
__key__
stringlengths 23
88
| __url__
stringclasses 1
value | csv
unknown |
|---|---|---|
data/pretrain/test/info | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "ZGlybmFtZSxjb21wb3NpdGVfaWQsY3BzLGNvcmUsY29tcG9zaXRlX2RlcHRoX21tLHNlY3Rpb25fZGVwdGhfbW0sZmlsZW5hbWU(...TRUNCATED) |
data/pretrain/test/spe/1978 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAo(...TRUNCATED) |
data/pretrain/test/spe/3310 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAoxCjAKMAowCjAKMgowCjEKMwowCjIKMAo(...TRUNCATED) |
data/pretrain/test/spe/4457 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAoxCjAKMQoyCjIKMgoyCjEKMAo(...TRUNCATED) |
data/pretrain/test/spe/1803 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAo(...TRUNCATED) |
data/pretrain/test/spe/4258 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjEKMAowCjEKMQoxCjEKMQowCjIKMwo(...TRUNCATED) |
data/pretrain/test/spe/3005 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMQowCjIKMQoyCjIKNAo(...TRUNCATED) |
data/pretrain/test/spe/1280 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAo(...TRUNCATED) |
data/pretrain/test/spe/2943 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAoxCjAKMAowCjIKMwo2CjUKMTA(...TRUNCATED) |
data/pretrain/test/spe/3630 | hf://datasets/paoyw/max-dataset@2bb60dbe5d9996afbcada9d0ba5b35b434cd06da/data.tar.gz | "MAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMAowCjAKMQowCjAKMQowCjAKMQo0CjEKMwowCjAKMwozCjMKNAo(...TRUNCATED) |
Pretraining Foundation Models: Unleashing the Power of Forgotten Spectra for Advanced Geological Applications
The dataset for masked autoencoder for X-ray fluorescence (XRF) is a following development after the dataset (Chao et al., 2022). Besides the published XRF spectra-target measurements (CaCO3 and TOC) pairs of data, we further upload the XRF spectra in that project but without alignments of the target measurements here. They are compiled in a machine learning ready format, which we expect for convenient implementation of other studies.
The investigated cores, which form the datast, are mostly retrieved across the high- to mid-latitude Northwest Pacific (37°N-52°N) and the Pacific sector of the Southern Ocean (53°S-63°S), with a water depth coverage from 1211 to 4853 m:
- Cruise SO264 in the subarctic Northwest Pacific with R/V SONNE in 2018
- Cruise PS97 in the central Drake Passage with RV Polarstern in 2016
- Cruise PS75 in the Pacific sector of the Southern Ocean in 2009/2010.
- Cruise KOMEX I and KOMEX II with R/V Akademik Lavrentyev in 1998 and cruise SO178 in 2004 in the Okhotsk Sea.
For more information, please checkout the published paper (Lee et al., 2022) and previous dataset (Chao et al., 2022). The direct use of this dataset is documented in the GitHub repo.
Data structure
- raw: Raw spectra in the Avaatech XRF Core Scanner format. Each subfolder contains the raw data for a core series.
- legacy: Previously compiled and raw data in (Lee et al., 2022).
- pretrain: Data used for pre-training and is built from the previously compiled spectra data
legacy/spe_dataset_20220629.csv. Thetrainsubfolder has the training and validation sets. Thetestsubfolder contains the data selected during fine-tuning as the zero-shot test, i.e., case study in the published paper.
+- train
+- spe (all spetra)
+- info.csv (training set spectrum list)
+- val.csv (validation set spectrum list)
+- test
+- spe
+- info.csv (case study spectrum list)
- fine-tune: Data used for fine-tuning. The
trainsubfolder has the training and validation sets. Thetestsubfolder is the data for zero-shot test, i.e., case study in the published paper.
