
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
---
description: HTTP Server Timing
---
elton可以非常方便的获取各中间件的处理时长,获取统计时长之后,则可方便的写入相关的统计数据或HTTP响应的Server-Timing了。
如图所示在chrome中network面板所能看得到Server-Timing展示:

```go
package main
import (
"github.com/vicanso/elton"
"github.com/vicanso/elton/middleware"
)
func main() {
e := elton.New()
e.EnableTrace = true
e.OnTrace(func(c *elton.Context, traceInfos elton.TraceInfos) {
serverTiming := string(traceInfos.ServerTiming("elton-"))
c.SetHeader(elton.HeaderServerTiming, serverTiming)
})
entry := func(c *elton.Context) (err error) {
c.ID = "random id"
c.NoCache()
return c.Next()
}
e.Use(entry)
// 设置中间件的名称,若不设置从runtime中获取
// 对于公共的中间件,建议指定名称
e.SetFunctionName(entry, "entry")
fn := middleware.NewDefaultResponder()
e.Use(fn)
e.SetFunctionName(fn, "responder")
e.GET("/", func(c *elton.Context) (err error) {
c.Body = &struct {
Name string `json:"name,omitempty"`
Content string `json:"content,omitempty"`
}{
"tree.xie",
"Hello, World!",
}
return
})
err := e.ListenAndServe(":3000")
if err != nil {
panic(err)
}
}
```
```
curl -v 'http://127.0.0.1:3000/'
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 3000 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1:3000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Cache-Control: no-cache
< Content-Length: 44
< Content-Type: application/json; charset=utf-8
< Server-Timing: elton-0;dur=0;desc="entry",elton-1;dur=0.03;desc="responder",elton-2;dur=0;desc="main.main.func3"
< Date: Fri, 03 Jan 2020 13:08:50 GMT
<
* Connection #0 to host 127.0.0.1 left intact
{"name":"tree.xie","content":"Hello, World!"}
``` | 1,736 | MIT |
---
author: admin
comments: true
date: 2012-06-18 05:21:56+00:00
layout: post
slug: makefile-variables-and-assignments
title: makefile变量和赋值
wordpress_id: 400
categories:
- makefile
tags:
- make
- makefile
- 区别
- 大括号
- 括号
---
**makefile变量表示**
在makefile中,表示一个变量要用$(VAR) ${VAR}两种都行,但是在shell中必须要用大括号。其实makefile要求用小括号,只是在shell中解析用哪个都行。如果在makefile中要解析shell变量,要使用$${PWD}才可以。
**makefile赋值<!-- more -->**
VARIABLE = value
普通的赋值,如果使用值的时候会递归展开,并不是在定义的之后就把值赋好。
VARIABLE ?= value
只有在VARIABLE 为空的时候才赋值
VARIABLE := value
在声明的时候就把值给赋值好了,后面value的值改变不影响VARIABLE 。
VARIABLE += value
在VARIABLE 的值后面增加value的值。
> #example
a = orginal_value
b = $(a)
a = later_value
all:
@echo $(b)
运行make
#make
later_value
#example
a = orginal_value
b := $(a)
a = later_value
all:
@echo
$(b)
#make
original_value | 792 | MIT |
# tina-router
> An elegant enhanced router for Tina.js based Wechat-Mini-Program
[](https://www.npmjs.com/package/@tinajs/tina-router)
[](./LICENSE)
[](http://makeapullrequest.com)
## 快速上手
我们假设你已经在使用 [Tina](https://github.com/tinajs/tina) 和 [mina-webpack](https://github.com/tinajs/mina-webpack) 开发小程序项目。
### 安装
```bash
npm i --save @tinajs/tina-router
```
```javascript
/**
* <script> in /app.mina
*/
import Tina from '@tinajs/tina'
import router from '@tinajs/tina-router'
Tina.use(router)
App(......)
```
### 使用
```javascript
/**
* <script> in /pages/demo.mina
*/
import { Page } from '@tinajs/tina'
import { api } from '../api'
Page.define({
onLoad () {
api.fetchUser({ id: this.$route.query.id }).then((data) => this.setData(data))
},
methods: {
toLogin () {
this.$router.navigate(`/pages/login?from=${this.$route.fullPath}`)
},
},
})
```
## 常见问题
### 无法正确地自动获取底部 tab 列表
若 tina-router 无法正确地自动获取底部 tab 列表,请尝试将微信开发者工具的 "ES6 转 ES5" 功能关闭:

若仍不生效,可以在注册插件时手动设置:
```javascript
/**
* <script> in /app.mina
*/
import Tina from '@tinajs/tina'
import router from '@tinajs/tina-router'
Tina.use(router, {
tabs: [
'page/home',
'page/mine',
],
})
App(......)
```
## API
### Plugin.install
- 参数:
- ``{Object} Tina`` Tina
- ``{Object} config`` 同 ``createRouterMixin`` 中的参数 ``config``
- 说明:
以插件的形式安装入 Tina。
### createRouterMixin
- 参数:
- ``{Object} config``
- ``{Array <String>} tabs`` MINA [tabbar](https://mp.weixin.qq.com/debug/wxadoc/dev/framework/config.html#tabbar) 中的所有页面路径。
插件默认将自动从全局配置中读取该信息。
- 说明:
创建混合对象。
### 对页面 / 组件的注入
#### $route
- 说明:
路由信息对象。
**仅页面可用,混入组件不生效。**
##### path
- 类型: ``String``
- 说明:
当前页面的路径。
```javascript
// /pages/demo?foo=bar
Page.define({
onLoad () {
console.log(this.$route.path)
// '/page/demo'
},
})
```
##### query
- 类型: ``Object``
- 说明:
当前页面的参数对象。
与小程序中 `onLoad(Object query)` 传入的 `query` 不同,这里的 `$route.query` 会对各个值进行 `decodeURIComponent` 解码。
```javascript
// /pages/demo?foo=bar
Page.define({
onLoad () {
console.log(this.$route.query)
// { foo: 'bar }
},
})
```
##### fullPath
- 类型: ``String``
- 说明:
当前页面的完整路径。
```javascript
// /pages/demo?foo=bar
Page.define({
onLoad () {
console.log(this.$route.fullPath)
// /pages/demo?full=bar
},
})
```
#### $router
- 说明:
Router 实例。
### Router 实例
##### navigate(location, query)
- 参数:
- ``{String} location`` 前往的路径
- ``{Object} query`` query 对象
- 返回值: ``Promise``
- 说明:
前往具体的路径。
当目标路径属于导航栏标签 *(tabs)* 时,实际触发 ``reLaunch``
*(需正确地设置导航栏页面列表)* 。
```javascript
Page.define({
onLoad () {
this.$router.navigate('/page/home', { message: 'hi' })
},
})
```
##### redirect(location, query)
- 参数:
- ``{String} location`` 重定向的路径
- ``{Object} query`` query 对象
- 返回值: ``Promise``
- 说明:
重定向具体的路径。
当目标路径属于导航栏标签 *(tabs)* 时,实际触发 ``reLaunch``
*(需正确地设置导航栏页面列表)* 。
```javascript
Page.define({
onLoad () {
this.$router.redirect('/page/login')
},
})
```
##### switchTab(location)
- 参数:
- ``{String} location`` 重定向的路径
- 返回值: ``Promise``
- 说明:
切换到具体的一级页面 (属于导航栏标签的页面)。该方法运行效率更高,但不支持 query 参数。
```javascript
Page.define({
onLoad () {
this.$router.switchTab('/page/login')
},
})
```
##### back()
- 参数:
- 无
- 返回值: ``Promise``
- 说明:
后退。
```javascript
Page.define({
onLoad () {
this.$router.back()
},
})
```
##### isTab(location)
- 参数:
- ``{String} location`` 路径
- 返回值: ``Boolean``
- 说明:
返回某路径是否属于导航栏项。
*需正确地设置导航栏页面列表*
```javascript
Page.define({
onLoad () {
if (this.$router.isTab('/page/home')) {
console.log('homepage is one of the tabs')
}
},
})
```
## License
Apache-2.0 @ [yelo](https://github.com/imyelo) | 4,113 | Apache-2.0 |
---
title: 将 gitRepo 卷装载到容器组
description: 了解如何在容器实例中装载 gitRepo 卷以克隆 Git 存储库
ms.topic: article
origin.date: 06/15/2018
author: rockboyfor
ms.date: 11/02/2020
ms.author: v-yeche
ms.openlocfilehash: b5277de464bd354a4f9cff1c766f7c275936626c
ms.sourcegitcommit: 93309cd649b17b3312b3b52cd9ad1de6f3542beb
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/30/2020
ms.locfileid: "93104988"
---
<!--Verified successfully-->
# <a name="mount-a-gitrepo-volume-in-azure-container-instances"></a>在 Azure 容器实例中装载 gitRepo 卷
了解如何在容器实例中装载 *gitRepo* 卷以克隆 Git 存储库。
> [!NOTE]
> 当前只有 Linux 容器能装载 *gitRepo* 卷。 虽然我们正致力于为 Windows 容器提供全部功能,但你可在[概述](container-instances-overview.md#linux-and-windows-containers)中了解当前的平台差异。
## <a name="gitrepo-volume"></a>gitRepo 卷
*gitRepo* 卷可在容器启动时装载目录,并将指定的 Git 存储库克隆到该目录。 在容器实例中使用 *gitRepo* 卷,可避免在应用程序中为执行此操作添加代码。
装载 *gitRepo* 卷时,可以设置三个属性以对卷进行配置:
| 属性 | 必须 | 说明 |
| -------- | -------- | ----------- |
| `repository` | 是 | 要克隆的 Git 存储库的完整 URL,包括 `http://` 或 `https://`。|
| `directory` | 否 | 存储库应克隆到的目录。 路径不得包含“`..`”,也不能以其开头。 如果指定“`.`”,存储库将克隆到卷的目录。 否则,Git 存储库将克隆到卷目录中给定名称的子目录。 |
| `revision` | 否 | 要克隆的修订的提交哈希。 如果未指定,则克隆 `HEAD` 修订。 |
## <a name="mount-gitrepo-volume-azure-cli"></a>装载 gitRepo 卷:Azure CLI
若要在使用 [Azure CLI](https://docs.azure.cn/cli) 部署容器实例时装载 gitRepo 卷,请在 [az container create][az-container-create] 命令中提供 `--gitrepo-url` 和 `--gitrepo-mount-path` 参数。 还可以指定要将卷克隆到其中的目录 (`--gitrepo-dir`) 和要克隆的修订版的提交哈希 (`--gitrepo-revision`)。
此示例命令将 Microsoft [aci-helloworld][aci-helloworld] 示例应用程序克隆到容器实例中的 `/mnt/aci-helloworld`:
<!--Not Avaialble on Microsoft [aci-helloworld]-->
```azurecli
az container create \
--resource-group myResourceGroup \
--name hellogitrepo \
--image mcr.microsoft.com/azuredocs/aci-helloworld \
--dns-name-label aci-demo \
--ports 80 \
--gitrepo-url https://github.com/Azure-Samples/aci-helloworld \
--gitrepo-mount-path /mnt/aci-helloworld
```
若要验证 gitRepo 卷是否已装载,请使用 [az container exec][az-container-exec] 在该容器中启动 shell 并列出目录:
```azurecli
az container exec --resource-group myResourceGroup --name hellogitrepo --exec-command /bin/sh
```
```output
/usr/src/app # ls -l /mnt/aci-helloworld/
total 16
-rw-r--r-- 1 root root 144 Apr 16 16:35 Dockerfile
-rw-r--r-- 1 root root 1162 Apr 16 16:35 LICENSE
-rw-r--r-- 1 root root 1237 Apr 16 16:35 README.md
drwxr-xr-x 2 root root 4096 Apr 16 16:35 app
```
## <a name="mount-gitrepo-volume-resource-manager"></a>装载 gitRepo 卷:Resource Manager
若要在使用 Azure 资源管理器模板部署容器实例时装载 gitRepo 卷,请首先填充模板的容器组 `properties` 节中的 `volumes` 数组。 然后,针对容器组中希望装载 *gitRepo* 卷的每个容器,在容器定义的 `properties` 节中填充 `volumeMounts` 数组。
<!--Not Avaiable on [Azure Resource Manager template](https://docs.microsoft.com/azure/templates/microsoft.containerinstance/containergroups)-->
例如,以下资源管理器模板创建了一个包含单个容器的容器组。 该容器克隆由 *gitRepo* 卷块指定的两个 GitHub 存储库。 第二个卷包括其他属性以指定要克隆到的目录和要克隆的特定修订的提交哈希。
<!-- https://github.com/Azure/azure-docs-json-samples/blob/master/container-instances/aci-deploy-volume-gitrepo.json -->
```json
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"variables": {
"container1name": "aci-tutorial-app",
"container1image": "microsoft/aci-helloworld:latest"
},
"resources": [
{
"name": "volume-demo-gitrepo",
"type": "Microsoft.ContainerInstance/containerGroups",
"apiVersion": "2018-02-01-preview",
"location": "[resourceGroup().location]",
"properties": {
"containers": [
{
"name": "[variables('container1name')]",
"properties": {
"image": "[variables('container1image')]",
"resources": {
"requests": {
"cpu": 1,
"memoryInGb": 1.5
}
},
"ports": [
{
"port": 80
}
],
"volumeMounts": [
{
"name": "gitrepo1",
"mountPath": "/mnt/repo1"
},
{
"name": "gitrepo2",
"mountPath": "/mnt/repo2"
}
]
}
}
],
"osType": "Linux",
"ipAddress": {
"type": "Public",
"ports": [
{
"protocol": "tcp",
"port": "80"
}
]
},
"volumes": [
{
"name": "gitrepo1",
"gitRepo": {
"repository": "https://github.com/Azure-Samples/aci-helloworld"
}
},
{
"name": "gitrepo2",
"gitRepo": {
"directory": "my-custom-clone-directory",
"repository": "https://github.com/Azure-Samples/aci-helloworld",
"revision": "d5ccfcedc0d81f7ca5e3dbe6e5a7705b579101f1"
}
}
]
}
}
]
}
```
前面的模板中定义的两个克隆存储库的生成目录结构如下:
```
/mnt/repo1/aci-helloworld
/mnt/repo2/my-custom-clone-directory
```
若要查看使用 Azure 资源管理器模板进行的容器实例部署示例,请参阅[在 Azure 容器实例中部署多容器组](container-instances-multi-container-group.md)。
## <a name="private-git-repo-authentication"></a>专用 Git 存储库身份验证
若要为专用 Git 存储库装载 gitRepo 卷,请在存储库 URL 中指定凭据。 通常,凭据采用用户名和个人访问令牌 (PAT) 的形式,授予对存储库的范围访问权限。
例如,专用 GitHub 存储库的 Azure CLI `--gitrepo-url` 参数将类似于以下内容(其中“gituser”是 GitHub 用户名,“abcdef1234fdsa4321abcdef”是用户的个人访问令牌):
```console
--gitrepo-url https://gituser:abcdef1234fdsa4321abcdef@github.com/GitUser/some-private-repository
```
对于 Azure Repos Git 存储库,请指定任何用户名(可以使用“azurereposuser”,如下例所示)并结合有效的 PAT:
```console
--gitrepo-url https://azurereposuser:abcdef1234fdsa4321abcdef@dev.azure.com/your-org/_git/some-private-repository
```
有关 GitHub 和 Azure Repos 的个人访问令牌的详细信息,请参阅以下内容:
GitHub:[创建命令行的个人访问令牌][pat-github]
<!--Not Available on Azure Repos: [Create personal access tokens to authenticate access][pat-repos]-->
## <a name="next-steps"></a>后续步骤
了解如何在 Azure 容器实例中装载其他卷类型:
* [在 Azure 容器实例中装载 Azure 文件共享](container-instances-volume-azure-files.md)
* [在 Azure 容器实例中装载 emptyDir 卷](container-instances-volume-emptydir.md)
* [在 Azure 容器实例中装载机密卷](container-instances-volume-secret.md)
<!-- LINKS - External -->
[aci-helloworld]: https://github.com/Azure-Samples/aci-helloworld
[pat-github]: https://help.github.com/articles/creating-a-personal-access-token-for-the-command-line/
<!--Not Available on [pat-repos]: /devops/organizations/accounts/use-personal-access-tokens-to-authenticate-->
<!-- LINKS - Internal -->
[az-container-create]: https://docs.microsoft.com/cli/azure/container#az_container_create
[az-container-exec]: https://docs.microsoft.com/cli/azure/container#az_container_exec
<!-- Update_Description: update meta properties, wording update, update link --> | 6,907 | CC-BY-4.0 |
#### 必要條件
- Azure 帳戶;您可以建立一個[免費帳戶](https://azure.microsoft.com/free)
- [Office 365](https://office365.com) 帳戶
在於邏輯應用程式中使用您的 Office 365 帳戶之前,請先授權該邏輯應用程式連線到您的 Office 365 帳戶。您可以在 Azure 入口網站上,從邏輯應用程式內輕鬆完成此操作。
請使用下列步驟來授權邏輯應用程式連線到您的 Office 365 帳戶:
1. 建立邏輯應用程式。在 Logic Apps 設計工具中,從下拉式清單中選取 [顯示 Microsoft Managed API],然後在搜尋方塊中輸入 "office 365"。選取其中一個觸發程序或動作︰
2. 如果您之前尚未建立與 Office 365 的任何連線,系統將會提示您使用 Office 365 認證來進行登入:
3. 選取 [登入],然後輸入您的使用者名稱和密碼。選取 [登入]:
這些認證會用來授權邏輯應用程式連線及存取您的 Office 365 帳戶。
4. 請注意,已建立連線。現在,請繼續進行您邏輯應用程式中的其他步驟:
<!---HONumber=AcomDC_0727_2016--> | 969 | CC-BY-3.0 |
---
title: 调试Kubernetes集群中的网络停顿问题
layout: post
category: k8s
author: 夏泽民
---
https://mp.weixin.qq.com/s/u5aEQhZTDtLrVdC8AO_ogQ
https://mp.weixin.qq.com/s/zoTOv7oFS0k86jKfL5azfQ
<!-- more -->
https://mp.weixin.qq.com/s/P9bVFtXeduZ8Lv-0vFaXAg
https://github.com/augmentable-dev/gitqlite | 286 | MIT |
# Button 按钮
### 基础按钮
通过 `type` 设置方按钮类型,可选值有 `default` `danger ` `primary ` `success ` `warning ` `link` 默认可不填。
可通过 `inline` 设置行内元素,不设置为块元素。
## 代码示例
```html
<Button type="primary">Primary</Button>
<Button type="success">Success</Button>
<Button type="warning">Warning</Button>
<Button type="danger">Danger</Button>
<Button type="default" inline>Default</Button>
<Button type="link" inline>Link</Button>
```
### 尺寸、边框
通过 `size` 设置方按钮类型,可选值有 `large` `default ` `small ` 默认可不填。
通过 `hairline` 设置细边框。
```html
<Button type="primary" size="large">Primary Large</Button>
<Button type="primary" size="default">Primary Default</Button>
<Button type="primary" size="small">Primary Small</Button>
<Button type="primary" hairline>Primary Hairline</Button>
<Button type="success" hairline>Success Hairline</Button>
<Button type="success" block>Success block</Button>
```
### 禁用
```html
<Button type="primary" disabled>Primary Disabled</Button>
```
## API
属性 | 说明 | 类型 | 默认值
----|-----|------|------
| type | 按钮类型,可选值为`default`、`danger`、`primary`、`success`、`warning`、`link`或者不设 | string | - |
| size | 按钮大小,可选值为`default`、`large`、`small` | string | `default`|
| disabled | 设置禁用 | boolean | false |
| onClick | 点击按钮的点击回调函数 | (e: Object): void | 无 |
| style | 自定义样式 | Object | 无 |
| inline | 是否设置为行内按钮 | boolean | false |
| hairline | 是否细边框按钮 | boolean | false |
| className | 样式类名 | string | 无 |
<!-- | activeStyle | ~~点击反馈的自定义样式 (设为 false 时表示禁止点击反馈)~~ | {}/false | {} | -->
<!-- | activeClassName | ~~点击反馈的自定义类名~~ | string | | -->
<!-- | loading | ~~设置按钮载入状态~~ | boolean | false | -->
<!-- | icon | ~~可以是 [Icon]组件里内置的某个 icon 的 type 值,也可以是任意合法的 ReactElement (注意: `loading`设置后此项设置失效)~~ | `string`/`React.Element` | - | -->
### 其他
`activeStyle` `activeClassName` `icon` 将在后期进行完善。 | 1,838 | MIT |
# 概述
Spring Boot 提供了 Maven 插件 [`spring-boot-maven-plugin`](https://docs.spring.io/spring-boot/docs/current/reference/html/build-tool-plugins.html#build-tool-plugins-maven-plugin),可以方便的将 Spring Boot 项目打成 `jar` 包或者 `war` 包。
* 考虑到部署的便利性,我们绝大多数 99.99% 的场景下,我们会选择打成 `jar` 包。这样,我们就无需在部署项目的服务器上,配置相应的 Tomcat、Jetty 等 Servlet 容器。
下面,我们来打开一个 Spring Boot `jar` 包,看看其里面的结构。如下图所示,一共分成四部分:
<img src="http://www.iocoder.cn/images/Spring-Boot/2019-01-07/01.png" width="75%"/>
- ① `META-INF` 目录:通过 `MANIFEST.MF` 文件提供 `jar` 包的**元数据**,声明了 `jar` 的启动类。
- ② `org` 目录:为 Spring Boot 提供的 `spring-boot-loader` 项目,它是 `java -jar` 启动 Spring Boot 项目的秘密所在,也是稍后我们将深入了解的部分。
- ③ `BOOT-INF/lib` 目录:我们 Spring Boot 项目中引入的**依赖**的 `jar` 包们。`spring-boot-loader` 项目很大的一个作用,就是**解决 `jar` 包里嵌套 `jar` 的情况**,如何加载到其中的类。
- ④ `BOOT-INF/classes` 目录:我们在 Spring Boot 项目中 Java 类所编译的 `.class`、配置文件等等。
先简单剧透下,`spring-boot-loader` 项目需要解决两个问题:
- 第一,如何引导执行我们创建的 Spring Boot 应用的启动类,例如上述图中的 Application 类。
- 第二,如何加载 `BOOT-INF/class` 目录下的类,以及 `BOOT-INF/lib` 目录下内嵌的 `jar` 包中的类。
# MANIFEST.MF
我们来查看 `META-INF/MANIFEST.MF` 文件,里面的内容如下:
```
Manifest-Version: 1.0
Implementation-Title: lab-39-demo
Implementation-Version: 2.2.2.RELEASE
Spring-Boot-Classes: BOOT-INF/classes/
Spring-Boot-Lib: BOOT-INF/lib/
Build-Jdk-Spec: 1.8
Spring-Boot-Version: 2.2.2.RELEASE
Created-By: Maven Archiver 3.4.0
Main-Class: org.springframework.boot.loader.JarLauncher
Start-Class: cn.iocoder.springboot.lab39.skywalkingdemo.Application
```
它实际是一个 **Properties** 配置文件,每一行都是一个配置项目。重点来看看两个配置项:
- `Main-Class` 配置项:Java 规定的 `jar` 包的启动类,这里设置为 `spring-boot-loader` 项目的 JarLauncher 类,进行 Spring Boot 应用的启动。
- `Start-Class` 配置项:Spring Boot 规定的**主**启动类,这里设置为我们定义的 Application 类。
> 小知识补充:为什么会有 `Main-Class`/`Start-Class` 配置项呢?因为我们是通过 Spring Boot 提供的 Maven 插件 `spring-boot-maven-plugin` 进行打包,该插件将该配置项写入到 `MANIFEST.MF` 中,从而能让 `spring-boot-loader` 能够引导启动 Spring Boot 应用。
可能胖友会有疑惑,`Start-Class` 对应的 Application 类自带了 `#main(String[] args)` 方法,为什么我们不能直接运行会如何呢?我们来简单尝试一下哈,控制台执行如下:
```
$ java -classpath lab-39-demo-2.2.2.RELEASE.jar cn.iocoder.springboot.lab39.skywalkingdemo.Application
错误: 找不到或无法加载主类 cn.iocoder.springboot.lab39.skywalkingdemo.Application
```
直接找不到 Application 类,因为它在 `BOOT-INF/classes` 目录下,不符合 Java 默认的 `jar` 包的加载规则。因此,需要通过 JarLauncher 启动加载。
当然实际还有一个更重要的原因,Java 规定可执行器的 `jar` 包禁止嵌套其它 `jar` 包。但是我们可以看到 `BOOT-INF/lib` 目录下,实际有 Spring Boot 应用依赖的所有 `jar` 包。因此,`spring-boot-loader` 项目自定义实现了 ClassLoader 实现类 LaunchedURLClassLoader,支持加载 `BOOT-INF/classes` 目录下的 `.class` 文件,以及 `BOOT-INF/lib` 目录下的 `jar` 包。
# JarLauncher
JarLauncher 类是针对 Spring Boot `jar` 包的启动类,整体类图如下所示:
<img src="https://img-blog.csdnimg.cn/img_convert/eb683727697492d3094302f072d339ba.png" width="45%"/>
> 友情提示:WarLauncher 类,是针对 Spring Boot `war` 包的启动类,后续胖友可以自己瞅瞅,差别并不大哈~
JarLauncher 的源码比较简单,如下图所示:
```java
public class JarLauncher extends ExecutableArchiveLauncher {
static final String BOOT_INF_CLASSES = "BOOT-INF/classes/";
static final String BOOT_INF_LIB = "BOOT-INF/lib/";
public JarLauncher() {
}
protected JarLauncher(Archive archive) {
super(archive);
}
@Override
protected boolean isNestedArchive(Archive.Entry entry) {
if (entry.isDirectory()) {
return entry.getName().equals(BOOT_INF_CLASSES);
}
return entry.getName().startsWith(BOOT_INF_LIB);
}
public static void main(String[] args) throws Exception {
new JarLauncher().launch(args);
}
}
```
通过 `#main(String[] args)` 方法,创建 JarLauncher 对象,并调用其 `#launch(String[] args)` 方法进行启动。整体的启动逻辑,其实是由父类 Launcher 所提供
父类 Launcher 的 `#launch(String[] args)` 方法,代码如下:
```java
// Launcher.java
protected void launch(String[] args) throws Exception {
// <1> 注册 URL 协议的处理器
JarFile.registerUrlProtocolHandler();
// <2> 创建类加载器
ClassLoader classLoader = createClassLoader(getClassPathArchives());
// <3> 执行启动类的 main 方法
// getMainClass() 返回的是 META-INF/MANIFEST.MF 里的 startClass
launch(args, getMainClass(), classLoader);
}
```
- `<1>` 处,调用 JarFile 的 `#registerUrlProtocolHandler()` 方法,注册 Spring Boot 自定义的 URLStreamHandler 实现类,用于 `jar` 包的加载读取。
- `<2>` 处,调用自身的 `#createClassLoader(List<Archive> archives)` 方法,创建自定义的 ClassLoader 实现类,用于从 `jar` 包中加载类。
- `<3>` 处,执行我们声明的 Spring Boot 启动类,进行 Spring Boot 应用的启动。
简单来说,就是整一个可以读取 `jar` 包中类的加载器,保证 `BOOT-INF/lib` 目录下的类和 `BOOT-classes` 内嵌的 `jar` 中的类能够被正常加载到,之后执行 Spring Boot 应用的启动。
## 1、registerUrlProtocolHandler
> 友情提示:对应 `JarFile.registerUrlProtocolHandler();` 代码段,不要迷路。
**这一步的原因**
* 因为 JDK 的 classLoader 只能加载一层 jar 包,对于 classPath 下 `a.jar/b.jar` 不会解析 b.jar(即 UrlClassPath 里的 jarLoader,默认只加载一层,对于常规打包方式(即不使用 maven 也不使用别的打包插件),例如 IDEA 自带的打 jar 包的方式,如果项目有依赖 jar 包的话,都会进行解压,然后把解压后的路径信息放在 META-INFO/INDEX.LIST)
<img src="https://img-blog.csdnimg.cn/20210301170933293.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzkzNDYwNw==,size_16,color_FFFFFF,t_70" width="25%"/>
* JarLoader
```java
Resource getResource(String var1, boolean var2) {
if (this.metaIndex != null && !this.metaIndex.mayContain(var1)) {
return null;
} else {
try {
this.ensureOpen();
} catch (IOException var5) {
throw new InternalError(var5);
}
// 直接从 jar 包下一级取(即用户编写的类)
JarEntry var3 = this.jar.getJarEntry(var1);
if (var3 != null) {
return this.checkResource(var1, var2, var3);
} else if (this.index == null) {
return null;
} else { // jar 包如果存在解压后的依赖(即存在 META-INFO/INDEX.LIST)
HashSet var4 = new HashSet();
// 根据 META-INFO/INDEX.LIST 里的信息取
return this.getResource(var1, var2, var4);
}
}
}
```
JarFile 是SpringBoot 里继承 `java.util.jar.JarFile` 的子类,如下所示:
```java
public class JarFile extends java.util.jar.JarFile {
// ... 省略其它代码
}
```
OK,介绍完之后,让我们回到 JarFile 的 `#registerUrlProtocolHandler()` 方法,注册 Spring Boot 自定义的 URL 协议的处理器。代码如下:
```java
// JarFile.java
private static final String PROTOCOL_HANDLER = "java.protocol.handler.pkgs";
private static final String HANDLERS_PACKAGE = "org.springframework.boot.loader";
/**
* Register a {@literal 'java.protocol.handler.pkgs'} property so that a
* {@link URLStreamHandler} will be located to deal with jar URLs.
*/
public static void registerUrlProtocolHandler() {
// 获得 URLStreamHandler 的路径
String handlers = System.getProperty(PROTOCOL_HANDLER, "");
// 将 Spring Boot 自定义的 HANDLERS_PACKAGE(org.springframework.boot.loader) 补充上去
System.setProperty(PROTOCOL_HANDLER, ("".equals(handlers) ? HANDLERS_PACKAGE
: handlers + "|" + HANDLERS_PACKAGE));
// 重置已缓存的 URLStreamHandler 处理器们
resetCachedUrlHandlers();
}
/**
* 重置 URL 中的 URLStreamHandler 的缓存,防止 `jar://` 协议对应的 URLStreamHandler 已经创建
* 我们通过设置 URLStreamHandlerFactory 为 null 的方式,清空 URL 中的该缓存。
*/
private static void resetCachedUrlHandlers() {
try {
URL.setURLStreamHandlerFactory(null);
} catch (Error ex) {
// Ignore
}
}
```
目的很明确,通过将 `org.springframework.boot.loader` 包设置到 `"java.protocol.handler.pkgs"` 环境变量,从而使用到自定义的 URLStreamHandler 实现类 Handler,处理 `jar:` 协议的 URL。
## 2、createClassLoader
> 友情提示:对应 `ClassLoader classLoader = createClassLoader(getClassPathArchives())` 代码段,不要迷路。
### 2.1 getClassPathArchives
首先,我们先来看看 `#getClassPathArchives()` 方法,它是由 ExecutableArchiveLauncher 所实现,代码如下:
```java
// ExecutableArchiveLauncher.java
private final Archive archive;
@Override
protected List<Archive> getClassPathArchives() throws Exception {
// <1> 获得所有 Archive
List<Archive> archives = new ArrayList<>(
this.archive.getNestedArchives(this::isNestedArchive));
// <2> 后续处理
postProcessClassPathArchives(archives);
return archives;
}
protected abstract boolean isNestedArchive(Archive.Entry entry);
protected void postProcessClassPathArchives(List<Archive> archives) throws Exception {
}
```
> 友情提示:这里我们会看到一个 Archive 对象,先可以暂时理解成一个一个的**档案**,稍后会清晰认识的~
#### 2.1.1 `this::isNestedArchive`
`this::isNestedArchive` 代码段,创建了 EntryFilter 匿名实现类,用于过滤 `jar` 包不需要的目录。
```java
// Archive.java
interface Entry {
boolean isDirectory();
String getName();
}
interface EntryFilter {
boolean matches(Entry entry);
}
```
这里在它的内部,调用了 `#isNestedArchive(Archive.Entry entry)` 方法,它是由 JarLauncher 所实现,代码如下:
```java
// JarLauncher.java
static final String BOOT_INF_CLASSES = "BOOT-INF/classes/";
static final String BOOT_INF_LIB = "BOOT-INF/lib/";
@Override
protected boolean isNestedArchive(Archive.Entry entry) {
// 如果是目录的情况,只要 BOOT-INF/classes/ 目录
if (entry.isDirectory()) {
return entry.getName().equals(BOOT_INF_CLASSES);
}
// 如果是文件的情况,只要 BOOT-INF/lib/ 目录下的 `jar` 包
return entry.getName().startsWith(BOOT_INF_LIB);
}
```
- 目的就是过滤获得,`BOOT-INF/classes/` 目录下的类,以及 `BOOT-INF/lib/` 的内嵌 `jar` 包。
#### 2.1.2 `this.archive.getNestedArchives`
`this.archive.getNestedArchives` 代码段,调用 Archive 的 `#getNestedArchives(EntryFilter filter)` 方法,获得 `archive` 内嵌的 Archive 集合。代码如下:
```java
// Archive.java
List<Archive> getNestedArchives(EntryFilter filter) throws IOException;
```
Archive 接口,是 `spring-boot-loader` 项目定义的**档案**抽象,其子类如下图所示:
<img src="https://img-blog.csdnimg.cn/img_convert/b2a6b42265139165c9f5a96bd3af4bc2.png" width="45%"/>
- ExplodedArchive 是针对**目录**的 Archive 实现类。
- JarFileArchive 是针对 **`jar` 包**的 Archive 实现类。
**根 archive 的创建**
* 我们在 ExecutableArchiveLauncher 的 `archive` 属性是怎么来的呢?答案在 ExecutableArchiveLauncher 的构造方法中,代码如下:
```java
// ExecutableArchiveLauncher.java
public abstract class ExecutableArchiveLauncher extends Launcher {
private final Archive archive;
public ExecutableArchiveLauncher() {
try {
this.archive = createArchive();
} catch (Exception ex) {
throw new IllegalStateException(ex);
}
}
protected ExecutableArchiveLauncher(Archive archive) {
this.archive = archive;
}
// ... 省略其它
}
// Launcher.java
public abstract class Launcher {
protected final Archive createArchive() throws Exception {
// 获得 jar 所在的绝对路径
// 例如 /Users/yunai/Java/SpringBoot-Labs/lab-39/lab-39-demo/target/lab-39-demo-2.2.2.RELEASE.jar
ProtectionDomain protectionDomain = getClass().getProtectionDomain();
CodeSource codeSource = protectionDomain.getCodeSource();
URI location = (codeSource != null) ? codeSource.getLocation().toURI() : null;
String path = (location != null) ? location.getSchemeSpecificPart() : null;
if (path == null) {
throw new IllegalStateException("Unable to determine code source archive");
}
File root = new File(path);
if (!root.exists()) {
throw new IllegalStateException(
"Unable to determine code source archive from " + root);
}
// 如果是目录,则使用 ExplodedArchive 进行展开
// 如果不是目录,则使用 JarFileArchive
return (root.isDirectory() ? new ExplodedArchive(root)
: new JarFileArchive(root));
}
}
```
* 根据根路径**是否为目录**的情况,创建 ExplodedArchive 或 JarFileArchive 对象。
JarFileArchive.getNestedArchives()
* JarFileArchive:有一个重要的包含关系:JarFileArchive -> JarFile -> Url
```java
public List<Archive> getNestedArchives(EntryFilter filter) throws IOException {
List<Archive> nestedArchives = new ArrayList();
// 因为 Archive 实现了 Iterator
// 会遍历当前 JarFileArchive 里 jarFile 的下一级
Iterator var3 = this.iterator();
while(var3.hasNext()) {
Entry entry = (Entry)var3.next();
// 如果是BOOT-INF/classes/ 或 BOOT-INF/libs/
if (filter.matches(entry)) {
// 再把 entry 里对应的 jarFile 包装成 JarFileArchive
nestedArchives.add(this.getNestedArchive(entry));
}
}
return Collections.unmodifiableList(nestedArchives);
}
protected Archive getNestedArchive(Entry entry) throws IOException {
JarEntry jarEntry = ((JarFileArchive.JarFileEntry)entry).getJarEntry();
// 如果不是 Jar 包,即 BOOT-INF/classes/
// UnpackedNestedArchive 不会再往下解析
if (jarEntry.getComment().startsWith("UNPACK:")) {
return this.getUnpackedNestedArchive(jarEntry);
} else {
try {
JarFile jarFile = this.jarFile.getNestedJarFile(jarEntry);
return new JarFileArchive(jarFile);
} catch (Exception var4) {
throw new IllegalStateException("Failed to get nested archive for entry " + entry.getName(), var4);
}
}
}
```
### 2.2 createClassLoader
然后,我再来看看 `#createClassLoader(List<Archive> archives)` 方法,它是由 ExecutableArchiveLauncher 所实现,代码如下:
```java
// ExecutableArchiveLauncher.java
protected ClassLoader createClassLoader(List<Archive> archives) throws Exception {
// 获得所有 Archive 的 URL 地址
List<URL> urls = new ArrayList<>(archives.size());
for (Archive archive : archives) {
urls.add(archive.getUrl());
}
// 创建加载这些 URL 的 ClassLoader
return createClassLoader(urls.toArray(new URL[0]));
}
protected ClassLoader createClassLoader(URL[] urls) throws Exception {
return new LaunchedURLClassLoader(urls, getClass().getClassLoader());
}
```
基于获得的 Archive 数组,创建自定义 ClassLoader 实现类 LaunchedURLClassLoade,通过它来加载 `BOOT-INF/classes` 目录下的类,以及 `BOOT-INF/lib` 目录下的 `jar` 包中的类。
### 2.3 LaunchedURLClassLoader
LaunchedURLClassLoader 是 `spring-boot-loader` 项目自定义的**类加载器**,实现对 `jar` 包中 `META-INF/classes` 目录下的**类**和 `META-INF/lib` 内嵌的 `jar` 包中的**类**的**加载**。
```java
public class LaunchedURLClassLoader extends URLClassLoader {
public LaunchedURLClassLoader(URL[] urls, ClassLoader parent) {
super(urls, parent);
}
}
```
- 第一个参数 `urls`,使用的是 Archive 集合对应的 URL 地址们,从而告诉 LaunchedURLClassLoader 读取 `jar` 的**地址**。
- 第二个参数 `parent`,设置 LaunchedURLClassLoader 的**父**加载器。这里后续胖友可以理解下,类加载器的**双亲委派模型**,这里就拓展开了。
LaunchedURLClassLoader 的实现代码并不多,我们主要来看看它是如何从 `jar` 包中加载类的。核心如下图所示:
<img src="https://img-blog.csdnimg.cn/img_convert/0b51304c325f7b929238886e205113f9.png" width="65%"/>
- `<1>` 处,在通过**父类(URLClassLoader )** 的 `#getPackage(String name)` 方法获取不到指定类所在的包时,**会通过遍历 `urls` 数组,从 `jar` 包中加载类所在的包**。当找到包时,会调用 `URLClassLoader#definePackage(String name, Manifest man, URL url)` 方法,设置包所在的 **Archive** 对应的 `url`。
- `<2>` 处,调用**父类(URLClassLoader )** 的 `#loadClass(String name, boolean resolve)` 方法,加载对应的类。
如此,我们就实现了通过 LaunchedURLClassLoader 加载 `jar` 包中内嵌的类。
## 3、launch
> 友情提示:对应 `launch(args, getMainClass(), classLoader)` 代码段,不要迷路。
### 3.1 getMainClass
首先,我们先来看看`#getMainClass()` 方法,它是由 ExecutableArchiveLauncher 所实现,代码如下:
```java
// ExecutableArchiveLauncher.java
@Override
protected String getMainClass() throws Exception {
// 获得启动的类的全名
Manifest manifest = this.archive.getManifest();
String mainClass = null;
if (manifest != null) {
mainClass = manifest.getMainAttributes().getValue("Start-Class");
}
if (mainClass == null) {
throw new IllegalStateException(
"No 'Start-Class' manifest entry specified in " + this);
}
return mainClass;
}
```
从 `jar` 包的 `MANIFEST.MF` 文件的 `Start-Class` 配置项,,获得我们设置的 Spring Boot 的**主**启动类。
### 3.2 createMainMethodRunner
然后,我们再来看看 `#launch()` 方法,它是由 Launcher 所实现,代码如下:
```java
protected void launch(String[] args, String mainClass, ClassLoader classLoader)
throws Exception {
// <1> 设置 LaunchedURLClassLoader 作为类加载器
Thread.currentThread().setContextClassLoader(classLoader);
// <2> 创建 MainMethodRunner 对象,并执行 run 方法,启动 Spring Boot 应用
createMainMethodRunner(mainClass, args, classLoader).run();
}
```
该方法负责最终的 Spring Boot 应用真正的**启动**。
- `<1>` 处:设置 createClassLoader 创建的 LaunchedURLClassLoader 作为类加载器,从而保证能够从 `jar` 加载到相应的类。
- `<2>` 处,调用 `#createMainMethodRunner(String mainClass, String[] args, ClassLoader classLoader)` 方法,创建 MainMethodRunner 对象,并执行其 `#run()` 方法来启动 Spring Boot 应用。
下面,我们来看看 **MainMethodRunner** 类,负责 Spring Boot 应用的启动。代码如下:
```java
public class MainMethodRunner {
private final String mainClassName;
private final String[] args;
/**
* Create a new {@link MainMethodRunner} instance.
* @param mainClass the main class
* @param args incoming arguments
*/
public MainMethodRunner(String mainClass, String[] args) {
this.mainClassName = mainClass;
this.args = (args != null) ? args.clone() : null;
}
public void run() throws Exception {
// <1> 加载 Spring Boot
Class<?> mainClass = Thread.currentThread().getContextClassLoader().loadClass(this.mainClassName);
// <2> 反射调用 main 方法
Method mainMethod = mainClass.getDeclaredMethod("main", String[].class);
mainMethod.invoke(null, new Object[] { this.args });
}
}
```
- `<1>` 处:通过 LaunchedURLClassLoader 类加载器,加载到我们设置的 Spring Boot 的主启动类。
- `<2>` 处:通过**反射**调用主启动类的 `#main(String[] args)` 方法,启动 Spring Boot 应用。这里也告诉了我们答案,为什么我们通过编写一个带有 `#main(String[] args)` 方法的类,就能够启动 Spring Boot 应用。
# 小结
总体来说,Spring Boot `jar` 启动的原理是非常清晰的,整体如下图所示:
[](http://www.iocoder.cn/images/Spring-Boot/2019-01-07/30.png)Spring Boot `jar` 启动原理
**红色**部分,解决 `jar` 包中的**类加载**问题:
- 通过 Archive ,实现 `jar` 包的**遍历**,将 `META-INF/classes` 目录和 `META-INF/lib` 的每一个内嵌的 `jar` 解析成一个 Archive 对象。
- 通过 Handler,处理 `jar:` 协议的 URL 的资源**读取**,也就是读取了每个 Archive 里的内容。
- 通过 LaunchedURLClassLoade,实现 `META-INF/classes` 目录下的类和 `META-INF/classes` 目录下内嵌的 `jar` 包中的类的加载。具体的 URL 来源,是通过 Archive 提供;具体 URL 的读取,是通过 Handler 提供。
**橘色**部分,解决 Spring Boot 应用的**启动**问题:
- 通过 MainMethodRunner ,实现 Spring Boot 应用的启动类的执行。
当然,上述的一切都是通过 Launcher 来完成引导和启动,通过 `MANIFEST.MF` 进行具体配置。 | 17,421 | Apache-2.0 |
# 2021-08-30
共 19 条
<!-- BEGIN -->
<!-- 最后更新时间 Mon Aug 30 2021 23:06:31 GMT+0800 (China Standard Time) -->
1. [《扫黑风暴》导演亲自答](https://www.zhihu.com/search?q=扫黑风暴)
1. [前妻指控李阳家暴女儿](https://www.zhihu.com/search?q=李阳家暴)
1. [前国际奥委会主席罗格去世](https://www.zhihu.com/search?q=罗格)
1. [电影《失控玩家》](https://www.zhihu.com/search?q=失控玩家)
1. [《理想之城》主演亲自答](https://www.zhihu.com/search?q=理想之城)
1. [EDG 晋级 LPL 总决赛](https://www.zhihu.com/search?q=EDG)
1. [华夏航空一航班冲出跑道](https://www.zhihu.com/search?q=华夏航空)
1. [斗破苍穹第四季 24 集](https://www.zhihu.com/search?q=斗破苍穹)
1. [教育部要求不得设置重点班](https://www.zhihu.com/search?q=重点班)
1. [华为海外发布 EMUI 12](https://www.zhihu.com/search?q=华为 EMUI12)
1. [QGhappy 世冠杯夺冠](https://www.zhihu.com/search?q=QGhappy)
1. [QQ 音乐限制专辑重复购买](https://www.zhihu.com/search?q=QQ音乐)
1. [DK 战胜 T1 LCK 夏季赛夺冠](https://www.zhihu.com/search?q=DK)
1. [梅西上演巴黎首秀](https://www.zhihu.com/search?q=梅西)
1. [残奥会中国队被取消一金一银](https://www.zhihu.com/search?q=残奥会)
1. [吴谢宇不服死刑判决](https://www.zhihu.com/search?q=吴谢宇)
1. [全国网游用户锐减](https://www.zhihu.com/search?q=网络游戏)
1. [《光恋》齐司礼生日卡](https://www.zhihu.com/search?q=光与夜之恋)
1. [媒体发文批评游戏圈](https://www.zhihu.com/search?q=手机游戏)
<!-- END --> | 1,156 | MIT |
---
layout: post
title: How to seek job?
subtitle:
author: tanchao
date: 2016-08-10 20:56:17 +0800
categories: career
tags: career
---
# 关于找工作
以下内容转载自:[***Random Mumble***](http://randommumble.blogspot.com/),初衷是方便国内朋友浏览。
如有不便请与我联系删除,谢谢。
感谢原作者分享!
以及一些我现在(2016-08-10)的理解和建议({==黄底==})
不知为何MD渲染和我想象的不一致,还是有道云笔记吧,看[这里](http://note.youdao.com/share/?id=9f205f59f0f0fb0c825730f81dfa37f9&type=note)
## BEGIN
---
---
---
## 关于找工作(〇 前言)
== 此文原发于mitbbs的jobhunting版。我的原创,并非转载。 ==
先声明一下,纯属个人经验,不负法律责任的啊 — 开玩笑了,当然不会故意误导的。会不会是象国内的某些记者一样,拿着不知道哪儿捡来的破烂当宝贝?有这个可能,但是可能性不大。至少不会是故意编瞎话骗人。
说起来是有不少经验/想法的,估计一次也说不完,想到哪儿说到哪儿吧。按老美的习惯,先给个提纲(agenda):
1. 简历
2. cover letter (对不起,实在不知道中文怎么说。丢人啊,邯郸学步的当代版)
3. 面试
4. 找工作期间(有点倒叙了。原因以后解释 — 怕挨砖)。
还是按照老美的习惯,讲正题前先跑题 — 背景知识(background).
(谁在扔鸡蛋?在老美的地头混,不学老美的门路,怎么去和老美斗?)
俺的“理论”可是科班,去老美的一个帮助找工作(outplacement, career placement)的公司,认认真真学来的。当然了,学习班里什么样的人都有,教练教的要顾及多数人,很多和俺的工程师背景不适用,所以俺也就基本上是左耳进右耳出了。有些有印象的,还是会提一提的,毕竟不是所有人都是工程师。
## 关于找工作(一 简历【之一】)
首先澄清一下,resume 和CV都是简历,名字不同,用处不同,写法也不一样。各位(特别是离开学校不太久的)先看一看自己的简历,是不是既可以当resume用,也可以当cv用?或者你根本分不清这两个有什么区别?如果答案是是的话,恭喜你,你找工作的第一个大障碍已经找到了。现在可以把你的简历扔到垃圾桶里了。
那么,resume和cv有什么区别?要总结出区别,挺不容易说清楚的。从用处上说吧,如果你要找工业界的工作,你需要resume; 如果找学校,国家实验室的科研工作,你需要cv。 那么如果是工业界的研发呢?多数情况下,你需要resume。(我其实想说绝大多数情况下的,怕有人鄙视我 — 你才见过多少世面?)
明确了这个,俺就讲一讲resume的写法吧。
resume第一个要求:短。一页纸最好,不过估计大家都是经验累累,成绩硕硕的,一页
纸大概不够。那就两页吧,不过主要内容要在第一页上。什么?两页还不够,您老人家实在是比俺还唐僧。那些自我评定留着到面试时和老美/老印昏天黑地地胡侃再用吧。
为什么要短?因为有调查,绝大多数的简历是先被人事部(Human Resource, HR)的审核。又有调查,HR平均只花20秒看一份简历。您老人家的简历那么长,就算有拿诺贝尔奖的实力,HR的人有时间看么?(且不说他/她能不能看懂)。更何况,他/她把你这么优秀的候选人(candidate)错误地毙掉了,他/她会有什么损失吗?
长度限制住了,字体呢?俺的一点小诀窍:如果你是用word之类的软件准备的resume (
这点后面会讲), 先把字体换了。大家都用一样的sans serif,HR的人也会审美疲劳不是。用什么字体,有一个不二之选:==Garamond==. 为什么?先把你的换了,你就知道为什么了。
附带声明,Garamond (其实是一个修正版的)在苹果的地位相当于==MS sans serif== 在微软的地位。俺不是果轮,不过喜欢苹果的MacOS/OSX胜过喜欢微软的windows倒是事实。
其实还有一个技术原因:有一些公司用OCR(又邯郸学步了),Garamond一定会兼容,别的字体不一定。– 还是那个老问题,如果HR的人要多在你的简历上费工夫(而且不是一点半点–你能指望HR的人计算机玩的多溜?),你自己掂量一下你的机会吧。{==字体不兼容的话会转换为默认字体,所以不要使用自己喜欢的但是小众的字体,除非你准备发pdf版本==}
字体有了,大小呢?间距呢?==正文大小以11号为宜==,实在紧张用10号。再小了费眼,大
了吓人。一段的==标题(section titles)用12号==,你的==名字用14号==。间距是单行就行,但是段与段之间一定要空行,而且每段不要超过4行。同样的原则,不能累着HR的先生/小姐/叔叔/阿姨/。。。{==我个人的习惯是不空行,完全靠调节段落格式前后间距来负责空间美╮(╯_╰)╭==}
## 关于找工作(一 简历【之二】)
要写resume,得用软件吧。基本上只有一个选择:office (word) 2003。有人会说了,那破玩意,早淘汰了。我用office 2007/2010, openoffice, latex, 等等等等,或者我保存为pdf。我的意见:word 是烂,但没办法。为什么?
1. 很多公司还在用office 2003,不是因为没钱,而是公司的软件通常都要落后一些。想想吧,一个公司至少几十台机器,赶潮流升级了,出了虫子(bug)不得把IT的人累死?office 2007的文件也许能用office 2003打开(得安装一个程序包),但你愿意不愿意用你的工作机会去试一试?有一点基本可以保证,如果HR的人打不开你的文件,哪怕坐他/她旁边的人能毫不费力的打开,你的机会也差不多到头了。
2. 很多公司存电子文件,只接受.doc文件。
3. 很多时候(特别是通过recruiter的时候),他们要修改一下你的简历的,最常见的是
删去你的通信方式。原因不一,比如避免公司绕过recruiter直接去和候选人谈(这样
recruiter就赚不到钱了), 或者公司的规定(避免地域歧视)。{==doc不会错的不过现在docx也没有什么问题毕竟又过去很多年了Windows都10了==}
## 关于找工作(一 简历 【之三】)
下面开始详细解释resume的写法。请参考(随机找来的)样板 — google image 搜索”resume sample”,第一个结果,http://www.resume-resource.com/exleg3.html。 我们只用格式,不用它的内容。
1. 名字:
14号字, 全大写,第一个字母大一些(不是你手动调大的,word里==格式选all capital==,你原来大写的字母会比原来是小写的个头大一些)。
如果你的名老美很难念(是念不出来,念得准不准没关系,你知道是找你的就行),可以加一个英文名,用引号括起来。比如,ZUXIE “SOCCER” QU。 加引号是告诉他们那部分在正式文件里是没有的,免得HR的人用你的”全名“去调查,调查出一个”查无此人“。
名字后面加不加头衔(PH.D., MBA, RN什么的),取决于要申请的位置有没有明确要求某一个学位。通常说起来,加不加都一般没什么大问题,但以不加更保险一些。
名字的下面(样板里地址的地方),如果你有绿卡/公民,可以写上(11号字, 斜体,可能需要bold)”US Permanent Resident” /“US Citizen”。当然如果您老人家已经把名字改了,就不必了。
(不是哪个学校有位中国人教授就给自己起了一个完全美式的名字?–以前看到的,细节不记得了。谁给考考古?)
2. 下一行,电话,地址,email:
11号字,照抄样板的格式就行。 注意”telephone”, ”address”, “email” 这些词完全不出现,因为谁也不会把niuren@hotmail.com当成电话号码。
电话建议留8AM-6PM开机的手机。如果你的手机比较忙(朋友多,或者忙着谈恋爱),建议去搞一个prepaid的。个人推荐, 如果可以找到闲置的verizon的手机,所在地verizon的信号也好的话,买pagepluscellular的卡(号),价格便宜量又足。[Edit Aug/2010: apparently there have been some changes that make my recommendations invalid. Please check this blog for (hopefully ) up-to-date recommendations. http://blog.wenxuecity.com/myindex.php?blogID=46849 ]强烈不建议买verizon或者ATT的prepaid (太贵)。
email建议用私人的(gmail之类)。==新申请一个专门用来找工作==比较好。你如果是在用gmail (web interface),可以设置自动去取别的新开的信箱的信,这样就不用换来换去了。
地址用家庭地址,强烈不建议用工作/学校的地址。如果不想列出具体的门牌号,可以去邮局租一个信箱,没多少钱的。和手机,email一样,专门用来找工作,比较容易管理。
3.下一行,一条贯穿文本宽度的线 ,单的双的都可以。怎么搞出来?google is your friend.
{==连续输入三个-或者=如---然后敲回车看看==}
## 关于找工作(一 简历 【之四】)
最重要的一块来了,睡觉的同学醒一醒。
4. 下面是正文了。第一块: qualification,但是不要标题行(样板里的 “QUALIFICATION”)。 为什么?脱裤子放P,浪费宝贵的空间。更重要的是,HR的人要多看一行没用的东东。这一段怎么写?说难也难,说容易也容易,因为基本上是八股文。
有同学问了:objective一段哪儿去了?答案很简单,不需要。因为也是脱裤子放P的事(后面讲到cover letter的时候会讲如何放这个P。 cover letter会在resume的前面,所以resume就不需要再重复了。– 以老美的唐僧风格,这实在是难得。)有一个HR的 VP(老美)告诉我,有objective的简历,或者出自在校学生之手,或者是古董级的简历。不管是哪个,都反映了简历的作者对自己职业发展及其重要的文档都没下够工夫。”The objective section has been unnecessary for at least ten years. Having it in the resume does nothing more than leaving a somewhat negative impression.”
那么qualification这一块到底怎么写呢?给个样板(独家产品,转载请付版税):
第一句:先把招工广告上的职位(比如,senior nuclear engineer) 抄上。在前面加上“评价”自己的褒义词。什么褒义词?什么好听说什么,experienced (这个慎重,不是不好,而是因为后面还要经常用experience这个词,会“撞车”,读起来不顺), motived, diligent, proven, 等等, 自己网上找吧。然后,
后面加 with 100 years of experience in nuclear bomb making之类的自我吹嘘, 具体语言请参照老印的简历 – 瞧不起老印?人家老印绝对是这方面的专家。
细心的会注意到这不是一句话,只是一个短语。对了,要的就是短语。后面几句也是。
第二句,第三句,甚至第四句,全都差不多,注意和招工广告对应上。给个例子:excellent hands-on skills building an atomic bomb from dog poo.
要点有三:1. 要敢于给自已客观的,正确的,不谦虚的评价。怎么样才算合格?这么说吧,只要没说“地球离了我不转”都不算太过分。2.长度要合适,总共四行,可以少一行,不可以多。即, 每一句都是控制在短于一行或者一行多一点点的长度。排版是要两头对齐。3. 要敢于用demonstrated, proven, exceptional 此类的形容词。
从一定程度上讲,你能不能通过/混过HR这一关,一大半在这一段上面。你的目标是15秒之内把他/她忽悠晕。有一个简单的测试方法:找一个不太熟的人,最好也不懂你的专业,(朋友的朋友)让他/她看30秒你的简历,然后把简历收回来,开始问问题,看看他/她能对这一段的内容有多少印象。
如果招工广告上有非常详细的要求(软件啦[office这样的大路货就算了],仪器啦),可以跟上一个小列表(bullet list),三到四项。比如:50 years of solid experience operating dog-poop-scooping machines.
又有人要问了:你总提招工广告,岂不是每个广告的写一份???我没说一份简历打天下吧。每个广告一份简历看起来挺罗嗦的,其实没什么。你只要能捣鼓出第一份,剩下的照猫画虎就是了。
补充一点:关于评价自己:对学生而言,要强调well-trained, diligent/hard-working, proactive (不要直接用这个词,想办法表述出来你学习的风格不是老板指哪儿才打哪儿), 以及wide range of knowledge (举个例子吧,如果你学的是机械, 可以强调你还懂材料,电子,甚至物理,化学,当然这些要和你的本行相关)。有工作经验的人,要强调这些方面:hands-on (特别是如果你的背景偏理论和数值),motivated, customer-driven, result-driven, versatile, team-work, leadership(如果找比较高的位置 — technical leadership也是leadership)。
{==注意到区分对待!!!有没有工作经验和**不是**一份简历打天下==}
## 关于找工作(一 简历 【之五】)
5. 下一块:EXPERIENCE。只要这个词就好了,样板里的PROFESSIONAL EXPERIENCE有脱裤子放P之嫌。有不是应召做男朋友/女朋友/老公/老婆/女婿/媳妇,谁关心你的PERSONAL EXPERIENCE?
如果你是在校或者刚毕业的学生找工业界的工作,建议你把这一块放在EDUCATION的前面,除非你在学校里只上课,别的什么都没干。如果你已经有工作经验。。。没有商量的余地。
EXPERIENCE (还有后面的EDUCATION)要按时间==倒叙==(最近的经历在最前面)。格式可以照抄样板的。基本上是这个样:
职称(Nuclear Scientist), 11号字,斜体,黑体, 左对齐。
另起一行,左对齐,公司/学校, 镇子, 州。比如, ATOMIC DOGPOO INC, Dogtown, DG, 11号, 大小写照样板来。
同一行,右对齐,开始-结束。 比如, 1900-Present. 只列年份就可以。
有同学说了,俺的经验太牛,在一个公司被提升了5次,怎搞?答案:您的位置那么高了,还来听俺罗嗦,what’s wrong with you? –开玩笑的,别见怪。对你的情况,如果位置是类似的, 建议合并到一起。比如变成这样: Junior Nuclear Scientist (1900-1910), Senior Nuclear Scientist (1910 – 1950), Super-senior Nuclear Scientist (1950 – present).
之下的内容就有门道了,先留点悬念,请仔细研究样板里的EXPERIENCE有什么最大的特点?
答案是– 每一条都是以动词开始的。其实样板并不很好,更好的应该是以动词的过去时开始,因为现在时可以理解成工作任务的描述,不代表你一定做过。
用动词有什么意义?这得从简历的目的说起。公司看简历的目的是什么?一个非常非常重要的原因是看你过去做过什么。注意,关键词是“做过”, 不是“什么”。中国人习惯强调“什么”,因为做的怎么样是不言而喻的,谁愿意哪壶不开提哪壶啊?可是老美不一样,你不说自己做的好我怎么知道你做的好啊?(唐僧的传人)所以一定要强调”做过”(所以是过去时)。
另一个要点(样板里体现的不好),要==强调结果==, 因为公司找你是要解决问题赚钱的。你做得再漂亮,不解决实际问题也没用。至于怎么做的,在面试前基本上没人关心。(等你去工作以后,就更没有人关心了)
要点明确了,怎么做呢?和QUALIFICATION那段差不多,要用(老美的说法)“powerful keywords”。哪些算呢?developed, advanced, solved, improved, reduced (cost), organized, led。 那些不算呢?worked (废话,你拿了公司/学校的钱,当然要干活了), studied, served, collaborated, supported (除非你要找非常低的位置或者秘书之类的工作), contributed(基本没用)。有点概念了没有?
有同学反映了:我刚毕业没多久, 没什么好说的。其实工作过的很多人也一样(包括我),因为很多工作每天就是固定的程序 — 太新的东西不容易带来直接经济效益,而公司的第一目标是要赚钱的,所以稳定自然是第一位的了。我坚决反对无中生有(万一面试遇上明白人,你能拿到的工作也拿不到了),但是建议大家要学会从无聊的工作里找到闪光点。 对工作的人来说,这个工作给公司带来了什么效益(不一定是直接的金钱,当然如果是的话更好)。举个例子吧,也许你琢磨出来的小改进让一个零件的成本降低1毛钱(没什么吧),可是公司一年要生产1000万个,你就可以说reduced annual cost by $1Million(厉害不?),或者产量只有10个,可是原来的成本是4毛,你可是reduced cost of the critical part by 25% (那个零件到底是不是critical, 谁能核实?)。【 这里有一个不太诚实的招数(我学的),如果你有大概的印象/估计,凑一个偏大的数。因为牵扯到钱(商业秘密),具体数是没法核实的。而对你的简历而言,有实际数字绝对是很有说服力的。一点警告,别吹的过头,让人家揪着小辫子你就完蛋了。】试着从赞助你做那个项目的公司的管理层想一想,他们为什么愿意花这个钱?找到了这个原因,你也就知道该怎么写了。 {==请认真体会领悟贯彻本段==}
对还在学校/刚离开学校的人来说,好像又跑题了。我打包票:没有。学校里也是一样的,你老板能搞到钱,还是有原因的。什么?老板当初就是不知道怎么骗来钱的?那也没关系,去和老板聊聊,别太露骨的问问“如果那个项目成功了,会有什么样的应用?”是啊,项目还没完呢/已经给废了,可是你的工作不也推进了项目的进展吗?无论多么难看的工作,闪光点总是有的,就看你能不能发掘出来了。我见过的最牛的,是实验做了三年,试验了n种方法,没有一种成功。结果老哥(老美)写的是”comprehensively evaluated existing experimental techniques on … and demonstrated the necessity for developing technology in new directions”, 还被认为是”very impressive work”,拿到了工作。
另外一个问题:对学生而言,列什么项目?很简单,所有和专业相关的,只有不是那么课的学期论文,都可以列,哪怕是你只给老板帮忙了一个星期。为什么不列学期论文?原因是为未来的面试未雨绸缪:万一被问出来是学期论文,你想问你的人郁闷不郁闷?(既然问你,自然是对那个项目有兴趣了)
当然凡事都不是绝对的(impossible is nothing, 呵呵),如果你实在想列,也不是完全不能,只是要慎重,做好被穷追猛打的准备。学期论文的问题主要有两个:1.缺乏实际意义; 2. 为了应付工事。如果你能把这两点的回答准备好,尽管列。给你一点提示吧:如果论文来自于实际问题(比如,分析911世贸大楼倒掉的工程原因)或科研课题,要抓住这一点狠强调。如果是用来练手的题目,得好好琢磨琢磨怎么说怎么这么花费了远超过课程要求的精力去做的。
好了,现在去总结分析你过去若干年有多牛了吧。打开你的简历草稿,往多里列,目标:至少填满一个纸。什么?不是说简历最好一页吗?这么多哪放得下?不用担心,现在是草稿, 先列出来以后再根据需要筛选。
EXPERIENCE这一块是简历里最最重要的一部分,因为一个公司要了解你,差不多唯一的方法就是看你做过什么。这么说吧,能不能过recruiter/HR那一个基本上靠QUALIFICATION,而能不能过技术方面的第一关基本上靠EXPERIENCE。所以,EXPERIENCE 要占简历总长度的30-50%(甚至更长)。
## 关于找工作(一 简历 【之六】)
6. 下一块:PATENTS。这一块不是必须的,因为多数人都没有专利,但是如果你有的话,把它提到前面来。为什么?一个字,钱。别忘了,公司找你是为了赚更多的钱的。你有专利,至少说明了几个事实:1. 你有创造力; 2. 你的创造力有经济意义。 要知道,申请专利是一个费时费钱的事,如果没有潜在的经济效益,公司是不会去费那事的。
有工作过的同学问了:Invention disclosure算不算?回答这个问题之前,我们先给不知道invention disclosure是什么东东的同学解释一下。所谓的invention disclosure, 通常是公司为了留下“原创”性的工作的法律依据,而要求职工提交给公司的律师的文件。一项发明/改进能不能申请专利,你说了不算,我说了也不算,得律师说了才算。所以很多公司都鼓励职工写invention disclosure,甚至把invention disclosure和业绩/奖金挂钩。对公司来说,invention disclosure变不成专利申请通常不会损失什么,可是如果漏掉了专利,可亏大发了。所以公司的政策常常是宁可错交3000,不可漏过一个。这种情况下,你说invention disclosure的意义大不大?
7. 再下一块:AWARDS。这下许多同学高兴了:这玩意,咱哥们多的是。抱歉,多数(比如奖学金什么的)恐怕没什么用。但是如果你有全国性的奖,哪怕是针对每个行业的,一定要列出来。简单的标准,如果奖项牵扯到多个学校/公司,基本上可以算。为什么?因为那说明你的成绩得到了同行的认可,不是一般的牛。所以如果有同学得过,比如说,美国化学会的最佳论文, 千万不要谦虚。
好了,容易让人郁闷的两块过去了,可以开讲每个人都得写的部分了。
7a. 再下一个:CERTIFICATION, 如果你有什么相关的认证的话。
## 关于找工作(一 简历 【之七】)
8. 最常见(基本上每份简历里都有)也容易是最没用的部分来了:EDUCATION.
差不多没干招工广告的第一条都是关于学位要求的,而且HR的人在怎么忽略 你的简历,总要看一看你的出身是什么。不是俺搞出身论,牛校出来的人就是要占一些便宜,这是没办法的事。那为什么说这一部分容易是最没用的部分?
请您看看你的简历,是不是这样的?
Ph.D, Web Posting, University of Nowhere, Some Town, SomeState, 2000
Advisor: Professor Post A. Lot
Thesie/Dissertation: On How to Create 1,000,000 Posts in an hour
差不多? 你刚刚浪费了HR的给你的宝贵的20秒里的1/3.为什么说是浪费了?因为由于的信息只有第一行。剩下的部分对HR的人来说就是天书,对管技术的呢?也基本上是天书。这又为什么?
先说ADVISOR。测试:10秒钟,列举你所在一行的排前五位的大牛。有多少人能说出来?恐怕多数人都做不到吧。所以如果你的老板不是Albert Einstein这样的牛人+名人,你其实完全可以说你的老板是Professor Random Mumble, 效果是差不多的。什么?你的老板就是本行业的前五名的大牛?那么只有两种情况你要列出老板的名字:1. 你要去的公司做的东东刚好是你老板出名的领域(你还是得先搞清楚那个公司技术上把关的人和你老板不是对头 — 文人相轻的事不是只有中国才有); 2. 能影响是否招你的人是你老板的本人/fan/学生/哥们/朋友/小舅子(这个好像也不太安全)– 如果是这种情况,你也不需要靠resume去通关,有更有效的方法(以后再讲)。
再说论文:不客气的说,完全(100%)没有用处。ADVISOR至少还有可能因为name recognition给你帮点忙,论文的题目只能浪费所有人的时间。说的难听点,你的学位已经拿/骗(比如我)到手了,学位论文的历史使命也就结束了。
那么EDUCATION到底要写成什么样?有三个版本:
版本一(适用于有若干(>5)年经验的老油条):
Ph.D. in Web Posting, 2005, University of Internet, Cybertown, Cyberstate
M.S. in Web Posting, 2001, University of Internet, Cybertown, Cyberstate
B.S. in Goofing Around, 2000, University of Nowhere, Notown, China
版本二(适用于有 < 5年经验的新鲜油条):
Ph.D. in Web Posting, 2005, University of Internet, Cybertown, Cyberstate
research was focused on developing new methods to create 1,000,000 posts in a day.
M.S. in Web Posting, 2001, University of Internet, Cybertown, Cyberstate
thesis work/research was focused on….
B.S. in Goofing Around, 2000, University of Nowhere, Notown, China
concentration: playing video games all day long
版本三(适用于没有经验的生油条):
Ph.D. in Web Posting, 2005, University of Internet, Cybertown, Cyberstate GPA= 4.0
research was focused on …..
responsible for maintaining the … equipment in the xxx Lab. (put a couple [1- 3] descriptions of your activities besides taking courses)
M.S. in Web Posting, 2001, University of Internet, Cybertown, Cyberstate GPA= 3.9
thesis work/research was focused on….
responsible for maintaining the … equipment in the xxx Lab. (put a couple [1- 3] descriptions of your activities besides taking courses — do not resue what you mentioned already)
B.S. in Goofing Around, 2000, University of Nowhere, City, China GPA= 0.1
concentration: playing video games all day long
格式注意: 1. 学位 (不包括专业)和年份是黑体; 2. 注意没有学校的zip和具体的地址; 3. 如果是中国的学校,不要列省/自治区; 4. GPA=xxx右对齐。
有同学提了:我读博士/硕士期间做的东西就不提了?要提, 但不是这儿,应该是在EXPERIENCE里(你的头衔是research assistant).
## 关于找工作(一 简历 【之八】)
到这儿,你的简历就差不多了。如果你有论文,可以加一小节 SELECTED PUBLICATIONS,列1到3篇, 最好是在比较牛的杂志上的。
不要有的部分:Objective(已经讲过了), Interests/Hobbies/etc (没人关心,而且与你的工作基本无关。唯一的例外是如果你是跑马拉松的, 想办法把这一条塞到什么地方去 — 公司里的人往往有家有业,没多少时间参加体育活动,所以最流行的锻炼方式是跑步。如果你是跑马拉松的,说好听的是反映了你这个人有毅力,实际的情况是遇上被共鸣的机会比较多。), references (所有人都是“available upon request”)。
草稿弄好了,下一步怎么办?存文件。把你的文件名命名为 ZUQUO-SOCCER-QU-SR-NUCLEAR-ENGR-ALQAEDA.DOC. 即, 你的名字-工作位置-公司名字。其中,公司名(Al Qaeda)是给你看的,剩下的是给HR准备的 — 设想一下,HR的计算机某个文件夹里有20个my resume.doc, 头大不大?他/她的头大了,拿谁出气?
然后,开始读。一个词一个词的读,坚决断绝拼写错,语法错,单复数错,时态错之类的小问题。自己读(每天吃饭前读一遍),发动所以能发动的人读(老婆/老公/女朋友/男朋友, 同学,朋友),最好能找到native speaker帮你读(可以贿赂顿饭什么的),但是不建议找不认识的人(因为不太会用心)。
然后,就是改。刚开始时改得面目全非是很正常的。总要有三五七八个(不是三千五百七十八)版本才会基本定型。然后就可以广而告之了。如何广而告之后面再讲。
关于找工作(一 简历 【之九】)
讲了这么多写resume的细节,有没有体会出最根本的指导思想是什么?
其实说出来很简单 — 当然对新毕业/还在校的同学来说,这有点难 –要给公司一个==雇你的理由==。算一算经济账吧,公司雇一个人(professional)的开支大概是所付工资的1.5倍(老美劳动统计局的数据,http://www.bls.gov/news.release/ecec.t01.htm),如果你不能给公司赚回这么多钱,公司为什么要雇你?所以当你读你的resume的时候,这个问题要时时响在你的耳边:我过去的经历能不能说服他们我有足够的能力给公司带来好处?记住这儿的关键词是“==过去的经历==”– 公司不是NBA, 靠potential是找不到工作的。
这一点搞清楚,写cv也就不是很难了。想一想,看cv的人需要什么样的人? 当然是能做科研的。所以和科研相关的东西就需要突出了(你如果要找工业界的工作,强调科研很容易把别人吓着)。具体表现在哪儿呢?(我所接触的科研类的工作,基本上都要求有博士学位,所以我的看法就限于那个范围了)
1. 博士论文做的是什么?老板是谁?这个有点不合理,但是没办法:如果你的老板牛/人气广,你的机会要好得多。
2. 发了什么论文?什么样的杂志?被引用多少次?
这两条决定了你的cv和resume要有本质的不同:resume里education和publication是尽量精简,而cv里这两块要详细。
那么如果你的“出身”不是很好怎么办?很遗憾,这个世界不公平,不过你的机会也不是没有。因为多数情况下,博士之后的科研与博士论文不是完全一样的。所以出身固然重要,更重要的是你所受的做科研的训练。怎么在CV中体现出你受了良好的训练?一个重要的部分是experience。 这儿,和resume 又不一样了:resume要强调解决实际问题,强调结果; cv要强调的是怎么做的,具体说就是你琢磨出了什么新鲜独门的招数。说到招数,给个开武馆的类别吧:工业界要找到相对于武馆的工作人员,打群架是要好用;科研圈子要找到是武馆的正式弟子,基本套路要熟,最有吸引力的还是有开创新局面能力的好苗子。(日月神教这样的不算数)
具体的细节就不讲了(我也讲不好 –经历有限)。
一个小建议:如果你还和你的老板/导师有联系,建议你找机会(一起喝个咖啡什么的)和老板好好谈一谈,一个重要的方面是让老板不客气地评价一下你的学术水平,毕竟你老板见过的世面比你多多了。知道了自己的弱项,现补可能来不及了,但是你在面谈的时候可以有意识的避开那些方面–能读出Ph.D.的,学术上都是有两把刷子的,可别哪壶不开提哪壶。
最后明确一下工业界/科研圈子的分类(好象应该在最前面):通常说起来,学校(如果你去做教授/postdoc/research scientist), 国家实验室基本上都是科研圈子,工业界大多数是工业界(废话)/非学术圈子。有几个注意的:
1. 大公司的研发不一定是科研圈子(因公司而异),甚至有的公司的研发的不同部门定位都不一样。这个没有一刀切的标准,只有你自己想办法去打听了(有一个不一定管用的方法:看他们的论文多少。说不一定管用是因为很多公司【有可能是大多数】是基本不允许发文章的 –牵涉到公司的商业机密)。
2.好象药厂的研发部门普遍都是要有postdoc经历的。我道听途说,不负法律责任啊。
3.有些公司(比如consulting公司)看起来不起眼,research其实是很牛的。如果你申请他们的工作,做好被问的稀里哗啦的准备(因为那儿的人虽然未必是牛人,但在他/她所做的一块去很有可能是非常的牛,基本上对没在那个题目上下过大工夫/有过相当的经验的人是见一个灭一个)。
罗里八嗦写了这么长,希望能对你准备简历有一点帮助。基于我的经验,你去outplacement/career placement公司培训,或者找专业写手,他们能给你的也就这么多了。所以如果你原来有这方面的预算,我有一个小小的建议:把预算的90%留给你自己,剩下的10%拿去帮助需要帮助的人。如果你现在是处于骑驴找马的阶段,建议把比例变成75%/25%. 如果你想不出去帮助谁,我还有两个建议:1. 海外中国教育基金会(Overseas China Education Foundation), http://www.ocef.org; 2.帮助陈伟宁的遗孀和小女儿(http://chenweining.org)。声明:我不是清华/北大的,也不认识她们。
{==虽然无须donation,请你常怀感恩之心,若能乐于助人更佳==}
## 关于找工作(二 Cover Letter)
准备好了简历,下一个文档就是cover letter了。其实对衡量你是否是一个好的候选人来说,cover letter的作用==几乎是零==(很多情况下主管技术工作的人或者雇人经理根本见不到cover letter)。那么为什么还要准备cover letter呢?答案和简历的qualification那一段差不多 — 主要目的是帮助你顺利度过/混过recruiter/HR这一关。{==这是大实话 所以内推优先 social network优先==}
写cover letter也是有固定的套路的,而且这个套路更简单(一两个字)。不过俺已经吊了大家这么长时间的胃口了,就再多吊一会儿吧。
先说说recruiter/HR是怎么衡量一个候选人的。简历里的qualification毋庸置疑是非常非常重要的,但是qualification其实还不是他们/她们的“第一印象”。第一印象是什么?就是cover letter了。这么说吧, 找工作就和(通过介绍人)找对象差不多,小伙/姑娘再好,介绍人那儿没有好印象,要再进一步也不容易吧?那么怎么留下一个好印象呢?差不多唯一的办法就是想办法减轻介绍人的工作负担了。所以俺的罗嗦一下recruiter/HR是怎么衡量一个申请人会不会的。
有一点基本可以确定,recruiter/HR对你的专业所知非常有限。可是他们/她们 也要工作不是?怎么办呢?很简单,把招工广告拿过来,把简历拿来,对照招人的要求一二三四五六七, 一条条的比较,符合一条打一个勾,最后数有多少个勾–勾越多的越好。有同学说了,你不是说他们只花20秒吗?哪有时间来一条条地过?没错,他们是没时间。大多数人根本过不了前20秒这一关,所以也不会被打勾了。那么为什么要在讲cover letter的时候提这个呢?还是一个原因:减轻recruiter/HR的工作负担。试想如果你已经替他/她老人家做了这项工作了,他/她对你的印象也会好很多不是。再说了,有些要求你马马虎虎可以算达到,也可以算没达到,你先入为主地说达到了,也多少占一些便宜吧。
好了,进入正题:cover letter 怎么写?正式书信的格式不用我提了吧(如果不清楚,去随便那个图书馆找本书信格式的书看看)。cover letter的主体有一个模式(就是我说的一两个字的样板):Q-letter。现在你知道了,网上随便google吧。我给一个我用的版本:
第一段:I am writing in response to your recent advertisement for a Nuclear Scientist (用招工广告里的title) (position opening # 12345) on your website/monster.com/careerbuilder.com/wherever(选一个,或者类似的). Based on my experience/background(选一个,或者排列组合,不要用“/”), I believe I am a good/strong candidate for the position.
简单不简单?别的什么话都不需要说,没用。
第二段:查入一个三列,4-6行的表格。左面一列(第一列), 题头(11号字,全大写, 或者变黑体)YOUR NEEDS; 右边一列(第三列), 题头MY QUALIFICATION. 第二列空着,不用。
下一行开始,左面一列,抄招工广告里的具体要求,基本上是copy&paste;右边一列,对应的你的资历。
这么 列上3-5条就可以了,再多了recruiter/HR也没空看。
然后,把表格的线/框全去掉,修改字体(表格里的字体常常和文本里的不一样),对齐,表格的宽度(总宽度比正文的宽度稍小,第二列用来调节左面和右面的距离)/高度,让这个表格看不大出来是一个表格。
第三段:Thank you for your considerations. If you would like to discuss further about my qualifications, please do not hesitate to contact me via email at (把简历里的email地址抄过来) or via telephone at 123-1234-567 (知道为什么前面建议搞一个prepaid的手机专物专用了吧?)。I look forward to talking with you.
然后, Sincerely, 空三四行(签名用),敲上你的名字(和简历里的要一致)。
有了这个样板,申请每个位置时把列表里的内容改一改就差不多了。(简历也要相应的改一下)
下一步,把cover letter和简历合成一个文件(不是压缩成一个文件啊),即第一页是cover letter, 第二(三)页是简历。用简历的文件名(参见前面讲过的文件命名方案)。
都弄好了,就可以email给recruiter了。Email很简单:
Dear Mr/Ms xxx,
I am writing … (把cover letter的第一句话抄上). Attached please find the cover letter and my resume.
Thank you.
Job Hunter
下一步,就是等鱼上钩了。
学习班里教的:cover letter里最后一句和recruiter约一个时间电话联系 I look forward to talking with you over the phone this coming Friday (大概两三天后吧)between 10 and 11 AM. 我个人不喜欢这样做,一是觉得有些唐突(如果recruiter刚好那时候忙,你这不是添乱吗?), 再者感觉没必要,反正他/她给你的时间就是20秒,你或者过关,或者不过关,有什么好废话的。如果你过关了,他/她自然会和你联系;如果你不过关,再去罗里八嗦,第一未必会改变他/她的想法,第二搞不好你就此被打入冷宫(recruiter一定会再有类似的工作机会的),那可亏大发了。
## 关于找工作(二1/2 简历/cover letter的补充说明)
前面详详细细地解释了简历和cover letter怎么写会对HR/recruiter的喜好,据说应该是有效的(俺去的那个outplacement 公司大大小小有百十号人,如果教的东东不管用,要维持下去大概也不容易吧?)。当然不管用的时候也是有的,比如公司根本不用recruiter。(俺做hiring manager的时候公司里的HR只负责把简历输入到数据库里,俺得一个一个看。虽然不至于每个只用20秒,但一个小时看个四五十是没有问题的。)那种情况下能不能过关主要靠申请人的实际经验了。可是(1)作为申请人你是无法预知你会遇到这种情况的; (2)即使是hiring manager直接看,读起来容易些也不会有副作用,所以我的建议是尽量照着模板来。也许刚开始把自己的简历改成模板的样子比较费劲,但俺的经验是后面的修改就轻松多了。
当然俺的经验毕竟有限,所以如果您有不同的意见,欢迎评论/分享。
{==俺想开发一个软件帮助这些可怜的HR分析简历,你们觉得咋样==}
## 关于找工作(二3/4 常见问题FAQ)
== 需要的话,这个帖子会不断更新 ==
Q:这些东东可靠不可靠/管用不管用?是不是楼主在闭门造车?
A: 管用不管用要你自己去试。俺的感觉还是有帮助的。大多数内容是基于俺在一个叫Right Management的公司听的课总结/抄袭下来的。如果你感兴趣,可以去他们的网站看一看http://www.right.com。据他们自己说他们是北美同类公司里最大的。俺感觉他们教的东东基本上是靠谱的,但是考虑到去听课的人什么背景都有,有些东西不是很适用,所以俺根据他们讲的主题思想发挥了一下(多数发挥都和他们的专业人士讨论过)。举个例子吧:在experience里,他们讲的要==强调结果==,举的例子是marketing方面,开发了什么什么方案拓展了多大多大的市场。对做技术的人来说,俺就给发挥成解决了什么样什么样的问题了(最好还有导致了多少多少的额外利润/生产率提高)。
Q: 这些信息对非工程师有用吗?
A: 应该是有用的。象我提起过的,我的本行是工程,所以只能提一些我觉得合理的观点。至于这些观点是不是最好?俺不知道,也不可能知道。俺费了牛劲解释为什么的原因就是希望你能触类旁通,把自己的优势放到招人的人感觉舒服的地方。
Q: 我就没见过一页的简历。。。
A: 同意你的观点。我也很少见一页的简历(特别是当申请人有研究生学位的时候)。事实上, 我的简历也是2页,但是主要的内容(qualification 和 experience 【俺的工作历史比较长,做过的东西跨度也比较大】)都在第一页上,第二页其实只要一半多一点的样子,都是不得不列的东东(education, patents, 等等)。俺的recruiter说他曾经想帮我压缩到一页,可是实在是放不下。 所以俺的建议是一页最好,两页也凑合。也许有的行业惯例是长篇大论,但至少俺做招人经理的时候是没耐心看长篇大论的(其实我基本上只看qualification 和experience,大概靠谱了才去看education什么的)
Q: 我有几十篇论文,怎么列?
A: 俺曾经负责招过研发工程师(R&D engineer, research scientist),也负责招过“普通”的工程师(比如application engineer)。俺的经验是文章太多未必是好事,因为有时会有先入为主的印象:做科研太牛的人转型到工业界比较吃力。当然凡事不能一概而论,你如果是申请去要拼技术的地方(比如大药厂的研发,石油公司的研发,一部分小的consulting firm),论文多应该不是坏事。俺的建议是宁缺勿滥,牛杂志上的要列,很一般的杂志上的和会议论文就不要列了(因为很多会议论文是可以随便发的,不需要经过peer review的过程,所以容易给人一个错误的印象:这个人没有多少像样的东西,靠发会议论文凑数混学位)。当然,如果你所在的行业对会议论文要求也是很严(是整个行业,不是某一个会议),又另当别论。
Q:你能不能把你的简历贴出来给大家看看?
A:抱歉,我的经历有一些相当特殊的东西(比如在某年做某方面的东西),即使把细节略去,同行也基本上能猜出我是谁,所以我很不倾向于把简历(即使是修改过的)贴出来。
Q:你能不能帮我改一下简历?
A:再次抱歉,原则上俺不能。主要原因是俺的空余时间非常不固定,没法保证时间/质量。以后也许会考虑适当地帮一下。但是即使是帮的话,数量也不会大。
## 关于找工作(三 广而告之【之一】)
简历准备好了,下一步就是想办法把自己“卖” 出去了。可是怎么“卖”呢?
中国人有句老话:“酒香不怕巷子深”,又有“敏于行,慎于言”,可惜在老美这儿统统行不通(好象在中国也行不通)。从某种意义上讲,要有效地推销自己,必须得把自己“广而告之” — 你想想, 如果招工的人根本不知道世上还有你这么一个人,机会能到你的头上吗?
以俺的经验,找工作大概有三条路,一条条的讲吧。
第一条路:最简单的方法,通过网络找。这主要是两件事。1. 挂简历; 2. 看广告。
先说挂简历。建议把你的简历放到两个大的网站:monster.com 和 careerbuilder.com。这两个网站基本上是属于“通用型”网站,recruiter基本上都会去看一看的。用什么格式的简历呢?pdf版或者word版。俺倾向于pdf版,因为有的网站太“聪明”,会把你的word文件的格式弄乱。除了这两个网站,你可以放到一些比较“专门”的网站,比如你如果是做计算机相关的,还可以放到dice.com上。简历挂上去之后,这一部分工作就基本算结束了。你要做的只剩下等鱼儿自己上钩了。
稍微跑题一下:建议不要把简历放到太多的网站山。因为一旦你把简历挂到网站上,你的简历基本上就是公共信息了,recruiter能看到,伪recruiter也能看到,而且伪recruiter会不屈不挠地试图说服你。怎么鉴别伪recruiter?俺也没办法。基本上靠直觉吧,如果有什么来的太简单(比如说让你直接去on-site interview什么的 — 不是没有,很少),多留点心吧。一点小经验,如果你的专业与保险业没有什么关系,那些邀请你去interview的保险公司(的分支/代理), 比如比较臭名昭著的metlife和aflec, 基本上是逗你玩的。他们会说“我们有很多很成功的雇员和你一样是工程背景,。。。”什么的,好象你可以一步迈入finance挣大钱了。事实是什么呢?你确实会很容易那到工作,但也仅此而已。固定的工资基本上是没有的,搞不好你还得自己掏培训费,自己买工作用品等等。高收入有没有?当然有,只有你一个月卖出多少份保险。
2.看广告。现在网络这么发达,好多以前几乎不可能得到的信息,都可以很容易的找到了。招工信息也是这样。俺的建议是每天拿出0.5-1个小时,在网上看有什么新的工作机会。一点小窍门:你不一定要去monster啊,careerbuilder啊,yahoo hotjobs啊,dice啊什么的一遍又一遍的搜索. 现在有很多“检索”网站,提供“一站式”服务,即你只要去一个网站,他们可以替你搜索若干网站。俺用的是indeed.com, 基本上可以包括绝大部分工作信息,每天把最多七八页招工信息列表看一看,也就是半个小时的事。另外一个类似网站是simplyhired.com。大同小异。
说到网络,俺有一些小的经验:
1. 搜索的关键词覆盖的范围越宽越好。的确,会有很多不着调的搜索结果,可是也会有很多你容易漏掉的结果会出来。举个例子吧,如果你做的是机械控制, 只搜索"mechanical"会比搜索“mechanical & control” 得到多的多的结果(当然也包括不太着调的,比如修房子的mechanical engineer)。
2. 关于indeed.com的小tips: (1) 不要轻信indeed给出的招工广告的“年龄”,因为indeed有时候(比较经常)会把很古老的招工广告翻出来当成新的。所以最好再用google查一下那个具体的广告,有时你会发现那个广告已经在那儿好几个月了。 (2) indeed上的工资水平过滤(左面的面板)基本上可以忽略,很多数时候不着调。
3. 提防利用找工作的人的心态赚黑心钱的公司。比如有一个网站叫6figurejobs.com(他们还有很多别的域名), 建议你躲着一点。如果你不幸在他们的网站上注册了,他们会不停的骚扰你,甚至会给你提供一些免费的服务(好象有一本书,还有免费的resume review), 然后会和你电话约谈,给你一个去一个号称花了几百万研究出来的什么找工作的网站(忘了叫什么名字了)的帐号,其实目的就是吓唬你,让你和他们签约,让他们帮你找工作。签约费据说在七八千的量级(你付给他们),而且绝对没有“不满意退款”一说。类似的公司还有很多。所以如果有公司联系你,你要做的第一件事是去google公司的名字,看看他们到底是干什么的。第二件事比第一件重要的多(因为6figurejobs.com网站看起来挺正式),去google 公司名字+spam,你会发现你不是第一个他们试图想骗的人。
4. 有一个网站叫jobfox.com。 这个网站说起来还不能算黑心网站,但是他们的所谓的"smarter approach"基本上是胡言乱语,实在没必要在这个网站浪费时间。
5. 网上有很多专业的简历修改服务,收费几十到几百不等。俺个人的建议是没有必要用他们的服务。有几个更有效的方法。(1)如果你还在学校的话,可以去学校的career center/career office寻求帮助。那儿的人多少都是受过一些训练的,有些还本身就是专业写手,他们应该可以给你一些建议; (2)去图书馆找关于写简历的书照猫画虎; (3)[比较无耻的自我宣传] 看俺博客里的经验。这些经验是俺第一手的积累。如果说专业写手/书上写的是武术套路的话,俺的就是军体拳,虽然不太好看,管用还是挺管用的。
## 关于找工作(三 广而告之【之二】)
找工作的第二条路:recruiter。recruiter, 也就是常说的head hunter, 是专门的以帮公司招人为生的人/公司。recruiter 大概有两类:1. (通常是比较大的公司)他们常常和一些公司有合同,是那些公司的exclusive recruiter。也就是说,如果那个公司要通过recruiter招人,他们必须通过这家公司。这样的好处是什么呢?如果一个公司每年招的人比较多,通过签一个exclusive recruiter, 他们通常只要付一个固定的费用(有时会根据招人的数目稍做调整),这样往往比雇用一批non-exclusive要省钱。2. non-exclusive recruiters。简单的说,招人的公司把招人信息放出去,一堆recruiter帮他们招人, 谁找到了谁拿commission。
明白了这个区别,对“recruiter为什么问我申请过这个位置没有?”的答案应该很清楚了吧—对他们来说,如果你已经被毙过,他们就没必要浪费时间了。而对你来说,等于间接地告诉了你他们不是exclusive的(他们有可能是别的公司的exclusive recruiter)。
如果有recruiter和你联系,你该怎么办呢?第一,约一个时间电话里细谈(如果是recruiter直接打电话给你,让他们把工作位置的信息email给你,同时找个借口[现在不方便说话什么的]另外约时间)。问什么?因为你需要做第二步的工作:调查和工作位置相关的背景内容,比如什么公司,公司的主要业务是什么,要找的是干什么的人。记住,打有准备之仗会大大增加你成功的几率。然后就是和recruiter的电话了。
电话里你该做的第一件事就是在开始的“how are you doing?”之类的废话之后,想办法(比如“thank you for your interest. Before we start, can I ask you a question?“)问第一个问题:“are you an exclusive recruiter for them?” 因为答案会给你一些线索。比如,如果他们是exclusive recruiter, 你基本上可以确定是招人的公司考虑的有限的几个人之一,而如果他们不是exclusive recruiter, 你有可能只是一大堆潜在候选人中的一个。另外,exclusive recruiter通常对招人公司很了解,甚至直接认识hiring manager, 所以他们会(只要你去问)告诉你面试要注意什么,面试人都有什么样的背景, 等等有用的信息。
不管是不是exclusive recruiter, 对找工作的你来说都是免费的服务(如果有向你要钱的,比如6figurejobs.com这样的,躲着点),而且他们在绝大多数情况下会极力帮助你的(比如帮你改简历,准备面试)。原因很简单,只有你成功了,他们才有钱赚— 对non-exclusive recruiter来说,成功一个拿一个的commission (顺便说一句,这个commission可不是小数目,行业的标准据说是所招的人的两个月的工资 — 不是被招的人出, 而是招人的公司出); 对exclusive recruiter来说,成功一个剩下的工作量就少一个。
俺个人对和recruiter的谈的态度是实事求是,有一说一,原因在“面试”一节里。
如果recruiter对你比较满意,他们会去和公司谈(他们会告诉你他/她下一步的计划),你基本上可以开始着手准备hiring manager的电话interview了。这个电话interview基本上是板上钉钉的,因为不需要花公司什么钱。— 俗不俗?凡事都是以钱来衡量的。
那么怎么找recruiter呢?等他们自己上钩是一个办法。还有一个办法是靠别人推荐。再有一个办法是半主动出击:如果招工广告是列出了让你联系的人的名字,google他的公司地址,然后在cover letter里的收信人一块里直接用他/她的名字/地址。这实际上是一点心理学的小花招,据说这样会使收信人中文感觉比较重要。心情好一些,就会愿意帮忙一些。那么如果没有联系人的名字怎么办?还是心理学的小花招。cover letter的题头(就是dear xxx一行)写dear hiring executive。当然收你的信的人一般也就是个打工仔,可是被人尊称为executive还是挺爽的不是?
## 关于找工作(三 广而告之【之三】)
找工作的第三条路:==关系网==。俺个人的感觉,这是==**最**==有效的方法。因为如果有“内线”,你成功的几率大大的大大的(不是俺输重复了)增加了。另外很多情况下,你的“内线”可以帮你探听一些内部消息,这些内部消息可是无价之宝吧。
那么怎么找内线呢?首先,如果你要找工作,除非你是在骑驴找马,不能悄没声地找。先给你的朋友,哥们,姐们发一封email:“兄弟打算找工作了,简历在附件里,你们谁知道合适的机会拉兄弟一把啊”。也许你会问,某某朋友没在工作,这个email就免了吧。俺的答案是,发封email又不花钱(网络真是好啊,寄封信还得四毛多呢),您老人家省什么省?朋友不工作, 你就知道朋友的朋友(的朋友)也不工作?有的时候,工作机会会“莫名其妙”地出来。给你们讲一个真实的例子吧。俺的一个朋友,悄没声地找了小半年,也没什么动静。后来老哥无意中和平时一起打网球的一个人(A) 提起,当时也没有什么动静。A去教会,和B(我的朋友不认识B)闲聊是提起来,B说,“唉,好像我老婆公司在招人,我给问问吧。” B的老婆是做会计的,按理说也不着调(俺的朋友是做计算机的)。可是小公司里就那么多中国人,随便问了问,结果真有一个组在打算招人。于是大概两三个星期后,我的那个朋友去面试了,然后拿到了Offer。最绝的是,那个招人信息根本就没公开过。这个例子也许有点不可思议,可是很多事情就是不可思议的。你如果不去试一下,就是有不可思议的事情也轮不到你的头上啊。
第二个办法:如果你还在学校的话,或者离开学校没多久的话,并且还你的老板/导师的关系还可以,去骚扰你的老板/导师。他/她应该会有一些关系(肯定比你的多)。虽然他/她不一定会直接帮你,你总可以虚心地请教一下“去什么行业比较合适?”吧?他给你的建议往往是他有熟人的行业。这样即使他/她不直接帮你,保不准你要申请的位置的hiring manager是知道他呢。当然如果老板肯帮忙(很多老板都愿意帮忙的,有学生毕业也是衡量教授的工作的一个方面),事情就好办多了。特别是如果他/她愿意帮你联系他/她以前的学生,你的便宜可占大了— 至少对俺来说,如果俺的老板发话说如果有机会帮帮忙,俺一定会大大的上心的。
第三个办法:linkedin。 你有没有linkedin的帐号?没有的话,赶紧去申请一个,然后把你认识的人统统加进去。linkedin的最大的好处是你可以看到某个人是你的第几层关系网上的 – 朋友(contact)是第一层,朋友的朋友是第二层,朋友的朋友的朋友是第三层。我不记得在哪儿看过,在这个世界上,任何两个人之间的关系网都不超过四(五,六,不记得具体是几了,总之是一个不大的数)层,也就是说从你开始,你认识的人的n(n 不大)次方可以包括世界上任何一个人。这个信息有什么用呢?如果你想申请某个公司的位置,而公司要求你直接到网站去投简历,那样的话你的几率基本上是和买彩票差不多(除非你的简历一下子把他们镇住)。这时候你就可以去linkedin看看,有没有那个公司有没有什么人是在你的关系网里。如果有,你会看到你们之间的联系(你的第一/二层关系网上的朋友)是谁,找你的朋友, 请他/她帮忙。如果你把你的学校(大学,研究生)都列上了,有时候你会找到校友(尽管你们入学的时间可能相差了十几年)。有了这一点共同点,你就可以试图把你的校友加到你的关系网里,然后请他/她帮忙了— 如果你的背景差不多,多数人是愿意帮忙的(只是把简历转发给HR而已,而且很多公司有referral bonus)。但是如果人家不想帮忙,也不要有怨言,以为公司里招人有时候针对性是非常强的,背景差一点都不行。而作为公司里的雇员来说,如果推荐的人太离谱,也不太好(以后再推荐人就不太好用了)。
用linkedin还有一个好处:很多很多recruiter都用linkedin,而且有成百上千的contact。你和他们/她们建立关系,你的关系网一下子就增大了很多。另外如果你拿到了on-site interview的日程安排,你也可能能在linkedin上查到要见的人的背景(不建议你把他/她加为contact,会让人不舒服)。
第四个办法是俺从Right Management的学习班上听来的,没实践过,不过俺打赌大多数找工作的同学都没听说过这档子事:在美国有很多networking group,说白了就是找工作的人的碰头会。这儿有一个目录:http://www.job-hunt.org/job-search-networking/job-search-networking.shtml 。 俺的猜想是networking group对象俺一样的工程师可能帮助不太大,因为象俺们这样的工程师是靠技术吃饭的,太专门话,不是象sales,marketing之类的专业性不是非常的强。当然俺是乱猜的,你如果有时间,自己去参加几次也没有什么害处。如果你打算去,准备好一个"30 seconds sales pitch", 基本上就是以三四句话概括一下你的背景和你想要找的工作(和你简历里的qualification差不多),练熟了,因为你会被要求做一个自我介绍(要不然别人怎么知道你是哪路神仙?)
{==对于软件工程师或者创业者而言 现在很多技术讨论会还有meetup是很不错的渠道 尤其是技术人才 找找业内论坛或者知名博主发起的一些活动 当地线下最好 见到真人交流沟通一下 如果合适效果完全相当于内推 说实话 那些读MBA的不也是多认识些高富帅白富美知道些人生赢家的机会么==}
## 关于找工作(四 面试)
好了,现在有公司的人给你打电话/发email约谈了。恭喜你,你基本上已经度过了做没谱/不着调/撞大运的一关了。接下来是什么程序呢?
一般说来,公司的面试会是两步:1.电话面试 (telephone interview); 2. 面对面面试(on-site interview).
先说电话面试:电话面试有可能是两个电话。第一个,和recruiter/HR谈。找一个基本上没什么担心的,因为recruiter/HR对你的技术能力的判断力几乎是零。他们打电话的目的一般是想搞清楚一些非技术的问题, 比如你的身份问题,是否需要搬家,什么时候available, 等等。对这些问题就实话实说好了,因为很多事情(比如身份问题)不是个人/公司能控制了的。相对来说,recruiter给你打电话要好办一些,因为他们通常会尽量帮助你(别忘了,他们的收入是和帮助公司招到人挂钩的, 有的甚至是直接挂钩[招到一个人,拿一个人的钱])。
一个很普遍的,让很多人不舒服的问题是recruiter有时会问你对工资的期望值是多少。我的经验是如果你有大概的概念,不妨直言(反正俺都是明着说的)。提醒一下,如果你是骑驴找马,而现在的工作有奖金,记得把奖金包括进去。recruiter问这个问题的原因很简单:如果你的期望值是10万,而那个位置最多给7万,那就不要浪费大家的时间了。
{==建议给个range 也可以直接让HR先说职位offer的range==}
同时,你可以问recruiter这些问题:1. 那个位置的pay band 是多少? (如果recruiter问你的期望值是多少,而你基本上没概念的话,可以用这个问题来反问recruiter — 当然得委婉一点,比如:I’m quite flexible on the level of pay, may I ask you what the pay band for that position is?) 2. 如果recruiter提起和hiring manager 的电话面试,可以问他/她 hiring manager的背景以及面试需要注意哪些方面。正常情况下,recruiter会尽量帮助你的。
下一步,就是技术方面的面试了。你能不能拿到工作,这一步是至关重要的。遗憾的是,这一步也是最没法准备的。为什么?很简单,前面过HR/recruite关,HR/recruiter的训练都是大同小异的,所以可以对症下药;而技术方面,隔行如隔山,而且参与面试的人有各种各样的风格(多数公司都没有固定的面试问题),能不能说服他们你是合适的人选,只有靠你自己的能耐了。
那么是不是说只有去碰运气了?也不完全是。面试之前,至少有一项准备工作:==调查==一下公司的背景以及面试你的人的背景(如果可能的话)。公司的背景包括主要的业务(总不能人家问你“对我们公司知道什么?”回答“nothing‘吧),最近的新闻(一般公司的主页上会有,另外google), 主要的竞争对手等等。面试你的人的背景有什么用?通常情况下,他们未必都是你的同行(比如有的人是工程师,有的人是学物理的,有的人是做marketing的),知道了会和什么样的人面谈,才好有的放矢的准备啊。面谈的时候,也可以有选择地吹吹牛。
面试的程序有什么呢?基本上是两块:1. presentation and/or hands-on project. 2. 和不同的人面谈。hands-on project好象在找软件工程师的工作是特别普遍。俺不是学软件的,所以也没什么经验。建议去网上(比如mitbbs)找”面经“。 presentation对工作经验不多的申请人来说几乎是必须的(对多年工作经验的人来说,做presentation有时不现实, 因为大多数公司里做的东西是不能随便出去讲的)。面试时的presentation其实和学校里的差不多,( 当然每个人在学校里受的训练也不一样),但是要注意淡化技术细节,把重点放在解释清楚到底是怎么做的。原因很简单,在学校里做presentation, 听众基本上都是同行,所以你可以不厌其烦地讲解细节,把别人都灌晕了才牛;而在公司里,第一同行未必占多数,再者基本上没人喜欢看公式,特别是说话管用的经理们。如果你不能用大白话把你的东西讲清楚,你觉得经理们会不会帮你说话?
至于和不同的人面谈,俺能给的经验就两条:1. 要尽量给人留下一个容易相处的印象。为什么?因为以后大家要做同事的。虽然未必会做同一个项目,但谁也不能断定以后绝对不会合作。如果有一个P股上的痛(hehe, 老美的说法,pain in the *ss), 不是给自己找麻烦吗?2. 吹牛不要紧,不要漏。特别是和技术背景强的人聊天,他/她问某个问题,通常是有一定概念的。如果你乱吹,牛皮吹破了,你的面试成绩也就差不多了。其实有时候老老实实说”我所知有限“也不一定是坏事,因为有时候面试的人是故意来看你到底懂多少的。
几个与面试相关的非技术经验:
1. 面试前一天,最好开车去面试地点一趟。熟悉一下路程,以防万一第二天路上耽搁(比如有时候公司的门面很小,或者gps不准确)。
2. 面试时西装革履(除非公司明确告诉你不需要)。建议开车时把西装挂起来,到了公司再穿上。进了房间后,可以把西装脱下来。
3. 比约定的面试时间提前大概10分钟到。如果到早了,在公司的停车场等一会儿;如果迟到(最好不要),提前打电话给hiring manager告诉大概会迟到几分钟。
4. 面谈后记得要名片。在面试后的24小时内给每个人发一封感谢的email。内容可以基本一样,但是要每人一封(不要群发)。多数情况下,对方不会回你的email,那是正常的,没有什么可紧张的。
{==这个很重要 你要相信他面试了这么多人 如果没什么人给他发感谢信 你很突出 如果大部分人给他发感谢信 你很突兀==}
5.最重要的一点,放松。要相信自己的实力。
## 关于找工作(五 找工作的心态问题【之一】)
技术细节基本讲完了,下面开始讲一点虚的 — 找工作的心态问题。
先声明一下,俺找工作的时候一没身份的压力,二没经济的压力(或者是在骑驴找马,或者是正拿着被裁的package,开开心心地领着失业救济"度长假"),所以有可能是站着说话不腰疼。您要是正一肚子火呢,等消消气再来看。
其实找工作的心态说起来非常简单,就一句话:“要相信自己的实力”。想想您老人家背井离乡,飘洋过海地跑到这个地方来,说着鸟语,看着写满鸟字的书,还拿到了鬼子都不容易拿到的老鸟学位(骂死他/屁挨着地),搞定个把鸟工作还不只是时间早晚的问题。咱们和老美相比差什么?一是不太清楚他们游戏的规则/套路(这个希望俺费牛劲写的这些帖子能管点用),二是没有老美的关系网(先天不足,没法子,老美到了中国还不是一样没辙?),第三个就是中国人普遍太谦虚,以致于有些畏畏缩缩(不是wsn的ws),不敢/不会象老美一样装牛B。
所以俺说根本的根本是要有自信,要有近于自大的自信。你自信满满了,写的简历才能吓住人(因为你做的东西只能用一个字概括:牛),面试时才能说服人,(就算稍微吹点牛,别人也不敢乱问啊)。你也许会觉得俺在说胡话,俺是故意这么说的,因为中国人普遍认技术挂帅,总觉得别人能看出来自己的技术有多牛。技术要好是对的,但它顶多是七分,剩下的三分可就得靠吆喝,忽悠之类的软能耐了。有一点您可以基本放心,您在怎么自信满满,和很多老印/老美比起来也是小儿科的很。(by the way, 那样的老美基本上是无知者无畏,老印吗,就不好说了)
找着了这个根源因素,网上(特别是mitbbs上)找工作的时候常见的“什么什么可怎么办啊?”这样的问题也就不能成为问题了(怎么象方鸿渐的成名演讲的语气?)。下一节具体晒一晒那些不成为问题的问题。
## 关于找工作 — 文摘之一
=== 说明 ===
文摘系列没有固定的计划/蓝图,我在网上看到的东西随看随贴,会穿插于正常的“关于找工作”系列之中。
=== 说明结束 ===
(文摘之一)
小背景: Steve Allard是我打过一点交道的recruiter(他一度反复游说我去一家startup)。此人的能耐大小不清楚,但磨嘴皮子的工夫那是相当的美国,基本上能把死的说成活的。
介绍这个背景的原因是希望不要给你留下我支持/推荐或者不支持/不推荐他的印象。只是觉得他写的一些东东有些道理,所以给大家节省一点时间,做个压缩饼干式的文摘。
有时间/兴趣的话,原文(英文)在这儿:http://talentretriever.wordpress.com/2009/04/16/6-steps-to-a-winning-resume/
要点:
获奖简历6要素:
1. 目标明确。
【俺的评论】即俺所说的有一个大框,根据实际情况照方下药。所不同的是他强调的是以简历作者的追求为准则(以人为本嘛),俺说的是以招工单位的要求为参考准则—前面提过了,俺的一套往好听里说是军体拳(实用,但不好看),往不好里说就是野路子,有点偏阴损。
2. 列表(bullet items),但是也不要全列表。
【俺的评论】和俺说的基本一致,两三句三四句易读的话(短语),然后是列表。
3. 具体,有数据,可以吹牛[他没敢明着说],但不能漏
【俺的评论】和俺说的基本一致
4. 动词
【俺的评论】和俺说的一致, 动词开头,挑吓人的词用
5. 废话少说
【俺的评论】和俺说的又一致,宝贵的空间不要用来说屁话(实在想说屁话,象俺一个开个博客)。还有,俺说的不要列reference也提到了(讲的比俺讲的还生动)
6. 短
【俺的评论】老美能做到这一点可不简单,我看他们的教材/文章有90%以上是废话连篇,又臭又长。
呵呵,看来俺业余也可以琢磨着干干recruiter的活了。
另外这一片也可一看,是关于如果使用linkedin的,俺就不摘要了。 http://talentretriever.wordpress.com/2010/03/03/building-your-linkedin-brand/
现在有工作的同学可以看看这个:http://talentretriever.wordpress.com/2010/05/04/“but-i-have-a-job-and-i’m-happy-”/, 有点意思。不过俺建议不要被他完全忽悠了,俺就是对他太客气,被他穷追猛打了两个星期(那个位置简直就是照着俺的背景/经验写的,也难怪他不屈不挠。不幸的是那个startup实在是太绿了,俺实在是不敢冒险赌一把)。
剩下的文章基本上没必要看,主要是写给公司看的。这家伙也许正在努力给自己找铁饭碗。
给他免费做一个广告吧:你如果想和他联系,可以在linkedin上找到他。
## 关于找工作 — 文摘之二
== 感谢zjh67同学同意俺免费用他的原创文章 ==
MITBBS 上zjh67的文章,面试的真实例子分析,非常有帮助。 原文在这儿: http://www.mitbbs.com/article_t/THU/31222293.html
【俺的点评】这个经历和俺有一次招人的情况机会一模一样。中国人一般技术基础是不错的,但是吃亏在两三个方面:
1. 技术面太窄。我见过不少自己的东西搞得很熟的,但是也仅限于自己的那一点东西。其实不需要你对别的多么精通,大概有些印象, 能马马虎虎说一说就可以了。因为工作以后的东西通常和你以前做的是不同的,如果看不到你的触类旁通的能力,公司是会很犹豫的;
2. 太学术化。在校的时候做presentation是越复杂越好,可是在公司里更重要的是别人能大概听懂你的东西。在去面试之前,要想办法搞清楚那个公司的风格是什么—有的公司(比如consulting)很注重研究,但更多的公司是希望找到的人能短平快地解决问题。在准备presentation的时候,可以有两个方法:(1)对每一个公式都问一下自己:这个公式删去的话,我还能不能把我的做法大概讲出来?追根究底的话,你会发现绝大多数公式都没有必要出现。(2)找一个对你的东西没有多少概念的同行(比如新进实验室的小师弟),看看他能不能基本上跟着你的思路走。要记住,公司的任务是要赚钱的。如果你的工作不解决实际问题,或者你的方法先进的别人根本听不懂,做的再漂亮也没用。说到底,最重要的东西不是你做的细节有多漂亮(能拿到学位,在细节上都是有两把刷子的),而是你的分析问题,解决问题,表述问题的能力。为什么要用表述问题的能力?管理层对你做什么总得有点概念吧,另外一个重要的原因就是你迟早是要和别人合作的,曲高和寡可不好办。
3. 和第二点差不多,但是可能短时间内不太容易提高:基本概念要清楚。这个不是指你能把基本定理背出来,还是要真的明白为什么一个问题可以那样做。举个材料力学的例子吧,悬臂梁理论是解决工字钢相关的问题的一个基本工具(大学二年级的东西,学机械,土木,航天,力学的人大概都能把公式从头到尾推出来),可是你有没有注意什么情况下不能用悬臂梁理论?
= 以下为转发的文章 ====
我在一家半导体设备公司任职。前些日子我们组有两个机械设计工程师的位置空缺。印度同事推荐了许多印度人。 我也通过别人介绍联系了两个师弟。可是面试结果下来,offer 全给了小印。虽然参加面试的六人中有两个小印manager, 但我的感觉是师弟们的背景和表现和小印们相比的确差强人意,落选当在情理之中。我想在这里将过程简单回顾一下,希望对其他正在或将来要找工作的师弟师妹们能有所帮助。 由于各个行业各个公司各个小组的情况不尽相同, 所言不当之处还请各位包涵, 就当是他山之石吧。
首先要说明的是我们要招的机械工程师必须具备很强的分析问题能力。当然基本的专业训练如结构应力,流体传热,材料应用等是不可缺少的。
师弟A:
本科和硕士都在清华,有机械和材料的背景。即将从一工程排名前20的学校博士毕业,无工作经验。据说其导师是行业中的牛人。在面试前我和他通过几次电话,请他至少要做一个准备,那就是用5 分钟的时间总结一下他所完成的最重要的项目。这是因为在他之前我们面试了一个明大的小印硕士,他准备了一份非常漂亮的彩色打印的presentation,highlight 了他所承担的项目,而且简明扼要地介绍了他所面对的问题、难点,解决问题的思路,得到的结果,优缺点以及后续工作等等,给我们所有的面试人员留下深刻印象。由于他是硕士,我问的几个问题他都没能正确回答,但是他尽了最大努力从他所理解的机理出发试图得到正确答案。这使得我这个对小印有所抵触的人都在心里赞叹。
回到师弟A。面试那天他的 attitude其实很不错。我不知道他是否按我的提示做好了准备,因为我本人在给他面试时并没有谈及这些。在面试结束后的讨论会上,我们的CTO(白人)坚决反对雇用A,理由是他对所承担的博士课题缺乏深度的了解,而且只局限于他所做项目本身而已(他的课题是一个大课题中的一部分),他对上下游的情况几乎一问三不知。这不是一个博士应有的表现。所以尽管personally他觉得A是个good guy
,他还是反对。一个资深的白人工程师也持反对态度。他向A提了一个压力计算的工程问题,他本期望A能将问题简化,给出一个估计值(量级之内)。可是A却告诉他要构造一个模型然后用simulation软件找到答案。所以这个资深工程师的结论是A缺乏工程师的素养,不会猜结果。两个小印manager的评价倒并不很负面,其中一个表示他持中性。另一个觉得对fresh的博士不能要求太高,有些方面毕竟工作后才能学到。可是我们组招人的标准是全体一致通过。就这样这个位置给了那个明大的小印硕士。
师弟B:
本科在清华,流体背景。硕士在北大,应用力学。工程排名前20 的学校博士毕业,专攻传热模拟计算。在一个专业咨询公司工作了3-4年后,刚失掉工作。我找他除校友因素外还因为他的博士学校在传热领域很强。由于A的前车之鉴,我再三嘱咐他要做好相应的准备。可是面试的结果B还不如A,一是他的知识面窄。即使是他专攻的传热领域,他的基本素养也没有给人留下印象。二是他的精神面貌没有表现出他对所应聘工作的兴
趣和热情。所有面试人员都觉得他是为面试而面试。其后我们又面试了一个明大的小印应届博士(不明白为什么来这么多明大的。估计都是其中一个小印manager引荐的)。他对他的博士课题充满了激情(有关energy harvest在交通领域的应用),也看得出他的确在研究中下了大功夫。和前一个小印一样,他对不知道答案的问题敢于从基础知识出发尽最大努力去分析。结果他也拿到了offer。
总结一下:
1.也许大家在平时要注意知识的积累,尤其是专业知识面要宽,不要只局限于博士课题。对于所做课题,一定要200%地了然于胸,包括来龙去脉,问题难点,解决方法,独到之处,局限性,等等。
2.未必要记住什么公式,但一定要了解物理现象的本质和机理。清华的学生应该在这上面有优势。
3.做好面试的准备。要对所面试职位表现出一定的了解和兴趣。不然你来面试干嘛。正确理解面试人员的问题。不清楚一定要问。回答问题要言简意赅,击中要害。
衷心希望师弟师妹们能找到理想的工作,学有所用。
## 关于找工作的补充【之一】
记不记得俺提到过的experience里要用“吓人”的动词? 给你们一个小列表 (不是我的原创,不记得从哪儿抄来的了)。注意(1)全都是过去时; (2) 没有studies, investigated, worked on, supported 这些无关痛痒的词。
1. Accelerated 35. Empowered 69. Motivated
2. Accomplished 36. Enabled 70. Negotiated
3. Achieved 37. Encouraged 71. Obtained
4. Acted 38. Engineered 72. Operated
5. Adapted 39. Enhanced 73. Orchestrated
6. Administered 40. Enlisted 74. Organized
7. Allocated 41. Established 75. Originated
8. Analyzed 42. Evaluated 76. Overhauled
9. Approved 43. Examined 77. Oversaw
10. Assembled 44. Executed 78. Performed
11. Attained 45. Expedited 79. Pinpointed
12. Boosted 46. Focused 80. Planned
13. Budgeted 47. Forecasted 81. Prepared
14. Built 48. Formulated 82. Prioritized
15. Calculated 49. Founded 83. Processed
16. Catalogued 50. Generated 84. Produced
17. Chaired 51. Guided 85. Reconciled
18. Coached 52. Harnessed 86. Repaired
19. Collaborated 53. Identified 87. Researched
20. Communicated 54. Illustrated 88. Revitalized
21. Compiled 55. Implemented 89. Selected
22. Consolidated 56. Improved 90. Solved
23. Coordinated 57. Increased 91. Spearheaded
24. Created 58. Initiated 92. Stimulated
25. Cultivated 59. Instituted 93. Strengthened
26. Decreased 60. Integrated 94. Succeeded
27. Demonstrated 61. Introduced 95. Surpassed
28. Designed 62. Invented 96. Synergized
29. Developed 63. Launched 97. Troubleshot
30. Diagnosed 64. Led 98. Uncovered
31. Directed 65. Maintained 99. Upgraded
32. Documented 66. Managed 100. Utilized
33. Doubled 67. Mastered
34. Educated 68. Mediated
## 关于找工作(五 找工作的心态问题【之二】)
长周末临时决定去探望一个朋友,耽误了接着往下写,见谅******
所谓“不成为问题的问题”,基本上是在bbs上,网上论坛上差不多每个星期都会见到的一些问题。从俺个人的角度看,大多数问题都已经被回答过若干次了— 当然俺这个观点大有站着说话不腰疼的嫌疑,因为想当初俺找工作时也有差不多的疑问。俺有一个比喻,找工作这件事就和骑自行车差不多,当你没经过(还不会骑)的时候,它看起来挺神秘/吓人,但是一旦你知道了是怎么回事,真的是没有什么门道。
列一下俺常看到的“问题”。假如某个问题恰巧是您问过的,而俺的意见/答案比较不好听,请包涵。
1. 没接到HR/recruiter的电话,怎么办?
没什么要担心的。如果他们真的觉得你的背景很合适的话,会在给你打电话的。即使不给你打电话也无妨,你的机会本来也不是很好— 如果好的话,他们通常会给你给你留言。(顺便说一句,如果你有一个专物专用的手机,这样的事就不太会发生了)。
2. 约好了电话面试,我被放鸽子了。。。
如果是对方(特别是hiring manager)和你约的某个时间给你打电话却没打过来,那说明他们不想要你了—。。。—骗你的,当然不是了。要知道hiring manager没有专职的, 也就是说,他/她还有别的工作要做,而招人面试的优先级通常不会很高。所以他/她可能哪儿耽误了(如果hiring manager约了几个电话面试,晚点的情况非常常见),也可能一时脱不开身(如果他/她临时和老板开会,总不能把老板晾那儿吧), 也可能就是忘了(谁让你的优先级太低呢)。那么遇到这样的情况怎么办?在约好的开始时间之后大概15分钟给对方打一个电话。如果他在办公室(即使是在讲电话),一般会马上和你说一下的;如果不在,给他/她留个言,客客气气地说明你没接到电话,然后告诉对方什么时候找你比较方便。遇到这样的事你偷着乐吧,hiring manager多多少少有点理亏了,面试时会对你松一点点。
3. 电话/on-site面试过了,多长时间有动静?
你现在才想起来问这个问题?早干什么去了?这个问题的答案,只有hiring manager才知道—如果你后面还有好几个要面试的人,等个几个星期也不是什么新鲜事。所以在面试的最后,hiring manager通常会问你还有什么问题吗?这个时候要就得问他下一步的计划和时间表(plan & timetable)。(当然还要问别的问题)hiring manager给你的时间表就是你应该开始关心(如果到时还没有动静的话)的时间表。
如果过了他们/她们告诉你的时间还没有动静,写封email或者打个电话问一问,有的时候公司里有别的事情耽误了,但是公司一般不会逐个通知候选人。问一问不会损失什么的。
4. 某某位置是个什么级别的位置?
这个问题除了那个公司的人没有人能回答你。同样的位置,在有点公司可能是要10年以上的经验才会拿到,在另外一个公司可能只要有研究生学位就可以拿到。俺曾经遇见过一个做了好几年senior staff scientist的老哥,当时俺的敬仰那是如滔滔江水,后来才知道他以前的公司Ph.D.工作三到五年基本上全可以升到senior staff scientist的位置。(那个公司再往上的位置是没有任何修饰的scientist)
有时候从job description上大概可以看出位置的高低。最可靠的途径还是电话面试时直接问HR / Recruiter / Hiring Manager.
先这些吧。如果有什么问题,尽管问。
## 关于找工作的补充【之二】
如果你还是对你的简历不放心,这个网站列了一些职业写简历的网站:
http://www.resumeobjective.info/Reviews-of-Resume-Writing-Services.html
我不知道那个网站和他们所列的网站的关系,但是俺的感觉是这个钱实在是没必要花 — 简历再难写,总比您的硕士/博士学位容易吧?当然您如果想花钱买个安心,也没人拦着您不是。
还有一个很多人注意不到的找工作的地方:你所在(想去的)州的就业办公室。名字各个州不一样,有的叫office of employment, 有的叫labor force development,还有的直接归Department of Labor管。网上查一下,应该很容易找到相应的网址的。在那些网站上,一般会有job board,有时候公司直接到那些"官方"的job board上贴广告(特别是如果他们想找有工作经验的)。另外,你可以找一下离你住的地方近的office, 他们有时会有免费的讲座,还有网络,打印,复印,简历修改等等服务(有可能是免费的)。
## 关于找工作 — 文摘之三
找教授位置的同学必读:http://quattro.me.uiuc.edu/~jon/ACAJOB/index.html
Professor Dantzig 是UIUC机械科学与工程系(不知道是那个神人想出来的名字,没听说过有“机械科学”这档子事)faculty recruiting committee的主席,他所写的建议绝对是第一手的信息,如假包换。
即使你不找faculty的位置,建议你也读一读,有些东西可以借鉴。你也可以看到CV和resume有多大的不同—如果你的resume写成Prof Dantzig给的CV sample那样,你被HR/recruiter毙掉的可能性相当的高。
## 关于找工作的补充【之三】
经常在网上看到有同学发帖子说运气极好/极糟被是中国人面试。俺自己曾经参与过若干次面试,而且因为俺的技术头衔比较高,如果要招的方向与俺的差不多,俺的意见有时是决定性的。事实上,曾经有被大家不看好的人因为俺的意见而给招进来的,也有大家都看好的人被俺一句话废掉的。所以估计被俺面试过的人对俺也是毁誉参半,而且可能是毁>>誉。
为什么说这些?是因为俺打算讲一讲俺作为“面试官”心里是怎么想的。当然俺的想法不一定有代表性,但是普遍性应该还是有一点的。
先晒晒俺的背景。俺马马虎虎可以算是学机械的,但是俺在学校里是做实验的日子用一只手就可以数的过来,也就是说俺的东西基本上是玩虚的(理论,计算什么的)。再有就是俺做学生时,特别是离屁挨着地学位比较远的时候,没少因为脑袋犯糊涂被老板臭骂(现在想想老板的脾气真好啊,居然忍住了没揍俺),所以现在俺看一个人行不行/牛不牛的标准第一是看他/她做东西的大方向对不对头,也就是脑袋清楚不清楚—细节可以学,经验可以积累,脑袋糊涂可不好办。
俺觉得俺的这个调调在负责技术的“面试官”中间还是有一定普遍性的,特别是如果你是Ph.D.并且/或者申请的是R&D的位置。(别的情况,直接跳到下面的3)。当然“面试官”的水平也参差不齐—技术头衔高不代表技术水平高,但是不幸的是技术头衔高的人的意见往往比较管用—所以不排除他/她看不出来你的水平高低乱评一气的情况。不过如果你不幸遇上了技术一塌糊涂的“面试官”,而他又被你这个超级高手当成了低低手把您给毙了,你要学会看事情的积极方面:如果你去了那家公司,向那个“面试官”汇报(他/她当然要指导你的工作了),你会不会心情好?
现在假定“面试官”的技术水平与其技术头衔相称(呵呵,恬不知耻地说,比如俺),你怎么做能赢呢?有几个方面:
1. 你对自己的东东(Ph.D.论文,或者presentation的东西)要熟。这个熟不是说要抠多小的细节,而是说要对为什么做这个,做的思路是什么,理论基础是什么,别的可选的方案有什么,为什么选现在的做法,现在的做法有什么不足,这些看起来无厘头的问题要想清楚。清楚到什么程度?要清楚到能和同行针尖对麦芒地就这个题目辩论的地步—当然不是要你去和别人辩论。为什么这么强调这个问题呢?直接的原因是如果你在细节问题上被问倒,通常问题不会太大;可是如果在大方向(技术名词,approach)上说不清楚,或者给人留下一个你只是跟着老板跑的印象,可大大的不好办。
有同学说了,我就是老板指哪儿我打哪儿,怎么办?赶紧去问老板啊。通常情况下你老板应该会很高兴的(俺知道俺当时[不是要找工作的时候]去问老板,老板那个高兴啊[榆木疙瘩总算开窍了],直接拉俺出去吃了一顿);
2.大方向明确了,怎么做也是一个门道。记不记得俺前面提过被presentation里的公式尽量省略?是有原因的。你讲自己的东东,底下的听众通常是多少有一点概念,但是其实不懂。那么你想想在三四十分钟内他们/她们能理解你三/四/五年的心血的百分之几?(想想你在学校里听讲座,能听明白多少?)可是还是要对你有些技术上的观点吧?这个观点从哪儿来?几个途径:(A)你看起来对自己的东东有没有自信心?这个就是上面第一点要解决的问题; (B)你讲的清楚不清楚?同样,不是细节清楚不清楚,而是大框架清楚不清楚。这就需要你有能力把阳春白雪给白菜豆腐化,用大白话把高深的东东讲清楚。而大白话和罗里八嗦的公式是不沾边的。另外,你讲的过程中,肯定有人听着听着就跟不上了,那个时候再看到满眼的公式,大概谁也没兴趣了。
记住,做presentation最理想的结果,是别人听完你的presentation, 能大概说出你是这么这么做的,可是具体细节一概不知。
那么是不是就彻底不要公式了?当然不是。有些不得不用的(by the way, 那样的很少很少),还得留着。其他的,转移到backup slides里,预备有人和你死抠公式。
3. presentation重点是给人留下你学有所专的印象。但是仅有专是不够的(俺曾经毙过一个presentation非常好,博士论文也很有深度/难度的—老哥后来以同样的presentation拿到了教授的位子),另外一个可能更重要的方面就是你对专业知识的"杂"和"活"。这个通常在一对一的面试时被考察。从某种程度上说,这个"杂"和"活"其实是决定你能不能拿到工作的主要因素。
俺通常会问一些稀奇古怪的问题(比如给我一个悬臂梁/Bernoulli梁不适用的例子)或者一些很基本的问题(比如问学流体力学的,固体材料的弹性塑性变形是怎么回事?)或者一些和被面试人专业相关的东东(比如和做材料加工的人扯扯thermocouple的设计和选择)。这些东西说起来都是挺恶毒的,因为你根本没办法临时准备。更恶毒的是,有些是期待你明白的,有些是看看你有没有概念(有时候没有概念也没什么,但是如果你不懂装懂又被我抓到,你基本上就被俺毙掉了)。所以能给你的建议就是放松,把你的真实水平发挥出来。这么想:即使被废,也没什么,反正和俺这么恶毒的人共事也没有可期待的。
遇到不会的问题时的具体的建议:如果是非常基础的问题,老老实实说不会;如果是具体一些的问题,可以先说不是很确定答案(这句话不要用的过度,用的太多会给人一个不自信的印象,大大的不妙),然后说我可以试着这么做,blah blah。(参见前面贴的文摘之二),这样的话会给人留下一个此人不是死读书,读死书的人的印象,是大大的好事。(其实还有一个原因:俺个人一般不这么做,但是俺知道有人拿自己工作中的难题去考面试的人。想想如果你能给他/她支点(歪)招,他/她还能不大说你的好话?)
如果你现在有时间,把那些“introduction to。。。”的书翻出来看前两三章吧。
4. 另外一个决定你能不能拿到工作的主要因素,是你与人相处的能力。每个“面试官”都在衡量,如果我以后和这个人同事,会不会别扭?这个没有什么办法,如果你的性格太内向/外向,注意收敛一下(一句话不说的木头没人喜欢,叽叽喳喳的喜鹊也让很多人头痛)。一般人说起来应该都没有什么问题的。如果你的口语不好,也不要担心,只要你能维持正常的谈话,一般不会被挑剔的(你的电话面试已经通过了不是?)。另外也不要紧张,因为紧张也没什么用。
5. 俺觉得去面试最重要的心态是自信和淡定,或者说是战术上重视(因此认真准备,在技术上吓死他们),战略上藐视(一方面充满自信,一方面想清楚就算拿不到offer也没什么,权当攒经验值了,这样你就不会紧张了)。俺在前面的回帖里说过,不要给自己找什么“这可是dream job”这种自己和自己过不去的心理压力。一个工作好不好,不是简简单单的技术内容+工资水平决定的,你不去经历,你永远不会知道那个工作是不是你的dream job。(别的不说,再好的工作,让你赶上一个指手画脚,容不得人的老板,每十分钟检查一次你的工作,你还dream不dream?)
6. 一些小小小小的建议:
(1)不要一见面试的人是某国人就有心理预定位(stereotype)。俺不讳言俺不怎么待见老印,但俺也认识很多非常出色的老印。每个人都是不一样的,某国人怎么样,可能整体上(统计上)和文化背景有关,但个体上和国籍无关。
(2)(还是要淡定)不要想三想四。面试的人和善不代表他/她会说你好话,凶恶也不代表他/她会毙掉你。无论你的感觉怎么样,和每个人面谈的时候都要一样的态度。
(3)有不懂中文的人在场的时候不要讲中文。第一不礼貌,更重要的是别人会怀疑你unethical。
(4)一般说起来,中国人会尽量帮忙的。但是这种帮忙是有限度的,不要因为自己面试的不好回去就骂“被老中面试”怎么怎么的。
(5)和中国人面谈,不要主动要求讲中文。如果他/她想和你讲中文,他/她会提的(俺个人一般统统用中文,但是如果错过了presentation, 会用英文扯淡10分钟,看看对方的英文到底怎么样)。
(6)吃中饭时,简单第一,不要吃有可能出乱子的东西(比如meatball sandwich),因为一旦你把衣服搞脏了,下午不好办(总不能打赤膊吧?)
(7)注意一下吃饭的礼仪,不要出声音,特别是不要吧唧嘴。俺知道在一些地方吧唧嘴是吃的好的表现,但是俺见过太多因为这个大大丢分的同学了(偏偏俺的厚脸皮遇到这样的事突然奇薄无比,提醒的话怎么也说不出口)。你如果有这种习惯,现在就要注意改,因为如果需要有意识的注意的话,到时候你一定会露馅。如果你拿不准,问你的老婆/女朋友/室友。(俺到现在还没见过女生有吧唧嘴的)
(8)如果你出来没去吃过西餐(快餐不算),建议你找时间去一次。也不用什么高档的地方,applebee这样的大路货就可以。如果有钱,建议你美式(applebee,TGI Friday之类),墨西哥式, 意大利式各去一下,熟悉一下环境,免得万一面试有比较正式的晚餐,不知道怎么点东西。
## 关于找工作 — 文摘之No. 4
An excellent blog I stumbled upon… lots of insights/suggestions/advices if you have time to read it.
http://recareered.blogspot.com
(Disclaimer: I don’t know the blog author. Neither am I affiliated/conneccted with him.)
Personal note:
I’m getting really (I mean REALLY) busy with life and work so I won’t be able to update the blog often. But every now and then when I see something nice, I’ll post the link.
小广播
我不是做HR/recruiter的,所以有些经验难免会一叶障目,不见森林。如果你有什么建议/意见/不同观点,请不要犹豫提出。
如果不太麻烦的话,麻烦你点一下右面的google广告。所有广告收入我都会捐给和中国相关的慈善机构(我工作的公司会提供1:1的match)。谢谢。
## END
---
---
---
# 个人意见
如果你已经翻到这个地方,恭喜你。
这一系列文章是RandomMumble(不好意思还不不知道其本尊大名)发在Google BlogSpot上的,2010年5-6月,最后两篇是晚些时候,还是开篇的地址,原文请移步:*http://randommumble.blogspot.com/*
再次感谢他的无私分享和友情建议
### comments by tc on 2013
当初的LinkedIn现在已经成为必然选择
CS的同学如果进大公司的话,刷题也是新的必然
Amazon为代表的公司开始向OOD转移面试思路
细节很重要,坚持很重要。
### comments by tc on 2016
若干年后我也终于成为IT大厂的一员(亚麻需要内推的请戮[这里](http://jobs.amazon.com/)看职位,邮件联系[我](mailto:tan.chao.hawk@foxmail.com)),回过头来看这篇文章,很多预测以及建议已经成为常识,但其基本思路和技巧即使在现在来看仍然很有价值,因为知乎朋友反应文章无法打开才意识到我的[page](http://tanchao.github.io/)迁移覆盖了原文章。今天整理一下,也算是对 *掉线* 的弥补。
目前我给朋友的建议发生了改变,不再是积极寻找开放职位然后面试,而是**积极准备然后等待机会**。可能因为工作年限增加,现在市场上的工作可能很多,但是符合自己的期望和标准的机会不一定多,这个时候选择好目标公司的目标职位(确切的说是dream position),积极准备并等待开放职位出现一蹴而就,一般来说更好。简单理解,以前可能决定要换工作,然后一个月练习一个月面试然后offer(**钱**)合适就接受;现在是确定好几家公司的大致职位,弄清楚要求和主要技能,然后开始针对性的准备,同时关注这些职位是否开放机会,一旦出现就联系内推或者HR,这个过程可能持续几个月。
另外相信面试更多是考核**合适**,而不是优秀,成为这个开放职位最合适的候选人最重要(所以内推的重要性不仅仅是过简历海选,还有内幕交易)。仔细研究职位描述,more attentions to "**PREFERRED QUALIFICATION**",尽量打听面试的具体题目和考核点,大部分公司的面试比实际工作的要求要高一些(所以不要觉得这样展示的不是真实的自我,相信我,调查这一切信息是非常值得value的能力)。
谈一下如何像面试官提问(之前我也有一个文章整理了一些内容,可能过几天也整理一下放过来),这个环节就两个方向,一个求稳,一个求胜,求稳不多说,问问工作相关的比较具体的问题展示期待和关心即好。求胜就要站在面试官角度思考,我希望招什么样的人(适合并胜任职位的人,聪明人,有趣或者新奇的人或者符合我审美观的人,美女帅哥,对公司理念或者文化或者模式习惯甚至于痴迷对人,学弟学妹亲朋好友八杆子打得着关系对人,等等等等),举个例子,比如面试的时候问老板,我注意到你们团队同时在招比您这个级别的人,不知道是不是report line有什么变动?(政治敏感性也很重要),再比如问面试官,刚刚您的介绍里面谈到了你们在探索某项技术运用到某个业务的可能性,根据我以前的经验blabla,不知道你们是否有这样的考虑或者有什么应对计划?(我认真听您BB了,而且我也很聪明,甚至还有相关经验)再然后就是注意具体的问题比宽泛的问题好,宽泛的问题属于求稳型,比如理想和星辰大海。
该下班了,就这样push。 | 42,707 | MIT |
---
layout: post
title: "大絕滅─從地史學觀點說「人類世」的弔詭之處 | 2020 春季展望科普演講"
date: 2021-02-11T11:00:04.000Z
author: 臺大演講網
from: https://www.youtube.com/watch?v=3hJeW5qt9Bk
tags: [ 臺大演講網 ]
categories: [ 臺大演講網 ]
---
<!--1613041204000-->
[大絕滅─從地史學觀點說「人類世」的弔詭之處 | 2020 春季展望科普演講](https://www.youtube.com/watch?v=3hJeW5qt9Bk)
------
<div>
拍攝日期:2020/5/15主講人:魏國彥 (國立臺灣大學永續地球尖端科學研究中心教授)地質時間分四個宙,最年輕的宙稱為「顯生宙」,以「寒武大爆發」為起點。而顯生宙分為三個代,前兩個都以「大絕滅」做終點:古生代的終結是以95%的物種絕滅為代價,中生代的結束有75%物種一去不復返。「人類世」的提出隱含著地球浩劫的末世預言,如此興致勃勃地成立「人類世」意謂著我們將迎來一個「大絕滅」嗎?如果預言成真,「人類世」將是最短的一個地質年代單位,就像地質時間長河流中的一滴水,難道人類真的是快閃的一道煙塵?放棄「人類世」吧!讓我們在「全新世」裡永續發展,瓜瓞綿綿。「全新世」就是「當下」,我們要整頓與營建我們的「現代性」,如此而已。►►臺大演講網Website: http://speech.ntu.edu.twFacebook: http://www.facebook.com/ntuspeech
</div> | 723 | MIT |
---
outline: deep
---
# 渲染机制 {#rendering-mechanism}
Vue 是如何将一份模板转换为真实的 DOM 节点的呢?又是如何高效地更新 DOM 节点的呢?我们接下来就将尝试通过深入研究 Vue 的内部渲染机制来解释这些问题。
## 虚拟 DOM {#virtual-dom}
你可能已经听说过虚拟 DOM 的概念了,Vue 的渲染系统正是基于这个概念构建的。
虚拟 DOM(VDOM) 是一种编程概念,意为将将目标所需的 UI 通过数据结构“虚拟”地表示出来,保存在内存中,并与真实的 DOM 保持同步。这个概念是由 [React](https://reactjs.org/) 率先开拓,随后在各个不同的框架中都有不同的实现,当然也包括 Vue。
与其说虚拟 DOM 是一种具体的技术,不如说是一种模式。所以没有一个标准的实现。我们可以用一个简单的例子来说明:
```js
const vnode = {
type: 'div',
props: {
id: 'hello'
},
children: [
/* 更多 vnode */
]
}
```
这里所说的 `vnode` 即一个纯 JavaScript 的对象 (一个“虚拟节点”),它代表着一个 `<div>` 元素。它包含我们创建实际元素所需的所有信息。它还包含更多的子节点,这使它成为虚拟 DOM 树的根节点。
一个运行时渲染器将会遍历整个虚拟 DOM 树,并据此构建真实的 DOM 树。这个过程被称为**挂载 (mount)**。
如果我们有两份虚拟 DOM 树,渲染器将会有比较地遍历它们,找出它们之间的区别,并应用这其中的变化到真实的 DOM 上。这个过程被称为**修补 (patch)**,又被称为“比较差异 (diffing)”或“协调 (reconciliation)”。
虚拟 DOM 带来的主要收益是它赋予了开发者编程式地、声明式地创建、审查和组合所需 UI 结构的能力,而把直接与 DOM 相关的操作交给了渲染器。
## 渲染管线 {#render-pipeline}
以更高层面的视角看,Vue 组件挂载后发生了如下这几件事:
1. **编译**:Vue 模板被编译为了**渲染函数**:即用来返回虚拟 DOM 树的函数。这一步骤可以通过构建步骤提前完成,也可以通过使用运行时编译器即时完成。
2. **挂载**:运行时渲染器调用渲染函数,遍历返回的虚拟 DOM 树,并基于它创建实际的 DOM 节点。这一步会作为[响应式副作用](./reactivity-in-depth)执行,因此它会追踪其中所用到的所有响应式依赖。
3. **修补**:当一个依赖发生变化后,副作用会重新运行,这时候会创建一个更新后的虚拟 DOM 树。运行时渲染器遍历这棵新树,将它与旧树进行比较,然后将必要的更新应用到真实 DOM 上去。

