IP-Adapter
IP-Adapter is an image prompt adapter that can be plugged into diffusion models to enable image prompting without any changes to the underlying model. Furthermore, this adapter can be reused with other models finetuned from the same base model and it can be combined with other adapters like ControlNet. The key idea behind IP-Adapter is the decoupled cross-attention mechanism which adds a separate cross-attention layer just for image features instead of using the same cross-attention layer for both text and image features. This allows the model to learn more image-specific features.
Learn how to load an IP-Adapter in the Load adapters guide, and make sure you check out the IP-Adapter Plus section which requires manually loading the image encoder.
This guide will walk you through using IP-Adapter for various tasks and use cases.
General tasks
Let’s take a look at how to use IP-Adapter’s image prompting capabilities with the StableDiffusionXLPipeline for tasks like text-to-image, image-to-image, and inpainting. We also encourage you to try out other pipelines such as Stable Diffusion, LCM-LoRA, ControlNet, T2I-Adapter, or AnimateDiff!
In all the following examples, you’ll see the set_ip_adapter_scale() method. This method controls the amount of text or image conditioning to apply to the model. A value of 1.0 means the model is only conditioned on the image prompt. Lowering this value encourages the model to produce more diverse images, but they may not be as aligned with the image prompt. Typically, a value of 0.5 achieves a good balance between the two prompt types and produces good results.
In the examples below, try adding low_cpu_mem_usage=True to the load_ip_adapter() method to speed up the loading time.
Crafting the precise text prompt to generate the image you want can be difficult because it may not always capture what you’d like to express. Adding an image alongside the text prompt helps the model better understand what it should generate and can lead to more accurate results.
Load a Stable Diffusion XL (SDXL) model and insert an IP-Adapter into the model with the load_ip_adapter() method. Use the subfolder parameter to load the SDXL model weights.
from diffusers import AutoPipelineForText2Image
from diffusers.utils import load_image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
pipeline.set_ip_adapter_scale(0.6)Create a text prompt and load an image prompt before passing them to the pipeline to generate an image.
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_adapter_diner.png")
generator = torch.Generator(device="cpu").manual_seed(0)
images = pipeline(
prompt="a polar bear sitting in a chair drinking a milkshake",
ip_adapter_image=image,
negative_prompt="deformed, ugly, wrong proportion, low res, bad anatomy, worst quality, low quality",
num_inference_steps=100,
generator=generator,
).images
images[0]

Configure parameters
There are a couple of IP-Adapter parameters that are useful to know about and can help you with your image generation tasks. These parameters can make your workflow more efficient or give you more control over image generation.
Image embeddings
IP-Adapter enabled pipelines provide the ip_adapter_image_embeds parameter to accept precomputed image embeddings. This is particularly useful in scenarios where you need to run the IP-Adapter pipeline multiple times because you have more than one image. For example, multi IP-Adapter is a specific use case where you provide multiple styling images to generate a specific image in a specific style. Loading and encoding multiple images each time you use the pipeline would be inefficient. Instead, you can precompute and save the image embeddings to disk (which can save a lot of space if you’re using high-quality images) and load them when you need them.
This parameter also gives you the flexibility to load embeddings from other sources. For example, ComfyUI image embeddings for IP-Adapters are compatible with Diffusers and should work ouf-of-the-box!
Call the prepare_ip_adapter_image_embeds() method to encode and generate the image embeddings. Then you can save them to disk with torch.save.
If you’re using IP-Adapter with ip_adapter_image_embedding instead of ip_adapter_image’, you can set load_ip_adapter(image_encoder_folder=None,...) because you don’t need to load an encoder to generate the image embeddings.
image_embeds = pipeline.prepare_ip_adapter_image_embeds(
ip_adapter_image=image,
ip_adapter_image_embeds=None,
device="cuda",
num_images_per_prompt=1,
do_classifier_free_guidance=True,
)
torch.save(image_embeds, "image_embeds.ipadpt")Now load the image embeddings by passing them to the ip_adapter_image_embeds parameter.
image_embeds = torch.load("image_embeds.ipadpt")
images = pipeline(
prompt="a polar bear sitting in a chair drinking a milkshake",
ip_adapter_image_embeds=image_embeds,
negative_prompt="deformed, ugly, wrong proportion, low res, bad anatomy, worst quality, low quality",
num_inference_steps=100,
generator=generator,
).imagesIP-Adapter masking
Binary masks specify which portion of the output image should be assigned to an IP-Adapter. This is useful for composing more than one IP-Adapter image. For each input IP-Adapter image, you must provide a binary mask.
To start, preprocess the input IP-Adapter images with the ~image_processor.IPAdapterMaskProcessor.preprocess() to generate their masks. For optimal results, provide the output height and width to ~image_processor.IPAdapterMaskProcessor.preprocess(). This ensures masks with different aspect ratios are appropriately stretched. If the input masks already match the aspect ratio of the generated image, you don’t have to set the height and width.
from diffusers.image_processor import IPAdapterMaskProcessor
mask1 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_mask1.png")
mask2 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_mask2.png")
output_height = 1024
output_width = 1024
processor = IPAdapterMaskProcessor()
masks = processor.preprocess([mask1, mask2], height=output_height, width=output_width)

