
Werewolf Among Us: Multimodal Resources for Modeling Persuasion Behaviors in Social Deduction Games
ACL Findings 2023
Project Page | Paper | Code
Bolin Lai*, Hongxin Zhang*, Miao Liu*, Aryan Pariani*, Fiona Ryan, Wenqi Jia, Shirley Anugrah Hayati, James M. Rehg, Diyi Yang
Introduction
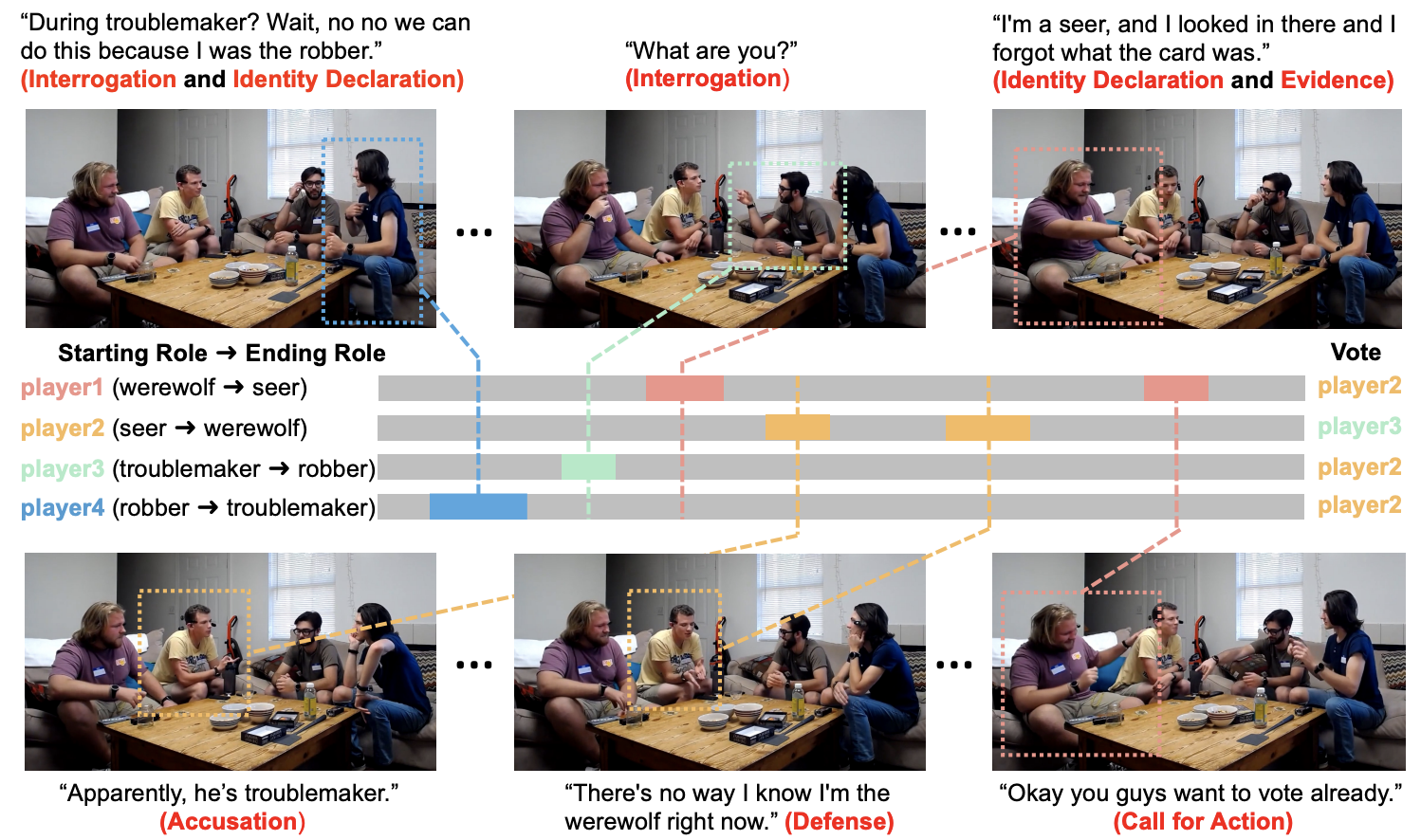
Werewolf Among Us is the first multi-modal (video+audio+text) dataset for social scenario interpretation. The dataset is composed of videos of 199 social deduction games and transcripts, sourced from Youtube (151 games) and Ego4D dataset (48 games). In the majority of the videos, participants are playing One Night Werewolf. In a handful of videos, people are playing Avalon.
