
text
stringlengths 5
22M
| id
stringlengths 12
177
| metadata
dict | __index_level_0__
int64 0
1.37k
|
|---|---|---|---|
const axios = require('axios')
const fs = require('fs')
const pjson = require('../package.json')
const { convertData, convertNum } = require('../src/float-utils-node.js')
const CollaborativeTrainer64 = artifacts.require("./CollaborativeTrainer64")
const DataHandler64 = artifacts.require("./data/DataHandler64")
const Classifier = artifacts.require("./classification/SparsePerceptron")
const Stakeable64 = artifacts.require("./incentive/Stakeable64")
module.exports = async function (deployer) {
if (deployer.network === 'skipMigrations') {
return
}
// Information to persist to the database.
const name = "IMDB Review Sentiment Classifier"
const description = "A simple IMDB sentiment analysis model."
const encoder = 'IMDB vocab'
const modelInfo = {
name,
description,
accuracy: '0.829',
modelType: 'Classifier64',
encoder,
}
const toFloat = 1E9
// Low default times for testing.
const refundTimeS = 15
const anyAddressClaimWaitTimeS = 20
const ownerClaimWaitTimeS = 20
// Weight for deposit cost in wei.
const costWeight = 1E15
const data = fs.readFileSync('./src/ml-models/imdb-sentiment-model.json', 'utf8')
const model = JSON.parse(data)
const { classifications } = model
const weights = convertData(model.weights, web3, toFloat)
const initNumWords = 250
const numWordsPerUpdate = 250
console.log(`Deploying IMDB model with ${weights.length} weights.`)
const intercept = convertNum(model.intercept || model.bias, web3, toFloat)
const learningRate = convertNum(model.learningRate, web3, toFloat)
console.log(`Deploying DataHandler.`)
return deployer.deploy(DataHandler64).then(dataHandler => {
console.log(` Deployed data handler to ${dataHandler.address}.`)
return deployer.deploy(Stakeable64,
refundTimeS,
ownerClaimWaitTimeS,
anyAddressClaimWaitTimeS,
costWeight
).then(incentiveMechanism => {
console.log(` Deployed incentive mechanism to ${incentiveMechanism.address}.`)
console.log(`Deploying classifier.`)
return deployer.deploy(Classifier,
classifications, weights.slice(0, initNumWords), intercept, learningRate,
{ gas: 7.9E6 }).then(async classifier => {
console.log(` Deployed classifier to ${classifier.address}.`)
for (let i = initNumWords; i < weights.length; i += numWordsPerUpdate) {
await classifier.initializeWeights(i, weights.slice(i, i + numWordsPerUpdate),
{ gas: 7.9E6 })
console.log(` Added ${i + numWordsPerUpdate} weights.`)
}
console.log(`Deploying collaborative trainer contract.`)
return deployer.deploy(CollaborativeTrainer64,
name, description, encoder,
dataHandler.address,
incentiveMechanism.address,
classifier.address
).then(instance => {
console.log(` Deployed IMDB collaborative classifier to ${instance.address}.`)
return Promise.all([
dataHandler.transferOwnership(instance.address),
incentiveMechanism.transferOwnership(instance.address),
classifier.transferOwnership(instance.address),
]).then(() => {
modelInfo.address = instance.address
return axios.post(`${pjson.proxy}api/models`, modelInfo).then(() => {
console.log("Added model to the database.")
}).catch(err => {
if (process.env.CI !== "true" && process.env.REACT_APP_ENABLE_SERVICE_DATA_STORE === 'true') {
// It is okay to fail adding the model in CI but otherwise it should work.
console.error("Error adding model to the database.")
console.error(err)
throw err
}
})
})
})
})
})
})
}
| 0xDeCA10B/demo/client/migrations/2_deploy_sentiment_classifier.js/0 | {
"file_path": "0xDeCA10B/demo/client/migrations/2_deploy_sentiment_classifier.js",
"repo_id": "0xDeCA10B",
"token_count": 1284
} | 0 |
import Button from '@material-ui/core/Button'
import CircularProgress from '@material-ui/core/CircularProgress'
import Container from '@material-ui/core/Container'
import IconButton from '@material-ui/core/IconButton'
import Link from '@material-ui/core/Link'
import List from '@material-ui/core/List'
import ListItem from '@material-ui/core/ListItem'
import ListItemSecondaryAction from '@material-ui/core/ListItemSecondaryAction'
import ListItemText from '@material-ui/core/ListItemText'
import Modal from '@material-ui/core/Modal'
import Paper from '@material-ui/core/Paper'
import { withStyles } from '@material-ui/core/styles'
import Typography from '@material-ui/core/Typography'
import ClearIcon from '@material-ui/icons/Clear'
import DeleteIcon from '@material-ui/icons/Delete'
import { withSnackbar } from 'notistack'
import PropTypes from 'prop-types'
import React from 'react'
import update from 'immutability-helper'
import { checkStorages } from '../components/storageSelector'
import { getNetworkType } from '../getWeb3'
import { OnlineSafetyValidator } from '../safety/validator'
import { DataStoreFactory } from '../storage/data-store-factory'
import { BASE_TITLE } from '../title'
const styles = theme => ({
descriptionDiv: {
// Indent a bit to better align with text in the list.
marginLeft: theme.spacing(1),
marginRight: theme.spacing(1),
},
button: {
marginTop: 20,
marginBottom: 20,
marginLeft: 10,
},
spinnerDiv: {
textAlign: 'center',
marginTop: theme.spacing(2),
},
listDiv: {
marginTop: theme.spacing(2),
},
nextButtonContainer: {
textAlign: 'end',
},
removeModal: {
display: 'flex',
alignItems: 'center',
justifyContent: 'center',
},
removePaper: {
border: '2px solid lightgrey',
padding: '8px',
'box-shadow': 'lightgrey',
},
})
class ModelList extends React.Component {
constructor(props) {
super(props)
this.validator = new OnlineSafetyValidator()
this.storages = DataStoreFactory.getAll()
this.storageAfterAddress = {}
this.state = {
loadingModels: true,
numModelsRemaining: 0,
models: [],
permittedStorageTypes: [],
}
this.nextModels = this.nextModels.bind(this)
this.RemoveItemModal = this.RemoveItemModal.bind(this)
}
componentDidMount = async () => {
document.title = BASE_TITLE
checkStorages(this.storages).then(permittedStorageTypes => {
permittedStorageTypes = permittedStorageTypes.filter(storageType => storageType !== undefined)
this.setState({ permittedStorageTypes }, () => {
this.updateModels().then(() => {
// These checks are done after `updateModels`, otherwise a cycle of refreshes is triggered somehow.
if (typeof window !== "undefined" && window.ethereum) {
window.ethereum.on('accountsChanged', _accounts => { window.location.reload() })
window.ethereum.on('chainChanged', _chainId => { window.location.reload() })
}
})
})
})
}
notify(...args) {
return this.props.enqueueSnackbar(...args)
}
dismissNotification(...args) {
return this.props.closeSnackbar(...args)
}
nextModels() {
this.setState({
loadingModels: true,
models: [],
numModelsRemaining: 0
}, this.updateModels)
}
async updateModels() {
// TODO Also get valid contracts that the account has already interacted with.
// TODO Filter out models that are not on this network.
const networkType = await getNetworkType()
const limit = 6
return Promise.all(this.state.permittedStorageTypes.map(storageType => {
const afterId = this.storageAfterAddress[storageType]
return this.storages[storageType].getModels(afterId, limit).then(response => {
const newModels = response.models
const { remaining } = response
newModels.forEach(model => {
model.restrictInfo = storageType !== 'local' && !this.validator.isPermitted(networkType, model.address)
model.metaDataLocation = storageType
})
if (newModels.length > 0) {
this.storageAfterAddress[storageType] = newModels[newModels.length - 1].address
}
this.setState(prevState => ({
models: prevState.models.concat(newModels),
numModelsRemaining: prevState.numModelsRemaining + remaining
}))
}).catch(err => {
this.notify(`Could not get ${storageType} models`, { variant: 'error' })
console.error(`Could not get ${storageType} models.`)
console.error(err)
})
})).finally(_ => {
this.setState({ loadingModels: false })
})
}
handleStartRemove(removeItem, removeItemIndex) {
this.setState({
removeItem,
removeItemIndex
})
}
handleCancelRemove() {
this.setState({
removeItem: undefined,
removeItemIndex: undefined,
})
}
handleRemove() {
const { removeItem, removeItemIndex } = this.state
this.storages.local.removeModel(removeItem).then(response => {
const { success } = response
if (success) {
// Remove from the list.
this.setState({
removeItem: undefined,
removeItemIndex: undefined,
models: update(this.state.models, { $splice: [[removeItemIndex, 1]] }),
})
this.notify("Removed", { variant: "success" })
} else {
throw new Error("Error removing.")
}
}).catch(err => {
console.error("Error removing.")
console.error(err)
this.notify("Error while removing", { variant: "error" })
})
}
RemoveItemModal() {
return (<Modal
aria-labelledby="remove-item-modal-title"
aria-describedby="remove-modal-title"
open={this.state.removeItem !== undefined}
onClose={() => { this.setState({ removeItem: undefined }) }}
className={this.props.classes.removeModal}
>
<Paper className={this.props.classes.removePaper}>
<Typography component="p" id="remove-choice-modal-title">
{this.state.removeItem &&
`Are you sure you would like to remove "${this.state.removeItem.name || this.state.removeItem.description}" from your local meta-data? This does not remove the model from the blockchain.`}
</Typography>
<Button className={this.props.classes.button} variant="outlined" //color="primary"
size="small" onClick={() => this.handleRemove()}>
Remove <DeleteIcon color="error" />
</Button>
<Button className={this.props.classes.button} variant="outlined" //color="primary"
size="small" onClick={() => this.handleCancelRemove()}>
Cancel <ClearIcon color="action" />
</Button>
</Paper>
</Modal>)
}
render() {
const listItems = this.state.models.map((m, index) => {
const url = `/model?${m.id ? `modelId=${m.id}&` : ''}address=${m.address}&metaDataLocation=${m.metaDataLocation}&tab=predict`
const allowRemoval = m.metaDataLocation === 'local'
return (
<ListItem key={`model-${index}`} button component="a" href={url}>
<ListItemText primary={m.restrictInfo ? `(name hidden) Address: ${m.address}` : m.name}
secondary={m.accuracy && `Accuracy: ${(m.accuracy * 100).toFixed(1)}%`} />
{/* For accessibility: keep secondary action even when disabled so that the <li> is used. */}
<ListItemSecondaryAction>
{allowRemoval &&
<IconButton edge="end" aria-label="delete" onClick={(event) => {
this.handleStartRemove(m, index); event.preventDefault()
}} >
<DeleteIcon />
</IconButton>
}
</ListItemSecondaryAction>
</ListItem>
)
})
const serviceStorageEnabled = this.state.permittedStorageTypes.indexOf('service') > 0
return (
<div>
<this.RemoveItemModal />
<Container>
<div className={this.props.classes.descriptionDiv}>
<Typography variant="h5" component="h5">
Welcome to Sharing Updatable Models
</Typography>
<Typography component="p">
Here you will find models stored on a blockchain that you can interact with.
Models are added to this list if you have recorded them on your device in this browser
{serviceStorageEnabled ? " or if they are listed on a centralized database" : ""}.
</Typography>
<Typography component="p">
You can deploy your own model <Link href='/add'>here</Link> or use an already deployed model by filling in the information <Link href='/addDeployedModel'>here</Link>.
</Typography>
</div>
{this.state.loadingModels ?
<div className={this.props.classes.spinnerDiv}>
<CircularProgress size={100} />
</div>
: listItems.length > 0 ?
<div className={this.props.classes.listDiv}>
{this.state.numModelsRemaining > 0 &&
<div className={this.props.classes.nextButtonContainer}>
<Button className={this.props.classes.button} variant="outlined" color="primary"
onClick={this.nextModels}
>
Next
</Button>
</div>
}
<Paper>
<List className={this.props.classes.list}>
{listItems}
</List>
</Paper>
{this.state.numModelsRemaining > 0 &&
<div className={this.props.classes.nextButtonContainer}>
<Button className={this.props.classes.button} variant="outlined" color="primary"
onClick={this.nextModels}
>
Next
</Button>
</div>
}
</div>
:
<div className={this.props.classes.descriptionDiv}>
<Typography component="p">
You do not have any models listed.
</Typography>
</div>
}
</Container>
</div>
)
}
}
ModelList.propTypes = {
classes: PropTypes.object.isRequired,
}
export default withSnackbar(withStyles(styles)(ModelList))
| 0xDeCA10B/demo/client/src/containers/modelList.js/0 | {
"file_path": "0xDeCA10B/demo/client/src/containers/modelList.js",
"repo_id": "0xDeCA10B",
"token_count": 3691
} | 1 |
/**
* Possible types of encoders.
* The string values can be stored in smart contracts on public blockchains so do not make changes to the values.
* Changing the casing of a value should be fine.
*/
export enum Encoder {
// Simple encoders:
None = "none",
Mult1E9Round = "Multiply by 1E9, then round",
// Hash encoders:
MurmurHash3 = "MurmurHash3",
// More complicated encoders:
ImdbVocab = "IMDB vocab",
MobileNetV2 = "MobileNetV2",
USE = "universal sentence encoder",
}
export function normalizeEncoderName(encoderName: string): string {
if (!encoderName) {
return encoderName
}
return encoderName.toLocaleLowerCase('en')
}
| 0xDeCA10B/demo/client/src/encoding/encoder.ts/0 | {
"file_path": "0xDeCA10B/demo/client/src/encoding/encoder.ts",
"repo_id": "0xDeCA10B",
"token_count": 213
} | 2 |
const fs = require('fs')
const path = require('path')
const mobilenet = require('@tensorflow-models/mobilenet')
const tf = require('@tensorflow/tfjs-node')
const { createCanvas, loadImage } = require('canvas')
const { normalize1d } = require('../tensor-utils-node')
const dataPath = path.join(__dirname, './seefood')
const POSITIVE_CLASS = "HOT DOG"
const NEGATIVE_CLASS = "NOT HOT DOG"
const INTENTS = {
'hot_dog': POSITIVE_CLASS,
'not_hot_dog': NEGATIVE_CLASS,
}
// Normalize each sample like what will happen in production to avoid changing the centroid by too much.
const NORMALIZE_EACH_EMBEDDING = true
// Reduce the size of the embeddings.
const REDUCE_EMBEDDINGS = false
const EMB_SIZE = 1280
const EMB_REDUCTION_FACTOR = REDUCE_EMBEDDINGS ? 4 : 1
// Classifier type can be: ncc/perceptron
const args = process.argv.slice(2)
const CLASSIFIER_TYPE = args.length > 0 ? args[0] : 'perceptron'
console.log(`Training a ${CLASSIFIER_TYPE} classifier.`)
// Perceptron Classifier Config
// Take only the top features.
const PERCEPTRON_NUM_FEATS = 400
// Sort of like regularization but it does not converge.
// Probably because it ruins the Perceptron assumption of updating weights.
const NORMALIZE_PERCEPTRON_WEIGHTS = false
let learningRate = 1
const LEARNING_RATE_CHANGE_FACTOR = 0.8618
const LEARNING_RATE_CUTTING_PERCENT_OF_BEST = 0.8618
const MAX_STABILITY_COUNT = 3
const PERCENT_OF_TRAINING_SET_TO_FIT = 0.99
const classes = {
[POSITIVE_CLASS]: +1,
[NEGATIVE_CLASS]: -1,
}
// Nearest Centroid Classifier Config
// Normalizing the centroid didn't change performance by much.
// It was slightly worse for HOT_DOG accuracy.
const NORMALIZE_CENTROID = false
let embeddingCache
const embeddingCachePath = path.join(__dirname, 'embedding_cache.json')
if (fs.existsSync(embeddingCachePath)) {
try {
embeddingCache = fs.readFileSync(embeddingCachePath, 'utf8')
embeddingCache = JSON.parse(embeddingCache)
console.debug(`Loaded ${Object.keys(embeddingCache).length} cached embeddings.`)
} catch (error) {
console.error("Error loading embedding cache.\nWill create a new one.")
console.error(error)
embeddingCache = {}
}
} else {
embeddingCache = {}
}
// Useful for making the embedding smaller.
// This did not change the accuracy by much.
if (EMB_SIZE % EMB_REDUCTION_FACTOR !== 0) {
throw new Error("The embedding reduction factor is not a multiple of the embedding size.")
}
const EMB_MAPPER =
tf.tidy(_ => {
const mapper = tf.fill([EMB_SIZE / EMB_REDUCTION_FACTOR, EMB_SIZE], 0, 'int32')
const buffer = mapper.bufferSync()
for (let i = 0; i < mapper.shape[0]; ++i) {
for (let j = 0; j < EMB_REDUCTION_FACTOR; ++j) {
buffer.set(1, i, 2 * i + j)
}
}
return buffer.toTensor()
})
/**
* @param {string} sample The relative path from `dataPath` for the image.
* @returns The embedding for the image. Shape has 1 dimension.
*/
async function getEmbedding(sample) {
let result = embeddingCache[sample]
if (result !== undefined) {
result = tf.tensor1d(result)
} else {
const img = await loadImage(path.join(dataPath, sample))
const canvas = createCanvas(img.width, img.height)
const ctx = canvas.getContext('2d')
ctx.drawImage(img, 0, 0)
const emb = await encoder.infer(canvas, { embedding: true })
if (emb.shape[1] !== EMB_SIZE) {
throw new Error(`Expected embedding to have ${EMB_SIZE} dimensions. Got shape: ${emb.shape}.`)
}
result = tf.tidy(_ => {
let result = emb.gather(0)
embeddingCache[sample] = result.arraySync()
if (REDUCE_EMBEDDINGS) {
result = EMB_MAPPER.dot(result)
}
return result
})
emb.dispose()
}
if (NORMALIZE_EACH_EMBEDDING) {
const normalizedResult = normalize1d(result)
result.dispose()
result = normalizedResult
}
return result
}
/**
* Shuffles array in place.
* @param {Array} a items An array containing the items.
*/
// From https://stackoverflow.com/a/6274381/1226799
function shuffle(a) {
for (let i = a.length - 1; i > 0; i--) {
const j = Math.floor(Math.random() * (i + 1));
[a[i], a[j]] = [a[j], a[i]]
}
return a
}
async function predict(model, sample) {
switch (CLASSIFIER_TYPE) {
case 'ncc':
return await predictNearestCentroidModel(model, sample)
case 'perceptron':
return await predictPerceptron(model, sample)
default:
throw new Error(`Unrecognized classifierType: "${CLASSIFIER_TYPE}"`)
}
}
async function evaluate(model) {
const evalStats = []
const evalIntents = Object.entries(INTENTS)
for (let i = 0; i < evalIntents.length; ++i) {
const [intent, expectedIntent] = evalIntents[i]
const stats = {
intent: expectedIntent,
recall: undefined,
numCorrect: 0,
confusion: {},
}
const pathPrefix = path.join('test', intent)
const dataDir = path.join(dataPath, pathPrefix)
const samples = fs.readdirSync(dataDir)
console.log(`Evaluating with ${samples.length} samples for ${INTENTS[intent]}.`)
for (let i = 0; i < samples.length; ++i) {
if (i % Math.round(samples.length / 5) == 0) {
// console.log(` ${expectedIntent}: ${(100 * i / samples.length).toFixed(1)}% (${i}/${samples.length})`);
}
const prediction = await predict(model, path.join(pathPrefix, samples[i]))
if (prediction === expectedIntent) {
stats.numCorrect += 1
} else {
if (!(prediction in stats.confusion)) {
stats.confusion[prediction] = 0
}
stats.confusion[prediction] += 1
}
}
stats.recall = stats.numCorrect / samples.length
evalStats.push(stats)
// console.log(` ${expectedIntent}: Done evaluating.`);
}
console.log(`NORMALIZE_EACH_EMBEDDING: ${NORMALIZE_EACH_EMBEDDING}`)
console.log(`NORMALIZE_PERCEPTRON_WEIGHTS: ${NORMALIZE_PERCEPTRON_WEIGHTS}`)
switch (CLASSIFIER_TYPE) {
case 'ncc':
console.log(`normalizeCentroid: ${NORMALIZE_CENTROID}`)
break
case 'perceptron':
console.log(`learningRate: ${learningRate}`)
break
default:
throw new Error(`Unrecognized classifierType: "${CLASSIFIER_TYPE}"`)
}
// Compute precision.
Object.values(INTENTS).forEach(intent => {
evalStats.forEach(stats => {
if (stats.intent === intent) {
let numFalsePositives = 0
evalStats.forEach(otherStats => {
if (otherStats.intent !== intent) {
if (otherStats.confusion[intent] !== undefined) {
numFalsePositives += otherStats.confusion[intent]
}
}
})
stats.precision = stats.numCorrect / (stats.numCorrect + numFalsePositives)
stats.f1 = 2 / (1 / stats.precision + 1 / stats.recall)
}
})
})
console.log(JSON.stringify(evalStats, null, 2))
let f1HarmonicMean = 0
for (let i = 0; i < evalStats.length; ++i) {
f1HarmonicMean += 1 / evalStats[i].f1
}
f1HarmonicMean = evalStats.length / f1HarmonicMean
console.log(`f1 harmonic mean: ${f1HarmonicMean.toFixed(3)}`)
}
// Nearest Centroid Classifier Section
async function getCentroid(intent) {
const pathPrefix = path.join('train', intent)
const dataDir = path.join(dataPath, pathPrefix)
const samples = fs.readdirSync(dataDir)
console.log(`Training with ${samples.length} samples for ${INTENTS[intent]}.`)
const allEmbeddings = []
for (let i = 0; i < samples.length; ++i) {
if (i % 100 == 0) {
console.log(` ${INTENTS[intent]}: ${(100 * i / samples.length).toFixed(1)}% (${i}/${samples.length})`)
}
const emb = await getEmbedding(path.join(pathPrefix, samples[i]))
allEmbeddings.push(emb.expandDims())
}
console.log(` ${INTENTS[intent]}: Done getting embeddings.`)
const centroid = tf.tidy(() => {
const allEmbTensor = tf.concat(allEmbeddings)
if (allEmbTensor.shape[0] !== samples.length) {
throw new Error(`Some embeddings are missing: allEmbTensor.shape[0] !== samples.length: ${allEmbTensor.shape[0]} !== ${samples.length}`)
}
let centroid = allEmbTensor.mean(axis = 0)
if (NORMALIZE_CENTROID) {
centroid = normalize1d(centroid)
}
return centroid.arraySync()
})
allEmbeddings.forEach(emb => emb.dispose())
return {
centroid,
dataCount: samples.length,
}
}
function getNearestCentroidModel() {
return new Promise((resolve, reject) => {
Promise.all(Object.keys(INTENTS).map(getCentroid))
.then(async centroidInfos => {
const model = { intents: {} }
Object.values(INTENTS).forEach((intent, i) => {
model.intents[intent] = centroidInfos[i]
})
const modelPath = path.join(__dirname, 'classifier-centroids.json')
console.log(`Saving centroids to "${modelPath}".`)
model.type = 'nearest centroid classifier'
fs.writeFileSync(modelPath, JSON.stringify(model))
resolve(model)
}).catch(reject)
})
}
async function predictNearestCentroidModel(model, sample) {
let minDistance = Number.MAX_VALUE
let result
const emb = await getEmbedding(sample)
tf.tidy(() => {
Object.entries(model.intents).forEach(([intent, centroidInfo]) => {
const centroid = tf.tensor1d(centroidInfo.centroid)
const distance = centroid.sub(emb).pow(2).sum()
if (distance.less(minDistance).dataSync()[0]) {
result = intent
minDistance = distance
}
})
})
emb.dispose()
return result
}
// Perceptron Section
async function getPerceptronModel() {
return new Promise(async (resolve, reject) => {
// Load data.
const samples = []
Object.keys(INTENTS).forEach(intent => {
const pathPrefix = path.join('train', intent)
const dataDir = path.join(dataPath, pathPrefix)
const samplesForClass = fs.readdirSync(dataDir).map(sample => {
return {
classification: INTENTS[intent],
path: path.join(pathPrefix, sample)
}
})
samples.push(...samplesForClass)
})
const model = {
bias: 0,
}
// Initialize the weights.
console.log(` Training with ${EMB_SIZE} weights.`)
model.weights = new Array(EMB_SIZE)
for (let j = 0; j < model.weights.length; ++j) {
// Can initialize randomly with `Math.random() - 0.5` but it doesn't seem to make much of a difference.
// model.weights[j] = 0;
model.weights[j] = Math.random() - 0.5
}
model.weights = tf.tidy(_ => {
return normalize1d(tf.tensor1d(model.weights))
})
let numUpdates, bestNumUpdatesBeforeLearningRateChange
let epoch = 0
let stabilityCount = 0
do {
if (model.weights !== undefined && NORMALIZE_PERCEPTRON_WEIGHTS) {
// Sort of like regularization.
model.weights = normalize1d(model.weights)
}
numUpdates = 0
shuffle(samples)
for (let i = 0; i < samples.length; ++i) {
if (i % Math.round(samples.length / 4) == 0) {
// console.log(` training: ${(100 * i / samples.length).toFixed(1)}% (${i}/${samples.length})`);
}
const sample = samples[i]
const emb = await getEmbedding(sample.path)
const { classification } = sample
const prediction = await predictPerceptron(model, emb)
if (prediction !== classification) {
numUpdates += 1
const sign = classes[classification]
model.weights = tf.tidy(_ => { return model.weights.add(emb.mul(sign * learningRate)) })
}
emb.dispose()
}
console.log(`Training epoch: ${epoch.toString().padStart(4, '0')}: numUpdates: ${numUpdates}`)
if (numUpdates === 0) {
// There cannot be any more updates.
break
}
epoch += 1
if (bestNumUpdatesBeforeLearningRateChange !== undefined &&
numUpdates < bestNumUpdatesBeforeLearningRateChange * LEARNING_RATE_CUTTING_PERCENT_OF_BEST) {
learningRate *= LEARNING_RATE_CHANGE_FACTOR
console.debug(` Changed learning rate to: ${learningRate.toFixed(3)}`)
bestNumUpdatesBeforeLearningRateChange = numUpdates
}
if (bestNumUpdatesBeforeLearningRateChange === undefined) {
bestNumUpdatesBeforeLearningRateChange = numUpdates
}
if (numUpdates < Math.max(samples.length * (1 - PERCENT_OF_TRAINING_SET_TO_FIT), 1)) {
stabilityCount += 1
} else {
stabilityCount = 0
}
} while (stabilityCount < MAX_STABILITY_COUNT)
const modelPath = path.join(__dirname, 'classifier-perceptron.json')
console.log(`Saving Perceptron to "${modelPath}".`)
fs.writeFileSync(modelPath, JSON.stringify({
type: 'perceptron',
weights: model.weights.arraySync(),
classifications: [NEGATIVE_CLASS, POSITIVE_CLASS],
bias: model.bias
}))
resolve(model)
})
}
async function predictPerceptron(model, sample) {
let result
let emb = sample
if (typeof sample === 'string') {
emb = await getEmbedding(sample)
}
tf.tidy(() => {
if (model.featureIndices !== undefined) {
emb = emb.gather(model.featureIndices)
}
let prediction = model.weights.dot(emb)
prediction = prediction.add(model.bias)
if (prediction.greater(0).dataSync()[0]) {
result = POSITIVE_CLASS
} else {
result = NEGATIVE_CLASS
}
})
if (typeof sample === 'string') {
emb.dispose()
}
return result
}
async function main() {
global.encoder = await mobilenet.load(
{
version: 2,
alpha: 1,
}
)
let model
switch (CLASSIFIER_TYPE) {
case 'ncc':
model = await getNearestCentroidModel()
break
case 'perceptron':
model = await getPerceptronModel()
break
default:
throw new Error(`Unrecognized classifierType: "${CLASSIFIER_TYPE}"`)
}
await evaluate(model)
fs.writeFileSync(embeddingCachePath, JSON.stringify(embeddingCache))
console.debug(`Wrote embedding cache to \"${embeddingCachePath}\" with ${Object.keys(embeddingCache).length} cached embeddings.`)
if (CLASSIFIER_TYPE === 'perceptron' && PERCEPTRON_NUM_FEATS !== EMB_SIZE) {
console.log(`Reducing weights to ${PERCEPTRON_NUM_FEATS} dimensions.`)
model.featureIndices = tf.tidy(_ => {
return tf.abs(model.weights).topk(PERCEPTRON_NUM_FEATS).indices
})
model.weights = tf.tidy(_ => {
return model.weights.gather(model.featureIndices)
})
const modelPath = path.join(__dirname, `classifier-perceptron-${PERCEPTRON_NUM_FEATS}.json`)
console.log(`Saving Perceptron with ${PERCEPTRON_NUM_FEATS} weights to "${modelPath}".`)
fs.writeFileSync(modelPath, JSON.stringify({
type: 'perceptron',
classifications: [NEGATIVE_CLASS, POSITIVE_CLASS],
featureIndices: model.featureIndices.arraySync(),
weights: model.weights.arraySync(),
bias: model.bias
}))
await evaluate(model)
}
}
main()
| 0xDeCA10B/demo/client/src/ml-models/hot_dog-not/train-classifier.js/0 | {
"file_path": "0xDeCA10B/demo/client/src/ml-models/hot_dog-not/train-classifier.js",
"repo_id": "0xDeCA10B",
"token_count": 5504
} | 3 |
import { DataStore, DataStoreHealthStatus, ModelInformation, ModelsResponse, OriginalData, RemoveResponse } from './data-store'
export class LocalDataStore implements DataStore {
errorOpening?: boolean
db?: IDBDatabase
private readonly dataStoreName = 'data'
private readonly modelStoreName = 'model'
constructor() {
const openRequest = indexedDB.open("database", 1)
openRequest.onerror = (event: any) => {
this.errorOpening = true
console.error("Could not open the database.")
console.error(event)
throw new Error("Could not open the database.")
}
openRequest.onsuccess = (event: any) => {
this.db = event.target.result
}
openRequest.onupgradeneeded = (event: any) => {
const db: IDBDatabase = event.target.result
// Index by transaction hash.
db.createObjectStore(this.dataStoreName, { keyPath: 'tx' })
const modelStore = db.createObjectStore(this.modelStoreName, { keyPath: 'address' })
modelStore.createIndex('address', 'address')
}
}
private checkOpened(timeout = 0): Promise<void> {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (this.db) {
resolve()
} else if (this.errorOpening) {
reject(new Error("The database could not be opened."))
} else {
this.checkOpened(Math.min(500, 1.618 * timeout + 10))
.then(resolve)
.catch(reject)
}
}, timeout)
})
}
health(): Promise<DataStoreHealthStatus> {
return this.checkOpened().then(() => {
return new DataStoreHealthStatus(true)
})
}
async saveOriginalData(transactionHash: string, originalData: OriginalData): Promise<any> {
await this.checkOpened()
return new Promise((resolve, reject) => {
const transaction = this.db!.transaction(this.dataStoreName, 'readwrite')
transaction.onerror = reject
const dataStore = transaction.objectStore(this.dataStoreName)
const request = dataStore.add({ tx: transactionHash, text: originalData.text })
request.onerror = reject
request.onsuccess = resolve
})
}
async getOriginalData(transactionHash: string): Promise<OriginalData> {
await this.checkOpened()
return new Promise((resolve, reject) => {
const transaction = this.db!.transaction(this.dataStoreName, 'readonly')
transaction.onerror = reject
const dataStore = transaction.objectStore(this.dataStoreName)
const request = dataStore.get(transactionHash)
request.onerror = reject
request.onsuccess = (event: any) => {
const originalData = event.target.result
if (originalData === undefined) {
reject(new Error("Data not found."))
} else {
const { text } = originalData
resolve(new OriginalData(text))
}
}
})
}
async saveModelInformation(modelInformation: ModelInformation): Promise<any> {
await this.checkOpened()
return new Promise((resolve, reject) => {
const transaction = this.db!.transaction(this.modelStoreName, 'readwrite')
transaction.onerror = reject
const modelStore = transaction.objectStore(this.modelStoreName)
const request = modelStore.add(modelInformation)
request.onerror = reject
request.onsuccess = resolve
})
}
async getModels(afterAddress?: string, limit?: number): Promise<ModelsResponse> {
await this.checkOpened()
return new Promise((resolve, reject) => {
const transaction = this.db!.transaction(this.modelStoreName, 'readonly')
transaction.onerror = reject
const modelStore = transaction.objectStore(this.modelStoreName)
const index = modelStore.index('address')
const models: ModelInformation[] = []
if (afterAddress == null) {
afterAddress = ''
}
const open = true
const range = IDBKeyRange.lowerBound(afterAddress, open)
let count = 0
index.openCursor(range).onsuccess = (event: any) => {
const cursor = event.target.result
if (cursor && (limit == null || count++ < limit)) {
models.push(new ModelInformation(cursor.value))
cursor.continue()
} else {
const countRequest = index.count(range)
countRequest.onsuccess = () => {
const remaining = countRequest.result - models.length
resolve(new ModelsResponse(models, remaining))
}
}
}
})
}
async getModel(_modelId?: number, address?: string): Promise<ModelInformation> {
if (address === null || address === undefined) {
throw new Error("An address is required.")
}
await this.checkOpened()
return new Promise((resolve, reject) => {
const transaction = this.db!.transaction(this.modelStoreName, 'readonly')
transaction.onerror = reject
const modelStore = transaction.objectStore(this.modelStoreName)
const request = modelStore.get(address)
request.onerror = reject
request.onsuccess = (event: any) => {
const model = event.target.result
if (model === undefined) {
reject(new Error("Model not found."))
} else {
resolve(new ModelInformation(model))
}
}
})
}
async removeModel(modelInformation: ModelInformation): Promise<RemoveResponse> {
await this.checkOpened()
return new Promise((resolve, reject) => {
const transaction = this.db!.transaction(this.modelStoreName, 'readwrite')
transaction.onerror = reject
const modelStore = transaction.objectStore(this.modelStoreName)
const request = modelStore.delete(modelInformation.address)
request.onerror = reject
request.onsuccess = () => {
const success = true
resolve(new RemoveResponse(success))
}
})
}
}
| 0xDeCA10B/demo/client/src/storage/local-data-store.ts/0 | {
"file_path": "0xDeCA10B/demo/client/src/storage/local-data-store.ts",
"repo_id": "0xDeCA10B",
"token_count": 1893
} | 4 |
const Environment = require('jest-environment-jsdom')
/**
* A custom environment to set the TextEncoder that is required by TensorFlow.js.
*/
module.exports = class CustomTestEnvironment extends Environment {
// Following https://stackoverflow.com/a/57713960/1226799
async setup() {
await super.setup()
if (typeof this.global.TextEncoder === 'undefined') {
const { TextEncoder } = require('util')
this.global.TextEncoder = TextEncoder
}
if (typeof this.global.indexedDB === 'undefined') {
this.global.indexedDB = require('fake-indexeddb')
}
if (typeof this.global.IDBKeyRange === 'undefined') {
this.global.IDBKeyRange = require("fake-indexeddb/lib/FDBKeyRange")
}
if (typeof this.global.web3 === 'undefined') {
const Web3 = require('web3')
const truffleConfig = require('../truffle')
const networkConfig = truffleConfig.networks.development
this.global.web3 = new Web3(new Web3.providers.HttpProvider(`http://${networkConfig.host}:${networkConfig.port}`))
}
}
}
| 0xDeCA10B/demo/client/test/custom-test-env.js/0 | {
"file_path": "0xDeCA10B/demo/client/test/custom-test-env.js",
"repo_id": "0xDeCA10B",
"token_count": 356
} | 5 |
import random
import unittest
import numpy as np
from injector import Injector
from decai.simulation.contract.balances import Balances
from decai.simulation.contract.classification.classifier import Classifier
from decai.simulation.contract.classification.perceptron import PerceptronModule
from decai.simulation.contract.collab_trainer import CollaborativeTrainer, DefaultCollaborativeTrainerModule
from decai.simulation.contract.incentive.stakeable import StakeableImModule
from decai.simulation.contract.objects import Msg, RejectException, TimeMock
from decai.simulation.logging_module import LoggingModule
def _ground_truth(data):
return data[0] * data[2]
class TestCollaborativeTrainer(unittest.TestCase):
@classmethod
def setUpClass(cls):
inj = Injector([
DefaultCollaborativeTrainerModule,
LoggingModule,
PerceptronModule,
StakeableImModule,
])
cls.balances = inj.get(Balances)
cls.decai = inj.get(CollaborativeTrainer)
cls.time_method = inj.get(TimeMock)
cls.good_address = 'sender'
initial_balance = 1E6
cls.balances.initialize(cls.good_address, initial_balance)
msg = Msg(cls.good_address, cls.balances[cls.good_address])
X = np.array([
# Initialization Data
[0, 0, 0],
[1, 1, 1],
# Data to Add
[0, 0, 1],
[0, 1, 0],
[0, 1, 1],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0],
])
y = np.array([_ground_truth(x) for x in X])
cls.decai.model.init_model(np.array([X[0, :], X[1, :]]),
np.array([y[0], y[1]]))
score = cls.decai.model.evaluate(X, y)
assert score != 1, "Model shouldn't fit the data yet."
# Add all data.
first_added_time = None
for i in range(X.shape[0]):
x = X[i]
cls.time_method.set_time(cls.time_method() + 1)
if first_added_time is None:
first_added_time = cls.time_method()
cls.decai.add_data(msg, x, y[i])
for _ in range(1000):
score = cls.decai.model.evaluate(X, y)
if score >= 1:
break
i = random.randint(0, X.shape[0] - 1)
x = X[i]
cls.time_method.set_time(cls.time_method() + 1)
cls.decai.add_data(msg, x, y[i])
assert score == 1, "Model didn't fit the data."
bal = cls.balances[msg.sender]
assert bal < initial_balance, "Adding data should have a cost."
# Make sure sender has some good data refunded so that they can report data later.
cls.time_method.set_time(cls.time_method() + cls.decai.im.refund_time_s + 1)
cls.decai.refund(msg, X[0], y[0], first_added_time)
assert cls.balances[msg.sender] > bal, "Refunding should return value."
def test_predict(self):
data = np.array([0, 1, 0])
correct_class = _ground_truth(data)
prediction = self.decai.model.predict(data)
self.assertEqual(prediction, correct_class)
def test_refund(self):
data = np.array([0, 2, 0])
correct_class = _ground_truth(data)
orig_address = "Orig"
bal = 1E5
self.balances.initialize(orig_address, bal)
msg = Msg(orig_address, 1E3)
self.time_method.set_time(self.time_method() + 1)
added_time = self.time_method()
self.decai.add_data(msg, data, correct_class)
self.assertLess(self.balances[orig_address], bal)
# Add same data from another address.
msg = Msg(self.good_address, 1E3)
self.time_method.set_time(self.time_method() + 1)
bal = self.balances[self.good_address]
self.decai.add_data(msg, data, correct_class)
self.assertLess(self.balances[self.good_address], bal)
# Original address refunds.
msg = Msg(orig_address, 1E3)
bal = self.balances[orig_address]
self.time_method.set_time(self.time_method() + self.decai.im.refund_time_s + 1)
self.decai.refund(msg, data, correct_class, added_time)
self.assertGreater(self.balances[orig_address], bal)
def test_report(self):
data = np.array([0, 0, 0])
correct_class = _ground_truth(data)
submitted_classification = 1 - correct_class
# Add bad data.
malicious_address = 'malicious'
self.balances.initialize(malicious_address, 1E6)
bal = self.balances[malicious_address]
msg = Msg(malicious_address, bal)
self.time_method.set_time(self.time_method() + 1)
added_time = self.time_method()
self.decai.add_data(msg, data, submitted_classification)
self.assertLess(self.balances[malicious_address], bal,
"Adding data should have a cost.")
self.time_method.set_time(self.time_method() + self.decai.im.refund_time_s + 1)
# Can't refund.
msg = Msg(malicious_address, self.balances[malicious_address])
try:
self.decai.refund(msg, data, submitted_classification, added_time)
self.fail("Should have failed.")
except RejectException as e:
self.assertEqual("The model doesn't agree with your contribution.", e.args[0])
bal = self.balances[self.good_address]
msg = Msg(self.good_address, bal)
self.decai.report(msg, data, submitted_classification, added_time, malicious_address)
self.assertGreater(self.balances[self.good_address], bal)
def test_report_take_all(self):
data = np.array([0, 0, 0])
correct_class = _ground_truth(data)
submitted_classification = 1 - correct_class
# Add bad data.
malicious_address = 'malicious_take_backer'
self.balances.initialize(malicious_address, 1E6)
bal = self.balances[malicious_address]
msg = Msg(malicious_address, bal)
self.time_method.set_time(self.time_method() + 1)
added_time = self.time_method()
self.decai.add_data(msg, data, submitted_classification)
self.assertLess(self.balances[malicious_address], bal,
"Adding data should have a cost.")
self.time_method.set_time(self.time_method() + self.decai.im.any_address_claim_wait_time_s + 1)
# Can't refund.
msg = Msg(malicious_address, self.balances[malicious_address])
try:
self.decai.refund(msg, data, submitted_classification, added_time)
self.fail("Should have failed.")
except RejectException as e:
self.assertEqual("The model doesn't agree with your contribution.", e.args[0])
bal = self.balances[malicious_address]
msg = Msg(malicious_address, bal)
self.decai.report(msg, data, submitted_classification, added_time, malicious_address)
self.assertGreater(self.balances[malicious_address], bal)
def test_reset(self):
inj = Injector([
LoggingModule,
PerceptronModule,
])
m = inj.get(Classifier)
X = np.array([
# Initialization Data
[0, 0, 0],
[1, 1, 1],
])
y = np.array([_ground_truth(x) for x in X])
m.init_model(X, y, save_model=True)
data = np.array([
[0, 0, 0],
[0, 0, 1],
[0, 1, 0],
[0, 1, 1],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0],
[1, 1, 1],
])
original_predictions = [m.predict(x) for x in data]
labels = np.array([_ground_truth(x) for x in data])
for x, y in zip(data, labels):
m.update(x, y)
predictions_after_training = [m.predict(x) for x in data]
self.assertNotEqual(original_predictions, predictions_after_training)
m.reset_model()
new_predictions = [m.predict(x) for x in data]
self.assertEqual(original_predictions, new_predictions)
| 0xDeCA10B/simulation/decai/simulation/contract/classification/tests/test_perceptron.py/0 | {
"file_path": "0xDeCA10B/simulation/decai/simulation/contract/classification/tests/test_perceptron.py",
"repo_id": "0xDeCA10B",
"token_count": 3780
} | 6 |
import unittest
from typing import cast
from injector import Injector
from decai.simulation.data.data_loader import DataLoader
from decai.simulation.data.ttt_data_loader import TicTacToeDataLoader, TicTacToeDataModule
from decai.simulation.logging_module import LoggingModule
class TestTicTacToeDataLoader(unittest.TestCase):
@classmethod
def setUpClass(cls):
inj = Injector([
LoggingModule,
TicTacToeDataModule,
])
cls.ttt = inj.get(DataLoader)
assert isinstance(cls.ttt, TicTacToeDataLoader)
cls.ttt = cast(TicTacToeDataLoader, cls.ttt)
def test_classifications(self):
classifications = self.ttt.classifications()
assert classifications == ["(0, 0)", "(0, 1)", "(0, 2)",
"(1, 0)", "(1, 1)", "(1, 2)",
"(2, 0)", "(2, 1)", "(2, 2)"]
def test_boards(self):
(x_train, y_train), (x_test, y_test) = self.ttt.load_data()
assert x_train.shape[1] == self.ttt.width * self.ttt.length
assert set(x_train[x_train != 0]) == {1, -1}
assert x_test.shape[1] == self.ttt.width * self.ttt.length
assert set(x_test[x_test != 0]) == {1, -1}
assert set(y_train) <= set(range(9))
assert set(y_test) <= set(range(9))
| 0xDeCA10B/simulation/decai/simulation/data/tests/test_ttt_data_loader.py/0 | {
"file_path": "0xDeCA10B/simulation/decai/simulation/data/tests/test_ttt_data_loader.py",
"repo_id": "0xDeCA10B",
"token_count": 633
} | 7 |
# MIT License
# Copyright (c) Microsoft Corporation.
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE
import torch
import torch.nn as nn
class DropPath(nn.Module):
def __init__(self, p=0.):
"""
Drop path with probability.
Parameters
----------
p : float
Probability of an path to be zeroed.
"""
super().__init__()
self.p = p
def forward(self, x):
if self.training and self.p > 0.:
keep_prob = 1. - self.p
# per data point mask
mask = torch.zeros((x.size(0), 1, 1, 1), device=x.device).bernoulli_(keep_prob)
return x / keep_prob * mask
return x
class PoolBN(nn.Module):
"""
AvgPool or MaxPool with BN. `pool_type` must be `max` or `avg`.
"""
def __init__(self, pool_type, C, kernel_size, stride, padding, affine=True):
super().__init__()
if pool_type.lower() == 'max':
self.pool = nn.MaxPool2d(kernel_size, stride, padding)
elif pool_type.lower() == 'avg':
self.pool = nn.AvgPool2d(kernel_size, stride, padding, count_include_pad=False)
else:
raise ValueError()
self.bn = nn.BatchNorm2d(C, affine=affine)
def forward(self, x):
out = self.pool(x)
out = self.bn(out)
return out
class StdConv(nn.Module):
"""
Standard conv: ReLU - Conv - BN
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True):
super().__init__()
self.net = nn.Sequential(
nn.ReLU(),
nn.Conv2d(C_in, C_out, kernel_size, stride, padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
def forward(self, x):
return self.net(x)
class FacConv(nn.Module):
"""
Factorized conv: ReLU - Conv(Kx1) - Conv(1xK) - BN
"""
def __init__(self, C_in, C_out, kernel_length, stride, padding, affine=True):
super().__init__()
self.net = nn.Sequential(
nn.ReLU(),
nn.Conv2d(C_in, C_in, (kernel_length, 1), stride, padding, bias=False),
nn.Conv2d(C_in, C_out, (1, kernel_length), stride, padding, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
def forward(self, x):
return self.net(x)
class DilConv(nn.Module):
"""
(Dilated) depthwise separable conv.
ReLU - (Dilated) depthwise separable - Pointwise - BN.
If dilation == 2, 3x3 conv => 5x5 receptive field, 5x5 conv => 9x9 receptive field.
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True):
super().__init__()
self.net = nn.Sequential(
nn.ReLU(),
nn.Conv2d(C_in, C_in, kernel_size, stride, padding, dilation=dilation, groups=C_in,
bias=False),
nn.Conv2d(C_in, C_out, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine)
)
def forward(self, x):
return self.net(x)
class SepConv(nn.Module):
"""
Depthwise separable conv.
DilConv(dilation=1) * 2.
"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True):
super().__init__()
self.net = nn.Sequential(
DilConv(C_in, C_in, kernel_size, stride, padding, dilation=1, affine=affine),
DilConv(C_in, C_out, kernel_size, 1, padding, dilation=1, affine=affine)
)
def forward(self, x):
return self.net(x)
class FactorizedReduce(nn.Module):
"""
Reduce feature map size by factorized pointwise (stride=2).
"""
def __init__(self, C_in, C_out, affine=True):
super().__init__()
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(C_in, C_out // 2, 1, stride=2, padding=0, bias=False)
self.conv2 = nn.Conv2d(C_in, C_out // 2, 1, stride=2, padding=0, bias=False)
self.bn = nn.BatchNorm2d(C_out, affine=affine)
def forward(self, x):
x = self.relu(x)
out = torch.cat([self.conv1(x), self.conv2(x[:, :, 1:, 1:])], dim=1)
out = self.bn(out)
return out
| AI-System/Labs/AdvancedLabs/Lab8/nas/ops.py/0 | {
"file_path": "AI-System/Labs/AdvancedLabs/Lab8/nas/ops.py",
"repo_id": "AI-System",
"token_count": 2296
} | 8 |
<!--Copyright © Microsoft Corporation. All rights reserved.
适用于[License](https://github.com/microsoft/AI-System/blob/main/LICENSE)版权许可-->
# 12.3 人工智能服务安全与隐私
- [12.3 人工智能服务安全与隐私](#122-人工智能训练安全与隐私)
- [12.3.1 服务时安全](#1221-服务时安全)
- [12.3.2 服务时的用户隐私](#1222-服务时的用户隐私)
- [12.3.3 服务时的模型隐私](#1223-服务时的模型隐私)
- [小结与讨论](#小结与讨论)
- [参考文献](#参考文献)
本节介绍人工智能服务时的安全与隐私问题及缓解方法。这些问题涉及到人工智能推理的完整性与机密性,反映了可信人工智能推理系统的重要性。
## 12.2.1 服务时安全
对于一个部署好的深度学习服务,推理系统通常将模型参数存储在内存中。但是,内存在长期的使用后是可能发生错误的,例如其中的一些比特发生了反转。Guanpeng Li 等人[<sup>[1]</sup>](#softerror)在 2017 年研究发现深度学习推理系统常常使用的高性能硬件更容易出现这种内存错误(如果这种错误可以通过重启消除,则称为软错误),而软错误会在深度神经网络中传导,导致模型的结果出错。这种现象如果被恶意攻击者利用,就可以通过故障注入攻击(Fault Injection Attack)来篡改内存中存储的模型参数,从而影响模型的行为。Sanghyun Hong 等人[<sup>[2]</sup>](#braindamage)在 2019 年提出如果精心选择,一个比特翻转就能让模型的精度下降超过
90%。他们还通过 Rowhammer 故障注入攻击(恶意程序通过大量反复读写内存的特定位置来使目标内存位置的数据出错)成功让运行在同一台机器上的受害模型下降 99% 的分类精度。这种攻击的危害之处在于它无需攻击者物理访问目标设备,只需要软件干扰就能让模型失效。如果模型部署在手机、自动驾驶汽车等不受部署者控制的终端设备上,可能会造成更严重的安全问题。
对于这种攻击,最简单的缓解方式是使用量化后的模型,因为量化后的模型参数是以整数存储的,而整数对于比特翻转的敏感性比浮点数小。但是,Adnan Siraj Rakin 等人[<sup>[3]</sup>](#bitflip)在 2019 年提出了一种针对量化深度神经网络的攻击,利用梯度下降的思想来搜索模型中最敏感的几个参数。例如,对于一个有九千多万比特参数的量化深度神经网络,找到并翻转其中最敏感的 13 个比特,成功地使其分类精度降到只有 0.1%。
由此可见,对于攻击者来说深度神经网络是非常脆弱的,这颠覆了之前很多人的观点——之前认为深度神经网络是健壮的,一些微小的改动并不会产生大的影响。对此弱点,比较好的缓解方法是将模型部署到拥有纠错功能的内存(ECC 内存)中,因为 ECC 内存会在硬件中自动维护纠错码(Error Correction Code),其能够对于每个字节自动更正一比特的错误,或者发现但不更正(可以通知系统通过重启解决)两比特的错误。这是基于汉明码(Hamming Code)来实现的,下面简单介绍:
<style>
table {
margin: auto;
}
</style>
<center>表 12.3.1 带附加奇偶校验位的 (7, 4)-汉明码</center>
| |p1|p2|d1|p3|d2|d3|d4|p4|
|---|---|---|---|---|---|---|---|---|
|p1|x| |x| |x| |x| |
|p2| |x|x| | |x|x| |
|p3| | | |x|x|x|x| |
|p4|x|x|x|x|x|x|x|x|
如果要编码 4 位数据 $(d_1, d_2, d_3, d_4)$,需要增加 3 位奇偶校验位 $(p_1, p_2, p_3)$ 以及附加的一位奇偶校验位 $p_4$,总共 8 位排列成 $(p_1, p_2, d_1, p_3, d_2, d_3, d_4, p_4)$ 的顺序,构成所谓“带附加奇偶校验位的汉明码”(其前 7 位称为“(7, 4)-汉明码”,最后一位为附加的奇偶校验位 $p_4$)。奇偶校验位的取值应该使所覆盖的位置(即表中的 x 所在的位置)中有且仅有**偶数个** 1,即:
$$
p_1=d_1\oplus d_2\oplus d_4 \\
p_2=d_1\oplus d_3\oplus d_4 \\
p_3=d_2\oplus d_3\oplus d_4 \\
p_4=p_1\oplus p_2\oplus d_1\oplus p_3\oplus d_2\oplus d_3\oplus d_4
$$
其中 $\oplus$ 表示异或。这样,如果出现了位翻转错误,无论是 $(p_1, p_2, d_1, p_3, d_2, d_3, d_4, p_4)$ 中的哪一位出错,都可以通过上面的公式推算出错的是哪一个,并且进行更正。通过验证上面的公式是否成立,也可以确定是否发生了(两位以内的)错误。目前流行的 ECC 内存一般采用的是带附加奇偶校验位的 (71,64)-汉明码,即每 64 比特的数据需要 72 比特进行编码。
## 12.2.2 服务时的用户隐私
深度学习服务时最直接的隐私就是用户隐私。服务以用户传来的数据作为输入,那么这些数据可能会直接暴露给服务方,服务方能够看到、甚至收集这些输入数据(以及最后的输出数据),在很多时候这是可能侵犯到用户隐私的。例如使用医疗模型进行辅助诊断时,用户很可能并不希望自己的输入数据被模型拥有者或者运营商知晓。
这时候,可以使用 12.2.2 节中提到过的安全多方计算技术来保护用户隐私,同时完成深度神经网络的推理计算。2017 年,Jian Liu 等人[<sup>[4]</sup>](#minionn)设计了针对深度神经网络推理计算的安全多方计算协议,这个协议的参与方是用户和服务方两方,在个算过程中用户的输入和中间结果都是保持着秘密共享的状态,因此服务方无法知道关于用户数据的信息。虽然安全多方计算可能有成千上万倍的开销,但对于小规模的模型推理计算(例如 LeNet-5)来说可以做到一秒以内的延迟了。近几年来,有大量的研究工作致力于提升安全多方计算的效率。目前,最新的工作[<sup>[5]</sup>](#cheetah)可以在十几秒的时间内完成 ResNet32 的安全推理计算。
除了安全多方计算之外,同态加密和可信执行环境都是进行安全推理计算的常用隐私计算技术。其目的与安全多方计算一样,都是保护模型推理时的输入(以及输出)数据隐私,使服务方在不知道输入的情况下完成计算。用同态加密做深度神经网络计算的代表工作是 2016 年由 Ran Gilad-Bachrach 等人提出的 CryptoNets[<sup>[6]</sup>](#cryptonets):通过对输入数据进行同态加密,可以将密文发送给服务方并让服务方在密文上做计算,最终将密文结果发回用户,用户用私钥对其解密得到计算结果。CryptoNets 使用的[微软 SEAL 库](https://github.com/microsoft/SEAL)也是目前最为广泛使用的同态加密库。然而,同态加密也有非常大的开销,目前来看其计算开销比安全多方计算的计算开销更大,但通信开销更小。此外,同态加密有一个与安全多方计算相似的局限:对于加法、乘法的支持很好,计算开销也比较小;但对于其他类型的计算(如深度神经网络中的非线性激活函数)的支持并不好,计算开销非常大,因此为了提升性能会用多项式来进行近似,从而有计算开销与计算精度(近似的程度)之间的权衡问题。
相比于安全多方计算、同态加密的性能瓶颈,基于可信执行环境的方案有着很最高的性能。可信执行环境是处理器在内存中隔离出的一个安全的区域,由处理器硬件保证区域内数据的机密性、完整性。以 Intel 处理器的 SGX(Software Guard Extensions)技术为例,处理器中的内存控制器保证其他进程无法访问或篡改可信执行环境(Intel 称之为 enclave)中的代码和数据,并且保证这些数据在存储、传输过程中都是加密保护的,密钥只掌握在处理器硬件中;只有使用这些数据时,才会在处理器内部对其解密并使用。基于这种技术,只要将模型推理系统部署在服务器的可信执行环境中,就能保护用户数据的隐私,因为这种技术让服务方自己都不能获取可信执行环境中的数据。尽管早期的 SGX 有可用容量的问题(不到 128 MB),但这个问题可以通过软件设计[<sup>[7]</sup>](#occ)或硬件设计[<sup>[8]</sup>](#graviton)的方法进行改善。目前,更先进的 TEE 架构设计已经出现在了商用产品上:Intel 的 Ice Lake 架构的服务器端 CPU 已经支持了 SGX 2,大大扩展了可用容量;NVIDIA 最新的 H100 处理器成为了首个提供 TEE 的 GPU。可信执行环境的缺点是开发难度高,又存在引入额外信任的问题——这一方案只有在信任处理器制造方的情况下才是安全的。近年来针对可信执行环境的攻击也非常多,暴露了许多安全缺陷[<sup>[9]</sup>](#sok)[<sup>[10]</sup>](#survey),说明这一信任并不一定是可靠的。
以上三种隐私计算技术都各有利弊,需要根据实际场景的特点进行选择和适配。这些领域还在快速发展中,相信未来一定会有高效、易用的解决方案,让保护用户隐私的深度学习服务能更广泛地部署在人们的日常生活中。
## 12.2.3 服务时的模型隐私
上一小节主要站在用户的角度,探讨了输入数据的隐私保护问题。事实上,站在开发者以及模型拥有者的角度,模型也是一种高度敏感的数据。考虑到模型在实际使用中可能涉及到知识产权问题,以及训练该模型所需要的大量数据和大量计算成本,保证其机密性对于深度学习服务来说是个重要问题。本小节将讨论跟模型数据保护相关的攻击。
一种最常见的针对模型数据的攻击就是模型窃取攻击(Model Stealing Attack)。模型窃取有两种方式,第一种是直接窃取,即通过直接攻克模型的开发、存储或部署环境,获得原模型的拷贝;第二种是间接窃取,通过不断调用服务提供的 API(Application Programming Interface),重构出一个与原模型等效或近似等效的模型。前者的例子有 Lejla Batina 等人在 2019 年提出的通过侧信道攻击进行的模型窃取[<sup>[11]</sup>](#sidechannel)。而人工智能安全领域关注的模型窃取攻击通常属于第二种,因为这种攻击看上去并没有违背深度学习服务系统的完整性与机密性,只通过 API 调用这一看起来正常的手段就窃取了模型;而且,即使使用了 12.2.2 节中的隐私计算技术保护了用户隐私,但攻击者(伪装成普通用户)仍然知道自己的输入和服务返回的结果,因此隐私计算对于防御这种攻击无能为力。
最简单的模型窃取攻击是针对线性模型 $f(x)=\textrm{sigmoid}(wx+b)$ 的:通过选取足够多个不同的 $x$ 并调用服务 API 得到相应的 $y$,将其组成一个以 $w$ 和 $b$ 为未知数的线性方程组,就可以解出该线性方程组,得到模型参数 $w$ 和 $b$。2016 年,Florian Tramèr 等人将这种方法扩展到了多层的神经网络上:由于深度神经网络的非线性层,组成的方程组不再是一个线性方程组,没有解析解,所以改用优化方法来求解近似解[<sup>[12]</sup>](#extract)。这种方法本质上就像把深度学习服务当作一个标注机,然后利用它来进行监督学习。
不过需要注意的是,调用服务 API 是有成本的,因为这些服务往往是按次收费的。所以,如果所需的调用次数太多导致成本过高,攻击就变得没有意义了。近几年关于模型窃取攻击的一大研究方向就是如何提升攻击的效率,即如何用更少的询问次数来得到与目标模型等效或近似等效的模型。2020 年 Matthew Jagielski 等人优化了学习策略,通过半监督学习的方式大大提升了攻击的效率[<sup>[13]</sup>](#extract2)。同时,他们还讨论了另一种攻击目标:精准度,即能否像攻击线性模型那样准确地恢复出模型的参数。他们注意到采用 ReLU 激活函数的深度神经网络其实是一个分段线性函数,因此可以在各个线性区域内确定分类面的位置,从而恢复出模型参数。同样是 2020 年,Nicholas Carlini 等人通过密码分析学的方法进行模型提取攻击,也精确恢复了深度神经网络的参数[<sup>[14]</sup>](#extract3)。事实上,如果模型参数被精确提取出来了,那除了模型参数泄露之外还会有更大的安全问题:这时模型对于攻击者来说变成白盒了,因此更容易发起成员推断攻击和模型反向攻击了(见 12.1.2),从而导致训练模型时所用的训练数据的隐私泄露。
如何保护模型的隐私呢?由于模型窃取攻击往往需要大量请求服务 API,可以通过限制请求次数来进行缓解。另一种防御方法是去检测模型窃取攻击:Mika Juuti 等人在 2019 年提出模型窃取攻击时发出的请求和正常的请求有不同的特征,可以由此判断什么样的请求是的攻击者发起的请求[<sup>[15]</sup>](#prada)。还有一种防御的策略是事后溯源以及追责:如果模型被窃取,假如可以验证模型的所有权,那么可以通过法律手段制裁攻击者。这种策略可以通过模型水印技术(见 12.2.1)来实现。
## 小结与讨论
本小节主要围绕深度学习的服务安全与隐私问题,讨论了故障注入攻击、模型提取攻击等攻击技术,服务时的用户隐私与模型隐私问题,以及 ECC 内存、安全多方计算、同态加密、可信执行环境等防御技术。
看完本章内容后,我们可以思考以下几点问题:
- 纠错码检查错误和纠错的具体过程是什么?如何用硬件实现?效率如何?
- 不同隐私计算技术的异同是什么?
- 能否利用可信执行环境来防止模型窃取攻击?
## 参考文献
<div id=softerror></div>
1. Guanpeng Li, Siva Kumar Sastry Hari, Michael B. Sullivan, Timothy Tsai, Karthik Pattabiraman, Joel S. Emer, and Stephen W. Keckler. 2017. [Understanding Error Propagation in Deep Learning Neural Network (DNN) Accelerators and Applications](https://doi.org/10.1145/3126908.3126964). In International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 8:1-8:12.
<div id=braindamage></div>
2. Sanghyun Hong, Pietro Frigo, Yigitcan Kaya, Cristiano Giuffrida, and Tudor Dumitras. 2019. [Terminal Brain Damage: Exposing the Graceless Degradation in Deep Neural Networks Under Hardware Fault Attacks](https://www.usenix.org/conference/usenixsecurity19/presentation/hong). In USENIX Security Symposium, 497–514.
<div id=bitflip></div>
3. Adnan Siraj Rakin, Zhezhi He, and Deliang Fan. 2019. [Bit-Flip Attack: Crushing Neural Network With Progressive Bit Search](https://doi.org/10.1109/ICCV.2019.00130). In IEEE International Conference on Computer Vision (ICCV), 1211–1220.
<div id=minionn></div>
4. Jian Liu, Mika Juuti, Yao Lu, and N. Asokan. 2017. [Oblivious Neural Network Predictions via MiniONN Transformations](https://doi.org/10.1145/3133956.3134056). In ACM Conference on Computer and Communications Security (CCS), 619–631.
<div id=cheetah></div>
5. Zhicong Huang, Wen-jie Lu, Cheng Hong, and Jiansheng Ding. 2022. [Cheetah: Lean and Fast Secure Two-Party Deep Neural Network Inference](https://www.usenix.org/system/files/sec22fall_huang-zhicong.pdf). In USENIX Security Symposium.
<div id=cryptonets></div>
6. Ran Gilad-Bachrach, Nathan Dowlin, Kim Laine, Kristin E. Lauter, Michael Naehrig, and John Wernsing. 2016. [CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy](http://proceedings.mlr.press/v48/gilad-bachrach16.html). In International Conference on Machine Learning (ICML), 201–210.
<div id=occ></div>
7. Taegyeong Lee, Zhiqi Lin, Saumay Pushp, Caihua Li, Yunxin Liu, Youngki Lee, Fengyuan Xu, Chenren Xu, Lintao Zhang, and Junehwa Song. 2019. [Occlumency: Privacy-preserving Remote Deep-learning Inference Using SGX](https://doi.org/10.1145/3300061.3345447). In International Conference on Mobile Computing and Networking (MobiCom), 46:1-46:17.
<div id=graviton></div>
8. Stavros Volos, Kapil Vaswani, and Rodrigo Bruno. 2018. [Graviton: Trusted Execution Environments on GPUs](https://www.usenix.org/conference/osdi18/presentation/volos). In USENIX Symposium on Operating Systems Design and Implementation (OSDI), 681–696.
<div id=sok></div>
9. David Cerdeira, Nuno Santos, Pedro Fonseca, and Sandro Pinto. 2020. [SoK: Understanding the Prevailing Security Vulnerabilities in TrustZone-assisted TEE Systems](https://doi.org/10.1109/SP40000.2020.00061). In IEEE Symposium on Security and Privacy (S&P), 1416–1432.
<div id=sok></div>
10. Shufan Fei, Zheng Yan, Wenxiu Ding, and Haomeng Xie. 2021. [Security Vulnerabilities of SGX and Countermeasures: A Survey](https://doi.org/10.1145/3456631). ACM Computing Surveys 54, 6 (2021), 126:1-126:36.
<div id=sidechannel></div>
11. Lejla Batina, Shivam Bhasin, Dirmanto Jap, and Stjepan Picek. 2019. [CSI NN: Reverse Engineering of Neural Network Architectures Through Electromagnetic Side Channel](https://www.usenix.org/conference/usenixsecurity19/presentation/batina). In USENIX Security Symposium, 515–532.
<div id=extract></div>
12. Florian Tramèr, Fan Zhang, Ari Juels, Michael K. Reiter, and Thomas Ristenpart. 2016. [Stealing Machine Learning Models via Prediction APIs](https://www.usenix.org/conference/usenixsecurity16/technical-sessions/presentation/tramer). In USENIX Security Symposium, 601–618.
<div id=extract2></div>
13. Matthew Jagielski, Nicholas Carlini, David Berthelot, Alex Kurakin, and Nicolas Papernot. 2020. [High Accuracy and High Fidelity Extraction of Neural Networks](https://www.usenix.org/conference/usenixsecurity20/presentation/jagielski). In USENIX Security Symposium, 1345–1362.
<div id=extract3></div>
14. Nicholas Carlini, Matthew Jagielski, and Ilya Mironov. 2020. [Cryptanalytic Extraction of Neural Network Models](https://doi.org/10.1007/978-3-030-56877-1_7). In Annual International Cryptology Conference (CRYPTO), 189–218.
<div id=prada></div>
15. Mika Juuti, Sebastian Szyller, Samuel Marchal, and N. Asokan. 2019. [PRADA: Protecting Against DNN Model Stealing Attacks](https://doi.org/10.1109/EuroSP.2019.00044). In European Symposium on Security and Privacy (EuroS&P), 512–527.
| AI-System/Textbook/第12章-人工智能安全与隐私/12.3-人工智能服务安全与隐私.md/0 | {
"file_path": "AI-System/Textbook/第12章-人工智能安全与隐私/12.3-人工智能服务安全与隐私.md",
"repo_id": "AI-System",
"token_count": 11352
} | 9 |
<!--Copyright © Microsoft Corporation. All rights reserved.
适用于[License](https://github.com/microsoft/AI-System/blob/main/LICENSE)版权许可-->
## 2.3 解决回归问题
本小节主要围绕解决回归问题中的各个环节和知识点展开,包含提出问题,万能近似定力,定义神经网络结构,前向计算和反向传播等内容。
- [2.3 解决回归问题](#23-解决回归问题)
- [2.3.1 提出问题](#231-提出问题)
- [2.3.2 万能近似定理](#232-万能近似定理)
- [2.3.3 定义神经网络结构](#233-定义神经网络结构)
- [输入层](#输入层)
- [权重矩阵W1/B1](#权重矩阵w1b1)
- [隐层](#隐层)
- [权重矩阵W2/B2](#权重矩阵w2b2)
- [输出层](#输出层)
- [2.3.4 前向计算](#234-前向计算)
- [隐层](#隐层-1)
- [输出层](#输出层-1)
- [损失函数](#损失函数)
- [代码](#代码)
- [2.3.5 反向传播](#235-反向传播)
- [求损失函数对输出层的反向误差](#求损失函数对输出层的反向误差)
- [求W2的梯度](#求w2的梯度)
- [求B2的梯度](#求b2的梯度)
- [求损失函数对隐层的反向误差](#求损失函数对隐层的反向误差)
- [代码](#代码-1)
- [2.3.6 运行结果](#236-运行结果)
- [小结与讨论](#小结与讨论)
- [参考文献](#参考文献)
### 2.3.1 提出问题
前面的正弦函数,看上去是非常有规律的,也许单层神经网络很容易就做到了。如果是更复杂的曲线,单层神经网络还能轻易做到吗?比如图9-2所示的样本点和表9-2的所示的样本值,如何使用神经网络方法来拟合这条曲线?
<img src="./img/Sample.png"/>
图 2.3.1 复杂曲线样本可视化
表 2.3.1 复杂曲线样本数据
|样本|x|y|
|---|---|---|
|1|0.606|-0.113|
|2|0.129|-0.269|
|3|0.582|0.027|
|...|...|...|
|1000|0.199|-0.281|
上面这条“蛇形”曲线,实际上是由下面这个公式添加噪音后生成的:
$$y=0.4x^2 + 0.3x\sin(15x) + 0.01\cos(50x)-0.3$$
我们特意把数据限制在[0,1]之间,避免做归一化的麻烦。要是觉得这个公式还不够复杂,大家可以用更复杂的公式去自己做试验。
以上问题可以叫做非线性回归,即自变量X和因变量Y之间不是线性关系。常用的传统的处理方法有线性迭代法、分段回归法、迭代最小二乘法等。在神经网络中,解决这类问题的思路非常简单,就是使用带有一个隐层的两层神经网络。
### 2.3.2 万能近似定理
万能近似定理(universal approximation theorem) $^{[1]}$,是深度学习最根本的理论依据。它证明了在给定网络具有足够多的隐藏单元的条件下,配备一个线性输出层和一个带有任何“挤压”性质的激活函数(如Sigmoid激活函数)的隐藏层的前馈神经网络,能够以任何想要的误差量近似任何从一个有限维度的空间映射到另一个有限维度空间的Borel可测的函数。
前馈网络的导数也可以以任意好地程度近似函数的导数。
万能近似定理其实说明了理论上神经网络可以近似任何函数。但实践上我们不能保证学习算法一定能学习到目标函数。即使网络可以表示这个函数,学习也可能因为两个不同的原因而失败:
1. 用于训练的优化算法可能找不到用于期望函数的参数值;
2. 训练算法可能由于过拟合而选择了错误的函数。
根据“没有免费的午餐”定理,说明了没有普遍优越的机器学习算法。前馈网络提供了表示函数的万能系统,在这种意义上,给定一个函数,存在一个前馈网络能够近似该函数。但不存在万能的过程既能够验证训练集上的特殊样本,又能够选择一个函数来扩展到训练集上没有的点。
总之,具有单层的前馈网络足以表示任何函数,但是网络层可能大得不可实现,并且可能无法正确地学习和泛化。在很多情况下,使用更深的模型能够减少表示期望函数所需的单元的数量,并且可以减少泛化误差。
### 2.3.3 定义神经网络结构
根据万能近似定理的要求,我们定义一个两层的神经网络,输入层不算,一个隐藏层,含3个神经元,一个输出层。图 2.3.2 显示了此次用到的神经网络结构。
<img src="./img/nn1.png" />
图 2.3.2 单入单出的双层神经网络
为什么用3个神经元呢?这也是笔者经过多次试验的最佳结果。因为输入层只有一个特征值,我们不需要在隐层放很多的神经元,先用3个神经元试验一下。如果不够的话再增加,神经元数量是由超参控制的。
#### 输入层
输入层就是一个标量x值,如果是成批输入,则是一个矢量或者矩阵,但是特征值数量总为1,因为只有一个横坐标值做为输入。
$$X = (x)$$
#### 权重矩阵W1/B1
$$
W1=
\begin{pmatrix}
w1_{11} & w1_{12} & w1_{13}
\end{pmatrix}
$$
$$
B1=
\begin{pmatrix}
b1_{1} & b1_{2} & b1_{3}
\end{pmatrix}
$$
#### 隐层
我们用3个神经元:
$$
Z1 = \begin{pmatrix}
z1_1 & z1_2 & z1_3
\end{pmatrix}
$$
$$
A1 = \begin{pmatrix}
a1_1 & a1_2 & a1_3
\end{pmatrix}
$$
#### 权重矩阵W2/B2
W2的尺寸是3x1,B2的尺寸是1x1。
$$
W2=
\begin{pmatrix}
w2_{11} \\\\
w2_{21} \\\\
w2_{31}
\end{pmatrix}
$$
$$
B2=
\begin{pmatrix}
b2_{1}
\end{pmatrix}
$$
#### 输出层
由于我们只想完成一个拟合任务,所以输出层只有一个神经元,尺寸为1x1:
$$
Z2 =
\begin{pmatrix}
z2_{1}
\end{pmatrix}
$$
### 2.3.4 前向计算
根据图 2.3.2 的网络结构,我们可以得到如图 2.3.3 的前向计算图。
<img src="./img/forward.png" />
图 2.3.3 前向计算图
#### 隐层
- 线性计算
$$
z1_{1} = x \cdot w1_{11} + b1_{1}
$$
$$
z1_{2} = x \cdot w1_{12} + b1_{2}
$$
$$
z1_{3} = x \cdot w1_{13} + b1_{3}
$$
矩阵形式:
$$
\begin{aligned}
Z1 &=x \cdot
\begin{pmatrix}
w1_{11} & w1_{12} & w1_{13}
\end{pmatrix}
+
\begin{pmatrix}
b1_{1} & b1_{2} & b1_{3}
\end{pmatrix}
\\\\
&= X \cdot W1 + B1
\end{aligned}
$$
- 激活函数
$$
a1_{1} = Sigmoid(z1_{1})
$$
$$
a1_{2} = Sigmoid(z1_{2})
$$
$$
a1_{3} = Sigmoid(z1_{3})
$$
矩阵形式:
$$
A1 = Sigmoid(Z1)
$$
#### 输出层
由于我们只想完成一个拟合任务,所以输出层只有一个神经元:
$$
\begin{aligned}
Z2&=a1_{1}w2_{11}+a1_{2}w2_{21}+a1_{3}w2_{31}+b2_{1} \\\\
&=
\begin{pmatrix}
a1_{1} & a1_{2} & a1_{3}
\end{pmatrix}
\begin{pmatrix}
w2_{11} \\\\ w2_{21} \\\\ w2_{31}
\end{pmatrix}
+b2_1 \\\\
&=A1 \cdot W2+B2
\end{aligned}
$$
#### 损失函数
均方差损失函数:
$$loss(w,b) = \frac{1}{2} (z2-y)^2$$
其中,$z2$是预测值,$y$是样本的标签值。
#### 代码
```Python
class NeuralNet(object):
def forward(self, batch_x):
# layer 1
self.Z1 = np.dot(batch_x, self.wb1.W) + self.wb1.B
self.A1 = Sigmoid().forward(self.Z1)
# layer 2
self.Z2 = np.dot(self.A1, self.wb2.W) + self.wb2.B
if self.hp.net_type == NetType.BinaryClassifier:
self.A2 = Logistic().forward(self.Z2)
elif self.hp.net_type == NetType.MultipleClassifier:
self.A2 = Softmax().forward(self.Z2)
else: # NetType.Fitting
self.A2 = self.Z2
#end if
self.output = self.A2
```
### 2.3.5 反向传播
#### 求损失函数对输出层的反向误差
根据公式4:
$$
\frac{\partial loss}{\partial z2} = z2 - y \rightarrow dZ2
$$
#### 求W2的梯度
根据公式3和W2的矩阵形状,把标量对矩阵的求导分解到矩阵中的每一元素:
$$
\begin{aligned}
\frac{\partial loss}{\partial W2} &=
\begin{pmatrix}
\frac{\partial loss}{\partial z2}\frac{\partial z2}{\partial w2_{11}} \\\\
\frac{\partial loss}{\partial z2}\frac{\partial z2}{\partial w2_{21}} \\\\
\frac{\partial loss}{\partial z2}\frac{\partial z2}{\partial w2_{31}}
\end{pmatrix}
\begin{pmatrix}
dZ2 \cdot a1_{1} \\\\
dZ2 \cdot a1_{2} \\\\
dZ2 \cdot a1_{3}
\end{pmatrix} \\\\
&=\begin{pmatrix}
a1_{1} \\\\ a1_{2} \\\\ a1_{3}
\end{pmatrix} \cdot dZ2
=A1^{\top} \cdot dZ2 \rightarrow dW2
\end{aligned}
$$
#### 求B2的梯度
$$
\frac{\partial loss}{\partial B2}=dZ2 \rightarrow dB2
$$
#### 求损失函数对隐层的反向误差
下面的内容是双层神经网络独有的内容,也是深度神经网络的基础,请大家仔细阅读体会。我们先看看正向计算和反向计算图,即图9-9。
<img src="./img/backward.png" />
图 2.3.4 正向计算和反向传播路径图
图 2.3.4 中:
- 蓝色矩形表示数值或矩阵;
- 蓝色圆形表示计算单元;
- 蓝色的箭头表示正向计算过程;
- 红色的箭头表示反向计算过程。
如果想计算W1和B1的反向误差,必须先得到Z1的反向误差,再向上追溯,可以看到Z1->A1->Z2->Loss这条线,Z1->A1是一个激活函数的运算,比较特殊,所以我们先看Loss->Z->A1如何解决。
根据公式3和A1矩阵的形状:
$$
\begin{aligned}
\frac{\partial loss}{\partial A1}&=
\begin{pmatrix}
\frac{\partial loss}{\partial Z2}\frac{\partial Z2}{\partial a1_{11}}
&
\frac{\partial loss}{\partial Z2}\frac{\partial Z2}{\partial a1_{12}}
&
\frac{\partial loss}{\partial Z2}\frac{\partial Z2}{\partial a1_{13}}
\end{pmatrix} \\\\
&=
\begin{pmatrix}
dZ2 \cdot w2_{11} & dZ2 \cdot w2_{12} & dZ2 \cdot w2_{13}
\end{pmatrix} \\\\
&=dZ2 \cdot
\begin{pmatrix}
w2_{11} & w2_{21} & w2_{31}
\end{pmatrix} \\\\
&=dZ2 \cdot
\begin{pmatrix}
w2_{11} \\\\ w2_{21} \\\\ w2_{31}
\end{pmatrix}^{\top}=dZ2 \cdot W2^{\top}
\end{aligned}
$$
现在来看激活函数的误差传播问题,由于公式2在计算时,并没有改变矩阵的形状,相当于做了一个矩阵内逐元素的计算,所以它的导数也应该是逐元素的计算,不改变误差矩阵的形状。根据 Sigmoid 激活函数的导数公式,有:
$$
\frac{\partial A1}{\partial Z1}= Sigmoid'(A1) = A1 \odot (1-A1)
$$
所以最后到达Z1的误差矩阵是:
$$
\begin{aligned}
\frac{\partial loss}{\partial Z1}&=\frac{\partial loss}{\partial A1}\frac{\partial A1}{\partial Z1} \\\\
&=dZ2 \cdot W2^T \odot Sigmoid'(A1) \rightarrow dZ1
\end{aligned}
$$
有了dZ1后,再向前求W1和B1的误差,就和第5章中一样了,我们直接列在下面:
$$
dW1=X^T \cdot dZ1
$$
$$
dB1=dZ1
$$
#### 代码
```Python
class NeuralNet(object):
def backward(self, batch_x, batch_y, batch_a):
# 批量下降,需要除以样本数量,否则会造成梯度爆炸
m = batch_x.shape[0]
# 第二层的梯度输入 公式5
dZ2 = self.A2 - batch_y
# 第二层的权重和偏移 公式6
self.wb2.dW = np.dot(self.A1.T, dZ2)/m
# 公式7 对于多样本计算,需要在横轴上做sum,得到平均值
self.wb2.dB = np.sum(dZ2, axis=0, keepdims=True)/m
# 第一层的梯度输入 公式8
d1 = np.dot(dZ2, self.wb2.W.T)
# 第一层的dZ 公式10
dZ1,_ = Sigmoid().backward(None, self.A1, d1)
# 第一层的权重和偏移 公式11
self.wb1.dW = np.dot(batch_x.T, dZ1)/m
# 公式12 对于多样本计算,需要在横轴上做sum,得到平均值
self.wb1.dB = np.sum(dZ1, axis=0, keepdims=True)/m
```
### 2.3.6 运行结果
图 2.3.5 为损失函数曲线和验证集精度曲线,都比较正常。图 2.3.6 是拟合效果。
<img src="./img/complex_loss_3n.png" />
图 2.3.5 三个神经元的训练过程中损失函数值和准确率的变化
<img src="./img/complex_result_3n.png"/>
图 2.3.6 三个神经元的拟合效果
再看下面的打印输出结果,最后测试集的精度为97.6%,已经令人比较满意了。如果需要精度更高的话,可以增加迭代次数。
```
......
epoch=4199, total_iteration=377999
loss_train=0.001152, accuracy_train=0.963756
loss_valid=0.000863, accuracy_valid=0.944908
testing...
0.9765910104463337
```
以下就是笔者找到的最佳组合:
- 隐层3个神经元
- 学习率=0.5
- 批量=10
## 小结与讨论
本小节主要介绍了回归问题中的,提出问题,万能近似定力,定义神经网络结构,前向计算和反向传播。
请读者尝试用PyTorch定义网络结构并解决一个简单的回归问题的。
## 参考文献
1. 《智能之门》,胡晓武等著,高等教育出版社
2. Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul), 2121-2159.
3. Zeiler, M. D. (2012). ADADELTA: an adaptive learning rate method. arXiv preprint arXiv:1212.5701.
4. Tieleman, T., & Hinton, G. (2012). Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2), 26-31.
5. Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
6. 周志华老师的西瓜书《机器学习》
7. Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1):321-357.
8. Inoue H. Data Augmentation by Pairing Samples for Images Classification[J]. 2018.
9. Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond Empirical Risk Minimization[J]. 2017.
10. 《深度学习》- 伊恩·古德费洛
11. Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Link: https://arxiv.org/pdf/1506.01497v3.pdf
| AI-System/Textbook/第2章-神经网络基础/2.3-解决回归问题.md/0 | {
"file_path": "AI-System/Textbook/第2章-神经网络基础/2.3-解决回归问题.md",
"repo_id": "AI-System",
"token_count": 8848
} | 10 |
<!--Copyright © Microsoft Corporation. All rights reserved.
适用于[License](https://github.com/microsoft/AI-System/blob/main/LICENSE)版权许可-->
# 5.3 内存优化
- [5.3 内存优化](#53-内存优化)
- [5.3.1 基于拓扑序的最小内存分配](#531-基于拓扑序的最小内存分配)
- [5.3.2 张量换入换出](#532-张量换入换出)
- [5.3.3 张量重计算](#533-张量重计算)
- [小结与讨论](#小结与讨论)
- [参考文献](#参考文献)
深度学习的计算任务大多执行在像GPU这样的加速器上,一般这样的加速器上的内存资源都比较宝贵,如几GB到几十GB的空间。随着深度学习模型的规模越来越大,从近来的BERT,到各种基于Transformer网络的模型,再到GPT-3等超大模型的出现,加速器上的内存资源变得越来越稀缺。因此,除了计算性能之外,神经网络编译器对深度学习计算任务的内存占用优化也是一个非常重要的目标。
一个深度学习计算任务中的内存占用主要包括输入数据、中间计算结果和模型参数,在模型推理的场景中,一般前面算子计算完的中间结果所占用的内存,后面的算子都可以复用,但是在训练场景中,由于反向求导计算需要使用到前向输出的中间结果,因此,前面计算出的算子需要一直保留到对应的反向计算结束后才能释放,对整个计算任务的内存占用挑战比较大。所幸的是,在计算图中,这些所有的数据都被统一建模成计算图中的张量,都可以表示成一些算子的输出。计算图可以精确的描述出所有张量之前的依赖关系以及每个张量的生命周期,因此,根据计算图对张量进行合理的分配,可以尽可能的优化计算内存的占用。
<center> <img src="./img/5-3-1-mem.png" /></center>
<center>图5-3-1. 根据计算图优化张量分配的例子</center>
图5-3-1展示了一个根据计算图优化内存分配的例子,在上图中,默认的执行会为每一个算子的输出张量都分配一块内存空间,假设每个张量的内存大小为N,则执行该图需要4N的内存。但是通过分析计算图可知,其中的张量a可以复用张量x,张量c可以复用a,因此,总的内存分配可以降低到2N。
基于计算图进行内存优化的方法有很多,本章中主要以三类不同的方法为例具体介绍如果介绍深度学习计算中的内存优化。
## 5.3.1 基于拓扑序的最小内存分配
计算图中的张量内存分配可以分成两个部分:张量生命期的分析和内存分配。首先,给定计算图之后,唯一决定张量生命期的就是节点(算子)的执行顺序。在计算框架中,由于执行顺序是运行时决定的,所以内存也都是运行时分配的。但在编译器中,我们可以通过生成固定顺序的代码来保证最终的节点以确定的顺序执行,因此在编译期就可以为所有张量决定内存分配的方案。一般只要以某种拓扑序要遍历计算图就可以生成一个依赖正确的节点的执行顺序,如BFS、Reverse DFS等,进而决定出每个张量的生命期,即分配和释放的时间点。
接下来,就是根据每个张量的分配和释放顺序分配对应的内存空间,使得总内存占用最小。一种常用的内存分配方法是建立一个内存池,由一个块内存分配管理器(如BFC内存分配器)管理起来,然后按照每个张量的分配和释放顺序依次向内存池申请和释放对应大小的内存空间,并记录每个张量分配的地址偏移。当一个张量被释放回内存池时,后续的张量分配就可以自动复用前面的空间。当所有张量分配完时,内存池使用到的最大内存空间即为执行该计算图所需要的最小内存。在真实的运行时,我们只需要在内存中申请一块该大小的内存空间,并按照之前的记录的地址偏移为每个张量分配内存即可。这样即可以优化总内存的占用量,也可以避免运行时的内存分配维护开销。
值得注意的是,不同拓扑序的选择会同时影响模型的计算时间和最大内存占用,同时也强制了运行时算子的执行顺序,可难会带来一定的性能损失。
## 5.3.2 张量换入换出
上面的方法中只考虑了张量放置在加速器(如GPU)的内存中,而实际上如果内存不够的话,我们还可以将一部分张量放置到外存中(如CPU的内存中),等需要的时候再移动回GPU的内存中即可。虽然从CPU的内存到GPU的内存的拷贝延时和带宽都比较受限,但是因为计算图中有些张量的产生到消费中间会经过较长的时间,我们可以合理安排内存的搬运时机使得其和其它算子的计算重叠起来。
<center> <img src="./img/5-3-2-ilp.png" /></center>
<center>图5-3-2. 利用整数线性规划优化计算图内存分配的示</center>
给定上述假设以及必要的数据(如每个内核的执行时间、算子的执行顺序等),关于每个张量在什么时间放在什么地方的问题就可以被形式化的描述成一个最优化问题。AutoTM[]就提出了一种把计算图中张量内在异构内存环境中规的问题划建模成一个整数线性规划的问题并进行求解。图5-3-2展示了一个利用整数线性规划优化计算图内存分配的优化空间示例,图中每一行表示一个张量,每一列表示算子的执行顺序。每一行中,黄色Source表示张量的生成时间,紫色的SINK表示张量被消费的时间,每个张量都可以选择是在内存中(DRAM)还是外存(PMM)中。那么问题优化目标为就是给定任意的计算图最小化其执行时间,约束为主存的占用空间,优化变量就是决定放在哪个存储中,在有限的节点规模下,这个问题可以通过整数线性规划模型求解。同时,该文章中还扩展该方法并考虑了更复杂的换入换出的情形。
## 5.3.3 张量重计算
深度学习计算图的大多算子都是确定性的,即给定相同的输入其计算结果也是相同的。因此,我们可以进一步利用这个特点来优化内存的使用。当我们对连续的多个张量决定换入换出的方案时,如果产生这些张量的算子都具有计算确定性的话,我们可以选择只换出其中一个或一少部分张量,并把剩下的张量直接释放,当到了这些张量使用的时机,我们可以再换入这些少量的张量,并利用确定性的特点重新计算之前被释放的张量,这样就可以一定程序上缓解CPU和GPU之前的贷款压力,也为内存优化提供了更大的空间。如果考虑上换入换出,内存优化方案需要更加仔细的考虑每个算子的执行时间,从而保证重计算出的张量在需要的时候能及时的计算完成。
## 小结与讨论
本章我们主要围绕内存优化展开,包含基于拓扑序的最小内存分配,张量换入换出,张量重计算等内容。这里讨论的都是无损的内存优化方法,在有些场景下,在所有无损内存优化方法都不能进一步降低内存使用时,我们也会采取一些有损的内存优化,如量化、有损压缩等等。
请读者思考内存和计算的优化之间是否互相影响?还有哪些有损的内存优化方法可以用在深度学习计算中?
