
anchor
stringlengths 58
24.4k
| positive
stringlengths 9
13.4k
| negative
stringlengths 166
14k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Overview
We made a gorgeous website to plan flights with Jet Blue's data sets. Come check us out! | ## Inspiration
We were inspired by the numerous Facebook posts, Slack messages, WeChat messages, emails, and even Google Sheets that students at Stanford create in order to coordinate Ubers/Lyfts to the airport as holiday breaks approach. This was mainly for two reasons, one being the safety of sharing a ride with other trusted Stanford students (often at late/early hours), and the other being cost reduction. We quickly realized that this idea of coordinating rides could also be used not just for ride sharing to the airport, but simply transportation to anywhere!
## What it does
Students can access our website with their .edu accounts and add "trips" that they would like to be matched with other users for. Our site will create these pairings using a matching algorithm and automatically connect students with their matches through email and a live chatroom in the site.
## How we built it
We utilized Wix Code to build the site and took advantage of many features including Wix Users, Members, Forms, Databases, etc. We also integrated SendGrid API for automatic email notifications for matches.
## Challenges we ran into
## Accomplishments that we're proud of
Most of us are new to Wix Code, JavaScript, and web development, and we are proud of ourselves for being able to build this project from scratch in a short amount of time.
## What we learned
## What's next for Runway | ## Inspiration
Have you wondered where to travel or how to plan your trip more interesting?
Wanna make trips more adventerous ?
## What it does
Xplore is an **AI based-travel application** that allows you to experience destinations in a whole new way. It keeps your adrenaline pumping by keeping your vacation destinations undisclosed.
## How we built it
* Xplore is completely functional web application built with Html, Css, Bootstrap, Javscript and Sqlite.
* Multiple Google Cloud Api's such as Geolocation API, Maps Javascript API, Directions API were used to achieve our map functionalities.
* Web3.storage was also used for data storage service and to retrieves data on IPFS and Filecoin.
## Challenges we ran into
While integrating multiple cloud API's and API token from Web3.Strorage with our project, we discovered that it was a little complex.
## What's next for Xplore
* Mobile Application for easier access.
* Multiple language Support
* Seasonal travel suggestions. | partial |
## Inspiration
Everyone gets tired waiting for their large downloads to complete. BitTorrent is awesome, but you may not have a bunch of peers ready to seed it. Fastify, a download accelerator as a service, solves both these problems and regularly enables 4x download speeds.
## What it does
The service accepts a URL and spits out a `.torrent` file. This `.torrent` file allows you to tap into Fastify's speedy seed servers for your download.
We even cache some downloads so popular downloads will be able to be pulled from Fastify even speedier!
Without any cache hits, we saw the following improvements in download speeds with our test files:
```
| | 512Mb | 1Gb | 2Gb | 5Gb |
|-------------------|----------|--------|---------|---------|
| Regular Download | 3 mins | 7 mins | 13 mins | 30 mins |
| Fastify | 1.5 mins | 3 mins | 5 mins | 9 mins |
|-------------------|----------|--------|---------|---------|
| Effective Speedup | 2x | 2.33x | 2.6x | 3.3x |
```
*test was performed with slices of the ubuntu 16.04 iso file, on the eduroam network*
## How we built it
Created an AWS cluster and began writing Go code to accept requests and the front-end to send them. Over time we added more workers to the AWS cluster and improved the front-end. Also, we generously received some well-needed Vitamin Water.
## Challenges we ran into
The BitTorrent protocol and architecture was more complicated for seeding than we thought. We were able to create `.torrent` files that enabled downloads on some BitTorrent clients but not others.
Also, our "buddy" (*\*cough\** James *\*cough\**) ditched our team, so we were down to only 2 people off the bat.
## Accomplishments that we're proud of
We're able to accelerate large downloads by 2-5 times as fast as the regular download. That's only with a cluster of 4 computers.
## What we learned
Bittorrent is tricky. James can't be trusted.
## What's next for Fastify
More servers on the cluster. Demo soon too. | ## Inspiration
You use Apple Music. Your friends all use Spotify. But you're all stuck in a car together on the way to Tahoe and have the perfect song to add to the road trip playlist. With TrainTrax, you can all add songs to the same playlist without passing the streaming device around or hassling with aux cords.
Have you ever been out with friends on a road trip or at a party and wished there was a way to more seamlessly share music? TrainTrax is a music streaming middleware that lets cross platform users share music without pulling out the aux cord.
## How it Works
The app authenticates a “host” user sign through their Apple Music or Spotify Premium accounts and let's them create a party where they can invite friends to upload music to a shared playlist. Friends with or without those streaming service accounts can port through the host account to queue up their favorite songs. Hear a song you like? TrainTrax uses Button to deep links songs directly to your iTunes account, so that amazing song you heard is just a click away from being yours.
## How We Built It
The application is built with Swift 3 and Node.js/Express. A RESTful API let’s users create parties, invite friends, and add songs to a queue. The app integrates with Button to deep link users to songs on iTunes, letting them purchase songs directly through the application.
## Challenges We Ran Into
• The application depended a lot on third party tools, which did not always have great documentation or support.
• This was the first hackathon for three of our four members, so a lot of the experience came with a learning curve. In the spirit of collaboration, our team approached this as a learning opportunity, and each member worked to develop a new skill to support the building of the application. The end result was an experience focused more on learning and less on optimization.
• Rain.
## Accomplishments that we're proud of
• SDK Integrations: Successful integration with Apple Music and Spotify SDKs!
• Button: Deep linking with Button
• UX: There are some strange UX flows involved with adding songs to a shared playlist, but we kicked of the project with a post-it design thinking brainstorm session that set us up well for creating these complex user flows later on.
• Team bonding: Most of us just met on Friday, and we built a strong fun team culture.
## What we learned
Everyone on our team learned different things.
## What's next for TrainTrax
• A web application for non-iPhone users to host and join parties
• Improved UI and additional features to fine tune the user experience — we've got a lot of ideas for the next version in the pipeline, including some already designed in this prototype: [TrainTrax prototype link](https://invis.io/CSAIRSU6U#/219754962_Invision-_User_Types) | ## Inspiration
I like looking at things. I do not enjoy bad quality videos . I do not enjoy waiting. My CPU is a lazy fool. He just lays there like a drunkard on new years eve. My poor router has a heart attack every other day so I can stream the latest Kylie Jenner video blog post, or has the kids these days call it, a 'vlog' post.
CPU isn't being effectively leveraged to improve video quality. Deep learning methods are in their own world, concerned more with accuracy than applications. We decided to develop a machine learning application to enhance resolution while developing our models in such a way that they can effective run without 10,000 GPUs.
## What it does
We reduce your streaming bill. We let you stream Kylie's vlog in high definition. We connect first world medical resources to developing nations. We make convert an unrecognizeable figure in a cop's body cam to a human being. We improve video resolution.
## How I built it
Wow. So lots of stuff.
Web scraping youtube videos for datasets of 144, 240, 360, 480 pixels. Error catching, thread timeouts, yada, yada. Data is the most import part of machine learning, and no one cares in the slightest. So I'll move on.
## ML stuff now. Where the challenges begin
We tried research papers. Super Resolution Generative Adversarial Model [link](https://arxiv.org/abs/1609.04802). SRGAN with an attention layer [link](https://arxiv.org/pdf/1812.04821.pdf). These were so bad. The models were to large to hold in our laptop, much less in real time. The model's weights alone consisted of over 16GB. And yeah, they get pretty good accuracy. That's the result of training a million residual layers (actually *only* 80 layers) for months on GPU clusters. We did not have the time or resources to build anything similar to these papers. We did not follow onward with this path.
We instead looked to our own experience. Our team had previously analyzed the connection between image recognition and natural language processing and their shared relationship to high dimensional spaces [see here](https://arxiv.org/abs/1809.05286). We took these learnings and built a model that minimized the root mean squared error as it upscaled from 240 to 480 px.
However, we quickly hit a wall, as this pixel based loss consistently left the upscaled output with blurry edges. In order to address these edges, we used our model as the Generator in a Generative Adversarial Network. However, our generator was too powerful, and the discriminator was lost.
We decided then to leverage the work of the researchers before us in order to build this application for the people. We loaded a pretrained VGG network and leveraged its image embeddings as preprocessing for our discriminator. Leveraging this pretrained model, we were able to effectively iron out the blurry edges while still minimizing mean squared error.
Now model built. We then worked at 4 AM to build an application that can convert videos into high resolution.
## Accomplishments that I'm proud of
Building it good.
## What I learned
Balanced approaches and leveraging past learning
## What's next for Crystallize
Real time stream-enhance app. | partial |
## Inspiration
Provide valuable data to on-premise coordinators just seconds before the firefighters make entry to a building on fire, minimizing the time required to search for and rescue victims. Reports conditions around high-risk areas to alert firefighters for what lies ahead in their path. Increase operational awareness through live, autonomous data collection.
## What it does
We are able to control the drone from a remote location, allowing it to take off, fly in patterns, and autonomously navigate through an enclosed area in order to look for dangerous conditions and potential victims, using a proprietary face-detection algorithm. The web interface then relays a live video stream, location, temperature, and humidity data back to the remote user. The drone saves locations of faces detected, and coordinators are able to quickly pinpoint the location of individuals at risk. The firefighters make use of this information in order to quickly diffuse life-threatening conditions with increased awareness of the conditions inside of the affected area.
## How we built it
We used a JS and HTML front-end, using Solace's PubSub+ broker in order to relay commands sent from the web UI to the drone with minimal latency. Our AI stack consists of an HaaR cascade that finds AI markers and detects faces using a unique face detection algorithm through OpenCV. In order to find fires, we're looking for areas with the highest light intensity and heat, which instructs the drone to fly near and around the areas of concern. Once a face is found, a picture is taken and telemetry information is relayed back to the remote web console. We have our Solace PubSub+ broker instance running on Google Cloud Platform.
## Challenges we ran into
Setting up the live video stream on the Raspberry Pi 4B proved to be an impossible task, as the .h264 raw output from the Raspberry Pi's GPU was impossible to encode into a .mp4 container on the fly. However, when the script was run on Windows, the live video stream, as well as all AI functionality, worked perfectly. We spent a lot of time trying to debug the program on the Raspberry Pi in order to acquire our UDP video live stream, as all ML and AI functionality was inoperational without it. In the end, we somehow got it to work.
Brute forcing into every port of the DJI Tello drone in order to collect serial output took nearly 5 hours and required us to spin up a DigitalOcean instance in order to allow us access to the drone's control surfaces and video data.
## Accomplishments that we're proud of
We were really proud to get the autonomous flying of the drone working using facial recognition. It was quite the task to brute force every wifi port on the drone in order to manipulate it the way we wanted it to, so we were super happy to get all the functionality working by the end of the makeathon.
## What we learned
You can't use GPS indoors because it's impossible to get a satellite lock.
## What's next for FireFly
Commercialization. | ## Inspiration
In times of disaster, the capacity of rigid networks like cell service and internet dramatically decreases at the same time demand increases as people try to get information and contact loved ones. This can lead to crippled telecom services which can significantly impact first responders in disaster struck areas, especially in dense urban environments where traditional radios don't work well. We wanted to test newer radio and AI/ML technologies to see if we could make a better solution to this problem, which led to this project.
## What it does
Device nodes in the field network to each other and to the command node through LoRa to send messages, which helps increase the range and resiliency as more device nodes join. The command & control center is provided with summaries of reports coming from the field, which are visualized on the map.
## How we built it
We built the local devices using Wio Terminals and LoRa modules provided by Seeed Studio; we also integrated magnetometers into the devices to provide a basic sense of direction. Whisper was used for speech-to-text with Prediction Guard for summarization, keyword extraction, and command extraction, and trained a neural network on Intel Developer Cloud to perform binary image classification to distinguish damaged and undamaged buildings.
## Challenges we ran into
The limited RAM and storage of microcontrollers made it more difficult to record audio and run TinyML as we intended. Many modules, especially the LoRa and magnetometer, did not have existing libraries so these needed to be coded as well which added to the complexity of the project.
## Accomplishments that we're proud of:
* We wrote a library so that LoRa modules can communicate with each other across long distances
* We integrated Intel's optimization of AI models to make efficient, effective AI models
* We worked together to create something that works
## What we learned:
* How to prompt AI models
* How to write drivers and libraries from scratch by reading datasheets
* How to use the Wio Terminal and the LoRa module
## What's next for Meshworks - NLP LoRa Mesh Network for Emergency Response
* We will improve the audio quality captured by the Wio Terminal and move edge-processing of the speech-to-text to increase the transmission speed and reduce bandwidth use.
* We will add a high-speed LoRa network to allow for faster communication between first responders in a localized area
* We will integrate the microcontroller and the LoRa modules onto a single board with GPS in order to improve ease of transportation and reliability | ## Inspiration
Alex K's girlfriend Allie is a writer and loves to read, but has had trouble with reading for the last few years because of an eye tracking disorder. She now tends towards listening to audiobooks when possible, but misses the experience of reading a physical book.
Millions of other people also struggle with reading, whether for medical reasons or because of dyslexia (15-43 million Americans) or not knowing how to read. They face significant limitations in life, both for reading books and things like street signs, but existing phone apps that read text out loud are cumbersome to use, and existing "reading glasses" are thousands of dollars!
Thankfully, modern technology makes developing "reading glasses" much cheaper and easier, thanks to advances in AI for the software side and 3D printing for rapid prototyping. We set out to prove through this hackathon that glasses that open the world of written text to those who have trouble entering it themselves can be cheap and accessible.
## What it does
Our device attaches magnetically to a pair of glasses to allow users to wear it comfortably while reading, whether that's on a couch, at a desk or elsewhere. The software tracks what they are seeing and when written words appear in front of it, chooses the clearest frame and transcribes the text and then reads it out loud.
## How we built it
**Software (Alex K)** -
On the software side, we first needed to get image-to-text (OCR or optical character recognition) and text-to-speech (TTS) working. After trying a couple of libraries for each, we found Google's Cloud Vision API to have the best performance for OCR and their Google Cloud Text-to-Speech to also be the top pick for TTS.
The TTS performance was perfect for our purposes out of the box, but bizarrely, the OCR API seemed to predict characters with an excellent level of accuracy individually, but poor accuracy overall due to seemingly not including any knowledge of the English language in the process. (E.g. errors like "Intreduction" etc.) So the next step was implementing a simple unigram language model to filter down the Google library's predictions to the most likely words.
Stringing everything together was done in Python with a combination of Google API calls and various libraries including OpenCV for camera/image work, pydub for audio and PIL and matplotlib for image manipulation.
**Hardware (Alex G)**: We tore apart an unsuspecting Logitech webcam, and had to do some minor surgery to focus the lens at an arms-length reading distance. We CAD-ed a custom housing for the camera with mounts for magnets to easily attach to the legs of glasses. This was 3D printed on a Form 2 printer, and a set of magnets glued in to the slots, with a corresponding set on some NerdNation glasses.
## Challenges we ran into
The Google Cloud Vision API was very easy to use for individual images, but making synchronous batched calls proved to be challenging!
Finding the best video frame to use for the OCR software was also not easy and writing that code took up a good fraction of the total time.
Perhaps most annoyingly, the Logitech webcam did not focus well at any distance! When we cracked it open we were able to carefully remove bits of glue holding the lens to the seller’s configuration, and dial it to the right distance for holding a book at arm’s length.
We also couldn’t find magnets until the last minute and made a guess on the magnet mount hole sizes and had an *exciting* Dremel session to fit them which resulted in the part cracking and being beautifully epoxied back together.
## Acknowledgements
The Alexes would like to thank our girlfriends, Allie and Min Joo, for their patience and understanding while we went off to be each other's Valentine's at this hackathon. | partial |
## Overview of Siacoin
Sia is a decentralized storage platform secured by blockchain technology. The Sia Storage Platform leverages underutilized hard drive capacity around the world to create a data storage marketplace that is more reliable and lower cost than traditional cloud storage providers.
Your data is sliced up, encrypted, and stored on nodes all across the globe to eliminate any single point of failure and ensure the highest possible uptime. Since you hold the keys, you own your data. No outside company can access or control your files.
## Inspiration
Currently, Siacoin runs on charging the host for bandwidth and storage used for the file. We think this leaves the file especially vulnerable when the host stops watching and paying for the file. Additionally, the host might not have the ability to buy Siacoin quickly. We want to make decentralized storage truly free for all.
## What it does
To mitigate this issue, we're creating an ad-supported upload and download web server portal that will allow the file to sustain itself monetarily on the network.
To use, the user will visit the site, upload the file after watching an ad and then receive a download link as well as their Sia permanent link. They could then disseminate the links to the users who would like to access the file.
## Based on these calculations the Sia Cost: (prices as of 9/4/19)
Storage $0.68 / 1TB $6.8E-7/1MB
Upload $0.11 /1TB $1.1E-7/1MB
Download $0.59 /1TB $5.9E-7/1MB
We can clearly see that one 30 second video ad ~$0.01 can conservatively handle the price of 1gb of data on a download. One 30 second video ad on upload can also cover close to a year of hosting. One could say this isn't the true cost as explained below but we'll use this as a rough order of magnitude approximation.
## Prototype Status:
We tried using a Node.Js server backend to get the files into the Siacoin. We had some difficulties understanding the API and understanding how the Sia daemon uses the Node.Js server to fully do everything we need. Additionally, It was difficult to get the Sia client working.
Still if we got the right configuration working, the upload side of the file would have to go to the web server, then uploaded to Sia. On the reverse side, the file needs to be queried from Sia to the web server, then downloaded to the client. In summary, this increases the bandwidth requirements considerably to use Sia as the final destination which will increase costs.
However, there are situations that this could make sense. On fairly small files, few ads could cover all of these costs anyway. One could assert that the bandwidth is the majority cost of the file hosting so this is only useful for mostly cold storage.
However, as long as the original Sia path is known, the file is not reliant on the central web server shutting down. This allows the file to stay up indefinitely as multiple client software can still access the file. One could simply recover their password for their Sia files they uploaded and still access them.
## What's next for Sustainable Ad-Supported Blockchain File Storage
Of course, this is all in the abstract. Due to difficulties getting the wallet working, much development would have to be done in the future. This idea was thought up by our hackathon team and we think might have promise in the future for Sia. | ## Inspiration
As the lines between AI-generated and real-world images blur, the integrity and trustworthiness of visual content have become critical concerns. Traditional metadata isn't as reliable as it once was, prompting us to seek out groundbreaking solutions to ensure authenticity.
## What it does
"The Mask" introduces a revolutionary approach to differentiate between AI-generated images and real-world photos. By integrating a masking layer during the propagation step of stable diffusion, it embeds a unique hash. This hash is directly obtained from the Solana blockchain, acting as a verifiable seal of authenticity. Whenever someone encounters an image, they can instantly verify its origin: whether it's an AI creation or an authentic capture from the real world.
## How we built it
Our team began with an in-depth study of the stable diffusion mechanism, pinpointing the most effective point to integrate the masking layer. We then collaborated with blockchain experts to harness Solana's robust infrastructure, ensuring seamless and secure hash integration. Through iterative testing and refining, we combined these components into a cohesive, reliable system.
## Challenges we ran into
Melding the complex world of blockchain with the intricacies of stable diffusion was no small feat. We faced hurdles in ensuring the hash's non-intrusiveness, so it didn't distort the image. Achieving real-time hash retrieval and embedding while maintaining system efficiency was another significant challenge.
As the lines between AI-generated and real-world images blur, the integrity and trustworthiness of visual content have become critical concerns. Traditional metadata isn't as reliable as it once was, prompting us to seek out groundbreaking solutions to ensure authenticity.
## Accomplishments that we're proud of
Successfully integrating a seamless masking layer that does not compromise image quality.
Achieving instantaneous hash retrieval from Solana, ensuring real-time verification.
Pioneering a solution that addresses a pressing concern in the AI and digital era.
Garnering interest from major digital platforms for potential integration.
## What we learned
The journey taught us the importance of interdisciplinary collaboration. Bringing together experts in AI, image processing, and blockchain was crucial. We also discovered the potential of blockchain beyond cryptocurrency, especially in preserving digital integrity.\
## What's next for The Mask
We envision "The Mask" as the future gold standard for digital content verification. We're in talks with online platforms and content creators to integrate our solution. Furthermore, we're exploring the potential to expand beyond images, offering verification solutions for videos, audio, and other digital content forms. | ## Inspiration
There are 1.3 billion iMessage users and 600 million Discord users. Furtermore, 65% of phones use SMS and SMS does not allow video sharing. File sharing is IMPORTANT! Unfortunately, these applications use cloud-sharing with heavy limitations, and other cloud based video-upload systems such as Youtube and Google Drive take too long. Sometimes we just want to send videos to our friends without having to compress, crop, or have to upload them on a lengthy system. Furthermore, once users upload their videos, centralized systems own their data and users are not the ones in control. Being able to monetize and encrypt your own data without losing autonomy to the bigger players is essential.
## What it does
VidTooLong allows the user to not only upload videos onto the Fabric, but also allows easy link sharing within seconds. The user is also given the autonomy to monetize and encrypt their data before sending it out. This allows it so the receipients cannot leverage the content against the sender. It's easy and helps fix the issues within most big cloud sharing platforms as well as beating the smaller competition as its free!
## How we built it
I built this using Vercel, NextJS, TypeScript, React, & Eluv.io
## Challenges we ran into
My biggest challenge was working solo on this project and starting very late on Saturday. As I flew in from Toronto, Canada and arrived Saturday morning, I spent most of the day playing catch-up and getting to know all the sponsors better. Eluv.io caught my eye and I had to spend all night working. Furthermore, nobody was awake to load my wallet so I couldn't experiment with the API
## Accomplishments that we're proud of
Making a useful and intuitive web2 and web3 product!
## What's next for VidTooLong
Incorporate Web3 and Web2 Wallet integration and a Firebase Authentication system for more personalization and security.
Further build the full-stack elements so that the website can be useable and properly implements the API
Make it so that the user can control how long the link will be active for, further putting their content within their control
Web3 Venmo for Media Content
Add Photo Sharing as well | partial |
## Inspiration
Have you ever had to stand in line and tediously fill out your information for contact tracing at your favorite local restaurant? Have you ever asked yourself what's the point of traffic jams at restaurants which rather than reducing the risk of contributing to the spreading of the outbreak ends up increasing social contact and germ propagation? If yes, JamFree is for you!
## What it does
JamFree is a web application that supports small businesses and restaurants during the pandemic by completely automating contact tracing in order to minimize physical exposure and eliminate the possibility of human error in the event where tracing back on customer visits is necessary. This application helps support local restaurants and small businesses by alleviating the pressure and negative impact this pandemic has had on their business.
In order to accomplish this goal, here's how it would be used:
1. Customer creates an account by filling out the required information restaurants would use for contact tracing such as name, email, and phone number.
2. A QR code is generated by our application
3. Restaurants also create a JamFree account with the possibility of integrating with their favorite POS software
4. Upon arrival at their favorite restaurant, the restaurant staff would scan the customer's QR code from our application
5. Customer visit has now been recorded on the restaurant's POS as well as JamFree's records
## How we built it
We divided the project into two main components; the front-end with react components to make things interactive while the back-end used Express to create a REST API that interacts with a cockroach database. The whole project was deployed using amazon-web services (serverless servers for a quick and efficient deployment).
## Challenges we ran into
We had to figure out how to complete the integration of QR codes for the first time, how to integrate our application with third-party software such as Square or Shopify (OAuth), and how to level out the playing field with the adaptability of new technologies and different languages used across the team.
## Accomplishments that we're proud of
We successfully and simply integrated or app with POS software (e.g. using a free Square Account and Square APIs in order to access the customer base of restaurants while keeping everything centralized and easily accessible).
## What we learned
We became familiar with OAuth 2.0 Protocols, React, and Node. Half of our team was compromised of first-time hackers who had to quickly become familiar with the technologies we used. We learnt that coding can be a pain in the behind but it is well worth it in the end! Teamwork makes the dream work ;)
## What's next for JamFree
We are planning to improve and expand on our services in order to provide them to local restaurants. We will start by integrating it into one of our teammate's family-owned restaurant as well as pitch it to our local parishes to make things safer and easier. We are looking into integrating geofencing in the future in order to provide targeted advertisements and better support our clients in this difficult time for small businesses. | **Inspiration**
Toronto ranks among the top five cities in the world with the worst traffic congestion. As both students and professionals, we faced the daily challenge of navigating this chaos and saving time on our commutes. This led us to question the accuracy of traditional navigation tools like Google Maps. We wondered if there were better, faster routes that could be discovered through innovative technology.
**What it does**
ruteX is an AI-driven navigation app that revolutionizes how users find their way. By integrating Large Language Models (LLMs) and action agents, ruteX facilitates seamless voice-to-voice communication with users. This allows the app to create customized routes based on various factors, including multi-modal transportation options (both private and public), environmental considerations such as carbon emissions, health metrics like calories burned, and cost factors like the cheapest parking garages and gas savings.
**How we built it**
We developed ruteX by leveraging cutting-edge AI technologies. The core of our system is powered by LLMs that interact with action agents, ensuring that users receive personalized route recommendations. We focused on creating a user-friendly interface that simplifies the navigation process while providing comprehensive data on various routing options.
**Challenges we ran into**
Throughout the development process, we encountered challenges such as integrating real-time data for traffic and environmental factors, ensuring accuracy in route recommendations, and maintaining a smooth user experience in the face of complex interactions. Balancing these elements while keeping the app intuitive required significant iterative testing and refinement.
**Accomplishments that we're proud of**
We take pride in our app's simplistic user interface that enhances usability without sacrificing functionality. Our innovative LLM action agents (using fetch ai) effectively communicate with users, making navigation a more interactive experience. Additionally, utilizing Gemini as the "brain" of our ecosystem has allowed us to optimize our AI capabilities, setting ruteX apart from existing navigation solutions.
**What we learned**
This journey has taught us the importance of user feedback in refining our app's features. We've learned how critical it is to prioritize user needs and preferences while also staying flexible in our approach to integrating AI technologies. Our experience also highlighted the potential of AI in transforming traditional industries like navigation.
**What's next for ruteX**
Looking ahead, we plan to scale ruteX to its full potential, aiming to completely revolutionize traditional navigation methods. We are exploring integration with wearables like smartwatches and smart lenses, allowing users to interact with their travel assistant effortlessly. Our vision is for users to simply voice their needs and enjoy their journey without the complexities of conventional navigation. | ## Inspiration
Ideas for interactions from:
* <http://paperprograms.org/>
* <http://dynamicland.org/>
but I wanted to go from the existing computer down, rather from the bottom up, and make something that was a twist on the existing desktop: Web browser, Terminal, chat apps, keyboard, windows.
## What it does
Maps your Mac desktop windows onto pieces of paper + tracks a keyboard and lets you focus on whichever one is closest to the keyboard. Goal is to make something you might use day-to-day as a full computer.
## How I built it
A webcam and pico projector mounted above desk + OpenCV doing basic computer vision to find all the pieces of paper and the keyboard.
## Challenges I ran into
* Reliable tracking under different light conditions.
* Feedback effects from projected light.
* Tracking the keyboard reliably.
* Hooking into macOS to control window focus
## Accomplishments that I'm proud of
Learning some CV stuff, simplifying the pipelines I saw online by a lot and getting better performance (binary thresholds are great), getting a surprisingly usable system.
Cool emergent things like combining pieces of paper + the side ideas I mention below.
## What I learned
Some interesting side ideas here:
* Playing with the calibrated camera is fun on its own; you can render it in place and get a cool ghost effect
* Would be fun to use a deep learning thing to identify and compute with arbitrary objects
## What's next for Computertop Desk
* Pointing tool (laser pointer?)
* More robust CV pipeline? Machine learning?
* Optimizations: run stuff on GPU, cut latency down, improve throughput
* More 'multiplayer' stuff: arbitrary rotations of pages, multiple keyboards at once | losing |
## Inspiration
Amidst the hectic lives and pandemic struck world, mental health has taken a back seat. This thought gave birth to our inspiration of this web based app that would provide activities customised to a person’s mood that will help relax and rejuvenate.
## What it does
We planned to create a platform that could detect a users mood through facial recognition, recommends yoga poses to enlighten the mood and evaluates their correctness, helps user jot their thoughts in self care journal.
## How we built it
Frontend: HTML5, CSS(frameworks used:Tailwind,CSS),Javascript
Backend: Python,Javascript
Server side> Nodejs, Passport js
Database> MongoDB( for user login), MySQL(for mood based music recommendations)
## Challenges we ran into
Incooperating the open CV in our project was a challenge, but it was very rewarding once it all worked .
But since all of us being first time hacker and due to time constraints we couldn't deploy our website externally.
## Accomplishments that we're proud of
Mental health issues are the least addressed diseases even though medically they rank in top 5 chronic health conditions.
We at umang are proud to have taken notice of such an issue and help people realise their moods and cope up with stresses encountered in their daily lives. Through are app we hope to give people are better perspective as well as push them towards a more sound mind and body
We are really proud that we could create a website that could help break the stigma associated with mental health. It was an achievement that in this website includes so many features to help improving the user's mental health like making the user vibe to music curated just for their mood, engaging the user into physical activity like yoga to relax their mind and soul and helping them evaluate their yoga posture just by sitting at home with an AI instructor.
Furthermore, completing this within 24 hours was an achievement in itself since it was our first hackathon which was very fun and challenging.
## What we learned
We have learnt on how to implement open CV in projects. Another skill set we gained was on how to use Css Tailwind. Besides, we learned a lot about backend and databases and how to create shareable links and how to create to do lists.
## What's next for Umang
While the core functionality of our app is complete, it can of course be further improved .
1)We would like to add a chatbot which can be the user's guide/best friend and give advice to the user when in condition of mental distress.
2)We would also like to add a mood log which can keep a track of the user's daily mood and if a serious degradation of mental health is seen it can directly connect the user to medical helpers, therapist for proper treatement.
This lays grounds for further expansion of our website. Our spirits are up and the sky is our limit | ## Inspiration
As students, we’ve all heard it from friends, read it on social media or even experienced it ourselves: students in need of mental health support will book counselling appointments, only to be waitlisted for the foreseeable future without knowing alternatives. Or worse, they get overwhelmed by the process of finding a suitable mental health service for their needs, give up and deal with their struggles alone.
The search for the right mental health service can be daunting but it doesn’t need to be!
## What it does
MindfulU centralizes information on mental health services offered by UBC, SFU, and other organizations. It assists students in finding, learning about, and using mental health resources through features like a chatbot, meditation mode, and an interactive services map.
## How we built it
Before building, we designed the UI of the website first with Figma to visualize how the website should look like.
The website is built with React and Twilio API for its core feature to connect users with the Twilio chatbot to connect them with the correct helpline. We also utilized many npm libraries to ensure the website has a smooth look to it.
Lastly, we deployed the website using Vercel.
## Challenges We ran into
We had a problem in making the website responsive for the smaller screens. As this is a hackathon, we were focusing on trying to implement the designs and critical features for laptop screen size.
## Accomplishments that we're proud of
We are proud that we had the time to implement the core features that we wanted, especially implementing all the designs from Figma into React components and ensuring it fits in a laptop screen size.
## What we learned
We learned that it's not only the tech stack and implementation of the project that matters but also the purpose and message that the project is trying to convey.
## What's next for MindfulU
We want to make the website more responsive towards any screen size to ensure every user can access it from any device. | ## Inspiration
We wanted to create a convenient, modernized journaling application with methods and components that are backed by science. Our spin on the readily available journal logging application is our take on the idea of awareness itself. What does it mean to be aware? What form or shape can mental health awareness come in? These were the key questions that we were curious about exploring, and we wanted to integrate this idea of awareness into our application. The “awareness” approach of the journal functions by providing users with the tools to track and analyze their moods and thoughts, as well as allowing them to engage with the visualizations of the journal entries to foster meaningful reflections.
## What it does
Our product provides a user-friendly platform for logging and recording journal entries and incorporates natural language processing (NLP) to conduct sentiment analysis. Users will be able to see generated insights from their journal entries, such as how their sentiments have changed over time.
## How we built it
Our front-end is powered by the ReactJS library, while our backend is powered by ExpressJS. Our sentiment analyzer was integrated with our NodeJS backend, which is also connected to a MySQL database.
## Challenges we ran into
Creating this app idea under such a short period of time proved to be more challenge than we anticipated. Our product was meant to comprise of more features that helped the journaling aspect of the app as well as the mood tracking aspect of the app. We had planned on showcasing an aggregation of the user's mood over different time periods, for instance, daily, weekly, monthly, etc. And on top of that, we had initially planned on deploying our web app on a remote hosting server but due to the time constraint, we had decided to reduce our proof-of-concept to the most essential cores features for our idea.
## Accomplishments that we're proud of
Designing and building such an amazing web app has been a wonderful experience. To think that we created a web app that could potentially be used by individuals all over the world and could help them keep track of their mental health has been such a proud moment. It really embraces the essence of a hackathon in its entirety. And this accomplishment has been a moment that our team can proud of. The animation video is an added bonus, visual presentations have a way of captivating an audience.
## What we learned
By going through the whole cycle of app development, we learned how one single part does not comprise the whole. What we mean is that designing an app is more than just coding it, the real work starts in showcasing the idea to others. In addition to that, we learned the importance of a clear roadmap for approaching issues (for example, coming up with an idea) and that complicated problems do not require complicated solutions, for instance, our app in simplicity allows for users to engage in a journal activity and to keep track of their moods over time. And most importantly, we learned how the simplest of ideas can be the most useful if they are thought right.
## What's next for Mood for Thought
Making a mobile app could have been better, given that it would align with our goals of making journaling as easy as possible. Users could also retain a degree of functionality offline. This could have also enabled a notification feature that would encourage healthy habits.
More sophisticated machine learning would have the potential to greatly improve the functionality of our app. Right now, simply determining either positive/negative sentiment could be a bit vague.
Adding recommendations on good journaling practices could have been an excellent addition to the project. These recommendations could be based on further sentiment analysis via NLP. | partial |
## Inspiration
Being students in a technical field, we all have to write and submit resumes and CVs on a daily basis. We wanted to incorporate multiple non-supervised machine learning algorithms to allow users to view their resumes from different lenses, all the while avoiding the bias introduced from the labeling of supervised machine learning.
## What it does
The app accepts a resume in .pdf or image format as well as a prompt describing the target job. We wanted to judge the resume based on layout and content. Layout encapsulates font, color, etc., and the coordination of such features. Content encapsulates semantic clustering for relevance to the target job and preventing repeated mentions.
### Optimal Experience Selection
Suppose you are applying for a job and you want to mention five experiences, but only have room for three. cv.ai will compare the experience section in your CV with the job posting's requirements and determine the three most relevant experiences you should keep.
### Text/Space Analysis
Many professionals do not use the space on their resume effectively. Our text/space analysis feature determines the ratio of characters to resume space in each section of your resume and provides insights and suggestions about how you could improve your use of space.
### Word Analysis
This feature analyzes each bullet point of a section and highlights areas where redundant words can be eliminated, freeing up more resume space and allowing for a cleaner representation of the user.
## How we built it
We used a word-encoder TensorFlow model to provide insights about semantic similarity between two words, phrases or sentences. We created a REST API with Flask for querying the TF model. Our front end uses Angular to deliver a clean, friendly user interface.
## Challenges we ran into
We are a team of two new hackers and two seasoned hackers. We ran into problems with deploying the TensorFlow model, as it was initially available only in a restricted Colab environment. To resolve this issue, we built a RESTful API that allowed us to process user data through the TensorFlow model.
## Accomplishments that we're proud of
We spent a lot of time planning and defining our problem and working out the layers of abstraction that led to actual processes with a real, concrete TensorFlow model, which is arguably the hardest part of creating a useful AI application.
## What we learned
* Deploy Flask as a RESTful API to GCP Kubernetes platform
* Use most Google Cloud Vision services
## What's next for cv.ai
We plan on adding a few more features and making cv.ai into a real web-based tool that working professionals can use to improve their resumes or CVs. Furthermore, we will extend our application to include LinkedIn analysis between a user's LinkedIn profile and a chosen job posting on LinkedIn. | # 🎓 **Inspiration**
Entering our **junior year**, we realized we were unprepared for **college applications**. Over the last couple of weeks, we scrambled to find professors to work with to possibly land a research internship. There was one big problem though: **we had no idea which professors we wanted to contact**. This naturally led us to our newest product, **"ScholarFlow"**. With our website, we assure you that finding professors and research papers that interest you will feel **effortless**, like **flowing down a stream**. 🌊
# 💡 **What it Does**
Similar to the popular dating app **Tinder**, we provide you with **hundreds of research articles** and papers, and you choose whether to approve or discard them by **swiping right or left**. Our **recommendation system** will then provide you with what we think might interest you. Additionally, you can talk to our chatbot, **"Scholar Chat"** 🤖. This chatbot allows you to ask specific questions like, "What are some **Machine Learning** papers?". Both the recommendation system and chatbot will provide you with **links, names, colleges, and descriptions**, giving you all the information you need to find your next internship and accelerate your career 🚀.
# 🛠️ **How We Built It**
While half of our team worked on **REST API endpoints** and **front-end development**, the rest worked on **scraping Google Scholar** for data on published papers. The website was built using **HTML/CSS/JS** with the **Bulma** CSS framework. We used **Flask** to create API endpoints for JSON-based communication between the server and the front end.
To process the data, we used **sentence-transformers from HuggingFace** to vectorize everything. Afterward, we performed **calculations on the vectors** to find the optimal vector for the highest accuracy in recommendations. **MongoDB Vector Search** was key to retrieving documents at lightning speed, which helped provide context to the **Cerebras Llama3 LLM** 🧠. The query is summarized, keywords are extracted, and top-k similar documents are retrieved from the vector database. We then combined context with some **prompt engineering** to create a seamless and **human-like interaction** with the LLM.
# 🚧 **Challenges We Ran Into**
The biggest challenge we faced was gathering data from **Google Scholar** due to their servers blocking requests from automated bots 🤖⛔. It took several hours of debugging and thinking to obtain a large enough dataset. Another challenge was collaboration – **LiveShare from Visual Studio Code** would frequently disconnect, making teamwork difficult. Many tasks were dependent on one another, so we often had to wait for one person to finish before another could begin. However, we overcame these obstacles and created something we're **truly proud of**! 💪
# 🏆 **Accomplishments That We're Proud Of**
We’re most proud of the **chatbot**, both in its front and backend implementations. What amazed us the most was how **accurately** the **Llama3** model understood the context and delivered relevant answers. We could even ask follow-up questions and receive **blazing-fast responses**, thanks to **Cerebras** 🏅.
# 📚 **What We Learned**
The most important lesson was learning how to **work together as a team**. Despite the challenges, we **pushed each other to the limit** to reach our goal and finish the project. On the technical side, we learned how to use **Bulma** and **Vector Search** from MongoDB. But the most valuable lesson was using **Cerebras** – the speed and accuracy were simply incredible! **Cerebras is the future of LLMs**, and we can't wait to use it in future projects. 🚀
# 🔮 **What's Next for ScholarFlow**
Currently, our data is **limited**. In the future, we’re excited to **expand our dataset by collaborating with Google Scholar** to gain even more information for our platform. Additionally, we have plans to develop an **iOS app** 📱 so people can discover new professors on the go! | ## Inspiration
Inspired by a team member's desire to study through his courses by listening to his textbook readings recited by his favorite anime characters, functionality that does not exist on any app on the market, we realized that there was an opportunity to build a similar app that would bring about even deeper social impact. Dyslexics, the visually impaired, and those who simply enjoy learning by having their favorite characters read to them (e.g. children, fans of TV series, etc.) would benefit from a highly personalized app.
## What it does
Our web app, EduVoicer, allows a user to upload a segment of their favorite template voice audio (only needs to be a few seconds long) and a PDF of a textbook and uses existing Deepfake technology to synthesize the dictation from the textbook using the users' favorite voice. The Deepfake tech relies on a multi-network model trained using transfer learning on hours of voice data. The encoder first generates a fixed embedding of a given voice sample of only a few seconds, which characterizes the unique features of the voice. Then, this embedding is used in conjunction with a seq2seq synthesis network that generates a mel spectrogram based on the text (obtained via optical character recognition from the PDF). Finally, this mel spectrogram is converted into the time-domain via the Wave-RNN vocoder (see [this](https://arxiv.org/pdf/1806.04558.pdf) paper for more technical details). Then, the user automatically downloads the .WAV file of his/her favorite voice reading the PDF contents!
## How we built it
We combined a number of different APIs and technologies to build this app. For leveraging scalable machine learning and intelligence compute, we heavily relied on the Google Cloud APIs -- including the Google Cloud PDF-to-text API, Google Cloud Compute Engine VMs, and Google Cloud Storage; for the deep learning techniques, we mainly relied on existing Deepfake code written for Python and Tensorflow (see Github repo [here](https://github.com/rodrigo-castellon/Real-Time-Voice-Cloning), which is a fork). For web server functionality, we relied on Python's Flask module, the Python standard library, HTML, and CSS. In the end, we pieced together the web server with Google Cloud Platform (GCP) via the GCP API, utilizing Google Cloud Storage buckets to store and manage the data the app would be manipulating.
## Challenges we ran into
Some of the greatest difficulties were encountered in the superficially simplest implementations. For example, the front-end initially seemed trivial (what's more to it than a page with two upload buttons?), but many of the intricacies associated with communicating with Google Cloud meant that we had to spend multiple hours creating even a landing page with just drag-and-drop and upload functionality. On the backend, 10 excruciating hours were spent attempting (successfully) to integrate existing Deepfake/Voice-cloning code with the Google Cloud Platform. Many mistakes were made, and in the process, there was much learning.
## Accomplishments that we're proud of
We're immensely proud of piecing all of these disparate components together quickly and managing to arrive at a functioning build. What started out as merely an idea manifested itself into usable app within hours.
## What we learned
We learned today that sometimes the seemingly simplest things (dealing with python/CUDA versions for hours) can be the greatest barriers to building something that could be socially impactful. We also realized the value of well-developed, well-documented APIs (e.g. Google Cloud Platform) for programmers who want to create great products.
## What's next for EduVoicer
EduVoicer still has a long way to go before it could gain users. Our first next step is to implementing functionality, possibly with some image segmentation techniques, to decide what parts of the PDF should be scanned; this way, tables and charts could be intelligently discarded (or, even better, referenced throughout the audio dictation). The app is also not robust enough to handle large multi-page PDF files; the preliminary app was designed as a minimum viable product, only including enough to process a single-page PDF. Thus, we plan on ways of both increasing efficiency (time-wise) and scaling the app by splitting up PDFs into fragments, processing them in parallel, and returning the output to the user after collating individual text-to-speech outputs. In the same vein, the voice cloning algorithm was restricted by length of input text, so this is an area we seek to scale and parallelize in the future. Finally, we are thinking of using some caching mechanisms server-side to reduce waiting time for the output audio file. | partial |
## Inspiration
We want to fix healthcare! 48% of physicians in the US are burned out, which is a driver for higher rates of medical error, lower patient satisfaction, higher rates of depression and suicide. Three graduate students at Stanford have been applying design thinking to the burnout epidemic. A CS grad from USC joined us for TreeHacks!
We conducted 300 hours of interviews, learned iteratively using low-fidelity prototypes, to discover,
i) There was no “check engine” light that went off warning individuals to “re-balance”
ii) Current wellness services weren’t designed for individuals working 80+ hour weeks
iii) Employers will pay a premium to prevent burnout
And Code Coral was born.
## What it does
Our platform helps highly-trained individuals and teams working in stressful environments proactively manage their burnout. The platform captures your phones’ digital phenotype to monitor the key predictors of burnout using machine learning. With timely, bite-sized reminders we reinforce individuals’ atomic wellness habits and provide personalized services from laundry to life-coaching.
Check out more information about our project goals: <https://youtu.be/zjV3KeNv-ok>
## How we built it
We built the backend using a combination of API's to Fitbit/Googlemaps/Apple Health/Beiwe; Built a machine learning algorithm and relied on an App Builder for the front end.
## Challenges we ran into
API's not working the way we want. Collecting and aggregating "tagged" data for our machine learning algorithm. Trying to figure out which features are the most relevant!
## Accomplishments that we're proud of
We had figured out a unique solution to addressing burnout but hadn't written any lines of code yet! We are really proud to have gotten this project off the ground!
i) Setting up a system to collect digital phenotyping features from a smart phone ii) Building machine learning experiments to hypothesis test going from our digital phenotype to metrics of burnout iii) We figured out how to detect anomalies using an individual's baseline data on driving, walking and time at home using the Microsoft Azure platform iv) Build a working front end with actual data!
Note - login information to codecoral.net: username - test password - testtest
## What we learned
We are learning how to set up AWS, a functioning back end, building supervised learning models, integrating data from many source to give new insights. We also flexed our web development skills.
## What's next for Coral Board
We would like to connect the backend data and validating our platform with real data! | ## Inspiration
Our hack was inspired by CANSOFCOM's "Help Build a Better Quantum Computer Using Orqestra-quantum library". Our team was interested in exploring quantum computing so it was a natural step to choose this challenge.
## What it does
We implemented a Zapata QuantumBackend called PauliSandwichBackend to perform Pauli sandwiching on a given gate in a circuit. This decreases noise in near-term quantum computers and returns a new circuit with this decreased noise. It will then run this new circuit with a given backend.
## How we built it
Using python we built upon the Zapata QuantumBackend API. Using advanced math and quantum theory to build an algorithms dedicated to lessening the noise and removing error from quantum computing. We implanted a new error migration technique with Pauli Sandwiching
## Challenges we ran into
We found it challenging to find clear documentation on the subject of quantum computing. Between the new API and for the most of us a first time experience with quantum theory we had to delicate a large chunk of our time on research and trial and error.
## Accomplishments that we're proud of
We are extremely proud of the fact we were able to get so far into a very niche section of computer science. While we did not have much experience we have jump a new experience that a very small group of people actually get work with.
## What we learned
We learned much about facing unfamiliar ground. While we have a strong background in code and math we did run into many challenge trying to understand quantum physics. Not only did this open a new software to us it was a great experience to be put back into the unknown with logic we were unfamiliar with it
## What's next for Better Quantum Computer
We hope to push forward our new knowledge on quantum computers to develop not only this algorithm, but many to come as quantum computing is such an unstable and untap resource at this time | ## Inspiration
So many people around the world, including those dear to us, suffer from mental health issues such as depression. Here in Berkeley, for example, the resources put aside to combat these problems are constrained. Journaling is one method commonly employed to fight mental issues; it evokes mindfulness and provides greater sense of confidence and self-identity.
## What it does
SmartJournal is a place for people to write entries into an online journal. These entries are then routed to and monitored by a therapist, who can see the journals of multiple people under their care. The entries are analyzed via Natural Language Processing and data analytics to give the therapist better information with which they can help their patient, such as an evolving sentiment and scans for problematic language. The therapist in turn monitors these journals with the help of these statistics and can give feedback to their patients.
## How we built it
We built the web application using the Flask web framework, with Firebase acting as our backend. Additionally, we utilized Microsoft Azure for sentiment analysis and Key Phrase Extraction. We linked everything together using HTML, CSS, and Native Javascript.
## Challenges we ran into
We struggled with vectorizing lots of Tweets to figure out key phrases linked with depression, and it was very hard to test as every time we did so we would have to wait another 40 minutes. However, it ended up working out finally in the end!
## Accomplishments that we're proud of
We managed to navigate through Microsoft Azure and implement Firebase correctly. It was really cool building a live application over the course of this hackathon and we are happy that we were able to tie everything together at the end, even if at times it seemed very difficult
## What we learned
We learned a lot about Natural Language Processing, both naively doing analysis and utilizing other resources. Additionally, we gained a lot of web development experience from trial and error.
## What's next for SmartJournal
We aim to provide better analysis on the actual journal entires to further aid the therapist in their treatments, and moreover to potentially actually launch the web application as we feel that it could be really useful for a lot of people in our community. | partial |
# 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
## 💫 Inspiration
>
> "Art is the signature of civilizations." - Beverly Sills
>
>
>
Art is a gateway to creative expression. With [VizArt](https://vizart.tech/create), we are pushing the boundaries of what's possible with computer vision and enabling a new level of artistic expression. ***We envision a world where people can interact with both the physical and digital realms in creative ways.***
We started by pushing the limits of what's possible with customizable deep learning, streaming media, and AR technologies. With VizArt, you can draw in art, interact with the real world digitally, and share your creations with your friends!
>
> "Art is the reflection of life, and life is the reflection of art." - Unknow
>
>
>
Air writing is made possible with hand gestures, such as a pen gesture to draw and an eraser gesture to erase lines. With VizArt, you can turn your ideas into reality by sketching in the air.
Our computer vision algorithm enables you to interact with the world using a color picker gesture and a snipping tool to manipulate real-world objects.
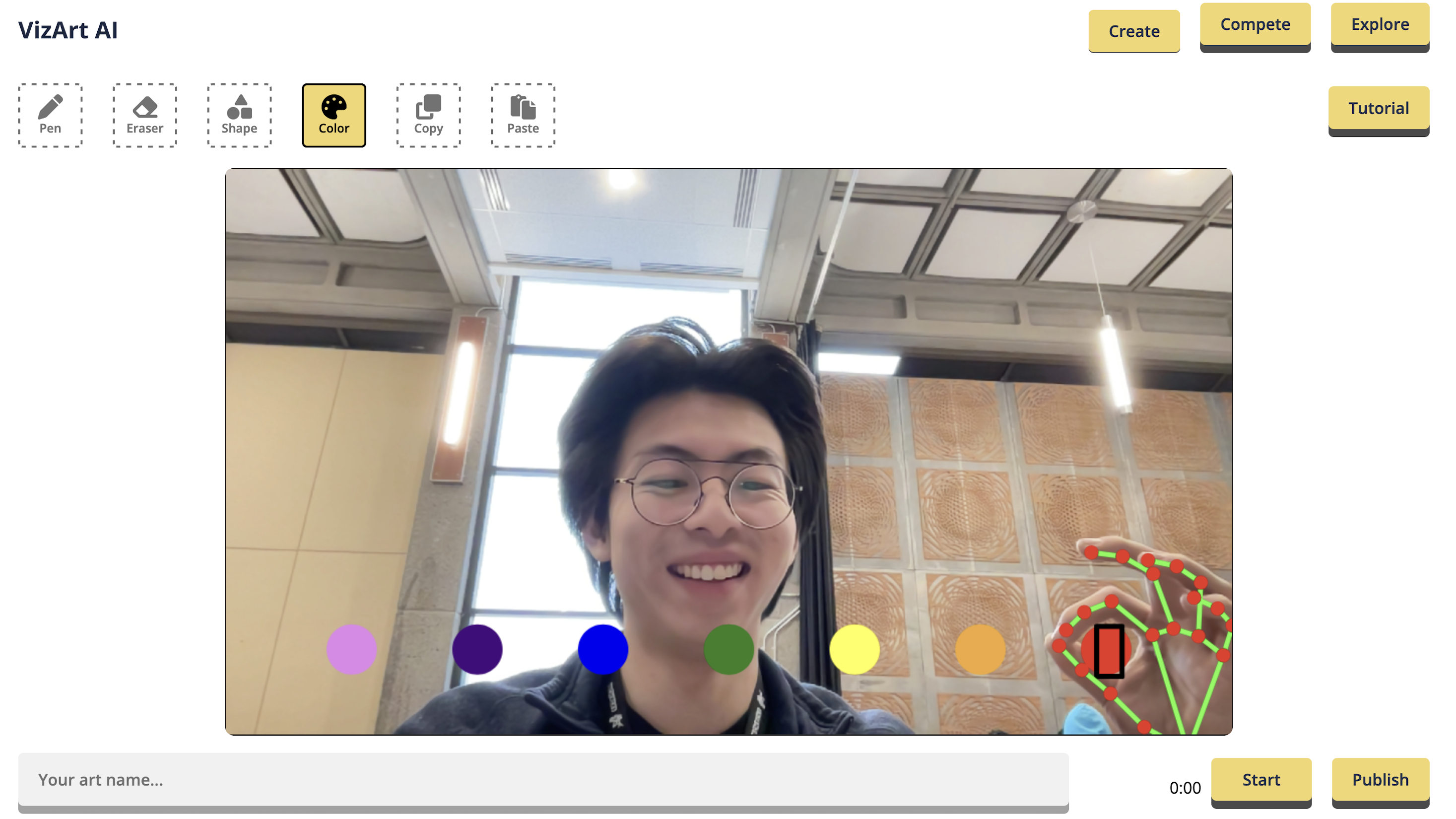
>
> "Art is not what you see, but what you make others see." - Claude Monet
>
>
>
The features I listed above are great! But what's the point of creating something if you can't share it with the world? That's why we've built a platform for you to showcase your art. You'll be able to record and share your drawings with friends.
I hope you will enjoy using VizArt and share it with your friends. Remember: Make good gifts, Make good art.
# ❤️ Use Cases
### Drawing Competition/Game
VizArt can be used to host a fun and interactive drawing competition or game. Players can challenge each other to create the best masterpiece, using the computer vision features such as the color picker and eraser.
### Whiteboard Replacement
VizArt is a great alternative to traditional whiteboards. It can be used in classrooms and offices to present ideas, collaborate with others, and make annotations. Its computer vision features make drawing and erasing easier.
### People with Disabilities
VizArt enables people with disabilities to express their creativity. Its computer vision capabilities facilitate drawing, erasing, and annotating without the need for physical tools or contact.
### Strategy Games
VizArt can be used to create and play strategy games with friends. Players can draw their own boards and pieces, and then use the computer vision features to move them around the board. This allows for a more interactive and engaging experience than traditional board games.
### Remote Collaboration
With VizArt, teams can collaborate remotely and in real-time. The platform is equipped with features such as the color picker, eraser, and snipping tool, making it easy to interact with the environment. It also has a sharing platform where users can record and share their drawings with anyone. This makes VizArt a great tool for remote collaboration and creativity.
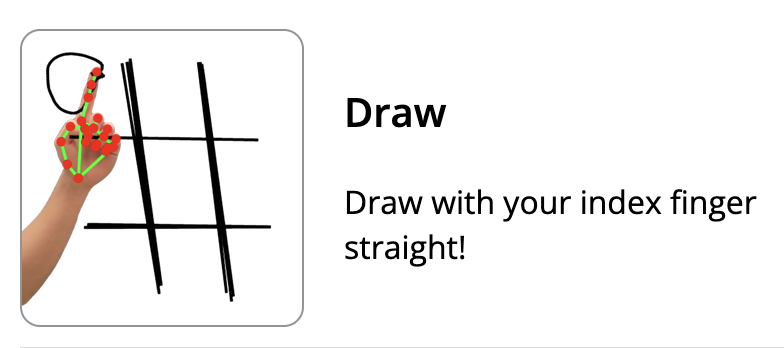
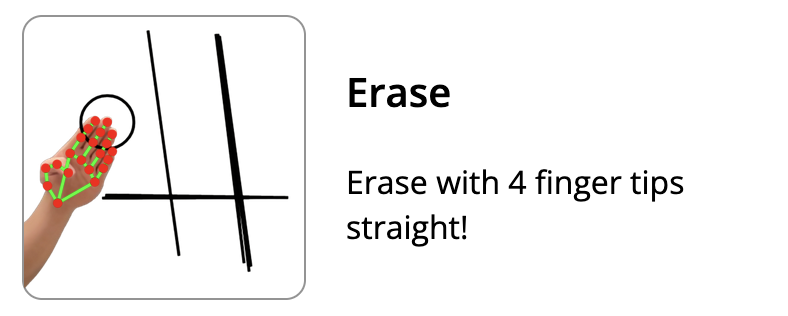
# 👋 Gestures Tutorial


# ⚒️ Engineering
Ah, this is where even more fun begins!
## Stack
### Frontend
We designed the frontend with Figma and after a few iterations, we had an initial design to begin working with. The frontend was made with React and Typescript and styled with Sass.
### Backend
We wrote the backend in Flask. To implement uploading videos along with their thumbnails we simply use a filesystem database.
## Computer Vision AI
We use MediaPipe to grab the coordinates of the joints and upload images. WIth the coordinates, we plot with CanvasRenderingContext2D on the canvas, where we use algorithms and vector calculations to determinate the gesture. Then, for image generation, we use the DeepAI open source library.
# Experimentation
We were using generative AI to generate images, however we ran out of time.
# 👨💻 Team (”The Sprint Team”)
@Sheheryar Pavaz
@Anton Otaner
@Jingxiang Mo
@Tommy He | ## Inspiration
Ever wish you didn’t need to purchase a stylus to handwrite your digital notes? Each person at some point hasn’t had the free hands to touch their keyboard. Whether you are a student learning to type or a parent juggling many tasks, sometimes a keyboard and stylus are not accessible. We believe the future of technology won’t even need to touch anything in order to take notes. HoverTouch utilizes touchless drawings and converts your (finger)written notes to typed text! We also have a text to speech function that is Google adjacent.
## What it does
Using your index finger as a touchless stylus, you can write new words and undo previous strokes, similar to features on popular note-taking apps like Goodnotes and OneNote. As a result, users can eat a slice of pizza or hold another device in hand while achieving their goal. HoverTouch tackles efficiency, convenience, and retention all in one.
## How we built it
Our pre-trained model from media pipe works in tandem with an Arduino nano, flex sensors, and resistors to track your index finger’s drawings. Once complete, you can tap your pinky to your thumb and HoverTouch captures a screenshot of your notes as a JPG. Afterward, the JPG undergoes a masking process where it is converted to a black and white picture. The blue ink (from the user’s pen strokes) becomes black and all other components of the screenshot such as the background become white. With our game-changing Google Cloud Vision API, custom ML model, and vertex AI vision, it reads the API and converts your text to be displayed on our web browser application.
## Challenges we ran into
Given that this was our first hackathon, we had to make many decisions regarding feasibility of our ideas and researching ways to implement them. In addition, this entire event has been an ongoing learning process where we have felt so many emotions — confusion, frustration, and excitement. This truly tested our grit but we persevered by uplifting one another’s spirits, recognizing our strengths, and helping each other out wherever we could.
One challenge we faced was importing the Google Cloud Vision API. For example, we learned that we were misusing the terminal and our disorganized downloads made it difficult to integrate the software with our backend components. Secondly, while developing the hand tracking system, we struggled with producing functional Python lists. We wanted to make line strokes when the index finger traced thin air, but we eventually transitioned to using dots instead to achieve the same outcome.
## Accomplishments that we're proud of
Ultimately, we are proud to have a working prototype that combines high-level knowledge and a solution with significance to the real world. Imagine how many students, parents, friends, in settings like your home, classroom, and workplace could benefit from HoverTouch's hands free writing technology.
This was the first hackathon for ¾ of our team, so we are thrilled to have undergone a time-bounded competition and all the stages of software development (ideation, designing, prototyping, etc.) toward a final product. We worked with many cutting-edge softwares and hardwares despite having zero experience before the hackathon.
In terms of technicals, we were able to develop varying thickness of the pen strokes based on the pressure of the index finger. This means you could write in a calligraphy style and it would be translated from image to text in the same manner.
## What we learned
This past weekend we learned that our **collaborative** efforts led to the best outcomes as our teamwork motivated us to preserve even in the face of adversity. Our continued **curiosity** led to novel ideas and encouraged new ways of thinking given our vastly different skill sets.
## What's next for HoverTouch
In the short term, we would like to develop shape recognition. This is similar to Goodnotes feature where a hand-drawn square or circle automatically corrects to perfection.
In the long term, we want to integrate our software into web-conferencing applications like Zoom. We initially tried to do this using WebRTC, something we were unfamiliar with, but the Zoom SDK had many complexities that were beyond our scope of knowledge and exceeded the amount of time we could spend on this stage.
### [HoverTouch Website](hoverpoggers.tech) | ## Inspiration
## What it does
You can point your phone's camera at a checkers board and it will show you all of the legal moves and mark the best one.
## How we built it
We used Android studio to develop an Android app that streams camera captures to a python server that handles
## Challenges we ran into
Detection of the orientation of the checkers board and the location of the pieces.
## Accomplishments that we're proud of
We used markers to provide us easy to detect reference points which we used to infer the orientation of the board.
## What we learned
* Android Camera API
* Computer Vision never works as robust as you think it will.
## What's next for Augmented Checkers
* Better graphics and UI
* Other games | winning |
# SlideDown
## Inspiration
Recently, we had to make a set of workshops for one of our organizations at school. We created all of the curriculum in Markdown, so that it could be reviewed and changed easily, but once we were done, we had 10+ Markdown files to convert into actual slidedecks. That was our inspiration for SlideDown: a way to save time and effort when making slides.
## What it does
SlideDown is a command-line tool that takes in a Markdown file, parses through the content, and makes a Google Slides presentation that maintains the same content and formatting.
## How we built it
SlideDown was made with a Python script that uses the Google Slides API to create slides and content. It's pure Python3 :).
## Challenges we ran into
One of the biggest hurdles was figuring out how the Google Slides API worked. There is documentation available, but some of it can be confusing, especially for the Python implementation.
## Accomplishments that we're proud of
Getting the tool to actually make a presentation!
## What's next for SlideDown
Implement more tag support from Markdown, improve looks, actually get it working :^). | ## Inspiration
Having to prepare presentations is already dreadful enough. But also having to prepare slides to accompany it? So much worse. As students, we could not be any more familiar with this situation. While our speeches for English class may be a valid indicator of our English skills, the slides we make are not. The time we spend making these slides is better allocated elsewhere, and this is where Script2Slides comes in.
## What it does
This productivity tool we created automatically generates a visually appealing slideshow containing key information and relevant images. All you need to do is copy and paste your script into the textbox on our website, and your brand-new slideshow will be downloaded for you to use!
## How we built it
Script2Slides was created with HTML and styled with CSS. The script is summarized into bullet points in GPT-3.5 using the OpenAI API, and an image description is generated. We then use this description to find relevant images for the slides using Google Image Search API. With both bullet points and images, we create a PowerPoint file downloaded for the user.
## Challenges we ran into
We decided on the idea quite late — around 11:30 a.m. on Saturday! This meant we only had a day to work on the project. A few more challenges we ran into included crafting a prompt that worked well with GPT and downloading the slideshow as a PowerPoint since the formatting would have problems.
## Accomplishments that we're proud of
We’re proud of creating our first hack that successfully implements AI. But beyond that, we’re simply happy to solve an issue the whole team can relate to.
## What we learned
Since this is our first time implementing AI, we learned how to use OpenAI API, and more specifically, Victor learned how to use Flask.
## What's next for Script2Slides
In the future, we wish to run Script2Slides in a way that is more personalized. It would be nice to make things more customizable; for instance, the software can detect the theme of a presentation, i.e. formal, business, technology, etc. and then design the slides accordingly. We’d also like to allow the user to download the slides in formats other than PowerPoint. | ## Inspiration
A brief recap of the inspiration for Presentalk 1.0: We wanted to make it easier to navigate presentations. Handheld clickers are useful for going to the next and last slide, but they are unable to skip to specific slides in the presentation. Also, we wanted to make it easier to pull up additional information like maps, charts, and pictures during a presentation without breaking the visual continuity of the presentation. To do that, we added the ability to search for and pull up images using voice commands, without leaving the presentation.
Last year, we finished our prototype, but it was a very hacky and unclean implementation of Presentalk. After the positive feedback we heard after the event, despite our code's problems, we resolved to come back this year to make the product something we could actually host online and let everyone use.
## What it does
Presentalk solves this problem with voice commands that allow you to move forward and back, skip to specific slides and keywords, and go to specific images in your presentation using image recognition. Presentalk recognizes voice commands, including:
* Next Slide
+ Goes to the next slide
* Last Slide
+ Goes to the previous slide
* Go to Slide 3
+ Goes to the 3rd slide
* Go to the slide with the dog
+ Uses google cloud vision to parse each slide's images, and will take you to the slide it thinks has a dog in it.
* Go to the slide titled APIs
+ Goes to the first slide with APIs in its title
* Search for "voice recognition"
+ Parses the text of each slide for a matching phrase and goes to that slide.
* Show me a picture of UC Berkeley
+ Uses Bing image search to find the first image result of UC Berkeley
* Zoom in on the Graph
+ Uses Google Cloud Vision to identify an object, and if it matches the query, zooms in on the object.
* Tell me the product of 857 and 458
+ Uses Wolfram Alpha's Short Answer API to answer computation and knowledge based questions
Video: <https://vimeo.com/chanan/calhacks3>
## How we built it
* Built a backend in python that linked to our voice recognition, which we built all of our other features off of.
## Challenges we ran into
* Accepting microphone input through Google Chrome (people can have different security settings)
* Refactor entire messy, undocumented codebase from last year
## Accomplishments that we're proud of
Getting Presentalk from weekend pet project to something that could actually scale with many users on a server in yet another weekend.
## What we learned
* Sometimes the best APIs are hidden right under your nose. (Web Speech API was released in 2013 and we didn't use it last year. It's awesome!)
* Re-factoring code you don't really remember is difficult.
## What's next for Presentalk
Release to the general public! (Hopefully) | losing |
## Inspiration
"Thrice upon a time, our four incredible ninjas decided to attend a hackathon. After winning, some other salty ninjas decide to take them out. In order to get home and sleep after a long night of coding, our heroic ninjas must dodge incoming attacks to escape. "
## What it does
Sleepy ninja allows the user to play randomly as one of four characters, Sleepy Ninja, Angry Ninja, Happy Ninja, and Naruto.
Press 'Space' to jump over deadly ninja stars. Beware, they all come at you at different speeds! Some of them even come from the air... | ## Github REPO
<https://github.com/charlesjin123/medicine-scanner>
## Inspiration
We believe everyone deserves easy, safe access to their medication – yet the small fine print that often takes up hundreds to thousands of words printed on the back of medicine bottles is incredibly inaccessible for a huge market. Watching elderly patients struggle to read fine print, and non-English speakers feeling overwhelmed by confusing medical terms, inspired us to act. Imagine the power of a tool that turns every medication bottle into a personalized, simplified guide in the simple to understand form of cards — that’s the project we’re building. With Med-Scanner, we’re bridging gaps in healthcare access and redefining patient safety.
## What it does
Med-Scanner is a game changer, transforming complex medication information into easy-to-understand digital cards. By simply scanning a medication with your phone, users instantly get critical info like dosages, side effects, and interactions, all laid out clearly and concisely. We even speak the instructions for those who are visually impaired. Med-Scanner is the safe and accessible patient care solution for everyone.
## How we built it
Using cutting-edge tech like React, Python, and NLP models, we built Med-Scanner from the ground up. The app scans medication labels using advanced OCR and analyzes it with NLP. But we didn’t stop there. We infused text-to-speech for the blind, and personalized chatbots for even further support.
## Challenges we ran into
We thrived under time pressure to build a Med-Scanner. One of our greatest challenges was perfecting the OCR to handle blurry, inconsistent images from different formats. Plus, developing an interface that’s accessible, intuitive, and incredibly simple for older users pushed us to innovate like never before. However, with our team of four bring together a multitude of talents, we were able to overcome these challenges to fulfill our mission.
## Accomplishments that we're proud of
The fact that we did it — we brought this ambitious project to life — fills us with pride. We built a prototype that not only works but works brilliantly, turning complex medical details into clear, actionable cards. We’re especially proud of the accuracy of our OCR model and the seamless voice-over features that make this tool genuinely accessible. We’re also proud of creating a product that’s not just tech-savvy, but mission-driven— making healthcare safer for millions of people. | ## Inspiration
Growing up in the early 2000s, communiplant's founding team knew what it was like to grow up in vibrant communities, interconnected interpersonal and naturally.
Today's post-covid fragmented society lacks the community and optimism that kept us going. The lack of optimism is especially evident through our climate crisis: an issue that falls outside most individuals loci of control.
That said, we owe it to ourselves and future generations to keep hope for a better future alive, **and that future starts on the communal level**. Here at Communiplant, we hope to help communities realize the beauty of street-level biodiversity, shepherding the optimism needed for a brighter future.
## What it does
Communiplant allows community members to engage with their community while realizing their jurisdiction's potential for sustainable development. Firstly, the communiplant analyzes satellite imagery using machine learning and computer vision models to calculate the community's NDMI vegetation indices. Beyond that, community members can individually contribute to their community on Commuiplant by uploading images of various flora and fauna they see daily in their community. Using computer vision models, our system can label the plantlife uploaded to the system, serving as a mosaic representing the communities biodiversity.
Finally, to further engage with their communities, users can participate in the community through participation in a variety of community events.
## How we built it
Communitech is a fullstack web application developed using React & Vite for the frontend, and Django on the backend. We used AWS's cloud suite for relational data storage: storing user records. Beyond that, however, we used AWS to implement the algorithms necessary for the complex categorizations that we needed to make. Namely. we used AWS S3 object storage to maintain our various clusters.
Finally, we used a variety of browser-level apis, including but not limited to the google maps API and the google earth engine API.
## Challenges we ran into
While UOttahack6 has been incredibly rewarding, it has not been without it challenges. Namely, we found that attempting to use bleeding-edge new technologies that we had little experience with in conjunction led to a host of technical issues.
First and most significantly, we found it difficult implementing cloud based artificial intelligence workflows for the first time.
We also had a lot of issues with some of the browser-level maps APIs, as we found that the documentation for some of those resources was insufficient for our experience level.
## Accomplishments that we're proud of
Regardless of the final result, we are happy to have made a final product with a concrete use case that has potential to become major player in the sustainability space.
All in all however, we are mainly proud that through it all we were able to show technical resilience. There were many late night moments where we didn't really see a way out, or where we would have to cut out a significant amount of functionality from our final product. Regardless we pushed though, and those experiences are what we will end up remembering UOttahack for.
## What's next for Communiplant
The future is bright for Communplant with many features on the way. Of these, the most significant are related to the mapping functionality. Currently, user inputted flora and fauna live only in a photo album on the community page. Going forwards we hope to have images linked to geographic points, or pins on the map.
Regardless of Communiplant's future actions, however, we will keep our guarantee to support sustainability on all scales. | losing |
## Inspiration
While attending Hack the 6ix, our team had a chance to speak to Advait from the Warp team. We got to learn about terminals and how he got involved with Warp, as well as his interest in developing something completely new for the 21st century. Through this interaction, my team decided we wanted to make an AI-powered developer tool as well, which gave us the idea for Code Cure!
## What it does
Code Cure can call your python file and run it for you. Once it runs, you will see your output as usual in your terminal, but if you experience any errors, our extension runs and gives some suggestions in a pop-up as to how you may fix it.
## How we built it
We made use of Azure's OpenAI service to power our AI code fixing suggestions and used javascript to program the rest of the logic behind our VS code extension.
## Accomplishments that we're proud of
We were able to develop an awesome AI-powered tool that can help users fix errors in their python code. We believe this project will serve as a gateway for more people to learn about programming, as it provides an easier way for people to find solutions to their errors.
## What's next for Code Cure
As of now, we are only able to send our output through a popup on the user's screen. In the future, we would like to implement a stylized tab where we are able to show the user different suggestions using the most powerful AI models available to us. | We were inspired to create a tool that would make it easier for people to understand and learn from code, regardless of their experience level.
What it does:
Code Assistant is a Firefox extension that uses AI to provide simple, easy-to-understand explanations of any code you come across. With just a few clicks, you can select any piece of text and get a clear explanation of what it does and how it works.
How we built it:
We used a combination of natural language processing and machine learning techniques to analyze and understand code. The extension was built using JavaScript and is compatible with Firefox.
Challenges we ran into:
One of the biggest challenges we faced was developing an AI that could accurately understand and explain code in a way that was accessible to users of all experience levels. Additionally, we encountered challenges in integrating our AI with the Firefox extension.
Accomplishments that we're proud of:
We're proud of the fact that Code Assistant is able to provide clear, accurate explanations of code that are easy for anyone to understand. We're also proud of the user-friendly interface we've created.
What we learned:
We learned a lot about natural language processing and machine learning techniques, as well as the process of building a Firefox extension.
What's next for Code Assistant:
We plan to continue improving and updating the AI behind Code Assistant and to make it compatible with other browsers. We also hope to add new features such as code snippets and examples in the future. | ## Inspiration
All of us have gone through the painstaking and difficult process of onboarding as interns and making sense of huge repositories with many layers of folders and files. We hoped to shorten this or remove it completely through the use of Code Flow.
## What it does
Code Flow exists to speed up onboarding and make code easy to understand for non-technical people such as Project Managers and Business Analysts. Once the user has uploaded the repo, it has 2 main features. First, it can visualize the entire repo by showing how different folders and files are connected and providing a brief summary of each file and folder. It can also visualize a file by showing how the different functions are connected for a more technical user. The second feature is a specialized chatbot that allows you to ask questions about the entire project as a whole or even specific files. For example, "Which file do I need to change to implement this new feature?"
## How we built it
We used React to build the front end. Any folders uploaded by the user through the UI are stored using MongoDB. The backend is built using Python-Flask. If the user chooses a visualization, we first summarize what every file and folder does and display that in a graph data structure using the library pyvis. We analyze whether files are connected in the graph based on an algorithm that checks features such as the functions imported, etc. For the file-level visualization, we analyze the file's code using an AST and figure out which functions are interacting with each other. Finally for the chatbot, when the user asks a question we first use Cohere's embeddings to check the similarity of the question with the description we generated for the files. After narrowing down the correct file, we use its code to answer the question using Cohere generate.
## Challenges we ran into
We struggled a lot with narrowing down which file to use to answer the user's questions. We initially thought to simply use Cohere generate to reply with the correct file but knew that it isn't specialized for that purpose. We decided to use embeddings and then had to figure out how to use those numbers to actually get a valid result. We also struggled with getting all of our tech stacks to work as we used React, MongoDB and Flask. Making the API calls seamless proved to be very difficult.
## Accomplishments that we're proud of
This was our first time using Cohere's embeddings feature and accurately analyzing the result to match the best file. We are also proud of being able to combine various different stacks and have a working application.
## What we learned
We learned a lot about NLP, how embeddings work, and what they can be used for. In addition, we learned how to problem solve and step out of our comfort zones to test new technologies.
## What's next for Code Flow
We plan on adding annotations for key sections of the code, possibly using a new UI so that the user can quickly understand important parts without wasting time. | losing |
## Inspiration
Physiotherapy is expensive for what it provides you with, A therapist stepping you through simple exercises and giving feedback and evaluation? WE CAN TOTALLY AUTOMATE THAT! We are undergoing the 4th industrial revolution and technology exists to help people in need of medical aid despite not having the time and money to see a real therapist every week.
## What it does
IMU and muscle sensors strapped onto the arm accurately track the state of the patient's arm as they are performing simple arm exercises for recovery. A 3d interactive GUI is set up to direct patients to move their arm from one location to another by performing localization using IMU data. A classifier is run on this variable-length data stream to determine the status of the patient and how well the patient is recovering. This whole process can be initialized with the touch of a button on your very own mobile application.
## How WE built it
on the embedded system side of things, we used a single raspberry pi for all the sensor processing. The Pi is in charge of interfacing with the IMU while another Arduino interfaces with the other IMU and a muscle sensor. The Arduino then relays this info over a bridged connection to a central processing device where it displays the 3D interactive GUI and processes the ML data. all the data in the backend is relayed and managed using ROS. This data is then uploaded to firebase where the information is saved on the cloud and can be accessed anytime by a smartphone. The firebase also handles plotting data to give accurate numerical feedback of the many values orientation trajectory, and improvement over time.
## Challenges WE ran into
hooking up 2 IMU to the same rpy is very difficult. We attempted to create a multiplexer system with little luck.
To run the second IMU we had to hook it up to the Arduino. Setting up the library was also difficult.
Another challenge we ran into was creating training data that was general enough and creating a preprocessing script that was able to overcome the variable size input data issue.
The last one was setting up a firebase connection with the app that supported the high data volume that we were able to send over and to create a graphing mechanism that is meaningful. | ## Inspiration
A deep and unreasonable love of xylophones
## What it does
An air xylophone right in your browser!
Play such classic songs as twinkle twinkle little star, ba ba rainbow sheep and the alphabet song or come up with the next club banger in free play.
We also added an air guitar mode where you can play any classic 4 chord song such as Wonderwall
## How we built it
We built a static website using React which utilised Posenet from TensorflowJS to track the users hand positions and translate these to specific xylophone keys.
We then extended this by creating Xylophone Hero, a fun game that lets you play your favourite tunes without requiring any physical instruments.
## Challenges we ran into
Fine tuning the machine learning model to provide a good balance of speed and accuracy
## Accomplishments that we're proud of
I can get 100% on Never Gonna Give You Up on XylophoneHero (I've practised since the video)
## What we learned
We learnt about fine tuning neural nets to achieve maximum performance for real time rendering in the browser.
## What's next for XylophoneHero
We would like to:
* Add further instruments including a ~~guitar~~ and drum set in both freeplay and hero modes
* Allow for dynamic tuning of Posenet based on individual hardware configurations
* Add new and exciting songs to Xylophone
* Add a multiplayer jam mode | # Inspiration 🌟
**What is the problem?**
Physical activity early on can drastically increase longevity and productivity for later stages of life. Without finding a dependable routine during your younger years, you may experience physical impairment in the future. 50% of functional decline that occurs in those 30 to 70 years old is due to lack of exercise.
During the peak of the COVID-19 pandemic in Canada, nationwide isolation brought everyone indoors. There was still a vast number of people that managed to work out in their homes, which motivated us to create an application that further encouraged engaging in fitness, using their devices, from the convenience of their homes.
# Webapp Summary 📜
Inspired, our team decided to tackle this idea by creating a web app that helps its users maintain a consistent and disciplined routine.
# What does it do? 💻
*my trAIner* plans to aid you and your journey to healthy fitness by displaying the number of calories you have burned while also counting your reps. It additionally helps to motivate you through words of encouragement. For example, whenever nearing a rep goal, *my trAIner* will use phrases like, “almost there!” or “keep going!” to push you to the last rep. Once completing your set goal *my trAIner* will congratulate you.
We hope that people may utilize this to make the best of their workouts. Utilizing AI technology to help those reach their rep standard and track calories, we believe could help students and adults in the present and future.
# How we built it:🛠
To build this application, we used **JavaScript, CSS,** and **HTML.** To make the body mapping technology, we used a **TensorFlow** library. We mapped out different joints on the body and compared them as they moved, in order to determine when an exercise was completed. We also included features like parallax scrolling and sound effects from DeltaHacks staff.
# Challenges that we ran into 🚫
Learning how to use **TensorFlow**’s pose detection proved to be a challenge, as well as integrating our own artwork into the parallax scrolling. We also had to refine our backend as the library’s detection was shaky at times. Additional challenges included cleanly linking **HTML, JS, and CSS** as well as managing the short amount of time we were given.
# Accomplishments that we’re proud of 🎊
We are proud that we put out a product with great visual aesthetics as well as a refined detection method. We’re also proud that we were able to take a difficult idea and prove to ourselves that we were capable of creating this project in a short amount of time. More than that though, we are most proud that we could make a web app that could help out people trying to be more healthy.
# What we learned 🍎
Not only did we develop our technical skills like web development and AI, but we also learned crucial things about planning, dividing work, and time management. We learned the importance of keeping organized with things like to-do lists and constantly communicating to see what each other’s limitations and abilities were. When challenges arose, we weren't afraid to delve into unknown territories.
# Future plans 📅
Due to time constraints, we were not able to completely actualize our ideas, however, we will continue growing and raising efficiency by giving ourselves more time to work on *my trAIner*. Potential future ideas to incorporate may include constructive form correction, calorie intake calculator, meal preps, goal setting, recommended workouts based on BMI, and much more. We hope to keep on learning and applying newly obtained concepts to *my trAIner*. | winning |
## 💡 Inspiration
Generation Z is all about renting - buying land is simply out of our budgets. But the tides are changing: with Pocket Plots, an entirely new generation can unlock the power of land ownership without a budget.
Traditional land ownership goes like this: you find a property, spend weeks negotiating a price, and secure a loan. Then, you have to pay out agents, contractors, utilities, and more. Next, you have to go through legal documents, processing, and more. All while you are shelling out tens to hundreds of thousands of dollars.
Yuck.
Pocket Plots handles all of that for you.
We, as a future LLC, buy up large parcels of land, stacking over 10 acres per purchase. Under the company name, we automatically generate internal contracts that outline a customer's rights to a certain portion of the land, defined by 4 coordinate points on a map.
Each parcel is now divided into individual plots ranging from 1,000 to 10,000 sq ft, and only one person can own a contract to each plot to the plot.
This is what makes us fundamentally novel: we simulate land ownership without needing to physically create deeds for every person. This skips all the costs and legal details of creating deeds and gives everyone the opportunity to land ownership.
These contracts are 99 years and infinitely renewable, so when it's time to sell, you'll have buyers flocking to buy from you first.
You can try out our app here: <https://warm-cendol-1db56b.netlify.app/>
(AI features are available locally. Please check our Github repo for more.)
## ⚙️What it does
### Buy land like it's ebay:

We aren't just a business: we're a platform. Our technology allows for fast transactions, instant legal document generation, and resale of properties like it's the world's first ebay land marketplace.
We've not just a business.
We've got what it takes to launch your next biggest investment.
### Pocket as a new financial asset class...
In fintech, the last boom has been in blockchain. But after FTX and the bitcoin crash, cryptocurrency has been shaken up: blockchain is no longer the future of finance.
Instead, the market is shifting into tangible assets, and at the forefront of this is land. However, land investments have been gatekept by the wealthy, leaving little opportunity for an entire generation
That's where pocket comes in. By following our novel perpetual-lease model, we sell contracts to tangible buildable plots of land on our properties for pennies on the dollar.
We buy the land, and you buy the contract.
It's that simple.
We take care of everything legal: the deeds, easements, taxes, logistics, and costs. No more expensive real estate agents, commissions, and hefty fees.
With the power of Pocket, we give you land for just $99, no strings attached.
With our resell marketplace, you can sell your land the exact same way we sell ours: on our very own website.
We handle all logistics, from the legal forms to the system data - and give you 100% of the sell value, with no seller fees at all.
We even will run ads for you, giving your investment free attention.
So how much return does a Pocket Plot bring?
Well, once a parcel sells out its plots, it's gone - whoever wants to buy land from that parcel has to buy from you.
We've seen plots sell for 3x the original investment value in under one week. Now how insane is that? The tides are shifting, and Pocket is leading the way.
### ...powered by artificial intelligence
**Caption generation**
*Pocket Plots* scrapes data from sites like Landwatch to find plots of land available for purchase. Most land postings lack insightful descriptions of their plots, making it hard for users to find the exact type of land they want. With *Pocket Plots*, we transformed links into images, into helpful captions.

**Captions → Personalized recommendations**
These captions also inform the user's recommended plots and what parcels they might buy. Along with inputting preferences like desired price range or size of land, the user can submit a text description of what kind of land they want. For example, do they want a flat terrain or a lot of mountains? Do they want to be near a body of water? This description is compared with the generated captions to help pick the user's best match!

### **Chatbot**
Minute Land can be confusing. All the legal confusion, the way we work, and how we make land so affordable makes our operations a mystery to many. That is why we developed a supplemental AI chatbot that has learned our system and can answer questions about how we operate.
*Pocket Plots* offers a built-in chatbot service to automate question-answering for clients with questions about how the application works. Powered by openAI, our chat bot reads our community forums and uses previous questions to best help you.

## 🛠️ How we built it
Our AI focused products (chatbot, caption generation, and recommendation system) run on Python, OpenAI products, and Huggingface transformers. We also used a conglomerate of other related libraries as needed.
Our front-end was primarily built with Tailwind, MaterialUI, and React. For AI focused tasks, we also used Streamlit to speed up deployment.
### We run on Convex
We spent a long time mastering Convex, and it was worth it. With Convex's powerful backend services, we did not need to spend infinite amounts of time developing it out, and instead, we could focus on making the most aesthetically pleasing UI possible.
### Checkbook makes payments easy and fast
We are an e-commerce site for land and rely heavily on payments. While stripe and other platforms offer that capability, nothing compares to what Checkbook has allowed us to do: send invoices with just an email. Utilizing Checkbook's powerful API, we were able to integrate Checkbook into our system for safe and fast transactions, and down the line, we will use it to pay out our sellers without needing them to jump through stripe's 10 different hoops.
## 🤔 Challenges we ran into
Our biggest challenge was synthesizing all of our individual features together into one cohesive project, with compatible front and back-end. Building a project that relied on so many different technologies was also pretty difficult, especially with regards to AI-based features. For example, we built a downstream task, where we had to both generate captions from images, and use those outputs to create a recommendation algorithm.