Here are two kinds of annotations provided in this dataset:
- Persuasion strategies for each utterance from 6 pre-defined categories, including identity declaration, interrogation, evidence, accusation defense and call for action.
- Voting outcome of each player at the end of each game (only for One Night Werewolf).
- Start roles of each player at the beginning of the game, and end roles of each player at the end of the game.
Hence, our dataset is designed for two tasks:
- Multi-modal persuasion strategy recognition.
- Human intention (voting) prediction.
We also provide extended annotations to support various tasks in our following work. Please checkout their websites for more details:
(CVPR 2024, Oral) Modeling Multimodal Social Interactions: New Challenges and Baselines with Densely Aligned Representations
- New tasks: speaking target identification, pronoun coreference resolution, mentioned player prediction.
- New annotations: key points (face and body) of each player.
(In submission, coming soon) Social gesture
- New tasks: social gesture temporal detection, social gesture spatial location, social gesture understanding VQA.
- New annotations: timestamp of social gestures, social question-answer pairs.
Youtube Subset
All videos are downloaded from Youtube website. We provide all video ids in
Youtube/youtube_urls_released.json. The video can be accessed and downloaded through https://www.youtube.com/watch?v={video_id}. For example, if the video id isMjnGiInji-U, the corresponding video url is https://www.youtube.com/watch?v=MjnGiInji-U. All videos we used are in the resolution of 640x320.Players might play multiple games in one long video. We trimmed videos into a bunch of segments. Each segment corresponds to only one game. The start and end timestamps can be found under
Youtube/vote_outcome_youtube_released. The trimmed videos are inYoutube/videos.The transcripts are available under
Youtube/transcripts. We annotated the speakers and the timestamps of all utterances.The train/val/test split of the dataset is in
Youtube/split. To make things easier, we integrated both voting outcomes and persuasion strategy of each utterance in the json files. You can obtain all annotations we provded by simply loading these files.We also annotated the voting outcomes, start roles and end roles of all players which can be found in
Youtube/vote_outcome_youtube_released. Players' names are listed in order of players from left to right in the videos.We also released the video features we used in our experiments, which are in
Youtube/mvit_24_k400_features.zip. In each numpy file, the features are in the shape of(N, 3, 768).Ncorresponds to theNutterances in each game. For each utterance, we cropped the frame on the left, center and right, so there are3features for each utterance.768is the length of flattened feature vectors. A 24-layer multisacle vision transformer (MViT) pretrained on Kinetics-400 was used for video feature extraction. Note that we froze the video encoder in training. We encourage users to explore other video encoders to get better video representations.
Ego4D Subset
All videos are downloaded from Ego4D official website.
Players might play multiple games in one long video. We trimmed videos into a bunch of segments. Each segment corresponds to only one game. The start and end timestamps can be found under
Ego4D/game_timestamp. The trimmed videos are inEgo4D/videos. Note: Players were asked to complete some surveys during the game. The script removes all footage during the survey which trims the video of one game into 2-3 segments. Each clip is named as{uid}_{gameid}_{part}. The clips having the same{uid}_{gameid}and different{part}belong to one game, so they have one voting outcome.The transcripts are available under
Ego4D/transcripts. We annotated the speakers and the timestamps of all utterances.The train/val/test split of the dataset is in
Ego4D/split. To make things easier, we integrated both voting outcomes and persuasion strategy of each utterance in the json files. You can obtain all annotations we provded by simply loading these files.We also annotated the voting outcomes, start roles and end roles of all players which can be found in
Ego4D/vote_outcome_ego4d. Players' names are listed in order of players from left to right in the videos.We also released the video features we used in our experiments, which are in
Ego4D/mvit_24_k400_features.zip. In each numpy file, the features are in the shape of(N, 3, 768).Ncorresponds to theNutterances in each game. For each utterance, we cropped the frame on the left, center and right, so there are3features for each utterance.768is the length of flattened feature vectors. A 24-layer multisacle vision transformer (MViT) pretrained on Kinetics-400 was used for video feature extraction. Note that we froze the video encoder in training. We encourage users to explore other video encoders to get better video representations.
BibTex
Please cite our paper if the dataset is helpful to your research.
@inproceedings{lai2023werewolf,
title={Werewolf among us: Multimodal resources for modeling persuasion behaviors in social deduction games},
author={Lai, Bolin and Zhang, Hongxin and Liu, Miao and Pariani, Aryan and Ryan, Fiona and Jia, Wenqi and Hayati, Shirley Anugrah and Rehg, James and Yang, Diyi},
booktitle={Findings of the Association for Computational Linguistics: ACL 2023},
pages={6570--6588},
year={2023}
}
- Downloads last month
- 258