
qid
int64 46k
74.7M
| question
stringlengths 54
37.8k
| date
stringlengths 10
10
| metadata
sequencelengths 3
3
| response_j
stringlengths 29
22k
| response_k
stringlengths 26
13.4k
| __index_level_0__
int64 0
17.8k
|
|---|---|---|---|---|---|---|
21,977,987 | When I run a program from a USB memory, and remove the USB memory the program still goes on running (I mean with out really copying the program into the Windows PC).
However, does the program make its copy inside the Windows in any hidden location or temporary folder while running by the python IDLE. From where the python IDLE receive the code to be running after removing the USB memory? I am going to run python program in a public shared PC so I do not want anyone find out my code, I just want to run it, and get the result next day. Does someone can get my code even I remove the USB memory? | 2014/02/24 | [
"https://Stackoverflow.com/questions/21977987",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] | There are plenty of ways someone can get your program, even if you remove the USB drive.
* They can install a program that triggers when a USB stick is inserted, search the stick for `.py` files, and copies them to disk.
* If the Python installation you're using is on the disk instead of the USB drive, they can replace the Python executable with a wrapper that saves copies of any file the Python interpreter opens.
* Your program is going to go into RAM, and depending on what it does and what else is using the machine, it may get swapped to disk. An attacker may be able to read your program out of RAM or reconstruct it from the swap file. | It sounds like you are doing something you probably shouldn't be doing. Depending on how much people want your code they could go as far as physically freezing the ram and doing a forensic IT analysis. In short, you can't prevent code cloning on a machine you don't administer. | 1,469 |
17,973,507 | I have a long list of xy coordinates, and would like to convert it into numpy array.
```
>>> import numpy as np
>>> xy = np.random.rand(1000000, 2).tolist()
```
The obvious way would be:
```
>>> a = np.array(xy) # Very slow...
```
However, the above code is unreasonably slow. Interestingly, to transpose the long list first, convert it into numpy array, and then transpose back would be much faster (20x on my laptop).
```
>>> def longlist2array(longlist):
... wide = [[row[c] for row in longlist] for c in range(len(longlist[0]))]
... return np.array(wide).T
>>> a = longlist2array(xy) # 20x faster!
```
Is this a bug of numpy?
EDIT:
This is a list of points (with xy coordinates) generated on-the-fly, so instead of preallocating an array and enlarging it when necessary, or maintaining two 1D lists for x and y, I think current representation is most natural.
Why is looping through 2nd index faster than 1st index, given that we are iterating through a python list in both directions?
EDIT 2:
Based on @tiago's answer and [this question](https://stackoverflow.com/questions/367565/how-do-i-build-a-numpy-array-from-a-generator), I found the following code twice as fast as my original version:
```
>>> from itertools import chain
>>> def longlist2array(longlist):
... flat = np.fromiter(chain.from_iterable(longlist), np.array(longlist[0][0]).dtype, -1) # Without intermediate list:)
... return flat.reshape((len(longlist), -1))
``` | 2013/07/31 | [
"https://Stackoverflow.com/questions/17973507",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2003079/"
] | Implementing this in Cython without the extra checking involved to determine dimensionality, etc. nearly eliminates the time difference you are seeing.
Here's the `.pyx` file I used to verify that.
```
from numpy cimport ndarray as ar
import numpy as np
cimport cython
@cython.boundscheck(False)
@cython.wraparound(False)
def toarr(xy):
cdef int i, j, h=len(xy), w=len(xy[0])
cdef ar[double,ndim=2] new = np.empty((h,w))
for i in xrange(h):
for j in xrange(w):
new[i,j] = xy[i][j]
return new
```
I would assume that the extra time is spent in checking the length and content of each sublist in order to determine the datatype, dimension, and size of the desired array.
When there are only two sublists, it only has to check two lengths to determine the number of columns in the array, instead of checking 1000000 of them. | This is because the fastest-varying index of your list is the last one, so `np.array()` has to traverse the array many times because the first index is much larger. If your list was transposed, `np.array()` would be faster than your `longlist2array`:
```
In [65]: import numpy as np
In [66]: xy = np.random.rand(10000, 2).tolist()
In [67]: %timeit longlist2array(xy)
100 loops, best of 3: 3.38 ms per loop
In [68]: %timeit np.array(xy)
10 loops, best of 3: 55.8 ms per loop
In [69]: xy = np.random.rand(2, 10000).tolist()
In [70]: %timeit longlist2array(xy)
10 loops, best of 3: 59.8 ms per loop
In [71]: %timeit np.array(xy)
1000 loops, best of 3: 1.96 ms per loop
```
There is no magical solution for your problem. It's just how Python stores your list in memory. Do you really need to have a list with that shape? Can't you reverse it? (And do you really need a list, given that you're converting to numpy?)
If you must convert a list, this function is about 10% faster than your `longlist2array`:
```
from itertools import chain
def convertlist(longlist)
tmp = list(chain.from_iterable(longlist))
return np.array(tmp).reshape((len(longlist), len(longlist[0])))
``` | 1,470 |
68,957,505 | ```
input = (Columbia and (India or Singapore) and Malaysia)
output = [Columbia, India, Singapore, Malaysia]
```
Basically ignore the python keywords and brackets
I tried with the below code, but still not able to eliminate the braces.
```
import keyword
my_str=input()
l1=list(my_str.split(" "))
l2=[x for x in l1 if not keyword.iskeyword((x.lower()))]
print(l2)
``` | 2021/08/27 | [
"https://Stackoverflow.com/questions/68957505",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15695277/"
] | If you want to do it using first principles, you can use the code that is presented on the [Wikipedia page for Halton sequence](https://en.wikipedia.org/wiki/Halton_sequence):
```py
def halton(b):
"""Generator function for Halton sequence."""
n, d = 0, 1
while True:
x = d - n
if x == 1:
n = 1
d *= b
else:
y = d // b
while x <= y:
y //= b
n = (b + 1) * y - x
yield n / d
```
Here is a way to take the first 256 points of the 2- and 3- sequences, and plot them:
```py
n = 256
df = pd.DataFrame([
(x, y) for _, x, y in zip(range(n), halton(2), halton(3))
], columns=list('xy'))
ax = df.plot.scatter(x='x', y='y')
ax.set_aspect('equal')
```

**Addendum** "if I want to take for example 200 points and 8 dimensions for all sequences what should I do?"
Assuming you have access to a prime number sequence generator, then you can use e.g.:
```py
m = 8
p = list(primes(m * m))[:m] # first m primes
n = 200
z = pd.DataFrame([a for _, *a in zip(range(n), *[halton(k) for k in p])])
>>> z
0 1 2 3 4 5 6 7
0 0.500000 0.333333 0.2000 0.142857 0.090909 0.076923 0.058824 0.052632
1 0.250000 0.666667 0.4000 0.285714 0.181818 0.153846 0.117647 0.105263
2 0.750000 0.111111 0.6000 0.428571 0.272727 0.230769 0.176471 0.157895
3 0.125000 0.444444 0.8000 0.571429 0.363636 0.307692 0.235294 0.210526
4 0.625000 0.777778 0.0400 0.714286 0.454545 0.384615 0.294118 0.263158
.. ... ... ... ... ... ... ... ...
195 0.136719 0.576132 0.3776 0.011662 0.868520 0.089213 0.567474 0.343490
196 0.636719 0.909465 0.5776 0.154519 0.959429 0.166136 0.626298 0.396122
197 0.386719 0.057613 0.7776 0.297376 0.058603 0.243059 0.685121 0.448753
198 0.886719 0.390947 0.9776 0.440233 0.149512 0.319982 0.743945 0.501385
199 0.074219 0.724280 0.0256 0.583090 0.240421 0.396905 0.802768 0.554017
```
**Bonus**
Primes sequence using [Atkin's sieve](http://en.wikipedia.org/wiki/Prime_number):
```py
import numpy as np
def primes(limit):
# Generates prime numbers between 2 and n
# Atkin's sieve -- see http://en.wikipedia.org/wiki/Prime_number
sqrtLimit = int(np.sqrt(limit)) + 1
# initialize the sieve
is_prime = [False, False, True, True, False] + [False for _ in range(5, limit + 1)]
# put in candidate primes:
# integers which have an odd number of
# representations by certain quadratic forms
for x in range(1, sqrtLimit):
x2 = x * x
for y in range(1, sqrtLimit):
y2 = y*y
n = 4 * x2 + y2
if n <= limit and (n % 12 == 1 or n % 12 == 5): is_prime[n] ^= True
n = 3 * x2 + y2
if n <= limit and (n % 12 == 7): is_prime[n] ^= True
n = 3*x2-y2
if n <= limit and x > y and n % 12 == 11: is_prime[n] ^= True
# eliminate composites by sieving
for n in range(5, sqrtLimit):
if is_prime[n]:
sqN = n**2
# n is prime, omit multiples of its square; this is sufficient because
# composites which managed to get on the list cannot be square-free
for i in range(1, int(limit/sqN) + 1):
k = i * sqN # k ∈ {n², 2n², 3n², ..., limit}
is_prime[k] = False
for i, truth in enumerate(is_prime):
if truth: yield i
``` | In Python, SciPy is the main scientific computing package, and it [contains a Halton sequence generator](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.qmc.Halton.html), among other QMC functions.
For plotting, the standard way with SciPy is matplotlib; if you're not familiar with that, the [tutorial for SciPy](https://docs.scipy.org/doc/scipy/tutorial/general.html) is also a great place to start.
A basic example:
```py
from scipy.stats import qmc
import matplotlib.pyplot as plt
sampler = qmc.Halton(d=2, scramble=True)
sample = sampler.random(n=5)
plt.plot(sample)
``` | 1,473 |
73,104,518 | using opencv for capturing image in python
i want to make this image :
code for this :
```
# Image Processing
gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (51,51), 15)
th3 = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 2)
ret, test_image = cv2.threshold(th3, 10, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
```
[](https://i.stack.imgur.com/TmGlM.jpg)
to somewhat like this:
[](https://i.stack.imgur.com/sCLfc.jpg) | 2022/07/25 | [
"https://Stackoverflow.com/questions/73104518",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/16383903/"
] | For each position, look for the 4 possibles values, that for each a condition of existance
```
for i in range(len(arr)):
for j in range(len(arr[i])):
key = f'{i}{j}'
if i != 0:
d[key].append(arr[i - 1][j])
if j != 0:
d[key].append(arr[i][j - 1])
if i != (len(arr) - 1):
d[key].append(arr[i + 1][j])
if j != (len(arr[i]) - 1):
d[key].append(arr[i][j + 1])
```
```
{"00": [2, 2], "01": [0, 0, 3], "02": [2, 4],
"10": [0, 3, 0], "11": [2, 2, 4, 4], "12": [3, 0, 0],
"20": [2, 4], "21": [0, 3, 0], "22": [4, 4]}
```
---
Also it is useless to use a f-string to pass **one** thing only, | One approach using a dictionary comprehension:
```
from itertools import product
arr = [[0, 2, 3],
[2, 0, 4],
[3, 4, 0]]
def cross(i, j, a):
res = []
for ii, jj in zip([0, 1, 0, -1], [-1, 0, 1, 0]):
ni = (i + ii)
nj = (j + jj)
if (-1 < ni < len(a[0])) and (-1 < nj < len(a)):
res.append(a[nj][ni])
return res
res = {"".join(map(str, co)): cross(co[0], co[1], arr) for co in product(range(3), repeat=2)}
print(res)
```
**Output**
```
{'00': [2, 2], '01': [0, 0, 3], '02': [2, 4], '10': [3, 0, 0], '11': [2, 4, 4, 2], '12': [0, 0, 3], '20': [4, 2], '21': [3, 0, 0], '22': [4, 4]}
``` | 1,474 |
28,376,849 | The Eclipse PyDev plugin includes fantastic integrated `autopep8` support. It formats the code to PEP8 style automatically on save, with several knobs and options to tailor it to your needs.
But the `autopep8` import formatter breaks `site.addsitedir()` usage.
```
import site
site.addsitedir('/opt/path/lib/python')
# 'ourlib' is a package in '/opt/path/lib/python', which
# without the above addsitedir() would otherwise not import.
from ourlib import do_stuff
```
And after PyDev's `autopep8` import formatter, it changes it to:
```
import site
from ourlib import do_stuff
site.addsitedir('/opt/path/lib/python')
```
Which breaks `from ourlib import do_stuff` with `ImportError: No module named ourlib`.
**Question:**
Is there a PyDev setting or `autopep8` command-line option to keep it from moving `site.addsitedir()` calls? | 2015/02/07 | [
"https://Stackoverflow.com/questions/28376849",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2125392/"
] | Oldie but still relevant as I found this one issue.
I'm using VSCode and autopep8.
You can disable formatting by adding `# nopep8` to the relevant lines.
ps. Checked the docs for a link but could not find it :( | The best option I can find is to turn off import sorts in PyDev. This is not a complete solution, but it's better than completely turning off `autopep8` code formatting.
Just uncheck the `Sort imports on save?` option in the Eclipse/PyDev Preferences.
For Eclipse Kepler, Service Release 2, with PyDev 3.9.2, you can find it here:
```
Windows -> Preferences
--> PyDev -> Editor -> Save Actions
----> "Sort imports on save?" (uncheck)
``` | 1,479 |
6,916,054 | I'm working with python using Matplotlib and PIL and a need to look into a image select and cut the area that i have to work with, leaving only the image of the selected area.I alredy know how to cut imagens with pil(using im.crop) but how can i select the coordinates to croped the image with mouse clicks?
To better explain, i crop the image like this:
```
import Pil
import Image
im = Image.open("test.jpg")
crop_rectangle = (50, 50, 200, 200)
cropped_im = im.crop(crop_rectangle)
cropped_im.show()
```
I need to give the coordinates "crop\_rectangle" with the mouse click in a rectangle that i wanna work with, how can i do it?
Thank you | 2011/08/02 | [
"https://Stackoverflow.com/questions/6916054",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/669332/"
] | You could use [matplotlib.widgets.RectangleSelector](http://matplotlib.sourceforge.net/api/widgets_api.html?highlight=matplotlib.widgets#matplotlib.widgets.RectangleSelector) (thanks to Joe Kington for this suggestion) to handle button press events:
```
import numpy as np
import matplotlib.pyplot as plt
import Image
import matplotlib.widgets as widgets
def onselect(eclick, erelease):
if eclick.ydata>erelease.ydata:
eclick.ydata,erelease.ydata=erelease.ydata,eclick.ydata
if eclick.xdata>erelease.xdata:
eclick.xdata,erelease.xdata=erelease.xdata,eclick.xdata
ax.set_ylim(erelease.ydata,eclick.ydata)
ax.set_xlim(eclick.xdata,erelease.xdata)
fig.canvas.draw()
fig = plt.figure()
ax = fig.add_subplot(111)
filename="test.png"
im = Image.open(filename)
arr = np.asarray(im)
plt_image=plt.imshow(arr)
rs=widgets.RectangleSelector(
ax, onselect, drawtype='box',
rectprops = dict(facecolor='red', edgecolor = 'black', alpha=0.5, fill=True))
plt.show()
``` | are you using tk? it will depend on what window management you are using. High level though, you'll want something like:
```
def onMouseDown():
// get and save your coordinates
def onMouseUp():
// save these coordinates as well
// now compare your coordinates to fingure out which corners
// are being used and define your rectangle
```
The callbacks themselves will differ from window tool to window tool, but the concept will be the same: capture the click down event and release event and compare the points where the events were triggered to create your rectangle. The trick is to remember to figure out which corner they are starting at (the second point is always opposite that corner) and creating your rectangle to be cropped, relative to the original image itself.
Again, depending on the tool, you will probably need to put your click events in your image's coordinate space. | 1,480 |
50,489,637 | I am learning C++, is there something like python-pip in C++? I am uing `json`/`YAML` packages in my 1st project, I want to know which is the correct way to manage dependencies in my project, and after I finished developing, which is the correct way to migrate dependencies to production environment? | 2018/05/23 | [
"https://Stackoverflow.com/questions/50489637",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5735646/"
] | C++ doesn't have a standard package manager or build system: this is one of the major pain points of the language. You have a few options:
* Manually install dependencies when required.
* Use your OS's package manager.
* Adopt a third-party package manager such as [conan.io](http://conan.io).
None of the above solutions is perfect and dependency management will likely always require some more effort on your part compared to languages such as Python or Rust. | As far as I know, there is no central library management system in C++ similar to `pip`. You need to download and install the packages you need manually or through some package manager if your OS supports it.
As for managing multiple libraries in a C++ project, you could use [CMAKE](https://cmake.org/) or something similar. If you link your libraries dynamically (i.e., though .dll or .so files), then you need to supply these dynamic library binaries along with your application. To find out which dll files may be needed, you could something like the [Dependency Walker](http://www.dependencywalker.com/) or [ELF Library Viewer](http://www.purinchu.net/software/elflibviewer.php).
Personally, I use a development environment - specifically [Qt](https://www.qt.io/) (with the QtCreator), containing many of these components like `qmake` etc. - which simplifies the process of development and distribution. | 1,481 |
18,755,963 | I have designed a GUI using python tkinter. And now I want to set style for Checkbutton and Labelframe, such as the font, the color .etc
I have read some answers on the topics of tkinter style, and I have used the following method to set style for both Checkbutton and Labelframe.
But they don't actually work.
```
Root = tkinter.Tk()
ttk.Style().configure('Font.TLabelframe', font="15", foreground = "red")
LabelFrame = ttk.Labelframe(Root, text = "Test", style = "Font.TLabelframe")
LabelFrame .pack( anchor = "w", ipadx = 10, ipady = 5, padx = 10, pady = 0, side = "top")
```
Can you tell me the reasons, or do you have some other valid methods? Thank you very much! | 2013/09/12 | [
"https://Stackoverflow.com/questions/18755963",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2771241/"
] | You need to configure the Label sub-component:
```
from tkinter import *
from tkinter import ttk
root = Tk()
s = ttk.Style()
s.configure('Red.TLabelframe.Label', font=('courier', 15, 'bold'))
s.configure('Red.TLabelframe.Label', foreground ='red')
s.configure('Red.TLabelframe.Label', background='blue')
lf = ttk.LabelFrame(root, text = "Test", style = "Red.TLabelframe")
lf.pack( anchor = "w", ipadx = 10, ipady = 5, padx = 10,
pady = 0, side = "top")
Frame(lf, width=100, height=100, bg='black').pack()
print(s.lookup('Red.TLabelframe.Label', 'font'))
root.mainloop()
``` | As the accepted answer didn't really help me when I wanted to do a simple changing of weight of a `ttk.LabelFrame` font (if you do it like recommended, you end up with a misplaced label), I'll provide what worked for me.
You have to use `labelwidget` option argument of `ttk.LabelFrame` first preparing a seperate `ttk.Label` that you style earlier accordingly. **Important:** using `labelwidget` means you don't use the usual `text` option argument for your `ttk.LabelFrame` (just do it in the label).
```
# changing a labelframe font's weight to bold
root = Tk()
style = ttk.Style()
style.configure("Bold.TLabel", font=("TkDefaultFont", 9, "bold"))
label = ttk.Label(text="Foo", style="Bold.TLabel")
lf = ttk.LabelFrame(root, labelwidget=label)
``` | 1,482 |
38,163,087 | Having an issue where I would fill out the form and when I click to save the input, it would show the info submitted into the `query` but my `production_id` value would return as `None`.
**Here is the error:**
```
Environment:
Request Method: POST
Request URL: http://192.168.33.10:8000/podfunnel/episodeinfo/
Django Version: 1.9
Python Version: 2.7.6
Installed Applications:
('producer',
'django.contrib.admin',
'django.contrib.sites',
'registration',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'storages',
'django_extensions',
'randomslugfield',
'adminsortable2',
'crispy_forms')
Installed Middleware:
('django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.middleware.security.SecurityMiddleware')
Traceback:
File "/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py" in get_response
149. response = self.process_exception_by_middleware(e, request)
File "/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py" in get_response
147. response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/usr/local/lib/python2.7/dist-packages/django/views/generic/base.py" in view
68. return self.dispatch(request, *args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/django/contrib/auth/mixins.py" in dispatch
56. return super(LoginRequiredMixin, self).dispatch(request, *args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/django/views/generic/base.py" in dispatch
88. return handler(request, *args, **kwargs)
File "/home/vagrant/fullcast_project/producer/views/pod_funnel.py" in post
601. return HttpResponseRedirect(reverse('podfunnel:episodeimagefiles', kwargs={'production_id':production_id}))
File "/usr/local/lib/python2.7/dist-packages/django/core/urlresolvers.py" in reverse
600. return force_text(iri_to_uri(resolver._reverse_with_prefix(view, prefix, *args, **kwargs)))
File "/usr/local/lib/python2.7/dist-packages/django/core/urlresolvers.py" in _reverse_with_prefix
508. (lookup_view_s, args, kwargs, len(patterns), patterns))
Exception Type: NoReverseMatch at /podfunnel/episodeinfo/
Exception Value: Reverse for 'episodeimagefiles' with arguments '()' and keyword arguments '{'production_id': None}' not found. 1 pattern(s) tried: [u'podfunnel/episodeimagefiles/(?P<production_id>[0-9]+)/$']
```
**Here is my `pod_funnel.py` view:**
```
from django.http import HttpResponseRedirect, Http404, HttpResponseForbidden
from django.shortcuts import render, get_object_or_404
from django.views.generic import View, RedirectView, TemplateView
from django.contrib.auth.decorators import login_required
from django.contrib.auth.mixins import LoginRequiredMixin
from .forms.client_setup import ClientSetupForm
from .forms.podcast_setup import PodcastSetupForm
from .forms.episode_info import EpisodeInfoForm
from .forms.image_files import EpisodeImageFilesForm
from .forms.wordpress_info import EpisodeWordpressInfoForm
from .forms.chapter_marks import EpisodeChapterMarksForm
from .forms.show_links import ShowLinksForm
from .forms.tweetables import TweetablesForm
from .forms.clicktotweet import ClickToTweetForm
from .forms.schedule import ScheduleForm
from .forms.wordpress_account import WordpressAccountForm
from .forms.wordpress_account_setup import WordpressAccountSetupForm
from .forms.wordpress_account_sortable import WordpressAccountSortableForm
from .forms.soundcloud_account import SoundcloudAccountForm
from .forms.twitter_account import TwitterAccountForm
from producer.helpers import get_podfunnel_client_and_podcast_for_user
from producer.helpers.soundcloud_api import SoundcloudAPI
from producer.helpers.twitter import TwitterAPI
from django.conf import settings
from producer.models import Client, Production, ChapterMark, ProductionLink, ProductionTweet, Podcast, WordpressConfig, Credentials, WordPressSortableSection, \
TwitterConfig, SoundcloudConfig
from django.core.urlresolvers import reverse
from producer.tasks.auphonic import update_or_create_preset_for_podcast
class EpisodeInfoView(LoginRequiredMixin, View):
form_class = EpisodeInfoForm
template_name = 'pod_funnel/forms_episode_info.html'
def get(self, request, *args, **kwargs):
initial_values = {}
user = request.user
# Lets get client and podcast for the user already. if not existent raise 404
client, podcast = get_podfunnel_client_and_podcast_for_user(user)
if client is None or podcast is None:
raise Http404
# See if a production_id is passed on the kwargs, if so, retrieve and fill current data.
# if not just provide empty form since will be new.
production_id = kwargs.get('production_id', None)
if production_id:
production = get_object_or_404(Production, id=production_id)
# Ensure this production belongs to this user, if not Unauthorized, 403
if production.podcast_id != podcast.id:
return HttpResponseForbidden()
initial_values['production_id'] = production.id
initial_values['episode_number'] = production.episode_number
initial_values['episode_title'] = production.episode_title
initial_values['episode_guest_first_name'] = production.episode_guest_first_name
initial_values['episode_guest_last_name'] = production.episode_guest_last_name
initial_values['episode_guest_twitter_name'] = production.episode_guest_twitter_name
initial_values['episode_summary'] = production.episode_summary
form = self.form_class(initial=initial_values)
return render(request, self.template_name, {'form': form})
def post(self, request, *args, **kwargs):
form = self.form_class(request.POST)
client, podcast = get_podfunnel_client_and_podcast_for_user(request.user)
if form.is_valid():
# lets get the data
production_id = form.cleaned_data.get('production_id')
episode_number = form.cleaned_data.get('episode_number')
episode_title = form.cleaned_data.get('episode_title')
episode_guest_first_name = form.cleaned_data.get('episode_guest_first_name')
episode_guest_last_name = form.cleaned_data.get('episode_guest_last_name')
episode_guest_twitter_name = form.cleaned_data.get('episode_guest_twitter_name')
episode_summary = form.cleaned_data.get('episode_summary')
#if a production existed, we update, if not we create
if production_id is not None:
production = Production.objects.get(id=production_id)
else:
production = Production(podcast=podcast)
production.episode_number = episode_number
production.episode_title = episode_title
production.episode_guest_first_name = episode_guest_first_name
production.episode_guest_last_name = episode_guest_last_name
production.episode_guest_twitter_name = episode_guest_twitter_name
production.episode_summary = episode_summary
production.save()
return HttpResponseRedirect(reverse('podfunnel:episodeimagefiles', kwargs={'production_id':production_id}))
return render(request, self.template_name, {'form': form})
```
**`episode_info.py` form:**
```
from django import forms
class EpisodeInfoForm(forms.Form):
production_id = forms.IntegerField(widget=forms.Field.hidden_widget, required=False)
episode_number = forms.IntegerField(widget=forms.NumberInput, required=True)
episode_title = forms.CharField(max_length=255, required=True)
episode_guest_first_name = forms.CharField(max_length=128)
episode_guest_last_name = forms.CharField(max_length=128)
episode_guest_twitter_name = forms.CharField(max_length=64)
episode_summary = forms.CharField(widget=forms.Textarea)
```
**And `url.py`:**
```
from django.conf.urls import url
from django.views.generic import TemplateView
import producer.views.pod_funnel as views
urlpatterns = [
url(r'^dashboard/', views.dashboard, name="dashboard"),
url(r'^clientsetup/', views.ClientSetupView.as_view(), name="clientsetup"),
url(r'^podcastsetup/', views.PodcastSetupView.as_view(), name="podcastsetup"),
url(r'^episodeinfo/$', views.EpisodeInfoView.as_view(), name="episodeinfo"),
url(r'^episodeinfo/(?P<production_id>[0-9]+)/$', views.EpisodeInfoView.as_view(), name="episodeinfo_edit"),
url(r'^episodeimagefiles/(?P<production_id>[0-9]+)/$', views.EpisodeImageFilesView.as_view(), name="episodeimagefiles"),
```
**Any suggestion would be appreciated.** | 2016/07/02 | [
"https://Stackoverflow.com/questions/38163087",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3557390/"
] | It looks like `production_id` can be `None` in your view, in which case you can't use it when you call reverse. It would be better to use `production.id` instead. You have just saved the production in your view, so `production.id` will be set.
```
return HttpResponseRedirect(reverse('podfunnel:episodeimagefiles', kwargs={'production_id':production.id}))
```
Note that you can simplify this line by using the `redirect` shortcut. Add the import,
```
from django.shortcuts import redirect
```
then change the line to
```
return redirect('podfunnel:episodeimagefiles', production_id=production.id)
``` | You can't always redirect to `episodeimagefiles` if you didn't provide appropriate initial value for `production_id`:
```
# See if a production_id is passed on the kwargs, if so, retrieve and fill current data.
# if not just provide empty form since will be new.
production_id = kwargs.get('production_id', None) <-- here you set production_id variable to None if no `production_id` in kwargs
```
Look at your exception:
```
Exception Value: Reverse for 'episodeimagefiles' with arguments '()' and keyword arguments '{'production_id': None}' not found. 1 pattern(s) tried: [u'podfunnel/episodeimagefiles/(?P<production_id>[0-9]+)/$']
```
It means you passed `None` value for `production_id` variable, but `episodeimagefiles` pattern required some int value to resolve url, so it raises `NoReverseMatch` exception.
Your form is valid in `EpisodeInfoView.post` because you set `required=False` for `production_id` attribute in your form:
```
class EpisodeInfoForm(forms.Form):
production_id = forms.IntegerField(widget=forms.Field.hidden_widget, required=False)
```
I guess, if you debug your generated form before submit it, you can see something like `<input type="hidden" name="production_id" value="None" />` | 1,485 |
63,033,970 | Using python3.8.1, installing newest version, on Windows 10:
`pip install PyNaCl` gives me this error (last 10 lines):
```
File "C:\Program Files (x86)\Python3\lib\distutils\cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "C:\Program Files (x86)\Python3\lib\distutils\dist.py", line 985, in run_command
cmd_obj.run()
File "setup.py", line 161, in run
raise Exception("ERROR: The 'make' utility is missing from PATH")
Exception: ERROR: The 'make' utility is missing from PATH
----------------------------------------
Failed building wheel for PyNaCl
Running setup.py clean for PyNaCl
Failed to build PyNaCl
Could not build wheels for PyNaCl which use PEP 517 and cannot be installed directly
```
It seems to be related to wheels, so i tried to install it with `no-binary`, which also failed:
```
File "C:\Program Files (x86)\Python3\lib\distutils\dist.py", line 985, in run_command
cmd_obj.run()
File "C:\Users\Administrator\AppData\Local\Temp\pip-install-q0db5s_n\PyNaCl\setup.py", line 161, in run
raise Exception("ERROR: The 'make' utility is missing from PATH")
Exception: ERROR: The 'make' utility is missing from PATH
----------------------------------------
Command "C:\Users\Administrator\Documents\DiscordBot\venv\Scripts\python.exe -u -c "import setuptools, tokenize;__file__='C:\\Users\\Administrator\\AppData\\Local\\Temp\\pip-install-q0db5s_n\\PyNaCl\\setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record C:\Users\Administrator\AppData\Local\Temp\pip-record-s27dvlrv\install-record.txt --single-version-externally-managed --compile --install-headers C:\Users\Administrator\Documents\DiscordBot\venv\include\site\python3.8\PyNaCl" failed with error code 1 in C:\Users\Administrator\AppData\Local\Temp\pip-install-q0db5s_n\PyNaCl\
```
EDIT: This only seems to be an issue in my venv (made by Pycharm) - i have no clue what the issue is, both setuptools and wheel are installed. | 2020/07/22 | [
"https://Stackoverflow.com/questions/63033970",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8558929/"
] | I ultimately solved it by using `python -m pip install --no-use-pep517 pynacl` | Upgrading pip within the venv worked for me:
```
.\env\Scripts\activate
pip install -U pip
pip install -r requirements.txt
deactivate
``` | 1,486 |
28,891,405 | I am trying to contract some vertices in igraph (using the python api) while keeping the names of the vertices. It isn't clear to me how to keep the name attribute of the graph. The nodes of the graph are people and I'm trying to collapse people with corrupted names.
I looked at the R documentation and I still don't see how to do it.
For example, if I do either of the following I get an error.
```
smallgraph.contract_vertices([0,1,2,3,4,2,6],vertex.attr.comb=[name='first'])
smallgraph.contract_vertices([0,1,2,3,4,2,6],vertex.attr.comb=['first'])
``` | 2015/03/06 | [
"https://Stackoverflow.com/questions/28891405",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4639290/"
] | In Python, the keyword argument you need is called `combine_attrs` and not `vertex.attr.comb`. See `help(Graph.contract_vertices)` from the Python command line after having imported igraph. Also, the keyword argument accepts either a single specifier (such as `first`) or a dictionary. Your first example is invalid because it is simply not valid Python syntax. The second example won't work because you pass a *list* with a single item instead of just the single item.
So, the correct variants would be:
```
smallgraph.contract_vertices([0,1,2,3,4,2,6], combine_attrs=dict(name="first"))
smallgraph.contract_vertices([0,1,2,3,4,2,6], combine_attrs="first")
``` | Nevermind. You can just enter a dictionary without using the wording
```
vertex.attr.comb
``` | 1,487 |
70,806,221 | So I have a "terminal" like program written in python and in this program I need to accept "mkdir" and another input and save the input after mkdir as a variable. It would work how sys.argv works when executing a python program but this would have to work from inside the program and I have no idea how to make this work. Also, sorry for the amount of times I said "input" in the title, I wasn't sure how to ask this question.