## 😎 Accomplishments that we're proud of
We are proud of building several completely functional features for *Pocket Plots*. We're especially excited about our applications of AI, and how they make users' *Pocket Plots* experience more customizable and unique.
## 🧠 What we learned
We learned a lot about combining different technologies and fusing our diverse skillsets with each other. We also learned a lot about using some of the hackathon's sponsor products, like Convex and OpenAI.
## 🔎 What's next for Pocket Plots
We hope to expand *Pocket Plots* to have a real user base. We think our idea has real potential commercially. Supplemental AI features also provide a strong technological advantage. | ## FLEX [Freelancing Linking Expertise Xchange]
## Inspiration
Freelancers deserve a platform where they can fully showcase their skills, without worrying about high fees or delayed payments. Companies need fast, reliable access to talent with specific expertise to complete jobs efficiently. "FLEX" bridges the gap, enabling recruiters to instantly find top candidates through AI-powered conversations, ensuring the right fit, right away.
## What it does
Clients talk to our AI, explaining the type of candidate they need and any specific skills they're looking for. As they speak, the AI highlights important keywords and asks any more factors that they would need with the candidate. This data is then analyzed and parsed through our vast database of Freelancers or the best matching candidates. The AI then talks back to the recruiter, showing the top candidates based on the recruiter’s requirements. Once the recruiter picks the right candidate, they can create a smart contract that’s securely stored and managed on the blockchain for transparent payments and agreements.
## How we built it
We built starting with the Frontend using **Next.JS**, and deployed the entire application on **Terraform** for seamless scalability. For voice interaction, we integrated **Deepgram** to generate human-like voice and process recruiter inputs, which are then handled by **Fetch.ai**'s agents. These agents work in tandem: one agent interacts with **Flask** to analyze keywords from the recruiter's speech, another queries the **SingleStore** database, and the third handles communication with **Deepgram**.
Using SingleStore's real-time data analysis and Full-Text Search, we find the best candidates based on factors provided by the client. For secure transactions, we utilized **SUI** blockchain, creating an agreement object once the recruiter posts a job. When a freelancer is selected and both parties reach an agreement, the object gets updated, and escrowed funds are released upon task completion—all through Smart Contracts developed in **Move**. We also used Flask and **Express.js** to manage backend and routing efficiently.
## Challenges we ran into
We faced challenges integrating Fetch.ai agents for the first time, particularly with getting smooth communication between them. Learning Move for SUI and connecting smart contracts with the frontend also proved tricky. Setting up reliable Speech to Text was tough, as we struggled to control when voice input should stop. Despite these hurdles, we persevered and successfully developed this full stack application.
## Accomplishments that we're proud of
We’re proud to have built a fully finished application while learning and implementing new technologies here at CalHacks. Successfully integrating blockchain and AI into a cohesive solution was a major achievement, especially given how cutting-edge both are. It’s exciting to create something that leverages the potential of these rapidly emerging technologies.
## What we learned
We learned how to work with a range of new technologies, including SUI for blockchain transactions, Fetch.ai for agent communication, and SingleStore for real-time data analysis. We also gained experience with Deepgram for voice AI integration.
## What's next for FLEX
Next, we plan to implement DAOs for conflict resolution, allowing decentralized governance to handle disputes between freelancers and clients. We also aim to launch on the SUI mainnet and conduct thorough testing to ensure scalability and performance. | ## Introduction
Introducing **NFTree**, the innovative new platform that allows users to take control of their carbon footprint. On NFTree, you can purchase NFTs of a piece of a forest. Each NFT represents a real piece of land that will be preserved and protected, offsetting your carbon emissions. Not only are you making a positive impact on the environment, but you also get to own a piece of nature and leave a lasting legacy.
## Inspiration
We have always been passionate about environmental sustainability. We've seen the effects of climate change on the planet and knew we wanted to make a difference. We found that corporations attempts at achieving "carbon neutrality" by offsetting there output by purchasing planted trees from third party companies frustrating. What happens to those trees? What if they are cut down? What if we could use the blockchain to give people the opportunity to own a piece of protected land, and in doing so, offset their carbon emissions? We hope that NFTree can not only make a positive impact on the environment, but also provide a unique and meaningful way for people to connect with nature and leave a lasting legacy.
## What it does
NFTree utilizes the blockchain and non fungible tokens to give people the opportunity to own a piece of a protected forest and offset their carbon emissions. The process starts with the opportunity for individuals and corporations to purchase and protect land through government agencies across the world. After this, the purchaser can sell off parts of the land, offering a permanently protected piece of Forrest.
When a user wants to buy a piece of a forest, they can browse through the marketplace of available forest lots. The marketplace is filterable by forest grade, with grade A being the highest quality and F being the worst. The user can choose the forest lot that they want to purchase and use the cryptocurrency HBAR to make the transaction.
Once the transaction is complete, the user officially owns the NFT representing that piece of land. They can view and manage their ownership on the website, and can also see the specific location and coordinates of their forest lot on a map.
In addition to buying a piece of a forest, users can also sell their NFTs on the marketplace. They can set their own price in HBAR and put their forest lot up for sale. Other users can then purchase the NFT from them, becoming the new owner of that piece of land.
The NFTs on NFTree are unique, scarce, and verifiable, and their ownership is recorded on the blockchain, providing transparency and security for all transactions. The ownership of the forest land is also recorded on the blockchain, and all the transaction fees are used to protect the land and preserve it for the future.
The team behind NFTree is committed to making a positive impact on the environment and connecting people with nature. NFTree offers a new way to offset carbon emissions and leave a lasting legacy, while also providing a unique investment opportunity.
## Market Trends
The market trends that will help NFTree succeed are multifaceted and include the growing interest in NFTs, the increasing awareness and concern about climate change, and the desire for unique and meaningful investments.
First and foremost, the NFT market is rapidly growing and gaining mainstream attention. This is driven by the increasing adoption of blockchain technology, which allows for the creation of unique digital assets that can be bought and sold like physical assets. NFTs have already been successful in the art, music, and gaming industries, and now, it's time for the environmental and sustainable sector to benefit from it.
Secondly, the issue of climate change is becoming more pressing and is top of mind for many individuals and organizations. People are looking for ways to make a positive impact on the environment and are increasingly considering investments that align with their values. NFTree offers an opportunity to do just that, by allowing individuals to own a piece of a forest, which not only helps to combat climate change by supporting reforestation efforts, but also, it becomes a carbon decreasing asset.
Lastly, people are looking for unique and meaningful investments that go beyond traditional stocks and bonds. NFTree offers a unique investment opportunity that not only has the potential for financial gain, but also has a tangible and emotional connection to nature. As people become more interested in sustainable and environmentally friendly products, NFTree stands to benefit from this trend as well.
In summary, NFTree is well-positioned to succeed in the current market due to the growing interest in NFTs, the increasing awareness and concern about climate change, and the desire for unique and meaningful investments. NFTree is a one-of-a-kind opportunity to own a piece of nature and make a positive impact on the environment while also getting a financial return.
## Technical Aspects
We wrote our backend server in Kotlin using Ktor as our rest framework and Ebeans ORM with a Postgresql database. We used Hedera, a open source public ledger to build the NFT aspect, facilitating transfers and minting. On the frontend, we used React as well as Firebase for user authentication. Functionality includes creating, viewing, agreeing to transfer and buying the NFTs. At registration, at 12 part mnemonic passphrase is provided to the user and needs to be remembered as it is required for any transfers. The currency used for transfers is HBar, the native currency used by the Hedera chain.
## Challenges we ran into
We have faced a number of challenges while building our platform. One of the biggest challenges we faced was figuring out how to properly use Hedera, the blockchain technology we chose to use for our platform. It was a new technology for us and we had to spend a lot of time learning how it worked and how to properly implement it into our platform. We also encountered challenges in terms of interoperability and scalability, as we needed to ensure that our platform could easily integrate with other systems and handle a large volume of transactions.
## What we learned
We have learned a great deal throughout the process of building our platform. One of the most important things we learned is the importance of flexibility and adaptability. The world of blockchain technology and NFTs is constantly changing and evolving, and we had to be willing to adapt and pivot as needed in order to stay ahead of the curve.
We also learned the importance of user experience and customer satisfaction. We had to put ourselves in the shoes of our customers, understand their needs and wants, and build the platform in a way that caters to them. We had to make sure that the platform was easy to use, reliable, and secure for all of our customers.
Finally, we learned about the power of blockchain technology and how it can be used to create a more sustainable future. We were inspired by the potential of NFTs to transform the way we own and invest in natural resources, and we believe that NFTree can play a key role in making this happen.
Overall, building NFTree has been a valuable learning experience for us, and we are excited to continue working on the platform and to see where it will take us in the future.
## What's next for NFTree
We are excited to see the success of our platform and the positive impact it has had on the environment. In the future, we plan to expand the types of land that can be represented by NFTs on our platform. We also plan to work with more organizations that are involved in land conservation and reforestation, to increase the impact of NFTree. Additionally, we want to explore new use cases for NFTs, such as creating virtual reality experiences that allow users to explore and interact with their forest lots in a more immersive way. We are dedicated to making NFTree the go-to platform for environmental conservation and sustainable investing. | winning |
## Inspiration
Too many impersonal doctor's office experiences, combined with the love of technology and a desire to aid the healthcare industry.
## What it does
Takes a conversation between a patient and a doctor and analyzes all symptoms mentioned in the conversation to improve diagnosis. Ensures the doctor will not have to transcribe the interaction and can focus on the patient for more accurate, timely and personal care.
## How we built it
Ruby on Rails for the structure with a little bit of React. Bayesian Classification procedures for the natural language processing.
## Challenges we ran into
Working in a noisy environment was difficult considering the audio data that we needed to process repeatedly to test our project.
## Accomplishments that we're proud of
Getting keywords, including negatives, to match up in our natural language processor.
## What we learned
How difficult natural language processing is and all of the minute challenges with a machine understanding humans.
## What's next for Pegasus
Turning it into a virtual doctor that can predict illnesses using machine learning and experience with human doctors. | ## Inspiration
What if you could automate one of the most creative performances that combine music and spoken word? Everyone's watched those viral videos of insanely talented rappers online but what if you could get that level of skill? Enter **ghostwriter**, freestyling reimagined.
## What it does
**ghostwriter** allows you to skip through pre-selected beats where it will then listen to your bars, suggesting possible rhymes to help you freestyle. With the 'record' option, you can listen back to your freestyles and even upload them to share with your friends and listen to your friend's freestyles.
## How we built it
In order to build **ghostwriter** we used Google Cloud Services for speech-to-text transcription, the Cohere API for rhyming suggestions, Socket.io for reload time communication between frontend and backend, Express.js for backend, and the CockroachDB distributed SQL database to store transcription as well as the audio files. We used React for the fronted and styled with the Material UI library.
## Challenges we ran into
We had some challenges detecting when the end of a bar might be as different rhyming schemes and flows will have varying pauses. Instead, we decided to display rhyming suggestions for each word as the user then has the freedom to determine when they want to end their bar and start another. Another issue we had was figuring out the latency of the API calls to make sure the data was retrieved in time for the user to think of another bar. Finally, we also had some trouble using audio media players to record the user's freestyle along with the background music, however, we were able to find a solution in the end.
## Accomplishments that we're proud of
We are really proud to say that what we created during the past 36 hours is meeting its intended purpose. We were able to put all the components of this project in motion for the software to successfully hear our words and to generate rhyming suggestions in time for the user to think of another line and continue their freestyle. Additionally, using technologies that were new to us and coding away until it reached our goal expanded our technological expertise.
## What we learned
We learned how to use react and move the text around to match our desired styling. Next, we learned how to interact with numerous APIs (including Cohere's) in order to get the data we want to be organized in the way most efficient for us to display to the user. Finally, we learned how to freestyle better a bit ourselves.
## What's next for Ghostwriter
For **ghostwriter**, we aim to have a higher curation for freestyle beats and to build a social community to highlight the most fire freestyles. Our goal is to turn today's rappers into tomorrow's Hip-Hop legends! | ## Inspiration
We've all left a doctor's office feeling more confused than when we arrived. This common experience highlights a critical issue: over 80% of Americans say access to their complete health records is crucial, yet 63% lack their medical history and vaccination records since birth. Recognizing this gap, we developed our app to empower patients with real-time transcriptions of doctor visits, easy access to health records, and instant answers from our AI doctor avatar. Our goal is to ensure EVERYONE has the tools to manage their health confidently and effectively.
## What it does
Our app provides real-time transcription of doctor visits, easy access to personal health records, and an AI doctor for instant follow-up questions, empowering patients to manage their health effectively.
## How we built it
We used Node.js, Next.js, webRTC, React, Figma, Spline, Firebase, Gemini, Deepgram.
## Challenges we ran into
One of the primary challenges we faced was navigating the extensive documentation associated with new technologies. Learning to implement these tools effectively required us to read closely and understand how to integrate them in unique ways to ensure seamless functionality within our website. Balancing these complexities while maintaining a cohesive user experience tested our problem-solving skills and adaptability. Along the way, we struggled with Git and debugging.
## Accomplishments that we're proud of
Our proudest achievement is developing the AI avatar, as there was very little documentation available on how to build it. This project required us to navigate through various coding languages and integrate the demo effectively, which presented significant challenges. Overcoming these obstacles not only showcased our technical skills but also demonstrated our determination and creativity in bringing a unique feature to life within our application.
## What we learned
We learned the importance of breaking problems down into smaller, manageable pieces to construct something big and impactful. This approach not only made complex challenges more approachable but also fostered collaboration and innovation within our team. By focusing on individual components, we were able to create a cohesive and effective solution that truly enhances patient care. Also, learned a valuable lesson on the importance of sleep!
## What's next for MedicAI
With the AI medical industry projected to exceed $188 billion, we plan to scale our website to accommodate a growing number of users. Our next steps include partnering with hospitals to enhance patient access to our services, ensuring that individuals can seamlessly utilize our platform during their healthcare journey. By expanding our reach, we aim to empower more patients with the tools they need to manage their health effectively. | partial |
## 💡Inspiration
Gaming is often associated with sitting for long periods of time in front of a computer screen, which can have negative physical effects. In recent years, consoles such as the Kinect and Wii have been created to encourage physical fitness through games such as "Just Dance". However, these consoles are simply incompatible with many of the computer and arcade games that we love and cherish.
## ❓What it does
We came up with Motional at HackTheValley wanting to create a technological solution that pushes the boundaries of what we’re used to and what we can expect. Our product, Motional, delivers on that by introducing a new, cost-efficient, and platform-agnostic solution to universally interact with video games through motion capture, and reimagining the gaming experience.
Using state-of-the-art machine learning models, Motional can detect over 500 features on the human body (468 facial features, 21 hand features, and 33 body features) and use these features as control inputs to any video game.
Motional operates in 3 modes: using hand gestures, face gestures, or full-body gestures. We ship certain games out-of-the-box such as Flappy Bird and Snake, with predefined gesture-to-key mappings, so you can play the game directly with the click of a button. For many of these games, jumping in real-life (body gesture) /opening the mouth (face gesture) will be mapped to pressing the "space-bar"/"up" button.
However, the true power of Motional comes with customization. Every simple possible pose can be trained and clustered to provide a custom command. Motional will also play a role in creating a more inclusive gaming space for people with accessibility needs, who might not physically be able to operate a keyboard dexterously.
## 🤔 How we built it
First, a camera feed is taken through Python OpenCV. We then use Google's Mediapipe models to estimate the positions of the features of our subject. To learn a new gesture, we first take a capture of the gesture and store its feature coordinates generated by Mediapipe. Then, for future poses, we compute a similarity score using euclidean distances. If this score is below a certain threshold, we conclude that this gesture is the one we trained on. An annotated image is generated as an output through OpenCV. The actual keyboard presses are done using PyAutoGUI.
We used Tkinter to create a graphical user interface (GUI) where users can switch between different gesture modes, as well as select from our current offering of games. We used MongoDB as our database to keep track of scores and make a universal leaderboard.
## 👨🏫 Challenges we ran into
Our team didn't have much experience with any of the stack before, so it was a big learning curve. Two of us didn't have a lot of experience in Python. We ran into many dependencies issues, and package import errors, which took a lot of time to resolve. When we initially were trying to set up MongoDB, we also kept timing out for weird reasons. But the biggest challenge was probably trying to write code while running on 2 hours of sleep...
## 🏆 Accomplishments that we're proud of
We are very proud to have been able to execute our original idea from start to finish. We managed to actually play games through motion capture, both with our faces, our bodies, and our hands. We were able to store new gestures, and these gestures were detected with very high precision and low recall after careful hyperparameter tuning.
## 📝 What we learned
We learned a lot, both from a technical and non-technical perspective. From a technical perspective, we learned a lot about the tech stack (Python + MongoDB + working with Machine Learning models). From a non-technical perspective, we worked a lot working together as a team and divided up tasks!
## ⏩ What's next for Motional
We would like to implement a better GUI for our application and release it for a small subscription fee as we believe there is a market for people that would be willing to invest money into an application that will help them automate and speed up everyday tasks while providing the ability to play any game they want the way they would like. Furthermore, this could be an interesting niche market to help gamify muscle rehabilition, especially for children. | ## Inspiration
MISSION: Our mission is to create an intuitive and precisely controlled arm for situations that are tough or dangerous for humans to be in.
VISION: This robotic arm application can be used in the medical industry, disaster relief, and toxic environments.
## What it does
The arm imitates the user in a remote destination. The 6DOF range of motion allows the hardware to behave close to a human arm. This would be ideal in environments where human life would be in danger if physically present.
The HelpingHand can be used with a variety of applications, with our simple design the arm can be easily mounted on a wall or a rover. With the simple controls any user will find using the HelpingHand easy and intuitive. Our high speed video camera will allow the user to see the arm and its environment so users can remotely control our hand.
## How I built it
The arm is controlled using a PWM Servo arduino library. The arduino code receives control instructions via serial from the python script. The python script is using opencv to track the user's actions. An additional feature use Intel Realsense and Tensorflow to detect and track user's hand. It uses the depth camera to locate the hand, and use CNN to identity the gesture of the hand out of the 10 types trained. It gave the robotic arm an additional dimension and gave it a more realistic feeling to it.
## Challenges I ran into
The main challenge was working with all 6 degrees of freedom on the arm without tangling it. This being a POC, we simplified the problem to 3DOF, allowing for yaw, pitch and gripper control only. Also, learning the realsense SDK and also processing depth image was an unique experiences, thanks to the hardware provided by Dr. Putz at the nwhacks.
## Accomplishments that I'm proud of
This POC project has scope in a majority of applications. Finishing a working project within the given time frame, that involves software and hardware debugging is a major accomplishment.
## What I learned
We learned about doing hardware hacks at a hackathon. We learned how to control servo motors and serial communication. We learned how to use camera vision efficiently. We learned how to write modular functions for easy integration.
## What's next for The Helping Hand
Improve control on the arm to imitate smooth human arm movements, incorporate the remaining 3 dof and custom build for specific applications, for example, high torque motors would be necessary for heavy lifting applications. | ## Inspiration
The release of Google Cardboard in 2014 launched a movement of using inexpensive materials to create modules that complement existing, commonly available devices such as smartphones, to create revolutionary experiences for users. Thus, in the same vein, we decided to bring retro to the new age using up-cycled materials found in everyday life and an Android phone. This new jukebox will change the way you listen to and interact with music on your phone.
## What it does
There are two main components of this project: (1) the interpretation of human interaction via computer vision, and (2) visualization of the selected tunes. We use the front camera of a Nexus 5 phone to determine whether the user is turning the knobs (aka cups) by looking at the movement of markers drawn on the cup. The volume is then adjusted accordingly. The music is also represented visually through a disco ball. The disco ball uses the phone's screen as a light source and thus has the potential to show different patterns and colors.
## How we built it
We used a cardboard box as the frame of the project. A Styrofoam cup was used as the volume knob, with a smartphone tracking markers along the cup's rim. The phone also serves as the source of music.
A disco ball also hangs from the top of the jukebox. It was made out of aluminum foil taped to a ping pong ball, and the glow of the phone's screen from below is enough to light the ball up.
## Challenges we ran into
Lack of materials
## Accomplishments that we're proud of
Building a cohesive product with both input (volume knob) and output (lit disco ball, music) channels.
## What we learned
* The challenge of lacking materials can make even seemingly simple ideas very difficult.
* Smartphones can be incredibly powerful in both sensing and actuation.
## What's next for CardBox JukeBoard
* Finding ways to amplify the phone's speakers using passive elements.
* Finding ways to concentrate the phone's screen light to make the disco ball even brighter.
* Making it easier to assemble and releasing it to the community. | partial |
## Inspiration
There are a lot of text-to-image, image-to-text AI generators, only a few image-to-video AI generators, but from our research, we couldn't find an AI generator that converted live images to video (.gif). We wanted to fill this void, since it has a few useful applications, and so we created Fleurish!
## What it does
When the user inputs an image, selects a theme and clicks the "Imagine" button, an AI-generated gif based on the inputted image will be generated after a few seconds. Alternatively, if the user connects their phone to their computer, they can also use the "live image" option to get the application to read images from the phone camera video in real time.
## How we built it
We used a Convex template with a built-in Replicate integration as our backend, and then added on a Replicate [https://replicate.com/lucataco/dreamshaper7-img2img-lcm](model) in order to convert images to AI-generated images. For the live image option, we used RTC peer connections to send camera feed to a Python backend, which then compresses the image (to optimize the AI generation) and feeds to the front-end, built in Next.js with the WebSocket API.
## Challenges we ran into
We spent a lot of time testing and searching for a model that gave us satisfactory results, and even then, it took us time to learn how to integrate that with our application. Also, we did not have previous experience with a lot of the technologies used, namely generative AI (with images), WebSocket API, and using the RTC peer connection to allow the communication between a phone and our application.
## Accomplishments that we're proud of
Our application is highly optimized and generates the gif within 1-2 seconds. Also, the themes and the gifs produced give very accurate results.
## What we learned
We learned a lot of new technologies, such as Convex, WebSocket API and RTC peer connection. We also gained experience with image generative AI, which is vastly different than text generative AI. Also, learning to integrate all of the technologies used together was a very insightful learning experience.
## What's next for Fleurish
Better, faster models, user management (so there is no overlap between users). | ## Inspiration
* As ardent content consumers, we relish exploring links from influencers and content creators. However, the sheer volume of links often makes finding the right one a daunting task.
* For example, a Sephora beauty product can be buried under a maze of 30+ links, each with vague and unhelpful titles.
* Our conversations with aspiring content creators echoed this frustration. They lamented the cookie-cutter sameness of everyone's link trees, which stifled their creativity and self-expression due to the lack of personalization.
* We aspired to elevate this experience, not only for influencers but also for their discerning audience.
## What it does
* Flink simplifies domain creation while preserving the freedom of personalization, just like other link platforms.
* How do we do it? We harness the power of AI to streamline the process and add a touch of uniqueness.
Creators can share a few key details, like their profession and brand colors, to craft a personalized site that truly represents them.
* But here's where Flink shines: We ask creators for three words that describe them, and we use this to create a one-of-a-kind background image. Imagine 'Gamer, Minecraft, Streamer' conjuring up a techno-inspired image with Minecraft blocks!
* Perhaps our most valuable feature is the ability to add MEANINGFUL links. Many creators need to showcase products, but navigating to them can be a hassle. With Flink, simply provide the product link, and we'll do the rest – image, accurate title, and a professional yet concise description that markets it effectively.
* After registration, creators have full control. They can add or remove links, tweak content, and toggle between creator and viewer perspectives on their dashboard. Plus, we provide analytics and data insights for creators really understand the trends in their audience.
## How we built it
* We used **React** and **Javascript** for the frontend
* **Node.js, Express, and MongoDB** for backend and storage
* We used **Cohere** for text generation and **OpenAI** for image generation
## Challenges we ran into
* Testing Cohere and OpenAI prompts posed an interesting challenge. We aimed for optimal product descriptions and images while using minimal tokens and context. For instance, generating a background image from just 3 words could result in bizarre, unsuitable images without a precise prompt. Our solution? Crafting prompts like 'Generate a very minimalistic background for...' to refine results.
* Designing the domain creation experience was another puzzle. We needed to strike a balance: collect enough user data for personalization without overwhelming creators. Prolonged surveys would mimic tedious and overwhelming website creation sites. So we really had to come to a consensus on what the necessary info we should collect from them was, and find innovative solutions.
## Accomplishments that we're proud of
* We are very proud of being able to succesfully use the Cohere and OpenAI APIs and use them effectively. We have never implemented AI technology in an application before, so this was a huge milestone for each of us, as this was a foot in the door to the future.
* Each of us had our own skills and weaknesses, and we were able to try new things that maybe we weren't the best at comfortably because of how helpful and resourceful we were.
## What's next for Flink
* Making the site more secure, such as two-factor authentication because of the sensitive nature of the information of the famous people that would potentially use it.
* Ideally, each generated page should have its own generated short link. We did not have enough time to implement this feature, but it would be a very useful feature to have.
* More personalization! With the growing power of AI, there is so much we can do and create with AI, and so there is a lot more features that Flink can implement in the future! | ## **Inspiration:**
Our inspiration stemmed from the realization that the pinnacle of innovation occurs at the intersection of deep curiosity and an expansive space to explore one's imagination. Recognizing the barriers faced by learners—particularly their inability to gain real-time, personalized, and contextualized support—we envisioned a solution that would empower anyone, anywhere to seamlessly pursue their inherent curiosity and desire to learn.
## **What it does:**
Our platform is a revolutionary step forward in the realm of AI-assisted learning. It integrates advanced AI technologies with intuitive human-computer interactions to enhance the context a generative AI model can work within. By analyzing screen content—be it text, graphics, or diagrams—and amalgamating it with the user's audio explanation, our platform grasps a nuanced understanding of the user's specific pain points. Imagine a learner pointing at a perplexing diagram while voicing out their doubts; our system swiftly responds by offering immediate clarifications, both verbally and with on-screen annotations.
## **How we built it**:
We architected a Flask-based backend, creating RESTful APIs to seamlessly interface with user input and machine learning models. Integration of Google's Speech-to-Text enabled the transcription of users' learning preferences, and the incorporation of the Mathpix API facilitated image content extraction. Harnessing the prowess of the GPT-4 model, we've been able to produce contextually rich textual and audio feedback based on captured screen content and stored user data. For frontend fluidity, audio responses were encoded into base64 format, ensuring efficient playback without unnecessary re-renders.
## **Challenges we ran into**:
Scaling the model to accommodate diverse learning scenarios, especially in the broad fields of maths and chemistry, was a notable challenge. Ensuring the accuracy of content extraction and effectively translating that into meaningful AI feedback required meticulous fine-tuning.
## **Accomplishments that we're proud of**:
Successfully building a digital platform that not only deciphers image and audio content but also produces high utility, real-time feedback stands out as a paramount achievement. This platform has the potential to revolutionize how learners interact with digital content, breaking down barriers of confusion in real-time. One of the aspects of our implementation that separates us from other approaches is that we allow the user to perform ICL (In Context Learning), a feature that not many large language models don't allow the user to do seamlessly.
## **What we learned**:
We learned the immense value of integrating multiple AI technologies for a holistic user experience. The project also reinforced the importance of continuous feedback loops in learning and the transformative potential of merging generative AI models with real-time user input. | losing |
## Inspiration
eCommerce is a field that has seen astronomical growth in recent years, and shows no signs of slowing down. With a forecasted growth rate of 10.4% this year, up to $6.3 trillion in global revenues, we decided to tackle Noibu’s challenge to develop an extension to aide ecommerce developers with the impossible task of staying ahead amongst the fierce competitions in this space, all whilst providing a tremendous unique value to shoppers and eCommerce brands alike.
## What it does
Our extension. ShopSmart, aim to provide developers and brands with an accurate idea of how their website is being used, naturally. Unlike A/B testing, which forces a participant to use a given platform and provide feedback, ShopSmart analyzes user activity on any given website and produces a heatmap showing their exact usage patterns, all without collecting user identifying data. In tandem with the heatmap, ShopSmart provides insights as to the sequences of actions taken on their website, correlated with their heatmap usage, allowing an ever deeper understanding of what average usage truly looks like. To incentivize consumers, brands may elect to provide exclusive discount codes only available through ShopSmart, giving the shoppers a kickback for their invaluable input to the brand partners.
## How we built it
ShopSmart was built using the classic web languages HTML, CSS, and Javascript, keeping it simple, lightweight, and speedy.
## Challenges we ran into
We ran into several challenges throughout our development process, largely due to the complexity of the extension in theory being limited in execution to HTML, CSS, and Javascript (as those are the only allowed languages for use in developing extensions). One issue we had was finding a way to overlay the heatmap over the website so as to visually show the paths the user took. Whilst we were able to solve that challenge, we were sadly unable to finish fully integrating our database within the given timeframe into the extension due to the frequency of data collection/communication, and the complexity of the data itself.
## Accomplishments that we're proud of
Our team is very proud in being able to put out a working extension capable of tracking usage and overlaying the resulting heatmap data over the used website, especially as neither of us had any experience with developing extensions. Despite not being able to showcase our extensive database connections in the end as they are not finalized, we are proud of achieving reliable and consistent data flow to our cloud-based database within our testing environment. We are also proud of coming together and solving a problem none of us had considered before, and of course, of the sheer amount we learned over this short time span.
## What we learned
Our hackathon experience was truly transformative, as we not only gained invaluable technical knowledge in Javascript, but also cultivated essential soft skills that will serve us well in any future endeavors. By working together as a team, we were able to pool our unique strengths and collaborate effectively to solve complex problems and bring our ideas to life.
## What's next for ShopSmart
The next steps for ShopSmart are to focus on expanding its capabilities and increasing its reach. One area of focus could be on integrating the extension with more e-commerce platforms to make it more widely accessible to developers and brands. Another area for improvement could be on enhancing the heatmap visualization and adding more advanced analytics features to provide even deeper insights into user behavior. With the help of Machine Learning, developers and brands can utilize the data provided by ShopSmart to better recognize patterns within their customer's usage of their site to make better adjustments and improvements. Additionally, exploring partnerships with e-commerce brands to promote the extension and offer more exclusive discount codes to incentivize consumers could help increase its adoption. Overall, the goal is to continuously improve the extension and make it an indispensable tool for e-commerce businesses looking to stay ahead of the competition. | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | ## Inspiration
As a team, we had a collective interest in sustainability and knew that if we could focus on online consumerism, we would have much greater potential to influence sustainable purchases. We also were inspired by Honey -- we wanted to create something that is easily accessible across many websites, with readily available information for people to compare.
Lots of people we know don’t take the time to look for sustainable items. People typically say if they had a choice between sustainable and non-sustainable products around the same price point, they would choose the sustainable option. But, consumers often don't make the deliberate effort themselves. We’re making it easier for people to buy sustainably -- placing the products right in front of consumers.
## What it does
greenbeans is a Chrome extension that pops up when users are shopping for items online, offering similar alternative products that are more eco-friendly. The extension also displays a message if the product meets our sustainability criteria.
## How we built it
Designs in Figma, Bubble for backend, React for frontend.
## Challenges we ran into
Three beginner hackers! First time at a hackathon for three of us, for two of those three it was our first time formally coding in a product experience. Ideation was also challenging to decide which broad issue to focus on (nutrition, mental health, environment, education, etc.) and in determining specifics of project (how to implement, what audience/products we wanted to focus on, etc.)
## Accomplishments that we're proud of
Navigating Bubble for the first time, multiple members coding in a product setting for the first time... Pretty much creating a solid MVP with a team of beginners!
## What we learned
In order to ensure that a project is feasible, at times it’s necessary to scale back features and implementation to consider constraints. Especially when working on a team with 3 first time hackathon-goers, we had to ensure we were working in spaces where we could balance learning with making progress on the project.
## What's next for greenbeans
Lots to add on in the future:
Systems to reward sustainable product purchases. Storing data over time and tracking sustainable purchases. Incorporating a community aspect, where small businesses can link their products or websites to certain searches.
Including information on best prices for the various sustainable alternatives, or indicators that a product is being sold by a small business. More tailored or specific product recommendations that recognize style, scent, or other niche qualities. | partial |
## Inspiration
COVID-19 has drastically transformed education from in-person to online. While being more accessible, e-learning imposes challenges in terms of attention for both educators and students. Attention is key to any learning experience, and it could normally be assessed approximately by the instructor from the physical feedback of students. However, it is not feasible for instructors to assess the attention levels of students in a remote environment. Therefore, we aim to build a web app that could assess attention based on eye-tracking, body-gesture, and facial expression using the Microsoft Azure Face API.
## What it does
C.L.A.A.S takes the video recordings of students watching lectures (with explicit consent and ethics approval) and process them using Microsoft Azure Face API. Three features including eye-tracking, body posture, and facial expression with sub-metrics will be extracted from the output of the API and analyzed to determine the attention level of the student during specific periods of time. An attention average score will be assigned to each learner at different time intervals based on the evaluation of these three features, and the class attention average score will be calculated and displayed across time on our web app. The results would better inform instructors on sections of the lecture that gain attraction and lose attention in order for more innovative and engaging curriculum design.
## How we built it
1. The front end of the web app is developed using Python and the Microsoft Azure Face API. Video streaming decomposes the video into individual frames from which key features are extracted using the Microsoft Azure Face API.
2. The back end of the web app is also written with Python. With literature review, we created an algorithm which assesses attention based on three metrics (blink frequency, head position, leaning) from two of the above-mentioned features (eye-tracking and body gesture). Finally, we output the attention scores averaged across all students with respect to time on our web app.
## Challenges we ran into
1. Lack of online datasets and limitation on time prevents us from collecting our own data or using machine learning models to classify attention.
2. Insufficient literature to provide quantitative measure for the criteria of each metric.
3. Decomposing a video into frames of image on a web app.
4. Lag during data collection.
## Accomplishments that we're proud of
1. Relevance of the project for education
2. Successfully extracting features from video data using the Microsoft Azure Face API
3. Web design
## What we learned
1. Utilizing the Face API to obtain different facial data
2. Computer vision features that could be used to classify attention
## What's next for C.L.A.A.S.
1. Machine learning model after collection of accurate and labelled baseline data from a larger sample size.
2. Address the subjectiveness of the classification algorithm by considering more scenarios and doing more lit review
3. Test the validity of the algorithm with more students
4. Improve web design, functionalities
5. Address limitations of the program from UX standpoint, such as lower resolution camera, position of their webcam relative to their face | ## Inspiration
The inspiration behind our machine learning app that can diagnose blood diseases runs deep within us. Both of us, as teammates, have been touched by the impact of blood diseases within our own families. Witnessing our loved ones facing the challenges posed by these conditions ignited a passion to create a tool that could potentially alleviate the suffering of others. Our personal connections served as a powerful driving force, propelling us to combine our technical expertise with our heartfelt motivations. Through this app, we aim to provide timely and accurate diagnoses, ultimately contributing to better healthcare outcomes for those at risk and underscoring the importance of empathy-driven innovation.
## What it does
The web application prompts the user to upload an image of their blood cells. The application will then utilize machine learning to identify possible diseases and inform the user of their diagnosis. The possible diagnoses include sickle cell disease, thalassemia, and leukemia. If there were no distinguishable features of a listed disease, the application will inform the user that their blood cells are healthy. It also includes a very brief explanation of the diseases and their symptoms.
## How we built it
First, we used fast.ai libraries to create a machine-learning model built within Kaggle. This first step uses ResNet-18 as a neural network to train our specified model. ResNet-18 is a convolutional neural network that holds millions of reference photos in thousands of different categories and works to identify objects. Next, we trained our specific model using 8000 images of the diseases and healthy blood cells with various conditions and edge cases. This model was then implemented into a second file that uses our pre-trained model to apply to our web application. To create the web application, we used Gradio to locally host a website that could apply the machine learning model. We then refined the UI and added text to guide the user through the process.
## Challenges we ran into
One of the biggest challenges that we ran into was learning how to implement our model into Gradio. Having never applied a model to Gradio in the past, we were tasked with learning the development process and application of Gradio. Eventually, we were able to overcome the difficulties by lots of trial and error and various video tutorials regarding model application and the syntax of Gradio in python.
## Accomplishments that we're proud of
We are extremely proud of the accuracy rate yielded by our model and the intuitive nature of the web application. Having yielded an approximate 95% accuracy from our test trial images, we are thrilled with the high rate of correctness that our machine learning app has achieved. The app's user-friendly interface is designed with accessibility in mind, ensuring that individuals, medical professionals, and caregivers can navigate it with ease. Seeing our project come to fruition has deepened our conviction in the potential of technology to bridge gaps in healthcare, and it reinforces our commitment to applying our skills to causes that hold personal significance.
## What we learned
As a whole, we expanded our knowledge regarding maching learning models and web application development as a whole. Having gone through the process of creating a functioning application required the use of new concepts such as using Gradio and increasing error rate percentage rates within the model.
## What's next for Blood Cell Disease Identifier using Machine Learning
We hope to expand the web application in the future. While easy and simple to use as of now, we hope to add more to the app to increase accuracy, information retention, and advice. One of the biggest improvements to be made is increasing the variety of blood diseases detectable by our model. With more time available after this event, we will be able to advance our front regarding the number of detectable diseases. | ## Inspiration
Disasters can strike quickly and without notice. Most people are unprepared for situations such as earthquakes which occur with alarming frequency along the Pacific Rim. When wifi and cell service are unavailable, medical aid, food, water, and shelter struggle to be shared as the community can only communicate and connect in person.
## What it does
In disaster situations, Rebuild allows users to share and receive information about nearby resources and dangers by placing icons on a map. Rebuild uses a mesh network to automatically transfer data between nearby devices, ensuring that users have the most recent information in their area. What makes Rebuild a unique and effective app is that it does not require WIFI to share and receive data.
## How we built it
We built it with Android and the Nearby Connections API, a built-in Android library which manages the
## Challenges we ran into
The main challenges we faced while making this project were updating the device location so that the markers are placed accurately, and establishing a reliable mesh-network connection between the app users. While these features still aren't perfect, after a long night we managed to reach something we are satisfied with.
## Accomplishments that we're proud of
WORKING MESH NETWORK! (If you heard the scream of joy last night I apologize.)
## What we learned
## What's next for Rebuild | losing |
## What Is It
The Air Synth is a virtual synthesizer that can be played without the need for a physical instrument. By simply moving your fingers in the air, the Air Synth matches your motions to the correct pitches and allows you to practice, jam, and compose wherever and whenever you want.
## How It Works
The Air Synth uses OpenCV to detect the contours of a hand. This is done with background subtraction, a technique that compares a static background image with the live camera feed. The resulting image is passed through a series of filters: black and white filter and a gaussian blur. Then the contour lines are drawn over the hand and critical points are identified. We map these critical points to a range of y-values on the GUI in order to determine which note should be played. | ## Inspiration
Like most university students, we understand and experience the turbulence that comes with relocating every 4 months due to coop sequences while keeping personal spendings to a minimum. It is essential for students to be able to obtain an affordable and effortless way to release their stresses and have hobbies during these pressing times of student life.
## What it does
AirDrum uses computer vision to mirror the standard drum set without the need for heavy equipment, high costs and is accessible in any environment.
## How we built it
We used python (NumPy, OpenCV, MatPlotLib, PyGame, WinSound) to build the entire project.
## Challenges we ran into
The documentation for OpenCV is less robust than what we wanted, which lead to a lot of deep dives on Stack Overflow.
## Accomplishments that we're proud of
We're really happy that we managed to actually get something done.
## What we learned
It was our first time ever trying to do anything with OpenCV, so we learned a lot about the library, and how it works in conjunction with NumPy.
## What's next for AirDrums
The next step for AirDrums is to add more functionality, allowing the user to have more freedom with choosing which drums parts they would like and to be able to save beats created by the user. We also envision a guitar hero type mode where users could try to play the drum part of a song or two. We could also expand to different instruments. | ## Inspiration:
Our inspiration for the project was the rhythm video game Osu!.
## What it does:
The game operates like a regular Osu! game except it is controlled entirely through moving your fingers in front of your webcam. There will be notes that appear on the screen with an approach circle. You must hover the corresponding finger over the note as the approach circle hits in order to gain points. Notes continue to appear as the song continues and the game will finish when the song ends.
## How we built it:
We used the game engine Unity along with the packages Barracuda and MediaPipe to track the fingers.
## Challenges we ran into:
Getting the hand tracking to work, creating key features such as the approach circles, sliders + their paths, and beatmapping
## Accomplishments that we're proud of
Working finger tracking, getting any shape paths of sliders through Bezier curves
## What we learned:
Better time management, how to use Unity with neural networks, and MediaPipe
## What's next for Finger Dance!:
If we continue this project we plan on adding more UI, note types and songs along with general polish. | partial |
## Inspiration
Vision is perhaps our most important sense; we use our sight every waking moment to navigate the world safely, to make decisions, and to connect with others. As such, keeping our eyes healthy is extremely important to our quality of life. In spite of this, we often neglect to get our vision tested regularly, even as we subject our eyes to many varieties of strain in our computer-saturated lives. Because visiting the optometrist can be both time-consuming and difficult to schedule, we sought to create MySight – a simple and inexpensive way to test our vision anywhere, using only a smartphone and a Google Cardboard virtual reality (VR) headset. This app also has large potential impact in developing nations, where administering eye tests cheaply using portable, readily available equipment can change many lives for the better.
## What it does
MySight is a general vision testing application that runs on any modern smartphone in concert with a Google Cardboard VR headset. It allows you to perform a variety of clinical vision tests quickly and easily, including tests for color blindness, stereo vision, visual acuity, and irregular blindspots in the visual field. Beyond informing the user about the current state of their visual health, the results of these tests can be used to recommend that the patient follow up with an optometrist for further treatment. One salient example would be if the app detects one or more especially large blindspots in the patient’s visual field, which is indicative of conditions requiring medical attention, such as glaucoma or an ischemic stroke.
## How we built it
We built MySight using the Unity gaming engine and the Google Cardboard SDK. All scripts were written in C#. Our website (whatswrongwithmyeyes.org) was generated using Angular2.
## Challenges we ran into
None of us on the team had ever used Unity before, and only two of us had even minimal exposure to the C# language in the past. As such, we needed to learn both Unity and C#.
## Accomplishments that we're proud of
We are very pleased to have produced a working version of MySight, which will run on any modern smartphone.
## What we learned
Beyond learning the basics of Unity and C#, we also learned a great deal more about how we see, and how our eyes can be tested.
## What's next for MySight
We envision MySight as a general platform for diagnosing our eyes’ health, and potentially for *improving* eye health in the future, as we plan to implement eye and vision training exercises (c.f. Ultimeyes). | ## Inspiration
Retinal degeneration affects 1 in 3000 people, slowly robbing them of vision over the course of their mid-life. The need to adjust to life without vision, often after decades of relying on it for daily life, presents a unique challenge to individuals facing genetic disease or ocular injury, one which our teammate saw firsthand in his family, and inspired our group to work on a modular, affordable solution. Current technologies which provide similar proximity awareness often cost many thousands of dollars, and require a niche replacement in the user's environment; (shoes with active proximity sensing similar to our system often cost $3-4k for a single pair of shoes). Instead, our group has worked to create a versatile module which can be attached to any shoe, walker, or wheelchair, to provide situational awareness to the thousands of people adjusting to their loss of vision.
## What it does (Higher quality demo on google drive link!: <https://drive.google.com/file/d/1o2mxJXDgxnnhsT8eL4pCnbk_yFVVWiNM/view?usp=share_link> )
The module is constantly pinging its surroundings through a combination of IR and ultrasonic sensors. These are readily visible on the prototype, with the ultrasound device looking forward, and the IR sensor looking to the outward flank. These readings are referenced, alongside measurements from an Inertial Measurement Unit (IMU), to tell when the user is nearing an obstacle. The combination of sensors allows detection of a wide gamut of materials, including those of room walls, furniture, and people. The device is powered by a 7.4v LiPo cell, which displays a charging port on the front of the module. The device has a three hour battery life, but with more compact PCB-based electronics, it could easily be doubled. While the primary use case is envisioned to be clipped onto the top surface of a shoe, the device, roughly the size of a wallet, can be attached to a wide range of mobility devices.
The internal logic uses IMU data to determine when the shoe is on the bottom of a step 'cycle', and touching the ground. The Arduino Nano MCU polls the IMU's gyroscope to check that the shoe's angular speed is close to zero, and that the module is not accelerating significantly. After the MCU has established that the shoe is on the ground, it will then compare ultrasonic and IR proximity sensor readings to see if an obstacle is within a configurable range (in our case, 75cm front, 10cm side).
If the shoe detects an obstacle, it will activate a pager motor which vibrates the wearer's shoe (or other device). The pager motor will continue vibrating until the wearer takes a step which encounters no obstacles, thus acting as a toggle flip-flop.
An RGB LED is added for our debugging of the prototype:
RED - Shoe is moving - In the middle of a step
GREEN - Shoe is at bottom of step and sees an obstacle
BLUE - Shoe is at bottom of step and sees no obstacles
While our group's concept is to package these electronics into a sleek, clip-on plastic case, for now the electronics have simply been folded into a wearable form factor for demonstration.
## How we built it
Our group used an Arduino Nano, batteries, voltage regulators, and proximity sensors from the venue, and supplied our own IMU, kapton tape, and zip ties. (yay zip ties!)
I2C code for basic communication and calibration was taken from a user's guide of the IMU sensor. Code used for logic, sensor polling, and all other functions of the shoe was custom.
All electronics were custom.
Testing was done on the circuits by first assembling the Arduino Microcontroller Unit (MCU) and sensors on a breadboard, powered by laptop. We used this setup to test our code and fine tune our sensors, so that the module would behave how we wanted. We tested and wrote the code for the ultrasonic sensor, the IR sensor, and the gyro separately, before integrating as a system.
Next, we assembled a second breadboard with LiPo cells and a 5v regulator. The two 3.7v cells are wired in series to produce a single 7.4v 2S battery, which is then regulated back down to 5v by an LM7805 regulator chip. One by one, we switched all the MCU/sensor components off of laptop power, and onto our power supply unit. Unfortunately, this took a few tries, and resulted in a lot of debugging.
. After a circuit was finalized, we moved all of the breadboard circuitry to harnessing only, then folded the harnessing and PCB components into a wearable shape for the user.
## Challenges we ran into
The largest challenge we ran into was designing the power supply circuitry, as the combined load of the sensor DAQ package exceeds amp limits on the MCU. This took a few tries (and smoked components) to get right. The rest of the build went fairly smoothly, with the other main pain points being the calibration and stabilization of the IMU readings (this simply necessitated more trials) and the complex folding of the harnessing, which took many hours to arrange into its final shape.
## Accomplishments that we're proud of
We're proud to find a good solution to balance the sensibility of the sensors. We're also proud of integrating all the parts together, supplying them with appropriate power, and assembling the final product as small as possible all in one day.
## What we learned
Power was the largest challenge, both in terms of the electrical engineering, and the product design- ensuring that enough power can be supplied for long enough, while not compromising on the wearability of the product, as it is designed to be a versatile solution for many different shoes. Currently the design has a 3 hour battery life, and is easily rechargeable through a pair of front ports. The challenges with the power system really taught us firsthand how picking the right power source for a product can determine its usability. We were also forced to consider hard questions about our product, such as if there was really a need for such a solution, and what kind of form factor would be needed for a real impact to be made. Likely the biggest thing we learned from our hackathon project was the importance of the end user, and of the impact that engineering decisions have on the daily life of people who use your solution. For example, one of our primary goals was making our solution modular and affordable. Solutions in this space already exist, but their high price and uni-functional design mean that they are unable to have the impact they could. Our modular design hopes to allow for greater flexibility, acting as a more general tool for situational awareness.
## What's next for Smart Shoe Module
Our original idea was to use a combination of miniaturized LiDAR and ultrasound, so our next steps would likely involve the integration of these higher quality sensors, as well as a switch to custom PCBs, allowing for a much more compact sensing package, which could better fit into the sleek, usable clip on design our group envisions.
Additional features might include the use of different vibration modes to signal directional obstacles and paths, and indeed expanding our group's concept of modular assistive devices to other solution types.
We would also look forward to making a more professional demo video
Current example clip of the prototype module taking measurements:(<https://youtube.com/shorts/ECUF5daD5pU?feature=share>) | ## Inspiration
Vision—our most dominant sense—plays a critical role in every faucet and stage in our lives. Over 40 million people worldwide (and increasing) struggle with blindness and 20% of those over 85 experience permanent vision loss. In a world catered to the visually-abled, developing assistive technologies to help blind individuals regain autonomy over their living spaces is becoming increasingly important.
## What it does
ReVision is a pair of smart glasses that seamlessly intertwines the features of AI and computer vision to help blind people navigate their surroundings. One of our main features is the integration of an environmental scan system to describe a person’s surroundings in great detail—voiced through Google text-to-speech. Not only this, but the user is able to have a conversation with ALICE (Artificial Lenses Integrated Computer Eyes), ReVision’s own AI assistant. “Alice, what am I looking at?”, “Alice, how much cash am I holding?”, “Alice, how’s the weather?” are all examples of questions ReVision can successfully answer. Our glasses also detect nearby objects and signals buzzing when the user approaches an obstacle or wall.
Furthermore, ReVision is capable of scanning to find a specific object. For example—at an aisle of the grocery store—” Alice, where is the milk?” will have Alice scan the view for milk to let the user know of its position. With ReVision, we are helping blind people regain independence within society.
## How we built it
To build ReVision, we used a combination of hardware components and modules along with CV. For hardware, we integrated an Arduino uno to seamlessly communicate back and forth between some of the inputs and outputs like the ultrasonic sensor and vibrating buzzer for haptic feedback. Our features that helped the user navigate their world heavily relied on a dismantled webcam that is hooked up to a coco-ssd model and ChatGPT 4 to identify objects and describe the environment. We also used text-to-speech and speech-to-text to make interacting with ALICE friendly and natural.
As for the prototype of the actual product, we used stockpaper, and glue—held together with the framework of an old pair of glasses. We attached the hardware components to the inside of the frame, which pokes out to retain information. An additional feature of ReVision is the effortless attachment of the shade cover, covering the lens of our glasses. We did this using magnets, allowing for a sleek and cohesive design.
## Challenges we ran into
One of the most prominent challenges we conquered was soldering ourselves for the first time as well as DIYing our USB cord for this project. As well, our web camera somehow ended up getting ripped once we had finished our prototype and ended up not working. To fix this, we had to solder the wires and dissect our goggles to fix their composition within the frames.
## Accomplishments that we're proud of
Through human design thinking, we knew that we wanted to create technology that not only promotes accessibility and equity but also does not look too distinctive. We are incredibly proud of the fact that we created a wearable assistive device that is disguised as an everyday accessory.
## What we learned
With half our team being completely new to hackathons and working with AI, taking on this project was a large jump into STEM for us. We learned how to program AI, wearable technologies, and even how to solder since our wires were all so short for some reason. Combining and exchanging our skills and strengths, our team also learned design skills—making the most compact, fashionable glasses to act as a container for all the technologies they hold.
## What's next for ReVision
Our mission is to make the world a better place; step-by-step. For the future of ReVision, we want to expand our horizons to help those with other sensory disabilities such as deafness and even touch. | partial |
## Check out our site -> [Saga](http://sagaverse.app)
## Inspiration
There are few better feelings in the world than reading together with a child that you care about. “Just one more story!” — “I promise I’ll go to bed after the next one” — or even simply “Zzzzzzz” — these moments forge lasting memories and provide important educational development during bedtime routines. We wanted to make sure that our loved ones never run out of good stories. Even more, we wanted to create a unique, dynamic reading experience for kids that makes reading even more fun.
After helping to build the components of the story, kids are able to help the character make decisions along the way. “Should Balthazar the bear search near the park for his lost friend? or should he look in the desert?” These decisions help children learn and develop key skills like decisiveness and action. The story updates in real time, ensuring an engaging experience for kids and parents.
Through copious amounts of delirious research, we learned that children can actually learn better and retain more when reading with parents on a tablet. After talking to 8 users (parents and kiddos) over the course of the weekend, we defined our problem space and set out to create a truly “Neverending Story.”
## What it does
Each day, *Saga* creates a new, illustrated bedtime story for children aged 0-7. Using OpenAI technology, the app generates and then illustrates an age and interest-appropriate story based on what they want to hear and what will help them learn. Along the way, our application keeps kids engaged by prompting decisions; like a real-time choose-your-own-adventure story.
We’re helping parents broaden the stories available for their children — imprinting values of diversity, inclusion, community, and a strong moral compass. With *Saga*, parents and children can create a universe of stories, with their specific interests at the center.
## How we built it
We took an intentional approach to developing a working MVP
* **Needs finding:** We began with a desire to uncover a need and build a solution based on user input. We interviewed 8 users over the weekend (parents and kids) and used their insights to develop our application.
* **Defined MVP:** A deployable application that generates a unique story and illustrations while allowing for dynamic reader inputs using OpenAI. We indexed on story, picture, and educational quality over reproducibility.
* **Tech Stack:** We used the latest LLM models (GPT-3 and DALLE-2), Flutter for the client, a Node/Express backend, and MongoDB for data management
* **Prompt Engineering:** Finding the limitations of the underlying LLM technology and instead using Guess and check until we narrowed down the prompt to produce to more consistent results. We explored borderline use cases to learn where the model breaks.
* **Final Touches:** Quality control and lots of tweaking of the image prompting functionality
## Challenges we ran into
Our biggest challenges revolved around fully understanding the power of, and the difficulties stemming from prompt generation for OpenAI. This struggle hit us on several different fronts:
1. **Text generation** - Early on, we asked for specific stories and prompts resembling “write me a 500-word story.” Unsurprisingly, the API completely disregarded the constraints, and the outputs were similar regardless of how we bounded by word count. We eventually became more familiar with the structure of quality prompts, but we hit our heads against this particular problem for a long time.
2. **Illustration generation** - We weren’t able to predictably write OpenAI illustration prompts that provided consistently quality images. This was a particularly difficult problem for us since we had planned on having a consistent character illustration throughout the story. Eventually, we found style modifiers to help bound the problem.
3. **Child-safe content** - We wanted to be completely certain that we only presented safe and age-appropriate information back to the users. With this in mind, we built several layers of passive and active protection to ensure all content is family friendly.
## What we learned
So many things about OpenAI!
1. Creating consistent images using OpenAI generation is super hard, especially when focusing on one primary protagonist. We addressed this by specifically using art styles to decrease the variability between images.
2. GPT-3's input / output length limitations are much more stringent than ChatGPT's -- this meant we had to be pretty innovative with how we maintained the context over the course of 10+ page stories.
3. How to reduce overall response time while using OpenAI's API, which was really important when generating so many images and using GPT-3 to describe and summarize so many things.
4. Simply instructing GPT to not do something doesn’t seem to work as well as carefully crafting a prompt of behavior you would like it to model. You need to trick it into thinking it is someone or something -- from there, it will behave.
## Accomplishments that we're proud of
We’re super excited about what we were able to create given that this is the first hackathon for 3 of our team members! Specifically, we’re proud of:
* Developing a fun solution to help make learning engaging for future generations
* Solving a real need for people in our lives
* Delivering a well-scoped and functional MVP based on multiple user interviews
* Integrating varied team member skill sets from barely technical to full-stack
## What's next for Saga
### **Test and Iterate**
We’re excited to get our prototype project in the hands of users and see what real-world feedback looks like. Using this customer feedback, we’ll quickly iterate and make sure that our application is really solving a user need. We hope to get this on the App Store ASAP!!
### **Add functionality**
Based on the feedback that we’ll receive from our initial MVP, we will prioritize additional functionality:
**Reading level that grows with the child** — adding more complex vocabulary and situations for a story and character that the child knows and loves.
**Allow for ongoing universe creation** — saving favorite characters, settings, and situations to create a rich, ongoing world.
**Unbounded story attributes** — rather than prompting parents with fixed attributes, give an open-ended prompt for more control of the story, increasing child engagement
**Real-time user feedback on a story to refine the prompts** — at the end of each story, capture user feedback to help personalize future prompts and stories.
### **Monetize**
Evaluate unit economics and determine the best path to market. Current possible ideas:
* SaaS subscription based on one book per day or unlimited access
* Audible tokens model to access a fixed amount of stories per month
* Identify and partner with mid-market publishers to license IP and leverage existing fan bases
* Whitelabel the solution on a services level to publishers who don’t have a robust engineering team
## References
<https://www.frontiersin.org/articles/10.3389/fpsyg.2017.00677/full> | ## Inspiration 🌈
According to mentalhealth.uk, over 45% of children asked said they felt lonely 'often' or 'some of the time'.
That is way too high in our team's opinion.
At Teddy.ai, our inspiration is simple yet powerful: to ensure that no child or individual ever feels lonely. We believe in harnessing the potential of technology to create companionship, connection, and a brighter future for everyone. 🤗
## What It Does 🐻
Teddy.ai is not just a teddy bear; it's a gateway to a world of possibilities. 🌌
* It leverages the blockchain to introduce children to concepts like NFTs and FLOW tokens through fun and interactive experiences, while also leveraging Starknet to ensure privacy and scalability. 🧸🔗
* Teddy.ai is your child's snuggable best friend who understands them, rewards positive behavior, and ensures no child feels alone. 🎉
* With Teddy.ai, you can now seamlessly integrate your social media links and personal websites, allowing the bear to know all the details about its owner's life. It's like having a friend who truly understands you! 📱🌐
## How We Built It 🛠️
We built Teddy.ai with a combination of cutting-edge technologies:
* **Verbwire API**: Utilized for minting NFTs of precious memories in real-time. 🖼️
* **Flow Blockchain**: Integrated to enable transactions through speech, making it accessible for children. 🗣️
* **OpenAI Language Models (LLMs)**: Utilized OpenAI's language models for understanding and responding to users. 🤖
* **OpenAI Whisper**: Employed for Speech-to-Text (STT) functionality. 🎤
* **Beautiful Soup**: Used for web scraping to gather information. 🕸️
* **Elevenlabs**: Leveraged for Text-to-Speech (TTS) capabilities. 🔊
* **OpenCV**: Captured memories with a user's webcam. 📸
* **Sounddevice**: Recorded audio from interaction between the user and their teddy. 🎶
* **Starknet**: Leveraged Starknet mainnet to mint unique Teddy Bear NFTs for each teddy bear, immutably recording their owner on the blockchain.
## Challenges We Ran Into 🚧
During our journey, we faced several challenges, including:
* Working with Cadence as well as Flow Client Library for the first time. 💻
* Getting Flow transactions working in JavaScript and integrating them with our Python background. 🤯
* Integrating Starknet with the rest of our software given the intensive implementation necessary. 🧩
## Accomplishments That We're Proud Of 🏆
Our proudest accomplishments include:
* Successfully integrating web3 features seamlessly with our backend. 🌐
* Lowering the barrier so that even children can mint NFTs and send blockchain transactions. 🚀
* Integrating audio and video capture to make Teddy.ai a reality. 🎥🔊
## What We Learned 📚
First, working with Flow and Starknet for the first time was a significant learning experience for us, and it has enriched our understanding of blockchain technology. 🤓
In addition, integrating the frontend and backend proved to be quite the challenge. We were able to do so, but it took many hours. Thankfully, we were able to do so just in time for the hackathon submission deadline. 🕰️
Finally, we really love working with the new OpenAI Assistants and function calling APIs - we were able to streamline processes that would otherwise be incredibly complicated. 🤖
## What's Next For Teddy.ai 🚀
The journey has just begun! We envision Teddy.ai becoming a global symbol of companionship and learning. We'll continue to enhance its capabilities, expand its educational features, and explore new horizons in technology and education. Our mission remains clear: to ensure that no one ever feels alone, and that Teddy.ai is there to provide comfort, connection, and a bright future for all. 🌍💖
Join us on this exciting journey to redefine companionship and education with Teddy.ai! 🐻💡 | ## Inspiration
After playing Minecraft until 5am for the first time the weekend prior to YHack, I thought about building the basic features of Minecraft would be fun and challenging.
## What it does
This is a single player game where the camera is controlled by WASD keys for planar movements and cursor for rotation. When looking at a clickable object, the camera rotation is prevented (different from the actual game). To "mine" the blocks, players must click on the block object multiple times until its "health" goes down (differs from actual game). Particle Systems (mini blocks that fly out) are then launched out of the block for interaction feedback. Once a block is "mined," a compact version drops, floats, and rotates above the ground.
## How I built it
Using material assets from Unity's Tanks! tutorial and the cube self-rotation concept from Roll-A-Ball tutorial, I was able to create animations with simple assets.
## Challenges I ran into
This was my first time learning and using Particle Systems and customizing the produced particles. Another challenge was the camera rotation using the cursor's position. The most difficult challenge (that I could not solve) was making the Particle System output the same material as the cube it is attached to. The goal was to be able to scale up the cubes with different materials without creating a separate particle system for each block type the map maker creates. Further investigation is needed here.
## Accomplishments that I'm proud of
Having the Particle System in the game really saved time and unnecessary loading of new objects. It make made it look more like Minecraft which was a huge plus. I am really proud of finally knowing how to move the camera based off of arrow key inputs. Even though it the planar movement may be considered trivial, it was definitely a milestone in my books after many different Unity projects.
## What I learned
I learned what is a Particle System and how to move/rotate the camera with arrow key inputs and cursor.
## What's next for Minecraft - POC
Listing from highest priority to least:
* Make cubes scalable
* Add a weapon to simulate attacking
* Collecting cubes and having a storage
* Having a map maker (Bonus: environmental effects)
* Crafting
* Enemies | partial |
## Inspiration
We were all chronically addicted to Reddit, and all the productivity extensions out there took a "cold turkey" approach. We felt like our method of gradual addiction treatment is more effective.
## What it does
Over time, we slowly remove elements on reddit that are addicting (CTA's, voting counters, comment counts, etc.). This way, the user willingly develops indifference towards the platform opposed to fighting the hard wired behaviour that Reddit expertly ingrained.
## How we built it
We performed research on how drug rehabilitation is performed at rehab centres, and incorporated those practices into the design of the extension. We used jQuery to manipulate the DOM elements.
## Challenges we ran into
Time was the main constraint, as we spent the first half of the hackathon discarding dead-end ideas midway.
## Accomplishments that we're proud of
Finishing in time and shipping an application that can be used immediately by other addicted redditors.
## What we learned
jQuery and better familiarity with building chrome extensions. | ## Inspiration
One of our team members, an international student from India, shocked us with troubling statistics about the organ donation infrastructure in his home country. Where 200,000 people need new kidneys and 100,000 need new livers each year, only **around 2%** actually receive them. This figure is a product of bureaucratic red tape and inefficient donor matching. Though the system in the United States is far from perfect, we take the associated medical infrastructure almost for granted. We were truly humbled by this realization and spent our Pennapps trying to tackle this problem in any way possible.
## HOW SODA WORKS
In developing countries (such as India) where there is little existing infrastructure for electronic patient records as well as a lack of an efficient emergency organ donation system, SODA serves as a comprehensive web application to store patient records online, efficiently and rapidly match available organs (in the case of accidental death) to nearby acceptors based on a host of medical factors such as disease history, blood type, behavioral patterns and other significant elements. SODA's is grant thousands of organ recipients a second chance at life and save many more lives!
SODA provides an online infrastructure for hospitals to store information necessary for patients receiving and giving organ transplants and match viable candidates using a prioritization algorithm. Hospitals create accounts on the webapp and register patients in lists of donors and acceptors through a detailed form. If a donor passes away and their organs are avavilable, a separate form feeds into an organ-acceptor matching algorithm to determine the viable locations and candidates.
## How we built it
HTML/CSS, Google Maps API, Python/Flask, Bootstrap, MongoDB, Github
## Challenges we ran into
-Setting up the database backend
-Building an efficient matching algorithm, when none of us had a medical/biology background
* Conflicting CSS schemes
* Multiple people editing template files
## Accomplishments that we're proud of
Putting our research efforts to good use by using the data we collected to make a comprehensive medical form for patients (Donors and Acceptors) and organ matching algorithm.
Pulling through at 5 am with the database component with no prior experience and building a successful, non-local database (MongoDB)
## What's next for Soda
Amazon Alexa!
According to a study, many doctors spend 2/3 or more of their daily schedule filling out paperwork. We originally explored integration of organ donation checklists with Alexa, but based on our interests and priorities, decided to focus solely on the web app for this hackathon. In the future, we would like to link voice control to the patient medical database to save doctors energy and time. Furthermore, Alexa could ask patient history questions and tabulate answers so as to use this data to determine whether a person is an eligible donor for an organ as well to find the optimal acceptor match. | ## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and news literacy in the general public by making them aware of syntax and vocabulary manipulation. We hope that others are inspired to be more critical of wording and truly see the real news behind the sentiment -- especially considering today's current events.
## What it does
Using Indico's machine learning textual analysis API, we created a Google Chrome extension and web application that allows users to **analyze financial/news articles for political bias, sentiment, positivity, and significant keywords.** Based on a short glance on our visualized data, users can immediately gauge if the article is worth further reading in their valuable time based on their own views.
The Google Chrome extension allows users to analyze their articles in real-time, with a single button press, popping up a minimalistic window with visualized data. The web application allows users to more thoroughly analyze their articles, adding highlights to keywords in the article on top of the previous functions so users can get to reading the most important parts.
Though there is a possibilitiy of opening this to the general public, we see tremendous opportunity in the financial and political sector in optimizing time and wording.
## How we built it
We used Indico's machine learning textual analysis API, React, NodeJS, JavaScript, MongoDB, HTML5, and CSS3 to create the Google Chrome Extension, web application, back-end server, and database.
## Challenges we ran into
Surprisingly, one of the more challenging parts was implementing a performant Chrome extension. Design patterns we knew had to be put aside to follow a specific one, to which we gradually aligned with. It was overall a good experience using Google's APIs.
## Accomplishments that we're proud of
We are especially proud of being able to launch a minimalist Google Chrome Extension in tandem with a web application, allowing users to either analyze news articles at their leisure, or in a more professional degree. We reached more than several of our stretch goals, and couldn't have done it without the amazing team dynamic we had.
## What we learned
Trusting your teammates to tackle goals they never did before, understanding compromise, and putting the team ahead of personal views was what made this Hackathon one of the most memorable for everyone. Emotional intelligence played just as an important a role as technical intelligence, and we learned all the better how rewarding and exciting it can be when everyone's rowing in the same direction.
## What's next for Need 2 Know
We would like to consider what we have now as a proof of concept. There is so much growing potential, and we hope to further work together in making a more professional product capable of automatically parsing entire sites, detecting new articles in real-time, working with big data to visualize news sites differences/biases, topic-centric analysis, and more. Working on this product has been a real eye-opener, and we're excited for the future. | losing |
## Inspiration
We think improving cybersecurity does not always entail passively anticipating possible attacks. It is an equally valid strategy to go on the offensive against the transgressors. Hence, we employed the strategy of the aggressors against themselves --- by making what's basically a phishing bank app that allows us to gather information about potentially stolen phones.
## What it does
Our main app, Bait Master, is a cloud application linked to Firebase. Once the user finishes the initial setup, the app will disguise itself as a banking application with fairly convincing UI/UX with fake bank account information. Should the phone be ever stolen or password-cracked, the aggressor will likely be tempted to take a look at the obvious bank information. When they open the app, they fall for the phishing bait. The app will discreetly take several pictures of the aggressor's face from the front camera, as well as uploading location/time information periodically in the background to Firebase. The user can then check these information by logging in to our companion app --- Trap Master Tracker --- using any other mobile device with the credentials they used to set up the main phishing app, where we use Google Cloud services such as Map API to display the said information.
## How we built it
Both the main app and the companion app are developed in Java Android using Android Studio. We used Google's Firebase as a cloud platform to store user information such as credentials, pictures taken, and location data. Our companion app is also developed in Android and uses Firebase, and it uses Google Cloud APIs such as Map API to display information.
## Challenges we ran into
1) The camera2 library of Android is very difficult to use. Taking a picture is one thing --- but taking a photo secretly without using the native camera intent and to save it took us a long time to figure out. Even now, the front camera configuration sometimes fails in older phones --- we are still trying to figure that out.
2) The original idea was to use Twilio to send SMS messages to the back-up phone number of the owner of the stolen phone. However, we could not find an easy way to implement Twilio in Android Studio without hosting another server, which we think will hinder maintainability. We eventually decided to opt out of this idea as we ran out of time.
## Accomplishments that we're proud of
I think we really pushed the boundary of our Android dev abilities by using features of Android that we did not even know existed. For instance, the main Bait Master app is capable of morphing its own launcher to acquire a new icon as well as a new app name to disguise itself as a banking app. Furthermore, discreetly taking pictures without any form of notification and uploading them is technically challenging, but we pulled it off nonetheless. We are really proud of the product that we built at the end of this weekend.
## What we learned
Appearances can be misleading. Don't trust everything that you see. Be careful when apps ask for access permission that it shouldn't use (such as camera and location).
## What's next for Bait Master
We want to add more system-level mobile device management feature such as remote password reset, wiping sensitive data, etc. We also want to make the app more accessible by adding more disguise appearance options, as well as improving our client support by making the app more easy to understand. | ## Inspiration
The inspiration came from the two women on the team, as the app is geared toward female security.
## What it does
A common issue and concern for women on dates is safety. Now that online dating sites are more popular, this raises the concern women may have about going out to meet their date-- is the person crazy? Will they hurt me? Will they abduct me?
While this web app cannot stop something from happening, it was meant to assure the woman that if she was taken against her will then a contact of choice or even the police will be alerted as soon as possible.
The idea is a woman makes a profile and enters her choice of emergency contacts. Before going out on a date, she would select the "DateKnight" option and log where the date was taking place, what time it was taking place, an uploaded picture of the date, a selected check-in time, and a selfie of herself before leaving.
When she is on her date, if she does not check into the app within 10 minutes of her selected check-in time, the emergency contact of her choice is then texted and alerted that she is not responding on her date and she may be in trouble.
After a specified time that alert is sent, if the user still has not checked in the police are called and alerted the location of where the woman should be. Now the date information the woman uploaded before can be used in finding her if she has been abducted.
While this was originally intended for women, it can be used by either gender to make the user feel like even if something were to happen then contacts and the police were quickly alerted that something is wrong.
## How we built it
We created the back end using MySQL in order to effectively store and access the users data across the web app. We also implemented PHP/CSS/HTML to create the front end and bridge it to the back to create core functionality. Using the Twilio API, we filtered fields from our database into real communications with demo users. All components are running a LAMP stack (Linux, Apache, MySQL, PHP) on an EC2 (Elastic Cloud-Compute) instance with Amazon Web Services. We are also using their Cloud9 collaborative IDE to work together in real-time on our project files. We acquired a custom domain (safetea.tech) from Domain.com and connected it to our EC2 instance.
## Challenges we ran into
The idea that we started out with (and spent quite a bit of time on) did not end up being the one we brought to completion. We initially wanted to create a web-app with Python for various data analysis purposes. Unfortunately, this soon became all about learning how to make a web-app with Python rather than how to create a useful implementation of the technology. One of our ideas was not reliant on Python and could easily be adapted to the newly chosen language. There was, however, no way to make up for lost time.
Programming in PHP, error messages were often hidden during the development process and made isolating (and therefore fixing) problems quite tricky. We also only had one member who had prior-experience with this stack's languages, but the general coding backgrounds helped them quickly acquire new and valuable skills.
## Accomplishments that we're proud of
We are proud that we have a demo-ready project. Though we most certainly faced our share of adversity (the person writing this sentence has a net 1 hour(s) of sleep and is so nauseous he does not even want the Insomnia cookies that were purchased for him; Well, they were not all for him but he has a large appetite for the soft, chewy, chocolate chip cookies of Insomnia (use promo code HARRYLOVESINSOMNIA), I digress), we worked together to overcome obstacles.
## What we learned
We learned that maybe if we had planned ahead on the 7 hour car ride like we were SUPPOSED to, then MAYBE we would have shown up knowing what we wanted to pursue and not had to madly scrape ideas together until we got one we really liked and was doable.
## What's next for SafeTEA
Another feature we talked about creating was one called “Party Mode”. The concept behind this is that if a group of friends is planning on going out and drinking they would all log the location they planned to be, the names and contacts of the people they were going with, and then a selected radius.
If the app sensed that a member of the group was outside of the radius selected, it would alert them first that they were too far and give them 10 minutes to get back to their friends. If they did not get back in that radius within 10 minutes, the other people they were out with would be alerted that their friend was beyond the set radius and then tell them the last location they were detected at.
This was designed so that if a group of friends went out and they got separated, no one would be too far away without the others knowing. If one of the friends were abducted and then taken far enough away from the determined location the others would be alerted someone was outside the radius and would be able to try and contact the user, and if given no response, the police quickly.
The feature would be able to be turned off if a member decided they wanted to leave early but would still alert the others that someone had turned it off in case they were not aware.
While this option appears on the web app home page, we were unable to link the location portion (the major component behind it) because we were unable to fund this. | ## Inspiration
It sometimes feels so innate to find inspiration from everyday routine. One such case is when my teammates and I were on a group call when we discussed about how we got **calls from spammers \*\*almost every day and how convincing it seemed to everyone who talked to them for a while. As we discussed further we found the problem continued in the current technological world of social media where we find \*\*spams on Twitter** as well. So, we decided to create an app for the problems faced by people in the virtual world.
## What it does
The application is designed for easy usage while keeping every user in mind. The app targets **phone numbers** and **twitter accounts** of spammers and lets the users review the person behind it. The users can also look up the reviews added by other people on the platform along with relevant photos and tags. To make the app more secure we have **integrated OTP services** for new user registration.
## How we built it
We tried to build the application with a simple idea in mind. We made it keeping the everyday challenges that we faced in mind and all the technologies and software that we are good at. For seamless integration into all mobile operating systems we developed the front end using **React Native** and the back end was made using **Node.js** hosted on **Google Cloud** app engine for synchronous code execution. As for our messaging and OTP services we decided to go with **Twilio** for reliable connectivity anywhere in the world. We even used Twitter API for collecting and analysing tweets. Finally, for database management we incorporated **NoSQL Cloud Firestone** and consolidated **Google Cloud** storage for blob files.
## Challenges we ran into
The primary challenge that we ran into was the **long-distance communication** with the team. As the event was online our team was based from different parts of the world. With that we had different time zones. This led to lack of communication and longer response time. As we proceeded further into the event we **adapted to each other’s schedule and work**, which all in all was a great experience in itself.
## Accomplishments that we're proud of
While creating the whole project we accomplished a lot of things and overcame a lot of challenges. Looking back, we think that making a **fully functional app in less that 36 hours** is the greatest accomplishment in itself.
## What we learned
Our team enjoyed a lot during the project as we learned to make our way through. The key points that all of us can say we learned was **cooperation** and **efficiency** all while staying online the whole time. There was a unspoken understanding that we developed in the past few hours that we can say we are really proud of.
## What's next for SafeView
We developed SafeView keeping the future in mind. Our team has a lot of plans and hopes for the application. But first we will try to **improve our UI** and make it more user friendly along with covering **more test cases** for the better learning of the app and covering all possibilities. Finally, we plan to **add location for our app** and help real world users to stay aware of bad neighbourhoods all this while improving any bugs that we can find in the app. | partial |
## Inspiration
Last year when I arrived at MIT, I was a fish out of water. I was lost in the whirlpool of deadlines, club events, and registration. I struggled to complete problem sets on time and didn't even consider making connections and friends. Thankfully, I quickly met my next dorm neighbor, Hassan. This experienced third-year student knew everything about the courses I was taking and where to go to explore MIT. Without Hassan, I would have failed 8.01 because of my lack of knowledge about Professor Mohammad's office hours and review sessions. Without Hassan, I would have missed out on so many internship opportunities because of my lack of knowledge of applications and their deadlines. I was extremely grateful for Hassan, but I constantly thought about all the students just like me who did not have this resource. Enter ChatMIT: a chatbot trained on insider secrets and up-to-date data about MIT. Know struggling students can always have a resource they could rely on.
## What it does
ChatMIT is a chatbot that prospective and current MIT students alike can use to answer their questions and curiosities about this immensely wonderful, yet confusing institute! Ask it about good study spots. Ask it where to find certain buildings. Ask it for student testimonials about UROPs. The possibilities are endless.
## How we built it
ChatMIT is a large language model built off of ChatGPT3.5-Turbo. It is trained on data from MIT's blog posts, registration websites, club websites, academic resources, and more. The front-end interface is made using React.
## Challenges we ran into
There were two main problems that our group ran into: first, training the GPT model; second, collecting immense troves of data. Training a GPT model proved to be a tall task in a 24-hour timeframe. However, our group managed to do so after hours of experimentation and trial-and-error. Collecting the data to train the model also was extremely time-consuming: MIT's public data is commonly regarded as "confusing" and "hard to navigate." Our team spent hours sifting through this data across the web, finally creating the finished database.
## Accomplishments that we're proud of
We are proud of our unique, utilitarian idea that was actually implemented in a 24-hour timeframe. We had plenty of doubters, but also plenty of supporters - all of whom motivated us to persevere. Furthermore, we are super happy with the UI, as it has the color scheme of MIT, with Tim the Beaver offering the advice!
## What we learned
Creating chatbots is hard, yet rewarding work. We also learned a lot about React properties, such as state and loading screens.
## What's next for ChatMIT
More data, adding schedules, etc. | ## Inspiration
We noticed a lot of stress among students around midterm season and wanted to utilize our programming skills to support them both mentally and academically. Our implementation was profoundly inspired by Jerry Xu's Simply Python Chatbot repository, which was built on a different framework called Keras. Through this project, we hoped to build a platform where students can freely reach out and find help whenever needed.
## What it does
Students can communicate their feelings, seek academic advice, or say anything else that is on their mind to the eTA. The eTA will respond with words of encouragement, point to helpful resources relevant to the student's coursework, or even make light conversation.
## How we built it
Our team used python as the main programming language including various frameworks, such as PyTorch for machine learning and Tkinter for the GUI. The machine learning model was trained by a manually produced dataset by considering possible user inputs and creating appropriate responses to given inputs.
## Challenges we ran into
It was difficult to fine tune the number of epochs of the machine learning algorithm in a way that it yielded the best final results. Using many of the necessary frameworks and packages generally posed a challenge as well.
## Accomplishments that we're proud of
We were impressed by the relative efficacy and stability of the final product, taking into account the fast-paced and time-sensitive nature of the event. We are also proud of the strong bonds that we have formed among team members through our collaborative efforts.
## What we learned
We discovered the versatility of machine learning algorithms but also their limitations in terms of accuracy and consistency under unexpected or ambiguous circumstances. We believe, however, that this drawback can be addressed with the usage of a more complex model, allotment of more resources, and a larger supply of training data.
## What's next for eTA
We would like to accommodate a wider variety of topics in the program by expanding the scope of the dataset--potentially through the collection of more diverse user inputs from a wider sample population at Berkeley. | ## Inspiration
Since the beginning of the hackathon, all of us were interested in building something related to helping the community. Initially we began with the idea of a trash bot, but quickly realized the scope of the project would make it unrealistic. We eventually decided to work on a project that would help ease the burden on both the teachers and students through technologies that not only make learning new things easier and more approachable, but also giving teachers more opportunities to interact and learn about their students.
## What it does
We built a Google Action that gives Google Assistant the ability to help the user learn a new language by quizzing the user on words of several languages, including Spanish and Mandarin. In addition to the Google Action, we also built a very PRETTY user interface that allows a user to add new words to the teacher's dictionary.
## How we built it
The Google Action was built using the Google DialogFlow Console. We designed a number of intents for the Action and implemented robust server code in Node.js and a Firebase database to control the behavior of Google Assistant. The PRETTY user interface to insert new words into the dictionary was built using React.js along with the same Firebase database.
## Challenges we ran into
We initially wanted to implement this project by using both Android Things and a Google Home. The Google Home would control verbal interaction and the Android Things screen would display visual information, helping with the user's experience. However, we had difficulty with both components, and we eventually decided to focus more on improving the user's experience through the Google Assistant itself rather than through external hardware. We also wanted to interface with Android things display to show words on screen, to strengthen the ability to read and write. An interface is easy to code, but a PRETTY interface is not.
## Accomplishments that we're proud of
None of the members of our group were at all familiar with any natural language parsing, interactive project. Yet, despite all the early and late bumps in the road, we were still able to create a robust, interactive, and useful piece of software. We all second guessed our ability to accomplish this project several times through this process, but we persevered and built something we're all proud of. And did we mention again that our interface is PRETTY and approachable?
Yes, we are THAT proud of our interface.
## What we learned
None of the members of our group were familiar with any aspects of this project. As a result, we all learned a substantial amount about natural language processing, serverless code, non-relational databases, JavaScript, Android Studio, and much more. This experience gave us exposure to a number of technologies we would've never seen otherwise, and we are all more capable because of it.
## What's next for Language Teacher
We have a number of ideas for improving and extending Language Teacher. We would like to make the conversational aspect of Language Teacher more natural. We would also like to have the capability to adjust the Action's behavior based on the student's level. Additionally, we would like to implement a visual interface that we were unable to implement with Android Things. Most importantly, an analyst of students performance and responses to better help teachers learn about the level of their students and how best to help them. | losing |
## Inspiration
I like web design, I like 90's web design, and I like 90's tech. So it all came together very naturally.
## What it does
nineties.tech is a love letter to the silly, chunky, and experimental technology of the 90s. There's a Brian Eno quote about how we end up cherishing the annoyances of "outdated" tech: *Whatever you now find weird, ugly, uncomfortable and nasty about a new medium will surely become its signature.* I think this attitude persists today, and making a website in 90s web design style helped me put myself in the shoes of web designers from 30 years ago (albeit, with flexbox!)
## How we built it
Built with Sveltekit, pure CSS and HTML, deployed with Cloudflare, domain name from get.tech.
## Challenges we ran into
First time using Cloudflare. I repeatedly tried to deploy a non-working branch and was close to tears. Then I exited out to the Deployments page and realized that the fix I'd thrown into the config file actually worked.
## Accomplishments that we're proud of
Grinded out this website in the span of a few hours; came up with a cool domain name; first time deploying a website through Cloudflare; first time using Svelte.
## What we learned
My friend Ivan helped me through the process of starting off with Svelte and serving sites through Cloudflare. This will be used for further nefarious and well-intentioned purposes in the future.
## What's next for nineties.tech
User submissions? Longer, better-written out entries? Branch the site out into several different pages instead of putting everything into one page? Adding a classic 90's style navigation sidebar? Many ideas... | ## Inspiration
The best way to learn to code is usually through trial and error. As a team, we all know first hand how hard it can be to maintain the proper standards, techniques, and security practices necessary to keep your applications secure. SQLidify is a teaching tool and a security tool all in one, with the goal of helping coders keep their applications secure.
## What it does
SQLidify uses our own unique dataset/training model which consists of over 250 labelled data entries to identify SQL vulnerabilities in an application. To use it, simply paste your code into our website where our machine learning model will identify vulnerabilities in your back-end code, and then will suggest strategies to fix these issues.
## How we built it
We used a Flask, python based backend that handles API calls from a front end designed in React.js and Tailwind CSS. When called, our python backend reads data from users and then sends the data to our AI model. At the same time, our own simplified natural language processing model identifies keywords in specific lines of code and sends these lines individually to our AI model. The model makes a prediction for each which is then compared to help improve reliability. If the predictions don't match, further instructions are sent to the user in order to improve our accuracy.
The AI is designed using Cohere's classification workflow. We generated over 250 code snippets labeled as either vulnerable or safe. We have another model that is triggered if the code is determined to be vulnerable, which will then generate 3 appropriate options to resolve the vulnerabilities.
## Challenges we ran into
We had trouble setting up cohere and getting it to integrate with our application, but we were luckily able to resolve the issues in time to build our app. We also had a lot of trouble finding a dataset fit for our needs so we ended up creating our own from scratch.
## Accomplishments that we're proud of
Despite setbacks, we managed to integrate the AI and React frontend and Flask backend all together in less than 24 hours.
## What we learned
We all learned so much about machine learning and Cohere in particular, since none of us were experienced at working with AI until McHacks.
## What's next for SQLidify
Expansion. We hope to eventually integrate detection for other vulnerabilities such as buffer overflow and many more. | ## Inspiration
Ricky and I are big fans of the software culture. It's very open and free, much like the ideals of our great nation. As U.S. military veterans, we are drawn to software that liberates the oppressed and gives a voice to those unheard.