## 参考文献
1. [AutoTM: Automatic Tensor Movement in Heterogeneous Memory Systems using Integer Linear Programming](https://dl.acm.org/doi/10.1145/3373376.3378465)
2. [Training Deep Nets with Sublinear Memory Cost](https://arxiv.org/abs/1604.06174)
3. [Capuchin: Tensor-based GPU Memory Management for Deep Learning](https://dl.acm.org/doi/10.1145/3373376.3378505)
| AI-System/Textbook/第5章-深度学习框架的编译与优化/5.3-内存优化.md/0 | {
"file_path": "AI-System/Textbook/第5章-深度学习框架的编译与优化/5.3-内存优化.md",
"repo_id": "AI-System",
"token_count": 5392
} | 11 |
<!--Copyright © Microsoft Corporation. All rights reserved.
适用于[License](https://github.com/microsoft/AI-System/blob/main/LICENSE)版权许可-->
# 6.4 分布式训练系统简介
- [6.4 分布式训练系统简介](#64-分布式训练系统简介)
- [6.4.1 TensorFlow 中的分布式支持](#641-tensorflow-中的分布式支持)
- [6.4.2 PyTorch 中的分布式支持](#642-pytorch-中的分布式支持)
- [6.4.3 通用的数据并行系统Horovod](#643-通用的数据并行系统horovod)
- [小结与讨论](#小结与讨论)
- [课后实验 分布式训练任务练习](#课后实验-分布式训练任务练习)
- [参考文献](#参考文献)
模型的分布式训练依靠相应的分布式训练系统协助完成。这样的系统通常分为:分布式用户接口、单节点训练执行模块、通信协调三个组成部分。用户通过接口表述采用何种模型的分布化策略,单节点训练执行模块产生本地执行的逻辑,通信协调模块实现多节点之间的通信协调。系统的设计目的是提供易于使用,高效率的分布式训练。
目前广泛使用的深度学习训练框架例如Tensor
Flow和PyTorch已经内嵌了分布式训练的功能并逐步提供了多种分布式的算法。除此之外,也有单独的系统库针对多个训练框架提供分布训练功能,例如Horovod等。
目前分布式训练系统的理论和系统实现都处于不断的发展当中。我们仅以TensorFlow、PyTorch和Horovod为例,从用户接口等方面分别介绍他们的设计思想和技术要点。
## 6.4.1 TensorFlow 中的分布式支持
经过长期的迭代发展,目前TensorFlow通过不同的API支持多种分布式策略(distributed
strategies)[<sup>[1]</sup>](#ref1),如下表所示。其中最为经典的基于参数服务器“Parameter
Server”的分布式训练,TensorFlow早在版本(v0.8)中就加入了。其思路为多工作节点(Worker)独立进行本地计算,分布式共享参数。
<style>table{margin: auto;}</style>
| 训练接口\策略名称 | Mirrored <br>(镜像策略) | TPU <br>(TPU策略) | MultiWorker-Mirrored <br>(多机镜像策略) | CentralStorage <br>(中心化存储策略) | ParameterServer <br>(参数服务器策略) | OneDevice <br>(单设备策略) |
| -- |:--:|:--:|:--:|:--:|:--:|:--:|
|**Keras 接口** | 支持 | 实验性支持 | 实验性支持 | 实验性支持 | 支持 (规划2.0之后) | 支持 |
|**自定义训练循环** | 实验性支持 | 实验性支持 | 支持 (规划2.0之后) | 支持 (规划2.0之后) | 尚不支持 | 支持 |
|**Estimator 接口** | 部分支持 | 不支持 | 部分支持 | 部分支持 | 部分支持 | 部分支持 |
<center>表6-5-1: TensorFlow 中多种并行化方式在不同接口下的支持 (<a href=https://www.tensorflow.org/guide/distributed\_training>表格来源</a>)</center>
TensorFlow参数服务器用户接口包含定义模型和执行模型两部分。如下图所示,其中定义模型需要完成指定节点信息以及将
“原模型”逻辑包含于工作节点;而执行模型需要指定角色 job\_name是ps参数服务器还是worker工作节点,以及通过index指定自己是第几个参数服务器或工作节点[<sup>[2]</sup>](#ref2)。
```python
cluster = tf.train.ClusterSpec({
"worker": [
{1:"worker1.example.com:2222"},
]
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222"
]})
if job\_name == “ps”:
server.join()
elif job\_name == “worker”:
…
```
<!-- <center><img src="./img/image25.png" width="400" height="" /></center> -->
<center>图6-4-1: TensorFlow 定义节点信息和参数服务器方式并行化模型 (<a href=https://www.tensorflow.org/api_docs/python/tf/train/ClusterSpec>参考来源</a>)</center>
在TensorFlow的用户接口之下,系统在底层实现了数据流图的分布式切分。如下图所示的基本数据流图切分中,TensorFlow根据不同operator的设备分配信息,将整个数据流图图划分为每个设备的子图,并将跨越设备的边替换为“发送”和“接收”的通信原语。
<center><img src="./img/image26.png" width="600" height="" /></center>
<center>图6-4-2:数据流图的跨节点切分</center>
<center><img src="./img/image27.png" width="600" height="" /></center>
<center>图6-4-3: 采用参数服务器并行的数据流图</center>
在参数服务器这样的数据并行中,参数以及更新参数的操作被放置于参数服务器之上,而每个工作节点负责读取训练数据并根据最新的模型参数产生对应的梯度并上传参数服务器。而在其它涉及模型并行的情况下,每个工作节点负责整个模型的一部分,相互传递激活数据进行沟通协调,完成整个模型的训练。
我们可以注意到每条跨设备的边在每个mini-batch中通信一次,频率较高。而传统的实现方式会调用通信库将数据拷贝给通信库的存储区域用于发送,而接收端还会将收到通信库存储区域的数据再次拷贝给计算区域。多次的拷贝会浪费存储的空间和带宽。
而且由于深度模型训练的迭代特性,每次通信都是完全一样的。因此,我们可以通过“预分配+RDMA+零拷贝”的方式对这样的通信进行优化。其基本思想是将GPU中需要发送的计算结果直接存储于RDMA网卡可见的连续显存区域,并在计算完成后通知接收端直接读取,避免拷贝[<sup>[3]</sup>](#ref3)
。
通过这样的介绍我们可以看到,在TensorFlow训练框架的系统设计思想是将用户接口用于定义并行的基本策略,而将策略到并行化的执行等复杂操作隐藏于系统内部。这样的做法好处是用户接口较为简洁,无需显示地调用通信原语。但随之而来的缺陷是用户无法灵活地定义自己希望的并行及协调通信方式。
## 6.4.2 PyTorch 中的分布式支持
与TensorFlow相对的,PyTorch
的用户接口更倾向于暴露底层的通信原语用于搭建更为灵活的并行方式。PyTorch的通信原语包含**点对点通信**和**集体式通信**。
点对点(P2P)式的通信是指每次通信只涉及两个设备,期间采用基础的发送(send)和接受(receive)原语进行数据交换。而集体式通信,则在单次通信中有多个设备参与,例如广播操作(broadcast)就是一个设备将数据发送给多个设备的通信[<sup>[4]</sup>](#ref4)
。
分布式机器学习中使用的集体式通信大多沿袭自MPI标准的集体式通信接口。
PyTorch 点对点通信可以实现用户指定的同步 send/recv,例如下图表达了:rank 0 *send* rank 1 *recv* 的操作。
```python
"""Blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' has data ', tensor\[0\])
```
<!-- <center><img src="./img/image28.png" width="600" height="" /></center> -->
<center>图6-4-4: PyTorch中采用点对点同步通信 (<a href=https://pytorch.org/tutorials/intermediate/dist_tuto.html>参考来源</a>)</center>
除了同步通信,PyTorch还提供了对应的异步发送接收操作。
```python
"""Non-blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
# Send the tensor to process 1
req = dist.isend(tensor=tensor, dst=1)
print('Rank 0 started sending')
else:
# Receive tensor from process 0
req = dist.irecv(tensor=tensor, src=0)
print('Rank 1 started receiving')
req.wait()
print('Rank ', rank, ' has data ', tensor\[0\])
```
<!-- <center><img src="./img/image29.png" width="600" height="" /></center> -->
<center>图6-4-5: PyTorch中采用点对点异步通信 (<a href=https://pytorch.org/tutorials/intermediate/dist_tuto.html>参考来源</a>)</center>
PyTorch 集体式通信包含了一对多的 Scatter / Broadcast, 多对一的 Gather / Reduce 以及多对多的 *All-Reduce* / *AllGather*。
<center><img src="./img/image30.png" width="600" height="" /></center>
<center>图6-4-6: PyTorch中的集体式通信 (<a href=https://pytorch.org/tutorials/intermediate/dist_tuto.html>图片来源</a>)</center>
下图以常用的调用All-Reduce为例,它默认的参与者是全体成员,也可以在调用中以列表的形式指定集体式通信的参与者。比如这里的参与者就是rank 0 和 1。
```python
""" All-Reduce example."""
def run(rank, size):
""" Simple collective communication. """
group = dist.new\_group(\[0, 1\])
tensor = torch.ones(1)
dist.all\_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor\[0\])
```
<!-- <center><img src="./img/image31.png" width="600" height="" /></center> -->
<center>图6-4-7: 指定参与成员的集体式通信 (<a href=https://pytorch.org/tutorials/intermediate/dist_tuto.html>图片来源</a>) </center>
通过这样的通信原语,PyTorch也可以构建数据并行等算法,且以功能函数的方式提供给用户调用。但是这样的设计思想并不包含TensorFlow中系统下层的数据流图抽象上的各种操作,而将整个过程在用户可见的层级加以实现,相比之下更为灵活,但在深度优化上欠缺全局信息。
## 6.4.3 通用的数据并行系统Horovod
*“Horovod is a distributed deep learning training framework for
**TensorFlow, Keras, PyTorch**, and **Apache MXNet**. The goal of
Horovod is to make distributed deep learning fast and easy to use.”*
在各个深度框架针对自身加强分布式功能的同时,Horovod[<sup>[5]</sup>](#ref5)专注于数据并行的优化,并广泛支持多训练平台且强调易用性,依然获得了很多使用者的青睐。
<center><img src="./img/image32.png" width="600" height="" /></center>
<center>图6-4-8: Horovod 实现数据并行的原理 (<a href=https://arxiv.org/pdf/1802.05799.pdf>图片来源</a>) </center>
如果需要并行化一个已有的模型,Horovod在用户接口方面需要的模型代码修改非常少,其主要是增加一行利用Horovod的DistributedOptimizer分布式优化子嵌套原模型中优化子:
```python
opt = DistributedOptimizer(opt)
```
而模型的执行只需调用MPI命令:
```
mpirun –n <worker number>; train.py
```
即可方便实现并行启动。
```python
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
torch.cuda.set_device(hvd.local_rank())
# Define dataset...
train_dataset = ...
# Partition dataset among workers using DistributedSampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=..., sampler=train_sampler)
# Build model...
model = ...
model.cuda()
optimizer = optim.SGD(model.parameters())
# Add Horovod Distributed Optimizer
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=model.named_parameters())
# Broadcast parameters from rank 0 to all other processes.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{}]tLoss: {}'.format(
epoch, batch_idx * len(data), len(train_sampler), loss.item()))
```
<!-- <center><img src="./img/image33.png" width="600" height="" /></center> -->
<center>图6-4-9: 调用 Horovod 需要的代码修改 (<a href=https://github.com/horovod/horovod>参考来源</a>) </center>
Horovod通过DistributedOptimizer 插入针对梯度数据的 Allreduce 逻辑实现数据并行。对于TensorFlow,插入通信 Allreduce 算子,而在PyTorch中插入通信 Allreduce 函数。二者插入的操作都会调用底层统一的Allreduce功能模块。
为了保证性能的高效性,Horovod实现了专用的**协调机制算法**:
目标:确保 Allreduce 的执行全局统一进行
- 每个工作节点拥有 Allreduce 执行队列,初始为空
- 全局协调节点(Coordinator),维护每个工作节点各个 梯度张量 状态
执行:
- 工作节点\_i产生梯度g\_j后会调用Allreduce(g\_j),通知协调节点 “g\_j\[i\]
ready”
- 当协调节点收集到所有”g\_j\[\*\] ready”,
通知所有工作节点将g\_i加入Allreduce执行队列
- 工作节点背景线程不断pop Allreduce队列并执行
这里需要确保Allreduce全局统一执行主要为了:确保相同执行顺序,保证Allreduce针对同一个梯度进行操作;Allreduce通常是同步调用,为了防止提前执行的成员会空等,导致资源浪费。
Horovod通过一系列优化的设计实现,以独特的角度推进了分布式训练系统的发展。其中的设计被很多其它系统借鉴吸收,持续发挥更为广泛的作用。
## 小结与讨论
本节通过实际分布式机器学习功能的介绍,提供给读者实际实现的参考。同时通过不同系统的比较与讨论,提出系统设计的理念与反思。
### 课后实验 分布式训练任务练习
<!-- 本章的内容学习之后可以参考[实验4](../../Labs/BasicLabs/Lab4/README.md)以及[实验7](../../Labs/BasicLabs/Lab7/README.md)进行对应的部署练习以加深理解分布式通信算法以及实际的训练性能。 -->
**实验目的**
1. 学习使用Horovod库。
2. 通过调用不同的通信后端实现数据并行的并行/分布式训练,了解各种后端的基本原理和适用范围。
3. 通过实际操作,灵活掌握安装部署。
实验环境(参考)
* Ubuntu 18.04
* CUDA 10.0
* PyTorch==1.5.0
* Horovod==0.19.4
实验原理:通过测试MPI、NCCL、Gloo、oneCCL后端完成相同的allreduce通信,通过不同的链路实现数据传输。
**实验内容**
实验流程图
<!--  -->
<center><img src="./img/Lab7-flow.png" width="300" height="" /></center>
<center>图6-4-10: 分布式训练任务练习 实验流程图 </center>
具体步骤
1. 安装依赖支持:OpenMPI[<sup>[10]</sup>](#ref10), Horovod[<sup>[6]</sup>](#ref6)。
2. 运行Horovod MNIST测试用例 `pytorch_mnist_horovod.py`[<sup>[7]</sup>](#ref7) ,验证Horovod正确安装。
<!-- (`Lab7/pytorch_mnist_horovod.py`) -->
3. 按照MPI/Gloo/NCCL的顺序,选用不同的通信后端,测试不同GPU数、不同机器数时,MNIST样例下iteration耗时和吞吐率,记录GPU和机器数目,以及测试结果,并完成表格绘制。
3.1. 安装MPI,并测试多卡、多机并行训练耗时和吞吐率。可参考如下命令:
```
//单机多CPU
$horovodrun -np 2 python pytorch_mnist_horovod.py --no-cuda
//多机单GPU
$horovodrun -np 4 -H server1:1,server2:1,server3:1,server4:1 python pytorch_mnist_horovod_basic.py
```
3.2. 测试Gloo下的多卡、多机并行训练耗时。
3.3. 安装NCCL2[<sup>[9]</sup>](#ref9)后重新安装horovod并测试多卡、多机并行训练耗时和吞吐率。
4. (可选)安装支持GPU通信的MPI后重新安装horovod[<sup>[8]</sup>](#ref8)并测试多卡、多机并行训练耗时和吞吐率。
```
$ HOROVOD_GPU_ALLREDUCE=MPI pip install --no-cache-dir horovod
```
5. (可选)若机器有Tesla/Quadro GPU + RDMA环境,尝试设置GPUDirect RDMA 以达到更高的通信性能
6. 统计数据,绘制系统的scalability曲线H
7. (可选)选取任意RNN网络进行并行训练,测试horovod并行训练耗时和吞吐率。
**实验报告**
实验环境
||||
|--------|--------------|--------------------------|
|硬件环境|服务器数目| |
||网卡型号、数目||
||GPU型号、数目||
||GPU连接方式||
|软件环境|OS版本||
||GPU driver、(opt. NIC driver)||
||深度学习框架<br>python包名称及版本||
||CUDA版本||
||NCCL版本||
||||
<center>表6-5-2: 实验环境记录</center>
实验结果
1. 测试服务器内多显卡加速比
|||||||
|-----|-----|-----|-----|------|------|
| 通信后端 | 服务器数量 | 每台服务器显卡数量 | 平均每步耗时 | 平均吞吐率 | 加速比 |
| MPI / Gloo / NCCL | 1/2/4/8 | (固定) | | | |
|||||||
<center>表6-5-3: 单节点内加速比实验记录</center>
2. 测试服务器间加速比
|||||||
|-----|-----|-----|-----|------|------|
| 通信后端 | 服务器数量 | 每台服务器显卡数量 | 平均每步耗时 | 平均吞吐率 | 加速比 |
| MPI / Gloo / NCCL | (固定) | 1/2/4/8 ||||
|||||||
<center>表6-5-4: 跨机加速比实验记录</center>
3. 总结加速比的图表、比较不同通信后端的性能差异、分析可能的原因
4. (可选)比较不同模型的并行加速差异、分析可能的原因(提示:计算/通信比)
**参考代码**
1. 安装依赖支持
安装OpenMPI:`sudo apt install openmpi-bin`
安装Horovod:`python3 -m pip install horovod==0.19.4 --user`
2. 验证Horovod正确安装
运行mnist样例程序
```
python pytorch_mnist_horovod_basic.py
```
3. 选用不同的通信后端测试命令
1. 安装MPI,并测试多卡、多机并行训练耗时和吞吐率。
```
//单机多CPU
$horovodrun -np 2 python pytorch_mnist_horovod.py --no-cuda
//单机多GPU
$horovodrun -np 2 python pytorch_mnist_horovod.py
//多机单GPU
$horovodrun -np 4 -H server1:1,server2:1,server3:1,server4:1 python pytorch_mnist_horovod_basic.py
//多机多CPU
$horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python pytorch_mnist_horovod_basic.py --no-cuda
//多机多GPU
$horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python pytorch_mnist_horovod_basic.py
```
2. 测试Gloo下的多卡、多机并行训练耗时。
```
$horovodrun --gloo -np 2 python pytorch_mnist_horovod.py --no-cuda
$horovodrun -np 4 -H server1:1,server2:1,server3:1,server4:1 python pytorch_mnist_horovod_basic.py
$horovodrun –gloo -np 16 -H server1:4,server2:4,server3:4,server4:4 python pytorch_mnist_horovod_basic.py --no-cuda
```
3. 安装NCCL2后重新安装horovod并测试多卡、多机并行训练耗时和吞吐率。
```
$HOROVOD_GPU_OPERATIONS=NCCL pip install --no-cache-dir horovod
$horovodrun -np 2 -H server1:1,server2:1 python pytorch_mnist_horovod.py
```
4. 安装支持GPU通信的MPI后重新安装horovod并测试多卡、多机并行训练耗时和吞吐率。
```
HOROVOD_GPU_ALLREDUCE=MPI pip install --no-cache-dir horovod
```
## 参考文献
<div id="ref1"></div>
1. [TensorFlow Distributed Training](https://www.tensorflow.org/guide/distributed\_training)
<div id="ref2"></div>
2. [TensorFlow ClusterSpec](https://www.tensorflow.org/api_docs/python/tf/train/ClusterSpec)
<div id="ref3"></div>
3. [Fast Distributed Deep Learning over RDMA. (EuroSys'19)](https://dl.acm.org/doi/10.1145/3302424.3303975)
<div id="ref4"></div>
4. [PyTorch Distributed Tutorial](https://pytorch.org/tutorials/intermediate/dist_tuto.html)
<div id="ref5"></div>
5. [Horovod: fast and easy distributed deep learning in TensorFlow](https://arxiv.org/pdf/1802.05799.pdf)
<div id="ref6"></div>
6. [Horovod on Github](https://github.com/horovod/horovod)
<div id="ref7"></div>
7. [PyTorch MNIST 测试用例](https://github.com/horovod/horovod/blob/master/examples/pytorch/pytorch_mnist.py)
<div id="ref8"></div>
8. [Horovod on GPU](https://github.com/horovod/horovod/blob/master/docs/gpus.rst)
<div id="ref9"></div>
9. [NCCL2 download](https://developer.nvidia.com/nccl/nccl-download)
<div id="ref10"></div>
10. [OpenMPI](https://www.open-mpi.org/software/ompi/v4.0/) | AI-System/Textbook/第6章-分布式训练算法与系统/6.4-分布式训练系统简介.md/0 | {
"file_path": "AI-System/Textbook/第6章-分布式训练算法与系统/6.4-分布式训练系统简介.md",
"repo_id": "AI-System",
"token_count": 12272
} | 12 |
#!/usr/bin/python3
import argparse
from azure.keyvault import KeyVaultClient
from azure.common.client_factory import get_client_from_cli_profile
from dotenv import load_dotenv
import os
def set_secret(kv_endpoint, secret_name, secret_value):
client = get_client_from_cli_profile(KeyVaultClient)
client.set_secret(kv_endpoint, secret_name, secret_value)
return "Successfully created secret: {secret_name} in keyvault: {kv_endpoint}".format(
secret_name=secret_name, kv_endpoint=kv_endpoint)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--secretName', required=True,
help="The name of the secret")
return parser.parse_args()
if __name__ == "__main__":
load_dotenv(override=True)
# hard coded for now
kv_endpoint = "https://t3scriptkeyvault.vault.azure.net/"
args = parse_args()
key = os.getenv("storage_conn_string")
print(key)
message = set_secret(kv_endpoint, args.secretName, key)
print(message)
| AI/.ci/scripts/set_secret.py/0 | {
"file_path": "AI/.ci/scripts/set_secret.py",
"repo_id": "AI",
"token_count": 408
} | 13 |
parameters:
notebook: # defaults for any parameters that aren't specified
location: "."
azureSubscription: 'x'
azure_subscription: 'x'
timeoutInMinutes: 90
steps:
- task: AzureCLI@1
displayName: ${{parameters.notebook}}
inputs:
azureSubscription: ${{parameters.azureSubscription}}
scriptLocation: inlineScript
timeoutInMinutes: ${{parameters.timeoutInMinutes}}
failOnStderr: True
inlineScript: |
cd ${{parameters.location}}
echo Execute ${{parameters.notebook}}
pwd
ls
Rscript ./${{parameters.notebook}}
| AI/.ci/steps/azure_r.yml/0 | {
"file_path": "AI/.ci/steps/azure_r.yml",
"repo_id": "AI",
"token_count": 212
} | 14 |
parameters:
deployment_name: ''
template: ''
azureSubscription: ''
azure_subscription: ''
azureresourcegroup: ''
workspacename: ''
azureregion: ''
aksimagename: ''
environment: 'tridant-ai'
doCleanup: True
alias: '-'
project: '-'
expires : "2019-08-01"
agent: 'AI-GPU'
conda: ''
python_path: "$(System.DefaultWorkingDirectory)/submodules/DeployMLModelKubernetes/{{cookiecutter.project_name}}"
location: submodules/DeployMLModelKubernetes/{{cookiecutter.project_name}}
aks_name: "aksdl"
steps:
- template: createResourceGroupTemplate.yml
parameters:
azureSubscription: ${{parameters.azureSubscription}}
azureresourcegroup: ${{parameters.azureresourcegroup}}
location: ${{parameters.azureregion}}
alias : ${{parameters.alias}}
project : ${{parameters.project}}
expires : ${{parameters.expires}}
- template: config_conda.yml
parameters:
conda_location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
- template: azpapermill.yml
parameters:
notebook: 00_AMLConfiguration.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
azure_subscription: ${{parameters.azure_subscription}}
azureresourcegroup: ${{parameters.azureresourcegroup}}
workspacename: ${{parameters.workspacename}}
azureregion: ${{parameters.azureregion}}
aksimagename: ${{parameters.aksimagename}}
- template: azpapermill.yml
parameters:
notebook: 01_DataPrep.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
- template: azpapermill.yml
parameters:
notebook: 02_TrainOnLocal.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
- template: azpapermill.yml
parameters:
notebook: 03_DevelopScoringScript.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
- template: azpapermill.yml
parameters:
notebook: 04_CreateImage.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
aksimagename: "myimage"
- template: azpapermill.yml
parameters:
notebook: 05_DeployOnAKS.ipynb
location: ${{parameters.location}}/aks
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
aks_name: ${{parameters.aks_name}}
azureregion: ${{parameters.azureregion}}
aks_service_name: ${{parameters.aks_service_name}}
python_path: ${{parameters.python_path}}
aksimagename: "myimage"
- template: azpapermill.yml
parameters:
notebook: 06_SpeedTestWebApp.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
- template: azpapermill.yml
parameters:
notebook: 07_RealTimeScoring.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
- template: azpapermill.yml
parameters:
notebook: 08_TearDown.ipynb
location: ${{parameters.location}}
azureSubscription: ${{parameters.azureSubscription}}
conda: ${{parameters.conda}}
| AI/.ci/steps/deploy_rts.yml/0 | {
"file_path": "AI/.ci/steps/deploy_rts.yml",
"repo_id": "AI",
"token_count": 1402
} | 15 |
variables:
TridentWorkloadTypeShort: dsdevito
DeployLocation: eastus
ProjectLocation: "contrib/examples/imaging/azureml_devito/notebooks/"
PythonPath: "environment/anaconda/local/"
Template: DevitoDeployAMLJob.yml
| AI/.ci/vars/deep_seismic_devito.yml/0 | {
"file_path": "AI/.ci/vars/deep_seismic_devito.yml",
"repo_id": "AI",
"token_count": 75
} | 16 |
# Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Lee Xiong*, Chenyan Xiong*, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, Arnold Overwijk
This repo provides the code for reproducing the experiments in [Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval](https://arxiv.org/pdf/2007.00808.pdf)
Conducting text retrieval in a dense learned representation space has many intriguing advantages over sparse retrieval. Yet the effectiveness of dense retrieval (DR)
often requires combination with sparse retrieval. In this paper, we identify that
the main bottleneck is in the training mechanisms, where the negative instances
used in training are not representative of the irrelevant documents in testing. This
paper presents Approximate nearest neighbor Negative Contrastive Estimation
(ANCE), a training mechanism that constructs negatives from an Approximate
Nearest Neighbor (ANN) index of the corpus, which is parallelly updated with the
learning process to select more realistic negative training instances. This fundamentally resolves the discrepancy between the data distribution used in the training
and testing of DR. In our experiments, ANCE boosts the BERT-Siamese DR
model to outperform all competitive dense and sparse retrieval baselines. It nearly
matches the accuracy of sparse-retrieval-and-BERT-reranking using dot-product in
the ANCE-learned representation space and provides almost 100x speed-up.
Our analyses further confirm that the negatives from sparse retrieval or other sampling methods differ
drastically from the actual negatives in DR, and that ANCE fundamentally resolves this mismatch.
We also show the influence of the asynchronous ANN refreshing on learning convergence and
demonstrate that the efficiency bottleneck is in the encoding update, not in the ANN part during
ANCE training. These qualifications demonstrate the advantages, perhaps also the necessity, of our
asynchronous ANCE learning in dense retrieval.
## What's new
* [September 2021 Released SEED-Encoder fine-tuning code.](https://github.com/microsoft/ANCE/tree/master/model/SEED_Encoder/SEED-Encoder.md)
## Requirements
To install requirements, run the following commands:
```setup
git clone https://github.com/microsoft/ANCE
cd ANCE
python setup.py install
```
## Data Download
To download all the needed data, run:
```
bash commands/data_download.sh
```
## Data Preprocessing
The command to preprocess passage and document data is listed below:
```
python data/msmarco_data.py
--data_dir $raw_data_dir \
--out_data_dir $preprocessed_data_dir \
--model_type {use rdot_nll for ANCE FirstP, rdot_nll_multi_chunk for ANCE MaxP} \
--model_name_or_path roberta-base \
--max_seq_length {use 512 for ANCE FirstP, 2048 for ANCE MaxP} \
--data_type {use 1 for passage, 0 for document}
```
The data preprocessing command is included as the first step in the training command file commands/run_train.sh
## Warmup for Training
ANCE training starts from a pretrained BM25 warmup checkpoint. The command with our used parameters to train this warmup checkpoint is in commands/run_train_warmup.py and is shown below:
python3 -m torch.distributed.launch --nproc_per_node=1 ../drivers/run_warmup.py \
--train_model_type rdot_nll \
--model_name_or_path roberta-base \
--task_name MSMarco \
--do_train \
--evaluate_during_training \
--data_dir ${location of your raw data}
--max_seq_length 128
--per_gpu_eval_batch_size=256 \
--per_gpu_train_batch_size=32 \
--learning_rate 2e-4 \
--logging_steps 100 \
--num_train_epochs 2.0 \
--output_dir ${location for checkpoint saving} \
--warmup_steps 1000 \
--overwrite_output_dir \
--save_steps 30000 \
--gradient_accumulation_steps 1 \
--expected_train_size 35000000 \
--logging_steps_per_eval 1 \
--fp16 \
--optimizer lamb \
--log_dir ~/tensorboard/${DLWS_JOB_ID}/logs/OSpass
## Training
To train the model(s) in the paper, you need to start two commands in the following order:
1. run commands/run_train.sh which does three things in a sequence:
a. Data preprocessing: this is explained in the previous data preprocessing section. This step will check if the preprocess data folder exists, and will be skipped if the checking is positive.
b. Initial ANN data generation: this step will use the pretrained BM25 warmup checkpoint to generate the initial training data. The command is as follow:
python -m torch.distributed.launch --nproc_per_node=$gpu_no ../drivers/run_ann_data_gen.py
--training_dir {# checkpoint location, not used for initial data generation} \
--init_model_dir {pretrained BM25 warmup checkpoint location} \
--model_type rdot_nll \
--output_dir $model_ann_data_dir \
--cache_dir $model_ann_data_dir_cache \
--data_dir $preprocessed_data_dir \
--max_seq_length 512 \
--per_gpu_eval_batch_size 16 \
--topk_training {top k candidates for ANN search(ie:200)} \
--negative_sample {negative samples per query(20)} \
--end_output_num 0 # only set as 0 for initial data generation, do not set this otherwise
c. Training: ANCE training with the most recently generated ANN data, the command is as follow:
python -m torch.distributed.launch --nproc_per_node=$gpu_no ../drivers/run_ann.py
--model_type rdot_nll \
--model_name_or_path $pretrained_checkpoint_dir \
--task_name MSMarco \
--triplet {# default = False, action="store_true", help="Whether to run training}\
--data_dir $preprocessed_data_dir \
--ann_dir {location of the ANN generated training data} \
--max_seq_length 512 \
--per_gpu_train_batch_size=8 \
--gradient_accumulation_steps 2 \
--learning_rate 1e-6 \
--output_dir $model_dir \
--warmup_steps 5000 \
--logging_steps 100 \
--save_steps 10000 \
--optimizer lamb
2. Once training starts, start another job in parallel to fetch the latest checkpoint from the ongoing training and update the training data. To do that, run
bash commands/run_ann_data_gen.sh
The command is similar to the initial ANN data generation command explained previously
## Inference
The command for inferencing query and passage/doc embeddings is the same as that for Initial ANN data generation described above as the first step in ANN data generation is inference. However you need to add --inference to the command to have the program to stop after the initial inference step. commands/run_inference.sh provides a sample command.
## Evaluation
The evaluation is done through "Calculate Metrics.ipynb". This notebook calculates full ranking and reranking metrics used in the paper including NDCG, MRR, hole rate, recall for passage/document, dev/eval set specified by user. In order to run it, you need to define the following parameters at the beginning of the Jupyter notebook.
checkpoint_path = {location for dumpped query and passage/document embeddings which is output_dir from run_ann_data_gen.py}
checkpoint = {embedding from which checkpoint(ie: 200000)}
data_type = {0 for document, 1 for passage}
test_set = {0 for MSMARCO dev_set, 1 for TREC eval_set}
raw_data_dir =
processed_data_dir =
## ANCE VS DPR on OpenQA Benchmarks
We also evaluate ANCE on the OpenQA benchmark used in a parallel work ([DPR](https://github.com/facebookresearch/DPR)). At the time of our experiment, only the pre-processed NQ and TriviaQA data are released.
Our experiments use the two released tasks and inherit DPR retriever evaluation. The evaluation uses the Coverage@20/100 which is whether the Top-20/100 retrieved passages include the answer. We explain the steps to
reproduce our results on OpenQA Benchmarks in this section.
### Download data
commands/data_download.sh takes care of this step.
### ANN data generation & ANCE training
Following the same training philosophy discussed before, the ann data generation and ANCE training for OpenQA require two parallel jobs.
1. We need to preprocess data and generate an initial training set for ANCE to start training. The command for that is provided in:
```
commands/run_ann_data_gen_dpr.sh
```
We keep this data generation job running after it creates an initial training set as it will later keep generating training data with newest checkpoints from the training process.
2. After an initial training set is generated, we start an ANCE training job with commands provided in:
```
commands/run_train_dpr.sh
```
During training, the evaluation metrics will be printed to tensorboards each time it receives new training data. Alternatively, you could check the metrics in the dumped file "ann_ndcg_#" in the directory specified by "model_ann_data_dir" in commands/run_ann_data_gen_dpr.sh each time new training data is generated.
## Results
The run_train.sh and run_ann_data_gen.sh files contain the command with the parameters we used for passage ANCE(FirstP), document ANCE(FirstP) and document ANCE(MaxP)
Our model achieves the following performance on MSMARCO dev set and TREC eval set :
| MSMARCO Dev Passage Retrieval | MRR@10 | Recall@1k | Steps |
|---------------- | -------------- |-------------- | -------------- |
| ANCE(FirstP) | 0.330 | 0.959 | [600K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Passage_ANCE_FirstP_Checkpoint.zip) |
| ANCE(MaxP) | - | - | - |
| TREC DL Passage NDCG@10 | Rerank | Retrieval | Steps |
|---------------- | -------------- |-------------- | -------------- |
| ANCE(FirstP) | 0.677 | 0.648 | [600K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Passage_ANCE_FirstP_Checkpoint.zip) |
| ANCE(MaxP) | - | - | - |
| TREC DL Document NDCG@10 | Rerank | Retrieval | Steps |
|---------------- | -------------- |-------------- | -------------- |
| ANCE(FirstP) | 0.641 | 0.615 | [210K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Document_ANCE_FirstP_Checkpoint.zip) |
| ANCE(MaxP) | 0.671 | 0.628 | [139K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Document_ANCE_MaxP_Checkpoint.zip) |
| MSMARCO Dev Passage Retrieval | MRR@10 | Steps |
|---------------- | -------------- | -------------- |
| pretrained BM25 warmup checkpoint | 0.311 | [60K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/warmup_checpoint.zip) |
| ANCE Single-task Training | Top-20 | Top-100 | Steps |
|---------------- | -------------- | -------------- |-------------- |
| NQ | 81.9 | 87.5 | [136K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/nq.cp) |
| TriviaQA | 80.3 | 85.3 | [100K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/trivia.cp) |
| ANCE Multi-task Training | Top-20 | Top-100 | Steps |
|---------------- | -------------- | -------------- |-------------- |
| NQ | 82.1 | 87.9 | [300K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/multi.cp) |
| TriviaQA | 80.3 | 85.2 | [300K](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/multi.cp) |
Click the steps in the table to download the corresponding checkpoints.
Our result for document ANCE(FirstP) TREC eval set top 100 retrieved document per query could be downloaded [here](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Results/ance_512_eval_top100.txt).
Our result for document ANCE(MaxP) TREC eval set top 100 retrieved document per query could be downloaded [here](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Results/ance_2048_eval_top100.txt).
The TREC eval set query embedding and their ids for our passage ANCE(FirstP) experiment could be downloaded [here](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Passage_ANCE_FirstP_Embedding.zip).
The TREC eval set query embedding and their ids for our document ANCE(FirstP) experiment could be downloaded [here](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Document_ANCE_FirstP_Embedding.zip).
The TREC eval set query embedding and their ids for our document 2048 ANCE(MaxP) experiment could be downloaded [here](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/Document_ANCE_MaxP_Embedding.zip).
The t-SNE plots for all the queries in the TREC document eval set for ANCE(FirstP) could be viewed [here](https://webdatamltrainingdiag842.blob.core.windows.net/semistructstore/OpenSource/t-SNE.zip).
run_train.sh and run_ann_data_gen.sh files contain the commands with the parameters we used for passage ANCE(FirstP), document ANCE(FirstP) and document 2048 ANCE(MaxP) to reproduce the results in this section.
run_train_warmup.sh contains the commands to reproduce the results for the pretrained BM25 warmup checkpoint in this section
Note the steps to reproduce similar results as shown in the table might be a little different due to different synchronizing between training and ann data generation processes and other possible environment differences of the user experiments.
| ANCE/README.md/0 | {
"file_path": "ANCE/README.md",
"repo_id": "ANCE",
"token_count": 4664
} | 17 |
import sys
sys.path += ["../"]
import pandas as pd
from transformers import glue_compute_metrics as compute_metrics, glue_output_modes as output_modes, glue_processors as processors
from transformers import (
AdamW,
RobertaConfig,
RobertaForSequenceClassification,
RobertaTokenizer,
get_linear_schedule_with_warmup,
RobertaModel,
)
import transformers
from utils.eval_mrr import passage_dist_eval
from model.models import MSMarcoConfigDict
from utils.lamb import Lamb
import os
from os import listdir
from os.path import isfile, join
import argparse
import glob
import json
import logging
import random
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from tqdm import tqdm, trange
import torch.distributed as dist
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch import nn
from utils.util import getattr_recursive, set_seed, is_first_worker, StreamingDataset
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
def train(args, model, tokenizer, f, train_fn):
""" Train the model """
tb_writer = None
if is_first_worker():
tb_writer = SummaryWriter(log_dir=args.log_dir)
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
real_batch_size = args.train_batch_size * args.gradient_accumulation_steps * \
(torch.distributed.get_world_size() if args.local_rank != -1 else 1)
if args.max_steps > 0:
t_total = args.max_steps
else:
t_total = args.expected_train_size // real_batch_size * args.num_train_epochs
# layerwise optimization for lamb
optimizer_grouped_parameters = []
layer_optim_params = set()
for layer_name in ["roberta.embeddings", "score_out", "downsample1", "downsample2", "downsample3", "embeddingHead"]:
layer = getattr_recursive(model, layer_name)
if layer is not None:
optimizer_grouped_parameters.append({"params": layer.parameters()})
for p in layer.parameters():
layer_optim_params.add(p)
if getattr_recursive(model, "roberta.encoder.layer") is not None:
for layer in model.roberta.encoder.layer:
optimizer_grouped_parameters.append({"params": layer.parameters()})
for p in layer.parameters():
layer_optim_params.add(p)
optimizer_grouped_parameters.append(
{"params": [p for p in model.parameters() if p not in layer_optim_params]})
if args.optimizer.lower() == "lamb":
optimizer = Lamb(optimizer_grouped_parameters,
lr=args.learning_rate, eps=args.adam_epsilon)
elif args.optimizer.lower() == "adamw":
optimizer = AdamW(optimizer_grouped_parameters,
lr=args.learning_rate, eps=args.adam_epsilon)
else:
raise Exception(
"optimizer {0} not recognized! Can only be lamb or adamW".format(args.optimizer))
if args.scheduler.lower() == "linear":
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
elif args.scheduler.lower() == "cosine":
scheduler = CosineAnnealingLR(optimizer, t_total, 1e-8)
else:
raise Exception(
"Scheduler {0} not recognized! Can only be linear or cosine".format(args.scheduler))
# Check if saved optimizer or scheduler states exist
if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
os.path.join(args.model_name_or_path, "scheduler.pt")
) and args.load_optimizer_scheduler:
# Load in optimizer and scheduler states
optimizer.load_state_dict(torch.load(
os.path.join(args.model_name_or_path, "optimizer.pt")))
scheduler.load_state_dict(torch.load(
os.path.join(args.model_name_or_path, "scheduler.pt")))
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError(
"Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(
model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[
args.local_rank], output_device=args.local_rank, find_unused_parameters=True,
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d",
args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d",
args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 0
epochs_trained = 0
steps_trained_in_current_epoch = 0
# Check if continuing training from a checkpoint
if os.path.exists(args.model_name_or_path):
# set global_step to gobal_step of last saved checkpoint from model path
try:
global_step = int(
args.model_name_or_path.split("-")[-1].split("/")[0])
epochs_trained = global_step // (args.expected_train_size //
args.gradient_accumulation_steps)
steps_trained_in_current_epoch = global_step % (
args.expected_train_size // args.gradient_accumulation_steps)
logger.info(
" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(
" Continuing training from global step %d", global_step)
logger.info(" Will skip the first %d steps in the first epoch",
steps_trained_in_current_epoch)
except:
logger.info(" Start training from a pretrained model")
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0],
)
set_seed(args) # Added here for reproductibility
for m_epoch in train_iterator:
f.seek(0)
sds = StreamingDataset(f,train_fn)
epoch_iterator = DataLoader(sds, batch_size=args.per_gpu_train_batch_size, num_workers=1)
for step, batch in tqdm(enumerate(epoch_iterator),desc="Iteration",disable=args.local_rank not in [-1,0]):
# Skip past any already trained steps if resuming training
if steps_trained_in_current_epoch > 0:
steps_trained_in_current_epoch -= 1
continue
model.train()
batch = tuple(t.to(args.device).long() for t in batch)
if (step + 1) % args.gradient_accumulation_steps == 0:
outputs = model(*batch)
else:
with model.no_sync():
outputs = model(*batch)
# model outputs are always tuple in transformers (see doc)
loss = outputs[0]
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
if (step + 1) % args.gradient_accumulation_steps == 0:
loss.backward()
else:
with model.no_sync():
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
torch.nn.utils.clip_grad_norm_(
amp.master_params(optimizer), args.max_grad_norm)
else:
torch.nn.utils.clip_grad_norm_(
model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
if is_first_worker() and args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(
args.output_dir, "checkpoint-{}".format(global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(args, os.path.join(
output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
torch.save(optimizer.state_dict(), os.path.join(
output_dir, "optimizer.pt"))
torch.save(scheduler.state_dict(), os.path.join(
output_dir, "scheduler.pt"))
logger.info(
"Saving optimizer and scheduler states to %s", output_dir)
dist.barrier()
if args.logging_steps > 0 and global_step % args.logging_steps == 0:
logs = {}
if args.evaluate_during_training and global_step % (args.logging_steps_per_eval*args.logging_steps) == 0:
model.eval()
reranking_mrr, full_ranking_mrr = passage_dist_eval(
args, model, tokenizer)
if is_first_worker():
print(
"Reranking/Full ranking mrr: {0}/{1}".format(str(reranking_mrr), str(full_ranking_mrr)))
mrr_dict = {"reranking": float(
reranking_mrr), "full_raking": float(full_ranking_mrr)}
tb_writer.add_scalars("mrr", mrr_dict, global_step)
print(args.output_dir)
loss_scalar = (tr_loss - logging_loss) / args.logging_steps
learning_rate_scalar = scheduler.get_lr()[0]
logs["learning_rate"] = learning_rate_scalar
logs["loss"] = loss_scalar
logging_loss = tr_loss
if is_first_worker():
for key, value in logs.items():
print(key, type(value))
tb_writer.add_scalar(key, value, global_step)
tb_writer.add_scalar("epoch", m_epoch, global_step)
print(json.dumps({**logs, **{"step": global_step}}))
dist.barrier()
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank == -1 or torch.distributed.get_rank() == 0:
tb_writer.close()
return global_step, tr_loss / global_step
def load_stuff(model_type, args):
# Prepare GLUE task
args.task_name = args.task_name.lower()
args.output_mode = "classification"
label_list = ["0", "1"]
num_labels = len(label_list)
args.num_labels = num_labels
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
configObj = MSMarcoConfigDict[model_type]
model_args = type('', (), {})()
model_args.use_mean = configObj.use_mean
config = configObj.config_class.from_pretrained(
args.config_name if args.config_name else args.model_name_or_path,
num_labels=args.num_labels,
finetuning_task=args.task_name,
cache_dir=args.cache_dir if args.cache_dir else None,
)
tokenizer = configObj.tokenizer_class.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir if args.cache_dir else None,
)
model = configObj.model_class.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir if args.cache_dir else None,
model_argobj=model_args,
)
#model = configObj.model_class(config,model_argobj=model_args)
if args.local_rank == 0:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
model.to(args.device)
return config, tokenizer, model, configObj
def get_arguments():
parser = argparse.ArgumentParser()
# required arguments
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the .tsv files (or other data files) for the task.",
)
parser.add_argument(
"--train_model_type",
default=None,
type=str,
required=True,
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
)
parser.add_argument(
"--task_name",
default=None,
type=str,
required=True,
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
# Other parameters
parser.add_argument(
"--config_name",
default="",
type=str,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from s3",
)
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help="The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded.",
)
parser.add_argument(
"--do_train",
action="store_true",
help="Whether to run training.",
)
parser.add_argument(
"--do_eval",
action="store_true",
help="Whether to run eval on the dev set.",
)
parser.add_argument(
"--evaluate_during_training",
action="store_true",
help="Rul evaluation during training at each logging step.",
)
parser.add_argument(
"--do_lower_case",
action="store_true",
help="Set this flag if you are using an uncased model.",
)
parser.add_argument(
"--log_dir",
default=None,
type=str,
help="Tensorboard log dir",
)
parser.add_argument(
"--eval_type",
default="full",
type=str,
help="MSMarco eval type - dev full or small",
)
parser.add_argument(
"--optimizer",
default="lamb",
type=str,
help="Optimizer - lamb or adamW",
)
parser.add_argument(
"--scheduler",
default="linear",
type=str,
help="Scheduler - linear or cosine",
)
parser.add_argument(
"--per_gpu_train_batch_size",
default=8,
type=int,
help="Batch size per GPU/CPU for training.",
)
parser.add_argument(
"--per_gpu_eval_batch_size",
default=8,
type=int,
help="Batch size per GPU/CPU for evaluation.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--learning_rate",
default=5e-5,
type=float,
help="The initial learning rate for Adam.",
)
parser.add_argument(
"--weight_decay",
default=0.0,
type=float,
help="Weight decay if we apply some.",
)
parser.add_argument(
"--adam_epsilon",
default=1e-8,
type=float,
help="Epsilon for Adam optimizer.",
)
parser.add_argument(
"--max_grad_norm",
default=1.0,
type=float,
help="Max gradient norm.",
)
parser.add_argument(
"--num_train_epochs",
default=3.0,
type=float,
help="Total number of training epochs to perform.",
)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument(
"--warmup_steps",
default=0,
type=int,
help="Linear warmup over warmup_steps.",
)
parser.add_argument(
"--logging_steps",
type=int,
default=500,
help="Log every X updates steps.",
)
parser.add_argument(
"--logging_steps_per_eval",
type=int,
default=10,
help="Eval every X logging steps.",
)
parser.add_argument(
"--save_steps",
type=int,
default=500,
help="Save checkpoint every X updates steps.",
)
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument(
"--no_cuda",
action="store_true",
help="Avoid using CUDA when available",
)
parser.add_argument(
"--overwrite_output_dir",
action="store_true",
help="Overwrite the content of the output directory",
)
parser.add_argument(
"--overwrite_cache",
action="store_true",
help="Overwrite the cached training and evaluation sets",
)
parser.add_argument(
"--seed",
type=int,
default=42,
help="random seed for initialization",
)
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
"See details at https://nvidia.github.io/apex/amp.html",
)
parser.add_argument(
"--expected_train_size",
default=100000,
type=int,
help="Expected train dataset size",
)
parser.add_argument(
"--load_optimizer_scheduler",
default=False,
action="store_true",
help="load scheduler from checkpoint or not",
)
parser.add_argument(
"--local_rank",
type=int,
default=-1,
help="For distributed training: local_rank",
)
parser.add_argument(
"--server_ip",
type=str,
default="",
help="For distant debugging.",
)
parser.add_argument(
"--server_port",
type=str,
default="",
help="For distant debugging.",
)
args = parser.parse_args()
return args
def set_env(args):
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(
address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device(
"cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set seed
set_seed(args)
def save_checkpoint(args, model, tokenizer):
# Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
if args.do_train and is_first_worker():
# Create output directory if needed
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
dist.barrier()
def evaluation(args, model, tokenizer):
# Evaluation
results = {}
if args.do_eval:
model_dir = args.model_name_or_path if args.model_name_or_path else args.output_dir
checkpoints = [model_dir]
for checkpoint in checkpoints:
global_step = checkpoint.split(
"-")[-1] if len(checkpoints) > 1 else ""
prefix = checkpoint.split(
"/")[-1] if checkpoint.find("checkpoint") != -1 else ""
model.eval()
reranking_mrr, full_ranking_mrr = passage_dist_eval(
args, model, tokenizer)
if is_first_worker():
print(
"Reranking/Full ranking mrr: {0}/{1}".format(str(reranking_mrr), str(full_ranking_mrr)))
dist.barrier()
return results
def main():
args = get_arguments()
set_env(args)
config, tokenizer, model, configObj = load_stuff(
args.train_model_type, args)
# Training
if args.do_train:
logger.info("Training/evaluation parameters %s", args)
def train_fn(line, i):
return configObj.process_fn(line, i, tokenizer, args)
with open(args.data_dir+"/triples.train.small.tsv", encoding="utf-8-sig") as f:
train_batch_size = args.per_gpu_train_batch_size * \
max(1, args.n_gpu)
global_step, tr_loss = train(
args, model, tokenizer, f, train_fn)
logger.info(" global_step = %s, average loss = %s",
global_step, tr_loss)
save_checkpoint(args, model, tokenizer)
results = evaluation(args, model, tokenizer)
return results
if __name__ == "__main__":
main()
| ANCE/drivers/run_warmup.py/0 | {
"file_path": "ANCE/drivers/run_warmup.py",
"repo_id": "ANCE",
"token_count": 11644
} | 18 |
import sys
sys.path += ["../"]
from utils.msmarco_eval import quality_checks_qids, compute_metrics, load_reference
import torch.distributed as dist
import gzip
import faiss
import numpy as np
from data.process_fn import dual_process_fn
from tqdm import tqdm
import torch
import os
from utils.util import concat_key, is_first_worker, all_gather, StreamingDataset
from torch.utils.data import DataLoader
def embedding_inference(args, path, model, fn, bz, num_workers=2, is_query=True):
f = open(path, encoding="utf-8")
model = model.module if hasattr(model, "module") else model
sds = StreamingDataset(f, fn)
loader = DataLoader(sds, batch_size=bz, num_workers=1)
emb_list, id_list = [], []
model.eval()
for i, batch in tqdm(enumerate(loader), desc="Eval", disable=args.local_rank not in [-1, 0]):
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {"input_ids": batch[0].long(
), "attention_mask": batch[1].long()}
idx = batch[3].long()
if is_query:
embs = model.query_emb(**inputs)
else:
embs = model.body_emb(**inputs)
if len(embs.shape) == 3:
B, C, E = embs.shape
# [b1c1, b1c2, b1c3, b1c4, b2c1 ....]
embs = embs.view(B*C, -1)
idx = idx.repeat_interleave(C)
assert embs.shape[0] == idx.shape[0]
emb_list.append(embs.detach().cpu().numpy())
id_list.append(idx.detach().cpu().numpy())
f.close()
emb_arr = np.concatenate(emb_list, axis=0)
id_arr = np.concatenate(id_list, axis=0)
return emb_arr, id_arr
def parse_top_dev(input_path, qid_col, pid_col):
ret = {}
with open(input_path, encoding="utf-8") as f:
for line in f:
cells = line.strip().split("\t")
qid = int(cells[qid_col])
pid = int(cells[pid_col])
if qid not in ret:
ret[qid] = []
ret[qid].append(pid)
return ret
def search_knn(xq, xb, k, distance_type=faiss.METRIC_L2):
""" wrapper around the faiss knn functions without index """
nq, d = xq.shape
nb, d2 = xb.shape
assert d == d2
I = np.empty((nq, k), dtype='int64')
D = np.empty((nq, k), dtype='float32')
if distance_type == faiss.METRIC_L2:
heaps = faiss.float_maxheap_array_t()
heaps.k = k
heaps.nh = nq
heaps.val = faiss.swig_ptr(D)
heaps.ids = faiss.swig_ptr(I)
faiss.knn_L2sqr(
faiss.swig_ptr(xq), faiss.swig_ptr(xb),
d, nq, nb, heaps
)
elif distance_type == faiss.METRIC_INNER_PRODUCT:
heaps = faiss.float_minheap_array_t()
heaps.k = k
heaps.nh = nq
heaps.val = faiss.swig_ptr(D)
heaps.ids = faiss.swig_ptr(I)
faiss.knn_inner_product(
faiss.swig_ptr(xq), faiss.swig_ptr(xb),
d, nq, nb, heaps
)
return D, I
def get_topk_restricted(q_emb, psg_emb_arr, pid_dict, psg_ids, pid_subset, top_k):
subset_ix = np.array([pid_dict[x]
for x in pid_subset if x != -1 and x in pid_dict])
if len(subset_ix) == 0:
_D = np.ones((top_k,))*-128
_I = (np.ones((top_k,))*-1).astype(int)
return _D, _I
else:
sub_emb = psg_emb_arr[subset_ix]
_D, _I = search_knn(q_emb, sub_emb, top_k,
distance_type=faiss.METRIC_INNER_PRODUCT)
return _D.squeeze(), psg_ids[subset_ix[_I]].squeeze() # (top_k,)
def passage_dist_eval(args, model, tokenizer):
base_path = args.data_dir
passage_path = os.path.join(base_path, "collection.tsv")
queries_path = os.path.join(base_path, "queries.dev.small.tsv")
def fn(line, i):
return dual_process_fn(line, i, tokenizer, args)
top1000_path = os.path.join(base_path, "top1000.dev")
top1k_qid_pid = parse_top_dev(top1000_path, qid_col=0, pid_col=1)
mrr_ref_path = os.path.join(base_path, "qrels.dev.small.tsv")
ref_dict = load_reference(mrr_ref_path)
reranking_mrr, full_ranking_mrr = combined_dist_eval(
args, model, queries_path, passage_path, fn, fn, top1k_qid_pid, ref_dict)
return reranking_mrr, full_ranking_mrr
def combined_dist_eval(args, model, queries_path, passage_path, query_fn, psg_fn, topk_dev_qid_pid, ref_dict):
# get query/psg embeddings here
eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
query_embs, query_ids = embedding_inference(
args, queries_path, model, query_fn, eval_batch_size, 1, True)
query_pkl = {"emb": query_embs, "id": query_ids}
all_query_list = all_gather(query_pkl)
query_embs = concat_key(all_query_list, "emb")
query_ids = concat_key(all_query_list, "id")
print(query_embs.shape, query_ids.shape)
psg_embs, psg_ids = embedding_inference(
args, passage_path, model, psg_fn, eval_batch_size, 2, False)
print(psg_embs.shape)
top_k = 100
D, I = search_knn(query_embs, psg_embs, top_k,
distance_type=faiss.METRIC_INNER_PRODUCT)
I = psg_ids[I]
# compute reranking and full ranking mrr here
# topk_dev_qid_pid is used for computing reranking mrr
pid_dict = dict([(p, i) for i, p in enumerate(psg_ids)])
arr_data = []
d_data = []
for i, qid in enumerate(query_ids):
q_emb = query_embs[i:i+1]
pid_subset = topk_dev_qid_pid[qid]
ds, top_pids = get_topk_restricted(
q_emb, psg_embs, pid_dict, psg_ids, pid_subset, 10)
arr_data.append(top_pids)
d_data.append(ds)
_D = np.array(d_data)
_I = np.array(arr_data)
# reranking mrr
reranking_mrr = compute_mrr(_D, _I, query_ids, ref_dict)
D2 = D[:, :100]
I2 = I[:, :100]
# full mrr
full_ranking_mrr = compute_mrr(D2, I2, query_ids, ref_dict)
del psg_embs
torch.cuda.empty_cache()
dist.barrier()
return reranking_mrr, full_ranking_mrr
def compute_mrr(D, I, qids, ref_dict):
knn_pkl = {"D": D, "I": I}
all_knn_list = all_gather(knn_pkl)
mrr = 0.0
if is_first_worker():
D_merged = concat_key(all_knn_list, "D", axis=1)
I_merged = concat_key(all_knn_list, "I", axis=1)
print(D_merged.shape, I_merged.shape)
# we pad with negative pids and distance -128 - if they make it to the top we have a problem
idx = np.argsort(D_merged, axis=1)[:, ::-1][:, :10]
sorted_I = np.take_along_axis(I_merged, idx, axis=1)
candidate_dict = {}
for i, qid in enumerate(qids):
seen_pids = set()
if qid not in candidate_dict:
candidate_dict[qid] = [0]*1000
j = 0
for pid in sorted_I[i]:
if pid >= 0 and pid not in seen_pids:
candidate_dict[qid][j] = pid
j += 1
seen_pids.add(pid)
allowed, message = quality_checks_qids(ref_dict, candidate_dict)
if message != '':
print(message)
mrr_metrics = compute_metrics(ref_dict, candidate_dict)
mrr = mrr_metrics["MRR @10"]
print(mrr)
return mrr
| ANCE/utils/eval_mrr.py/0 | {
"file_path": "ANCE/utils/eval_mrr.py",
"repo_id": "ANCE",
"token_count": 3642
} | 19 |
# Self-Training with Weak Supervision
This repo holds the code for our weak supervision framework, ASTRA, described in our NAACL 2021 paper: "[Self-Training with Weak Supervision](https://www.microsoft.com/en-us/research/publication/leaving-no-valuable-knowledge-behind-weak-supervision-with-self-training-and-domain-specific-rules/)"
## Overview of ASTRA
ASTRA is a weak supervision framework for training deep neural networks by automatically generating weakly-labeled data. Our framework can be used for tasks where it is expensive to manually collect large-scale labeled training data.
ASTRA leverages domain-specific **rules**, a large amount of **unlabeled data**, and a small amount of **labeled data** through a **teacher-student** architecture:
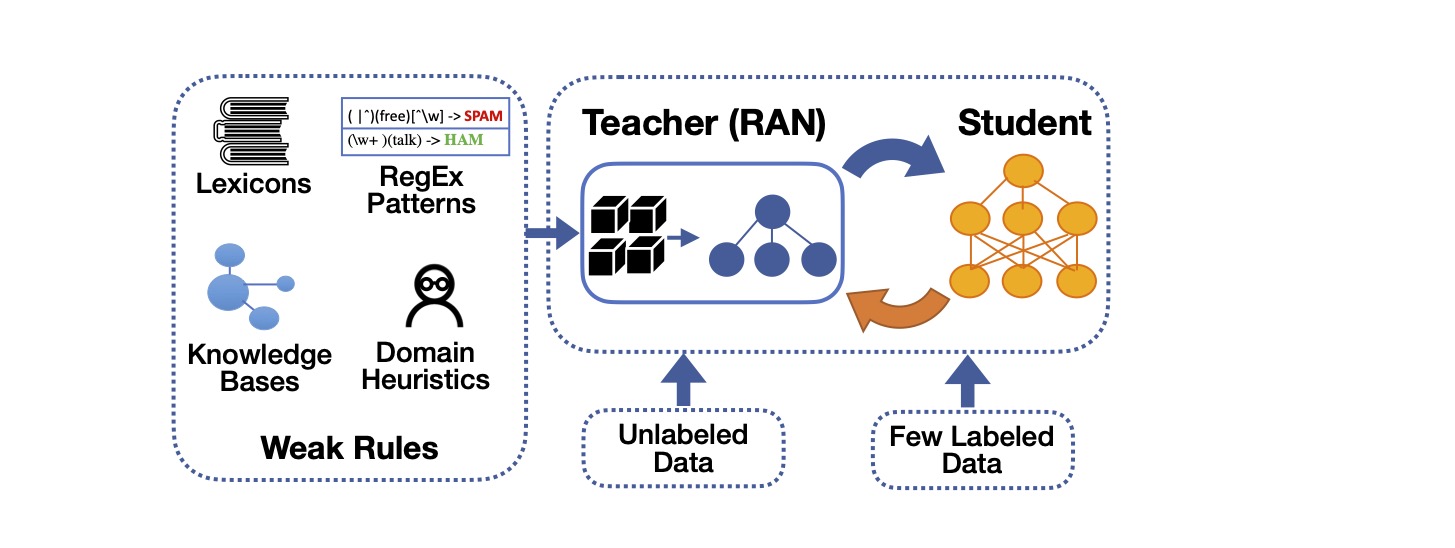
Main components:
* **Weak Rules**: domain-specific rules, expressed as Python labeling functions. Weak supervision usually considers multiple rules that rely on heuristics (e.g., regular expressions) for annotating text instances with weak labels.
* **Student**: a base model (e.g., a BERT-based classifier) that provides pseudo-labels as in standard self-training. In contrast to heuristic rules that cover a subset of the instances, the student can predict pseudo-labels for all instances.
* **RAN Teacher**: our Rule Attention Teacher Network that aggregates the predictions of multiple weak sources (rules and student) with instance-specific weights to compute a single pseudo-label for each instance.
The following table reports classification results over 6 benchmark datasets averaged over multiple runs.
Method | TREC | SMS | YouTube | CENSUS | MIT-R | Spouse
--- | --- | --- | --- |--- |--- |---
Majority Voting | 60.9 | 48.4 | 82.2 | 80.1 | 40.9 | 44.2
Snorkel | 65.3 | 94.7 | 93.5 | 79.1 | 75.6 | 49.2
Classic Self-training | 71.1 | 95.1 | 92.5 | 78.6 | 72.3 | 51.4
**ASTRA** | **80.3** | **95.3** | **95.3** | **83.1** | **76.1** | **62.3**
Our [NAACL'21 paper](https://www.microsoft.com/en-us/research/publication/leaving-no-valuable-knowledge-behind-weak-supervision-with-self-training-and-domain-specific-rules/) describes our ASTRA framework and more experimental results in detail.
## Installation
First, create a conda environment running Python 3.6:
```
conda create --name astra python=3.6
conda activate astra
```
Then, install the required dependencies:
```
pip install -r requirements.txt
```
## Download Data
For reproducibility, you can directly download our pre-processed data files (split into multiple unlabeled/train/dev sets):
```
cd data
bash prepare_data.sh
```
The original datasets are available [here](https://github.com/awasthiabhijeet/Learning-From-Rules).
## Running ASTRA
To replicate our NAACL '21 experiments, you can directly run our bash script:
```
cd scripts
bash run_experiments.sh
```
The above script will run ASTRA and report results under a new "experiments" folder.
You can alternatively run ASTRA with custom arguments as:
```
cd astra
python main.py --dataset <DATASET> --student_name <STUDENT> --teacher_name <TEACHER>
```
Supported STUDENT models:
1. **logreg**: Bag-of-words Logistic Regression classifier
2. **elmo**: ELMO-based classifier
3. **bert**: BERT-based classifier
Supported TEACHER models:
1. **ran**: our Rule Attention Network (RAN)
We will soon add instructions for supporting custom datasets as well as student and teacher components.
## Citation
```
@InProceedings{karamanolakis2021self-training,
author = {Karamanolakis, Giannis and Mukherjee, Subhabrata (Subho) and Zheng, Guoqing and Awadallah, Ahmed H.},
title = {Self-training with Weak Supervision},
booktitle = {NAACL 2021},
year = {2021},
month = {May},
publisher = {NAACL 2021},
url = {https://www.microsoft.com/en-us/research/publication/self-training-weak-supervision-astra/},
}
```
## Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a
Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us
the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide
a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions
provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with any additional questions or comments.
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft
trademarks or logos is subject to and must follow
[Microsoft's Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general).
Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship.
Any use of third-party trademarks or logos are subject to those third-party's policies.
| ASTRA/README.md/0 | {
"file_path": "ASTRA/README.md",
"repo_id": "ASTRA",
"token_count": 1498
} | 20 |
from .LogReg import LogRegTrainer
from .BERT import BertTrainer
from .default_model import DefaultModelTrainer | ASTRA/astra/model/__init__.py/0 | {
"file_path": "ASTRA/astra/model/__init__.py",
"repo_id": "ASTRA",
"token_count": 29
} | 21 |
. ./venv/bin/activate
sudo apt install default-jre -y
seed=110
n_experts=8
vv=lora_adamix
while [[ $# -gt 0 ]]
do
key="$1"
case $key in
--seed)
seed=$2
shift
shift
;;
--n_experts)
n_experts=$2
shift
shift
;;
--vv)
vv=$2
shift
shift
;;
esac
done
python -m torch.distributed.launch --nproc_per_node=16 src/gpt2_beam.py \
--data ./data/e2e/test.jsonl \
--batch_size 1 \
--seq_len 128 \
--eval_len 64 \
--model_card gpt2.md \
--init_checkpoint ./trained_models/GPT2_M/e2e/$seed/$vv/model.final.pt \
--platform local \
--lora_dim 4 \
--lora_alpha 32 \
--beam 10 \
--length_penalty 0.8 \
--no_repeat_ngram_size 4 \
--repetition_penalty 1.0 \
--eos_token_id 628 \
--work_dir ./trained_models/GPT2_M/e2e/$seed/$vv \
--output_file predict.jsonl \
--n_experts $n_experts \
--share_A 0 \
--share_B 1
python src/gpt2_decode.py \
--vocab ./vocab \
--sample_file ./trained_models/GPT2_M/e2e/$seed/$vv/predict.jsonl \
--input_file ./data/e2e/test_formatted.jsonl \
--output_ref_file e2e_ref.txt \
--output_pred_file e2e_pred.txt
python eval/e2e/measure_scores.py e2e_ref.txt e2e_pred.txt -p | AdaMix/NLG/run_eval_e2e.sh/0 | {
"file_path": "AdaMix/NLG/run_eval_e2e.sh",
"repo_id": "AdaMix",
"token_count": 605
} | 22 |
# ------------------------------------------------------------------------------------------
# Copyright (c). All rights reserved.
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
# ------------------------------------------------------------------------------------------
import sys
import io
import json
with open(sys.argv[1], 'r', encoding='utf8') as reader, \
open(sys.argv[2], 'w', encoding='utf8') as writer :
lines_dict = json.load(reader)
full_rela_lst = []
full_src_lst = []
full_tgt_lst = []
unique_src = 0
for example in lines_dict:
rela_lst = []
temp_triples = ''
for i, tripleset in enumerate(example['tripleset']):
subj, rela, obj = tripleset
rela = rela.lower()
rela_lst.append(rela)
if i > 0:
temp_triples += ' | '
temp_triples += '{} : {} : {}'.format(subj, rela, obj)
unique_src += 1
for sent in example['annotations']:
full_tgt_lst.append(sent['text'])
full_src_lst.append(temp_triples)
full_rela_lst.append(rela_lst)
print('unique source is', unique_src)
for src, tgt in zip(full_src_lst, full_tgt_lst):
x = {}
x['context'] = src # context #+ '||'
x['completion'] = tgt #completion
writer.write(json.dumps(x)+'\n') | AdaMix/NLG/src/format_converting_dart.py/0 | {
"file_path": "AdaMix/NLG/src/format_converting_dart.py",
"repo_id": "AdaMix",
"token_count": 597
} | 23 |
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, at the root of the code repository:
```bash
pip install -e ".[docs]"
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look like before committing for instance). You don't have to commit the built documentation.
---
## Packages installed
Here's an overview of all the packages installed. If you ran the previous command installing all packages from
`requirements.txt`, you do not need to run the following commands.
Building it requires the package `sphinx` that you can
install using:
```bash
pip install -U sphinx
```
You would also need the custom installed [theme](https://github.com/readthedocs/sphinx_rtd_theme) by
[Read The Docs](https://readthedocs.org/). You can install it using the following command:
```bash
pip install sphinx_rtd_theme
```
The third necessary package is the `recommonmark` package to accept Markdown as well as Restructured text:
```bash
pip install recommonmark
```
## Building the documentation
Once you have setup `sphinx`, you can build the documentation by running the following command in the `/docs` folder:
```bash
make html
```
A folder called ``_build/html`` should have been created. You can now open the file ``_build/html/index.html`` in your
browser.
---
**NOTE**
If you are adding/removing elements from the toc-tree or from any structural item, it is recommended to clean the build
directory before rebuilding. Run the following command to clean and build:
```bash
make clean && make html
```
---
It should build the static app that will be available under `/docs/_build/html`
## Adding a new element to the tree (toc-tree)
Accepted files are reStructuredText (.rst) and Markdown (.md). Create a file with its extension and put it
in the source directory. You can then link it to the toc-tree by putting the filename without the extension.
## Preview the documentation in a pull request
Once you have made your pull request, you can check what the documentation will look like after it's merged by
following these steps:
- Look at the checks at the bottom of the conversation page of your PR (you may need to click on "show all checks" to
expand them).
- Click on "details" next to the `ci/circleci: build_doc` check.
- In the new window, click on the "Artifacts" tab.
- Locate the file "docs/_build/html/index.html" (or any specific page you want to check) and click on it to get a
preview.
## Writing Documentation - Specification
The `huggingface/transformers` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style. It is
mostly written in ReStructuredText
([Sphinx simple documentation](https://www.sphinx-doc.org/en/master/usage/restructuredtext/index.html),
[Sourceforge complete documentation](https://docutils.sourceforge.io/docs/ref/rst/restructuredtext.html)).
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
- Link that file in `./source/index.rst` on the correct toc-tree.
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
depending on the intended targets (beginners, more advanced users or researchers) it should go in section two, three or
four.
### Adding a new model
When adding a new model:
- Create a file `xxx.rst` under `./source/model_doc` (don't hesitate to copy an existing file as template).
- Link that file in `./source/index.rst` on the `model_doc` toc-tree.
- Write a short overview of the model:
- Overview with paper & authors
- Paper abstract
- Tips and tricks and how to use it best
- Add the classes that should be linked in the model. This generally includes the configuration, the tokenizer, and
every model of that class (the base model, alongside models with additional heads), both in PyTorch and TensorFlow.
The order is generally:
- Configuration,
- Tokenizer
- PyTorch base model
- PyTorch head models
- TensorFlow base model
- TensorFlow head models
These classes should be added using the RST syntax. Usually as follows:
```
XXXConfig
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.XXXConfig
:members:
```
This will include every public method of the configuration that is documented. If for some reason you wish for a method
not to be displayed in the documentation, you can do so by specifying which methods should be in the docs:
```
XXXTokenizer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.XXXTokenizer
:members: build_inputs_with_special_tokens, get_special_tokens_mask,
create_token_type_ids_from_sequences, save_vocabulary
```
### Writing source documentation
Values that should be put in `code` should either be surrounded by double backticks: \`\`like so\`\` or be written as
an object using the :obj: syntax: :obj:\`like so\`. Note that argument names and objects like True, None or any strings
should usually be put in `code`.
When mentionning a class, it is recommended to use the :class: syntax as the mentioned class will be automatically
linked by Sphinx: :class:\`~transformers.XXXClass\`
When mentioning a function, it is recommended to use the :func: syntax as the mentioned function will be automatically
linked by Sphinx: :func:\`~transformers.function\`.
When mentioning a method, it is recommended to use the :meth: syntax as the mentioned method will be automatically
linked by Sphinx: :meth:\`~transformers.XXXClass.method\`.
Links should be done as so (note the double underscore at the end): \`text for the link <./local-link-or-global-link#loc>\`__
#### Defining arguments in a method
Arguments should be defined with the `Args:` prefix, followed by a line return and an indentation.
The argument should be followed by its type, with its shape if it is a tensor, and a line return.
Another indentation is necessary before writing the description of the argument.
Here's an example showcasing everything so far:
```
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using :class:`~transformers.AlbertTokenizer`.
See :meth:`~transformers.PreTrainedTokenizer.encode` and
:meth:`~transformers.PreTrainedTokenizer.__call__` for details.
`What are input IDs? <../glossary.html#input-ids>`__
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```
def my_function(x: str = None, a: float = 1):
```
then its documentation should look like this:
```
Args:
x (:obj:`str`, `optional`):
This argument controls ...
a (:obj:`float`, `optional`, defaults to 1):
This argument is used to ...
```
Note that we always omit the "defaults to :obj:\`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done like so:
```
Example::
# first line of code
# second line
# etc
```
The `Example` string at the beginning can be replaced by anything as long as there are two semicolons following it.
We follow the [doctest](https://docs.python.org/3/library/doctest.html) syntax for the examples to automatically test
the results stay consistent with the library.
#### Writing a return block
Arguments should be defined with the `Args:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example for tuple return, comprising several objects:
```
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
loss (`optional`, returned when ``masked_lm_labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
prediction_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`)
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
Here's an example for a single value return:
```
Returns:
:obj:`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
#### Adding a new section
In ReST section headers are designated as such with the help of a line of underlying characters, e.g.,:
```
Section 1
^^^^^^^^^^^^^^^^^^
Sub-section 1
~~~~~~~~~~~~~~~~~~
```
ReST allows the use of any characters to designate different section levels, as long as they are used consistently within the same document. For details see [sections doc](https://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html#sections). Because there is no standard different documents often end up using different characters for the same levels which makes it very difficult to know which character to use when creating a new section.
Specifically, if when running `make docs` you get an error like:
```
docs/source/main_classes/trainer.rst:127:Title level inconsistent:
```
you picked an inconsistent character for some of the levels.
But how do you know which characters you must use for an already existing level or when adding a new level?
You can use this helper script:
```
perl -ne '/^(.)\1{100,}/ && do { $h{$1}=++$c if !$h{$1} }; END { %h = reverse %h ; print "$_ $h{$_}\n" for sort keys %h}' docs/source/main_classes/trainer.rst
1 -
2 ~
3 ^
4 =
5 "
```
This tells you which characters have already been assigned for each level.
So using this particular example's output -- if your current section's header uses `=` as its underline character, you now know you're at level 4, and if you want to add a sub-section header you know you want `"` as it'd level 5.
If you needed to add yet another sub-level, then pick a character that is not used already. That is you must pick a character that is not in the output of that script.
Here is the full list of characters that can be used in this context: `= - ` : ' " ~ ^ _ * + # < >`
| AdaMix/docs/README.md/0 | {
"file_path": "AdaMix/docs/README.md",
"repo_id": "AdaMix",
"token_count": 3321
} | 24 |
..
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
Fine-tuning with custom datasets
=======================================================================================================================
.. note::
The datasets used in this tutorial are available and can be more easily accessed using the `🤗 NLP library
<https://github.com/huggingface/nlp>`_. We do not use this library to access the datasets here since this tutorial
meant to illustrate how to work with your own data. A brief of introduction can be found at the end of the tutorial
in the section ":ref:`nlplib`".
This tutorial will take you through several examples of using 🤗 Transformers models with your own datasets. The guide
shows one of many valid workflows for using these models and is meant to be illustrative rather than definitive. We
show examples of reading in several data formats, preprocessing the data for several types of tasks, and then preparing
the data into PyTorch/TensorFlow ``Dataset`` objects which can easily be used either with
:class:`~transformers.Trainer`/:class:`~transformers.TFTrainer` or with native PyTorch/TensorFlow.
We include several examples, each of which demonstrates a different type of common downstream task:
- :ref:`seq_imdb`
- :ref:`tok_ner`
- :ref:`qa_squad`
- :ref:`resources`
.. _seq_imdb:
Sequence Classification with IMDb Reviews
-----------------------------------------------------------------------------------------------------------------------
.. note::
This dataset can be explored in the Hugging Face model hub (`IMDb <https://huggingface.co/datasets/imdb>`_), and
can be alternatively downloaded with the 🤗 NLP library with ``load_dataset("imdb")``.
In this example, we'll show how to download, tokenize, and train a model on the IMDb reviews dataset. This task takes
the text of a review and requires the model to predict whether the sentiment of the review is positive or negative.
Let's start by downloading the dataset from the `Large Movie Review Dataset
<http://ai.stanford.edu/~amaas/data/sentiment/>`_ webpage.
.. code-block:: bash
wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
tar -xf aclImdb_v1.tar.gz
This data is organized into ``pos`` and ``neg`` folders with one text file per example. Let's write a function that can
read this in.
.. code-block:: python
from pathlib import Path
def read_imdb_split(split_dir):
split_dir = Path(split_dir)
texts = []
labels = []
for label_dir in ["pos", "neg"]:
for text_file in (split_dir/label_dir).iterdir():
texts.append(text_file.read_text())
labels.append(0 if label_dir is "neg" else 1)
return texts, labels
train_texts, train_labels = read_imdb_split('aclImdb/train')
test_texts, test_labels = read_imdb_split('aclImdb/test')
We now have a train and test dataset, but let's also also create a validation set which we can use for for evaluation
and tuning without tainting our test set results. Sklearn has a convenient utility for creating such splits:
.. code-block:: python
from sklearn.model_selection import train_test_split
train_texts, val_texts, train_labels, val_labels = train_test_split(train_texts, train_labels, test_size=.2)
Alright, we've read in our dataset. Now let's tackle tokenization. We'll eventually train a classifier using
pre-trained DistilBert, so let's use the DistilBert tokenizer.
.. code-block:: python
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')
Now we can simply pass our texts to the tokenizer. We'll pass ``truncation=True`` and ``padding=True``, which will
ensure that all of our sequences are padded to the same length and are truncated to be no longer model's maximum input
length. This will allow us to feed batches of sequences into the model at the same time.
.. code-block:: python
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)
Now, let's turn our labels and encodings into a Dataset object. In PyTorch, this is done by subclassing a
``torch.utils.data.Dataset`` object and implementing ``__len__`` and ``__getitem__``. In TensorFlow, we pass our input
encodings and labels to the ``from_tensor_slices`` constructor method. We put the data in this format so that the data
can be easily batched such that each key in the batch encoding corresponds to a named parameter of the
:meth:`~transformers.DistilBertForSequenceClassification.forward` method of the model we will train.
.. code-block:: python
## PYTORCH CODE
import torch
class IMDbDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = IMDbDataset(train_encodings, train_labels)
val_dataset = IMDbDataset(val_encodings, val_labels)
test_dataset = IMDbDataset(test_encodings, test_labels)
## TENSORFLOW CODE
import tensorflow as tf
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(train_encodings),
train_labels
))
val_dataset = tf.data.Dataset.from_tensor_slices((
dict(val_encodings),
val_labels
))
test_dataset = tf.data.Dataset.from_tensor_slices((
dict(test_encodings),
test_labels
))
Now that our datasets our ready, we can fine-tune a model either with the 🤗
:class:`~transformers.Trainer`/:class:`~transformers.TFTrainer` or with native PyTorch/TensorFlow. See :doc:`training
<training>`.
.. _ft_trainer:
Fine-tuning with Trainer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The steps above prepared the datasets in the way that the trainer is expected. Now all we need to do is create a model
to fine-tune, define the :class:`~transformers.TrainingArguments`/:class:`~transformers.TFTrainingArguments` and
instantiate a :class:`~transformers.Trainer`/:class:`~transformers.TFTrainer`.
.. code-block:: python
## PYTORCH CODE
from transformers import DistilBertForSequenceClassification, Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
trainer.train()
## TENSORFLOW CODE
from transformers import TFDistilBertForSequenceClassification, TFTrainer, TFTrainingArguments
training_args = TFTrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
with training_args.strategy.scope():
model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
trainer = TFTrainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
trainer.train()
.. _ft_native:
Fine-tuning with native PyTorch/TensorFlow
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We can also train use native PyTorch or TensorFlow:
.. code-block:: python
## PYTORCH CODE
from torch.utils.data import DataLoader
from transformers import DistilBertForSequenceClassification, AdamW
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
model.to(device)
model.train()
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
optim = AdamW(model.parameters(), lr=5e-5)
for epoch in range(3):
for batch in train_loader:
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
loss.backward()
optim.step()
model.eval()
## TENSORFLOW CODE
from transformers import TFDistilBertForSequenceClassification
model = TFDistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
model.compile(optimizer=optimizer, loss=model.compute_loss) # can also use any keras loss fn
model.fit(train_dataset.shuffle(1000).batch(16), epochs=3, batch_size=16)
.. _tok_ner:
Token Classification with W-NUT Emerging Entities
-----------------------------------------------------------------------------------------------------------------------
.. note::
This dataset can be explored in the Hugging Face model hub (`WNUT-17 <https://huggingface.co/datasets/wnut_17>`_),
and can be alternatively downloaded with the 🤗 NLP library with ``load_dataset("wnut_17")``.
Next we will look at token classification. Rather than classifying an entire sequence, this task classifies token by
token. We'll demonstrate how to do this with `Named Entity Recognition
<http://nlpprogress.com/english/named_entity_recognition.html>`_, which involves identifying tokens which correspond to
a predefined set of "entities". Specifically, we'll use the `W-NUT Emerging and Rare entities
<http://noisy-text.github.io/2017/emerging-rare-entities.html>`_ corpus. The data is given as a collection of
pre-tokenized documents where each token is assigned a tag.
Let's start by downloading the data.
.. code-block:: bash
wget http://noisy-text.github.io/2017/files/wnut17train.conll
In this case, we'll just download the train set, which is a single text file. Each line of the file contains either (1)
a word and tag separated by a tab, or (2) a blank line indicating the end of a document. Let's write a function to read
this in. We'll take in the file path and return ``token_docs`` which is a list of lists of token strings, and
``token_tags`` which is a list of lists of tag strings.
.. code-block:: python
from pathlib import Path
import re
def read_wnut(file_path):
file_path = Path(file_path)
raw_text = file_path.read_text().strip()
raw_docs = re.split(r'\n\t?\n', raw_text)
token_docs = []
tag_docs = []
for doc in raw_docs:
tokens = []
tags = []
for line in doc.split('\n'):
token, tag = line.split('\t')
tokens.append(token)
tags.append(tag)
token_docs.append(tokens)
tag_docs.append(tags)
return token_docs, tag_docs
texts, tags = read_wnut('wnut17train.conll')
Just to see what this data looks like, let's take a look at a segment of the first document.
.. code-block:: python
>>> print(texts[0][10:17], tags[0][10:17], sep='\n')
['for', 'two', 'weeks', '.', 'Empire', 'State', 'Building']
['O', 'O', 'O', 'O', 'B-location', 'I-location', 'I-location']
``location`` is an entity type, ``B-`` indicates the beginning of an entity, and ``I-`` indicates consecutive positions
of the same entity ("Empire State Building" is considered one entity). ``O`` indicates the token does not correspond to
any entity.
Now that we've read the data in, let's create a train/validation split:
.. code-block:: python
from sklearn.model_selection import train_test_split
train_texts, val_texts, train_tags, val_tags = train_test_split(texts, tags, test_size=.2)
Next, let's create encodings for our tokens and tags. For the tags, we can start by just create a simple mapping which
we'll use in a moment:
.. code-block:: python
unique_tags = set(tag for doc in tags for tag in doc)
tag2id = {tag: id for id, tag in enumerate(unique_tags)}
id2tag = {id: tag for tag, id in tag2id.items()}
To encode the tokens, we'll use a pre-trained DistilBert tokenizer. We can tell the tokenizer that we're dealing with
ready-split tokens rather than full sentence strings by passing ``is_split_into_words=True``. We'll also pass
``padding=True`` and ``truncation=True`` to pad the sequences to be the same length. Lastly, we can tell the model to
return information about the tokens which are split by the wordpiece tokenization process, which we will need in a
moment.
.. code-block:: python
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-cased')
train_encodings = tokenizer(train_texts, is_split_into_words=True, return_offsets_mapping=True, padding=True, truncation=True)
val_encodings = tokenizer(val_texts, is_split_into_words=True, return_offsets_mapping=True, padding=True, truncation=True)
Great, so now our tokens are nicely encoded in the format that they need to be in to feed them into our DistilBert
model below.
Now we arrive at a common obstacle with using pre-trained models for token-level classification: many of the tokens in
the W-NUT corpus are not in DistilBert's vocabulary. Bert and many models like it use a method called WordPiece
Tokenization, meaning that single words are split into multiple tokens such that each token is likely to be in the
vocabulary. For example, DistilBert's tokenizer would split the Twitter handle ``@huggingface`` into the tokens ``['@',
'hugging', '##face']``. This is a problem for us because we have exactly one tag per token. If the tokenizer splits a
token into multiple sub-tokens, then we will end up with a mismatch between our tokens and our labels.
One way to handle this is to only train on the tag labels for the first subtoken of a split token. We can do this in 🤗
Transformers by setting the labels we wish to ignore to ``-100``. In the example above, if the label for
``@HuggingFace`` is ``3`` (indexing ``B-corporation``), we would set the labels of ``['@', 'hugging', '##face']`` to
``[3, -100, -100]``.