```
user = 'user'
def cmd1():
cmd = input(user + '#')
while True:
if cmd == 'mkdir ' + sys.argv[1]: #trying to accept second input here
print('sys.argv[1]')
break
else:
print('Input not valid')
break
``` | 2022/01/21 | [
"https://Stackoverflow.com/questions/70806221",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/17746152/"
] | May use the pattern (`\\[[^\\]]+(\\[|$)|(^|\\])[^\\[]+\\]`) in `str_detect`
```
library(dplyr)
library(stringr)
df %>%
filter(str_detect(Utterance, "\\[[^\\]]+(\\[|$)|(^|\\])[^\\[]+\\]"))
id Utterance
1 1 [but if I came !ho!me
2 3 =[yeah] I mean [does it
3 4 bu[t if (.) you know
4 5 =ye::a:h]
5 6 [that's right] YEAH (laughs)] [ye::a:h]
6 8 [cos] I've [heard very sketchy [stories]
7 9 oh well] that's great
```
Here we check for a opening bracket `[` followed by one or more characters that are not `]` followed by a `[` or the end of the string (`$`) or a similar pattern for the closing bracket | If you need a function to validate (nested) parenthesis, here is a stack based one.
```
valid_delim <- function(x, delim = c(open = "[", close = "]"), max_stack_size = 10L){
f <- function(x, delim, max_stack_size){
if(is.null(names(delim))) {
names(delim) <- c("open", "close")
}
if(nchar(x) > 0L){
valid <- TRUE
stack <- character(max_stack_size)
i_stack <- 0L
y <- unlist(strsplit(x, ""))
for(i in seq_along(y)){
if(y[i] == delim["open"]){
i_stack <- i_stack + 1L
stack[i_stack] <- delim["close"]
} else if(y[i] == delim["close"]) {
valid <- (stack[i_stack] == delim["close"]) && (i_stack > 0L)
if(valid)
i_stack <- i_stack - 1L
else break
}
}
valid && (i_stack == 0L)
} else NULL
}
x <- as.character(x)
y <- sapply(x, f, delim = delim, max_stack_size = max_stack_size)
unname(y)
}
library(dplyr)
valid_delim(df$Utterance)
#[1] FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
df %>% filter(valid_delim(Utterance))
# id Utterance
#1 2 =[ye::a:h]
#2 7 cos I've [heard] very sketchy stories
``` | 1,488 |
66,830,558 | I just started a new project in django, I run the command 'django-admin startproject + project\_name', and 'python manage.py startapp + app\_name'. Created a project and app.
I also added my new app to the settings:
[settings pic](https://i.stack.imgur.com/aMIpy.png)
After that I tried to create my first module on 'modules.py' file on my app, but when I do it and run the file, it gives me this error message:
[Error message](https://i.stack.imgur.com/LX3n1.png)
The entire error message says:
" django.core.exceptions.ImproperlyConfigured: Requested setting INSTALLED\_APPS, but settings are not configured. You must either define the environment variable DJANGO\_SETTINGS\_MODULE or call settings.configure() before accessing settings. "
I created a few projects before, and never had this problem.
I discovered that if I dont use the 'models.Model' on my class, it does not gives me this error.
[No error message on this case](https://i.stack.imgur.com/v5Dg2.png)
Someone knows what it is about, and why it gives me this error? I didnt change anything on settings, just added the app. | 2021/03/27 | [
"https://Stackoverflow.com/questions/66830558",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/15493450/"
] | You want a `dict: {letter:positions}` , for that a `defaultdict` is well suited
```
from collections import defaultdict
def nb_occurances(word):
dict_occ = {}
positions = defaultdict(list)
for i, c in enumerate(word):
dict_occ[c] = word.count(c)
positions[c].append(i)
return dict_occ, positions
print(nb_occurances("hello"))
# ({'h': 1, 'e': 1, 'l': 2, 'o': 1}, {'h': [0], 'e': [1], 'l': [2, 3], 'o': [4]}))
```
Know that `collections.Counter` do the job of `dict_occ`
```
from collections import Counter
dict_occ = Counter(word) # {'h': 1, 'e': 1, 'l': 2, 'o': 1}
``` | Did you consider using the `collections.Counter` class?
```py
from collections import Counter
def nb_occurances(str):
ctr = Counter(str)
for ch, cnt in ctr.items():
print(ch, '->', cnt)
nb_occurances('ababccab')
```
Prints:
```
a -> 3
b -> 3
c -> 2
``` | 1,490 |
43,573,582 | I'm trying to make a graph with a pretty massive key:
```
my_plot = degrees.plot(kind='bar',stacked=True,title="% of Degrees by Field",fontsize=20,figsize=(24, 16))
my_plot.set_xlabel("Institution", fontsize=20)
my_plot.set_ylabel("% of Degrees by Field", fontsize=20)
my_plot.legend(["Agriculture, Agriculture Operations, and Related Sciences", "Architecture and Related Services",
"Area, Ethnic, Cultural, Gender, and Group Studies", "Biological and Biomedical Sciences",
"Business, Management, Marketing, and Related Support Services",
"Communication, Journalism, and Related Programs",
"Communications Technologies/Technicians and Support Services",
"Computer and Information Sciences and Support Services", "Construction Trades", "Education",
"Engineering Technologies and Engineering-Related Fields", "Engineering",
"English Language and Literature/Letters", "Family and Consumer Sciences/Human Sciences",
"Foreign Languages, Literatures, and Linguistics", "Health Professions and Related Programs", "History",
"Homeland Security, Law Enforcement, Firefighting and Related Protective Services",
"Legal Professions and Studies", "Liberal Arts and Sciences, General Studies and Humanities",
"Library Science", "Mathematics and Statistics", "Mechanic and Repair Technologies/Technicians",
"Military Technologies and Applied Sciences", "Multi/Interdisciplinary Studies",
"Natural Resources and Conservation", "Parks, Recreation, Leisure, and Fitness Studies",
"Personal and Culinary Services", "Philosophy and Religious Studies", "Physical Sciences",
"Precision Production", "Psychology", "Public Administration and Social Service Professions",
"Science Technologies/Technicians", "Social Sciences", "Theology and Religious Vocations",
"Transportation and Materials Moving", "Visual and Performing Arts"])
plt.savefig("Degrees by Field.png")
```
and I'm trying to edit the key so that it's on the right side of the entire graph as listed [here](http://matplotlib.org/users/legend_guide.html).
I'm trying to add this code
```
#Place a legend to the right of this smaller subplot.
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
```
and I get errors when I add that line to my lengthy code. Can someone tell me where to put this so my legend is on the right?
THANK YOU!
**Edited to add**
Ran the code with location specific language:
```
my_plot = degrees.plot(kind='bar',stacked=True,title="% of Degrees by Field",fontsize=20,figsize=(24, 16))
my_plot.set_xlabel("Institution", fontsize=20)
my_plot.set_ylabel("% of Degrees by Field", fontsize=20)
my_plot.legend(["Agriculture, Agriculture Operations, and Related Sciences", "Architecture and Related Services",
"Area, Ethnic, Cultural, Gender, and Group Studies", "Biological and Biomedical Sciences",
"Business, Management, Marketing, and Related Support Services",
"Communication, Journalism, and Related Programs",
"Communications Technologies/Technicians and Support Services",
"Computer and Information Sciences and Support Services", "Construction Trades", "Education",
"Engineering Technologies and Engineering-Related Fields", "Engineering",
"English Language and Literature/Letters", "Family and Consumer Sciences/Human Sciences",
"Foreign Languages, Literatures, and Linguistics", "Health Professions and Related Programs", "History",
"Homeland Security, Law Enforcement, Firefighting and Related Protective Services",
"Legal Professions and Studies", "Liberal Arts and Sciences, General Studies and Humanities",
"Library Science", "Mathematics and Statistics", "Mechanic and Repair Technologies/Technicians",
"Military Technologies and Applied Sciences", "Multi/Interdisciplinary Studies",
"Natural Resources and Conservation", "Parks, Recreation, Leisure, and Fitness Studies",
"Personal and Culinary Services", "Philosophy and Religious Studies", "Physical Sciences",
"Precision Production", "Psychology", "Public Administration and Social Service Professions",
"Science Technologies/Technicians", "Social Sciences", "Theology and Religious Vocations",
"Transportation and Materials Moving", "Visual and Performing Arts"]plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.))
plt.savefig("Degrees by Field.png")
```
And then got this warning/error:
```
File "<ipython-input-101-9066269a61aa>", line 21
"Transportation and Materials Moving", "Visual and Performing Arts"]plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.))
^
SyntaxError: invalid syntax
``` | 2017/04/23 | [
"https://Stackoverflow.com/questions/43573582",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7907634/"
] | >
> but as a2[][] is locally declared then its elements should not be initialosed by deaflt
>
>
>
There's a big difference between a *variable* and an array entry.
`b` not being initialized is a common coding error, so the compiler calls it out.
But `a2` is initialized, and the contents of an array are set to the default value for the array's element type when the array is allocated — `int[]` (or `a2[0]`) and `int` (for `a2[0][0]`), in your case. | ```
public class HelloWorld{
public static void main(String []args){
System.out.println("sampleArray[0] is ");
int sampleArray[] = new int[7];
System.out.println(sampleArray[0]);
}
}
Output
sampleArray[0] is
0
``` | 1,494 |
54,445,338 | A python list consist of a number of items that is equally divided by 3.
The list looks like this:
```
the_list = ['ab','cd','e','fgh','i', 'jklm']
```
I want to merge 3 items at the time for the entire list. How should I do that? (the list could have any number of items as long as the number of items can be divided by 3)
```
expected_output = ['abcde', 'fghijklm']
``` | 2019/01/30 | [
"https://Stackoverflow.com/questions/54445338",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2466763/"
] | You can slice the list while iterating an index over the length of the list with a step of 3 in a list comprehension:
```
[''.join(the_list[i:i + 3]) for i in range(0, len(the_list), 3)]
```
You can also create an iterator from the list and use `zip` with `itertools.repeat` to group 3 items at a time:
```
from itertools import repeat
i = iter(the_list)
[''.join(t) for t in zip(*repeat(i, 3))]
```
Both of the above return:
```
['abcde', 'fghijklm']
``` | Here's one way using a list comprehension and `range`:
```
output = [''.join(the_list[i:i+3]) for i in range(0, len(the_list), 3)]
``` | 1,495 |
9,701,227 | I don't understand the answers for a [similar question.](https://stackoverflow.com/questions/9359677/why-python-reduce-skip-over-the-none-element)
It is clear that this should return `True`
```
l = [1,1,1]
reduce(lambda x,y: x== y, l)
```
However, how do you explain this retuns `False` (when `None==None` is `True`)
```
l = [None,None,None]
reduce(lambda x,y: x== y, l)
``` | 2012/03/14 | [
"https://Stackoverflow.com/questions/9701227",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/94363/"
] | Because
```
1 == True # 1 == (1 == 1)
```
is `True`, but
```
None == True # None == (None == None)
```
is `False` (and `None == False` is `False` as well, so once you got `False`, it stays `False`).
That's how `reduce` works: It passes each element and the **result** of the previous evaluation to the callback. And by that it *reduces* a sequence of values to one value. | Your second example return `False` because the first time `None == None` gives `True`, but `True == None` gives `False`.
Take a look at the [`reduce` doc](http://docs.python.org/library/functions.html#reduce) to see how it works.
Also note that "comparisons to singletons like `None` should always be done with `is` or `is not`, **never the equality operators**." - [[PEP8]](http://www.python.org/dev/peps/pep-0008/) | 1,496 |
56,966,429 | I want to do this
```py
from some_cool_library import fancy_calculation
arr = [1,2,3,4,5]
for i, item in enumerate(arr):
the_rest = arr[:i] + arr[i+1:]
print(item, fancy_calculation(the_rest))
[Expected output:] # some fancy output from the fancy_calculation
12.13452134
2416245.4315432
542.343152
15150.1152
10.1591
```
But I wonder if there is a more pythonic way or existing library to get pairs as shown above.
The problem with the current implementation is that we need about O(n) more memory for the `the_rest` variable. Is there any way on how we can do this without additional memory allocation?
```py
for item, the_rest in some_cool_function(arr):
print(item, fancy_calculation(the_rest))
``` | 2019/07/10 | [
"https://Stackoverflow.com/questions/56966429",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8809992/"
] | Try This-
```
SELECT A.smanTeam,
A.TotalTarget,
B.TotalSales,
B.TotalSales*100/A.TotalTarget TotalPercentage
FROM
(
SELECT smanTeam,SUM(Target) TotalTarget
FROM Sman S
INNER JOIN SalesTarget ST ON S.smanID = ST.smanID
GROUP BY smanTeam
)A
LEFT JOIN
(
SELECT smanTeam, SUM(Amount) TotalSales
FROM Sman S
INNER JOIN Sales SA ON S.smanID = SA.smanID
GROUP BY smanTeam
)B ON A.smanTeam = B.smanTeam
``` | Try below query:
```
select smanTeam, sum(Target) TotalTarget, sum(Amount) TotalSales , sum(Target)/sum(Amount) TotalPercentage from (
select smanTeam, Target, Amount from Sman sm
join
(select smanID, sum(Target) Target from SalesTarget group by smanID) st
on sm.smanID = st.smanID
join
(select smanID, sum(Amount) Amount from Sales group by smanID) s
on sm.smanID = s.smanID
) a group by smanTeam
``` | 1,501 |
48,435,417 | If I have python code that requires indenting (`for`, `with`, function, etc), will a single line comment end potentially the context of the construct if I place it incorrectly? For example, presuming `step1`, `step2` and `step3` are functions already defined, will:
```
def myFunc():
step1()
# step2()
step3()
```
(unintentionally) reduce the scope of `myFunc()` so that it only contains `step1`? If I only want to remove `step2` from the 3-step sequence, must I place the `#` at the same level of indentation as the statements within the scope of the construct? All the code I have seen so far suggests this is a requirement, but it might just be a coding habit. | 2018/01/25 | [
"https://Stackoverflow.com/questions/48435417",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1099237/"
] | Try it out:
```
def myFunc():
print(1)
# print(2)
print(3)
myFunc()
```
which outputs:
```
1
3
```
So yeah, the answer is "Line comments don't need to match indentation". That said, [PEP8 really prefers that they do, just for readability](https://www.python.org/dev/peps/pep-0008/#block-comments). | It doesn't really matter where you place the `#`
Either in the first identation level or close to the instruction, everything underneath it is going to be executed.
I suggest you to play with the code below and You'll figure it out yourself.
```
a = 1
b = 10
c = 100
d = 1000
if (a == 1):
result = a+b
# result = result + c
result = result + d
print(result)
``` | 1,502 |
32,270,272 | I need to get a particular attribute value from a tag whose inner word matches my query word. For example, consider a target html-
```html
<span data-attr="something" attr1="" ><i>other_word</i></span>
<span data-attr="required" attr1="" ><i>word_to_match</i></span>
<span data-attr="something1" attr1="" ><i>some_other_word</i></span>
```
Now, I need to get the '**required**' value from the **data-attr** attribute for the tag where the inner word(in this case **word\_to\_match**) matches my query word.
The problem is that the regexes that I'm writing are returning the other spans as well. I haven't been able to make a non greedy regex in this case.
If it helps, I'm doing this in python and kindly no "don't use regex here" solutions. | 2015/08/28 | [
"https://Stackoverflow.com/questions/32270272",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2636802/"
] | You're not too far off. You need to iterate the words in each line and check if they are in the dictionary. Also, you need to call `read_words`, otherwise `ret` doesn't exist in the `for` loop.
```
dictionary = read_words(dictionary)
for paper in library:
file = os.path.join(path, paper)
text = open(file, "r")
hit_count = 0
for line in text:
for word in line:
if word in dictionary:
hit_count = hit_count + 1
print >> output, paper + "|" + line,
``` | If you want to check if any element in the list are in the line
**change this from this :**
```
if re.match("(.*)(ret[])(.*)", line):
```
**To this :**
```
if any(word in line for word in ret)
``` | 1,506 |
34,048,316 | I have a sample file which looks like
```
emp_id(int),name(string),age(int)
1,hasa,34
2,dafa,45
3,fasa,12
8f,123Rag,12
8,fafl,12
```
Requirement: Column data types are specified as strings and integers. Emp\_id should be a integer not string. these conditions ll be the same for name and age columns.
**My output should look like#**
```
Actual column Emp_id type is INT but string was found at the position 4, value is 8f
Actual column name type is STRING but numbers were found at the position 4, value is 123Rag
```
continues..
here is my code
Shell script
```
read input
if [ $input -eq $input 2>/dev/null ]
then
echo "$input is an integer"
else
echo "$input is not an integer"
fi
```
In python, i was trying with Isinstance(obj,type) but it is not serving the purpose.
can any guide me in this regard, Any shell/python/perl script help would be appreciated! | 2015/12/02 | [
"https://Stackoverflow.com/questions/34048316",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1696853/"
] | Here is an awk-solution:
```
awk -F"," 'NR==1{for(i=1; i <= NF; i++){
split($i,a,"(");
name[i]=a[1];
type[i] = ($i ~ "int" ? "INT" : "String")}next}
{for(i=1; i <= NF; i++){
if($i != int($i) && type[i] == "INT"){error[i][NR] = $i}
if($i ~ /[0-9]+/ && type[i] == "String"){error[i][NR] = $i}
}}
END{for(i in error){
for(key in error[i]){
print "Actual column "name[i]" type is "type[i]\
" but string was found at the position "key-1\
", value is "error[i][key]}}}' inputFile
```
The output is - as desired:
```
Actual column emp_id type is INT but string was found at the position 4, value is 8f
Actual column name type is String but string was found at the position 4, value is 123Rag
```
However, in my opinion `123Rag` is a string and should not be indicated as an incorrect entry in the second column. | With `perl` I would tackle it like this:
* Define some regex patterns that match/don't match the string content.
* pick out the header row - separate it into names and types. (Optionally reporting if a type doesn't match).
* iterate your fields, matching by column, figuring out type and applying the regex to validate
Something like:
```
#!/usr/bin/env perl
use strict;
use warnings;
use Data::Dumper;
#define regex to apply for a given data type
my %pattern_for = (
int => qr/^\d+$/,
string => qr/^[A-Z]+$/i,
);
print Dumper \%pattern_for;
#read the first line.
# <> is a magic filehandle, that reads files specified as arguments
# or piped input - like grep/sed do.
my $header_row = <>;
#extract just the names, in order.
my @headers = $header_row =~ m/(\w+)\(/g;
#create a type lookup for the named headers.
my %type_for = $header_row =~ m|(\w+)\((\w+)\)|g;
print Dumper \@headers;
print Dumper \%type_for;
#iterate input again
while (<>) {
#remove trailing linefeed
chomp;
#parse incoming data into named fields based on ordering.
my %fields;
@fields{@headers} = split /,/;
#print for diag
print Dumper \%fields;
#iterate the headers, applying the looked up 'type' regex
foreach my $field_name (@headers) {
if ( $fields{$field_name} =~ m/$pattern_for{$type_for{$field_name}}/ ) {
print
"$field_name => $fields{$field_name} is valid, $type_for{$field_name} matching $pattern_for{$type_for{$field_name}}\n";
}
else {
print "$field_name $fields{$field_name} not valid $type_for{$field_name} matching $pattern_for{$type_for{$field_name}}\n";
}
}
}
```
This gives for your input (just the invalids for brevity):
```
name 123Rag not valid string matching (?^i:^[A-Z]+$)
emp_id 8f not valid int matching (?^:^\d+$)
```
Note - it only supports 'simple' CSV style (no nested commas or quotes) but could easily be adapted to use the `Text::CSV` module. | 1,507 |
71,448,461 | I was writing a python code in VS Code and somehow it's not detecting the input() function like it should.
Suppose, the code is as simple as
```
def main():
x= int ( input() )
print(x)
if __name__ == "__main__":
main()
```
even then, for some reason it is throwing error and I cannot figure out why.
The error being-
[](https://i.stack.imgur.com/gkMHA.png)
P.S. 1)I am using Python 3.10 2) I tried removing the int() and it still doesn't work. | 2022/03/12 | [
"https://Stackoverflow.com/questions/71448461",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/16979277/"
] | The traceback shows you where to look. It's actually the `int` function throwing a `ValueError`. It looks as if you're feeding it a filepath whereas it it's expecting a number.
You could add a check to repeat the input if incorrect like so:
```py
user_input = None
while not user_input:
raw_input = input("Put in a number: ")
try:
user_input = int(raw_input)
except ValueError:
continue
print(f"Number is: {user_input}")
``` | it's working!!!
see my example that says why you don't understand this:
```py
>>> x1 = input('enter a number: ')
enter a number: 10
>>> x1
'10'
>>> x2 = int(x1)
>>> x2
10
>>> x1 = input() # no text
100
>>> # it takes
>>> x1
'100'
>>> # but how you try?
>>> x1 = input()
NOT-NUMBER OR EMPTY-TEXT
>>> x2 = int(x1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'IS-NOT-NUMBER OR EMPTY TEXT'
>>>
```
I thing this is enough. | 1,508 |
37,124,504 | All,
I wrote a small python program to create a file which is used as an input file to run an external program called srce3d. Here it is:
```
fin = open('eff.pwr.template','r')
fout = open('eff.pwr','wr')
for line in fin:
if 'li' in line:
fout.write( line.replace('-2.000000E+00', `-15.0`) )
else:
fout.write(line)
fin.close
fout.close
os.chmod('eff.pwr',0744)
# call srce3d
os.system("srce3d -bat -pwr eff.pwr >& junk.out")
```
This does not work. The input file gets written properly but srce3d complains of an end of file during read. The os.system command works fine with a pre-existing file, without any need to open that file.
Thanks for your help | 2016/05/09 | [
"https://Stackoverflow.com/questions/37124504",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5590629/"
] | Firstly you are missing the function calls for close.
```
fin.close() ## the round braces () were missing.
fout.close()
```
A better way to do the same is using contexts.
```
with open('eff.pwr.template','r') as fin, open('eff.pwr','wr') as fout:
## do all processing here
``` | You didn't actually close the file – you have to *call* `file.close`. So,
```
fin.close
fout.close
```
should be
```
fin.close()
fout.close()
``` | 1,510 |
29,411,952 | I need to delete all the rows in a csv file which have more than a certain number of columns.
This happens because sometimes the code, which generates the csv file, skips some values and prints the following on the same line.
Example: Consider the following file to parse. I want to remove all the rows which have more than 3 columns (i.e. the columns of the header):
```
timestamp,header2,header3
1,1val2,1val3
2,2val2,2val3
3,4,4val2,4val3
5val1,5val2,5val3
6,6val2,6val3
```
The output file I would like to have is:
```
timestamp,header2,header3
1,1val2,1val3
2,2val2,2val3
5val1,5val2,5val3
6,6val2,6val3
```
I don't care if the row with timestamp 4 is missing.
I would prefer a solution in bash or perhaps using awk, rather than a python one, so that I can learn how to use it. | 2015/04/02 | [
"https://Stackoverflow.com/questions/29411952",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3014331/"
] | This can be done straight forward with `awk`:
```
awk -F, 'NF<=3' file
```
This uses the `awk` variable `NF` that holds the number of fields in the current line. Since we have set the field separator to the comma (with `-F,` or, equivalent, `-v FS=","`), then it is just a matter of checking when the number of fields is not higher than 3. This is done with `NF<=3`: when this is true, the line will be printed automatically.
### Test
```
$ awk -F, 'NF<=3' a
timestamp,header2,header3
1,1val2,1val3
2,2val2,2val3
5val1,5val2,5val3
6,6val2,6val3
``` | Try the following (do not omit to replace your file path and your max column):
```bash
#! /bin/bash
filepath=test.csv
max_columns=3
for line in $(cat $filepath);
do
count=$(echo "$line" | grep -o "," | wc -l)
if [ $(($count + 1)) -le $max_columns ]
then
echo $line
fi
done
```
Copy this in a `.sh` file (*cropper.sh* for example), make it executable `chmod +x cropper.sh` and run `./cropper.sh`).
This will output only the valid lines. You can then catch the result in a file this way:
`./cropper.sh > result.txt` | 1,511 |
47,635,838 | I'm trying to use the LinearSVC of sklearn and export the decision tree to a .dot file. I can fit the classifier with sample data and then use it on some test data but the export to the .dot file gives a NotFittedError.
```
data = pd.read_csv("census-income-data.data", skipinitialspace=True, usecols=list(range(0, 41)))
data = data.fillna('Missing value').apply(pp.LabelEncoder().fit_transform)
target = pd.read_csv("census-income-data.data", skipinitialspace=True, usecols=[41])
dataTest = pd.read_csv("census-income-test.test", skipinitialspace=True, usecols=list(range(0, 41)))
dataTest = dataTest.fillna('Missing value').apply(pp.LabelEncoder().fit_transform)
targetTest = pd.read_csv("census-income-test.test", skipinitialspace=True, usecols=[41])
clfSVC = LinearSVC(random_state=0)
clfSVC = clfSVC.fit(data, target.target)
scoreSVC = clfSVC.score(dataTest, targetTest.target)
print(scoreSVC)
tree.export_graphviz(clfSVC, out_file='tree.dot')
```
Here is the output:
```
> Traceback (most recent call last):
File "D:\Documents\Telecom\IA\ai-person-income\project\sklearn_test.py", line 49, in <module>
tree.export_graphviz(clfSVC, out_file='tree.dot')
File "D:\Program Files\WinPython-64bit-3.6.3.0Qt5\python-3.6.3.amd64\lib\site-packages\sklearn\tree\export.py", line 392, in export_graphviz
check_is_fitted(decision_tree, 'tree_')
File "D:\Program Files\WinPython-64bit-3.6.3.0Qt5\python-3.6.3.amd64\lib\site-packages\sklearn\utils\validation.py", line 768, in check_is_fitted
raise NotFittedError(msg % {'name': type(estimator).__name__})
sklearn.exceptions.NotFittedError: This LinearSVC instance is not fitted yet. Call 'fit' with appropriate arguments before using this method.
```
What am I missing ? | 2017/12/04 | [
"https://Stackoverflow.com/questions/47635838",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6534294/"
] | You are using a [function](http://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html#sklearn-tree-export-graphviz) to plot a decision-tree. Look at the first argument: *decision\_tree*, like an object of [this](http://scikit-learn.org/stable/modules/tree.html).
A SVM is not a decision-tree! It isn't any kind of tree and you can't use this function and it also makes no sense in theory.
The error itself is based on [this code](https://github.com/scikit-learn/scikit-learn/blob/a24c8b46/sklearn/tree/export.py#L392):
```
check_is_fitted(decision_tree, 'tree_')
```
where the internal tree of a decision-tree object is queried. This does not exists for SVMs. | In `sklearn.tree.export_graphviz`, the first parameter is a fitted decision tree.
You give a fitted estimator, but not a decision tree.
**Indeed, `LinearSVC` is not a decision tree.**
Try with `sklearn.tree.DecisionTreeClassifier` instead of `sklearn.svm.LinearSVC`. | 1,512 |
47,443,434 | I'm new to python/data science in general, trying to understand why the below isn't working:
```
import pandas as pd
url = 'https://s3.amazonaws.com/nyc-tlc/trip+data/fhv_tripdata_2017-06.csv'
trip_df = []
for chunk in pd.read_csv(url, chunksize=1000, nrows=10000):
trip_df.append(chunk)
trip_df = pd.concat(trip_df, axis='rows')
```
It's returning a MemoryError, but I was under the impression that loading the file in chunks was a workaround for that. I'd prefer not to save the csv to my hard drive, plus I'm not entirely sure if that would help.
My computer's pretty limited, only 4GB of RAM (2.9 usable). I imagine that's a factor here, but if importing the whole file isn't an option, how would I just get part of it, say 5,000 rows? | 2017/11/22 | [
"https://Stackoverflow.com/questions/47443434",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8992936/"
] | Try this:
```
reader = pd.read_csv(url, chunksize=1000, nrows=10000)
df = pd.concat([x for x in reader], ignore_index=True)
```
>
> how would I just get part of it, say 5,000 rows?
>
>
>
```
df = pd.read_csv(url, nrows=5000)
``` | Just get the 5000 rows in the command line with
```
wget -q -O - https://s3.amazonaws.com/nyc-tlc/trip+data/fhv_tripdata_2017-06.csv | head -n 5000 > tmp.csv
```
and then proceed with tmp.csv | 1,513 |
10,931,150 | php has the [`strtr`](http://php.net/manual/en/function.strtr.php) function:
```
strtr('aa-bb-cc', array('aa' => 'bbz', 'bb' => 'x', 'cc' => 'y'));
# bbz-x-y
```
It replaces dictionary keys in a string with corresponding values and (important) doesn't replace already replaced strings. A naive attempt to write the same in python:
```
def strtr(strng, replace):
for s, r in replace.items():
strng = strng.replace(s, r)
return strng
strtr('aa-bb-cc', {'aa': 'bbz', 'bb': 'x', 'cc': 'y'})
```
returns `xz-x-y` which is not we want (`bb` got replaced again). How to change the above function so that it behaves like its php counterpart?
(I would prefer an answer without regular expressions, if possible).
Upd: some great answers here. I timed them and found that for short strings Gumbo's version appears to be the fastest, on longer strings the winner is the `re` solution:
```
# 'aa-bb-cc'
0.0258 strtr_thg
0.0274 strtr_gumbo
0.0447 strtr_kojiro
0.0701 strtr_aix
# 'aa-bb-cc'*10
0.1474 strtr_aix
0.2261 strtr_thg
0.2366 strtr_gumbo
0.3226 strtr_kojiro
```
My own version (which is slightly optimized Gumbo's):
```
def strtr(strng, replace):
buf, i = [], 0
while i < len(strng):
for s, r in replace.items():
if strng[i:len(s)+i] == s:
buf.append(r)
i += len(s)
break
else:
buf.append(strng[i])
i += 1
return ''.join(buf)
```
Complete codes and timings: <https://gist.github.com/2889181> | 2012/06/07 | [
"https://Stackoverflow.com/questions/10931150",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/989121/"
] | Here is a naive algorithm:
Use an index to walk the original string character by character and check for each index whether one of the search strings is equal to the string from the current index on. If a match is found, push the replacement in a buffer and proceed the index by the length of the matched string. If no match is found, proceed the index by one. At the end, concatenate the strings in the buffer to a single string.
```
def strtr(strng, replace):
buffer = []
i, n = 0, len(strng)
while i < n:
match = False
for s, r in replace.items():
if strng[i:len(s)+i] == s:
buffer.append(r)
i = i + len(s)
match = True
break
if not match:
buffer.append(strng[i])
i = i + 1
return ''.join(buffer)
``` | [`str.translate`](http://docs.python.org/library/stdtypes.html#str.translate) is the equivalent, but can only map to single characters. | 1,515 |
36,900,272 | Being a complete begginer in python, I decided to install the python interpreter 3.4.4, and also PyDev plugin for eclipse IDE. I am also using windows 10.
I have encountered a problem regarding certain imports, namely : `from PIL import Image, ImageTk`, which is apparently an unresolved import.
I have looked at certain questions which were similar to my situation, but most of them gave a solution like installing packaged from the linux apt-get. Here are some topics I visited :
1. [Uninstalling and reinstalling Pillow and pip,](https://stackoverflow.com/questions/26505958/why-cant-python-import-image-from-pil)
2. [Installing pillow-imaging-tk on Ubuntu,](https://stackoverflow.com/questions/22788454/importerror-no-module-named-imagingtk/22788542#22788542)
3. [This topic which left me very confused,](https://stackoverflow.com/questions/8209819/unresolved-import-error-with-pydev-while-using-from-import-as)
4. [This one seemed helpful, but is on Unix OS again](https://stackoverflow.com/questions/6171749/how-do-i-add-pil-to-pydev-in-eclipse-so-i-could-import-it-and-use-it-in-my-proj)
So please, could someone explain to me why I am seeing this error, and how could I correct it if I absolutely want to use Eclipse, Pydev, windows 10 and Python 3. | 2016/04/27 | [
"https://Stackoverflow.com/questions/36900272",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4375983/"
] | Found the solution, here's what I did:
1. Set the PYTHONPATH [like it is shown in this article](https://stackoverflow.com/questions/3701646/how-to-add-to-the-pythonpath-in-windows-7/4855685#4855685), make sure python.exe is accessible via cmd,
2. Via cmd, type `pip install pillow`. Alternatively, you can enter the same command from Windows+R,
3. (Not sure if relevant step) Via eclipse, `Windows->Preferences->PyDev->PythonInterpreter`remove your interpreter to re-add it,
4. Restart eclipse. | For Python import problems in PyDev, the project web site has a page on [interpreter configuration](http://www.pydev.org/manual_101_interpreter.html) that is a good place to start. I recently had a similar problem that I solved by adding a module to the forced builtins tab. | 1,522 |
21,845,390 | hello friends i just started to use GitHub and i just want to know it is possible to download github repository to my local computer through by Using GitHub Api or Api libraries (ie. python library " pygithub3" for Github api) | 2014/02/18 | [
"https://Stackoverflow.com/questions/21845390",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3321823/"
] | Using [`github3.py`](http://github3py.rtfd.org/) you can clone all of your repositories (including forks and private repositories) by doing:
```
import github3
import subprocess
g = github3.login('username', 'password')
for repo in g.iter_repos(type='all'):
subprocess.call(['git', 'clone', repo.clone_url])
```
If you're looking to clone an arbitrary repository you can do this:
```
import github3
import subprocess
r = github3.repository('owner', 'repository_name')
subprocess.call(['git', 'clone', repo.clone_url])
```
pygithub3 has not been actively developed in over a year. I would advise not use it since it is unmaintained and missing a large number of the additions GitHub has made to their API since then. | As illustrated in [this Gist](https://gist.github.com/jharjono/1159239), the simplest solution is simply to call git clone.