**Senate Joint Resolution 34** is awaiting ratification from the President, and if this happens, internet traffic will become a commodity. This means that Internet Service Providers (ISPs) will have the capability of using their users' browsing data for financial gain. This is a clear infringement on user privacy and is diametrically opposed to the idea of an open-internet. As such, we decided to build **chaos**, which gives a voice... many voices to the user. We feel that it's hard to listen in on a conversation in a noisy room.
## What it does
Chaos hides browsing patterns.
Chaos leverages **chaos.js**, a custom headless browser we built on top of PhantomJS and QT, to scramble incoming/outgoing requests that distorts browsing data beyond use. Further, Chaos leverages its proxy network to supply users with highly-reliable and secure HTTPS proxies on their system.
By using our own custom browser, we are able to dispatch a lightweight headless browser that mimics human-computer interaction, making its behavior indistinguishable from our user's behavior. There are two modes: **chaos** and **frenzy**. The first mode scrambles requests at an average of 50 sites per minute. The second mode scrambles requests at an average of 300 sites per minute, and stops at 9000 sites. We use a dynamically-updating list of over **26,000** approved sites in order to ensure diverse and organic browsing patterns.
## How we built it
### Development of the chaos is broken down into **3** layers we had to build
* OS X Client
* Headless browser engine (chaos.js)
* Chaos VPN/Proxy Layer
### Layer 1: OS X Client
---

The Chaos OS X Client scrambles outgoing internet traffic. This crowds IP data collection and hides browsing habits beneath layers of organic, randomized traffic.
###### OS X Client implementation
* Chaos OS X is a light-weight Swift menubar application
* Chaos OS X is built on top of **chaos.js**, a custom WebKit-driven headless-browser that revolutionizes the way that code interacts with the internet. chaos.js allows for outgoing traffic to appear **completely organic** to any external observer.
* Chaos OS X scrambles traffic and provides high-quality proxies. This is a result of our development of **chaos.js** headless browser and the **Chaos VPN/Proxy layer**.
* Chaos OS X has two primary modes:
+ **chaos**: Scrambles traffic on average of 50 sites per minute.
+ **frenzy**: Scrambles traffic on average of 500 sites per minute, stops at 9000 sites.
### Layer 2: Headless browser engine (chaos.js)
---
Chaos is built on top of the chaos.js engine that we've built, a new approach to WebKit-driven headless browsing. Chaos is **completely** indiscernible from a human user. All traffic coming from Chaos will appear as if it is actually coming from a human-user. This was, by far, the most technically challenging aspect of this hack. Here are a few of the changes we made:
##### #Step 1: Modify header ordering in the QTNetwork layer
##### Chrome headers

##### PhantomJS headers

The header order between other **WebKit** browsers come in static ordering. PhantomJS accesses **WebKit** through the **Qt networking layer**.
```
Modified: qhttpnetworkrequest.cpp
```
---
###### Step 2: Hide exposed footprints
```
Modified: examples/pagecallback.js
src/ghostdriver/request_handlers/session_request_handler.js
src/webpage.cpp
test/lib/www/*
```
---
###### Step 3: Client API implementation
* User agent randomization
* Pseudo-random bezier mouse path generation
* Speed trap reactive DOM interactions
* Dynamic view-port
* Other changes...
### Layer 3: Chaos VPN/Proxy Layer
---
The Chaos VPN back-end is made up of **two cloud systems** hosted on Linode: an OpenVPN and a server. The server deploys an Ubuntu 16.10 distro, which functions as a dynamic proxy-tester that continuously parses the Chaos Proxies to ensure performance and security standards. It then automatically removes inadequate proxies and replaces them with new ones, as well as maintaining a minimum number of proxies necessary. This ensures the Chaos Proxy database is only populated with efficient nodes.
The purpose of the OpenVPN layer is to route https traffic from the host through our VPN encryption layer and then through one of the proxies mentioned above, and finally to the destination. The VPN serves as a very safe and ethical layer that adds extra privacy for https traffic. This way, the ISP only sees traffic from the host to the VPN. Not from the VPN to the proxy, from the proxy to the destination, and all the way back. There is no connection between host and destination.
Moving forward we will implement further ways of checking and gathering safe proxies. Moreover, we've begun development on a machine learning layer which will run on the server. This will help determine which sites to scramble internet history with based on general site sentiment. This will be acomplished by running natural-language processing, sentiment analysis, and entity analytics on the sites.
## Challenges we ran into
This project was **huge**. As we peeled back layer after layer, we realized that the tools we needed simply didn't exist or weren't adequate. This required us to spend a lot of time in several different programming languages/environments in order to build the diverse elements of the platform. We also had a few blocks in terms of architecture cohesion. We wrote the platform in 6 different languages in 5 different environments, and all of the pieces had to work together *exceedingly well*. We spent a lot of time at the data layer of the respective modules, and it slowed us down considerably at times.

## Accomplishments that we're proud of
* We began by contributing to the open-source project **pak**, which allowed us to build complex build-scripts with ease. This was an early decision that helped us tremendously when dealing with `netstat`, network diagnostics and complex python/node scrape scripts.
* We're most proud of the work we did with **chaos.js**. We found that **every** headless browser that is publicly available is easily detectable. We tried PhantomJS, Selenium, Nightmare, and Casper (just to name a few), and we could expose many of them in a matter of minutes. As such, we set out to build our own layer on top of PhantomJS in order to create the first, truly undetectable headless browser.
* This was massively complex, with programming done in C++ and Javascript and nested Makefile dependencies, we found ourselves facing a giant. However, we could not afford for ISPs to be able to distinguish a pattern in the browsing data, so this technology really sits at the core of our system, alongside some other cool elements.
## What we learned
In terms of code, we learned a ton about HTTP/HTTPS and the TCP/IP protocols. We also learned first how to detect "bot" traffic on a webpage and then how to manipulate WebKit behavior to expose key behaviors that mask the code behind the IP. Neither of us had ever used Linode, and standing up two instances (a proper server and a VPN server) was an interesting experience. Fitting all of the parts together was really cool and exposed us to technology stacks on the front-end, back-end, and system level.
## What's next for chaos
More code! We're planning on deploying this as an open-source solution, which most immediately requires a build script to handle the many disparate elements of the system. Further, we plan on continued research into the deep layers of web interaction in order to find other ways of preserving anonymity and the essence of the internet for all users! | partial |
# better.me, AI Journaling
## Project Description
better.me is an AI journaling tool that helps you analyze your emotions and provide you with smart recommendations for your well being. We used NLP emotion analytics to process text data and incorporated a suicidal prevention algorithm that will help you make better informed decisions about your mental health.
## Motivation
Poor mental health is a growing pandemic that is still being stigmatized. Even after spending $5 Billion in federal investments for mental health, 1.3 million adults attempted suicide and 1.1 million plans to commit suicide.
>
> Our mission is to provide a private environment to help people analyze their emotions and receive mental health support.
>
>
>
## MVP Product Features Overview
| Features | Description |
| --- | --- |
| Personal Journal | Better Me is a personal AI-powered journal where users can write daily notes reflecting on their life's progress. |
| NLP Emotion Analytics | With the help of natural language process, Better Me will classify the user's emotional situation and keep a track of the data. |
| Smart Recommendations | It uses this monitored data to suggest appropriate mental health resources to the users and also provides them with suitable data analytics. |
| Suicide Prevention | In order to take a step forward towards suicide prevention, it also incorporates a suicidal text detection algorithm that triggers a preventive measure . |
## How we built it
We used Google T5 NLP model for emotional recognition and categorizing emotions. We trained data set with deep learning to develop a fine tuned BERT model to prevent suicide. We also implemented our own algorithm to make resource recommendations to users based on their emotional changes, and also did some data analytics. Due to time restraints and a member's absence, we had to change from React.js plus Firebase stack to Streamlit, a python library design framework.
## Challenges
Initially, we tried creating a dashboard using full-stack web development, however, it proved to be quite a challenging task with the little amount of time we had. We decided to shift our focus to quickly prototyping using a lightweight tool, and streamlit was the ideal choice for our needs. While deploying our suicide prevention algorithm on Google Cloud Function, we had trouble deploying due to memory availability constraints.
## Accomplishments
We are proud that we came up with such a novel idea that could be useful to innumerable people suffering from mental health issues, or those who are like to stay reserved with themselves or in a confused state about their mental well-being, just by writing about their daily lives. We are also proud of incorporating a suicide prevention algorithm, which could be life-saving for many.
## Roadmap
| Future Implementations | Description |
| --- | --- |
| Firebase Back End Architecture | We hope to design a scalable backend which accommodates for the users needs. |
| AI Mental Health Chat bot | Provide on the spot, mental health support using Dialogflow AI chat bot. |
| Connect with Therapists | Elevate data analytical features to connect and report to personal therapists. |
| Scaling Up | Fund our project and develop this project with scalable front and back end. |
| Languages Support | Support multiple languages, including French, Mandarin, and Spanish. | | ## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages. | ## Inspiration
Whether you’re thriving in life or really going through it, research shows that writing down your thoughts throughout the day has many benefits. We wanted to add a social element to this valuable habit and build a sense of community through sharing and acknowledging each other’s feelings. However, even on the internet, we've noticed that it is difficult for people to be vulnerable for fear of judgement, criticism, or rejection.
Thus, we centred our problem around this challenge and asked the question: How might we create a sense of community and connection among journalers without compromising their sense of safety and authenticity when sharing their thoughts?
## What it does
With Yapyap, you can write daily journal entries and share them anonymously with the public. Before posting, our AI model analyzes your written entry and provides you with an emotion, helping to label and acknowledge your feelings.
Once your thoughts are out in the world, you can see how other people's days are going too and offer mutual support and encouragement through post reactions.
Then, the next day comes, and the cycle repeats.
## How we built it
After careful consideration, we recognized that most users of our app would favour a mobile version as it is more versatile and accessible throughout the day. We used Figma to create an interesting and interactive design before implementing it in React Native. On the backend, we created an API using AWS Lambda and API Gateway to read and modify our MongoDB database. As a bonus, we prepared a sentimental analyzer using Tensorflow that could predict the overall mood of the written entry.
## Challenges we ran into
Learning new technologies and figuring out how to deploy our app so that they could all communicate were huge challenges for us.
## Accomplishments that we're proud of
Being able to apply what we learned about the new technologies in an efficient and collaborative way. We're also proud of getting a Bidirectional RNN for sentiment analysis ready in a few hours!
## What we learned
How to easily deal with merge conflicts, what it's like developing software as a group, and overall just knowing how to have fun even when you're pulling an all-nighter!
## What's next for yapyap
More personable AI Chatbots, and more emotions available for analysis! | winning |
## Inspiration
We were inspired by Pokemon Go and Duolingo. We believe that exploring the world and learning a new language pair up well together. Associating new vocabulary with real experiences helps you memorize it better.
## What it does
* Explore your surroundings to find landmarks around you.
* To conquer a landmark you will have to find and photograph objects that represent the vocabulary words we assigned to the land mark.
* As you conquer landmarks you will level up and more advanced landmarks (with more advanced vocab) will be unlocked.
* Can you conquer all the landmarks and become a Vocab Master?
## How we built it
* We used react native for the app, we used react-native-maps for the map, we used expo camera for the camera, and we used Python for the backend.
* we used Google Cloud Vision API for object recognition and annotated images with identified key object labels
-we used Google Cloud Translate API to translate the names of identified objects to the user's selected target language.
* we used the Gemini API to generate useful questions based on identified objects in the picture the user takes.
## Challenges we ran into
-Stitching together our front and back end
-We ran into issues with Firebase deployment in particular, as with other Flask app hosting services
## Accomplishments that we're proud of
-Created a unique UI that interfaces with the camera on the user's mobile device
-Creating a landmark exploration map for users to embark on vocabulary challenges
-Creating a quiz functionality using react native that ensures users review their learned vocabulary regularly. This works by requiring users to select the correct translations of words and phrases from previous photos every fifth photo taken.
-Developing a Python backend that takes the URI of an image as input and returns an image annotated with key objects, as well as translations for those objects in selected target language and example sentences using the identified objects in the target language based on the user's surroundings.
## What we learned
-Repository branch organization is important (keep git good)
-Dividing tasks among teammates leads to more rapid progress, but integration can be challenging
-Prioritization is key, when one thing is not working it is better to get some working functionality given the time constraints of the Hackathon.
## What's next for Pocket Vocab by Purple Cow
-Polishing the UI and integration between all the services and ensuring features work seamlessly together
-Add additional features to increase social aspects of the app. Such as conquering landmarks by holding the record for largest vocabulary at a certain landmark | ## DnD PvP Mode - AI-Generated Text-Based Adventure/ PvP Game
Inspiration
The inspiration for DnD PvP Mode stemmed from our love for traditional tabletop role-playing games like Dungeons & Dragons. We wanted to create an immersive and dynamic experience where players could engage in turn-based combat using natural language input, leveraging the power of AI to generate combat art through Dall-E 3.
## What it does
DnD PvP Mode is a text-based adventure and player versus player (PvP) game that brings the magic of Dungeons & Dragons into the digital realm. Two players enter the game from different computers, each choosing their character's name and class. The AI Dungeon Master (DM) takes charge, setting the scene with detailed descriptions of the environment and characters. Players are then free to interact with the world, unleashing their creativity and convincing the DM with their decisions.
The game's core revolves around turn-based combat, where players input their actions and strategies using natural language. The AI DM parses this input, orchestrating a thrilling battle that unfolds in the minds of the players. To enhance the immersive experience, we incorporated Dall-E 3, an AI model that generates stunning combat art based on the DM's descriptions, bringing the characters and scenes to life.
## How we built it
We used Python as our primary programming language, making heavy use of the OpenAI API for GPT3.5 to power the AI Dungeon Master. This intelligence enabled it to understand and respond to the players' unrestrained natural language input and parse out function calls to progress the game. To generate captivating combat art, we integrated Dall-E 3 into the game flow, turning textual descriptions into striking images.
We used Flask for the web server (along with HTML, CSS, and JavaScript) to create an intuitive and responsive user experience. Flask's simplicity let us rapidly prototype our game to create the best version of it we could as fast as we could. The web-based design also let players join in the game from their own devices, allowing them to make their decisions and witnessing the unfolding narrative from anywhere they chose.
## Challenges we ran into
One of the main challenges we faced was parsing and integrating user input into a solid underlying game system. Using GPT functions to parse natural language output and consistently produce quality outputs was a challenging task, but rewarding. Coordinating the communication between the AI Dungeon Master, Dall-E 3, and the web interface took a lot of work, especially to guarantee that each player's client remained in-sync and avoided race conditions.
Ensuring that the generated combat art aligned with the narrative and remained stylistically consistent between prompts posed a creative and technical challenge that required a lot of careful prompt engineering. Although we managed to stabilize the style, we weren't able to generate consistent characters between turns (although this could likely be done with fine-tuned models trained to output only a few characters). Additionally, although AI generated art has improved drastically as of late, it still lacks a human touch and direction to it, and each image does not necessarily play well into the next as it would in a hand-drawn and planned story. Further, dungeon masters usually make funny voices, and ours doesn't.
## Accomplishments that we're proud of
We are proud to have successfully combined traditional tabletop RPG elements with cutting-edge AI technology. The ability to have our unrestricted natural-language input consistently parsed into game terms and rapidly illustrated is a joy and a significant achievement for our team.
## What we learned
Throughout the hackathon, we learned a great deal about using AI for interactive storytelling and visual art generation, as well as a first foray into game design. Also, the effective integration of GPT3.5 and Dall-E 3 required us to attain a deeper level of understanding of both technologies. Having made this prototype with these tools, we are excited to continue exploring their potential in future projects.
## What's next for DnD PvP Mode
The journey doesn't end here! In the future, we plan to expand DnD PvP Mode by incorporating more status features, classes, and environments. We aim to enhance the AI Dungeon Master's capabilities with a broader range of functions to call, allowing for even more intricate and personalized storytelling and statuses that it may inflict upon the players. In future, we may also be able to create stable characters which the AI art generation models may be able to recreate in each scene for a consistent visual story to pair with the text. Stay tuned for more adventures in the world of DnD PvP Mode! | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine. | losing |
## Inspiration
Students spend hours getting their resumes ready and then application portals ask them to rewrite it all on their terribly designed webform. Worst of all, autofill does not work! Making it a very tedious manual effort. So we designed a site that goes around this, and let's our users automatically apply to as many relevant job postings as possible. We initially planned our app to programmatically generate a Resume and Cover Letter based on the job description and the user's skill set.
## What it does
Instead of going to every single website to apply, you list all the jobs you want by entering their addresses or by selecting the jobs we think match you. Then, you simply enter your information **once** and our website will handle all those applications and get back to you with their statuses!
## How I built it
Our web app was built using React and on a Redux app hosted on Firebase. We used Firebase functions, database, storage and authentication. We used UI-Path (the automation application) to automatically fill out the forms based on the users preferences. We used a Windows server to run our UiPath application on the Google Cloud Platform, we also set up a flask server on the VM to be ready to take inputs.
## Challenges I ran into
The UI-Path application does not have the functionality to run tasks based on external inputs, and to dynamically generate applications, we had to do some complicated powershell scripting and save all our our input as files that the ui-path would open.
## Accomplishments that I'm proud of
Anyone can access the site and apply now! The whole site is connected to firebase and all users have their own storage and accounts immediately when logging into the platform.
## What I learned
It was our first times using redux and firebase and we covered almost all firebase functionality and implemented all of our website functions in redux so we ended up learning quite a bit. Shoutout to FreeCodeCamp!
## What's next for While(1);
Get our summer internships through this. If we use our own application enough times, then there's no limit to how many rejections you can get! | ## Inspiration
Recruiters typically spend only a few seconds scanning each resume before deciding whether to move forward with a candidate. Given the volume of applications they receive, they rarely have the time to thoroughly check each candidate’s GitHub and other supporting documents to verify their competency (GitHub activities can be easily manipulated). Verifying the quality of code and ensuring the authenticity of claims is crucial but often impractical. Our solution, Verify, helps recruiters streamline their verification process and make informed hiring decisions with confidence.
## What it does
Verify revolutionizes the recruitment process by providing a comprehensive, evidence-based evaluation of candidates' skills and experience, and helps recruiters make informed decisions quickly by validating the authenticity of resumes and other candidate claims.
Our platform analyzes and cross-references data from multiple sources, such as GitHub repositories, to validate the authenticity of resume claims. It goes beyond surface-level information, diving deep into project complexities and coding patterns to generate a holistic view of a candidate's technical abilities. Verify also employs advanced natural language processing to match candidate profiles with job descriptions, offering recruiters a clear, data-driven basis for their hiring decisions. This approach not only saves time but also significantly reduces the risk of hiring based on inflated or inaccurate resume claims.
## How we built it
We developed Verify using a robust and scalable tech stack, blending cutting-edge frontend and backend technologies to create a powerful, user-friendly platform.
Our frontend leverages Next.js, React, Tailwind CSSm and Shadcn for a sleek, responsive UI. This combination ensures a visually appealing and intuitive user experience, particularly on individual applicant pages where recruiters can quickly review data. Tailwind's utility-first approach allows for rapid styling and customization, resulting in a polished interface.
The backend is built with FastAPI, chosen for its high performance and asynchronous capabilities. We chose MongoDB as our primary database, utilizing its flexibility for storing varied data structures (Collections) and its powerful vector search capabilities (Atlas Vector Search) for semantic matching. MongoDB also plays a crucial role in our Applicant Tracking System (ATS), storing and retrieving resume text and keywords to power efficient resume analysis and matching.
Authentication is handled through Auth0, implementing features such as Universal Login, Auth0 Actions, and the Management API to ensure a secure and flexible authentication process. Firebase supports our file storage needs, particularly for handling resume PDF uploads and retrievals.
Our analysis leverages the GitHub API to fetch both public and private repositories of applicants. We securely and privately process this data using natural language processing techniques to derive user-specific, job-specific insights, and employ SentenceTransformers for advanced semantic search and matching skills mentioned in resumes with actual work demonstrated in repositories.
A key component of our system is the integration with Google's Generative AI (Gemini) for in-depth code analysis and insight generation. We utilize the Instructor library (shoutout Jason Liu) in conjunction with Pydantic to structure the output from our language models. This approach was crucial for handling the complex, nested data often encountered in repository analyses, allowing us to maintain consistent data structures throughout our application and enhancing reliability and ease of data manipulation.
This comprehensive tech stack enables Verify to deliver fast, accurate, and insightful candidate assessments, transforming the recruitment process for technical roles by providing a data-driven, evidence-based evaluation of candidates' skills and experience.
## Challenges we ran into
We faced several challenges during the development of our project, particularly with the frontend and backend integration. Initial issues included problems with connecting the frontend to backend API endpoints, difficulties in displaying the radar chart, and managing resume storage. Crafting an optimal user experience also proved challenging due to time constraints.
Initially, we planned to host our backend API on GCP Cloud Run. While this setup worked at first, it soon became problematic as our API grew more complex. One notable issue occurred when our GCP instance crashed due to a BIOS data file error, which was traced back to a version mismatch in a dependency in the Google AI library (1.65.7 instead of 1.64.0) [as a result of this, we discovered a recent thread on Github where two people got into an argument over this and one threatened to sue the other for defamation in the Github discussion section lol].
As we integrated transformer-based embedding models into our API, we encountered additional complications: the build times increased significantly and the builds frequently failed on GCP. To address these inefficiencies and meet our tight deadlines, we decided to switch to hosting the API locally.
## Accomplishments that we're proud of
We successfully integrated a diverse tech stack, including FastAPI, MongoDB, Next.js, React, and Google's Generative AI, to creating a cohesive, powerful, and scalable platform, and implemented a pipeline to derive context-specific and structured insights from Github repositories about a candidate's coding skills and project experiences. We streamline the recruitment process and allow recruiters to gain a better understanding of a candidate's skills without sacrificing time.
## What we learned
Rudraksh: I learned how to model data with Pydantic and how to extract structured data from LLMs. I spent a lot of time tinkering with GCP, teaching myself FastAPI, and brainstorming how to architect our system to allow data to flow where we needed it to go.
Alec: I used Auth0 for the first time and learned to use their universal login, the management api + actions, forms + flows, and how to customize pages with HTML/CSS. I also learned a lot about API integration and LLM usage.
Hamza: During this hackathon, I gained hands-on experience with MongoDB, Auth0, and integrating Next.js with a FastAPI backend. Diving into so many APIs was a new challenge for me, but it significantly enhanced my backend skills. I spent considerable time understanding how to model and manage data effectively, and I now feel more confident in my ability to handle complex backend systems.
Sarah: As the UI/UX designer, I didn’t learn any new tools. However, since there was limited reference material for a recruiter-facing job platform, I had to use my imagination to envision a B2B interface. I started by creating low-fidelity wireframes and user flows to communicate my ideas with the front-end developers. I experimented with clean and Bento grid designs and was pleased to receive positive feedback from individuals with recruiting experience. I learned a lot about different LLMs and about libraries used for front end web development from this hackathon.
## What's next for Verify
1. Intelligent Recommendations: We want to develop a recommendation engine that will suggest alternative job opportunities when a candidate doesn't quite fit the original position. This feature will help recruiters maximize the potential of their candidate pool and help candidates find roles that best match their skills.
2. Chatbot Assistant: We want to integrate a recruiter-facing AI chatbot that will allow recruiters to make natural language queries like "Find me a candidate who applied within the last month and has expertise in machine learning and cloud computing." This chatbot will streamline the search process, making it more intuitive and efficient.
3. Predictive Analytics: We think it would be amazing if we could implement predictive models that could forecast a candidate's potential performance and growth within a role, based on their past projects and learning patterns. | ## Inspiration
We wanted to build an application that would make university students lives less stressful.
A common issue we heard about from students is navigating changes to their degree, whether it be courses, modules, or the entire degree itself. Students would have to go through multiple sources to figure out how to keep their degree on track. We thought it would be a lot more convenient to have a single website that allows you to do all this minus the stress.
## What it does
Degree Planner is a web platform that allows students to plan out their degree and evaluate their options. Students can see a dynamic chart that lays out all the necessary courses for a specific program. Degree Planner has access to all courses offered by a student's university.
## How we built it
We organized ourselves by creating user stories and assigning tasks using agile technology like Jira.
As for the frontend, we chose to use React.js, Redux, Bootstrap, and Apache E-Charts.
We used React.js because it has helped most of us produce stable code in the past, Redux for state management, Bootstrap for its grid and other built in classes, and E-Charts for data visualization.
In the backend we used Express.js, Node.js, MongoDB, and Redis. Express.js was an easy way to handle http requests to our server. Node.js was great for installing 3rd party modules for easier development. MongoDB, a NoSQL database might not be as robust as a SQL database, but we chose to use MongoDB because of Mongo Atlas, an online database that allowed all of us to share data. Redis was chosen because it was a great way to persist users after they have been authenticated.
## Challenges we ran into
We were originally going to use an open source Western API that would get information on Western's courses/programs. However, 4 hours into the hacking, the API was down. We had to switch to another school's API.
E-Charts.js is great, because it has a lot of built-in data visualization functionality, but it was challenging to customize the chart relative to our page, because of this built-in functionality. We had to make our page around the chart instead of making the chart fit our page.
## Accomplishments that we're proud of
We are proud that we managed to get a fully functioning application finished within a short time frame. We are also proud of our team members for trying their best, and helping each other out.
## What we learned
Some of members who were less familiar with frontend and more familiar with backend learned frontend tricks, while some of our members who were less familiar with backend and more familiar with frontend learned some backend architecture.
It was really great to see how people went out of their comfort zones to grow as developers.
## What's next for Degree Planner
We want to expand our website's scope to include multiple universities, including Western University. We also want to add more data visualization tools so that our site is even more user-friendly. Even though we completed a lot of features in less than 36 hours, we still wish that we had more time, because we were just starting to scratch the surface of our website's capabilities. | partial |
## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where the programming language BASIC was prevalent. A world where coding on paper and on **office memo pads** were so popular. It is time, for you all to re-experience the programming of the **past**.
## What it does
It's a programming language compiler and runtime for the BASIC programming language. It allows users to write interactive programs for the web with the simple syntax and features of the BASIC language. Users can read our sample the BASIC code to understand what's happening, and write their own programs to deploy on the web. We're transforming code from paper to the internet.
## How we built it
The major part of the code is written in TypeScript, which includes the parser, compiler, and runtime, designed by us from scratch. After we parse and resolve the code, we generate an intermediate representation. This abstract syntax tree is parsed by the runtime library, which generates HTML code.
Using GitHub actions and GitHub Pages, we are able to implement a CI/CD pipeline to deploy the webpage, which is **entirely** written in BASIC! We also have GitHub Dependabot scanning for npm vulnerabilities.
We use Webpack to bundle code into one HTML file for easy deployment.
## Challenges we ran into
Creating a compiler from scratch within the 36-hour time frame was no easy feat, as most of us did not have prior experience in compiler concepts or building a compiler. Constructing and deciding on the syntactical features was quite confusing since BASIC was such a foreign language to all of us. Parsing the string took us the longest time due to the tedious procedure in processing strings and tokens, as well as understanding recursive descent parsing. Last but **definitely not least**, building the runtime library and constructing code samples caused us issues as minor errors can be difficult to detect.
## Accomplishments that we're proud of
We are very proud to have successfully "summoned" the **nostalgic** old times of programming and deployed all the syntactical features that we desired to create interactive features using just the BASIC language. We are delighted to come up with this innovative idea to fit with the theme **nostalgia**, and to retell the tales of programming.
## What we learned
We learned the basics of making a compiler and what is actually happening underneath the hood while compiling our code, through the *painstaking* process of writing compiler code and manually writing code samples as if we were the compiler.
## What's next for BASIC Web
This project can be integrated with a lot of modern features that is popular today. One of future directions can be to merge this project with generative AI, where we can feed the AI models with some of the syntactical features of the BASIC language and it will output code that is translated from the modern programming languages. Moreover, this can be a revamp of Bootstrap and React in creating interactive and eye-catching web pages. | ## Inspiration
The whiteboard or chalkboard is an essential tool in instructional settings - to learn better, students need a way to directly transport code from a non-text medium to a more workable environment.
## What it does
Enables someone to take a picture of handwritten or printed text converts it directly to code or text on your favorite text editor on your computer.
## How we built it
On the front end, we built an app using Ionic/Cordova so the user could take a picture of their code. Behind the scenes, using JavaScript, our software harnesses the power of the Google Cloud Vision API to perform intelligent character recognition (ICR) of handwritten words. Following that, we applied our own formatting algorithms to prettify the code. Finally, our server sends the formatted code to the desired computer, which opens it with the appropriate file extension in your favorite IDE. In addition, the client handles all scripting of minimization and fileOS.
## Challenges we ran into
The vision API is trained on text with correct grammar and punctuation. This makes recognition of code quite difficult, especially indentation and camel case. We were able to overcome this issue with some clever algorithms. Also, despite a general lack of JavaScript knowledge, we were able to make good use of documentation to solve our issues.
## Accomplishments that we're proud of
A beautiful spacing algorithm that recursively categorizes lines into indentation levels.
Getting the app to talk to the main server to talk to the target computer.
Scripting the client to display final result in a matter of seconds.
## What we learned
How to integrate and use the Google Cloud Vision API.
How to build and communicate across servers in JavaScript.
How to interact with native functions of a phone.
## What's next for Codify
It's feasibly to increase accuracy by using the Levenshtein distance between words. In addition, we can improve algorithms to work well with code. Finally, we can add image preprocessing (heighten image contrast, rotate accordingly) to make it more readable to the vision API. | ## Inspiration
Internet Addiction, while not yet codified within a psychological framework, is growing both in prevalence as a potentially problematic condition with many parallels to existing recognized disorders. How much time do you spend on your phone a day? On your laptop? Using the internet? What fraction of that time is used doing things that are actually productive? Over the past years, there is seen to be a stronger and stronger link between an increasing online presence and a deteriorating mental health. We spend more time online than we do taking care of ourselves and our mental/emotional wellbeing.
However, people are becoming more aware of their own mental health, more open to sharing their struggles and dealing with them. However the distractions of social media, games, and scrolling are constantly undermining our efforts. Even with an understanding of the harmful nature of these technologies, we still find it so difficult to take our attention away from them. Much of the media we consume online is built to be addicting, to hook us in. How can we pull ourselves away from these distractions in a way that doesn’t feel punishing?
## What it does
Presents an audio visual stimulation that allows the user to become more aware of their “mind space”
Lo fi audio and slow moving figures
A timer that resets everytime keyboard or mouse is moved
Program awards the player a new plant for every time the timer comes to an end
## How we built it
UI/UX design using sigma
Frontend using HTML, JS, and CSS
AWS Amplify for deploying our webapp
Github for version control
## Challenges we ran into
Initially wanted to use react.js and develop our server backend ourselves but since we are inexperienced, we had to scale back our goals.
Team consisted mostly of people with backend experience, it was difficult to convert to front-end.
Furthermore, Most of our members were participating in their first hackathon.
## Accomplishments that we're proud of
We're very proud of learning how to work together as a team, and manage projects in github for the first time. We're proud of having an end product, even though it didn't fully meet our expectations. We're happy to have this experience, and can't wait to participate in more hackathons in the future.
## What we learned
We developed a lot of web development skills, specifically with javascript, as most of our member have never used it in the past. We also learned a lot about AWS. We're all very excited about how we can leverage AWS to develop more serverless web applications in the future.
## What's next for Mind-Space
We want to develop Mind-Space to play more like an idle game, where the user can choose their choice of relaxing music, or guided meditation. As the player spends more time in their space, different plants will grow, some animals will be introduced, and eventually what started as just one sprout will become a whole living ecosystem. We want to add social features, where players can add friends and visit each other's Mind-Space, leveraging AWS Lambda and MongoDB to achieve this. | winning |
## Inspiration
Supreme brings spreadsheets into the modern era by enabling seamless interaction between spreadsheets and Python, D3, and other data science tools.
Excel is the most widely-used programming language in the world. While it doesn't look like other languages which developers use, its accessibility allows non-programmers to develop complex applications and models within spreadsheets. Its ease of use and discoverability is unparalleled and Supreme leverages that by building a full data science toolkit around Excel.
## How I built it
Supreme is built on top of the Beaker Notebook, which enables interactive computing with Python, JavaScript, and other languages. I built a plugin for Beaker Notebook which makes spreadsheets a full-fledged "language" on the platform, enabling data to seamlessly move between spreadsheets and programs.
## Use case
To demonstrate the power of this system, I did a sample analysis of FINRA short data which combines Supreme spreadsheets, Python, and D3. | ## Inspiration
Data analytics can be **extremely** time-consuming. We strove to create a tool utilizing modern AI technology to generate analysis such as trend recognition on user-uploaded datasets.The inspiration behind our product stemmed from the growing complexity and volume of data in today's digital age. As businesses and organizations grapple with increasingly massive datasets, the need for efficient, accurate, and rapid data analysis became evident. We even saw this within one of our sponsor's work, CapitalOne, in which they have volumes of financial transaction data, which is very difficult to manually, or even programmatically parse.
We recognized the frustration many professionals faced when dealing with cumbersome manual data analysis processes. By combining **advanced machine learning algorithms** with **user-friendly design**, we aimed to empower users from various domains to effortlessly extract valuable insights from their data.
## What it does
On our website, a user can upload their data, generally in the form of a .csv file, which will then be sent to our backend processes. These backend processes utilize Docker and MLBot to train a LLM which performs the proper data analyses.
## How we built it
Front-end was very simple. We created the platform using Next.js and React.js and hosted on Vercel.
The back-end was created using Python, in which we employed use of technologies such as Docker and MLBot to perform data analyses as well as return charts, which were then processed on the front-end using ApexCharts.js.
## Challenges we ran into
* It was some of our first times working in live time with multiple people on the same project. This advanced our understand of how Git's features worked.
* There was difficulty getting the Docker server to be publicly available to our front-end, since we had our server locally hosted on the back-end.
* Even once it was publicly available, it was difficult to figure out how to actually connect it to the front-end.
## Accomplishments that we're proud of
* We were able to create a full-fledged, functional product within the allotted time we were given.
* We utilized our knowledge of how APIs worked to incorporate multiple of them into our project.
* We worked positively as a team even though we had not met each other before.
## What we learned
* Learning how to incorporate multiple APIs into one product with Next.
* Learned a new tech-stack
* Learned how to work simultaneously on the same product with multiple people.
## What's next for DataDaddy
### Short Term
* Add a more diverse applicability to different types of datasets and statistical analyses.
* Add more compatibility with SQL/NoSQL commands from Natural Language.
* Attend more hackathons :)
### Long Term
* Minimize the amount of work workers need to do for their data analyses, almost creating a pipeline from data to results.
* Have the product be able to interpret what type of data it has (e.g. financial, physical, etc.) to perform the most appropriate analyses. | ## Inspiration
There should be an effective way to evaluate company value by examining the individual values of those that make up the company.
## What it does
Simplifies the research process of examining a company by showing it in a dynamic web design that is free-flowing and easy to follow.
## How we built it
It was originally built using a web scraper that scraped from LinkedIn which was written in python. The web visualizer was built using javascript and the VisJS library to have a dynamic view and aesthetically pleasing physics. In order to have a clean display, web components were used.
## Challenges we ran into
Gathering and scraping the data was a big obstacle, had to pattern match using LinkedIn's data
## Accomplishments that we're proud of
It works!!!
## What we learned
Learning to use various libraries and how to setup a website
## What's next for Yeevaluation
Finetuning and reimplementing dynamic node graph, history. Revamping project, considering it was only made in 24 hours. | partial |
## Inspiration
* Smart homes are taking over the industry
* Current solutions are WAY too expensive(almost $30) for one simple lightbulb
* Can fail from time to time
* Complicated to connect
## What it does
* It simplifies the whole idea of a smart home
* Three part system
+ App(to control the hub device)
+ Hub(used to listen to the Firebase database and control all of the devices)
+ Individual Devices(used to do individual tasks such as turn on lights, locks, etc.)
* It allows as many devices as you want to be controlled through one app
* Can be controlled from anywhere in the world
* Cheap in cost
* Based on usage data, provides feedback on how to be more efficient with trained algorithm
## How I built it
* App built with XCode and Swift
* Individual devices made with Arduino's and Node-MCU's
* Arduino's intercommunicate with RF24 Radio modules
* Main Hub device connects to Firebase with wifi
## Challenges I ran into
* Using RF24 radios to talk between Arduinos
* Communicating Firebase with the Hub device
* Getting live updates from Firebase(constant listening)
## Accomplishments that I'm proud of
* Getting a low latency period, almost instant from anywhere in the world
* Dual way communication(Input and Output Devices)
* Communicating multiple non-native devices with Firebase
## What I learned
* How RF24 radios work at the core
* How to connect Firebase to many devices
* How to keep listening for changes from Firebase
* How to inter-communicate between Arduinos and Wifi modules
## What's next for The Smarter Home
* Create more types of devices
* Decrease latency
* Create more appropriate and suitable covers | ## Inspiration
The need for faster and more reliable emergency communication in remote areas inspired the creation of FRED (Fire & Rescue Emergency Dispatch). Whether due to natural disasters, accidents in isolated locations, or a lack of cellular network coverage, emergencies in remote areas often result in delayed response times and first-responders rarely getting the full picture of the emergency at hand. We wanted to bridge this gap by leveraging cutting-edge satellite communication technology to create a reliable, individualized, and automated emergency dispatch system. Our goal was to create a tool that could enhance the quality of information transmitted between users and emergency responders, ensuring swift, better informed rescue operations on a case-by-case basis.
## What it does
FRED is an innovative emergency response system designed for remote areas with limited or no cellular coverage. Using satellite capabilities, an agentic system, and a basic chain of thought FRED allows users to call for help from virtually any location. What sets FRED apart is its ability to transmit critical data to emergency responders, including GPS coordinates, detailed captions of the images taken at the site of the emergency, and voice recordings of the situation. Once this information is collected, the system processes it to help responders assess the situation quickly. FRED streamlines emergency communication in situations where every second matters, offering precise, real-time data that can save lives.
## How we built it
FRED is composed of three main components: a mobile application, a transmitter, and a backend data processing system.
```
1. Mobile Application: The mobile app is designed to be lightweight and user-friendly. It collects critical data from the user, including their GPS location, images of the scene, and voice recordings.
2. Transmitter: The app sends this data to the transmitter, which consists of a Raspberry Pi integrated with Skylo’s Satellite/Cellular combo board. The Raspberry Pi performs some local data processing, such as image transcription, to optimize the data size before sending it to the backend. This minimizes the amount of data transmitted via satellite, allowing for faster communication.
3. Backend: The backend receives the data, performs further processing using a multi-agent system, and routes it to the appropriate emergency responders. The backend system is designed to handle multiple inputs and prioritize critical situations, ensuring responders get the information they need without delay.
4. Frontend: We built a simple front-end to display the dispatch notifications as well as the source of the SOS message on a live-map feed.
```
## Challenges we ran into
One major challenge was managing image data transmission via satellite. Initially, we underestimated the limitations on data size, which led to our satellite server rejecting the images. Since transmitting images was essential to our product, we needed a quick and efficient solution. To overcome this, we implemented a lightweight machine learning model on the Raspberry Pi that transcribes the images into text descriptions. This drastically reduced the data size while still conveying critical visual information to emergency responders. This solution enabled us to meet satellite data constraints and ensure the smooth transmission of essential data.
## Accomplishments that we’re proud of
We are proud of how our team successfully integrated several complex components—mobile application, hardware, and AI powered backend—into a functional product. Seeing the workflow from data collection to emergency dispatch in action was a gratifying moment for all of us. Each part of the project could stand alone, showcasing the rapid pace and scalability of our development process. Most importantly, we are proud to have built a tool that has the potential to save lives in real-world emergency scenarios, fulfilling our goal of using technology to make a positive impact.
## What we learned
Throughout the development of FRED, we gained valuable experience working with the Raspberry Pi and integrating hardware with the power of Large Language Models to build advanced IOT system. We also learned about the importance of optimizing data transmission in systems with hardware and bandwidth constraints, especially in critical applications like emergency services. Moreover, this project highlighted the power of building modular systems that function independently, akin to a microservice architecture. This approach allowed us to test each component separately and ensure that the system as a whole worked seamlessly.
## What’s next for FRED
Looking ahead, we plan to refine the image transmission process and improve the accuracy and efficiency of our data processing. Our immediate goal is to ensure that image data is captioned with more technical details and that transmission is seamless and reliable, overcoming the constraints we faced during development. In the long term, we aim to connect FRED directly to local emergency departments, allowing us to test the system in real-world scenarios. By establishing communication channels between FRED and official emergency dispatch systems, we can ensure that our product delivers its intended value—saving lives in critical situations. | ## Inspiration
This project was heavily inspired by CANBus and its unique network arbitration method for devices on the network. However while CANBus requires a specialised circuit to be a part of the network, Monopoly Bus does not, and moreover only requires a single wire.
## What it does
Monopoly Bus allows devices to broadcast messages, commands and data onto a single wire asynchronous network without any specialized peripherals. Thus, it is built for DIYers and hobbyists and will allow them to build large device networks without any extra parts or lots of wiring.
## How we built it
The protocol uses a "virtual clock" which is essentially a timer that the GPIO uses to send or receive a value every time the timer ticks. The clock is activated once the line has been pulled down, synchronizing all nodes. Thus, the clock translates the digital signal into a stream of bits.
## Challenges we ran into
Currently the protocol is only capable of sending 1 byte in a single frame. It is also quite error prone at higher tick rates/frequencies. A major issue initially was syncing devices on the network together itself.
## Accomplishments that we're proud of
Randomness based networks have been built before (in fact the first wireless packet data network utilized randomness for network arbitration) but I am proud to have developed something unique that hobbyists could use for their projects.
## What we learned
Low level signal processing and synchronization
Network Arbitration Mechanisms
Decimal - Binary Conversions and vice versa
## What's next for Monopoly Bus!
I hope to see this project bloom into a popular open source framework. I also plan on porting this to other MCUs. | winning |
## Inspiration
To set our goal, we were grandly inspired by the Swiss system, which has proven to be one of the most functional democracy in the world. In Switzerland, there is a free mobile application, VoteInfo, which is managed by a governmental institution, but is not linked to any political groups, where infos about votes and democratic events happening at a national, regional and communal scale are explained, vulgarized and promoted. The goal is to provide the population a deep understanding of the current political discussions and therefore to imply everyone in the Swiss political life, where every citizen can vote approximately 3 times a year on national referendum to decide the future of their country. We also thought it would be interesting to expand that idea to enable elected representative, elected staff and media to have a better sense of the needs and desires of a certain population.
Here is a [link](https://www.bfs.admin.ch/bfs/fr/home/statistiques/politique/votations/voteinfo.html) to the swiss application website (in french, german and italian only).
## What it does
We developed a mobile application where anyone over 18 can have an account. After creating their account and entering their information (which will NOT be sold for profit), they will have the ability to navigate through many "causes", on different scales. For example, a McGill student could join the "McGill" group, and see many ideas proposed by member of elected staff, or even by regular students. They could vote for or against those, or they could choose to give visibility to an idea that they believe is important. The elected staff of McGill could then use the data from the votes, plotted in the app in the form of histograms, to see how the McGill community feels about many different subjects. One could also join the "Montreal Nightlife" group. For instance, a non-profit organization with governmental partnerships like [mtl2424](https://www.mtl2424.ca/), which is currently investigating the possibility of extending the alcohol permit fixed to 3 a.m., could therefore get a good understanding of how the Montreal population feels about this idea, by looking on the different opinion depending on the voters' age, their neighbourhood, or even both!
## How we built it
We used Figma for the graphic interface, and Python (using Spyder IDE) for the data analysis and the graph plotting ,with Matplotlib and Numpy libraries.
## Challenges we ran into
We tried to build a dynamic interface where one could easily be able to set graphs and histograms to certain conditions, i.e. age, gender, occupation... However, the implementation of such deep features happened to be too complicated and time-consuming for our level of understanding of software design, therefore, we abandoned that aspect.
Also, as neither of us had any real background in software design, building the app interface was very challenging.
## Accomplishments that we're proud of
We are really proud of the idea in itself, as we really and honestly believe that, especially in small communities like McGill, it could have a real positive impact. We put a lot of effort into building a realistic and useful tool that we, as students and members of different communities, would really like to have access to.
## What we learned
The thing we mainly learned was how to create a mobile app interface. As stipulated before, it was a real challenge, as neither of us had any experience in software development, so we had to learn while creating our interface.
As we were limited in time and knowledge, we also learned how to understand the priorities of our projects and to focus on them in the first place, and only afterward try to add some features.
## What's next for Kairos
The first step would be to implement our application's back-end and link it to the front-end.
In the future, we would really like to create a nice, dynamic and clean UI, to be attractive and easy to use for anyone, of any age, as the main problem with implementing technological tools for democracy is that the seniors are often under-represented.
We would also like to implement a lot of features, like a special registration menu for organizations to create groups, dynamic maps, discussion channels etc...
Probably the largest challenge in the upcoming implementations will be to find a good way to ensure each user has only one account, to prevent pollution in the sampling. | ## Inspiration
Examining our own internet-related tendencies revealed to us that although the internet presents itself as a connective hub, it can often be a very solitary place. As the internet continues to become a virtual extension of our physical world, we decided that working on an app that keeps people connected on the internet in a location-based way would be an interesting project. Building Surf led us to the realization that the most meaningful experiences are as unique as they are because of the people we experience them with. Social media, although built for connection, often serves only to widen gaps. In a nutshell, Surf serves to connect people across the internet in a more genuine way.
## What it does
Surf is a Chrome extension that allows you to converse with others on the same web page as you. For example, say you're chilling on Netflix, you could open up Surf and talk to anyone else watching the same episode of Breaking Bad as you. Surf also has a "Topics" feature which allows users to create their own personal discussion pages on sites. Similarly to how you may strike up a friendship discussing a painting with a stranger at the art museum, we designed Surf to encourage conversation between individuals from different backgrounds with similar interests.
## How we built it
We used Firebase Realtime Database for our chatrooms and Firebase Authentication for login. Paired with a Chrome extension leveraging some neat Bootstrap on the front end, we ended up with a pretty good looking build.
## Challenges we ran into
The hardest challenge for us was to come up with an idea that we were happy with. At first, all the ideas we came up with were either too complex or too basic. We longed for an idea that made us feel lucky to have thought of it. It wasn't until after many hours of brainstorming that we came up with Surf. Some earlier ideas included a CLI game in which you attempt to make guacamole and a timer that only starts from three minutes and thirty-four seconds.
## Accomplishments that we're proud of
We released a finished build on the Chrome Web Store in under twelve hours. Letting go of some perfectionism and going balls to the wall on our long-term goal really served us well in the end. However, despite having finished our hack early, we built in a huge V2 feature, which added up to twenty solid hours of hacking.
## What we learned
On top of figuring out how to authenticate users in a Chrome extension, we discovered the effects that five Red Bulls can have on the human bladder.
## What's next for Surf
Surf's site-specific chat data makes for a very nice business model – site owners crave user data, and the consensual, natural data generated by Surf is worth its weight in gold to web admins. On top of being economically capable, Surf has a means of providing users with analytics and recommendations, including letting them know how much time they spend on particular sites and which other pages they might enjoy based on their conversations and habits. We also envision a full-fledged browser for Surf, with a built in chat functionality. | ## Inspiration
We were inspired by our own experiences and by those of our classmates. Despite having started our degree in-person, before the pandemic, most of our time in college has been spent online. We know people who started post-secondary studies during the pandemic and some of them have never even been to campus.
We noted that when pandemic recovery plans are discussed, economic recovery seems to be the focus. And while it is quite important, restoring the social lives and mental health of people is also crucial to building a better world after this situation. Our concept is designed to facilitate both, social and economic restoration.
## What it does
We created the concept prototype for an app that helps students, specially those who have done school online for the last two years, make real-life connections with their classmates and people around them.
During the onboarding process, users are asked about their interests along with some personal information, like what school they go to and what program/major they are taking.
Because we understand that safety and boundaries are important, users are asked covid safety related questions as well. Things like vaccination status, how many people they would feel comfortable meeting with at a time, and what kind of settings they would feel safe in (restaurants, parks, malls, etc.), are all imputed by the user.
Using the information provided, users are matched with a group of people or with a person, whom with the app has determined they are compatible with. Users are then prompted to start a chat or group chat.
After the app detects a certain number of messages has been exchanged, the app will suggest meeting up to the users. The app, based on the users interests, will suggest a small local venue where they should hang out.
## How we built it
We used Figma for the whole process, from brainstorming to user flows and wireframes.
Our final prototype can be viewed in Figma,
## Challenges we ran into
When we were brainstorming we found it difficult to find an idea that would help people's mental health recover along with the economy.
After we came up with our concept we found ourselves having to narrow down or scope. We had to curate the user flow that we showed in our video to display the core idea of our project.
## Accomplishments that we're proud of
We managed to find a way to effectively display our project within the required timeframe.
We overcame feature creep and made sure that we only included what was essential for our project.
We created a fun and effective visual identity for our project
## What we learned
We refined our skills in Figma. We got to apply creative problem techniques we had been taught in classes in a practical situation.
## What's next for IRL✨
User research and testing. Improving our prototype and eventually making it a real thing! | partial |
## Inspiration
Relationships between mentees and mentors are very important for career success. People want to connect with others in a professional manner to give and receive career advice. While many professional mentoring relationships form naturally, it can be particularly difficult for people in minority groups, such as women and people of color, to find mentors who can relate to their personal challenges and offer genuine advice. This website can provide a platform for those people to find mentors that can help them in their professional career.
## What it does
This web application is a platform that connects mentors and mentees online.
## How we built it
Our team used a MongoDB Atlas database in the backend for users. In addition, the team used jQuery (JavaScript) and Flask (Python) to increase the functionality of the site.
## Challenges we ran into
There were many challenges that we ran into. Some of the biggest ones include authenticating the MongoDB server and connecting jQuery to Python.
## Accomplishments that I'm proud of
We are proud of our ability to create many different aspects of the project in parallel. In addition, we are proud of setting up a cloud database, organizing a multi-page frontend, designing a searching algorithm, and much of the stitching completed in Flask.
## What we learned
We learned a lot about Python, JavaScript, MongoDB, and GET/POST requests.
## What's next for Mentors In Tech
More mentors and advanced searching could further optimize our platform. | ## Where we got the spark?
**No one is born without talents**.
We all get this situation in our childhood, No one gets a chance to reveal their skills and gets guided for their ideas. Some skills are buried without proper guidance, we don't even have mates to talk about it and develop our skills in the respective field. Even in college if we are starters we have trouble in implementation. So we started working for a solution to help others who found themselves in this same crisis.
## How it works?
**Connect with neuron of your same kind**
From the problem faced we are bridging all bloomers on respective fields to experts, people in same field who need a team mate (or) a friend to develop the idea along. They can become aware of source needed to develop themselves in that field by the guidance of experts and also experienced professors.
We can also connect with people all over globe using language translator, this makes us feels everyone feel native.
## How we built it
**1.Problem analysis:**
We ran through all problems all over the globe in the field of education and came across several problems and we chose a problem that gives solution for several problems.
**2.Idea Development:**
We started to examine the problems and lack of features and solution for topic we chose and solved all queries as much as possible and developed it as much as we can.
**3.Prototype development:**
We developed a working prototype and got a good experience developing it.
## Challenges we ran into
Our plan is to get our application to every bloomers and expertise, but what will make them to join in our community. It will be hard to convince them that our application will help them to learn new things.
## Accomplishments that we're proud of
The jobs which are currently popular may or may not be popular after 10 years. Our World will always looks for a better version of our current version . We are satisfied that our idea will help 100's of children like us who don't even know about the new things in todays new world. Our application may help them to know the things earlier than usual. Which may help them to lead a path in their interest. We are proud that we are part of their development.
## What we learned
We learnt that many people are suffering from lack of help for their idea/project and we felt useless when we learnt this. So we planned to build an web application for them to help with their project/idea with experts and same kind of their own. So, **Guidance is important. No one is born pro**
We learnt how to make people understand new things based on the interest of study by guiding them through the path of their dream.
## What's next for EXPERTISE WITH
We're planning to advertise about our web application through all social medias and help all the people who are not able to get help for development their idea/project and implement from all over the world. to the world. | ## Inspiration
Are you tired of the traditional and mundane way of practicing competitive programming? Do you want to make learning DSA (Data Structures and Algorithms) more engaging and exciting? Look no further! Introducing CodeClash, the innovative platform that combines the thrill of racing with the challenge of solving LeetCode-style coding problems.
## What it does
With CodeClash, you and your friends can compete head-to-head in real-time coding battles. Challenge each other to solve coding problems as quickly and efficiently as possible. The platform provides a wide range of problem sets, from beginner to advanced, ensuring that there's something for everyone.
## How we built it
For our Backend we made it in Python with the Flask framework, we used MongoDB as our database and used Auth0 for authentication.
Our Front end is next.js.
## Challenges we ran into
Our whole Frontend UI was written in plain javascript where all the other project was in next.js and typescript also due to some other errors we could not use the UI so we had to rewrite everything again. So due to that and a team member leaving us we were able to under major difficultes get it back to tip-top shape.
## Accomplishments that we're proud of
the Implementation of MongoDB to store everything was something we were proud of. We were able to store all user data and all the question data in the database.
## What we learned
Even when you think you are cooked, and your whole hackathon career is in disarray you still can control your emotions and expectations lock in secure the victory.
## What's next for CodeClash
First task would be deployment on a VPS, then furthermore, adding a difficulty level so that the user can change the difficult for the questions you want to answer. Giving the User control of time Limit and more. | partial |
## Inspiration
We were inspired to build Loki to illustrate the plausibility of social media platforms tracking user emotions to manipulate the content (and advertisements) that they view.
## What it does
Loki presents a news feed to the user much like other popular social networking apps. However, in the background, it uses iOS’ ARKit to gather the user’s facial data. This data is piped through a neural network model we trained to map facial data to emotions. We use the currently-detected emotion to modify the type of content that gets loaded into the news feed.
## How we built it
Our project consists of three parts:
1. Gather training data to infer emotions from facial expression
* We built a native iOS application view that displays the 51 facial attributes returned by ARKit.
* On the screen, a snapshot of the current face can be taken and manually annotated with one of four emotions [happiness, sadness, anger, and surprise]. That data is then posted to our backend server and stored in a Postgres database.
2. Train a neural network with the stored data to map the 51-dimensional facial data to one of four emotion classes. Therefore, we:
* Format the data from the database in a preprocessing step to fit into the purely numeric neural network
* Train the machine learning algorithm to discriminate different emotions
* Save the final network state and transform it into a mobile-enabled format using CoreMLTools
3. Use the machine learning approach to discreetly detect the emotion of iPhone users in a Facebook-like application.
* The iOS application utilizes the neural network to infer user emotions in real time and show post that fit the emotional state of the user
* With this proof of concept we showed how easy applications can use the camera feature to spy on users.
## Challenges we ran into
One of the challenges we ran into was the problem of converting the raw facial data into emotions. Since there are 51 distinct data points returned by the API, it would have been difficult to manually encode notions of different emotions. However, using our machine learning pipeline, we were able to solve this.
## Accomplishments that we're proud of
We’re proud of managing to build an entire machine learning pipeline that harnesses CoreML — a feature that is new in iOS 11 — to perform on-device prediction.
## What we learned
We learned that it is remarkably easy to detect a user’s emotion with a surprising level of accuracy using very few data points, which suggests that large platforms could be doing this right now.
## What's next for Loki
Loki is currently not saving any new data that it encounters. One possibility is for the application to record the expression of the user mapped to the social media post. Another possibility is to expand on our current list of emotions (happy, sad, anger, and surprise) as well as train on more data to provide more accurate recognition. Furthermore, we can utilize the model’s data points to create additional functionalities. | ## Inspiration
What if I want to take an audio tour of a national park or a University campus on my own time? What if I want to take an audio tour of a place that doesn't even offer audio tours?
With Toor, we are able to harness people's passions for the places they love to serve the curiosity of our users.
## What it does
We enable users to submit their own audio tours of the places they love, and we allow them to listen to other user submissions as well. Users can also elect to receive a text alert if a new audio tour has been updated for a specific location.
## How we built it
We built the front-end using React, and back-end with multiple REST API endpoints using Flask. Flask then uses SQLAlchemy, an ORM to submit records to the SQLite3 database and query data to and from. The audio files are stored in Google Cloud Firebase database. The front end is also hosted on Firebase.
## Challenges we ran into
Enabling users to listen to audio without having to repeatedly download the files was our first major obstacle. With some research we found that either an AWS S3 bucket or a Google Firebase database would solve our problems. After issues with permission with the AWS S3 bucket, we decided that Google Firebase would be a more apt solution to our issue.
## Accomplishments that we're proud of
Enabling audio streaming was a big win for us. We are also proud of the our team synergy and how we got things done quickly. We also are proud of the fact that we applied a lot of the things we learned from our internships this summer.
## What we learned
* Audio streaming, audio file upload
* Upload audio player on react
* Thinking about minimal viable product
* Flask
* Soft skills such as interpersonal communication with fellow hackers
## What's next for Toor
Adding the ability to comment on an audio tour, expanding the scope outside of just college campus, using Google Cloud Platform to implement Speech-To-Text and NLP to filter out "bad" comments and words in audio files. | ## Inspiration
Our team sometimes gets tempered when using a computer, and we set out to minimize that. Our initial idea was related to video games, as they can often be causes of frustration, especially online ones. But we realized this idea could be scaled to cover emotions throughout all computer usage, not just video games. Whether that be working on homework, playing online games, or programming a project, there are a variety of actions you do on a computer that can get frustrating. This application seeks to alleviate.
## What it does
Once the app is open, it starts tracking your emotions via webcam, and when anger is detected, a creative calming notification will be sent to your desktop. This calming notification utilizes Google's Gemini API to generate an infinite amount of creative messages. These messages help remind the user that despite their frustration, everything is going okay and to take a break from the computer.
## How we built it
We used Python to build both the front and back end of the application. Using a model that could detect faces within a webcam, we developed a program in the backend that can predict a person's facial expression and emotion. This prediction is quite accurate with facial tracking. We then implemented Google's Gemini API as the creative source for the calming notification messages.
## Challenges we ran into
The biggest challenge we came across was finding and fine-tuning a model that catered to both our facial recognition needs and our calming message needs. Initially, we tried to use Google's MediaPipe facial detection software to track and detect faces being captured in the webcam. Unfortunately, it was incompatible with the model that we were using. Instead, we used openCV to perform facial recognition within our program. We also ran into issues with the webcam capturing weird and low-resolution angles, making it hard to capture a face within the frame. Another issue we came across was complications with Google Gemini simply not working with the API key we generated as well as text not generating correctly.
## Accomplishments that we're proud of
Getting the facial recognition working was our first hurdle that we accomplished and are extremely proud of. The fact that we were able to get our program to somewhat accurately predict facial expressions is something that we are extremely proud of. As we are both novice programmers, getting any of the above items to work was an accomplishment in and of itself.
## What we learned
We got a glimpse into the world of facial recognition and AI fine-tuning. We also learned how to utilize the Google Gemini API and integrate it into our project.
## What's next for DontClashOutAI
In the future, we hope to implement Google's Mediapipe for more advanced facial and emotion recognition. We would also like to retrain the model for more accurate and consistent results when predicting facial expressions. We're also working hard to clean up the GUI of the application allowing for a more streamlined and efficient experience.
This is where we sourced the model from: [link](https://www.kaggle.com/datasets/abhisheksingh016/machine-model-for-emotion-detection/data) | partial |
## Inspiration
this is a project which is given to me by an organization and my collegues inspierd me to do this project
## What it does
It can remind what we have to do in future and also set time when it is to be done
## How we built it
I built it using command time utility in python programming
## Challenges we ran into
Many challanges such as storing data in file and many bugs ae come in between middle of this program
## Accomplishments that we're proud of
I am proud that i make this real time project which reminds a person todo his tasks
## What we learned
I leraned more about command line utility of python
## What's next for Todo list
Next I am doing various projects such as Virtual assistant and game development | ## Inspiration
I really like to make game using programming ang wanted to became a game developer in future
## What it does
This is a fun game made using python. In this game we have to help ninja to no to collide with obstacles so that it can pass easily ..
## How I built it
I built it using various modules of python mainly pygame module
## Challenges I ran into
Many challanges are arrived in between this game such that screen bliting issues,pipe width,background change etc but at last i overcame all this problems and finally made a game
## Accomplishments that I'm proud of
I'm proud of that this is my second game after snake game using python
## What I learned
python is really a very great language to built a project and i learned to use many modules of python for doing this project
## What's next for Flappy Ninja (Game) Made using python
Next I mainly make projects using pythin .Currently i am working on automatic alarm project using python | ## Inspiration
This project inspires me to add what suitable feature which amaze to me
## What it does
It teaches me (reminds me) the basic thing in python and the importance of GUI for user to play it smoothly
## How we built it
I did it solely based on Python language, using Stack, loop, while loop and etc.. basic things
## Challenges we ran into
I did this by myself so at the halfway, I lost my motivation to complete this project
## Accomplishments that we're proud of
Add some feature that is to add your own name to the text file for reviewing your result
## What we learned
It is better to work on with multiple people so that a lot of idea will be come up
## What's next for Number Guessing Game | partial |
## Inspiration: We're trying to get involved in the AI chat-bot craze and pull together cool pieces of technology -> including Google Cloud for our backend, Microsoft Cognitive Services and Facebook Messenger API
## What it does: Have a look - message Black Box on Facebook and find out!
## How we built it: SO MUCH PYTHON
## Challenges we ran into: State machines (i.e. mapping out the whole user flow and making it as seamless as possible) and NLP training
## Accomplishments that we're proud of: Working NLP, Many API integrations including Eventful and Zapato
## What we learned
## What's next for BlackBox: Integration with google calendar - and movement towards a more general interactive calendar application. Its an assistant that will actively engage with you to try and get your tasks/events/other parts of your life managed. This has a lot of potential - but for the sake of the hackathon, we thought we'd try do it on a topic that's more fun (and of course, I'm sure quite a few us can benefit from it's advice :) ) | ## Inspiration
Globally, one in ten people do not know how to interpret their feelings. There's a huge global shift towards sadness and depression. At the same time, AI models like Dall-E and Stable Diffusion are creating beautiful works of art, completely automatically. Our team saw the opportunity to leverage AI image models and the emerging industry of Brain Computer Interfaces (BCIs) to create works of art from brainwaves: enabling people to learn more about themselves and
## What it does
A user puts on a Brain Computer Interface (BCI) and logs in to the app. As they work in front of front of their computer or go throughout their day, the user's brainwaves are measured. These differing brainwaves are interpreted as indicative of different moods, for which key words are then fed into the Stable Diffusion model. The model produces several pieces, which are sent back to the user through the web platform.
## How we built it
We created this project using Python for the backend, and Flask, HTML, and CSS for the frontend. We made use of a BCI library available to us to process and interpret brainwaves, as well as Google OAuth for sign-ins. We made use of an OpenBCI Ganglion interface provided by one of our group members to measure brainwaves.
## Challenges we ran into
We faced a series of challenges throughout the Hackathon, which is perhaps the essential route of all Hackathons. Initially, we had struggles setting up the electrodes on the BCI to ensure that they were receptive enough, as well as working our way around the Twitter API. Later, we had trouble integrating our Python backend with the React frontend, so we decided to move to a Flask frontend. It was our team's first ever hackathon and first in-person hackathon, so we definitely had our struggles with time management and aligning on priorities.
## Accomplishments that we're proud of
We're proud to have built a functioning product, especially with our limited experience programming and operating under a time constraint. We're especially happy that we had the opportunity to use hardware in our hack, as it provides a unique aspect to our solution.
## What we learned
Our team had our first experience with a 'real' hackathon, working under a time constraint to come up with a functioning solution, which is a valuable lesson in and of itself. We learned the importance of time management throughout the hackathon, as well as the importance of a storyboard and a plan of action going into the event. We gained exposure to various new technologies and APIs, including React, Flask, Twitter API and OAuth2.0.
## What's next for BrAInstorm
We're currently building a 'Be Real' like social media plattform, where people will be able to post the art they generated on a daily basis to their peers. We're also planning integrating a brain2music feature, where users can not only see how they feel, but what it sounds like as well | ## Inspiration
We wanted to solve a unique problem we felt was impacting many people but was not receiving enough attention. With emerging and developing technology, we implemented neural network models to recognize objects and images, and converting them to an auditory output.
## What it does
XTS takes an **X** and turns it **T**o **S**peech.
## How we built it
We used PyTorch, Torchvision, and OpenCV using Python. This allowed us to utilize pre-trained convolutional neural network models and region-based convolutional neural network models without investing too much time into training an accurate model, as we had limited time to build this program.
## Challenges we ran into
While attempting to run the Python code, the video rendering and text-to-speech were out of sync and the frame-by-frame object recognition was limited in speed by our system's graphics processing and machine-learning model implementing capabilities. We also faced an issue while trying to use our computer's GPU for faster video rendering, which led to long periods of frustration trying to solve this issue due to backwards incompatibilities between module versions.
## Accomplishments that we're proud of
We are so proud that we were able to implement neural networks as well as implement object detection using Python. We were also happy to be able to test our program with various images and video recordings, and get an accurate output. Lastly we were able to create a sleek user-interface that would be able to integrate our program.
## What we learned
We learned how neural networks function and how to augment the machine learning model including dataset creation. We also learned object detection using Python. | winning |
## Inspiration
In recent history, waste misplacement and ignorance has harmed countless animal, degraded our environment and health, and has costed us millions of dollars each year. Even with our current progressive education system, Canadians are still often unsure as to what their waste is categorized by. For this reason, we believe that we have a duty to show them where their waste should go, in a simple, and innovative way.
## What it does
Garb-Sort is a mobile app that allows users to find out how to dispose of their garbage at the touch of a button. By taking a picture of the garbage, Garb-Sort will tell you if it belongs in the recycling, compost, landfill or should be disposed specially.
## How we built it
On the back end, Garb-Sort passes the taken photo to Microsoft Azure’s Cognitive Services to identify the object in the photo. Garb-Sort then queries a SQL Database based on Microsoft Azure for where the recognized item should be disposed.
## Challenges we ran into
Throughout Garb-Sort’s development, we were faced with several challenges. A main feature of our app is to implement Microsoft’s Azure Computer Vision API to detect and classify objects within photos passing through our system. The challenge here was to figure out how to transfer the Computer Vision API with our SQL database that we developed on a separate platform. Implementing within Android Studio was difficult as some functions were depreciated.
## Accomplishments that we're proud of
We are proud to take a step towards improving environmental care.
## What we learned
It is hard to utilize Microsoft Azure APIs. Documentations are sparse for some languages.
## What's next for Garb Sort
In the future, we would like to add a map that details the location of waste bins so that waste disposal would require minimal effort. | ## Inspiration
Ask a student: do you know Van Gogh's art? Of course. Do you know advanced trig or Euler’s formula? Nah...not really a math student. Some students fear advanced topics in math. Current Apps offer lecture and practice problems at various levels. However, none intuitively shows the beauty of mathematics. TechArt combines art design and math to demonstrate the beauty and application of math. In doing so, it connects quantitative and qualitative, hard and soft, as well as technology and humanity.
## What it does
TechArt has two parts. First, it allows users to draw the edges of designated symmetric graphs. It generates a model based on users' drawing. Also, it is a mystery curve random generator. It generates new designs and allows users to save them.
## How I built it
I implemented a function presented in IEEE journal's article: "The Mystery Curve: A Signal Processing View". The equation c(t)=a1\*exp(i\*r1\*t)+a2\*exp(i\*r2\*t)+a3\*exp(i\*r3\*t) generates hugely different graphs by changing the 6 variables.
For the random design generator, I ran the SelectCurve file to select designated curves and their corresponding points. The points are saved and loaded into a showcase class.
## Challenges I ran into
Choosing the desired symmetric graphs was time-consuming.
Implementing the Gauss-Newton Algorithm.
## Accomplishments that I'm proud of
It worked!
Our previous group project didn't work out and I had to pivot late Saturday night:/ but still did it!
## What I learned
Embracing interdisciplinary subjects. It's really fun! Also, I tried to use javascript earlier but found Matlab was much easier to use and test when it comes to more complex math functions.
Persistence is key.
## What's next for TechArt
putting it together and make it cross-platform | ## Inspiration
Let's start by taking a look at some statistics on waste from Ontario and Canada. In Canada, only nine percent of plastics are recycled, while the rest is sent to landfills. More locally, in Ontario, over 3.6 million metric tonnes of plastic ended up as garbage due to tainted recycling bins. Tainted recycling bins occur when someone disposes of their waste into the wrong bin, causing the entire bin to be sent to the landfill. Mark Badger, executive vice-president of Canada Fibers, which runs 12 plants that sort about 60 percent of the curbside recycling collected in Ontario has said that one in three pounds of what people put into blue bins should not be there. This is a major problem, as it is causing our greenhouse gas emissions to grow exponentially. However, if we can reverse this, not only will emissions lower, but according to Deloitte, around 42,000 new jobs will be created. Now let's turn our focus locally. The City of Kingston is seeking input on the implementation of new waste strategies to reach its goal of diverting 65 percent of household waste from landfill by 2025. This project is now in its public engagement phase. That’s where we come in.
## What it does
Cycle AI is an app that uses machine learning to classify certain articles of trash/recyclables to incentivize awareness of what a user throws away. You simply pull out your phone, snap a shot of whatever it is that you want to dispose of and Cycle AI will inform you where to throw it out as well as what it is that you are throwing out. On top of that, there are achievements for doing things such as using the app to sort your recycling every day for a certain amount of days. You keep track of your achievements and daily usage through a personal account.
## How We built it
In a team of four, we separated into three groups. For the most part, two of us focused on the front end with Kivy, one on UI design, and one on the backend with TensorFlow. From these groups, we divided into subsections that held certain responsibilities like gathering data to train the neural network. This was done by using photos taken from waste picked out of, relatively unsorted, waste bins around Goodwin Hall at Queen's University. 200 photos were taken for each subcategory, amounting to quite a bit of data by the end of it. The data was used to train the neural network backend. The front end was all programmed on Python using Kivy. After the frontend and backend were completed, a connection was created between them to seamlessly feed data from end to end. This allows a user of the application to take a photo of whatever it is they want to be sorted, having the photo feed to the neural network, and then returned to the front end with a displayed message. The user can also create an account with a username and password, for which they can use to store their number of scans as well as achievements.
## Challenges We ran into
The two hardest challenges we had to overcome as a group was the need to build an adequate dataset as well as learning the framework Kivy. In our first attempt at gathering a dataset, the images we got online turned out to be too noisy when grouped together. This caused the neural network to become overfit, relying on patterns to heavily. We decided to fix this by gathering our own data. I wen around Goodwin Hall and went into the bins to gather "data". After washing my hands thoroughly, I took ~175 photos of each category to train the neural network with real data. This seemed to work well, overcoming that challenge. The second challenge I, as well as my team, ran into was our little familiarity with Kivy. For the most part, we had all just began learning Kivy the day of QHacks. This posed to be quite a time-consuming problem, but we simply pushed through it to get the hang of it.
## 24 Hour Time Lapse
**Bellow is a 24 hour time-lapse of my team and I work. The naps on the tables weren't the most comfortable.**
<https://www.youtube.com/watch?v=oyCeM9XfFmY&t=49s> | losing |
## Inspiration
When we thought about tackling the pandemic, it was clear to us that we'd have to **think outside the box**. The concept of a hardware device to enforce social distancing quickly came to mind, and thus we decided to create the SDE device.
## What it does
We utilized an ultra-sonic sensor to detect bodies within 2m of the user, and relay that data to the Arduino. If we detect a body within 2m, the buzzer and speaker go off, and a display notifies others that they are not obeying social distancing procedures and should relocate.
## How we built it
We started by creating a wiring diagram for the hardware internals using [Circuito](circuito.io). This also provided us some starter code including the libraries and tester code for the hardware components.
We then had part of the team start the assembly of the circuit and troubleshoot the components while the other focused on getting the CAD model of the casing designed for 3D printing.
Once this was all completed, we printed the device and tested it for any bugs in the system.
## Challenges we ran into
We initially wanted to make an Android partner application to log the incidence rate of individuals/objects within 2m via Bluetooth but quickly found this to be a challenge as the team was split geographically, and we did not have Bluetooth components to attach to our Arduino model. The development of the Android application also proved difficult, as no one on our team had experience developing Android applications in a Bluetooth environment.
## Accomplishments that we're proud of
Effectively troubleshooting the SDE device and getting a functional prototype finished.
## What we learned
Hardware debugging skills, how hard it is to make an Android app if you have no previous experience, and project management skills for distanced hardware projects.
## What's next for Social Distancing Enforcement (SDE)
Develop the Android application, add Bluetooth functionality, and decrease the size of the SDE device to a more usable size. | ## Inspiration
Our inspiration for the project stems from our experience with elderly and visually impaired people, and understanding that there is an imminent need for a solution that integrates AI to bring a new level of convenience and safety to modern day navigation tools.
## What it does
IntelliCane firstly employs an ultrasonic sensor to identify any object, person, or thing within a 2 meter range and when that happens, a piezo buzzer alarm alerts the user. Simultaneously, a camera identifies the object infront of the user and provides them with voice feedback identifying what is infront of them.
## How we built it
The project firstly employs an ultrasonic sensor to identify an object, person or thing close by. Then the piezo buzzer is turned on and alerts the user. Then the Picamera that is on the raspberrypi 5 identifies the object. We have employed a CNN algorithm to train the data and improve the accuracy of identifying the objects. From there this data is transferred to a text-to-speech function which provides voice feedback describing the object infront of them. The project was built on YOLO V8 platform.
## Challenges we ran into
We ran into multiple problems during our project. For instance, we initially tried to used tensorflow, however due to the incompatibility of our version of python with the raspberrypi 5, we switched to the YOLO V8 Platform.
## Accomplishments that we're proud of
There are many accomplishments we are proud of, such as successfully creating an the ultrasonic-piezo buzzer system for the arduino, and successfully mounting everything onto the PVC Pipe. However, we are most proud of developing a CNN algorithm that accurately identifies objects and provides voice feedback identifying the object that is infront of the user.
## What we learned
We learned more about developing ML algorithms and became more proficient with the raspberrypi IDE.
## What's next for IntelliCane
Next steps for IntelliCane include integrating GPS modules and Bluetooth modules to add another level of convenience to navigation tools. | ## What it does
flarg.io is an Augmented Reality platform that allows you to play games and physical activities with your friends from across the world. The relative positions of each person will be recorded and displayed on a single augmented reality plane, so that you can interact with your friends as if they were in your own backyard.
The primary application is a capture the flag game, where your group will be split into two teams. Each team's goal is to capture the opposing flag and bring it back to the home-base. Tagging opposing players in non-safe-zones would put them on temporary time out, forcing them go back to their own home-base. May the best team win!
## What's next for flarg.io
Capture the flag is just the first of our suite of possible mini-games. Building off of the AR framework that we have built, the team foresees making other games like "floor is lava" and "sharks and minnows" with the same technology. | partial |
## Inspiration
Our team’s mission is to create a space of understanding, compassion, and curiosity through facilitating cross-cultural conversations.
At a time where a pandemic and social media algorithms keep us tightly wound in our own homes and echo chambers, we’ve made a platform to push people out of their comfort zones and into a diverse environment where they can learn more about other cultures.
Cross-cultural conversations are immensely effective at eliminating biases and fostering understanding. However, these interactions can also be challenging and awkward. We designed Perspectives to eliminate that tension by putting the focus back on similarities instead of differences. We hope that through hearing the stories of other cultures, users will be able to drop their assumptions and become more accepting of the people around them.
## What it does
Perspectives guides users through cross-cultural conversation with prompts that help facilitate understanding and reflection.
Users have the ability to create a user profile that details their cultural identity, cross-cultural interests, and personal passions. Then, through the platform’s matching system, users are connected through video with like-minded individuals of different backgrounds.
## How we built it
The main codebase for our project was the MERN stack (MongoDB, Express.js, React.js, Node.js). We used the Daily API for our video calling and RxJS to handle our async events. We spent most of our time either planning different features for our application or coding over Zoom together.
## Challenges we ran into
A big challenge we encountered was deciding on what peer-to-peer communication platform we should use for our project. At first, our project was structured to be a mobile application, but after evaluating our time and resources, we felt that we would be able to build a higher quality desktop application. We knew that video calling was a key component to our idea, and so we tested a variety of the video call technology platforms in order to determine which one would be the best fit for us.
## Accomplishments that we're proud of
With so many moving pieces and only two of us working on the project, we were so enthusiastic when our project was able to come together and run smoothly. Developing a live pairing and video call system was definitely not something either of us had experience in, and so we were ecstatic to see our functioning final product.
## What we learned
We learned that ideation is EVERYTHING. Instead of jumping straight into our first couple project ideas like we’ve done in the past, we decided to spend more time on ideating and looking for pain points in our everyday lives. For certain project ideas, we needed a long time to do research and decide whether or not they were viable, but in the end, our patience paid off. Speaking of patience, another big piece of wisdom we learned is that sleep is important! After tucking in on Friday night, we were rejuvenated and hungry to work through Saturday, where we definitely saw most of our productiveness.
## What's next for Perspectives
A definite next step for the project would be to develop a Perspectives mobile app which would increase the project’s accessibility as well as introduce a new level of convenience to cross-cultural conversation. We are also excited to develop new features like in-app speaker panel events and large community discussions which would revolutionize the way we communicate outside our comfort zones. | Inspiration
Our project is driven by a deep-seated commitment to address the escalating issues of hate speech and crime in the digital realm. We recognized that technology holds immense potential in playing a pivotal role in combating these societal challenges and nurturing a sense of community and safety.
## What It Does
Our platform serves as a beacon of hope, empowering users to report incidents of hate speech and crime. In doing so, we have created a vibrant community of individuals wholeheartedly devoted to eradicating such toxic behaviors. Users can not only report but also engage with the reported incidents through posts, reactions, and comments, thereby fostering awareness and strengthening the bonds of solidarity among its users. Furthermore, our platform features an AI chatbot that simplifies and enhances the reporting process, ensuring accessibility and ease of use.
## How We Built It
The foundation of our platform is a fusion of cutting-edge front-end and back-end technologies. The user interface came to life through MERN stack, ensuring an engaging and user-friendly experience. The backend infrastructure, meanwhile, was meticulously crafted using Node.js, providing robust support for our APIs and server-side operations. To house the wealth of user-generated content, we harnessed the prowess of MongoDB, a NoSQL database. Authentication and user data privacy were fortified through the seamless integration of Auth0, a rock-solid authentication solution.
## Challenges We Ran Into
Our journey was not without its trials. Securing the platform, effective content moderation, and the development of a user-friendly AI chatbot presented formidable challenges. However, with unwavering dedication and substantial effort, we overcame these obstacles, emerging stronger and more resilient, ready to tackle any adversity.
## Accomplishments That We're Proud Of
Our proudest accomplishment is the creation of a platform that emboldens individuals to stand up against hate speech and crime. Our achievement is rooted in the nurturing of a safe and supportive digital environment where users come together to share their experiences, ultimately challenging and combatting hatred head-on.
## What We Learned
The journey was not just about development; it was a profound learning experience. We gained valuable insights into the vast potential of technology as a force for social good. User privacy, effective content moderation, and the vital role of community-building have all come to the forefront of our understanding, enhancing our commitment to addressing these critical issues.
## What's Next for JustIT
The future holds exciting prospects for JustIT. We envision expanding our platform's reach and impact. Plans are underway to enhance the AI chatbot's capabilities, streamline the reporting process, and implement more robust content moderation techniques. Our ultimate aspiration is to create a digital space that is inclusive, empathetic, and, above all, safe for everyone. | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | losing |
## Inspiration
The lack of good music at parties is criminal. Pretty rare to find the DJs that are not absorbed in their playlist as well. Someone had to do it, so we did it.
## What it does
It looks at the movement of the crowd using computer vision and using Spotify's data-set of over 42000 songs we find the song that makes you groove by matching the energy of the room. That is why we are the groove genie.
## How we built it
We used OpenCV to find the change in the movement, and we take the derivative of the movement over the period of the song. Change in movement is directly proportional to the energy level. From Spotify's data set, we download (no ads yay!) and play the music that best describes the way the audience is feeling.
To further optimize the song choice we keep track of the 40 songs that the audience responded to as expected. These are the songs that are reflective of superior data quality. So we choose songs that are the most similar to these songs after you have heard over 40 songs, while still matching the energy.
## Challenges we ran into
Stopping the similarity checks from overriding the movement score currently being displayed by the audience. We fixed this by changing how much value we gave to similarity.
## Accomplishments that we're proud of
Being able to detect the speed of and changes in movement using OpenCV, and the automatic player.
## What we learned
Movement detection using computer vision, data processing with Spotify's database, and integrating Youtube into the project to play songs.
## What's next for Groove Genie
A solo mode for Groove Genie, for listening to music on your own, which changes the music based on your emotional reaction. | ## Inspiration
What inspired the beginning of the idea was terrible gym music and the thought of a automatic music selection based on the tastes of people in the vicinity. Our end goal is to sell a hosting service to play music that people in a local area would want to listen to.
## What it does
The app has two parts. A client side connects to Spotify and allows our app to collect users' tokens, userID, email and the top played songs. These values are placed inside a Mongoose database and the userID and top songs are the main values needed. The host side can control the location and the radius they want to cover. This allows the server to be populated with nearby users and their top songs are added to the host accounts playlist. The songs most commonly added to the playlist have a higher chance of being played.
This app could be used at parties to avoid issues discussing songs, retail stores to play songs that cater to specific groups, weddings or all kinds of social events. Inherently, creating an automatic DJ to cater to the tastes of people around an area.
## How we built it
We began by planning and fleshing out the app idea then from there the tasks were split into four sections: location, front end, Spotify and database. At this point we decided to use React-Native for the mobile app and NodeJS for the backend was set into place. After getting started the help of the mentors and the sponsors were crucial, they showed us all the many different JS libraries and api's available to make life easier. Programming in Full Stack MERN was a first for everyone in this team. We all hoped to learn something new and create an something cool.
## Challenges we ran into
We ran into plenty of problems. We experienced many syntax errors and plenty of bugs. At the same time dependencies such as Compatibility concerns between the different APIs and libraries had to be maintained, along with the general stress of completing on time. In the end We are happy with the product that we made.
## Accomplishments that we are proud of
Learning something we were not familiar with and being able to make it this far into our project is a feat we are proud of. .
## What we learned
Learning about the minutia about Javascript development was fun. It was because of the mentors assistance that we were able to resolve problems and develop at a efficiently so we can finish. The versatility of Javascript was surprising, the ways that it is able to interact with and the immense catalog of open source projects was staggering. We definitely learned plenty... now we just need a good sleep.
## What's next for SurroundSound
We hope to add more features and see this application to its full potential. We would make it as autonomous as possible with seamless location based switching and database logging. Being able to collect proper user information would be a benefit for businesses. There were features that did not make it into the final product, such as voting for the next song on the client side and the ability for both client and host to see the playlist. The host would have more granular control such as allowing explicit songs, specifying genres and anything that is accessible by the Spotify API. While the client side can be gamified to keep the GPS scanning enabled on their devices, such as collecting points for visiting more areas. | ## What it does
flarg.io is an Augmented Reality platform that allows you to play games and physical activities with your friends from across the world. The relative positions of each person will be recorded and displayed on a single augmented reality plane, so that you can interact with your friends as if they were in your own backyard.
The primary application is a capture the flag game, where your group will be split into two teams. Each team's goal is to capture the opposing flag and bring it back to the home-base. Tagging opposing players in non-safe-zones would put them on temporary time out, forcing them go back to their own home-base. May the best team win!
## What's next for flarg.io
Capture the flag is just the first of our suite of possible mini-games. Building off of the AR framework that we have built, the team foresees making other games like "floor is lava" and "sharks and minnows" with the same technology. | losing |
## Bringing your music to life, not just to your ears but to your eyes 🎶
## Inspiration 🍐
Composing music through scribbling notes or drag-and-dropping from MuseScore couldn't be more tedious. As pianists ourselves, we know the struggle of trying to bring our impromptu improvisation sessions to life without forgetting what we just played or having to record ourselves and write out the notes one by one.
