Datasets:

annotations_creators:
- crowdsourced
license: other
pretty_name: DocLayNet small
size_categories:
- 1K<n<10K
tags:
- DocLayNet
- COCO
- PDF
- IBM
- Financial-Reports
- Finance
- Manuals
- Scientific-Articles
- Science
- Laws
- Law
- Regulations
- Patents
- Government-Tenders
- object-detection
- image-segmentation
- token-classification
task_categories:
- object-detection
- image-segmentation
- token-classification
task_ids:
- instance-segmentation
language:
- en
- de
- fr
- ja
Dataset Card for DocLayNet small
About this card (01/27/2023)
Property and license
All information from this page but the content of this paragraph "About this card (01/27/2023)" has been copied/pasted from Dataset Card for DocLayNet.
DocLayNet is a dataset created by Deep Search (IBM Research) published under license CDLA-Permissive-1.0.
I do not claim any rights to the data taken from this dataset and published on this page.
DocLayNet dataset
DocLayNet dataset (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face dataset library: dataset DocLayNet
Paper: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (06/02/2022)
Processing into a format facilitating its use by HF notebooks
These 2 options require the downloading of all the data (approximately 30GBi), which requires downloading time (about 45 mn in Google Colab) and a large space on the hard disk. These could limit experimentation for people with low resources.
Moreover, even when using the download via HF datasets library, it is necessary to download the EXTRA zip separately (doclaynet_extra.zip, 7.5 GiB) to associate the annotated bounding boxes with the text extracted by OCR from the PDFs. This operation also requires additional code because the boundings boxes of the texts do not necessarily correspond to those annotated (a calculation of the percentage of area in common between the boundings boxes annotated and those of the texts makes it possible to make a comparison between them).
At last, in order to use Hugging Face notebooks on fine-tuning layout models like LayoutLMv3 or LiLT, DocLayNet data must be processed in a proper format.
For all these reasons, I decided to process the DocLayNet dataset:
- into 3 datasets of different sizes:
- DocLayNet small (about 1% of DocLayNet) < 1.000k document images (691 train, 64 val, 49 test)
- DocLayNet base (about 10% of DocLayNet) < 10.000k document images (6910 train, 648 val, 499 test)
- DocLayNet large (about 100% of DocLayNet) < 100.000k document images (69.103 train, 6.480 val, 4.994 test)
- with associated texts and PDFs (base64 format),
- and in a format facilitating their use by HF notebooks.
Note: the layout HF notebooks will greatly help participants of the IBM ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents!
About PDFs languages
Citation of the page 3 of the DocLayNet paper: "We did not control the document selection with regard to language. The vast majority of documents contained in DocLayNet (close to 95%) are published in English language. However, DocLayNet also contains a number of documents in other languages such as German (2.5%), French (1.0%) and Japanese (1.0%). While the document language has negligible impact on the performance of computer vision methods such as object detection and segmentation models, it might prove challenging for layout analysis methods which exploit textual features."
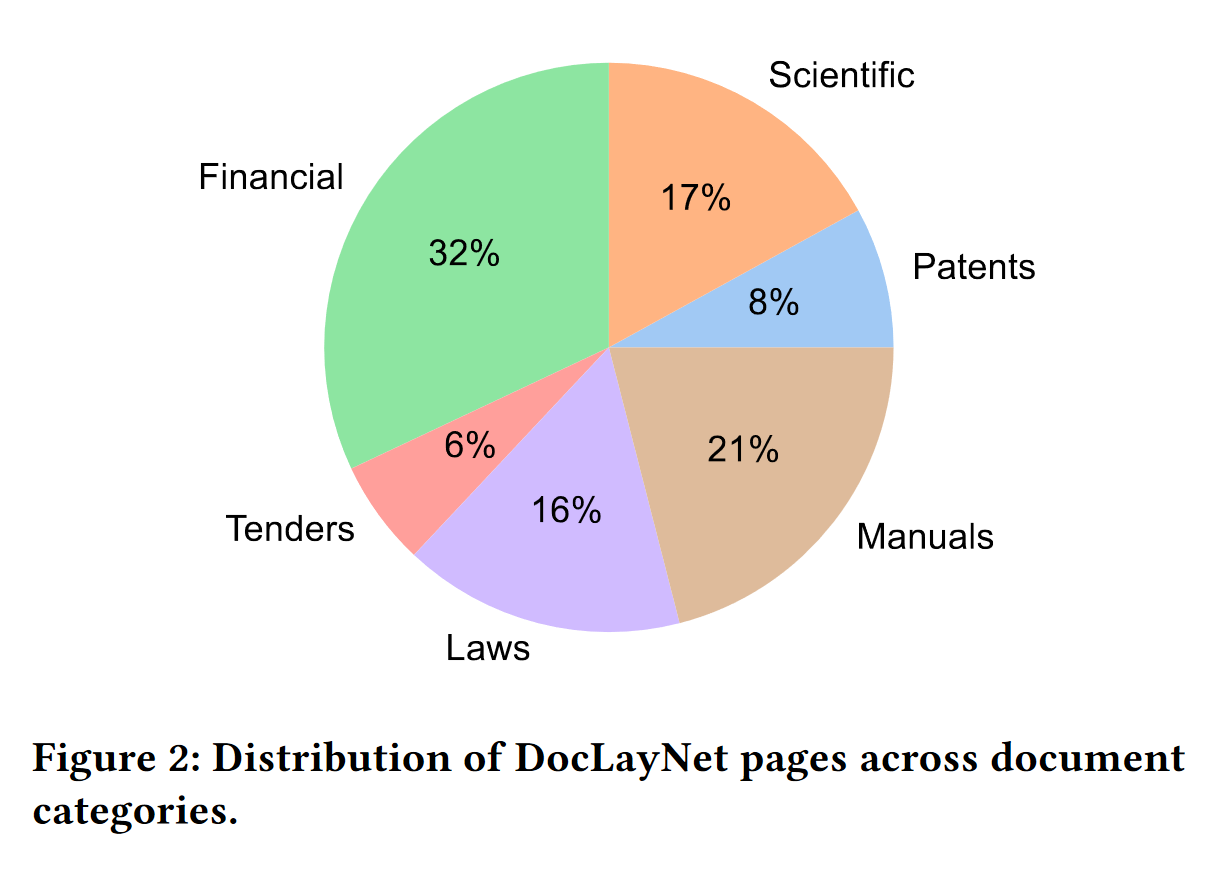
About PDFs categories distribution
Citation of the page 3 of the DocLayNet paper: "The pages in DocLayNet can be grouped into six distinct categories, namely Financial Reports, Manuals, Scientific Articles, Laws & Regulations, Patents and Government Tenders. Each document category was sourced from various repositories. For example, Financial Reports contain both free-style format annual reports which expose company-specific, artistic layouts as well as the more formal SEC filings. The two largest categories (Financial Reports and Manuals) contain a large amount of free-style layouts in order to obtain maximum variability. In the other four categories, we boosted the variability by mixing documents from independent providers, such as different government websites or publishers. In Figure 2, we show the document categories contained in DocLayNet with their respective sizes."
Download & overview
The size of the DocLayNet small is about 1% of the DocLayNet dataset (random selection respectively in the train, val and test files).
# !pip install -q datasets
from datasets import load_dataset
dataset_small = load_dataset("pierreguillou/DocLayNet-small")
# overview of dataset_small
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 691
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 64
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 49
})
})
Annotated bounding boxes
The DocLayNet base makes easy to display document image with the annotaed bounding boxes of paragraphes or lines.
Check the notebook processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb in order to get the code.
Paragraphes