```python
#!/usr/bin/env python
# Script to clone all the github repos that a user is watching
import requests
import json
import subprocess
# Grab all the URLs of the watched repo
user = 'jharjono'
r = requests.get("http://github.com/api/users/%s/subscriptions" % (user))
repos = json.loads(r.content)
urls = [repo['url'] for repo in repos['repositories']]
# Clone them all
for url in urls:
cmd = 'git clone ' + url
pipe = subprocess.Popen(cmd, shell=True)
pipe.wait()
print "Finished cloning %d watched repos!" % (len(urls))
```
[This gist](https://gist.github.com/decause/5777114#file-list-all-repos-py), which uses **[pygithub3](http://pygithub3.readthedocs.org/en/latest/)**, will call git clone on the repos it finds:
```python
#!/usr/bin/env python
import pygithub3
gh = None
def gather_clone_urls(organization, no_forks=True):
all_repos = gh.repos.list(user=organization).all()
for repo in all_repos:
# Don't print the urls for repos that are forks.
if no_forks and repo.fork:
continue
yield repo.clone_url
if __name__ == '__main__':
gh = pygithub3.Github()
clone_urls = gather_clone_urls("gittip")
for url in clone_urls:
print url
``` | 1,523 |
36,238,155 | I have a script in python that consists of multiple list of functions, and at every end of a list I want to put a back function that will let me return to the beginning of the script and choose another list. for example:
```
list = ("1. List of all users",
"2. List of all groups",
"3. Reset password",
"4. Create new user",
"5. Create new group",
"6. List all kernel drivers",
"7. List all mounts",
"8. Mount a folder",
"9. Exit")
for i in list:
print(i)
```
And if I choose 1 another list opens:
```
list = "1) Show user Groups \n2) Show user ID \n3) Show user aliases \n4) Add new aliases \n5) Change password \n6) Back"
print
print list
```
A more specific example. | 2016/03/26 | [
"https://Stackoverflow.com/questions/36238155",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5974999/"
] | Maybe your EditTexts are not initialized, you need something like `quantity1 = (EditText) findViewById(R.id.YOUR_EDIT_TEXT_ID)` for both. | Check what you are passing...check my example.
```
package general;
public class TestNumberFormat {
public static void main(String[] args){
String addquantity = "40";
String subquantity = "30";
int final_ = Integer.parseInt(addquantity) - Integer.parseInt(subquantity);
System.out.println("PRINT :" + final_);
String addquantity1 = "D40";
String subquantity1 = "D30";
int final1_ = Integer.parseInt(addquantity1) - Integer.parseInt(subquantity1);
System.out.println("PRINT :" + final1_);
}
}
```
Output:
PRINT :10
```
Exception in thread "main" java.lang.NumberFormatException: For input string: "D40"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.parseInt(Integer.java:615)
at general.TestNumberFormat.main(TestNumberFormat.java:13)
``` | 1,524 |
66,602,480 | I am learning fastapi, and I am starting a uvicorn server on localhost. Whenever there is an error/exception, I am not getting the traceback.
All I am getting is : `INFO: 127.0.0.1:56914 - "POST /create/user/ HTTP/1.1" 500 Internal Server Error`
So, It is difficult to debug, I am trying out logging module of python
```
import logging
log = logging.getLogger("uvicorn")
log.setLevel(logging.DEBUG)
```
I have also tried starting uvicorn with debug parameter
```
if __name__ == "__main__":
dev = 1
print("printing")
if dev == 1:
uvicorn.run('main:app', host="127.0.0.1", port=5000, log_level="info", reload=True, debug=True)
if dev == 2:
uvicorn.run('main:app', host="127.0.0.1", port=5000, log_level="info", workers=2)
still the same problem persists. I am in development phase and I need to error traceback,please guide.
``` | 2021/03/12 | [
"https://Stackoverflow.com/questions/66602480",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14354318/"
] | Solution / Fix
==============
Now, when you execute uvicorn by the in-Python command `uvicorn.run(app)`, this is your next move:
take the ucivorn default logging config and add the handler from your application to it:
```py
config = {}
# this is default (site-packages\uvicorn\main.py)
config['log_config'] = {
'version': 1, 'disable_existing_loggers': True,
'formatters': {'default': {'()': 'uvicorn.logging.DefaultFormatter', 'fmt': '%(levelprefix)s %(message)s', 'use_colors': None},
'access': {'()': 'uvicorn.logging.AccessFormatter', 'fmt': '%(levelprefix)s %(client_addr)s - "%(request_line)s" %(status_code)s'}},
'handlers': {'default': {'formatter': 'default', 'class': 'logging.StreamHandler', 'stream': 'ext://sys.stderr'},
'access': {'formatter': 'access', 'class': 'logging.StreamHandler', 'stream': 'ext://sys.stdout'}},
'loggers': {'uvicorn': {'handlers': ['default'], 'level': 'INFO'},
'uvicorn.error': {'level': 'INFO', 'handlers': ['default'], 'propagate': True},
'uvicorn.access': {'handlers': ['access'], 'level': 'INFO', 'propagate': False},
},
}
# add your handler to it (in my case, I'm working with quart, but you can do this with Flask etc. as well, they're all the same)
config['log_config']['loggers']['quart'] = {'handlers': ['default'], 'level': 'INFO'}
```
this will keep the logger from quart/Flask/etc. enabled when uvicorn starts. Alternatively, you can set `disable_existing_loggers` to False. But this will keep all loggers enabled and then you will probable get more messages than you wish.
Finally, pass the config to uvicorn:
```
uvicorn.run(app, **config)
```
Explanation
===========
When uvicorn's logging config has set `disable_existing_loggers` to True, all other loggers will be disabled. This also means that the logger quart and Flask use (which prints the traceback) get disabled. You can either set the config to NOT disable other loggers, or re-add them to the config so uvicorn doesn't disable them in the first place. | For "500 Internal Server Error" occurring during a post request, if you invoke FastAPI in debug mode:
```
app = FastAPI(debug=True)
```
Retry the request with Chrome dev tools Network tab open. When you see the failing request show up (note - my route url was '/rule' here):
[](https://i.stack.imgur.com/eHfvi.png)
Click on it, and you'll see the Traceback text in the Fetch/XHR / Response tab window.
[](https://i.stack.imgur.com/6ivcF.png)
You can quickly verify it by inserting "assert False" in your post handler. | 1,526 |
35,744,408 | I have an astrophysic project by using data file. It's a csv data file.
I'm using the following code in Python :
```
#!/usr/bin/python
# coding: utf-8
import numpy as np
# Fichier contenant le champ 169 #
file = '/astromaster/home/xxx/Bureau/Stage/Champs/Field_169/Field169_combined_final_roughcal.csv'
###############################
# Lecture du fichier field169 #
###############################
field169 = np.loadtxt(fname = file,
dtype = [('ID',object),
('RA','f10'),
('DEC','f10'),
('NDET','i2'),
('DEPTHFAG','i2'),
('SEPINDX',object),
('SEPFINDX',object),
('U','f10'),
('UERR','f10'),
('G','f10'),
('GERR','f10'),
('R','f10'),
('RERR','f10'),
('I','f10'),
('IERR','f10'),
('Z','f10'),
('ZERR','f10'),
('CHI','f10'),
('SHARP','f10'),
('FLAG','i3'),
('PROB','f10'),
('EBV','f10')],
delimiter=",")
print field169
```
But, when I print this array, I just have half of my array .. and I don't understand why ?
Thanks for your answers :) | 2016/03/02 | [
"https://Stackoverflow.com/questions/35744408",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] | The [recommendation](https://docs.openshift.org/latest/creating_images/guidelines.html#openshift-specific-guidelines) of Red Hat is to make files group owned by GID 0 - the user in the container is always in the root group. You won't be able to chown, but you can selectively expose which files to write to.
A second option:
*In order to allow images that use either named users or the root (0) user to build in OpenShift, you can add the project’s builder service account (system:serviceaccount::builder) to the privileged security context constraint (SCC). Alternatively, you can allow all images to run as any user.* | Can you see the logs using
```
kubectl logs <podname> -p
```
This should give you the errors why the pod failed. | 1,527 |
62,056,688 | ```
eleUserMessage = driver.find_element_by_id("xxxxxxx")
eleUserMessage.send_keys(email)
```
Im trying to use selenium with python to auto fill out a form and fill in my details. So far I have read in my info from a .txt file and stored them in variables for easy reference. When I Find the element and try to fill it out with send\_keys, after each send\_keys line, the form highlights the other fields that aren't filled in and says I need to fill them in before I submit. My code to submit the info is way after this code segment.
Why does send\_keys try to submit the form or even send the enter key when I didn't tell it to? and how do I stop this from happening?
The main issue that this is causing is that the element ids change when they are highlighted in red since they are required fields. I need to get around that somehow. Please let me know what I can do. | 2020/05/28 | [
"https://Stackoverflow.com/questions/62056688",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13631666/"
] | Because you are storing your details in a text file, it is likely that when you create the email variable there is a newline at the end of the string as this is how text files work. This would explain why the form gets submitted because it is the equivalent of typing the email followed by the enter key. You can try to fix this by using
```py
eleUserMessage.send_keys(email.rstrip())
```
rstrip() is a builtin function and it by default, with no parameters, strips the whitespace and newlines from the right side. | if you just want to fill out a form ,then submit the finished form.
you can try :
```
eleUserMessage = driver.find_element_by_xpath("//select[@name='name']")
all_options = eleUserMessage.find_elements_by_tag_name("option")
for option in all_options:
print("Value is: %s" % option.get_attribute("value"))
option.click()
eleUserMessage.send_keys(email)
``` | 1,532 |
57,275,797 | This question may seem very basic, however, I would like to improve the code I have written. I have a function that will need either 2 or 3 parameters, depending on some other conditions. I'm checking the length and passing either 2 or 3 with and if statement (see code). I'm sure there must be a better and compact way to re-write in one line/sentence instead of using IIFs. Sorry i'm fairly new to python.
```py
dist = distr.gum
# ... or: dist = distr.gev
# parFitHist has length 2 for distr.gum or 3 for distr.gev
parFitHist = dist.fit(ppt_hist)
# now I check if
if len(parFitBase) > 2:
# 3 parameters for distr.gev
t_mp = dist.cdf(ppt_fut, parFitFut[0], parFitFut[1], parFitBase[2])
else:
# 2 parameters for distr.gum
t_mp = dist.cdf(ppt_fut, parFitFut[0], parFitFut[1])
``` | 2019/07/30 | [
"https://Stackoverflow.com/questions/57275797",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2255752/"
] | Not sure what data types you have and how your method looks like, but with \*args you can solve that:
```
def cdf(ppt_fut, *params):
print(ppt_fut)
print(params)
```
Then you can call it like that:
```
cdf(1, 2, 3, 4) # -> prints: 1 (2,3,4)
cdf(1, 2, 3) # -> prints: 1 (2,3)
```
The `params` is in this case a tuple with all arguments except the first one. | You can unpack elements of a list into a function call with `*`.
You don't need to know how many items there are in the list to do this. But this means you can introduce errors if the number of items don't match the function arguments. It's therefore a good idea to check your data for some basic sanity as well.
For example:
```
if 1 < len(parFitBase) < 4:
t_mp = dist.cdf(ppt_fut, *parFitFut)
else:
raise ValueError('Array must have length 2 or 3')
```
You can read more about that here: [Unpacking Argument Lists](https://docs.python.org/2/tutorial/controlflow.html#unpacking-argument-lists) | 1,533 |
26,328,648 | [Answered first part, please scroll for second question edit]
Currently coding a web scraper in python.
I have the following example string:
`Columbus Blue Jackets at Buffalo Sabres - 10/09/2014`
I want to split it so that I have [Columbus Blue Jackets, Buffalo Sabres, 10/09/2014]
I read up on regular expressions including a few answers on this site but can't figure out how to format my particular example. The best I could come up with was something like this, although it doesn't work.
`re.split('\w+\s\w\w\s\w+\s\.\s\w+', teams)`
My second try is:
`re.split("\w+\s'at'\s\w+\s'-'\s\w+", teams)`, but I'm not sure if you can even enter exact strings like ['at' and '-'] inside a regex function.
Please let me know where I'm going wrong with the regex function or if there's another way to delimit my particular example in python.
(Also note that the team names can be either 2 or 3 words for each team, eg. `Montreal Canadiens at Buffalo Sabres`)
***EDIT:***
`re.split(r"\s+at\s+|\s+-\s+", teams)` seems to do the trick. However I now have a second problem. Testing it in its own file, this works, but in my program for some reason it doesn`t.
Code:
```
def getTable(url):
currentMatchup = Crawl.setup(url)
teams = currentMatchup.title.string
print(teams)
re.split(r"\s+at\s+|\s+-\s+", teams)
print(teams)
```
The output is:
```
Columbus Blue Jackets at Buffalo Sabres - 10/09/2014
Columbus Blue Jackets at Buffalo Sabres - 10/09/2014
```
Any ideas? | 2014/10/12 | [
"https://Stackoverflow.com/questions/26328648",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2621303/"
] | ```
print re.split(r"\s+at\s+|\s+-\s+",teams)
```
Output:`['Columbus Blue Jackets', 'Buffalo Sabres', '10/09/2014']`
Try this.You can do it in one line.Here `teams` is your string.This will give you desired results.
Edit:
```
def getTable(url):
currentMatchup = Crawl.setup(url)
teams = currentMatchup.title.string
print(teams)
y=re.split(r"\s+at\s+|\s+-\s+", teams)
print(y)
``` | Capture them into groups with lazy dot-match-all repetition.
```
(.*?)\s+at\s+(.*?)\s+-\s+(\d{2}/\d{2}/\d{4})
```
[***Demo***](http://regex101.com/r/lU3wV3/1)
---
```
import re;
match = re.search(r"(.*?)\s+at\s+(.*?)\s+-\s+(\d{2}/\d{2}/\d{4})", "Columbus Blue Jackets at Buffalo Sabres - 10/09/2014")
print match.groups()
# ('Columbus Blue Jackets', 'Buffalo Sabres', '10/09/2014')
``` | 1,535 |
63,557,957 | I am a beginner in python, pycharm and Linux, I want to open an existing Django project. But when I use "python manage.py runserver", I am getting a series of trace-back errors which I am attaching below.
I have installed all the LAMP stack i.e., Linux OS, Apache2 Web server,MariaDB and MYSQLclient with latest versions and have also tried updating the versions in requirements.txt. However, I haven't installed PhpMyAdmin yet, for time basis I would want to just use terminal for viewing my data tables.
Could you please explain me about the tracebacks and what can I do to run the program. It would be of great support if you can provide me with a solution.
Thank you.
Keep safe and kind regards,
SD.

 | 2020/08/24 | [
"https://Stackoverflow.com/questions/63557957",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14156220/"
] | The input pipeline of a dataset is always traced into a graph (as if you used [`@tf.function`](https://www.tensorflow.org/api_docs/python/tf/function)) to make it faster, which means, among other things, that you cannot use `.numpy()`. You can however use [`tf.numpy_function`](https://www.tensorflow.org/api_docs/python/tf/numpy_function) to access the data as a NumPy array within the graph:
```py
def transform(example):
# example will now by a NumPy array
str_example = example.decode("utf-8")
json_example = json.loads(str_example)
overall = json_example.get('overall', None)
text = json_example.get('reviewText', None)
return (overall, text)
line_dataset = tf.data.TextLineDataset(filenames = [file_path])
line_dataset = line_dataset.map(
lambda row: tf.numpy_function(transform, row, (tf.float32, tf.string)))
for example in line_dataset.take(5):
print(example)
``` | A bit wordy, but try it like this:
```
def transform(example):
str_example = example.numpy().decode("utf-8")
json_example = json.loads(str_example)
overall = json_example.get('overall', None)
text = json_example.get('reviewText', None)
return (overall, text)
line_dataset = tf.data.TextLineDataset(filenames = [file_path])
line_dataset = line_dataset.map(
lambda input:
tf.py_function(transform, [input], (tf.float32, tf.string))
)
for example in line_dataset.take(5):
print(example)
```
This particular snippet works for any python function, not only the for numpy functions. So, if you need functions like `print`, `input` and so on, you can use this. You don't have to know all the details, but if you are interested, please ask me. :) | 1,538 |
2,293,968 | For my project, the role of the Lecturer (defined as a class) is to offer projects to students. Project itself is also a class. I have some global dictionaries, keyed by the unique numeric id's for lecturers and projects that map to objects.
Thus for the "lecturers" dictionary (currently):
```
lecturer[id] = Lecturer(lec_name, lec_id, max_students)
```
I'm currently reading in a white-space delimited text file that has been generated from a database. I have no direct access to the database so I haven't much say on how the file is formatted. Here's a fictionalised snippet that shows how the text file is structured. Please pardon the cheesiness.
```
0001 001 "Miyamoto, S." "Even Newer Super Mario Bros"
0002 001 "Miyamoto, S." "Legend of Zelda: Skies of Hyrule"
0003 002 "Molyneux, P." "Project Milo"
0004 002 "Molyneux, P." "Fable III"
0005 003 "Blow, J." "Ponytail"
```
The structure of each line is basically `proj_id, lec_id, lec_name, proj_name`.
Now, I'm currently reading the relevant data into the relevant objects. Thus, `proj_id` is stored in `class Project` whereas `lec_name` is a `class Lecturer` object, et al. The `Lecturer` and `Project` classes are not currently related.
However, as I read in each line from the text file, for that line, I wish to read in the project offered by the lecturer into the `Lecturer` class; I'm already reading the `proj_id` into the `Project` class. I'd like to create an object in `Lecturer` called `offered_proj` which should be a set or list of the projects offered by that lecturer. Thus whenever, for a line, I read in a new project under the same `lec_id`, `offered_proj` will be updated with that project. If I wanted to get display a list of projects offered by a lecturer I'd ideally just want to use `print lecturers[lec_id].offered_proj`.
My Python isn't great and I'd appreciate it if someone could show me a way to do that. I'm not sure if it's better as a set or a list, as well.
`Update`
After the advice from [Alex Martelli](https://stackoverflow.com/questions/2293968/how-do-i-create-a-list-or-set-object-in-a-class-in-python/2293998#2293998) and [Oddthinking](https://stackoverflow.com/questions/2293968/how-do-i-create-a-list-or-set-object-in-a-class-in-python/2294002#2294002) I went back and made some changes and tried to print the results.
Here's the code snippet:
```
for line in csv_file:
proj_id = int(line[0])
lec_id = int(line[1])
lec_name = line[2]
proj_name = line[3]
projects[proj_id] = Project(proj_id, proj_name)
lecturers[lec_id] = Lecturer(lec_id, lec_name)
if lec_id in lecturers.keys():
lecturers[lec_id].offered_proj.add(proj_id)
print lec_id, lecturers[lec_id].offered_proj
```
The `print lecturers[lec_id].offered_proj` line prints the following output:
```
001 set([0001])
001 set([0002])
002 set([0003])
002 set([0004])
003 set([0005])
```
It basically feels like the set is being over-written or somesuch. So if I try to print for a specific lecturer `print lec_id, lecturers[001].offered_proj` all I get is the last the `proj_id` that has been read in. | 2010/02/19 | [
"https://Stackoverflow.com/questions/2293968",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/273875/"
] | `set` is better since you don't care about order and have no duplicate.
You can parse the file easily with the [csv](http://docs.python.org/library/csv.html?highlight=sv#module-csv) module (with a `delimiter` of `' '`).
Once you have the `lec_name` you must check if that lecturer's already know; for that purpose, keep a dictionary from `lec_name` to lecturer objects (that's just another reference to the same lecturer object which you also refer to from the `lecturer` dictionary). On finding a `lec_name` that's not in that dictionary you know it's a lecturer not previously seen, so make a new lecturer object (and stick it in both dicts) in that case only, with an empty set of offered courses. Finally, just `.add` the course to the current lecturer's `offered_proj`. It's really a pretty smooth flow.
Have you tried implementing this flow? If so, what problems have you had? Can you show us the relevant code -- should be a dozen lines or so, at most?
**Edit**: since the OP has posted code now, I can spot the bug -- it's here:
```
lecturers[lec_id] = Lecturer(lec_id, lec_name)
if lec_id in lecturers.keys():
lecturers[lec_id].offered_proj.add(proj_id)
```
this is **unconditionally** creating a new lecturer object (trampling over the old one in the `lecturers` dict, if any) so of course the previous set gets tossed away. This is the code you need: **first** check, and create only if needed! (also, minor bug, **don't** check `in....keys()`, that's horribly inefficient - just check for presence in the dict). As follows:
```
if lec_id in lecturers:
thelec = lecturers[lec_id]
else:
thelec = lecturers[lec_id] = Lecturer(lec_id, lec_name)
thelec.offered_proj.add(proj_id)
```
You could express this in several different ways, but I hope this is clear enough. Just for completeness, the way I would normally phrase it (to avoid two lookups into the dictionary) is as follows:
```
thelec = lecturers.get(lec_id)
if thelec is None:
thelec = lecturers[lec_id] = Lecturer(lec_id, lec_name)
thelec.offered_proj.add(proj_id)
``` | Sets are useful when you want to guarantee you only have one instance of each item. They are also faster than a list at calculating whether an item is present in the collection.
Lists are faster at adding items, and also have an ordering.
This sounds like you would like a set. You sound like you are very close already.
in Lecturer.**init**, add a line:
```
self.offered_proj = set()
```
That will make an empty set.
When you read in the project, you can simply add to that set:
```
lecturer.offered_proj.add(project)
```
And you can print, just as you suggest (although you may like to pretty it up.) | 1,539 |
2,112,632 | Is it possible to create a grid like below?
I didn't found anything in the forum.
```
#euler-project problem number 11
#In the 20 times 20 grid below,
#four numbers along a diagonal line have been marked in red.
#The product of these numbers is 26 times 63 times 78 times 14 = 1788696.
#What is the greatest product of four adjacent numbers in any direction
#(up, down, left, right, or diagonally) in the 20 times 20 grid?
import numpy
number = numpy.array([[08 02 22 97 38 15 00 40 00 75 04 05 07 78 52 12 50 77 91 08]
[49 49 99 40 17 81 18 57 60 87 17 40 98 43 69 48 04 56 62 00]
[81 49 31 73 55 79 14 29 93 71 40 67 53 88 30 03 49 13 36 65]
[52 70 95 23 04 60 11 42 69 24 68 56 01 32 56 71 37 02 36 91]
[22 31 16 71 51 67 63 89 41 92 36 54 22 40 40 28 66 33 13 80]
[24 47 32 60 99 03 45 02 44 75 33 53 78 36 84 20 35 17 12 50]
[32 98 81 28 64 23 67 10 26 38 40 67 59 54 70 66 18 38 64 70]
[67 26 20 68 02 62 12 20 95 63 94 39 63 08 40 91 66 49 94 21]
[24 55 58 05 66 73 99 26 97 17 78 78 96 83 14 88 34 89 63 72]
[21 36 23 09 75 00 76 44 20 45 35 14 00 61 33 97 34 31 33 95]
[78 17 53 28 22 75 31 67 15 94 03 80 04 62 16 14 09 53 56 92]
[16 39 05 42 96 35 31 47 55 58 88 24 00 17 54 24 36 29 85 57]
[86 56 00 48 35 71 89 07 05 44 44 37 44 60 21 58 51 54 17 58]
[19 80 81 68 05 94 47 69 28 73 92 13 86 52 17 77 04 89 55 40]
[04 52 08 83 97 35 99 16 07 97 57 32 16 26 26 79 33 27 98 66]
[88 36 68 87 57 62 20 72 03 46 33 67 46 55 12 32 63 93 53 69]
[04 42 16 73 38 25 39 11 24 94 72 18 08 46 29 32 40 62 76 36]
[20 69 36 41 72 30 23 88 34 62 99 69 82 67 59 85 74 04 36 16]
[20 73 35 29 78 31 90 01 74 31 49 71 48 86 81 16 23 57 05 54]
[01 70 54 71 83 51 54 69 16 92 33 48 61 43 52 01 89 19 67 48]])
```
EDIT no.1:
I found numpy-array now.
```
x = np.array([[1, 2, 3], [4, 5, 6]], np.int32)
```
Is there a way to do it without the commas?
EDIT no.2:
I also found a new problem.
[Python: Invalid Token](https://stackoverflow.com/questions/336181/python-invalid-token)
Invalid token in number 08! :) | 2010/01/21 | [
"https://Stackoverflow.com/questions/2112632",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/237934/"
] | Check out [NumPy](http://numpy.scipy.org/) - specifically, the [N-dimensional array](http://docs.scipy.org/doc/numpy/reference/arrays.ndarray.html) object. | Your code example won't compile unless you put commas between the list elements.
For example, this will compile:
```
value = [
[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9,10,11,12]
]
```
If you're interested in taking strings like you show, and **parsing** them into a list of lists (or numpy multi-dimensional array), or if you have a list of lists or numpy array and want to print them out like you describe, you can do that too with a clever couple of list comprehensions. | 1,542 |
58,846,573 | I'm building a voice assistant using python. I want to make it available as a web application. How do I build the same?
Thanks | 2019/11/13 | [
"https://Stackoverflow.com/questions/58846573",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10441927/"
] | When you set
```
channel_shift_range=10,
brightness_range=(0.7, 1.3)
```
This modifies the RNG of this generator so that the Image RNG and the Mask RNG are not in sync anymore.
I propose you use a custom Sequence for this task until the KP new API is released. (see <https://github.com/keras-team/governance/blob/master/rfcs/20190729-keras-preprocessing-redesign.md>)
For an example of a custom Sequence, I propose an example here: <https://dref360.github.io/deterministic-da/> | For anyone else struggling with this - concatenating the images and masks along the channel axis is a handy way to synchronise the augmentations
```
image_mask = np.concatenate([image, mask], axis=3)
image_mask = augmenter.flow(image_mask).next()
image = image_mask [:, :, :, 0]
mask = image_mask [:, :, :, 1]
``` | 1,550 |
56,047,365 | I need a python code to extract the selected word using python.
```
<a class="tel ttel">
<span class="mobilesv icon-hg"></span>
<span class="mobilesv icon-rq"></span>
<span class="mobilesv icon-ba"></span>
<span class="mobilesv icon-rq"></span>
<span class="mobilesv icon-ba"></span>
<span class="mobilesv icon-ikj"></span>
<span class="mobilesv icon-dc"></span>
<span class="mobilesv icon-acb"></span>
<span class="mobilesv icon-lk"></span>
<span class="mobilesv icon-ba"></span>
<span class="mobilesv icon-nm"></span>
<span class="mobilesv icon-ba"></span>
<span class="mobilesv icon-yz"></span>
</a>
```
I need to extract the words which start with the "icon"
The Output which I required is
icon-hg, icon-rq, icon-ba, icon-rq, icon-ba, icon-ikj, icon-dc, icon-acb, icon-lk, icon-ba, icon-nm, icon-ba, icon-yz | 2019/05/08 | [
"https://Stackoverflow.com/questions/56047365",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8235643/"
] | You can change line 1 to `import Data.List hiding (find)`, assuming you never intend to use the `find` defined there. | In your situation your options are:
1. Rename your own `find` into something else.
2. Import `Data.List` as qualified: `import qualified Data.List`. You can add `as L` to shorten code that uses stuff from `Data.List`. | 1,551 |
35,811,400 | I have about 650 csv-based matrices. I plan on loading each one using Numpy as in the following example:
```
m1 = numpy.loadtext(open("matrix1.txt", "rb"), delimiter=",", skiprows=1)
```
There are matrix2.txt, matrix3.txt, ..., matrix650.txt files that I need to process.
My end goal is to multiply each matrix by each other, meaning I don't necessarily have to maintain 650 matrices but rather just 2 (1 ongoing and 1 that I am currently multiplying my ongoing by.)
Here is an example of what I mean with matrices defined from 1 to n: M1, M2, M3, .., Mn.
M1\*M2\*M3\*...\*Mn
The dimensions on all the matrices are the same. **The matrices are not square. There are 197 rows and 11 columns.** None of the matrices are sparse and every cell comes into play.
What is the best/most efficient way to do this in python?
EDIT: I took what was suggested and got it to work by taking the transpose since it isn't a square matrix. As an addendum to the question, i**s there a way in Numpy to do element by element multiplication**? | 2016/03/05 | [
"https://Stackoverflow.com/questions/35811400",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3973851/"
] | **1. Variant: Nice code but reads all matrices at once**
```
matrixFileCount = 3
matrices = [np.loadtxt(open("matrix%s.txt" % i ), delimiter=",", skiprows=1) for i in range(1,matrixFileCount+1)]
allC = itertools.combinations([x for x in range(matrixFileCount)], 2)
allCMultiply = [np.dot(matrices[c[0]], matrices[c[1]]) for c in allC]
print allCMultiply
```
**2. Variant: Only load 2 Files at once, nice code but a lot of reloading**
```
allCMulitply = []
fileList = ["matrix%s.txt" % x for x in range(1,matrixFileCount+1)]
allC = itertools.combinations(fileList, 2)
for c in allC:
m = [np.loadtxt(open(file), delimiter=",", skiprows=1) for file in c]
allCMulitply.append(np.dot(m[0], m[1]))
print allCMulitply
```
**3. Variant: like the second but avoid loading every time. But only 2 matrix at one point in memory**
Cause the permutations created with itertools are like `(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)` you can avoid somtimes loading both of the 2 matrices.
```
matrixFileCount = 3
allCMulitply = []
mLoaded = {'file' : None, 'matrix' : None}
fileList = ["matrix%s.txt" % x for x in range(1,matrixFileCount+1)]
allC = itertools.combinations(fileList, 2)
for c in allC:
if c[0] is mLoaded['file']:
m = [mLoaded['matrix'], np.loadtxt(open(c[1]), delimiter=",", skiprows=1)]
else:
mLoaded = {'file' : None, 'matrix' : None}
m = [np.loadtxt(open(file), delimiter=",", skiprows=1) for file in c]
mLoaded = {'file' : c[0], 'matrix' : m[0]}
allCMulitply.append(np.dot(m[0], m[1]))
print allCMulitply
```
**Performance**
If you can load all Matrix at once in the memory, the first part is faster then the second, cause in the second you reload matrices a lot. Third part slower than first, but faster than second, cause it avoids sometimes to reloading matrices.
```
0.943613052368 (Part 1: 10 Matrices a 2,2 with 1000 executions)
7.75622487068 (Part 2: 10 Matrices a 2,2 with 1000 executions)
4.83783197403 (Part 3: 10 Matrices a 2,2 with 1000 executions)
``` | Kordi's answer loads *all* of the matrices before doing the multiplication. And that's fine if you know the matrices are going to be small. If you want to conserve memory, however, I'd do the following:
```
import numpy as np
def get_dot_product(fnames):
assert len(fnames) > 0
accum_val = np.loadtxt(fnames[0], delimiter=',', skiprows=1)
return reduce(_product_from_file, fnames[1:], initializer=accum_val)
def _product_from_file(running_product, fname):
return running_product.dot(np.loadtxt(fname, delimiter=',', skiprows=1))
```
If the matrices are large and irregular in shape (not square), there are also optimization algorithms for determining the optimal associative groupings (i.e., where to put the parentheses), but in most cases I doubt it would be worth the overhead of loading and unloading each file twice, once to figure out the associative groupings and then once to carry it out. NumPy is surprisingly fast even on pretty big matrices. | 1,552 |
43,814,236 | Example dataset columns: ["A","B","C","D","num1","num2"]. So I have 6 columns - first 4 for grouping and last 2 are numeric and means will be calculated based on groupBy statements.
