Hub documentation
GGUF
GGUF
Hugging Face Hub supports all file formats, but has built-in features for GGUF format, a binary format that is optimized for quick loading and saving of models, making it highly efficient for inference purposes. GGUF is designed for use with GGML and other executors. GGUF was developed by @ggerganov who is also the developer of llama.cpp, a popular C/C++ LLM inference framework. Models initially developed in frameworks like PyTorch can be converted to GGUF format for use with those engines.

As we can see in this graph, unlike tensor-only file formats like safetensors – which is also a recommended model format for the Hub – GGUF encodes both the tensors and a standardized set of metadata.
Finding GGUF files
You can browse all models with GGUF files filtering by the GGUF tag: hf.co/models?library=gguf. Moreover, you can use ggml-org/gguf-my-repo tool to convert/quantize your model weights into GGUF weights.
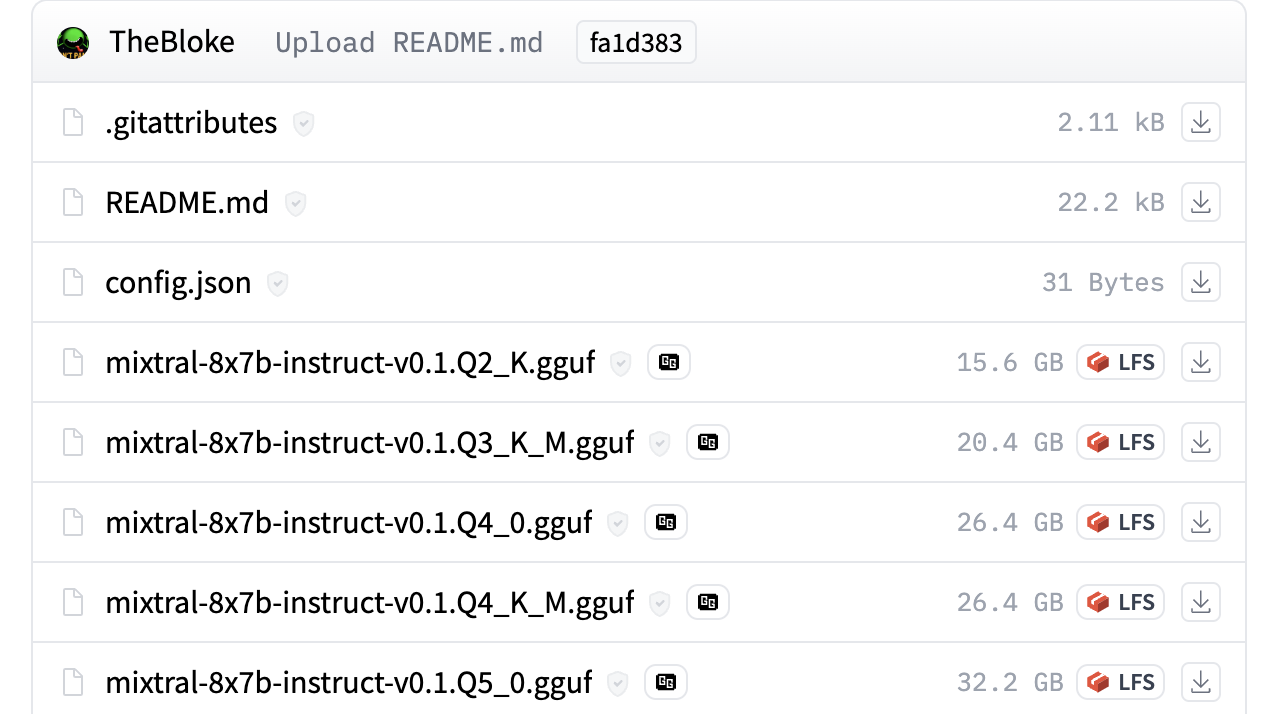
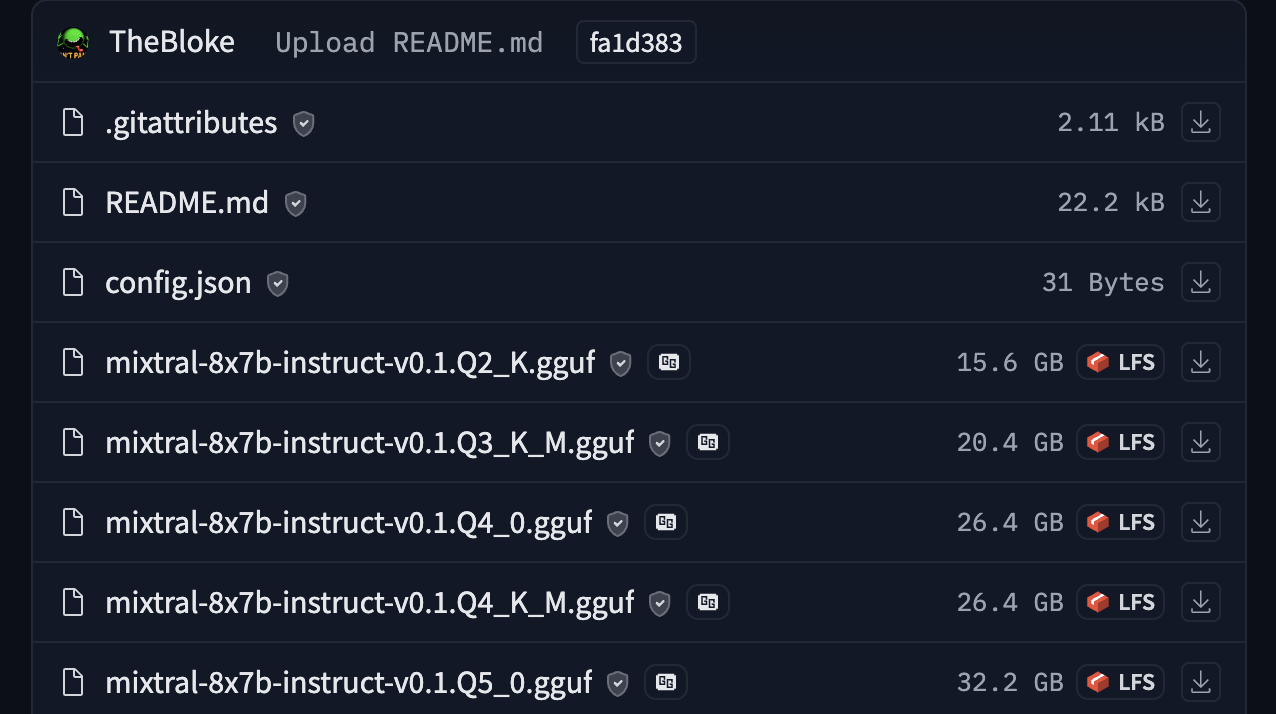
For example, you can check out TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF for seeing GGUF files in action.
Viewer for metadata & tensors info
The Hub has a viewer for GGUF files that lets a user check out metadata & tensors info (name, shape, precison). The viewer is available on model page (example) & files page (example).