Let's write a function to do this. This is where we will use the ``offset_mapping`` from the tokenizer as mentioned
above. For each sub-token returned by the tokenizer, the offset mapping gives us a tuple indicating the sub-token's
start position and end position relative to the original token it was split from. That means that if the first position
in the tuple is anything other than ``0``, we will set its corresponding label to ``-100``. While we're at it, we can
also set labels to ``-100`` if the second position of the offset mapping is ``0``, since this means it must be a
special token like ``[PAD]`` or ``[CLS]``.
.. note::
Due to a recently fixed bug, -1 must be used instead of -100 when using TensorFlow in 🤗 Transformers <= 3.02.
.. code-block:: python
import numpy as np
def encode_tags(tags, encodings):
labels = [[tag2id[tag] for tag in doc] for doc in tags]
encoded_labels = []
for doc_labels, doc_offset in zip(labels, encodings.offset_mapping):
# create an empty array of -100
doc_enc_labels = np.ones(len(doc_offset),dtype=int) * -100
arr_offset = np.array(doc_offset)
# set labels whose first offset position is 0 and the second is not 0
doc_enc_labels[(arr_offset[:,0] == 0) & (arr_offset[:,1] != 0)] = doc_labels
encoded_labels.append(doc_enc_labels.tolist())
return encoded_labels
train_labels = encode_tags(train_tags, train_encodings)
val_labels = encode_tags(val_tags, val_encodings)
The hard part is now done. Just as in the sequence classification example above, we can create a dataset object:
.. code-block:: python
## PYTORCH CODE
import torch
class WNUTDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_encodings.pop("offset_mapping") # we don't want to pass this to the model
val_encodings.pop("offset_mapping")
train_dataset = WNUTDataset(train_encodings, train_labels)
val_dataset = WNUTDataset(val_encodings, val_labels)
## TENSORFLOW CODE
import tensorflow as tf
train_encodings.pop("offset_mapping") # we don't want to pass this to the model
val_encodings.pop("offset_mapping")
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(train_encodings),
train_labels
))
val_dataset = tf.data.Dataset.from_tensor_slices((
dict(val_encodings),
val_labels
))
Now load in a token classification model and specify the number of labels:
.. code-block:: python
## PYTORCH CODE
from transformers import DistilBertForTokenClassification
model = DistilBertForTokenClassification.from_pretrained('distilbert-base-cased', num_labels=len(unique_tags))
## TENSORFLOW CODE
from transformers import TFDistilBertForTokenClassification
model = TFDistilBertForTokenClassification.from_pretrained('distilbert-base-cased', num_labels=len(unique_tags))
The data and model are both ready to go. You can train the model either with
:class:`~transformers.Trainer`/:class:`~transformers.TFTrainer` or with native PyTorch/TensorFlow, exactly as in the
sequence classification example above.
- :ref:`ft_trainer`
- :ref:`ft_native`
.. _qa_squad:
Question Answering with SQuAD 2.0
-----------------------------------------------------------------------------------------------------------------------
.. note::
This dataset can be explored in the Hugging Face model hub (`SQuAD V2
<https://huggingface.co/datasets/squad_v2>`_), and can be alternatively downloaded with the 🤗 NLP library with
``load_dataset("squad_v2")``.
Question answering comes in many forms. In this example, we'll look at the particular type of extractive QA that
involves answering a question about a passage by highlighting the segment of the passage that answers the question.
This involves fine-tuning a model which predicts a start position and an end position in the passage. We will use the
`Stanford Question Answering Dataset (SQuAD) 2.0 <https://rajpurkar.github.io/SQuAD-explorer/>`_.
We will start by downloading the data:
.. code-block:: bash
mkdir squad
wget https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json -O squad/train-v2.0.json
wget https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json -O squad/dev-v2.0.json
Each split is in a structured json file with a number of questions and answers for each passage (or context). We'll
take this apart into parallel lists of contexts, questions, and answers (note that the contexts here are repeated since
there are multiple questions per context):
.. code-block:: python
import json
from pathlib import Path
def read_squad(path):
path = Path(path)
with open(path, 'rb') as f:
squad_dict = json.load(f)
contexts = []
questions = []
answers = []
for group in squad_dict['data']:
for passage in group['paragraphs']:
context = passage['context']
for qa in passage['qas']:
question = qa['question']
for answer in qa['answers']:
contexts.append(context)
questions.append(question)
answers.append(answer)
return contexts, questions, answers
train_contexts, train_questions, train_answers = read_squad('squad/train-v2.0.json')
val_contexts, val_questions, val_answers = read_squad('squad/dev-v2.0.json')
The contexts and questions are just strings. The answers are dicts containing the subsequence of the passage with the
correct answer as well as an integer indicating the character at which the answer begins. In order to train a model on
this data we need (1) the tokenized context/question pairs, and (2) integers indicating at which *token* positions the
answer begins and ends.
First, let's get the *character* position at which the answer ends in the passage (we are given the starting position).
Sometimes SQuAD answers are off by one or two characters, so we will also adjust for that.
.. code-block:: python
def add_end_idx(answers, contexts):
for answer, context in zip(answers, contexts):
gold_text = answer['text']
start_idx = answer['answer_start']
end_idx = start_idx + len(gold_text)
# sometimes squad answers are off by a character or two – fix this
if context[start_idx:end_idx] == gold_text:
answer['answer_end'] = end_idx
elif context[start_idx-1:end_idx-1] == gold_text:
answer['answer_start'] = start_idx - 1
answer['answer_end'] = end_idx - 1 # When the gold label is off by one character
elif context[start_idx-2:end_idx-2] == gold_text:
answer['answer_start'] = start_idx - 2
answer['answer_end'] = end_idx - 2 # When the gold label is off by two characters
add_end_idx(train_answers, train_contexts)
add_end_idx(val_answers, val_contexts)
Now ``train_answers`` and ``val_answers`` include the character end positions and the corrected start positions. Next,
let's tokenize our context/question pairs. 🤗 Tokenizers can accept parallel lists of sequences and encode them together
as sequence pairs.
.. code-block:: python
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')
train_encodings = tokenizer(train_contexts, train_questions, truncation=True, padding=True)
val_encodings = tokenizer(val_contexts, val_questions, truncation=True, padding=True)
Next we need to convert our character start/end positions to token start/end positions. When using 🤗 Fast Tokenizers,
we can use the built in :func:`~transformers.BatchEncoding.char_to_token` method.
.. code-block:: python
def add_token_positions(encodings, answers):
start_positions = []
end_positions = []
for i in range(len(answers)):
start_positions.append(encodings.char_to_token(i, answers[i]['answer_start']))
end_positions.append(encodings.char_to_token(i, answers[i]['answer_end'] - 1))
# if start position is None, the answer passage has been truncated
if start_positions[-1] is None:
start_positions[-1] = tokenizer.model_max_length
if end_positions[-1] is None:
end_positions[-1] = tokenizer.model_max_length
encodings.update({'start_positions': start_positions, 'end_positions': end_positions})
add_token_positions(train_encodings, train_answers)
add_token_positions(val_encodings, val_answers)
Our data is ready. Let's just put it in a PyTorch/TensorFlow dataset so that we can easily use it for training. In
PyTorch, we define a custom ``Dataset`` class. In TensorFlow, we pass a tuple of ``(inputs_dict, labels_dict)`` to the
``from_tensor_slices`` method.
.. code-block:: python
## PYTORCH CODE
import torch
class SquadDataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __getitem__(self, idx):
return {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
def __len__(self):
return len(self.encodings.input_ids)
train_dataset = SquadDataset(train_encodings)
val_dataset = SquadDataset(val_encodings)
## TENSORFLOW CODE
import tensorflow as tf
train_dataset = tf.data.Dataset.from_tensor_slices((
{key: train_encodings[key] for key in ['input_ids', 'attention_mask']},
{key: train_encodings[key] for key in ['start_positions', 'end_positions']}
))
val_dataset = tf.data.Dataset.from_tensor_slices((
{key: val_encodings[key] for key in ['input_ids', 'attention_mask']},
{key: val_encodings[key] for key in ['start_positions', 'end_positions']}
))
Now we can use a DistilBert model with a QA head for training:
.. code-block:: python
## PYTORCH CODE
from transformers import DistilBertForQuestionAnswering
model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
## TENSORFLOW CODE
from transformers import TFDistilBertForQuestionAnswering
model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
The data and model are both ready to go. You can train the model with
:class:`~transformers.Trainer`/:class:`~transformers.TFTrainer` exactly as in the sequence classification example
above. If using native PyTorch, replace ``labels`` with ``start_positions`` and ``end_positions`` in the training
example. If using Keras's ``fit``, we need to make a minor modification to handle this example since it involves
multiple model outputs.
- :ref:`ft_trainer`
.. code-block:: python
## PYTORCH CODE
from torch.utils.data import DataLoader
from transformers import AdamW
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.train()
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
optim = AdamW(model.parameters(), lr=5e-5)
for epoch in range(3):
for batch in train_loader:
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
start_positions = batch['start_positions'].to(device)
end_positions = batch['end_positions'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, start_positions=start_positions, end_positions=end_positions)
loss = outputs[0]
loss.backward()
optim.step()
model.eval()
## TENSORFLOW CODE
# Keras will expect a tuple when dealing with labels
train_dataset = train_dataset.map(lambda x, y: (x, (y['start_positions'], y['end_positions'])))
# Keras will assign a separate loss for each output and add them together. So we'll just use the standard CE loss
# instead of using the built-in model.compute_loss, which expects a dict of outputs and averages the two terms.
# Note that this means the loss will be 2x of when using TFTrainer since we're adding instead of averaging them.
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.distilbert.return_dict = False # if using 🤗 Transformers >3.02, make sure outputs are tuples
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
model.compile(optimizer=optimizer, loss=loss) # can also use any keras loss fn
model.fit(train_dataset.shuffle(1000).batch(16), epochs=3, batch_size=16)
.. _resources:
Additional Resources
-----------------------------------------------------------------------------------------------------------------------
- `How to train a new language model from scratch using Transformers and Tokenizers
<https://huggingface.co/blog/how-to-train>`_. Blog post showing the steps to load in Esperanto data and train a
masked language model from scratch.
- :doc:`Preprocessing <preprocessing>`. Docs page on data preprocessing.
- :doc:`Training <training>`. Docs page on training and fine-tuning.
.. _nlplib:
Using the 🤗 NLP Datasets & Metrics library
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
This tutorial demonstrates how to read in datasets from various raw text formats and prepare them for training with 🤗
Transformers so that you can do the same thing with your own custom datasets. However, we recommend users use the `🤗
NLP library <https://github.com/huggingface/nlp>`_ for working with the 150+ datasets included in the `hub
<https://huggingface.co/datasets>`_, including the three datasets used in this tutorial. As a very brief overview, we
will show how to use the NLP library to download and prepare the IMDb dataset from the first example, :ref:`seq_imdb`.
Start by downloading the dataset:
.. code-block:: python
from nlp import load_dataset
train = load_dataset("imdb", split="train")
Each dataset has multiple columns corresponding to different features. Let's see what our columns are.
.. code-block:: python
>>> print(train.column_names)
['label', 'text']
Great. Now let's tokenize the text. We can do this using the ``map`` method. We'll also rename the ``label`` column to
``labels`` to match the model's input arguments.
.. code-block:: python
train = train.map(lambda batch: tokenizer(batch["text"], truncation=True, padding=True), batched=True)
train.rename_column_("label", "labels")
Lastly, we can use the ``set_format`` method to determine which columns and in what data format we want to access
dataset elements.
.. code-block:: python
## PYTORCH CODE
>>> train.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
>>> {key: val.shape for key, val in train[0].items()})
{'labels': torch.Size([]), 'input_ids': torch.Size([512]), 'attention_mask': torch.Size([512])}
## TENSORFLOW CODE
>>> train.set_format("tensorflow", columns=["input_ids", "attention_mask", "labels"])
>>> {key: val.shape for key, val in train[0].items()})
{'labels': TensorShape([]), 'input_ids': TensorShape([512]), 'attention_mask': TensorShape([512])}
We now have a fully-prepared dataset. Check out `the 🤗 NLP docs <https://huggingface.co/nlp/processing.html>`_ for a
more thorough introduction.
| AdaMix/docs/source/custom_datasets.rst/0 | {
"file_path": "AdaMix/docs/source/custom_datasets.rst",
"repo_id": "AdaMix",
"token_count": 11369
} | 25 |
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Installation
🤗 Transformers is tested on Python 3.6+, and PyTorch 1.1.0+ or TensorFlow 2.0+.
You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're
unfamiliar with Python virtual environments, check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Create a virtual environment with the version of Python you're going
to use and activate it.
Now, if you want to use 🤗 Transformers, you can install it with pip. If you'd like to play with the examples, you
must install it from source.
## Installation with pip
First you need to install one of, or both, TensorFlow 2.0 and PyTorch.
Please refer to [TensorFlow installation page](https://www.tensorflow.org/install/pip#tensorflow-2.0-rc-is-available),
[PyTorch installation page](https://pytorch.org/get-started/locally/#start-locally) and/or
[Flax installation page](https://github.com/google/flax#quick-install)
regarding the specific install command for your platform.
When TensorFlow 2.0 and/or PyTorch has been installed, 🤗 Transformers can be installed using pip as follows:
```bash
pip install transformers
```
Alternatively, for CPU-support only, you can install 🤗 Transformers and PyTorch in one line with:
```bash
pip install transformers[torch]
```
or 🤗 Transformers and TensorFlow 2.0 in one line with:
```bash
pip install transformers[tf-cpu]
```
or 🤗 Transformers and Flax in one line with:
```bash
pip install transformers[flax]
```
To check 🤗 Transformers is properly installed, run the following command:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
It should download a pretrained model then print something like
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
(Note that TensorFlow will print additional stuff before that last statement.)
## Installing from source
Here is how to quickly install `transformers` from source:
```bash
pip install git+https://github.com/huggingface/transformers
```
Note that this will install not the latest released version, but the bleeding edge `master` version, which you may want to use in case a bug has been fixed since the last official release and a new release hasn't been yet rolled out.
While we strive to keep `master` operational at all times, if you notice some issues, they usually get fixed within a few hours or a day and and you're more than welcome to help us detect any problems by opening an [Issue](https://github.com/huggingface/transformers/issues) and this way, things will get fixed even sooner.
Again, you can run:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I hate you'))"
```
to check 🤗 Transformers is properly installed.
## Editable install
If you want to constantly use the bleeding edge `master` version of the source code, or if you want to contribute to the library and need to test the changes in the code you're making, you will need an editable install. This is done by cloning the repository and installing with the following commands:
``` bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
This command performs a magical link between the folder you cloned the repository to and your python library paths, and it'll look inside this folder in addition to the normal library-wide paths. So if normally your python packages get installed into:
```
~/anaconda3/envs/main/lib/python3.7/site-packages/
```
now this editable install will reside where you clone the folder to, e.g. `~/transformers/` and python will search it too.
Do note that you have to keep that `transformers` folder around and not delete it to continue using the `transfomers` library.
Now, let's get to the real benefit of this installation approach. Say, you saw some new feature has been just committed into `master`. If you have already performed all the steps above, to update your transformers to include all the latest commits, all you need to do is to `cd` into that cloned repository folder and update the clone to the latest version:
```
cd ~/transformers/
git pull
```
There is nothing else to do. Your python environment will find the bleeding edge version of `transformers` on the next run.
## With conda
Since Transformers version v4.0.0, we now have a conda channel: `huggingface`.
🤗 Transformers can be installed using conda as follows:
```
conda install -c huggingface transformers
```
Follow the installation pages of TensorFlow, PyTorch or Flax to see how to install them with conda.
## Caching models
This library provides pretrained models that will be downloaded and cached locally. Unless you specify a location with
`cache_dir=...` when you use methods like `from_pretrained`, these models will automatically be downloaded in the
folder given by the shell environment variable ``TRANSFORMERS_CACHE``. The default value for it will be the Hugging
Face cache home followed by ``/transformers/``. This is (by order of priority):
* shell environment variable ``HF_HOME``
* shell environment variable ``XDG_CACHE_HOME`` + ``/huggingface/``
* default: ``~/.cache/huggingface/``
So if you don't have any specific environment variable set, the cache directory will be at
``~/.cache/huggingface/transformers/``.
**Note:** If you have set a shell environment variable for one of the predecessors of this library
(``PYTORCH_TRANSFORMERS_CACHE`` or ``PYTORCH_PRETRAINED_BERT_CACHE``), those will be used if there is no shell
environment variable for ``TRANSFORMERS_CACHE``.
### Note on model downloads (Continuous Integration or large-scale deployments)
If you expect to be downloading large volumes of models (more than 1,000) from our hosted bucket (for instance through
your CI setup, or a large-scale production deployment), please cache the model files on your end. It will be way
faster, and cheaper. Feel free to contact us privately if you need any help.
### Offline mode
It's possible to run 🤗 Transformers in a firewalled or a no-network environment.
Setting environment variable `TRANSFORMERS_OFFLINE=1` will tell 🤗 Transformers to use local files only and will not try to look things up.
Most likely you may want to couple this with `HF_DATASETS_OFFLINE=1` that performs the same for 🤗 Datasets if you're using the latter.
Here is an example of how this can be used on a filesystem that is shared between a normally networked and a firewalled to the external world instances.
On the instance with the normal network run your program which will download and cache models (and optionally datasets if you use 🤗 Datasets). For example:
```
python examples/seq2seq/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
and then with the same filesystem you can now run the same program on a firewalled instance:
```
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/seq2seq/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
and it should succeed without any hanging waiting to timeout.
## Do you want to run a Transformer model on a mobile device?
You should check out our [swift-coreml-transformers](https://github.com/huggingface/swift-coreml-transformers) repo.
It contains a set of tools to convert PyTorch or TensorFlow 2.0 trained Transformer models (currently contains `GPT-2`,
`DistilGPT-2`, `BERT`, and `DistilBERT`) to CoreML models that run on iOS devices.
At some point in the future, you'll be able to seamlessly move from pretraining or fine-tuning models in PyTorch or
TensorFlow 2.0 to productizing them in CoreML, or prototype a model or an app in CoreML then research its
hyperparameters or architecture from PyTorch or TensorFlow 2.0. Super exciting!
| AdaMix/docs/source/installation.md/0 | {
"file_path": "AdaMix/docs/source/installation.md",
"repo_id": "AdaMix",
"token_count": 2341
} | 26 |
..
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
Tokenizer
-----------------------------------------------------------------------------------------------------------------------
A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models. Most
of the tokenizers are available in two flavors: a full python implementation and a "Fast" implementation based on the
Rust library `tokenizers <https://github.com/huggingface/tokenizers>`__. The "Fast" implementations allows:
1. a significant speed-up in particular when doing batched tokenization and
2. additional methods to map between the original string (character and words) and the token space (e.g. getting the
index of the token comprising a given character or the span of characters corresponding to a given token). Currently
no "Fast" implementation is available for the SentencePiece-based tokenizers (for T5, ALBERT, CamemBERT, XLMRoBERTa
and XLNet models).
The base classes :class:`~transformers.PreTrainedTokenizer` and :class:`~transformers.PreTrainedTokenizerFast`
implement the common methods for encoding string inputs in model inputs (see below) and instantiating/saving python and
"Fast" tokenizers either from a local file or directory or from a pretrained tokenizer provided by the library
(downloaded from HuggingFace's AWS S3 repository). They both rely on
:class:`~transformers.tokenization_utils_base.PreTrainedTokenizerBase` that contains the common methods, and
:class:`~transformers.tokenization_utils_base.SpecialTokensMixin`.
:class:`~transformers.PreTrainedTokenizer` and :class:`~transformers.PreTrainedTokenizerFast` thus implement the main
methods for using all the tokenizers:
- Tokenizing (splitting strings in sub-word token strings), converting tokens strings to ids and back, and
encoding/decoding (i.e., tokenizing and converting to integers).
- Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece...).
- Managing special tokens (like mask, beginning-of-sentence, etc.): adding them, assigning them to attributes in the
tokenizer for easy access and making sure they are not split during tokenization.
:class:`~transformers.BatchEncoding` holds the output of the tokenizer's encoding methods (``__call__``,
``encode_plus`` and ``batch_encode_plus``) and is derived from a Python dictionary. When the tokenizer is a pure python
tokenizer, this class behaves just like a standard python dictionary and holds the various model inputs computed by
these methods (``input_ids``, ``attention_mask``...). When the tokenizer is a "Fast" tokenizer (i.e., backed by
HuggingFace `tokenizers library <https://github.com/huggingface/tokenizers>`__), this class provides in addition
several advanced alignment methods which can be used to map between the original string (character and words) and the
token space (e.g., getting the index of the token comprising a given character or the span of characters corresponding
to a given token).
PreTrainedTokenizer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.PreTrainedTokenizer
:special-members: __call__
:members: batch_decode, convert_ids_to_tokens, convert_tokens_to_ids, convert_tokens_to_string, decode, encode,
get_added_vocab, get_special_tokens_mask, num_special_tokens_to_add, prepare_for_tokenization, tokenize,
vocab_size
PreTrainedTokenizerFast
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.PreTrainedTokenizerFast
:special-members: __call__
:members: batch_decode, convert_ids_to_tokens, convert_tokens_to_ids, convert_tokens_to_string, decode, encode,
get_added_vocab, get_special_tokens_mask, num_special_tokens_to_add,
set_truncation_and_padding,tokenize, vocab_size
BatchEncoding
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.BatchEncoding
:members:
| AdaMix/docs/source/main_classes/tokenizer.rst/0 | {
"file_path": "AdaMix/docs/source/main_classes/tokenizer.rst",
"repo_id": "AdaMix",
"token_count": 1233
} | 27 |
..
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
DeBERTa
-----------------------------------------------------------------------------------------------------------------------
Overview
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The DeBERTa model was proposed in `DeBERTa: Decoding-enhanced BERT with Disentangled Attention
<https://arxiv.org/abs/2006.03654>`__ by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
BERT model released in 2018 and Facebook's RoBERTa model released in 2019.
It builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in
RoBERTa.
The abstract from the paper is the following:
*Recent progress in pre-trained neural language models has significantly improved the performance of many natural
language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with
disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the
disentangled attention mechanism, where each word is represented using two vectors that encode its content and
position, respectively, and the attention weights among words are computed using disentangled matrices on their
contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to
predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency
of model pretraining and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of
the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9%
(90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and
pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.*
The original code can be found `here <https://github.com/microsoft/DeBERTa>`__.
DebertaConfig
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaConfig
:members:
DebertaTokenizer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaTokenizer
:members: build_inputs_with_special_tokens, get_special_tokens_mask,
create_token_type_ids_from_sequences, save_vocabulary
DebertaModel
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaModel
:members: forward
DebertaPreTrainedModel
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaPreTrainedModel
:members:
DebertaForMaskedLM
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaForMaskedLM
:members: forward
DebertaForSequenceClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaForSequenceClassification
:members: forward
DebertaForTokenClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaForTokenClassification
:members: forward
DebertaForQuestionAnswering
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.DebertaForQuestionAnswering
:members: forward
| AdaMix/docs/source/model_doc/deberta.rst/0 | {
"file_path": "AdaMix/docs/source/model_doc/deberta.rst",
"repo_id": "AdaMix",
"token_count": 1039
} | 28 |
..
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
Longformer
-----------------------------------------------------------------------------------------------------------------------
**DISCLAIMER:** This model is still a work in progress, if you see something strange, file a `Github Issue
<https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title>`__.
Overview
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The Longformer model was presented in `Longformer: The Long-Document Transformer
<https://arxiv.org/pdf/2004.05150.pdf>`__ by Iz Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
WikiHop and TriviaQA.*
Tips:
- Since the Longformer is based on RoBERTa, it doesn't have :obj:`token_type_ids`. You don't need to indicate which
token belongs to which segment. Just separate your segments with the separation token :obj:`tokenizer.sep_token` (or
:obj:`</s>`).
The Authors' code can be found `here <https://github.com/allenai/longformer>`__.
Longformer Self Attention
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Longformer self attention employs self attention on both a "local" context and a "global" context. Most tokens only
attend "locally" to each other meaning that each token attends to its :math:`\frac{1}{2} w` previous tokens and
:math:`\frac{1}{2} w` succeding tokens with :math:`w` being the window length as defined in
:obj:`config.attention_window`. Note that :obj:`config.attention_window` can be of type :obj:`List` to define a
different :math:`w` for each layer. A selected few tokens attend "globally" to all other tokens, as it is
conventionally done for all tokens in :obj:`BertSelfAttention`.
Note that "locally" and "globally" attending tokens are projected by different query, key and value matrices. Also note
that every "locally" attending token not only attends to tokens within its window :math:`w`, but also to all "globally"
attending tokens so that global attention is *symmetric*.
The user can define which tokens attend "locally" and which tokens attend "globally" by setting the tensor
:obj:`global_attention_mask` at run-time appropriately. All Longformer models employ the following logic for
:obj:`global_attention_mask`:
- 0: the token attends "locally",
- 1: the token attends "globally".
For more information please also refer to :meth:`~transformers.LongformerModel.forward` method.
Using Longformer self attention, the memory and time complexity of the query-key matmul operation, which usually
represents the memory and time bottleneck, can be reduced from :math:`\mathcal{O}(n_s \times n_s)` to
:math:`\mathcal{O}(n_s \times w)`, with :math:`n_s` being the sequence length and :math:`w` being the average window
size. It is assumed that the number of "globally" attending tokens is insignificant as compared to the number of
"locally" attending tokens.
For more information, please refer to the official `paper <https://arxiv.org/pdf/2004.05150.pdf>`__.
Training
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
:class:`~transformers.LongformerForMaskedLM` is trained the exact same way :class:`~transformers.RobertaForMaskedLM` is
trained and should be used as follows:
.. code-block::
input_ids = tokenizer.encode('This is a sentence from [MASK] training data', return_tensors='pt')
mlm_labels = tokenizer.encode('This is a sentence from the training data', return_tensors='pt')
loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
LongformerConfig
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerConfig
:members:
LongformerTokenizer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerTokenizer
:members:
LongformerTokenizerFast
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerTokenizerFast
:members:
Longformer specific outputs
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.models.longformer.modeling_longformer.LongformerBaseModelOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_longformer.LongformerBaseModelOutputWithPooling
:members:
.. autoclass:: transformers.models.longformer.modeling_longformer.LongformerMaskedLMOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_longformer.LongformerQuestionAnsweringModelOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_longformer.LongformerSequenceClassifierOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_longformer.LongformerMultipleChoiceModelOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_longformer.LongformerTokenClassifierOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutputWithPooling
:members:
.. autoclass:: transformers.models.longformer.modeling_tf_longformer.TFLongformerMaskedLMOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_tf_longformer.TFLongformerQuestionAnsweringModelOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_tf_longformer.TFLongformerSequenceClassifierOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_tf_longformer.TFLongformerMultipleChoiceModelOutput
:members:
.. autoclass:: transformers.models.longformer.modeling_tf_longformer.TFLongformerTokenClassifierOutput
:members:
LongformerModel
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerModel
:members: forward
LongformerForMaskedLM
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerForMaskedLM
:members: forward
LongformerForSequenceClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerForSequenceClassification
:members: forward
LongformerForMultipleChoice
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerForMultipleChoice
:members: forward
LongformerForTokenClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerForTokenClassification
:members: forward
LongformerForQuestionAnswering
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.LongformerForQuestionAnswering
:members: forward
TFLongformerModel
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.TFLongformerModel
:members: call
TFLongformerForMaskedLM
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.TFLongformerForMaskedLM
:members: call
TFLongformerForQuestionAnswering
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.TFLongformerForQuestionAnswering
:members: call
TFLongformerForSequenceClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.TFLongformerForSequenceClassification
:members: call
TFLongformerForTokenClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.TFLongformerForTokenClassification
:members: call
TFLongformerForMultipleChoice
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.TFLongformerForMultipleChoice
:members: call
| AdaMix/docs/source/model_doc/longformer.rst/0 | {
"file_path": "AdaMix/docs/source/model_doc/longformer.rst",
"repo_id": "AdaMix",
"token_count": 2558
} | 29 |
..
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
SqueezeBERT
-----------------------------------------------------------------------------------------------------------------------
Overview
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The SqueezeBERT model was proposed in `SqueezeBERT: What can computer vision teach NLP about efficient neural networks?
<https://arxiv.org/abs/2006.11316>`__ by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
SqueezeBERT architecture is that SqueezeBERT uses `grouped convolutions <https://blog.yani.io/filter-group-tutorial>`__
instead of fully-connected layers for the Q, K, V and FFN layers.
The abstract from the paper is the following:
*Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets,
large computing systems, and better neural network models, natural language processing (NLP) technology has made
significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant
opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we
consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today's
highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with
BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods
such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these
techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in
self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called
SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test
set. The SqueezeBERT code will be released.*
Tips:
- SqueezeBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
rather than the left.
- SqueezeBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
with a causal language modeling (CLM) objective are better in that regard.
- For best results when finetuning on sequence classification tasks, it is recommended to start with the
`squeezebert/squeezebert-mnli-headless` checkpoint.
SqueezeBertConfig
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertConfig
:members:
SqueezeBertTokenizer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertTokenizer
:members: build_inputs_with_special_tokens, get_special_tokens_mask,
create_token_type_ids_from_sequences, save_vocabulary
SqueezeBertTokenizerFast
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertTokenizerFast
:members:
SqueezeBertModel
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertModel
:members:
SqueezeBertForMaskedLM
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertForMaskedLM
:members:
SqueezeBertForSequenceClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertForSequenceClassification
:members:
SqueezeBertForMultipleChoice
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertForMultipleChoice
:members:
SqueezeBertForTokenClassification
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertForTokenClassification
:members:
SqueezeBertForQuestionAnswering
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: transformers.SqueezeBertForQuestionAnswering
:members:
| AdaMix/docs/source/model_doc/squeezebert.rst/0 | {
"file_path": "AdaMix/docs/source/model_doc/squeezebert.rst",
"repo_id": "AdaMix",
"token_count": 1251
} | 30 |
..
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
Preprocessing data
=======================================================================================================================
In this tutorial, we'll explore how to preprocess your data using 🤗 Transformers. The main tool for this is what we
call a :doc:`tokenizer <main_classes/tokenizer>`. You can build one using the tokenizer class associated to the model
you would like to use, or directly with the :class:`~transformers.AutoTokenizer` class.
As we saw in the :doc:`quick tour </quicktour>`, the tokenizer will first split a given text in words (or part of
words, punctuation symbols, etc.) usually called `tokens`. Then it will convert those `tokens` into numbers, to be able
to build a tensor out of them and feed them to the model. It will also add any additional inputs the model might expect
to work properly.
.. note::
If you plan on using a pretrained model, it's important to use the associated pretrained tokenizer: it will split
the text you give it in tokens the same way for the pretraining corpus, and it will use the same correspondence
token to index (that we usually call a `vocab`) as during pretraining.
To automatically download the vocab used during pretraining or fine-tuning a given model, you can use the
:func:`~transformers.AutoTokenizer.from_pretrained` method:
.. code-block::
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
Base use
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A :class:`~transformers.PreTrainedTokenizer` has many methods, but the only one you need to remember for preprocessing
is its ``__call__``: you just need to feed your sentence to your tokenizer object.
.. code-block::
>>> encoded_input = tokenizer("Hello, I'm a single sentence!")
>>> print(encoded_input)
{'input_ids': [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
This returns a dictionary string to list of ints. The `input_ids <glossary.html#input-ids>`__ are the indices
corresponding to each token in our sentence. We will see below what the `attention_mask
<glossary.html#attention-mask>`__ is used for and in :ref:`the next section <sentence-pairs>` the goal of
`token_type_ids <glossary.html#token-type-ids>`__.
The tokenizer can decode a list of token ids in a proper sentence:
.. code-block::
>>> tokenizer.decode(encoded_input["input_ids"])
"[CLS] Hello, I'm a single sentence! [SEP]"
As you can see, the tokenizer automatically added some special tokens that the model expects. Not all models need
special tokens; for instance, if we had used `gpt2-medium` instead of `bert-base-cased` to create our tokenizer, we
would have seen the same sentence as the original one here. You can disable this behavior (which is only advised if you
have added those special tokens yourself) by passing ``add_special_tokens=False``.
If you have several sentences you want to process, you can do this efficiently by sending them as a list to the
tokenizer:
.. code-block::
>>> batch_sentences = ["Hello I'm a single sentence",
... "And another sentence",
... "And the very very last one"]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
[101, 1262, 1330, 5650, 102],
[101, 1262, 1103, 1304, 1304, 1314, 1141, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]]}
We get back a dictionary once again, this time with values being lists of lists of ints.
If the purpose of sending several sentences at a time to the tokenizer is to build a batch to feed the model, you will
probably want:
- To pad each sentence to the maximum length there is in your batch.
- To truncate each sentence to the maximum length the model can accept (if applicable).
- To return tensors.
You can do all of this by using the following options when feeding your list of sentences to the tokenizer:
.. code-block::
>>> ## PYTORCH CODE
>>> batch = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(batch)
{'input_ids': tensor([[ 101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
[ 101, 1262, 1330, 5650, 102, 0, 0, 0, 0],
[ 101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0]])}
>>> ## TENSORFLOW CODE
>>> batch = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
>>> print(batch)
{'input_ids': tf.Tensor([[ 101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
[ 101, 1262, 1330, 5650, 102, 0, 0, 0, 0],
[ 101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 0]]),
'token_type_ids': tf.Tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tf.Tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0]])}
It returns a dictionary with string keys and tensor values. We can now see what the `attention_mask
<glossary.html#attention-mask>`__ is all about: it points out which tokens the model should pay attention to and which
ones it should not (because they represent padding in this case).
Note that if your model does not have a maximum length associated to it, the command above will throw a warning. You
can safely ignore it. You can also pass ``verbose=False`` to stop the tokenizer from throwing those kinds of warnings.
.. _sentence-pairs:
Preprocessing pairs of sentences
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Sometimes you need to feed a pair of sentences to your model. For instance, if you want to classify if two sentences in
a pair are similar, or for question-answering models, which take a context and a question. For BERT models, the input
is then represented like this: :obj:`[CLS] Sequence A [SEP] Sequence B [SEP]`
You can encode a pair of sentences in the format expected by your model by supplying the two sentences as two arguments
(not a list since a list of two sentences will be interpreted as a batch of two single sentences, as we saw before).
This will once again return a dict string to list of ints:
.. code-block::
>>> encoded_input = tokenizer("How old are you?", "I'm 6 years old")
>>> print(encoded_input)
{'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, 1201, 1385, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
This shows us what the `token_type_ids <glossary.html#token-type-ids>`__ are for: they indicate to the model which part
of the inputs correspond to the first sentence and which part corresponds to the second sentence. Note that
`token_type_ids` are not required or handled by all models. By default, a tokenizer will only return the inputs that
its associated model expects. You can force the return (or the non-return) of any of those special arguments by using
``return_input_ids`` or ``return_token_type_ids``.
If we decode the token ids we obtained, we will see that the special tokens have been properly added.
.. code-block::
>>> tokenizer.decode(encoded_input["input_ids"])
"[CLS] How old are you? [SEP] I'm 6 years old [SEP]"
If you have a list of pairs of sequences you want to process, you should feed them as two lists to your tokenizer: the
list of first sentences and the list of second sentences:
.. code-block::
>>> batch_sentences = ["Hello I'm a single sentence",
... "And another sentence",
... "And the very very last one"]
>>> batch_of_second_sentences = ["I'm a sentence that goes with the first sentence",
... "And I should be encoded with the second sentence",
... "And I go with the very last one"]
>>> encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102, 146, 112, 182, 170, 5650, 1115, 2947, 1114, 1103, 1148, 5650, 102],
[101, 1262, 1330, 5650, 102, 1262, 146, 1431, 1129, 12544, 1114, 1103, 1248, 5650, 102],
[101, 1262, 1103, 1304, 1304, 1314, 1141, 102, 1262, 146, 1301, 1114, 1103, 1304, 1314, 1141, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
As we can see, it returns a dictionary where each value is a list of lists of ints.
To double-check what is fed to the model, we can decode each list in `input_ids` one by one:
.. code-block::
>>> for ids in encoded_inputs["input_ids"]:
>>> print(tokenizer.decode(ids))
[CLS] Hello I'm a single sentence [SEP] I'm a sentence that goes with the first sentence [SEP]
[CLS] And another sentence [SEP] And I should be encoded with the second sentence [SEP]
[CLS] And the very very last one [SEP] And I go with the very last one [SEP]
Once again, you can automatically pad your inputs to the maximum sentence length in the batch, truncate to the maximum
length the model can accept and return tensors directly with the following:
.. code-block::
## PYTORCH CODE
batch = tokenizer(batch_sentences, batch_of_second_sentences, padding=True, truncation=True, return_tensors="pt")
## TENSORFLOW CODE
batch = tokenizer(batch_sentences, batch_of_second_sentences, padding=True, truncation=True, return_tensors="tf")
Everything you always wanted to know about padding and truncation
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We have seen the commands that will work for most cases (pad your batch to the length of the maximum sentence and
truncate to the maximum length the mode can accept). However, the API supports more strategies if you need them. The
three arguments you need to know for this are :obj:`padding`, :obj:`truncation` and :obj:`max_length`.
- :obj:`padding` controls the padding. It can be a boolean or a string which should be:
- :obj:`True` or :obj:`'longest'` to pad to the longest sequence in the batch (doing no padding if you only provide
a single sequence).
- :obj:`'max_length'` to pad to a length specified by the :obj:`max_length` argument or the maximum length accepted
by the model if no :obj:`max_length` is provided (``max_length=None``). If you only provide a single sequence,
padding will still be applied to it.
- :obj:`False` or :obj:`'do_not_pad'` to not pad the sequences. As we have seen before, this is the default
behavior.
- :obj:`truncation` controls the truncation. It can be a boolean or a string which should be:
- :obj:`True` or :obj:`'only_first'` truncate to a maximum length specified by the :obj:`max_length` argument or
the maximum length accepted by the model if no :obj:`max_length` is provided (``max_length=None``). This will
only truncate the first sentence of a pair if a pair of sequence (or a batch of pairs of sequences) is provided.
- :obj:`'only_second'` truncate to a maximum length specified by the :obj:`max_length` argument or the maximum
length accepted by the model if no :obj:`max_length` is provided (``max_length=None``). This will only truncate
the second sentence of a pair if a pair of sequence (or a batch of pairs of sequences) is provided.
- :obj:`'longest_first'` truncate to a maximum length specified by the :obj:`max_length` argument or the maximum
length accepted by the model if no :obj:`max_length` is provided (``max_length=None``). This will truncate token
by token, removing a token from the longest sequence in the pair until the proper length is reached.
- :obj:`False` or :obj:`'do_not_truncate'` to not truncate the sequences. As we have seen before, this is the
default behavior.
- :obj:`max_length` to control the length of the padding/truncation. It can be an integer or :obj:`None`, in which case
it will default to the maximum length the model can accept. If the model has no specific maximum input length,
truncation/padding to :obj:`max_length` is deactivated.
Here is a table summarizing the recommend way to setup padding and truncation. If you use pair of inputs sequence in
any of the following examples, you can replace :obj:`truncation=True` by a :obj:`STRATEGY` selected in
:obj:`['only_first', 'only_second', 'longest_first']`, i.e. :obj:`truncation='only_second'` or :obj:`truncation=
'longest_first'` to control how both sequence in the pair are truncated as detailed before.
+--------------------------------------+-----------------------------------+---------------------------------------------------------------------------------------------+
| Truncation | Padding | Instruction |
+======================================+===================================+=============================================================================================+
| no truncation | no padding | :obj:`tokenizer(batch_sentences)` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to max sequence in batch | :obj:`tokenizer(batch_sentences, padding=True)` or |
| | | :obj:`tokenizer(batch_sentences, padding='longest')` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to max model input length | :obj:`tokenizer(batch_sentences, padding='max_length')` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to specific length | :obj:`tokenizer(batch_sentences, padding='max_length', max_length=42)` |
+--------------------------------------+-----------------------------------+---------------------------------------------------------------------------------------------+
| truncation to max model input length | no padding | :obj:`tokenizer(batch_sentences, truncation=True)` or |
| | | :obj:`tokenizer(batch_sentences, truncation=STRATEGY)` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to max sequence in batch | :obj:`tokenizer(batch_sentences, padding=True, truncation=True)` or |
| | | :obj:`tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to max model input length | :obj:`tokenizer(batch_sentences, padding='max_length', truncation=True)` or |
| | | :obj:`tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to specific length | Not possible |
+--------------------------------------+-----------------------------------+---------------------------------------------------------------------------------------------+
| truncation to specific length | no padding | :obj:`tokenizer(batch_sentences, truncation=True, max_length=42)` or |
| | | :obj:`tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to max sequence in batch | :obj:`tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` or |
| | | :obj:`tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to max model input length | Not possible |
| +-----------------------------------+---------------------------------------------------------------------------------------------+
| | padding to specific length | :obj:`tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` or |
| | | :obj:`tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
+--------------------------------------+-----------------------------------+---------------------------------------------------------------------------------------------+
Pre-tokenized inputs
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The tokenizer also accept pre-tokenized inputs. This is particularly useful when you want to compute labels and extract
predictions in `named entity recognition (NER) <https://en.wikipedia.org/wiki/Named-entity_recognition>`__ or
`part-of-speech tagging (POS tagging) <https://en.wikipedia.org/wiki/Part-of-speech_tagging>`__.
.. warning::
Pre-tokenized does not mean your inputs are already tokenized (you wouldn't need to pass them through the tokenizer
if that was the case) but just split into words (which is often the first step in subword tokenization algorithms
like BPE).
If you want to use pre-tokenized inputs, just set :obj:`is_split_into_words=True` when passing your inputs to the
tokenizer. For instance, we have:
.. code-block::
>>> encoded_input = tokenizer(["Hello", "I'm", "a", "single", "sentence"], is_split_into_words=True)
>>> print(encoded_input)
{'input_ids': [101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
Note that the tokenizer still adds the ids of special tokens (if applicable) unless you pass
``add_special_tokens=False``.
This works exactly as before for batch of sentences or batch of pairs of sentences. You can encode a batch of sentences
like this:
.. code-block::
batch_sentences = [["Hello", "I'm", "a", "single", "sentence"],
["And", "another", "sentence"],
["And", "the", "very", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, is_split_into_words=True)
or a batch of pair sentences like this:
.. code-block::
batch_of_second_sentences = [["I'm", "a", "sentence", "that", "goes", "with", "the", "first", "sentence"],
["And", "I", "should", "be", "encoded", "with", "the", "second", "sentence"],
["And", "I", "go", "with", "the", "very", "last", "one"]]
encoded_inputs = tokenizer(batch_sentences, batch_of_second_sentences, is_split_into_words=True)
And you can add padding, truncation as well as directly return tensors like before:
.. code-block::
## PYTORCH CODE
batch = tokenizer(batch_sentences,
batch_of_second_sentences,
is_split_into_words=True,
padding=True,
truncation=True,
return_tensors="pt")
## TENSORFLOW CODE
batch = tokenizer(batch_sentences,
batch_of_second_sentences,
is_split_into_words=True,
padding=True,
truncation=True,
return_tensors="tf")
| AdaMix/docs/source/preprocessing.rst/0 | {
"file_path": "AdaMix/docs/source/preprocessing.rst",
"repo_id": "AdaMix",
"token_count": 9253
} | 31 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Benchmarking the library on inference and training in TensorFlow"""
from transformers import HfArgumentParser, TensorFlowBenchmark, TensorFlowBenchmarkArguments
def main():
parser = HfArgumentParser(TensorFlowBenchmarkArguments)
benchmark_args = parser.parse_args_into_dataclasses()[0]
benchmark = TensorFlowBenchmark(args=benchmark_args)
try:
benchmark_args = parser.parse_args_into_dataclasses()[0]
except ValueError as e:
arg_error_msg = "Arg --no_{0} is no longer used, please use --no-{0} instead."
begin_error_msg = " ".join(str(e).split(" ")[:-1])
full_error_msg = ""
depreciated_args = eval(str(e).split(" ")[-1])
wrong_args = []
for arg in depreciated_args:
# arg[2:] removes '--'
if arg[2:] in TensorFlowBenchmark.deprecated_args:
# arg[5:] removes '--no_'
full_error_msg += arg_error_msg.format(arg[5:])
else:
wrong_args.append(arg)
if len(wrong_args) > 0:
full_error_msg = full_error_msg + begin_error_msg + str(wrong_args)
raise ValueError(full_error_msg)
benchmark.run()
if __name__ == "__main__":
main()
| AdaMix/examples/benchmarking/run_benchmark_tf.py/0 | {
"file_path": "AdaMix/examples/benchmarking/run_benchmark_tf.py",
"repo_id": "AdaMix",
"token_count": 724
} | 32 |
#!/usr/bin/env bash
# for seqeval metrics import
pip install -r ../requirements.txt
## The relevant files are currently on a shared Google
## drive at https://drive.google.com/drive/folders/1kC0I2UGl2ltrluI9NqDjaQJGw5iliw_J
## Monitor for changes and eventually migrate to nlp dataset
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SEED=1
export OUTPUT_DIR_NAME=germeval-model
export CURRENT_DIR=${PWD}
export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
mkdir -p $OUTPUT_DIR
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
python3 run_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--train_batch_size $BATCH_SIZE \
--seed $SEED \
--gpus 1 \
--do_train \
--do_predict
| AdaMix/examples/legacy/pytorch-lightning/run_ner.sh/0 | {
"file_path": "AdaMix/examples/legacy/pytorch-lightning/run_ner.sh",
"repo_id": "AdaMix",
"token_count": 719
} | 33 |
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
import transformers
from seq2seq_trainer import Seq2SeqTrainer
from seq2seq_training_args import Seq2SeqTrainingArguments
from transformers import (
AutoConfig,
AutoModelForSeq2SeqLM,
AutoTokenizer,
HfArgumentParser,
MBartTokenizer,
MBartTokenizerFast,
set_seed,
)
from transformers.trainer_utils import EvaluationStrategy, is_main_process
from transformers.training_args import ParallelMode
from utils import (
Seq2SeqDataCollator,
Seq2SeqDataset,
assert_all_frozen,
build_compute_metrics_fn,
check_output_dir,
freeze_embeds,
freeze_params,
lmap,
save_json,
use_task_specific_params,
write_txt_file,
)
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
freeze_encoder: bool = field(default=False, metadata={"help": "Whether tp freeze the encoder."})
freeze_embeds: bool = field(default=False, metadata={"help": "Whether to freeze the embeddings."})
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
data_dir: str = field(
metadata={"help": "The input data dir. Should contain the .tsv files (or other data files) for the task."}
)
task: Optional[str] = field(
default="summarization",
metadata={"help": "Task name, summarization (or summarization_{dataset} for pegasus) or translation"},
)
max_source_length: Optional[int] = field(
default=1024,
metadata={
"help": "The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
max_target_length: Optional[int] = field(
default=128,
metadata={
"help": "The maximum total sequence length for target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
val_max_target_length: Optional[int] = field(
default=142,
metadata={
"help": "The maximum total sequence length for validation target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded. "
"This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
"during ``evaluate`` and ``predict``."
},
)
test_max_target_length: Optional[int] = field(
default=142,
metadata={
"help": "The maximum total sequence length for test target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
n_train: Optional[int] = field(default=-1, metadata={"help": "# training examples. -1 means use all."})
n_val: Optional[int] = field(default=-1, metadata={"help": "# validation examples. -1 means use all."})
n_test: Optional[int] = field(default=-1, metadata={"help": "# test examples. -1 means use all."})
src_lang: Optional[str] = field(default=None, metadata={"help": "Source language id for translation."})
tgt_lang: Optional[str] = field(default=None, metadata={"help": "Target language id for translation."})
eval_beams: Optional[int] = field(default=None, metadata={"help": "# num_beams to use for evaluation."})
ignore_pad_token_for_loss: bool = field(
default=True,
metadata={"help": "If only pad tokens should be ignored. This assumes that `config.pad_token_id` is defined."},
)
def handle_metrics(split, metrics, output_dir):
"""
Log and save metrics
Args:
- split: one of train, val, test
- metrics: metrics dict
- output_dir: where to save the metrics
"""
logger.info(f"***** {split} metrics *****")
for key in sorted(metrics.keys()):
logger.info(f" {key} = {metrics[key]}")
save_json(metrics, os.path.join(output_dir, f"{split}_results.json"))
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
check_output_dir(training_args)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.parallel_mode == ParallelMode.DISTRIBUTED),
training_args.fp16,
)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed
set_seed(training_args.seed)
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
)
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
if getattr(training_args, p, None):
assert hasattr(config, p), f"({config.__class__.__name__}) doesn't have a `{p}` attribute"
setattr(config, p, getattr(training_args, p))
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
)
model = AutoModelForSeq2SeqLM.from_pretrained(
model_args.model_name_or_path,
from_tf=".ckpt" in model_args.model_name_or_path,
config=config,
cache_dir=model_args.cache_dir,
)
# use task specific params
use_task_specific_params(model, data_args.task)
# set num_beams for evaluation
if data_args.eval_beams is None:
data_args.eval_beams = model.config.num_beams
# set decoder_start_token_id for MBart
if model.config.decoder_start_token_id is None and isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
assert (
data_args.tgt_lang is not None and data_args.src_lang is not None
), "mBart requires --tgt_lang and --src_lang"
if isinstance(tokenizer, MBartTokenizer):
model.config.decoder_start_token_id = tokenizer.lang_code_to_id[data_args.tgt_lang]
else:
model.config.decoder_start_token_id = tokenizer.convert_tokens_to_ids(data_args.tgt_lang)
if model_args.freeze_embeds:
freeze_embeds(model)
if model_args.freeze_encoder:
freeze_params(model.get_encoder())
assert_all_frozen(model.get_encoder())
dataset_class = Seq2SeqDataset
# Get datasets
train_dataset = (
dataset_class(
tokenizer,
type_path="train",
data_dir=data_args.data_dir,
n_obs=data_args.n_train,
max_target_length=data_args.max_target_length,
max_source_length=data_args.max_source_length,
prefix=model.config.prefix or "",
)
if training_args.do_train
else None
)
eval_dataset = (
dataset_class(
tokenizer,
type_path="val",
data_dir=data_args.data_dir,
n_obs=data_args.n_val,
max_target_length=data_args.val_max_target_length,
max_source_length=data_args.max_source_length,
prefix=model.config.prefix or "",
)
if training_args.do_eval or training_args.evaluation_strategy != EvaluationStrategy.NO
else None
)
test_dataset = (
dataset_class(
tokenizer,
type_path="test",
data_dir=data_args.data_dir,
n_obs=data_args.n_test,
max_target_length=data_args.test_max_target_length,
max_source_length=data_args.max_source_length,
prefix=model.config.prefix or "",
)
if training_args.do_predict
else None
)
# Initialize our Trainer
compute_metrics_fn = (
build_compute_metrics_fn(data_args.task, tokenizer) if training_args.predict_with_generate else None
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
data_args=data_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=Seq2SeqDataCollator(
tokenizer, data_args, model.config.decoder_start_token_id, training_args.tpu_num_cores
),
compute_metrics=compute_metrics_fn,
tokenizer=tokenizer,
)
all_metrics = {}
# Training
if training_args.do_train:
logger.info("*** Train ***")
train_result = trainer.train(
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
)
metrics = train_result.metrics
metrics["train_n_objs"] = data_args.n_train
trainer.save_model() # this also saves the tokenizer
if trainer.is_world_process_zero():
handle_metrics("train", metrics, training_args.output_dir)
all_metrics.update(metrics)
# Need to save the state, since Trainer.save_model saves only the tokenizer with the model
trainer.state.save_to_json(os.path.join(training_args.output_dir, "trainer_state.json"))
# For convenience, we also re-save the tokenizer to the same directory,
# so that you can share your model easily on huggingface.co/models =)
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate(metric_key_prefix="val")
metrics["val_n_objs"] = data_args.n_val
metrics["val_loss"] = round(metrics["val_loss"], 4)
if trainer.is_world_process_zero():
handle_metrics("val", metrics, training_args.output_dir)
all_metrics.update(metrics)
if training_args.do_predict:
logger.info("*** Predict ***")
test_output = trainer.predict(test_dataset=test_dataset, metric_key_prefix="test")
metrics = test_output.metrics
metrics["test_n_objs"] = data_args.n_test
if trainer.is_world_process_zero():
metrics["test_loss"] = round(metrics["test_loss"], 4)
handle_metrics("test", metrics, training_args.output_dir)
all_metrics.update(metrics)
if training_args.predict_with_generate:
test_preds = tokenizer.batch_decode(
test_output.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
test_preds = lmap(str.strip, test_preds)
write_txt_file(test_preds, os.path.join(training_args.output_dir, "test_generations.txt"))
if trainer.is_world_process_zero():
save_json(all_metrics, os.path.join(training_args.output_dir, "all_results.json"))
return all_metrics
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| AdaMix/examples/legacy/seq2seq/finetune_trainer.py/0 | {
"file_path": "AdaMix/examples/legacy/seq2seq/finetune_trainer.py",
"repo_id": "AdaMix",
"token_count": 5583
} | 34 |
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import fire
from transformers import AutoConfig, AutoModelForSeq2SeqLM, AutoTokenizer
def save_randomly_initialized_version(config_name: str, save_dir: str, **config_kwargs):
"""Save a randomly initialized version of a model using a pretrained config.
Args:
config_name: which config to use
save_dir: where to save the resulting model and tokenizer
config_kwargs: Passed to AutoConfig
Usage::
save_randomly_initialized_version("facebook/bart-large-cnn", "distilbart_random_cnn_6_3", encoder_layers=6, decoder_layers=3, num_beams=3)
"""
cfg = AutoConfig.from_pretrained(config_name, **config_kwargs)
model = AutoModelForSeq2SeqLM.from_config(cfg)
model.save_pretrained(save_dir)
AutoTokenizer.from_pretrained(config_name).save_pretrained(save_dir)
return model
if __name__ == "__main__":
fire.Fire(save_randomly_initialized_version)
| AdaMix/examples/legacy/seq2seq/save_randomly_initialized_model.py/0 | {
"file_path": "AdaMix/examples/legacy/seq2seq/save_randomly_initialized_model.py",
"repo_id": "AdaMix",
"token_count": 498
} | 35 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
export WANDB_PROJECT=distilbart-trainer
export BS=32
export m=sshleifer/student_cnn_12_6
export tok=facebook/bart-large
export MAX_TGT_LEN=142
python finetune_trainer.py \
--model_name_or_path $m --tokenizer_name $tok \
--data_dir cnn_dm \
--output_dir distilbart-cnn-12-6 --overwrite_output_dir \
--learning_rate=3e-5 \
--warmup_steps 500 --sortish_sampler \
--fp16 \
--n_val 500 \
--gradient_accumulation_steps=1 \
--per_device_train_batch_size=$BS --per_device_eval_batch_size=$BS \
--freeze_encoder --freeze_embeds \
--num_train_epochs=2 \
--save_steps 3000 --eval_steps 3000 \
--logging_first_step \
--max_target_length 56 --val_max_target_length $MAX_TGT_LEN --test_max_target_length $MAX_TGT_LEN\
--do_train --do_eval --do_predict \
--evaluation_strategy steps \
--predict_with_generate --sortish_sampler \
"$@"
| AdaMix/examples/legacy/seq2seq/train_distilbart_cnn.sh/0 | {
"file_path": "AdaMix/examples/legacy/seq2seq/train_distilbart_cnn.sh",
"repo_id": "AdaMix",
"token_count": 541
} | 36 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Finetuning the library models for multiple choice (Bert, Roberta, XLNet)."""
import logging
import os
from dataclasses import dataclass, field
from typing import Dict, Optional
import numpy as np
from transformers import (
AutoConfig,
AutoTokenizer,
EvalPrediction,
HfArgumentParser,
TFAutoModelForMultipleChoice,
TFTrainer,
TFTrainingArguments,
set_seed,
)
from transformers.utils import logging as hf_logging
from utils_multiple_choice import Split, TFMultipleChoiceDataset, processors
hf_logging.set_verbosity_info()
hf_logging.enable_default_handler()
hf_logging.enable_explicit_format()
logger = logging.getLogger(__name__)
def simple_accuracy(preds, labels):
return (preds == labels).mean()
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: str = field(metadata={"help": "The name of the task to train on: " + ", ".join(processors.keys())})
data_dir: str = field(metadata={"help": "Should contain the data files for the task."})
max_seq_length: int = field(
default=128,
metadata={
"help": "The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.warning(
"device: %s, n_replicas: %s, 16-bits training: %s",
training_args.device,
training_args.n_replicas,
training_args.fp16,
)
logger.info("Training/evaluation parameters %s", training_args)
# Set seed
set_seed(training_args.seed)
try:
processor = processors[data_args.task_name]()
label_list = processor.get_labels()
num_labels = len(label_list)
except KeyError:
raise ValueError("Task not found: %s" % (data_args.task_name))
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
)
with training_args.strategy.scope():
model = TFAutoModelForMultipleChoice.from_pretrained(
model_args.model_name_or_path,
from_pt=bool(".bin" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
# Get datasets
train_dataset = (
TFMultipleChoiceDataset(
data_dir=data_args.data_dir,
tokenizer=tokenizer,
task=data_args.task_name,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.train,
)
if training_args.do_train
else None
)
eval_dataset = (
TFMultipleChoiceDataset(
data_dir=data_args.data_dir,
tokenizer=tokenizer,
task=data_args.task_name,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.dev,
)
if training_args.do_eval
else None
)
def compute_metrics(p: EvalPrediction) -> Dict:
preds = np.argmax(p.predictions, axis=1)
return {"acc": simple_accuracy(preds, p.label_ids)}
# Initialize our Trainer
trainer = TFTrainer(
model=model,
args=training_args,
train_dataset=train_dataset.get_dataset() if train_dataset else None,
eval_dataset=eval_dataset.get_dataset() if eval_dataset else None,
compute_metrics=compute_metrics,
)
# Training
if training_args.do_train:
trainer.train()
trainer.save_model()
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
result = trainer.evaluate()
output_eval_file = os.path.join(training_args.output_dir, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key, value in result.items():
logger.info(" %s = %s", key, value)
writer.write("%s = %s\n" % (key, value))
results.update(result)
return results
if __name__ == "__main__":
main()
| AdaMix/examples/multiple-choice/run_tf_multiple_choice.py/0 | {
"file_path": "AdaMix/examples/multiple-choice/run_tf_multiple_choice.py",
"repo_id": "AdaMix",
"token_count": 2933
} | 37 |
# coding=utf-8
# Copyright 2020 Google AI, Google Brain, the HuggingFace Inc. team and Microsoft Corporation.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch ALBERT model with Patience-based Early Exit. """
import logging
import torch
import torch.nn as nn
from torch.nn import CrossEntropyLoss, MSELoss
from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
from transformers.models.albert.modeling_albert import (
ALBERT_INPUTS_DOCSTRING,
ALBERT_START_DOCSTRING,
AlbertModel,
AlbertPreTrainedModel,
AlbertTransformer,
)
logger = logging.getLogger(__name__)
class AlbertTransformerWithPabee(AlbertTransformer):
def adaptive_forward(self, hidden_states, current_layer, attention_mask=None, head_mask=None):
if current_layer == 0:
hidden_states = self.embedding_hidden_mapping_in(hidden_states)
else:
hidden_states = hidden_states[0]
layers_per_group = int(self.config.num_hidden_layers / self.config.num_hidden_groups)
# Index of the hidden group
group_idx = int(current_layer / (self.config.num_hidden_layers / self.config.num_hidden_groups))
layer_group_output = self.albert_layer_groups[group_idx](
hidden_states,
attention_mask,
head_mask[group_idx * layers_per_group : (group_idx + 1) * layers_per_group],
)
hidden_states = layer_group_output[0]
return (hidden_states,)
@add_start_docstrings(
"The bare ALBERT Model transformer with PABEE outputting raw hidden-states without any specific head on top.",
ALBERT_START_DOCSTRING,
)
class AlbertModelWithPabee(AlbertModel):
def __init__(self, config):
super().__init__(config)
self.encoder = AlbertTransformerWithPabee(config)
self.init_weights()
self.patience = 0
self.inference_instances_num = 0
self.inference_layers_num = 0
self.regression_threshold = 0
def set_regression_threshold(self, threshold):
self.regression_threshold = threshold
def set_patience(self, patience):
self.patience = patience
def reset_stats(self):
self.inference_instances_num = 0
self.inference_layers_num = 0
def log_stats(self):
avg_inf_layers = self.inference_layers_num / self.inference_instances_num
message = f"*** Patience = {self.patience} Avg. Inference Layers = {avg_inf_layers:.2f} Speed Up = {1 - avg_inf_layers / self.config.num_hidden_layers:.2f} ***"
print(message)
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_dropout=None,
output_layers=None,
regression=False,
):
r"""
Return:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token)
further processed by a Linear layer and a Tanh activation function. The Linear
layer weights are trained from the next sentence prediction (classification)
objective during pre-training.
This output is usually *not* a good summary
of the semantic content of the input, you're often better with averaging or pooling
the sequence of hidden-states for the whole input sequence.
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = embedding_output
if self.training:
res = []
for i in range(self.config.num_hidden_layers):
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs,
current_layer=i,
attention_mask=extended_attention_mask,
head_mask=head_mask,
)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
logits = output_layers[i](output_dropout(pooled_output))
res.append(logits)
elif self.patience == 0: # Use all layers for inference
encoder_outputs = self.encoder(encoder_outputs, extended_attention_mask, head_mask=head_mask)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
res = [output_layers[self.config.num_hidden_layers - 1](pooled_output)]
else:
patient_counter = 0
patient_result = None
calculated_layer_num = 0
for i in range(self.config.num_hidden_layers):
calculated_layer_num += 1
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs,
current_layer=i,
attention_mask=extended_attention_mask,
head_mask=head_mask,
)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
logits = output_layers[i](pooled_output)
if regression:
labels = logits.detach()
if patient_result is not None:
patient_labels = patient_result.detach()
if (patient_result is not None) and torch.abs(patient_result - labels) < self.regression_threshold:
patient_counter += 1
else:
patient_counter = 0
else:
labels = logits.detach().argmax(dim=1)
if patient_result is not None:
patient_labels = patient_result.detach().argmax(dim=1)
if (patient_result is not None) and torch.all(labels.eq(patient_labels)):
patient_counter += 1
else:
patient_counter = 0
patient_result = logits
if patient_counter == self.patience:
break
res = [patient_result]
self.inference_layers_num += calculated_layer_num
self.inference_instances_num += 1
return res
@add_start_docstrings(
"""Albert Model transformer with PABEE and a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
ALBERT_START_DOCSTRING,
)
class AlbertForSequenceClassificationWithPabee(AlbertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.albert = AlbertModelWithPabee(config)
self.dropout = nn.Dropout(config.classifier_dropout_prob)
self.classifiers = nn.ModuleList(
[nn.Linear(config.hidden_size, self.config.num_labels) for _ in range(config.num_hidden_layers)]
)
self.init_weights()
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss.
Indices should be in ``[0, ..., config.num_labels - 1]``.
If ``config.num_labels == 1`` a regression loss is computed (Mean-Square loss),
If ``config.num_labels > 1`` a classification loss is computed (Cross-Entropy).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
loss: (`optional`, returned when ``labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
Classification (or regression if config.num_labels==1) loss.
logits ``torch.FloatTensor`` of shape ``(batch_size, config.num_labels)``
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples::
from transformers import AlbertTokenizer
from pabee import AlbertForSequenceClassificationWithPabee
import torch
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertForSequenceClassificationWithPabee.from_pretrained('albert-base-v2')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=labels)
loss, logits = outputs[:2]
"""
logits = self.albert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_dropout=self.dropout,
output_layers=self.classifiers,
regression=self.num_labels == 1,
)
outputs = (logits[-1],)
if labels is not None:
total_loss = None
total_weights = 0
for ix, logits_item in enumerate(logits):
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits_item.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits_item.view(-1, self.num_labels), labels.view(-1))
if total_loss is None:
total_loss = loss
else:
total_loss += loss * (ix + 1)
total_weights += ix + 1
outputs = (total_loss / total_weights,) + outputs
return outputs
| AdaMix/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_albert.py/0 | {
"file_path": "AdaMix/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_albert.py",
"repo_id": "AdaMix",
"token_count": 6256
} | 38 |
#!/usr/bin/env python3
""" This script is adapted from the Bertology pruning code (https://github.com/huggingface/transformers/blob/783d7d2629e97c5f0c5f9ef01b8c66410275c204/examples/research_projects/bertology/run_bertology.py)
to prune GPT-like models. The author is @altsoph.
"""
import argparse
import logging
import os
from datetime import datetime
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, TensorDataset
from tqdm import tqdm
from transformers import GPT2LMHeadModel
logger = logging.getLogger(__name__)
def save_model(model, dirpath):
# save results
if os.path.exists(dirpath):
if os.path.exists(os.path.join(dirpath, "config.json")) and os.path.isfile(
os.path.join(dirpath, "config.json")
):
os.remove(os.path.join(dirpath, "config.json"))
if os.path.exists(os.path.join(dirpath, "pytorch_model.bin")) and os.path.isfile(
os.path.join(dirpath, "pytorch_model.bin")
):
os.remove(os.path.join(dirpath, "pytorch_model.bin"))
else:
os.makedirs(dirpath)
model.save_pretrained(dirpath)
def entropy(p, unlogit=False):
""" Compute the entropy of a probability distribution """
exponent = 2
if unlogit:
p = torch.pow(p, exponent)
plogp = p * torch.log(p)
plogp[p == 0] = 0
return -plogp.sum(dim=-1)
def print_2d_tensor(tensor):
""" Print a 2D tensor """
logger.info("lv, h >\t" + "\t".join(f"{x + 1}" for x in range(len(tensor))))
for row in range(len(tensor)):
if tensor.dtype != torch.long:
logger.info(f"layer {row + 1}:\t" + "\t".join(f"{x:.5f}" for x in tensor[row].cpu().data))
else:
logger.info(f"layer {row + 1}:\t" + "\t".join(f"{x:d}" for x in tensor[row].cpu().data))
def compute_heads_importance(
args, model, eval_dataloader, compute_entropy=True, compute_importance=True, head_mask=None, actually_pruned=False
):
"""This method shows how to compute:
- head attention entropy
- head importance scores according to http://arxiv.org/abs/1905.10650
"""
# Prepare our tensors
n_layers, n_heads = model.config.num_hidden_layers, model.config.num_attention_heads
head_importance = torch.zeros(n_layers, n_heads).to(args.device)
attn_entropy = torch.zeros(n_layers, n_heads).to(args.device)
if head_mask is None:
head_mask = torch.ones(n_layers, n_heads).to(args.device)
head_mask.requires_grad_(requires_grad=True)
# If actually pruned attention multi-head, set head mask to None to avoid shape mismatch
if actually_pruned:
head_mask = None
tot_tokens = 0.0
total_loss = 0.0
for step, inputs in enumerate(tqdm(eval_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])):
inputs = tuple(t.to(args.device) for t in inputs)
(input_ids,) = inputs
# Do a forward pass (not with torch.no_grad() since we need gradients for importance score - see below)
outputs = model(input_ids, labels=input_ids, head_mask=head_mask)
# (loss), lm_logits, presents, (all hidden_states), (attentions)
loss, _, all_attentions = (
outputs[0],
outputs[1],
outputs[-1],
) # Loss and logits are the first, attention the last
loss.backward() # Backpropagate to populate the gradients in the head mask
total_loss += loss.detach().cpu().numpy()
if compute_entropy:
for layer, attn in enumerate(all_attentions):
masked_entropy = entropy(attn.detach(), True)
attn_entropy[layer] += masked_entropy.sum(-1).sum(0).sum(0).detach()
if compute_importance:
head_importance += head_mask.grad.abs().detach()
tot_tokens += torch.ones_like(input_ids).float().detach().sum().data
# Normalize
attn_entropy /= tot_tokens
head_importance /= tot_tokens
# Layerwise importance normalization
if not args.dont_normalize_importance_by_layer:
exponent = 2
norm_by_layer = torch.pow(torch.pow(head_importance, exponent).sum(-1), 1 / exponent)
head_importance /= norm_by_layer.unsqueeze(-1) + 1e-20
if not args.dont_normalize_global_importance:
head_importance = (head_importance - head_importance.min()) / (head_importance.max() - head_importance.min())
# Print matrices
if compute_entropy:
logger.info("Attention entropies")
print_2d_tensor(attn_entropy)
if compute_importance:
logger.info("Head importance scores")
print_2d_tensor(head_importance)
logger.info("Head ranked by importance scores")
head_ranks = torch.zeros(head_importance.numel(), dtype=torch.long, device=args.device)
head_ranks[head_importance.view(-1).sort(descending=True)[1]] = torch.arange(
head_importance.numel(), device=args.device
)
head_ranks = head_ranks.view_as(head_importance)
print_2d_tensor(head_ranks)
return attn_entropy, head_importance, total_loss
def mask_heads(args, model, eval_dataloader):
"""This method shows how to mask head (set some heads to zero), to test the effect on the network,
based on the head importance scores, as described in Michel et al. (http://arxiv.org/abs/1905.10650)
"""
_, head_importance, loss = compute_heads_importance(args, model, eval_dataloader, compute_entropy=False)
original_score = 1 / loss # instead of downsteam score use the LM loss
logger.info("Pruning: original score: %f, threshold: %f", original_score, original_score * args.masking_threshold)
new_head_mask = torch.ones_like(head_importance)
num_to_mask = max(1, int(new_head_mask.numel() * args.masking_amount))
current_score = original_score
while current_score >= original_score * args.masking_threshold:
head_mask = new_head_mask.clone().detach() # save current head mask
# heads from least important to most - keep only not-masked heads
head_importance[head_mask == 0.0] = float("Inf")
current_heads_to_mask = head_importance.view(-1).sort()[1]
if len(current_heads_to_mask) <= num_to_mask:
print("BREAK BY num_to_mask")
break
# mask heads
current_heads_to_mask = current_heads_to_mask[:num_to_mask]
logger.info("Heads to mask: %s", str(current_heads_to_mask.tolist()))
new_head_mask = new_head_mask.view(-1)
new_head_mask[current_heads_to_mask] = 0.0
new_head_mask = new_head_mask.view_as(head_mask)
new_head_mask = new_head_mask.clone().detach()
print_2d_tensor(new_head_mask)
# Compute metric and head importance again
_, head_importance, loss = compute_heads_importance(
args, model, eval_dataloader, compute_entropy=False, head_mask=new_head_mask
)
current_score = 1 / loss
logger.info(
"Masking: current score: %f, remaining heads %d (%.1f percents)",
current_score,
new_head_mask.sum(),
new_head_mask.sum() / new_head_mask.numel() * 100,
)
logger.info("Final head mask")
print_2d_tensor(head_mask)
np.save(os.path.join(args.output_dir, "head_mask.npy"), head_mask.detach().cpu().numpy())
return head_mask
def prune_heads(args, model, eval_dataloader, head_mask):
"""This method shows how to prune head (remove heads weights) based on
the head importance scores as described in Michel et al. (http://arxiv.org/abs/1905.10650)
"""
# Try pruning and test time speedup
# Pruning is like masking but we actually remove the masked weights
before_time = datetime.now()
_, _, loss = compute_heads_importance(
args, model, eval_dataloader, compute_entropy=False, compute_importance=False, head_mask=head_mask
)
score_masking = 1 / loss
original_time = datetime.now() - before_time
original_num_params = sum(p.numel() for p in model.parameters())
heads_to_prune = dict(
(layer, (1 - head_mask[layer].long()).nonzero().squeeze().tolist()) for layer in range(len(head_mask))
)
for k, v in heads_to_prune.items():
if isinstance(v, int):
heads_to_prune[k] = [
v,
]
assert sum(len(h) for h in heads_to_prune.values()) == (1 - head_mask.long()).sum().item()
model.prune_heads(heads_to_prune)
pruned_num_params = sum(p.numel() for p in model.parameters())
before_time = datetime.now()
_, _, loss = compute_heads_importance(
args,
model,
eval_dataloader,
compute_entropy=False,
compute_importance=False,
head_mask=None,
actually_pruned=True,
)
score_pruning = 1 / loss
new_time = datetime.now() - before_time
logger.info(
"Pruning: original num of params: %.2e, after pruning %.2e (%.1f percents)",
original_num_params,
pruned_num_params,
pruned_num_params / original_num_params * 100,
)
logger.info("Pruning: score with masking: %f score with pruning: %f", score_masking, score_pruning)
logger.info("Pruning: speed ratio (original timing / new timing): %f percents", original_time / new_time * 100)
save_model(model, args.output_dir)
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the .tsv files (or other data files) for the task.",
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
# Other parameters
parser.add_argument(
"--config_name",
default="",
type=str,
help="Pretrained config name or path if not the same as model_name_or_path",
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name_or_path",
)
parser.add_argument(
"--cache_dir",
default=None,
type=str,
help="Where do you want to store the pre-trained models downloaded from s3",
)
parser.add_argument(
"--data_subset", type=int, default=-1, help="If > 0: limit the data to a subset of data_subset instances."
)
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Whether to overwrite data in output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--dont_normalize_importance_by_layer", action="store_true", help="Don't normalize importance score by layers"
)
parser.add_argument(
"--dont_normalize_global_importance",
action="store_true",
help="Don't normalize all importance scores between 0 and 1",
)
parser.add_argument(
"--try_masking", action="store_true", help="Whether to try to mask head until a threshold of accuracy."
)
parser.add_argument(
"--masking_threshold",
default=0.9,
type=float,
help="masking threshold in term of metrics (stop masking when metric < threshold * original metric value).",
)
parser.add_argument(
"--masking_amount", default=0.1, type=float, help="Amount to heads to masking at each masking step."
)
parser.add_argument("--metric_name", default="acc", type=str, help="Metric to use for head masking.")
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help="The maximum total input sequence length after WordPiece tokenization. \n"
"Sequences longer than this will be truncated, sequences shorter padded.",
)
parser.add_argument("--batch_size", default=1, type=int, help="Batch size.")
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
args = parser.parse_args()
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup devices and distributed training
if args.local_rank == -1 or args.no_cuda:
args.device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else:
torch.cuda.set_device(args.local_rank)
args.device = torch.device("cuda", args.local_rank)
args.n_gpu = 1
torch.distributed.init_process_group(backend="nccl") # Initializes the distributed backend
# Setup logging
logging.basicConfig(level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN)
logger.info("device: {} n_gpu: {}, distributed: {}".format(args.device, args.n_gpu, bool(args.local_rank != -1)))
model = GPT2LMHeadModel.from_pretrained(args.model_name_or_path)
# Distributed and parallel training
model.to(args.device)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
elif args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Print/save training arguments
os.makedirs(args.output_dir, exist_ok=True)
torch.save(args, os.path.join(args.output_dir, "run_args.bin"))
logger.info("Training/evaluation parameters %s", args)
# Prepare dataset
numpy_data = np.concatenate(
[
np.loadtxt(args.data_dir, dtype=np.int64),
]
)
train_tensor_dataset = (torch.from_numpy(numpy_data),)
train_data = TensorDataset(*train_tensor_dataset)
train_sampler = RandomSampler(train_data)
eval_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.batch_size)
# Compute head entropy and importance score
compute_heads_importance(args, model, eval_dataloader)
# Try head masking (set heads to zero until the score goes under a threshole)
# and head pruning (remove masked heads and see the effect on the network)
if args.try_masking and args.masking_threshold > 0.0 and args.masking_threshold < 1.0:
head_mask = mask_heads(args, model, eval_dataloader)
prune_heads(args, model, eval_dataloader, head_mask)
if __name__ == "__main__":
main()
| AdaMix/examples/research_projects/bertology/run_prune_gpt.py/0 | {
"file_path": "AdaMix/examples/research_projects/bertology/run_prune_gpt.py",
"repo_id": "AdaMix",
"token_count": 6310
} | 39 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" This is the exact same script as `examples/question-answering/run_squad.py` (as of 2020, January 8th) with an additional and optional step of distillation."""
import argparse
import glob
import logging
import os
import random
import timeit
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
import transformers
from transformers import (
WEIGHTS_NAME,
AdamW,
BertConfig,
BertForQuestionAnswering,
BertTokenizer,
DistilBertConfig,
DistilBertForQuestionAnswering,
DistilBertTokenizer,
RobertaConfig,
RobertaForQuestionAnswering,
RobertaTokenizer,
XLMConfig,
XLMForQuestionAnswering,
XLMTokenizer,
XLNetConfig,
XLNetForQuestionAnswering,
XLNetTokenizer,
get_linear_schedule_with_warmup,
squad_convert_examples_to_features,
)
from transformers.data.metrics.squad_metrics import (
compute_predictions_log_probs,
compute_predictions_logits,
squad_evaluate,
)
from transformers.data.processors.squad import SquadResult, SquadV1Processor, SquadV2Processor
from transformers.trainer_utils import is_main_process
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
MODEL_CLASSES = {
"bert": (BertConfig, BertForQuestionAnswering, BertTokenizer),
"xlnet": (XLNetConfig, XLNetForQuestionAnswering, XLNetTokenizer),
"xlm": (XLMConfig, XLMForQuestionAnswering, XLMTokenizer),
"distilbert": (DistilBertConfig, DistilBertForQuestionAnswering, DistilBertTokenizer),
"roberta": (RobertaConfig, RobertaForQuestionAnswering, RobertaTokenizer),
}
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def to_list(tensor):
return tensor.detach().cpu().tolist()
def train(args, train_dataset, model, tokenizer, teacher=None):
""" Train the model """
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
# Check if saved optimizer or scheduler states exist
if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
os.path.join(args.model_name_or_path, "scheduler.pt")
):
# Load in optimizer and scheduler states
optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 1
epochs_trained = 0
steps_trained_in_current_epoch = 0
# Check if continuing training from a checkpoint
if os.path.exists(args.model_name_or_path):
try:
# set global_step to gobal_step of last saved checkpoint from model path
checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
global_step = int(checkpoint_suffix)
epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
logger.info(" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(" Continuing training from global step %d", global_step)
logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
except ValueError:
logger.info(" Starting fine-tuning.")
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
)
# Added here for reproductibility
set_seed(args)
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
# Skip past any already trained steps if resuming training
if steps_trained_in_current_epoch > 0:
steps_trained_in_current_epoch -= 1
continue
model.train()
if teacher is not None:
teacher.eval()
batch = tuple(t.to(args.device) for t in batch)
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"start_positions": batch[3],
"end_positions": batch[4],
}
if args.model_type != "distilbert":
inputs["token_type_ids"] = None if args.model_type == "xlm" else batch[2]
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
if args.version_2_with_negative:
inputs.update({"is_impossible": batch[7]})
outputs = model(**inputs)
loss, start_logits_stu, end_logits_stu = outputs
# Distillation loss
if teacher is not None:
if "token_type_ids" not in inputs:
inputs["token_type_ids"] = None if args.teacher_type == "xlm" else batch[2]
with torch.no_grad():
start_logits_tea, end_logits_tea = teacher(
input_ids=inputs["input_ids"],
token_type_ids=inputs["token_type_ids"],
attention_mask=inputs["attention_mask"],
)
assert start_logits_tea.size() == start_logits_stu.size()
assert end_logits_tea.size() == end_logits_stu.size()
loss_fct = nn.KLDivLoss(reduction="batchmean")
loss_start = (
loss_fct(
F.log_softmax(start_logits_stu / args.temperature, dim=-1),
F.softmax(start_logits_tea / args.temperature, dim=-1),
)
* (args.temperature ** 2)
)
loss_end = (
loss_fct(
F.log_softmax(end_logits_stu / args.temperature, dim=-1),
F.softmax(end_logits_tea / args.temperature, dim=-1),
)
* (args.temperature ** 2)
)
loss_ce = (loss_start + loss_end) / 2.0
loss = args.alpha_ce * loss_ce + args.alpha_squad * loss
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
# Log metrics
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Only evaluate when single GPU otherwise metrics may not average well
if args.local_rank == -1 and args.evaluate_during_training:
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar("eval_{}".format(key), value, global_step)
tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
logging_loss = tr_loss
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
logger.info("Saving optimizer and scheduler states to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, model, tokenizer, prefix=""):
dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
os.makedirs(args.output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu evaluate
if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):
model = torch.nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
all_results = []
start_time = timeit.default_timer()
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {"input_ids": batch[0], "attention_mask": batch[1]}
if args.model_type != "distilbert":
inputs["token_type_ids"] = None if args.model_type == "xlm" else batch[2] # XLM don't use segment_ids
example_indices = batch[3]
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
outputs = model(**inputs)
for i, example_index in enumerate(example_indices):
eval_feature = features[example_index.item()]
unique_id = int(eval_feature.unique_id)
output = [to_list(output[i]) for output in outputs]
# Some models (XLNet, XLM) use 5 arguments for their predictions, while the other "simpler"
# models only use two.
if len(output) >= 5:
start_logits = output[0]
start_top_index = output[1]
end_logits = output[2]
end_top_index = output[3]
cls_logits = output[4]
result = SquadResult(
unique_id,
start_logits,
end_logits,
start_top_index=start_top_index,
end_top_index=end_top_index,
cls_logits=cls_logits,
)
else:
start_logits, end_logits = output
result = SquadResult(unique_id, start_logits, end_logits)
all_results.append(result)
evalTime = timeit.default_timer() - start_time
logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(dataset))
# Compute predictions
output_prediction_file = os.path.join(args.output_dir, "predictions_{}.json".format(prefix))
output_nbest_file = os.path.join(args.output_dir, "nbest_predictions_{}.json".format(prefix))
if args.version_2_with_negative:
output_null_log_odds_file = os.path.join(args.output_dir, "null_odds_{}.json".format(prefix))
else:
output_null_log_odds_file = None
if args.model_type in ["xlnet", "xlm"]:
# XLNet uses a more complex post-processing procedure
predictions = compute_predictions_log_probs(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
model.config.start_n_top,
model.config.end_n_top,
args.version_2_with_negative,
tokenizer,
args.verbose_logging,
)
else:
predictions = compute_predictions_logits(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
args.do_lower_case,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
args.verbose_logging,
args.version_2_with_negative,
args.null_score_diff_threshold,
tokenizer,
)
# Compute the F1 and exact scores.
results = squad_evaluate(examples, predictions)
return results
def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
if args.local_rank not in [-1, 0] and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
# Load data features from cache or dataset file
input_file = args.predict_file if evaluate else args.train_file
cached_features_file = os.path.join(
os.path.dirname(input_file),
"cached_distillation_{}_{}_{}".format(
"dev" if evaluate else "train",
list(filter(None, args.model_name_or_path.split("/"))).pop(),
str(args.max_seq_length),
),
)
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features_and_dataset = torch.load(cached_features_file)
try:
features, dataset, examples = (
features_and_dataset["features"],
features_and_dataset["dataset"],
features_and_dataset["examples"],
)
except KeyError:
raise DeprecationWarning(
"You seem to be loading features from an older version of this script please delete the "
"file %s in order for it to be created again" % cached_features_file
)
else:
logger.info("Creating features from dataset file at %s", input_file)
processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
if evaluate:
examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
else:
examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
features, dataset = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
return_dataset="pt",
threads=args.threads,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save({"features": features, "dataset": dataset, "examples": examples}, cached_features_file)
if args.local_rank == 0 and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
if output_examples:
return dataset, examples, features
return dataset
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model checkpoints and predictions will be written.",
)
# Distillation parameters (optional)
parser.add_argument(
"--teacher_type",
default=None,
type=str,
help="Teacher type. Teacher tokenizer and student (model) tokenizer must output the same tokenization. Only for distillation.",
)
parser.add_argument(
"--teacher_name_or_path",
default=None,
type=str,
help="Path to the already SQuAD fine-tuned teacher model. Only for distillation.",
)
parser.add_argument(
"--alpha_ce", default=0.5, type=float, help="Distillation loss linear weight. Only for distillation."
)
parser.add_argument(
"--alpha_squad", default=0.5, type=float, help="True SQuAD loss linear weight. Only for distillation."
)
parser.add_argument(
"--temperature", default=2.0, type=float, help="Distillation temperature. Only for distillation."
)
# Other parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
help="The input data dir. Should contain the .json files for the task."
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--train_file",
default=None,
type=str,
help="The input training file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--predict_file",
default=None,
type=str,
help="The input evaluation file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--version_2_with_negative",
action="store_true",
help="If true, the SQuAD examples contain some that do not have an answer.",
)
parser.add_argument(
"--null_score_diff_threshold",
type=float,
default=0.0,
help="If null_score - best_non_null is greater than the threshold predict null.",
)
parser.add_argument(
"--max_seq_length",
default=384,
type=int,
help="The maximum total input sequence length after WordPiece tokenization. Sequences "
"longer than this will be truncated, and sequences shorter than this will be padded.",
)
parser.add_argument(
"--doc_stride",
default=128,
type=int,
help="When splitting up a long document into chunks, how much stride to take between chunks.",
)
parser.add_argument(
"--max_query_length",
default=64,
type=int,
help="The maximum number of tokens for the question. Questions longer than this will "
"be truncated to this length.",
)
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--evaluate_during_training", action="store_true", help="Rul evaluation during training at each logging step."
)
parser.add_argument(
"--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
)
parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument(
"--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument(
"--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument(
"--n_best_size",
default=20,
type=int,
help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
)
parser.add_argument(
"--max_answer_length",
default=30,
type=int,
help="The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another.",
)
parser.add_argument(
"--verbose_logging",
action="store_true",
help="If true, all of the warnings related to data processing will be printed. "
"A number of warnings are expected for a normal SQuAD evaluation.",
)
parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
"See details at https://nvidia.github.io/apex/amp.html",
)
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--threads", type=int, default=1, help="multiple threads for converting example to features")
args = parser.parse_args()
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Set seed
set_seed(args)
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
args.model_type = args.model_type.lower()
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
config = config_class.from_pretrained(
args.config_name if args.config_name else args.model_name_or_path,
cache_dir=args.cache_dir if args.cache_dir else None,
)
tokenizer = tokenizer_class.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir if args.cache_dir else None,
)
model = model_class.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir if args.cache_dir else None,
)
if args.teacher_type is not None:
assert args.teacher_name_or_path is not None
assert args.alpha_ce > 0.0
assert args.alpha_ce + args.alpha_squad > 0.0
assert args.teacher_type != "distilbert", "We constraint teachers not to be of type DistilBERT."
teacher_config_class, teacher_model_class, _ = MODEL_CLASSES[args.teacher_type]
teacher_config = teacher_config_class.from_pretrained(
args.teacher_name_or_path, cache_dir=args.cache_dir if args.cache_dir else None
)
teacher = teacher_model_class.from_pretrained(
args.teacher_name_or_path, config=teacher_config, cache_dir=args.cache_dir if args.cache_dir else None
)
teacher.to(args.device)
else:
teacher = None
if args.local_rank == 0:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
# Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum if args.fp16 is set.