I want to groupBy all possible combinations of the 4 grouping columns.
I wish to avoid explicitly typing all possible groupBy's such as groupBy["A","B","C","D"] then groupBy["A","B","D","C"] etc.
I'm new to Python - in python how can I automate group by in a loop so that it does a groupBy calc for all possible combinations - in this case 4\*3\*2\*1 = 24 combinations?
Ta.
Thanks for your help so far. Any idea why the 'a =' part isn't working?
```
import itertools
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0,10,size=(100, 5)), columns=list('ABCDE'))
group_by_vars = list(df.columns)[0:4]
perms = [perm for perm in itertools.permutations(group_by_vars)]
print list(itertools.combinations(group_by_vars,2))
a = [x for x in itertools.combinations(group_by_vars,group_by_n+1) for group_by_n in range(len(group_by_vars))]
```
a doesn't error I just get an empty object. Why???
Something like [comb for comb in itertools.combinations(group\_by\_vars,2)] is easy enough but how to get a = [x for x in itertools.combinations(group\_by\_vars,group\_by\_n+1) for group\_by\_n in range(len(group\_by\_vars))]?? | 2017/05/05 | [
"https://Stackoverflow.com/questions/43814236",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6647085/"
] | Syntax errors are a computer not being able to posses an imput.
Like this:
`answer = 1 +/ 6`
The computer does not recognize the `+/`
a semantics error are human errors. The computer will execute the code, but it will not be as wanted
Like this:
```
if(player = win){
print "You Lose"
}
```
It will print "You Lose" if they player won.
A logical error is a synonym for semantics error. | Syntax error is an error which will make your code "unprocessable".
```
if true {}
```
instead of
```
if (true) {}
```
for example
Semantics error and logical errors are the same. Your code is correct, but doesn't do what you think it does.
```
while(c = true) {}
```
instead of
```
while (c == true) {}
```
for example | 1,557 |
38,686,830 | I'm using python to input data to my script
then trying to return it back
on demand to show the results
I tried to write it as simple as possible since it's only practicing and trying to get the hang of python
here's how my script looks like
```
#!/usr/python
## imports #####
##################
import os
import sys
## functions
##################
# GET INSERT DATA
def getdata():
clientname = raw_input(" *** Enter Client Name > ")
phone = raw_input(" *** Enter Client Phone > ")
location = raw_input(" *** Enter Client Location > ")
email = raw_input(" *** Enter Client email > ")
website = raw_input(" *** Enter Client Website > ")
return clientname, phone, location, email, website
# VIEW DATA
def showdata():
print "==================="
print ""
print clientname
print ""
print phone
print ""
print location
print ""
print email
print ""
print website
print ""
print "==================="
# CLEAR
def clear():
os.system("clear") #linux
os.system("cls") #windows
# SHOW INSTRUCTIONS
def welcome():
clear()
while True:
choice = raw_input(" Select Option > ")
# INSERT DATA
if choice == "1":
getdata()
# VIEW DATA
elif choice == "2":
showdata()
else:
print "Invalid Selection.. "
print "Terminating... "
#exit()
welcome()
```
what am i doing wrong ? what am i missing? | 2016/07/31 | [
"https://Stackoverflow.com/questions/38686830",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2310584/"
] | You are getting an error because your JSON data is an array and what you have done is:
```
XmlNode xml = JsonConvert.DeserializeXmlNode(sBody, "BiddingHistory");
```
the above line of code will only work for JSON objects.
So, if your JSON is an Array, then try this:
```
XmlNode xml = JsonConvert.DeserializeXmlNode("{\"Row\":" + sBody + "}", "BiddingHistory").ToXmlString();
``` | Use service stack from nuget [Service Stack](https://www.nuget.org/packages/ServiceStack/)
add reference to your program
```
using ServiceStack;
```
Convert your json to object
```
var jRst = JsonConvert.DeserializeObject(body);
```
after that you can get xml using service stack like below
```
var xml = jRst.ToXml();
``` | 1,558 |
9,372,672 | I want to use vlc.py to play mpeg2 stream <http://wiki.videolan.org/Python_bindings>.
There are some examples here: <http://git.videolan.org/?p=vlc/bindings/python.git;a=tree;f=examples;hb=HEAD>
When I run the examples, it just can play video file, I want to know is there any examples to play video stream ? | 2012/02/21 | [
"https://Stackoverflow.com/questions/9372672",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/335499/"
] | According to [this](http://pastebin.com/edncPpW0) Pastebin entry, linked to in [this](https://mailman.videolan.org/pipermail/vlc-devel/2012-September/090310.html) mailing list, it can be solved using a method like this:
```
import vlc
i = vlc.Instance('--verbose 2'.split())
p = i.media_player_new()
p.set_mrl('rtp://@224.1.1.1')
p.play()
```
I haven't tried it though, so please let me know if it works. | This is a bare bones solution:
```
import vlc
Instance = vlc.Instance()
player = Instance.media_player_new()
Media = Instance.media_new('http://localhost/postcard/GWPE.avi')
Media.get_mrl()
player.set_media(Media)
player.play()
```
if the media is a local file you will have to alter:
```
Media = Instance.media_new('http://localhost/postcard/GWPE.avi')
Media.get_mrl()
```
to:
```
Media = Instance.media_new_path('/path/to_your/file/filename.avi')
```
note that you must lose the `get_mrl()` as well as changing the function. | 1,559 |
40,890,768 | Tensorflow is now available on Windows:
```
https://developers.googleblog.com/2016/11/tensorflow-0-12-adds-support-for-windows.html
```
I used pip install tensorflow.
I try running the intro code:
```
https://www.tensorflow.org/versions/r0.12/get_started/index.html
```
I get this error:
```
C:\Python\Python35-32\python.exe "C:/tensorflow_tutorial.py"
Traceback (most recent call last):
File "C:\Python\Python35-32\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 18, in swig_import_helper
return importlib.import_module(mname)
File "C:\Python\Python35-32\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 986, in _gcd_import
File "<frozen importlib._bootstrap>", line 969, in _find_and_load
File "<frozen importlib._bootstrap>", line 958, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 666, in _load_unlocked
File "<frozen importlib._bootstrap>", line 577, in module_from_spec
File "<frozen importlib._bootstrap_external>", line 903, in create_module
File "<frozen importlib._bootstrap>", line 222, in _call_with_frames_removed
ImportError: DLL load failed: %1 is not a valid Win32 application.
```
This site had some suggestions on DLL's that were missing but anyones guess is good:
```
https://github.com/tensorflow/tensorflow/issues/5949
```
Update: I switched to x64 I get this error:
```
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:119] Couldn't open CUDA library cublas64_80.dll
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\cuda\cuda_blas.cc:2294] Unable to load cuBLAS DSO.
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:119] Couldn't open CUDA library cudnn64_5.dll
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\cuda\cuda_dnn.cc:3459] Unable to load cuDNN DSO
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:119] Couldn't open CUDA library cufft64_80.dll
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\cuda\cuda_fft.cc:344] Unable to load cuFFT DSO.
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:119] Couldn't open CUDA library nvcuda.dll
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\cuda\cuda_diagnostics.cc:165] hostname: ����
```
Update2:
I installed the nvidia cuda files
```
https://developer.nvidia.com/cuda-downloads
```
Im getting these errors:
```
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:128] successfully opened CUDA library cublas64_80.dll locally
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:119] Couldn't open CUDA library cudnn64_5.dll
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\cuda\cuda_dnn.cc:3459] Unable to load cuDNN DSO
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:128] successfully opened CUDA library cufft64_80.dll locally
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:119] Couldn't open CUDA library nvcuda.dll
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\cuda\cuda_diagnostics.cc:165] hostname: �٩��
```
Update3:
I registered and downloaded the cudnn packge from NVIDIA
```
https://developer.nvidia.com/cudnn
```
Moved the file location
```
C:\Desktop\cudnn-8.0-windows10-x64-v5.1.zip\cuda\bin\cudnn64_5.dll to C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin\cudnn64_5.dll
```
Still get this error:
```
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_loader.cc:119] Couldn't open CUDA library nvcuda.dll
```
Update 4:
Downloaded nvcuda.dll into C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin
This resolved my issue. | 2016/11/30 | [
"https://Stackoverflow.com/questions/40890768",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1239984/"
] | From the path of your Python interpreter (`C:\Python\Python35-32`), it appears that you are using the 32-bit version of Python 3.5. The official TensorFlow packages are only available for 64-bit architectures (`x64`/`amd64`), so you have two options:
1. Install the [64-bit version](https://www.python.org/ftp/python/3.5.2/python-3.5.2-amd64.exe) of Python 3.5 (either from Python.org or Anaconda), *or*
2. Compile the PIP package yourself for 32-bit Python 3.5. You may be able to do this using the experimental CMake build (see [here](https://github.com/tensorflow/tensorflow/tree/r0.12/tensorflow/contrib/cmake) for details), but this is not a supported or tested configuration.
(Note that I'm not sure how you installed the package on a 32-bit version of Python, because when I tried to do that I got an error message: "Not a supported wheel on this platform.") | The problem is not with platform (amd64) but with GPU drivers. You need to either install packages which runs on CPU or use that GPU ones you already installed but install also CUDA drivers. | 1,562 |
55,681,488 | There is an existing question [How to write binary data to stdout in python 3?](https://stackoverflow.com/questions/908331/how-to-write-binary-data-to-stdout-in-python-3) but all of the answers suggest `sys.stdout.buffer` or variants thereof (e.g., manually rewrapping the file descriptor), which have a problem: they don't respect buffering:
```
MacBook-Pro-116:~ ezyang$ cat test.py
import sys
sys.stdout.write("A")
sys.stdout.buffer.write(b"B")
MacBook-Pro-116:~ ezyang$ python3 test.py | cat
BA
```
Is there a way to write binary data to stdout while respecting buffering with respect to `sys.stdout` and unadorned `print` statements? (The actual use-case is, I have "text-like" data of an unknown encoding and I just want to pass it straight to stdout without making a commitment to a particular encoding.) | 2019/04/15 | [
"https://Stackoverflow.com/questions/55681488",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/23845/"
] | Can't you interleave calls to `write` with `flush` ?
```
sys.stdout.write("A")
sys.stdout.buffer.write(b"B")
```
Results in:
>
> BA
>
>
>
---
```
sys.stdout.write("A")
sys.stdout.flush()
sys.stdout.buffer.write(b"B")
sys.stdout.flush()
```
Results in:
>
> AB
>
>
> | You can define a local function called `_print` (or even override the system `print` function by naming it `print`) as follows:
```
import sys
def _print(data):
"""
If data is bytes, write to stdout using sys.stdout.buffer.write,
otherwise, assume it's str and convert to bytes with utf-8
encoding before writing.
"""
if type(data) != bytes:
data = bytes(data, 'utf-8')
sys.stdout.buffer.write(data)
_print('A')
_print(b'B')
```
The output should be `AB`.
Note: normally the system `print` function adds a newline to the output. The above `_print` just outputs the data (either `bytes` or by assuming it's `str`) without the newline.
### buffered implementation
If you want buffered I/O, you can manage that by using the tools from the `io` library.
Simple example:
```
import io
import sys
output_buffer = None
text_wrapper = None
def init_buffer():
global output_buffer, text_wrapper
if not output_buffer:
output_buffer = io.BytesIO()
text_wrapper = io.TextIOWrapper(
output_buffer,
encoding='utf-8',
write_through=True)
def write(data):
if type(data) == bytes:
output_buffer.write(data)
else:
text_wrapper.write(data)
def flush():
sys.stdout.buffer.write(output_buffer.getvalue())
# initialize buffer, write some data, and then flush to stdout
init_buffer()
write("A")
write(b"B")
write("foo")
write(b"bar")
flush()
```
If you are performing all the output writes in a function, for example, you can use the `contextlib.contextmanager` to create a factory function that allow you to use the `with ...` statement:
```
# This uses the vars and functions in the example above.
import contextlib
@contextlib.contextmanager
def buffered_stdout():
"""
Create a factory function for using the `with` statement
to write to the output buffer.
"""
global output_buffer
init_buffer()
fh = sys.stdout.buffer
try:
yield fh
finally:
try:
fh.write(output_buffer.getvalue())
except AttributeError:
pass
# open the buffered output stream and write some data to it
with buffered_stdout():
write("A")
write(b"B")
write("foo")
write(b"bar")
```
See:
* [PyMOTW-3 - io — Text, Binary, and Raw Stream I/O Tools](https://pymotw.com/3/io/)
* [Python 3 - io — Core tools for working with streams](https://docs.python.org/3/library/io.html)
* [Python 3 - contextlib — Utilities for with-statement contexts](https://docs.python.org/3/library/contextlib.html)
* [This answer on stackoverflow: Difference between `open` and `io.BytesIO` in binary streams](https://stackoverflow.com/a/42800629/220783) | 1,565 |
48,935,995 | I am a newbie in python. I have a question about the dimension of array.
I have (10,192,192,1) array which type is (class 'numpy.ndarray').
I would like to divid this array to 10 separated array like 10 \* (1,192,192,1). but I always got (192,192,1) array when I separate.
How can I get separated arrays as a same dimension type of original one?
below is my code.
```
b = np.ndarray((a.shape[0],a.shape[1],a.shape[2],a.shape[3]))
print(b.shape) # (10,192,192,1)
for i in range(a.shape[0]):
b[i] = a[i]
print(b[i].shape) # (192,192,1), but I want to get (1,192,192,1)
``` | 2018/02/22 | [
"https://Stackoverflow.com/questions/48935995",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8032125/"
] | An intent object couldn't be created after the finish. Try it before `finish();`
```
Intent intent = new Intent(MainActivity.this, LoginActivity.class);
startActivity(intent);
finish();
```
**Update:** In your case import the intent like this.
```
import android.content.Intent
``` | As your code implies, you are calling `finish()` method before calling your new activity. In other words, the following lines of code will never run:
```
// Opening the Login Activity using Intent.
Intent intent = new Intent(MainActivity.this, LoginActivity.class);
startActivity(intent);
```
In order to solve the problem, add `finish()` method after above block of code. | 1,566 |
15,512,741 | I have a .txt file that is UTF-8 formatted and have problems to read it into Python. I have a large number of files and a conversion would be cumbersome.
So if I read the file in via
```
for line in file_obj:
...
```
I get the following error:
```
File "/Library/Frameworks/Python.framework/Versions/3.3/lib/python3.3/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc2 in position 291: ordinal not in range(128)
```
I guess `x.decode("utf-8")` wouldn't work since the error occurs before the line is even read in. | 2013/03/19 | [
"https://Stackoverflow.com/questions/15512741",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] | There are two choices.
1. Specify the encoding when opening the file, instead of using the default.
2. Open the file in binary mode, and explicitly `decode` from `bytes` to `str`.
The first is obviously the simpler one. You don't show how you're opening the file, but assuming your code looks like this:
```
with open(path) as file_obj:
for line in file_obj:
```
Do this:
```
with open(path, encoding='utf-8') as file_obj:
for line in file_obj:
```
That's it.
As [the docs](http://docs.python.org/3/library/functions.html#open) explain, if you don't specify an encoding in text mode:
>
> The default encoding is platform dependent (whatever `locale.getpreferredencoding()` returns), but any encoding supported by Python can be used.
>
>
>
In some cases (e.g., any OS X, or linux with an appropriate configuration), `locale.getpreferredencoding()` will always be 'UTF-8'. But it'll obviously never be "automatically whatever's right for any file I might open". So if you know a file is UTF-8, you should specify it explicitly. | For Python 2 and 3 solution, use codecs:
```
import codecs
file_obj = codecs.open('ur file', "r", "utf-8")
for line in file_obj:
...
```
Otherwise -- Python 3 -- use abarnert's [solution](https://stackoverflow.com/a/15512760/298607) | 1,568 |
45,414,796 | I have a list of objects with multiple attributes. I want to filter the list based on one attribute of the object (country\_code), i.e.
Current list
```
elems = [{'region_code': 'EUD', 'country_code': 'ROM', 'country_desc': 'Romania', 'event_number': '6880'},
{'region_code': 'EUD', 'country_code': 'ROM', 'country_desc':'Romania', 'event_number': '3200'},
{'region_code': 'EUD', 'country_code': 'ROM', 'country_desc': 'Romania', 'event_number': '4000'},
{'region_code': 'EUD', 'country_code': 'SVN', 'country_desc': 'Slovenia', 'event_number': '6880'},
{'region_code': 'EUD', 'country_code': 'NLD', 'country_desc':'Netherlands', 'event_number': '6880'},
{'region_code': 'EUD', 'country_code': 'BEL', 'country_desc':'Belgium', 'event_number': '6880'}]
```
Desired list
```
elems = [{'region_code': 'EUD', 'country_code': 'ROM', 'country_desc': 'Romania', 'event_number': '6880'},
{'region_code': 'EUD', 'country_code': 'SVN', 'country_desc': 'Slovenia', 'event_number': '6880'},
{'region_code': 'EUD', 'country_code': 'NLD', 'country_desc': 'Netherlands', 'event_number': '6880'},
{'region_code': 'EUD', 'country_code': 'BEL', 'country_desc': 'Belgium', 'event_number': '6880'}]
```
I can achieve this by creating a dictionary and a for-loop, but I feel like there's an easier way in python using the filter() or reduce() functions, I just can't figure out how.
**Can anyone simplify the below code using in-built python functions? Performance is a big factor because the real data will be substantial.**
Working code:
```
unique = {}
for elem in elems:
if elem['country_code'] not in unique.keys():
unique[elem['country_code']] = elem
print(unique.values())
```
Worth noting I have also tried the code below, but it performs worse than the current working code:
```
unique = []
for elem in elems:
if not any(u['country_code'] == elem['country_code'] for u in unique):
unique.append(elem)
``` | 2017/07/31 | [
"https://Stackoverflow.com/questions/45414796",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5142595/"
] | I think your first approach is already pretty close to being optimal. Dictionary lookup is fast (just as fast as in a `set`) and the loop is easy to understand, even though a bit lengthy (by Python standards), but you should not sacrifice readability for brevity.
You can, however, shave off one line using `setdefault`, and you might want to use [`collections.OrderedDict()`](https://docs.python.org/3/library/collections.html#collections.OrderedDict) so that the elements in the resulting list are in their orginal order. Also, note that in Python 3, `unique.values()` is not a list but a view on the dict.
```
unique = collections.OrderedDict()
for elem in elems:
unique.setdefault(elem["country_code"], elem)
```
If you really, *really* want to use `reduce`, you can use the empty dict as an initializer and then use `d.setdefault(k,v) and d` to set the value (if not present) and return the modified dict.
```
unique = reduce(lambda unique, elem: unique.setdefault(elem["country_code"], elem) and unique,
elems, collections.OrderedDict())
```
I would just use the loop, though. | I think that your approach is just fine. It would be slightly better to check `elem['country_code'] not in unique` instead of `elem['country_code'] not in unique.keys()`.
However, here is another way to do it with a list comprehension:
```
visited = set()
res = [e for e in elems
if e['country_code'] not in visited
and not visited.add(e['country_code'])]
```
The last bit abuses the fact that `not None == True` and `list.add` returns `None`. | 1,569 |
58,997,105 | Fatal Python error: failed to get random numbers to initialize Python
Environment windows 10, VSC 15
Using CreateProcessA winapi and passing lpenvironment variable to run python with scripts.
when lpenvironment is passed null, it works fine.
If I set environment variable PATH and PYTHONPATH = "paths", and pass that LPSTR(env.c\_Str()), it throws above error on running.
The python version is 3.5.6
Any help?
---
Some more details.
1. I run child process python.exe "C:\Program Files\endpoint\Python\_ML\mlprocessor\_server.py" using CreateProcessA WINAPI.
2. I want to run child process with two environmental variables "PYTHONPATH" and "PATH".
PYTHONPATH="C:\Program Files\endpoint\Python";"C:\Program Files\endpoint\Python\Scripts";"C:\Program Files\endpoint\Python\include";"C:\Program Files\endpoint\Python\Lib";"C:\Program Files\endpoint\Python\libs";"C:\Program Files\endpoint\Python\Lib\site-packages";"C:\Program Files\endpoint\Python\_ML"
PATH="C:\Program Files\endpoint\Python";"C:\Program Files\endpoint\Python\Lib";"C:\Program Files\endpoint\Python\Scripts";"C:\Program Files\endpoint\Python\libs"
For some reason, the 7th parameter in CreateProcessA fails, the python.exe runs successfully if it is null, or else it prints "Fatal Python error: failed to get random numbers to initialize Python".
The way I set the parameter as follows...
-----------------------------------------
std::string Base = Configuration::getBasePath();
```
std::string environPython = Base;
environPython.append("\\Python;");
environPython.append(Base);
environPython.append("\\Python\\Scripts;");
environPython.append(Base);
environPython.append("\\Python\\include;");
environPython.append(Base);
environPython.append("\\Python\\Lib;");
environPython.append(Base);
environPython.append("\\Python\\libs;");
environPython.append(Base);
environPython.append("\\Python\\Lib\\site-packages;");
environPython.append(Base);
environPython.append("\\Python\\_ML;");
environPython.push_back('\0');
std::string environPath = Base;
environPath.append("\\Python;");
environPath.append(Base);
environPath.append("\\Python\\Lib;");
environPath.append(Base);
environPath.append("\\Python\\Scripts;");
environPath.append(Base);
environPath.append("\\Python\\libs;");
environPath.push_back('\0');
std::string cmd = Base;
cmd.append("\\Python\\python.exe");
std::string params = "\"";
params.append(cmd);
params.append("\" \"");
params.append(Base);
params.append("\\Python\\_ML\\mlprocessor_server.py\"");
```
std::map env = { { "PYTHONPATH", environPython.data() },
{ "PATH", environPath.data() }};
```
// example for generating block of strings
std::vector<char> envBlock;
std::for_each(env.begin(), env.end(),
[&envBlock](const std::pair<std::string, std::string> & p) {
std::copy(p.first.begin(), p.first.end(), std::back_inserter(envBlock));
envBlock.push_back('=');
std::copy(p.second.begin(), p.second.end(), std::back_inserter(envBlock));
envBlock.push_back('\0');
}
);
envBlock.push_back('\0');
// feed this into ::CreateProcess()
LPVOID lpEnvironment = (LPVOID)envBlock.data();
bool result = CreateProcessA(cmd.c_str(), (LPSTR)params.c_str(), NULL, NULL, FALSE, CREATE_NO_WINDOW, lpEnvironment, NULL, &info, &pi);
```
---
The result is always true, python.exe is not shown up in task manager and gives Fatal Python error: failed to get random numbers to initialize Python.
If the lpEnvironment is NULL, python.exe is shown up in task manager. | 2019/11/22 | [
"https://Stackoverflow.com/questions/58997105",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/9758247/"
] | The environment you pass to `CreateProcessA` must include `SYSTEMROOT`, otherwise the Win32 API call `CryptAcquireContext` will fail when called inside python during initialization.
When passing in NULL as lpEnvironment, your new process inherits the environment of the calling process, which has `SYSTEMROOT` already defined. | To follow up with an example how this can very easily be triggered in pure Python software out in the real world, there are times where it is useful for Python to open up an instance of itself to do some task, where the sub-task need a specific `PYTHONPATH` be set. Often times this may be done lazily on less fussy platforms (i.e. not Windows) like so:
```
import sys
from subprocess import Popen
p = Popen([sys.executable, '-c', 'print("hello world")'], env={
'PYTHONPATH': '', # set it to somewhere
})
```
However, doing so on Windows, will lead to the following perplexing failure:
```
Python 3.8.10 (tags/v3.8.10:3d8993a, May 3 2021, 11:34:34) [MSC v.1928 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> from subprocess import Popen
>>> p = Popen([sys.executable, '-c', 'print("hello world")'], env={
... 'PYTHONPATH': ''
... })
Fatal Python error: _Py_HashRandomization_Init: failed to get random numbers to initialize Python
Python runtime state: preinitialized
```
The fix is obvious: clone the `os.environ` to ensure `SYSTEMROOT` is in place such that the issue pointed out by @Joe Savage's answer be averted, e.g.:
```
>>> import os
>>> env = os.environ.copy()
>>> env['PYTHONPATH'] = ''
>>> p = Popen([sys.executable, '-c', 'print("hello world")'], env=env)
hello world
```
A real world example where this type of fix was needed:
* [Glean SDK](https://github.com/mozilla/glean/pull/1908/commits/b44f9f7c0c10fde9b495f61794253b051a0d3f62) | 1,570 |
28,859,295 | If I am in **/home/usr** and I call python **/usr/local/rcom/bin/something.py**
How can I make the script inside **something.py** know he resides in **/usr/local/rcom/bin**?
The `os.path.abspath` is calculated with the `cwd` which is **/home/usr** in this case. | 2015/03/04 | [
"https://Stackoverflow.com/questions/28859295",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/67153/"
] | Assign the result of `df.groupby('User_ID')['Datetime'].apply(lambda g: len(g)>1)` to a variable so you can perform boolean indexing and then use the index from this to call `isin` and filter your orig df:
```
In [366]:
users = df.groupby('User_ID')['Datetime'].apply(lambda g: len(g)>1)
users
Out[366]:
User_ID
189757330 False
222583401 False
287280509 False
329757763 False
414673119 True
624921653 False
Name: Datetime, dtype: bool
In [367]:
users[users]
Out[367]:
User_ID
414673119 True
Name: Datetime, dtype: bool
In [368]:
users[users].index
Out[368]:
Int64Index([414673119], dtype='int64')
In [361]:
df[df['User_ID'].isin(users[users].index)]
Out[361]:
User_ID Latitude Longitude Datetime
5 414673119 41.555014 2.096583 2014-02-24 20:15:30
6 414673119 41.555014 2.097583 2014-02-24 20:16:30
7 414673119 41.555014 2.098583 2014-02-24 20:17:30
```
You can then call `to_csv` on the above as normal | first, make sure you have no duplicate entries:
```
df = df.drop_duplicates()
```
then, figure out the counts for each:
```
counts = df.groupby('User_ID').Datetime.count()
```
finally, figure out where the indexes overlap:
```
df[df.User_ID.isin(counts[counts > 1].index)]
``` | 1,571 |
4,585,776 | I am trying for a while installing [Hg-Git addon](http://hg-git.github.com/) to my Windows 7 Operating system
1. I have crossed several difficulties like installing Python and other utilities described in [this blog](http://blog.sadphaeton.com/2009/01/20/python-development-windows-part-2-installing-easyinstallcould-be-easier.html).
2. I had even after this manual problems and could not install this addon because of errors described in [this log](http://pastebin.com/C3i1hMJB).
3. I searched google and I have found [this manual](http://blog.nlift.com/2009/06/python-on-windows-c-extensions-and.html)
4. Now i have these errors showed in [this log](http://pastebin.com/iQYp4n5C).
Any help with these errors? Thank you for your help. | 2011/01/03 | [
"https://Stackoverflow.com/questions/4585776",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/559792/"
] | Ok i got it so ... For others - you need to clone this repo
**HTTPS:**
```
git clone https://github.com/jelmer/dulwich.git
```
**SSH:**
```
git clone git@github.com:jelmer/dulwich.git
```
or just download source - after that you need to go to its folder when you downloaded in command line type:
```
python setup.py install
```
You are done after you can simply do:
```
easy_install hg-git
```
On windows and make it work - so congratulations :-) Close. | I created a powershell script which does the installation in one step. The prereq is you have some build tools and python already installed:
<http://ig2600.blogspot.com/2013/02/using-git-via-hg-on-windows.html> | 1,572 |
25,343,981 | I'm writing a preprocessor in python, part of which works with an AST.
There is a `render()` method that takes care of converting various statements to source code.
Now, I have it like this (shortened):
```
def render(self, s):
""" Render a statement by type. """
# code block (used in structures)
if isinstance(s, S_Block):
# delegate to private method that does the work
return self._render_block(s)
# empty statement
if isinstance(s, S_Empty):
return self._render_empty(s)
# a function declaration
if isinstance(s, S_Function):
return self._render_function(s)
# ...
```
As you can see, it's tedious, prone to errors and the code is quite long (I have many more kinds of statements).
The ideal solution would be (in Java syntax):
```
String render(S_Block s)
{
// render block
}
String render(S_Empty s)
{
// render empty statement
}
String render(S_Function s)
{
// render function statement
}
// ...
```
Of course, python can't do this, because it has dynamic typing. When I searched for how to mimick method overloading, all answers just said "You don't want to do that in python". I guess that is true in some cases, but here `kwargs` is really not useful at all.
How would I do this in python, without the hideous kilometre-long sequence if type checking ifs, as shown above? Also, preferably a "pythonic" way to do so?
**Note:** There can be multiple "Renderer" implementations, which render the statements in different manners. I can't therefore move the rendering code to the statements and just call `s.render()`. It must be done in the renderer class.
(I've found some [interesting "visitor" code](http://curtis.schlak.com/2013/06/20/follow-up-to-python-visitor-pattern.html), but I'm not sure if it's really the thing I want). | 2014/08/16 | [
"https://Stackoverflow.com/questions/25343981",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2180189/"
] | Would something like this work?
```
self.map = {
S_Block : self._render_block,
S_Empty : self._render_empty,
S_Function: self._render_function
}
def render(self, s):
return self.map[type(s)](s)
```
Keeping a reference to a class object as a key in a dictionary and having it's value be the function object you want to call will make your code shorter and less error prone. The only place an error could occur here would be in the definition of the dictionary. Or one of your internal functions of course. | The overloading syntax you are looking for can be achieved using [Guido van Rossum's multimethod decorator](http://www.artima.com/weblogs/viewpost.jsp?thread=101605).
Here is a variant of the multimethod decorator which can decorate class methods (the original decorates plain functions). I've named the variant `multidispatch` to disambiguate it from the original:
```
import functools
def multidispatch(*types):
def register(function):
name = function.__name__
mm = multidispatch.registry.get(name)
if mm is None:
@functools.wraps(function)
def wrapper(self, *args):
types = tuple(arg.__class__ for arg in args)
function = wrapper.typemap.get(types)
if function is None:
raise TypeError("no match")
return function(self, *args)
wrapper.typemap = {}
mm = multidispatch.registry[name] = wrapper
if types in mm.typemap:
raise TypeError("duplicate registration")
mm.typemap[types] = function
return mm
return register
multidispatch.registry = {}
```
and it can be used like this:
```
class Foo(object):
@multidispatch(str)
def render(self, s):
print('string: {}'.format(s))
@multidispatch(float)
def render(self, s):
print('float: {}'.format(s))
@multidispatch(float, int)
def render(self, s, t):
print('float, int: {}, {}'.format(s, t))
foo = Foo()
foo.render('text')
# string: text
foo.render(1.234)
# float: 1.234
foo.render(1.234, 2)
# float, int: 1.234, 2
```
The demo code above shows how to overload the `Foo.render` method based on the types of its arguments.
This code searches for exact matching types as opposed to checking for `isinstance` relationships. It could be modified to handle that (at the expense of making the lookups O(n) instead of O(1)) but since it sounds like you don't need this anyway, I'll leave the code in this simpler form. | 1,574 |
13,621,095 | I want to use mmseg in Go as in other languages, for example, in python you can use pymmseg
So, is there is a similar Go package?
Or, how can I call the C functions from Go?
Or, how can I call shared library (\*.so) from Go like in python? | 2012/11/29 | [
"https://Stackoverflow.com/questions/13621095",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/860788/"
] | you can call use C Libs as described in this tutorial:
<http://cheesesun.blogspot.de/2009/12/basic-cgo.html>
and:
<http://siganakis.com/linking-c-libraries-with-go-lang-and-stdc99>
or you may have a look at this library:
<https://github.com/awsong/MMSEGO>
its for chinese, but you may could use it to put your own algorithm there. | Use `cgo` to call C code from Go.
[Command cgo](http://golang.org/cmd/cgo/)
[C? Go? Cgo!](http://blog.golang.org/2011/03/c-go-cgo.html) | 1,583 |
64,143,930 | I'm trying to read a json file as a pandas dataframe and convert it to a numpy array:
```
sample.json = [[["1", "2"], ["3", "4"]], [["7", "8"], ["9", "10"]]]
-------------------------------------------------------------------
df = pd.read_json('sample.json', dtype=float)
data = df.to_numpy()
print(df)
print(data)
```
However, this yields a numpy array of python lists:
```
0 1
0 [1, 2] [3, 4]
1 [7, 8] [9, 10]
[[list(['1', '2']) list(['3', '4'])]
[list(['7', '8']) list(['9', '10'])]]
```
When I want it to look like this:
```
[[1, 2], [3, 4]],
[[7, 8], [9, 10]]
```
I understand this can be accomplished by iterating over the array manually, but I'd rather avoid doing that as the data set is quite large. I have read that using `df.values()` is not encouraged. Any help appreciated | 2020/09/30 | [
"https://Stackoverflow.com/questions/64143930",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14061296/"
] | Why not load the JSON file with the builtin `json` module and convert to a numpy array?