+- CaCO3%
+- train
+- spe (all spetra)
+- target (all target measurements)
+- info.csv (training set spectrum-target pair list)
+- info_#.csv (splits from the info.csv in different data amounts)
+- val.csv (validation set spectrum-target pair list)
+- test
(same as in train)
+- TOC%
(same as in CaCO3%)
The target data (CaCO3 and TOC) distribution:
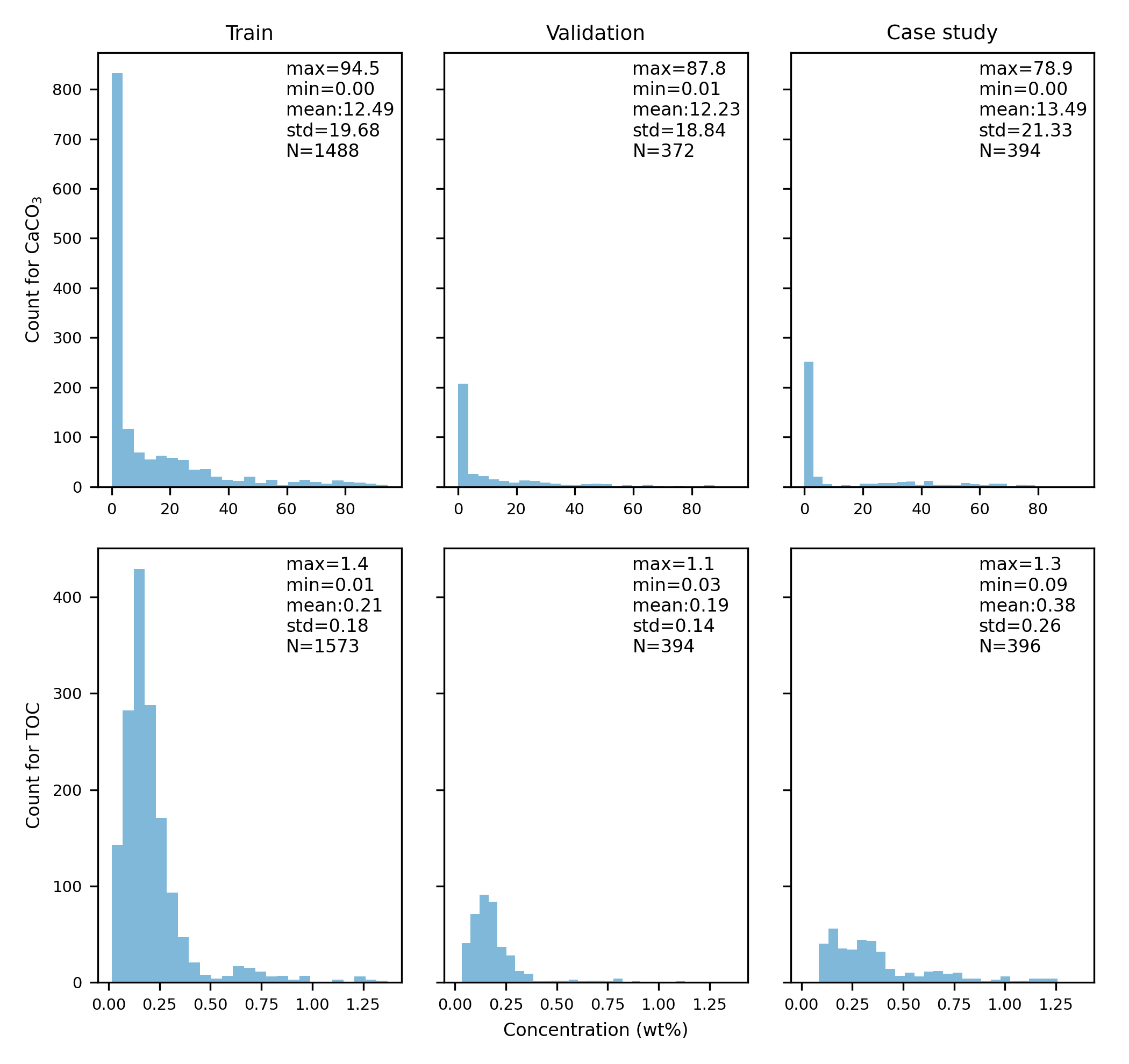
The case study (i.e., test set) is composed of three cores ('PS75-056-1', 'LV28-44-3', 'SO264-69-2') isolated from the beginning and not used in both the pre-training and fine-tuning process.
The rest of data are randomly split in to the trainging and validation sets wtih 4:2 ratio.
The script is src/datas/build_data.py in the GitHub repo.
Acknowledgements We thank the crew and the science parties of different cruises for their contributions to core and sample acquisition on the respective expeditions. We are very grateful to Dr. Weng‐Si Chao, Dr. Lester Lembke‐Jene, and Dr. Frank Lamy for providing these data. We also sincerely thank Valéa Schumacher, Susanne Wiebe, and Rita Fröhlking and student assistants at the AWI Marine Geology Laboratory in Bremerhaven for technical assistance with XRF-scanning, CaCO3 and TOC measurements.
- Downloads last month
- 2