## What it does 🎹
Introducing PearPiano, a cute little pear that helps you pair the notes to your thoughts. As a musician's best friend, Pear guides pianists through an augmented simulation of a piano where played notes are directly translated into a recording and stored for future use. Pear can read both single notes and chords played on the virtual piano, allowing playback of your music with cascading tiles for full immersion. Seek musical guidance from Pear by asking, "What is the key signature of C-major?" or "Tell me the notes of the E-major diminished 7th chord." To fine tune your compositions, use "Edit mode," where musicians can rewind the clip and drag-and-drop notes for instant changes.
## How we built it 🔧
Using Unity Game Engine and the Oculus Quest, musicians can airplay their music on an augmented piano for real-time music composition. We used OpenAI's Whisper for voice dictation and C# for all game-development scripts. The AR environment is entirely designed and generated using the Unity UI Toolkit, allowing our engineers to realize an immersive yet functional musical corner.
## Challenges we ran into 🏁
* Calibrating and configuring hand tracking on the Oculus Quest
* Reducing positional offset when making contact with the virtual piano keys
* Building the piano in Unity: setting the pitch of the notes and being able to play multiple at once
## Accomplishments that we're proud of 🌟
* Bringing a scaled **AR piano** to life with close-to-perfect functionalities
* Working with OpenAI to synthesize text from speech to provide guidance for users
* Designing an interactive and aesthetic UI/UX with cascading tiles upon recording playback
## What we learned 📖
* Designing and implementing our character/piano/interface in 3D
* Emily had 5 cups of coffee in half a day and is somehow alive
## What's next for PearPiano 📈
* VR overlay feature to attach the augmented piano to a real one, enriching each practice or composition session
* A rhythm checker to support an aspiring pianist to stay on-beat and in-tune
* A smart chord suggester to streamline harmonization and enhance the composition process
* Depth detection for each note-press to provide feedback on the pianist's musical dynamics
* With the up-coming release of Apple Vision Pro and Meta Quest 3, full colour AR pass-through will be more accessible than ever — Pear piano will "pair" great with all those headsets! | ## Inspiration
Every musician knows that moment of confusion, that painful silence as onlookers shuffle awkward as you frantically turn the page of the sheet music in front of you. While large solo performances may have people in charge of turning pages, for larger scale ensemble works this obviously proves impractical. At this hackathon, inspired by the discussion around technology and music at the keynote speech, we wanted to develop a tool that could aid musicians.
Seeing AdHawks's MindLink demoed at the sponsor booths, ultimately give us a clear vision for our hack. MindLink, a deceptively ordinary looking pair of glasses, has the ability to track the user's gaze in three dimensions, recognizes events such as blinks and even has an external camera to display the user's view. Blown away by the possibility and opportunities this device offered, we set out to build a hands-free sheet music tool that simplifies working with digital sheet music.
## What it does
Noteation is a powerful sheet music reader and annotator. All the musician needs to do is to upload a pdf of the piece they plan to play. Noteation then displays the first page of the music and waits for eye commands to turn to the next page, providing a simple, efficient and most importantly stress-free experience for the musician as they practice and perform. Noteation also enables users to annotate on the sheet music, just as they would on printed sheet music and there are touch controls that allow the user to select, draw, scroll and flip as they please.
## How we built it
Noteation is a web app built using React and Typescript. Interfacing with the MindLink hardware was done on Python using AdHawk's SDK with Flask and CockroachDB to link the frontend with the backend.
## Challenges we ran into
One challenge we came across was deciding how to optimally allow the user to turn page using eye gestures. We tried building regression-based models using the eye-gaze data stream to predict when to turn the page and built applications using Qt to study the effectiveness of these methods. Ultimately, we decided to turn the page using right and left wink commands as this was the most reliable technique that also preserved the musicians' autonomy, allowing them to flip back and forth as needed.
Strategizing how to structure the communication between the front and backend was also a challenging problem to work on as it is important that there is low latency between receiving a command and turning the page. Our solution using Flask and CockroachDB provided us with a streamlined and efficient way to communicate the data stream as well as providing detailed logs of all events.
## Accomplishments that we're proud of
We're so proud we managed to build a functioning tool that we, for certain, believe is super useful. As musicians this is something that we've legitimately thought would be useful in the past, and granted access to pioneering technology to make that happen was super exciting. All while working with a piece of cutting-edge hardware technology that we had zero experience in using before this weekend.
## What we learned
One of the most important things we learnt this weekend were the best practices to use when collaborating on project in a time crunch. We also learnt to trust each other to deliver on our sub-tasks and helped where we could. The most exciting thing that we learnt while learning to use these cool technologies, is that the opportunities are endless in tech and the impact, limitless.
## What's next for Noteation: Music made Intuitive
Some immediate features we would like to add to Noteation is to enable users to save the pdf with their annotations and add landscape mode where the pages can be displayed two at a time. We would also really like to explore more features of MindLink and allow users to customize their control gestures. There's even possibility of expanding the feature set beyond just changing pages, especially for non-classical musicians who might have other electronic devices to potentially control. The possibilities really are endless and are super exciting to think about! | ## Inspiration
I hate reading through job descriptions and trying to figure out what skills they are looking for in a developer amidst the shameless self-promotion and flagrant buzz-word spamming. So I decided to train a custom AI model to do so, and ended up building a whole AI training UI in the process!
## What it does
Nina allows a user to generate training code for custom MITIE models. It is project-agnositic, meaning it can be used to generate code for any kind of MITIE NER custom model.
Lumbergh is a custom trained MITIE model which parses through a job description and pulls out the required developer skills.
## How I built it
I build Nina using HTML, CSS, and JS (jQuery + Vue.js)
For Lumbergh I used MITIE, a deep learning library that is designed for perfoming Named Entity Recognition. I used Nina to generate custom MITIE training code, and then trained a model based on data which I pulled from the Indeed.com API and tagged by hand
## Challenges I ran into
Initially the model I designed was far too complex, and lead to very long AI training times (the first training session took an hour and a half, and that was only for 8 data sets!). I then simplified the model to pull just
one entity instead of 3. This not only lowered the training time, but it ended up leading to a more accurate model
## Accomplishments that I'm proud of
The accomplishment I am most proud of is the F1-Score I obtained on the custom model after optimizing it. An F1 score is a measure of accuracy for models. The highest F1 score I achieved was 91.2% on my final model.
## What I learned
I had never used machine learning before this weekend, I learned a ton about how deep learning and NER work behind the scenes. I also learned Vue.js for the first time to build the front end.
## What's next for Nina & Lumbergh
The plan is to continue improving the accuracy of Lumbergh and eventually use it as a feature in another app of mine called [ResOptim](https://github.com/jaydenwindle/mchacks2017), which automatically optimizes resumes based on a set of skill criteria. Currently Lumbergh is only trained on a dataset of 25 job descriptions, I would like to push that up to 100.
I plan to release Nina as a standalone tool to make generating MITIE model code easier for everyone who is working on NER models, as there are currently no good GUIs for that process | winning |
## Inspiration
While we were coming up with ideas on what to make, we looked around at each other while sitting in the room and realized that our postures weren't that great. You We knew that it was pretty unhealthy for us to be seated like this for prolonged periods. This inspired us to create a program that could help remind us when our posture is terrible and needs to be adjusted.
## What it does
Our program uses computer vision to analyze our position in front of the camera. Sit Up! takes your position at a specific frame and measures different distances and angles between critical points such as your shoulders, nose, and ears. From there, the program throws all these measurements together into mathematical equations. The program compares the results to a database of thousands of positions to see if yours is good.
## How we built it
We built it using Flask, Javascript, Tensorflow, Sklearn.
## Challenges we ran into
The biggest challenge we faced, is how inefficient and slow it is for us to actually do this. Initially our plan was to use Django for an API that gives us the necessary information but it was slower than anything we’ve seen before, that is when we came up with client side rendering. Doing everything in flask, made this project 10x faster and much more efficient.
## Accomplishments that we're proud of
Implementing client side rendering for an ML model
Getting out of our comfort zone by using flask
Having nearly perfect accuracy with our model
Being able to pivot our tech stack and be so versatile
## What we learned
We learned a lot about flask
We learned a lot about the basis of ANN
We learned more on how to implement computer vision for a use case
## What's next for Sit Up!
Implement a phone app
Calculate the accuracy of our model
Enlarge our data set
Support higher frame rates | ## Inspiration
It's easy to zone off in online meetings/lectures, and it's difficult to rewind without losing focus at the moment. It could also be disrespectful to others if you expose the fact that you weren't paying attention. Wouldn't it be nice if we can just quickly skim through a list of keywords to immediately see what happened?
## What it does
Rewind is an intelligent, collaborative and interactive web canvas with built in voice chat that maintains a list of live-updated keywords that summarize the voice chat history. You can see timestamps of the keywords and click on them to reveal the actual transcribed text.
## How we built it
Communications: WebRTC, WebSockets, HTTPS
We used WebRTC, a peer-to-peer protocol to connect the users though a voice channel, and we used websockets to update the web pages dynamically, so the users would get instant feedback for others actions. Additionally, a web server is used to maintain stateful information.
For summarization and live transcript generation, we used Google Cloud APIs, including natural language processing as well as voice recognition.
Audio transcription and summary: Google Cloud Speech (live transcription) and natural language APIs (for summarization)
## Challenges we ran into
There are many challenges that we ran into when we tried to bring this project to reality. For the backend development, one of the most challenging problems was getting WebRTC to work on both the backend and the frontend. We spent more than 18 hours on it to come to a working prototype. In addition, the frontend development was also full of challenges. The design and implementation of the canvas involved many trial and errors and the history rewinding page was also time-consuming. Overall, most components of the project took the combined effort of everyone on the team and we have learned a lot from this experience.
## Accomplishments that we're proud of
Despite all the challenges we ran into, we were able to have a working product with many different features. Although the final product is by no means perfect, we had fun working on it utilizing every bit of intelligence we had. We were proud to have learned many new tools and get through all the bugs!
## What we learned
For the backend, the main thing we learned was how to use WebRTC, which includes client negotiations and management. We also learned how to use Google Cloud Platform in a Python backend and integrate it with the websockets. As for the frontend, we learned to use various javascript elements to help develop interactive client webapp. We also learned event delegation in javascript to help with an essential component of the history page of the frontend.
## What's next for Rewind
We imagined a mini dashboard that also shows other live-updated information, such as the sentiment, summary of the entire meeting, as well as the ability to examine information on a particular user. | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materials more seamless and convenient.
## What it does
Wise Up is a website that takes many different types of file format, as well as plain text, and separates the information into "pages". Using text embeddings, it can then quickly search through all the pages in a text and figure out which ones are most likely to contain the answer to a question that the user sends. It can also recursively summarize the file at different levels of compression.
## How we built it
With blood, sweat and tears! We used many tools offered to us throughout the challenge to simplify our life. We used Javascript, HTML and CSS for the website, and used it to communicate to a Flask backend that can run our python scripts involving API calls and such. We have API calls to openAI text embeddings, to cohere's xlarge model, to GPT-3's API, OpenAI's Whisper Speech-to-Text model, and several modules for getting an mp4 from a youtube link, a text from a pdf, and so on.
## Challenges we ran into
We had problems getting the backend on Flask to run on a Ubuntu server, and later had to instead run it on a Windows machine. Moreover, getting the backend to communicate effectively with the frontend in real time was a real challenge. Extracting text and page data from files and links ended up taking more time than expected, and finally, since the latency of sending information back and forth from the front end to the backend would lead to a worse user experience, we attempted to implement some features of our semantic search algorithm in the frontend, which led to a lot of difficulties in transferring code from Python to Javascript.
## Accomplishments that we're proud of
Since OpenAI's text embeddings are very good and very new, and we use GPT-3.5 based on extracted information to formulate the answer, we believe we likely equal the state of the art in the task of quickly analyzing text and answer complex questions on it, and the ease of use for many different file formats makes us proud that this project and website can be useful for so many people so often. To understand a textbook and answer questions about its content, or to find specific information without knowing any relevant keywords, this product is simply incredibly good, and costs pennies to run. Moreover, we have added an identification system (users signing up with a username and password) to ensure that a specific account is capped at a certain usage of the API, which is at our own costs (pennies, but we wish to avoid it becoming many dollars without our awareness of it.
## What we learned
As time goes on, not only do LLMs get better, but new methods are developed to use them more efficiently and for greater results. Web development is quite unintuitive for beginners, especially when different programming languages need to interact. One tool that has saved us a few different times is using json for data transfer, and aws services to store Mbs of data very cheaply. Another thing we learned is that, unfortunately, as time goes on, LLMs get bigger and so sometimes much, much slower; api calls to GPT3 and to Whisper are often slow, taking minutes for 1000+ page textbooks.
## What's next for Wise Up
What's next for Wise Up is to make our product faster and more user-friendly. A feature we could add is to summarize text with a fine-tuned model rather than zero-shot learning with GPT-3. Additionally, a next step is to explore partnerships with educational institutions and companies to bring Wise Up to a wider audience and help even more students and educators in their learning journey, or attempt for the website to go viral on social media by advertising its usefulness. Moreover, adding a financial component to the account system could let our users cover the low costs of the APIs, aws and CPU running Whisper. | winning |
## Inspiration
We were inspired by how there were many instances of fraud with regards to how donations were handled. It is heartbreaking to see how mismanagement can lead to victims of disasters not receiving the help that they desperately need.
## What it does
TrustTrace introduces unparalleled levels of transparency and accountability to charities and fundraisers. Donors will now feel more comfortable donating to causes such as helping earthquake victims since they will now know how their money will be spent, and where every dollar raised is going to.
## How we built it
We created a smart contract that allowed organisations to specify how much money they want to raise and how they want to segment their spending into specific categories. This is then enforced by the smart contract, which puts donors at ease as they know that their donations will not be misused, and will go to those who are truly in need.
## Challenges we ran into
The integration of smart contracts and the web development frameworks were more difficult than we expected, and we overcame them with lots of trial and error.
## Accomplishments that we're proud of
We are proud of being able to create this in under 36 hours for a noble cause. We hope that this creation can eventually evolve into a product that can raise interest, trust, and participation in donating to humanitarian causes across the world.
## What we learned
We learnt a lot about how smart contract works, how they are deployed, and how they can be used to enforce trust.
## What's next for TrustTrace
Expanding towards serving a wider range of fundraisers such as GoFundMes, Kickstarters, etc. | # Inspiration
Traditional startup fundraising is often restricted by stringent regulations, which make it difficult for small investors and emerging founders to participate. These barriers favor established VC firms and high-networth individuals, limiting innovation and excluding a broad range of potential investors. Our goal is to break down these barriers by creating a decentralized, community-driven fundraising platform that democratizes startup investments through a Decentralized Autonomous Organization, also known as DAO.
# What It Does
To achieve this, our platform leverages blockchain technology and the DAO structure. Here’s how it works:
* **Tokenization**: We use blockchain technology to allow startups to issue digital tokens that represent company equity or utility, creating an investment proposal through the DAO.
* **Lender Participation**: Lenders join the DAO, where they use cryptocurrency, such as USDC, to review and invest in the startup proposals.
-**Startup Proposals**: Startup founders create proposals to request funding from the DAO. These proposals outline key details about the startup, its goals, and its token structure. Once submitted, DAO members review the proposal and decide whether to fund the startup based on its merits.
* **Governance-based Voting**: DAO members vote on which startups receive funding, ensuring that all investment decisions are made democratically and transparently. The voting is weighted based on the amount lent in a particular DAO.
# How We Built It
### Backend:
* **Solidity** for writing secure smart contracts to manage token issuance, investments, and voting in the DAO.
* **The Ethereum Blockchain** for decentralized investment and governance, where every transaction and vote is publicly recorded.
* **Hardhat** as our development environment for compiling, deploying, and testing the smart contracts efficiently.
* **Node.js** to handle API integrations and the interface between the blockchain and our frontend.
* **Sepolia** where the smart contracts have been deployed and connected to the web application.
### Frontend:
* **MetaMask** Integration to enable users to seamlessly connect their wallets and interact with the blockchain for transactions and voting.
* **React** and **Next.js** for building an intuitive, responsive user interface.
* **TypeScript** for type safety and better maintainability.
* **TailwindCSS** for rapid, visually appealing design.
* **Shadcn UI** for accessible and consistent component design.
# Challenges We Faced, Solutions, and Learning
### Challenge 1 - Creating a Unique Concept:
Our biggest challenge was coming up with an original, impactful idea. We explored various concepts, but many were already being implemented.
**Solution**:
After brainstorming, the idea of a DAO-driven decentralized fundraising platform emerged as the best way to democratize access to startup capital, offering a novel and innovative solution that stood out.
### Challenge 2 - DAO Governance:
Building a secure, fair, and transparent voting system within the DAO was complex, requiring deep integration with smart contracts, and we needed to ensure that all members, regardless of technical expertise, could participate easily.
**Solution**:
We developed a simple and intuitive voting interface, while implementing robust smart contracts to automate and secure the entire process. This ensured that users could engage in the decision-making process without needing to understand the underlying blockchain mechanics.
## Accomplishments that we're proud of
* **Developing a Fully Functional DAO-Driven Platform**: We successfully built a decentralized platform that allows startups to tokenize their assets and engage with a global community of investors.
* **Integration of Robust Smart Contracts for Secure Transactions**: We implemented robust smart contracts that govern token issuance, investments, and governance-based voting bhy writing extensice unit and e2e tests.
* **User-Friendly Interface**: Despite the complexities of blockchain and DAOs, we are proud of creating an intuitive and accessible user experience. This lowers the barrier for non-technical users to participate in the platform, making decentralized fundraising more inclusive.
## What we learned
* **The Importance of User Education**: As blockchain and DAOs can be intimidating for everyday users, we learned the value of simplifying the user experience and providing educational resources to help users understand the platform's functions and benefits.
* **Balancing Security with Usability**: Developing a secure voting and investment system with smart contracts was challenging, but we learned how to balance high-level security with a smooth user experience. Security doesn't have to come at the cost of usability, and this balance was key to making our platform accessible.
* **Iterative Problem Solving**: Throughout the project, we faced numerous technical challenges, particularly around integrating blockchain technology. We learned the importance of iterating on solutions and adapting quickly to overcome obstacles.
# What’s Next for DAFP
Looking ahead, we plan to:
* **Attract DAO Members**: Our immediate focus is to onboard more lenders to the DAO, building a large and diverse community that can fund a variety of startups.
* **Expand Stablecoin Options**: While USDC is our starting point, we plan to incorporate more blockchain networks to offer a wider range of stablecoin options for lenders (EURC, Tether, or Curve).
* **Compliance and Legal Framework**: Even though DAOs are decentralized, we recognize the importance of working within the law. We are actively exploring ways to ensure compliance with global regulations on securities, while maintaining the ethos of decentralized governance. | ## Inspiration
This project was inspired by one of the group member's grandmother and her friends. Each month, the grandmother and her friends each contribute $100 to a group donation, then discuss and decide where the money should be donated to. We found this to be a really interesting concept for those that aren't set on always donating to the same charity. As well, it is a unique way to spread awareness and promote charity in communities. We wanted to take this concept, and make it possible to join globally.
## What it does
Each user is prompted to sign up for a monthly Stripe donation. The user can then either create a new "Collective" with a specific purpose, or join an existing one. Once in a collective, the user is able to add new charities to the poll, vote for a charity, or post comments to convince others on why their chosen charity needs the money the most.
## How we built it
We used MongoDB as the database with Node.js + Express for the back-end, hosted on a Azure Linux Virtual Machine. We made the front-end a web app created with Vue. Finally, we used Pusher to implement real time updates to the poll as people vote.
## Challenges we ran into
Setting up real-time polling proved to be a challenge. We wanted to allow the user to see updates to the poll without having to refresh their page. We needed to subscribe to only certain channels of notifications, depending on which collective the user is a member of. This real-time aspect required a fair bit of thought on race conditions for when to subscribe, as well as how to display the data in real time. In the end, we implemented the real-time poll as a pie graph, which resizes as people vote for charities.
## Accomplishments that we're proud of
Our team has competed in several hackathons now. Since this isn't our first time putting a project together in 24 hours, we wanted to try to create a polished product that could be used in the real world. In the end, we think we met this goal.
## What we learned
Two of our team of three had never used Vue before, so it was an interesting framework to learn. As well, we learned how to manage our time and plan early, which saved us from having to scramble at the end.
## What's next for Collective
We plan to continue developing Collective to support multiple subscriptions from the same person, and a single person entering multiple collectives. | winning |
## Inspiration
At work, we use a tele-presence robot call the BEAM. It is a very cool piece of technology that works to enable more personal remote meetings between people, and increase the amount of "presence" a person may have remotely. However, upon checking the cost of such technology, the 2.5k USD to 15k+ USD price tag per unit is very discouraging for adoption by everyone other than the largest of corporations. We as a team decided to leverage the ease-of-use for modern cloud servers, the power low cost IoT hardware, and powerful embedded code and iOS application through Swift, to tackle this challenge.
## What it does
Aura is a telepresence system that incorporates both hardware and software. The exception, is that the hardware and software are now separated, and any drive train can pair with any aura app holder to enable the use of the aura system. We aim to provide telepresence at a low cost, increased convenience, and flexibility. It allows multi-party video calling, and incorporates overlay UI to control the drive train.
## How we built it
Using Swift for iOS, Arduino for the ESP32, and NodeRED for the web application service, plus Watson IoT Platform and Twilio Video API.
## Challenges we ran into
One does not simply run into challenges, when working with the awesomeness that is aura.
## What's next for Aura
Add bluetooth support for local pairing, avoid extra complexity of IoT. Better UI with more time, and develop different sizes of drive trains that support life-sized telepresence, like the beam, with iPads and other tablets. | ## Inspiration
The world is constantly chasing after smartphones with bigger screens and smaller bezels. But why wait for costly display technology, and why get rid of old phones that work just fine? We wanted to build an app to create the effect of the big screen using the power of multiple small screens.
## What it does
InfiniScreen quickly and seamlessly links multiple smartphones to play videos across all of their screens. Breathe life into old phones by turning them into a portable TV. Make an eye-popping art piece. Display a digital sign in a way that is impossible to ignore. Or gather some friends and strangers and laugh at memes together. Creative possibilities abound.
## How we built it
Forget Bluetooth, InfiniScreen seamlessly pairs nearby phones using ultrasonic communication! Once paired, devices communicate with a Heroku-powered server written in node.js, express.js, and socket.io for control and synchronization. After the device arrangement is specified and a YouTube video is chosen on the hosting phone, the server assigns each device a region of the video to play. Left/right sound channels are mapped based on each phone's location to provide true stereo sound support. Socket-emitted messages keep the devices in sync and provide play/pause functionality.
## Challenges we ran into
We spent a lot of time trying to implement all functionality using the Bluetooth-based Nearby Connections API for Android, but ended up finding that pairing was slow and unreliable. The ultrasonic+socket.io based architecture we ended up using created a much more seamless experience but required a large rewrite. We also encountered many implementation challenges while creating the custom grid arrangement feature, and trying to figure out certain nuances of Android (file permissions, UI threads) cost us precious hours of sleep.
## Accomplishments that we're proud of
It works! It felt great to take on a rather ambitious project and complete it without sacrificing any major functionality. The effect is pretty cool, too—we originally thought the phones might fall out of sync too easily, but this didn't turn out to be the case. The larger combined screen area also emphasizes our stereo sound feature, creating a surprisingly captivating experience.
## What we learned
Bluetooth is a traitor. Mad respect for UI designers.
## What's next for InfiniScreen
Support for different device orientations, and improved support for unusual aspect ratios. Larger selection of video sources (Dailymotion, Vimeo, random MP4 urls, etc.). Seeking/skip controls instead of just play/pause. | ## Inspiration
There are over 1.3 billion people in the world who live with some form of vision impairment. Often, retrieving small objects, especially off the ground, can be tedious for those without complete seeing ability. We wanted to create a solution for those people where technology can not only advise them, but physically guide their muscles in their daily life interacting with the world.
## What it does
ForeSight was meant to be as intuitive as possible in assisting people with their daily lives. This means tapping into people's sense of touch and guiding their muscles without the user having to think about it. ForeSight straps on the user's forearm and detects objects nearby. If the user begins to reach the object to grab it, ForeSight emits multidimensional vibrations in the armband which guide the muscles to move in the direction of the object to grab it without the user seeing its exact location.
## How we built it
This project involved multiple different disciplines and leveraged our entire team's past experience. We used a Logitech C615 camera and ran two different deep learning algorithms, specifically convolutional neural networks, to detect the object. One CNN was using the Tensorflow platform and served as our offline solution. Our other object detection algorithm uses AWS Sagemaker recorded significantly better results, but only works with an Internet connection. Thus, we use a two-sided approach where we used Tensorflow if no or weak connection was available and AWS Sagemaker if there was a suitable connection. The object detection and processing component can be done on any computer; specifically, a single-board computer like the NVIDIA Jetson Nano is a great choice. From there, we powered an ESP32 that drove the 14 different vibration motors that provided the haptic feedback in the armband. To supply power to the motors, we used transistor arrays to use power from an external Lithium-Ion battery. From a software side, we implemented an algorithm that accurately selected and set the right strength level of all the vibration motors. We used an approach that calculates the angular difference between the center of the object and the center of the frame as well as the distance between them to calculate the given vibration motors' strength. We also built a piece of simulation software that draws a circular histogram and graphs the usage of each vibration motor at any given time.
## Challenges we ran into
One of the major challenges we ran into was the capability of Deep Learning algorithms on the market. We had the impression that CNN could work like a “black box” and have nearly-perfect accuracy. However, this is not the case, and we experienced several glitches and inaccuracies. It then became our job to prevent these glitches from reaching the user’s experience.
Another challenge we ran into was fitting all of the hardware onto an armband without overwhelming the user. Especially on a body part as used as an arm, users prioritize movement and lack of weight on their devices. Therefore, we aimed to provide a device that is light and small.
## Accomplishments that we're proud of
We’re very proud that we were able to create a project that solves a true problem that a large population faces. In addition, we're proud that the project works and can't wait to take it further!
Specifically, we're particularly happy with the user experience of the project. The vibration motors work very well for influencing movement in the arms without involving too much thought or effort from the user.
## What we learned
We all learned how to implement a project that has mechanical, electrical, and software components and how to pack it seamlessly into one product.
From a more technical side, we gained more experience with Tensorflow and AWS. Also, working with various single board computers taught us a lot about how to use these in our projects.
## What's next for ForeSight
We’re looking forward to building our version 2 by ironing out some bugs and making the mechanical design more approachable. In addition, we’re looking at new features like facial recognition and voice control. | winning |
## Inspiration
For three out of four of us, cryptocurrency, Web3, and NFTs were uncharted territory. With the continuous growth within the space, our team decided we wanted to learn more about the field this weekend.
An ongoing trend we noticed when talking to others at Hack the North was that many others lacked knowledge on the subject, or felt intimidated.
Inspired by the randomly generated words and QR codes on our hacker badges, we decided to create a tool around these that would provide an engaging soft introduction to NFTs for those attending Hack the North. Through bringing accessible knowledge and practice directly to hackers, Mint the North includes those who may be on the fence, uncomfortable with approaching subject experts, and existing enthusiasts alike.
## What It Does
Mint the North creates AI-generated NFTs based on the words associated with each hacker's QR code. When going through the process, the web app provides participants with the opportunity to learn the basics of NFTs in a non-intimidating way. By the end of the process, hackers will sign off with a solid understanding of the basics of NFTs and their own personalized NFTs. Along with the tumblers, shirts, and stickers hackers get as swag throughout the event, participants can leave Hack the North with personalized NFTs and potentially a newly sparked interest and motivation to learn more.
## How We Built It
**Smart Contract**
Written in Solidity and deployed on Ethereum (testnet).
**Backend**
Written in node.js and express.js. Deployed on Google Firebase and assets are stored on Google Cloud Services.
**Frontend**
Designed in Figma and built using React.
## Challenges We Ran Into
The primary challenge was finding an API for the AI-generated images. While many exist, there were different barriers restricting our use. After digging through several sources, we were able to find a solution. The solution also had issues at the start, so we had to make adjustments to the code and eventually ensured it worked well.
Hosting has been a consistent challenge throughout the process as well due to a lack of free hub platforms to use for hosting our backend services. We use Google firebase as they have a built-in emulator that allows us to make use of advanced functionality while running locally.
## Accomplishments that We're Proud Of
Those of us in the group that were new to the topic are proud of the amount we were able to learn and adapt in a short time.
As we continued to build and adjust our project, new challenges occurred. Challenges like finding a functional API or hosting pushed our team to communicate, reorganize, and ultimately consider various solutions with limited resources.
# What We Learned
Aside from learning a lot about Web3, blockchain, crypto, and NFTs, the challenges that occurred throughout the process taught us a lot about problem-solving with limited resources and time.
# What's Next for Mint the North
While Mint the North utilized resources specific to Hack the North 2022, we envision the tool expanding to other hackathons and tech education settings. For Web3 company sponsors or supporters, the tool provides a direct connection and offering to communities that may be difficult to reach, or are interested but unsure how to proceed. | ## Inspiration:
We were inspired by the inconvenience faced by novice artists creating large murals, who struggle to use reference images for guiding their work. It can also help give confidence to young artists who need a confidence boost and are looking for a simple way to replicate references.
## What it does
An **AR** and **CV** based artist's aid that enables easy image tracing and color blocking guides (almost like "paint-by-numbers"!)
It achieves this by allowing the user to upload an image of their choosing, which is then processed into its traceable outlines and dominant colors. These images are then displayed in the real world on a surface of the artist's choosing, such as paper or a wall.
## How we built it
The base for the image processing functionality (edge-detection and color blocking) were **Python, OpenCV, numpy** and the **K-means** grouping algorithm. The image processing module was hosted on **Firebase**.
The end-user experience was driven using **Unity**. The user uploads an image to the app. The image is ported to Firebase, which then returns the generated images. We used the Unity engine along with **ARCore** to implement surface detection and virtually position the images in the real world. The UI was also designed through packages from Unity.
## Challenges we ran into
Our biggest challenge was the experience level of our team with the tech stack we chose to use. Since we were all new to Unity, we faced several bugs along the way and had to slowly learn our way through the project.
## Accomplishments that we're proud of
We are very excited to have demonstrated the accumulation of our image processing knowledge and to make contributions to Git.
## What we learned
We learned that our aptitude lies lower level, in robust languages like C++, as opposed to using pre-built systems to assist development, such as Unity. In the future, we may find easier success building projects to refine our current tech stacks as opposed to expanding them.
## What's next for [AR]t
After Hack the North, we intend to continue the project using C++ as the base for AR, which is more familiar to our team and robust. | ## Inspiration
Greenhouses require increased disease control and need to closely monitor their plants to ensure they're healthy. In particular, the project aims to capitalize on the recent cannabis interest.
## What it Does
It's a sensor system composed of cameras, temperature and humidity sensors layered with smart analytics that allows the user to tell when plants in his/her greenhouse are diseased.
## How We built it
We used the Telus IoT Dev Kit to build the sensor platform along with Twillio to send emergency texts (pending installation of the IoT edge runtime as of 8 am today).
Then we used azure to do transfer learning on vggnet to identify diseased plants and identify them to the user. The model is deployed to be used with IoT edge. Moreover, there is a web app that can be used to show that the
## Challenges We Ran Into
The data-sets for greenhouse plants are in fairly short supply so we had to use an existing network to help with saliency detection. Moreover, the low light conditions in the dataset were in direct contrast (pun intended) to the PlantVillage dataset used to train for diseased plants. As a result, we had to implement a few image preprocessing methods, including something that's been used for plant health detection in the past: eulerian magnification.
## Accomplishments that We're Proud of
Training a pytorch model at a hackathon and sending sensor data from the STM Nucleo board to Azure IoT Hub and Twilio SMS.
## What We Learned
When your model doesn't do what you want it to, hyperparameter tuning shouldn't always be the go to option. There might be (in this case, was) some intrinsic aspect of the model that needed to be looked over.
## What's next for Intelligent Agriculture Analytics with IoT Edge | losing |
## What Inspired Us
A good customer experience leaves a lasting impression across every stage of their journey. This is exemplified in the airline and travel industry. To give credit and show appreciation to the hardworking employees of JetBlue, we chose to scrape and analyze customer feedback on review and social media sites to both highlight their impact on customers and provide currently untracked, valuable data to build a more personalized brand that outshines its market competitors.
## What Our Project does
Our customer feedback analytics dashboard, BlueVisuals, provides JetBlue with highly visual presentations, summaries, and highlights of customers' thoughts and opinions on social media and review sites. Visuals such as word clouds and word-frequency charts highlight critical areas of focus where the customers reported having either positive or negative experiences, suggesting either areas of improvement or strengths. The users can read individual comments to review the exact situation of the customers or skim through to get a general sense of their social media interactions with their customers. Through this dashboard, we hope that the users are able to draw solid conclusions and pursue action based on those said conclusions.
Humans of JetBlue is a side product resulting from such conclusions users (such as ourselves) may draw from the dashboard that showcases the efforts and dedication of individuals working at JetBlue and their positive impacts on customers. This product highlights our inspiration for building the main dashboard and is a tool we would recommend to JetBlue.
## How we designed and built BlueVisuals and Humans of JetBlue
After establishing the goals of our project, we focused on data collection via web scraping and building the data processing pipeline using Python and Google Cloud's NLP API. After understanding our data, we drew up a website and corresponding visualizations. Then, we implemented the front end using React.
Finally, we drew conclusions from our dashboard and designed 'Humans of JetBlue' as an example usage of BlueVisuals.
## What's next for BlueVisuals and Humans of JetBlue
* collecting more data to get a more representative survey of consumer sentiment online
* building a back-end database to support data processing, storage, and organization
* expanding employee-centric
## Challenges we ran into
* Polishing scraped data and extracting important information.
* Finalizing direction and purpose of the project
* Sleeping on the floor.
## Accomplishments that we're proud of
* effectively processed, organized, and built visualizations for text data
* picking up new skills (JS, matplotlib, GCloud NLP API)
* working as a team to manage loads of work under time constraints
## What we learned
* value of teamwork in a coding environment
* technical skills | ## Inspiration
Data analytics can be **extremely** time-consuming. We strove to create a tool utilizing modern AI technology to generate analysis such as trend recognition on user-uploaded datasets.The inspiration behind our product stemmed from the growing complexity and volume of data in today's digital age. As businesses and organizations grapple with increasingly massive datasets, the need for efficient, accurate, and rapid data analysis became evident. We even saw this within one of our sponsor's work, CapitalOne, in which they have volumes of financial transaction data, which is very difficult to manually, or even programmatically parse.
We recognized the frustration many professionals faced when dealing with cumbersome manual data analysis processes. By combining **advanced machine learning algorithms** with **user-friendly design**, we aimed to empower users from various domains to effortlessly extract valuable insights from their data.
## What it does
On our website, a user can upload their data, generally in the form of a .csv file, which will then be sent to our backend processes. These backend processes utilize Docker and MLBot to train a LLM which performs the proper data analyses.
## How we built it
Front-end was very simple. We created the platform using Next.js and React.js and hosted on Vercel.
The back-end was created using Python, in which we employed use of technologies such as Docker and MLBot to perform data analyses as well as return charts, which were then processed on the front-end using ApexCharts.js.
## Challenges we ran into
* It was some of our first times working in live time with multiple people on the same project. This advanced our understand of how Git's features worked.
* There was difficulty getting the Docker server to be publicly available to our front-end, since we had our server locally hosted on the back-end.
* Even once it was publicly available, it was difficult to figure out how to actually connect it to the front-end.
## Accomplishments that we're proud of
* We were able to create a full-fledged, functional product within the allotted time we were given.
* We utilized our knowledge of how APIs worked to incorporate multiple of them into our project.
* We worked positively as a team even though we had not met each other before.
## What we learned
* Learning how to incorporate multiple APIs into one product with Next.
* Learned a new tech-stack
* Learned how to work simultaneously on the same product with multiple people.
## What's next for DataDaddy
### Short Term
* Add a more diverse applicability to different types of datasets and statistical analyses.
* Add more compatibility with SQL/NoSQL commands from Natural Language.
* Attend more hackathons :)
### Long Term
* Minimize the amount of work workers need to do for their data analyses, almost creating a pipeline from data to results.
* Have the product be able to interpret what type of data it has (e.g. financial, physical, etc.) to perform the most appropriate analyses. | ## Inspiration
There should be an effective way to evaluate company value by examining the individual values of those that make up the company.
## What it does
Simplifies the research process of examining a company by showing it in a dynamic web design that is free-flowing and easy to follow.
## How we built it
It was originally built using a web scraper that scraped from LinkedIn which was written in python. The web visualizer was built using javascript and the VisJS library to have a dynamic view and aesthetically pleasing physics. In order to have a clean display, web components were used.
## Challenges we ran into
Gathering and scraping the data was a big obstacle, had to pattern match using LinkedIn's data
## Accomplishments that we're proud of
It works!!!
## What we learned
Learning to use various libraries and how to setup a website
## What's next for Yeevaluation
Finetuning and reimplementing dynamic node graph, history. Revamping project, considering it was only made in 24 hours. | partial |
## 💡 Inspiration
We got inspiration from or back-end developer Minh. He mentioned that he was interested in the idea of an app that helped people record their positive progress and showcase their accomplishments there. This then led to our product/UX designer Jenny to think about what this app would target as a problem and what kind of solution would it offer. From our research, we came to the conclusion quantity over quality social media use resulted in people feeling less accomplished and more anxious. As a solution, we wanted to focus on an app that helps people stay focused on their own goals and accomplishments.
## ⚙ What it does
Our app is a journalling app that has the user enter 2 journal entries a day. One in the morning and one in the evening. During these journal entries, it would ask the user about their mood at the moment, generate am appropriate response based on their mood, and then ask questions that get the user to think about such as gratuity, their plans for the day, and what advice would they give themselves. Our questions follow many of the common journalling practices. The second journal entry then follows a similar format of mood and questions with a different set of questions to finish off the user's day. These help them reflect and look forward to the upcoming future. Our most powerful feature would be the AI that takes data such as emotions and keywords from answers and helps users generate journal summaries across weeks, months, and years. These summaries would then provide actionable steps the user could take to make self-improvements.
## 🔧 How we built it
### Product & UX
* Online research, user interviews, looked at stakeholders, competitors, infinity mapping, and user flows.
* Doing the research allowed our group to have a unified understanding for the app.
### 👩💻 Frontend
* Used React.JS to design the website
* Used Figma for prototyping the website
### 🔚 Backend
* Flask, CockroachDB, and Cohere for ChatAI function.
## 💪 Challenges we ran into
The challenge we ran into was the time limit. For this project, we invested most of our time in understanding the pinpoint in a very sensitive topic such as mental health and psychology. We truly want to identify and solve a meaningful challenge; we had to sacrifice some portions of the project such as front-end code implementation. Some team members were also working with the developers for the first time and it was a good learning experience for everyone to see how different roles come together and how we could improve for next time.
## 🙌 Accomplishments that we're proud of
Jenny, our team designer, did tons of research on problem space such as competitive analysis, research on similar products, and user interviews. We produced a high-fidelity prototype and were able to show the feasibility of the technology we built for this project. (Jenny: I am also very proud of everyone else who had the patience to listen to my views as a designer and be open-minded about what a final solution may look like. I think I'm very proud that we were able to build a good team together although the experience was relatively short over the weekend. I had personally never met the other two team members and the way we were able to have a vision together is something I think we should be proud of.)
## 📚 What we learned
We learned preparing some plans ahead of time next time would make it easier for developers and designers to get started. However, the experience of starting from nothing and making a full project over 2 and a half days was great for learning. We learned a lot about how we think and approach work not only as developers and designer, but as team members.
## 💭 What's next for budEjournal
Next, we would like to test out budEjournal on some real users and make adjustments based on our findings. We would also like to spend more time to build out the front-end. | ## Inspiration
Our inspiration for this project comes from our own experiences as University students. As students, we understand the importance of mental health and the role it plays in one's day to day life. With increasing workloads, stress of obtaining a good co-op and maintaining good marks, people’s mental health takes a big hit and without a good balance can often lead to many problems. That is why we wanted to tackle this challenge while also putting a fun twist.
Our goal with our product is to help provide users with mental health resources, but that can easily be done with any google search so that is why we wanted to add an “experience” part to our project where users can explore and learn more about themselves while also aiding in their mental health.
## What it does
Our project is a simulation where users are placed in a very calm and peaceful world open to exploration. Along their journey, they are accompanied by an entity that they can talk to whenever they want. This entity is there to support them and is there to demonstrate that they are not alone. As the user walks through the world, there are various characters they can meet that can provide the user with resources such as links, articles, etc. that can help better their mental health. When the user becomes more comfortable and interested, they have the choice to learn more and provide more information about themselves. This allows the user to have more personal resources such as local support groups in their area, etc.
## How we built it
We divided ourselves into two separate teams where one team works on the front end and the other on the back end. For our front end, we used unity to develop our world and characters. For the back end, we used openai’s chat API in order to generate our helpful resources with it all being coded in python. To connect our backend with our front end, we decided to use flask and a server website called Pythonanywhere.
## Challenges we ran into
We ran into multiple challenges during our time building this project. The first challenge was really nailing down on how we would want to execute our project. We spent a lot of time discussing how we would want to make our project unique while still achieving our goals. Furthermore, another challenge came with the front end as building the project on unity was challenging itself. We had to figure out how to receive input by the user and make sure that our back end gives us the correct information.
Finally, to adhere to all types of accessibility, we also decided to add a VR option to our simulation for more immersion so that the user can really feel like they are in a safe space to talk and that there are people to help them. Getting the VR setup was very difficult but also a super fun challenge.
For our back end, we encountered many challenges, especially getting the exact responses we wanted. We really had to be kinda creative on how we wanted to give the user the right responses and ensure they get the necessary resources.
## Accomplishments that we're proud of
We are very proud of the final product that we have come up with, especially our front end as that was the most challenging part. This entire project definitely pushed all of us past our skill level and we most definitely learned a lot.
## What we learned
We learnt a lot during this project. We most definitely learnt more about working as a team as this was our second official time working together. Not only that, but in terms of technical skills, we all believe that we had learnt something new and definitely improved the way we think about certain aspects of coding
## What's next for a conversation…
While we could not fully complete our project in time as we encountered many issues with combining the front end and back end, we are still proud | ## Inspiration
Our inspiration for the website was Discord.
Seeing how that software could bring gamers together. We decided we we wanted to do the same thing but with with coworkers, and friends giving them a place where people can relax and have a laugh with people during their free time from work, especially with the pandemic affecting mental health. To bring as many people together to de-stress was our goal.
## What it does
RELIEF is a place for you to take a step back, relax, and collect yourself before getting back into your daily routine. RELIEF has many different ways to help you de-stress, whether your stress is caused by individual, organizational, or environmental factors, we definitely have a way to help you! RELEIF has multiple stress relief options including meditation, gameplay, and an interactive chatroom.
## How we built it
We built it using react with firebase.
## Challenges we ran into
We are all fairly new to web development so we were learning everything on the fly. Getting things in the desired position on the website was a challenge. As well as making the website looks as intended on different screen sizes.
## Accomplishments that we're proud of
We're proud of the final submitted product. The simple chic look gives our website the intended relaxing, stress free environment. We are proud of how much we accomplished with how little knowledge we had to begin with.
## What we learned
We learned that there's a bunch of resources outside of school that teaches you how to code things (YouTube)
We learned our productivity level sky rocketed while participating in the hackathon.
We learned that even in isolation there are still people willing to share their wisdom despite not know who we are, it gives us the motivation to eventually do what the mentor, organizers, and sponsors are doing.
## What's next for RELIEF
We are focusing on developing a mobile app just like how we had it
Adding multiple single player and multi player games for users to enjoy. Adding more functionality to the chat. Adding more music to the meditation room with a more interactive interface. | losing |
## Inspiration
When thinking about how we could make a difference within local communities impacted by Covid-19, what came to mind are our frontline workers. Our doctors, nurses, grocery store workers, and Covid-19 testing volunteers, who have tirelessly been putting themselves and their families on the line. They are the backbone and heartbeat of our society during these past 10 months and counting. We want them to feel the appreciation and gratitude they deserve. With our app, we hope to bring moments of positivity and joy to those difficult and trying moments of our frontline workers. Thank you!
## What it does
Love 4 Heroes is a web app to support our frontline workers by expressing our gratitude for them. We want to let them know they are loved, cared for, and appreciated. In the app, a user can make a thank you card, save it, and share it with a frontline worker. A user's card is also posted to the "Warm Messages" board, a community space where you can see all the other thank-you-cards.
## How we built it
Our backend is built with Firebase. The front-end is built with Next.js, and our design framework is Tailwind CSS.
## Challenges we ran into
* Working with different time zones [12 hour time difference].
* We ran into trickiness figuring out how to save our thank you cards to a user's phone or laptop.
* Persisting likes with Firebase and Local Storage
## Accomplishments that we're proud of
* Our first Hackathon
+ We're not in the same state, but came together to be here!
+ Some of us used new technologies like Next.js, Tailwind.css, and Firebase for the first time!
+ We're happy with how the app turned out from a user's experience
+ We liked that we were able to create our own custom card designs and logos, utilizing custom made design-textiles
## What we learned
* New Technologies: Next.js, Firebase
* Managing time-zone differences
* How to convert a DOM element into a .jpeg file.
* How to make a Responsive Web App
* Coding endurance and mental focus
-Good Git workflow
## What's next for love4heroes
More cards, more love! Hopefully, we can share this with a wide community of frontline workers. | ## Inspiration
Traffic is a pain and hurdle for everyone. It costs time and money for everyone stuck within it. We wanted to empower everyone to focus on what they truly enjoy instead of having to waste their time in traffic. We found the challenge to connect autonomous vehicles and enable them to work closely with each other to make maximize traffic flow to be very interesting. We were specifically interested in aggregating real data to make decisions and evolve those over time using artificial intelligence.
## What it does
We engineered an autonomous network that minimizes the time delay for each car in the network as it moves from its source to its destination. The idea is to have 0 intersections, 0 accidents, and maximize traffic flow.
We did this by developing a simulation in P5.js and training a network of cars to interact with each other in such a way that they do not collide and still travel from their source to target destination safely. We slowly iterated on this idea by first creating the idea of incentivizing factors and negative points. This allowed the cars to learn to not collide with each other and follow the goal they're set out to do. After creating a full simulation with intersections (allowing cars to turn and drive so they stop the least number of times), we created a simulation on Unity. This simulation looked much nicer and took the values trained by our best result from our genetic AI. From the video, we can see that the generation is flawless; there are no accidents, and traffic flows seamlessly. This was the result of over hundreds of generations of training of the genetic AI. You can see our video for more information!
## How I built it
We trained an evolutionary AI on many physical parameters to optimize for no accidents and maximal speed. The allowed the AI to experiment with different weights for each factor in order to reach our goal; having the cars reach from source to destination while staying a safe distance away from all other cars.
## Challenges we ran into
Deciding which parameters to tune, removing any bias, and setting up the testing environment. To remove bias, we ended up introducing randomly generated parameters in our genetic AI and "breeding" two good outcomes. Setting up the simulation was also tricky as it involved a lot of vector math.
## Accomplishments that I'm proud of
Getting the network to communicate autonomously and work in unison to avoid accidents and maximize speed. It's really cool to see the genetic AI evolve from not being able to drive at all, to fully being autonomous in our simulation. If we wanted to apply this to the real world, we can add more parameters and have the genetic AI optimize to find the parameters needed to reach our goals in the fastest time.
## What I learned
We learned how to model and train a genetic AI. We also learned how to deal with common issues and deal with performance constraints effectively. Lastly, we learned how to decouple the components of our application to make it scalable and easier to update in the future.
## What's next for Traffix
We want to increasing the user-facing features for the mobile app and improving the data analytics platform for the city. We also want to be able to extend this to more generalized parameters so that it could be applied in more dimensions. | Hello and thank you for judging my project. I am listing below two different links and an explanation of what the two different videos are. Due to the time constraints of some hackathons, I have a shorter video for those who require a lower time. As default I will be placing the lower time video up above, but if you have time or your hackathon allows so please go ahead and watch the full video at the link below. Thanks!
[3 Minute Video Demo](https://youtu.be/8tns9b9Fl7o)
[5 Minute Demo & Presentation](https://youtu.be/Rpx7LNqh7nw)
For any questions or concerns, please email me at [joshiom28@gmail.com](mailto:joshiom28@gmail.com)
## Inspiration
Resource extraction has tripled since 1970. That leaves us on track to run out of non-renewable resources by 2060. To fight this extremely dangerous issue, I used my app development skills to help everyone support the environment.
As a human and a person residing in this environment, I felt that I needed to used my technological development skills in order to help us take care of the environment better, especially in industrial countries such as the United States. In order to do my part in the movement to help sustain the environment. I used the symbolism of the LORAX to name LORAX app; inspired to help the environment.
\_ side note: when referencing firebase I mean firebase as a whole since two different databases were used; one to upload images and the other to upload data (ex. form data) in realtime. Firestore is the specific realtime database for user data versus firebase storage for image uploading \_
## Main Features of the App
To start out we are prompted with the **authentication panel** where we are able to either sign in with an existing email or sign up with a new account. Since we are new, we will go ahead and create a new account. After registering we are signed in and now are at the home page of the app. Here I will type in my name, email and password and log in. Now if we go back to firebase authentication, we see a new user pop up over here and a new user is added to firestore with their user associated data such as their **points, their user ID, Name and email.** Now lets go back to the main app. Here at the home page we can see the various things we can do. Lets start out with the Rewards tab where we can choose rewards depending on the amount of points we have.
If we press redeem rewards, it takes us to the rewards tab, where we can choose various coupons from companies and redeem them with the points we have. Since we start out with zero points, we can‘t redeem any rewards right now.
Let's go back to the home page.
The first three pages I will introduce are apart of the point incentive system for purchasing items that help the environment
If we press the view requests button, we are then navigated to a page where we are able to view our requests we have made in the past. These requests are used in order to redeem points from items you have purchased that help support the environment. Here we would we able to **view some details and the status of the requests**, but since we haven’t submitted any yet, we see there are none upon refreshing. Let’s come back to this page after submitting a request.
If we go back, we can now press the request rewards button. By pressing it, we are navigated to a form where we are able to **submit details regarding our purchase and an image of proof to ensure the user truly did indeed purchase the item**. After pressing submit, **this data and image is pushed to firebase’s realtime storage (for picture) and Firestore (other data)** which I will show in a moment.
Here if we go to firebase, we see a document with the details of our request we submitted and if we go to storage we are able to **view the image that we submitted**. And here we see the details. Here we can review the details, approve the status and assign points to the user based on their requests. Now let’s go back to the app itself.
Now let’s go to the view requests tab again now that we have submitted our request. If we go there, we see our request, the status of the request and other details such as how many points you received if the request was approved, the time, the date and other such details.
Now to the Footprint Calculator tab, where you are able to input some details and see the global footprint you have on the environment and its resources based on your house, food and overall lifestyle. Here I will type in some data and see the results. **Here its says I would take up 8 earths, if everyone used the same amount of resources as me.** The goal of this is to be able to reach only one earth since then Earth and its resources would be able to sustain for a much longer time. We can also share it with our friends to encourage them to do the same.
Now to the last tab, is the savings tab. Here we are able to find daily tasks we can simply do to no only save thousands and thousands of dollars but also heavily help sustain and help the environment. \**Here we have some things we can do to save in terms of transportation and by clicking on the saving, we are navigated to a website where we are able to view what we can do to achieve these savings and do it ourselves. \**
This has been the demonstration of the LORAX app and thank you for listening.
## How I built it
For the navigation, I used react native navigation in order to create the authentication navigator and the tab and stack navigators in each of the respective tabs.
## For the incentive system
I used Google Firebase’s Firestore in order to view, add and upload details and images to the cloud for reviewal and data transfer. For authentication, I also used **Google Firebase’s Authentication** which allowed me to create custom user data such as their user, the points associated with it and the complaints associated with their **user ID**. Overall, **Firebase made it EXTREMELY easy** to create a high level application. For this entire application, I used Google Firebase for the backend.
## For the UI
for the tabs such as Request Submitter, Request Viewer I used React-native-base library to create modern looking components which allowed me to create a modern looking application.
## For the Prize Redemption section and Savings Sections
I created the UI from scratch trialing and erroring with different designs and shadow effects to make it look cool. The user react-native-deeplinking to navigate to the specific websites for the savings tab.
## For the Footprint Calculator
I embedded the **Global Footprint Network’s Footprint Calculator** with my application in this tab to be able to use it for the reference of the user of this app. The website is shown in the **tab app and is functional on that UI**, similar to the website.
I used expo for wifi-application testing, allowing me to develop the app without any wires over the wifi network.
For the Request submission tab, I used react-native-base components to create the form UI elements and firebase to upload the data.
For the Request Viewer, I used firebase to retrieve and view the data as seen.
## Challenges I ran into
Some last second challenges I ran to was the manipulation of the database on Google Firebase. While creating the video in fact, I realize that some of the parameters were missing and were not being updated properly. I eventually realized that the naming conventions for some of the parameters being updated both in the state and in firebase got mixed up. Another issue I encountered was being able to retrieve the image from firebase. I was able to log the url, however, due to some issues with the state, I wasnt able to get the uri to the image component, and due to lack of time I left that off. Firebase made it very very easy to push, read and upload files after installing their dependencies.
Thanks to all the great documentation and other tutorials I was able to effectively implement the rest.
## What I learned
I learned a lot. Prior to this, I had not had experience with **data modelling, and creating custom user data points. \*\*However, due to my previous experience with \*\*firebase, and some documentation referencing** I was able to see firebase’s built in commands allowing me to query and add specific User ID’s to the the database, allowing me to search for data base on their UIDs. Overall, it was a great experience learning how to model data, using authentication and create custom user data and modify that using google firebase.
## Theme and How This Helps The Environment
Overall, this application used **incentives and educates** the user about their impact on the environment to better help the environment.
## Design
I created a comprehensive and simple UI to make it easy for users to navigate and understand the purposes of the Application. Additionally, I used previously mentioned utilities in order to create a modern look.
## What's next for LORAX (Luring Others to Retain our Abode Extensively)
I hope to create my **own backend in the future**, using **ML** and an **AI** to classify these images and details to automate the submission process and **create my own footprint calculator** rather than using the one provided by the global footprint network. | partial |
## Inspiration
The time-consuming process of watching videos and taking notes can discourage students from retaining knowledge and staying engaged. By creating a notes, bullet point, or essay summary from any YouTube link, YouWrite is an efficient way for students to grasp knowledge from videos.
## What it does
After logging in, the application will redirect you to another page that will allow you to make your conversions. All you need is to submit a YouTube link, include a timestamp, and input approximately how many words you want your summary to be.
## How we built it
The YouTube URL to summary functionality was built using the OpenAI API and youtube-to-transcript API,. Here, the user can input a YouTube URL and it will be converted to transcript and then summarized using AI.
The login system was created using Flask and MongoDB, where a user's login information inputed through our web application and then securely routed to our database through Flask.
The front end was built using React and provides a responsive user interface for the user to route data to the back end.
## Challenges we ran into
Integrating the HTML forms with MongoDB was a big challenge we faced during this project. Also, working on a time crunch with limited experience with the tech stack we wanted to use was very difficult since many of our team members had to learn them from scratch.
## Accomplishments that we're proud of
While we ran into a lot of technical issues because we were new to many of the things that we worked with, we were able to persevere, problem solve, and get the majority of our project finished and integrated together!
## What we learned
We learned how to integrate Python backend with React frontend through Flask, how to use Mongodb, and how to use OpenAI API. More importantly, we learned how fun (but difficult) hackathons can be and how to manage our time effectively working in a project setting!
## What's next for YouWriter
Creating another database to store the notes a user has generated so they can continue to access these documents in the future. Another goal for YouWriter is to generate images onto the notes for more comprehensive learning and cohesive notes. | ## Inspiration
Oftentimes when we find ourselves not understanding the content that has been taught in class and rarely remembering what exactly is being conveyed. And some of us have the habit of mismatching notes and forgetting where we put them. So to help all the ailing students, there was this idea to make an app that would give the students curated automatic content from the notes which they upload online.
## What it does
A student uploads his notes to the application. The application creates a summary of the notes, additional information on the subject of the notes, flashcards for easy remembering and quizzes to test his knowledge. There is also the option to view other student's notes (who have uploaded it in the same platform) and do all of the above with them as well. We made an interactive website that can help students digitize and share notes!
## How we built it
Google cloud vision was used to convert images into text files. We used Google cloud NLP API for the formation of questions from the plain text by identifying the entities and syntax of the notes. We also identified the most salient features of the conversation and assumed it to be the topic of interest. By doing this, we are able to scrape more detailed information on the topic using google custom search engine API. We also scrape information from Wikipedia. Then we make flashcards based on the questions and answers and also make quizzes to test the knowledge of the student. We used Django as the backend to create a web app. We also made a chatbot in google dialog-flow to inherently enable the use of google assistant skills.
## Challenges we ran into
Extending the platform to a collaborative domain was tough. Connecting the chatbot framework to the backend and sending back dynamic responses using webhook was more complicated than we expected.
Also, we had to go through multiple iterations to get our question formation framework right. We used the assumption that the main topic would be the noun at the beginning of the sentence. Also, we had to replace pronouns in order to keep track of the conversation.
## Accomplishments that we're proud of
We have only 3 members in the team and one of them has a background in electronics engineering and no experience in computer science and as we only had the idea of what we were planning to make but no idea of how we will make. We are very proud to have achieved a fully functional application at the end of this 36-hour hackathon. We learned a lot of concepts regarding UI/UX design, backend logic formation, connecting backend and frontend in Django and general software engineering techniques.
## What we learned
We learned a lot about the problems of integrations and deploying an application. We also had a lot of fun making this application because we had the motive to contribute to a large number of people in day to day life. Also, we learned about NLP, UI/UX and the importance of having a well-set plan.
## What's next for Noted
In the best-case scenario, we would want to convert this into an open-source startup and help millions of students with their studies. So that they can score good marks in their upcoming examinations. | ## Inspiration
Us college students all can relate to having a teacher that was not engaging enough during lectures or mumbling to the point where we cannot hear them at all. Instead of finding solutions to help the students outside of the classroom, we realized that the teachers need better feedback to see how they can improve themselves to create better lecture sessions and better ratemyprofessor ratings.
## What it does
Morpheus is a machine learning system that analyzes a professor’s lesson audio in order to differentiate between various emotions portrayed through his speech. We then use an original algorithm to grade the lecture. Similarly we record and score the professor’s body language throughout the lesson using motion detection/analyzing software. We then store everything on a database and show the data on a dashboard which the professor can access and utilize to improve their body and voice engagement with students. This is all in hopes of allowing the professor to be more engaging and effective during their lectures through their speech and body language.
## How we built it
### Visual Studio Code/Front End Development: Sovannratana Khek
Used a premade React foundation with Material UI to create a basic dashboard. I deleted and added certain pages which we needed for our specific purpose. Since the foundation came with components pre build, I looked into how they worked and edited them to work for our purpose instead of working from scratch to save time on styling to a theme. I needed to add a couple new original functionalities and connect to our database endpoints which required learning a fetching library in React. In the end we have a dashboard with a development history displayed through a line graph representing a score per lecture (refer to section 2) and a selection for a single lecture summary display. This is based on our backend database setup. There is also space available for scalability and added functionality.
### PHP-MySQL-Docker/Backend Development & DevOps: Giuseppe Steduto
I developed the backend for the application and connected the different pieces of the software together. I designed a relational database using MySQL and created API endpoints for the frontend using PHP. These endpoints filter and process the data generated by our machine learning algorithm before presenting it to the frontend side of the dashboard. I chose PHP because it gives the developer the option to quickly get an application running, avoiding the hassle of converters and compilers, and gives easy access to the SQL database. Since we’re dealing with personal data about the professor, every endpoint is only accessible prior authentication (handled with session tokens) and stored following security best-practices (e.g. salting and hashing passwords). I deployed a PhpMyAdmin instance to easily manage the database in a user-friendly way.
In order to make the software easily portable across different platforms, I containerized the whole tech stack using docker and docker-compose to handle the interaction among several containers at once.
### MATLAB/Machine Learning Model for Speech and Emotion Recognition: Braulio Aguilar Islas
I developed a machine learning model to recognize speech emotion patterns using MATLAB’s audio toolbox, simulink and deep learning toolbox. I used the Berlin Database of Emotional Speech To train my model. I augmented the dataset in order to increase accuracy of my results, normalized the data in order to seamlessly visualize it using a pie chart, providing an easy and seamless integration with our database that connects to our website.
### Solidworks/Product Design Engineering: Riki Osako
Utilizing Solidworks, I created the 3D model design of Morpheus including fixtures, sensors, and materials. Our team had to consider how this device would be tracking the teacher’s movements and hearing the volume while not disturbing the flow of class. Currently the main sensors being utilized in this product are a microphone (to detect volume for recording and data), nfc sensor (for card tapping), front camera, and tilt sensor (for vertical tilting and tracking professor). The device also has a magnetic connector on the bottom to allow itself to change from stationary position to mobility position. It’s able to modularly connect to a holonomic drivetrain to move freely around the classroom if the professor moves around a lot. Overall, this allowed us to create a visual model of how our product would look and how the professor could possibly interact with it. To keep the device and drivetrain up and running, it does require USB-C charging.
### Figma/UI Design of the Product: Riki Osako
Utilizing Figma, I created the UI design of Morpheus to show how the professor would interact with it. In the demo shown, we made it a simple interface for the professor so that all they would need to do is to scan in using their school ID, then either check his lecture data or start the lecture. Overall, the professor is able to see if the device is tracking his movements and volume throughout the lecture and see the results of their lecture at the end.
## Challenges we ran into
Riki Osako: Two issues I faced was learning how to model the product in a way that would feel simple for the user to understand through Solidworks and Figma (using it for the first time). I had to do a lot of research through Amazon videos and see how they created their amazon echo model and looking back in my UI/UX notes in the Google Coursera Certification course that I’m taking.
Sovannratana Khek: The main issues I ran into stemmed from my inexperience with the React framework. Oftentimes, I’m confused as to how to implement a certain feature I want to add. I overcame these by researching existing documentation on errors and utilizing existing libraries. There were some problems that couldn’t be solved with this method as it was logic specific to our software. Fortunately, these problems just needed time and a lot of debugging with some help from peers, existing resources, and since React is javascript based, I was able to use past experiences with JS and django to help despite using an unfamiliar framework.
Giuseppe Steduto: The main issue I faced was making everything run in a smooth way and interact in the correct manner. Often I ended up in a dependency hell, and had to rethink the architecture of the whole project to not over engineer it without losing speed or consistency.
Braulio Aguilar Islas: The main issue I faced was working with audio data in order to train my model and finding a way to quantify the fluctuations that resulted in different emotions when speaking. Also, the dataset was in german
## Accomplishments that we're proud of
Achieved about 60% accuracy in detecting speech emotion patterns, wrote data to our database, and created an attractive dashboard to present the results of the data analysis while learning new technologies (such as React and Docker), even though our time was short.
## What we learned
As a team coming from different backgrounds, we learned how we could utilize our strengths in different aspects of the project to smoothly operate. For example, Riki is a mechanical engineering major with little coding experience, but we were able to allow his strengths in that area to create us a visual model of our product and create a UI design interface using Figma. Sovannratana is a freshman that had his first hackathon experience and was able to utilize his experience to create a website for the first time. Braulio and Gisueppe were the most experienced in the team but we were all able to help each other not just in the coding aspect, with different ideas as well.
## What's next for Untitled
We have a couple of ideas on how we would like to proceed with this project after HackHarvard and after hibernating for a couple of days.
From a coding standpoint, we would like to improve the UI experience for the user on the website by adding more features and better style designs for the professor to interact with. In addition, add motion tracking data feedback to the professor to get a general idea of how they should be changing their gestures.
We would also like to integrate a student portal and gather data on their performance and help the teacher better understand where the students need most help with.
From a business standpoint, we would like to possibly see if we could team up with our university, Illinois Institute of Technology, and test the functionality of it in actual classrooms. | losing |
## Inspiration
As post secondary students, our mental health is directly affected. Constantly being overwhelmed with large amounts of work causes us to stress over these large loads, in turn resulting in our efforts and productivity to also decrease. A common occurrence we as students continuously endure is this notion that there is a relationship and cycle between mental health and productivity; when we are unproductive, it results in us stressing, which further results in unproductivity.
## What it does
Moodivity is a web application that improves productivity for users while guiding users to be more in tune with their mental health, as well as aware of their own mental well-being.
Users can create a profile, setting daily goals for themselves, and different activities linked to the work they will be doing. They can then start their daily work, timing themselves as they do so. Once they are finished for the day, they are prompted to record an audio log to reflect on the work done in the day.
These logs are transcribed and analyzed using powerful Machine Learning models, and saved to the database so that users can reflect later on days they did better, or worse, and how their sentiment reflected that.
## How we built it
***Backend and Frontend connected through REST API***
**Frontend**
* React
+ UI framework the application was written in
* JavaScript
+ Language the frontend was written in
* Redux
+ Library used for state management in React
* Redux-Sagas
+ Library used for asynchronous requests and complex state management
**Backend**
* Django
+ Backend framework the application was written in
* Python
+ Language the backend was written in
* Django Rest Framework
+ built in library to connect backend to frontend
* Google Cloud API
+ Speech To Text API for audio transcription
+ NLP Sentiment Analysis for mood analysis of transcription
+ Google Cloud Storage to store audio files recorded by users
**Database**
* PostgreSQL
+ used for data storage of Users, Logs, Profiles, etc.
## Challenges we ran into
Creating a full-stack application from the ground up was a huge challenge. In fact, we were almost unable to accomplish this. Luckily, with lots of motivation and some mentorship, we are comfortable with naming our application *full-stack*.
Additionally, many of our issues were niche and didn't have much documentation. For example, we spent a lot of time on figuring out how to send audio through HTTP requests and manipulating the request to be interpreted by Google-Cloud's APIs.
## Accomplishments that we're proud of
Many of our team members are unfamiliar with Django let alone Python. Being able to interact with the Google-Cloud APIs is an amazing accomplishment considering where we started from.
## What we learned
* How to integrate Google-Cloud's API into a full-stack application.
* Sending audio files over HTTP and interpreting them in Python.
* Using NLP to analyze text
* Transcribing audio through powerful Machine Learning Models
## What's next for Moodivity
The Moodivity team really wanted to implement visual statistics like graphs and calendars to really drive home visual trends between productivity and mental health. In a distant future, we would love to add a mobile app to make our tool more easily accessible for day to day use. Furthermore, the idea of email push notifications can make being productive and tracking mental health even easier. | ## Inspiration
The other day when we were taking the train to get from New Jersey to New York City we started to talk about how much energy we are saving by taking the train rather than driving, and slowly we realized that a lot of people always default to driving as their only mode of transit. We realized that because of this there is a significant amount of CO2 emissions entering our atmosphere. We already have many map apps and websites out there, but none of them take eco-friendliness into account, EcoMaps on the other hand does.
## What it does
EcoMaps allows users to input an origin and destination and then gives them the most eco-friendly way to get from their origin to destination. It uses Google Maps API in order to get the directions for the 4 different ways of travel (walking, biking, public transportation, and driving). From those 4 ways of travel it then chooses what would be the most convenient and most eco friendly way to get from point A to point B. Additionally it tells users how to get to their destination. If the best form of transportation is not driving, EcoMaps tells the user how much carbon emissions they are saving, but if driving is the best form of transportation it will tell them approximately how much carbon emissions they are putting out into our atmosphere. Our website also gives users a random fun fact about going green!
## How we built it
We started this project by importing the Google Maps API into javascript and learning the basics of how the basics worked such as getting a map on screen and going to certain positions. After this, Dan was able to encode the API’s direction function by converting the text strings entered by users into latitude and longitude coordinates through a built-in function. Once the directions started working, Dan built another function which extracted the time it takes to go from one place to another based on all 4 of our different transportation options: walking, biking, driving, and using public transit. Dan then used all of the times and availability of certain methods to determine the optimal method which users should use to help reduce emissions. Obviously, walking or biking is always the optimal option for this, however, the algorithm took into account that many trips are far too long to walk or bike. In other words, it combines both logic and sustainability of our environment. While Dan worked on the backend Rumi created the user interface using Figma and then used HTML and CSS to create a website design based off of the Figma design. Once this was all done, Dan worked on ensuring that the integration of his code and Rumi’s front end display integrated properly.
## Challenges we ran into
One problem we ran into during our project was the fact that Javascript is a single-threaded language. This means that it can only process one thing at a time, which especially came into play when getting data on 4 different trips varying by travel method. This caused the problem of the code skipping certain functions as opposed to waiting and then proceeding. In order to solve this, we learned about the asynchronous option which Javascript allows for in order to await for certain functions to finish before progressing forward in the code. This process of learning included both a quick Stack Overflow question as well as some quick google scans.
Another problem that we faced was dealing with different screen sizes for our website. Throughout our testing, we were solely using devices of the same monitor size, so once we switched to testing on a larger screen all of the proportions were off. At first, we were very confused as to why this was the case, but we soon realized that it was due to our CSS being specific to only our initial screen size. We then had to go through all of our HTML and CSS and adjust the properties so that it was based on percentages of whichever screen size the user had. Although it was a painstaking process, it was worth it in our end product!
## Accomplishments that we're proud of
We are proud of coming up with a website that gives users the most eco-friendly way to travel. This will push individuals to be more conscious of their travel and what form of transportation they end up taking. This is also our second ever hackathon and we are happily surprised by the fact that we were able to make a functioning product in such a short time. EcoMaps also functions in real time meaning that it updates according to variables such as traffic, stations closing, and transit lines closing. This makes EcoMaps more useful in the real world as we all function in real time as well.
## What we learned
Throughout the creation of EcoMaps we learned a host of new skills and information. We learned just how much traveling via car actually pollutes the environment around us, and just how convenient other forms of transportation can be. On the more technical side, we learned how to use Figma to create a website design and then how to create a website with HTML, CSS, and JavaScript based on this framework. We also learned how to implement Google Maps API in our software, and just how useful it can be. Most importantly we learned how to effectively combine our expertise in frontend and backend to create our now functional website, EcoMaps!
## What's next for EcoMaps
In the future we hope to make the app take weather into account and how that may impact the different travel options that are available. Turning EcoMaps into an app that is supported by mobile devices is a major future goal of ours, as most people primarily use their phones to navigate. | ## Inspiration
Mental health has become an increasingly vital issue on our campus. The facade of the perfect Stanford student (Stanford Duck Syndrome) means that real emotions and struggles are often suppressed. It is heartwarming to be able to connect with people on campus and see how they feel, in a familiar, yet anonymous way. Having the moment to connect with another person's experience of struggling with a Mid-Term or the Happiness after Stanford beats Cal can be amazingly uplifting.
## What it does
Our cross-platform app allows users to share how they feel in words. Their feelings are geolocated onto a map with a circle and with a timestamp anonymously. Our NLP sentiment analyzer creates a color for the feeling based on the sentiment of the feeling expressed. This provides a cool visualization to see how people feel across different geographic levels. For example, you can zoom into a building to observe that people are generally happy in the Huang Engineering Center because of TreeHacks currently and Zoom Out to see people in Stanford are generally stressed during midterm season. The ability to zoom in and even tap on a specific circle to see how a person feels in words allows you to go local while zooming out allows you to go global and gauge the general sentiment of an area or building as transparent colors overlap into generalized shades. It is a fascinating way to connect with people's deepest feelings and find the humanity in our everyday life.
## How we built it
Our front end was built in React Native through Google Maps and uses Node.js. Our backend consisted of a Flask server written in Python, on which our NLP sentiment analysis is done (Artificial Intelligence), determining colors for the circle based on the feeling estimated by the language model. Our database of feelings entries is stored in Firebase on the Cloud, with data being written to and from, to overlay feelings entries on the map. We also have a script running on Firebase to remove entries from a map after a certain time period (example 6 hours, so only the most recent entries are displayed on the map to the user). Our Flask Server is deployed on Heroku through the Cloud.
## Challenges we ran into
Getting Flask to communicate with our React Native app to produce the NLP sentiment analysis. Setting up our backend through Firebase to create markers on the map and persist user's responses in the long run.
## Accomplishments that we're proud of
Integrating all the different components was fascinating from Firebase to ReactNative to the NLP Sentiment Analysis through Flask.
## What we learned
We had no prior experience with React Native and Node.JS, so we learned this from scratch. Integrating all the different aspects of the solution from the frontend to backend to cloud storage was a thrilling experience.
## What's next for CampusFeels
We hope to add features to track the emotional wellbeing of areas in the long run as well as encourage users to develop the skills to track their own emotional well-being in the long run. We hope to apply data analytics to do this and track people's emotions related to different events/criteria e.g. Housing Choices, Weather, Big Game etc. | partial |
# Inspiration
Our inspiration for PennDrive came from the need to make meetings more accessible and productive. We often found ourselves missing important meetings due to conflicting schedules or other commitments, and catching up on what was discussed was a daunting task. We wanted to leverage the power of AI and technology to bridge this gap, making it possible for anyone to quickly grasp the essence of a meeting, even if they couldn't attend in person.
# What It Does
PennDrive is a revolutionary tool that simplifies meeting management and information retrieval. Here's what it does:
1. **Automated Transcription:** When a user inserts a USB Club USB Drive and drops a video file into it, PennDrive automatically transcribes the meeting video's content.
2. **Error Correction:** It then cleans up transcription errors to ensure the accuracy of the transcribed text.
3. **Content Analysis:** PennDrive analyzes the transcribed content to identify key points and agenda items discussed during the meeting.
4. **Meeting Summary:** Using the power of AI, PennDrive generates a concise summary of the meeting, highlighting the most crucial information and key takeaways.
5. **Additional Resources:** PennDrive doesn't stop at summaries; it also provides users with relevant resources to further explore and understand the meeting topics.
6. **User Notification:** Twilio's Sendgrid integration ensures that users receive timely notifications when their meeting summary is ready.
# How We Built It
Building PennDrive was a multidisciplinary effort that involved various technologies and steps:
1. **USB Club Integration:** We integrated USB Club's USB Drive to create a user-friendly experience. Users plug in the drive and drop their video files into it to trigger the automated process.
2. **AI-Powered Transcription:** We utilized GPT-4 and OpenAI's Whisper for accurate transcription and language processing. This step also involved error correction to improve transcript quality.
3. **Content Analysis:** PennDrive identifies key points and agenda items through AI-driven content analysis, ensuring that users can quickly grasp the most important information.
4. **Summary Generation:** AI is used to generate concise meeting summaries, enabling users to catch up on what they missed efficiently.
5. **Additional Resources:** The application provides users with relevant resources to deepen their understanding of the meeting topics, enhancing the overall experience.
6. **User Notification:** Integration with Twilio's Sendgrid ensures that users are promptly notified when their meeting summary is ready for review.
7. **Distribution:** We employed PyInstaller to package the application into an executable for easy distribution and use on various computers.
# Challenges We Ran Into
The development of PennDrive presented several challenges:
1. **API Integration Complexity:** Integrating multiple APIs, including those from USB Club, Metaphor, and Twilio's Sendgrid, required meticulous attention to detail and robust error handling to ensure a seamless user experience.
2. **Data Privacy Concerns:** Handling sensitive meeting content raised significant data privacy and security concerns. We implemented rigorous measures to protect user data and maintain confidentiality.
3. **Accuracy and Error Handling:** Achieving high accuracy in transcription and error correction was an ongoing challenge. We conducted extensive model fine-tuning to minimize errors and enhance reliability.
4. **User Interface Design:** Designing an intuitive user interface that accommodates users with varying technical backgrounds proved to be a complex task. We conducted user testing and gathered feedback to refine the design continually.
# Accomplishments That We're Proud Of
We are immensely proud of several accomplishments:
* **Seamless Integration:** Successfully integrating multiple third-party APIs and technologies into a cohesive and user-friendly tool.
* **High Accuracy:** Achieving a high level of accuracy in transcription and content analysis, ensuring that our meeting summaries are reliable and informative.
* **User-Centric Design:** Crafting an intuitive user interface that caters to a diverse user base and conducting user testing to optimize the user experience.
* **Data Privacy Measures:** Implementing robust data privacy and security measures to safeguard user data and maintain trust.
# What We Learned
Our journey with PennDrive was a profound learning experience:
* **AI Potential:** Realizing the incredible potential of AI, especially GPT-4 and OpenAI's Whisper, in transcribing and analyzing audio content accurately.
* **API Integration Skills:** Gaining expertise in integrating third-party APIs to enhance application functionality and user experience.
* **Video Processing Expertise:** Acquiring in-depth knowledge of video processing using Python and MoviePy to extract valuable insights from meeting recordings.
* **User-Centered Design:** Understanding the importance of designing applications with the end user in mind and the value of user testing in refining design choices.
# What's Next for PennDrive
The journey doesn't end here. We have ambitious plans for PennDrive's future:
* **Continuous Improvement:** We will continue to enhance the accuracy and capabilities of PennDrive by exploring advancements in AI and transcription technologies.
* **Integration Expansion:** We aim to integrate with more collaboration and communication platforms to offer seamless meeting management across various channels.
* **Enhanced User Experience:** Our focus will be on refining the user interface and incorporating user feedback to make PennDrive even more user-friendly.
* **Global Reach:** We aspire to make PennDrive accessible to users worldwide, breaking down language barriers and facilitating efficient meetings across cultures.
PennDrive is not a tool, it is a framework that we use often in our day-to-day lives, in our keychains, in backpacks, pockets, and pencil cases, so you are always ready. | ## Inspiration
Due to COVID-19, millions of students across the world have been forced to quickly adapt to video lectures and online education. To ease this transition and make studying more efficient, we wanted to help students by summarizing their lecture transcripts while also capturing the full lecture transcript so students can pay full attention to the lecture instead of being distracted with taking notes.
## What it does
A website that summarizes video lectures for efficient studying. Users can upload their video lectures to receive a full text transcript and timestamps of the most important sentences. The video timestamps have not been formatted to "minutes : seconds" yet.
## How We built it
We made made a microservice out of a pre-trained BERT model to summarize text, and an Express web server that works with Vue for the UI to make a web app. The web app accepts video uploads, sends the video to Azure's Speech-to-Text API to get a full transcript, sends the transcript to the microservice to get a summary with timestamps, and sends the summary and timestamps to Vue for display and video playback.
## Challenges we ran into
Managing cloud platform credentials in a team of 4 was difficult. Coordinating ourselves to avoid duplicating work. Managing packages and dependencies. Scope creep. Timestamps need to formatted to "minutes : seconds".
## Accomplishments that we're proud of
Most technically sophisticated hackathon project so far, as the project has many moving parts like Azure Media Services (for video playback), Azure Cognitive Services (for the Speech-to-Text API), and BERT (for text summarization).
Fun name ;)
## What we learned
CORS, JavaScript Promises, Microservice Architecture
## What's next for AweSummarizer
Adding video lecture subtitles automatically generated with Azure Media Services. Adding clickable timestamps to play the video at that timestamp for more convenient navigation. | ## Inspiration
When I was in Grade 12 and planned to apply for universities, I was pretty confused at the beginning. I may have access to the information of many programs and universities through their official websites and webinars; however, it is still difficult to find the answers to many questions. How about students’ daily life in particular universities/programs? What extracurricular activities did students participate in before applying for university? What kind of contests are valuable to help me stand out among thousands of applicants? Personally, I believe these questions can only be answered by experienced senior university students.
I hope that there is a platform that can connect senior university representative students and highschool students, sharing more detailed and valuable information to more highschool students and supporting them on their way to apply for universities.
## What it does
University Wing is essentially a web blog app that shares university students’ application experiences, which can support more highschool students, guide them on the right track and develop their skills as early as possible. All of the comments and posts would be sent to the content management system for review before being released, protecting students from any inappropriate content. There are many information categories, which include interview preparation, application process, extracurricular resources and much more. I believe highschool students can definitely gain valuable and helpful information here for their university applications.
## How I built it
The front-end part of this full-stack web app is developed using React.js and Next.js, and the design is completed by Tailwind CSS. Meanwhile, I implemented the back-end using GraphQL to fetch and post data through GraphCMS, which is a content management system that can administrate all the contents of my web app, allowing me to create models and generate API request.
## Challenges I ran into
* This is the first time I incorporate a content management system to my project. Although I was unfamiliar with it at the beginning, I eventually learnt how to create models and play around API with it.
* I encountered many difficulties when posting requests using GraphQL, including the authentication setting, improper data formatting when submitting and much more. Fortunately, after spending some time on debugging and research, all bugs were fixed.
## Accomplishments that I've proud of
* Successfully connected the web application with a content management system, ensuring the content exposed to students are all appropriate.
* Managed to create a information platform that can deal with the real-world problem.
## What we learned
* Use GraphCMS to restore data and user information, ensuring content are always safe and appropriate.
* Develop bank-end using GraphQL with predefined schema and API directly generated by GraphCMS.
* Generate pages with dynamic routes using getStaticPaths and fetch data at the build time using getStaticProps.
## What's next for University Wing
Currently, this web app only allows the authorized users, i.e. university representatives to access the content management system, meaning that they have to collect information from many students of different backgrounds. Obviously, writing these posts may impose great workload on these university representatives; therefore, I may develop the login and sign up features, and allow users to post in the University Wing themselves. As a result, we only need to review posts rather than edit them ourselves, which not only reduces our stress, but also brings more valuable content to the platform. | partial |
## Inspiration
At reFresh, we are a group of students looking to revolutionize the way we cook and use our ingredients so they don't go to waste. Today, America faces a problem of food waste. Waste of food contributes to the acceleration of global warming as more produce is needed to maintain the same levels of demand. In a startling report from the Atlantic, "the average value of discarded produce is nearly $1,600 annually" for an American family of four. In terms of Double-Doubles from In-n-Out, that goes to around 400 burgers. At reFresh, we believe that this level of waste is unacceptable in our modern society, imagine every family in America throwing away 400 perfectly fine burgers. Therefore we hope that our product can help reduce food waste and help the environment.
## What It Does
reFresh offers users the ability to input ingredients they have lying around and to find the corresponding recipes that use those ingredients making sure nothing goes to waste! Then, from the ingredients left over of a recipe that we suggested to you, more recipes utilizing those same ingredients are then suggested to you so you get the most usage possible. Users have the ability to build weekly meal plans from our recipes and we also offer a way to search for specific recipes. Finally, we provide an easy way to view how much of an ingredient you need and the cost of those ingredients.
## How We Built It
To make our idea come to life, we utilized the Flask framework to create our web application that allows users to use our application easily and smoothly. In addition, we utilized a Walmart Store API to retrieve various ingredient information such as prices, and a Spoonacular API to retrieve recipe information such as ingredients needed. All the data is then backed by SQLAlchemy to store ingredient, recipe, and meal data.
## Challenges We Ran Into
Throughout the process, we ran into various challenges that helped us grow as a team. In a broad sense, some of us struggled with learning a new framework in such a short period of time and using that framework to build something. We also had issues with communication and ensuring that the features we wanted implemented were made clear. There were times that we implemented things that could have been better done if we had better communication. In terms of technical challenges, it definitely proved to be a challenge to parse product information from Walmart, to use the SQLAlchemy database to store various product information, and to utilize Flask's framework to continuously update the database every time we added a new recipe.
However, these challenges definitely taught us a lot of things, ranging from a better understanding to programming languages, to learning how to work and communicate better in a team.
## Accomplishments That We're Proud Of
Together, we are definitely proud of what we have created. Highlights of this project include the implementation of a SQLAlchemy database, a pleasing and easy to look at splash page complete with an infographic, and being able to manipulate two different APIs to feed of off each other and provide users with a new experience.
## What We Learned
This was all of our first hackathon, and needless to say, we learned a lot. As we tested our physical and mental limits, we familiarized ourselves with web development, became more comfortable with stitching together multiple platforms to create a product, and gained a better understanding of what it means to collaborate and communicate effectively in a team. Members of our team gained more knowledge in databases, UI/UX work, and popular frameworks like Boostrap and Flask. We also definitely learned the value of concise communication.
## What's Next for reFresh
There are a number of features that we would like to implement going forward. Possible avenues of improvement would include:
* User accounts to allow ingredients and plans to be saved and shared
* Improvement in our search to fetch more mainstream and relevant recipes
* Simplification of ingredient selection page by combining ingredients and meals in one centralized page | ## Inspiration
We recognized that packages left on porch are unsafe and can be easily stolen by passerby and mailmen. Delivery that requires signatures is safer, but since homeowners are not always home, deliveries often fail, causing inconvenience for both homeowners and mailmen.