<!-- https://www.figma.com/file/elViLsnxGJ9lsQVsuhwqxM/Rendering-Mechanism -->
## 模板 vs. 渲染函数 {#template-vs-render-functions}
Vue 模板会被预编译成虚拟 DOM 渲染函数。Vue 也提供了 API 使我们可以不使用模板编译,直接手写渲染函数。在处理高度动态的逻辑时,渲染函数相比于模板更加灵活,因为你可以完全地使用 JavaScript 来构造你想要的 vnode。
那么为什么 Vue 默认推荐使用模板呢?有以下几点原因:
1. 模板更贴近实际的 HTML。这使得我们能够更方便地重用一些已有的 HTML 代码片段,能够带来更好的可访问性体验、能更方便地使用 CSS 应用样式,并且更容易使设计师理解和修改。
2. 由于其确定的语法,更容易对模板做静态分析。这使得 Vue 的模板编译器能够应用许多编译时优化来提升虚拟 DOM 的性能表现 (下面我们将展开讨论)。
在实践中,模板对大多数的应用场景都是够用且高效的。渲染函数一般只会在需要处理高度动态渲染逻辑的可重用组件中使用。想了解渲染函数的更多使用细节可以去到[渲染函数 & JSX](./render-function) 章节继续阅读。
## 带编译时信息的虚拟 DOM {#compiler-informed-virtual-dom}
虚拟 DOM 在 React 和大多数其他实现中都是纯运行时的:协调算法无法预知新的虚拟 DOM 树会是怎样,因此它总是需要遍历整棵树、比较每个 vnode 上 props 的区别来确保正确性。另外,即使一棵树的某个部分从未改变,还是会在每次重渲染时创建新的 vnode,带来了完全不必要的内存压力。这也是虚拟 DOM 最受诟病的地方之一:这种有点暴力的协调过程通过牺牲效率来换取可声明性和正确性。
但实际上我们并不需要这样。在 Vue 中,框架同时控制着编译器和运行时。这使得我们可以为紧密耦合的模板渲染器应用许多编译时优化。编译器可以静态分析模板并在生成的代码中留下标记,使得运行时尽可能地走捷径。与此同时,我们仍旧保留了边界情况时用户想要使用底层渲染函数的能力。我们称这种混合解决方案为**带编译时信息的虚拟 DOM**。
下面,我们将讨论一些 Vue 编译器用来提高虚拟 DOM 运行时性能的主要优化:
### 静态提升 {#static-hoisting}
在模板中常常有部分内容是不带任何动态绑定的:
```vue-html{2-3}
<div>
<div>foo</div> <!-- 需提升 -->
<div>bar</div> <!-- 需提升 -->
<div>{{ dynamic }}</div>
</div>
```
[在模板编译预览中查看](https://vue-next-template-explorer.netlify.app/#eyJzcmMiOiI8ZGl2PlxuICA8ZGl2PmZvbzwvZGl2PlxuICA8ZGl2PmJhcjwvZGl2PlxuICA8ZGl2Pnt7IGR5bmFtaWMgfX08L2Rpdj5cbjwvZGl2PiIsInNzciI6ZmFsc2UsIm9wdGlvbnMiOnsiaG9pc3RTdGF0aWMiOnRydWV9fQ==)
`foo` 和 `bar` 这两个 div 是完全静态的,没有必要在重新渲染时再次创建和比对它们。Vue 编译器自动地会提升这部分 vnode 创建函数到这个模板的渲染函数之外,并在每次渲染时都使用这份相同的 vnode,渲染器知道新旧 vnode 在这部分是完全相同的,所以会完全跳过对它们的差异比对。
此外,当有足够多连续的静态元素时,它们还会再被压缩为一个“静态 vnode”,其中包含的是这些节点相应的纯 HTML 字符串。([示例](https://vue-next-template-explorer.netlify.app/#eyJzcmMiOiI8ZGl2PlxuICA8ZGl2IGNsYXNzPVwiZm9vXCI+Zm9vPC9kaXY+XG4gIDxkaXYgY2xhc3M9XCJmb29cIj5mb288L2Rpdj5cbiAgPGRpdiBjbGFzcz1cImZvb1wiPmZvbzwvZGl2PlxuICA8ZGl2IGNsYXNzPVwiZm9vXCI+Zm9vPC9kaXY+XG4gIDxkaXYgY2xhc3M9XCJmb29cIj5mb288L2Rpdj5cbiAgPGRpdj57eyBkeW5hbWljIH19PC9kaXY+XG48L2Rpdj4iLCJzc3IiOmZhbHNlLCJvcHRpb25zIjp7ImhvaXN0U3RhdGljIjp0cnVlfX0=))。这些静态节点会直接通过 `innerHTML` 来挂载。同时还会在初次挂载后缓存相应的 DOM 节点。如果这部分内容在应用中其他地方被重用,那么将会使用原生的 `cloneNode()` 方法来克隆新的 DOM 节点,这会非常高效。
### 修补标记 Flags {#patch-flags}
对于单个有动态绑定的元素来说,我们可以在编译时推断出大量信息:
```vue-html
<!-- 仅含 class 绑定 -->
<div :class="{ active }"></div>
<!-- 仅含 id 和 value 绑定 -->
<input :id="id" :value="value">
<!-- 仅含文本子节点 -->
<div>{{ dynamic }}</div>
```
[在模板编译预览中查看](https://template-explorer.vuejs.org/#eyJzcmMiOiI8ZGl2IDpjbGFzcz1cInsgYWN0aXZlIH1cIj48L2Rpdj5cblxuPGlucHV0IDppZD1cImlkXCIgOnZhbHVlPVwidmFsdWVcIj5cblxuPGRpdj57eyBkeW5hbWljIH19PC9kaXY+Iiwib3B0aW9ucyI6e319)
在为这些元素生成渲染函数时,Vue 在 vnode 创建调用中直接编码了每个元素所需的更新类型:
```js{3}
createElementVNode("div", {
class: _normalizeClass({ active: _ctx.active })
}, null, 2 /* CLASS */)
```
最后这个参数 `2` 就是一个[修补标记 (patch flag)](https://github.com/vuejs/core/blob/main/packages/shared/src/patchFlags.ts)。一个元素可以有多个修补标记,会被合并成一个数字。运行时渲染器也将会使用[位运算](https://en.wikipedia.org/wiki/Bitwise_operation)来检查这些标记,确定相应的更新操作:
```js
if (vnode.patchFlag & PatchFlags.CLASS /* 2 */) {
// 更新节点的 CSS class
}
```
位运算检查是非常快的。通过这样的修补标记,Vue 能够在更新带有动态绑定的元素时做最少的操作。
Vue 也为 vnode 的子节点标记了类型。举个例子,包含多个根节点的模板被表示为一个片段 (fragment),大多数情况下,我们可以确定其顺序是永远不变的,所以这部分信息就可以提供给运行时作为一个修补标记。
```js{4}
export function render() {
return (_openBlock(), _createElementBlock(_Fragment, null, [
/* children */
], 64 /* STABLE_FRAGMENT */))
}
```
运行时会完全跳过对这个根片段中子元素顺序的重新协调过程。
### 树结构打平 {#tree-flattening}
再来看看上面这个例子中生成的代码,你会发现所返回的虚拟 DOM 树是经一个特殊的 `createElementBlock()` 调用创建的:
```js{2}
export function render() {
return (_openBlock(), _createElementBlock(_Fragment, null, [
/* children */
], 64 /* STABLE_FRAGMENT */))
}
```
这里我们引入一个概念“区块”,内部结构是稳定的一个部分可被称之为一个区块。在这个用例中,整个模板只有一个区块,因为这里没有用到任何结构性指令 (比如 `v-if` 或者 `v-for`)。
每一个块都会追踪其所有带修补标记的后代节点 (不只是直接子节点),举个例子:
```vue-html{3,5}
<div> <!-- root block -->
<div>...</div> <!-- 不会追踪 -->
<div :id="id"></div> <!-- 要追踪 -->
<div> <!-- 不会追踪 -->
<div>{{ bar }}</div> <!-- 要追踪 -->
</div>
</div>
```
编译的结果会被打平为一个数组,仅包含所有动态的后代节点:
```
div (block root)
- div 带有 :id 绑定
- div 带有 {{ bar }} 绑定
```
当这个组件需要重渲染时,只需要遍历这个打平的树而非整棵树。这也就是我们所说的**树结构打平**,这大大减少了我们在虚拟 DOM 协调时需要遍历的节点数量。模板中任何的静态部分都会被高效地略过。
`v-if` 和 `v-for` 指令会创建新的区块节点:
```vue-html
<div> <!-- 根区块 -->
<div>
<div v-if> <!-- if 区块 -->
...
<div>
</div>
</div>
```
一个子区块会在父区块的动态子节点数组中被追踪,这为他们的父区块保留了一个稳定的结构。
### 对 SSR 激活的影响 {#impact-on-ssr-hydration}
修补标记和树结构打平都大大提升了 Vue [SSR 激活](/guide/scaling-up/ssr.html#client-hydration)的性能表现:
- 单个元素的激活可以基于相应 vnode 的修补标记走更快的捷径。
- 在激活时只有区块节点和其动态子节点需要被遍历,这在模板层面上实现更高效的部分激活。 | 5,944 | MIT |
---
title: 准备 Azure Migrate 来使用 ISV 工具/Movere
description: 本文介绍了如何准备 Azure Migrate 以使用 ISV 工具或 Movere,然后介绍如何开始使用该工具。
ms.topic: how-to
ms.date: 06/10/2020
ms.openlocfilehash: 885e64536e516e4fd96233c37a68f6e77fb84e33
ms.sourcegitcommit: 28c5fdc3828316f45f7c20fc4de4b2c05a1c5548
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/22/2020
ms.locfileid: "92369142"
---
# <a name="prepare-to-work-with-an-isv-tool-or-movere"></a>准备使用 ISV 工具或 Movere
如果已将 [ISV 工具](migrate-services-overview.md#isv-integration) 或 Movere 添加到 Azure Migrate 项目中,则请在链接该工具并将数据发送到 Azure Migrate 之前执行几个步骤。
## <a name="check-azure-ad-permissions"></a>检查 Azure AD 权限
你的 Azure 用户帐户需要以下权限:
- 可使用 Azure 租户注册 Azure Active Directory (Azure AD) 应用的权限
- 可在订阅级别将角色分配给 Azure AD 应用的权限
### <a name="set-permissions-to-register-an-azure-ad-app"></a>设置权限来注册 Azure AD 应用
1. 在 Azure AD 中,查看你的帐户的角色。
2. 如果你有用户角色,请在左侧选择“用户设置”,并验证用户是否可注册应用程序。 如果设置为“是”,则 Active AD 租户中的任何用户都可注册应用。 如果设置为“否”,则只有管理员用户可注册应用。
3. 如果你没有权限,则管理员用户可为你的用户帐户提供[应用程序管理员](../active-directory/roles/permissions-reference.md#application-administrator)角色,以便你可注册应用。
4. 将该工具链接到 Azure Migrate 后,管理员可从你的帐户中删除该角色。
### <a name="set-permissions-to-assign-a-role-to-an-azure-ad-app"></a>设置权限来将角色分配给 Azure AD 应用
要将角色分配给 Azure AD 应用,你的帐户需要在 Azure 订阅中拥有 Microsoft.Authorization/*/Write 访问权限。
1. 在 Azure 门户中,打开 **订阅**。
2. 选择相关订阅。 如果看不到它,请选择“全局订阅筛选器”。
3. 选择“我的权限”。 然后,选择“单击此处查看此订阅的完整访问详细信息”。
4. 在“角色分配” > “视图中查看权限” 。 如果你的帐户没有权限,请让订阅管理员将你添加到[用户访问管理员](../role-based-access-control/built-in-roles.md#user-access-administrator)角色和[所有者](../role-based-access-control/built-in-roles.md#owner)角色。
## <a name="allow-access-to-urls"></a>允许访问 URL
对于 ISV 工具和 Azure 数据库迁移助手,允许访问表中汇总的公有云 Url。 如果使用基于 URL 的代理连接到 Internet,请确保代理在查找 URL 时会解析接收到的任何 CNAME 记录。
**URL** | **详细信息**
--- | ---
*.portal.azure.com | 导航到 Azure 门户。
*.windows.net<br/> *.msftauth.net<br/> *.msauth.net <br/> *.microsoft.com<br/> *.live.com | 登录到 Azure 订阅。
*.microsoftonline.com<br/> *.microsoftonline-p.com | 为设备创建 Azure Active Directory (AD) 应用,以便与 Azure Migrate 通信。
management.azure.com | 对 Azure Migrate 项目进行 Azure 资源管理器调用。
*.servicebus.windows.net | 设备与 EventHub 之间用于发送消息的通信。
## <a name="start-using-the-tool"></a>开始使用该工具
1. 如果你还没有该工具的许可证或免费试用版,请在 Azure Migrate 的工具项中,选择“注册”下的“了解详细信息” 。
2. 在工具中,按照说明从工具链接到 Azure Migrate 项目,或者将数据发送到 Azure Migrate。
## <a name="next-steps"></a>后续步骤
按照 ISV 或 Movere 中的说明将数据发送到 Azure Migrate。 | 2,433 | CC-BY-4.0 |
---
title: 冲刺春招-精选笔面试66题大通关day6
link: coding-train/leetcode/bytedance/bytedance-day6
catalog: true
subtitle: 今日知识点:二分、模拟、01背包,难度为中等、中等、字节の简单
date: 2022-03-13 23:40:22
header-img: /img/header_img/milky-way-over-bow-lake-alberta-canada-wallpaper-for-1920x1080-63-873.jpg
tags:
- leetcode
- 二分
- 背包
categories:
- 题目记录
---
day6题目:[33. 搜索旋转排序数组](https://leetcode-cn.com/problems/search-in-rotated-sorted-array/)、[54. 螺旋矩阵](https://leetcode-cn.com/problems/spiral-matrix/)、[bytedance-006. 夏季特惠](https://leetcode-cn.com/problems/tJau2o/)
学习计划链接:[冲刺春招-精选笔面试 66 题大通关](https://leetcode-cn.com/study-plan/bytedancecampus/?progress=dcmyjb3)
今日知识点:二分、模拟、01背包,难度为中等、中等、字节の简单
<!-- more -->
# 33. 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
**示例 1:**
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
**示例 2:**
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
**示例 3:**
输入:nums = [1], target = 0
输出:-1
## 思路
两次二分,第一次查找分界点如例1、2中的0([153. 寻找旋转排序数组中的最小值](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array/)),分界点左侧数一定都比右侧大且为升序,故根据target与第一个数比较判断在左侧找还是右侧找。注意特判一下nums[n-1] > nums[0]的情况(即旋转多次回到原数组的情况)
## 代码
```cpp
class Solution {
public:
int binarySearch(vector<int>& nums, int target, int s, int e) {
int l = s, r = e;
while(l <= r) {
int mid = (l+r)>>1;
if(nums[mid] == target) return mid;
if(nums[mid] < target) l = mid+1;
else r = mid-1;
}
return -1;
}
int search(vector<int>& nums, int target) {
int n = nums.size();
int l = 0, r = n-1;
int idx;
if(nums[r] > nums[l]) idx = n-1;
else {
while(l < r) { // 找分界点 如0
int mid = (l+r)>>1;
if(nums[mid] == target) return mid;
if(nums[mid] > nums[l]) l = mid;
else r = mid;
}
idx = l;
}
if(target < nums[0])
return binarySearch(nums, target, idx+1, n-1);
else
return binarySearch(nums, target, 0, idx);
}
};
```
# 54. 螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
**示例 1:**
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
## 思路
某蓝桥杯经典真题稍稍变形- -
模拟每次就一直往右下左上的顺序走就行了
## 代码
```js
/**
* @param {number[][]} matrix
* @return {number[]}
*/
var spiralOrder = function(matrix) {
let m = matrix.length;
let n = matrix[0].length;
let sum = n*m;
let vis = -200;
let ans = [matrix[0][0]];
matrix[0][0] = vis;
let [i, j] = [0, 0];
let cnt = 1;
while(cnt < sum) {
while(j+1 < n && matrix[i][j+1] != vis) { // 往右走
ans.push(matrix[i][j+1]);
matrix[i][++j] = vis;
++cnt;
}
while(i+1 < m && matrix[i+1][j] != vis) { // 往下走
ans.push(matrix[i+1][j]);
matrix[++i][j] = vis;
++cnt;
}
while(j-1 >= 0 && matrix[i][j-1] != vis) { // 往左走
ans.push(matrix[i][j-1]);
matrix[i][--j] = vis;
++cnt;
}
while(i-1 >= 0 && matrix[i-1][j] != vis) { // 往上走
ans.push(matrix[i-1][j]);
matrix[--i][j] = vis;
++cnt;
}
}
return ans;
};
```
# bytedance-006. 夏季特惠
某公司游戏平台的夏季特惠开始了,你决定入手一些游戏。现在你一共有X元的预算,该平台上所有的 n 个游戏均有折扣,标号为 i 的游戏的**原价a[i]**元,**现价**只要 **b[i]** 元(也就是说该游戏可以**优惠 a[i]-b[i]** 元)并且你购买该游戏能获得快乐值为 w[i] ,由于优惠的存在,你可能做出一些冲动消费导致最终买游戏的总费用超过预算,但只要满足**获得的总优惠金额**不低于**超过预算的总金额**,那在心理上就不会觉得吃亏。现在你希望在心理上不觉得吃亏的前提下,获得尽可能多的快乐值。
- 输入
- 第一行包含两个数 n 和 x 。
- 接下来 n 行包含每个游戏的信息,原价 ai , 现价 bi,能获得的快乐值为 wi 。
- 输出
- 输出一个数字,表示你能获得的最大快乐值。
**示例 1:**
输入:
4 100
100 73 60
100 89 35
30 21 30
10 8 10
输出:100
解释:买 1、3、4 三款游戏,获得总优惠 38 元,总金额 102 元超预算 2 元,满足条件,获得 100 快乐值。
**示例 2:**
输入:
3 100
100 100 60
80 80 35
21 21 30
输出:60
解释:只能买下第一个游戏,获得 60 的快乐值。
## 思路
经典01背包问题,难点在于如何转换成背包问题qwq,看了题解才晓得
背包问题可看这篇博客:[01背包问题详解(浅显易懂)](https://blog.csdn.net/Iseno_V/article/details/100001133)
由题意易知(其实想了半天)每买一个游戏都会**使预算加上该游戏的优惠价**,再**从预算里减掉现价**,那么设优惠价为dis,若当前游戏优惠价 >= 现价的话买了是绝对不亏的(预算反而增加了),否则就将该游戏视作等待进行01背包的一员(取或不取)
还要注意下数据范围,w贼大,所以要用long long
## 完整代码
```cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef long long ll;
const int maxn = 505;
const int maxm = 3e5;
int n, x, a, b, c, cnt; // x为预算
int v[maxn];// 容量
ll ans, w[maxn];
int main() {
cin >> n >> x;
for(int i = 0; i < n; ++i) {
cin >> a >> b >> c; // 原价 现价 快乐值
int dis = a-b; // 优惠 每买一个游戏都会使预算加上优惠价,再从预算里减掉现价。
if(dis > b) { // 所以优惠价大于现价的话一定买
x += dis-b;
ans += c;
} else {
v[cnt] = b-dis;
w[cnt++] = c;
}
}
vector<ll> dp(maxm, 0);
for(int i = 0; i < cnt; ++i) {
for(int j = x; j >= v[i]; --j) {
dp[j] = max(dp[j], dp[j-v[i]]+w[i]);
}
}
ans += dp[x];
cout << ans << endl;
return 0;
}
``` | 5,269 | Apache-2.0 |
---
components: CssBaseline, ScopedCssBaseline
---
# CSSベースライン
<p class="description">Material-UIはCssBaselineコンポーネントを提供することで、エレガントで一貫性のあるシンプルなベースラインを構築します。</p>
## Global reset
貴方はもしかしたら、HTMLの要素と属性のスタイル正規化のコレクションである [normalize.css](https://github.com/necolas/normalize.css)精通しているかもしれません。
```jsx
import React from 'react';
import CssBaseline from '@material-ui/core/CssBaseline';
export default function MyApp() {
return (
<React.Fragment>
<CssBaseline />
{/* The rest of your application */}
</React.Fragment>
);
}
```
## Scoping on children
However, you might be progressively migrating a website to Material-UI, using a global reset might not be an option. It's possible to apply the baseline only to the children by using the `ScopedCssBaseline` component.
```jsx
import React from 'react';
import ScopedCssBaseline from '@material-ui/core/ScopedCssBaseline';
import MyApp from './MyApp';
export default function MyApp() {
return (
<ScopedCssBaseline>
{/* The rest of your application */}
<MyApp />
</ScopedCssBaseline>
);
}
```
⚠️ Make sure you import `ScopedCssBaseline` first to avoid box-sizing conflicts as in the above example.
## アプローチ
### ページ
`<html>` および `<body>` 要素は、ページ全体のデフォルトが改善されるように更新されています。 具体的には:
- すべてのブラウザの余白が削除されています。
- デフォルトのマテリアルデザインの背景色が適用されます。 標準のデバイスや、白背景に印刷されたデバイスの為に[`theme.palette.background.default`](/customization/default-theme/?expand-path=$.palette.background) が使われています。
### レイアウト
- `ボックスサイズ` は、 `<html>` 要素で `border-box`グローバルに設定されます。 すべての要素( `*:: before` および `*:: after` を含む)は、このプロパティを継承するように宣言されています は、要素の宣言された幅がパディングまたは境界のために超過しないことを保証されます。
### タイポグラフィ
- `<html>`には基本フォントサイズは宣言されていませんが、16pxが想定されています(ブラウザのデフォルト)。 デフォルトのフォントサイズの`<html>`を変更した場合の影響については、ここをクリックしてください。[the theme documentation](/customization/typography/#typography-html-font-size)
- `<body>` 要素に `theme.typography.body2` スタイルを設定します。
- Set the font-weight to `theme.typography.fontWeightBold` for the `<b>` and `<strong>` elements.
- Custom font-smoothing is enabled for better display of the Roboto font.
## カスタマイズ
Head to the [global customization](/customization/globals/#global-css) section of the documentation to change the output of these components. | 2,227 | MIT |
---
title: 为容器分派扩展资源
content_type: task
weight: 40
---
<!--
title: Assign Extended Resources to a Container
content_type: task
weight: 40
-->
<!-- overview -->
{{< feature-state state="stable" >}}
<!--
This page shows how to assign extended resources to a Container.
-->
本文介绍如何为容器指定扩展资源。
## {{% heading "prerequisites" %}}
{{< include "task-tutorial-prereqs.md" >}} {{< version-check >}}
<!--
Before you do this exercise, do the exercise in
[Advertise Extended Resources for a Node](/docs/tasks/administer-cluster/extended-resource-node/).
That will configure one of your Nodes to advertise a dongle resource.
-->
在你开始此练习前,请先练习
[为节点广播扩展资源](/zh/docs/tasks/administer-cluster/extended-resource-node/)。
在那个练习中将配置你的一个节点来广播 dongle 资源。
<!-- steps -->
<!--
## Assign an extended resource to a Pod
To request an extended resource, include the `resources:requests` field in your
Container manifest. Extended resources are fully qualified with any domain outside of
`*.kubernetes.io/`. Valid extended resource names have the form `example.com/foo` where
`example.com` is replaced with your organization's domain and `foo` is a
descriptive resource name.
Here is the configuration file for a Pod that has one Container:
-->
## 给 Pod 分派扩展资源
要请求扩展资源,需要在你的容器清单中包括 `resources:requests` 字段。
扩展资源可以使用任何完全限定名称,只是不能使用 `*.kubernetes.io/`。
有效的扩展资源名的格式为 `example.com/foo`,其中 `example.com` 应被替换为
你的组织的域名,而 `foo` 则是描述性的资源名称。
下面是包含一个容器的 Pod 配置文件:
{{< codenew file="pods/resource/extended-resource-pod.yaml" >}}
<!--
In the configuration file, you can see that the Container requests 3 dongles.
Create a Pod:
-->
在配置文件中,你可以看到容器请求了 3 个 dongles。
创建 Pod:
```shell
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod.yaml
```
<!--
Verify that the Pod is running:
-->
检查 Pod 是否运行正常:
```shell
kubectl get pod extended-resource-demo
```
<!--
Describe the Pod:
-->
描述 Pod:
```shell
kubectl describe pod extended-resource-demo
```
<!--
The output shows dongle requests:
-->
输出结果显示 dongle 请求如下:
```yaml
Limits:
example.com/dongle: 3
Requests:
example.com/dongle: 3
```
<!--
## Attempt to create a second Pod
Here is the configuration file for a Pod that has one Container. The Container requests
two dongles.
-->
## 尝试创建第二个 Pod
下面是包含一个容器的 Pod 配置文件,容器请求了 2 个 dongles。
{{< codenew file="pods/resource/extended-resource-pod-2.yaml" >}}
<!--
Kubernetes will not be able to satisfy the request for two dongles, because the first Pod
used three of the four available dongles.
Attempt to create a Pod:
-->
Kubernetes 将不能满足 2 个 dongles 的请求,因为第一个 Pod 已经使用了 4 个可用 dongles 中的 3 个。
尝试创建 Pod:
```shell
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod-2.yaml
```
<!--
Describe the Pod
-->
描述 Pod:
```shell
kubectl describe pod extended-resource-demo-2
```
<!--
The output shows that the Pod cannot be scheduled, because there is no Node that has
2 dongles available:
-->
输出结果表明 Pod 不能被调度,因为没有一个节点上存在两个可用的 dongles。
```
Conditions:
Type Status
PodScheduled False
...
Events:
...
... Warning FailedScheduling pod (extended-resource-demo-2) failed to fit in any node
fit failure summary on nodes : Insufficient example.com/dongle (1)
```
<!--
View the Pod status:
-->
查看 Pod 的状态:
```shell
kubectl get pod extended-resource-demo-2
```
<!--
The output shows that the Pod was created, but not scheduled to run on a Node.
It has a status of Pending:
-->
输出结果表明 Pod 虽然被创建了,但没有被调度到节点上正常运行。Pod 的状态为 Pending:
```
NAME READY STATUS RESTARTS AGE
extended-resource-demo-2 0/1 Pending 0 6m
```
<!--
## Clean up
Delete the Pods that you created for this exercise:
-->
## 清理
删除本练习中创建的 Pod:
```shell
kubectl delete pod extended-resource-demo
kubectl delete pod extended-resource-demo-2
```
## {{% heading "whatsnext" %}}
<!--
### For application developers
* [Assign Memory Resources to Containers and Pods](/docs/tasks/configure-pod-container/assign-memory-resource/)
* [Assign CPU Resources to Containers and Pods](/docs/tasks/configure-pod-container/assign-cpu-resource/)
-->
## 应用开发者参考
* [为容器和 Pod 分配内存资源](/zh/docs/tasks/configure-pod-container/assign-memory-resource/)
* [为容器和 Pod 分配 CPU 资源](/zh/docs/tasks/configure-pod-container/assign-cpu-resource/)
<!--
### For cluster administrators
* [Advertise Extended Resources for a Node](/docs/tasks/administer-cluster/extended-resource-node/)
-->
### 集群管理员参考
* [为节点广播扩展资源](/zh/docs/tasks/administer-cluster/extended-resource-node/) | 4,489 | CC-BY-4.0 |
# face_mnn
Android 人脸检测和识别
[](https://jitpack.io/#com.gitee.zhu260824/face_mnn)
#### 开源算法说明
- 推理算法:[MNN](https://github.com/alibaba/MNN)
- 检测算法:[Ultra](https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB)
- 识别算法:mobilefacenet
#### 使用
- 添加依赖
1. Add it in your root build.gradle at the end of repositories:
```
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
```
2. Add the dependency
```
dependencies {
implementation 'com.gitee.zhu260824:face_mnn:xxxxx'
}
```
- 代码中使用
1. 初始化SDK(默认初始化)
```
/**
* 初始化SDK的模型
*
* @param mContext 上下文环境
* @return 初始话结果
*/
public boolean init(Context mContext){}
```
单独初始化
```
/**
* 初始化算法
*
* @param mnnPath 模型文件地址
* @param resizeWidth 图片压缩宽
* @param resizeHeight 图片压缩高
* @param numThread 线程数
* @param openCL 是否打开opencl,默认打开
* @return 人脸信息
*/
public native boolean initDetector(String mnnPath, int resizeWidth, int resizeHeight, int numThread, boolean openCL);
```
2. 使用
```
/**
* 解析人脸信息
*
* @param imgPath 图片地址
* @return 人脸信息
*/
public native FaceInfo[] detect(String imgPath);
/**
* 解析人脸信息
*
* @param yuv 摄像图输出的预览帧
* @param width 帧的宽度
* @param height 帧的高度
* @deprecated 使用这个方法,需要将摄像图帧旋转至0度
*/
public native FaceInfo[] detectYuv(byte[] yuv, int width, int height);
```
- 根据使用设备减少so包,缩小apk大小
```
android {
...
defaultConfig {
...
ndk {
abiFilters "armeabi-v7a", "arm64-v8a"
}
}
}
```
#### 总结 | 2,003 | Apache-2.0 |
###ipv4 header

85 struct iphdr {
86 #if defined(__LITTLE_ENDIAN_BITFIELD)
/* 如果是小端,高位存ihl 头长度4Bytes单位,低位存version 版本v4、v6 */
87 __u8 ihl:4, //5<=ihl<=15,ipv4头长度可变,ipv6是固定的
88 version:4; //版本4
89 #elif defined (__BIG_ENDIAN_BITFIELD)
90 __u8 version:4,
91 ihl:4;
92 #else
93 #error "Please fix <asm/byteorder.h>"
94 #endif
95 __u8 tos; //QoS
96 __be16 tot_len; //总长度
97 __be16 id; //分片id号
98 __be16 frag_off; //3位分片标志,13位分片偏移量
99 __u8 ttl; //time to live,为0时丢弃,避免无止尽转发
100 __u8 protocol; //4层协议 TCP or UDP
101 __sum16 check; //校验和
102 __be32 saddr; //源ip
103 __be32 daddr; //目的ip
104 /*The options start here. */
105 };
###ipv4初始化
ipv4报文在二层头中类型为0x0800;每一个协议需要定义一个处理器,当网络协议栈收到属于该协议的报文时调用。
初始化代码如下:
1691 static struct packet_type ip_packet_type __read_mostly = {
1692 .type = cpu_to_be16(ETH_P_IP), //定义报文类型 0x0800
1693 .func = ip_rcv, //处理函数
1694 };
1696 static int __init inet_init(void) //boot时初始化
1697 {
...
1808 dev_add_pack(&ip_packet_type);
...
1822 }
###接收ipv4报文
ipv4接收报文的主要函数是ip_rcv(),该函数主要做合法性检测,实际工作调用ip_rcv_finish()完成,在两者之间有注册的netfilter NF_INET_PRE_ROUTING回调函数调用;在ip_rcv_finish之后会执行路由查找来决定是转发报文还是本地接收,去调用ip_forward()与ip_local_deliver().
/* linux-3.10.93/net/ipv4/ip_input.c:375 */
375 int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *o rig_dev)
376 {
377 const struct iphdr *iph;
378 u32 len;
379
380 /* When the interface is in promisc. mode, drop all the crap
381 * that it receives, do not try to analyse it.
382 */
/* 当网络接口处于混杂模式,会丢弃那些目的地址不是本机的报文,skb->pkt_type在二层调用eth_type_trans()处理时会设置该值,如果报文是单播且mac地址与net_device中不同会设置为PACKET_OTHERHOST */
383 if (skb->pkt_type == PACKET_OTHERHOST)
384 goto drop;
385
386 //修改snmp计数
387 IP_UPD_PO_STATS_BH(dev_net(dev), IPSTATS_MIB_IN, skb->len);
388 //检测是否需要共享skb,当对同类报文有多个处理函数时
389 if ((skb = skb_share_check(skb, GFP_ATOMIC)) == NULL) {
390 IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
391 goto out;
392 }
393
394 if (!pskb_may_pull(skb, sizeof(struct iphdr)))
395 goto inhdr_error;
396
397 iph = ip_hdr(skb);
410 if (iph->ihl < 5 || iph->version != 4) //检测报文头长度最小20,IPV4版本
411 goto inhdr_error;
412
413 if (!pskb_may_pull(skb, iph->ihl*4))
414 goto inhdr_error;
415
416 iph = ip_hdr(skb);
417
418 if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl))) //检测checksum是否正确,报文头校验和
419 goto csum_error;
420
421 len = ntohs(iph->tot_len);
422 if (skb->len < len) {
423 IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INTRUNCATEDPKTS);
424 goto drop;
425 } else if (len < (iph->ihl*4)) //skb长度小于报文长度或报文长度小于ipv4头长度显然错误
426 goto inhdr_error;
...
//交给netfilter函数处理,回调函数为ip_rcv_finish
445 return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,
446 ip_rcv_finish);
...
}
311 static int ip_rcv_finish(struct sk_buff *skb)
312 {
313 const struct iphdr *iph = ip_hdr(skb);
314 struct rtable *rt;
315 //sysctl_ip_early_demux 路由缓存使能标志,存储在skb->sk中
316 if (sysctl_ip_early_demux && !skb_dst(skb) && skb->sk == NULL) {
317 const struct net_protocol *ipprot;
318 int protocol = iph->protocol;
319 //获得对应协议的处理函数并调用early_demux
320 ipprot = rcu_dereference(inet_protos[protocol]);
321 if (ipprot && ipprot->early_demux) {
322 ipprot->early_demux(skb);
323 /* must reload iph, skb->head might have changed */
324 iph = ip_hdr(skb);
325 }
326 }
327
328 /*
329 * Initialise the virtual path cache for the packet. It describes
330 * how the packet travels inside Linux networking.
331 */
//路由查找,设置dst_entry input函数地址,可以为ip_forward(),ip_local_deliver(),ip_mr_input()
332 if (!skb_dst(skb)) {
333 int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
334 iph->tos, skb->dev);
335 if (unlikely(err)) {
336 if (err == -EXDEV)
337 NET_INC_STATS_BH(dev_net(skb->dev),
338 LINUX_MIB_IPRPFILTER);
339 goto drop;
340 }
341 }
...
//调用回调函数,如果为ip_local_deliver()会检测是否分片,然后执行netfilter NF_INET_LOCAL_IN回调函数,最后执行ip_local_deliver_finish(),在该函数中调用对应上层协议的处理函数
365 return dst_input(skb); | 4,694 | MIT |
# 从零开始的 JSON 库教程(八):访问与其他功能
* Milo Yip
* 2018/6/2
本文是[《从零开始的 JSON 库教程》](https://zhuanlan.zhihu.com/json-tutorial)的第八个单元。代码位于 [json-tutorial/tutorial08](https://github.com/miloyip/json-tutorial/blob/master/tutorial08)。
本单元内容:
1. [对象键值查询](#1-对象键值查询)
2. [相等比较](#2-相等比较)
3. [复制、移动与交换](#3-复制移动与交换)
4. [动态数组](#4-动态数组)
5. [动态对象](#5-动态对象)
6. [总结与练习](#6-总结与练习)
## 1. 对象键值查询
我们在第六个单元实现了 JSON 对象的数据结构,它仅为一个 `lept_value` 的数组:
~~~c
struct lept_value {
union {
struct { lept_member* m; size_t size; }o;
/* ... */
}u;
lept_type type;
};
struct lept_member {
char* k; size_t klen; /* member key string, key string length */
lept_value v; /* member value */
};
~~~
为了做相应的解析测试,我们实现了最基本的查询功能:
~~~c
size_t lept_get_object_size(const lept_value* v);
const char* lept_get_object_key(const lept_value* v, size_t index);
size_t lept_get_object_key_length(const lept_value* v, size_t index);
lept_value* lept_get_object_value(lept_value* v, size_t index);
~~~
在实际使用时,我们许多时候需要查询一个键值是否存在,如存在,要获得其相应的值。我们可以提供一个函数,简单地用线性搜寻实现这个查询功能(时间复杂度 $\mathrm{O}(n)$):
~~~c
#define LEPT_KEY_NOT_EXIST ((size_t)-1)
size_t lept_find_object_index(const lept_value* v, const char* key, size_t klen) {
size_t i;
assert(v != NULL && v->type == LEPT_OBJECT && key != NULL);
for (i = 0; i < v->u.o.size; i++)
if (v->u.o.m[i].klen == klen && memcmp(v->u.o.m[i].k, key, klen) == 0)
return i;
return LEPT_KEY_NOT_EXIST;
}}
~~~
若对象内没有所需的键,此函数返回 `LEPT_KEY_NOT_EXIST`。使用时:
~~~c
lept_value o;
size_t index;
lept_init(&o);
lept_parse(&o, "{\"name\":\"Milo\", \"gender\":\"M\"}");
index = lept_find_object_index(&o, "name", 4);
if (index != LEPT_KEY_NOT_EXIST) {
lept_value* v = lept_get_object_value(&o, index);
printf("%s\n", lept_get_string(v));
}
lept_free(&o);
~~~
由于一般也是希望获取键对应的值,而不需要索引,我们再加入一个辅助函数,返回类型改为 `lept_value*`:
~~~c
lept_value* lept_find_object_value(lept_value* v, const char* key, size_t klen) {
size_t index = lept_find_object_index(v, key, klen);
return index != LEPT_KEY_NOT_EXIST ? &v->u.o.m[index].v : NULL;
}
~~~
上述例子便可简化为:
~~~c
lept_value o, *v;
/* ... */
if ((v = lept_find_object_value(&o, "name", 4)) != NULL)
printf("%s\n", lept_get_string(v));
~~~
## 2. 相等比较
在实现数组和对象的修改之前,为了测试结果的正确性,我们先实现 `lept_value` 的[相等比较](https://zh.wikipedia.org/zh-cn/%E9%97%9C%E4%BF%82%E9%81%8B%E7%AE%97%E5%AD%90)(equality comparison)。首先,两个值的类型必须相同,对于 true、false、null 这三种类型,比较类型后便完成比较。而对于数字和字符串,需进一步检查是否相等:
~~~c
int lept_is_equal(const lept_value* lhs, const lept_value* rhs) {
assert(lhs != NULL && rhs != NULL);
if (lhs->type != rhs->type)
return 0;
switch (lhs->type) {
case LEPT_STRING:
return lhs->u.s.len == rhs->u.s.len &&
memcmp(lhs->u.s.s, rhs->u.s.s, lhs->u.s.len) == 0;
case LEPT_NUMBER:
return lhs->u.n == rhs->u.n;
/* ... */
default:
return 1;
}
}
~~~
由于值可能复合类型(数组和对象),也就是一个树形结构。当我们要比较两个树是否相等,可通过递归实现。例如,对于数组,我们先比较元素数目是否相等,然后递归检查对应的元素是否相等:
~~~c
int lept_is_equal(const lept_value* lhs, const lept_value* rhs) {
size_t i;
/* ... */
switch (lhs->type) {
/* ... */
case LEPT_ARRAY:
if (lhs->u.a.size != rhs->u.a.size)
return 0;
for (i = 0; i < lhs->u.a.size; i++)
if (!lept_is_equal(&lhs->u.a.e[i], &rhs->u.a.e[i]))
return 0;
return 1;
/* ... */
}
}
~~~
而对象与数组的不同之处,在于概念上对象的键值对是无序的。例如,`{"a":1,"b":2}` 和 `{"b":2,"a":1}` 虽然键值的次序不同,但这两个 JSON 对象是相等的。我们可以简单地利用 `lept_find_object_index()` 去找出对应的值,然后递归作比较。这部分留给读者作为练习。
## 3. 复制、移动与交换
本单元的重点,在于修改数组和对象的内容。我们将会实现一些接口做修改的操作,例如,为对象设置一个键值,我们可能会这么设计:
~~~c
void lept_set_object_value(lept_value* v, const char* key, size_t klen, const lept_value* value);
void f() {
lept_value v, s;
lept_init(&v);
lept_parse(&v, "{}");
lept_init(&s);
lept_set_string(&s, "Hello", 5);
lept_set_object_keyvalue(&v, "s", &s); /* {"s":"Hello"} */
lept_free(&v)
lept_free(&s); /* 第二次释放!*/
}
~~~
凡涉及赋值,都可能会引起资源拥有权(resource ownership)的问题。值 `s` 并不能以指针方式简单地写入对象 `v`,因为这样便会有两个地方都拥有 `s`,会做成重复释放的 bug。我们有两个选择:
1. 在 `lept_set_object_value()` 中,把参数 `value` [深度复制](https://en.wikipedia.org/wiki/Object_copying#Deep_copy)(deep copy)一个值,即把整个树复制一份,写入其新增的键值对中。
2. 在 `lept_set_object_value()` 中,把参数 `value` 拥有权转移至新增的键值对,再把 `value` 设置成 null 值。这就是所谓的移动语意(move semantics)。
深度复制是一个常用功能,使用者也可能会用到,例如把一个 JSON 复制一个版本出来修改,保持原来的不变。所以,我们实现一个公开的深度复制函数:
~~~c
void lept_copy(lept_value* dst, const lept_value* src) {
size_t i;
assert(src != NULL && dst != NULL && src != dst);
switch (src->type) {
case LEPT_STRING:
lept_set_string(dst, src->u.s.s, src->u.s.len);
break;
case LEPT_ARRAY:
/* \todo */
break;
case LEPT_OBJECT:
/* \todo */
break;
default:
lept_free(dst);
memcpy(dst, src, sizeof(lept_value));
break;
}
}
~~~
C++11 加入了右值引用的功能,可以从语言层面区分复制和移动语意。而在 C 语言中,我们也可以通过实现不同版本的接口(不同名字的函数),实现这两种语意。但为了令接口更简单和正交(orthgonal),我们修改了 `lept_set_object_value()` 的设计,让它返回新增键值对的值指针,所以我们可以用 `lept_copy()` 去复制赋值,也可以简单地改变新增的键值:
~~~c
/* 返回新增键值对的指针 */
lept_value* lept_set_object_value(lept_value* v, const char* key, size_t klen);
void f() {
lept_value v;
lept_init(&v);
lept_parse(&v, "{}");
lept_set_string(lept_set_object_value(&v, "s"), "Hello", 5);
/* {"s":"Hello"} */
lept_copy(
lept_add_object_keyvalue(&v, "t"),
lept_get_object_keyvalue(&v, "s", 1));
/* {"s":"Hello","t":"Hello"} */
lept_free(&v);
}
~~~
我们还提供了 `lept_move()`,它的实现也非常简单:
~~~c
void lept_move(lept_value* dst, lept_value* src) {
assert(dst != NULL && src != NULL && src != dst);
lept_free(dst);
memcpy(dst, src, sizeof(lept_value));
lept_init(src);
}
~~~
类似地,我们也实现了一个交换值的接口:
~~~c
void lept_swap(lept_value* lhs, lept_value* rhs) {
assert(lhs != NULL && rhs != NULL);
if (lhs != rhs) {
lept_value temp;
memcpy(&temp, lhs, sizeof(lept_value));
memcpy(lhs, rhs, sizeof(lept_value));
memcpy(rhs, &temp, sizeof(lept_value));
}
}
~~~
当我们要修改对象或数组里的值时,我们可以利用这 3 个函数。例如:
~~~c
const char* json = "{\"a\":[1,2],\"b\":3}";
char *out;
lept_value v;
lept_init(&v);
lept_parse(&v, json);
lept_copy(
lept_find_object_value(&v, "b", 1),
lept_find_object_value(&v, "a", 1));
printf("%s\n", out = lept_stringify(&v, NULL)); /* {"a":[1,2],"b":[1,2]} */
free(out);
lept_parse(&v, json);
lept_move(
lept_find_object_value(&v, "b", 1),
lept_find_object_value(&v, "a", 1));
printf("%s\n", out = lept_stringify(&v, NULL)); /* {"a":null,"b":[1,2]} */
free(out);
lept_parse(&v, json);
lept_swap(
lept_find_object_value(&v, "b", 1),
lept_find_object_value(&v, "a", 1));
printf("%s\n", out = lept_stringify(&v, NULL)); /* {"a":3,"b":[1,2]} */
free(out);
lept_free(&v);
~~~
在使用时,可尽量避免 `lept_copy()`,而改用 `lept_move()` 或 `lept_swap()`,因为后者不需要分配内存。当中 `lept_swap()` 更是无须做释放的工作,令它达到 $\mathrm{O}(1)$ 时间复杂度,其性能与值的内容无关。
## 4. 动态数组
在此单元之前的实现里,每个数组的元素数目在解析后是固定不变的,其数据结构是:
~~~c
struct lept_value {
union {
/* ... */
struct { lept_value* e; size_t size; }a; /* array: elements, element count*/
/* ... */
}u;
lept_type type;
};
~~~
用这种数据结构增删元素时,我们需要重新分配一个数组,把适当的旧数据拷贝过去。但这种做法是非常低效的。例如我们想要从一个空的数组加入 $n$ 个元素,便要做 $n(n - 1)/2$ 次元素复制,即 $\mathrm{O}(n^2)$ 的时间复杂度。
其中一个改进方法,是使用动态数组(dynamic array,或称可增长数组/growable array)的数据结构。C++ STL 标准库中最常用的 `std::vector` 也是使用这种数据结构的容器。
改动也很简单,只需要在数组中加入容量 `capacity` 字段,表示当前已分配的元素数目,而 `size` 则表示现时的有效元素数目:
~~~c
/* ... */
struct { lept_value* e; size_t size, capacity; }a; /* array: elements, element count, capacity */
/* ... */
~~~
我们终于提供设置数组的函数,而且它可提供初始的容量:
~~~c
void lept_set_array(lept_value* v, size_t capacity) {
assert(v != NULL);
lept_free(v);
v->type = LEPT_ARRAY;
v->u.a.size = 0;
v->u.a.capacity = capacity;
v->u.a.e = capacity > 0 ? (lept_value*)malloc(capacity * sizeof(lept_value)) : NULL;
}
~~~
我们需要稍修改 `lept_parse_array()`,调用 `lept_set_array()` 去设置类型和分配空间。
另外,类似于 `lept_get_array_size()`,也加入获取当前容量的函数:
~~~c
size_t lept_get_array_capacity(const lept_value* v) {
assert(v != NULL && v->type == LEPT_ARRAY);
return v->u.a.capacity;
}
~~~
如果当前的容量不足,我们需要扩大容量,标准库的 `realloc()` 可以分配新的内存并把旧的数据拷背过去:
~~~c
void lept_reserve_array(lept_value* v, size_t capacity) {
assert(v != NULL && v->type == LEPT_ARRAY);
if (v->u.a.capacity < capacity) {
v->u.a.capacity = capacity;
v->u.a.e = (lept_value*)realloc(v->u.a.e, capacity * sizeof(lept_value));
}
}
~~~
当数组不需要再修改,可以使用以下的函数,把容量缩小至刚好能放置现有元素:
~~~c
void lept_shrink_array(lept_value* v) {
assert(v != NULL && v->type == LEPT_ARRAY);
if (v->u.a.capacity > v->u.a.size) {
v->u.a.capacity = v->u.a.size;
v->u.a.e = (lept_value*)realloc(v->u.a.e, v->u.a.capacity * sizeof(lept_value));
}
}
~~~
我们不逐一检视每个数组修改函数,仅介绍一下两个例子:
~~~c
lept_value* lept_pushback_array_element(lept_value* v) {
assert(v != NULL && v->type == LEPT_ARRAY);
if (v->u.a.size == v->u.a.capacity)
lept_reserve_array(v, v->u.a.capacity == 0 ? 1 : v->u.a.capacity * 2);
lept_init(&v->u.a.e[v->u.a.size]);
return &v->u.a.e[v->u.a.size++];
}
void lept_popback_array_element(lept_value* v) {
assert(v != NULL && v->type == LEPT_ARRAY && v->u.a.size > 0);
lept_free(&v->u.a.e[--v->u.a.size]);
}
~~~
`lept_pushback_array_element()` 在数组末端压入一个元素,返回新的元素指针。如果现有的容量不足,就需要调用 `lept_reserve_array()` 扩容。我们现在用了一个最简单的扩容公式:若容量为 0,则分配 1 个元素;其他情况倍增容量。
`lept_popback_array_element()` 则做相反的工作,记得删去的元素需要调用 `lept_free()`。
下面这 3 个函数留给读者练习:
1. `lept_insert_array_element()` 在 `index` 位置插入一个元素;
2. `lept_erase_array_element()` 删去在 `index` 位置开始共 `count` 个元素(不改容量);
3. `lept_clear_array()` 清除所有元素(不改容量)。
~~~c
lept_value* lept_insert_array_element(lept_value* v, size_t index);
void lept_erase_array_element(lept_value* v, size_t index, size_t count);
void lept_clear_array(lept_value* v);
~~~
## 5. 动态对象
动态对象也是采用上述相同的结构,所以直接留给读者修改结构体,并实现以下函数:
~~~c
void lept_set_object(lept_value* v, size_t capacity);
size_t lept_get_object_capacity(const lept_value* v);
void lept_reserve_object(lept_value* v, size_t capacity);
void lept_shrink_object(lept_value* v);
void lept_clear_object(lept_value* v);
lept_value* lept_set_object_value(lept_value* v, const char* key, size_t klen);
void lept_remove_object_value(lept_value* v, size_t index);
~~~
注意 `lept_set_object_value()` 会先搜寻是否存在现有的键,若存在则直接返回该值的指针,不存在时才新增。
## 6. 总结与练习
本单元主要加入了数组和对象的访问、修改方法。当中的赋值又引申了三种赋值的方式(复制、移动、交换)。这些问题是各种编程语言中都需要考虑的事情,为了减少深度复制的成本,有些程序库或运行时还会采用[写入时复制](https://zh.wikipedia.org/zh-cn/%E5%AF%AB%E5%85%A5%E6%99%82%E8%A4%87%E8%A3%BD)(copy-on-write, COW)。而浅复制(shallow copy)则需要 [引用计数](https://zh.wikipedia.org/wiki/%E5%BC%95%E7%94%A8%E8%AE%A1%E6%95%B0)(reference count)或 [垃圾回收](https://zh.wikipedia.org/zh-cn/%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6_(%E8%A8%88%E7%AE%97%E6%A9%9F%E7%A7%91%E5%AD%B8))(garbage collection, GC)等技术。
另外,我们实现了以动态数组的数据结构,能较高效地对数组和对象进行增删操作。至此,我们已经完成本教程的所有核心功能。做完下面的练习后,我们还会作简单讲解,然后将迎来本教程的最后一个单元。
本单元练习内容:
1. 完成 `lept_is_equal()` 里的对象比较部分。不需要考虑对象内有重复键的情况。
2. 打开 `test_access_array()` 里的 `#if 0`,实现 `lept_insert_array_element()`、`lept_erase_array_element()` 和 `lept_clear_array()`。
3. 打开 `test_access_object()` 里的 `#if 0`,参考动态数组,实现第 5 部分列出的所有函数。
4. 完成 `lept_copy()` 里的数组和对象的复制部分。
如果你遇到问题,有不理解的地方,或是有建议,都欢迎在评论或 [issue](https://github.com/miloyip/json-tutorial/issues) 中提出,让所有人一起讨论。 | 11,551 | MIT |
# vue2-x-multiple
> A Multiple Pages Vue.js project
### webpack打包编译过程中的几个变量
Template | Description
-- | --
[hash] |
The hash of the module identifier
[chunkhash] |
The hash of the chunk content
[name] |
The module name
[id] |
The module identifier
[query] |
The module query, i.e., the string following ? in the filename
### webpack.config.js的详细解说配置
```js
var path = require('path');
var webpack = require('webpack');
/*
extract-text-webpack-plugin插件,
有了它就可以将你的样式提取到单独的css文件里,
妈妈再也不用担心样式会被打包到js文件里了。
*/
var ExtractTextPlugin = require('extract-text-webpack-plugin');
/*
html-webpack-plugin插件,重中之重,webpack中生成HTML的插件,
具体可以去这里查看https://www.npmjs.com/package/html-webpack-plugin
*/
var HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry: { //配置入口文件,有几个写几个
index: './src/js/page/index.js',
list: './src/js/page/list.js',
about: './src/js/page/about.js',
},
// https://webpack.js.org/configuration/output/
output: {
path: path.join(__dirname, 'dist'), //输出目录的配置,模板、样式、脚本、图片等资源的路径配置都相对于它;path中的[hash]会替换编译后的hash值
publicPath: '/dist/', //模板、样式、脚本、图片等资源对应的server上的路径
filename: 'js/[name].js', //每个页面对应的主js的生成配置
chunkFilename: 'js/[id].chunk.js' //设置不是入口文件JS的打包配置,比如异步加载require.ensure([],Fn)
},
module: {
loaders: [ //加载器,关于各个加载器的参数配置,可自行搜索之。
{
test: /\.css$/,
//配置css的抽取器、加载器。'-loader'可以省去
loader: ExtractTextPlugin.extract('style-loader', 'css-loader')
}, {
test: /\.less$/,
//配置less的抽取器、加载器。中间!有必要解释一下,
//根据从右到左的顺序依次调用less、css加载器,前一个的输出是后一个的输入
//你也可以开发自己的loader哟。有关loader的写法可自行谷歌之。
loader: ExtractTextPlugin.extract('css!less')
}, {
//html模板加载器,可以处理引用的静态资源,默认配置参数attrs=img:src,处理图片的src引用的资源
//比如你配置,attrs=img:src img:data-src就可以一并处理data-src引用的资源了,就像下面这样
test: /\.html$/,
loader: "html?attrs=img:src img:data-src"
}, {
//文件加载器,处理文件静态资源
test: /\.(woff|woff2|ttf|eot|svg)(\?v=[0-9]\.[0-9]\.[0-9])?$/,
loader: 'file-loader?name=./fonts/[name].[ext]'
}, {
//图片加载器,雷同file-loader,更适合图片,可以将较小的图片转成base64,减少http请求
//如下配置,将小于8192byte的图片转成base64码
test: /\.(png|jpg|gif)$/,
loader: 'url-loader?limit=8192&name=./img/[hash].[ext]'
}
]
},
plugins: [
new webpack.ProvidePlugin({ //加载jq
$: 'jquery'
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendors', // 将公共模块提取,生成名为`vendors`的chunk
chunks: ['index','list','about'], //提取哪些模块共有的部分
minChunks: 3 // 提取至少3个模块共有的部分
}),
new ExtractTextPlugin('css/[name].css'), //单独使用link标签加载css并设置路径,相对于output配置中的publickPath
//HtmlWebpackPlugin,模板生成相关的配置,每个对于一个页面的配置,有几个写几个
new HtmlWebpackPlugin({ //根据模板插入css/js等生成最终HTML
favicon: './src/img/favicon.ico', //favicon路径,通过webpack引入同时可以生成hash值
filename: './view/index.html', //生成的html存放路径,相对于path
template: './src/view/index.html', //html模板路径
inject: 'body', //js插入的位置,true/'head'/'body'/false
hash: true, //为静态资源生成hash值
chunks: ['vendors', 'index'],//需要引入的chunk,不配置就会引入所有页面的资源
minify: { //压缩HTML文件
removeComments: true, //移除HTML中的注释
collapseWhitespace: false //删除空白符与换行符
}
}),
new HtmlWebpackPlugin({ //根据模板插入css/js等生成最终HTML
favicon: './src/img/favicon.ico', //favicon路径,通过webpack引入同时可以生成hash值
filename: './view/list.html', //生成的html存放路径,相对于path
template: './src/view/list.html', //html模板路径
inject: true, //js插入的位置,true/'head'/'body'/false
hash: true, //为静态资源生成hash值
chunks: ['vendors', 'list'],//需要引入的chunk,不配置就会引入所有页面的资源
minify: { //压缩HTML文件
removeComments: true, //移除HTML中的注释
collapseWhitespace: false //删除空白符与换行符
}
}),
new HtmlWebpackPlugin({ //根据模板插入css/js等生成最终HTML
favicon: './src/img/favicon.ico', //favicon路径,通过webpack引入同时可以生成hash值
filename: './view/about.html', //生成的html存放路径,相对于path
template: './src/view/about.html', //html模板路径
inject: true, //js插入的位置,true/'head'/'body'/false
hash: true, //为静态资源生成hash值
chunks: ['vendors', 'about'],//需要引入的chunk,不配置就会引入所有页面的资源
minify: { //压缩HTML文件
removeComments: true, //移除HTML中的注释
collapseWhitespace: false //删除空白符与换行符
}
}),
new webpack.HotModuleReplacementPlugin() //热加载
],
//使用webpack-dev-server,提高开发效率
devServer: {
contentBase: './',
host: 'localhost',
port: 9090, //默认8080
inline: true, //可以监控js变化
hot: true, //热启动
}
};
```
```js
var path = require('path')
module.exports = {
build: { // production 环境
env: require('./prod.env'), // 使用 config/prod.env.js 中定义的编译环境
index: path.resolve(__dirname, '../dist/index.html'), // 编译输入的 index.html 文件
assetsRoot: path.resolve(__dirname, '../dist'), // 编译输出的静态资源路径
assetsSubDirectory: 'static', // 编译输出的二级目录
assetsPublicPath: '/', // 编译发布的根目录,可配置为资源服务器域名或 CDN 域名
productionSourceMap: true, // 是否开启 cssSourceMap
// Gzip off by default as many popular static hosts such as
// Surge or Netlify already gzip all static assets for you.
// Before setting to `true`, make sure to:
// npm install --save-dev compression-webpack-plugin
productionGzip: false, // 是否开启 gzip
productionGzipExtensions: ['js', 'css'] // 需要使用 gzip 压缩的文件扩展名
},
dev: { // dev 环境
env: require('./dev.env'), // 使用 config/dev.env.js 中定义的编译环境
port: 8080, // 运行测试页面的端口
assetsSubDirectory: 'static', // 编译输出的二级目录
assetsPublicPath: '/', // 编译发布的根目录,可配置为资源服务器域名或 CDN 域名
proxyTable: {}, // 需要 proxyTable 代理的接口(可跨域)
// CSS Sourcemaps off by default because relative paths are "buggy"
// with this option, according to the CSS-Loader README
// (https://github.com/webpack/css-loader#sourcemaps)
// In our experience, they generally work as expected,
// just be aware of this issue when enabling this option.
cssSourceMap: false // 是否开启 cssSourceMap
}
}
``` | 5,690 | MIT |
---
layout: post
title: "胡耀邦忌日:緬懷胡耀邦也要認真總結8964事件的前因後果胡耀邦習仲勳患難相助堪稱典範都是黨內殘酷鬥爭極左思想的犧牲者極左思想又席捲而來誰應該承擔這個責任重難誰還有機會撥亂反正?"
date: 2021-04-15T10:36:27.000Z
author: 老楊到處說
from: https://www.youtube.com/watch?v=JeQa_AeJXIU
tags: [ 老楊到處說 ]
categories: [ 老楊到處說 ]
---
<!--1618482987000-->
[胡耀邦忌日:緬懷胡耀邦也要認真總結8964事件的前因後果胡耀邦習仲勳患難相助堪稱典範都是黨內殘酷鬥爭極左思想的犧牲者極左思想又席捲而來誰應該承擔這個責任重難誰還有機會撥亂反正?](https://www.youtube.com/watch?v=JeQa_AeJXIU)
------
<div>
訂閱楊錦麟頻道,每天免費收看最新影片:https://bit.ly/yangjinlin歡迎各位透過PayPal支持我們的創作:http://bit.ly/support-laoyang4月15日是中共前總書記#胡耀邦忌日,1989年4月15日,胡耀邦病逝,這一天之後,北京和全國各地開始出現自發組織的悼念胡耀邦活動,活動迅速演變成大規模學生運動,反貪腐成為主要訴求,這成了#八九六四 運動的導火線。1986年12月,合肥的中國科學技術大學 開始的學潮蔓延到北京,#中共元老 將學潮的爆發歸咎#自由化知識分子 煽動、以及#胡耀邦 的縱容。這裡主要談談胡耀邦,#習仲勳 在歷史重要轉折關頭的 肝膽相照、精誠團結、同舟共濟,以及其後的患難相助。1,如果沒有胡耀邦,習仲勳的平反未必得到盡速解決2,習仲勳在廣東推行改革得到胡耀邦的支持鼓勵3,胡耀邦習仲勳在轉折關頭患難相助 友誼堪稱典範(1)緬懷胡耀邦,同時也要認真總結8964事件的前因後果,避免歷史的再度重演;(2)從習仲勳與胡耀邦的患難與共,重情重義的患難相助,看到的不僅僅是早期共產黨人人品,人格,人性的光輝,無論是不是他們的後人,都應該真正學習這種一以貫之的品格;(3)習仲勳的大徹大悟,為胡耀邦拍案而起,為主張立法保護不同意見,被匆忙去職,驅出京城,失去了出任#全國人大常委會委員長 的機會,晚年才獲準回京治病,這一切對習近平理應要有所觸動才對。(4)習仲勳,胡耀邦都是黨內不同歷史時期黨內殘酷鬥爭的受害者,都是極左思想,路線的犧牲者,那一套極左的思想路線眼睜睜地看著又席捲而來,誰應該承擔這個責任,誰還有機會挺身而出撥亂反正?但看歷史之後的發展吧。(5)中國歷史上的兩個百年政黨,前一個已經兩度失去政權,現在是否能重返執政黨位置,還存在諸多未卜之數,後者一路跋涉至今,獲得成就與所犯錯誤付出的代價均可等量齊觀。
</div> | 1,229 | MIT |
---
layout: post
title: spel
subtitle: spel 表达式解析
date: 2020-04-12
author: lijian
header-img: img/post-bg-hacker.jpg
catalog: true
tags:
- spel
---
### 用法
```
StandardEvaluationContext context = SpelUtils.getContext(method,args);
Boolean frozen = SpelUtils.getContextValue(context,"#request.frozen",Boolean.class);
```
### 代码
```
import lombok.experimental.UtilityClass;
import lombok.extern.slf4j.Slf4j;
import org.springframework.core.LocalVariableTableParameterNameDiscoverer;
import org.springframework.expression.spel.standard.SpelExpressionParser;
import org.springframework.expression.spel.support.StandardEvaluationContext;
import java.lang.reflect.Method;
import java.util.Objects;
/**
* spel 表达式帮助类,一般情况,通过 aop 拦截获取到 method && args[] , 从而可以获取到 参数上下文, 再根据参数上下文就可以获取到对应的 spel 表达式的参数值
*
* @author lijian@jovision.com
* @date 2020/10/15
**/
@Slf4j
@UtilityClass
public class SpelUtils {
/**
* SpEL表达式parser
*/
private static final SpelExpressionParser EXPRESSION_PARSER = new SpelExpressionParser();
/**
* 获取方法参数定义
*/
private static final LocalVariableTableParameterNameDiscoverer NAME_DISCOVERER = new LocalVariableTableParameterNameDiscoverer();
/**
* 获取参数上下文
*/
public StandardEvaluationContext getContext(Method method, Object[] args) {
StandardEvaluationContext context = new StandardEvaluationContext();
if (Objects.nonNull(args) && args.length > 0) {
String[] paraNameArr = NAME_DISCOVERER.getParameterNames(method);
if (Objects.nonNull(paraNameArr)) {
for (int i = 0; i < paraNameArr.length; i++) {
context.setVariable(paraNameArr[i], args[i]);
}
}
}
return context;
}
/**
* 获取上下文参数
*
* @param spelExpression spel 表达式 eq:#{userSaveDto.userId}
*/
public <T> T getContextValue(StandardEvaluationContext context, String spelExpression, Class<T> clazz) {
return EXPRESSION_PARSER.parseExpression(spelExpression).getValue(context, clazz);
}
/**
* 更新上下文参数
*
* @param spelExpression spel 表达式 eq:#{userSaveDto.userId}
*/
public void updateContextValue(StandardEvaluationContext context, String spelExpression, Object value) {
EXPRESSION_PARSER.parseExpression(spelExpression).setValue(context, value);
}
}
``` | 2,415 | MIT |
---
last_modified: 2015/07/17
translation_status: complete
language: ja
title: Datadog-SNMP Integration
integration_title: SNMP Check
kind: integration
doclevel:
sidebar:
nav:
- header: SNMP Integration
- text: SNMP インテグレーションの設定
href: "#agent"
- text: 独自MIBの変換
href: "#convert-mib"
---
<!-- ### Configure the SNMP Agent Check -->
### SNMP インテグレーションの設定
<!-- To use the SNMP checks, add a `snmp.yaml` file to your `conf.d` directory, following [this example](https://github.com/DataDog/dd-agent/blob/master/conf.d/snmp.yaml.example). -->
SNMP Checkを使用するには、`conf.d`ディレクトリにある`snmp.yaml.example`をコピーし、`snmp.yaml`を追加します。
<!-- For each device that you want to monitor, you need to specify at least an ip_address and an authentication method. If not specified, a default port of 161 will be assumed. -->
デバイスを監視するには、少なくともIP_ADDRESSと認証方法を指定する必要があります。又、アクセスするポート番号の指定がない場合は、デフォルトとして161番ポートを使用します。
<!-- <p> Our agent allows you to monitor the SNMP Counters and Gauge of your choice. Specify for each device the metrics that you want to monitor in the <code>metrics</code> subsection using one of the following method:</p>
<dl class='snmp'> -->
Datadog Agentは、瞬間値や積算値をSNMPから取得出来ます。次に示す方法で監視対象となる`metrics`を、それぞれのデバイスに対して指定してください:
<!-- #### Specify a MIB and the symbol that you want to export
metrics:
- MIB: UDP-MIB
symbol: udpInDatagrams
#### Specify an OID and the name you want the metric to appear under in Datadog.
metrics:
- OID: 1.3.6.1.2.1.6.5
name: tcpActiveOpens
*The name here is the one specified in the MIB but you could use any name.*
#### Specify a MIB and a table you want to extract information from.
metrics:
- MIB: IF-MIB
table: ifTable
symbols:
- ifInOctets
metric_tags:
- tag: interface
column: ifDescr
This allows you to gather information on all the table's row, as well as to specify tags to gather.
Use the `symbols` list to specify the metric to gather and the `metric_tags` list to specify the name of the tags and the source to use.
In this example the agent would gather the rate of octets received on each interface and tag it with the interface name (found in the ifDescr column), resulting in a tag such as `interface:eth0`
metrics:
- MIB: IP-MIB
table: ipSystemStatsTable
symbols:
- ipSystemStatsInReceives
metric_tags:
- tag: ipversion
index: 1
You can also gather tags based on the indices of your row, in case they are meaningful. In this example, the first row index contains the ip version that the row describes (ipv4 vs. ipv6) -->
##### MIBとエクスポートしたいシンボルを指定します。
metrics:
- MIB: UDP-MIB
symbol: udpInDatagrams
##### OIDとDatadogで使用するメトリクス名を指定します。
metrics:
- OID: 1.3.6.1.2.1.6.5
name: tcpActiveOpens
##### MIBと情報を取得するテーブルを指定します。
metrics:
- MIB: IF-MIB
table: ifTable
symbols:
- ifInOctets
metric_tags:
- tag: interface
column: ifDescr
この方法により、テーブルの全行の情報が取得でき、タグ付けすることが出来ます。`symbols`のリストを使って取得するメトリクスを指定し、`metric_tags`のリストを使ってそれらのメトリクスに付与しておくタグを指定します。
この例では、各インターフェイスで受信した通信量のレートを取得し、ifDescr列のインターフェース毎に`interface:eth0`のタグを付与します。
metrics:
- MIB: IP-MIB
table: ipSystemStatsTable
symbols:
- ipSystemStatsInReceives
metric_tags:
- tag: ipversion
index: 1
必要に応じて行のインデックスに基づいてタグを付与することも出来ます。この例では、最初の行のインデックスがIPのバージョン(IPv6, IPv4)を見分け、タグ付けするように指定しています。
<!-- ### Use your own Mib
{: #convert-mib}
To use your own MIB with the datadog-agent, you need to convert them to the pysnmp format. This can be done using the `build-pysnmp-mibs` script that ships with pysnmp.
It has a dependency on `smidump`, from the libsmi2ldbl package so make sure it is installed. Make also sure that you have all the dependencies of your MIB in your mib folder or it won't be able to convert your MIB correctly.
Run
$ build-pysnmp-mibs -o YOUR-MIB.py YOUR-MIB.mib
where YOUR-MIB.mib is the MIB you want to convert.
Put all your pysnmp mibs into a folder and specify this folder's path in your `snmp.yaml` file, in the `init_config` section.` -->
### 独自MIBの変換
{: #convert-mib}
独自のMIBを使用するには、ysnmp形式に変換する必要があります。この変換には、pysnmpのパッケージに含まれている`build-pysnmp-mibs`を使うことが出来ます。
この`build-pysnmp-mibs`を使うには、`smidump`がインストールされている必要があります。従って、`smidump`を包含している`libsmi2ldbl`パッケージが正しくインストールできていることを確認して下さい。更に、MIBが依存している全てのファイルがmibディレクトリに設置されていることも確認して下さい。(依存ファイルがない場合は、正しく変換ができません。)
変換の実行
$ build-pysnmp-mibs -o YOUR-MIB.py YOUR-MIB.mib
`OUR-MIB.mib`は、変換したいMIBファイルの名前です。
pysmpで変換した全てのmibファイルを任意のフォルダーに移動し、そのフォルダーへのパスを`snmp.yaml`ファイルの`init_config`セクションに指定します。 | 4,830 | BSD-3-Clause |
---
title: Azure App Service と Azure SQL Database Managed Instance に移行してアプリをリファクタリングする
description: Contoso がオンプレミス アプリを Azure App Service Web アプリと Azure SQL Server Database Managed Instance に移行して、オンプレミス アプリをリホストする方法について説明します。
author: givenscj
ms.author: abuck
ms.date: 04/02/2020
ms.topic: conceptual
ms.service: cloud-adoption-framework
ms.subservice: migrate
services: azure-migrate
ms.openlocfilehash: 0e288b29077d68ee4b0c0522537abe0baaa276ac
ms.sourcegitcommit: 60d8b863d431b5d7c005f2f14488620b6c4c49be
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 05/12/2020
ms.locfileid: "83223696"
---
<!-- cSpell:ignore givenscj WEBVM SQLVM contosohost vcenter contosodc smarthotel SQLMI SHWCF SHWEB -->
# <a name="refactor-an-on-premises-app-to-an-azure-app-service-web-app-and-azure-sql-managed-instance"></a>Azure App Service Web アプリと Azure SQL Managed Instance にオンプレミス アプリをリファクタリングする
この記事では、Contoso という架空の会社が、Azure への移行の一環として、VMware VM 上で実行される 2 層の Windows .NET アプリをリファクターする方法を示します。 アプリのフロントエンド VM を、Azure App Service の Web アプリに移行します。 また、Contoso がアプリ データベースを Azure SQL Database Managed Instance に移行する方法も説明します。
この例で使用される SmartHotel360 アプリは、オープン ソースとして提供されています。 独自のテスト目的に沿って使用する場合は、[GitHub](https://github.com/Microsoft/SmartHotel360) からダウンロードできます。
## <a name="business-drivers"></a>ビジネス ドライバー
IT リーダーシップ チームは、ビジネス パートナーと密接に連絡を取り合い、彼らがこの移行で何を達成しようとしているのかを理解しました。
- **ビジネスの成長への対応。** Contoso は成長を続けており、オンプレミスのシステムとインフラストラクチャに負荷がかかっています。
- **効率化。** Contoso では、不要な手順を取り除き、開発者とユーザーのプロセスを効率化する必要があります。 ビジネス部門は IT に対して、時間やコストを無駄にせず、迅速に作業を行ってもらう必要があります。これは、例えば、顧客の要求に素早く対応するためです。
- **機敏性の向上。** Contoso IT は、ビジネス部門の要求に対して、対応力を向上させる必要があります。 また、グローバル経済で成功を収めるために、市場の変化に対して、より迅速な対応ができる必要があります。 ビジネスの妨げになったり、ビジネスの機会を壊すようなことがあってはなりません。
- **スケール。** ビジネスが順調に成長していく中で、Contoso IT は、同じペースで拡張できるシステムを提供する必要があります。
- **コストを削減する。** Contoso はライセンス コストを最小限に抑えたいと考えています。
## <a name="migration-goals"></a>移行の目標
Contoso クラウド チームは、この移行の目標を設定しました。 これらの目標を使用して、最良の移行方法を決定しました。
<!-- markdownlint-disable MD033 -->
**必要条件** | **詳細**
--- | ---
**App** | このアプリは、Azure でも現在と同じくクリティカルです。 <br><br> 現在の VMWare と同等のパフォーマンス機能が必要です。 <br><br> チームはアプリへの投資を望んでいません。 現在のところ、管理者は単にアプリをクラウドに安全に移行します。 <br><br> チームは、アプリが現在実行されている Windows Server 2008 R2 のサポートを終了したいと考えています。 <br><br> また、SQL Server 2008 R2 から最新の PaaS Database プラットフォームに移行したいと考えています。これにより、管理の必要性を最小限に抑えられます。 <br><br> Contoso では、可能であれば、SQL Server ライセンスとソフトウェア アシュアランスへの投資を活かしたいと考えています。 <br><br> さらに、Contoso は Web 層の単一障害点を軽減したいと考えています。
**制限事項** | このアプリは、同じ VM 上で実行されている ASP.NET アプリと WCF サービスで構成されています。 Azure App Service を使用して 2 つの Web アプリに分割したいと考えています。
**Azure** | Contoso は Azure にアプリを移行したいと考えていますが、VM 上では実行したくありません。 Contoso では、Azure PaaS サービスを Web 層とデータ層の両方に利用したいと考えています。
**DevOps** | Contoso は、ビルドとリリース パイプラインに Azure DevOps を使用して DevOps モデルに移行したいと考えています。
<!-- markdownlint-enable MD033 -->
## <a name="solution-design"></a>ソリューション設計
Contoso は目標と要件を決定した後、デプロイ ソリューションを設計およびレビューし、移行に使用する Azure サービスを含め、移行プロセスを決めます。
### <a name="current-app"></a>現在のアプリ
- SmartHotel360 オンプレミス アプリは 2 つの VM (WEBVM と SQLVM) に階層化されています。
- VM は、VMware ESXi ホスト **contosohost1.contoso.com** (バージョン 6.5) 上に配置されます。
- VMware 環境は、VM 上で実行中の vCenter Server 6.5 (**vcenter.contoso.com**) によって管理されています。
- Contoso にはオンプレミスのデータセンター (contoso-datacenter) があり、そこにオンプレミスのドメイン コントローラー (**contosodc1**) が含まれています。
- Contoso データセンター内のオンプレミス VM は、移行が行われた後に使用停止にされます。
### <a name="proposed-solution"></a>提案されるソリューション
- アプリの Web 層については、Azure App Service を使用することに決めました。 この PaaS サービスにより、わずかな構成変更だけでアプリをデプロイできます。 Visual Studio を使用して変更を加え、2 つの Web アプリをデプロイします。 1 つは Web サイト用、もう 1 つは WCF サービス用です。
- DevOps パイプラインの要件を満たすため、Contoso はソース コード管理のために、Git リポジトリと共に Azure DevOps を選択しました。 コードをビルドして Azure App Service へデプロイするには、自動ビルドとリリースが使用されます。
### <a name="database-considerations"></a>データベースの考慮事項
Contoso はソリューション設計プロセスの一環として、Azure SQL Database と SQL Server Managed Instance の機能を比較しました。 Managed Instance にすることを決定するにあたり、次の考慮事項が役に立ちました。
- Managed Instance では、最新のオンプレミス SQL Server バージョンとのほぼ 100% の互換性を提供することが目的とされています。 Microsoft は、SQL Server をオンプレミスまたは IaaS VM で実行していて、最小限の設計変更で完全に管理されたサービスにアプリを移行することを望んでいるお客様に、Managed Instance を推奨しています。
- Contoso は、多数のアプリをオンプレミスから IaaS に移行することを計画しています。 それらの多くは、ISV から提供されたものです。 Contoso は、サポートされていない可能性がある SQL Database を使用するのではなく、Managed Instance を使用すると、これらのアプリのデータベース互換性を確保するのに役立つことを理解しています。
- Contoso は、完全に自動化された Azure Database Migration Service を使用して、Managed Instance へのリフトアンドシフト移行を簡単に実行できます。 このサービスを導入すると、Contoso は将来のデータベース移行にそれを再利用できます。
- SQL Managed Instance では、SmartHotel360 アプリの重要な問題である SQL Server エージェントがサポートされています。 Contoso ではこの互換性が必要です。互換性がないと、アプリで必要なメンテナンス プランを再設計する必要があります。
- ソフトウェア アシュアランスに基づき、Contoso は、SQL Database Managed Instance で SQL Server 用の Azure ハイブリッド特典を利用して、既存のライセンスを割引料金のライセンスに交換することができます。 これによって、Contoso は Managed Instance を最大 30% 節約することができます。
- SQL Managed Instance は仮想ネットワークに完全に含まれるため、Contoso のデータに対して高い分離性とセキュリティが提供されます。 Contoso は、パブリック インターネットから分離された環境を維持しながら、パブリック クラウドのメリットを得ることができます。
- Managed Instance では、常時暗号化、動的データ マスキング、行レベルのセキュリティ、脅威検出など、多くのセキュリティ機能がサポートされています。
### <a name="solution-review"></a>ソリューションのレビュー
Contoso は、長所と短所の一覧をまとめて、提案されたデザインを評価します。
<!-- markdownlint-disable MD033 -->
**考慮事項** | **詳細**
--- | ---
**長所** | Azure に移行するために SmartHotel360 アプリ コードを変更する必要はありません。 <br><br> Contoso では、SQL Server と Windows Server の両方に Azure ハイブリッド特典を使用して、ソフトウェア アシュアランスへの投資を活かすことができます。 <br><br> 移行後は、Windows Server 2008 R2 をサポートする必要がなくなります。 詳細については、「[Microsoft ライフサイクル ポリシー](https://aka.ms/lifecycle)」を参照してください。 <br><br> Contoso は複数のインスタンスがあるアプリの Web 層を構成することができたので、単一障害点ではなくなりました。 <br><br> データベースは古い SQL Server 2008 R2 に依存しなくなります。 <br><br> SQL Managed Instance では、Contoso の技術面の要件と目標がサポートされています。 <br><br> Managed Instance では、SQL Server 2008 R2 から移行するときに、現在の展開との 100% の互換性が提供されます。 <br><br> ソフトウェア アシュアランスと、SQL Server および Windows Server の Azure ハイブリッド特典を使用して、投資を活用できます。 <br><br> 将来の移行では、Azure Database Migration Service を再利用できます。 <br><br> SQL Managed Instance には、Contoso が構成する必要のないフォールト トレランスが組み込まれています。 そのため、データ層がフェールオーバーの単一ポイントではなくなります。
**短所** | Azure App Services は、各 Web アプリに対して 1 つのアプリのデプロイのみをサポートしています。 これは、2 つの Web アプリをプロビジョニングする必要がある (Web サイト用に 1 つと WCF サービス用に 1 つ) ことを意味します。 <br><br> データ層については、Contoso がオペレーティング システムやデータベース サーバーをカスタマイズしたい場合、または SQL Server と共にサードパーティ製アプリを実行したい場合は、Managed Instance は最適なソリューションではない可能性があります。 IaaS VM で SQL Server を実行すると、このような柔軟性が提供されます。
<!-- markdownlint-enable MD033 -->
## <a name="proposed-architecture"></a>提案されたアーキテクチャ

### <a name="migration-process"></a>移行プロセス
1. Contoso は、Azure SQL Database Managed Instance をプロビジョニングし、Azure Database Migration Service (DMS) を使用して SmartHotel360 データベースをそれに移行します。
2. Contoso は Web アプリをプロビジョニングして構成し、そこに SmartHotel360 アプリをデプロイします。

### <a name="azure-services"></a>Azure サービス
**サービス** | **説明** | **コスト**
--- | --- | ---
[Azure Database Migration Service](https://docs.microsoft.com/azure/dms/dms-overview) | Azure Database Migration Service を使用すると、複数のデータベース ソースから Azure データ プラットフォームに、ダウンタイムを最小限に抑えながらシームレスに移行できます。 | [サポートされているリージョン](https://docs.microsoft.com/azure/dms/dms-overview#regional-availability)に関する情報と、[Database Migration Service の価格](https://azure.microsoft.com/pricing/details/database-migration)に関する情報をご覧ください。
[Azure SQL Database マネージド インスタンス](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance) | Managed Instance は、Azure クラウド内の完全に管理された SQL Server インスタンスを表すマネージド データベース サービスです。 最新バージョンの SQL Server データベース エンジンと同じコードを使用し、最新の機能、パフォーマンスの向上、およびセキュリティ更新プログラムが適用されています。 | Azure で実行されている SQL Database Managed Instance を使用すると、容量に基づく料金がかかります。 [Managed Instance の価格の詳細については、こちらを参照してください](https://azure.microsoft.com/pricing/details/sql-database/managed)。
[Azure App Service](https://docs.microsoft.com/azure/app-service/overview) | フルマネージド プラットフォームで強力なクラウド アプリを作成 | サイズ、場所、使用時間に基づくコスト。 [詳細については、こちらを参照してください](https://azure.microsoft.com/pricing/details/app-service/windows)。
[Azure Pipelines](https://docs.microsoft.com/azure/devops/pipelines/get-started/what-is-azure-pipelines) | 継続的インテグレーションと継続的デプロイ (CI/CD) パイプラインをアプリの開発に提供します。 パイプラインは、アプリ コードを管理する Git リポジトリで始まり、パッケージおよびその他のビルド成果物を生成するためのビルド システム、開発、テスト、および運用環境での変更を配置するリリース管理システムへと続きます。
## <a name="prerequisites"></a>前提条件
このシナリオを実行するために Contoso に必要なものを以下に示します。
<!-- markdownlint-disable MD033 -->
**必要条件** | **詳細**
--- | ---
**Azure サブスクリプション** | Contoso は前の記事でサブスクリプションを作成しました。 Azure サブスクリプションをお持ちでない場合は、[無料アカウント](https://azure.microsoft.com/pricing/free-trial)を作成してください。 <br><br> 無料アカウントを作成する場合、サブスクリプションの管理者としてすべてのアクションを実行できます。 <br><br> 既存のサブスクリプションを使用しており、管理者でない場合は、管理者に依頼して所有者アクセス許可または共同作成者アクセス許可を割り当ててもらう必要があります。
**Azure インフラストラクチャ** | [Contoso で Azure インフラストラクチャを設定する方法](./contoso-migration-infrastructure.md)を確認してください。
<!--markdownlint-enable MD033 -->
## <a name="scenario-steps"></a>シナリオのステップ
Contoso が移行を実行する方法を次に示します。
> [!div class="checklist"]
>
> - **ステップ 1:SQL Database Managed Instance を設定する。** Contoso では、オンプレミス SQL Server データベースの移行先となる既存のマネージド インスタンスが必要です。
> - **手順 2:Azure Database Migration Service (DMS) を使用して移行する。** Contoso は、Azure Data Migration Service を使用してアプリのデータベースを移行します。
> - **ステップ 3:Web アプリをプロビジョニングする。** Contoso は 2 つの Web アプリをプロビジョニングします。
> - **手順 4:Azure DevOps を設定する。** Contoso は新しい Azure DevOps プロジェクトを作成し、Git リポジトリをインポートします。
> - **手順 5:接続文字列を構成する。** Contoso は Web 層 Web アプリ、WCF サービス Web アプリ、および SQL インスタンスが通信できるように接続文字列を構成します。
> - **手順 6:ビルドとリリース パイプラインを設定する。** 最後の手順として、Contoso はアプリを作成するようにビルドとリリース パイプラインを設定し、それらを 2 つの個別の Web アプリにデプロイします。
## <a name="step-1-set-up-a-sql-database-managed-instance"></a>手順 1:SQL Database Managed Instance を設定する
Azure SQL Database Managed Instance を設定するため、Contoso には次の要件を満たしているサブネットが必要です。
- サブネットは専用でなければなりません。 また、サブネットは空で他のクラウド サービスを含んでいない必要があります。 サブネットはゲートウェイ サブネットであってはなりません。
- Managed Instance を作成した後は、サブネットにリソースを追加することはできません。
- サブネットにネットワーク セキュリティ グループを関連付けることはできません。
- サブネットにはユーザー定義のルート テーブルが必要です。 割り当てられている唯一のルートが 0.0.0.0/0 の次ホップ インターネットである必要があります。
- 仮想ネットワーク用に省略可能なカスタム DNS が指定されている場合、Azure 内の再帰的なリゾルバーの仮想 IP アドレス `168.63.129.16` をリストに追加する必要があります。 [Azure SQL Database Managed Instance のカスタム DNS を構成する](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance-custom-dns)方法についてご確認ください。
- サブネットにサービス エンドポイント (ストレージまたは SQL) を関連付けることはできません。 仮想ネットワークではサービス エンドポイントを無効にする必要があります。
- サブネットには 16 個以上の IP アドレスが必要です。 [Managed Instance サブネットのサイズを指定する方法については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance-configure-vnet-subnet)。
- Contoso のハイブリッド環境では、カスタム DNS 設定が必要です。 Contoso は、自社の 1 つ以上の Azure DNS サーバーを使用するように DNS 設定を構成します。 [DNS のカスタマイズの詳細については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance-custom-dns)。
### <a name="set-up-a-virtual-network-for-the-managed-instance"></a>Managed Instance 用の仮想ネットワークを設定する
Contoso の管理者は仮想ネットワークを次のように設定します。
1. 米国東部 2 プライマリ リージョンに新しい仮想ネットワーク (**VNET-SQLMI-EU2**) を作成します。 その仮想ネットワークを **ContosoNetworkingRG** リソース グループに追加します。
2. 10.235.0.0/24 のアドレス空間を割り当てます。 その範囲がエンタープライズ内の他のどのネットワークとも重複しないことを確認します。
3. ネットワークに以下の 2 つのサブネットを追加します。
- **SQLMI-DS-EUS2** (10.235.0.0.25)
- **SQLMI-SAW-EUS2** (10.235.0.128/29) このサブネットは、Managed Instance にディレクトリを接続するために使用されます。

4. 仮想ネットワークとサブネットがデプロイされた後、ネットワークを以下のようにピアリングします。
- **VNET-SQLMI-EUS2** と **VNET-HUB-EUS2** (米国東部 2 のハブ仮想ネットワーク) とピアリングします。
- **VNET-SQLMI-EUS2** と **VNET-PROD-EUS2** (実稼働ネットワーク) をピアリングします。

5. Contoso は、カスタム DNS 設定を行います。 DNS は、最初は Contoso の Azure ドメイン コント ローラーを指しています。 Azure DNS はセカンダリです。 Contoso Azure ドメイン コントローラーは、以下のように配置されます。
- 配置先は **PROD-DC-EUS2** サブネットで、これは米国東部 2 の実稼働ネットワーク (**VNET-PROD-EUS2**) 内にあります。
- **CONTOSODC3** アドレス: 10.245.42.4
- **CONTOSODC4** アドレス: 10.245.42.5
- Azure DNS リゾルバー: 168.63.129.16

**さらにサポートが必要な場合**
- [SQL Database Managed Instance の概要については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance)。
- [SQL Database Managed Instance 用の仮想ネットワークを作成する方法については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance-configure-vnet-subnet)。
- [ピアリングを設定する方法については、こちらを参照してください](https://docs.microsoft.com/azure/virtual-network/virtual-network-manage-peering)。
- [Azure Active Directory DNS 設定を更新する方法については、こちらを参照してください](https://docs.microsoft.com/azure/active-directory-domain-services/tutorial-create-instance)。
### <a name="set-up-routing"></a>ルーティングを設定する
Managed Instance は、プライベート仮想ネットワーク内に配置されます。 仮想ネットワークが Azure Management Service と通信するためのルート テーブルが必要です。 仮想ネットワークが、仮想ネットワークを管理するサービスと通信できない場合、仮想ネットワークへのアクセスができなくなります。
Contoso は以下の点を考慮します。
- ルート テーブルには、Managed Instance から送信されたパケットを仮想ネットワーク内でルーティングする方法を指定した一連のルール (ルート) が含まれています。
- ルート テーブルは、Managed Instance がデプロイされているサブネットに関連付けられています。 サブネットから離れる各パケットは、関連付けられたルート テーブルに基づいて処理されます。
- 1 つのサブネットは、1 つのルート テーブルにのみ関連付けることができます。
- Microsoft Azure では、ルート テーブルの作成に追加料金はかかりません。
Contoso の管理者は次のようにしてルーティングを設定します。
1. **ContosoNetworkingRG** リソース グループ内にユーザー定義ル-ト テーブルを作成します。

2. Managed Instance の要件に準拠するため、ルート テーブル (**MIRouteTable**) を展開した後、アドレス プレフィックスが 0.0.0.0/0 のルートを追加します。 **[次ホップの種類]** オプションは **[インターネット]** に設定します。

3. (**VNET-SQLMI-EUS2** ネットワーク内の) **SQLMI-DB-EUS2** サブネットにルート テーブルを関連付けます。

**さらにサポートが必要な場合**
[Managed Instance 用のルートを設定する方法については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance-get-started)。
### <a name="create-a-managed-instance"></a>マネージド インスタンスを作成する
以上で Contoso の管理者は、SQL Database Managed Instance をプロビジョニングできるようになりました。
1. Managed Instance はビジネス アプリにサービスを提供するため、米国東部 2 プライマリ リージョンに Managed Instance をデプロイします。 その Managed Instance を **ContosoRG** リソース グループに追加します。
2. 価格レベルを選択し、インスタンスのコンピューティングとストレージのサイズを設定します。 [Managed Instance の価格の詳細については、こちらを参照してください](https://azure.microsoft.com/pricing/details/sql-database/managed)。

3. Managed Instance をデプロイすると、**ContosoRG** リソース グループ内に 2 つの新しいリソースが表示されます。
- 仮想クラスター (複数の Managed Instance が存在する場合)
- SQL Server Database Managed Instance

**さらにサポートが必要な場合**
[Managed Instance をプロビジョニングする方法については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-managed-instance-get-started)。
## <a name="step-2-migrate-with-azure-database-migration-service-dms"></a>手順 2:Azure Database Migration Service (DMS) を使用して移行する
Contoso の管理者は、[ステップバイステップの移行チュートリアル](https://docs.microsoft.com/azure/dms/tutorial-sql-server-azure-sql-online)を使い、Azure Database Migration Service (DMS) を使用して移行します。 オンライン、オフラインの両方、およびハイブリッド (プレビュー) の移行を実行できます。
まとめると、次を実行する必要があります。
- VNet に接続されている `Premium` SKU を持つ Azure Database Migration Service (DMS) を作成します。
- Azure Database Migration Service (DMS) が仮想ネットワーク経由でリモート SQL Server にアクセスできることを確認します。 これには、仮想ネットワーク レベル、ネットワーク VPN、および SQL Server をホストするマシンで、 Azure から SQL サーバーにすべての受信ポートが許可されていることの確認が伴います。
- Azure Database Migration Service を構成する:
- 移行プロジェクトを作成します。
- ソース (オンプレミス データベース) を追加します。
- ターゲットを選択します。
- 移行するデータベースを選択します。
- 詳細設定を構成します。
- レプリケーション を開始します。
- すべてのエラーを解決します。
- 最終的なカットオーバーを実行します。
## <a name="step-3-provision-web-apps"></a>手順 3:Web アプリをプロビジョニングする
データベースの移行が完了し、Contoso 管理者は 2 つの Web アプリをプロビジョニングできるようになりました。
1. ポータルで **[Web アプリ]** を選択します。

2. アプリ名 (**SHWEB-EUS2**) を指定し、Windows 上で実行し、運用リソース グループ **ContosoRG** に配置します。 新しい Web アプリと Azure App Service プランを作成します。

3. Web アプリがプロビジョニングされた後、WCF サービス (**SHWCF-EUS2**) 用に Web アプリを作成するプロセスを繰り返します

4. 完了したら、アプリのアドレスを参照して、アプリが正常に作成されたことを確認します。
## <a name="step-4-set-up-azure-devops"></a>手順 4:Azure DevOps を設定する
Contoso は、アプリケーションのために DevOps インフラストラクチャとパイプラインを構築する必要があります。 これを行うために、Contoso 管理者は新しい DevOps プロジェクトを作成し、コードをインポートしてから、ビルドとリリース パイプラインを設定します。
1. Contoso Azure DevOps アカウントで、新しいプロジェクト (**ContosoSmartHotelRefactor**) を作成し、バージョン コントロールに **[Git]** を選択します。

2. アプリ コードを現在保持している Git リポジトリをインポートします。 [GitHub のパブリック リポジトリ](https://github.com/Microsoft/SmartHotel360-Registration)内にあるので、ダウンロードすることができます。

3. コードをインポートしたら、Visual Studio をリポジトリに接続し、チーム エクスプローラーを使用してコードを複製します。

4. リポジトリが開発者のコンピューターに複製された後に、アプリ用のソリューション ファイルを開きます。 Web アプリと wcf サービスは、ファイル内にそれぞれ別のプロジェクトを持っています。

## <a name="step-5-configure-connection-strings"></a>手順 5:接続文字列の構成
Contoso 管理者は、Web アプリとデータベースがすべて通信できることを確認する必要があります。 そのために、コードと Web アプリで接続文字列を構成します。
1. WCF サービス (**SHWCF-EUS2**) の Web アプリで、 **[設定]** > **[アプリケーションの設定]** の順に選択し、**DefaultConnection** という新しい接続文字列を追加します。
2. 接続文字列は **SmartHotel-Registration** データベースからプルされ、正しい資格情報で更新する必要があります。

3. Visual Studio を使用して、ソリューション ファイルから **SmartHotel.Registration.wcf** プロジェクトを開きます。 WCF サービス **SmartHotel.Registration.Wcf** の web.config ファイルの **connectionStrings** セクションを、接続文字列を指定して更新する必要があります。

4. **SmartHotel.Registration.Web** の web.config ファイルの **client** セクションは、WCF サービスの新しい場所を指すように変更する必要があります。 これは、サービス エンドポイントをホストする WCF Web アプリの URL です。

5. コードの変更が完了したら、管理者はその変更をコミットする必要があります。 Visual Studio でチーム エクスプローラーを使用して、コミットと同期を行います。
## <a name="step-6-set-up-build-and-release-pipelines-in-azure-devops"></a>手順 6:ビルドとリリース パイプラインを Azure DevOps で設定する
次に、Contoso 管理者は、Azure DevOps を構成して、ビルドおよびリリース プロセスを実行します。
1. Azure DevOps 内で、 **[Build and release]\(ビルドとリリース\)** > **[新しいパイプライン]** の順に選択します。

2. **[Azure Repos Git]** を選択し、関連するリポジトリを選択します。

3. **[テンプレートの選択]** で、ビルド用の ASP.NET テンプレートを選択します。

4. ビルドには **ContosoSmartHotelRefactor-ASP.NET-CI** という名前が使用されます。 **[保存してキューに登録]** を選択します。

5. これで最初のビルドが開始されます。 プロセスを監視するビルド番号を選択します。 完了後、プロセスのフィードバックを表示し、 **[成果物]** を選択してビルドの結果を確認できます。

6. **Drop** フォルダーにはビルドの結果が格納されています。
- 2 つの zip ファイルは、アプリを格納するパッケージです。
- これらのファイルは、Azure App Service にデプロイするためにリリース パイプライン内で使用されます。

7. **[リリース]** > **[+New pipeline]\(+新しいパイプライン\)** の順に選択します。

8. Azure App Service 用のデプロイ テンプレートを選択します。

9. リリース パイプラインに **ContosoSmartHotel360Refactor** という名前を付けて、WCF Web アプリの名前 (SHWCF-EUS2) を**ステージ**として指定します。

10. ステージ下で、 **[1 個のジョブ、1 個のタスク]** を選択して WCF サービスのデプロイを構成します。

11. サブスクリプションが選択および承認されていることを確認し、 **[App Service の名前]** を選択します。

12. パイプライン > **[成果物]** で、 **[+Add an artifact]\(成果物の追加\)** を選択し、**ContosoSmarthotel360Refactor** パイプラインを使用してビルドするように選択します。

13. 成果物にある稲妻アイコンを選択して、継続的配置トリガーを有効にします。

14. 継続的配置トリガーを **[有効]** に設定する必要があります。

15. ここで、ステージ 1 のジョブ (I タスク) に戻り **[Deploy Azure App Service]\(Azure App Service のデプロイ\)** を選択します。

16. **[Select a file or folder]\(ファイルまたはフォルダーの選択\)** で、ビルド中に作成していた **SmartHotel.Registration.Wcf.zip** ファイルを探して、 **[保存]** を選択します。

17. **[パイプライン]** > **[ステージ]** と選択し、 **[+追加]** を選択して **SHWEB EUS2** 用の環境を追加します。 別の Azure App Service のデプロイを選択します。

18. Web アプリ (**SmartHotel.Registration.Web.zip**) ファイルを発行するためにプロセスを繰り返して Web アプリを修正します。

19. Web アプリを保存すると、リリース パイプラインが次のように表示されます。

20. **[ビルド]** に戻り、 **[トリガー]** > **[継続的インテグレーションを有効にする]** の順に選択します。 これでパイプラインが有効になり、変更がコードに対してコミットされると、フル ビルドとリリースが発生します。

21. **[保存してキューに登録]** を選択し、フル パイプラインを実行します。 新しいビルドがトリガーされ、続いてアプリの最初のリリースが Azure App Service に対して作成されます。