# Otherwise it'll default to "promote" mode, and we'll get fp32 operations. Note that running `--fp16_opt_level="O2"` will
# remove the need for this code, but it is still valid.
if args.fp16:
try:
import apex
apex.amp.register_half_function(torch, "einsum")
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
# Training
if args.do_train:
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer, teacher=teacher)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Save the trained model and the tokenizer
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = model_class.from_pretrained(args.output_dir)
tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
model.to(args.device)
# Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
if args.do_train:
logger.info("Loading checkpoints saved during training for evaluation")
checkpoints = [args.output_dir]
if args.eval_all_checkpoints:
checkpoints = list(
os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
)
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
# Reload the model
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
model = model_class.from_pretrained(checkpoint)
model.to(args.device)
# Evaluate
result = evaluate(args, model, tokenizer, prefix=global_step)
result = dict((k + ("_{}".format(global_step) if global_step else ""), v) for k, v in result.items())
results.update(result)
logger.info("Results: {}".format(results))
return results
if __name__ == "__main__":
main()
| AdaMix/examples/research_projects/distillation/run_squad_w_distillation.py/0 | {
"file_path": "AdaMix/examples/research_projects/distillation/run_squad_w_distillation.py",
"repo_id": "AdaMix",
"token_count": 15414
} | 40 |
# LXMERT DEMO
1. make a virtualenv: ``virtualenv venv`` and activate ``source venv/bin/activate``
2. install reqs: ``pip install -r ./requirements.txt``
3. usage is as shown in demo.ipynb
| AdaMix/examples/research_projects/lxmert/README.md/0 | {
"file_path": "AdaMix/examples/research_projects/lxmert/README.md",
"repo_id": "AdaMix",
"token_count": 65
} | 41 |
<jupyter_start><jupyter_text>Saving PruneBERTThis notebook aims at showcasing how we can leverage standard tools to save (and load) an extremely sparse model fine-pruned with [movement pruning](https://arxiv.org/abs/2005.07683) (or any other unstructured pruning mehtod).In this example, we used BERT (base-uncased, but the procedure described here is not specific to BERT and can be applied to a large variety of models.We first obtain an extremely sparse model by fine-pruning with movement pruning on SQuAD v1.1. We then used the following combination of standard tools:- We reduce the precision of the model with Int8 dynamic quantization using [PyTorch implementation](https://pytorch.org/tutorials/intermediate/dynamic_quantization_bert_tutorial.html). We only quantized the Fully Connected Layers.- Sparse quantized matrices are converted into the [Compressed Sparse Row format](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html).- We use HDF5 with `gzip` compression to store the weights.We experiment with a question answering model with only 6% of total remaining weights in the encoder (previously obtained with movement pruning). **We are able to reduce the memory size of the encoder from 340MB (original dense BERT) to 11MB**, which fits on a [91' floppy disk](https://en.wikipedia.org/wiki/Floptical)!*Note: this notebook is compatible with `torch>=1.5.0` If you are using, `torch==1.4.0`, please refer to [this previous version of the notebook](https://github.com/huggingface/transformers/commit/b11386e158e86e62d4041eabd86d044cd1695737).*<jupyter_code># Includes
import h5py
import os
import json
from collections import OrderedDict
from scipy import sparse
import numpy as np
import torch
from torch import nn
from transformers import *
os.chdir('../../')<jupyter_output><empty_output><jupyter_text>Saving Dynamic quantization induces little or no loss of performance while significantly reducing the memory footprint.<jupyter_code># Load fine-pruned model and quantize the model
model = BertForQuestionAnswering.from_pretrained("huggingface/prunebert-base-uncased-6-finepruned-w-distil-squad")
model.to('cpu')
quantized_model = torch.quantization.quantize_dynamic(
model=model,
qconfig_spec = {
torch.nn.Linear : torch.quantization.default_dynamic_qconfig,
},
dtype=torch.qint8,
)
# print(quantized_model)
qtz_st = quantized_model.state_dict()
# Saving the original (encoder + classifier) in the standard torch.save format
dense_st = {name: param for name, param in model.state_dict().items()
if "embedding" not in name and "pooler" not in name}
torch.save(dense_st, 'dbg/dense_squad.pt',)
dense_mb_size = os.path.getsize("dbg/dense_squad.pt")
# Elementary representation: we decompose the quantized tensors into (scale, zero_point, int_repr).
# See https://pytorch.org/docs/stable/quantization.html
# We further leverage the fact that int_repr is sparse matrix to optimize the storage: we decompose int_repr into
# its CSR representation (data, indptr, indices).
elementary_qtz_st = {}
for name, param in qtz_st.items():
if "dtype" not in name and param.is_quantized:
print("Decompose quantization for", name)
# We need to extract the scale, the zero_point and the int_repr for the quantized tensor and modules
scale = param.q_scale() # torch.tensor(1,) - float32
zero_point = param.q_zero_point() # torch.tensor(1,) - int32
elementary_qtz_st[f"{name}.scale"] = scale
elementary_qtz_st[f"{name}.zero_point"] = zero_point
# We assume the int_repr is sparse and compute its CSR representation
# Only the FCs in the encoder are actually sparse
int_repr = param.int_repr() # torch.tensor(nb_rows, nb_columns) - int8
int_repr_cs = sparse.csr_matrix(int_repr) # scipy.sparse.csr.csr_matrix
elementary_qtz_st[f"{name}.int_repr.data"] = int_repr_cs.data # np.array int8
elementary_qtz_st[f"{name}.int_repr.indptr"] = int_repr_cs.indptr # np.array int32
assert max(int_repr_cs.indices) < 65535 # If not, we shall fall back to int32
elementary_qtz_st[f"{name}.int_repr.indices"] = np.uint16(int_repr_cs.indices) # np.array uint16
elementary_qtz_st[f"{name}.int_repr.shape"] = int_repr_cs.shape # tuple(int, int)
else:
elementary_qtz_st[name] = param
# Create mapping from torch.dtype to string description (we could also used an int8 instead of string)
str_2_dtype = {"qint8": torch.qint8}
dtype_2_str = {torch.qint8: "qint8"}
# Saving the pruned (encoder + classifier) in the standard torch.save format
dense_optimized_st = {name: param for name, param in elementary_qtz_st.items()
if "embedding" not in name and "pooler" not in name}
torch.save(dense_optimized_st, 'dbg/dense_squad_optimized.pt',)
print("Encoder Size (MB) - Sparse & Quantized - `torch.save`:",
round(os.path.getsize("dbg/dense_squad_optimized.pt")/1e6, 2))
# Save the decomposed state_dict with an HDF5 file
# Saving only the encoder + QA Head
with h5py.File('dbg/squad_sparse.h5','w') as hf:
for name, param in elementary_qtz_st.items():
if "embedding" in name:
print(f"Skip {name}")
continue
if "pooler" in name:
print(f"Skip {name}")
continue
if type(param) == torch.Tensor:
if param.numel() == 1:
# module scale
# module zero_point
hf.attrs[name] = param
continue
if param.requires_grad:
# LayerNorm
param = param.detach().numpy()
hf.create_dataset(name, data=param, compression="gzip", compression_opts=9)
elif type(param) == float or type(param) == int or type(param) == tuple:
# float - tensor _packed_params.weight.scale
# int - tensor _packed_params.weight.zero_point
# tuple - tensor _packed_params.weight.shape
hf.attrs[name] = param
elif type(param) == torch.dtype:
# dtype - tensor _packed_params.dtype
hf.attrs[name] = dtype_2_str[param]
else:
hf.create_dataset(name, data=param, compression="gzip", compression_opts=9)
with open('dbg/metadata.json', 'w') as f:
f.write(json.dumps(qtz_st._metadata))
size = os.path.getsize("dbg/squad_sparse.h5") + os.path.getsize("dbg/metadata.json")
print("")
print("Encoder Size (MB) - Dense: ", round(dense_mb_size/1e6, 2))
print("Encoder Size (MB) - Sparse & Quantized:", round(size/1e6, 2))
# Save the decomposed state_dict to HDF5 storage
# Save everything in the architecutre (embedding + encoder + QA Head)
with h5py.File('dbg/squad_sparse_with_embs.h5','w') as hf:
for name, param in elementary_qtz_st.items():
# if "embedding" in name:
# print(f"Skip {name}")
# continue
# if "pooler" in name:
# print(f"Skip {name}")
# continue
if type(param) == torch.Tensor:
if param.numel() == 1:
# module scale
# module zero_point
hf.attrs[name] = param
continue
if param.requires_grad:
# LayerNorm
param = param.detach().numpy()
hf.create_dataset(name, data=param, compression="gzip", compression_opts=9)
elif type(param) == float or type(param) == int or type(param) == tuple:
# float - tensor _packed_params.weight.scale
# int - tensor _packed_params.weight.zero_point
# tuple - tensor _packed_params.weight.shape
hf.attrs[name] = param
elif type(param) == torch.dtype:
# dtype - tensor _packed_params.dtype
hf.attrs[name] = dtype_2_str[param]
else:
hf.create_dataset(name, data=param, compression="gzip", compression_opts=9)
with open('dbg/metadata.json', 'w') as f:
f.write(json.dumps(qtz_st._metadata))
size = os.path.getsize("dbg/squad_sparse_with_embs.h5") + os.path.getsize("dbg/metadata.json")
print('\nSize (MB):', round(size/1e6, 2))<jupyter_output>Size (MB): 99.41<jupyter_text>Loading<jupyter_code># Reconstruct the elementary state dict
reconstructed_elementary_qtz_st = {}
hf = h5py.File('dbg/squad_sparse_with_embs.h5','r')
for attr_name, attr_param in hf.attrs.items():
if 'shape' in attr_name:
attr_param = tuple(attr_param)
elif ".scale" in attr_name:
if "_packed_params" in attr_name:
attr_param = float(attr_param)
else:
attr_param = torch.tensor(attr_param)
elif ".zero_point" in attr_name:
if "_packed_params" in attr_name:
attr_param = int(attr_param)
else:
attr_param = torch.tensor(attr_param)
elif ".dtype" in attr_name:
attr_param = str_2_dtype[attr_param]
reconstructed_elementary_qtz_st[attr_name] = attr_param
# print(f"Unpack {attr_name}")
# Get the tensors/arrays
for data_name, data_param in hf.items():
if "LayerNorm" in data_name or "_packed_params.bias" in data_name:
reconstructed_elementary_qtz_st[data_name] = torch.from_numpy(np.array(data_param))
elif "embedding" in data_name:
reconstructed_elementary_qtz_st[data_name] = torch.from_numpy(np.array(data_param))
else: # _packed_params.weight.int_repr.data, _packed_params.weight.int_repr.indices and _packed_params.weight.int_repr.indptr
data_param = np.array(data_param)
if "indices" in data_name:
data_param = np.array(data_param, dtype=np.int32)
reconstructed_elementary_qtz_st[data_name] = data_param
# print(f"Unpack {data_name}")
hf.close()
# Sanity checks
for name, param in reconstructed_elementary_qtz_st.items():
assert name in elementary_qtz_st
for name, param in elementary_qtz_st.items():
assert name in reconstructed_elementary_qtz_st, name
for name, param in reconstructed_elementary_qtz_st.items():
assert type(param) == type(elementary_qtz_st[name]), name
if type(param) == torch.Tensor:
assert torch.all(torch.eq(param, elementary_qtz_st[name])), name
elif type(param) == np.ndarray:
assert (param == elementary_qtz_st[name]).all(), name
else:
assert param == elementary_qtz_st[name], name
# Re-assemble the sparse int_repr from the CSR format
reconstructed_qtz_st = {}
for name, param in reconstructed_elementary_qtz_st.items():
if "weight.int_repr.indptr" in name:
prefix_ = name[:-16]
data = reconstructed_elementary_qtz_st[f"{prefix_}.int_repr.data"]
indptr = reconstructed_elementary_qtz_st[f"{prefix_}.int_repr.indptr"]
indices = reconstructed_elementary_qtz_st[f"{prefix_}.int_repr.indices"]
shape = reconstructed_elementary_qtz_st[f"{prefix_}.int_repr.shape"]
int_repr = sparse.csr_matrix(arg1=(data, indices, indptr),
shape=shape)
int_repr = torch.tensor(int_repr.todense())
scale = reconstructed_elementary_qtz_st[f"{prefix_}.scale"]
zero_point = reconstructed_elementary_qtz_st[f"{prefix_}.zero_point"]
weight = torch._make_per_tensor_quantized_tensor(int_repr,
scale,
zero_point)
reconstructed_qtz_st[f"{prefix_}"] = weight
elif "int_repr.data" in name or "int_repr.shape" in name or "int_repr.indices" in name or \
"weight.scale" in name or "weight.zero_point" in name:
continue
else:
reconstructed_qtz_st[name] = param
# Sanity checks
for name, param in reconstructed_qtz_st.items():
assert name in qtz_st
for name, param in qtz_st.items():
assert name in reconstructed_qtz_st, name
for name, param in reconstructed_qtz_st.items():
assert type(param) == type(qtz_st[name]), name
if type(param) == torch.Tensor:
assert torch.all(torch.eq(param, qtz_st[name])), name
elif type(param) == np.ndarray:
assert (param == qtz_st[name]).all(), name
else:
assert param == qtz_st[name], name<jupyter_output><empty_output><jupyter_text>Sanity checks<jupyter_code># Load the re-constructed state dict into a model
dummy_model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
dummy_model.to('cpu')
reconstructed_qtz_model = torch.quantization.quantize_dynamic(
model=dummy_model,
qconfig_spec = None,
dtype=torch.qint8,
)
reconstructed_qtz_st = OrderedDict(reconstructed_qtz_st)
with open('dbg/metadata.json', 'r') as read_file:
metadata = json.loads(read_file.read())
reconstructed_qtz_st._metadata = metadata
reconstructed_qtz_model.load_state_dict(reconstructed_qtz_st)
# Sanity checks on the infernce
N = 32
for _ in range(25):
inputs = torch.randint(low=0, high=30000, size=(N, 128))
mask = torch.ones(size=(N, 128))
y_reconstructed = reconstructed_qtz_model(input_ids=inputs, attention_mask=mask)[0]
y = quantized_model(input_ids=inputs, attention_mask=mask)[0]
assert torch.all(torch.eq(y, y_reconstructed))
print("Sanity check passed")<jupyter_output>Sanity check passed | AdaMix/examples/research_projects/movement-pruning/Saving_PruneBERT.ipynb/0 | {
"file_path": "AdaMix/examples/research_projects/movement-pruning/Saving_PruneBERT.ipynb",
"repo_id": "AdaMix",
"token_count": 5972
} | 42 |
# coding=utf-8
# Copyright 2020 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...) with whole word masking on a
text file or a dataset.
Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
https://huggingface.co/models?filter=masked-lm
"""
import logging
import os
import sys
from dataclasses import dataclass, field
# You can also adapt this script on your own masked language modeling task. Pointers for this are left as comments.
from pathlib import Path
from typing import Dict, List, Optional, Tuple
import numpy as np
from datasets import load_dataset
from tqdm import tqdm
import jax
import jax.numpy as jnp
from flax import jax_utils
from flax.optim import Adam
from flax.training import common_utils
from flax.training.common_utils import get_metrics
from jax.nn import log_softmax
from modeling_flax_performer import FlaxPerformerForMaskedLM
from transformers import (
MODEL_FOR_MASKED_LM_MAPPING,
AutoTokenizer,
BertConfig,
FlaxBertForMaskedLM,
HfArgumentParser,
PreTrainedTokenizerBase,
TensorType,
TrainingArguments,
is_tensorboard_available,
set_seed,
)
# Cache the result
has_tensorboard = is_tensorboard_available()
if has_tensorboard:
try:
from flax.metrics.tensorboard import SummaryWriter
except ImportError as ie:
has_tensorboard = False
print(f"Unable to display metrics through TensorBoard because some package are not installed: {ie}")
else:
print(
"Unable to display metrics through TensorBoard because the package is not installed: "
"Please run pip install tensorboard to enable."
)
MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_LM_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class WandbArguments:
"""
Arguments for logging
"""
wandb_user_name: Optional[str] = field(
default=None,
metadata={"help": "The WandB user name for potential logging. If left None, no logging"},
)
wandb_project_name: Optional[str] = field(
default="performer-experiments",
metadata={"help": "The WandB project name for potential logging"},
)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": "The model checkpoint for weights initialization."
"Don't set if you want to train a model from scratch."
},
)
performer: bool = field(
default=False,
metadata={"help": "Whether to use FAVOR+ attention"},
)
reinitialize: bool = field(
default=False,
metadata={"help": "Whether to use a blank model without pretraining"},
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
train_ref_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input train ref data file for whole word masking in Chinese."},
)
validation_ref_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input validation ref data file for whole word masking in Chinese."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
validation_split_percentage: Optional[int] = field(
default=5,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
max_seq_length: Optional[int] = field(
default=None,
metadata={
"help": "The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated. Default to the max input length of the model."
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
mlm_probability: float = field(
default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
)
pad_to_max_length: bool = field(
default=False,
metadata={
"help": "Whether to pad all samples to `max_seq_length`. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
# Adapted from transformers/data/data_collator.py
# Letting here for now, let's discuss where it should live
@dataclass
class FlaxDataCollatorForLanguageModeling:
"""
Data collator used for language modeling. Inputs are dynamically padded to the maximum length of a batch if they
are not all of the same length.
Args:
tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
The tokenizer used for encoding the data.
mlm (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to use masked language modeling. If set to :obj:`False`, the labels are the same as the
inputs with the padding tokens ignored (by setting them to -100). Otherwise, the labels are -100 for
non-masked tokens and the value to predict for the masked token.
mlm_probability (:obj:`float`, `optional`, defaults to 0.15):
The probability with which to (randomly) mask tokens in the input, when :obj:`mlm` is set to :obj:`True`.
.. note::
For best performance, this data collator should be used with a dataset having items that are dictionaries or
BatchEncoding, with the :obj:`"special_tokens_mask"` key, as returned by a
:class:`~transformers.PreTrainedTokenizer` or a :class:`~transformers.PreTrainedTokenizerFast` with the
argument :obj:`return_special_tokens_mask=True`.
"""
tokenizer: PreTrainedTokenizerBase
mlm: bool = True
mlm_probability: float = 0.15
def __post_init__(self):
if self.mlm and self.tokenizer.mask_token is None:
raise ValueError(
"This tokenizer does not have a mask token which is necessary for masked language modeling. "
"You should pass `mlm=False` to train on causal language modeling instead."
)
def __call__(self, examples: List[Dict[str, np.ndarray]], pad_to_multiple_of: int) -> Dict[str, np.ndarray]:
# Handle dict or lists with proper padding and conversion to tensor.
batch = self.tokenizer.pad(examples, pad_to_multiple_of=pad_to_multiple_of, return_tensors=TensorType.NUMPY)
# If special token mask has been preprocessed, pop it from the dict.
special_tokens_mask = batch.pop("special_tokens_mask", None)
if self.mlm:
batch["input_ids"], batch["labels"] = self.mask_tokens(
batch["input_ids"], special_tokens_mask=special_tokens_mask
)
else:
labels = batch["input_ids"].copy()
if self.tokenizer.pad_token_id is not None:
labels[labels == self.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
def mask_tokens(
self, inputs: np.ndarray, special_tokens_mask: Optional[np.ndarray]
) -> Tuple[jnp.ndarray, jnp.ndarray]:
"""
Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
"""
labels = inputs.copy()
# We sample a few tokens in each sequence for MLM training (with probability `self.mlm_probability`)
probability_matrix = np.full(labels.shape, self.mlm_probability)
special_tokens_mask = special_tokens_mask.astype("bool")
probability_matrix[special_tokens_mask] = 0.0
masked_indices = np.random.binomial(1, probability_matrix).astype("bool")
labels[~masked_indices] = -100 # We only compute loss on masked tokens
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
indices_replaced = np.random.binomial(1, np.full(labels.shape, 0.8)).astype("bool") & masked_indices
inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
# 10% of the time, we replace masked input tokens with random word
indices_random = np.random.binomial(1, np.full(labels.shape, 0.5)).astype("bool")
indices_random &= masked_indices & ~indices_replaced
random_words = np.random.randint(self.tokenizer.vocab_size, size=labels.shape, dtype="i4")
inputs[indices_random] = random_words[indices_random]
# The rest of the time (10% of the time) we keep the masked input tokens unchanged
return inputs, labels
def create_learning_rate_scheduler(
factors="constant * linear_warmup * rsqrt_decay",
base_learning_rate=0.5,
warmup_steps=1000,
decay_factor=0.5,
steps_per_decay=20000,
steps_per_cycle=100000,
):
"""Creates learning rate schedule.
Interprets factors in the factors string which can consist of:
* constant: interpreted as the constant value,
* linear_warmup: interpreted as linear warmup until warmup_steps,
* rsqrt_decay: divide by square root of max(step, warmup_steps)
* rsqrt_normalized_decay: divide by square root of max(step/warmup_steps, 1)
* decay_every: Every k steps decay the learning rate by decay_factor.
* cosine_decay: Cyclic cosine decay, uses steps_per_cycle parameter.
Args:
factors: string, factors separated by "*" that defines the schedule.
base_learning_rate: float, the starting constant for the lr schedule.
warmup_steps: int, how many steps to warm up for in the warmup schedule.
decay_factor: float, the amount to decay the learning rate by.
steps_per_decay: int, how often to decay the learning rate.
steps_per_cycle: int, steps per cycle when using cosine decay.
Returns:
a function learning_rate(step): float -> {"learning_rate": float}, the
step-dependent lr.
"""
factors = [n.strip() for n in factors.split("*")]
def step_fn(step):
"""Step to learning rate function."""
ret = 1.0
for name in factors:
if name == "constant":
ret *= base_learning_rate
elif name == "linear_warmup":
ret *= jnp.minimum(1.0, step / warmup_steps)
elif name == "rsqrt_decay":
ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
elif name == "rsqrt_normalized_decay":
ret *= jnp.sqrt(warmup_steps)
ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
elif name == "decay_every":
ret *= decay_factor ** (step // steps_per_decay)
elif name == "cosine_decay":
progress = jnp.maximum(0.0, (step - warmup_steps) / float(steps_per_cycle))
ret *= jnp.maximum(0.0, 0.5 * (1.0 + jnp.cos(jnp.pi * (progress % 1.0))))
else:
raise ValueError("Unknown factor %s." % name)
return jnp.asarray(ret, dtype=jnp.float32)
return step_fn
def compute_metrics(logits, labels, weights, label_smoothing=0.0):
"""Compute summary metrics."""
loss, normalizer = cross_entropy(logits, labels, weights, label_smoothing)
acc, _ = accuracy(logits, labels, weights)
metrics = {"loss": loss, "accuracy": acc, "normalizer": normalizer}
metrics = jax.lax.psum(metrics, axis_name="batch")
return metrics
def accuracy(logits, targets, weights=None):
"""Compute weighted accuracy for log probs and targets.
Args:
logits: [batch, length, num_classes] float array.
targets: categorical targets [batch, length] int array.
weights: None or array of shape [batch, length]
Returns:
Tuple of scalar loss and batch normalizing factor.
"""
if logits.ndim != targets.ndim + 1:
raise ValueError(
"Incorrect shapes. Got shape %s logits and %s targets" % (str(logits.shape), str(targets.shape))
)
loss = jnp.equal(jnp.argmax(logits, axis=-1), targets)
loss *= weights
return loss.sum(), weights.sum()
def cross_entropy(logits, targets, weights=None, label_smoothing=0.0):
"""Compute cross entropy and entropy for log probs and targets.
Args:
logits: [batch, length, num_classes] float array.
targets: categorical targets [batch, length] int array.
weights: None or array of shape [batch, length]
label_smoothing: label smoothing constant, used to determine the on and off values.
Returns:
Tuple of scalar loss and batch normalizing factor.
"""
if logits.ndim != targets.ndim + 1:
raise ValueError(
"Incorrect shapes. Got shape %s logits and %s targets" % (str(logits.shape), str(targets.shape))
)
vocab_size = logits.shape[-1]
confidence = 1.0 - label_smoothing
low_confidence = (1.0 - confidence) / (vocab_size - 1)
normalizing_constant = -(
confidence * jnp.log(confidence) + (vocab_size - 1) * low_confidence * jnp.log(low_confidence + 1e-20)
)
soft_targets = common_utils.onehot(targets, vocab_size, on_value=confidence, off_value=low_confidence)
loss = -jnp.sum(soft_targets * log_softmax(logits), axis=-1)
loss = loss - normalizing_constant
if weights is not None:
loss = loss * weights
normalizing_factor = weights.sum()
else:
normalizing_factor = np.prod(targets.shape)
return loss.sum(), normalizing_factor
def training_step(optimizer, batch, dropout_rng):
dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
def loss_fn(params):
targets = batch.pop("labels")
# Hide away tokens which doesn't participate in the optimization
token_mask = jnp.where(targets > 0, 1.0, 0.0)
logits = model(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
loss, weight_sum = cross_entropy(logits, targets, token_mask)
return loss / weight_sum
step = optimizer.state.step
lr = lr_scheduler_fn(step)
grad_fn = jax.value_and_grad(loss_fn)
loss, grad = grad_fn(optimizer.target)
grad = jax.lax.pmean(grad, "batch")
optimizer = optimizer.apply_gradient(grad, learning_rate=lr)
return loss, optimizer, new_dropout_rng
def eval_step(params, batch):
"""
Calculate evaluation metrics on a batch.
"""
targets = batch.pop("labels")
# Hide away tokens which doesn't participate in the optimization
token_mask = jnp.where(targets > 0, 1.0, 0.0)
logits = model(**batch, params=params, train=False)[0]
return compute_metrics(logits, targets, token_mask)
def generate_batch_splits(samples_idx: jnp.ndarray, batch_size: int) -> jnp.ndarray:
nb_samples = len(samples_idx)
samples_to_remove = nb_samples % batch_size
if samples_to_remove != 0:
samples_idx = samples_idx[:-samples_to_remove]
sections_split = nb_samples // batch_size
batch_idx = np.split(samples_idx, sections_split)
return batch_idx
if __name__ == "__main__":
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments, WandbArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args, wandb_args = parser.parse_json_file(
json_file=os.path.abspath(sys.argv[1])
)
else:
model_args, data_args, training_args, wandb_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty."
"Use --overwrite_output_dir to overcome."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
level="NOTSET",
datefmt="[%X]",
)
# Log on each process the small summary:
logger = logging.getLogger(__name__)
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
# Set the verbosity to info of the Transformers logger (on main process only):
logger.info("Training/evaluation parameters %s", training_args)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
if "validation" not in datasets.keys():
datasets["validation"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[:{data_args.validation_split_percentage}%]",
)
datasets["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[{data_args.validation_split_percentage}%:]",
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.train_file.split(".")[-1]
if extension == "txt":
extension = "text"
datasets = load_dataset(extension, data_files=data_files)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.html.
# Load pretrained model and tokenizer
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
rng = jax.random.PRNGKey(training_args.seed)
dropout_rngs = jax.random.split(rng, jax.local_device_count())
config = BertConfig.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
lm_class = FlaxPerformerForMaskedLM if model_args.performer else FlaxBertForMaskedLM
if model_args.reinitialize:
model = lm_class(config=BertConfig.from_pretrained(model_args.model_name_or_path))
else:
model = lm_class.from_pretrained(
model_args.model_name_or_path,
dtype=jnp.float32,
input_shape=(training_args.train_batch_size, config.max_position_embeddings),
seed=training_args.seed,
dropout_rate=0.1,
)
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
# Preprocessing the datasets.
# First we tokenize all the texts.
if training_args.do_train:
column_names = datasets["train"].column_names
else:
column_names = datasets["validation"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
padding = "max_length" if data_args.pad_to_max_length else False
def tokenize_function(examples):
# Remove empty lines
examples = [line for line in examples if len(line) > 0 and not line.isspace()]
return tokenizer(
examples,
return_special_tokens_mask=True,
padding=padding,
truncation=True,
max_length=data_args.max_seq_length,
)
tokenized_datasets = datasets.map(
tokenize_function,
input_columns=[text_column_name],
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
# Enable tensorboard only on the master node
if has_tensorboard and jax.host_id() == 0:
summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir).joinpath("logs").as_posix())
# Data collator
# This one will take care of randomly masking the tokens.
data_collator = FlaxDataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=data_args.mlm_probability)
# Setup optimizer
optimizer = Adam(
learning_rate=training_args.learning_rate,
weight_decay=training_args.weight_decay,
beta1=training_args.adam_beta1,
beta2=training_args.adam_beta2,
).create(model.params)
# Create learning rate scheduler
lr_scheduler_fn = create_learning_rate_scheduler(
base_learning_rate=training_args.learning_rate, warmup_steps=max(training_args.warmup_steps, 1)
)
# Create parallel version of the training and evaluation steps
p_training_step = jax.pmap(training_step, "batch", donate_argnums=(0,))
p_eval_step = jax.pmap(eval_step, "batch", donate_argnums=(0,))
# Replicate the optimizer on each device
optimizer = jax_utils.replicate(optimizer)
# Store some constant
nb_epochs = int(training_args.num_train_epochs)
batch_size = int(training_args.train_batch_size)
eval_batch_size = int(training_args.eval_batch_size)
if wandb_args.wandb_user_name is not None:
import wandb
wandb.init(project=wandb_args.wandb_project_name, entity=wandb_args.wandb_user_name)
epochs = tqdm(range(nb_epochs), desc=f"Epoch ... (1/{nb_epochs})", position=0)
for epoch in epochs:
# ======================== Training ================================
# Create sampling rng
rng, training_rng, eval_rng = jax.random.split(rng, 3)
# Generate an epoch by shuffling sampling indices from the train dataset
nb_training_samples = len(tokenized_datasets["train"])
training_samples_idx = jax.random.permutation(training_rng, jnp.arange(nb_training_samples))
training_batch_idx = generate_batch_splits(training_samples_idx, batch_size)
# Gather the indexes for creating the batch and do a training step
for batch_idx in tqdm(training_batch_idx, desc="Training...", position=1):
samples = [tokenized_datasets["train"][int(idx)] for idx in batch_idx]
model_inputs = data_collator(samples, pad_to_multiple_of=16)
# Model forward
model_inputs = common_utils.shard(model_inputs.data)
loss, optimizer, dropout_rngs = p_training_step(optimizer, model_inputs, dropout_rngs)
if wandb_args.wandb_user_name is not None:
wandb.log({"Training loss": np.array(loss).mean()})
epochs.write(f"Loss: {loss}")
# ======================== Evaluating ==============================
nb_eval_samples = len(tokenized_datasets["validation"])
eval_samples_idx = jnp.arange(nb_eval_samples)
eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size)
eval_metrics = []
for i, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
model_inputs = data_collator(samples, pad_to_multiple_of=16)
# Model forward
model_inputs = common_utils.shard(model_inputs.data)
metrics = p_eval_step(optimizer.target, model_inputs)
eval_metrics.append(metrics)
eval_metrics_np = get_metrics(eval_metrics)
eval_metrics_np = jax.tree_map(jnp.sum, eval_metrics_np)
eval_normalizer = eval_metrics_np.pop("normalizer")
eval_summary = jax.tree_map(lambda x: x / eval_normalizer, eval_metrics_np)
# Update progress bar
epochs.desc = (
f"Epoch... ({epoch + 1}/{nb_epochs} | Loss: {eval_summary['loss']}, Acc: {eval_summary['accuracy']})"
)
if wandb_args.wandb_user_name is not None:
wandb.log({"Eval loss": np.array(eval_summary["loss"]).mean()})
# Save metrics
if has_tensorboard and jax.host_id() == 0:
for name, value in eval_summary.items():
summary_writer.scalar(name, value, epoch)
| AdaMix/examples/research_projects/performer/run_mlm_performer.py/0 | {
"file_path": "AdaMix/examples/research_projects/performer/run_mlm_performer.py",
"repo_id": "AdaMix",
"token_count": 11240
} | 43 |
""" Evaluation script for RAG models."""
import argparse
import ast
import logging
import os
import sys
import pandas as pd
import torch
from tqdm import tqdm
from transformers import BartForConditionalGeneration, RagRetriever, RagSequenceForGeneration, RagTokenForGeneration
from transformers import logging as transformers_logging
sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # isort:skip
from utils_rag import exact_match_score, f1_score # noqa: E402 # isort:skip
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
transformers_logging.set_verbosity_info()
def infer_model_type(model_name_or_path):
if "token" in model_name_or_path:
return "rag_token"
if "sequence" in model_name_or_path:
return "rag_sequence"
if "bart" in model_name_or_path:
return "bart"
return None
def metric_max_over_ground_truths(metric_fn, prediction, ground_truths):
return max(metric_fn(prediction, gt) for gt in ground_truths)
def get_scores(args, preds_path, gold_data_path):
hypos = [line.strip() for line in open(preds_path, "r").readlines()]
answers = []
if args.gold_data_mode == "qa":
data = pd.read_csv(gold_data_path, sep="\t", header=None)
for answer_list in data[1]:
ground_truths = ast.literal_eval(answer_list)
answers.append(ground_truths)
else:
references = [line.strip() for line in open(gold_data_path, "r").readlines()]
answers = [[reference] for reference in references]
f1 = em = total = 0
for prediction, ground_truths in zip(hypos, answers):
total += 1
em += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
f1 += metric_max_over_ground_truths(f1_score, prediction, ground_truths)
em = 100.0 * em / total
f1 = 100.0 * f1 / total
logger.info(f"F1: {f1:.2f}")
logger.info(f"EM: {em:.2f}")
def get_precision_at_k(args, preds_path, gold_data_path):
k = args.k
hypos = [line.strip() for line in open(preds_path, "r").readlines()]
references = [line.strip() for line in open(gold_data_path, "r").readlines()]
em = total = 0
for hypo, reference in zip(hypos, references):
hypo_provenance = set(hypo.split("\t")[:k])
ref_provenance = set(reference.split("\t"))
total += 1
em += len(hypo_provenance & ref_provenance) / k
em = 100.0 * em / total
logger.info(f"Precision@{k}: {em: .2f}")
def evaluate_batch_retrieval(args, rag_model, questions):
def strip_title(title):
if title.startswith('"'):
title = title[1:]
if title.endswith('"'):
title = title[:-1]
return title
retriever_input_ids = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
questions,
return_tensors="pt",
padding=True,
truncation=True,
)["input_ids"].to(args.device)
question_enc_outputs = rag_model.rag.question_encoder(retriever_input_ids)
question_enc_pool_output = question_enc_outputs[0]
result = rag_model.retriever(
retriever_input_ids,
question_enc_pool_output.cpu().detach().to(torch.float32).numpy(),
prefix=rag_model.rag.generator.config.prefix,
n_docs=rag_model.config.n_docs,
return_tensors="pt",
)
all_docs = rag_model.retriever.index.get_doc_dicts(result.doc_ids)
provenance_strings = []
for docs in all_docs:
provenance = [strip_title(title) for title in docs["title"]]
provenance_strings.append("\t".join(provenance))
return provenance_strings
def evaluate_batch_e2e(args, rag_model, questions):
with torch.no_grad():
inputs_dict = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
questions, return_tensors="pt", padding=True, truncation=True
)
input_ids = inputs_dict.input_ids.to(args.device)
attention_mask = inputs_dict.attention_mask.to(args.device)
outputs = rag_model.generate( # rag_model overwrites generate
input_ids,
attention_mask=attention_mask,
num_beams=args.num_beams,
min_length=args.min_length,
max_length=args.max_length,
early_stopping=False,
num_return_sequences=1,
bad_words_ids=[[0, 0]], # BART likes to repeat BOS tokens, dont allow it to generate more than one
)
answers = rag_model.retriever.generator_tokenizer.batch_decode(outputs, skip_special_tokens=True)
if args.print_predictions:
for q, a in zip(questions, answers):
logger.info("Q: {} - A: {}".format(q, a))
return answers
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token", "bart"],
type=str,
help="RAG model type: rag_sequence, rag_token or bart, if none specified, the type is inferred from the model_name_or_path",
)
parser.add_argument(
"--index_name",
default=None,
choices=["exact", "compressed", "legacy"],
type=str,
help="RAG model retriever type",
)
parser.add_argument(
"--index_path",
default=None,
type=str,
help="Path to the retrieval index",
)
parser.add_argument("--n_docs", default=5, type=int, help="Number of retrieved docs")
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained checkpoints or model identifier from huggingface.co/models",
)
parser.add_argument(
"--eval_mode",
choices=["e2e", "retrieval"],
default="e2e",
type=str,
help="Evaluation mode, e2e calculates exact match and F1 of the downstream task, retrieval calculates precision@k.",
)
parser.add_argument("--k", default=1, type=int, help="k for the precision@k calculation")
parser.add_argument(
"--evaluation_set",
default=None,
type=str,
required=True,
help="Path to a file containing evaluation samples",
)
parser.add_argument(
"--gold_data_path",
default=None,
type=str,
required=True,
help="Path to a tab-separated file with gold samples",
)
parser.add_argument(
"--gold_data_mode",
default="qa",
type=str,
choices=["qa", "ans"],
help="Format of the gold data file"
"qa - a single line in the following format: question [tab] answer_list"
"ans - a single line of the gold file contains the expected answer string",
)
parser.add_argument(
"--predictions_path",
type=str,
default="predictions.txt",
help="Name of the predictions file, to be stored in the checkpoints directory",
)
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument(
"--eval_batch_size",
default=8,
type=int,
help="Batch size per GPU/CPU for evaluation.",
)
parser.add_argument(
"--recalculate",
help="Recalculate predictions even if the prediction file exists",
action="store_true",
)
parser.add_argument(
"--num_beams",
default=4,
type=int,
help="Number of beams to be used when generating answers",
)
parser.add_argument("--min_length", default=1, type=int, help="Min length of the generated answers")
parser.add_argument("--max_length", default=50, type=int, help="Max length of the generated answers")
parser.add_argument(
"--print_predictions",
action="store_true",
help="If True, prints predictions while evaluating.",
)
parser.add_argument(
"--print_docs",
action="store_true",
help="If True, prints docs retried while generating.",
)
args = parser.parse_args()
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
return args
def main(args):
model_kwargs = {}
if args.model_type is None:
args.model_type = infer_model_type(args.model_name_or_path)
assert args.model_type is not None
if args.model_type.startswith("rag"):
model_class = RagTokenForGeneration if args.model_type == "rag_token" else RagSequenceForGeneration
model_kwargs["n_docs"] = args.n_docs
if args.index_name is not None:
model_kwargs["index_name"] = args.index_name
if args.index_path is not None:
model_kwargs["index_path"] = args.index_path
else:
model_class = BartForConditionalGeneration
checkpoints = (
[f.path for f in os.scandir(args.model_name_or_path) if f.is_dir()]
if args.eval_all_checkpoints
else [args.model_name_or_path]
)
logger.info("Evaluate the following checkpoints: %s", checkpoints)
score_fn = get_scores if args.eval_mode == "e2e" else get_precision_at_k
evaluate_batch_fn = evaluate_batch_e2e if args.eval_mode == "e2e" else evaluate_batch_retrieval
for checkpoint in checkpoints:
if os.path.exists(args.predictions_path) and (not args.recalculate):
logger.info("Calculating metrics based on an existing predictions file: {}".format(args.predictions_path))
score_fn(args, args.predictions_path, args.gold_data_path)
continue
logger.info("***** Running evaluation for {} *****".format(checkpoint))
logger.info(" Batch size = %d", args.eval_batch_size)
logger.info(" Predictions will be stored under {}".format(args.predictions_path))
if args.model_type.startswith("rag"):
retriever = RagRetriever.from_pretrained(checkpoint, **model_kwargs)
model = model_class.from_pretrained(checkpoint, retriever=retriever, **model_kwargs)
model.retriever.init_retrieval()
else:
model = model_class.from_pretrained(checkpoint, **model_kwargs)
model.to(args.device)
with open(args.evaluation_set, "r") as eval_file, open(args.predictions_path, "w") as preds_file:
questions = []
for line in tqdm(eval_file):
questions.append(line.strip())
if len(questions) == args.eval_batch_size:
answers = evaluate_batch_fn(args, model, questions)
preds_file.write("\n".join(answers) + "\n")
preds_file.flush()
questions = []
if len(questions) > 0:
answers = evaluate_batch_fn(args, model, questions)
preds_file.write("\n".join(answers))
preds_file.flush()
score_fn(args, args.predictions_path, args.gold_data_path)
if __name__ == "__main__":
args = get_args()
main(args)
| AdaMix/examples/research_projects/rag/eval_rag.py/0 | {
"file_path": "AdaMix/examples/research_projects/rag/eval_rag.py",
"repo_id": "AdaMix",
"token_count": 4752
} | 44 |
import logging
from pathlib import Path
import numpy as np
import pytorch_lightning as pl
import torch
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from pytorch_lightning.utilities import rank_zero_only
from utils import save_json
def count_trainable_parameters(model):
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
return params
logger = logging.getLogger(__name__)
class Seq2SeqLoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
pl_module.logger.log_metrics(lrs)
@rank_zero_only
def _write_logs(
self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
) -> None:
logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
metrics = trainer.callback_metrics
trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
# Log results
od = Path(pl_module.hparams.output_dir)
if type_path == "test":
results_file = od / "test_results.txt"
generations_file = od / "test_generations.txt"
else:
# this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
# If people want this it will be easy enough to add back.
results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
results_file.parent.mkdir(exist_ok=True)
generations_file.parent.mkdir(exist_ok=True)
with open(results_file, "a+") as writer:
for key in sorted(metrics):
if key in ["log", "progress_bar", "preds"]:
continue
val = metrics[key]
if isinstance(val, torch.Tensor):
val = val.item()
msg = f"{key}: {val:.6f}\n"
writer.write(msg)
if not save_generations:
return
if "preds" in metrics:
content = "\n".join(metrics["preds"])
generations_file.open("w+").write(content)
@rank_zero_only
def on_train_start(self, trainer, pl_module):
try:
npars = pl_module.model.model.num_parameters()
except AttributeError:
npars = pl_module.model.num_parameters()
n_trainable_pars = count_trainable_parameters(pl_module)
# mp stands for million parameters
trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
@rank_zero_only
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
save_json(pl_module.metrics, pl_module.metrics_save_path)
return self._write_logs(trainer, pl_module, "test")
@rank_zero_only
def on_validation_end(self, trainer: pl.Trainer, pl_module):
save_json(pl_module.metrics, pl_module.metrics_save_path)
# Uncommenting this will save val generations
# return self._write_logs(trainer, pl_module, "valid")
def get_checkpoint_callback(output_dir, metric, save_top_k=1, lower_is_better=False):
"""Saves the best model by validation ROUGE2 score."""
if metric == "rouge2":
exp = "{val_avg_rouge2:.4f}-{step_count}"
elif metric == "bleu":
exp = "{val_avg_bleu:.4f}-{step_count}"
elif metric == "loss":
exp = "{val_avg_loss:.4f}-{step_count}"
else:
raise NotImplementedError(
f"seq2seq callbacks only support rouge2, bleu and loss, got {metric}, You can make your own by adding to this function."
)
checkpoint_callback = ModelCheckpoint(
dirpath=output_dir,
filename=exp,
monitor=f"val_{metric}",
mode="min" if "loss" in metric else "max",
save_top_k=save_top_k,
)
return checkpoint_callback
def get_early_stopping_callback(metric, patience):
return EarlyStopping(
monitor=f"val_{metric}", # does this need avg?
mode="min" if "loss" in metric else "max",
patience=patience,
verbose=True,
)
| AdaMix/examples/research_projects/seq2seq-distillation/callbacks.py/0 | {
"file_path": "AdaMix/examples/research_projects/seq2seq-distillation/callbacks.py",
"repo_id": "AdaMix",
"token_count": 1930
} | 45 |
import re
from filelock import FileLock
try:
import nltk
NLTK_AVAILABLE = True
except (ImportError, ModuleNotFoundError):
NLTK_AVAILABLE = False
if NLTK_AVAILABLE:
with FileLock(".lock") as lock:
nltk.download("punkt", quiet=True)
def add_newline_to_end_of_each_sentence(x: str) -> str:
"""This was added to get rougeLsum scores matching published rougeL scores for BART and PEGASUS."""
re.sub("<n>", "", x) # remove pegasus newline char
assert NLTK_AVAILABLE, "nltk must be installed to separate newlines between sentences. (pip install nltk)"
return "\n".join(nltk.sent_tokenize(x))
| AdaMix/examples/research_projects/seq2seq-distillation/sentence_splitter.py/0 | {
"file_path": "AdaMix/examples/research_projects/seq2seq-distillation/sentence_splitter.py",
"repo_id": "AdaMix",
"token_count": 247
} | 46 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
SRC_DIR = os.path.join(os.path.dirname(__file__), "src")
sys.path.append(SRC_DIR)
from transformers import (
AutoConfig,
AutoModel,
AutoModelForQuestionAnswering,
AutoModelForSequenceClassification,
AutoModelWithLMHead,
AutoTokenizer,
add_start_docstrings,
)
dependencies = ["torch", "numpy", "tokenizers", "filelock", "requests", "tqdm", "regex", "sentencepiece", "sacremoses", "importlib_metadata"]
@add_start_docstrings(AutoConfig.__doc__)
def config(*args, **kwargs):
r"""
# Using torch.hub !
import torch
config = torch.hub.load('huggingface/transformers', 'config', 'bert-base-uncased') # Download configuration from huggingface.co and cache.
config = torch.hub.load('huggingface/transformers', 'config', './test/bert_saved_model/') # E.g. config (or model) was saved using `save_pretrained('./test/saved_model/')`
config = torch.hub.load('huggingface/transformers', 'config', './test/bert_saved_model/my_configuration.json')
config = torch.hub.load('huggingface/transformers', 'config', 'bert-base-uncased', output_attentions=True, foo=False)
assert config.output_attentions == True
config, unused_kwargs = torch.hub.load('huggingface/transformers', 'config', 'bert-base-uncased', output_attentions=True, foo=False, return_unused_kwargs=True)
assert config.output_attentions == True
assert unused_kwargs == {'foo': False}
"""
return AutoConfig.from_pretrained(*args, **kwargs)
@add_start_docstrings(AutoTokenizer.__doc__)
def tokenizer(*args, **kwargs):
r"""
# Using torch.hub !
import torch
tokenizer = torch.hub.load('huggingface/transformers', 'tokenizer', 'bert-base-uncased') # Download vocabulary from huggingface.co and cache.
tokenizer = torch.hub.load('huggingface/transformers', 'tokenizer', './test/bert_saved_model/') # E.g. tokenizer was saved using `save_pretrained('./test/saved_model/')`
"""
return AutoTokenizer.from_pretrained(*args, **kwargs)
@add_start_docstrings(AutoModel.__doc__)
def model(*args, **kwargs):
r"""
# Using torch.hub !
import torch
model = torch.hub.load('huggingface/transformers', 'model', 'bert-base-uncased') # Download model and configuration from huggingface.co and cache.
model = torch.hub.load('huggingface/transformers', 'model', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
model = torch.hub.load('huggingface/transformers', 'model', 'bert-base-uncased', output_attentions=True) # Update configuration during loading
assert model.config.output_attentions == True
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
model = torch.hub.load('huggingface/transformers', 'model', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)
"""
return AutoModel.from_pretrained(*args, **kwargs)
@add_start_docstrings(AutoModelWithLMHead.__doc__)
def modelWithLMHead(*args, **kwargs):
r"""
# Using torch.hub !
import torch
model = torch.hub.load('huggingface/transformers', 'modelWithLMHead', 'bert-base-uncased') # Download model and configuration from huggingface.co and cache.
model = torch.hub.load('huggingface/transformers', 'modelWithLMHead', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
model = torch.hub.load('huggingface/transformers', 'modelWithLMHead', 'bert-base-uncased', output_attentions=True) # Update configuration during loading
assert model.config.output_attentions == True
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
model = torch.hub.load('huggingface/transformers', 'modelWithLMHead', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)
"""
return AutoModelWithLMHead.from_pretrained(*args, **kwargs)
@add_start_docstrings(AutoModelForSequenceClassification.__doc__)
def modelForSequenceClassification(*args, **kwargs):
r"""
# Using torch.hub !
import torch
model = torch.hub.load('huggingface/transformers', 'modelForSequenceClassification', 'bert-base-uncased') # Download model and configuration from huggingface.co and cache.
model = torch.hub.load('huggingface/transformers', 'modelForSequenceClassification', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
model = torch.hub.load('huggingface/transformers', 'modelForSequenceClassification', 'bert-base-uncased', output_attentions=True) # Update configuration during loading
assert model.config.output_attentions == True
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
model = torch.hub.load('huggingface/transformers', 'modelForSequenceClassification', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)
"""
return AutoModelForSequenceClassification.from_pretrained(*args, **kwargs)
@add_start_docstrings(AutoModelForQuestionAnswering.__doc__)
def modelForQuestionAnswering(*args, **kwargs):
r"""
# Using torch.hub !
import torch
model = torch.hub.load('huggingface/transformers', 'modelForQuestionAnswering', 'bert-base-uncased') # Download model and configuration from huggingface.co and cache.
model = torch.hub.load('huggingface/transformers', 'modelForQuestionAnswering', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
model = torch.hub.load('huggingface/transformers', 'modelForQuestionAnswering', 'bert-base-uncased', output_attentions=True) # Update configuration during loading
assert model.config.output_attentions == True
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
model = torch.hub.load('huggingface/transformers', 'modelForQuestionAnswering', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)
"""
return AutoModelForQuestionAnswering.from_pretrained(*args, **kwargs)
| AdaMix/hubconf.py/0 | {
"file_path": "AdaMix/hubconf.py",
"repo_id": "AdaMix",
"token_count": 2719
} | 47 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
import tensorflow as tf
from packaging import version
def _gelu(x):
"""
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
https://arxiv.org/abs/1606.08415
"""
x = tf.convert_to_tensor(x)
cdf = 0.5 * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))
return x * cdf
def _gelu_new(x):
"""
Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://arxiv.org/abs/1606.0841
Args:
x: float Tensor to perform activation
Returns:
`x` with the GELU activation applied.
"""
x = tf.convert_to_tensor(x)
pi = tf.cast(math.pi, x.dtype)
coeff = tf.cast(0.044715, x.dtype)
cdf = 0.5 * (1.0 + tf.tanh(tf.sqrt(2.0 / pi) * (x + coeff * tf.pow(x, 3))))
return x * cdf
def mish(x):
x = tf.convert_to_tensor(x)
return x * tf.tanh(tf.math.softplus(x))
def gelu_fast(x):
x = tf.convert_to_tensor(x)
coeff1 = tf.cast(0.7978845608, x.dtype)
coeff2 = tf.cast(0.044715, x.dtype)
return 0.5 * x * (1.0 + tf.tanh(x * coeff2 * (1.0 + coeff1 * x * x)))
if version.parse(tf.version.VERSION) >= version.parse("2.4"):
def approximate_gelu_wrap(x):
return tf.keras.activations.gelu(x, approximate=True)
gelu = tf.keras.activations.gelu
gelu_new = approximate_gelu_wrap
else:
gelu = _gelu
gelu_new = _gelu_new
ACT2FN = {
"gelu": gelu,
"relu": tf.keras.activations.relu,
"swish": tf.keras.activations.swish,
"silu": tf.keras.activations.swish,
"gelu_new": gelu_new,
"mish": mish,
"tanh": tf.keras.activations.tanh,
"gelu_fast": gelu_fast,
}
def get_tf_activation(activation_string):
if activation_string in ACT2FN:
return ACT2FN[activation_string]
else:
raise KeyError("function {} not found in ACT2FN mapping {}".format(activation_string, list(ACT2FN.keys())))
| AdaMix/src/transformers/activations_tf.py/0 | {
"file_path": "AdaMix/src/transformers/activations_tf.py",
"repo_id": "AdaMix",
"token_count": 1111
} | 48 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
from argparse import ArgumentParser, Namespace
from ..data import SingleSentenceClassificationProcessor as Processor
from ..file_utils import is_tf_available, is_torch_available
from ..pipelines import TextClassificationPipeline
from ..utils import logging
from . import BaseTransformersCLICommand
if not is_tf_available() and not is_torch_available():
raise RuntimeError("At least one of PyTorch or TensorFlow 2.0+ should be installed to use CLI training")
# TF training parameters
USE_XLA = False
USE_AMP = False
def train_command_factory(args: Namespace):
"""
Factory function used to instantiate training command from provided command line arguments.
Returns: TrainCommand
"""
return TrainCommand(args)
class TrainCommand(BaseTransformersCLICommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
"""
Register this command to argparse so it's available for the transformer-cli
Args:
parser: Root parser to register command-specific arguments
"""
train_parser = parser.add_parser("train", help="CLI tool to train a model on a task.")
train_parser.add_argument(
"--train_data",
type=str,
required=True,
help="path to train (and optionally evaluation) dataset as a csv with "
"tab separated labels and sentences.",
)
train_parser.add_argument(
"--column_label", type=int, default=0, help="Column of the dataset csv file with example labels."
)
train_parser.add_argument(
"--column_text", type=int, default=1, help="Column of the dataset csv file with example texts."
)
train_parser.add_argument(
"--column_id", type=int, default=2, help="Column of the dataset csv file with example ids."
)
train_parser.add_argument(
"--skip_first_row", action="store_true", help="Skip the first row of the csv file (headers)."
)
train_parser.add_argument("--validation_data", type=str, default="", help="path to validation dataset.")
train_parser.add_argument(
"--validation_split",
type=float,
default=0.1,
help="if validation dataset is not provided, fraction of train dataset " "to use as validation dataset.",
)
train_parser.add_argument("--output", type=str, default="./", help="path to saved the trained model.")
train_parser.add_argument(
"--task", type=str, default="text_classification", help="Task to train the model on."
)
train_parser.add_argument(
"--model", type=str, default="bert-base-uncased", help="Model's name or path to stored model."
)
train_parser.add_argument("--train_batch_size", type=int, default=32, help="Batch size for training.")
train_parser.add_argument("--valid_batch_size", type=int, default=64, help="Batch size for validation.")
train_parser.add_argument("--learning_rate", type=float, default=3e-5, help="Learning rate.")
train_parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon for Adam optimizer.")
train_parser.set_defaults(func=train_command_factory)
def __init__(self, args: Namespace):
self.logger = logging.get_logger("transformers-cli/training")
self.framework = "tf" if is_tf_available() else "torch"
os.makedirs(args.output, exist_ok=True)
self.output = args.output
self.column_label = args.column_label
self.column_text = args.column_text
self.column_id = args.column_id
self.logger.info("Loading {} pipeline for {}".format(args.task, args.model))
if args.task == "text_classification":
self.pipeline = TextClassificationPipeline.from_pretrained(args.model)
elif args.task == "token_classification":
raise NotImplementedError
elif args.task == "question_answering":
raise NotImplementedError
self.logger.info("Loading dataset from {}".format(args.train_data))
self.train_dataset = Processor.create_from_csv(
args.train_data,
column_label=args.column_label,
column_text=args.column_text,
column_id=args.column_id,
skip_first_row=args.skip_first_row,
)
self.valid_dataset = None
if args.validation_data:
self.logger.info("Loading validation dataset from {}".format(args.validation_data))
self.valid_dataset = Processor.create_from_csv(
args.validation_data,
column_label=args.column_label,
column_text=args.column_text,
column_id=args.column_id,
skip_first_row=args.skip_first_row,
)
self.validation_split = args.validation_split
self.train_batch_size = args.train_batch_size
self.valid_batch_size = args.valid_batch_size
self.learning_rate = args.learning_rate
self.adam_epsilon = args.adam_epsilon
def run(self):
if self.framework == "tf":
return self.run_tf()
return self.run_torch()
def run_torch(self):
raise NotImplementedError
def run_tf(self):
self.pipeline.fit(
self.train_dataset,
validation_data=self.valid_dataset,
validation_split=self.validation_split,
learning_rate=self.learning_rate,
adam_epsilon=self.adam_epsilon,
train_batch_size=self.train_batch_size,
valid_batch_size=self.valid_batch_size,
)
# Save trained pipeline
self.pipeline.save_pretrained(self.output)
| AdaMix/src/transformers/commands/train.py/0 | {
"file_path": "AdaMix/src/transformers/commands/train.py",
"repo_id": "AdaMix",
"token_count": 2557
} | 49 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import time
from dataclasses import dataclass, field
from enum import Enum
from typing import Dict, List, Optional, Union
import torch
from torch.utils.data.dataset import Dataset
from filelock import FileLock
from ...models.auto.modeling_auto import MODEL_FOR_QUESTION_ANSWERING_MAPPING
from ...tokenization_utils import PreTrainedTokenizer
from ...utils import logging
from ..processors.squad import SquadFeatures, SquadV1Processor, SquadV2Processor, squad_convert_examples_to_features
logger = logging.get_logger(__name__)
MODEL_CONFIG_CLASSES = list(MODEL_FOR_QUESTION_ANSWERING_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class SquadDataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
model_type: str = field(
default=None, metadata={"help": "Model type selected in the list: " + ", ".join(MODEL_TYPES)}
)
data_dir: str = field(
default=None, metadata={"help": "The input data dir. Should contain the .json files for the SQuAD task."}
)
max_seq_length: int = field(
default=128,
metadata={
"help": "The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
doc_stride: int = field(
default=128,
metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
)
max_query_length: int = field(
default=64,
metadata={
"help": "The maximum number of tokens for the question. Questions longer than this will "
"be truncated to this length."
},
)
max_answer_length: int = field(
default=30,
metadata={
"help": "The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
version_2_with_negative: bool = field(
default=False, metadata={"help": "If true, the SQuAD examples contain some that do not have an answer."}
)
null_score_diff_threshold: float = field(
default=0.0, metadata={"help": "If null_score - best_non_null is greater than the threshold predict null."}
)
n_best_size: int = field(
default=20, metadata={"help": "If null_score - best_non_null is greater than the threshold predict null."}
)
lang_id: int = field(
default=0,
metadata={
"help": "language id of input for language-specific xlm models (see tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)"
},
)
threads: int = field(default=1, metadata={"help": "multiple threads for converting example to features"})
class Split(Enum):
train = "train"
dev = "dev"
class SquadDataset(Dataset):
"""
This will be superseded by a framework-agnostic approach soon.
"""
args: SquadDataTrainingArguments
features: List[SquadFeatures]
mode: Split
is_language_sensitive: bool
def __init__(
self,
args: SquadDataTrainingArguments,
tokenizer: PreTrainedTokenizer,
limit_length: Optional[int] = None,
mode: Union[str, Split] = Split.train,
is_language_sensitive: Optional[bool] = False,
cache_dir: Optional[str] = None,
dataset_format: Optional[str] = "pt",
):
self.args = args
self.is_language_sensitive = is_language_sensitive
self.processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
if isinstance(mode, str):
try:
mode = Split[mode]
except KeyError:
raise KeyError("mode is not a valid split name")
self.mode = mode
# Load data features from cache or dataset file
version_tag = "v2" if args.version_2_with_negative else "v1"
cached_features_file = os.path.join(
cache_dir if cache_dir is not None else args.data_dir,
"cached_{}_{}_{}_{}".format(
mode.value,
tokenizer.__class__.__name__,
str(args.max_seq_length),
version_tag,
),
)
# Make sure only the first process in distributed training processes the dataset,
# and the others will use the cache.
lock_path = cached_features_file + ".lock"
with FileLock(lock_path):
if os.path.exists(cached_features_file) and not args.overwrite_cache:
start = time.time()
self.old_features = torch.load(cached_features_file)
# Legacy cache files have only features, while new cache files
# will have dataset and examples also.
self.features = self.old_features["features"]
self.dataset = self.old_features.get("dataset", None)
self.examples = self.old_features.get("examples", None)
logger.info(
f"Loading features from cached file {cached_features_file} [took %.3f s]", time.time() - start
)
if self.dataset is None or self.examples is None:
logger.warn(
f"Deleting cached file {cached_features_file} will allow dataset and examples to be cached in future run"
)
else:
if mode == Split.dev:
self.examples = self.processor.get_dev_examples(args.data_dir)
else:
self.examples = self.processor.get_train_examples(args.data_dir)
self.features, self.dataset = squad_convert_examples_to_features(
examples=self.examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=mode == Split.train,
threads=args.threads,
return_dataset=dataset_format,
)
start = time.time()
torch.save(
{"features": self.features, "dataset": self.dataset, "examples": self.examples},
cached_features_file,
)
# ^ This seems to take a lot of time so I want to investigate why and how we can improve.
logger.info(
"Saving features into cached file %s [took %.3f s]", cached_features_file, time.time() - start
)
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
# Convert to Tensors and build dataset
feature = self.features[i]
input_ids = torch.tensor(feature.input_ids, dtype=torch.long)
attention_mask = torch.tensor(feature.attention_mask, dtype=torch.long)
token_type_ids = torch.tensor(feature.token_type_ids, dtype=torch.long)
cls_index = torch.tensor(feature.cls_index, dtype=torch.long)
p_mask = torch.tensor(feature.p_mask, dtype=torch.float)
is_impossible = torch.tensor(feature.is_impossible, dtype=torch.float)
inputs = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
if self.args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
del inputs["token_type_ids"]
if self.args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": cls_index, "p_mask": p_mask})
if self.args.version_2_with_negative:
inputs.update({"is_impossible": is_impossible})
if self.is_language_sensitive:
inputs.update({"langs": (torch.ones(input_ids.shape, dtype=torch.int64) * self.args.lang_id)})
if self.mode == Split.train:
start_positions = torch.tensor(feature.start_position, dtype=torch.long)
end_positions = torch.tensor(feature.end_position, dtype=torch.long)
inputs.update({"start_positions": start_positions, "end_positions": end_positions})
return inputs
| AdaMix/src/transformers/data/datasets/squad.py/0 | {
"file_path": "AdaMix/src/transformers/data/datasets/squad.py",
"repo_id": "AdaMix",
"token_count": 3917
} | 50 |
# THIS FILE HAS BEEN AUTOGENERATED. To update:
# 1. modify the `_deps` dict in setup.py
# 2. run `make deps_table_update``
deps = {
"black": "black>=20.8b1",
"cookiecutter": "cookiecutter==1.7.2",
"dataclasses": "dataclasses",
"datasets": "datasets",
"faiss-cpu": "faiss-cpu",
"fastapi": "fastapi",
"filelock": "filelock",
"flake8": "flake8>=3.8.3",
"flax": "flax>=0.3.2",
"fugashi": "fugashi>=1.0",
"importlib_metadata": "importlib_metadata",
"ipadic": "ipadic>=1.0.0,<2.0",
"isort": "isort>=5.5.4",
"jax": "jax>=0.2.8",
"jaxlib": "jaxlib>=0.1.59",
"keras2onnx": "keras2onnx",
"numpy": "numpy>=1.17",
"onnxconverter-common": "onnxconverter-common",
"onnxruntime-tools": "onnxruntime-tools>=1.4.2",
"onnxruntime": "onnxruntime>=1.4.0",
"packaging": "packaging",
"parameterized": "parameterized",
"protobuf": "protobuf",
"psutil": "psutil",
"pydantic": "pydantic",
"pytest": "pytest",
"pytest-sugar": "pytest-sugar",
"pytest-xdist": "pytest-xdist",
"python": "python>=3.6.0",
"recommonmark": "recommonmark",
"regex": "regex!=2019.12.17",
"requests": "requests",
"sacremoses": "sacremoses",
"scikit-learn": "scikit-learn",
"sentencepiece": "sentencepiece==0.1.91",
"soundfile": "soundfile",
"sphinx-copybutton": "sphinx-copybutton",
"sphinx-markdown-tables": "sphinx-markdown-tables",
"sphinx-rtd-theme": "sphinx-rtd-theme==0.4.3",
"sphinx": "sphinx==3.2.1",
"starlette": "starlette",
"tensorflow-cpu": "tensorflow-cpu>=2.3",
"tensorflow": "tensorflow>=2.3",
"timeout-decorator": "timeout-decorator",
"tokenizers": "tokenizers>=0.10.1,<0.11",
"torch": "torch>=1.0",
"torchaudio": "torchaudio",
"tqdm": "tqdm>=4.27",
"unidic": "unidic>=1.0.2",
"unidic_lite": "unidic_lite>=1.0.7",
"uvicorn": "uvicorn",
}
| AdaMix/src/transformers/dependency_versions_table.py/0 | {
"file_path": "AdaMix/src/transformers/dependency_versions_table.py",
"repo_id": "AdaMix",
"token_count": 965
} | 51 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch - TF 2.0 general utilities."""
import os
import re
import numpy
from .utils import logging
logger = logging.get_logger(__name__)
def convert_tf_weight_name_to_pt_weight_name(tf_name, start_prefix_to_remove=""):
"""
Convert a TF 2.0 model variable name in a pytorch model weight name.
Conventions for TF2.0 scopes -> PyTorch attribute names conversions:
- '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch)
- '_._' is replaced by a new level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList)
return tuple with:
- pytorch model weight name
- transpose: boolean indicating whether TF2.0 and PyTorch weights matrices are transposed with regards to each
other
"""
tf_name = tf_name.replace(":0", "") # device ids
tf_name = re.sub(
r"/[^/]*___([^/]*)/", r"/\1/", tf_name
) # '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch)
tf_name = tf_name.replace(
"_._", "/"
) # '_._' is replaced by a level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList)
tf_name = re.sub(r"//+", "/", tf_name) # Remove empty levels at the end
tf_name = tf_name.split("/") # Convert from TF2.0 '/' separators to PyTorch '.' separators
# Some weights have a single name withtout "/" such as final_logits_bias in BART
if len(tf_name) > 1:
tf_name = tf_name[1:] # Remove level zero
# When should we transpose the weights
transpose = bool(
tf_name[-1] in ["kernel", "pointwise_kernel", "depthwise_kernel"]
or "emb_projs" in tf_name
or "out_projs" in tf_name
)
# Convert standard TF2.0 names in PyTorch names
if tf_name[-1] == "kernel" or tf_name[-1] == "embeddings" or tf_name[-1] == "gamma":
tf_name[-1] = "weight"
if tf_name[-1] == "beta":
tf_name[-1] = "bias"
# The SeparableConv1D TF layer contains two weights that are translated to PyTorch Conv1D here
if tf_name[-1] == "pointwise_kernel" or tf_name[-1] == "depthwise_kernel":
tf_name[-1] = tf_name[-1].replace("_kernel", ".weight")
# Remove prefix if needed
tf_name = ".".join(tf_name)
if start_prefix_to_remove:
tf_name = tf_name.replace(start_prefix_to_remove, "", 1)
return tf_name, transpose
#####################
# PyTorch => TF 2.0 #
#####################
def load_pytorch_checkpoint_in_tf2_model(tf_model, pytorch_checkpoint_path, tf_inputs=None, allow_missing_keys=False):
"""Load pytorch checkpoints in a TF 2.0 model"""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
pt_path = os.path.abspath(pytorch_checkpoint_path)
logger.info("Loading PyTorch weights from {}".format(pt_path))
pt_state_dict = torch.load(pt_path, map_location="cpu")
logger.info("PyTorch checkpoint contains {:,} parameters".format(sum(t.numel() for t in pt_state_dict.values())))
return load_pytorch_weights_in_tf2_model(
tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys
)
def load_pytorch_model_in_tf2_model(tf_model, pt_model, tf_inputs=None, allow_missing_keys=False):
"""Load pytorch checkpoints in a TF 2.0 model"""
pt_state_dict = pt_model.state_dict()
return load_pytorch_weights_in_tf2_model(
tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys
)
def load_pytorch_weights_in_tf2_model(tf_model, pt_state_dict, tf_inputs=None, allow_missing_keys=False):
"""Load pytorch state_dict in a TF 2.0 model."""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
from tensorflow.python.keras import backend as K
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
if tf_inputs is None:
tf_inputs = tf_model.dummy_inputs
if tf_inputs is not None:
tf_model(tf_inputs, training=False) # Make sure model is built
# Adapt state dict - TODO remove this and update the AWS weights files instead
# Convert old format to new format if needed from a PyTorch state_dict
old_keys = []
new_keys = []
for key in pt_state_dict.keys():
new_key = None
if "gamma" in key:
new_key = key.replace("gamma", "weight")
if "beta" in key:
new_key = key.replace("beta", "bias")
if new_key:
old_keys.append(key)
new_keys.append(new_key)
for old_key, new_key in zip(old_keys, new_keys):
pt_state_dict[new_key] = pt_state_dict.pop(old_key)
# Make sure we are able to load PyTorch base models as well as derived models (with heads)
# TF models always have a prefix, some of PyTorch models (base ones) don't
start_prefix_to_remove = ""
if not any(s.startswith(tf_model.base_model_prefix) for s in pt_state_dict.keys()):
start_prefix_to_remove = tf_model.base_model_prefix + "."
symbolic_weights = tf_model.trainable_weights + tf_model.non_trainable_weights
tf_loaded_numel = 0
weight_value_tuples = []
all_pytorch_weights = set(list(pt_state_dict.keys()))
missing_keys = []
for symbolic_weight in symbolic_weights:
sw_name = symbolic_weight.name
name, transpose = convert_tf_weight_name_to_pt_weight_name(
sw_name, start_prefix_to_remove=start_prefix_to_remove
)
# Find associated numpy array in pytorch model state dict
if name not in pt_state_dict:
if allow_missing_keys:
missing_keys.append(name)
continue
elif tf_model._keys_to_ignore_on_load_missing is not None:
# authorized missing keys don't have to be loaded
if any(re.search(pat, name) is not None for pat in tf_model._keys_to_ignore_on_load_missing):
continue
raise AttributeError("{} not found in PyTorch model".format(name))
array = pt_state_dict[name].numpy()
if transpose:
array = numpy.transpose(array)
if len(symbolic_weight.shape) < len(array.shape):
array = numpy.squeeze(array)
elif len(symbolic_weight.shape) > len(array.shape):
array = numpy.expand_dims(array, axis=0)
if list(symbolic_weight.shape) != list(array.shape):
try:
array = numpy.reshape(array, symbolic_weight.shape)
except AssertionError as e:
e.args += (symbolic_weight.shape, array.shape)
raise e
try:
assert list(symbolic_weight.shape) == list(array.shape)
except AssertionError as e:
e.args += (symbolic_weight.shape, array.shape)
raise e
tf_loaded_numel += array.size
# logger.warning("Initialize TF weight {}".format(symbolic_weight.name))
weight_value_tuples.append((symbolic_weight, array))
all_pytorch_weights.discard(name)
K.batch_set_value(weight_value_tuples)
if tf_inputs is not None:
tf_model(tf_inputs, training=False) # Make sure restore ops are run
logger.info("Loaded {:,} parameters in the TF 2.0 model.".format(tf_loaded_numel))
unexpected_keys = list(all_pytorch_weights)
if tf_model._keys_to_ignore_on_load_missing is not None:
for pat in tf_model._keys_to_ignore_on_load_missing:
missing_keys = [k for k in missing_keys if re.search(pat, k) is None]
if tf_model._keys_to_ignore_on_load_unexpected is not None:
for pat in tf_model._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the PyTorch model were not used when "
f"initializing the TF 2.0 model {tf_model.__class__.__name__}: {unexpected_keys}\n"
f"- This IS expected if you are initializing {tf_model.__class__.__name__} from a PyTorch model trained on another task "
f"or with another architecture (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).\n"
f"- This IS NOT expected if you are initializing {tf_model.__class__.__name__} from a PyTorch model that you expect "
f"to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a BertForSequenceClassification model)."
)
else:
logger.warning(f"All PyTorch model weights were used when initializing {tf_model.__class__.__name__}.\n")
if len(missing_keys) > 0:
logger.warning(
f"Some weights or buffers of the TF 2.0 model {tf_model.__class__.__name__} were not initialized from the PyTorch model "
f"and are newly initialized: {missing_keys}\n"
f"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference."
)
else:
logger.warning(
f"All the weights of {tf_model.__class__.__name__} were initialized from the PyTorch model.\n"
f"If your task is similar to the task the model of the checkpoint was trained on, "
f"you can already use {tf_model.__class__.__name__} for predictions without further training."
)
return tf_model
#####################
# TF 2.0 => PyTorch #
#####################
def load_tf2_checkpoint_in_pytorch_model(pt_model, tf_checkpoint_path, tf_inputs=None, allow_missing_keys=False):
"""
Load TF 2.0 HDF5 checkpoint in a PyTorch model We use HDF5 to easily do transfer learning (see
https://github.com/tensorflow/tensorflow/blob/ee16fcac960ae660e0e4496658a366e2f745e1f0/tensorflow/python/keras/engine/network.py#L1352-L1357).
"""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
import transformers
from .modeling_tf_utils import load_tf_weights
logger.info("Loading TensorFlow weights from {}".format(tf_checkpoint_path))
# Instantiate and load the associated TF 2.0 model
tf_model_class_name = "TF" + pt_model.__class__.__name__ # Add "TF" at the beginning
tf_model_class = getattr(transformers, tf_model_class_name)
tf_model = tf_model_class(pt_model.config)
if tf_inputs is None:
tf_inputs = tf_model.dummy_inputs
if tf_inputs is not None:
tf_model(tf_inputs, training=False) # Make sure model is built
load_tf_weights(tf_model, tf_checkpoint_path)
return load_tf2_model_in_pytorch_model(pt_model, tf_model, allow_missing_keys=allow_missing_keys)
def load_tf2_model_in_pytorch_model(pt_model, tf_model, allow_missing_keys=False):
"""Load TF 2.0 model in a pytorch model"""
weights = tf_model.weights
return load_tf2_weights_in_pytorch_model(pt_model, weights, allow_missing_keys=allow_missing_keys)
def load_tf2_weights_in_pytorch_model(pt_model, tf_weights, allow_missing_keys=False):
"""Load TF2.0 symbolic weights in a PyTorch model"""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
new_pt_params_dict = {}
current_pt_params_dict = dict(pt_model.named_parameters())
# Make sure we are able to load PyTorch base models as well as derived models (with heads)
# TF models always have a prefix, some of PyTorch models (base ones) don't
start_prefix_to_remove = ""
if not any(s.startswith(pt_model.base_model_prefix) for s in current_pt_params_dict.keys()):
start_prefix_to_remove = pt_model.base_model_prefix + "."
# Build a map from potential PyTorch weight names to TF 2.0 Variables
tf_weights_map = {}
for tf_weight in tf_weights:
pt_name, transpose = convert_tf_weight_name_to_pt_weight_name(
tf_weight.name, start_prefix_to_remove=start_prefix_to_remove
)
tf_weights_map[pt_name] = (tf_weight.numpy(), transpose)
all_tf_weights = set(list(tf_weights_map.keys()))
loaded_pt_weights_data_ptr = {}
missing_keys_pt = []
for pt_weight_name, pt_weight in current_pt_params_dict.items():
# Handle PyTorch shared weight ()not duplicated in TF 2.0
if pt_weight.data_ptr() in loaded_pt_weights_data_ptr:
new_pt_params_dict[pt_weight_name] = loaded_pt_weights_data_ptr[pt_weight.data_ptr()]
continue
# Find associated numpy array in pytorch model state dict
if pt_weight_name not in tf_weights_map:
if allow_missing_keys:
missing_keys_pt.append(pt_weight_name)
continue
raise AttributeError("{} not found in TF 2.0 model".format(pt_weight_name))
array, transpose = tf_weights_map[pt_weight_name]
if transpose:
array = numpy.transpose(array)
if len(pt_weight.shape) < len(array.shape):
array = numpy.squeeze(array)
elif len(pt_weight.shape) > len(array.shape):
array = numpy.expand_dims(array, axis=0)
if list(pt_weight.shape) != list(array.shape):
try:
array = numpy.reshape(array, pt_weight.shape)
except AssertionError as e:
e.args += (pt_weight.shape, array.shape)
raise e
try:
assert list(pt_weight.shape) == list(array.shape)
except AssertionError as e:
e.args += (pt_weight.shape, array.shape)
raise e
# logger.warning("Initialize PyTorch weight {}".format(pt_weight_name))
new_pt_params_dict[pt_weight_name] = torch.from_numpy(array)
loaded_pt_weights_data_ptr[pt_weight.data_ptr()] = torch.from_numpy(array)
all_tf_weights.discard(pt_weight_name)
missing_keys, unexpected_keys = pt_model.load_state_dict(new_pt_params_dict, strict=False)
missing_keys += missing_keys_pt
if len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the TF 2.0 model were not used when "
f"initializing the PyTorch model {pt_model.__class__.__name__}: {unexpected_keys}\n"
f"- This IS expected if you are initializing {pt_model.__class__.__name__} from a TF 2.0 model trained on another task "
f"or with another architecture (e.g. initializing a BertForSequenceClassification model from a TFBertForPreTraining model).\n"
f"- This IS NOT expected if you are initializing {pt_model.__class__.__name__} from a TF 2.0 model that you expect "
f"to be exactly identical (e.g. initializing a BertForSequenceClassification model from a TFBertForSequenceClassification model)."
)
else:
logger.warning(f"All TF 2.0 model weights were used when initializing {pt_model.__class__.__name__}.\n")
if len(missing_keys) > 0:
logger.warning(
f"Some weights of {pt_model.__class__.__name__} were not initialized from the TF 2.0 model "
f"and are newly initialized: {missing_keys}\n"
f"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference."
)
else:
logger.warning(
f"All the weights of {pt_model.__class__.__name__} were initialized from the TF 2.0 model.\n"
f"If your task is similar to the task the model of the checkpoint was trained on, "
f"you can already use {pt_model.__class__.__name__} for predictions without further training."
)
logger.info("Weights or buffers not loaded from TF 2.0 model: {}".format(all_tf_weights))
return pt_model
| AdaMix/src/transformers/modeling_tf_pytorch_utils.py/0 | {
"file_path": "AdaMix/src/transformers/modeling_tf_pytorch_utils.py",
"repo_id": "AdaMix",
"token_count": 7093
} | 52 |
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch ALBERT model. """
import math
import os
from dataclasses import dataclass
from typing import Optional, Tuple
import torch
import torch.nn as nn
from torch.nn import CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...file_utils import (
ModelOutput,
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPooling,
MaskedLMOutput,
MultipleChoiceModelOutput,
QuestionAnsweringModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import (
PreTrainedModel,
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
prune_linear_layer,
)
from ...utils import logging
from .configuration_albert import AlbertConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "albert-base-v2"
_CONFIG_FOR_DOC = "AlbertConfig"
_TOKENIZER_FOR_DOC = "AlbertTokenizer"
ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
"albert-base-v1",
"albert-large-v1",
"albert-xlarge-v1",
"albert-xxlarge-v1",
"albert-base-v2",
"albert-large-v2",
"albert-xlarge-v2",
"albert-xxlarge-v2",
# See all ALBERT models at https://huggingface.co/models?filter=albert
]
def load_tf_weights_in_albert(model, config, tf_checkpoint_path):
""" Load tf checkpoints in a pytorch model."""
try:
import re
import numpy as np
import tensorflow as tf
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
"https://www.tensorflow.org/install/ for installation instructions."
)
raise
tf_path = os.path.abspath(tf_checkpoint_path)
logger.info("Converting TensorFlow checkpoint from {}".format(tf_path))
# Load weights from TF model
init_vars = tf.train.list_variables(tf_path)
names = []
arrays = []
for name, shape in init_vars:
logger.info("Loading TF weight {} with shape {}".format(name, shape))
array = tf.train.load_variable(tf_path, name)
names.append(name)
arrays.append(array)
for name, array in zip(names, arrays):
print(name)
for name, array in zip(names, arrays):
original_name = name
# If saved from the TF HUB module
name = name.replace("module/", "")
# Renaming and simplifying
name = name.replace("ffn_1", "ffn")
name = name.replace("bert/", "albert/")
name = name.replace("attention_1", "attention")
name = name.replace("transform/", "")
name = name.replace("LayerNorm_1", "full_layer_layer_norm")
name = name.replace("LayerNorm", "attention/LayerNorm")
name = name.replace("transformer/", "")
# The feed forward layer had an 'intermediate' step which has been abstracted away
name = name.replace("intermediate/dense/", "")
name = name.replace("ffn/intermediate/output/dense/", "ffn_output/")
# ALBERT attention was split between self and output which have been abstracted away
name = name.replace("/output/", "/")
name = name.replace("/self/", "/")
# The pooler is a linear layer
name = name.replace("pooler/dense", "pooler")
# The classifier was simplified to predictions from cls/predictions
name = name.replace("cls/predictions", "predictions")
name = name.replace("predictions/attention", "predictions")
# Naming was changed to be more explicit
name = name.replace("embeddings/attention", "embeddings")
name = name.replace("inner_group_", "albert_layers/")
name = name.replace("group_", "albert_layer_groups/")
# Classifier
if len(name.split("/")) == 1 and ("output_bias" in name or "output_weights" in name):
name = "classifier/" + name
# No ALBERT model currently handles the next sentence prediction task
if "seq_relationship" in name:
name = name.replace("seq_relationship/output_", "sop_classifier/classifier/")
name = name.replace("weights", "weight")
name = name.split("/")
# Ignore the gradients applied by the LAMB/ADAM optimizers.
if (
"adam_m" in name
or "adam_v" in name
or "AdamWeightDecayOptimizer" in name
or "AdamWeightDecayOptimizer_1" in name
or "global_step" in name
):
logger.info("Skipping {}".format("/".join(name)))
continue
pointer = model
for m_name in name:
if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
scope_names = re.split(r"_(\d+)", m_name)
else:
scope_names = [m_name]
if scope_names[0] == "kernel" or scope_names[0] == "gamma":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
pointer = getattr(pointer, "bias")
elif scope_names[0] == "output_weights":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "squad":
pointer = getattr(pointer, "classifier")
else:
try:
pointer = getattr(pointer, scope_names[0])
except AttributeError:
logger.info("Skipping {}".format("/".join(name)))
continue
if len(scope_names) >= 2:
num = int(scope_names[1])
pointer = pointer[num]
if m_name[-11:] == "_embeddings":
pointer = getattr(pointer, "weight")
elif m_name == "kernel":
array = np.transpose(array)
try:
assert (
pointer.shape == array.shape
), f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched"
except AssertionError as e:
e.args += (pointer.shape, array.shape)
raise
print("Initialize PyTorch weight {} from {}".format(name, original_name))
pointer.data = torch.from_numpy(array)
return model
class AlbertEmbeddings(nn.Module):
"""
Construct the embeddings from word, position and token_type embeddings.
"""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.embedding_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.embedding_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
# Copied from transformers.models.bert.modeling_bert.BertEmbeddings.forward
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class AlbertAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
self.num_attention_heads = config.num_attention_heads
self.hidden_size = config.hidden_size
self.attention_head_size = config.hidden_size // config.num_attention_heads
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.attention_dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.output_dropout = nn.Dropout(config.hidden_dropout_prob)
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.pruned_heads = set()
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention.transpose_for_scores
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.num_attention_heads, self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.query = prune_linear_layer(self.query, index)
self.key = prune_linear_layer(self.key, index)
self.value = prune_linear_layer(self.value, index)
self.dense = prune_linear_layer(self.dense, index, dim=1)
# Update hyper params and store pruned heads
self.num_attention_heads = self.num_attention_heads - len(heads)
self.all_head_size = self.attention_head_size * self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.attention_dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
# Should find a better way to do this
w = (
self.dense.weight.t()
.view(self.num_attention_heads, self.attention_head_size, self.hidden_size)
.to(context_layer.dtype)
)
b = self.dense.bias.to(context_layer.dtype)
projected_context_layer = torch.einsum("bfnd,ndh->bfh", context_layer, w) + b
projected_context_layer_dropout = self.output_dropout(projected_context_layer)
layernormed_context_layer = self.LayerNorm(hidden_states + projected_context_layer_dropout)
return (layernormed_context_layer, attention_probs) if output_attentions else (layernormed_context_layer,)
class AlbertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.full_layer_layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.attention = AlbertAttention(config)
self.ffn = nn.Linear(config.hidden_size, config.intermediate_size)
self.ffn_output = nn.Linear(config.intermediate_size, config.hidden_size)
self.activation = ACT2FN[config.hidden_act]
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(
self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False, output_hidden_states=False
):
attention_output = self.attention(hidden_states, attention_mask, head_mask, output_attentions)
ffn_output = apply_chunking_to_forward(
self.ff_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output[0],
)
hidden_states = self.full_layer_layer_norm(ffn_output + attention_output[0])
return (hidden_states,) + attention_output[1:] # add attentions if we output them
def ff_chunk(self, attention_output):
ffn_output = self.ffn(attention_output)
ffn_output = self.activation(ffn_output)
ffn_output = self.ffn_output(ffn_output)
return ffn_output
class AlbertLayerGroup(nn.Module):
def __init__(self, config):
super().__init__()
self.albert_layers = nn.ModuleList([AlbertLayer(config) for _ in range(config.inner_group_num)])
def forward(
self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False, output_hidden_states=False
):
layer_hidden_states = ()
layer_attentions = ()
for layer_index, albert_layer in enumerate(self.albert_layers):
layer_output = albert_layer(hidden_states, attention_mask, head_mask[layer_index], output_attentions)
hidden_states = layer_output[0]
if output_attentions:
layer_attentions = layer_attentions + (layer_output[1],)
if output_hidden_states:
layer_hidden_states = layer_hidden_states + (hidden_states,)
outputs = (hidden_states,)
if output_hidden_states:
outputs = outputs + (layer_hidden_states,)
if output_attentions:
outputs = outputs + (layer_attentions,)
return outputs # last-layer hidden state, (layer hidden states), (layer attentions)
class AlbertTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding_hidden_mapping_in = nn.Linear(config.embedding_size, config.hidden_size)
self.albert_layer_groups = nn.ModuleList([AlbertLayerGroup(config) for _ in range(config.num_hidden_groups)])
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
hidden_states = self.embedding_hidden_mapping_in(hidden_states)
all_hidden_states = (hidden_states,) if output_hidden_states else None
all_attentions = () if output_attentions else None
for i in range(self.config.num_hidden_layers):
# Number of layers in a hidden group
layers_per_group = int(self.config.num_hidden_layers / self.config.num_hidden_groups)
# Index of the hidden group
group_idx = int(i / (self.config.num_hidden_layers / self.config.num_hidden_groups))
layer_group_output = self.albert_layer_groups[group_idx](
hidden_states,
attention_mask,
head_mask[group_idx * layers_per_group : (group_idx + 1) * layers_per_group],
output_attentions,
output_hidden_states,
)
hidden_states = layer_group_output[0]
if output_attentions:
all_attentions = all_attentions + layer_group_output[-1]
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
)
class AlbertPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = AlbertConfig
base_model_prefix = "albert"
_keys_to_ignore_on_load_missing = [r"position_ids"]
def _init_weights(self, module):
"""Initialize the weights."""
