Datasets:

プレビュー.
このリポジトリは、so-vits-svc-4.0によって訓練されたさまざまな音声モデルの効果をプレビューするために使用されます。
キャラクター名をクリックすると、対応するトレーニングパラメーターに自動的に移動します。
Google Chromeを
使用することをお勧めします。他のブラウザでは、プレビューされたオーディオが正しく読み込まれない場合があります。
通常の話し声の音色変換は比較的正確ですが、曲には広範な音域が含まれており、BGMや声などのノイズが除去しきれない場合があり、
効果が割り引かれることがあります。
変換して聴いてみたいお勧めの曲や、その他の提案がある場合は、
ここをクリックしてディスカッショ
ンを開始してください。
以下はプレビューオーディオです。上下左右にスクロールするとすべてを見ることができます。
もし変換して聴いてみたい曲や、その他の提案がある場合は、
ここをクリックして提案してください。
| キャラクター名 | オリジナルボイスA | 変換されたボイスB | Aの音色がBに置換される | Aのボイスカバー(クリックしてダウンロード) |
|---|---|---|---|---|
| 放浪者 | 夢で会えたら | |||
| フータオ | ......... | ......... | moonlight shadow, 云烟成雨, 原点, 夢で逢えたら, 贝加尔湖畔 | |
| 神里綾華 | アムリタ, 大鱼, 遊園施設, the day you want away | |||
| 宵宮 | 昨夜书, lemon, my heart will go on, | |||
| こくせい | 嚣张, ファティマ, hero, | |||
| クレー | 樱花草, 夢をかなえてドラえもん, sun_shine, | |||
| imallryt | 海阔天空, |
キーパラメータ:
audio duration: 訓練データセットの合計時間
epoch: 訓練の回数
その他のパラメータ:
batch*_size* = 1ステップあたりのトレーニングセグメントの数
segments = オーディオが分割されるセグメントの数
step = セグメント*エポック/バッチサイズ。これがモデルファイル名の数字の由来です。
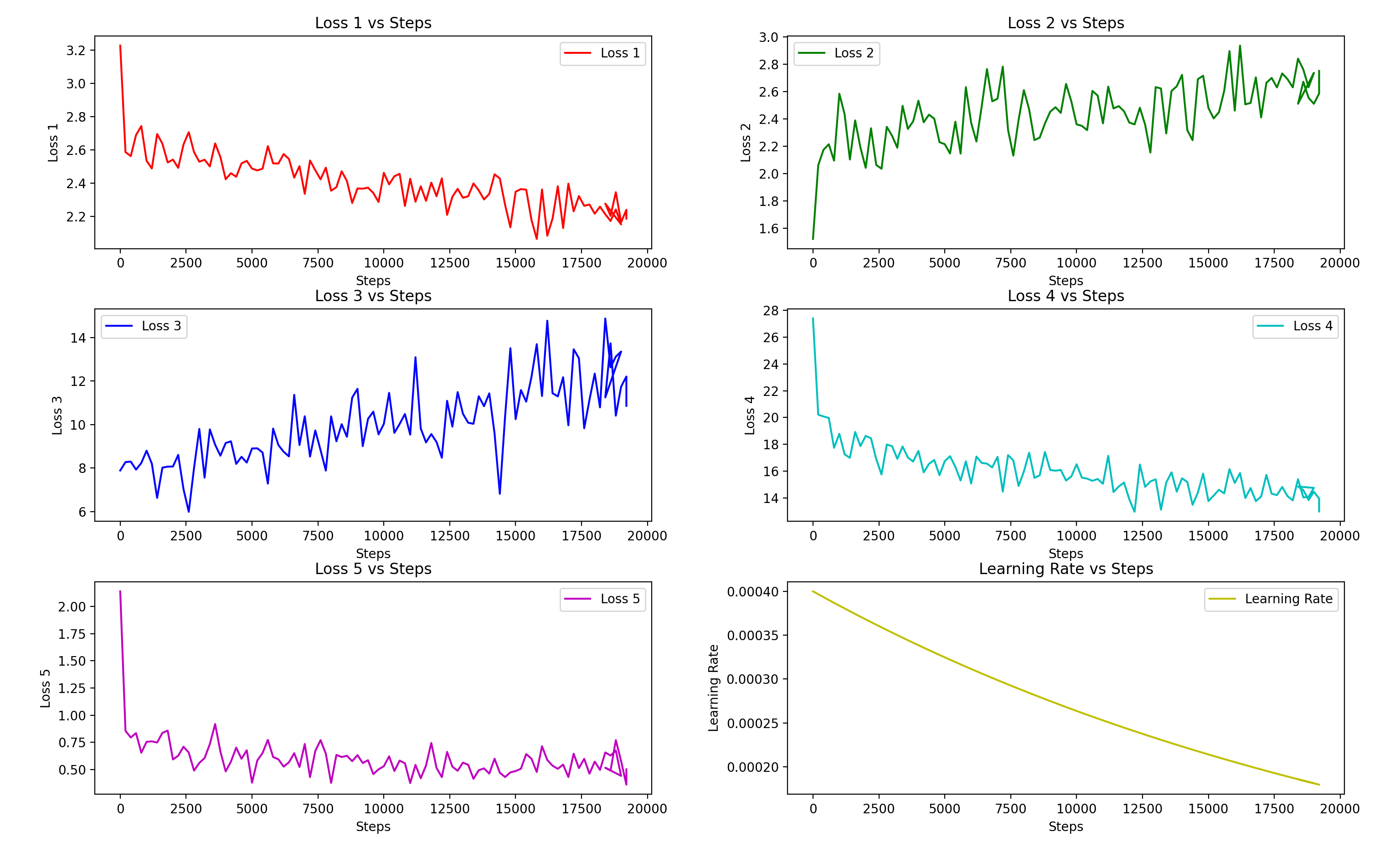
「放浪者」を例にとると: 損失関数グラフ:stepとloss5に注目します。たとえば:
高音の女性声が原音声の場合、10分の純粋な人声で訓練した場合、約2800epoch(10,000step)で結果が出ました。
実際に使用したのは5571epoch(19,500step)で、訓練された音色と元の音色にはわずかな違いがあります。詳細は、
上記のプレビューオーディオをご覧ください。通常のトレーニングでは、10分は十分なトレーニングセットの時間ではありません。