22. Contoso 管理者は、Azure DevOps からビルドとリリース パイプラインのプロセスに従うことができます。 ビルドが完了すると、リリースが開始されます。

23. パイプラインが完了すると、両方のサイトがデプロイされ、アプリが稼働します。

この時点で、アプリは正常に Azure に移行されています。
## <a name="clean-up-after-migration"></a>移行後にクリーンアップする
移行後、Contoso は、以下のクリーンアップ手順を完了する必要があります。
- vCenter のインベントリからオンプレミスの VM を削除します。
- ローカルのバックアップ ジョブからから VM を削除します。
- SmartHotel360 アプリの新しい場所を示すように社内ドキュメントを更新します。 Azure SQL Managed Instance データベースでデータベースは実行中と表示され、2 つの Web アプリでフロント エンドは実行中と表示されます。
- 使用停止されている VM と対話しているリソースがないか確認します。また、関連する設定やドキュメントがあれば、更新して新しい構成を反映します。
## <a name="review-the-deployment"></a>デプロイを再調査する
リソースを Azure に移行したら、新しいインフラストラクチャを完全に操作可能にして、セキュリティ保護する必要があります。
### <a name="security"></a>Security
- Contoso は新しい **SmartHotel-Registration** データベースがセキュリティで保護されていることを確認する必要があります。 [詳細については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-security-overview)。
- 特に、証明書で SSL を使用するように Web アプリを更新する必要があります。
### <a name="backups"></a>バックアップ
- Contoso は、Azure SQL Managed Instance データベースのバックアップ要件を確認する必要があります。 [詳細については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-automated-backups)。
- また、Contoso は SQL Database のバックアップと復元の管理について確認する必要があります。 自動バックアップについては、[こちら](https://docs.microsoft.com/azure/sql-database/sql-database-automated-backups)をご覧ください。
- Contoso は、データベースのリージョン内フェールオーバーを提供するようにフェールオーバー グループを実装することを検討する必要があります。 [詳細については、こちらを参照してください](https://docs.microsoft.com/azure/sql-database/sql-database-geo-replication-overview)。
- Contoso では、復元性のために、主要な米国東部 2 リージョンと米国中部リージョンに Web アプリをデプロイすることを検討する必要があります。 リージョンの障害が発生したときに確実にフェールオーバーするように Traffic Manager を構成できます。
### <a name="licensing-and-cost-optimization"></a>ライセンスとコストの最適化
- すべてのリソースをデプロイした後、Contoso は[インフラストラクチャ計画](./contoso-migration-infrastructure.md#set-up-tagging)に基づいて Azure タグを割り当てる必要があります。
- すべてのライセンスは、Contoso が使用している PaaS サービスのコストに組み込まれています。 これは EA から差し引かれます。
- Contoso は [Azure Cost Management](https://azure.microsoft.com/services/cost-management) を使用して、IT リーダーが定めた予算内に確実に収まるようにします。
## <a name="conclusion"></a>まとめ
この記事の中で、Contoso は、アプリのフロントエンド VM を 2 つの Azure App Service Web アプリに移行することで、Azure にある SmartHotel360 アプリをリファクターしました。 アプリ データベースを Azure SQL Managed Instance に移行しました。 | 25,031 | CC-BY-4.0 |
---
layout: post
title: "印度的“驭龙”之梦"
date: 2012-10-24
author: 宿亮
from: http://cnpolitics.org/2012/10/india-towards-china/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
印度的“驭龙”之梦
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
#中印关系 #印度 #外交
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/suliang/">宿亮</a-->
<a href="http://cnpolitics.org/author/suliang/">
宿亮
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2012-10-24
</span>
</p>
<!--p class="post-lead">中印这两个新兴经济体之间的政治外交关系“剪不清、理还乱”,历史的恩怨与现实的博弈一直纠结着喜马拉雅山南北的两个大国。印度学者把边界问题看成是双边关系的核心,批评政府对华政策过于软弱。这种评论反映了印度学者对中国的敌对态度及长久以来“驭龙”的图谋。</p-->
<div class="post-body">
<p>
<strong>
□“政见”观察员 宿亮
</strong>
</p>
<p>
<img alt="" class="aligncenter size-full wp-image-2102" height="499" sizes="(max-width: 500px) 100vw, 500px" src="http://cnpolitics.org/wp-content/uploads/2012/10/Img320004473.jpg" srcset="http://cnpolitics.org/wp-content/uploads/2012/10/Img320004473.jpg 500w, http://cnpolitics.org/wp-content/uploads/2012/10/Img320004473-150x150.jpg 150w, http://cnpolitics.org/wp-content/uploads/2012/10/Img320004473-300x300.jpg 300w, http://cnpolitics.org/wp-content/uploads/2012/10/Img320004473-125x125.jpg 125w" width="500"/>
</p>
<p>
中国和印度的人口加在一起超过25亿,与全球总人口的一半相去不远。进入21世纪,“中国崛起”和印度经济的快速发展成为全球经济发展的“现象级”事件。不过,中印这两个新兴经济体之间的政治外交关系“剪不清、理还乱”,历史的恩怨与现实的博弈一直纠结着喜马拉雅山南北的两个大国。
</p>
<p>
美国东密歇根大学印度学者
<strong>
尼特娅·辛格(Nitya Singh)
</strong>
近日在期刊《印度评论》上撰文分析印度对华外交政策,试图为印度政府寻找“驭龙之术”。
</p>
<p>
谈论印度对华政策,首先要分析印度外交政策制定过程。辛格认为,印度外交政策制定过于官僚和混乱,导致在处理对外关系时没有“大战略”眼光。
</p>
<p>
与其他国家类似,印度外交政策也受到议会、公众舆论等方面的影响,但值得注意的是,印度外交政策制定并非充分征求意见后的集体决策,而是带有强烈的个人色彩。大多数总理外交顾问倾向于追求自身目标而不是着眼全面的外交议程。顾问们甚至随意增减自己所负责的国家或地区。
</p>
<p>
另外,由于最近15年印度政治走向联盟政府时代,一些地方小党开始有机会影响外交事务。它们只是从地区性的世界观出发,却要影响政府的全球决策。
</p>
<p>
辛格认为,在这种外交体系下制定的对华政策可谓“无力”,急需改革。
</p>
<p>
印度对华外交可以分成三个阶段。第一阶段从1947年印度独立到1962年中印边境战争前,期间印度主张不结盟和经济自主政策。这种主张一定程度上契合中国的外交理念,直到1959年之前中印关系都处于“黄金时期”。但1959年之后,印度卷入中国内部事务,导致中国认定印度归属“西方阵营”并最终发展到双方交战。
</p>
<p>
第二阶段从1962年到1991年印度经济改革前夕,期间印度主张以更现实主义的方法对待中国。中印边境战争后,无论印度政府还是民众都对中国缺乏信任。印度开始改善对苏关系。直到1984年拉吉夫·甘地上台并于1988年访问中国,双方关系才有所改进。拉吉夫·甘地强调西藏问题是中国内政,这一姿态减少了中国对印度的敌意。
</p>
<p>
第三阶段是1991年至今的这段时间。中印互访增加,但中国经济的崛起和印度核武器试验成功导致双方的敌意和紧张关系加深。2004年团结进步联盟上台后谋求在政治和经济上接近中国。这一政府推动多领域合作,一定程度上改变了印度对华印象:尽管两国今后关系有不确定性,但已不再是紧迫的安全威胁。
</p>
<p>
辛格认为,中印关系的核心是双边的边界问题。
</p>
<p>
中印边界问题的起源是“麦克马洪线”。1976年中印关系改善之后到20世纪80年代,双方举行了8轮谈判,中方接受印度提议,分段逐一讨论边界划分,双方紧张态势得以缓解,但没有实质性进展。随后,双方于1993年双方签订和平与稳定备忘录;1996年江泽民访印期间双方又达成军队从实际控制线各后撤200米的协议。
</p>
<p>
21世纪头十年,中印双方特使于2003年启动新边界谈判,于2005年签订《解决边境问题政治指导原则》;2006年就机制化军事交流达成一致;2009年开启新一轮谈判。眼下,谈判仍在继续。
</p>
<p>
辛格指出,中国在处理边界问题时是否采用强硬态度,取决于国内政治稳定是否会受到影响,特别是涉及西藏问题时更是如此。2003年中印关系“回暖”,印度总理瓦杰帕伊访华,重申西藏问题是中国内政;而中国同时做出表态,支持印度对锡金的主权声明。
</p>
<p>
不过,在辛格看来,中国方面虽然在对印政策中具备了较多灵活性,但整体对印度政策趋于强硬。在经济上,中国或许希望与印度“双赢”;但在军事上,中国极力限制印度。中国在地区问题上仍是力保印巴之间实力均衡,避免印度在南亚建立霸权。
</p>
<p>
基于这种判断,中国在边界问题上最终会采取更加强硬的态度,希望以此限制印度的发展,让其陷于安全问题无法关注于经济建设。
</p>
<p>
辛格批评印度政府对华政策过于软弱——印度官方情报机构和智库不认为中国在2050年前会对印度构成威胁,所以没有把应对中国作为首要任务,这种方式不利于印度长期战略目标的达成。辛格“支招”:印度应该采取“胡萝卜加大棒”的方式,在支持中国在西藏问题立场的同时,趁中国与越南、菲律宾、印度尼西亚以及日本等国发生矛盾孤立中国,为边界谈判赢得更多筹码。
</p>
<p>
辛格的文章站在印度的立场上要求对话强硬,这反映了印度学者对中国的敌对以及印度长久以来“驭龙”的图谋。眼下中印政府之间关系保持稳定,但民间敌对情绪有恶化趋势。面对这种态度,中国有必要重视这个发展中的邻国,发挥自身软实力,谋取“驯象”之道,避免再次陷入双边紧张关系之中。
</p>
<p>
</p>
<p>
<strong>
【参考文献】
</strong>
Nitya Singh, How to Tame Your Dragon: An Evaluation of India’s Foreign Policy Toward China, India Review, vol. 11, no. 3, 2012, pp. 139-160
</p>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 3,907 | MIT |
---
title: ドキュメンテーション
layout: ja/detail
description: Step by step starting guide
---
## 基本
### インストール
npm を介して Riot をインストールできます:
```sh
npm i -S riot
```
または yarn を介して:
```sh
yarn add riot
```
### 使い方
[webpack](https://github.com/riot/webpack-loader)、[Rollup](https://github.com/riot/rollup-plugin-riot)、[Parcel](https://github.com/riot/parcel-plugin-riot) または [Browserify](https://github.com/riot/riotify) を用いて Riot.js のアプリケーションをバンドルできます。
また Riot タグは、[ブラウザ上で]({{ '/ja/compiler/#in-browser-compilation' | prepend:site.baseurl }})直接的にコンパイルすることもでき、プロトタイプやテストを素早く行うことができます。
### テンプレートを用いてスタート
もしプロジェクトを我々の公式テンプレートを用いてスタートしたい場合は、以下のコマンドが使用できます:
```sh
npm init riot
```
このコマンドは好きなバンドラを選択させ、最初に Riot.js アプリケーションのコーディングを開始するために必要な全てのファイルを現在のフォルダ内に生成されます。
### クイックスタート
すべてのアプリケーション・バンドラーをワイヤリングする(または、我々の公式テンプレートの1つを利用する)と、おそらくコードは次のようになります:
`index.html`
```html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Riot App</title>
</head>
<body>
<div id="root"></div>
<script src="dist/bundle.js"></script>
</body>
</html>
```
`app.riot`
```html
<app>
<p>{ props.message }</p>
</app>
```
`main.js`
```js
import * as riot from 'riot'
import App from './app.riot'
const mountApp = riot.component(App)
const app = mountApp(
document.getElementById('root'),
{ message: 'Hello World' }
)
```
## Todo の例
Riot のカスタムコンポーネントはユーザーインターフェイスの構成要素です。アプリケーションの "ビュー" 部分を作成します。では、Riot のさまざまな機能を強調し拡張された `<todo>` の例から始めましょう。
```html
<todo>
<h3>{ props.title }</h3>
<ul>
<li each={ item in state.items }>
<label class={ item.done ? 'completed' : null }>
<input
type="checkbox"
checked={ item.done }
onclick={ () => toggle(item) } />
{ item.title }
</label>
</li>
</ul>
<form onsubmit={ add }>
<input onkeyup={ edit } value={ state.text } />
<button disabled={ !state.text }>
Add #{ state.items.length + 1 }
</button>
</form>
<script>
export default {
onBeforeMount(props, state) {
// state の初期化
this.state = {
items: props.items,
text: ''
}
},
edit(e) {
// text の状態のみ更新
this.update({
text: e.target.value
})
},
add(e) {
e.preventDefault()
if (this.state.text) {
this.update({
items: [
...this.state.items,
// 新しい item を追加
{title: this.state.text}
],
text: ''
})
}
},
toggle(item) {
item.done = !item.done
// コンポーネントの update を発火
this.update()
}
}
</script>
</todo>
```
カスタムコンポーネントは JavaScript に[コンパイル]({{ '/compiler/' | prepend:site.baseurl }})されます。
[ライブデモ](https://riot.js.org/examples/plunker/?app=todo-app)をご覧になるか、ブラウザで[ソース](https://github.com/riot/examples/tree/gh-pages/todo-app)を閲覧するか、[zip](https://github.com/riot/examples/archive/gh-pages.zip) ファイルをダウンロードしてください。
## 構文
Riot コンポーネントはレイアウト(HTML)とロジック(JavaScript)のコンビネーションです。基本的なルールは次のとおりです:
* 各 `.riot` ファイル含めることができるのは、1つのコンポーネントのロジックのみ
* HTML は初めに定義され、ロジックは `<script>` タグで囲われる
* カスタムコンポーネントは空にもでき、HTML のみ、または JavaScript のみにもできる
* すべてのテンプレートの式は "JavaScript™️": `<pre>{ JSON.stringify(props) }</pre>`
* `this` というキーワードはオプショナル: `<p>{ name }</p>` と `<p>{ this.name }</p>` はともに有効
* 引用符はオプショナル: `<foo bar={ baz }>` と `<foo bar="{ baz }">` はともに有効
* 式の値が falsy の場合、Boolean の属性(checked, selected など)は無視される: `<input checked={ undefined }>` を `<input>` として評価する
* 標準の HTML タグ(`label`、`table`、`a` など)はカスタマイズすることもできるが、必ずしもそうすることが賢明というわけではない
* **ルート** のタグ定義も属性を保つ場合がある: `<my-component onclick={ click } class={ props.class }>`
注意: ネイティブのタグを再定義するのはあまりよろしくありません。もし安全性を確保したいのならばダッシュ(-)付きの名前をつけるべきです。(詳しくは [FAQ](https://riot.js.org/ja/faq/#タグ名にダッシュを使うべき) を参照してください。)
## プリプロセッサ
`type` 属性でプリプロセッサを指定できます。例:
```html
<my-component>
<script type="coffee">
# coffeescript ロジックをここに書く
</script>
</my-component>
````
コンポーネントは選択したプリプロセッサによりコンパイルされます。ただし、プリプロセッサが[事前に登録]({{ '/ja/compiler#プリプロセッサ' | prepend:site.baseurl }})されている場合に限ります。
## スタイリング
`style` タグを中に置くことができます。Riot.js はスタイルを自動的に切り出し、`<head>` 内に注入します。これはコンポーネントが何回初期化される回数に関係なく、ただ1回だけ発生します。
```html
<my-component>
<!-- layout -->
<h3>{ props.title }</h3>
<style>
/** 他のコンポーネント固有のスタイル **/
h3 { font-size: 120% }
/** 他のコンポーネント固有のスタイル **/
</style>
</my-component>
```
### スコープ付き CSS
[スコープ付き css と :host 擬似クラス](https://developer.mozilla.org/en-US/docs/Web/CSS/:host()) はすべてのブラウザで使用できます。Riot.js は JS に独自のカスタム実装を持っており、ブラウザの実装に依存したり、フォールバックしたりすることはありません。次の例は、最初の例と同じです。メモ:次の例では、コンポーネント名を使用してスタイルのスコープを設定する代わりに `:host` `擬似クラス` を使用しています。
```html
<my-component>
<!-- レイアウト -->
<h3>{ props.title }</h3>
<style>
:host { display: block }
h3 { font-size: 120% }
/** 他のコンポーネント固有のスタイル **/
</style>
</my-component>
```
## マウント
コンポーネントを作成したら、次の手順でページにマウントできます:
```html
<body>
<!-- body 内の任意の位置にカスタムコンポーネントを配置 -->
<my-component></my-component>
<!-- riot.js を導入 -->
<script src="riot.min.js"></script>
<!-- コンポーネントをマウント -->
<script type="module">
// @riotjs/compiler で生成されたコンポーネントの JavaScript の出力をインポートする
import MyComponent from './my-component.js'
// the riot コンポーネントを登録
riot.register('my-component', MyComponent)
riot.mount('my-component')
</script>
</body>
```
ページの `body` 内のカスタムコンポーネントは通常どおりに閉じる必要があります: `<my-component></my-component>` かつ、自己終了: `<my-component/>` はサポートされていません。
mount メソッドを使用したいくつかの例:
```js
// 指定した id の要素をマウント
riot.mount('#my-element')
// 選択した要素をマウント
riot.mount('todo, forum, comments')
```
ドキュメントには、同じコンポーネントのインスタンスを複数含めることができます。
### DOM 要素へのアクセス
Riot は `this.$` と `this.$$` ヘルパーメソッドを介してコンポーネントの DOM 要素へのアクセスを提供します。
```html
<my-component>
<h1>My todo list</h1>
<ul>
<li>Learn Riot.js</li>
<li>Build something cool</li>
</ul>
<script>
export default {
onMounted() {
const title = this.$('h1') // 単体の要素
const items = this.$$('li') // 複数の要素
}
}
</script>
</my-component>
```
### jQuery、Zepto、querySelector などの使い方
Riot 内の DOM にアクセスする必要がある場合、[riot コンポーネントのライフサイクル](#riot-コンポーネントのライフサイクル) を見たいと思うでしょう。DOM 要素は最初に `mount` イベントが発火するまで、インスタンス化されないことに注意してください。つまり、先に要素の選択を試みると失敗することを意味しています。
```html
<my-component>
<p id="findMe">Do I even Exist?</p>
<script>
var test1 = document.getElementById('findMe')
console.log('test1', test1) // 失敗
export default {
onMounted() {
const test2 = document.getElementById('findMe')
console.log('test2', test2) // 成功、一度発火(マウントごとに)
},
onUpdated() {
const test3 = document.getElementById('findMe')
console.log('test3', test3) // 成功、更新ごとに発火
}
}
</script>
</my-component>
```
### コンテキスト DOM クエリ
`onUpdated` コールバックまたは `onMounted` コールバックで DOM 要素を取得する方法がわかりましたが、要素のクエリにコンテキストを `root element`(作成した Riot タグ)に追加することによっても、これを便利なものにできます。
```html
<my-component>
<p id="findMe">Do I even Exist?</p>
<p>Is this real life?</p>
<p>Or just fantasy?</p>
<script>
export default {
onMounted() {
// jQuery コンテキスト
$('p', this.root) // this.$ に似ている
// クエリセレクタコンテキスト
this.root.querySelectorAll('p') // this.$$ に似ている
}
}
</script>
</my-component>
```
### プロパティ
コンポーネントの初期プロパティを2番目の引数に渡すことができます。
```html
<script>
riot.mount('todo', { title: 'My TODO app', items: [ ... ] })
</script>
```
渡されるデータは、単純なオブジェクトから完全なアプリケーション API まで、あらゆるものが可能です。または、Redux ストアも許されます。設計されたアーキテクチャに依存します。
タグ内では、プロパティは次のように `this.props` 属性でプロパティを参照できます:
```html
<my-component>
<!-- HTML 内の props -->
<h3>{ props.title }</h3>
<script>
export default {
onMounted() {
// JavaScript 内の props
const title = this.props.title
// this.props は固定かつ不変
this.props.description = 'my description' // これは動作しない
}
}
</script>
</my-component>
```
### 状態
各 Riot コンポーネントは `this.state` オブジェクトを使用して、内部の状態を格納または変更できます。
`this.props` 属性がフリーズされている間は、`this.state` オブジェクトは完全に変更可能であり、手動または `this.update()` メソッドを使用して更新できます:
```html
<my-component id="{ state.name }-{ state.surname }">
<p>{ state.name } - { state.surname }</p>
<script>
export default {
onMounted() {
// これは良いがコンポーネント DOM は更新しない
this.state.name = 'Jack'
// このコールは状態とコンポーネント DOM も更新する
this.update({
surname: 'Black'
})
}
}
</script>
</my-component>
```
### Riot コンポーネントのライフサイクル
コンポーネントは以下の一連の流れで生成されます:
1. コンポーネントのオブジェクトが生成される
2. JavaScript ロジックが評価、実行される
3. すべての HTML の式が計算される
4. コンポーネント DOM がページにマウントされ、"onMounted" コールバックが呼び出される
マウントされたコンポーネントの更新は次のような挙動になります:
1. 現在のコンポーネントインスタンスで `this.update()` が呼び出されたとき
2. 親コンポーネントまたは、任意の親方向(上位)のコンポーネントで `this.update()` が呼び出されたとき。親から子への単方向のフローで更新する。
"onUpdated" コールバックはコンポーネントタグが更新される度に呼び出されます。
### ライフサイクルコールバック
コンポーネントのライフサイクルを以下のように設定できます:
```html
<my-component>
<script>
export default {
onBeforeMount(props, state) {
// コンポーネントのマウント前
},
onMounted(props, state) {
// コンポーネントがページにマウントされた直後
},
onBeforeUpdate(props, state) {
// 更新前にコンテキストデータの再計算が許可されている
},
onUpdated(props, state) {
// update が呼び出され、コンポーネントのテンプレートが更新された直後
},
onBeforeUnmount(props, state) {
// コンポーネントが削除される前
},
onUnmounted(props, state) {
// ページからコンポーネントが削除されたとき
}
}
</script>
</my-component>
```
すべてのコールバックは常に現在の `this.props` と `this.state` という引数を受け取ります。
## プラグイン
Riot は自身のコンポーネントをアップグレードする簡単な方法を提供します。コンポーネントが生成されたとき、`riot.install` を介して登録されたプラグインにより拡張されます。
```js
// riot-observable.js
let id = 0
riot.install(function(component) {
// すべてのコンポーネントはここを通過する
component.uid = id++
})
```
```html
<!-- my-component.riot -->
<my-component>
<h1>{ uid }</h1>
</my-component>
```
## 式(テンプレート変数)
HTMLは、中カッコで囲まれた式と混在させることができます:
```js
{ /* 自分の式をここに書く */ }
```
式には、属性やネストしたテキストノードを設定できます:
```html
<h3 id={ /* 属性式 */ }>
{ /* ネストされた式 */ }
</h3>
```
式は 100% JavaScript です。いくつかの例:
```js
{ title || 'Untitled' }
{ results ? 'ready' : 'loading' }
{ new Date() }
{ message.length > 140 && 'Message is too long' }
{ Math.round(rating) }
```
目標は、式を小さくして、HTML をできるだけクリーンな状態に保つことです。もし式が複雑になってきたら、ロジックの一部を "onBeforeUpdate" コールバックに移すことを検討してください。例:
```html
<my-component>
<!-- `val` は以下で計算された値〜 -->
<p>{ val }</p>
<script>
export default {
onBeforeUpdate() {
// 〜更新ごとに
this.val = some / complex * expression ^ here
}
}
</script>
</my-component>
```
### Boolean 属性
式の値が falsy の場合、Boolean 属性(checked、selected …など)は無視されます:
`<input checked={ null }>` は `<input>` となります。
W3C では、属性が存在していれば(その値が `false`、空であっても)boolean 型のプロパティは true であると記述しています。
以下の式は動作しません:
```html
<input type="checkbox" { true ? 'checked' : ''}>
```
属性式とネストされたテキスト式のみが有効です。Riot は有効な html の boolean 属性をすべて自動的に検出します。
### スプレッド属性のオブジェクト
複数の属性を定義するために、スプレッド式のオブジェクトを使うこともできます。例:
```html
<my-component>
<p { ...attributes }></p>
<script>
export default {
attributes: {
id: 'my-id',
role: 'contentinfo',
class: 'main-paragraph'
}
}
</script>
</my-component>
```
`<p id="my-id" role="contentinfo" class="main-paragraph">` と評価されます。
### 括弧の出力
括弧の開始をエスケープすることで、式を評価することなしに出力できます:
`\{ this is not evaluated }` は `{ this is not evaluated }` と出力されます。
括弧を評価すべきでない場合は、必ず括弧をエスケープしてください。例えば、以下の Regex パターンは意図した入力(任意の2つの数字)を検証することに失敗し、代わりに単一の数字(以下では数字の "2")のみを受け付けます。
```html
<my-component>
<input type="text" pattern="\d{2}">
</my-component>
```
正しい実装は次のとおりです:
```html
<my-component>
<input type="text" pattern="\d\{2}">
</my-component>
```
### その他
`style` タグ内の式は無視されます。
### エスケープされていない HTML のレンダリング
Riot の式では、HTML フォーマットなしのテキスト値のみをレンダリングできます。ただし、カスタムタグを作成してジョブを行うことができます。例:
```html
<raw>
<script>
export default {
setInnerHTML() {
this.root.innerHTML = this.props.html
},
onMounted() {
this.setInnerHTML()
},
onUpdated() {
this.setInnerHTML()
}
}
</script>
</raw>
```
タグが定義されると、そのタグを他のタグ内で使うことができます。例:
```html
<my-component>
<p>Here is some raw content: <raw html={ content }/> </p>
<script>
export default {
onBeforeMount() {
this.content = 'Hello, <strong>world!</strong>'
}
}
</script>
</my-component>
```
[jsfiddle でのデモ](http://jsfiddle.net/23g73yvx/)
<aside class="note note--warning">:warning: これによりユーザーが XSS 攻撃を受ける可能性があるため、信頼できないソースからデータをロードしないようにしてください。</aside>
## ネストしたコンポーネント
ネストしたタグ `<subscription>` とセットで親タグ `<account>` を定義してみてください:
```html
<account>
<subscription plan={ props.plan } show-details={ true } />
</account>
```
```html
<subscription>
<h3>{ props.plan.name }</h3>
<script>
export default {
onMounted(props) {
// props への JS のハンドルを取得
const {plan, showDetails} = props
}
}
</script>
</subscription>
```
<aside class="note note--info">
<code>show-details</code> 属性にどのような名前を付けたかに注意してください。これはダッシュケースで書かれていますが、<code>this.props</code> オブジェクト内ではキャメルケースに変換されます。
</aside>
次に、`plan` 設定オブジェクトを持つページに `account` コンポーネントをマウントします。
```html
<body>
<account></account>
</body>
<script>
riot.mount('account', { plan: { name: 'small', term: 'monthly' } })
</script>
```
親コンポーネントのプロパティは `riot.mount` メソッドで渡され、子コンポーネントのプロパティはタグの属性を介して渡されます。
ネストしたタグは `riot.register` をコールして登録すべきか、または親コンポーネントに直接読み込むことができます。もしアプリケーションをバンドルすると、`<account>` テンプレートは次のようになります:
```html
<account>
<subscription/>
<script>
import Subscription from './subscription.riot'
export default {
components: {
Subscription
}
}
</script>
</account>
```
### スロット
`<slot>` タグを使用すると、カスタム HTML テンプレートを親コンポーネントから子コンポーネントに挿入できます。
子コンポーネントの定義:
```html
<greeting>
<p>Hello <slot/></p>
</greeting>
```
子コンポーネントは、カスタム HTML を挿入する親コンポーネントの中に配置されます:
```html
<user>
<greeting>
<b>{ text }</b>
</greeting>
<script>
export default {
text: 'world'
}
</script>
</user>
```
結果:
```html
<user>
<greeting>
<p>Hello <b>world</b><p>
</greeting>
</user>
```
[API ドキュメント]({{ '/ja/api/#スロット' | prepend:site.baseurl }}) の `slots` を参照ください。
<aside class="note note--info">
スロットはコンパイルされたコンポーネントでのみ動作し、ページ DOM に直接配置されたコンポーネントのすべての内部 HTML は無視されます。
</aside>
<aside class="note note--warning">
:warning: slot タグでは、Riot の <code>if</code>、<code>each</code>、<code>is</code> ディレクティブはサポートされていません。
</aside>
## イベントハンドラ
DOM イベントを処理する関数は "イベントハンドラ" と呼ばれます。イベントハンドラは次のように定義されます:
<aside class="note note--warning">
注意: デフォルトのイベントハンドラが呼ばれます。e.preventDefault() を使用してそれを停止してください。
</aside>
```html
<login>
<form onsubmit={ submit }>
</form>
<script>
export default {
// このメソッドは上記のフォームがサブミットされたときに呼び出される
submit(e) {
e.preventDefault() // 任意
}
}
</script>
</login>
```
"on" で始まる属性(`onclick`、`onsubmit`、`oninput`...など)は、イベントが発火した際に呼び出される関数の値を受け取ります。この関数は、式とともに直接定義することもできます。例:
```html
<form onsubmit={ condition ? method_a : method_b }>
```
すべてのイベントハンドラは自動でバインドされ、`this` は現在のコンポーネントインスタンスを参照します。
したがって、次のようにプロパティの値から動的に関数を呼び出すこともできます
```html
<button onclick={ this[props.myfunc] }>Reset</button>
```
イベントハンドラはコンポーネントを更新しません。ゆえに、`this.update()` を呼び出すことで更新内容をコンポーネントに結びつける必要があります:
```html
<login>
<input value={ state.val }/>
<button onclick={ resetValue }>Reset</button>
<script>
export default {
state: {
val: 'initial value'
},
resetValue() {
this.update({
val: ''
})
}
}
</script>
</login>
```
### イベントハンドラのオプション
イベントリスナのコールバックの代わりに配列を介して [ネイティブのイベントリスナオプション](https://developer.mozilla.org/ja/docs/Web/API/EventTarget/addEventListener) を使うことができます:
```html
<div onscroll={ [updateScroll, { passive: true }] }></div>
```
{% include version_badge.html version=">=4.11.0" %}
## 入力フィールド
入力フィールドの値は、`value={newValue}` 式を使って簡単に更新できます。Riot.js は、入力、選択、テキストエリア要素に対してこの動作を正規化しています。
### ノートのケース - テキストエリアタグと値
テキストエリアタグがそのような `value` 属性を持たないのは HTML 標準に反していますが、Riot.js ではテキストエリアを入力コンポーネントとして見るため、コンテキスト更新のために `value` 属性を識別しています。
Riot.js はこの場合、期待通りにネイティブの `input.value` 属性を設定してくれます。
```html
<textarea value={state.value}>{state.text}</textarea>
<button onclick={updateText}>update</button>
<script>
export default {
state: {
value: '',
text: ''
},
updateText (event) {
this.update({
text: 'this does not work',
value: 'this works'
});
}
}
</script>
```
## 条件
条件付きでは、その条件に基づいて dom およびコンポーネントをマウント / アンマウントできます。例:
```html
<div if={ isPremium }>
<p>This is for premium users only</p>
</div>
```
この場合も、式はシンプルなプロパティか、または完全な JavaScript の式になりえます。`if` ディレクティブは特殊な属性です:
- `true (or truthy)`: ネストされたコンポーネントをマウントする、または要素をテンプレートに追加する
- `false (or falsy)`: 要素またはコンポーネントをアンマウントする
### 条件付きフラグメント
{% include version_badge.html version=">=4.2.0" %}
`if` ディレクティブを利用するだけのために、わざわざラッパータグを用意する必要はありません。`<template>` タグを使えば、if 条件によってその内容だけを描画できます:
```html
<template if="isReady">
<header></header>
<main></main>
<footer></footer>
</template>
```
`<template>` タグは Riot.js ディレクティブに依存する HTML フラグメントをラップする目的で使われます。この機能は[ループ](#html-フラグメントのループ)でも有効です
## ループ
以下のように、ループは `each` 属性にて実装されます:
```html
<my-component>
<ul>
<li each={ item in items } class={ item.done ? 'completed' : null }>
<input type="checkbox" checked={ item.done }> { item.title }
</li>
</ul>
<script>
export default {
items: [
{ title: 'First item', done: true },
{ title: 'Second item' },
{ title: 'Third item' }
]
}
</script>
</my-component>
```
`each` 属性を持つ要素は、配列内のすべての項目に対して繰り返されます。例えば、 `push()`、`slice()`、`splice` などのメソッドを使用して items 配列を操作すると、新しい要素が自動的に追加 / 作成されます。
### カスタムコンポーネントのループ
カスタムコンポーネントもループが可能です。例:
```html
<todo-item each="{ item in items }" { ...item }></todo-item>
```
現在ループされているアイテムのプロパティは、ループしているタグに直接渡すことができます。
### 非オブジェクト配列
`each` ディレクティブは内部的に`Array.from` を使用しています。これは、プリミティブな値のみを含む文字列、マップ、セットもループできることを意味します:
```html
<my-component>
<p each={ (name, index) in stuff }>{ index }: { name }</p>
<p each={ letter in letters }>{ letter }</p>
<p each={ meal in food }>{ meal }</p>
<script>
export default {
stuff: [ true, 110, Math.random(), 'fourth'],
food: new Map().set('pasta', 'spaghetti').set('pizza', 'margherita'),
letters: 'hello'
}
</script>
</my-component>
```
`name` は要素の名前で、`index` はインデックスの番号です。どちらのラベルも、状況に応じて最も適したものにできます。
### オブジェクトのループ
プレーンオブジェクトは [`Object.entries`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/entries) でループできます。例:
```html
<my-component>
<p each={ element in Object.entries(obj) }>
key = { element[0] }
value = { element[1] }
</p>
<script>
export default {
obj: {
key1: 'value1',
key2: 1110.8900,
key3: Math.random()
}
}
</script>
</my-component>
```
オブジェクトのフラグメントだけをループしたい場合は、[`Object.keys`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/keys) や [`Object.values`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/values) を使うことができます。
```html
<my-component>
<p>
The Event will start at:
<time each={ value in Object.values(aDate) }>{ value }</time>
</p>
<script>
export default {
aDate: {
hour: '10:00',
day: '22',
month: 'December',
year: '2050'
}
}
</script>
</my-component>
```
### Html フラグメントのループ
{% include version_badge.html version=">=4.2.0" %}
Html のループの際、特定のラッパータグを使わないほうがいいケースもあります。そのときには <template> タグの出番です。次の例のように記述すると、タグ自体は取り除かれ、ラップされた HTML タグだけがレンダリングされるようになります:
```html
<dl>
<template each={item in items}>
<dt>{item.key}</dt>
<dd>{item.value}</dd>
</template>
</dl>
```
この HTML フラグメント戦略は、ループ専用というものではありません。任意のタグに対して、 [`if` と組み合わせて](#条件付き-html-フラグメント)使用できます。
### ループの発展的な tips
#### キー
ループされたタグに `key` 属性を追加すると、より正確な方法でアイテムの位置を追跡できます。これにより、コレクションが不変の場合のループパフォーマンスが大幅に向上します。
```html
<loop>
<ul>
<li each={ user in users } key={ user.id }>{ user.name }</li>
</ul>
<script>
export default {
users: [
{ name: 'Gian', id: 0 },
{ name: 'Dan', id: 1 },
{ name: 'Teo', id: 2 }
]
}
</script>
</loop>
```
`key` 属性は式を使用してランタイムでも生成できます。
```html
<loop>
<ul>
<li each={ user in users } key={ user.id() }>{ user.name }</li>
</ul>
<script>
export default {
users: [
{ name: 'Gian', id() { return 0 } },
{ name: 'Dan', id() { return 1 } },
{ name: 'Teo', id() { return 2 } }
]
}
</script>
</loop>
```
## コンポーネントとしての HTML 要素
標準の HTML 要素は、`is` 属性を追加することで、ページの body 内で Riot コンポーネントとして使用できます。
```html
<ul is="my-list"></ul>
```
これにより、CSS フレームワークとの互換性を高められる代替手段がユーザーに提供されます。タグは、他のカスタムコンポーネントと同様に扱われます。
```js
riot.mount('my-list')
```
まるで `<my-list></my-list>` のように、上で示された `ul` 要素をマウントします。
メモ `is` 属性には式も使用でき、Riot は同じ DOM ノード上で異なるタグを動的にレンダリングできます。
```html
<my-component>
<!-- 動的なコンポーネント -->
<div is={ animal }></div>
<button onclick={ switchComponent }>
Switch
</button>
<script>
export default {
animal: 'dog',
switchComponent() {
// riot は<cat> コンポーネントをレンダリングする
// <dog> に置換する
this.animal = 'cat'
this.update()
}
}
</script>
</my-component>
```
メモ `is` 属性を使用する場合は、どのように定義されているかにかかわらず、タグ名をすべて小文字で表示する必要があります。
```html
<MyComponent></MyComponent> <!-- 正しい -->
<div is="mycomponent"></div> <!-- これも正しい -->
<div is="MyComponent"></div> <!-- 誤り -->
<script>
riot.mount('[is="mycomponent"]');
</script>
```
メモ `is` 属性は任意の HTML タグで使用できますが、[`template` タグ](#html-フラグメントのループ) では使用できません。
## 純粋なコンポーネント
コンポーネントのレンダリングを完全にコントロールしたい場合、`riot.pure` を使うことで Riot.js の内部ロジックを迂回できます。例:
```html
<my-pure-component>
<script>
import { pure } from 'riot'
export default pure(() => {
return {
mount(el) {
this.el = el
this.el.innerHTML = 'Hello There'
},
update() {
this.el.innerHTML = 'I got updated!'
},
unmount() {
this.el.parentNode.removeChild(this.el)
}
}
})
</script>
</my-pure-component>
```
#### 純粋なコンポーネントでの props の取得
純粋なコンポーネントは更新のたびに props を含むオブジェクトを受け取らないため、自分で props を取得する必要があります。
それには [getProps](https://www.npmjs.com/package/riot-pure-props) が利用可能です。
<aside class="note note--warning">:warning: 純粋なコンポーネントに HTML または CSS を含めることはできません。これらは、default エクスポートステートメントとして純粋な関数呼び出しのみを持つことができます。</aside>
## サーバーサイドレンダリング
Riot は Node.js を使用して[サーバーサイドレンダリングをサポート](https://github.com/riot/ssr) しています。コンポーネントを `require` し、それらをレンダリングできます:
```js
const render = require('@riotjs/ssr')
const Timer = require('timer.riot')
const html = render('timer', Timer, { start: 42 })
console.log(html) // <timer><p>Seconds Elapsed: 42</p></timer>
```
## Riot DOM の注意事項
Riot コンポーネントはブラウザのレンダリングに依存するため、コンポーネントがテンプレートを正しくレンダリングできない場合があることに注意する必要があります。
以下のタグを考えてみましょう:
```html
<my-fancy-options>
<option>foo</option>
<option>bar</option>
</my-fancy-options>
```
`<select>` タグに挿入されていない場合、このマークアップは無効です:
```html
<!-- 無効、select タグは <option> 子どもたちのみを許可 -->
<select>
<my-fancy-options />
</select>
<!-- 有効、 なぜなら <select> をルートノードとして使用して <option> タグをレンダリングするから -->
<select is="my-fancy-options"></select>
```
`table, select, svg...` のようなタグは、カスタムの子タグを許可していません。したがって、 カスタム Riot タグの使用は禁止されています。代わりに、上記のデモのように `is` を使用してください。[詳細情報](https://github.com/riot/riot/issues/2206) | 23,443 | MIT |
---
layout: post
title: "给流浪者发钱去,吃播陆续踩雷,北京发消费券市民喜大普奔(小叔TV EP081)"
date: 2020-08-14T03:04:01.000Z
author: 小叔TV
from: https://www.youtube.com/watch?v=czBsFaAeY4g
tags: [ 小叔TV ]
categories: [ 小叔TV ]
---
<!--1597374241000-->
[给流浪者发钱去,吃播陆续踩雷,北京发消费券市民喜大普奔(小叔TV EP081)](https://www.youtube.com/watch?v=czBsFaAeY4g)
------
<div>
几位朋友发红包让我帮助流浪者,我又去回访流浪者,我还能看到他们吗?国家禁止铺张浪费陆续采取N-1点餐制,国内的吃播是否将成为昨日黄花?北京消费券使用实测,看看消费券是否好用和资本主义国家的直接发钱比起来,促进内消费好还是直接给实惠好?我的哔哩哔哩: https://space.bilibili.com/432616227支持我的方式可以请我喝杯咖啡,就这么简单http://paypal.me/beitong
</div> | 535 | MIT |
---
layout: about-release-schedule.hbs
title: リリース
statuses:
maintenance: 'メンテナンス LTS'
active: 'アクティブ LTS'
current: '現行'
pending: '次期'
columns:
- 'リリース'
- 'ステータス'
- 'コードネーム'
- '初回リリース'
- 'アクティブ LTS 開始'
- 'メンテナンス LTS 開始'
- 'サポート終了'
schedule-footer: 日程は変更される場合があります。
---
<!--
# Releases
Major Node.js versions enter _Current_ release status for six months, which gives library authors time to add support for them.
After six months, odd-numbered releases (9, 11, etc.) become unsupported, and even-numbered releases (10, 12, etc.) move to _Active LTS_ status and are ready for general use.
_LTS_ release status is "long-term support", which typically guarantees that critical bugs will be fixed for a total of 30 months.
Production applications should only use _Active LTS_ or _Maintenance LTS_ releases.
-->
# リリース
Node.js のメジャーバージョンは 6 ヶ月間 _現行_ リリースの状態になり、ライブラリの作者はそれらのサポートを追加する時間を与えられます。
6 ヶ月後、奇数番号のリリース (9, 11 など) はサポートされなくなり、偶数番号のリリース (10, 12 など) は _アクティブ LTS_ ステータスに移行し、一般的に使用できるようになります。
_LTS_ のリリースステータスは「長期サポート」であり、基本的に重要なバグは 30 ヶ月の間修正されることが保証されています。
プロダクションアプリケーションでは、_アクティブ LTS_ または _メンテナンス LTS_ リリースのみを使用してください。 | 1,149 | MIT |
# UnityAutoModifyXcode是一个自动化修改Unity-iPhone.xcodeproj工程配置的解决方案.
## 背景说明:
Unity5.X开始针对Xcode工程提供了自动修改工程相关配置的API方法,但是官方文档说明和代码演示的不足,老版本Unity不能使用,只能借助第三方python等脚本实现这些问题,该示例工程为解决这些问题提供了一种参考方案。
## 环境兼容:
Unity4.x~Unity2018.3.11f1
## 目前代码演示实现的需求有:
1.修改工程Build Phases配置,比如添加Run Script,系统.framework和.dylib. (兼容任意路径)
2.添加Embedded Framework.(兼容任意路径)
4.修改Build Settings,比如签名证书,provisioning_profile,部署目标,entitlements,Other_Link_Flags.
5.修改Info.plist.
6.修改UnityAppController.mm.
7.修改Capabilities,比如PushNotification,InAppPurchase,BackgroundModes.
8.build后自动打开XCode工程.
## 如何使用?
1. 拷贝工程代码下Assets/Editor/Users路径下的文件到你Unity工程项目的对应文件夹下
2. 参考UserOnPostBuild.cs下的代码演示,进行你的自定义配置!(API方法定义在CustomXcodeAPI.cs下,你可以自行拓展和修改)
## 如何测试?
由于在Unity里打包Xcode工程耗时问题,不便于测试,这里提供了另一种测试方案,你可以用Visual Studio打开UnityAutoModifyXcode.sln,参考TestApplication项目下的Form1.cs类代码,这里附上XCode测试工程文件:https://pan.baidu.com/s/1k7zu1PD16uxm4m3UBy7yNg 提取码: vkd9, 以方便测试!
## 鸣谢 🙏
** https://bitbucket.org/Unity-Technologies/xcodeapi/src/stable/** | 1,014 | MIT |
## 带你打造一套 APM 监控系统
> APM 是 Application Performance Monitoring 的缩写,监视和管理软件应用程序的性能和可用性。应用性能管理对一个应用的持续稳定运行至关重要。所以这篇文章就从一个 iOS App 的性能管理的纬度谈谈如何精确监控以及数据如何上报等技术点
App 的性能问题是影响用户体验的重要因素之一。性能问题主要包含:Crash、网络请求错误或者超时、UI 响应速度慢、主线程卡顿、CPU 和内存使用率高、耗电量大等等。大多数的问题原因在于开发者错误地使用了线程锁、系统函数、编程规范问题、数据结构等等。解决问题的关键在于尽早的发现和定位问题。
本篇文章着重总结了 APM 的原因以及如何收集数据。APM 数据收集后结合数据上报机制,按照一定策略上传数据到服务端。服务端消费这些信息并产出报告。请结合[姊妹篇](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md), 总结了如何打造一款灵活可配置、功能强大的数据上报组件。
## 一、卡顿监控
卡顿问题,程度较低就是掉帧,比如用户在滑动某个列表的时候会有不流畅的体验,但是应用程序还是可以相应的。严重些就是 ANR,就是短时间在主线程上无法响应用户交互的问题。影响着用户的直接体验,所以针对 App 的卡顿监控是 APM 里面重要的一环。
FPS(frame per second)每秒钟的帧刷新次数,iPhone 手机以 60 为最佳,iPad 某些型号是 120,也是作为卡顿监控的一项参考参数,为什么说是参考参数?因为它不准确。先说说怎么获取到 FPS。CADisplayLink 是一个系统定时器,会以帧刷新频率一样的速率来刷新视图。 `[CADisplayLink displayLinkWithTarget:self selector:@selector(###:)]`。至于为什么不准我们来看看下面的示例代码
```Objective-C
_displayLink = [CADisplayLink displayLinkWithTarget:self selector:@selector(p_displayLinkTick:)];
[_displayLink setPaused:YES];
[_displayLink addToRunLoop:[NSRunLoop currentRunLoop] forMode:NSRunLoopCommonModes];
```
代码所示,CADisplayLink 对象是被添加到指定的 RunLoop 的某个 Mode 下。所以还是 CPU 层面的操作,卡顿的体验是整个图像渲染的结果:CPU + GPU。请继续往下看
### 1. 屏幕绘制原理
讲讲老式的 CRT 显示器的原理。 CRT 电子枪按照上面方式,从上到下一行行扫描,扫面完成后显示器就呈现一帧画面,随后电子枪回到初始位置继续下一次扫描。为了把显示器的显示过程和系统的视频控制器进行同步,显示器(或者其他硬件)会用硬件时钟产生一系列的定时信号。当电子枪换到新的一行,准备进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync;当一帧画面绘制完成后,电子枪恢复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(Vertical synchronization),简称 VSync。显示器通常以固定的频率进行刷新,这个固定的刷新频率就是 VSync 信号产生的频率。虽然现在的显示器基本都是液晶显示屏,但是原理保持不变。
通常,屏幕上一张画面的显示是由 CPU、GPU 和显示器是按照上图的方式协同工作的。CPU 根据工程师写的代码计算好需要现实的内容(比如视图创建、布局计算、图片解码、文本绘制等),然后把计算结果提交到 GPU,GPU 负责图层合成、纹理渲染,随后 GPU 将渲染结果提交到帧缓冲区。随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过数模转换传递给显示器显示。
在帧缓冲区只有一个的情况下,帧缓冲区的读取和刷新都存在效率问题,为了解决效率问题,显示系统会引入 2 个缓冲区,即双缓冲机制。在这种情况下,GPU 会预先渲染好一帧放入帧缓冲区,让视频控制器来读取,当下一帧渲染好后,GPU 直接把视频控制器的指针指向第二个缓冲区。提升了效率。
目前来看,双缓冲区提高了效率,但是带来了新的问题:当视频控制器还未读取完成时,即屏幕内容显示了部分,GPU 将新渲染好的一帧提交到另一个帧缓冲区并把视频控制器的指针指向新的帧缓冲区,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂的情况。
为了解决这个问题,GPU 通常有一个机制叫垂直同步信号(V-Sync),当开启垂直同步信号后,GPU 会等到视频控制器发送 V-Sync 信号后,才进行新的一帧的渲染和帧缓冲区的更新。这样的几个机制解决了画面撕裂的情况,也增加了画面流畅度。但需要更多的计算资源
答疑
可能有些人会看到「当开启垂直同步信号后,GPU 会等到视频控制器发送 V-Sync 信号后,才进行新的一帧的渲染和帧缓冲区的更新」这里会想,GPU 收到 V-Sync 才进行新的一帧渲染和帧缓冲区的更新,那是不是双缓冲区就失去意义了?
设想一个显示器显示第一帧图像和第二帧图像的过程。首先在双缓冲区的情况下,GPU 首先渲染好一帧图像存入到帧缓冲区,然后让视频控制器的指针直接直接这个缓冲区,显示第一帧图像。第一帧图像的内容显示完成后,视频控制器发送 V-Sync 信号,GPU 收到 V-Sync 信号后渲染第二帧图像并将视频控制器的指针指向第二个帧缓冲区。
**看上去第二帧图像是在等第一帧显示后的视频控制器发送 V-Sync 信号。是吗?真是这样的吗? 😭 想啥呢,当然不是。 🐷 不然双缓冲区就没有存在的意义了**
揭秘。请看下图
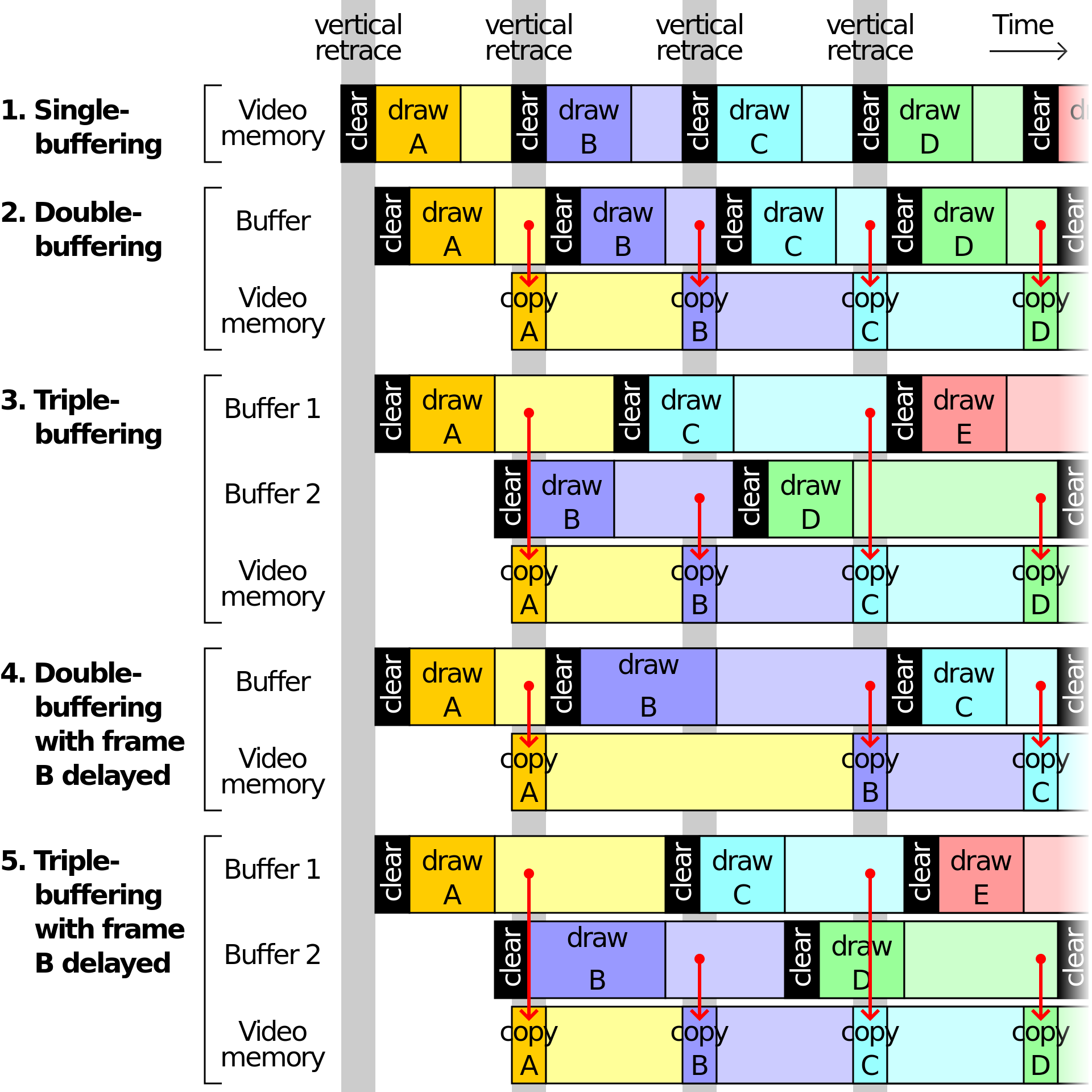
当第一次 V-Sync 信号到来时,先渲染好一帧图像放到帧缓冲区,但是不展示,当收到第二个 V-Sync 信号后读取第一次渲染好的结果(视频控制器的指针指向第一个帧缓冲区),并同时渲染新的一帧图像并将结果存入第二个帧缓冲区,等收到第三个 V-Sync 信号后,读取第二个帧缓冲区的内容(视频控制器的指针指向第二个帧缓冲区),并开始第三帧图像的渲染并送入第一个帧缓冲区,依次不断循环往复。
请查看资料,需要梯子:[Multiple buffering](https://en.m.wikipedia.org/wiki/Multiple_buffering)
### 2. 卡顿产生的原因
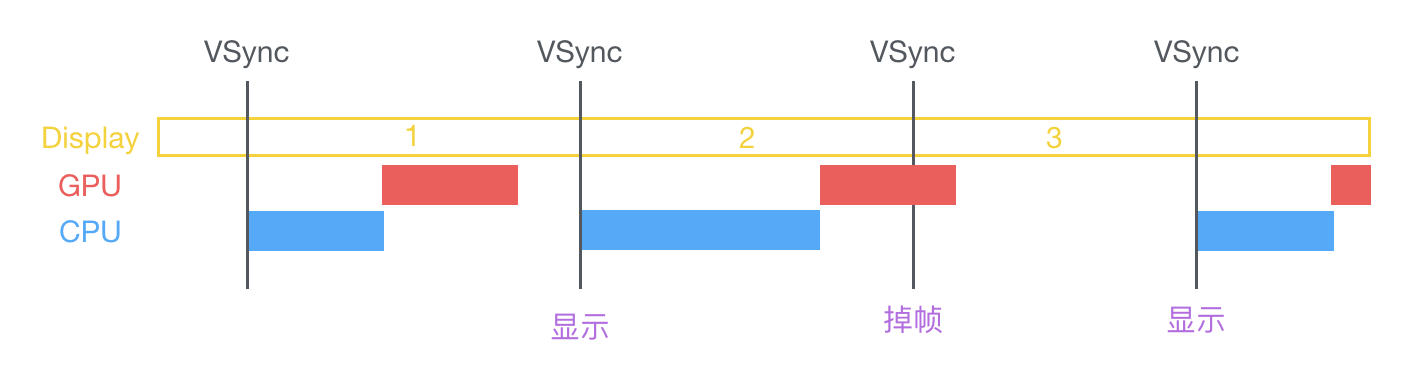
VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容(视图创建、布局计算、图片解码、文本绘制等)。然后将计算的内容提交到 GPU,GPU 经过图层的变换、合成、渲染,随后 GPU 把渲染结果提交到帧缓冲区,等待下一次 VSync 信号到来再显示之前渲染好的结果。在垂直同步机制的情况下,如果在一个 VSync 时间周期内,CPU 或者 GPU 没有完成内容的提交,就会造成该帧的丢弃,等待下一次机会再显示,这时候屏幕上还是之前渲染的图像,所以这就是 CPU、GPU 层面界面卡顿的原因。
目前 iOS 设备有双缓存机制,也有三缓冲机制,Android 现在主流是三缓冲机制,在早期是单缓冲机制。
[iOS 三缓冲机制例子](https://ios.developreference.com/article/12261072/Metal+newBufferWithBytes+usage)
CPU 和 GPU 资源消耗原因很多,比如对象的频繁创建、属性调整、文件读取、视图层级的调整、布局的计算(AutoLayout 视图个数多了就是线性方程求解难度变大)、图片解码(大图的读取优化)、图像绘制、文本渲染、数据库读取(多读还是多写乐观锁、悲观锁的场景)、锁的使用(举例:自旋锁使用不当会浪费 CPU)等方面。开发者根据自身经验寻找最优解(这里不是本文重点)。
### 3. APM 如何监控卡顿并上报
CADisplayLink 肯定不用了,这个 FPS 仅作为参考。一般来讲,卡顿的监测有 2 种方案:**监听 RunLoop 状态回调、子线程 ping 主线程**
#### 3.1 RunLoop 状态监听的方式
RunLoop 负责监听输入源进行调度处理。比如网络、输入设备、周期性或者延迟事件、异步回调等。RunLoop 会接收 2 种类型的输入源:一种是来自另一个线程或者来自不同应用的异步消息(source0 事件)、另一种是来自预定或者重复间隔的事件。
RunLoop 状态如下图
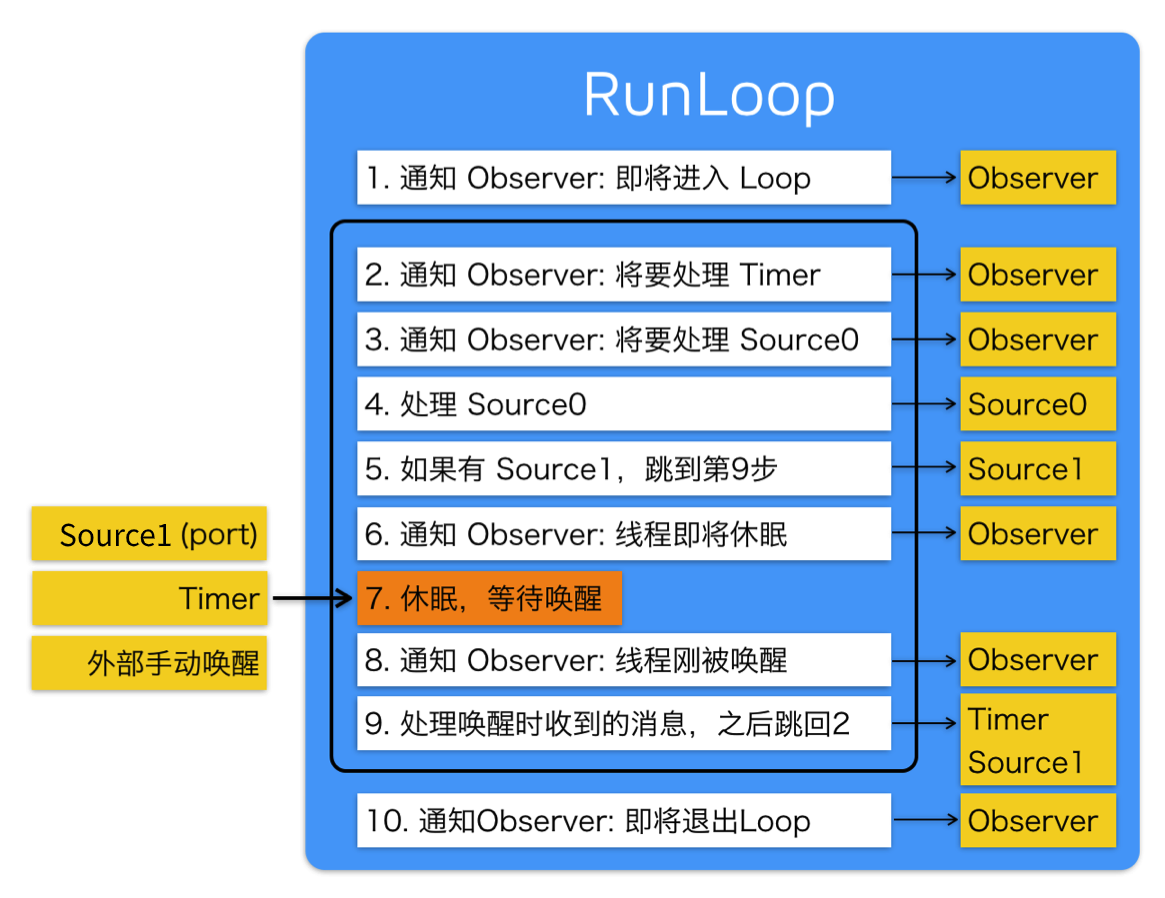
第一步:通知 Observers,RunLoop 要开始进入 loop,紧接着进入 loop
```Objective-c
if (currentMode->_observerMask & kCFRunLoopEntry )
// 通知 Observers: RunLoop 即将进入 loop
__CFRunLoopDoObservers(rl, currentMode, kCFRunLoopEntry);
// 进入loop
result = __CFRunLoopRun(rl, currentMode, seconds, returnAfterSourceHandled, previousMode);
```
第二步:开启 do while 循环保活线程,通知 Observers,RunLoop 触发 Timer 回调、Source0 回调,接着执行被加入的 block
```Objective-c
if (rlm->_observerMask & kCFRunLoopBeforeTimers)
// 通知 Observers: RunLoop 即将触发 Timer 回调
__CFRunLoopDoObservers(rl, rlm, kCFRunLoopBeforeTimers);
if (rlm->_observerMask & kCFRunLoopBeforeSources)
// 通知 Observers: RunLoop 即将触发 Source 回调
__CFRunLoopDoObservers(rl, rlm, kCFRunLoopBeforeSources);
// 执行被加入的block
__CFRunLoopDoBlocks(rl, rlm);
```
第三步:RunLoop 在触发 Source0 回调后,如果 Source1 是 ready 状态,就会跳转到 handle_msg 去处理消息。
```Objective-c
// 如果有 Source1 (基于port) 处于 ready 状态,直接处理这个 Source1 然后跳转去处理消息
if (MACH_PORT_NULL != dispatchPort && !didDispatchPortLastTime) {
#if DEPLOYMENT_TARGET_MACOSX || DEPLOYMENT_TARGET_EMBEDDED || DEPLOYMENT_TARGET_EMBEDDED_MINI
msg = (mach_msg_header_t *)msg_buffer;
if (__CFRunLoopServiceMachPort(dispatchPort, &msg, sizeof(msg_buffer), &livePort, 0, &voucherState, NULL)) {
goto handle_msg;
}
#elif DEPLOYMENT_TARGET_WINDOWS
if (__CFRunLoopWaitForMultipleObjects(NULL, &dispatchPort, 0, 0, &livePort, NULL)) {
goto handle_msg;
}
#endif
}
```
第四步:回调触发后,通知 Observers 即将进入休眠状态
```Objective-c
Boolean poll = sourceHandledThisLoop || (0ULL == timeout_context->termTSR);
// 通知 Observers: RunLoop 的线程即将进入休眠(sleep)
if (!poll && (rlm->_observerMask & kCFRunLoopBeforeWaiting)) __CFRunLoopDoObservers(rl, rlm, kCFRunLoopBeforeWaiting);
__CFRunLoopSetSleeping(rl);
```
第五步:进入休眠后,会等待 mach_port 消息,以便再次唤醒。只有以下 4 种情况才可以被再次唤醒。
- 基于 port 的 source 事件
- Timer 时间到
- RunLoop 超时
- 被调用者唤醒
```Objective-c
do {
if (kCFUseCollectableAllocator) {
// objc_clear_stack(0);
// <rdar://problem/16393959>
memset(msg_buffer, 0, sizeof(msg_buffer));
}
msg = (mach_msg_header_t *)msg_buffer;
__CFRunLoopServiceMachPort(waitSet, &msg, sizeof(msg_buffer), &livePort, poll ? 0 : TIMEOUT_INFINITY, &voucherState, &voucherCopy);
if (modeQueuePort != MACH_PORT_NULL && livePort == modeQueuePort) {
// Drain the internal queue. If one of the callout blocks sets the timerFired flag, break out and service the timer.
while (_dispatch_runloop_root_queue_perform_4CF(rlm->_queue));
if (rlm->_timerFired) {
// Leave livePort as the queue port, and service timers below
rlm->_timerFired = false;
break;
} else {
if (msg && msg != (mach_msg_header_t *)msg_buffer) free(msg);
}
} else {
// Go ahead and leave the inner loop.
break;
}
} while (1);
```
第六步:唤醒时通知 Observer,RunLoop 的线程刚刚被唤醒了
```Objective-C
// 通知 Observers: RunLoop 的线程刚刚被唤醒了
if (!poll && (rlm->_observerMask & kCFRunLoopAfterWaiting)) __CFRunLoopDoObservers(rl, rlm, kCFRunLoopAfterWaiting);
// 处理消息
handle_msg:;
__CFRunLoopSetIgnoreWakeUps(rl);
```
第七步:RunLoop 唤醒后,处理唤醒时收到的消息
- 如果是 Timer 时间到,则触发 Timer 的回调
- 如果是 dispatch,则执行 block
- 如果是 source1 事件,则处理这个事件
```Objective-C
#if USE_MK_TIMER_TOO
// 如果一个 Timer 到时间了,触发这个Timer的回调
else if (rlm->_timerPort != MACH_PORT_NULL && livePort == rlm->_timerPort) {
CFRUNLOOP_WAKEUP_FOR_TIMER();
// On Windows, we have observed an issue where the timer port is set before the time which we requested it to be set. For example, we set the fire time to be TSR 167646765860, but it is actually observed firing at TSR 167646764145, which is 1715 ticks early. The result is that, when __CFRunLoopDoTimers checks to see if any of the run loop timers should be firing, it appears to be 'too early' for the next timer, and no timers are handled.
// In this case, the timer port has been automatically reset (since it was returned from MsgWaitForMultipleObjectsEx), and if we do not re-arm it, then no timers will ever be serviced again unless something adjusts the timer list (e.g. adding or removing timers). The fix for the issue is to reset the timer here if CFRunLoopDoTimers did not handle a timer itself. 9308754
if (!__CFRunLoopDoTimers(rl, rlm, mach_absolute_time())) {
// Re-arm the next timer
__CFArmNextTimerInMode(rlm, rl);
}
}
#endif
// 如果有dispatch到main_queue的block,执行block
else if (livePort == dispatchPort) {
CFRUNLOOP_WAKEUP_FOR_DISPATCH();
__CFRunLoopModeUnlock(rlm);
__CFRunLoopUnlock(rl);
_CFSetTSD(__CFTSDKeyIsInGCDMainQ, (void *)6, NULL);
#if DEPLOYMENT_TARGET_WINDOWS
void *msg = 0;
#endif
__CFRUNLOOP_IS_SERVICING_THE_MAIN_DISPATCH_QUEUE__(msg);
_CFSetTSD(__CFTSDKeyIsInGCDMainQ, (void *)0, NULL);
__CFRunLoopLock(rl);
__CFRunLoopModeLock(rlm);
sourceHandledThisLoop = true;
didDispatchPortLastTime = true;
}
// 如果一个 Source1 (基于port) 发出事件了,处理这个事件
else {
CFRUNLOOP_WAKEUP_FOR_SOURCE();
// If we received a voucher from this mach_msg, then put a copy of the new voucher into TSD. CFMachPortBoost will look in the TSD for the voucher. By using the value in the TSD we tie the CFMachPortBoost to this received mach_msg explicitly without a chance for anything in between the two pieces of code to set the voucher again.
voucher_t previousVoucher = _CFSetTSD(__CFTSDKeyMachMessageHasVoucher, (void *)voucherCopy, os_release);
CFRunLoopSourceRef rls = __CFRunLoopModeFindSourceForMachPort(rl, rlm, livePort);
if (rls) {
#if DEPLOYMENT_TARGET_MACOSX || DEPLOYMENT_TARGET_EMBEDDED || DEPLOYMENT_TARGET_EMBEDDED_MINI
mach_msg_header_t *reply = NULL;
sourceHandledThisLoop = __CFRunLoopDoSource1(rl, rlm, rls, msg, msg->msgh_size, &reply) || sourceHandledThisLoop;
if (NULL != reply) {
(void)mach_msg(reply, MACH_SEND_MSG, reply->msgh_size, 0, MACH_PORT_NULL, 0, MACH_PORT_NULL);
CFAllocatorDeallocate(kCFAllocatorSystemDefault, reply);
}
#elif DEPLOYMENT_TARGET_WINDOWS
sourceHandledThisLoop = __CFRunLoopDoSource1(rl, rlm, rls) || sourceHandledThisLoop;
#endif
```
第八步:根据当前 RunLoop 状态判断是否需要进入下一个 loop。当被外部强制停止或者 loop 超时,就不继续下一个 loop,否则进入下一个 loop
```Objective-C
if (sourceHandledThisLoop && stopAfterHandle) {
// 进入loop时参数说处理完事件就返回
retVal = kCFRunLoopRunHandledSource;
} else if (timeout_context->termTSR < mach_absolute_time()) {
// 超出传入参数标记的超时时间了
retVal = kCFRunLoopRunTimedOut;
} else if (__CFRunLoopIsStopped(rl)) {
__CFRunLoopUnsetStopped(rl);
// 被外部调用者强制停止了
retVal = kCFRunLoopRunStopped;
} else if (rlm->_stopped) {
rlm->_stopped = false;
retVal = kCFRunLoopRunStopped;
} else if (__CFRunLoopModeIsEmpty(rl, rlm, previousMode)) {
// source/timer一个都没有
retVal = kCFRunLoopRunFinished;
}
```
完整且带有注释的 RunLoop 代码见[此处](https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/CFRunLoop.c)。 Source1 是 RunLoop 用来处理 Mach port 传来的系统事件的,Source0 是用来处理用户事件的。收到 Source1 的系统事件后本质还是调用 Source0 事件的处理函数。
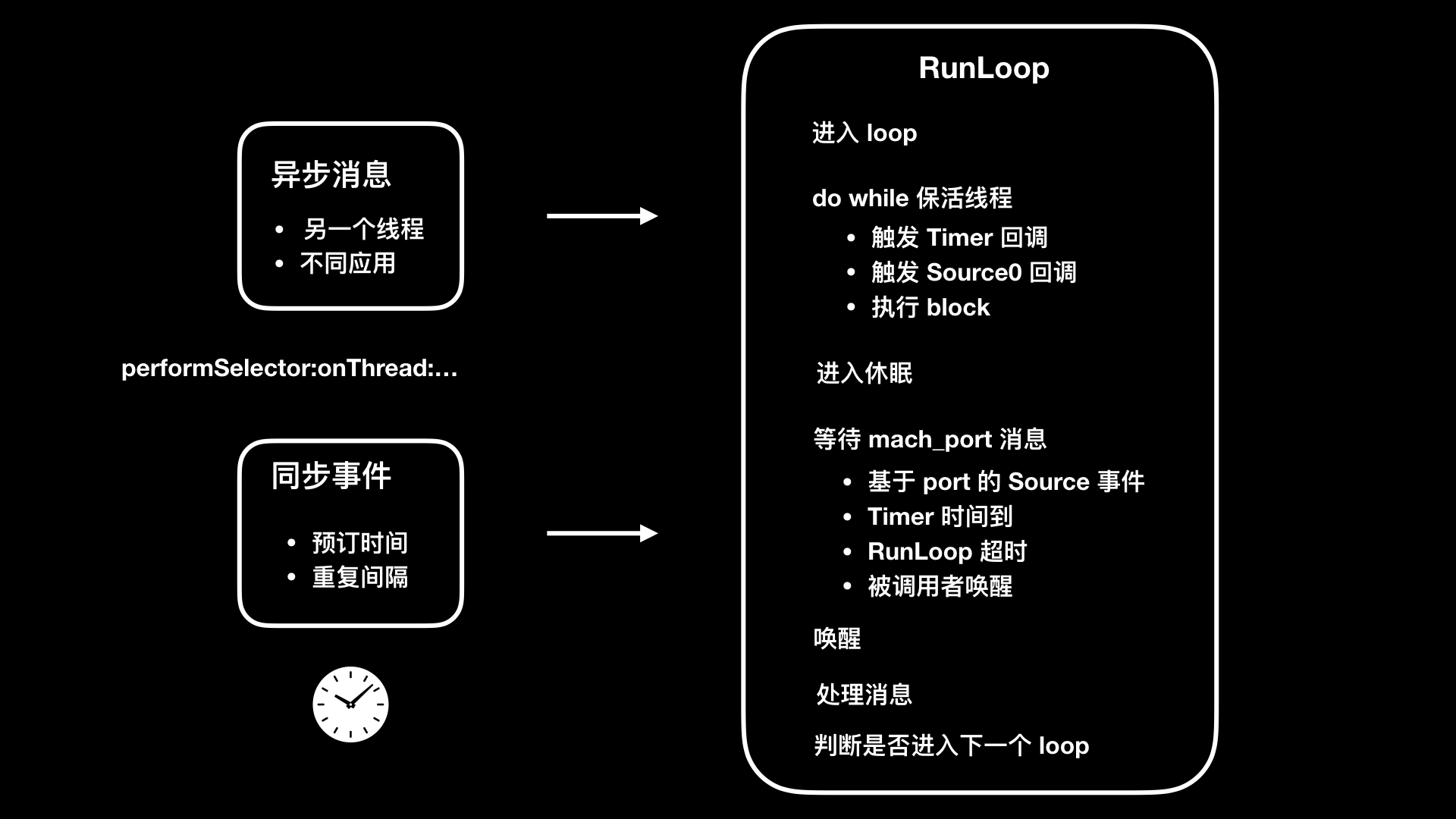
RunLoop 6 个状态
```Objective-C
typedef CF_OPTIONS(CFOptionFlags, CFRunLoopActivity) {
kCFRunLoopEntry , // 进入 loop
kCFRunLoopBeforeTimers , // 触发 Timer 回调
kCFRunLoopBeforeSources , // 触发 Source0 回调
kCFRunLoopBeforeWaiting , // 等待 mach_port 消息
kCFRunLoopAfterWaiting, // 接收 mach_port 消息
kCFRunLoopExit, // 退出 loop
kCFRunLoopAllActivities // loop 所有状态改变
}
```
RunLoop 在进入睡眠前的方法执行时间过长而导致无法进入睡眠,或者线程唤醒后接收消息时间过长而无法进入下一步,都会阻塞线程。如果是主线程,则表现为卡顿。
一旦发现进入睡眠前的 KCFRunLoopBeforeSources 状态,或者唤醒后 KCFRunLoopAfterWaiting,在设置的时间阈值内没有变化,则可判断为卡顿,此时 dump 堆栈信息,还原案发现场,进而解决卡顿问题。
开启一个子线程,不断进行循环监测是否卡顿了。在 n 次都超过卡顿阈值后则认为卡顿了。卡顿之后进行堆栈 dump 并上报(具有一定的机制,数据处理在下一 part 讲)。
WatchDog 在不同状态下具有不同的值。
- 启动(Launch):20s
- 恢复(Resume):10s
- 挂起(Suspend):10s
- 退出(Quit):6s
- 后台(Background):3min(在 iOS7 之前可以申请 10min;之后改为 3min;可连续申请,最多到 10min)
卡顿阈值的设置的依据是 WatchDog 的机制。APM 系统里面的阈值需要小于 WatchDog 的值,所以取值范围在 [1, 6] 之间,业界通常选择 3 秒。
通过 `long dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)` 方法判断是否阻塞主线程,`Returns zero on success, or non-zero if the timeout occurred.` 返回非 0 则代表超时阻塞了主线程。
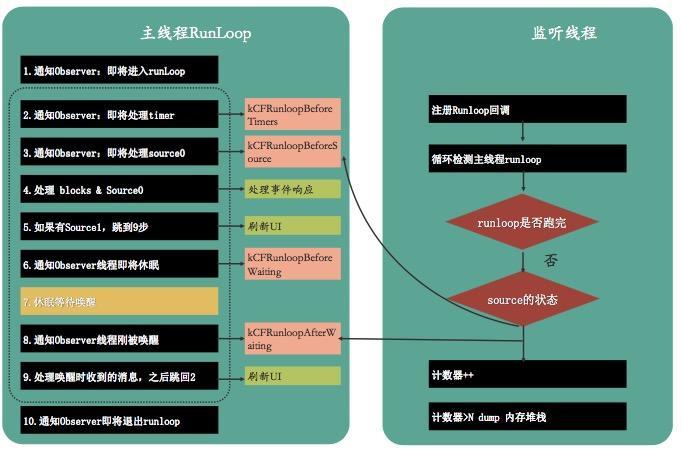
可能很多人纳闷 RunLoop 状态那么多,为什么选择 KCFRunLoopBeforeSources 和 KCFRunLoopAfterWaiting?因为大部分卡顿都是在 KCFRunLoopBeforeSources 和 KCFRunLoopAfterWaiting 之间。比如 Source0 类型的 App 内部事件等
Runloop 检测卡顿流程图如下:
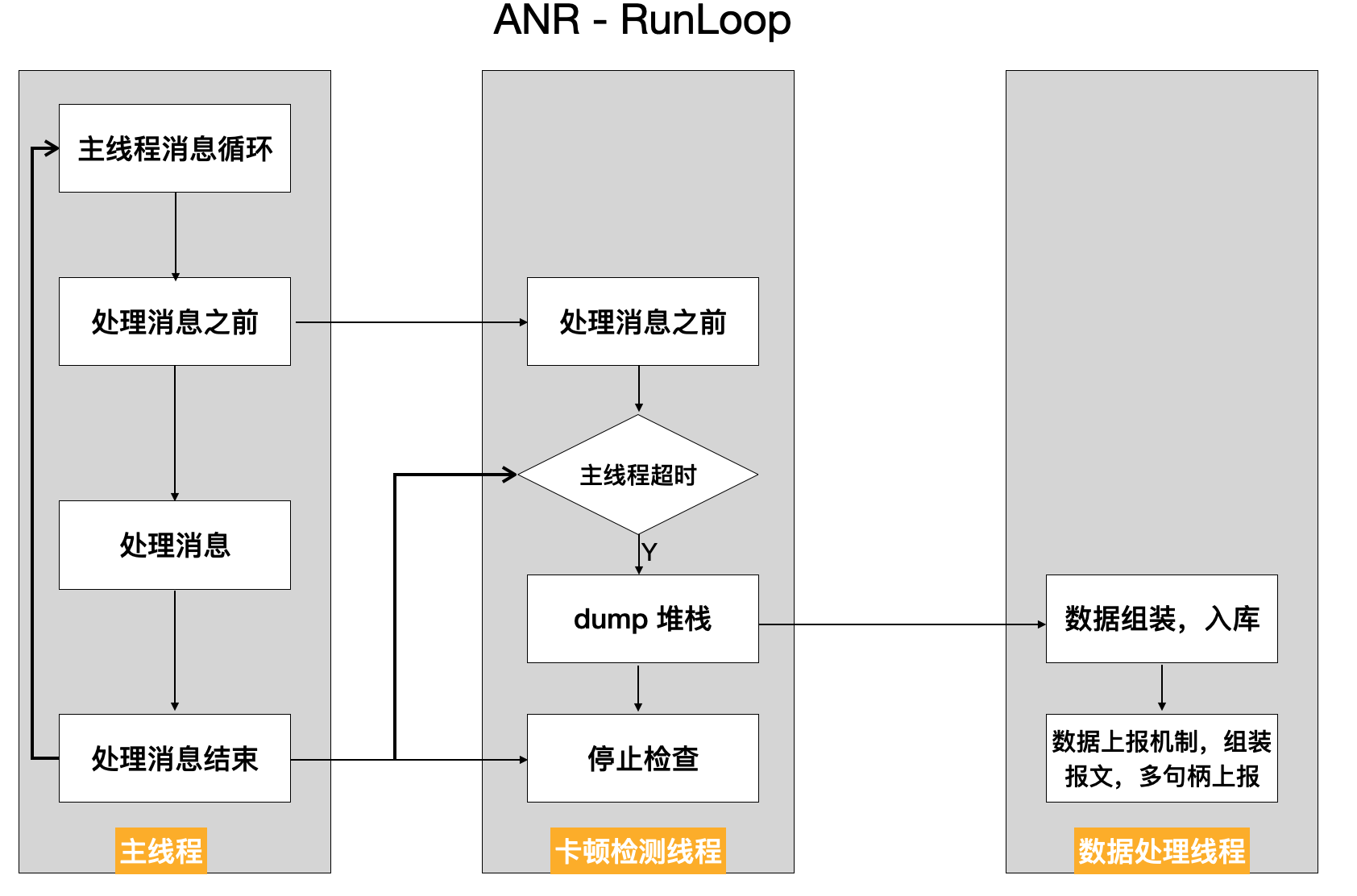
关键代码如下:
```Objective-c
// 设置Runloop observer的运行环境
CFRunLoopObserverContext context = {0, (__bridge void *)self, NULL, NULL};
// 创建Runloop observer对象
_observer = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
0,
&runLoopObserverCallBack,
&context);
// 将新建的observer加入到当前thread的runloop
CFRunLoopAddObserver(CFRunLoopGetMain(), _observer, kCFRunLoopCommonModes);
// 创建信号
_semaphore = dispatch_semaphore_create(0);
__weak __typeof(self) weakSelf = self;
// 在子线程监控时长
dispatch_async(dispatch_get_global_queue(0, 0), ^{
__strong __typeof(weakSelf) strongSelf = weakSelf;
if (!strongSelf) {
return;
}
while (YES) {
if (strongSelf.isCancel) {
return;
}
// N次卡顿超过阈值T记录为一次卡顿
long semaphoreWait = dispatch_semaphore_wait(self->_semaphore, dispatch_time(DISPATCH_TIME_NOW, strongSelf.limitMillisecond * NSEC_PER_MSEC));
if (semaphoreWait != 0) {
if (self->_activity == kCFRunLoopBeforeSources || self->_activity == kCFRunLoopAfterWaiting) {
if (++strongSelf.countTime < strongSelf.standstillCount){
continue;
}
// 堆栈信息 dump 并结合数据上报机制,按照一定策略上传数据到服务器。堆栈 dump 会在下面讲解。数据上报会在 [打造功能强大、灵活可配置的数据上报组件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md) 讲
}
}
strongSelf.countTime = 0;
}
});
```
#### 3.2 子线程 ping 主线程监听的方式
开启一个子线程,创建一个初始值为 0 的信号量、一个初始值为 YES 的布尔值类型标志位。将设置标志位为 NO 的任务派发到主线程中去,子线程休眠阈值时间,时间到后判断标志位是否被主线程成功(值为 NO),如果没成功则认为主线程发生了卡顿情况,此时 dump 堆栈信息并结合数据上报机制,按照一定策略上传数据到服务器。数据上报会在 [打造功能强大、灵活可配置的数据上报组件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md) 讲
```Objective-c
while (self.isCancelled == NO) {
@autoreleasepool {
__block BOOL isMainThreadNoRespond = YES;
dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);
dispatch_async(dispatch_get_main_queue(), ^{
isMainThreadNoRespond = NO;
dispatch_semaphore_signal(semaphore);
});
[NSThread sleepForTimeInterval:self.threshold];
if (isMainThreadNoRespond) {
if (self.handlerBlock) {
self.handlerBlock(); // 外部在 block 内部 dump 堆栈(下面会讲),数据上报
}
}
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
}
}
```
### 4. 堆栈 dump
方法堆栈的获取是一个麻烦事。理一下思路。`[NSThread callStackSymbols]` 可以获取当前线程的调用栈。但是当监控到卡顿发生,需要拿到主线程的堆栈信息就无能为力了。从任何线程回到主线程这条路走不通。先做个知识回顾。
在计算机科学中,调用堆栈是一种栈类型的数据结构,用于存储有关计算机程序的线程信息。这种栈也叫做执行堆栈、程序堆栈、控制堆栈、运行时堆栈、机器堆栈等。调用堆栈用于跟踪每个活动的子例程在完成执行后应该返回控制的点。
维基百科搜索到 “Call Stack” 的一张图和例子,如下
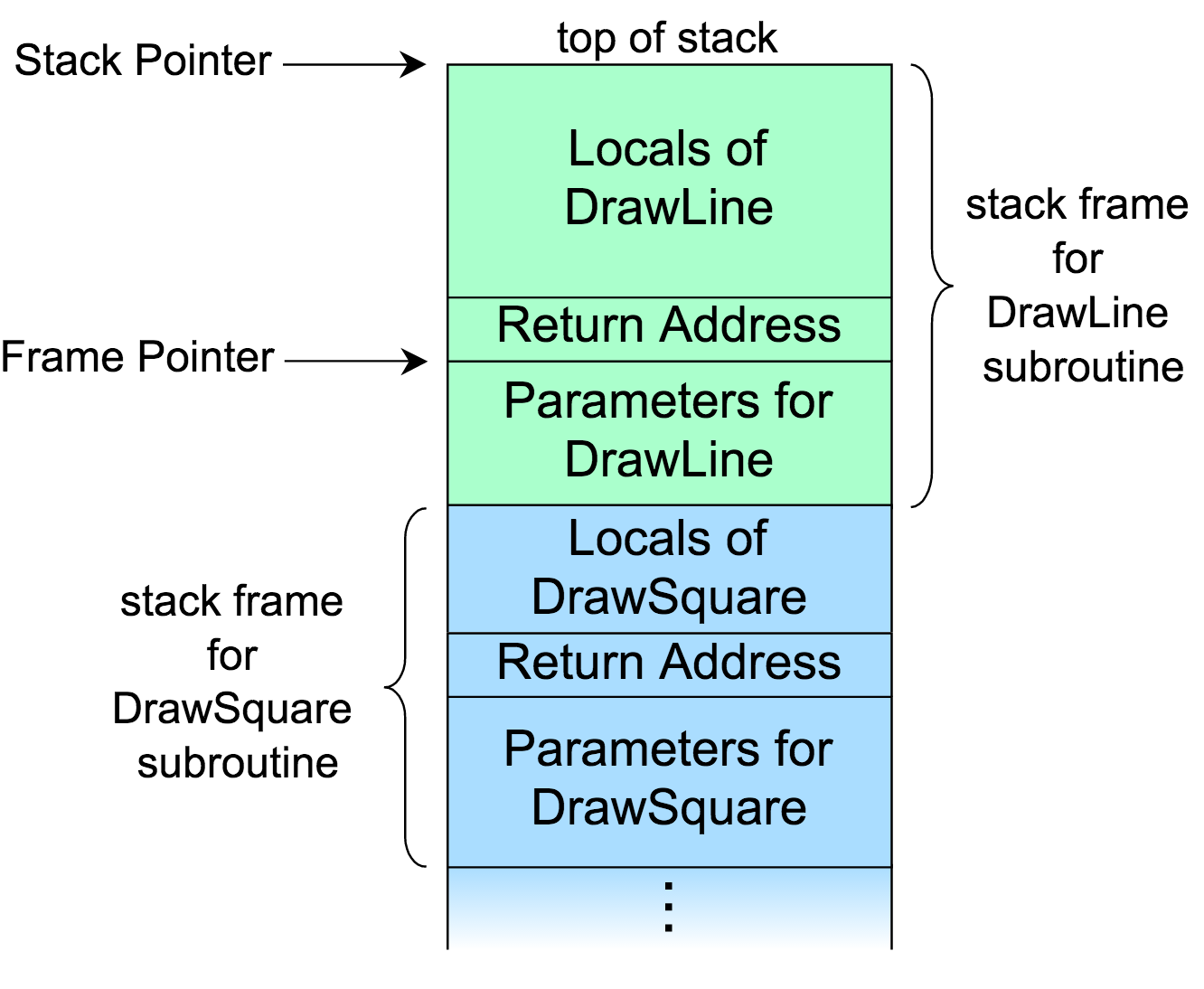
上图表示为一个栈。分为若干个栈帧(Frame),每个栈帧对应一个函数调用。下面蓝色部分表示 `DrawSquare` 函数,它在执行的过程中调用了 `DrawLine` 函数,用绿色部分表示。
可以看到栈帧由三部分组成:函数参数、返回地址、局部变量。比如在 DrawSquare 内部调用了 DrawLine 函数:第一先把 DrawLine 函数需要的参数入栈;第二把返回地址(控制信息。举例:函数 A 内调用函数 B,调用函数 B 的下一行代码的地址就是返回地址)入栈;第三函数内部的局部变量也在该栈中存储。
栈指针 Stack Pointer 表示当前栈的顶部,大多部分操作系统都是栈向下生长,所以栈指针是最小值。帧指针 Frame Pointer 指向的地址中,存储了上一次 Stack Pointer 的值,也就是返回地址。
大多数操作系统中,每个栈帧还保存了上一个栈帧的帧指针。因此知道当前栈帧的 Stack Pointer 和 Frame Pointer 就可以不断回溯,递归获取栈底的帧。
接下来的步骤就是拿到所有线程的 Stack Pointer 和 Frame Pointer。然后不断回溯,还原案发现场。
### 5. Mach Task 知识
**Mach task:**
App 在运行的时候,会对应一个 Mach Task,而 Task 下可能有多条线程同时执行任务。《OS X and iOS Kernel Programming》 中描述 Mach Task 为:任务(Task)是一种容器对象,虚拟内存空间和其他资源都是通过这个容器对象管理的,这些资源包括设备和其他句柄。简单概括为:Mack task 是一个机器无关的 thread 的执行环境抽象。
作用: task 可以理解为一个进程,包含它的线程列表。
结构体:task_threads,将 target_task 任务下的所有线程保存在 act_list 数组中,数组个数为 act_listCnt
```c++
kern_return_t task_threads
(
task_t traget_task,
thread_act_array_t *act_list, //线程指针列表
mach_msg_type_number_t *act_listCnt //线程个数
)
```
thread_info:
```c++
kern_return_t thread_info
(
thread_act_t target_act,
thread_flavor_t flavor,
thread_info_t thread_info_out,
mach_msg_type_number_t *thread_info_outCnt
);
```
如何获取线程的堆栈数据:
系统方法 `kern_return_t task_threads(task_inspect_t target_task, thread_act_array_t *act_list, mach_msg_type_number_t *act_listCnt);` 可以获取到所有的线程,不过这种方法获取到的线程信息是最底层的 **mach 线程**。
对于每个线程,可以用 `kern_return_t thread_get_state(thread_act_t target_act, thread_state_flavor_t flavor, thread_state_t old_state, mach_msg_type_number_t *old_stateCnt);` 方法获取它的所有信息,信息填充在 `_STRUCT_MCONTEXT` 类型的参数中,这个方法中有 2 个参数随着 CPU 架构不同而不同。所以需要定义宏屏蔽不同 CPU 之间的区别。
`_STRUCT_MCONTEXT` 结构体中,存储了当前线程的 Stack Pointer 和最顶部栈帧的 Frame pointer,进而回溯整个线程调用堆栈。
但是上述方法拿到的是内核线程,我们需要的信息是 NSThread,所以需要将内核线程转换为 NSThread。
pthread 的 p 是 **POSIX** 的缩写,表示「可移植操作系统接口」(Portable Operating System Interface)。设计初衷是每个系统都有自己独特的线程模型,且不同系统对于线程操作的 API 都不一样。所以 POSIX 的目的就是提供抽象的 pthread 以及相关 API。这些 API 在不同的操作系统中有不同的实现,但是完成的功能一致。
Unix 系统提供的 `task_threads` 和 `thread_get_state` 操作的都是内核系统,每个内核线程由 thread_t 类型的 id 唯一标识。pthread 的唯一标识是 pthread_t 类型。其中内核线程和 pthread 的转换(即 thread_t 和 pthread_t)很容易,因为 pthread 设计初衷就是「抽象内核线程」。
`memorystatus_action_neededpthread_create` 方法创建线程的回调函数为 **nsthreadLauncher**。
```Objective-c
static void *nsthreadLauncher(void* thread)
{
NSThread *t = (NSThread*)thread;
[nc postNotificationName: NSThreadDidStartNotification object:t userInfo: nil];
[t _setName: [t name]];
[t main];
[NSThread exit];
return NULL;
}
```
NSThreadDidStartNotification 其实就是字符串 @"\_NSThreadDidStartNotification"。
```Objective-c
<NSThread: 0x...>{number = 1, name = main}
```
为了 NSThread 和内核线程对应起来,只能通过 name 一一对应。 pthread 的 API `pthread_getname_np` 也可获取内核线程名字。np 代表 not POSIX,所以不能跨平台使用。
思路概括为:将 NSThread 的原始名字存储起来,再将名字改为某个随机数(时间戳),然后遍历内核线程 pthread 的名字,名字匹配则 NSThread 和内核线程对应了起来。找到后将线程的名字还原成原本的名字。对于主线程,由于不能使用 `pthread_getname_np`,所以在当前代码的 load 方法中获取到 thread_t,然后匹配名字。
```Objective-c
static mach_port_t main_thread_id;
+ (void)load {
main_thread_id = mach_thread_self();
}
```
## 二、 App 启动时间监控
### 1. App 启动时间的监控
应用启动时间是影响用户体验的重要因素之一,所以我们需要量化去衡量一个 App 的启动速度到底有多快。启动分为冷启动和热启动。
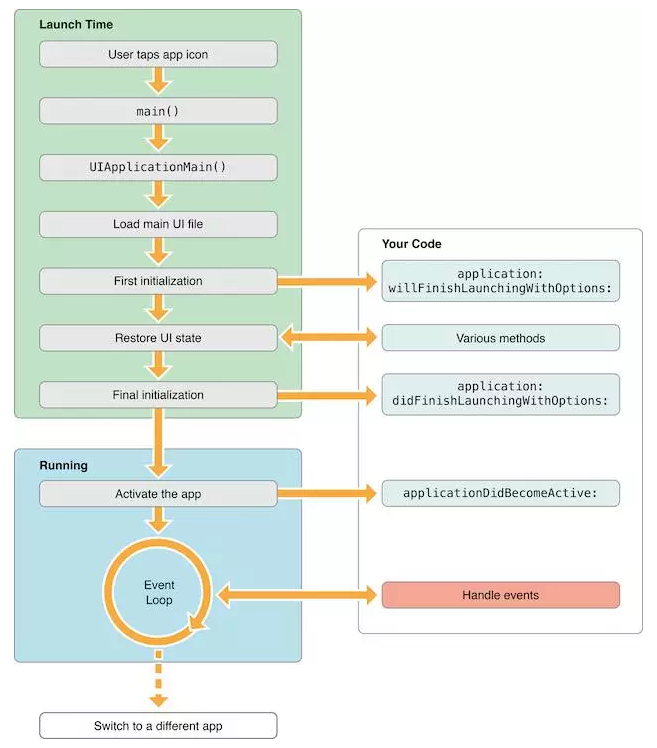
冷启动:App 尚未运行,必须加载并构建整个应用。完成应用的初始化。冷启动存在较大优化空间。冷启动时间从 `application: didFinishLaunchingWithOptions:` 方法开始计算,App 一般在这里进行各种 SDK 和 App 的基础初始化工作。
热启动:应用已经在后台运行(常见场景:比如用户使用 App 过程中点击 Home 键,再打开 App),由于某些事件将应用唤醒到前台,App 会在 `applicationWillEnterForeground:` 方法接受应用进入前台的事件
思路比较简单。如下
- 在监控类的 `load` 方法中先拿到当前的时间值
- 监听 App 启动完成后的通知 `UIApplicationDidFinishLaunchingNotification`
- 收到通知后拿到当前的时间
- 步骤 1 和 3 的时间差就是 App 启动时间。
`mach_absolute_time` 是一个 CPU/总线依赖函数,返回一个 CPU 时钟周期数。系统休眠时不会增加。是一个纳秒级别的数字。获取前后 2 个纳秒后需要转换到秒。需要基于系统时间的基准,通过 `mach_timebase_info` 获得。
```Objective-c
mach_timebase_info_data_t g_apmmStartupMonitorTimebaseInfoData = 0;
mach_timebase_info(&g_apmmStartupMonitorTimebaseInfoData);
uint64_t timelapse = mach_absolute_time() - g_apmmLoadTime;
double timeSpan = (timelapse * g_apmmStartupMonitorTimebaseInfoData.numer) / (g_apmmStartupMonitorTimebaseInfoData.denom * 1e9);
```
### 2. 线上监控启动时间就好,但是在开发阶段需要对启动时间做优化。
要优化启动时间,就先得知道在启动阶段到底做了什么事情,针对现状作出方案。
pre-main 阶段定义为 App 开始启动到系统调用 main 函数这个阶段;main 阶段定义为 main 函数入口到主 UI 框架的 viewDidAppear。
App 启动过程:
- 解析 Info.plist:加载相关信息例如闪屏;沙盒建立、权限检查;
- Mach-O 加载:如果是胖二进制文件,寻找合适当前 CPU 架构的部分;加载所有依赖的 Mach-O 文件(递归调用 Mach-O 加载的方法);定义内部、外部指针引用,例如字符串、函数等;加载分类中的方法;c++ 静态对象加载、调用 Objc 的 `+load()` 函数;执行声明为 \__attribute_((constructor)) 的 c 函数;
- 程序执行:调用 main();调用 UIApplicationMain();调用 applicationWillFinishLaunching();
Pre-Main 阶段
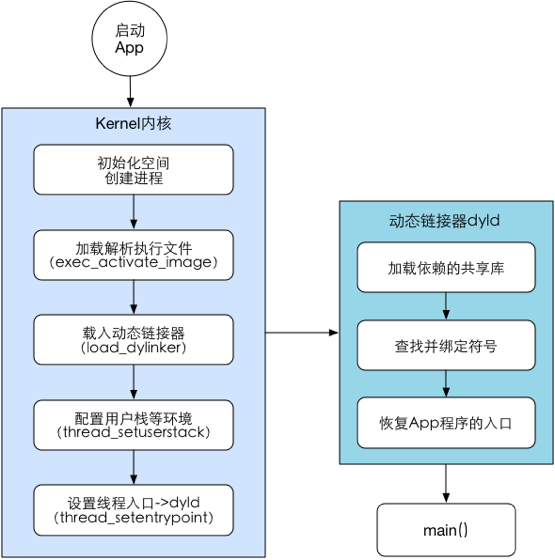
Main 阶段
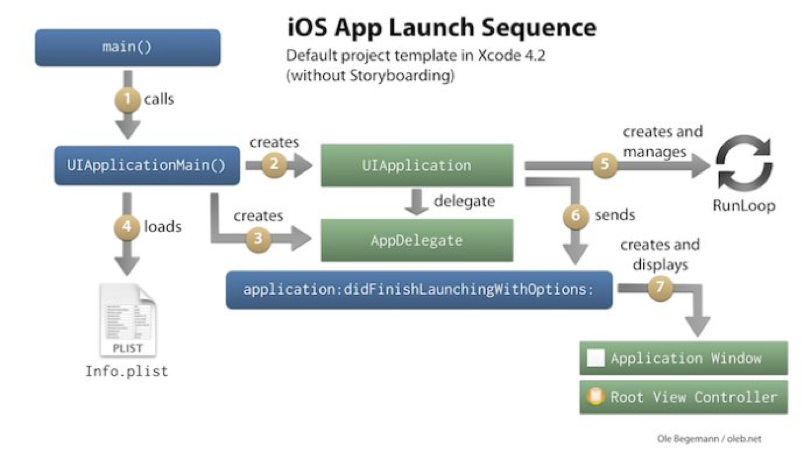
#### 2.1 加载 Dylib
每个动态库的加载,dyld 需要
- 分析所依赖的动态库
- 找到动态库的 Mach-O 文件
- 打开文件
- 验证文件
- 在系统核心注册文件签名
- 对动态库的每一个 segment 调用 mmap()
优化:
- 减少非系统库的依赖
- 使用静态库而不是动态库
- 合并非系统动态库为一个动态库
#### 2.2 Rebase && Binding
优化:
- 减少 Objc 类数量,减少 selector 数量,把未使用的类和函数都可以删掉
- 减少 c++ 虚函数数量
- 转而使用 Swift struct(本质就是减少符号的数量)
#### 2.3 Initializers
优化:
- 使用 `+initialize` 代替 `+load`
- 不要使用过 attribute\*((constructor)) 将方法显示标记为初始化器,而是让初始化方法调用时才执行。比如使用 dispatch_one、pthread_once() 或 std::once()。也就是第一次使用时才初始化,推迟了一部分工作耗时也尽量不要使用 c++ 的静态对象
#### 2.4 pre-main 阶段影响因素
- 动态库加载越多,启动越慢。
- ObjC 类越多,函数越多,启动越慢。
- 可执行文件越大启动越慢。
- C 的 constructor 函数越多,启动越慢。
- C++ 静态对象越多,启动越慢。
- ObjC 的 +load 越多,启动越慢。
优化手段:
- 减少依赖不必要的库,不管是动态库还是静态库;如果可以的话,把动态库改造成静态库;如果必须依赖动态库,则把多个非系统的动态库合并成一个动态库
- 检查下 framework 应当设为 optional 和 required,如果该 framework 在当前 App 支持的所有 iOS 系统版本都存在,那么就设为 required,否则就设为 optional,因为 optional 会有些额外的检查
- 合并或者删减一些 OC 类和函数。关于清理项目中没用到的类,使用工具 AppCode 代码检查功能,查到当前项目中没有用到的类(也可以用根据 linkmap 文件来分析,但是准确度不算很高)
有一个叫做[FUI](https://github.com/dblock/fui)的开源项目能很好的分析出不再使用的类,准确率非常高,唯一的问题是它处理不了动态库和静态库里提供的类,也处理不了 C++的类模板
- 删减一些无用的静态变量
- 删减没有被调用到或者已经废弃的方法
- 将不必须在 +load 方法中做的事情延迟到 +initialize 中,尽量不要用 C++ 虚函数(创建虚函数表有开销)
- 类和方法名不要太长:iOS 每个类和方法名都在 \_\_cstring 段里都存了相应的字符串值,所以类和方法名的长短也是对可执行文件大小是有影响的
因还是 Object-c 的动态特性,因为需要通过类/方法名反射找到这个类/方法进行调用,Object-c 对象模型会把类/方法名字符串都保存下来;
- 用 dispatch_once() 代替所有的 attribute((constructor)) 函数、C++ 静态对象初始化、ObjC 的 +load 函数;
- 在设计师可接受的范围内压缩图片的大小,会有意外收获。
压缩图片为什么能加快启动速度呢?因为启动的时候大大小小的图片加载个十来二十个是很正常的,
图片小了,IO 操作量就小了,启动当然就会快了,比较靠谱的压缩算法是 TinyPNG。
#### 2.5 main 阶段优化
- 减少启动初始化的流程。能懒加载就懒加载,能放后台初始化就放后台初始化,能延迟初始化的就延迟初始化,不要卡主线程的启动时间,已经下线的业务代码直接删除
- 优化代码逻辑。去除一些非必要的逻辑和代码,减小每个流程所消耗的时间
- 启动阶段使用多线程来进行初始化,把 CPU 性能发挥最大
- 使用纯代码而不是 xib 或者 storyboard 来描述 UI,尤其是主 UI 框架,比如 TabBarController。因为 xib 和 storyboard 还是需要解析成代码来渲染页面,多了一步。
### 3. 启动时间加速
内存缺页异常?在使用中,访问虚拟内存的一个 page 而对应的物理内存缺不存在(没有被加载到物理内存中),则发生缺页异常。影响耗时,在几毫秒之内。
什么时候发生大量的缺页异常?一个应用程序刚启动的时候。
启动时所需要的代码分布在 VM 的第一页、第二页、第三页...,这样的情况下启动时间会影响较大,所以解决思路就是将应用程序启动刻所需要的代码(二进制优化一下),统一放到某几页,这样就可以避免内存缺页异常,则优化了 App 启动时间。
二进制重排提升 App 启动速度是通过「解决内存缺页异常」(内存缺页会有几毫秒的耗时)来提速的。
一个 App 发生大量「内存缺页」的时机就是 App 刚启动的时候。所以优化手段就是「将影响 App 启动的方法集中处理,放到某一页或者某几页」(虚拟内存中的页)。Xcode 工程允许开发者指定 「Order File」,可以「按照文件中的方法顺序去加载」,可以查看 linkMap 文件(需要在 Xcode 中的 「Buiild Settings」中设置 Order File、Write Link Map Files 参数)。
其实难点是如何拿到启动时刻所调用的所用方法?代码可能是 Swift、block、c、OC,所以 hook 肯定不行、fishhook 也不行,用 clang 插桩可以满足需求。
## 三、 CPU 使用率监控
### 1. CPU 架构
CPU(Central Processing Unit)中央处理器,市场上主流的架构有 ARM(arm64)、Intel(x86)、AMD 等。其中 Intel 使用 CISC(Complex Instruction Set Computer),ARM 使用 RISC(Reduced Instruction Set Computer)。区别在于**不同的 CPU 设计理念和方法**。
早期 CPU 全部是 CISC 架构,设计目的是**用最少的机器语言指令来完成所需的计算任务**。比如对于乘法运算,在 CISC 架构的 CPU 上。一条指令 `MUL ADDRA, ADDRB` 就可以将内存 ADDRA 和内存 ADDRB 中的数香乘,并将结果存储在 ADDRA 中。做的事情就是:将 ADDRA、ADDRB 中的数据读入到寄存器,相乘的结果写入到内存的操作依赖于 CPU 设计,所以 **CISC 架构会增加 CPU 的复杂性和对 CPU 工艺的要求。**
RISC 架构要求软件来指定各个操作步骤。比如上面的乘法,指令实现为 `MOVE A, ADDRA; MOVE B, ADDRB; MUL A, B; STR ADDRA, A;`。这种架构可以降低 CPU 的复杂性以及允许在同样的工艺水平下生产出功能更加强大的 CPU,但是对于编译器的设计要求更高。
目前市场是大部分的 iPhone 都是基于 arm64 架构的。且 arm 架构能耗低。
### 2. 获取线程信息<a name="threadInfo"></a>
讲完了区别来讲下如何做 CPU 使用率的监控
- 开启定时器,按照设定的周期不断执行下面的逻辑
- 获取当前任务 task。从当前 task 中获取所有的线程信息(线程个数、线程数组)
- 遍历所有的线程信息,判断是否有线程的 CPU 使用率超过设置的阈值
- 假如有线程使用率超过阈值,则 dump 堆栈
- 组装数据,上报数据
线程信息结构体
```Objective-c
struct thread_basic_info {
time_value_t user_time; /* user run time(用户运行时长) */
time_value_t system_time; /* system run time(系统运行时长) */
integer_t cpu_usage; /* scaled cpu usage percentage(CPU使用率,上限1000) */
policy_t policy; /* scheduling policy in effect(有效调度策略) */
integer_t run_state; /* run state (运行状态,见下) */
integer_t flags; /* various flags (各种各样的标记) */
integer_t suspend_count; /* suspend count for thread(线程挂起次数) */
integer_t sleep_time; /* number of seconds that thread
* has been sleeping(休眠时间) */
};
```
代码在讲堆栈还原的时候讲过,忘记的看一下上面的分析
```Objective-C
thread_act_array_t threads;
mach_msg_type_number_t threadCount = 0;
const task_t thisTask = mach_task_self();
kern_return_t kr = task_threads(thisTask, &threads, &threadCount);
if (kr != KERN_SUCCESS) {
return ;
}
for (int i = 0; i < threadCount; i++) {
thread_info_data_t threadInfo;
thread_basic_info_t threadBaseInfo;
mach_msg_type_number_t threadInfoCount;
kern_return_t kr = thread_info((thread_inspect_t)threads[i], THREAD_BASIC_INFO, (thread_info_t)threadInfo, &threadInfoCount);
if (kr == KERN_SUCCESS) {
threadBaseInfo = (thread_basic_info_t)threadInfo;
// todo:条件判断,看不明白
if (!(threadBaseInfo->flags & TH_FLAGS_IDLE)) {
integer_t cpuUsage = threadBaseInfo->cpu_usage / 10;
if (cpuUsage > CPUMONITORRATE) {
NSMutableDictionary *CPUMetaDictionary = [NSMutableDictionary dictionary];
NSData *CPUPayloadData = [NSData data];
NSString *backtraceOfAllThread = [BacktraceLogger backtraceOfAllThread];
// 1. 组装卡顿的 Meta 信息
CPUMetaDictionary[@"MONITOR_TYPE"] = APMMonitorCPUType;
// 2. 组装卡顿的 Payload 信息(一个JSON对象,对象的 Key 为约定好的 STACK_TRACE, value 为 base64 后的堆栈信息)
NSData *CPUData = [SAFE_STRING(backtraceOfAllThread) dataUsingEncoding:NSUTF8StringEncoding];
NSString *CPUDataBase64String = [CPUData base64EncodedStringWithOptions:0];
NSDictionary *CPUPayloadDictionary = @{@"STACK_TRACE": SAFE_STRING(CPUDataBase64String)};
NSError *error;
// NSJSONWritingOptions 参数一定要传0,因为服务端需要根据 \n 处理逻辑,传递 0 则生成的 json 串不带 \n
NSData *parsedData = [NSJSONSerialization dataWithJSONObject:CPUPayloadDictionary options:0 error:&error];
if (error) {
APMMLog(@"%@", error);
return;
}
CPUPayloadData = [parsedData copy];
// 3. 数据上报会在 [打造功能强大、灵活可配置的数据上报组件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md) 讲
[[HermesClient sharedInstance] sendWithType:APMMonitorCPUType meta:CPUMetaDictionary payload:CPUPayloadData];
}
}
}
}
```
## 四、 OOM 问题
### 1. 基础知识准备
硬盘:也叫做磁盘,用于存储数据。你存储的歌曲、图片、视频都是在硬盘里。
内存:由于硬盘读取速度较慢,如果 CPU 运行程序期间,所有的数据都直接从硬盘中读取,则非常影响效率。所以 CPU 会将程序运行所需要的数据从硬盘中读取到内存中。然后 CPU 与内存中的数据进行计算、交换。内存是易失性存储器(断电后,数据消失)。内存条区是计算机内部(在主板上)的一些存储器,用来保存 CPU 运算的中间数据和结果。内存是程序与 CPU 之间的桥梁。从硬盘读取出数据或者运行程序提供给 CPU。
**虚拟内存** 是计算机系统内存管理的一种技术。它使得程序认为它拥有连续的可用内存,而实际上,它通常被分割成多个物理内存碎片,可能部分暂时存储在外部磁盘(硬盘)存储器上(当需要使用时则用硬盘中数据交换到内存中)。Windows 系统中称为 “虚拟内存”,Linux/Unix 系统中称为 ”交换空间“。
iOS 不支持交换空间?不只是 iOS 不支持交换空间,大多数手机系统都不支持。因为移动设备的大量存储器是**闪存**,它的读写速度远远小电脑所使用的硬盘,也就是说手机即使使用了**交换空间**技术,也因为闪存慢的问题,不能提升性能,所以索性就没有交换空间技术。
### 2. iOS 内存知识
内存(RAM)与 CPU 一样都是系统中最稀少的资源,也很容易发生竞争,应用内存与性能直接相关。iOS 没有交换空间作为备选资源,所以内存资源尤为重要。
什么是 OOM?是 out-of-memory 的缩写,字面意思是超过了内存限制。分为 FOOM(Foreground Out Of Memory,应用在前台运行的过程中崩溃。用户在使用的过程中产生的,这样的崩溃会使得活跃用户流失,业务上是非常不愿意看到的)和 BOOM(Background Out Of Memory,应用在后台运行的过程崩溃)。它是由 iOS 的 `Jetsam` 机制造成的一种非主流 Crash,它不能通过 Signal 这种监控方案所捕获。
什么是 Jetsam 机制?Jetsam 机制可以理解为系统为了控制内存资源过度使用而采用的一种管理机制。Jetsam 机制是运行在一个独立的进程中,每个进程都有一个内存阈值,一旦超过这个内存阈值,Jetsam 会立即杀掉这个进程。
为什么设计 Jetsam 机制?因为设备的内存是有限的,所以内存资源非常重要。系统进程以及其他使用的 App 都会抢占这个资源。由于 iOS 不支持交换空间,一旦触发低内存事件,Jetsam 就会尽可能多的释放 App 所在内存,这样 iOS 系统上出现内存不足时,App 就会被系统杀掉,变现为 crash。
2 种情况触发 OOM:系统由于整体内存使用过高,会基于优先级策略杀死优先级较低的 App;当前 App 达到了 "**highg water mark**" ,系统也会强杀当前 App(超过系统对当前单个 App 的内存限制值)。
读了源码(xnu/bsd/kern/kern_memorystatus.c)会发现内存被杀也有 2 种机制,如下
highwater 处理 -> 我们的 App 占用内存不能超过单个限制
1. 从优先级列表里循环寻找线程
2. 判断是否满足 p_memstat_memlimit 的限制条件
3. DiagonoseActive、FREEZE 过滤
4. 杀进程,成功则 exit,否则循环
memorystatus_act_aggressive 处理 -> 内存占用高,按照优先级杀死
1. 根据 policy 家在 jld_bucket_count,用来判断是否被杀
2. 从 JETSAM_PRIORITY_ELEVATED_INACTIVE 开始杀
3. Old_bucket_count 和 memorystatus_jld_eval_period_msecs 判断是否开杀
4. 根据优先级从低到高开始杀,直到 memorystatus_avail_pages_below_pressure
内存过大的几种情况
- App 内存消耗较低,同时其他 App 内存管理也很棒,那么即使切换到其他 App,我们自己的 App 依旧是“活着”的,保留了用户状态。体验好
- App 内存消耗较低,但其他 App 内存消耗太大(可能是内存管理糟糕,也可能是本身就耗费资源,比如游戏),那么除了在前台的线程,其他 App 都会被系统杀死,回收内存资源,用来给活跃的进程提供内存。
- App 内存消耗较大,切换到其他 App 后,即使其他 App 向系统申请的内存不大,系统也会因为内存资源紧张,优先把内存消耗大的 App 杀死。表现为用户将 App 退出到后台,过会儿再次打开会发现 App 重新加载启动。
- App 内存消耗非常大,在前台运行时就被系统杀死,造成闪退。
App 内存不足时,系统会按照一定策略来腾出更多的空间供使用。比较常见的做法是将一部分优先级低的数据挪到磁盘上,该操作为称为 **page out**。之后再次访问这块数据的时候,系统会负责将它重新搬回到内存中,该操作被称为 **page in**。
Memory page\*\* 是内存管理中的最小单位,是系统分配的,可能一个 page 持有多个对象,也可能一个大的对象跨越多个 page。通常它是 16KB 大小,且有 3 种类型的 page。