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@dataclass
class AlbertForPreTrainingOutput(ModelOutput):
"""
Output type of :class:`~transformers.AlbertForPreTraining`.
Args:
loss (`optional`, returned when ``labels`` is provided, ``torch.FloatTensor`` of shape :obj:`(1,)`):
Total loss as the sum of the masked language modeling loss and the next sequence prediction
(classification) loss.
prediction_logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
sop_logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, 2)`):
Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``output_hidden_states=True`` is passed or when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``output_attentions=True`` is passed or when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape :obj:`(batch_size, num_heads,
sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
prediction_logits: torch.FloatTensor = None
sop_logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
ALBERT_START_DOCSTRING = r"""
This model inherits from :class:`~transformers.PreTrainedModel`. Check the superclass documentation for the generic
methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
pruning heads etc.)
This model is also a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`__
subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
general usage and behavior.
Args:
config (:class:`~transformers.AlbertConfig`): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model
weights.
"""
ALBERT_INPUTS_DOCSTRING = r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using :class:`~transformers.AlbertTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.__call__` and :meth:`transformers.PreTrainedTokenizer.encode` for
details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.FloatTensor` of shape :obj:`({0})`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
token_type_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in ``[0,
1]``:
- 0 corresponds to a `sentence A` token,
- 1 corresponds to a `sentence B` token.
`What are token type IDs? <../glossary.html#token-type-ids>`_
position_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range ``[0,
config.max_position_embeddings - 1]``.
`What are position IDs? <../glossary.html#position-ids>`_
head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the self-attention modules. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`({0}, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert :obj:`input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned
tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for
more detail.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
"""
@add_start_docstrings(
"The bare ALBERT Model transformer outputting raw hidden-states without any specific head on top.",
ALBERT_START_DOCSTRING,
)
class AlbertModel(AlbertPreTrainedModel):
config_class = AlbertConfig
load_tf_weights = load_tf_weights_in_albert
base_model_prefix = "albert"
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = AlbertEmbeddings(config)
self.encoder = AlbertTransformer(config)
if add_pooling_layer:
self.pooler = nn.Linear(config.hidden_size, config.hidden_size)
self.pooler_activation = nn.Tanh()
else:
self.pooler = None
self.pooler_activation = None
self.init_weights()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} ALBERT has
a different architecture in that its layers are shared across groups, which then has inner groups. If an ALBERT
model has 12 hidden layers and 2 hidden groups, with two inner groups, there is a total of 4 different layers.
These layers are flattened: the indices [0,1] correspond to the two inner groups of the first hidden layer,
while [2,3] correspond to the two inner groups of the second hidden layer.
Any layer with in index other than [0,1,2,3] will result in an error. See base class PreTrainedModel for more
information about head pruning
"""
for layer, heads in heads_to_prune.items():
group_idx = int(layer / self.config.inner_group_num)
inner_group_idx = int(layer - group_idx * self.config.inner_group_num)
self.encoder.albert_layer_groups[group_idx].albert_layers[inner_group_idx].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPooling,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = self.encoder(
embedding_output,
extended_attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler_activation(self.pooler(sequence_output[:, 0])) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
@add_start_docstrings(
"""
Albert Model with two heads on top as done during the pretraining: a `masked language modeling` head and a
`sentence order prediction (classification)` head.
""",
ALBERT_START_DOCSTRING,
)
class AlbertForPreTraining(AlbertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.albert = AlbertModel(config)
self.predictions = AlbertMLMHead(config)
self.sop_classifier = AlbertSOPHead(config)
self.init_weights()
def get_output_embeddings(self):
return self.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.predictions.decoder = new_embeddings
def get_input_embeddings(self):
return self.albert.embeddings.word_embeddings
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=AlbertForPreTrainingOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
sentence_order_label=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (``torch.LongTensor`` of shape ``(batch_size, sequence_length)``, `optional`):
Labels for computing the masked language modeling loss. Indices should be in ``[-100, 0, ...,
config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are ignored
(masked), the loss is only computed for the tokens with labels in ``[0, ..., config.vocab_size]``
sentence_order_label (``torch.LongTensor`` of shape ``(batch_size,)``, `optional`):
Labels for computing the next sequence prediction (classification) loss. Input should be a sequence pair
(see :obj:`input_ids` docstring) Indices should be in ``[0, 1]``. ``0`` indicates original order (sequence
A, then sequence B), ``1`` indicates switched order (sequence B, then sequence A).
Returns:
Example::
>>> from transformers import AlbertTokenizer, AlbertForPreTraining
>>> import torch
>>> tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
>>> model = AlbertForPreTraining.from_pretrained('albert-base-v2')
>>> input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
>>> outputs = model(input_ids)
>>> prediction_logits = outputs.prediction_logits
>>> sop_logits = outputs.sop_logits
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.albert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output, pooled_output = outputs[:2]
prediction_scores = self.predictions(sequence_output)
sop_scores = self.sop_classifier(pooled_output)
total_loss = None
if labels is not None and sentence_order_label is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
sentence_order_loss = loss_fct(sop_scores.view(-1, 2), sentence_order_label.view(-1))
total_loss = masked_lm_loss + sentence_order_loss
if not return_dict:
output = (prediction_scores, sop_scores) + outputs[2:]
return ((total_loss,) + output) if total_loss is not None else output
return AlbertForPreTrainingOutput(
loss=total_loss,
prediction_logits=prediction_scores,
sop_logits=sop_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class AlbertMLMHead(nn.Module):
def __init__(self, config):
super().__init__()
self.LayerNorm = nn.LayerNorm(config.embedding_size)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
self.dense = nn.Linear(config.hidden_size, config.embedding_size)
self.decoder = nn.Linear(config.embedding_size, config.vocab_size)
self.activation = ACT2FN[config.hidden_act]
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.activation(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
hidden_states = self.decoder(hidden_states)
prediction_scores = hidden_states
return prediction_scores
class AlbertSOPHead(nn.Module):
def __init__(self, config):
super().__init__()
self.dropout = nn.Dropout(config.classifier_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, pooled_output):
dropout_pooled_output = self.dropout(pooled_output)
logits = self.classifier(dropout_pooled_output)
return logits
@add_start_docstrings(
"Albert Model with a `language modeling` head on top.",
ALBERT_START_DOCSTRING,
)
class AlbertForMaskedLM(AlbertPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
def __init__(self, config):
super().__init__(config)
self.albert = AlbertModel(config, add_pooling_layer=False)
self.predictions = AlbertMLMHead(config)
self.init_weights()
def get_output_embeddings(self):
return self.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.predictions.decoder = new_embeddings
def get_input_embeddings(self):
return self.albert.embeddings.word_embeddings
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the masked language modeling loss. Indices should be in ``[-100, 0, ...,
config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are ignored
(masked), the loss is only computed for the tokens with labels in ``[0, ..., config.vocab_size]``
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.albert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_outputs = outputs[0]
prediction_scores = self.predictions(sequence_outputs)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Albert Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
output) e.g. for GLUE tasks.
""",
ALBERT_START_DOCSTRING,
)
class AlbertForSequenceClassification(AlbertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.albert = AlbertModel(config)
self.dropout = nn.Dropout(config.classifier_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss. Indices should be in ``[0, ...,
config.num_labels - 1]``. If ``config.num_labels == 1`` a regression loss is computed (Mean-Square loss),
If ``config.num_labels > 1`` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.albert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Albert Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
ALBERT_START_DOCSTRING,
)
class AlbertForTokenClassification(AlbertPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.albert = AlbertModel(config, add_pooling_layer=False)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the token classification loss. Indices should be in ``[0, ..., config.num_labels -
1]``.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.albert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
# Only keep active parts of the loss
if attention_mask is not None:
active_loss = attention_mask.view(-1) == 1
active_logits = logits.view(-1, self.num_labels)[active_loss]
active_labels = labels.view(-1)[active_loss]
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Albert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
ALBERT_START_DOCSTRING,
)
class AlbertForQuestionAnswering(AlbertPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.albert = AlbertModel(config, add_pooling_layer=False)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
start_positions=None,
end_positions=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
start_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (:obj:`sequence_length`). Position outside of the
sequence are not taken into account for computing the loss.
end_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (:obj:`sequence_length`). Position outside of the
sequence are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.albert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions.clamp_(0, ignored_index)
end_positions.clamp_(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Albert Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
softmax) e.g. for RocStories/SWAG tasks.
""",
ALBERT_START_DOCSTRING,
)
class AlbertForMultipleChoice(AlbertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.albert = AlbertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, 1)
self.init_weights()
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the multiple choice classification loss. Indices should be in ``[0, ...,
num_choices-1]`` where `num_choices` is the size of the second dimension of the input tensors. (see
`input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
outputs = self.albert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
output = (reshaped_logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return MultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
| AdaMix/src/transformers/models/albert/modeling_albert.py/0 | {
"file_path": "AdaMix/src/transformers/models/albert/modeling_albert.py",
"repo_id": "AdaMix",
"token_count": 23191
} | 53 |
# coding=utf-8
# Copyright 2018 Salesforce and HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Salesforce CTRL configuration """
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP = {"ctrl": "https://huggingface.co/ctrl/resolve/main/config.json"}
class CTRLConfig(PretrainedConfig):
"""
This is the configuration class to store the configuration of a :class:`~transformers.CTRLModel` or a
:class:`~transformers.TFCTRLModel`. It is used to instantiate a CTRL model according to the specified arguments,
defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration
to that of the `ctrl <https://huggingface.co/ctrl>`__ architecture from SalesForce.
Configuration objects inherit from :class:`~transformers.PretrainedConfig` and can be used to control the model
outputs. Read the documentation from :class:`~transformers.PretrainedConfig` for more information.
Args:
vocab_size (:obj:`int`, `optional`, defaults to 246534):
Vocabulary size of the CTRL model. Defines the number of different tokens that can be represented by the
:obj:`inputs_ids` passed when calling :class:`~transformers.CTRLModel` or
:class:`~transformers.TFCTRLModel`.
n_positions (:obj:`int`, `optional`, defaults to 256):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
n_ctx (:obj:`int`, `optional`, defaults to 256):
Dimensionality of the causal mask (usually same as n_positions).
n_embd (:obj:`int`, `optional`, defaults to 1280):
Dimensionality of the embeddings and hidden states.
dff (:obj:`int`, `optional`, defaults to 8192):
Dimensionality of the inner dimension of the feed forward networks (FFN).
n_layer (:obj:`int`, `optional`, defaults to 48):
Number of hidden layers in the Transformer encoder.
n_head (:obj:`int`, `optional`, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
resid_pdrop (:obj:`float`, `optional`, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
embd_pdrop (:obj:`int`, `optional`, defaults to 0.1):
The dropout ratio for the embeddings.
attn_pdrop (:obj:`float`, `optional`, defaults to 0.1):
The dropout ratio for the attention.
layer_norm_epsilon (:obj:`float`, `optional`, defaults to 1e-6):
The epsilon to use in the layer normalization layers
initializer_range (:obj:`float`, `optional`, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
use_cache (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not the model should return the last key/values attentions (not used by all models).
Examples::
>>> from transformers import CTRLModel, CTRLConfig
>>> # Initializing a CTRL configuration
>>> configuration = CTRLConfig()
>>> # Initializing a model from the configuration
>>> model = CTRLModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
"""
model_type = "ctrl"
keys_to_ignore_at_inference = ["past_key_values"]
def __init__(
self,
vocab_size=246534,
n_positions=256,
n_ctx=256,
n_embd=1280,
dff=8192,
n_layer=48,
n_head=16,
resid_pdrop=0.1,
embd_pdrop=0.1,
attn_pdrop=0.1,
layer_norm_epsilon=1e-6,
initializer_range=0.02,
summary_type="cls_index",
summary_use_proj=True,
summary_activation=None,
summary_proj_to_labels=True,
summary_first_dropout=0.1,
use_cache=True,
**kwargs
):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.n_ctx = n_ctx
self.n_positions = n_positions
self.n_embd = n_embd
self.n_layer = n_layer
self.n_head = n_head
self.dff = dff
self.resid_pdrop = resid_pdrop
self.embd_pdrop = embd_pdrop
self.attn_pdrop = attn_pdrop
self.layer_norm_epsilon = layer_norm_epsilon
self.initializer_range = initializer_range
self.summary_type = summary_type
self.summary_use_proj = summary_use_proj
self.summary_activation = summary_activation
self.summary_first_dropout = summary_first_dropout
self.summary_proj_to_labels = summary_proj_to_labels
self.use_cache = use_cache
@property
def max_position_embeddings(self):
return self.n_positions
@property
def hidden_size(self):
return self.n_embd
@property
def num_attention_heads(self):
return self.n_head
@property
def num_hidden_layers(self):
return self.n_layer
| AdaMix/src/transformers/models/ctrl/configuration_ctrl.py/0 | {
"file_path": "AdaMix/src/transformers/models/ctrl/configuration_ctrl.py",
"repo_id": "AdaMix",
"token_count": 2249
} | 54 |
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for DistilBERT."""
from ...utils import logging
from ..bert.tokenization_bert import BertTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"distilbert-base-uncased": "https://huggingface.co/distilbert-base-uncased/resolve/main/vocab.txt",
"distilbert-base-uncased-distilled-squad": "https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/vocab.txt",
"distilbert-base-cased": "https://huggingface.co/distilbert-base-cased/resolve/main/vocab.txt",
"distilbert-base-cased-distilled-squad": "https://huggingface.co/distilbert-base-cased-distilled-squad/resolve/main/vocab.txt",
"distilbert-base-german-cased": "https://huggingface.co/distilbert-base-german-cased/resolve/main/vocab.txt",
"distilbert-base-multilingual-cased": "https://huggingface.co/distilbert-base-multilingual-cased/resolve/main/vocab.txt",
}
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"distilbert-base-uncased": 512,
"distilbert-base-uncased-distilled-squad": 512,
"distilbert-base-cased": 512,
"distilbert-base-cased-distilled-squad": 512,
"distilbert-base-german-cased": 512,
"distilbert-base-multilingual-cased": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"distilbert-base-uncased": {"do_lower_case": True},
"distilbert-base-uncased-distilled-squad": {"do_lower_case": True},
"distilbert-base-cased": {"do_lower_case": False},
"distilbert-base-cased-distilled-squad": {"do_lower_case": False},
"distilbert-base-german-cased": {"do_lower_case": False},
"distilbert-base-multilingual-cased": {"do_lower_case": False},
}
class DistilBertTokenizer(BertTokenizer):
r"""
Construct a DistilBERT tokenizer.
:class:`~transformers.DistilBertTokenizer` is identical to :class:`~transformers.BertTokenizer` and runs end-to-end
tokenization: punctuation splitting and wordpiece.
Refer to superclass :class:`~transformers.BertTokenizer` for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
model_input_names = ["input_ids", "attention_mask"]
| AdaMix/src/transformers/models/distilbert/tokenization_distilbert.py/0 | {
"file_path": "AdaMix/src/transformers/models/distilbert/tokenization_distilbert.py",
"repo_id": "AdaMix",
"token_count": 1155
} | 55 |
from torch import nn
from transformers.activations import get_activation
import torch
from torch import Tensor
import torch.distributed as dist
from torch.nn import Module, ModuleList
import torch.nn.functional as F
import copy
import typing
class MixtureSoup(torch.nn.Module):
def __init__(self, expert, num_local_experts=1, inference_level=0):
super(MixtureSoup, self).__init__()
self.deepspeed_experts = torch.nn.ModuleList(
[copy.deepcopy(expert) for i in range(num_local_experts)])
self.num_local_experts = num_local_experts
self.inference_level = inference_level
self.expert_score_weight = torch.nn.Parameter(torch.zeros(self.num_local_experts), requires_grad=False)
def get_expert_by_idx(self, idx):
return self.deepspeed_experts[idx]
def expert_soup_forward(self, input):
output = F.linear(input,
self.parameter_dict["weight"],
self.parameter_dict["bias"])
return output
def expert_soup(self):
weight = F.softmax(self.expert_score_weight)
self.parameter_dict = {"weight": 0, "bias": 0}
for idx in range(self.num_local_experts):
single_expert = self.deepspeed_experts[idx]
for s_name, s_param in single_expert.named_parameters():
if "weight" in s_name:
p_name = "weight"
self.parameter_dict[p_name] = self.parameter_dict[p_name] + (weight[idx] * s_param)
else:
p_name = "bias"
self.parameter_dict[p_name] = self.parameter_dict[p_name] + (weight[idx] * s_param)
def forward(self, *input: Tensor):
expert_output = None
if self.deepspeed_experts[0].training:
expert_idx = torch.randint(low=0, high=self.num_local_experts, size=(1,)).item() # selected expert
if self.expert_score_weight.requires_grad:
self.expert_soup()
expert_output = self.expert_soup_forward(input[0])
else:
expert_output = self.get_expert_by_idx(expert_idx)(input[0])
else:
if self.inference_level != 3:
result = []
for expert_idx in range(self.num_local_experts):
temp = self.get_expert_by_idx(expert_idx)(input[0])
result.append(temp)
result = torch.stack(result, dim=0)
if self.inference_level == 0: # token level
mask = torch.randint(0, self.num_local_experts,
size=(result.size(1), result.size(2)), device=result.device)
for i in range(self.num_local_experts):
expert_mask = mask.eq(i)
result[i] *= expert_mask.unsqueeze(-1)
expert_output = result.sum(0)
elif self.inference_level == 1: # sentence level
mask = torch.randint(0, self.num_local_experts,
size=(result.size(1),), device=result.device)
for i in range(self.num_local_experts):
expert_mask = mask.eq(i)
result[i] *= expert_mask.unsqueeze(-1).unsqueeze(-1)
expert_output = result.sum(0)
elif self.inference_level == 3:
self.expert_soup()
expert_output = self.expert_soup_forward(input[0])
return expert_output
class ExpertSoup(nn.Module):
def __init__(self, dim, r, act=None, num_expert=4, inference_level=0, sharing_down=0, sharing_up=0):
super().__init__()
self.act = act
if sharing_down == 1:
self.MoA_A = MixtureSoup(nn.Linear(dim, r), 1, inference_level)
else:
self.MoA_A = MixtureSoup(nn.Linear(dim, r), num_expert, inference_level)
if act is not None:
self.act = get_activation(act)
if sharing_up == 1:
self.MoA_B = MixtureSoup(nn.Linear(r, dim), 1, inference_level)
else:
self.MoA_B = MixtureSoup(nn.Linear(r, dim), num_expert, inference_level)
def forward(self, x, residual):
result = self.MoA_A(x)
if self.act is not None:
result = self.act(result)
result = self.MoA_B(result)
return result + residual
| AdaMix/src/transformers/models/expert_soup.py/0 | {
"file_path": "AdaMix/src/transformers/models/expert_soup.py",
"repo_id": "AdaMix",
"token_count": 2254
} | 56 |
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Note: if you intend to run this script make sure you look under scripts/fsmt/
# to locate the appropriate script to do the work correctly. There is a set of scripts to:
# - download and prepare data and run the conversion script
# - perform eval to get the best hparam into the config
# - generate model_cards - useful if you have multiple models from the same paper
import argparse
import json
import os
import re
from collections import OrderedDict
from os.path import basename, dirname
import fairseq
import torch
from fairseq import hub_utils
from fairseq.data.dictionary import Dictionary
from transformers import FSMTConfig, FSMTForConditionalGeneration
from transformers.file_utils import WEIGHTS_NAME
from transformers.models.fsmt.tokenization_fsmt import VOCAB_FILES_NAMES
from transformers.tokenization_utils_base import TOKENIZER_CONFIG_FILE
from transformers.utils import logging
logging.set_verbosity_warning()
json_indent = 2
# based on the results of a search on a range of `num_beams`, `length_penalty` and `early_stopping`
# values against wmt19 test data to obtain the best BLEU scores, we will use the following defaults:
#
# * `num_beams`: 5 (higher scores better, but requires more memory/is slower, can be adjusted by users)
# * `early_stopping`: `False` consistently scored better
# * `length_penalty` varied, so will assign the best one depending on the model
best_score_hparams = {
# fairseq:
"wmt19-ru-en": {"length_penalty": 1.1},
"wmt19-en-ru": {"length_penalty": 1.15},
"wmt19-en-de": {"length_penalty": 1.0},
"wmt19-de-en": {"length_penalty": 1.1},
# allenai:
"wmt16-en-de-dist-12-1": {"length_penalty": 0.6},
"wmt16-en-de-dist-6-1": {"length_penalty": 0.6},
"wmt16-en-de-12-1": {"length_penalty": 0.8},
"wmt19-de-en-6-6-base": {"length_penalty": 0.6},
"wmt19-de-en-6-6-big": {"length_penalty": 0.6},
}
# this remaps the different models to their organization names
org_names = {}
for m in ["wmt19-ru-en", "wmt19-en-ru", "wmt19-en-de", "wmt19-de-en"]:
org_names[m] = "facebook"
for m in [
"wmt16-en-de-dist-12-1",
"wmt16-en-de-dist-6-1",
"wmt16-en-de-12-1",
"wmt19-de-en-6-6-base",
"wmt19-de-en-6-6-big",
]:
org_names[m] = "allenai"
def rewrite_dict_keys(d):
# (1) remove word breaking symbol, (2) add word ending symbol where the word is not broken up,
# e.g.: d = {'le@@': 5, 'tt@@': 6, 'er': 7} => {'le': 5, 'tt': 6, 'er</w>': 7}
d2 = dict((re.sub(r"@@$", "", k), v) if k.endswith("@@") else (re.sub(r"$", "</w>", k), v) for k, v in d.items())
keep_keys = "<s> <pad> </s> <unk>".split()
# restore the special tokens
for k in keep_keys:
del d2[f"{k}</w>"]
d2[k] = d[k] # restore
return d2
def convert_fsmt_checkpoint_to_pytorch(fsmt_checkpoint_path, pytorch_dump_folder_path):
# prep
assert os.path.exists(fsmt_checkpoint_path)
os.makedirs(pytorch_dump_folder_path, exist_ok=True)
print(f"Writing results to {pytorch_dump_folder_path}")
# handle various types of models
checkpoint_file = basename(fsmt_checkpoint_path)
fsmt_folder_path = dirname(fsmt_checkpoint_path)
cls = fairseq.model_parallel.models.transformer.ModelParallelTransformerModel
models = cls.hub_models()
kwargs = {"bpe": "fastbpe", "tokenizer": "moses"}
data_name_or_path = "."
# note: since the model dump is old, fairseq has upgraded its model some
# time later, and it does a whole lot of rewrites and splits on the saved
# weights, therefore we can't use torch.load() directly on the model file.
# see: upgrade_state_dict(state_dict) in fairseq_model.py
print(f"using checkpoint {checkpoint_file}")
chkpt = hub_utils.from_pretrained(
fsmt_folder_path, checkpoint_file, data_name_or_path, archive_map=models, **kwargs
)
args = vars(chkpt["args"]["model"])
src_lang = args["source_lang"]
tgt_lang = args["target_lang"]
data_root = dirname(pytorch_dump_folder_path)
model_dir = basename(pytorch_dump_folder_path)
# dicts
src_dict_file = os.path.join(fsmt_folder_path, f"dict.{src_lang}.txt")
tgt_dict_file = os.path.join(fsmt_folder_path, f"dict.{tgt_lang}.txt")
src_dict = Dictionary.load(src_dict_file)
src_vocab = rewrite_dict_keys(src_dict.indices)
src_vocab_size = len(src_vocab)
src_vocab_file = os.path.join(pytorch_dump_folder_path, "vocab-src.json")
print(f"Generating {src_vocab_file} of {src_vocab_size} of {src_lang} records")
with open(src_vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(src_vocab, ensure_ascii=False, indent=json_indent))
# detect whether this is a do_lower_case situation, which can be derived by checking whether we
# have at least one upcase letter in the source vocab
do_lower_case = True
for k in src_vocab.keys():
if not k.islower():
do_lower_case = False
break
tgt_dict = Dictionary.load(tgt_dict_file)
tgt_vocab = rewrite_dict_keys(tgt_dict.indices)
tgt_vocab_size = len(tgt_vocab)
tgt_vocab_file = os.path.join(pytorch_dump_folder_path, "vocab-tgt.json")
print(f"Generating {tgt_vocab_file} of {tgt_vocab_size} of {tgt_lang} records")
with open(tgt_vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(tgt_vocab, ensure_ascii=False, indent=json_indent))
# merges_file (bpecodes)
merges_file = os.path.join(pytorch_dump_folder_path, VOCAB_FILES_NAMES["merges_file"])
for fn in ["bpecodes", "code"]: # older fairseq called the merges file "code"
fsmt_merges_file = os.path.join(fsmt_folder_path, fn)
if os.path.exists(fsmt_merges_file):
break
with open(fsmt_merges_file, encoding="utf-8") as fin:
merges = fin.read()
merges = re.sub(r" \d+$", "", merges, 0, re.M) # remove frequency number
print(f"Generating {merges_file}")
with open(merges_file, "w", encoding="utf-8") as fout:
fout.write(merges)
# model config
fsmt_model_config_file = os.path.join(pytorch_dump_folder_path, "config.json")
# validate bpe/tokenizer config, as currently it's hardcoded to moses+fastbpe -
# may have to modify the tokenizer if a different type is used by a future model
assert args["bpe"] == "fastbpe", f"need to extend tokenizer to support bpe={args['bpe']}"
assert args["tokenizer"] == "moses", f"need to extend tokenizer to support bpe={args['tokenizer']}"
model_conf = {
"architectures": ["FSMTForConditionalGeneration"],
"model_type": "fsmt",
"activation_dropout": args["activation_dropout"],
"activation_function": "relu",
"attention_dropout": args["attention_dropout"],
"d_model": args["decoder_embed_dim"],
"dropout": args["dropout"],
"init_std": 0.02,
"max_position_embeddings": args["max_source_positions"],
"num_hidden_layers": args["encoder_layers"],
"src_vocab_size": src_vocab_size,
"tgt_vocab_size": tgt_vocab_size,
"langs": [src_lang, tgt_lang],
"encoder_attention_heads": args["encoder_attention_heads"],
"encoder_ffn_dim": args["encoder_ffn_embed_dim"],
"encoder_layerdrop": args["encoder_layerdrop"],
"encoder_layers": args["encoder_layers"],
"decoder_attention_heads": args["decoder_attention_heads"],
"decoder_ffn_dim": args["decoder_ffn_embed_dim"],
"decoder_layerdrop": args["decoder_layerdrop"],
"decoder_layers": args["decoder_layers"],
"bos_token_id": 0,
"pad_token_id": 1,
"eos_token_id": 2,
"is_encoder_decoder": True,
"scale_embedding": not args["no_scale_embedding"],
"tie_word_embeddings": args["share_all_embeddings"],
}
# good hparam defaults to start with
model_conf["num_beams"] = 5
model_conf["early_stopping"] = False
if model_dir in best_score_hparams and "length_penalty" in best_score_hparams[model_dir]:
model_conf["length_penalty"] = best_score_hparams[model_dir]["length_penalty"]
else:
model_conf["length_penalty"] = 1.0
print(f"Generating {fsmt_model_config_file}")
with open(fsmt_model_config_file, "w", encoding="utf-8") as f:
f.write(json.dumps(model_conf, ensure_ascii=False, indent=json_indent))
# tokenizer config
fsmt_tokenizer_config_file = os.path.join(pytorch_dump_folder_path, TOKENIZER_CONFIG_FILE)
tokenizer_conf = {
"langs": [src_lang, tgt_lang],
"model_max_length": 1024,
"do_lower_case": do_lower_case,
}
print(f"Generating {fsmt_tokenizer_config_file}")
with open(fsmt_tokenizer_config_file, "w", encoding="utf-8") as f:
f.write(json.dumps(tokenizer_conf, ensure_ascii=False, indent=json_indent))
# model
model = chkpt["models"][0]
model_state_dict = model.state_dict()
# rename keys to start with 'model.'
model_state_dict = OrderedDict(("model." + k, v) for k, v in model_state_dict.items())
# remove unneeded keys
ignore_keys = [
"model.model",
"model.encoder.version",
"model.decoder.version",
"model.encoder_embed_tokens.weight",
"model.decoder_embed_tokens.weight",
"model.encoder.embed_positions._float_tensor",
"model.decoder.embed_positions._float_tensor",
]
for k in ignore_keys:
model_state_dict.pop(k, None)
config = FSMTConfig.from_pretrained(pytorch_dump_folder_path)
model_new = FSMTForConditionalGeneration(config)
# check that it loads ok
model_new.load_state_dict(model_state_dict, strict=False)
# save
pytorch_weights_dump_path = os.path.join(pytorch_dump_folder_path, WEIGHTS_NAME)
print(f"Generating {pytorch_weights_dump_path}")
torch.save(model_state_dict, pytorch_weights_dump_path)
print("Conversion is done!")
print("\nLast step is to upload the files to s3")
print(f"cd {data_root}")
print(f"transformers-cli upload {model_dir}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--fsmt_checkpoint_path",
default=None,
type=str,
required=True,
help="Path to the official PyTorch checkpoint file which is expected to reside in the dump dir with dicts, bpecodes, etc.",
)
parser.add_argument(
"--pytorch_dump_folder_path", default=None, type=str, required=True, help="Path to the output PyTorch model."
)
args = parser.parse_args()
convert_fsmt_checkpoint_to_pytorch(args.fsmt_checkpoint_path, args.pytorch_dump_folder_path)
| AdaMix/src/transformers/models/fsmt/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py/0 | {
"file_path": "AdaMix/src/transformers/models/fsmt/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py",
"repo_id": "AdaMix",
"token_count": 4589
} | 57 |
# coding=utf-8
# Copyright 2020 The Google AI Language Team Authors, Allegro.pl, Facebook Inc. and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Tuple
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
from .tokenization_herbert import HerbertTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {
"vocab_file": "vocab.json",
"merges_file": "merges.txt",
}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"allegro/herbert-base-cased": "https://huggingface.co/allegro/herbert-base-cased/resolve/main/vocab.json"
},
"merges_file": {
"allegro/herbert-base-cased": "https://huggingface.co/allegro/herbert-base-cased/resolve/main/merges.txt"
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"allegro/herbert-base-cased": 514}
PRETRAINED_INIT_CONFIGURATION = {}
class HerbertTokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "Fast" BPE tokenizer for HerBERT (backed by HuggingFace's `tokenizers` library).
Peculiarities:
- uses BERT's pre-tokenizer: BertPreTokenizer splits tokens on spaces, and also on punctuation. Each occurrence of
a punctuation character will be treated separately.
This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the methods. Users
should refer to the superclass for more information regarding methods.
Args:
vocab_file (:obj:`str`):
Path to the vocabulary file.
merges_file (:obj:`str`):
Path to the merges file.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = HerbertTokenizer
def __init__(self, vocab_file, merges_file, tokenizer_file=None, **kwargs):
kwargs["cls_token"] = "<s>"
kwargs["unk_token"] = "<unk>"
kwargs["pad_token"] = "<pad>"
kwargs["mask_token"] = "<mask>"
kwargs["sep_token"] = "</s>"
super().__init__(
vocab_file,
merges_file,
tokenizer_file=tokenizer_file,
**kwargs,
)
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. An HerBERT, like BERT sequence has the following format:
- single sequence: ``<s> X </s>``
- pair of sequences: ``<s> A </s> B </s>``
Args:
token_ids_0 (:obj:`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (:obj:`List[int]`, `optional`):
Optional second list of IDs for sequence pairs.
Returns:
:obj:`List[int]`: List of `input IDs <../glossary.html#input-ids>`__ with the appropriate special tokens.
"""
cls = [self.cls_token_id]
sep = [self.sep_token_id]
if token_ids_1 is None:
return cls + token_ids_0 + sep
return cls + token_ids_0 + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer ``prepare_for_model`` method.
Args:
token_ids_0 (:obj:`List[int]`):
List of IDs.
token_ids_1 (:obj:`List[int]`, `optional`):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
:obj:`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formatted with special tokens for the model."
)
return list(map(lambda x: 1 if x in [self.sep_token_id, self.cls_token_id] else 0, token_ids_0))
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task. HerBERT, like
BERT sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
Args:
token_ids_0 (:obj:`List[int]`):
List of IDs.
token_ids_1 (:obj:`List[int]`, `optional`):
Optional second list of IDs for sequence pairs.
Returns:
:obj:`List[int]`: List of `token type IDs <../glossary.html#token-type-ids>`_ according to the given
sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
files = self._tokenizer.model.save(save_directory, name=filename_prefix)
return tuple(files)
| AdaMix/src/transformers/models/herbert/tokenization_herbert_fast.py/0 | {
"file_path": "AdaMix/src/transformers/models/herbert/tokenization_herbert_fast.py",
"repo_id": "AdaMix",
"token_count": 2828
} | 58 |
# coding=utf-8
# Copyright 2018 The Microsoft Research Asia LayoutLM Team Authors and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch LayoutLM model. """
import math
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...file_utils import add_start_docstrings, add_start_docstrings_to_model_forward, replace_return_docstrings
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
BaseModelOutputWithPoolingAndCrossAttentions,
MaskedLMOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import (
PreTrainedModel,
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
prune_linear_layer,
)
from ...utils import logging
from .configuration_layoutlm import LayoutLMConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "LayoutLMConfig"
_TOKENIZER_FOR_DOC = "LayoutLMTokenizer"
LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
"layoutlm-base-uncased",
"layoutlm-large-uncased",
]
LayoutLMLayerNorm = torch.nn.LayerNorm
class LayoutLMEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super(LayoutLMEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.x_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size)
self.y_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size)
self.h_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size)
self.w_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = LayoutLMLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
def forward(
self,
input_ids=None,
bbox=None,
token_type_ids=None,
position_ids=None,
inputs_embeds=None,
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
device = input_ids.device if input_ids is not None else inputs_embeds.device
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
words_embeddings = inputs_embeds
position_embeddings = self.position_embeddings(position_ids)
try:
left_position_embeddings = self.x_position_embeddings(bbox[:, :, 0])
upper_position_embeddings = self.y_position_embeddings(bbox[:, :, 1])
right_position_embeddings = self.x_position_embeddings(bbox[:, :, 2])
lower_position_embeddings = self.y_position_embeddings(bbox[:, :, 3])
except IndexError as e:
raise IndexError("The :obj:`bbox`coordinate values should be within 0-1000 range.") from e
h_position_embeddings = self.h_position_embeddings(bbox[:, :, 3] - bbox[:, :, 1])
w_position_embeddings = self.w_position_embeddings(bbox[:, :, 2] - bbox[:, :, 0])
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = (
words_embeddings
+ position_embeddings
+ left_position_embeddings
+ upper_position_embeddings
+ right_position_embeddings
+ lower_position_embeddings
+ h_position_embeddings
+ w_position_embeddings
+ token_type_embeddings
)
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention with Bert->LayoutLM
class LayoutLMSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in LayoutLMModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->LayoutLM
class LayoutLMSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->LayoutLM
class LayoutLMAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = LayoutLMSelfAttention(config)
self.output = LayoutLMSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.bert.modeling_bert.BertIntermediate
class LayoutLMIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOutput with Bert->LayoutLM
class LayoutLMOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertLayer with Bert->LayoutLM
class LayoutLMLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = LayoutLMAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
assert self.is_decoder, f"{self} should be used as a decoder model if cross attention is added"
self.crossattention = LayoutLMAttention(config)
self.intermediate = LayoutLMIntermediate(config)
self.output = LayoutLMOutput(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
assert hasattr(
self, "crossattention"
), f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers by setting `config.add_cross_attention=True`"
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
# Copied from transformers.models.bert.modeling_bert.BertEncoder with Bert->LayoutLM
class LayoutLMEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([LayoutLMLayer(config) for _ in range(config.num_hidden_layers)])
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if getattr(self.config, "gradient_checkpointing", False) and self.training:
if use_cache:
logger.warn(
"`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
"`use_cache=False`..."
)
use_cache = False
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, past_key_value, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(layer_module),
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_bert.BertPooler
class LayoutLMPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
# Copied from transformers.models.bert.modeling_bert.BertPredictionHeadTransform with Bert->LayoutLM
class LayoutLMPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertLMPredictionHead with Bert->LayoutLM
class LayoutLMLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = LayoutLMPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOnlyMLMHead with Bert->LayoutLM
class LayoutLMOnlyMLMHead(nn.Module):
def __init__(self, config):
super().__init__()
self.predictions = LayoutLMLMPredictionHead(config)
def forward(self, sequence_output):
prediction_scores = self.predictions(sequence_output)
return prediction_scores
class LayoutLMPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = LayoutLMConfig
pretrained_model_archive_map = LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST
base_model_prefix = "layoutlm"
_keys_to_ignore_on_load_missing = [r"position_ids"]
def _init_weights(self, module):
""" Initialize the weights """
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, LayoutLMLayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
LAYOUTLM_START_DOCSTRING = r"""
The LayoutLM model was proposed in `LayoutLM: Pre-training of Text and Layout for Document Image Understanding
<https://arxiv.org/abs/1912.13318>`__ by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei and Ming Zhou.
This model is a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`_ sub-class. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config (:class:`~transformers.LayoutLMConfig`): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model
weights.
"""
LAYOUTLM_INPUTS_DOCSTRING = r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using :class:`transformers.LayoutLMTokenizer`. See
:func:`transformers.PreTrainedTokenizer.encode` and :func:`transformers.PreTrainedTokenizer.__call__` for
details.
`What are input IDs? <../glossary.html#input-ids>`__
bbox (:obj:`torch.LongTensor` of shape :obj:`({0}, 4)`, `optional`):
Bounding boxes of each input sequence tokens. Selected in the range ``[0,
config.max_2d_position_embeddings-1]``. Each bounding box should be a normalized version in (x0, y0, x1,
y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and
(x1, y1) represents the position of the lower right corner. See :ref:`Overview` for normalization.
attention_mask (:obj:`torch.FloatTensor` of shape :obj:`({0})`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``: ``1`` for
tokens that are NOT MASKED, ``0`` for MASKED tokens.
`What are attention masks? <../glossary.html#attention-mask>`__
token_type_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in ``[0,
1]``: ``0`` corresponds to a `sentence A` token, ``1`` corresponds to a `sentence B` token
`What are token type IDs? <../glossary.html#token-type-ids>`_
position_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range ``[0,
config.max_position_embeddings - 1]``.
`What are position IDs? <../glossary.html#position-ids>`_
head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the self-attention modules. Mask values selected in ``[0, 1]``: :obj:`1`
indicates the head is **not masked**, :obj:`0` indicates the head is **masked**.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (:obj:`bool`, `optional`):
If set to ``True``, the attentions tensors of all attention layers are returned. See ``attentions`` under
returned tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
If set to ``True``, the hidden states of all layers are returned. See ``hidden_states`` under returned
tensors for more detail.
return_dict (:obj:`bool`, `optional`):
If set to ``True``, the model will return a :class:`~transformers.file_utils.ModelOutput` instead of a
plain tuple.
"""
@add_start_docstrings(
"The bare LayoutLM Model transformer outputting raw hidden-states without any specific head on top.",
LAYOUTLM_START_DOCSTRING,
)
class LayoutLMModel(LayoutLMPreTrainedModel):
def __init__(self, config):
super(LayoutLMModel, self).__init__(config)
self.config = config
self.embeddings = LayoutLMEmbeddings(config)
self.encoder = LayoutLMEncoder(config)
self.pooler = LayoutLMPooler(config)
self.init_weights()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(LAYOUTLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=BaseModelOutputWithPoolingAndCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
bbox=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Returns:
Examples::
>>> from transformers import LayoutLMTokenizer, LayoutLMModel
>>> import torch
>>> tokenizer = LayoutLMTokenizer.from_pretrained('microsoft/layoutlm-base-uncased')
>>> model = LayoutLMModel.from_pretrained('microsoft/layoutlm-base-uncased')
>>> words = ["Hello", "world"]
>>> normalized_word_boxes = [637, 773, 693, 782], [698, 773, 733, 782]
>>> token_boxes = []
>>> for word, box in zip(words, normalized_word_boxes):
... word_tokens = tokenizer.tokenize(word)
... token_boxes.extend([box] * len(word_tokens))
>>> # add bounding boxes of cls + sep tokens
>>> token_boxes = [[0, 0, 0, 0]] + token_boxes + [[1000, 1000, 1000, 1000]]
>>> encoding = tokenizer(' '.join(words), return_tensors="pt")
>>> input_ids = encoding["input_ids"]
>>> attention_mask = encoding["attention_mask"]
>>> token_type_ids = encoding["token_type_ids"]
>>> bbox = torch.tensor([token_boxes])
>>> outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids)
>>> last_hidden_states = outputs.last_hidden_state
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
if bbox is None:
bbox = torch.zeros(tuple(list(input_shape) + [4]), dtype=torch.long, device=device)
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype)
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
if head_mask is not None:
if head_mask.dim() == 1:
head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)
elif head_mask.dim() == 2:
head_mask = head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1)
head_mask = head_mask.to(dtype=next(self.parameters()).dtype)
else:
head_mask = [None] * self.config.num_hidden_layers
embedding_output = self.embeddings(
input_ids=input_ids,
bbox=bbox,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
)
encoder_outputs = self.encoder(
embedding_output,
extended_attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output)
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings("""LayoutLM Model with a `language modeling` head on top. """, LAYOUTLM_START_DOCSTRING)
class LayoutLMForMaskedLM(LayoutLMPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.layoutlm = LayoutLMModel(config)
self.cls = LayoutLMOnlyMLMHead(config)
self.init_weights()
def get_input_embeddings(self):
return self.layoutlm.embeddings.word_embeddings
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward(LAYOUTLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
bbox=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the masked language modeling loss. Indices should be in ``[-100, 0, ...,
config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are ignored
(masked), the loss is only computed for the tokens with labels in ``[0, ..., config.vocab_size]``
Returns:
Examples::
>>> from transformers import LayoutLMTokenizer, LayoutLMForMaskedLM
>>> import torch
>>> tokenizer = LayoutLMTokenizer.from_pretrained('microsoft/layoutlm-base-uncased')
>>> model = LayoutLMForMaskedLM.from_pretrained('microsoft/layoutlm-base-uncased')
>>> words = ["Hello", "[MASK]"]
>>> normalized_word_boxes = [637, 773, 693, 782], [698, 773, 733, 782]
>>> token_boxes = []
>>> for word, box in zip(words, normalized_word_boxes):
... word_tokens = tokenizer.tokenize(word)
... token_boxes.extend([box] * len(word_tokens))
>>> # add bounding boxes of cls + sep tokens
>>> token_boxes = [[0, 0, 0, 0]] + token_boxes + [[1000, 1000, 1000, 1000]]
>>> encoding = tokenizer(' '.join(words), return_tensors="pt")
>>> input_ids = encoding["input_ids"]
>>> attention_mask = encoding["attention_mask"]
>>> token_type_ids = encoding["token_type_ids"]
>>> bbox = torch.tensor([token_boxes])
>>> labels = tokenizer("Hello world", return_tensors="pt")["input_ids"]
>>> outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids,
... labels=labels)
>>> loss = outputs.loss
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.layoutlm(
input_ids,
bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(
prediction_scores.view(-1, self.config.vocab_size),
labels.view(-1),
)
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
LayoutLM Model with a sequence classification head on top (a linear layer on top of the pooled output) e.g. for
document image classification tasks such as the `RVL-CDIP <https://www.cs.cmu.edu/~aharley/rvl-cdip/>`__ dataset.
""",
LAYOUTLM_START_DOCSTRING,
)
class LayoutLMForSequenceClassification(LayoutLMPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.layoutlm = LayoutLMModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
def get_input_embeddings(self):
return self.layoutlm.embeddings.word_embeddings
@add_start_docstrings_to_model_forward(LAYOUTLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
bbox=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss. Indices should be in :obj:`[0, ...,
config.num_labels - 1]`. If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
Examples::
>>> from transformers import LayoutLMTokenizer, LayoutLMForSequenceClassification
>>> import torch
>>> tokenizer = LayoutLMTokenizer.from_pretrained('microsoft/layoutlm-base-uncased')
>>> model = LayoutLMForSequenceClassification.from_pretrained('microsoft/layoutlm-base-uncased')
>>> words = ["Hello", "world"]
>>> normalized_word_boxes = [637, 773, 693, 782], [698, 773, 733, 782]
>>> token_boxes = []
>>> for word, box in zip(words, normalized_word_boxes):
... word_tokens = tokenizer.tokenize(word)
... token_boxes.extend([box] * len(word_tokens))
>>> # add bounding boxes of cls + sep tokens
>>> token_boxes = [[0, 0, 0, 0]] + token_boxes + [[1000, 1000, 1000, 1000]]
>>> encoding = tokenizer(' '.join(words), return_tensors="pt")
>>> input_ids = encoding["input_ids"]
>>> attention_mask = encoding["attention_mask"]
>>> token_type_ids = encoding["token_type_ids"]
>>> bbox = torch.tensor([token_boxes])
>>> sequence_label = torch.tensor([1])
>>> outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids,
... labels=sequence_label)
>>> loss = outputs.loss
>>> logits = outputs.logits
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.layoutlm(
input_ids=input_ids,
bbox=bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
LayoutLM Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
sequence labeling (information extraction) tasks such as the `FUNSD <https://guillaumejaume.github.io/FUNSD/>`__
dataset and the `SROIE <https://rrc.cvc.uab.es/?ch=13>`__ dataset.
""",
LAYOUTLM_START_DOCSTRING,
)
class LayoutLMForTokenClassification(LayoutLMPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.layoutlm = LayoutLMModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
def get_input_embeddings(self):
return self.layoutlm.embeddings.word_embeddings
@add_start_docstrings_to_model_forward(LAYOUTLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=TokenClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
bbox=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the token classification loss. Indices should be in ``[0, ..., config.num_labels -
1]``.
Returns:
Examples::
>>> from transformers import LayoutLMTokenizer, LayoutLMForTokenClassification
>>> import torch
>>> tokenizer = LayoutLMTokenizer.from_pretrained('microsoft/layoutlm-base-uncased')
>>> model = LayoutLMForTokenClassification.from_pretrained('microsoft/layoutlm-base-uncased')
>>> words = ["Hello", "world"]
>>> normalized_word_boxes = [637, 773, 693, 782], [698, 773, 733, 782]
>>> token_boxes = []
>>> for word, box in zip(words, normalized_word_boxes):
... word_tokens = tokenizer.tokenize(word)
... token_boxes.extend([box] * len(word_tokens))
>>> # add bounding boxes of cls + sep tokens
>>> token_boxes = [[0, 0, 0, 0]] + token_boxes + [[1000, 1000, 1000, 1000]]
>>> encoding = tokenizer(' '.join(words), return_tensors="pt")
>>> input_ids = encoding["input_ids"]
>>> attention_mask = encoding["attention_mask"]
>>> token_type_ids = encoding["token_type_ids"]
>>> bbox = torch.tensor([token_boxes])
>>> token_labels = torch.tensor([1,1,0,0]).unsqueeze(0) # batch size of 1
>>> outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids,
... labels=token_labels)
>>> loss = outputs.loss
>>> logits = outputs.logits
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.layoutlm(
input_ids=input_ids,
bbox=bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
if attention_mask is not None:
active_loss = attention_mask.view(-1) == 1
active_logits = logits.view(-1, self.num_labels)[active_loss]
active_labels = labels.view(-1)[active_loss]
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
| AdaMix/src/transformers/models/layoutlm/modeling_layoutlm.py/0 | {
"file_path": "AdaMix/src/transformers/models/layoutlm/modeling_layoutlm.py",
"repo_id": "AdaMix",
"token_count": 22171
} | 59 |
# coding=utf-8
# Copyright 2018, Hao Tan, Mohit Bansal
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" LXMERT model configuration """
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"unc-nlp/lxmert-base-uncased": "",
}
class LxmertConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a :class:`~transformers.LxmertModel` or a
:class:`~transformers.TFLxmertModel`. It is used to instantiate a LXMERT model according to the specified
arguments, defining the model architecture.
Configuration objects inherit from :class:`~transformers.PretrainedConfig` and can be used to control the model
outputs. Read the documentation from :class:`~transformers.PretrainedConfig` for more information.
Args:
vocab_size (:obj:`int`, `optional`, defaults to 30522):
Vocabulary size of the LXMERT model. Defines the number of different tokens that can be represented by the
:obj:`inputs_ids` passed when calling :class:`~transformers.LxmertModel` or
:class:`~transformers.TFLxmertModel`.
hidden_size (:obj:`int`, `optional`, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
r_layers (:obj:`int`, `optional`, defaults to 5):
Number of hidden layers in the Transformer visual encoder.
l_layers (:obj:`int`, `optional`, defaults to 9):
Number of hidden layers in the Transformer language encoder.
x_layers (:obj:`int`, `optional`, defaults to 5):
Number of hidden layers in the Transformer cross modality encoder.
num_attention_heads (:obj:`int`, `optional`, defaults to 5):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (:obj:`int`, `optional`, defaults to 3072):
Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
hidden_act (:obj:`str` or :obj:`Callable`, `optional`, defaults to :obj:`"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string,
:obj:`"gelu"`, :obj:`"relu"`, :obj:`"silu"` and :obj:`"gelu_new"` are supported.
hidden_dropout_prob (:obj:`float`, `optional`, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (:obj:`float`, `optional`, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (:obj:`int`, `optional`, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (:obj:`int`, `optional`, defaults to 2):
The vocabulary size of the `token_type_ids` passed into :class:`~transformers.BertModel`.
initializer_range (:obj:`float`, `optional`, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (:obj:`float`, `optional`, defaults to 1e-12):
The epsilon used by the layer normalization layers.
visual_feat_dim (:obj:`int`, `optional`, defaults to 2048):
This represents the last dimension of the pooled-object features used as input for the model, representing
the size of each object feature itself.
visual_pos_dim (:obj:`int`, `optional`, defaults to 4):
This represents the number of spacial features that are mixed into the visual features. The default is set
to 4 because most commonly this will represent the location of a bounding box. i.e., (x, y, width, height)
visual_loss_normalizer (:obj:`float`, `optional`, defaults to 1/15):
This represents the scaling factor in which each visual loss is multiplied by if during pretraining, one
decided to train with multiple vision-based loss objectives.
num_qa_labels (:obj:`int`, `optional`, defaults to 9500):
This represents the total number of different question answering (QA) labels there are. If using more than
one dataset with QA, the user will need to account for the total number of labels that all of the datasets
have in total.
num_object_labels (:obj:`int`, `optional`, defaults to 1600):
This represents the total number of semantically unique objects that lxmert will be able to classify a
pooled-object feature as belonging too.
num_attr_labels (:obj:`int`, `optional`, defaults to 400):
This represents the total number of semantically unique attributes that lxmert will be able to classify a
pooled-object feature as possessing.
task_matched (:obj:`bool`, `optional`, defaults to :obj:`True`):
This task is used for sentence-image matching. If the sentence correctly describes the image the label will
be 1. If the sentence does not correctly describe the image, the label will be 0.
task_mask_lm (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to add masked language modeling (as used in pretraining models such as BERT) to the loss
objective.
task_obj_predict (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to add object prediction, attribute ppredictionand feature regression to the loss objective.
task_qa (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to add the question-asansweringoss to the objective
visual_obj_loss (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to calculate the object-prediction loss objective
visual_attr_loss (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to calculate the attribute-prediction loss objective
visual_feat_loss (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to calculate the feature-regression loss objective
output_attentions (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not the model should return the attentions from the vision, language, and cross-modality layers
should be returned.
output_hidden_states (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not the model should return the hidden states from the vision, language, and cross-modality
layers should be returned.
"""
model_type = "lxmert"
def __init__(
self,
vocab_size=30522,
hidden_size=768,
num_attention_heads=12,
num_labels=2,
num_qa_labels=9500,
num_object_labels=1600,
num_attr_labels=400,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
pad_token_id=0,
l_layers=9,
x_layers=5,
r_layers=5,
visual_feat_dim=2048,
visual_pos_dim=4,
visual_loss_normalizer=6.67,
task_matched=True,
task_mask_lm=True,
task_obj_predict=True,
task_qa=True,
visual_obj_loss=True,
visual_attr_loss=True,
visual_feat_loss=True,
output_attentions=False,
output_hidden_states=False,
**kwargs,
):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_attention_heads = num_attention_heads
self.num_labels = num_labels
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.num_qa_labels = num_qa_labels
self.num_object_labels = num_object_labels
self.num_attr_labels = num_attr_labels
self.l_layers = l_layers
self.x_layers = x_layers
self.r_layers = r_layers
self.visual_feat_dim = visual_feat_dim
self.visual_pos_dim = visual_pos_dim
self.visual_loss_normalizer = visual_loss_normalizer
self.task_matched = task_matched
self.task_mask_lm = task_mask_lm
self.task_obj_predict = task_obj_predict
self.task_qa = task_qa
self.visual_obj_loss = visual_obj_loss
self.visual_attr_loss = visual_attr_loss
self.visual_feat_loss = visual_feat_loss
self.output_hidden_states = output_hidden_states
self.output_attentions = self.output_attentions
self.num_hidden_layers = {"vision": r_layers, "cross_encoder": x_layers, "language": l_layers}
| AdaMix/src/transformers/models/lxmert/configuration_lxmert.py/0 | {
"file_path": "AdaMix/src/transformers/models/lxmert/configuration_lxmert.py",
"repo_id": "AdaMix",
"token_count": 3802
} | 60 |
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team, Microsoft Corporation.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" MPNet model configuration """
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
MPNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"microsoft/mpnet-base": "https://huggingface.co/microsoft/mpnet-base/resolve/main/config.json",
}
class MPNetConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a :class:`~transformers.MPNetModel` or a
:class:`~transformers.TFMPNetModel`. It is used to instantiate a MPNet model according to the specified arguments,
defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration
to that of the MPNet `mpnet-base <https://huggingface.co/mpnet-base>`__ architecture.
Configuration objects inherit from :class:`~transformers.PretrainedConfig` and can be used to control the model
outputs. Read the documentation from :class:`~transformers.PretrainedConfig` for more information.
Args:
vocab_size (:obj:`int`, `optional`, defaults to 30527):
Vocabulary size of the MPNet model. Defines the number of different tokens that can be represented by the
:obj:`inputs_ids` passed when calling :class:`~transformers.MPNetModel` or
:class:`~transformers.TFMPNetModel`.
hidden_size (:obj:`int`, `optional`, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (:obj:`int`, `optional`, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (:obj:`int`, `optional`, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (:obj:`int`, `optional`, defaults to 3072):
Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
hidden_act (:obj:`str` or :obj:`Callable`, `optional`, defaults to :obj:`"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string,
:obj:`"gelu"`, :obj:`"relu"`, :obj:`"silu"` and :obj:`"gelu_new"` are supported.
hidden_dropout_prob (:obj:`float`, `optional`, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (:obj:`float`, `optional`, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (:obj:`int`, `optional`, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
initializer_range (:obj:`float`, `optional`, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (:obj:`float`, `optional`, defaults to 1e-12):
The epsilon used by the layer normalization layers.
relative_attention_num_buckets (:obj:`int`, `optional`, defaults to 32):
The number of buckets to use for each attention layer.
Examples::
>>> from transformers import MPNetModel, MPNetConfig
>>> # Initializing a MPNet mpnet-base style configuration
>>> configuration = MPNetConfig()
>>> # Initializing a model from the mpnet-base style configuration
>>> model = MPNetModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
"""
model_type = "mpnet"
def __init__(
self,
vocab_size=30527,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
initializer_range=0.02,
layer_norm_eps=1e-12,
relative_attention_num_buckets=32,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.relative_attention_num_buckets = relative_attention_num_buckets
| AdaMix/src/transformers/models/mpnet/configuration_mpnet.py/0 | {
"file_path": "AdaMix/src/transformers/models/mpnet/configuration_mpnet.py",
"repo_id": "AdaMix",
"token_count": 2093
} | 61 |
# coding=utf-8
# Copyright 2021, Google and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch PEGASUS model. """
import copy
import math
import random
from typing import Optional, Tuple
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
from torch import nn
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
from ...file_utils import (
add_end_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
Seq2SeqLMOutput,
Seq2SeqModelOutput,
)
from ...modeling_utils import PreTrainedModel
from ...utils import logging
from .configuration_pegasus import PegasusConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "PegasusConfig"
_TOKENIZER_FOR_DOC = "PegasusTokenizer"
PEGASUS_PRETRAINED_MODEL_ARCHIVE_LIST = [
"google/pegasus-large",
# See all PEGASUS models at https://huggingface.co/models?filter=pegasus
]
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
"""
Shift input ids one token to the right.
"""
shifted_input_ids = input_ids.new_zeros(input_ids.shape)
shifted_input_ids[:, 1:] = input_ids[:, :-1].clone()
shifted_input_ids[:, 0] = decoder_start_token_id
assert pad_token_id is not None, "self.model.config.pad_token_id has to be defined."
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
return shifted_input_ids
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, past_key_values_length: int = 0):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz, tgt_len = input_ids_shape
mask = torch.full((tgt_len, tgt_len), float("-inf"))
mask_cond = torch.arange(mask.size(-1))
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
mask = mask.to(dtype)
if past_key_values_length > 0:
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask], dim=-1)
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
# Copied from transformers.models.bart.modeling_bart._expand_mask
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
bsz, src_len = mask.size()
tgt_len = tgt_len if tgt_len is not None else src_len
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
inverted_mask = 1.0 - expanded_mask
return inverted_mask.masked_fill(inverted_mask.bool(), torch.finfo(dtype).min)
# Copied from transformers.models.marian.modeling_marian.MarianSinusoidalPositionalEmbedding with Marian->Pegasus
class PegasusSinusoidalPositionalEmbedding(nn.Embedding):
"""This module produces sinusoidal positional embeddings of any length."""
def __init__(self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None):
super().__init__(num_positions, embedding_dim)
self.weight = self._init_weight(self.weight)
@staticmethod
def _init_weight(out: nn.Parameter):
"""
Identical to the XLM create_sinusoidal_embeddings except features are not interleaved. The cos features are in
the 2nd half of the vector. [dim // 2:]
"""
n_pos, dim = out.shape
position_enc = np.array(
[[pos / np.power(10000, 2 * (j // 2) / dim) for j in range(dim)] for pos in range(n_pos)]
)
out.requires_grad = False # set early to avoid an error in pytorch-1.8+
sentinel = dim // 2 if dim % 2 == 0 else (dim // 2) + 1
out[:, 0:sentinel] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))
out[:, sentinel:] = torch.FloatTensor(np.cos(position_enc[:, 1::2]))
out.detach_()
return out
@torch.no_grad()
def forward(self, input_ids_shape: torch.Size, past_key_values_length: int = 0):
"""`input_ids_shape` is expected to be [bsz x seqlen]."""
bsz, seq_len = input_ids_shape[:2]
positions = torch.arange(
past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
)
return super().forward(positions)
# Copied from transformers.models.bart.modeling_bart.BartAttention with Bart->Pegasus
class PegasusAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
assert (
self.head_dim * num_heads == self.embed_dim
), f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`: {num_heads})."
self.scaling = self.head_dim ** -0.5
self.is_decoder = is_decoder
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, embed_dim = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
assert attn_weights.size() == (
bsz * self.num_heads,
tgt_len,
src_len,
), f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is {attn_weights.size()}"
if attention_mask is not None:
assert attention_mask.size() == (
bsz,
1,
tgt_len,
src_len,
), f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = F.softmax(attn_weights, dim=-1)
if layer_head_mask is not None:
assert layer_head_mask.size() == (
self.num_heads,
), f"Head mask for a single layer should be of size {(self.num_heads,)}, but is {layer_head_mask.size()}"
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if output_attentions:
# this operation is a bit akward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = F.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
assert attn_output.size() == (
bsz * self.num_heads,
tgt_len,
self.head_dim,
), f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is {attn_output.size()}"
attn_output = (
attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
.transpose(1, 2)
.reshape(bsz, tgt_len, embed_dim)
)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped, past_key_value
# Copied from transformers.models.mbart.modeling_mbart.MBartEncoderLayer with MBart->Pegasus
class PegasusEncoderLayer(nn.Module):
def __init__(self, config: PegasusConfig):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = PegasusAttention(
embed_dim=self.embed_dim,
num_heads=config.encoder_attention_heads,
dropout=config.attention_dropout,
)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
layer_head_mask: torch.Tensor,
output_attentions: bool = False,
):
"""
Args:
hidden_states (:obj:`torch.FloatTensor`): input to the layer of shape `(seq_len, batch, embed_dim)`
attention_mask (:obj:`torch.FloatTensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
layer_head_mask (:obj:`torch.FloatTensor`): mask for attention heads in a given layer of size
`(config.encoder_attention_heads,)`.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
hidden_states, attn_weights, _ = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = F.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.final_layer_norm(hidden_states)
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = F.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = F.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
if hidden_states.dtype == torch.float16 and (
torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
):
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
# Copied from transformers.models.mbart.modeling_mbart.MBartDecoderLayer with MBart->Pegasus
class PegasusDecoderLayer(nn.Module):
def __init__(self, config: PegasusConfig):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = PegasusAttention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.encoder_attn = PegasusAttention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
encoder_layer_head_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = True,
):
"""
Args:
hidden_states (:obj:`torch.FloatTensor`): input to the layer of shape `(seq_len, batch, embed_dim)`
attention_mask (:obj:`torch.FloatTensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
encoder_hidden_states (:obj:`torch.FloatTensor`): cross attention input to the layer of shape `(seq_len, batch, embed_dim)`
encoder_attention_mask (:obj:`torch.FloatTensor`): encoder attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
layer_head_mask (:obj:`torch.FloatTensor`): mask for attention heads in a given layer of size
`(config.encoder_attention_heads,)`.
encoder_layer_head_mask (:obj:`torch.FloatTensor`): mask for encoder attention heads in a given layer of
size `(config.encoder_attention_heads,)`.
past_key_value (:obj:`Tuple(torch.FloatTensor)`): cached past key and value projection states
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = F.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=layer_head_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
)
hidden_states = F.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.final_layer_norm(hidden_states)
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = F.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = F.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
if use_cache:
outputs += (present_key_value,)
return outputs
class PegasusPreTrainedModel(PreTrainedModel):
config_class = PegasusConfig
base_model_prefix = "model"
def _init_weights(self, module):
std = self.config.init_std
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, PegasusSinusoidalPositionalEmbedding):
pass
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
@property
def dummy_inputs(self):
pad_token = self.config.pad_token_id
input_ids = torch.tensor([[0, 6, 10, 4, 2], [0, 8, 12, 2, pad_token]], device=self.device)
dummy_inputs = {
"attention_mask": input_ids.ne(pad_token),
"input_ids": input_ids,
"decoder_input_ids": input_ids,
}
return dummy_inputs
PEGASUS_START_DOCSTRING = r"""
This model inherits from :class:`~transformers.PreTrainedModel`. Check the superclass documentation for the generic
methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
pruning heads etc.)
This model is also a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`__
subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
general usage and behavior.
Parameters:
config (:class:`~transformers.PegasusConfig`):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
:meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
"""
PEGASUS_GENERATION_EXAMPLE = r"""
Summarization example::
>>> from transformers import PegasusTokenizer, PegasusForConditionalGeneration
>>> model = PegasusForConditionalGeneration.from_pretrained('google/pegasus-xsum')
>>> tokenizer = PegasusTokenizer.from_pretrained('google/pegasus-xsum')
>>> ARTICLE_TO_SUMMARIZE = (
... "PG&E stated it scheduled the blackouts in response to forecasts for high winds "
... "amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were "
... "scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."
... )
>>> inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors='pt')
>>> # Generate Summary
>>> summary_ids = model.generate(inputs['input_ids'])
>>> print([tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in summary_ids])
"""
PEGASUS_INPUTS_DOCSTRING = r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using :class:`~transformers.PegasusTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__` for
details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.Tensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
decoder_input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, target_sequence_length)`, `optional`):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using :class:`~transformers.PegasusTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__` for
details.
`What are input IDs? <../glossary.html#input-ids>`__
Pegasus uses the :obj:`pad_token_id` as the starting token for :obj:`decoder_input_ids` generation. If
:obj:`past_key_values` is used, optionally only the last :obj:`decoder_input_ids` have to be input (see
:obj:`past_key_values`).
decoder_attention_mask (:obj:`torch.LongTensor` of shape :obj:`(batch_size, target_sequence_length)`, `optional`):
Default behavior: generate a tensor that ignores pad tokens in :obj:`decoder_input_ids`. Causal mask will
also be used by default.
If you want to change padding behavior, you should read :func:`modeling_pegasus._prepare_decoder_inputs`
and modify to your needs. See diagram 1 in `the paper <https://arxiv.org/abs/1910.13461>`__ for more
information on the default strategy.
head_mask (:obj:`torch.Tensor` of shape :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the heas is **masked**.
decoder_head_mask (:obj:`torch.Tensor` of shape :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_outputs (:obj:`tuple(tuple(torch.FloatTensor)`, `optional`):
Tuple consists of (:obj:`last_hidden_state`, `optional`: :obj:`hidden_states`, `optional`:
:obj:`attentions`) :obj:`last_hidden_state` of shape :obj:`(batch_size, sequence_length, hidden_size)`,
`optional`) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the
cross-attention of the decoder.
past_key_values (:obj:`Tuple[Tuple[torch.Tensor]]` of length :obj:`config.n_layers` with each tuple having 2 tuples each of which has 2 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up decoding.
If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
(those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
instead of all :obj:`decoder_input_ids`` of shape :obj:`(batch_size, sequence_length)`.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert :obj:`input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
decoder_inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, target_sequence_length, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`decoder_input_ids` you can choose to directly pass an embedded
representation. If :obj:`past_key_values` is used, optionally only the last :obj:`decoder_inputs_embeds`
have to be input (see :obj:`past_key_values`). This is useful if you want more control over how to convert
:obj:`decoder_input_ids` indices into associated vectors than the model's internal embedding lookup matrix.
If :obj:`decoder_input_ids` and :obj:`decoder_inputs_embeds` are both unset, :obj:`decoder_inputs_embeds`
takes the value of :obj:`inputs_embeds`.
use_cache (:obj:`bool`, `optional`):
If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
decoding (see :obj:`past_key_values`).
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned
tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for
more detail.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
"""
class PegasusEncoder(PegasusPreTrainedModel):
"""
Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
:class:`PegasusEncoderLayer`.
Args:
config: PegasusConfig
embed_tokens (torch.nn.Embedding): output embedding
"""
def __init__(self, config: PegasusConfig, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.encoder_layerdrop
embed_dim = config.d_model
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(embed_dim) if config.scale_embedding else 1.0
if embed_tokens is not None:
self.embed_tokens = embed_tokens
else:
self.embed_tokens = nn.Embedding(config.vocab_size, embed_dim, self.padding_idx)
self.embed_positions = PegasusSinusoidalPositionalEmbedding(
config.max_position_embeddings,
embed_dim,
self.padding_idx,
)
self.layers = nn.ModuleList([PegasusEncoderLayer(config) for _ in range(config.encoder_layers)])
self.layer_norm = nn.LayerNorm(config.d_model)
self.init_weights()
def forward(
self,
input_ids=None,
attention_mask=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using :class:`~transformers.PegasusTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__`
for details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.Tensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
head_mask (:obj:`torch.Tensor` of shape :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the attention modules. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the heas is **masked**.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded
representation. This is useful if you want more control over how to convert :obj:`input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under
returned tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors
for more detail.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(input_shape)
hidden_states = inputs_embeds + embed_pos
hidden_states = F.dropout(hidden_states, p=self.dropout, training=self.training)
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _expand_mask(attention_mask, inputs_embeds.dtype)
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
assert head_mask.size()[0] == (
len(self.layers)
), f"The head_mask should be specified for {len(self.layers)} layers, but it is for {head_mask.size()[0]}."
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if self.training and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
else:
if getattr(self.config, "gradient_checkpointing", False) and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(encoder_layer),
hidden_states,
attention_mask,
(head_mask[idx] if head_mask is not None else None),
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
hidden_states = self.layer_norm(hidden_states)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
class PegasusDecoder(PegasusPreTrainedModel):
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a :class:`PegasusDecoderLayer`
Args:
config: PegasusConfig
embed_tokens (torch.nn.Embedding): output embedding
"""
def __init__(self, config: PegasusConfig, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.decoder_layerdrop
self.padding_idx = config.pad_token_id
self.max_target_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(config.d_model) if config.scale_embedding else 1.0
if embed_tokens is not None:
self.embed_tokens = embed_tokens
else:
self.embed_tokens = nn.Embedding(config.vocab_size, config.d_model, self.padding_idx)
self.embed_positions = PegasusSinusoidalPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
self.padding_idx,
)
self.layers = nn.ModuleList([PegasusDecoderLayer(config) for _ in range(config.decoder_layers)])
self.layer_norm = nn.LayerNorm(config.d_model)
self.init_weights()
def get_input_embeddings(self):
return self.embed_tokens
def set_input_embeddings(self, value):
self.embed_tokens = value
# Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
# create causal mask
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
combined_attention_mask = None
if input_shape[-1] > 1:
combined_attention_mask = _make_causal_mask(
input_shape, inputs_embeds.dtype, past_key_values_length=past_key_values_length
).to(self.device)
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
combined_attention_mask = (
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
)
return combined_attention_mask
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
encoder_head_mask=None,
past_key_values=None,
inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using :class:`~transformers.PegasusTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__`
for details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.Tensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, encoder_sequence_length, hidden_size)`, `optional`):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (:obj:`torch.LongTensor` of shape :obj:`(batch_size, encoder_sequence_length)`, `optional`):
Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
head_mask (:obj:`torch.Tensor` of shape :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the attention modules. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the heas is **masked**.
encoder_head_mask (:obj:`torch.Tensor` of shape :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the attention modules in encoder to avoid performing cross-attention
on hidden heads. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the heas is **masked**.
past_key_values (:obj:`Tuple[Tuple[torch.Tensor]]` of length :obj:`config.n_layers` with each tuple having 2 tuples each of which has 2 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up
decoding.
If :obj:`past_key_values` are used, the user can optionally input only the last
:obj:`decoder_input_ids` (those that don't have their past key value states given to this model) of
shape :obj:`(batch_size, 1)` instead of all :obj:`decoder_input_ids`` of shape :obj:`(batch_size,
sequence_length)`.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded
representation. This is useful if you want more control over how to convert :obj:`input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under
returned tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors
for more detail.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
attention_mask = self._prepare_decoder_attention_mask(
attention_mask, input_shape, inputs_embeds, past_key_values_length
)
# expand encoder attention mask
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _expand_mask(encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
# embed positions
positions = self.embed_positions(input_shape, past_key_values_length)
hidden_states = inputs_embeds + positions
hidden_states = F.dropout(hidden_states, p=self.dropout, training=self.training)
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
next_decoder_cache = () if use_cache else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
assert head_mask.size()[0] == (
len(self.layers)
), f"The head_mask should be specified for {len(self.layers)} layers, but it is for {head_mask.size()[0]}."
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
if self.training and (dropout_probability < self.layerdrop):
continue
past_key_value = past_key_values[idx] if past_key_values is not None else None
if getattr(self.config, "gradient_checkpointing", False) and self.training:
if use_cache:
logger.warn(
"`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
"`use_cache=False`..."
)
use_cache = False
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
return module(*inputs, output_attentions, use_cache)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(decoder_layer),
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
head_mask[idx] if head_mask is not None else None,
encoder_head_mask[idx] if encoder_head_mask is not None else None,
None,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
encoder_layer_head_mask=(encoder_head_mask[idx] if encoder_head_mask is not None else None),
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[3 if output_attentions else 1],)
if output_attentions:
all_self_attns += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
hidden_states = self.layer_norm(hidden_states)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
return tuple(
v
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_cache,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
)
@add_start_docstrings(
"The bare PEGASUS Model outputting raw hidden-states without any specific head on top.",
PEGASUS_START_DOCSTRING,
)
class PegasusModel(PegasusPreTrainedModel):
def __init__(self, config: PegasusConfig):
super().__init__(config)
padding_idx, vocab_size = config.pad_token_id, config.vocab_size
self.shared = nn.Embedding(vocab_size, config.d_model, padding_idx)
self.encoder = PegasusEncoder(config, self.shared)
self.decoder = PegasusDecoder(config, self.shared)
self.init_weights()
def get_input_embeddings(self):
return self.shared
def set_input_embeddings(self, value):
self.shared = value
self.encoder.embed_tokens = self.shared
self.decoder.embed_tokens = self.shared
def get_encoder(self):
return self.encoder
def get_decoder(self):
return self.decoder
@add_start_docstrings_to_model_forward(PEGASUS_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Seq2SeqModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
encoder_outputs=None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Returns:
Example::
>>> from transformers import PegasusTokenizer, PegasusModel
>>> tokenizer = PegasusTokenizer.from_pretrained("google/pegasus-large")
>>> model = PegasusModel.from_pretrained("google/pegasus-large")
>>> input_ids = tokenizer("Studies have been shown that owning a dog is good for you", return_tensors="pt").input_ids # Batch size 1
>>> decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
>>> outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
>>> last_hidden_states = outputs.last_hidden_state
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if encoder_outputs is None:
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# If the user passed a tuple for encoder_outputs, we wrap it in a BaseModelOutput when return_dict=True
elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
encoder_outputs = BaseModelOutput(
last_hidden_state=encoder_outputs[0],
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
)
# decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
encoder_head_mask=head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return Seq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
@add_start_docstrings(
"The PEGASUS Model with a language modeling head. Can be used for summarization.", PEGASUS_START_DOCSTRING
)
class PegasusForConditionalGeneration(PegasusPreTrainedModel):
base_model_prefix = "model"
_keys_to_ignore_on_load_missing = [
r"final_logits_bias",
r"encoder\.version",
r"decoder\.version",
r"lm_head\.weight",
r"embed_positions\.weight",
]
def __init__(self, config: PegasusConfig):
super().__init__(config)
self.model = PegasusModel(config)
self.register_buffer("final_logits_bias", torch.zeros((1, self.model.shared.num_embeddings)))
self.lm_head = nn.Linear(config.d_model, self.model.shared.num_embeddings, bias=False)
self.init_weights()
def get_encoder(self):
return self.model.get_encoder()
def get_decoder(self):
return self.model.get_decoder()
def resize_token_embeddings(self, new_num_tokens: int) -> nn.Embedding:
new_embeddings = super().resize_token_embeddings(new_num_tokens)
self._resize_final_logits_bias(new_num_tokens)
return new_embeddings
def _resize_final_logits_bias(self, new_num_tokens: int) -> None:
old_num_tokens = self.final_logits_bias.shape[-1]
if new_num_tokens <= old_num_tokens:
new_bias = self.final_logits_bias[:, :new_num_tokens]
else:
extra_bias = torch.zeros((1, new_num_tokens - old_num_tokens), device=self.final_logits_bias.device)
new_bias = torch.cat([self.final_logits_bias, extra_bias], dim=1)
self.register_buffer("final_logits_bias", new_bias)
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
@add_start_docstrings_to_model_forward(PEGASUS_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Seq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
@add_end_docstrings(PEGASUS_GENERATION_EXAMPLE)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
encoder_outputs=None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the masked language modeling loss. Indices should either be in ``[0, ...,
config.vocab_size]`` or -100 (see ``input_ids`` docstring). Tokens with indices set to ``-100`` are ignored
(masked), the loss is only computed for the tokens with labels in ``[0, ..., config.vocab_size]``.
Returns:
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
encoder_outputs=encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
lm_logits = self.lm_head(outputs[0]) + self.final_logits_bias
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(lm_logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (lm_logits,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return Seq2SeqLMOutput(
loss=masked_lm_loss,
logits=lm_logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past=None,
attention_mask=None,
head_mask=None,
use_cache=None,
encoder_outputs=None,
**kwargs
):
# cut decoder_input_ids if past is used
if past is not None:
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # encoder_outputs is defined. input_ids not needed
"encoder_outputs": encoder_outputs,
"past_key_values": past,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"head_mask": head_mask,
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
}
def prepare_decoder_input_ids_from_labels(self, labels: torch.Tensor):
return shift_tokens_right(labels, self.config.pad_token_id, self.config.decoder_start_token_id)
@staticmethod
def _reorder_cache(past, beam_idx):
reordered_past = ()
for layer_past in past:
# cached cross_attention states don't have to be reordered -> they are always the same
reordered_past += (
tuple(past_state.index_select(0, beam_idx) for past_state in layer_past[:2]) + layer_past[2:],
)
return reordered_past
# Copied from transformers.models.bart.modeling_bart.BartDecoderWrapper with Bart->Pegasus
class PegasusDecoderWrapper(PegasusPreTrainedModel):
"""
This wrapper class is a helper class to correctly load pretrained checkpoints when the causal language model is
used in combination with the :class:`~transformers.EncoderDecoderModel` framework.
"""
def __init__(self, config):
super().__init__(config)
self.decoder = PegasusDecoder(config)
def forward(self, *args, **kwargs):
return self.decoder(*args, **kwargs)
# Copied from transformers.models.bart.modeling_bart.BartForCausalLM with Bart->Pegasus
class PegasusForCausalLM(PegasusPreTrainedModel):
def __init__(self, config):
super().__init__(config)
config = copy.deepcopy(config)
config.is_decoder = True
config.is_encoder_decoder = False
self.model = PegasusDecoderWrapper(config)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.init_weights()
def get_input_embeddings(self):
return self.model.decoder.embed_tokens
def set_input_embeddings(self, value):
self.model.decoder.embed_tokens = value
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
def set_decoder(self, decoder):
self.model.decoder = decoder
def get_decoder(self):
return self.model.decoder
@replace_return_docstrings(output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
encoder_head_mask=None,
past_key_values=None,
inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using :class:`~transformers.PegasusTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__`
for details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.Tensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
if the model is configured as a decoder.
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used
in the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
head_mask (:obj:`torch.Tensor` of shape :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the attention modules. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the heas is **masked**.
encoder_head_mask (:obj:`torch.Tensor` of shape :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the attention modules in encoder to avoid performing cross-attention
on hidden heads. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the heas is **masked**.
past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up
decoding.
If :obj:`past_key_values` are used, the user can optionally input only the last ``decoder_input_ids``
(those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
instead of all ``decoder_input_ids`` of shape :obj:`(batch_size, sequence_length)`.
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the masked language modeling loss. Indices should either be in ``[0, ...,
config.vocab_size]`` or -100 (see ``input_ids`` docstring). Tokens with indices set to ``-100`` are
ignored (masked), the loss is only computed for the tokens with labels in ``[0, ...,
config.vocab_size]``.
use_cache (:obj:`bool`, `optional`):
If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
decoding (see :obj:`past_key_values`).
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under
returned tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors
for more detail.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
Returns:
Example::
>>> from transformers import PegasusTokenizer, PegasusForCausalLM
>>> tokenizer = PegasusTokenizer.from_pretrained('facebook/bart-large')
>>> model = PegasusForCausalLM.from_pretrained('facebook/bart-large', add_cross_attention=False)
>>> assert model.config.is_decoder, f"{model.__class__} has to be configured as a decoder."
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model.decoder(
input_ids=input_ids,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
head_mask=head_mask,
encoder_head_mask=encoder_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
logits = self.lm_head(outputs[0])
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return (loss,) + output if loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(self, input_ids, past=None, attention_mask=None, use_cache=None, **kwargs):
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_ids.shape)
if past:
input_ids = input_ids[:, -1:]
# first step, decoder_cached_states are empty
return {
"input_ids": input_ids, # encoder_outputs is defined. input_ids not needed
"attention_mask": attention_mask,
"past_key_values": past,
"use_cache": use_cache,
}
@staticmethod
def _reorder_cache(past, beam_idx):
reordered_past = ()
for layer_past in past:
reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
return reordered_past
| AdaMix/src/transformers/models/pegasus/modeling_pegasus.py/0 | {
"file_path": "AdaMix/src/transformers/models/pegasus/modeling_pegasus.py",
"repo_id": "AdaMix",
"token_count": 31334
} | 62 |
# coding=utf-8
# Copyright 2020 The Microsoft Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import collections
import os
from typing import List, Optional, Tuple
from ...tokenization_utils import PreTrainedTokenizer
from ...utils import logging
from ..bert.tokenization_bert import BasicTokenizer, WordpieceTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "prophetnet.tokenizer"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"microsoft/prophetnet-large-uncased": "https://huggingface.co/microsoft/prophetnet-large-uncased/resolve/main/prophetnet.tokenizer",
}
}
PRETRAINED_INIT_CONFIGURATION = {
"microsoft/prophetnet-large-uncased": {"do_lower_case": True},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"microsoft/prophetnet-large-uncased": 512,
}
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
vocab = collections.OrderedDict()
with open(vocab_file, "r", encoding="utf-8") as reader:
tokens = reader.readlines()
for index, token in enumerate(tokens):
token = token.rstrip("\n")
vocab[token] = index
return vocab
class ProphetNetTokenizer(PreTrainedTokenizer):
r"""
Construct a ProphetNetTokenizer. Based on WordPiece.
This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods.
Users should refer to this superclass for more information regarding those methods.
Args:
vocab_file (:obj:`str`):
File containing the vocabulary.
do_lower_case (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to lowercase the input when tokenizing.
do_basic_tokenize (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to do basic tokenization before WordPiece.
never_split (:obj:`Iterable`, `optional`):
Collection of tokens which will never be split during tokenization. Only has an effect when
:obj:`do_basic_tokenize=True`
unk_token (:obj:`str`, `optional`, defaults to :obj:`"[UNK]"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
sep_token (:obj:`str`, `optional`, defaults to :obj:`"[SEP]"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
x_sep_token (:obj:`str`, `optional`, defaults to :obj:`"[X_SEP]"`):
Special second separator token, which can be generated by
:class:`~transformers.ProphetNetForConditionalGeneration`. It is used to separate bullet-point like
sentences in summarization, *e.g.*.
pad_token (:obj:`str`, `optional`, defaults to :obj:`"[PAD]"`):
The token used for padding, for example when batching sequences of different lengths.
cls_token (:obj:`str`, `optional`, defaults to :obj:`"[CLS]"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
mask_token (:obj:`str`, `optional`, defaults to :obj:`"[MASK]"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
tokenize_chinese_chars (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether or not to tokenize Chinese characters.
This should likely be deactivated for Japanese (see this `issue
<https://github.com/huggingface/transformers/issues/328>`__).
strip_accents: (:obj:`bool`, `optional`):
Whether or not to strip all accents. If this option is not specified, then it will be determined by the
value for :obj:`lowercase` (as in the original BERT).
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
vocab_file,
do_lower_case=True,
do_basic_tokenize=True,
never_split=None,
unk_token="[UNK]",
sep_token="[SEP]",
x_sep_token="[X_SEP]",
pad_token="[PAD]",
mask_token="[MASK]",
tokenize_chinese_chars=True,
strip_accents=None,
**kwargs
):
super().__init__(
do_lower_case=do_lower_case,
do_basic_tokenize=do_basic_tokenize,
never_split=never_split,
unk_token=unk_token,
sep_token=sep_token,
x_sep_token=x_sep_token,
pad_token=pad_token,
mask_token=mask_token,
tokenize_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
**kwargs,
)
self.unique_no_split_tokens.append(x_sep_token)
if not os.path.isfile(vocab_file):
raise ValueError(
"Can't find a vocabulary file at path '{}'. To load the vocabulary from a Google pretrained "
"model use `tokenizer = ProphetNetTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)`".format(vocab_file)
)
self.vocab = load_vocab(vocab_file)
self.ids_to_tokens = collections.OrderedDict([(ids, tok) for tok, ids in self.vocab.items()])
self.do_basic_tokenize = do_basic_tokenize
if do_basic_tokenize:
self.basic_tokenizer = BasicTokenizer(
do_lower_case=do_lower_case,
never_split=never_split,
tokenize_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
)
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab, unk_token=self.unk_token)
@property
def vocab_size(self):
return len(self.vocab)
def get_vocab(self):
return dict(self.vocab, **self.added_tokens_encoder)
def _tokenize(self, text):
split_tokens = []
if self.do_basic_tokenize:
for token in self.basic_tokenizer.tokenize(text, never_split=self.all_special_tokens):
# If the token is part of the never_split set
if token in self.basic_tokenizer.never_split:
split_tokens.append(token)
else:
split_tokens += self.wordpiece_tokenizer.tokenize(token)
else:
split_tokens = self.wordpiece_tokenizer.tokenize(text)
return split_tokens
def _convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
return self.vocab.get(token, self.vocab.get(self.unk_token))
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.ids_to_tokens.get(index, self.unk_token)
def convert_tokens_to_string(self, tokens):
""" Converts a sequence of tokens (string) in a single string. """
out_string = " ".join(tokens).replace(" ##", "").strip()
return out_string
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer ``prepare_for_model`` method.
Args:
token_ids_0 (:obj:`List[int]`):
List of IDs.
token_ids_1 (:obj:`List[int]`, `optional`):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
:obj:`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formatted with special tokens for the model."
)
return list(map(lambda x: 1 if x in [self.sep_token_id, self.cls_token_id] else 0, token_ids_0))
if token_ids_1 is None:
return ([0] * len(token_ids_0)) + [1]
return ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task. A ProphetNet
sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If :obj:`token_ids_1` is :obj:`None`, this method only returns the first portion of the mask (0s).
Args:
token_ids_0 (:obj:`List[int]`):
List of IDs.
token_ids_1 (:obj:`List[int]`, `optional`):
Optional second list of IDs for sequence pairs.
Returns:
:obj:`List[int]`: List of `token type IDs <../glossary.html#token-type-ids>`_ according to the given
sequence(s).
"""
sep = [self.sep_token_id]
if token_ids_1 is None:
return len(token_ids_0 + sep) * [0]
return len(token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
index = 0
if os.path.isdir(save_directory):
vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
else:
vocab_file = (filename_prefix + "-" if filename_prefix else "") + save_directory
with open(vocab_file, "w", encoding="utf-8") as writer:
for token, token_index in sorted(self.vocab.items(), key=lambda kv: kv[1]):
if index != token_index:
logger.warning(
"Saving vocabulary to {}: vocabulary indices are not consecutive."
" Please check that the vocabulary is not corrupted!".format(vocab_file)
)
index = token_index
writer.write(token + "\n")
index += 1
return (vocab_file,)
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A BERT sequence has the following format:
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
Args:
token_ids_0 (:obj:`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (:obj:`List[int]`, `optional`):
Optional second list of IDs for sequence pairs.
Returns:
:obj:`List[int]`: List of `input IDs <../glossary.html#input-ids>`__ with the appropriate special tokens.
