://buildbot.rust-lang.org/builders/auto-win-gnu-64-opt/builds/5821), [auto-win-msvc-32-opt](https://buildbot.rust-lang.org/builders/auto-win-msvc-32-opt/builds/5015), [auto-win-msvc-64-cargotest](https://buildbot.rust-lang.org/builders/auto-win-msvc-64-cargotest/builds/2031), [auto-win-msvc-64-opt](https://buildbot.rust-lang.org/builders/auto-win-msvc-64-opt/builds/5834), [auto-win-msvc-64-opt-rustbuild](https://buildbot.rust-lang.org/builders/auto-win-msvc-64-opt-rustbuild/builds/2706)
Approved by: username_1
Pushing a3bc191b5f41df5143cc65084b13999896411817 to master...
<issue_comment>username_4: Accepting for beta because terrible regression. However, this *is* bumping LLVM, incorporating the [following commits](https://github.com/rust-lang/llvm/compare/3e03f7374169cd41547d75e62ac2ab8a103a913c...ac1c94226e9fa17005ce7e2dd52dd6d1875f3137), all of which seem relatively targeted to me.
cc @rust-lang/compiler | {'fraction_non_alphanumeric': 0.15135478408128705, 'fraction_numerical': 0.0814987298899238, 'mean_word_length': 5.46374829001368, 'pattern_counts': {'":': 0, '<': 23, '<?xml version=': 0, '>': 23, 'https://': 24, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13016358', 'n_tokens_mistral': 1942, 'n_tokens_neox': 1743, 'n_words': 277} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add `BlameScript` only if not all signaled readiness
username_0: The `BlameScript` is added only when not all alices are ready.
<issue_comment>username_1: What if all signals ready, yet 5 BTC outputs are missing from output registration? In that case it'll create absurdly high fee RPC error and successfully DoS the coinjoin without any punishment?
<issue_comment>username_2: Two ideas:
- Calculate amount of number of inputs * minregistrable ouput = maxacceptable loss. Assume that every input is one client and can loss at max min reg output.
- Try to build the tx or make sanity check, if fail then add the blame script.
<issue_comment>username_0: Here we have the conjunction of two things that shouldn't exist. First of all, _lose money/max acceptable loss/whatever_ is the root cause of problem and it doesn't look/sound good.
Then, and because of the existence of that thing, the coordinator cannot know whether the missing money is okay or not so it assumes that in case that not all alices are ready then at least one alice failed to register the output and for that reason we need to add an output a static blamescript in order to prevent the creation of gaps in the coordinator wallet (assuming wrongly that someone will not sign, what is also a wrong assumption). That's something that is not correct and no gap is created because we increase the counter after the coinjoin transaction is broadcasted. Blamescript should exist.
Finally blamescript is there to take all the money that is not mining fees or coordination fee and made sense in WW1 but it doesn't in WW2.
Now it is much clear that the concept is not only unnecessary and serves no purpose but also that it is counter productive.
This is how it should work:
The coordination fee output takes all the money after mining fee. period. In case there is a problem wit that then the client loosing money will not sign, that's it.
<issue_comment>username_2: ACK from my side.
<issue_comment>username_1: @username_0 please take over this PR: https://github.com/zkSNACKs/WalletWasabi/pull/7316 | {'fraction_non_alphanumeric': 0.03595080416272469, 'fraction_numerical': 0.006622516556291391, 'mean_word_length': 4.5078125, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '27667261', 'n_tokens_mistral': 540, 'n_tokens_neox': 510, 'n_words': 334} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: add examples + refactor jss stringify from css2jss into cli
username_0: I don't need the jss to be stringified when i use it inside my app. I actually need the jss, so i hope this kind of refactoring is cool with you :-)
<issue_comment>username_1: I like the changes, just a view small things and we can merge it.
<issue_comment>username_1: https://github.com/jsstyles/jss-cli/pull/3#discussion_r39318869
https://github.com/jsstyles/jss-cli/pull/3#discussion_r39318993 | {'fraction_non_alphanumeric': 0.08102766798418973, 'fraction_numerical': 0.043478260869565216, 'mean_word_length': 5.035714285714286, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '17033511', 'n_tokens_mistral': 176, 'n_tokens_neox': 159, 'n_words': 60} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Gke helm example has no example
username_0: https://github.com/gruntwork-io/terraform-google-gke/tree/master/examples/gke-basic-helm
There is a readme, no actual code.
<issue_comment>username_1: Hi @username_0, admittedly we can make it more clear, but the [root of this repo has an example for using Helm](https://github.com/gruntwork-io/terraform-google-gke#quickstart). I'll leave this issue open until we update the READMEs with further clarity.
<issue_comment>username_0: Can you show me where?
This looks like the path, there is nothing there example wise.
https://github.com/gruntwork-io/terraform-google-gke/tree/master/examples/gke-basic-helm
<issue_comment>username_1: Hi @username_0, look at the Terraform files in the root of the repo: https://github.com/gruntwork-io/terraform-google-gke
<issue_comment>username_2: @username_0 Howdy. So, you literally need to look at the *root* of the repo - aka the top level of the repo, for the files ending in .tf. :) NOT in the folder named 'root' that has the README. They have to do it this way so that they can have a README that represents the entire repo at the top level, and then in `<repo>/root/` have a README that documents the example that's in `<repo>/`. Check out the `main.tf`, `variables.tf`, etc. in the top-level directory in this repo. Those are the examples you seek. :) It *is* confusing, but a common pattern with Gruntwork's modules. It makes sense once you get used to it. Hope this helps. Cheers. | {'fraction_non_alphanumeric': 0.0891089108910891, 'fraction_numerical': 0.005280528052805281, 'mean_word_length': 4.433691756272402, 'pattern_counts': {'":': 0, '<': 8, '<?xml version=': 0, '>': 8, 'https://': 4, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30912608', 'n_tokens_mistral': 455, 'n_tokens_neox': 447, 'n_words': 201} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: remove reCAPTCHA from contact form
username_0: A Lighthouse report of the Contact page shows that the performance score for low-end mobile devices (e.g. Moto 4G) is too low when including the reCAPTCHA.
Moreover, reCAPTCHA challeges are too annoying.
Better to remove the reCAPTCHA for good.
<issue_comment>username_0: Here are the results for the contact page on a Moto 4G.
**With the reCAPTCHA**
---
**Without the reCAPTCHA**
 | {'fraction_non_alphanumeric': 0.09537166900420757, 'fraction_numerical': 0.12061711079943899, 'mean_word_length': 5.102564102564102, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '3348113', 'n_tokens_mistral': 304, 'n_tokens_neox': 247, 'n_words': 67} |