- Clean Memory
Clean memory 包括 3 类:可以 `page out` 的内存、内存映射文件、App 使用到的 framework(每个 framework 都有 \_DATA_CONST 段,通常都是 clean 状态,但使用 runtime swizling,那么变为 dirty)。
一开始分配的 page 都是干净的(堆里面的对象分配除外),我们 App 数据写入时候变为 dirty。从硬盘读进内存的文件,也是只读的、clean page。
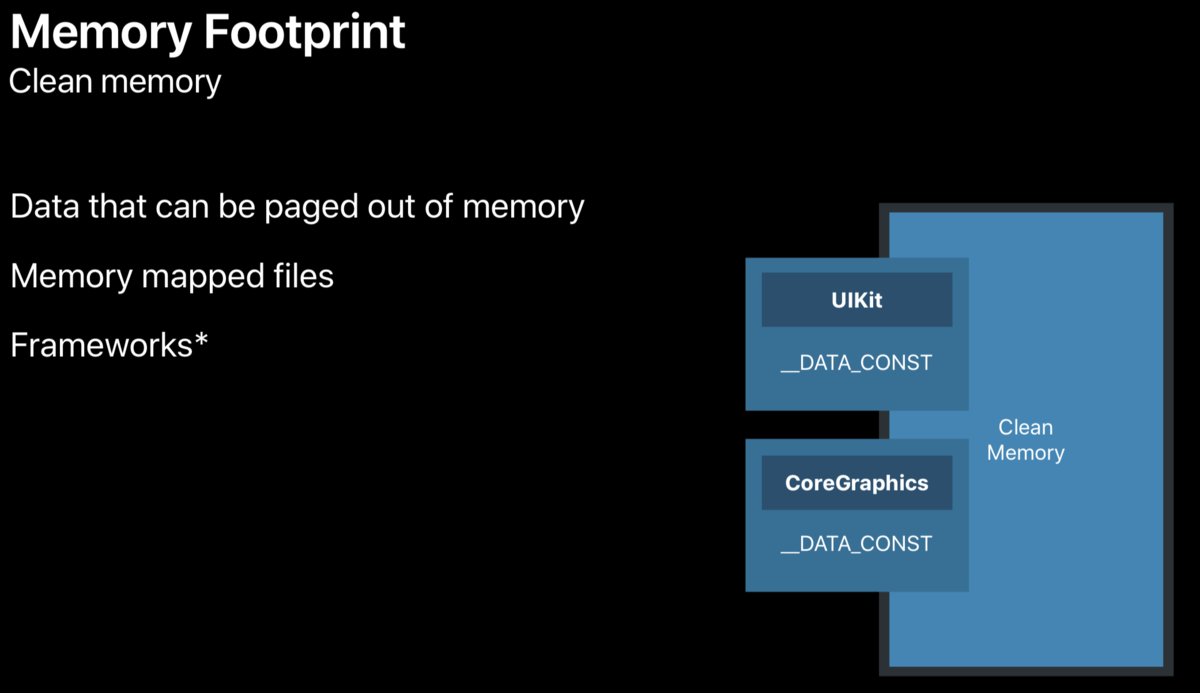
- Dirty Memory
Dirty memory 包括 4 类:被 App 写入过数据的内存、所有堆区分配的对象、图像解码缓冲区、framework(framework 都有 \_DATA 段和 \_DATA_DIRTY 段,它们的内存都是 dirty)。
在使用 framework 的过程中会产生 Dirty memory,使用单例或者全局初始化方法有助于帮助减少 Dirty memory(因为单例一旦创建就不销毁,一直在内存中,系统不认为是 Dirty memory)。
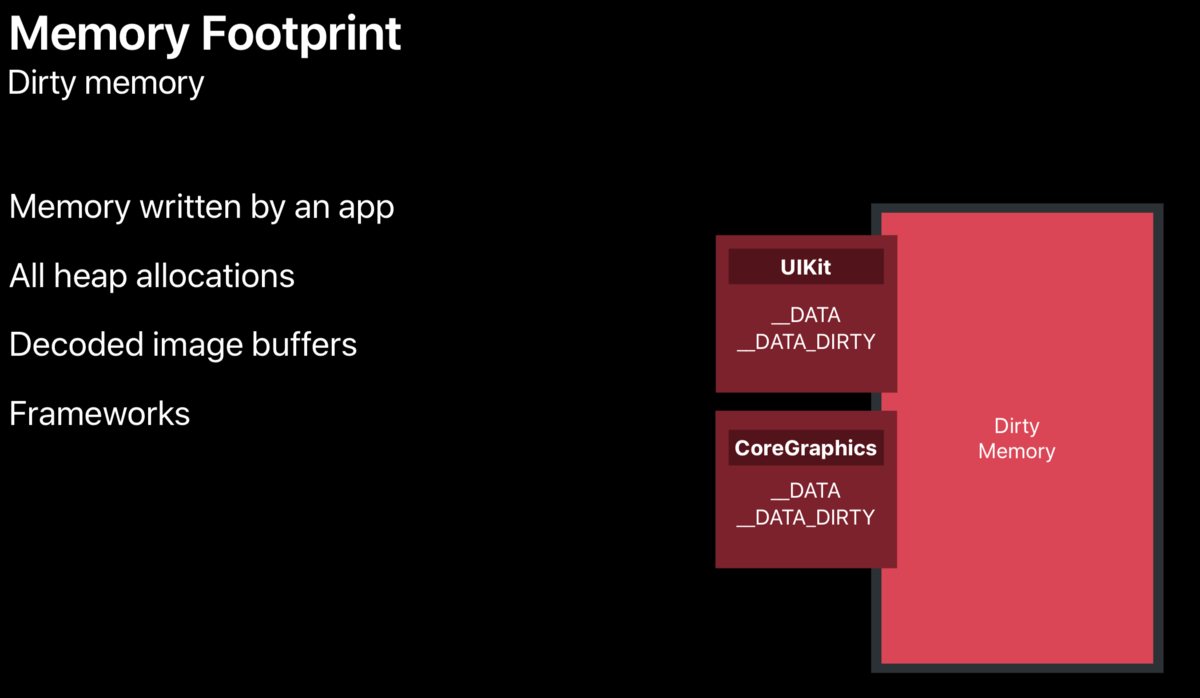
- Compressed Memory
由于闪存容量和读写限制,iOS 没有交换空间机制,而是在 iOS7 引入了 **memory compressor**。它是在内存紧张时候能够将最近一段时间未使用过的内存对象,内存压缩器会把对象压缩,释放出更多的 page。在需要时内存压缩器对其解压复用。在节省内存的同时提高了响应速度。
比如 App 使用某 Framework,内部有个 NSDictionary 属性存储数据,使用了 3 pages 内存,在近期未被访问的时候 memory compressor 将其压缩为 1 page,再次使用的时候还原为 3 pages。
App 运行内存 = pageNumbers \* pageSize。因为 Compressed Memory 属于 Dirty memory。所以 Memory footprint = dirtySize + CompressedSize
设备不同,内存占用上限不同,App 上限较高,extension 上限较低,超过上限 crash 到 `EXC_RESOURCE_EXCEPTION`。
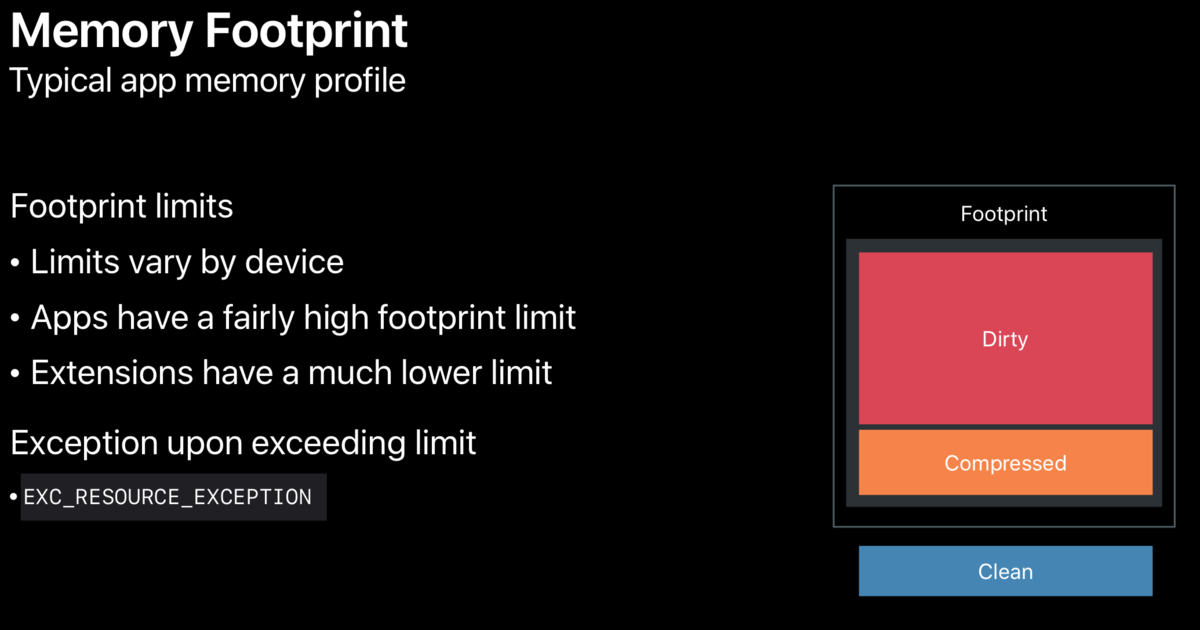
接下来谈一下如何获取内存上限,以及如何监控 App 因为占用内存过大而被强杀。
### 3. 获取内存信息
#### 3.1 通过 JetsamEvent 日志计算内存限制值
当 App 被 Jetsam 机制杀死时,手机会生成系统日志。查看路径:Settings-Privacy-Analytics & Improvements- Analytics Data(设置-隐私- 分析与改进-分析数据),可以看到 `JetsamEvent-2020-03-14-161828.ips` 形式的日志,以 JetsamEvent 开头。这些 JetsamEvent 日志都是 iOS 系统内核强杀掉那些优先级不高(idle、frontmost、suspended)且占用内存超过系统内存限制的 App 留下的。
日志包含了 App 的内存信息。可以查看到 日志最顶部有 `pageSize` 字段,查找到 per-process-limit,该节点所在结构里的 `rpages` ,将 rpages \* pageSize 即可得到 OOM 的阈值。
日志中 largestProcess 字段代表 App 名称;reason 字段代表内存原因;states 字段代表奔溃时 App 的状态( idle、suspended、frontmost...)。
为了测试数据的准确性,我将测试 2 台设备(iPhone 6s plus/13.3.1,iPhone 11 Pro/13.3.1)的所有 App 彻底退出,只跑了一个为了测试内存临界值的 Demo App。 循环申请内存,ViewController 代码如下
```objective-c
- (void)viewDidLoad {
[super viewDidLoad];
NSMutableArray *array = [NSMutableArray array];
for (NSInteger index = 0; index < 10000000; index++) {
UIImageView *imageView = [[UIImageView alloc] initWithFrame:CGRectMake(0, 0, 100, 100)];
UIImage *image = [UIImage imageNamed:@"AppIcon"];
imageView.image = image;
[array addObject:imageView];
}
}
```
iPhone 6s plus/13.3.1 数据如下:
```shell
{"bug_type":"298","timestamp":"2020-03-19 17:23:45.94 +0800","os_version":"iPhone OS 13.3.1 (17D50)","incident_id":"DA8AF66D-24E8-458C-8734-981866942168"}
{
"crashReporterKey" : "fc9b659ce486df1ed1b8062d5c7c977a7eb8c851",
"kernel" : "Darwin Kernel Version 19.3.0: Thu Jan 9 21:10:44 PST 2020; root:xnu-6153.82.3~1\/RELEASE_ARM64_S8000",
"product" : "iPhone8,2",
"incident" : "DA8AF66D-24E8-458C-8734-981866942168",
"date" : "2020-03-19 17:23:45.93 +0800",
"build" : "iPhone OS 13.3.1 (17D50)",
"timeDelta" : 332,
"memoryStatus" : {
"compressorSize" : 48499,
"compressions" : 7458651,
"decompressions" : 5190200,
"zoneMapCap" : 744407040,
"largestZone" : "APFS_4K_OBJS",
"largestZoneSize" : 41402368,
"pageSize" : 16384,
"uncompressed" : 104065,
"zoneMapSize" : 141606912,
"memoryPages" : {
"active" : 26214,
"throttled" : 0,
"fileBacked" : 14903,
"wired" : 20019,
"anonymous" : 37140,
"purgeable" : 142,
"inactive" : 23669,
"free" : 2967,
"speculative" : 2160
}
},
"largestProcess" : "Test",
"genCounter" : 0,
"processes" : [
{
"uuid" : "39c5738b-b321-3865-a731-68064c4f7a6f",
"states" : [
"daemon",
"idle"
],
"lifetimeMax" : 188,
"age" : 948223699030,
"purgeable" : 0,
"fds" : 25,
"coalition" : 422,
"rpages" : 177,
"pid" : 282,
"idleDelta" : 824711280,
"name" : "com.apple.Safari.SafeBrowsing.Se",
"cpuTime" : 10.275422000000001
},
// ...
{
"uuid" : "83dbf121-7c0c-3ab5-9b66-77ee926e1561",
"states" : [
"frontmost"
],
"killDelta" : 2592,
"genCount" : 0,
"age" : 1531004794,
"purgeable" : 0,
"fds" : 50,
"coalition" : 1047,
"rpages" : 92806,
"reason" : "per-process-limit",
"pid" : 2384,
"cpuTime" : 59.464373999999999,
"name" : "Test",
"lifetimeMax" : 92806
},
// ...
]
}
```
iPhone 6s plus/13.3.1 手机 OOM 临界值为:(16384\*92806)/(1024\*1024)=1450.09375M
iPhone 11 Pro/13.3.1 数据如下:
```shell
{"bug_type":"298","timestamp":"2020-03-19 17:30:28.39 +0800","os_version":"iPhone OS 13.3.1 (17D50)","incident_id":"7F111601-BC7A-4BD7-A468-CE3370053057"}
{
"crashReporterKey" : "bc2445adc164c399b330f812a48248e029e26276",
"kernel" : "Darwin Kernel Version 19.3.0: Thu Jan 9 21:11:10 PST 2020; root:xnu-6153.82.3~1\/RELEASE_ARM64_T8030",
"product" : "iPhone12,3",
"incident" : "7F111601-BC7A-4BD7-A468-CE3370053057",
"date" : "2020-03-19 17:30:28.39 +0800",
"build" : "iPhone OS 13.3.1 (17D50)",
"timeDelta" : 189,
"memoryStatus" : {
"compressorSize" : 66443,
"compressions" : 25498129,
"decompressions" : 15532621,
"zoneMapCap" : 1395015680,
"largestZone" : "APFS_4K_OBJS",
"largestZoneSize" : 41222144,
"pageSize" : 16384,
"uncompressed" : 127027,
"zoneMapSize" : 169639936,
"memoryPages" : {
"active" : 58652,
"throttled" : 0,
"fileBacked" : 20291,
"wired" : 45838,
"anonymous" : 96445,
"purgeable" : 4,
"inactive" : 54368,
"free" : 5461,
"speculative" : 3716
}
},
"largestProcess" : "杭城小刘",
"genCounter" : 0,
"processes" : [
{
"uuid" : "2dd5eb1e-fd31-36c2-99d9-bcbff44efbb7",
"states" : [
"daemon",
"idle"
],
"lifetimeMax" : 171,
"age" : 5151034269954,
"purgeable" : 0,
"fds" : 50,
"coalition" : 66,
"rpages" : 164,
"pid" : 11276,
"idleDelta" : 3801132318,
"name" : "wcd",
"cpuTime" : 3.430787
},
// ...
{
"uuid" : "63158edc-915f-3a2b-975c-0e0ac4ed44c0",
"states" : [
"frontmost"
],
"killDelta" : 4345,
"genCount" : 0,
"age" : 654480778,
"purgeable" : 0,
"fds" : 50,
"coalition" : 1718,
"rpages" : 134278,
"reason" : "per-process-limit",
"pid" : 14206,
"cpuTime" : 23.955463999999999,
"name" : "杭城小刘",
"lifetimeMax" : 134278
},
// ...
]
}
```
iPhone 11 Pro/13.3.1 手机 OOM 临界值为:(16384\*134278)/(1024\*1024)=2098.09375M
**iOS 系统如何发现 Jetsam ?**
MacOS/iOS 是一个 BSD 衍生而来的系统,其内核是 Mach,但是对于上层暴露的接口一般是基于 BSD 层对 Mach 的包装后的。Mach 是一个微内核的架构,真正的虚拟内存管理也是在其中进行的,BSD 对内存管理提供了上层接口。Jetsam 事件也是由 BSD 产生的。`bsd_init` 函数是入口,其中基本都是在初始化各个子系统,比如虚拟内存管理等。
```c++
// 1. Initialize the kernel memory allocator, 初始化 BSD 内存 Zone,这个 Zone 是基于 Mach 内核的zone 构建
kmeminit();
// 2. Initialise background freezing, iOS 上独有的特性,内存和进程的休眠的常驻监控线程
#if CONFIG_FREEZE
#ifndef CONFIG_MEMORYSTATUS
#error "CONFIG_FREEZE defined without matching CONFIG_MEMORYSTATUS"
#endif
/* Initialise background freezing */
bsd_init_kprintf("calling memorystatus_freeze_init\n");
memorystatus_freeze_init();
#endif>
// 3. iOS 独有,JetSAM(即低内存事件的常驻监控线程)
#if CONFIG_MEMORYSTATUS
/* Initialize kernel memory status notifications */
bsd_init_kprintf("calling memorystatus_init\n");
memorystatus_init();
#endif /* CONFIG_MEMORYSTATUS */
```
**主要作用就是开启了 2 个优先级最高的线程,来监控整个系统的内存情况。**
CONFIG_FREEZE 开启时,内核对进程进行冷冻而不是杀死。冷冻功能是由内核中启动一个 `memorystatus_freeze_thread` 进行,这个进程在收到信号后调用 `memorystatus_freeze_top_process` 进行冷冻。
iOS 系统会开启优先级最高的线程 `vm_pressure_monitor` 来监控系统的内存压力情况,并通过一个堆栈来维护所有 App 进程。iOS 系统还会维护一个内存快照表,用于保存每个进程内存页的消耗情况。有关 Jetsam 也就是 memorystatus 相关的逻辑,可以在 XNU 项目中的 **kern_memorystatus.h** 和 **kern_memorystatus.c **源码中查看。
iOS 系统因内存占用过高会强杀 App 前,至少有 6 秒钟可以用来做优先级判断,JetsamEvent 日志也是在这 6 秒内生成的。
上文提到了 iOS 系统没有交换空间,于是引入了 **MemoryStatus 机制(也称为 Jetsam)**。也就是说在 iOS 系统上释放尽可能多的内存供当前 App 使用。这个机制表现在优先级上,就是先强杀后台应用;如果内存还是不够多,就强杀掉当前应用。在 MacOS 中,MemoryStatus 只会强杀掉标记为空闲退出的进程。
MemoryStatus 机制会开启一个 memorystatus_jetsam_thread 的线程,它负责强杀 App 和记录日志,不会发送消息,所以内存压力检测线程无法获取到强杀 App 的消息。
当监控线程发现某 App 有内存压力时,就发出通知,此时有内存的 App 就去执行 `didReceiveMemoryWarning` 代理方法。在这个时机,我们还有机会做一些内存资源释放的逻辑,也许会避免 App 被系统杀死。
**源码角度查看问题**
iOS 系统内核有一个数组,专门维护线程的优先级。数组的每一项是一个包含进程链表的结构体。结构体如下:
```objective-c
#define MEMSTAT_BUCKET_COUNT (JETSAM_PRIORITY_MAX + 1)
typedef struct memstat_bucket {
TAILQ_HEAD(, proc) list;
int count;
} memstat_bucket_t;
memstat_bucket_t memstat_bucket[MEMSTAT_BUCKET_COUNT];
```
在 kern_memorystatus.h 中可以看到进行优先级信息
```objective-c
#define JETSAM_PRIORITY_IDLE_HEAD -2
/* The value -1 is an alias to JETSAM_PRIORITY_DEFAULT */
#define JETSAM_PRIORITY_IDLE 0
#define JETSAM_PRIORITY_IDLE_DEFERRED 1 /* Keeping this around till all xnu_quick_tests can be moved away from it.*/
#define JETSAM_PRIORITY_AGING_BAND1 JETSAM_PRIORITY_IDLE_DEFERRED
#define JETSAM_PRIORITY_BACKGROUND_OPPORTUNISTIC 2
#define JETSAM_PRIORITY_AGING_BAND2 JETSAM_PRIORITY_BACKGROUND_OPPORTUNISTIC
#define JETSAM_PRIORITY_BACKGROUND 3
#define JETSAM_PRIORITY_ELEVATED_INACTIVE JETSAM_PRIORITY_BACKGROUND
#define JETSAM_PRIORITY_MAIL 4
#define JETSAM_PRIORITY_PHONE 5
#define JETSAM_PRIORITY_UI_SUPPORT 8
#define JETSAM_PRIORITY_FOREGROUND_SUPPORT 9
#define JETSAM_PRIORITY_FOREGROUND 10
#define JETSAM_PRIORITY_AUDIO_AND_ACCESSORY 12
#define JETSAM_PRIORITY_CONDUCTOR 13
#define JETSAM_PRIORITY_HOME 16
#define JETSAM_PRIORITY_EXECUTIVE 17
#define JETSAM_PRIORITY_IMPORTANT 18
#define JETSAM_PRIORITY_CRITICAL 19
#define JETSAM_PRIORITY_MAX 21
```
可以明显的看到,后台 App 优先级 JETSAM_PRIORITY_BACKGROUND 为 3,前台 App 优先级 JETSAM_PRIORITY_FOREGROUND 为 10。
优先级规则是:内核线程优先级 > 操作系统优先级 > App 优先级。且前台 App 优先级高于后台运行的 App;当线程的优先级相同时, CPU 占用多的线程的优先级会被降低。
在 kern_memorystatus.c 中可以看到 OOM 可能的原因:
```shell
/* For logging clarity */
static const char *memorystatus_kill_cause_name[] = {
"" , /* kMemorystatusInvalid */
"jettisoned" , /* kMemorystatusKilled */
"highwater" , /* kMemorystatusKilledHiwat */
"vnode-limit" , /* kMemorystatusKilledVnodes */
"vm-pageshortage" , /* kMemorystatusKilledVMPageShortage */
"proc-thrashing" , /* kMemorystatusKilledProcThrashing */
"fc-thrashing" , /* kMemorystatusKilledFCThrashing */
"per-process-limit" , /* kMemorystatusKilledPerProcessLimit */
"disk-space-shortage" , /* kMemorystatusKilledDiskSpaceShortage */
"idle-exit" , /* kMemorystatusKilledIdleExit */
"zone-map-exhaustion" , /* kMemorystatusKilledZoneMapExhaustion */
"vm-compressor-thrashing" , /* kMemorystatusKilledVMCompressorThrashing */
"vm-compressor-space-shortage" , /* kMemorystatusKilledVMCompressorSpaceShortage */
};
```
查看 memorystatus_init 这个函数中初始化 Jetsam 线程的关键代码
```c++
__private_extern__ void
memorystatus_init(void)
{
// ...
/* Initialize the jetsam_threads state array */
jetsam_threads = kalloc(sizeof(struct jetsam_thread_state) * max_jetsam_threads);
/* Initialize all the jetsam threads */
for (i = 0; i < max_jetsam_threads; i++) {
result = kernel_thread_start_priority(memorystatus_thread, NULL, 95 /* MAXPRI_KERNEL */, &jetsam_threads[i].thread);
if (result == KERN_SUCCESS) {
jetsam_threads[i].inited = FALSE;
jetsam_threads[i].index = i;
thread_deallocate(jetsam_threads[i].thread);
} else {
panic("Could not create memorystatus_thread %d", i);
}
}
}
```
```shell
/*
* High-level priority assignments
*
*************************************************************************
* 127 Reserved (real-time)
* A
* +
* (32 levels)
* +
* V
* 96 Reserved (real-time)
* 95 Kernel mode only
* A
* +
* (16 levels)
* +
* V
* 80 Kernel mode only
* 79 System high priority
* A
* +
* (16 levels)
* +
* V
* 64 System high priority
* 63 Elevated priorities
* A
* +
* (12 levels)
* +
* V
* 52 Elevated priorities
* 51 Elevated priorities (incl. BSD +nice)
* A
* +
* (20 levels)
* +
* V
* 32 Elevated priorities (incl. BSD +nice)
* 31 Default (default base for threads)
* 30 Lowered priorities (incl. BSD -nice)
* A
* +
* (20 levels)
* +
* V
* 11 Lowered priorities (incl. BSD -nice)
* 10 Lowered priorities (aged pri's)
* A
* +
* (11 levels)
* +
* V
* 0 Lowered priorities (aged pri's / idle)
*************************************************************************
*/
```
可以看出:用户态的应用程序的线程不可能高于操作系统和内核。而且,用户态的应用程序间的线程优先级分配也有区别,比如处于前台的应用程序优先级高于处于后台的应用程序优先级。iOS 上应用程序优先级最高的是 SpringBoard;此外线程的优先级不是一成不变的。Mach 会根据线程的利用率和系统整体负载动态调整线程优先级。如果耗费 CPU 太多就降低线程优先级,如果线程过度挨饿,则会提升线程优先级。但是无论怎么变,程序都不能超过其所在线程的优先级区间范围。
可以看出,系统会根据内核启动参数和设备性能,开启 max_jetsam_threads 个(一般情况为 1,特殊情况下可能为 3)jetsam 线程,且这些线程的优先级为 95,也就是 MAXPRI_KERNEL(注意这里的 95 是线程的优先级,XNU 的线程优先级区间为:0 ~ 127。上文的宏定义是进程优先级,区间为:-2~19)。
紧接着,分析下 memorystatus_thread 函数,主要负责线程启动的初始化
```c++
static void
memorystatus_thread(void *param __unused, wait_result_t wr __unused)
{
//...
while (memorystatus_action_needed()) {
boolean_t killed;
int32_t priority;
uint32_t cause;
uint64_t jetsam_reason_code = JETSAM_REASON_INVALID;
os_reason_t jetsam_reason = OS_REASON_NULL;
cause = kill_under_pressure_cause;
switch (cause) {
case kMemorystatusKilledFCThrashing:
jetsam_reason_code = JETSAM_REASON_MEMORY_FCTHRASHING;
break;
case kMemorystatusKilledVMCompressorThrashing:
jetsam_reason_code = JETSAM_REASON_MEMORY_VMCOMPRESSOR_THRASHING;
break;
case kMemorystatusKilledVMCompressorSpaceShortage:
jetsam_reason_code = JETSAM_REASON_MEMORY_VMCOMPRESSOR_SPACE_SHORTAGE;
break;
case kMemorystatusKilledZoneMapExhaustion:
jetsam_reason_code = JETSAM_REASON_ZONE_MAP_EXHAUSTION;
break;
case kMemorystatusKilledVMPageShortage:
/* falls through */
default:
jetsam_reason_code = JETSAM_REASON_MEMORY_VMPAGESHORTAGE;
cause = kMemorystatusKilledVMPageShortage;
break;
}
/* Highwater */
boolean_t is_critical = TRUE;
if (memorystatus_act_on_hiwat_processes(&errors, &hwm_kill, &post_snapshot, &is_critical)) {
if (is_critical == FALSE) {
/*
* For now, don't kill any other processes.
*/
break;
} else {
goto done;
}
}
jetsam_reason = os_reason_create(OS_REASON_JETSAM, jetsam_reason_code);
if (jetsam_reason == OS_REASON_NULL) {
printf("memorystatus_thread: failed to allocate jetsam reason\n");
}
if (memorystatus_act_aggressive(cause, jetsam_reason, &jld_idle_kills, &corpse_list_purged, &post_snapshot)) {
goto done;
}
/*
* memorystatus_kill_top_process() drops a reference,
* so take another one so we can continue to use this exit reason
* even after it returns
*/
os_reason_ref(jetsam_reason);
/* LRU */
killed = memorystatus_kill_top_process(TRUE, sort_flag, cause, jetsam_reason, &priority, &errors);
sort_flag = FALSE;
if (killed) {
if (memorystatus_post_snapshot(priority, cause) == TRUE) {
post_snapshot = TRUE;
}
/* Jetsam Loop Detection */
if (memorystatus_jld_enabled == TRUE) {
if ((priority == JETSAM_PRIORITY_IDLE) || (priority == system_procs_aging_band) || (priority == applications_aging_band)) {
jld_idle_kills++;
} else {
/*
* We've reached into bands beyond idle deferred.
* We make no attempt to monitor them
*/
}
}
if ((priority >= JETSAM_PRIORITY_UI_SUPPORT) && (total_corpses_count() > 0) && (corpse_list_purged == FALSE)) {
/*
* If we have jetsammed a process in or above JETSAM_PRIORITY_UI_SUPPORT
* then we attempt to relieve pressure by purging corpse memory.
*/
task_purge_all_corpses();
corpse_list_purged = TRUE;
}
goto done;
}
if (memorystatus_avail_pages_below_critical()) {
/*
* Still under pressure and unable to kill a process - purge corpse memory
*/
if (total_corpses_count() > 0) {
task_purge_all_corpses();
corpse_list_purged = TRUE;
}
if (memorystatus_avail_pages_below_critical()) {
/*
* Still under pressure and unable to kill a process - panic
*/
panic("memorystatus_jetsam_thread: no victim! available pages:%llu\n", (uint64_t)memorystatus_available_pages);
}
}
done:
}
```
可以看到它开启了一个 循环,memorystatus_action_needed() 来作为循环条件,持续释放内存。
```c++
static boolean_t
memorystatus_action_needed(void)
{
#if CONFIG_EMBEDDED
return (is_reason_thrashing(kill_under_pressure_cause) ||
is_reason_zone_map_exhaustion(kill_under_pressure_cause) ||
memorystatus_available_pages <= memorystatus_available_pages_pressure);
#else /* CONFIG_EMBEDDED */
return (is_reason_thrashing(kill_under_pressure_cause) ||
is_reason_zone_map_exhaustion(kill_under_pressure_cause));
#endif /* CONFIG_EMBEDDED */
}
```
它通过 vm_pagepout 发送的内存压力来判断当前内存资源是否紧张。几种情况:频繁的页面换出换进 is_reason_thrashing, Mach Zone 耗尽了 is_reason_zone_map_exhaustion、以及可用的页低于了 memory status_available_pages 这个门槛。
继续看 memorystatus_thread,会发现内存紧张时,将先触发 High-water 类型的 OOM,也就是说假如某个进程使用过程中超过了其使用内存的最高限制 hight water mark 时会发生 OOM。在 memorystatus_act_on_hiwat_processes() 中,通过 memorystatus_kill_hiwat_proc() 在优先级数组 memstat_bucket 中查找优先级最低的进程,如果进程的内存小于阈值(footprint_in_bytes <= memlimit_in_bytes)则继续寻找次优先级较低的进程,直到找到占用内存超过阈值的进程并杀死。
通常来说单个 App 很难触碰到 high water mark,如果不能结束任何进程,最终走到 memorystatus_act_aggressive,也就是大多数 OOM 发生的地方。
```c++
static boolean_t
memorystatus_act_aggressive(uint32_t cause, os_reason_t jetsam_reason, int *jld_idle_kills, boolean_t *corpse_list_purged, boolean_t *post_snapshot)
{
// ...
if ( (jld_bucket_count == 0) ||
(jld_now_msecs > (jld_timestamp_msecs + memorystatus_jld_eval_period_msecs))) {
/*
* Refresh evaluation parameters
*/
jld_timestamp_msecs = jld_now_msecs;
jld_idle_kill_candidates = jld_bucket_count;
*jld_idle_kills = 0;
jld_eval_aggressive_count = 0;
jld_priority_band_max = JETSAM_PRIORITY_UI_SUPPORT;
}
//...
}
```
上述代码看到,判断要不要真正执行 kill 是根据一定的时间间判断的,条件是 `jld_now_msecs > (jld_timestamp_msecs + memorystatus_jld_eval_period_msecs`。 也就是在 memorystatus_jld_eval_period_msecs 后才发生条件里面的 kill。
```C
/* Jetsam Loop Detection */
if (max_mem <= (512 * 1024 * 1024)) {
/* 512 MB devices */
memorystatus_jld_eval_period_msecs = 8000; /* 8000 msecs == 8 second window */
} else {
/* 1GB and larger devices */
memorystatus_jld_eval_period_msecs = 6000; /* 6000 msecs == 6 second window */
}
```
其中 memorystatus_jld_eval_period_msecs 取值最小 6 秒。所以我们可以在 6 秒内做些处理。
#### 3.2 开发者们整理所得
[stackoverflow](https://stackoverflow.com/questions/5887248/ios-app-maximum-memory-budget/15200855#15200855) 上有一份数据,整理了各种设备的 OOM 临界值
| device | crash amount:MB | total amount:MB | percentage of total |
| :--------------------------------: | :-------------: | :-------------: | :-----------------: |
| iPad1 | 127 | 256 | 49% |
| iPad2 | 275 | 512 | 53% |
| iPad3 | 645 | 1024 | 62% |
| iPad4(iOS 8.1) | 585 | 1024 | 57% |
| Pad Mini 1st Generation | 297 | 512 | 58% |
| iPad Mini retina(iOS 7.1) | 696 | 1024 | 68% |
| iPad Air | 697 | 1024 | 68% |
| iPad Air 2(iOS 10.2.1) | 1383 | 2048 | 68% |
| iPad Pro 9.7"(iOS 10.0.2 (14A456)) | 1395 | 1971 | 71% |
| iPad Pro 10.5”(iOS 11 beta4) | 3057 | 4000 | 76% |
| iPad Pro 12.9” (2015)(iOS 11.2.1) | 3058 | 3999 | 76% |
| iPad 10.2(iOS 13.2.3) | 1844 | 2998 | 62% |
| iPod touch 4th gen(iOS 6.1.1) | 130 | 256 | 51% |
| iPod touch 5th gen | 286 | 512 | 56% |
| iPhone4 | 325 | 512 | 63% |
| iPhone4s | 286 | 512 | 56% |
| iPhone5 | 645 | 1024 | 62% |
| iPhone5s | 646 | 1024 | 63% |
| iPhone6(iOS 8.x) | 645 | 1024 | 62% |
| iPhone6 Plus(iOS 8.x) | 645 | 1024 | 62% |
| iPhone6s(iOS 9.2) | 1396 | 2048 | 68% |
| iPhone6s Plus(iOS 10.2.1) | 1396 | 2048 | 68% |
| iPhoneSE(iOS 9.3) | 1395 | 2048 | 68% |
| iPhone7(iOS 10.2) | 1395 | 2048 | 68% |
| iPhone7 Plus(iOS 10.2.1) | 2040 | 3072 | 66% |
| iPhone8(iOS 12.1) | 1364 | 1990 | 70% |
| iPhoneX(iOS 11.2.1) | 1392 | 2785 | 50% |
| iPhoneXS(iOS 12.1) | 2040 | 3754 | 54% |
| iPhoneXS Max(iOS 12.1) | 2039 | 3735 | 55% |
| iPhoneXR(iOS 12.1) | 1792 | 2813 | 63% |
| iPhone11(iOS 13.1.3) | 2068 | 3844 | 54% |
| iPhone11 Pro Max(iOS 13.2.3) | 2067 | 3740 | 55% |
#### 3.3 触发当前 App 的 high water mark
我们可以写定时器,不断的申请内存,之后再通过 `phys_footprint` 打印当前占用内存,按道理来说不断申请内存即可触发 Jetsam 机制,强杀 App,那么**最后一次打印的内存占用也就是当前设备的内存上限值**。
```objective-c
timer = [NSTimer scheduledTimerWithTimeInterval:0.01 target:self selector:@selector(allocateMemory) userInfo:nil repeats:YES];
- (void)allocateMemory {
UIImageView *imageView = [[UIImageView alloc] initWithFrame:CGRectMake(0, 0, 100, 100)];
UIImage *image = [UIImage imageNamed:@"AppIcon"];
imageView.image = image;
[array addObject:imageView];
memoryLimitSizeMB = [self usedSizeOfMemory];
if (memoryWarningSizeMB && memoryLimitSizeMB) {
NSLog(@"----- memory warnning:%dMB, memory limit:%dMB", memoryWarningSizeMB, memoryLimitSizeMB);
}
}
- (int)usedSizeOfMemory {
task_vm_info_data_t taskInfo;
mach_msg_type_number_t infoCount = TASK_VM_INFO_COUNT;
kern_return_t kernReturn = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t)&taskInfo, &infoCount);
if (kernReturn != KERN_SUCCESS) {
return 0;
}
return (int)(taskInfo.phys_footprint/1024.0/1024.0);
}
```
#### 3.4 适用于 iOS13 系统的获取方式
iOS13 开始 <os/proc.h> 中 `size_t os_proc_available_memory(void); ` 可以查看当前可用内存。
> Return Value
>
> The number of bytes that the app may allocate before it hits its memory limit. If the calling process isn't an app, or if the process has already exceeded its memory limit, this function returns `0`.
>
> Discussion
>
> Call this function to determine the amount of memory available to your app. The returned value corresponds to the current memory limit minus the memory footprint of your app at the time of the function call. Your app's memory footprint consists of the data that you allocated in RAM, and that must stay in RAM (or the equivalent) at all times. Memory limits can change during the app life cycle and don't necessarily correspond to the amount of physical memory available on the device.
>
> Use the returned value as advisory information only and don't cache it. The precise value changes when your app does any work that affects memory, which can happen frequently.
>
> Although this function lets you determine the amount of memory your app may safely consume, don't use it to maximize your app's memory usage. Significant memory use, even when under the current memory limit, affects system performance. For example, when your app consumes all of its available memory, the system may need to terminate other apps and system processes to accommodate your app's requests. Instead, always consume the smallest amount of memory you need to be responsive to the user's needs.
>
> If you need more detailed information about the available memory resources, you can call [`task_info`](apple-reference-documentation://hcPGvbcfam). However, be aware that `task_info` is an expensive call, whereas this function is much more efficient.
```objective-c
if (@available(iOS 13.0, *)) {
return os_proc_available_memory() / 1024.0 / 1024.0;
}
```
App 内存信息的 API 可以在 Mach 层找到,`mach_task_basic_info` 结构体存储了 Mach task 的内存使用信息,其中 phys_footprint 就是应用使用的物理内存大小,virtual_size 是虚拟内存大小。
```Objective-c
#define MACH_TASK_BASIC_INFO 20 /* always 64-bit basic info */
struct mach_task_basic_info {
mach_vm_size_t virtual_size; /* virtual memory size (bytes) */
mach_vm_size_t resident_size; /* resident memory size (bytes) */
mach_vm_size_t resident_size_max; /* maximum resident memory size (bytes) */
time_value_t user_time; /* total user run time for
terminated threads */
time_value_t system_time; /* total system run time for
terminated threads */
policy_t policy; /* default policy for new threads */
integer_t suspend_count; /* suspend count for task */
};
```
所以获取代码为
```Objective-c
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
kern_return_t kr = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t)&vmInfo, &count);
if (kr != KERN_SUCCESS) {
return ;
}
CGFloat memoryUsed = (CGFloat)(vmInfo.phys_footprint/1024.0/1024.0);
```
可能有人好奇不应该是 `resident_size` 这个字段获取内存的使用情况吗?一开始测试后发现 resident_size 和 Xcode 测量结果差距较大。而使用 phys_footprint 则接近于 Xcode 给出的结果。且可以从 [WebKit 源码](https://github.com/WebKit/webkit/blob/52bc6f0a96a062cb0eb76e9a81497183dc87c268/Source/WTF/wtf/cocoa/MemoryFootprintCocoa.cpp)中得到印证。
所以在 iOS13 上,我们可以通过 `os_proc_available_memory` 获取到当前可以用内存,通过 `phys_footprint` 获取到当前 App 占用内存,2 者的和也就是当前设备的内存上限,超过即触发 Jetsam 机制。
```objective-c
- (CGFloat)limitSizeOfMemory {
if (@available(iOS 13.0, *)) {
task_vm_info_data_t taskInfo;
mach_msg_type_number_t infoCount = TASK_VM_INFO_COUNT;
kern_return_t kernReturn = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t)&taskInfo, &infoCount);
if (kernReturn != KERN_SUCCESS) {
return 0;
}
return (CGFloat)((taskInfo.phys_footprint + os_proc_available_memory()) / (1024.0 * 1024.0);
}
return 0;
}
```
当前可以使用内存:1435.936752MB;当前 App 已占用内存:14.5MB,临界值:1435.936752MB + 14.5MB= 1450.436MB, 和 3.1 方法中获取到的内存临界值一样「iPhone 6s plus/13.3.1 手机 OOM 临界值为:(16384\*92806)/(1024\*1024)=1450.09375M」。
#### 3.5 通过 XNU 获取内存限制值
在 XNU 中,有专门用于获取内存上限值的函数和宏,可以通过 `memorystatus_priority_entry` 这个结构体得到所有进程的优先级和内存限制值。
```objective-c
typedef struct memorystatus_priority_entry {
pid_t pid;
int32_t priority;
uint64_t user_data;
int32_t limit;
uint32_t state;
} memorystatus_priority_entry_t;
```
其中,priority 代表进程优先级,limit 代表进程的内存限制值。但是这种方式需要 root 权限,由于没有越狱设备,我没有尝试过。
相关代码可查阅 `kern_memorystatus.h` 文件。需要用到函数 `int memorystatus_control(uint32_t command, int32_t pid, uint32_t flags, void *buffer, size_t buffersize);`
```c
/* Commands */
#define MEMORYSTATUS_CMD_GET_PRIORITY_LIST 1
#define MEMORYSTATUS_CMD_SET_PRIORITY_PROPERTIES 2
#define MEMORYSTATUS_CMD_GET_JETSAM_SNAPSHOT 3
#define MEMORYSTATUS_CMD_GET_PRESSURE_STATUS 4
#define MEMORYSTATUS_CMD_SET_JETSAM_HIGH_WATER_MARK 5 /* Set active memory limit = inactive memory limit, both non-fatal */
#define MEMORYSTATUS_CMD_SET_JETSAM_TASK_LIMIT 6 /* Set active memory limit = inactive memory limit, both fatal */
#define MEMORYSTATUS_CMD_SET_MEMLIMIT_PROPERTIES 7 /* Set memory limits plus attributes independently */
#define MEMORYSTATUS_CMD_GET_MEMLIMIT_PROPERTIES 8 /* Get memory limits plus attributes */
#define MEMORYSTATUS_CMD_PRIVILEGED_LISTENER_ENABLE 9 /* Set the task's status as a privileged listener w.r.t memory notifications */
#define MEMORYSTATUS_CMD_PRIVILEGED_LISTENER_DISABLE 10 /* Reset the task's status as a privileged listener w.r.t memory notifications */
#define MEMORYSTATUS_CMD_AGGRESSIVE_JETSAM_LENIENT_MODE_ENABLE 11 /* Enable the 'lenient' mode for aggressive jetsam. See comments in kern_memorystatus.c near the top. */
#define MEMORYSTATUS_CMD_AGGRESSIVE_JETSAM_LENIENT_MODE_DISABLE 12 /* Disable the 'lenient' mode for aggressive jetsam. */
#define MEMORYSTATUS_CMD_GET_MEMLIMIT_EXCESS 13 /* Compute how much a process's phys_footprint exceeds inactive memory limit */
#define MEMORYSTATUS_CMD_ELEVATED_INACTIVEJETSAMPRIORITY_ENABLE 14 /* Set the inactive jetsam band for a process to JETSAM_PRIORITY_ELEVATED_INACTIVE */
#define MEMORYSTATUS_CMD_ELEVATED_INACTIVEJETSAMPRIORITY_DISABLE 15 /* Reset the inactive jetsam band for a process to the default band (0)*/
#define MEMORYSTATUS_CMD_SET_PROCESS_IS_MANAGED 16 /* (Re-)Set state on a process that marks it as (un-)managed by a system entity e.g. assertiond */
#define MEMORYSTATUS_CMD_GET_PROCESS_IS_MANAGED 17 /* Return the 'managed' status of a process */
#define MEMORYSTATUS_CMD_SET_PROCESS_IS_FREEZABLE 18 /* Is the process eligible for freezing? Apps and extensions can pass in FALSE to opt out of freezing, i.e.,
```
伪代码
```objective-c
struct memorystatus_priority_entry memStatus[NUM_ENTRIES];
size_t count = sizeof(struct memorystatus_priority_entry) * NUM_ENTRIES;
int kernResult = memorystatus_control(MEMORYSTATUS_CMD_GET_PRIORITY_LIST, 0, 0, memStatus, count);
if (rc < 0) {
NSLog(@"memorystatus_control");
return ;
}
int entry = 0;
for (; rc > 0; rc -= sizeof(struct memorystatus_priority_entry)){
printf ("PID: %5d\tPriority:%2d\tUser Data: %llx\tLimit:%2d\tState:%s\n",
memstatus[entry].pid,
memstatus[entry].priority,
memstatus[entry].user_data,
memstatus[entry].limit,
state_to_text(memstatus[entry].state));
entry++;
}
```
for 循环打印出每个进程(也就是 App)的 pid、Priority、User Data、Limit、State 信息。从 log 中找出优先级为 10 的进程,即我们前台运行的 App。为什么是 10? 因为 `#define JETSAM_PRIORITY_FOREGROUND 10` 我们的目的就是获取前台 App 的内存上限值。
### 4. 如何判定发生了 OOM
OOM 导致 crash 前,app 一定会收到低内存警告吗?
做 2 组对比实验:
```objective-c
// 实验1
NSMutableArray *array = [NSMutableArray array];
for (NSInteger index = 0; index < 10000000; index++) {
NSString *filePath = [[NSBundle mainBundle] pathForResource:@"Info" ofType:@"plist"];
NSData *data = [NSData dataWithContentsOfFile:filePath];
[array addObject:data];
}
```
```objective-c
// 实验2
// ViewController.m
- (void)viewDidLoad {
[super viewDidLoad];
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSMutableArray *array = [NSMutableArray array];
for (NSInteger index = 0; index < 10000000; index++) {
NSString *filePath = [[NSBundle mainBundle] pathForResource:@"Info" ofType:@"plist"];
NSData *data = [NSData dataWithContentsOfFile:filePath];
[array addObject:data];
}
});
}
- (void)didReceiveMemoryWarning
{
NSLog(@"2");
}
// AppDelegate.m
- (void)applicationDidReceiveMemoryWarning:(UIApplication *)application
{
NSLog(@"1");
}
```
现象:
1. 在 viewDidLoad 也就是主线程中内存消耗过大,系统并不会发出低内存警告,直接 Crash。因为内存增长过快,主线程很忙。
2. 多线程的情况下,App 因内存增长过快,会收到低内存警告,AppDelegate 中的`applicationDidReceiveMemoryWarning` 先执行,随后是当前 VC 的 `didReceiveMemoryWarning`。
结论:
**收到低内存警告不一定会 Crash,因为有 6 秒钟的系统判断时间,6 秒内内存下降了则不会 crash。发生 OOM 也不一定会收到低内存警告。**
### 5. 内存信息收集
要想精确的定位问题,就需要 dump 所有对象及其内存信息。当内存接近系统内存上限的时候,收集并记录所需信息,结合一定的数据上报机制,上传到服务器,分析并修复。
还需要知道每个对象具体是在哪个函数里创建出来的,以便还原“案发现场”。
源代码(libmalloc/malloc),内存分配函数 malloc 和 calloc 等默认使用 nano_zone,nano_zone 是小于 256B 以下的内存分配,大于 256B 则使用 scalable_zone 来分配。
主要针对大内存的分配监控。malloc 函数用的是 malloc_zone_malloc, calloc 用的是 malloc_zone_calloc。
使用 scalable_zone 分配内存的函数都会调用 malloc_logger 函数,因为系统为了有个地方专门统计并管理内存分配情况。这样的设计也满足「收口原则」。
```c++
void *
malloc(size_t size)
{
void *retval;
retval = malloc_zone_malloc(default_zone, size);
if (retval == NULL) {
errno = ENOMEM;
}
return retval;
}
void *
calloc(size_t num_items, size_t size)
{
void *retval;
retval = malloc_zone_calloc(default_zone, num_items, size);
if (retval == NULL) {
errno = ENOMEM;
}
return retval;
}
```
首先来看看这个 `default_zone` 是什么东西, 代码如下
```c++
typedef struct {
malloc_zone_t malloc_zone;
uint8_t pad[PAGE_MAX_SIZE - sizeof(malloc_zone_t)];
} virtual_default_zone_t;
static virtual_default_zone_t virtual_default_zone
__attribute__((section("__DATA,__v_zone")))
__attribute__((aligned(PAGE_MAX_SIZE))) = {
NULL,
NULL,
default_zone_size,
default_zone_malloc,
default_zone_calloc,
default_zone_valloc,
default_zone_free,
default_zone_realloc,
default_zone_destroy,
DEFAULT_MALLOC_ZONE_STRING,
default_zone_batch_malloc,
default_zone_batch_free,
&default_zone_introspect,
10,
default_zone_memalign,
default_zone_free_definite_size,
default_zone_pressure_relief,
default_zone_malloc_claimed_address,
};
static malloc_zone_t *default_zone = &virtual_default_zone.malloc_zone;
static void *
default_zone_malloc(malloc_zone_t *zone, size_t size)
{
zone = runtime_default_zone();
return zone->malloc(zone, size);
}
MALLOC_ALWAYS_INLINE
static inline malloc_zone_t *
runtime_default_zone() {
return (lite_zone) ? lite_zone : inline_malloc_default_zone();
}
```
可以看到 `default_zone` 通过这种方式来初始化
```c++
static inline malloc_zone_t *
inline_malloc_default_zone(void)
{
_malloc_initialize_once();
// malloc_report(ASL_LEVEL_INFO, "In inline_malloc_default_zone with %d %d\n", malloc_num_zones, malloc_has_debug_zone);
return malloc_zones[0];
}
```
**随后的调用如下**
`_malloc_initialize` -> `create_scalable_zone` -> `create_scalable_szone` 最终我们创建了 szone_t 类型的对象,通过类型转换,得到了我们的 default_zone。
```c++
malloc_zone_t *
create_scalable_zone(size_t initial_size, unsigned debug_flags) {
return (malloc_zone_t *) create_scalable_szone(initial_size, debug_flags);
}
```
```c++
void *malloc_zone_malloc(malloc_zone_t *zone, size_t size)
{
MALLOC_TRACE(TRACE_malloc | DBG_FUNC_START, (uintptr_t)zone, size, 0, 0);
void *ptr;
if (malloc_check_start && (malloc_check_counter++ >= malloc_check_start)) {
internal_check();
}
if (size > MALLOC_ABSOLUTE_MAX_SIZE) {
return NULL;
}
ptr = zone->malloc(zone, size);
// 在 zone 分配完内存后就开始使用 malloc_logger 进行进行记录
if (malloc_logger) {
malloc_logger(MALLOC_LOG_TYPE_ALLOCATE | MALLOC_LOG_TYPE_HAS_ZONE, (uintptr_t)zone, (uintptr_t)size, 0, (uintptr_t)ptr, 0);
}
MALLOC_TRACE(TRACE_malloc | DBG_FUNC_END, (uintptr_t)zone, size, (uintptr_t)ptr, 0);
return ptr;
}
```
其分配实现是 `zone->malloc` 根据之前的分析,就是 szone_t 结构体对象中对应的 malloc 实现。
在创建 szone 之后,做了一系列如下的初始化操作。
```c++
// Initialize the security token.
szone->cookie = (uintptr_t)malloc_entropy[0];
szone->basic_zone.version = 12;
szone->basic_zone.size = (void *)szone_size;
szone->basic_zone.malloc = (void *)szone_malloc;
szone->basic_zone.calloc = (void *)szone_calloc;
szone->basic_zone.valloc = (void *)szone_valloc;
szone->basic_zone.free = (void *)szone_free;
szone->basic_zone.realloc = (void *)szone_realloc;
szone->basic_zone.destroy = (void *)szone_destroy;
szone->basic_zone.batch_malloc = (void *)szone_batch_malloc;
szone->basic_zone.batch_free = (void *)szone_batch_free;
szone->basic_zone.introspect = (struct malloc_introspection_t *)&szone_introspect;
szone->basic_zone.memalign = (void *)szone_memalign;
szone->basic_zone.free_definite_size = (void *)szone_free_definite_size;
szone->basic_zone.pressure_relief = (void *)szone_pressure_relief;
szone->basic_zone.claimed_address = (void *)szone_claimed_address;
```
其他使用 scalable_zone 分配内存的函数的方法也类似,所以大内存的分配,不管外部函数如何封装,最终都会调用到 malloc_logger 函数。所以我们可以用 fishhook 去 hook 这个函数,然后记录内存分配情况,结合一定的数据上报机制,上传到服务器,分析并修复。
```
// For logging VM allocation and deallocation, arg1 here
// is the mach_port_name_t of the target task in which the
// alloc or dealloc is occurring. For example, for mmap()
// that would be mach_task_self(), but for a cross-task-capable
// call such as mach_vm_map(), it is the target task.
typedef void (malloc_logger_t)(uint32_t type, uintptr_t arg1, uintptr_t arg2, uintptr_t arg3, uintptr_t result, uint32_t num_hot_frames_to_skip);
extern malloc_logger_t *__syscall_logger;
```
当 malloc_logger 和 \_\_syscall_logger 函数指针不为空时,malloc/free、vm_allocate/vm_deallocate 等内存分配/释放通过这两个指针通知上层,这也是内存调试工具 malloc stack 的实现原理。有了这两个函数指针,我们很容易记录当前存活对象的内存分配信息(包括分配大小和分配堆栈)。分配堆栈可以用 backtrace 函数捕获,但捕获到的地址是虚拟内存地址,不能从符号表 DSYM 解析符号。所以还要记录每个 image 加载时的偏移 slide,这样 **符号表地址 = 堆栈地址 - slide。**
小 tips:
ASLR(Address space layout randomization):常见称呼为位址空间随机载入、位址空间配置随机化、位址空间布局随机化,是一种防止内存损坏漏洞被利用的计算机安全技术,通过随机放置进程关键数据区域的定址空间来放置攻击者能可靠地跳转到内存的特定位置来操作函数。现代作业系统一般都具备该机制。
函数地址 add: 函数真实的实现地址;
函数虚拟地址:`vm_add`;
ASLR: `slide` 函数虚拟地址加载到进程内存的随机偏移量,每个 mach-o 的 slide 各不相同。`vm_add + slide = add`。也就是:`*(base +offset)= imp`。
由于腾讯也开源了自己的 OOM 定位方案- [OOMDetector](https://github.com/Tencent/OOMDetector) ,有了现成的轮子,那么用好就可以了,所以对于内存的监控思路就是找到系统给 App 的内存上限,然后当接近内存上限值的时候,dump 内存情况,组装基础数据信息成一个合格的上报数据,经过一定的数据上报策略到服务端,服务端消费数据,分析产生报表,客户端工程师根据报表分析问题。不同工程的数据以邮件、短信、企业微信等形式通知到该项目的 owner、开发者。(情况严重的会直接电话给开发者,并给主管跟进每一步的处理结果)。
问题分析处理后要么发布新版本,要么 hot fix。
### 6. 开发阶段针对内存我们能做些什么
1. 图片缩放
WWDC 2018 Session 416 - iOS Memory Deep Dive,处理图片缩放的时候直接使用 UIImage 会在解码时读取文件而占用一部分内存,还会生成中间位图 bitmap 消耗大量内存。而 **ImageIO** 不存在上述 2 种弊端,只会占用最终图片大小的内存
做了 2 组对比实验:给 App 显示一张图片
```objective-c
// 方法1: 19.6M
UIImage *imageResult = [self scaleImage:[UIImage imageNamed:@"test"] newSize:CGSizeMake(self.view.frame.size.width, self.view.frame.size.height)];
self.imageView.image = imageResult;
// 方法2: 14M
NSData *data = UIImagePNGRepresentation([UIImage imageNamed:@"test"]);
UIImage *imageResult = [self scaledImageWithData:data withSize:CGSizeMake(self.view.frame.size.width, self.view.frame.size.height) scale:3 orientation:UIImageOrientationUp];
self.imageView.image = imageResult;
- (UIImage *)scaleImage:(UIImage *)image newSize:(CGSize)newSize
{
UIGraphicsBeginImageContextWithOptions(newSize, NO, 0);
[image drawInRect:CGRectMake(0, 0, newSize.width, newSize.height)];
UIImage *newImage = UIGraphicsGetImageFromCurrentImageContext();
UIGraphicsEndImageContext();
return newImage;
}
- (UIImage *)scaledImageWithData:(NSData *)data withSize:(CGSize)size scale:(CGFloat)scale orientation:(UIImageOrientation)orientation
{
CGFloat maxPixelSize = MAX(size.width, size.height);
CGImageSourceRef sourceRef = CGImageSourceCreateWithData((__bridge CFDataRef)data, nil);
NSDictionary *options = @{(__bridge id)kCGImageSourceCreateThumbnailFromImageAlways : (__bridge id)kCFBooleanTrue,
(__bridge id)kCGImageSourceThumbnailMaxPixelSize : [NSNumber numberWithFloat:maxPixelSize]};
CGImageRef imageRef = CGImageSourceCreateThumbnailAtIndex(sourceRef, 0, (__bridge CFDictionaryRef)options);
UIImage *resultImage = [UIImage imageWithCGImage:imageRef scale:scale orientation:orientation];
CGImageRelease(imageRef);
CFRelease(sourceRef);
return resultImage;
}
```
可以看出使用 ImageIO 比使用 UIImage 直接缩放占用内存更低。
2. 合理使用 autoreleasepool
我们知道 autoreleasepool 对象是在 RunLoop 结束时才释放。在 ARC 下,我们如果在不断申请内存,比如各种循环,那么我们就需要手动添加 autoreleasepool,避免短时间内内存猛涨发生 OOM。
对比实验
```objective-c
// 实验1
NSMutableArray *array = [NSMutableArray array];
for (NSInteger index = 0; index < 10000000; index++) {
NSString *indexStrng = [NSString stringWithFormat:@"%zd", index];
NSString *resultString = [NSString stringWithFormat:@"%zd-%@", index, indexStrng];
[array addObject:resultString];
}
// 实验2
NSMutableArray *array = [NSMutableArray array];
for (NSInteger index = 0; index < 10000000; index++) {
@autoreleasepool {
NSString *indexStrng = [NSString stringWithFormat:@"%zd", index];
NSString *resultString = [NSString stringWithFormat:@"%zd-%@", index, indexStrng];
[array addObject:resultString];
}
}
```
实验 1 消耗内存 739.6M,实验 2 消耗内存 587M。
3. UIGraphicsBeginImageContext 和 UIGraphicsEndImageContext 必须成双出现,不然会造成 context 泄漏。另外 XCode 的 Analyze 也能扫出这类问题。
4. 不管是打开网页,还是执行 js,都应该使用 WKWebView。UIWebView 会占用大量内存,从而导致 App 发生 OOM 的几率增加,而 WKWebView 是一个多进程组件,Network Loading 以及 UI Rendering 在其它进程中执行,比 UIWebView 占用更低的内存开销。
5. 在做 SDK 或者 App,如果场景是缓存相关,尽量使用 NSCache 而不是 NSMutableDictionary。它是系统提供的专门处理缓存的类,NSCache 分配的内存是 `Purgeable Memory`,可以由系统自动释放。NSCache 与 NSPureableData 的结合使用可以让系统根据情况回收内存,也可以在内存清理时移除对象。
其他的开发习惯就不一一描述了,良好的开发习惯和代码意识是需要平时注意修炼的。
### 7. 现状及其改进
在使用了一波业界优秀的的内存监控工具后发现了一些问题,比如 `MLeaksFinder`、`OOMDetector`、`FBRetainCycleDetector`等都有一些问题。比如 `MLeaksFinder` 因为单纯通过 VC 的 push、pop 等检测内存泄露的情况,会存在误报的情况。`FBRetainCycleDetector` 则因为对象深度优先遍历,会有一些性能问题,影响 App 性能。`OOMDetector` 因为没有合适的触发时机。
思路有 2 种:
- `MLeaksFinder` + `FBRetainCycleDetector` 结合提高准确性
- 借鉴头条的实现方案:基于内存快照技术的线上方案,我们称之为——线上 Memory Graph。(引用如下)
> - 基于 Objective-C 对象引用关系找循环引用的方案,适用范围比较小,只能处理部分循环引用问题,而内存问题通常是复杂的,类似于内存堆积,Root Leak,C/C++层问题都无法解决。
> - 基于分配堆栈信息聚类的方案需要常驻运行,对内存、CPU 等资源存在较大消耗,无法针对有内存问题的用户进行监控,只能广撒网,用户体验影响较大。同时,通过某些比较通用的堆栈分配的内存无法定位出实际的内存使用场景,对于循环引用等常见泄漏也无法分析。
核心原理是: 扫描进程中所有的 Dirty 内存,通过内存节点中保存的其他内存节点的地址值,建立起内存节点之间的引用关系的有向图。
全部的讲解可以看[这里](<(https://mp.weixin.qq.com/s/4-4M9E8NziAgshlwB7Sc6g)>)。对于 Memory Graph 的实现细节感兴趣的可以看这篇[文章](https://juejin.cn/post/6895583288451465230)
## 五、 App 网络监控
移动网络环境一直很复杂,WIFI、2G、3G、4G、5G 等,用户使用 App 的过程中可能在这几种类型之间切换,这也是移动网络和传统网络间的一个区别,被称为「Connection Migration」。此外还存在 DNS 解析缓慢、失败率高、运营商劫持等问题。用户在使用 App 时因为某些原因导致体验很差,要想针对网络情况进行改善,必须有清晰的监控手段。
### 1. App 网络请求过程
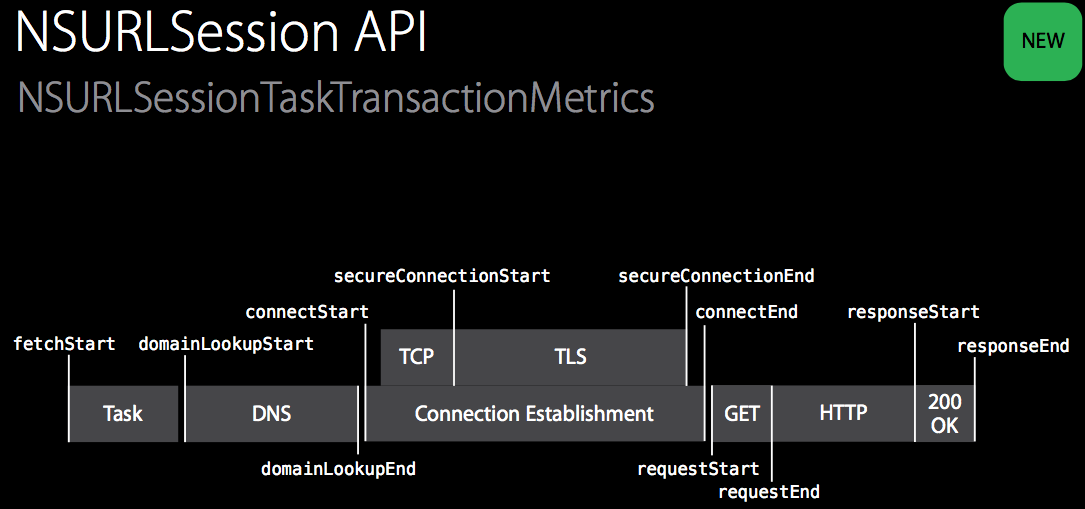
App 发送一次网络请求一般会经历下面几个关键步骤:
- DNS 解析
Domain Name system,网络域名名称系统,本质上就是将`域名`和`IP 地址` 相互映射的一个分布式数据库,使人们更方便的访问互联网。首先会查询本地的 DNS 缓存,查找失败就去 DNS 服务器查询,这其中可能会经过非常多的节点,涉及到**递归查询和迭代查询**的过程。运营商可能不干人事:一种情况就是出现运营商劫持的现象,表现为你在 App 内访问某个网页的时候会看到和内容不相关的广告;另一种可能的情况就是把你的请求丢给非常远的基站去做 DNS 解析,导致我们 App 的 DNS 解析时间较长,App 网络效率低。一般做 HTTPDNS 方案去自行解决 DNS 的问题。
- TCP 3 次握手
关于 TCP 握手过程中为什么是 3 次握手而不是 2 次、4 次,可以查看这篇[文章](https://draveness.me/whys-the-design-tcp-three-way-handshake/)。
- TLS 握手
对于 HTTPS 请求还需要做 TLS 握手,也就是密钥协商的过程。
- 发送请求
连接建立好之后就可以发送 request,此时可以记录下 request start 时间
- 等待回应
等待服务器返回响应。这个时间主要取决于资源大小,也是网络请求过程中最为耗时的一个阶段。
- 返回响应
服务端返回响应给客户端,根据 HTTP header 信息中的状态码判断本次请求是否成功、是否走缓存、是否需要重定向。
### 2. 监控原理
| 名称 | 说明 |
| :-------------: | :---------------------: |
| NSURLConnection | 已经被废弃。用法简单 |
| NSURLSession | iOS7.0 推出,功能更强大 |
| CFNetwork | NSURL 的底层,纯 C 实现 |
iOS 网络框架层级关系如下:
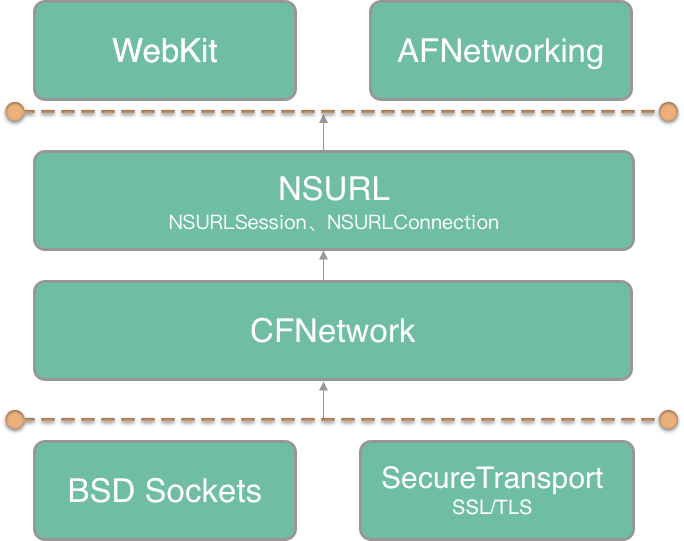
iOS 网络现状是由 4 层组成的:最底层的 BSD Sockets、SecureTransport;次级底层是 CFNetwork、NSURLSession、NSURLConnection、WebView 是用 Objective-C 实现的,且调用 CFNetwork;应用层框架 AFNetworking 基于 NSURLSession、NSURLConnection 实现。
目前业界对于网络监控主要有 2 种:一种是通过 NSURLProtocol 监控、一种是通过 Hook 来监控。下面介绍几种办法来监控网络请求,各有优缺点。
#### 2.1 方案一:NSURLProtocol 监控 App 网络请求<a name="network-2.1"></a>
NSURLProtocol 作为上层接口,使用较为简单,但 NSURLProtocol 属于 URL Loading System 体系中。应用协议的支持程度有限,支持 FTP、HTTP、HTTPS 等几个应用层协议,对于其他的协议则无法监控,存在一定的局限性。如果监控底层网络库 CFNetwork 则没有这个限制。
对于 NSURLProtocol 的具体做法在[这篇文章](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.83.md)中讲过,继承抽象类并实现相应的方法,自定义去发起网络请求来实现监控的目的。
iOS 10 之后,NSURLSessionTaskDelegate 中增加了一个新的代理方法:
```objective-c
/*
* Sent when complete statistics information has been collected for the task.
*/
- (void)URLSession:(NSURLSession *)session task:(NSURLSessionTask *)task didFinishCollectingMetrics:(NSURLSessionTaskMetrics *)metrics API_AVAILABLE(macosx(10.12), ios(10.0), watchos(3.0), tvos(10.0));
```
可以从 `NSURLSessionTaskMetrics` 中获取到网络情况的各项指标。各项参数如下
```objective-c
@interface NSURLSessionTaskMetrics : NSObject
/*
* transactionMetrics array contains the metrics collected for every request/response transaction created during the task execution.
*/
@property (copy, readonly) NSArray<NSURLSessionTaskTransactionMetrics *> *transactionMetrics;
/*
* Interval from the task creation time to the task completion time.
* Task creation time is the time when the task was instantiated.
* Task completion time is the time when the task is about to change its internal state to completed.
*/
@property (copy, readonly) NSDateInterval *taskInterval;
/*
* redirectCount is the number of redirects that were recorded.
*/
@property (assign, readonly) NSUInteger redirectCount;
- (instancetype)init API_DEPRECATED("Not supported", macos(10.12,10.15), ios(10.0,13.0), watchos(3.0,6.0), tvos(10.0,13.0));
+ (instancetype)new API_DEPRECATED("Not supported", macos(10.12,10.15), ios(10.0,13.0), watchos(3.0,6.0), tvos(10.0,13.0));
@end
```
其中:`taskInterval` 表示任务从创建到完成话费的总时间,任务的创建时间是任务被实例化时的时间,任务完成时间是任务的内部状态将要变为完成的时间;`redirectCount` 表示被重定向的次数;`transactionMetrics` 数组包含了任务执行过程中每个请求/响应事务中收集的指标,各项参数如下:
```objective-c
/*
* This class defines the performance metrics collected for a request/response transaction during the task execution.
*/
API_AVAILABLE(macosx(10.12), ios(10.0), watchos(3.0), tvos(10.0))
@interface NSURLSessionTaskTransactionMetrics : NSObject
/*
* Represents the transaction request. 请求事务
*/
@property (copy, readonly) NSURLRequest *request;
/*
* Represents the transaction response. Can be nil if error occurred and no response was generated. 响应事务
*/
@property (nullable, copy, readonly) NSURLResponse *response;
/*
* For all NSDate metrics below, if that aspect of the task could not be completed, then the corresponding “EndDate” metric will be nil.
* For example, if a name lookup was started but the name lookup timed out, failed, or the client canceled the task before the name could be resolved -- then while domainLookupStartDate may be set, domainLookupEndDate will be nil along with all later metrics.
*/
/*
* 客户端开始请求的时间,无论是从服务器还是从本地缓存中获取
* fetchStartDate returns the time when the user agent started fetching the resource, whether or not the resource was retrieved from the server or local resources.
*
* The following metrics will be set to nil, if a persistent connection was used or the resource was retrieved from local resources:
*
* domainLookupStartDate
* domainLookupEndDate
* connectStartDate
* connectEndDate
* secureConnectionStartDate
* secureConnectionEndDate
*/
@property (nullable, copy, readonly) NSDate *fetchStartDate;
/*
* domainLookupStartDate returns the time immediately before the user agent started the name lookup for the resource. DNS 开始解析的时间
*/
@property (nullable, copy, readonly) NSDate *domainLookupStartDate;
/*
* domainLookupEndDate returns the time after the name lookup was completed. DNS 解析完成的时间
*/
@property (nullable, copy, readonly) NSDate *domainLookupEndDate;
/*
* connectStartDate is the time immediately before the user agent started establishing the connection to the server.
*
* For example, this would correspond to the time immediately before the user agent started trying to establish the TCP connection. 客户端与服务端开始建立 TCP 连接的时间
*/
@property (nullable, copy, readonly) NSDate *connectStartDate;
/*
* If an encrypted connection was used, secureConnectionStartDate is the time immediately before the user agent started the security handshake to secure the current connection. HTTPS 的 TLS 握手开始的时间
*
* For example, this would correspond to the time immediately before the user agent started the TLS handshake.
*
* If an encrypted connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSDate *secureConnectionStartDate;
/*
* If an encrypted connection was used, secureConnectionEndDate is the time immediately after the security handshake completed. HTTPS 的 TLS 握手结束的时间
*
* If an encrypted connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSDate *secureConnectionEndDate;
/*
* connectEndDate is the time immediately after the user agent finished establishing the connection to the server, including completion of security-related and other handshakes. 客户端与服务器建立 TCP 连接完成的时间,包括 TLS 握手时间
*/
@property (nullable, copy, readonly) NSDate *connectEndDate;
/*
* requestStartDate is the time immediately before the user agent started requesting the source, regardless of whether the resource was retrieved from the server or local resources.
客户端请求开始的时间,可以理解为开始传输 HTTP 请求的 header 的第一个字节时间
*
* For example, this would correspond to the time immediately before the user agent sent an HTTP GET request.
*/
@property (nullable, copy, readonly) NSDate *requestStartDate;
/*
* requestEndDate is the time immediately after the user agent finished requesting the source, regardless of whether the resource was retrieved from the server or local resources.
客户端请求结束的时间,可以理解为 HTTP 请求的最后一个字节传输完成的时间
*
* For example, this would correspond to the time immediately after the user agent finished sending the last byte of the request.
*/
@property (nullable, copy, readonly) NSDate *requestEndDate;
/*
* responseStartDate is the time immediately after the user agent received the first byte of the response from the server or from local resources.
客户端从服务端接收响应的第一个字节的时间
*
* For example, this would correspond to the time immediately after the user agent received the first byte of an HTTP response.
*/
@property (nullable, copy, readonly) NSDate *responseStartDate;
/*
* responseEndDate is the time immediately after the user agent received the last byte of the resource. 客户端从服务端接收到最后一个请求的时间
*/
@property (nullable, copy, readonly) NSDate *responseEndDate;
/*
* The network protocol used to fetch the resource, as identified by the ALPN Protocol ID Identification Sequence [RFC7301].
* E.g., h2, http/1.1, spdy/3.1.
网络协议名,比如 http/1.1, spdy/3.1
*
* When a proxy is configured AND a tunnel connection is established, then this attribute returns the value for the tunneled protocol.
*
* For example:
* If no proxy were used, and HTTP/2 was negotiated, then h2 would be returned.
* If HTTP/1.1 were used to the proxy, and the tunneled connection was HTTP/2, then h2 would be returned.
* If HTTP/1.1 were used to the proxy, and there were no tunnel, then http/1.1 would be returned.
*
*/
@property (nullable, copy, readonly) NSString *networkProtocolName;
/*
* This property is set to YES if a proxy connection was used to fetch the resource.
该连接是否使用了代理
*/
@property (assign, readonly, getter=isProxyConnection) BOOL proxyConnection;
/*
* This property is set to YES if a persistent connection was used to fetch the resource.
是否复用了现有连接
*/
@property (assign, readonly, getter=isReusedConnection) BOOL reusedConnection;
/*
* Indicates whether the resource was loaded, pushed or retrieved from the local cache.
获取资源来源
*/
@property (assign, readonly) NSURLSessionTaskMetricsResourceFetchType resourceFetchType;
/*
* countOfRequestHeaderBytesSent is the number of bytes transferred for request header.
请求头的字节数
*/
@property (readonly) int64_t countOfRequestHeaderBytesSent API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* countOfRequestBodyBytesSent is the number of bytes transferred for request body.
请求体的字节数
* It includes protocol-specific framing, transfer encoding, and content encoding.
*/
@property (readonly) int64_t countOfRequestBodyBytesSent API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* countOfRequestBodyBytesBeforeEncoding is the size of upload body data, file, or stream.
上传体数据、文件、流的大小
*/
@property (readonly) int64_t countOfRequestBodyBytesBeforeEncoding API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* countOfResponseHeaderBytesReceived is the number of bytes transferred for response header.
响应头的字节数
*/
@property (readonly) int64_t countOfResponseHeaderBytesReceived API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* countOfResponseBodyBytesReceived is the number of bytes transferred for response body.
响应体的字节数
* It includes protocol-specific framing, transfer encoding, and content encoding.
*/
@property (readonly) int64_t countOfResponseBodyBytesReceived API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* countOfResponseBodyBytesAfterDecoding is the size of data delivered to your delegate or completion handler.
给代理方法或者完成后处理的回调的数据大小
*/
@property (readonly) int64_t countOfResponseBodyBytesAfterDecoding API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* localAddress is the IP address string of the local interface for the connection.
当前连接下的本地接口 IP 地址
*
* For multipath protocols, this is the local address of the initial flow.
*
* If a connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSString *localAddress API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* localPort is the port number of the local interface for the connection.
当前连接下的本地端口号
*
* For multipath protocols, this is the local port of the initial flow.
*
* If a connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSNumber *localPort API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* remoteAddress is the IP address string of the remote interface for the connection.
当前连接下的远端 IP 地址
*
* For multipath protocols, this is the remote address of the initial flow.
*
* If a connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSString *remoteAddress API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* remotePort is the port number of the remote interface for the connection.
当前连接下的远端端口号
*
* For multipath protocols, this is the remote port of the initial flow.
*
* If a connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSNumber *remotePort API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* negotiatedTLSProtocolVersion is the TLS protocol version negotiated for the connection.
连接协商用的 TLS 协议版本号
* It is a 2-byte sequence in host byte order.
*
* Please refer to tls_protocol_version_t enum in Security/SecProtocolTypes.h
*
* If an encrypted connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSNumber *negotiatedTLSProtocolVersion API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* negotiatedTLSCipherSuite is the TLS cipher suite negotiated for the connection.
连接协商用的 TLS 密码套件
* It is a 2-byte sequence in host byte order.
*
* Please refer to tls_ciphersuite_t enum in Security/SecProtocolTypes.h
*
* If an encrypted connection was not used, this attribute is set to nil.
*/
@property (nullable, copy, readonly) NSNumber *negotiatedTLSCipherSuite API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* Whether the connection is established over a cellular interface.
是否是通过蜂窝网络建立的连接
*/
@property (readonly, getter=isCellular) BOOL cellular API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* Whether the connection is established over an expensive interface.
是否通过昂贵的接口建立的连接
*/
@property (readonly, getter=isExpensive) BOOL expensive API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* Whether the connection is established over a constrained interface.
是否通过受限接口建立的连接
*/
@property (readonly, getter=isConstrained) BOOL constrained API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
/*
* Whether a multipath protocol is successfully negotiated for the connection.
是否为了连接成功协商了多路径协议
*/
@property (readonly, getter=isMultipath) BOOL multipath API_AVAILABLE(macos(10.15), ios(13.0), watchos(6.0), tvos(13.0));
- (instancetype)init API_DEPRECATED("Not supported", macos(10.12,10.15), ios(10.0,13.0), watchos(3.0,6.0), tvos(10.0,13.0));
+ (instancetype)new API_DEPRECATED("Not supported", macos(10.12,10.15), ios(10.0,13.0), watchos(3.0,6.0), tvos(10.0,13.0));
@end
```
网络监控简单代码
```objective-c
// 监控基础信息
@interface NetworkMonitorBaseDataModel : NSObject
// 请求的 URL 地址
@property (nonatomic, strong) NSString *requestUrl;
//请求头
@property (nonatomic, strong) NSArray *requestHeaders;
//响应头
@property (nonatomic, strong) NSArray *responseHeaders;
//GET方法 的请求参数
@property (nonatomic, strong) NSString *getRequestParams;
//HTTP 方法, 比如 POST
@property (nonatomic, strong) NSString *httpMethod;
//协议名,如http1.0 / http1.1 / http2.0
@property (nonatomic, strong) NSString *httpProtocol;
//是否使用代理
@property (nonatomic, assign) BOOL useProxy;
//DNS解析后的 IP 地址
@property (nonatomic, strong) NSString *ip;
@end
// 监控信息模型
@interface NetworkMonitorDataModel : NetworkMonitorBaseDataModel
//客户端发起请求的时间
@property (nonatomic, assign) UInt64 requestDate;
//客户端开始请求到开始dns解析的等待时间,单位ms
@property (nonatomic, assign) int waitDNSTime;
//DNS 解析耗时
@property (nonatomic, assign) int dnsLookupTime;
//tcp 三次握手耗时,单位ms
@property (nonatomic, assign) int tcpTime;
//ssl 握手耗时
@property (nonatomic, assign) int sslTime;
//一个完整请求的耗时,单位ms
@property (nonatomic, assign) int requestTime;
//http 响应码
@property (nonatomic, assign) NSUInteger httpCode;
//发送的字节数
@property (nonatomic, assign) UInt64 sendBytes;
//接收的字节数
@property (nonatomic, assign) UInt64 receiveBytes;
// 错误信息模型
@interface NetworkMonitorErrorModel : NetworkMonitorBaseDataModel
//错误码
@property (nonatomic, assign) NSInteger errorCode;
//错误次数
@property (nonatomic, assign) NSUInteger errCount;
//异常名
@property (nonatomic, strong) NSString *exceptionName;
//异常详情
@property (nonatomic, strong) NSString *exceptionDetail;
//异常堆栈
@property (nonatomic, strong) NSString *stackTrace;
@end
// 继承自 NSURLProtocol 抽象类,实现响应方法,代理网络请求
@interface CustomURLProtocol () <NSURLSessionTaskDelegate>
@property (nonatomic, strong) NSURLSessionDataTask *dataTask;
@property (nonatomic, strong) NSOperationQueue *sessionDelegateQueue;
@property (nonatomic, strong) NetworkMonitorDataModel *dataModel;
@property (nonatomic, strong) NetworkMonitorErrorModel *errModel;
@end
//使用NSURLSessionDataTask请求网络
- (void)startLoading {
NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration];
NSURLSession *session = [NSURLSession sessionWithConfiguration:configuration
delegate:self
delegateQueue:nil];
NSURLSession *session = [NSURLSession sessionWithConfiguration:configuration delegate:self delegateQueue:nil];
self.sessionDelegateQueue = [[NSOperationQueue alloc] init];
self.sessionDelegateQueue.maxConcurrentOperationCount = 1;
self.sessionDelegateQueue.name = @"com.networkMonitor.session.queue";
self.dataTask = [session dataTaskWithRequest:self.request];
[self.dataTask resume];
}
#pragma mark - NSURLSessionTaskDelegate
- (void)URLSession:(NSURLSession *)session task:(NSURLSessionTask *)task didCompleteWithError:(NSError *)error {
if (error) {
[self.client URLProtocol:self didFailWithError:error];
} else {
[self.client URLProtocolDidFinishLoading:self];
}
if (error) {
NSURLRequest *request = task.currentRequest;
if (request) {
self.errModel.requestUrl = request.URL.absoluteString;
self.errModel.httpMethod = request.HTTPMethod;
self.errModel.requestParams = request.URL.query;
}
self.errModel.errorCode = error.code;
self.errModel.exceptionName = error.domain;
self.errModel.exceptionDetail = error.description;
// 上传 Network 数据到数据上报组件,数据上报会在 [打造功能强大、灵活可配置的数据上报组件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md) 讲
}
self.dataTask = nil;
}
- (void)URLSession:(NSURLSession *)session task:(NSURLSessionTask *)task didFinishCollectingMetrics:(NSURLSessionTaskMetrics *)metrics {
if (@available(iOS 10.0, *) && [metrics.transactionMetrics count] > 0) {
[metrics.transactionMetrics enumerateObjectsUsingBlock:^(NSURLSessionTaskTransactionMetrics *_Nonnull obj, NSUInteger idx, BOOL *_Nonnull stop) {
if (obj.resourceFetchType == NSURLSessionTaskMetricsResourceFetchTypeNetworkLoad) {
if (obj.fetchStartDate) {
self.dataModel.requestDate = [obj.fetchStartDate timeIntervalSince1970] * 1000;
}
if (obj.domainLookupStartDate && obj.domainLookupEndDate) {
self.dataModel. waitDNSTime = ceil([obj.domainLookupStartDate timeIntervalSinceDate:obj.fetchStartDate] * 1000);
self.dataModel. dnsLookupTime = ceil([obj.domainLookupEndDate timeIntervalSinceDate:obj.domainLookupStartDate] * 1000);
}
if (obj.connectStartDate) {
if (obj.secureConnectionStartDate) {
self.dataModel. waitDNSTime = ceil([obj.secureConnectionStartDate timeIntervalSinceDate:obj.connectStartDate] * 1000);
} else if (obj.connectEndDate) {
self.dataModel.tcpTime = ceil([obj.connectEndDate timeIntervalSinceDate:obj.connectStartDate] * 1000);
}
}
if (obj.secureConnectionEndDate && obj.secureConnectionStartDate) {
self.dataModel.sslTime = ceil([obj.secureConnectionEndDate timeIntervalSinceDate:obj.secureConnectionStartDate] * 1000);
}
if (obj.fetchStartDate && obj.responseEndDate) {
self.dataModel.requestTime = ceil([obj.responseEndDate timeIntervalSinceDate:obj.fetchStartDate] * 1000);
}
self.dataModel.httpProtocol = obj.networkProtocolName;
NSHTTPURLResponse *response = (NSHTTPURLResponse *)obj.response;
if ([response isKindOfClass:NSHTTPURLResponse.class]) {
self.dataModel.receiveBytes = response.expectedContentLength;
}
if ([obj respondsToSelector:@selector(_remoteAddressAndPort)]) {
self.dataModel.ip = [obj valueForKey:@"_remoteAddressAndPort"];
}
if ([obj respondsToSelector:@selector(_requestHeaderBytesSent)]) {
self.dataModel.sendBytes = [[obj valueForKey:@"_requestHeaderBytesSent"] unsignedIntegerValue];
}
if ([obj respondsToSelector:@selector(_responseHeaderBytesReceived)]) {
self.dataModel.receiveBytes = [[obj valueForKey:@"_responseHeaderBytesReceived"] unsignedIntegerValue];
}
self.dataModel.requestUrl = [obj.request.URL absoluteString];
self.dataModel.httpMethod = obj.request.HTTPMethod;
self.dataModel.useProxy = obj.isProxyConnection;
}
}];
// 上传 Network 数据到数据上报组件,数据上报会在 [打造功能强大、灵活可配置的数据上报组件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md) 讲
}
}
```
#### 2.2 方案二:NSURLProtocol 监控 App 网络请求之黑魔法篇 <a name="network-2.2"></a>
文章上面 [2.1 ](#network-2.1)分析到了 NSURLSessionTaskMetrics 由于兼容性问题,对于网络监控来说似乎不太完美,但是自后在搜资料的时候看到了一篇[文章](https://www.jianshu.com/p/1c34147030d1)。文章在分析 WebView 的网络监控的时候分析 Webkit 源码的时候发现了下面代码
```objective-c
#if !HAVE(TIMINGDATAOPTIONS)
void setCollectsTimingData()
{
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
[NSURLConnection _setCollectsTimingData:YES];
...
});
}
#endif
```
也就是说明 NSURLConnection 本身有一套 `TimingData` 的收集 API,只是没有暴露给开发者,苹果自己在用而已。在 runtime header 中找到了 NSURLConnection 的 `_setCollectsTimingData:` 、`_timingData` 2 个 api(iOS8 以后可以使用)。
NSURLSession 在 iOS9 之前使用 `_setCollectsTimingData:` 就可以使用 TimingData 了。
注意:
- 因为是私有 API,所以在使用的时候注意混淆。比如 `[[@"_setC" stringByAppendingString:@"ollectsT"] stringByAppendingString:@"imingData:"]`。
- 不推荐私有 API,一般做 APM 的属于公共团队,你想想看虽然你做的 SDK 达到网络监控的目的了,但是万一给业务线的 App 上架造成了问题,那就得不偿失了。一般这种投机取巧,不是百分百确定的事情可以在玩具阶段使用。
```objective-c
@interface _NSURLConnectionProxy : DelegateProxy
@end
@implementation _NSURLConnectionProxy
- (BOOL)respondsToSelector:(SEL)aSelector
{
if ([NSStringFromSelector(aSelector) isEqualToString:@"connectionDidFinishLoading:"]) {
return YES;
}
return [self.target respondsToSelector:aSelector];
}
- (void)forwardInvocation:(NSInvocation *)invocation
{
[super forwardInvocation:invocation];
if ([NSStringFromSelector(invocation.selector) isEqualToString:@"connectionDidFinishLoading:"]) {
__unsafe_unretained NSURLConnection *conn;
[invocation getArgument:&conn atIndex:2];
SEL selector = NSSelectorFromString([@"_timin" stringByAppendingString:@"gData"]);
NSDictionary *timingData = [conn performSelector:selector];
[[NTDataKeeper shareInstance] trackTimingData:timingData request:conn.currentRequest];
}
}
@end
@implementation NSURLConnection(tracker)
+ (void)load
{
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
Class class = [self class];
SEL originalSelector = @selector(initWithRequest:delegate:);
SEL swizzledSelector = @selector(swizzledInitWithRequest:delegate:);
Method originalMethod = class_getInstanceMethod(class, originalSelector);
Method swizzledMethod = class_getInstanceMethod(class, swizzledSelector);
method_exchangeImplementations(originalMethod, swizzledMethod);
NSString *selectorName = [[@"_setC" stringByAppendingString:@"ollectsT"] stringByAppendingString:@"imingData:"];
SEL selector = NSSelectorFromString(selectorName);
[NSURLConnection performSelector:selector withObject:@(YES)];
});
}
- (instancetype)swizzledInitWithRequest:(NSURLRequest *)request delegate:(id<NSURLConnectionDelegate>)delegate
{
if (delegate) {
_NSURLConnectionProxy *proxy = [[_NSURLConnectionProxy alloc] initWithTarget:delegate];
objc_setAssociatedObject(delegate ,@"_NSURLConnectionProxy" ,proxy, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
return [self swizzledInitWithRequest:request delegate:(id<NSURLConnectionDelegate>)proxy];
}else{
return [self swizzledInitWithRequest:request delegate:delegate];
}
}
@end
```
#### 2.3 方案三:Hook
iOS 中 hook 技术有 2 类,一种是 NSProxy,一种是 method swizzling(isa swizzling)
##### 2.3.1 方法一
写 SDK 肯定不可能手动侵入业务代码(你没那个权限提交到线上代码 😂),所以不管是 APM 还是无痕埋点都是通过 Hook 的方式。
面向切面程序设计(Aspect-oriented Programming,AOP)是计算机科学中的一种程序设计范型,将**横切关注点**与业务主体进一步分离,以提高程序代码的模块化程度。在不修改源代码的情况下给程序动态增加功能。其核心思想是将业务逻辑(核心关注点,系统主要功能)与公共功能(横切关注点,比如日志系统)进行分离,降低复杂性,保持系统模块化程度、可维护性、可重用性。常被用在日志系统、性能统计、安全控制、事务处理、异常处理等场景下。
在 iOS 中 AOP 的实现是基于 Runtime 机制,目前由 3 种方式:Method Swizzling、NSProxy、FishHook(主要用用于 hook c 代码)。
文章上面 [2.1 ](#network-2.1)讨论了满足大多数的需求的场景,NSURLProtocol 监控了 NSURLConnection、NSURLSession 的网络请求,自身代理后可以发起网络请求并得到诸如请求开始时间、请求结束时间、header 信息等,但是无法得到非常详细的网络性能数据,比如 DNS 开始解析时间、DNS 解析用了多久、reponse 开始返回的时间、返回了多久等。 iOS10 之后 NSURLSessionTaskDelegate 增加了一个代理方法 `- (void)URLSession:(NSURLSession *)session task:(NSURLSessionTask *)task didFinishCollectingMetrics:(NSURLSessionTaskMetrics *)metrics API_AVAILABLE(macosx(10.12), ios(10.0), watchos(3.0), tvos(10.0));`,可以获取到精确的各项网络数据。但是具有兼容性。文章上面 [2.2 ](#network-2.2)讨论了从 Webkit 源码中得到的信息,通过私有方法 `_setCollectsTimingData:` 、`_timingData` 可以获取到 TimingData。
但是如果需要监全部的网络请求就不能满足需求了,查阅资料后发现了阿里百川有 APM 的解决方案,于是有了方案 3,对于网络监控需要做如下的处理
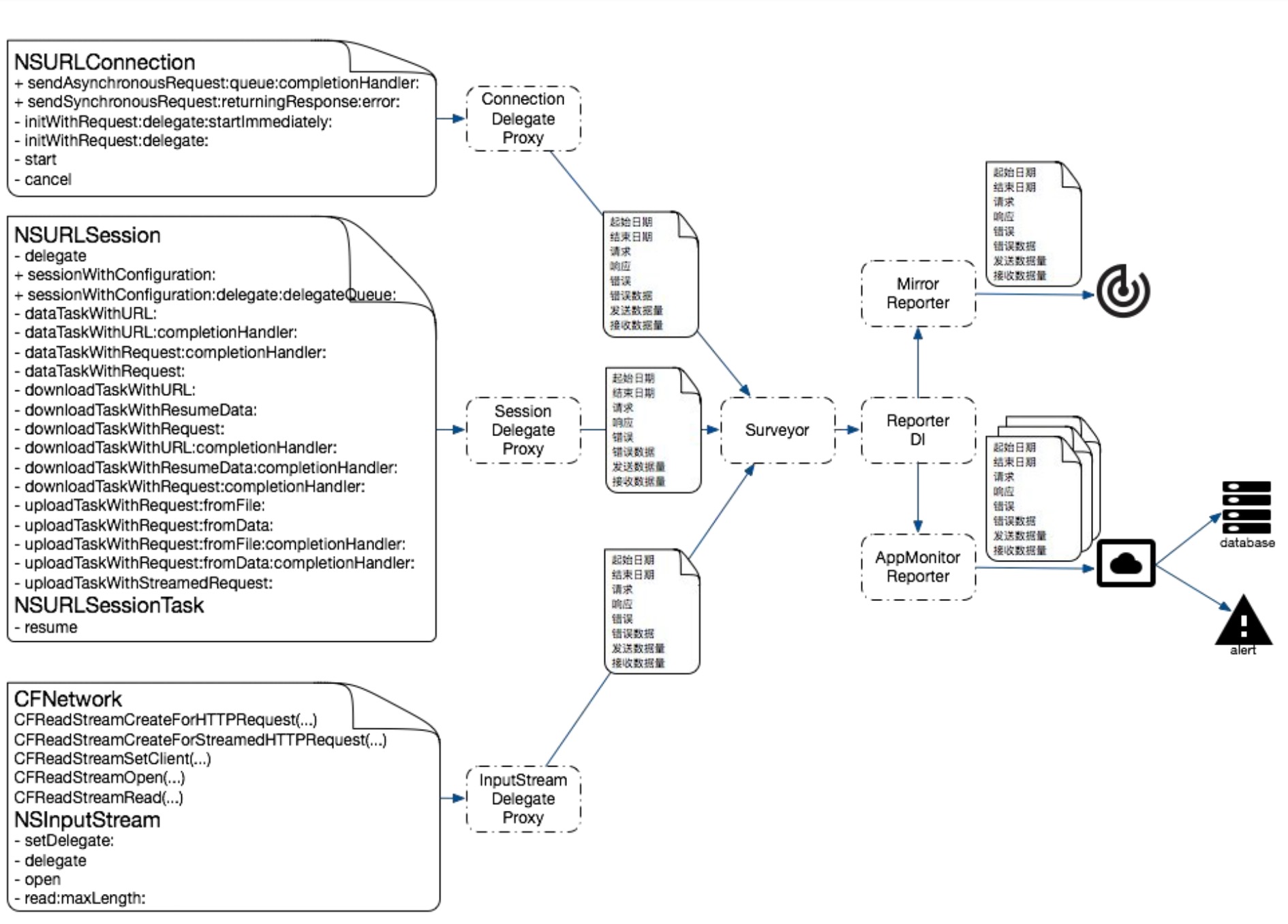
可能对于 CFNetwork 比较陌生,可以看一下 CFNetwork 的层级和简单用法
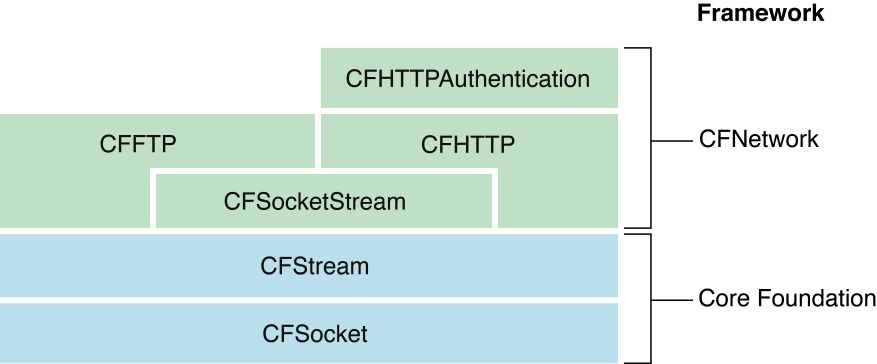
CFNetwork 的基础是 CFSocket 和 CFStream。
CFSocket:Socket 是网络通信的底层基础,可以让 2 个 socket 端口互发数据,iOS 中最常用的 socket 抽象是 BSD socket。而 CFSocket 是 BSD socket 的 OC 包装,几乎实现了所有的 BSD 功能,此外加入了 RunLoop。
CFStream:提供了与设备无关的读写数据方法,使用它可以为内存、文件、网络(使用 socket)的数据建立流,使用 stream 可以不必将所有数据写入到内存中。CFStream 提供 API 对 2 种 CFType 对象提供抽象:CFReadStream、CFWriteStream。同时也是 CFHTTP、CFFTP 的基础。
简单 Demo
```objective-c
- (void)testCFNetwork
{
CFURLRef urlRef = CFURLCreateWithString(kCFAllocatorDefault, CFSTR("https://httpbin.org/get"), NULL);
CFHTTPMessageRef httpMessageRef = CFHTTPMessageCreateRequest(kCFAllocatorDefault, CFSTR("GET"), urlRef, kCFHTTPVersion1_1);
CFRelease(urlRef);
CFReadStreamRef readStream = CFReadStreamCreateForHTTPRequest(kCFAllocatorDefault, httpMessageRef);
CFRelease(httpMessageRef);
CFReadStreamScheduleWithRunLoop(readStream, CFRunLoopGetCurrent(), kCFRunLoopCommonModes);
CFOptionFlags eventFlags = (kCFStreamEventHasBytesAvailable | kCFStreamEventErrorOccurred | kCFStreamEventEndEncountered);
CFStreamClientContext context = {
0,
NULL,
NULL,
NULL,
NULL
} ;
// Assigns a client to a stream, which receives callbacks when certain events occur.
CFReadStreamSetClient(readStream, eventFlags, CFNetworkRequestCallback, &context);
// Opens a stream for reading.
CFReadStreamOpen(readStream);
}
// callback
void CFNetworkRequestCallback (CFReadStreamRef _Null_unspecified stream, CFStreamEventType type, void * _Null_unspecified clientCallBackInfo) {
CFMutableDataRef responseBytes = CFDataCreateMutable(kCFAllocatorDefault, 0);
CFIndex numberOfBytesRead = 0;
do {
UInt8 buffer[2014];
numberOfBytesRead = CFReadStreamRead(stream, buffer, sizeof(buffer));
if (numberOfBytesRead > 0) {
CFDataAppendBytes(responseBytes, buffer, numberOfBytesRead);
}
} while (numberOfBytesRead > 0);
CFHTTPMessageRef response = (CFHTTPMessageRef)CFReadStreamCopyProperty(stream, kCFStreamPropertyHTTPResponseHeader);
if (responseBytes) {
if (response) {
CFHTTPMessageSetBody(response, responseBytes);
}
CFRelease(responseBytes);
}
// close and cleanup
CFReadStreamClose(stream);
CFReadStreamUnscheduleFromRunLoop(stream, CFRunLoopGetCurrent(), kCFRunLoopCommonModes);
CFRelease(stream);
// print response
if (response) {
CFDataRef reponseBodyData = CFHTTPMessageCopyBody(response);
CFRelease(response);
printResponseData(reponseBodyData);
CFRelease(reponseBodyData);
}
}
void printResponseData (CFDataRef responseData) {
CFIndex dataLength = CFDataGetLength(responseData);
UInt8 *bytes = (UInt8 *)malloc(dataLength);
CFDataGetBytes(responseData, CFRangeMake(0, CFDataGetLength(responseData)), bytes);
CFStringRef responseString = CFStringCreateWithBytes(kCFAllocatorDefault, bytes, dataLength, kCFStringEncodingUTF8, TRUE);
CFShow(responseString);
CFRelease(responseString);
free(bytes);
}
// console
{
"args": {},
"headers": {
"Host": "httpbin.org",
"User-Agent": "Test/1 CFNetwork/1125.2 Darwin/19.3.0",
"X-Amzn-Trace-Id": "Root=1-5e8980d0-581f3f44724c7140614c2564"
},
"origin": "183.159.122.102",
"url": "https://httpbin.org/get"
}
```
我们知道 NSURLSession、NSURLConnection、CFNetwork 的使用都需要调用一堆方法进行设置然后需要设置代理对象,实现代理方法。所以针对这种情况进行监控首先想到的是使用 runtime hook 掉方法层级。但是针对设置的代理对象的代理方法没办法 hook,因为不知道代理对象是哪个类。所以想办法可以 hook 设置代理对象这个步骤,将代理对象替换成我们设计好的某个类,然后让这个类去实现 NSURLConnection、NSURLSession、CFNetwork 相关的代理方法。然后在这些方法的内部都去调用一下原代理对象的方法实现。所以我们的需求得以满足,我们在相应的方法里面可以拿到监控数据,比如请求开始时间、结束时间、状态码、内容大小等。
NSURLSession、NSURLConnection hook 如下。
业界有 APM 针对 CFNetwork 的方案,整理描述下:
CFNetwork 是 c 语言实现的,要对 c 代码进行 hook 需要使用 Dynamic Loader Hook 库 - [fishhook](https://github.com/facebook/fishhook)。
> **Dynamic Loader**(dyld)通过更新 **Mach-O** 文件中保存的指针的方法来绑定符号。借用它可以在 **Runtime** 修改 **C** 函数调用的函数指针。**fishhook** 的实现原理:遍历 `__DATA segment` 里面 `__nl_symbol_ptr` 、`__la_symbol_ptr` 两个 section 里面的符号,通过 Indirect Symbol Table、Symbol Table 和 String Table 的配合,找到自己要替换的函数,达到 hook 的目的。
> /\* Returns the number of bytes read, or -1 if an error occurs preventing any
>
> bytes from being read, or 0 if the stream's end was encountered.
>
> It is an error to try and read from a stream that hasn't been opened first.
>
> This call will block until at least one byte is available; it will NOT block
>
> until the entire buffer can be filled. To avoid blocking, either poll using
>
> CFReadStreamHasBytesAvailable() or use the run loop and listen for the
>
> kCFStreamEventHasBytesAvailable event for notification of data available. \*/
>
> CF_EXPORT
>
> CFIndex CFReadStreamRead(CFReadStreamRef **\_Null_unspecified** stream, UInt8 \* **\_Null_unspecified** buffer, CFIndex bufferLength);
CFNetwork 使用 CFReadStreamRef 来传递数据,使用回调函数的形式来接受服务器的响应。当回调函数受到
具体步骤及其关键代码如下,以 NSURLConnection 举例
- 因为要 Hook 挺多地方,所以写一个 method swizzling 的工具类
```objective-c
#import <Foundation/Foundation.h>
NS_ASSUME_NONNULL_BEGIN
@interface NSObject (hook)
/**
hook对象方法
@param originalSelector 需要hook的原始对象方法
@param swizzledSelector 需要替换的对象方法
*/
+ (void)apm_swizzleMethod:(SEL)originalSelector swizzledSelector:(SEL)swizzledSelector;
/**
hook类方法
@param originalSelector 需要hook的原始类方法
@param swizzledSelector 需要替换的类方法
*/
+ (void)apm_swizzleClassMethod:(SEL)originalSelector swizzledSelector:(SEL)swizzledSelector;
@end
NS_ASSUME_NONNULL_END
+ (void)apm_swizzleMethod:(SEL)originalSelector swizzledSelector:(SEL)swizzledSelector
{
class_swizzleInstanceMethod(self, originalSelector, swizzledSelector);
}
+ (void)apm_swizzleClassMethod:(SEL)originalSelector swizzledSelector:(SEL)swizzledSelector
{
//类方法实际上是储存在类对象的类(即元类)中,即类方法相当于元类的实例方法,所以只需要把元类传入,其他逻辑和交互实例方法一样。
Class class2 = object_getClass(self);
class_swizzleInstanceMethod(class2, originalSelector, swizzledSelector);
}
void class_swizzleInstanceMethod(Class class, SEL originalSEL, SEL replacementSEL)
{
Method originMethod = class_getInstanceMethod(class, originalSEL);
Method replaceMethod = class_getInstanceMethod(class, replacementSEL);
if(class_addMethod(class, originalSEL, method_getImplementation(replaceMethod),method_getTypeEncoding(replaceMethod)))
{
class_replaceMethod(class,replacementSEL, method_getImplementation(originMethod), method_getTypeEncoding(originMethod));
}else {
method_exchangeImplementations(originMethod, replaceMethod);
}
}
```
- 建立一个继承自 NSProxy 抽象类的类,实现相应方法。
```objective-c
#import <Foundation/Foundation.h>
NS_ASSUME_NONNULL_BEGIN
// 为 NSURLConnection、NSURLSession、CFNetwork 代理设置代理转发
@interface NetworkDelegateProxy : NSProxy
+ (instancetype)setProxyForObject:(id)originalTarget withNewDelegate:(id)newDelegate;
@end
NS_ASSUME_NONNULL_END
// .m
@interface NetworkDelegateProxy () {
id _originalTarget;
id _NewDelegate;
}
@end
```
@implementation NetworkDelegateProxy
#pragma mark - life cycle
+ (instancetype)sharedInstance {
static NetworkDelegateProxy *_sharedInstance = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
_sharedInstance = [NetworkDelegateProxy alloc];
});
return _sharedInstance;
}
#pragma mark - public Method
+ (instancetype)setProxyForObject:(id)originalTarget withNewDelegate:(id)newDelegate
{
NetworkDelegateProxy *instance = [NetworkDelegateProxy sharedInstance];
instance->_originalTarget = originalTarget;
instance->_NewDelegate = newDelegate;
return instance;
}
- (void)forwardInvocation:(NSInvocation *)invocation
{
if ([_originalTarget respondsToSelector:invocation.selector]) {
[invocation invokeWithTarget:_originalTarget];
[((NSURLSessionAndConnectionImplementor *)_NewDelegate) invoke:invocation];
}
}
- (nullable NSMethodSignature *)methodSignatureForSelector:(SEL)sel
{
return [_originalTarget methodSignatureForSelector:sel];
}
@end
```
- 创建一个对象,实现 NSURLConnection、NSURLSession、NSIuputStream 代理方法
```objective-c
// NetworkImplementor.m
#pragma mark-NSURLConnectionDelegate
- (void)connection:(NSURLConnection *)connection didFailWithError:(NSError *)error {
NSLog(@"%s", __func__);
}
- (nullable NSURLRequest *)connection:(NSURLConnection *)connection willSendRequest:(NSURLRequest *)request redirectResponse:(nullable NSURLResponse *)response {
NSLog(@"%s", __func__);
return request;
}
#pragma mark-NSURLConnectionDataDelegate
- (void)connection:(NSURLConnection *)connection didReceiveResponse:(NSURLResponse *)response {
NSLog(@"%s", __func__);
}
- (void)connection:(NSURLConnection *)connection didReceiveData:(NSData *)data {
NSLog(@"%s", __func__);
}
- (void)connection:(NSURLConnection *)connection didSendBodyData:(NSInteger)bytesWritten
totalBytesWritten:(NSInteger)totalBytesWritten
totalBytesExpectedToWrite:(NSInteger)totalBytesExpectedToWrite {
NSLog(@"%s", __func__);
}
- (void)connectionDidFinishLoading:(NSURLConnection *)connection {
NSLog(@"%s", __func__);
}
#pragma mark-NSURLConnectionDownloadDelegate
- (void)connection:(NSURLConnection *)connection didWriteData:(long long)bytesWritten totalBytesWritten:(long long)totalBytesWritten expectedTotalBytes:(long long) expectedTotalBytes {
NSLog(@"%s", __func__);
}
- (void)connectionDidResumeDownloading:(NSURLConnection *)connection totalBytesWritten:(long long)totalBytesWritten expectedTotalBytes:(long long) expectedTotalBytes {
NSLog(@"%s", __func__);
}
- (void)connectionDidFinishDownloading:(NSURLConnection *)connection destinationURL:(NSURL *) destinationURL {
NSLog(@"%s", __func__);
}
// 根据需求自己去写需要监控的数据项
```
- 给 NSURLConnection 添加 Category,专门设置 hook 代理对象、hook NSURLConnection 对象方法
```objective-c
// NSURLConnection+Monitor.m
@implementation NSURLConnection (Monitor)
+ (void)load
{
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
@autoreleasepool {
[[self class] apm_swizzleMethod:@selector(apm_initWithRequest:delegate:) swizzledSelector:@selector(initWithRequest: delegate:)];
}
});
}
- (_Nonnull instancetype)apm_initWithRequest:(NSURLRequest *)request delegate:(nullable id)delegate
{
/*
1. 在设置 Delegate 的时候替换 delegate。
2. 因为要在每个代理方法里面,监控数据,所以需要将代理方法都 hook 下
3. 在原代理方法执行的时候,让新的代理对象里面,去执行方法的转发,
*/
NSString *traceId = @"traceId";
NSMutableURLRequest *rq = [request mutableCopy];
NSString *preTraceId = [request.allHTTPHeaderFields valueForKey:@"head_key_traceid"];
if (preTraceId) {
// 调用 hook 之前的初始化方法,返回 NSURLConnection
return [self apm_initWithRequest:rq delegate:delegate];
} else {
[rq setValue:traceId forHTTPHeaderField:@"head_key_traceid"];
NSURLSessionAndConnectionImplementor *mockDelegate = [NSURLSessionAndConnectionImplementor new];
[self registerDelegateMethod:@"connection:didFailWithError:" originalDelegate:delegate newDelegate:mockDelegate flag:"v@:@@"];
[self registerDelegateMethod:@"connection:didReceiveResponse:" originalDelegate:delegate newDelegate:mockDelegate flag:"v@:@@"];
[self registerDelegateMethod:@"connection:didReceiveData:" originalDelegate:delegate newDelegate:mockDelegate flag:"v@:@@"];
[self registerDelegateMethod:@"connection:didFailWithError:" originalDelegate:delegate newDelegate:mockDelegate flag:"v@:@@"];
[self registerDelegateMethod:@"connectionDidFinishLoading:" originalDelegate:delegate newDelegate:mockDelegate flag:"v@:@"];
[self registerDelegateMethod:@"connection:willSendRequest:redirectResponse:" originalDelegate:delegate newDelegate:mockDelegate flag:"@@:@@"];
delegate = [NetworkDelegateProxy setProxyForObject:delegate withNewDelegate:mockDelegate];
// 调用 hook 之前的初始化方法,返回 NSURLConnection
return [self apm_initWithRequest:rq delegate:delegate];
}
}
- (void)registerDelegateMethod:(NSString *)methodName originalDelegate:(id<NSURLConnectionDelegate>)originalDelegate newDelegate:(NSURLSessionAndConnectionImplementor *)newDelegate flag:(const char *)flag
{
if ([originalDelegate respondsToSelector:NSSelectorFromString(methodName)]) {
IMP originalMethodImp = class_getMethodImplementation([originalDelegate class], NSSelectorFromString(methodName));
IMP newMethodImp = class_getMethodImplementation([newDelegate class], NSSelectorFromString(methodName));
if (originalMethodImp != newMethodImp) {
[newDelegate registerSelector: methodName];
NSLog(@"");
}
} else {
class_addMethod([originalDelegate class], NSSelectorFromString(methodName), class_getMethodImplementation([newDelegate class], NSSelectorFromString(methodName)), flag);
}
}
@end
```
这样下来就是可以监控到网络信息了,然后将数据交给数据上报 SDK,按照下发的数据上报策略去上报数据。
##### 2.3.2 方法二
其实,针对上述的需求还有另一种方法一样可以达到目的,那就是 **isa swizzling**。
顺道说一句,上面针对 NSURLConnection、NSURLSession、NSInputStream 代理对象的 hook 之后,利用 NSProxy 实现代理对象方法的转发,有另一种方法可以实现,那就是 **isa swizzling**。
- Method swizzling 原理
```objective-c
struct old_method {
SEL method_name;
char *method_types;
IMP method_imp;
};
```
method swizzling 改进版如下
```objective-c
Method originalMethod = class_getInstanceMethod(aClass, aSEL);
IMP originalIMP = method_getImplementation(originalMethod);
char *cd = method_getTypeEncoding(originalMethod);
IMP newIMP = imp_implementationWithBlock(^(id self) {
void (*tmp)(id self, SEL _cmd) = originalIMP;
tmp(self, aSEL);
});
class_replaceMethod(aClass, aSEL, newIMP, cd);
```
- isa swizzling
```objective-c
/// Represents an instance of a class.
struct objc_object {
Class _Nonnull isa OBJC_ISA_AVAILABILITY;
};
/// A pointer to an instance of a class.
typedef struct objc_object *id;
```
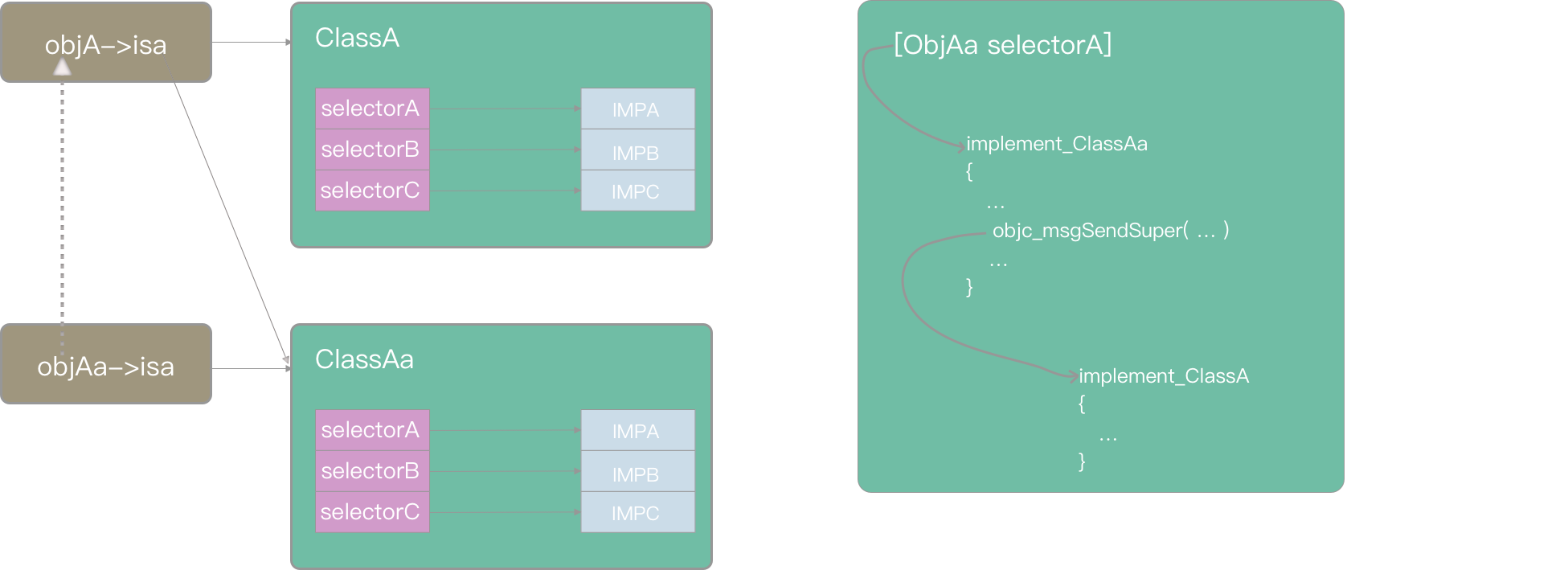
我们来分析一下为什么修改 `isa` 可以实现目的呢?
1. 写 APM 监控的人没办法确定业务代码
2. 不可能为了方便监控 APM,写某些类,让业务线开发者别使用系统 NSURLSession、NSURLConnection 类
想想 KVO 的实现原理?结合上面的图
- 创建监控对象子类
- 重写子类中属性的 getter、setter
- 将监控对象的 isa 指针指向新创建的子类
- 在子类的 getter、setter 中拦截值的变化,通知监控对象值的变化
- 监控完之后将监控对象的 isa 还原回去
按照这个思路,我们也可以对 NSURLConnection、NSURLSession 的 load 方法中动态创建子类,在子类中重写方法,比如 `- (**nullable** **instancetype**)initWithRequest:(NSURLRequest *)request delegate:(**nullable** **id**)delegate startImmediately:(**BOOL**)startImmediately;` ,然后将 NSURLSession、NSURLConnection 的 isa 指向动态创建的子类。在这些方法处理完之后还原本身的 isa 指针。
不过 isa swizzling 针对的还是 method swizzling,代理对象不确定,还是需要 NSProxy 进行动态处理。
至于如何修改 isa,我写一个简单的 Demo 来模拟 KVO
```objective-c
- (void)lbpKVO_addObserver:(NSObject *)observer forKeyPath:(NSString *)keyPath options:(NSKeyValueObservingOptions)options context:(nullable void *)context {
//生成自定义的名称
NSString *className = NSStringFromClass(self.class);
NSString *currentClassName = [@"LBPKVONotifying_" stringByAppendingString:className];
//1. runtime 生成类
Class myclass = objc_allocateClassPair(self.class, [currentClassName UTF8String], 0);
// 生成后不能马上使用,必须先注册
objc_registerClassPair(myclass);
//2. 重写 setter 方法
class_addMethod(myclass,@selector(say) , (IMP)say, "v@:@");
// class_addMethod(myclass,@selector(setName:) , (IMP)setName, "v@:@");
//3. 修改 isa
object_setClass(self, myclass);
//4. 将观察者保存到当前对象里面
objc_setAssociatedObject(self, "observer", observer, OBJC_ASSOCIATION_ASSIGN);
//5. 将传递的上下文绑定到当前对象里面
objc_setAssociatedObject(self, "context", (__bridge id _Nullable)(context), OBJC_ASSOCIATION_RETAIN);
}
void say(id self, SEL _cmd)
{
// 调用父类方法一
struct objc_super superclass = {self, [self superclass]};
((void(*)(struct objc_super *,SEL))objc_msgSendSuper)(&superclass,@selector(say));
NSLog(@"%s", __func__);
// 调用父类方法二
// Class class = [self class];
// object_setClass(self, class_getSuperclass(class));
// objc_msgSend(self, @selector(say));
}
void setName (id self, SEL _cmd, NSString *name) {
NSLog(@"come here");
//先切换到当前类的父类,然后发送消息 setName,然后切换当前子类
//1. 切换到父类
Class class = [self class];
object_setClass(self, class_getSuperclass(class));
//2. 调用父类的 setName 方法
objc_msgSend(self, @selector(setName:), name);
//3. 调用观察
id observer = objc_getAssociatedObject(self, "observer");
id context = objc_getAssociatedObject(self, "context");
if (observer) {
objc_msgSend(observer, @selector(observeValueForKeyPath:ofObject:change:context:), @"name", self, @{@"new": name, @"kind": @1 } , context);
}
//4. 改回子类
object_setClass(self, class);
}
@end
```
#### 2.4 方案四:监控 App 常见网络请求
本着成本的原因,由于现在大多数的项目的网络能力都是通过 [AFNetworking](https://github.com/AFNetworking/AFNetworking) 完成的,所以本文的网络监控可以快速完成。
AFNetworking 在发起网络的时候会有相应的通知。`AFNetworkingTaskDidResumeNotification` 和 `AFNetworkingTaskDidCompleteNotification`。通过监听通知携带的参数获取网络情况信息。
```Objective-c
self.didResumeObserver = [[NSNotificationCenter defaultCenter] addObserverForName:AFNetworkingTaskDidResumeNotification object:nil queue:self.queue usingBlock:^(NSNotification * _Nonnull note) {
// 开始
__strong __typeof(weakSelf)strongSelf = weakSelf;
NSURLSessionTask *task = note.object;
NSString *requestId = [[NSUUID UUID] UUIDString];
task.apm_requestId = requestId;
[strongSelf.networkRecoder recordStartRequestWithRequestID:requestId task:task];
}];
self.didCompleteObserver = [[NSNotificationCenter defaultCenter] addObserverForName:AFNetworkingTaskDidCompleteNotification object:nil queue:self.queue usingBlock:^(NSNotification * _Nonnull note) {
__strong __typeof(weakSelf)strongSelf = weakSelf;
NSError *error = note.userInfo[AFNetworkingTaskDidCompleteErrorKey];
NSURLSessionTask *task = note.object;
if (!error) {
// 成功
[strongSelf.networkRecoder recordFinishRequestWithRequestID:task.apmn_requestId task:task];
} else {
// 失败
[strongSelf.networkRecoder recordResponseErrorWithRequestID:task.apmn_requestId task:task error:error];
}
}];
```
在 networkRecoder 的方法里面去组装数据,交给数据上报组件,等到合适的时机策略去上报。
因为网络是一个异步的过程,所以当网络请求开始的时候需要为每个网络设置唯一标识,等到网络请求完成后再根据每个请求的标识,判断该网络耗时多久、是否成功等。所以措施是为 **NSURLSessionTask** 添加分类,通过 runtime 增加一个属性,也就是唯一标识。
这里插一嘴,为 Category 命名、以及内部的属性和方法命名的时候需要注意下。假如不注意会怎么样呢?假如你要为 NSString 类增加身份证号码中间位数隐藏的功能,那么写代码久了的老司机 A,为 NSString 增加了一个方法名,叫做 getMaskedIdCardNumber,但是他的需求是从 [9, 12] 这 4 位字符串隐藏掉。过了几天同事 B 也遇到了类似的需求,他也是一位老司机,为 NSString 增加了一个也叫 getMaskedIdCardNumber 的方法,但是他的需求是从 [8, 11] 这 4 位字符串隐藏,但是他引入工程后发现输出并不符合预期,为该方法写的单测没通过,他以为自己写错了截取方法,检查了几遍才发现工程引入了另一个 NSString 分类,里面的方法同名 😂 真坑。
下面的例子是 SDK,但是日常开发也是一样。
- Category 类名:建议按照当前 SDK 名称的简写作为前缀,再加下划线,再加当前分类的功能,也就是`类名+SDK名称简写_功能名称`。比如当前 SDK 叫 JuhuaSuanAPM,那么该 NSURLSessionTask Category 名称就叫做 `NSURLSessionTask+JuHuaSuanAPM_NetworkMonitor.h`
- Category 属性名:建议按照当前 SDK 名称的简写作为前缀,再加下划线,再加属性名,也就是`SDK名称简写_属性名称`。比如 JuhuaSuanAPM_requestId`
- Category 方法名:建议按照当前 SDK 名称的简写作为前缀,再加下划线,再加方法名,也就是`SDK名称简写_方法名称`。比如 `-(BOOL)JuhuaSuanAPM__isGzippedData`
例子如下:
```Objective-c
#import <Foundation/Foundation.h>
@interface NSURLSessionTask (JuhuaSuanAPM_NetworkMonitor)
@property (nonatomic, copy) NSString* JuhuaSuanAPM_requestId;
@end
#import "NSURLSessionTask+JuHuaSuanAPM_NetworkMonitor.h"
#import <objc/runtime.h>
@implementation NSURLSessionTask (JuHuaSuanAPM_NetworkMonitor)
- (NSString*)JuhuaSuanAPM_requestId
{
return objc_getAssociatedObject(self, _cmd);
}
- (void)setJuhuaSuanAPM_requestId:(NSString*)requestId
{
objc_setAssociatedObject(self, @selector(JuhuaSuanAPM_requestId), requestId, OBJC_ASSOCIATION_COPY_NONATOMIC);
}
@end
```
#### 2.5 iOS 流量监控
##### 2.5.1 HTTP 请求、响应数据结构
HTTP 请求报文结构
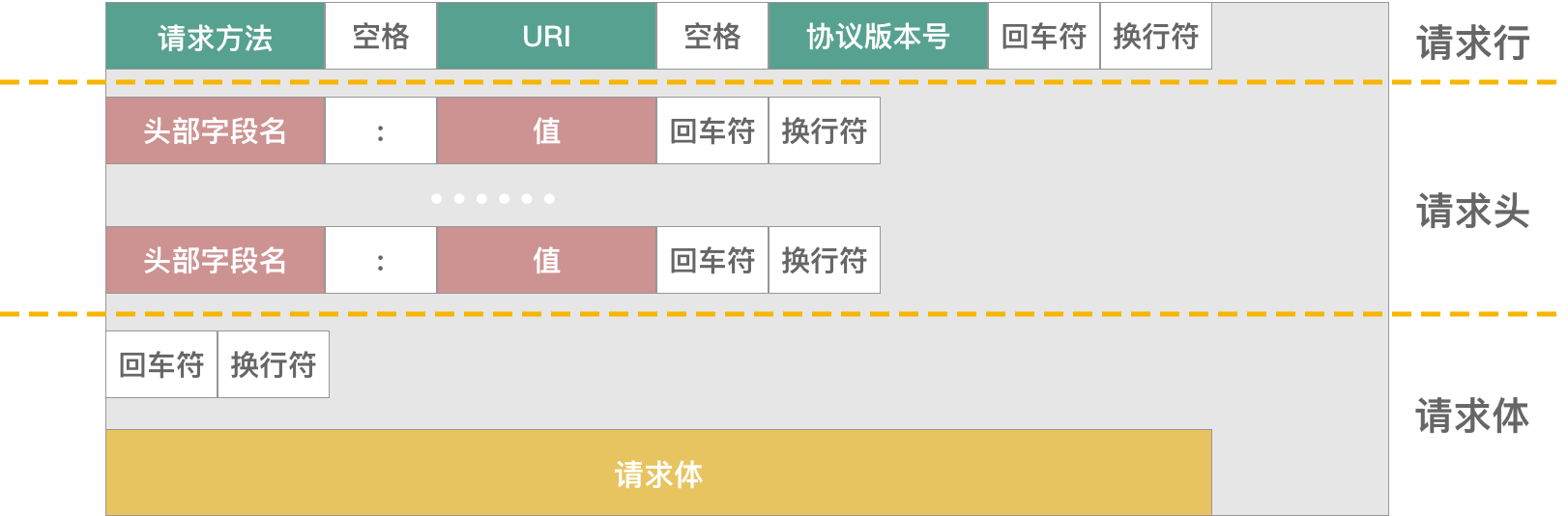
响应报文的结构
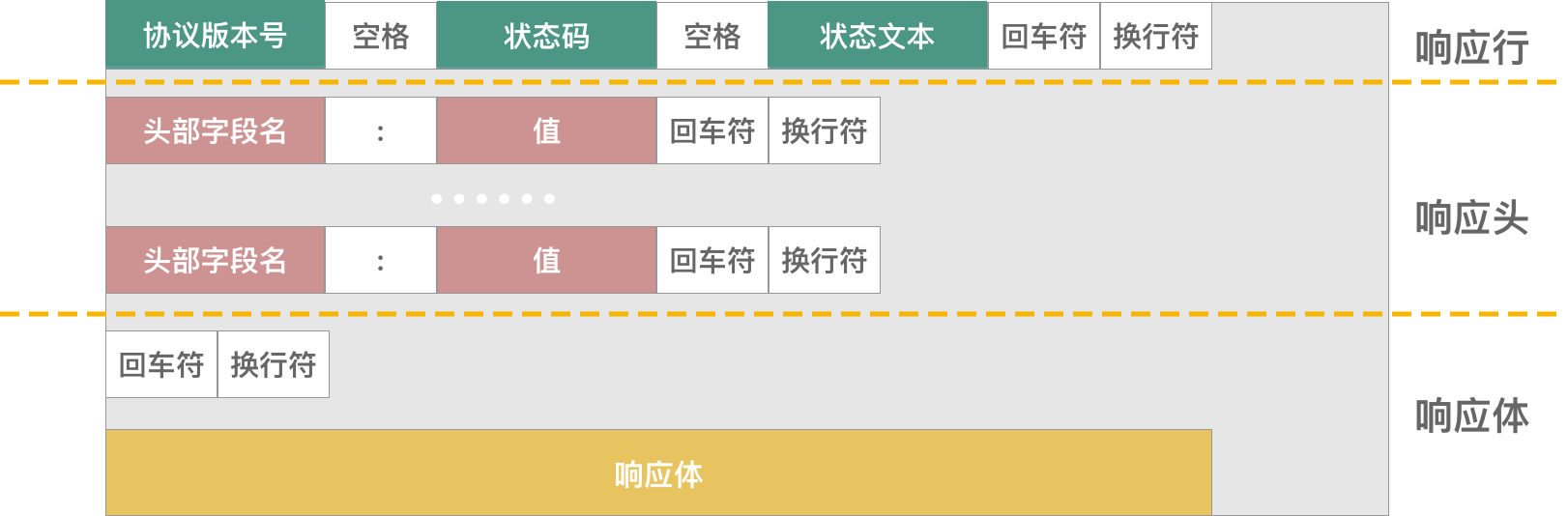
1. HTTP 报文是格式化的数据块,每条报文由三部分组成:对报文进行描述的起始行、包含属性的首部块、以及可选的包含数据的主体部分。
2. 起始行和手部就是由行分隔符的 ASCII 文本,每行都以一个由 2 个字符组成的行终止序列作为结束(包括一个回车符、一个换行符)
3. 实体的主体或者报文的主体是一个可选的数据块。与起始行和首部不同的是,主体中可以包含文本或者二进制数据,也可以为空。
4. HTTP 首部(也就是 Headers)总是应该以一个空行结束,即使没有实体部分。浏览器发送了一个空白行来通知服务器,它已经结束了该头信息的发送。
请求报文的格式
```powershell
<method> <request-URI> <version>
<headers>
<entity-body>
```
响应报文的格式
```shell
<version> <status> <reason-phrase>
<headers>
<entity-body>
```
下图是打开 Chrome 查看极课时间网页的请求信息。包括响应行、响应头、响应体等信息。
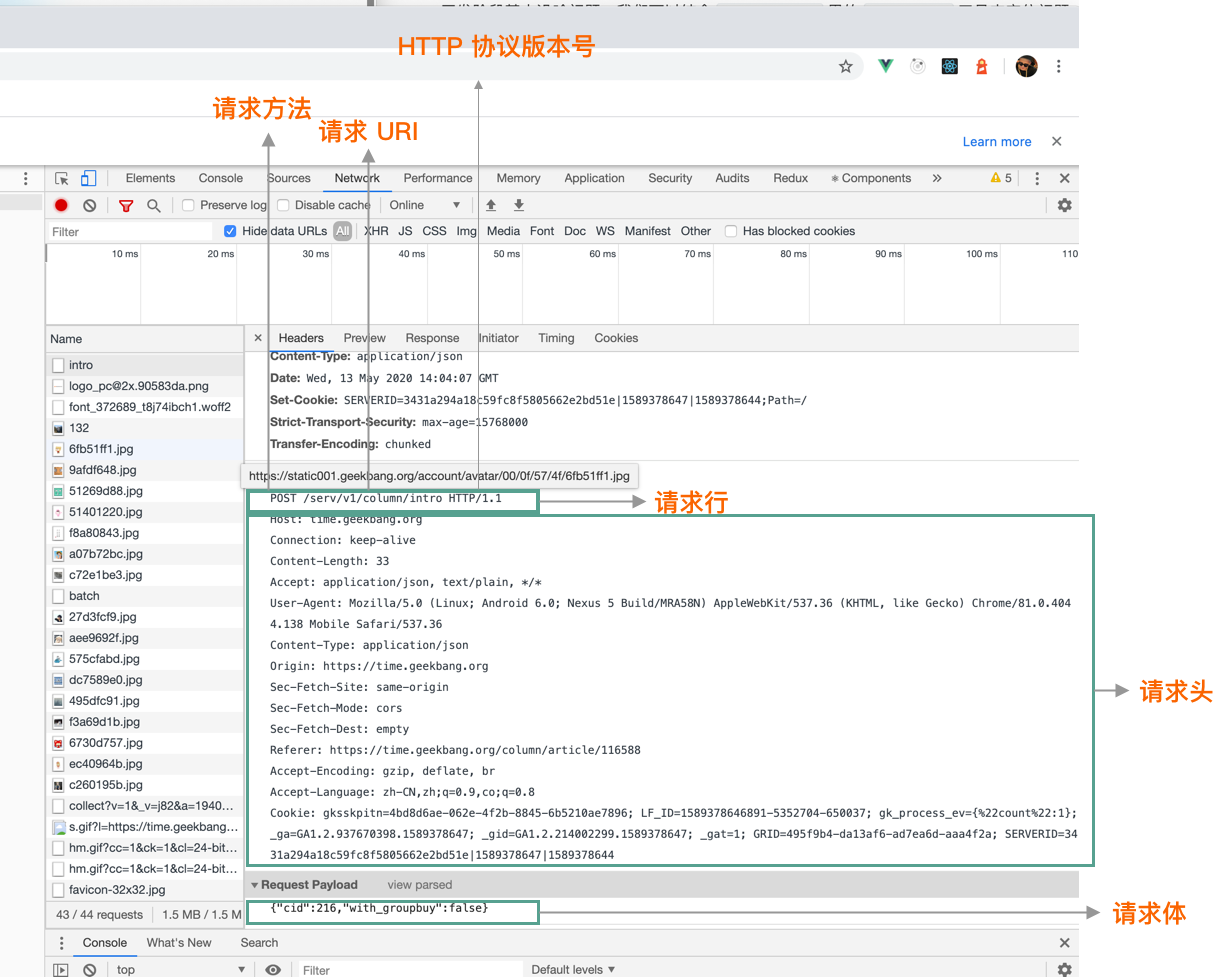
下图是在终端使用 `curl` 查看一个完整的请求和响应数据
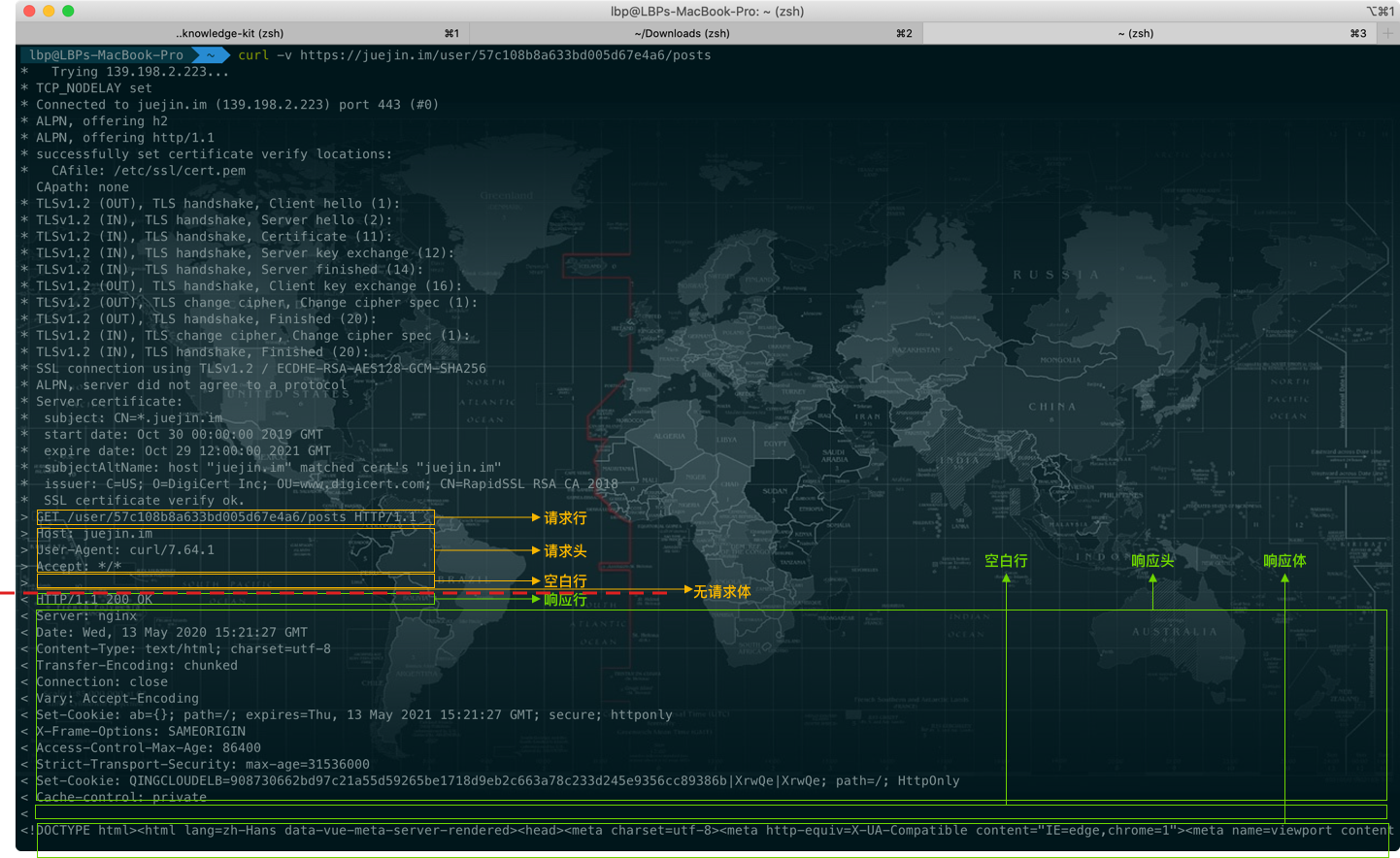
我们都知道在 HTTP 通信中,响应数据会使用 gzip 或其他压缩方式压缩,用 NSURLProtocol 等方案监听,用 NSData 类型去计算分析流量等会造成数据的不精确,因为正常一个 HTTP 响应体的内容是使用 gzip 或其他压缩方式压缩的,所以使用 NSData 会偏大。
##### 2.5.2 问题
1. Request 和 Response 不一定成对存在
比如网络断开、App 突然 Crash 等,所以 Request 和 Response 监控后不应该记录在一条记录里
2. 请求流量计算方式不精确
主要原因有:
- 监控技术方案忽略了请求头和请求行部分的数据大小
- 监控技术方案忽略了 Cookie 部分的数据大小
- 监控技术方案在对请求体大小计算的时候直接使用 `HTTPBody.length`,导致不够精确
3. 响应流量计算方式不精确
主要原因有:
- 监控技术方案忽略了响应头和响应行部分的数据大小
- 监控技术方案在对 body 部分的字节大小计算,因采用 `exceptedContentLength` 导致不够准确
- 监控技术方案忽略了响应体使用 gzip 压缩。真正的网络通信过程中,客户端在发起请求的请求头中 `Accept-Encoding` 字段代表客户端支持的数据压缩方式(表明客户端可以正常使用数据时支持的压缩方法),同样服务端根据客户端想要的压缩方式、服务端当前支持的压缩方式,最后处理数据,在响应头中`Content-Encoding` 字段表示当前服务器采用了什么压缩方式。
##### 2.5.3 技术实现
第五部分讲了网络拦截的各种原理和技术方案,这里拿 NSURLProtocol 来说实现流量监控(Hook 的方式)。从上述知道了我们需要什么样的,那么就逐步实现吧。
###### 2.5.3.1 Request 部分
1. 先利用网络监控方案将 NSURLProtocol 管理 App 的各种网络请求
2. 在各个方法内部记录各项所需参数(NSURLProtocol 不能分析请求握手、挥手等数据大小和时间消耗,不过对于正常情况的接口流量分析足够了,最底层需要 Socket 层)
```objective-c
@property(nonatomic, strong) NSURLConnection *internalConnection;
@property(nonatomic, strong) NSURLResponse *internalResponse;
@property(nonatomic, strong) NSMutableData *responseData;
@property (nonatomic, strong) NSURLRequest *internalRequest;
```
```objective-c
- (void)startLoading
{
NSMutableURLRequest *mutableRequest = [[self request] mutableCopy];
self.internalConnection = [[NSURLConnection alloc] initWithRequest:mutableRequest delegate:self];
self.internalRequest = self.request;
}
- (void)connection:(NSURLConnection *)connection didReceiveResponse:(NSURLResponse *)response
{
[self.client URLProtocol:self didReceiveResponse:response cacheStoragePolicy:NSURLCacheStorageNotAllowed];
self.internalResponse = response;
}
- (void)connection:(NSURLConnection *)connection didReceiveData:(NSData *)data
{
[self.responseData appendData:data];
[self.client URLProtocol:self didLoadData:data];
}
```
3. Status Line 部分
NSURLResponse 没有 Status Line 等属性或者接口,HTTP Version 信息也没有,所以要想获取 Status Line 想办法转换到 CFNetwork 层试试看。发现有私有 API 可以实现。
**思路:将 NSURLResponse 通过 `_CFURLResponse` 转换为 `CFTypeRef`,然后再将 `CFTypeRef` 转换为 `CFHTTPMessageRef`,再通过 `CFHTTPMessageCopyResponseStatusLine` 获取 `CFHTTPMessageRef` 的 Status Line 信息。**
将读取 Status Line 的功能添加一个 NSURLResponse 的分类。
```objective-c
// NSURLResponse+apm_FetchStatusLineFromCFNetwork.h
#import <Foundation/Foundation.h>
NS_ASSUME_NONNULL_BEGIN
@interface NSURLResponse (apm_FetchStatusLineFromCFNetwork)
- (NSString *)apm_fetchStatusLineFromCFNetwork;
@end
NS_ASSUME_NONNULL_END
// NSURLResponse+apm_FetchStatusLineFromCFNetwork.m
#import "NSURLResponse+apm_FetchStatusLineFromCFNetwork.h"
#import <dlfcn.h>
#define SuppressPerformSelectorLeakWarning(Stuff) \
do { \
_Pragma("clang diagnostic push") \
_Pragma("clang diagnostic ignored \"-Warc-performSelector-leaks\"") \
Stuff; \
_Pragma("clang diagnostic pop") \
} while (0)
typedef CFHTTPMessageRef (*APMURLResponseFetchHTTPResponse)(CFURLRef response);
@implementation NSURLResponse (apm_FetchStatusLineFromCFNetwork)
- (NSString *)apm_fetchStatusLineFromCFNetwork
{
NSString *statusLine = @"";
NSString *funcName = @"CFURLResponseGetHTTPResponse";
APMURLResponseFetchHTTPResponse originalURLResponseFetchHTTPResponse = dlsym(RTLD_DEFAULT, [funcName UTF8String]);
SEL getSelector = NSSelectorFromString(@"_CFURLResponse");
if ([self respondsToSelector:getSelector] && NULL != originalURLResponseFetchHTTPResponse) {
CFTypeRef cfResponse;
SuppressPerformSelectorLeakWarning(
cfResponse = CFBridgingRetain([self performSelector:getSelector]);
);
if (NULL != cfResponse) {
CFHTTPMessageRef messageRef = originalURLResponseFetchHTTPResponse(cfResponse);
statusLine = (__bridge_transfer NSString *)CFHTTPMessageCopyResponseStatusLine(messageRef);
CFRelease(cfResponse);
}
}
return statusLine;
}
@end
```
4. 将获取到的 Status Line 转换为 NSData,再计算大小
```objective-c
- (NSUInteger)apm_getLineLength {
NSString *statusLineString = @"";
if ([self isKindOfClass:[NSHTTPURLResponse class]]) {
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)self;
statusLineString = [self apm_fetchStatusLineFromCFNetwork];
}
NSData *lineData = [statusLineString dataUsingEncoding:NSUTF8StringEncoding];
return lineData.length;
}
```
5. Header 部分
`allHeaderFields` 获取到 NSDictionary,然后按照 `key: value` 拼接成字符串,然后转换成 NSData 计算大小
注意:`key: value` key 后是有空格的,curl 或者 chrome Network 面板可以查看印证下。
```objective-c
- (NSUInteger)apm_getHeadersLength
{
NSUInteger headersLength = 0;
if ([self isKindOfClass:[NSHTTPURLResponse class]]) {
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)self;
NSDictionary *headerFields = httpResponse.allHeaderFields;
NSString *headerString = @"";
for (NSString *key in headerFields.allKeys) {
headerString = [headerStr stringByAppendingString:key];
headheaderStringerStr = [headerString stringByAppendingString:@": "];
if ([headerFields objectForKey:key]) {
headerString = [headerString stringByAppendingString:headerFields[key]];
}
headerString = [headerString stringByAppendingString:@"\n"];
}
NSData *headerData = [headerString dataUsingEncoding:NSUTF8StringEncoding];
headersLength = headerData.length;
}
return headersLength;
}
```
6. Body 部分
Body 大小的计算不能直接使用 excepectedContentLength,官方文档说明了其不准确性,只可以作为参考。或者 `allHeaderFields` 中的 `Content-Length` 值也是不够准确的。
> /\*!
>
> **@abstract** Returns the expected content length of the receiver.
>
> **@discussion** Some protocol implementations report a content length
>
> as part of delivering load metadata, but not all protocols
>
> guarantee the amount of data that will be delivered in actuality.
>
> Hence, this method returns an expected amount. Clients should use
>
> this value as an advisory, and should be prepared to deal with
>
> either more or less data.
>
> **@result** The expected content length of the receiver, or -1 if
>
> there is no expectation that can be arrived at regarding expected
>
> content length.
>
> \*/
>
> **@property** (**readonly**) **long** **long** expectedContentLength;
- HTTP 1.1 版本规定,如果存在 `Transfer-Encoding: chunked`,则在 header 中不能有 `Content-Length`,有也会被忽视。
- 在 HTTP 1.0 及之前版本中,`content-length` 字段可有可无
- 在 HTTP 1.1 及之后版本。如果是 `keep alive`,则 `Content-Length` 和 `chunked` 必然是二选一。若是非`keep alive`,则和 HTTP 1.0 一样。`Content-Length` 可有可无。
什么是 `Transfer-Encoding: chunked`
数据以一系列分块的形式进行发送 `Content-Length` 首部在这种情况下不被发送. 在每一个分块的开头需要添加当前分块的长度, 以十六进制的形式表示,后面紧跟着 `\r\n` , 之后是分块本身, 后面也是 `\r\n` ,终止块是一个常规的分块, 不同之处在于其长度为 0.
我们之前拿 NSMutableData 记录了数据,所以我们可以在 `stopLoading `方法中计算出 Body 大小。步骤如下:
- 在 `didReceiveData` 中不断添加 data
```objective-c
- (void)connection:(NSURLConnection *)connection didReceiveData:(NSData *)data
{
[self.responseData appendData:data];
[self.client URLProtocol:self didLoadData:data];
}
```
- 在 `stopLoading` 方法中拿到 `allHeaderFields` 字典,获取 `Content-Encoding` key 的值,如果是 **gzip**,则在 `stopLoading` 中将 NSData 处理为 gzip 压缩后的数据,再计算大小。(gzip 相关功能可以使用这个[工具](https://github.com/nicklockwood/GZIP))
需要额外计算一个空白行的长度
```objective-c
- (void)stopLoadi
{
[self.internalConnection cancel];
HCTNetworkTrafficModel *model = [[HCTNetworkTrafficModel alloc] init];
model.path = self.request.URL.path;
model.host = self.request.URL.host;
model.type = DMNetworkTrafficDataTypeResponse;
model.lineLength = [self.internalResponse apm_getStatusLineLength];
model.headerLength = [self.internalResponse apm_getHeadersLength];
model.emptyLineLength = [self.internalResponse apm_getEmptyLineLength];
if ([self.dm_response isKindOfClass:[NSHTTPURLResponse class]]) {
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)self.dm_response;
NSData *data = self.dm_data;
if ([[httpResponse.allHeaderFields objectForKey:@"Content-Encoding"] isEqualToString:@"gzip"]) {
data = [self.dm_data gzippedData];
}
model.bodyLength = data.length;
}
model.length = model.lineLength + model.headerLength + model.bodyLength + model.emptyLineLength;
NSDictionary *networkTrafficDictionary = [model convertToDictionary];
[[HermesClient sharedInstance] sendWithType:APMMonitorNetworkTrafficType meta:networkTrafficDictionary payload:nil];
}
```
###### 2.5.3.2 Resquest 部分
1. 先利用网络监控方案将 NSURLProtocol 管理 App 的各种网络请求
2. 在各个方法内部记录各项所需参数(NSURLProtocol 不能分析请求握手、挥手等数据大小和时间消耗,不过对于正常情况的接口流量分析足够了,最底层需要 Socket 层)
```objective-c
@property(nonatomic, strong) NSURLConnection *internalConnection;
@property(nonatomic, strong) NSURLResponse *internalResponse;
@property(nonatomic, strong) NSMutableData *responseData;
@property (nonatomic, strong) NSURLRequest *internalRequest;
```
```objective-c
- (void)startLoading
{
NSMutableURLRequest *mutableRequest = [[self request] mutableCopy];
self.internalConnection = [[NSURLConnection alloc] initWithRequest:mutableRequest delegate:self];
self.internalRequest = self.request;
}
- (void)connection:(NSURLConnection *)connection didReceiveResponse:(NSURLResponse *)response
{
[self.client URLProtocol:self didReceiveResponse:response cacheStoragePolicy:NSURLCacheStorageNotAllowed];
self.internalResponse = response;
}
- (void)connection:(NSURLConnection *)connection didReceiveData:(NSData *)data
{
[self.responseData appendData:data];
[self.client URLProtocol:self didLoadData:data];
}
```
3. Status Line 部分
对于 NSURLRequest 没有像 NSURLResponse 一样的方法找到 StatusLine。所以兜底方案是自己根据 Status Line 的结构,自己手动构造一个。结构为:`协议版本号+空格+状态码+空格+状态文本+换行`
为 NSURLRequest 添加一个专门获取 Status Line 的分类。
```objective-c
// NSURLResquest+apm_FetchStatusLineFromCFNetwork.m
- (NSUInteger)apm_fetchStatusLineLength
{
NSString *statusLineString = [NSString stringWithFormat:@"%@ %@ %@\n", self.HTTPMethod, self.URL.path, @"HTTP/1.1"];
NSData *statusLineData = [statusLineString dataUsingEncoding:NSUTF8StringEncoding];
return statusLineData.length;
}
```
4. Header 部分
一个 HTTP 请求会先构建判断是否存在缓存,然后进行 DNS 域名解析以获取请求域名的服务器 IP 地址。如果请求协议是 HTTPS,那么还需要建立 TLS 连接。接下来就是利用 IP 地址和服务器建立 TCP 连接。连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的 Cookie 等数据附加到请求头中,然后向服务器发送构建的请求信息。
所以一个网络监控不考虑 cookie 😂,借用王多鱼的一句话「那不完犊子了吗」。
看过一些文章说 NSURLRequest 不能完整获取到请求头信息。其实问题不大, 几个信息获取不完全也没办法。衡量监控方案本身就是看接口在不同版本或者某些情况下数据消耗是否异常,WebView 资源请求是否过大,类似于控制变量法的思想。
所以获取到 NSURLRequest 的 `allHeaderFields` 后,加上 cookie 信息,计算完整的 Header 大小
```objective-c
// NSURLResquest+apm_FetchHeaderWithCookies.m
- (NSUInteger)apm_fetchHeaderLengthWithCookie
{
NSDictionary *headerFields = self.allHTTPHeaderFields;
NSDictionary *cookiesHeader = [self apm_fetchCookies];
if (cookiesHeader.count) {
NSMutableDictionary *headerDictionaryWithCookies = [NSMutableDictionary dictionaryWithDictionary:headerFields];
[headerDictionaryWithCookies addEntriesFromDictionary:cookiesHeader];
headerFields = [headerDictionaryWithCookies copy];
}
NSString *headerString = @"";
for (NSString *key in headerFields.allKeys) {
headerString = [headerString stringByAppendingString:key];
headerString = [headerString stringByAppendingString:@": "];
if ([headerFields objectForKey:key]) {
headerString = [headerString stringByAppendingString:headerFields[key]];
}
headerString = [headerString stringByAppendingString:@"\n"];
}
NSData *headerData = [headerString dataUsingEncoding:NSUTF8StringEncoding];
headersLength = headerData.length;
return headerString;
}
- (NSDictionary *)apm_fetchCookies
{
NSDictionary *cookiesHeaderDictionary;
NSHTTPCookieStorage *cookieStorage = [NSHTTPCookieStorage sharedHTTPCookieStorage];
NSArray<NSHTTPCookie *> *cookies = [cookieStorage cookiesForURL:self.URL];
if (cookies.count) {
cookiesHeaderDictionary = [NSHTTPCookie requestHeaderFieldsWithCookies:cookies];
}
return cookiesHeaderDictionary;
}
```
5. Body 部分
NSURLConnection 的 `HTTPBody` 有可能获取不到,问题类似于 WebView 上 ajax 等情况。所以可以通过 `HTTPBodyStream` 读取 stream 来计算 body 大小.
```objective-c
- (NSUInteger)apm_fetchRequestBody
{
NSDictionary *headerFields = self.allHTTPHeaderFields;
NSUInteger bodyLength = [self.HTTPBody length];
if ([headerFields objectForKey:@"Content-Encoding"]) {
NSData *bodyData;
if (self.HTTPBody == nil) {
uint8_t d[1024] = {0};
NSInputStream *stream = self.HTTPBodyStream;
NSMutableData *data = [[NSMutableData alloc] init];
[stream open];
while ([stream hasBytesAvailable]) {
NSInteger len = [stream read:d maxLength:1024];
if (len > 0 && stream.streamError == nil) {
[data appendBytes:(void *)d length:len];
}
}
bodyData = [data copy];
[stream close];
} else {
bodyData = self.HTTPBody;
}
bodyLength = [[bodyData gzippedData] length];
}
return bodyLength;
}
```
6. 在 `- (NSURLRequest *)connection:(NSURLConnection *)connection willSendRequest:(NSURLRequest *)request redirectResponse:(NSURLResponse *)response` 方法中将数据上报会在 [打造功能强大、灵活可配置的数据上报组件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md) 讲
```objective-c
-(NSURLRequest *)connection:(NSURLConnection *)connection willSendRequest:(NSURLRequest *)request redirectResponse:(NSURLResponse *)response
{
if (response != nil) {
self.internalResponse = response;
[self.client URLProtocol:self wasRedirectedToRequest:request redirectResponse:response];
}
HCTNetworkTrafficModel *model = [[HCTNetworkTrafficModel alloc] init];
model.path = request.URL.path;
model.host = request.URL.host;
model.type = DMNetworkTrafficDataTypeRequest;
model.lineLength = [connection.currentRequest dgm_getLineLength];
model.headerLength = [connection.currentRequest dgm_getHeadersLengthWithCookie];
model.bodyLength = [connection.currentRequest dgm_getBodyLength];
model.emptyLineLength = [self.internalResponse apm_getEmptyLineLength];
model.length = model.lineLength + model.headerLength + model.bodyLength + model.emptyLineLength;
NSDictionary *networkTrafficDictionary = [model convertToDictionary];
[[HermesClient sharedInstance] sendWithType:APMMonitorNetworkTrafficType meta:networkTrafficDictionary payload:nil];
return request;
}
```
## 六、 电量消耗
移动设备上电量一直是比较敏感的问题,如果用户在某款 App 的时候发现耗电量严重、手机发热严重,那么用户很大可能会马上卸载这款 App。所以需要在开发阶段关心耗电量问题。
一般来说遇到耗电量较大,我们立马会想到是不是使用了定位、是不是使用了频繁网络请求、是不是不断循环做某件事情?
开发阶段基本没啥问题,我们可以结合 `Instrucments` 里的 `Energy Log` 工具来定位问题。但是线上问题就需要代码去监控耗电量,可以作为 APM 的能力之一。
### 1. 如何获取电量
在 iOS 中,`IOKit` 是一个私有框架,用来获取硬件和设备的详细信息,也是硬件和内核服务通信的底层框架。所以我们可以通过 `IOKit `来获取硬件信息,从而获取到电量信息。步骤如下:
- 首先在苹果开放源代码 opensource 中找到 [IOPowerSources.h](https://opensource.apple.com/source/IOKitUser/IOKitUser-647.6/ps.subproj/IOPowerSources.h.auto.html)、[IOPSKeys.h](https://opensource.apple.com/source/IOKitUser/IOKitUser-647.6/ps.subproj/IOPSKeys.h)。在 Xcode 的 `Package Contents` 里面找到 `IOKit.framework`。 路径为 `/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS.sdk/System/Library/Frameworks/IOKit.framework`
- 然后将 IOPowerSources.h、IOPSKeys.h、IOKit.framework 导入项目工程
- 设置 UIDevice 的 batteryMonitoringEnabled 为 true
- 获取到的耗电量精确度为 1%
### 2. 定位问题
通常我们通过 Instrucments 里的 Energy Log 解决了很多问题后,App 上线了,线上的耗电量解决就需要使用 APM 来解决了。耗电地方可能是二方库、三方库,也可能是某个同事的代码。
思路是:在检测到耗电后,先找到有问题的线程,然后堆栈 dump,还原案发现场。
在上面部分我们知道了线程信息的结构, `thread_basic_info` 中有个记录 CPU 使用率百分比的字段 `cpu_usage`。所以我们可以通过遍历当前线程,判断哪个线程的 CPU 使用率较高,从而找出有问题的线程。然后再 dump 堆栈,从而定位到发生耗电量的代码。详细请看 [3.2](#threadInfo) 部分。
```objective-c
- (double)fetchBatteryCostUsage
{
// returns a blob of power source information in an opaque CFTypeRef
CFTypeRef blob = IOPSCopyPowerSourcesInfo();
// returns a CFArray of power source handles, each of type CFTypeRef
CFArrayRef sources = IOPSCopyPowerSourcesList(blob);
CFDictionaryRef pSource = NULL;
const void *psValue;
// returns the number of values currently in an array
int numOfSources = CFArrayGetCount(sources);
// error in CFArrayGetCount
if (numOfSources == 0) {
NSLog(@"Error in CFArrayGetCount");
return -1.0f;
}
// calculating the remaining energy
for (int i=0; i<numOfSources; i++) {
// returns a CFDictionary with readable information about the specific power source
pSource = IOPSGetPowerSourceDescription(blob, CFArrayGetValueAtIndex(sources, i));
if (!pSource) {
NSLog(@"Error in IOPSGetPowerSourceDescription");
return -1.0f;
}
psValue = (CFStringRef) CFDictionaryGetValue(pSource, CFSTR(kIOPSNameKey));
int curCapacity = 0;
int maxCapacity = 0;
double percentage;
psValue = CFDictionaryGetValue(pSource, CFSTR(kIOPSCurrentCapacityKey));
CFNumberGetValue((CFNumberRef)psValue, kCFNumberSInt32Type, &curCapacity);
psValue = CFDictionaryGetValue(pSource, CFSTR(kIOPSMaxCapacityKey));
CFNumberGetValue((CFNumberRef)psValue, kCFNumberSInt32Type, &maxCapacity);
percentage = ((double) curCapacity / (double) maxCapacity * 100.0f);
NSLog(@"curCapacity : %d / maxCapacity: %d , percentage: %.1f ", curCapacity, maxCapacity, percentage);
return percentage;
}
return -1.0f;
}
```
### 3. 开发阶段针对电量消耗我们能做什么
CPU 密集运算是耗电量主要原因。所以我们对 CPU 的使用需要精打细算。尽量避免让 CPU 做无用功。对于大量数据的复杂运算,可以借助服务器的能力、GPU 的能力。如果方案设计必须是在 CPU 上完成数据的运算,则可以利用 GCD 技术,使用 `dispatch_block_create_with_qos_class(<#dispatch_block_flags_t flags#>, dispatch_qos_class_t qos_class, <#int relative_priority#>, <#^(void)block#>)()` 并指定 队列的 qos 为 `QOS_CLASS_UTILITY`。将任务提交到这个队列的 block 中,在 QOS_CLASS_UTILITY 模式下,系统针对大量数据的计算,做了电量优化
除了 CPU 大量运算,I/O 操作也是耗电主要原因。业界常见方案都是将「碎片化的数据写入磁盘存储」这个操作延后,先在内存中聚合吗,然后再进行磁盘存储。碎片化数据先聚合,在内存中进行存储的机制,iOS 提供 `NSCache` 这个对象。
NSCache 是线程安全的,NSCache 会在达到达预设的缓存空间的条件时清理缓存,此时会触发 `- (**void**)cache:(NSCache *)cache willEvictObject:(**id**)obj;` 方法回调,在该方法内部对数据进行 I/O 操作,达到将聚合的数据 I/O 延后的目的。I/O 次数少了,对电量的消耗也就减少了。
NSCache 的使用可以查看 SDWebImage 这个图片加载框架。在图片读取缓存处理时,没直接读取硬盘文件(I/O),而是使用系统的 NSCache。
```objective-c
- (nullable UIImage *)imageFromMemoryCacheForKey:(nullable NSString *)key {
return [self.memoryCache objectForKey:key];
}
- (nullable UIImage *)imageFromDiskCacheForKey:(nullable NSString *)key {
UIImage *diskImage = [self diskImageForKey:key];
if (diskImage && self.config.shouldCacheImagesInMemory) {
NSUInteger cost = diskImage.sd_memoryCost;
[self.memoryCache setObject:diskImage forKey:key cost:cost];
}
return diskImage;
}
```
可以看到主要逻辑是先从磁盘中读取图片,如果配置允许开启内存缓存,则将图片保存到 NSCache 中,使用的时候也是从 NSCache 中读取图片。NSCache 的 `totalCostLimit、countLimit` 属性,
`- (void)setObject:(ObjectType)obj forKey:(KeyType)key cost:(NSUInteger)g;` 方法用来设置缓存条件。所以我们写磁盘、内存的文件操作时可以借鉴该策略,以优化耗电量。
## 七、 Crash 监控
### 1. 异常相关知识回顾
#### 1.1 Mach 层对异常的处理
Mach 在消息传递基础上实现了一套独特的异常处理方法。Mach 异常处理在设计时考虑到:
- 带有一致的语义的单一异常处理设施:Mach 只提供一个异常处理机制用于处理所有类型的异常(包括用户定义的异常、平台无关的异常以及平台特定的异常)。根据异常类型进行分组,具体的平台可以定义具体的子类型。
- 清晰和简洁:异常处理的接口依赖于 Mach 已有的具有良好定义的消息和端口架构,因此非常优雅(不会影响效率)。这就允许调试器和外部处理程序的拓展-甚至在理论上还支持拓展基于网络的异常处理。
在 Mach 中,异常是通过内核中的基础设施-消息传递机制处理的。一个异常并不比一条消息复杂多少,异常由出错的线程或者任务(通过 msg_send()) 抛出,然后由一个处理程序通过 msg_recv())捕捉。处理程序可以处理异常,也可以清楚异常(将异常标记为已完成并继续),还可以决定终止线程。
Mach 的异常处理模型和其他的异常处理模型不同,其他模型的异常处理程序运行在出错的线程上下文中,而 Mach 的异常处理程序在不同的上下文中运行异常处理程序,出错的线程向预先指定好的异常端口发送消息,然后等待应答。每一个任务都可以注册一个异常处理端口,这个异常处理端口会对该任务中的所有线程生效。此外,每个线程都可以通过 `thread_set_exception_ports(<#thread_act_t thread#>, <#exception_mask_t exception_mask#>, <#mach_port_t new_port#>, <#exception_behavior_t behavior#>, <#thread_state_flavor_t new_flavor#>)` 注册自己的异常处理端口。通常情况下,任务和线程的异常端口都是 NULL,也就是异常不会被处理,而一旦创建异常端口,这些端口就像系统中的其他端口一样,可以转交给其他任务或者其他主机。(有了端口,就可以使用 UDP 协议,通过网络能力让其他的主机上应用程序处理异常)。
发生异常时,首先尝试将异常抛给线程的异常端口,然后尝试抛给任务的异常端口,最后再抛给主机的异常端口(即主机注册的默认端口)。如果没有一个端口返回 `KERN_SUCCESS`,那么整个任务将被终止。也就是 Mach 不提供异常处理逻辑,只提供传递异常通知的框架。
异常首先是由处理器陷阱引发的。为了处理陷阱,每一个现代的内核都会安插陷阱处理程序。这些底层函数是由内核的汇编部分安插的。
#### 1.2 BSD 层对异常的处理
BSD 层是用户态主要使用的 XUN 接口,这一层展示了一个符合 POSIX 标准的接口。开发者可以使用 UNIX 系统的一切功能,但不需要了解 Mach 层的细节实现。
Mach 已经通过异常机制提供了底层的陷进处理,而 BSD 则在异常机制之上构建了信号处理机制。硬件产生的信号被 Mach 层捕捉,然后转换为对应的 UNIX 信号,为了维护一个统一的机制,操作系统和用户产生的信号首先被转换为 Mach 异常,然后再转换为信号。
Mach 异常都在 host 层被 `ux_exception` 转换为相应的 unix 信号,并通过 `threadsignal` 将信号投递到出错的线程。
### 2. Crash 收集方式
iOS 系统自带的 Apples`s Crash Reporter 在设置中记录 Crash 日志,我们先观察下 Crash 日志
```shell
Incident Identifier: 7FA6736D-09E8-47A1-95EC-76C4522BDE1A
CrashReporter Key: 4e2d36419259f14413c3229e8b7235bcc74847f3
Hardware Model: iPhone7,1
Process: APMMonitorExample [3608]
Path: /var/containers/Bundle/Application/9518A4F4-59B7-44E9-BDDA-9FBEE8CA18E5/APMMonitorExample.app/APMMonitorExample
Identifier: com.Wacai.APMMonitorExample
Version: 1.0 (1)
Code Type: ARM-64
Parent Process: ? [1]
Date/Time: 2017-01-03 11:43:03.000 +0800
OS Version: iOS 10.2 (14C92)
Report Version: 104
Exception Type: EXC_CRASH (SIGABRT)
Exception Codes: 0x00000000 at 0x0000000000000000
Crashed Thread: 0
Application Specific Information:
*** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '-[__NSSingleObjectArrayI objectForKey:]: unrecognized selector sent to instance 0x174015060'
Thread 0 Crashed:
0 CoreFoundation 0x0000000188f291b8 0x188df9000 + 1245624 (<redacted> + 124)
1 libobjc.A.dylib 0x000000018796055c 0x187958000 + 34140 (objc_exception_throw + 56)
2 CoreFoundation 0x0000000188f30268 0x188df9000 + 1274472 (<redacted> + 140)
3 CoreFoundation 0x0000000188f2d270 0x188df9000 + 1262192 (<redacted> + 916)
4 CoreFoundation 0x0000000188e2680c 0x188df9000 + 186380 (_CF_forwarding_prep_0 + 92)
5 APMMonitorExample 0x000000010004c618 0x100044000 + 34328 (-[MakeCrashHandler throwUncaughtNSException] + 80)
```
会发现,Crash 日志中 `Exception Type` 项由 2 部分组成:Mach 异常 + Unix 信号。
所以 `Exception Type: EXC_CRASH (SIGABRT)` 表示:Mach 层发生了 `EXC_CRASH` 异常,在 host 层被转换为 `SIGABRT` 信号投递到出错的线程。
**问题:** 捕获 Mach 层异常、注册 Unix 信号处理都可以捕获 Crash,这两种方式如何选择?
**答:** 优选 Mach 层异常拦截。根据上面 1.2 中的描述我们知道 Mach 层异常处理时机更早些,假如 Mach 层异常处理程序让进程退出,这样 Unix 信号永远不会发生了。
业界关于崩溃日志的收集开源项目很多,著名的有: KSCrash、plcrashreporter,提供一条龙服务的 Bugly、友盟等。我们一般使用开源项目在此基础上开发成符合公司内部需求的 bug 收集工具。一番对比后选择 KSCrash。为什么选择 KSCrash 不在本文重点。
KSCrash 功能齐全,可以捕获如下类型的 Crash
- Mach kernel exceptions
- Fatal signals
- C++ exceptions
- Objective-C exceptions
- Main thread deadlock (experimental)
- Custom crashes (e.g. from scripting languages)
所以分析 iOS 端的 Crash 收集方案也就是分析 KSCrash 的 Crash 监控实现原理。
#### 2.1. Mach 层异常处理
大体思路是:先创建一个异常处理端口,为该端口申请权限,再设置异常端口、新建一个内核线程,在该线程内循环等待异常。但是为了防止自己注册的 Mach 层异常处理抢占了其他 SDK、或者业务线开发者设置的逻辑,我们需要在最开始保存其他的异常处理端口,等逻辑执行完后将异常处理交给其他的端口内的逻辑处理。收集到 Crash 信息后组装数据,写入 json 文件。
流程图如下:
对于 Mach 异常捕获,可以注册一个异常端口,该端口负责对当前任务的所有线程进行监听。
下面来看看关键代码:
注册 Mach 层异常监听代码
```objective-c
static bool installExceptionHandler()
{
KSLOG_DEBUG("Installing mach exception handler.");
bool attributes_created = false;
pthread_attr_t attr;
kern_return_t kr;
int error;
// 拿到当前进程
const task_t thisTask = mach_task_self();
exception_mask_t mask = EXC_MASK_BAD_ACCESS |
EXC_MASK_BAD_INSTRUCTION |
EXC_MASK_ARITHMETIC |
EXC_MASK_SOFTWARE |
EXC_MASK_BREAKPOINT;
KSLOG_DEBUG("Backing up original exception ports.");
// 获取该 Task 上的注册好的异常端口
kr = task_get_exception_ports(thisTask,
mask,
g_previousExceptionPorts.masks,
&g_previousExceptionPorts.count,
g_previousExceptionPorts.ports,
g_previousExceptionPorts.behaviors,
g_previousExceptionPorts.flavors);
// 获取失败走 failed 逻辑
if(kr != KERN_SUCCESS)
{
KSLOG_ERROR("task_get_exception_ports: %s", mach_error_string(kr));
goto failed;
}
// KSCrash 的异常为空则走执行逻辑
if(g_exceptionPort == MACH_PORT_NULL)
{
KSLOG_DEBUG("Allocating new port with receive rights.");
// 申请异常处理端口
kr = mach_port_allocate(thisTask,
MACH_PORT_RIGHT_RECEIVE,
&g_exceptionPort);
if(kr != KERN_SUCCESS)
{
KSLOG_ERROR("mach_port_allocate: %s", mach_error_string(kr));
goto failed;
}
KSLOG_DEBUG("Adding send rights to port.");
// 为异常处理端口申请权限:MACH_MSG_TYPE_MAKE_SEND
kr = mach_port_insert_right(thisTask,
g_exceptionPort,
g_exceptionPort,
MACH_MSG_TYPE_MAKE_SEND);
if(kr != KERN_SUCCESS)
{
KSLOG_ERROR("mach_port_insert_right: %s", mach_error_string(kr));
goto failed;
}
}
KSLOG_DEBUG("Installing port as exception handler.");
// 为该 Task 设置异常处理端口
kr = task_set_exception_ports(thisTask,
mask,
g_exceptionPort,
EXCEPTION_DEFAULT,
THREAD_STATE_NONE);
if(kr != KERN_SUCCESS)
{
KSLOG_ERROR("task_set_exception_ports: %s", mach_error_string(kr));
goto failed;
}
KSLOG_DEBUG("Creating secondary exception thread (suspended).");
pthread_attr_init(&attr);
attributes_created = true;
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
// 设置监控线程
error = pthread_create(&g_secondaryPThread,
&attr,
&handleExceptions,
kThreadSecondary);
if(error != 0)
{
KSLOG_ERROR("pthread_create_suspended_np: %s", strerror(error));
goto failed;
}
// 转换为 Mach 内核线程
g_secondaryMachThread = pthread_mach_thread_np(g_secondaryPThread);
ksmc_addReservedThread(g_secondaryMachThread);
KSLOG_DEBUG("Creating primary exception thread.");
error = pthread_create(&g_primaryPThread,
&attr,
&handleExceptions,
kThreadPrimary);
if(error != 0)
{
KSLOG_ERROR("pthread_create: %s", strerror(error));
goto failed;
}
pthread_attr_destroy(&attr);
g_primaryMachThread = pthread_mach_thread_np(g_primaryPThread);
ksmc_addReservedThread(g_primaryMachThread);
KSLOG_DEBUG("Mach exception handler installed.");
return true;
failed:
KSLOG_DEBUG("Failed to install mach exception handler.");
if(attributes_created)
{
pthread_attr_destroy(&attr);
}
// 还原之前的异常注册端口,将控制权还原
uninstallExceptionHandler();
return false;
}
```
处理异常的逻辑、组装崩溃信息
```objective-c
/** Our exception handler thread routine.
* Wait for an exception message, uninstall our exception port, record the
* exception information, and write a report.
*/
static void* handleExceptions(void* const userData)
{
MachExceptionMessage exceptionMessage = {{0}};
MachReplyMessage replyMessage = {{0}};
char* eventID = g_primaryEventID;
const char* threadName = (const char*) userData;
pthread_setname_np(threadName);
if(threadName == kThreadSecondary)
{
KSLOG_DEBUG("This is the secondary thread. Suspending.");
thread_suspend((thread_t)ksthread_self());
eventID = g_secondaryEventID;
}
// 循环读取注册好的异常端口信息
for(;;)
{
KSLOG_DEBUG("Waiting for mach exception");
// Wait for a message.
kern_return_t kr = mach_msg(&exceptionMessage.header,
MACH_RCV_MSG,
0,
sizeof(exceptionMessage),
g_exceptionPort,
MACH_MSG_TIMEOUT_NONE,
MACH_PORT_NULL);
// 获取到信息后则代表发生了 Mach 层异常,跳出 for 循环,组装数据
if(kr == KERN_SUCCESS)
{
break;
}
// Loop and try again on failure.
KSLOG_ERROR("mach_msg: %s", mach_error_string(kr));
}
KSLOG_DEBUG("Trapped mach exception code 0x%x, subcode 0x%x",
exceptionMessage.code[0], exceptionMessage.code[1]);
if(g_isEnabled)
{
// 挂起所有线程
ksmc_suspendEnvironment();
g_isHandlingCrash = true;
// 通知发生了异常
kscm_notifyFatalExceptionCaptured(true);
KSLOG_DEBUG("Exception handler is installed. Continuing exception handling.");
// Switch to the secondary thread if necessary, or uninstall the handler
// to avoid a death loop.
if(ksthread_self() == g_primaryMachThread)
{
KSLOG_DEBUG("This is the primary exception thread. Activating secondary thread.");
// TODO: This was put here to avoid a freeze. Does secondary thread ever fire?
restoreExceptionPorts();
if(thread_resume(g_secondaryMachThread) != KERN_SUCCESS)
{
KSLOG_DEBUG("Could not activate secondary thread. Restoring original exception ports.");
}
}
else
{
KSLOG_DEBUG("This is the secondary exception thread. Restoring original exception ports.");
// restoreExceptionPorts();
}
// Fill out crash information
// 组装异常所需要的方案现场信息
KSLOG_DEBUG("Fetching machine state.");
KSMC_NEW_CONTEXT(machineContext);
KSCrash_MonitorContext* crashContext = &g_monitorContext;
crashContext->offendingMachineContext = machineContext;
kssc_initCursor(&g_stackCursor, NULL, NULL);
if(ksmc_getContextForThread(exceptionMessage.thread.name, machineContext, true))
{
kssc_initWithMachineContext(&g_stackCursor, 100, machineContext);
KSLOG_TRACE("Fault address 0x%x, instruction address 0x%x", kscpu_faultAddress(machineContext), kscpu_instructionAddress(machineContext));
if(exceptionMessage.exception == EXC_BAD_ACCESS)
{
crashContext->faultAddress = kscpu_faultAddress(machineContext);
}
else
{
crashContext->faultAddress = kscpu_instructionAddress(machineContext);
}
}
KSLOG_DEBUG("Filling out context.");
crashContext->crashType = KSCrashMonitorTypeMachException;
crashContext->eventID = eventID;
crashContext->registersAreValid = true;
crashContext->mach.type = exceptionMessage.exception;
crashContext->mach.code = exceptionMessage.code[0];
crashContext->mach.subcode = exceptionMessage.code[1];
if(crashContext->mach.code == KERN_PROTECTION_FAILURE && crashContext->isStackOverflow)
{
// A stack overflow should return KERN_INVALID_ADDRESS, but
// when a stack blasts through the guard pages at the top of the stack,
// it generates KERN_PROTECTION_FAILURE. Correct for this.
crashContext->mach.code = KERN_INVALID_ADDRESS;
}
crashContext->signal.signum = signalForMachException(crashContext->mach.type, crashContext->mach.code);
crashContext->stackCursor = &g_stackCursor;
kscm_handleException(crashContext);
KSLOG_DEBUG("Crash handling complete. Restoring original handlers.");
g_isHandlingCrash = false;
ksmc_resumeEnvironment();
}
KSLOG_DEBUG("Replying to mach exception message.");
// Send a reply saying "I didn't handle this exception".
replyMessage.header = exceptionMessage.header;
replyMessage.NDR = exceptionMessage.NDR;
replyMessage.returnCode = KERN_FAILURE;
mach_msg(&replyMessage.header,
MACH_SEND_MSG,
sizeof(replyMessage),
0,
MACH_PORT_NULL,
MACH_MSG_TIMEOUT_NONE,
MACH_PORT_NULL);
return NULL;
}
```
还原异常处理端口,转移控制权
```objective-c
/** Restore the original mach exception ports.
*/
static void restoreExceptionPorts(void)
{
KSLOG_DEBUG("Restoring original exception ports.");
if(g_previousExceptionPorts.count == 0)
{
KSLOG_DEBUG("Original exception ports were already restored.");
return;
}
const task_t thisTask = mach_task_self();
kern_return_t kr;
// Reinstall old exception ports.
// for 循环去除保存好的在 KSCrash 之前注册好的异常端口,将每个端口注册回去
for(mach_msg_type_number_t i = 0; i < g_previousExceptionPorts.count; i++)
{
KSLOG_TRACE("Restoring port index %d", i);
kr = task_set_exception_ports(thisTask,
g_previousExceptionPorts.masks[i],
g_previousExceptionPorts.ports[i],
g_previousExceptionPorts.behaviors[i],
g_previousExceptionPorts.flavors[i]);
if(kr != KERN_SUCCESS)
{
KSLOG_ERROR("task_set_exception_ports: %s",
mach_error_string(kr));
}
}
KSLOG_DEBUG("Exception ports restored.");
g_previousExceptionPorts.count = 0;
}
```
#### 2.2. Signal 异常处理
对于 Mach 异常,操作系统会将其转换为对应的 `Unix 信号`,所以开发者可以通过注册 `signanHandler` 的方式来处理。
KSCrash 在这里的处理逻辑如下图:
看一下关键代码:
设置信号处理函数
```objective-c
static bool installSignalHandler()
{
KSLOG_DEBUG("Installing signal handler.");
#if KSCRASH_HAS_SIGNAL_STACK
// 在堆上分配一块内存,
if(g_signalStack.ss_size == 0)
{
KSLOG_DEBUG("Allocating signal stack area.");
g_signalStack.ss_size = SIGSTKSZ;
g_signalStack.ss_sp = malloc(g_signalStack.ss_size);
}
// 信号处理函数的栈挪到堆中,而不和进程共用一块栈区
// sigaltstack() 函数,该函数的第 1 个参数 sigstack 是一个 stack_t 结构的指针,该结构存储了一个“可替换信号栈” 的位置及属性信息。第 2 个参数 old_sigstack 也是一个 stack_t 类型指针,它用来返回上一次建立的“可替换信号栈”的信息(如果有的话)
KSLOG_DEBUG("Setting signal stack area.");
// sigaltstack 第一个参数为创建的新的可替换信号栈,第二个参数可以设置为NULL,如果不为NULL的话,将会将旧的可替换信号栈的信息保存在里面。函数成功返回0,失败返回-1.
if(sigaltstack(&g_signalStack, NULL) != 0)
{
KSLOG_ERROR("signalstack: %s", strerror(errno));
goto failed;
}
#endif
const int* fatalSignals = kssignal_fatalSignals();
int fatalSignalsCount = kssignal_numFatalSignals();
if(g_previousSignalHandlers == NULL)
{
KSLOG_DEBUG("Allocating memory to store previous signal handlers.");
g_previousSignalHandlers = malloc(sizeof(*g_previousSignalHandlers)
* (unsigned)fatalSignalsCount);
}
// 设置信号处理函数 sigaction 的第二个参数,类型为 sigaction 结构体
struct sigaction action = {{0}};
// sa_flags 成员设立 SA_ONSTACK 标志,该标志告诉内核信号处理函数的栈帧就在“可替换信号栈”上建立。
action.sa_flags = SA_SIGINFO | SA_ONSTACK;
#if KSCRASH_HOST_APPLE && defined(__LP64__)
action.sa_flags |= SA_64REGSET;
#endif
sigemptyset(&action.sa_mask);
action.sa_sigaction = &handleSignal;
// 遍历需要处理的信号数组
for(int i = 0; i < fatalSignalsCount; i++)
{
// 将每个信号的处理函数绑定到上面声明的 action 去,另外用 g_previousSignalHandlers 保存当前信号的处理函数
KSLOG_DEBUG("Assigning handler for signal %d", fatalSignals[i]);
if(sigaction(fatalSignals[i], &action, &g_previousSignalHandlers[i]) != 0)
{
char sigNameBuff[30];
const char* sigName = kssignal_signalName(fatalSignals[i]);
if(sigName == NULL)
{
snprintf(sigNameBuff, sizeof(sigNameBuff), "%d", fatalSignals[i]);
sigName = sigNameBuff;
}
KSLOG_ERROR("sigaction (%s): %s", sigName, strerror(errno));
// Try to reverse the damage
for(i--;i >= 0; i--)
{
sigaction(fatalSignals[i], &g_previousSignalHandlers[i], NULL);
}
goto failed;
}
}
KSLOG_DEBUG("Signal handlers installed.");
return true;
failed:
KSLOG_DEBUG("Failed to install signal handlers.");
return false;
}
```
信号处理时记录线程等上下文信息
```objective-c
static void handleSignal(int sigNum, siginfo_t* signalInfo, void* userContext)
{
KSLOG_DEBUG("Trapped signal %d", sigNum);
if(g_isEnabled)
{
ksmc_suspendEnvironment();
kscm_notifyFatalExceptionCaptured(false);
KSLOG_DEBUG("Filling out context.");
KSMC_NEW_CONTEXT(machineContext);
ksmc_getContextForSignal(userContext, machineContext);
kssc_initWithMachineContext(&g_stackCursor, 100, machineContext);
// 记录信号处理时的上下文信息
KSCrash_MonitorContext* crashContext = &g_monitorContext;
memset(crashContext, 0, sizeof(*crashContext));
crashContext->crashType = KSCrashMonitorTypeSignal;
crashContext->eventID = g_eventID;
crashContext->offendingMachineContext = machineContext;
crashContext->registersAreValid = true;
crashContext->faultAddress = (uintptr_t)signalInfo->si_addr;
crashContext->signal.userContext = userContext;
crashContext->signal.signum = signalInfo->si_signo;
crashContext->signal.sigcode = signalInfo->si_code;
crashContext->stackCursor = &g_stackCursor;
kscm_handleException(crashContext);
ksmc_resumeEnvironment();
}
KSLOG_DEBUG("Re-raising signal for regular handlers to catch.");
// This is technically not allowed, but it works in OSX and iOS.
raise(sigNum);
}
```
KSCrash 信号处理后还原之前的信号处理权限
```objective-c
static void uninstallSignalHandler(void)
{
KSLOG_DEBUG("Uninstalling signal handlers.");
const int* fatalSignals = kssignal_fatalSignals();
int fatalSignalsCount = kssignal_numFatalSignals();
// 遍历需要处理信号数组,将之前的信号处理函数还原
for(int i = 0; i < fatalSignalsCount; i++)
{
KSLOG_DEBUG("Restoring original handler for signal %d", fatalSignals[i]);
sigaction(fatalSignals[i], &g_previousSignalHandlers[i], NULL);
}
KSLOG_DEBUG("Signal handlers uninstalled.");
}
```
说明:
1. 先从堆上分配一块内存区域,被称为“可替换信号栈”,目的是将信号处理函数的栈干掉,用堆上的内存区域代替,而不和进程共用一块栈区。
为什么这么做?一个进程可能有 n 个线程,每个线程都有自己的任务,假如某个线程执行出错,这样就会导致整个进程的崩溃。所以为了信号处理函数正常运行,需要为信号处理函数设置单独的运行空间。另一种情况是递归函数将系统默认的栈空间用尽了,但是信号处理函数使用的栈是它实现在堆中分配的空间,而不是系统默认的栈,所以它仍旧可以正常工作。
2. `int sigaltstack(const stack_t * __restrict, stack_t * __restrict)` 函数的二个参数都是 `stack_t` 结构的指针,存储了可替换信号栈的信息(栈的起始地址、栈的长度、状态)。第 1 个参数该结构存储了一个“可替换信号栈” 的位置及属性信息。第 2 个参数用来返回上一次建立的“可替换信号栈”的信息(如果有的话)。
```c
_STRUCT_SIGALTSTACK
{
void *ss_sp; /* signal stack base */
__darwin_size_t ss_size; /* signal stack length */
int ss_flags; /* SA_DISABLE and/or SA_ONSTACK */
};
typedef _STRUCT_SIGALTSTACK stack_t; /* [???] signal stack */
```
新创建的可替换信号栈,`ss_flags` 必须设置为 0。系统定义了 `SIGSTKSZ` 常量,可满足绝大多可替换信号栈的需求。
```c
/*
* Structure used in sigaltstack call.
*/
#define SS_ONSTACK 0x0001 /* take signal on signal stack */
#define SS_DISABLE 0x0004 /* disable taking signals on alternate stack */
#define MINSIGSTKSZ 32768 /* (32K)minimum allowable stack */
#define SIGSTKSZ 131072 /* (128K)recommended stack size */
```
`sigaltstack` 系统调用通知内核“可替换信号栈”已经建立。
`ss_flags` 为 `SS_ONSTACK` 时,表示进程当前正在“可替换信号栈”中执行,如果此时试图去建立一个新的“可替换信号栈”,那么会遇到 `EPERM` (禁止该动作) 的错误;为 `SS_DISABLE` 说明当前没有已建立的“可替换信号栈”,禁止建立“可替换信号栈”。
3. `int sigaction(int, const struct sigaction * __restrict, struct sigaction * __restrict);`
第一个函数表示需要处理的信号值,但不能是 `SIGKILL` 和 `SIGSTOP` ,这两个信号的处理函数不允许用户重写,因为它们给超级用户提供了终止程序的方法( `SIGKILL` and `SIGSTOP` cannot be caught, blocked, or ignored);
第二个和第三个参数是一个 `sigaction` 结构体。如果第二个参数不为空则代表将其指向信号处理函数,第三个参数不为空,则将之前的信号处理函数保存到该指针中。如果第二个参数为空,第三个参数不为空,则可以获取当前的信号处理函数。
```c
/*
* Signal vector "template" used in sigaction call.
*/
struct sigaction {
union __sigaction_u __sigaction_u; /* signal handler */
sigset_t sa_mask; /* signal mask to apply */
int sa_flags; /* see signal options below */
};
```
`sigaction` 函数的 `sa_flags` 参数需要设置 `SA_ONSTACK` 标志,告诉内核信号处理函数的栈帧就在“可替换信号栈”上建立。
#### 2.3. C++ 异常处理
c++ 异常处理的实现是依靠了标准库的 `std::set_terminate(CPPExceptionTerminate)` 函数。
iOS 工程中某些功能的实现可能使用了 C、C++等。假如抛出 C++ 异常,如果该异常可以被转换为 NSException,则走 OC 异常捕获机制,如果不能转换,则继续走 C++ 异常流程,也就是 `default_terminate_handler`。这个 C++ 异常的默认 terminate 函数内部调用 `abort_message` 函数,最后触发了一个 `abort` 调用,系统产生一个 `SIGABRT` 信号。
在系统抛出 C++ 异常后,加一层 `try...catch...` 来判断该异常是否可以转换为 `NSException`,再重新抛出的 C++异常。此时异常的现场堆栈已经消失,所以上层通过捕获 `SIGABRT` 信号是无法还原发生异常时的场景,即异常堆栈缺失。
为什么?`try...catch...` 语句内部会调用 `__cxa_rethrow()` 抛出异常,`__cxa_rethrow()` 内部又会调用 `unwind`,`unwind` 可以简单理解为函数调用的逆调用,主要用来清理函数调用过程中每个函数生成的局部变量,一直到最外层的 catch 语句所在的函数,并把控制移交给 catch 语句,这就是 C++异常的堆栈消失原因。
```c++
static void setEnabled(bool isEnabled)
{
if(isEnabled != g_isEnabled)
{
g_isEnabled = isEnabled;
if(isEnabled)
{
initialize();
ksid_generate(g_eventID);
g_originalTerminateHandler = std::set_terminate(CPPExceptionTerminate);
}
else
{
std::set_terminate(g_originalTerminateHandler);
}
g_captureNextStackTrace = isEnabled;
}
}
static void initialize()
{
static bool isInitialized = false;
if(!isInitialized)
{
isInitialized = true;
kssc_initCursor(&g_stackCursor, NULL, NULL);
}
}
void kssc_initCursor(KSStackCursor *cursor,
void (*resetCursor)(KSStackCursor*),
bool (*advanceCursor)(KSStackCursor*))
{
cursor->symbolicate = kssymbolicator_symbolicate;
cursor->advanceCursor = advanceCursor != NULL ? advanceCursor : g_advanceCursor;
cursor->resetCursor = resetCursor != NULL ? resetCursor : kssc_resetCursor;
cursor->resetCursor(cursor);
}
```
```c++
static void CPPExceptionTerminate(void)
{
ksmc_suspendEnvironment();
KSLOG_DEBUG("Trapped c++ exception");
const char* name = NULL;
std::type_info* tinfo = __cxxabiv1::__cxa_current_exception_type();
if(tinfo != NULL)
{
name = tinfo->name();
}
if(name == NULL || strcmp(name, "NSException") != 0)
{
kscm_notifyFatalExceptionCaptured(false);
KSCrash_MonitorContext* crashContext = &g_monitorContext;
memset(crashContext, 0, sizeof(*crashContext));
char descriptionBuff[DESCRIPTION_BUFFER_LENGTH];
const char* description = descriptionBuff;
descriptionBuff[0] = 0;
KSLOG_DEBUG("Discovering what kind of exception was thrown.");
g_captureNextStackTrace = false;
try
{
throw;
}
catch(std::exception& exc)
{
strncpy(descriptionBuff, exc.what(), sizeof(descriptionBuff));
}
#define CATCH_VALUE(TYPE, PRINTFTYPE) \
catch(TYPE value)\
{ \
snprintf(descriptionBuff, sizeof(descriptionBuff), "%" #PRINTFTYPE, value); \
}
CATCH_VALUE(char, d)
CATCH_VALUE(short, d)
CATCH_VALUE(int, d)
CATCH_VALUE(long, ld)
CATCH_VALUE(long long, lld)
CATCH_VALUE(unsigned char, u)
CATCH_VALUE(unsigned short, u)
CATCH_VALUE(unsigned int, u)
CATCH_VALUE(unsigned long, lu)
CATCH_VALUE(unsigned long long, llu)
CATCH_VALUE(float, f)
CATCH_VALUE(double, f)
CATCH_VALUE(long double, Lf)
CATCH_VALUE(char*, s)
catch(...)
{
description = NULL;
}
g_captureNextStackTrace = g_isEnabled;
// TODO: Should this be done here? Maybe better in the exception handler?
KSMC_NEW_CONTEXT(machineContext);
ksmc_getContextForThread(ksthread_self(), machineContext, true);
KSLOG_DEBUG("Filling out context.");
crashContext->crashType = KSCrashMonitorTypeCPPException;
crashContext->eventID = g_eventID;
crashContext->registersAreValid = false;
crashContext->stackCursor = &g_stackCursor;
crashContext->CPPException.name = name;
crashContext->exceptionName = name;
crashContext->crashReason = description;
crashContext->offendingMachineContext = machineContext;
kscm_handleException(crashContext);
}
else
{
KSLOG_DEBUG("Detected NSException. Letting the current NSException handler deal with it.");
}
ksmc_resumeEnvironment();
KSLOG_DEBUG("Calling original terminate handler.");
g_originalTerminateHandler();
}
```
#### 2.4. Objective-C 异常处理
对于 OC 层面的 NSException 异常处理较为容易,可以通过注册 `NSUncaughtExceptionHandler` 来捕获异常信息,通过 NSException 参数来做 Crash 信息的收集,交给数据上报组件。
```c++
static void setEnabled(bool isEnabled)
{
if(isEnabled != g_isEnabled)
{
g_isEnabled = isEnabled;
if(isEnabled)
{
KSLOG_DEBUG(@"Backing up original handler.");
// 记录之前的 OC 异常处理函数
g_previousUncaughtExceptionHandler = NSGetUncaughtExceptionHandler();
KSLOG_DEBUG(@"Setting new handler.");
// 设置新的 OC 异常处理函数
NSSetUncaughtExceptionHandler(&handleException);
KSCrash.sharedInstance.uncaughtExceptionHandler = &handleException;
}
else
{
KSLOG_DEBUG(@"Restoring original handler.");
NSSetUncaughtExceptionHandler(g_previousUncaughtExceptionHandler);
}
}
}
```
#### 2.5. 主线程死锁
主线程死锁的检测和 ANR 的检测有些类似
- 创建一个线程,在线程运行方法中用 `do...while...` 循环处理逻辑,加了 autorelease 避免内存过高
- 有一个 `awaitingResponse` 属性和 `watchdogPulse` 方法。watchdogPulse 主要逻辑为设置 `awaitingResponse` 为 YES,切换到主线程中,设置 `awaitingResponse` 为 NO,
```objective-c
- (void) watchdogPulse
{
__block id blockSelf = self;
self.awaitingResponse = YES;
dispatch_async(dispatch_get_main_queue(), ^
{
[blockSelf watchdogAnswer];
});
}
```
- 线程的执行方法里面不断循环,等待设置的 `g_watchdogInterval` 后判断 `awaitingResponse` 的属性值是不是初始状态的值,否则判断为死锁
```objective-c
- (void) runMonitor
{
BOOL cancelled = NO;
do
{
// Only do a watchdog check if the watchdog interval is > 0.
// If the interval is <= 0, just idle until the user changes it.
@autoreleasepool {
NSTimeInterval sleepInterval = g_watchdogInterval;
BOOL runWatchdogCheck = sleepInterval > 0;
if(!runWatchdogCheck)
{
sleepInterval = kIdleInterval;
}
[NSThread sleepForTimeInterval:sleepInterval];
cancelled = self.monitorThread.isCancelled;
if(!cancelled && runWatchdogCheck)
{
if(self.awaitingResponse)
{
[self handleDeadlock];
}
else
{
[self watchdogPulse];
}
}
}
} while (!cancelled);
}
```
#### 2.6 Crash 的生成与保存
##### 2.6.1 Crash 日志的生成逻辑
上面的部分讲过了 iOS 应用开发中的各种 crash 监控逻辑,接下来就应该分析下 crash 捕获后如何将 crash 信息记录下来,也就是保存到应用沙盒中。
拿主线程死锁这种 crash 举例子,看看 KSCrash 是如何记录 crash 信息的。
```c
// KSCrashMonitor_Deadlock.m
- (void) handleDeadlock
{
ksmc_suspendEnvironment();
kscm_notifyFatalExceptionCaptured(false);
KSMC_NEW_CONTEXT(machineContext);
ksmc_getContextForThread(g_mainQueueThread, machineContext, false);
KSStackCursor stackCursor;
kssc_initWithMachineContext(&stackCursor, 100, machineContext);
char eventID[37];
ksid_generate(eventID);
KSLOG_DEBUG(@"Filling out context.");
KSCrash_MonitorContext* crashContext = &g_monitorContext;
memset(crashContext, 0, sizeof(*crashContext));
crashContext->crashType = KSCrashMonitorTypeMainThreadDeadlock;
crashContext->eventID = eventID;
crashContext->registersAreValid = false;
crashContext->offendingMachineContext = machineContext;
crashContext->stackCursor = &stackCursor;
kscm_handleException(crashContext);
ksmc_resumeEnvironment();
KSLOG_DEBUG(@"Calling abort()");
abort();
}
```
其他几个 crash 也是一样,异常信息经过包装交给 `kscm_handleException()` 函数处理。可以看到这个函数被其他几种 crash 捕获后所调用。
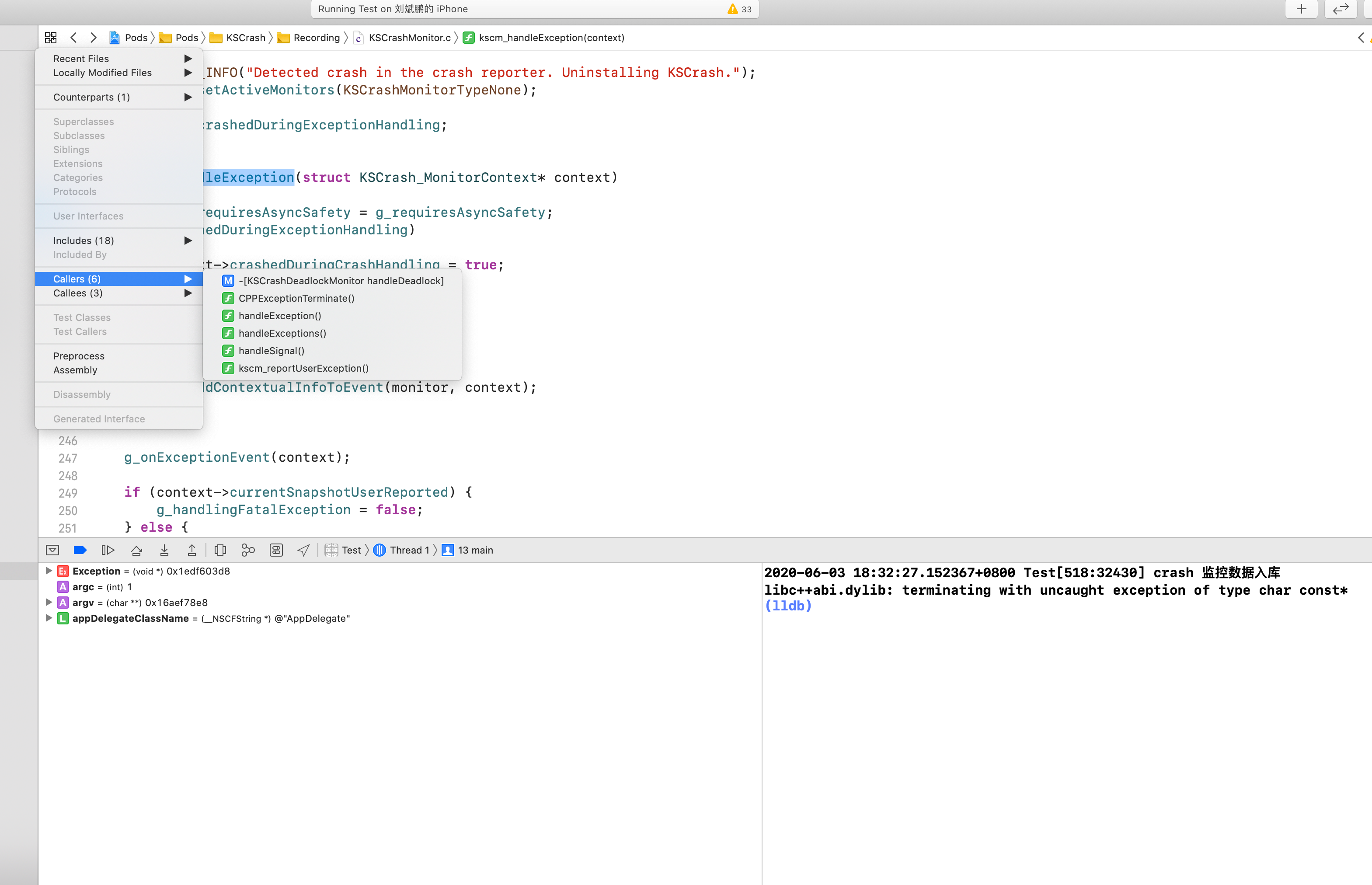
```c
/** Start general exception processing.
*
* @oaram context Contextual information about the exception.
*/
void kscm_handleException(struct KSCrash_MonitorContext* context)
{
context->requiresAsyncSafety = g_requiresAsyncSafety;
if(g_crashedDuringExceptionHandling)
{
context->crashedDuringCrashHandling = true;
}
for(int i = 0; i < g_monitorsCount; i++)
{
Monitor* monitor = &g_monitors[i];
// 判断当前的 crash 监控是开启状态
if(isMonitorEnabled(monitor))
{
// 针对每种 crash 类型做一些额外的补充信息
addContextualInfoToEvent(monitor, context);
}
}
// 真正处理 crash 信息,保存 json 格式的 crash 信息
g_onExceptionEvent(context);
if(g_handlingFatalException && !g_crashedDuringExceptionHandling)
{
KSLOG_DEBUG("Exception is fatal. Restoring original handlers.");
kscm_setActiveMonitors(KSCrashMonitorTypeNone);
}
}
```
`g_onExceptionEvent` 是一个 block,声明为 `static void (*g_onExceptionEvent)(struct KSCrash_MonitorContext* monitorContext);` 在 `KSCrashMonitor.c` 中被赋值
```c
void kscm_setEventCallback(void (*onEvent)(struct KSCrash_MonitorContext* monitorContext))
{
g_onExceptionEvent = onEvent;
}
```
`kscm_setEventCallback()` 函数在 `KSCrashC.c` 文件中被调用
```c
KSCrashMonitorType kscrash_install(const char* appName, const char* const installPath)
{
KSLOG_DEBUG("Installing crash reporter.");
if(g_installed)
{
KSLOG_DEBUG("Crash reporter already installed.");
return g_monitoring;
}
g_installed = 1;
char path[KSFU_MAX_PATH_LENGTH];
snprintf(path, sizeof(path), "%s/Reports", installPath);
ksfu_makePath(path);
kscrs_initialize(appName, path);
snprintf(path, sizeof(path), "%s/Data", installPath);
ksfu_makePath(path);
snprintf(path, sizeof(path), "%s/Data/CrashState.json", installPath);
kscrashstate_initialize(path);
snprintf(g_consoleLogPath, sizeof(g_consoleLogPath), "%s/Data/ConsoleLog.txt", installPath);
if(g_shouldPrintPreviousLog)
{
printPreviousLog(g_consoleLogPath);
}
kslog_setLogFilename(g_consoleLogPath, true);
ksccd_init(60);
// 设置 crash 发生时的 callback 函数
kscm_setEventCallback(onCrash);
KSCrashMonitorType monitors = kscrash_setMonitoring(g_monitoring);
KSLOG_DEBUG("Installation complete.");
return monitors;
}
/** Called when a crash occurs.
*
* This function gets passed as a callback to a crash handler.
*/
static void onCrash(struct KSCrash_MonitorContext* monitorContext)
{
KSLOG_DEBUG("Updating application state to note crash.");
kscrashstate_notifyAppCrash();
monitorContext->consoleLogPath = g_shouldAddConsoleLogToReport ? g_consoleLogPath : NULL;
// 正在处理 crash 的时候,发生了再次 crash
if(monitorContext->crashedDuringCrashHandling)
{
kscrashreport_writeRecrashReport(monitorContext, g_lastCrashReportFilePath);
}
else
{
// 1. 先根据当前时间创建新的 crash 的文件路径
char crashReportFilePath[KSFU_MAX_PATH_LENGTH];
kscrs_getNextCrashReportPath(crashReportFilePath);
// 2. 将新生成的文件路径保存到 g_lastCrashReportFilePath
strncpy(g_lastCrashReportFilePath, crashReportFilePath, sizeof(g_lastCrashReportFilePath));
// 3. 将新生成的文件路径传入函数进行 crash 写入
kscrashreport_writeStandardReport(monitorContext, crashReportFilePath);
}
}
```
接下来的函数就是具体的日志写入文件的实现。2 个函数做的事情相似,都是格式化为 json 形式并写入文件。区别在于 crash 写入时如果再次发生 crash, 则走简易版的写入逻辑 `kscrashreport_writeRecrashReport()`,否则走标准的写入逻辑 `kscrashreport_writeStandardReport()`。
```c
bool ksfu_openBufferedWriter(KSBufferedWriter* writer, const char* const path, char* writeBuffer, int writeBufferLength)
{
writer->buffer = writeBuffer;
writer->bufferLength = writeBufferLength;
writer->position = 0;
/*
open() 的第二个参数描述的是文件操作的权限
#define O_RDONLY 0x0000 open for reading only
#define O_WRONLY 0x0001 open for writing only
#define O_RDWR 0x0002 open for reading and writing
#define O_ACCMODE 0x0003 mask for above mode
#define O_CREAT 0x0200 create if nonexistant
#define O_TRUNC 0x0400 truncate to zero length
#define O_EXCL 0x0800 error if already exists
0755:即用户具有读/写/执行权限,组用户和其它用户具有读写权限;
0644:即用户具有读写权限,组用户和其它用户具有只读权限;
成功则返回文件描述符,若出现则返回 -1
*/
writer->fd = open(path, O_RDWR | O_CREAT | O_EXCL, 0644);
if(writer->fd < 0)
{
KSLOG_ERROR("Could not open crash report file %s: %s", path, strerror(errno));
return false;
}
return true;
}
```
```c
/**
* Write a standard crash report to a file.
*
* @param monitorContext Contextual information about the crash and environment.
* The caller must fill this out before passing it in.
*
* @param path The file to write to.
*/
void kscrashreport_writeStandardReport(const struct KSCrash_MonitorContext* const monitorContext,
const char* path)
{
KSLOG_INFO("Writing crash report to %s", path);
char writeBuffer[1024];
KSBufferedWriter bufferedWriter;
if(!ksfu_openBufferedWriter(&bufferedWriter, path, writeBuffer, sizeof(writeBuffer)))
{
return;
}
ksccd_freeze();
KSJSONEncodeContext jsonContext;
jsonContext.userData = &bufferedWriter;
KSCrashReportWriter concreteWriter;
KSCrashReportWriter* writer = &concreteWriter;
prepareReportWriter(writer, &jsonContext);
ksjson_beginEncode(getJsonContext(writer), true, addJSONData, &bufferedWriter);
writer->beginObject(writer, KSCrashField_Report);
{
writeReportInfo(writer,
KSCrashField_Report,
KSCrashReportType_Standard,
monitorContext->eventID,
monitorContext->System.processName);
ksfu_flushBufferedWriter(&bufferedWriter);
writeBinaryImages(writer, KSCrashField_BinaryImages);
ksfu_flushBufferedWriter(&bufferedWriter);
writeProcessState(writer, KSCrashField_ProcessState, monitorContext);
ksfu_flushBufferedWriter(&bufferedWriter);
writeSystemInfo(writer, KSCrashField_System, monitorContext);
ksfu_flushBufferedWriter(&bufferedWriter);
writer->beginObject(writer, KSCrashField_Crash);
{
writeError(writer, KSCrashField_Error, monitorContext);
ksfu_flushBufferedWriter(&bufferedWriter);
writeAllThreads(writer,
KSCrashField_Threads,
monitorContext,
g_introspectionRules.enabled);
ksfu_flushBufferedWriter(&bufferedWriter);
}
writer->endContainer(writer);
if(g_userInfoJSON != NULL)
{
addJSONElement(writer, KSCrashField_User, g_userInfoJSON, false);
ksfu_flushBufferedWriter(&bufferedWriter);
}
else
{
writer->beginObject(writer, KSCrashField_User);
}
if(g_userSectionWriteCallback != NULL)
{
ksfu_flushBufferedWriter(&bufferedWriter);
g_userSectionWriteCallback(writer);
}
writer->endContainer(writer);
ksfu_flushBufferedWriter(&bufferedWriter);
writeDebugInfo(writer, KSCrashField_Debug, monitorContext);
}
writer->endContainer(writer);
ksjson_endEncode(getJsonContext(writer));
ksfu_closeBufferedWriter(&bufferedWriter);
ksccd_unfreeze();
}
/** Write a minimal crash report to a file.
*
* @param monitorContext Contextual information about the crash and environment.
* The caller must fill this out before passing it in.
*
* @param path The file to write to.
*/
void kscrashreport_writeRecrashReport(const struct KSCrash_MonitorContext* const monitorContext,
const char* path)
{
char writeBuffer[1024];
KSBufferedWriter bufferedWriter;
static char tempPath[KSFU_MAX_PATH_LENGTH];
// 将传递过来的上份 crash report 文件名路径(/var/mobile/Containers/Data/Application/******/Library/Caches/KSCrash/Test/Reports/Test-report-******.json)修改为去掉 .json ,加上 .old 成为新的文件路径 /var/mobile/Containers/Data/Application/******/Library/Caches/KSCrash/Test/Reports/Test-report-******.old
strncpy(tempPath, path, sizeof(tempPath) - 10);
strncpy(tempPath + strlen(tempPath) - 5, ".old", 5);
KSLOG_INFO("Writing recrash report to %s", path);
if(rename(path, tempPath) < 0)
{
KSLOG_ERROR("Could not rename %s to %s: %s", path, tempPath, strerror(errno));
}
// 根据传入路径来打开内存写入需要的文件
if(!ksfu_openBufferedWriter(&bufferedWriter, path, writeBuffer, sizeof(writeBuffer)))
{
return;
}
ksccd_freeze();
// json 解析的 c 代码
KSJSONEncodeContext jsonContext;
jsonContext.userData = &bufferedWriter;
KSCrashReportWriter concreteWriter;
KSCrashReportWriter* writer = &concreteWriter;
prepareReportWriter(writer, &jsonContext);
ksjson_beginEncode(getJsonContext(writer), true, addJSONData, &bufferedWriter);
writer->beginObject(writer, KSCrashField_Report);
{
writeRecrash(writer, KSCrashField_RecrashReport, tempPath);
ksfu_flushBufferedWriter(&bufferedWriter);
if(remove(tempPath) < 0)
{
KSLOG_ERROR("Could not remove %s: %s", tempPath, strerror(errno));
}
writeReportInfo(writer,
KSCrashField_Report,
KSCrashReportType_Minimal,
monitorContext->eventID,
monitorContext->System.processName);
ksfu_flushBufferedWriter(&bufferedWriter);
writer->beginObject(writer, KSCrashField_Crash);
{
writeError(writer, KSCrashField_Error, monitorContext);
ksfu_flushBufferedWriter(&bufferedWriter);
int threadIndex = ksmc_indexOfThread(monitorContext->offendingMachineContext,
ksmc_getThreadFromContext(monitorContext->offendingMachineContext));
writeThread(writer,
KSCrashField_CrashedThread,
monitorContext,
monitorContext->offendingMachineContext,
threadIndex,
false);
ksfu_flushBufferedWriter(&bufferedWriter);
}
writer->endContainer(writer);
}
writer->endContainer(writer);
ksjson_endEncode(getJsonContext(writer));
ksfu_closeBufferedWriter(&bufferedWriter);
ksccd_unfreeze();
}
```
##### 2.6.2 Crash 日志的读取逻辑
当前 App 在 Crash 之后,KSCrash 将数据保存到 App 沙盒目录下,App 下次启动后我们读取存储的 crash 文件,然后处理数据并上传。
App 启动后函数调用:
` [KSCrashInstallation sendAllReportsWithCompletion:]` -> `[KSCrash sendAllReportsWithCompletion:]` -> `[KSCrash allReports]` -> `[KSCrash reportWithIntID:]` ->`[KSCrash loadCrashReportJSONWithID:]` -> `kscrs_readReport `
在 `sendAllReportsWithCompletion` 里读取沙盒里的 Crash 数据。
```objective-c
// 先通过读取文件夹,遍历文件夹内的文件数量来判断 crash 报告的个数
static int getReportCount()
{
int count = 0;
DIR* dir = opendir(g_reportsPath);
if(dir == NULL)
{
KSLOG_ERROR("Could not open directory %s", g_reportsPath);
goto done;
}
struct dirent* ent;
while((ent = readdir(dir)) != NULL)
{
if(getReportIDFromFilename(ent->d_name) > 0)
{
count++;
}
}
done:
if(dir != NULL)
{
closedir(dir);
}
return count;
}
// 通过 crash 文件个数、文件夹信息去遍历,一次获取到文件名(文件名的最后一部分就是 reportID),拿到 reportID 再去读取 crash 报告内的文件内容,写入数组
- (NSArray*) allReports
{
int reportCount = kscrash_getReportCount();
int64_t reportIDs[reportCount];
reportCount = kscrash_getReportIDs(reportIDs, reportCount);
NSMutableArray* reports = [NSMutableArray arrayWithCapacity:(NSUInteger)reportCount];
for(int i = 0; i < reportCount; i++)
{
NSDictionary* report = [self reportWithIntID:reportIDs[i]];
if(report != nil)
{
[reports addObject:report];
}
}
return reports;
}
// 根据 reportID 找到 crash 信息
- (NSDictionary*) reportWithIntID:(int64_t) reportID
{
NSData* jsonData = [self loadCrashReportJSONWithID:reportID];
if(jsonData == nil)
{
return nil;
}
NSError* error = nil;
NSMutableDictionary* crashReport = [KSJSONCodec decode:jsonData
options:KSJSONDecodeOptionIgnoreNullInArray |
KSJSONDecodeOptionIgnoreNullInObject |
KSJSONDecodeOptionKeepPartialObject
error:&error];
if(error != nil)
{
KSLOG_ERROR(@"Encountered error loading crash report %" PRIx64 ": %@", reportID, error);
}
if(crashReport == nil)
{
KSLOG_ERROR(@"Could not load crash report");
return nil;
}
[self doctorReport:crashReport];
return crashReport;
}
// reportID 读取 crash 内容并转换为 NSData 类型
- (NSData*) loadCrashReportJSONWithID:(int64_t) reportID
{
char* report = kscrash_readReport(reportID);
if(report != NULL)
{
return [NSData dataWithBytesNoCopy:report length:strlen(report) freeWhenDone:YES];
}
return nil;
}
// reportID 读取 crash 数据到 char 类型
char* kscrash_readReport(int64_t reportID)
{
if(reportID <= 0)
{
KSLOG_ERROR("Report ID was %" PRIx64, reportID);
return NULL;
}
char* rawReport = kscrs_readReport(reportID);
if(rawReport == NULL)
{
KSLOG_ERROR("Failed to load report ID %" PRIx64, reportID);
return NULL;
}
char* fixedReport = kscrf_fixupCrashReport(rawReport);
if(fixedReport == NULL)
{
KSLOG_ERROR("Failed to fixup report ID %" PRIx64, reportID);
}
free(rawReport);
return fixedReport;
}
// 多线程加锁,通过 reportID 执行 c 函数 getCrashReportPathByID,将路径设置到 path 上。然后执行 ksfu_readEntireFile 读取 crash 信息到 result
char* kscrs_readReport(int64_t reportID)
{
pthread_mutex_lock(&g_mutex);
char path[KSCRS_MAX_PATH_LENGTH];
getCrashReportPathByID(reportID, path);
char* result;
ksfu_readEntireFile(path, &result, NULL, 2000000);
pthread_mutex_unlock(&g_mutex);
return result;
}
int kscrash_getReportIDs(int64_t* reportIDs, int count)
{
return kscrs_getReportIDs(reportIDs, count);
}
int kscrs_getReportIDs(int64_t* reportIDs, int count)
{
pthread_mutex_lock(&g_mutex);
count = getReportIDs(reportIDs, count);
pthread_mutex_unlock(&g_mutex);
return count;
}
// 循环读取文件夹内容,根据 ent->d_name 调用 getReportIDFromFilename 函数,来获取 reportID,循环内部填充数组
static int getReportIDs(int64_t* reportIDs, int count)
{
int index = 0;
DIR* dir = opendir(g_reportsPath);
if(dir == NULL)
{
KSLOG_ERROR("Could not open directory %s", g_reportsPath);
goto done;
}
struct dirent* ent;
while((ent = readdir(dir)) != NULL && index < count)
{
int64_t reportID = getReportIDFromFilename(ent->d_name);
if(reportID > 0)
{
reportIDs[index++] = reportID;
}
}
qsort(reportIDs, (unsigned)count, sizeof(reportIDs[0]), compareInt64);
done:
if(dir != NULL)
{
closedir(dir);
}
return index;
}
// sprintf(参数1, 格式2) 函数将格式2的值返回到参数1上,然后执行 sscanf(参数1, 参数2, 参数3),函数将字符串参数1的内容,按照参数2的格式,写入到参数3上。crash 文件命名为 "App名称-report-reportID.json"
static int64_t getReportIDFromFilename(const char* filename)
{
char scanFormat[100];
sprintf(scanFormat, "%s-report-%%" PRIx64 ".json", g_appName);
int64_t reportID = 0;
sscanf(filename, scanFormat, &reportID);
return reportID;
}
```
#### 2.7 前端 js 相关的 Crash 的监控
##### 2.7.1 JavascriptCore 异常监控
这部分简单粗暴,直接通过 JSContext 对象的 exceptionHandler 属性来监控,比如下面的代码
```objective-c
jsContext.exceptionHandler = ^(JSContext *context, JSValue *exception) {
// 处理 jscore 相关的异常信息
};
```
##### 2.7.2 h5 页面异常监控
当 h5 页面内的 Javascript 运行异常时会 window 对象会触发 `ErrorEvent` 接口的 error 事件,并执行 `window.onerror()`。
```js
window.onerror = function (msg, url, lineNumber, columnNumber, error) {
// 处理异常信息
};
```
##### 2.7.3 React Native 异常监控
小实验:下图是写了一个 RN Demo 工程,在 Debug Text 控件上加了事件监听代码,内部人为触发 crash
```jsx
<Text
style={styles.sectionTitle}
onPress={() => {
1 + qw;
}}
>
Debug
</Text>
```
对比组 1:
条件: iOS 项目 debug 模式。在 RN 端增加了异常处理的代码。
模拟器点击 `command + d` 调出面板,选择 Debug,打开 Chrome 浏览器, Mac 下快捷键 `Command + Option + J` 打开调试面板,就可以像调试 React 一样调试 RN 代码了。
查看到 crash stack 后点击可以跳转到 sourceMap 的地方。
Tips:RN 项目打 Release 包
- 在项目根目录下创建文件夹( release_iOS),作为资源的输出文件夹
- 在终端切换到工程目录,然后执行下面的代码
```shell
react-native bundle --entry-file index.js --platform ios --dev false --bundle-output release_ios/main.jsbundle --assets-dest release_iOS --sourcemap-output release_ios/index.ios.map;
```
- 将 release_iOS 文件夹内的 `.jsbundle` 和 `assets` 文件夹内容拖入到 iOS 工程中即可
对比组 2:
条件:iOS 项目 release 模式。在 RN 端不增加异常处理代码
操作:运行 iOS 工程,点击按钮模拟 crash
现象:iOS 项目奔溃。截图以及日志如下
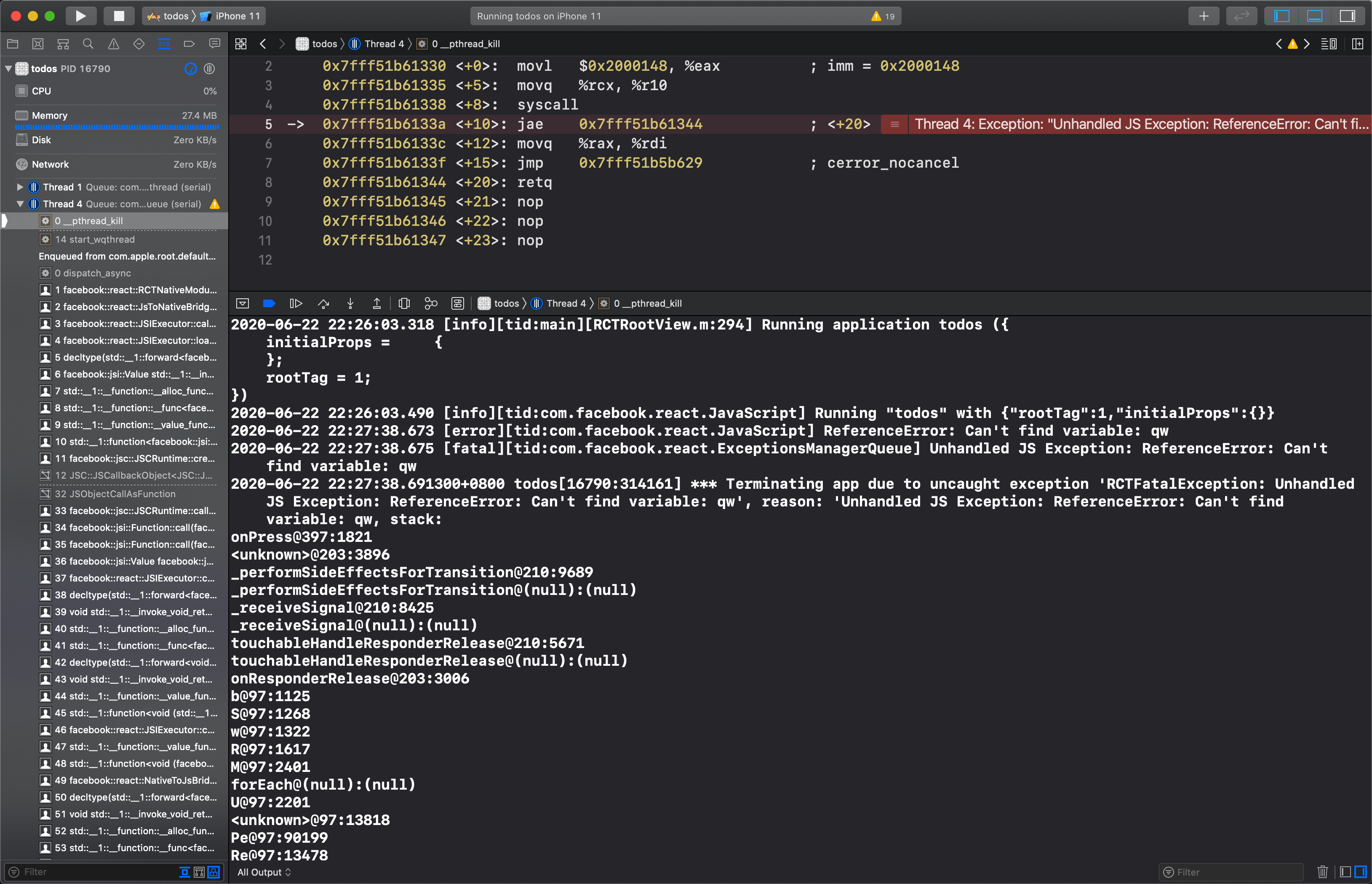
```shell
2020-06-22 22:26:03.318 [info][tid:main][RCTRootView.m:294] Running application todos ({
initialProps = {
};
rootTag = 1;
})
2020-06-22 22:26:03.490 [info][tid:com.facebook.react.JavaScript] Running "todos" with {"rootTag":1,"initialProps":{}}
2020-06-22 22:27:38.673 [error][tid:com.facebook.react.JavaScript] ReferenceError: Can't find variable: qw
2020-06-22 22:27:38.675 [fatal][tid:com.facebook.react.ExceptionsManagerQueue] Unhandled JS Exception: ReferenceError: Can't find variable: qw
2020-06-22 22:27:38.691300+0800 todos[16790:314161] *** Terminating app due to uncaught exception 'RCTFatalException: Unhandled JS Exception: ReferenceError: Can't find variable: qw', reason: 'Unhandled JS Exception: ReferenceError: Can't find variable: qw, stack:
onPress@397:1821
<unknown>@203:3896
_performSideEffectsForTransition@210:9689
_performSideEffectsForTransition@(null):(null)
_receiveSignal@210:8425
_receiveSignal@(null):(null)
touchableHandleResponderRelease@210:5671
touchableHandleResponderRelease@(null):(null)
onResponderRelease@203:3006
b@97:1125
S@97:1268
w@97:1322
R@97:1617
M@97:2401
forEach@(null):(null)
U@97:2201
<unknown>@97:13818
Pe@97:90199
Re@97:13478
Ie@97:13664
receiveTouches@97:14448
value@27:3544
<unknown>@27:840
value@27:2798
value@27:812
value@(null):(null)
'
*** First throw call stack:
(
0 CoreFoundation 0x00007fff23e3cf0e __exceptionPreprocess + 350
1 libobjc.A.dylib 0x00007fff50ba89b2 objc_exception_throw + 48
2 todos 0x00000001017b0510 RCTFormatError + 0
3 todos 0x000000010182d8ca -[RCTExceptionsManager reportFatal:stack:exceptionId:suppressRedBox:] + 503
4 todos 0x000000010182e34e -[RCTExceptionsManager reportException:] + 1658
5 CoreFoundation 0x00007fff23e43e8c __invoking___ + 140
6 CoreFoundation 0x00007fff23e41071 -[NSInvocation invoke] + 321
7 CoreFoundation 0x00007fff23e41344 -[NSInvocation invokeWithTarget:] + 68
8 todos 0x00000001017e07fa -[RCTModuleMethod invokeWithBridge:module:arguments:] + 578
9 todos 0x00000001017e2a84 _ZN8facebook5reactL11invokeInnerEP9RCTBridgeP13RCTModuleDatajRKN5folly7dynamicE + 246
10 todos 0x00000001017e280c ___ZN8facebook5react15RCTNativeModule6invokeEjON5folly7dynamicEi_block_invoke + 78
11 libdispatch.dylib 0x00000001025b5f11 _dispatch_call_block_and_release + 12
12 libdispatch.dylib 0x00000001025b6e8e _dispatch_client_callout + 8
13 libdispatch.dylib 0x00000001025bd6fd _dispatch_lane_serial_drain + 788
14 libdispatch.dylib 0x00000001025be28f _dispatch_lane_invoke + 422
15 libdispatch.dylib 0x00000001025c9b65 _dispatch_workloop_worker_thread + 719
16 libsystem_pthread.dylib 0x00007fff51c08a3d _pthread_wqthread + 290
17 libsystem_pthread.dylib 0x00007fff51c07b77 start_wqthread + 15
)
libc++abi.dylib: terminating with uncaught exception of type NSException
(lldb)
```
Tips:如何在 RN release 模式下调试(看到 js 侧的 console 信息)
- 在 `AppDelegate.m` 中引入 `#import <React/RCTLog.h>`
- 在 `- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions` 中加入 `RCTSetLogThreshold(RCTLogLevelTrace);`
对比组 3:
条件:iOS 项目 release 模式。在 RN 端增加异常处理代码。
```js
global.ErrorUtils.setGlobalHandler((e) => {
console.log(e);
let message = { name: e.name, message: e.message, stack: e.stack };
axios
.get("http://192.168.1.100:8888/test.php", {
params: { message: JSON.stringify(message) },
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
}, true);
```
操作:运行 iOS 工程,点击按钮模拟 crash。
现象:iOS 项目不奔溃。日志信息如下,对比 bundle 包中的 js。
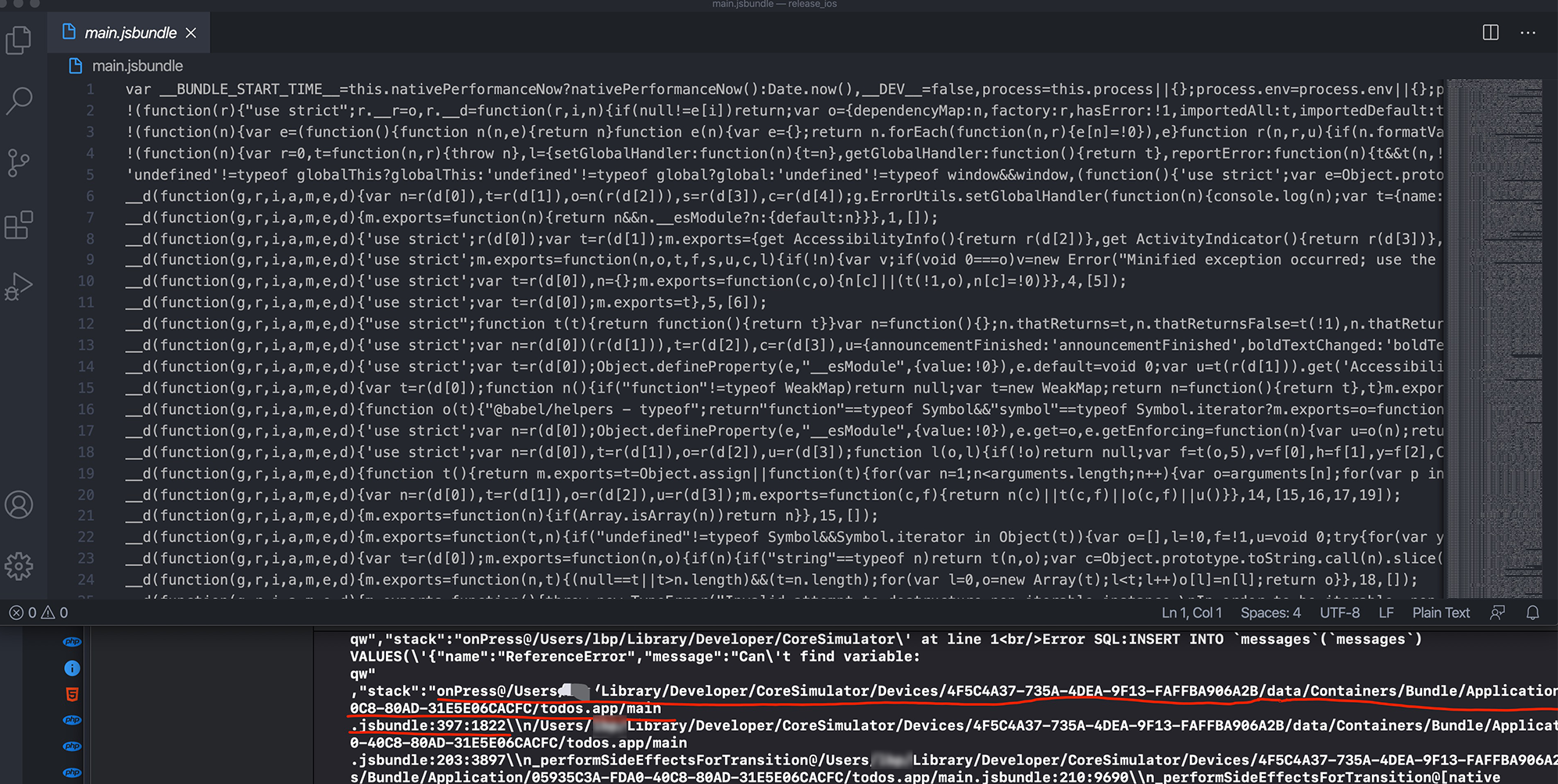
结论:
在 RN 项目中,如果发生了 crash 则会在 Native 侧有相应体现。如果 RN 侧写了 crash 捕获的代码,则 Native 侧不会奔溃。如果 RN 侧的 crash 没有捕获,则 Native 直接奔溃。
RN 项目写了 crash 监控,监控后将堆栈信息打印出来发现对应的 js 信息是经过 webpack 处理的,crash 分析难度很大。所以我们针对 RN 的 crash 需要在 RN 侧写监控代码,监控后需要上报,此外针对监控后的信息需要写专门的 crash 信息还原给你,也就是 sourceMap 解析。
###### 2.7.3.1 js 逻辑错误
写过 RN 的人都知道在 DEBUG 模式下 js 代码有问题则会产生红屏,在 RELEASE 模式下则会白屏或者闪退,为了体验和质量把控需要做异常监控。
在看 RN 源码时候发现了 `ErrorUtils`,看代码可以设置处理错误信息。
```js
/**
* Copyright (c) Facebook, Inc. and its affiliates.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*
* @format
* @flow strict
* @polyfill
*/
let _inGuard = 0;
type ErrorHandler = (error: mixed, isFatal: boolean) => void;
type Fn<Args, Return> = (...Args) => Return;
/**
* This is the error handler that is called when we encounter an exception
* when loading a module. This will report any errors encountered before
* ExceptionsManager is configured.
*/
let _globalHandler: ErrorHandler = function onError(
e: mixed,
isFatal: boolean
) {
throw e;
};
/**
* The particular require runtime that we are using looks for a global
* `ErrorUtils` object and if it exists, then it requires modules with the
* error handler specified via ErrorUtils.setGlobalHandler by calling the
* require function with applyWithGuard. Since the require module is loaded
* before any of the modules, this ErrorUtils must be defined (and the handler
* set) globally before requiring anything.
*/
const ErrorUtils = {
setGlobalHandler(fun: ErrorHandler): void {
_globalHandler = fun;
},
getGlobalHandler(): ErrorHandler {
return _globalHandler;
},
reportError(error: mixed): void {
_globalHandler && _globalHandler(error, false);
},
reportFatalError(error: mixed): void {
// NOTE: This has an untyped call site in Metro.
_globalHandler && _globalHandler(error, true);
},
applyWithGuard<TArgs: $ReadOnlyArray<mixed>, TOut>(
fun: Fn<TArgs, TOut>,
context?: ?mixed,
args?: ?TArgs,
// Unused, but some code synced from www sets it to null.
unused_onError?: null,
// Some callers pass a name here, which we ignore.
unused_name?: ?string
): ?TOut {
try {
_inGuard++;
// $FlowFixMe: TODO T48204745 (1) apply(context, null) is fine. (2) array -> rest array should work
return fun.apply(context, args);
} catch (e) {
ErrorUtils.reportError(e);
} finally {
_inGuard--;
}
return null;
},
applyWithGuardIfNeeded<TArgs: $ReadOnlyArray<mixed>, TOut>(
fun: Fn<TArgs, TOut>,
context?: ?mixed,
args?: ?TArgs
): ?TOut {
if (ErrorUtils.inGuard()) {
// $FlowFixMe: TODO T48204745 (1) apply(context, null) is fine. (2) array -> rest array should work
return fun.apply(context, args);
} else {
ErrorUtils.applyWithGuard(fun, context, args);
}
return null;
},
inGuard(): boolean {
return !!_inGuard;
},
guard<TArgs: $ReadOnlyArray<mixed>, TOut>(
fun: Fn<TArgs, TOut>,
name?: ?string,
context?: ?mixed
): ?(...TArgs) => ?TOut {
// TODO: (moti) T48204753 Make sure this warning is never hit and remove it - types
// should be sufficient.
if (typeof fun !== "function") {
console.warn("A function must be passed to ErrorUtils.guard, got ", fun);
return null;
}
const guardName = name ?? fun.name ?? "<generated guard>";
function guarded(...args: TArgs): ?TOut {
return ErrorUtils.applyWithGuard(
fun,
context ?? this,
args,
null,
guardName
);
}
return guarded;
},
};
global.ErrorUtils = ErrorUtils;
export type ErrorUtilsT = typeof ErrorUtils;
```
所以 RN 的异常可以使用 `global.ErrorUtils` 来设置错误处理。举个例子
```
global.ErrorUtils.setGlobalHandler(e => {
// e.name e.message e.stack
}, true);
```
###### 2.7.3.2 组件问题
其实对于 RN 的 crash 处理还有个需要注意的就是 **React Error Boundaries**。[详细资料](https://zh-hans.reactjs.org/docs/error-boundaries.html)
> 过去,组件内的 JavaScript 错误会导致 React 的内部状态被破坏,并且在下一次渲染时 [产生](https://github.com/facebook/react/issues/4026) [可能无法追踪的](https://github.com/facebook/react/issues/6895) [错误](https://github.com/facebook/react/issues/8579)。这些错误基本上是由较早的其他代码(非 React 组件代码)错误引起的,但 React 并没有提供一种在组件中优雅处理这些错误的方式,也无法从错误中恢复。
>
> 部分 UI 的 JavaScript 错误不应该导致整个应用崩溃,为了解决这个问题,React 16 引入了一个新的概念 —— 错误边界。
>
> 错误边界是一种 React 组件,这种组件**可以捕获并打印发生在其子组件树任何位置的 JavaScript 错误,并且,它会渲染出备用 UI**,而不是渲染那些崩溃了的子组件树。错误边界在渲染期间、生命周期方法和整个组件树的构造函数中捕获错误。
它能捕获子组件生命周期函数中的异常,包括构造函数(constructor)和 render 函数
而不能捕获以下异常:
- Event handlers(事件处理函数)
- Asynchronous code(异步代码,如 setTimeout、promise 等)
- Server side rendering(服务端渲染)
- Errors thrown in the error boundary itself (rather than its children)(异常边界组件本身抛出的异常)
所以可以通过异常边界组件捕获组件生命周期内的所有异常然后渲染兜底组件 ,防止 App crash,提高用户体验。也可引导用户反馈问题,方便问题的排查和修复
至此 RN 的 crash 分为 2 种,分别是 js 逻辑错误、组件 js 错误,都已经被监控处理了。接下来就看看如何从工程化层面解决这些问题
##### 2.7.4 RN Crash 还原
SourceMap 文件对于前端日志的解析至关重要,SourceMap 文件中各个参数和如何计算的步骤都在里面有写,可以查看[这篇文章](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.41.md)。
有了 SourceMap 文件,借助于 [mozilla ](https://github.com/mozilla) 的 [source-map](https://github.com/mozilla/source-map) 项目,可以很好的还原 RN 的 crash 日志。
我写了个 NodeJS 脚本,代码如下
```js
var fs = require('fs');
var sourceMap = require('source-map');
var arguments = process.argv.splice(2);
function parseJSError(aLine, aColumn) {
fs.readFile('./index.ios.map', 'utf8', function (err, data) {
const whatever = sourceMap.SourceMapConsumer.with(data, null, consumer => {
// 读取 crash 日志的行号、列号
let parseData = consumer.originalPositionFor({
line: parseInt(aLine),
column: parseInt(aColumn)
});
// 输出到控制台
console.log(parseData);
// 输出到文件中
fs.writeFileSync('./parsed.txt', JSON.stringify(parseData) + '\n', 'utf8', function(err) {
if(err) {
console.log(err);
}
});
});
});
}
var line = arguments[0];
var column = arguments[1];
parseJSError(line, column);
```
接下来做个实验,还是上述的 todos 项目。
1. 在 Text 的点击事件上模拟 crash
```jsx
<Text
style={styles.sectionTitle}
onPress={() => {
1 + qw;
}}
>
Debug
</Text>
```
2. 将 RN 项目打 bundle 包、产出 sourceMap 文件。执行命令,
```shell
react-native bundle --entry-file index.js --platform android --dev false --bundle-output release_ios/main.jsbundle --assets-dest release_iOS --sourcemap-output release_ios/index.android.map;
```
因为高频使用,所以给 iterm2 增加 alias 别名设置,修改 `.zshrc` 文件
```shell
alias RNRelease='react-native bundle --entry-file index.js --platform ios --dev false --bundle-output release_ios/main.jsbundle --assets-dest release_iOS --sourcemap-output release_ios/index.ios.map;' # RN 打 Release 包
```
3. 将 js bundle 和图片资源拷贝到 Xcode 工程中
4. 点击模拟 crash,将日志下面的行号和列号拷贝,在 Node 项目下,执行下面命令
```shell
node index.js 397 1822
```
5. 拿脚本解析好的行号、列号、文件信息去和源代码文件比较,结果很正确。
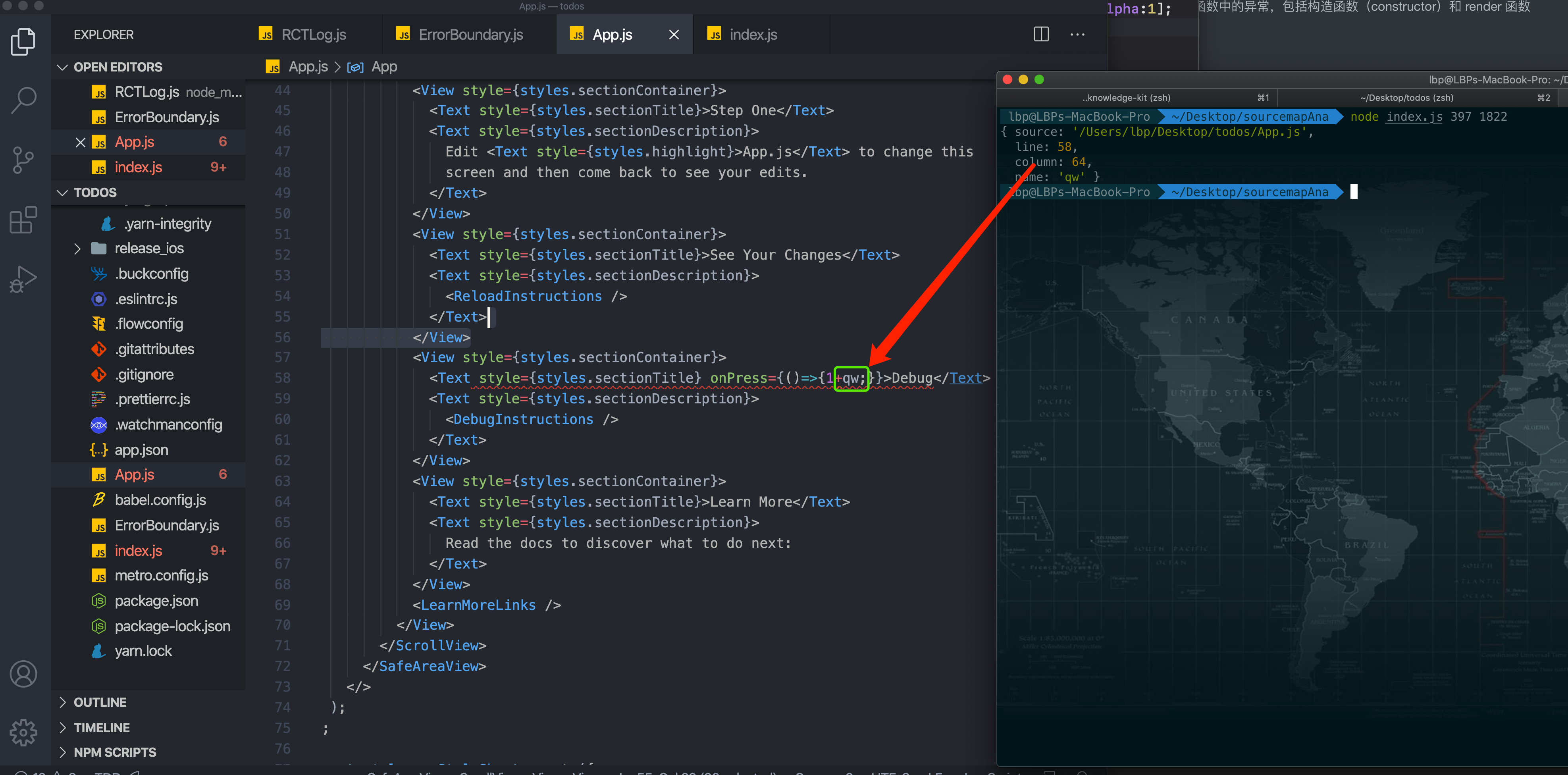
##### 2.7.5 SourceMap 解析系统设计
目的:通过平台可以将 RN 项目线上 crash 可以还原到具体的文件、代码行数、代码列数。可以看到具体的代码,可以看到 RN stack trace、提供源文件下载功能。
1. 打包系统下管理的服务器:
- 生产环境下打包才生成 source map 文件
- 存储打包前的所有文件(install)
2. 开发产品侧 RN 分析界面。点击收集到的 RN crash,在详情页可以看到具体的文件、代码行数、代码列数。可以看到具体的代码,可以看到 RN stack trace、Native stack trace。(具体技术实现上面讲过了)
3. 由于 souece map 文件较大,RN 解析过长虽然不久,但是是对计算资源的消耗,所以需要设计高效读取方式
4. SourceMap 在 iOS、Android 模式下不一样,所以 SoureceMap 存储需要区分 os。
### 3. KSCrash 的使用包装
然后再封装自己的 Crash 处理逻辑。比如要做的事情就是:
- 继承自 KSCrashInstallation 这个抽象类,设置初始化工作(抽象类比如 NSURLProtocol 必须继承后使用),实现抽象类中的 `sink` 方法。
```c++
/**
* Crash system installation which handles backend-specific details.
*
* Only one installation can be installed at a time.
*
* This is an abstract class.
*/
@interface KSCrashInstallation : NSObject
```
```objective-c
#import "APMCrashInstallation.h"
#import <KSCrash/KSCrashInstallation+Private.h>
#import "APMCrashReporterSink.h"
@implementation APMCrashInstallation
+ (instancetype)sharedInstance {
static APMCrashInstallation *sharedInstance = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
sharedInstance = [[APMCrashInstallation alloc] init];
});
return sharedInstance;
}
- (id)init {
return [super initWithRequiredProperties: nil];
}
- (id<KSCrashReportFilter>)sink {
APMCrashReporterSink *sink = [[APMCrashReporterSink alloc] init];
return [sink defaultCrashReportFilterSetAppleFmt];
}
@end
```
- `sink` 方法内部的 `APMCrashReporterSink` 类,遵循了 **KSCrashReportFilter** 协议,声明了公有方法 `defaultCrashReportFilterSetAppleFmt`
```objective-c
// .h
#import <Foundation/Foundation.h>
#import <KSCrash/KSCrashReportFilter.h>
@interface APMCrashReporterSink : NSObject<KSCrashReportFilter>
- (id <KSCrashReportFilter>) defaultCrashReportFilterSetAppleFmt;
@end
// .m
#pragma mark - public Method
- (id <KSCrashReportFilter>) defaultCrashReportFilterSetAppleFmt
{
return [KSCrashReportFilterPipeline filterWithFilters:
[APMCrashReportFilterAppleFmt filterWithReportStyle:KSAppleReportStyleSymbolicatedSideBySide],
self,
nil];
}
```
其中 `defaultCrashReportFilterSetAppleFmt` 方法内部返回了一个 `KSCrashReportFilterPipeline` 类方法 `filterWithFilters` 的结果。
`APMCrashReportFilterAppleFmt` 是一个继承自 `KSCrashReportFilterAppleFmt` 的类,遵循了 `KSCrashReportFilter` 协议。协议方法允许开发者处理 Crash 的数据格式。
```objective-c
/** Filter the specified reports.
*
* @param reports The reports to process.
* @param onCompletion Block to call when processing is complete.
*/
- (void) filterReports:(NSArray*) reports
onCompletion:(KSCrashReportFilterCompletion) onCompletion;
```
```objective-c
#import <KSCrash/KSCrashReportFilterAppleFmt.h>
@interface APMCrashReportFilterAppleFmt : KSCrashReportFilterAppleFmt<KSCrashReportFilter>
@end
// .m
- (void) filterReports:(NSArray*)reports onCompletion:(KSCrashReportFilterCompletion)onCompletion
{
NSMutableArray* filteredReports = [NSMutableArray arrayWithCapacity:[reports count]];
for(NSDictionary *report in reports){
if([self majorVersion:report] == kExpectedMajorVersion){
id monitorInfo = [self generateMonitorInfoFromCrashReport:report];
if(monitorInfo != nil){
[filteredReports addObject:monitorInfo];
}
}
}
kscrash_callCompletion(onCompletion, filteredReports, YES, nil);
}
/**
@brief 获取Crash JSON中的crash时间、mach name、signal name和apple report
*/
- (NSDictionary *)generateMonitorInfoFromCrashReport:(NSDictionary *)crashReport
{
NSDictionary *infoReport = [crashReport objectForKey:@"report"];
// ...
id appleReport = [self toAppleFormat:crashReport];
NSMutableDictionary *info = [NSMutableDictionary dictionary];
[info setValue:crashTime forKey:@"crashTime"];
[info setValue:appleReport forKey:@"appleReport"];
[info setValue:userException forKey:@"userException"];
[info setValue:userInfo forKey:@"custom"];
return [info copy];
}
```
```objective-c
/**
* A pipeline of filters. Reports get passed through each subfilter in order.
*
* Input: Depends on what's in the pipeline.
* Output: Depends on what's in the pipeline.
*/
@interface KSCrashReportFilterPipeline : NSObject <KSCrashReportFilter>
```
- APM 能力中为 Crash 模块设置一个启动器。启动器内部设置 KSCrash 的初始化工作,以及触发 Crash 时候监控所需数据的组装。比如:SESSION_ID、App 启动时间、App 名称、崩溃时间、App 版本号、当前页面信息等基础信息。
```objective-c
/** C Function to call during a crash report to give the callee an opportunity to
* add to the report. NULL = ignore.
*
* WARNING: Only call async-safe functions from this function! DO NOT call
* Objective-C methods!!!
*/
@property(atomic,readwrite,assign) KSReportWriteCallback onCrash;
```
```objective-c
+ (instancetype)sharedInstance
{
static APMCrashMonitor *_sharedManager = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
_sharedManager = [[APMCrashMonitor alloc] init];
});
return _sharedManager;
}
```
#pragma mark - public Method
- (void)startMonitor
{
APMMLog(@"crash monitor started");
#ifdef DEBUG
BOOL _trackingCrashOnDebug = [APMMonitorConfig sharedInstance].trackingCrashOnDebug;
if (_trackingCrashOnDebug) {
[self installKSCrash];
}
#else
[self installKSCrash];
#endif
}
#pragma mark - private method
static void onCrash(const KSCrashReportWriter* writer)
{
NSString *sessionId = [NSString stringWithFormat:@"\"%@\"", ***]];
writer->addJSONElement(writer, "SESSION_ID", [sessionId UTF8String], true);
NSString *appLaunchTime = ***;
writer->addJSONElement(writer, "USER_APP_START_DATE", [[NSString stringWithFormat:@"\"%@\"", appLaunchTime] UTF8String], true);
// ...
}
- (void)installKSCrash
{
[[APMCrashInstallation sharedInstance] install];
[[APMCrashInstallation sharedInstance] sendAllReportsWithCompletion:nil];
[APMCrashInstallation sharedInstance].onCrash = onCrash;
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(5.f * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
_isCanAddCrashCount = NO;
});
}
```
在 `installKSCrash` 方法中调用了 `[[APMCrashInstallation sharedInstance] sendAllReportsWithCompletion: nil]`,内部实现如下
```objective-c
- (void) sendAllReportsWithCompletion:(KSCrashReportFilterCompletion) onCompletion
{
NSError* error = [self validateProperties];
if(error != nil)
{
if(onCompletion != nil)
{
onCompletion(nil, NO, error);
}
return;
}
id<KSCrashReportFilter> sink = [self sink];
if(sink == nil)
{
onCompletion(nil, NO, [NSError errorWithDomain:[[self class] description]
code:0
description:@"Sink was nil (subclasses must implement method \"sink\")"]);
return;
}
sink = [KSCrashReportFilterPipeline filterWithFilters:self.prependedFilters, sink, nil];
KSCrash* handler = [KSCrash sharedInstance];
handler.sink = sink;
[handler sendAllReportsWithCompletion:onCompletion];
}
```
方法内部将 `KSCrashInstallation` 的 `sink` 赋值给 `KSCrash` 对象。 内部还是调用了 `KSCrash` 的 `sendAllReportsWithCompletion` 方法,实现如下
```objective-c
- (void) sendAllReportsWithCompletion:(KSCrashReportFilterCompletion) onCompletion
{
NSArray* reports = [self allReports];
KSLOG_INFO(@"Sending %d crash reports", [reports count]);
[self sendReports:reports
onCompletion:^(NSArray* filteredReports, BOOL completed, NSError* error)
{
KSLOG_DEBUG(@"Process finished with completion: %d", completed);
if(error != nil)
{
KSLOG_ERROR(@"Failed to send reports: %@", error);
}
if((self.deleteBehaviorAfterSendAll == KSCDeleteOnSucess && completed) ||
self.deleteBehaviorAfterSendAll == KSCDeleteAlways)
{
kscrash_deleteAllReports();
}
kscrash_callCompletion(onCompletion, filteredReports, completed, error);
}];
}
```
该方法内部调用了对象方法 `sendReports: onCompletion:`,如下所示
```objective-c
- (void) sendReports:(NSArray*) reports onCompletion:(KSCrashReportFilterCompletion) onCompletion
{
if([reports count] == 0)
{
kscrash_callCompletion(onCompletion, reports, YES, nil);
return;
}
if(self.sink == nil)
{
kscrash_callCompletion(onCompletion, reports, NO,
[NSError errorWithDomain:[[self class] description]
code:0
description:@"No sink set. Crash reports not sent."]);
return;
}
[self.sink filterReports:reports
onCompletion:^(NSArray* filteredReports, BOOL completed, NSError* error)
{
kscrash_callCompletion(onCompletion, filteredReports, completed, error);
}];
}
```
方法内部的 `[self.sink filterReports: onCompletion: ]` 实现其实就是 `APMCrashInstallation` 中设置的 `sink` getter 方法,内部返回了 `APMCrashReporterSink` 对象的 `defaultCrashReportFilterSetAppleFmt` 方法的返回值。内部实现如下
```objective-c
- (id <KSCrashReportFilter>) defaultCrashReportFilterSetAppleFmt
{
return [KSCrashReportFilterPipeline filterWithFilters:
[APMCrashReportFilterAppleFmt filterWithReportStyle:KSAppleReportStyleSymbolicatedSideBySide],
self,
nil];
}
```
可以看到这个函数内部设置了多个 **filters**,其中一个就是 **self**,也就是 `APMCrashReporterSink` 对象,所以上面的 ` [self.sink filterReports: onCompletion:]` ,也就是调用 `APMCrashReporterSink` 内的数据处理方法。完了之后通过 `kscrash_callCompletion(onCompletion, reports, YES, nil);` 告诉 `KSCrash` 本地保存的 Crash 日志已经处理完毕,可以删除了。
```objective-c
- (void)filterReports:(NSArray *)reports onCompletion:(KSCrashReportFilterCompletion)onCompletion
{
for (NSDictionary *report in reports) {
// 处理 Crash 数据,将数据交给统一的数据上报组件处理...
}
kscrash_callCompletion(onCompletion, reports, YES, nil);
}
```
至此,概括下 KSCrash 做的事情,提供各种 crash 的监控能力,在 crash 后将进程信息、基本信息、异常信息、线程信息等用 c 高效转换为 json 写入文件,App 下次启动后读取本地的 crash 文件夹中的 crash 日志,让开发者可以自定义 key、value 然后去上报日志到 APM 系统,然后删除本地 crash 文件夹中的日志。
### 4. 符号化
应用 crash 之后,系统会生成一份崩溃日志,存储在设置中,应用的运行状态、调用堆栈、所处线程等信息会记录在日志中。但是这些日志是地址,并不可读,所以需要进行符号化还原。
#### 4.1 .DSYM 文件<a name="DSYM"></a>
`.DSYM` (debugging symbol)文件是保存十六进制函数地址映射信息的中转文件,调试信息(symbols)都包含在该文件中。Xcode 工程每次编译运行都会生成新的 `.DSYM` 文件。默认情况下 debug 模式时不生成 `.DSYM` ,可以在 Build Settings -> Build Options -> Debug Information Format 后将值 `DWARF` 修改为 `DWARF with DSYM File`,这样再次编译运行就可以生成 `.DSYM` 文件。
所以每次 App 打包的时候都需要保存每个版本的 `.DSYM` 文件。
`.DSYM` 文件中包含 DWARF 信息,打开文件的包内容 `Test.app.DSYM/Contents/Resources/DWARF/Test` 保存的就是 `DWARF` 文件。
`.DSYM` 文件是从 Mach-O 文件中抽取调试信息而得到的文件目录,发布的时候为了安全,会把调试信息存储在单独的文件,`.DSYM` 其实是一个文件目录,结构如下:
#### 4.2 DWARF 文件
> DWARF is a debugging file format used by many compilers and debuggers to support source level debugging. It addresses the requirements of a number of procedural languages, such as C, C++, and Fortran, and is designed to be extensible to other languages. DWARF is architecture independent and applicable to any processor or operating system. It is widely used on Unix, Linux and other operating systems, as well as in stand-alone environments.
**DWARF 是一种调试文件格式,它被许多编译器和调试器所广泛使用以支持源代码级别的调试**。它满足许多过程语言(C、C++、Fortran)的需求,它被设计为支持拓展到其他语言。DWARF 是架构独立的,适用于其他任何的处理器和操作系统。被广泛使用在 Unix、Linux 和其他的操作系统上,以及独立环境上。
DWARF 全称是 Debugging With Arbitrary Record Formats,是一种使用属性化记录格式的调试文件。
DWARF 是可执行程序与源代码关系的一个紧凑表示。
大多数现代编程语言都是块结构:每个实体(一个类、一个函数)被包含在另一个实体中。一个 c 程序,每个文件可能包含多个数据定义、多个变量、多个函数,所以 DWARF 遵循这个模型,也是块结构。DWARF 里基本的描述项是调试信息项 DIE(Debugging Information Entry)。一个 DIE 有一个标签,表示这个 DIE 描述了什么以及一个填入了细节并进一步描述该项的属性列表(类比 html、xml 结构)。一个 DIE(除了最顶层的)被一个父 DIE 包含,可能存在兄弟 DIE 或者子 DIE,属性可能包含各种值:常量(比如一个函数名),变量(比如一个函数的起始地址),或对另一个 DIE 的引用(比如一个函数的返回值类型)。
DWARF 文件中的数据如下:
| 数据列 | 信息说明 |
| --------------- | -------------------------------------- |
| .debug_loc | 在 DW_AT_location 属性中使用的位置列表 |
| .debug_macinfo | 宏信息 |
| .debug_pubnames | 全局对象和函数的查找表 |
| .debug_pubtypes | 全局类型的查找表 |
| .debug_ranges | 在 DW_AT_ranges 属性中使用的地址范围 |
| .debug_str | 在 .debug_info 中使用的字符串表 |
| .debug_types | 类型描述 |
常用的标记与属性如下:
| 数据列 | 信息说明 |
| --------------------------- | ----------------------------- |
| DW_TAG_class_type | 表示类名称和类型信息 |
| DW_TAG_structure_type | 表示结构名称和类型信息 |
| DW_TAG_union_type | 表示联合名称和类型信息 |
| DW_TAG_enumeration_type | 表示枚举名称和类型信息 |
| DW_TAG_typedef | 表示 typedef 的名称和类型信息 |
| DW_TAG_array_type | 表示数组名称和类型信息 |
| DW_TAG_subrange_type | 表示数组的大小信息 |
| DW_TAG_inheritance | 表示继承的类名称和类型信息 |
| DW_TAG_member | 表示类的成员 |
| DW_TAG_subprogram | 表示函数的名称信息 |
| DW_TAG_formal_parameter | 表示函数的参数信息 |
| DW_TAG_name | 表示名称字符串 |
| DW_TAG_type | 表示类型信息 |
| DW_TAG_artifical | 在创建时由编译程序设置 |
| DW_TAG_sibling | 表示兄弟位置信息 |
| DW_TAG_data_memver_location | 表示位置信息 |
| DW_TAG_virtuality | 在虚拟时设置 |
简单看一个 DWARF 的例子:将测试工程的 `.DSYM` 文件夹下的 DWARF 文件用下面命令解析
```shell
dwarfdump -F --debug-info Test.app.DSYM/Contents/Resources/DWARF/Test > debug-info.txt
```
打开如下
```shell
Test.app.DSYM/Contents/Resources/DWARF/Test: file format Mach-O arm64
.debug_info contents:
0x00000000: Compile Unit: length = 0x0000004f version = 0x0004 abbr_offset = 0x0000 addr_size = 0x08 (next unit at 0x00000053)
0x0000000b: DW_TAG_compile_unit
DW_AT_producer [DW_FORM_strp] ("Apple clang version 11.0.3 (clang-1103.0.32.62)")
DW_AT_language [DW_FORM_data2] (DW_LANG_ObjC)
DW_AT_name [DW_FORM_strp] ("_Builtin_stddef_max_align_t")
DW_AT_stmt_list [DW_FORM_sec_offset] (0x00000000)
DW_AT_comp_dir [DW_FORM_strp] ("/Users/lbp/Desktop/Test")
DW_AT_APPLE_major_runtime_vers [DW_FORM_data1] (0x02)
DW_AT_GNU_dwo_id [DW_FORM_data8] (0x392b5344d415340c)
0x00000027: DW_TAG_module
DW_AT_name [DW_FORM_strp] ("_Builtin_stddef_max_align_t")
DW_AT_LLVM_config_macros [DW_FORM_strp] ("\"-DDEBUG=1\" \"-DOBJC_OLD_DISPATCH_PROTOTYPES=1\"")
DW_AT_LLVM_include_path [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/11.0.3/include")
DW_AT_LLVM_isysroot [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk")
0x00000038: DW_TAG_typedef
DW_AT_type [DW_FORM_ref4] (0x0000004b "long double")
DW_AT_name [DW_FORM_strp] ("max_align_t")
DW_AT_decl_file [DW_FORM_data1] ("/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/11.0.3/include/__stddef_max_align_t.h")
DW_AT_decl_line [DW_FORM_data1] (16)
0x00000043: DW_TAG_imported_declaration
DW_AT_decl_file [DW_FORM_data1] ("/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/11.0.3/include/__stddef_max_align_t.h")
DW_AT_decl_line [DW_FORM_data1] (27)
DW_AT_import [DW_FORM_ref_addr] (0x0000000000000027)
0x0000004a: NULL
0x0000004b: DW_TAG_base_type
DW_AT_name [DW_FORM_strp] ("long double")
DW_AT_encoding [DW_FORM_data1] (DW_ATE_float)
DW_AT_byte_size [DW_FORM_data1] (0x08)
0x00000052: NULL
0x00000053: Compile Unit: length = 0x000183dc version = 0x0004 abbr_offset = 0x0000 addr_size = 0x08 (next unit at 0x00018433)
0x0000005e: DW_TAG_compile_unit
DW_AT_producer [DW_FORM_strp] ("Apple clang version 11.0.3 (clang-1103.0.32.62)")
DW_AT_language [DW_FORM_data2] (DW_LANG_ObjC)
DW_AT_name [DW_FORM_strp] ("Darwin")
DW_AT_stmt_list [DW_FORM_sec_offset] (0x000000a7)
DW_AT_comp_dir [DW_FORM_strp] ("/Users/lbp/Desktop/Test")
DW_AT_APPLE_major_runtime_vers [DW_FORM_data1] (0x02)
DW_AT_GNU_dwo_id [DW_FORM_data8] (0xa4a1d339379e18a5)
0x0000007a: DW_TAG_module
DW_AT_name [DW_FORM_strp] ("Darwin")
DW_AT_LLVM_config_macros [DW_FORM_strp] ("\"-DDEBUG=1\" \"-DOBJC_OLD_DISPATCH_PROTOTYPES=1\"")
DW_AT_LLVM_include_path [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include")
DW_AT_LLVM_isysroot [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk")
0x0000008b: DW_TAG_module
DW_AT_name [DW_FORM_strp] ("C")
DW_AT_LLVM_config_macros [DW_FORM_strp] ("\"-DDEBUG=1\" \"-DOBJC_OLD_DISPATCH_PROTOTYPES=1\"")
DW_AT_LLVM_include_path [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include")
DW_AT_LLVM_isysroot [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk")
0x0000009c: DW_TAG_module
DW_AT_name [DW_FORM_strp] ("fenv")
DW_AT_LLVM_config_macros [DW_FORM_strp] ("\"-DDEBUG=1\" \"-DOBJC_OLD_DISPATCH_PROTOTYPES=1\"")
DW_AT_LLVM_include_path [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include")
DW_AT_LLVM_isysroot [DW_FORM_strp] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk")
0x000000ad: DW_TAG_enumeration_type
DW_AT_type [DW_FORM_ref4] (0x00017276 "unsigned int")
DW_AT_byte_size [DW_FORM_data1] (0x04)
DW_AT_decl_file [DW_FORM_data1] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/fenv.h")
DW_AT_decl_line [DW_FORM_data1] (154)
0x000000b5: DW_TAG_enumerator
DW_AT_name [DW_FORM_strp] ("__fpcr_trap_invalid")
DW_AT_const_value [DW_FORM_udata] (256)
0x000000bc: DW_TAG_enumerator
DW_AT_name [DW_FORM_strp] ("__fpcr_trap_divbyzero")
DW_AT_const_value [DW_FORM_udata] (512)
0x000000c3: DW_TAG_enumerator
DW_AT_name [DW_FORM_strp] ("__fpcr_trap_overflow")
DW_AT_const_value [DW_FORM_udata] (1024)
0x000000ca: DW_TAG_enumerator
DW_AT_name [DW_FORM_strp] ("__fpcr_trap_underflow")
// ......
0x000466ee: DW_TAG_subprogram
DW_AT_name [DW_FORM_strp] ("CFBridgingRetain")
DW_AT_decl_file [DW_FORM_data1] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/System/Library/Frameworks/Foundation.framework/Headers/NSObject.h")
DW_AT_decl_line [DW_FORM_data1] (105)
DW_AT_prototyped [DW_FORM_flag_present] (true)
DW_AT_type [DW_FORM_ref_addr] (0x0000000000019155 "CFTypeRef")
DW_AT_inline [DW_FORM_data1] (DW_INL_inlined)
0x000466fa: DW_TAG_formal_parameter
DW_AT_name [DW_FORM_strp] ("X")
DW_AT_decl_file [DW_FORM_data1] ("/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/System/Library/Frameworks/Foundation.framework/Headers/NSObject.h")
DW_AT_decl_line [DW_FORM_data1] (105)
DW_AT_type [DW_FORM_ref4] (0x00046706 "id")
0x00046705: NULL
0x00046706: DW_TAG_typedef
DW_AT_type [DW_FORM_ref4] (0x00046711 "objc_object*")
DW_AT_name [DW_FORM_strp] ("id")
DW_AT_decl_file [DW_FORM_data1] ("/Users/lbp/Desktop/Test/Test/NetworkAPM/NSURLResponse+apm_FetchStatusLineFromCFNetwork.m")
DW_AT_decl_line [DW_FORM_data1] (44)
0x00046711: DW_TAG_pointer_type
DW_AT_type [DW_FORM_ref4] (0x00046716 "objc_object")
0x00046716: DW_TAG_structure_type
DW_AT_name [DW_FORM_strp] ("objc_object")
DW_AT_byte_size [DW_FORM_data1] (0x00)
0x0004671c: DW_TAG_member
DW_AT_name [DW_FORM_strp] ("isa")
DW_AT_type [DW_FORM_ref4] (0x00046727 "objc_class*")
DW_AT_data_member_location [DW_FORM_data1] (0x00)
// ......
```
这里就不粘贴全部内容了(太长了)。可以看到 DIE 包含了函数开始地址、结束地址、函数名、文件名、所在行数,对于给定的地址,找到函数开始地址、结束地址之间包含该地址的 DIE,则可以还原函数名和文件名信息。
debug_line 可以还原文件行数等信息
```shell
dwarfdump -F --debug-line Test.app.DSYM/Contents/Resources/DWARF/Test > debug-inline.txt
```
贴部分信息
```shell
Test.app.DSYM/Contents/Resources/DWARF/Test: file format Mach-O arm64
.debug_line contents:
debug_line[0x00000000]
Line table prologue:
total_length: 0x000000a3
version: 4
prologue_length: 0x0000009a
min_inst_length: 1
max_ops_per_inst: 1
default_is_stmt: 1
line_base: -5
line_range: 14
opcode_base: 13
standard_opcode_lengths[DW_LNS_copy] = 0
standard_opcode_lengths[DW_LNS_advance_pc] = 1
standard_opcode_lengths[DW_LNS_advance_line] = 1
standard_opcode_lengths[DW_LNS_set_file] = 1
standard_opcode_lengths[DW_LNS_set_column] = 1
standard_opcode_lengths[DW_LNS_negate_stmt] = 0
standard_opcode_lengths[DW_LNS_set_basic_block] = 0
standard_opcode_lengths[DW_LNS_const_add_pc] = 0
standard_opcode_lengths[DW_LNS_fixed_advance_pc] = 1
standard_opcode_lengths[DW_LNS_set_prologue_end] = 0
standard_opcode_lengths[DW_LNS_set_epilogue_begin] = 0
standard_opcode_lengths[DW_LNS_set_isa] = 1
include_directories[ 1] = "/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/11.0.3/include"
file_names[ 1]:
name: "__stddef_max_align_t.h"
dir_index: 1
mod_time: 0x00000000
length: 0x00000000
Address Line Column File ISA Discriminator Flags
------------------ ------ ------ ------ --- ------------- -------------
0x0000000000000000 1 0 1 0 0 is_stmt end_sequence
debug_line[0x000000a7]
Line table prologue:
total_length: 0x0000230a
version: 4
prologue_length: 0x00002301
min_inst_length: 1
max_ops_per_inst: 1
default_is_stmt: 1
line_base: -5
line_range: 14
opcode_base: 13
standard_opcode_lengths[DW_LNS_copy] = 0
standard_opcode_lengths[DW_LNS_advance_pc] = 1
standard_opcode_lengths[DW_LNS_advance_line] = 1
standard_opcode_lengths[DW_LNS_set_file] = 1
standard_opcode_lengths[DW_LNS_set_column] = 1
standard_opcode_lengths[DW_LNS_negate_stmt] = 0
standard_opcode_lengths[DW_LNS_set_basic_block] = 0
standard_opcode_lengths[DW_LNS_const_add_pc] = 0
standard_opcode_lengths[DW_LNS_fixed_advance_pc] = 1
standard_opcode_lengths[DW_LNS_set_prologue_end] = 0
standard_opcode_lengths[DW_LNS_set_epilogue_begin] = 0
standard_opcode_lengths[DW_LNS_set_isa] = 1
include_directories[ 1] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include"
include_directories[ 2] = "/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/11.0.3/include"
include_directories[ 3] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/sys"
include_directories[ 4] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/mach"
include_directories[ 5] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/libkern"
include_directories[ 6] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/architecture"
include_directories[ 7] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/sys/_types"
include_directories[ 8] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/_types"
include_directories[ 9] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/arm"
include_directories[ 10] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/sys/_pthread"
include_directories[ 11] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/mach/arm"
include_directories[ 12] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/libkern/arm"
include_directories[ 13] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/uuid"
include_directories[ 14] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/netinet"
include_directories[ 15] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/netinet6"
include_directories[ 16] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/net"
include_directories[ 17] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/pthread"
include_directories[ 18] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/mach_debug"
include_directories[ 19] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/os"
include_directories[ 20] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/malloc"
include_directories[ 21] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/bsm"
include_directories[ 22] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/machine"
include_directories[ 23] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/mach/machine"
include_directories[ 24] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/secure"
include_directories[ 25] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/xlocale"
include_directories[ 26] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/arpa"
file_names[ 1]:
name: "fenv.h"
dir_index: 1
mod_time: 0x00000000
length: 0x00000000
file_names[ 2]:
name: "stdatomic.h"
dir_index: 2
mod_time: 0x00000000
length: 0x00000000
file_names[ 3]:
name: "wait.h"
dir_index: 3
mod_time: 0x00000000
length: 0x00000000
// ......
Address Line Column File ISA Discriminator Flags
------------------ ------ ------ ------ --- ------------- -------------
0x000000010000b588 14 0 2 0 0 is_stmt
0x000000010000b5b4 16 5 2 0 0 is_stmt prologue_end
0x000000010000b5d0 17 11 2 0 0 is_stmt
0x000000010000b5d4 0 0 2 0 0
0x000000010000b5d8 17 5 2 0 0
0x000000010000b5dc 17 11 2 0 0
0x000000010000b5e8 18 1 2 0 0 is_stmt
0x000000010000b608 20 0 2 0 0 is_stmt
0x000000010000b61c 22 5 2 0 0 is_stmt prologue_end
0x000000010000b628 23 5 2 0 0 is_stmt
0x000000010000b644 24 1 2 0 0 is_stmt
0x000000010000b650 15 0 1 0 0 is_stmt
0x000000010000b65c 15 41 1 0 0 is_stmt prologue_end
0x000000010000b66c 11 0 2 0 0 is_stmt
0x000000010000b680 11 17 2 0 0 is_stmt prologue_end
0x000000010000b6a4 11 17 2 0 0 is_stmt end_sequence
debug_line[0x0000def9]
Line table prologue:
total_length: 0x0000015a
version: 4
prologue_length: 0x000000eb
min_inst_length: 1
max_ops_per_inst: 1
default_is_stmt: 1
line_base: -5
line_range: 14
opcode_base: 13
standard_opcode_lengths[DW_LNS_copy] = 0
standard_opcode_lengths[DW_LNS_advance_pc] = 1
standard_opcode_lengths[DW_LNS_advance_line] = 1
standard_opcode_lengths[DW_LNS_set_file] = 1
standard_opcode_lengths[DW_LNS_set_column] = 1
standard_opcode_lengths[DW_LNS_negate_stmt] = 0
standard_opcode_lengths[DW_LNS_set_basic_block] = 0
standard_opcode_lengths[DW_LNS_const_add_pc] = 0
standard_opcode_lengths[DW_LNS_fixed_advance_pc] = 1
standard_opcode_lengths[DW_LNS_set_prologue_end] = 0
standard_opcode_lengths[DW_LNS_set_epilogue_begin] = 0
standard_opcode_lengths[DW_LNS_set_isa] = 1
include_directories[ 1] = "Test"
include_directories[ 2] = "Test/NetworkAPM"
include_directories[ 3] = "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS13.5.sdk/usr/include/objc"
file_names[ 1]:
name: "AppDelegate.h"
dir_index: 1
mod_time: 0x00000000
length: 0x00000000
file_names[ 2]:
name: "JMWebResourceURLProtocol.h"
dir_index: 2
mod_time: 0x00000000
length: 0x00000000
file_names[ 3]:
name: "AppDelegate.m"
dir_index: 1
mod_time: 0x00000000
length: 0x00000000
file_names[ 4]:
name: "objc.h"
dir_index: 3
mod_time: 0x00000000
length: 0x00000000
// ......
```
可以看到 debug_line 里包含了每个代码地址对应的行数。上面贴了 AppDelegate 的部分。
#### 4.3 symbols
> 在链接中,我们将函数和变量统称为符合(Symbol),函数名或变量名就是符号名(Symbol Name),我们可以将符号看成是链接中的粘合剂,整个链接过程正是基于符号才能正确完成的。
上述文字来自《程序员的自我修养》。所以符号就是函数、变量、类的统称。
按照类型划分,符号可以分为三类:
- 全局符号:目标文件外可见的符号,可以被其他目标文件所引用,或者需要其他目标文件定义
- 局部符号:只在目标文件内可见的符号,指只在目标文件内可见的函数和变量
- 调试符号:包括行号信息的调试符号信息,行号信息记录了函数和变量对应的文件和文件行号。
**符号表(Symbol Table)**:是内存地址与函数名、文件名、行号的映射表。每个定义的符号都有一个对应的值得,叫做符号值(Symbol Value),对于变量和函数来说,符号值就是地址,符号表组成如下
```shell
<起始地址> <结束地址> <函数> [<文件名:行号>]
```
#### 4.4 **如何获取地址?**
image 加载的时候会进行相对基地址进行重定位,并且每次加载的基地址都不一样,函数栈 frame 的地址是重定位后的绝对地址,我们要的是重定位前的相对地址。
Binary Images
拿测试工程的 crash 日志举例子,打开贴部分 Binary Images 内容
```shell
// ...
Binary Images:
0x102fe0000 - 0x102ff3fff Test arm64 <37eaa57df2523d95969e47a9a1d69ce5> /var/containers/Bundle/Application/643F0DFE-A710-4136-A278-A89D780B7208/Test.app/Test
0x1030e0000 - 0x1030ebfff libobjc-trampolines.dylib arm64 <181f3aa866d93165ac54344385ac6e1d> /usr/lib/libobjc-trampolines.dylib
0x103204000 - 0x103267fff dyld arm64 <6f1c86b640a3352a8529bca213946dd5> /usr/lib/dyld
0x189a78000 - 0x189a8efff libsystem_trace.dylib arm64 <b7477df8f6ab3b2b9275ad23c6cc0b75> /usr/lib/system/libsystem_trace.dylib
// ...
```
可以看到 Crash 日志的 Binary Images 包含每个 Image 的加载开始地址、结束地址、image 名称、arm 架构、uuid、image 路径。
crash 日志中的信息
```shell
Last Exception Backtrace:
// ...
5 Test 0x102fe592c -[ViewController testMonitorCrash] + 22828 (ViewController.mm:58)
```
```sh
Binary Images:
0x102fe0000 - 0x102ff3fff Test arm64 <37eaa57df2523d95969e47a9a1d69ce5> /var/containers/Bundle/Application/643F0DFE-A710-4136-A278-A89D780B7208/Test.app/Test
```
所以 frame 5 的相对地址为 `0x102fe592c - 0x102fe0000 `。再使用 命令可以还原符号信息。
使用 atos 来解析,`0x102fe0000` 为 image 加载的开始地址,`0x102fe592c` 为 frame 需要还原的地址。
```shell
atos -o Test.app.DSYM/Contents/Resources/DWARF/Test-arch arm64 -l 0x102fe0000 0x102fe592c
```
#### 4.5 UUID
- crash 文件的 UUID
```shell
grep --after-context=2 "Binary Images:" *.crash
```
```shell
Test 5-28-20, 7-47 PM.crash:Binary Images:
Test 5-28-20, 7-47 PM.crash-0x102fe0000 - 0x102ff3fff Test arm64 <37eaa57df2523d95969e47a9a1d69ce5> /var/containers/Bundle/Application/643F0DFE-A710-4136-A278-A89D780B7208/Test.app/Test
Test 5-28-20, 7-47 PM.crash-0x1030e0000 - 0x1030ebfff libobjc-trampolines.dylib arm64 <181f3aa866d93165ac54344385ac6e1d> /usr/lib/libobjc-trampolines.dylib
--
Test.crash:Binary Images:
Test.crash-0x102fe0000 - 0x102ff3fff Test arm64 <37eaa57df2523d95969e47a9a1d69ce5> /var/containers/Bundle/Application/643F0DFE-A710-4136-A278-A89D780B7208/Test.app/Test
Test.crash-0x1030e0000 - 0x1030ebfff libobjc-trampolines.dylib arm64 <181f3aa866d93165ac54344385ac6e1d> /usr/lib/libobjc-trampolines.dylib
```
Test App 的 UUID 为 `37eaa57df2523d95969e47a9a1d69ce5`.
- .DSYM 文件的 UUID
```shell
dwarfdump --uuid Test.app.DSYM
```
结果为
```shell
UUID: 37EAA57D-F252-3D95-969E-47A9A1D69CE5 (arm64) Test.app.DSYM/Contents/Resources/DWARF/Test
```
- app 的 UUID
```shell
dwarfdump --uuid Test.app/Test
```
结果为
```shell
UUID: 37EAA57D-F252-3D95-969E-47A9A1D69CE5 (arm64) Test.app/Test
```
#### 4.6 符号化(解析 Crash 日志)
上述篇幅分析了如何捕获各种类型的 crash,App 在用户手中我们通过技术手段可以获取 crash 案发现场信息并结合一定的机制去上报,但是这种堆栈是十六进制的地址,无法定位问题,所以需要做符号化处理。
上面也说明了[.DSYM 文件](#DSYM) 的作用,**通过符号地址结合 DSYM 文件来还原文件名、所在行、函数名,这个过程叫符号化**。但是 .DSYM 文件必须和 crash log 文件的 bundle id、version 严格对应。
获取 Crash 日志可以通过 Xcode -> Window -> Devices and Simulators 选择对应设备,找到 Crash 日志文件,根据时间和 App 名称定位。
app 和 .DSYM 文件可以通过打包的产物得到,路径为 `~/Library/Developer/Xcode/Archives`。
解析方法一般有 2 种:
- 使用 **symbolicatecrash**
symbolicatecrash 是 Xcode 自带的 crash 日志分析工具,先确定所在路径,在终端执行下面的命令
```shell
find /Applications/Xcode.app -name symbolicatecrash -type f
```
会返回几个路径,找到 `iPhoneSimulator.platform` 所在那一行
```
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/Library/PrivateFrameworks/DVTFoundation.framework/symbolicatecrash
```
将 symbolicatecrash 拷贝到指定文件夹下(保存了 app、DSYM、crash 文件的文件夹)
执行命令
```shell
./symbolicatecrash Test.crash Test.DSYM > Test.crash
```
第一次做这事儿应该会报错 `Error: "DEVELOPER_DIR" is not defined at ./symbolicatecrash line 69.`,解决方案:在终端执行下面命令
```shell
export DEVELOPER_DIR=/Applications/Xcode.app/Contents/Developer
```
- 使用 atos
区别于 symbolicatecrash,atos 较为灵活,只要 `.crash` 和 `.DSYM` 或者 `.crash` 和 `.app` 文件对应即可。
用法如下,-l 最后跟得是符号地址
```shell
xcrun atos -o Test.app.DSYM/Contents/Resources/DWARF/Test -arch armv7 -l 0x1023c592c
```
也可以解析 .app 文件(不存在 .DSYM 文件),其中 xxx 为段地址,xx 为偏移地址
```shell
atos -arch architecture -o binary -l xxx xx
```
因为我们的 App 可能有很多,每个 App 在用户手中可能是不同的版本,所以在 APM 拦截之后需要符号化的时候需要将 crash 文件和 `.DSYM` 文件一一对应,才能正确符号化,对应的原则就是 **UUID** 一致。
#### 4.7 系统库符号化解析
我们每次真机连接 Xcode 运行程序,会提示等待,其实系统为了堆栈解析,都会把当前版本的系统符号库自动导入到 `/Users/你自己的用户名/Library/Developer/Xcode/iOS DeviceSupport` 目录下安装了一大堆系统库的符号化文件。你可以访问下面目录看看
```shell
/Users/你自己的用户名/Library/Developer/Xcode/iOS DeviceSupport/
```
### 5. 服务端处理
##### 5.1 ELK 日志系统
业界设计日志监控系统一般会采用基于 ELK 技术。ELK 是 Elasticsearch、Logstash、Kibana 三个开源框架缩写。Elasticsearch 是一个分布式、通过 Restful 方式进行交互的近实时搜索的平台框架。Logstash 是一个中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集不同格式的数据,经过过滤后支持输出到不同目的地(文件/MQ/Redis/ElasticsSearch/Kafka)。Kibana 可以将 Elasticserarch 的数据通过友好的页面展示出来,提供可视化分析功能。所以 ELK 可以搭建一个高效、企业级的日志分析系统。
早期单体应用时代,几乎应用的所有功能都在一台机器上运行,出了问题,运维人员打开终端输入命令直接查看系统日志,进而定位问题、解决问题。随着系统的功能越来越复杂,用户体量越来越大,单体应用几乎很难满足需求,所以技术架构迭代了,通过水平拓展来支持庞大的用户量,将单体应用进行拆分为多个应用,每个应用采用集群方式部署,负载均衡控制调度,假如某个子模块发生问题,去找这台服务器上终端找日志分析吗?显然台落后,所以日志管理平台便应运而生。通过 Logstash 去收集分析每台服务器的日志文件,然后按照定义的正则模版过滤后传输到 Kafka 或 Redis,然后由另一个 Logstash 从 Kafka 或 Redis 上读取日志存储到 ES 中创建索引,最后通过 Kibana 进行可视化分析。此外可以将收集到的数据进行数据分析,做更进一步的维护和决策。
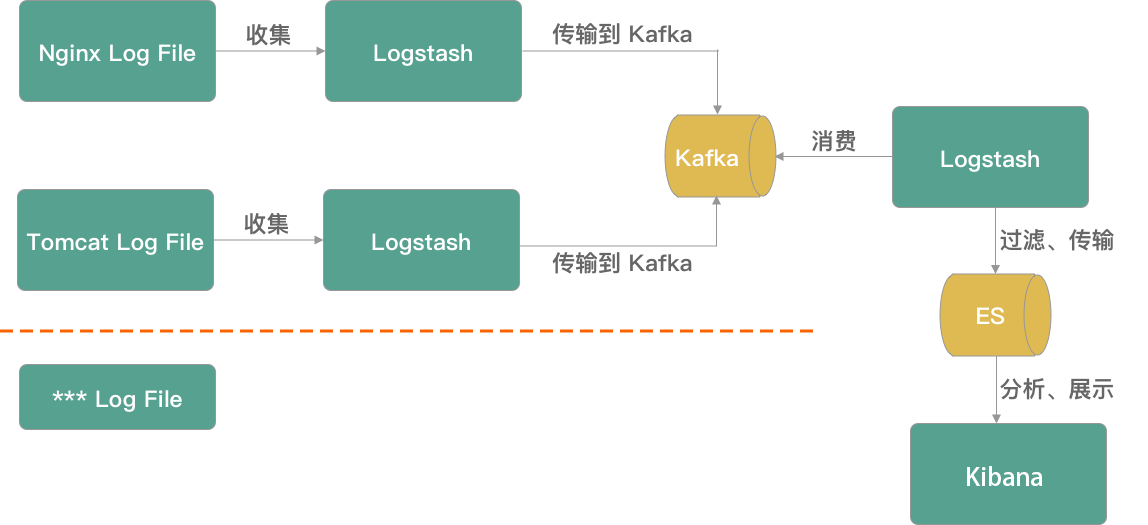
上图展示了一个 ELK 的日志架构图。简单说明下:
- Logstash 和 ES 之前存在一个 Kafka 层,因为 Logstash 是架设在数据资源服务器上,将收集到的数据进行实时过滤,过滤需要消耗时间和内存,所以存在 Kafka,起到了数据缓冲存储作用,因为 Kafka 具备非常出色的读写性能。
- 再一步就是 Logstash 从 Kafka 里面进行读取数据,将数据过滤、处理,将结果传输到 ES
- 这个设计不但性能好、耦合低,还具备可拓展性。比如可以从 n 个不同的 Logstash 上读取传输到 n 个 Kafka 上,再由 n 个 Logstash 过滤处理。日志来源可以是 m 个,比如 App 日志、Tomcat 日志、Nginx 日志等等
下图贴一个 Elasticsearch 社区分享的一个 “Elastic APM 动手实战”[主题](https://elasticsearch.cn/slides/257#page=3)的内容截图。
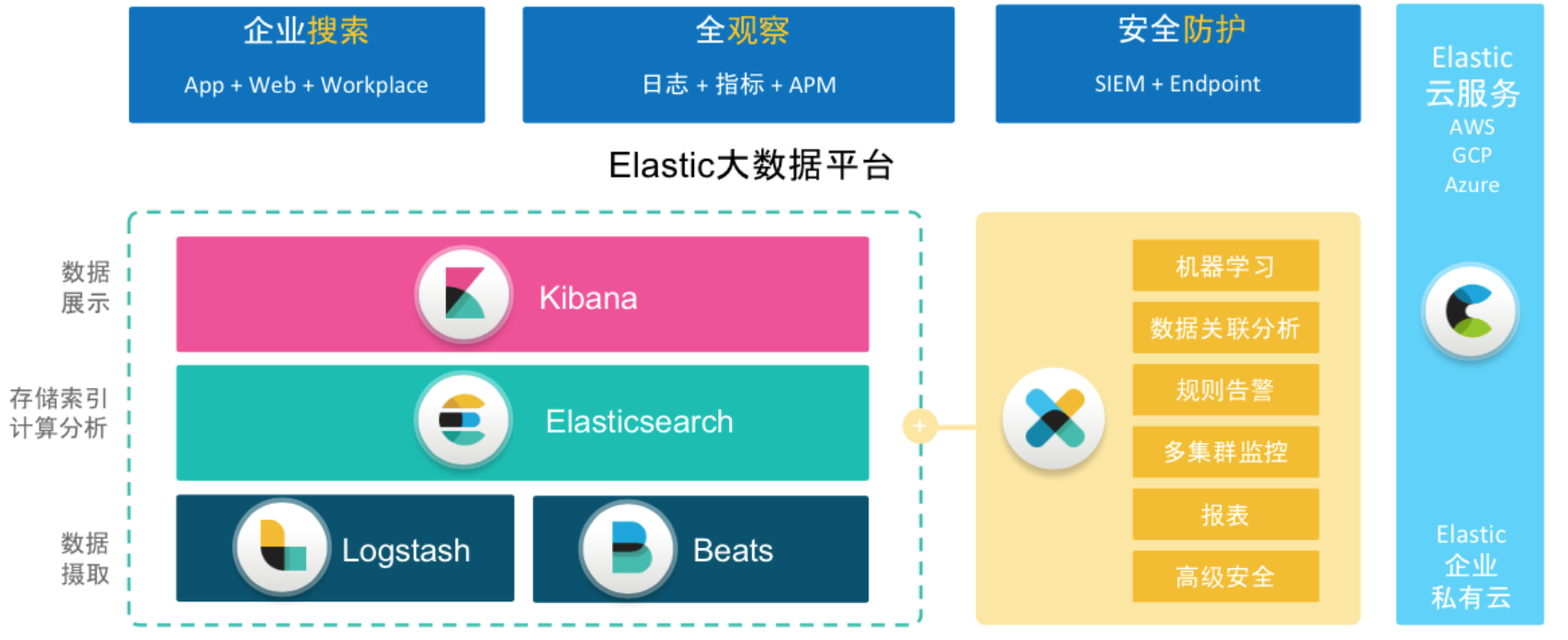
##### 5.2 服务侧
Crash log 统一入库 Kibana 时是没有符号化的,所以需要符号化处理,以方便定位问题、crash 产生报表和后续处理。
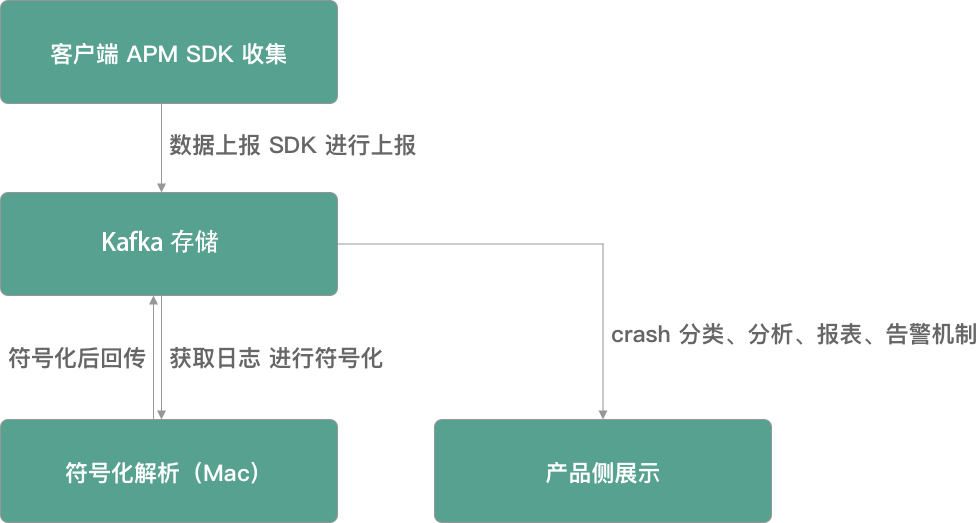
所以整个流程就是:客户端 APM SDK 收集 crash log -> Kafka 存储 -> Mac 机执行定时任务符号化 -> 数据回传 Kafka -> 产品侧(显示端)对数据进行分类、报表、报警等操作。
因为公司的产品线有多条,相应的 App 有多个,用户使用的 App 版本也各不相同,所以 crash 日志分析必须要有正确的 .DSYM 文件,那么多 App 的不同版本,自动化就变得非常重要了。
自动化有 2 种手段,规模小一点的公司或者图省事,可以在 Xcode 中 添加 runScript 脚本代码来自动在 release 模式下上传 DSYM)。
因为我们大前端有一套体系,可以同时管理 iOS SDK、iOS App、Android SDK、Android App、Node、React、React Native 工程项目的初始化、依赖管理、构建(持续集成、Unit Test、Lint、统跳检测)、测试、打包、部署、动态能力(热更新、统跳路由下发)等能力于一身。可以基于各个阶段做能力的插入,所以可以在打包系统中,当调用打包后在打包机上传 `.DSYM` 文件到七牛云存储(规则可以是以 AppName + Version 为 key,value 为 .DSYM 文件)。
现在很多架构设计都是微服务,至于为什么选微服务,不在本文范畴。所以 crash 日志的符号化被设计为一个微服务。架构图如下
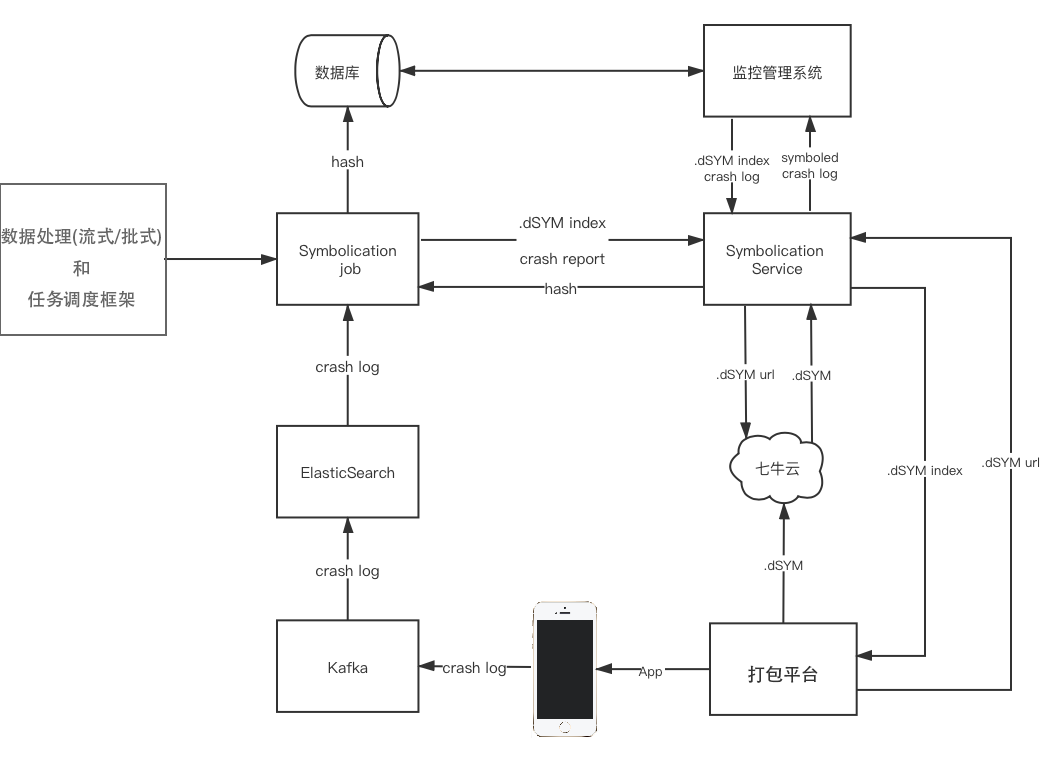
说明:
- Symbolication Service 作为整个监控系统的一个组成部分,是专注于 crash report 符号化的微服务。
- 接收来自任务调度框架的包含预处理过的 crash report 和 DSYM index 的请求,从七牛拉取对应的 DSYM,对 crash report 做符号化解析,计算 hash,并将 hash 响应给「数据处理和任务调度框架」。
- 接收来自 APM 管理系统的包含原始 crash report 和 DSYM index 的请求,从七牛拉取对应的 DSYM,对 crash report 做符号化解析,并将符号化的 crash report 响应给 APM 管理系统。
- 脚手架 cli 有个能力就是调用打包系统的打包构建能力,会根据项目的特点,选择合适的打包机(打包平台是维护了多个打包任务,不同任务根据特点被派发到不同的打包机上,任务详情页可以看到依赖的下载、编译、运行过程等,打包好的产物包括二进制包、下载二维码等等)
其中符号化服务是大前端背景下大前端团队的产物,所以是 NodeJS 实现的(单线程,所以为了提高机器利用率,就要开启多进程能力)。iOS 的符号化机器是 双核的 Mac mini,这就需要做实验测评到底需要开启几个 worker 进程做符号化服务。结果是双进程处理 crash log,比单进程效率高近一倍,而四进程比双进程效率提升不明显,符合双核 mac mini 的特点。所以开启两个 worker 进程做符号化处理。
下图是完整设计图
简单说明下,符号化流程是一个主从模式,一台 master 机,多个 slave 机,master 机读取 .DSYM 和 crash 结果的 cache。「数据处理和任务调度框架」调度符号化服务(内部 2 个 symbolocate worker)同时从七牛云上获取 .DSYM 文件。
系统架构图如下
## 八、 APM 小结
1. 通常来说各个端的监控能力是不太一致的,技术实现细节也不统一。所以在技术方案评审的时候需要将监控能力对齐统一。每个能力在各个端的数据字段必须对齐(字段个数、名称、数据类型和精度),因为 APM 本身是一个闭环,监控了之后需符号化解析、数据整理,进行产品化开发、最后需要监控大盘展示等
2. 一些 crash 或者 ANR 等根据等级需要邮件、短信、企业内容通信工具告知干系人,之后快速发布版本、hot fix 等。
3. 监控的各个能力需要做成可配置,灵活开启关闭。
4. 监控数据需要做内存到文件的写入处理,需要注意策略。监控数据需要存储数据库,数据库大小、设计规则等。存入数据库后如何上报,上报机制等会在另一篇文章讲:[打造一个通用、可配置的数据上报 SDK](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md)
5. 尽量在技术评审后,将各端的技术实现写进文档中,同步给相关人员。比如 ANR 的实现
```objective-c
/*
android 端
根据设备分级,一般超过 300ms 视为一次卡顿
hook 系统 loop,在消息处理前后插桩,用以计算每条消息的时长
开启另外线程 dump 堆栈,处理结束后关闭
*/
new ExceptionProcessor().init(this, new Runnable() {
@Override
public void run() {
//监测卡顿
try {
ProxyPrinter proxyPrinter = new ProxyPrinter(PerformanceMonitor.this);
Looper.getMainLooper().setMessageLogging(proxyPrinter);
mWeakPrinter = new WeakReference<ProxyPrinter>(proxyPrinter);
} catch (FileNotFoundException e) {
}
}
})
/*
iOS 端
子线程通过 ping 主线程来确认主线程当前是否卡顿。
卡顿阈值设置为 300ms,超过阈值时认为卡顿。
卡顿时获取主线程的堆栈,并存储上传。
*/
- (void) main() {
while (self.cancle == NO) {
self.isMainThreadBlocked = YES;
dispatch_async(dispatch_get_main_queue(), ^{
self.isMainThreadBlocked = YES;
[self.semaphore singal];
});
[Thread sleep:300];
if (self.isMainThreadBlocked) {
[self handleMainThreadBlock];
}
[self.semaphore wait];
}
}
```
6. 整个 APM 的架构图如下
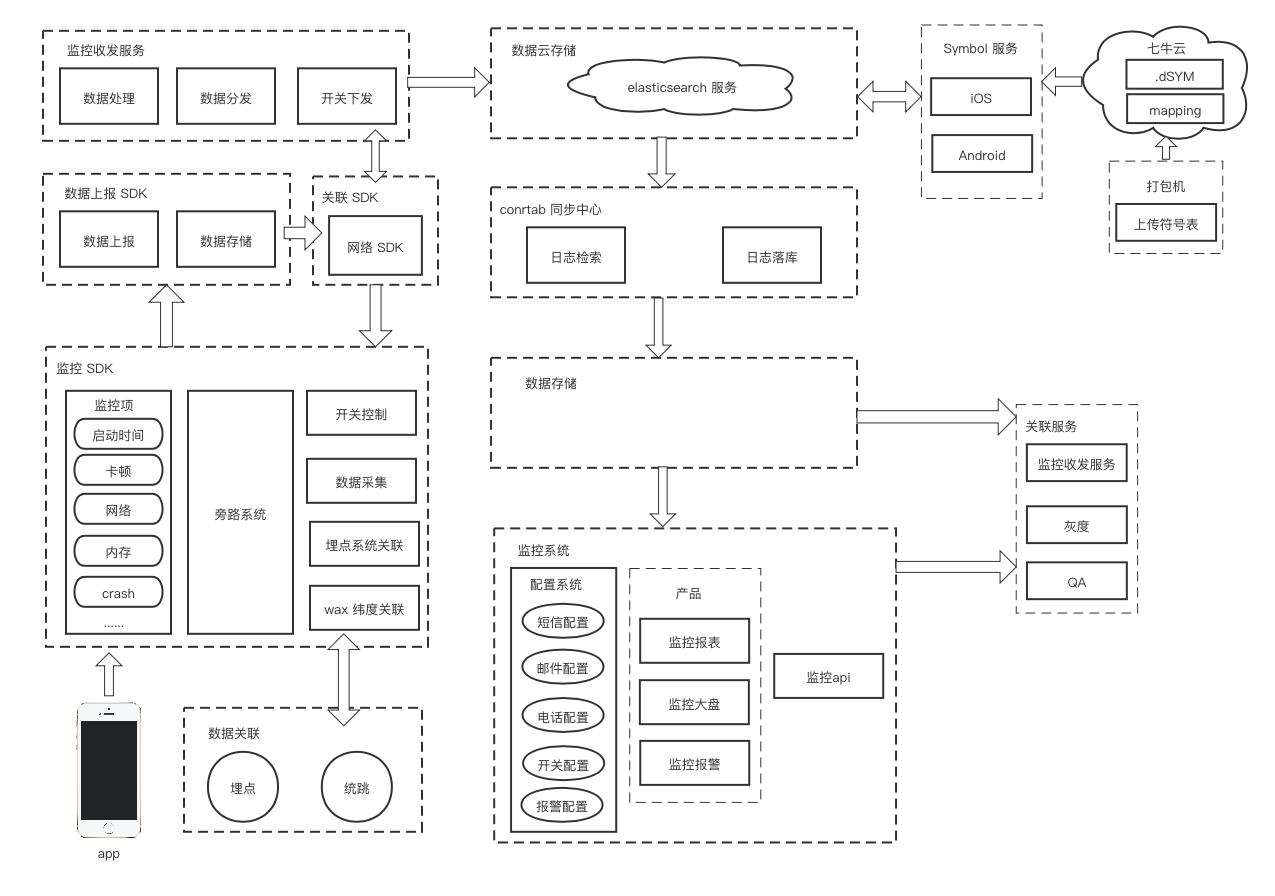
说明:
- 埋点 SDK,通过 sessionId 来关联日志数据
7. APM 技术方案本身是随着技术手段、分析需求不断调整升级的。上图的几个结构示意图是早期几个版本的,目前使用的是在此基础上进行了升级和结构调整,提几个关键词:Hermes、Flink SQL、InfluxDB。
## 参考资料
- [iOS 保持界面流畅的技巧](https://blog.ibireme.com/2015/11/12/smooth_user_interfaces_for_ios/)
- [Call Stack](https://en.wikipedia.org/wiki/Call_stack)
- [关于函数调用栈(call stack)的个人理解](https://blog.csdn.net/VarusK/article/details/83031643)
- [获取任意线程调用栈的那些事](https://bestswifter.com/callstack/)
- [iOS 启动时间优化](https://www.zoomfeng.com/blog/launch-time.html)
- [WWDC2019 之启动时间与 Dyld3](https://www.zoomfeng.com/blog/launch-optimize-from-wwdc2019.html)
- [Apple-libmalloc](https://opensource.apple.com/tarballs/libmalloc/)
- [Apple-XNU](https://opensource.apple.com/tarballs/xnu/)
- [OOM 探究:XNU 内存状态管理](https://www.jianshu.com/p/4458700a8ba8)
- [Reducing FOOMs in the Facebook iOS app](https://engineering.fb.com/ios/reducing-fooms-in-the-facebook-ios-app/)
- [iOS 内存 abort(Jetsam) 原理探究](https://satanwoo.github.io/2017/10/18/abort/)
- [iOS 微信内存监控](https://wetest.qq.com/lab/view/367.html?from=coop_gad)
- [iOS 堆栈信息解析(函数地址与符号关联)](https://www.jianshu.com/p/df5b08330afd)
- [Apple-CFNetwork Programming Guide](https://developer.apple.com/library/archive/documentation/Networking/Conceptual/CFNetwork/Introduction/Introduction.html#//apple_ref/doc/uid/TP30001132-CH1-DontLinkElementID_30)
- [MDN-HTTP Messages](https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages)
- [DWARF 和符号化](https://junyixie.github.io/2018/09/30/dwarf和符号化/) | 242,078 | MIT |
---
layout: post
title: "党建工作如何在私人企业开展?"
date: 2018-04-02
author: 杨鸣宇
from: http://cnpolitics.org/2018/04/grassroots-party-workers-for-chinas-non-public-sector-of-the-economy/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
党建工作如何在私人企业开展?
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/yangmingyu/">杨鸣宇</a-->
<a href="http://cnpolitics.org/author/yangmingyu/">
杨鸣宇
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2018-04-02
</span>
</p>
<!--p class="post-lead">私企党政工作事实上包含人员招聘和激励机制两个相互关联的部分。</p-->
<div class="post-body">
<p>
<a href="http://cnpolitics.org/wp-content/uploads/2018/08/640-13.jpg">
<img alt="" class="alignnone size-full wp-image-12422" height="280" sizes="(max-width: 500px) 100vw, 500px" src="http://cnpolitics.org/wp-content/uploads/2018/08/640-13.jpg" srcset="http://cnpolitics.org/wp-content/uploads/2018/08/640-13.jpg 500w, http://cnpolitics.org/wp-content/uploads/2018/08/640-13-300x168.jpg 300w" width="500"/>
</a>
</p>
<p>
非公有的私人企业成立党支部在近年变得越来越普遍。然而和公有单位不同,私企里的党支部人员通常都没有编制,这意味着中国发达的干部绩效考核机制在这些人身上不会发挥激励作用(因为不具备政治晋升的可能)。那么为何会有激励去完成这些需要付出额外时间的党政工作?在最近一篇发表在《当代中国》上的论文里,研究者带着上述的疑问在北京、杭州、宁波和上海四个在这方面工作被评为“先进”的城市进行了田野调查,尝试寻找出答案。
</p>
<p>
研究者发现私企党政工作事实上包含两个相互关联的部分─人员招聘和激励机制。了解以上工作在现实中是如何开展的因此是解答研究问题的关键。
</p>
<h3>
人员招聘
</h3>
<p>
党支部由党支书和普通职工两类人员组成。前者通常是兼职性质,负责招收、教化和动员党员支持党的政策和方针。后者则为全职员工,从事日常的文书工作。人员的招聘往往采取以下三种形式。
</p>
<p>
第一种形式是因地制宜。比方说私企老板或者其信任的员工自己就能当党支书,或者当地党政部门能够从目前编制中抽调人手到私企工作是最理想的情况。但现实中这两类群体往往因为本身的工作已经足够繁忙而无法长期胜任。这就需要依赖第二种招聘形式─返聘。退休干部通常是私企最喜欢的返聘对象,因为体制内的经历和关系能使他们快速把党建工作建立起来。最后一种招聘形式是公开招考。以公开招考形式招聘的一般是普通职工。或许是因为职位工作要求的关系,公开招考招聘的员工通常年龄较轻但教育程度和社会经验均低于党支书。他们往往以社工身份接受地方民政部门以合同的形式支付薪水,但实际上更多的处理和党建相关的工作。
</p>
<h3>
激励机制
</h3>
<p>
合理的激励机制需要和人员的社会阶层身份相配套,因此先要了解党支书和普通职工的人口背景。根据研究者在宁波对211位党支书和35位普通职工的问卷调查结果显示,前者更可能是男性(65.2%),年龄偏大(40-60之间),大多持有大专或以上学历,拥有体面的职业(八成以上在企业中从事主管或以上职业或者本身就是老板)、收入(一半以上月收入在5000以上)和个人资产(几乎全部拥有自置物业)。后者则更可能是女性(84.4%),年轻(70后和80后为主)。虽然在学历上和党支书没有明显差异,收入却有着明显差距(月收入大多在5000以下),因此一半人目前需要以和父母同住等方式解决住房。显而易见的是党支书和普通职工处于两者不同社会阶层,相应的激励机制自然也会有所区别,但总的来说可以分为物质和非物质两大类。
</p>
<p>
首先来看物质激励。对于处身中等偏上阶层的党支书,兼职党务的物质回报相对于正式工作收入而言可谓只具有象征性质(比如说报销电话费)。然而对于中下阶层的普通职工而言,这份工作即便收入不高(通常以当地上一年的平均收入作为基准),却有着一些其他工作没有的额外好处。比如较为自由的工作时间,一位接受访问的女职工就向研究者表示,自己本来在企业工作,虽然收入比现在高一倍,但非常辛苦,加班是常态。现在转换工作后可以有更多时间照顾家庭。另外,也有不少年轻人视普通职工这份工作为“跳板”,因为拥有基层工作经验能在将来增加投考公务员时加分。换言之,对于党支书而言真正管用的是非物质激励。比方说假如未来希望进入体制内工作,党支书经历就是一项不错的政治资本。当然,对于部份有过从军或公有部门经历的党支书而言,这份工作本身就能带来“为党服务”的精神满足感。
</p>
<h3>
结语
</h3>
<p>
总括而言,这篇研究带来两方面的贡献。一方面,它展示了基层党组织是如何适应快速变化的中国社会。另一方面,它提醒那些关心中国社会稳定的研究者,应该更多注意本研究提及的那些维护社会稳定的日常机制。
</p>
<p>
<strong>
本文系网易新闻·网易号“各有态度”特色内容。
</strong>
</p>
<div class="post-endnote">
<h4>
参考文献
</h4>
<ul>
<li>
Han Zhang, “Who Serves the Party on the Ground? Grassroots Party Workers for China’s Non-Public Sector of the Economy”, Journal of Contemporary China, 2018, 27(110):244-260.
</li>
</ul>
</div>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 3,370 | MIT |
---
title: Azure 流分析的输出
description: 本文介绍可用于 Azure 流分析的数据输出选项。
author: Johnnytechn
ms.author: v-johya
ms.reviewer: mamccrea
ms.service: stream-analytics
ms.topic: conceptual
ms.custom: contperfq1
ms.date: 11/16/2020
ms.openlocfilehash: 38eae524496fe110748acfc08e9b99d06b2f3a31
ms.sourcegitcommit: c2c9dc65b886542d220ae17afcb1d1ab0a941932
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/20/2020
ms.locfileid: "94977427"
---
# <a name="outputs-from-azure-stream-analytics"></a>Azure 流分析的输出
Azure 流分析作业由输入、查询和输出构成。 可以将转换后的数据发送到多个输出类型。 本文列出了支持的流分析输出。 设计流分析查询时,使用 [INTO 子句](https://docs.microsoft.com/stream-analytics-query/into-azure-stream-analytics)引用输出的名称。 可针对每个作业使用单个输出,也可通过向查询添加多个 INTO 子句,针对每个流式处理作业使用多个输出(如果需要)。
要创建、编辑和测试流分析作业输出,可使用 [Azure 门户](stream-analytics-quick-create-portal.md#configure-job-output)、[Azure PowerShell](stream-analytics-quick-create-powershell.md#configure-output-to-the-job)、[.NET API](/dotnet/api/microsoft.azure.management.streamanalytics.ioutputsoperations) 和 [REST API](https://docs.microsoft.com/rest/api/streamanalytics/)。
部分输出类型支持[分区](#partitioning),并且[输出批大小](#output-batch-size)可变化以优化吞吐量。 下表显示了每种输出类型支持的功能:
| 输出类型 | 分区 | 安全 |
|-------------|--------------|----------|
|[Azure SQL 数据库](sql-database-output.md)|是,可选。|SQL 用户身份验证 </br> MSI(预览)|
|[Blob 存储和 Azure Data Lake Gen 2](blob-storage-azure-data-lake-gen2-output.md)|是|MSI </br> 访问密钥|
|[Azure 事件中心](event-hubs-output.md)|是,需要在输出配置中设置分区键列。|访问密钥|
|[Azure 表存储](table-storage-output.md)|是|帐户密钥|
|[Azure 服务总线队列](service-bus-queues-output.md)|是|访问密钥|
|[Azure 服务总线主题](service-bus-topics-output.md)|是|访问密钥|
|[Azure Cosmos DB](azure-cosmos-db-output.md)|是|访问密钥|
|[Azure Functions](azure-functions-output.md)|是|访问密钥|
<!-- Not Available for Power BI, Data Lake Storage Gen 1 and Synapse Analytics -->
## <a name="partitioning"></a>分区
流分析支持所有输出的分区。 有关分区键和输出编写器数目的详细信息,请参阅你感兴趣的特定输出类型的文章。 在上一节中链接了所有输出文章。
<!-- Not Available ## Power BI-->
另外,若要对分区进行更高级的优化,可以在查询中使用 `INTO <partition count>`(请参阅 [INTO](https://docs.microsoft.com/stream-analytics-query/into-azure-stream-analytics#into-shard-count))子句来控制输出写入器的数量,这可能有助于实现所需的作业拓扑。 如果输出适配器未分区,则一个输入分区中缺少数据将导致延迟最多可达延迟到达的时间量。 在这种情况下,输出将合并到单个写入器,这可能会导致管道中出现瓶颈。 若要了解有关延迟到达策略的详细信息,请参阅 [Azure 流分析事件顺序注意事项](./stream-analytics-time-handling.md)。
## <a name="output-batch-size"></a>输出批大小
所有输出都支持批处理,但仅部分输出显式支持批处理大小。 Azure 流分析使用大小可变的批来处理事件和写入到输出。 通常流分析引擎不会一次写入一条消息,而是使用批来提高效率。 当传入和传出事件的速率较高时,流分析将使用更大的批。 输出速率低时,使用较小的批来保证低延迟。
## <a name="parquet-output-batching-window-properties"></a>Parquet 输出批处理窗口属性
使用 Azure 资源管理器模板部署或 REST API 时,两个批处理窗口属性为:
1. *timeWindow*
每批的最长等待时间。 该值应为时间跨度的字符串。 例如,“00:02:00”表示两分钟。 在此时间后,即使不满足最小行数要求,也会将该批写入输出。 默认值为 1 分钟,允许的最大值为 2 小时。 如果 blob 输出具有路径模式频率,则等待时间不能超出分区时间范围。
2. *sizeWindow*
每批的最小行数。 对于 Parquet,每个批处理都将创建一个新文件。 当前默认值为 2000 行,允许的最大值为 10000 行。
这些批处理窗口属性仅受 API 版本“2017-04-01-preview”支持。 下面是 REST API 调用的 JSON 有效负载的示例:
```json
"type": "stream",
"serialization": {
"type": "Parquet",
"properties": {}
},
"timeWindow": "00:02:00",
"sizeWindow": "2000",
"datasource": {
"type": "Microsoft.Storage/Blob",
"properties": {
"storageAccounts" : [
{
"accountName": "{accountName}",
"accountKey": "{accountKey}",
}
],
```
## <a name="next-steps"></a>后续步骤
> [!div class="nextstepaction"]
>
> [快速入门:使用 Azure 门户创建流分析作业](stream-analytics-quick-create-portal.md)
<!--Link references-->
<!-- URL is not Correct on stream-analytics-developer-guide.md -->
[stream.analytics.scale.jobs]: stream-analytics-scale-jobs.md
[stream.analytics.introduction]: stream-analytics-introduction.md
[stream.analytics.get.started]: stream-analytics-real-time-fraud-detection.md
[stream.analytics.query.language.reference]: https://docs.microsoft.com/stream-analytics-query/stream-analytics-query-language-reference
[stream.analytics.rest.api.reference]: https://docs.microsoft.com/rest/api/streamanalytics/ | 3,988 | CC-BY-4.0 |
---
title: 建立變數值檔案(AccessToSQL) |Microsoft Docs
ms.prod: sql
ms.custom: ''
ms.date: 08/17/2017
ms.reviewer: ''
ms.technology: ssma
ms.topic: conceptual
ms.assetid: 808595c3-8ef1-40bd-a93e-5cf237950e08
author: Shamikg
ms.author: Shamikg
ms.openlocfilehash: 051ded7d675f81998718b858c71488ba968ec680
ms.sourcegitcommit: e042272a38fb646df05152c676e5cbeae3f9cd13
ms.translationtype: MT
ms.contentlocale: zh-TW
ms.lasthandoff: 04/27/2020
ms.locfileid: "68006600"
---
# <a name="creating-variable-value-files-accesstosql"></a>建立變數值檔案(AccessToSQL)
變數值檔案是一個 XML 檔案,其中包含經常跨伺服器遷移而變更的命令參數值(例如來源或目的地伺服器名稱)。 當發生大量的資料庫移轉時,會在命令列上使用 **-v**參數來建立及參考用於儲存每個來源伺服器值的多個變數檔案。 這個行為有助於以多個變數檔案中的變數值來維護一些腳本檔案中的靜態值。
> [!NOTE]
> - 變數名稱前面會加上 $ (美元)符號的前置詞和尾碼。 如果變數未獲指派變數值檔案中的值,則會在剖析腳本檔案期間發生錯誤,而導致主控台執行程式停止。
> - 的逸出字元**$** 為**$$**。 如果參數的變數或靜態值值包含**$** (美元)符號,則**$$** 必須將它指定為將它視為字元,而不是變數。
> - 基於可維護性的考慮,變數可以`'variable-group'`在專案內宣告,以進行使用者定義變數的邏輯分隔。 此元素的使用不是強制的。
**範例:**
**範例 1:**
```xml
<!--Sample of variable value file commands-->
<variables>
<variable-group name="ProjectSpecs">
<variable name="$type$" value="MyProject"/>
<variable name="$project_folder$" value=".\$project_name$"/>
<variable name="$project_name$" value="$type$ConsoleProject"/>
<variable name="$project_overwrite$" value="true"/>
<variable name="$project_type$" value="sql-server-2008"/>
</variable-group>
</variables>
```
**範例2:**
```xml
<!--Sample of variable value file commands-->
<variables>
<variable-group name="SQLServerParams">
<variable-group name="SqlServerConnectionParams">
<variable name="$TargetServerName$" value="xxx"/>
<variable name="$TargetDB$" value="xxx"/>
<variable name="$TargetUserName$" value="xxx"/>
<variable name="$TargetPassword$" value="xxx"/>
<variable name="$TargetIsTrusted$" value="xxx"/>
<variable name="$TrustedConnection$" value="xxx"/>
</variable-group>
<variable-group name="SqlServerObjectParams">
<variable name="$ObjectName1$" value="TestTable1"/>
<variable name="$ObjectName2$" value="TestProc1"/>
</variable-group>
</variable-group>
</variables>
```
## <a name="variable-value-file-validation"></a>變數值檔案驗證
使用者可以針對 [架構] 資料夾中提供的架構定義檔**ConsoleScriptVariablesSchema** ,輕鬆地驗證其變數值檔案。
## <a name="next-step"></a>後續步驟
操作主控台的下一個步驟是[(AccessToSQL 建立伺服器連接檔案)](../../ssma/access/creating-the-server-connection-files-accesstosql.md)
## <a name="see-also"></a>另請參閱
[建立伺服器連接檔案(存取)](https://msdn.microsoft.com/829153be-aa8e-4162-87e8-69882feecf19) | 2,709 | CC-BY-4.0 |
# 说明
+ 只支持单主键或者无主键。多个主键需要自己写。
+ 模板仿照MyBatis-Generator自动生成的模板,并且在其中加入了一些优化
+ 需要导入模板和全局配置文件,具体配置参考配置文件中的说明
+ 配置项目:
```vm
## 是否使用Lombok
#set($useLombok=true)
## 是否生成GetterSetter方法
#set($useGetterSetter=false)
## 实体保存的包名
#set($entityPackage='entity.po')
## example保存的包名
#set($examplePackage='entity.po.example')
## example后缀
#set($exampleSuffix='Example')
## mapper接口保存的包名
#set($mapperPackage='dao')
## mapper接口后缀
#set($mapperSuffix='Mapper')
## mapperXMl路径:默认路径已经包含/src/main/resources/
#set($mapperXMLPath='mapper')
## 是否生成Example(只是会指示是否生成Example相关方法,具体是否生成Example还是看是否勾选了Example)
#set($useExample=true)
## 是否添加selectSelective方法(会根据填入的字段选择指定内容。为了提高性能没使用枚举类,请通过约定来约束),前提是必须开启了useExample
#set($selectSelective=true)
## 是否在Example中添加Column内部类,记录所有表字段
#set($createColumn=true)
```
# 导入
+ `Entity.vm`、`EntityExample.vm`、`Example.vm`、`JavaMapper.vm`、`XmlMapper.vm`需要导入到Template Setting中。如下图:
+ 
+ `config.vm`需要导入到Global config中(**注:由于用到了默认的几个全局文件,所以最好不要创建新的模板,直接在默认的模板添加**)。如下图:
+ 
# 生成代码
## 测试表
```sql
create table user
(
id bigint unsigned auto_increment
primary key,
account varchar(100) null,
password varchar(100) null
);
```
## 生成的实体类
```java
package cn.gloduck.onlinetest.entity.po;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
/**
* (User)实体类
*
* @author Gloduck
* @since 2020-12-08 11:28:23
*/
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User implements Serializable {
private static final long serialVersionUID = -28183071851891684L;
private Long id;
private String account;
private String password;
}
```
## 生成的BaseExample
```java
package cn.gloduck.onlinetest.entity.po.example;
import java.util.LinkedList;
import java.util.List;
/**
* @author Gloduck
*/
public class EntityExample {
/**
* 排序条件
*/
protected String orderByClause;
/**
* 是否倒序
*/
protected boolean desc;
/**
* 条件列表
*/
protected List<Criteria> criterias;
/**
* 选择列列表
*/
protected List<String> selectColumns;
/**
* 当前正在操作的条件
*/
protected Criteria currentCriteria;
/**
* 是否去重
*/
protected boolean distinct;
/**
* 限制量
*/
protected Integer limit;
/**
* 偏移量
*/
protected Long offset;
public EntityExample() {
this.criterias = new LinkedList<>();
}
/**
* 创建一个新的条件列表
*
* @return
*/
public EntityExample newCriteria() {
Criteria criteria = new Criteria();
this.criterias.add(criteria);
this.currentCriteria = criteria;
return this;
}
/**
* 创建一个新的条件列表
*
* @return
*/
public EntityExample or() {
return newCriteria();
}
/**
* 设置限制量
*
* @param limit
* @return
*/
public EntityExample setLimit(Integer limit) {
this.limit = limit;
return this;
}
/**
* 设置起始量
*
* @param offset
* @return
*/
public EntityExample setOffset(Long offset) {
this.offset = offset;
return this;
}
/**
* 设置是否唯一
*
* @param distinct
* @return
*/
public EntityExample setDistinct(boolean distinct) {
this.distinct = distinct;
return this;
}
/**
* 设置当前页数
*
* @param current
* @param perPage
* @return
*/
public EntityExample setPage(Integer current, Integer perPage) {
if (current == null || current < 1 || perPage == null || perPage < 1) {
throw new IllegalArgumentException("Argument invalid");
}
long offset = (current.longValue() - 1) * perPage;
this.offset = offset;
this.limit = perPage;
return this;
}
/**
* 设置是否倒序
*
* @return
*/
public EntityExample setOrderByDesc() {
this.desc = true;
return this;
}
/**
* 设置排序条件
*
* @param clauses
* @return
*/
public EntityExample setOrderByClause(String... clauses) {
if (clauses != null) {
StringBuilder builder = new StringBuilder();
builder.append("order by ");
int length = clauses.length - 1;
for (int i = 0; i < length; i++) {
builder.append(clauses[i]);
builder.append(" , ");
}
builder.append(clauses[length]);
this.orderByClause = builder.toString();
}
return this;
}
public EntityExample addStringCondition(String condition) {
if (currentCriteria == null) {
newCriteria();
}
this.currentCriteria.addCondition(condition);
return this;
}
public EntityExample addStringCondition(String condition, Object value) {
if (currentCriteria == null) {
newCriteria();
}
this.currentCriteria.addCondition(condition, value);
return this;
}
public EntityExample addStringCondition(String condition, Object firstValue, Object secondValue) {
if (currentCriteria == null) {
newCriteria();
}
this.currentCriteria.addCondition(condition, firstValue, secondValue);
return this;
}
/**
* 添加选择列名,如果为null默认选择所有
*
* @param columns
* @return
*/
public EntityExample addSelectColumn(String... columns) {
if (selectColumns == null) {
this.selectColumns = new LinkedList<>();
}
for (int i = 0; i < columns.length; i++) {
selectColumns.add(columns[i]);
}
return this;
}
protected class Criteria {
protected List<Condition> conditions;
public boolean isValid() {
return conditions.size() > 0;
}
public Criteria() {
this.conditions = new LinkedList<>();
}
public void setConditions(List<Condition> conditions) {
this.conditions = conditions;
}
public void getConditions(List<Condition> conditions) {
this.conditions = conditions;
}
protected void addCondition(String condition) {
if (condition == null) {
throw new IllegalArgumentException("condition can't be null");
}
this.conditions.add(new Condition(condition));
}
protected void addCondition(String condition, Object value, String typeHandler) {
if (value == null) {
throw new IllegalArgumentException("value can't be null");
}
this.conditions.add(new Condition(condition, value, typeHandler));
}
protected void addCondition(String condition, Object value) {
if (value == null) {
throw new IllegalArgumentException("value can't be null");
}
this.conditions.add(new Condition(condition, value));
}
protected void addCondition(String condition, Object firstValue, Object secondValue, String typeHandler) {
if (firstValue == null || secondValue == null) {
throw new IllegalArgumentException("value can't be null");
}
this.conditions.add(new Condition(condition, firstValue, secondValue, typeHandler));
}
protected void addCondition(String condition, Object firstValue, Object secondValue) {
if (firstValue == null || secondValue == null) {
throw new IllegalArgumentException("value can't be null");
}
this.conditions.add(new Condition(condition, firstValue, secondValue));
}
@Override
public String toString() {
return "Criteria{" +
"conditions=" + conditions +
'}';
}
}
protected static class Condition {
protected static int NO_VALUE = 0;
protected static int SINGLE_VALUE = 1;
protected static int DOUBLE_VALUE = 2;
protected static int LIST_VALUE = 3;
/**
* where条件
*/
private final String condition;
/**
* 第一个值
*/
private Object value;
/**
* 第二个值
*/
private Object secondValue;
/**
* 类型转换器
*/
private final String typeHandler;
private final int initMode;
protected Condition(String condition) {
this.condition = condition;
this.typeHandler = null;
this.initMode = NO_VALUE;
}
protected Condition(String condition, Object value, String typeHandler) {
this.condition = condition;
this.value = value;
this.typeHandler = typeHandler;
if (value instanceof List<?>) {
this.initMode = LIST_VALUE;
} else {
this.initMode = SINGLE_VALUE;
}
}
protected Condition(String condition, Object value) {
this(condition, value, null);
}
protected Condition(String condition, Object value, Object secondValue, String typeHandler) {
this.condition = condition;
this.value = value;
this.secondValue = secondValue;
this.typeHandler = typeHandler;
this.initMode = DOUBLE_VALUE;
}
protected Condition(String condition, Object value, Object secondValue) {
this(condition, value, secondValue, null);
}
public String getCondition() {
return condition;
}
public Object getValue() {
return value;
}
public Object getSecondValue() {
return secondValue;
}
public String getTypeHandler() {
return typeHandler;
}
public int getInitMode() {
return initMode;
}
@Override
public String toString() {
return "Condition{" +
"condition='" + condition + '\'' +
", value=" + value +
", secondValue=" + secondValue +
", typeHandler='" + typeHandler + '\'' +
", initMode=" + initMode +
'}';
}
}
public String getOrderByClause() {
return orderByClause;
}
public List<Criteria> getCriterias() {
return criterias;
}
public Criteria getCurrentCriteria() {
return currentCriteria;
}
public boolean isDistinct() {
return distinct;
}
public Integer getLimit() {
return limit;
}
public Long getOffset() {
return offset;
}
public boolean isDesc() {
return desc;
}
}
```
## 生成的Example
```java
package cn.gloduck.onlinetest.entity.po.example;
import java.util.List;
public class UserExample extends EntityExample {
private static final long serialVersionUID = 605730317926504527L;
private final EntityExample example = this;
/**
* 创建一个新的条件列表
*
* @return
*/
@Override
public UserExample newCriteria() {
return (UserExample) super.newCriteria();
}
/**
* 创建一个新的条件列表
*
* @return
*/
@Override
public UserExample or() {
return (UserExample) super.newCriteria();
}
/**
* 设置限制量
*
* @param limit
* @return
*/
@Override
public UserExample setLimit(Integer limit) {
return (UserExample) super.setLimit(limit);
}
/**
* 设置起始量
*
* @param offset
* @return
*/
@Override
public UserExample setOffset(Long offset) {
return (UserExample) super.setOffset(offset);
}
/**
* 设置是否唯一
*
* @param distinct
* @return
*/
@Override
public UserExample setDistinct(boolean distinct) {
return (UserExample) super.setDistinct(distinct);
}
/**
* 设置当前页数
*
* @param current
* @param perPage
* @return
*/
@Override
public UserExample setPage(Integer current, Integer perPage) {
return (UserExample) super.setPage(current, perPage);
}
/**
* 设置是否倒序
*
* @return
*/
@Override
public UserExample setOrderByDesc() {
return (UserExample) super.setOrderByDesc();
}
/**
* 设置排序条件
*
* @param clauses
* @return
*/
@Override
public UserExample setOrderByClause(String... clauses) {
return (UserExample) super.setOrderByClause(clauses);
}
@Override
public UserExample addStringCondition(String condition) {
return (UserExample) super.addStringCondition(condition);
}
@Override
public UserExample addStringCondition(String condition, Object value) {
return (UserExample) super.addStringCondition(condition, value);
}
@Override
public UserExample addStringCondition(String condition, Object firstValue, Object secondValue) {
return (UserExample) super.addStringCondition(condition, firstValue, secondValue);
}
/**
* 添加选择列名,如果为null默认选择所有
*
* @param columns
* @return
*/
@Override
public UserExample addSelectColumn(String... columns) {
return (UserExample) super.addSelectColumn(columns);
}
public static final String ID = "id";
public static final String ACCOUNT = "account";
public static final String PASSWORD = "password";
public UserExample andIdIsNull() {
addStringCondition("id is null");
return this;
}
public UserExample andIdIsNotNull() {
addStringCondition("id is not null");
return this;
}
public UserExample andIdEqualTo(Long value) {
addStringCondition("id = ", value);
return this;
}
public UserExample andIdNotEqualTo(Long value) {
addStringCondition("id <> ", value);
return this;
}
public UserExample andIdBiggerThan(Long value) {
addStringCondition("id > ", value);
return this;
}
public UserExample andIdBiggerThanOrEqualTo(Long value) {
addStringCondition("id >= ", value);
return this;
}
public UserExample andIdSmallerThan(Long value) {
addStringCondition("id < ", value);
return this;
}
public UserExample andIdSmallerThanOrEqualTo(Long value) {
addStringCondition("id <= ", value);
return this;
}
public UserExample andIdIn(List<Long> values) {
addStringCondition("id in ", values);
return this;
}
public UserExample andIdNotIn(List<Long> values) {
addStringCondition("id not in ", values);
return this;
}
public UserExample andIdLike(Long value) {
addStringCondition("id like ", value);
return this;
}
public UserExample andIdNotLike(Long value) {
addStringCondition("id not like ", value);
return this;
}
public UserExample andIdBetween(Long value1, Long value2) {
addStringCondition("id between ", value1, value2);
return this;
}
public UserExample andIdNotBetween(Long value1, Long value2) {
addStringCondition("id not between ", value1, value2);
return this;
}
public UserExample andAccountIsNull() {
addStringCondition("account is null");
return this;
}
public UserExample andAccountIsNotNull() {
addStringCondition("account is not null");
return this;
}
public UserExample andAccountEqualTo(String value) {
addStringCondition("account = ", value);
return this;
}
public UserExample andAccountNotEqualTo(String value) {
addStringCondition("account <> ", value);
return this;
}
public UserExample andAccountBiggerThan(String value) {
addStringCondition("account > ", value);
return this;
}
public UserExample andAccountBiggerThanOrEqualTo(String value) {
addStringCondition("account >= ", value);
return this;
}
public UserExample andAccountSmallerThan(String value) {
addStringCondition("account < ", value);
return this;
}
public UserExample andAccountSmallerThanOrEqualTo(String value) {
addStringCondition("account <= ", value);
return this;
}
public UserExample andAccountIn(List<String> values) {
addStringCondition("account in ", values);
return this;
}
public UserExample andAccountNotIn(List<String> values) {
addStringCondition("account not in ", values);
return this;
}
public UserExample andAccountLike(String value) {
addStringCondition("account like ", value);
return this;
}
public UserExample andAccountNotLike(String value) {
addStringCondition("account not like ", value);
return this;
}
public UserExample andAccountBetween(String value1, String value2) {
addStringCondition("account between ", value1, value2);
return this;
}
public UserExample andAccountNotBetween(String value1, String value2) {
addStringCondition("account not between ", value1, value2);
return this;
}
public UserExample andPasswordIsNull() {
addStringCondition("password is null");
return this;
}
public UserExample andPasswordIsNotNull() {
addStringCondition("password is not null");
return this;
}
public UserExample andPasswordEqualTo(String value) {
addStringCondition("password = ", value);
return this;
}
public UserExample andPasswordNotEqualTo(String value) {
addStringCondition("password <> ", value);
return this;
}
public UserExample andPasswordBiggerThan(String value) {
addStringCondition("password > ", value);
return this;
}
public UserExample andPasswordBiggerThanOrEqualTo(String value) {
addStringCondition("password >= ", value);
return this;
}
public UserExample andPasswordSmallerThan(String value) {
addStringCondition("password < ", value);
return this;
}
public UserExample andPasswordSmallerThanOrEqualTo(String value) {
addStringCondition("password <= ", value);
return this;
}
public UserExample andPasswordIn(List<String> values) {
addStringCondition("password in ", values);
return this;
}
public UserExample andPasswordNotIn(List<String> values) {
addStringCondition("password not in ", values);
return this;
}
public UserExample andPasswordLike(String value) {
addStringCondition("password like ", value);
return this;
}
public UserExample andPasswordNotLike(String value) {
addStringCondition("password not like ", value);
return this;
}
public UserExample andPasswordBetween(String value1, String value2) {
addStringCondition("password between ", value1, value2);
return this;
}
public UserExample andPasswordNotBetween(String value1, String value2) {
addStringCondition("password not between ", value1, value2);
return this;
}
}
```
## 生成的Mapper接口
```java
package cn.gloduck.onlinetest.dao;
import cn.gloduck.onlinetest.entity.po.User;
import cn.gloduck.onlinetest.entity.po.example.EntityExample;
import org.apache.ibatis.annotations.Param;
import java.util.List;
/**
* (User)表数据库访问层
*
* @author Gloduck
* @since 2020-12-08 11:28:21
*/
public interface UserMapper {
/**
* 插入数据
*
* @param user
* @return
*/
int insert(User user);
/**
* 插入数据,忽略null
*
* @param user
* @return
*/
int insertSelective(User user);
/**
* 批量插入
*
* @param userList
* @return
*/
int insertList(List<User> userList);
/**
* 根据主键删除
*
* @param id
* @return
*/
int deleteByPrimaryKey(Long id);
/**
* 根据实体类删除
*
* @param user
* @return
*/
int deleteByEntity(User user);
/**
* 根据Example删除
*
* @param example
* @return
*/
int deleteByExample(EntityExample example);
/**
* 通过主键更新
*
* @param user
* @return
*/
int updateByPrimaryKey(User user);
/**
* 通过主键更新,忽略null和主键
*
* @param user
* @return
*/
int updateByPrimaryKeySelective(User user);
/**
* 通过Example更新
*
* @param user
* @param example
* @return
*/
int updateByExample(@Param("user") User user, @Param("example") EntityExample example);
/**
* 通过Example更新,忽略null
*
* @param user
* @param example
* @return
*/
int updateByExampleSelective(@Param("user") User user, @Param("example") EntityExample example);
/**
* 统计所有记录
*
* @return
*/
long countRecord();
/**
* 根据Example计算总数
*
* @param example
* @return
*/
long countByExample(EntityExample example);
/**
* 根据主键查找
*
* @param id
* @return
*/
User selectByPrimaryKey(Long id);
/**
* 通过主键集合查找
*
* @param idList
* @return
*/
List<User> selectByPrimaryKeyList(List<Long> idList);
/**
* 根据实体查找
*
* @param user
* @return
*/
List<User> selectByEntity(User user);
/**
* 根据Example查找
*
* @param example
* @return
*/
List<User> selectByExample(EntityExample example);
/**
* 根据Example查找主键
*
* @param example
* @return
*/
List<Long> selectPrimaryKeyByExample(EntityExample example);
/**
* 有范围限制。offset大时使用
*
* @param offset
* @param limit
* @return
*/
List<User> selectByLimit(@Param("offset") Long offset, @Param("limit") Integer limit);
/**
* 根据Example查找选择列
*
* @param example
* @return
*/
List<User> selectByExampleSelective(EntityExample example);
}
```
## 生成的Mapper.xml
```java
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.gloduck.onlinetest.dao.UserMapper">
<resultMap type="cn.gloduck.onlinetest.entity.po.User" id="UserMap">
<id property="id" column="id" jdbcType="INTEGER"/>
<result property="account" column="account" jdbcType="VARCHAR"/>
<result property="password" column="password" jdbcType="VARCHAR"/>
</resultMap>
<sql id="All_Columns">
`id`, `account`, `password` </sql>
<sql id="Other_Columns">
`account`, `password` </sql>
<sql id="Example_Where_Clause">
<where>
<foreach collection="example.criterias" item="criteria" separator="or">
<if test="criteria.valid">
<trim prefix="(" prefixOverrides="and" suffix=")">
<foreach collection="criteria.conditions" item="condition">
<choose>
<when test="condition.initMode == 0">
and ${condition.condition}
</when>
<when test="condition.initMode == 1">
and ${condition.condition} #{condition.value}
</when>
<when test="condition.initMode == 2">
and ${condition.condition} #{condition.value} and #{condition.secondValue}
</when>
<when test="condition.initMode == 3">
and ${condition.condition}
<foreach close=")" collection="condition.value" item="listItem" open="("
separator=",">
#{listItem}
</foreach>
</when>
</choose>
</foreach>
</trim>
</if>
</foreach>
</where>
</sql>
<!--插入数据-->
<insert id="insert" parameterType="cn.gloduck.onlinetest.entity.po.User" useGeneratedKeys="true" keyColumn="id"
keyProperty="id">
insert into `user`
(`account`, `password`)
values
(#{account}, #{password})
</insert>
<!--插入数据,忽略null-->
<insert id="insertSelective" parameterType="cn.gloduck.onlinetest.entity.po.User" useGeneratedKeys="true"
keyColumn="id" keyProperty="id">
insert into `user`
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="account != null and account != ''">
`account`,
</if>
<if test="password != null and password != ''">
`password`,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="account != null and account != ''">
#{account},
</if>
<if test="password != null and password != ''">
#{password},
</if>
</trim>
</insert>
<!--批量插入-->
<insert id="insertList"
parameterType="java.util.List" useGeneratedKeys="true" keyColumn="id" keyProperty="id">
insert into `user`
(`account`, `password`)
values
<foreach collection="userList" item="item" separator=",">
(#{item.account}, #{item.password})
</foreach>
</insert>
<!-- 根据主键删除-->
<delete id="deleteByPrimaryKey" parameterType="Long">
delete from `user`
where
id = #{id}
</delete>
<!-- 根据实体类删除-->
<delete id="deleteByEntity" parameterType="cn.gloduck.onlinetest.entity.po.User">
delete from `user`
<where>
<if test="id != null">
and `id` = #{id}
</if>
<if test="account != null and account != ''">
and `account` = #{account}
</if>
<if test="password != null and password != ''">
and `password` = #{password}
</if>
</where>
</delete>
<!-- 根据Example删除 -->
<delete id="deleteByExample" parameterType="cn.gloduck.onlinetest.entity.po.example.EntityExample">
delete from `user`
<if test="_parameter != null">
<include refid="Example_Where_Clause"/>
</if>
</delete>
<!-- 根据主键更新-->
<update id="updateByPrimaryKey" parameterType="cn.gloduck.onlinetest.entity.po.User">
update `user`
set
`id` = #{id}, `account` = #{account}, `password` = #{password} where
`id` = #{id}
</update>
<!-- 根据主键更新,忽略null和主键-->
<update id="updateByPrimaryKeySelective" parameterType="cn.gloduck.onlinetest.entity.po.User">
update `user`
<set>
<if test="account != null and account != ''">
`account` = #{account},
</if>
<if test="password != null and password != ''">
`password` = #{password},
</if>
</set>
where `id` = #{id}
</update>
<!-- 通过Example更新-->
<update id="updateByExample" parameterType="map">
update `user`
set
`id` = #{user.id}, `account` = #{user.account}, `password` = #{user.password}
<if test="_parameter != null">
<include refid="Example_Where_Clause"/>
</if>
</update>
<!-- 根据Example更新,忽略null和主键-->
<update id="updateByExampleSelective" parameterType="map">
update `user`
<set>
<if test="user.account != null and user.account != ''">
`account` = #{user.account},
</if>
<if test="user.password != null and user.password != ''">
`password` = #{user.password},
</if>
</set>
<if test="_parameter != null">
<include refid="Example_Where_Clause"/>
</if>
</update>
<!--统计所有记录-->
<select id="countRecord" resultType="Long">
select count(*) from `user`
</select>
<!--根据Example计算总数-->
<select id="countByExample" resultType="Long" parameterType="cn.gloduck.onlinetest.entity.po.example.EntityExample">
select count(*) from `user`
<if test="_parameter != null">
<include refid="Example_Where_Clause"/>
</if>
</select>
<!--根据主键查找-->
<select id="selectByPrimaryKey" parameterType="Long" resultMap="UserMap">
select
<include refid="All_Columns"/>
from `user`
where `id` = #{id}
</select>
<!--通过主键集合查找-->
<select id="selectByPrimaryKeyList" parameterType="java.util.List" resultMap="UserMap">
select
<include refid="All_Columns"/>
from `user`
where `id` in
<foreach collection="idList" separator="," open="(" close=")" item="item">
#{item}
</foreach>
</select>
<!--根据实体查找-->
<select id="selectByEntity" parameterType="cn.gloduck.onlinetest.entity.po.User" resultMap="UserMap">
select
<include refid="All_Columns"/>
from `user`
<where>
<if test="id != null">
and id = #{id}
</if>
<if test="account != null and account != ''">
and account = #{account}
</if>
<if test="password != null and password != ''">
and password = #{password}
</if>
</where>
</select>
<!--根据Example查找-->
<select id="selectByExample" parameterType="cn.gloduck.onlinetest.entity.po.example.EntityExample"
resultMap="UserMap">
select
<if test="distinct">
distinct
</if>
<include refid="All_Columns"/>
from `user`
<if test="_parameter != null">
<include refid="Example_Where_Clause"/>
</if>
<if test="orderByClause != null">
order by ${orderByClause}
<if test="desc">
desc
</if>
</if>
<if test="limit != null">
<if test="offset != null">
limit ${offset}, ${limit}
</if>
<if test="offset == null">
limit ${limit}
</if>
</if>
</select>
<!--根据Example查找选择列-->
<select id="selectByExampleSelective" parameterType="cn.gloduck.onlinetest.entity.po.example.EntityExample"
resultMap="UserMap">
select
<if test="distinct">
distinct
</if>
<if test="_parameter != null and example.selectColumns != null">
<foreach collection="example.selectColumns" item="item" separator=",">
`${item}`
</foreach>
</if>
<if test="_parameter == null or example.selectColumns == null">
<include refid="All_Columns"/>
</if>
from `user`
<if test="_parameter != null">
<include refid="Example_Where_Clause"/>
</if>
<if test="orderByClause != null">
order by ${orderByClause}
<if test="desc">
desc
</if>
</if>
<if test="limit != null">
<if test="offset != null">
limit ${offset}, ${limit}
</if>
<if test="offset == null">
limit ${limit}
</if>
</if>
</select>
<!--根据Example查找主键-->
<select id="selectPrimaryKeyByExample" parameterType="cn.gloduck.onlinetest.entity.po.example.EntityExample"
resultType="java.lang.Long">
select
`id`
from `user`
<if test="_parameter != null">
<include refid="Example_Where_Clause"/>
</if>
<if test="orderByClause != null">
order by ${orderByClause}
<if test="desc">
desc
</if>
</if>
<if test="limit != null">
<if test="offset != null">
limit ${offset}, ${limit}
</if>
<if test="offset == null">
limit ${limit}
</if>
</if>
</select>
<!--有范围限制。offset大时使用-->
<select id="selectByLimit" resultMap="UserMap">
select
<include refid="All_Columns"/>
from `user`
where id >=
(select id from `user` limit ${offset}, 1)
limit ${limit}
</select>
</mapper>
```
# 文档
属性
$author 设置中的作者 java.lang.String
$modulePath 选中的module路径 java.lang.String
$projectPath 项目绝对路径 java.lang.String
对象
$tableInfo 表对象
obj 表原始对象 com.intellij.database.model.DasTable
name 表名(转换后的首字母大写)java.lang.String
comment 表注释 java.lang.String
fullColumn 所有列 java.util.List<ColumnInfo>
pkColumn 主键列 java.util.List<ColumnInfo>
otherColumn 其他列 java.util.List<ColumnInfo>,除主键以外的列
savePackageName 保存的包名 java.lang.String
savePath 保存路径 java.lang.String
saveModelName 保存的model名称 java.lang.String
columnInfo 列对象
obj 列原始对象 com.intellij.database.model.DasColumn
name 列名(首字母小写) java.lang.String
comment 列注释 java.lang.String
type 列类型(类型全名) java.lang.String
shortType 列类型(短类型) java.lang.String
custom 是否附加列 java.lang.Boolean
ext 附加字段(Map类型) java.lang.Map<java.lang.String, java.lang.Object>
$tableInfoList java.util.List<TableInfo>所有选中的表
$importList 所有需要导入的包集合 java.util.Set<java.lang.String>
回调
&callback 回调对象
setFileName(String) 设置文件储存名字
setSavePath(String) 设置文件储存路径,默认使用选中路径
setReformat(Boolean) 设置是否重新格式化生成后的代码,默认为true
工具
$tool
firstUpperCase(String name) 首字母大写方法
firstLowerCase(String name) 首字母小写方法
getClsNameByFullName(String fullName) 通过包全名获取类名
getJavaName(String name) 将下划线分割字符串转驼峰命名(属性名)
getClassName(String name) 将下划线分割字符串转驼峰命名(类名)
hump2Underline(String str) 将驼峰字符串转下划线字符串
append(Object... objs) 多个数据进行拼接
newHashSet(Object... objs) 创建一个HashSet对象
newArrayList(Object... objs) 创建一个ArrayList对象
newLinkedHashMap() 创建一个LinkedHashMap()对象
newHashMap() 创建一个HashMap()对象
getField(Object obj, String fieldName) 获取对象的属性值,可以访问任意修饰符修饰的属性.配合debug方法使用.
call(Object... objs) 空白执行方法,用于调用某些方法时消除返回值
debug(Object obj) 调式方法,用于查询对象结构.可查看对象所有属性与public方法
serial() 随机获取序列化的UID
service(String serviceName, Object... param)远程服务调用
parseJson(String) 将字符串转Map对象
toJson(Object, Boolean) 将对象转json对象,Boolean:是否格式化json,不填时为不格式化。
toUnicode(String, Boolean) 将String转换为unicode形式,Boolean:是否转换所有符号,不填时只转换中文及中文符号。
$time
currTime(String format) 获取当前时间,指定时间格式(默认:yyyy-MM-dd HH:mm:ss)
$generateService
run(String, Map<String,Object>) 代码生成服务,参数1:模板名称,参数2:附加参数。
$dasUtil Database提供的工具类,具体可方法请查看源码,适用于高端玩家
$dbUtil Database提供的工具类,具体可方法请查看源码,适用于高端玩家 | 36,990 | Apache-2.0 |
---
title: "Swiftの勉強"
header:
overlay_image: /assets/images/xcodeimage-freephoto.jpg
overlay_filter: 0.5
excerpt: "ちょっと勉強方法ミスったので、戒めも込めて記録しておく。"
categories:
- System
- Programming
tags:
- MacBook
- Xcode
- Swift
---
図書館にあったので、「絶対に挫折しない iPhoneアプリ開発「超」入門 第8版 【Xcode 11 & iOS 13】 完全対応」にまず取り掛かった。
<!-- START MoshimoAffiliateEasyLink -->
<script type="text/javascript" src="{{ '/assets/js/affiliate/zettainizasetsushinai.js' | relative_url }}"></script>
<div id="msmaflink-gt6FU">リンク</div>
<p></p>
<!-- MoshimoAffiliateEasyLink END -->
[2021-01-20Progateの利用方法]({{ site.baseurl }}{% link _posts/2021-01-20-blog20210120.md %})と同様にしようかと思ったが、サンプルコードがかなり単純だったのと、あとで検索したり読み返しやすくするため、グーグルスプレッドシートに用語等を記録していきながら読み進めた。
その際、サンプルコードを写経してはいたが、あまり内容を覚えようと意識してはいなかった。UI部品は大量だし、関係するプロトコルやクラスも膨大なので、利用する段になって改めて検索するなりスプレッドシートを見返したら良いと考えていた。一応、クラスの使い方はRuby等多くの言語と似ているし、Progateで概要は理解しているから同じようなノリでストラクチャーも雰囲気はつかめたし大丈夫だろうと。これぞまさに「完全に理解した」状態......。
実際は、クラスと継承、ストラクチャー、プロトコルやデリゲートの内容がごっちゃになってどれも実践で利用できるほど理解できていなかった。記法がうろ覚えなので、書かれている用語がクラスか、プロトコルか、はたまた型なのか区別できない。なまじ`Int`や`Double`は馴染みがあるので、それ以外のSwift特有の型表現(`some View`や`Context`他いろいろ)が型だと認識できない。記法が頭に入っていればまだ対応できそうなものだが、Swiftは記述をよく省略するのでさらに難易度が上がる。型の省略、引数がなければカッコの省略、1行のみなら`return`の省略、etc.。
区別がつかない以上、ネット上のサンプルコードをある程度でも理解しようとすると、片っ端から単語の意味を確認せざるを得ない。もちろん根本的な知識不足もあるが、概要すら把握できないので、サンプルコードを編集することすらままならない。
結果、「超入門」を一通り読み終えてから、通話関連のアプリを作ろうと考えてCallKitのサンプルコードをネットで見つけたが利用方法もろくにイメージできなかった。かなりの時間をかけてコードを理解しようと試みたにもかかわらず(一応、概要は理解できた)。
ちょっとゴチャついたが、現状の問題点は
- Swift特有の記述方法をぼんやりとしか理解していないので他人のコードが読めない
- オブジェクト指向の利用経験が皆無なので肌感がない
- Swiftに慣れてなさすぎる
自分の力量を過信していたので、まずは「超入門」の実習にある見本コードを思い出しながら自分で同じアプリを作成してみる。その際、死ぬほど記法を意識する。結局自分で書いていないことがほぼ元凶なので、書く。
あと、通話関連のアプリは時期尚早と見て、実習にもあった英単語のアプリ作りにかかる。
以上。 | 1,734 | MIT |
---
layout: post
title: Docker技术入门与实战 - 使用 dockerfile定制镜像
category: 技术
tags: Docker
keywords:
description: 介绍Dockerfile常用命令
---
[Docker检查](https://docs.docker.com/docker-for-mac/)
## dockerfile 指令
### FROM
指定基础镜像。所谓定制镜像,就是在一个基础镜像上进行定制。所以需要通过 `FROM`指定基础镜像,且必须是第一条指令
### RUN
RUN 指令用来执行命令行命令
1. shell格式。run <命令>
2. exec 格式。 run ['可执行文件','参数1','参数2']
每个 RUN 命令执行完后都会提交一个 commit,产生一层。多个 RUN 就会产生多层.
RUN 虽然可以像执行 shell命令那样执行,但在 docker 中运行其 RUN 命令要记得,这是在构建层,而不是在写 shell 脚本
### COPY
`COPY <上下文中的 源文件path>` `容器内的目标路径或者工作目录的相对路径`
### ADD
与 COPY 性质相同。
不过
1. ADD 的源文件路径可以执行为 URL,docker 引擎会下载该文件并复制到目标目录中。下载文件的权限设置为 600。
对于下载的文件还得重新调整权限,对于压缩文件还得解压缩。不如使用 RUN 实用。不推荐使用。
对于tar 压缩文件,`ADD`指令会自动解压到目标目录。这是最适合`ADD`命令的场景
### CMD
容器启动命令。格式与`RUN`格式相似。
1. shell 格式: CMD <命令>
2. exec格式: CMD ['可执行文件','参数1','参数2']
3. 参数列表格式:CMD ['参数1','参数2'] 。 CMD 指令就是用于指定默认的容器主进程的启动命令的。
docker 不是虚拟机,没有前台后台的概念。容器中的应用都应该前台运行。在容器中不能使用`systemctl`命令的原因。
**对于容器而言,其启动程序就是容器应用进程。容器就是为主进程而存在的,主进程退出,容器就失去了存在的意义,从而退出了。**
### ENTRYPOINT
格式和`RUN`命令一样。
作用和 CMD 类似,都是在指定容器启动程序和参数
应用场景:
1. 让镜像变得像命令一样可用。
2. 应用运行前的准备工作
### ENV
设置环境变量
格式:
```
ENV <key> <value>
ENV <Key1>=<value1> <Key2>=<value2> <Key3>=<value3>,
```
在其他位置使用时,使用`$`引用变量。
支持环境变量的指令: `ADD`,`COPY`,`ENV`,`EXPOSE`,`LABEL`,`USER`,`WORKDIR`,`VOLUME`,`STOPSIGNAL`,`ONBUILD`。
### ARG
设置环境变量,但与 `ENV`不同的是,`ENV`的环境变量在容器运行时可用,而`ARG`设置的变量是在容器构建环境中可用,在运行环境中不存在。
格式:
```
ARG <参数名>=[=<默认值>]
```
该值可以在构建命令`docker build`中使用参数`--build <参数名>=<值>`
### VOLUME
指定匿名卷
格式
```
VOLUME ["路径 1","路径 2"]
VOLUME <"路径">
```
如`VOLUME /data`可以保证容器运行时在向/data 写数据时,不会写入到容器存储层,而是实际保存在卷中。
也可以在执行 `run` 命令时通过`-v`参数指定命名卷`mydata=/data`
### EXPOSE
声明端口,但只会告诉使用者本镜像可以开启哪些服务端口。但是在容器运行时不会自动开启。在容器启动指定随机映射时,可以随机映射`EXPOSE`的端口。
格式
```
EXPOSE <port1> <port2>
```
### WORKDIR
格式
```
WORKDIR <工作目录路径>
```
指定工作目录,dockfile 中的所有的`.`都代表着工作目录。该目录必须提前已经存在,`WORKDIR`指令不会自动创建不存在的目录。
在 docker 中,每个`RUN`命令都是不同的容器。所以两个命令的执行环境不同。不同于 shell 中的命令可以依赖上一条命令执行的结果。
### USER
指定当前用户,该用户切换前需要已经存在,否则无法切换
格式
```
USER <用户名>
```
该指定和`WORKDIR`都会改变环境状态并影响以后的层。
### HEALTHCHECK
检查容器的健康状态
格式
```
HEALTHCHECK [选项] CMD <命令> # 设置容器检查状态的命令
--interval=<间隔> #检查时间间隔,默认 30s
--timeout=<时长> #检查检查超时时间,默认 30s
--retries=<次数> #连续失败次数,默认 3 次。超过该次数则容器设置为unhealthy
HEALTHCHECK NONE # 如果基础镜像有检查指定,使用该命令可以屏蔽之
```
该指定只可以出现一次,且如果出现多次,只有最后一次生效。
### ONBUILD
为以当前镜像作为基础镜像构建其他镜像时使用。
格式: `ONBUILD <其他指令>`
## dockerfile例子
```dockerfile
FROM debian:jessie
# 将多个命令合并在一起执行
RUN buildDeps='gcc libc6-dev make' \
&& apt-get update \
&& apt-get install -y $buildDeps \
&& wget -O redis.tar.gz "http://download.redis.io/releases/r
edis-3.2.5.tar.gz" \
&& mkdir -p /usr/src/redis \
&& tar -xzf redis.tar.gz -C /usr/src/redis --strip-component
s=1 \
&& make -C /usr/src/redis \
&& make -C /usr/src/redis install \
&& rm -rf /var/lib/apt/lists/* \
&& rm redis.tar.gz \
&& rm -r /usr/src/redis \
&& apt-get purge -y --auto-remove $buildDeps
``` | 2,986 | MIT |
# NSObject
## 功能
- 动态添加分类、删除动态添加的分类、获取版本号、获取对象所有属性、获取手机型号 、为UI添加倒计时、拦截方法,覆盖方法等
## NSObject+Category
#### 属性
属性 | 说明 | 类型 | 默认值
--- | --- | --- | ---
associatedObjectNames | 相关对象的名字(只读属性) | NSMutableArray | -
#### 方法
```objective-c
/**
为当前的object动态增加分类
@param propertyName 分类名称
@param value 分类值
@param policy 分类内存管理类型
*/
- (void)objc_setAssociatedObject:(NSString *)propertyName value:(id)value policy:(objc_AssociationPolicy)policy;
/**
* 获取当前object某个动态增加的分类
*
* @param propertyName 分类名称
*
* @return 值
*/
- (id)objc_getAssociatedObject:(NSString *)propertyName;
/**
* 删除动态增加的所有分类
*/
- (void)objc_removeAssociatedObjects;
/**
* 获取对象的所有属性
*
* @return 属性dict
*/
- (NSArray *)getProperties;
/**
获取版本号
@return 版本号
*/
+ (NSString *)wya_version;
/**
获取build版本号
@return build版本号
*/
+ (NSInteger)wya_build;
/**
获取BundleID
@return BundleID
*/
+ (NSString *)wya_identifier;
/**
当前语言
@return 语言
*/
+ (NSString *)wya_currentLanguage;
/**
获取手机具体型号
@return 型号
*/
+ (NSString *)wya_deviceModel;
/**
按钮倒计时
@param time 倒计时总时间
@param countDownBlock 每秒倒计时会执行的block
@param finishBlock 倒计时完成会执行的block
*/
- (void)wya_countDownTime:(NSUInteger)time countDownBlock:(TYNCountDownBlock)countDownBlock outTimeBlock:(TYNFinishBlock)finishBlock;
```
## NSObject+PerformBlock
```objective-c
+ (NSException *)tryCatch:(void (^) (void))block;
+ (NSException *)tryCatch:(void (^) (void))block finally:(void (^) (void))aFinisheBlock;
/**
* 在主线程运行block
*
* @param aInMainBlock 被运行的block
*/
+ (void)performInMainThreadBlock:(void (^) (void))aInMainBlock;
/**
* 延时在主线程运行block
*
* @param aInMainBlock 被运行的block
* @param delay 延时时间
*/
+ (void)performInMainThreadBlock:(void (^) (void))aInMainBlock afterSecond:(NSTimeInterval)delay;
/**
* 在非主线程运行block
*
* @param aInThreadBlock 被运行的block
*/
+ (void)performInThreadBlock:(void (^) (void))aInThreadBlock;
/**
* 延时在非主线程运行block
*
* @param aInThreadBlock 被运行的block
* @param delay 延时时间
*/
+ (void)performInThreadBlock:(void (^) (void))aInThreadBlock afterSecond:(NSTimeInterval)delay;
```
## NSObject+Swizzle
```objective-c
/**
覆盖实例方法
@param origSelector 源方法
@param newSelector 新方法
*/
+ (void)overrideInstanceMethod:(SEL)origSelector withInstanceMethod:(SEL)newSelector;
/**
覆盖类方法
@param origSelector 源方法
@param newSelector 新方法
*/
+ (void)overrideClassMethod:(SEL)origSelector withClassMethod:(SEL)newSelector;
/**
拦截实例方法
@param origSelector 源方法
@param newSelector 新方法
*/
+ (void)exchangeInstanceMethod:(SEL)origSelector withInstanceMethod:(SEL)newSelector;
/**
拦截类方法
@param origSelector 源方法
@param newSelector 新方法
*/
+ (void)exchangeClassMethod:(SEL)origSelector withClassMethod:(SEL)newSelector;
``` | 2,723 | MIT |
---
title: "Effective Objective-C (5) Memory Management"
categories: [Effective Objective-C]
---
<!-- prettier-ignore -->
* Do not remove this line (it will not be displayed)
{:toc}
## 29: Reference Counting
在引用计数的架构下,每个对象都有个“计数器”,表示有多少事物想令对象存活下去。
- `retain`: increment the retain count (reference count)
- `release`: decrement the retain count
- `autorelease`: decrement the retain count later, when the autorelease pool is drained.
Object may has reference to other objects, thereby forming what is known as an object graph.
Objects are said to own other objects if they hold a strong reference to them. This means that they have registered their interest in keeping them alive by retaining them. When they are finished with them, they release them.
```objc
- (void)setFoo:(id)foo {
[foo retain];
[_foo release];
_foo = foo;
}
```
The order is important. If the old value was release before the new value was retained and the two values are exactly the same, the release would mean that the object could potentially be deallocated prematurely.
In a garbage-collected environment, retain cycle would usually be picked up as a "island of isolation", the collector would deallocate all three objects.
In a reference counting environment, this leads to memory leaks, and usually solved by using weak reference.
## 30: Auto Reference Counting
编译器知道哪些语句会令对象的引用计数增加,如果没有对应的减少操作,那么就会有内存泄漏。既然编译器知道,那么它现在多做了一步——自动帮我们管理引用计数。
ARC 比 MRC 效率更高,因为它直接调用底层 C 的函数,而不是封装后的 Objective-C 方法。MRC 时代的方法在 ARC 环境下都不允许调用,包括 `retain`、`release`、`autorelease`、`dealloc`。
ARC 管理对象生命周期的基本方法是:在合适的地方插入“保留”和“释放”操作。在 ARC 环境下,变量的内存管理语义可以通过修饰符来指明。
如果调用了以 alloc, new, copy, mutableCopy 开头的方法(owning prefix),那么其返回的对象归调用者拥有,调用者必须负责将它们释放。
Any other method name indicates that any returned object will be returned not owned by the calling code. In these cases, the object will be returned autoreleased, so that the value is alive across the method call boundary. If it wants to ensure that the object stays alive longer, the calling code must retain it.
举例:
```objc
+ (EOCPerson*)newPerson {
EOCPerson *person = [[EOCPerson alloc] init];
return person;
/**
* The method name begins with 'new', and since 'person'
* already has an unbalanced +1 retain count from the
* 'alloc', no retains, releases, or autoreleases are
* required when returning.
*/
}
+ (EOCPerson*)somePerson {
EOCPerson *person = [[EOCPerson alloc] init];
return person;
/**
* The method name does not begin with one of the "owning"
* prefixes, therefore ARC will add an autorelease when
* returning 'person'.
* The equivalent manual reference counting statement is:
* return [person autorelease];
*/
}
- (void)doSomething {
EOCPerson *personOne = [EOCPerson newPerson];
// ...
EOCPerson *personTwo = [EOCPerson somePerson];
// ...
/**
* At this point, 'personOne' and 'personTwo' go out of
* scope, therefore ARC needs to clean them up as required.
* - 'personOne' was returned as owned by this block of
* code, so it needs to be released.
* - 'personTwo' was returned not owned by this block of
* code, so it does not need to be released.
* The equivalent manual reference counting cleanup code
* is:
* [personOne release];
*/
}
```
Objective-C 通过上述的命名约定,将内存管理标准化。
ARC 也包含运行时组件。处理优化 `autorelease` 和 `retain` 先后出现等情况。
The semantics of local and instance variables can be altered through the application of the following qualifiers:
- `__strong`: The default; the value is retained.
- `__unsafe__unretained`: The value is not retained and is potentially unsafe, as the object may have been deallocated already by the time the variable is used again.
- `__weak`: The value is not retained but is safe because it is automatically set to nil if the current object is ever deallocated.
- `__autoreleasing`: This special qualifier is used when an object is passed by reference to a method. The value is autoreleased on return.
You still need to clean up any non-Objective-C objects if you have any, such as CoreFoundation objects or heap-allocated memory with `malloc()`.
```objc
- (void)dealloc {
CFRelease(_coreFoundationObject);
free(_heapAllocatedMemoryBlob);
}
```
`__autoreleasing` 我们一般很少显式使用,通常由编译器隐式添加。比如 NSFileManager 的接口:
`- (nullable NSArray<NSString *> *)contentsOfDirectoryAtPath:(NSString *)path error:(NSError **)error);`
## 31: Release References and Clean Up Observation State Only in dealloc
你绝对不应该自己调用 dealloc 方法,Runtime 会在适当时候调用。
在 dealloc 方法中,应该做的是释放其它对象的引用,取消订阅的 KVO 或 NSNotificationCenter 通知,不要做其他事情。
```objc
- (void)dealloc {
CFRelease(coreFoundationObject); // CoreFoundation object 不归 ARC 管理,须自行释放
[[NSNotificationCenter defaultCenter] removeObserver: self]; // 解除监听
}
```
## 32: Beware of Memory Management with Exception-Safe Code
C++ and Objective-C exceptions are compatible, meaning that an exception thrown from one language can be caught using a handler from the other language.
Inside a try block, if an object is retained and then an exception is thrown before the object has been released, the object will leak unless this case is handled in the catch block. C++ destructors are run by the Objective-C exception-handling routines. This is important for C++ because any object whose lifetime has been cut short by a thrown exception needs to be destructed; otherwise, the memory it uses will be leaked, not to mention all the other system resources, such as file handles, that may not be cleaned up properly.
## 33: Use Weak References to Avoid Retain Cycles
`@property(nonatomic, unsafe_unretained) EOCPerson *other;` 用 unsafe_unretained 修饰的属性,语义上同 assign 等价,表明属性值可能不安全,并且不归此实例所拥有。
weak 与 unsafe_unretained 的作用完全相同。只要系统把属性回收,属性值就会自动设为 nil;而 unsafe_unretained 属性仍然指向原来的位置,不安全。
## 34: Use Autorelease Pool Blocks to Reduce High-Memory Waterline
One of the features of Objective-C’s reference-counted architecture is a concept known as autorelease pools. Releasing an object means that its retain count either is decremented immediately through a call `[obj release]` or is added to an auto-release pool through a call `[obj autorelease]`.
An autorelease pool is used as a collection of objects that will need releasing at some point in the future. When a pool is drained, all the objects in the pool at that time are sent the release message.
If no autorelease pool is in place when an object is sent the autorelease message, you will see a message like this in the console:
> Object 0xabcd0123 of class `__NSCFString` autoreleased with no pool in place - just leaking - break on objc_autoreleaseNoPool() to debug
Often, the only one you will ever see in an application is the one that wraps the main application entry point in the main function:
```objc
int main(int argc, char *argv[]) {
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, @"EOCAppDelegate");
}
}
```
Technically, this autorelease pool block is **unnecessary**. The end of the block coincides with the application terminating, at which point the operating system releases all memory used by the application. Without it, any objects autoreleased by the UIApplicationMain function would not have a pool to go into and would log a warning saying just that. So this pool can be thought of as an outer catch-all pool.
The braces in `@autoreleasepool {}` define the scope of the autorelease pool. A pool is created at the first brace and is automatically drained at the end of the scope. Any object autoreleased within the scope is therefore sent the release message at the end of the scope.
Autorelease pools can be nested. When an object is autoreleased, it is added to the innermost pool. This nesting of autorelease pools can be taken advantage of to allow the control of the _high memory mark_ of an application.
Autorelease pools can be thought of as being in a stack. When an autorelease pool is created, it is pushed onto the stack; when it is drained, it is pulled off the stack. When an object is autoreleased, it is put into the topmost pool in the stack.
The need to make this additional pool optimization depends entirely on your application. It is certainly not something that should be done without first monitoring the memory footprint to decide whether a problem needs addressing. Autorelease pool blocks do not incur too much overhead, but they do incur at least some overhead, so if the extra autorelease pool can be avoided, it should be.
```objc
for (int i = 0; i < 10e5; i++) {
NSString *filePath = [[NSBundle mainBundle] pathForResource:@"10-14-Day-6k" ofType:@"jpg"];
UIImage *image = [[UIImage alloc] initWithContentsOfFile:filePath];
NSLog(@"%@", image);
}
// 降低内存峰值
for (int i = 0; i < 10e5; i++) {
@autoreleasepool {
NSString *filePath = [[NSBundle mainBundle] pathForResource:@"10-14-Day-6k" ofType:@"jpg"];
UIImage *image = [[UIImage alloc] initWithContentsOfFile:filePath];
NSLog(@"%@", image);
}
}
```
## 35: Use Zombies to Help Debug Memory-Management Problems
启用了 "Zombie Object" 这个调试功能之后,Runtime 会把所有已经释放的实例转化为特殊的僵尸对象,而不会真正回收他们。僵尸对象所在的核心内存无法被重用,不可能被覆写,当尝试向僵尸对象发送消息时,程序会抛出异常,其中准确说明了发送过来的消息,并描述了回收之前的那个对象。僵尸对象是调试内存管理问题的最佳方式。
## 36: Avoid Using retainCount
When ARC came along, the retainCount method was deprecated, and using it causes a compiler error to be emitted. | 9,431 | Apache-2.0 |
---
title: 重装系统后如何恢复使用scoop
date: 2019-03-19 17:30:49
tags: scoop
categories: 技术
---
重装系统之后, 如果把原有的scoop文件夹粘贴回去user文件夹,然后在powershell中再次输入[Windows下的软件管理神器:scoop](<https://jiayaoo3o.github.io/2019/01/30/Windows%E4%B8%8B%E7%9A%84%E8%BD%AF%E4%BB%B6%E7%AE%A1%E7%90%86%E7%A5%9E%E5%99%A8-scoop/>)文章中的安装命令,会得到一个**Scoop is already installed**错误,要想正确恢复scoop,根据[官方回答](https://github.com/lukesampson/scoop/issues/2894),请按照以下步骤:
<!-- more -->
1. 重装系统之前,先完整复制用户目录下的scoop文件夹到别的地方
2. 重装系统之后,将scoop文件夹粘贴回去用户目录
3. 在环境变量设置中,新建一个用户变量,名字为SCOOP,值为当前scoop文件夹的地址,即:
```
C:\Users\xxxx\scoop
```
4. 允许脚本执行:
```
set-executionpolicy remotesigned -s currentuser
```
5. 双击用户变量中的path,新建一个路径,填入 :
```
%SCOOP%\shims
```
6. 管理员权限powershell中运行:
```powershell
scoop reset *
```
即可恢复所有软件的正常使用. | 809 | MIT |
---
title: 使用嵌套 AUTO 模式查询生成同级 | Microsoft Docs
ms.custom: ''
ms.date: 06/13/2017
ms.prod: sql-server-2014
ms.reviewer: ''
ms.technology: xml
ms.topic: conceptual
helpviewer_keywords:
- queries [XML in SQL Server], nested AUTO mode
- nested AUTO mode query
ms.assetid: 748d9899-589d-4420-8048-1258e9e67c20
author: douglaslMS
ms.author: douglasl
manager: craigg
ms.openlocfilehash: 883d66d07c776a7391b28f59c6f091c3f42ca3e0
ms.sourcegitcommit: 3da2edf82763852cff6772a1a282ace3034b4936
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/02/2018
ms.locfileid: "48164967"
---
# <a name="generate-siblings-with-a-nested-auto-mode-query"></a>使用嵌套 AUTO 模式查询生成同级
以下示例显示了如何使用嵌套 AUTO 模式查询来生成同级。 生成此类 XML 的其他方式只有这一种,即使用 EXPLICIT 模式。 但是,这样做可能会很麻烦。
## <a name="example"></a>示例
此查询将构造用于提供销售订单信息的 XML。 其中包括:
- 销售订单表头信息、 `SalesOrderID`、 `SalesPersonID`和 `OrderDate`。 [!INCLUDE[ssSampleDBobject](../../includes/sssampledbobject-md.md)] 将此信息存储在 `SalesOrderHeader` 表中。
- 销售订单详细信息。 这包括所订购的一个或多个产品、单价和订购数量。 此信息存储在 `SalesOrderDetail` 表中。
- 销售人员信息。 这是获得订单的销售人员。 `SalesPerson` 表提供 `SalesPersonID`。 对于此查询,必须将此表联接到 `Employee` 表以查找销售人员的姓名。
后面两个不同的 `SELECT` 查询生成外形略有不同的 XML。
第一个查询生成的 XML 中的 <`SalesPerson`> 和 <`SalesOrderHeader`> 显示为 <`SalesOrder`> 的同级子成员。
```
SELECT
(SELECT top 2 SalesOrderID, SalesPersonID, CustomerID,
(select top 3 SalesOrderID, ProductID, OrderQty, UnitPrice
from Sales.SalesOrderDetail
WHERE SalesOrderDetail.SalesOrderID =
SalesOrderHeader.SalesOrderID
FOR XML AUTO, TYPE)
FROM Sales.SalesOrderHeader
WHERE SalesOrderHeader.SalesOrderID = SalesOrder.SalesOrderID
for xml auto, type),
(SELECT *
FROM (SELECT SalesPersonID, EmployeeID
FROM Sales.SalesPerson, HumanResources.Employee
WHERE SalesPerson.SalesPersonID = Employee.EmployeeID) As
SalesPerson
WHERE SalesPerson.SalesPersonID = SalesOrder.SalesPersonID
FOR XML AUTO, TYPE)
FROM (SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.SalesPersonID
FROM Sales.SalesOrderHeader, Sales.SalesPerson
WHERE SalesOrderHeader.SalesPersonID = SalesPerson.SalesPersonID
) as SalesOrder
ORDER BY SalesOrder.SalesOrderID
FOR XML AUTO, TYPE
```
在先前的查询中,最外面的 `SELECT` 语句执行下列操作:
- 查询在 `SalesOrder` 子句中指定的行集 `FROM`。 结果是包含一个或多个 <`SalesOrder`> 元素的 XML。
- 指定 `AUTO` 模式和 `TYPE` 指令。 `AUTO` 模式将查询结果转换为 XML,并`TYPE`指令将返回结果作为`xml`类型。
- 包括两个以逗号分隔的嵌套 `SELECT` 语句。 第一个嵌套 `SELECT` 语句检索销售订单信息、表头和详细信息,第二个嵌套 `SELECT` 语句检索销售人员信息。
- 检索 `SELECT` 、 `SalesOrderID`和 `SalesPersonID`的 `CustomerID` 语句本身包括另一个返回销售订单详细信息的嵌套 `SELECT ... FOR XML` 语句(使用 `AUTO` 模式和 `TYPE` 指令)。
检索销售人员信息的 `SELECT` 语句查询在 `SalesPerson`子句中创建的行集 `FROM` 。 若要使用 `FOR XML` 查询,必须提供在 `FROM` 子句中生成的匿名行集的名称。 在本例中,提供的名称为 `SalesPerson`。
下面是部分结果:
```
<SalesOrder>
<Sales.SalesOrderHeader SalesOrderID="43659" SalesPersonID="279" CustomerID="676">
<Sales.SalesOrderDetail SalesOrderID="43659" ProductID="776" OrderQty="1" UnitPrice="2024.9940" />
<Sales.SalesOrderDetail SalesOrderID="43659" ProductID="777" OrderQty="3" UnitPrice="2024.9940" />
<Sales.SalesOrderDetail SalesOrderID="43659" ProductID="778" OrderQty="1" UnitPrice="2024.9940" />
</Sales.SalesOrderHeader>
<SalesPerson SalesPersonID="279" EmployeeID="279" />
</SalesOrder>
...
```
以下查询生成的销售订单信息基本相同,只是在结果 XML 中,<`SalesPerson`> 显示为 <`SalesOrderDetail`> 的同级:
```
<SalesOrder>
<SalesOrderHeader ...>
<SalesOrderDetail .../>
<SalesOrderDetail .../>
...
<SalesPerson .../>
</SalesOrderHeader>
</SalesOrder>
<SalesOrder>
...
</SalesOrder>
```
以下是查询语句:
```
SELECT SalesOrderID, SalesPersonID, CustomerID,
(select top 3 SalesOrderID, ProductID, OrderQty, UnitPrice
from Sales.SalesOrderDetail
WHERE SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID
FOR XML AUTO, TYPE),
(SELECT *
FROM (SELECT SalesPersonID, EmployeeID
FROM Sales.SalesPerson, HumanResources.Employee
WHERE SalesPerson.SalesPersonID = Employee.EmployeeID) As SalesPerson
WHERE SalesPerson.SalesPersonID = SalesOrderHeader.SalesPersonID
FOR XML AUTO, TYPE)
FROM Sales.SalesOrderHeader
WHERE SalesOrderID=43659 or SalesOrderID=43660
FOR XML AUTO, TYPE
```
结果如下:
```
<Sales.SalesOrderHeader SalesOrderID="43659" SalesPersonID="279" CustomerID="676">
<Sales.SalesOrderDetail SalesOrderID="43659" ProductID="776" OrderQty="1" UnitPrice="2024.9940" />
<Sales.SalesOrderDetail SalesOrderID="43659" ProductID="777" OrderQty="3" UnitPrice="2024.9940" />
<Sales.SalesOrderDetail SalesOrderID="43659" ProductID="778" OrderQty="1" UnitPrice="2024.9940" />
<SalesPerson SalesPersonID="279" EmployeeID="279" />
</Sales.SalesOrderHeader>
<Sales.SalesOrderHeader SalesOrderID="43660" SalesPersonID="279" CustomerID="117">
<Sales.SalesOrderDetail SalesOrderID="43660" ProductID="762" OrderQty="1" UnitPrice="419.4589" />
<Sales.SalesOrderDetail SalesOrderID="43660" ProductID="758" OrderQty="1" UnitPrice="874.7940" />
<SalesPerson SalesPersonID="279" EmployeeID="279" />
</Sales.SalesOrderHeader>
```
由于 `TYPE` 指令将查询结果作为 `xml` 类型返回,因此,可以使用各种 `xml` 数据类型方法查询生成的 XML。 有关详细信息,请参阅 [xml 数据类型方法](/sql/t-sql/xml/xml-data-type-methods)。 在以下查询中,注意:
- 将先前的查询添加到 `FROM` 子句。 查询结果返回为表。 注意添加的 `XmlCol` 别名。
- `SELECT` 子句对 `XmlCol` 子句中返回的 `FROM` 指定 XQuery。 `query()`方法的`xml`数据类型用于指定 XQuery。 有关详细信息,请参阅 [query() 方法(xml 数据类型)](/sql/t-sql/xml/query-method-xml-data-type)。
```
SELECT XmlCol.query('<Root> { /* } </Root>')
FROM (
SELECT SalesOrderID, SalesPersonID, CustomerID,
(select top 3 SalesOrderID, ProductID, OrderQty, UnitPrice
from Sales.SalesOrderDetail
WHERE SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID
FOR XML AUTO, TYPE),
(SELECT *
FROM (SELECT SalesPersonID, EmployeeID
FROM Sales.SalesPerson, HumanResources.Employee
WHERE SalesPerson.SalesPersonID = Employee.EmployeeID) As SalesPerson
WHERE SalesPerson.SalesPersonID = SalesOrderHeader.SalesPersonID
FOR XML AUTO, TYPE)
FROM Sales.SalesOrderHeader
WHERE SalesOrderID='43659' or SalesOrderID='43660'
FOR XML AUTO, TYPE ) as T(XmlCol)
```
## <a name="see-also"></a>请参阅
[使用嵌套 FOR XML 查询](use-nested-for-xml-queries.md) | 6,905 | CC-BY-4.0 |
---
title: 控制器组件 Action 实验
date: 2020-02-26 11:10:20
categories:
- tech
tags:
- struts
- Action
- JavaEE
- 总结
- 实验
---
包含 控制器组件 Action 知识梳理、实验步骤、实验整理方面的总结。
<!--more-->
## 知识梳理
1、Action 类中的默认方法名是 execute()方法,可以被自动调用;
2、在 Action 中也允许定义其它方法名,可以同时定义多个方法,分别处理不同的逻辑;
3、当 Action 中使用了自定义方法,则该 Action 就需要特定的配置,一般有四种调用方式:
- 在 struts.xml 文件中通过 method 属性指定方法名;
- 使用动态方法调用方式(DMI);
- 使用提交按钮的 method 属性;
- 使用通配符配置 Action;
4、Action 类是多实例的,Action 类的属性是线程安全的;
5、在 JSP 页面中,可以通过 Struts2 标签调用 Action 中对应的 getter 方法,从而输出 Action 的属性值;
6、当一个 Action 处理用户请求结束后,返回一个字符串作为逻辑视图名,再通过 `struts.xml` 文件中的配置将逻辑视图名与物理视图资源关联起来;Struts2默认提供了一系列的结果类型(`struts-default.xml` 配置文件的 result-types 标签里列出了所支持的结果类型),结果类型决定了 Action 处理结束后,将调用哪种视图资源来呈现处理结果。
7、为了让用户开发的 Action 类更规范,Struts2 提供了一个 Action 接口,该接口定义了 Struts2 的 Action 处理类应该实现的规范;
8、Struts2 还为 Action 接口提供了一个实现类:ActionSupport,该类提供了若干默认方法,包括:默认的处理用户请求的方法(excute()方法)、数据校验的方法、添加校验错误信息的方法、获取国际化信息的方法等,部分重要方法列表如下:

9、Struts2 框架提供了校验器和手工编码两种方式对请求参数进行数据校验,当 Action 类继承了 ActionSupport 类,就可以通过定义名为“<ActionClassName>- <ActionAliasName>-validation.xml”的校验规则文件的方法进行校验器校验, 也可以通过重写 ActionSupport 类的 validate()方法或 validateXxx()方法进行手动校验;
10、在 JSP 页面中使用 Struts2 标签生成的表单,能将域级别的错误信息将自动显示到表单元素处;
11、在 JSP 页面中使用 fielderror 标签,可以集中显示所有的域级错误信息;使用 actionerror 标签,可以显示所有的 Action 级别错误信息;使用 actionmessage 标签,可以显示 Action 消息;
12、Struts2 框架中提供了部分内置的类型转换器,可以将请求参数的 String 类型转换成基本数据类型及对应的包装器类型、日期类型、数组类型、集合类型等,当 Action 类继承了 ActionSupport 类,则内置的类型转换器将默认生效,可以直接使用;
13、如需修改默认的类型转换校验信息,则要在 Action 类的包中声明名为“Action 类名.properties”的局部属性文件;
14、Struts2 框架同时支持自定义类型转换器,将请求参数转换成任意一种类型。
15、Struts2 框架中的 Action 类没有与任何 Servlet API 耦合,因此 Action 类可以脱 离 Servlet 容器环境进行单元测试;
16、ActionContext 是 `com.opensymphony.xwork2` 包中的一个类,该类表示一个 Action 运行时的上下文;
17、当 Action 类需要通过请求、会话或上下文存取属性时,可以通过 ActionContext 类完成, 也可以通过实现 Struts 提供的接口:RequestAware、SessionAware 和 ApplicationAware 完成,而不必调用 Servlet API 中的 HttpServletRequest、 HttpSession 和 ServletContext 对象,从而保持 Action 与 Servlet API 的解耦;
18、在 Action 类中直接访问 Servlet API, 可以通过实现 Struts2 提供的接口: ServletContextAware、ServletRequestAware、ServletResponseAware 完成,也可以通过 ServletActionContext 工具类实现,但 Action 将与 Servlet API 直接耦合。
## 实验总结
**1、总结 Action 自定义方法的四种调用和配置方式**
- 在 `struts.xml` 文件中通过method属性指定方法名:以actionName.action形式访问,但是要配置多个action较为麻烦
- 使用动态方法调用方式:以 actionName!methodName.action 形式访问,要注意UserAction下的login和register方法不能有相同的result返回值
- 使用提交按钮的method属性:以actionName!methodName.action形式访问,但是需要在.jsp页面中配置,只能用于表单中
- 使用通配符配置Action:以actionName.action形式访问,相对更为普遍的方式
**2、Action 的实例化情况,将 Action 与 Servlet 在实例化情况上进行对比**
在Struts2中每提交一次表单数据Action就被实例化一次,而Servlet在被创建时就被实例化,多次访问页面Servlet不会被多次实例化。
**3、分析 JSP 文件中获取 Action 属性的主要过程**
JSP 文件中获取 Action 属性以JavaBean来实现,所封装的属性和表单的属性一一对应,JavaBean将成为数据传递的载体来进行数据的传递。
**4、观察两次 `loginSuccess.jsp` 页面输出上的区别,分析原因并记录下来**
redirect采用客户端重定向的方式,而默认的dispatcher采用服务器内部跳转的方式,所以当result的type属性被设置为redirect时无法获取到Action中的count属性而dispatcher的方式可以。
**5、解压缩 Struts2 的核心包 struts2-core-2.3.15.1.jar,找到 struts-`default.xml` 配置文件,在其中的 result-types 标签里列出了 Struts2 所支持的结果类型,查找相关资料,总结这些结果类型的作用和特点,并记录下来;**
- chain:服务器内部跳转,调用其他action,完成自定义的拦截器堆栈和结果。只能请求action,如果请求视图资源会报错。
- dispatcher: 默认值,服务器内部跳转(跳转到web组件)
- freemarker:使用Freemarker模板引擎呈现一个视图
- httpheader:通过设置HTTP headers和status的值来发送错误信息给客户端。
- redirect: 作客户端重定向(重定向到web组件)
- redirectAction: 作客户端重定向(重定向到其他Action)
- stream:用作下载文件或者在浏览器上显示PDF等文档
- velocity:使用Servlet容器的JspFactory,模拟JSP执行环境,显示Velocity模板,将直接传输到Servlet输出。
- plaintext:响应以plain形式返回给客户端,相当于`response.setContentType("text/plain; charset="+charSet);`
**6、总结 Action 类中 validate()方法和 validateXxx()方法的作用**
- validate()方法:将对页面表单验证的内容写到validate()方法中,实现验证和业务处理内容的分离,validate()方法会对Action类中所有业务方法起作用
- validateXxx()方法:当多个表单提交到同一个action页面是,validate()方法对所有表单生效,可以使用validateXxx()方法实现对某一个业务的验证,validate()方法和 validateXxx()方法同时存在时都会起作用;validateXxx()方法的调用优于validate()方法
**7、总结使用校验器校验的方法;在 Struts2 的核心包 xwork-core-**
**2.3.15.1.jar\com\opensymphony\xwork2\validator\validators路径下找到 default.xml 文件,总结校验规则文件中主要元素的作用和配置方法**
- required:必填校验器
- requiredstring:必填字符串校验器
- stringlength:字符串长度校验器
- date:日期校验器
- expression:表达式校验器
- int:整数校验器
- fieldexpression:字段表达式校验器
- url:网址校验器
- regex:正则表达式校验器
```xml
<validators>
<field name="被校验的字段">
<field-validator type="校验器的类型">
<param name="参数名">参数值</param>
<message> 提示信息</message>
</field-validator>
</field>
<!--下一个要验证的字段-->
</validators>
```
```xml
<valiators>
<validator type="校验器类型名">
<!--fieldName固定的 N必须大写-->
<param name="fieldName">需要被校验的字段</param>
<!--下面的param元素可以有0个或者多个-->
<param name="参数名">参数值</param>
<message key="I18NKey">提示信息</message>
</validator>
</validators>
```
**8、总结在 Action 中使用国际化资源文件的步骤及方法**
首先创建不同语言环境下的.properties文件,在文件中写入不同key字段的国际化资源,使用ActionSupport类的getText方法,该方法可以接受一个name参数,指定国际化资源文件中的key数值,最后使用native2ascii工具进行处理。
**9、总结 Struts2 中常用的内置类型转换器及其使用方法**
- String:将int,double,boolean,String类型的数组或java.util.Date类型转换成字符串。
- boolean和Boolean:在字符串与boolean之间转换
- char/Character:在字符串和字符之间转换
- int/Integer,float/Float,long/Long,double/Double:在字符串与数值类型之间进行转换
- date:在字符串和日期类型之间进行转换,默认格式是:YYYY-MM-DD
- 数组:由于数组本身就有类型,可以将多个同名参数,转换到数组中(在之前总结的兴趣爱好多选择,如果你选择多个,同时他们name属性相同就自动变为数组)
- 集合:支持将数据保存到List或者Map集合
**10、观察 Action 中访问 Servlet API 的四种方法,总结四种方法的区别,并记录下来**
- 通过ActionContext类访问:
使用这种方法访问的前提是必须先要获取ActionContext对象,优点是Action和Servlet API完全解耦,缺点是并不能调用原生的Servlet API
- Action直接访问:
使用这种方法可以调用原生的Servlet API,但是需要实现对应的接口
- 通过ServletActionContext访问:
使用ServletActionContext工具类无需实现接口,就可以直接访问Servlet API,但是会加强Action和Servlet API的耦合,不利于Action的再利用。
- 实现ServletContextAware、ServletRequestAware、ServletResponseAware接口访问:
Action与Servlet API直接耦合,需要调用ServletContext和ServletRequest等set方法。
## 实验步骤
### 基础实验
1、新建 Web 工程 struts-prj2,并将 Struts2 中的 8 个核心包添加到工程中;
2、在 struts-prj2 中新建 login.jsp 页面,作为用户登录的视图;新建 loginFail.jsp 页面,作为登录失败的视图;新建 loginSuccess.jsp 页面,作为登录成功的视图;
3、在 struts-prj2 中新建 register.jsp 页面,作为用户注册的视图;新建regFail.jsp 页面,作为注册失败的视图;新建 regSuccess.jsp 页面,作为注册成功的视图;
4、在 struts-prj2 中新建 cn.edu.zjut.bean 包,并在其中创建 UserBean.java,用于 记录用户信息 (可重用“实验二 Struts 基础应用 ”中提高实验里的 UserBean.java 代码);
5、在 struts-prj2 中新建 cn.edu.zjut.service 包,并在其中创UserService.java, 用于实现登录逻辑和注册逻辑;
6、在 struts-prj2 中新建 cn.edu.zjut.action 包,并在其中创建 UserAction.java,定义login()方法和 register()方法
7、在工程struts-prj2 的 src 目录中创建 struts.xml 文件,用于配置 Action 并设置 页面导航,通过 action 标签中 method 属性指定方法名;
8、编辑 Web 应用的 web.xml 文件,增加 Struts2 核心 Filter 的配置;
9、将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 login.jsp 与 register.jsp页面,并记录运行结果;
10、查找相关资料, 尝试使用 Action 自定义方法的其它三种调用和配置方式:动态方法调用方式(DMI)、提交按钮的 method 属性、通配符配置 Action,并记录关键配置和运行结果;