The act of picking up packages and carrying packages into home can also be physically straining for some.
Package storage systems are available in condos and urban locations, such as concierge or Amazon lockers, but unavailable in the suburbs or rural region, such as many areas of Brampton.
Because of these pain points, we believe there is market potential for homeowners in rural areas for a personal delivery storage solution. With smart home hacking and AI innovation in mind, we improve the lives of all homeowners by ensuring their packages are efficiently delivered and securely stored.
## What it does
OWO is a novel package storage system designed to prevent theft in residential homes. It uses facial recognition, user ID, and passcode to verify the identity of mailman before unlocking the device and placing the package on the device. The automated device is connected to the interior of the house and contains a uniquely designed joint to securely bring packages into home. Named "One Way Only", it effectively prevents any possible theft by passerby or even another mailman who have access to the device.
## How I built it
We built a fully animated CAD design with Fusion 360. Then, we proceeded with an operating and automated prototype and user interface using Arduino, C++, light fabrication, 3D printing. Finally, we set up an environment to integrate facial recognition and other Smart Home monitoring measures using Huawei Atlas 310 AI processor.
## What's next for One Way Only (OWO)
Build a 1:1 scaled high fidelity prototype for real-world testing. Design for manufacturing and installation. Reach out to potential partners to implement the system, such as Amazon. | ## Inspiration
We love cooking and watching food videos. From the Great British Baking Show to Instagram reels, we are foodies in every way. However, with the 119 billion pounds of food that is wasted annually in the United States, we wanted to create a simple way to reduce waste and try out new recipes.
## What it does
lettuce enables users to create a food inventory using a mobile receipt scanner. It then alerts users when a product approaches its expiration date and prompts them to notify their network if they possess excess food they won't consume in time. In such cases, lettuce notifies fellow users in their network that they can collect the surplus item. Moreover, lettuce offers recipe exploration and automatically checks your pantry and any other food shared by your network's users before suggesting new purchases.
## How we built it
lettuce uses React and Bootstrap for its frontend and uses Firebase for the database, which stores information on all the different foods users have stored in their pantry. We also use a pre-trained image-to-text neural network that enables users to inventory their food by scanning their grocery receipts. We also developed an algorithm to parse receipt text to extract just the food from the receipt.
## Challenges we ran into
One big challenge was finding a way to map the receipt food text to the actual food item. Receipts often use annoying abbreviations for food, and we had to find databases that allow us to map the receipt item to the food item.
## Accomplishments that we're proud of
lettuce has a lot of work ahead of it, but we are proud of our idea and teamwork to create an initial prototype of an app that may contribute to something meaningful to us and the world at large.
## What we learned
We learned that there are many things to account for when it comes to sustainability, as we must balance accessibility and convenience with efficiency and efficacy. Not having food waste would be great, but it's not easy to finish everything in your pantry, and we hope that our app can help find a balance between the two.
## What's next for lettuce
We hope to improve our recipe suggestion algorithm as well as the estimates for when food expires. For example, a green banana will have a different expiration date compared to a ripe banana, and our scanner has a universal deadline for all bananas. | partial |
In their paper "A Maze Solver for Android", Rohan Paranjpe and Armon Saied devised a method to automate solving mazes with nothing but a picture of said maze. My partner and I decided that this would be cool to implement ourselves, and did so accordingly. Many of the things we found in the paper were absolutely crucial to the success of the project, such as using a median and Otsu's filter to preprocess the image, and using the Zhang-Suen algorithm to generate a 1-pixel wide path. However, we innovated on some of their methods, like generating a graph out of the thinned path so that future iterations of the project can handle a more robust problem space (like multiple entrances or exits). Our entire algorithm runs in a little less than a minute on average for a 720x1080 image. The run time of this algorithm is comparable to the time it would take the intended audience of these mazes, elementary school children, to solve. Improvements to the run time of this algorithm can be made by improving our implementation of the Zhang-Suen algorithm, as this is currently the most computationally expensive step. | ## Inspiration
No matter where our families go, whether it be the supermarket or the next state over, they always insist on taking the most beautiful route. Driving by breathtaking scenery is one of life's finest pleasures, yet it is near impossible to find the prettiest route to take. Google Maps can get you from point A to point B the fastest, but it falls short when asked to give you a scenic route. This inspired us to build Sceniq—an app that will point you towards the most beautiful route for your journey.
## What it does
Sceniq will take in a starting location and a destination, and will return back to you the most scenic route between those two points.
## How we built it
Our algorithm identifies all of the key routes between two points and retrieves image data of those routes through Google Maps. This information is fed into a neural network that was trained on over 6,000 images to distinguish between scenic and non-scenic imagery. Using the network's output, a score is assigned to each route indicating how scenic it is. This data is returned to the user.
## Challenges we ran into
We ran into several challenges. While working on the neural network, Adith struggled with optimizing the prediction speed. After he got around this, he realized that there was a fundamental flaw in how he was labeling the data, which took a while to fix.
Adam had his own set of problems. He had to reverse engineer the Unsplash API because it wasn't well formed. Additionally, he was getting timeout errors because he was making simultaneous requests, which he got around by implementing a randomized incremental back-off algorithm. Finally, he was very proud of the fact that he created a recursive generator algorithm that was able to divide a geographic polyline into n equal parts.
## Accomplishments that we're proud of
We're proud of the project as a whole. Not only did we train, test, and fine-tune a neural network, but we also were able to implement an algorithm that interfaces with Google Maps to get image data for routes.
## What we learned
1) How to break down a problem into smaller chunks that are later combined into a cohesive solution.
2) How to use CNNs to differentiate between various types of images.
3) How to interface with Google's various map/direction APIs.
## What's next for Sceniq
We need a better front-end interface. Additionally, we could also improve our route visualization. These changes would make our program more user-friendly. | ## Inspiration
We got lost so many times inside MIT... And no one could help us :( No Google Maps, no Apple Maps, NO ONE. Since now, we always dreamed about the idea of a more precise navigation platform working inside buildings. And here it is. But that's not all: as traffic GPS usually do, we also want to avoid the big crowds that sometimes stand in corridors.
## What it does
Using just the pdf of the floor plans, it builds a digital map and creates the data structures needed to find the shortest path between two points, considering walls, stairs and even elevators. Moreover, using fictional crowd data, it avoids big crowds so that it is safer and faster to walk inside buildings.
## How we built it
Using k-means, we created nodes and clustered them using the elbow diminishing returns optimization. We obtained the hallways centers combining scikit-learn and filtering them applying k-means. Finally, we created the edges between nodes, simulated crowd hotspots and calculated the shortest path accordingly. Each wifi hotspot takes into account the number of devices connected to the internet to estimate the number of nearby people. This information allows us to weight some paths and penalize those with large nearby crowds.
A path can be searched on a website powered by Flask, where the corresponding result is shown.
## Challenges we ran into
At first, we didn't know which was the best approach to convert a pdf map to useful data.
The maps we worked with are taken from the MIT intranet and we are not allowed to share them, so our web app cannot be published as it uses those maps...
Furthermore, we had limited experience with Machine Learning and Computer Vision algorithms.
## Accomplishments that we're proud of
We're proud of having developed a useful application that can be employed by many people and can be extended automatically to any building thanks to our map recognition algorithms. Also, using real data from sensors (wifi hotspots or any other similar devices) to detect crowds and penalize nearby paths.
## What we learned
We learned more about Python, Flask, Computer Vision algorithms and Machine Learning. Also about frienship :)
## What's next for SmartPaths
The next steps would be honing the Machine Learning part and using real data from sensors. | losing |
## Inspiration
We love traveling, but it's a great pity to travel somewhere, take a picture of it, then forget about it. Booking a tour guide to learn about local sites is too expensive, and tourist apps are a great hassle. We want to build a complete tourist companion app that is both informative and useful.
## What it does
Once you take a picture, it automatically uploads this picture into an online album for easy management (think Google Photos). This album is updated live and interactive! Crucially, we run Google Cloud's vision analytics engine to determine what tourist attraction it is, then fetch information about it online and play it back in audio to the user.
## How we built it
The user side is built with Raspberry Pi, and once it takes a picture (controlled by a click button) that picture is sent to a server. The server runs Google Cloud Vision on the image, labels the image with a landmark name, then puts the image in a folder that is automatically synchronized with the web album that we created. If the picture does not contain a landmark, then we would use another algorithm (using pertained weights from YOLO <https://github.com/pjreddie/darknet>) to detect objects in this image.
Any information that needs to be returned to the user is put through a text-to-speech engine, which converts it into an audio file, then sent back to Raspberry Pi for playing.
## Challenges we ran into
Raspberry Pi refuses to connect to U of T internet, and we spent a long time figuring out a solution. In the end, we decided to connect the Raspberry Pi to a smartphone's hot spot, which solved the issue.
It's very difficult to send files seamlessly between Raspberry Pi and our computer. We attempted many methods and settled on using SSH, because it is not limited to local connections only (unlike Samba). This means that our program can truly work anywhere in the world.
## Accomplishments that we're proud of
It all works! Better than we thought.
## What we learned
Raspberry Pi 4, Google Cloud, OpenCV, javascript, React, IoT, SSH, Text to Speech, Python
## What's next for iStick
Optimize the time required to obtain a result: currently a bottleneck is the image-taking process, and we hope to speed this up. We can also add a screen so the user can see what the camera is capturing. | ## Inspiration
When looking at the themes from the Make-a-thon, one specifically stood out to us: accessibility. We thought about common disabilities, and one that we see on a regular basis is people who are visually impaired. We thought about how people who are visually impaired navigate around the world, and we realized there isn't a good solution besides holding your phone out that allows them to get around the world. We decided we would create a device that uses Google Maps API to read directions and sense the world around it to be able to help people who are blind navigate the world without running into things.
## What it does
Based on the user's desired destination, the program reads from Google API the checkpoints needed to cross in our path and audibly directs the user on how far they are from it. Their location is also repeatedly gathered through Google API to determine their longitude and latitude. Once the user reaches
the nearest checkpoint, they will be directed to the next checkpoint until they reach their destination.
## How we built it
Under a local hotspot host, we connected a phone and Google API to a Raspberry Pi 4. The phone would update the Raspberry Pi with our current location and Google API to determine the necessary checkpoints to get there. With all of the data being compiled on the microcontroller, it is then connected to a speaker through a Stereo Audio Amplifier Module (powered by an external power supply), which amplifies the audio sent out into the Raspberry Pi's audio jack. With all that, the directions conveyed to the user can be heard clearly.
## Challenges we ran into
Some of the challenges we faced were getting the stereo speaker to work and indicating to the user the distance from their next checkpoint, frequently within the range of the local network.
## Accomplishments that we're proud of
We were proud to have the user's current position updated according to the movement of the phone connected to the local network and be able to update the user's distance from a checkpoint in real time.
## What we learned
We learned to set up and work with a Raspberry Pi 4 through SSH.
We also learned how to use text-to-speech for the microcontroller using Python and how we can implement it in a practical application.
Finally, we were
## What's next for GPS Tracker for the Visually Impaired
During the hackathon, we were unable to implement the camera sensing the world around it to give the user live directions on what the world looks like in front of them and if they are going to run into anything or not. The next steps would include a depth camera implementation as well as an OpenCV object detection model to be able to sense the distance of things in front of you | ## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras18b/afouras18b.pdf). The repo for the model used as a base template can be found [here](https://github.com/afourast/deep_lip_reading).
The second source of inspiration is an existing product on the market, [Focals by North](https://www.bynorth.com/). Focals are smart glasses that aim to put the important parts of your life right in front of you through a projected heads up display. We thought it would be a great idea to build onto a platform like this through adding a camera and using artificial intelligence to gain valuable insights about what you see, which in our case, is deciphering speech from visual input. This has applications in aiding individuals who are deaf or hard-of-hearing, noisy environments where automatic speech recognition is difficult, and in conjunction with speech recognition for ultra-accurate, real-time transcripts.
## What it does
The user presses a button on the side of the glasses, which begins recording, and upon pressing the button again, recording ends. The camera is connected to a raspberry pi, which is a web enabled device. The raspberry pi uploads the recording to google cloud, and submits a post to a web server along with the file name uploaded. The web server downloads the video from google cloud, runs facial detection through a haar cascade classifier, and feeds that into a transformer network which transcribes the video. Upon finished, a front-end web application is notified through socket communication, and this results in the front-end streaming the video from google cloud as well as displaying the transcription output from the back-end server.
## How we built it
The hardware platform is a raspberry pi zero interfaced with a pi camera. A python script is run on the raspberry pi to listen for GPIO, record video, upload to google cloud, and post to the back-end server. The back-end server is implemented using Flask, a web framework in Python. The back-end server runs the processing pipeline, which utilizes TensorFlow and OpenCV. The front-end is implemented using React in JavaScript.
## Challenges we ran into
* TensorFlow proved to be difficult to integrate with the back-end server due to dependency and driver compatibility issues, forcing us to run it on CPU only, which does not yield maximum performance
* It was difficult to establish a network connection on the Raspberry Pi, which we worked around through USB-tethering with a mobile device
## Accomplishments that we're proud of
* Establishing a multi-step pipeline that features hardware, cloud storage, a back-end server, and a front-end web application
* Design of the glasses prototype
## What we learned
* How to setup a back-end web server using Flask
* How to facilitate socket communication between Flask and React
* How to setup a web server through local host tunneling using ngrok
* How to convert a video into a text prediction through 3D spatio-temporal convolutions and transformer networks
* How to interface with Google Cloud for data storage between various components such as hardware, back-end, and front-end
## What's next for Synviz
* With stronger on-board battery, 5G network connection, and a computationally stronger compute server, we believe it will be possible to achieve near real-time transcription from a video feed that can be implemented on an existing platform like North's Focals to deliver a promising business appeal | losing |
## Inspiration
This was inspired from an article we read about the impact mobile devices were making in third world countries, such as Africa. Mobile development in these countries are increasing by the second and we wanted to take part in that development.
## What it does
This app allows users to get answers to a large variety of questions at almost any time. This is achieved through the use of the Twilio and Wolfram API. A user can text the application a question such as; integrate x^2, 2+4, plot(logx), what time is it, etc. Users can also ask for some dictionary definitions such as economics, ball, and H2O for example. This is all done by making a request to Wolfram and parsing the data into a readable sms or mms message.
## How I built it
This was built by running a server with node.js/express and having it listen for a POST request done by Twilio. The server will use the query given in the body of the text to make a request to the Wolfram API and it will then parse the data and send it back as a sms message. Depending on if there is an image it may send a mms message instead.
## Challenges I ran into
Twilio was a little difficult to get running, although the initial messaging was not too hard it was difficult to have a message sent back with authentication because it required many things to be setup. Parsing the data and displaying it in a proper format for the response also took some time because Wolfram can send back a lot of data that may not be relevant.
## Accomplishments that I'm proud of
I am pretty proud that we were able to get this application running because offline services is something that I've never worked with before and I always thought was pretty cool. In fact just getting Twilio to work with the server and being able to have it send pictures was pretty amazing.
## What I learned
Wolfram actually knows everything. The wolfram request can be amazingly broad, initially we thought we would need to tap into multiple APIs to get a broader range of data, but after further investigation we realized that Wolfram actually covers a pretty large variety of topics. I also learned a lot about the Twilio API and how to connect Twilio services with server.
## What's next for AnswerMeThis
Increase the amount of data that is being sent and further improve the response speed, as well as improving visualization of the data. We also want tap into other APIs to give users a broader range of topics to choose from. | ## Inspiration
With the effects of climate change becoming more and more apparent, we wanted to make a tool that allows users to stay informed on current climate events and stay safe by being warned of nearby climate warnings.
## What it does
Our web app has two functions. One of the functions is to show a map of the entire world that displays markers on locations of current climate events like hurricanes, wildfires, etc. The other function allows users to submit their phone numbers to us, which subscribes the user to regular SMS updates through Twilio if there are any dangerous climate events in their vicinity. This SMS update is sent regardless of whether the user has the app open or not, allowing users to be sure that they will get the latest updates in case of any severe or dangerous weather patterns.
## How we built it
We used Angular to build our frontend. With that, we used the Google Maps API to show the world map along with markers, with information we got from our server. The server gets this climate data from the NASA EONET API. The server also uses Twilio along with Google Firebase to allow users to sign up and receive text message updates about severe climate events in their vicinity (within 50km).
## Challenges we ran into
For the front end, one of the biggest challenges was the markers on the map. Not only, did we need to place markers on many different climate event locations, but we wanted the markers to have different icons based on weather events. We also wanted to be able to filter the marker types for a better user experience. For the back end, we had challenges to figure out Twilio to be able to text users, Google firebase for user sign-in, and MongoDB for database operation. Using these tools was a challenge at first because this was our first time using these tools. We also ran into problems trying to accurately calculate a user's vicinity to current events due to the complex nature of geographical math, but after a lot of number crunching, and the use of a helpful library, we were accurately able to determine if any given event is within 50km of a users position based solely on the coordiantes.
## Accomplishments that we're proud of
We are really proud to make an app that not only informs users but can also help them in dangerous situations. We are also proud of ourselves for finding solutions to the tough technical challenges we ran into.
## What we learned
We learned how to use all the different tools that we used for the first time while making this project. We also refined our front-end and back-end experience and knowledge.
## What's next for Natural Event Tracker
We want to perhaps make the map run faster and have more features for the user, like more information, etc. We also are interested in finding more ways to help our users stay safer during future climate events that they may experience. | ## Inspiration
Billmastr was inspired by the team's quarantine hobbies. We were brainstorming and realized we had one quarantine activity in common. This is the high usage of streaming subscription services. We want to build an app to manage all the subscription services for users so that we can continue this activity while making wiser financial decisions.
## What it does
Billmastr assists users in better managing their subscription services. It has three features.
The first is to provide an overview of spending for the user - such as total spending on subscription services per month, spending in each category of subscriptions, and how the spending compares to past months.
The second feature is to provide easy access to manage all the subscriptions at once. Users can view all their subscriptions on this tab and spending for each specific subscription. There is a link to each app should the user wish to alter their subscription.
The last feature is notifying users when subscription bills are coming due. In the notification tab, the app also sends out a personal finance tip of the day every day to inform users of best budgeting practices.
## How we built it
This app was built with Angular. Heather put together prototype screens in Figma and researched the business question on hand, while Erika developed the logic and styling.
## Challenges we ran into
Our biggest challenge was to distinguish this app from similar apps that already exist. Although we were not able to implement it in the timespan of the hackathon, we decided that we would like to add household bill-type expenses to the app, so users can track their usage of their utilities, as well as more commonly regarded subscription services. This way, users can track all their consistent monthly costs in one app, whether they are essential or a luxury.
## Accomplishments that we're proud of
This was our first time building an app from scratch and we're happy that we were able to put together a presentable product for this hackathon.
## What we learned
From a technical perspective, we learned a lot about the features of Angular such as routing and navigation, as well as styling in HTML and SCSS. From a business perspective, we looked at many similar apps and their designs to get a better idea of how to create a user-friendly end product.
## What's next for Billmastr
Currently, our application has a high focus on billing and spending, but we want to get into user usage patterns.
We may get into other subscription-like bills, such as variable monthly bills (e.g. hydro, wifi, phone bills).
We also do not have a designer on the team, so we'd love to make Billmastr easier to use and easier on the eyes. | partial |
## Inspiration
Other educational games like [OhMyGit](https://ohmygit.org/).
Some gameplay aspects of a popular rhythm game: Friday Night Funkin'
## What it does
Players will be able to select a topic to battle in and enter a pop-quiz style battle where getting correct answers attacks your opponent and getting incorrect ones allow the opponent to attack you.
Ideally, the game would have fun animations and visual cues to show the user was correct or not, these effects mainly in seeing the player attack the enemy or vice versa if the answer was incorrect.
## How we built it
Using the Unity game engine.
## Challenges we ran into
Team members we're quite busy over the weekend, and a lack of knowledge in Unity.
## Accomplishments that we're proud of
The main gameplay mechanic is mostly refined, and we were able to complete it in essentially a day's work with 2 people.
## What we learned
Some unique Unity mechanics and planning is key to put out a project this quickly.
## What's next for Saturday Evening Studyin'
Adding the other question types specified in our design (listed in the README.md), adding animations to the actual battle, adding character dialogue and depth.
One of the original ideas that were too complex to implement in this short amount of time is for 2 human players to battle each other, where the battle is turn-based and players can select the difficulty of question to determine the damage they can deal, with some questions having a margin of error for partial correctness to deal a fraction of the normal amount. | # Inspiration
Roblox has been an integral part of our upbringing, a space where we connected with others and embraced the joy of gaming. As we transitioned into adulthood, our focus shifted from gaming to our passion for education and academic excellence. The traditional lecture-style learning transformed into digital flashcards on Quizlet as we pursued success in school. While we cherished interactive trivia games in the classroom, we yearned to create a more immersive and engaging experience.
Through Roblox Studio, we've created a game where education knows no boundaries. Where every learner, regardless of background or circumstance, has access to quality learning opportunities. That's the vision behind Questi. We're tackling the pressing issue of global education inequality head-on by providing a gamified platform that not only bridges educational divides but also fosters collaboration and supports learners' mental well-being. With Questi, learners embark on an immersive journey of discovery, connecting with peers, mastering subjects, and unlocking their full potential.
---
## What it does
"Questi," is an educational gameplay experience designed to promote collaborative learning and teamwork. Users can join with their friends, classmates, or team members to tackle course-related questions within a set timeframe. By leveraging their collective knowledge and collaborating effectively, players work together to answer all the questions and complete the game before time runs out. "Questi" transforms traditional learning into an immersive and engaging multiplayer experience, where participants not only deepen their understanding of course material but also develop essential teamwork and problem-solving skills.
---
## How we built it
Our team utilized Roblox Studio to create our virtual world. Through precise scripting in Luau, we engineered dynamic gameplay mechanics, seamlessly integrating an API to fetch course material questions. With an eye for design and optimization, we fine-tuned every aspect of the project to ensure optimal performance and user experience. Effective communication and collaboration were critical as we navigated technical challenges and brought our collective vision to life, culminating in a groundbreaking educational platform that blends gaming and learning seamlessly.
---
## Challenges we ran into
* Designing the UI/UX for smooth progression proved tricky
* Connecting the script to track group progress was complex.
* We encountered difficulties with client-to-server communication
* Most of us had to learn Luau syntax and Roblox Studio from scratch
* Sometimes the API did not respond correctly
---
## Next Steps
* Integrating with an API that allows you to customize questions (users can make their own custom quizzes)
* Add more maps/levels and types of challenges/game modes to keep the users engaged
* Reward users for completing quests with a leaderboard and currency that can be used to purchase in-game items | ## Inspiration
The inspiration for our project came from three of our members being involved with Smash in their community. From one of us being an avid competitor, one being an avid watcher and one of us who works in an office where Smash is played quite frequently, we agreed that the way Smash Bro games were matched and organized needed to be leveled up. We hope that this becomes a frequently used bot for big and small organizations alike.
## How it Works
We broke the project up into three components, the front end made using React, the back end made using Golang and a middle part connecting the back end to Slack by using StdLib.
## Challenges We Ran Into
A big challenge we ran into was understanding how exactly to create a bot using StdLib. There were many nuances that had to be accounted for. However, we were helped by amazing mentors from StdLib's booth. Our first specific challenge was getting messages to be ephemeral for the user that called the function. Another adversity was getting DM's to work using our custom bot. Finally, we struggled to get the input from the buttons and commands in Slack to the back-end server. However, it was fairly simple to connect the front end to the back end.
## The Future for 'For Glory'
Due to the time constraints and difficulty, we did not get to implement a tournament function. This is a future goal because this would allow workspaces and other organizations that would use a Slack channel to implement a casual tournament that would keep the environment light-hearted, competitive and fun. Our tournament function could also extend to help hold local competitive tournaments within universities. We also want to extend the range of rankings to have different types of rankings in the future. One thing we want to integrate into the future for the front end is to have a more interactive display for matches and tournaments with live updates and useful statistics. | partial |
## 💡 Inspiration
From farmers' protest around the world, subsidies to keep agriculture afloat, to the regular use of pesticides that kills organisms and pollutes the environment, the agriculture industry has an issue in optimizing resources. So, we want to make technology that would efficiently manage a farm through AI fully automated to reduce human energy costs. Not only that, but we would also open crowdfunding for farm plants as a form of an environmental investment that rewards you with money and carbon credits offset.
## 💻 What it does
Drone:
The drone communicates with the ground sensors which include, UV, pest vision detection, humidity sensor, CO2 sensor, and more. Based on this data then the drone would execute a cloud command to solve it. For example, if it detects a pest, it will call the second drone with the pest spray. Or if its lacking water, it would command the pump using wifi to pump the water, creating an efficient fully automated cycle that reduces resources as it's based on need.
Farmer’s Dashboard:
View the latest data on your plant from its growth, pest status, watering status, fertilizing status, etc. Open your farm for crowdfunding, in terms of land share for extra money. Harvest money would be split based on that share.
Plant Adopter:
Adopt a plan and see how much carbon offset it did in real time until harvest. Other than collecting carbon points you could also potentially get a capital gain from the selling of the harvest. Have a less worry investment by being able to check on it anytime you want with extra data such as height when it’s last sprayed, etc.
On Field Sensor Array and horticulture system:
Collects various information about the plants using a custom built sensor array, and then automatically adjusts lighting, heat, irrigation and fertilization accordingly. The sensor data is stored on cockroachdb using an onramping function deployed on Google Cloud which also hosts the pest detection and weed detection machine learning models.
## 🔨 How we built it:
* Hardware Setup:
SoC Hub: Raspberry PI
Sensor MCU: Arduino Mega 2560
Actuation MCU Arduino UNO R3
Temperature (outdoor/indoor): SHT40, CCS811, MR115A2
Humidity: SHT40
Barometric Pressure: MR115A2
Soil Temperature: Adafruit Stemma Soil Sensing Module
Soil Moisture: Adafruit Stemma Soil Sensing Module
Carbon Dioxide Emitted/Absorbed: CCS811
UV Index/incident: VEML6070
Ventilation Control: SG90 Mini Servo
Lighting: AdaFruit NeoPixel Strip x8
Irrigation Pump: EK1893 3-5V Submersible Pump
\*Drones: DJI TELLO RoboMaster TT
\*Database: CockroachDB
\*Cloud: Google Cloud Services
\*Machine Learning (for pest and weed detection): Cloud Vision, AutoML
Design: Figma
Arduino, Google Vision Cloud, Raspberry pi, Drones, Cockroach DB, etc
We trained ML models for pest (saddleback caterpillar,true armyworm) and weed detection using images dataset from "ipmimages". We used google cloud Auto ML to train our model.
## 📖 What we learned
This is the first time some of us have coded a drone, so it’s an amazing experience to be able to automate the code like that. It is also a struggle to find a solution that can be realistically implemented in a business sense. | ## Inspiration
Our inspiration for this project was from the recent spread of pests throughout the U.S., such as Japanese beetles, which have wreaked havoc for crops and home gardens. We personally have gardens at home where we grow plants like cucumbers and tomatoes, and were tired of seeing half-eaten leaves and destroyed plants.
## What it does
PestNet is a computer vision model that takes in videos and classifies up to 19 different pests throughout the video. Our webapp creates an easy interface for users to upload their videos, on which we perform inference using our vision model. We provide a list of all pests that appeared on their crops or plants, as well as descriptions for how to combat those pests.
## How we built it
To build the computer vision model, we used Roboflow to develop a classification model from a checkpoint of a custom pre-trained on the ImageNet dataset. We aggregated images from two datasets and performed data augmentations to create a combined dataset of about 15,000 images. After fine-tuning the model on our data, we achieved a validation accuracy of 93.5% over 19 classes.
To build the web app, we first sketched a wireframe with intended behavior on Figma. We created it with a React frontend (Typescript, Vite, Tailwind CSS, Toastify) with a Python backend (FastAPI). The backend contains both code for the CV model as well as Python processing that we use to clean the results of the CV model. The frontend contains an interactive carousel and a video player for the user to view the results themselves.
## Challenges we ran into
One challenge we ran into was integrating Roboflow into our computer vision workflow, since we had never used the platform and ran into some version control issues. Another challenge we ran into was integrating video uploads into our web app. It was difficult at first to get the types right for sending files across our REST API. A third challenge was processing the data from Roboflow, and getting it to the right format for our web app. All in all, we learned that communication was key: with so many moving parts, it was important that each person working on a separate part of the project made clear what they had made, so we could connect them all together in the end.
## Accomplishments that we're proud of
We're proud of the web app we made! We're also proud of working together and not giving up. We spent at least the first quarter of the hackathon brainstorming ideas and constantly reviewing. We were worried that we had wasted too much time on thinking of a good plan, but it turned out that our current project used a little bit of all of our previous ideas, and we were able to hack together something by the end!
## What we learned
We learned how to easily and quickly prototype computer vision models with Roboflow, as well as how to perform inference using Roboflow's APIs. We also learned how to make a full-stack webapp that incorporates AI models and designs from Figma. Most importantly, we learned how to brainstorm ideas, collaborate, and work under a time crunch :)
## What's next for PennApps
If we had more time, we would develop a more sophisticated computer vision model with more aggregated and labeled data. With the time constraints of the hackathon, we did not have time to manually find and label images that would be more difficult to classify (ex. where bugs are smaller). We would also deploy the Roboflow model locally instead of using the Hosted Video Inference API, so that we could perform inference in real-time. Finally, we also want to add more features to the webapp, such as a method to jump to different parts of the video based on the labels. | # Inspiration
We came to Stanford expecting a vibrant college atmosphere. Yet walk past a volleyball or basketball court at Stanford mid-Winter quarter, and you’ll probably find it empty. As college students, our lives revolve around two pillars: productivity and play. In an ideal world, we spend intentional parts of our day fully productive–activities dedicated to our fulfillment–and some parts of our day fully immersed in play–activities dedicated solely to our joy. In reality, though, students might party, but how often do they play? Large chunks of their day are spent in their dorm room, caught between these two choices, doing essentially nothing. This doesn’t improve their mental health.
Imagine, or rather, remember, when you were last in that spot. Even if you were struck by inspiration to get out and do something fun, who with? You could text your friends, but you don’t know enough people to play 4-on-4 soccer, or if anyone’s interested in joining you for some baking between classes.
# A Solution
When encountering this problem, frolic can help. Users can:
See existing events, sorted by events “containing” most of their friends at the top
Join an event, getting access to the names of all members of event (not just their friends)
Or, save/bookmark an event for later (no notification sent to others)
Access full info of events they’ve joined or saved in the “My Events” tab
Additional, nice-to-have features include:
Notification if their friend(s) have joined an event in case they’d like to join as well
# Challenges & An Important Lesson
Not only had none of us had iOS app development experience, but with less than 12 hours to go, we realized with the original environment and language we were working in (Swift and XCode), the learning curve to create the full app was far too steep. Thus, we essentially started anew. We realized the importance of reaching out for guidance from more experienced people early on, whether at a hackathon, academic, or career-setting.
/\* Deep down, we know how important times of play are–though, we often never seem to “have time” for it. In reality, this often is correlated with us being caught in a rift between the two poles we mentioned: not being totally productive, nor totally grasping the joy that we should ideally get from some everyday activities. \*/ | partial |
## 💫 Inspiration
It all started when I found VCR tapes of when I was born! I was simply watching the videos fascinated with how much younger everyone looked when I noticed someone unknown, present in the home videos, helping my mom!
After asking my mom, I found out there used to be a program where Nurses/Caretakers would actually make trips to their homes, teaching them how to take care of the baby, and helping them maneuver the first few months of motherhood!
And so, I became intrigued. Why haven't I heard of this before? Why does it not exist anymore? I researched at the federal, provincial and municipal levels to uncover a myriad of online resources available to first-time mothers/parents which aren't well known, and we decided, let's bring it back, better than ever!
## 👶🏻 What BabyBloom does
BabyBloom, is an all-in-one app that targets the needs of first-time mothers in Canada! It provides a simple interface to browse a variety of governmental resources, filtered based off your residential location, and a partnering service with potential caregivers and nurses to help you navigate your very first childbirth.
## 🔨 How we built it
We’re always learning and trying new things! For this app, we aimed to implement an MVC (Model, View, Controller) application structure, and focus on the user's experience and the potential for this project. We've opted for a mobile application to facilitate ease for mothers to easily access it through their phones and tablets. Design-wise, we chose a calming purple monochromatic scheme, as it is one of the main colours associated with pregnancy!
## 😰 Challenges we ran into
* Narrowing the features we intend to provide!
* Specifying the details and specs that we would feed the algorithm to choose the best caregiver for the patient.
* As the app scaled in the prototype, developing the front-end view was becoming increasingly heavier.
## 😤 Accomplishments that we're proud of
This is the first HackTheNorth for many of us, as well as the first time working with people we are unfamiliar with, so we're rather proud of how well we coordinated tasks, communicated ideas and solidified our final product! We're also pretty happy about all the various workshops and events we attended, and the amazing memories we've created.
## 🧠 What we learned
We learned…
* How to scale our idea for the prototype
* How to use AI to create connections between 2 entities
* Figma tips and Know-how to fast-track development
* An approach to modularize solutions
## 💜 What's next for BabyBloom
We can upgrade our designs to full implementation potentially using Flutter due to its cross-platform advantages, and researching the successful implementations in other countries, with their own physical hubs dedicated to mothers during and after their pregnancy! | ## Inspiration
We wanted to create a convenient, modernized journaling application with methods and components that are backed by science. Our spin on the readily available journal logging application is our take on the idea of awareness itself. What does it mean to be aware? What form or shape can mental health awareness come in? These were the key questions that we were curious about exploring, and we wanted to integrate this idea of awareness into our application. The “awareness” approach of the journal functions by providing users with the tools to track and analyze their moods and thoughts, as well as allowing them to engage with the visualizations of the journal entries to foster meaningful reflections.
## What it does
Our product provides a user-friendly platform for logging and recording journal entries and incorporates natural language processing (NLP) to conduct sentiment analysis. Users will be able to see generated insights from their journal entries, such as how their sentiments have changed over time.
## How we built it
Our front-end is powered by the ReactJS library, while our backend is powered by ExpressJS. Our sentiment analyzer was integrated with our NodeJS backend, which is also connected to a MySQL database.
## Challenges we ran into
Creating this app idea under such a short period of time proved to be more challenge than we anticipated. Our product was meant to comprise of more features that helped the journaling aspect of the app as well as the mood tracking aspect of the app. We had planned on showcasing an aggregation of the user's mood over different time periods, for instance, daily, weekly, monthly, etc. And on top of that, we had initially planned on deploying our web app on a remote hosting server but due to the time constraint, we had decided to reduce our proof-of-concept to the most essential cores features for our idea.
## Accomplishments that we're proud of
Designing and building such an amazing web app has been a wonderful experience. To think that we created a web app that could potentially be used by individuals all over the world and could help them keep track of their mental health has been such a proud moment. It really embraces the essence of a hackathon in its entirety. And this accomplishment has been a moment that our team can proud of. The animation video is an added bonus, visual presentations have a way of captivating an audience.
## What we learned
By going through the whole cycle of app development, we learned how one single part does not comprise the whole. What we mean is that designing an app is more than just coding it, the real work starts in showcasing the idea to others. In addition to that, we learned the importance of a clear roadmap for approaching issues (for example, coming up with an idea) and that complicated problems do not require complicated solutions, for instance, our app in simplicity allows for users to engage in a journal activity and to keep track of their moods over time. And most importantly, we learned how the simplest of ideas can be the most useful if they are thought right.
## What's next for Mood for Thought
Making a mobile app could have been better, given that it would align with our goals of making journaling as easy as possible. Users could also retain a degree of functionality offline. This could have also enabled a notification feature that would encourage healthy habits.
More sophisticated machine learning would have the potential to greatly improve the functionality of our app. Right now, simply determining either positive/negative sentiment could be a bit vague.
Adding recommendations on good journaling practices could have been an excellent addition to the project. These recommendations could be based on further sentiment analysis via NLP. | ## Inspiration
In 2012 in the U.S infants and newborns made up 73% of hospitals stays and 57.9% of hospital costs. This adds up to $21,654.6 million dollars. As a group of students eager to make a change in the healthcare industry utilizing machine learning software, we thought this was the perfect project for us. Statistical data showed an increase in infant hospital visits in recent years which further solidified our mission to tackle this problem at its core.
## What it does
Our software uses a website with user authentication to collect data about an infant. This data considers factors such as temperature, time of last meal, fluid intake, etc. This data is then pushed onto a MySQL server and is fetched by a remote device using a python script. After loading the data onto a local machine, it is passed into a linear regression machine learning model which outputs the probability of the infant requiring medical attention. Analysis results from the ML model is passed back into the website where it is displayed through graphs and other means of data visualization. This created dashboard is visible to users through their accounts and to their family doctors. Family doctors can analyze the data for themselves and agree or disagree with the model result. This iterative process trains the model over time. This process looks to ease the stress on parents and insure those who seriously need medical attention are the ones receiving it. Alongside optimizing the procedure, the product also decreases hospital costs thereby lowering taxes. We also implemented a secure hash to uniquely and securely identify each user. Using a hyper-secure combination of the user's data, we gave each patient a way to receive the status of their infant's evaluation from our AI and doctor verification.
## Challenges we ran into
At first, we challenged ourselves to create an ethical hacking platform. After discussing and developing the idea, we realized it was already done. We were challenged to think of something new with the same amount of complexity. As first year students with little to no experience, we wanted to tinker with AI and push the bounds of healthcare efficiency. The algorithms didn't work, the server wouldn't connect, and the website wouldn't deploy. We persevered and through the help of mentors and peers we were able to make a fully functional product. As a team, we were able to pick up on ML concepts and data-basing at an accelerated pace. We were challenged as students, upcoming engineers, and as people. Our ability to push through and deliver results were shown over the course of this hackathon.
## Accomplishments that we're proud of
We're proud of our functional database that can be accessed from a remote device. The ML algorithm, python script, and website were all commendable achievements for us. These components on their own are fairly useless, our biggest accomplishment was interfacing all of these with one another and creating an overall user experience that delivers in performance and results. Using sha256 we securely passed each user a unique and near impossible to reverse hash to allow them to check the status of their evaluation.
## What we learned
We learnt about important concepts in neural networks using TensorFlow and the inner workings of the HTML code in a website. We also learnt how to set-up a server and configure it for remote access. We learned a lot about how cyber-security plays a crucial role in the information technology industry. This opportunity allowed us to connect on a more personal level with the users around us, being able to create a more reliable and user friendly interface.
## What's next for InfantXpert
We're looking to develop a mobile application in IOS and Android for this app. We'd like to provide this as a free service so everyone can access the application regardless of their financial status. | losing |
## Inspiration
Have you ever wished to give a memorable dining experience to your loved ones, regardless of their location? We were inspired by the desire to provide our friends and family with a taste of our favorite dining experiences, no matter where they might be.
## What it does
It lets you book and pay for a meal of someone you care about.
## How we built it
Languages:-
Javascript, html, mongoDB, Aello API
Methodologies:-
- Simple and accessible UI
- database management
- blockchain contract validation
- AI chatBot
## Challenges we ran into
1. We have to design the friendly front-end user interface for both customers and restaurant partner which of them have their own functionality. Furthermore, we needed to integrate numerous concepts into our backend system, aggregating information from various APIs and utilizing Google Cloud for the storage of user data.
2. Given the abundance of information requiring straightforward organization, we had to carefully consider how to ensure an efficient user experience.
## Accomplishments that we're proud of
We have designed the flow of product development that clearly show us the potential of idea that able to scale in the future.
## What we learned
3. System Design: Through this project, we have delved deep into the intricacies of system design. We've learned how to architect and structure systems efficiently, considering scalability, performance, and user experience. This understanding is invaluable as it forms the foundation for creating robust and user-friendly solutions.
4. Collaboration: Working as a team has taught us the significance of effective collaboration. We've realized that diverse skill sets and perspectives can lead to innovative solutions. Communication, coordination, and the ability to leverage each team member's strengths have been essential in achieving our project goals.
5. Problem-Solving: Challenges inevitably arise during any project. Our experiences have honed our problem-solving skills, enabling us to approach obstacles with creativity and resilience. We've learned to break down complex issues into manageable tasks and find solutions collaboratively.
6. Adaptability: In the ever-evolving field of technology, adaptability is crucial. We've learned to embrace new tools, technologies, and methodologies as needed to keep our project on track and ensure it remains relevant in a dynamic landscape.collaborative as a team.
## What's next for Meal Treat
We want to integrate more tools for personalization, including a chatbot that supports customers in RSVPing their spot in the restaurant. This chatbot, utilizing Google Cloud's Dialogflow, will be trained to handle scheduling tasks. Next, we also plan to use Twilio's services to communicate with our customers through text SMS. Last but not least, we expect to incorporate blockchain technology to encrypt customer information, making it easier for the restaurant to manage and enhance protection, especially given our international services. Lastly, we aim to design an ecosystem that enhances the dining experience for everyone and fosters stronger relationships through meal care. | ## Inspiration
We were inspired by the increasing cost of eating out and the social pressure caused by having to accept such social invitations. We wanted to create a technology-enabled platform where individuals can plan a fun potluck with their friends and family with much of the burden of planning such an event eliminated by having the app plan it all out for you and direct individuals on how to gather and prepare the ingredients.
## What it does
Users can create their accounts with their food preferences selected. Afterwards the potluck 'host' is able to create the event, which generates ingredients and meal preparation instructions. All users are then able to view the ingredients they are supposed to get and how to cook the meal.
## How we built it
We used React for the front end and flask for the back end. We utilized Open Ai API to generate the meal ingredients and preparation instructions.
## Challenges we ran into
Pennapps is the first hackathon for all of our group members and we didn't know exactly what to expect. We also were not all very familiar with developing webapps and fullstack development. We had a lot of issues setting up the project with the appropriate technologies and have them all successfully interact with each other.
## Accomplishments that we're proud of
We learned React and Flask for this project and were able to connect the two sides for a nearly fully functioning webapp. There was a TON that we were not familiar with and we learned so much from the process of creating a webapp that we didn't know before.
## What we learned
We learned a ton about full stack development and how to create webapps. We are in a program that emphasizes the theory behind computer science, but almost none of the practical applications. Therefore, this has been a very wide opening experience for all of us. We have also not collaborated on a project with as many people as we are doing now. It was interesting seeing how we could all help each other out in different ways.
## What's next for LuckyPot
Some group members are eager to continue the project after the Hackathon to further flesh out the idea and possibly turn it into a fully functioning app in production that others could use. | ## Inspiration
Over the course of the past year, one of the most heavily impacted industries due to the COVID-19 pandemic is the service sector. Specifically, COVID-19 has transformed the financial viability of restaurant models. Moving forward, it is projected that 36,000 small restaurants will not survive the winter as successful restaurants have thus far relied on online dining services such as Grubhub or Doordash. However, these methods come at the cost of flat premiums on every sale, driving up the food price and cutting at least 20% from a given restaurant’s revenue. Within these platforms, the most popular, established restaurants are prioritized due to built-in search algorithms. As such, not all small restaurants can join these otherwise expensive options, and there is no meaningful way for small restaurants to survive during COVID.
## What it does
Potluck provides a platform for chefs to conveniently advertise their services to customers who will likewise be able to easily find nearby places to get their favorite foods. Chefs are able to upload information about their restaurant, such as their menus and locations, which is stored in Potluck’s encrypted database. Customers are presented with a personalized dashboard containing a list of ten nearby restaurants which are generated using an algorithm that factors in the customer’s preferences and sentiment analysis of previous customers. There is also a search function which will allow customers to find additional restaurants that they may enjoy.
## How I built it
We built a web app with Flask where users can feed in data for a specific location, cuisine of food, and restaurant-related tags. Based on this input, restaurants in our database are filtered and ranked based on the distance to the given user location calculated using Google Maps API and the Natural Language Toolkit (NLTK), and a sentiment score based on any comments on the restaurant calculated using Google Cloud NLP. Within the page, consumers can provide comments on their dining experience with a certain restaurant and chefs can add information for their restaurant, including cuisine, menu items, location, and contact information. Data is stored in a PostgreSQL-based database on Google Cloud.
## Challenges I ran into
One of the challenges that we faced was coming up a solution that matched the timeframe and bandwidth of our team. We did not want to be too ambitious with our ideas and technology yet provide a product that we felt was novel and meaningful.
We also found it difficult to integrate the backend with the frontend. For example, we needed the results from the Natural Language Toolkit (NLTK) in the backend to be used by the Google Maps JavaScript API in the frontend. By utilizing Jinja templates, we were able to serve the webpage and modify its script code based on the backend results from NLTK.
## Accomplishments that I'm proud of
We were able to identify a problem that was not only very meaningful to us and our community, but also one that we had a reasonable chance of approaching with our experience and tools. Not only did we get our functions and app to work very smoothly, we ended up with time to create a very pleasant user-experience and UI. We believe that how comfortable the user is when using the app is equally as important as how sophisticated the technology is.
Additionally, we were happy that we were able to tie in our product into many meaningful ideas on community and small businesses, which we believe are very important in the current times.
## What I learned
Tools we tried for the first time: Flask (with the additional challenge of running HTTPS), Jinja templates for dynamic HTML code, Google Cloud products (including Google Maps JS API), and PostgreSQL.
For many of us, this was our first experience with a group technical project, and it was very instructive to find ways to best communicate and collaborate, especially in this virtual setting. We benefited from each other’s experiences and were able to learn when to use certain ML algorithms or how to make a dynamic frontend.
## What's next for Potluck
For example, we want to incorporate an account system to make user-specific recommendations (Firebase). Additionally, regarding our Google Maps interface, we would like to have dynamic location identification. Furthermore, the capacity of our platform could help us expand program to pair people with any type of service, not just food. We believe that the flexibility of our app could be used for other ideas as well. | losing |
## Inspiration
We started off having the idea of how people could progressively integrate technology into their lives, and with all the smart electronic device and household appliances, we want to further integrate technology into the textile industry. Our team is particularly interested in computer vision and image processing so we want to create a jacket (cuz it is winter coming) that can be applied to security and healthcare.
## What it does
1. Recent reports from PoliceOne.com says that it is vital to integrate these body-worn cameras into their duty to increase efficiency and effectiveness, so we are planning to build these cameras into officers' and police-dogs' jackets for early detection of targeted individuals from police records databases, especially during civil unrest.
2. Our device would provide a platform for the visually-impaired to get real-time information of objects, signs, and other people in front of them. This program can be connected to smart blind glasses with headphones to benefit the disabled population.
## How I built it
We used a Raspberry Pi camera as a reasonably-sized device to fit in the jacket, then we implemented openCV to capture real-time data with its built-in object recognition functions.
## Challenges I ran into
First, two out of three people in our team are better with software so we needed to spend some time getting used to the hardware tools. Then comes the software problem, we initially started off with openCV and we tried different tutorials to install it into the Raspberry Pi. That took us a huge amount of time and we did not get the code to compile.
Then we were thinking of implementing Google Vision API instead and spend quite a while to realize that the API does not take in video inputs but static images. Therefore, we decided to go back to OpenCV, tried out using pre-compiled binary openCV, but we ran into some error. Finally, we realized that we need to resize our OS's partition to have enough space on our SD card to run OpenCV.
## Accomplishments that I'm proud of
Our team got to explore the potential applications of several hardware tools, learned some cool problem-solving skills, especially when we stepped through how to get OpenCV installed. We also finally came up with an idea that can benefit public goods in terms of security and health safety.
## What's next for Konnex Jacket
The next steps are we need to find a portable battery to use as a power source for our cameras. We are also trying to put in some fluorescent reflecting paint as a safety feature. To serve as a police public safety device, we need to connect the camera with the police records database, and to serve as a health assistance tool, we need to filter the information reported to the user. | ## Inspiration
Sometimes in lecture you need to point to something tiny on the presentation but no one really knows what you're pointing to. So we decided to build something that can read where you are pointing using a camera, and points a laser in that direction, which makes engagement in lectures and presentations much more accessible. We also realized that this idea actually branches off into a lot of other potential accessibility applications; it allows robotic control with pure human actions as input. For example, it could help artists paint large canvases by painting at where they point, or even be used as a new type of remote control if we replaced the laser with an RF signal.
## What it does
It tracks where the user's forearm is using a fully custom-built computer vision object detection program. All dimensions of the forearm are approximated via only one camera and it is able to generate a set of projected XY coordinates on the supposed presentation for the laser to point to. This corresponds to where the user is pointing at.
## How we built it
We heavily used OpenCV in Python to built the entire computer vision framework, which was tied to a USB webcam. Generated projection points were sent to an ESP32 via wifi, which fed separate coordinates to a dual-servo motor system which then moves the laser pointer to the correct spot. This was done using arduino.
## Challenges we ran into
First of all, none of us had actually used OpenCV on a project this size, especially not for object tracking. This took a lot of learning on the spot, online tutorials and experimenting
There were also plenty of challenges that all revolved around the robustness of the system. Sometimes the contour detection software would detect multiple contours, so a challenge was finding a way to join them so the system wouldn't break. The projection system was quite off at the start, so a lot of manual tuning had to be done to fix that. The wifi data transmission also took a long time to figure out, as none of us had ever touched that stuff before.
## Accomplishments that we're proud of
We're quite proud of the fact that we were able to build a fully functional object tracking system without any premade online code in such a short amount of time, and how robust it was in action. It was also quite cool to see the motors react in real time to user input.
## What we learned
We learned some pretty advanced image processing and video capture techniques in OpenCV, and how to use the ESP32 controller to do stuff.
## What's next for Laser Larry
The biggest step is to make the projection system more accurate, as this would take a lot more tuning. Another camera also wouldn't hurt to get more accurate readings, and it would be cool to expand the idea to more accessibility applications discussed above. | ## Inspiration
Our project, "**Jarvis**," was born out of a deep-seated desire to empower individuals with visual impairments by providing them with a groundbreaking tool for comprehending and navigating their surroundings. Our aspiration was to bridge the accessibility gap and ensure that blind individuals can fully grasp their environment. By providing the visually impaired community access to **auditory descriptions** of their surroundings, a **personal assistant**, and an understanding of **non-verbal cues**, we have built the world's most advanced tool for the visually impaired community.
## What it does
"**Jarvis**" is a revolutionary technology that boasts a multifaceted array of functionalities. It not only perceives and identifies elements in the blind person's surroundings but also offers **auditory descriptions**, effectively narrating the environmental aspects they encounter. We utilize a **speech-to-text** and **text-to-speech model** similar to **Siri** / **Alexa**, enabling ease of access. Moreover, our model possesses the remarkable capability to recognize and interpret the **facial expressions** of individuals who stand in close proximity to the blind person, providing them with invaluable social cues. Furthermore, users can ask questions that may require critical reasoning, such as what to order from a menu or navigating complex public-transport-maps. Our system is extended to the **Amazfit**, enabling users to get a description of their surroundings or identify the people around them with a single press.
## How we built it
The development of "**Jarvis**" was a meticulous and collaborative endeavor that involved a comprehensive array of cutting-edge technologies and methodologies. Our team harnessed state-of-the-art **machine learning frameworks** and sophisticated **computer vision techniques** to get analysis about the environment, like , **Hume**, **LlaVa**, **OpenCV**, a sophisticated computer vision techniques to get analysis about the environment, and used **next.js** to create our frontend which was established with the **ZeppOS** using **Amazfit smartwatch**.
## Challenges we ran into
Throughout the development process, we encountered a host of formidable challenges. These obstacles included the intricacies of training a model to recognize and interpret a diverse range of environmental elements and human expressions. We also had to grapple with the intricacies of optimizing the model for real-time usage on the **Zepp smartwatch** and get through the **vibrations** get enabled according to the **Hume** emotional analysis model, we faced issues while integrating **OCR (Optical Character Recognition)** capabilities with the **text-to speech** model. However, our team's relentless commitment and problem-solving skills enabled us to surmount these challenges.
## Accomplishments that we're proud of
Our proudest achievements in the course of this project encompass several remarkable milestones. These include the successful development of "**Jarvis**" a model that can audibly describe complex environments to blind individuals, thus enhancing their **situational awareness**. Furthermore, our model's ability to discern and interpret **human facial expressions** stands as a noteworthy accomplishment.
## What we learned
# Hume
**Hume** is instrumental for our project's **emotion-analysis**. This information is then translated into **audio descriptions** and the **vibrations** onto **Amazfit smartwatch**, providing users with valuable insights about their surroundings. By capturing facial expressions and analyzing them, our system can provide feedback on the **emotions** displayed by individuals in the user's vicinity. This feature is particularly beneficial in social interactions, as it aids users in understanding **non-verbal cues**.
# Zepp
Our project involved a deep dive into the capabilities of **ZeppOS**, and we successfully integrated the **Amazfit smartwatch** into our web application. This integration is not just a technical achievement; it has far-reaching implications for the visually impaired. With this technology, we've created a user-friendly application that provides an in-depth understanding of the user's surroundings, significantly enhancing their daily experiences. By using the **vibrations**, the visually impaired are notified of their actions. Furthermore, the intensity of the vibration is proportional to the intensity of the emotion measured through **Hume**.
# Ziiliz
We used **Zilliz** to host **Milvus** online, and stored a dataset of images and their vector embeddings. Each image was classified as a person; hence, we were able to build an **identity-classification** tool using **Zilliz's** reverse-image-search tool. We further set a minimum threshold below which people's identities were not recognized, i.e. their data was not in **Zilliz**. We estimate the accuracy of this model to be around **95%**.
# Github
We acquired a comprehensive understanding of the capabilities of version control using **Git** and established an organization. Within this organization, we allocated specific tasks labeled as "**TODO**" to each team member. **Git** was effectively employed to facilitate team discussions, workflows, and identify issues within each other's contributions.
The overall development of "**Jarvis**" has been a rich learning experience for our team. We have acquired a deep understanding of cutting-edge **machine learning**, **computer vision**, and **speech synthesis** techniques. Moreover, we have gained invaluable insights into the complexities of real-world application, particularly when adapting technology for wearable devices. This project has not only broadened our technical knowledge but has also instilled in us a profound sense of empathy and a commitment to enhancing the lives of visually impaired individuals.
## What's next for Jarvis
The future holds exciting prospects for "**Jarvis.**" We envision continuous development and refinement of our model, with a focus on expanding its capabilities to provide even more comprehensive **environmental descriptions**. In the pipeline are plans to extend its compatibility to a wider range of **wearable devices**, ensuring its accessibility to a broader audience. Additionally, we are exploring opportunities for collaboration with organizations dedicated to the betterment of **accessibility technology**. The journey ahead involves further advancements in **assistive technology** and greater empowerment for individuals with visual impairments. | losing |
# BlockOJ
>
> Boundless creativity.
>
>
>
## What is BlockOJ?
BlockOJ is an online judge built around Google's Blockly library that teaches children how to code. The library allows us to implement a code editor which lets the user program with various blocks (function blocks, variable blocks, etc.).

On BlockOJ, users can sign up and use our lego-like code editor to solve instructive programming challenges! Solutions can be verified by pitting them against numerous test cases hidden in our servers :) -- simply click the "submit" button and we'll take care of the rest.
Our lightning fast judge, painstakingly written in C, will provide instantaneous feedback on the correctness of your solution (ie. how many of the test cases did your program evaluate correctly?).

## Inspiration and Design Motivation
Back in late June, our team came across the article announcing the "[new Ontario elementary math curriculum to include coding starting in Grade 1](https://www.thestar.com/politics/provincial/2020/06/23/new-ontario-elementary-math-curriculum-to-include-coding-starting-in-grade-1.html)." During Hack The 6ix, we wanted to build a practical application that can aid our hard working elementary school teachers deliver the coding aspect of this new curriculum.
We wanted a tool that was
1. Intuitive to use,
2. Instructive, and most important of all
3. Engaging
Using the Blockly library, we were able to use a code editor which resembles building with LEGO: the block-by-block assembly process is **procedural** and children can easily look at the **big picture** of programming by looking at how the blocks interlock with each other.
Our programming challenges aim to gameify learning, making it less intimidating and more appealing to younger audiences. Not only will children using BlockOJ **learn by doing**, but they will also slowly accumulate basic programming know-how through our carefully designed sequence of problems.
Finally, not all our problems are easy. Some are hard (in fact, the problem in our demo is extremely difficult for elementary students). In our opinion, it is beneficial to mix in one or two difficult challenges in problemsets, for they give children the opportunity to gain valuable problem solving experience. Difficult problems also pave room for students to engage with teachers. Solutions are saved so children can easily come back to a difficult problem after they gain more experience.
## How we built it
Here's the tl;dr version.
* AWS EC2
* PostgreSQL
* NodeJS
* Express
* C
* Pug
* SASS
* JavaScript
*We used a link shortener for our "Try it out" link because DevPost doesn't like URLs with ports.* | ## Inspiration
We've noticed that many educators draw common structures on boards, just to erase them and redraw them in common ways to portray something. Imagine your CS teacher drawing an array to show you how bubble sort works, and erasing elements for every swap. This learning experience can be optimized with AI.
## What It Does
Our software recognizes digits drawn and digitizes the information. If you draw a list of numbers, it'll recognize it as an array and let you visualize bubble sort automatically. If you draw a pair of axes, it'll recognize this and let you write an equation that it will automatically graph.
The voice assisted list operator allows one to execute the most commonly used list operation, "append" through voice alone. A typical use case would be a professor free to roam around the classroom and incorporate a more intimate learning experience, since edits need no longer be made by hand.
## How We Built It
The digits are recognized using a neural network trained on the MNIST hand written digits data set. Our code scans the canvas to find digits written in one continuous stroke, puts bounding boxes on them and cuts them out, shrinks them to run through the neural network, and outputs the digit and location info to the results canvas.
For the voice driven list operator, the backend server's written in Node.js/Express.js. It accepts voice commands through Bixby and sends them to Almond, which stores and updates the list in a remote server, and also in the web user interface.
## Challenges We Ran Into
* The canvas was difficult to work with using JavaScript
* It is unbelievably hard to test voice-driven applications amidst a room full of noisy hackers haha
## Accomplishments that We're Proud Of
* Our software can accurately recognize digits and digitize the info!
## What We Learned
* Almond's, like, *really* cool
* Speech recognition has a long way to go, but is also quite impressive in its current form.
## What's Next for Super Smart Board
* Recognizing trees and visualizing search algorithms
* Recognizing structures commonly found in humanities classes and implementing operations for them
* Leveraging Almond's unique capabilities to facilitate operations like inserting at a specific index and expanding uses to data structures besides lists
* More robust error handling, in case the voice command is misinterpreted (as it often is)
* Generating code to represent the changes made alongside the visual data structure representation | ## Inspiration
I was inspired by the silence and disconnect in the job market. The barrier between employers and job seekers leaves many in the dark—people are uncertain about callbacks, interviews, and successes. I hope to promote job transparency, bridge this gap, empower job seekers with knowledge, and foster a more interactive, informed, and fair employment landscape for everyone. This website is meant to be like downdetector.com but for the job market.
## What it does
This website revolutionizes the job search experience by providing real-time data on job applications, including callbacks, non-responses, interviews, and successful hires. It aims to empower job seekers, fostering transparency and interactivity in the job market.
## How we built it
I built it using HTML, CSS, and some JavaScript.
## Challenges we ran into
I had trouble making the buttons on the front page look pretty and engaging. When I first tried to put a picture inside the button the text disappeared and the button became blank. Fortunately, I was able to ask a mentor for help and I was able to make pretty buttons like the ones on downdetector.com.
My teammates got busy and had to quit the hackathon, so I had to finish the project on my own!
## Accomplishments that we're proud of
The buttons on the front page. They look so pretty and the buttons actually do stuff!
## What we learned
I learned about the HTML ![]() src Attribute, how to make a drop-down button, and how to use Javascript to read values inside buttons and save it.
## What's next for JobPostTI
I would like to move the website from Replit, which limits me to using only HTML, CSS, and JavaScript for my project to my own personal public webpage so that I can implement the backend to add graphs and track data using SQL and Python. | partial |
## Overview
According to the WHO, at least 2.2 billion people worldwide have a vision impairment or blindness. Out of these, an estimated 1 billion cases could have been prevented or have yet to be addressed. This underscores the vast number of people who lack access to necessary eye care services. Even as developers, our screens have been both our canvas and our cage. We're intimately familiar with the strain they exert on our eyes, a plight shared by millions globally.
We need a **CHANGE**.
What if vision care could be democratized, made accessible, and seamlessly integrated with cutting-edge technology? Introducing OPTimism.
## Inspiration
The very genesis of OPTimism is rooted in empathy. Many in underserved communities lack access to quality eye care, a necessity that most of us take for granted. Coupled with the increasing screen time in today's digital age, the need for effective and accessible solutions becomes even more pressing. Our team has felt this on a personal level, providing the emotional catalyst for OPTimism. We didn't just want to create another app; we aspired to make a tangible difference.
## Core Highlights
**Vision Care Chatbot:** Using advanced AI algorithms, our vision chatbot assists users in answering vital eye care questions, offering guidance and support when professional help might not be immediately accessible.
**Analytics & Feedback:** Through innovative hardware integrations like posture warnings via a gyroscope and distance tracking with ultrasonic sensors, users get real-time feedback on their habits, empowering them to make healthier decisions.
**Scientifically-Backed Exercises:** Grounded in research, our platform suggests eye exercises designed to alleviate strain, offering a holistic approach to vision care.
**Gamified Redemption & Leaderboard System:** Users are not just passive recipients but active participants. They can earn optimism credits, leading to a gamified experience where they can redeem valuable eye care products. This not only incentivizes regular engagement but also underscores the importance of proactive vision care. The donation system using Circle allows users to make the vision care product possible.
## Technical Process
Bridging the gap between the technical and the tangible was our biggest challenge. We leaned on technologies such as React, Google Cloud, Flask, Taipy, and more to build a robust frontend and backend, containerized using Docker and Kubernetes and deployed on Netlify. Arduino's integration added a layer of real-world interaction, allowing users to receive physical feedback. The vision care chatbot was a product of countless hours spent on refining algorithms to ensure accuracy and reliability.
## Tech Stack
React, JavaScript, Vite, Tailwind CSS, Ant Design, Babel, NodeJS, Python, Flask, Taipy, GitHub, Docker, Kubernetes, Firebase, Google Cloud, Netlify, Circle, OpenAI
**Hardware List:** Arduino, Ultrasonic sensor, smart glasses, gyroscope, LEDs, breadboard
## Challenges we ran into
* Connecting the live data retrieved from the Arduino into the backend application for manipulating and converting into appropriate metrics
* Circle API key not authorized
* Lack of documentation for different hardwares and support for APIs.
## Summary
OPTimism isn't just about employing the latest technologies; it's about leveraging them for a genuine cause. We've seamlessly merged various features, from chatbots to hardware integrations, under one cohesive platform. Our aim? Clear, healthy vision for all, irrespective of their socio-economic background.
We believe OPTimism is more than just a project. It's a vision, a mission, and a commitment. We will convert the hope to light the path to a brighter, clearer future for everyone into reality. | # Check out our [slides](https://docs.google.com/presentation/d/1K41ArhGy6HgdhWuWSoGtBkhscxycKVTnzTSsnapsv9o/edit#slide=id.g30ccbcf1a6f_0_150) and come over for a demo!
## Inspiration
The inspiration for EYEdentity came from the need to enhance patient care through technology. Observing the challenges healthcare professionals face in quickly accessing patient information, we envisioned a solution that combines facial recognition and augmented reality to streamline interactions and improve efficiency.
## What it does
EYEdentity is an innovative AR interface that scans patient faces to display their names and critical medical data in real-time. This technology allows healthcare providers to access essential information instantly, enhancing the patient experience and enabling informed decision-making on the spot.
## How we built it
We built EYEdentity using a combination of advanced facial recognition and facial tracking algorithms and the new Snap Spectacles. The facial recognition component was developed using machine learning techniques to ensure high accuracy, while the AR interface was created using cutting-edge software tools that allow for seamless integration of data visualization in a spatial format. Building on the Snap Spectacles provided us with a unique opportunity to leverage their advanced AR capabilities, resulting in a truly immersive user experience.
## Challenges we ran into
One of the main challenges we faced was ensuring the accuracy and speed of the facial recognition system in various lighting conditions and angles. Additionally, integrating real-time data updates into the AR interface required overcoming technical hurdles related to data synchronization and display.
## Accomplishments that we're proud of
We are proud of successfully developing a prototype that demonstrates the potential of our technology in a real-world healthcare setting. The experience of building on the Snap Spectacles allowed us to create a user experience that feels natural and intuitive, making it easier for healthcare professionals to engage with patient data.
## What we learned
Throughout the development process, we learned the importance of user-centered design in healthcare technology. Communicating with healthcare professionals helped us understand their needs and refine our solution to better serve them. We also gained valuable insights into the technical challenges of integrating AR with real-time data.
## What's next for EYEdentity
Moving forward, we plan to start testing in clinical environments to gather more feedback and refine our technology. Our goal is to enhance the system's capabilities, expand its features, and ultimately deploy EYEdentity in healthcare facilities to revolutionize patient care. | ## Inspiration
We were inspired by the tedium of organizing tasks for our housemates.
## What it does
It is supposed to allow a group of friends/housemates/coworkers to requests favors or tasks from one another and keep track of who is working on what task.
## How we built it
We used react-native and Figma to design the UI.
## Challenges I ran into
1. Too many...
2. AsyncStorage
## Accomplishments that I'm proud of
We can actually add a favor!
## What I learned
JavaScript is difficult for even the pros. And we learned some React. I think...
## What's next for Anytime.
Anywhere, the global vocation planning app used worldwide. | partial |
## Inspiration
Inspired by leap motion applications
## What it does
User can their gesture to control motor, speaker, and led matrix.
## How we built it
Use arduino to control motor, speaker, led matrix and use Bluetooth to connect with computer that is connected to Oculus and leap-motion.
## Challenges we ran into
Put augmented reality overlay onto the things that we want to control.
## Accomplishments that we're proud of
Successfully controlled their components using gestures.
## What we learned
How to make use of Oculus and Leap-motion.
## What's next for Augmented Reality Control Experience (ARCX)
People with disabilities can use this technology to control their technologies such as turning on lights and playing music. | ## Inspiration
We realized how visually-impaired people find it difficult to perceive the objects coming near to them, or when they are either out on road, or when they are inside a building. They encounter potholes and stairs and things get really hard for them. We decided to tackle the issue of accessibility to support the Government of Canada's initiative to make work and public places completely accessible!
## What it does
This is an IoT device which is designed to be something wearable or that can be attached to any visual aid being used. What it does is that it uses depth perception to perform obstacle detection, as well as integrates Google Assistant for outdoor navigation and all the other "smart activities" that the assistant can do. The assistant will provide voice directions (which can be geared towards using bluetooth devices easily) and the sensors will help in avoiding obstacles which helps in increasing self-awareness. Another beta-feature was to identify moving obstacles and play sounds so the person can recognize those moving objects (eg. barking sounds for a dog etc.)
## How we built it
Its a raspberry-pi based device and we integrated Google Cloud SDK to be able to use the vision API and the Assistant and all the other features offered by GCP. We have sensors for depth perception and buzzers to play alert sounds as well as camera and microphone.
## Challenges we ran into
It was hard for us to set up raspberry-pi, having had no background with it. We had to learn how to integrate cloud platforms with embedded systems and understand how micro controllers work, especially not being from the engineering background and 2 members being high school students. Also, multi-threading was a challenge for us in embedded architecture
## Accomplishments that we're proud of
After hours of grinding, we were able to get the raspberry-pi working, as well as implementing depth perception and location tracking using Google Assistant, as well as object recognition.
## What we learned
Working with hardware is tough, even though you could see what is happening, it was hard to interface software and hardware.
## What's next for i4Noi
We want to explore more ways where i4Noi can help make things more accessible for blind people. Since we already have Google Cloud integration, we could integrate our another feature where we play sounds of living obstacles so special care can be done, for example when a dog comes in front, we produce barking sounds to alert the person. We would also like to implement multi-threading for our two processes and make this device as wearable as possible, so it can make a difference to the lives of the people. | ## Inspiration
One of our friends is blind. She describes using her cane as a hassle, and explains that when she is often stressed about accidentally touching someone with her cane, doing two-handed tasks like carrying groceries or giving a friend a hug, and setting the cane down or leaning it against the wall when she sits down. So, we set out to build a device that would free up two hands, reduce her mobility related stresses, and remain as or more intuitive than the cane is.
## What it does
Our prototype employs an infrared distance sensor, which feeds into an Arduino Nano, and outputs as a haptic signal on your forearm via a servo motor. In this way, by pointing your wrist at various surfaces, you will be able to get an idea of how close or far they are, allowing you to intuitively navigate your physical environment.
## How we built it
We used an infrared distance sensor with an accurate range of 0.2m - 1.5m, an Arduino Nano, a servo motor to provide haptic feedback, and a 3D printer to build a case and wrist-mount for the components.
## Challenges we ran into
1. The Arduino Nano, due to budgetary constraints, was frankly sketchy and did not have the correct bootloader and drivers installed. Fixing this and getting the Arduino to integrate with our other components was a fairly big project of its own.
2. The mapping of the sensor was non-linear, so we had to figure out how to correctly assign the output of the sensor to a specific haptic feedback that felt intuitive. This was difficult, and primarily done through experimentation.
3. Finally, making the device compact, wearable, and comfortable was a big design challenge.
## Accomplishments that we're proud of
Our critical test and initial goal was having someone who is fully blindfolded navigate a small obstacle course using the device. After multiple iterations and experimentation with what haptic feedback was useful and intuitive, we were able to have a team-member navigate the obstacle course successfully without the use of his sight. Great success!
## What we learned
We learned about loading bootloaders onto different devices, different chipsets and custom drivers, mapping input to output in components non-linearly, 3D printing casing for components, and finally making this housing comfortably wearable.
## What's next for Mobile Optical Infrared Sensory Transmitter
Next up, we are hoping to swap out the external battery powering the device to either human-heat power or at least rechargeable batteries. We also want to switch the infrared sensor out for a LIDAR sensor which would give us greater range and accuracy. Additionally, we are hoping to make the device much more compact. Finally, we also want to increase the comfort of the wrist-mount of the device so that it can be used comfortably over longer periods of time. | winning |
## Inspiration
Sexual assault survivors are in tremendously difficult situations after being assaulted, having to sacrifice privacy and anonymity to receive basic medical, legal, and emotional support. And understanding how to proceed with one's life after being assaulted is challenging due to how scattered information on resources for these victims is for different communities, whether the victim is on an American college campus, in a foreign country, or any number of other situations. Instead of building a single solution or organizing one set of resources to help sexual assault victims everywhere, we believe a simple, community-driven solution to this problem lies in Echo.
## What it does
Using Blockstack, Echo facilitates anonymized communication among sexual assault victims, legal and medical help, and local authorities to foster a supportive online community for victims. Members of this community can share their stories, advice, and support for each other knowing that they truly own their data and it is anonymous to other users, using Blockstack. Victims may also anonymously report incidents of assault on the platform as they happen, and these reports are shared with local authorities if a particular individual has been reported as an offender on the platform several times by multiple users. This incident data is also used to geographically map where in small communities sexual assault happens, to provide users of the app information on safe walking routes.
## How we built it
A crucial part to feeling safe as a sexual harassment survivor stems from the ability to stay anonymous in interactions with others. Our backend is built with this key foundation in mind. We used Blockstack’s Radiks server to create a decentralized application that would keep all user’s data local to that user. By encrypting their information when storing the data, we ensure user privacy and mitigate all risks to sacrificing user data. The user owns their own data. We integrated Radiks into our Node and Express backend server and used this technology to manage our database for our app.
On the frontend, we wanted to create an experience that was eager to welcome users to a safe community and to share an abundance of information to empower victims to take action. To do this, we built the frontend from React and Redux, and styling with SASS. We use blockstack’s Radiks API to gather anonymous messages in the Support Room feature. We used Twilio’s message forwarding API to ensure that victims could very easily start anonymous conversations with professionals such as healthcare providers, mental health therapists, lawyers, and other administrators who could empower them. We created an admin dashboard for police officials to supervise communities, equipped with Esri’s maps that plot where the sexual assaults happen so they can patrol areas more often. On the other pages, we aggregate online resources and research into an easy guide to provide victims the ability to take action easily. We used Azure in our backend cloud hosting with Blockstack.
## Challenges we ran into
We ran into issues of time, as we had ambitious goals for our multi-functional platform. Generally, we faced the learning curve of using Blockstack’s APIs and integrating that into our application. We also ran into issues with React Router as the Express routes were being overwritten by our frontend routes.
## Accomplishments that we're proud of
We had very little experience developing blockchain apps before and this gave us hands-on experience with a use-case we feel is really important.
## What we learned
We learned about decentralized data apps and the importance of keeping user data private. We learned about blockchain’s application beyond just cryptocurrency.
## What's next for Echo
Our hope is to get feedback from people impacted by sexual assault on how well our app can foster community, and factor this feedback into a next version of the application. We also want to build out shadowbanning, a feature to block abusive content from spammers on the app, using a trust system between users. | ## Inspiration
Our inspiration came from a common story that we have been seeing on the news lately - the wildfires that are impacting people on a nationwide scale. These natural disasters strike at uncertain times, and we don't know if we are necessarily going to be in the danger zone or not. So, we decided to ease the tensions that occur during these high-stress situations by acting as the middle persons.
## What it does
At RescueNet, we have two types of people with using our service - either subscribers or homeowners. The subscriber pays RescueNet monthly or annually at a rate which is cheaper than insurance! Our infrastructure mainly targets people who live in natural disaster-prone areas. In the event such a disaster happens, the homeowners will provide temporary housing and will receive a stipend after the temporary guests move away. We also provide driving services for people to escape their emergency situations.
## How we built it
We divided our work into the clientside and the backend. Diving into the clientside, we bootstrapped our project using Vite.js for faster loadtimes. Apart from that, React.js was used along with React Router to link the pages and organize the file structure accordingly. Tailwind CSS was employed to simplify styling along with Material Tailwind, where its pre-built UI components were used in the about page.
Our backend server is made using Node.js and Express.js, and it connects to a MongoDB Atlas database making use of a JavaScript ORM - Mongoose. We make use of city data from WikiData, geographic locations from GeoDB API, text messaging functionality of Twilio, and crypto payment handling of Circle.
## Challenges we ran into
Some challenges we ran into initially is to make the entire web app responsive across devices while still keeping our styles to be rendered. At the end, we figured out a great way of displaying it in a mobile setting while including a proper navbar as well. In addition, we ran into trouble working with the Circle API for the first time. Since we've never worked with cryptocurrency before, we didn't understand some of the implications of the code we wrote, and that made it difficult to continue with Circle.
## Accomplishments that we're proud of
An accomplishment we are proud of is rendering the user dashboard along with the form component, which allowed the user to either enlist as a subscriber or homeowner. The info received from this component would later be parsed into the dashboard would be available for show.
We are also proud of how we integrated Twilio's SMS messaging services into the backend algorithm for matching subscribers with homeowners. This algorithm used information queried from our database, accessed from WikiData, and returned from various API calls to make an "optimal" matching based on distance and convenience, and it was nice to see this concept work in real life by texting those who were matched.
## What we learned
We learned many things such as how to use React Router in linking to pages in an easy way. Also, leaving breadcrumbs in our Main.jsx allowed us to manually navigate to such pages when we didn't necessarily had anything set up in our web app. We also learned how to use many backend tools like Twilio and Circle.
## What's next for RescueNet
What's next for RescueNet includes many things. We are planning on completing the payment model using Circle API, including implementing automatic monthly charges and the ability to unsubscribe. Additionally, we plan on marketing to a few customers nationwide, this will allow us to conceptualize and iterate on our ideas till they are well polished. It will also help in scaling things to include countries such as the U.S.A and Mexico. | ## Inspiration
Going home for winter break and seeing friends was a great time, but throughout all the banter, I realized that our conversations often took a darker turn, and I worried for my friends' mental health. During the school year, it was a busy time and I wasn't able to stay in touch with my friends as well as I had wanted to. After this realization, I also began to question my own mental health - was I neglecting my health?
We were inspired to build a web app that would increase awareness about how friends were doing mentally that could also provide analytics for ourselves. We thought there was good potential in text due to the massive volumes of digital communication and how digital messages can often reveal some the that may be hidden in everyday communication.
## What it does
It parses user text input into a sentiment score, using Microsoft Azure, where 0 is very negative and 1 is very positive. Over a day, it averages the input for a specific user and logs the text files. Friends of the user can view the weekly emoji graphs, and receive a text message if it seems like the user is going through a rough spot and needs someone to talk to.
We also have an emoji map for displaying sentiments of senders around the world, allowing us to see events that invoke emotional responses in a particular area. We hope that this is useful data for increased global and cultural awareness.
## How we built it
We used React.js for the front-end and used Flask with Python for the backend. We used Azure for the sentiment analysis and Twillio to send text messages.
## Challenges we ran into
One of the biggest bottlenecks was connecting our front-end and back-end. Additionally, we had security concerns regarding cross origin resource sharing that made it much more difficult to interface with all the different databases. We had too many APIs that we wanted to connect that made things difficult too.
## Accomplishments that we're proud of
We were able to create a full-stack app web app on our own, despite the challenges. Some of the members of the team had never worked on front-end before and it was a great, fun experience learning how to use JS, Flask, and HTML.
## What we learned
We learned about full stack web app development and the different languages required. We also became more aware of the moving parts behind a web app, how they communicate with each other, and the challenges associated with that.
## What's next for ment.ally
Our original idea was actually a Chrome extension that could detect emotionally charged messages the user types in real-time and offer alternatives in an attempt to reduce miscommunication potentially hurtful to both sides. We would like to build off of our existing sentiment analysis capabilities to do this. Our next step would be to set up a way to parse what the user is typing and underline any overly strong phrases (similar to how Word underlines misspelt words in red). Then we could set up a database that maps some common emotionally charged phrases with some milder ones and offers those as suggestions, possibly along with the reason (e.g. "words in this sentence can trigger feelings of anger!). | partial |
## Inspiration
With the recent Corona Virus outbreak, we noticed a major issue in charitable donations of equipment/supplies ending up in the wrong hands or are lost in transit. How can donors know their support is really reaching those in need? At the same time, those in need would benefit from a way of customizing what they require, almost like a purchasing experience.
With these two needs in mind, we created Promise. A charity donation platform to ensure the right aid is provided to the right place.
## What it does
Promise has two components. First, a donation request view to submitting aid requests and confirm aids was received. Second, a donor world map view of where donation requests are coming from.
The request view allows aid workers, doctors, and responders to specificity the quantity/type of aid required (for our demo we've chosen quantity of syringes, medicine, and face masks as examples) after verifying their identity by taking a picture with their government IDs. We verify identities through Microsoft Azure's face verification service. Once a request is submitted, it and all previous requests will be visible in the donor world view.
The donor world view provides a Google Map overlay for potential donors to look at all current donation requests as pins. Donors can select these pins, see their details and make the choice to make a donation. Upon donating, donors are presented with a QR code that would be applied to the aid's packaging.
Once the aid has been received by the requesting individual(s), they would scan the QR code, confirm it has been received or notify the donor there's been an issue with the item/loss of items. The comments of the recipient are visible to the donor on the same pin.
## How we built it
Frontend: React
Backend: Flask, Node
DB: MySQL, Firebase Realtime DB
Hosting: Firebase, Oracle Cloud
Storage: Firebase
API: Google Maps, Azure Face Detection, Azure Face Verification
Design: Figma, Sketch
## Challenges we ran into
Some of the APIs we used had outdated documentation.
Finding a good of ensuring information flow (the correct request was referred to each time) for both the donor and recipient.
## Accomplishments that we're proud of
We utilized a good number of new technologies and created a solid project in the end which we believe has great potential for good.
We've built a platform that is design-led, and that we believe works well in practice, for both end-users and the overall experience.
## What we learned
Utilizing React states in a way that benefits a multi-page web app
Building facial recognition authentication with MS Azure
## What's next for Promise
Improve detail of information provided by a recipient on QR scan. Give donors a statistical view of how much aid is being received so both donors and recipients can better action going forward.
Add location-based package tracking similar to Amazon/Arrival by Shopify for transparency | ## Inspiration
Covid-19 has turned every aspect of the world upside down. Unwanted things happen, situation been changed. Lack of communication and economic crisis cannot be prevented. Thus, we develop an application that can help people to survive during this pandemic situation by providing them **a shift-taker job platform which creates a win-win solution for both parties.**
## What it does
This application offers the ability to connect companies/manager that need employees to cover a shift for their absence employee in certain period of time without any contract. As a result, they will be able to cover their needs to survive in this pandemic. Despite its main goal, this app can generally be use to help people to **gain income anytime, anywhere, and with anyone.** They can adjust their time, their needs, and their ability to get a job with job-dash.
## How we built it
For the design, Figma is the application that we use to design all the layout and give a smooth transitions between frames. While working on the UI, developers started to code the function to make the application work.
The front end was made using react, we used react bootstrap and some custom styling to make the pages according to the UI. State management was done using Context API to keep it simple. We used node.js on the backend for easy context switching between Frontend and backend. Used express and SQLite database for development. Authentication was done using JWT allowing use to not store session cookies.
## Challenges we ran into
In the terms of UI/UX, dealing with the user information ethics have been a challenge for us and also providing complete details for both party. On the developer side, using bootstrap components ended up slowing us down more as our design was custom requiring us to override most of the styles. Would have been better to use tailwind as it would’ve given us more flexibility while also cutting down time vs using css from scratch.Due to the online nature of the hackathon, some tasks took longer.
## Accomplishments that we're proud of
Some of use picked up new technology logins while working on it and also creating a smooth UI/UX on Figma, including every features have satisfied ourselves.
Here's the link to the Figma prototype - User point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=68%3A3872&scaling=min-zoom)
Here's the link to the Figma prototype - Company/Business point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=107%3A10&scaling=min-zoom)
## What we learned
We learned that we should narrow down the scope more for future Hackathon so it would be easier and more focus to one unique feature of the app.
## What's next for Job-Dash
In terms of UI/UX, we would love to make some more improvement in the layout to better serve its purpose to help people find an additional income in job dash effectively. While on the developer side, we would like to continue developing the features. We spent a long time thinking about different features that will be helpful to people but due to the short nature of the hackathon implementation was only a small part as we underestimated the time that it will take. On the brightside we have the design ready, and exciting features to work on. | **Previously named NeatBeat**
## Inspiration
We wanted to make it easier to understand your pressure, so you **really** are not pressured about what your heart deserves.
## What it does
**Track and chart blood pressure readings** 📈❤️
* Input your systolic and diastolic to be stored on the cloud
* See and compare your current and past blood pressure readings
**Doctor and Patient system** 🩺
* Create doctor and patient accounts
* Doctors will be able to see all their patients and their associated blood pressure readings
* Doctors are able to make suggestions based on their patient readings
* Patients can see suggestions that their doctor makes
## How we built it
Using Django web framework, backend with Python and front development with HTML, Bootstrap and chart.js for charting.
## Challenges we ran into
* Too many front end issues to count 😞
## Accomplishments that we're proud of
* Being able to come together to collaborate and complete a project solely over the internet.
* Successfully splitting the projects into parts and integrating them together for a functioning product
## What we learned
* Hacking under a monumental school workload and a global pandemic
## What's next for NeatBeat
* Mobile-friendly interface | winning |
## Inspiration
While biking this week a member of our team fell onto the street, injuring his chin and requiring stitches. This experience highlighted how unsafe a fallen biker may be while lying in pain or unconscious on a busy street. Also, as avid hikers, our team recognizes the risk of being trapped or knocked unconscious in a fall; unable to call for help. We recognized the need for a solution that detects and calls for help when help is needed.
## What it does
HORN uses motion tracking to detect falls or crashes. If it detects an accident and then the user falls still within 60 seconds, it will provide a warning. If the user does not indicate that they are not incapacitated HORN contacts emergency services and notifies them of the time and location of the accident.
If anyone texts HORN while the user is incapacitated it provides a loud horn sound to help nearby searchers. Because HORN relies on the emergency service network it is capable of sending and receiving messages even while out of range of regular coverage.
## How we built it
The HORN prototype is controlled on a Raspberry Pi 4 which interfaces with the sensing and acting devices. It uses a BNO055 inertial measurement unit to track the acceleration of the user, a BN 880 GPS to track the location, a SIM800L GSM to send and receive SMS messages, and a modified car horn to honk.
