
license: cc-by-4.0
task_categories:
- zero-shot-classification
- text-classification
- feature-extraction
language:
- en
tags:
- climate
pretty_name: ClimateX Expert Confidence in Climate Statements dataset
size_categories:
- 1K<n<10K
ClimateX: Expert Confidence in Climate Statements
What do LLMs know about climate? Let's find out!
ClimateX Dataset
We introduce the Expert Confidence in Climate Statements (ClimateX) dataset, a novel, curated, expert-labeled, natural language dataset of 8094 statements extracted or paraphrased from the IPCC Assessment Report 6: Working Group I report, Working Group II report, and Working Group III report, respectively.
Each statement is labeled with the corresponding IPCC report source, the page number in the report PDF, and the corresponding confidence level, along with their associated confidence levels (low, medium, high, or very high) as assessed by IPCC climate scientists based on available evidence and agreement among their peers.
Confidence Labels
The authors of the United Nations International Panel on Climate Change (IPCC) reports have developed a structured framework to communicate the confidence and uncertainty levels of statements regarding our knowledge of climate change (Mastrandrea, 2010).
Our dataset leverages this distinctive and consistent approach to labelling uncertainty across topics, disciplines, and report chapters, to help NLP and climate communication researchers evaluate how well LLMs can assess human expert confidence in a set of climate science statements from the IPCC reports.
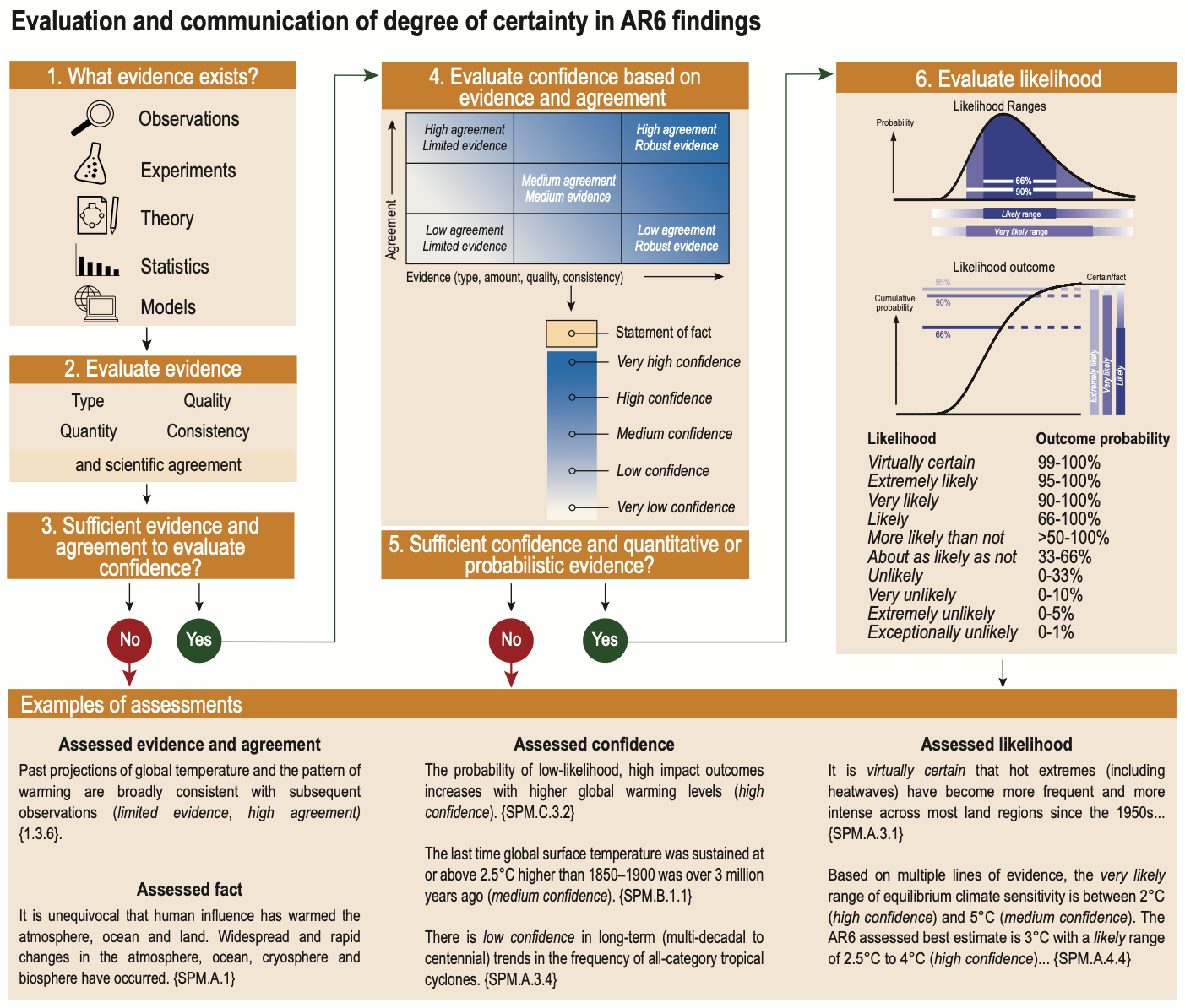
Source: IPCC AR6 Working Group I report
Dataset Construction
To construct the dataset, we retrieved the complete raw text from each of the three IPCC report PDFs that are available online using an open-source library pypdf2. We then normalized the whitespace, tokenized the text into sentences using NLTK , and used regex search to filter for complete sentences including a parenthetical confidence label at the end of the statement, of the form sentence (low|medium|high|very high confidence). The final ClimateX dataset contains 8094 labeled sentences.
From the full 8094 labeled sentences, we further selected 300 statements to form a smaller and more tractable test dataset. We performed a random selection of sentences within each report and confidence category, with the following objectives:
- Making the test set distribution representative of the confidence class distribution in the overall train set and within each report;
- Making the breakdown between source reports representative of the number of statements from each report;
- Making sure the test set contains at least 5 sentences from each class and from each source, to ensure our results are statistically robust.
Then, we manually reviewed and cleaned each sentence in the test set to provide for a fairer assessment of model capacity. We then progamatically cleaned up the train set (removing references and extraneous confidence labels, and explaining acronyms)
The remaining 7794 sentences not allocated to the test split form our train split.
Of note: while the IPCC report uses a 5 levels scale for confidence, almost no very low confidence statement makes it through the peer review process to the final reports, such that no statement of the form sentence (very low confidence) was retrievable. Therefore, we chose to build our data set with only statements labeled as low, medium, high and very high confidence.
Code Download
The code to reproduce dataset collection and our LLM benchmarking experiments is released on GitHub.