11、修改 UserAction.java,增加 UserAction 类的构造方法 UserAction(),增加 count属性,用于测试 Action 的实例化情况

12、修改 `loginSuccess.jsp`,在页面中使用<s:property>标签输出 Action 中的 count 值;
```
<s:property value="count" />
```
13、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 login.jsp 页面, 并刷新多次,记录运行结果;

14、修改 struts.xml 文件,将 UserAction 的页面导航设置为 redirect 结果类型;
```
<result name="success" type="redirect">/loginSuccess.jsp</result>
```
15、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 login.jsp 页面, 观察登录成功后 loginSuccess.jsp 页面的输出,并记录下来。

### 提高实验
1、在 struts-prj2 中修改 UserAction 类,使其继承 ActionSupport 类,并在 UserAction 类中覆盖 ActionSupport 类的 validate()方法, 用于对用户登录的请求参 数 account 和 password 进行校验:若用户名或密码为空,则使用 addFieldError (域 级)添加错误信息。

2、修改 `struts.xml` 文件,在 Action 的配置中增加 validate()方法校验出错时的页面导航`<result name="input">`

3、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `login.jsp` 页面,观察并记录运行结果;

4、修改 `login.jsp` 页面,在表单前增加 fielderror 标签:`<s:fielderror/>`,再通过浏览器访问 login.jsp 页面,观察并记录运行结果

5、修改 UserAction.java,在调用登录逻辑的 login()方法中,对登录情况进行校验: 若登录成功,使用 addActionMessage()方法添加“登录成功!”的 Action 提示消息,若 登录失败,使用 addActionError()方法添加 Action 级别的错误信息

6、修改 login.jsp 页面,增加 actionerror 标签(<s:actionerror/>)Action 级别的 错 误信息;修改 `loginSuccess.jsp`,使用 actionmessage 标签`<s:actionmessage/>` 显示 Action 提示消息;
7、修改 `struts.xml` 文件中用户登录的页面导航设置,将登录失败时转向的页面从 loginFail.jsp 修改为 login.jsp;
8、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 login.jsp 页面, 观察并记录运行结果;

9、在工程 struts-prj2 中创建“UserAction-login-validation.xml”校验规则文件,使 其与 UserAction 类位于同一目录下,配置校验信息,使用校验器对请求参数进行校验
10、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 login.jsp 页面, 观察并记录运行结果;

11、将 login.jsp、 loginSuccess.jsp、 loginFail.jsp 三个页面进行国际化处理,把需要进行国际化的内容 以键值对的形式写入资源文件 `message_zh_CN.properties` 和 `message_en_US.properties` 中;
12、在资源文件中添加校验信息的键值对, 并使用 native2ASCII 工具,将 `message_zh_CN.properties` 重新编码,将中文字符都转化为 unicode 码
13、在工程 struts-prj2 的 src 目录中创建 `struts.properties` 文件,通过它加载资源文件
14、修改 `UserAction.java`,使用 ActionSupport 类的 getText()方法,获取国际化资 源文件中的信息
15、修改 `UserAction-login-validation.xml`,获取国际化资源文件中的信息
16、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `login.jsp` 页面, 观察并记录运行结果;

17、修改 `UserBean.java`,将用于保存注册用户生日的变量类型改为 Date 类型,使用 Struts2 内置的类型转换器对请求参数进行校验;
18、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `register.jsp` 页 面,当用户输入的生日不合法时,观察并记录运行结果;

19、在工程 struts-prj2 的 cn.edu.zjut.action 包中创建局部属性文件`UserAction.properties`,修改类型转换的校验信息,并使用 native2ASCII 工具将 `UserAction.properties` 重新编码
20、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `register.jsp` 页 面,当用户输入的生日不合法时,观察并记录运行结果;

21、参考实验步骤 9,在工程 struts-prj2 的 cn.edu.zjut.action 包中创建 `UserAction-register-validation.xml` 文件,增加校验信息的配置,使用校验器对用户 注册的请求参数进行校验,要求注册时两次密码输入相同、email 地址格式符合要求等;
22、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `register.jsp` 页 面,观察并记录运行结果;

23、修改 UserAction 类, 将 validate()的方法名改为 validateLogin(), 并增加 validateRegister()方法,参考实验步骤 1,使用手工编码方式对请求参数进行数据校验;
24、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `register.jsp` 页 面,观察并记录运行结果。

### 拓展实验
1、在 struts-prj2 中修改 UserAction 类,通过 ActionContext 获取请求、会话和上下文对象相关联的 Map 对象来实现存取属性的功能
2、修改 `loginSuccess.jsp` 页面,从请求、会话和上下文对象中获取属性值并显示 在页面中
3、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `login.jsp` 页面,观察并记录运行结果;

**每提交一次刷新,次数就会增加一次,只有重新部署访问次数才会重置**
4、修改 UserAction 类,通过实现 Struts 提供的接口:RequestAware、SessionAware 和 ApplicationAware,获取请求、会话和上下文对象相关联的 Map 对象来实现存取属性的功能
5、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `login.jsp` 页面,观察并记录运行结果;

6、修改 UserAction 类,查找相关资料,尝试通过接口:ServletContextAware、 ServletRequestAware、ServletResponseAware 直接访问 Servlet API,实现以上实验步骤 1-3 的相同功能,重新运行并记录结果;


7、修改 UserAction 类,查找相关资料,尝试通过 ServletActionContext 工具类直接访 问 Servlet API,实现以上实验步骤 1-3 的相同功能,重新运行并记录结果;