When there is more than one input IP-Adapter image, load them as a list and provide the IP-Adapter scale list. Each of the input IP-Adapter images here corresponds to one of the masks generated above.
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name=["ip-adapter-plus-face_sdxl_vit-h.safetensors"])
pipeline.set_ip_adapter_scale([[0.7, 0.7]]) # one scale for each image-mask pair
face_image1 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_girl1.png")
face_image2 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_girl2.png")
ip_images = [[face_image1, face_image2]]
masks = [masks.reshape(1, masks.shape[0], masks.shape[2], masks.shape[3])]

Now pass the preprocessed masks to cross_attention_kwargs in the pipeline call.
generator = torch.Generator(device="cpu").manual_seed(0)
num_images = 1
image = pipeline(
prompt="2 girls",
ip_adapter_image=ip_images,
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
num_inference_steps=20,
num_images_per_prompt=num_images,
generator=generator,
cross_attention_kwargs={"ip_adapter_masks": masks}
).images[0]
image

Specific use cases
IP-Adapter’s image prompting and compatibility with other adapters and models makes it a versatile tool for a variety of use cases. This section covers some of the more popular applications of IP-Adapter, and we can’t wait to see what you come up with!
Face model
Generating accurate faces is challenging because they are complex and nuanced. Diffusers supports two IP-Adapter checkpoints specifically trained to generate faces from the h94/IP-Adapter repository:
- ip-adapter-full-face_sd15.safetensors is conditioned with images of cropped faces and removed backgrounds
- ip-adapter-plus-face_sd15.safetensors uses patch embeddings and is conditioned with images of cropped faces
Additionally, Diffusers supports all IP-Adapter checkpoints trained with face embeddings extracted by insightface face models. Supported models are from the h94/IP-Adapter-FaceID repository.
For face models, use the h94/IP-Adapter checkpoint. It is also recommended to use DDIMScheduler or EulerDiscreteScheduler for face models.
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler
from diffusers.utils import load_image
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
).to("cuda")
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter-full-face_sd15.bin")
pipeline.set_ip_adapter_scale(0.5)
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_adapter_einstein_base.png")
generator = torch.Generator(device="cpu").manual_seed(26)
image = pipeline(
prompt="A photo of Einstein as a chef, wearing an apron, cooking in a French restaurant",
ip_adapter_image=image,
negative_prompt="lowres, bad anatomy, worst quality, low quality",
num_inference_steps=100,
generator=generator,
).images[0]
image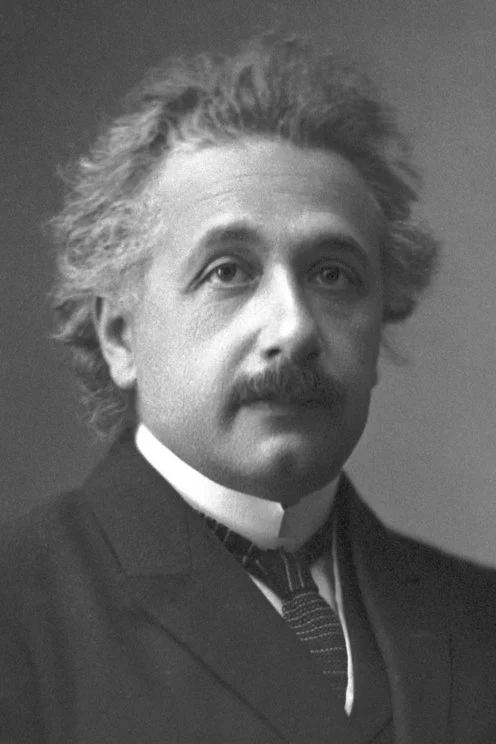