To detect impacts, there is a thread that measures when the user experiences very high G-forces in any direction (>10 Gs, ) and also monitors if the user is completely still (indicates that they may be unconscious).
## Challenges we ran into
Communicating over SMS required us to learn about AT commands which are essentially an antiquated interface for server communication.
Finding a horn loud enough to be useful in a search and rescue situation meant we needed to branch out from traditional buzzers or speakers. After 3D printing a siren design found online, we realized a makeshift whistle would not be nearly loud enough, so we brainstormed to select a car horn - a very nontraditional component - as the main local notification device.
The accelerometer sometimes peaks at very high erroneous values. To avoid this setting off the impact detection, we limited the maximum jerk so if the acceleration value changes too much, it is considered erroneous and the previous data point is used for calculations.
## Accomplishments that we're proud of
Making the GSM work was very difficult since there was no library to use so we had to write our own serial interface. Getting this to work was a huge victory for us.
## What we learned
We learned how to parse NEMA sentences from GPS modules which contain a large amount of difficult-to-read information.
We also learned about programming systems as a team and getting separate subsystems to work together. Over the course of the hack, we realized it would make it much easier to collaborate if we wrote each of our subsystems in separate classes with simple functions to interact with each other. This meant that we had to use threading for continuous tasks like monitoring the accelerometer, which is something I did not have a lot of experience with.
## What's next for High-impact Orientation Relocation Notification system
In the future instead of only detecting high G-forces, it might be more useful to collect data from normal activity and use a machine learning model to detect unusual behaviour, like falls. This could let us apply our device to more complicated scenarios, such as a skier getting stuck in a tree well or avalanche. Also, for use in more remote areas, integration with satellite networks rather than cellular would expand HORN’s safety capabilities. | ## Inspiration
Our team wanted to hack something that would promote public safety. A discussion on the length of the bus ride from UCLA to Cal introduced a discussion on how to safely drive long distances. There were two big problems to tackle: staying awake, and safely communicating.
## What it does
The MyoMessenger offers two safety features. The first harnesses Myo technology and allows you to send common text messages to any person on a predetermined emergency list (e.g. text "I'll call you back later" to Mom) using hand gestures. This allows you to communicate your whereabouts safely with friends and family without needing to deviate your eyes from the road.
The second safety feature uses the Muse headband's accelerometer to detect when a driver's head starts bobbing in exhaustion or fatigue. When the driver is detected to be falling asleep, it will send an audiovisual signal for the driver to wake up.
## How I built it
For the Muse accelerometer, we obtain the accelerometer's position points and calculate the acceleration at those points. If there is a peak in the acceleration curve, surpassing a threshold, it indicates the head is bobbing, suggesting the driver has fallen asleep.
## Challenges I ran into
We were trying to connect many components together (Myo, Twilio text messaging, Muse headband, etc) and this proved difficult to provide a smooth continuous user experience between all devices.
## What's next for MyoMessenger
We want to eventually upgrade the MyoMessenger to be able to send one of the predetermined text messages to whomever called or texted last. The limitation of the current model is the user must take initiative to select which contact to send a message to first. We would also like to incorporate a speech to text functionality as well. Lastly, we want the Muse accelerometer to ping the Myo when it receives a spike in acceleration to create a seamless user experience rather than outsourcing the signal. | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before. | losing |
## Inspiration
In today's world, Public Speaking is one of the greatest skills any individual can have. From pitching at a hackathon to simply conversing with friends, being able to speak clearly, be passionate and modulate your voice are key features of any great speech. To tackle this problem of becoming a better public speaker, we created Talky.
## What it does
It helps you improve your speaking skills by giving you suggestions based on what you said to the phone. Once you finish presenting your speech to the app, an audio file of the speech will be sent to a flask server running on Heroku. The server will analyze the audio file by examining pauses, loudness, accuracy and how fast user spoke. In addition, the server will do a comparative analysis with the past data stored in Firebase. Then the server will return the performance of the speech.The app also provides the community functionality which allows the user to check out other people’s audio files and view community speeches.
## How we built it
We used Firebase to store the users’ speech data. Having past data will allow the server to do a comparative analysis and inform the users if they have improved or not.
The Flask server uses similar Audio python libraries to extract meaning patterns: Speech Recognition library to extract the words, Pydub to detect silences and Soundfile to find the length of the audio file.
On the iOS side, we used Alamofire to make the Http request to our server to send data and retrieve a response.
## Challenges we ran into
Everyone on our team was unfamiliar with the properties of audio, so discovering the nuances of wavelengths in particular and the information it provides was challenging and integral part of our project.
## Accomplishments that we're proud of
We successfully recognize the speeches and extract parameters from the sound file to perform the analysis.
We successfully provide the users with an interactive bot-like UI.
We successfully bridge the IOS to the Flask server and perform efficient connections.
## What we learned
We learned how to upload audio file properly and process them using python libraries.
We learned to utilize Azure voice recognition to perform operations from speech to text.
We learned the fluent UI design using dynamic table views.
We learned how to analyze the audio files from different perspectives and given an overall judgment to the performance of the speech.
## What's next for Talky
We added the community functionality while it is still basic. In the future, we can expand this functionality and add more social aspects to the existing app.
Also, the current version is focused on only the audio file. In the future, we can add the video files to enrich the post libraries and support video analyze which will be promising. | ## Inspiration
Many people feel unconfident, shy, and/or awkward doing interview speaking. It can be challenging for them to know how to improve and what aspects are key to better performance. With Talkology, they will be able to practice in a rather private setting while receiving relatively objective speaking feedback based on numerical analysis instead of individual opinions. We hope this helps more students and general job seekers become more confident and comfortable, crack their behavioral interviews, and land that dream offer!
## What it does
* Gives users interview questions (behavioural, future expansion to questions specific to the job/industry)
* Performs quantitative analysis of users’ responses using speech-to-text & linguistic software package praat to study acoustic features of their speech
* Displays performance metrics with suggestions in a user-friendly, interactive dashboard
## How we built it
* React/JavaScript for the frontend dashboard and Flask/Python for backend server and requests
* My-voice-analysis package for voice analysis in Python
* AssemblyAI APIs for speech-to-text and sentiment analysis
* MediaStream Recording API to get user’s voice recordings
* Figma for the interactive display and prototyping
## Challenges we ran into
We went through many conversations to reach this idea and as a result, only started hacking around 8AM on Saturday. On top of this time constraint layer, we also lacked experience in frontend and full stack development. Many of us had to spend a lot of our time debugging with package setup, server errors, and for some of us even M1-chip specific problems.
## Accomplishments that we're proud of
This was Aidan’s first full-stack application ever. Though we started developing kind of late in the event, we were able to pull most of the pieces together within a day of time on Saturday. We really believe that this product (and/or future versions of it) will help other people with not only their job search process but also daily communication as well. The friendships we made along the way is also definitely something we cherish and feel grateful about <3
## What we learned
* Aidan: Basics of React and Flask
* Spark: Introduction to Git and full-stack development with sprinkles of life advice
* Cathleen: Deeper dive into Flask and React and structural induction
* Helen: Better understanding of API calls & language models and managing many different parts of a product at once
## What's next for Talkology
We hope to integrate computer vision approaches by collecting video recordings (rather than just audio) to perform analysis on hand gestures, overall posture, and body language. We also want to extend our language analysis to explore novel models aimed at performing tone analysis on live speech. Apart from our analysis methods, we hope to improve our question bank to be more than just behavioural questions and better cater to each user's specific job demands. Lastly, there are general loose ends that could be easily tied up to make the project more cohesive, such as integrating the live voice recording functionality and optimizing some remaining components of the interactive dashboard. | ## Inspiration
We wanted to solve a problem that was real for us, something that we could get value out of. We decided upon Vocally as it solves an issue faced by a lot of people during job interviews, presentations, and other occasions which include speaking in a clear and concise manner. The problem was that it takes a long time to record yourself and re-listen to it just to spot any sentence fillers like "um" or "like". We would like to make it easier to display statistics of one's speech.
## What it does
The user clicks the record button and starts speaking. The application first converts speech-to-text using React's built-in speech recognition. After analyzing the results various text processing techniques (e.g. sentiment analysis), it displays feedback.
## How we built it
* First, we needed to see how keywords could be extracted from an audio recording in the back-end. We settled with React's speech-to-text feature.
* Next, we created API endpoints in Flask (a python web framework) for the React app to make requests from.
* Fuzzy string matching, grammatical, and sentiment analysis were used to process and return the stats to the user using data visualization.
* The last task was deployment to the pythonanywhere.com domain for demo testing purposes.
## Challenges I ran into
Using flask as an API was easy, but we initially tried to host it on GCP, which proved to be difficult as our firewall rules were not configured properly. We moved onto pythonanywhere.com for hosting. For the front-end, we first decided to take a look at the Flutter framework to be able to make the application mobile accessible but the framework was introduced in 2018, and there were a lot of configuration issues that needed to be resolved.
## Accomplishments that we are proud of
Getting the sound recorder to work on the front-end took longer than expected, but the end result was very satisfying. We're proud that we actually achieved creating an end-to-end solution.
## What I learned
Exploring different framework options like Flutter, in the beginning, was a journey for us. The API that was created needed to delve deeper into the python programming language. We learned about various syntactical and natural language processing techniques.
## What's next for Vocally
We may re-explore the concept of natural language processing, perhaps build our own algorithm from scratch and do more over a longer time period. | partial |
# Doctors Within Borders
### A crowdsourcing app that improves first response time to emergencies by connecting city 911 dispatchers with certified civilians
## 1. The Challenge
In Toronto, ambulances get to the patient in 9 minutes 90% of the time. We all know
that the first few minutes after an emergency occurs are critical, and the difference of
just a few minutes could mean the difference between life and death.
Doctors Within Borders aims to get the closest responder within 5 minutes of
the patient to arrive on scene so as to give the patient the help needed earlier.
## 2. Main Features
### a. Web view: The Dispatcher
The dispatcher takes down information about an ongoing emergency from a 911 call, and dispatches a Doctor with the help of our dashboard.
### b. Mobile view: The Doctor
A Doctor is a certified individual who is registered with Doctors Within Borders. Each Doctor is identified by their unique code.
The Doctor can choose when they are on duty.
On-duty Doctors are notified whenever a new emergency occurs that is both within a reasonable distance and the Doctor's certified skill level.
## 3. The Technology
The app uses *Flask* to run a server, which communicates between the web app and the mobile app. The server supports an API which is used by the web and mobile app to get information on doctor positions, identify emergencies, and dispatch doctors. The web app was created in *Angular 2* with *Bootstrap 4*. The mobile app was created with *Ionic 3*.
Created by Asic Chen, Christine KC Cheng, Andrey Boris Khesin and Dmitry Ten. | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before. | ## Inspiration
“Why do I have to go to school?” — a common complaint among both elementary and college students alike. Most of us are told that school is necessary for teaching us marketable skills; but when was the last time you recall hand-computing an integral? Or being forced to memorize a direct quote from a book?
This computational, methodical brand of education has children simply regurgitating information while limiting their ability to retain concepts in the long-term. Picture this: You have a test in two days and your professor has just released the study guide. It reads like a dictionary, with multiple topics to memorize. You do fine on the test, but six weeks later, you have your final and have to sit down and memorize the topics again since you’ve already forgotten them.
This current educational structure isn’t conducive to learning the why and how behind academic topics. Instead, it prioritizes unmarketable, rote memorization tactics at the expense of a holistic understanding toward a given problem.
Students are learning to plug and chug algorithms without learning why they are doing the operation in the first place. This is further leading to a lack of overall learning and a decrease in natural curiosity about subject matter.
Educational disparities between regional school systems also prevent students from receiving contextualized lesson plans that promote a deep understanding.
With Feynman, we wanted to create a study tool that helps students review concepts conceptually to figure out gaps in their knowledge and to ensure that they understand the concepts instead of just memorizing quantitative answers.
## What it does
Feynman quizzes a student using prompts. The student qualitatively responds to the prompt through a text box submission. Once they submit their response, Feynman determines whether or not the response sufficiently addresses the response through a ranking from 1 – 10, where 9 – 10 reflects a sufficient response. If the response is sufficient, the user can move on. If it is not sufficient, the student has three options: resubmit another response, take a hint, or display the correct answer. If the student decides to take a hint, then Feynman will provide a list of topics that the student may want to review in order to sufficiently answer the question. If the student decides to display the correct answer, then Feynman will provide a detailed answer to the question, as well as a specific explanation for why the student’s response was not sufficient.
## How we built it
We integrated the OpenAI ChatGPT API, as well as prompt engineering, to perform a correctness evaluation of a student’s response to a given prompt. We further applied prompt engineering to the API for the “Hints” and “View Correct Answer” tools.
## Challenges we ran into
We struggled with the prompt engineering to ensure that our responses were accurate. We wanted the first response to only grade the numerical accuracy of the input. We also had to maneuver our queries so the responses identified key subjects that the student should review before it explained why the answer was wrong.
## Accomplishments that we're proud of
Flexibility of program — it is very easy to adjust the prompt of the question
Integrating API through natural English — a very cool application of code 3.0 (prompt engineering)
## What's next for Feynman
We want to expanding into multiple subjects and integrate the feedback with a database of lesson plans so the study topics are tailored to a specific class the student is in. This program can also function as an an automated grader for professors so exams are reliant on conceptual understanding rather than formulaic answers. By implementing an automated grader, written responses are as efficient as numeric values for assessments. | winning |
## Inspiration
As we all know the world has come to a halt in the last couple of years. Our motive behind this project was to help people come out of their shells and express themselves. Connecting various people around the world and making them feel that they are not the only ones fighting this battle was our main objective.
## What it does
People share their thought processes through speaking and our application identifies the problem the speaker is facing and connects him to a specialist in that particular domain so that his/her problem could be resolved. There is also a **Group Chat** option available where people facing similar issues can discuss their problems among themselves.
For example, if our application identifies that the topics spoken by the speaker are related to mental health, then it connects them to a specialist in the mental health field and also the user has an option to get into a group discussion which contains people who are also discussing mental health.
## How we built it
The front-end of the project was built by using HTML, CSS, Javascript, and Bootstrap. The back-end part was exclusively written in python and developed using the Django framework. We integrated the **Assembly AI** file created by using assembly ai functions to our back-end and were successful in creating a fully functional web application within 36 hours.
## Challenges we ran into
The first challenge was to understand the working of Assembly AI. None of us had used it before and it took us time to first understand it's working. Integrating the audio part into our application was also a major challenge. Apart from Assembly AI, we also faced issues while connecting our front-end to the back-end. Thanks to the internet and the mentors of **HackHarvard**, especially **Assembly AI Mentors** who were very supportive and helped us resolve our errors.
## Accomplishments that we're proud of
Firstly, we are proud of creating a fully functional application within 36 hours taking into consideration all the setbacks we had. We are also proud of building an application from which society can be benefitted. Finally and mainly we are proud of exploring and learning new things which is the very reason for hackathons.
## What we learned
We learned how working as a team can do wonders. Working under a time constraint can be a really challenging task, aspects such as time management, working under pressure, the never give up attitude and finally solving errors which we never came across are some of the few but very important things which we were successful in learning. | ## Inspiration
As software engineers, we constantly seek ways to optimize efficiency and productivity. While we thrive on tackling challenging problems, sometimes we need assistance or a nudge to remember that support is available. Our app assists engineers by monitoring their states and employs Machine Learning to predict their efficiency in resolving issues.
## What it does
Our app leverages LLMs to predict the complexity of GitHub issues based on their title, description, and the stress level of the assigned software engineer. To gauge the stress level, we utilize a machine learning model that examines the developer’s sleep patterns, sourced from TerraAPI. The app provides task completion time estimates and periodically checks in with the developer, suggesting when to seek help. All this is integrated into a visually appealing and responsive front-end that fits effortlessly into a developer's routine.
## How we built it
A range of technologies power our app. The front-end is crafted with Electron and ReactJS, offering compatibility across numerous operating systems. On the backend, we harness the potential of webhooks, Terra API, ChatGPT API, Scikit-learn, Flask, NodeJS, and ExpressJS. The core programming languages deployed include JavaScript, Python, HTML, and CSS.
## Challenges we ran into
Constructing the app was a blend of excitement and hurdles due to the multifaceted issues at hand. Setting up multiple webhooks was essential for real-time model updates, as they depend on current data such as fresh Github issues and health metrics from wearables. Additionally, we ventured into sourcing datasets and crafting machine learning models for predicting an engineer's stress levels and employed natural language processing for issue resolution time estimates.
## Accomplishments that we're proud of
In our journey, we scripted close to 15,000 lines of code and overcame numerous challenges. Our preliminary vision had the front end majorly scripted in JavaScript, HTML, and CSS — a considerable endeavor in contemporary development. The pinnacle of our pride is the realization of our app, all achieved within a 3-day hackathon.
## What we learned
Our team was unfamiliar to one another before the hackathon. Yet, our decision to trust each other paid off as everyone contributed valiantly. We honed our skills in task delegation among the four engineers and encountered and overcame issues previously uncharted for us, like running multiple webhooks and integrating a desktop application with an array of server-side technologies.
## What's next for TBox 16 Pro Max (titanium purple)
The future brims with potential for this project. Our aspirations include introducing real-time stress management using intricate time-series models. User customization options are also on the horizon to enrich our time predictions. And certainly, front-end personalizations, like dark mode and themes, are part of our roadmap. | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What it does
The app connects students with teachers in a whole new fashion. Students can provide live feedback to their professors on various aspects of the lecture, such as the volume and pace. Professors, on the other hand, get an opportunity to receive live feedback on their teaching style and also give students a few warm-up exercises with a built-in clicker functionality.
The web portion of the project ties the classroom experience to the home. Students receive live transcripts of what the professor is currently saying, along with a summary at the end of the lecture which includes key points. The backend will also generate further reading material based on keywords from the lecture, which will further solidify the students’ understanding of the material.
## How we built it
We built the mobile portion using react-native for the front-end and firebase for the backend. The web app is built with react for the front end and firebase for the backend. We also implemented a few custom python modules to facilitate the client-server interaction to ensure a smooth experience for both the instructor and the student.
## Challenges we ran into
One major challenge we ran into was getting and processing live audio and giving a real-time transcription of it to all students enrolled in the class. We were able to solve this issue through a python script that would help bridge the gap between opening an audio stream and doing operations on it while still serving the student a live version of the rest of the site.
## Accomplishments that we’re proud of
Being able to process text data to the point that we were able to get a summary and information on tone/emotions from it. We are also extremely proud of the
## What we learned
We learned more about React and its usefulness when coding in JavaScript. Especially when there were many repeating elements in our Material Design. We also learned that first creating a mockup of what we want will facilitate coding as everyone will be on the same page on what is going on and all thats needs to be done is made very evident. We used some API’s such as the Google Speech to Text API and a Summary API. We were able to work around the constraints of the API’s to create a working product. We also learned more about other technologies that we used such as: Firebase, Adobe XD, React-native, and Python.
## What's next for Gradian
The next goal for Gradian is to implement a grading system for teachers that will automatically integrate with their native grading platform so that clicker data and other quiz material can instantly be graded and imported without any issues. Beyond that, we can see the potential for Gradian to be used in office scenarios as well so that people will never miss a beat thanks to the live transcription that happens. | losing |
## Inspiration
**Powerful semantic search for your life does not currently exist.**
Google and ChatGPT have brought the world’s information to our fingertips, yet our personal search engines — Spotlight on Mac, and search on iOS or Android — are insufficient.
Google Assistant and Siri tried to solve these problems by allowing us to search and perform tasks with just our voice, yet their use remains limited to a narrow range of tasks. **Recent advancement in large language models has enabled a significant transformation in what's possible with our devices.**
## What it does
That's why we made Best AI Buddy, or BAIB for short.
**BAIB (pronounced "babe") is designed to seamlessly answer natural language queries about your life.** BAIB builds an index of your personal data — text messages, emails, photos, among others — and runs a search pipeline on top of that data to answer questions.
For example, you can ask BAIB to give you gift recommendations for a close friend. BAIB looks pertinent interactions you've had with that friend and generates gift ideas based on their hobbies, interests, and personality. To support its recommendations, **BAIB cites parts of past text conversations you had with that friend.**
Or you can ask BAIB to tell you about what happened the last time you went skiing with friends. BAIB intelligently combines information from the ski group chat, AirBnB booking information from email, and your Google Photos to provide you a beautiful synopsis of your recent adventure.
**BAIB understands “hidden deadlines”** — that form you need to fill out by Friday or that internship decision deadline due next week — and keeps track of them for you, sending you notifications as these “hidden deadlines” approach.
**Privacy is an essential concern.** BAIB currently only runs on M1+ Macs. We are working on running a full-fledged LLM on the Apple Neural Engine to ensure that all information and processing is kept on-device. We believe that this is the only future of BAIB that is both safe and maximally helpful.
## How we built it
Eventually, we plan to build a full-fledged desktop application, but for now we have built a prototype using the SvelteKit framework and the Skeleton.dev UI library. We use **Bun as our TypeScript runtime & toolkit.**
**Python backend.** Our backend is built in Python with FastAPI, using a few hacks (check out our GitHub) to connect to your Mac’s contacts and iMessage database. We use the Google API to connect to Gmail + photos.
**LLM-guided search.** A language model makes the decisions about what information should be retrieved — what keywords to search through different databases — and when to generate a response or continue accumulating more information. A beautiful, concise answer to a user query is often a result of many LLM prompts and aggregation events.
**Retrieval augmented generation.** We experimented with vector databases and context-window based RAG, finding the latter to be more effective.
**Notifications.** We have a series of “notepads” on which the LLM can jot down information, such as deadlines. We then later use a language model to generate notifications to ensure you don’t miss any crucial events.
## Challenges we ran into
**Speed.** LLM-guided search is inherently slow, bottlenecked by inference performance. We had a lot of difficulty filtering data before giving it to the LLM for summarization and reasoning in a way that maximizes flexibility while minimizing cost.
**Prompt engineering.** LLMs don’t do what you tell them, especially the smaller ones. Learning to deal with it in a natural way and work around the LLMs idiosyncrasies was important for achieving good results in the end.
**Vector search.** Had issues with InterSystems and getting the vector database to work.
## Accomplishments that we're proud of
**BAIB is significantly more powerful than we thought.** As we played around with BAIB and asked fun questions like “what are the weirdest texts that Tony has sent me?”, its in-depth analysis on Tony’s weird texts were incredibly accurate: “Tony mentions that maybe his taste buds have become too American… This reflection on cultural and dietary shifts is interesting and a bit unusual in the context of a casual conversation.” This has increased our conviction in the long-term potential of this idea. We truly believe that this product must and will exist with or without us.
**Our team organization was good (for a hackathon).** We split our team into the backend team and the frontend team. We’re proud that we made something useful and beautiful.
## What we learned
Prompt engineering is very important. As we progressed through the project, we were able to speed up the response significantly and increase the quality by just changing the way we framed our question.
ChatGPT 4.0 is more expensive than we thought.
Further conviction that personal assistants will have a huge stake in the future.
Energy drinks were not as effective as expected.
## What's next for BAIB
Building this powerful prototype gave us a glimpse of what BAIB could really become. We believe that BAIB can be integrated into all aspects of life. For example, integrating with other communication methods like Discord, Slack, and Facebook will allow the personal assistant to gain a level of organization and analysis that would not be previously possible.
Imagine getting competing offers at different companies and being able to ask BAIB, who can combine the knowledge of the internet with the context of your family and friends to help give you enough information to make a decision.
We want to continue the development of BAIB after this hackathon and build it as an app on your phone to truly become the Best AI Buddy. | ## Inspiration
**The Immigration Story**
While brainstorming a problem to tackle in this challenge, we were intrigued by the lengths that many immigrants are willing to take for a new beginning. We wanted to come up with a way to try and ease this oftentimes difficult, intimidating transition to a new country and culture by creating a platform that would allow immigrants to connect with communities and resources relating to them. Current politics highlight the rising crisis of immigration and the major implications that it could have on current and future generations. An immigrants story does not end after they arrive in the US, their struggle can continue for years after their move. Hopefully, Pangea can bridge the gap between immigrants and their new environment, improving their lives in their new home.
## What is It?
**There are no borders in Pangea**
Pangea provides a user-friendly platform that immigrants can use to locate and connect with cultural resources, communities, and organizations near them. Our website fosters a close connection to cultural centers and allows immigrants to easily find resources near them that can ease their transition into the US. Some of Pangea's major features include an interactive heat map that shows various restaurants, shops, community centers, and resources based on the users' selected features and a plug-in to the telegram social media platform, an app commonly used by many immigrants. This plug-in links directly to a translation bot that allows users to practice their english or perform a quick translation if they need to do so.
## How We Built It
**Used HTML, Javascript, CSS, PHP, a Google Map API, NLP, and a Telegram plugin**
Using HTML and a Google Maps API we created a homepage and a heat map showing resources in the area that may be useful for immigrants. For the plug in, we found a Telegram plugin online that was simple to integrate into our code and create a helpful little translator accessible via a small bubble in the homepage.
We also researched data for a couple of ethnicities and created code that added these data points to the heat map to show densities of what resources are where.
## Challenges
As with any project, it was not always smooth sailing. Throughout our time creating this platform, we ran into many problems such as dealing with an unfamiliar language (most of us had not used Javascript before), tackling new programming techniques (such as building a website, creating a heat map, and utilizing API's and plug-ins), and fighting through the growing exhaustion as our lack of sleep caught up to us.
## Accomplishments
Our team is extremely proud of what we have accomplished this weekend. As a team composed of freshman and sophomores with little to no experience with hackathons, we were able to produce a working website that incorporates many different features. Despite not having done many of the things we attempted this weekend, we succeeded in using plug-ins, an API, and natural language processing in our prototype. We also worked very well together as a team and formed bonds that will last long after HackMIT ends.
## What We Learned
Throughout this experience, we learned many new skills that we will now be able to take with us in our future studies and projects. A few of the things we learned are listed below:
* How to build a website
* How to install a plug-in
* How to integrate API's into our website
* Natural Language Processing (NLP)
* How to create a heat map
* How to code in Javascript
## What's Next for Pangea?
**Pangea knows no bounds**
The applications for this site are near limitless. We hope to see Pangea grow as not only a resource for immigrants, but also a means of connection between them. In the future, we would like to incorporate profiles into our website, even expanding it into an app to create a social network for immigrants to connect with people of similar backgrounds, different cultures, and resources such as translators, lawyers, or social activists. In addition, we would like to add more data to our heat map to expand our reach past the local span of the Boston area. We plan to do this by scraping more data from the internet and including a more diverse scope of cultures in our database. Finally, we hope to further refine the translation bot by adding more language options so that Pangea will expand to even more cultural groups. | ## Inspiration
Have you ever wondered what's actually in your shampoo or body wash? Have you ever been concerned about the toxicity of certain chemicals in them on your body and to the environment?
If you answered yes, you came to the right place. Welcome to the wonderful world of Goodgredients! 😀
Goodgredients provides a simple way to answer these questions. But how you may ask.
## What it does
Goodgredients provides a simple way to check the toxicity of certain chemicals in them on your body and to the environment. Simply take a picture of your Shampoo or body wash and check which ingredient might harmful to you.
## How I built it
The project built with React Native, Node JS, Express js, and Einstein API. The backend API has been deployed with Heroku.
The core of this application is Salesforce Einstein Vision. In particular, we are using Einstein OCR (Optical Character Recognition), which uses deep learning models to detect alphanumeric text in an image. You can find out more info about Einstein Vision here.
Essentially, we've created a backend api service that takes an image request from a client, uses the Einstein OCR model to extract text from the image, compares it to our dataset of chemical details (ex. toxicity, allergy, etc.), and sends a response containing the comparison results back to the client.
## Challenges I ran into
As first-time ReactNative developers, we have encountered a lot of environment set up issue, however, we could figure out within time!
## Accomplishments that I'm proud of
We had no experience with ReactNative but finished project with fully functional within 24hours.
## What I learned
## What's next for Goodgredients | losing |
## Inspiration
Video games evolved when the Xbox Kinect was released in 2010 but for some reason we reverted back to controller based games. We are here to bring back the amazingness of movement controlled games with a new twist- re innovating how mobile games are played!
## What it does
AR.cade uses a body part detection model to track movements that correspond to controls for classic games that are ran through an online browser. The user can choose from a variety of classic games such as temple run, super mario, and play them with their body movements.
## How we built it
* The first step was setting up opencv and importing the a body part tracking model from google mediapipe
* Next, based off the position and angles between the landmarks, we created classification functions that detected specific movements such as when an arm or leg was raised or the user jumped.
* Then we correlated these movement identifications to keybinds on the computer. For example when the user raises their right arm it corresponds to the right arrow key
* We then embedded some online games of our choice into our front and and when the user makes a certain movement which corresponds to a certain key, the respective action would happen
* Finally, we created a visually appealing and interactive frontend/loading page where the user can select which game they want to play
## Challenges we ran into
A large challenge we ran into was embedding the video output window into the front end. We tried passing it through an API and it worked with a basic plane video, however the difficulties arose when we tried to pass the video with the body tracking model overlay on it
## Accomplishments that we're proud of
We are proud of the fact that we are able to have a functioning product in the sense that multiple games can be controlled with body part commands of our specification. Thanks to threading optimization there is little latency between user input and video output which was a fear when starting the project.
## What we learned
We learned that it is possible to embed other websites (such as simple games) into our own local HTML sites.
We learned how to map landmark node positions into meaningful movement classifications considering positions, and angles.
We learned how to resize, move, and give priority to external windows such as the video output window
We learned how to run python files from JavaScript to make automated calls to further processes
## What's next for AR.cade
The next steps for AR.cade are to implement a more accurate body tracking model in order to track more precise parameters. This would allow us to scale our product to more modern games that require more user inputs such as Fortnite or Minecraft. | ## Inspiration
There is a growing number of people sharing gardens in Montreal. As a lot of people share apartment buildings, it is indeed more convenient to share gardens than to have their own.
## What it does
With that in mind, we decided to create a smart garden platform that is meant to make sharing gardens as fast, intuitive, and community friendly as possible.
## How I built it
We use a plethora of sensors that are connected to a Raspberry Pi. Sensors range from temperature to light-sensitivity, with one sensor even detecting humidity levels. Through this, we're able to collect data from the sensors and post it on a google sheet, using the Google Drive API.
Once the data is posted on the google sheet, we use a python script to retrieve the 3 latest values and make an average of those values. This allows us to detect a change and send a flag to other parts of our algorithm.
For the user, it is very simple. They simply have to text a number dedicated to a certain garden. This will allow them to create an account and to receive alerts if a plant needs attention.
This part is done through the Twilio API and python scripts that are triggered when the user sends an SMS to the dedicated cell-phone number.
We even thought about implementing credit and verification systems that allow active users to gain points over time. These points are earned once the user decides to take action in the garden after receiving a notification from the Twilio API. The points can be redeemed through the app via Interac transfer or by simply keeping the plant once it is fully grown. In order to verify that the user actually takes action in the garden, we use a visual recognition software that runs the Azure API. Through a very simple system of QR codes, the user can scan its QR code to verify his identity. | ## Inspiration
Like most of the hackathons, we were initially thinking of making another Software Hack using some cool APIs. But our team came to a mutual conclusion that we need to step outside our comfort zone and make a Hardware Hack this time. While browsing through the hardware made available to us, courtesy of MLH, we came across the Myo Gesture Control Armband and decided to use it for our hack.
While playing around with it and observing the motion control it gives us, we thought nothing would be cooler than recreating a classic endless runner video game, but with motion control! And here we have the final result - Neon
## What it does
Its a classic endless runner video game based on the 80s retro theme with some twists. The player puts the Myo Armband and controls a bike with their arm gestures. The controls are as following -
1) Double Tap Gesture - Unlock the armband
2) Spread Fingers - Start the game
3) Hover Arm Right - Move the biker towards right
4) Hover Arm Left - Move the biker towards left
5) Rock your Arm Up - Shoot bullets
## How we built it
We use an abstraction of WebGL called three.js to code our game. For integrating Myo Armband gestures we used a nice javascript binding made available on GitHub by *thalmiclabs* called myo.js. We also used NodeJS, ExpressJS and python HTTPServer to serve off our static files.
## Challenges we ran into
Integrating the game logic with Myo gestures was one of the hardest challenges. Putting together two completely different APIs and making them work is always challenging but fun. Mapping even the slightest gestures to add precise control took us hours but it was necessary for good user experience.
## Accomplishments that we're proud of
We have a working in-browser video game!
## What we learned
None of us had ever done a hardware hack before. So we are proud that we have a working hardware hack this time. We also learned WebGL for the first time so that was definitely challenging and fun at the same time.
## What's next for Neon
We would like to make it a multiplayer game that users can play with friends. Eventually, we would add more arenas, difficulty levels and an option to choose your avatar.
# TO-DO
* Offline caching for highscores
* Online multiplayer over WebRTC
* Keyboard + mouse support
* Language support
* Audio/sound effects | winning |
## Inspiration
This app is inspired by the Prompt feature from Instagram Story. A lot of people participated and share pictures, including videos around one topic but at the end of the day, those stories disappear. We want to be a platform for short-video that people can enjoy interacting and sharing their moments or thoughts around topics and if they think the content will go viral, they can collect the video as an NFT.
## What it does
The app randomly selects a prompt (generated by us and the users) then the user will upload a short video that relates to the prompt. In the future, people can search for a keyword or prompt and see all videos relating to it.
## How we built it
* The videos are uploaded and stored on the Livepeer network and the web app is built using React.
## Challenges we ran into
* We had some difficulty linking firebase with Livepeer and React.
* We faced challenges when we tried to deploy local react code to /public web host
## Accomplishments that we're proud of
* Distributing work efficiently
## What we learned
* decentralized video infrastructure network.
* How to use Livepeer with React applications
* How to use firebase/firestore nosql dataase
## What's next for Chit Chat
* Using OpenAI to randomly generate prompts
* Allows users to choose categories and add prompts to the system
* Optimize it for mobile
* add an option to mint video as NFT on the web app | ## Inspiration
While we are gradually normalizing discussion surrounding burnout and productivity, it still feels like many of us find trouble in balancing ourselves and ambition. The drive to achieve has been deeply baked into our culture and education, and it is not unusual to resort to measuring ourselves with external accomplishments, oftentimes at the cost of our own well-being. Our project aims to challenge these norms and ultimately the social stigmas surrounding setting smaller, incremental or “trivial” goals, reinventing discourse and framing the issues in a new context that tries to put us and our ambition in harmony.
## What it does
It’s simple. Have a task you need to do? Form a pact with someone, be it a friend, someone who’s in the same boat, or someone else. Write out what you’re going to do, go do it, and then memorialize it as an NFT commemorating both of your achievements. You’re rewarded for taking it slow, as to build your confidence and self-accountability. The NFT represents the fact that no task is too small, and builds towards who you are as a whole across your lifetime. We found that in practice, it’s nice to do things together.
## How we built it
Pact is built on Next.js, MongoDB, Express server, Websocket, Crossmint API, Magic UI and Gsap.
## Challenges we ran into
One issue that we had to face was ideation and trying to come up with something feasible and relatable. We spent almost the entire first day bouncing around topics and debating whether or not we should continue with our idea. One learning curve that we had to face was trying to fully utilize a database and a websocket at the same time. We faced issues with running the express server, managing connections, and trying to fully understand where the websocket would come into play within our entire application. | ## Inspiration
There are millions of people around the world who have a physical or learning disability which makes creating visual presentations extremely difficult. They may be visually impaired, suffer from ADHD or have disabilities like Parkinsons. For these people, being unable to create presentations isn’t just a hassle. It’s a barrier to learning, a reason for feeling left out, or a career disadvantage in the workplace. That’s why we created **Pitch.ai.**
## What it does
Pitch.ai is a web app which creates visual presentations for you as you present. Once you open the web app, just start talking! Pitch.ai will listen to what you say and in real-time and generate a slide deck based on the content of your speech, just as if you had a slideshow prepared in advance.
## How we built it
We used a **React** client combined with a **Flask** server to make our API calls. To continuously listen for audio to convert to text, we used a react library called “react-speech-recognition”. Then, we designed an algorithm to detect pauses in the speech in order to separate sentences, which would be sent to the Flask server.
The Flask server would then use multithreading in order to make several API calls simultaneously. Firstly, the **Monkeylearn** API is used to find the most relevant keyword in the sentence. Then, the keyword is sent to **SerpAPI** in order to find an image to add to the presentation. At the same time, an API call is sent to OpenAPI’s GPT-3 in order to generate a caption to put on the slide. The caption, keyword and image of a single slide deck are all combined into an object to be sent back to the client.
## Challenges we ran into
* Learning how to make dynamic websites
* Optimizing audio processing time
* Increasing efficiency of server
## Accomplishments that we're proud of
* Made an aesthetic user interface
* Distributing work efficiently
* Good organization and integration of many APIs
## What we learned
* Multithreading
* How to use continuous audio input
* How to use React hooks, Animations, Figma
## What's next for Pitch.ai
* Faster and more accurate picture, keyword and caption generation
* "Presentation mode”
* Integrate a database to save your generated presentation
* Customizable templates for slide structure, color, etc.
* Build our own web scraping API to find images | losing |
## Inspiration
```
We were inspired to work on this project to serve to aid the miscommunication that's all too present in our world today. Leaders, professors, and authority figures of all shapes and sizes throughout the ages have had to determine their audience's sentiment for one reason or another while they garnered support or searched for a solution. Single individuals simply do not have the time or ability to interview each person of the audience to find out what they all thought and are usually left to make guesses of how they felt by cheers of support or boos of hate. Our goal was to give those over arching figures another tool to observe their audience to ultimately gain a better understanding of their ideas, feelings, and sentiment.
```
## What it does
```
Sentithink attempts to solve this problem by using the concept of the Internet of Things to track, categorize, and visualize the audible sentiment of a geographically large group of people. Using multiple microphones dispersed throughout an area, Sentithink records 1 minute snippets of sound, transcribes it to text, parses out keywords, and tracks their frequencies over time. These frequencies, and their associated sentiments, are then visualized for the overseers to utilize to essentially see what's trending and how people are interpreting the event.
```
## How we built it
```
Sentithink was built in three main parts consisting of microphone client side code, a Web API backend in Azure, and a front end visualization built in javascript.
```
Client Side: Microphones on machines running Python script to send snippets to Azure API endpoint
Backend: Microsoft Azure Function API to record/produce results from speech to text
Frontend: Javascript utilization of d3.js to show relative frequencies
## Challenges we ran into
```
We weren't exactly sure how to use the microphones on the client side before hand but Google turned out to be a great resource. We did have some prior experience with Azure Cloud services but it seemed most of our trouble came from trying to visualize our data in javascript at the very end.
```
## Accomplishments that we're proud of
```
We were able to set up all Azure aspects of our program:
SQL Database
Azure Function Web App
Front end visualization
Proof of concept demo
Lightweight clientside app
```
## What we learned
```
We got a better understanding of Azure web services, javascript, and python utilization in a connect API driven environment
```
## What's next for Sentithink
```
Get actual IoT devices to scale the product and test our product on a large area
``` | ## Inspiration
Imagine, for example, a situation where you're the manager of a call centre station, and you want to assure the quality of your workers' calls. But how do you measure the "quality" of each call? And how do you manage the quality of all the calls of all the workers (there may be a lot). This is where sensiment comes in. Tracking call sentiments has never been easier. Sensiment combines two key technologies to serve users a platform where they can input an audio stream and obtain the sentiment data of the audio. There are many applications to this technology beyond call centres, including personal data collection about calls (for example if you wanted to record the emotion level of all the people you are on a call with), and live emotion data collection.
## What it does
Sensiment displays live or recorded sentiment information in elegant visual charts to show the sentiment information extracted from audio, There are many applications to this which include call centre quality assurance, individuals to measure their emotions with their friends, and can detect domestic violence/abuse over text and/or live call.
## How we built it
We used google's speech-to-text API to convert calls/recorded media to text then utilized IBM's watson NLU api to get different sentiments from the call/text and provide the data in an elegant manner by creating a RESTful api. REST api was built using python flask library and the data was then sent to the frontend built using React JS.
## Challenges we ran into
We struggled with connecting the frontend and backend to a web socket to measure sentiment of a live video or voice call. We also struggled with managing the various APIs we used and connecting them all together into one application.
## Accomplishments that we're proud of
We were able to successfully complete the batch portion of the application and we were able to connect both APIs in a chain and achieved our goal.
## What we learned
We learned that live streaming of data is a very challenging idea and hopefully we find a better method to achieve this. We also learned a lot about the GCP API and we were introduced to the IBM NLU API.
## What's next for Sensiment
We plan to finish the live portion of our app so that users can stream data from their calls or from their microphone to and obtain live data about the emotions in their conversations. | ## Inspiration
Too many times have broke college students looked at their bank statements and lament on how much money they could've saved if they had known about alternative purchases or savings earlier.
## What it does
SharkFin helps people analyze and improve their personal spending habits. SharkFin uses bank statements and online banking information to determine areas in which the user could save money. We identified multiple different patterns in spending that we then provide feedback on to help the user save money and spend less.
## How we built it
We used Node.js to create the backend for SharkFin, and we used the Viacom DataPoint API to manage multiple other API's. The front end, in the form of a web app, is written in JavaScript.
## Challenges we ran into
The Viacom DataPoint API, although extremely useful, was something brand new to our team, and there were few online resources we could look at We had to understand completely how the API simplified and managed all the APIs we were using.
## Accomplishments that we're proud of
Our data processing routine is highly streamlined and modular and our statistical model identifies and tags recurring events, or "habits," very accurately. By using the DataPoint API, our app can very easily accept new APIs without structurally modifying the back-end.
## What we learned
## What's next for SharkFin | losing |
## Inspiration
We are a team of engineering science students with backgrounds in mathematics, physics and computer science. A common passion for the implementation of mathematical methods in innovative computing contexts and the application of these technologies to physical phenomena motivated us to create this project [Parallel Fourier Computing].
## What it does
Our project is a Discrete Fourier Transform [DFT] algorithm implemented in JavaScript for sinusoid spectral decomposition with explicit support for parallel computing task distribution. This algorithm is called by a web page front-end that allows a user to program the frequency/periodicity of a sum of three sinusoids, see this function on a graphical figure, and to calculate and display the resultant DFT for this sinusoid. The program successfully identifies the constituent fundamental frequencies of a sum of three sinusoids by use of this DFT.
## How We built it
This project was built in parallel, with some team members working on DCL integration, web page front ends and algorithm writing. The DFT algorithm used was initially prototyped in Python before being ported over to JavaScript for integration with the DCL network. We tested the function of our algorithm from a wide range of frequencies and sampling rates within the human spectrum of hearing. All team members contributed to component integration towards the end of the project, ensuring compliance with the DCL method of task distribution.
## Challenges We ran into
Though our team has an educational background in Fourier analysis, we were unfamiliar with the workflows and utilities of parallel computing systems. We were principly concerned with (1) how we can fundamentally divide the job of computing a Discrete Fourier Transform into a set of sequentially uncoupled tasks for parallel processing, and (2) how we implement such an algorithm design in the JavaScript foundation that DCL relies on. Initially, our team struggled to define clearly independent computing tasks that we could offload to parallel processing units to speed up our algorithm. We overcame this challenge when we realized that we could produce analytic functions for any partial sum term in our series and pass these exact functions off for processing in parallel. One challenge we faced when adapting our code to the task distribution method of the DCL system was writing a work function that was entirely self-contained without a dependence on external libraries or extraneously long procedural logic. To avoid library dependency, we wrote our own procedural logic to handle the complex number arithmetic that's needed for a Discrete Fourier Transform.
## Accomplishments that We're proud of
Our team successfully wrote a Discrete Fourier Transform algorithm designed for parallel computing uses. We encoded custom complex number arithmetic operations into a self-contained JavaScript function. We have integrated our algorithm with the DCL task scheduler and built a web page front end with interactive controls to program sinusoid functions and to graph these functions and their Discrete Fourier Transforms. Our algorithm can successfully decompose a sum of sinusoids into its constituent frequency components.
## What We learned
Our team learned about some of the constraints that task distribution in a parallel computing network can have on the procedural logic used in task definitions. Not having access to external JavaScript libraries, for example, required custom encoding of complex number arithmetic operations needed to compute DFT terms. Our team also learned more about how DFTs can be used to decompose musical chords into its fundamental pitches.
## What's next for Parallel Fourier Computing
Next steps for our project in the back-end are to optimize the algorithm to decrease the computation time. On the front-end we would like to increase the utility of the application by allowing the user to play a note and have the algorithm determine the pitches used in making the note.
#### Domain.com submission
Our domain name is <http://parallelfouriercomputing.tech/>
#### Team Information
Team 3: Jordan Curnew, Benjamin Beggs, Philip Basaric | ## Inspiration:
We wanted to combine our passions of art and computer science to form a product that produces some benefit to the world.
## What it does:
Our app converts measured audio readings into images through integer arrays, as well as value ranges that are assigned specific colors and shapes to be displayed on the user's screen. Our program features two audio options, the first allows the user to speak, sing, or play an instrument into the sound sensor, and the second option allows the user to upload an audio file that will automatically be played for our sensor to detect. Our code also features theme options, which are different variations of the shape and color settings. Users can chose an art theme, such as abstract, modern, or impressionist, which will each produce different images for the same audio input.
## How we built it:
Our first task was using Arduino sound sensor to detect the voltages produced by an audio file. We began this process by applying Firmata onto our Arduino so that it could be controlled using python. Then we defined our port and analog pin 2 so that we could take the voltage reading and convert them into an array of decimals.
Once we obtained the decimal values from the Arduino we used python's Pygame module to program a visual display. We used the draw attribute to correlate the drawing of certain shapes and colours to certain voltages. Then we used a for loop to iterate through the length of the array so that an image would be drawn for each value that was recorded by the Arduino.
We also decided to build a figma-based prototype to present how our app would prompt the user for inputs and display the final output.
## Challenges we ran into:
We are all beginner programmers, and we ran into a lot of information roadblocks, where we weren't sure how to approach certain aspects of our program. Some of our challenges included figuring out how to work with Arduino in python, getting the sound sensor to work, as well as learning how to work with the pygame module. A big issue we ran into was that our code functioned but would produce similar images for different audio inputs, making the program appear to function but not achieve our initial goal of producing unique outputs for each audio input.
## Accomplishments that we're proud of
We're proud that we were able to produce an output from our code. We expected to run into a lot of error messages in our initial trials, but we were capable of tackling all the logic and syntax errors that appeared by researching and using our (limited) prior knowledge from class. We are also proud that we got the Arduino board functioning as none of us had experience working with the sound sensor. Another accomplishment of ours was our figma prototype, as we were able to build a professional and fully functioning prototype of our app with no prior experience working with figma.
## What we learned
We gained a lot of technical skills throughout the hackathon, as well as interpersonal skills. We learnt how to optimize our collaboration by incorporating everyone's skill sets and dividing up tasks, which allowed us to tackle the creative, technical and communicational aspects of this challenge in a timely manner.
## What's next for Voltify
Our current prototype is a combination of many components, such as the audio processing code, the visual output code, and the front end app design. The next step would to combine them and streamline their connections. Specifically, we would want to find a way for the two code processes to work simultaneously, outputting the developing image as the audio segment plays. In the future we would also want to make our product independent of the Arduino to improve accessibility, as we know we can achieve a similar product using mobile device microphones. We would also want to refine the image development process, giving the audio more control over the final art piece. We would also want to make the drawings more artistically appealing, which would require a lot of trial and error to see what systems work best together to produce an artistic output. The use of the pygame module limited the types of shapes we could use in our drawing, so we would also like to find a module that allows a wider range of shape and line options to produce more unique art pieces. | ## Inspiration
With two of our team members being musicians in the jazz and classical world since middle school, we've seen time and time again an overemphasis on enforcing a standardized approach toward teaching and assessing all student musicians. Yet we believe that with each student's musical journey being unique, so too must be the process of musical education. Currently, with an explosion of personalized education through tools like Duolingo for language acquisition and Khan Academy for academics, there's a surprising gap for personalized teaching curricula for music.
More specifically, we know that music lessons are not cheap. We wanted to build a product that would allow students to independently assess themselves and receive real-time feedback to improve their skills, especially for students who may not have access to private lessons due to financial or geographical barriers.
## What it does
Polyhymnia.ai is an application that allows users to gauge their skills with their choice of musical instrument and be given personalized sheet music based on their skill level so that they can improve at a gradual pace and be given individualized attention. It consists of two parts, first a generative section which constructs sheet music based on a Markov chain of note probabilities and another section which judges how well a student played the music in terms of pitch, rhythm and time.
## How we built it
We used Next.js and MongoDB for our front end and database. For the backend, we used a variety of music libraries (Lilypond, Midi, etc) as well as traditional AI libraries like TensorFlow.
## Challenges we ran into
Standardization of sound: minor differences in recorded frequency and expected frequency caused a hassle. There was quite a lot of difficulty in developing an algorithm which could systematically and consistently map imperfect audio recordings to musical symbols with the text of music being the chosen method of comparison.
Setting up API routes to communicate with the database and the currently logged-in user. It was the first time building a full-stack application for all three of us.
## Accomplishments that we're proud of
A key challenge we faced was developing a judging algorithm in the face of many potential sources of student mistakes, i.e. how do you compare the weights penalties such as a missed note compared to a note that was played in the wrong pitch or wrong rhythm? After deep consideration, one of our teammates realized that the Needleman-Wunsch algorithm he learned in his algorithms class for sequence alignment in DNA was surprisingly applicable for finding a method to standardize comparisons between the correct sheet music and a student's submission. We're particularly grateful to have the opportunity to apply what was previously theory in class to real world problems; seems like all those hours spent studying for class are useful after all!
We were also pleasantly surprised that our initial approach of infinite music generation with random walks through Markov chains; given some loose constraints with the key, this method allowed for unlimited possibilities for material for the student to experiment, play and assess with.
## What we learned
Since it was our first time building an application, we learned frontend with Next.js and backend development with Flask. We also learned about mathematical applications of Markov Chains and experimented with random walks. Perhaps most interestingly, spending hours translating and fiddling with the audio to notes pipeline has left us with not just a newfound appreciation for hashmaps, but also the unexpected repercussion of an ingrained map in our minds between notes and their frequencies.
## What's next for Polyhymnia.ai
We aim to expand Polyhymnia.ai beyond its current form, with the current short four-measure-token being just a proof of concept for future projects which may be longer, more complex, and able to handle harmonization. We hope to scale Polyhymnia.ai to an overall teaching assistant, able to generate personalized lesson plans in scales, exercises, and songs. | winning |
## Inspiration
As post secondary students, our mental health is directly affected. Constantly being overwhelmed with large amounts of work causes us to stress over these large loads, in turn resulting in our efforts and productivity to also decrease. A common occurrence we as students continuously endure is this notion that there is a relationship and cycle between mental health and productivity; when we are unproductive, it results in us stressing, which further results in unproductivity.
## What it does
Moodivity is a web application that improves productivity for users while guiding users to be more in tune with their mental health, as well as aware of their own mental well-being.
Users can create a profile, setting daily goals for themselves, and different activities linked to the work they will be doing. They can then start their daily work, timing themselves as they do so. Once they are finished for the day, they are prompted to record an audio log to reflect on the work done in the day.
These logs are transcribed and analyzed using powerful Machine Learning models, and saved to the database so that users can reflect later on days they did better, or worse, and how their sentiment reflected that.
## How we built it
***Backend and Frontend connected through REST API***
**Frontend**
* React
+ UI framework the application was written in
* JavaScript
+ Language the frontend was written in
* Redux
+ Library used for state management in React
* Redux-Sagas
+ Library used for asynchronous requests and complex state management
**Backend**
* Django
+ Backend framework the application was written in
* Python
+ Language the backend was written in
* Django Rest Framework
+ built in library to connect backend to frontend
* Google Cloud API
+ Speech To Text API for audio transcription
+ NLP Sentiment Analysis for mood analysis of transcription
+ Google Cloud Storage to store audio files recorded by users
**Database**
* PostgreSQL
+ used for data storage of Users, Logs, Profiles, etc.
## Challenges we ran into
Creating a full-stack application from the ground up was a huge challenge. In fact, we were almost unable to accomplish this. Luckily, with lots of motivation and some mentorship, we are comfortable with naming our application *full-stack*.
Additionally, many of our issues were niche and didn't have much documentation. For example, we spent a lot of time on figuring out how to send audio through HTTP requests and manipulating the request to be interpreted by Google-Cloud's APIs.
## Accomplishments that we're proud of
Many of our team members are unfamiliar with Django let alone Python. Being able to interact with the Google-Cloud APIs is an amazing accomplishment considering where we started from.
## What we learned
* How to integrate Google-Cloud's API into a full-stack application.
* Sending audio files over HTTP and interpreting them in Python.
* Using NLP to analyze text
* Transcribing audio through powerful Machine Learning Models
## What's next for Moodivity
The Moodivity team really wanted to implement visual statistics like graphs and calendars to really drive home visual trends between productivity and mental health. In a distant future, we would love to add a mobile app to make our tool more easily accessible for day to day use. Furthermore, the idea of email push notifications can make being productive and tracking mental health even easier. | # Mental-Health-Tracker
## Mental & Emotional Health Diary
This project was made because we all know how much of a pressing issue that mental health and depression can have not only on ourselves, but thousands of other students. Our goal was to make something where someone could have the chance to accurately assess and track their own mental health using the tools that Google has made available to access. We wanted the person to be able to openly express their feelings towards the diary for their own personal benefit. Along the way, we learned about using Google's Natural Language processor, developing using Android Studio, as well as deploying an app using Google's App Engine with a `node.js` framework. Those last two parts turned out to be the greatest challenges. Android Studio was a challenge as one of our developers had not used Java for a long time, nor had he ever developed using `.xml`. He was pushed to learn a lot about the program in a limited amount of time. The greatest challenge, however, was deploying the app using Google App Engine. This tool is extremely useful, and was made to seem that it would be easy to use, but we struggled to implement it using `node.js`. Issues arose with errors involving `favicon.ico` and `index.js`. It took us hours to resolve this issue and we were very discouraged, but we pushed though. After all, we had everything else - we knew we could push through this.
The end product involves and app in which the user signs in using their google account. It opens to the home page, where the user is prompted to answer four question relating to their mental health for the day, and then rate themselves on a scale of 1-10 in terms of their happiness for the day. After this is finished, the user is given their mental health score, along with an encouraging message tagged with a cute picture. After this, the user has the option to view a graph of their mental health and happiness statistics to see how they progressed over the past week, or else a calendar option to see their happiness scores and specific answers for any day of the year.
Overall, we are very happy with how this turned out. We even have ideas for how we could do more, as we know there is always room to improve! | ## Inspiration
There are two types of pets wandering unsupervised in the streets - ones that are lost and ones that don't have a home to go to. Pet's Palace portable mini-shelters services these animals and connects them to necessary services while leveraging the power of IoT.
## What it does
The units are placed in streets and alleyways. As an animal approaches the unit, an ultrasonic sensor triggers the door to open and dispenses a pellet of food. Once inside, a live stream of the interior of the unit is sent to local animal shelters which they can then analyze and dispatch representatives accordingly. Backend analysis of the footage provides information on breed identification, custom trained data, and uploads an image to a lost and found database. A chatbot is implemented between the unit and a responder at the animal shelter.
## How we built it
Several Arduino microcontrollers distribute the hardware tasks within the unit with the aide of a wifi chip coded in Python. IBM Watson powers machine learning analysis of the video content generated in the interior of the unit. The adoption agency views the live stream and related data from a web interface coded with Javascript.
## Challenges we ran into
Integrating the various technologies/endpoints with one Firebase backend.
## Accomplishments that we're proud of
A fully functional prototype! | partial |
## Inspiration
The beginnings of this idea came from long road trips. When driving having good
visibility is very important. When driving into the sun, the sun visor never seemed
to be able to actually cover the sun. When driving at night, the headlights of
oncoming cars made for a few moments of dangerous low visibility. Why isn't there
a better solution for these things? We decided to see if we could make one, and
discovered a wide range of applications for this technology, going far beyond
simply blocking light.
## What it does
EyeHUD is able to track objects on opposite sides of a transparent LCD screen in order to
render graphics on the screen relative to all of the objects it is tracking. i.e. Depending on where the observer and the object of interest are located on the each side of the screen, the location of the graphical renderings are adjusted
Our basic demonstration is based on our original goal of blocking light. When sitting
in front of the screen, eyeHUD uses facial recognition to track the position of
the users eyes. It also tracks the location of a bright flash light on the opposite side
of the screen with a second camera. It then calculates the exact position to render a dot on the screen
that completely blocks the flash light from the view of the user no matter where
the user moves their head, or where the flash light moves. By tracking both objects
in 3D space it can calculate the line that connects the two objects and then where
that line intersects the monitor to find the exact position it needs to render graphics
for the particular application.
## How we built it
We found an LCD monitor that had a broken backlight. Removing the case and the backlight
from the monitor left us with just the glass and liquid crystal part of the display.
Although this part of the monitor is not completely transparent, a bright light would
shine through it easily. Unfortunately we couldn't source a fully transparent display
but we were able to use what we had lying around. The camera on a laptop and a small webcam
gave us the ability to track objects on both sides of the screen.
On the software side we used OpenCV's haar cascade classifier in python to perform facial recognition.
Once the facial recognition is done we must locate the users eyes in their face in pixel space for
the user camera, and locate the light with the other camera in its own pixel space. We then wrote
an algorithm that was able to translate the two separate pixel spaces into real 3D space, calculate
the line that connects the object and the user, finds the intersection of this line and the monitor,
then finally translates this position into pixel space on the monitor in order to render a dot.
## Challenges we ran Into
First we needed to determine a set of equations that would allow us to translate between the three separate
pixel spaces and real space. It was important not only to be able to calculate this transformation, but
we also needed to be able to calibrate the position and the angular resolution of the cameras. This meant
that when we found our equations we needed to identify the linearly independent parts of the equation to figure
out which parameters actually needed to be calibrated.
Coming up with a calibration procedure was a bit of a challenge. There were a number of calibration parameters
that we needed to constrain by making some measurements. We eventually solved this by having the monitor render
a dot on the screen in a random position. Then the user would move their head until the dot completely blocked the
light on the far side of the monitor. We then had the computer record the positions in pixel space of all three objects.
This then told the computer that these three pixel space points correspond to a straight line in real space.
This provided one data point. We then repeated this process several times (enough to constrain all of the degrees of freedom
in the system). After we had a number of data points we performed a chi-squared fit to the line defined by these points
in the multidimensional calibration space. The parameters of the best fit line determined our calibration parameters to use
in the transformation algorithm.
This calibration procedure took us a while to perfect but we were very happy with the speed and accuracy we were able to calibrate at.
Another difficulty was getting accurate tracking on the bright light on the far side of the monitor. The web cam we were
using was cheap and we had almost no access to the settings like aperture and exposure which made it so the light would
easily saturate the CCD in the camera. Because the light was saturating and the camera was trying to adjust its own exposure,
other lights in the room were also saturating the CCD and so even bright spots on the white walls were being tracked as well.
We eventually solved this problem by reusing the radial diffuser that was on the backlight of the monitor we took apart.
This made any bright spots on the walls diffused well under the threshold for tracking. Even after this we had a bit of trouble
locating the exact center of the light as we were still getting a bit of glare from the light on the camera lens. We were
able to solve this problem by applying a gaussian convolution to the raw video before trying any tracking. This allowed us
to accurately locate the center of the light.
## Accomplishments that we are proud of
The fact that our tracking display worked at all we felt was a huge accomplishments. Every stage of this project felt like a
huge victory. We started with a broken LCD monitor and two white boards full of math. Reaching a well working final product
was extremely exciting for all of us.
## What we learned
None of our group had any experience with facial recognition or the OpenCV library. This was a great opportunity to dig into
a part of machine learning that we had not used before and build something fun with it.
## What's next for eyeHUD
Expanding the scope of applicability.
* Infrared detection for pedestrians and wildlife in night time conditions
* Displaying information on objects of interest
* Police information via license plate recognition
Transition to a fully transparent display and more sophisticated cameras.
General optimization of software. | ## Inspiration
Knowtworthy is a startup that all three of us founded together, with the mission to make meetings awesome. We have spent this past summer at the University of Toronto’s Entrepreneurship Hatchery’s incubator executing on our vision. We’ve built a sweet platform that solves many of the issues surrounding meetings but we wanted a glimpse of the future: entirely automated meetings. So we decided to challenge ourselves and create something that the world has never seen before: sentiment analysis for meetings while transcribing and attributing all speech.
## What it does
While we focused on meetings specifically, as we built the software we realized that the applications for real-time sentiment analysis are far more varied than initially anticipated. Voice transcription and diarisation are very powerful for keeping track of what happened during a meeting but sentiment can be used anywhere from the boardroom to the classroom to a psychologist’s office.
## How I built it
We felt a web app was best suited for software like this so that it can be accessible to anyone at any time. We built the frontend on React leveraging Material UI, React-Motion, Socket IO and ChartJS. The backed was built on Node (with Express) as well as python for some computational tasks. We used GRPC, Docker and Kubernetes to launch the software, making it scalable right out of the box.
For all relevant processing, we used Google Speech-to-text, Google Diarization, Stanford Empath, SKLearn and Glove (for word-to-vec).
## Challenges I ran into
Integrating so many moving parts into one cohesive platform was a challenge to keep organized but we used trello to stay on track throughout the 36 hours.
Audio encoding was also quite challenging as we ran up against some limitations of javascript while trying to stream audio in the correct and acceptable format.
Apart from that, we didn’t encounter any major roadblocks but we were each working for almost the entire 36-hour stretch as there were a lot of features to implement.
## Accomplishments that I'm proud of
We are super proud of the fact that we were able to pull it off as we knew this was a challenging task to start and we ran into some unexpected roadblocks. There is nothing else like this software currently on the market so being first is always awesome.
## What I learned
We learned a whole lot about integration both on the frontend and the backend. We prototyped before coding, introduced animations to improve user experience, too much about computer store numbers (:p) and doing a whole lot of stuff all in real time.
## What's next for Knowtworthy Sentiment
Knowtworthy Sentiment aligns well with our startup’s vision for the future of meetings so we will continue to develop it and make it more robust before integrating it directly into our existing software. If you want to check out our stuff you can do so here: <https://knowtworthy.com/> | ## Inspiration
I came up with these idea from two thoughts:
(1) We live in a world in which sensors are everywhere and on everything. In this world, coming up with an embedded system isn't as hard as it used to be. Rather, now the issue is what kind of sensor and how accurate the sensor is to retrieve the data from.
(2) Humans have five major senses: touch, smell, sight, sound, and taste. How much do we know about these? Do the computers know what we are feeling in terms of these senses? The answer is that we only know what we are listening to (a.k.a. Shazam). **Why can't we do this for vision?**
The closest platform I know of that indirectly solves this problem is Google Glass. However, how do you tell what you are exactly looking at when there are multiple objects within the camera capture? This is where I got the idea for this project; I want to specify where your sight lies on the Google Glass-like camera capture and identify what that exact object is.
## What it does
As I briefly mentioned above, it reads the electrical potential difference across your eyes, horizontally and vertically. Then, it maps these readings into a 2D coordinate on the picture that is taken from the camera that lies on pair of glasses. This represents what you are looking at in that picture.
On this version, I identify all known objects within the picture, get the boundaries, and find the closest object boundary to the sight-point. That is the final output of this platform; the predicted object that you are looking at.
## How I built it
I started off with the hardware. I knew that the Electroocculogram signals have few mV and 1~30Hz signal range. Therefore, I put an instrumentation amplifier and few high pass and low pass filters to get rid of noise.
This voltage output is then fed into Arduino for ADC, from which I can get the digital serial data.
Finally, I used OpenCV 3.0.0 library to do basic computer vision process. I register few objects that are relatively easy to recognize, and I spot all of them within the camera capture. SIFT and FLANN was used for this purpose. I find the closest object boundary from this list of detected objects.
## Challenges I ran into
There were a LOT of challenges due to this project's cross-hardware-software nature:
**(1) Hardware debugging.** I fried two op-amps and one instrumentation amplifier because I fed in wrong voltage into them. I also had to play around with resistor values and add few filters to get useable data.
**(2) Arduino and PySerial interface.** Controlling serial data flow from Python's end was quite difficult. Lots of errors popping up, and had to debug a lot.
**(3) OpenCV 3.0.0.** This newest version of OpenCV is notoriously hard to install. It really should not be. I lost precious team members because OpenCV 3.0.0 refused to work with Windows 10.
**(4) Noisy Signal.** Body signals are noisy by nature. Coming up with a scheme that will work well with this noisy data was quite hard.
**(5) Solo project (unintentionally).** As stated from point above, OpenCV 3.0.0 took my team members away, and I had to come up with the entire project myself.
**(5+) Lack of sleep.** It's hard.
## Accomplishments that I'm proud of
I am proud that I was able to complete this project with little time and little manpower. Project could have been a lot more sophisticated otherwise, but I am very satisfied that I was able to pull all the way from hardware data collection onto computer vision identification to decently functional level.
## What I learned
(1) For projects dealing with unknown concepts, it is not only important for you to be knowledgeable with the material but also your teammates. Keep them updated and prepared as much as you are.
(2) Body signal is probably the next wave of sensors that should be mastered, and I think there is a lot of potential there. Even with this time limited, undermanned project, I was able to get somewhat of a working product which I think can be used for a lot of different things. Namely, Google Glass, Microsoft Hololense, and Oculus VR.
## What's next for Oqulo
As mentioned above, more noise reduction on the hardware side, better runtime optimization of the Python code, and using external object identification API are on the table. Object identification is no new subject and there are people with efficient algorithms and large object image library sitting in their database. Should be very easy to improve object identification performance.
Also, "wet" electrodes are very uncomfortable to keep them on for 2 days straight. Dry electrodes that gently sit on the face will definitely be better. | winning |
## Virality Pro: 95% reduced content production costs, 2.5x rate of going viral, 4 high ticket clients
We’re already helping companies go viral on instagram & TikTok, slash the need for large ad spend, and propel unparalleled growth at a 20x lower price.
## The problem: growing a company is **HARD and EXPENSIVE**
Here are the current ways companies grow reliably:
1. **Facebook ads / Google Ads**: Expensive Paid Ads
Producing ads often cost $2K - $10K+
Customer acquisition cost on Facebook can be as much as $100+, with clicks being as high as $10 on google ads
Simply untenable for lower-ticket products
2. **Organic Social Media**: Slow growth
Takes a long time and can be unreliable; some brands just cannot grow
Content production, posting, and effective social media management is expensive
Low engagement rates even at 100K+ followers, and hard to stay consistent
## Solution: Going viral with Virality Pro, Complete Done-For-You Viral Marketing
Brands and startups need the potential for explosive growth without needing to spend $5K+ on marketing agencies, $20K+ on ad spend, and getting a headache hiring and managing middle management.
We take care of everything so that you just give us your company name and product, and we manage everything from there.
The solution: **viral social media content at scale**.
Using our AI-assisted system, we can produce content following the form of proven viral videos at scale for brands to enable **consistent** posting with **rapid** growth.
## Other brands: Spends $5K to produce an ad, $20K on ad spend.
They have extremely thin margins with unprofitable growth.
## With Virality Pro: $30-50 per video, 0 ad spend, produced reliably for fast viral growth
Professional marketers and marketing agencies cost hundreds of thousands of dollars per year.
With Virality Pro, we can churn out **400% more content for 5 times less.**
This content can easily get 100,000+ views on tik tok and instagram for under $1000, while the same level of engagement would cost 20x more traditionally.
## Startups, Profitable Companies, and Brands use Virality Pro to grow
Our viral videos drive growth for early to medium-sized startups and companies, providing them a lifeline to expand rapidly.
## 4 clients use Virality Pro and are working with us for growth
1. **Minute Land** is looking to use Virality Pro to consistently produce ads, scaling to **$400K+** through viral videos off $0 in ad spend
2. **Ivy Roots Consulting** is looking to use Virality Pro to scale their college consulting business in a way that is profitable **without the need for VC money**. Instead of $100 CAC through paid ads, the costs with Virality Pro are close to 0 at scale.
3. **Manifold** is looking to use Virality Pro to go viral on social media over and over again to promote their new products without needing to hire a marketing department
4. **Yoodli** is looking to use Virality Pro to manage rapid social media growth on TikTok/Instagram without the need to expend limited funding for hiring middle managers and content producers to take on headache-inducing media projects
## Our team: Founders with multiple exits, Stanford CS+Math, University of Cambridge engineers
Our team consists of the best of the best, including Stanford CS/Math experts with Jane Street experience, founders with multiple large-scale exits multiple times, Singaporean top engineers making hundreds of thousands of dollars through past ventures, and a Cambridge student selected as the top dozen computer scientists in the entire UK.
## Business Model
Our pricing system charges $1900 per month for our base plan (5 videos per week), with our highest value plan being $9500 per month (8 videos per day).
With our projected goal of 100 customers within the next 6 months, we can make $400K in MRR with the average client paying $4K per month.
## How our system works
Our technology is split into two sectors: semi-automated production and fully-automated production.
Currently, our main offer is semi-automated production, with the fully-automated content creation sequence still in production.
## Semi-Automated AI-Powered Production Technology
We utilize a series of templates built around prompt engineering and fine-tuning models to create a large variety of content for companies around a single format.
We then scale the number of templates currently available to be able to produce hundreds and thousands of videos for a single brand off of many dozens of formats, each with the potential to go viral (having gone viral in the past).
## Creating the scripts and audios
Our template system uses AI to produce the scripts and the on-screen text, which is then fed into a database system. Here, a marketing expert verifies these scripts and adjusts them to improve its viral nature. For each template, a series of seperate audios are given as options and scripts are built around it.
## Sourcing Footage
For each client, we source a large database of footage found through filmed clips, AI-generated video, motion-graphic images, and taking large videos on youtube and using software to break them down into small clips, each representing a shot.
## Text to Speech
We use realistic-sounding AI voices and default AI voices to power the audio. This has proven to work in the past and can be produced consistently at scale.
## Stitching it all together
Using our system, we then compile the footage, text script, and audio into one streamlined sequence, after which it can be reviewed and posted onto social media.
## All done within 5 to 15 minutes per video
Instead of taking hours, we can get it done in **5 to 15 minutes**, which we are continuing to shave down.
## Fully Automated System
Our fully automated system is a work in progress that removes the need for human interaction and fully automates the video production, text creation, and other components, stitched together without the need for anyone to be involved in the process.
## Building the Fully Automated AI System
Our project was built employing Reflex for web development, OpenAI for language model integration, and DALL-E for image generation. Utilizing Prompt Engineering alongside FFmpeg, we synthesized relevant images to enhance our business narrative.
## Challenges Faced
Challenges encountered included slow Wi-Fi, the steep learning curve with Prompt Engineering and adapting to Reflex, diverging from conventional frameworks like React or Next.js for web application development.
## Future of Virality Pro
We are continuing to innovate our fully-automated production system and create further templates for our semi-automated systems. We hope that we can reduce the costs of production on our backend and increase the growth.
## Projections
We project to scale to 100 clients in 6 months to produce $400K in Monthly Recurring Revenue, and within a year, scale to 500 clients for $1.5M in MRR. | ## Inspiration
In 2010, when Haiti was rocked by an earthquake that killed over 150,000 people, aid workers manned SMS help lines where victims could reach out for help. Even with the international humanitarian effort, there was not enough manpower to effectively handle the volume of communication. We set out to fix that.
## What it does
EmergAlert takes the place of a humanitarian volunteer at the phone lines, automating basic contact. It allows victims to request help, tell their location, place calls and messages to other people, and inform aid workers about their situation.
## How we built it
We used Mix.NLU to create a Natural Language Understanding model that categorizes and interprets text messages, paired with the Smooch API to handle SMS and Slack contact. We use FHIR to search for an individual's medical history to give more accurate advice.
## Challenges we ran into
Mentoring first time hackers was both a challenge and a joy.
## Accomplishments that we're proud of
Coming to Canada.
## What we learned
Project management is integral to a good hacking experience, as is realistic goal-setting.
## What's next for EmergAlert
Bringing more depth to the NLU responses and available actions would improve the app's helpfulness in disaster situations, and is a good next step for our group. | ## Inspiration
The main inspiration for this project was to create a service that allows users, especially content creators, to be able to review their media and be sure of their content before uploading it onto the internet. Many people want to be sure that their content is quality or safe for the internet and our service aims to provide a great place for this to be thoroughly analyzed.
## What it does
AudioAssembly is a web application that receives an audio/video file and generates a detailed report. The report includes a confidence score, number of speakers, number of disfluencies, language, number of swear words, keywords, content safety score, tone information, and important entities.
## How we built it
We built our project using Flask, a Python web framework that uses the MVC architecture to develop full-stack web applications. Alongside this, we used AssemblyAI's API service in order to implement a major part of our site's functionality.

## Challenges we ran into
There were many challenges on both the client- and server-side. Regarding the client-side, we ran into many issues with formatting content appropriately so that it looks good. Regarding the server-side, we ran into complications on how exactly we were going to use AssemblyAI's API.
## Accomplishments that we're proud of
We're extremely proud that we were able to completely finish our main idea. Sometimes there can be a situation where a project seems easier in hindsight than expected. However, due to our team's adept programming ability, we were able to snuff out the difficulty of the project on the get-go and have an extremely productive experience.
## What we learned
We learned a great deal about web technologies. We learned how to better use Flask along with its templating system, Jinja. Along with this, we learned many aspects of web structure with HTML and styling with CSS. Overall, we've improved our full-stack web development capabilities.
## What's next for AudioAssembly
Due to limited time, we were unable to make our report as detailed as we wanted to. We definitely got a lot of great information on there, but if we're given more time, we will spend it making sure that all the aspects of the report are clear so that users can better fix their content issues.
## Credit
upload icons PNG Designed By GraphixsArt from [Pngtree.com](https://pngtree.com) | winning |
## Inspiration
Have you ever turned on your car to a dashboard full of alarming, unspecific, flashing symbols ⚠️❗️❌? All of a sudden, you’re not sure if you just forgot to fill that windshield washer fluid💧 or if there’s a bigger problem that’s going to leave you stranded in the middle of nowhere. Modern dashboard symbols are nearly impossible to decipher and can put you in a panic🤯. DashBuddy is an app that can identify warning symbols and their potential causes, potentially saving you from a costly trip to the auto repair shop🚗⚙️!
## What it does
The DashBuddy app lets you take a picture 📸 of your dashboard and identifies the warning symbol that is displayed. It then provides you with information on what your vehicle's issue could be and proposes a solution💡.
## How we built it
We created our custom dataset by annotating 200+ images of dashboard warning symbols using Roboflow💻. We generated a training set of 400+ images using data augmentation for our custom object detection training model with a precision of 95%📈. The detected result is added to the prompt for the Cohere API, which uses language AI and is built on the GPT-3 model🤖 to determine what the issue is and generate a solution for the symbol🛠️. The Frontend of the mobile application was implemented using React-Native after designing and prototyping in Figma📱.
## Challenges we ran into
A significant challenge we faced was the scarcity of datasets containing car dashboard images to train our image-detection neural network. We decided to instead create our own dataset using Roboflow, by taking and annotating 200+ images of dashboard symbols. Another one of our challenges was integrating the camera📸 functionality in React-Native with the object detection API.
## What's next for DashBuddy
In the future, we hope to implement a vehicle damage assessment feature that suggests the appropriate action to take for external damage🚗💥. | ## Inspiration
As with many drivers, when a major incident occurs while driving, we are often left afraid, anxious, and overwhelmed. Just as many of our peers, we had little experience behind the wheel and barely understood how insurance claims worked and what steps we should be taking if an accident occurs. We decided to innovate the process of filing insurance claims for people of all ages and diverse backgrounds to allow for a quicker, accessible, and user-friendly experience through SWIFT DETECT.
## What it does
SWIFT DETECT is an app that utilizes machine learning to extract information from user fed pictures and environmental context to auto-fill an insurance claims form. The automated process gives the user an informed and step-by-step guide on steps to take collision. The machine learning software can also make informed decisions on whether to contact emergency services, towing services, or whether the user will need a temporary vehicle based off of the picture evidence the user submits. This automated process allows the user to gain control over the situation and get back on track with their day-to-day activities faster than the traditional methods practiced.
## How we built it
SWIFT DETECT was made using Node.JS and CARSXE ML API.
## Challenges we ran into
Initially, we had tried creating our own ML model however we faced issues gathering datasets to train our model with. We thus utilized the pre-existing CARSXE ML API. However, this API proved to be very challenging to use.
## Accomplishments that we're proud of
We are proud to have utilized our knowledge of tech to engineer a meaningful product that impacts our society in a positive way. We are proud to have engineered a product that caters to a diverse group of end-users and ultimately puts the user first.
## What we learned
Through the process of planning and executing our hack, we have learned a lot about the insurance industry and ML models.
## What's next for SWIFT DETECT
SWIFT DETECT hopes to take a preventative approach when it comes to vehicle collisions. We will do so by becoming the primary source of information when it comes to your vehicle's health and longevity.
We aim to reduce the amount of collisions by analyzing a car’s mechanical parts and alerting the user when it is time for replacement or repair. Through the use of smart car features, we want to deliver rapid and accurate results of the current status of your vehicle. | ## Inspiration
We get the inspiration from the idea provided by Stanley Black&Decker, which is to show users how would the product like in real place and in real size using AR technic. We choose to solve this problem because we also encounter same problem in our daily life. When we are browsing website for buying furnitures or other space-taking product, the first wonders that we come up with is always these two: How much room would it take and would it suit the overall arrangement.
## What it does
It provides customer with 3D models of products which they might be interested in and enable the customers to place, arrange (move and rotate) and interact with these models in their exact size in reality space to help they make decision on whether to buy it or not.
## How we built it
We use iOS AR kit.
## Challenges we ran into
Plane detection; How to open and close the drawer; how to build 3D model by ourselves from nothing
## Accomplishments that we're proud of
We are able to open and close drawer
## What we learned
How to make AR animation
## What's next for Y.Cabinet
We want to enable the change of size and color of a series/set of products directly in AR view, without the need to go back to choose. We also want to make the products look more realistic by finding a way to add light and shadow to it. | losing |
## Inspiration 🌟
Creative writing is hard. Like really REALLY hard. Trying to come up with a fresh story can seem very intimidating, and if given a blank page, most people would probably just ponder endlessly... "where do I even start???"
## What it does 📕
Introducing **TaleTeller**, an interactive gamified experience designed to help young storytellers create their own unique short stories. It utilizes a "mad libs" style game format where players input five words to inspire the start of their story. The AI will incorporate these words into the narrative, guiding the direction of the tale. Players continue the tale by filling in blanks with words of their choice, actively shaping the story as it unfolds. It's an engaging experience that encourages creativity and fosters a love for storytelling.
## How we built it 🔧
TaleTeller utilizes the Unity Game Engine for its immersive storytelling experience. The AI responses are powered by OpenAI's GPT4-Turbo API while story images are created using OpenAI's DALL-E. The aesthetic UI of the project includes a mix of open course and custom 2D assets.
## Challenges we ran into 🏁
One of the main challenges we faced was fine-tuning the AI to generate cohesive and engaging storylines based on the player's input (prompt engineering is harder than it seems!). We also had a lot of trouble trying to integrate DALL-E within Unity, but after much blood, sweat, and tears, we got the job done :)
## Accomplishments that we're proud of 👏
* Having tons of fun creating fully fledged stories with the AI
* Getting both GPT and DALL-E to work in Unity (it actually took forever...)
* Our ✨ *gorgeous* ✨ UI
## What we learned 🔍
* How to prompt engineer GPT to give us consistent responses
* How to integrate APIs in Unity
* C# is Tony's mortal enemy
## What's next for TaleTeller 📈
Training an AI Text-to-Speech to read out the story in the voice of Morgan Freeman 😂 | ## Inspiration
In a world where screens and the passive consumption of content have become the norm, we sought to make a game that was fun while also allowing friends to work together and exercise their creative muscles to build stories together. We hoped to blend our passion for games and software development with our love of reading.
## What it does
Story Builder empowers youth and teenagers to become 'Authors' of their own stories and inspire a lifelong love for reading. Writers explore a gamified world of storytelling, collaborating with others to craft engaging narratives. Authors join an online room where the game code is the "Title" of their story, and they take turns putting a single word or sentence to the story. At any point, any author can end the adventure, moving on to the next phase.
An API call to OpenAi is made to summarize the written story and engineer the prompt to interface well with the Metaphor API, whose AI model reads the summary and returns links to books that align with the creative journey.
In simpler words, what Story Building does is to inspire a love of storytelling and imagination among people who play it 📚.
## How we built it
We used React, Bootstrap, and CSS were used to develop the frontend, along with Node.js, Socket.io, and Puppeteer to implement the backend. We utilize the LLM provided by OpenAI's API for the story summarization and leveraged Metaphor API to provide book recommendations and their websites, as scraped from goodreads.com.
## Challenges we ran into
* Designing the platform to give a smooth user interaction
* Web scraping the Goodreads website (we had to use a package called Puppeteer in order to wait for javascript scripts to finish dynamically rendering before we could access the raw webpage html)
* Integrating frontend ~ backend
* Discovering the best use of Metaphor's capabilities in our project (we explored a TON of different applications before we settled on this one because we felt it best leveraged the creative advantage of the API as compared to more generic search models)
## Accomplishments that we're proud of
We are proud of the number of features and technologies we could implement given our limited crew, in addition to the new skills that uniquely aggregate us despite our different hackathon familiarity. We learned a ton of new technologies. We were a team of 2, one of whom is a beginner, so it was a great learning experience :)
## What we learned
On top of the technical knowledge of software development, we felt the importance of collaboration and organization, both of which are essential for delivering successful projects and fostering a productive work environment.
## What's next for Story Builder
* Story Archives: Create an archive where players can revisit and edit their completed stories. We were thinking of implementing this using USBs.
* AI Image Summary: Given the summary used in Metaphor to return the books, we can also use it as a prompt into a text-to-image model, illustrating the story.
* AI-driven Story Guidance: Utilize AI algorithms to provide subtle hints or suggestions to guide the story when players encounter creative blocks.
* E-commerce referral links: Instead of listing books' websites, we can connect referral links like Amazon's to generate revenue for each time an Author buys a book from our list, creating a business model. | ## Inspiration
Initially, we struggled to find a project idea. After circling through dozens of ideas and the occasional hacker's block, we were still faced with a huge ***blank space***. In the midst of all our confusion, it hit us that this feeling of desperation and anguish is familiar to all thinkers and creators. There came our inspiration - the search for inspiration. Tailor is a tool that enables artists to overcome their mental blocks in a fun and engaging manner, while leveraging AI technology. AI is very powerful, but finding the right prompt can sometimes be tricky, especially for children or those with special needs. With our easy to use app, anyone can find inspiration as swiftly as possible.
## What it does
The site generates prompts artists to generate creative prompts for DALLE. By clicking the "add" button, a react component containing a random noun is added to the main container. Users can then specify the color and size of this noun. They can add as many nouns as they want, then specify the style and location of the final artwork. After hitting submit, a prompt is generated and sent to OpenAI's API, which returns an image.
## How we built it
It was built using React Remix, OpenAI's API, and a random noun generator API. TailwindCSS was used for styling which made it easy to create beautiful components.
## Challenges we ran into
Getting tailwind installed, and installing dependencies in general. Sometimes our API wouldn't connect, and OpenAI rotated our keys since we were developing together. Even with tailwind, it was sometimes hard for the CSS to do what we wanted it to. Passing around functions and state between parent and child components in react was also difficult. We tried to integrate twiliio with an API call but it wouldn't work, so we had to setup a separate backend on Vercel and manually paste the image link and phone number. Also, we learned Remix can't use react-speech libraries so that was annoying.
## Accomplishments that we're proud of
* Great UI/UX!
* Connecting to the OpenAI Dalle API
* Coming up with a cool domain name
* Sleeping more than 2 hours this weekend
## What we learned
We weren't really familiar with React as none of use had really used it before this hackathon. We really wanted to up our frontend skills and selected Remix, a metaframework based on React, to do multipage routing. It turned out to be a little overkill, but we learned a lot and are thankful to mentors. They showed us how to avoid overuse of Hooks, troubleshoot API connection problems, and use asynchrous functions. We also learned many more tailwindcss classes and how to use gradients.