8、尝试利用 Servlet API 添加购物车功能,在工程 struts-prj2 的 cn.edu.zjut.bean 包中创建 `Item.java` 用于记录商品信息
9、在工程 struts-prj2 的 cn.edu.zjut.bean 包中创建 `ShopppingCart.java` 用于记录用户的购物车信息,为简化操作,在购物车的构造函数中加入商品信息
10、重新将 struts-prj2 部署在 Tomcat 服务器上,通过浏览器访问 `login.jsp `页面, 观察并记录运行结果。
 | 10,735 | MIT |
# acm-template
## 模板编写规范说明
- 使用markdown语法(便于赛前打印和生成目录)
- 所有的算法模板都写在这一个md文件中
- 代码名称
- 需要有接口说明(可以看下面示例)
- 代码最小原则,不添加任何不必要的变量和函数(最小不意味着最少,不要为了减短代码而去减短代码)
- 代码块要使用如下的markdown包裹
```
```c++
your code
```
```
- 其他细则在实践过程中添加
## 快速幂
简介:介绍算法干啥,哪些情况用的上
### 非递归版算法
描述:简要描述算法实现框架(便于找错)。
```c++
/*
Version: 1.0
Author: 徐祥昊
Date: 2018.7.27
Function List:
1.q_pow(__int64 a,__int64 b)
a:这里是a参数的说明;
b:这里是b参数的说明;
ret:这里是返回值的说明;
2.some else func
3.some else func
*/
bool q_pow(__int64 a,__int64 b)
{
__int64 res=1,mod=b,carry=a;
while(b)
{
if(b%2)
{
res=res*a%mod;
}
a=a*a%mod;
b>>=1;
}
if(res == carry)return true;
else return false;
}
```
## 快速幂
dls 板
```c++
ll powmod(ll a,ll b) {ll res=1;a%=mod; assert(b>=0); for(;b;b>>=1){if(b&1)res=res*a%mod;a=a*a%mod;}return res;}
```
## O(log(n)) 素数判定
目前已知的最快的单个素数判定方法
```c++
/*
Version: 1.0
Author: 王峰
Date: 2018.8.26
Function List:
isPrime(long long n)
返回值为n是否是质数
*/
#include <iostream>
#include <cmath>
long long pow_mod(int a, long long d, long long mod) {
long long res = 1, k = a;
while(d) {
if(d & 1) res = (res * k) % mod;
k = k * k % mod;
d >>= 1;
}
return res;
}
bool test(long long n, int a, long long d) {
if(n == 2) return true;
if(n == a) return true;
if((n & 1) == 0) return false;
while(!(d & 1)) d = d >> 1;
long long t = pow_mod(a, d, n);
while((d != n - 1) && (t != 1) && (t != n - 1)) {
t = t * t % n;
d <<= 1;
}
return (t == n - 1 || (d & 1) == 1);
}
bool isPrime(long long n) {
if(n < 2LL) return false;
int a[] = {2, 3, 61};
for (int i = 0; i <= 2; ++i) if(!test(n, a[i], n - 1)) return false;
return true;
}
```
## 欧拉筛法求素数表
时间复杂度 O(n)
```c++
/*
Version: 1.0
Author: 王峰
Date: 2018.8.26
Function List:
get_prime()
check[i]表示i是否为合数
prime[i]表示第i个质数,i从0开始计数
*/
#include<cstdio>
#include<cstring>
const int MAXN = 10000001;
const int MAXL = 10000001;
int prime[MAXN];
int check[MAXL];
int get_prime() {
int tot = 0;
memset(check, 0, sizeof(check));
for (int i = 2; i < MAXL; ++i) {
if (!check[i]){
prime[tot++] = i;
}
for (int j = 0; j < tot; ++j) {
if (i * prime[j] > MAXL) {
break;
}
check[i*prime[j]] = 1;
if (i % prime[j] == 0) {
break;
}
}
}
return tot;
}
```
## 乘法逆元
用于实现取模意义下的除法
例如 (a*b/n)%m == (a%m)*(b%m)%m*inv(n,m)%m;
扩展欧几里得实现,时间复杂度O(log(n)), 适用于a与m互质的情况;
原理: n*inv|m == 1 => n*inv == k*m+1
==> n*inv + k*m == 1, 若n与m互质,则
n*inv + k*m == gcd(n, m) //扩展欧几里得原理
故用欧几里得算法求得n在模m下的乘法逆元inv
```c++
typedef long long LL;
LL ex_gcd(LL a,LL b,LL &x,LL &y) {
if(b==0) {
x=1;
y=0;
return a;
}
LL ans=ex_gcd(b,a%b,x,y);
LL tmp=x;
x=y;
y=tmp-a/b*y;
return ans;
}
LL mod_inverse(LL a,LL m) {
long long x,y;
ex_gcd(a,m,x,y);
return (x%m+m)%m;
}
```
O(n) 求逆元表的板子
```c++
int inv[1]=1;
for(int i=2; i<n; i++) inv[i] = inv[mod%i]*(mod-mod/i)%mod;
```
## ST表
用于快速查询RMQ问题 建表时间复杂度O(log(n))空间复杂度O(log(n)) 查询时间复杂度O(1) 不可动态更改
```c++
/*
Version: 1.0
Author: 王峰
Date: 2018.8.27
Function List:
init_table(n) n为原数组a的长度
query_table(L, R) 查询原数组内区间[L,R]的最值
*/
#include <cstdio>
#include <algorithm>
using std::min;
const int N = 1000010;
int table[N][100];
int lg[N];
int a[N];
void init_table(int n) {
for(int i=0; i<n; i++) table[i][0]=a[i];
for(int j=1; (1<<j)<=n; j++) {
for(int i=0; i+(1<<j)-1<n; i++) {
table[i][j] = min(table[i][j-1],table[i+(1<<(j-1))][j-1]);
}
}
for(int i=2, k=0; i<=n; i++) {
if(i>(1<<k)) k++;
lg[i] = k-1;
}
}
int query_table(int L, int R) {
int k = lg[R-L+1];
return min(table[L][k],table[R-(1<<k)+1][k]);
}
```
## 树状数组(二叉索引树)模板
用于求可单点更新的前缀和,时间复杂度O(log(n))
```c++
/*
Version: 1.0
Author: 王峰
Date: 2018.8.27
Function List:
add(k, v) 将数组中的第k个元素的值+v,注意k从1开始计数
query(k) 查询profix[k]
*/
#include <cstdio>
const int N = 1000010;
int n; //实际数组的长度
long long tree[4*N];
void add(int k, long long v) {
while(k<=n){
tree[k]+=v;
k+=(k&-k);
}
}
long long query(int k) {
long long ans = 0;
while(k>0) {
ans+=tree[k];
k-=k&-k;
}
return ans;
}
```
## 求和线段树模板
RMQ线段树小改即可
```c++
/*
Function List:
Build(1,n,1); 建树
Add(L,C,1,n,1); 点更新
Update(L,R,C,1,n,1); 区间更新
ANS=Query(L,R,1,n,1); 区间查询
*/
typedef long long LL;
const int MAXN=1e5+7;
LL a[MAXN],ans[MAXN<<2],lazy[MAXN<<2];
void PushUp(int rt) {
ans[rt]=ans[rt<<1]+ans[rt<<1|1];
}
void Build(int l,int r,int rt) {
if (l==r) {
ans[rt]=0;
return;
}
int mid=(l+r)>>1;
Build(l,mid,rt<<1);
Build(mid+1,r,rt<<1|1);
PushUp(rt);
}
void PushDown(int rt,LL ln,LL rn) {
if (lazy[rt]) {
lazy[rt<<1]+=lazy[rt];
lazy[rt<<1|1]+=lazy[rt];
ans[rt<<1]+=lazy[rt]*ln;
ans[rt<<1|1]+=lazy[rt]*rn;
lazy[rt]=0;
}
}
void Add(int L,int C,int l,int r,int rt)
{
if (l==r)
{
ans[rt]+=C;
return;
}
int mid=(l+r)>>1;
//PushDown(rt,mid-l+1,r-mid); 若既有点更新又有区间更新,需要这句话
if (L<=mid)
Add(L,C,l,mid,rt<<1);
else
Add(L,C,mid+1,r,rt<<1|1);
PushUp(rt);
}
void Update(int L,int R,long long C,int l,int r,int rt) {
if (L<=l&&r<=R) {
ans[rt]+=C*(r-l+1);
lazy[rt]+=C;
return;
}
int mid=(l+r)>>1;
PushDown(rt,mid-l+1,r-mid);
if (L<=mid) Update(L,R,C,l,mid,rt<<1);
if (R>mid) Update(L,R,C,mid+1,r,rt<<1|1);
PushUp(rt);
}
LL Query(int L,int R,int l,int r,int rt) {
if (L<=l&&r<=R)
return ans[rt];
int mid=(l+r)>>1;
PushDown(rt,mid-l+1,r-mid);
LL ANS=0;
if (L<=mid) ANS+=Query(L,R,l,mid,rt<<1);
if (R>mid) ANS+=Query(L,R,mid+1,r,rt<<1|1);
return ANS;
}
```
## 主席树
主席树:可持久化线段树, 在nlog(n)空内维护多个权值线段树 离线数据结构不支持修改
```c++
#include <cstdio>
#include <vector>
#include <algorithm>
/*
Version: 1.0
Author: 王峰
Date: 2018.9.25
Function List:
本例为查询区间第K大,有一个基于排序去重的哈希,有时间分离出来单独成板.
*/
using std::lower_bound;
using std::vector;
const int maxn = 1e5+6;
int cnt, root[maxn], a[maxn];
struct node{
int l, r, sum;
}T[maxn*40];
vector<int > v;
int getid(int x) {
return lower_bound(v.begin(), v.end(),x)-v.begin()+1;
}
void update(int l, int r, int &x, int y, int pos) {
T[++cnt]=T[y],T[cnt].sum++,x=cnt;
if(l==r)return ;
int mid=(l+r)/2;
if(mid>=pos)update(l, mid, T[x].l, T[y].l, pos);
else update(mid+1, r, T[x].r, T[y].r, pos);
}
int query(int l, int r, int x, int y, int k) {
if(l==r) return l;
int mid = (l+r)/2;
int sum = T[T[y].l].sum - T[T[x].l].sum;
if(sum>=k)return query(l, mid, T[x].l, T[y].l, k);
else return query(mid+1, r, T[x].r, T[y].r, k-sum);
}
int main() {
int n, q;
scanf("%d%d", &n, &q);
for(int i=1; i<=n; i++) {
scanf("%d", &a[i]);
v.push_back(a[i]);
}
sort(v.begin(), v.end()),v.erase(unique(v.begin(), v.end()), v.end());
for(int i=1; i<=n; i++) update(1, n, root[i], root[i-1], getid(a[i]));
for(int i=1; i<=q; i++) {
int x, y, k;
scanf("%d%d%d", &x, &y, &k);
printf("%d\n", v[query(1,n,root[x-1],root[y],k)-1]);
}
return 0;
}
```
## dijkstra+priority_queue
用于求单源最短路径,不能处理负环
```c++
/*
Version: 1.0
Author: 王峰
Date: 2018.9.3
Function List:
init(int n) 将带n个点的图初始化
addEdge(int from, int to, int dist) 增加一条单向边
dijkstra(int s) 求s为源点的最短路
print(t, s) 打印从s为源点t为终点的一条路径
*/
#include <cstdio>
#include <vector>
#include <queue>
#include <cstring>
using std::vector;
using std::priority_queue;
const int maxn = 1e6+7;
const int INF = 0x3f3f3f3f;
struct Edge {
int from, to, dist;
};
struct HeapNode {
int d, u;
bool operator < (const HeapNode& rhs) const {
return d > rhs.d;
}
};
struct Dijkstra {
int n, m; //点数和边数
vector<Edge> edges; //边列表
vector<int> G[maxn]; //每个节点出发的边编号, 从0开始编号
bool vis[maxn]; //是否已经标记
int d[maxn]; //s到各个点的距离
//int p[maxn]; //最短路的上一条边
void init(int n) {
this->n = n;
for(int i=0; i<=n; i++) {
G[i].clear();
}
edges.clear();
}
/*
void print(int t, int s) {
int pre = edges[p[t]].from;
if(t==s) {
printf("%d ", s);
return ;
}else{
print(pre,s);
printf("%d ", t);
}
}
*/
void addEdge(int from, int to, int dist) {
edges.push_back((Edge){from, to, dist});
m = edges.size();
G[from].push_back(m-1);
}
void dijkstra(int s) {
priority_queue<HeapNode> Q;
for(int i=0; i<=n; i++) d[i] = INF;
d[s]=0;
memset(vis, 0, sizeof(vis));
Q.push((HeapNode){0, s});
while(!Q.empty()) {
HeapNode x = Q.top(); Q.pop();
int u = x.u;
if(vis[u]) continue;
vis[u] = true;
for(int i=0; i<G[u].size(); i++) {
Edge & e = edges[G[u][i]];
if(d[e.to] > d[u] + e.dist) {
d[e.to] = d[u] + e.dist;
//p[e.to] = G[u][i];
Q.push((HeapNode){d[e.to], e.to});
}
}
}
}
}D;
```
## Bellman-Ford
单源最短路-可以判负环 队列实现,时间复杂度 <del>O(玄学)</del> O(VE)
```c++
/*
Version: 1.0
Author: 王峰
Date: 2018.9.30
Function List: the same as dijkstra algorithm
*/
#include <iostream>
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
const int maxn = 1e5+7;
struct Edge {
int from, to;
double dist;
};
struct BellmanFord {
int n, m;
vector<Edge> edges;
vector<int> G[maxn];
bool inq[maxn];
double d[maxn];
int p[maxn];
int cnt[maxn];
void init(int n) {
this->n = n;
for(int i=0; i<=n; i++) {
G[i].clear();
}
edges.clear();
}
void AddEdge(int from, int to, double dist) {
edges.push_back((Edge){from, to, dist});
m = edges.size();
G[from].push_back(m-1);
}
bool negativeCycle() {
queue<int> Q;
memset(inq, 0, sizeof(inq));
memset(cnt, 0, sizeof(cnt));
for(int i=1; i<=n; i++) {
d[i]=0;
inq[0]=true;
Q.push(i);
}
while(!Q.empty()) {
int u = Q.front();
Q.pop();
inq[u] = false;
for(int i=0; i<G[u].size(); i++) {
Edge & e = edges[G[u][i]];
if(d[e.to] > d[u] + e.dist) {
d[e.to] = d[u] + e.dist;
p[e.to] = G[u][i];
if(!inq[e.to]) {
Q.push(e.to);
inq[e.to] = true;
if(++cnt[e.to] > n) return true;
}
}
}
}
return false;
}
};
```
## hlpp
最大流-最强算法,时间复杂度O(|E|^2*sqrt(|V|))
最高标号预流推进算法High Level Preflow Push
```c++
/*
copy from https://blog.csdn.net/KirinBill/article/details/60882828
有时间的话参照算法自己实现一遍
*/
#include <cstdio>
#include <queue>
#include <cstring>
using namespace std;
#define min(a,b) (a<b ? a:b)
const int MAXN=305,MAXM=100005,INF=~0U>>1;
int cnt,head[MAXN];
bool vis[MAXN];
struct line{
int to,next,cap;
line(){
next=-1;
}
}edge[MAXM];
struct data{
int x,h,ef;
friend bool operator< (const data &a,const data &b){
return a.h<b.h;
}
}node[MAXN];
priority_queue<data> q;
queue<int> tmpq;
inline void add(int u,int v,int w){
edge[cnt].next=head[u];
head[u]=cnt;
edge[cnt].to=v;
edge[cnt].cap=w;
++cnt;
}
void bfs(int t){
tmpq.push(t);
vis[t]=true;
int u,v;
while(tmpq.size()){
u=tmpq.front();
for(int i=head[u];i!=-1;i=edge[i].next){
v=edge[i].to;
if(!vis[v]){
node[v].h=node[u].h+1;
tmpq.push(v);
vis[v]=true;
}
}
tmpq.pop();
}
}
int hlpp(int n,int s,int t){
for(int i=1;i<=n;++i)
node[i].x=i;
bfs();
data tmp;
int u,v,f,tmph;
for(int i=head[s];i!=-1;i=edge[i].next){
v=edge[i].to;
edge[i^1].cap+=edge[i].cap;
node[v].ef+=edge[i].cap;
edge[i].cap=0;
q.push(node[v]);
}
node[s].h=n;
while(q.size()){
tmp=q.top();
q.pop();
u=tmp.x;
tmph=INF;
for(int i=head[u];i!=-1 && node[u].ef;i=edge[i].next){
v=edge[i].to;
if(edge[i].cap){
if(node[u].h==node[v].h+1){
if(v!=s && v!=t && node[v].ef==0)
q.push(node[v]);
f=min(edge[i].cap,node[u].ef);
edge[i].cap-=f;
edge[i^1].cap+=f;
node[u].ef-=f;
node[v].ef+=f;
}
else tmph=min(tmph,node[v].h);
}
if(node[u].ef){
node[u].h=tmph+1;
q.push(node[u]);
}
}
return node[t].ef;
}
int main(){
memset(head,-1,sizeof(head));
int n,m,s,t,tmpu,tmpv,tmpw;
scanf("%d%d%d%d",&n,&m,&s,&t);
for(int i=1;i<=m;++i){
scanf("%d%d%d",&tmpu,&tmpv,&tmpw);
add(tmpu,tmpv,tmpw);
add(tmpv,tmpu,tmpw);
}
printf("%d",hlpp(n,s,t));
return 0;
}
```
## 最小费用最大流算法
时间复杂度:O(VE)
```c++
#define N 3000
#define INF 100000000
using namespace std;
struct Edge
{
int from,to,cap,flow,cost;
};
struct MCMF
{
int n,m,s,t;
vector<Edge>edges;
vector<int>G[N];
int inq[N];//是否在队列中
int d[N];//Bellman-Ford
int p[N];//上一条弧
int a[N];//可改进量
void init(int n)
{
this->n=n;
for(int i=0;i<=n;i++)
G[i].clear();
edges.clear();
}
void addedge(int from,int to,int cap,int cost)
{
edges.push_back((Edge){from,to,cap,0,cost});
edges.push_back((Edge){to,from,0,0,-cost});
m=edges.size();
G[from].push_back(m-2);
G[to].push_back(m-1);
}
bool BellmanFord(int s,int t,int&flow,long long&cost)//沿着最短路增广
{
for(int i=0;i<n;i++)
d[i]=INF;
memset(inq,0,sizeof(inq));
d[s]=0,inq[s]=1,p[s]=0,a[s]=INF;
queue<int>q;
q.push(s);
while(!q.empty())
{
int u=q.front();q.pop();
inq[u]=0;
for(int i=0;i<G[u].size();i++)
{
Edge&e=edges[G[u][i]];
if(e.cap>e.flow&&d[e.to]>d[u]+e.cost)//松弛操作
{
d[e.to]=d[u]+e.cost;
p[e.to]=G[u][i];//记录父边
a[e.to]=min(a[u],e.cap-e.flow);//更新可改进量,等于min{到达u时候的可改进量,e边的残量}
if(!inq[e.to]){q.push(e.to);inq[e.to]=1;}
}
}
}
if(d[t]==INF)//仍为初始时候的INF,s-t不连通,失败退出
return false;
flow+=a[t];
cost+=(long long)d[t]*a[t];//d[t]一方面代表了最短路长度,另一方面代表了这条最短路的单位费用的大小
int u=t;
while(u!=s)//逆向修改每条边的流量值
{
edges[p[u]].flow+=a[t];
edges[p[u]^1].flow-=a[t];
u=edges[p[u]].from;
}
return true;
}
int MincostMaxflow(int s,int t,long long&cost)//返回最大流,同时用引用返回达到最大流时的最小费用
{
int flow=0;
cost=0;
while(BellmanFord(s,t,flow,cost));//直到不存在最短路时停止
return flow;
}
} D;
```
## C组合数板子
时间复杂度O(2^n)
```c++
/*
Version: 1.0
Author: 王峰
Date: 2018.9.17
*/
C[1][0] = C[1][1] = 1;
for (int i = 2; i < N; i++){
C[i][0] = 1;
for (int j = 1; j < N; j++)
C[i][j] = (C[i - 1][j] + C[i - 1][j - 1]);
}
```
## 容斥原理
时间复杂度O(n^2)
```c++
ll ans = 0;
for(int i=0; i<(1<<tot); i++) {
int cnt = 0;
for(int j=0; j<tot; j++) {
if(i&(1<<j)) cnt++;
}
ll tmp = 0;
/*
得到当前状态下的贡献值
*/
if(cnt&1) {
ans ++ tmp;
} else {
ans -= tmp;
}
}
```
## some else algorithm
### some else | 15,540 | MIT |
---
layout: post
category: il y a là cendre
title: 冬至和什麼都沒有做
tags: []
---
吐槽也不是不可以,只是也不應該每天就只是吐槽?只是今天也確實什麼都沒有做成。
看不完的布克哈特,看不進的算法,甚至還是看不完的赫西俄德。
說是感冒的緣故,早一點睡覺好了?
其實是又愚蠢地裝了opensuse什麼的。好吧,這確實是一個失誤。
都是在圖什麼呢。水逆結束前最後的瘋狂?好吧,還是用leap穩定一點啊,說是。
其他就更沒有進展了。昨天還算是摘橙子的話,今天完全就是虛度。
所以不免驚慌?本來不甘心對應的就是晚睡的。
只是感冒了,確實熬不動了。所以也只能帶着一點感冒似的憤怒早一點睡覺了。
倒是想的確實,前面這個org其實貌似還是沒有把現在各種串起來。
比如看不進去的書。還是需要再想想的scip。好吧,這個也急不來。
感冷是不是有可能發燒了呢。說還是如何先照顧好自己?貌似確實年紀大了,恢復都不如以前了哈,還是每年都有這種喝酒後的重感冒。
各種嘗試都沒有成功,說的就是今天把,倒是下了vc++6,不過都還沒有安裝。然後就算是可以睡覺了吧。
matlab要不要繼續下着呢。還是慢慢來好了。晚上網速也不知道如何?
其實沒有價值的話,說得再多只能更突顯沒有價值,絮絮叨叨也是圖什麼呢。
更好的書寫在哪裏。或者真的需要寫英文作文了。起碼會又一個中心和主題。
<!-- more --> | 634 | CC0-1.0 |
---
layout: article
title: 不用中间变量交换两个数字变量
tags:
- code
lang: zh-Hans
---
<!--more-->
C#或其他:
```java
int a = 3, b = 5;
if(a <= b){
a = a + b;
b = a - b;
a = a - b;
}
```
Python:
```python
a, b = 3, 5
a, b = b, a
``` | 237 | MIT |
### 通过Kubeadm安装K8S集群
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
准备工作:
1. Swap disabled
2. 网卡MAC地址和product_uuid唯一
3. Letting iptables see bridged traffic
```sh
# 确保br_netfilter模块已加载
lsmod | grep br_netfilter
```
4. 安装容器运行时,我们使用已经安装的docker
```sh
支持以下:
Runtime Path to Unix domain socket
Docker /var/run/dockershim.sock
containerd /run/containerd/containerd.sock
CRI-O /var/run/crio/crio.sock
```
5. 其他
```sh
#禁用SELINUX
$ sudo setenforce 0 #0代表permissive 1代表enforcing
# 开启ipv4转发
vi /etc/sysctl.conf
net.ipv4.ip_forward = 1
# 关闭防火墙
$ sudo iptables -P FORWARD ACCEPT
# 永久生效
/usr/sbin/iptables -P FORWARD ACCEPT
# 关闭docker 的iptable
{
"iptables":false
}
# 禁用swap
swapoff -a
# 配置iptables参数,使得流经网桥的流量也经过iptables/netfilter防火墙
$ sudo tee /etc/sysctl.d/k8s.conf <<-'EOF'
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
$ sudo sysctl --system
```
6. 安装工具
+ kubeadm 创建集群
+ kubelet 运行在所有节点的服务,控制容器启停
+ kubectl 集群命令行工具
```sh
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
sudo curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
sudo tee /etc/apt/sources.list.d/kubernetes.list <<-'EOF'
deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main
EOF
sudo apt-get update
#删除之前的版本
kubeadm reset
systemctl stop kubelet
rm -rf /var/lib/cni/
rm -rf /var/lib/kubelet/*
rm -rf /run/flannel
rm -rf /etc/cni/
ifconfig cni0 down
ifconfig flannel.1 down
ip link delete cni0
ip link delete flannel.1
ipvsadm --clear
rm -rf $HOME/.kube/config
apt purge -y kubelet kubeadm kubectl kubernetes-cni
systemctl daemon-reload
# 查看可用版本
apt-cache madison kubeadm
# 安装指定版本
# 这里加上 --allow-downgrades --allow-change-held-packages 是因为之前尝试安装1.23后,需要进行降级处理
sudo apt-get install -y --allow-downgrades --allow-change-held-packages kubelet=1.18.3-00 kubeadm=1.18.3-00 kubectl=1.18.3-00
sudo apt-mark hold kubelet=1.18.3-00 kubeadm=1.18.3-00 kubectl=1.18.3-00
# 随系统启动
sudo systemctl enable kubelet && sudo systemctl start kubelet
# 查看需要哪些镜像
kubeadm config images list --kubernetes-version=v1.18.3
#docker pull镜像拉取命令
docker pull mirrorgcrio/kube-apiserver:v1.18.3
docker pull mirrorgcrio/kube-controller-manager:v1.18.3
docker pull mirrorgcrio/kube-scheduler:v1.18.3
docker pull mirrorgcrio/kube-proxy:v1.18.3
docker pull mirrorgcrio/pause:3.2
docker pull mirrorgcrio/etcd:3.4.3-0
docker pull mirrorgcrio/coredns:1.6.7
#docker tag镜像重命名
docker tag mirrorgcrio/kube-apiserver:v1.18.3 k8s.gcr.io/kube-apiserver:v1.18.3
docker tag mirrorgcrio/kube-controller-manager:v1.18.3 k8s.gcr.io/kube-controller-manager:v1.18.3
docker tag mirrorgcrio/kube-scheduler:v1.18.3 k8s.gcr.io/kube-scheduler:v1.18.3
docker tag mirrorgcrio/kube-proxy:v1.18.3 k8s.gcr.io/kube-proxy:v1.18.3
docker tag mirrorgcrio/pause:3.2 k8s.gcr.io/pause:3.2
docker tag mirrorgcrio/etcd:3.4.3-0 k8s.gcr.io/etcd:3.4.3-0
docker tag mirrorgcrio/coredns:1.6.7 k8s.gcr.io/coredns:1.6.7
# master
kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=1.18.3 --apiserver-advertise-address=10.8.30.38
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# slave
kubeadm join 10.8.30.38:6443 --token wfwsdf.xja48e2nrxp0jj9t \
--discovery-token-ca-cert-hash sha256:bde8eab3fd3b96d2fe98b27d2d0f5692042feace0f59944b4a6ba15cb7a2c9a9
# 将本地hosts加入core-dns。
kubectl get cm -n kube-system coredns -o yaml > /home/anxin/core-dns.yaml
```
```yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
hosts {
10.8.30.35 node35
10.8.30.36 node36
10.8.30.37 node37
10.8.30.38 node38
10.8.30.39 node39
10.8.30.40 node40
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
...
```
```sh
# 重启core-dns pods
```
[别人的安装指南](https://www.cnblogs.com/xiao987334176/p/12696740.html)
[通过阿里云获取gcr.io上的镜像](https://blog.csdn.net/yjf147369/article/details/80290881)
5. VMMEM 占用过高
Hyper-V Manager中关闭 | 4,999 | MIT |
---
layout: post
title: ant工具使用
category: 工具
tags: [java,ant]
keywords: [java,ant]
---
### 使用心得
日常开发常使用eclipse+myeclipse 或者 idea 工具,因为这些工具都是直接封装好的编译和部署到web服务器的过程;
然而初学或者需要在编译和部署的流程中插播其他拓展操作(比如复制或删除一些额外的文件到项目目录)的时候,直接使用IDE工具是不提供灵活的配置;这个时候使用ant可以弥补工具的不足;
对于开发人员所需要面对的各种PC和服务环境各部相同;
同时各个终端不一定拥有相同的和熟悉的IDE工具版本;个人更多的时候喜欢使用sublime和vscode文本编辑器进行程序直接编写(目前使用PHP语言日常sublime已经足够);
常遇到工作终端配置不够所以安装大型IDE比较消耗资源(如myeclipse高版本非常消耗内存);在非java IDE的时候使用ant开发的可以非常了解各个所以环境配置和编译部署的各个步骤的来龙去脉.而且各个环节可以自主控制;
ant 通用的功能:copy(文件/目录复制) , delete(文件/目录删除) , javac(java编译) , java(java运行) , jar(生成jar包) 等等
### ant执行异常
```java
ant XML parser factory has not been configured correctly: Provider org.apach
```
处理: 由于ant缺少xml文件解析工具包, 解决办法下载复制一个xercesImpl到jdk对应jre/lib下即可
### 使用简介
以下内容引用自: [https://www.cnblogs.com/wufengxyz/archive/2011/11/24/2261797.html](https://www.cnblogs.com/wufengxyz/archive/2011/11/24/2261797.html)
#### 1,什么是ant
ant是构建工具
#### 2,什么是构建
概念到处可查到,形象来说,你要把代码从某个地方拿来,编译,再拷贝到某个地方去等等操作,当然不仅与此,但是主要用来干这个
#### 3,ant的好处
跨平台 --因为ant是使用java实现的,所以它跨平台
使用简单--与ant的兄弟make比起来
语法清晰--同样是和make相比
功能强大--ant能做的事情很多,可能你用了很久,你仍然不知道它能有多少功能。当你自己开发一些ant插件的时候,你会发现它更多的功能。
#### 4,ant的兄弟make
ant做的很多事情,大部分是曾经有一个叫make的所做的,不过对象不同,make更多应用于c/c++ ,ant更多应用于Java。当然这不是一定的,但大部分人如此。
### ant使用
#### 一,构建ant环境
要使用ant首先要构建一个ant环境,步骤很简单:
- 1),安装jdk,设置JAVA_HOME ,PATH ,CLASS_PATH(这些应该是看这篇文章的人应该知道的)
- 2),下载ant 地址http://www.apache.org/找一个你喜欢的版本,或者干脆最新的版本
- 3),解压ant 你得到的是一个压缩包,解压缩它,并把它放在一个尽量简单的目录,例如D:\ant-1.6虽然你不一 定要这么做,但这么做是有好处的。
- 4),设置ANT_HOME, PATH中添加ANT_HOME目录下的bin目录(我设置的:ANT_HOME:D:\apache-ant-1.8.2,PATH:%ANT_HOME%\bin)
- 5),测试一下你的设置,开始-->运行-->cmd进入命令行-->键入 ant 回车,如果看到
Buildfile: build.xml does not exist!
Build failed
那么恭喜你你已经完成ant的设置
#### 二,体验ant
就像每个语言都有HelloWorld一样,一个最简单的应用能让人感受一下Ant
1,首先你要知道你要干什么,我现在想做的事情是:
编写一些程序
编译它们
把它打包成jar包
把他们放在应该放置的地方
运行它们
这里为了简单起见只写一个程序,就是HelloWorld.java程序代码如下:
```java
package test.ant;
public class HelloWorld{
public static void main(String[] args){
System.out.println("Hello world1");
}
};
```
2,为了达到上边的目的,你可以手动的用javac 、copy 、jar、java来完成,但是考虑一下如果你有成百上千个类,在多次调试,部署的时候,一次次的javac 、copy、jar、
java那将是一份辛苦的工作。现在看看ant怎么优雅的完成它们。
要运行ant需要有一个build.xml虽然不一定要叫这个名字,但是建议你这么做
下边就是一个完整的build.xml,然后我们来详细的解释每一句
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<project name="HelloWorld" default="run" basedir=".">
<property name="src" value="src"/>
<property name="dest" value="classes"/>
<property name="hello_jar" value="hello1.jar"/>
<target name="init">
<mkdir dir="${dest}"/>
</target>
<target name="compile" depends="init">
<javac srcdir="${src}" destdir="${dest}"/>
</target>
<target name="build" depends="compile">
<jar jarfile="${hello_jar}" basedir="${dest}"/>
</target>
<target name="run" depends="build">
<java classname="test.ant.HelloWorld" classpath="${hello_jar}"/>
</target>
<target name="clean">
<delete dir="${dest}" />
<delete file="${hello_jar}" />
</target>
<target name="rerun" depends="clean,run">
<ant target="clean" />
<ant target="run" />
</target>
</project>
```
解释:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
```
build.xml中的第一句话,没有实际的意义
```xml
<project name="HelloWorld" default="run" basedir=".">
</project>
```
ant的所有内容必须包含在这个里边,name是你给它取的名字,basedir故名思意就是工作的根目录 .代表当前目录。default代表默认要做的事情。
```xml
<property name="src" value="src"/>
```
类似程序中的变量,为什么这么做想一下变量的作用
```xml
<target name="compile" depends="init">
<javac srcdir="${src}" destdir="${dest}"/>
</target>
```
把你想做的每一件事情写成一个target ,它有一个名字,depends是它所依赖的target,在执行这个target 例如这里的compile之前ant会先检查init是否曾经被执行过,如果执行
过则直接直接执行compile,如果没有则会先执行它依赖的target例如这里的init,然后在执行这个target
如我们的计划
编译:
```xml
<target name="compile" depends="init">
<javac srcdir="${src}" destdir="${dest}"/>
</target>
```
做jar包:
```xml
<target name="build" depends="compile">
<jar jarfile="${hello_jar}" basedir="${dest}"/>
</target>
```
运行:
```xml
<target name="run" depends="build">
<java classname="test.ant.HelloWorld" classpath="${hello_jar}"/>
</target>
```
为了不用拷贝,我们可以在最开始定义好目标文件夹,这样ant直接把结果就放在目标文件夹中了
新建文件夹:
```xml
<target name="init">
<mkdir dir="${dest}"/>
</target>
```
为了更多一点的功能体现,又加入了两个target
删除生成的文件
```xml
<target name="clean">
<delete dir="${dest}" />
<delete file="${hello_jar}" />
</target>
```
再次运行,这里显示了如何在一个target里边调用其他的target
```xml
<target name="rerun" depends="clean,run">
<ant target="clean" />
<ant target="run" />
</target>
```
好了,解释完成了,下边检验一下你的ant吧
新建一个src的文件夹,然后把HelloWorld.java按照包目录放进去
做好build.xml文件,最好将这些放到一个文件夹中,在cmd中进入该文件夹,
在命令行下键入ant ,你会发现一个个任务都完成了。每次更改完代码只需要再次键入ant
有的时候我们可能并不想运行程序,只想执行这些步骤中的某一两个步骤,例如我只想重新部署而不想运行,键入
```java
ant build
```
ant中的每一个任务都可以这样调用ant + target name
好了,这样一个简单的ant任务完成了。
#### 什么时候使用ant
也许你听到别人说起ant,一时冲动准备学习一下ant,当你看完了上边的第一个实例,也许你感觉ant真好,也许你感觉ant不过如此,得出这些结论都不能说错,虽然ant很好用,
但并不是在任何情况下都是最好的选择,例如windows上有更多更简单,更容易使用的工具,比如eclipse+myeclipse eclipse+wtp等等,无论是编译,部署,运行使用起来比ant更
容易,方便但有些情况则是ant发挥的好地方:
#### 服务器上部署的时候
当你的程序开发完成,部署人员要部署在服务器上的时候,总不能因为因为安装一个程序就配置一个eclipse+myeclipse吧,ant在这个时候是个很好的选择,因为它小巧,容易配
置,你带着你写好的build.xml到任何一台服务器上,只需要做简单的修改(一些设定,例如目录),然后一两个命令完成,这难道不是一件美好的事情吗。
#### linux操作系统
很多时候是这样的,程序开发是在windows下,但是程序要在linux或者unix上运行,在linux或者
在unix(特别是unix上)部署是个麻烦的事情,这个时候ant的特点又出来了,因为ant是跨平台的,你在build.xml可以在大多数操作系统上使用,基本不需要修改。
#### 当服务器维护者不懂编程的时候
很多人都有过这样的经历,使用你们程序的人,并不懂得写程序。你得程序因为版本更新,因为修正bug需要一次又一次得重新部署。这个时候你会发现教一个人是如此得困难。但
是有ant后,你只需要告诉他,输入ant xxx等一两个命令,一切ok.
以上是我遇到得一些情况。
看完以上得情况,好好考虑一下,你是否需要使用ant,如果是继续。
进一步学习一个稍微复杂一点点的ant
在实际的工作过程中可能会出现以下一些情况,一个项目分成很多个模块,每个小组或者部门负责一个模块,为了测试,他们自己写了一个build.xml,而你负责把这些模块组合到
一起使用,写一个build.xml
这个时候你有两种选择:
1,自己重新写一个build.xml ,这将是一个麻烦的事情
2,尽量利用他们已经写好的build.xml,减少自己的工作
举个例子:
假设你下边有三个小组,每个小组负责一个部分,他们分别有一个src 和一个写好的build.xml
这个时候你拿到他们的src,你需要做的是建立三个文件夹src1 ,src2, src3分别把他们的src和build.xml放进去,然后写一个build.xml
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<project name="main" default="build" basedir=".">
<property name="bin" value="${basedir}\bin" />
<property name="src1" value="${basedir}\src1" />
<property name="src2" value="${basedir}\src2" />
<property name="src3" value="${basedir}\src3" />
<target name="init">
<mkdir dir="${bin}" />
</target>
<target name="run">
<ant dir="${src1}" target="run" />
<ant dir="${src2}" target="run" />
<ant dir="${src3}" target="run" />
</target>
<target name="clean">
<ant dir="${src1}" target="clean" />
<ant dir="${src2}" target="clean" />
<ant dir="${src3}" target="clean" />
</target>
<target name="build" depends="init,call">
<copy todir="${bin}">
<fileset dir="${src1}">
<include name="*.jar" />
</fileset>
<fileset dir="${src2}">
<include name="*.jar" />
</fileset>
<fileset dir="${src3}">
<include name="*.jar" />
</fileset>
</copy>
</target>
<target name="rebuild" depends="build,clean">
<ant target="clean" />
<ant target="build" />
</target>
</project>
```
ok你的任务完成了。
ok,上边你完成了任务,但是你是否有些感触呢,在那些build.xml中,大多数是重复的,而且更改一次目录需要更改不少东西。是否能让工作做的更好一点呢,答案是肯定的。
引入两个东西:
1,propery
2,xml include
这两个东西都有一个功能,就是能把build.xml中<propery />中的内容分离出来,共同使用
除此之外它们各有特点:
propery的特点是维护简单,只需要简单的键值对,因为并不是所有人都喜欢xml的格式
xml include的特点是不单可以提取出属性来,连target也可以。
还是以前的例子:
例如我们想把src1 src2 src3这三个属性从xml中提出来,可以新建一个文件叫all.properties
里边的内容
```properties
src1=D:\\study\\ant\\src1
src2=D:\\study\\ant\\src2
src3=D:\\study\\ant\\src3
```
然后你的build.xml文件可以这样写,别人只需要更改配置文件,而不许要更改你的build.xml文件了
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<project name="main" default="build" basedir=".">
<property file="all.properties" />
<property name="bin" value="${basedir}\bin" />
<target name="init">
<mkdir dir="${bin}" />
</target>
<target name="run">
<ant dir="${src1}" target="run" />
<ant dir="${src2}" target="run" />
<ant dir="${src3}" target="run" />
</target>
<target name="clean">
<ant dir="${src1}" target="clean" />
<ant dir="${src2}" target="clean" />
<ant dir="${src3}" target="clean" />
</target>
<target name="build" depends="init,call">
<copy todir="${bin}">
<fileset dir="${src1}">
<include name="*.jar" />
</fileset>
<fileset dir="${src2}">
<include name="*.jar" />
</fileset>
<fileset dir="${src3}">
<include name="*.jar" />
</fileset>
</copy>
</target>
<target name="rebuild" depends="build,clean">
<ant target="clean" />
<ant target="build" />
</target>
<target name="test">
<ant dir="${src1}" target="test" />
<ant dir="${src2}" target="test" />
<ant dir="${src3}" target="test" />
</target>
</project>
```
如果你自己看的话你会看到这样一个target
```xml
<target name="test">
<ant dir="${src1}" target="test" />
<ant dir="${src2}" target="test" />
<ant dir="${src3}" target="test" />
</target>
```
有的时候你想给每个小组的build.xml加入几个target,一种做法是每个里边写,然后在这里调用
但是有一种更好的方法。
你可以写一个include.xml文件,内容如下
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<property name="src" value="src"/>
<property name="dest" value="classes"/>
<target name="test" >
<ant target="run" />
</target>
```
然后更改你三个小组的build.xml文件,每个里边加入如下内容
```xml
<!--include a xml file ,it can be common propery ,can be also a target -->
<!DOCTYPE project [
<!ENTITY share-variable SYSTEM "file:../include.xml">
]>
```
变成如下的样子
这个时候,你只要在include.xml添加propery , 添加target,三个build.xml会同时添加这些propery和target
而且不会让三个组的build.xml变得更复杂。
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--include a xml file ,it can be common propery ,can be also a target -->
<!DOCTYPE project [
<!ENTITY share-variable SYSTEM "file:../include.xml">
]>
<project name="HelloWorld" default="run" basedir=".">
<!--use the include -->
&share-variable;
<!--defined the property-->
<!--via include
<property name="src" value="src"/>
<property name="dest" value="classes"/>
-->
<property name="hello_jar" value="hello1.jar"/>
<!--define the op-->
<target name="init">
<mkdir dir="${dest}"/>
</target>
<target name="compile" depends="init">
<javac srcdir="${src}" destdir="${dest}"/>
</target>
<target name="build" depends="compile">
<jar jarfile="${hello_jar}" basedir="${dest}"/>
</target>
<target name="run" depends="build">
<java classname="test.ant.HelloWorld" classpath="${hello_jar}"/>
</target>
<target name="clean">
<delete dir="${dest}" />
<delete file="${hello_jar}" />
</target>
<target name="rerun" depends="clean,run">
<ant target="clean" />
<ant target="run" />
</target>
</project>
```
掌握了上边的那些内容之后,你就知道如何去写一个好的ant,但是你会发现当你真的想去做的时候,你不能马上作出好的build.xml,因为你知道太少的ant的默认提供的命令.这
个时候如果你想完成任务,并提高自己,有很多办法:
1,很多开源的程序都带有build.xml,看看它们如何写的
2,ant的document,里边详细列写了ant的各种默认命令,及其丰富
3,google,永远不要忘记它
ok,在这之后随着你写的ant build越来越多,你知道的命令就越多,ant在你的手里也就越来越强大了。
这个是一个慢慢积累的过程。
ant的例子很好找,各种开源框架都会带有一个build.xml仔细看看,会有很大收获
另外一个经常会用到的,但是在开源框架的build.xml一般没有的是cvs
如果使用的是远程的cvs,可以这样使用
```xml
<xml version="1.0" encoding="utf-8"?>
<project>
<property name="cvsroot" value=":pserver:wang:@192.168.1.2:/cvsroot"/>
<property name="basedir" value="/tmp/testant/"/>
<property name="cvs.password" value="wang"/>
<property name="cvs.passfile" value="${basedir}/ant.cvspass"/>
<target name="initpass">
<cvspass cvsroot="${cvsroot}" password="${cvs.password}" passfile="${cvs.passfile}"/>
</target>
<target name="checkout" depends="initpass">
<cvs cvsroot="${cvsroot}" command="checkout" cvsrsh="ssh" package="myproject" dest="${basedir}"
passfile="${cvs.passfile}"/>
</target>
</project>
```
在eclipse里边先天支持ant,所以你可以在eclipse里边直接写build.xml
因为eclipse提供了提示功能,自动补充功能,它能让你事半功倍。
使用方法,只需要建立一个工程,然后建立一个叫build.xml的文件。然后就可以在里边写你的ant build了
但是时刻记住http://www.apache.org/永远能找到你需要的东西
### 使用案例
rpt_2017 部署到adcloud 生成环境ant 编译打包测试
```xml
<?xml version="1.0" encoding="UTF-8"?>
<!--模式执行build -->
<project name="adcloud" default="build" basedir=".">
<property name="tomcat.home" value="E:/apache-tomcat-8.5.47"/>
<property name="dist" value="/app/dist"/>
<property name="tmp" value="/app/tmp"/>
<!--动态设置jdk版本 , javac/java 这里不一定生效,最好还是再环境变量更改即可-->
<property name="env.JAVA_HOME" value="C:\Program Files\Java8\jdk1.8.0_102"/>
<!-- <property file="xx.properties" /> 这里如果是配置文件路径 , 后面变量引用也是一样 -->
<!-- 初始ant所需目录和文件 -->
<target name="init">
<!-- 会在所属驱动盘根目录创建两个文件夹 -->
<echo message="环境初始化.." />
<mkdir dir="${dist}"/>
<mkdir dir="${tmp}"/>
<!--复制webRoot目录到${tmp}目录 ./标示当前目录根据 ant 相对命令执行所处目录(执行是进入到项目名下执行) -->
<echo message="文件备份.." />
<copydir src="./WebRoot" dest="${tmp}" forceoverwrite="true">
<!--复制文件筛选规则(这里标示目录下所有文件) -->
<include name="**/*" />
</copydir>
<!--先删除再创建 -->
<deltree dir="${tmp}/WEB-INF/classes"/>
<mkdir dir="${tmp}/WEB-INF/classes"/>
</target>
<!--编译 依赖 init 已经执行成功的基础上 -->
<target name="compile" depends="init" >
<!--执行javac命令 srcdir:源目录 destdir:编译后存储目录 -->
<echo message="批量编译.." />
<javac encoding="UTF-8" srcdir="./src" destdir="${tmp}/WEB-INF/classes" debug="on" debuglevel="lines,vars,source" nowarn="true" failonerror="true">
<!-- javac源文件所依赖jar包文件所处目录 -->
<classpath>
<fileset dir="${tmp}/WEB-INF/lib" includes="*.jar"/>
</classpath>
<!-- 编译该目录下所有文件 -->
<include name="**/*.*"/>
</javac>
<!-- 编辑过程直接复制配置类文件到目标目录 -->
<copydir src="./src/" dest="${tmp}/WEB-INF/classes" forceoverwrite="true">
<include name="**/*.properties"/>
<include name="**/*.log"/>
<include name="**/*.xml"/>
</copydir>
</target>
<!-- 部署构建发布所需*.war包 依赖 compile步骤 -->
<target name="build" depends="compile">
<echo message="打包部署war.." />
<jar jarfile="${tomcat.home}/webapps/ROOT.war">
<fileset dir="${tmp}/">
<include name="**/*.*" />
</fileset>
</jar>
</target>
<!-- 清理临时目录 -->
<target name="clean">
<deltree dir="${tmp}"/>
<deltree dir="${dist}"/>
<deltree dir="${tomcat.home}/webapps/ROOT"/>
<delete file="${tomcat.home}/webapps/ROOT.war"/>
</target>
<!-- 标签内无任何操作,但是会自动调用依赖clean , build 操作; 即先清理临时目录,然后再构建项目 -->
<target name="create" depends="clean,build">
</target>
<!-- 修改JSP页面重新复制到 tomcat目录,不用重新编译 -->
<target name="modify.reload">
<echo message="删除*.jsp文件"></echo>
<delete verbose="true" includeemptydirs="true">
<fileset dir="${tomcat.home}/webapps/ROOT" includes="**/*.jsp" defaultexcludes="false"/>
</delete>
<!-- <echo message="删除非 *.jsp文件"></echo>
<delete verbose="true" includeemptydirs="true">
<fileset dir="${tomcat.home}/webapps/ROOT" includes="**/*.jsp" defaultexcludes="false"/>
</delete> -->
<echo message="复制WebRoot下所有jsp文件到tomcat"></echo>
<copydir src="./WebRoot" dest="${tomcat.home}/webapps/ROOT" forceoverwrite="true">
<include name="**/*.jsp" />
</copydir>
</target>
<target name="stop_tomcat">
<echo message="停止tomcat..." />
<exec executable="cmd" dir="${tomcat.home}/bin" failonerror="false"
output="${log.file}" append="true" >
<!-- <arg value="/c" /> -->
<env key="CATALINA_HOME" path="${tomcat.home}"/>
<arg value="/c shutdown.bat" />
</exec>
</target>
<target name="start_tomcat" depends="build">
<echo message="启动tomcat..." />
<exec executable="cmd" dir="${tomcat.home}/bin" failonerror="false"
output="${log.file}" append="true" >
<!-- <arg value="/c" /> -->
<env key="CATALINA_HOME" path="${tomcat.home}"/>
<arg value="/c startup.bat" />
</exec>
</target>
<!--这里是一个执行带有 main函数的例子,这里依赖整个项目编译完成的基础 -->
<target name="java.all" depends="compile">
<!--classpath 属性设置编译好的java文件路径-->
<java classname="com.maizhi.util.AESEncryptParamSVImpl" classpath="${tmp}/WEB-INF/classes">
<arg/>
<!--设置所需依赖包存储位置-->
<classpath>
<fileset dir="${tmp}/WEB-INF/lib" includes="*.jar"/>
</classpath>
</java>
</target>
<!--这里是一个执行带有 main函数的例子,这里只是单独编译impl类然后java执行main方法,忽略其他的编译文件,一定程度上速度稍快些 -->
<target name="java.main">
<javac encoding="UTF-8" srcdir="./src" destdir="./WebRoot/WEB-INF/classes" debug="on" debuglevel="lines,vars,source" nowarn="true" failonerror="true">
<!-- javac源文件所依赖jar包文件所处目录 -->
<classpath>
<fileset dir="./WebRoot/WEB-INF/lib" includes="*.jar"/>
</classpath>
<!-- 编译该目录下指定文件,编译过程中会自动编译该类import过的其他类 -->
<include name="**/com/maizhi/util/AESEncryptParamSVImpl.java"/>
</javac>
<!--classpath 属性设置编译好的java文件路径-->
<java classname="com.maizhi.util.AESEncryptParamSVImpl" classpath="./WebRoot/WEB-INF/classes">
<arg/>
<!--设置所需依赖包存储位置-->
<classpath>
<fileset dir="${tmp}/WEB-INF/lib" includes="*.jar"/>
</classpath>
</java>
</target>
</project>
``` | 17,163 | MIT |
<!-- YAML
added: v0.5.9
-->
* {http.Agent}
`Agent` 的全局实例,作为所有 HTTP 客户端请求的默认 `Agent`。 | 88 | MIT |
---
name: Feature/Bug Issue
about: 请使用此模型提出您的建议/问题
title: ''
labels: ''
assignees: ''
---
<!-- 请您简介清晰的描述您遇到的问题 -->
## 环境
1.系统环境:
2.MegEngine版本:
3.python版本:
4.模型名称:
## 复现步骤
1.
2.
3.
## 请提供关键的代码片段便于追查问题
## 请提供完整的日志及报错信息 | 225 | Apache-2.0 |
# 2021-05-20
共 23 条
<!-- BEGIN ZHIHUSEARCH -->
<!-- 最后更新时间 Thu May 20 2021 23:09:53 GMT+0800 (China Standard Time) -->
1. [520 文案](https://www.zhihu.com/search?q=520文案)
1. [赛格大厦晃动原因初步查明](https://www.zhihu.com/search?q=赛格大厦)
1. [剑风传奇作者三浦逝世](https://www.zhihu.com/search?q=剑风传奇)
1. [窥探大结局](https://www.zhihu.com/search?q=窥探)
1. [日媒曝石原里美或退圈从政](https://www.zhihu.com/search?q=石原里美)
1. [虚拟货币全线暴跌](https://www.zhihu.com/search?q=币圈崩盘)
1. [新垣结衣和星野源结婚](https://www.zhihu.com/search?q=新垣结衣结婚)
1. [王彦霖结婚](https://www.zhihu.com/search?q=王彦霖)
1. [《画江湖之不良人》第四季第 5 集](https://www.zhihu.com/search?q=画江湖之不良人第四季)
1. [特朗普集团被刑事调查](https://www.zhihu.com/search?q=特朗普)
1. [进击的巨人加页全出炉](https://www.zhihu.com/search?q=进击的巨人)
1. [林书豪谈无法重返 NBA](https://www.zhihu.com/search?q=林书豪)
1. [《魔道祖师》完结篇预告](https://www.zhihu.com/search?q=魔道祖师)
1. [华为发布会](https://www.zhihu.com/search?q=华为发布会)
1. [赛格大厦疑再发生晃动](https://www.zhihu.com/search?q=赛格大厦)
1. [深圳赛格大厦晃动原因查明](https://www.zhihu.com/search?q=赛格大厦)
1. [曹县县长回应走红](https://www.zhihu.com/search?q=曹县)
1. [情书内地重映](https://www.zhihu.com/search?q=电影情书)
1. [浙江一特斯拉撞倒两名交警](https://www.zhihu.com/search?q=特斯拉)
1. [台湾医院爆发院内感染](https://www.zhihu.com/search?q=台湾疫情)
1. [祝融号传回火星照片](https://www.zhihu.com/search?q=祝融号火星照片)
1. [盖茨承认曾与女员工婚外情](https://www.zhihu.com/search?q=比尔盖茨)
1. [鸿蒙系统将支持第三方手机](https://www.zhihu.com/search?q=鸿蒙系统)
<!-- END ZHIHUSEARCH --> | 1,365 | MIT |
---
layout: article
title: "「Python」 分析招聘信息"
date: 2019-09-26 17:07:40 +0800
key: job-analysis-20190926
aside:
toc: true
category: [software, python, spider]
---
<span id='head'></span>
<!--more-->
# 目标
1. 哪些工具对岗位比较重要;
网页抓取,关键字提取 + 词频统计;
# 所需工具
# 流程
## 初始化
## 数据清洗
## 数据处理
## 信息展示
-------------------
[End](#head)
{:.warning}
# 附录
## A 参考资料
1. [Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗](http://www.jtahstu.com/blog/scrapy_zhipin_detail.html)
1. [BOSS直聘-数据分析师的职位详情分析](https://zhuanlan.zhihu.com/p/60704321)
1. [python--boss直聘数据可视化](https://blog.csdn.net/qq_31468321/article/details/83247185) | 624 | MIT |
# 2022-03-04
共 278 条
<!-- BEGIN TOUTIAO -->
<!-- 最后更新时间 Fri Mar 04 2022 23:22:59 GMT+0800 (China Standard Time) -->
1. [北京冬残奥会开幕](https://so.toutiao.com/search?keyword=北京冬残奥会开幕)
1. [俄方称乌克兰总统已离乌 乌方否认](https://so.toutiao.com/search?keyword=俄方称乌克兰总统已离乌+乌方否认)
1. [奋进 向着全过程人民民主的新图景](https://so.toutiao.com/search?keyword=奋进+向着全过程人民民主的新图景)
1. [乌方:第3轮俄乌会谈5日或6日举行](https://so.toutiao.com/search?keyword=乌方:第3轮俄乌会谈5日或6日举行)
1. [亚努科维奇要回乌执政?俄乌均否认](https://so.toutiao.com/search?keyword=亚努科维奇要回乌执政?俄乌均否认)
1. [全国政协十三届五次会议开幕](https://so.toutiao.com/search?keyword=全国政协十三届五次会议开幕)
1. [委员:建议救护车在高速免费通行](https://so.toutiao.com/search?keyword=委员:建议救护车在高速免费通行)
1. [人大代表:建议推广高铁静音车厢](https://so.toutiao.com/search?keyword=人大代表:建议推广高铁静音车厢)
1. [超10位代表委员呼吁买卖妇女应同罪](https://so.toutiao.com/search?keyword=超10位代表委员呼吁买卖妇女应同罪)
1. [委员建议允许满30岁单身女性生一胎](https://so.toutiao.com/search?keyword=委员建议允许满30岁单身女性生一胎)
1. [民进中央建议:推行每周2.5天假](https://so.toutiao.com/search?keyword=民进中央建议:推行每周2.5天假)
1. [普京向在乌阵亡官兵致哀](https://so.toutiao.com/search?keyword=普京向在乌阵亡官兵致哀)
1. [普京:在乌军事行动将全面完成任务](https://so.toutiao.com/search?keyword=普京:在乌军事行动将全面完成任务)
1. [俄军确认:已控制乌克兰最大核电站](https://so.toutiao.com/search?keyword=俄军确认:已控制乌克兰最大核电站)
1. [乌媒:俄军已进入尼古拉耶夫州首府](https://so.toutiao.com/search?keyword=乌媒:俄军已进入尼古拉耶夫州首府)
1. [基辅或不是俄军真正目标](https://so.toutiao.com/search?keyword=基辅或不是俄军真正目标)
1. [媒体:好家伙真轮到柴可夫斯基了](https://so.toutiao.com/search?keyword=媒体:好家伙真轮到柴可夫斯基了)
1. [韩国获得美国对俄制裁豁免](https://so.toutiao.com/search?keyword=韩国获得美国对俄制裁豁免)
1. [美国政府正在考虑对印度实施制裁](https://so.toutiao.com/search?keyword=美国政府正在考虑对印度实施制裁)
1. [雪容融穿轮滑鞋出场](https://so.toutiao.com/search?keyword=雪容融穿轮滑鞋出场)
1. [德国总理敦促前总理辞去在俄企职务](https://so.toutiao.com/search?keyword=德国总理敦促前总理辞去在俄企职务)
1. [冯远征谈演员片酬](https://so.toutiao.com/search?keyword=冯远征谈演员片酬)
1. [世界最大飞机还有可能被修好吗](https://so.toutiao.com/search?keyword=世界最大飞机还有可能被修好吗)
1. [美方一再散布虚假信息 汪文斌三连问](https://so.toutiao.com/search?keyword=美方一再散布虚假信息+汪文斌三连问)
1. [德总理:暂不考虑乌克兰入欧盟事宜](https://so.toutiao.com/search?keyword=德总理:暂不考虑乌克兰入欧盟事宜)
1. [巴拿马运河拒绝不让俄船通航](https://so.toutiao.com/search?keyword=巴拿马运河拒绝不让俄船通航)
1. [巴基斯坦一清真寺爆炸致数十人死亡](https://so.toutiao.com/search?keyword=巴基斯坦一清真寺爆炸致数十人死亡)
1. [失聪清华博士回应当选感动中国人物](https://so.toutiao.com/search?keyword=失聪清华博士回应当选感动中国人物)
1. [世界最大飞机遭炸毁 遍地残骸](https://so.toutiao.com/search?keyword=世界最大飞机遭炸毁+遍地残骸)
1. [港星何家劲在街头排队剪发](https://so.toutiao.com/search?keyword=港星何家劲在街头排队剪发)
1. [冬残奥会开幕式盲人如何点燃火炬](https://so.toutiao.com/search?keyword=冬残奥会开幕式盲人如何点燃火炬)
1. [俄乌就临时停火达成一致](https://so.toutiao.com/search?keyword=俄乌就临时停火达成一致)
1. [79岁大爷在线批改网友书法作业](https://so.toutiao.com/search?keyword=79岁大爷在线批改网友书法作业)
1. [《奔跑吧》第十季官宣嘉宾阵容](https://so.toutiao.com/search?keyword=《奔跑吧》第十季官宣嘉宾阵容)
1. [英美宣布冻结多名俄罗斯富豪资产](https://so.toutiao.com/search?keyword=英美宣布冻结多名俄罗斯富豪资产)
1. [俄称在乌外籍雇佣军无权享战俘地位](https://so.toutiao.com/search?keyword=俄称在乌外籍雇佣军无权享战俘地位)
1. [1月新疆跨境人民币收付金额39.8亿](https://so.toutiao.com/search?keyword=1月新疆跨境人民币收付金额39.8亿)
1. [《感动中国》走过20年](https://so.toutiao.com/search?keyword=《感动中国》走过20年)
1. [美军从南海打捞起坠毁战机残骸](https://so.toutiao.com/search?keyword=美军从南海打捞起坠毁战机残骸)
1. [直击基辅火车站被炸后现场](https://so.toutiao.com/search?keyword=直击基辅火车站被炸后现场)
1. [普京:特别军事行动正按计划进行](https://so.toutiao.com/search?keyword=普京:特别军事行动正按计划进行)
1. [政协委员:应全面实行商品房现房销售](https://so.toutiao.com/search?keyword=政协委员:应全面实行商品房现房销售)
1. [2022世界移动通信大会闭幕](https://so.toutiao.com/search?keyword=2022世界移动通信大会闭幕)
1. [广西调查“夫妇生育15孩”](https://so.toutiao.com/search?keyword=广西调查“夫妇生育15孩”)
1. [全台大停电恐致上百亿损失](https://so.toutiao.com/search?keyword=全台大停电恐致上百亿损失)
1. [长安欧尚X7 PLUS红版正式上市](https://so.toutiao.com/search?keyword=长安欧尚X7+PLUS红版正式上市)
1. [林毅夫:为何驳斥“民营企业退场论”](https://so.toutiao.com/search?keyword=林毅夫:为何驳斥“民营企业退场论”)
1. [疑因政局不稳 利比亚最大油田停产](https://so.toutiao.com/search?keyword=疑因政局不稳+利比亚最大油田停产)
1. [乌方就核电站事件要求对俄追加制裁](https://so.toutiao.com/search?keyword=乌方就核电站事件要求对俄追加制裁)
1. [清华召开论坛呼吁女性投身工程领域](https://so.toutiao.com/search?keyword=清华召开论坛呼吁女性投身工程领域)
1. [俄方:乌克兰总统已离乌 身处波兰](https://so.toutiao.com/search?keyword=俄方:乌克兰总统已离乌+身处波兰)
1. [全国人大会议议程来了](https://so.toutiao.com/search?keyword=全国人大会议议程来了)
1. [中国2留学生遭炮击身亡?使馆辟谣](https://so.toutiao.com/search?keyword=中国2留学生遭炮击身亡?使馆辟谣)
1. [北京冬残奥会开幕式](https://so.toutiao.com/search?keyword=北京冬残奥会开幕式)
1. [俄媒:英法等国请求俄协助从乌撤侨](https://so.toutiao.com/search?keyword=俄媒:英法等国请求俄协助从乌撤侨)
1. [武大靖和苏炳添比腿粗](https://so.toutiao.com/search?keyword=武大靖和苏炳添比腿粗)
1. [委员建议:统一A股涨跌幅限制为10%](https://so.toutiao.com/search?keyword=委员建议:统一A股涨跌幅限制为10%)
1. [小伙一年从员工晋升为董事长](https://so.toutiao.com/search?keyword=小伙一年从员工晋升为董事长)
1. [医生防护服上写“老爸走好”隔屏跪别](https://so.toutiao.com/search?keyword=医生防护服上写“老爸走好”隔屏跪别)
1. [唐山推出公积金贷款新政](https://so.toutiao.com/search?keyword=唐山推出公积金贷款新政)
1. [3785只基金年内亏损超过10%](https://so.toutiao.com/search?keyword=3785只基金年内亏损超过10%)
1. [中方在联合国阐述在乌问题上的立场](https://so.toutiao.com/search?keyword=中方在联合国阐述在乌问题上的立场)
1. [台湾全台大停电 郭台铭发声](https://so.toutiao.com/search?keyword=台湾全台大停电+郭台铭发声)
1. [韩媒批总统人选尹锡悦“仇中”言论](https://so.toutiao.com/search?keyword=韩媒批总统人选尹锡悦“仇中”言论)
1. [台籍人大代表廖海鹰的“两个身份”](https://so.toutiao.com/search?keyword=台籍人大代表廖海鹰的“两个身份”)
1. [中国将成高收入国家?央媒:清醒看待](https://so.toutiao.com/search?keyword=中国将成高收入国家?央媒:清醒看待)
1. [俄乌冲突以来约67万人自乌进入波兰](https://so.toutiao.com/search?keyword=俄乌冲突以来约67万人自乌进入波兰)
1. [U23国足将进行全队体脂检测](https://so.toutiao.com/search?keyword=U23国足将进行全队体脂检测)
1. [专家: “网络喷子”需要惩治吗](https://so.toutiao.com/search?keyword=专家:+“网络喷子”需要惩治吗)
1. [《DNF》五一时装提前透露](https://so.toutiao.com/search?keyword=《DNF》五一时装提前透露)
1. [香港主持人陈贝儿获感动中国年度人物](https://so.toutiao.com/search?keyword=香港主持人陈贝儿获感动中国年度人物)
1. [建议丰富中小学课后延时服务形式](https://so.toutiao.com/search?keyword=建议丰富中小学课后延时服务形式)
1. [传大疆Mini 3 Pro或有前后避障功能](https://so.toutiao.com/search?keyword=传大疆Mini+3 Pro或有前后避障功能)
1. [雷吉:快船拥有联盟最佳教练](https://so.toutiao.com/search?keyword=雷吉:快船拥有联盟最佳教练)
1. [美疾控估算全美1.4亿人感染过新冠](https://so.toutiao.com/search?keyword=美疾控估算全美1.4亿人感染过新冠)
1. [直击乌克兰撤侨航班接同胞回家](https://so.toutiao.com/search?keyword=直击乌克兰撤侨航班接同胞回家)
1. [政协委员用手语“演唱”国歌](https://so.toutiao.com/search?keyword=政协委员用手语“演唱”国歌)
1. [广东官宣发放消费券](https://so.toutiao.com/search?keyword=广东官宣发放消费券)
1. [外交部:蓬佩奥的狂言妄语不可能得逞](https://so.toutiao.com/search?keyword=外交部:蓬佩奥的狂言妄语不可能得逞)
1. [“动态清零”不是追求“零感染”](https://so.toutiao.com/search?keyword=“动态清零”不是追求“零感染”)
1. [拜登与乌总统泽连斯基通话](https://so.toutiao.com/search?keyword=拜登与乌总统泽连斯基通话)
1. [乌总统:首批1.6万外国雇佣军抵乌](https://so.toutiao.com/search?keyword=乌总统:首批1.6万外国雇佣军抵乌)
1. [乌克兰总统呼吁西方向乌提供军机](https://so.toutiao.com/search?keyword=乌克兰总统呼吁西方向乌提供军机)
1. [冯巩晒“二月二”剃头视频](https://so.toutiao.com/search?keyword=冯巩晒“二月二”剃头视频)
1. [温碧霞分享健身心得](https://so.toutiao.com/search?keyword=温碧霞分享健身心得)
1. [德国经济部长反对禁止从俄进口能源](https://so.toutiao.com/search?keyword=德国经济部长反对禁止从俄进口能源)
1. [著名京剧演员童寿苓去世](https://so.toutiao.com/search?keyword=著名京剧演员童寿苓去世)
1. [男子卖父亲自制酸菜被索赔千元](https://so.toutiao.com/search?keyword=男子卖父亲自制酸菜被索赔千元)
1. [沙特王储谈与以色列和伊朗关系](https://so.toutiao.com/search?keyword=沙特王储谈与以色列和伊朗关系)
1. [中方对乌境内核设施安全严重关切](https://so.toutiao.com/search?keyword=中方对乌境内核设施安全严重关切)
1. [编剧汪海林谈在乌克兰拍戏经历](https://so.toutiao.com/search?keyword=编剧汪海林谈在乌克兰拍戏经历)
1. [俄外长:核战争是西方政客的想法](https://so.toutiao.com/search?keyword=俄外长:核战争是西方政客的想法)
1. [乌克兰凿沉海军舰艇防落俄军之手](https://so.toutiao.com/search?keyword=乌克兰凿沉海军舰艇防落俄军之手)
1. [着眼于中国的可持续发展](https://so.toutiao.com/search?keyword=着眼于中国的可持续发展)
1. [代表建议抑郁症及心理咨询入医保](https://so.toutiao.com/search?keyword=代表建议抑郁症及心理咨询入医保)
1. [外媒称扎波罗热核电站起火 乌方否认](https://so.toutiao.com/search?keyword=外媒称扎波罗热核电站起火+乌方否认)
1. [稀土办公室就稀土价格约谈重点企业](https://so.toutiao.com/search?keyword=稀土办公室就稀土价格约谈重点企业)
1. [阿外长:阿根廷不会制裁俄罗斯](https://so.toutiao.com/search?keyword=阿外长:阿根廷不会制裁俄罗斯)
1. [太空出差三人组4月将返回地球](https://so.toutiao.com/search?keyword=太空出差三人组4月将返回地球)
1. [上海队球员更衣室嘲讽郭艾伦赵继伟](https://so.toutiao.com/search?keyword=上海队球员更衣室嘲讽郭艾伦赵继伟)
1. [美国宣布制裁8名普京亲信](https://so.toutiao.com/search?keyword=美国宣布制裁8名普京亲信)
1. [软件巨头欧特克宣布在俄暂停运营](https://so.toutiao.com/search?keyword=软件巨头欧特克宣布在俄暂停运营)
1. [白岩松:延迟退休应自愿](https://so.toutiao.com/search?keyword=白岩松:延迟退休应自愿)
1. [国台办:蓬佩奥谬论暴露其险恶用心](https://so.toutiao.com/search?keyword=国台办:蓬佩奥谬论暴露其险恶用心)
1. [机构称近期油价还要涨](https://so.toutiao.com/search?keyword=机构称近期油价还要涨)
1. [代表建议老人退休金城乡要同步增长](https://so.toutiao.com/search?keyword=代表建议老人退休金城乡要同步增长)
1. [俄媒:世界最大飞机遭炸毁 遍地残骸](https://so.toutiao.com/search?keyword=俄媒:世界最大飞机遭炸毁+遍地残骸)
1. [又到了二月二龙抬头](https://so.toutiao.com/search?keyword=又到了二月二龙抬头)
1. [收评:A股三大指数集体收跌](https://so.toutiao.com/search?keyword=收评:A股三大指数集体收跌)
1. [英媒:制裁俄罗斯影响英国人吃鱼](https://so.toutiao.com/search?keyword=英媒:制裁俄罗斯影响英国人吃鱼)
1. [今年将再送6名航天员进入空间站](https://so.toutiao.com/search?keyword=今年将再送6名航天员进入空间站)
1. [加拿大扣押一架载有俄罗斯人客机](https://so.toutiao.com/search?keyword=加拿大扣押一架载有俄罗斯人客机)
1. [白俄:边防人员未参加在乌军事行动](https://so.toutiao.com/search?keyword=白俄:边防人员未参加在乌军事行动)
1. [一针290万的国产抗癌药效果如何](https://so.toutiao.com/search?keyword=一针290万的国产抗癌药效果如何)
1. [台湾大停电事故原因初判为人为疏失](https://so.toutiao.com/search?keyword=台湾大停电事故原因初判为人为疏失)
1. [验房师遭3人威胁殴打 官方回应](https://so.toutiao.com/search?keyword=验房师遭3人威胁殴打+官方回应)
1. [柬埔寨国王西哈莫尼和太后来华](https://so.toutiao.com/search?keyword=柬埔寨国王西哈莫尼和太后来华)
1. [有消息称李嘉诚拟售英国最大配电商](https://so.toutiao.com/search?keyword=有消息称李嘉诚拟售英国最大配电商)
1. [政协委员将就制定祖国统一法提案](https://so.toutiao.com/search?keyword=政协委员将就制定祖国统一法提案)
1. [程序员成北京冬残奥会火炬手](https://so.toutiao.com/search?keyword=程序员成北京冬残奥会火炬手)
1. [韩国日增新冠确诊首超26万例](https://so.toutiao.com/search?keyword=韩国日增新冠确诊首超26万例)
1. [多地区92号汽油将迈入“8元时代”](https://so.toutiao.com/search?keyword=多地区92号汽油将迈入“8元时代”)
1. [女孩回高原当农民年销200吨枸杞](https://so.toutiao.com/search?keyword=女孩回高原当农民年销200吨枸杞)
1. [乌方:扎波罗热核电站已被俄军控制](https://so.toutiao.com/search?keyword=乌方:扎波罗热核电站已被俄军控制)
1. [委员建议建立性侵犯罪信息查询平台](https://so.toutiao.com/search?keyword=委员建议建立性侵犯罪信息查询平台)
1. [十三届全国人大五次会议会期6.5天](https://so.toutiao.com/search?keyword=十三届全国人大五次会议会期6.5天)
1. [董明珠建议个税起征点提高到1万元](https://so.toutiao.com/search?keyword=董明珠建议个税起征点提高到1万元)
1. [理发师二月二在顾客头上剃出一条龙](https://so.toutiao.com/search?keyword=理发师二月二在顾客头上剃出一条龙)
1. [关于SWIFT制裁有哪六大误解](https://so.toutiao.com/search?keyword=关于SWIFT制裁有哪六大误解)
1. [神十四、十五乘组年底前会师太空](https://so.toutiao.com/search?keyword=神十四、十五乘组年底前会师太空)
1. [100秒回顾俄乌3天举行2轮谈判](https://so.toutiao.com/search?keyword=100秒回顾俄乌3天举行2轮谈判)
1. [76人正式签下小乔丹](https://so.toutiao.com/search?keyword=76人正式签下小乔丹)
1. [全国政协委员都提了哪些医疗建议](https://so.toutiao.com/search?keyword=全国政协委员都提了哪些医疗建议)
1. [人大代表建议要进一步为家长减负](https://so.toutiao.com/search?keyword=人大代表建议要进一步为家长减负)
1. [是否采取措施保障乌安全?中方回应](https://so.toutiao.com/search?keyword=是否采取措施保障乌安全?中方回应)
1. [上海昨日新增本土“2+14”](https://so.toutiao.com/search?keyword=上海昨日新增本土“2+14”)
1. [摩根大通:油价有望飙涨至185美元](https://so.toutiao.com/search?keyword=摩根大通:油价有望飙涨至185美元)
1. [杨鸣:郭艾伦和韩德君是球队基石](https://so.toutiao.com/search?keyword=杨鸣:郭艾伦和韩德君是球队基石)
1. [甘肃监狱系统一官员落马 曾荣立战功](https://so.toutiao.com/search?keyword=甘肃监狱系统一官员落马+曾荣立战功)
1. [官方:把中国当对手只会破坏中美互信](https://so.toutiao.com/search?keyword=官方:把中国当对手只会破坏中美互信)
1. [让冬残奥会同样精彩](https://so.toutiao.com/search?keyword=让冬残奥会同样精彩)
1. [直播:首场“委员通道”开启](https://so.toutiao.com/search?keyword=直播:首场“委员通道”开启)
1. [政协常委建议取消中小学生艺术考级](https://so.toutiao.com/search?keyword=政协常委建议取消中小学生艺术考级)
1. [台“经济部长”曾赌鸡排保证不缺电](https://so.toutiao.com/search?keyword=台“经济部长”曾赌鸡排保证不缺电)
1. [汽油与柴油价格再上调](https://so.toutiao.com/search?keyword=汽油与柴油价格再上调)
1. [董明珠建议允许企业弹性安排节假日](https://so.toutiao.com/search?keyword=董明珠建议允许企业弹性安排节假日)
1. [尹锡悦安哲秀“合纵”冲击韩国大选](https://so.toutiao.com/search?keyword=尹锡悦安哲秀“合纵”冲击韩国大选)
1. [建行行长王江将赴任光大集团董事长](https://so.toutiao.com/search?keyword=建行行长王江将赴任光大集团董事长)
1. [两会日历:政协会议今日开幕](https://so.toutiao.com/search?keyword=两会日历:政协会议今日开幕)
1. [恒力石化抛出百亿“兜底”持股计划](https://so.toutiao.com/search?keyword=恒力石化抛出百亿“兜底”持股计划)
1. [31省份增本土确诊61例 涉12省市](https://so.toutiao.com/search?keyword=31省份增本土确诊61例+涉12省市)
1. [专家:中国最晚2025年成高收入国家](https://so.toutiao.com/search?keyword=专家:中国最晚2025年成高收入国家)
1. [李书福退出吉利汽车集团公司董事](https://so.toutiao.com/search?keyword=李书福退出吉利汽车集团公司董事)
1. [武大靖给苏炳添送限量版冰墩墩](https://so.toutiao.com/search?keyword=武大靖给苏炳添送限量版冰墩墩)
1. [印媒:印俄贸易将绕过西方制裁](https://so.toutiao.com/search?keyword=印媒:印俄贸易将绕过西方制裁)
1. [爱车送4S店维修越修越坏](https://so.toutiao.com/search?keyword=爱车送4S店维修越修越坏)
1. [直播:全国人大首场新闻发布会](https://so.toutiao.com/search?keyword=直播:全国人大首场新闻发布会)
1. [李想:没有OKR可能公司就不在了](https://so.toutiao.com/search?keyword=李想:没有OKR可能公司就不在了)
1. [乌总统:国际社会没能及时解决问题](https://so.toutiao.com/search?keyword=乌总统:国际社会没能及时解决问题)
1. [人均2千吃不饱?上海一餐厅被指宰客](https://so.toutiao.com/search?keyword=人均2千吃不饱?上海一餐厅被指宰客)
1. [篮网经理谈哈里斯赛季报销](https://so.toutiao.com/search?keyword=篮网经理谈哈里斯赛季报销)
1. [乌克兰:暂停向境外出口天然气](https://so.toutiao.com/search?keyword=乌克兰:暂停向境外出口天然气)
1. [韩政府:无许可入境乌克兰会被处罚](https://so.toutiao.com/search?keyword=韩政府:无许可入境乌克兰会被处罚)
1. [俄高官:乌克兰中立地位非常重要](https://so.toutiao.com/search?keyword=俄高官:乌克兰中立地位非常重要)
1. [电影《人生大事》发布新海报](https://so.toutiao.com/search?keyword=电影《人生大事》发布新海报)
1. [湖北新生女婴被弃多人愿领养](https://so.toutiao.com/search?keyword=湖北新生女婴被弃多人愿领养)
1. [曝阿布已收到几份价值30亿英镑报价](https://so.toutiao.com/search?keyword=曝阿布已收到几份价值30亿英镑报价)
1. [二月二融抬头](https://so.toutiao.com/search?keyword=二月二融抬头)
1. [苏炳添回应当选感动中国人物](https://so.toutiao.com/search?keyword=苏炳添回应当选感动中国人物)
1. [俄国防部解释俄军车上的神秘符号](https://so.toutiao.com/search?keyword=俄国防部解释俄军车上的神秘符号)
1. [代表:当前产假规定对女性就业不利](https://so.toutiao.com/search?keyword=代表:当前产假规定对女性就业不利)
1. [女子采血后晕倒医护翻越柜台抢救](https://so.toutiao.com/search?keyword=女子采血后晕倒医护翻越柜台抢救)
1. [石家庄新增1例确诊 系学生](https://so.toutiao.com/search?keyword=石家庄新增1例确诊+系学生)
1. [名记:欧文聘请其继母担任经纪人](https://so.toutiao.com/search?keyword=名记:欧文聘请其继母担任经纪人)
1. [网络暴力立法存在什么困难?](https://so.toutiao.com/search?keyword=网络暴力立法存在什么困难?)
1. [白宫要求国会授权追加百亿美元援乌](https://so.toutiao.com/search?keyword=白宫要求国会授权追加百亿美元援乌)
1. [B站回应今日俄罗斯RT被封号](https://so.toutiao.com/search?keyword=B站回应今日俄罗斯RT被封号)
1. [代表建议儿童DNA普采防拐 有风险吗](https://so.toutiao.com/search?keyword=代表建议儿童DNA普采防拐+有风险吗)
1. [欧盟:向乌克兰难民提供三年居住权](https://so.toutiao.com/search?keyword=欧盟:向乌克兰难民提供三年居住权)
1. [特朗普称美应从俄乌冲突中“赚钱”](https://so.toutiao.com/search?keyword=特朗普称美应从俄乌冲突中“赚钱”)
1. [网友1元网购大象 卖家称200天到货](https://so.toutiao.com/search?keyword=网友1元网购大象+卖家称200天到货)
1. [挪威政府全球养老基金公布去年持仓](https://so.toutiao.com/search?keyword=挪威政府全球养老基金公布去年持仓)
1. [美国防官员:美俄已建立通信渠道](https://so.toutiao.com/search?keyword=美国防官员:美俄已建立通信渠道)
1. [乌克兰扎波罗热核电站起火](https://so.toutiao.com/search?keyword=乌克兰扎波罗热核电站起火)
1. [乌克兰招募1.6万志愿兵释放啥信号](https://so.toutiao.com/search?keyword=乌克兰招募1.6万志愿兵释放啥信号)
1. [普京:乌方拖延只会导致俄要求更多](https://so.toutiao.com/search?keyword=普京:乌方拖延只会导致俄要求更多)
1. [杨鸣:不能接受最后时刻的执行力](https://so.toutiao.com/search?keyword=杨鸣:不能接受最后时刻的执行力)
1. [台当局决定停止补助黄郁婷两年经费](https://so.toutiao.com/search?keyword=台当局决定停止补助黄郁婷两年经费)
1. [切费林:两年一届世界杯提议已取消](https://so.toutiao.com/search?keyword=切费林:两年一届世界杯提议已取消)
1. [杜兰特:我不想上场只打10分钟](https://so.toutiao.com/search?keyword=杜兰特:我不想上场只打10分钟)
1. [乌克兰最高拉达批准总统征兵动员令](https://so.toutiao.com/search?keyword=乌克兰最高拉达批准总统征兵动员令)
1. [国际油价3日明显下跌](https://so.toutiao.com/search?keyword=国际油价3日明显下跌)
1. [法国将取消疫苗通行证](https://so.toutiao.com/search?keyword=法国将取消疫苗通行证)
1. [高校招聘被指因人设岗引考生投诉](https://so.toutiao.com/search?keyword=高校招聘被指因人设岗引考生投诉)
1. [疫情下香港娱乐圈百态](https://so.toutiao.com/search?keyword=疫情下香港娱乐圈百态)
1. [广东昨增本土确诊28例:深圳23例](https://so.toutiao.com/search?keyword=广东昨增本土确诊28例:深圳23例)
1. [全国政协十三届五次会议为期6天](https://so.toutiao.com/search?keyword=全国政协十三届五次会议为期6天)
1. [乌方:乌军将从防御转为反攻](https://so.toutiao.com/search?keyword=乌方:乌军将从防御转为反攻)
1. [台湾已逐步恢复供电](https://so.toutiao.com/search?keyword=台湾已逐步恢复供电)
1. [大学生车上看寻人启事发现人在窗外](https://so.toutiao.com/search?keyword=大学生车上看寻人启事发现人在窗外)
1. [印媒:美政府正考虑是否制裁印度](https://so.toutiao.com/search?keyword=印媒:美政府正考虑是否制裁印度)
1. [乌总统:将迎首批1.6万名外国志愿兵](https://so.toutiao.com/search?keyword=乌总统:将迎首批1.6万名外国志愿兵)
1. [杨振宁苏炳添等获感动中国年度人物](https://so.toutiao.com/search?keyword=杨振宁苏炳添等获感动中国年度人物)
1. [委员:建议配偶有权查询另一方财产](https://so.toutiao.com/search?keyword=委员:建议配偶有权查询另一方财产)
1. [情侣住四星级酒店 凌晨醉汉闯入](https://so.toutiao.com/search?keyword=情侣住四星级酒店+凌晨醉汉闯入)
1. [湖南人大常委会秘书长曹炯芳被查](https://so.toutiao.com/search?keyword=湖南人大常委会秘书长曹炯芳被查)
1. [青岛确诊与已知病例基因库均不同源](https://so.toutiao.com/search?keyword=青岛确诊与已知病例基因库均不同源)
1. [俄方:俄乌冲突是西方导致的结果](https://so.toutiao.com/search?keyword=俄方:俄乌冲突是西方导致的结果)
1. [动态清零政策会变吗?郭卫民回应](https://so.toutiao.com/search?keyword=动态清零政策会变吗?郭卫民回应)
1. [俄罗斯停止向美国提供火箭发动机](https://so.toutiao.com/search?keyword=俄罗斯停止向美国提供火箭发动机)
1. [联大通过决议草案:要求俄从乌撤军](https://so.toutiao.com/search?keyword=联大通过决议草案:要求俄从乌撤军)
1. [俄外长:美方行为欲置俄罗斯于死地](https://so.toutiao.com/search?keyword=俄外长:美方行为欲置俄罗斯于死地)
1. [丁笑滢否认与郭麒麟恋情](https://so.toutiao.com/search?keyword=丁笑滢否认与郭麒麟恋情)
1. [高圆圆打扮休闲现身公司开会](https://so.toutiao.com/search?keyword=高圆圆打扮休闲现身公司开会)
1. [蓬佩奥与蔡英文会面 外交部:无耻](https://so.toutiao.com/search?keyword=蓬佩奥与蔡英文会面+外交部:无耻)
1. [俄乌冲突中俄军使用了哪些作战样式](https://so.toutiao.com/search?keyword=俄乌冲突中俄军使用了哪些作战样式)
1. [杨幂与男子同回小区](https://so.toutiao.com/search?keyword=杨幂与男子同回小区)
1. [妈妈顺路买葱5分钟被隔离14天](https://so.toutiao.com/search?keyword=妈妈顺路买葱5分钟被隔离14天)
1. [美团外卖和饿了么接连宣布降佣金](https://so.toutiao.com/search?keyword=美团外卖和饿了么接连宣布降佣金)
1. [云南将新组建三所职业学院](https://so.toutiao.com/search?keyword=云南将新组建三所职业学院)
1. [古力娜扎晒健身照](https://so.toutiao.com/search?keyword=古力娜扎晒健身照)
1. [外媒:俄罗斯人又能购买苹果产品了](https://so.toutiao.com/search?keyword=外媒:俄罗斯人又能购买苹果产品了)
1. [全台大停电“经济部长”自请处分](https://so.toutiao.com/search?keyword=全台大停电“经济部长”自请处分)
1. [民调:近七成韩国人因疫情收入下降](https://so.toutiao.com/search?keyword=民调:近七成韩国人因疫情收入下降)
1. [90后打工女生:借钱买房网恋结婚](https://so.toutiao.com/search?keyword=90后打工女生:借钱买房网恋结婚)
1. [台湾艺人澎恰恰被曝已离婚](https://so.toutiao.com/search?keyword=台湾艺人澎恰恰被曝已离婚)
1. [今年首个沙尘暴蓝色预警发布](https://so.toutiao.com/search?keyword=今年首个沙尘暴蓝色预警发布)
1. [张承中回应Selina新恋情](https://so.toutiao.com/search?keyword=张承中回应Selina新恋情)
1. [代表建议宅基地有偿退出 你怎么看](https://so.toutiao.com/search?keyword=代表建议宅基地有偿退出+你怎么看)
1. [外交部回击美再次散布涉疆谎言](https://so.toutiao.com/search?keyword=外交部回击美再次散布涉疆谎言)
1. [代表建议允许每周1-2天远程办公](https://so.toutiao.com/search?keyword=代表建议允许每周1-2天远程办公)
1. [第二轮俄乌谈判开始](https://so.toutiao.com/search?keyword=第二轮俄乌谈判开始)
1. [中方提醒美方还钱非慷慨是天经地义](https://so.toutiao.com/search?keyword=中方提醒美方还钱非慷慨是天经地义)
1. [有位全国人大代表还在太空“出差”](https://so.toutiao.com/search?keyword=有位全国人大代表还在太空“出差”)
1. [俄外长:乌克兰正在准备发动挑衅](https://so.toutiao.com/search?keyword=俄外长:乌克兰正在准备发动挑衅)
1. [美国务卿向中亚五国提建军事基地](https://so.toutiao.com/search?keyword=美国务卿向中亚五国提建军事基地)
1. [基辅之战怎样了](https://so.toutiao.com/search?keyword=基辅之战怎样了)
1. [多国拒绝制裁俄罗斯](https://so.toutiao.com/search?keyword=多国拒绝制裁俄罗斯)
1. [联大通过乌局势决议 中国为何弃权](https://so.toutiao.com/search?keyword=联大通过乌局势决议+中国为何弃权)
1. [法国14名士兵疑赴乌参战在巴黎被捕](https://so.toutiao.com/search?keyword=法国14名士兵疑赴乌参战在巴黎被捕)
1. [华人撤离乌克兰时的团结互助](https://so.toutiao.com/search?keyword=华人撤离乌克兰时的团结互助)
1. [拜登欲借俄乌冲突转移美国内矛盾](https://so.toutiao.com/search?keyword=拜登欲借俄乌冲突转移美国内矛盾)
1. [台湾学者深究全台大停电根本原因](https://so.toutiao.com/search?keyword=台湾学者深究全台大停电根本原因)
1. [广东女生在线煲汤拯救自家店铺](https://so.toutiao.com/search?keyword=广东女生在线煲汤拯救自家店铺)
1. [俄央行:最近三个月将动用国际储备](https://so.toutiao.com/search?keyword=俄央行:最近三个月将动用国际储备)
1. [全球新增确诊和死亡病例持续下降](https://so.toutiao.com/search?keyword=全球新增确诊和死亡病例持续下降)
1. [蒋依依否认与郭麒麟恋情](https://so.toutiao.com/search?keyword=蒋依依否认与郭麒麟恋情)
1. [香港确诊病例数为何激增](https://so.toutiao.com/search?keyword=香港确诊病例数为何激增)
1. [俄罗斯有哪些出名的本土猫](https://so.toutiao.com/search?keyword=俄罗斯有哪些出名的本土猫)
1. [国产宝马X5价格分析](https://so.toutiao.com/search?keyword=国产宝马X5价格分析)
1. [罗马尼亚两架军机坠毁至少7人死亡](https://so.toutiao.com/search?keyword=罗马尼亚两架军机坠毁至少7人死亡)
1. [德国将向乌提供2700枚苏制防空导弹](https://so.toutiao.com/search?keyword=德国将向乌提供2700枚苏制防空导弹)
1. [民航局对2个国际航班实施熔断措施](https://so.toutiao.com/search?keyword=民航局对2个国际航班实施熔断措施)
1. [Selina官宣新恋情](https://so.toutiao.com/search?keyword=Selina官宣新恋情)
1. [普京与印度总理莫迪通话](https://so.toutiao.com/search?keyword=普京与印度总理莫迪通话)
1. [长安第二代CS75PLUS购车手册](https://so.toutiao.com/search?keyword=长安第二代CS75PLUS购车手册)
1. [媒体:第二轮俄乌会谈地点或更改](https://so.toutiao.com/search?keyword=媒体:第二轮俄乌会谈地点或更改)
1. [法属圭亚那航天中心的俄专家已离开](https://so.toutiao.com/search?keyword=法属圭亚那航天中心的俄专家已离开)
1. [德国没收俄罗斯富豪一艘38亿元游艇](https://so.toutiao.com/search?keyword=德国没收俄罗斯富豪一艘38亿元游艇)
1. [对俄军事行动有部分了解?中方驳斥](https://so.toutiao.com/search?keyword=对俄军事行动有部分了解?中方驳斥)
1. [蔡英文为大停电致歉引岛内网民嘲讽](https://so.toutiao.com/search?keyword=蔡英文为大停电致歉引岛内网民嘲讽)
1. [放开考公年龄能缓解35岁职场恐惧吗](https://so.toutiao.com/search?keyword=放开考公年龄能缓解35岁职场恐惧吗)
1. [两位乌克兰华人历经30小时撤离](https://so.toutiao.com/search?keyword=两位乌克兰华人历经30小时撤离)
1. [赵少康:民进党不倒 用电不会好](https://so.toutiao.com/search?keyword=赵少康:民进党不倒+用电不会好)
1. [俄方:30余吨援助物资运抵乌西北部](https://so.toutiao.com/search?keyword=俄方:30余吨援助物资运抵乌西北部)
1. [上海一永辉超市5人感染 升为中风险](https://so.toutiao.com/search?keyword=上海一永辉超市5人感染+升为中风险)
1. [图集:乌克兰首都民众躲地铁站避难](https://so.toutiao.com/search?keyword=图集:乌克兰首都民众躲地铁站避难)
1. [白俄总统称是其子促成俄乌首轮谈判](https://so.toutiao.com/search?keyword=白俄总统称是其子促成俄乌首轮谈判)
1. [在乌留学生持中国护照撤离一路绿灯](https://so.toutiao.com/search?keyword=在乌留学生持中国护照撤离一路绿灯)
1. [俄方:已瘫痪乌方1612个军事设施](https://so.toutiao.com/search?keyword=俄方:已瘫痪乌方1612个军事设施)
1. [普京提请修改集安组织维和行动协议](https://so.toutiao.com/search?keyword=普京提请修改集安组织维和行动协议)
1. [雪容融上班慢悠悠下班一路小跑](https://so.toutiao.com/search?keyword=雪容融上班慢悠悠下班一路小跑)
1. [俄国防部:继续打击乌军事基础设施](https://so.toutiao.com/search?keyword=俄国防部:继续打击乌军事基础设施)
1. [中方:3000名在乌中国公民安全转移](https://so.toutiao.com/search?keyword=中方:3000名在乌中国公民安全转移)
1. [蔡英文与蓬佩奥见面直播停电暂取消](https://so.toutiao.com/search?keyword=蔡英文与蓬佩奥见面直播停电暂取消)
1. [张九南与女子牵手被拍](https://so.toutiao.com/search?keyword=张九南与女子牵手被拍)
1. [台媒:乌克兰都没停电 台湾停了](https://so.toutiao.com/search?keyword=台媒:乌克兰都没停电+台湾停了)
1. [格力电器被执行9.78万元](https://so.toutiao.com/search?keyword=格力电器被执行9.78万元)
<!-- END TOUTIAO --> | 21,015 | MIT |
### 33. 搜索旋转排序数组
> 题目
升序排列的整数数组 nums 在预先未知的某个点上进行了旋转(例如, [0,1,2,4,5,6,7] 经旋转后可能变为[4,5,6,7,0,1,2] )。
请你在数组中搜索target ,如果数组中存在这个目标值,则返回它的索引,否则返回-1。
示例 1:
```
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
```
示例2:
```
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
```
示例 3:
```
输入:nums = [1], target = 0
输出:-1
```
提示:
1 <= nums.length <= 5000
-10^4 <= nums[i] <= 10^4
nums 中的每个值都 独一无二
nums 肯定会在某个点上旋转
-10^4 <= target <= 10^4
> 思路
要注意是排序的数组,然后肯定翻转一次。所以可以用二分法逼近。
先取 mid,当 mid > target, right > mid,则在左侧找。若 mid < target,left < mid,则在右侧找。
> 代码
```js
/**
* @param {number[]} nums
* @param {number} target
* @return {number}
*/
var search = function (nums, target) {
let left = 0;
let right = nums.length - 1;
while (left <= right) {
const mid = left + Math.floor((right - left) / 2);
if (nums[mid] === target) {
return mid;
} else if (nums[mid] > target) {
if (nums[right] > nums[mid]) {
right = mid - 1;
} else {
if (nums[right] === target) {
return right;
} else {
right--;
}
}
} else {
if (nums[left] < nums[mid]) {
left = mid + 1;
} else {
if (nums[left] === target) {
return left;
} else {
left++;
}
}
}
}
return -1;
};
```
> 复杂度分析
时间复杂度:O(n)。最坏情况下为
空间复杂度:O(1)。
> 执行
执行用时:76 ms, 在所有 JavaScript 提交中击败了93.51%的用户
内存消耗:38.9 MB, 在所有 JavaScript 提交中击败了58.57%的用户 | 1,637 | MIT |
# tabler-loading
加载数据时显示动效。
## 使用方式
```html
<!-- 引入 -->
<script type="module">
import './node_modules/xy-ui/components/tabler-loading.js';
</script>
<!-- 使用 -->
<tabler-loading></tabler-loading>
```
## 尺寸`size`
通过`size`可以设置加载器尺寸,默认为`font-size`大小。
<tabler-loading></tabler-loading>
<tabler-loading size="30"></tabler-loading>
<tabler-loading size="40"></tabler-loading>
<tabler-loading size="50"></tabler-loading>
```html
<tabler-loading></tabler-loading>
<tabler-loading size="30"></tabler-loading>
<tabler-loading size="40"></tabler-loading>
<tabler-loading size="50"></tabler-loading>
```
CSS操作(推荐)
```css
tabler-loading{
font-size:30px;
}
```
JavaScript操作`get`、`set`
```js
loading.size;
loading.size = 30;
//原生属性操作
loading.getAttribute('size');
loading.setAttribute('size',30);
```
> CSS操作更灵活,可以写在样式中,属性值和JavaScript操作优先级更高,下同
## 颜色`color`
通过`color`可以设置加载器颜色,默认为主题颜色`themeColor`。
<tabler-loading size="40"></tabler-loading>
<tabler-loading size="40" color="green"></tabler-loading>
<tabler-loading size="40" color="olivedrab"></tabler-loading>
<tabler-loading size="40" color="orange"></tabler-loading>
```html
<tabler-loading size="40"></tabler-loading>
<tabler-loading size="40" color="green"></tabler-loading>
<tabler-loading size="40" color="olivedrab"></tabler-loading>
<tabler-loading size="40" color="orange"></tabler-loading>
```
CSS操作(推荐)
```css
tabler-loading{
color:orangered;
}
```
JavaScript操作`get`、`set`
```js
loading.color;
loading.color = 'orangered';
//原生属性操作
loading.getAttribute('color');
loading.setAttribute('color','orangered');
```
## 其他
可以直接嵌套文本作为加载提示语
<tabler-loading>loading...</tabler-loading>
```html
<tabler-loading>loading...</tabler-loading>
```
如果需要垂直排列,设置一下`css`就可以了
<tabler-loading style="flex-direction:column">loading...</tabler-loading>
```html
<style>
tabler-loading{
flex-direction:column
}
</style>
<tabler-loading>loading...</tabler-loading>
``` | 1,931 | MIT |
## 开发准备
### SDK 获取
腾讯云 iotsuite C语言版 SDK的下载地址: [tencent-cloud-iotsuite-embedded-c.git](https://github.com/tencentyun/tencent-cloud-iotsuite-embedded-c.git)
```shell
git clone https://github.com/tencentyun/tencent-cloud-iotsuite-embedded-c.git
```
### 开发环境
1. 安装cmake工具 [http://www.cmake.org/download/](http://www.cmake.org/download/)
2. 从控制台创建产品和设备,获取对应的 MQTT Server Host、Product ID、DeviceName、DeviceSecret,详情请登录[控制台](https://console.qcloud.com/iotsuite/product)。
3. 打开 examples/linux/tc_iot_device_config.h ,配置文件,配置设备参数:
```c
/************************************************************************/
/**********************************必填项********************************/
// 以下配置需要先在官网创建产品和设备,然后获取相关信息更新
// MQ服务地址,可以在产品“基本信息”->“mqtt链接地址”位置找到。
#define TC_IOT_CONFIG_SERVER_HOST "<mqtt-xxx.ap-guangzhou.mqtt.tencentcloudmq.com>"
// MQ服务端口,直连一般为1883,无需改动
#define TC_IOT_CONFIG_SERVER_PORT 1883
// 产品id,可以在产品“基本信息”->“产品id”位置找到
#define TC_IOT_CONFIG_DEVICE_PRODUCT_ID "<iot-xxx>"
// 设备密钥,可以在产品“设备管理”->“设备证书”->“Device Secret”位置找到
#define TC_IOT_CONFIG_DEVICE_SECRET "<0000000000000000>"
// 设备名称,可以在产品“设备管理”->“设备名称”位置找到
#define TC_IOT_CONFIG_DEVICE_NAME "<device001>"
// client id,
// 由两部分组成,组成形式为“Instanceid@DeviceID”,ClientID 的长度不超过 64个字符
// ,请不要使用不可见字符。其中
// Instanceid 为 IoT MQ 的实例 ID,可以在“基本信息”->“产品 key”位置找到。
// DeviceID 为每个设备独一无二的标识,由业务方自己指定,需保证全局唯一,例如,每个
// 传感器设备的序列号,或者设备名称等。
#define TC_IOT_CONFIG_DEVICE_CLIENT_ID "mqtt-xxx@" TC_IOT_CONFIG_DEVICE_NAME
/************************************************************************/
```
### 编译及运行
1. 执行下面的命令,编译示例程序:
```shell
cd tencent-cloud-iotsuite-embedded-c
mkdir -p build
cd build
cmake ../
make
```
2. 编译后,build目录下的关键输出及说明如下:
```shell
bin
|-- demo_mqtt # MQTT 连接云服务演示程序
|-- demo_shadow # Shadow 影子设备操作演示程序
lib
|-- libtc_iot_suite.a # SDK 的核心层, libtc_iot_hal、libtc_iot_common 提供连接云服务的能力
|-- libtc_iot_common.a # SDK 基础工具库,负责http、json、base64等解析和编解码功能
|-- libtc_iot_hal.a # SDK 的硬件及操作系统抽象,负责内存、定时器、网络交互等功能
```
3. 执行示例程序:
```shell
cd bin
# 运行demo程序
./demo_mqtt
# or
./demo_shadow
```
## 移植说明
### 硬件及操作系统平台抽象层(HAL 层)
SDK 抽象定义了硬件及操作系统平台抽象层(HAL 层),将所依赖的内存、定时器、网络传输交互等功能,
都封装在 HAL 层(对应库libtc_iot_hal)中,进行跨平台移植时,首先都需要根据对应平台的硬件及操作系统情况,
对应适配或实现相关的功能。
平台移植相关的头文件及源文件代码结构如下:
```shell
include/platform/
|-- linux # 不同的平台或系统,单独建立独立的目录
| |-- tc_iot_platform.h # 引入对应平台相关的定义或系统头文件
|-- tc_iot_hal_network.h # 网络相关定义
|-- tc_iot_hal_os.h # 操作系统内存、时间戳等相关定义
|-- tc_iot_hal_timer.h # 定时器相关定义
src/platform/
|-- CMakeLists.txt
|-- linux
|-- CMakeLists.txt
|-- tc_iot_hal_net.c # TCP 非加密直连方式网络接口实现
|-- tc_iot_hal_os.c # 内存及时间戳实现
|-- tc_iot_hal_timer.c # 定时器相关实现
|-- tc_iot_hal_tls.c # TLS 加密网络接口实现
```
C-SDK 中提供的 HAL 层是基于 Linux 等 POSIX 体系系统的参考实现,但并不强耦合要求实现按照 POSIX 接口方式,移植时可根据目标系统的情况,灵活调整。
所有 HAL 层函数都在 include/platform/tc_iot_hal*.h 中进行声明,函数都以 tc_iot_hal为前缀。
以下是需要实现的 HAL 层接口,详细信息可以参考注释。
#### 基础功能
| 功能分类 | 函数名 | 说明 | 是否可选 |
| ---------- | ---------- | ---------- | ---------- |
| 内存 | tc_iot_hal_malloc | 分配所需的内存空间,并返回一个指向它的指针。 | 基础必选 |
| 内存 | tc_iot_hal_free | 释放之前调用 tc_iot_hal_malloc 所分配的内存空间。 | 基础必选 |
| 输入输出 | tc_iot_hal_printf | 发送格式化输出到标准输出 stdout。 | 基础必选 |
| 输入输出 | tc_iot_hal_snprintf | 发送格式化输出到字符串。 | 基础必选 |
| 时间日期 | tc_iot_hal_timestamp | 系统时间戳,格林威治时间 1970-1-1 00点起总秒数 | 基础必选 |
| 定时器 | tc_iot_hal_sleep_ms | 睡眠挂起一定时长,单位:ms | 基础必选 |
| 定时器 | tc_iot_hal_timer_init | 初始化或重置定时器 | 基础必选 |
| 定时器 | tc_iot_hal_timer_is_expired | 判断定时器是否已经过期 | 基础必选 |
| 定时器 | tc_iot_hal_timer_countdown_ms | 设定定时器时延,单位:ms | 基础必选 |
| 定时器 | tc_iot_hal_timer_countdown_second | 设定定时器时延,单位:s | 基础必选 |
| 定时器 | tc_iot_hal_timer_left_ms | 检查定时器剩余时长,单位:ms | 基础必选 |
| 随机数 | tc_iot_hal_srandom | 设置随机数种子值 | 基础必选 |
| 随机数 | tc_iot_hal_random | 获取随机数 | 基础必选 |
#### 网络功能(二选一或全选)
根据实际连接方式选择,如是否走MQTT over TLS加密,是否通过HTTPS接口获取Token等,选择性实现 TCP 或 TLS 相关接口。
##### TCP
| 功能分类 | 函数名 | 说明 | 是否可选 |
| ---------- | ---------- | ---------- | ---------- |
| TCP 连接 | tc_iot_hal_net_init | 初始化网络连接数据 | 可选,非加密直连时实现 |
| TCP 连接 | tc_iot_hal_net_connect | 连接服务端 | 可选,非加密直连时实现 |
| TCP 连接 | tc_iot_hal_net_is_connected | 判断当前是否已成功建立网络连接 | 可选,非加密直连时实现 |
| TCP 连接 | tc_iot_hal_net_write | 发送数据到网络对端 | 可选,非加密直连时实现 |
| TCP 连接 | tc_iot_hal_net_read | 接收网络对端发送的数据 | 可选,非加密直连时实现 |
| TCP 连接 | tc_iot_hal_net_disconnect | 断开网络连接 | 可选,非加密直连时实现 |
| TCP 连接 | tc_iot_hal_net_destroy | 释放网络相关资源 | 可选,非加密直连时实现 |
##### TLS
| 功能分类 | 函数名 | 说明 | 是否可选 |
| ---------- | ---------- | ---------- | ---------- |
| TLS 连接 | tc_iot_hal_tls_init | 初始化 TLS 连接数据 | 可选,基于TLS加密通讯时实现 |
| TLS 连接 | tc_iot_hal_tls_connect | 连接 TLS 服务端并进行相关握手及认证 | 可选,基于TLS加密通讯时实现 |
| TLS 连接 | tc_iot_hal_tls_is_connected | 判断当前是否已成功建立 TLS 连接 | 可选,基于TLS加密通讯时实现 |
| TLS 连接 | tc_iot_hal_tls_write | 发送数据到 TLS 对端 | 可选,基于TLS加密通讯时实现 |
| TLS 连接 | tc_iot_hal_tls_read | 接收 TLS 对端发送的数据 | 可选,基于TLS加密通讯时实现 |
| TLS 连接 | tc_iot_hal_tls_disconnect | 断开 TLS 连接 | 可选,基于TLS加密通讯时实现 |
| TLS 连接 | tc_iot_hal_tls_destroy | 释放 TLS 相关资源 | 可选,基于TLS加密通讯时实现 | | 5,056 | MIT |
# mx-utils模块
[](http://doge.mit-license.org)
## 安装和引用
*Maven*
```xml
<dependency>
<groupId>org.mx</groupId>
<artifactId>mx-spring</artifactId>
<version>1.1.8</version>
</dependency>
```
*Gradle*
```gradle
compile 'org.mx:mx-spring:1.1.8'
```
## 工具类
- org.mx.spring.utils.SpringContextHolder<br>
基于Spring的`ApplicationContextAware`实现的全局静态的获取Spring IoC容器中Bean的工具类,便于在Spring IoC容器托管之外的应用代码获取并调用Spring IoC容器托管代码。<br>
该工具本身是一个`@Component`,会自动载入到Spring IoC中,在需要的地方可以如下调用:
```java
// 根据接口类型获取服务对象接口
OrgService orgService = SpringContextHolder.getBean(OrgService.class);
// 根据指定名称和接口类型获取服务对象接口
OrgService orgService = SpringContextHolder.getBean("orgService", OrgService.class);
```
## 可配置任务
实现了一个基于Executors的多线程后台任务执行工厂`TaskFactory`,并对任务进行顶层抽象,任务定义接口为`Task`,定义了顶层的任务抽象类`BaseTask`。<br>
任务调度方式分为三种情况:
1. 串行任务<br>
仅执行一次,且设定到其中的任务将会严格按照输入顺序串行执行。
2. 单个异步任务<br>
仅执行一次,且设定到其中的任务将会在独立线程中并行执行,系统不保障任务之间的执行顺序,一般针对后台长周期任务。
3. 可调度任务<br>
可执行一次,也可以周期性执行,必须设定该调度任务的调度参数,包括:执行延时、执行间隔等。
### 样例
```java
// 创建一个任务工厂
TaskFactory factory = new TaskFactory();
// 加入并执行一系列串行任务
factory.addSerialTask(task1)
.addSerialTask(task2)
.addSerialTask(task3)
.runSerialTasks();
// 加入并执行一系列异步任务
factory.addSingleAsyncTask(task1);
factory.addSingleAsyncTask(task2);
factory.addSingleAsyncTask(task3);
// 延迟10秒运行一次一个调度任务
factory.addScheduledTask(task1, new Task.ScheduledConfig(true, 10, TimeUnit.SECONDS));
// 每4个小时运行一次一个调度任务,运行前无延时
factory.addSecheduledTask(task1, Task.ScheduledConfig().H(0, 4));
// 或者
factory.addSecheduledTask(task1, new Task.ScheduledConfig(false, 0, 4, TimeUnit.HOURS);
```
### 应用初始化任务
一般的,应用初始化任务意味着在应用系统初始化过程中被单次执行的任务序列,可能是串行执行的任务,也可能是异步执行的长周期任务。<br>
应用初始化任务基于`TaskFactory`中的串行任务和异步任务实现,可以通过简单的配置(零代码,当然任务代码还是需要你实现的:))来实现初始化任务的调度。<br>
应用初始化任务定义了一个宿主在Spring IoC中的工厂`InitializeTaskFactory`,并定义了一个初始任务的抽象类`InitializeTask`。
要实现一个任务,你需要:
- 第一步<br>
继承`InitializeTask`抽象类,实现你自己的初始化任务的业务逻辑,如果你的逻辑代码在Spring IoC中,别忘了使用SpringContextHolder:),因为我们的Task都不在Spring IoC中。代码如:
```java
package org.mx.spring;
public class InitializeTask1 extends InitializeTask {
public InitializeTask1() {
super("Initialize task1", false);
}
public void invokeTask() {
System.out.println("Invoke task: ***********.");
}
}
```
- 第二步<br>
基于Java Config方式(也可以使用传统的XML配置方式,大同小异)将你实现的初始化任务注入到Spring IoC中,*注意*:初始化任务的Bean Name必须为"initializeTasks"。如:
```java
package org.mx.spring.config;
import org.mx.spring.InitializeTask;
import org.mx.spring.InitializeTask1;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import java.util.Arrays;
import java.util.List;
@Import(SpringConfig.class)
public class TestTaskConfig {
@Bean(name = "initializeTasks")
public List<Class<? extends InitializeTask>> initialiseTasks() {
return Arrays.asList(InitializeTask1.class);
}
}
```
以上两步,就实现了一个应用初始化任务的工作。<br>
*注意*:初始化应用初始化任务工厂的代码已经封装在`SpringConfig`中,如下所示:
```java
/**
* 创建初始化任务工厂
*
* @return 初始化任务工厂
*/
@Bean
public InitializeTaskFactory initializeTaskFactory() {
return new InitializeTaskFactory(SpringContextHolder.getBean(ApplicationContext.class));
}
```
## redis支持
- 第一步:配置redis<br>
要使用Redis,必须要设置一个名为`redis.properties`的配置文件,其中内容如:
```properties
redis.enable=false
# 类型:standalone | sentinel | cluster
redis.type=standalone
redis.pool.maxIdle=300
redis.pool.maxWaitMillis=3000
redis.pool.testOnBorrow=true
redis.standalone.host=localhost
redis.standalone.port=6379
redis.standalone.database=0
redis.standalone.password=
redis.sentinel.master=master
redis.sentinel.database=0
redis.sentinel.password=
redis.sentinel.sentinelHostAndPorts[0]=localhost:23679
redis.sentinel.sentinelHostAndPorts[1]=localhost:23680
redis.cluster.maxRedirects=1
redis.cluster.password=
redis.cluster.clusterHostAndPorts[0]=localhost:23679
redis.cluster.clusterHostAndPorts[1]=localhost:23680
```
*注意*:需要将`redis.enable`设置为true,并根据实际情况配置使用redis的类型,即`redis.type`配置项。
- 第二步:引入Redis配置<br>
`redis.properties`配置文件需要在应用创建的配置文件中被引入,如下所示:
```java
@Configuration
@PropertySource({
"classpath:redis.properties"
})
public class YourApplicationConfig {
// TODO 你的应用配置代码
}
```
- 最后一步:在应用配置类中引入`SpringRedisConfig`<br>
需要在应用的Java Config类中引入`SpringRedisConfig`,如下所示:
```java
@Import({YourApplicationConfig.class})
public class TestRedisConfig {
}
```
然后在你的应用中就使用获取到RedisTemplate工具类来使用Redis了。
## 缓存
通过配置的方式可以支持:interal、ehcache、redis三种缓存。
- 第一步:配置缓存配置文件<br>
要使用缓存,必须配置`cache.properties`配置文件,其内容如下所示:
```properties
# 类型:internal | ehcache | redis
cache.type=internal
cache.internal.list=test1,test2
cache.ehcache.config=ehcache.xml
cache.redis.list=test1,test2
```
- 第二步:引入缓存配置<br>
`cache.properties`配置文件在应用创建的配置文件中被引入,如下所示:
```java
@Configuration
@PropertySource({
"classpath:cache.properties"
})
public class YourApplicationConfig {
// TODO 你的应用配置代码
}
```
- 最后一步:在应用配置类中引入`SpringCacheConfig`<br>
需要在应用的Java Config类中引入`SpringCacheConfig`,如下所示:
```java
@Import({SpringCacheConfig.class})
public class TestCacheConfig {
}
```
如果需要使用基于redis的缓存,还必须引入`SpringRedisConfig`,如下所示:
```java
@Import({
SpringRedisConfig.class,
SpringCacheConfig.class
})
public class TestRedisCacheConfig {
}
```
然后在你的应用中就使用`@CacheConfig`、`@Cachable`、`@CachePut`、`@CacheEvict`等注解来使用缓存功能了,是不是接近"零编码"呢?
*详细说明参阅本模块的Javadoc。* | 5,409 | MIT |
---
title: 如何:分配存储的过程以便执行更新、 插入和删除操作 (O-R 设计器) |Microsoft Docs
ms.date: 11/15/2016
ms.prod: visual-studio-dev14
ms.technology: vs-data-tools
ms.topic: conceptual
ms.assetid: e88224ab-ff61-4a3a-b6b8-6f3694546cac
caps.latest.revision: 5
author: gewarren
ms.author: gewarren
manager: jillfra
ms.openlocfilehash: 759b3268edd6155d733c18779ebf7ca4efc44a44
ms.sourcegitcommit: 08fc78516f1107b83f46e2401888df4868bb1e40
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 05/15/2019
ms.locfileid: "65688857"
---
# <a name="how-to-assign-stored-procedures-to-perform-updates-inserts-and-deletes-or-designer"></a>如何:分配存储过程以便执行更新、插入和删除操作(O/R 设计器)
[!INCLUDE[vs2017banner](../includes/vs2017banner.md)]
可以将存储过程添加到 O/R 设计器并作为典型的 <xref:System.Data.Linq.DataContext> 方法执行。 将更改从实体类保存到数据库时(例如在调用 [!INCLUDE[vbtecdlinq](../includes/vbtecdlinq-md.md)] 方法时),还可以使用存储过程重写执行插入、更新和删除操作的默认 <xref:System.Data.Linq.DataContext.SubmitChanges%2A> 运行时行为。
> [!NOTE]
> 如果存储过程的返回值需要发送回客户端(例如在存储过程中计算出的值),则在存储过程中创建输出参数。 如果无法使用输出参数,则编写分部方法实现,而不是依靠 O/R 设计器生成的重写。 在成功完成 INSERT 或 UPDATE 操作后,需要将映射到数据库生成的值的成员设置为相应的值。 有关详细信息,请参阅[开发人员在重写默认行为的职责](https://msdn.microsoft.com/library/c6909ddd-e053-46a8-980c-0e12a9797be1)。
> [!NOTE]
> [!INCLUDE[vbtecdlinq](../includes/vbtecdlinq-md.md)] 会自动为标识(自动递增)列、rowguidcol(数据库生成的 GUID)列和时间戳列处理数据库生成的值。 在其他列类型中,数据库生成的值将意外导致 Null 值。 若要返回数据库生成的值,应手动将 <xref:System.Data.Linq.Mapping.ColumnAttribute.IsDbGenerated%2A> 设置为 `true` 并将 <xref:System.Data.Linq.Mapping.ColumnAttribute.AutoSync%2A> 设置为下列值之一:<xref:System.Data.Linq.Mapping.AutoSync>、<xref:System.Data.Linq.Mapping.AutoSync> 或 <xref:System.Data.Linq.Mapping.AutoSync>。
## <a name="configuring-the-update-behavior-of-an-entity-class"></a>配置实体类的更新行为
默认情况下,在使用对 [!INCLUDE[vbtecdlinq](../includes/vbtecdlinq-md.md)] 实体类中的数据所做的更改来更新数据库(插入、更新和删除)时,更新逻辑是由 [!INCLUDE[vbtecdlinq](../includes/vbtecdlinq-md.md)] 运行时提供的。 在运行时创建默认的基于表 (列和主键信息) 的架构的 Insert、 Update 和 Delete 命令。 当不需要默认行为时,可以通过分配特定的存储过程,以执行操作表中数据所必需的插入、更新和删除来配置更新行为。 在不生成默认行为时(例如,实体类映射到视图时),也可以这样做。 最后,在数据库要求通过存储过程访问表时,您可以重写默认的更新行为。
[!INCLUDE[note_settings_general](../includes/note-settings-general-md.md)]
#### <a name="to-assign-stored-procedures-to-override-the-default-behavior-of-an-entity-class"></a>指定存储过程以重写实体类的默认行为
1. 在设计器中打开“LINQ to SQL”文件。 (双击.dbml 文件中的**解决方案资源管理器**。)
2. 在中**服务器资源管理器**/**数据库资源管理器**,展开**存储过程**并找到想要用于插入、 更新、 存储的过程和/或删除的实体类的命令。
3. 将该存储过程拖到 O/R 设计器上。
该存储过程将作为 <xref:System.Data.Linq.DataContext> 方法添加到方法窗格中。 有关详细信息,请参阅[DataContext 方法 (O/R 设计器)](../data-tools/datacontext-methods-o-r-designer.md)。
4. 选择要使用存储过程对其执行更新的实体类。
5. 在“属性”窗口中选择要替代的命令(“插入”、“更新”或“删除”)。
6. 单击“使用运行时”旁边的省略号 (...) 以打开“配置行为”对话框。
7. 选择“自定义”。
8. 在“自定义”列表中选择所需的存储过程。
9. 检查“方法自变量”和“类属性”列表以验证“方法自变量”是否映射到相应的“类属性”。 映射原始方法自变量 (Original_*ArgumentName*) 到原始属性 (*PropertyName* (原始)) 的 Update 和 Delete 命令。
> [!NOTE]
> 默认情况下,名称匹配时方法自变量映射到类属性。 如果更改的属性名称在表和实体类之间不再匹配,而设计器无法确定正确的映射,您可能需要选择等效的类属性进行映射。
10. 单击“确定”或“应用”。
> [!NOTE]
> 只要在每次更改后单击“应用”,就可以继续为每个类/行为组合配置行为。 如果您更改的类或行为之前单击**应用**、 提供商机应用任何更改将出现一个警告对话框。
若要恢复为使用默认运行时逻辑进行更新,请单击 Insert、 Update、 旁边的省略号或 Delete 中的命令**属性**窗口,然后选择**使用运行时**中**配置行为**对话框。
## <a name="see-also"></a>请参阅
[LINQ to SQL 工具在 Visual Studio 中](../data-tools/linq-to-sql-tools-in-visual-studio2.md)
[DataContext 方法 (O/R 设计器)](../data-tools/datacontext-methods-o-r-designer.md)
[演练:创建 LINQ to SQL 类 (O-R 设计器)](https://msdn.microsoft.com/library/35aad4a4-2e8a-46e2-ae09-5fbfd333c233)
[LINQ to SQL](https://msdn.microsoft.com/library/73d13345-eece-471a-af40-4cc7a2f11655)
[插入、更新和删除操作](https://msdn.microsoft.com/library/26a43a4f-83c9-4732-806d-bb23aad0ff6b) | 3,716 | CC-BY-4.0 |
---
layout: article
title: SystemVerilog中6种数组形式的使用
tags:
- SystemVerilog
- 数组
key: a202107101
---
数组在SV中是四种数据类型(数组,结构体,枚举类型,字符串)中的其中一种。
<!--more-->
### SV中可以定义六种形式的数组 (定宽数组,多维数组,合并数组,非合并数组,动态数组,队列):
* 定宽数组 int arr[0:15]; 声明一个单位为int类型深度为16的数组。
* 多维数组 int arr[0:1][0:2]; 声明一个2行3列的数组。
* 合并数组 bit [3:0][7:0] bytes; 将32个bits分为4组,其中每一组都是8个bits的数据。注意合并数组只能使用单bit的数据结构进行声明。
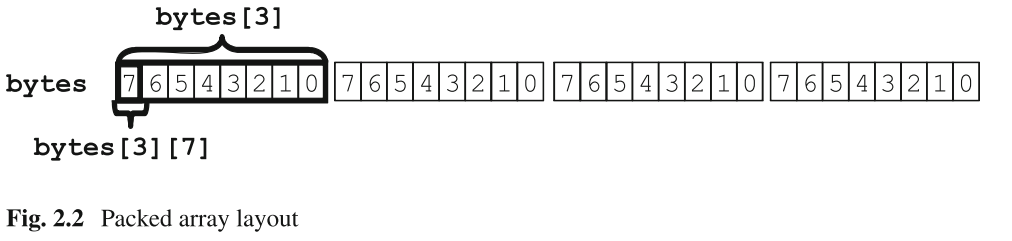
* 非合并数组 bit [7:0] b_unpack[3]; 储存单位8个bit, 深度为3.
> 使用合并数组还是非合并数组主要是看需不需要把数据当成一个整体来访问。
* 动态数组; 在声明数组的时候可以对数组进行留空,但是需要在调用之前通过new[]来指定宽度。
* 队列;使用\$符号进行声明,如int q[\$] = {2,3,5}; 声明队列并给定3个元素。队列的声明需要
* 对数组进行赋值时可以使用'{4{2}}表示重复2的值四次,注意在每个包含两个值以上的{ }块前面都必须加上' 以区分数值之间的连接。
* 在声明数组赋值的时候在值的前面使用**单引号**;`int array[2][3]='{'{0,1,2}, '{3,4,5}}` 以区分使用{ }来concatenation数值。
concatenation和assigned pattern重合了。
---
本文原创,错误之处在所难免!盼指出! | 874 | MIT |
<!-- YAML
added: v0.1.25
changes:
- version: v6.0.0
pr-url: https://github.com/nodejs/node/pull/5348
description: Passing a non-string as the `path` argument will throw now.
-->
* `path` {string}
* 返回: {string}
`path.extname()` 方法返回 `path` 的扩展名,从最后一次出现 `.`(句点)字符到 `path` 最后一部分的字符串结束。
如果在 `path` 的最后一部分中没有 `.` ,或者如果 `path` 的基本名称(参阅 `path.basename()`)除了第一个字符以外没有 `.`,则返回空字符串。
```js
path.extname('index.html');
// 返回: '.html'
path.extname('index.coffee.md');
// 返回: '.md'
path.extname('index.');
// 返回: '.'
path.extname('index');
// 返回: ''
path.extname('.index');
// 返回: ''
path.extname('.index.md');
// 返回: '.md'
```
如果 `path` 不是字符串,则抛出 [`TypeError`]。 | 671 | CC-BY-4.0 |
## [返回目录][catalogue]or[上一章][pre_chap]or[下一章][next_chap]
-----------------------------------------------------------------------------------
## 7.5 发布包
+ 让别人使用自己编写的程序
+ 放到github.com上是一种方式
+ 在python生态环境中,还可以放到pypi.org上,让它成为每个开发者可以通过pip安装的第三方包
+ 发布包流程
+ 第一步,创建一个包
```
root@kali-book:~/python-laoqi/chap7/test_project_release# tree -F
.
├── __init__.py
├── javaspeak/
│ ├── __init__.py
│ └── javaspeak.py
├── langspeak.py
├── pythonspeak/
│ ├── __init__.py
│ └── pythonspeak.py
├── rustspeak/
│ ├── __init__.py
│ └── rustspeak.py
└── setup.py
3 directories, 9 files
```
+ 第二步,编写 `setup.py`
```
#coding=utf-8
'''
filename:setup.py
setup config for the package.
'''
import os
from setuptools import setup,find_packages
setup(
name='test_pkg_marble',
version='0.0.1',
author='marble_z',
author_email='516018505@qq.com',
description='this is a test package. test_pkg',
url='',
py_modules=['langspeak'],
packages=find_packages(),
classifiers=[
'Programming Language :: Python :: 3',
'License :: OSI Approved :: MIT License',
'Operating System :: OS Independent',
],
)
```
+ [setuptools keywords](https://setuptools.readthedocs.io/en/latest/references/keywords.html)
+ name:`str`将来发布到Pypi上时显示的名称(不一定与import或本包的顶级目录名称相同)
+ py_modules:`list`本包中与setup.py同级的`.py`模块
+ packages:`list`用于声明本包中的子包
```
name
A string specifying the name of the package.
version
A string specifying the version number of the package.
description
A string describing the package in a single line.
long_description
A string providing a longer description of the package.
long_description_content_type
A string specifying the content type is used for the long_description (e.g. text/markdown)
author
A string specifying the author of the package.
author_email
A string specifying the email address of the package author.
url
A string specifying the URL for the package homepage.
packages
A list of strings specifying the packages that setuptools will manipulate.
py_modules
A list of strings specifying the modules that setuptools will manipulate.
classifiers
A list of strings describing the categories for the package.
```
+ 第三步,本地安装测试
```
python3 setup.py install
python3
....
```
+ 第四步,安装,升级 `setuptools,wheel,twine`
```
pip install -U setuptools wheel twine
```
+ 文件打包,创建分发包,源码包,二进制包
```
python3 setup.py sdist bdist
├── dist
│ ├── test_pkg_marble-0.0.1-py3-none-any.whl
│ └── test_pkg_marble-0.0.1.tar.gz
root@kali-book:~/python-laoqi/chap7/test_project_release# tree
.
├── build
│ ├── bdist.linux-x86_64
│ └── lib
│ ├── javaspeak
│ │ ├── __init__.py
│ │ └── javaspeak.py
│ ├── langspeak.py
│ ├── pythonspeak
│ │ ├── __init__.py
│ │ └── pythonspeak.py
│ └── rustspeak
│ ├── __init__.py
│ └── rustspeak.py
├── dist
│ ├── test_pkg_marble-0.0.1-py3-none-any.whl
│ └── test_pkg_marble-0.0.1.tar.gz
├── __init__.py
├── javaspeak
│ ├── __init__.py
│ └── javaspeak.py
├── langspeak.py
├── LICENSE
├── pythonspeak
│ ├── __init__.py
│ └── pythonspeak.py
├── README.md
├── rustspeak
│ ├── __init__.py
│ └── rustspeak.py
├── setup.py
└── test_pkg_marble.egg-info
├── dependency_links.txt
├── PKG-INFO
├── SOURCES.txt
└── top_level.txt
```
+ 第五步,发布包
```
root@kali-book:~/python-laoqi/chap7/test_project_release# twine upload --repository-url https://test.pypi.org/legacy/ dist/*
Uploading distributions to https://test.pypi.org/legacy/
Enter your username: marble-pypi
Enter your password:
Uploading test_pkg_marble-0.0.1-py3-none-any.whl
100%|█████████████████████████████████████████████████████████████████████████████████████████████| 5.86k/5.86k [00:07<00:00, 803B/s]
Uploading test_pkg_marble-0.0.1.tar.gz
100%|███████████████████████████████████████████████████████████████████████████████████████████| 4.54k/4.54k [00:01<00:00, 3.74kB/s]
View at:
https://test.pypi.org/project/test-pkg-marble/0.0.1/
```
+ 下载,安装,测试
```
root@kali-book:~# pip install -i https://test.pypi.org/simple/ test-pkg-marble==0.0.1
Looking in indexes: https://test.pypi.org/simple/
Collecting test-pkg-marble==0.0.1
Downloading https://test-files.pythonhosted.org/packages/69/63/ebae2eee89b16a81291ed40c0dab6b2b775600366166fb4cbb1ca3196108/test_pkg_marble-0.0.1-py3-none-any.whl (2.9 kB)
Installing collected packages: test-pkg-marble
Successfully installed test-pkg-marble-0.0.1
WARNING: Running pip as root will break packages and permissions. You should install packages reliably by using venv: https://pip.pypa.io/warnings/venv
root@kali-book:~# pip show test-pkg-marble
Name: test-pkg-marble
Version: 0.0.1
Summary: this is a test package. test_pkg
Home-page: UNKNOWN
Author: marble_z
Author-email: 516018505@qq.com
License: UNKNOWN
Location: /usr/local/lib/python3.9/dist-packages
Requires:
Required-by:
```
-----------------------------------------------------------------------------------
## [返回目录][catalogue]or[上一章][pre_chap]or[下一章][next_chap]
[catalogue]: ../2021-01-21-chap7.md
[pre_chap]: chap7_4_third_party_package.md
[next_chap]: ../2021-01-21-chap7.md | 5,304 | MIT |
---
title: 如何:创建模型及映射文件嵌入资源
ms.date: 03/30/2017
ms.assetid: 20dfae4d-e95a-4264-9540-f5ad23b462d3
ms.openlocfilehash: eae3681664ab1fd095487a7b7ed395302faf2588
ms.sourcegitcommit: 0be8a279af6d8a43e03141e349d3efd5d35f8767
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/18/2019
ms.locfileid: "59329526"
---
# <a name="how-to-make-model-and-mapping-files-embedded-resources"></a>如何:创建模型及映射文件嵌入资源
[!INCLUDE[adonet_ef](../../../../../includes/adonet-ef-md.md)] ,你可以为应用程序的嵌入资源部署模型和映射文件。 包含嵌入模型和映射文件的程序集必须加载到实体连接所在的应用程序域中。 有关详细信息,请参阅[连接字符串](../../../../../docs/framework/data/adonet/ef/connection-strings.md)。 默认情况下,[!INCLUDE[adonet_edm](../../../../../includes/adonet-edm-md.md)]工具嵌入模型和映射文件。 手动定义模型和映射文件时,请使用下面的过程以确保文件作为嵌入资源与[!INCLUDE[adonet_ef](../../../../../includes/adonet-ef-md.md)]应用程序一起部署。
> [!NOTE]
> 若要维护嵌入资源,每次修改模型和映射文件时都必须重复此过程。
### <a name="to-embed-model-and-mapping-files"></a>嵌入模型和映射文件
1. 在中**解决方案资源管理器**,选择的概念 (.csdl) 文件。
2. 在中**属性**窗格中,设置**生成操作**到**嵌入的资源**。
3. 对存储文件 (.ssdl) 和映射文件 (.msl) 重复步骤 1 和步骤 2。
4. 在中**解决方案资源管理器**,双击 App.config 文件,然后修改`Metadata`中的参数`connectionString`属性基于以下格式之一:
- `Metadata=` `res://<assemblyFullName>/<resourceName>;`
- `Metadata=` `res://*/<resourceName>;`
- `Metadata=res://*;`
有关详细信息,请参阅[连接字符串](../../../../../docs/framework/data/adonet/ef/connection-strings.md)。
## <a name="example"></a>示例
下面的连接字符串引用嵌入的模型和映射文件[AdventureWorks 销售模型](https://github.com/Microsoft/sql-server-samples/releases/tag/adventureworks)。 该连接字符串存储在项目的 App.config 文件中。
## <a name="see-also"></a>请参阅
- [建模和映射](../../../../../docs/framework/data/adonet/ef/modeling-and-mapping.md)
- [如何:定义连接字符串](../../../../../docs/framework/data/adonet/ef/how-to-define-the-connection-string.md)
- [如何:生成 EntityConnection 连接字符串](../../../../../docs/framework/data/adonet/ef/how-to-build-an-entityconnection-connection-string.md)
- [ADO.NET 实体数据模型工具](https://docs.microsoft.com/previous-versions/dotnet/netframework-4.0/bb399249(v=vs.100)) | 2,036 | CC-BY-4.0 |
# 创建功能模块
当我们的根模块开始增长时,一些元素(组件,指令等)开始明显地以某种方式相关,几乎成了可以“插入”的库。
在我们前面的例子中,我们开始看到了。 我们的根模块有一个组件,一个管道和一个服务,其唯一的目的是处理信用卡。 如果我们将这三个元素提取到自己的**功能模块**,然后将它们导入我们的**根模块**怎么办?
我们将这样做。第一步是创建两个文件夹以区分属于根模块的元素和属于要素模块的元素。
```
.
├── app
│ ├── app.component.ts
│ └── app.module.ts
├── credit-card
│ ├── credit-card-mask.pipe.ts
│ ├── credit-card.component.ts
│ ├── credit-card.module.ts
│ └── credit-card.service.ts
├── index.html
└── main.ts
```
注意每个模块文件夹下的模块文件:*app.module.ts*和*credit-card.module.ts*.。让我们先关注后者。
*credit-card/credit-card.module.ts*
```typescript
import { NgModule } from '@angular/core';
import { CommonModule } from '@angular/common';
import { CreditCardMaskPipe } from './credit-card-mask.pipe';
import { CreditCardService } from './credit-card.service';
import { CreditCardComponent } from './credit-card.component';
@NgModule({
imports: [CommonModule],
declarations: [
CreditCardMaskPipe,
CreditCardComponent
],
providers: [CreditCardService],
exports: [CreditCardComponent]
})
export class CreditCardModule {}
```
`CreditCardModule`和`AppModule`很像,但是有几个很重要的区别:
- 我们不导入`BrowserModule`,而是导入`CommonModule`。 如果我们在这里看到`BrowserModule`的文档,我们可以看到它是重新导出`CommonModule`与许多其他服务,有助于在浏览器中呈现Angular 2应用程序。 这些服务将我们的根模块与特定平台(浏览器)耦合,但我们希望我们的特性模块与平台无关。 这就是为什么我们只导入`CommonModule,`它只导出公共指令和管道。
> 当涉及到组件,管道和指令时,每个模块都应该导入自己的依赖关系,而忽略在根模块或任何其他功能模块中导入相同的依赖关系。 总之,即使有多个特征模块,每个特征模块都需要导入`CommonModule`。
- 我们使用一个名为`exports`的新属性。 默认情况下,声明数组中定义的每个元素都是**私有的**。 我们应该只导出应用程序中其他模块需要执行的工作。 在我们的例子中,我们只需要使`CreditCardComponent`可见,因为它在`AppComponent`的模板中使用。
*app/app.component.ts*
```typescript
...
@Component({
...
template: `
...
<rio-credit-card></rio-credit-card>
`
})
export class AppComponent {}
```
> 我们保持`CreditCardMaskPipe`是私有的,因为它只在`CreditCardModule`中使用,没有其他模块应该直接使用它。
我们现在可以将此功能模块导入到我们的简化根模块中。
*app/app.module.ts*
```typescript
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { CreditCardModule } from '../credit-card/credit-card.module';
import { AppComponent } from './app.component';
@NgModule({
imports: [
BrowserModule,
CreditCardModule
],
declarations: [AppComponent],
bootstrap: [AppComponent]
})
export class AppModule { }
```
在这一点上,我们完成了,我们的应用程序按预期运行。
[View Example](https://plnkr.co/edit/0j1jS5PIHI8MAbZjECnK?p=preview)
## 服务和懒加载
这里是Angular模块的棘手部分。 除非明确导出组件,管道和指令的范围限于其模块,否则服务全局可用,除非模块延迟加载。
很难理解,首先,让我们试着看看在我们的例子中`CreditCardService`发生了什么。 首先请注意,服务不在`exports`数组中,而是在`providers`数组中。 有了这个配置,我们的服务将随处可用,即使在`AppComponent`,它居住在另一个模块。 所以,即使使用模块,没有办法有一个“私人”服务,除非...模块正在懒加载。
当模块被延迟加载时,Angular将创建一个子注入器(它是根模块的根注入器的一个子进程),并将在那里创建一个服务实例。
想象一下,我们的`CreditCardModule`配置为延迟加载。 使用我们当前的配置,当应用程序被引导并且我们的根模块被加载到内存中时,`CreditCardService`(一个单例)的一个实例将被添加到根注入器。 但是,当`CreditCardModule`在未来的某个时间被延迟加载时,将使用`CreditCardService`的新实例为该模块创建子注入器。 在这一点上,我们有一个分层注入器,具有相同服务的两个实例,这通常不是我们想要的。
考虑进行认证的服务的示例。 我们想在整个应用程序中只有一个单例,忽略我们的模块是在引导或延迟加载时加载。 因此,为了使我们的特性模块的服务**仅**添加到根注入器,我们需要使用不同的方法。
*credit-card/credit-card.module.ts*
```typescript
import { NgModule, ModuleWithProviders } from '@angular/core';
/* ...other imports... */
@NgModule({
imports: [CommonModule],
declarations: [
CreditCardMaskPipe,
CreditCardComponent
],
exports: [CreditCardComponent]
})
export class CreditCardModule {
static forRoot(): ModuleWithProviders {
return {
ngModule: CreditCardModule,
providers: [CreditCardService]
}
}
}
```
与以前不同,我们不是将我们的服务直接放在`NgModule`装饰器的`providers`属性。 这次我们定义一个称为`forRoot`的静态方法,其中我们定义模块和要导出的服务。
有了这个新的语法,我们的根模块略有不同。
*app/app.module.ts*
```typescript
/* ...imports... */
@NgModule({
imports: [
BrowserModule,
CreditCardModule.forRoot()
],
declarations: [AppComponent],
bootstrap: [AppComponent]
})
export class AppModule { }
```
你能发现差别吗? 我们不直接导入`CreditCardModule`,而是我们正在导入的是从`forRoot`方法返回的对象,其中包括`CreditCardService`。 尽管这种语法比原始语法更复杂,但它将保证我们只有一个`CreditCardService`实例被添加到根模块。 当`CreditCardModule`被加载(即使是延迟加载)时,该服务的新实例不会被添加到子注入器。
[View Example](https://plnkr.co/edit/nnyE8L4ciKCL2uBruM12?p=preview)
作为经验法则,在从功能模块导出服务时,**始终使用`forRoot`语法**,除非您有非常特殊的需求,需要在依赖注入树的不同级别有多个实例。 | 4,131 | MIT |
---
title: 小程序-实现类似新浪头条新闻上下间歇性滚动
autoGroup-1: 小程序实用案例
---
<div id="container">
## 小程序-实现类似新浪头条新闻上下间歇性滚动
## 快速导航
<TOC />
## 需求分析
在做用户信息展示页的时候,有时候需要将用户名,联系方式放置在前端展示,但是用户名与电话号码属于私密信息,需要做加密处理
这里的加密只是用于在前端展示特殊处理,也就是只显示姓,名字用特殊字符替代,电话号码:中间四位用\*替代,如下效果展示如下所示
<div align="center">
<img class="medium-zoom lazy" loading="lazy" src ="../images/new-scroll-up-down/notice-bar-scroll.gif" alt="效果展示" />
</div>
## 完成效果示例
<div align="center">
<img class="medium-zoom lazy" loading="lazy" width="500" height="500" src ="../images/new-scroll-up-down/demo-shixian.gif" alt="效果展示" />
</div>
## 实现方式
主要借助的是小程序官方提供的`swiper`组件,对于横向的,普通的轮播,很多小伙伴都不陌生,但是对于这种垂直方式的滚动,有些同学,可能比较棘手
## 完成页面布局
如下是`wxml`
```html
<view class="order-list-wrap">
<view class="order-title"><text>预约用户</text></view>
<swiper
class="swiper"
vertical="true"
autoplay="true"
circular="true"
interval="3000"
display-multiple-items="4"
>
<block wx:for="{{ orderLists }}" wx:key="*this">
<swiper-item>
<view class="swiper-item-box">
<view class="username">{{item.username}}</view>
<view>{{item.phonenumber}}</view>
<view>已预约</view>
<view>{{item.createtime}}</view>
</view>
</swiper-item>
</block>
</swiper>
</view>
```
这里主要借助的是`swiper`组件
- `vertical`的属性值为`true`,代表的是垂直方向
- `display-multiple-items`表示的是同时显示的滑块数量,这里设置的是显示 4 个
`swiper`组件中各个属性含义,具体可看参考文档[swiper 组件使用](https://developers.weixin.qq.com/miniprogram/dev/component/swiper.html)
如下是 wxss
::: details 点击即可查看详情
```css
.order-list-wrap {
padding: 10rpx 0 10rpx 0;
font-size: 28rpx;
background: #23d5ab;
margin: 0 20rpx 20rpx 20rpx;
color: #fff;
}
.order-title {
text-align: center;
padding: 8rpx;
}
.swiper {
height: 320rpx;
overflow: hidden;
}
.swiper-item-box {
display: flex;
justify-content: space-around;
border-bottom: 1px dashed #ede1d4;
}
.swiper-item-box view {
line-height: 80rpx;
}
.swiper-item-box .username {
width: 90rpx;
}
```
:::
如下预约列表的数据格式
```js
orderLists: [
{
phonenumber: 15210927743,
username: '杨海龙',
createtime: '2020-06-17T07:54:41.146Z',
},
{
createtime: '2020-06-18T13:35:02.944Z',
phonenumber: 13141467811,
username: '洋洋',
},
{
createtime: '2020-06-18T14:18:51.307Z',
phonenumber: '15210927639',
username: '郑霞',
},
{
phonenumber: 13801135148,
username: '王海勇',
createtime: '2020-06-17T07:53:34.584Z',
},
{
createtime: '2020-06-17T09:28:47.062Z',
phonenumber: 15810923375,
username: '向生明',
},
];
```
如果仅仅是这样,在页面中,姓名和电话号码会完全被显示,但是往往我们需要对姓名和电话进行特殊处理的
而这里的时间是从服务器返回给前端的时间,仍然需要做处理,进行转化
- **用户名格式化处理,保留姓氏**
::: details 点击即可查看详情
```js
// 格式化名字,只留姓,名字中间用*替代
function _formatName(name) {
let newStr;
if (name.length === 2) {
newStr = name.substr(0, 1) + '*'; // 通过substr截取字符串从第0位开始截取,截取1个
} else if (name.length > 2) {
// 当名字大于2位时
let char = '';
for (let i = 0, len = name.length - 2; i < len; i++) {
// 循环遍历字符串
char += '*';
}
newStr = name.substr(0, 1) + char + name.substr(-1, 1);
} else {
newStr = name;
}
return newStr;
}
console.log(_formatName('李海涛')); // 输出李*涛
```
:::
- **电话号码格式化处理**
::: details 点击即可查看详情
```js
// 格式化电话号码
function _formatPhone(phone) {
return `${phone.substr(0, 3)}****${phone.substr(7)}`;
}
console.log(_formatPhone(15210927743)); // 输出:15****7743
```
:::
- **时间格式化处理**
::: details 点击即可查看详情
```js
function _formatTime(date) {
let fmt = 'yyyy-MM-dd hh:mm:ss';
const o = {
'M+': date.getMonth() + 1, // 月份
'd+': date.getDate(), // 日
'h+': date.getHours(), // 小时
'm+': date.getMinutes(), // 分钟
's+': date.getSeconds(), // 秒
};
if (/(y+)/.test(fmt)) {
fmt = fmt.replace(RegExp.$1, date.getFullYear());
}
for (let k in o) {
if (new RegExp('(' + k + ')').test(fmt)) {
fmt = fmt.replace(
RegExp.$1,
o[k].toString().length == 1 ? '0' + o[k] : o[k]
);
}
}
// console.log(fmt)
return fmt;
}
console.log(_formatTime(new Date('2020-06-17T07:54:41.146Z'))); // 2020-06-18 21:35:02
```
:::
如下是完整的示例逻辑代码 JS
在实际开发中,这些数据是在小程序端请求云数据库,然后渲染到页面当中去的
::: details 完整示例代码
```js
// pages/profile/profile.js
const db = wx.cloud.database(); // 初始化数据库
Page({
/**
* 页面的初始数据
*/
data: {
orderLists: []
},
},
/**
* 生命周期函数--监听页面加载
*/
onLoad: function (options) {
this._getOrderMsgList(); // 获取预约用户信息列表
},
// 获取预约用户
_getOrderMsgList() {
db.collection('orderMessage')
.orderBy('createtime', 'desc') // 作了一个排序
.get()
.then(res => {
console.log(res);
const orderList = res.data;
const orderLists = orderList.map((item) => {
return {
username: this._formatName(item.username),
phonenumber: this._formatPhone(item.phonenumber),
createtime: this._formatTime(item.createtime)
}
})
this.setData({
orderLists,
})
})
.catch(err => {
console.error(err);
})
},
// 格式化名字,只留姓,名字中间用*替代
_formatName(name) {
let newStr;
if (name.length === 2) {
newStr = name.substr(0, 1) + '*'; // 通过substr截取字符串从第0位开始截取,截取1个
} else if (name.length > 2) { // 当名字大于2位时
let char = '';
for (let i = 0, len = name.length - 2; i < len; i++) { // 循环遍历字符串
char += '*';
}
newStr = name.substr(0, 1) + char + name.substr(-1, 1);
} else {
newStr = name;
}
return newStr;
},
// 格式化电话号码
_formatPhone(phone) {
return `${phone.substr(0, 3)}****${phone.substr(7)}`
},
// 格式化时间
_formatTime(date) {
let fmt = 'yyyy-MM-dd hh:mm:ss'
const o = {
'M+': date.getMonth() + 1, // 月份
'd+': date.getDate(), // 日
'h+': date.getHours(), // 小时
'm+': date.getMinutes(), // 分钟
's+': date.getSeconds(), // 秒
}
if (/(y+)/.test(fmt)) {
fmt = fmt.replace(RegExp.$1, date.getFullYear())
}
for (let k in o) {
if (new RegExp('(' + k + ')').test(fmt)) {
fmt = fmt.replace(RegExp.$1, o[k].toString().length == 1 ? '0' + o[k] : o[k])
}
}
// console.log(fmt)
return fmt
},
})
```
:::
当然,对于这个时间格式化处理,是灵活多变的,也是可以转化成格式`刚刚`,`几分钟前`,`几小时前`,`几天前`,`几个月前`的
您可以扫下面的小程序码,感受一下示例的
<div align="center">
<img class="medium-zoom lazy" loading="lazy" width="200" height="200" src ="../images/new-scroll-up-down/jiahaoruisen-min-code.jpg" alt="佳豪瑞森装饰" />
</div>
如下示例代码所示
::: details 点击即可查看详情
```js
function _formatTimeDetail() {
var pretime = '2020-06-20 14:38:16'; // 将整个时间格式转换为几分钟前,几小时前,几个月之前等
var minute = 1000 * 60;
var hour = minute * 60;
var day = hour * 24;
var halfamonth = day * 15;
var month = day * 30;
getDate(pretime);
//然后再每隔一分钟更新一次时间
setInterval(function() {
getDate(pretime);
}, 60000);
function getDate(dateTimeStamp) {
if (dateTimeStamp == undefined) {
return false;
} else {
dateTimeStamp = dateTimeStamp.replace(/\-/g, '/');
var sTime = new Date(dateTimeStamp).getTime(); //把时间pretime的值转为时间戳
var now = new Date().getTime(); //获取当前时间的时间戳
var diffValue = now - sTime;
if (diffValue < 0) {
return false;
}
var monthC = diffValue / month;
var weekC = diffValue / (7 * day);
var dayC = diffValue / day;
var hourC = diffValue / hour;
var minC = diffValue / minute;
if (monthC >= 1) {
console.log(parseInt(monthC) + '个月前');
return `${parseInt(monthC)}个月前`;
} else if (weekC >= 1) {
console.log(parseInt(weekC) + '周前');
return `${parseInt(weekC)}周前`;
} else if (dayC >= 1) {
console.log(parseInt(dayC) + '天前');
return `${parseInt(weekC)}天前`;
} else if (hourC >= 1) {
console.log(parseInt(hourC) + '个小时前');
return `${parseInt(hourC)}个小时前`;
} else if (minC >= 1) {
console.log(parseInt(minC) + '分钟前');
return `${parseInt(minC)}分钟前`;
} else {
console.log('刚刚');
return '刚刚';
}
}
}
return getDate(pretime);
}
_formatTimeDetail(); // 3小时前,上面的传入的是可控制的
```
:::
上面的代码无论是在小程序中还是在网页中,直接在控制台,测试一下就知道这个函数具体是做什么的
前面那个`_formatTime`函数主要是将服务器端的时间转化为类似这种`2020-06-20 14:38:16`格式,而后面的`_formatTimeDetail`这个函数是将`年-月-日 时 分 秒`这种格式转化为多少分钟前,几天前,几周前等这种格式
关于用户名与手机号的处理方式,也可参考[用户名-手机号加密特殊处理](/fontend/js/utils-name-mobile-encrye)
## 结语
本文主要介绍了利用`swiper`这个组件实现类似新浪头条上下间歇性滚动的效果,并怎么对用户名,电话号码在小程序端进行加密处理
注意,这个用户名和电话号码,存到数据库当中是完整的,我们只是从云数据库中读取到这个数据后,然后做特殊处理的
还有就是怎么将时间进行格式化,转化为自己想要的格式,对于新手来说,这是一个难点,也比较灵活多变,具体需求,具体分析
</div>
<footer-FooterLink :isShareLink="true" :isDaShang="true" />
<footer-FeedBack /> | 8,509 | MIT |
---
layout: post
title: "一步一步开始使用redis缓存"
categories: redis
tags: redis
author: hanjianchun
---
* content
{:toc}
项目里的API提供接口调用,每个用户每日限制调用次数,之前用的memcached缓存,缓存的key是用户ID+日期,过期时间是1天。这么做没什么毛病,虽然memcached速度快但是不能持久化。所以现在改用redis来缓存每日每个用户的访问次数。
## 安装redis
>首先到[https://redis.io/download](https://redis.io/download "redis官网")去下载最新的redis*.tar.gz,我下载的是3.2.8版本。
>将redis放到某个文件夹里然后运行命令
$ tar xzf redis-3.2.8.tar.gz
$ cd redis-3.2.8
$ make && make install
>到这里就安装完成了!之后启动redis server
$ src/redis-server
>使用命令查看redis服务是否启动
$ ps -ef | grep redis
>使用客户端验证是否安装成功:
$ src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
## 在项目里使用redis
>首次连接会发现无法连接redis,因为redis有保护模式,在redis.conf里面去掉保护模式,然后启动的时候指定配置文件 src/redis-server redis.conf
protected-mode no
>需要redis的jar包,去maven仓库搜索jedis就会出现,使用jedis作为redis的客户端
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
> 1.新建redis.properties作为自己的配置文件,里面存储redis的一些连接配置信息
redis.master.server.ip=10.20.70.89
redis.master.server.port=6379
redis.master.pool.max_active=50
redis.master.pool.max_idle=5
redis.master.pool.max_wait=1000
redis.master.pool.testOnBorrow=true
redis.master.pool.testOnReturn=true
> 2.新建redis客户端jedis缓冲池类 RedisClientPool.java
```java
public class RedisClientPool {
public static JedisPool pool;
public static JedisPool getPool() {
if (pool == null) {
ResourceBundle bundle = ResourceBundle.getBundle("redis");
if (bundle == null) {
throw new IllegalArgumentException("[redis.properties] is not found!");
}
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(Integer.valueOf(bundle.getString("redis.master.pool.max_active")));
config.setMaxIdle(Integer.valueOf(bundle.getString("redis.master.pool.max_idle")));
config.setMaxWaitMillis(Long.valueOf(bundle.getString("redis.master.pool.max_wait")));
config.setTestOnBorrow(Boolean.valueOf(bundle.getString("redis.master.pool.testOnBorrow")));
config.setTestOnReturn(Boolean.valueOf(bundle.getString("redis.master.pool.testOnReturn")));
pool = new JedisPool(config, bundle.getString("redis.master.server.ip"), Integer.valueOf(bundle.getString("redis.master.server.port")));
}
return pool;
}
}
```
> 3.新建一个redis的工具类,操作缓存 RedisClientUtils.java
```java
public class RedisClientUtils {
/**
* 判断该键是否存在,存在返回1,否则返回0
*
* @param key
* @return
*/
public static boolean exists(final String key) {
Jedis jedis = RedisClientPool.getPool().getResource();
boolean bool = jedis.exists(key);
RedisClientPool.getPool().returnResource(jedis);
return bool;
}
/**
* 设定该Key持有指定的字符串Value,如果该Key已经存在,则覆盖其原有值。
*
* @param key
* @param value
*/
public static void set(final String key, final String value) {
Jedis jedis = RedisClientPool.getPool().getResource();
jedis.set(key, value);
RedisClientPool.getPool().returnResource(jedis);
}
/**
* 获取指定Key的Value,如果该Key不存在,返回null。
*
* @param key
* @return
*/
public static String get(final String key) {
Jedis jedis = RedisClientPool.getPool().getResource();
String str = jedis.get(key);
RedisClientPool.getPool().returnResource(jedis);
return str;
}
/**
* 删除指定的Key
*
* @param keys
* @return
*/
public static long delete(final String... keys) {
Jedis jedis = RedisClientPool.getPool().getResource();
long l = jedis.del(keys);
RedisClientPool.getPool().returnResource(jedis);
return l;
}
/**
* 命名指定的Key, 如果参数中的两个Keys的命令相同,或者是源Key不存在,该命令都会返回相关的错误信息。如果newKey已经存在,则直接覆盖。
*
* @param oldkey
* @param newkey
*/
public static void rename(final String oldkey, final String newkey) {
Jedis jedis = RedisClientPool.getPool().getResource();
jedis.rename(oldkey, newkey);
RedisClientPool.getPool().returnResource(jedis);
}
/**
* 设置某个key的过期时间(单位:秒), 在超过该时间后,Key被自动的删除。如果该Key在超时之前被修改,与该键关联的超时将被移除。
*
* @param key
* @param seconds
* @return
*/
public static void setTime(final String key, final int seconds) {
Jedis jedis = RedisClientPool.getPool().getResource();
jedis.expire(key, seconds);
RedisClientPool.getPool().returnResource(jedis);
}
/**
* 在指定Key所关联的List
* Value的头部插入参数中给出的所有Values。如果该Key不存在,该命令将在插入之前创建一个与该Key关联的空链表
* ,之后再将数据从链表的头部插入。如果该键的Value不是链表类型,该命令将返回相关的错误信息。
*
* @param key
* @param obj
* @return
*/
public static boolean leftPush(String key, Object obj) {
if (StringUtils.isBlank(key) || obj == null) {
return false;
}
Jedis jedis = RedisClientPool.getPool().getResource();
jedis.lpush(SerializeUtil.serialize(key), SerializeUtil.serialize(obj));
RedisClientPool.getPool().returnResource(jedis);
return true;
}
/**
* 存入list对象,不覆盖之前在原来的key基础上存
*
* @param key
* @param objList
* @return
*/
public static boolean listPush(String key, List<Object> objList) {
if (StringUtils.isBlank(key) || objList == null) {
return false;
}
Jedis jedis = RedisClientPool.getPool().getResource();
for (Object object : objList) {
if (object != null) {
jedis.lpush(SerializeUtil.serialize(key), SerializeUtil.serialize(object));
}
}
RedisClientPool.getPool().returnResource(jedis);
return true;
}
/**
* 存入object数组对象,不覆盖之前在原来的key基础上存
*
* @param key
* @param objs
* @return
*/
public static boolean listPush(String key, Object... objs) {
if (StringUtils.isBlank(key) || objs.length <= 0) {
return false;
}
Jedis jedis = RedisClientPool.getPool().getResource();
for (Object obj : objs) {
if (obj != null) {
jedis.lpush(SerializeUtil.serialize(key), SerializeUtil.serialize(obj));
}
}
RedisClientPool.getPool().returnResource(jedis);
return true;
}
/**
* 在指定Key所关联的List
* Value的尾部插入参数中给出的所有Values。如果该Key不存在,该命令将在插入之前创建一个与该Key关联的空链表
* ,之后再将数据从链表的尾部插入。如果该键的Value不是链表类型,该命令将返回相关的错误信息。
*
* @param key
* @param obj
* @return
*/
public static boolean rightPush(String key, Object obj) {
if (StringUtils.isBlank(key) || obj == null) {
return false;
}
Jedis jedis = RedisClientPool.getPool().getResource();
jedis.rpush(SerializeUtil.serialize(key), SerializeUtil.serialize(obj));
RedisClientPool.getPool().returnResource(jedis);
return true;
}
/**
* 查询list类型的缓存数据
*
* @param key
* @return
*/
public static List<Object> getListValueByKey(String key) {
Jedis jedis = RedisClientPool.getPool().getResource();
List<Object> valueList = new ArrayList<Object>();
long size = jedis.llen(SerializeUtil.serialize(key));
if (size > 0) {
List<byte[]> tempList = jedis.lrange(SerializeUtil.serialize(key), 0, -1);
if (tempList != null) {
for (byte[] temp : tempList) {
Object obj = SerializeUtil.unserialize(temp);
valueList.add(obj);
}
}
}
RedisClientPool.getPool().returnResource(jedis);
return valueList;
}
/**
* 根据条件删除缓存队列
*
* @param key
*/
public static void removeListTypeRedisByKey(String key) {
Jedis jedis = RedisClientPool.getPool().getResource();
long size = jedis.llen(SerializeUtil.serialize(key));
if (size > 0) {
for (int i = 0; i < size; i++) {
jedis.lpop(SerializeUtil.serialize(key));
}
}
RedisClientPool.getPool().returnResource(jedis);
}
}
```
> 4.有了这些后就可以开始测试缓存工具类的使用
//放数据
RedisClientUtils.set("han", "value");
//取数据
RedisClientUtils.get("han");
其它的方法需要自己去摸索尝试
## redis与Spring项目整合
>不同之处在于将缓冲池交给redis进行管理
<!-- master连接池参数 -->
<bean id="masterPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- <property name="maxActive" value="${redis.master.pool.max_active}"/> -->
<property name="maxIdle" value="${redis.master.pool.max_idle}" />
<property name="maxWaitMillis" value="${redis.master.pool.max_wait}" />
<property name="testOnBorrow" value="${redis.master.pool.testOnBorrow}" />
<property name="testOnReturn" value="${redis.master.pool.testOnReturn}" />
</bean>
<bean id="jedisPool" class="redis.clients.jedis.JedisPool"
destroy-method="destroy">
<constructor-arg index="0" ref="masterPoolConfig" />
<constructor-arg index="1" value="${redis.master.server.ip}" />
<constructor-arg index="2" value="${redis.master.server.port}" type="int" />
</bean>
> 访问客户端,这里仅提供操作key的一个方法,还可以操作List,Hash,Set,String等
```java
@Service
public class JedisService {
private static final int REDIS_DB_INDEX = 0;
private static Logger LOG = LoggerFactory.getLogger(JedisService.class.getSimpleName());
@Autowired
private JedisPool jedisPool;
private void saveAndReturnResource(Jedis jedis) {
String result = jedis.save();
LOG.debug("Redis数据保存结果:{}", result);
returnResource(jedis);
}
private void returnResource(Jedis jedis){
jedisPool.returnResource(jedis);
}
private Jedis getJedis(){
Jedis jedis = jedisPool.getResource();
String select = jedis.select(REDIS_DB_INDEX);
LOG.debug("Redis {}号数据库选择结果:{}", REDIS_DB_INDEX, select);
return jedis;
}
/**
* 清空当前数据库
* @return 状态码
* */
public String flushDB() {
Jedis jedis = getJedis();
String stata = jedis.flushDB();
saveAndReturnResource(jedis);
return stata;
}
/**操作Key的方法*/
public Keys KEYS = new Keys();
public class Keys {
/**
* 更改key
* @param String oldkey
* @param String newkey
* @return 状态码
* */
public String rename(String oldkey, String newkey) {
return rename(SafeEncoder.encode(oldkey), SafeEncoder.encode(newkey));
}
/**
* 更改key,仅当新key不存在时才执行
* @param String oldkey
* @param String newkey
* @return 状态码
* */
public long renamenx(String oldkey, String newkey) {
Jedis jedis = getJedis();
long status = jedis.renamenx(oldkey, newkey);
saveAndReturnResource(jedis);
return status;
}
/**
* 更改key
* @param String oldkey
* @param String newkey
* @return 状态码
* */
public String rename(byte[] oldkey, byte[] newkey) {
Jedis jedis = getJedis();
String status = jedis.rename(oldkey, newkey);
saveAndReturnResource(jedis);
return status;
}
/**
* 设置key的过期时间,以秒为单位
* @param String key
* @param 时间,已秒为单位
* @return 影响的记录数
* */
public long expired(String key, int seconds) {
Jedis jedis = getJedis();
long count = jedis.expire(key, seconds);
returnResource(jedis);
return count;
}
/**
* 设置key的过期时间,它是距历元(即格林威治标准时间 1970 年 1 月 1 日的 00:00:00,格里高利历)的偏移量。
* @param String key
* @param 时间,已秒为单位
* @return 影响的记录数
* */
public long expireAt(String key, long timestamp) {
Jedis jedis = getJedis();
long count = jedis.expireAt(key, timestamp);
returnResource(jedis);
return count;
}
/**
* 查询key的过期时间
* @param String key
* @return 以秒为单位的时间表示
* */
public long ttl(String key) {
Jedis jedis = getJedis();
long len = jedis.ttl(key);
returnResource(jedis);
return len;
}
/**
* 取消对key过期时间的设置
*@param key
*@return 影响的记录数
* */
public long persist(String key) {
Jedis jedis = getJedis();
long count = jedis.persist(key);
returnResource(jedis);
return count;
}
/**
* 删除keys对应的记录,可以是多个key
* @param String... keys
* @return 删除的记录数
* */
public long del(String... keys) {
Jedis jedis = getJedis();
long count = jedis.del(keys);
saveAndReturnResource(jedis);
return count;
}
/**
* 删除keys对应的记录,可以是多个key
* @param String... keys
* @return 删除的记录数
* */
public long del(byte[]... keys) {
Jedis jedis = getJedis();
long count = jedis.del(keys);
saveAndReturnResource(jedis);
return count;
}
/**
* 判断key是否存在
* @param String key
* @return boolean
* */
public boolean exists(String key) {
Jedis jedis = getJedis();
boolean exis = jedis.exists(key);
returnResource(jedis);
return exis;
}
/**
* 对List,Set,SortSet进行排序,如果集合数据较大应避免使用这个方法
* @param String key
* @return List<String> 集合的全部记录
* **/
public List<String> sort(String key) {
Jedis jedis = getJedis();
List<String> list = jedis.sort(key);
saveAndReturnResource(jedis);
return list;
}
/**
* 对List,Set,SortSet进行排序或limit
* @param String key
* @param SortingParams parame 定义排序类型或limit的起止位置.
* @return List<String> 全部或部分记录
* **/
public List<String> sort(String key, SortingParams parame) {
Jedis jedis = getJedis();
List<String> list = jedis.sort(key, parame);
saveAndReturnResource(jedis);
return list;
}
/**
* 返回指定key存储的类型
* @param String key
* @return String string|list|set|zset|hash
* **/
public String type(String key) {
Jedis jedis = getJedis();
String type = jedis.type(key);
returnResource(jedis);
return type;
}
/**
* 查找所有匹配给定的模式的键
* @param String key的表达式,*表示多个,?表示一个
* */
public Set<String> kyes(String pattern) {
Jedis jedis = getJedis();
Set<String> set = jedis.keys(pattern);
returnResource(jedis);
return set;
}
}
}
```
> redis不提供直接存储实体类的功能,当时可以先把实体类转为bytes[],然后存入,取得时候再反转一下,下面是工具类:
```java
public class SerializeUtil {
public static byte[] serialize(Object object) {
ObjectOutputStream oos = null;
ByteArrayOutputStream baos = null;
try {
//序列化
baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(object);
byte[] bytes = baos.toByteArray();
return bytes;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static Object unserialize(byte[] bytes) {
ByteArrayInputStream bais = null;
try {
//反序列化
bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
} catch (Exception e) {
}
return null;
}
}
```
## 结束
到这里如何在项目里使用redis就结束了,欢迎讨论! | 13,695 | MIT |
---
layout: post
title: "這就是沒有娶上媳婦的下場,所以年輕人一定要努力,否則晚年可悲"
date: 2021-03-22T04:30:01.000Z
author: 盧保貴視覺影像
from: https://www.youtube.com/watch?v=be-YooVQ2LU
tags: [ 盧保貴 ]
categories: [ 盧保貴 ]
---
<!--1616387401000-->
[這就是沒有娶上媳婦的下場,所以年輕人一定要努力,否則晚年可悲](https://www.youtube.com/watch?v=be-YooVQ2LU)
------
<div>
期待影像能為將來保留文獻,給人們帶來更多的意義與思考。希望大家訂閱我們的頻道,多多支持我們!#盧保貴視覺影像#珍貴攝影#三農
</div> | 375 | MIT |
---
title: 行集和参数中的数据类型映射 |Microsoft 文档
description: 行集和参数中的数据类型映射
ms.custom: ''
ms.date: 03/26/2018
ms.prod: sql
ms.prod_service: database-engine, sql-database, sql-data-warehouse, pdw
ms.component: ole-db-data-types
ms.reviewer: ''
ms.suite: sql
ms.technology: connectivity
ms.tgt_pltfrm: ''
ms.topic: reference
helpviewer_keywords:
- mapping data types [OLE DB]
- DBTYPE_SQLVARIANT data type
- OLE DB Driver for SQL Server, data types
- rowsets [OLE DB], data type mapping
- data types [OLE DB]
- GetColumnInfo function
- parameters [OLE DB]
- SSPROP_ALLOWNATIVEVARIANT property
- GetParameterInfo function
- OLE DB, data types
author: pmasl
ms.author: Pedro.Lopes
manager: craigg
ms.openlocfilehash: 4e44de3f10573d9ef892999ad933756cfa737863
ms.sourcegitcommit: 1740f3090b168c0e809611a7aa6fd514075616bf
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 05/03/2018
---
# <a name="data-type-mapping-in-rowsets-and-parameters"></a>行集和参数中的数据类型映射
[!INCLUDE[appliesto-ss-asdb-asdw-pdw-md](../../../includes/appliesto-ss-asdb-asdw-pdw-md.md)]
SQL Server 的 OLE DB 驱动程序在行集和作为参数值,表示[!INCLUDE[ssNoVersion](../../../includes/ssnoversion-md.md)]通过使用以下 OLE DB 的数据定义的数据类型,在函数中报告**IColumnsInfo::GetColumnInfo**和**ICommandWithParameters::GetParameterInfo**。
|SQL Server 数据类型|OLE DB 数据类型|
|--------------------------|----------------------|
|**bigint**|DBTYPE_I8|
|**binary**|DBTYPE_BYTES|
|**bit**|DBTYPE_BOOL|
|**char**|DBTYPE_STR|
|**datetime**|DBTYPE_DBTIMESTAMP|
|**datetime2**|DBTYPE_DBTIME2|
|**decimal**|DBTYPE_NUMERIC|
|**float**|DBTYPE_R8|
|**image**|DBTYPE_BYTES|
|**int**|DBTYPE_I4|
|**money**|DBTYPE_CY|
|**nchar**|DBTYPE_WSTR|
|**ntext**|DBTYPE_WSTR|
|**numeric**|DBTYPE_NUMERIC|
|**nvarchar**|DBTYPE_WSTR|
|**real**|DBTYPE_R4|
|**smalldatetime**|DBTYPE_DBTIMESTAMP|
|**int**|DBTYPE_I2|
|**smallmoney**|DBTYPE_CY|
|**sql_variant**|DBTYPE_VARIANT、DBTYPE_SQLVARIANT|
|**sysname**|DBTYPE_WSTR|
|**text**|DBTYPE_STR|
|**timestamp**|DBTYPE_BYTES|
|**tinyint**|DBTYPE_UI1|
|**UDT**|DBTYPE_UDT|
|**uniqueidentifier**|DBTYPE_GUID|
|**varbinary**|DBTYPE_BYTES|
|**varchar**|DBTYPE_STR|
|**XML**|DBTYPE_XML|
SQL Server 的 OLE DB 驱动程序支持使用者请求数据转换图中所示。
**Sql_variant**对象可以保存数据的任何[!INCLUDE[ssNoVersion](../../../includes/ssnoversion-md.md)]数据类型除外文本、 ntext、 图像、 varchar (max)、 nvarchar (max)、 varbinary (max)、 xml、 时间戳和 Microsoft.NET Framework 公共语言运行时 (CLR)用户定义的类型。 另外,sql_variant 数据实例还不能将 sql_variant 作为其基础的基本数据类型。 例如,列可以包含**smallint**某些行的值**float**其他行的值和**char**/**nchar**的其余部分中的值。
> [!NOTE]
> **Sql_variant**数据类型是类似于在 Microsoft Visual Basic® 和 DBTYPE_VARIANT、 DBTYPE_SQLVARIANT 中 OLEDB Variant 数据类型。
当**sql_variant**作为 DBTYPE_VARIANT 提取数据,它将放入缓冲区中的变体结构。 变体结构中的子类型可能不会映射到在中定义的子类型,但**sql_variant**数据类型。 **Sql_variant**数据必须然后提取作为 DBTYPE_SQLVARIANT 顺序以匹配的所有子类型。
## <a name="dbtypesqlvariant-data-type"></a>DBTYPE_SQLVARIANT 数据类型
若要支持**sql_variant**数据类型,用于 SQL Server 的 OLE DB 驱动程序公开了调用 DBTYPE_SQLVARIANT 一个提供程序特定数据类型。 当**sql_variant**作为 DBTYPE_SQLVARIANT 提取数据,它存储在提供程序特定 SSVARIANT 结构。 SSVARIANT 结构包含所有匹配的子类型的子类型**sql_variant**数据类型。
此外,还必须将 SSPROP_ALLOWNATIVEVARIANT 会话属性设置为 TRUE。
## <a name="provider-specific-property-sspropallownativevariant"></a>特定于访问接口的 SSPROP_ALLOWNATIVEVARIANT 属性
提取数据时,您可以显式指定应为列或参数返回的数据类型。 **IColumnsInfo**还可获取列信息并使用它进行绑定。 当**IColumnsInfo**用来获取列信息出于绑定目的,如果属性为 FALSE (默认值),SSPROP_ALLOWNATIVEVARIANT 会话,将返回 DBTYPE_VARIANT **sql_variant**列。 如果 SSPROP_ALLOWNATIVEVARIANT 属性为 FALSE,则不支持 DBTYPE_SQLVARIANT。 如果 SSPROP_ALLOWNATIVEVARIANT 属性设置为 TRUE,列类型将作为 DBTYPE_SQLVARIANT 返回,在这种情况下,缓冲区将保留 SSVARIANT 结构。 在提取**sql_variant**数据作为 DBTYPE_SQLVARIANT,会话属性 SSPROP_ALLOWNATIVEVARIANT 必须设置为 TRUE。
SSPROP_ALLOWNATIVEVARIANT 属性是特定于访问接口的 DBPROPSET_SQLSERVERSESSION 属性集的一部分,因此,该属性是一个会话属性。
DBTYPE_VARIANT 适用于所有其他 OLE DB 访问接口。
## <a name="sspropallownativevariant"></a>SSPROP_ALLOWNATIVEVARIANT
SSPROP_ALLOWNATIVEVARIANT 是一个会话属性,并且是 DBPROPSET_SQLSERVERSESSION 属性集的一部分。
|||
|-|-|
|SSPROP_ALLOWNATIVEVARIANT|类型:VT_BOOL<br /><br /> R/W:读/写<br /><br /> 默认值:VARIANT_FALSE<br /><br /> 说明:确定提取的数据是作为 DBTYPE_VARIANT 还是作为 DBTYPE_SQLVARIANT。<br /><br /> VARIANT_TRUE:列类型作为 DBTYPE_SQLVARIANT 返回,这种情况下缓冲区将保留 SSVARIANT 结构。<br /><br /> VARIANT_FALSE:列类型作为 DBTYPE_VARIANT 返回,且缓冲区将具有 VARIANT 结构。|
## <a name="see-also"></a>另请参阅
[数据类型 & #40; OLE DB & #41;](../../oledb/ole-db-data-types/data-types-ole-db.md) | 4,481 | CC-BY-4.0 |
---
layout: post
title: 奥里与迷失之森
date: 2017-9-17 01:21
comments: true
reward: true
tags:
- Game
---
奥里与迷失之森,Ori and the blind forest,是由Moon Studios GmbH研发的一款动作游戏,于2015年3月11日发行。该游戏采用的是2D画面,但是有3D效果,和《雷曼》颇有几分相似之处,只不过色调更加阴暗。游戏讲述的是奥里(Ori)在一场暴风雨中被吹离了世界树后的一次次奇遇。
<!-- more -->
<embed id="STK_137722048114034" width="640" height="480" wmode="transparent" quality="high" allowfullscreen="true" flashvars="playMovie=true&auto=1" pluginspage="http://get.adobe.com/cn/flashplayer/" allowscriptaccess="never" src="http://static.hdslb.com/miniloader.swf?aid=2129528&page=1" type="application/x-shockwave-flash" style="visibility: visible;"></embed> | 641 | CC0-1.0 |
# CN Address Parse
国内地址地区智能解析,无需完整地址也能正确匹配
如有识别不准的地址请 [issuse](https://github.com/akebe/address-parse/issues)
可通过这个简单的页面在线测试一下识别精度
[address parse 地址解析测试](https://asseek.gitee.io/address-parse/)
### Install
`npm install address-parse --save`
### Start
````
import AddressParse from 'address-parse';
const [result] = AddressParse.parse('福建省福州市福清市石竹街道义明综合楼3F,15000000000,asseek');
console.log(result);
/*
{
'province': '福建省',
'city': '福州市',
'area': '福清市',
'details': '石竹街道义明综合楼3F',
'name': 'asseek',
'code': '350181',
'__type': 'parseByProvince', //结果解析使用函数 parseByProvince parseByCity parseByArea
'__parse': 4, //数值越高 可信度越高
'mobile': '15000000000',
'zip_code': '',
'phone': '',
};
*/
````
parse默认识别到第一个可信结果就会返回内容,但这不一定准确,特别是没有正确省市区的地址
这时如果传入第二个参数会执行所有解析方法,并将所有解析内容返回
内部有进行判断,可信度较高的地址会在数组前面
````
const [result, ...results] = AddressParse.parse('张l,15222222222,和林格尔 盛乐经济工业园区内蒙古师范大学盛乐校区', true);
console.log(result, results);
````
包内暴露了地址数据对象`AREA`和工具函数对象`Utils`
````
import AddressParse, {AREA, Utils} from 'address-parse';
const {
province_list, // 以地区编码为键名的省份对象
city_list, // 以地区编码为键名的城市对象
area_list, // 以地区编码为键名的地区对象
} = AREA;
// 通过地区编码返回省市区对象
const {province, city, area, code} = Utils.getAreaByCode('350181');
// 根据省市县类型和对应的code获取数据列表
const list = Utils.getTargetAreaListByCode('city', '350000'); //获得福建所有城市
list = Utils.getTargetAreaListByCode('area', '350000'); //获得福建所有地区
// 传入第三个参数返回code父级
const [province, city] = Utils.getTargetAreaListByCode('province', '350181', true);
const [city] = Utils.getTargetAreaListByCode('city', '350181', true);
// 非标准地区对象转换为标准地区对象
const result = Utils.getAreaByAddress({province: '福建', city: '福州', area: '福清'});
// {"code":"350181","province":"福建省","city":"福州市","area":"福清市"}
// 提供几个内置正则表达式
Utils.Reg. //mobile phone zipCode
````
### 页面直接引入使用
已打包成单文件`dist/bundle.js`
可以直接通过标签引用
```
<script src="./bundle.js"></script>
<script>
var results = AddressParse.parse('福建省福州市福清市石竹街道义明综合楼3F,15000000000,asseek');
console.log(results);
</script>
```
可以使用全局变量`AddressParse`来调用。
包内暴露的方法已经直接挂载在`AddressParse`实例上以供调用
### 组件库
[element-address](https://github.com/akebe/element-address)
基于 [address-parse](https://github.com/akebe/address-parse) 通过 [element-ui](https://github.com/ElemeFE/element) 实现的即开即用地址类组件库
### LICENSE
[MIT](https://en.wikipedia.org/wiki/MIT_License) | 2,394 | MIT |
---
title: "Data Factory - 名前付け規則 | Microsoft Docs"
description: "Data Factory エンティティの名前付け規則について説明します。"
services: data-factory
documentationcenter:
author: sharonlo101
manager: jhubbard
editor: monicar
ms.assetid: bc5e801d-0b3b-48ec-9501-bb4146ea17f1
ms.service: data-factory
ms.workload: data-services
ms.tgt_pltfrm: na
ms.devlang: na
ms.topic: article
ms.date: 12/05/2016
ms.author: shlo
translationtype: Human Translation
ms.sourcegitcommit: 219dcbfdca145bedb570eb9ef747ee00cc0342eb
ms.openlocfilehash: db9bdc5eeedf5f57605862ea7e8c2cfe63074b19
---
# <a name="azure-data-factory---naming-rules"></a>Azure Data Factory - 名前付け規則
次の表に、Data Factory アーティファクトの名前付け規則を示します。
| 名前 | 名前の一意性 | 検証チェック |
|:--- |:--- |:--- |
| Data Factory |Microsoft Azure 全体で一意です。 名前の大文字と小文字を区別されません。つまり、MyDF と mydf は同じデータ ファクトリを表します。 |<ul><li>各データ ファクトリは、厳密に 1 つの Azure サブスクリプションに関連付けられます。</li><li>オブジェクト名は英文字または数字で始まり、英文字、数字、ダッシュ (-) 文字のみを含めることができます。</li><li>すべてのダッシュ (-) 文字は、その直前または直後に文字または数字が使用されている必要があります。 連続するダッシュ文字はコンテナー名では使用できません。</li><li>名前は 3 ~ 63 文字の長さにすることができます。</li></ul> |
| リンクされたサービス/テーブル/パイプライン |データ ファクトリ内で一意です。 名前の大文字と小文字は区別されません。 |<ul><li>テーブル名の最大文字数: 260。</li><li>オブジェクト名は、文字、数字、アンダー スコア (_) のいずれかで始める必要があります。</li><li>次の文字は使用できません: "."、"+"、"?"、"/"、"<"、">"、"*"、"%"、"&"、":"、"\\"</li></ul> |
| [リソース グループ] |Microsoft Azure 全体で一意です。 名前の大文字と小文字は区別されません。 |<ul><li>最大文字数: 1,000。</li><li>名前には、文字、数字、および、次の文字を含めることができます。"-"、"_"、"," および "."。</li></ul> |
<!--HONumber=Nov16_HO3--> | 1,499 | CC-BY-3.0 |
# Spring Event 阅读指南
- 资料: https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#context-functionality-events
- 作者: [Huifer](https://github.com/huifer)
## 核心类
1. ApplicationEvent: 事件对象
1. ApplicationListener: 事件监听器
1. ApplicationEventPublisher: 事件发布者
## Spring 所提供的事件类
- 资料来自: https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#context-functionality-events
| Event | Explanation | 作用 |
| :--------------------------- | :----------------------------------------------------------- | ------------------------------------ |
| `ContextRefreshedEvent` | Published when the `ApplicationContext` is initialized or refreshed (for example, by using the `refresh()` method on the `ConfigurableApplicationContext` interface). Here, “initialized” means that all beans are loaded, post-processor beans are detected and activated, singletons are pre-instantiated, and the `ApplicationContext` object is ready for use. As long as the context has not been closed, a refresh can be triggered multiple times, provided that the chosen `ApplicationContext` actually supports such “hot” refreshes. For example, `XmlWebApplicationContext` supports hot refreshes, but `GenericApplicationContext` does not. | 上下文刷新事件 |
| `ContextStartedEvent` | Published when the `ApplicationContext` is started by using the `start()` method on the `ConfigurableApplicationContext` interface. Here, “started” means that all `Lifecycle` beans receive an explicit start signal. Typically, this signal is used to restart beans after an explicit stop, but it may also be used to start components that have not been configured for autostart (for example, components that have not already started on initialization). | 上下文初始化事件 |
| `ContextStoppedEvent` | Published when the `ApplicationContext` is stopped by using the `stop()` method on the `ConfigurableApplicationContext` interface. Here, “stopped” means that all `Lifecycle` beans receive an explicit stop signal. A stopped context may be restarted through a `start()` call. | 上下文停止事件 |
| `ContextClosedEvent` | Published when the `ApplicationContext` is being closed by using the `close()` method on the `ConfigurableApplicationContext` interface or via a JVM shutdown hook. Here, "closed" means that all singleton beans will be destroyed. Once the context is closed, it reaches its end of life and cannot be refreshed or restarted. | 上下文关闭事件 |
| `RequestHandledEvent` | A web-specific event telling all beans that an HTTP request has been serviced. This event is published after the request is complete. This event is only applicable to web applications that use Spring’s `DispatcherServlet`. | 请求处理事件 |
| `ServletRequestHandledEvent` | A subclass of `RequestHandledEvent` that adds Servlet-specific context information. | 对于 `RequestHandledEvent`的增强事件 |
## 阅读事件相关源码
- 首先我们对核心类进行基本分析, 事件一般包括事件本体、事件处理者、事件发布者. Spring 中的事件核心类如何和前三者进行映射
1. ApplicationEvent: 事件本体
1. ApplicationListener: 事件处理者
1. ApplicationEventPublisher: 事件发布者
### ApplicationEvent
首先我们来看 `ApplicationEvent`
下面是一张关于 `ApplicationEvent` 的类图

看一下`ApplicationEvent`成员变量的信息
1. `timestamp`: 事件发生的时间戳
2. `source`: 事件传递的信息 (由 JDK 中 `EventObject` 提供)
### ApplicationListener
其次我们来看`ApplicationListener`对象
这是一个处理事件的接口, 详细代码如下
```java
@FunctionalInterface
public interface ApplicationListener<E extends ApplicationEvent> extends EventListener {
/**
* Handle an application event.
* 处理事件
* @param event the event to respond to
*/
void onApplicationEvent(E event);
}
```

- 在这产生一个疑问: 这么多实现类如何找到对应的事件和事件处理类
- 从 `ApplicationListener` 的泛型上可以得到一定的信息. 比如我需要查询`ContextRefreshedEvent`的事件处理有哪些形式,那么我们只需要去搜索 `ApplicationListener<ContextRefreshedEvent>` 在那些地方出现即可
`org.springframework.web.servlet.resource.ResourceUrlProvider#onApplicationEvent` 实现
```java
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
if (isAutodetect()) {
this.handlerMap.clear();
detectResourceHandlers(event.getApplicationContext());
if (!this.handlerMap.isEmpty()) {
this.autodetect = false;
}
}
}
```
- 其他的事件和事件处理类也通过同样的方式进行搜索即可
### ApplicationEventPublisher
- 最后我们来看`ApplicationEventPublisher` 事件发布者
```java
@FunctionalInterface
public interface ApplicationEventPublisher {
/**
* 推送事件
*/
default void publishEvent(ApplicationEvent event) {
publishEvent((Object) event);
}
/**
* 推送事件
*/
void publishEvent(Object event);
}
```
### ApplicationEventMulticaster
- 处理事件的核心类
```
public interface ApplicationEventMulticaster {
/**
* 添加应用监听器
*/
void addApplicationListener(ApplicationListener<?> listener);
/**
* 添加应用监听器的名称
*/
void addApplicationListenerBean(String listenerBeanName);
/**
* 移除一个应用监听器
*/
void removeApplicationListener(ApplicationListener<?> listener);
/**
* 移除一个应用监听器的名称
*/
void removeApplicationListenerBean(String listenerBeanName);
/**
* 移除所有的应用监听器
*/
void removeAllListeners();
/**
* 广播事件
*/
void multicastEvent(ApplicationEvent event);
/**
* 广播事件
*/
void multicastEvent(ApplicationEvent event, @Nullable ResolvableType eventType);
}
```
前几个方法不是很重要 宅这里着重对 **广播事件** 方法进行分析
- 核心逻辑就是从容器中找到 事件对应的处理器列表(ApplicationListener) , 循环处理每个事件
```java
@Override
public void multicastEvent(final ApplicationEvent event, @Nullable ResolvableType eventType) {
ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event));
Executor executor = getTaskExecutor();
for (ApplicationListener<?> listener : getApplicationListeners(event, type)) {
if (executor != null) {
executor.execute(() -> invokeListener(listener, event));
}
else {
invokeListener(listener, event);
}
}
}
```
- `doInvokeListener` 执行`ApplicationListener` 方法
```java
@SuppressWarnings({"rawtypes", "unchecked"})
private void doInvokeListener(ApplicationListener listener, ApplicationEvent event) {
try {
listener.onApplicationEvent(event);
}
catch (ClassCastException ex) {
String msg = ex.getMessage();
if (msg == null || matchesClassCastMessage(msg, event.getClass())) {
// Possibly a lambda-defined listener which we could not resolve the generic event type for
// -> let's suppress the exception and just log a debug message.
Log logger = LogFactory.getLog(getClass());
if (logger.isTraceEnabled()) {
logger.trace("Non-matching event type for listener: " + listener, ex);
}
}
else {
throw ex;
}
}
}
```
到此 Spring-Event 相关的整体流程分析完成, 细节方法等待笔者后续的文字吧
## 其他
- 仓库地址
- [GitHub](https://github.com/huifer/spring-analysis)
- [Gitee](https://gitee.com/pychfarm_admin/spring-analysis) | 7,205 | Apache-2.0 |
---
title: 註解 (MDX) |Microsoft Docs
ms.date: 06/04/2018
ms.prod: sql
ms.technology: analysis-services
ms.custom: mdx
ms.topic: reference
ms.author: owend
ms.reviewer: owend
author: minewiskan
ms.openlocfilehash: f0aa1455ffd9f52fd917f68d2bb0bb80e3f25a94
ms.sourcegitcommit: b2464064c0566590e486a3aafae6d67ce2645cef
ms.translationtype: MT
ms.contentlocale: zh-TW
ms.lasthandoff: 07/15/2019
ms.locfileid: "68006269"
---
# <a name="comment-mdx"></a>註解 (MDX)
指出使用者提供的註解文字。
## <a name="syntax"></a>語法
```
/* Comment_Text */
```
#### <a name="parameters"></a>參數
*Comment_Text*
包含註解文字的字串。
## <a name="remarks"></a>備註
伺服器不會評估註解字元之間的文字 / * 和\*/。 註解可以插在單獨一行或多維度運算式 (MDX) 陳述式之中。 多行註解必須以 /\*和\*/。
註解沒有長度上限。 註解可以為巢狀;例如 `/* Test /*Comment*/ Text*/` 就是巢狀註解的範例。
## <a name="examples"></a>範例
以下範例示範此運算子的用法。
```
/* This member returns the gross profit margin for product types
and reseller types crossjoined by year. */
SELECT
[Date].[Calendar].[Calendar Year].Members *
[Reseller].[Reseller Type].Children ON 0,
[Product].[Category].[Category].Members ON 1
FROM /* Select from the Adventure Works cube. */
[Adventure Works]
WHERE
[Measures].[Gross Profit Margin]
```
## <a name="see-also"></a>另請參閱
[(註解) (MDX)](../mdx/comment-mdx-double-slash.md)
[-- (註解) (MDX)](../mdx/comment-mdx-operator-reference.md)
[MDX 運算子參考(MDX)](../mdx/mdx-operator-reference-mdx.md) | 1,514 | CC-BY-4.0 |
# 167. Two Sum II - Input array is sorted
标签(空格分隔): leetcode easy array
---
给一个升序的整数数组,找到两个整数,他们之和为一个给定的数,返回他们的索引(注意索引从1开始)。你可以假定有且只有1种解法,且不能用同一个元素两次。
```md
Input: numbers={2, 7, 11, 15}, target=9
Output: index1 = 1, index2 = 2
```
## 思路
```md
因为是升序的,我第一个就想到了先过滤数组,把大于target的数滤掉,但其实是有负数的情况的,如[-1,0],target=-1的情况。
原来想到的是用indexOf(target-number[i])来查找,但是他第一个查找到的可能是本身,所以要用indexOf(target-number[i], i+1),但是如果数组太大就超时了
```
## 代码
```js
/**
* @param {number[]} numbers
* @param {number} target
* @return {number[]}
*/
var twoSum = function(numbers, target) {
for(var i=0;i<numbers.length;i++) {
var value = target - numbers[i];
for(var j=i+1;j<numbers.length;j++) {
if(numbers[j] === value) return [i+1, j+1];
}
}
};
```
但是运行时间是400多ms,更好的解法是要充分利用**升序数组**。
```js
/**
* @param {number[]} numbers
* @param {number} target
* @return {number[]}
*/
var twoSum = function(numbers, target) {
var start = 0, end = numbers.length - 1;
if(numbers === null || end < 1) return false;
while(start < end) {
var sum = numbers[start] + numbers[end];
if(sum < target) start++; //如果小了,start就增加
else if(sum > target) end--; //如果大了,end就减小
else break;
}
return [start+1, end+1];
};
``` | 1,271 | MIT |
# YQGameCenterTool
#### 微博:畸形滴小男孩
### iOS端对GameCenter的封装
#### 集成方法:
##### 1把文件拖到XCodeg工程中,并开启工程的GameCenter:

##### 2引入头文件
```Objective-C
#import "YQGameCenterTool.h"
```
##### 3使用
- [检测GameCenter是否可用](#检测GameCenter是否可用)
- [使用GameCenter登录](#使用GameCenter登录)
- [获取所有排行榜](#获取所有排行榜)
- [显示系统自带GameCenter排行榜VC](#显示系统自带GameCenter排行榜VC)
- [向排行榜提交分数](#向排行榜提交分数)
- [手动下载GameCenter排行榜的分数](#手动下载GameCenter排行榜的分数)
- [报告玩家取得了成就](#报告玩家取得了成就)
- [获取玩家在线的好友](#获取玩家在线的好友)
###### 检测GameCenter是否可用
```Objective-C
if([YQGameCenterTool isAvailable]){
//GameCenter可用"
}else{
//GameCenter不可用"
}
```
###### 使用GameCenter登录
```Objective-C
[[YQGameCenterTool defaultTool] getGameCenterAccountWithBlock:^(bool success, UIViewController *viewcontroller)
{
//未登陆GameCenter,需要弹出GC的VC提示用户登陆
if(viewcontroller)
{
//需要Present一个VC
//弹出GC的登录VC
[self presentViewController:viewcontroller animated:YES completion:nil];
}
//同步走,判断GC的登陆状态
//登陆状态改变会自动重走此方法
if(success)
{//GC已登陆成功
//NSLog(@"GC已登陆成功");
//NSLog(@"GC 的 ID 是:%@",[YQGameCenterTool defaultTool].Player.playerID);
}
else
{//使用GC登录失败
//NSLog(@"使用GC登录失败");
}
}];
```
###### 获取所有排行榜
```Objective-C
[[YQGameCenterTool defaultTool]GetAllLeaderBoardWithBlock:^(bool success, NSArray *array)
{
if(success){
//NSLog(@"已获取所有排行榜:%@",array);
}else{
//获取所有排行榜失败
}
}];
```
###### 显示系统自带GameCenter排行榜VC
```Objective-C
//1得到排行榜VC
//type: today,week,all
UIViewController *vc = [[YQGameCenterTool defaultTool]GetLeaderBoardVCWithLeaderboardID:kLeaderboardID
andType:@"all"];
//2弹出VC
[self presentViewController:vc animated:YES completion:nil];
//3检测排行榜VC关闭了,会在排行榜关闭时触发
[YQGameCenterTool defaultTool].LeaderBoardClosedBlock = ^(BOOL closed){
[self dismissViewControllerAnimated:YES completion:nil];
};
```
###### 向排行榜提交分数
```Objective-C
//score:分数
//leaderboardID:排行榜ID
[[YQGameCenterTool defaultTool] setRaitScoreWithSocre:@80
andLeaderboardID:kLeaderboardID
withBlock:^(bool success, NSError *error)
{
if(success){
//上传分数成功
}else{
//上传分数失败
}
}];
```
###### 手动下载GameCenter排行榜的分数
```Objective-C
//type: today,week,all
//begin: 从第几名开始1~100
//number:获取多少名用户1~100
[[YQGameCenterTool defaultTool]downloadLeaderBoardScoreWithLeaderBoardID:kLeaderboardID
andType:@"all"
andBeginRank:@1
andNumber:@10
WithBlock:^(bool success, NSArray *array)
{
if(success){
//分数下载成功,已Log;
/*
for (GKScore *obj in array) {
NSLog(@"玩家ID : %@",obj.player.playerID);
NSLog(@"玩家昵称 : %@",obj.player.displayName);
NSLog(@"时间 : %@",obj.date);
NSLog(@"带 单位的 分数 : %@",obj.formattedValue);
NSLog(@"分数 : %lld",obj.value);
NSLog(@"排名 : %ld",(long)obj.rank);
NSLog(@"------------------------");
}
*/
}else{
//分数下载失败
}
}];
```
###### 报告玩家取得了成就
```Objective-C
//identifier :成就ID
//percentComplete:游戏完成进度1~1000
[[YQGameCenterTool defaultTool]reportAchievment:kAchievementID
andPercentageComplete:101
withBlock:^(bool success, NSError *error)
{
if(success){
//成就已提交成功
}else{
//成就提交失败
}
}];
```
###### 获取玩家在线的好友
```Objective-C
[[YQGameCenterTool defaultTool] getOnlineFriendsWithArrBlock:^(bool success, NSArray *array)
{
if(success)
{
//获取在线好友成功,已Log
/*
for (GKPlayer *player in array) {
NSLog(@"玩家ID : %@",player.playerID);
NSLog(@"name : %@",player.displayName);
NSLog(@"alisa : %@",player.alias);
NSLog(@"------------------------");
}
*/
}else{
//获取在线好友失败了
}
}];
``` | 4,498 | MIT |
# Gitbook发布文档
##概要
markdown已经被大多数人接受且越来越流行,用它来编写和生成文档已经成为一种趋势。
我们采用[Gitbook](https://github.com/GitbookIO/gitbook)来生成文档。
通常我们使用[atom](https://atom.io)或者[mou](http://mouapp.com)来作为markdown的编辑器,
因为它们提供了良好的预览功能。
##目录结构
1. docs
存储所有的markdown形式的文档,docs下又分为不同的书目,包括:
1. docs/get_started 为EMP产品的用户手册和开发指南
2. docs/info_center 为EMP产品的参考手册(API及配置说明)
3. docs/inner_docs 为产品内部开发规范,包含hg_guide,ci_guide和coding_convention等内容
2. theme
这里保存了生成站点所用的模板,默认的模板会引用一个在墙外的js资源,导致生成的页面打开速度和运行效果及其缓慢,所以对模板进行了修改。
##生成HTML流程
1. 首先,你需要通过nodejs的npm包管理工具安装gitbook:`npm install gitbook -g`;
2. 由于默认写的markdown文件是没有目录的,为了增加可读性,需要安装相关插件支持目录的生成。使用步骤如下:
1. 安装`npm install gitbook-plugin-toc`
2. 修改gitbook代码
由于gitbook生成标题ID的逻辑和gitbook-plugin-toc所使用的marked-toc生成锚点的逻辑不一致,
导致生成的目录不能跳转,所以我们需要修改`lib/parse/renderer.js`文件,方法如下:
```sh
cd /usr/local/lib/node_modules/gitbook
vi +150 lib/parse/renderer.js
```
将150行中的`raw.toLowerCase().replace(/[^\w -]+/g,...`改为`raw.toLowerCase().replace(/ /g, '-').replace(/\./g,'')`
3. 配置 book.json 以引用这个插件 `"plugins": ["toc"],`
4. 在需要增加目录的markdown文件相应位置插入`<!-- toc -->`, 注意此行紧随一个标题,这两行之间一定**不要**有空行
5. 再用gitbook生成的html页面就有目录了
2. 通过执行
```bash
gitbook build ./docs/get_started
gitbook build ./docs/info_center
...
```
生成的 `get_started/` 等图书目录包含了完整的HTML格式文档,可以通过本地浏览器打开`get_started/index.html`阅读
(首次需要联网,因为需要下载远程服务器上的脚本及样式)
##输出PDF
1. 输入为PDF文件,需要先使用NPM安装上gitbook pdf:
```
npm install gitbook-pdf -g
```
2. 在安装这个模块的时候,当下载一个名为phantomjs的包时,出现请求未能响应的情况,
可以点击[phantomjs](http://phantomjs.org/)下载自行安装。
3. 生成PDF文件:
```
gitbook pdf ./图书目录
```
4. 如果你在图书目录内容,也可以这样做:
```
gitbook pdf .
```
生成完成后,当前目录会出现一个名为book.pdf的文件。
5. `gitbook-pdf`还支持生成`epub`格式文件,命令如下:
```
gitbook epub ./图书目录
```
##发布流程
目前整个发布流程基本实现了自动化
1. 编写markdown并提交到hg repo.
2. 配置book.json,增加:`"download": "/get_started.zip"`配置生成Web页面上的下载链接(这个是自定义的配置)
3. Jenkins自动执行脚本,生成静态站点并发布到Web Server. 这个过程可以设置为定时触发,或可由用户手动触发
```bash
gitbook build ./docs/get_started
rm -rf /Library/WebServer/Documents/emp/get_started
cp -R ./get_started /Library/WebServer/Documents/emp/get_started
gitbook build ./docs/info_center
rm -rf /Library/WebServer/Documents/emp/info_center
cp -R ./info_center /Library/WebServer/Documents/emp/info_center
```
4. 目前文档部署在内部服务器,请访问如下地址查看
* http://192.168.64.165/emp/get_started/
* http://192.168.64.165/emp/info_center/
##发布插件使用
Jenkins的Gitbook自动化发布插件:

参数解释:
* Doc Name:需要发布的文档名称,和代码下的文件夹名称相同。
可以同时写多个文档名称使用`,`和空格区分开来。
* Doc Version:需要发布的文档版本,当前可选的版本有emp、emp5.2、
emp5.3等版本对应主干,5.2分支,5.3分支。
* PDF和epub:选中代表发布pdf和epub格式的文件。
* Deploy Network(64.10):选中代表发布文档至64.10的外网环境,
为选中则发布至当前执行任务的本地机器。
* Document Root:当前默认的文档发布目录为`/Library/WebServer/Documents`,
当发布地址变更时需要输入目录。
参数配置完成后,触发jenkins构建任务发布文档。 | 2,749 | MIT |
# CharacterTest
This is a tiny project of Django to test which character you are.
## 简介
这是一个练手做的Django小项目,它旨在使用一套已经成熟的气质类型测试题对测试者进行测试。在测试者提交了他们的答案后(不需要全部提交,只需答满足够的题目数量),系统自动计算出来测试结果。
- [网站入口](123.207.5.36)
- [测试题出处](https://www.wjx.cn/jq/183158.aspx)
## 项目详解
现在让我们开始从头分析完成这个小项目需要做些什么。
最核心的需求就是
1. 从数据库中提取出题目,生成一个测试页面
2. 每当测试者点击完答案,则返回下一道题的页面
3. 为了防止有人跳页,上述逻辑不能使用静态页面生成
### 模型构建
那么现在首先需要建立一个关于问题的数据模型。这个模型包括以下几个字段
- 问题内容
- 问题类别(这是因为本套测试题将问题本身分为四类,并在对四个气质分别相加,故在输入问题时就要界定该问题是对哪一种气质的计算)
- 问题归属(为了服务的可拓展性,例如以后再增设新的测试题,则可以继续使用该模型,但两套测试题不能混在一起,故设置一个问题归属,本次60题全部属于一个名叫`tmt`的类别)
- 问题id(这是该套题的第几个题)
在总项目下,新建一个服务并命名为tmt,接着在其中的models.py中建立模型
```python
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.db import models
class Question(models.Model):
question_text = models.CharField(max_length=200)
attribute = models.CharField(max_length=12)
project = models.CharField(max_length=32,default ="")
project_id = models.CharField(max_length=12,default="")
def __unicode__(self):
return self.question_text
```
### 路由设置
模型建立好了以后,我们来思考一下页面的设置是怎样的。它应该有如下逻辑
1. 点击测试题页面,首先是一篇简介,点击简介里的开始答题方开始输出问题,这个简介的页面可以设置为tmt的首页,即url为 `ip_address/tmt/`
2. 开始答题了以后,为了防止有人跳页回答,产生无效答卷,url只使用一个,即是`ip_address/tmt/testing`,用户向这个页面提交表单,服务器收到表单之后一边记录,一边生成新的单页返回。
3. 所有前面已经答过的题及答案,可以使用session保存,在交互中不断增加,当点击提交按钮后,服务器提取session中的所有问题,进行计算并返回结果
因此主页urls.py及tmt服务的urls.py设置如下
```python
from django.conf.urls import url,include
from django.contrib import admin
from . import views
urlpatterns = [
url(r'^$',views.index,name='index'),
url(r'^admin/', admin.site.urls),
url(r'^tmt/',include('tmt.urls',namespace='tmt')),
]
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^$',views.index,name='index'),
url(r'^testing/$',views.deal,name='testing'),
url(r'^submit/$',views.calculate,name='submit'),
]
```
### 首页设置与静态资源调取
我们首先解决index首页的问题,在urls.py中,我们已经将`ip_address/tmt/`的页面交由views.index函数来处理,因此只需要在views.py文件中设置好index函数即可。在这个函数中,我们套用了一个静态模板,tmtindex.html是一个静态页面,Django一般规定放置于该服务下的templates/目录下。
```python
def index(request):
request.session['dict_choice'] = {}
request.session['pagenumber'] = 1
return render(request,'tmt/tmtindex.html')
```
以下是tmtindex.html模板页面,需要注意的是,Django有自身的静态资源引用方式,不可以直接使用相对路径表示CSS资源或JS资源,静态资源一般需要放置在该服务下的static目录下,而引用方式为`href="{% static 'dist/image/icon_snowman.ico' %}"`
```html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- The above 3 meta tags *must* come first in the head; any other head content must come *after* these tags -->
<meta name="description" content="">
<meta name="author" content="">
{% load static %}
<link rel="icon" href="{% static 'dist/image/icon_snowman.ico' %}">
<title>气质测试|首页</title>
<!-- Bootstrap core CSS -->
<link href="{% static 'dist/css/bootstrap.min.css' %}" rel="stylesheet">
<!-- IE10 viewport hack for Surface/desktop Windows 8 bug -->
<link href="{% static 'dist/css/ie10-viewport-bug-workaround.css' %}" rel="stylesheet">
<!-- Custom styles for this template -->
<link href="{% static 'dist/css/navbar-static-top.css' %}" rel="stylesheet">
<!-- Just for debugging purposes. Don't actually copy these 2 lines! -->
<!--[if lt IE 9]><script src="../../assets/js/ie8-responsive-file-warning.js"></script><![endif]-->
<script src="{% static 'dist/js/ie-emulation-modes-warning.js' %}"></script>
<!-- HTML5 shim and Respond.js for IE8 support of HTML5 elements and media queries -->
<!--[if lt IE 9]>
<script src="https://oss.maxcdn.com/html5shiv/3.7.3/html5shiv.min.js"></script>
<script src="https://oss.maxcdn.com/respond/1.4.2/respond.min.js"></script>
<![endif]-->
</head>
<body>
<div class="container">
<!-- Main component for a primary marketing message or call to action -->
<div class="jumbotron">
<h1>气质测试简介</h1>
<p>根据希波克拉底的四液说,人的气质类型分为:多血质、粘液质、抑郁质和胆汁质。分别对应着人们气质行为的四种类别,随着生活变化,人的气质类型也会发生变化。测试题共60题整,本站经过前期数据优化,可以以尽可能少的题目数量得知您的气质类型,但我们更加推荐您做完这60道题获得最准确的判断。</p>
<p>
<a class="btn btn-lg btn-primary" href="./testing/" role="button">开始答题</a>
</p>
</div>
</div> <!-- /container -->
<!-- Bootstrap core JavaScript
================================================== -->
<!-- Placed at the end of the document so the pages load faster -->
<script src="{% static 'dist/js/jquery.min.js' %}"></script>
<script src="{% static 'dist/js/bootstrap.min.js' %}"></script>
<!-- IE10 viewport hack for Surface/desktop Windows 8 bug -->
<script src="{% static 'dist/js/ie10-viewport-bug-workaround.js' %}"></script>
</body>
</html>
```
### views处理函数
现在我们就来到了最关键的views.py部分,在这个文件中,主要是deal函数,用于接收用户传来的答案,并存入session中,并且依据问题id返回下一个问题渲染的单页,将session附回去。而calculate函数用于计算session中提交的问题。
```python
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.shortcuts import render,get_object_or_404
from django.template import RequestContext,loader
from .models import Question
from django.http import HttpResponse
def deal(request):
question_id = request.session['pagenumber']
p = get_object_or_404(Question,project_id=question_id)
request.session['pagenumber'] = request.session['pagenumber'] + 1
if request.POST and request.POST.has_key('choice'):
if request.POST['choice'] == "":
pass
else:
request.session['dict_choice'][question_id] = request.POST['choice']
else:
request.session['pagenumber'] = request.session['pagenumber'] - 1
return render(request,'tmt/ss_input.html',{'s_question':p,'pagenumber':request.session['pagenumber'],})
if question_id < 60:
pnext = get_object_or_404(Question,project_id=str(int(question_id)+1))
else:
pnext = p
return render(request,'tmt/ss_input.html',{'s_question':pnext,'pagenumber':request.session['pagenumber'],})
def calculate(request):
dict_choice = request.session['dict_choice']
score_tree = {'1':0,'2':0,'3':0,'4':0}
for unit in dict_choice:
attr = get_object_or_404(Question,project_id = unit).attribute
score_tree[attr] = score_tree[attr] - int(dict_choice[unit]) + 3
scorelist = [score_tree['1'],score_tree['2'],score_tree['3'],score_tree['4']]
temp = scorelist[:]
temp.sort()
enddict = {'胆汁质':score_tree['1'],'多血质':score_tree['2'],'黏液质':score_tree['3'],'抑郁质':score_tree['4'],}
res_dict = ['胆汁质','多血质','黏液质','抑郁质']
if temp[-1] - temp[-2] > 4:
result = res_dict[scorelist.index(temp[-1])]
elif temp[-2] - temp[-3] > 4:
result = res_dict[scorelist.index(temp[-1])]
scorelist[scorelist.index(temp[-1])] = -50
result = result + '+' + res_dict[scorelist.index(temp[-2])]
elif temp[-3] - temp[-4] > 4:
result = res_dict[scorelist.index(temp[-1])]
scorelist[scorelist.index(temp[-1])] = -50
result = result + '+' + res_dict[scorelist.index(temp[-2])]
scorelist[scorelist.index(temp[-2])]
result = result + '+' + res_dict[scorelist.index(temp[-3])]
else:
result = "混合气质"
if len(dict_choice) > 10:
with open("/home/tmtlog.txt",'a') as f:
for key,value in dict_choice.items():
f.write(key+','+value+'\t')
f.write('\n')
return render(request,'tmt/result.html',{'score_tree':enddict,'result':result,})
```
当然,细心的同学会发现,我在calculate的最后部分加入了点奇怪的东西,当表单长度大于10,即答完了10道题以上,我会在后台将此次问卷记录下来,视为有效问卷。
这个部分如果有什么值得说的,就是关于表单提交的问题。
### 细节:表单提交
首先我们可以看一下deal函数最后返回的渲染页面是`return render(request,'tmt/ss_input.html',{'s_question':pnext,'pagenumber':request.session['pagenumber'],})`
在这里,模板是ss_input.html,传参为当前需要渲染的新问题pnext,以及当前已经答了多少题pagenumber。那么之前答卷的session呢?它们已经包含在了request里了,会一并转发回来。deal函数里如果判定本次回答有效,则会给request.session加入新的内容。现在我们来看ss_input.html内容
```html
{% load static %}
<link rel="icon" href="{% static 'dist/image/icon_snowman.ico' %}">
<title>第 {{ pagenumber }} 题</title>
...
{% if s_question %}
<form action="{% url 'tmt:testing' %}" method="post">
...
{% ifnotequal pagenumber 61 %}
<div class="jumbotron">
<h3>{{ s_question.question_text }}</h3>
</div>
<div class="row">
<div class="col-lg-8">
<p><button type="submit" name="choice" class="btn btn-lg btn-success" id="choice1" value="1"/>非常符合</button></p>
</div><!-- /.col-lg-6 -->
<div class="col-lg-8">
<p><button type="submit" name="choice" class="btn btn-lg btn-success" id="choice2" value="2"/>比较符合</button></p>
</div><!-- /.col-lg-6 -->
<div class="col-lg-8">
<p><button type="submit" name="choice" class="btn btn-lg btn-success" id="choice3" value="3"/>不能确定</button></p>
</div><!-- /.col-lg-6 -->
<div class="col-lg-8">
<p><button type="submit" name="choice" class="btn btn-lg btn-success" id="choice4" value="4"/>较不符合</button></p>
</div><!-- /.col-lg-6 -->
<div class="col-lg-8">
<p><button type="submit" name="choice" class="btn btn-lg btn-success" id="choice5" value="5"/>完全不符</button></p>
</div><!-- /.col-lg-6 -->
</div><!-- /.row -->
{% else %}
<div class="row">
<div class="col-lg-3">
<p><a name="choice" class="btn btn-lg btn-success" href="{% url 'tmt:submit' %}">提交</a></p>
</div>
</div>
{% endifnotequal %}
</form>
{% endif %}
```
可以看到,模板页面的主体就是一个form表单,五个值代表从完全相符到完全不符的五个按钮,点击后直接提交,返回给服务器的deal函数,这时提交的回答被保存在了`request.POST['choice']`里面。
## 联系我
一个小小的练习作品,帮助自己了解了Django的基础应用和想象空间,非常有趣。如果您对该项目有什么兴趣或者疑问,欢迎联系我。
- E-mail: zhijunzhang_hi@163.com
- Github: https://github.com/SnowmanZhang
- 测试网站(域名snowman1995.cn正在申请中): 123.207.5.36
- Wechat: renxdu | 9,886 | MIT |
---
title: "产品动态"
description: 本小节主要介绍 MySQL Plus 产品动态
keyword: 数据库,MySQL PLus,关系型数据库,MySQL,产品动态
weight: 05
collapsible: false
draft: false
product:
- time: 2021-12-21
title: MySQL Plus 1.1.0 版本正式上线
content: MySQL Plus 1.1.0 版本基于 MySQL 5.6、5.7、8.0 内核构建。<br>- 新增逻辑备份和备份回档功能;<br>- 新增分析实例日志查询和下载功能;<br>- 新放开 `Block_encryption_mode`、`Binlog_transaction_dependency_tracking`、`Group_replication_transaction_size_limit`参数;<br>- 支持动态设定 `Max_connections` 参数值;<br>- `Sql_mode` 参数新增 NULL 值选项;<br>- 修复集群自动化运维问题,加强集群高可用稳定性。
url: ../../intro/version/
tags:
- 新功能
- 体验优化
zone: 全部
- time: 2021-12-21
title: MySQL Plus 支持逻辑备份
content: MySQL Plus 1.1.0 版本全新支持基于数据库对象级的逻辑备份,并支持恢复集群到指定时间点。
url: ../../manual/backup_restoration/backup_info/
tags:
- 新功能
zone: 全部
- time: 2021-07-12
title: MySQL Plus 支持外网地址连接
content: MySQL Plus 通过在管理控制台申请外网地址和设置 IP 白名单,支持使用外网地址连接数据库。
url: ../../manual/mgt_connect/enable_external_network/
tags:
- 新功能
- 体验优化
zone: 全部
- time: 2021-07-09
title: MySQL Plus 1.0.9 版本正式上线
content: MySQL Plus 1.0.9版本基于 MySQL 5.6、5.7、8.0内核构建。<br>- 新增分析实例节点,支持 HTAP 方案将 ClickHouse 作为 MySQL Plus 的一个分析实例,实现从主节点同步并分析数据;<br>- 新增重启节点功能,支持重启单个节点服务;<br>- 新增指定 Master 节点功能;<br>- 新增服务地址模块,支持一键查询节点日志服务地址。
url: ../../intro/version/
- time: 2021-01-31
title: MySQL Plus 1.0.8 版本正式上线
content: MySQL Plus 1.0.8版本基于 MySQL 5.6、5.7、8.0内核构建。<br>- 支持自动重建复制异常从库或只读实例;<br>- 新增 innodb_adaptive_hash_index、performance_schema、innodb_autoinc_lock_mode 配置参数管理;<br>- 优化 max_allowed_packet、slave_pending_jobs_size_max、innodb_log_file_size 配置参数默认值。
url: ../../intro/version/
- time: 2020-12-25
title: MySQL Plus 1.0.7 版本正式上线
content: MySQL Plus 1.0.7版本基于 MySQL 5.6、5.7、8.0内核构建。<br>- 支持从旧形态升级到新形态;<br>- 支持创建三节点主实例;<br>- 支持灾备功能和 zabbix_agent 功能;<br>- 支持连接控制插件;<br>- 新增 election-timeout、semi-sync timeout 配置参数管理;<br>- 新增 Innodb_row_lock_waits、Innodb_row_lock_time_avg 监控项;<br>- sql_mode 支持 PIPES_AS_CONCAT, IGNORE_SPACE;<br>- 取消高级权限用户个数限制,支持创建多个高级权限账号;<br>- 高可用读 IP 支持指定分发请求的角色;<br>- 修复集群自动化运维问题,加强集群高可用稳定性。
url: ../../intro/version/
- time: 2020-09-19
title: MySQL Plus 1.0.6 版本正式上线
content: MySQL Plus 1.0.6版本基于 MySQL 5.6、5.7、8.0内核构建。<br>- 新增兼容 MySQL 8.0内核;<br>- 支持 xtrabackup 在线迁移服务;<br>- 支持关闭 SSL 传输加密时,自动清空 FTP 目录下 SSL 配置文件;<br>- 支持通过 HTTP 服务预览、下载日志;<br>- 支持在管理控制台重建只读实例;<br>- 支持磁盘大小最小默认为 20GB;<br>- 优化 audit_log_rotations 配置参数最高可配置48个文件;<br>- 修复集群自动化运维问题。
url: ../../intro/version/
- time: 2020-06-03
title: MySQL Plus 1.0.3 版本正式上线
content: MySQL Plus 1.0.3版本基于 MySQL 5.6和5.7内核构建。<br>- 新增在线迁移后交换预留 IP 功能;<br>- 优化集群扩容流程,并缩小主丢失时间窗口;<br>- 支持选用企业型e2 主机;<br>- 新增 innodb_flush_method 和 innodb_use_native_aio 配置参数管理;<br>- 支持自动订正 root 和 proxy 节点账号;<br>- 支持串行升级功能;<br>- 修复集群自动化运维问题。
url: ../../intro/version/
- time: 2019-12-08
title: MySQL Plus 1.0.1 版本正式上线
content: MySQL Plus 1.0.1版本基于 MySQL 5.6和5.7内核构建。<br>- 新增 MySQL 审计功能;<br>- 新增密码强度规则配置参数;<br>- 新增 Innodb_row_lock_time_avg 监控项;<br>- 新增自动订正运维账号功能;<br>- 新增主节点只读状态的自动检测和订正功能;<br>- 新增云服务器 64核256G 规格;<br>- 修复集群自动化运维问题。
url: ../../intro/version/
- time: 2019-07-26
title: MySQL Plus 全新形态上线
content: 青云QingCloud MySQL Plus 为了提高用户使用体验和提供更多的优惠,发布了全新的版本,支持基础版、高可用版、金融版三个产品系列;同时为提高使用性能,新增读写分离和只读实例节点。
url: ../../intro/list/
- time: 2017-06-29
title: MySQL Plus 上线 AppCenter
content: 青云QingCloud MySQL Plus 通过 AppCenter 管理平台以独立应用方式提供服务。<br>MySQL Plus 是一款具备金融级强一致性、主从秒级切换,集 InnoDB+TokuDB 双存储引擎支持的增强型 MySQL 集群应用。作为 QingCloud 关系型数据库 RDB 的升级版本,QingCloud MySQL Plus 主要面向对数据一致性和高可用性有着强烈需求的高端企业级用户。
url: ../../intro/introduction/
---
<!-- 设置上述参数可生成产品动态页 --> | 3,783 | Apache-2.0 |
# google_pinyinim


[](https://github.com/aron566/google_pinyinim/blob/master/LICENSE)

```
_ _ _ _
| | (_) (_) (_)
__ _ ___ ___ __ _ | | ___ _ __ _ _ __ _ _ _ _ __ _ _ __ ___
/ _` | / _ \ / _ \ / _` || | / _ \ | '_ \ | || '_ \ | | | || || '_ \ | || '_ ` _ \
| (_| || (_) || (_) || (_| || || __/ | |_) || || | | || |_| || || | | || || | | | | |
\__, | \___/ \___/ \__, ||_| \___| | .__/ |_||_| |_| \__, ||_||_| |_||_||_| |_| |_|
__/ | __/ | ______ | | __/ |
|___/ |___/ |______||_| |___/
```
谷歌拼音输入法移植至QT
# 移植方法
## 第一种直接带入源码编译
### 这个无需多讲,直接将所有的工程包含到你所需的工程中去即可,可查看.pro文件涉及哪些文件。
## 第二种链接方式
1、clone工程到你的本地目录,打开项目
2、动态库的生成:修改项目中.pro文件中TEMPLATE = **app**改为**lib**即可生成动态库文件
```bash
# 生成库文件
TARGET = virtualkeyboard
TEMPLATE = lib
```
3、静态库的生成(不会更新之前已生成的动态库文件!):
```bash
# 生成库文件
TARGET = virtualkeyboard
TEMPLATE = lib
# 指定生成为静态库
CONFIG += staticlib
```
4、取出工程中所有.h文件及编译生成的库文件
5、将.h文件加入到**你需要用到的工程中**,.pro文件中链接此动态库文件即可
项目中`.pro`文件增加的内容如下(或者右键添加库->选择外部->选择对应库文件):
```bash
# 软键盘
include(keyboard/keyboard.pri)
# 软键盘linux
unix:!macx: LIBS += -L$$PWD/keyboard/
unix:!macx: LIBS += -lvirtualkeyboard
# 软键盘windows
win32: LIBS += -L$$PWD/keyboard/
win32: LIBS += -lvirtualkeyboard
```
```bash
# 链接静态库时,多添加一行定义,否者在.h的头文件中声明了导入(Q_DECL_IMPORT),则在windows平台编译会找动态库,此时找不到会报未定义的错误
DEFINES += VIRTUALKEYBOARD_LIBRARY
```
5.1、在你的工程中新建keyboard文件夹
5.2、在keyboard文件夹中新建keyboard.pri文件
填入如下内容:
```bash
HEADERS += \
$$PWD/customerqpushbutton.h \
$$PWD/keyboard.h \
$$PWD/lib/atomdictbase.h \
$$PWD/lib/dictbuilder.h \
$$PWD/lib/dictdef.h \
$$PWD/lib/dictlist.h \
$$PWD/lib/dicttrie.h \
$$PWD/lib/lpicache.h \
$$PWD/lib/matrixsearch.h \
$$PWD/lib/mystdlib.h \
$$PWD/lib/ngram.h \
$$PWD/lib/pinyinime.h \
$$PWD/lib/pinyinime_global.h \
$$PWD/lib/searchutility.h \
$$PWD/lib/spellingtable.h \
$$PWD/lib/spellingtrie.h \
$$PWD/lib/splparser.h \
$$PWD/lib/sync.h \
$$PWD/lib/userdict.h \
$$PWD/lib/utf16char.h \
$$PWD/lib/utf16reader.h \
$$PWD/virtualkeyboard.h
```
5.3、复制`customerqpushbutton.h` `keyboard.h` `virtualkeyboard.h`到`keyboard`文件夹
5.4、复制编译的动态库文件或者静态库文件到`keyboard`文件夹
5.5、在**keyboard**文件夹中新建**lib**文件夹
将克隆的工程中`googlelib`文件夹中所有.h后缀的文件复制到此
5.6、修改`keyboard.h` 中`#include <pinyinime.h>`改为 `#include <keyboard/lib/pinyinime.h>`
5.7、复制`data`目录下的词典文件到**keyboard**文件夹内,(在其他目标板上运行,需将词典复制过去,实例化时指定加载路径信息)
6、点击小锤子编译即可
7、如果动态库则上传动态库文件到特定硬件上
## 修改相关参数
### 修改输入法界面尺寸大小
- 打开`virtualkeyboard.h`文件,文件中定义皆以**pixel**为单位
修改其中`UI_KEYBOARDWINDOW_WIDTH`与`UI_KEYBOARDWINDOW_HEIGHT`宏定义为多少pixel
修改显示中文结果的间隙大小:水平间隙`CHINESESEARCH_BLOCKSTYLE_MULTI_RECT_X_GAP`,垂直间隙`CHINESESEARCH_BLOCKSTYLE_MULTI_RECT_Y_GAP`
修改每页显示数目:列数目`CHINESESEARCH_BLOCKSTYLE_RECT_H_NUM_MAX`,行数目`CHINESESEARCH_BLOCKSTYLE_RECT_V_NUM_MAX`
**其他修改直接看文件中说明**
# 使用方式
输入框使用单一`QLineEdit`控件便于管理
## 初始化部分
1、实例化键盘
```cpp
keyboard *pKeyboard = new keyboard(this ,"谷歌词典文件路径" ,"用户词典文件路径");
```
2、连接键盘输入结束信号
```cpp
connect(pKeyboard ,&keyboard::editisModifiedok ,this ,&MainWindow::slotKeyboardReturn);
```
6、槽函数处理,参数str为输入的内容
```cpp
void MainWindow::slotKeyboardReturn(QString str)
{
/*do something...*/
}
```
## 调用键盘
```cpp
/*设置显示键盘*/
void showKeyboard(QString title = "键入xx的内容:" ,QString str = "2020");
/*单独设置标题*/
void set_editTips(QString title = "键入xx的内容:");
/*单独设置输入框内容*/
void set_editBox(QString str = "2020");
/*设置键盘模式*/
void set_keyboardmode(KEYBOARD_MODE mode);
```
**1、调整键盘模式**
```c
enum KEYBOARD_MODE
{
NUM_ONLY = 0,/**< 数字模式,字母键将不可用*/
EN_ONLY,/**< 英文模式,数字键将不可用*/
ANY,/**< 全功能,默认模式*/
};
```
eg:
```cpp
pKeyboard->set_keyboardmode(keyboard::NUM_ONLY);
```
## 互动
1、主线程的主界面部分管理
```cpp
private:
QWidget* pLastCallobj;/**< 保存着上次隐藏的页面,也可不用,但需要调用键盘的页面不隐藏*/
QLineEdit *pLastCallwidget;/**< 保存上次调用键盘的控件*/
```
2、主线程建立槽,调用键盘显示
```cpp
/*连接子界面要求显示键盘的信号*/
connect(parameterui, ¶meter::show_keyboard, this, &MainWindow::slotprocessedit);
```
```cpp
void MainWindow::slotprocessedit(QWidget *pObject, QLineEdit *pwidget, QString title, QString edittext)
{
pLastCallobj = pObject;
pLastCallwidget = pwidget;
pKeyboard->showKeyboard(title, edittext);
}
```
3、主线程,连接键盘输入完成信号
```cpp
connect(pKeyboard, &keyboard::editisModifiedok, this, &MainWindow::slotKeyboardReturn);
```
```cpp
void MainWindow::slotKeyboardReturn(QString str)
{
/*重新显示子级页面*/
pLastCallobj->show();
/*将键盘的字符串给编辑框*/
pLastCallwidget->setText(str);
}
```
4、主线程子级页面,输入控件被点击处理
QLineEdit控件有以下几个信号:
```cpp
// returnPressed:聚焦在控件上按下回车键时发出,通常用作不带触摸屏的环境
// selectionChanged:聚焦到时发出一次信号
// 连接信号:
connect(ui->clientiplineEdit, &QLineEdit::selectionChanged, this, ¶meter::on_clientip_Pressed);
connect(ui->clientiplineEdit, &QLineEdit::returnPressed, this, ¶meter::on_clientip_Pressed);
/*需要注意的是,当控件代码由UI设计器自动生成时,信号与槽的建立应当在UI设计器中完成*/
```
```cpp
signals:
void show_keyboard(QWidget *, QLineEdit *, QString, QString);
```
```cpp
/*在parameter界面,clientip输入框被点击*/
void parameter::on_clientip_Pressed()
{
emit show_keyboard(this ,ui->clientip,"输入客户端IP" ,ui->clientip->text());
this->hide();
}
```
5、连接信号与槽
```cpp
connect(parameterui ,¶meter::show_keyboard ,this ,&MainWindow::slotprocessedit);/*parameterui为主界面的子级页面*/
``` | 5,923 | Apache-2.0 |
##页面标记
对页面主题和内容的性质进行标记的引用
###源码
####html
<div>
<span class="blend-badge">default</span>
<span class="blend-badge blend-badge-primary">primary</span>
<span class="blend-badge blend-badge-secondary">secondary</span>
<span class="blend-badge blend-badge-success">success</span>
<span class="blend-badge blend-badge-info">info</span>
<span class="blend-badge blend-badge-warning">warning</span>
<span class="blend-badge blend-badge-danger">danger</span>
<hr />
<span class="blend-badge">在线支付</span>
<span class="blend-badge blend-badge-empty">随订随用</span>
<span class="blend-badge blend-badge-empty">有效期内可退</span>
</div>
###效果示例