To use IP-Adapter FaceID models, first extract face embeddings with insightface. Then pass the list of tensors to the pipeline as ip_adapter_image_embeds.
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler
from diffusers.utils import load_image
from insightface.app import FaceAnalysis
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
).to("cuda")
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
pipeline.load_ip_adapter("h94/IP-Adapter-FaceID", subfolder=None, weight_name="ip-adapter-faceid_sd15.bin", image_encoder_folder=None)
pipeline.set_ip_adapter_scale(0.6)
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_girl1.png")
ref_images_embeds = []
app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_BGR2RGB)
faces = app.get(image)
image = torch.from_numpy(faces[0].normed_embedding)
ref_images_embeds.append(image.unsqueeze(0))
ref_images_embeds = torch.stack(ref_images_embeds, dim=0).unsqueeze(0)
neg_ref_images_embeds = torch.zeros_like(ref_images_embeds)
id_embeds = torch.cat([neg_ref_images_embeds, ref_images_embeds]).to(dtype=torch.float16, device="cuda")
generator = torch.Generator(device="cpu").manual_seed(42)
images = pipeline(
prompt="A photo of a girl",
ip_adapter_image_embeds=[id_embeds],
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
num_inference_steps=20, num_images_per_prompt=1,
generator=generator
).imagesBoth IP-Adapter FaceID Plus and Plus v2 models require CLIP image embeddings. You can prepare face embeddings as shown previously, then you can extract and pass CLIP embeddings to the hidden image projection layers.
from insightface.utils import face_align
ref_images_embeds = []
ip_adapter_images = []
app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_BGR2RGB)
faces = app.get(image)
ip_adapter_images.append(face_align.norm_crop(image, landmark=faces[0].kps, image_size=224))
image = torch.from_numpy(faces[0].normed_embedding)
ref_images_embeds.append(image.unsqueeze(0))
ref_images_embeds = torch.stack(ref_images_embeds, dim=0).unsqueeze(0)
neg_ref_images_embeds = torch.zeros_like(ref_images_embeds)
id_embeds = torch.cat([neg_ref_images_embeds, ref_images_embeds]).to(dtype=torch.float16, device="cuda")
clip_embeds = pipeline.prepare_ip_adapter_image_embeds(
[ip_adapter_images], None, torch.device("cuda"), num_images, True)[0]
pipeline.unet.encoder_hid_proj.image_projection_layers[0].clip_embeds = clip_embeds.to(dtype=torch.float16)
pipeline.unet.encoder_hid_proj.image_projection_layers[0].shortcut = False # True if Plus v2Multi IP-Adapter
More than one IP-Adapter can be used at the same time to generate specific images in more diverse styles. For example, you can use IP-Adapter-Face to generate consistent faces and characters, and IP-Adapter Plus to generate those faces in a specific style.
Read the IP-Adapter Plus section to learn why you need to manually load the image encoder.
Load the image encoder with CLIPVisionModelWithProjection.
import torch
from diffusers import AutoPipelineForText2Image, DDIMScheduler
from transformers import CLIPVisionModelWithProjection
from diffusers.utils import load_image
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
"h94/IP-Adapter",
subfolder="models/image_encoder",
torch_dtype=torch.float16,
)Next, you’ll load a base model, scheduler, and the IP-Adapters. The IP-Adapters to use are passed as a list to the weight_name parameter:
- ip-adapter-plus_sdxl_vit-h uses patch embeddings and a ViT-H image encoder
- ip-adapter-plus-face_sdxl_vit-h has the same architecture but it is conditioned with images of cropped faces
pipeline = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
image_encoder=image_encoder,
)
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
pipeline.load_ip_adapter(
"h94/IP-Adapter",
subfolder="sdxl_models",
weight_name=["ip-adapter-plus_sdxl_vit-h.safetensors", "ip-adapter-plus-face_sdxl_vit-h.safetensors"]
)
pipeline.set_ip_adapter_scale([0.7, 0.3])
pipeline.enable_model_cpu_offload()Load an image prompt and a folder containing images of a certain style you want to use.
face_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/women_input.png")
style_folder = "https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/style_ziggy"
style_images = [load_image(f"{style_folder}/img{i}.png") for i in range(10)]