"""
if token_ids_1 is None:
return token_ids_0 + [self.sep_token_id]
sep = [self.sep_token_id]
return token_ids_0 + sep + token_ids_1 + sep
| AdaMix/src/transformers/models/prophetnet/tokenization_prophetnet.py/0 | {
"file_path": "AdaMix/src/transformers/models/prophetnet/tokenization_prophetnet.py",
"repo_id": "AdaMix",
"token_count": 5476
} | 63 |
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for RetriBERT."""
from ...utils import logging
from ..bert.tokenization_bert_fast import BertTokenizerFast
from .tokenization_retribert import RetriBertTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"yjernite/retribert-base-uncased": "https://huggingface.co/yjernite/retribert-base-uncased/resolve/main/vocab.txt",
},
"tokenizer_file": {
"yjernite/retribert-base-uncased": "https://huggingface.co/yjernite/retribert-base-uncased/resolve/main/tokenizer.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"yjernite/retribert-base-uncased": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"yjernite/retribert-base-uncased": {"do_lower_case": True},
}
class RetriBertTokenizerFast(BertTokenizerFast):
r"""
Construct a "fast" RetriBERT tokenizer (backed by HuggingFace's `tokenizers` library).
:class:`~transformers.RetriBertTokenizerFast` is identical to :class:`~transformers.BertTokenizerFast` and runs
end-to-end tokenization: punctuation splitting and wordpiece.
Refer to superclass :class:`~transformers.BertTokenizerFast` for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = RetriBertTokenizer
model_input_names = ["input_ids", "attention_mask"]
| AdaMix/src/transformers/models/retribert/tokenization_retribert_fast.py/0 | {
"file_path": "AdaMix/src/transformers/models/retribert/tokenization_retribert_fast.py",
"repo_id": "AdaMix",
"token_count": 814
} | 64 |
# coding=utf-8
# Copyright 2020 The SqueezeBert authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch SqueezeBert model. """
import math
import torch
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPooling,
MaskedLMOutput,
MultipleChoiceModelOutput,
QuestionAnsweringModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel
from ...utils import logging
from .configuration_squeezebert import SqueezeBertConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "squeezebert/squeezebert-uncased"
_CONFIG_FOR_DOC = "SqueezeBertConfig"
_TOKENIZER_FOR_DOC = "SqueezeBertTokenizer"
SQUEEZEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
"squeezebert/squeezebert-uncased",
"squeezebert/squeezebert-mnli",
"squeezebert/squeezebert-mnli-headless",
]
class SqueezeBertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.embedding_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.embedding_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class MatMulWrapper(torch.nn.Module):
"""
Wrapper for torch.matmul(). This makes flop-counting easier to implement. Note that if you directly call
torch.matmul() in your code, the flop counter will typically ignore the flops of the matmul.
"""
def __init__(self):
super().__init__()
def forward(self, mat1, mat2):
"""
:param inputs: two torch tensors :return: matmul of these tensors
Here are the typical dimensions found in BERT (the B is optional) mat1.shape: [B, <optional extra dims>, M, K]
mat2.shape: [B, <optional extra dims>, K, N] output shape: [B, <optional extra dims>, M, N]
"""
return torch.matmul(mat1, mat2)
class SqueezeBertLayerNorm(nn.LayerNorm):
"""
This is a nn.LayerNorm subclass that accepts NCW data layout and performs normalization in the C dimension.
N = batch C = channels W = sequence length
"""
def __init__(self, hidden_size, eps=1e-12):
nn.LayerNorm.__init__(self, normalized_shape=hidden_size, eps=eps) # instantiates self.{weight, bias, eps}
def forward(self, x):
x = x.permute(0, 2, 1)
x = nn.LayerNorm.forward(self, x)
return x.permute(0, 2, 1)
class ConvDropoutLayerNorm(nn.Module):
"""
ConvDropoutLayerNorm: Conv, Dropout, LayerNorm
"""
def __init__(self, cin, cout, groups, dropout_prob):
super().__init__()
self.conv1d = nn.Conv1d(in_channels=cin, out_channels=cout, kernel_size=1, groups=groups)
self.layernorm = SqueezeBertLayerNorm(cout)
self.dropout = nn.Dropout(dropout_prob)
def forward(self, hidden_states, input_tensor):
x = self.conv1d(hidden_states)
x = self.dropout(x)
x = x + input_tensor
x = self.layernorm(x)
return x
class ConvActivation(nn.Module):
"""
ConvActivation: Conv, Activation
"""
def __init__(self, cin, cout, groups, act):
super().__init__()
self.conv1d = nn.Conv1d(in_channels=cin, out_channels=cout, kernel_size=1, groups=groups)
self.act = ACT2FN[act]
def forward(self, x):
output = self.conv1d(x)
return self.act(output)
class SqueezeBertSelfAttention(nn.Module):
def __init__(self, config, cin, q_groups=1, k_groups=1, v_groups=1):
"""
config = used for some things; ignored for others (work in progress...) cin = input channels = output channels
groups = number of groups to use in conv1d layers
"""
super().__init__()
if cin % config.num_attention_heads != 0:
raise ValueError(
"cin (%d) is not a multiple of the number of attention "
"heads (%d)" % (cin, config.num_attention_heads)
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(cin / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Conv1d(in_channels=cin, out_channels=cin, kernel_size=1, groups=q_groups)
self.key = nn.Conv1d(in_channels=cin, out_channels=cin, kernel_size=1, groups=k_groups)
self.value = nn.Conv1d(in_channels=cin, out_channels=cin, kernel_size=1, groups=v_groups)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.softmax = nn.Softmax(dim=-1)
self.matmul_qk = MatMulWrapper()
self.matmul_qkv = MatMulWrapper()
def transpose_for_scores(self, x):
"""
- input: [N, C, W]
- output: [N, C1, W, C2] where C1 is the head index, and C2 is one head's contents
"""
new_x_shape = (x.size()[0], self.num_attention_heads, self.attention_head_size, x.size()[-1]) # [N, C1, C2, W]
x = x.view(*new_x_shape)
return x.permute(0, 1, 3, 2) # [N, C1, C2, W] --> [N, C1, W, C2]
def transpose_key_for_scores(self, x):
"""
- input: [N, C, W]
- output: [N, C1, C2, W] where C1 is the head index, and C2 is one head's contents
"""
new_x_shape = (x.size()[0], self.num_attention_heads, self.attention_head_size, x.size()[-1]) # [N, C1, C2, W]
x = x.view(*new_x_shape)
# no `permute` needed
return x
def transpose_output(self, x):
"""
- input: [N, C1, W, C2]
- output: [N, C, W]
"""
x = x.permute(0, 1, 3, 2).contiguous() # [N, C1, C2, W]
new_x_shape = (x.size()[0], self.all_head_size, x.size()[3]) # [N, C, W]
x = x.view(*new_x_shape)
return x
def forward(self, hidden_states, attention_mask, output_attentions):
"""
expects hidden_states in [N, C, W] data layout.
The attention_mask data layout is [N, W], and it does not need to be transposed.
"""
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_key_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_score = self.matmul_qk(query_layer, key_layer)
attention_score = attention_score / math.sqrt(self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_score = attention_score + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = self.softmax(attention_score)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
context_layer = self.matmul_qkv(attention_probs, value_layer)
context_layer = self.transpose_output(context_layer)
result = {"context_layer": context_layer}
if output_attentions:
result["attention_score"] = attention_score
return result
class SqueezeBertModule(nn.Module):
def __init__(self, config):
"""
- hidden_size = input chans = output chans for Q, K, V (they are all the same ... for now) = output chans for
the module
- intermediate_size = output chans for intermediate layer
- groups = number of groups for all layers in the BertModule. (eventually we could change the interface to
allow different groups for different layers)
"""
super().__init__()
c0 = config.hidden_size
c1 = config.hidden_size
c2 = config.intermediate_size
c3 = config.hidden_size
self.attention = SqueezeBertSelfAttention(
config=config, cin=c0, q_groups=config.q_groups, k_groups=config.k_groups, v_groups=config.v_groups
)
self.post_attention = ConvDropoutLayerNorm(
cin=c0, cout=c1, groups=config.post_attention_groups, dropout_prob=config.hidden_dropout_prob
)
self.intermediate = ConvActivation(cin=c1, cout=c2, groups=config.intermediate_groups, act=config.hidden_act)
self.output = ConvDropoutLayerNorm(
cin=c2, cout=c3, groups=config.output_groups, dropout_prob=config.hidden_dropout_prob
)
def forward(self, hidden_states, attention_mask, output_attentions):
att = self.attention(hidden_states, attention_mask, output_attentions)
attention_output = att["context_layer"]
post_attention_output = self.post_attention(attention_output, hidden_states)
intermediate_output = self.intermediate(post_attention_output)
layer_output = self.output(intermediate_output, post_attention_output)
output_dict = {"feature_map": layer_output}
if output_attentions:
output_dict["attention_score"] = att["attention_score"]
return output_dict
class SqueezeBertEncoder(nn.Module):
def __init__(self, config):
super().__init__()
assert config.embedding_size == config.hidden_size, (
"If you want embedding_size != intermediate hidden_size,"
"please insert a Conv1d layer to adjust the number of channels "
"before the first SqueezeBertModule."
)
self.layers = nn.ModuleList(SqueezeBertModule(config) for _ in range(config.num_hidden_layers))
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
if head_mask is None:
head_mask_is_all_none = True
elif head_mask.count(None) == len(head_mask):
head_mask_is_all_none = True
else:
head_mask_is_all_none = False
assert head_mask_is_all_none is True, "head_mask is not yet supported in the SqueezeBert implementation."
# [batch_size, sequence_length, hidden_size] --> [batch_size, hidden_size, sequence_length]
hidden_states = hidden_states.permute(0, 2, 1)
all_hidden_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
for layer in self.layers:
if output_hidden_states:
hidden_states = hidden_states.permute(0, 2, 1)
all_hidden_states += (hidden_states,)
hidden_states = hidden_states.permute(0, 2, 1)
layer_output = layer.forward(hidden_states, attention_mask, output_attentions)
hidden_states = layer_output["feature_map"]
if output_attentions:
all_attentions += (layer_output["attention_score"],)
# [batch_size, hidden_size, sequence_length] --> [batch_size, sequence_length, hidden_size]
hidden_states = hidden_states.permute(0, 2, 1)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
)
class SqueezeBertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class SqueezeBertPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
class SqueezeBertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = SqueezeBertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
class SqueezeBertOnlyMLMHead(nn.Module):
def __init__(self, config):
super().__init__()
self.predictions = SqueezeBertLMPredictionHead(config)
def forward(self, sequence_output):
prediction_scores = self.predictions(sequence_output)
return prediction_scores
class SqueezeBertPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = SqueezeBertConfig
base_model_prefix = "transformer"
_keys_to_ignore_on_load_missing = [r"position_ids"]
def _init_weights(self, module):
""" Initialize the weights """
if isinstance(module, (nn.Linear, nn.Conv1d)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, SqueezeBertLayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
SQUEEZEBERT_START_DOCSTRING = r"""
The SqueezeBERT model was proposed in `SqueezeBERT: What can computer vision teach NLP about efficient neural
networks? <https://arxiv.org/abs/2006.11316>`__ by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W.
Keutzer
This model inherits from :class:`~transformers.PreTrainedModel`. Check the superclass documentation for the generic
methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
pruning heads etc.)
This model is also a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`__
subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
general usage and behavior.
For best results finetuning SqueezeBERT on text classification tasks, it is recommended to use the
`squeezebert/squeezebert-mnli-headless` checkpoint as a starting point.
Parameters:
config (:class:`~transformers.SqueezeBertConfig`): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model
weights.
Hierarchy::
Internal class hierarchy:
SqueezeBertModel
SqueezeBertEncoder
SqueezeBertModule
SqueezeBertSelfAttention
ConvActivation
ConvDropoutLayerNorm
Data layouts::
Input data is in [batch, sequence_length, hidden_size] format.
Data inside the encoder is in [batch, hidden_size, sequence_length] format. But, if :obj:`output_hidden_states
== True`, the data from inside the encoder is returned in [batch, sequence_length, hidden_size] format.
The final output of the encoder is in [batch, sequence_length, hidden_size] format.
"""
SQUEEZEBERT_INPUTS_DOCSTRING = r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using :class:`~transformers.SqueezeBertTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__` for
details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.FloatTensor` of shape :obj:`({0})`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
token_type_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in ``[0,
1]``:
- 0 corresponds to a `sentence A` token,
- 1 corresponds to a `sentence B` token.
`What are token type IDs? <../glossary.html#token-type-ids>`_
position_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range ``[0,
config.max_position_embeddings - 1]``.
`What are position IDs? <../glossary.html#position-ids>`_
head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the self-attention modules. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`({0}, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert :obj:`input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned
tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for
more detail.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
"""
@add_start_docstrings(
"The bare SqueezeBERT Model transformer outputting raw hidden-states without any specific head on top.",
SQUEEZEBERT_START_DOCSTRING,
)
class SqueezeBertModel(SqueezeBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.embeddings = SqueezeBertEmbeddings(config)
self.encoder = SqueezeBertEncoder(config)
self.pooler = SqueezeBertPooler(config)
self.init_weights()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, new_embeddings):
self.embeddings.word_embeddings = new_embeddings
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(SQUEEZEBERT_INPUTS_DOCSTRING.format("(batch_size, sequence_length)"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPooling,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape, device)
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = self.encoder(
hidden_states=embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output)
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
@add_start_docstrings("""SqueezeBERT Model with a `language modeling` head on top. """, SQUEEZEBERT_START_DOCSTRING)
class SqueezeBertForMaskedLM(SqueezeBertPreTrainedModel):
_keys_to_ignore_on_load_missing = [r"predictions.decoder.bias"]
def __init__(self, config):
super().__init__(config)
self.transformer = SqueezeBertModel(config)
self.cls = SqueezeBertOnlyMLMHead(config)
self.init_weights()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward(SQUEEZEBERT_INPUTS_DOCSTRING.format("(batch_size, sequence_length)"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the masked language modeling loss. Indices should be in ``[-100, 0, ...,
config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are ignored
(masked), the loss is only computed for the tokens with labels in ``[0, ..., config.vocab_size]``
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
SqueezeBERT Model transformer with a sequence classification/regression head on top (a linear layer on top of the
pooled output) e.g. for GLUE tasks.
""",
SQUEEZEBERT_START_DOCSTRING,
)
class SqueezeBertForSequenceClassification(SqueezeBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.transformer = SqueezeBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(SQUEEZEBERT_INPUTS_DOCSTRING.format("(batch_size, sequence_length)"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss. Indices should be in :obj:`[0, ...,
config.num_labels - 1]`. If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
SqueezeBERT Model with a multiple choice classification head on top (a linear layer on top of the pooled output and
a softmax) e.g. for RocStories/SWAG tasks.
""",
SQUEEZEBERT_START_DOCSTRING,
)
class SqueezeBertForMultipleChoice(SqueezeBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.transformer = SqueezeBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, 1)
self.init_weights()
@add_start_docstrings_to_model_forward(
SQUEEZEBERT_INPUTS_DOCSTRING.format("(batch_size, num_choices, sequence_length)")
)
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the multiple choice classification loss. Indices should be in ``[0, ...,
num_choices-1]`` where `num_choices` is the size of the second dimension of the input tensors. (see
`input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
output = (reshaped_logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return MultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
SqueezeBERT Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g.
for Named-Entity-Recognition (NER) tasks.
""",
SQUEEZEBERT_START_DOCSTRING,
)
class SqueezeBertForTokenClassification(SqueezeBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.transformer = SqueezeBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(SQUEEZEBERT_INPUTS_DOCSTRING.format("(batch_size, sequence_length)"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the token classification loss. Indices should be in ``[0, ..., config.num_labels -
1]``.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
# Only keep active parts of the loss
if attention_mask is not None:
active_loss = attention_mask.view(-1) == 1
active_logits = logits.view(-1, self.num_labels)
active_labels = torch.where(
active_loss, labels.view(-1), torch.tensor(loss_fct.ignore_index).type_as(labels)
)
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
SqueezeBERT Model with a span classification head on top for extractive question-answering tasks like SQuAD (a
linear layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
SQUEEZEBERT_START_DOCSTRING,
)
class SqueezeBertForQuestionAnswering(SqueezeBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.transformer = SqueezeBertModel(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(SQUEEZEBERT_INPUTS_DOCSTRING.format("(batch_size, sequence_length)"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
start_positions=None,
end_positions=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
start_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions.clamp_(0, ignored_index)
end_positions.clamp_(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
| AdaMix/src/transformers/models/squeezebert/modeling_squeezebert.py/0 | {
"file_path": "AdaMix/src/transformers/models/squeezebert/modeling_squeezebert.py",
"repo_id": "AdaMix",
"token_count": 18614
} | 65 |
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
TF 2.0 Transformer XL model.
"""
from dataclasses import dataclass
from typing import List, Optional, Tuple
import tensorflow as tf
from ...file_utils import (
ModelOutput,
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
)
from ...modeling_tf_utils import (
TFPreTrainedModel,
TFSequenceClassificationLoss,
get_initializer,
input_processing,
keras_serializable,
shape_list,
)
from ...utils import logging
from .configuration_transfo_xl import TransfoXLConfig
from .modeling_tf_transfo_xl_utilities import TFAdaptiveSoftmaxMask
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "transfo-xl-wt103"
_CONFIG_FOR_DOC = "TransfoXLConfig"
_TOKENIZER_FOR_DOC = "TransfoXLTokenizer"
TF_TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST = [
"transfo-xl-wt103",
# See all Transformer XL models at https://huggingface.co/models?filter=transfo-xl
]
class TFPositionalEmbedding(tf.keras.layers.Layer):
def __init__(self, demb, **kwargs):
super().__init__(**kwargs)
self.inv_freq = 1 / (10000 ** (tf.range(0, demb, 2.0) / demb))
def call(self, pos_seq, bsz=None):
self.inv_freq = tf.cast(self.inv_freq, dtype=pos_seq.dtype)
sinusoid_inp = tf.einsum("i,j->ij", pos_seq, self.inv_freq)
pos_emb = tf.concat([tf.sin(sinusoid_inp), tf.cos(sinusoid_inp)], -1)
if bsz is not None:
return tf.tile(pos_emb[:, None, :], [1, bsz, 1])
else:
return pos_emb[:, None, :]
class TFPositionwiseFF(tf.keras.layers.Layer):
def __init__(self, d_model, d_inner, dropout, pre_lnorm=False, layer_norm_epsilon=1e-5, init_std=0.02, **kwargs):
super().__init__(**kwargs)
self.d_model = d_model
self.d_inner = d_inner
self.dropout = dropout
self.layer_1 = tf.keras.layers.Dense(
d_inner, kernel_initializer=get_initializer(init_std), activation=tf.nn.relu, name="CoreNet_._0"
)
self.drop_1 = tf.keras.layers.Dropout(dropout)
self.layer_2 = tf.keras.layers.Dense(d_model, kernel_initializer=get_initializer(init_std), name="CoreNet_._3")
self.drop_2 = tf.keras.layers.Dropout(dropout)
self.layer_norm = tf.keras.layers.LayerNormalization(epsilon=layer_norm_epsilon, name="layer_norm")
self.pre_lnorm = pre_lnorm
def call(self, inp, training=False):
if self.pre_lnorm:
# layer normalization + positionwise feed-forward
core_out = self.layer_norm(inp)
core_out = self.layer_1(core_out)
core_out = self.drop_1(core_out, training=training)
core_out = self.layer_2(core_out)
core_out = self.drop_2(core_out, training=training)
# residual connection
output = core_out + inp
else:
# positionwise feed-forward
core_out = self.layer_1(inp)
core_out = self.drop_1(core_out, training=training)
core_out = self.layer_2(core_out)
core_out = self.drop_2(core_out, training=training)
# residual connection + layer normalization
output = self.layer_norm(inp + core_out)
return output
class TFRelPartialLearnableMultiHeadAttn(tf.keras.layers.Layer):
def __init__(
self,
n_head,
d_model,
d_head,
dropout,
dropatt=0.0,
pre_lnorm=False,
r_r_bias=None,
r_w_bias=None,
layer_norm_epsilon=1e-5,
init_std=0.02,
output_attentions=False,
**kwargs
):
super().__init__(**kwargs)
self.n_head = n_head
self.d_model = d_model
self.d_head = d_head
self.dropout = dropout
self.output_attentions = output_attentions
self.qkv_net = tf.keras.layers.Dense(
3 * n_head * d_head, kernel_initializer=get_initializer(init_std), use_bias=False, name="qkv_net"
)
self.drop = tf.keras.layers.Dropout(dropout)
self.dropatt = tf.keras.layers.Dropout(dropatt)
self.o_net = tf.keras.layers.Dense(
d_model, kernel_initializer=get_initializer(init_std), use_bias=False, name="o_net"
)
self.layer_norm = tf.keras.layers.LayerNormalization(epsilon=layer_norm_epsilon, name="layer_norm")
self.scale = 1 / (d_head ** 0.5)
self.pre_lnorm = pre_lnorm
if r_r_bias is not None and r_w_bias is not None: # Biases are shared
self.r_r_bias = r_r_bias
self.r_w_bias = r_w_bias
else:
self.r_r_bias = None
self.r_w_bias = None
self.r_net = tf.keras.layers.Dense(
self.n_head * self.d_head, kernel_initializer=get_initializer(init_std), use_bias=False, name="r_net"
)
def build(self, input_shape):
if self.r_r_bias is None or self.r_w_bias is None: # Biases are not shared
self.r_r_bias = self.add_weight(
shape=(self.n_head, self.d_head), initializer="zeros", trainable=True, name="r_r_bias"
)
self.r_w_bias = self.add_weight(
shape=(self.n_head, self.d_head), initializer="zeros", trainable=True, name="r_w_bias"
)
super().build(input_shape)
def _rel_shift(self, x):
x_size = shape_list(x)
x = tf.pad(x, [[0, 0], [1, 0], [0, 0], [0, 0]])
x = tf.reshape(x, [x_size[1] + 1, x_size[0], x_size[2], x_size[3]])
x = tf.slice(x, [1, 0, 0, 0], [-1, -1, -1, -1])
x = tf.reshape(x, x_size)
return x
def call(self, w, r, attn_mask, mems, head_mask, output_attentions, training=False):
qlen, rlen, bsz = shape_list(w)[0], shape_list(r)[0], shape_list(w)[1]
if mems is not None:
mems = tf.cast(mems, dtype=w.dtype)
cat = tf.concat([mems, w], 0)
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(cat))
else:
w_heads = self.qkv_net(cat)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = tf.split(w_heads, 3, axis=-1)
w_head_q = w_head_q[-qlen:]
else:
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(w))
else:
w_heads = self.qkv_net(w)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = tf.split(w_heads, 3, axis=-1)
klen = shape_list(w_head_k)[0]
w_head_q = tf.reshape(w_head_q, (qlen, bsz, self.n_head, self.d_head)) # qlen x bsz x n_head x d_head
w_head_k = tf.reshape(w_head_k, (klen, bsz, self.n_head, self.d_head)) # qlen x bsz x n_head x d_head
w_head_v = tf.reshape(w_head_v, (klen, bsz, self.n_head, self.d_head)) # qlen x bsz x n_head x d_head
r_head_k = tf.reshape(r_head_k, (rlen, self.n_head, self.d_head)) # qlen x n_head x d_head
# compute attention score
rw_head_q = w_head_q + self.r_w_bias # qlen x bsz x n_head x d_head
AC = tf.einsum("ibnd,jbnd->ijbn", rw_head_q, w_head_k) # qlen x klen x bsz x n_head
rr_head_q = w_head_q + self.r_r_bias
BD = tf.einsum("ibnd,jnd->ijbn", rr_head_q, r_head_k) # qlen x klen x bsz x n_head
BD = self._rel_shift(BD)
# [qlen x klen x bsz x n_head]
attn_score = AC + BD
attn_score = attn_score * self.scale
# compute attention probability
if attn_mask is not None:
attn_mask_t = attn_mask[:, :, None, None]
attn_mask_t = tf.cast(attn_mask_t, dtype=attn_score.dtype)
attn_score = attn_score * (1.0 - attn_mask_t) - 1e30 * attn_mask_t
# [qlen x klen x bsz x n_head]
attn_prob = tf.nn.softmax(attn_score, axis=1)
attn_prob = self.dropatt(attn_prob, training=training)
# Mask heads if we want to
if head_mask is not None:
attn_prob = attn_prob * head_mask
# compute attention vector
attn_vec = tf.einsum("ijbn,jbnd->ibnd", attn_prob, w_head_v)
# [qlen x bsz x n_head x d_head]
attn_vec_sizes = shape_list(attn_vec)
attn_vec = tf.reshape(attn_vec, (attn_vec_sizes[0], attn_vec_sizes[1], self.n_head * self.d_head))
# linear projection
attn_out = self.o_net(attn_vec)
attn_out = self.drop(attn_out, training=training)
if self.pre_lnorm:
# residual connection
outputs = [w + attn_out]
else:
# residual connection + layer normalization
outputs = [self.layer_norm(w + attn_out)]
if output_attentions:
outputs.append(attn_prob)
return outputs
class TFRelPartialLearnableDecoderLayer(tf.keras.layers.Layer):
def __init__(
self,
n_head,
d_model,
d_head,
d_inner,
dropout,
dropatt=0.0,
pre_lnorm=False,
r_w_bias=None,
r_r_bias=None,
layer_norm_epsilon=1e-5,
init_std=0.02,
output_attentions=False,
**kwargs
):
super().__init__(**kwargs)
self.dec_attn = TFRelPartialLearnableMultiHeadAttn(
n_head,
d_model,
d_head,
dropout,
dropatt=dropatt,
pre_lnorm=pre_lnorm,
r_w_bias=r_w_bias,
r_r_bias=r_r_bias,
init_std=init_std,
layer_norm_epsilon=layer_norm_epsilon,
output_attentions=output_attentions,
name="dec_attn",
)
self.pos_ff = TFPositionwiseFF(
d_model,
d_inner,
dropout,
pre_lnorm=pre_lnorm,
init_std=init_std,
layer_norm_epsilon=layer_norm_epsilon,
name="pos_ff",
)
def call(self, dec_inp, r, dec_attn_mask, mems, head_mask, output_attentions, training=False):
attn_outputs = self.dec_attn(dec_inp, r, dec_attn_mask, mems, head_mask, output_attentions, training=training)
ff_output = self.pos_ff(attn_outputs[0], training=training)
outputs = [ff_output] + attn_outputs[1:]
return outputs
class TFTransfoEmbeddings(tf.keras.layers.Layer):
def __init__(self, vocab_size, emb_size, init_std, **kwargs):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.emb_size = emb_size
self.init_std = init_std
def build(self, input_shape):
self.weight = self.add_weight(
shape=(self.vocab_size, self.emb_size),
initializer=get_initializer(self.init_std),
name="embeddings",
)
super().build(input_shape)
def call(self, inputs):
return tf.gather(self.weight, inputs)
class TFAdaptiveEmbedding(tf.keras.layers.Layer):
def __init__(self, n_token, d_embed, d_proj, cutoffs, div_val=1, init_std=0.02, sample_softmax=False, **kwargs):
super().__init__(**kwargs)
self.n_token = n_token
self.d_embed = d_embed
self.init_std = init_std
self.cutoffs = cutoffs + [n_token]
self.div_val = div_val
self.d_proj = d_proj
self.emb_scale = d_proj ** 0.5
self.cutoff_ends = [0] + self.cutoffs
self.emb_layers = []
self.emb_projs = []
if div_val == 1:
raise NotImplementedError # Removed these to avoid maintaining dead code - They are not used in our pretrained checkpoint
else:
for i in range(len(self.cutoffs)):
l_idx, r_idx = self.cutoff_ends[i], self.cutoff_ends[i + 1]
d_emb_i = d_embed // (div_val ** i)
self.emb_layers.append(
TFTransfoEmbeddings(
r_idx - l_idx,
d_emb_i,
init_std,
name="emb_layers_._{}".format(i),
)
)
def build(self, input_shape):
for i in range(len(self.cutoffs)):
d_emb_i = self.d_embed // (self.div_val ** i)
self.emb_projs.append(
self.add_weight(
shape=(d_emb_i, self.d_proj),
initializer=get_initializer(self.init_std),
trainable=True,
name="emb_projs_._{}".format(i),
)
)
super().build(input_shape)
def call(self, inp):
if self.div_val == 1:
raise NotImplementedError # Removed these to avoid maintaining dead code - They are not used in our pretrained checkpoint
else:
inp_flat = tf.reshape(inp, (-1,))
emb_flat = tf.zeros([shape_list(inp_flat)[0], self.d_proj])
for i in range(len(self.cutoffs)):
l_idx, r_idx = self.cutoff_ends[i], self.cutoff_ends[i + 1]
mask_i = (inp_flat >= l_idx) & (inp_flat < r_idx)
inp_i = tf.boolean_mask(inp_flat, mask_i) - l_idx
emb_i = self.emb_layers[i](inp_i)
emb_i = tf.einsum("id,de->ie", emb_i, self.emb_projs[i])
mask_idx = tf.where(mask_i)
scatter = tf.scatter_nd(mask_idx, emb_i, shape_list(emb_flat))
emb_flat = tf.cast(emb_flat, dtype=scatter.dtype)
emb_flat += scatter
embed_shape = shape_list(inp) + [self.d_proj]
embed = tf.reshape(emb_flat, embed_shape)
embed *= self.emb_scale
return embed
@keras_serializable
class TFTransfoXLMainLayer(tf.keras.layers.Layer):
config_class = TransfoXLConfig
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.output_hidden_states = config.output_hidden_states
self.output_attentions = config.output_attentions
self.return_dict = config.use_return_dict
self.n_token = config.vocab_size
self.d_embed = config.d_embed
self.d_model = config.d_model
self.n_head = config.n_head
self.d_head = config.d_head
self.untie_r = config.untie_r
self.word_emb = TFAdaptiveEmbedding(
config.vocab_size,
config.d_embed,
config.d_model,
config.cutoffs,
div_val=config.div_val,
init_std=config.init_std,
name="word_emb",
)
self.drop = tf.keras.layers.Dropout(config.dropout)
self.n_layer = config.n_layer
self.mem_len = config.mem_len
self.attn_type = config.attn_type
self.layers = []
if config.attn_type == 0: # the default attention
for i in range(config.n_layer):
self.layers.append(
TFRelPartialLearnableDecoderLayer(
config.n_head,
config.d_model,
config.d_head,
config.d_inner,
config.dropout,
dropatt=config.dropatt,
pre_lnorm=config.pre_lnorm,
r_w_bias=None if self.untie_r else self.r_w_bias,
r_r_bias=None if self.untie_r else self.r_r_bias,
layer_norm_epsilon=config.layer_norm_epsilon,
init_std=config.init_std,
output_attentions=self.output_attentions,
name="layers_._{}".format(i),
)
)
else: # learnable embeddings and absolute embeddings
raise NotImplementedError # Removed these to avoid maintaining dead code - They are not used in our pretrained checkpoint
self.same_length = config.same_length
self.clamp_len = config.clamp_len
if self.attn_type == 0: # default attention
self.pos_emb = TFPositionalEmbedding(self.d_model, name="pos_emb")
else: # learnable embeddings and absolute embeddings
raise NotImplementedError # Removed these to avoid maintaining dead code - They are not used in our pretrained checkpoint
def build(self, input_shape):
if not self.untie_r:
self.r_w_bias = self.add_weight(
shape=(self.n_head, self.d_head), initializer="zeros", trainable=True, name="r_w_bias"
)
self.r_r_bias = self.add_weight(
shape=(self.n_head, self.d_head), initializer="zeros", trainable=True, name="r_r_bias"
)
super().build(input_shape)
def get_input_embeddings(self):
return self.word_emb
def set_input_embeddings(self, value):
raise NotImplementedError
def backward_compatible(self):
self.sample_softmax = -1
def reset_memory_length(self, mem_len):
self.mem_len = mem_len
def _prune_heads(self, heads):
raise NotImplementedError
def init_mems(self, bsz):
if self.mem_len > 0:
mems = []
for i in range(self.n_layer):
empty = tf.zeros([self.mem_len, bsz, self.d_model])
mems.append(empty)
return mems
else:
return None
def _update_mems(self, hids, mems, mlen, qlen):
# does not deal with None
if mems is None:
return None
# mems is not None
assert len(hids) == len(mems), "len(hids) != len(mems)"
# There are `mlen + qlen` steps that can be cached into mems
new_mems = []
end_idx = mlen + tf.math.maximum(0, qlen)
beg_idx = tf.math.maximum(0, end_idx - tf.convert_to_tensor(self.mem_len))
for i in range(len(hids)):
mems[i] = tf.cast(mems[i], dtype=hids[i].dtype)
cat = tf.concat([mems[i], hids[i]], axis=0)
tf.stop_gradient(cat)
new_mems.append(cat[beg_idx:end_idx])
return new_mems
def call(
self,
input_ids=None,
mems=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
**kwargs,
):
inputs = input_processing(
func=self.call,
config=self.config,
input_ids=input_ids,
mems=mems,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
kwargs_call=kwargs,
)
# the original code for Transformer-XL used shapes [len, bsz] but we want a unified interface in the library
# so we transpose here from shape [bsz, len] to shape [len, bsz]
if inputs["input_ids"] is not None and inputs["inputs_embeds"] is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif inputs["input_ids"] is not None:
inputs["input_ids"] = tf.transpose(inputs["input_ids"], perm=(1, 0))
qlen, bsz = shape_list(inputs["input_ids"])
elif inputs["inputs_embeds"] is not None:
inputs["inputs_embeds"] = tf.transpose(inputs["inputs_embeds"], perm=(1, 0, 2))
qlen, bsz = shape_list(inputs["inputs_embeds"])[:2]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs["mems"] is None:
inputs["mems"] = self.init_mems(bsz)
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads] (a head_mask for each layer)
# and head_mask is converted to shape [num_hidden_layers x qlen x klen x bsz x n_head]
if inputs["head_mask"] is not None:
raise NotImplementedError
else:
inputs["head_mask"] = [None] * self.n_layer
if inputs["inputs_embeds"] is not None:
word_emb = inputs["inputs_embeds"]
else:
word_emb = self.word_emb(inputs["input_ids"])
mlen = shape_list(inputs["mems"][0])[0] if inputs["mems"] is not None else 0
klen = mlen + qlen
attn_mask = tf.ones([qlen, qlen])
mask_u = tf.linalg.band_part(attn_mask, 0, -1)
mask_dia = tf.linalg.band_part(attn_mask, 0, 0)
attn_mask_pad = tf.zeros([qlen, mlen])
dec_attn_mask = tf.concat([attn_mask_pad, mask_u - mask_dia], 1)
if self.same_length:
mask_l = tf.linalg.band_part(attn_mask, -1, 0)
dec_attn_mask = tf.concat([dec_attn_mask[:, :qlen] + mask_l - mask_dia, dec_attn_mask[:, qlen:]], 1)
# ::: PyTorch masking code for reference :::
# if self.same_length:
# all_ones = word_emb.new_ones((qlen, klen), dtype=torch.uint8)
# mask_len = klen - self.mem_len
# if mask_len > 0:
# mask_shift_len = qlen - mask_len
# else:
# mask_shift_len = qlen
# dec_attn_mask = (torch.triu(all_ones, 1+mlen)
# + torch.tril(all_ones, -mask_shift_len))[:, :, None] # -1
# else:
# dec_attn_mask = torch.triu(
# word_emb.new_ones((qlen, klen), dtype=torch.uint8), diagonal=1+mlen)[:,:,None]
hids = []
attentions = [] if inputs["output_attentions"] else None
if self.attn_type == 0: # default
pos_seq = tf.range(klen - 1, -1, -1.0)
if self.clamp_len > 0:
pos_seq = tf.minimum(pos_seq, self.clamp_len)
pos_emb = self.pos_emb(pos_seq)
core_out = self.drop(word_emb, training=inputs["training"])
pos_emb = self.drop(pos_emb, training=inputs["training"])
for i, layer in enumerate(self.layers):
hids.append(core_out)
mems_i = None if inputs["mems"] is None else inputs["mems"][i]
layer_outputs = layer(
core_out,
pos_emb,
dec_attn_mask,
mems_i,
inputs["head_mask"][i],
inputs["output_attentions"],
training=inputs["training"],
)
core_out = layer_outputs[0]
if inputs["output_attentions"]:
attentions.append(layer_outputs[1])
else: # learnable embeddings and absolute embeddings
raise NotImplementedError # Removed these to avoid maintaining dead code - They are not used in our pretrained checkpoint
core_out = self.drop(core_out, training=inputs["training"])
new_mems = self._update_mems(hids, inputs["mems"], mlen, qlen)
# We transpose back here to shape [bsz, len, hidden_dim]
core_out = tf.transpose(core_out, perm=(1, 0, 2))
if inputs["output_hidden_states"]:
# Transpose to library standard shape [bsz, len, hidden_dim] and add last layer
hids = tuple(tf.transpose(t, perm=(1, 0, 2)) for t in hids)
hids = hids + (core_out,)
else:
hids = None
if inputs["output_attentions"]:
# Transpose to library standard shape [bsz, n_heads, query_seq_len, key_seq_len]
attentions = tuple(tf.transpose(t, perm=(2, 3, 0, 1)) for t in attentions)
if not inputs["return_dict"]:
return tuple(v for v in [core_out, new_mems, hids, attentions] if v is not None)
return TFTransfoXLModelOutput(
last_hidden_state=core_out,
mems=new_mems,
hidden_states=hids,
attentions=attentions,
)
class TFTransfoXLPreTrainedModel(TFPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = TransfoXLConfig
base_model_prefix = "transformer"
@tf.function(
input_signature=[
{
"input_ids": tf.TensorSpec((None, None), tf.int32, name="input_ids"),
}
]
)
def serving(self, inputs):
output = self.call(inputs)
return self.serving_output(output)
@dataclass
class TFTransfoXLModelOutput(ModelOutput):
"""
Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
Args:
last_hidden_state (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
mems (:obj:`List[tf.Tensor]` of length :obj:`config.n_layers`):
Contains pre-computed hidden-states (key and values in the attention blocks). Can be used (see :obj:`mems`
input) to speed up sequential decoding. The token ids which have their past given to this model should not
be passed as input ids as they have already been computed.
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``output_hidden_states=True`` is passed or when ``config.output_hidden_states=True``):
Tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of
shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``output_attentions=True`` is passed or when ``config.output_attentions=True``):
Tuple of :obj:`tf.Tensor` (one for each layer) of shape :obj:`(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
last_hidden_state: tf.Tensor = None
mems: List[tf.Tensor] = None
hidden_states: Optional[Tuple[tf.Tensor]] = None
attentions: Optional[Tuple[tf.Tensor]] = None
@dataclass
class TFTransfoXLLMHeadModelOutput(ModelOutput):
"""
Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
Args:
losses (:obj:`tf.Tensor` of shape `(batch_size, sequence_length-1)`, `optional`, returned when ``labels`` is provided)
Language modeling losses (not reduced).
prediction_scores (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token after SoftMax).
mems (:obj:`List[tf.Tensor]` of length :obj:`config.n_layers`):
Contains pre-computed hidden-states (key and values in the attention blocks). Can be used (see :obj:`mems`
input) to speed up sequential decoding. The token ids which have their past given to this model should not
be passed as input ids as they have already been computed.
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``output_hidden_states=True`` is passed or when ``config.output_hidden_states=True``):
Tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of
shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``output_attentions=True`` is passed or when ``config.output_attentions=True``):
Tuple of :obj:`tf.Tensor` (one for each layer) of shape :obj:`(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
prediction_scores: tf.Tensor = None
mems: List[tf.Tensor] = None
hidden_states: Optional[Tuple[tf.Tensor]] = None
attentions: Optional[Tuple[tf.Tensor]] = None
@dataclass
class TFTransfoXLSequenceClassifierOutputWithPast(ModelOutput):
"""
Base class for outputs of sentence classification models.
Args:
loss (:obj:`tf.Tensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`labels` is provided):
Classification (or regression if config.num_labels==1) loss.
logits (:obj:`tf.Tensor` of shape :obj:`(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
mems (:obj:`List[tf.Tensor]` of length :obj:`config.n_layers`):
Contains pre-computed hidden-states (key and values in the attention blocks). Can be used (see :obj:`mems`
input) to speed up sequential decoding. The token ids which have their past given to this model should not
be passed as input ids as they have already been computed.
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``output_hidden_states=True`` is passed or when ``config.output_hidden_states=True``):
Tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of
shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``output_attentions=True`` is passed or when ``config.output_attentions=True``):
Tuple of :obj:`tf.Tensor` (one for each layer) of shape :obj:`(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[tf.Tensor] = None
logits: tf.Tensor = None
mems: List[tf.Tensor] = None
hidden_states: Optional[Tuple[tf.Tensor]] = None
attentions: Optional[Tuple[tf.Tensor]] = None
TRANSFO_XL_START_DOCSTRING = r"""
This model inherits from :class:`~transformers.TFPreTrainedModel`. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading or saving, resizing the input
embeddings, pruning heads etc.)
This model is also a `tf.keras.Model <https://www.tensorflow.org/api_docs/python/tf/keras/Model>`__ subclass. Use
it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage
and behavior.
.. note::
TF 2.0 models accepts two formats as inputs:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional arguments.
This second option is useful when using :meth:`tf.keras.Model.fit` method which currently requires having all
the tensors in the first argument of the model call function: :obj:`model(inputs)`.
If you choose this second option, there are three possibilities you can use to gather all the input Tensors in
the first positional argument :
- a single Tensor with :obj:`input_ids` only and nothing else: :obj:`model(inputs_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
:obj:`model([input_ids, attention_mask])` or :obj:`model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
:obj:`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
Parameters:
config (:class:`~transformers.TransfoXLConfig`): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model
weights.
"""
TRANSFO_XL_INPUTS_DOCSTRING = r"""
Args:
input_ids (:obj:`tf.Tensor` or :obj:`Numpy array` of shape :obj:`(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using :class:`~transformers.BertTokenizer`. See
:func:`transformers.PreTrainedTokenizer.__call__` and :func:`transformers.PreTrainedTokenizer.encode` for
details.
`What are input IDs? <../glossary.html#input-ids>`__
mems (:obj:`List[tf.Tensor]` of length :obj:`config.n_layers`):
Contains pre-computed hidden-states (key and values in the attention blocks) as computed by the model (see
:obj:`mems` output below). Can be used to speed up sequential decoding. The token ids which have their mems
given to this model should not be passed as :obj:`input_ids` as they have already been computed.
head_mask (:obj:`tf.Tensor` or :obj:`Numpy array` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the self-attention modules. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (:obj:`tf.Tensor` or :obj:`Numpy array` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert :obj:`input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
@add_start_docstrings(
"The bare Bert Model transformer outputting raw hidden-states without any specific head on top.",
TRANSFO_XL_START_DOCSTRING,
)
class TFTransfoXLModel(TFTransfoXLPreTrainedModel):
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.transformer = TFTransfoXLMainLayer(config, name="transformer")
@add_start_docstrings_to_model_forward(TRANSFO_XL_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFTransfoXLModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids=None,
mems=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
**kwargs,
):
inputs = input_processing(
func=self.call,
config=self.config,
input_ids=input_ids,
mems=mems,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
kwargs_call=kwargs,
)
outputs = self.transformer(
input_ids=inputs["input_ids"],
mems=inputs["mems"],
head_mask=inputs["head_mask"],
inputs_embeds=inputs["inputs_embeds"],
output_attentions=inputs["output_attentions"],
output_hidden_states=inputs["output_hidden_states"],
return_dict=inputs["return_dict"],
training=inputs["training"],
)
return outputs
def serving_output(self, output):
hs = tf.convert_to_tensor(output.hidden_states) if self.config.output_hidden_states else None
attns = tf.convert_to_tensor(output.attentions) if self.config.output_attentions else None
return TFTransfoXLModelOutput(
last_hidden_state=output.last_hidden_state,
mems=tf.convert_to_tensor(output.mems),
hidden_states=hs,
attentions=attns,
)
@add_start_docstrings(
"""
The Transformer-XL Model with a language modeling head on top (adaptive softmax with weights tied to the adaptive
input embeddings)
""",
TRANSFO_XL_START_DOCSTRING,
)
class TFTransfoXLLMHeadModel(TFTransfoXLPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.transformer = TFTransfoXLMainLayer(config, name="transformer")
self.sample_softmax = config.sample_softmax
assert (
self.sample_softmax <= 0
), "Sampling from the softmax is not implemented yet. Please look at issue: #3310: https://github.com/huggingface/transformers/issues/3310"
self.crit = TFAdaptiveSoftmaxMask(
config.vocab_size, config.d_embed, config.d_model, config.cutoffs, div_val=config.div_val, name="crit"
)
def _resize_token_embeddings(self, new_num_tokens):
raise NotImplementedError()
def get_output_embeddings(self):
"""Double-check if you are using adaptive softmax."""
if len(self.crit.out_layers) > 0:
return self.crit.out_layers[-1]
return None
def reset_memory_length(self, mem_len):
self.transformer.reset_memory_length(mem_len)
def init_mems(self, bsz):
return self.transformer.init_mems(bsz)
@add_start_docstrings_to_model_forward(TRANSFO_XL_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFTransfoXLLMHeadModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids=None,
mems=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
labels=None,
training=False,
**kwargs,
):
inputs = input_processing(
func=self.call,
config=self.config,
input_ids=input_ids,
mems=mems,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
kwargs_call=kwargs,
)
if inputs["input_ids"] is not None:
bsz, tgt_len = shape_list(inputs["input_ids"])[:2]
else:
bsz, tgt_len = shape_list(inputs["inputs_embeds"])[:2]
transformer_outputs = self.transformer(
inputs["input_ids"],
inputs["mems"],
inputs["head_mask"],
inputs["inputs_embeds"],
inputs["output_attentions"],
inputs["output_hidden_states"],
inputs["return_dict"],
training=inputs["training"],
)
last_hidden = transformer_outputs[0]
pred_hid = last_hidden[:, -tgt_len:]
softmax_output = self.crit(pred_hid, labels, training=inputs["training"])
if not inputs["return_dict"]:
return (softmax_output,) + transformer_outputs[1:]
return TFTransfoXLLMHeadModelOutput(
prediction_scores=softmax_output,
mems=transformer_outputs.mems,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
def serving_output(self, output):
hs = tf.convert_to_tensor(output.hidden_states) if self.config.output_hidden_states else None
attns = tf.convert_to_tensor(output.attentions) if self.config.output_attentions else None
return TFTransfoXLLMHeadModelOutput(
prediction_scores=output.prediction_scores,
mems=tf.convert_to_tensor(output.mems),
hidden_states=hs,
attentions=attns,
)
def prepare_inputs_for_generation(self, inputs, past, **model_kwargs):
inputs = {"input_ids": inputs}
# if past is defined in model kwargs then use it for faster decoding
if past:
inputs["mems"] = past
return inputs
@add_start_docstrings(
"""
The Transfo XL Model transformer with a sequence classification head on top (linear layer).
:class:`~transformers.TFTransfoXLForSequenceClassification` uses the last token in order to do the classification,
as other causal models (e.g. GPT-1,GPT-2) do.
Since it does classification on the last token, it requires to know the position of the last token. If a
:obj:`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each
row. If no :obj:`pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot
guess the padding tokens when :obj:`inputs_embeds` are passed instead of :obj:`input_ids`, it does the same (take
the last value in each row of the batch).
""",
TRANSFO_XL_START_DOCSTRING,
)
class TFTransfoXLForSequenceClassification(TFTransfoXLPreTrainedModel, TFSequenceClassificationLoss):
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.score = tf.keras.layers.Dense(
config.num_labels,
kernel_initializer=get_initializer(config.init_range),
name="score",
use_bias=False,
)
self.transformer = TFTransfoXLMainLayer(config, name="transformer")
def get_output_embeddings(self):
return self.transformer.word_emb
@add_start_docstrings_to_model_forward(TRANSFO_XL_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFTransfoXLSequenceClassifierOutputWithPast,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids=None,
mems=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
labels=None,
training=False,
**kwargs,
):
r"""
labels (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the cross entropy classification loss. Indices should be in ``[0, ...,
config.vocab_size - 1]``.
"""
inputs = input_processing(
func=self.call,
config=self.config,
input_ids=input_ids,
mems=mems,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
labels=labels,
training=training,
kwargs_call=kwargs,
)
transformer_outputs = self.transformer(
input_ids=inputs["input_ids"],
mems=inputs["mems"],
head_mask=inputs["head_mask"],
inputs_embeds=inputs["inputs_embeds"],
output_attentions=inputs["output_attentions"],
output_hidden_states=inputs["output_hidden_states"],
return_dict=inputs["return_dict"],
training=inputs["training"],
)
hidden_states = transformer_outputs[0]
logits = self.score(hidden_states)
in_logits = None
if self.config.pad_token_id is None:
sequence_lengths = -1
else:
if inputs["input_ids"] is not None:
sequence_lengths = (
tf.reduce_sum(
tf.cast(
tf.math.not_equal(inputs["input_ids"], self.config.pad_token_id),
dtype=inputs["input_ids"].dtype,
),
-1,
keepdims=False,
)
- 1
)
in_logits = tf.gather(logits, sequence_lengths, batch_dims=1, axis=1)
else:
sequence_lengths = -1
logger.warning(
f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
f"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
loss = None
if inputs["labels"] is not None:
if input_ids is not None:
batch_size, sequence_length = shape_list(inputs["input_ids"])[:2]
else:
batch_size, sequence_length = shape_list(inputs["inputs_embeds"])[:2]
assert (
self.config.pad_token_id is not None or batch_size == 1
), "Cannot handle batch sizes > 1 if no padding token is defined."
if not tf.is_tensor(sequence_lengths):
in_logits = logits[0:batch_size, sequence_lengths]
loss = self.compute_loss(
tf.reshape(inputs["labels"], [-1, 1]), tf.reshape(in_logits, [-1, self.num_labels])
)
pooled_logits = in_logits if in_logits is not None else logits
if not inputs["return_dict"]:
output = (pooled_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return TFTransfoXLSequenceClassifierOutputWithPast(
loss=loss,
logits=pooled_logits,
mems=transformer_outputs.mems,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
def serving_output(self, output):
hs = tf.convert_to_tensor(output.hidden_states) if self.config.output_hidden_states else None
attns = tf.convert_to_tensor(output.attentions) if self.config.output_attentions else None
return TFTransfoXLSequenceClassifierOutputWithPast(
logits=output.logits, mems=tf.convert_to_tensor(output.mems), hidden_states=hs, attentions=attns
)
| AdaMix/src/transformers/models/transfo_xl/modeling_tf_transfo_xl.py/0 | {
"file_path": "AdaMix/src/transformers/models/transfo_xl/modeling_tf_transfo_xl.py",
"repo_id": "AdaMix",
"token_count": 22597
} | 66 |
# coding=utf-8
# Copyright 2020 The Microsoft Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch XLM-ProphetNet model."""
from ...utils import logging
from ..prophetnet.modeling_prophetnet import (
ProphetNetDecoder,
ProphetNetEncoder,
ProphetNetForCausalLM,
ProphetNetForConditionalGeneration,
ProphetNetModel,
)
from .configuration_xlm_prophetnet import XLMProphetNetConfig
logger = logging.get_logger(__name__)
_TOKENIZER_FOR_DOC = "XLMProphetNetTokenizer"
XLM_PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
"microsoft/xprophetnet-large-wiki100-cased",
# See all ProphetNet models at https://huggingface.co/models?filter=xprophetnet
]
class XLMProphetNetEncoder(ProphetNetEncoder):
r"""
This class overrides :class:`~transformers.ProphetNetEncoder`. Please check the superclass for the appropriate
documentation alongside usage examples.
Example::
>>> from transformers import XLMProphetNetTokenizer, XLMProphetNetEncoder
>>> import torch
>>> tokenizer = XLMProphetNetTokenizer.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> model = XLMProphetNetEncoder.from_pretrained('patrickvonplaten/xprophetnet-large-uncased-standalone')
>>> assert model.config.is_decoder, f"{model.__class__} has to be configured as a decoder."
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
"""
config_class = XLMProphetNetConfig
class XLMProphetNetDecoder(ProphetNetDecoder):
r"""
This class overrides :class:`~transformers.ProphetNetDecoder`. Please check the superclass for the appropriate
documentation alongside usage examples.
Example::
>>> from transformers import XLMProphetNetTokenizer, XLMProphetNetDecoder
>>> import torch
>>> tokenizer = XLMProphetNetTokenizer.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> model = XLMProphetNetDecoder.from_pretrained('patrickvonplaten/xprophetnet-large-uncased-standalone', add_cross_attention=False)
>>> assert model.config.is_decoder, f"{model.__class__} has to be configured as a decoder."
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
"""
config_class = XLMProphetNetConfig
class XLMProphetNetModel(ProphetNetModel):
r"""
This class overrides :class:`~transformers.ProphetNetModel`. Please check the superclass for the appropriate
documentation alongside usage examples.
Example::
>>> from transformers import XLMProphetNetTokenizer, XLMProphetNetModel
>>> tokenizer = XLMProphetNetTokenizer.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> model = XLMProphetNetModel.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> input_ids = tokenizer("Studies have been shown that owning a dog is good for you", return_tensors="pt").input_ids # Batch size 1
>>> decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
>>> outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
>>> last_hidden_states = outputs.last_hidden_state # main stream hidden states
>>> last_hidden_states_ngram = outputs.last_hidden_state_ngram # predict hidden states
"""
config_class = XLMProphetNetConfig
class XLMProphetNetForConditionalGeneration(ProphetNetForConditionalGeneration):
r"""
This class overrides :class:`~transformers.ProphetNetForConditionalGeneration`. Please check the superclass for the
appropriate documentation alongside usage examples.
Example::
>>> from transformers import XLMProphetNetTokenizer, XLMProphetNetForConditionalGeneration
>>> tokenizer = XLMProphetNetTokenizer.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> model = XLMProphetNetForConditionalGeneration.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> input_ids = tokenizer("Studies have been shown that owning a dog is good for you", return_tensors="pt").input_ids # Batch size 1
>>> decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
>>> outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
>>> logits_next_token = outputs.logits # logits to predict next token as usual
>>> logits_ngram_next_tokens = outputs.logits_ngram # logits to predict 2nd, 3rd, ... next tokens
"""
config_class = XLMProphetNetConfig
class XLMProphetNetForCausalLM(ProphetNetForCausalLM):
r"""
This class overrides :class:`~transformers.ProphetNetForCausalLM`. Please check the superclass for the appropriate
documentation alongside usage examples.
Example::
>>> from transformers import XLMProphetNetTokenizer, XLMProphetNetForCausalLM
>>> import torch
>>> tokenizer = XLMProphetNetTokenizer.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> model = XLMProphetNetForCausalLM.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> assert model.config.is_decoder, f"{model.__class__} has to be configured as a decoder."
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # Model can also be used with EncoderDecoder framework
>>> from transformers import EncoderDecoderModel, XLMProphetNetTokenizer, XLMRobertaTokenizer
>>> import torch
>>> tokenizer_enc = XLMRobertaTokenizer.from_pretrained('xlm-roberta-large')
>>> tokenizer_dec = XLMProphetNetTokenizer.from_pretrained('microsoft/xprophetnet-large-wiki100-cased')
>>> model = EncoderDecoderModel.from_encoder_decoder_pretrained("xlm-roberta-large", 'microsoft/xprophetnet-large-wiki100-cased')
>>> ARTICLE = (
... "the us state department said wednesday it had received no "
... "formal word from bolivia that it was expelling the us ambassador there "
... "but said the charges made against him are `` baseless ."
... )
>>> input_ids = tokenizer_enc(ARTICLE, return_tensors="pt").input_ids
>>> labels = tokenizer_dec("us rejects charges against its ambassador in bolivia", return_tensors="pt").input_ids
>>> outputs = model(input_ids=input_ids, decoder_input_ids=labels[:, :-1], labels=labels[:, 1:])
>>> loss = outputs.loss
"""
config_class = XLMProphetNetConfig
| AdaMix/src/transformers/models/xlm_prophetnet/modeling_xlm_prophetnet.py/0 | {
"file_path": "AdaMix/src/transformers/models/xlm_prophetnet/modeling_xlm_prophetnet.py",
"repo_id": "AdaMix",
"token_count": 2529
} | 67 |
from collections.abc import Iterable
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
import numpy as np
from ..data import SquadExample, SquadFeatures, squad_convert_examples_to_features
from ..file_utils import PaddingStrategy, add_end_docstrings, is_tf_available, is_torch_available
from ..modelcard import ModelCard
from ..tokenization_utils import PreTrainedTokenizer
from .base import PIPELINE_INIT_ARGS, ArgumentHandler, Pipeline
if TYPE_CHECKING:
from ..modeling_tf_utils import TFPreTrainedModel
from ..modeling_utils import PreTrainedModel
if is_tf_available():
import tensorflow as tf
from ..models.auto.modeling_tf_auto import TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING
if is_torch_available():
import torch
from ..models.auto.modeling_auto import MODEL_FOR_QUESTION_ANSWERING_MAPPING
class QuestionAnsweringArgumentHandler(ArgumentHandler):
"""
QuestionAnsweringPipeline requires the user to provide multiple arguments (i.e. question & context) to be mapped to
internal :class:`~transformers.SquadExample`.
QuestionAnsweringArgumentHandler manages all the possible to create a :class:`~transformers.SquadExample` from the
command-line supplied arguments.
"""
def normalize(self, item):
if isinstance(item, SquadExample):
return item
elif isinstance(item, dict):
for k in ["question", "context"]:
if k not in item:
raise KeyError("You need to provide a dictionary with keys {question:..., context:...}")
elif item[k] is None:
raise ValueError("`{}` cannot be None".format(k))
elif isinstance(item[k], str) and len(item[k]) == 0:
raise ValueError("`{}` cannot be empty".format(k))
return QuestionAnsweringPipeline.create_sample(**item)
raise ValueError("{} argument needs to be of type (SquadExample, dict)".format(item))
def __call__(self, *args, **kwargs):
# Detect where the actual inputs are
if args is not None and len(args) > 0:
if len(args) == 1:
inputs = args[0]
elif len(args) == 2 and {type(el) for el in args} == {str}:
inputs = [{"question": args[0], "context": args[1]}]
else:
inputs = list(args)
# Generic compatibility with sklearn and Keras
# Batched data
elif "X" in kwargs:
inputs = kwargs["X"]
elif "data" in kwargs:
inputs = kwargs["data"]
elif "question" in kwargs and "context" in kwargs:
if isinstance(kwargs["question"], list) and isinstance(kwargs["context"], str):
inputs = [{"question": Q, "context": kwargs["context"]} for Q in kwargs["question"]]
elif isinstance(kwargs["question"], list) and isinstance(kwargs["context"], list):
if len(kwargs["question"]) != len(kwargs["context"]):
raise ValueError("Questions and contexts don't have the same lengths")
inputs = [{"question": Q, "context": C} for Q, C in zip(kwargs["question"], kwargs["context"])]
elif isinstance(kwargs["question"], str) and isinstance(kwargs["context"], str):
inputs = [{"question": kwargs["question"], "context": kwargs["context"]}]
else:
raise ValueError("Arguments can't be understood")
else:
raise ValueError("Unknown arguments {}".format(kwargs))
# Normalize inputs
if isinstance(inputs, dict):
inputs = [inputs]
elif isinstance(inputs, Iterable):
# Copy to avoid overriding arguments
inputs = [i for i in inputs]
else:
raise ValueError("Invalid arguments {}".format(inputs))
for i, item in enumerate(inputs):
inputs[i] = self.normalize(item)
return inputs
@add_end_docstrings(PIPELINE_INIT_ARGS)
class QuestionAnsweringPipeline(Pipeline):
"""
Question Answering pipeline using any :obj:`ModelForQuestionAnswering`. See the `question answering examples
<../task_summary.html#question-answering>`__ for more information.
This question answering pipeline can currently be loaded from :func:`~transformers.pipeline` using the following
task identifier: :obj:`"question-answering"`.
The models that this pipeline can use are models that have been fine-tuned on a question answering task. See the
up-to-date list of available models on `huggingface.co/models
<https://huggingface.co/models?filter=question-answering>`__.
"""
default_input_names = "question,context"
def __init__(
self,
model: Union["PreTrainedModel", "TFPreTrainedModel"],
tokenizer: PreTrainedTokenizer,
modelcard: Optional[ModelCard] = None,
framework: Optional[str] = None,
device: int = -1,
task: str = "",
**kwargs
):
super().__init__(
model=model,
tokenizer=tokenizer,
modelcard=modelcard,
framework=framework,
device=device,
task=task,
**kwargs,
)
self._args_parser = QuestionAnsweringArgumentHandler()
self.check_model_type(
TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING if self.framework == "tf" else MODEL_FOR_QUESTION_ANSWERING_MAPPING
)
@staticmethod
def create_sample(
question: Union[str, List[str]], context: Union[str, List[str]]
) -> Union[SquadExample, List[SquadExample]]:
"""
QuestionAnsweringPipeline leverages the :class:`~transformers.SquadExample` internally. This helper method
encapsulate all the logic for converting question(s) and context(s) to :class:`~transformers.SquadExample`.
We currently support extractive question answering.
Arguments:
question (:obj:`str` or :obj:`List[str]`): The question(s) asked.
context (:obj:`str` or :obj:`List[str]`): The context(s) in which we will look for the answer.
Returns:
One or a list of :class:`~transformers.SquadExample`: The corresponding :class:`~transformers.SquadExample`
grouping question and context.
"""
if isinstance(question, list):
return [SquadExample(None, q, c, None, None, None) for q, c in zip(question, context)]
else:
return SquadExample(None, question, context, None, None, None)
def __call__(self, *args, **kwargs):
"""
Answer the question(s) given as inputs by using the context(s).
Args:
args (:class:`~transformers.SquadExample` or a list of :class:`~transformers.SquadExample`):
One or several :class:`~transformers.SquadExample` containing the question and context.
X (:class:`~transformers.SquadExample` or a list of :class:`~transformers.SquadExample`, `optional`):
One or several :class:`~transformers.SquadExample` containing the question and context (will be treated
the same way as if passed as the first positional argument).
data (:class:`~transformers.SquadExample` or a list of :class:`~transformers.SquadExample`, `optional`):
One or several :class:`~transformers.SquadExample` containing the question and context (will be treated
the same way as if passed as the first positional argument).
question (:obj:`str` or :obj:`List[str]`):
One or several question(s) (must be used in conjunction with the :obj:`context` argument).
context (:obj:`str` or :obj:`List[str]`):
One or several context(s) associated with the question(s) (must be used in conjunction with the
:obj:`question` argument).
topk (:obj:`int`, `optional`, defaults to 1):
The number of answers to return (will be chosen by order of likelihood).
doc_stride (:obj:`int`, `optional`, defaults to 128):
If the context is too long to fit with the question for the model, it will be split in several chunks
with some overlap. This argument controls the size of that overlap.
max_answer_len (:obj:`int`, `optional`, defaults to 15):
The maximum length of predicted answers (e.g., only answers with a shorter length are considered).
max_seq_len (:obj:`int`, `optional`, defaults to 384):
The maximum length of the total sentence (context + question) after tokenization. The context will be
split in several chunks (using :obj:`doc_stride`) if needed.
max_question_len (:obj:`int`, `optional`, defaults to 64):
The maximum length of the question after tokenization. It will be truncated if needed.
handle_impossible_answer (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not we accept impossible as an answer.
Return:
A :obj:`dict` or a list of :obj:`dict`: Each result comes as a dictionary with the following keys:
- **score** (:obj:`float`) -- The probability associated to the answer.
- **start** (:obj:`int`) -- The character start index of the answer (in the tokenized version of the
input).
- **end** (:obj:`int`) -- The character end index of the answer (in the tokenized version of the input).
- **answer** (:obj:`str`) -- The answer to the question.
"""
# Set defaults values
kwargs.setdefault("padding", "longest")
kwargs.setdefault("topk", 1)
kwargs.setdefault("doc_stride", 128)
kwargs.setdefault("max_answer_len", 15)
kwargs.setdefault("max_seq_len", 384)
kwargs.setdefault("max_question_len", 64)
kwargs.setdefault("handle_impossible_answer", False)
if kwargs["topk"] < 1:
raise ValueError("topk parameter should be >= 1 (got {})".format(kwargs["topk"]))
if kwargs["max_answer_len"] < 1:
raise ValueError("max_answer_len parameter should be >= 1 (got {})".format(kwargs["max_answer_len"]))
# Convert inputs to features
examples = self._args_parser(*args, **kwargs)
if not self.tokenizer.is_fast:
features_list = [
squad_convert_examples_to_features(
examples=[example],
tokenizer=self.tokenizer,
max_seq_length=kwargs["max_seq_len"],
doc_stride=kwargs["doc_stride"],
max_query_length=kwargs["max_question_len"],
padding_strategy=PaddingStrategy.MAX_LENGTH.value,
is_training=False,
tqdm_enabled=False,
)
for example in examples
]
else:
features_list = []
for example in examples:
# Define the side we want to truncate / pad and the text/pair sorting
question_first = bool(self.tokenizer.padding_side == "right")
encoded_inputs = self.tokenizer(
text=example.question_text if question_first else example.context_text,
text_pair=example.context_text if question_first else example.question_text,
padding=kwargs["padding"],
truncation="only_second" if question_first else "only_first",
max_length=kwargs["max_seq_len"],
stride=kwargs["doc_stride"],
return_tensors="np",
return_token_type_ids=True,
return_overflowing_tokens=True,
return_offsets_mapping=True,
return_special_tokens_mask=True,
)
# When the input is too long, it's converted in a batch of inputs with overflowing tokens
# and a stride of overlap between the inputs. If a batch of inputs is given, a special output
# "overflow_to_sample_mapping" indicate which member of the encoded batch belong to which original batch sample.
# Here we tokenize examples one-by-one so we don't need to use "overflow_to_sample_mapping".
# "num_span" is the number of output samples generated from the overflowing tokens.
num_spans = len(encoded_inputs["input_ids"])
# p_mask: mask with 1 for token than cannot be in the answer (0 for token which can be in an answer)
# We put 0 on the tokens from the context and 1 everywhere else (question and special tokens)
p_mask = np.asarray(
[
[tok != 1 if question_first else 0 for tok in encoded_inputs.sequence_ids(span_id)]
for span_id in range(num_spans)
]
)
# keep the cls_token unmasked (some models use it to indicate unanswerable questions)
if self.tokenizer.cls_token_id:
cls_index = np.nonzero(encoded_inputs["input_ids"] == self.tokenizer.cls_token_id)
p_mask[cls_index] = 0
features = []
for span_idx in range(num_spans):
features.append(
SquadFeatures(
input_ids=encoded_inputs["input_ids"][span_idx],
attention_mask=encoded_inputs["attention_mask"][span_idx],
token_type_ids=encoded_inputs["token_type_ids"][span_idx],
p_mask=p_mask[span_idx].tolist(),
encoding=encoded_inputs[span_idx],
# We don't use the rest of the values - and actually
# for Fast tokenizer we could totally avoid using SquadFeatures and SquadExample
cls_index=None,
token_to_orig_map={},
example_index=0,
unique_id=0,
paragraph_len=0,
token_is_max_context=0,
tokens=[],
start_position=0,
end_position=0,
is_impossible=False,
qas_id=None,
)
)
features_list.append(features)
all_answers = []
for features, example in zip(features_list, examples):
model_input_names = self.tokenizer.model_input_names
fw_args = {k: [feature.__dict__[k] for feature in features] for k in model_input_names}
# Manage tensor allocation on correct device
with self.device_placement():
if self.framework == "tf":
fw_args = {k: tf.constant(v) for (k, v) in fw_args.items()}
start, end = self.model(fw_args)[:2]
start, end = start.numpy(), end.numpy()
else:
with torch.no_grad():
# Retrieve the score for the context tokens only (removing question tokens)
fw_args = {k: torch.tensor(v, device=self.device) for (k, v) in fw_args.items()}
# On Windows, the default int type in numpy is np.int32 so we get some non-long tensors.
fw_args = {k: v.long() if v.dtype == torch.int32 else v for (k, v) in fw_args.items()}
start, end = self.model(**fw_args)[:2]
start, end = start.cpu().numpy(), end.cpu().numpy()
min_null_score = 1000000 # large and positive
answers = []
for (feature, start_, end_) in zip(features, start, end):
# Ensure padded tokens & question tokens cannot belong to the set of candidate answers.
undesired_tokens = np.abs(np.array(feature.p_mask) - 1) & feature.attention_mask
# Generate mask
undesired_tokens_mask = undesired_tokens == 0.0
# Make sure non-context indexes in the tensor cannot contribute to the softmax
start_ = np.where(undesired_tokens_mask, -10000.0, start_)
end_ = np.where(undesired_tokens_mask, -10000.0, end_)
# Normalize logits and spans to retrieve the answer
start_ = np.exp(start_ - np.log(np.sum(np.exp(start_), axis=-1, keepdims=True)))
end_ = np.exp(end_ - np.log(np.sum(np.exp(end_), axis=-1, keepdims=True)))
if kwargs["handle_impossible_answer"]:
min_null_score = min(min_null_score, (start_[0] * end_[0]).item())
# Mask CLS
start_[0] = end_[0] = 0.0
starts, ends, scores = self.decode(start_, end_, kwargs["topk"], kwargs["max_answer_len"])
if not self.tokenizer.is_fast:
char_to_word = np.array(example.char_to_word_offset)
# Convert the answer (tokens) back to the original text
# Score: score from the model
# Start: Index of the first character of the answer in the context string
# End: Index of the character following the last character of the answer in the context string
# Answer: Plain text of the answer
answers += [
{
"score": score.item(),
"start": np.where(char_to_word == feature.token_to_orig_map[s])[0][0].item(),
"end": np.where(char_to_word == feature.token_to_orig_map[e])[0][-1].item(),
"answer": " ".join(
example.doc_tokens[feature.token_to_orig_map[s] : feature.token_to_orig_map[e] + 1]
),
}
for s, e, score in zip(starts, ends, scores)
]
else:
# Convert the answer (tokens) back to the original text
# Score: score from the model
# Start: Index of the first character of the answer in the context string
# End: Index of the character following the last character of the answer in the context string
# Answer: Plain text of the answer
question_first = bool(self.tokenizer.padding_side == "right")
enc = feature.encoding
# Sometimes the max probability token is in the middle of a word so:
# - we start by finding the right word containing the token with `token_to_word`
# - then we convert this word in a character span with `word_to_chars`
answers += [
{
"score": score.item(),
"start": enc.word_to_chars(
enc.token_to_word(s), sequence_index=1 if question_first else 0
)[0],
"end": enc.word_to_chars(enc.token_to_word(e), sequence_index=1 if question_first else 0)[
1
],
"answer": example.context_text[
enc.word_to_chars(enc.token_to_word(s), sequence_index=1 if question_first else 0)[
0
] : enc.word_to_chars(enc.token_to_word(e), sequence_index=1 if question_first else 0)[
1
]
],
}
for s, e, score in zip(starts, ends, scores)
]
if kwargs["handle_impossible_answer"]:
answers.append({"score": min_null_score, "start": 0, "end": 0, "answer": ""})
answers = sorted(answers, key=lambda x: x["score"], reverse=True)[: kwargs["topk"]]
all_answers += answers
if len(all_answers) == 1:
return all_answers[0]
return all_answers
def decode(self, start: np.ndarray, end: np.ndarray, topk: int, max_answer_len: int) -> Tuple:
"""
Take the output of any :obj:`ModelForQuestionAnswering` and will generate probabilities for each span to be the
actual answer.
In addition, it filters out some unwanted/impossible cases like answer len being greater than max_answer_len or
answer end position being before the starting position. The method supports output the k-best answer through
the topk argument.
Args:
start (:obj:`np.ndarray`): Individual start probabilities for each token.
end (:obj:`np.ndarray`): Individual end probabilities for each token.
topk (:obj:`int`): Indicates how many possible answer span(s) to extract from the model output.
max_answer_len (:obj:`int`): Maximum size of the answer to extract from the model's output.
"""
# Ensure we have batch axis
if start.ndim == 1:
start = start[None]
if end.ndim == 1:
end = end[None]
# Compute the score of each tuple(start, end) to be the real answer
outer = np.matmul(np.expand_dims(start, -1), np.expand_dims(end, 1))
# Remove candidate with end < start and end - start > max_answer_len
candidates = np.tril(np.triu(outer), max_answer_len - 1)
# Inspired by Chen & al. (https://github.com/facebookresearch/DrQA)
scores_flat = candidates.flatten()
if topk == 1:
idx_sort = [np.argmax(scores_flat)]
elif len(scores_flat) < topk:
idx_sort = np.argsort(-scores_flat)
else:
idx = np.argpartition(-scores_flat, topk)[0:topk]
idx_sort = idx[np.argsort(-scores_flat[idx])]
start, end = np.unravel_index(idx_sort, candidates.shape)[1:]
return start, end, candidates[0, start, end]
def span_to_answer(self, text: str, start: int, end: int) -> Dict[str, Union[str, int]]:
"""
When decoding from token probabilities, this method maps token indexes to actual word in the initial context.
Args:
text (:obj:`str`): The actual context to extract the answer from.
start (:obj:`int`): The answer starting token index.
end (:obj:`int`): The answer end token index.
Returns:
Dictionary like :obj:`{'answer': str, 'start': int, 'end': int}`
"""
words = []
token_idx = char_start_idx = char_end_idx = chars_idx = 0
for i, word in enumerate(text.split(" ")):
token = self.tokenizer.tokenize(word)
# Append words if they are in the span
if start <= token_idx <= end:
if token_idx == start:
char_start_idx = chars_idx
if token_idx == end:
char_end_idx = chars_idx + len(word)
words += [word]
# Stop if we went over the end of the answer
if token_idx > end:
break
# Append the subtokenization length to the running index
token_idx += len(token)
chars_idx += len(word) + 1
# Join text with spaces
return {
"answer": " ".join(words),
"start": max(0, char_start_idx),
"end": min(len(text), char_end_idx),
}
| AdaMix/src/transformers/pipelines/question_answering.py/0 | {
"file_path": "AdaMix/src/transformers/pipelines/question_answering.py",
"repo_id": "AdaMix",
"token_count": 11275
} | 68 |
# coding=utf-8
# Copyright 2020-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Torch utilities for the Trainer class.
"""
import json
import math
import os
import warnings
from contextlib import contextmanager
from dataclasses import dataclass
from typing import Dict, Iterator, List, Optional, Union
import numpy as np
import torch
from packaging import version
from torch.utils.data.dataset import Dataset
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data.sampler import RandomSampler, Sampler
from .file_utils import is_sagemaker_distributed_available, is_torch_tpu_available
from .utils import logging
if is_sagemaker_distributed_available():
import smdistributed.dataparallel.torch.distributed as dist
else:
import torch.distributed as dist
if is_torch_tpu_available():
import torch_xla.core.xla_model as xm
# this is used to suppress an undesired warning emitted by pytorch versions 1.4.2-1.7.0
try:
from torch.optim.lr_scheduler import SAVE_STATE_WARNING
except ImportError:
SAVE_STATE_WARNING = ""
logger = logging.get_logger(__name__)
def torch_pad_and_concatenate(tensor1, tensor2, padding_index=-100):
"""Concatenates `tensor1` and `tensor2` on first axis, applying padding on the second if necessary."""
if len(tensor1.shape) == 1 or tensor1.shape[1] == tensor2.shape[1]:
return torch.cat((tensor1, tensor2), dim=0)
# Let's figure out the new shape
new_shape = (tensor1.shape[0] + tensor2.shape[0], max(tensor1.shape[1], tensor2.shape[1])) + tensor1.shape[2:]
# Now let's fill the result tensor
result = tensor1.new_full(new_shape, padding_index)
result[: tensor1.shape[0], : tensor1.shape[1]] = tensor1
result[tensor1.shape[0] :, : tensor2.shape[1]] = tensor2
return result
def numpy_pad_and_concatenate(array1, array2, padding_index=-100):
"""Concatenates `array1` and `array2` on first axis, applying padding on the second if necessary."""
if len(array1.shape) == 1 or array1.shape[1] == array2.shape[1]:
return np.concatenate((array1, array2), dim=0)
# Let's figure out the new shape
new_shape = (array1.shape[0] + array2.shape[0], max(array1.shape[1], array2.shape[1])) + array1.shape[2:]
# Now let's fill the result tensor
result = np.full_like(array1, padding_index, shape=new_shape)
result[: array1.shape[0], : array1.shape[1]] = array1
result[array1.shape[0] :, : array2.shape[1]] = array2
return result
def nested_concat(tensors, new_tensors, padding_index=-100):
"""
Concat the `new_tensors` to `tensors` on the first dim and pad them on the second if needed. Works for tensors or
nested list/tuples of tensors.
"""
assert type(tensors) == type(
new_tensors
), f"Expected `tensors` and `new_tensors` to have the same type but found {type(tensors)} and {type(new_tensors)}."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_concat(t, n, padding_index=padding_index) for t, n in zip(tensors, new_tensors))
elif isinstance(tensors, torch.Tensor):
return torch_pad_and_concatenate(tensors, new_tensors, padding_index=padding_index)
elif isinstance(tensors, np.ndarray):
return numpy_pad_and_concatenate(tensors, new_tensors, padding_index=padding_index)
else:
raise TypeError(f"Unsupported type for concatenation: got {type(tensors)}")
def nested_numpify(tensors):
"Numpify `tensors` (even if it's a nested list/tuple of tensors)."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_numpify(t) for t in tensors)
return tensors.cpu().numpy()
def nested_detach(tensors):
"Detach `tensors` (even if it's a nested list/tuple of tensors)."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_detach(t) for t in tensors)
return tensors.detach()
def nested_xla_mesh_reduce(tensors, name):
if is_torch_tpu_available():
import torch_xla.core.xla_model as xm
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_xla_mesh_reduce(t, f"{name}_{i}") for i, t in enumerate(tensors))
return xm.mesh_reduce(name, tensors, torch.cat)
else:
raise ImportError("Torch xla must be installed to use `nested_xla_mesh_reduce`")
def distributed_concat(tensor: "torch.Tensor", num_total_examples: Optional[int] = None) -> torch.Tensor:
try:
if isinstance(tensor, (tuple, list)):
return type(tensor)(distributed_concat(t, num_total_examples) for t in tensor)
output_tensors = [tensor.clone() for _ in range(dist.get_world_size())]
dist.all_gather(output_tensors, tensor)
concat = torch.cat(output_tensors, dim=0)
# truncate the dummy elements added by SequentialDistributedSampler
if num_total_examples is not None:
concat = concat[:num_total_examples]
return concat
except AssertionError:
raise AssertionError("Not currently using distributed training")
def distributed_broadcast_scalars(
scalars: List[Union[int, float]], num_total_examples: Optional[int] = None
) -> torch.Tensor:
try:
tensorized_scalar = torch.tensor(scalars).cuda()
output_tensors = [tensorized_scalar.clone() for _ in range(dist.get_world_size())]
dist.all_gather(output_tensors, tensorized_scalar)
concat = torch.cat(output_tensors, dim=0)
# truncate the dummy elements added by SequentialDistributedSampler
if num_total_examples is not None:
concat = concat[:num_total_examples]
return concat
except AssertionError:
raise AssertionError("Not currently using distributed training")
def reissue_pt_warnings(caught_warnings):
# Reissue warnings that are not the SAVE_STATE_WARNING
if len(caught_warnings) > 1:
for w in caught_warnings:
if w.category != UserWarning or w.message != SAVE_STATE_WARNING:
warnings.warn(w.message, w.category)
@contextmanager
def torch_distributed_zero_first(local_rank: int):
"""
Decorator to make all processes in distributed training wait for each local_master to do something.
Args:
local_rank (:obj:`int`): The rank of the local process.
"""
if local_rank not in [-1, 0]:
dist.barrier()
yield
if local_rank == 0:
dist.barrier()
class DistributedSamplerWithLoop(DistributedSampler):
"""
Like a :obj:torch.utils.data.distributed.DistributedSampler` but loops at the end back to the beginning of the
shuffled samples to make each process have a round multiple of batch_size samples.
Args:
dataset (:obj:`torch.utils.data.Dataset`):
Dataset used for sampling.
batch_size (:obj:`int`):
The batch size used with this sampler
kwargs:
All other keyword arguments passed to :obj:`DistributedSampler`.
"""
def __init__(self, dataset, batch_size, **kwargs):
super().__init__(dataset, **kwargs)
self.batch_size = batch_size
def __iter__(self):
indices = list(super().__iter__())
remainder = 0 if len(indices) % self.batch_size == 0 else self.batch_size - len(indices) % self.batch_size
# DistributedSampler already added samples from the beginning to make the number of samples a round multiple
# of the world size, so we skip those.
start_remainder = 1 if self.rank < len(self.dataset) % self.num_replicas else 0
indices += indices[start_remainder : start_remainder + remainder]
return iter(indices)
class SequentialDistributedSampler(Sampler):
"""
Distributed Sampler that subsamples indices sequentially, making it easier to collate all results at the end.
Even though we only use this sampler for eval and predict (no training), which means that the model params won't
have to be synced (i.e. will not hang for synchronization even if varied number of forward passes), we still add
extra samples to the sampler to make it evenly divisible (like in `DistributedSampler`) to make it easy to `gather`
or `reduce` resulting tensors at the end of the loop.
"""
def __init__(self, dataset, num_replicas=None, rank=None, batch_size=None):
if num_replicas is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
num_replicas = dist.get_world_size()
if rank is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
rank = dist.get_rank()
self.dataset = dataset
self.num_replicas = num_replicas
self.rank = rank
num_samples = len(self.dataset)
# Add extra samples to make num_samples a multiple of batch_size if passed
if batch_size is not None:
self.num_samples = int(math.ceil(num_samples / (batch_size * num_replicas))) * batch_size
else:
self.num_samples = int(math.ceil(num_samples / num_replicas))
self.total_size = self.num_samples * self.num_replicas
self.batch_size = batch_size
def __iter__(self):
indices = list(range(len(self.dataset)))
# add extra samples to make it evenly divisible
indices += indices[: (self.total_size - len(indices))]
assert (
len(indices) == self.total_size
), f"Indices length {len(indices)} and total size {self.total_size} mismatched"
# subsample
indices = indices[self.rank * self.num_samples : (self.rank + 1) * self.num_samples]
assert (
len(indices) == self.num_samples
), f"Indices length {len(indices)} and sample number {self.num_samples} mismatched"
return iter(indices)
def __len__(self):
return self.num_samples
def get_tpu_sampler(dataset: torch.utils.data.dataset.Dataset, bach_size: int):
if xm.xrt_world_size() <= 1:
return RandomSampler(dataset)
return DistributedSampler(dataset, num_replicas=xm.xrt_world_size(), rank=xm.get_ordinal())
def nested_new_like(arrays, num_samples, padding_index=-100):
""" Create the same nested structure as `arrays` with a first dimension always at `num_samples`."""
if isinstance(arrays, (list, tuple)):
return type(arrays)(nested_new_like(x, num_samples) for x in arrays)
return np.full_like(arrays, padding_index, shape=(num_samples, *arrays.shape[1:]))
def nested_expand_like(arrays, new_seq_length, padding_index=-100):
""" Expand the `arrays` so that the second dimension grows to `new_seq_length`. Uses `padding_index` for padding."""
if isinstance(arrays, (list, tuple)):
return type(arrays)(nested_expand_like(x, new_seq_length, padding_index=padding_index) for x in arrays)
result = np.full_like(arrays, padding_index, shape=(arrays.shape[0], new_seq_length) + arrays.shape[2:])
result[:, : arrays.shape[1]] = arrays
return result
def nested_truncate(tensors, limit):
"Truncate `tensors` at `limit` (even if it's a nested list/tuple of tensors)."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_truncate(t, limit) for t in tensors)
return tensors[:limit]
def _get_first_shape(arrays):
"""Return the shape of the first array found in the nested struct `arrays`."""
if isinstance(arrays, (list, tuple)):
return _get_first_shape(arrays[0])
return arrays.shape
class DistributedTensorGatherer:
"""
A class responsible for properly gathering tensors (or nested list/tuple of tensors) on the CPU by chunks.
If our dataset has 16 samples with a batch size of 2 on 3 processes and we gather then transfer on CPU at every
step, our sampler will generate the following indices:
:obj:`[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 0, 1]`
to get something of size a multiple of 3 (so that each process gets the same dataset length). Then process 0, 1 and
2 will be responsible of making predictions for the following samples:
- P0: :obj:`[0, 1, 2, 3, 4, 5]`
- P1: :obj:`[6, 7, 8, 9, 10, 11]`
- P2: :obj:`[12, 13, 14, 15, 0, 1]`
The first batch treated on each process will be
- P0: :obj:`[0, 1]`
- P1: :obj:`[6, 7]`
- P2: :obj:`[12, 13]`
So if we gather at the end of the first batch, we will get a tensor (nested list/tuple of tensor) corresponding to
the following indices:
:obj:`[0, 1, 6, 7, 12, 13]`
If we directly concatenate our results without taking any precautions, the user will then get the predictions for
the indices in this order at the end of the prediction loop:
:obj:`[0, 1, 6, 7, 12, 13, 2, 3, 8, 9, 14, 15, 4, 5, 10, 11, 0, 1]`
For some reason, that's not going to roll their boat. This class is there to solve that problem.
Args:
world_size (:obj:`int`):
The number of processes used in the distributed training.
num_samples (:obj:`int`):
The number of samples in our dataset.
make_multiple_of (:obj:`int`, `optional`):
If passed, the class assumes the datasets passed to each process are made to be a multiple of this argument
(by adding samples).
padding_index (:obj:`int`, `optional`, defaults to -100):
The padding index to use if the arrays don't all have the same sequence length.
"""
def __init__(self, world_size, num_samples, make_multiple_of=None, padding_index=-100):
self.world_size = world_size
self.num_samples = num_samples
total_size = world_size if make_multiple_of is None else world_size * make_multiple_of
self.total_samples = int(np.ceil(num_samples / total_size)) * total_size
self.process_length = self.total_samples // world_size
self._storage = None
self._offsets = None
self.padding_index = padding_index
def add_arrays(self, arrays):
"""
Add :obj:`arrays` to the internal storage, Will initialize the storage to the full size at the first arrays
passed so that if we're bound to get an OOM, it happens at the beginning.