```
import json
import numpy as np
data = json.loads("""[[["1", "2"], ["3", "4"]], [["7", "8"], ["9", "10"]]]""")
np.array(data, dtype=float)
array([[[ 1., 2.],
[ 3., 4.]],
[[ 7., 8.],
[ 9., 10.]]])
``` | Your data is 3-dimensional, not 2-dimensional. DataFrames are 2-dimensional, so the only way that it can convert your `sample.json` to a dataframe is by having a 2-dimensional table containing 1-dimensional items.
The easiest is to skip the pandas part completely:
```
import json
with open('/home/robby/temp/sample.json', 'r') as f:
jsonarray = json.load(f)
np.array(jsonarray, dtype=float)
``` | 1,584 |
52,090,461 | I want to use firebase-admin on GAE.
So I installed firebase-admin following method.
<https://cloud.google.com/appengine/docs/standard/python/tools/using-libraries-python-27>
appengine\_config.py
```
from google.appengine.ext import vendor
# Add any libraries install in the "lib" folder.
vendor.add('lib')
```
requirements.txt
```
firebase-admin
```
and install it.
```
pip install -t lib -r requirements.txt
```
Then I checked in the "lib" folder, six is existed.
And six version is 1.11.0.
But I've already use built-in six.
app.yaml
```
libraries:
- name: six
version: latest
```
Built-in six version is "1.9.0".
Does these difference have any effect on the process of GAE?
If there is any effect, How to solve this? | 2018/08/30 | [
"https://Stackoverflow.com/questions/52090461",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8118439/"
] | The `firebase-admin` package [requires `six>=1.6.1`](http://%60https://github.com/firebase/firebase-admin-python/blob/master/setup.py#L45), so manually copying in version `1.11.0` to your app won't cause problems with that library.
However, you should ensure that the code in your app that you originally added the `six` dependency for will work with this later version, as copied-in libraries will take precedence over any [built-in libraries](https://cloud.google.com/appengine/docs/standard/python/tools/built-in-libraries-27) (thus specifying it in `app.yaml` is unnecessary as well).
It's worth mentioning that copied-in libraries count towards file quotas, because the library is uploaded to App Engine along with your application code. If you're concerned about hitting this quota, [you can use this this technique to only install the dependencies that aren't already built-in](https://stackoverflow.com/questions/33441033/pip-install-to-custom-target-directory-and-exclude-specific-dependencies), which will cut down on the overall file size. | If there's a different version of a library in the lib directory and in the app.yaml, the one in the lib directory is the one which will be available to your app.
So, effectively, your app will be using six 1.11.0. You can verify that by logging `six.__version__` and see what version you get.
To avoid confusions, I would probably delete the six library entry in app.yaml. | 1,585 |
53,908,319 | Numbers that do not contain 4 convert just fine, but once number that contain 4 is tested, it does not convert properly.
I am new to python and I am struggling to see what was wrong in the code. The code for converting Arabic number to Roman numerals work for numbers that does not contain 4 in them. I have tried to test with different combination of numbers. The codes before the one below pretty much determine how many thousands, five hundreds, hundreds, etc that is in the number inputted. Could anyone help me?
```
def display_roman(M, D, C, L, X, V, I):
CM = 0
CD = 0
XC = 0
XL = 0
IX = 0
IV = 0
if D == 2:
M += 1
D -= 2
elif L == 2:
C += 1
L -= 2
elif V == 2:
X += 1
V -= 2
if V == 1 and I == 4:
V = 0
I = 0
IX = 1
elif I == 4:
I == 0
IV == 1
if X == 4:
X == 0
XL == 1
if L == 1 and X == 4:
L == 0
X == 0
XC == 1
if C == 4:
C == 0
CD == 1
if D == 1 and C == 4:
D == 0
C == 0
CM == 1
print("The roman numeral of your number is: ")
print("M" * M, "CM" * CM, "D" * D, "CD" * CD, "C" * C,"XC" * XC, "L" * L, "XL" * XL, "X" * X, "IX" * IX, "V" * V, "IV" * IV, "I" * I)
```
If I input numbers like 4 or 14, I expect to get IV and XIV respectively. But the actual outputs are IIII and XIIII respectively.
Please help. I'm sorry if there is something wrong with the format of my question as I am also new to stackoverflow. Thank you in advance. | 2018/12/24 | [
"https://Stackoverflow.com/questions/53908319",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10827443/"
] | Welcome to SO!
The problem is the way you are trying to define and change your variables. For example, this piece of code:
```
elif I == 4:
I == 0
IV == 1
```
should look like this instead:
```
elif I == 4:
I = 0
IV = 1
```
`==` is a boolean Operator that will return `True` if two values are the same and `False` if they are not. `=` is the correct way to assign a new value to a variable. After changing this, all works as intended.
---
```
display_roman(0, 0, 0, 0, 0, 0, 4)
display_roman(0, 0, 0, 0, 0, 1, 4)
The roman numeral of your number is:
IV
The roman numeral of your number is:
IX
``` | This converts any positive integer to roman numeral string:
```
def roman(num: int) -> str:
chlist = "VXLCDM"
rev = [int(ch) for ch in reversed(str(num))]
chlist = ["I"] + [chlist[i % len(chlist)] + "\u0304" * (i // len(chlist))
for i in range(0, len(rev) * 2)]
def period(p: int, ten: str, five: str, one: str) -> str:
if p == 9:
return one + ten
elif p >= 5:
return five + one * (p - 5)
elif p == 4:
return one + five
else:
return one * p
return "".join(reversed([period(rev[i], chlist[i * 2 + 2], chlist[i * 2 + 1], chlist[i * 2])
for i in range(0, len(rev))]))
```
Test code:
```
print(roman(6))
print(roman(78))
print(roman(901))
print(roman(2345))
print(roman(67890))
print(roman(123456))
print(roman(7890123))
print(roman(45678901))
print(roman(234567890))
```
Output:
```
VI
LXXVIII
CMI
MMCCCXLV
L̄X̄V̄MMDCCCXC
C̄X̄X̄MMMCDLVI
V̄̄M̄M̄D̄C̄C̄C̄X̄C̄CXXIII
X̄̄L̄̄V̄̄D̄C̄L̄X̄X̄V̄MMMCMI
C̄̄C̄̄X̄̄X̄̄X̄̄M̄V̄̄D̄L̄X̄V̄MMDCCCXC
```
Note that integers greater than 9 million are represented by the characters that contains 2 or more macrons, which are very unclear unless they are badly scaled-up | 1,586 |
33,797,793 | Here is part of program 'Trackbar as the Color Palette' in python which is include with opencv. I want to use it in c++.
My problem is the last line.
```
r = cv2.getTrackbarPos('R','image')
g = cv2.getTrackbarPos('G','image')
b = cv2.getTrackbarPos('B','image')
img[:] = [b,g,r]
```
Without this command I just have a black image. | 2015/11/19 | [
"https://Stackoverflow.com/questions/33797793",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5580005/"
] | You probably want to set all pixels of the `CV_8UC3` image `img` to the color given by `b`, `g` and `r`;
You can do this in OpenCV like:
```
img.setTo(Vec3b(b, g, r));
```
or equivalently:
```
img.setTo(Scalar(b, g, r));
```
---
In your code you're missing basically all the important parts:
* the infinite loop (so you exit the program without refreshing the image color)
* the assignment of the new color
* you are mixing obsolete C syntax and C++ syntax.
This is what you need:
```
#include <opencv2/opencv.hpp>
using namespace cv;
int main(int argc, char** argv)
{
// Initialize a black image
Mat3b imgScribble(256, 512, Vec3b(0,0,0));
namedWindow("Image", WINDOW_AUTOSIZE);
createTrackbar("R", "Image", 0, 255);
createTrackbar("G", "Image", 0, 255);
createTrackbar("B", "Image", 0, 255);
while (true)
{
int r = getTrackbarPos("R", "Image");
int g = getTrackbarPos("G", "Image");
int b = getTrackbarPos("B", "Image");
// Fill image with new color
imgScribble.setTo(Vec3b(b, g, r));
imshow("Image", imgScribble);
if (waitKey(1) == 27 /*ESC*/) break;
}
return 0;
}
``` | I think, you are looking for std::for\_each(). This code is untested. It is intended to show the concept, It might contain bugs:
```
// color type - use whatever you have
using color = std::array<char, 3>;
// prepare image, wherever you get that from
auto img = std::vector<color>{width * height, color{{0x00, 0x00, 0x00}}};
// define the color we want to have: white
char r = 0xff;
char g = 0xff;
char b = 0xff;
std::for_each(std::begin(img), std::end(img),
[&](color& i){
i = {r, g, b};
});
```
By choosing iterators different from `std::begin()` and `std::end()` you can of course select any slice of your vector.
Yes, the idioms in C++ are different to the ones in Python. | 1,591 |
36,308,537 | I am trying to create a variable in python with prefix as `list` and then number which will be generated dynamically in the script. For example
I am trying to have a list10 where list is the prefix and 10 is the number generated dynamically.
In TCL we give like
```
list${i}
```
Is there same way in python too? | 2016/03/30 | [
"https://Stackoverflow.com/questions/36308537",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1336962/"
] | The pythonic way to do this would be to make a dictionary to store your lists with the generated names as the dictionary's keys:
```
d = {}
d['list1'] = [1, 2, 3]
d['list2'] = ['a', 'b', 'c']
```
EDIT: generate key names
You can create keys like this:
```
key = 'list' + str(1) # or whatever number you are using
d[key] = [your list]
```
END EDIT
Or if you don't really need to know the names, store your lists in a list and retrieve them by index:
`lists = [[1, 2, 3], ['a', 'b', 'c']]` | You can use `locals()`, `vars()`, or `globals()` and inject your variable name there. For eg.
```
>>> list10
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'list10' is not defined
>>> locals()
{'__builtins__': <module '__builtin__' (built-in)>, '__package__': None, 'x': [], '__name__': '__main__', '__doc__': None}
>>> locals()['list10'] = []
>>> locals()
{'__builtins__': <module '__builtin__' (built-in)>, 'list10': [], '__package__': None, 'x': [], '__name__': '__main__', '__doc__': None}
>>> list10
[]
```
Generally, if you're doing something like this, you'd probably be better off with using a dictionary to store the variable name and the value(s).
For eg.
```
>>> my_lists = {}
>>> my_lists['list10'] = []
```
And then when you want to look it up, you can `.get()` it if you want robustness against a variable name not existing, or directly accessing it if you're going to guard against non-existence yourself.
```
>>> the_list_i_want = my_lists.get('list10')
>>> the_list_i_want = my_lists['list10'] # Will raise a KeyError if it does not exist
``` | 1,592 |
5,882,362 | What is the difference between `thread.start_new_thread` and `threading.Thread.start` in python?
I have noticed that when `start_new_thread` is called, the new thread terminates as soon as the calling thread terminates. `threading.Thread.start` is the opposite: the calling thread waits for other threads to terminate. | 2011/05/04 | [
"https://Stackoverflow.com/questions/5882362",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/322419/"
] | The `thread` module is the low-level threading API of Python. Its direct usage isn't recommended, unless you really need to. The `threading` module is a high-level API, built on top of `thread`. The `Thread.start` method is actually implemented using `thread.start_new_thread`.
The `daemon` attribute of `Thread` must be set before calling `start`, specifying whether the thread should be a daemon. The entire Python program exits when no alive non-daemon threads are left. By default, `daemon` is `False`, so the thread is not a daemon, and hence the process will wait for all its non-daemon thread to exit, which is the behavior you're observing.
---
P.S. `start_new_thread` really is very low-level. It's just a thin wrapper around the Python core thread launcher, which itself calls the OS thread spawning function. | See the [threading.Thread.daemon](http://docs.python.org/library/threading.html#threading.Thread.daemon) flag - basically whenever no non-daemon threads are running, the interpreter terminates. | 1,593 |
53,748,145 | I'm trying to containerize my django file, and I keep running into the issue:`(2006, ’Can\‘t connect to local MySQL server through socket \‘/var/run/mysqld/mysqld.sock\’ (2 “No such file or directory”)`
I found out later mysql.sock is in this location:`/tmp/mysql.sock` instead of `/var/run/mysqld/mysqld.sock`, how do I change the location for docker to see `/tmp/mysql.sock`
Here is my docker-composr.yml:
```
version: '3'
services:
db:
image: mysql
command: --default-authentication-plugin=mysql_native_password
restart: always
environment:
MYSQL_ROOT_PASSWORD: somepassword
adminer:
image: adminer
restart: always
ports:
- 8080:8080
web:
build: .
command: python manage.py runserver 0.0.0.0:8000
volumes:
- .:/code
ports:
- "8000:8000"
depends_on:
- db
```
I have followed the instructions on the mysql docker website to link mysql instance to a container
EDIT: I read another stack overflow similar to this, I changed my django code to `'HOST': '127.0.0.1'` in `DATABASES` now I get : `(2006, 'Can\'t connect to MySQL server on \'127.0.0.1\' (111 "Connection refused")')` | 2018/12/12 | [
"https://Stackoverflow.com/questions/53748145",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10241176/"
] | Without external dependencies, you can use [`filter`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/filter) to extract elements from `A` that don't have ids in `B` and `concat` that with `B`:
```js
const A = [{id: 1, name: 'x'}, {id: 2, name: 'y'}, {id: 3, name: 'z'}];
const B = [{id: 2, name: 'hello'}];
let ids = new Set(B.map(e => e.id));
let newState = A.filter(a => !ids.has(a.id)).concat(B);
console.log(newState);
``` | Since you are already using lodash, you can use `_.unionBy` which merges the arrays using a criterion by which uniqueness is computed:
```
let result = _.unionBy(B, A, "id");
```
Start with `B` before `A`, so that in case of duplicates, `B` values are taken instead of `A` ones.
**Example:**
```js
let A = [
{ id: "a", arr: "A" },
{ id: "b", arr: "A" },
{ id: "c", arr: "A" },
{ id: "d", arr: "A" }
];
let B = [
{ id: "b", arr: "B" },
{ id: "d", arr: "B" }
];
let result = _.unionBy(B, A, "id");
console.log(result);
```
```html
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.11/lodash.min.js"></script>
```
**Note:** This messes up the order of the items, the duplicates come first, then the rest. | 1,594 |
55,577,893 | I want to run a recursive function in Numba, using nopython mode. Until now I'm only getting errors. This is a very simple code, the user gives a tuple with less than five elements and then the function creates another tuple with a new value added to the tuple (in this case, the number 3). This is repeated until the final tuple has length 5. For some reason this is not working, don't know why.
```py
@njit
def tup(a):
if len(a) == 5:
return a
else:
b = a + (3,)
b = tup(b)
return b
```
For example, if `a = (0,1)`, I would expect the final result to be tuple `(0,1,3,3,3)`.
EDIT: I'm using Numba 0.41.0 and the error I'm getting is the kernel dying, 'The kernel appears to have died. It will restart automatically.' | 2019/04/08 | [
"https://Stackoverflow.com/questions/55577893",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2136601/"
] | There are several reasons why you shouldn't do that:
* This is generally a kind of approach that will likely be faster in pure Python than in a numba-decorated function.
* Iteration will be simpler and probably faster, however beware that concatenating tuples is generally an `O(n)` operation, even in numba. So the overall performance of the function will be `O(n**2)`. This can be improved by using a data-structure that supports `O(1)` appends or a data-structure that supports pre-allocating the size. Or simply by not using a "loopy" or "recursive" approach.
* Have you tried what happens if you leave out the `njit` decorator and pass in a tuple that contains 6 elements? (hint: it will hit the recursion limit because it never fulfills the end condition of the recursion).
Numba, at the time of writing 0.43.1, only supports simple recursions when the type of the arguments don't change between recursions. In your case the type does change, you pass in a `tuple(int64 x 2)` but the recursive call tries to pass in a `tuple(int64 x 3)` which is a different type. Strangely it runs into a `StackOverflow` on my computer - which seems like a bug in numba.
My suggestion would be to use this (no numba, no recursion):
```
def tup(a):
if len(a) < 5:
a += (3, ) * (5 - len(a))
return a
```
Which also returns the expected result:
```
>>> tup((1,))
(1, 3, 3, 3, 3)
>>> tup((1, 2))
(1, 2, 3, 3, 3)
``` | According to [this list of proposals](https://numba.pydata.org/numba-doc/latest/proposals/typing_recursion.html) in the current releases:
>
> Recursion support in numba is currently limited to self-recursion with
> explicit type annotation for the function. This limitation comes from
> the inability to determine the return type of a recursive call.
>
>
>
So, instead try:
```
from numba import jit
@jit()
def tup(a:tuple) -> tuple:
if len(a) == 5:
return a
return tup(a + (3,))
print(tup((0, 1)))
```
To see if that works any better for you. | 1,599 |
65,770,185 | I try to make a python script that gets the dam occupancy rates from a website. Here is the code:
```
baraj_link = "https://www.turkiye.gov.tr/istanbul-su-ve-kanalizasyon-idaresi-baraj-doluluk-oranlari"
response = requests.get(baraj_link)
soup = BeautifulSoup(response.text, "lxml")
values_list = []
values = soup.find_all('dl',{re.compile('compact')})
for val in values:
text = val.find_next('dt').text
value = val.text
values_list.append((text,value))
baraj = values_list[0][1]
```
The output is like this:
```
Tarih
18/01/2021
Genel Doluluk Oranı (%)
29,48
```
Genel Doluluk Oranı means occupancy rate. I need the value of occupancy rate which writes in next line like 29,48. How can I get this value from output? | 2021/01/18 | [
"https://Stackoverflow.com/questions/65770185",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14375618/"
] | ### Solution
For the descending order we multiply here by -1 each value in the array then sort the array and then multiply back with -1.
Ultimately we build the result string with string concatenation and print it out
```
import java.util.Arrays;
public class MyClass {
public static void main(String args[]) {
int[] array = {3,1,9};
for (int l = 0; l < array.length; l++){
array[l] = array[l]*-1;
}
Arrays.sort(array);
for (int l = 0; l < array.length; l++){
array[l] = array[l]*-1;
}
String res = "";
for(int i = 0; i < array.length; i++){
res+=array[i];
}
System.out.println(res);
}
}
```
### Output
```
931
```
### Alternatively
Or as @Matt has mentioned in the comments you can basically concat the string in reverse order. Then there is no need anymore for the ascending to descending transformation with `*-1`
```
import java.util.Arrays;
public class MyClass {
public static void main(String args[]) {
int[] array = {
9,
1,
3
};
String res = "";
Arrays.sort(array);
for (int l = array.length - 1; l >= 0; l--) {
res += array[l];
}
System.out.println(res);
}
}
``` | Hope it will work as per your requirement->
```
public static void main(String[] args) {
Integer[] arr = {1,3,3,9,60 };
List<Integer> flat = Arrays.stream(arr).sorted((a, b) -> findfirst(b) - findfirst(a)).collect(Collectors.toList());
System.out.println(flat);
}
private static int findfirst(Integer a) {
int val = a;
if(val>=10) {
while (val >= 10) {
val = val / 10;
}
}
return val;
}
``` | 1,600 |
30,207,041 | Been using the safe and easy confines of PyCharm for a bit now, but I'm trying to get more familiar with using a text editor and the terminal together, so I've forced myself to start using iPython Notebook and Emacs. Aaaaand I have some really dumb questions.
* after firing up ipython notebook from terminal with the command 'ipython notebook', it pops up on my browser and lets me code. but can i not use terminal while it's connected to ipython notebook server?
* after writing my code in ipython notebook, i'm left with a something.ipynb file. How do I run this file from terminal? If it was a .py file, i know i could execute it by tying python something.py from the command line; but it doesn't work if i type python something.ipynb in the command line. And of course, I assume I hit Control-C to quit out of the running server in terminal first? or do I run the command without quitting that? Or am i doomed to test it in iPython and then copy and paste it to a different txt editor like Emacs and save it in a .py file to run it?
* what good is the .ipynb file if i can't run it in terminal or outside the iPython Notebook browser? Could I get my code in a .py from iPython Notebook if I wanted to? (i assume I'll be able to easily run it in terminal by tying something.py then)
thanks in advance. I'm still very much trying to figure out how to use this thing and there aren't many answers out there for questions this elementary. | 2015/05/13 | [
"https://Stackoverflow.com/questions/30207041",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4698759/"
] | * Yes, you can not use the same terminal. Solutions: open another terminal or run `ipython notebook` inside [`screen`](http://www.gnu.org/software/screen/manual/screen.html). If you use Windows you might want to take a look into [this question](https://stackoverflow.com/questions/5473384/terminal-multiplexer-for-microsoft-windows-installers-for-gnu-screen-or-tmux)
* Notebook documents (`ipynb` files) can be converted to a range of static formats including LaTeX, HTML, PDF and Python. Read more about converting notebooks in [manual](http://ipython.org/ipython-doc/stable/notebook/nbconvert.html#nbconvert)
* Notebooks are great, because you can show other people your interactive sessions accompanied with text, which may have rich formatting. And if someone can run notebook server he can easily reproduce your computations and maybe modify them. Check out [awesome notebook](http://nbviewer.ipython.org/url/norvig.com/ipython/TSPv3.ipynb) on traveling salesperson problem by Peter Norvig as an example of what you can do with `ipynb`. Or [this notebook](https://dato.com/learn/gallery/notebooks/graph_analytics_movies.html). More examples are available [here](https://github.com/ipython/ipython/wiki/A-gallery-of-interesting-IPython-Notebooks) | * You can run your IPython notebook process in background.
On Unix platforms you can perform that with (note the leading `&`):
```
ipython notebook &
```
Or after a "normal" run, hit `[Control+z]` and run the `bg` command
([some lecture](http://web.mit.edu/gnu/doc/html/features_5.html)).
* you can convert `.ipynb` file into `.py` file using `nbconvert`
with Ipython notebook 2.x ([some lecture](http://ipython.org/ipython-doc/2/notebook/nbconvert.html)):
```
ipython nbconvert --to python mynotebook.ipynb
```
with Ipython notebook 3.x ([some lecture](http://ipython.org/ipython-doc/3/notebook/nbconvert.html)):
```
ipython nbconvert --to script mynotebook.ipynb
```
* `.ipynb` contains your script **AND results AND formatted text**.
You can compare it to a [literate script](http://en.wikipedia.org/wiki/Literate_programming) (but using "machine programming language"). | 1,606 |
44,813,375 | I am interested in the truth value of Python sets like `{'a', 'b'}`, or the empty set `set()` (which is not the same as the empty dictionary `{}`). In particular, I would like to know whether `bool(my_set)` is `False` if and only if the set `my_set` is empty.
Ignoring primitive (such as numerals) as well as user-defined types, <https://docs.python.org/3/library/stdtypes.html#truth> says:
>
> The following values are considered false:
>
>
> * [...]
> * any empty sequence, for example, `''`, `()`, `[]`.
> * any empty mapping, for example, `{}`.
> * [...]
>
>
> All other values are considered true
>
>
>
According to <https://docs.python.org/3/library/stdtypes.html#sequence-types-list-tuple-range>, a set is not a sequence (it is unordered, its elements do not have indices, etc.):
>
> There are three basic sequence types: lists, tuples, and range objects.
>
>
>
And, according to <https://docs.python.org/3/library/stdtypes.html#mapping-types-dict>,
>
> There is currently only one standard mapping type, the *dictionary*.
>
>
>
So, as far as I understand, the set type is not a type that can ever be `False`. However, when I try, `bool(set())` evaluates to `False`.
Questions:
* Is this a documentation problem, or am I getting something wrong?
* Is the empty set the only set whose truth value is `False`? | 2017/06/28 | [
"https://Stackoverflow.com/questions/44813375",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/6867099/"
] | After looking at the source code for CPython, I would guess this is a documentation error, however, it could be implementation dependent and therefore would be a good issue to raise on the Python bug tracker.
Specifically, [object.c](https://github.com/python/cpython/blob/a66f9c6bb134561a24374f10e8c35417d356ce14/Objects/object.c#L1313) defines the truth value of an item as follows:
```
int
PyObject_IsTrue(PyObject *v)
{
Py_ssize_t res;
if (v == Py_True)
return 1;
if (v == Py_False)
return 0;
if (v == Py_None)
return 0;
else if (v->ob_type->tp_as_number != NULL &&
v->ob_type->tp_as_number->nb_bool != NULL)
res = (*v->ob_type->tp_as_number->nb_bool)(v);
else if (v->ob_type->tp_as_mapping != NULL &&
v->ob_type->tp_as_mapping->mp_length != NULL)
res = (*v->ob_type->tp_as_mapping->mp_length)(v);
else if (v->ob_type->tp_as_sequence != NULL &&
v->ob_type->tp_as_sequence->sq_length != NULL)
res = (*v->ob_type->tp_as_sequence->sq_length)(v);
else
return 1;
/* if it is negative, it should be either -1 or -2 */
return (res > 0) ? 1 : Py_SAFE_DOWNCAST(res, Py_ssize_t, int);
}
```
We can clearly see that the value is value would be always true if it is not a boolean type, None, a sequence, or a mapping type, which would require tp\_as\_sequence or tp\_as\_mapping to be set.
Fortunately, looking at [setobject.c](https://github.com/python/cpython/blob/master/Objects/setobject.c#L2127) shows that sets do implement tp\_as\_sequence, suggesting the documentation seems to be incorrect.
```
PyTypeObject PySet_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"set", /* tp_name */
sizeof(PySetObject), /* tp_basicsize */
0, /* tp_itemsize */
/* methods */
(destructor)set_dealloc, /* tp_dealloc */
0, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_reserved */
(reprfunc)set_repr, /* tp_repr */
&set_as_number, /* tp_as_number */
&set_as_sequence, /* tp_as_sequence */
0, /* tp_as_mapping */
/* ellipsed lines */
};
```
[Dicts](https://github.com/python/cpython/blob/master/Objects/dictobject.c#L3254) also implement tp\_as\_sequence, so it seems that although it is not a sequence type, it sequence-like, enough to be truthy.
In my opionion, the documentation should clarify this: mapping-like types, or sequence-like types will be truthy dependent on their length.
**Edit** As user2357112 correctly points out, `tp_as_sequence` and `tp_as_mapping` do not mean the type is a sequence or a map. For example, dict implements `tp_as_sequence`, and list implements `tp_as_mapping`. | That part of the docs is poorly written, or rather, poorly maintained. The following clause:
>
> instances of user-defined classes, if the class defines a `__bool__()` or `__len__()` method, when that method returns the integer zero or bool value False.
>
>
>
really applies to *all* classes, user-defined or not, including `set`, `dict`, and even the types listed in all the other clauses (all of which define either `__bool__` or `__len__`). (In Python 2, `None` is false despite not having a `__len__` or Python 2's equivalent of `__bool__`, but that exception is [gone since Python 3.3](http://bugs.python.org/issue12647).)
I say poorly maintained because this section has been almost unchanged since at least [Python 1.4](https://docs.python.org/release/1.4/lib/node5.html#SECTION00311000000000000000), and maybe earlier. It's been updated for the addition of `False` and the removal of separate int/long types, but not for type/class unification or the introduction of sets.
Back when the quoted clause was written, user-defined classes and built-in types really did behave differently, and I don't think built-in types actually had `__bool__` or `__len__` at the time. | 1,607 |
59,063,829 | I tried to get a vector dot product in a nested list
For example :
```
A = np.array([[1,2,1,3],[2,1,2,3],[3,1,2,4]])
```
And I tried to get:
```
B = [[15], [19, 23]]
```
Where 15 = np.dot(A[0],A[1]),
19 = np.dot(A[0],A[2]),
23 = np.dot(A[1],A[2])
The fist inner\_list in B is the dot product of A[0] and A[1],
The second inner\_list in B is
dot product of A[0] and A[2], dot product of A[1] and A[2]
I tried to write some loop in python but failed
How to get B in Python? | 2019/11/27 | [
"https://Stackoverflow.com/questions/59063829",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10595338/"
] | Here is a explicit for loop coupled with list comprehension solution:
```
In [1]: import numpy as np
In [2]: A = np.array([[1,2,1,3],[2,1,2,3],[3,1,2,4]])
In [5]: def get_dp(A):
...: out = []
...: for i, a in enumerate(A[1:]):
...: out.append([np.dot(a, b) for b in A[:i+1]])
...: return out
In [6]: get_dp(A)
Out[6]: [[15], [19, 23]]
```
Explanation: The for loop is running from 2nd elements and the list comprehension is running from the beginning to the current iterated element. | An iterator class that spits out elements same as B.
If you want the full list, you can `list(iter_dotprod(A))`
example:
```py
class iter_dotprod:
def __init__(self, nested_arr):
self.nested_arr = nested_arr
self.hist = []
def __iter__(self):
self.n = 0
return self
def __next__(self):
if self.n > len(self.nested_arr) -2:
raise StopIteration
res = np.dot(self.nested_arr[self.n], self.nested_arr[self.n+1])
self.hist.append(res)
self.n += 1
return self.hist
A = np.array([[1,2,1,3],[2,1,2,3],[3,1,2,4]])
tt = iter_dotprod(A)
for b in iter_dotprod(A):
print(b)
``` | 1,610 |
64,799,010 | I am trying to get all ec2 instances details in a csv file, followed another post "https://stackoverflow.com/questions/62815990/export-aws-ec2-details-to-xlsx-csv-using-boto3-and-python". But was having attribute error for Instances. So I am trying this:
```
import boto3
import datetime
import csv
ec2 = boto3.resource('ec2')
for i in ec2.instances.all():
Id = i.id
State = i.state['Name']
Launched = i.launch_time
InstanceType = i.instance_type
Platform = i.platform
if i.tags:
for idx, tag in enumerate(i.tags, start=1):
if tag['Key'] == 'Name':
Instancename = tag['Value']
output = Instancename + ',' + Id + ',' + State + ',' + str(Platform) + ',' + InstanceType + ',' + str(Launched)
with open('ec2_list.csv', 'w', newline='') as csvfile:
header = ['Instancename', 'Id', 'State', 'Platform', 'InstanceType', 'Launched']
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerow(output)
```
For above I am having below error:
```
traceback (most recent call last):
File "list_instances_2.py", line 23, in <module>
writer.writerow(output)
File "/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/csv.py", line 155, in writerow
return self.writer.writerow(self._dict_to_list(rowdict))
File "/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/csv.py", line 148, in _dict_to_list
wrong_fields = rowdict.keys() - self.fieldnames
AttributeError: 'str' object has no attribute 'keys'
```
I can see that this is not creating a dict output. Need suggestions on how can I create a dictionary of 'output' and publish that in a .csv file. | 2020/11/12 | [
"https://Stackoverflow.com/questions/64799010",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14614887/"
] | Since you are using `DictWriter`, your `output` should be:
```
output = {
'Instancename': Instancename,
'Id': Id,
'State': State,
'Platform': str(Platform),
'InstanceType': InstanceType ,
'Launched': str(Launched)
}
```
Your function will also just keep **overwriting** your `ec2_list.csv` in each iteration, so you should probably re-factor it anyway. | A [`DictWriter`](https://docs.python.org/3/library/csv.html#csv.DictWriter) - as the name would suggest - writes `dicts` i.e. dictionaries to a CSV file. The dictionary must have the keys that correspond to the column names. See the example in the docs I linked.
In the code you posted, you are passing `output` - a string - to the `writerow` function. Which will not work because, a string is not a `dict`.
You'll have to convert your `output` to something that `writerow` can accept, like a `dict`:
```
output = {'Instancename': Instancename, 'Id': Id ... }
```
And then try that. | 1,611 |
72,842,182 | I am using flask with this code:
```py
from flask import Flask, request, render_template
app = Flask(__name__)
@app.route('/')
def home():
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True, port=8000)
```
```html
<form method="GET">
<p>Phone number:</p>
<input name="phone_number" type="number">
<br><br>
<input type="submit">
</form>
```
I want to be able to use the inputted phone number text as a variable in my python code when it is submitted. How do I do that? | 2022/07/02 | [
"https://Stackoverflow.com/questions/72842182",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/19409503/"
] | In most cases, if you are using `react-hook-form`, you don't need to track form fields with `useState` hook.