##按钮
页面中使用的所有按钮样式
###源码
####html
<div>
<button class="blend-button">default</button>
<button class="blend-button blend-button-primary">primary</button>
<button class="blend-button blend-button-secondary">secondary</button>
<button class="blend-button blend-button-success">success</button>
<button class="blend-button blend-button-info">info</button>
<button class="blend-button blend-button-warning">warning</button>
<button class="blend-button blend-button-danger">danger</button>
<br />
<a href="http://www.baidu.com" class="blend-button">在线支付</a>
<a href="http://www.baidu.com" class="blend-button blend-button-primary">购买</a>
<a href="http://www.baidu.com" class="blend-button blend-button-secondary">购买</a>
<a href="http://www.baidu.com" class="blend-button blend-button-success">购买</a>
<a href="http://www.baidu.com" class="blend-button blend-button-info">购买</a>
<a href="http://www.baidu.com" class="blend-button blend-button-warning">购买</a>
<a href="http://www.baidu.com" class="blend-button blend-button-danger">购买</a>
<a href="http://www.baidu.com" class="blend-button blend-button-link">购买</a>
<a href="http://www.baidu.com">购买</a>
</div>
###效果示例

##选择框
页面中的选择框
###源码
####html
<div id="check1" data-blend-widget="checkbox" data-blend-checkbox= '{"type":"group","values":["1","22","333"]}'>
<br><br>
<span class="blend-checkbox blend-checkbox-default blend-checkbox-checked"></span>
<span class="blend-checkbox blend-checkbox-default"></span>
<span class="blend-checkbox blend-checkbox-default"></span>
<br><br>
</div>
<div id="check2" data-blend-widget="checkbox" >
<br><br>
<span class="item blend-checkbox blend-checkbox-square blend-checkbox-checked"></span>
<span class="item blend-checkbox blend-checkbox-square"></span>
</div>
<div id="check3" data-blend-widget="checkbox" data-blend-checkbox='{"type":"radio","values":["radio1","radio2","radio3"]}'>
<br><br>
<span class="blend-checkbox blend-checkbox-default"></span>
<span class="blend-checkbox blend-checkbox-default"></span>
</div>
<br><br>
<button id="getData1" >获取第一组值</button>
<button id="getData2" >获取第二组值</button>
<button id="getData3" >获取第三组值</button>
<br>
<textarea id="rs"></textarea>
####Javascript
<script>
$(function () {
// 选择元素
$('#check1').checkbox();
$('#check2').checkbox({
"itemSelector":".item",
"type":"radio",
"values":["aa","b","ccc"]
});
$('#check3').checkbox();
/*$('[data-blend-widget="checkbox"]').on("checkbox:statusChange",function(data){
console.log(data);
});*/
$("#getData1").on('click',function(s){
var a = $('#check1').checkbox("getValues");
$("#rs").val(JSON.stringify(a));
});
$("#getData2").on('click',function(s){
var a = $('#check2').checkbox("getValues");
$("#rs").val(a);
});
$("#getData3").on('click',function(s){
var a = $('#check3').checkbox("getValues");
$("#rs").val(JSON.stringify(a));
});
});
</script>
###效果示例

##计数器
计数器,用作数量的加减
###源码
####html
<div data-blend-widget="counter" data-blend-counter='{"step":2,"maxValue":10}' class="blend-counter">
<div class="blend-counter-minus">-</div>
<input class="blend-counter-input" type="text">
<div class="blend-counter-plus">+</div>
</div>
<div data-blend-widget="counter" data-blend-counter='{"step":2,"maxValue":10}' class="blend-counter">
<div class="blend-counter-minus">-</div>
<input class="blend-counter-input" type="text">
<div class="blend-counter-plus">+</div>
</div>
####Javascript
<script>
// var $ = $.;
$(function () {
// 选择元素
var $counter = $('[data-blend-widget="counter"]')
// 初始化, 已经由默认初始化
//.counter({
// step: 2
//})
//监听事件
.on("counter:update", function (e) {
console.log(arguments);
})
// 函数调用
.counter("value", 100);
var options = $counter.counter("option");
console.log(options);
console.log($counter);
setTimeout(function () {
$counter.counter("destroy");
console.log("destroyed");
}, 5000);
});
</script>
###效果示例

##对话框
用作提示的对话框
###源码
####html
<button onclick="dialog2.show()">两个按钮dialog</button>
<br/><br/><br/><br/><br/><br/>
<button onclick="dialog1.show()">一个按钮dialog</button>
<div data-blend-widget="dialog" class="blend-dialog blend-dialog-hidden j_test_dialog">
<div class="blend-dialog-header"> 标题 </div>
<div class="blend-dialog-body"> 内容 </div>
<div class="blend-dialog-footer">
<a href="javascript:void(0);" class="blend-dialog-cancel">取消</a>
<a href="javascript:void(0);" class="blend-dialog-done">确认</a>
</div>
</div>
</div>
####Javascript
<script>
var dialog1 = $.blend.dialog({
message: "hello world!!!",
cancelOnly: 1,
cancelText: '确定'
});
var dialog2 = $.blend.dialog({
message: "hello world!!!",
maskTapClose: true
});
$('.j_test_dialog').dialog().on('dialog:show', function(){
alert('show')
});
</script>
###效果示例

##固定页眉页脚
可拉长的页眉页脚
###源码
####html
<div data-blend-widget="fixedBar" class="blend-fixedBar blend-fixedBar-top">
我是头部固定人
</div>
<div data-blend-widget="fixedBar" class="blend-fixedBar blend-fixedBar-bottom">
我是尾部固定人
</div>
####Javascript
<script>
$.blend.fixedBar();
</script>
###效果示例

##图片集
可以滑动展示的图片集
###源码
####html
<div id="gallery_wrapper" class="blend-gallery" data-blend-gallery=''>
<div id="gallery_wrapper1" class="blend-gallery" data-blend-gallery=''>
</div>
<button id="show" class="show">click to show</button>
<button id="show1" class="show">click to show1</button>
####Javascript
<script type="text/javascript">
// var $ = blend;
;(function(){
require.config({
baseUrl: "../../../BlendUI2/src/",
urlArgs: "_=" + +new Date()
});
var list = [{
// height: 414,
// width: 300,
image: "http://a.hiphotos.baidu.com/image/pic/item/4b90f603738da977a9aac626b251f8198618e332.jpg",
description:"这是第1张图片啊!!!!!",
title:"图片集"
},{
// height: 414,
// width: 300,
image: "http://b.hiphotos.baidu.com/image/pic/item/b8389b504fc2d5627c886ee4e51190ef76c66c33.jpg",
description:"这是第2张图片啊!!!!!",
title:"图片集"
},{
// height: 414,
// width: 300,
image: "http://c.hiphotos.baidu.com/image/pic/item/4034970a304e251f17a2e38ba486c9177f3e536f.jpg",
description:"这是第3张图片啊!!!!!",
title:"图片集"
},{
// height: 414,
// width: 300,
image: "http://t12.baidu.com/it/u=4224136820,222817142&fm=32&s=CE73A55661C252F05E652DCE010070E2&w=623&h=799&img.JPEG",
description:"这是第4张图片啊!!!!!",
title:"图片集"
},{
// height: 414,
// width: 300,
image: "http://d.hiphotos.baidu.com/image/pic/item/00e93901213fb80e80d7d65437d12f2eb938942b.jpg",
description:"这是第5张图片啊!!!!!",
title:"图片集"
},{
// height: 414,
// width: 300,
image: "http://h.hiphotos.baidu.com/image/pic/item/d439b6003af33a87069d591bc45c10385343b53b.jpg",
description:"超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!超长的描述!!!!",
title:"图片集"
}];
var wrapper = boost("#gallery_wrapper").gallery({
data:list,
duration:2000,
isLooping:true,
useZoom:true,
isAutoplay:false //是否自动播放
});
boost("#show").on("click",function(){
wrapper.gallery("show");
});
var list1 = [{
// height: 414,
// width: 300,
image: "http://be-fe.github.io/iSlider/demo/picture/imgs/long/4.jpg",
description:"这是第4张图片啊!!!!!",
title:"图片集"
},{
// height: 414,
// width: 300,
image: "http://be-fe.github.io/iSlider/demo/picture/imgs/long/5.jpg",
description:"这是第5张图片啊!!!!!",
title:"图片集"
},{
// height: 414,
// width: 300,
image: "http://be-fe.github.io/iSlider/demo/picture/imgs/long/6.jpg",
description:"这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!这是第6张图片啊!!!!!",
title:"图片集"
}];
/*var wrapper1 = boost("#gallery_wrapper1").gallery({
data:list1,
// isDebug:true,
duration:2000,
isLooping:true,
useZoom:true,
isAutoplay:false //是否自动播放
});
boost("#show1").on("click",function(){
wrapper1.gallery("show");
});*/
/*var wrapper2 = boost(".show").gallery({
data:list1,
// isDebug:true,
duration:2000,
isLooping:true,
useZoom:true,
isAutoplay:false //是否自动播放
});
boost(".show").on("click",function(){
console.log(boost(this));
boost(this).gallery("show");
// setTimeout(function(){
// alert("show time is up!");
// wrapper.gallery("hide");
// },10000);
});*/
document.addEventListener("click",function(){
console.log(121212);
});
})();
</script>
###效果示例

##页头
页头的样式
###源码
####html
<header data-blend-widget="header" class="blend-header">
<span class="blend-header-left">
<a class="blend-header-item blend-action-back" href="javascript:history.back();">返回</a>
</span>
<span class="blend-header-title">
<span class="blend-header-item">第二个页面</span>
</span>
<span class="blend-header-right">
<a class="blend-header-item" href="http://www.google.com">Google</a>
<a class="blend-header-item blend-button blend-button-info" href="header.test.html">测试1</a>
</span>
</header>
<a class="blend-header-item blend-button blend-button-info" href="header.test.html">测试1</a>
####Javascript
<script>
require.config({
baseUrl: "../../../BlendUI2/src/",
urlArgs: "_=" + +new Date()
});
//require(['blend'], function (blend) {
// var header = blend.create("title", {
// text:"header"
// });
// header.setStyle({
// backgroundColor:"#ff0000",
// color:"#cccccc"
// });
// header.addLeftItem({
// text: "返回",
// action: {
// operator: 'back'
// }
// });
// header.addRightItem({
// text:"菜单",
// action:{
// url: "http://www.baidu.com"
// }
// });
//});
</script>
###效果示例

##列表
页面中用来展示数据的列表
###源码
####html
<section data-blend-widget="list" class="blend-list">
<div class="blend-list-item">
<div class="blend-list-item-content">123</div>
<span class="blend-list-item-delete">删除</span>
</div>
<div class="blend-list-item">
<div class="blend-list-item-content">1323423</div>
<span class="blend-list-item-delete">删除</span>
</div>
<div class="blend-list-item">
<div class="blend-list-item-content">12432343</div>
<span class="blend-list-item-delete">删除</span>
</div>
</section>
<button id="revert">revert</button><br>
<button id="add">add</button><br>
<button id="refresh">refresh</button><br>
<button id="destroy">destroy</button><br>
<button id="create">create</button><br>
####Javascript
<script>
var $blendList = $('.blend-list').eq(0);
$blendList.list();//.list('destroy');
$('#revert').click(function() {
$blendList.list('revert');
});
$('#add').click(function() {
$blendList.append([
'<div class="blend-list-item">',
'<div class="blend-list-item-content">12432343</div>',
'<span class="blend-list-item-delete">删除</span>',
'</div>'
].join(''));
$blendList.list('refresh');
});
$('#refresh').click(function() {
$blendList.list('refresh');
});
$('#destroy').click(function() {
$blendList.list('destroy');
});
$('#create').click(function() {
$blendList.list();
});
</script>
###效果示例

##加载界面
加载内容过程中的等待界面
###源码
####html
<button onclick="triggerLoading()">打开loading</button>
<br/><br/>
<button onclick="closeLoading()">关闭loading</button>
<div class="j_test_loading" style="display:none">loading</div>
####Javascript
<script>
var loading = $.blend.loading();
function triggerLoading(){
loading.show();
}
function closeLoading(){
loading.hide();
}
$('.j_test_loading').loading();
</script>
###效果示例

##对话框
用作提示的对话框
###源码
####html
<button onclick="dialog2.show()">两个按钮dialog</button>
<br/><br/><br/><br/><br/><br/>
<button onclick="dialog1.show()">一个按钮dialog</button>
<div data-blend-widget="dialog" class="blend-dialog blend-dialog-hidden j_test_dialog">
<div class="blend-dialog-header"> 标题 </div>
<div class="blend-dialog-body"> 内容 </div>
<div class="blend-dialog-footer">
<a href="javascript:void(0);" class="blend-dialog-cancel">取消</a>
<a href="javascript:void(0);" class="blend-dialog-done">确认</a>
</div>
</div>
</div>
####Javascript
<script>
var dialog1 = $.blend.dialog({
message: "hello world!!!",
cancelOnly: 1,
cancelText: '确定'
});
var dialog2 = $.blend.dialog({
message: "hello world!!!",
maskTapClose: true
});
$('.j_test_dialog').dialog().on('dialog:show', function(){
alert('show')
});
</script>
###效果示例

##内容面板
展示内容的面板
###源码
####html
<div data-blend-widget="panel" class="blend-panel">
<div class="blend-panel-header blend-panel-left">
长途汽车:
</div>
<div class="blend-panel-body">
成都新南门车站——峨眉山客运中心(峨眉山市票价43元/人),30分钟一班。
旅游专线:乐山客运中心站——峨眉山市乐山港——峨眉山报国寺乐山客运中心站——沙湾乐山港
<br/>【有效期】 2015.03.15
<br/>【退票规则】 使用前均可提前退票
</div>
<div class="blend-panel-footer blend-panel-center">
加载更多
</div>
</div>
###效果示例

##图片样式
不同的图片展示样式
###源码
####html
<figure data-widget="picture" class="blend-picture blend-picture-default blend-picture-radius" data-picture="{}">
<a calss="picture-link" href="http://www.baidu.com" target="_blank">
<img src="http://c.hiphotos.baidu.com/image/pic/item/91ef76c6a7efce1b1769fdd6ac51f3deb48f656f.jpg">
</a>
<figcaption class="blend-picture-title blend-picture-title-default">bottom,带链接,default图片</figcaption>
</figure>
<figure data-widget="picture" class="blend-picture blend-picture-full " data-picture="{}">
<img src="http://img5.imgtn.bdimg.com/it/u=2144620322,1877482059&fm=23&gp=0.jpg">
<figcaption class="blend-picture-title blend-picture-title-default">bottom,不带链接,full图片</figcaption>
</figure>
<figure data-widget="picture" class="blend-picture blend-picture-full" data-picture="{}">
<img src="http://pic.4j4j.cn/upload/pic/20130530/f41069c61a.jpg">
<figcaption class="blend-picture-title blend-picture-title-cover">黑底,不带链接,full图片</figcaption>
</figure>
<figure data-widget="blend-picture" class="blend-picture blend-picture-default" data-picture="{}">
<a calss="blend-picture-link" href="http://www.baidu.com" target="_blank">
<img src="http://c.hiphotos.baidu.com/image/pic/item/91ef76c6a7efce1b1769fdd6ac51f3deb48f656f.jpg">
</a>
<figcaption class="blend-picture-title blend-picture-title-cover">黑底,不带链接,default图片</figcaption>
</figure>
###效果示例



##滑动图片展示框
用作展示图片的滑动窗口
###源码
####html
<div id="slider1" data-blend-widget="slider" class="blend-slider" data-blend-slider='{"theme":"d2"}'>
<ul class="blend-slides">
<li>
<img src="http://img5.imgtn.bdimg.com/it/u=2144620322,1877482059&fm=23&gp=0.jpg"/>
<div class="blend-slider-title">这是图片1的标题</div>
</li>
<li>
<img src="http://b.hiphotos.baidu.com/image/pic/item/95eef01f3a292df5b933a51fbe315c6035a873c3.jpg"/>
<div class="blend-slider-title">这是图片2的标题</div>
</li>
<li>
<a href="http://www.baidu.com" target="_blank">
<img src="http://a.hiphotos.baidu.com/image/pic/item/c83d70cf3bc79f3dc8225e37b8a1cd11738b29f1.jpg"/>
</a>
<div class="blend-slider-title">这是图片3的标题</div>
</li>
<li>
<a href="http://www.baidu.com" target="_blank">
<img src="http://g.hiphotos.baidu.com/image/pic/item/50da81cb39dbb6fd2ca88b260b24ab18972b373a.jpg"/>
</a>
<div class="blend-slider-title">这是图片4的标题</div>
</li>
</ul>
</div>
<button id="prev">上一张</button>
<button id="paused">暂停</button>
<button id="next">下一张</button>
####Javascript
<script>
;(function(){
$("#slider1").slider();
$("#next").on('click',function(){
$("#slider1").slider('next');
});
$("#paused").on('click',function(){
$("#slider1").slider('paused');
});
$("#prev").on('click',function(){
$("#slider1").slider('prev');
});
})();
</script>
###效果示例

##标签
切换容器内容的标签
###源码
####html
<section class="blend-tab">
<div class="blend-tab-header">
<div class="blend-tab-header-item">我的</div>
<div class="blend-tab-header-item">你的</div>
<div class="blend-tab-header-active"></div>
</div>
<div class="blend-tab-content">
<div class="blend-tab-content-item">我的</div>
<div class="blend-tab-content-item">你的</div>
</div>
</section>
<button id="active">active</button><br>
<button id="destroy">destroy</button><br>
<button id="create">create</button><br>
####Javascript
<script>
$('.blend-tab').tab();
$('#active').click(function() {
$('.blend-tab').tab('active', 1);
});
$('#destroy').click(function() {
$('.blend-tab').tab('destroy');
});
$('#create').click(function() {
$('.blend-tab').tab();
});
</script>
###效果示例

##导航标签
页面导航位置上,可以切换内容的标签
###源码
####html
<nav data-blend-widget="tabnav" class="blend-tabnav blend-tabnav-dash" style="margin-bottom: 20px;">
<a class="blend-tabnav-item blend-tabnav-item-active" href="#">
<span class="blend-tabnav-item-text">NIHAO</span>
</a>
<a class="blend-tabnav-item" href="#">
<span class="blend-tabnav-item-text">GEREN</span>
</a>
</nav>
<nav data-blend-widget="tabnav" class="blend-tabnav">
<a class="blend-tabnav-item blend-tabnav-item-active" href="#">
<span class="blend-tabnav-item-text">NIHAO</span>
</a>
<a class="blend-tabnav-item" href="#">
<span class="blend-tabnav-item-text">GEREN</span>
</a>
<a class="blend-tabnav-item" href="#">
<span class="blend-tabnav-item-text">NIHAO</span>
</a>
<a class="blend-tabnav-item" href="#">
<span class="blend-tabnav-item-text">GEREN</span>
</a>
</nav>
###效果示例

##闪现的提示内容
在页面上淡出的提示内容
###源码
####html
<div class="j_test_toast">{%content%}</div>
<button onclick="triggerToast()">点我,点我</button>
####Javascript
<script>
function triggerToast(){
var toast = $.blend.toast();
toast.show('test', 3000);
}
$('.j_test_toast').toast().toast('show', 'hello', 2000);
</script>
###效果示例
 | 22,641 | MIT |
<!-- YAML
added: v11.13.0
-->
* 返回: {stream.Readable} 包含 V8 堆快照的可读流。
生成当前 V8 堆的快照,并返回可读流,该可读流可用于读取 JSON 序列化表示。
此 JSON 流格式旨在与 Chrome DevTools 等工具一起使用。
JSON 模式未记录且特定于V8引擎。
因此,该模式可能从 V8 的一个版本更改为下一个版本。
```js
// 打印堆快照到控制台。
const v8 = require('v8');
const stream = v8.getHeapSnapshot();
stream.pipe(process.stdout);
``` | 320 | CC-BY-4.0 |
---
title: 'チュートリアル: ASP.NET Core の Razor ページの概要'
author: rick-anderson
description: このチュートリアル シリーズでは、ASP.NET Core で Razor ページを使用する方法を示します。 モデルの作成、Razor ページのコードの生成、Entity Framework Core と SQL Server を使用したデータ アクセス、検索機能の追加、入力検証の追加、および移行を使用したモデルの更新の方法について説明します。
ms.author: riande
ms.date: 11/12/2019
uid: tutorials/razor-pages/razor-pages-start
ms.openlocfilehash: 6e1d58ccd83f7d7c1083dc2bf9ce7476650812a1
ms.sourcegitcommit: da2fb2d78ce70accdba903ccbfdcfffdd0112123
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 01/07/2020
ms.locfileid: "75723016"
---
# <a name="tutorial-get-started-with-razor-pages-in-aspnet-core"></a>チュートリアル: ASP.NET Core の Razor ページの概要
作成者: [Rick Anderson](https://twitter.com/RickAndMSFT)
::: moniker range=">= aspnetcore-3.0"
これは、ASP.NET Core の Razor Pages Web アプリの構築の基礎について説明する、シリーズの最初のチュートリアルです。
[!INCLUDE[](~/includes/advancedRP.md)]
シリーズの最後には、映画のデータベースを管理できるアプリができあがります。
[!INCLUDE[View or download sample code](~/includes/rp/download.md)]
このチュートリアルでは、次の作業を行いました。
> [!div class="checklist"]
> * Razor Pages Web アプリを作成する。
> * アプリを実行します。
> * プロジェクト ファイルを確認する
このチュートリアルの最後には、以降のチュートリアルでビルドする作業用 Razor Pages Web アプリができあがります。

## <a name="prerequisites"></a>必須コンポーネント
# <a name="visual-studiotabvisual-studio"></a>[Visual Studio](#tab/visual-studio)
[!INCLUDE[](~/includes/net-core-prereqs-vs-3.1.md)]
# <a name="visual-studio-codetabvisual-studio-code"></a>[Visual Studio Code](#tab/visual-studio-code)
[!INCLUDE[](~/includes/net-core-prereqs-vsc-3.1.md)]
# <a name="visual-studio-for-mactabvisual-studio-mac"></a>[Visual Studio for Mac](#tab/visual-studio-mac)
[!INCLUDE[](~/includes/net-core-prereqs-mac-3.1.md)]
---
## <a name="create-a-razor-pages-web-app"></a>Razor ページ Web アプリを作成する
# <a name="visual-studiotabvisual-studio"></a>[Visual Studio](#tab/visual-studio)
* Visual Studio の **[ファイル]** メニューから、 **[新規作成]** > **[プロジェクト]** の順に選択します。
* 新しい ASP.NET CoreWeb アプリケーションを作成し、 **[次へ]** を選択します。

* プロジェクトに **RazorPagesMovie** という名前を付けます。 コードのコピーおよび貼り付けを行う際に名前空間が一致するように、プロジェクトに *RazorPagesMovie* という名前を付けることが重要です。

* ドロップダウンの **[ASP.NET Core 3.1]** 、 **[Web アプリケーション]** の順に選択し、 **[作成]** を選択します。

次のスターター プロジェクトが作成されます。

# <a name="visual-studio-codetabvisual-studio-code"></a>[Visual Studio Code](#tab/visual-studio-code)
* [統合ターミナル](https://code.visualstudio.com/docs/editor/integrated-terminal)を開きます。
* プロジェクトを格納するディレクトリ (`cd`) に変更します。
* 次のコマンドを実行します。
```dotnetcli
dotnet new webapp -o RazorPagesMovie
code -r RazorPagesMovie
```
* `dotnet new` コマンド: *RazorPagesMovie* フォルダーに新しい Razor Pages プロジェクトが作成されます。
* `code` コマンドは、Visual Studio Code の現在のインスタンス内で *RazorPagesMovie* フォルダーを開きます。
* 状態バーの OmniSharp フレーム アイコンが緑色になり、"**ビルドとデバッグに必要な資産が 'RazorPagesMovie' にありません。追加しますか?** " という内容のダイアログ ボックスが表示されたら、 **[はい]** を選択します。
*launch.json* ファイルと *tasks.json* ファイルを格納している *.vscode* ディレクトリが、プロジェクトのルート ディレクトリに追加されます。
# <a name="visual-studio-for-mactabvisual-studio-mac"></a>[Visual Studio for Mac](#tab/visual-studio-mac)
* **[ファイル]** > **[新しいソリューション]** の順に選択します。

* **[.NET Core]** > **[アプリ]** > **[Web アプリケーション]** > **[次へ]** の順に選択します。
![macOS の [新しいプロジェクト] ダイアログ](razor-pages-start/_static/webapp.png)
* **[Configure your new Web Application]\(新しい Web アプリケーションを構成する\)** ダイアログで、 **[ターゲット フレームワーク]** を **[.NET Core 3.1]** に設定します。

* プロジェクトに **RazorPagesMovie** という名前を付けて、 **[作成]** を選択します。

<!-- End of VS tabs -->
---
## <a name="run-the-app"></a>アプリを実行する
[!INCLUDE[](~/includes/run-the-app.md)]
## <a name="examine-the-project-files"></a>プロジェクト ファイルを確認する
以降のチュートリアルで使用するメイン プロジェクト フォルダーとファイルの概要を次に示します。
### <a name="pages-folder"></a>Pages フォルダー
Razor ページとサポート ファイルが格納されます。 各 Razor ページは、次のファイルのペアとなります。
* *.cshtml* ファイル: HTML マークアップと、Razor 構文を使用した C# コードが保存されます。
* *.cshtml.cs* ファイル: ページ イベントを処理する C# コードが保存されます。
サポート ファイルには、アンダー スコアで始まる名前が付けられます。 たとえば、 *_Layout.cshtml* ファイルでは、すべてのページに共通の UI 要素が構成されます。 このファイルでは、ページの上部に表示されるナビゲーション メニューと、ページの下部に表示される著作権の通知が設定されます。 詳細については、「<xref:mvc/views/layout>」を参照してください。
### <a name="wwwroot-folder"></a>wwwroot フォルダー
HTML ファイル、JavaScript ファイル、CSS ファイルなどの静的ファイルが格納されます。 詳細については、「<xref:fundamentals/static-files>」を参照してください。
### <a name="appsettingsjson"></a>appSettings.json
接続文字列などの構成データが保存されます。 詳細については、「<xref:fundamentals/configuration/index>」を参照してください。
### <a name="programcs"></a>Program.cs
プログラムのエントリ ポイントが保存されます。 詳細については、「<xref:fundamentals/host/generic-host>」を参照してください。
### <a name="startupcs"></a>Startup.cs
アプリの動作を構成するコードが含まれています。 詳細については、「<xref:fundamentals/startup>」を参照してください。
## <a name="next-steps"></a>次の手順
このシリーズの次のチュートリアルに進んでください。
> [!div class="step-by-step"]
> [モデルの追加](xref:tutorials/razor-pages/model)
::: moniker-end
<!--::: moniker range=">= aspnetcore-3.0" -->
::: moniker range="< aspnetcore-3.0"
これは、シリーズの最初のチュートリアルです。 [このシリーズ](xref:tutorials/razor-pages/index)では、ASP.NET Core の Razor Pages Web アプリの構築の基礎について説明します。
[!INCLUDE[](~/includes/advancedRP.md)]
シリーズの最後には、映画のデータベースを管理できるアプリができあがります。
[!INCLUDE[View or download sample code](~/includes/rp/download.md)]
このチュートリアルでは、次の作業を行いました。
> [!div class="checklist"]
> * Razor Pages Web アプリを作成する。
> * アプリを実行します。
> * プロジェクト ファイルを確認する
このチュートリアルの最後には、以降のチュートリアルでビルドする作業用 Razor Pages Web アプリができあがります。

## <a name="prerequisites"></a>必須コンポーネント
# <a name="visual-studiotabvisual-studio"></a>[Visual Studio](#tab/visual-studio)
[!INCLUDE[](~/includes/net-core-prereqs-vs2019-2.2.md)]
# <a name="visual-studio-codetabvisual-studio-code"></a>[Visual Studio Code](#tab/visual-studio-code)
[!INCLUDE[](~/includes/net-core-prereqs-vsc-2.2.md)]
# <a name="visual-studio-for-mactabvisual-studio-mac"></a>[Visual Studio for Mac](#tab/visual-studio-mac)
[!INCLUDE[](~/includes/net-core-prereqs-mac-2.2.md)]
---
## <a name="create-a-razor-pages-web-app"></a>Razor ページ Web アプリを作成する
# <a name="visual-studiotabvisual-studio"></a>[Visual Studio](#tab/visual-studio)
* Visual Studio の **[ファイル]** メニューから、 **[新規作成]** > **[プロジェクト]** の順に選択します。
* 新しい ASP.NET CoreWeb アプリケーションを作成し、 **[次へ]** を選択します。

* プロジェクトに **RazorPagesMovie** という名前を付けます。 コードのコピーおよび貼り付けを行う際に名前空間が一致するように、プロジェクトに *RazorPagesMovie* という名前を付けることが重要です。

* ドロップダウンの **[ASP.NET Core 2.2]** 、 **[Web アプリケーション]** の順に選択し、 **[作成]** を選択します。

次のスターター プロジェクトが作成されます。

# <a name="visual-studio-codetabvisual-studio-code"></a>[Visual Studio Code](#tab/visual-studio-code)
* [統合ターミナル](https://code.visualstudio.com/docs/editor/integrated-terminal)を開きます。
* プロジェクトを格納するディレクトリ (`cd`) に変更します。
* 次のコマンドを実行します。
```dotnetcli
dotnet new webapp -o RazorPagesMovie
code -r RazorPagesMovie
```
* `dotnet new` コマンド: *RazorPagesMovie* フォルダーに新しい Razor Pages プロジェクトが作成されます。
* `code` コマンドは、Visual Studio Code の現在のインスタンス内で *RazorPagesMovie* フォルダーを開きます。
* 状態バーの OmniSharp フレーム アイコンが緑色になり、"**ビルドとデバッグに必要な資産が 'RazorPagesMovie' にありません。追加しますか?** " という内容のダイアログ ボックスが表示されたら、 **[はい]** を選択します。
*launch.json* ファイルと *tasks.json* ファイルを格納している *.vscode* ディレクトリが、プロジェクトのルート ディレクトリに追加されます。
# <a name="visual-studio-for-mactabvisual-studio-mac"></a>[Visual Studio for Mac](#tab/visual-studio-mac)
* **[ファイル]** > **[新しいソリューション]** の順に選択します。

* **[.NET Core]** > **[アプリ]** > **[Web アプリケーション]** > **[次へ]** の順に選択します。
![macOS の [新しいプロジェクト] ダイアログ](razor-pages-start/_static/webapp.png)
* **[Configure your new ASP.NET Core Web API]\(新しい ASP.NET Core Web API を構成する\)** ダイアログで、 **[ターゲット フレームワーク]** を **[.NET Core 3.1]** に設定します。

* プロジェクトに **RazorPagesMovie** という名前を付けて、 **[作成]** を選択します。

<!-- End of VS tabs -->
---
## <a name="run-the-app"></a>アプリを実行する
# <a name="visual-studiotabvisual-studio"></a>[Visual Studio](#tab/visual-studio)
* Ctrl + F5 キーを押して、デバッガーなしで実行します。
[!INCLUDE[](~/includes/trustCertVS.md)]
Visual Studio で [IIS Express](/iis/extensions/introduction-to-iis-express/iis-express-overview) が開始され、アプリが実行されます。 アドレス バーには、`example.com` などではなく、`localhost:port#` が表示されます。 これは、`localhost` がローカル コンピューターの標準のホスト名であるためです。 localhost では、ローカル コンピューターからの Web 要求のみが処理されます。 Visual Studio が Web プロジェクトを作成する場合は、Web サーバーにランダム ポートが使用されます。
* アプリのホーム ページ上で、 **[同意する]** を選択して、追跡に同意します。
このアプリによって個人情報は追跡されません。しかし、欧州連合の[一般データ保護規則 (GDPR)](xref:security/gdpr) に準拠するための同意機能が必要な場合は、プロジェクト テンプレートにその機能が含められます。

次の図では、追跡に同意した後のアプリを示しています。

# <a name="visual-studio-codetabvisual-studio-code"></a>[Visual Studio Code](#tab/visual-studio-code)
[!INCLUDE[](~/includes/trustCertVSC.md)]
* **Ctrl + F5** キーを押して、デバッガーなしで実行します。
Visual Studio Code で [Kestrel](xref:fundamentals/servers/kestrel) が開始され、ブラウザーが起動して、`http://localhost:5001` に移動します。 アドレス バーには、`example.com` などではなく、`localhost:port#` が表示されます。 これは、`localhost` がローカル コンピューターの標準のホスト名であるためです。 localhost では、ローカル コンピューターからの Web 要求のみが処理されます。
* アプリのホーム ページ上で、 **[同意する]** を選択して、追跡に同意します。
このアプリによって個人情報は追跡されません。しかし、欧州連合の[一般データ保護規則 (GDPR)](xref:security/gdpr) に準拠するための同意機能が必要な場合は、プロジェクト テンプレートにその機能が含められます。

次の図では、追跡に同意した後のアプリを示しています。

# <a name="visual-studio-for-mactabvisual-studio-mac"></a>[Visual Studio for Mac](#tab/visual-studio-mac)
[!INCLUDE[](~/includes/trustCertMac.md)]
* **Cmd - Opt - F5** キーを押して、デバッガーなしで実行します。
Visual Studio は [Kestrel](xref:fundamentals/servers/kestrel) を開始し、ブラウザーを起動して、`http://localhost:5001` に移動します。
* アプリのホーム ページ上で、 **[同意する]** を選択して、追跡に同意します。
このアプリによって個人情報は追跡されません。しかし、欧州連合の[一般データ保護規則 (GDPR)](xref:security/gdpr) に準拠するための同意機能が必要な場合は、プロジェクト テンプレートにその機能が含められます。

次の図では、追跡に同意した後のアプリを示しています。

<!-- End of VS tabs -->
---
## <a name="examine-the-project-files"></a>プロジェクト ファイルを確認する
以降のチュートリアルで使用するメイン プロジェクト フォルダーとファイルの概要を次に示します。
### <a name="pages-folder"></a>Pages フォルダー
Razor ページとサポート ファイルが格納されます。 各 Razor ページは、次のファイルのペアとなります。
* *.cshtml* ファイル: HTML マークアップと、Razor 構文を使用した C# コードが保存されます。
* *.cshtml.cs* ファイル: ページ イベントを処理する C# コードが保存されます。
サポート ファイルには、アンダー スコアで始まる名前が付けられます。 たとえば、 *_Layout.cshtml* ファイルでは、すべてのページに共通の UI 要素が構成されます。 このファイルでは、ページの上部に表示されるナビゲーション メニューと、ページの下部に表示される著作権の通知が設定されます。 詳細については、「<xref:mvc/views/layout>」を参照してください。
### <a name="wwwroot-folder"></a>wwwroot フォルダー
HTML ファイル、JavaScript ファイル、CSS ファイルなどの静的ファイルが格納されます。 詳細については、「<xref:fundamentals/static-files>」を参照してください。
### <a name="appsettingsjson"></a>appSettings.json
接続文字列などの構成データが保存されます。 詳細については、「<xref:fundamentals/configuration/index>」を参照してください。
### <a name="programcs"></a>Program.cs
プログラムのエントリ ポイントが保存されます。 詳細については、「<xref:fundamentals/host/generic-host>」を参照してください。
### <a name="startupcs"></a>Startup.cs
cookie に対する同意が必要かどうかなど、アプリの動作を構成するコードが保存されます。 詳細については、「<xref:fundamentals/startup>」を参照してください。
## <a name="additional-resources"></a>その他の技術情報
* [このチュートリアルの YouTube バージョン](https://www.youtube.com/watch?v=F0SP7Ry4flQ&feature=youtu.be)
## <a name="next-steps"></a>次の手順
このシリーズの次のチュートリアルに進んでください。
> [!div class="step-by-step"]
> [モデルの追加](xref:tutorials/razor-pages/model)
::: moniker-end | 12,247 | CC-BY-4.0 |
# Spring5 新特性 - spring.components
- Author: [HuiFer](https://github.com/huifer)
- 源码阅读仓库: [huifer-spring](https://github.com/huifer/spring-framework-read)
## 解析
- 相关类: `org.springframework.context.index.CandidateComponentsIndexLoader`
- 测试用例: `org.springframework.context.annotation.ClassPathScanningCandidateComponentProviderTests.defaultsWithIndex`,`org.springframework.context.index.CandidateComponentsIndexLoaderTests`
- `CandidateComponentsIndexLoader`是怎么找出来的,全文搜索`spring.components`
### 使用介绍
- 下面是从`resources/example/scannable/spring.components`测试用例中复制过来的,从中可以发现等号左侧放的是我们写的组件,等号右边是属于什么组件
```
example.scannable.AutowiredQualifierFooService=example.scannable.FooService
example.scannable.DefaultNamedComponent=org.springframework.stereotype.Component
example.scannable.NamedComponent=org.springframework.stereotype.Component
example.scannable.FooService=example.scannable.FooService
example.scannable.FooServiceImpl=org.springframework.stereotype.Component,example.scannable.FooService
example.scannable.ScopedProxyTestBean=example.scannable.FooService
example.scannable.StubFooDao=org.springframework.stereotype.Component
example.scannable.NamedStubDao=org.springframework.stereotype.Component
example.scannable.ServiceInvocationCounter=org.springframework.stereotype.Component
example.scannable.sub.BarComponent=org.springframework.stereotype.Component
```
### debug
- 入口 `org.springframework.context.index.CandidateComponentsIndexLoader.loadIndex`
```java
@Nullable
public static CandidateComponentsIndex loadIndex(@Nullable ClassLoader classLoader) {
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = CandidateComponentsIndexLoader.class.getClassLoader();
}
return cache.computeIfAbsent(classLoaderToUse, CandidateComponentsIndexLoader::doLoadIndex);
}
```
```java
/**
* 解析 META-INF/spring.components 文件
* @param classLoader
* @return
*/
@Nullable
private static CandidateComponentsIndex doLoadIndex(ClassLoader classLoader) {
if (shouldIgnoreIndex) {
return null;
}
try {
Enumeration<URL> urls = classLoader.getResources(COMPONENTS_RESOURCE_LOCATION);
if (!urls.hasMoreElements()) {
return null;
}
List<Properties> result = new ArrayList<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
// 读取META-INF/spring.components文件转换成map对象
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
result.add(properties);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + result.size() + "] index(es)");
}
int totalCount = result.stream().mapToInt(Properties::size).sum();
// 查看CandidateComponentsIndex方法
return (totalCount > 0 ? new CandidateComponentsIndex(result) : null);
}
catch (IOException ex) {
throw new IllegalStateException("Unable to load indexes from location [" +
COMPONENTS_RESOURCE_LOCATION + "]", ex);
}
}
```
```java
CandidateComponentsIndex(List<Properties> content) {
this.index = parseIndex(content);
}
/**
* 解析 MATE-INF\spring.components 转换成 map
*
* @param content
* @return
*/
private static MultiValueMap<String, Entry> parseIndex(List<Properties> content) {
MultiValueMap<String, Entry> index = new LinkedMultiValueMap<>();
for (Properties entry : content) {
entry.forEach((type, values) -> {
String[] stereotypes = ((String) values).split(",");
for (String stereotype : stereotypes) {
index.add(stereotype, new Entry((String) type));
}
});
}
return index;
}
```

- 该类给`org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider.findCandidateComponents`提供了帮助
```java
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
// 扫描
/**
* if 测试用例: {@link org.springframework.context.annotation.ClassPathScanningCandidateComponentProviderTests#defaultsWithIndex()}
* 解析 spring.components文件
*/
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
``` | 4,728 | Apache-2.0 |
# Nv-pro
下载下来后,安装相关依赖
> clone相关代码
> $ yarn install
> $ gulp
### 主题更换和支持
默认是`极客蓝`,另外还支持`经典红`、`幽暗黑`、`深空灰`、`活力橙`
更换很简单
**极客蓝**
```html
<!--css样式请放在head标签内部-->
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/nv.min.css" />
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/pro/dark.min.css" />
```
***切记,`data-theme`必须添加,否则组件库无法识别当前的主题色***
### 各种皮肤主题
**经典红**
```html
<!--css样式请放在head标签内部-->
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/nv.red.min.css" />
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/pro/red.min.css" />
```
**活力橙**
```html
<!--css样式请放在head标签内部-->
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/nv.orange.min.css" />
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/pro/orange.min.css" />
```
**深空灰**
```html
<!--css样式请放在head标签内部-->
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/nv.grey.min.css" />
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/pro/grey.min.css" />
```
**幽暗黑,全套暗黑联盟**
```html
<!--css样式请放在head标签内部-->
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/nv.black.min.css" />
<link type="text/css" rel="stylesheet" data-theme href="//storage.360buyimg.com/v2.0.0/pro/black.min.css" />
```
### 快速导航
+ [官网](http://www.nv-js.com)
+ [引擎常用方法](https://github.com/Nv-js/Nv-engine/blob/master/docs/API.md)
+ [快速导航](https://github.com/Nv-js/Nv-engine/blob/master/docs/quick.md)
+ [多语言支持](https://github.com/Nv-js/Nv-engine/blob/master/docs/language.md)
+ [组件库常用方法](https://github.com/Nv-js/Nv-source)
+ [PRO系统解决方案](https://github.com/Nv-js/Nv-pro) | 1,908 | MIT |
---
layout: post
title: "HTML & CSS要点"
date: 2016-05-18
author: "Sim"
catalog: true
tags:
- CSS
- HTML
---
#HTML
1. HTML和XHTML文档类型定义
1) HTML 4.01 Strict DTD:`<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">`
2) HTML 4.01 Transitional DTD:`<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/1999/REC-html401-19991224/loose.dtd">`
3) HTML 4.01 Frameset DTD:`<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/1999/REC-html401-19991224/frameset.dtd">`
4) XHTML 1.0 Strict DTD:`<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xtml1/DTD/xhtml1-strict.dtd">`
5) XHTML 1.0 Transitional DTD:`<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xtml1/DTD/xhtml1-transitional.dtd">`
6) XHTML 1.0 Frameset DTD:`<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xtml1/DTD/xhtml1-frameset.dtd">`
7) XHTML 1.1 DTD:`<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xtml11/DTD/xhtml11.dtd">`
-----
#CSS
1. CSS 盒模型包含
* 内容(content) -- 处于盒的中央
* 内边距(padding) -- 紧贴内容的区域
* 边框(border) -- 包围内边距的外层,构成盒的边界
* 外边距(margin) -- 从边框边界开始向外延伸的**透明**盒
默认的外边距值是0,这时与边框边界对齐。如果边框值为0,则边框与内边距对齐
所以,内边距为0时,内边距将紧贴内容,值大于0时,会撑大盒子
2. 使用`@media`在同一样式表中指定不同的媒体类型
e.g
```css
/* 一般情况 */
p {
font-size: 13px;
}
/* 需要进行打印时 */
@media print {
p {
font-size: 10px;
}
}
```
3. font的简写属性中,如果需要同时使用`font-size`和`line-height`的话,可以用'/'进行分割
4. 1em = 10px
5. 将文本设置为左右对齐式
```CSS
p {
width: 600px;
text-align: justify;
}
```
6. 居中显示
1)表格
```html
<div class="center">
<table width=50% border="1" cellpadding="30">
<tr>
<td>This is the first cell</td>
<td>This is the second cell</td>
</tr>
</table>
</div>
```
```CSS
.center {
text-align: center;
}
.center table {
width: 50%;
margin-left: auto;
margin-right: auto;
text-align: left;
}
```
2) 图片
```html
<div class="flagicon"><img src="flag.gif" alt="Flag" width="160" height="100"></div>
```
```CSS
.flagicon {
text-align: center;
}
```
如果是显示定宽元素的话,首先可以把父元素的`padding-left`设置为50%,然后取需要居中元素的宽度值的一半,将该值取负给margin-left
```html
<img src="img.jpg" width="256" height="192">
```
```css
body { padding-left: 50%; }
img { margin-left: -138px; }
/* 也可以这样 */
img { display: block; margin: 0 auto; }
```
7. 在所有浏览器上是列表左侧保持一致
```css
ul {
margin-left: 40px;
padding-left: 0px;
}
```
8. 在列表项之间添加列表分隔符
```css
li { border-top: 1px solid black; }
ul { border-bottom: 1px solid black; }
```
9. 自定义列表文本标记符
```css
ul { list-sytle: none; }
li:before { content: "XX"; }
/* 如果是图片的话, 可以这样做 */
ul { list-style-type: disc; list-sytle-image: none; }
```
10. 超链接伪类优先级: link > visited > hover > active | 2,942 | MIT |
---
layout: post
title: "Kafka的有且仅有一次语义与事务消息"
keywords: "Kafka"
description: "Kafka的有且仅有一次语义与事务消息"
date: 2018-07-28 01:00
categories: "Kafka"
---
最近看到Kafka官方wiki上有一篇关于有且仅有一次语义与事务消息的文档(见[这里](https://cwiki.apache.org/confluence/display/KAFKA/KIP-98+-+Exactly+Once+Delivery+and+Transactional+Messaging#KIP-98-ExactlyOnceDeliveryandTransactionalMessaging-Alittlebitabouttransactionsandstreams)),里面说的非常详细。对于有且仅有一次语义与事务消息是什么东西,大家可以看我的上一篇博客,或者看Kafka的这篇wiki,这里不做展开。这篇文章主要整理关于该语义和事务消息的API接口、数据流和配置。
## 生产者接口
### 生产者API的改动
生产者新增了5个新的方法(initTransactions, beginTransaction, sendOffsets, commitTransaction, abortTransaction),并且发送接口也增加了一个新的异常。见下面:
{% highlight java %}
public interface Producer<K,V> extends Closeable {
/*
* Needs to be called before any of the other transaction methods. Assumes that
* the transactional.id is specified in the producer configuration.
*
* This method does the following:
* 1. Ensures any transactions initiated by previous instances of the producer
* are completed. If the previous instance had failed with a transaction in
* progress, it will be aborted. If the last transaction had begun completion,
* but not yet finished, this method awaits its completion.
* 2. Gets the internal producer id and epoch, used in all future transactional
* messages issued by the producer.
*
* @throws IllegalStateException if the TransactionalId for the producer is not set
* in the configuration.
*/
void initTransactions() throws IllegalStateException;
/*
* Should be called before the start of each new transaction.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void beginTransaction() throws ProducerFencedException;
/*
* Sends a list of consumed offsets to the consumer group coordinator, and also marks
* those offsets as part of the current transaction. These offsets will be considered
* consumed only if the transaction is committed successfully.
*
* This method should be used when you need to batch consumed and produced messages
* together, typically in a consume-transform-produce pattern.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException;
/*
* Commits the ongoing transaction.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void commitTransaction() throws ProducerFencedException;
/*
* Aborts the ongoing transaction.
*
* @throws ProducerFencedException if another producer is with the same
* transactional.id is active.
*/
void abortTransaction() throws ProducerFencedException;
/*
* Send the given record asynchronously and return a future which will eventually contain the response information.
*
* @param record The record to send
* @return A future which will eventually contain the response information
*
*/
public Future<RecordMetadata> send(ProducerRecord<K, V> record);
/*
* Send a record and invoke the given callback when the record has been acknowledged by the server
**/
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
}
{% endhighlight %}
### OutOfOrderSequence异常
如果broker检测出数据丢失,生产者接口会抛出OutOfOrderSequenceException异常。换句话说,就是broker发现序列号比预期序列号高。异常会在Future中返回,并且如果存在callback的话会把异常传给callback。这是一个严重异常,生产者后续调用send, beginTransaction, commitTransaction等方法都会抛出一个IlegalStateException。
## 应用示例
以下是一个使用上述API的简单应用:
{% highlight java %}
public class KafkaTransactionsExample {
public static void main(String args[]) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfig);
// Note that the ‘transactional.id’ configuration _must_ be specified in the
// producer config in order to use transactions.
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
// We need to initialize transactions once per producer instance. To use transactions,
// it is assumed that the application id is specified in the config with the key
// transactional.id.
//
// This method will recover or abort transactions initiated by previous instances of a
// producer with the same app id. Any other transactional messages will report an error
// if initialization was not performed.
//
// The response indicates success or failure. Some failures are irrecoverable and will
// require a new producer instance. See the documentation for TransactionMetadata for a
// list of error codes.
producer.initTransactions();
while(true) {
ConsumerRecords<String, String> records = consumer.poll(CONSUMER_POLL_TIMEOUT);
if (!records.isEmpty()) {
// Start a new transaction. This will begin the process of batching the consumed
// records as well
// as an records produced as a result of processing the input records.
//
// We need to check the response to make sure that this producer is able to initiate
// a new transaction.
producer.beginTransaction();
// Process the input records and send them to the output topic(s).
List<ProducerRecord<String, String>> outputRecords = processRecords(records);
for (ProducerRecord<String, String> outputRecord : outputRecords) {
producer.send(outputRecord);
}
// To ensure that the consumed and produced messages are batched, we need to commit
// the offsets through
// the producer and not the consumer.
//
// If this returns an error, we should abort the transaction.
sendOffsetsResult = producer.sendOffsetsToTransaction(getUncommittedOffsets());
// Now that we have consumed, processed, and produced a batch of messages, let's
// commit the results.
// If this does not report success, then the transaction will be rolled back.
producer.endTransaction();
}
}
}
}
{% endhighlight %}
## 新的配置
### broker配置
* transactional.id.timeout.ms:事务协调者超过多长时间没有收到生产者TransactionalId的事务状态更新就认为其过期。默认值为604800000(7天),这个值使得每星期执行一次的生产者任务可以持续维护其ID。
* max.transaction.timeout.ms:事务超时时间。如果client请求事务时间超过这个值,那么broker会在InitPidRequest中返回一个InvalidTransactionTimeout异常。这防止client出现超时时间太长,这会使得消费者消费事务相关的主题时变慢。默认值为900000(15分钟),这是一个保守的上限值。
* transaction.state.log.replication.facto:事务状态主题的副本个数,默认值为3。
* transaction.state.log.num.partitions:事务状态主题的分区个数,默认值为50。
* transaction.state.log.min.isr:事务状态主题每个分区拥有多少个insync的副本才被视为上线。默认为2。
* transaction.state.log.segment.bytes:事务状态主题的日志段大小,默认为104857600字节。
### 生产者配置
* enable.idempotence:是否使用幂等写(默认为false)。如果为false,生产者发送消息请求时不会携带PID字段,保持为与之前的语义一样。如果希望使用事务,那么这个值必须置位true。如果为true,那么会额外要求acks=all,retries > 1,和 max.inflight.requests.per.connection=1。因为如果这些条件不满足,那么无法保证幂等性。如果应用没有显示指明这些属性,那么在启用幂等性时生产者会设置acks=all,retries=Integer.MAX_VALUE,和 max.inflight.requests.per.connection=1。
* transaction.timeout.ms:生产者超过多久没有更新事务状态,事务协调者会将其进行中的事务回滚。这个值会随着InitPidRequest一起发送给事务协调者。如果这个值大于broker设置的max.transaction.timeout.ms,那么请求会抛出InvalidTransactionTimeout异常。默认值为60000,防止下游消费阻塞等待超过1分钟。
* transactional.id:事务投递所使用的TransactionalId值。这个可以保证多个生产者会话的可靠性语义,因为这可以保证在使用相同TransactionalId的情况下,老的事务必须完成才能开启新的事务。需要注意的是,如果启用这个值,必须先设置enable.idempotence为true。此值默认为空,意味着没有使用事务。
### 消费者配置
* isolation.level:以下是可以取的值(默认为read_uncommitted):1)read_uncommitted:按位移顺序按序消费消息,无论其为提交还是未提交。2)read_committed:按位移顺序按序消费消息,但只消费非事务消息和已提交的事务消息;为了保持位移顺序,read_committed会使得消费者需要在获取到同一事务中的所有消息前需要缓存消息。
## 语义保证
### 生产者幂等性保证
为了实现生产者幂等性语义,我们引入了生产者ID(也称为PID)和消息序列号的概念。每一个新的生产者在初始化的时候都会赋予一个PID。PID的设置是对使用者透明的,不会在客户端中暴露出来。
对于一个指定的PID,序列号从0开始并且单调递增,每个主题分区都有一个序列号序列。生产者发送消息到broker后会增加序列号。broker则在内存中维护每个PID发到主题分区的序列号,一旦发现当前收到的序列号没有比上一次收到的序列号刚好大1,那么就会拒绝当前的生产者请求。如果消息携带的序列号比预期低而导致重复异常,生产者会忽略掉这个异常;如果消息携带的序列号比预期高而导致乱序异常,这就意味着有一些消息可能丢失了,这个异常是非常严重的。
通过这样的方法,就保证了即便生产者在出现失败的情况下进行重试,每个消息也只会在日志中仅出现一次。由于每个新的生产者实例都会分配一个新的唯一PID,因此只能保证单个生产者会话中实现幂等性。
这些幂等的生产者语义对于像指标跟踪和审计等应用可能非常有用。
### 事务保证
事务保证的核心就是,使得应用能够原子性的生产消息到多个分区,写入到这些分区的消息要么都成功要么都失败。
进一步地,由于消费者也是通过写入到位移主题来进行记录的,因此事务的能力可以用来使得应用将消费动作和生产动作原子化,也就是说消息被消费了当且仅当整个“消费-转换-生产”的链条都执行完毕。
另外,有状态的应用也可以实现跨越多个会话的连续性。也就是说,Kafka可以保证跨越应用边界的生产幂等性和事务性。为了达到这个目标,应用需要提供一个唯一ID,而且这个唯一ID能够跨越应用边界保持稳定不变。在下面的阐述中,会使用TransactionalId表示这个ID。TransactionalId和PID是一一对应的,区别在于TransactionalId是用户提供的,至于为什么TransactionalId能够保证跨越生产者会话的幂等性的原因下面来分析。
当提供了这样的一个TransactionalId,Kafka保证:
1. 对于一个TransactionalId,只会有一个活跃的生产者。当具有相同TransactionalId的生产者上线时,会把老的生产者强制下线。
2. 事务恢复跨越应用会话。如果一个应用实例死亡,下一个实例启动时会保证之前进行中的事务会被结束(提交或回滚),这样就保证了新的实例处于一个干净的状态。
需要注意的是,这里提到的事务保证是从生产者的角度来看的。对于消费者,这个保证会稍微弱一点。具体来讲,我们不能保证一个已提交事务的所有消息可以一起被消费。原因如下:
1. 对于compact类型的主题,一个事务中的消息可能被更新的版本所代替。
2. 事务可能跨越日志段。因此当老的日志段被删除了,可能会损失一个事务的开始部分。
3. 消费者可以定位到事务中的任意位置开始消费,因此可能会丢失该事务的开始部分消息。
4. 消费者可能消费不到事务中涉及到的分区。因此不能读取到该事务的所有消息。
## 核心概念
为了实现事务,也就是保证一组消息可以原子性生产和消费,Kafka引入了如下概念;
1. 引入了事务协调者(Transaction Coordinator)的概念。与消费者的组协调者类似,每个生产者会有对应的事务协调者,赋予PID和管理事务的逻辑都由事务协调者来完成。
2. 引入了事务日志(Transaction Log)的内部主题。与消费者位移主题类似,事务日志是每个事务的持久化多副本存储。事务协调者使用事务日志来保存当前活跃事务的最新状态快照。
3. 引入了控制消息(Control Message)的概念。这些消息是客户端产生的并写入到主题的特殊消息,但对于使用者来说不可见。它们是用来让broker告知消费者之前拉取的消息是否被原子性提交。控制消息之前在[这里](https://issues.apache.org/jira/browse/KAFKA-1639)被提到过。
4. 引入了TransactionalId的概念,TransactionalId可以让使用者唯一标识一个生产者。一个生产者被设置了相同的TransactionalId的话,那么该生产者的不同实例会恢复或回滚之前实例的未完成事务。
5. 引入了生产者epoch的概念。生产者epoch可以保证对于一个指定的TransactionalId只会有一个合法的生产者实例,从而保证事务性即便出现故障的情况下。
除了引入了上述概念之外,Kafka还有新的请求类型、已有请求类型的版本升级和新的消息格式,以支持事务。这些细节在本篇文章中不过多涉及。
## 数据流

在上面这幅图中,尖角框代表不同的机器,圆角框代表Kafka的主题分区(TopicPartition),对角线圆角框代表运行在broker中的逻辑实体。
每个箭头代表一个rpc或者主题的写入。这些操作的先后顺序见旁边的数字,下面按顺序来介绍这些操作。
### 1. 查询事务协调者(FindCoordinatorRequest请求)
事务协调者是设置PID和管理事务的核心,因此生产者第一件事就是向broker发起FindCoordinatorRequest请求(之前命名为GroupCoordinatorRequest,此版本将其重命名)获取其协调者。
### 2. 获取生产者ID(InitPidRequest请求)
在查询到事务协调者之后,生产者下一步就是获取其生产者ID,这一步是通过向事务协调者发送InitPidRequest来实现。
#### 2.1 如果指定了TransactionalId的话
如果在配置中指定了transactional.id,transactional.id会在InitPidRequest请求中传递过来,transactional.id与生产者ID的映射会在步骤2a中记录到事务日志。这样未来的生产者如果发送了相同的transactional.id则返回这个相同的PID,从而可以恢复或回滚之前未完成的事务。
在返回PID之外,InitPidRequest还会完成如下任务:
1. 增加生产者的epoch值,这样之前的生产者僵尸实例会被断开,不能继续操作事务。
2. 恢复(提交或回滚)之前该PID对应的生产者实例的未完成事务。
InitPidRequest请求是同步的,一旦返回,生产者可以发送数据和开启新的事务。
#### 2.2 如果TransactionalId未指定
如果TransactionalId未指定,会赋予一个新的PID,该生产者可以在其当前会话期间实现幂等性和事务性语义。
### 3. 开启事务(beginTransaction方法)
新的KafkaProducer有一个beginTransaction()方法,调用该方法会开启一个新的事务。生产者在本地状态中记录事务已经开始,只有发送第一个记录时协调者才会知道事务开始状态。
### 4. 消费-转换-生产的循环
在这个阶段中,生产者开始事务中的消费-转换-生产循环,这个阶段比较长而且可能由多个请求组成。
#### 4.1 AddPartitionsToTxnRequest
在一个事务中,如果需要写入一个新的主题分区,那么生产者会发送此请求到事务协调者。协调者在步骤4.1a中会记录该分区添加到事务中。这个信息是必要的,因为这样才能写入提交或回滚标记到事务中的每个分区(见5.2步骤)。如果这是事务写入的第一个分区,那么协调者还会开始事务定时器。
#### 4.2 ProduceRequest
生产者通过一个或多个ProduceRequests请求(在生产者send方法内部发出)写入消息到主题中。这些请求包含PID,epoch和序列号,见图中的4.2a。
#### 4.3 AddOffsetCommitsToTxnRequest
生产者有一个新的sendOffsetsToTransaction方法,该方法可以将消息消费和生产结合起来。方法参数包含一个Map<TopicPartitions, OffsetAndMetadata>和一个groupId。
sendOffsetsToTransaction内部发送一个带有groupId的AddOffsetCommitsToTxnRequests请求到事务协调者,事务协调者从内部的__consumer-offsets主题中根据此消费者组获取到相应的主题分区。事务协调者在步骤4.3a中把这个主题分区记录到事务日志中。
#### 4.4 TxnOffsetCommitRequest
生产者发送TxnOffsetCommitRequest请求到消费协调者来在主题__consumer-offsets中持久化位移(见4.4a)。消费协调者通过请求中的PID和生产者epoch来验证生产者是否允许发起该请求。
已消费的位移在提交事务之后才对外可见,此过程在下面来讨论。
### 5. 提交或回滚事务
消息数据写入之后,使用者需要调用KafkaProducer中的commitTransaction或abortTransaction方法,这两个方法分别为事务的提交和回滚处理方法。
#### 5.1 EndTxnRequest
当生产者结束事务的时候,需要调用KafkaProducer.endTransaction或者KafkaProducer.abortTransaction方法。前者使得步骤4中的数据对下游的消费者可见,后者则从日志中抹除已生产的数据:这些数据不会对用户可见,也就是说下游消费者会读取并丢弃这些回滚消息。
无论调用哪个方法,生产者都是会发起EndTxnRequest请求到事务协调者,然后通过参数来指明事务提交或回滚。接收到此请求后,协调者会:
1. 写入PREPARE_COMMIT或PREPARE_ABORT消息到事务日志(见5.1a)
2. 通过WriteTxnMarkerRequest请求写入命令消息(COMMIT或ABORT)到用户日志中(见下面5.2)
3. 写入COMMITTED或ABORTED消息到事务日志中
#### 5.2 WriteTxnMarkerRequest请求
这个请求是事务协调者发给事务中每个分区的leader的。接收到此请求后,每个broker会写入COMMIT(PID)或ABORT(PID) 控制消息到日志中(步骤5.2a)。
这个消息向消费者指明该PID的消息传递给用户还是丢弃。因此,消费者接收到带有PID的消息后会缓存起来,直到读取到COMMIT或者ABORT消息,然后决定消息是通知用户还是丢弃。
另外,如果事务中涉及到__consumer-offsets主题,那么commit或者abort的标记同样写入到日志中,消费协调者会被告知这些位移是否标记为已消费(事务提交则为已消费,事务回滚则忽略这些位移)。见步骤4.2a。
#### 5.3 写入最后的提交或回滚消息
在commit或abort标记写入到数据日志后,事务协调者写入最终的COMMITTED或ABORTED消息到事务日志,标记该事务已经完成(见图中的步骤5.3)。在这个时候,事务日志中关于这个事务的大部分消息都可以被删除;只需要保留该事务的PID和时间戳,这样可以最终删除关于该生产者的TransactionalId->PID映射,详情可参考PID过期的相关资料。 | 12,695 | Apache-2.0 |
CountDown 计时器 性能优化
===================
### 参数配置
```js
/*
* 说明:
* 开始时间参数必须,结束时间不是必须
* 如果没有结束时间,则初始化为计时器,时间递增,如果两个参数齐全,则初始化为倒计时
*/
{
startTime: 'Date String',
endTime: 'Date String',
unit: {
day: true,
hour: true,
minute: true,
second: true
},
onStart: function(){
// do something when start
},
onChange: function(value){
// value -> object include formated time by unit in options
},
onStop: function(){
// do something when stop
}
}
```
### 调用
```js
// 支持所有的加载方式CommonJs、AMD、Script标签
// for example
var CountDown = require('CountDown');
var countDown = CountDown.init({
startTime: '2016-01-01 19:35:11:0',
unit: {
day: true,
hour: true,
minute: true,
second: true
},
onStart: function() {
console.log('start!');
},
onChange: function(value) {
// console.log(value)
// like: { day: 107,hour: 20,minute: 41,second: 10 }
},
onStop: function() {
console.log('stop!');
}
});
countDown.start = function(){}; // 开始时触发事件
countDown.change = function(){}; // 改变时触发事件
countDown.toggle(); // 暂停或继续
countDown.stop(); // 停止
``` | 1,077 | MIT |
# 编程高手
## 第13章 树型结构
郭竞离职之后,一直悠闲于算法的研究。但有一天,有一保山然的机会,却入职了一下以营销为主业的公司。一开始,郭竞挺开心的,因为,他听创始人讲,公司目前要向技术公司转型。
但是,入职第一天,郭竞接到的第一项任务是,做一个SAAS平台,这个平台兼有CRM(客户关系管理),PM(项目管理),OA(办公自动化)等功能。既然是SAAS,那么,首先考虑的是用户画像。具体是哪一群用户。结果,沟通下来,则是首先切合公司目前的需求。但公司需求也太多了。整个项目没有优先级。 郭竞想到,一个平台的成功,特别是要做到技术驱动,则必须要有技术创新。所以,接手这一任务之后,想着手先做方案设计。希望有可能在目前最具体最切实的需求之下,能够找到一些创新点。
于是,郭竞开始先进行竞品调研。根据郭竞的了解,他希望研究一下SUTE-CRM, OPENERP, SALEFORCE等知名品牌。 于是,他开始下载SUTE-CRM,并进行安装配置。完成后,打开进行界面操作,以及数据结构分析。可正在此时,公司微信群中,公司的某位创始人突然发了个消息。“发现公司有两名同事没有在干本公司的活。希望这两位同事注意一下!”。郭竞没当回事。
第二天,技术会议上,有同事居然不会把数组展开成树。为此,会后,郭竞向技术总监在微信中发了代码。
```
/**
* @param $parent_id_key
*
* @return array
*/
public function toTreeArray($parent_id_key = 'parent_id')
{
$src_array = $this->toArray();
$out_array = [];
$ref_array = [];
foreach ($src_array as $key => $item) {
$parent_id = $item[$parent_id_key];
$item['is_leaf'] = 1;
$item['children'] = [];
$id = $item['id'];
if (0 == $parent_id) {
$ref_array[$id] = &$out_array[];
$ref_array[$id] = $item;
continue;
}
$ref_array[$id] = &$ref_array[$parent_id]['children'][];
$ref_array[$id] = $item;
$ref_array[$parent_id]['is_leaf'] = 0;
}
return $out_array;
}
```
这可是郭竞多年来一直使用的代码。其一,可以指定parent_id的字段名。同时,向客户端提供了'is_leaf',方便客户端判断是否还有子节点。其次, 通过引用,未使用任何临时变量。郭竞出于好意,发给了技术总监。但万万没有想到的是,这位CTO却回复了:“不要这么复杂,4行代码就够了!”。CTO的代码如下:
```
foreach ($items as $item){
if($item['id'] == $items[$item['id']]['id'])
$items[$item['pid']]['son'][] = &$items[$item['id']];
}
```
郭竞拿到此代码,怎么也看不明白,并且,通过某在线代码运行,也写了很多测试用例,可就是得不到想要的结果。对此,郭竞认为,如果这个代码可以运行,那也是一个奇技淫巧,并且,这个要展开成树的数组肯定有特定的一些先决条件。并且,这个所谓的四行,还刻意省掉了两个括号。所以,郭竞心想,难怪这家公司要向技术转型,本来技术就不怎样。
当新的一天到来,技术部在次技术会议时,CTO并没有检查郭竞,那个平台方案设计如何,而是直接布置了一个小工具。这时,郭竞猜测,因为那个树结构,CTO可能认为郭竞写代码不行,所以,直接改为考核写代码了。
要写的东西也相当简单,面试人填表,公司HR审核。后端接口,很快开发完成了。同时,接口中也增加了基于OPENAP的SWAGGER测试页面。但让郭竞没想到的是,团队居然没有人用过SWAGGER.
第二天会议上,涉及到移动端的技术选型问题。郭竞提出来使用UNI-APP,以方便未来多端支持。CTO则说,哪个快用哪个,你最熟悉哪个就用哪个。前端负责人则说,UNI-APP太重了。就一个页面,直接通过SCRIPT SRC引用即可。郭竞不解,凭什么说这个交互就相当的简单,要填写将近30个字段,三步表单,凭什么就不要用VUE CLI创建项目,后续如何扩展与维护?可是,官大一级压死人。
最后会议也没有明确给出方案。郭竞最后与CTO沟通,结果是,为加快速度,选一个已配置好的START-KIT。最终确定为vue-h5-template.
监于后续要用微信与求职人联系,郭竞想到,最好添加微信登录。没想到CTO说,能用微信登录那就太好了。可以拿到求职人的手机号。郭竞不解,微信登录能拿到手机号,所以,与CTO再次确认了一下。结果,得到的答复是,可以的,现在微信登录只要静默登录,就能拿到!
尽管郭竞心中有很多怀疑,但因为时间紧,并没有去网上验证他的说法。直接开干了。花了一天时间完成了微信登录。但却得不到想要的结果,其后,他只好找CTO去要获取手机号的方法,结果呢,拿到了一个获取收货地址的代码。
郭竞不得不问,假如在腾讯平台产从未有过购物行为,哪里来的收货地址?这就是说,并不是每一个人都有收货地址的。结果,费了一天开发的功能只能废弃。郭竞觉得相当郁闷。
两天后,郭竞按要求,要发布开发完成的东西了。结果,服务器是专人管的。第一天晚上,发布了一个多小时,结果测试下来有问题。服务器本身配置了宝塔LINUX面板,但是,居然没有配置GIT的钩子。所以,要用U盘把SQL以及前后端源码先复制上去。郭竞不解,既然这么做, 为什么还要用宝塔?即使没有配置GIT的钩子,上传代码也相当方便呀。并且,服务器是UBUNTU系列的。可发布项目的人,每一次操作都忘了使用sudo。
把简单的事情弄复杂,相当简单。把复杂的事情弄简单,真的相当复杂。郭竞想,本来,宝塔密码提供一下,三分钟就能解决的问题。并且,有问题,后续改一下宝塔密码即行。这多简单,结果,等到最终发布时,因为,多次数据库导入不成功,前后折腾了4个多小时。
又一天,公司某合伙人追责项目超期原因。认为,郭竞作为这么资深的专家,不应该走微信登录的弯路,并且,前端应当安排给前端的人来开发。而不是做自己不擅长的。并且,不由分说,公司某合伙人说完后即通知郭竞,因为,这个三个页面的项目超期,所以,试用期不合格,让郭竞主动申请离职。郭竞突然发现,他的猜测一点都没错。顿觉一身轻构松。
郭竞深深感到,一家公司的遗传基因,决定了这家公司未来的发展,转型是相当痛的。特别是传统行业要向技术型公司转型,风险是相当大的。因为,没有一个合伙人懂技术。特别是软件与程序相关的技术,结果,做出来的东西就是技术负债,而不是技术资本。而一个资深技术人,如果不在合伙层面,而是在技术团队中,特别这样的公司的技术团队中,束手束脚地干活,只能是一事无成。
另一方面,郭竞也觉得,为什么微软的副总裁当年到ADOB,最后觉得各种不适应。但即使如此,人家能够做下来,挺过来,那是因为,他首先仍是管理层的人士。所以,除了自身要能适应公司的不同的情况的同时,另一方面,也要认请,当你做过项目经理,最好不要再做程序员,否则,你的价值根本发挥不出来。所以,人才如何与公司匹配,这是双方都要考虑的,并且是相当重要的问题。
[上一章](https://github.com/BardoQi/CodeGuru/blob/master/docs/chapter_011.md "下一章")
[目录](https://github.com/BardoQi/CodeGuru "目录")
[下一章](https://github.com/BardoQi/CodeGuru/blob/master/docs/chapter_013.md "下一章") | 3,750 | MIT |
---
name: Feature request
about: 为此项目提供新的功能想法
title: "[Feature]: 请修改你的标题,尽量准确"
labels: Feature
assignees: huarxia
---
**请具体描述你的功能请求.**
描述以及截图等.
**描述你想要的解决方案**
描述以及截图等.
**描述你考虑过的替代方案**
对您考虑过的任何替代解决方案或功能的清晰而简明的描述.
**附加上下文附加上下文**
在此处添加有关该问题的任何其他上下文.
<!--
注意:请在最后执行: npm run lint 检查代码格式
--> | 294 | MIT |
---
title: 为代码添加注释
description: 本指南介绍如何使用 Visual Studio for Mac 的源代码编辑器中的注释
author: conceptdev
ms.author: crdun
ms.date: 05/06/2018
ms.assetid: 0FE5E929-1846-4F48-B5E3-70990FAF9504
ms.openlocfilehash: 1f792e5ba670854e4a3a9ce703212d18c16e5512
ms.sourcegitcommit: 94b3a052fb1229c7e7f8804b09c1d403385c7630
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/23/2019
ms.locfileid: "62933031"
---
# <a name="comments"></a>注释
通过代码进行调试或试验时,它可用来临时或长期注释代码块。
注释掉整个代码块:
* 选择代码并从上下文菜单中选择“切换行注释”
或
* 在所选代码上使用 `cmd + /` 键绑定。
这些方法可用来注释和取消注释代码部分。 在 C# 文件中,可以添加其他级别的行注释,以允许注释和取消注释代码区域,同时仍然保留实际注释:

注释还可用于为可能与之交互的未来开发者编写代码。 这些功能通常以多行注释的形式完成,可以在每种语言中通过以下方法添加:
**C#**
```csharp
/*
This is a multi-line
comment in C#
*/
```
**F#**
```fsharp
(*
This is a multi-line
comment in F#
*)
```
## <a name="see-also"></a>请参阅
- [为代码添加注释(Windows 上的 Visual Studio)](/visualstudio/ide/quickstart-editor#comment-out-code) | 959 | CC-BY-4.0 |
## 修复于 ClickHouse Release 18.12.13, 2018-09-10 {#xiu-fu-yu-clickhouse-release-18-12-13-2018-09-10}
### CVE-2018-14672 {#cve-2018-14672}
加载CatBoost模型的功能,允许遍历路径并通过错误消息读取任意文件。
来源: Yandex信息安全团队的Andrey Krasichkov
## 修复于 ClickHouse Release 18.10.3, 2018-08-13 {#xiu-fu-yu-clickhouse-release-18-10-3-2018-08-13}
### CVE-2018-14671 {#cve-2018-14671}
unixODBC允许从文件系统加载任意共享对象,从而导致«远程执行代码»漏洞。
来源:Yandex信息安全团队的Andrey Krasichkov和Evgeny Sidorov
## 修复于 ClickHouse Release 1.1.54388, 2018-06-28 {#xiu-fu-yu-clickhouse-release-1-1-54388-2018-06-28}
### CVE-2018-14668 {#cve-2018-14668}
远程表函数功能允许在 «user», «password» 及 «default\_database» 字段中使用任意符号,从而导致跨协议请求伪造攻击。
来源:Yandex信息安全团队的Andrey Krasichkov
## 修复于 ClickHouse Release 1.1.54390, 2018-07-06 {#xiu-fu-yu-clickhouse-release-1-1-54390-2018-07-06}
### CVE-2018-14669 {#cve-2018-14669}
ClickHouse MySQL客户端启用了 «LOAD DATA LOCAL INFILE» 功能,该功能允许恶意MySQL数据库从连接的ClickHouse服务器读取任意文件。
来源:Yandex信息安全团队的Andrey Krasichkov和Evgeny Sidorov
## 修复于 ClickHouse Release 1.1.54131, 2017-01-10 {#xiu-fu-yu-clickhouse-release-1-1-54131-2017-01-10}
### CVE-2018-14670 {#cve-2018-14670}
deb软件包中的错误配置可能导致使用未经授权的数据库。
来源:英国国家网络安全中心(NCSC)
[来源文章](https://clickhouse.tech/docs/en/security_changelog/) <!--hide--> | 1,236 | Apache-2.0 |
---
layout: post
title: English Learning(基础英文口语二十二句! (日常生活中最常用的英语 #32) )
categories: English
description: 基础英文口语二十二句! (日常生活中最常用的英语 #32)
keywords: English Speaking
---
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
- [基础英文口语二十二句! (日常生活中最常用的英语 #32)](#%E5%9F%BA%E7%A1%80%E8%8B%B1%E6%96%87%E5%8F%A3%E8%AF%AD%E4%BA%8C%E5%8D%81%E4%BA%8C%E5%8F%A5-%E6%97%A5%E5%B8%B8%E7%94%9F%E6%B4%BB%E4%B8%AD%E6%9C%80%E5%B8%B8%E7%94%A8%E7%9A%84%E8%8B%B1%E8%AF%AD-32)
- [中文](#%E4%B8%AD%E6%96%87)
- [English](#english)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# 基础英文口语二十二句! (日常生活中最常用的英语 #32)
## 中文
1. 我喜欢你说话的方式
2. 听到你这句话我很高兴
3. 我不喜欢你走路的方式
4. 你走路太快了
5. 请不要忽视别人的感觉
6. 我从来没有忽视过你的感觉
7. 请不要让他知道这个惊喜聚会
8. 我会尽力的
9. 我不确定他会不会出现
10. 我们会知道的
11. 如果你能改变你的语气就更好了
12. 我很尊重你的意见
13. 我想说话说的更流利,更具有逻辑性
14. 你已经说的挺不错
15. 有时候我太优柔寡断了
16. 但是这次,我下决定了
17. 在点菜的时候,我总是犹豫不决
18. 我也有相同的问题
19. 在选衣服的时候,我总是犹豫不决
20. 怪不得你今天吃到了
21. 我要辞掉这份工作,我要找别的工作
22. 如果我是你,我不会这样做
## English
1. I like the way you talk.
2. I'm so pleased to hear that.
3. I don't like the way you walk.
4. You are walking way too fast.
5. Please don't ignore other people's feelings.
6. I've never ignored your feelings.
7. Please make sure he doesn't know about this surprise party.
8. I'll do as much as I can.
9. I'm not sure whether he'll show up.
10. We'll see.
11. I think it would be much better if you changed your tone.
12. I fully respect your opinion.
13. I want to speak more smoothly and logically.
14. You are already speaking quite well.
15. Sometimes I'm so indecisive.
16. But this time, I have made my decision.
17. I'm so indecisive when it comes to ordering food.
18. I've got the same problem, too.
19. I'm so indecisive when it comes to choosing outfits.
20. No wander you were late today.
21. I'll quit this job and find another one.
22. If I were you I wouldn't do that. | 1,955 | MIT |
<!-- ---
layout: post
title: gallery 之 handlebars
date: 2015-02-04
categories: gallery
tags: [gallery, handlebars]
shortContent: "handlebars强大的js模板引擎"
---
{% include JB/setup %}
# gallery 之 handlebars
---
#### handlebars 介绍: -->
<!--break--> | 244 | MIT |
---
layout: post
title: DB,mysql相关
date: 2020-03-12
tags: [语言]
comments: true
toc: true
---
* content
{:toc}
# 分布式关系数据库(DRDS)
### why
```
任何问题都是太大或者太小的问题,我们这里面对的数据量太大的问题。
1.用户请求量太大
因为单服务器TPS,内存,IO都是有限的。
解决方法:分散请求到多个服务器上; 其实用户请求和执行一个sql查询是本质是一样的,都是请求一个资源,只是用户请求还会经过网关,路由,http服务器等。
2.单库太大
单个数据库处理能力有限;单库所在服务器上磁盘空间不足;单库上操作的IO瓶颈
解决方法:切分成更多更小的库
3.单表太大
CRUD都成问题;索引膨胀,查询超时
解决方法:切分成多个数据集更小的表。
```
### how
```
扩展性本质在于分而治之。
1.垂直拆分
垂直拆分是具备业务语义的,比如和交易紧相关的表组成一个交易库,和用户紧相关的表组成一个用户库,和商品紧相关的表组成一个商品库,分别放置在不同或相同的MySQL 实例上。
2.水平拆分
数据放置按照一定的规则进行计算和路由,从而达到分散到多个实例的目的。
3.主从复制,读写分离
在主实例的读请求较多、读压力比较大的时候,可以通过读写分离功能对读流量进行分流,减轻主实例的读压力。
```
### mysql
```sql
--含义是跳过2条取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据
select * from table limit 2,1;
--含义是从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条
select * from table limit 2 offset 1;
/**
使用navicat导出mysql表结构字段信息
*/
SELECT
COLUMN_NAME 列名,
COLUMN_TYPE 数据类型,
DATA_TYPE 字段类型,
CHARACTER_MAXIMUM_LENGTH 长度,
IS_NULLABLE 是否为空,
COLUMN_DEFAULT 默认值,
COLUMN_COMMENT 备注
FROM
INFORMATION_SCHEMA. COLUMNS
WHERE
-- sxepp为数据库名称,到时候只需要修改成你要导出表结构的数据库即可
table_schema = 'databaseName'
AND
-- sx_jc_car为表名,到时候换成你要导出的表的名称
-- 如果不写的话,默认会查询出所有表中的数据,这样可能就分不清到底哪些字段是哪张表中的了,所以还是建议写上要导出的名名称
table_name = 'tableName'
--执行外部sql
\. sql文件地址
-- 查看mysql版本
select version();
``` | 1,293 | MIT |
---
layout: daily
title: option infoCallback 表格概要信息显示回调 《不定时一讲》 DataTables中文网
short: option infoCallback 表格概要信息显示回调
date: 2016-8-30
group: 2016-8
caption: 《不定时一讲》
categories: blog
tags: [不定时一讲]
author: DataTables中文网
redirect_from: /manual/daily/2016/08/30/option-infoCallback.html
---
参数详解连接{% include href/option/Callbacks.html param="infoCallback" %}
表格通常有一个描述信息,用来显示当前表格总共多少记录,当前显示的是多少条到多少条记录,或者其他自定义的信息,如果你需要自定义这些,这个回调函数会帮你处理这个问题
<!--more-->
基本语法:
{% highlight javascript linenos %}
//首页右下角表格效果
$('#example').dataTable( {
"infoCallback": function( settings, start, end, max, total, pre ) {
return start +"-"+ end+"(共"+total+"个热心网友 )<a class='button button-success' href='/about/index.html#donate'>我也要赞一个 >></a>";
}
} );
//使用api获取分页信息
$('#example').dataTable( {
"infoCallback": function( settings, start, end, max, total, pre ) {
var api = this.api();
var pageInfo = api.page.info();
return 'Page '+ (pageInfo.page+1) +' of '+ pageInfo.pages;
}
} );
{% endhighlight %} | 1,005 | CC0-1.0 |
---
title: Hexo Nunjucks Error
date: 2020-08-01 07:00:00
tags: 'Hexo'
categories:
- ['使用说明', '软件']
permalink: hexo-nunjucks-error
---
## 简介
今天看了下 Hexo 的日志发现最近都没部署成功, 看来这个自动化日程还很漫长
错误如下
```sh
FATAL Something's wrong. Maybe you can find the solution here: https://hexo.io/docs/troubleshooting.html
Nunjucks Error: [Line 4, Column 27] expected variable end
===== Context Dump =====
=== (line number probably different from source) ===
1 | <h2 id="简介"><a href="#简介" class="headerlink" title="简介"></a>简介</h2><p>单调栈是一种特殊的栈, 栈内的元素都保存一个单调性, 递增或递减, 利用这个特性可以解决一些特殊的问题</p>
2 | <h2 id="问题"><a href="#问题" class="headerlink" title="问题"></a>问题</h2><p>给定一个数组 arr, 找出每一个元素左边和右边离当前位置最近且比当前值小的位置, 返回所有位置相关信息</p>
3 | <p>例如 <code>arr = {3, 4, 1, 5, 6, 2, 7}</code></p>
4 | <p>返回二维数组 <code>res = {{-1, 2}, {0, 2}, {-1, -1}, {2, 5}, {3, 5}, {2, -1}, {5, -1}}</code>, -1 表示不存在</p>
5 | <!-- more -->
6 |
7 | <h2 id="分析"><a href="#分析" class="headerlink" title="分析"></a>分析</h2><p>通过对每个位置向左右方向分别遍历一下可以解决问题, 这样时间复杂度就是 $O(N^2)$</p>
8 | <p>使用单调栈结构可以使得时间复杂度为 $O(N)$, 保证栈里的值都是递增的, 分析情况如下</p>
9 | <ul>
===== Context Dump Ends =====
at formatNunjucksError (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/hexo/lib/extend/tag.js:99:13)
at Promise.fromCallback.catch.err (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/hexo/lib/extend/tag.js:121:34)
at tryCatcher (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/util.js:16:23)
at Promise._settlePromiseFromHandler (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/promise.js:547:31)
at Promise._settlePromise (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/promise.js:604:18)
at Promise._settlePromise0 (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/promise.js:649:10)
at Promise._settlePromises (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/promise.js:725:18)
at _drainQueueStep (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/async.js:93:12)
at _drainQueue (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/async.js:86:9)
at Async._drainQueues (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/async.js:102:5)
at Immediate.Async.drainQueues [as _onImmediate] (/home/jenkins/agent/workspace/hexo-notes/hexo-notes/node_modules/bluebird/js/release/async.js:15:14)
at runCallback (timers.js:705:18)
at tryOnImmediate (timers.js:676:5)
at processImmediate (timers.js:658:5)
error Command failed with exit code 2.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
```
初看一下没发现什么问题, 但是这个错误第一次碰见, 看描述只知道 `format` 就是格式有问题
查了一下发现是因为双大括号的问题, nunjucks 模板引擎用到了这些占位符, 包括
```
{{}}
{# #}
{% %}
```
如果这些标签没有被 ` ``` ` 标记为代码块, 那么解析时模板引擎就好把这些占位符解析, 导致出错
## 解决
最简单的就是使用 ` ``` ` 代码块包裹, 当然官方提供如下的标签进行处理
```
{% raw %}
{{ 双大括号内包裹的内容 }}
{% endraw %}
```
尽管比较繁琐, 但是可以解决问题, 就是以后新增文档时需要注意
注意: **为双引号添加反斜杠是不能解决问题的, 可以替换为 ASCII 码** `{` 和 `}`
## 参考
可以[参考文章](https://www.jianshu.com/p/6032a1a2dc25)修改下 nunjucks 模板引擎源码, 使用其他占位符即可 | 3,346 | MIT |
---
title: セルフホステッド統合ランタイムを SSIS のプロキシとして構成する
description: セルフホステッド統合ランタイムを Azure-SSIS IR のプロキシとして構成する方法について説明します。
services: data-factory
documentationcenter: ''
ms.service: data-factory
ms.workload: data-services
ms.topic: conceptual
author: swinarko
ms.author: sawinark
ms.reviewer: douglasl
manager: mflasko
ms.custom: seo-lt-2019
ms.date: 11/12/2019
ms.openlocfilehash: fa0f61ed0e280f11e693596f80e79f2e2c110678
ms.sourcegitcommit: a5ebf5026d9967c4c4f92432698cb1f8651c03bb
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 12/08/2019
ms.locfileid: "74932035"
---
# <a name="configure-self-hosted-ir-as-a-proxy-for-azure-ssis-ir-in-adf"></a>セルフホステッド IR を ADF で Azure-SSIS IR のプロキシとして構成する
この記事では、セルフホステッド統合ランタイム (IR) をプロキシとして構成して、Azure Data Factory (ADF) の Azure SSIS 統合ランタイム (IR) で SQL Server Integration Services (SSIS) パッケージを実行する方法について説明します。 この機能を使用すると、[Azure-SSIS IR を仮想ネットワークに参加](https://docs.microsoft.com/azure/data-factory/join-azure-ssis-integration-runtime-virtual-network)させずに、オンプレミスのデータにアクセスすることができます。 これは、企業ネットワークが、Azure SSIS IR を挿入するには複雑すぎる構成/制限の厳しいポリシーを持っている場合に役立ちます。
この機能は、オンプレミスのデータ ソースを使用するデータ フロー タスクを含むパッケージを 2 つのステージング タスクに分割します。セルフホステッド IR で実行されている 1 番目のタスクが、まずオンプレミスのデータ ソースから Azure Blog Storage のステージング領域にデータを移動し、Azure-SSIS IR で実行されている 2 番目のタスクが、ステージング領域から目的のデータ宛先にデータを移動します。
また、この機能には、まだ Azure SSIS IR でサポートされていないリージョンでのセルフホステッド IR のプロビジョニングが可能になったり、データ ソースのファイアウォールでのセルフホステッド IR のパブリック静的 IP アドレスが許可されたりするなど、他の利点や機能もあります。
## <a name="prepare-self-hosted-ir"></a>セルフホステッド IR を準備する
この機能を使用するには、[Azure-SSIS IR をプロビジョニングする方法](https://docs.microsoft.com/azure/data-factory/tutorial-deploy-ssis-packages-azure)に関する記事に従って、まず ADF を作成し、そこで Azure SSIS IR をプロビジョニングする必要があります (まだ行っていない場合)。
次に、[セルフホステッド IR を作成する方法](https://docs.microsoft.com/azure/data-factory/create-self-hosted-integration-runtime)に関する記事に従って、Azure-SSIS IR がプロビジョニングされている同じ ADF にセルフホステッド IR をプロビジョニングする必要があります。
最後に、次のように、オンプレミスのマシンまたは Azure 仮想マシン (VM) に、セルフホステッド IR の最新バージョン、および追加のドライバーとランタイムをダウンロードしてインストールする必要があります。
- セルフホステッド IR の最新バージョンは、[こちら](https://www.microsoft.com/download/details.aspx?id=39717)からダウンロードしてインストールしてください。
- パッケージで OLEDB コネクタを使用する場合は、セルフホステッド IR がインストールされている同じコンピューターに、関連する OLEDB ドライバーをダウンロードしてインストールしてください (まだそうしていない場合)。 SQL Server 用の OLEDB ドライバーの以前のバージョン (SQLNCLI) を使用する場合は、[こちら](https://www.microsoft.com/download/details.aspx?id=50402)から 64 ビット版をダウンロードできます。 SQL Server 用の OLEDB ドライバーの最新バージョン (MSOLEDBSQL) を使用する場合は、[こちら](https://www.microsoft.com/download/details.aspx?id=56730)から 64 ビット版をダウンロードできます。 PostgreSQL、MySQL、Oracle などの他のデータベースシステム用の OLEDB ドライバーを使用する場合は、それぞれの Web サイトから 64 ビット版をダウンロードできます。
- セルフホステッド IR がインストールされている同じコンピューターに、Visual C++ (VC) ランタイムをダウンロードしてインストールしてください (まだそうしていない場合)。 64 ビット版は、[こちら](https://www.microsoft.com/download/details.aspx?id=40784)からダウンロードできます。
## <a name="prepare-azure-blob-storage-linked-service-for-staging"></a>Azure Blob Storage のリンクされたサービスをステージング用に準備する
[ADF のリンクされたサービスを作成する方法](https://docs.microsoft.com/azure/data-factory/quickstart-create-data-factory-portal#create-a-linked-service)に関する記事に従って、Azure-SSIS IR がプロビジョニングされている同じ ADF に、Azure Blob Storage のリンクされたサービスを作成してください (またそうしていない場合)。 以下のことを確認してください。
- **データ ストア**に **Azure Blob Storage** が選択されている
- **[Connect via integration runtime]\(統合ランタイム経由で接続\)** に **AutoResolveIntegrationRuntime** が選択されている
- **[認証方法]** に **[アカウント キー]** / **[SAS URI]** / **[サービス プリンシパル]** のいずれかが選択されている

## <a name="configure-azure-ssis-ir-with-self-hosted-ir-as-a-proxy"></a>セルフホステッド IR をプロキシとして使用して Azure-SSIS IR を構成する
セルフホステッド IR と Azure Blob Storage のリンクされたサービスをステージング用に準備したので、次に ADF ポータル/アプリでセルフホステッド IR をプロキシとして使用して、新規/既存の Azure SSIS IR を構成することができます。 既存の Azure SSIS IR が実行されている場合は、これを実行する前に停止して、後で再起動してください。
**[詳細設定]** ページで、 **[Set up Self-Hosted Integration Runtime as a proxy for your Azure-SSIS Integration Runtime]\(セルフホステッド IR を Azure-SSIS 統合ランタイムのプロキシとして設定する\)** チェックボックスをオンにし、ステージング用にセルフホステッド IR と Azure Blob Storage のリンクされたサービスを選択し、必要に応じて、**ステージング パス**の BLOB コンテナー名を指定します。

## <a name="enable-ssis-packages-to-connect-by-proxy"></a>SSIS パッケージのプロキシでの接続を有効にする
Visual Studio 用の SSIS プロジェクト拡張機能 ([こちら](https://marketplace.visualstudio.com/items?itemName=SSIS.SqlServerIntegrationServicesProjects)からダウンロード可能) と共に、またはスタンドアロン インストーラ ([こちら](https://docs.microsoft.com/sql/ssdt/download-sql-server-data-tools-ssdt?view=sql-server-2017#ssdt-for-vs-2017-standalone-installer)からダウンロード可能) として最新の SSDT を使用することで、OLEDB/フラット ファイルの接続マネージャーに追加された新しい **ConnectByProxy** プロパティを検出できます。
オンプレミスのデータベース/ファイルにアクセスするために OLEDB/フラット ファイルのソースを使用するデータ フロー タスクを含む新しいパッケージを設計する場合、関連する接続マネージャーの [プロパティ] パネルで **True** に設定することでこのプロパティを有効にできます。

また、既存のパッケージの実行する場合も、それらを 1 つずつ手動で変更することなく、このプロパティを有効にできます。 2 つのオプションがあります。
- Azure SSIS-IR で実行する、最新の SSDT を備えたこれらのパッケージを含むプロジェクトを開いて、再構築し、再デプロイする:SSMS からパッケージを実行するときに [Execute Package]\(パッケージの実行\) ポップアップ ウィンドウの **[接続マネージャー]** タブに表示される、関連する接続マネージャーに対して **True** に設定することでプロパティを有効にできます。

ADF パイプラインでパッケージを実行するときに [SSIS パッケージの実行アクティビティ](https://docs.microsoft.com/azure/data-factory/how-to-invoke-ssis-package-ssis-activity)の **[接続マネージャー]** タブに表示される、関連する接続マネージャーに対して **True** に設定することでプロパティを有効にできます。

- SSIS IR で実行するこれらのパッケージを含むプロジェクトを再デプロイする:プロパティ パス `\Package.Connections[YourConnectionManagerName].Properties[ConnectByProxy]` を指定し、SSMS からパッケージを実行するときに [Execute Packages]\(パッケージの実行\) ポップアップ ウィンドウの **[詳細]** タブでプロパティ オーバーライドとして **True** に設定することでプロパティを有効にできます。

プロパティ パス `\Package.Connections[YourConnectionManagerName].Properties[ConnectByProxy]` を指定し、ADF パイプラインでパッケージを実行するときに [SSIS パッケージ実行アクティビティ](https://docs.microsoft.com/azure/data-factory/how-to-invoke-ssis-package-ssis-activity)の **[Property Overrides]\(プロパティ オーバーライド\)** タブでプロパティ オーバーライドとして **True** に設定することでプロパティを有効にできます。

## <a name="debug-the-first-and-second-staging-tasks"></a>1 番目と 2 番目のステージング タスクをデバッグする
セルフホステッド IR では、`C:\ProgramData\SSISTelemetry` フォルダーにランタイム ログ、`C:\ProgramData\SSISTelemetry\ExecutionLog` フォルダーに 1 番目のステージング タスクの実行ログがあります。 2 番目のステージング タスクの実行ログは、パッケージを格納した場所が SSISDB か、ファイル システム/ファイル共有/Azure Files かによって、それぞれ SSISDB 内、または指定されたロギング パスにあります。 1 番目のステージング タスクの一意の ID も、2 番目のステージング タスクの実行ログ内にあります。たとえば、次のようになります。

## <a name="billing-for-the-first-and-second-staging-tasks"></a>1 番目と 2 番目のステージング タスクの課金
セルフホステッド IR で実行されている 1 番目のステージング タスクは、[ADF データ パイプラインの価格](https://azure.microsoft.com/pricing/details/data-factory/data-pipeline/)に関する記事に指定されているように、セルフホステッド IR で実行されるすべてのデータ移動アクティビティの課金と同様に、別個に課金されます。
Azure-SSIS IR で実行されている 2 番目のステージング タスクは別個に課金されませんが、実行中の Azure-SSIS IR は、[Azure-SSIS IR の価格](https://azure.microsoft.com/pricing/details/data-factory/ssis/)に関する記事の指定どおりに課金されます。
## <a name="current-limitations"></a>現時点での制限事項
- ODBC、OLEDB、フラット ファイルの接続マネージャーと ODBC、OLEDB、フラット ファイルのソースを使用するデータ フロー タスクのみが現在サポートされています。
- **アカウント キー**/**SAS URI**/**サービス プリンシパル**の認証を使って構成された Azure Blob Storage のリンクされたサービスのみが現在サポートされています。
- Azure-SSIS IR がプロビジョニングされている同じ ADF にプロビジョニングされているセルフホステッド IR のみが現在サポートされています。
- ODBC、OLEDB、フラット ファイルのソースと接続マネージャーのプロパティ内での SSIS パラメーターまたは変数の使用は現在サポートされていません。
## <a name="next-steps"></a>次の手順
セルフホステッド IR を Azure-SSIS IR のプロキシとして構成したら、ADF パイプラインの SSIS パッケージ実行アクティビティとしてパッケージをデプロイおよび実行してオンプレミスのデータにアクセスできます。[ADF パイプラインの SSIS パッケージ実行アクティビティとしての SSIS パッケージの実行](https://docs.microsoft.com/azure/data-factory/how-to-invoke-ssis-package-ssis-activity)に関する記事を参照してください。 | 8,311 | CC-BY-4.0 |
---
title: ブログを Gatsby + Netlify に移行した
description: Wordpress で構築されていたブログを Gatsby + Netlify 構成で再構築した。ここまでできて無料の Netlfy すごい。
date: 2019-07-21
categories:
- blog
tags:
- blog
- gatsby
- netlify
---
Wordpress は CMS の中でもメジャーで、自身がブログを開始した際も特別深く考えずに Wordpress を採用した記憶がある。
テーマ、プラグイン共に非常に豊富で、運用面で特に不満があったわけではないが、どうせならエンジニア色の強いプロダクトを採用したいなという思いが急に湧き上がり、いくつかのライブラリを触ってみた結果、React(SPA) + GraphQL という何とも魅力的な技術要素を含んだ [GatsbyJS](https://www.gatsbyjs.org/) を採用してみることにした。
## GatsbyJS
GatsbyJS は、React, Webpack, CSS(SASS, CSS modules, styled components) といったモダンなフロントエンド技術を用い、かつ GraphQL によるシームレスなデータバインドを実現している。
GraphQL 自体、実際の運用で使うにはどうにもとっつき辛い印象であったが、マークダウンをデータリソースとして GraphQL でデータを吸い上げ → React コンポーネントにバインド → HTML を生成といった様に、ビルドシーケンスの中にうまく GraphQL が統合されている。
ビルド時にフックすることで、独自の処理を差し込んだりとカスタマイズ性も高く、単にブログとして記事を書く以外にも楽しめる部分が多いのではないだろうか。
## Netlify
高機能なホスティングサービスで、ホスティングのみに留まらず、Github などのコード管理システムと連携することで、ビルド → デプロイ → ホスティングを簡単な操作のみで構築できるようになる。また、無料の範囲でもカスタムドメイン、SSL 対応まで完備。
元々 Wordpress でブログを構築していたときは、XServer + お名前.com という構成であったが、ドメインはともかく、サーバー代を払い続けることにどうにも抵抗があり、今回 Netlify を採択した。
GitHub Pages でも同様のことはできるが、Netlify のマネージド DNS を利用することで CDN が利用できるということで魅力を感じた。
## 構築メモ
そう何回もやるものでも無いが、構築手順をメモしたので記載しておく。なお、実際に利用しているリポジトリは [syuni/aobako.net](https://github.com/syuni/aobako.net) である。
なお、下準備として Wordpress で構築していた際の記事は全て Markdown 化している。
### ローカル
ローカルの環境構築手順を記す。
まずは Gatsby コンテンツを操作 (開発サーバー、ビルド、サーブ) するための CLI を導入する。
```shell:title=bash
$ npm install -g gatsby-cli
```
つづいて、新規 Web サイトを作成する。
```shell:title=bash
$ cd /path/to/workspace
# スターターに gatsby-starter-blog を使用する
$ gatsby new aobako.net https://github.com/gatsbyjs/gatsby-starter-blog
```
つづいて、依存モジュールをインストールし、開発サーバーを立ちあげる。
```shell:title=bash
$ cd aobako.net
# 依存モジュールのインストール
$ yarn
# 開発サーバー (localhost:8000) の起動
$ yarn develop
```
`localhost:8000` にアクセスすることで、ブログが閲覧できることを確認する。
### GitHub
新規リポジトリを作成し、上記で作成したプロジェクトを Push しておく。
見栄えは違うだろうけど、多分  こんな感じになっているはず。
### Netlify
Netlify 側の設定 (アカウント作成、GitHub 連携、カスタムドメイン、SSL) 手順を記す。
- [公式 Web](https://www.netlify.com/) にて `Get started for free` ボタンをクリック。

- 各種サービスアカウント or Email にてサインアップする。

- (GitHub と連携した場合) `New site from Git` をクリック。

- `GitHub` ボタンをクリック。

- 連携するリポジトリを選択する (ここで先程作成したリポジトリを選択)。


- オーナー & デプロイするブランチを指定する。`Basic build settings` は好みの設定で (この手順に従うのであれば、特に変更はしない)。

- しばらく待って、デプロイが完了すれば、既にサイトに接続できる状態になっている。左上にあるアンカーが自身のサイト (Netlify ドメイン) となる。

### DNS
DNS 側 (お名前.com 利用) での設定手順を記す。
- Netlify 管理コンソールのルート (`xxx's team` 的な階層) の `Domain` タブから、カスタムドメインを登録する。
- Netlify ネームサーバーの次の 4 つのドメインを控えておく。
- お名前.com にログインし、ドメイン設定 → ネームサーバーの設定 → ネームサーバーの変更にて、先程控えたドメインを登録する。場合によっては更新完了に時間がかかることがあるので、気長にまつ。
### SSL
HTTPS に対応させるには、Netlify 管理コンソールのサイトの Settings → Domain management → HTTPS の項目にて、`Let's Encrypt` にて証明書を有効にすれば良い。
### リダイレクト
http でのアクセスを https にリダイレクトする or Netlify ドメインでのアクセスをカスタムドメインにリダイレクトするには、`static` ディレクトリに `_redirects` というファイルを用意してデプロイすれば良い。
参考までに、自分の設定は次のとおり。
```text:title=_redirects
http://aobako.netlify.com/* https://aobako.net/:splat 301!
https://aobako.netlify.com/* https://aobako.net/:splat 301!
http://aobako.net/* https://aobako.net/:splat 301!
http://www.aobako.net/* https://aobako.net/:splat 301!
https://www.aobako.net/* https://aobako.net/:splat 301!
```
## まとめ
Wordpress 時代から Markdown で執筆していたので、特に違和感なく移行できた。むしろ、管理画面に入らずにローカルマシンから記事の更新ができるなど、運用面で非常に快適となった。もちろんそれだけでなく、SPA であることを多いに活かした高速なレンダリングやページ遷移などすばらしい部分が多い。
デザイン面やその他のコンテンツについてはまだまだ対応できていないが、次第にパワーアップさせていきたい。 | 4,570 | MIT |
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [9.1 连接Spark SQL](#91-%E8%BF%9E%E6%8E%A5spark-sql)
- [9.2 在应用中使用Spark SQL](#92-%E5%9C%A8%E5%BA%94%E7%94%A8%E4%B8%AD%E4%BD%BF%E7%94%A8spark-sql)
- [9.2.1 初始化Spark SQL](#921-%E5%88%9D%E5%A7%8B%E5%8C%96spark-sql)
- [9.2.2 基本查询示例](#922-%E5%9F%BA%E6%9C%AC%E6%9F%A5%E8%AF%A2%E7%A4%BA%E4%BE%8B)
- [9.2.3 SchemaRDD](#923-schemardd)
- [9.2.4 缓存](#924-%E7%BC%93%E5%AD%98)
- [9.3 读取和存储数据](#93-%E8%AF%BB%E5%8F%96%E5%92%8C%E5%AD%98%E5%82%A8%E6%95%B0%E6%8D%AE)
- [9.3.1 Apache Hive](#931-apache-hive)
- [9.3.2 Parquet](#932-parquet)
- [9.3.3 JSON](#933-json)
- [9.3.4 基于RDD](#934-%E5%9F%BA%E4%BA%8Erdd)
- [9.4 JDBC/ODBC服务器](#94-jdbcodbc%E6%9C%8D%E5%8A%A1%E5%99%A8)
- [9.4.1 使用BeeLine](#941-%E4%BD%BF%E7%94%A8beeline)
- [9.4.2 长生命周期的表与查询](#942-%E9%95%BF%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E7%9A%84%E8%A1%A8%E4%B8%8E%E6%9F%A5%E8%AF%A2)
- [9.5 用户自定义函数](#95-%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0)
- [9.5.1 Spark SQL UDF](#951-spark-sql-udf)
- [9.5.2 Hive UDF](#952-hive-udf)
- [9.6 Spark SQL性能](#96-spark-sql%E6%80%A7%E8%83%BD)
- [导航](#%E5%AF%BC%E8%88%AA)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->

结构化数据是指任何有结构信息的数据。所谓结构信息,就是每条记录共用的已知的字段集合。当数据符合这样的条件时,Spark SQL 就会使得针对这些数据的读取和查询变得更加简单高效。具体来说,Spark SQL 提供了以下三大功能:
1. Spark SQL可以从各种结构化数据源(JSON、Hive、Parquet等)读取数据。
2. Spark SQL 不仅支持在 Spark 程序内使用 SQL 语句进行数据查询,也支持从类似商业智能软件 Tableau 这样的外部工具中通过标准数据库连接器(JDBC/ODBC)连接 Spark SQL 进行查询。
3. 当在 Spark 程序内使用 Spark SQL 时,Spark SQL 支持 SQL 与常规的 Python/Java/Scala 代码高度整合,包括连接 RDD 与 SQL 表、公开的自定义 SQL 函数接口等。
Spark SQL 提供了一种特殊的 RDD,叫作 SchemaRDD(新版本成为DataFrame)。SchemaRDD 是存放 Row 对象的 RDD,每个 Row 对象代表一行记录。SchemaRDD 还包含记录的结构信息(即数据字段)。SchemaRDD 可以利用结构信息更加高效地存储数据。此外,SchemaRDD 还支持 RDD 上所没有的一些新操作,比如运行 SQL 查询。SchemaRDD 可以从外部数据源创建,也可以从查询结果或普通 RDD 中创建。
# 9.1 连接Spark SQL
要在应用中引入 Spark SQL 需要添加一些额外的依赖。
带有 Hive 支持的 Spark SQL的 sbt:
```properties
libraryDependencies ++= Seq("org.apache.spark" %% "spark-hive_2.1.0" % "1.2.0")
```
如果你不能引入 Hive 依赖,那就应该使用工件 `spark-sql_2.10` 来代替 `spark-hive_2.10` 。
使用Spark SQL编程时,根据是否使用 Hive 支持,有两个不同的入口:
1. `HiveContext` ,它可以提供 HiveQL 以及其他依赖于 Hive 的功能的支持。使用`HiveContext`不需要实现部署好Hive。
2. 更为基础的 SQLContext 则支持 Spark SQL 功能的一个子集,子集中去掉了需要依赖于 Hive 的功能。
最后,若要把 Spark SQL 连接到一个部署好的 Hive 上,你必须把 `hive-site.xml` 复制到 Spark 的配置文件目录中(`$SPARK_HOME/conf`)。即使没有部署好 Hive,Spark SQL 也可以运行。
# 9.2 在应用中使用Spark SQL
基于已有的 `SparkContext` 创建出一个 `HiveContext`(如果使用的是去除了 Hive 支持的 Spark 版本,则创建出 `SQLContext`)。这个上下文环境提供了对 Spark SQL 的数据进行查询和交互的额外函数。使用 `HiveContext` 可以创建出表示结构化数据的 SchemaRDD,并且使用 SQL 或是类似 `map()` 的普通 RDD 操作来操作这些 SchemaRDD。
## 9.2.1 初始化Spark SQL
```scala
// 导入Spark SQL
import org.apache.spark.sql.hive.HiveContext
// 如果不能使用hive依赖的话
import org.apache.spark.sql.SQLContext
val sc = new SparkContext(...)
// 隐式转换
val hiveCtx = new HiveContext(sc)
```
## 9.2.2 基本查询示例
要在一张数据表上进行查询,需要调用 `HiveContext`或` SQLContext` 中的 `sql()` 方法。要做的第一件事就是告诉 Spark SQL 要查询的数据是什么。因此,需要先从 JSON 文件中读取一些推特数据,把这些数据注册为一张临时表并赋予该表一个名字,然后就可以用 SQL 来查询它了。
```scala
val input = hiveCtx.jsonFile(inputFile)
// 注册输入的SchemaRDD
input.registerTempTable("tweets")
// 依据retweetCount(转发计数)选出推文
val topTweets = hiveCtx.sql("SELECT text, retweetCount FROM
tweets ORDER BY retweetCount LIMIT 10")
```
## 9.2.3 SchemaRDD
读取数据和执行查询都会返回 SchemaRDD。SchemaRDD 和传统数据库中的表的概念类似。从内部机理来看,SchemaRDD 是一个由 Row 对象组成的 RDD,附带包含每列数据类型的结构信息。Row 对象只是对基本数据类型(如整型和字符串型等)的数组的封装。
SchemaRDD 仍然是 RDD,所以你可以对其应用已有的 RDD 转化操作,比如 `map()` 和 `filter()` 。然而,SchemaRDD 也提供了一些额外的功能支持。最重要的是,你可以把任意 SchemaRDD 注册为临时表(`registerTempTable()`),这样就可以使用 `HiveContext.sql` 或 `SQLContext.sql` 来对它进行查询了。
SchemaRDD 可以存储一些基本数据类型,也可以存储由这些类型组成的结构体和数组。
SchemaRDD 使用 [HiveQL 语法](https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL)定义的类型。
Row 对象表示 SchemaRDD 中的记录,其本质就是一个定长的字段数组。在 Scala 中,Row 对象有一系列 getter 方法,可以通过下标获取每个字段的值。
```scala
val topTweetText = topTweets.map(row => row.getString(0))
```
## 9.2.4 缓存
Spark SQL 的缓存机制与 Spark 中的稍有不同。由于我们知道每个列的类型信息,所以 Spark 可以更加高效地存储数据。为了确保使用更节约内存的表示方式进行缓存而不是储存整个对象,应当使用专门的 `hiveCtx.cacheTable("tableName")` 方法。当缓存数据表时,Spark SQL 使用一种列式存储格式在内存中表示数据。这些缓存下来的表只会在驱动器程序的生命周期里保留在内存中,所以如果驱动器进程退出,就需要重新缓存数据。
# 9.3 读取和存储数据
## 9.3.1 Apache Hive
当从 Hive 中读取数据时,Spark SQL 支持任何 Hive 支持的存储格式(SerDe),包括文本文件、RCFiles、ORC、Parquet、Avro,以及 Protocol Buffer。
```scala
import org.apache.spark.sql.hive.HiveContext
val hiveCtx = new HiveContext(sc)
val rows = hiveCtx.sql("SELECT key, value FROM mytable")
val keys = rows.map(row => row.getInt(0))
```
## 9.3.2 Parquet
[Parquet](http://parquet.apache.org/)是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。Parquet 格式经常在 Hadoop 生态圈中被使用,它也支持 Spark SQL 的全部数据类型。Spark SQL 提供了直接读取和存储 Parquet 格式文件的方法。
首先,你可以通过 HiveContext.parquetFile 或者 SQLContext.parquetFile 来读取数据:
```scala
val rows = hiveCtx.parseFile(parquetFile)
val names = rows.map(row => row.name)
println(names.collect())
```
也可以把我Parquet文件注册为Spark SQL的临时表,然后在表上执行查询语句:
```scala
val tbl = rows.registerTempTable("people")
val pandaFriends = hiveCtx.sql("SELECT name FROM people WHERE favouriteAnimal =
\"panda\"")
println(pandaFriends.map(lambda row: row.name).collect())
```
最后使用`svaAsParquetFile()`把SchemaRDD的内容以Parquet格式保存。
## 9.3.3 JSON
要读取 JSON 数据,只要调用 `hiveCtx` 中的 `jsonFile()` 方法即可。
```scala
val input = hiveCtx.jsonFile(inputFile)
```
## 9.3.4 基于RDD
除了读取数据,也可以基于 RDD 创建 SchemaRDD。在 Scala 中,带有 case class 的 RDD 可以隐式转换成 SchemaRDD。
```scala
case class HappyPerson(handle: String, favouriteBeverage: String)
...
// 创建了一个人的对象,并且把它转成SchemaRDD
val happyPeopleRDD = sc.parallelize(List(HappyPerson("holden", "coffee")))
// 注意:此处发生了隐式转换
// 该转换等价于sqlCtx.createSchemaRDD(happyPeopleRDD)
happyPeopleRDD.registerTempTable("happy_people")
```
# 9.4 JDBC/ODBC服务器
JDBC 服务器作为一个独立的 Spark 驱动器程序运行,可以在多用户之间共享。任意一个客户端都可以在内存中缓存数据表,对表进行查询。集群的资源以及缓存数据都在所有用户之间共享。
Spark SQL 的 JDBC 服务器与 Hive 中的 HiveServer2 相一致。由于使用了 Thrift 通信协议,它也被称为『Thrift server』。注意,JDBC 服务器支持需要 Spark 在打开 Hive 支持的选项下编译。
启动 JDBC 服务器:
```scala
./sbin/start-thriftserver.sh --master sparkMaster
```
Spark 也自带了 Beeline 客户端程序,我们可以使用它连接 JDBC 服务器。
Spark的ODBC服务器由Simba制作。
## 9.4.1 使用BeeLine
在 Beeline 客户端中,你可以使用标准的 HiveQL 命令来创建、列举以及查询数据表。
## 9.4.2 长生命周期的表与查询
使用 Spark SQL 的 JDBC 服务器的优点之一就是我们可以在多个不同程序之间共享缓存下来的数据表。JDBC Thrift 服务器是一个单驱动器程序,这就使得共享成为了可能。你只需要注册该数据表并对其运行 CACHE 命令,就可以利用缓存了。
# 9.5 用户自定义函数
用户自定义函数,也叫 UDF,可以让我们使用 Scala 注册自定义函数,并在 SQL 中调用。
## 9.5.1 Spark SQL UDF
```scala
registerFunction("strLenScala", (_: String).length)
val tweetLength = hiveCtx.sql("SELECT strLenScala('tweet') FROM tweets LIMIT 10")
```
## 9.5.2 Hive UDF
要使用 Hive UDF,应该使用 `HiveContext`,而不能使用常规的 `SQLContext`。要注册一个 Hive UDF,只需调用 `hiveCtx.sql("CREATE TEMPORARY FUNCTION name AS class.function")`。
# 9.6 Spark SQL性能
Spark SQL 可以利用其对类型的了解来高效地表示数据。当缓存数据时,Spark SQL 使用内存式的列式存储。这不仅仅节约了缓存的空间,而且尽可能地减少了后续查询中针对某几个字段查询时的数据读取。
Spark SQL中的性能选项
- `spark.sql.codegen`。设置为`true`时,Spark SQL会把每条查询语句在运行时编译为Java二进制节代码。这可以提高大型查询性能,降低小型查询性能。
- `spark.sql.inMemoryColumnarStorage.compressed`。自动对内存中的列式存储压缩。
- `spark.sql.inMemoryColumnarStorage.batchSize`。列式缓存时每个批处理的大小。
- `sql.sql.parquet.compression.codec`。使用哪种压缩编码器。
# 导航
[目录](README.md)
上一章:[8. Spark调优与调试](8. Spark调优与调试.md)
下一章:[10. Spark Streaming](10. Spark Streaming.md) | 7,457 | MIT |
### 在 React 中元素和组件之间有什么区别?
#### Answer
元素通常用来表示DOM节点或组件的纯JavaScript对象。元素是纯粹的,从不转换,并且创建的代价很小。
组件是函数或类。组件可以具有state并将props作为输入并返回元素树作为输出(尽管它们可以表示通用容器或包装器,并且不一定有DOM)。组件也可以在生命周期方法中组一些处理(例如,AJAX请求,DOM突变,与第三方库的接口),并且创建的代价可能很大。
```js
const Component = () => "Hello"
const componentElement = <Component />
const domNodeElement = <div />
```
#### Good to hear
* 元素是不可变的普通对象,用于描述要呈现的DOM节点或组件;
* 组件可以是类或函数,它将props作为输入并返回元素树作为输出。
##### Additional links
* [React docs on Rendering Elements](https://reactjs.org/docs/rendering-elements.html)
* [React docs on Components and Props](https://reactjs.org/docs/components-and-props.html)
<!-- tags: (react,javascript) -->
<!-- expertise: (0) --> | 686 | MIT |
# 对象检测-ASP.NET Core Web和WPF桌面示例
| ML.NET 版本 | API 类型 | 状态 | 应用程序类型 | 数据类型 | 场景 | 机器学习任务 | 算法 |
|----------------|-------------------|-------------------------------|-------------|-----------|---------------------|---------------------------|-----------------------------|
| v1.5.0 | 动态API | 最新 | 端到端应用 | 图像文件 | 对象检测 | 深度学习 | ONNX: Tiny YOLOv2 & Custom Vision |
## 问题
对象检测是计算机视觉中的经典问题之一:识别给定图像中包含哪些对象以及它们在图像中的位置。 对于这些情况,您可以使用预先训练的模型,也可以训练自己的模型对自定义域特定的图像进行分类。 默认情况下,此示例使用预先训练的模型,但是您也可以添加从[Custom Vision](https://www.customvision.a)导出的模型。
## 示例的工作原理
此示例由两个独立的应用程序组成:
- 一个**WPF Core 桌面应用程序**呈现摄像头的实时流,使用ML.NET通过对象检测模型运行视频帧,并用标签绘制边界框,指示实时检测到的对象。
- 一个允许用户上载或选择图像的**ASP.NET Core Web应用**。Web应用程序使用ML.NET通过一个对象检测模型运行图像,并用指示检测到的对象的标签绘制边界框。
Web应用程序显示右侧列出的图像,可以选择每个图像进行处理。一旦图像被处理,它将被绘制在屏幕的中间,每个检测到的对象周围都有标记的边界框,如下所示。

或者,您可以尝试上传自己的图片,如下所示。

## ONNX
开放式神经网络交换即[ONNX](http://onnx.ai/)是一种表示深度学习模型的开放格式。使用ONNX,开发人员可以在最先进的工具之间移动模型,并选择最适合他们的组合。ONNX是由包括微软在内的众多合作伙伴共同开发和支持的。
## 预训练模型
有多个预先训练的模型用于识别图像中的多个对象。**WPF app**和**Web app**都默认使用从[ONNX Model Zoo](https://github.com/onnx/models/tree/master/vision/object_detection_segmentation/tiny_yolov2)下载的预先训练好的模型**Tiny YOLOv2**; 一组经过预先训练的、最先进的ONNX格式模型。**Tiny YOLOv2**是一种用于目标检测的实时神经网络,用于检测[20个不同的类](./OnnxObjectDetection/ML/DataModels/TinyYoloModel.cs#L10-L6),并在[Pascal VOC](http://host.robots.ox.ac.uk/pascal/VOC/)数据集上进行训练。它由9个卷积层和6个最大池层组成,是更复杂的完整的[YOLOv2](https://pjreddie.com/darknet/yolov2/)网络的较小版本。
## Custom Vision 模型
此示例默认使用上述预先训练的Tiny YOLOv2模型。不过,它也支持从微软[Custom Vision](https://www.customvision.ai)导出的ONNX模型。
### 要使用自己的模型,请使用以下步骤
1. 使用 Custom Vision [创建和训练](https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/get-started-build-detector)物体探测器。要导出模型,请确保选择一个**紧凑**域,例如**常规(紧凑)**。 要导出现有的对象检测器,请通过选择右上角的齿轮图标将域转换为紧凑型。 在_ **设置** _中,选择一个紧凑的模型,保存并训练您的项目。
2. 转到_**性能**_选项卡[导出模型](https://docs.microsoft.com/azure/cognitive-services/custom-vision-service/export-your-model)。选择一个用紧凑域训练的迭代,将出现一个“导出”按钮。选择_导出_、_ONNX_、_ONNX1.2_,然后选择导出。文件准备好后,选择“下载”按钮。
3. 导出的是一个包含多个文件的zip文件,包括一些示例代码、标签列表和ONNX模型。将.zip文件放到[OnnxObjectDetection](./OnnxObjectDetection)项目中的[**OnnxModels**](./OnnxObjectDetection/ML/OnnxModels)文件夹中。
4. 在解决方案资源管理器中,右键单击[OnnxModels](./OnnxObjectDetection/ML/OnnxModels)文件夹,然后选择_添加现有项_。选择刚添加的.zip文件。
5. 在解决方案资源管理器中,从[OnnxModels](./OnnxObjectDetection/ML/OnnxModels)文件夹中选择.zip文件。更改文件的以下属性:
- _生成操作 -> 内容_
- _复制到输出目录 -> 如果较新则复制_
现在,当你生成和运行应用程序时,它将使用你的模型而不是Tiny YOLOv2模型。
## 模型输入和输出
为了解析ONNL模型的预测输出,我们需要了解输入和输出张量的格式(或形状)。为此,我们将首先使用[Netron](https://lutzroeder.github.io/netron/),一个用于神经网络和机器学习模型的GUI可视化工具,用于检查模型。
下面是一个例子,我们将看到使用Netron打开这个示例的Tiny YOLOv2模型:

从上面的输出中,我们可以看到Tiny YOLOv2模型具有以下输入/输出格式:
### 输入: 'image' 3x416x416
首先要注意的是,**输入张量的名称**是**'image'**。稍后在定义评估管道的**input**参数时,我们将需要这个名称。
我们还可以看到,**输入张量的形状**是**3x416x416**。这说明传入模型的位图图像应该是416高x 416宽。“3”表示图像应为BGR格式;前3个“通道”分别是蓝色、绿色和红色。
### 输出: 'data' 125x13x13
与输入张量一样,我们可以看到**输出名称**是**'data'**。同样,在定义评估管道的**output**参数时,我们会注意到这一点。
我们还可以看到, **输出张量的形状**是**125x13x13**。
125x13x13的“13x13”部分意味着图像被分成一个13x13的“单元格”网格(13列x 13行)。因为我们知道输入图像是416x416,所以我们可以推断出每个“单元”都是32高x 32宽(416/13=32)
```
├──────────────── 416 ─────────────────┤
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐ ┬ 416/13=32
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │ ┌──┐
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │ └──┘
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │ 32x32
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
13 ├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ 416
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
├──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┼──┤ │
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘ ┴
13
```
那125呢? “125”告诉我们,对于每个网格单元,模型返回125个“通道”(或数据)作为该单个单元的预测输出。
要了解为什么有125个通道,我们首先需要了解该模型不能预测对象的任意边界框。 相反,每个单元格负责预测5个预定的边界框。 这5个框是根据以下每个`anchor` 框的偏移量计算得出的:
```
┌───────────────────┐
│ ┌───┐ │
│ ┌─────┼───┼─────┐ │
│ │ ┌──┼───┼──┐ │ │
│ │ │ │┌─┐│ │ │ │
│ │ │ │└─┘│ │ │ │
│ │ └──┼───┼──┘ │ │
│ └─────┼───┼─────┘ │
│ └───┘ │
└───────────────────┘
```
因此,对于每个单独的单元格,该模型返回5个预测(每个锚定一个,由上面的框形表示),每个预测包括以下25个参数:
- 4个参数指示边界框的位置(x,y,宽度,高度)
- 1个参数指示盒子的置信度得分(或客观性)
- 20个类别的概率(每个类别一个概率分数,表明该对象是该类别的可能性)
5个盒子x 25个参数= 125个'通道'
_注意,如果对模型进行训练以检测不同数量的类,则该值将不同。例如,仅能检测3个不同类的模型的输出格式为40x13x13:_
- _(x,y,宽度,高度,客观性)+ 3个类别概率= 8个参数_
- _5个盒子 x 8个参数 = 40个'通道'_
## 解决方案
**此解决方案中的项目使用.NET Core 3.0。 为了运行此示例,您必须安装.NET Core SDK 3.0。 为此,请执行以下任一操作:**
1. 通过转到[.NET Core 3.0下载页面](https://aka.ms/netcore3download)手动安装SDK,并在“SDK”列中下载最新的“.NET Core安装程序”。
2. 或者,如果您使用的是Visual Studio 2019,请转至:_ **工具>选项>环境>预览功能** _,然后选中以下复选框:_ **使用.NET Core SDK的预览**
### 解决方案包含三个项目
- [**OnnxObjectDetection**](./OnnxObjectDetection)是WPF应用程序和Web应用程序都使用的.NET Standard库。 它包含用于通过模型运行图像并解析结果预测的大多数逻辑。 该项目还包含ONNX模型文件。 除了在图像/屏幕上绘制标签边界框之外,此项目包含下面的所有代码段。
- [**OnnxObjectDetectionWeb**](./OnnxObjectDetectionWeb) 包含一个ASP.NET Core Web App,其中包含**Razor UI页面**和**API controller**以处理和呈现图像。
- [**OnnxObjectDetectionApp**](./OnnxObjectDetectionApp) 包含一个.NET CORE WPF桌面应用程序,该应用程序使用[OpenCvSharp](https://github.com/shimat/opencvsharp)从设备的网络摄像头捕获视频。
## 代码演练
_该示例与[getting-started object detection sample](https://github.com/dotnet/machinelearning-samples/tree/main/samples/csharp/getting-started/DeepLearning_ObjectDetection_Onnx)不同,在这里我们加载/处理在内存中的图像**,而入门示例从**文件**中加载图像。_
创建一个类,该类定义将数据加载到IDataView中时要使用的数据模式。 ML.NET支持图像的`Bitmap`类型,因此我们将指定以`ImageTypeAttribute`修饰的`Bitmap`属性,并传入通过[检查模型]](#model-input-and-output)得到的高度和宽度尺寸,如下所示。
```csharp
public struct ImageSettings
{
public const int imageHeight = 416;
public const int imageWidth = 416;
}
public class ImageInputData
{
[ImageType(ImageSettings.imageHeight, ImageSettings.imageWidth)]
public Bitmap Image { get; set; }
}
```
### ML.NET: 配置模型
第一步是创建一个空的`DataView`,以获取配置模型时要使用的数据架构。
```csharp
var dataView = _mlContext.Data.LoadFromEnumerable(new List<ImageInputData>());
```
第二步是定义评估器管道。通常在处理深度神经网络时,必须使图像适应网络所期望的格式。因此,下面的代码将调整图像的大小并对其进行变换(所有R、G、B通道的像素值都已标准化)。
```csharp
var pipeline = mlContext.Transforms.ResizeImages(resizing: ImageResizingEstimator.ResizingKind.Fill, outputColumnName: onnxModel.ModelInput, imageWidth: ImageSettings.imageWidth, imageHeight: ImageSettings.imageHeight, inputColumnName: nameof(ImageInputData.Image))
.Append(mlContext.Transforms.ExtractPixels(outputColumnName: onnxModel.ModelInput))
.Append(mlContext.Transforms.ApplyOnnxModel(modelFile: onnxModel.ModelPath, outputColumnName: onnxModel.ModelOutput, inputColumnName: onnxModel.ModelInput));
```
接下来,我们将使用通过[检查模型](#model-input-and-output) 得到的输入和输出张量名称来定义Tiny YOLOv2 Onnx模型的**input**和**output**参数。
```csharp
public struct TinyYoloModelSettings
{
public const string ModelInput = "image";
public const string ModelOutput = "grid";
}
```
最后,通过拟合“DataView”来创建模型。
```csharp
var model = pipeline.Fit(dataView);
```
## 加载模型并创建PredictionEngine
配置模型后,我们需要保存模型,加载保存的模型,创建一个`PredictionEngine`,然后将图像传递给引擎以使用模型检测对象。这是一个**Web**应用程序和**WPF**应用程序略有不同的地方。
**Web**应用程序使用一个`PredictionEnginePool`来高效地管理服务,并为服务提供一个`PredictionEngine`来进行预测。在内部,它进行了优化,以便在创建这些对象时,以最小的开销在Http请求之间缓存和共享对象依赖关系。
```csharp
public ObjectDetectionService(PredictionEnginePool<ImageInputData, TinyYoloPrediction> predictionEngine)
{
this.predictionEngine = predictionEngine;
}
```
而**WPF**桌面应用程序创建一个`PredictionEngine`,并在本地缓存以用于每个帧预测。需要澄清的关键点是,实例化`PredictionEngine`的调用代码负责处理缓存(与`PredictionEnginePool`相比)。
```csharp
public PredictionEngine<ImageInputData, TinyYoloPrediction> GetMlNetPredictionEngine()
{
return mlModel.Model.CreatePredictionEngine<ImageInputData, TinyYoloPrediction>(mlModel);
}
```
## 检测图像中的对象
获取预测时,我们在`PredictedLabels`属性中得到一个大小为**21125**的 `float`数组。这是[前面讨论过的](#output-data-125x13x13)模型的125x13x13输出。然后,我们使用[`OnnxOutputParser`](./OnnxObjectDetection/OnnxOutputParser.cs)类解释并返回每个图像的多个边界框。同样,这些框被过滤,因此我们只检索到5个具有高置信度的框。
```csharp
var labels = tinyYoloPredictionEngine?.Predict(imageInputData).PredictedLabels;
var boundingBoxes = outputParser.ParseOutputs(labels);
var filteredBoxes = outputParser.FilterBoundingBoxes(boundingBoxes, 5, 0.5f);
```
## 在图像中检测到的对象周围绘制边界框
最后一步是在对象周围绘制边界框。
**Web**应用程序使用Paint API将框直接绘制到图像上,并返回图像以在浏览器中显示。
```csharp
var img = _objectDetectionService.DrawBoundingBox(imageFilePath);
using (MemoryStream m = new MemoryStream())
{
img.Save(m, img.RawFormat);
byte[] imageBytes = m.ToArray();
// Convert byte[] to Base64 String
base64String = Convert.ToBase64String(imageBytes);
var result = new Result { imageString = base64String };
return result;
}
```
另外,**WPF**应用程序在与流式视频播放重叠的[`Canvas`](https://docs.microsoft.com/en-us/dotnet/api/system.windows.controls.canvas?view=netcore-3.0) 元素上绘制边界框。
```csharp
DrawOverlays(filteredBoxes, WebCamImage.ActualHeight, WebCamImage.ActualWidth);
WebCamCanvas.Children.Clear();
foreach (var box in filteredBoxes)
{
var objBox = new Rectangle {/* ... */ };
var objDescription = new TextBlock {/* ... */ };
var objDescriptionBackground = new Rectangle {/* ... */ };
WebCamCanvas.Children.Add(objDescriptionBackground);
WebCamCanvas.Children.Add(objDescription);
WebCamCanvas.Children.Add(objBox);
}
```
## 关于准确性的说明
Tiny YOLOv2的精确度明显低于完整的YOLOv2模型,但是对于这个示例应用程序来说,Tiny版本已经足够了。
## 疑难解答(Web应用程序)
通过应用程序服务在Azure上部署此应用程序时,您可能会遇到一些常见问题。
1. 应用程序返回5xx代码
1. 部署应用程序后,您可能会得到5xx代码的一个原因是平台。web应用程序仅在64位体系结构上运行。在Azure中,更改**设置>配置>常规设置**菜单中相应应用程序服务中的**平台**设置。
1. 部署应用程序后使用5xx代码的另一个原因是web应用程序的目标框架是.NET Core 3.0,它目前正在预览中。您可以将应用程序和引用的项目还原为.NET Core 2.x或向应用程序服务添加扩展。
- 要在Azure门户中添加.NET Core 3.0支持,请选择相应应用程序服务的**开发工具>扩展**部分中的**添加**按钮。
- 然后,从扩展列表中选择**选择扩展**并选择**ASP.NET Core 3.0(x64)Runtime**并接受法律条款,继续将扩展添加到应用程序服务。
1. 相对路径
在本地和Azure上工作时,路径的工作方式略有不同。如果成功地部署了应用程序,但单击其中一个预加载的映像或上载自己的映像不起作用,请尝试更改相对路径。为此,在*Controllers/ObjectDetectionController.cs*文件中,更改构造函数中的`_imagesTmpFolder`的值。
```csharp
_imagesTmpFolder = CommonHelpers.GetAbsolutePath(@"ImagesTemp");
```
对`Get`操作中的`imageFileRelativePath`执行相同的操作。
```csharp
string imageFileRelativePath = @"assets" + url;
```
或者,您可以根据环境(dev / prod)设置条件,是使用路径的本地版本还是Azure首选的版本。 | 10,691 | MIT |
---
author: alkohli
ms.service: storsimple
ms.topic: include
ms.date: 10/26/2018
ms.author: alkohli
ms.openlocfilehash: cd7eafa251d50e5b5c4e84b1586926f8c5e27c5f
ms.sourcegitcommit: 48592dd2827c6f6f05455c56e8f600882adb80dc
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 10/26/2018
ms.locfileid: "50164310"
---
<!--author=alkohli last changed: 01/02/17-->
#### <a name="to-add-or-remove-a-volume"></a>ボリュームを追加または削除するには
1. StorSimple デバイスに移動して、**[バックアップ ポリシー]** をクリックします。
2. ポリシーの表形式の一覧で、変更するポリシーを選択してクリックします。 右クリックしてコンテキスト メニューを起動し、**[ボリュームの追加/削除]** を選択します。
![[スケジュールの管理]](./media/storsimple-8000-add-remove-volume-backup-policy-u2/addvolbupol1.png)
3. **[ボリュームの追加/削除]** ブレードで、チェック ボックスをオンまたはオフにして、ボリュームを追加または削除します。 対応する複数のチェック ボックスをオンまたはオフにすると、複数のボリュームが選択または選択解除されます。
![[スケジュールの管理]](./media/storsimple-8000-add-remove-volume-backup-policy-u2/addvolbupol3.png)
バックアップ ポリシーに別のボリューム コンテナーのボリュームを割り当てている場合、これらのボリューム コンテナーを共にフェールオーバーする必要があります。 その効果に関する警告が表示されます。
![[スケジュールの管理]](./media/storsimple-8000-add-remove-volume-backup-policy-u2/addvolbupol2.png)
4. バックアップ ポリシーが変更されると、その旨が通知されます。 バックアップ ポリシーの一覧も更新されます。
![[スケジュールの管理]](./media/storsimple-8000-add-remove-volume-backup-policy-u2/addvolbupol6.png) | 1,249 | BSD-Source-Code |
---
title: <dependentAssembly> 元素
ms.date: 03/30/2017
f1_keywords:
- http://schemas.microsoft.com/.NetConfiguration/v2.0#configuration/runtime/assemblyBinding/dependentAssembly
- http://schemas.microsoft.com/.NetConfiguration/v2.0#dependentAssembly
helpviewer_keywords:
- container tags, <dependentAssembly> element
- dependentAssembly element
- <dependentAssembly> element
ms.assetid: 14e95627-dd79-4b82-ac85-e682aa3a31d8
author: rpetrusha
ms.author: ronpet
ms.openlocfilehash: ac83a0b27a965721dabe1bdf2e05afbdc9b9c961
ms.sourcegitcommit: 0be8a279af6d8a43e03141e349d3efd5d35f8767
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/18/2019
ms.locfileid: "59083655"
---
# <a name="dependentassembly-element"></a>\<dependentAssembly > 元素
封装每个程序集的绑定策略和程序集位置。 使用一个`dependentAssembly`每个程序集的元素。
\<configuration>
\<运行时 >
\<assemblyBinding>
\<dependentAssembly>
## <a name="syntax"></a>语法
```xml
<dependentAssembly>
</dependentAssembly>
```
## <a name="attributes-and-elements"></a>特性和元素
下列各节描述了特性、子元素和父元素。
### <a name="attributes"></a>特性
无。
### <a name="child-elements"></a>子元素
|元素|描述|
|-------------|-----------------|
|`assemblyIdentity`|包含有关程序集的标识信息。 此元素必须包括在每个`dependentAssembly`元素。|
|`codeBase`|指定了运行时可以找到共享的程序集,如果计算机上未安装。|
|`bindingRedirect`|将一个程序集版本重定向到另一个版本。|
|`publisherPolicy`|指定是否在运行时应用此程序集发布者策略。|
### <a name="parent-elements"></a>父元素
|元素|描述|
|-------------|-----------------|
|`assemblyBinding`|包含有关程序集版本重定向和程序集位置的信息。|
|`configuration`|公共语言运行时和 .NET Framework 应用程序所使用的每个配置文件中的根元素。|
|`runtime`|包含有关程序集绑定和垃圾回收的信息。|
## <a name="example"></a>示例
下面的示例演示如何封装两个程序集的程序集信息。
```xml
<configuration>
<runtime>
<assemblyBinding xmlns="urn:schemas-microsoft-com:asm.v1">
<dependentAssembly>
<assemblyIdentity name="myAssembly"
publicKeyToken="32ab4ba45e0a69a1"
culture="neutral" />
<!--Redirection and codeBase policy for myAssembly.-->
</dependentAssembly>
<dependentAssembly>
<assemblyIdentity name="mySecondAssembly"
publicKeyToken="32ab4ba45e0a69a1"
culture="neutral" />
<!--Redirection and codeBase policy for mySecondAssembly.-->
</dependentAssembly>
</assemblyBinding>
</runtime>
</configuration>
```
## <a name="see-also"></a>请参阅
- [运行时设置架构](../../../../../docs/framework/configure-apps/file-schema/runtime/index.md)
- [配置文件架构](../../../../../docs/framework/configure-apps/file-schema/index.md)
- [重定向程序集版本](../../../../../docs/framework/configure-apps/redirect-assembly-versions.md) | 2,761 | CC-BY-4.0 |