"""
if arrays is None:
return
if self._storage is None:
self._storage = nested_new_like(arrays, self.total_samples, padding_index=self.padding_index)
self._offsets = list(range(0, self.total_samples, self.process_length))
else:
storage_shape = _get_first_shape(self._storage)
arrays_shape = _get_first_shape(arrays)
if len(storage_shape) > 1 and storage_shape[1] < arrays_shape[1]:
# If we get new arrays that are too big too fit, we expand the shape fo the storage
self._storage = nested_expand_like(self._storage, arrays_shape[1], padding_index=self.padding_index)
slice_len = self._nested_set_tensors(self._storage, arrays)
for i in range(self.world_size):
self._offsets[i] += slice_len
def _nested_set_tensors(self, storage, arrays):
if isinstance(arrays, (list, tuple)):
for x, y in zip(storage, arrays):
slice_len = self._nested_set_tensors(x, y)
return slice_len
assert (
arrays.shape[0] % self.world_size == 0
), f"Arrays passed should all have a first dimension multiple of {self.world_size}, found {arrays.shape[0]}."
slice_len = arrays.shape[0] // self.world_size
for i in range(self.world_size):
if len(arrays.shape) == 1:
storage[self._offsets[i] : self._offsets[i] + slice_len] = arrays[i * slice_len : (i + 1) * slice_len]
else:
storage[self._offsets[i] : self._offsets[i] + slice_len, : arrays.shape[1]] = arrays[
i * slice_len : (i + 1) * slice_len
]
return slice_len
def finalize(self):
"""
Return the properly gathered arrays and truncate to the number of samples (since the sampler added some extras
to get each process a dataset of the same length).
"""
if self._storage is None:
return
if self._offsets[0] != self.process_length:
logger.warn("Not all data has been set. Are you sure you passed all values?")
return nested_truncate(self._storage, self.num_samples)
@dataclass
class LabelSmoother:
"""
Adds label-smoothing on a pre-computed output from a Transformers model.
Args:
epsilon (:obj:`float`, `optional`, defaults to 0.1):
The label smoothing factor.
ignore_index (:obj:`int`, `optional`, defaults to -100):
The index in the labels to ignore when computing the loss.
"""
epsilon: float = 0.1
ignore_index: int = -100
def __call__(self, model_output, labels):
logits = model_output["logits"] if isinstance(model_output, dict) else model_output[0]
log_probs = -torch.nn.functional.log_softmax(logits, dim=-1)
if labels.dim() == log_probs.dim() - 1:
labels = labels.unsqueeze(-1)
padding_mask = labels.eq(self.ignore_index)
# In case the ignore_index is -100, the gather will fail, so we replace labels by 0. The padding_mask
# will ignore them in any case.
labels.clamp_min_(0)
nll_loss = log_probs.gather(dim=-1, index=labels)
smoothed_loss = log_probs.sum(dim=-1, keepdim=True)
nll_loss.masked_fill_(padding_mask, 0.0)
smoothed_loss.masked_fill_(padding_mask, 0.0)
# Take the mean over the label dimensions, then divide by the number of active elements (i.e. not-padded):
num_active_elements = padding_mask.numel() - padding_mask.long().sum()
nll_loss = nll_loss.sum() / num_active_elements
smoothed_loss = smoothed_loss.sum() / (num_active_elements * log_probs.shape[-1])
return (1 - self.epsilon) * nll_loss + self.epsilon * smoothed_loss
def get_length_grouped_indices(lengths, batch_size, mega_batch_mult=None, generator=None):
"""
Return a list of indices so that each slice of :obj:`batch_size` consecutive indices correspond to elements of
similar lengths. To do this, the indices are:
- randomly permuted
- grouped in mega-batches of size :obj:`mega_batch_mult * batch_size`
- sorted by length in each mega-batch
The result is the concatenation of all mega-batches, with the batch of :obj:`batch_size` containing the element of
maximum length placed first, so that an OOM happens sooner rather than later.
"""
# Default for mega_batch_mult: 50 or the number to get 4 megabatches, whichever is smaller.
if mega_batch_mult is None:
mega_batch_mult = min(len(lengths) // (batch_size * 4), 50)
# Just in case, for tiny datasets
if mega_batch_mult == 0:
mega_batch_mult = 1
# We need to use torch for the random part as a distributed sampler will set the random seed for torch.
indices = torch.randperm(len(lengths), generator=generator)
megabatch_size = mega_batch_mult * batch_size
megabatches = [indices[i : i + megabatch_size].tolist() for i in range(0, len(lengths), megabatch_size)]
megabatches = [list(sorted(megabatch, key=lambda i: lengths[i], reverse=True)) for megabatch in megabatches]
# The rest is to get the biggest batch first.
# Since each megabatch is sorted by descending length, the longest element is the first
megabatch_maximums = [lengths[megabatch[0]] for megabatch in megabatches]
max_idx = torch.argmax(torch.tensor(megabatch_maximums)).item()
# Switch to put the longest element in first position
megabatches[0][0], megabatches[max_idx][0] = megabatches[max_idx][0], megabatches[0][0]
return sum(megabatches, [])
class LengthGroupedSampler(Sampler):
r"""
Sampler that samples indices in a way that groups together features of the dataset of roughly the same length while
keeping a bit of randomness.
"""
def __init__(
self,
dataset: Dataset,
batch_size: int,
lengths: Optional[List[int]] = None,
model_input_name: Optional[str] = None,
):
self.dataset = dataset
self.batch_size = batch_size
self.model_input_name = model_input_name if model_input_name is not None else "input_ids"
if lengths is None:
if not isinstance(dataset[0], dict) or model_input_name not in dataset[0]:
raise ValueError(
"Can only automatically infer lengths for datasets whose items are dictionaries with an "
f"'{self.model_input_name}' key."
)
lengths = [len(feature[self.model_input_name]) for feature in dataset]
self.lengths = lengths
def __len__(self):
return len(self.lengths)
def __iter__(self):
indices = get_length_grouped_indices(self.lengths, self.batch_size)
return iter(indices)
class DistributedLengthGroupedSampler(DistributedSampler):
r"""
Distributed Sampler that samples indices in a way that groups together features of the dataset of roughly the same
length while keeping a bit of randomness.
"""
# Copied and adapted from PyTorch DistributedSampler.
def __init__(
self,
dataset: Dataset,
batch_size: int,
num_replicas: Optional[int] = None,
rank: Optional[int] = None,
seed: int = 0,
drop_last: bool = False,
lengths: Optional[List[int]] = None,
model_input_name: Optional[str] = None,
):
if num_replicas is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
num_replicas = dist.get_world_size()
if rank is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
rank = dist.get_rank()
self.dataset = dataset
self.batch_size = batch_size
self.num_replicas = num_replicas
self.rank = rank
self.epoch = 0
self.drop_last = drop_last
# If the dataset length is evenly divisible by # of replicas, then there
# is no need to drop any data, since the dataset will be split equally.
if self.drop_last and len(self.dataset) % self.num_replicas != 0:
# Split to nearest available length that is evenly divisible.
# This is to ensure each rank receives the same amount of data when
# using this Sampler.
self.num_samples = math.ceil((len(self.dataset) - self.num_replicas) / self.num_replicas)
else:
self.num_samples = math.ceil(len(self.dataset) / self.num_replicas)
self.total_size = self.num_samples * self.num_replicas
self.seed = seed
self.model_input_name = model_input_name if model_input_name is not None else "input_ids"
if lengths is None:
if not isinstance(dataset[0], dict) or self.model_input_name not in dataset[0]:
raise ValueError(
"Can only automatically infer lengths for datasets whose items are dictionaries with an "
f"'{self.model_input_name}' key."
)
lengths = [len(feature[self.model_input_name]) for feature in dataset]
self.lengths = lengths
def __iter__(self) -> Iterator:
# Deterministically shuffle based on epoch and seed
g = torch.Generator()
g.manual_seed(self.seed + self.epoch)
indices = get_length_grouped_indices(self.lengths, self.batch_size, generator=g)
if not self.drop_last:
# add extra samples to make it evenly divisible
indices += indices[: (self.total_size - len(indices))]
else:
# remove tail of data to make it evenly divisible.
indices = indices[: self.total_size]
assert len(indices) == self.total_size
# subsample
indices = indices[self.rank : self.total_size : self.num_replicas]
assert len(indices) == self.num_samples
return iter(indices)
# In order to keep `trainer.py` compact and easy to understand, place any secondary PT Trainer
# helper methods here
def _get_learning_rate(self):
if self.deepspeed:
# with deepspeed's fp16 and dynamic loss scale enabled the optimizer/scheduler steps may
# not run for the first few dozen steps while loss scale is too large, and thus during
# that time `get_last_lr` will fail if called during that warm up stage, so work around it:
try:
last_lr = self.lr_scheduler.get_last_lr()[0]
except AssertionError as e:
if "need to call step" in str(e):
logger.warn("tried to get lr value before scheduler/optimizer started stepping, returning lr=0")
last_lr = 0
else:
raise
else:
last_lr = (
# backward compatibility for pytorch schedulers
self.lr_scheduler.get_last_lr()[0]
if version.parse(torch.__version__) >= version.parse("1.4")
else self.lr_scheduler.get_lr()[0]
)
return last_lr
def metrics_format(self, metrics: Dict[str, float]) -> Dict[str, float]:
"""
Reformat Trainer metrics values to a human-readable format
Args:
metrics (:obj:`Dict[str, float]`):
The metrics returned from train/evaluate/predict
Returns:
metrics (:obj:`Dict[str, float]`): The reformatted metrics
"""
metrics_copy = metrics.copy()
for k, v in metrics_copy.items():
if "_mem_" in k:
metrics_copy[k] = f"{ v >> 20 }MB"
elif k == "total_flos":
metrics_copy[k] = f"{ int(v) >> 30 }GF"
elif type(metrics_copy[k]) == float:
metrics_copy[k] = round(v, 4)
return metrics_copy
def log_metrics(self, split, metrics):
"""
Log metrics in a specially formatted way
Under distributed environment this is done only for a process with rank 0.
Args:
split (:obj:`str`):
Mode/split name: one of ``train``, ``eval``, ``test``
metrics (:obj:`Dict[str, float]`):
The metrics returned from train/evaluate/predictmetrics: metrics dict
"""
if not self.is_world_process_zero():
return
logger.info(f"***** {split} metrics *****")
metrics_formatted = self.metrics_format(metrics)
k_width = max(len(str(x)) for x in metrics_formatted.keys())
v_width = max(len(str(x)) for x in metrics_formatted.values())
for key in sorted(metrics_formatted.keys()):
logger.info(f" {key: <{k_width}} = {metrics_formatted[key]:>{v_width}}")
def save_metrics(self, split, metrics, combined=True):
"""
Save metrics into a json file for that split, e.g. ``train_results.json``.
Under distributed environment this is done only for a process with rank 0.
Args:
split (:obj:`str`):
Mode/split name: one of ``train``, ``eval``, ``test``, ``all``
metrics (:obj:`Dict[str, float]`):
The metrics returned from train/evaluate/predict
combined (:obj:`bool`, `optional`, defaults to :obj:`True`):
Creates combined metrics by updating ``all_results.json`` with metrics of this call
"""
if not self.is_world_process_zero():
return
path = os.path.join(self.args.output_dir, f"{split}_results.json")
with open(path, "w") as f:
json.dump(metrics, f, indent=4, sort_keys=True)
if combined:
path = os.path.join(self.args.output_dir, "all_results.json")
if os.path.exists(path):
with open(path, "r") as f:
all_metrics = json.load(f)
else:
all_metrics = {}
all_metrics.update(metrics)
with open(path, "w") as f:
json.dump(all_metrics, f, indent=4, sort_keys=True)
def save_state(self):
"""
Saves the Trainer state, since Trainer.save_model saves only the tokenizer with the model
Under distributed environment this is done only for a process with rank 0.
"""
if not self.is_world_process_zero():
return
path = os.path.join(self.args.output_dir, "trainer_state.json")
self.state.save_to_json(path)
def get_parameter_names(model, forbidden_layer_types):
"""
Returns the names of the model parameters that are not inside a forbidden layer.
"""
result = []
for name, child in model.named_children():
result += [
f"{name}.{n}"
for n in get_parameter_names(child, forbidden_layer_types)
if not isinstance(child, tuple(forbidden_layer_types))
]
# Add model specific parameters (defined with nn.Parameter) since they are not in any child.
result += list(model._parameters.keys())
return result
| AdaMix/src/transformers/trainer_pt_utils.py/0 | {
"file_path": "AdaMix/src/transformers/trainer_pt_utils.py",
"repo_id": "AdaMix",
"token_count": 11864
} | 69 |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..file_utils import requires_pytorch
class PyTorchBenchmark:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class PyTorchBenchmarkArguments:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DataCollator:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DataCollatorForLanguageModeling:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DataCollatorForPermutationLanguageModeling:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DataCollatorForSeq2Seq:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DataCollatorForSOP:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DataCollatorForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DataCollatorForWholeWordMask:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DataCollatorWithPadding:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
def default_data_collator(*args, **kwargs):
requires_pytorch(default_data_collator)
class GlueDataset:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class GlueDataTrainingArguments:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LineByLineTextDataset:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LineByLineWithRefDataset:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LineByLineWithSOPTextDataset:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class SquadDataset:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class SquadDataTrainingArguments:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class TextDataset:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class TextDatasetForNextSentencePrediction:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BeamScorer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BeamSearchScorer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class HammingDiversityLogitsProcessor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LogitsProcessor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LogitsProcessorList:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LogitsWarper:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MinLengthLogitsProcessor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class NoBadWordsLogitsProcessor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class NoRepeatNGramLogitsProcessor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class PrefixConstrainedLogitsProcessor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class RepetitionPenaltyLogitsProcessor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class TemperatureLogitsWarper:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class TopKLogitsWarper:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class TopPLogitsWarper:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
def top_k_top_p_filtering(*args, **kwargs):
requires_pytorch(top_k_top_p_filtering)
class Conv1D:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class PreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def apply_chunking_to_forward(*args, **kwargs):
requires_pytorch(apply_chunking_to_forward)
def prune_layer(*args, **kwargs):
requires_pytorch(prune_layer)
ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class AlbertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AlbertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AlbertForPreTraining:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class AlbertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AlbertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AlbertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AlbertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AlbertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_albert(*args, **kwargs):
requires_pytorch(load_tf_weights_in_albert)
MODEL_FOR_CAUSAL_LM_MAPPING = None
MODEL_FOR_MASKED_LM_MAPPING = None
MODEL_FOR_MULTIPLE_CHOICE_MAPPING = None
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING = None
MODEL_FOR_PRETRAINING_MAPPING = None
MODEL_FOR_QUESTION_ANSWERING_MAPPING = None
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING = None
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING = None
MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING = None
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = None
MODEL_MAPPING = None
MODEL_WITH_LM_HEAD_MAPPING = None
class AutoModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForNextSentencePrediction:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForPreTraining:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForSeq2SeqLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForTableQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class AutoModelWithLMHead:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
BART_PRETRAINED_MODEL_ARCHIVE_LIST = None
class BartForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BartForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BartForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BartForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BartModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BartPretrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class PretrainedBartModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
BERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class BertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BertForNextSentencePrediction:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BertForPreTraining:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BertLayer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BertLMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_bert(*args, **kwargs):
requires_pytorch(load_tf_weights_in_bert)
class BertGenerationDecoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BertGenerationEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_bert_generation(*args, **kwargs):
requires_pytorch(load_tf_weights_in_bert_generation)
BLENDERBOT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class BlenderbotForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BlenderbotForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BlenderbotModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
BLENDERBOT_SMALL_PRETRAINED_MODEL_ARCHIVE_LIST = None
class BlenderbotSmallForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class BlenderbotSmallForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class BlenderbotSmallModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class CamembertForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class CamembertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CamembertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CamembertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CamembertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CamembertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CamembertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class ConvBertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ConvBertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ConvBertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ConvBertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ConvBertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ConvBertLayer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class ConvBertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ConvBertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_convbert(*args, **kwargs):
requires_pytorch(load_tf_weights_in_convbert)
CTRL_PRETRAINED_MODEL_ARCHIVE_LIST = None
class CTRLForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CTRLLMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CTRLModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class CTRLPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = None
class DebertaForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST = None
class DebertaV2ForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaV2ForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaV2ForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaV2ForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaV2Model:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DebertaV2PreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class DistilBertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DistilBertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DistilBertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DistilBertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DistilBertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DistilBertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class DistilBertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = None
DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = None
DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST = None
class DPRContextEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DPRPretrainedContextEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DPRPretrainedQuestionEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DPRPretrainedReader:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DPRQuestionEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class DPRReader:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST = None
class ElectraForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ElectraForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ElectraForPreTraining:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class ElectraForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ElectraForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ElectraForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ElectraModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ElectraPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_electra(*args, **kwargs):
requires_pytorch(load_tf_weights_in_electra)
class EncoderDecoderModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class FlaubertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FlaubertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FlaubertForQuestionAnsweringSimple:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FlaubertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FlaubertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FlaubertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FlaubertWithLMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FSMTForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FSMTModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class PretrainedFSMTModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
FUNNEL_PRETRAINED_MODEL_ARCHIVE_LIST = None
class FunnelBaseModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FunnelForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FunnelForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FunnelForPreTraining:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class FunnelForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FunnelForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FunnelForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class FunnelModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_funnel(*args, **kwargs):
requires_pytorch(load_tf_weights_in_funnel)
GPT2_PRETRAINED_MODEL_ARCHIVE_LIST = None
class GPT2DoubleHeadsModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class GPT2ForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class GPT2LMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class GPT2Model:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class GPT2PreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_gpt2(*args, **kwargs):
requires_pytorch(load_tf_weights_in_gpt2)
IBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class IBertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class IBertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class IBertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class IBertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class IBertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class IBertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST = None
class LayoutLMForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LayoutLMForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LayoutLMForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LayoutLMModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
LED_PRETRAINED_MODEL_ARCHIVE_LIST = None
class LEDForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LEDForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LEDForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LEDModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
class LongformerForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LongformerForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LongformerForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LongformerForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LongformerForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LongformerModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LongformerSelfAttention:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LxmertEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LxmertForPreTraining:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LxmertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LxmertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LxmertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class LxmertVisualFeatureEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class LxmertXLayer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
M2M_100_PRETRAINED_MODEL_ARCHIVE_LIST = None
class M2M100ForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class M2M100Model:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MarianForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MarianModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MarianMTModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MBartForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MBartForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MBartForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MBartForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MBartModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MMBTForClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MMBTModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ModalEmbeddings:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class MobileBertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertForNextSentencePrediction:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertForPreTraining:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertLayer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MobileBertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_mobilebert(*args, **kwargs):
requires_pytorch(load_tf_weights_in_mobilebert)
MPNET_PRETRAINED_MODEL_ARCHIVE_LIST = None
class MPNetForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MPNetForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MPNetForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MPNetForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MPNetForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MPNetLayer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class MPNetModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MPNetPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MT5EncoderModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MT5ForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class MT5Model:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class OpenAIGPTDoubleHeadsModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class OpenAIGPTForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class OpenAIGPTLMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class OpenAIGPTModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class OpenAIGPTPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_openai_gpt(*args, **kwargs):
requires_pytorch(load_tf_weights_in_openai_gpt)
class PegasusForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class PegasusForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class PegasusModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = None
class ProphetNetDecoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class ProphetNetEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class ProphetNetForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class ProphetNetForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ProphetNetModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ProphetNetPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RagModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RagSequenceForGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class RagTokenForGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
class ReformerAttention:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class ReformerForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ReformerForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ReformerForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ReformerLayer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class ReformerModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class ReformerModelWithLMHead:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
RETRIBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class RetriBertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RetriBertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = None
class RobertaForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class RobertaForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RobertaForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RobertaForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RobertaForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RobertaForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class RobertaModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class Speech2TextForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class Speech2TextModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
SQUEEZEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
class SqueezeBertForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class SqueezeBertForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class SqueezeBertForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class SqueezeBertForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class SqueezeBertForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class SqueezeBertModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class SqueezeBertModule:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class SqueezeBertPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
T5_PRETRAINED_MODEL_ARCHIVE_LIST = None
class T5EncoderModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class T5ForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class T5Model:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class T5PreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_t5(*args, **kwargs):
requires_pytorch(load_tf_weights_in_t5)
TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST = None
class TapasForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class TapasForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class TapasForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class TapasModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST = None
class AdaptiveEmbedding:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class TransfoXLForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class TransfoXLLMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class TransfoXLModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class TransfoXLPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_transfo_xl(*args, **kwargs):
requires_pytorch(load_tf_weights_in_transfo_xl)
WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST = None
class Wav2Vec2ForCTC:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class Wav2Vec2ForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class Wav2Vec2Model:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class Wav2Vec2PreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
XLM_PRETRAINED_MODEL_ARCHIVE_LIST = None
class XLMForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMForQuestionAnsweringSimple:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMWithLMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
XLM_PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = None
class XLMProphetNetDecoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class XLMProphetNetEncoder:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class XLMProphetNetForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class XLMProphetNetForConditionalGeneration:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMProphetNetModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = None
class XLMRobertaForCausalLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class XLMRobertaForMaskedLM:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMRobertaForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMRobertaForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMRobertaForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMRobertaForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLMRobertaModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
XLNET_PRETRAINED_MODEL_ARCHIVE_LIST = None
class XLNetForMultipleChoice:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLNetForQuestionAnswering:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLNetForQuestionAnsweringSimple:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLNetForSequenceClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLNetForTokenClassification:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLNetLMHeadModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLNetModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
class XLNetPreTrainedModel:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
@classmethod
def from_pretrained(self, *args, **kwargs):
requires_pytorch(self)
def load_tf_weights_in_xlnet(*args, **kwargs):
requires_pytorch(load_tf_weights_in_xlnet)
class Adafactor:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
class AdamW:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
def get_constant_schedule(*args, **kwargs):
requires_pytorch(get_constant_schedule)
def get_constant_schedule_with_warmup(*args, **kwargs):
requires_pytorch(get_constant_schedule_with_warmup)
def get_cosine_schedule_with_warmup(*args, **kwargs):
requires_pytorch(get_cosine_schedule_with_warmup)
def get_cosine_with_hard_restarts_schedule_with_warmup(*args, **kwargs):
requires_pytorch(get_cosine_with_hard_restarts_schedule_with_warmup)
def get_linear_schedule_with_warmup(*args, **kwargs):
requires_pytorch(get_linear_schedule_with_warmup)
def get_polynomial_decay_schedule_with_warmup(*args, **kwargs):
requires_pytorch(get_polynomial_decay_schedule_with_warmup)
def get_scheduler(*args, **kwargs):
requires_pytorch(get_scheduler)
class Trainer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
def torch_distributed_zero_first(*args, **kwargs):
requires_pytorch(torch_distributed_zero_first)
class Seq2SeqTrainer:
def __init__(self, *args, **kwargs):
requires_pytorch(self)
| AdaMix/src/transformers/utils/dummy_pt_objects.py/0 | {
"file_path": "AdaMix/src/transformers/utils/dummy_pt_objects.py",
"repo_id": "AdaMix",
"token_count": 25432
} | 70 |
# flake8: noqa
# There's no way to ignore "F401 '...' imported but unused" warnings in this
# module, but to preserve other warnings. So, don't check this module at all.
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
{%- if cookiecutter.generate_tensorflow_and_pytorch == "PyTorch & TensorFlow" %}
from ...file_utils import _BaseLazyModule, is_tf_available, is_torch_available, is_tokenizers_available
{%- elif cookiecutter.generate_tensorflow_and_pytorch == "PyTorch" %}
from ...file_utils import _BaseLazyModule, is_torch_available, is_tokenizers_available
{%- elif cookiecutter.generate_tensorflow_and_pytorch == "TensorFlow" %}
from ...file_utils import _BaseLazyModule, is_tf_available, is_tokenizers_available
{% endif %}
_import_structure = {
"configuration_{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP", "{{cookiecutter.camelcase_modelname}}Config"],
"tokenization_{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.camelcase_modelname}}Tokenizer"],
}
if is_tokenizers_available():
_import_structure["tokenization_{{cookiecutter.lowercase_modelname}}_fast"] = ["{{cookiecutter.camelcase_modelname}}TokenizerFast"]
{%- if (cookiecutter.generate_tensorflow_and_pytorch == "PyTorch & TensorFlow" or cookiecutter.generate_tensorflow_and_pytorch == "PyTorch") %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
if is_torch_available():
_import_structure["modeling_{{cookiecutter.lowercase_modelname}}"] = [
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"{{cookiecutter.camelcase_modelname}}Layer",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
"load_tf_weights_in_{{cookiecutter.lowercase_modelname}}",
]
{% else %}
if is_torch_available():
_import_structure["modeling_{{cookiecutter.lowercase_modelname}}"] = [
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
{%- if (cookiecutter.generate_tensorflow_and_pytorch == "PyTorch & TensorFlow" or cookiecutter.generate_tensorflow_and_pytorch == "TensorFlow") %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
if is_tf_available():
_import_structure["modeling_tf_{{cookiecutter.lowercase_modelname}}"] = [
"TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"TF{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"TF{{cookiecutter.camelcase_modelname}}ForCausalLM",
"TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"TF{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"TF{{cookiecutter.camelcase_modelname}}Layer",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% else %}
if is_tf_available():
_import_structure["modeling_tf_{{cookiecutter.lowercase_modelname}}"] = [
"TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
if TYPE_CHECKING:
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP, {{cookiecutter.camelcase_modelname}}Config
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
if is_tokenizers_available():
from .tokenization_{{cookiecutter.lowercase_modelname}}_fast import {{cookiecutter.camelcase_modelname}}TokenizerFast
{%- if (cookiecutter.generate_tensorflow_and_pytorch == "PyTorch & TensorFlow" or cookiecutter.generate_tensorflow_and_pytorch == "PyTorch") %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
if is_torch_available():
from .modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
{{cookiecutter.camelcase_modelname}}Layer,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
load_tf_weights_in_{{cookiecutter.lowercase_modelname}},
)
{% else %}
if is_torch_available():
from .modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
{%- if (cookiecutter.generate_tensorflow_and_pytorch == "PyTorch & TensorFlow" or cookiecutter.generate_tensorflow_and_pytorch == "TensorFlow") %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
if is_tf_available():
from .modeling_tf_{{cookiecutter.lowercase_modelname}} import (
TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}Layer,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
if is_tf_available():
from .modeling_tf_{{cookiecutter.lowercase_modelname}} import (
TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
else:
import importlib
import os
import sys
class _LazyModule(_BaseLazyModule):
"""
Module class that surfaces all objects but only performs associated imports when the objects are requested.
"""
__file__ = globals()["__file__"]
__path__ = [os.path.dirname(__file__)]
def _get_module(self, module_name: str):
return importlib.import_module("." + module_name, self.__name__)
sys.modules[__name__] = _LazyModule(__name__, _import_structure)
| AdaMix/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/__init__.py/0 | {
"file_path": "AdaMix/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/__init__.py",
"repo_id": "AdaMix",
"token_count": 3443
} | 71 |
{
"modelname": "NewENCDEC",
"uppercase_modelname": "NEW_ENC_DEC",
"lowercase_modelname": "new_enc_dec",
"camelcase_modelname": "NewEncDec",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "new-enc-dec-base",
"tokenizer_type": "Based on BART",
"generate_tensorflow_and_pytorch": "PyTorch",
"is_encoder_decoder_model": "True"
}
| AdaMix/templates/adding_a_new_model/tests/pt-seq-2-seq-bart-tokenizer.json/0 | {
"file_path": "AdaMix/templates/adding_a_new_model/tests/pt-seq-2-seq-bart-tokenizer.json",
"repo_id": "AdaMix",
"token_count": 144
} | 72 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import tempfile
import unittest
from pathlib import Path
from transformers import AutoConfig, is_tf_available
from transformers.testing_utils import require_tf
if is_tf_available():
import tensorflow as tf
from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments
@require_tf
class TFBenchmarkTest(unittest.TestCase):
def check_results_dict_not_empty(self, results):
for model_result in results.values():
for batch_size, sequence_length in zip(model_result["bs"], model_result["ss"]):
result = model_result["result"][batch_size][sequence_length]
self.assertIsNotNone(result)
def test_inference_no_configs_eager(self):
MODEL_ID = "sshleifer/tiny-gpt2"
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=False,
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
eager_mode=True,
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args)
results = benchmark.run()
self.check_results_dict_not_empty(results.time_inference_result)
self.check_results_dict_not_empty(results.memory_inference_result)
def test_inference_no_configs_only_pretrain(self):
MODEL_ID = "sshleifer/tiny-distilbert-base-uncased-finetuned-sst-2-english"
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=False,
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
multi_process=False,
only_pretrain_model=True,
)
benchmark = TensorFlowBenchmark(benchmark_args)
results = benchmark.run()
self.check_results_dict_not_empty(results.time_inference_result)
self.check_results_dict_not_empty(results.memory_inference_result)
def test_inference_no_configs_graph(self):
MODEL_ID = "sshleifer/tiny-gpt2"
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=False,
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args)
results = benchmark.run()
self.check_results_dict_not_empty(results.time_inference_result)
self.check_results_dict_not_empty(results.memory_inference_result)
def test_inference_with_configs_eager(self):
MODEL_ID = "sshleifer/tiny-gpt2"
config = AutoConfig.from_pretrained(MODEL_ID)
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=False,
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
eager_mode=True,
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args, [config])
results = benchmark.run()
self.check_results_dict_not_empty(results.time_inference_result)
self.check_results_dict_not_empty(results.memory_inference_result)
def test_inference_with_configs_graph(self):
MODEL_ID = "sshleifer/tiny-gpt2"
config = AutoConfig.from_pretrained(MODEL_ID)
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=False,
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args, [config])
results = benchmark.run()
self.check_results_dict_not_empty(results.time_inference_result)
self.check_results_dict_not_empty(results.memory_inference_result)
def test_train_no_configs(self):
MODEL_ID = "sshleifer/tiny-gpt2"
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=True,
inference=False,
sequence_lengths=[8],
batch_sizes=[1],
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args)
results = benchmark.run()
self.check_results_dict_not_empty(results.time_train_result)
self.check_results_dict_not_empty(results.memory_train_result)
def test_train_with_configs(self):
MODEL_ID = "sshleifer/tiny-gpt2"
config = AutoConfig.from_pretrained(MODEL_ID)
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=True,
inference=False,
sequence_lengths=[8],
batch_sizes=[1],
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args, [config])
results = benchmark.run()
self.check_results_dict_not_empty(results.time_train_result)
self.check_results_dict_not_empty(results.memory_train_result)
def test_inference_encoder_decoder_with_configs(self):
MODEL_ID = "patrickvonplaten/t5-tiny-random"
config = AutoConfig.from_pretrained(MODEL_ID)
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=False,
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args, configs=[config])
results = benchmark.run()
self.check_results_dict_not_empty(results.time_inference_result)
self.check_results_dict_not_empty(results.memory_inference_result)
@unittest.skipIf(is_tf_available() and len(tf.config.list_physical_devices("GPU")) == 0, "Cannot do xla on CPU.")
def test_inference_no_configs_xla(self):
MODEL_ID = "sshleifer/tiny-gpt2"
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
training=False,
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
use_xla=True,
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args)
results = benchmark.run()
self.check_results_dict_not_empty(results.time_inference_result)
self.check_results_dict_not_empty(results.memory_inference_result)
def test_save_csv_files(self):
MODEL_ID = "sshleifer/tiny-gpt2"
with tempfile.TemporaryDirectory() as tmp_dir:
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
inference=True,
save_to_csv=True,
sequence_lengths=[8],
batch_sizes=[1],
inference_time_csv_file=os.path.join(tmp_dir, "inf_time.csv"),
inference_memory_csv_file=os.path.join(tmp_dir, "inf_mem.csv"),
env_info_csv_file=os.path.join(tmp_dir, "env.csv"),
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args)
benchmark.run()
self.assertTrue(Path(os.path.join(tmp_dir, "inf_time.csv")).exists())
self.assertTrue(Path(os.path.join(tmp_dir, "inf_mem.csv")).exists())
self.assertTrue(Path(os.path.join(tmp_dir, "env.csv")).exists())
def test_trace_memory(self):
MODEL_ID = "sshleifer/tiny-gpt2"
def _check_summary_is_not_empty(summary):
self.assertTrue(hasattr(summary, "sequential"))
self.assertTrue(hasattr(summary, "cumulative"))
self.assertTrue(hasattr(summary, "current"))
self.assertTrue(hasattr(summary, "total"))
with tempfile.TemporaryDirectory() as tmp_dir:
benchmark_args = TensorFlowBenchmarkArguments(
models=[MODEL_ID],
inference=True,
sequence_lengths=[8],
batch_sizes=[1],
log_filename=os.path.join(tmp_dir, "log.txt"),
log_print=True,
trace_memory_line_by_line=True,
eager_mode=True,
multi_process=False,
)
benchmark = TensorFlowBenchmark(benchmark_args)
result = benchmark.run()
_check_summary_is_not_empty(result.inference_summary)
self.assertTrue(Path(os.path.join(tmp_dir, "log.txt")).exists())
| AdaMix/tests/test_benchmark_tf.py/0 | {
"file_path": "AdaMix/tests/test_benchmark_tf.py",
"repo_id": "AdaMix",
"token_count": 4144
} | 73 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import unittest
from argparse import Namespace
from dataclasses import dataclass, field
from enum import Enum
from typing import List, Optional
from transformers import HfArgumentParser, TrainingArguments
from transformers.hf_argparser import string_to_bool
def list_field(default=None, metadata=None):
return field(default_factory=lambda: default, metadata=metadata)
@dataclass
class BasicExample:
foo: int
bar: float
baz: str
flag: bool
@dataclass
class WithDefaultExample:
foo: int = 42
baz: str = field(default="toto", metadata={"help": "help message"})
@dataclass
class WithDefaultBoolExample:
foo: bool = False
baz: bool = True
opt: Optional[bool] = None
class BasicEnum(Enum):
titi = "titi"
toto = "toto"
@dataclass
class EnumExample:
foo: BasicEnum = "toto"
def __post_init__(self):
self.foo = BasicEnum(self.foo)
@dataclass
class OptionalExample:
foo: Optional[int] = None
bar: Optional[float] = field(default=None, metadata={"help": "help message"})
baz: Optional[str] = None
ces: Optional[List[str]] = list_field(default=[])
des: Optional[List[int]] = list_field(default=[])
@dataclass
class ListExample:
foo_int: List[int] = list_field(default=[])
bar_int: List[int] = list_field(default=[1, 2, 3])
foo_str: List[str] = list_field(default=["Hallo", "Bonjour", "Hello"])
foo_float: List[float] = list_field(default=[0.1, 0.2, 0.3])
@dataclass
class RequiredExample:
required_list: List[int] = field()
required_str: str = field()
required_enum: BasicEnum = field()
def __post_init__(self):
self.required_enum = BasicEnum(self.required_enum)
class HfArgumentParserTest(unittest.TestCase):
def argparsersEqual(self, a: argparse.ArgumentParser, b: argparse.ArgumentParser) -> bool:
"""
Small helper to check pseudo-equality of parsed arguments on `ArgumentParser` instances.
"""
self.assertEqual(len(a._actions), len(b._actions))
for x, y in zip(a._actions, b._actions):
xx = {k: v for k, v in vars(x).items() if k != "container"}
yy = {k: v for k, v in vars(y).items() if k != "container"}
self.assertEqual(xx, yy)
def test_basic(self):
parser = HfArgumentParser(BasicExample)
expected = argparse.ArgumentParser()
expected.add_argument("--foo", type=int, required=True)
expected.add_argument("--bar", type=float, required=True)
expected.add_argument("--baz", type=str, required=True)
expected.add_argument("--flag", type=string_to_bool, default=True, const=True, nargs="?")
self.argparsersEqual(parser, expected)
def test_with_default(self):
parser = HfArgumentParser(WithDefaultExample)
expected = argparse.ArgumentParser()
expected.add_argument("--foo", default=42, type=int)
expected.add_argument("--baz", default="toto", type=str, help="help message")
self.argparsersEqual(parser, expected)
def test_with_default_bool(self):
parser = HfArgumentParser(WithDefaultBoolExample)
expected = argparse.ArgumentParser()
expected.add_argument("--foo", type=string_to_bool, default=False, const=True, nargs="?")
expected.add_argument("--no_baz", action="store_false", dest="baz")
expected.add_argument("--baz", type=string_to_bool, default=True, const=True, nargs="?")
expected.add_argument("--opt", type=string_to_bool, default=None)
self.argparsersEqual(parser, expected)
args = parser.parse_args([])
self.assertEqual(args, Namespace(foo=False, baz=True, opt=None))
args = parser.parse_args(["--foo", "--no_baz"])
self.assertEqual(args, Namespace(foo=True, baz=False, opt=None))
args = parser.parse_args(["--foo", "--baz"])
self.assertEqual(args, Namespace(foo=True, baz=True, opt=None))
args = parser.parse_args(["--foo", "True", "--baz", "True", "--opt", "True"])
self.assertEqual(args, Namespace(foo=True, baz=True, opt=True))
args = parser.parse_args(["--foo", "False", "--baz", "False", "--opt", "False"])
self.assertEqual(args, Namespace(foo=False, baz=False, opt=False))
def test_with_enum(self):
parser = HfArgumentParser(EnumExample)
expected = argparse.ArgumentParser()
expected.add_argument("--foo", default="toto", choices=["titi", "toto"], type=str)
self.argparsersEqual(parser, expected)
args = parser.parse_args([])
self.assertEqual(args.foo, "toto")
enum_ex = parser.parse_args_into_dataclasses([])[0]
self.assertEqual(enum_ex.foo, BasicEnum.toto)
args = parser.parse_args(["--foo", "titi"])
self.assertEqual(args.foo, "titi")
enum_ex = parser.parse_args_into_dataclasses(["--foo", "titi"])[0]
self.assertEqual(enum_ex.foo, BasicEnum.titi)
def test_with_list(self):
parser = HfArgumentParser(ListExample)
expected = argparse.ArgumentParser()
expected.add_argument("--foo_int", nargs="+", default=[], type=int)
expected.add_argument("--bar_int", nargs="+", default=[1, 2, 3], type=int)
expected.add_argument("--foo_str", nargs="+", default=["Hallo", "Bonjour", "Hello"], type=str)
expected.add_argument("--foo_float", nargs="+", default=[0.1, 0.2, 0.3], type=float)
self.argparsersEqual(parser, expected)
args = parser.parse_args([])
self.assertEqual(
args,
Namespace(foo_int=[], bar_int=[1, 2, 3], foo_str=["Hallo", "Bonjour", "Hello"], foo_float=[0.1, 0.2, 0.3]),
)
args = parser.parse_args("--foo_int 1 --bar_int 2 3 --foo_str a b c --foo_float 0.1 0.7".split())
self.assertEqual(args, Namespace(foo_int=[1], bar_int=[2, 3], foo_str=["a", "b", "c"], foo_float=[0.1, 0.7]))
def test_with_optional(self):
parser = HfArgumentParser(OptionalExample)
expected = argparse.ArgumentParser()
expected.add_argument("--foo", default=None, type=int)
expected.add_argument("--bar", default=None, type=float, help="help message")
expected.add_argument("--baz", default=None, type=str)
expected.add_argument("--ces", nargs="+", default=[], type=str)
expected.add_argument("--des", nargs="+", default=[], type=int)
self.argparsersEqual(parser, expected)
args = parser.parse_args([])
self.assertEqual(args, Namespace(foo=None, bar=None, baz=None, ces=[], des=[]))
args = parser.parse_args("--foo 12 --bar 3.14 --baz 42 --ces a b c --des 1 2 3".split())
self.assertEqual(args, Namespace(foo=12, bar=3.14, baz="42", ces=["a", "b", "c"], des=[1, 2, 3]))
def test_with_required(self):
parser = HfArgumentParser(RequiredExample)
expected = argparse.ArgumentParser()
expected.add_argument("--required_list", nargs="+", type=int, required=True)
expected.add_argument("--required_str", type=str, required=True)
expected.add_argument("--required_enum", type=str, choices=["titi", "toto"], required=True)
self.argparsersEqual(parser, expected)
def test_parse_dict(self):
parser = HfArgumentParser(BasicExample)
args_dict = {
"foo": 12,
"bar": 3.14,
"baz": "42",
"flag": True,
}
parsed_args = parser.parse_dict(args_dict)[0]
args = BasicExample(**args_dict)
self.assertEqual(parsed_args, args)
def test_integration_training_args(self):
parser = HfArgumentParser(TrainingArguments)
self.assertIsNotNone(parser)
| AdaMix/tests/test_hf_argparser.py/0 | {
"file_path": "AdaMix/tests/test_hf_argparser.py",
"repo_id": "AdaMix",
"token_count": 3394
} | 74 |
# coding=utf-8
# Copyright 2018 Microsoft Authors and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import is_torch_available
from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
from .test_configuration_common import ConfigTester
from .test_modeling_common import ModelTesterMixin, ids_tensor
if is_torch_available():
import torch
from transformers import (
DebertaConfig,
DebertaForMaskedLM,
DebertaForQuestionAnswering,
DebertaForSequenceClassification,
DebertaForTokenClassification,
DebertaModel,
)
from transformers.models.deberta.modeling_deberta import DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST
@require_torch
class DebertaModelTest(ModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
DebertaModel,
DebertaForMaskedLM,
DebertaForSequenceClassification,
DebertaForTokenClassification,
DebertaForQuestionAnswering,
)
if is_torch_available()
else ()
)
test_torchscript = False
test_pruning = False
test_head_masking = False
is_encoder_decoder = False
class DebertaModelTester(object):
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
relative_attention=False,
position_biased_input=True,
pos_att_type="None",
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.relative_attention = relative_attention
self.position_biased_input = position_biased_input
self.pos_att_type = pos_att_type
self.scope = scope
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = DebertaConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
relative_attention=self.relative_attention,
position_biased_input=self.position_biased_input,
pos_att_type=self.pos_att_type,
)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def check_loss_output(self, result):
self.parent.assertListEqual(list(result.loss.size()), [])
def create_and_check_deberta_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = DebertaModel(config=config)
model.to(torch_device)
model.eval()
sequence_output = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)[0]
sequence_output = model(input_ids, token_type_ids=token_type_ids)[0]
sequence_output = model(input_ids)[0]
self.parent.assertListEqual(
list(sequence_output.size()), [self.batch_size, self.seq_length, self.hidden_size]
)
def create_and_check_deberta_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = DebertaForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_deberta_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = DebertaForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertListEqual(list(result.logits.size()), [self.batch_size, self.num_labels])
self.check_loss_output(result)
def create_and_check_deberta_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = DebertaForTokenClassification(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_deberta_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = DebertaForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
start_positions=sequence_labels,
end_positions=sequence_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
def setUp(self):
self.model_tester = DebertaModelTest.DebertaModelTester(self)
self.config_tester = ConfigTester(self, config_class=DebertaConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_deberta_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_deberta_model(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_deberta_for_sequence_classification(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_deberta_for_masked_lm(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_deberta_for_question_answering(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_deberta_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
for model_name in DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = DebertaModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_torch
@require_sentencepiece
@require_tokenizers
class DebertaModelIntegrationTest(unittest.TestCase):
@unittest.skip(reason="Model not available yet")
def test_inference_masked_lm(self):
pass
@slow
def test_inference_no_head(self):
model = DebertaModel.from_pretrained("microsoft/deberta-base")
input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
attention_mask = torch.tensor([[0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
output = model(input_ids, attention_mask=attention_mask)[0]
# compare the actual values for a slice.
expected_slice = torch.tensor(
[[[-0.5986, -0.8055, -0.8462], [1.4484, -0.9348, -0.8059], [0.3123, 0.0032, -1.4131]]]
)
self.assertTrue(torch.allclose(output[:, 1:4, 1:4], expected_slice, atol=1e-4), f"{output[:, 1:4, 1:4]}")
| AdaMix/tests/test_modeling_deberta.py/0 | {
"file_path": "AdaMix/tests/test_modeling_deberta.py",
"repo_id": "AdaMix",
"token_count": 5617
} | 75 |
# coding=utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import is_torch_available
from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
from .test_configuration_common import ConfigTester
from .test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
if is_torch_available():
import torch
from transformers import (
LongformerConfig,
LongformerForMaskedLM,
LongformerForMultipleChoice,
LongformerForQuestionAnswering,
LongformerForSequenceClassification,
LongformerForTokenClassification,
LongformerModel,
LongformerSelfAttention,
)
class LongformerModelTester:
def __init__(
self,
parent,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_input_mask = True
self.use_token_type_ids = True
self.use_labels = True
self.vocab_size = 99
self.hidden_size = 32
self.num_hidden_layers = 5
self.num_attention_heads = 4
self.intermediate_size = 37
self.hidden_act = "gelu"
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.scope = None
self.attention_window = 4
# `ModelTesterMixin.test_attention_outputs` is expecting attention tensors to be of size
# [num_attention_heads, encoder_seq_length, encoder_key_length], but LongformerSelfAttention
# returns attention of shape [num_attention_heads, encoder_seq_length, self.attention_window + 1]
# because its local attention only attends to `self.attention_window + 1` locations
# (assuming no token with global attention, otherwise the last dimension of attentions
# is x + self.attention_window + 1, where x is the number of tokens with global attention)
self.key_length = self.attention_window + 1
# because of padding `encoder_seq_length`, is different from `seq_length`. Relevant for
# the `test_attention_outputs` and `test_hidden_states_output` tests
self.encoder_seq_length = (
self.seq_length + (self.attention_window - self.seq_length % self.attention_window) % self.attention_window
)
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = LongformerConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
attention_window=self.attention_window,
)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def create_and_check_attention_mask_determinism(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = LongformerModel(config=config)
model.to(torch_device)
model.eval()
attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
output_with_mask = model(input_ids, attention_mask=attention_mask)["last_hidden_state"]
output_without_mask = model(input_ids)["last_hidden_state"]
self.parent.assertTrue(torch.allclose(output_with_mask[0, 0, :5], output_without_mask[0, 0, :5], atol=1e-4))
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = LongformerModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
def create_and_check_model_with_global_attention_mask(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = LongformerModel(config=config)
model.to(torch_device)
model.eval()
global_attention_mask = input_mask.clone()
global_attention_mask[:, input_mask.shape[-1] // 2] = 0
global_attention_mask = global_attention_mask.to(torch_device)
result = model(
input_ids,
attention_mask=input_mask,
global_attention_mask=global_attention_mask,
token_type_ids=token_type_ids,
)
result = model(input_ids, token_type_ids=token_type_ids, global_attention_mask=global_attention_mask)
result = model(input_ids, global_attention_mask=global_attention_mask)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = LongformerForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = LongformerForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
global_attention_mask=input_mask,
token_type_ids=token_type_ids,
start_positions=sequence_labels,
end_positions=sequence_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = LongformerForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = LongformerForTokenClassification(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = LongformerForMultipleChoice(config=config)
model.to(torch_device)
model.eval()
multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
result = model(
multiple_choice_inputs_ids,
attention_mask=multiple_choice_input_mask,
global_attention_mask=multiple_choice_input_mask,
token_type_ids=multiple_choice_token_type_ids,
labels=choice_labels,
)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
global_attention_mask = torch.zeros_like(input_ids)
inputs_dict = {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"attention_mask": input_mask,
"global_attention_mask": global_attention_mask,
}
return config, inputs_dict
def prepare_config_and_inputs_for_question_answering(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
# Replace sep_token_id by some random id
input_ids[input_ids == config.sep_token_id] = torch.randint(0, config.vocab_size, (1,)).item()
# Make sure there are exactly three sep_token_id
input_ids[:, -3:] = config.sep_token_id
input_mask = torch.ones_like(input_ids)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
@require_torch
class LongformerModelTest(ModelTesterMixin, unittest.TestCase):
test_pruning = False # pruning is not supported
test_torchscript = False
all_model_classes = (
(
LongformerModel,
LongformerForMaskedLM,
LongformerForSequenceClassification,
LongformerForQuestionAnswering,
LongformerForTokenClassification,
LongformerForMultipleChoice,
)
if is_torch_available()
else ()
)
def setUp(self):
self.model_tester = LongformerModelTester(self)
self.config_tester = ConfigTester(self, config_class=LongformerConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_attention_mask_determinism(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_attention_mask_determinism(*config_and_inputs)
def test_model_global_attention_mask(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_global_attention_mask(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_question_answering()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_retain_grad_hidden_states_attentions(self):
# longformer cannot keep gradients in attentions or hidden states
return
@require_torch
@require_sentencepiece
@require_tokenizers
class LongformerModelIntegrationTest(unittest.TestCase):
def _get_hidden_states(self):
return torch.tensor(
[
[
[
4.98332758e-01,
2.69175139e00,
-7.08081422e-03,
1.04915401e00,
-1.83476661e00,
7.67220476e-01,
2.98580543e-01,
2.84803992e-02,
],
[
-7.58357372e-01,
4.20635998e-01,
-4.04739919e-02,
1.59924145e-01,
2.05135748e00,
-1.15997978e00,
5.37166397e-01,
2.62873606e-01,
],
[
-1.69438001e00,
4.17574660e-01,
-1.49196962e00,
-1.76483717e00,
-1.94566312e-01,
-1.71183858e00,
7.72903565e-01,
-1.11557056e00,
],
[
5.44028163e-01,
2.05466114e-01,
-3.63045868e-01,
2.41865062e-01,
3.20348382e-01,
-9.05611176e-01,
-1.92690727e-01,
-1.19917547e00,
],
]
],
dtype=torch.float32,
device=torch_device,
)
def test_diagonalize(self):
hidden_states = self._get_hidden_states()
hidden_states = hidden_states.reshape((1, 8, 4)) # set seq length = 8, hidden dim = 4
chunked_hidden_states = LongformerSelfAttention._chunk(hidden_states, window_overlap=2)
window_overlap_size = chunked_hidden_states.shape[2]
self.assertTrue(window_overlap_size == 4)
padded_hidden_states = LongformerSelfAttention._pad_and_diagonalize(chunked_hidden_states)
self.assertTrue(padded_hidden_states.shape[-1] == chunked_hidden_states.shape[-1] + window_overlap_size - 1)
# first row => [0.4983, 2.6918, -0.0071, 1.0492, 0.0000, 0.0000, 0.0000]
self.assertTrue(torch.allclose(padded_hidden_states[0, 0, 0, :4], chunked_hidden_states[0, 0, 0], atol=1e-3))
self.assertTrue(
torch.allclose(
padded_hidden_states[0, 0, 0, 4:],
torch.zeros((3,), device=torch_device, dtype=torch.float32),
atol=1e-3,
)
)
# last row => [0.0000, 0.0000, 0.0000, 2.0514, -1.1600, 0.5372, 0.2629]
self.assertTrue(torch.allclose(padded_hidden_states[0, 0, -1, 3:], chunked_hidden_states[0, 0, -1], atol=1e-3))
self.assertTrue(
torch.allclose(
padded_hidden_states[0, 0, -1, :3],
torch.zeros((3,), device=torch_device, dtype=torch.float32),
atol=1e-3,
)
)
def test_pad_and_transpose_last_two_dims(self):
hidden_states = self._get_hidden_states()
self.assertTrue(hidden_states.shape, (1, 8, 4))
padding = (0, 0, 0, 1)
padded_hidden_states = LongformerSelfAttention._pad_and_transpose_last_two_dims(hidden_states, padding)
self.assertTrue(padded_hidden_states.shape, (1, 8, 5))
expected_added_dim = torch.zeros((5,), device=torch_device, dtype=torch.float32)
self.assertTrue(torch.allclose(expected_added_dim, padded_hidden_states[0, -1, :], atol=1e-6))
self.assertTrue(torch.allclose(hidden_states[0, -1, :], padded_hidden_states.view(1, -1)[0, 24:32], atol=1e-6))
def test_chunk(self):
hidden_states = self._get_hidden_states()
batch_size = 1
seq_length = 8
hidden_size = 4
hidden_states = hidden_states.reshape((batch_size, seq_length, hidden_size))
chunked_hidden_states = LongformerSelfAttention._chunk(hidden_states, window_overlap=2)
# expected slices across chunk and seq length dim
expected_slice_along_seq_length = torch.tensor(
[0.4983, -0.7584, -1.6944], device=torch_device, dtype=torch.float32
)
expected_slice_along_chunk = torch.tensor(
[0.4983, -1.8348, -0.7584, 2.0514], device=torch_device, dtype=torch.float32
)
self.assertTrue(torch.allclose(chunked_hidden_states[0, :, 0, 0], expected_slice_along_seq_length, atol=1e-3))
self.assertTrue(torch.allclose(chunked_hidden_states[0, 0, :, 0], expected_slice_along_chunk, atol=1e-3))
self.assertTrue(chunked_hidden_states.shape, (1, 3, 4, 4))
def test_mask_invalid_locations(self):
hidden_states = self._get_hidden_states()
batch_size = 1
seq_length = 8
hidden_size = 4
hidden_states = hidden_states.reshape((batch_size, seq_length, hidden_size))
chunked_hidden_states = LongformerSelfAttention._chunk(hidden_states, window_overlap=2)
hid_states_1 = chunked_hidden_states.clone()
LongformerSelfAttention._mask_invalid_locations(hid_states_1, 1)
self.assertTrue(torch.isinf(hid_states_1).sum().item() == 8)
hid_states_2 = chunked_hidden_states.clone()
LongformerSelfAttention._mask_invalid_locations(hid_states_2, 2)
self.assertTrue(torch.isinf(hid_states_2).sum().item() == 24)
hid_states_3 = chunked_hidden_states.clone()[:, :, :, :3]
LongformerSelfAttention._mask_invalid_locations(hid_states_3, 2)
self.assertTrue(torch.isinf(hid_states_3).sum().item() == 24)
hid_states_4 = chunked_hidden_states.clone()[:, :, 2:, :]
LongformerSelfAttention._mask_invalid_locations(hid_states_4, 2)
self.assertTrue(torch.isinf(hid_states_4).sum().item() == 12)
def test_layer_local_attn(self):
model = LongformerModel.from_pretrained("patrickvonplaten/longformer-random-tiny")
model.eval()
layer = model.encoder.layer[0].attention.self.to(torch_device)
hidden_states = self._get_hidden_states()
batch_size, seq_length, hidden_size = hidden_states.size()
attention_mask = torch.zeros((batch_size, seq_length), dtype=torch.float32, device=torch_device)
attention_mask[:, -2:] = -10000
is_index_masked = attention_mask < 0
is_index_global_attn = attention_mask > 0
is_global_attn = is_index_global_attn.flatten().any().item()
output_hidden_states = layer(
hidden_states,
attention_mask=attention_mask,
is_index_masked=is_index_masked,
is_index_global_attn=is_index_global_attn,
is_global_attn=is_global_attn,
)[0]
self.assertTrue(output_hidden_states.shape, (1, 4, 8))
self.assertTrue(
torch.allclose(
output_hidden_states[0, 1],
torch.tensor(
[0.0019, 0.0122, -0.0171, -0.0256, -0.0300, 0.0173, -0.0115, 0.0048],
dtype=torch.float32,
device=torch_device,
),
atol=1e-3,
)
)
def test_layer_global_attn(self):
model = LongformerModel.from_pretrained("patrickvonplaten/longformer-random-tiny")
model.eval()
layer = model.encoder.layer[0].attention.self.to(torch_device)
hidden_states = torch.cat([self._get_hidden_states(), self._get_hidden_states() - 0.5], dim=0)
batch_size, seq_length, hidden_size = hidden_states.size()
attention_mask = torch.zeros((batch_size, seq_length), dtype=torch.float32, device=torch_device)
# create attn mask
attention_mask[0, -2:] = 10000.0
attention_mask[0, -1:] = -10000.0
attention_mask[1, 1:] = 10000.0
is_index_masked = attention_mask < 0
is_index_global_attn = attention_mask > 0
is_global_attn = is_index_global_attn.flatten().any().item()
output_hidden_states = layer(
hidden_states,
attention_mask=attention_mask,
is_index_masked=is_index_masked,
is_index_global_attn=is_index_global_attn,
is_global_attn=is_global_attn,
)[0]
self.assertTrue(output_hidden_states.shape, (2, 4, 8))
self.assertTrue(
torch.allclose(
output_hidden_states[0, 2],
torch.tensor(
[-0.0651, -0.0393, 0.0309, -0.0342, -0.0066, -0.0155, -0.0209, -0.0494],
dtype=torch.float32,
device=torch_device,
),
atol=1e-3,
)
)
self.assertTrue(
torch.allclose(
output_hidden_states[1, -2],
torch.tensor(
[-0.0405, -0.0384, 0.0396, -0.0374, -0.0341, 0.0136, 0.0014, -0.0571],
dtype=torch.float32,
device=torch_device,
),
atol=1e-3,
)
)
def test_layer_attn_probs(self):
model = LongformerModel.from_pretrained("patrickvonplaten/longformer-random-tiny")
model.eval()
layer = model.encoder.layer[0].attention.self.to(torch_device)
hidden_states = torch.cat([self._get_hidden_states(), self._get_hidden_states() - 0.5], dim=0)
batch_size, seq_length, hidden_size = hidden_states.size()
attention_mask = torch.zeros((batch_size, seq_length), dtype=torch.float32, device=torch_device)
# create attn mask
attention_mask[0, -2:] = 10000.0
attention_mask[0, -1:] = -10000.0
attention_mask[1, 1:] = 10000.0
is_index_masked = attention_mask < 0
is_index_global_attn = attention_mask > 0
is_global_attn = is_index_global_attn.flatten().any().item()
output_hidden_states, local_attentions, global_attentions = layer(
hidden_states,
attention_mask=attention_mask,
is_index_masked=is_index_masked,
is_index_global_attn=is_index_global_attn,
is_global_attn=is_global_attn,
output_attentions=True,
)
self.assertEqual(local_attentions.shape, (2, 4, 2, 8))
self.assertEqual(global_attentions.shape, (2, 2, 3, 4))
# All tokens with global attention have weight 0 in local attentions.
self.assertTrue(torch.all(local_attentions[0, 2:4, :, :] == 0))
self.assertTrue(torch.all(local_attentions[1, 1:4, :, :] == 0))
# The weight of all tokens with local attention must sum to 1.
self.assertTrue(torch.all(torch.abs(global_attentions[0, :, :2, :].sum(dim=-1) - 1) < 1e-6))
self.assertTrue(torch.all(torch.abs(global_attentions[1, :, :1, :].sum(dim=-1) - 1) < 1e-6))
self.assertTrue(
torch.allclose(
local_attentions[0, 0, 0, :],
torch.tensor(
[0.3328, 0.0000, 0.0000, 0.0000, 0.0000, 0.3355, 0.3318, 0.0000],
dtype=torch.float32,
device=torch_device,
),
atol=1e-3,
)
)
self.assertTrue(
torch.allclose(
local_attentions[1, 0, 0, :],
torch.tensor(
[0.2492, 0.2502, 0.2502, 0.0000, 0.0000, 0.2505, 0.0000, 0.0000],
dtype=torch.float32,
device=torch_device,
),
atol=1e-3,
)
)
# All the global attention weights must sum to 1.
self.assertTrue(torch.all(torch.abs(global_attentions.sum(dim=-1) - 1) < 1e-6))
self.assertTrue(
torch.allclose(
global_attentions[0, 0, 1, :],
torch.tensor(
[0.2500, 0.2500, 0.2500, 0.2500],
dtype=torch.float32,
device=torch_device,
),
atol=1e-3,
)
)
self.assertTrue(
torch.allclose(
global_attentions[1, 0, 0, :],
torch.tensor(
[0.2497, 0.2500, 0.2499, 0.2504],
dtype=torch.float32,
device=torch_device,
),
atol=1e-3,
)
)
@slow
def test_inference_no_head(self):
model = LongformerModel.from_pretrained("allenai/longformer-base-4096")
model.to(torch_device)
# 'Hello world!'
input_ids = torch.tensor([[0, 20920, 232, 328, 1437, 2]], dtype=torch.long, device=torch_device)
attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
output = model(input_ids, attention_mask=attention_mask)[0]
output_without_mask = model(input_ids)[0]
expected_output_slice = torch.tensor([0.0549, 0.1087, -0.1119, -0.0368, 0.0250], device=torch_device)
self.assertTrue(torch.allclose(output[0, 0, -5:], expected_output_slice, atol=1e-4))
self.assertTrue(torch.allclose(output_without_mask[0, 0, -5:], expected_output_slice, atol=1e-4))
@slow
def test_inference_no_head_long(self):
model = LongformerModel.from_pretrained("allenai/longformer-base-4096")
model.to(torch_device)
# 'Hello world! ' repeated 1000 times
input_ids = torch.tensor(
[[0] + [20920, 232, 328, 1437] * 1000 + [2]], dtype=torch.long, device=torch_device
) # long input
attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=input_ids.device)
global_attention_mask = torch.zeros(input_ids.shape, dtype=torch.long, device=input_ids.device)
global_attention_mask[:, [1, 4, 21]] = 1 # Set global attention on a few random positions
output = model(input_ids, attention_mask=attention_mask, global_attention_mask=global_attention_mask)[0]
expected_output_sum = torch.tensor(74585.8594, device=torch_device)
expected_output_mean = torch.tensor(0.0243, device=torch_device)
self.assertTrue(torch.allclose(output.sum(), expected_output_sum, atol=1e-4))
self.assertTrue(torch.allclose(output.mean(), expected_output_mean, atol=1e-4))
@slow
def test_inference_masked_lm_long(self):
model = LongformerForMaskedLM.from_pretrained("allenai/longformer-base-4096")
model.to(torch_device)
# 'Hello world! ' repeated 1000 times
input_ids = torch.tensor(
[[0] + [20920, 232, 328, 1437] * 1000 + [2]], dtype=torch.long, device=torch_device
) # long input
input_ids = input_ids.to(torch_device)
loss, prediction_scores = model(input_ids, labels=input_ids).to_tuple()
expected_loss = torch.tensor(0.0074, device=torch_device)
expected_prediction_scores_sum = torch.tensor(-6.1048e08, device=torch_device)
expected_prediction_scores_mean = torch.tensor(-3.0348, device=torch_device)
self.assertTrue(torch.allclose(loss, expected_loss, atol=1e-4))
self.assertTrue(torch.allclose(prediction_scores.sum(), expected_prediction_scores_sum, atol=1e-4))
self.assertTrue(torch.allclose(prediction_scores.mean(), expected_prediction_scores_mean, atol=1e-4))
| AdaMix/tests/test_modeling_longformer.py/0 | {
"file_path": "AdaMix/tests/test_modeling_longformer.py",
"repo_id": "AdaMix",
"token_count": 14442
} | 76 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import is_tf_available
from transformers.testing_utils import require_sentencepiece, require_tf, require_tokenizers, slow
from .test_configuration_common import ConfigTester
from .test_modeling_tf_common import TFModelTesterMixin, ids_tensor
if is_tf_available():
import numpy as np
import tensorflow as tf
from transformers import (
TF_FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
FlaubertConfig,
TFFlaubertForMultipleChoice,
TFFlaubertForQuestionAnsweringSimple,
TFFlaubertForSequenceClassification,
TFFlaubertForTokenClassification,
TFFlaubertModel,
TFFlaubertWithLMHeadModel,
)
class TFFlaubertModelTester:
def __init__(
self,
parent,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_input_lengths = True
self.use_token_type_ids = True
self.use_labels = True
self.gelu_activation = True
self.sinusoidal_embeddings = False
self.causal = False
self.asm = False
self.n_langs = 2
self.vocab_size = 99
self.n_special = 0
self.hidden_size = 32
self.num_hidden_layers = 5
self.num_attention_heads = 4
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.summary_type = "last"
self.use_proj = True
self.scope = None
self.bos_token_id = 0
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = ids_tensor([self.batch_size, self.seq_length], 2, dtype=tf.float32)
input_lengths = None
if self.use_input_lengths:
input_lengths = (
ids_tensor([self.batch_size], vocab_size=2) + self.seq_length - 2
) # small variation of seq_length
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.n_langs)
sequence_labels = None
token_labels = None
is_impossible_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
is_impossible_labels = ids_tensor([self.batch_size], 2, dtype=tf.float32)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = FlaubertConfig(
vocab_size=self.vocab_size,
n_special=self.n_special,
emb_dim=self.hidden_size,
n_layers=self.num_hidden_layers,
n_heads=self.num_attention_heads,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
gelu_activation=self.gelu_activation,
sinusoidal_embeddings=self.sinusoidal_embeddings,
asm=self.asm,
causal=self.causal,
n_langs=self.n_langs,
max_position_embeddings=self.max_position_embeddings,
initializer_range=self.initializer_range,
summary_type=self.summary_type,
use_proj=self.use_proj,
bos_token_id=self.bos_token_id,
)
return (
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
)
def create_and_check_flaubert_model(
self,
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
):
model = TFFlaubertModel(config=config)
inputs = {"input_ids": input_ids, "lengths": input_lengths, "langs": token_type_ids}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_flaubert_lm_head(
self,
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
):
model = TFFlaubertWithLMHeadModel(config)
inputs = {"input_ids": input_ids, "lengths": input_lengths, "langs": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_flaubert_qa(
self,
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
):
model = TFFlaubertForQuestionAnsweringSimple(config)
inputs = {"input_ids": input_ids, "lengths": input_lengths}
result = model(inputs)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_flaubert_sequence_classif(
self,
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
):
model = TFFlaubertForSequenceClassification(config)
inputs = {"input_ids": input_ids, "lengths": input_lengths}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
def create_and_check_flaubert_for_token_classification(
self,
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
):
config.num_labels = self.num_labels
model = TFFlaubertForTokenClassification(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_flaubert_for_multiple_choice(
self,
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
):
config.num_choices = self.num_choices
model = TFFlaubertForMultipleChoice(config=config)
multiple_choice_inputs_ids = tf.tile(tf.expand_dims(input_ids, 1), (1, self.num_choices, 1))
multiple_choice_input_mask = tf.tile(tf.expand_dims(input_mask, 1), (1, self.num_choices, 1))
multiple_choice_token_type_ids = tf.tile(tf.expand_dims(token_type_ids, 1), (1, self.num_choices, 1))
inputs = {
"input_ids": multiple_choice_inputs_ids,
"attention_mask": multiple_choice_input_mask,
"token_type_ids": multiple_choice_token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_lengths,
sequence_labels,
token_labels,
is_impossible_labels,
choice_labels,
input_mask,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"langs": token_type_ids,
"lengths": input_lengths,
}
return config, inputs_dict
@require_tf
class TFFlaubertModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
TFFlaubertModel,
TFFlaubertWithLMHeadModel,
TFFlaubertForSequenceClassification,
TFFlaubertForQuestionAnsweringSimple,
TFFlaubertForTokenClassification,
TFFlaubertForMultipleChoice,
)
if is_tf_available()
else ()
)
all_generative_model_classes = (
(TFFlaubertWithLMHeadModel,) if is_tf_available() else ()
) # TODO (PVP): Check other models whether language generation is also applicable
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TFFlaubertModelTester(self)
self.config_tester = ConfigTester(self, config_class=FlaubertConfig, emb_dim=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_flaubert_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_model(*config_and_inputs)
def test_flaubert_lm_head(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_lm_head(*config_and_inputs)
def test_flaubert_qa(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_qa(*config_and_inputs)
def test_flaubert_sequence_classif(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_sequence_classif(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_for_token_classification(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_for_multiple_choice(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
for model_name in TF_FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = TFFlaubertModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_tf
@require_sentencepiece
@require_tokenizers
class TFFlaubertModelIntegrationTest(unittest.TestCase):
@slow
def test_output_embeds_base_model(self):
model = TFFlaubertModel.from_pretrained("jplu/tf-flaubert-small-cased")
input_ids = tf.convert_to_tensor(
[[0, 158, 735, 2592, 1424, 6727, 82, 1]],
dtype=tf.int32,
) # "J'aime flaubert !"
output = model(input_ids)[0]
expected_shape = tf.TensorShape((1, 8, 512))
self.assertEqual(output.shape, expected_shape)
# compare the actual values for a slice.
expected_slice = tf.convert_to_tensor(
[
[
[-1.8768773, -1.566555, 0.27072418],
[-1.6920038, -0.5873505, 1.9329599],
[-2.9563985, -1.6993835, 1.7972052],
]
],
dtype=tf.float32,
)
self.assertTrue(np.allclose(output[:, :3, :3].numpy(), expected_slice.numpy(), atol=1e-4))
| AdaMix/tests/test_modeling_tf_flaubert.py/0 | {
"file_path": "AdaMix/tests/test_modeling_tf_flaubert.py",
"repo_id": "AdaMix",
"token_count": 5919
} | 77 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import (
AutoModelForCausalLM,
AutoModelForSeq2SeqLM,
AutoTokenizer,
Conversation,
ConversationalPipeline,
is_torch_available,
pipeline,
)
from transformers.testing_utils import is_pipeline_test, require_torch, slow, torch_device
from .test_pipelines_common import MonoInputPipelineCommonMixin
if is_torch_available():
import torch
from transformers.models.gpt2 import GPT2Config, GPT2LMHeadModel
DEFAULT_DEVICE_NUM = -1 if torch_device == "cpu" else 0
@is_pipeline_test
class SimpleConversationPipelineTests(unittest.TestCase):
def get_pipeline(self):
# When
config = GPT2Config(
vocab_size=263,
n_ctx=128,
max_length=128,
n_embd=64,
n_layer=1,
n_head=8,
bos_token_id=256,
eos_token_id=257,
)
model = GPT2LMHeadModel(config)
# Force model output to be L
V, D = model.lm_head.weight.shape
bias = torch.zeros(V)
bias[76] = 1
weight = torch.zeros((V, D), requires_grad=True)
model.lm_head.bias = torch.nn.Parameter(bias)
model.lm_head.weight = torch.nn.Parameter(weight)
# # Created with:
# import tempfile
# from tokenizers import Tokenizer, models
# from transformers.tokenization_utils_fast import PreTrainedTokenizerFast
# vocab = [(chr(i), i) for i in range(256)]
# tokenizer = Tokenizer(models.Unigram(vocab))
# with tempfile.NamedTemporaryFile() as f:
# tokenizer.save(f.name)
# real_tokenizer = PreTrainedTokenizerFast(tokenizer_file=f.name, eos_token="<eos>", bos_token="<bos>")
# real_tokenizer._tokenizer.save("dummy.json")
# Special tokens are automatically added at load time.
tokenizer = AutoTokenizer.from_pretrained("Narsil/small_conversational_test")
conversation_agent = pipeline(
task="conversational", device=DEFAULT_DEVICE_NUM, model=model, tokenizer=tokenizer
)
return conversation_agent
@require_torch
def test_integration_torch_conversation(self):
conversation_agent = self.get_pipeline()
conversation_1 = Conversation("Going to the movies tonight - any suggestions?")
conversation_2 = Conversation("What's the last book you have read?")
self.assertEqual(len(conversation_1.past_user_inputs), 0)
self.assertEqual(len(conversation_2.past_user_inputs), 0)
result = conversation_agent([conversation_1, conversation_2], max_length=48)
# Two conversations in one pass
self.assertEqual(result, [conversation_1, conversation_2])
self.assertEqual(
result,
[
Conversation(
None,
past_user_inputs=["Going to the movies tonight - any suggestions?"],
generated_responses=["L"],
),
Conversation(
None, past_user_inputs=["What's the last book you have read?"], generated_responses=["L"]
),
],
)
# One conversation with history
conversation_2.add_user_input("Why do you recommend it?")
result = conversation_agent(conversation_2, max_length=64)
self.assertEqual(result, conversation_2)
self.assertEqual(
result,
Conversation(
None,
past_user_inputs=["What's the last book you have read?", "Why do you recommend it?"],
generated_responses=["L", "L"],
),
)
class ConversationalPipelineTests(MonoInputPipelineCommonMixin, unittest.TestCase):
pipeline_task = "conversational"
small_models = [] # Models tested without the @slow decorator
large_models = ["microsoft/DialoGPT-medium"] # Models tested with the @slow decorator
invalid_inputs = ["Hi there!", Conversation()]
def _test_pipeline(
self, nlp
): # override the default test method to check that the output is a `Conversation` object
self.assertIsNotNone(nlp)
# We need to recreate conversation for successive tests to pass as
# Conversation objects get *consumed* by the pipeline
conversation = Conversation("Hi there!")
mono_result = nlp(conversation)
self.assertIsInstance(mono_result, Conversation)
conversations = [Conversation("Hi there!"), Conversation("How are you?")]
multi_result = nlp(conversations)
self.assertIsInstance(multi_result, list)
self.assertIsInstance(multi_result[0], Conversation)
# Conversation have been consumed and are not valid anymore
# Inactive conversations passed to the pipeline raise a ValueError
self.assertRaises(ValueError, nlp, conversation)
self.assertRaises(ValueError, nlp, conversations)
for bad_input in self.invalid_inputs:
self.assertRaises(Exception, nlp, bad_input)
self.assertRaises(Exception, nlp, self.invalid_inputs)
@require_torch
@slow
def test_integration_torch_conversation(self):
# When
nlp = pipeline(task="conversational", device=DEFAULT_DEVICE_NUM)
conversation_1 = Conversation("Going to the movies tonight - any suggestions?")
conversation_2 = Conversation("What's the last book you have read?")
# Then
self.assertEqual(len(conversation_1.past_user_inputs), 0)
self.assertEqual(len(conversation_2.past_user_inputs), 0)
# When
result = nlp([conversation_1, conversation_2], do_sample=False, max_length=1000)
# Then
self.assertEqual(result, [conversation_1, conversation_2])
self.assertEqual(len(result[0].past_user_inputs), 1)
self.assertEqual(len(result[1].past_user_inputs), 1)
self.assertEqual(len(result[0].generated_responses), 1)
self.assertEqual(len(result[1].generated_responses), 1)
self.assertEqual(result[0].past_user_inputs[0], "Going to the movies tonight - any suggestions?")
self.assertEqual(result[0].generated_responses[0], "The Big Lebowski")
self.assertEqual(result[1].past_user_inputs[0], "What's the last book you have read?")
self.assertEqual(result[1].generated_responses[0], "The Last Question")
# When
conversation_2.add_user_input("Why do you recommend it?")
result = nlp(conversation_2, do_sample=False, max_length=1000)
# Then
self.assertEqual(result, conversation_2)
self.assertEqual(len(result.past_user_inputs), 2)
self.assertEqual(len(result.generated_responses), 2)
self.assertEqual(result.past_user_inputs[1], "Why do you recommend it?")
self.assertEqual(result.generated_responses[1], "It's a good book.")
@require_torch
@slow
def test_integration_torch_conversation_truncated_history(self):
# When
nlp = pipeline(task="conversational", min_length_for_response=24, device=DEFAULT_DEVICE_NUM)
conversation_1 = Conversation("Going to the movies tonight - any suggestions?")
# Then
self.assertEqual(len(conversation_1.past_user_inputs), 0)
# When
result = nlp(conversation_1, do_sample=False, max_length=36)
# Then
self.assertEqual(result, conversation_1)
self.assertEqual(len(result.past_user_inputs), 1)
self.assertEqual(len(result.generated_responses), 1)
self.assertEqual(result.past_user_inputs[0], "Going to the movies tonight - any suggestions?")
self.assertEqual(result.generated_responses[0], "The Big Lebowski")
# When
conversation_1.add_user_input("Is it an action movie?")
result = nlp(conversation_1, do_sample=False, max_length=36)
# Then
self.assertEqual(result, conversation_1)
self.assertEqual(len(result.past_user_inputs), 2)
self.assertEqual(len(result.generated_responses), 2)
self.assertEqual(result.past_user_inputs[1], "Is it an action movie?")
self.assertEqual(result.generated_responses[1], "It's a comedy.")
@require_torch
@slow
def test_integration_torch_conversation_dialogpt_input_ids(self):
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-small")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-small")
nlp = ConversationalPipeline(model=model, tokenizer=tokenizer)
conversation_1 = Conversation("hello")
inputs = nlp._parse_and_tokenize([conversation_1])
self.assertEqual(inputs["input_ids"].tolist(), [[31373, 50256]])
conversation_2 = Conversation("how are you ?", past_user_inputs=["hello"], generated_responses=["Hi there!"])
inputs = nlp._parse_and_tokenize([conversation_2])
self.assertEqual(
inputs["input_ids"].tolist(), [[31373, 50256, 17250, 612, 0, 50256, 4919, 389, 345, 5633, 50256]]
)
inputs = nlp._parse_and_tokenize([conversation_1, conversation_2])
self.assertEqual(
inputs["input_ids"].tolist(),
[
[31373, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256],
[31373, 50256, 17250, 612, 0, 50256, 4919, 389, 345, 5633, 50256],
],
)
@require_torch
@slow
def test_integration_torch_conversation_blenderbot_400M_input_ids(self):
tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/blenderbot-400M-distill")
nlp = ConversationalPipeline(model=model, tokenizer=tokenizer)
# test1
conversation_1 = Conversation("hello")
inputs = nlp._parse_and_tokenize([conversation_1])
self.assertEqual(inputs["input_ids"].tolist(), [[1710, 86, 2]])
# test2
conversation_1 = Conversation(
"I like lasagne.",
past_user_inputs=["hello"],
generated_responses=[
" Do you like lasagne? It is a traditional Italian dish consisting of a shepherd's pie."
],
)
inputs = nlp._parse_and_tokenize([conversation_1])
self.assertEqual(
inputs["input_ids"].tolist(),
[
# This should be compared with the same conversation on ParlAI `safe_interactive` demo.
[
1710, # hello
86,
228, # Double space
228,
946,
304,
398,
6881,
558,
964,
38,
452,
315,
265,
6252,
452,
322,
968,
6884,
3146,
278,
306,
265,
617,
87,
388,
75,
341,
286,
521,
21,
228, # Double space
228,
281, # I like lasagne.
398,
6881,
558,
964,
21,
2, # EOS
]
],
)
@require_torch
@slow
def test_integration_torch_conversation_blenderbot_400M(self):
tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/blenderbot-400M-distill")
nlp = ConversationalPipeline(model=model, tokenizer=tokenizer)
conversation_1 = Conversation("hello")
result = nlp(
conversation_1,
)
self.assertEqual(
result.generated_responses[0],
# ParlAI implementation output, we have a different one, but it's our
# second best, you can check by using num_return_sequences=10
# " Hello! How are you? I'm just getting ready to go to work, how about you?",
" Hello! How are you doing today? I just got back from a walk with my dog.",
)
conversation_1 = Conversation("Lasagne hello")
result = nlp(conversation_1, encoder_no_repeat_ngram_size=3)
self.assertEqual(
result.generated_responses[0],
" Do you like lasagne? It is a traditional Italian dish consisting of a shepherd's pie.",
)
conversation_1 = Conversation(
"Lasagne hello Lasagne is my favorite Italian dish. Do you like lasagne? I like lasagne."
)
result = nlp(
conversation_1,
encoder_no_repeat_ngram_size=3,
)
self.assertEqual(
result.generated_responses[0],
" Me too. I like how it can be topped with vegetables, meats, and condiments.",
)
@require_torch
@slow
def test_integration_torch_conversation_encoder_decoder(self):
# When
tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot_small-90M")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/blenderbot_small-90M")
nlp = ConversationalPipeline(model=model, tokenizer=tokenizer, device=DEFAULT_DEVICE_NUM)
conversation_1 = Conversation("My name is Sarah and I live in London")
conversation_2 = Conversation("Going to the movies tonight, What movie would you recommend? ")
# Then
self.assertEqual(len(conversation_1.past_user_inputs), 0)
self.assertEqual(len(conversation_2.past_user_inputs), 0)
# When
result = nlp([conversation_1, conversation_2], do_sample=False, max_length=1000)
# Then
self.assertEqual(result, [conversation_1, conversation_2])
self.assertEqual(len(result[0].past_user_inputs), 1)
self.assertEqual(len(result[1].past_user_inputs), 1)
self.assertEqual(len(result[0].generated_responses), 1)
self.assertEqual(len(result[1].generated_responses), 1)
self.assertEqual(result[0].past_user_inputs[0], "My name is Sarah and I live in London")
self.assertEqual(
result[0].generated_responses[0],
"hi sarah, i live in london as well. do you have any plans for the weekend?",
)
self.assertEqual(
result[1].past_user_inputs[0], "Going to the movies tonight, What movie would you recommend? "
)
self.assertEqual(
result[1].generated_responses[0], "i don't know... i'm not really sure. what movie are you going to see?"