Using a `Controller` component is the right way to go. But there is a problem with `onChange` handler in your 1st method.
When you submit form, you are getting default date `null` because `field` is destructed, but it's not passed to `DatePicker`. So, `onChange` prop of `field` is not triggered when date is changed and `react-hook-form` doesn't have new date.
Here's how your render method should be
```
render={({field}) =>
<LocalizationProvider dateAdapter={AdapterDateFns}>
<DatePicker
label="Original Release Date"
renderInput={(params) =>
<TextField
{...params}
/>}
{...field}
/>
</LocalizationProvider>
}
```
If for some reason, you need to update component state then you have to send data to `react-hook-form` and then update local state
```
render={({field: {onChange,...restField}) =>
<LocalizationProvider dateAdapter={AdapterDateFns}>
<DatePicker
label="Original Release Date"
onChange={(event) => {
onChange(event);
setOriginalReleaseDate(event.target.value);
}}
renderInput={(params) =>
<TextField
{...params}
/>}
{...restField}
/>
</LocalizationProvider>
}
``` | I couldn't replicate your setup, but my guess is that in the first render the
reference to the 'setOriginalReleaseDate' is lost when being passed through the Controller's render arrow function.
```
...
onChange={(newValue) => {
setOriginalReleaseDate(newValue);
}}
...
```
so, try putting the logic in a defined function like:
```
const handleOriginalReleaseDateChange = (newValue) => {
setOriginalReleaseDate(newValue);
};
```
and change the onChange to call the function.
```
...
onChange={handleOriginalReleaseDateChange}
...
``` | 1,612 |
48,399,812 | I have a python script that has to be executed with start and end dates. I want to execute this file for each day in the year 2012, so I thought a while-loop inside a bash script would do the job but my bash-skills are not sufficient.
This is what I tried:
```
day_start = 2012-01-01
while [ "$day_start" != 2013-01-01 ] ;
do
day_end =$(date -I -d "$day_start + 1 day")
python script.py --since ="$day_start" --until = "$day_end" ;
day_start =$(date -I -d "$day_start + 1 day")
echo $day_start
done
```
The error message I get is that python does not seem to like the "$bash-variable" input. Also, I thought this was the way to +1 for days inside bash, but I get an error for day\_end and day\_start as well. Can somebody help me out here? (Sorry if this is probably pretty basic!) | 2018/01/23 | [
"https://Stackoverflow.com/questions/48399812",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7436993/"
] | Answer is simply stupid... Just restart your OS X. I don't know why, it looks like that operation system needs to rebuild some data after doing scenario from this question | Found submitted issue and solved it using the steps given here <https://github.com/desktop/desktop/issues/3625>
* Open Keychain Access.app
* Right click on login
* Click locking
* Click unlocking | 1,617 |
8,957,186 | >
> **Possible Duplicate:**
>
> [Python Ternary Operator](https://stackoverflow.com/questions/394809/python-ternary-operator)
>
>
>
In some languages including Java, C/C++, C#, etc. you can assign a value based on the result of an inline boolean expression.
For example,
```
return (i < x) ? i : x
```
This will return i if i < x, otherwise it will return x. I like this because it is much more compact in many cases than the longer syntax which follows.
```
if (i < x)
return i
else
return x
```
Is it possible to use this syntax in python and if so, how? | 2012/01/21 | [
"https://Stackoverflow.com/questions/8957186",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1162865/"
] | `a if b else c` syntax was introduced in Python 2.5. Most people have already upgraded to the recent version but in legacy code you may find another approach:
```
some_var = a<b and a or c
```
If you ever will be using this syntax remember that `a` must not evaluate to False. | Try this in Python:
```
return i if i < x else x
```
It's exactly the equivalent of the following expression in Java, C, C++ C#
```
return i < x ? i : x;
```
Read more about Python's [conditional expressions](http://docs.python.org/reference/expressions.html#conditional-expressions). | 1,618 |
44,781,806 | I seem to be breaking `tkinter` on linux by using some multi-threading. As far as I can see, I am managing to trigger a garbage collection on a thread which is not the main GUI thread. This is causing `__del__` to be run on a `tk.StringVar` instance, which tries to call the `tcl` stack from the wrong thread, causing chaos on linux.
The code below is the minimal example I've been able to come up with. Notice that I'm not doing any real work with `matplotlib`, but I can't trigger the problem otherwise. The `__del__` method on `Widget` verifies that the `Widget` instance is being deleted from the other thread. Typical output is:
```
Running off thread on 140653207140096
Being deleted... <__main__.Widget object .!widget2> 140653210118576
Thread is 140653207140096
... (omitted stack from from `matplotlib`
File "/nfs/see-fs-02_users/matmdpd/anaconda3/lib/python3.6/site-packages/matplotlib/text.py", line 218, in __init__
elif is_string_like(fontproperties):
File "/nfs/see-fs-02_users/matmdpd/anaconda3/lib/python3.6/site-packages/matplotlib/cbook.py", line 693, in is_string_like
obj + ''
File "tk_threading.py", line 27, in __del__
traceback.print_stack()
...
Exception ignored in: <bound method Variable.__del__ of <tkinter.StringVar object at 0x7fec60a02ac8>>
Traceback (most recent call last):
File "/nfs/see-fs-02_users/matmdpd/anaconda3/lib/python3.6/tkinter/__init__.py", line 335, in __del__
if self._tk.getboolean(self._tk.call("info", "exists", self._name)):
_tkinter.TclError: out of stack space (infinite loop?)
```
By modifying the `tkinter` library code, I can verify that `__del__` is being called from the same place as `Widget.__del__`.
>
> Is my conclusion here correct? How can I stop this happening??
>
>
>
I really, really want to call `matplotlib` code from a separate thread, because I need to produce some complex plots which are slow to render, so making them off-thread, generating an image, and then displaying the image in a `tk.Canvas` widget seemed like an elegant solution.
Minimal example:
```
import tkinter as tk
import traceback
import threading
import matplotlib
matplotlib.use('Agg')
import matplotlib.figure as figure
from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
class Widget(tk.Frame):
def __init__(self, parent):
super().__init__(parent)
self.var = tk.StringVar()
#tk.Entry(self, textvariable=self.var).grid()
self._thing = tk.Frame(self)
def task():
print("Running off thread on", threading.get_ident())
fig = figure.Figure(figsize=(5,5))
FigureCanvas(fig)
fig.add_subplot(1,1,1)
print("All done off thread...")
#import gc
#gc.collect()
threading.Thread(target=task).start()
def __del__(self):
print("Being deleted...", self.__repr__(), id(self))
print("Thread is", threading.get_ident())
traceback.print_stack()
root = tk.Tk()
frame = Widget(root)
frame.grid(row=1, column=0)
def click():
global frame
frame.destroy()
frame = Widget(root)
frame.grid(row=1, column=0)
tk.Button(root, text="Click me", command=click).grid(row=0, column=0)
root.mainloop()
```
Notice that in the example, I don't need the `tk.Entry` widget. *However* if I comment out the line `self._thing = tk.Frame(self)` then I *cannot* recreate the problem! I don't understand this...
If I uncomment then `gc` lines, then also the problem goes away (which fits with my conclusion...)
*Update:* This seem to work the same way on Windows. `tkinter` on Windows seems more tolerant of being called on the "wrong" thread, so I don't get the `_tkinter.TclError` exception. But I can see the `__del__` destructor being called on the non-main thread. | 2017/06/27 | [
"https://Stackoverflow.com/questions/44781806",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3403507/"
] | I had exactly the same problem
It was a nightmare to find the cause of the issue. I exaustivelly verified that no tkinter object was being called from any thread. I made a mechanism based in queues to handle tkinter objects in threads.
There are many examples on the web on how to do that, or... search for a module 'mttkinter', a thread safe wrapper for Tkinter)
In a effort to force garbage collection, I used the "gc" method in the exit function of every TopLevel window of my App.
```
#garbage collector
import gc
...
gc.collect()
```
but for some reason, closing a toplevel window continued to reproduce the problem. Anyway... it was precisely using some prints in the aforementioned "mttkinter" module that I detected that, in spite the widgets are being created in the main thread, they could be garbage collected when garbage collector is triggered inside another thread. It looks like that the garbage collector gathers all the garbage without any distinction of its provenience (mainthread or other threads?). Someone please correct me if I'm wrong.
My solution was to call the garbage collector explicitly using the queue as well.
```
PutInQueue(gc.collect)
```
Where "PutInQueue" belongs to a module created by me to handle tkinter object and other kind of objects with thread safety.
Hope this report can be of great usefullness to someone or, it it is the case, to expose any eventual bug in garbage collector. | Tkinter is not thread safe. Calling Tkinter objects in a thread may cause things such as "The **del** method on Widget verifies that the Widget instance is being deleted from the other thread."
You can use locking and queues to make it done properly.
Check this example:
[Tkinter: How to use threads to preventing main event loop from "freezing"](https://stackoverflow.com/questions/16745507/tkinter-how-to-use-threads-to-preventing-main-event-loop-from-freezing)
and this example (there are many many other examples you can find):
[Mutli-threading python with Tkinter](https://stackoverflow.com/questions/14379106/mutli-threading-python-with-tkinter)
Hope this will put you in the right direction. | 1,628 |
72,882,082 | Can someone explain me what is going on here and how to prevent this?
I have a **main.py** with the following code:
```python
import utils
import torch
if __name__ == "__main__":
# Foo
print("Foo")
# Bar
utils.bar()
model = torch.hub.load("ultralytics/yolov5", "yolov5s")
```
I outsourced some functions into a module named **utils.py**:
```python
def bar():
print("Bar")
```
When I run this I get the following output:
```
(venv) jan@xxxxx test % python main.py
Foo
Bar
Using cache found in /Users/jan/.cache/torch/hub/ultralytics_yolov5_master
Traceback (most recent call last):
File "/Users/jan/PycharmProjects/test/main.py", line 12, in <module>
model = torch.hub.load("ultralytics/yolov5", "yolov5s")
File "/Users/jan/PycharmProjects/test/venv/lib/python3.10/site-packages/torch/hub.py", line 540, in load
model = _load_local(repo_or_dir, model, *args, **kwargs)
File "/Users/jan/PycharmProjects/test/venv/lib/python3.10/site-packages/torch/hub.py", line 569, in _load_local
model = entry(*args, **kwargs)
File "/Users/jan/.cache/torch/hub/ultralytics_yolov5_master/hubconf.py", line 81, in yolov5s
return _create('yolov5s', pretrained, channels, classes, autoshape, _verbose, device)
File "/Users/jan/.cache/torch/hub/ultralytics_yolov5_master/hubconf.py", line 31, in _create
from models.common import AutoShape, DetectMultiBackend
File "/Users/jan/.cache/torch/hub/ultralytics_yolov5_master/models/common.py", line 24, in <module>
from utils.dataloaders import exif_transpose, letterbox
ModuleNotFoundError: No module named 'utils.dataloaders'; 'utils' is not a package
```
So it seems like the **torch** package I imported has also a **utils** resource (package) and searches for a module named "utils.dataloaders". Okay. But why is it searching in my utils module? And why isn't it continuing searching in its own package if it doesn't find a matching resource in my code? And last but not least: How can I prevent this situation?
I changed `import utils` to `import utils as ut` and call my function with `ut.bar()` but it doesn't make any difference.
The only thing that worked is to **rename** my `utils.py` to something else but this cannot be the solution...
Thanks for your help. Cheers,
Jan | 2022/07/06 | [
"https://Stackoverflow.com/questions/72882082",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4875142/"
] | It is not `DELETE * FROM`, but `DELETE FROM`.
```
DELETE FROM mlode WHERE kd >= DATE '2019-01-01';
``` | ```
BEGIN TRANSACTION
DELETE FROM [TABLE] WHERE [DATEFIELD] > DATEFROMPARTS(2018, 12, 30)
COMMIT TRANSACTION
``` | 1,629 |
19,699,314 | Below is my test code.
When running with python2.7 it shows that the program won't receive any signal until all spawned threads finish.
While with python3.2, only the main thread's sigintHandler gets called.
I'am confused with how python handles threads and signal, so how do I spawn a thread and do signal handling within that thread? Is it possible at all?
```
from __future__ import print_function
from threading import Thread
import signal, os, sys
from time import sleep
def sigintHandler(signo, _):
print("signal %d caught"%signo)
def fn():
print("thread sleeping")
sleep(10)
print("thread awakes")
signal.signal(signal.SIGINT, sigintHandler)
ls = []
for i in range(5):
t = Thread(target=fn)
ls.append(t)
t.start()
print("All threads up, pid=%d"%os.getpid())
for i in ls:
i.join()
while True:
sleep(20)
``` | 2013/10/31 | [
"https://Stackoverflow.com/questions/19699314",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/922727/"
] | You can give like
```
$(this).datepicker({
"dateFormat": 'mm/dd/yy',
"changeMonth": true,
"changeYear": true,
"yearRange": year + ":" + year
});
``` | Read [yearRange](http://api.jqueryui.com/datepicker/#option-yearRange)
```
var year_text = year + ":" + year ;
```
or
```
"yearRange": year + ":" + year
``` | 1,630 |
48,577,536 | **Background**
I would like to do mini-batch training of "stateful" LSTMs in Keras. My input training data is in a large matrix "X" whose dimensions are m x n where
```python
m = number-of-subsequences
n = number-of-time-steps-per-sequence
```
Each row of X contains a subsequence which picks up where the subsequence on the preceding row leaves off. So given a long sequence of data,
```python
Data = ( t01, t02, t03, ... )
```
where "tK" means the token at position K in the original data, the sequence is layed out in X like so:
```python
X = [
t01 t02 t03 t04
t05 t06 t07 t08
t09 t10 t11 t12
t13 t14 t15 t16
t17 t18 t19 t20
t21 t22 t23 t24
]
```
**Question**
My question is about what happens when I do mini-batch training on data layed out this way with stateful LSTMs. Specifically, mini-batch training typically trains on "contiguous" groups of rows at a time. So if I use a mini-batch size of 2, then X would be split into three mini-batches X1, X2 and X3 where
```python
X1 = [
t01 t02 t03 t04
t05 t06 t07 t08
]
X2 = [
t09 t10 t11 t12
t13 t14 t15 t16
]
X3 = [
t17 t18 t19 t20
t21 t22 t23 t25
]
```
Notice that this type of mini-batching does not agree with training **stateful** LSTMs since the hidden states produced by processing the last column of the previous batch are not the hidden states that correspond to the time-step before the first column of the subsequent batch.
To see this, notice that the mini-batches will be processed as though from left-to-right like this:
```python
------ X1 ------+------- X2 ------+------- X3 -----
t01 t02 t03 t04 | t09 t10 t11 t12 | t17 t18 t19 t20
t05 t06 t07 t08 | t13 t14 t15 t16 | t21 t22 t23 t24
```
implying that
```python
- Token t04 comes immediately before t09
- Token t08 comes immediately before t13
- Token t12 comes immediately before t17
- Token t16 comes immediately before t21
```
But I want mini-batching to group rows so that we get this kind of temporal alignment across mini-batches:
```python
------ X1 ------+------- X2 ------+------- X3 -----
t01 t02 t03 t04 | t05 t06 t07 t08 | t09 t10 t11 t12
t13 t14 t15 t16 | t17 t18 t19 t20 | t21 t22 t23 t24
```
What is the standard way to accomplish this when training LSTMs in Keras?
Thanks for any pointers here. | 2018/02/02 | [
"https://Stackoverflow.com/questions/48577536",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4441470/"
] | You can set you ViewHolder class as [`inner`](https://kotlinlang.org/docs/reference/nested-classes.html) | Use the `companion object`:
```
class MyAdapter(private val dataList: ArrayList<String>) :
RecyclerView.Adapter<MyAdapter.ViewHolder>() {
class ViewHolder(v: View) : RecyclerView.ViewHolder(v), View.OnClickListener {
fun bindData() {
//some statements
}
override fun onClick(p0: View?) {
Log.d(TAG, "")
}
}
companion object {
val TAG: String? = MyAdapter::class.simpleName
}
}
``` | 1,632 |
2,111,765 | totally confused by now... I am developing in python/django and using python logging. All of my app requires unicode and all my models have only a **unicode**()`, return u'..' methods implemented. Now when logging I have come upon a really strange issue that it took a long time to discover that I could reproduce it. I have tried both Py 2.5.5 and Py 2.6.4 and same thing. So
Whenever I do some straight forward logging like:
```
logging.debug(u'new value %s' % group)
```
this calls the models group.**unicode**(): return unicode(group.name)
My unicode methods all looks like this:
```
def __unicode__(self):
return u'%s - %s (%s)' % (self.group, self.user.get_full_name(), self.role)
```
This works even if group.name is XXX or ÄÄÄ (requiring unicode). But when I for some reason want to log a set, list, dictionary, django-query set and the individual instances in e.g. the list might be unicode or not I get into trouble...
So this will get me a UnicodeDecodingError whenever a group.name requires unicode like Luleå (my hometown)
```
logging.debug(u'new groups %s' % list_of_groups)
```
Typically I get an error like this:
```
Exception Type: UnicodeDecodeError
Exception Value: ('ascii', '<RBACInstanceRoleSet: s2 | \xc3\x84\xc3\x96\xc3\x96\xc3\x85\xc3\x85\xc3\x85 Gruppen>]', 106, 107, 'ordinal not in range(128)')
```
But if I do `print list_of_groups` everything gets out nice on terminal
So, my understanding is that the list starts to generate itself and does repr() on all its elements and they return their values - in this case it should be 's2 | ÅÄÖÖ', then the list presents itself as (ascii, the-stuff-in-the-list) and then when trying to Decode the *ascii* into unicode this will of course not work -- since one of the elements in the list has returened a u'...' of itself when repr was done on it.
But why is this????´
And why do things work and unicode/ascii is handled correctly whenever I log simple things like group.name and so or group and the **unicode** methods are called. Whenever I get lazy and want to log a list, set or other things go bad whenever a unicode character is encountered...
Some more examples that work and fail. If `group.name` I go to the model field and `group` calls the `__unicode__()`
```
logging.debug("1. group: %s " % group.name) # WORKS
logging.debug(u"2. group: %s " % group) # WORKS
logging.debug("3. group: %s " % group) # FAILS
logging.debug(u"4. group: %s " % group.name) # WORKS
logging.debug("5. group: %s " % group.name) # WORKS
```
...and I really thought I had a grip on Unicode ;-( | 2010/01/21 | [
"https://Stackoverflow.com/questions/2111765",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/256037/"
] | I can't reproduce your problem with a simple test:
```
Python 2.6.4 (r264:75706, Dec 7 2009, 18:45:15)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import logging
>>> group = u'Luleå'
>>> logging.warning('Group: %s', group)
WARNING:root:Group: Luleå
>>> logging.warning(u'Group: %s', group)
WARNING:root:Group: Luleå
>>>
```
So, as Daniel says, there is probably something which is not proper Unicode in what you're passing to logging.
Also, I don't know what handlers you're using, but make sure if there are file handlers that you explicitly specify the output encoding to use, and if there are stream handlers you also wrap any output stream which needs it with an encoding wrapper such as is provided by the `codecs` module (and pass the wrapped stream to logging). | have you tried manually making any result unicode?
```
logging.debug(u'new groups %s' % unicode(list_of_groups("UTF-8"))
``` | 1,635 |
46,591,968 | im new to python and im failing to achieve this.
I have two lists of lists:
```
list1 = [['user1', 'id1'], ['user2', 'id2'], ['user3', 'id3']...]
list2 = [['id1', 'group1'], ['id1', 'group2'], ['id2', 'group1'], ['id2', 'group4']...]
```
And what i need is a single list like this:
```
[['user1','id1','group1'],['user1','id1','group2'],['user2','id2','group1']]
```
I suppose I could iterate all the lists and compare values but i think there must be some built-in function that allows me to saerch a value in a list of lists and return the key or something like that. But i cant find anything for multidimensional lists.
Note that the idN value in the first list not necessarily exists in the second one.
Thanks for your help! | 2017/10/05 | [
"https://Stackoverflow.com/questions/46591968",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8419741/"
] | There's no such thing in python. There are methods for multidimensional arrays in `numpy`, but they are not really suitable for text.
Your second list functions as a dictionary, so make one
```
dict2 = {key:value for key, value in list2}
```
and then
```
new_list = [[a, b, dict2[b]] for a, b in list1]
``` | If you have to use lists of lists, you can use a comprehension to achieve this.
```
list1 = [['user1', 'id1'], ['user2', 'id2']]
list2 = [['id1', 'group1'], ['id1', 'group2'], ['id2', 'group1'], ['id2', 'group4']]
listOut = [[x[0],x[1],y[1]] for x in list1 for y in list2 if x[1] == y[0]]
output => [['user1', 'id1', 'group1'], ['user1', 'id1', 'group2'], ['user2', 'id2', 'group1'], ['user2', 'id2', 'group4']]
``` | 1,645 |
57,660,887 | I just need contexts to be an Array ie., 'contexts' :[{}] instead of 'contexts':{}
Below is my python code which helps in converting python data-frame to required JSON format
This is the sample df for one row
```
name type aim context
xxx xxx specs 67646546 United States of America
data = {'entities':[]}
for key,grp in df.groupby('name'):
for idx, row in grp.iterrows():
temp_dict_alpha = {'name':key,'type':row['type'],'data' :{'contexts':{'attributes':{},'context':{'dcountry':row['dcountry']}}}}
attr_row = row[~row.index.isin(['name','type'])]
for idx2,row2 in attr_row.iteritems():
dict_temp = {}
dict_temp[idx2] = {'values':[]}
dict_temp[idx2]['values'].append({'value':row2,'source':'internal','locale':'en_Us'})
temp_dict_alpha['data']['contexts']['attributes'].update(dict_temp)
data['entities'].append(temp_dict_alpha)
print(json.dumps(data, indent = 4))
```
Desired output:
```
{
"entities": [{
"name": "XXX XXX",
"type": "specs",
"data": {
"contexts": [{
"attributes": {
"aim": {
"values": [{
"value": 67646546,
"source": "internal",
"locale": "en_Us"
}
]
}
},
"context": {
"country": "United States of America"
}
}
]
}
}
]
}
```
However I am getting below output
```
{
"entities": [{
"name": "XXX XXX",
"type": "specs",
"data": {
"contexts": {
"attributes": {
"aim": {
"values": [{
"value": 67646546,
"source": "internal",
"locale": "en_Us"
}
]
}
},
"context": {
"country": "United States of America"
}
}
}
}
]
}
```
Can any one please suggest ways for solving this problem using Python. | 2019/08/26 | [
"https://Stackoverflow.com/questions/57660887",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/11922956/"
] | I think this does it:
```
import pandas as pd
import json
df = pd.DataFrame([['xxx xxx','specs','67646546','United States of America']],
columns = ['name', 'type', 'aim', 'context' ])
data = {'entities':[]}
for key,grp in df.groupby('name'):
for idx, row in grp.iterrows():
temp_dict_alpha = {'name':key,'type':row['type'],'data' :{'contexts':[{'attributes':{},'context':{'country':row['context']}}]}}
attr_row = row[~row.index.isin(['name','type'])]
for idx2,row2 in attr_row.iteritems():
if idx2 != 'aim':
continue
dict_temp = {}
dict_temp[idx2] = {'values':[]}
dict_temp[idx2]['values'].append({'value':row2,'source':'internal','locale':'en_Us'})
temp_dict_alpha['data']['contexts'][0]['attributes'].update(dict_temp)
data['entities'].append(temp_dict_alpha)
print(json.dumps(data, indent = 4))
```
**Output:**
```
{
"entities": [
{
"name": "xxx xxx",
"type": "specs",
"data": {
"contexts": [
{
"attributes": {
"aim": {
"values": [
{
"value": "67646546",
"source": "internal",
"locale": "en_Us"
}
]
}
},
"context": {
"country": "United States of America"
}
}
]
}
}
]
}
``` | The problem is here in the following code
```
temp_dict_alpha = {'name':key,'type':row['type'],'data' :{'contexts':{'attributes':{},'context':{'dcountry':row['dcountry']}}}}
```
As you can see , you are already creating a `contexts` `dict` and assigning values to it. What you could do is something like this
```
contextObj = {'attributes':{},'context':{'dcountry':row['dcountry']}}
contextList = []
for idx, row in grp.iterrows():
temp_dict_alpha = {'name':key,'type':row['type'],'data' :{'contexts':{'attributes':{},'context':{'dcountry':row['dcountry']}}}}
attr_row = row[~row.index.isin(['name','type'])]
for idx2,row2 in attr_row.iteritems():
dict_temp = {}
dict_temp[idx2] = {'values':[]}
dict_temp[idx2]['values'].append({'value':row2,'source':'internal','locale':'en_Us'})
contextObj['attributes'].update(dict_temp)
contextList.append(contextObj)
```
Please Note - This code will have logical errors and might not run ( as it is difficult for me , to understand the logic behind it). But here is what you need to do .
You need to create a list of objects, which is not what you are doing. You are trying to manipulate an object and when its JSON dumped , you are getting an object back instead of a list. What you need is a list. You create context object for each and every iteration and keep on appending them to the local list `contextList` that we created earlier.
Once when the for loop terminates, you can update your original object by using the `contextList` and you will have a list of objects instead of and `object` which you are having now. | 1,647 |
3,764,791 | Is there any fb tag i can use to wrap around my html anchor tag so that if the user isn't logged in, they will get prompted to login before getting access to the link?
I'm using python/django in backend.
Thanks,
David | 2010/09/21 | [
"https://Stackoverflow.com/questions/3764791",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/225128/"
] | This is just an interpretation question, but I would say that you would take the decimal representation of a number, and count the total number of digits that are 6, 4, or 9. For example:
* 100 --> 0
* 4 --> 1
* 469 --> 3
* 444 --> 3
Get it now? | One interpretation - example:
Given `678799391`, the number of digits would be `0` for `4`, `1` for `6` and `3` for `9`. The sum of the occurences would be `0 + 1 + 3 = 4`. | 1,648 |
60,578,442 | When I tried to add value of language python3 returns error that this object is not JSON serializible.
models:
```
from django.db import models
from django.contrib.auth.models import AbstractUser, AbstractBaseUser
class Admin(AbstractUser):
class Meta(AbstractUser.Meta):
pass
class HahaUser(AbstractBaseUser):
is_admin = models.BooleanField(default=False, verbose_name='is administrator?')
born = models.PositiveSmallIntegerField(verbose_name='born year')
rating = models.PositiveIntegerField(default=0, verbose_name='user rating')
email = models.EmailField(verbose_name='email')
nickname = models.CharField(max_length=32, verbose_name='useraname')
password = models.CharField(max_length=100, verbose_name='password') # on forms add widget=forms.PasswordInput
language = models.ForeignKey('Language', on_delete=models.PROTECT)
country = models.ForeignKey('Country', on_delete=models.PROTECT)
def __str__(self):
return self.nickname
class Meta:
verbose_name = 'User'
verbose_name_plural = 'Users'
ordering = ['nickname']
class Language(models.Model):
name = models.CharField(max_length=20, verbose_name='language name')
def __str__(self):
return self.name
class Meta:
verbose_name = 'Language'
verbose_name_plural = 'Languages'
class Country(models.Model):
name_ua = models.CharField(max_length=20, verbose_name='country name in Ukranian')
name_en = models.CharField(max_length=20, verbose_name='country name in English')
name_ru = models.CharField(max_length=20, verbose_name='country name in Russian')
def __str__(self):
return self.name_en
class Meta:
verbose_name = 'Country'
verbose_name_plural = 'Countries'
```
Serializers:
```
from rest_framework import serializers
from main import models
class RegistrationSerializer(serializers.ModelSerializer):
password2 = serializers.CharField(style={'input_type': 'password'},
write_only=True, required=True)
class Meta:
model = models.HahaUser
fields = ['nickname', 'password', 'password2', 'language', 'country',
'email', 'born']
extra_kwargs = {
'password': {'write_only': True}
}
def save(self):
account = models.HahaUser.objects.create(
email=self.validated_data['email'],
nickname=self.validated_data['nickname'],
language=self.validated_data['language'],
born=self.validated_data['born'],
country=self.validated_data['country']
)
password = self.validated_data['password']
password2 = self.validated_data['password2']
if password != password2:
raise serializers.ValidationError({'password': 'Passwords must match.'})
account.set_password(password)
account.save()
return account
```
views:
```
from rest_framework import status
from rest_framework.response import Response
from rest_framework.decorators import api_view
from .serializers import RegistrationSerializer
@api_view(['POST',])
def registration_view(request):
if request.method == 'POST':
serializer = RegistrationSerializer(data=request.data)
data = {}
if serializer.is_valid():
account = serializer.save()
data['response'] = 'Successfully registrated a new user.'
data['email'] = account.email
data['nickname'] = account.nickname
data['language'] = account.language
data['born'] = account.born
data['country'] = account.country
else:
data = serializer.errors
return Response(data)
```
Full text of error:
```
Internal Server Error: /api/account/register/
Traceback (most recent call last):
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/django/core/handlers/exception.py", line 34, in inner
response = get_response(request)
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/django/core/handlers/base.py", line 145, in _get_response
response = self.process_exception_by_middleware(e, request)
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/django/core/handlers/base.py", line 143, in _get_response
response = response.render()
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/django/template/response.py", line 105, in render
self.content = self.rendered_content
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/rest_framework/response.py", line 70, in rendered_content
ret = renderer.render(self.data, accepted_media_type, context)
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/rest_framework/renderers.py", line 103, in render
allow_nan=not self.strict, separators=separators
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/rest_framework/utils/json.py", line 25, in dumps
return json.dumps(*args, **kwargs)
File "/usr/lib/python3.6/json/__init__.py", line 238, in dumps
**kw).encode(obj)
File "/usr/lib/python3.6/json/encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "/usr/lib/python3.6/json/encoder.py", line 257, in iterencode
return _iterencode(o, 0)
File "/home/dima/Стільниця/hahachat/lib/python3.6/site-packages/rest_framework/utils/encoders.py", line 67, in default
return super().default(obj)
File "/usr/lib/python3.6/json/encoder.py", line 180, in default
o.__class__.__name__)
TypeError: Object of type 'Language' is not JSON serializable
```
I tried a lot of things:
- add **json** method to language model
- post data to field language\_id
- create LanguageSerializer and work using it
but nothing work
Hope to your help)) | 2020/03/07 | [
"https://Stackoverflow.com/questions/60578442",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13023793/"
] | The result of account.language is an instance. So, in your `registration_view`, data['language'] got an instance rather than string or number. That's the reason why data's language is not JSON serializable.
Based on your requirements, you can change it to
`data['language'] = account.language.name` | As exception says, `language` is an object of `Language` model and it's not a primitive type. So you should use some attributes of Language model like `language_id` or `language_name` instead of language object.
```py
from rest_framework import serializers
from main import models
class RegistrationSerializer(serializers.ModelSerializer):
password2 = serializers.CharField(style={'input_type': 'password'},
write_only=True, required=True)
language_name = serializers.CharField(source='language.name')
class Meta:
model = models.HahaUser
fields = ['nickname', 'password', 'password2', 'language_name', 'country',
'email', 'born']
extra_kwargs = {
'password': {'write_only': True}
}
def save(self):
account = models.HahaUser.objects.create(
email=self.validated_data['email'],
nickname=self.validated_data['nickname'],
language=self.validated_data['language_name'],
born=self.validated_data['born'],
country=self.validated_data['country']
)
password = self.validated_data['password']
password2 = self.validated_data['password2']
if password != password2:
raise serializers.ValidationError({'password': 'Passwords must match.'})
account.set_password(password)
account.save()
return account
```
**NOTE:** If you fix Language serializable error, You'll get another exception for `Country` too. | 1,652 |
47,978,878 | Hi I am using APScheduler in a Django project. How can I plan a call of a function in python when the job is done? A callback function.
I store job as Django models in DB. As it completes, I want to mark it as `completed=1` in the table. | 2017/12/26 | [
"https://Stackoverflow.com/questions/47978878",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4537090/"
] | The easiest and generic way to do it would be to add your callback function to the end of the scheduled job. You can also build on top of the scheduler class to include a self.function\_callback() at the end of the tasks.