Pass the image prompt and style images as a list to the ip_adapter_image parameter, and run the pipeline!
generator = torch.Generator(device="cpu").manual_seed(0)
image = pipeline(
prompt="wonderwoman",
ip_adapter_image=[style_images, face_image],
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
num_inference_steps=50, num_images_per_prompt=1,
generator=generator,
).images[0]
image
Instant generation
Latent Consistency Models (LCM) are diffusion models that can generate images in as little as 4 steps compared to other diffusion models like SDXL that typically require way more steps. This is why image generation with an LCM feels “instantaneous”. IP-Adapters can be plugged into an LCM-LoRA model to instantly generate images with an image prompt.
The IP-Adapter weights need to be loaded first, then you can use load_lora_weights() to load the LoRA style and weight you want to apply to your image.
from diffusers import DiffusionPipeline, LCMScheduler
import torch
from diffusers.utils import load_image
model_id = "sd-dreambooth-library/herge-style"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
pipeline = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter_sd15.bin")
pipeline.load_lora_weights(lcm_lora_id)
pipeline.scheduler = LCMScheduler.from_config(pipeline.scheduler.config)
pipeline.enable_model_cpu_offload()Try using with a lower IP-Adapter scale to condition image generation more on the herge_style checkpoint, and remember to use the special token herge_style in your prompt to trigger and apply the style.
pipeline.set_ip_adapter_scale(0.4)
prompt = "herge_style woman in armor, best quality, high quality"
generator = torch.Generator(device="cpu").manual_seed(0)
ip_adapter_image = load_image("https://user-images.githubusercontent.com/24734142/266492875-2d50d223-8475-44f0-a7c6-08b51cb53572.png")
image = pipeline(
prompt=prompt,
ip_adapter_image=ip_adapter_image,
num_inference_steps=4,
guidance_scale=1,
).images[0]
image
Structural control
To control image generation to an even greater degree, you can combine IP-Adapter with a model like ControlNet. A ControlNet is also an adapter that can be inserted into a diffusion model to allow for conditioning on an additional control image. The control image can be depth maps, edge maps, pose estimations, and more.
Load a ControlNetModel checkpoint conditioned on depth maps, insert it into a diffusion model, and load the IP-Adapter.
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
from diffusers.utils import load_image
controlnet_model_path = "lllyasviel/control_v11f1p_sd15_depth"
controlnet = ControlNetModel.from_pretrained(controlnet_model_path, torch_dtype=torch.float16)
pipeline = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16)
pipeline.to("cuda")
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter_sd15.bin")Now load the IP-Adapter image and depth map.
ip_adapter_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/statue.png")
depth_map = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/depth.png")

Pass the depth map and IP-Adapter image to the pipeline to generate an image.
generator = torch.Generator(device="cpu").manual_seed(33)
image = pipeline(
prompt="best quality, high quality",
image=depth_map,
ip_adapter_image=ip_adapter_image,
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
num_inference_steps=50,
generator=generator,
).images[0]
image
Style & layout control
InstantStyle is a plug-and-play method on top of IP-Adapter, which disentangles style and layout from image prompt to control image generation. This way, you can generate images following only the style or layout from image prompt, with significantly improved diversity. This is achieved by only activating IP-Adapters to specific parts of the model.
By default IP-Adapters are inserted to all layers of the model. Use the set_ip_adapter_scale() method with a dictionary to assign scales to IP-Adapter at different layers.
from diffusers import AutoPipelineForText2Image
from diffusers.utils import load_image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
scale = {
"down": {"block_2": [0.0, 1.0]},
"up": {"block_0": [0.0, 1.0, 0.0]},
}
pipeline.set_ip_adapter_scale(scale)This will activate IP-Adapter at the second layer in the model’s down-part block 2 and up-part block 0. The former is the layer where IP-Adapter injects layout information and the latter injects style. Inserting IP-Adapter to these two layers you can generate images following both the style and layout from image prompt, but with contents more aligned to text prompt.
style_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg")
generator = torch.Generator(device="cpu").manual_seed(26)
image = pipeline(
prompt="a cat, masterpiece, best quality, high quality",
ip_adapter_image=style_image,
negative_prompt="text, watermark, lowres, low quality, worst quality, deformed, glitch, low contrast, noisy, saturation, blurry",
guidance_scale=5,
num_inference_steps=30,
generator=generator,
).images[0]
image

In contrast, inserting IP-Adapter to all layers will often generate images that overly focus on image prompt and diminish diversity.
Activate IP-Adapter only in the style layer and then call the pipeline again.
scale = {
"up": {"block_0": [0.0, 1.0, 0.0]},
}
pipeline.set_ip_adapter_scale(scale)
generator = torch.Generator(device="cpu").manual_seed(26)
image = pipeline(
prompt="a cat, masterpiece, best quality, high quality",
ip_adapter_image=style_image,
negative_prompt="text, watermark, lowres, low quality, worst quality, deformed, glitch, low contrast, noisy, saturation, blurry",
guidance_scale=5,
num_inference_steps=30,
generator=generator,
).images[0]
image

Note that you don’t have to specify all layers in the dictionary. Those not included in the dictionary will be set to scale 0 which means disable IP-Adapter by default.
< > Update on GitHub