## What's next for Tailor
It would be cool to have this website as a browser extension, maybe just to make it more accessible, or even to have it scrape websites for AI prompts. Also, it would be nice to implement speech to text, maybe through AssemblyAI | losing |
## Hack The Valley 4
Hack the Valley 2020 project
## On The Radar
**Inspiration**
Have you ever been walking through your campus and wondered what’s happening around you, but too unmotivated to search through Facebook, the school’s website and where ever else people post about social gatherings and just want to see what’s around?
Ever see an event online and think this looks like a lot of fun, just to realize that the event has already ended, or is on a different day?
Do you usually find yourself looking for nearby events in your neighborhood while you’re bored?
Looking for a better app that could give you notifications, and have all the events in one and accessible place?
These are some of the questions that inspired us to build “On the Radar” --- a user-friendly map navigation system that allows users to discover cool, real-time events that suit their interests and passion in the nearby area.
*Now you’ll be flying over the Radar!*
**Purpose**
On the Radar is a mobile application that allows users to match users with nearby events that suit their preferences.
The user’s location is detected using the “standard autocomplete search” that tracks your current location. Then, the app will display a customized set of events that are currently in progress in the user’s area which is catered to each user.
**Challenges**
* Lack of RAM in some computers, see Android Studio (This made some of our tests and emulations slow as it is a very resource-intensive program. We resolved this by having one of our team members run a massive virtual machine)
* Google Cloud (Implementing google maps integration and google app engine to host the rest API both proved more complicated than originally imagined.)
* Android Studio (As it was the first time for the majority of us using Android Studio and app development in general, it was quite the learning curve for all of us to help contribute to the app.)
* Domain.com (Linking our domain.com name, flyingovertheradar.space, to our github pages was a little bit more tricky than anticipated, needing a particular use of CNAME dns setup.)
* Radar.io (As it was our first time using Radar.io, and the first time implementing its sdk, it took a lot of trouble shooting to get it to work as desired.)
* Mongo DB (We decided to use Mongo DB Atlas to host our backend database needs, which took a while to get configured properly.)
* JSON objects/files (These proved to be the bain of our existence and took many hours to get them to convert into a usable format.)
* Rest API (Getting the rest API to respond correctly to our http requests was quite frustrating, we had to use many different http Java libraries before we found one that worked with our project.)
* Java/xml (As some of our members had no prior experience with both Java and xml, development proved even more difficult than originally anticipated.)
* Merge Conflicts (Ah, good old merge conflicts, a lot of fun trying to figure out what code you want to keep, delete or merge at 3am)
* Sleep deprivation (Over all our team of four got collectively 24 hours of sleep over this 36 hour hackathon.)
**Process of Building**
* For the front-end, we used Android Studio to develop the user interface of the app and its interactivity. This included a login page, a registration page and our home page in which has a map and events nearby you.
* MongoDB Atlas was used for back-end, we used it to store the users’ login and personal information along with events and their details.
* This link provides you with the Github repository of “On the Radar.” <https://github.com/maxerenberg/hackthevalley4/tree/master/app/src/main/java/com/hackthevalley4/hackthevalleyiv/controller>
* We also designed a prototype using Figma to plan out how the app could potentially look like.
The prototype’s link → <https://www.figma.com/proto/iKQ5ypH54mBKbhpLZDSzPX/On-The-Radar?node-id=13%3A0&scaling=scale-down>
* We also used a framework called Bootstrap to make our website. In this project, our team uploaded the website files through Github.
The website’s code → <https://github.com/arianneghislainerull/arianneghislainerull.github.io>
The website’s link → <https://flyingovertheradar.space/#>
*Look us up at*
# <http://flyingovertheradar.space> | ## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a restaurant; then voila! We give you suggestions based on what you can get in that price in different restaurants by providing all the menu items with price and calculated tax and tips! We keep the user history (the food items they chose) and by doing so we open the door to crowdsourcing massive amounts of user data and as well as the opportunity for machine learning so that we can give better suggestions for the foods that the user likes the most!
But we are not gonna stop here! Our goal is to implement the following in the future for this app:
* We can connect the app to delivery systems to get the food for you!
* Inform you about the food deals, coupons, and discounts near you
## How we built it
### Back-end
We have both an iOS and Android app that authenticates users via Facebook OAuth and stores user eating history in the Firebase database. We also made a REST server that conducts API calls (using Docker, Python and nginx) to amalgamate data from our targeted APIs and refine them for front-end use.
### iOS
Authentication using Facebook's OAuth with Firebase. Create UI using native iOS UI elements. Send API calls to Soheil’s backend server using json via HTTP. Using Google Map SDK to display geo location information. Using firebase to store user data on cloud and capability of updating to multiple devices in real time.
### Android
The android application is implemented with a great deal of material design while utilizing Firebase for OAuth and database purposes. The application utilizes HTTP POST/GET requests to retrieve data from our in-house backend server, uses the Google Maps API and SDK to display nearby restaurant information. The Android application also prompts the user for a rating of the visited stores based on how full they are; our goal was to compile a system that would incentive foodplaces to produce the highest “food per dollar” rating possible.
## Challenges we ran into
### Back-end
* Finding APIs to get menu items is really hard at least for Canada.
* An unknown API kept continuously pinging our server and used up a lot of our bandwith
### iOS
* First time using OAuth and Firebase
* Creating Tutorial page
### Android
* Implementing modern material design with deprecated/legacy Maps APIs and other various legacy code was a challenge
* Designing Firebase schema and generating structure for our API calls was very important
## Accomplishments that we're proud of
**A solid app for both Android and iOS that WORKS!**
### Back-end
* Dedicated server (VPS) on DigitalOcean!
### iOS
* Cool looking iOS animations and real time data update
* Nicely working location features
* Getting latest data from server
## What we learned
### Back-end
* How to use Docker
* How to setup VPS
* How to use nginx
### iOS
* How to use Firebase
* How to OAuth works
### Android
* How to utilize modern Android layouts such as the Coordinator, Appbar, and Collapsible Toolbar Layout
* Learned how to optimize applications when communicating with several different servers at once
## What's next for How Much
* If we get a chance we all wanted to work on it and hopefully publish the app.
* We were thinking to make it open source so everyone can contribute to the app. | ## Inspiration
Currently, there is an exponential growth of obesity in the world, leading to devastating consequences such as an increased rate of diabetes and heart diseases. All three of our team members are extremely passionate about nutrition issues and wish to educate others and promote healthy active living.
## What it does
This iOS app allows users to take pictures of meals that they eat and understand their daily nutrition intake. For each food that is imaged, the amount of calories, carbohydrates, fats and proteins are shown, contributing to the daily percentage on the nutrition tab. In the exercise tab, the users are able to see how much physical activities they need to do to burn off their calories, accounting for their age and weight differences. The data that is collected easily syncs with the iPhone built-in health app.
## How we built it
We built the iOS app in Swift programming language in Xcode. For the computer vision of the machine learning component, we used CoreML, and more specifically its Resnet 50 Model. We also implemented API calls to Edamam to receive nutrition details on each food item.
## Challenges we ran into
Two of our three team members have never used Swift before - it is definitely a challenge writing in an unfamiliar coding language. It was also challenging calling different APIs and integrating them back in Xcode, as the CoreML documentation is unclear.
## Accomplishments that we're proud of
We are proud of learning an entirely new programming language and building a substantial amount of a well-functioning app within 36 hours.
## What's next for NutriFitness
Building our own machine learning model and getting more accurate image descriptions. | partial |
## Inspiration
How do you define a sandwich? According to your definition is hotdog a sandwich? Well, according to Merriam Webster it is and so are sliders and many other food items that you might or might not consider sandwiches yourself (check out the link for more details- <https://www.merriam-webster.com/words-at-play/to-chew-on-10-kinds-of-sandwiches/sloppy-joe>)!
Expanding on this concept, this project aims to explore the classification of sandwiches and the boundaries to the definition.
## What it does
The Webapp determines whether an image classifies as a sandwich.
## How we built it
We downloaded 10,000 images from Google Images and 20,000 images from the Food101 dataset to train a binary classification algorithm on sandwiches using SqueezeNet Network in DeepLearning4J.
## Challenges we ran into
We had to switch from using Tensorflow and Python to using DeepLearning4J and Java because we wanted to do everything in memory of the server of the Webapp but the backend of the Webapp is in Java.
## What's next for Sandwichinator | ## Inspiration
Sign Language is what majority of the people who are part of the deaf and mute community use as a part of their daily conversing. **Not everyone knows sign language** and hence this necessitates the need for a tool to help others understand Sign. This basically emphasizes the possibility for the deaf and mute to be **solely independent** and not in need of translators when they have to address or even have a normal conversation with those who do not understand sign language.
## What it does
The platform basically takes in input via a camera of a hand gesture and tells you which alphabet does the letter stand for. It is based on the American Sign Language conventions and can recognize all the alphabets given the conditions are met which are derived from it's training data.
## How we built it
The backend was done using Python-Flask, Tailwind CSS was used for frontend development along with HTML and JS. For the AI part , Microsoft Azure Custom Vision service was used. The custom vision service can be used to train and deploy models with high availability and efficiency.
I used the ASL image dataset from Kaggle where 190 random images from the entire ASL was taken and used to train the model for each alphabet. Hence a total of 190\*26 images were used to train the Azure Custom Vision Model.
The application has been separately deployed on Azure WebApp service with GitHub Actions auto redeploying on new commit using a simple CI workflow.
## Challenges we ran into
1. Securing the critical keys in the code before pushing to github
2. Bottleneck on model efficiency when it comes to the use of real time data.
3. Azure Limitations on 5000 images per Custom Vision Project.
## Accomplishments that we're proud of
1. Making a model that successfully classified the ASL test data from Kaggle.
2. More deep understanding of Azure technologies and cloud.
## What we learned
1. Frontend Development with Tailwind CSS
2. Integrating Azure Services into Python Flask
3. Deployment on Azure
## What's next for Sign-To-Text
1. More efficient model.
2. Real-Time sign to text conversion followed by a text-to-voice converter.
3. Sign-To-Voice Converter | ## **Inspiration**
Ever had to wipe your hands constantly to search for recipes and ingredients while cooking?
Ever wondered about the difference between your daily nutrition needs and the nutrition of your diets?
Vocal Recipe is an integrated platform where users can easily find everything they need to know about home-cooked meals! Information includes recipes with nutrition information, measurement conversions, daily nutrition needs, cooking tools, and more! The coolest feature of Vocal Recipe is that users can access the platform through voice control, which means they do not need to constantly wipe their hands to search for information while cooking. Our platform aims to support healthy lifestyles and make cooking easier for everyone.
## **How we built Vocal Recipe**
Recipes and nutrition information is implemented by retrieving data from Spoonacular - an integrated food and recipe API.
The voice control system is implemented using Dasha AI - an AI voice recognition system that supports conversation between our platform and the end user.
The measurement conversion tool is implemented using a simple calculator.
## **Challenges and Learning Outcomes**
One of the main challenges we faced was the limited trials that Spoonacular offers for new users. To combat this difficulty, we had to switch between team members' accounts to retrieve data from the API.
Time constraint is another challenge that we faced. We do not have enough time to formulate and develop the whole platform in just 36 hours, thus we broke down the project into stages and completed the first three stages.
It is also our first time using Dasha AI - a relatively new platform which little open source code could be found. We got the opportunity to explore and experiment with this tool. It was a memorable experience. | losing |
## Inspiration
We got together a team passionate about social impact, and all the ideas we had kept going back to loneliness and isolation. We have all been in high pressure environments where mental health was not prioritized and we wanted to find a supportive and unobtrusive solution. After sharing some personal stories and observing our skillsets, the idea for Remy was born. **How can we create an AR buddy to be there for you?**
## What it does
**Remy** is an app that contains an AR buddy who serves as a mental health companion. Through information accessed from "Apple Health" and "Google Calendar," Remy is able to help you stay on top of your schedule. He gives you suggestions on when to eat, when to sleep, and personally recommends articles on mental health hygiene. All this data is aggregated into a report that can then be sent to medical professionals. Personally, our favorite feature is his suggestions on when to go on walks and your ability to meet other Remy owners.
## How we built it
We built an iOS application in Swift with ARKit and SceneKit with Apple Health data integration. Our 3D models were created from Mixima.
## Challenges we ran into
We did not want Remy to promote codependency in its users, so we specifically set time aside to think about how we could specifically create a feature that focused on socialization.
We've never worked with AR before, so this was an entirely new set of skills to learn. His biggest challenge was learning how to position AR models in a given scene.
## Accomplishments that we're proud of
We have a functioning app of an AR buddy that we have grown heavily attached to. We feel that we have created a virtual avatar that many people really can fall for.
## What we learned
Aside from this being many of the team's first times work on AR, the main learning point was about all the data that we gathered on the suicide epidemic for adolescents. Suicide rates have increased by 56% in the last 10 years, and this will only continue to get worse. We need change.
## What's next for Remy
While our team has set out for Remy to be used in a college setting, we envision many other relevant use cases where Remy will be able to better support one's mental health wellness.
Remy can be used as a tool by therapists to get better insights on sleep patterns and outdoor activity done by their clients, and this data can be used to further improve the client's recovery process. Clients who use Remy can send their activity logs to their therapists before sessions with a simple click of a button.
To top it off, we envisage the Remy application being a resource hub for users to improve their overall wellness. Through providing valuable sleep hygiene tips and even lifestyle advice, Remy will be the one-stop, holistic companion for users experiencing mental health difficulties to turn to as they take their steps towards recovery. | ## Inspiration
The project was inspired by looking at the challenges that artists face when dealing with traditional record labels and distributors. Artists often have to give up ownership of their music, lose creative control, and receive only a small fraction of the revenue generated from streams. Record labels and intermediaries take the bulk of the earnings, leaving the artists with limited financial security. Being a music producer and a DJ myself, I really wanted to make a product with potential to shake up this entire industry for the better. The music artists spend a lot of time creating high quality music and they deserve to be paid for it much more than they are right now.
## What it does
Blockify lets artists harness the power of smart contracts by attaching them to their music while uploading it and automating the process of royalty payments which is currently a very time consuming process. Our primary goal is to remove the record labels and distributors from the industry since they they take a majority of the revenue which the artists generate from their streams for the hard work which they do. By using a decentralized network to manage royalties and payments, there won't be any disputes regarding missed or delayed payments, and artists will have a clear understanding of how much money they are making from their streams since they will be dealing with the streaming services directly. This would allow artists to have full ownership over their work and receive a fair compensation from streams which is currently far from the reality.
## How we built it
BlockChain: We used the Sui blockchain for its scalability and low transaction costs. Smart contracts were written in Move, the programming language of Sui, to automate royalty distribution.
Spotify API: We integrated Spotify's API to track streams in real time and trigger royalty payments.
Wallet Integration: Sui wallets were integrated to enable direct payments to artists, with real-time updates on royalties as songs are streamed.
Frontend: A user-friendly web interface was built using React to allow artists to connect their wallets, and track their earnings. The frontend interacts with the smart contracts via the Sui SDK.
## Challenges we ran into
The most difficult challenge we faced was the Smart Contract Development using the Move language. Unlike commonly known language like Ethereum, Move is relatively new and specifically designed to handle asset management. Another challenge was trying to connect the smart wallets in the application and transferring money to the artist whenever a song was streamed, but thankfully the mentors from the Sui team were really helpful and guided us in the right path.
## Accomplishments that we're proud of
This was our first time working with blockchain, and me and my teammate were really proud of what we were able to achieve over the two days. We worked on creating smart contracts and even though getting started was the hardest part but we were able to complete it and learnt some great stuff along the way. My teammate had previously worked with React but I had zero experience with JavaScript, since I mostly work with other languages, but we did the entire project in Node and React and I was able to learn a lot of the concepts in such a less time which I am very proud of myself for.
## What we learned
We learned a lot about Blockchain technology and how can we use it to apply it to the real-world problems. One of the most significant lessons we learned was how smart contracts can be used to automate complex processes like royalty payments. We saw how blockchain provides an immutable and auditable record of every transaction, ensuring that every stream, payment, and contract interaction is permanently recorded and visible to all parties involved. Learning more and more about this technology everyday just makes me realize how much potential it holds and is certainly one aspect of technology which would rule the future. It is already being used in so many aspects of life and we are still discovering the surface.
## What's next for Blockify
We plan to add more features, such as NFTs for exclusive content or fan engagement, allowing artists to create new revenue streams beyond streaming. There have been some real-life examples of artists selling NFT's to their fans and earning millions from it, so we would like to tap into that industry as well. Our next step would be to collaborate with other streaming services like Apple Music and eliminate record labels to the best of our abilities. | ## Inspiration
Often as children, we were asked, "What do you want to be when you grow up?" Every time we changed our answers, we were sent to different classes to help us embrace our interests. But our answers were restricted and traditional: doctors, engineers or ballerinas. **We want to expand every child's scope: to make it more inclusive and diverse, and help them realize the vast opportunities that exist in this beautiful world in a fun way.**
Let's get them ready for the future where they follow their passion — let's hear them say designers, environmentalists, coders etc.
## What it does
The mobile application uses Augmented Reality technology to help children explore another world from a mobile phone or tablet and understand the importance of their surroundings. It opens up directly into the camera, where it asks the user to point at an object. The app detects the object and showcases various career paths that are related to the object. A child may then pick one and accomplish three simple tasks relevant to that career, which then unlocks a fun immersion into the chosen path's natural environment and the opportunity to "snap" a selfie as the professional using AR filters. The child can save their selfies and first-person immersion experience videos in their personal in-app gallery for future viewing, exploration, and even sharing.
## How I built it
Our team of three first approached the opportunity space. We held a brainstorming exercise to pinpoint the exact area where we can help, and then stepped into wireframing. We explored the best medium to play around with for the immersive, AR experience and decided upon Spectacles by Snap & Lens Studio, while exploring Xcode and iOS in parallel. For object detection, we used Google's MLKit Showcase App with Material Design to make use of Google's Object Detection and Tracking API. For the immersion, we used Snap's Spectacles to film real-world experiences that can be overlaid upon any setting, as well as Snap's Lens Studio to create a custom selfie filter to cap off the experience.
We brought in code together with design to bring the app alive with its colorful approach to appeal to kids.
## Challenges I ran into
We ran into the problem of truly understanding the perspectives of a younger age group and how our product would successfully be educational, accessible, and entertaining. We reflected upon our own experiences as children and teachers, and spoke to several parents before coming up with the final idea.
When we were exploring various AR/VR/MR technologies, we realized that many of the current tools available don't yet have the engaging user interfaces that we had been hoping for. Therefore we decided to work with Snap's Lens Studio, as the experience in-app on Snapchat is very exciting and accessible to our target age range.
On the technical side, Xcode and Apple have many peculiarities that we encountered over the course of Saturday. Additionally, we had not taken into consideration the restrictions and dependencies that Apple imposes upon iOS apps.
## Accomplishments that I'm proud of
We're proud that we did all of this in such a short span of time. Teamwork, rapid problem solving and being there for each other made for a final product that we are all proud to demo.
We're also proud that we took advantage of speaking to several sponsors from Snap and Google, and mentors from Google and Apple (and Stanford) throughout the course of the hackathon. We enjoyed technically collaborating with and meeting new people from all around the industry.
## What I learned
We learnt how to collaborate and bring design and code together, and how both go hand in hand. The engineers on the team learned a great amount about the product ideation and design thinking, and it was interesting for all of us to see our diverse perspectives coalesce into an idea we were all excited about.
## What's next for Inspo | An exploration tool for kids
On the technical side, we have many ideas for taking our project from a hackathon demo to the release version. This includes:
* Stronger integration with Snapchat and Google Cloud
* More mappings from objects to different career pathways
* Using ML models to provide recommendations for careers similar to the ones children have liked in the past
* An Android version
On the product side, we would like to expand to include:
* A small shopping list for parents to buy affordable, real-world projects related to careers
* A "Career of the Week" highlight
* Support for a network/community of children and potentially even professional mentors | winning |
# Recipe Finder - Project for NWHacks 2020
## The Problem
About 1/3 of food produced in the world is lost or wasted in the year. There are many reasons for this, including not being able to cook with said food, not having time to cook this food or cooking food that does not taste good. Albeit this, food waste is a serious problem that wastes money, wastes time and harms the environment.
## Our Solution
Our web app, Recipe Nest is a chat bot deployed on Slack, the Web, through calls. (Messenger and Google Assistant are currently awaiting approval). Users simply enter in all the filters they would like their recipe to contain and Recipe Nest finds a recipe conforming to the users' requests! We believe that making this application as accessible as possible reflects our goal of making it easy to get started with cooking at home and not wasting food!
## How we did it
We used Python, Flask, for the backend. Our chat bot was built with Google Cloud's Dialogflow in which we personally trained to be able to take user input. The front end was built with CSS, HTML, and Bootstrap.
## Going forward
We hope to add user logins via Firebase. We would then add features such as 1. Saving food in your fridge 2. Having the app remind you of this food 3. Allow the user to save recipes that they like. Additionally, we would like to add more filters, such as nutrition, cost, and excluding certain foods, and finally, create a better UI/UX experience for the user. | ## Inspiration
CookHack was inspired by the fact that students in university are always struggling with the responsibility of cooking their next healthy and nutritious meal. However, most of the time, we as students are always too busy to decide and learn how to cook basic meals, and we resort to the easy route and start ordering Uber Eats or Skip the Dishes. Now, the goal with CookHack was to eliminate the mental resistance and make the process of cooking healthy and delicious meals at home as streamlined as possible while sharing the process online.
## What it does
CookHack, in a nutshell, is a full-stack web application that provides users with the ability to log in to a personalized account to browse a catalog of 50 different recipes from our database and receive simple step-by-step instructions on how to cook delicious homemade dishes. CookHack also provides the ability for users to add the ingredients that they have readily available and start cooking recipes with those associated ingredients. Lastly, CookHack encourages the idea of interconnection by sharing their cooking experiences online by allowing users to post updates and blog forums about their cooking adventures.
## How we built it
The web application was built using the following tech stack: React, MongoDB, Firebase, and Flask. The frontend was developed with React to make the site fast and performant for the web application and allow for dynamic data to be passed to and from the backend server built with Flask. Flask connects to MongoDB to store our recipe documents on the backend, and Flask essentially serves as the delivery system for the recipes between MongoDB and React. For our authentication, Firebase was used to implement user authentication using Firebase Auth, and Firestore was used for storing and updating documents about the blog/forum posts on the site. Lastly, the Hammer of the Gods API was connected to the frontend, allowing us to use machine learning image detection.
## Challenges we ran into
* Lack of knowledge with Flask and how it works together with react.
* Implementing the user ingredients and sending back available recipes
* Had issues with the backend
* Developing the review page
* Implementing HoTG API
## Accomplishments that we're proud of
* The frontend UI and UX design for the site
* How to use Flask and React together
* The successful transfer of data flow between frontend, backend, and the database
* How to create a "forum" page in react
* The implementation of Hammer of the Gods API
* The overall functionality of the project
## What we learned
* How to setup Flask backend server
* How to use Figma and do UI and UX design
* How to implement Hammer of the Gods API
* How to make a RESTFUL API
* How to create a forum page
* How to create a login system
* How to implement Firebase Auth
* How to implement Firestore
* How to use MongoDB
## What's next for CookHack
* Fix any nit-picky things on each web page
* Make sure all the functionality works reliably
* Write error checking code to prevent the site from crashing due to unloaded data
* Add animations to the frontend UI
* Allow users to have more interconnections by allowing others to share their own recipes to the database
* Make sure all the images have the same size proportions | ## Inspiration
We wanted to protect our laptops with the power of rubber bands.
## What it does
It shoots rubber bands at aggressive screen lookers.
## How we built it
Willpower and bad code.
## Challenges we ran into
Ourselves.
## Accomplishments that we're proud of
Having something. Honestly.
## What we learned
Never use continuous servos.
## What's next for Rubber Security
IPO | partial |
## Inspiration
A recognized issue for our generation is mental health, specifically the intersection between social media toxicity and mental health. And yet, besides the universal solution ~therapy~, there are not many attractive options to choose from when struggling with mental health. Inspired by the community-favorite social media app, BeReal, we are taking a more direct approach of addressing mental wellness through its predetermined enemy: social media.
## What it does
Our take on the issue, JourNow, is a direct approach of addressing mental wellness through social media through targeted prompts at random times in the day as a daily check up between friends or a private journal entry. The app will promote communication and mental awareness in teenagers and young adults by providing the users a platform to share thoughts and experiences that are not always being heard. The underlying foundation of JourNow is to share a piece of their mind in a natural and spontaneous entry to encourage mental health awareness.
## How we built it
Used React Native and Javascript to create a cross-platform app for Android and iOS. Used Figma to create UI design prototype.
## Challenges we ran into
The first step of innovation, coming up with ideas, is always difficult. The opening ceremony ended and we had no idea where to start as for most of us, this was our first hackathon. To get moving, we held a 1-hour brainstorming session to share ideas and collectively selected which idea we thought was most feasible based on how difficult it would be to implement and social impact.
Also, none of us had prior experience with cross-platform app development, so we had to learn JavaScript, React, and React Native from the basics.
We also had to spend significant time figuring out how to install and run the technologies we were using such as React Native and Expo Go.
## Accomplishments that we're proud of
We are proud of getting a working mobile app running with navigation and text entry functionality. This is most of our group’s first time competing at a hackathon and we all had little to no experience with the technologies we were working with, so being able to make progress towards our app was a big achievement.
## What we learned
We learned collaborative skills through working together to build our app. We also learned how to use basic JavaScript and React Native to develop mobile applications. This is the first time applying classroom knowledge to other projects, so this was a really rewarding experience to work on applications of coding skills we learned in class
Learned how a hackathon works!
## What's next for JourNow
Completing a finished implementation of the application. Conduct user testing to evaluate effectiveness of current features for our target audience and determine and implement future improvements. | ## Inspiration
Life’s swift pace often causes us to overlook meaningful experiences, leading to nostalgia and a sense of lost connection with friends. Social media exacerbates this by showcasing others' highlight reels, which we envy, prompting a cycle of negative comparison and distraction through platforms like TikTok. This digital interaction cultivates social isolation and self-doubt.
We propose using personal data positively, steering attention from addictive social feeds to appreciating our life’s journey.
## What it does
Recall is a wellness app that helps people remember more of their life by letting people retain the smallest details of their life, see a big picture of it, and have a conversation with their past.
## How we built it
We kicked off by defining Recall’s key features and objectives, followed by UI design in Figma. Our plan for implementation was to use Flutter/Dart for app building and host the data locally. Google Cloud Platform and Google Maps SDK would have been used for mapping, Python for photo metadata, OpenAI API for data embedding and clustering, and Milvus for the Recall Bot chatbot function.
## Challenges we ran into
It was the first hackathon for 3/4 of us. There were roadblocks at every step of the way, but we worked hard as a team to adapt quickly and continue pushing through. Flutter/Dart was new territory for most of us, leading to a one-day project delay due to setup issues and unreliable internet. Figuring out the tech stack was difficult as our skill sets were essentially incompatible. Additionally, we had miscommunication at many steps in the implementation process. Lastly, we tackled our problems by dividing and conquering, but that was a misguided approach as we had difficulties integrating everything together since there was no centralized codebase.
## Accomplishments that we're proud of
We were able to make a few screens of the app on Flutter, having very little experience with it, so we are so freaking proud. We are proud of the team spirit, motivation, and positivity we all contributed while tackling so many roadblocks along our way. We had a great idea and an awesome UI!
## What we learned
Our entire project was a big learning experience and taught us invaluable skills. Key takeaways across the entire team:
1. Matching the idea to the skillset of the team is vital to success
2. The importance of a solid implementation plan from the start
3. Working on different features in isolation = bound for failure
4. Maintain composure during tough times to adapt quickly and find alternative solutions
5. Beware of activities that can distract the team along the way (like talking during quiet hack time)
6. Take advantage of the mentorship and resources
## What's next for Recall
We’ll take the skills and insights we’ve gained from the Hackathon to move the app forward. We believe there is a demand for an app like this, so the next step is for us to validate the market and gather the resources and skills to build out an MVP that we can test with users. :)))))) If you'd like to be an early adopter and feedback provider please reach out to Casey ([nguyen.casey@berkeley.edu](mailto:nguyen.casey@berkeley.edu)). | ## Inspiration
We have a desire to spread awareness surrounding health issues in modern society. We also love data and the insights in can provide, so we wanted to build an application that made it easy and fun to explore the data that we all create and learn something about being active and healthy.
## What it does
Our web application processes data exported by Apple health and provides visualizations of the data as well as the ability to share data with others and be encouraged to remain healthy. Our educational component uses real world health data to educate users about the topics surrounding their health. Our application also provides insight into just how much data we all constantly are producing.
## How we built it
We build the application from the ground up, with a custom data processing pipeline from raw data upload to visualization and sharing. We designed the interface carefully to allow for the greatest impact of the data while still being enjoyable and easy to use.
## Challenges we ran into
We had a lot to learn, especially about moving and storing large amounts of data and especially doing it in a timely and user-friendly manner. Our biggest struggle was handling the daunting task of taking in raw data from Apple health and storing it in a format that was easy to access and analyze.
## Accomplishments that we're proud of
We're proud of the completed product that we came to despite early struggles to find the best approach to the challenge at hand. An architecture this complicated with so many moving components - large data, authentication, user experience design, and security - was above the scope of projects we worked on in the past, especially to complete in under 48 hours. We're proud to have come out with a complete and working product that has value to us and hopefully to others as well.
## What we learned
We learned a lot about building large scale applications and the challenges that come with rapid development. We had to move quickly, making many decisions while still focusing on producing a quality product that would stand the test of time.
## What's next for Open Health Board
We plan to expand the scope of our application to incorporate more data insights and educational components. While our platform is built entirely mobile friendly, a native iPhone application is hopefully in the near future to aid in keeping data up to sync with minimal work from the user. We plan to continue developing our data sharing and social aspects of the platform to encourage communication around the topic of health and wellness. | losing |
## Inspiration
With everything going on nowadays, people are starting to feel less connected. While we are focused on physical illnesses during these times, we tend to forget to take care of our mental health. Our team wanted to make a game that would show a bit about how hard it is to live with depression to give a chance for people to have fun while learn more about mental health. We wanted to start conversations about mental health and allow people to connect.
## What it does
The mobile game, ‘Hope’ portrays the life of a girl who is going through depression, difficulties are solved through mini-games, while her daily life is being portrayed through animations and comic strips.
## How we built it
We used Unity to create this game, and we used Procreate to create all of the assets.
## Challenges we ran into
Some members of our team were new to programming, and they learned a lot of new skills like C# programming and navigating Unity. Also, we had a lot of assets to draw in such a short amount of time.
## Accomplishments that we're proud of
We are proud that we made a complete game with great purpose in such a short time.
## What we learned
Through the development of this game/project, we learnt various new skills regarding the use of unity and C#.
## What's next for Hope
We hope to continue adding more mini-games to showcase more aspects of mental health and depression. We may create other versions of the game focusing on different aspects of mental health.
APK download link: <https://github.com/SallyLim/Hope/releases/download/v1.0/hope.apk> | ## Inspiration
We noticed there were a ton of mental health websites and resources available to students, but they were marketed in a boring and patronizing way (or not at all). Also, there were so many websites and apps that it could get overwhelming for someone seeking help. Our game hoped to be an interface that gradually introduces new resources in a fun, accessible way. As for the style, we were inspired by retro pixel art games like shining gaiden 2 and Pokemon. The mechanics were inspired by gacha games (eg clash royale's box mechanic) where rewards are random, so people get hooked easily. The scenery is based on MY150 at Myhal at UofT.
## What it does
It's a pixel art mobile game where you collect points by grabbing items that are good for mental health (nature, doggos, and ironically sleep). Some of these doggos will activate buttons, with links that take you straight to a random mental health resource. We hoped to gamify mental health access so people aren't as intimidated when seeking help.
## How we built it
Unity and GIMP mostly
## Challenges we ran into
Endless errors, mostly because we're bad at Unity. The score counter wouldn't work because it was TextMeshPro but the tutorial used Text. Audio and particle effects from things exploding had to continue after destroying the object, so we delayed the destruction and just disabled the renderer (which is dumb but whatever). The colliders sometimes triggered effects multiple times per sprite, and finding the right velocity for spawned projectiles took forever. There were about 20 layers of sprites and sometimes nothing lined up correctly.
## Accomplishments that we're proud of
The game looks nice. Also it actually accomplishes the goal we set out to achieve, and is fun to play.
## What we learned
How to use most of Unity 2D. How to make UIs. What a jagged array is. C# in general.
## What's next for Myhal Mental Health Madness
More spawners, levels, and mental health links. | # Gait @ TreeHacks 2016
[](https://gitter.im/thepropterhoc/TreeHacks_2016?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
Diagnosing walking disorders with accelerometers and machine learning
**Based on the original work of Dr. Matt Smuck**

Author : *Shelby Vanhooser*
Mentor : *Dr. Matt Smuck*
---
### Goals
***Can we diagnose patient walking disorders?***
* Log data of walking behavior for a known distance through a smartphone
* Using nothing but an accelerometer on the smartphone, characterize walking behaviors as *good* or *bad* (classification)
* Collect enough meaningful data to distinguish between these two classes, and draw inferences about them
---
### Technologies
* Wireless headphone triggering of sampling
* Signal processing of collected data
* Internal database for storing collection
* Support Vector Machine (machine learning classification)
-> Over the course of the weekend, I was able to test the logging abilities of the app by taking my own phone outside, placing it in my pocket after selecting the desired sampling frequency and distance I would be walking (verified by Google Maps), and triggering its logging using my wireless headphones. This way, I made sure I was not influencing any data collected by having abnormal movements be recorded as I placed it in my pocket.
****Main screen of app I designed****
****The logging in action****

-> This way, we can go into the field, collect data from walking, and log if this behavior is 'good' or 'bad' so we can tell the difference on new data!
---
### Data
First, let us observe the time-domain samples recorded from the accelerometer:
It is immediately possible to see where my steps were! Very nice. Let's look at what the spectrums are like after we take the FFT...
*Frequency Spectrums of good walking behavior*
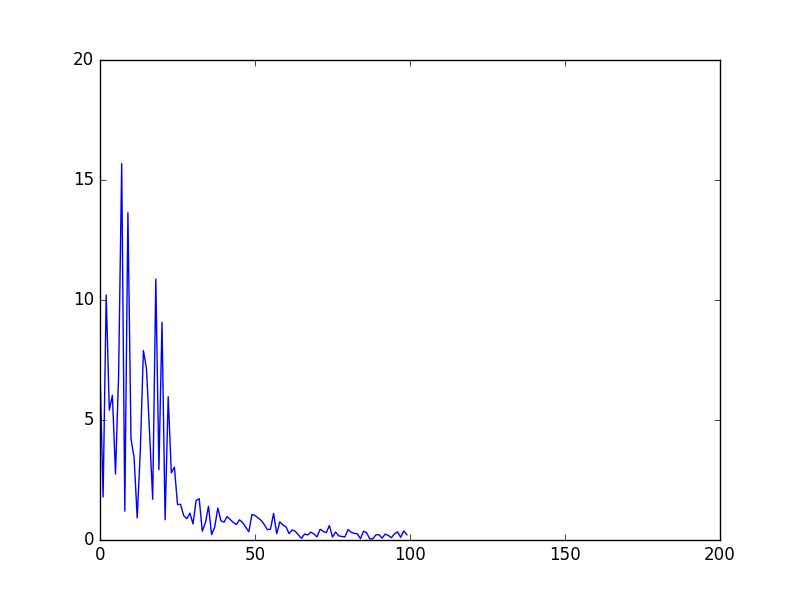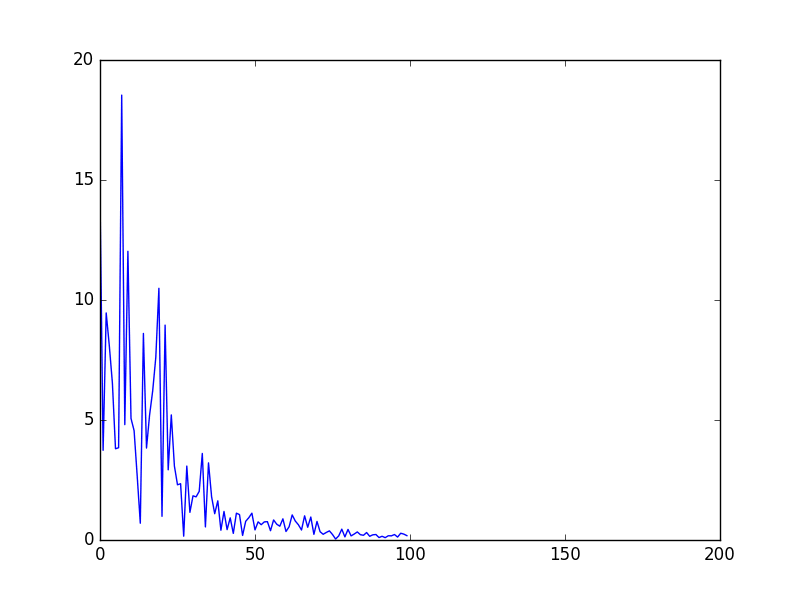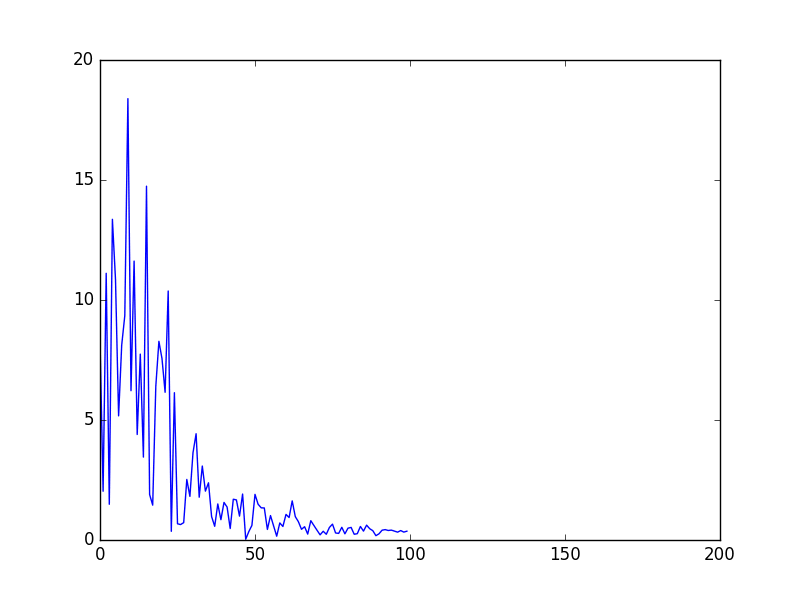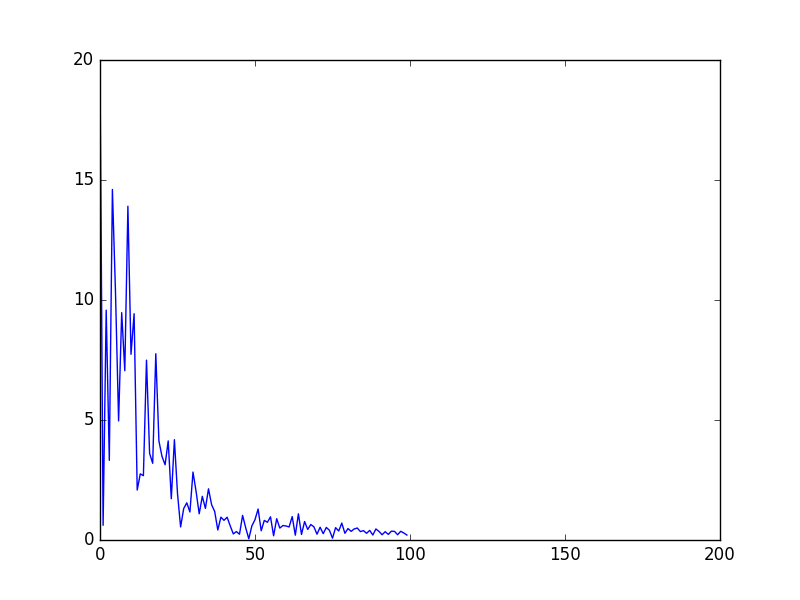
*Frequency spectrums of bad walking behavior*
19 'correct' walking samples and 5 'incorrect' samples were collected around the grounds of Stanford across reasonably flat ground with no obstacle interference.
***Let's now take these spectrums and use them as features for a machine learning classification problem***
-> Additionally, I ran numerous simulations to see what kernel in SVM would give the best output prediction accuracy:
**How many features do we need to get good prediction ability?**
*Linear kernel*
**Look at that characterization for so few features!**
Moving right along...
*Quadratic kernel*
Not as good as linear. What about cubic?
*Cubic kernel*
Conclusion: We can get 100% cross-validated accuracy with...
***A linear kernel***
Good to know. We can therefore predict on incoming patient data if their gait is problematic!
---
### Results
* From analysis of the data, its structure seems to be well-defined at several key points in the spectrum. That is, after feature selection was run on the collected samples, 11 frequencies were identified as dominating its behavior:
**[0, 18, 53, 67, 1000, 1018, 1053, 2037, 2051, 2052, 2069]**
***Note*** : it is curious that index 0 has been selected here, implying that the overall angle of an accelerometer on the body while walking has influence over the observed 'correctness' of gait
* From these initial results it is clear we *can* characterize 'correctness' of walking behavior using a smartphone application!
* In the future, it would seem very reasonable to have a patient download an application such as this, and, using a set of known walking types from measurements taken in the field, be able to diagnose and report to an unknown patient if they have a disorder in gait.
---
### Acknowledgments
* **Special thanks to Dr. Matt Smuck for his original work and aid in pushing this project in the correct direction**
* **Special thanks to [Realm](https://realm.io) for their amazing database software**
* **Special thanks to [JP Simard](https://cocoapods.org/?q=volume%20button) for his amazing code to detect volume changes for triggering this application**
* **Special thanks to everyone who developed [Libsvm](https://www.csie.ntu.edu.tw/%7Ecjlin/libsvm/) and for writing it in C so I could compile it in iOS** | losing |
## Inspiration
To introduce the most impartial and ensured form of voting submission in response to controversial democratic electoral polling following the 2018 US midterm elections. This event involved several encircling clauses of doubt and questioned authenticity of results by citizen voters. This propelled the idea of bringing enforced and much needed decentralized security to the polling process.
## What it does
Allows voters to vote through a web portal on a blockchain. This web portal is written in HTML and Javascript using the Bootstrap UI framework and JQuery to send Ajax HTTP requests through a flask server written in Python communicating with a blockchain running on the ARK platform. The polling station uses a web portal to generate a unique passphrase for each voter. The voter then uses said passphrase to cast their ballot anonymously and securely. Following this, their vote alongside passphrase go to a flask web server where it is properly parsed and sent to the ARK blockchain accounting it as a transaction. Is transaction is delegated by one ARK coin represented as the count. Finally, a paper trail is generated following the submission of vote on the web portal in the event of public verification.
## How we built it
The initial approach was to use Node.JS, however, Python with Flask was opted for as it proved to be a more optimally implementable solution. Visual studio code was used as a basis to present the HTML and CSS front end for visual representations of the voting interface. Alternatively, the ARK blockchain was constructed on the Docker container. These were used in a conjoined manner to deliver the web-based application.
## Challenges I ran into
* Integration for seamless formation of app between front and back-end merge
* Using flask as an intermediary to act as transitional fit for back-end
* Understanding incorporation, use, and capability of blockchain for security in the purpose applied to
## Accomplishments that I'm proud of
* Successful implementation of blockchain technology through an intuitive web-based medium to address a heavily relevant and critical societal concern
## What I learned
* Application of ARK.io blockchain and security protocols
* The multitude of transcriptional stages for encryption involving pass-phrases being converted to private and public keys
* Utilizing JQuery to compile a comprehensive program
## What's next for Block Vote
Expand Block Vote’s applicability in other areas requiring decentralized and trusted security, hence, introducing a universal initiative. | ## Inspiration
There are 1.1 billion people without Official Identity (ID). Without this proof of identity, they can't get access to basic financial and medical services, and often face many human rights offences, due the lack of accountability.
The concept of a Digital Identity is extremely powerful.
In Estonia, for example, everyone has a digital identity, a solution was developed in tight cooperation between the public and private sector organizations.
Digital identities are also the foundation of our future, enabling:
* P2P Lending
* Fractional Home Ownership
* Selling Energy Back to the Grid
* Fan Sharing Revenue
* Monetizing data
* bringing the unbanked, banked.
## What it does
Our project starts by getting the user to take a photo of themselves. Through the use of Node JS and AWS Rekognize, we do facial recognition in order to allow the user to log in or create their own digital identity. Through the use of both S3 and Firebase, that information is passed to both our dash board and our blockchain network!
It is stored on the Ethereum blockchain, enabling one source of truth that corrupt governments nor hackers can edit.
From there, users can get access to a bank account.
## How we built it
Front End: | HTML | CSS | JS
APIs: AWS Rekognize | AWS S3 | Firebase
Back End: Node JS | mvn
Crypto: Ethereum
## Challenges we ran into
Connecting the front end to the back end!!!! We had many different databases and components. As well theres a lot of accessing issues for APIs which makes it incredibly hard to do things on the client side.
## Accomplishments that we're proud of
Building an application that can better the lives people!!
## What we learned
Blockchain, facial verification using AWS, databases
## What's next for CredID
Expand on our idea. | ## Inspiration
A lot of the technology that we use today will become obsolete in future ( as it has been in the past ). However; with the current advancements in the field of cloud technology and AI, old hardware can now be transformed into their intelligent form. Which is what inspired us to build Jarvis as it would allow us to not only avoid a national waste crisis but to also to provide intelligent systems for the betterment of the world.
## What it does
Jarvis allows us to use a combination of existing hardware which may be obsolete (or soon to be) such as webcams, speakers, microphones, security systems and transform them into intelligent hardware. The platform uses the groundbreaking Google-Cloud-Vision APIs as the underlying engine which is then used to intelligently make use of the incoming input from the connected hardware. We also had to use a custom Natural - Language model in order to make accurate predictions. Further on, we are also making use of the Blockchain Technology to keep the data secure.
## How we built it
The underlying Google-Cloud engine was built entirely with Python 3, whereas the front-end was built with the standard web-development tools ( HTML, JS, CSS). Google Firebase was the only API that was used on both sides of the platform which improved the flow of data significantly. Since Python and JavaScript execute under different systems, we had to use the Flask API to make a connection between the two. The platform primarily focuses on connecting system video hardware (webcam, security systems) so we also had to use OpenCV and other streaming pythons libraries to configure a multi-camera stream. Further on, we also used GETH and Web3 APIs to spin up a private blockchain network, which is being used to secure the data produced by the engine.
## Challenges we ran into
One of the biggest challenges we ran into was in making the connection between the Python and Js portion of the project, which was mostly because our team had little knowledge on how the API worked (As it hosted its own server in-order to talk with the JS side of the project). Secondly, we also had trouble configuring multiple camera streams as the Linux OS is very specific on the default of the system. Thirdly, we also had trouble figuring out how exactly did the Google-Cloud-Vision works as some of the results were generalized.
## Accomplishments that we are proud of
Our major accomplishment is that we were able to produce a working version of the platform that would allow different camera streams to be combined and be accurately analyzed with the Google-Cloud Engine. Along with it, we also have an object analyzer that uses the Google-Cloud-Vision and Natural-Language Engine to spot specific items.
## What we learned
The most valuable that thing we learned is that an image can produce different sets of information, which if used correctly can predict its environment. Google-Cloud-Vision happens to be one of those tools that provided us with that technology and services.
## What's next for Jarvis - Scalable Platform
Jarvis has an infinite number of use cases, which is why the team will continue to build modules that will provide the user with useful usage of Google-Cloud services. We plan on integrating the compatibility of other hardware(s) that might become obsolete in the foreseeable future. | winning |
## Inspiration
My recent job application experience with a small company opened my eyes to the hiring challenges faced by recruiters. After taking time to thoughtfully evaluate each candidate, they explained how even a single bad hire wastes significant resources for small teams. This made me realize the need for a better system that saves time and reduces stress for both applicants and hiring teams. That sparked the idea for CareerChain.
## What it does
CareerChain allows job seekers and recruiters to create verified profiles on our blockchain-based platform.
For applicants, we use a microtransaction system similar to rental deposits or airport carts. A small fee is required to submit each application, refunded when checking status later. This adds friction against mass spam applications, ensuring only serious, passionate candidates apply.
For recruiters, our AI prescreens applicants, filtering out unqualified candidates. This reduces time wasted on low-quality applications, allowing teams to focus on best fits. Verified profiles also prevent fraud.
By addressing inefficiencies for both sides, CareerChain streamlines hiring through emerging technologies.
## How I built it
I built CareerChain using:
* XRP Ledger for blockchain transactions and smart contracts
* Node.js and Express for the backend REST API
* Next.js framework for the frontend
## Challenges we ran into
Implementing blockchain was challenging as it was my first time building on the technology. Learning the XRP Ledger and wiring up the components took significant learning and troubleshooting.
## Accomplishments that I'm proud of
I'm proud to have gained hands-on blockchain experience and built a working prototype leveraging these cutting-edge technologies.
## What I learned
I learned so much about blockchain capabilities and got exposure to innovative tools from sponsors. The hacking experience really expanded my skills.
## What's next for CareerChain
Enhancing fraud detection, improving the microtransaction UX, and exploring integrations like background checks to further optimize hiring efficiency. | ## Inspiration 🤔
Has there ever been a topic you wanted to learn about, and wished there was a fun, digestible, educational video for it? Whether it's about Newton's laws of physics or Locke's social contract.
In today's age, kids consume hours upon hours of video content every week (AACAP, Statista). What if there were a way for curious kids to instantly create a short educational video on any topic they wanted?
Or for teachers to created a curated lesson with a custom video and quiz following it.
## What it does 😯
Enter World of Vidcraft! Vidcraft is a website that allows users to enter in a topic they want to learn about (e.g. "What are Newton's laws of physics?") and sit back as a whole new video is automatically crafted on the topic they enter, complete with visuals and narration. While watching the video, users can interact with Vidcraft's video chat interface to ask questions about the content they've seen so far.
Upon completing the video, users are taken to a quiz page where their knowledge is tested on the new topic they learned. If they select a wrong answer choice, they are provided an explanation for why it is wrong, so that they can learn from their mistake.
In this manner, Vidcraft allows users of any age to instantly create a novel, never-seen-before educational video on ANY topic they want. Making learning more accessible, easy, and fun than before.
All in the matter of a minute. 🖐️🎤
## How we built it 🛠️
Vidcraft is built with a React & Next JS front-end hosted on Vercel, with Node as our backend.
We use OpenAI’s GPT API to perform tasks such as script writing, image prompt generation, and question generation; OpenAI’s Dall-E API for image generation; and ElevenLabs for text-to-speech generation.
## Challenges we ran into
There were a couple challenges we ran into. Several arose because of Node. For one, integrating the ffmpeg and videoshow libraries for video creation posed some issues with errors of missing modules, in particular one saying ‘Module not found ./lib-voc/fluent-ffmpeg’. We tried several things such as modifying our package.json, package-lock.json, reinstalling packages, uninstalling certain ones and consulted GitHub, StackOverflow, and chatgpt. The issues still persisted but we were able to resolve them. We had other issues with Node.
Prompt engineering for GPT took some trial and error before getting it to output the desired content in the correct format. Especially because there are several steps to the video generation process, we needed to ensure that GPT reliably generates video scripts and image prompts.
We also ran into issues with using image generation APIs due to content policy and moderation of the APIs. Stability AI doesn’t allow prompts with keywords related to children, something GPT might pick as example illustrations for the video. Similarly, OpenAI’s Dall-E API automatically revises prompts and the prompts that it itself revises violate OpenAI’s content policies. In addition to this, the Dall-E API has strict rate limits. These posed some challenges we had to overcome through carefully designed prompting, and handling of cases where certain images may be missing from the video.
## Accomplishments that we're proud of
We overcame the challenges we ran into to create a polished website that is fully functional. Given a topic or question as input, it crafts together a cohesive video teaching users about a topic.
We also only exposed our API keys one time 😀.
## What we learned
In general, we all gained further knowledge about Node.js as we relied on it heavily for our API logic and video generation, the core of our project. Another significant learning experience was dealing with issues, ranging in everything from sneaky API issues due to content policy moderation (which pervaded us for some time) to issues with libraries like ffmpeg. These challenges pushed us to develop better problem-solving skills and a deeper understanding of the tools we were working with.
## What's next for VidCraft
We want to build out additional features. Some ideas include:
incorporating Redis to store previously-made videos and quizzes
incorporating Redis’s vector database to provide relevant video suggestions via vector search
supporting mixed question types for quizzes (so mcq, full response, true-false, multi-select, etc)
Increasing the number of images per video (currently we are constrained by rate limits) and doing interpolations between images would also be nice.
And we want to start getting users! We’d love for the tool to be used in classrooms and just in general, by people who are curious and want a quick video to learn.
---
Discord usernames:
ishaanjav (Ishaan Javali)
aditya.k1 (Adi Kulkarni)
tonyyamin (Tony Yamin)
alexsima\_09642 (Alex Sima) | ## FLEX [Freelancing Linking Expertise Xchange]
## Inspiration
Freelancers deserve a platform where they can fully showcase their skills, without worrying about high fees or delayed payments. Companies need fast, reliable access to talent with specific expertise to complete jobs efficiently. "FLEX" bridges the gap, enabling recruiters to instantly find top candidates through AI-powered conversations, ensuring the right fit, right away.
## What it does
Clients talk to our AI, explaining the type of candidate they need and any specific skills they're looking for. As they speak, the AI highlights important keywords and asks any more factors that they would need with the candidate. This data is then analyzed and parsed through our vast database of Freelancers or the best matching candidates. The AI then talks back to the recruiter, showing the top candidates based on the recruiter’s requirements. Once the recruiter picks the right candidate, they can create a smart contract that’s securely stored and managed on the blockchain for transparent payments and agreements.
## How we built it
We built starting with the Frontend using **Next.JS**, and deployed the entire application on **Terraform** for seamless scalability. For voice interaction, we integrated **Deepgram** to generate human-like voice and process recruiter inputs, which are then handled by **Fetch.ai**'s agents. These agents work in tandem: one agent interacts with **Flask** to analyze keywords from the recruiter's speech, another queries the **SingleStore** database, and the third handles communication with **Deepgram**.
Using SingleStore's real-time data analysis and Full-Text Search, we find the best candidates based on factors provided by the client. For secure transactions, we utilized **SUI** blockchain, creating an agreement object once the recruiter posts a job. When a freelancer is selected and both parties reach an agreement, the object gets updated, and escrowed funds are released upon task completion—all through Smart Contracts developed in **Move**. We also used Flask and **Express.js** to manage backend and routing efficiently.
## Challenges we ran into
We faced challenges integrating Fetch.ai agents for the first time, particularly with getting smooth communication between them. Learning Move for SUI and connecting smart contracts with the frontend also proved tricky. Setting up reliable Speech to Text was tough, as we struggled to control when voice input should stop. Despite these hurdles, we persevered and successfully developed this full stack application.
## Accomplishments that we're proud of
We’re proud to have built a fully finished application while learning and implementing new technologies here at CalHacks. Successfully integrating blockchain and AI into a cohesive solution was a major achievement, especially given how cutting-edge both are. It’s exciting to create something that leverages the potential of these rapidly emerging technologies.
## What we learned
We learned how to work with a range of new technologies, including SUI for blockchain transactions, Fetch.ai for agent communication, and SingleStore for real-time data analysis. We also gained experience with Deepgram for voice AI integration.
## What's next for FLEX
Next, we plan to implement DAOs for conflict resolution, allowing decentralized governance to handle disputes between freelancers and clients. We also aim to launch on the SUI mainnet and conduct thorough testing to ensure scalability and performance. | partial |
## Inspiration
We visit many places, we know very less about the historic events or the historic places around us. Today In History notifies you of historic places near you so that you do not miss them.
## What it does
Today In History notifies you about important events that took place exactly on the same date as today but a number of years ago in history. It also notifies the historical places that are around you along with the distance and directions. Today In History is also available as an Amazon Alexa skill. You can always ask Alexa, "Hey Alexa, ask Today In History what's historic around me? What Happened Today? What happened today in India.......
## How we built it
We have two data sources: one is Wikipedia -- we are pulling all the events from the wiki for the date and filter them based on users location. We use the data from Philadelphia to fetch the historic places nearest to the user's location and used Mapquest libraries to give directions in real time.
## Challenges we ran into
Alexa does not know a person's location except the address it is registered with, but we built a novel backend that acts as a bridge between the web app and Alexa to keep them synchronized with the user's location. | ## Inspiration
Many hackers cast their vision forward, looking for futuristic solutions for problems in the present. Instead, we cast our eyes backwards in time, looking to find our change in restoration and recreation. We were drawn to the ancient Athenian Agora -- a marketplace; not one where merchants sold goods, but one where thinkers and orators debated, discussed, and deliberated (with one another?) pressing social-political ideas and concerns. The foundation of community engagement in its era, the premise of the Agora survived in one form or another over the years in the various public spaces that have been focal points for communities to come together -- from churches to community centers.
In recent years, however, local community engagement has dwindled with the rise in power of modern technology and the Internet. When you're talking to a friend on the other side of the world, you're not talking a friend on the other side of the street. When you're organising with activists across countries, you're not organising with activists in your neighbourhood. The Internet has been a powerful force internationally, but Agora aims to restore some of the important ideas and institutions that it has left behind -- to make it just as powerful a force locally.
## What it does
Agora uses users' mobile phone's GPS location to determine the neighbourhood or city district they're currently in. With that information, they may enter a chat group specific to that small area. Having logged-on via Facebook, they're identified by their first name and thumbnail. Users can then chat and communicate with one another -- making it easy to plan neighbourhood events and stay involved in your local community.
## How we built it
Agora coordinates a variety of public tools and services (for something...). The application was developed using Android Studio (Java, XML). We began with the Facebook login API, which we used to distinguish and provide some basic information about our users. That led directly into the Google Maps Android API, which was a crucial component of our application. We drew polygons onto the map corresponding to various local neighbourhoods near the user. For the detailed and precise neighbourhood boundary data, we relied on StatsCan's census tracts, exporting the data as a .gml and then parsing it via python. With this completed, we had almost 200 polygons -- easily covering Hamilton and the surrounding areas - and a total of over 50,000 individual vertices. Upon pressing the map within the borders of any neighbourhood, the user will join that area's respective chat group.
## Challenges we ran into
The chat server was our greatest challenge; in particular, large amounts of structural work would need to be implemented on both the client and the server in order to set it up. Unfortunately, the other challenges we faced while developing the Android application diverted attention and delayed process on it. The design of the chat component of the application was also closely tied with our other components as well; such as receiving the channel ID from the map's polygons, and retrieving Facebook-login results to display user identification.
A further challenge, and one generally unexpected, came in synchronizing our work as we each tackled various aspects of a complex project. With little prior experience in Git or Android development, we found ourselves quickly in a sink-or-swim environment; learning about both best practices and dangerous pitfalls. It was demanding, and often-frustrating early on, but paid off immensely as the hack came together and the night went on.
## Accomplishments that we're proud of
1) Building a functioning Android app that incorporated a number of challenging elements.
2) Being able to make something that is really unique and really important. This is an issue that isn't going away and that is at the heart of a lot of social deterioration. Fixing it is key to effective positive social change -- and hopefully this is one step in that direction.
## What we learned
1) Get Git to Get Good. It's incredible how much of a weight of our shoulders it was to not have to worry about file versions or maintenance, given the sprawling size of an Android app. Git handled it all, and I don't think any of us will be working on a project without it again.
## What's next for Agora
First and foremost, the chat service will be fully expanded and polished. The next most obvious next step is towards expansion, which could be easily done via incorporating further census data. StatsCan has data for all of Canada that could be easily extracted, and we could rely on similar data sets from the U.S. Census Bureau to move international. Beyond simply expanding our scope, however, we would also like to add various other methods of engaging with the local community. One example would be temporary chat groups that form around given events -- from arts festivals to protests -- which would be similarly narrow in scope but not constrained to pre-existing neighbourhood definitions. | ## Inspiration
A walk across campus looking at all the historical buildings and statues of the University of Pennsylvania.
## What it does
The project will be in the form of a web/mobile app. One or several locations are provided to the user. Along with each location an image is provided. The user aims to find the actual location and take a photo that best possibly replicates the image provided. The user has now "unlocked" said location.
The images that are intended to be used are historical images of landmarks, which are displayed to the user with a relatively low opacity and some interesting facts about the landmark. Making it both a thrilling geocaching-like and an educational experience (re-live history!).
## How we built it
Computer vision, API-handling, and web development will be critical elements of this project.
The biggest part of the application was to find a way to accurately decide if two pictures contain the same landmark, thus we spent a fairly big chunk of our development period just trying to make a model that worked as intended.
We built the web app by making a Flask backend, where we provided the utility to upload a picture to compare with, as well as implemented our Siamese Neural Network.
## Challenges we ran into
As the hackathon format doesn't allow for thoughtful and methodical development of AI, we decided to use a pre-existing Computer Vision model to be able to recognize a place, instead of having to train a model for ourselves. A problem we ran into was that most Open Source Computer Vision models are intended for object detection and classification, rather than comparison between two pictures of the same object. Unable to find a suitable model, we were forced to train our own, settling on a Siamese neural network.
## Accomplishments that we're proud of
We're especially proud of providing a proof of concept, with a self-trained Siamese neural network that works as intended. (with the pictures about the same angle)
## What we learned
We learned that getting everything to run smoothly and deploying a functioning model is more of a challenge than expected. Our plane also arrived very late, so we definitely learned that it's beneficial to get stated as soon as possible.
## What's next for Photo cache
A natural next move would be to make the concept into a functioning app for IOS/Android, and fully implement the more educational part of the application.
A website link should be provided in the GitHub repo. | winning |
## Inspiration
We were going to build a themed application to time portal you back to various points in the internet's history that we loved, but we found out prototyping with retro looking components is tough. Building each component takes a long time, and even longer to code. We started by automating parts of this process, kept going, and ended up focusing all our efforts on automating component construction from simple Figma prototypes.
## What it does
Give the plugin a Figma frame that has a component roughly sketched out in it. Our code will parse the frame and output JSX that matches the input frame. We use semantic detection with Cohere classify on the button labels combined with deterministic algorithms on the width, height, etc. to determine whether a box is a button, input field, etc. It's like magic! Try it!
## How we built it
Under the hood, the plugin is a transpiler for high level Figma designs.
Similar to a C compiler compiling C code to binary, our plugin uses an abstract syntax tree like approach to parse Figma designs into html code.
Figma stores all it's components (buttons, text, frames, input fields, etc) in nodes.. Nodes store properties about the component or type of element, such as height, width, absolute positions, fills, and also it's children nodes, other components that live within the parent component. Consequently, these nodes form a tree.
Our algorithm starts at the root node (root of the tree), and traverses downwards. Pushing-up the generated html from the leaf nodes to the root.
The base case is if the component was 'basic', one that can be represented with two or less html tags. These are our leaf nodes. Examples include buttons, body texts, headings, and input fields. To recognize whether a node was a basic component, we leveraged the power of LLM.
We parsed the information stored in node given to us by Figma into English sentences, then used it to train/fine tune our classification model provided by co:here. We decided to use an ML to do this since it is more flexible to unique and new designs. For example, we were easily able to create 8 different designs of a destructive button, and it would be time-consuming relative to the length of this hackathon to come up with a deterministic algorithm. We also opted to parse the information into English sentences instead of just feeding the model raw figma node information since the LLM would have a hard time understanding data that didn't resemble a human language.
At each node level in the tree, we grouped the children nodes based on a visual hierarchy. Humans do this all the time, if things are closer together, they're probably related, and we naturally group them. We achieved a similar effect by calculating the spacing between each component, then greedily grouped them based on spacing size. Components with spacings that were within a tolerance percentage of each other were grouped under one html
. We also determined the alignments (cross-axis, main-axis), of these grouped children to handle designs with different combinations of orientations. Finally, the function is recursed on their children, and their converted code is pushed back up to the parent to be composited, until the root contains the code for the design. Our recursive algorithm made it so our plugin was flexible to the countless designs possible in Figma.
## Challenges we ran into
We ran into three main challenges. One was calculating the spacing. Since while it was easy to just apply an algorithm to merge two components at a time (similar to mergesort), it would produce too many nested divs, and wouldn't really be useful for developers to use the created component. So we came up with our greedy algorithm. However, due to our perhaps mistaken focus on efficiency, we decided to implement a more difficult O(n) algorithm to determine spacing, where n is the number of children. This sapped a lot of time away, which could have been used for other tasks and supporting more elements.
The second main challenge was with ML. We were actually using Cohere Classify wrongly, not taking semantics into account and trying to feed it raw numerical data. We eventually settled on using ML for what it was good at - semantic analysis of the label, while using deterministic algorithms to take other factors into account. Huge thanks to the Cohere team for helping us during the hackathon! Especially Sylvie - you were super helpful!
We also ran into issues with theming on our demo website. To show how extensible and flexible theming could be on our components, we offered three themes - windows XP, 7, and a modern web layout. We were originally only planning to write out the code for windows XP, but extending the component systems to take themes into account was a refactor that took quite a while, and detracted from our plugin algorithm refinement.
## Accomplishments that we're proud of
We honestly didn't think this would work as well as it does. We've never built a compiler before, and from learning off blog posts about parsing abstract syntax trees to implementing and debugging highly asychronous tree algorithms, I'm proud of us for learning so much and building something that is genuinely useful for us on a daily basis.
## What we learned
Leetcode tree problems actually are useful, huh.
## What's next for wayback
More elements! We can only currently detect buttons, text form inputs, text elments, and pictures. We want to support forms too, and automatically insert the controlling componengs (eg. useState) where necessary. | ## Inspiration
We, as passionate tinkerers, understand the struggles that come with making a project come to life (especially for begineers). **80% of U.S. workers agree that learning new skills is important, but only 56% are actually learning something new**. From not knowing how electrical components should be wired, to not knowing what a particular component does, and what is the correct procedure to effectively assemble a creation, TinkerFlow is here to help you ease this process, all in one interface.
## What it does
-> Image identification/classification or text input of available electronic components
-> Powered by Cohere and Groq LLM, generates wiring scheme and detailed instructions (with personality!) to complete an interesting project that is possible with electronics available
-> Using React Flow, we developed our own library (as other existing softwares were depreciated) that generates electrical schematics to make the fine, precise and potentially tedious work of wiring projects easier.
-> Display generated text of instructions to complete project
## How we built it
We allowed the user to upload a photo, have it get sent to the backend (handled by Flask), used Python and Google Vision AI to do image classification and identify with 80% accuracy the component.
To provide our users with a high quality and creative response, we used a central LLM to find projects that could be created based on inputted components, and from there generate instructions, schematics, and codes for the user to use to create their project. For this central LLM, we offer two options: Cohere and Groq. Our default model is the Cohere LLM, which using its integrated RAG and preamble capability offers superior accuracy and a custom personality for our responses, providing more fun and engagement for the user. Our second option Groq though providing a lesser quality of a response, provides fast process times, a short coming of Cohere. Both of these LLM's are based on large meticulously defined prompts (characterizing from the output structure to the method of listing wires), which produce the results that are necessary in generating the final results seen by the user.
In order to provide the user with different forms of information, we decide to present electrical schematics on the webpage. However during the development due to many circumstances, our group had to use simple JavaScript libraries to create its functionality.
## Challenges we ran into
* LLM misbehaving: The biggest challenge in the incorporation of the Cohere LLM was the ability to generate consistent results through the prompts used to generate the results needed for all of the information provided about the project proposed. The solution to this was to include a very specifically defined prompts with examples to reduce the amount of errors generated by the LLM.
* Not able to find a predefined electrical schematics library to use to generate electrical schematics diagrams, there we had start from scratch and create our own schematic drawer based on basic js library.
## Accomplishments that we're proud of
Create electrical schematics using basic js library.
Create consistent outputting LLM's for multiple fields.
## What we learned
Ability to overcome troubles - consistently innovating for solutions, even if there may not have been an easy route (ex. existing library) to use - our schematic diagrams were custom made!
## What's next for TinkerFlow
Aiming for faster LLM processing speed.
Update the user interface of the website, especially for the electrical schematic graph generation.
Implement the export of code files, to allow for even more information being provided to the user for their project. | ## Inspiration
Our major source of motivation for leafy was an incident that took place recently. My mother and her friends are very enthusiastic about botany. My house has a big garden with innumerable plants. She usually spends a lot of her time catering to all their needs. Once my neighbour’s plant recently caught a infectious plant disease which was left undiagnosed. Due to this, the disease got communicated to our plants leading to their gradual death. Being nature lovers, it was a very traumatic experience for all of us. It made me wonder about the huge losses that the agriculture sector incurs because of the lack of right awareness at the right time. This prompted me to prepare a mobile application to prevent its reoccurrence.
## What it does
The backend uses a well trained CNN based model which is trained by dataset comprising of over 30000 plant images. It can accurately predict and classify leaf diseases to a degree of 94%. If the model finds the detected disease to be infectious, it notifies all the nearby mobile phones(in radius < 2 km) to take precautions to prevent the disease.
## How we built it
CNN model using Tensorflow, Scikit-learn, and OpenCV
App using android studio
API using flask(python)
and around 5 cups of coffee ☕️
## Challenges we ran into
We used our knowledge of java, python and html with a bit of css. Building a CNN model which could private the highest level of accuracy and F1 score was the main challenge for us. Another challenge was trying and testing the perfect combination of the CNN model parameters achieved desired results.
## Accomplishments that we're proud of
Through the course of this hackathon, we learnt the use of Google cloud AI notebooks which will go a long way in helping us become better hackers. The fact that we were able to document our imagination and ideas into code successfully and complete this project in time is probably a big accomplishment for both of us.
## What's next for Leafy
Just like we build Leafy for leaves, we can extend and develop another model which would be able to analyse soil through photos and predict about any lack of nutrients.
Room No:172
Team Name: MTC Hackers | winning |
## Inspiration 💭
We were up late at night brainstorming after eating a bunch of snacks. Then, someone picked up a piece of trash from the table, and... we knew what to do.
## What it does 🤷♀️
It's a mobile app that identifies trash in an image and sorts it to determine which bin it should go into (recycling, garbage, etc.).
## How we built it 👨💻
**Training the AI model**: The AI model was originally the YOLOv5 pre-trained model. However, it was not built for garbage detection, so we fine-tuned it with the TACO (Trash Annotations in Context) dataset for 16 epochs.
**Making the app**: We used Swift to create the iOS app, which consists of a camera that returns the images with identification boxes around the garbage.
## Challenges we ran into 🤔
**Finding a model and dataset**: Finding an effective and accurate pre-trained AI model was very challenging. To solve this issue, we trained a not-so-accurate AI model with a dataset to increase the accuracy.
**Training the dataset**: Training an AI model took a long time. We found that using Google Colab's GPU would speed up that process.
**Multiplatform support**: We originally wanted to support Android devices, but ran into many problems with React Native and Flutter
## Accomplishments that we're proud of 😄
We are very proud to be able to turn an inaccurate pre-trained model into a more precise version.
## What we learned 🏫
We learned a lot about mobile app development and object detection using machine learning.
## What's next for EcoVision❓
One major next step for EcoVision is to expand its accessibility further than iOS devices (eg. to Android users). We can add features such as using hardware to create specialized trash cans that sort the waste or creating a device to inform you of the category without using a phone. | ## Inspiration
This system was designed to make waste collection more efficient, organized and user-friendly.
Keeping the end users in mind we have created a system that detects what type of waste has been inserted in the bin and categorizes it as a recyclable or garbage.
The system then opens the appropriate shoot (using motors) and turns on an LED corresponding to the type of waste that was just disposed to educate the user.
## What it does
Able to sort out waste into recycling or garbage with the use of the Google Vision API to identify the waste object, Python to sort the object into recycling or garbage, and Arduino to move the bin/LED to show the appropriate waste bin.
## How we built it
We built our hack using the Google Cloud Vision API, Python to convert data received from the API, and then used that data to transmit to the Arduino on which bin to open. The bin was operated using a stepper motor and LED that indicated the appropriate bin, recycling or garbage, so that the waste object can automatically be correctly disposed of. We built our hardware model by using cardboard. We split a box into 2 sections and attached a motor onto the centre of a platform that allows it to rotate to each of the sections.
## Challenges we ran into
We were planning on using a camera interface with the Arduino to analyze the garbage at the input, unfortunately, the hardware component that was going to act as our camera ended up failing, forcing us to find an alternative way to analyze the garbage. Another challenge we ran into was getting the Google Cloud Vision API, but we stayed motivated and got it all to work. One of the biggest challenges we ran into was trying to use the Dragonboard 410c, due to inconsistent wifi, and the controller crashing frequently, it was hard for us to get anything concrete.
## Accomplishments that we're proud of
Something that we are really proud of is that we were able to come up with a hardware portion of our hack overnight. We finalized our idea late into the hackathon (around 7pm) and took up most of the night splitting our resources between the hardware and software components of our hack. Another accomplishment that we are proud of is that our hack has positive implications for the environment and society, something that all of our group members are really passionate about.
## What we learned
We learned a lot through our collaboration on this project. What stands out is our exploration of APIs and attempts at using new technologies like the Dragonboard 410c and sensors. We also learned how to use serial communications, and that there are endless possibilities when we look to integrate multiple different technologies together.
## What's next for Eco-Bin
In the future, we hope to have a camera that is built in with our hardware to take pictures and analyze the trash at the input. We would also like to add more features like a counter that keeps up with how many elements have been recycled and how many have been thrown into the trash. We can even go into specifics like counting the number of plastic water bottles that have been recycled. This data could also be used to help track the waste production of certain areas and neighbourhoods. | ## Inspiration
As university students, we and our peers have found that our garbage and recycling have not been taken by the garbage truck for some unknown reason. They give us papers or stickers with warnings, but these get lost in the wind, chewed up by animals, or destroyed because of the weather. For homeowners or residents, the lack of communication is frustrating because we want our garbage to be taken away and we don't know why it wasn't. For garbage disposal workers, the lack of communication is detrimental because residents do not know what to fix for the next time.
## What it does
This app allows garbage disposal employees to communicate to residents about what was incorrect with how the garbage and recycling are set out on the street. Through a checklist format, employees can select the various wrongs, which are then compiled into an email and sent to the house's residents.
## How we built it
The team built this by using a Python package called **Kivy** that allowed us to create a GUI interface that can then be packaged into an iOS or Android app.
## Challenges we ran into
The greatest challenge we faced was the learning curve that arrived when beginning to code the app. All team members had never worked on creating an app, or with back-end and front-end coding. However, it was an excellent day of learning.
## Accomplishments that we're proud of
The team is proud of having a working user interface to present. We are also proud of our easy to interactive and aesthetic UI/UX design.
## What we learned
We learned skills in front-end and back-end coding. We also furthered our skills in Python by using a new library, Kivy. We gained skills in teamwork and collaboration.
## What's next for Waste Notify
Further steps for Waste Notify would likely involve collecting data from Utilities Kingston and the city. It would also require more back-end coding to set up these databases and ensure that data is secure. Our target area was University District in Kingston, however, a further application of this could be expanding the geographical location. However, the biggest next step is adding a few APIs for weather, maps and schedule. | losing |
## Background
Before we **don't** give you financial advice, let's go through some brief history on the financial advisors and the changes they've seen since their introduction.
Financial advisors have been an essential part of the financial world for decades, offering individuals tailored advice on everything from investments to retirement plans. Traditionally, advisors would assess a client's financial situation and suggest investment strategies or products, charging a fee for their services. In Canada, these fees often range from 1% to 2% of a client's assets under management (AUM) annually. For example, if a client had $500,000 invested, they could be paying $5,000 to $10,000 a year in advisor fees.
However, over the past two decades, consumers have been migrating away from traditional financial advisors toward lower-cost alternatives like Exchange-Traded Funds (ETFs) and robo-advisors. ETFs, which are passively managed and track indexes like the S&P 500, became popular because they offer diversification at a fraction of the cost—typically charging less than 0.5% in fees. This shift is part of a broader trend toward fee transparency, where investors demand to know exactly what they're paying for and opt for lower-cost options when they can.
But while ETFs offer cost savings, they come with their own set of risks. For one, passive investing removes the active decision-making of traditional advisors, which can lead to market-wide issues. In times of high volatility, ETFs can exacerbate market instability because of their algorithmic trading patterns and herd-like behaviours. Furthermore, ETFs don't account for an investor's specific financial goals or risk tolerance, which is where human advisors can still play a critical role.
Understanding this transition helps illustrate why a tool like NFA (Not Financial Advice) can fill the gap—offering insights into personal finances without the high fees or potential drawbacks of fully passive investing or even the requirements to invest! Whether it be an individual who is looking to optimize their existing investments, or one who simply wants to learn about what their options are to begin with, NFA is a platform for all!
## Inspiration
The inspiration for NFA came from recognizing a gap in the market for accessible, personalized financial insights. Traditional financial advice is often expensive and not readily available to everyone. We wanted to create a platform that could analyze a user's financial situation and provide valuable insights without crossing the line into regulated financial advice.
The rise of fintech and the increasing financial literacy needs of younger generations also played a role in inspiring this project. We saw an opportunity to leverage technology to empower individuals to make more informed financial decisions.
## Team Background and Individual Inspiration
Our diverse team brings a unique blend of experiences and motivations to the NFA project:
1. **Cole Dermott**: A 21-year-old fourth-year student at the University of Waterloo (Computer Science) and Wilfrid Laurier University (Business Administration). With experience in various software fields, Cole's business background and frequent interactions with financial news and peer inquiries inspired him to develop a tool that could provide quick financial insights.
2. **Daniel Martinez**: A grade 12 student from Vaughan, Ontario, with experience in fullstack development including mobile, web, and web3. As a young startup founder (GradeAssist), Daniel has faced challenges navigating the financial world. These systemic and information barriers motivated him to join the NFA team and create a solution for others facing similar challenges.
3. **Musa Aqeel**: A second-year university student working full-time as a fullstack developer at Dayforce. Musa's personal goal of setting himself up for an early retirement drove him to develop a tool that would help him truly understand his finances in-depth and make informed decisions.
4. **Alex Starosta**: A second-year Software Engineering student at the University of Waterloo. Alex's meticulous approach to personal finance, including constant budgeting and calculations, inspired him to create a financial tool that would provide insights at a glance, eliminating the need for continuous manual checks.
## What it does
NFA is a comprehensive platform that:
1. Collects detailed user financial information, including:
* Age and location
* Invested assets and liabilities
* Credit score
* Interests and financial goals
* Cash and salary details
2. Analyzes this data to provide personalized insights.
3. Identifies potential "red flags" in the user's financial situation.
4. Offers notifications and alerts about these potential issues.
5. Provides educational resources tailored to the user's financial situation and goals.
All of this is done without crossing the line into providing direct financial advice, hence the name "Not Financial Advice" - since this is **MOST DEFINITELY NOT FINANCIAL ADVICE!!!!!**
## How we built it
We leveraged a modern tech stack to build NFA, focusing on scalability, performance, and developer experience. Our technology choices include:
1. **Frontend:**
* Next.js: For server-side rendering and optimized React applications
* React: As our primary frontend library
* TypeScript: For type-safe JavaScript development
* Tailwind CSS: For rapid and responsive UI development
2. **Backend and Database:**
* Firebase Auth: For secure user authentication
* Firestore: As our scalable, real-time NoSQL database
3. **API and AI Integration:**
* Cohere API: For advanced natural language processing, AI-driven insights, and it's web search functionality
4. **Development Tools:**
* ESLint: For code quality and consistency
* Vercel: For seamless deployment and hosting
This tech stack allowed us to create a robust, scalable application that can handle complex financial data processing while providing a smooth user experience. The combination of Firebase for backend services and Next.js for the frontend enabled us to rapidly develop and iterate on our platform.
The integration of Cohere API for AI capabilities was crucial in developing our intelligent insights engine, allowing us to analyze user financial data and provide personalized recommendations without crossing into direct financial advice territory.
## Challenges we ran into
Building NFA presented us with a unique set of challenges that pushed our skills and creativity to the limit:
1. **Navigating Regulatory Boundaries:**
One of our biggest challenges was designing a system that provides valuable financial insights without crossing into regulated financial advice territory. We had to carefully craft our algorithms and user interface to ensure we were providing information and analysis without making specific recommendations that could be construed as professional financial advice.
2. **Ensuring Data Privacy and Security:**
Given the sensitive nature of financial data, implementing robust security measures was paramount. We faced challenges in configuring Firebase Auth and Firestore to ensure end-to-end encryption of user data while maintaining high performance. This required a deep dive into Firebase's security rules and careful consideration of data structure to optimize for both security and query efficiency.
3. **Integrating AI Responsibly:**
Incorporating AI through the Cohere API and Groq presented unique challenges. We needed to ensure that the AI-generated insights were accurate, unbiased, and explainable. This involved extensive testing and fine-tuning of our prompts and models to avoid potential biases and ensure the AI's outputs were consistently reliable and understandable to users of varying financial literacy levels.
4. **Optimizing Performance with Complex Data Processing:**
Balancing the need for real-time insights with the computational intensity of processing complex financial data was a significant challenge. We had to optimize our Next.js and React components to handle large datasets efficiently, implementing techniques like virtualization for long lists and strategic data fetching to maintain a smooth user experience even when dealing with extensive financial histories.
5. **Creating an Intuitive User Interface for Complex Financial Data:**
Designing an interface that could present complex financial information in an accessible way to users with varying levels of financial literacy was a major hurdle. We leveraged Tailwind CSS to rapidly prototype and iterate on our UI designs, constantly balancing the need for comprehensive information with clarity and simplicity.
6. **Cross-Browser and Device Compatibility:**
Ensuring consistent functionality and appearance across different browsers and devices proved challenging, especially when dealing with complex visualizations of financial data. We had to implement various polyfills and CSS tweaks to guarantee a uniform experience for all users.
7. **Managing Team Dynamics and Skill Diversity:**
With team members ranging from high school to university students with varying levels of experience, we faced challenges in task allocation and knowledge sharing. We implemented a peer programming system and regular knowledge transfer sessions to leverage our diverse skillsets effectively.
8. **Handling Real-Time Updates and Notifications:**
Implementing a system to provide timely notifications about potential financial "red flags" without overwhelming the user was complex. We had to carefully design our notification system in Firebase to balance immediacy with user experience, ensuring critical alerts were not lost in a sea of notifications.
9. **Scalability Considerations:**
Although we're starting with a prototype, we had to design our database schema and server architecture with future scalability in mind. This meant making tough decisions about data normalization, caching strategies, and potential sharding approaches that would allow NFA to grow without requiring a complete overhaul.
10. **Ethical Considerations in Financial Technology:**
Throughout the development process, we grappled with the ethical implications of providing financial insights, especially to potentially vulnerable users. We had to carefully consider how to present information in a way that empowers users without encouraging risky financial behavior.
These challenges not only tested our technical skills but also pushed us to think critically about the broader implications of financial technology. Overcoming them required creativity, teamwork, and a deep commitment to our goal of empowering users with financial insights.
## Accomplishments that we're proud of
1. **Innovative Financial Insight Engine:**
We successfully developed a sophisticated algorithm that analyzes user financial data and provides valuable insights without crossing into regulated financial advice. This delicate balance showcases our understanding of both technology and financial regulations.
2. **Seamless Integration of AI Technologies:**
We effectively integrated Cohere API and Groq to power our AI-driven insights, creating a system that can understand and analyze complex financial situations. This accomplishment demonstrates our ability to work with cutting-edge AI technologies in a practical application.
3. **Robust and Scalable Architecture:**
Our implementation using Firebase, Firestore, and Next.js resulted in a highly scalable and performant application. We're particularly proud of our data model design, which allows for efficient querying and real-time updates while maintaining data integrity and security.
4. **User-Centric Design:**
We created an intuitive and accessible interface for complex financial data using React and Tailwind CSS. Our design makes financial insights understandable to users with varying levels of financial literacy, a crucial aspect for broadening financial education and accessibility.
5. **Advanced Data Visualization:**
We implemented sophisticated data visualization techniques that transform raw financial data into easily digestible graphs and charts. This feature significantly enhances user understanding of their financial situation at a glance.
6. **Responsive and Cross-Platform Compatibility:**
Our application works seamlessly across various devices and browsers, ensuring a consistent user experience whether accessed from a desktop, tablet, or smartphone.