Quick example:
```
def tick():
print('Tick! The time is: %s' % datetime.now())
time.sleep(10)
function_cb()
def function_cb():
print "CallBack Function"
#Do Something
if __name__ == '__main__':
scheduler = AsyncIOScheduler()
scheduler.add_job(tick, 'interval', seconds=2)
scheduler.start()
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
# Execution will block here until Ctrl+C (Ctrl+Break on Windows) is pressed.
try:
asyncio.get_event_loop().run_forever()
except (KeyboardInterrupt, SystemExit):
pass
scheduler.shutdown(wait=False)
``` | [Listener](https://apscheduler.readthedocs.io/en/latest/userguide.html#scheduler-events) allows to hook various [events](https://apscheduler.readthedocs.io/en/latest/modules/events.html#event-codes) of APScheduler. I have succeeded to get the *next run time* of my job using EVENT\_JOB\_SUBMITTED.
(Updated)
I confirmed whether it is able to hook these events.
```
from datetime import datetime
import os
from logging import getLogger, StreamHandler, Filter, basicConfig, INFO
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
logger = getLogger(__name__)
logger.setLevel(INFO)
def tick():
now = datetime.now()
logger.info('Tick! The time is: %s' % now)
if now.second % 2 == 0:
raise Exception('now.second % 2 == 0')
if __name__ == '__main__':
sh = StreamHandler()
sh.addFilter(Filter('__main__'))
basicConfig(
handlers = [sh],
format='[%(asctime)s] %(name)s %(levelname)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
def my_listener(event):
if event.exception:
logger.info('The job crashed')
else:
logger.info('The job worked')
scheduler = BlockingScheduler()
scheduler.add_job(tick, 'interval', seconds=3)
scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
pass
```
When this code is executed, the output is as follows:
```
Interrupt: Press ENTER or type command to continue
Press Ctrl+C to exit
[2019-11-30 09:24:12] __main__ INFO: Tick! The time is: 2019-11-30 09:24:12.663142
[2019-11-30 09:24:12] __main__ INFO: The job crashed
[2019-11-30 09:24:15] __main__ INFO: Tick! The time is: 2019-11-30 09:24:15.665845
[2019-11-30 09:24:15] __main__ INFO: The job worked
[2019-11-30 09:24:18] __main__ INFO: Tick! The time is: 2019-11-30 09:24:18.663215
[2019-11-30 09:24:18] __main__ INFO: The job crashed
``` | 1,655 |
1,780,066 | hopefully someone here can shed some light on my issue :D
I've been creating a Windows XP service in python that is designed to monitor/repair selected Windows/Application/Service settings, atm I have been focusing on default DCOM settings.
The idea is to backup our default configuration within another registry key for reference. Every 30 minutes (currently every 30 seconds for testing) I would like the service to query the current windows default DCOM settings from the registry and compare the results to the default configuration. If discrepancies are found, the service will replace the current windows settings with the custom configuration settings.
I have already created/tested my class to handle the registry checking/repairing and so far it runs flawlessly.. Until I compile it to an exe and run it as a service.
The service itself starts up just fine and it seems to loop every 30 seconds as defined, but my module to handle the registry checking/repairing does not seem to get run as specified.
I created a log file and was able to obtain the following error:
Traceback (most recent call last):
File "DCOMMon.pyc", line 52, in RepairDCOM
File "DCOMMon.pyc", line 97, in GetDefaultDCOM
File "pywmi.pyc", line 396, in **call**
File "pywmi.pyc", line 189, in handle\_com\_error
x\_wmi: -0x7ffdfff7 - Exception occurred.
Error in: SWbemObjectEx
-0x7ffbfe10 -
When I stop the service and run the exe manually, specifying the debug argument: **DCOMMon.exe debug**, the service starts up and runs just fine, performing all tasks as expected. The only differences that I can see is that the service starts the process as the SYSTEM user instead of the logged on user which leads me to believe (just guessing here) that it might be some sort of missed permission/policy for the SYSTEM user? I have tested running the service as another user but there was no difference there either.
Other thoughts were to add the wmi service to the dependencies of my service but truthfully I have no idea what that would do :P This is the first time I've attempted to create a windows service in python, without using something like srvany.exe.
I have spent the better part of last night and today trying to google around and find some information regarding py2exe and wmi compatibility but so far the suggestions I have found have not helped solve the above issue.
Any suggestions would be appreciated.
PS: Don't hate me for the poor logging, I cut/pasted my logger from a different scripts and I have not made the appropriate changes, it might double up each line :P. The log file can be found here: "%WINDIR%\system32\DCOMMon.log"
**UPDATE**
I have tried to split this project up into two exe files instead of one. Let the service make and external call to the other exe to run the wmi registry portion. Again, when running with the **debug** arg it works just fine, but when I start it as a service it logs the same error message. More and more this is starting to look like a permission issue an not a program issue :(
**UPDATE**
**DCOMMon.py - Requires pywin32, wmi (renamed to pywmi),**
```
# DCOMMon.py
import win32api, win32service, win32serviceutil, win32event, win32evtlogutil, win32traceutil
import logging, logging.handlers, os, re, sys, thread, time, traceback, pywmi # pywmi == wmi module renamed as suggested in online post
import _winreg as reg
DCOM_DEFAULT_CONFIGURATION = ["EnableDCOM", "EnableRemoteConnect", "LegacyAuthenticationLevel", "LegacyImpersonationLevel", "DefaultAccessPermission",
"DefaultLaunchPermission", "MachineAccessRestriction", "MachineLaunchRestriction"]
DCOM_DEFAULT_ACCESS_PERMISSION = [1, 0, 4, 128, 92, 0, 0, 0, 108, 0, 0, 0, 0, 0, 0, 0, 20, 0, 0, 0, 2, 0, 72, 0, 3, 0, 0, 0, 0, 0, 24, 0, 7, 0, 0, 0, 1, 2,
0, 0, 0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0, 0, 0, 20, 0, 7, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 5, 7, 0, 0, 0, 0, 0, 20, 0, 7,
0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0, 1, 2, 0, 0, 0, 0, 0, 5, 32,
0, 0, 0, 32, 2, 0, 0]
DCOM_DEFAULT_LAUNCH_PERMISSION = [1, 0, 4, 128, 132, 0, 0, 0, 148, 0, 0, 0, 0, 0, 0, 0, 20, 0, 0, 0, 2, 0, 112, 0, 5, 0, 0, 0, 0, 0, 24, 0, 31, 0, 0, 0, 1,
2, 0, 0, 0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0, 0, 0, 20, 0, 31, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 5, 7, 0, 0, 0, 0, 0, 20, 0,
31, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 20, 0, 31, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 5, 4, 0, 0, 0, 0, 0, 20, 0,
31, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 5, 18, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0, 1, 2, 0, 0, 0, 0, 0, 5,
32, 0, 0, 0, 32, 2, 0, 0]
DCOM_MACHINE_ACCESS_RESTRICTION = [1, 0, 4, 128, 68, 0, 0, 0, 84, 0, 0, 0, 0, 0, 0, 0, 20, 0, 0, 0, 2, 0, 48, 0, 2, 0, 0, 0, 0, 0, 20, 0, 3, 0, 0, 0, 1, 1,
0, 0, 0, 0, 0, 5, 7, 0, 0, 0, 0, 0, 20, 0, 7, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 5, 32, 0,
0, 0, 32, 2, 0, 0, 1, 2, 0, 0, 0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0]
DCOM_MACHINE_LAUNCH_RESTRICTION = [1, 0, 4, 128, 72, 0, 0, 0, 88, 0, 0, 0, 0, 0, 0, 0, 20, 0, 0, 0, 2, 0, 52, 0, 2, 0, 0, 0, 0, 0, 24, 0, 31, 0, 0, 0, 1,
2, 0, 0, 0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0, 0, 0, 20, 0, 31, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 2, 0, 0,
0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0, 1, 2, 0, 0, 0, 0, 0, 5, 32, 0, 0, 0, 32, 2, 0, 0]
COMPUTER = os.environ["COMPUTERNAME"]
REGISTRY = pywmi.WMI(COMPUTER, namespace="root/default").StdRegProv
LOGFILE = os.getcwd() + "\\DCOMMon.log"
def Logger(title, filename):
logger = logging.getLogger(title)
logger.setLevel(logging.DEBUG)
handler = logging.handlers.RotatingFileHandler(filename, maxBytes=0, backupCount=0)
handler.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger
def LogIt(filename=LOGFILE):
#try:
# if os.path.exists(filename):
# os.remove(filename)
#except:
# pass
log = Logger("DCOMMon", filename)
tb = str(traceback.format_exc()).split("\n")
log.error("")
for i, a in enumerate(tb):
if a.strip() != "":
log.error(a)
class Monitor:
def RepairDCOM(self):
try:
repaired = {}
dict1 = self.GetDefaultDCOM()
dict2 = self.GetCurrentDCOM()
compared = self.CompareDCOM(dict1, dict2)
for dobj in DCOM_DEFAULT_CONFIGURATION:
try:
compared[dobj]
if dobj == "LegacyAuthenticationLevel" or dobj == "LegacyImpersonationLevel":
REGISTRY.SetDWORDValue(hDefKey=reg.HKEY_LOCAL_MACHINE, sSubKeyName="SOFTWARE\\Microsoft\\Ole", sValueName=dobj, uValue=dict1[dobj])
elif dobj == "DefaultAccessPermission" or dobj == "DefaultLaunchPermission" or \
dobj == "MachineAccessRestriction" or dobj == "MachineLaunchRestriction":
REGISTRY.SetBinaryValue(hDefKey=reg.HKEY_LOCAL_MACHINE, sSubKeyName="SOFTWARE\\Microsoft\\Ole", sValueName=dobj, uValue=dict1[dobj])
elif dobj == "EnableDCOM" or dobj == "EnableRemoteConnect":
REGISTRY.SetStringValue(hDefKey=reg.HKEY_LOCAL_MACHINE, sSubKeyName="SOFTWARE\\Microsoft\\Ole", sValueName=dobj, sValue=dict1[dobj])
except KeyError:
pass
except:
LogIt(LOGFILE)
def CompareDCOM(self, dict1, dict2):
compare = {}
for (key, value) in dict2.iteritems():
try:
if dict1[key] != value:
compare[key] = value
except KeyError:
compare[key] = value
return compare
def GetCurrentDCOM(self):
current = {}
for name in REGISTRY.EnumValues(hDefKey=reg.HKEY_LOCAL_MACHINE, sSubKeyName="SOFTWARE\\Microsoft\\Ole")[1]:
value = REGISTRY.GetStringValue(hDefKey=reg.HKEY_LOCAL_MACHINE, sSubKeyName="SOFTWARE\\Microsoft\\Ole", sValueName=str(name))[1]
if value:
current[str(name)] = str(value)
else:
value = REGISTRY.GetDWORDValue(hDefKey=reg.HKEY_LOCAL_MACHINE, sSubKeyName="SOFTWARE\\Microsoft\\Ole", sValueName=str(name))[1]
if not value:
value = REGISTRY.GetBinaryValue(hDefKey=reg.HKEY_LOCAL_MACHINE, sSubKeyName="SOFTWARE\\Microsoft\\Ole", sValueName=str(name))[1]
current[str(name)] = value
return current
def GetDefaultDCOM(self):
default = {}
# Get Default DCOM Settings
for name in REGISTRY.EnumValues(hDefKey=reg.HKEY_CURRENT_USER, sSubKeyName="Software\\DCOMMon")[1]:
value = REGISTRY.GetStringValue(hDefKey=reg.HKEY_CURRENT_USER, sSubKeyName="Software\\DCOMMon", sValueName=str(name))[1]
if value:
default[str(name)] = str(value)
else:
value = REGISTRY.GetDWORDValue(hDefKey=reg.HKEY_CURRENT_USER, sSubKeyName="Software\\DCOMMon", sValueName=str(name))[1]
if not value:
value = REGISTRY.GetBinaryValue(hDefKey=reg.HKEY_CURRENT_USER, sSubKeyName="Software\\DCOMMon", sValueName=str(name))[1]
default[str(name)] = value
return default
class DCOMMon(win32serviceutil.ServiceFramework):
_svc_name_ = "DCOMMon"
_svc_display_name_ = "DCOM Monitoring Service"
_svc_description_ = "DCOM Monitoring Service"
_svc_deps_ = ["EventLog"]
def __init__(self, args):
win32serviceutil.ServiceFramework.__init__(self, args)
self.hWaitStop = win32event.CreateEvent(None, 0, 0, None)
self.isAlive = True
def SvcDoRun(self):
import servicemanager
servicemanager.LogMsg(servicemanager.EVENTLOG_INFORMATION_TYPE, servicemanager.PYS_SERVICE_STARTED,
(self._svc_name_, ': DCOM Monitoring Service - Service Started'))
self.timeout=30000 # In milliseconds
while self.isAlive:
rc = win32event.WaitForSingleObject(self.hWaitStop, self.timeout)
if rc == win32event.WAIT_OBJECT_0:
break
else:
servicemanager.LogMsg(servicemanager.EVENTLOG_INFORMATION_TYPE, servicemanager.PYS_SERVICE_STARTED,
(self._svc_name_, ': DCOM Monitoring Service - Examining DCOM Configuration'))
Monitor().RepairDCOM()
servicemanager.LogMsg(servicemanager.EVENTLOG_INFORMATION_TYPE, servicemanager.PYS_SERVICE_STOPPED,
(self._svc_name_, ': DCOM Monitoring Service - Service Stopped'))
return
def SvcStop(self):
self.ReportServiceStatus(win32service.SERVICE_STOP_PENDING)
win32event.SetEvent(self.hWaitStop)
LOG.close()
self.isAlive = False
return
#def ctrlHandler(ctrlType):
# return True
if __name__ == '__main__':
# win32api.SetConsoleCtrlHandler(ctrlHandler, True)
#print Monitor().RepairDCOM()
win32serviceutil.HandleCommandLine(DCOMMon)
```
**DCOMMon\_setup.py - Requires py2exe (self executable, no need for py2exe arg)**
```
# DCOMMon_setup.py (self executable, no need for py2exe arg)
# Usage:
# DCOMMon.exe install
# DCOMMon.exe start
# DCOMMon.exe stop
# DCOMMon.exe remove
# DCOMMon.exe debug
# you can see output of this program running python site-packages\win32\lib\win32traceutil
try:
# (snippet I found somewhere, searching something??)
# if this doesn't work, try import modulefinder
import py2exe.mf as modulefinder
import win32com, sys
for p in win32com.__path__[1:]:
modulefinder.AddPackagePath("win32com", p)
for extra in ["win32com.shell"]: #,"win32com.mapi"
__import__(extra)
m = sys.modules[extra]
for p in m.__path__[1:]:
modulefinder.AddPackagePath(extra, p)
except ImportError:
print "NOT FOUND"
from distutils.core import setup
import py2exe, sys
if len(sys.argv) == 1:
sys.argv.append("py2exe")
#sys.argv.append("-q")
class Target:
def __init__(self, **kw):
self.__dict__.update(kw)
# for the versioninfo resources
self.version = "1.0.0.1"
self.language = "English (Canada)"
self.company_name = "Whoever"
self.copyright = "Nobody"
self.name = "Nobody Home"
myservice = Target(
description = 'DCOM Monitoring Service',
modules = ['DCOMMon'],
cmdline_style='pywin32'
#dest_base = 'DCOMMon'
)
setup(
options = {"py2exe": {"compressed": 1, "bundle_files": 1, "ascii": 1, "packages": ["encodings"]} },
console=["DCOMMon.py"],
zipfile = None,
service=[myservice]
)
``` | 2009/11/22 | [
"https://Stackoverflow.com/questions/1780066",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/94071/"
] | So I guess it's time to admit my stupidity.... :P
It turns out this was not a python issue, py2exe issue, nor a WMI issue. :(
This was more or less a simple permission issue. So simple I overlooked it for the better part of a month. :(
Rule of thumb, if you want to create a service that calls to specific registry keys to obtain (in this case) default configuration settings....
maybe... **JUST MAYBE....**
One should place their default key within the **"HKEY\_LOCAL\_MACHINE"**, instead of **"HKEY\_CURRENT\_USER"**?? :P
Yeah, it's that simple...
I should have remembered this rule from other projects I have worked on in the past. When you are running as the Local System account, simply put, there is no **"HKEY\_CURRENT\_USER"** subkey to access. If you absolutely have to access a specific user's **"HKEY\_CURRENT\_USER"** subkey, I would guess the only way would be to impersonate the user. Luckily for me this is not necessary for what I am attempting to accomplish.
The below link provided me with what I needed to jog my memory and fix the issue:
<http://msdn.microsoft.com/en-us/library/ms684190%28VS.85%29.aspx>
So to make a long story short, I migrated all of my default values over to **"HKEY\_LOCAL\_MACHINE\SOFTWARE"** subkey and my service is working perfectly. :D
Thanks for your help guys but this problem is solved ;) | I am not an expert at this, but here are my two cents worth:
[This article](http://www.firebirdsql.org/devel/python/docs/3.3.0/installation.html) tells me that you might need to be logged in as someone with the required target system permissions.
However, I find that a little excessive. Have you tried compiling your script from the command line while running the command prompt as the administrator of the computer - so that you can unlock all permissions (on Windows Vista and Windows 7, this is achieved by right clicking on the command prompt icon in the start menu and clicking on "run as administrator").
Hope this helps | 1,656 |
69,153,402 | Lets say I have a list that references another list, as follows:
```
list1 = [1,2,3,4,5]
list2 = [list1[0], list1[1], list1[2]]
```
I wish to interact with list1 through list2, as follows:
```
list2[1] = 'a'
print(list1[1])
```
and that result should be 'a'.
Is this possible? Help me python geniuses | 2021/09/12 | [
"https://Stackoverflow.com/questions/69153402",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/14272990/"
] | What we do is not derive `ListOfSomething` from the list base class. We would make `ListOfSomething` the singleton and have a generic list class.
```cpp
class ListOfSomething
{
public:
static ListOfSomething& instance()
{
static ListOfSomething los;
return los;
}
// Obtain a reference to the list.
ListOf<Something>& get_list() { return the_list; }
private:
// Hide the constructor to force the use of the singleton instance.
ListOfSomething() {}
// The actual list of objects.
ListOf<Something> the_list;
// Add your properties.
};
```
An alternative would be to pass the type of the derived class to the base class. It is a bit obfuscated but will work. This is often used in [singleton base classes](https://stackoverflow.com/questions/41328038/singleton-template-as-base-class-in-c).
```cpp
template <class T, class L>
class ListOf<T>
{
public:
// I would advice to return a reference not a pointer.
static L& method()
{
static L list;
return L;
}
private:
// Hide the constructor.
ListOf();
~ListOf();
};
```
Next in your derived class:
```
class ListOfSomething : public ListOf<Something, ListOfSomething>
{
// To allow the construction of this object with private constructor in the base class.
friend class ListOf<Something, ListOfSomething>;
public:
// Add your public functions here.
private:
// Hide the constructor and destructor.
ListOfSomething();
~ListOfSomething();
};
``` | As explained by Bart, the trick here is to pass the name of the derived class as a template parameter. Here is the final form of the class that works as originally desired:
```
template <class T>
class ListOf<T>
{
public:
static T *method();
};
```
and you invoke it like this
```
class ListOfSomething : public ListOf<ListOfSomething>
{
public:
int payload;
};
```
Thus, the compiler is happy with:
```
ListOfSomething *ptr;
ptr = ListOfSomething::method();
``` | 1,657 |
45,561,366 | I'm a beginner at video processing using python.
I have a raw video data captured from a camera and I need to check whether the video has bright or dark frames in it.
So far what I have achieved is I can read the raw video using numpy in python.
Below is my code.
```
import numpy as np
fd = open('my_video_file.raw', 'rb')
rows = 4800
cols = 6400
f = np.fromfile(fd, dtype=np.uint8,count = rows*cols)
im = f.reshape((rows,cols)) #notice row, column format
print im
fd.close()
```
Output :
```
[[ 81 82 58 ..., 0 0 0] [ 0 0 0 ..., 0 0 0]
[ 0 0 0 ..., 0 0 0] ..., [141 128 136 ..., 1 2 2]
[ 40 39 35 ..., 192 192 192] [190 190 190 ..., 74 60 60]]
```
Based on the array or numpy output , is it possible to check whether the raw video data has dark(less bright) frames or not.
Also please tell me what does the numpy output (print im) mean ?
If you have any links which I can refer to, its most welcome. | 2017/08/08 | [
"https://Stackoverflow.com/questions/45561366",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/4680053/"
] | If you have colorfull frames with red, green and blue channels, i.e NxMx3 matrix then you can convert this matrix from RGB representation to HSV (Hue, Saturation, Value) representation which is also will be NxMx3 matrix. Then you can take Value page from this matrix, i.e. third channel of this matrix and calculate average of all elements in this matrix. Put any threshold like 0.5 and if average is less than this value then this frame can be considered as dark.
Read about HSV [here](https://en.wikipedia.org/wiki/HSL_and_HSV).
To convert RGB vector to HSV vector you can use [matplotlib.colors.rgb\_to\_hsv(arr)](http://matplotlib.org/api/colors_api.html#matplotlib.colors.rgb_to_hsv) function. | Just a little insight on your problem. (You might want to read up a little more on digital image representation, [e.g. here](http://pippin.gimp.org/image_processing/chap_dir.html)). The frames of your video are read in in `uint8` format, i.e. pixels are encoded with values ranging from 0 to 255.
In general, higher values represent brighter pixels. Depending on your video you can have colored or non-colored frames as mentioned by @Batyrkhan Saduanov. So what you want to do is define minimum and maximum levels to declare a frame as "dark" or "bright".
In case of a non-colored you can easily use the mean pixel values of each frame, an asign threshold levels as in:
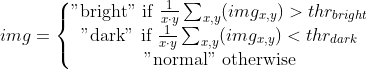 | 1,658 |
55,713,339 | I'm trying to implement the following formula in python for X and Y points
[](https://i.stack.imgur.com/Lv0au.png)
I have tried following approach
```
def f(c):
"""This function computes the curvature of the leaf."""
tt = c
n = (tt[0]*tt[3] - tt[1]*tt[2])
d = (tt[0]**2 + tt[1]**2)
k = n/d
R = 1/k # Radius of Curvature
return R
```
There is something incorrect as it is not giving me correct result. I think I'm making some mistake while computing derivatives in first two lines. How can I fix that?
Here are some of the points which are in a data frame:
```
pts = pd.DataFrame({'x': x, 'y': y})
x y
0.089631 97.710199
0.089831 97.904541
0.090030 98.099313
0.090229 98.294513
0.090428 98.490142
0.090627 98.686200
0.090827 98.882687
0.091026 99.079602
0.091225 99.276947
0.091424 99.474720
0.091623 99.672922
0.091822 99.871553
0.092022 100.070613
0.092221 100.270102
0.092420 100.470020
0.092619 100.670366
0.092818 100.871142
0.093017 101.072346
0.093217 101.273979
0.093416 101.476041
0.093615 101.678532
0.093814 101.881451
0.094013 102.084800
0.094213 102.288577
pts_x = np.gradient(x_c, t) # first derivatives
pts_y = np.gradient(y_c, t)
pts_xx = np.gradient(pts_x, t) # second derivatives
pts_yy = np.gradient(pts_y, t)
```
After getting the derivatives I am putting the derivatives x\_prim, x\_prim\_prim, y\_prim, y\_prim\_prim in another dataframe using the following code:
```
d = pd.DataFrame({'x_prim': pts_x, 'y_prim': pts_y, 'x_prim_prim': pts_xx, 'y_prim_prim':pts_yy})
```
after having everything in the data frame I am calling function for each row of the data frame to get curvature at that point using following code:
```
# Getting the curvature at each point
for i in range(len(d)):
temp = d.iloc[i]
c_temp = f(temp)
curv.append(c_temp)
``` | 2019/04/16 | [
"https://Stackoverflow.com/questions/55713339",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5347207/"
] | You do not specify exactly what the structure of the parameter `pts` is. But it seems that it is a two-dimensional array where each row has two values `x` and `y` and the rows are the points in your curve. That itself is problematic, since [the documentation](https://docs.scipy.org/doc/numpy/reference/generated/numpy.gradient.html) is not quite clear on what exactly is returned in such a case.
But you clearly are not getting the derivatives of `x` or `y`. If you supply only one array to `np.gradient` then numpy assumes that the points are evenly spaced with a distance of one. But that is probably not the case. The meaning of `x'` in your formula is the derivative of `x` *with respect to `t`*, the parameter variable for the curve (which is separate from the parameters to the computer functions). But you never supply the values of `t` to numpy. The values of `t` must be the second parameter passed to the `gradient` function.
So to get your derivatives, split the `x`, `y`, and `t` values into separate one-dimensional arrays--lets call them `x` and `y` and `t`. Then get your first and second derivatives with
```
pts_x = np.gradient(x, t) # first derivatives
pts_y = np.gradient(y, t)
pts_xx = np.gradient(pts_x, t) # second derivatives
pts_yy = np.gradient(pts_y, t)
```
Then continue from there. You no longer need the `t` values to calculate the curvatures, which is the point of the formula you are using. Note that `gradient` is not really designed to calculate the second derivatives, and it absolutely should not be used to calculate third or higher-order derivatives. More complex formulas are needed for those. Numpy's `gradient` uses "second order accurate central differences" which are pretty good for the first derivative, poor for the second derivative, and worthless for higher-order derivatives. | I think your problem is that x and y are arrays of double values.
The array x is the independent variable; I'd expect it to be sorted into ascending order. If I evaluate y[i], I expect to get the value of the curve at x[i].
When you call that numpy function you get an array of derivative values that are the same shape as the (x, y) arrays. If there are n pairs from (x, y), then
```
y'[i] gives the value of the first derivative of y w.r.t. x at x[i];
y''[i] gives the value of the second derivative of y w.r.t. x at x[i].
```
The curvature k will also be an array with n points:
```
k[i] = abs(x'[i]*y''[i] -y'[i]*x''[i])/(x'[i]**2 + y'[i]**2)**1.5
```
Think of x and y as both being functions of a parameter t. x' = dx/dt, etc. This means curvature k is also a function of that parameter t.
I like to have a well understood closed form solution available when I program a solution.
```
y(x) = sin(x) for 0 <= x <= pi
y'(x) = cos(x)
y''(x) = -sin(x)
k = sin(x)/(1+(cos(x))**2)**1.5
```
Now you have a nice formula for curvature as a function of x.
If you want to parameterize it, use
```
x(t) = pi*t for 0 <= t <= 1
x'(t) = pi
x''(t) = 0
```
See if you can plot those and make your Python solution match it. | 1,659 |
2,344,712 | The hindrance we have to ship python is the large size of the standard library.
Is there a minimal python distribution or an easy way to pick and choose what we want from
the standard library?
The platform is linux. | 2010/02/26 | [
"https://Stackoverflow.com/questions/2344712",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/282368/"
] | If all you want is to get the minimum subset you need (rather than build an `exe` which would constrain you to Windows systems), use the standard library module [modulefinder](http://docs.python.org/library/modulefinder.html) to list all modules your program requires (you'll get all dependencies, direct and indirect). Then you can `zip` all the relevant `.pyo` or `.pyc` files (depending on whether you run Python with or without the `-O` flag) and just use that zipfile as your `sys.path` (plus a directory for all the `.pyd` or `.so` native-code dynamic libraries you may need -- those need to live directly in the filesystem to let the OS load them in as needed, can't be loaded directly from a zipfile the way Python bytecode modules can, unfortunately). | Have you looked at [py2exe](http://www.py2exe.org/)? It provides a way to ship Python programs without requiring a Python installation. | 1,660 |
22,164,245 | I'm using a java program to split an array among histogram bins. Now, I want to manually label the histogram bins. So - I want to convert some thing like the sequence: {-0.9,-0.8,-0.7,-0.6,-0.5,-0.4,-0.3,-0.2,-0.1,0,0.1,0.5,1,1.5,2,2.5,4} into the following image -

Is there a way to do this using any software? I'm on Windows and some thing based on R, python, java or matlab would be awesome. I currently do it manually using mspaint. | 2014/03/04 | [
"https://Stackoverflow.com/questions/22164245",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1826912/"
] | Well, the simplest approach is (Python):
```
import matplotlib.pyplot as plt
d = [-0.9,-0.8,-0.7,-0.6,-0.5,-0.4,-0.3,-0.2,-0.1,0,0.1,0.5,1,1.5,2,2.5,4]
hist(d)
plt.show()
```
As for putting special labels on the histogram, that's covered in the question: [Matplotlib - label each bin](https://stackoverflow.com/questions/6352740/matplotlib-label-each-bin).
I'm guessing you want to keep it simple, so you can do this:
```
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
d = [-0.9,-0.8,-0.7,-0.6,-0.5,-0.4,-0.3,-0.2,-0.1,0,0.1,0.5,1,1.5,2,2.5,4]
counts, bins, patches = ax.hist(d)
ax.set_xticks(bins)
plt.show()
``` | On the java side, an useful (and not too big) library could be GRAL <http://trac.erichseifert.de/gral/>
An histogram example is here:
<http://trac.erichseifert.de/gral/browser/gral-examples/src/main/java/de/erichseifert/gral/examples/barplot/HistogramPlot.java>
And specifically about axis rotation:
<http://www.erichseifert.de/dev/gral/0.10/apidocs/de/erichseifert/gral/plots/axes/AxisRenderer.html#setLabelRotation%28double%29> | 1,663 |
35,050,766 | I am currently using Python and R together (using rmagic/rpy2) to help select different user input variables for a certain type of analysis.
I have read a csv file and created a dataframe in R. What I have also done is allowed the users to input a number of variables of which the names must match those in the header (using Python).
For example if I create a data frame as such
`%R data1 <- read.csv(filename, header =T)`
I then have a number of user input variables that are currently strings in pythons that would look like this.
```
var_1 = 'data1$age'
var_2 = 'data1$sex'
```
How can I then use this string as runable code in R to reach into the correct column of the data frame as such:
```
%R variable1 <- data1$sex
```
Currently I have tried the assign function and others (I understand this might be far from the mark) but I always just get it coming out as such:
```
%R -i var_1 assign('variable1', var_1)
%R print(variable1)
"data1$age"
```
I understand that I could assign values etc in R but I'm questioning if it is possible to turn a string into a runnable bit of code that could reach into a data.frame. | 2016/01/28 | [
"https://Stackoverflow.com/questions/35050766",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5849513/"
] | Consider having Python call the R script as child process via command line passing the string variables as arguments. In R, use the double bracket column reference to use strings:
**Python** Script *(using subprocess module)*
```
import subprocess
var_1 = 'age'
var_2 = 'sex'
Rfilename = '/path/to/SomeScript.R'
# BELOW ASSUMES RScript IS A SYSTEM PATH VARIABLE
p = subprocess.Popen(['RScript', Rfilename, var1, var2])
```
**R** Script
```
args <-commandArgs(trailingOnly=T)
var_1 <- as.character(args[1])
var_2 <- as.character(args[2])
data1 <- read.csv(filename, header =T)
variable1 <- data1[[var_1]]
variable2 <- data1[[var_2]]
``` | Yes it is possible:
```
var_1 <- "head(iris$Species)"
eval(parse(text=var_1))
# [1] setosa setosa setosa setosa setosa setosa
# Levels: setosa versicolor virginica
``` | 1,665 |
54,396,064 | I would like to ask how to exchange dates from loop in to an array in python?
I need an array of irregular, random dates with hours. So, I prepared a solution:
```
import datetime
import radar
r2 =()
for a in range(1,10):
r2 = r2+(radar.random_datetime(start='1985-05-01', stop='1985-05-04'),)
r3 = list(r2)
print(r3)
```
As the result I get a list like:
```
[datetime.datetime(1985, 5, 3, 17, 59, 13), datetime.datetime(1985, 5, 2, 15, 58, 30), datetime.datetime(1985, 5, 2, 9, 46, 35), datetime.datetime(1985, 5, 3, 10, 5, 45), datetime.datetime(1985, 5, 2, 4, 34, 43), datetime.datetime(1985, 5, 3, 9, 52, 51), datetime.datetime(1985, 5, 2, 22, 7, 17), datetime.datetime(1985, 5, 1, 15, 28, 14), datetime.datetime(1985, 5, 3, 13, 33, 56)]
```
But I need strings in the list like:
```
list2 = ['1985-05-02 08:48:46','1985-05-02 10:47:56','1985-05-03 22:07:11', '1985-05-03 22:07:11','1985-05-01 03:23:43']
``` | 2019/01/28 | [
"https://Stackoverflow.com/questions/54396064",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10842659/"
] | You can convert the datetime to a string with [`str()`](https://docs.python.org/3/library/stdtypes.html#str) like:
### Code:
```
str(radar.random_datetime(start='1985-05-01', stop='1985-05-04'))
```
### Test Code:
```
import radar
r2 = ()
for a in range(1, 10):
r2 = r2 + (str(
radar.random_datetime(start='1985-05-01', stop='1985-05-04')),)
r3 = list(r2)
print(r3)
```
### Results:
```
['1985-05-01 21:06:29', '1985-05-01 04:43:11', '1985-05-02 13:51:03',
'1985-05-03 03:20:44', '1985-05-03 19:59:14', '1985-05-02 21:50:34',
'1985-05-01 04:13:50', '1985-05-03 23:28:36', '1985-05-02 15:56:23']
``` | Use [strftime](http://docs.python.org/2/library/time.html#time.strftime) to convert the date generated by radar before adding it to the list.
e.g.