Lines

HF notebooks
- notebooks LayoutLM (Niels Rogge)
- notebooks LayoutLMv2 (Niels Rogge)
- notebooks LayoutLMv3 (Niels Rogge)
- notebooks LiLT (Niels Rogge)
- Document AI: Fine-tuning LiLT for document-understanding using Hugging Face Transformers (post of Phil Schmid)
Table of Contents
Dataset Description
- Homepage: https://developer.ibm.com/exchanges/data/all/doclaynet/
- Repository: https://github.com/DS4SD/DocLayNet
- Paper: https://doi.org/10.1145/3534678.3539043
- Leaderboard:
- Point of Contact:
Dataset Summary
DocLayNet provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories. It provides several unique features compared to related work such as PubLayNet or DocBank:
- Human Annotation: DocLayNet is hand-annotated by well-trained experts, providing a gold-standard in layout segmentation through human recognition and interpretation of each page layout
- Large layout variability: DocLayNet includes diverse and complex layouts from a large variety of public sources in Finance, Science, Patents, Tenders, Law texts and Manuals
- Detailed label set: DocLayNet defines 11 class labels to distinguish layout features in high detail.
- Redundant annotations: A fraction of the pages in DocLayNet are double- or triple-annotated, allowing to estimate annotation uncertainty and an upper-bound of achievable prediction accuracy with ML models
- Pre-defined train- test- and validation-sets: DocLayNet provides fixed sets for each to ensure proportional representation of the class-labels and avoid leakage of unique layout styles across the sets.
Supported Tasks and Leaderboards
We are hosting a competition in ICDAR 2023 based on the DocLayNet dataset. For more information see https://ds4sd.github.io/icdar23-doclaynet/.
Dataset Structure
Data Fields
DocLayNet provides four types of data assets:
- PNG images of all pages, resized to square
1025 x 1025px - Bounding-box annotations in COCO format for each PNG image
- Extra: Single-page PDF files matching each PNG image
- Extra: JSON file matching each PDF page, which provides the digital text cells with coordinates and content
The COCO image record are defined like this example
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// Custom fields:
"doc_category": "financial_reports" // high-level document category
"collection": "ann_reports_00_04_fancy", // sub-collection name
"doc_name": "NASDAQ_FFIN_2002.pdf", // original document filename
"page_no": 9, // page number in original document
"precedence": 0, // Annotation order, non-zero in case of redundant double- or triple-annotation
},
...
The doc_category field uses one of the following constants:
financial_reports,
scientific_articles,
laws_and_regulations,
government_tenders,
manuals,
patents
Data Splits
The dataset provides three splits
trainvaltest
Dataset Creation
Annotations
Annotation process
The labeling guideline used for training of the annotation experts are available at DocLayNet_Labeling_Guide_Public.pdf.
Who are the annotators?
Annotations are crowdsourced.
Additional Information
Dataset Curators
The dataset is curated by the Deep Search team at IBM Research. You can contact us at deepsearch-core@zurich.ibm.com.
Curators:
- Christoph Auer, @cau-git
- Michele Dolfi, @dolfim-ibm
- Ahmed Nassar, @nassarofficial
- Peter Staar, @PeterStaar-IBM
Licensing Information
License: CDLA-Permissive-1.0
Citation Information
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
Contributions
Thanks to @dolfim-ibm, @cau-git for adding this dataset.