Datasets:

Tasks:
Text Classification
Formats:
csv
Sub-tasks:
multi-label-classification
Languages:
English
Size:
10K - 100K
License:

| language: | |
| - en | |
| license: afl-3.0 | |
| source_datasets: | |
| - BioASQ Task A | |
| task_categories: | |
| - text-classification | |
| task_ids: | |
| - multi-label-classification | |
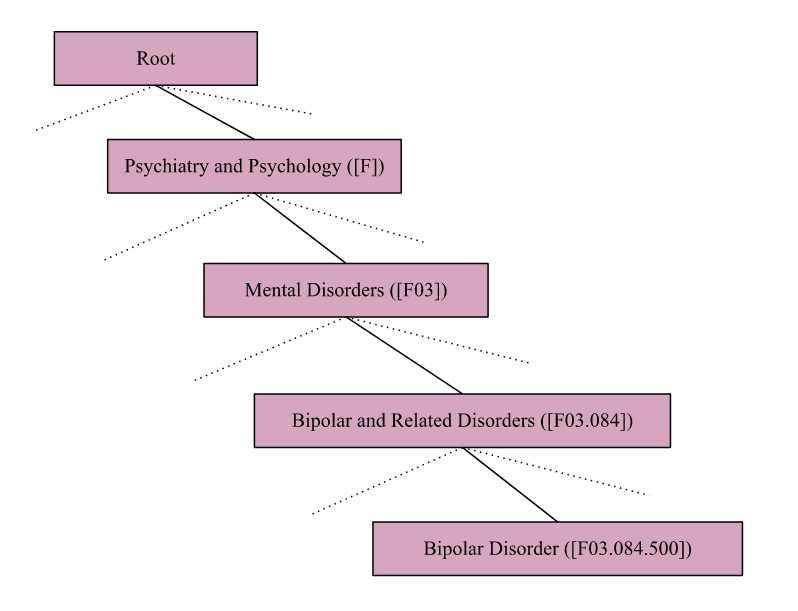
| This dataset consists of a approx 50k collection of research articles from **PubMed** repository. Originally these documents are manually annotated by Biomedical Experts with their MeSH labels and each articles are described in terms of 10-15 MeSH labels. In this Dataset we have huge numbers of labels present as a MeSH major which is raising the issue of extremely large output space and severe label sparsity issues. To solve this Issue Dataset has been Processed and mapped to its root as Described in the Below Figure. | |
|  | |
|  | |