)
# When
conversation_1.add_user_input("Not yet, what about you?")
conversation_2.add_user_input("What's your name?")
result = nlp([conversation_1, conversation_2], do_sample=False, max_length=1000)
# Then
self.assertEqual(result, [conversation_1, conversation_2])
self.assertEqual(len(result[0].past_user_inputs), 2)
self.assertEqual(len(result[1].past_user_inputs), 2)
self.assertEqual(len(result[0].generated_responses), 2)
self.assertEqual(len(result[1].generated_responses), 2)
self.assertEqual(result[0].past_user_inputs[1], "Not yet, what about you?")
self.assertEqual(result[0].generated_responses[1], "i don't have any plans yet. i'm not sure what to do yet.")
self.assertEqual(result[1].past_user_inputs[1], "What's your name?")
self.assertEqual(result[1].generated_responses[1], "i don't have a name, but i'm going to see a horror movie.")
| AdaMix/tests/test_pipelines_conversational.py/0 | {
"file_path": "AdaMix/tests/test_pipelines_conversational.py",
"repo_id": "AdaMix",
"token_count": 7444
} | 78 |
# coding=utf-8
# Copyright 2019-present, the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
#
#
# this test validates that we can stack skip decorators in groups and whether
# they work correctly with other decorators
#
# since the decorators have already built their decision params (like checking
# env[], we can't mock the env and test each of the combinations), so ideally
# the following 4 should be run. But since we have different CI jobs running
# different configs, all combinations should get covered
#
# RUN_SLOW=1 pytest -rA tests/test_skip_decorators.py
# RUN_SLOW=1 CUDA_VISIBLE_DEVICES="" pytest -rA tests/test_skip_decorators.py
# RUN_SLOW=0 pytest -rA tests/test_skip_decorators.py
# RUN_SLOW=0 CUDA_VISIBLE_DEVICES="" pytest -rA tests/test_skip_decorators.py
import os
import unittest
import pytest
from parameterized import parameterized
from transformers.testing_utils import require_torch, require_torch_gpu, slow, torch_device
# skipping in unittest tests
params = [(1,)]
# test that we can stack our skip decorators with 3rd party decorators
def check_slow():
run_slow = bool(os.getenv("RUN_SLOW", 0))
if run_slow:
assert True
else:
assert False, "should have been skipped"
# test that we can stack our skip decorators
def check_slow_torch_cuda():
run_slow = bool(os.getenv("RUN_SLOW", 0))
if run_slow and torch_device == "cuda":
assert True
else:
assert False, "should have been skipped"
@require_torch
class SkipTester(unittest.TestCase):
@slow
@require_torch_gpu
def test_2_skips_slow_first(self):
check_slow_torch_cuda()
@require_torch_gpu
@slow
def test_2_skips_slow_last(self):
check_slow_torch_cuda()
# The combination of any skip decorator, followed by parameterized fails to skip the tests
# 1. @slow manages to correctly skip `test_param_slow_first`
# 2. but then `parameterized` creates new tests, with a unique name for each parameter groups.
# It has no idea that they are to be skipped and so they all run, ignoring @slow
# Therefore skip decorators must come after `parameterized`
#
# @slow
# @parameterized.expand(params)
# def test_param_slow_first(self, param=None):
# check_slow()
# This works as expected:
# 1. `parameterized` creates new tests with unique names
# 2. each of them gets an opportunity to be skipped
@parameterized.expand(params)
@slow
def test_param_slow_last(self, param=None):
check_slow()
# skipping in non-unittest tests
# no problem at all here
@slow
@require_torch_gpu
def test_pytest_2_skips_slow_first():
check_slow_torch_cuda()
@require_torch_gpu
@slow
def test_pytest_2_skips_slow_last():
check_slow_torch_cuda()
@slow
@pytest.mark.parametrize("param", [1])
def test_pytest_param_slow_first(param):
check_slow()
@pytest.mark.parametrize("param", [1])
@slow
def test_pytest_param_slow_last(param):
check_slow()
| AdaMix/tests/test_skip_decorators.py/0 | {
"file_path": "AdaMix/tests/test_skip_decorators.py",
"repo_id": "AdaMix",
"token_count": 1214
} | 79 |
# coding=utf-8
# Copyright 2020 Huggingface
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from transformers import (
DPRContextEncoderTokenizer,
DPRContextEncoderTokenizerFast,
DPRQuestionEncoderTokenizer,
DPRQuestionEncoderTokenizerFast,
DPRReaderOutput,
DPRReaderTokenizer,
DPRReaderTokenizerFast,
)
from transformers.testing_utils import require_tokenizers, slow
from transformers.tokenization_utils_base import BatchEncoding
from .test_tokenization_bert import BertTokenizationTest
@require_tokenizers
class DPRContextEncoderTokenizationTest(BertTokenizationTest):
tokenizer_class = DPRContextEncoderTokenizer
rust_tokenizer_class = DPRContextEncoderTokenizerFast
test_rust_tokenizer = True
@require_tokenizers
class DPRQuestionEncoderTokenizationTest(BertTokenizationTest):
tokenizer_class = DPRQuestionEncoderTokenizer
rust_tokenizer_class = DPRQuestionEncoderTokenizerFast
test_rust_tokenizer = True
@require_tokenizers
class DPRReaderTokenizationTest(BertTokenizationTest):
tokenizer_class = DPRReaderTokenizer
rust_tokenizer_class = DPRReaderTokenizerFast
test_rust_tokenizer = True
@slow
def test_decode_best_spans(self):
tokenizer = self.tokenizer_class.from_pretrained("bert-base-uncased")
text_1 = tokenizer.encode("question sequence", add_special_tokens=False)
text_2 = tokenizer.encode("title sequence", add_special_tokens=False)
text_3 = tokenizer.encode("text sequence " * 4, add_special_tokens=False)
input_ids = [[101] + text_1 + [102] + text_2 + [102] + text_3]
reader_input = BatchEncoding({"input_ids": input_ids})
start_logits = [[0] * len(input_ids[0])]
end_logits = [[0] * len(input_ids[0])]
relevance_logits = [0]
reader_output = DPRReaderOutput(start_logits, end_logits, relevance_logits)
start_index, end_index = 8, 9
start_logits[0][start_index] = 10
end_logits[0][end_index] = 10
predicted_spans = tokenizer.decode_best_spans(reader_input, reader_output)
self.assertEqual(predicted_spans[0].start_index, start_index)
self.assertEqual(predicted_spans[0].end_index, end_index)
self.assertEqual(predicted_spans[0].doc_id, 0)
@slow
def test_call(self):
tokenizer = self.tokenizer_class.from_pretrained("bert-base-uncased")
text_1 = tokenizer.encode("question sequence", add_special_tokens=False)
text_2 = tokenizer.encode("title sequence", add_special_tokens=False)
text_3 = tokenizer.encode("text sequence", add_special_tokens=False)
expected_input_ids = [101] + text_1 + [102] + text_2 + [102] + text_3
encoded_input = tokenizer(questions=["question sequence"], titles=["title sequence"], texts=["text sequence"])
self.assertIn("input_ids", encoded_input)
self.assertIn("attention_mask", encoded_input)
self.assertListEqual(encoded_input["input_ids"][0], expected_input_ids)
| AdaMix/tests/test_tokenization_dpr.py/0 | {
"file_path": "AdaMix/tests/test_tokenization_dpr.py",
"repo_id": "AdaMix",
"token_count": 1261
} | 80 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
import shutil
import tempfile
from unittest import TestCase
from transformers import BartTokenizer, BartTokenizerFast, DPRQuestionEncoderTokenizer, DPRQuestionEncoderTokenizerFast
from transformers.file_utils import is_datasets_available, is_faiss_available, is_torch_available
from transformers.models.bart.configuration_bart import BartConfig
from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES as DPR_VOCAB_FILES_NAMES
from transformers.models.dpr.configuration_dpr import DPRConfig
from transformers.models.roberta.tokenization_roberta import VOCAB_FILES_NAMES as BART_VOCAB_FILES_NAMES
from transformers.testing_utils import require_datasets, require_faiss, require_tokenizers, require_torch, slow
if is_torch_available() and is_datasets_available() and is_faiss_available():
from transformers.models.rag.configuration_rag import RagConfig
from transformers.models.rag.tokenization_rag import RagTokenizer
@require_faiss
@require_datasets
@require_torch
class RagTokenizerTest(TestCase):
def setUp(self):
self.tmpdirname = tempfile.mkdtemp()
self.retrieval_vector_size = 8
# DPR tok
vocab_tokens = [
"[UNK]",
"[CLS]",
"[SEP]",
"[PAD]",
"[MASK]",
"want",
"##want",
"##ed",
"wa",
"un",
"runn",
"##ing",
",",
"low",
"lowest",
]
dpr_tokenizer_path = os.path.join(self.tmpdirname, "dpr_tokenizer")
os.makedirs(dpr_tokenizer_path, exist_ok=True)
self.vocab_file = os.path.join(dpr_tokenizer_path, DPR_VOCAB_FILES_NAMES["vocab_file"])
with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
# BART tok
vocab = [
"l",
"o",
"w",
"e",
"r",
"s",
"t",
"i",
"d",
"n",
"\u0120",
"\u0120l",
"\u0120n",
"\u0120lo",
"\u0120low",
"er",
"\u0120lowest",
"\u0120newer",
"\u0120wider",
"<unk>",
]
vocab_tokens = dict(zip(vocab, range(len(vocab))))
merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
self.special_tokens_map = {"unk_token": "<unk>"}
bart_tokenizer_path = os.path.join(self.tmpdirname, "bart_tokenizer")
os.makedirs(bart_tokenizer_path, exist_ok=True)
self.vocab_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["vocab_file"])
self.merges_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["merges_file"])
with open(self.vocab_file, "w", encoding="utf-8") as fp:
fp.write(json.dumps(vocab_tokens) + "\n")
with open(self.merges_file, "w", encoding="utf-8") as fp:
fp.write("\n".join(merges))
def get_dpr_tokenizer(self) -> DPRQuestionEncoderTokenizer:
return DPRQuestionEncoderTokenizer.from_pretrained(os.path.join(self.tmpdirname, "dpr_tokenizer"))
def get_bart_tokenizer(self) -> BartTokenizer:
return BartTokenizer.from_pretrained(os.path.join(self.tmpdirname, "bart_tokenizer"))
def tearDown(self):
shutil.rmtree(self.tmpdirname)
@require_tokenizers
def test_save_load_pretrained_with_saved_config(self):
save_dir = os.path.join(self.tmpdirname, "rag_tokenizer")
rag_config = RagConfig(question_encoder=DPRConfig().to_dict(), generator=BartConfig().to_dict())
rag_tokenizer = RagTokenizer(question_encoder=self.get_dpr_tokenizer(), generator=self.get_bart_tokenizer())
rag_config.save_pretrained(save_dir)
rag_tokenizer.save_pretrained(save_dir)
new_rag_tokenizer = RagTokenizer.from_pretrained(save_dir, config=rag_config)
self.assertIsInstance(new_rag_tokenizer.question_encoder, DPRQuestionEncoderTokenizerFast)
self.assertEqual(new_rag_tokenizer.question_encoder.get_vocab(), rag_tokenizer.question_encoder.get_vocab())
self.assertIsInstance(new_rag_tokenizer.generator, BartTokenizerFast)
self.assertEqual(new_rag_tokenizer.generator.get_vocab(), rag_tokenizer.generator.get_vocab())
@slow
def test_pretrained_token_nq_tokenizer(self):
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
input_strings = [
"who got the first nobel prize in physics",
"when is the next deadpool movie being released",
"which mode is used for short wave broadcast service",
"who is the owner of reading football club",
"when is the next scandal episode coming out",
"when is the last time the philadelphia won the superbowl",
"what is the most current adobe flash player version",
"how many episodes are there in dragon ball z",
"what is the first step in the evolution of the eye",
"where is gall bladder situated in human body",
"what is the main mineral in lithium batteries",
"who is the president of usa right now",
"where do the greasers live in the outsiders",
"panda is a national animal of which country",
"what is the name of manchester united stadium",
]
input_dict = tokenizer(input_strings)
self.assertIsNotNone(input_dict)
@slow
def test_pretrained_sequence_nq_tokenizer(self):
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
input_strings = [
"who got the first nobel prize in physics",
"when is the next deadpool movie being released",
"which mode is used for short wave broadcast service",
"who is the owner of reading football club",
"when is the next scandal episode coming out",
"when is the last time the philadelphia won the superbowl",
"what is the most current adobe flash player version",
"how many episodes are there in dragon ball z",
"what is the first step in the evolution of the eye",
"where is gall bladder situated in human body",
"what is the main mineral in lithium batteries",
"who is the president of usa right now",
"where do the greasers live in the outsiders",
"panda is a national animal of which country",
"what is the name of manchester united stadium",
]
input_dict = tokenizer(input_strings)
self.assertIsNotNone(input_dict)
| AdaMix/tests/test_tokenization_rag.py/0 | {
"file_path": "AdaMix/tests/test_tokenization_rag.py",
"repo_id": "AdaMix",
"token_count": 3158
} | 81 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import shutil
import tempfile
import unittest
from transformers import (
DefaultFlowCallback,
IntervalStrategy,
PrinterCallback,
ProgressCallback,
Trainer,
TrainerCallback,
TrainingArguments,
is_torch_available,
)
from transformers.testing_utils import require_torch
if is_torch_available():
from transformers.trainer import DEFAULT_CALLBACKS
from .test_trainer import RegressionDataset, RegressionModelConfig, RegressionPreTrainedModel
class MyTestTrainerCallback(TrainerCallback):
"A callback that registers the events that goes through."
def __init__(self):
self.events = []
def on_init_end(self, args, state, control, **kwargs):
self.events.append("on_init_end")
def on_train_begin(self, args, state, control, **kwargs):
self.events.append("on_train_begin")
def on_train_end(self, args, state, control, **kwargs):
self.events.append("on_train_end")
def on_epoch_begin(self, args, state, control, **kwargs):
self.events.append("on_epoch_begin")
def on_epoch_end(self, args, state, control, **kwargs):
self.events.append("on_epoch_end")
def on_step_begin(self, args, state, control, **kwargs):
self.events.append("on_step_begin")
def on_step_end(self, args, state, control, **kwargs):
self.events.append("on_step_end")
def on_evaluate(self, args, state, control, **kwargs):
self.events.append("on_evaluate")
def on_save(self, args, state, control, **kwargs):
self.events.append("on_save")
def on_log(self, args, state, control, **kwargs):
self.events.append("on_log")
def on_prediction_step(self, args, state, control, **kwargs):
self.events.append("on_prediction_step")
@require_torch
class TrainerCallbackTest(unittest.TestCase):
def setUp(self):
self.output_dir = tempfile.mkdtemp()
def tearDown(self):
shutil.rmtree(self.output_dir)
def get_trainer(self, a=0, b=0, train_len=64, eval_len=64, callbacks=None, disable_tqdm=False, **kwargs):
# disable_tqdm in TrainingArguments has a flaky default since it depends on the level of logging. We make sure
# its set to False since the tests later on depend on its value.
train_dataset = RegressionDataset(length=train_len)
eval_dataset = RegressionDataset(length=eval_len)
config = RegressionModelConfig(a=a, b=b)
model = RegressionPreTrainedModel(config)
args = TrainingArguments(self.output_dir, disable_tqdm=disable_tqdm, report_to=[], **kwargs)
return Trainer(
model,
args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=callbacks,
)
def check_callbacks_equality(self, cbs1, cbs2):
self.assertEqual(len(cbs1), len(cbs2))
# Order doesn't matter
cbs1 = list(sorted(cbs1, key=lambda cb: cb.__name__ if isinstance(cb, type) else cb.__class__.__name__))
cbs2 = list(sorted(cbs2, key=lambda cb: cb.__name__ if isinstance(cb, type) else cb.__class__.__name__))
for cb1, cb2 in zip(cbs1, cbs2):
if isinstance(cb1, type) and isinstance(cb2, type):
self.assertEqual(cb1, cb2)
elif isinstance(cb1, type) and not isinstance(cb2, type):
self.assertEqual(cb1, cb2.__class__)
elif not isinstance(cb1, type) and isinstance(cb2, type):
self.assertEqual(cb1.__class__, cb2)
else:
self.assertEqual(cb1, cb2)
def get_expected_events(self, trainer):
expected_events = ["on_init_end", "on_train_begin"]
step = 0
train_dl_len = len(trainer.get_eval_dataloader())
evaluation_events = ["on_prediction_step"] * len(trainer.get_eval_dataloader()) + ["on_log", "on_evaluate"]
for _ in range(trainer.state.num_train_epochs):
expected_events.append("on_epoch_begin")
for _ in range(train_dl_len):
step += 1
expected_events += ["on_step_begin", "on_step_end"]
if step % trainer.args.logging_steps == 0:
expected_events.append("on_log")
if trainer.args.evaluation_strategy == IntervalStrategy.STEPS and step % trainer.args.eval_steps == 0:
expected_events += evaluation_events.copy()
if step % trainer.args.save_steps == 0:
expected_events.append("on_save")
expected_events.append("on_epoch_end")
if trainer.args.evaluation_strategy == IntervalStrategy.EPOCH:
expected_events += evaluation_events.copy()
expected_events += ["on_log", "on_train_end"]
return expected_events
def test_init_callback(self):
trainer = self.get_trainer()
expected_callbacks = DEFAULT_CALLBACKS.copy() + [ProgressCallback]
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
# Callbacks passed at init are added to the default callbacks
trainer = self.get_trainer(callbacks=[MyTestTrainerCallback])
expected_callbacks.append(MyTestTrainerCallback)
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
# TrainingArguments.disable_tqdm controls if use ProgressCallback or PrinterCallback
trainer = self.get_trainer(disable_tqdm=True)
expected_callbacks = DEFAULT_CALLBACKS.copy() + [PrinterCallback]
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
def test_add_remove_callback(self):
expected_callbacks = DEFAULT_CALLBACKS.copy() + [ProgressCallback]
trainer = self.get_trainer()
# We can add, pop, or remove by class name
trainer.remove_callback(DefaultFlowCallback)
expected_callbacks.remove(DefaultFlowCallback)
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
trainer = self.get_trainer()
cb = trainer.pop_callback(DefaultFlowCallback)
self.assertEqual(cb.__class__, DefaultFlowCallback)
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
trainer.add_callback(DefaultFlowCallback)
expected_callbacks.insert(0, DefaultFlowCallback)
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
# We can also add, pop, or remove by instance
trainer = self.get_trainer()
cb = trainer.callback_handler.callbacks[0]
trainer.remove_callback(cb)
expected_callbacks.remove(DefaultFlowCallback)
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
trainer = self.get_trainer()
cb1 = trainer.callback_handler.callbacks[0]
cb2 = trainer.pop_callback(cb1)
self.assertEqual(cb1, cb2)
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
trainer.add_callback(cb1)
expected_callbacks.insert(0, DefaultFlowCallback)
self.check_callbacks_equality(trainer.callback_handler.callbacks, expected_callbacks)
def test_event_flow(self):
import warnings
# XXX: for now ignore scatter_gather warnings in this test since it's not relevant to what's being tested
warnings.simplefilter(action="ignore", category=UserWarning)
trainer = self.get_trainer(callbacks=[MyTestTrainerCallback])
trainer.train()
events = trainer.callback_handler.callbacks[-2].events
self.assertEqual(events, self.get_expected_events(trainer))
# Independent log/save/eval
trainer = self.get_trainer(callbacks=[MyTestTrainerCallback], logging_steps=5)
trainer.train()
events = trainer.callback_handler.callbacks[-2].events
self.assertEqual(events, self.get_expected_events(trainer))
trainer = self.get_trainer(callbacks=[MyTestTrainerCallback], save_steps=5)
trainer.train()
events = trainer.callback_handler.callbacks[-2].events
self.assertEqual(events, self.get_expected_events(trainer))
trainer = self.get_trainer(callbacks=[MyTestTrainerCallback], eval_steps=5, evaluation_strategy="steps")
trainer.train()
events = trainer.callback_handler.callbacks[-2].events
self.assertEqual(events, self.get_expected_events(trainer))
trainer = self.get_trainer(callbacks=[MyTestTrainerCallback], evaluation_strategy="epoch")
trainer.train()
events = trainer.callback_handler.callbacks[-2].events
self.assertEqual(events, self.get_expected_events(trainer))
# A bit of everything
trainer = self.get_trainer(
callbacks=[MyTestTrainerCallback],
logging_steps=3,
save_steps=10,
eval_steps=5,
evaluation_strategy="steps",
)
trainer.train()
events = trainer.callback_handler.callbacks[-2].events
self.assertEqual(events, self.get_expected_events(trainer))
# warning should be emitted for duplicated callbacks
with unittest.mock.patch("transformers.trainer_callback.logger.warn") as warn_mock:
trainer = self.get_trainer(
callbacks=[MyTestTrainerCallback, MyTestTrainerCallback],
)
assert str(MyTestTrainerCallback) in warn_mock.call_args[0][0]
| AdaMix/tests/test_trainer_callback.py/0 | {
"file_path": "AdaMix/tests/test_trainer_callback.py",
"repo_id": "AdaMix",
"token_count": 4105
} | 82 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Link tester.
This little utility reads all the python files in the repository,
scans for links pointing to S3 and tests the links one by one. Raises an error
at the end of the scan if at least one link was reported broken.
"""
import os
import re
import sys
import requests
REGEXP_FIND_S3_LINKS = r"""([\"'])(https:\/\/s3)(.*)?\1"""
S3_BUCKET_PREFIX = "https://s3.amazonaws.com/models.huggingface.co/bert"
def list_python_files_in_repository():
"""List all python files in the repository.
This function assumes that the script is executed in the root folder.
"""
source_code_files = []
for path, subdirs, files in os.walk("."):
if "templates" in path:
continue
for name in files:
if ".py" in name and ".pyc" not in name:
path_to_files = os.path.join(path, name)
source_code_files.append(path_to_files)
return source_code_files
def find_all_links(file_paths):
links = []
for path in file_paths:
links += scan_code_for_links(path)
return [link for link in links if link != S3_BUCKET_PREFIX]
def scan_code_for_links(source):
"""Scans the file to find links using a regular expression.
Returns a list of links.
"""
with open(source, "r") as content:
content = content.read()
raw_links = re.findall(REGEXP_FIND_S3_LINKS, content)
links = [prefix + suffix for _, prefix, suffix in raw_links]
return links
def check_all_links(links):
"""Check that the provided links are valid.
Links are considered valid if a HEAD request to the server
returns a 200 status code.
"""
broken_links = []
for link in links:
head = requests.head(link)
if head.status_code != 200:
broken_links.append(link)
return broken_links
if __name__ == "__main__":
file_paths = list_python_files_in_repository()
links = find_all_links(file_paths)
broken_links = check_all_links(links)
print("Looking for broken links to pre-trained models/configs/tokenizers...")
if broken_links:
print("The following links did not respond:")
for link in broken_links:
print("- {}".format(link))
sys.exit(1)
print("All links are ok.")
| AdaMix/utils/link_tester.py/0 | {
"file_path": "AdaMix/utils/link_tester.py",
"repo_id": "AdaMix",
"token_count": 1044
} | 83 |
## API overview
We added some new APIs (marked with 💚) to [AirSim](https://github.com/Microsoft/Airsim) for the NeurIPS competition binaries.
#### Loading Unreal Engine environments
- [`simLoadLevel(level_name)`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simLoadLevel) 💚
Possible values for `level_name` are:
- `Soccer_Field_Easy`
- `Soccer_Field_Medium`
- `ZhangJiaJie_Medium`
- `Building99_Hard`
- `Qualification_Tier_1`
- `Qualification_Tier_2`
- `Qualification_Tier_3`
- `Final_Tier_1`
- `Final_Tier_2`
- `Final_Tier_3`
Note that any race tier can be run for any level, irrespective of the `Tier_N` suffix. (Historic note: The names along with their suffixes are ported from [Game of Drones](https://github.com/microsoft/AirSim-NeurIPS2019-Drone-Racing))
- UI Menu
- Press `F10` to toggle the level menu
- Click your desired level. (Note: the UI lists all the pakfiles in the `ADRL/ADRL/Content/Paks` directory.)
#### Race APIs:
- Start a race:
[`simStartRace(tier=1/2/3)`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.simStartRace) 💚
- Reset race:
[`simResetRace()`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.simResetRace) 💚
- Check if racer is disqualified:
[`simIsRacerDisqualified()`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.simIsRacerDisqualified) 💚
- Get index of last gate passed:
[`simGetLastGatePassed()`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.simGetLastGatePassed) 💚
- Disable generation of logfiles by race APIs:
[`simDisableRaceLog`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.simDisableRaceLog) 💚
#### Lower level control APIs:
- FPV like Angle rate setpoint APIs:
- [`moveByAngleRatesThrottleAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByAngleRatesThrottleAsync) 💚
- [`moveByAngleRatesZAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByAngleRatesZAsync) 💚 (stabilizes altitude)
- Angle setpoint APIs:
- [`moveByRollPitchYawThrottleAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByRollPitchYawThrottleAsync) 💚
- [`moveByRollPitchYawZAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByRollPitchYawZAsync) 💚 (stabilizes altitude)
- RollPitchYawrate setpoint APIs:
- [`moveByRollPitchYawrateThrottleAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByRollPitchYawrateThrottleAsync) 💚
- [`moveByRollPitchYawrateZAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByRollPitchYawrateZAsync) 💚 (stabilizes altitude)
#### Medium level control APIs:
- Velocity setpoints
- [`moveByVelocityAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByVelocityAsync)
- [`moveByVelocityZAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveByVelocityZAsync) (stabilizes altitude)
- Position setpoints
- [`moveToPosition`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveToPositionAsync)
- [`moveOnPath`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveOnPathAsync)
- [`moveToZAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveToZAsync)
#### High level control APIs:
- Minimum jerk trajectory planning (using [ethz-asl/mav_trajectory_generation](https://github.com/ethz-asl/mav_trajectory_generation)), and trajectory tracking (using a pure pursuit like controller minimizing position and velocity errors), with position setpoints.
Optionally use the `*lookahead*` parameters to start new trajectory from a point sampled `n` seconds ahead for trajectory being tracked currently.
- [`moveOnSplineAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveOnSplineAsync) 💚
- Minimum jerk trajectory planning (using [ethz-asl/mav_trajectory_generation](https://github.com/ethz-asl/mav_trajectory_generation)), and trajectory tracking (using a pure pursuit like controller minimizing position and velocity errors), with position setpoints and corresponding velocity constraints. Useful for making a drone go through a gate waypoint, while obeying speed and direction constraints.
Optionally use the `*lookahead*` parameters to start new trajectory from a point sampled `n` seconds ahead for trajectory being tracked currently.
- [`moveOnSplineVelConstraintsAsync`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.moveOnSplineVelConstraintsAsync) 💚
- Clear and stop following current trajectory.
- [`clearTrajectory`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.clearTrajectory) 💚
#### Gain setter APIs:
- [`setAngleRateControllerGains`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.setAngleRateControllerGains) 💚
- [`setAngleLevelControllerGains`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.setAngleLevelControllerGains) 💚
- [`setVelocityControllerGains`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.setVelocityControllerGains) 💚
- [`setPositionControllerGains`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.setPositionControllerGains) 💚
- [`setTrajectoryTrackerGains`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.MultirotorClient.setTrajectoryTrackerGains) 💚
#### APIs to help generate gate detection datasets:
- Object pose setter and getter:
- [`simSetObjectPose`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simSetObjectPose)
- [`simGetObjectPose`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simGetObjectPose)
- Object scale setter and getter:
- [`simSetObjectScale`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simSetObjectScale) 💚
- [`simGetObjectScale`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simGetObjectScale) 💚
- Object segmentation ID setter and getter:
- [`simGetSegmentationObjectID`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simGetSegmentationObjectID)
- [`simSetSegmentationObjectID`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simSetSegmentationObjectID)
- Listing all the objects in the scene:
- [`simListSceneObjects`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simListSceneObjects) 💚
- Gate specific APIs:
- [`simGetNominalGateInnerDimensions`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simGetNominalGateInnerDimensions) 💚
- [`simGetNominalGateOuterDimensions`](https://microsoft.github.io/AirSim-Drone-Racing-Lab/autoapi/airsimdroneracinglab/client/index.html#airsimdroneracinglab.client.VehicleClient.simGetNominalGateOuterDimensions) 💚
| AirSim-Drone-Racing-Lab/docs/api_overview.md/0 | {
"file_path": "AirSim-Drone-Racing-Lab/docs/api_overview.md",
"repo_id": "AirSim-Drone-Racing-Lab",
"token_count": 3388
} | 84 |
import cv2
import numpy as np
import os
import sys
import airsimdroneracingvae as airsim
# print(os.path.abspath(airsim.__file__))
from airsimdroneracingvae.types import Pose, Vector3r, Quaternionr
import airsimdroneracingvae.types
import airsimdroneracingvae.utils
import time
# import utils
curr_dir = os.path.dirname(os.path.abspath(__file__))
import_path = os.path.join(curr_dir, '..', '..')
sys.path.insert(0, import_path)
import racing_utils
GATE_YAW_RANGE = [-np.pi, np.pi] # world theta gate
# GATE_YAW_RANGE = [-1, 1] # world theta gate -- this range is btw -pi and +pi
UAV_X_RANGE = [-30, 30] # world x quad
UAV_Y_RANGE = [-30, 30] # world y quad
UAV_Z_RANGE = [-2, -3] # world z quad
UAV_YAW_RANGE = [-np.pi, np.pi] #[-eps, eps] [-np.pi/4, np.pi/4]
eps = np.pi/10.0 # 18 degrees
UAV_PITCH_RANGE = [-eps, eps] #[-np.pi/4, np.pi/4]
UAV_ROLL_RANGE = [-eps, eps] #[-np.pi/4, np.pi/4]
R_RANGE = [0.1, 20] # in meters
correction = 0.85
CAM_FOV = 90.0*correction # in degrees -- needs to be a bit smaller than 90 in fact because of cone vs. square
class PoseSampler:
def __init__(self, num_samples, dataset_path, with_gate=True):
self.num_samples = num_samples
self.base_path = dataset_path
self.csv_path = os.path.join(self.base_path, 'gate_training_data.csv')
self.curr_idx = 0
self.with_gate = with_gate
self.client = airsim.MultirotorClient()
self.client.confirmConnection()
self.client.simLoadLevel('Soccer_Field_Easy')
time.sleep(4)
self.client = airsim.MultirotorClient()
self.configureEnvironment()
def update(self):
'''
convetion of names:
p_a_b: pose of frame b relative to frame a
t_a_b: translation vector from a to b
q_a_b: rotation quaternion from a to b
o: origin
b: UAV body frame
g: gate frame
'''
# create and set pose for the quad
p_o_b, phi_base = racing_utils.geom_utils.randomQuadPose(UAV_X_RANGE, UAV_Y_RANGE, UAV_Z_RANGE, UAV_YAW_RANGE, UAV_PITCH_RANGE, UAV_ROLL_RANGE)
self.client.simSetVehiclePose(p_o_b, True)
# create and set gate pose relative to the quad
p_o_g, r, theta, psi, phi_rel = racing_utils.geom_utils.randomGatePose(p_o_b, phi_base, R_RANGE, CAM_FOV, correction)
# self.client.simSetObjectPose(self.tgt_name, p_o_g_new, True)
if self.with_gate:
self.client.simSetObjectPose(self.tgt_name, p_o_g, True)
# self.client.plot_tf([p_o_g], duration=20.0)
# request quad img from AirSim
image_response = self.client.simGetImages([airsim.ImageRequest('0', airsim.ImageType.Scene, False, False)])[0]
# save all the necessary information to file
self.writeImgToFile(image_response)
self.writePosToFile(r, theta, psi, phi_rel)
self.curr_idx += 1
def configureEnvironment(self):
for gate_object in self.client.simListSceneObjects(".*[Gg]ate.*"):
self.client.simDestroyObject(gate_object)
time.sleep(0.05)
if self.with_gate:
self.tgt_name = self.client.simSpawnObject("gate", "RedGate16x16", Pose(position_val=Vector3r(0,0,15)), 0.75)
# self.tgt_name = self.client.simSpawnObject("gate", "CheckeredGate16x16", Pose(position_val=Vector3r(0,0,15)))
else:
self.tgt_name = "empty_target"
if os.path.exists(self.csv_path):
self.file = open(self.csv_path, "a")
else:
self.file = open(self.csv_path, "w")
# write image to file
def writeImgToFile(self, image_response):
if len(image_response.image_data_uint8) == image_response.width * image_response.height * 3:
img1d = np.fromstring(image_response.image_data_uint8, dtype=np.uint8) # get numpy array
img_rgb = img1d.reshape(image_response.height, image_response.width, 3) # reshape array to 4 channel image array H X W X 3
cv2.imwrite(os.path.join(self.base_path, 'images', str(self.curr_idx).zfill(len(str(self.num_samples))) + '.png'), img_rgb) # write to png
else:
print('ERROR IN IMAGE SIZE -- NOT SUPPOSED TO HAPPEN')
# writes your data to file
def writePosToFile(self, r, theta, psi, phi_rel):
data_string = '{0} {1} {2} {3}\n'.format(r, theta, psi, phi_rel)
self.file.write(data_string)
| AirSim-Drone-Racing-VAE-Imitation/datagen/img_generator/pose_sampler.py/0 | {
"file_path": "AirSim-Drone-Racing-VAE-Imitation/datagen/img_generator/pose_sampler.py",
"repo_id": "AirSim-Drone-Racing-VAE-Imitation",
"token_count": 2019
} | 85 |
import os
import h5py
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import random
import os
import matplotlib.pyplot as plt
import glob
from PIL import Image
import cv2
from sklearn.model_selection import train_test_split
def convert_bgr2rgb(img_bgr):
return cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
def convert_rgb2bgr(img_rgb):
return cv2.cvtColor(img_rgb, cv2.COLOR_RGB2BGR)
def normalize_v(v):
# normalization of velocities from whatever to [-1, 1] range
v_x_range = [-1, 7]
v_y_range = [-3, 3]
v_z_range = [-3, 3]
v_yaw_range = [-1, 1]
if len(v.shape) == 1:
# means that it's a 1D vector of velocities
v[0] = 2.0 * (v[0] - v_x_range[0]) / (v_x_range[1] - v_x_range[0]) - 1.0
v[1] = 2.0 * (v[1] - v_y_range[0]) / (v_y_range[1] - v_y_range[0]) - 1.0
v[2] = 2.0 * (v[2] - v_z_range[0]) / (v_z_range[1] - v_z_range[0]) - 1.0
v[3] = 2.0 * (v[3] - v_yaw_range[0]) / (v_yaw_range[1] - v_yaw_range[0]) - 1.0
elif len(v.shape) == 2:
# means that it's a 2D vector of velocities
v[:, 0] = 2.0 * (v[:, 0] - v_x_range[0]) / (v_x_range[1] - v_x_range[0]) - 1.0
v[:, 1] = 2.0 * (v[:, 1] - v_y_range[0]) / (v_y_range[1] - v_y_range[0]) - 1.0
v[:, 2] = 2.0 * (v[:, 2] - v_z_range[0]) / (v_z_range[1] - v_z_range[0]) - 1.0
v[:, 3] = 2.0 * (v[:, 3] - v_yaw_range[0]) / (v_yaw_range[1] - v_yaw_range[0]) - 1.0
else:
raise Exception('Error in data format of V shape: {}'.format(v.shape))
return v
def de_normalize_v(v):
# normalization of velocities from [-1, 1] range to whatever
v_x_range = [-1, 7]
v_y_range = [-3, 3]
v_z_range = [-3, 3]
v_yaw_range = [-1, 1]
if len(v.shape) == 1:
# means that it's a 1D vector of velocities
v[0] = (v[0] + 1.0) / 2.0 * (v_x_range[1] - v_x_range[0]) + v_x_range[0]
v[1] = (v[1] + 1.0) / 2.0 * (v_y_range[1] - v_y_range[0]) + v_y_range[0]
v[2] = (v[2] + 1.0) / 2.0 * (v_z_range[1] - v_z_range[0]) + v_z_range[0]
v[3] = (v[3] + 1.0) / 2.0 * (v_yaw_range[1] - v_yaw_range[0]) + v_yaw_range[0]
elif len(v.shape) == 2:
# means that it's a 2D vector of velocities
v[:, 0] = (v[:, 0] + 1.0) / 2.0 * (v_x_range[1] - v_x_range[0]) + v_x_range[0]
v[:, 1] = (v[:, 1] + 1.0) / 2.0 * (v_y_range[1] - v_y_range[0]) + v_y_range[0]
v[:, 2] = (v[:, 2] + 1.0) / 2.0 * (v_z_range[1] - v_z_range[0]) + v_z_range[0]
v[:, 3] = (v[:, 3] + 1.0) / 2.0 * (v_yaw_range[1] - v_yaw_range[0]) + v_yaw_range[0]
else:
raise Exception('Error in data format of V shape: {}'.format(v.shape))
return v
def normalize_gate(pose):
# normalization of velocities from whatever to [-1, 1] range
r_range = [0.1, 20]
cam_fov = 90*0.85 # in degrees -- needs to be a bit smaller than 90 in fact because of cone vs. square
alpha = cam_fov / 180.0 * np.pi / 2.0 # alpha is half of fov angle
theta_range = [-alpha, alpha]
psi_range = [np.pi / 2 - alpha, np.pi / 2 + alpha]
eps = 0.0
phi_rel_range = [-np.pi + eps, 0 - eps]
if len(pose.shape) == 1:
# means that it's a 1D vector of velocities
pose[0] = 2.0 * (pose[0] - r_range[0]) / (r_range[1] - r_range[0]) - 1.0
pose[1] = 2.0 * (pose[1] - theta_range[0]) / (theta_range[1] - theta_range[0]) - 1.0
pose[2] = 2.0 * (pose[2] - psi_range[0]) / (psi_range[1] - psi_range[0]) - 1.0
pose[3] = 2.0 * (pose[3] - phi_rel_range[0]) / (phi_rel_range[1] - phi_rel_range[0]) - 1.0
elif len(pose.shape) == 2:
# means that it's a 2D vector of velocities
pose[:, 0] = 2.0 * (pose[:, 0] - r_range[0]) / (r_range[1] - r_range[0]) - 1.0
pose[:, 1] = 2.0 * (pose[:, 1] - theta_range[0]) / (theta_range[1] - theta_range[0]) - 1.0
pose[:, 2] = 2.0 * (pose[:, 2] - psi_range[0]) / (psi_range[1] - psi_range[0]) - 1.0
pose[:, 3] = 2.0 * (pose[:, 3] - phi_rel_range[0]) / (phi_rel_range[1] - phi_rel_range[0]) - 1.0
else:
raise Exception('Error in data format of V shape: {}'.format(pose.shape))
return pose
def de_normalize_gate(pose):
# normalization of velocities from [-1, 1] range to whatever
r_range = [0.1, 20]
cam_fov = 90*0.85 # in degrees -- needs to be a bit smaller than 90 in fact because of cone vs. square
alpha = cam_fov / 180.0 * np.pi / 2.0 # alpha is half of fov angle
theta_range = [-alpha, alpha]
psi_range = [np.pi / 2 - alpha, np.pi / 2 + alpha]
eps = 0.0
phi_rel_range = [-np.pi + eps, 0 - eps]
if len(pose.shape) == 1:
# means that it's a 1D vector of velocities
pose[0] = (pose[0] + 1.0) / 2.0 * (r_range[1] - r_range[0]) + r_range[0]
pose[1] = (pose[1] + 1.0) / 2.0 * (theta_range[1] - theta_range[0]) + theta_range[0]
pose[2] = (pose[2] + 1.0) / 2.0 * (psi_range[1] - psi_range[0]) + psi_range[0]
pose[3] = (pose[3] + 1.0) / 2.0 * (phi_rel_range[1] - phi_rel_range[0]) + phi_rel_range[0]
elif len(pose.shape) == 2:
# means that it's a 2D vector of velocities
pose[:, 0] = (pose[:, 0] + 1.0) / 2.0 * (r_range[1] - r_range[0]) + r_range[0]
pose[:, 1] = (pose[:, 1] + 1.0) / 2.0 * (theta_range[1] - theta_range[0]) + theta_range[0]
pose[:, 2] = (pose[:, 2] + 1.0) / 2.0 * (psi_range[1] - psi_range[0]) + psi_range[0]
pose[:, 3] = (pose[:, 3] + 1.0) / 2.0 * (phi_rel_range[1] - phi_rel_range[0]) + phi_rel_range[0]
else:
raise Exception('Error in data format of V shape: {}'.format(pose.shape))
return pose
def read_images(data_dir, res, max_size=None):
print('Going to read image file list')
files_list = glob.glob(os.path.join(data_dir, 'images/*.png'))
print('Done. Starting sorting.')
files_list.sort() # make sure we're reading the images in order later
print('Done. Before images_np init')
if max_size is not None:
size_data = max_size
else:
size_data = len(files_list)
images_np = np.zeros((size_data, res, res, 3)).astype(np.float32)
print('Done. Going to read images.')
idx = 0
for img_name in files_list:
# read data in BGR format by default!!!
# notice that model is going to be trained in BGR
im = cv2.imread(img_name, cv2.IMREAD_COLOR)
im = cv2.resize(im, (res, res))
im = im / 255.0 * 2.0 - 1.0
images_np[idx, :] = im
if idx % 10000 == 0:
print ('image idx = {}'.format(idx))
idx = idx + 1
if idx == size_data:
# reached the last point -- exit loop of images
break
print('Done reading {} images.'.format(images_np.shape[0]))
return images_np
def create_dataset_csv(data_dir, batch_size, res, max_size=None):
print('Going to read file list')
files_list = glob.glob(os.path.join(data_dir, 'images/*.png'))
print('Done. Starting sorting.')
files_list.sort() # make sure we're reading the images in order later
print('Done. Before images_np init')
if max_size is not None:
size_data = max_size
else:
size_data = len(files_list)
images_np = np.zeros((size_data, res, res, 3)).astype(np.float32)
print('Done. Going to read images.')
idx = 0
for file in files_list:
# read data in BGR format by default!!!
# notice that model is going to be trained in BGR
im = cv2.imread(file, cv2.IMREAD_COLOR)
im = cv2.resize(im, (res, res))
im = im / 255.0 * 2.0 - 1.0
images_np[idx, :] = im
if idx % 10000 == 0:
print ('image idx = {}'.format(idx))
idx = idx + 1
if idx == size_data:
# reached the last point -- exit loop of images
break
print('Going to read csv file.')
# prepare gate R THETA PSI PHI as np array reading from a file
raw_table = np.loadtxt(data_dir + '/gate_training_data.csv', delimiter=' ')
raw_table = raw_table[:size_data, :]
# sanity check
if raw_table.shape[0] != images_np.shape[0]:
raise Exception('Number of images ({}) different than number of entries in table ({}): '.format(images_np.shape[0], raw_table.shape[0]))
raw_table.astype(np.float32)
# print some useful statistics
print("Average gate values: {}".format(np.mean(raw_table, axis=0)))
print("Median gate values: {}".format(np.median(raw_table, axis=0)))
print("STD of gate values: {}".format(np.std(raw_table, axis=0)))
print("Max of gate values: {}".format(np.max(raw_table, axis=0)))
print("Min of gate values: {}".format(np.min(raw_table, axis=0)))
# normalize distances to gate to [-1, 1] range
raw_table = normalize_gate(raw_table)
img_train, img_test, dist_train, dist_test = train_test_split(images_np, raw_table, test_size=0.1, random_state=42)
# convert to tf format dataset and prepare batches
ds_train = tf.data.Dataset.from_tensor_slices((img_train, dist_train)).batch(batch_size)
ds_test = tf.data.Dataset.from_tensor_slices((img_test, dist_test)).batch(batch_size)
return ds_train, ds_test
def create_unsup_dataset_multiple_sources(data_dir_list, batch_size, res):
# load all the images in one single large dataset
images_np = np.empty((0,res,res,3)).astype(np.float32)
for data_dir in data_dir_list:
img_array = read_images(data_dir, res, max_size=None)
images_np = np.concatenate((images_np, img_array), axis=0)
# make fake distances to gate as -1
num_items = images_np.shape[0]
print('Real_life dataset has {} images total'.format(num_items))
raw_table = (-1.0*np.ones((num_items, 4))).astype(np.float32)
# separate the actual dataset:
img_train, img_test, dist_train, dist_test = train_test_split(images_np, raw_table, test_size=0.1, random_state=42)
# convert to tf format dataset and prepare batches
ds_train = tf.data.Dataset.from_tensor_slices((img_train, dist_train)).batch(batch_size)
ds_test = tf.data.Dataset.from_tensor_slices((img_test, dist_test)).batch(batch_size)
return ds_train, ds_test
def create_test_dataset_csv(data_dir, res, read_table=True):
# prepare image dataset from a folder
print('Going to read file list')
files_list = glob.glob(os.path.join(data_dir, 'images/*.png'))
print('Done. Starting sorting.')
files_list.sort() # make sure we're reading the images in order later
print('Done. Before images_np init')
images_np = np.zeros((len(files_list), res, res, 3)).astype(np.float32)
print('After images_np init')
idx = 0
for file in files_list:
# read data in BGR format by default!!!
# notice that model was trained in BGR
im = cv2.imread(file, cv2.IMREAD_COLOR)
im = cv2.resize(im, (res, res))
im = im/255.0*2.0-1.0
images_np[idx, :] = im
idx = idx + 1
if not read_table:
return images_np, None
# prepare gate R THETA PSI PHI as np array reading from a file
raw_table = np.loadtxt(data_dir + '/gate_training_data.csv', delimiter=' ')
# sanity check
if raw_table.shape[0] != images_np.shape[0]:
raise Exception('Number of images ({}) different than number of entries in table ({}): '.format(images_np.shape[0], raw_table.shape[0]))
raw_table.astype(np.float32)
# print some useful statistics
print("Average gate values: {}".format(np.mean(raw_table, axis=0)))
print("Median gate values: {}".format(np.median(raw_table, axis=0)))
print("STD of gate values: {}".format(np.std(raw_table, axis=0)))
print("Max of gate values: {}".format(np.max(raw_table, axis=0)))
print("Min of gate values: {}".format(np.min(raw_table, axis=0)))
return images_np, raw_table
def create_dataset_txt(data_dir, batch_size, res, data_mode='train', base_path=None):
vel_table = np.loadtxt(data_dir + '/proc_vel.txt', delimiter=',').astype(np.float32)
with open(data_dir + '/proc_images.txt') as f:
img_table = f.read().splitlines()
# sanity check
if vel_table.shape[0] != len(img_table):
raise Exception('Number of images ({}) different than number of entries in table ({}): '.format(len(img_table), vel_table.shape[0]))
size_data = len(img_table)
images_np = np.zeros((size_data, res, res, 3)).astype(np.float32)
print('Done. Going to read images.')
idx = 0
for img_name in img_table:
if base_path is not None:
img_name = img_name.replace('/home/rb/data', base_path)
# read data in BGR format by default!!!
# notice that model is going to be trained in BGR
im = cv2.imread(img_name, cv2.IMREAD_COLOR)
im = cv2.resize(im, (res, res))
im = im / 255.0 * 2.0 - 1.0
images_np[idx, :] = im
if idx % 1000 == 0:
print ('image idx = {} out of {} images'.format(idx, size_data))
idx = idx + 1
if idx == size_data:
# reached the last point -- exit loop of images
break
# print some useful statistics and normalize distances
print("Num samples: {}".format(vel_table.shape[0]))
print("Average vx: {}".format(np.mean(vel_table[:, 0])))
print("Average vy: {}".format(np.mean(vel_table[:, 1])))
print("Average vz: {}".format(np.mean(vel_table[:, 2])))
print("Average vyaw: {}".format(np.mean(vel_table[:, 3])))
# normalize the values of velocities to the [-1, 1] range
vel_table = normalize_v(vel_table)
img_train, img_test, v_train, v_test = train_test_split(images_np, vel_table, test_size=0.1, random_state=42)
if data_mode == 'train':
# convert to tf format dataset and prepare batches
ds_train = tf.data.Dataset.from_tensor_slices((img_train, v_train)).batch(batch_size)
ds_test = tf.data.Dataset.from_tensor_slices((img_test, v_test)).batch(batch_size)
return ds_train, ds_test
elif data_mode == 'test':
return img_test, v_test
def create_dataset_multiple_sources(data_dir_list, batch_size, res, data_mode='train', base_path=None):
# load all the images and velocities in one single large dataset
images_np = np.empty((0,res,res,3)).astype(np.float32)
vel_table = np.empty((0,4)).astype(np.float32)
for data_dir in data_dir_list:
img_array, v_array = create_dataset_txt(data_dir, batch_size, res, data_mode='test', base_path=base_path)
images_np = np.concatenate((images_np, img_array), axis=0)
vel_table = np.concatenate((vel_table, v_array), axis=0)
# separate the actual dataset:
img_train, img_test, v_train, v_test = train_test_split(images_np, vel_table, test_size=0.1, random_state=42)
if data_mode == 'train':
# convert to tf format dataset and prepare batches
ds_train = tf.data.Dataset.from_tensor_slices((img_train, v_train)).batch(batch_size)
ds_test = tf.data.Dataset.from_tensor_slices((img_test, v_test)).batch(batch_size)
return ds_train, ds_test
elif data_mode == 'test':
return img_test, v_test | AirSim-Drone-Racing-VAE-Imitation/racing_utils/dataset_utils.py/0 | {
"file_path": "AirSim-Drone-Racing-VAE-Imitation/racing_utils/dataset_utils.py",
"repo_id": "AirSim-Drone-Racing-VAE-Imitation",
"token_count": 6838
} | 86 |
#!/bin/bash
wget -c https://github.com/microsoft/AirSim-NeurIPS2019-Drone-Racing/releases/download/v1.0-linux/AirSim.zip;
mkdir -p /home/$USER/Documents/AirSim;
unzip AirSim.zip;
mv AirSim AirSim_Qualification;
wget --directory-prefix=AirSim_Qualification/AirSimExe/Content/Paks -c https://github.com/microsoft/AirSim-NeurIPS2019-Drone-Racing/releases/download/v1.0-linux/Qual_Tier_1_and_Tier_3.pak;
wget --directory-prefix=AirSim_Qualification/AirSimExe/Content/Paks -c https://github.com/microsoft/AirSim-NeurIPS2019-Drone-Racing/releases/download/v1.0-linux/Qual_Tier_2.pak;
wget --directory-prefix=/home/$USER/Documents/AirSim -c https://github.com/microsoft/AirSim-NeurIPS2019-Drone-Racing/releases/download/v1.0-linux/settings.json;
rm AirSim.zip; | AirSim-NeurIPS2019-Drone-Racing/download_qualification_binaries.sh/0 | {
"file_path": "AirSim-NeurIPS2019-Drone-Racing/download_qualification_binaries.sh",
"repo_id": "AirSim-NeurIPS2019-Drone-Racing",
"token_count": 286
} | 87 |
# Azure Monitor Events Extension
The Azure Monitor Events Extension allows users to send custom events to Application Insights in conjunction with the [Azure Monitor OpenTelemetry Distro](https://learn.microsoft.com/azure/azure-monitor/app/opentelemetry-enable?tabs=python).
## Install the package
Install the `Azure Monitor OpenTelemetry Distro` and `Azure Monitor Events Extension`:
```Bash
pip install azure-monitor-opentelemetry
pip install azure-monitor-events-extension --pre
```
## Samples
Check out the [samples](https://github.com/microsoft/ApplicationInsights-Python/tree/main/azure-monitor-events-extension/samples) page to see how to use the events extention with the distro.
## Additional documentation
* [Azure Portal][azure_portal]
* [Official Azure monitor docs][azure_monitor_opentelemetry]
* [OpenTelemetry Python Official Docs][ot_python_docs]
<!-- LINKS -->
[azure_portal]: https://portal.azure.com
[azure_monitor_opentelemetry]: https://learn.microsoft.com/azure/azure-monitor/app/opentelemetry-enable?tabs=python
[ot_python_docs]: https://opentelemetry.io/docs/instrumentation/python/
| ApplicationInsights-Python/azure-monitor-events-extension/README.md/0 | {
"file_path": "ApplicationInsights-Python/azure-monitor-events-extension/README.md",
"repo_id": "ApplicationInsights-Python",
"token_count": 337
} | 88 |
[tox]
skipsdist = True
skip_missing_interpreters = True
envlist =
py3{7,8,9,10,11}-events-ext
lint
[testenv]
deps =
-r test-requirements.txt
changedir =
events-ext: azure-monitor-events-extension/tests
commands_pre =
py3{7,8,9,10,11}: python -m pip install -U pip setuptools wheel
events-ext: pip install {toxinidir}/azure-monitor-events-extension
commands =
; TODO: Enable when events tests are added
; events-ext: pytest {posargs}
[testenv:lint]
basepython: python3.11
recreate = True
deps =
-r lint-requirements.txt
commands_pre =
python -m pip install -e {toxinidir}/azure-monitor-events-extension
commands =
black --config pyproject.toml {toxinidir} --diff --check
isort --settings-path .isort.cfg {toxinidir} --diff --check-only
flake8 --config .flake8 {toxinidir}
; TODO
; pylint {toxinidir}
| ApplicationInsights-Python/tox.ini/0 | {
"file_path": "ApplicationInsights-Python/tox.ini",
"repo_id": "ApplicationInsights-Python",
"token_count": 337
} | 89 |
{
"excludeFiles": [
".yaspeller*",
"**/*devcontainer*",
".git",
".gitignore",
".gitattributes",
"node_modules",
"LICENSE",
"Makefile",
"**/.dockerignore",
"**/Dockerfile",
"**/*.tf*",
"**/*.terraform*",
"**/requirements.txt",
"**/*.py",
"**/*.yml",
"**/*.yaml",
"**/*.sh",
"**/.env.tmpl",
"**/requirements-dev.txt"
],
"fileExtensions": [
".md"
],
"lang": "en",
"ignoreTags": ["code", "script"],
"ignoreUrls": true,
"ignoreUppercase": true,
"ignoreDigits": true,
"dictionary": [
"api",
"AspNet",
"az",
"AzureTRE",
"Codespaces",
"Conda",
"dataset",
"datasets",
"dev",
"Dev",
"DevOps",
"DotNet",
"exfiltration",
"Endpoints",
"GitHub",
"lifecycle",
"maintainer",
"maintainers",
"PowerShell",
"PyPi",
"QuickStart",
"quickstart",
"repo",
"repos",
"screenshots",
"terraform",
"Terraform",
"tfvars",
"tmpl",
"TREs",
"Xamarin",
"devcontainer",
"DevContainer",
"endpoints",
"pytest",
"tre",
"VNet",
"resourceType",
"isCurrent",
"msfttreacr",
"azurecr",
"io",
"azuretre",
"cnab",
"aci",
"westeurope",
"idempotent",
"Versioning",
"mixins",
"yml",
"microsoft"
],
"ignoreText": [
// Code sections (anything between ``` and ``` or ` and `)
"`{1,3}([^`]{1,3})*`{1,3}",
// Markdown markdown relative paths
"(\\.\/|\\.\\.\/|\/)?([a-zA-Z_\\-0-9\/]+)(\\.\\w+)*(\\#[a-zA-Z_\\-0-9\/]+)?",
// Email addresses (http://emailregex.com/)
"(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|\"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*\")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])"
]
} | AzureTRE/.yaspellerrc.json/0 | {
"file_path": "AzureTRE/.yaspellerrc.json",
"repo_id": "AzureTRE",
"token_count": 1590
} | 90 |
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"name": "msg",
"type": "serviceBusTrigger",
"direction": "in",
"queueName": "%AIRLOCK_DATA_DELETION_QUEUE_NAME%",
"connection": "SB_CONNECTION_STRING"
}
]
}
| AzureTRE/airlock_processor/DataDeletionTrigger/function.json/0 | {
"file_path": "AzureTRE/airlock_processor/DataDeletionTrigger/function.json",
"repo_id": "AzureTRE",
"token_count": 130
} | 91 |
from collections import namedtuple
import json
import pytest
from mock import MagicMock, patch
from shared_code.blob_operations import get_blob_info_from_topic_and_subject, get_blob_info_from_blob_url, copy_data, get_blob_url, get_storage_endpoint_suffix
from exceptions import TooManyFilesInRequestException, NoFilesInRequestException
def get_test_blob():
return namedtuple("Blob", "name")
class TestBlobOperations():
def test_get_blob_info_from_topic_and_subject(self):
topic = "/subscriptions/SUB_ID/resourceGroups/RG_NAME/providers/Microsoft.Storage/storageAccounts/ST_ACC_NAME"
subject = "/blobServices/default/containers/c144728c-3c69-4a58-afec-48c2ec8bfd45/blobs/BLOB"
storage_account_name, container_name, blob_name = get_blob_info_from_topic_and_subject(topic=topic, subject=subject)
assert storage_account_name == "ST_ACC_NAME"
assert container_name == "c144728c-3c69-4a58-afec-48c2ec8bfd45"
assert blob_name == "BLOB"
def test_get_blob_info_from_url(self):
url = f"https://stalimextest.blob.{get_storage_endpoint_suffix()}/c144728c-3c69-4a58-afec-48c2ec8bfd45/test_dataset.txt"
storage_account_name, container_name, blob_name = get_blob_info_from_blob_url(blob_url=url)
assert storage_account_name == "stalimextest"
assert container_name == "c144728c-3c69-4a58-afec-48c2ec8bfd45"
assert blob_name == "test_dataset.txt"
@patch("shared_code.blob_operations.BlobServiceClient")
def test_copy_data_fails_if_too_many_blobs_to_copy(self, mock_blob_service_client):
mock_blob_service_client().get_container_client().list_blobs = MagicMock(return_value=[get_test_blob()("a"), get_test_blob()("b")])
with pytest.raises(TooManyFilesInRequestException):
copy_data("source_acc", "dest_acc", "req_id")
@patch("shared_code.blob_operations.BlobServiceClient")
def test_copy_data_fails_if_no_blobs_to_copy(self, mock_blob_service_client):
mock_blob_service_client().get_container_client().list_blobs = MagicMock(return_value=[])
with pytest.raises(NoFilesInRequestException):
copy_data("source_acc", "dest_acc", "req_id")
@patch("shared_code.blob_operations.BlobServiceClient")
@patch("shared_code.blob_operations.generate_container_sas", return_value="sas")
def test_copy_data_adds_copied_from_metadata(self, _, mock_blob_service_client):
source_url = f"http://storageacct.blob.{get_storage_endpoint_suffix()}/container/blob"
# Check for two scenarios: when there's no copied_from history in metadata, and when there is some
for source_metadata, dest_metadata in [
({"a": "b"}, {"a": "b", "copied_from": json.dumps([source_url])}),
({"a": "b", "copied_from": json.dumps(["old_url"])}, {"a": "b", "copied_from": json.dumps(["old_url", source_url])})
]:
source_blob_client_mock = MagicMock()
source_blob_client_mock.url = source_url
source_blob_client_mock.get_blob_properties = MagicMock(return_value={"metadata": source_metadata})
dest_blob_client_mock = MagicMock()
dest_blob_client_mock.bla = "bla"
dest_blob_client_mock.start_copy_from_url = MagicMock(return_value={"copy_id": "123", "copy_status": "status"})
# Set source blob mock
mock_blob_service_client().get_container_client().get_blob_client = MagicMock(return_value=source_blob_client_mock)
# Set dest blob mock
mock_blob_service_client().get_blob_client = MagicMock(return_value=dest_blob_client_mock)
# Any additional mocks for the copy_data method to work
mock_blob_service_client().get_user_delegation_key = MagicMock(return_value="key")
mock_blob_service_client().get_container_client().list_blobs = MagicMock(return_value=[get_test_blob()("a")])
copy_data("source_acc", "dest_acc", "req_id")
# Check that copied_from field was set correctly in the metadata
dest_blob_client_mock.start_copy_from_url.assert_called_with(f"{source_url}?sas", metadata=dest_metadata)
def test_get_blob_url_should_return_blob_url(self):
account_name = "account"
container_name = "container"
blob_name = "blob"
blob_url = get_blob_url(account_name, container_name, blob_name)
assert blob_url == f"https://{account_name}.blob.{get_storage_endpoint_suffix()}/{container_name}/{blob_name}"
def test_get_blob_url_without_blob_name_should_return_container_url(self):
account_name = "account"
container_name = "container"
blob_url = get_blob_url(account_name, container_name)
assert blob_url == f"https://{account_name}.blob.{get_storage_endpoint_suffix()}/{container_name}/"
| AzureTRE/airlock_processor/tests/shared_code/test_blob_operations.py/0 | {
"file_path": "AzureTRE/airlock_processor/tests/shared_code/test_blob_operations.py",
"repo_id": "AzureTRE",
"token_count": 2051
} | 92 |
from fastapi import HTTPException
from fastapi import Request
from fastapi.responses import PlainTextResponse
def http_error_handler(_: Request, exc: HTTPException) -> PlainTextResponse:
return PlainTextResponse(exc.detail, status_code=exc.status_code)
| AzureTRE/api_app/api/errors/http_error.py/0 | {
"file_path": "AzureTRE/api_app/api/errors/http_error.py",
"repo_id": "AzureTRE",
"token_count": 69
} | 93 |
from typing import Optional
from fastapi import APIRouter, Depends, HTTPException, status
from pydantic import parse_obj_as
from api.routes.resource_helpers import get_template
from db.errors import EntityVersionExist, InvalidInput
from api.helpers import get_repository
from db.repositories.resource_templates import ResourceTemplateRepository
from models.domain.resource import ResourceType
from models.schemas.resource_template import ResourceTemplateInResponse, ResourceTemplateInformationInList
from models.schemas.workspace_service_template import WorkspaceServiceTemplateInCreate, WorkspaceServiceTemplateInResponse
from resources import strings
from services.authentication import get_current_admin_user, get_current_tre_user_or_tre_admin
workspace_service_templates_core_router = APIRouter(dependencies=[Depends(get_current_tre_user_or_tre_admin)])
@workspace_service_templates_core_router.get("/workspace-service-templates", response_model=ResourceTemplateInformationInList, name=strings.API_GET_WORKSPACE_SERVICE_TEMPLATES, dependencies=[Depends(get_current_tre_user_or_tre_admin)])
async def get_workspace_service_templates(template_repo=Depends(get_repository(ResourceTemplateRepository))) -> ResourceTemplateInformationInList:
templates_infos = await template_repo.get_templates_information(ResourceType.WorkspaceService)
return ResourceTemplateInformationInList(templates=templates_infos)
@workspace_service_templates_core_router.get("/workspace-service-templates/{service_template_name}", response_model=WorkspaceServiceTemplateInResponse, response_model_exclude_none=True, name=strings.API_GET_WORKSPACE_SERVICE_TEMPLATE_BY_NAME, dependencies=[Depends(get_current_tre_user_or_tre_admin)])
async def get_workspace_service_template(service_template_name: str, is_update: bool = False, version: Optional[str] = None, template_repo=Depends(get_repository(ResourceTemplateRepository))) -> WorkspaceServiceTemplateInResponse:
template = await get_template(service_template_name, template_repo, ResourceType.WorkspaceService, is_update=is_update, version=version)
return parse_obj_as(WorkspaceServiceTemplateInResponse, template)
@workspace_service_templates_core_router.post("/workspace-service-templates", status_code=status.HTTP_201_CREATED, response_model=WorkspaceServiceTemplateInResponse, response_model_exclude_none=True, name=strings.API_CREATE_WORKSPACE_SERVICE_TEMPLATES, dependencies=[Depends(get_current_admin_user)])
async def register_workspace_service_template(template_input: WorkspaceServiceTemplateInCreate, template_repo=Depends(get_repository(ResourceTemplateRepository))) -> ResourceTemplateInResponse:
try:
return await template_repo.create_and_validate_template(template_input, ResourceType.WorkspaceService)
except EntityVersionExist:
raise HTTPException(status_code=status.HTTP_409_CONFLICT, detail=strings.WORKSPACE_TEMPLATE_VERSION_EXISTS)
except InvalidInput as e:
raise HTTPException(status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, detail=str(e))
| AzureTRE/api_app/api/routes/workspace_service_templates.py/0 | {
"file_path": "AzureTRE/api_app/api/routes/workspace_service_templates.py",
"repo_id": "AzureTRE",
"token_count": 908
} | 94 |
from datetime import datetime
import uuid
from typing import List
from pydantic import parse_obj_as
from db.repositories.resource_templates import ResourceTemplateRepository
from resources import strings
from models.domain.request_action import RequestAction
from models.domain.resource import ResourceType
from db.repositories.resources import ResourceRepository
from models.domain.authentication import User
from core import config
from db.repositories.base import BaseRepository
from db.errors import EntityDoesNotExist
from models.domain.operation import Operation, OperationStep, Status
class OperationRepository(BaseRepository):
@classmethod
async def create(cls):
cls = OperationRepository()
await super().create(config.STATE_STORE_OPERATIONS_CONTAINER)
return cls
@staticmethod
def operations_query():
return 'SELECT * FROM c WHERE'
@staticmethod
def get_timestamp() -> float:
return datetime.utcnow().timestamp()
@staticmethod
def create_operation_id() -> str:
return str(uuid.uuid4())
def create_main_step(self, resource_template: dict, action: str, resource_id: str, status: Status, message: str) -> OperationStep:
return OperationStep(
id=str(uuid.uuid4()),
templateStepId="main",
stepTitle=f"Main step for {resource_id}",
resourceId=resource_id,
resourceTemplateName=resource_template["name"],
resourceType=resource_template["resourceType"],
resourceAction=action,
sourceTemplateResourceId=resource_id,
status=status,
message=message,
updatedWhen=self.get_timestamp())
async def create_operation_item(self, resource_id: str, resource_list: List, action: str, resource_path: str, resource_version: int, user: User, resource_repo: ResourceRepository, resource_template_repo: ResourceTemplateRepository) -> Operation:
operation_id = self.create_operation_id()
# get the right "awaiting" message based on the action
status, message = self.get_initial_status(action)
all_steps = []
for resource in resource_list:
name = resource["templateName"]
version = resource["templateVersion"]
resource_type = ResourceType(resource["resourceType"])
primary_parent_service_name = None
if resource_type == ResourceType.UserResource:
primary_parent_workspace_service = await resource_repo.get_resource_by_id(resource["parentWorkspaceServiceId"])
primary_parent_service_name = primary_parent_workspace_service.templateName
resource_template = await resource_template_repo.get_template_by_name_and_version(name, version, resource_type, primary_parent_service_name)
resource_template_dict = resource_template.dict(exclude_none=True)
# if the template has a pipeline defined for this action, copy over all the steps to the ops document
steps = await self.build_step_list(
steps=[],
resource_template_dict=resource_template_dict,
action=action,
resource_repo=resource_repo,
resource_id=resource["id"],
status=status,
message=message
)
# if no pipeline is defined for this action, create a main step only
if len(steps) == 0:
all_steps.append(self.create_main_step(resource_template=resource_template_dict, action=action, resource_id=resource["id"], status=status, message=message))
else:
all_steps.extend(steps)
timestamp = self.get_timestamp()
operation = Operation(
id=operation_id,
resourceId=resource_id,
resourcePath=resource_path,
resourceVersion=resource_version,
status=status,
createdWhen=timestamp,
updatedWhen=timestamp,
action=action,
message=message,
user=user,
steps=all_steps
)
await self.save_item(operation)
return operation
async def build_step_list(self, steps: List[OperationStep], resource_template_dict: dict, action: str, resource_repo: ResourceRepository, resource_id: str, status: Status, message: str):
if "pipeline" in resource_template_dict and resource_template_dict["pipeline"] is not None:
if action in resource_template_dict["pipeline"] and resource_template_dict["pipeline"][action] is not None:
for step in resource_template_dict["pipeline"][action]:
if step["stepId"] == "main":
steps.append(self.create_main_step(resource_template=resource_template_dict, action=action, resource_id=resource_id, status=status, message=message))
else:
resource_for_step = None
# if it's a shared service, should be a singleton across the TRE, get it by template name
if step["resourceType"] == ResourceType.SharedService:
resource_for_step = await resource_repo.get_active_resource_by_template_name(step["resourceTemplateName"])
# if it's a workspace, find the parent workspace of where we are
if step["resourceType"] == ResourceType.Workspace:
primary_resource = await resource_repo.get_resource_by_id(uuid.UUID(resource_id))
if primary_resource.resourceType == ResourceType.SharedService or primary_resource.resourceType == ResourceType.Workspace:
raise Exception("You can only reference a workspace from a workspace service or user resource")
resource_for_step = await resource_repo.get_resource_by_id(uuid.UUID(primary_resource.workspaceId))
# if it's a workspace service, we must be a user-resource - find the parent
if step["resourceType"] == ResourceType.WorkspaceService:
primary_resource = await resource_repo.get_resource_by_id(uuid.UUID(resource_id))
if primary_resource.resourceType != ResourceType.UserResource:
raise Exception("Only user resources can update their parent workspace services")
resource_for_step = await resource_repo.get_resource_by_id(uuid.UUID(primary_resource.parentWorkspaceServiceId))
if resource_for_step is None:
raise Exception(f"Error finding resource to update, triggered by resource ID {resource_id}")
resource_for_step_status, resource_for_step_message = self.get_initial_status(step["resourceAction"])
steps.append(OperationStep(
id=str(uuid.uuid4()),
templateStepId=step["stepId"],
stepTitle=step["stepTitle"],
resourceId=resource_for_step.id,
resourceTemplateName=resource_for_step.templateName,
resourceType=resource_for_step.resourceType,
resourceAction=step["resourceAction"],
status=resource_for_step_status,
message=resource_for_step_message,
updatedWhen=self.get_timestamp(),
sourceTemplateResourceId=resource_id
))
return steps
def get_initial_status(self, action: RequestAction):
status = Status.AwaitingAction
message = strings.RESOURCE_STATUS_AWAITING_ACTION_MESSAGE
if action == RequestAction.Install:
status = Status.AwaitingDeployment
message = strings.RESOURCE_STATUS_AWAITING_DEPLOYMENT_MESSAGE
elif action == RequestAction.UnInstall:
status = Status.AwaitingDeletion
message = strings.RESOURCE_STATUS_AWAITING_DELETION_MESSAGE
elif action == RequestAction.Upgrade:
status = Status.AwaitingUpdate
message = strings.RESOURCE_STATUS_AWAITING_UPDATE_MESSAGE
return status, message
async def update_operation_status(self, operation_id: str, status: Status, message: str) -> Operation:
operation = await self.get_operation_by_id(operation_id)
operation.status = status
operation.message = message
operation.updatedWhen = datetime.utcnow().timestamp()
await self.update_item(operation)
return operation
async def get_operation_by_id(self, operation_id: str) -> Operation:
query = self.operations_query() + f' c.id = "{operation_id}"'
operation = await self.query(query=query)
if not operation:
raise EntityDoesNotExist
return parse_obj_as(Operation, operation[0])
async def get_my_operations(self, user_id: str) -> List[Operation]:
query = self.operations_query() + f' c.user.id = "{user_id}" AND c.status IN ("{Status.AwaitingAction}", "{Status.InvokingAction}", "{Status.AwaitingDeployment}", "{Status.Deploying}", "{Status.AwaitingDeletion}", "{Status.Deleting}", "{Status.AwaitingUpdate}", "{Status.Updating}", "{Status.PipelineRunning}") ORDER BY c.createdWhen ASC'
operations = await self.query(query=query)
return parse_obj_as(List[Operation], operations)
async def get_operations_by_resource_id(self, resource_id: str) -> List[Operation]:
query = self.operations_query() + f' c.resourceId = "{resource_id}"'
operations = await self.query(query=query)
return parse_obj_as(List[Operation], operations)
async def resource_has_deployed_operation(self, resource_id: str) -> bool:
query = self.operations_query() + f' c.resourceId = "{resource_id}" AND ((c.action = "{RequestAction.Install}" AND c.status = "{Status.Deployed}") OR (c.action = "{RequestAction.Upgrade}" AND c.status = "{Status.Updated}"))'
operations = await self.query(query=query)
return len(operations) > 0
| AzureTRE/api_app/db/repositories/operations.py/0 | {
"file_path": "AzureTRE/api_app/db/repositories/operations.py",
"repo_id": "AzureTRE",
"token_count": 4318
} | 95 |
from enum import Enum
from typing import List, Dict
from models.domain.azuretremodel import AzureTREModel
from pydantic import Field, validator
from pydantic.schema import Optional
from resources import strings
class AirlockRequestStatus(str, Enum):
"""
Airlock Resource status
"""
Draft = strings.AIRLOCK_RESOURCE_STATUS_DRAFT
Submitted = strings.AIRLOCK_RESOURCE_STATUS_SUBMITTED
InReview = strings.AIRLOCK_RESOURCE_STATUS_INREVIEW
ApprovalInProgress = strings.AIRLOCK_RESOURCE_STATUS_APPROVAL_INPROGRESS
Approved = strings.AIRLOCK_RESOURCE_STATUS_APPROVED
RejectionInProgress = strings.AIRLOCK_RESOURCE_STATUS_REJECTION_INPROGRESS
Rejected = strings.AIRLOCK_RESOURCE_STATUS_REJECTED
Cancelled = strings.AIRLOCK_RESOURCE_STATUS_CANCELLED
Blocked = strings.AIRLOCK_RESOURCE_STATUS_BLOCKED
BlockingInProgress = strings.AIRLOCK_RESOURCE_STATUS_BLOCKING_INPROGRESS
Failed = strings.AIRLOCK_RESOURCE_STATUS_FAILED
class AirlockRequestType(str, Enum):
Import = strings.AIRLOCK_REQUEST_TYPE_IMPORT
Export = strings.AIRLOCK_REQUEST_TYPE_EXPORT
class AirlockActions(str, Enum):
Review = strings.AIRLOCK_ACTION_REVIEW
Cancel = strings.AIRLOCK_ACTION_CANCEL
Submit = strings.AIRLOCK_ACTION_SUBMIT
class AirlockFile(AzureTREModel):
name: str = Field(title="name", description="name of the file")
size: float = Field(title="size", description="size of the file in bytes")
class AirlockReviewDecision(str, Enum):
Approved = strings.AIRLOCK_REVIEW_DECISION_APPROVED
Rejected = strings.AIRLOCK_REVIEW_DECISION_REJECTED
class AirlockReview(AzureTREModel):
"""
Airlock review
"""
id: str = Field(title="Id", description="GUID identifying the review")
reviewer: dict = {}
dateCreated: float = 0
reviewDecision: AirlockReviewDecision = Field("", title="Airlock review decision")
decisionExplanation: str = Field(False, title="Explanation why the request was approved/rejected")
class AirlockRequestHistoryItem(AzureTREModel):
"""
Resource History Item - to preserve history of resource properties
"""
resourceVersion: int
updatedWhen: float
updatedBy: dict = {}
properties: dict = {}
class AirlockReviewUserResource(AzureTREModel):
"""
User resource created for Airlock Review
"""
workspaceId: str = Field(title="Workspace ID")
workspaceServiceId: str = Field(title="Workspace Service ID")
userResourceId: str = Field(title="User Resource ID")
class AirlockRequest(AzureTREModel):
"""
Airlock request
"""
id: str = Field(title="Id", description="GUID identifying the resource")
resourceVersion: int = 0
createdBy: dict = {}
createdWhen: float = Field(None, title="Creation time of the request")
updatedBy: dict = {}
updatedWhen: float = 0
history: List[AirlockRequestHistoryItem] = []
workspaceId: str = Field("", title="Workspace ID", description="Service target Workspace id")
type: AirlockRequestType = Field("", title="Airlock request type")
files: List[AirlockFile] = Field([], title="Files of the request")
title: str = Field("Airlock Request", title="Brief title for the request")
businessJustification: str = Field("Business Justification", title="Explanation that will be provided to the request reviewer")
status = AirlockRequestStatus.Draft
statusMessage: Optional[str] = Field(title="Optional - contains additional information about the current status.")
reviews: Optional[List[AirlockReview]]
etag: Optional[str] = Field(title="_etag", alias="_etag")
reviewUserResources: Dict[str, AirlockReviewUserResource] = Field({}, title="User resources created for Airlock Reviews")
# SQL API CosmosDB saves ETag as an escaped string: https://github.com/microsoft/AzureTRE/issues/1931
@validator("etag", pre=True)
def parse_etag_to_remove_escaped_quotes(cls, value):
if value:
return value.replace('\"', '')
| AzureTRE/api_app/models/domain/airlock_request.py/0 | {
"file_path": "AzureTRE/api_app/models/domain/airlock_request.py",
"repo_id": "AzureTRE",
"token_count": 1326
} | 96 |
import uuid
from datetime import datetime
from typing import List
from pydantic import BaseModel, Field
from models.domain.operation import Operation
from models.schemas.operation import get_sample_operation
from models.domain.airlock_request import AirlockActions, AirlockRequest, AirlockRequestType
def get_sample_airlock_review(airlock_review_id: str) -> dict:
return {
"reviewId": airlock_review_id,
"reviewDecision": "Describe why the request was approved/rejected",
"decisionExplanation": "Describe why the request was approved/rejected"
}
def get_sample_airlock_request(workspace_id: str, airlock_request_id: str) -> dict:
return {
"requestId": airlock_request_id,
"workspaceId": workspace_id,
"status": "draft",
"type": "import",
"files": [],
"title": "a request title",
"businessJustification": "some business justification",
"createdBy": {
"id": "a user id",
"name": "a user name"
},
"createdWhen": datetime.utcnow().timestamp(),
"reviews": [
get_sample_airlock_review("29990431-5451-40e7-a58a-02e2b7c3d7c8"),
get_sample_airlock_review("02dc0f29-351a-43ec-87e7-3dd2b5177b7f")]
}
def get_sample_airlock_request_with_allowed_user_actions(workspace_id: str) -> dict:
return {
"airlockRequest": get_sample_airlock_request(workspace_id, str(uuid.uuid4())),
"allowedUserActions": [AirlockActions.Cancel, AirlockActions.Review, AirlockActions.Submit],
}
class AirlockRequestInResponse(BaseModel):
airlockRequest: AirlockRequest
class Config:
schema_extra = {
"example": {
"airlockRequest": get_sample_airlock_request("933ad738-7265-4b5f-9eae-a1a62928772e", "121e921f-a4aa-44b3-90a9-e8da030495ef")
}
}
class AirlockRequestAndOperationInResponse(BaseModel):
airlockRequest: AirlockRequest
operation: Operation
class Config:
schema_extra = {
"example": {
"airlockRequest": get_sample_airlock_request("933ad738-7265-4b5f-9eae-a1a62928772e", "121e921f-a4aa-44b3-90a9-e8da030495ef"),
"operation": get_sample_operation("121e921f-a4aa-44b3-90a9-e8da030495ef")
}
}
class AirlockRequestWithAllowedUserActions(BaseModel):
airlockRequest: AirlockRequest = Field([], title="Airlock Request")
allowedUserActions: List[str] = Field([], title="actions that the requesting user can do on the request")
class Config:
schema_extra = {
"example": get_sample_airlock_request_with_allowed_user_actions("933ad738-7265-4b5f-9eae-a1a62928772e"),
}
class AirlockRequestWithAllowedUserActionsInList(BaseModel):
airlockRequests: List[AirlockRequestWithAllowedUserActions] = Field([], title="Airlock Requests")
class Config:
schema_extra = {
"example": {
"airlockRequests": [
get_sample_airlock_request_with_allowed_user_actions("933ad738-7265-4b5f-9eae-a1a62928772e"),
get_sample_airlock_request_with_allowed_user_actions("933ad738-7265-4b5f-9eae-a1a62928772e")
]
}
}
class AirlockRequestInCreate(BaseModel):
type: AirlockRequestType = Field("", title="Airlock request type", description="Specifies if this is an import or an export request")
title: str = Field("Airlock Request", title="Brief title for the request")
businessJustification: str = Field("Business Justifications", title="Explanation that will be provided to the request reviewer")
properties: dict = Field({}, title="Airlock request parameters", description="Values for the parameters required by the Airlock request specification")
class Config:
schema_extra = {
"example": {
"type": "import",
"title": "a request title",
"businessJustification": "some business justification"
}
}
class AirlockReviewInCreate(BaseModel):
approval: bool = Field("", title="Airlock review decision", description="Airlock review decision")
decisionExplanation: str = Field("Decision Explanation", title="Explanation of the reviewer for the reviews decision")
class Config:
schema_extra = {
"example": {
"approval": "True",
"decisionExplanation": "the reason why this request was approved/rejected"
}
}
| AzureTRE/api_app/models/schemas/airlock_request.py/0 | {
"file_path": "AzureTRE/api_app/models/schemas/airlock_request.py",
"repo_id": "AzureTRE",
"token_count": 1910
} | 97 |
from models.domain.resource import ResourceType
from models.domain.resource_template import ResourceTemplate, Property, CustomAction
from models.schemas.resource_template import ResourceTemplateInCreate, ResourceTemplateInResponse
def get_sample_workspace_service_template_object(template_name: str = "tre-workspace-service") -> ResourceTemplate:
return ResourceTemplate(
id="a7a7a7bd-7f4e-4a4e-b970-dc86a6b31dfb",
name=template_name,
title="Workspace Service",
description="workspace service bundle",
version="0.1.0",
resourceType=ResourceType.WorkspaceService,
current=True,
type="object",
required=["display_name", "description"],
properties={
"display_name": Property(type="string"),
"description": Property(type="string")
},
customActions=[CustomAction()]
)
def get_sample_workspace_service_template() -> dict:
return get_sample_workspace_service_template_object().dict()
def get_sample_workspace_service_template_in_response() -> dict:
workspace_template = get_sample_workspace_service_template()
workspace_template["system_properties"] = {
"tre_id": Property(type="string"),
"workspace_id": Property(type="string"),
"azure_location": Property(type="string"),
}
return workspace_template
class WorkspaceServiceTemplateInCreate(ResourceTemplateInCreate):
class Config:
schema_extra = {
"example": {
"name": "my-tre-workspace-service",
"version": "0.0.1",
"current": "true",
"json_schema": {
"$schema": "http://json-schema.org/draft-07/schema",
"$id": "https://github.com/microsoft/AzureTRE/templates/workspaces/myworkspace/workspace_service.json",
"type": "object",
"title": "My Workspace Service Template",
"description": "These is a test workspace service resource template schema",
"required": [],
"authorizedRoles": [],
"properties": {}
},
"customActions": [
{
"name": "disable",
"description": "Deallocates resources"
}
]
}
}
class WorkspaceServiceTemplateInResponse(ResourceTemplateInResponse):
class Config:
schema_extra = {
"example": get_sample_workspace_service_template_in_response()
}
| AzureTRE/api_app/models/schemas/workspace_service_template.py/0 | {
"file_path": "AzureTRE/api_app/models/schemas/workspace_service_template.py",
"repo_id": "AzureTRE",
"token_count": 1165
} | 98 |
import asyncio
import json
import uuid
from pydantic import ValidationError, parse_obj_as
from api.routes.resource_helpers import get_timestamp
from models.domain.resource import Output
from db.repositories.resources_history import ResourceHistoryRepository
from models.domain.request_action import RequestAction
from db.repositories.resource_templates import ResourceTemplateRepository
from service_bus.helpers import send_deployment_message, update_resource_for_step
from azure.servicebus import NEXT_AVAILABLE_SESSION
from azure.servicebus.exceptions import OperationTimeoutError, ServiceBusConnectionError
from azure.servicebus.aio import ServiceBusClient, AutoLockRenewer
from db.repositories.operations import OperationRepository
from core import config, credentials
from db.errors import EntityDoesNotExist
from db.repositories.resources import ResourceRepository
from models.domain.operation import DeploymentStatusUpdateMessage, Operation, OperationStep, Status
from resources import strings
from services.logging import logger, tracer
class DeploymentStatusUpdater():
def __init__(self):
pass
async def init_repos(self):
self.operations_repo = await OperationRepository.create()
self.resource_repo = await ResourceRepository.create()
self.resource_template_repo = await ResourceTemplateRepository.create()
self.resource_history_repo = await ResourceHistoryRepository.create()
def run(self, *args, **kwargs):
asyncio.run(self.receive_messages())
async def receive_messages(self):
with tracer.start_as_current_span("deployment_status_receive_messages"):
while True:
try:
async with credentials.get_credential_async_context() as credential:
service_bus_client = ServiceBusClient(config.SERVICE_BUS_FULLY_QUALIFIED_NAMESPACE, credential)
logger.info(f"Looking for new messages on {config.SERVICE_BUS_DEPLOYMENT_STATUS_UPDATE_QUEUE} queue...")
# max_wait_time=1 -> don't hold the session open after processing of the message has finished
async with service_bus_client.get_queue_receiver(queue_name=config.SERVICE_BUS_DEPLOYMENT_STATUS_UPDATE_QUEUE, max_wait_time=1, session_id=NEXT_AVAILABLE_SESSION) as receiver:
logger.info(f"Got a session containing messages: {receiver.session.session_id}")
async with AutoLockRenewer() as renewer:
renewer.register(receiver, receiver.session, max_lock_renewal_duration=60)
async for msg in receiver:
complete_message = await self.process_message(msg)
if complete_message:
await receiver.complete_message(msg)
else:
# could have been any kind of transient issue, we'll abandon back to the queue, and retry
await receiver.abandon_message(msg)
logger.info(f"Closing session: {receiver.session.session_id}")
except OperationTimeoutError:
# Timeout occurred whilst connecting to a session - this is expected and indicates no non-empty sessions are available
logger.debug("No sessions for this process. Will look again...")
except ServiceBusConnectionError:
# Occasionally there will be a transient / network-level error in connecting to SB.
logger.info("Unknown Service Bus connection error. Will retry...")
except Exception as e:
# Catch all other exceptions, log them via .exception to get the stack trace, and reconnect
logger.exception(f"Unknown exception. Will retry - {e}")
async def process_message(self, msg):
complete_message = False
message = ""
with tracer.start_as_current_span("process_message") as current_span:
try:
message = parse_obj_as(DeploymentStatusUpdateMessage, json.loads(str(msg)))
current_span.set_attribute("step_id", message.stepId)
current_span.set_attribute("operation_id", message.operationId)
current_span.set_attribute("status", message.status)
logger.info(f"Received and parsed JSON for: {msg.correlation_id}")
complete_message = await self.update_status_in_database(message)
logger.info(f"Update status in DB for {message.operationId} - {message.status}")
except (json.JSONDecodeError, ValidationError):
logger.exception(f"{strings.DEPLOYMENT_STATUS_MESSAGE_FORMAT_INCORRECT}: {msg.correlation_id}")
except Exception:
logger.exception(f"Exception processing message: {msg.correlation_id}")
return complete_message
async def update_status_in_database(self, message: DeploymentStatusUpdateMessage):
"""
Get the operation the message references, and find the step within the operation that is to be updated
Update the status of the step. If it's a single step operation, copy the status into the operation status. If it's a multi step,
update the step and set the overall status to "pipeline_deploying".
If there is another step in the operation after this one, process the substitutions + patch, then enqueue a message to process it.
"""
result = False
try:
# update the op
operation = await self.operations_repo.get_operation_by_id(str(message.operationId))
step_to_update = None
is_last_step = False
current_step_index = 0
for i, step in enumerate(operation.steps):
# TODO more simple condition
if step.id == message.stepId and step.resourceId == str(message.id):
step_to_update = step
current_step_index = i
if i == (len(operation.steps) - 1):
is_last_step = True
if step_to_update is None:
raise f"Error finding step {message.stepId} in operation {message.operationId}"
# update the step status
step_to_update.status = message.status
step_to_update.message = message.message
step_to_update.updatedWhen = get_timestamp()
# update the overall headline operation status
await self.update_overall_operation_status(operation, step_to_update, is_last_step)
# save the operation
await self.operations_repo.update_item(operation)
# copy the step status to the resource item, for convenience
resource_id = uuid.UUID(step_to_update.resourceId)
resource = await self.resource_repo.get_resource_by_id(resource_id)
resource.deploymentStatus = step_to_update.status
await self.resource_repo.update_item(resource)
# if the step failed, or this queue message is an intermediary ("now deploying..."), return here.
if not step_to_update.is_success():
return True
# update the resource doc to persist any outputs
resource = await self.resource_repo.get_resource_dict_by_id(resource_id)
resource_to_persist = self.create_updated_resource_document(resource, message)
await self.resource_repo.update_item_dict(resource_to_persist)
# more steps in the op to do?
if is_last_step is False:
assert current_step_index < (len(operation.steps) - 1)
next_step = operation.steps[current_step_index + 1]
# catch any errors in updating the resource - maybe Cosmos / schema invalid etc, and report them back to the op
try:
# parent resource is always retrieved via cosmos, hence it is always with redacted sensitive values
parent_resource = await self.resource_repo.get_resource_by_id(next_step.sourceTemplateResourceId)
resource_to_send = await update_resource_for_step(
operation_step=next_step,
resource_repo=self.resource_repo,
resource_template_repo=self.resource_template_repo,
resource_history_repo=self.resource_history_repo,
root_resource=None,
step_resource=parent_resource,
resource_to_update_id=next_step.resourceId,
primary_action=operation.action,
user=operation.user)
# create + send the message
logger.info(f"Sending next step in operation to deployment queue -> step_id: {next_step.templateStepId}, action: {next_step.resourceAction}")
content = json.dumps(resource_to_send.get_resource_request_message_payload(operation_id=operation.id, step_id=next_step.id, action=next_step.resourceAction))
await send_deployment_message(content=content, correlation_id=operation.id, session_id=resource_to_send.id, action=next_step.resourceAction)
except Exception as e:
logger.exception("Unable to send update for resource in pipeline step")
next_step.message = repr(e)
next_step.status = Status.UpdatingFailed
await self.update_overall_operation_status(operation, next_step, is_last_step)
await self.operations_repo.update_item(operation)
result = True
except EntityDoesNotExist:
# Marking as true as this message will never succeed anyways and should be removed from the queue.
result = True
logger.exception(strings.DEPLOYMENT_STATUS_ID_NOT_FOUND.format(message.id))
except Exception:
logger.exception("Failed to update status")
return result
async def update_overall_operation_status(self, operation: Operation, step: OperationStep, is_last_step: bool):
operation.updatedWhen = get_timestamp()
# if it's a one step operation, just replicate the status
if len(operation.steps) == 1:
operation.status = step.status
operation.message = step.message
return
operation.status = Status.PipelineRunning
operation.message = "Multi step pipeline running. See steps for details."
if step.is_failure():
operation.status = self.get_failure_status_for_action(operation.action)
operation.message = f"Multi step pipeline failed on step {step.templateStepId}"
# pipeline failed - update the primary resource (from the main step) as failed too
main_step = None
for i, step in enumerate(operation.steps):
if step.templateStepId == "main":
main_step = step
break
if main_step:
primary_resource = await self.resource_repo.get_resource_by_id(uuid.UUID(main_step.resourceId))
primary_resource.deploymentStatus = operation.status
await self.resource_repo.update_item(primary_resource)
if step.is_success() and is_last_step:
operation.status = self.get_success_status_for_action(operation.action)
operation.message = "Multi step pipeline completed successfully"
def get_success_status_for_action(self, action: RequestAction):
status = Status.ActionSucceeded
if action == RequestAction.Install:
status = Status.Deployed
elif action == RequestAction.UnInstall:
status = Status.Deleted
elif action == RequestAction.Upgrade:
status = Status.Updated
return status
def get_failure_status_for_action(self, action: RequestAction):
status = Status.ActionFailed
if action == RequestAction.Install:
status = Status.DeploymentFailed
elif action == RequestAction.UnInstall:
status = Status.DeletingFailed
elif action == RequestAction.Upgrade:
status = Status.UpdatingFailed
return status
def create_updated_resource_document(self, resource: dict, message: DeploymentStatusUpdateMessage):
"""
Merge the outputs with the resource document to persist
"""
# although outputs are likely to be relevant when resources are moving to "deployed" status,
# lets not limit when we update them and have the resource process make that decision.
# need to convert porter outputs to dict so boolean values are converted to bools, not strings
output_dict = self.convert_outputs_to_dict(message.outputs)
resource["properties"].update(output_dict)
return resource
def convert_outputs_to_dict(self, outputs_list: [Output]):
"""
Convert a list of Porter outputs to a dictionary
"""
result_dict = {}
for msg in outputs_list:
if msg.Value is None:
continue
name = msg.Name
value = msg.Value
obj_type = msg.Type
#
if obj_type == 'string' and isinstance(value, str):
value = value.strip("'").strip('"')
elif obj_type == 'boolean':
if isinstance(value, str):
value = value.strip("'").strip('"')
value = (value.lower() == 'true')
result_dict[name] = value
return result_dict
| AzureTRE/api_app/service_bus/deployment_status_updater.py/0 | {
"file_path": "AzureTRE/api_app/service_bus/deployment_status_updater.py",
"repo_id": "AzureTRE",
"token_count": 5855
} | 99 |