```
import datetime
import radar
r2 =()
for a in range(1,10):
t=datetime.datetime(radar.random_datetime(start='1985-05-01', stop='1985-05-04'))
r2 = r2+(t.strftime('%Y-%m-%d %H:%M:%S'),)
r3 = list(r2)
print(r3)
``` | 1,666 |
23,086,078 | I have list that has 20 coordinates (x and y coordinates). I can calculate the distance between any two coordinates, but I have a hard time writing an algorithm that will iterate through the list and calculate the distance between the first node and every other node. for example,
```
ListOfCoordinates = [(1,2), (3,4), (5,6), (7,8), (9,10), (11,12)]
```
In this case I need a for loop that will interate the list and calculate the distance between the first coordinate and the second coordinates, distance between first coordinate and third coordinate, etc. I am in need of an algorithm to help me out, then I will transform it into a python code. Thanks
Thanks for ll the feedback. It's been helpful. | 2014/04/15 | [
"https://Stackoverflow.com/questions/23086078",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3536195/"
] | Whenever you need something combinatorics-oriented ("I need first and second, then first and third, then...") chances are the `itertools` module has what you need.
```
from math import hypot
def distance(p1,p2):
"""Euclidean distance between two points."""
x1,y1 = p1
x2,y2 = p2
return hypot(x2 - x1, y2 - y1)
from itertools import combinations
list_of_coords = [(1,2), (3,4), (5,6), (7,8), (9,10), (11,12)]
[distance(*combo) for combo in combinations(list_of_coords,2)]
Out[29]:
[2.8284271247461903,
5.656854249492381,
8.48528137423857,
11.313708498984761,
14.142135623730951,
2.8284271247461903,
5.656854249492381,
8.48528137423857,
11.313708498984761,
2.8284271247461903,
5.656854249492381,
8.48528137423857,
2.8284271247461903,
5.656854249492381,
2.8284271247461903]
```
edit: Your question is a bit confusing. Just in case you only want the first point compared against the other points:
```
from itertools import repeat
pts = [(1,2), (3,4), (5,6), (7,8), (9,10), (11,12)]
[distance(*pair) for pair in zip(repeat(pts[0]),pts[1:])]
Out[32]:
[2.8284271247461903,
5.656854249492381,
8.48528137423857,
11.313708498984761,
14.142135623730951]
```
But usually in this type of problem you care about *all* the combinations so I'll leave the first answer up there. | ```
In [6]: l = [(1,2), (3,4), (5,6), (7,8), (9,10), (11,12)]
In [7]: def distance(a, b):
return (a[0] - b[0], a[1] - b[1])
...:
In [8]: for m in l[1:]:
print(distance(l[0], m))
...:
(-2, -2)
(-4, -4)
(-6, -6)
(-8, -8)
(-10, -10)
```
Of course you would have to adapt `distance` to your needs. | 1,667 |
74,180,904 | I am learning python and I am almost done with making tick tack toe but the code for checking if the game is a tie seems more complicated then it needs to be. is there a way of simplifying this?
```
if a1 != " " and a2 != " " and a3 != " " and b1 != " " and b2 != " " and b3 != " " and c1 != " " and c2 != " " and c3 != " ":
board()
print("its a tie!")
quit()
``` | 2022/10/24 | [
"https://Stackoverflow.com/questions/74180904",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/20321517/"
] | I think there is no implemented method in the SDK for that but after looking a bit, I found this one: [request](https://cloud.google.com/storage/docs/json_api/v1/objects/list#request)
You could try to execute an HTTP GET specifying the parameters (you can find an example of the use of parameters here: [query\_parameters](https://cloud.google.com/storage/docs/json_api#query_parameters)) | By default the google API iterators manage page size for you. The RowIterator returns a single row by default, backed internally by fetched pages that rely on the backend to select an appropriate size.
If however you want to specify a fixed max page size, you can use the [`google.golang.org/api/iterator`](https://pkg.go.dev/google.golang.org/api/iterator) package to iterate by pages while specifying a specific size. The size, in this case, corresponds to `maxResults` for BigQuery's query APIs.
See <https://github.com/googleapis/google-cloud-go/wiki/Iterator-Guidelines> for more general information about advanced iterator usage.
Here's a quick test to demonstrate with the RowIterator in bigquery. It executes a query that returns a row for each day in October, and iterates by page:
```
func TestQueryPager(t *testing.T) {
ctx := context.Background()
pageSize := 5
client, err := bigquery.NewClient(ctx, "your-project-id here")
if err != nil {
t.Fatal(err)
}
defer client.Close()
q := client.Query("SELECT * FROM UNNEST(GENERATE_DATE_ARRAY('2022-10-01','2022-10-31', INTERVAL 1 DAY)) as d")
it, err := q.Read(ctx)
if err != nil {
t.Fatalf("query failure: %v", err)
}
pager := iterator.NewPager(it, pageSize, "")
var fetchedPages int
for {
var rows [][]bigquery.Value
nextToken, err := pager.NextPage(&rows)
if err != nil {
t.Fatalf("NextPage: %v", err)
}
fetchedPages = fetchedPages + 1
if len(rows) > pageSize {
t.Errorf("page size exceeded, got %d want %d", len(rows), pageSize)
}
t.Logf("(next token %s) page size: %d", nextToken, len(rows))
if nextToken == "" {
break
}
}
wantPages := 7
if fetchedPages != wantPages {
t.Fatalf("fetched %d pages, wanted %d pages", fetchedPages, wantPages)
}
}
``` | 1,670 |
18,004,605 | I got stuck on another part of this exercise. The program that is being coded allows you to drill phrases (It gives you a piece of code, you write out the English translation) and I'm confused on how the "convert" function works. Full code: <http://learnpythonthehardway.org/book/ex41.html>
```
def convert(snippet, phrase):
class_names = [w.capitalize() for w in
random.sample(WORDS, snippet.count("%%%"))]
other_names = random.sample(WORDS, snippet.count("***"))
results = []
param_names = []
for i in range(0, snippet.count("@@@")):
param_count = random.randint(1,3)
param_names.append(', '.join(random.sample(WORDS, param_count)))
for sentence in snippet, phrase:
result = sentence[:]
# fake class names
for word in class_names:
result = result.replace("%%%", word, 1)
# fake other names
for word in other_names:
result = result.replace("***", word, 1)
# fake parameter lists
for word in param_names:
result = result.replace("@@@", word, 1)
results.append(result)
return results
```
I'm pretty lost. Is "w" from `w.capitalize()` a file itself, or is it just referring to the objects in the list? I'm also not sure why the `.count()` function is in the argument for `.sample()` (or what `.sample()` really does). What is the purpose of the first for\_loop?
Thank you for any and all help - I'm sorry for the barrage of questions. | 2013/08/01 | [
"https://Stackoverflow.com/questions/18004605",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2640186/"
] | If it can help you,
```
class_names = [w.capitalize() for w in
random.sample(WORDS, snippet.count("%%%"))]
```
is equivalent to
```
class_names = []
for w in random.sample(WORDS, snippet.count("%%%")):
class_names.append(w.capitalize())
```
The .count() will return the number of occurence of "%%%" in the snippet string, so the random.sample will select a subset of N elements from the WORDS list where N is the element of "%%%" in the snippet string. | `w.capitalize()` is like `.uppercase()`, but it only captilizes the first character. | 1,671 |
17,708,683 | I'm trying to deploy a Flask app on a Linode VPS running Ubuntu 10.10. I've been following this tutorial (<https://library.linode.com/web-servers/nginx/python-uwsgi/ubuntu-10.10-maverick#sph_configure-nginx>) but I keep getting a 502 Bad Gateway error.
Here this is /etc/default/uwsgi:
```
PYTHONPATH=/var/www/reframeit-im
MODULE=wsgi
```
Here is /var/www/reframeit-im/wsgi.py:
```
# add the application directory to the python path
import sys
sys.path.append("/var/www/reframeit-im")
# run flask app
from reframeit import app as application
```
Here is the app's nginx config file, which is symlinked to the /sites-enabled directory (/opt/nginx/conf/sites-enabled/reframeit-im):
```
server {
listen 80;
server_name www.reframeit-im.coshx.com reframeit-im.coshx.com;
access_log /var/www/reframeit-im/logs/access.log;
error_log /var/www/reframeit-im/logs/error.log;
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:9001;
}
}
```
I checked the nginx error logs for the app and I found this:
```
2013/07/17 19:30:19 [error] 20037#0: *1 upstream prematurely closed connection while reading response header from upstream, client: 70.88.168.82, server: www.reframeit-im.coshx.com, request: "GET /favicon.ico HTTP/1.1", upstream: "uwsgi://127.0.0.1:9001", host: "reframeit-im.coshx.com"
```
Is there something wrong with my configuration? | 2013/07/17 | [
"https://Stackoverflow.com/questions/17708683",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2193598/"
] | With `uwsgi_pass 127.0.0.1:9001;` you declared to Nginx your intent to talk to uWSGI through TCP socket, but have not warned uWSGI about it.
Try adding a corresponding socket line to your `/etc/default/uwsgi` file:
```
PYTHONPATH=/var/www/reframeit-im
MODULE=wsgi
socket=127.0.0.1:9001
``` | Please add "protocol = uwsgi" apart from what Flavio has suggested. As below
```
PYTHONPATH=/var/www/reframeit-im
MODULE=wsgi
socket=127.0.0.1:9001
protocol = uwsgi
``` | 1,672 |
66,996,147 | I have a python list that looks like this:
```
my_list = [2, 4, 1 ,0, 3]
```
My goal is to iterate over this list in a manner where the next index is the current value and then to append all the index in another list and then stop the iteration once a cycle is over. Hence,
>
> Starting from 0 it contains the value 2 so you go to index 2.
>
> Index 2 contains the value 1 so you go to index 1
>
> Index 1 contains the value 4 so you go to index 4
>
> Index 4 contains the value 3 so you go to index 3
>
> Index 3 contains the value 0 so you go to index 0
>
>
>
and the new\_list looks like this:
```
new_list = [0,2,1,4,3]
```
My attempt:
```
In [14]: my_list = [2,4,1,0,3]
In [15]: new_list =[]
In [16]: for i,j in enumerate(my_list):
...: if i in new_list:
...: break
...: else:
...: new_list.append(i)
...: i=j
...: print(new_list)
[0, 1, 2, 3, 4]
```
This is obviously not working. Specifically, that **i=j** line has no effect since the for loop goes back to the initial counter. How can I achieve this? | 2021/04/08 | [
"https://Stackoverflow.com/questions/66996147",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1813039/"
] | A `while` loop is a better structure here; set `i` to point to the first element in `my_list` and then iterate until you find `i` in `new_list`:
```py
my_list = [2,4,1,0,3]
new_list = []
i = 0
while i not in new_list:
new_list.append(i)
i = my_list[i]
print(new_list)
```
Output:
```py
[0, 2, 1, 4, 3]
```
Note the code assumes that all values in `my_list` are valid indexes into `my_list`. If this is not the case, you would need to add a test for that and break the loop at that point. For example:
```py
my_list = [2,4,5,0,3]
new_list = []
i = 0
while i not in new_list:
new_list.append(i)
i = my_list[i]
if i not in range(len(my_list)):
break
print(new_list)
```
Output:
```py
[0, 2]
``` | You can try this. using variable swapping you can reassign rather than appending and creating a new variable
```
my_list = [2,4,1,0,3]
n= len(my_list)
for i in range(n-1):
for j in range(0,n-i-1):
if my_list[j] > my_list[j+1]:
my_list[j], my_list[j+1] = my_list[j+1],my_list[j]
print(my_list)
``` | 1,673 |
35,132,569 | What I'm trying to do is build a regressor based on a value in a feature.
That is to say, I have some columns where one of them is more important (let's suppose it is `gender`) (of course it is different from the target value Y).
I want to say:
- If the `gender` is Male then use the randomForest regressor
- Else use another regressor
Do you have any idea about if this is possible using `sklearn` or any other library in python? | 2016/02/01 | [
"https://Stackoverflow.com/questions/35132569",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3497084/"
] | You might be able to implement your own regressor. Let us assume that `gender` is the first feature. Then you could do something like
```
class MyRegressor():
'''uses different regressors internally'''
def __init__(self):
self.randomForest = initializeRandomForest()
self.kNN = initializekNN()
def fit(self, X, y):
'''calls the appropriate regressors'''
X1 = X[X[:,0] == 1]
y1 = y[X[:,0] == 1]
X2 = X[X[:,0] != 1]
y2 = y[X[:,0] != 1]
self.randomForest.fit(X1, y1)
self.kNN.fit(X2, y2)
def predict(self, X):
'''predicts values using regressors internally'''
results = np.zeros(X.shape[0])
results[X[:,0]==1] = self.randomForest.predict(X[X[:,0] == 1])
results[X[:,0]!=1] = self.kNN.predict(X[X[:,0] != 1])
return results
``` | I personally am new to Python but I would use the data type of a list. I would then proceed to making a membership check and reference the list you just wrote. Then proceed to say that if member = true then run/use randomForest regressor. If false use/run another regressor. | 1,674 |
60,873,608 | Need substition for using label/goto -used in languages like C,..- in python
So basically, I am a newb at python (and honestly, programming).I have been experimenting with super basic stuff and have hit a "roadblock".
```
print("Hello User!")
print("Welcome to your BMI Calculator.")
print("Please choose your system of measurement (Answer in terms of A or B):")
print("A)Inches and Pounds")
print("B)Meters and Kilograms")
ans = str(input("Input:A or B"))
if ans =="B":
h = float(input("Please enter your height (in meters)"))
w = float(input("Please enter your weight (in kilograms)"))
bmi = w/(h**2)
print("Your BMI is:")
print(bmi)
if bmi < 18.5:
print("You are in the UNDERWEIGHT category.")
elif 18.5 < bmi <24.9:
print("You are in the HEALTHY-WEIGHT category.")
else:
print("You are in the OVERWEIGHT category.")
print("THANK YOU FOR YOUR TIME.")
elif ans =="A":
h = float(input("Please enter your height (in inches)"))
w = float(input("Please enter your weight (in pounds)"))
bmi = (w*0.453592)/((h*0.0254)**2)
print("Your BMI is:")
print(bmi)
if bmi < 18.5:
print("You are in the UNDERWEIGHT category.")
elif 18.5 < bmi <24.9:
print("You are in the HEALTHY-WEIGHT category.")
else:
print("You are in the OVERWEIGHT category.")
print("THANK YOU FOR YOUR TIME.")
else:
print("ERROR")
```
In the final else, I want it to go back to asking for input for the measurement system in case the user did not type 'A' or 'B' exactly. Some substitute for goto in python should work for that.
Also, if there isn't a substitute for goto, the problem should be solved if it doesn't take any other input other than 'A' or 'B'.
Thanks for your time. | 2020/03/26 | [
"https://Stackoverflow.com/questions/60873608",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/13130669/"
] | I don't recommend you start your programming career with `goto`, that's how you can get perfectly written `spaghetti code`.
Let's review your use case here, you want to go back to asking user if he did not gave you an expected input, why not use a loop instead of `goto`?
```
ans = "unexpected"
while(ans != "A" and ans != "B"):
print("Hello User!")
print("Welcome to your BMI Calculator.")
print("Please choose your system of measurement (Answer in terms of A or B):")
print("A)Inches and Pounds")
print("B)Meters and Kilograms")
ans = str(input("Input:A or B"))
if ans =="B":
h = float(input("Please enter your height (in meters)"))
w = float(input("Please enter your weight (in kilograms)"))
bmi = w/(h**2)
print("Your BMI is:")
print(bmi)
if bmi < 18.5:
print("You are in the UNDERWEIGHT category.")
elif 18.5 < bmi <24.9:
print("You are in the HEALTHY-WEIGHT category.")
else:
print("You are in the OVERWEIGHT category.")
print("THANK YOU FOR YOUR TIME.")
elif ans =="A":
h = float(input("Please enter your height (in inches)"))
w = float(input("Please enter your weight (in pounds)"))
bmi = (w*0.453592)/((h*0.0254)**2)
print("Your BMI is:")
print(bmi)
if bmi < 18.5:
print("You are in the UNDERWEIGHT category.")
elif 18.5 < bmi <24.9:
print("You are in the HEALTHY-WEIGHT category.")
else:
print("You are in the OVERWEIGHT category.")
print("THANK YOU FOR YOUR TIME.")
```
With that the user will be kept in the input state as long as he does not give you the desired input format. | Put everything in 'while (true)' starting with first 'if' statement. And remove last 'else' statement. | 1,675 |
3,162,450 | I am looking for references (tutorials, books, academic literature) concerning structuring unstructured text in a manner similar to the google calendar quick add button.
I understand this may come under the NLP category, but I am interested only in the process of going from something like "Levi jeans size 32 A0b293"
to: Brand: Levi, Size: 32, Category: Jeans, code: A0b293
I imagine it would be some combination of lexical parsing and machine learning techniques.
I am rather language agnostic but if pushed would prefer python, Matlab or C++ references
Thanks | 2010/07/01 | [
"https://Stackoverflow.com/questions/3162450",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/93580/"
] | You need to provide more information about the source of the text (the web? user input?), the domain (is it just clothes?), the potential formatting and vocabulary...
Assuming worst case scenario you need to start learning NLP. A very good free book is the documentation of NLTK: <http://www.nltk.org/book> . It is also a very good introduction to Python and the SW is free (for various usages). Be warned: NLP is hard. It doesn't always work. It is not fun at times. The state of the art is no where near where you imagine it is.
Assuming a better scenario (your text is semi-structured) - a good free tool is [pyparsing](http://pyparsing.wikispaces.com/). There is a book, plenty of examples and the resulting code is extremely attractive.
I hope this helps... | Possibly look at "Collective Intelligence" by Toby Segaran. I seem to remember that addressing the basics of this in one chapter. | 1,676 |
68,890,393 | I'm trying to install a Python package called "mudes" on another server using terminal. When I want to install it using
```
pip install mudes
```
or
```
pip3 install mudes
```
, I get the following error:
```
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-hn4hol_z/spacy/
```
I have also used
```
pip install --no-cache-dir mudes
```
, which resulted in the same error and
```
pip3 install --upgrade setuptools --user python
```
, which resulted in the following:
```
Requirement already up-to-date: setuptools in ./pythonProject/venv/lib/python3.6/site-packages
Collecting python
Could not find a version that satisfies the requirement python (from versions: )
No matching distribution found for python
```
How can I solve this problem? | 2021/08/23 | [
"https://Stackoverflow.com/questions/68890393",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] | I had the same issue trying to install pycaret. I'm no expert so I don't know why but this work for me
```
pip3 install --upgrade pip
``` | The setuptools might be outdated. Try running this command first and see if it helps.
```
pip install --upgrade setuptools
``` | 1,681 |
46,510,770 | I'm kind of new to python and I need to run a script all day. However, the memory used by the script keeps increasing over time until python crashes... I've tried stuff but nothing works :( Maybe I'm doing something wrong I don't know. Here's what my code looks like :
```
while True:
try:
import functions and modules...
Init_Variables = ...
def a bunch of functions...
def clearall(): #Function to free memory
all = [var for var in globals() if var[0] != "_" and var != gc]
for var in all:
del globals()[var]
print('Cleared !')
gc.collect()
TimeLoop() #Getting out of "try" here because TimeLoop isn't defined anymore
def TimeLoop():
for i in range (1,101):
do stuff...
# Free memory after 100 iterations #############################
clearall()
TimeLoop() # Launches my function when i first start the script
except Exception as e:
print(e)
continue
break
```
After about 50.000 iterations of "do stuff..." python uses about 2GB of RAM and then crash :(
I spent hours trying to solve this issue but nothing seems to work. Any help would be very much appreciated! :D | 2017/10/01 | [
"https://Stackoverflow.com/questions/46510770",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/8703130/"
] | The closest thing Xcode has is a button at the bottom of the project navigator to show only files with source-control status. Clicking the button shows files that have uncommitted changes.
[](https://i.stack.imgur.com/PmT8M.png) | As Mark answered you can filter all the modified files, after that don't forget to turn on **Comparison**, so you can see where the code got changed.
[](https://i.stack.imgur.com/Wmugd.png) | 1,683 |
58,854,194 | I'm getting the following error when using the [Microsoft Python Speech-to-Text Quickstart ("Quickstart: Recognize speech from an audio file")](https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/quickstarts/speech-to-text-from-file?tabs=linux&pivots=programming-language-python#sample-code) with the [azure-cognitiveservices-speech v1.8.0 SDK](https://pypi.org/project/azure-cognitiveservices-speech/).
```
RuntimeError: Exception with an error code: 0xa (SPXERR_INVALID_HEADER)
```
* Quickstart Code: <https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/quickstarts/speech-to-text-from-file?tabs=linux&pivots=programming-language-python#sample-code>
* SDK: <https://pypi.org/project/azure-cognitiveservices-speech/>
There are just 3 inputs to this file:
* Azure Subscription Key
* Azure Service Region
* Filename
I'm using the following test MP3 file:
* <https://github.com/grokify/go-transcribe/blob/master/examples/mongodb-is-web-scale/web-scale_b2F-DItXtZs.mp3>
Here's the full output:
```
Traceback (most recent call last):
File "main.py", line 16, in <module>
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/azure/cognitiveservices/speech/speech.py", line 761, in __init__
self._impl = self._get_impl(impl.SpeechRecognizer, speech_config, audio_config)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/azure/cognitiveservices/speech/speech.py", line 547, in _get_impl
_impl = reco_type._from_config(speech_config._impl, audio_config._impl)
RuntimeError: Exception with an error code: 0xa (SPXERR_INVALID_HEADER)
[CALL STACK BEGIN]
3 libMicrosoft.CognitiveServices.Speech.core.dylib 0x0000000106ad88d2 CreateModuleObject + 1136482
4 libMicrosoft.CognitiveServices.Speech.core.dylib 0x0000000106ad7f4f CreateModuleObject + 1134047
5 libMicrosoft.CognitiveServices.Speech.core.dylib 0x00000001069d1803 CreateModuleObject + 59027
6 libMicrosoft.CognitiveServices.Speech.core.dylib 0x00000001069d1503 CreateModuleObject + 58259
7 libMicrosoft.CognitiveServices.Speech.core.dylib 0x0000000106a11c64 CreateModuleObject + 322292
8 libMicrosoft.CognitiveServices.Speech.core.dylib 0x0000000106a10be5 CreateModuleObject + 318069
9 libMicrosoft.CognitiveServices.Speech.core.dylib 0x0000000106a0e5a2 CreateModuleObject + 308274
10 libMicrosoft.CognitiveServices.Speech.core.dylib 0x0000000106a0e7c3 CreateModuleObject + 308819
11 libMicrosoft.CognitiveServices.Speech.core.dylib 0x0000000106960bc7 recognizer_create_speech_recognizer_from_config + 3863
12 libMicrosoft.CognitiveServices.Speech.core.dylib 0x000000010695fd74 recognizer_create_speech_recognizer_from_config + 196
13 _speech_py_impl.so 0x00000001067ff35b PyInit__speech_py_impl + 814939
14 _speech_py_impl.so 0x000000010679b530 PyInit__speech_py_impl + 405808
15 Python 0x00000001060f65dc _PyMethodDef_RawFastCallKeywords + 668
16 Python 0x00000001060f5a5a _PyCFunction_FastCallKeywords + 42
17 Python 0x00000001061b45a4 call_function + 724
18 Python 0x00000001061b1576 _PyEval_EvalFrameDefault + 25190
19 Python 0x00000001060f5e90 function_code_fastcall + 128
20 Python 0x00000001061b45b2 call_function + 738
21 Python 0x00000001061b1576 _PyEval_EvalFrameDefault + 25190
22 Python 0x00000001061b50d6 _PyEval_EvalCodeWithName + 2422
23 Python 0x00000001060f55fb _PyFunction_FastCallDict + 523
24 Python 0x00000001060f68cf _PyObject_Call_Prepend + 143
25 Python 0x0000000106144d51 slot_tp_init + 145
26 Python 0x00000001061406a9 type_call + 297
27 Python 0x00000001060f5871 _PyObject_FastCallKeywords + 433
28 Python 0x00000001061b4474 call_function + 420
29 Python 0x00000001061b16bd _PyEval_EvalFrameDefault + 25517
30 Python 0x00000001061b50d6 _PyEval_EvalCodeWithName + 2422
31 Python 0x00000001061ab234 PyEval_EvalCode + 100
32 Python 0x00000001061e88f1 PyRun_FileExFlags + 209
33 Python 0x00000001061e816a PyRun_SimpleFileExFlags + 890
34 Python 0x00000001062079db pymain_main + 6875
35 Python 0x0000000106207f2a _Py_UnixMain + 58
36 libdyld.dylib 0x00007fff5d8aaed9 start + 1
37 ??? 0x0000000000000002 0x0 + 2
```
Can anyone provide some pointers on what header this is referring to and how to resolve this. | 2019/11/14 | [
"https://Stackoverflow.com/questions/58854194",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1908967/"
] | mp3-encoded audio is not supported as an input format. Please use a WAV(PCM) file with 16-bit samples, 16 kHz sample rate, and a single channel (Mono). | The default audio streaming format is WAV (16kHz or 8kHz, 16-bit, and mono PCM). Outside of WAV / PCM, the compressed input formats listed below are also supported.
However if you use C#/Java/C++/Objective C and if you want to use compressed audio formats such as **.mp3**, you can handle it by using **GStreamer**
For more information follow this Microsoft documentation.
<https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/how-to-use-codec-compressed-audio-input-streams> | 1,684 |
10,865,483 | What is the easiest way to print the result from MySQL query in the same way MySQL print them in the console using Python? For example I would like to get something like that:
```
+---------------------+-----------+---------+
| font | documents | domains |
+---------------------+-----------+---------+
| arial | 99854 | 5741 |
| georgia | 52388 | 1955 |
| verdana | 43219 | 2388 |
| helvetica neue | 22179 | 1019 |
| helvetica | 16753 | 1036 |
| lucida grande | 15431 | 641 |
| tahoma | 10038 | 594 |
| trebuchet ms | 8868 | 417 |
| palatino | 5794 | 177 |
| lucida sans unicode | 3525 | 116 |
| sans-serif | 2947 | 216 |
| times new roman | 2554 | 161 |
| proxima-nova | 2076 | 36 |
| droid sans | 1773 | 78 |
| calibri | 1735 | 64 |
| open sans | 1479 | 60 |
| segoe ui | 1273 | 57 |
+---------------------+-----------+---------+
17 rows in set (19.43 sec)
```
Notice: I don't know the max width for each column a priori, and yet I would like to be able to that without going over the table twice. Should I add to the query length() for each column? How does MySQL do it, in order to not impact severely the memory or processing time?
*EDIT*
I did not think it was relevant to the question but, this is the query I send:
```
SELECT font.font as font,count(textfont.textid) as documents, count(DISTINCT td.domain) as domains
FROM textfont
RIGHT JOIN font
ON textfont.fontid = font.fontid
RIGHT JOIN (
SELECT text.text as text,url.domain as domain, text.textid as textid
FROM text
RIGHT JOIN url
ON text.texturl = url.urlid) as td
ON textfont.textid = td.textid
WHERE textfont.fontpriority <= 0
AND textfont.textlen > 100
GROUP BY font.font
HAVING documents >= 1000 AND domains >= 10
ORDER BY 2 DESC;
```
And this is the python code I use:
```
import MySQLdb as mdb
print "%s\t\t\t%s\t\t%s" % ("font","documents","domains")
res = cur.execute(query , (font_priority,text_len,min_texts,min_domains))
for res in cur.fetchall():
print "%s\t\t\t%d\t\t%d" % (res[0],res[1],res[2])
```
But this code produces a messy output due to different widths. | 2012/06/02 | [
"https://Stackoverflow.com/questions/10865483",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/986743/"
] | There is no need for an external library. The prints out the data with the column names. All lines with the 'columns' variable can be eliminated if you do not need the column names.
```
sql = "SELECT * FROM someTable"
cursor.execute(sql)
conn.commit()
results = cursor.fetchall()
widths = []
columns = []
tavnit = '|'
separator = '+'
for cd in cursor.description:
widths.append(max(cd[2], len(cd[0])))
columns.append(cd[0])
for w in widths:
tavnit += " %-"+"%ss |" % (w,)
separator += '-'*w + '--+'
print(separator)
print(tavnit % tuple(columns))
print(separator)
for row in results:
print(tavnit % row)
print(separator)
```
This is the output:
```
+--------+---------+---------------+------------+------------+
| ip_log | user_id | type_id | ip_address | time_stamp |
+--------+---------+---------------+------------+------------+
| 227 | 1 | session_login | 10.0.0.2 | 1358760386 |
| 140 | 1 | session_login | 10.0.0.2 | 1358321825 |
| 98 | 1 | session_login | 10.0.0.2 | 1358157588 |
+--------+---------+---------------+------------+------------+
```
The magic lies in the third column of each `cursor.description` line (called `cd[2]` in the code). This column represents the length in characters of the longest value. Thus we size the displayed column as the greater between that and the length of the column header itself (`max(cd[2], len(cd[0]))`). | The data is in some list it seems, and are printing the header. Consider some formatting like this:
```
res = ['trebuchet ms', 8868, 417]
res = ['lucida sans unicode', 3525, 116]
```
and
```
print(' {0[0]:20s} {0[1]:10d} {0[2]:10d}'.format(res))
```
give you
```
trebuchet ms 8868 417
lucida sans unicode 3525 116
```
Notice the indexing into the list is done inside the string, `format` only needs to supply the list or tuple.
*Alternatively*, you could specify widths programatically:
```
wid1 = 20
wid2 = 10
wid3 = 10
print(' {:{}s} {:{}d} {:{}d}'.format(res[0], wid1, res[1], wid2, res[2], wid3))
```
which gives identical output as above.
You'd have to adjust the field widths as required and loop through the list for each line of data instead of made up sample lines. Numbers are automatically right justified, string automatically left.
Advantage, to some, is of course that this doesn't rely on any external libraries, and is done with what Python already provides.
Learn More About String Formatting [here](https://www.python.org/dev/peps/pep-3101/) | 1,687 |
4,591,125 | I did several Boolean Comparisons:
```
>>> (True or False) is True
True
>>> (True or False) == True
True
```
It sounds like `==` and `is` are interchangeable for Boolean-values.
Sometimes it's more clear to use `is`
I want to know that:
Are `True` and `False` pre-allocated in python?
Is `bool(var)` always return the same `True`(or `False`) with the pre-allocated `True`(or `False`)?
Is it safe to replace `==` with `is` to compare Boolean-values?
---
It's not about Best-Practice.
I just want to know the Truth. | 2011/01/04 | [
"https://Stackoverflow.com/questions/4591125",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/348785/"
] | It seems that all answers deal with `True` and `False` as defined after an interpreter startup. Before booleans became part of Python they were often defined as part of a program. Even now (Python 2.6.6) they are only names that can be pointed to different objects:
```
>>> True = 1
>>> (2 > 1)
True
>>> (2 > 1) == True
True
>>> (2 > 1) is True
False
```
If you have to deal with older software, be aware of that. | `==` and `is` are both comparison operators, which would return a boolean value - `True` or `False`. True has a numeric value of 1 and False has a numeric value of 0.
The operator `==` compare the values of two objects and objects compared are most often are the same types (int vs int, float vs float), If you compare objects of different types, then they are unequal. The operator `is` tests for object identity, 'x is y' is true if both x and y have the same id. That is, they are same objects.
So, when you are comparing if you comparing the return values of same type, use == and if you are comparing if two objects are same (be it boolean or anything else), you can use `is`.
`42 is 42` is True and is same as `42 == 42`. | 1,697 |