7. **Real-Time Financial Alerts System:**
We developed a nuanced notification system that alerts users to potential financial issues or opportunities without being overwhelming. This feature demonstrates our attention to user experience and the practical application of our insights.
8. **Comprehensive Security Implementation:**
We implemented robust security measures to protect sensitive financial data, including end-to-end encryption and careful access control. This accomplishment showcases our commitment to user privacy and data protection.
9. **Efficient Team Collaboration:**
Despite our diverse backgrounds and experience levels, we established an effective collaboration system that leveraged each team member's strengths. This resulted in rapid development and a well-rounded final product.
10. **Ethical AI Implementation:**
We developed guidelines and implemented checks to ensure our AI-driven insights are unbiased and ethically sound. This proactive approach to ethical AI use in fintech sets our project apart and demonstrates our awareness of broader implications in the field.
11. **Rapid Prototyping and Iteration:**
Using our tech stack, particularly Next.js and Tailwind CSS, we were able to rapidly prototype and iterate on our designs. This allowed us to refine our product continuously based on feedback and testing throughout the hackathon.
12. **Innovative Use of TypeScript:**
We leveraged TypeScript to create a strongly-typed codebase, significantly reducing runtime errors and improving overall code quality. This showcases our commitment to writing maintainable, scalable code.
13. **Successful Integration of Multiple APIs:**
We seamlessly integrated various APIs and services (Firebase, Cohere, Groq) into a cohesive platform. This accomplishment highlights our ability to work with diverse technologies and create a unified, powerful solution.
14. **Creation of Educational Resources:**
Alongside the main application, we developed educational resources that help users understand their financial situations better. This additional feature demonstrates our holistic approach to financial empowerment.
15. **Performance Optimization:**
We implemented advanced performance optimization techniques, resulting in fast load times and smooth interactions even when dealing with large datasets. This showcases our technical proficiency and attention to user experience.
These accomplishments reflect not only our technical skills but also our ability to innovate in the fintech space, our commitment to user empowerment, and our forward-thinking approach to financial technology.
## What we learned
1. **Navigating Financial Regulations:**
We gained a deep understanding of the fine line between providing financial insights and giving regulated financial advice. This knowledge is crucial for anyone looking to innovate in the fintech space.
2. **The Power of AI in Finance:**
Through our work with Cohere API and Groq, we learned how AI can be leveraged to analyze complex financial data and provide valuable insights. We also understood the importance of responsible AI use in financial applications.
3. **Importance of Data Privacy and Security:**
Working with sensitive financial data reinforced the critical nature of robust security measures. We learned advanced techniques in data encryption and secure database management using Firebase and Firestore.
4. **User-Centric Design in Fintech:**
We discovered the challenges and importance of presenting complex financial information in an accessible manner. This taught us valuable lessons in UX/UI design for fintech applications.
5. **Full-Stack Development with Modern Technologies:**
Our team enhanced their skills in full-stack development, gaining hands-on experience with Next.js, React, TypeScript, and Tailwind CSS. We learned how these technologies can be integrated to create a seamless, efficient application.
6. **Real-Time Data Handling:**
We learned techniques for efficiently managing and updating real-time financial data, balancing the need for immediacy with performance considerations.
7. **Cross-Platform Development Challenges:**
Ensuring our application worked consistently across different devices and browsers taught us valuable lessons in responsive design and cross-platform compatibility.
8. **The Value of Rapid Prototyping:**
We learned how to quickly iterate on ideas and designs, allowing us to refine our product continuously throughout the hackathon.
9. **Effective Team Collaboration:**
Working in a diverse team with varying levels of experience taught us the importance of clear communication, task delegation, and knowledge sharing.
10. **Balancing Features and MVP:**
We learned to prioritize features effectively, focusing on creating a viable product within the hackathon's time constraints while planning for future enhancements.
11. **The Intersection of Finance and Technology:**
This project deepened our understanding of how technology can be used to democratize financial insights and empower individuals in their financial decision-making.
12. **Ethical Considerations in AI and Finance:**
We gained insights into the ethical implications of using AI in financial applications, learning to consider potential biases and the broader impact of our technology.
13. **Performance Optimization Techniques:**
We learned advanced techniques for optimizing application performance, especially when dealing with large datasets and complex calculations.
14. **The Importance of Financial Literacy:**
Through creating educational resources, we deepened our own understanding of financial concepts and the importance of financial education.
15. **API Integration and Management:**
We enhanced our skills in working with multiple APIs, learning how to integrate and manage various services within a single application.
16. **Scalability Considerations:**
We learned to think beyond the immediate project, considering how our application architecture could scale to accommodate future growth and features.
17. **The Power of Typed Programming:**
Using TypeScript taught us the benefits of strongly-typed languages in creating more robust, maintainable code, especially in complex applications.
18. **Data Visualization Techniques:**
We gained skills in transforming raw financial data into meaningful visual representations, learning about effective data visualization techniques.
19. **Agile Development in a Hackathon Setting:**
We applied agile methodologies in a compressed timeframe, learning how to adapt these principles to the fast-paced environment of a hackathon.
20. **The Potential of Open Banking:**
Although not directly implemented, our project made us aware of the possibilities and challenges in the emerging field of open banking and its potential impact on personal finance management.
These learnings not only enhanced our technical skills but also broadened our understanding of the fintech landscape, ethical technology use, and the importance of financial empowerment. The experience has equipped us with valuable insights that will inform our future projects and career paths in technology and finance.
## What's next for NFA (Not Financial Advice)
1. **Enhanced AI Capabilities:**
* Implement more advanced machine learning models to provide even more accurate and personalized financial insights.
* Develop predictive analytics to forecast potential financial outcomes based on user behavior and market trends.
2. **Open Banking Integration:**
* Partner with banks and financial institutions to integrate open banking APIs, allowing for real-time, comprehensive financial data analysis.
* Implement secure data sharing protocols to ensure user privacy while leveraging the power of open banking.
3. **Expanded Financial Education Platform:**
* Develop a comprehensive, interactive financial education module within the app.
* Create personalized learning paths based on user's financial knowledge and goals.
4. **Community Features:**
* Implement an anonymized peer comparison feature, allowing users to benchmark their financial health against similar demographics.
* Create a forum for users to share financial tips and experiences, moderated by AI to ensure quality and prevent misinformation.
5. **Gamification of Financial Goals:**
* Introduce gamification elements to encourage positive financial behaviors and goal achievement.
* Develop a reward system for reaching financial milestones, potentially partnering with financial institutions for tangible benefits.
6. **Advanced Data Visualization:**
* Implement more sophisticated data visualization techniques, including interactive charts and 3D visualizations of complex financial data.
* Develop AR/VR interfaces for immersive financial data exploration.
7. **Personalized Financial Product Recommendations:**
* Develop an AI-driven system to suggest financial products (savings accounts, investment options, etc.) based on user profiles and goals, while maintaining our commitment to not providing direct financial advice.
8. **Multi-Language Support:**
* Expand the platform to support multiple languages, making financial insights accessible to a global audience.
9. **Blockchain Integration:**
* Explore the integration of blockchain technology for enhanced security and transparency in financial tracking.
* Develop features to analyze and provide insights on cryptocurrency investments alongside traditional financial assets.
10. **Mobile App Development:**
* Create native mobile applications for iOS and Android to provide a seamless mobile experience and leverage device-specific features.
11. **API for Developers:**
* Develop and release an API that allows third-party developers to build applications on top of NFA's insights engine, fostering an ecosystem of financial tools.
12. **Sustainability Focus:**
* Implement features to help users understand the environmental impact of their financial decisions.
* Provide insights and recommendations for sustainable investing options.
13. **Customizable Dashboard:**
* Allow users to create fully customizable dashboards, tailoring the NFA experience to their specific financial interests and goals.
14. **Integration with Financial Advisors:**
* Develop a feature that allows users to safely share their NFA insights with professional financial advisors, bridging the gap between AI-driven insights and professional advice.
15. **Expanded AI Ethics Board:**
* Establish an AI ethics board comprising experts in finance, technology, and ethics to ensure ongoing responsible development and use of AI in our platform.
16. **Research Partnerships:**
* Collaborate with universities and financial institutions to conduct research on personal finance trends and the impact of AI-driven financial insights.
17. **Accessibility Enhancements:**
* Implement advanced accessibility features to make NFA usable for individuals with various disabilities, ensuring financial insights are available to everyone.
18. **Predictive Life Event Planning:**
* Develop features that help users plan for major life events (buying a home, having children, retirement) by predicting financial needs and suggesting preparation strategies.
19. **Voice Interface:**
* Implement a voice-activated interface for hands-free interaction with NFA, making financial insights even more accessible in users' daily lives.
20. **Continuous Learning AI:**
* Develop a system where the AI continuously learns and improves from anonymized user data and feedback, ensuring that insights become increasingly accurate and valuable over time.
By implementing these features, NFA aims to become a comprehensive, intelligent, and indispensable tool for personal financial management. Our goal is to democratize access to high-quality financial insights, empower individuals to make informed financial decisions, and ultimately contribute to improved financial well-being on a global scale. | ## Inspiration
Our project was inspired by the movie recommendation system algorithms used by companies like Netflix to recommend content to their users. Following along on this, our project uses a similar algorithm to recommend investment options to individuals based on their profiles.
## What Finvest Advisor does
This app suggests investment options for users based on the information they have provided about their own unique profiles. Using machine learning algorithms, we harness the data of previous customers to make the best recommendations that we can.
## How it works
We built our web app to work together with a machine-learning model that we designed. Using the cosine similarity algorithm, we compare how similar the user's profile is compared to other individuals already in our database. Then, based on this, our model is able to recommend investments that would be ideal for the user, given the parameters they have entered
## Our biggest challenge
Acquiring the data to get this project functional was nearly impossible, given that individuals' financial information is very well protected and banks would (for obvious reasons) not allow us to work with any real data that they would have had. Constructing our database was challenging, but we overcame it by constructing our own data that was modelled to be similar to real-world statistics.
## Going forward...
We hope to further improve the accuracy of our model by testing different kinds of algorithms with different kinds of data. Not to mention, we would also look forward to possibly pitching our project to larger financial firms, such as local banks, and getting their help to improve upon our model even more. With access to real-world data, we could make our model even more accurate, and give more specific recommendations. | ## Inspiration
My father put me in charge of his finances and in contact with his advisor, a young, enterprising financial consultant eager to make large returns. That might sound pretty good, but to someone financially conservative like my father doesn't really want that kind of risk in this stage of his life. The opposite happened to my brother, who has time to spare and money to lose, but had a conservative advisor that didn't have the same fire. Both stopped their advisory services, but that came with its own problems. The issue is that most advisors have a preferred field but knowledge of everything, which makes the unknowing client susceptible to settling with someone who doesn't share their goals.
## What it does
Resonance analyses personal and investment traits to make the best matches between an individual and an advisor. We use basic information any financial institution has about their clients and financial assets as well as past interactions to create a deep and objective measure of interaction quality and maximize it through optimal matches.
## How we built it
The whole program is built in python using several libraries for gathering financial data, processing and building scalable models using aws. The main differential of our model is its full utilization of past data during training to make analyses more wholistic and accurate. Instead of going with a classification solution or neural network, we combine several models to analyze specific user features and classify broad features before the main model, where we build a regression model for each category.
## Challenges we ran into
Our group member crucial to building a front-end could not make it, so our designs are not fully interactive. We also had much to code but not enough time to debug, which makes the software unable to fully work. We spent a significant amount of time to figure out a logical way to measure the quality of interaction between clients and financial consultants. We came up with our own algorithm to quantify non-numerical data, as well as rating clients' investment habits on a numerical scale. We assigned a numerical bonus to clients who consistently invest at a certain rate. The Mathematics behind Resonance was one of the biggest challenges we encountered, but it ended up being the foundation of the whole idea.
## Accomplishments that we're proud of
Learning a whole new machine learning framework using SageMaker and crafting custom, objective algorithms for measuring interaction quality and fully utilizing past interaction data during training by using an innovative approach to categorical model building.
## What we learned
Coding might not take that long, but making it fully work takes just as much time.
## What's next for Resonance
Finish building the model and possibly trying to incubate it. | losing |
## Hackers
Scott Blender and Jackie Gan
## Inspiration
This project was inspired by a book called "Hacking Healthcare". It discussed innovations and changes that were needed in the healthcare field and explained how human-centered design can make a positive impact in the field. This project seeks to use human-centered design as the inspiration for how the platform is built.
## What it does
Our application creates an ease-of-use communication pipeline to provide sustainable healthcare alternatives for patients. Our client utilizes Sonr technology to privatize sensitive patient data to allow them to control who has access to their records. In addition, the client helps facilitate communication between patients and doctors to allow doctors to recommend sustainable alternatives besides coming into the office, reducing the effects and need of transportation. These can include telehealth services, non-pharmaceutical interventions, and other sustainable options. By reducing the need for transportation to and from healthcare providers and pharmacies, more effective and sustainable ways can be advanced in the healthcare space for treating patient recovery,
## How we built it
This app is primarily built using golang and utilizes the Motor API built through Sonr. Due to the sensitive content shared across this site, Sonr is a great way to maximize patient privacy and provide confidential communication between patients and doctors.
## Challenges we ran into
Our team were the first users ever to develop a golang app that uses the Sonr platform on a Windows operating environment. This presented many difficulties, and ultimately, led us to having to focus on finishing the design of the backend in Sonr for the web application. This was caused by a persistent error in login authentication. Through this, though, we persisted and continued to develop out our backend system to integrate patient and primary care provider data transfer.
## Accomplishments that we're proud of
We were able to build a semi-working back-end in Sonr! Learning about blockchain, Web3, and what Sonr does inspired me and my teammate to work on developing an app that relies on sensitive data transfer. In addition, we already pitched to the Sonr team at PennApps and received positive feedback on the idea and plan for implementation using Sonr.
## What we learned
We learned a lot about back-end, schemas, objects, and buckets. Schemas, objects, and buckets are the primary ways data is structured in Sonr. By learning the building blocks of how to store, pass, and collect data, we learned how to appropriately construct a data storage solution. In addition, this was our teams first time ever using golang and competing at PennApps, so it was a great experience to learn and new language and make new connections.
## What's next for Sustainabilicare
The future looks bright. With continued support and debugging in using Sonr, we can continue to elevate our project and make it an actual backend solution. We plan on creating a formal pitch, building out a fully functional front-end, and learning more about Sonr structures to enhance the way our backend works. | ## Inspiration
Our inspiration for this project was the technological and communication gap between healthcare professionals and patients, restricted access to both one’s own health data and physicians, misdiagnosis due to lack of historical information, as well as rising demand in distance-healthcare due to the lack of physicians in rural areas and increasing patient medical home practices. Time is of the essence in the field of medicine, and we hope to save time, energy, money and empower self-care for both healthcare professionals and patients by automating standard vitals measurement, providing simple data visualization and communication channel.
## What it does
What eVital does is that it gets up-to-date daily data about our vitals from wearable technology and mobile health and sends that data to our family doctors, practitioners or caregivers so that they can monitor our health. eVital also allows for seamless communication and monitoring by allowing doctors to assign tasks and prescriptions and to monitor these through the app.
## How we built it
We built the app on iOS using data from the health kit API which leverages data from apple watch and the health app. The languages and technologies that we used to create this are MongoDB Atlas, React Native, Node.js, Azure, Tensor Flow, and Python (for a bit of Machine Learning).
## Challenges we ran into
The challenges we ran into are the following:
1) We had difficulty narrowing down the scope of our idea due to constraints like data-privacy laws, and the vast possibilities of the healthcare field.
2) Deploying using Azure
3) Having to use Vanilla React Native installation
## Accomplishments that we're proud of
We are very proud of the fact that we were able to bring our vision to life, even though in hindsight the scope of our project is very large. We are really happy with how much work we were able to complete given the scope and the time that we have. We are also proud that our idea is not only cool but it actually solves a real-life problem that we can work on in the long-term.
## What we learned
We learned how to manage time (or how to do it better next time). We learned a lot about the health care industry and what are the missing gaps in terms of pain points and possible technological intervention. We learned how to improve our cross-functional teamwork, since we are a team of 1 Designer, 1 Product Manager, 1 Back-End developer, 1 Front-End developer, and 1 Machine Learning Specialist.
## What's next for eVital
Our next steps are the following:
1) We want to be able to implement real-time updates for both doctors and patients.
2) We want to be able to integrate machine learning into the app for automated medical alerts.
3) Add more data visualization and data analytics.
4) Adding a functional log-in
5) Adding functionality for different user types aside from doctors and patients. (caregivers, parents etc)
6) We want to put push notifications for patients' tasks for better monitoring. | **Inspiration**
Brought up in his rural hometown of Faizabad in India, one of our team members has seen several villagers unable to access modern medical advice. This often led to unfortunate catastrophes that could have been prevented easily. To answer the medical information needs of the lower-income section of society, we created a forum for health-related questions such as medications and diet. We hoped to leverage the decentralized power of blockchain technology to help bridge the gap between quality healthcare advice and the resources of the less fortunate.
**What it does**
Faiza provides a decentralized user experience for posting and answering important medical questions. Each question asked by a user will create a tradeable NFT that is stored on a decentralized database available on the Sonr ecosystem. The prices of these posts are determined by the “karma,” or the number of upvotes that it has. Higher popularity signals increased karma and a larger associated intrinsic value of the “post” NFT. Hence, we create a self-regulating token marketplace to openly trade the created NFTs.
Additionally, we distribute the initial ownership between the post creator and the most upvoted comment to incentivize doctors to provide high-value, relevant information to patients.
Lastly, by using state-of-the-art natural language processing systems, we efficiently perform sentiment analysis on the posts and categorize them by certain tags. Additionally, we filter out relevant comments, deleting ones that are considered spam or derogatory.
**How we built it**
In order to establish a P2P NFT network, we employed Sonr.io, a decentralized network program. Our NFTs are stored on schemas that are pre-defined by us. The Sonr team was very helpful in helping us learn and implement their tech. In particular, we’d like to give a huge shout-out to Ian for helping us understand his speedway API, it really helped speed production :)
To incorporate the NLP, we utilized Cohere to create robust and easily deployable models. We created multiple models such as one to classify the toxicity of comments and another to perform sentiment analysis on a post and categorize it.
Furthermore, we utilized Node for the implementation of the backend and Bootstrap React to build out an aesthetically pleasing front end. Moreover, to facilitate the multiple API calls between our servers, we used Heroku to host them in the cloud and Postman to validate them.
**Challenges we ran into**
To be honest, we weren’t completely familiar with web3 and blockchain. So, it took us a while to conceptually understand Sonr and the integration of its ecosystem. We have to once again thank Ian for the tremendous amount of support he has provided to us on this journey!
Additionally, as we were making API calls between multiple servers (NLP, Node, Web3), they were often conflicting requests. Dealing with the sheer number of requests was difficult to handle and test using Postman.
**Accomplishments that we're proud of**
We’re proud to officially be Web 3.0 Developers :)
Prior to this hackathon, we had little to no experience working with web3 and blockchain technologies. However, this hackathon was a HUGE learning curve. While extremely difficult at first, we are proud to deploy a fully functional decentralized database, with the capability of storing tradeable NFTs and all the elements of a dApp.
**What we learned**
All of us have had a remarkable learning experience. While one of us became proficient in web3, the others learned about testing API calls using Postman, throttling speeds through developer tools, and deploying servers through Heroku CLI.
**What's next for Faiza**
Given the current functionality of Faiza, we hope to include all relevant features in the coming weeks. For instance, we haven’t been able to create a currency that can be liquidated into tangible assets.
Additionally, we hope to implement credibility levels for the users providing medical advice to a post. Using sorting algorithms, we can determine the rank of the importance of comments while displaying them on the user interface.
Lastly, we would love to simplify Faiza and deploy it in the native village of Faizabad, which was the initial fuel for the motivation of the project. We hope to see Faiza making a tangible difference at the grassroots level, changing lives one comment at a time. | partial |
## Inspiration
Loneliness affects countless people and over time, it can have significant consequences on a person's mental health. One quarter of Canada's 65+ population live completely alone, which has been scientifically connected to very serious health risks. With the growing population of seniors, this problem only seems to be growing worse, and so we wanted to find a way to help both elderly citizens take care of themselves and their loved ones to take care of them.
## What it does
Claire is an AI chatbot with a UX designed specifically for the less tech-savvy elderly population. It helps seniors to journal and self-reflect, both proven to have mental health benefits, through a simulated social experience. At the same time, it allows caregivers to stay up-to-date on the emotional wellbeing of the elderly. This is all done with natural language processing, used to identify the emotions associated with each conversation session.
## How we built it
We used a React front-end served by a node.js back-end. Messages were sent to Google Cloud's natural language processing API, where we could identify emotions for recording and entities for enhancing the simulated conversation experience. Information on user activity and profiles are maintained in a Firebase database.
## Challenges we ran into
We wanted to use speech-to-text so as to reach an even broader seniors' market, but we ran into technical difficulties with streaming audio from the browser in a consistent way. As a result, we chose simply to have a text-based conversation.
## Accomplishments that we're proud of
Designing a convincing AI chatbot was the biggest challenge. We found that the bot would often miss contextual cues, and interpret responses incorrectly. Over the course of the project, we had to tweak how our bot responded and prompted conversation so that these lapses were minimized. Also, as developers, it was very difficult to design to the needs of a less-tech-saavy target audience. We had to make sure our application was intuitive enough for all users.
## What we learned
We learned how to work with natural language processing to follow a conversation and respond appropriately to human input. As well, we got to further practise our technical skills by applying React, node.js, and Firebase to build a full-stack application.
## What's next for claire
We want to implement an accurate speech-to-text and text-to-speech functionality. We think this is the natural next step to making our product more widely accessible. | ## Inspiration
What is our first thought when we hear "health-care"? Is it an illness? Cancer? Disease? That is where we lose our focus from an exponential increasing crisis, especially in this post-COVID era. It is MENTAL HEALTH!
Studying at university, I have seen my friends suffer from depression and anxiety looking for someone to hear them out for once.
Statistically, an estimated 792 million individuals worldwide suffer from mental health diseases and concerns.
That's roughly one out of every ten persons on the planet.
In India, where I am from, the problem is even worse. Close to 14 per cent of India's population required active mental health interventions. Every year, about 2,00,000 Indians take their lives. The statistics are even higher if one starts to include the number of attempts to suicide.
The thought of being able to save even a fraction of this number is powerful enough to get me working this hard for it.
## What it does
Noor, TALKs because that's all it takes. She provides a comfortable environment to the user where they can share their thoughts very privately, and let that feelings out once and for all.
## How we built it
I built this app in certain steps:
1. Converting all the convolutional intents into a Machine Learning Model - Pytorch.
2. Building a framework where users can provide input and the model can output the best possible response that makes the most sense. Here, the threshold is set to 90% accuracy.
3. Building an elegant GUI.
## Challenges we ran into
Building Chatbots from scratch is extremely difficult. However, 36 hours were divided into sections where I could manage building a decent hack out of everything I got. Enhancing the bot's intelligence was challenging too. In the initial stages, I was experimenting with fewer intents, but with the addition of more intents, keeping track of the intents became difficult.
## Accomplishments that we're proud of
First, I built my own Chatbot for the first time!!! YAYYYYY! This is a really special project because of the fact that it is dealing with such a major issue in the world right now. Also, this was my first time making an entire hackathon project using Python and its frameworks only. Extremely new experience. I am proud of myself for pushing through the frustrating times when I felt like giving up.
## What we learned
Everything I made during this hackathon was something I had never done before. Legit, EVERYTHING! Let it be using NLP or Pytorch. Or even Tkinter for Graphic User Interface (GUI)! Honestly, may not be my best work ever but, definitely something that taught me the most!
## What's next for Noor
Switch from Tkinter to deploying my script into an application or web app. The only reason I went with Tkinter was to try learning something new. I'll be using flutter for app development and TFjs for a web-based application.
Discord: keivalya#8856 | ## 🤔 Problem Statement
* 55 million people worldwide struggle to engage with their past memories effectively (World Health Organization) and 40% of us will experience some form of memory loss (Alzhiemer's Society of Canada). This widespread struggle with nostalgia emphasizes the critical need for user-friendly solutions. Utilizing modern technology to support reminiscence therapy and enhance cognitive stimulation in this population is essential.
## 💡 Inspiration
* Alarming statistics from organizations like the Alzheimer's Society of Canada and the World Health Organization motivated us.
* Desire to create a solution to assist individuals experiencing memory loss and dementia.
* Urge to build a machine learning and computer vision project to test our skillsets.
## 🤖 What it does
* DementiaBuddy offers personalized support for individuals with dementia symptoms.
* Integrates machine learning, computer vision, and natural language processing technologies.
* Facilitates face recognition, memory recording, transcription, summarization, and conversation.
* Helps users stay grounded, recall memories, and manage symptoms effectively.
## 🧠 How we built it
* Backend developed using Python libraries including OpenCV, TensorFlow, and PyTorch.
* Integration with Supabase for data storage.
* Utilization of Cohere Summarize API for text summarization.
* Frontend built with Next.js, incorporating Voiceflow for chatbot functionality.
## 🧩 Challenges we ran into
* Limited team size with only two initial members.
* Late addition of two teammates on Saturday.
* Required efficient communication, task prioritization, and adaptability, especially with such unique circumstances for our team.
* Lack of experience in combining all these foreign sponsorship technology, as well as limited frontend and fullstack abilities.
## 🏆 Accomplishments that we're proud of
* Successful development of a functional prototype within the given timeframe.
* Implementation of key features including face recognition and memory recording.
* Integration of components into a cohesive system.
## 💻 What we learned
* Enhanced skills in machine learning, computer vision, and natural language processing.
* Improved project management, teamwork, and problem-solving abilities.
* Deepened understanding of dementia care and human-centered design principles.
## 🚀 What's next for DementiaBuddy
* Refining face recognition algorithm for improved accuracy and scalability.
* Expanding memory recording capabilities.
* Enhancing chatbot's conversational abilities.
* Collaborating with healthcare professionals for validation and tailoring to diverse needs.
## 📈 Why DementiaBuddy?
Asides from being considered for the Top 3 prizes, we worked really hard so that DementiaBuddy could be considered to win multiple sponsorship awards at this hackathon, including the Best Build with Co:Here, RBC's Retro-Revolution: Bridging Eras with Innovation Prize, Best Use of Auth0, Best Use of StarkNet, & Best .tech Domain Name. Our project stands out because we've successfully integrated multiple cutting-edge technologies to create a user-friendly and accessible platform for those with memory ailments. Here's how we've met each challenge:
* 💫 Best Build with Co:Here: Dementia Buddy should win the Best Build with Cohere award because it uses Cohere's Summarizing API to make remembering easier for people with memory issues. By summarizing long memories into shorter versions, it helps users connect with their past experiences better. This simple and effective use of Cohere's technology shows how well the project is made and how it focuses on helping users.
* 💫 RBC's Retro-Revolution - Bridging Eras with Innovation Prize: Dementia Buddy seamlessly combines nostalgia with modern technology, perfectly fitting the criteria of the RBC Bridging Eras prize. By updating the traditional photobook with dynamic video memories, it transforms the reminiscence experience, especially for individuals dealing with dementia and memory issues. Through leveraging advanced digital media tools, Dementia Buddy not only preserves cherished memories but also deepens emotional connections to the past. This innovative approach revitalizes traditional memory preservation methods, offering a valuable resource for stimulating cognitive function and improving overall well-being.
* 💫 Best Use of Auth0: We succesfully used Auth0's API within our Next.js frontend to help users login and ensure that our web app maintains a personalized experience for users.
* 💫 Best .tech Domain Name: AMachineLearningProjectToHelpYouTakeATripDownMemoryLane.tech, I can't think of a better domain name. It perfectly describes our project. | losing |
## **Problem**
* Less than a third of Canada’s fish populations, 29.4 per cent, can confidently be considered healthy and 17 per cent are in the critical zone, where conservation actions are crucial.
* A fishery audit conducted by Oceana Canada, reported that just 30.4 per cent of fisheries in Canada are considered “healthy” and nearly 20 per cent of stocks are “critically depleted.”
### **Lack of monitoring**
"However, short term economics versus long term population monitoring and rebuilding has always been a problem in fisheries decision making. This makes it difficult to manage dealing with major issues, such as species decline, right away." - Marine conservation coordinator, Susanna Fuller
"sharing observations of fish catches via phone apps, or following guidelines to prevent transfer of invasive species by boats, all contribute to helping freshwater fish populations" - The globe and mail
## **Our solution; Aquatrack**
aggregates a bunch of datasets from open canadian portal into a public dashboard!
slide link for more info: <https://www.canva.com/design/DAFCEO85hI0/c02cZwk92ByDkxMW98Iljw/view?utm_content=DAFCEO85hI0&utm_campaign=designshare&utm_medium=link2&utm_source=sharebutton>
The REPO github link: <https://github.com/HikaruSadashi/Aquatrack>
The datasets used:
1) <https://open.canada.ca/data/en/dataset/c9d45753-5820-4fa2-a1d1-55e3bf8e68f3/resource/7340c4ad-b909-4658-bbf3-165a612472de>
2)
<https://open.canada.ca/data/en/dataset/aca81811-4b08-4382-9af7-204e0b9d2448> | ## Inspiration Personal Experience
Save the global fish stocks from destruction by balancing hunger with overfishing!
## What it does
This is a Webgame that
## How we built it
Javascript, html, css, Google API
## Challenges we ran into
API and AI
## Accomplishments that we're proud of
AI for fish tracking
## What we learned
Programming is fun!!!!!
## What's next for Fish Simulator
Increase modern issues and their affects, and make sure the fish don't go on the end | ## Inspiration
Recognizing the disastrous effects of the auto industry on the environment, our team wanted to find a way to help the average consumer mitigate the effects of automobiles on global climate change. We felt that there was an untapped potential to create a tool that helps people visualize cars' eco-friendliness, and also helps them pick a vehicle that is right for them.
## What it does
CarChart is an eco-focused consumer tool which is designed to allow a consumer to make an informed decision when it comes to purchasing a car. However, this tool is also designed to measure the environmental impact that a consumer would incur as a result of purchasing a vehicle. With this tool, a customer can make an auto purhcase that both works for them, and the environment. This tool allows you to search by any combination of ranges including Year, Price, Seats, Engine Power, CO2 Emissions, Body type of the car, and fuel type of the car. In addition to this, it provides a nice visualization so that the consumer can compare the pros and cons of two different variables on a graph.
## How we built it
We started out by webscraping to gather and sanitize all of the datapoints needed for our visualization. This scraping was done in Python and we stored our data in a Google Cloud-hosted MySQL database. Our web app is built on the Django web framework, with Javascript and P5.js (along with CSS) powering the graphics. The Django site is also hosted in Google Cloud.
## Challenges we ran into
Collectively, the team ran into many problems throughout the weekend. Finding and scraping data proved to be much more difficult than expected since we could not find an appropriate API for our needs, and it took an extremely long time to correctly sanitize and save all of the data in our database, which also led to problems along the way.
Another large issue that we ran into was getting our App Engine to talk with our own database. Unfortunately, since our database requires a white-listed IP, and we were using Google's App Engine (which does not allow static IPs), we spent a lot of time with the Google Cloud engineers debugging our code.
The last challenge that we ran into was getting our front-end to play nicely with our backend code
## Accomplishments that we're proud of
We're proud of the fact that we were able to host a comprehensive database on the Google Cloud platform, in spite of the fact that no one in our group had Google Cloud experience. We are also proud of the fact that we were able to accomplish 90+% the goal we set out to do without the use of any APIs.
## What We learned
Our collaboration on this project necessitated a comprehensive review of git and the shared pain of having to integrate many moving parts into the same project. We learned how to utilize Google's App Engine and utilize Google's MySQL server.
## What's next for CarChart
We would like to expand the front-end to have even more functionality
Some of the features that we would like to include would be:
* Letting users pick lists of cars that they are interested and compare
* Displaying each datapoint with an image of the car
* Adding even more dimensions that the user is allowed to search by
## Check the Project out here!!
<https://pennapps-xx-252216.appspot.com/> | losing |
## Inspiration
As a result of the pandemic, most of the electric labs are moved online. Currently, we have software such as Multisim that can stimulate the circuits and aid the labs. However, we want to find a way to make the labs more "real" by allowing us to build actual circuits on the breadboard and implement an automaker to help the labs getting marked.
## What it does
The user can firstly login into the system by pre-registered username and password. Then, there will be a list of tutorials, from which the user can select one and enter the corresponding section. A sketch of the circuit will appear on the screen and the user needs to build the circuit on the breadboard and plug the pin into the appropriate position. Then, the system can read from the pin and check the value read from the board against the expected outcome.
## How we built it
* Login system: allow users (teachers or students) to register and login, record the marks and analysis the trend of study
+ For each student: must refer to a teacher, have username and password set
+ For each teacher: have him/herself an account with username and password, have a list of students that is under the teacher’s name
* Prototype database: pre-draw circuits and record them. Setting solutions to be checked
+ Main components of a circuit: battery, resistor, capacitor, potentiometer, thermistor
+ Very simple and easy circuits
- Parallel and serial connection of resistors
- Estimate the resistance of a potentiometer
- Design a specific current/resistance/voltage
* Hardware connection: read data from Arduino Uno and send it to the software.
+ Check the answers to the solutions and reflect the result in the form of a mark.
+ Collect the voltage/resistor/current from the breadboard and send them to the software
+ Compare the results with the solution and provide a mark for the overall performance
## Challenges we ran into
**Communication**:
* The team members are located in two different time zones so that the collaboration becomes harder and there is a very limited period of time that members can work at the same time.
* Only one of the team members owns the hardware (including the board and other components). Therefore, only this person can work on the hardware part and solve related problems.
**Hardware**:
* The proposed project offers tutorials for both DC and AC circuits and that's why we have an oscilloscope in our project. However, the Arduino Uno board does not have the Digital-to-Analog transfer, meaning that we are unable to generate AC waves without a wave generator. We could only truncate the project and focus only on DC circuit tutorials.
* The electric circuit components we own are limited to a small range, we are unable to build complicated circuits and test them. Moreover, we don't have access to a real oscilloscope or multimeter so that we are unable to detect potential errors in the circuit. To prevent detrimental effects to the board and other components, we decided to only work on the simple circuits.
**Software**:
* We wanted to design an user-friendly interface that allows users to drag the circuit diagram, however, we failed to do so.
## Accomplishments that we're proud of
This is the first time we work on a project that involves both software and hardware. Even though this project looks a bit simple, we put effort into communication within the team and building connections between the software and hardware. There are limitations due to the hardware we own, but we tried our best to build a project based on what we have and the majority of the proposed project has been realized.
## What we learned
* building connections between the hardware and software
* working on the Arduino Uno board
* collaboration and problem-solving with teammates under the remote condition and different time zones
## What's next for How Circuits Work
* We are looking for a method to generate the AC waves by using either the wave generator or the op-amp (if we have a chance to purchase one). This will allow us to build more complex circuits and use the built-in oscilloscope in a better way.
* We want to make the user interface more organized and introduce a playground where the users can customize their circuits and test functionalities (similar to the Multisim). | ## Inspiration
As an Econ major and Education minor, I'm really interested in development of new pathways that improve the education of future generations. I also like puns. By combining this background with a desire to do something more out-of-the-box, I knew I had to go Beyond the Pail.
## What it does
Beyond the Pail serves as a tech-enabled bundle of joy for the precocious and inquisitive child. With a focus on measurement technology (encompassing elementary lessons on weight and different measurement systems), this Pail helps target the K-5 demographic to develop their spatial-kinetic learning skills, which are often overlooked in our current test-focused and behavioral-dependent educational system.
Well, that's what I wanted it to do. During this hackathon, I managed to figure out how to jury-rig the Arduino and get the LCD to display "Beyond the Pail" on the side; that's about it.
## How I built it
I obtained an Arduino, breadboard panel, and LCD display from a friend. From there, I spent a few hours trying to figure out how to connect all the wires so that the LCD would actually display stuff (it turns out that I had two wires in the wrong spot, which, when corrected, finally made everything work).
After that, I spent some time learning how to code in Arduino, and created custom code to successfully change text on the bottom of the screen, but leave the top text the same.
Finally, I got my roll of duct tape and taped the Arduino board to a smiling Jack-O-Lantern bucket that was lying around.
## Challenges I ran into
I'm not a CS major. I'm not even an engineer! It was a steep learning curve to figure out how to actually put an Arduino together, especially since it's been a few years since I've played with electric circuits. After some trial-and-error, plus squinting at more than a few diagrams and online forums, I managed to make the LCD turn on. From there, I tackled the challenge of learning Arduino code (albeit a minor one - my CS106A knowledge came in handy!)
## Accomplishments that I'm proud of
I entered into this hackathon with very little development-focused coding background, and certainly no experience with "hardware hacks". Learning how to use Arduino to accomplish something on the hardware side was a really great accomplishment for me; it's something that I've wanted to do for years, but never had the impetus to do until now.
## What I learned
I learned how to build a functional Arduino circuit, troubleshoot physical and software-side bugs, and creatively imagine a better future through the EdTech space. I also learned that there are a lot of hardware-side ideas that are easy to create in theory, but hard to implement if you have no prior knowledge whatsoever on the hardware side.
## What's next for Beyond the Pail
Adding more features that help achieve the spatial-kinetic goals I have set, including a load cell connected to Arduino to measure weight real-time (which is what I originally wanted to try to create). | ## Inspiration
Have you ever finished up ECE lab or a small project like a PennApps hardware project and found that there were all of these screws, nuts, and resistors lying around everywhere? Or maybe you're just a hardware enthusiast but hate keeping track of all of your stuff (we like to do the old-fashioned way: the "hardware pile.")
With InvenTeX, there is finally an easy solution to inventory maintenance. Gone are the days of hoping you have quarter inch threads and settling for glue, or even having to remember the resistor color code. InvenTeX does all for your inventory, so you can focus your all on your hardware.
## What it does
InvenTeX identifies objects you want to keep in your inventory and helps you track them in groups so you don't have to.
The workflow of InvenTeX is simple.
When you first launch the app, you can choose to see what is in your inventory (at this point, nothing) and to insert something into the InvenTeX.
#### Taking a 100-ohm resistor as an example:
To insert, all you need to do is press the button on the app and take a picture of your resistor. It will then be identified and you can drop it and any other 100-ohm resistors into the loading bin. If you already have 100-ohm resistors stored in InvenTeX, your new resistor will be placed with the ones you already have in store.
To retrieve, you start from the drop down menu inside the app. There it will show everything that you have stored in InvenTeX. Pick the item you want to retrieve and InvenTeX will pop out the drawer with it. And once you're done grabbing what you need, the drawer will pull itself back in and you don't even need to remember where you got it from.
## How we built it
Initially, we wanted to use 3D printed parts for the hard to craft pieces of the enclosure and internal hardware. However, after finding out that we had access to laser cutters and an almost infinite supply of acrylic, we changed up our modeling plans and building timeline completely. We also initially intended on using a standard android app and using Bluetooth as the connection interface between it and the Raspberry Pi. And again, all plans changed with the introduction of Expo.io into the hack.
### Hardware
The entire enclosure and all of the internal structure is made with laser cut acrylic (1/8" and 1/4" black acrylic). We are also using two stepper motors to drive the belts and two servo motors to actuate the trap door (for part insertion) and magnetic arm (part retrieval).
### Controller
The Arduino Mega 2560 is the brain of the controls. The Arduino is only controlling movement and waiting for communication from the Raspberry Pi through I2C protocol. We are using an Adafruit Motor Shield (V2.3) for easy stepper and servo motor control with its built in stepper classes and PWM control for the servos. Everything draws power through a 5V external power source.
### Software
**Vision Processing**
Due to the Raspberry Pi camera not being clear enough to detect color bands of resistors, we switched over to phone cameras that had greater resolution (but also came with some other issues of connectivity, see below).
We started with simple color detection, differentiating between LEDs of different colors. Then moving on to shape and color detection, differentiating between different nuts and bolts. Finally moving on to pattern recognition and orientation detection, differentiating between resistors with different color bands.
**Communication**
Since we had replaced the Rapsberry Pi camera with the phone camera, we needed to transfer the image to the Raspberry Pi for vision processing. HTTP requests to send the image from the phone to the Raspberry Pi. HTTP requests to send retrieval signals to the Raspberry Pi.
## Challenges we ran into
### Software
**Vision processing:** Raspberry Pi camera is difficult to focus without a specialized tool. Resistor color codes had to be fine-tuned (HSV values). Resistor colors were also difficult to differentiate from each other and from the resistor itself, being heavily influenced by the color of the light source.
**Phone-to-Pi Communication:** We had to determine a system to send information to pi and get information back. We considered using bluetooth and an online database but ultimately decided to use HTTP protocols. Considerable thought went into organizing into which device ran what kind of processes and how to share information between the phone and pi.
**Expo Development:** No experience with React-Native. Rendering code changes would sometimes hang, so app development was not as ideally productive.
### Hardware
**Fitting Components:** Because all of the internal components of the enclosure must have slots and notches on the outer in order to fit properly, many of the internal structures that had to be swapped or structures that needed to be added in later for internal support had to be glued in making some areas less structurally stable than we would like.
**Stepper Motor Belt Tension:** The tension required for the stepper belts to drive properly was actually a bit too much for our structure to handle and some internal pieces broke off from the main frame due to tension forces. We fixed this by using zip ties instead of glue for a much stronger belt support structure.
## Accomplishments that we're proud of
**Integration:** We really had to utilize every possible piece of knowledge of every team member in order to fully integrate this project. There was (albeit simple) wiring to do be done with the microcontrollers, all the way up to implementing two different servers. In terms of code we wrote code in C, Python, and Javascript. We had to be able to pass information between all of our systems through wired and wireless connections. This extremely wide range of integration is not something we have ever done in so little time as a team and we're really excited that we pulled it off.
**Fully Assembled CAD Model:** We needed to know all of the tolerances in the system before printing or cutting any piece of it. In order to have everything fitted together as seamlessly as possible, we generated a fully assembled CAD model of every single component in the hack and cut almost every piece in one go. If we had completed the project by designing and cutting chunks at a time, without taking some time to look at the whole picture (literally) then there definitely would have been some more trips to the laser cutting room. We're glad that we took the time to fully CAD everything so that we could have all of the measurements and designs happening simultaneously between two CAD designers be integrated with each other.
## What we learned
## What's next for ToolHub
Bigger == Better. We want to try to use stronger materials with a stiffer frame that will not break down on us. We will also perform some stress analysis before redesigning some of the internal bracing in order for the structure to hold under the stepper torque.
The vision processing algorithms and implementation could also always be snappier and more robust. | losing |
## Inspiration
Blockchain has created new opportunities for financial empowerment and decentralized finance (DeFi), but it also introduces several new considerations. Despite its potential for equitability, malicious actors can currently take advantage of it to launder money and fund criminal activities. There has been a recent wave of effort to introduce regulations for crypto, but the ease of money laundering proves to be a serious challenge for regulatory bodies like the Canadian Revenue Agency. Recognizing these dangers, we aimed to tackle this issue through BlockXism!
## What it does
BlockXism is an attempt at placing more transparency in the blockchain ecosystem, through a simple verification system. It consists of (1) a self-authenticating service, (2) a ledger of verified users, and (3) rules for how verified and unverified users interact. Users can "verify" themselves by giving proof of identity to our self-authenticating service, which stores their encrypted identity on-chain. A ledger of verified users keeps track of which addresses have been verified, without giving away personal information. Finally, users will lose verification status if they make transactions with an unverified address, preventing suspicious funds from ever entering the verified economy. Importantly, verified users will remain anonymous as long as they are in good standing. Otherwise, such as if they transact with an unverified user, a regulatory body (like the CRA) will gain permission to view their identity (as determined by a smart contract).
Through this system, we create a verified market, where suspicious funds cannot enter the verified economy while flagging suspicious activity. With the addition of a legislation piece (e.g. requiring banks and stores to be verified and only transact with verified users), BlockXism creates a safer and more regulated crypto ecosystem, while maintaining benefits like blockchain’s decentralization, absence of a middleman, and anonymity.
## How we built it
BlockXism is built on a smart contract written in Solidity, which manages the ledger. For our self-authenticating service, we incorporated Circle wallets, which we plan to integrate into a self-sovereign identification system. We simulated the chain locally using Ganache and Metamask. On the application side, we used a combination of React, Tailwind, and ethers.js for the frontend and Express and MongoDB for our backend.
## Challenges we ran into
A challenge we faced was overcoming the constraints when connecting the different tools with one another, meaning we often ran into issues with our fetch requests. For instance, we realized you can only call MetaMask from the frontend, so we had to find an alternative for the backend. Additionally, there were multiple issues with versioning in our local test chain, leading to inconsistent behaviour and some very strange bugs.
## Accomplishments that we're proud of
Since most of our team had limited exposure to blockchain prior to this hackathon, we are proud to have quickly learned about the technologies used in a crypto ecosystem. We are also proud to have built a fully working full-stack web3 MVP with many of the features we originally planned to incorporate.
## What we learned
Firstly, from researching cryptocurrency transactions and fraud prevention on the blockchain, we learned about the advantages and challenges at the intersection of blockchain and finance. We also learned how to simulate how users interact with one another blockchain, such as through peer-to-peer verification and making secure transactions using Circle wallets. Furthermore, we learned how to write smart contracts and implement them with a web application.
## What's next for BlockXism
We plan to use IPFS instead of using MongoDB to better maintain decentralization. For our self-sovereign identity service, we want to incorporate an API to recognize valid proof of ID, and potentially move the logic into another smart contract. Finally, we plan on having a chain scraper to automatically recognize unverified transactions and edit the ledger accordingly. | ## Inspiration
At companies that want to introduce automation into their pipeline, finding the right robot, the cost of a specialized robotics system, and the time it takes to program a specialized robot is very expensive. We looked for solutions in general purpose robotics and imagining how these types of systems can be "trained" for certain tasks and "learn" to become a specialized robot.
## What it does
The Simon System consists of Simon, our robot that learns to perform the human's input actions. There are two "play" fields, one for the human to perform actions and the other for Simon to reproduce actions.
Everything starts with a human action. The Simon System detects human motion and records what happens. Then those actions are interpreted into actions that Simon can take. Then Simon performs those actions in the second play field, making sure to plan efficient paths taking into consideration that it is a robot in the field.
## How we built it
### Hardware
The hardware was really built from the ground up. We CADded the entire model of the two play fields as well as the arches that hold the smartphone cameras here at PennApps. The assembly of the two play fields consist of 100 individual CAD models and took over three hours to fully assemble, making full utilization of lap joints and mechanical advantage to create a structurally sound system. The LEDs in the enclosure communicate with the offboard field controllers using Unix Domain Sockets that simulate a serial port to allow color change for giving a user info on what the state of the fields is.
Simon, the robot, was also constructed completely from scratch. At its core, Simon is an Arduino Nano. It utilizes a dual H Bridge motor driver for controlling its two powered wheels and an IMU for its feedback controls system. It uses a MOSFET for controlling the electromagnet onboard for "grabbing" and "releasing" the cubes that it manipulates. With all of that, the entire motion planning library for Simon was written entirely from scratch. Simon uses a bluetooth module for communicating offboard with the path planning server.
### Software
There are four major software systems in this project. The path planning system uses a modified BFS algorithm taking into account path smoothing with realtime updates from the low-level controls to calibrate path plan throughout execution. The computer vision systems intelligently detect when updates are made to the human control field and acquire normalized grid size of the play field using QR boundaries to create a virtual enclosure. The cv system also determines the orientation of Simon on the field as it travels around. Servers and clients are also instantiated on every part of the stack for communicating with low latency.
## Challenges we ran into
Lack of acrylic for completing the system, so we had to refactor a lot of our hardware designs to accomodate. Robot rotation calibration and path planning due to very small inconsistencies in low level controllers. Building many things from scratch without using public libraries because they aren't specialized enough.
Dealing with smartphone cameras for CV and figuring out how to coordinate across phones with similar aspect ratios and not similar resolutions.
The programs we used don't run on windows such as Unix Domain Sockets so we had to switch to using a Mac as our main system.
## Accomplishments that we're proud of
This thing works, somehow. We wrote modular code this hackathon and a solid running github repo that was utilized.
## What we learned
We got better at CV. First real CV hackathon.
## What's next for The Simon System
More robustness. | ## Inspiration
Our time spent at home during COVID-19 caused us to have bad posture sometimes when sitting at our desks so we wanted to make an application to help keep us healthy and maintaining good posture.
## What it does
The application uses machine learning to monitor your body posture and track how long you spend sitting with bad posture and notify you if you have spent too long sitting that way. It also will guide you through stretching routines by monitoring your posture and guiding you into the correct position for the stretch.
## How we built it
We built this application using React which uses HTML, CSS, and JavaScript and we also used TensorFlow for the machine learning.
## Challenges we ran into
Our largest challenge was producing a machine learning model that accurately analyzes our posture and provides useful feedback that can be presented to the user as well as utilized in powering helpful functions of the application.
## Accomplishments that we're proud of
We are extremely proud that we have produced a model that works excellently not only for detecting poor posture but also explaining what is the source of the poor posture so the user can improve and not feel confused as to what they are doing wrong.
## What we learned
We learned that it is very important to provide plenty of examples and potential cases for the machine learning model in order for it to be effective in every scenario rather than only a couple.
## What's next for Posturefy
The next step for Posturefy is further development on the guided stretching functionality and adding more styling across the application for a better user experience. After this is complete we will have an excellent minimum viable product that we can begin to monetize in a wide variety of ways. | winning |
## What it does
MusiCrowd is an interactive democratic music streaming service that allows individuals to vote on what songs they want to play next (i.e. if three people added three different songs to the queue the song at the top of the queue will be the song with the most upvotes). This system was built with the intentions of allowing entertainment venues (pubs, restaurants, socials, etc.) to be inclusive allowing everyone to interact with the entertainment portion of the venue.
The system has administrators of rooms and users in the rooms. These administrators host a room where users can join from a code to start a queue. The administrator is able to play, pause, skip, and delete and songs they wish. Users are able to choose a song to add to the queue and upvote, downvote, or have no vote on a song in queue.
## How we built it
Our team used Node.js with express to write a server, REST API, and attach to a Mongo database. The MusiCrowd application first authorizes with the Spotify API, then queries music and controls playback through the Spotify Web SDK. The backend of the app was used primarily to the serve the site and hold an internal song queue, which is exposed to the front-end through various endpoints.
The front end of the app was written in Javascript with React.js. The web app has two main modes, user and admin. As an admin, you can create a ‘room’, administrate the song queue, and control song playback. As a user, you can join a ‘room’, add song suggestions to the queue, and upvote / downvote others suggestions. Multiple rooms can be active simultaneously, and each room continuously polls its respective queue, rendering a sorted list of the queued songs, sorted from most to least popular. When a song ends, the internal queue pops the next song off the queue (the song with the most votes), and sends a request to Spotify to play the song. A QR code reader was added to allow for easy access to active rooms. Users can point their phone camera at the code to link directly to the room.
## Challenges we ran into
* Deploying the server and front-end application, and getting both sides to communicate properly.
* React state mechanisms, particularly managing all possible voting states from multiple users simultaneously.
* React search boxes.
* Familiarizing ourselves with the Spotify API.
* Allowing anyone to query Spotify search results and add song suggestions / vote without authenticating through the site.
## Accomplishments that we're proud of
Our team is extremely proud of the MusiCrowd final product. We were able to build everything we originally planned and more. The following include accomplishments we are most proud of:
* An internal queue and voting system
* Frontloading the development & working hard throughout the hackathon > 24 hours of coding
* A live deployed application accessible by anyone
* Learning Node.js
## What we learned
Garrett learned javascript :) We learned all about React, Node.js, the Spotify API, web app deployment, managing a data queue and voting system, web app authentication, and so so much more.
## What's next for Musicrowd
* Authenticate and secure routes
* Add IP/device tracking to disable multiple votes for browser refresh
* Drop songs that are less than a certain threshold of votes or votes that are active
* Allow tv mode to have current song information and display upcoming queue with current number of votes | ## Inspiration 💡
*An address is a person's identity.*
In California, there are over 1.2 million vacant homes, yet more than 150,000 people (homeless population in California, 2019) don't have access to a stable address. Without an address, people lose access to government benefits (welfare, food stamps), healthcare, banks, jobs, and more. As the housing crisis continues to escalate and worsen throughout COVID-19, a lack of an address significantly reduces the support available to escape homelessness.
## This is Paper Homes: Connecting you with spaces so you can go places. 📃🏠
Paper Homes is a web application designed for individuals experiencing homelessness to get matched with an address donated by a property owner.
**Part 1: Donating an address**
Housing associations, real estate companies, and private donors will be our main sources of address donations. As a donor, you can sign up to donate addresses either manually or via CSV, and later view the addresses you donated and the individuals matched with them in a dashboard.
**Part 2: Receiving an address**
To mitigate security concerns and provide more accessible resources, Paper Homes will be partnering with California homeless shelters under the “Paper Homes” program. We will communicate with shelter staff to help facilitate the matching process and ensure operations run smoothly.
When signing up, a homeless individual can provide ID, however if they don’t have any forms of ID we facilitate the entire process in getting them an ID with pre-filled forms for application. Afterwards, they immediately get matched with a donated address! They can then access a dashboard with any documents (i.e. applying for a birth certificate, SSN, California ID Card, registering address with the government - all of which are free in California). During onboarding they can also set up mail forwarding ($1/year, funded by NPO grants and donations) to the homeless shelter they are associated with.
Note: We are solely providing addresses for people, not a place to live. Addresses will expire in 6 months to ensure our database is up to date with in-use addresses as well as mail forwarding, however people can choose to renew their addresses every 6 months as needed.
## How we built it 🧰
**Backend**
We built the backend in Node.js and utilized express to connect to our Firestore database. The routes were written with the Express.js framework. We used selenium and pdf editing packages to allow users to download any filled out pdf forms. Selenium was used to apply for documents on behalf of the users.
**Frontend**
We built a Node.js webpage to demo our Paper Homes platform, using React.js, HTML and CSS. The platform is made up of 2 main parts, the donor’s side and the recipient’s side. The front end includes a login/signup flow that populates and updates our Firestore database. Each side has its own dashboard. The donor side allows the user to add properties to donate and manage their properties (ie, if it is no longer vacant, see if the address is in use, etc). The recipient’s side shows the address provided to the user, steps to get any missing ID’s etc.
## Challenges we ran into 😤
There were a lot of non-technical challenges we ran into. Getting all the correct information into the website was challenging as the information we needed was spread out across the internet. In addition, it was the group’s first time using firebase, so we had some struggles getting that all set up and running. Also, some of our group members were relatively new to React so it was a learning curve to understand the workflow, routing and front end design.
## Accomplishments & what we learned 🏆
In just one weekend, we got a functional prototype of what the platform would look like. We have functional user flows for both donors and recipients that are fleshed out with good UI. The team learned a great deal about building web applications along with using firebase and React!
## What's next for Paper Homes 💭
Since our prototype is geared towards residents of California, the next step is to expand to other states! As each state has their own laws with how they deal with handing out ID and government benefits, there is still a lot of work ahead for Paper Homes!
## Ethics ⚖
In California alone, there are over 150,000 people experiencing homelessness. These people will find it significantly harder to find employment, receive government benefits, even vote without proper identification. The biggest hurdle is that many of these services are linked to an address, and since they do not have a permanent address that they can send mail to, they are locked out of these essential services. We believe that it is ethically wrong for us as a society to not act against the problem of the hole that the US government systems have put in place to make it almost impossible to escape homelessness. And this is not a small problem. An address is no longer just a location - it's now a de facto means of identification. If a person becomes homeless they are cut off from the basic services they need to recover.
People experiencing homelessness also encounter other difficulties. Getting your first piece of ID is notoriously hard because most ID’s require an existing form of ID. In California, there are new laws to help with this problem, but they are new and not widely known. While these laws do reduce the barriers to get an ID, without knowing the processes, having the right forms, and getting the right signatures from the right people, it can take over 2 years to get an ID.
Paper Homes attempts to solve these problems by providing a method for people to obtain essential pieces of ID, along with allowing people to receive a proxy address to use.
As of the 2018 census, there are 1.2 million vacant houses in California. Our platform allows for donors with vacant properties to allow people experiencing homelessness to put down their address to receive government benefits and other necessities that we take for granted. With the donated address, we set up mail forwarding with USPS to forward their mail from this donated address to a homeless shelter near them.
With proper identification and a permanent address, people experiencing homelessness can now vote, apply for government benefits, and apply for jobs, greatly increasing their chance of finding stability and recovering from this period of instability
Paper Homes unlocks access to the services needed to recover from homelessness. They will be able to open a bank account, receive mail, see a doctor, use libraries, get benefits, and apply for jobs.
However, we recognize the need to protect a person’s data and acknowledge that the use of an online platform makes this difficult. Additionally, while over 80% of people experiencing homelessness have access to a smartphone, access to this platform is still somewhat limited. Nevertheless, we believe that a free and highly effective platform could bring a large amount of benefit. So long that we prioritize the needs of a person experiencing homelessness first, we will able to greatly help them rather than harming them.
There are some ethical considerations that still need to be explored:
We must ensure that each user’s information security and confidentiality are of the highest importance. Given that we will be storing sensitive and confidential information about the user’s identity, this is top of mind. Without it, the benefit that our platform provides is offset by the damage to their security. Therefore, we will be keeping user data 100% confidential when receiving and storing by using hashing techniques, encryption, etc.
Secondly, as mentioned previously, while this will unlock access to services needed to recover from homelessness, there are some segments of the overall population that will not be able to access these services due to limited access to the internet. While we currently have focused the product on California, US where access to the internet is relatively high (80% of people facing homelessness have access to a smartphone and free wifi is common), there are other states and countries that are limited.
In addition to the ideas mentioned above, some next steps would be to design a proper user and donor consent form and agreement that both supports users’ rights and removes any concern about the confidentiality of the data. Our goal is to provide means for people facing homelessness to receive the resources they need to recover and thus should be as transparent as possible.
## Sources
[1](https://www.cnet.com/news/homeless-not-phoneless-askizzy-app-saving-societys-forgotten-smartphone-tech-users/#:%7E:text=%22Ninety%2Dfive%20percent%20of%20people,have%20smartphones%2C%22%20said%20Spriggs)
[2](https://calmatters.org/explainers/californias-homelessness-crisis-explained/)
[3](https://calmatters.org/housing/2020/03/vacancy-fines-california-housing-crisis-homeless/) | ## Inspiration
We feel really frustrated when we attend social events and have to listen to music that is really poorly suited to the occasion. Some of our most cherished memories like prom and social events in our senior year had poor music selection that really drained the energy of the event. We decided to create a solution to share, and play music as an audience.
## What it does
Pyro is a webapp that allows users to nominate and vote for music they would like to hear played next. The audience can **add heat** (upvote) a song in order to move it up in a priority queue to get played next. In this way the audience gets to jam out the music they really want to hear.
## How we built it
We used mongoDB Stitch to create a database of rooms and the queues in the respective rooms. We also employed node.js and called the Stitch APIs to interact with the database and complete the backend computation for displaying the queue in each room. The songs were searched and played from the youtube API. Our front-end is built with react and data is passed around with a react-router.
## Challenges we ran into
**User Interface**:
The data that we received from the youtube API was poorly formatted for display on mobile. It took considerable work to minimize the display of verbose youtube titles.
**Data Management**:
App data was relatively difficult to pass around with so we routed data with react router.
**Audio Playback**:
Spotify requires users to have a premium account and to repeatedly authenticate our application. We instead decided to use the youtubeAPI to make the app free for all.
The youtube API presented its own problems. The video and audio were delivered in a media player that we could not alter which we only needed the audio and have custom buttons for media control.
## What we learned
We ran into problems where poor planning lead to lost and useless work. After several hours of work, our group had to reset some foundational functions in our app which required us to refactor a large majority of the project. We learned that in the future we should plan structural components of our app first.
## What's next for Pyro
Some functionality we are looking to add:
Automatic track mixing.
Compatibility with other music services.
Algorithm to replace the DJs
Song Filtering | winning |
## Inspiration
Let's face it: Museums, parks, and exhibits need some work in this digital era. Why lean over to read a small plaque when you can get a summary and details by tagging exhibits with a portable device?
There is a solution for this of course: NFC tags are a fun modern technology, and they could be used to help people appreciate both modern and historic masterpieces. Also there's one on your chest right now!
## The Plan
Whenever a tour group, such as a student body, visits a museum, they can streamline their activities with our technology. When a member visits an exhibit, they can scan an NFC tag to get detailed information and receive a virtual collectible based on the artifact. The goal is to facilitate interaction amongst the museum patrons for collective appreciation of the culture. At any time, the members (or, as an option, group leaders only) will have access to a live slack feed of the interactions, keeping track of each other's whereabouts and learning.
## How it Works
When a user tags an exhibit with their device, the Android mobile app (built in Java) will send a request to the StdLib service (built in Node.js) that registers the action in our MongoDB database, and adds a public notification to the real-time feed on slack.
## The Hurdles and the Outcome
Our entire team was green to every technology we used, but our extensive experience and relentless dedication let us persevere. Along the way, we gained experience with deployment oriented web service development, and will put it towards our numerous future projects. Due to our work, we believe this technology could be a substantial improvement to the museum industry.
## Extensions
Our product can be easily tailored for ecotourism, business conferences, and even larger scale explorations (such as cities and campus). In addition, we are building extensions for geotags, collectibles, and information trading. | ## Inspiration
We are very interested in the intersection of the financial sector and engineering, and wanted to find a way to speed up computation time in relation to option pricing through simulations.
## What it does
Bellcrve is a distributed computing network that simulates monte carlo methods on financial instruments to perform option pricing. Using Wolfram as its power source, we are able to converge very fast. The idea was it showcase how much faster these computations become when we distribute across a network of 10 mchines, with up to 10,000 simulations running.
## How we built it
We spun up 10 Virtual Machines on DigitalOcean, setup 8 as the worker nodes, 1 node for the Master, and 1 for the Scheduler to distribute the simulations across the nodes as they became free. We implemented our model using a monte carlo simulation that takes advantage of the Geometric Brownian Motion and Black Scholes Model. GBM is responsible for modeling the assets price path over the course of the simulation. We start the simulation at the stocks current price and observe how it changes as the number of steps increases. The Black Scholes Model is responsible for pricing the stocks theoretical price based on the volatility and time decay. We observed how our simulation converges between the GBM and Black Scholes model as the number of steps and iterations increases, effectively giving us a low error rate.
We developed it using Wolfram, Python, Flask, Dask, React, and Next.JS, D3.JS. Wolfram and Python are responsible for most of the Monte Carlo simulations as well as the backend API and websocket. We used Dask to help manage our distributed network connecting us to our VM's in Digital Ocean. And we used React, and Next.JS to build out the web app and visualized all charts in real-time with D3.JS. Wolfram was crucial to our application being able to converge faster proving that distributing the simulations will help save resources, and speed up simulation times. We packaged up the math behind the Monte Carlo simulation and deployed it as Pypi for others to use.
## Challenges we ran into
We had many challenges along the way, across all fronts. First, we had issues with the websocket trying to connect to our client side, and found out it was due to WSS issues. We then ran into some CORS errors that we were able to sort out. Our formulas kept evolving as we made progress on our application, and we had to account for this change. We realized we needed a different metric from the model and needed to shift in that direction. Setting up the cluster of machines was challenging and took some time to dig into.
## Accomplishments that we're proud of
We are proud to say we pushed a completed application, and deployed it to Vercel. Our application allows users to simulate different stocks and price their options in real time and observe how it converges for different number of simulations.
## What we learned
We learned a lot about websockets, creating real-time visualizations, and having our project depend on the math. This was our first time using Wolfram for our project, and we really enjoyed working with it. We have used similar languages like matlab and python, but we found Wolfram to help us speed up our computations signficantly.
## What's next for Lambda Labs
We hope to continue to improve our application, and bring this to different areas in the financial sector, not just options pricing. | ## Inspiration
With the number of candidates rising in the industry in comparison to the job positions, conducting interviews and deciding on candidates carefully has become a critical task. Along with this ratio imbalance, there are an increasing number of candidates that are forging their experience to gain an unfair advantage over others.
## What it does
The project provides AI interview solution which conducts a human-like interview and deploy AI agents in the backend to verify the authenticity of the candidate.
## How we built it
The project was building NextJS as frontend, and NodeJS as backend. The AI service was provided by Hume, along with Single Store as the backend database. We also used Fetch AI to deploy the AI agents that verify the authenticity.
## Challenges we ran into
Some challenges we ran into were related to integrating Hume into our frontend. Managing the conversation data and inferring it to provide feedback was also tricky.
## Accomplishments that we're proud of
Being able to build a working MVP within 2 days of hacking. Integrating hume AI and being able to persist and maintain conversation transcripts that was later used to make inference.
## What we learned
We learned about using and integrating AI agents to help us with important tasks. Having used Hume AI also provided us with insights on different emotions captured by the AI service that can be used in a lot of downstream tasks.
## What's next for Candidate Compare
We plan on expanding the scope of our candidate information verification to include more thorough checks. We also plan to partner with a couple of early stage adopters to use Candidate Compare and benefit from reduced hiring loads. | winning |
#### For Evaluators/Sponsors
Scroll down for a handy guide to navigating our repository and our project's assets.
## 💥 - How it all started
Cancer is a disease that has affected our team quite directly. All of our team members know a relative or loved one that has endured or lost their life due to cancer. This makes us incredibly passionate about wanting to improve cancer patient care. We identi fied a common thread of roadblocks that our loved ones went through during their journey through their diagnosis/treatment/etc:
* **Diagnosis and Staging:** Properly diagnosing the type and stage of cancer is essential for determining the most appropriate treatment plan.
* **Treatment Options:** There are many different types of cancer, and treatment options can vary widely. Selecting the most effective and appropriate treatment for an individual patient can be challenging.
* **Multidisciplinary Care:** Coordinating care among various healthcare professionals, including oncologists, surgeons, radiologists, nurses, and others, can be complex but is necessary for comprehensive cancer care.
* **Communication:** Effective communication among patients, their families, and healthcare providers is crucial for making informed decisions and ensuring the patient's needs and preferences are met.
## 📖 - What it does
We built Cancer360° to create a novel, multimodal approach towards detecting and predicting lung cancer. We synthesized four modes of data qualitative (think demographics, patient history), image (of lung CT scans), text (collected by an interactive chatbot), and physicical (via the ZeppOS Smartwatch) with deep learning frameworks and large language models to copmute a holistic metric for patient likelihood of lung cancer. Through this data-driven approach, we aim to address what we view as "The BFSR": The 'Big Four' of Surmountable Roadblocks:
* **Diagnosis:** Our diagnosis system is truly multimodal through our 4 modes: quantitative (uses risk factors, family history, demographics), qualitative (analysis of medical records like CT Scans), physical measurements (through our Zepp OS App), and our AI Nurse.
* **Treatment Options:** Our nurse can suggest multiple roadmaps of treatment options that patients could consider. For accessibility and ease of understanding, we created an equivalent to Google's featured snippets when our nurse mentions treatment options or types of treatment.
* **Multidisciplinary Care:** The way Cancer360° has been built is to be a digital aid that bridges the gaps with the automated and manual aspects of cancer treatment. Our system prompts patients to enter relevant information for our nurse to analyze and distribute what's important to healthcare professionals.
* **Communication:** This is a major need for patients and families in the road to recovery. Cancer360's AI nurse accomplishes this through our emotionally-sensitive responses and clear/instant communication with patients that input their information, vitals, and symptoms.
## 🔧 - How we built it
To build our Quantitative Mode, we used the following:
* **numpy**: for general math and numpy.array
* **Pandas**: for data processing, storage
* **SKLearn**: for machine learning (train\_test\_split, classification\_report)
* **XGBoost**: Extreme Boosting Trees Decision Trees
To build our Qualitative Mode, we used the following:
* **OpenCV** and **PIL** (Python Imaging Library): For Working With Image Data
* **MatPlotLib** and **Seaborn** : For Scientific Plotting
* **Keras**: Image Data Augmentation (think rotating and zooming in), Model Optimizations (Reduce Learning Rate On Plateau)
* **Tensorflow**: For the Convolutional Neural Network (CNN)
To build our AI Nurse, we used the following:
* **Together.ai:** We built our chatbot with the Llama2 LLM API and used tree of thought prompt engineering to optimize our query responses
To build the portal, we used the following:
* **Reflex:** We utilized the Reflex platform to build our entire frontend and backend, along with all interactive elements. We utilized front end components such as forms, buttons, progress bars, and more. More importantly, Reflex enabled us to directly integrate python-native applications like machine learning models from our quantitative and qualitative modes or our AI Nurse directly into the backend.
## 📒 - The Efficacy of our Models
**With Quantitative/Tabular Data:**
We collected quantitative data for patient demographic, risk factors, and history (in the form of text, numbers, and binary (boolean values)). We used a simple keyword search algorithm to identify risk keywords like “Smoking” and “Wheezing” to transform the text into quantitative data. Then we aggregated all data into a single Pandas dataframe and applied one-hot-encoding on categorical variables like gender. We then used SKLearn to create a 80-20 test split, and tested various models via the SKLearn library, including Logistic Regression, Random Forest, SVM, and K Nearest Neighbors. We found that ultimately, XGBoost performed best with the highest 98.39% accuracy within a reasonable 16-hour timeframe. Our training dataset was used in a research paper and can be accessed [here.](https://www.kaggle.com/datasets/nancyalaswad90/lung-cancer) This high accuracy speaks to the reliability of our model. However, it's essential to remain vigilant against overfitting and conduct thorough validation to ensure its generalizability, a testament to our commitment to both performance and robustness.
[View our classification report here](https://imgur.com/a/YAvXwyk)
**With Image Data:**
Our solution is well-equipped to handle complex medical imaging tasks. Using data from the Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases (IQ-OTH/NCCD) lung cancer dataset, and deep learning frameworks from tensorflow and keras, we were able to build a convolution neural network to classify patient CT scans as malignant or benign. Our convolutional neural network was fine-tuned for binary image classification of 512x512 RGB images, with multiple convolutional, max-pooling, normalization, and dense layers, compiled using the Adam optimizer and binary crossentropy loss. We also used OpenCV, PIL, Matplotlib, and Numpy to deliver a commendable 93% accuracy over a 20-hour timeframe. The utilization of dedicated hardware resources, such as Intel developer cloud with TensorFlow GPU, accelerates processing by 24 times compared to standard hardware. While this signifies our technological edge, it's important to acknowledge that image classification accuracy can vary based on data quality and diversity, making the 93% accuracy an achievement that underscores our commitment to delivering high-quality results.
[Malignant CT Scan](https://imgur.com/a/8oGYz71)
[Benign CT Scan](https://imgur.com/a/3X3zb7k)
**AI Nurse:**
The AI Nurse powered by Together.ai and LLMs (such as Llama2) introduces an innovative approach to patient interaction and risk factor determination. Generating "trees of thoughts" showcases our ability to harness large language models for effective communication. Combining multiple AI models to determine risk factor percentages for lung cancer demonstrates our holistic approach to healthcare support. However, it's essential to acknowledge that the efficacy of this solution is contingent on the quality of language understanding, data processing, and the integration of AI models, reflecting our dedication to continuous improvement and fine-tuning.
## 🚩 - Challenges we ran into
* Challenges we fixed:
* Loading our neural network model into the Reflex backend. After using keras to save the model as a “.h5” extension, we were able to load and run the model locally on my jupyter notebook, however when we tried to load it in the Reflex backend, we kept getting a strange Adam optimizer build error. we tried everything: saving the model weights separately, using different file extensions like .keras, and even saving the model on as a .json file. Eventually, we realized that this was a [known issue with m1/m2 macs and tensorflow](https://github.com/tensorflow/tensorflow/issues/61915)
* Fixed the Get Started Button in Reflex header (Issue: button wouldn’t scale to match the text length) - Moved the button outside the inner hstack, but still the outer hstack
* Integrating together ai chatbot model into Reflex: A lot of our time was spent trying to get the integration working.
* Challenges we didn’t fix:
+ Left aligning the AI response and right aligning the user input in the chatbot
+ Fine tuning a second model to predict lung cancer rate from the chatbot responses from the first model - Could not get enough training data, too computationally taxing and few shot learning did not produce results
+ Fixing bugs related to running a virtual javascript environment within Python via PyV8
## 🏆 - Accomplishments that we're proud of
* Going from idea generation to working prototype, with integration of 4 data modalities - Qualitative Mode, Quantitative Mode, and our AI Nurse, and Smartwatch Data, within the span of less than two days
* Integrating machine learning models and large language models within our application in a way that is directly accessible to users
* Learning a completely new web development framework (Reflex) from scratch without extensive documentation and ChatGPT knowledge
* Working seamlessly as a team and take advantage of the component-centered nature of Reflex to work independently and together
## 📝 - What we learned
* Ameya: "I was fortunate enough to learn a lot about frameworks like Reflex and Together.ai."
* Marcus: "Using Reflex and learning its components to integrate backend and frontend seamlessly."
* Timothy: "I realized how I could leverage Reflex, Intel Developer Cloud, Together.ai, and Zepp Health to empower me in developing with cutting edge technologies like LLMs and deep learning models."
* Alex: "I learned a lot of front end development skills with Reflex that I otherwise wouldn’t have learned as a primarily back-end person."
## ✈️ - What's next for Cancer360°
Just like how a great trip has a great itinenary, we envision Cancer360° future plans in phases.
#### Phase 1: Solidifying our Roots
Phase 1 involves the following goals:
* Revamping our user interface to be more in-line with our mockups
* Increasing connectivity with healthcare professionals
#### Phase 2: Branching Out
View the gallery to see this. Phase 2 involves the following goals:
* Creating a mobile app for iOS and Android of this service
* Furthering development of our models to detect and analyze other types of cancers and create branches of approaches depending on the cancer
* Completing our integration of the physical tracker on Zepp OS
#### Phase 3: Big Leagues
Phase 3 involves the following goals:
* Expanding accessibility of the app through having our services be available in numerous different languages
* Working with healthcare institutions to further improve the usability of the suite
## 📋 - Evaluator's Guide to Cancer360°
##### Intended for judges, however the viewing public is welcome to take a look.
Hey! We wanted to make this guide in order to help provide you further information on our implementations of certain programs and provide a more in-depth look to cater to both the viewing audience and evaluators like yourself.
#### Sponsor Services We Have Used This Hackathon
##### Reflex
The founders (Nikhil and Alex) were not only eager to assist but also highly receptive to our feedback, contributing significantly to our project's success.
In our project, we made extensive use of Reflex for various aspects:
* **Project Organization and Hosting:** We hosted our website on Reflex, utilizing their component-state filesystem for seamless project organization.
* **Frontend:** We relied on Reflex components to render everything visible on our website, encompassing graphics, buttons, forms, and more.
* **Backend:** Reflex states played a crucial role in our project by facilitating data storage and manipulation across our components. In this backend implementation, we seamlessly integrated our website features, including the chatbot, machine learning model, Zepp integration, and X-ray scan model.
##### Together AI
In our project, Together AI played a pivotal role in enhancing various aspects:
* **Cloud Service:** We harnessed the robust capabilities of Together AI's cloud services to host, run, and fine-tune llama 2, a Large Language Model developed by META, featuring an impressive 70 billion parameters. To ensure seamless testing, we evaluated more than ten different chat and language models from various companies. This was made possible thanks to Together AI's commitment to hosting over 30 models on a single platform.
* **Integration:** We seamlessly integrated Together AI's feature set into our web app, combined with Reflex, to deliver a cohesive user experience.
* **Tuning:** Leveraging Together AI's user-friendly hyperparameter control and prompt engineering, we optimized our AI nurse model for peak performance. As a result, our AI nurse consistently generated the desired outputs at an accelerated rate, surpassing default performance levels, all without the need for extensive tuning or prompt engineering.
##### Intel Developer Cloud
Our project would not have been possible without the massive computing power of Intel cloud computers. For reference, [here is the CNN training time on my local computer.](https://imgur.com/a/rfYlVro)
And here is the [CNN training time on my Intel® Xeon 4th Gen ® Scalable processor virtual compute environment and tensorflow GPU.](https://imgur.com/a/h3ctSPY)
A remarkable 20x Speedup! This huge leap in compute speed empowered by Intel® cloud computing enabled us to re-train our models with lightning speed as we worked to debugg and worked to integrate it into our backend. It also made fine-tuning our model much easier as we can tweak the hyperparameters and see their effects on model performance within the span of minutes.
##### Zepp Health
We utilized the ZeppOS API to query real-time user data for calories burned, fat burned, blood oxygen, and PAI (Personal Activity Index). We worked set up a PyV8 virtual javascript environment to run javascript code within Python to integrate the ZeppOS API into our application. Using collected data from the API, we used an ensemble algorithm to compute a health metric evaluating patient health, which ultimately feeds into our algorithm to find patient risk for lung cancer.
##### GitHub
We used GitHub for our project by creating a GitHub repository to host our hackathon project's code. We also ensured that our use of GitHub stood out with a detailed ReadMe page, meaningful pull requests, and a collaboration history, showcasing our dedication to improving cancer patient care through Cancer360°. We leveraged GitHub not only for code hosting but also as a platform to collaborate, push code, and receive feedback.
##### .Tech Domains
We harnessed the potential of a .tech domain to visually embody our vision for Cancer360°, taking a step beyond traditional domains. By registering the website helpingcancerpatientswith.tech, we not only conveyed our commitment to innovative technology but also made a memorable online statement that reflects our dedication to improving the lives of cancer patients. | ## Inspiration
When we joined the hackathon, we began brainstorming about problems in our lives. After discussing some constant struggles in their lives with many friends and family, one response was ultimately shared: health. Interestingly, one of the biggest health concerns that impacts everyone in their lives comes from their *skin*. Even though the skin is the biggest organ in the body and is the first thing everyone notices, it is the most neglected part of the body.
As a result, we decided to create a user-friendly multi-modal model that can discover their skin discomfort through a simple picture. Then, through accessible communication with a dermatologist-like chatbot, they can receive recommendations, such as specific types of sunscreen or over-the-counter medications. Especially for families that struggle with insurance money or finding the time to go and wait for a doctor, it is an accessible way to understand the blemishes that appear on one's skin immediately.
## What it does
The app is a skin-detection model that detects skin diseases through pictures. Through a multi-modal neural network, we attempt to identify the disease through training on thousands of data entries from actual patients. Then, we provide them with information on their disease, recommendations on how to treat their disease (such as using specific SPF sunscreen or over-the-counter medications), and finally, we provide them with their nearest pharmacies and hospitals.
## How we built it
Our project, SkinSkan, was built through a systematic engineering process to create a user-friendly app for early detection of skin conditions. Initially, we researched publicly available datasets that included treatment recommendations for various skin diseases. We implemented a multi-modal neural network model after finding a diverse dataset with almost more than 2000 patients with multiple diseases. Through a combination of convolutional neural networks, ResNet, and feed-forward neural networks, we created a comprehensive model incorporating clinical and image datasets to predict possible skin conditions. Furthermore, to make customer interaction seamless, we implemented a chatbot using GPT 4o from Open API to provide users with accurate and tailored medical recommendations. By developing a robust multi-modal model capable of diagnosing skin conditions from images and user-provided symptoms, we make strides in making personalized medicine a reality.
## Challenges we ran into
The first challenge we faced was finding the appropriate data. Most of the data we encountered needed to be more comprehensive and include recommendations for skin diseases. The data we ultimately used was from Google Cloud, which included the dermatology and weighted dermatology labels. We also encountered overfitting on the training set. Thus, we experimented with the number of epochs, cropped the input images, and used ResNet layers to improve accuracy. We finally chose the most ideal epoch by plotting loss vs. epoch and the accuracy vs. epoch graphs. Another challenge included utilizing the free Google Colab TPU, which we were able to resolve this issue by switching from different devices. Last but not least, we had problems with our chatbot outputting random texts that tended to hallucinate based on specific responses. We fixed this by grounding its output in the information that the user gave.
## Accomplishments that we're proud of
We are all proud of the model we trained and put together, as this project had many moving parts. This experience has had its fair share of learning moments and pivoting directions. However, through a great deal of discussions and talking about exactly how we can adequately address our issue and support each other, we came up with a solution. Additionally, in the past 24 hours, we've learned a lot about learning quickly on our feet and moving forward. Last but not least, we've all bonded so much with each other through these past 24 hours. We've all seen each other struggle and grow; this experience has just been gratifying.
## What we learned
One of the aspects we learned from this experience was how to use prompt engineering effectively and ground an AI model and user information. We also learned how to incorporate multi-modal data to be fed into a generalized convolutional and feed forward neural network. In general, we just had more hands-on experience working with RESTful API. Overall, this experience was incredible. Not only did we elevate our knowledge and hands-on experience in building a comprehensive model as SkinSkan, we were able to solve a real world problem. From learning more about the intricate heterogeneities of various skin conditions to skincare recommendations, we were able to utilize our app on our own and several of our friends' skin using a simple smartphone camera to validate the performance of the model. It’s so gratifying to see the work that we’ve built being put into use and benefiting people.
## What's next for SkinSkan
We are incredibly excited for the future of SkinSkan. By expanding the model to incorporate more minute details of the skin and detect more subtle and milder conditions, SkinSkan will be able to help hundreds of people detect conditions that they may have ignored. Furthermore, by incorporating medical and family history alongside genetic background, our model could be a viable tool that hospitals around the world could use to direct them to the right treatment plan. Lastly, in the future, we hope to form partnerships with skincare and dermatology companies to expand the accessibility of our services for people of all backgrounds. | ## Inspiration
This project came to us when one of our teammates mentioned his grandma struggling to keep track of her cholesterol and the medications she was taking to lower it. We realized that to help alleviate this, we would need to approach the problem from both sides.
High blood cholesterol causes **4.4 million** deaths each year (World Heart Federation, 2019), and other nutrient deficiencies and surplusses take many more. By leveraging new multimodal LLMs, we set out to solve this complex and multi-faceted problem.
## What it does
MultiMed Vision+ allows users to track both their medications and nutrients with the snap of a picture. It then uses the information scanned by the user to generate advice in the context of the user's current health situation. MultiMed Vision+ integrates with our Raspberry Pi "watch", desktop app, and mobile app, easing access and user-friendliness for this demographic.
The project comprises several key components, including:
Integration of Prescription and Nutrition Data:
Incorporating scanned prescriptions and food items to provide personalized recommendations based on individual health contexts.
Analyzing prescription data to offer tailored health advice and reminders related to medication adherence.
Smartwatch Integration:
Facilitating easy access to health data without the need for a smartphone.
Streamlining the monitoring of vital health indicators for elderly individuals.
User-Friendly Interface:
Designing an intuitive and straightforward interface specifically tailored to the needs of older users.
Offering clear and concise advice on dietary choices and providing real-time health monitoring.
Real-Time Sensor Data Analysis:
Utilizing machine learning models integrated with real-time sensor data to predict the risk of heart attacks.
Providing timely alerts and notifications to both the user and their family members, enabling proactive health management and intervention.
## How we built it
Our project is split into a frontend and a backend stack. Our front end includes all of our UI/UX designs, and it utilizes Next.js + Typescript to build a UI design. It has authentication from Firebase + Clerk.js, and uses Tailwind CSS for styling. In the backend, we have our machine learning pipeline in Python as well as our API routes through FastAPI. We utilized OpenAI, Azure AI, Hugging Face, and Intersystems IntegratedML.
## Challenges we ran into
One of the main issues we ran into was understanding and integrating InterSystems into our product. Since it was the first time our entire team was working with the IntegratedML tool, we had to spend quite a bit of time debugging and reading tool documentation to understand how we could implement this pipeline.
## Accomplishments that we're proud of
We were able to simulate a real-life scenario where a user could scan their prescription and dishes from either their smartwatch (simulated through a raspberry pi) or mobile phone seamlessly. The integration of our tool into a wearable device allows a user to go about their entire day while also keeping track of their health in just a few seconds. We were able to hyper-personalize our context window and integrate an ML model so that our tool could give reliable insights to users based on their pre-existing conditions and eating habits.
## What we learned
We learned a lot about integrations with different systems and models. Specifically, we learn how to use InterSystems as well as integrations with Raspberry Pi.
## What's next for MultiMed Vision+
The next step for MultiMed Vision is to launch this idea fully, expanding our vast data sources and improving on our hardware + software systems. Moreover, we are looking to consider expanding our platform that can tell us more about where our food came form, such as where it's being produced/processed. We could potentially integrate with blockchain technology by briding the real world with web&web3. | winning |