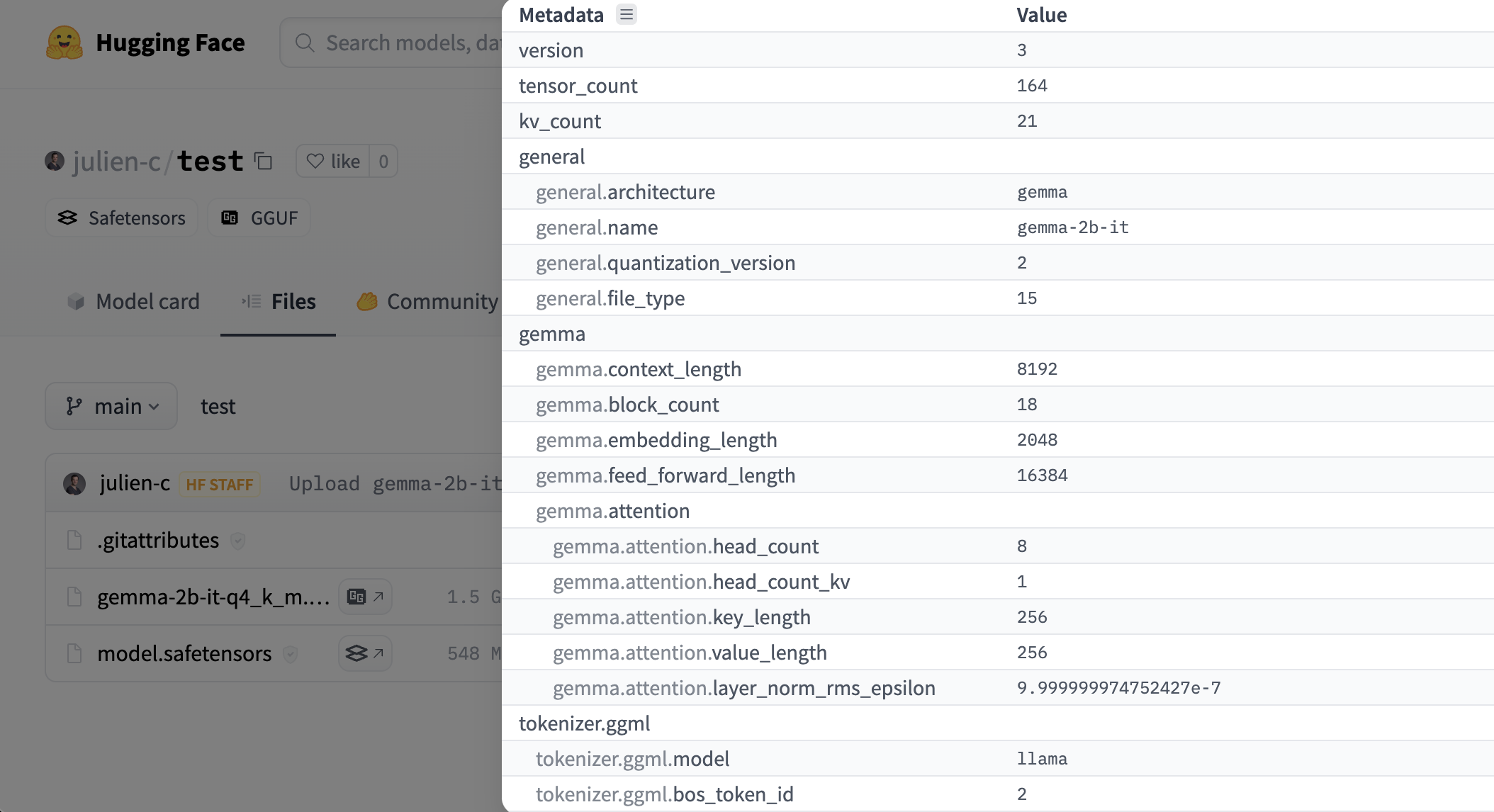
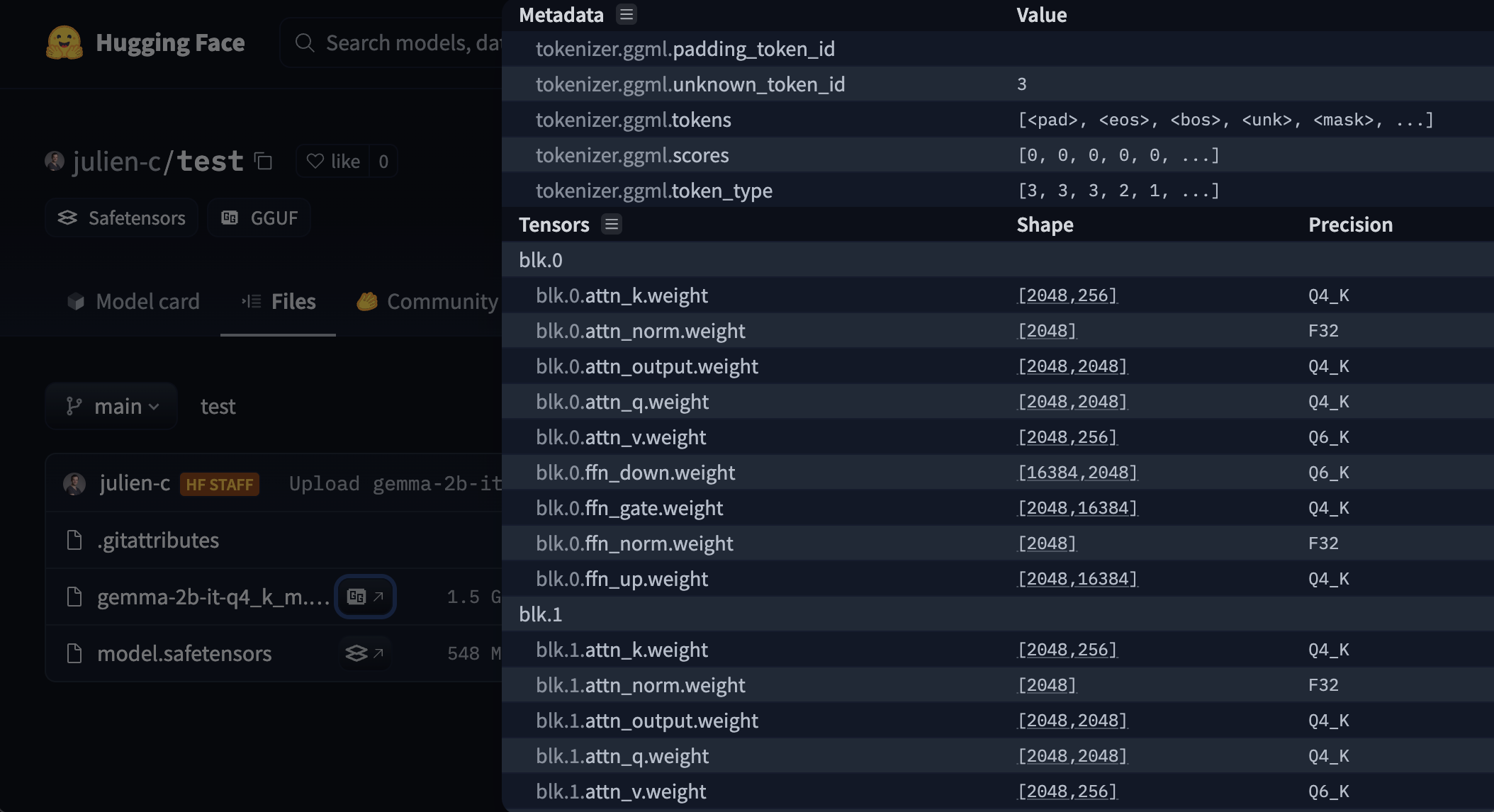
Usage with open-source tools
Parsing the metadata with @huggingface/gguf
We’ve also created a javascript GGUF parser that works on remotely hosted files (e.g. Hugging Face Hub).
npm install @huggingface/gguf
import { gguf } from "@huggingface/gguf";
// remote GGUF file from https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF
const URL_LLAMA = "https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/resolve/191239b/llama-2-7b-chat.Q2_K.gguf";
const { metadata, tensorInfos } = await gguf(URL_LLAMA);Find more information here.
Quantization Types
| type | source | description |
|---|---|---|
| F64 | Wikipedia | 64-bit standard IEEE 754 double-precision floating-point number. |
| I64 | GH | 64-bit fixed-width integer number. |
| F32 | Wikipedia | 32-bit standard IEEE 754 single-precision floating-point number. |
| I32 | GH | 32-bit fixed-width integer number. |
| F16 | Wikipedia | 16-bit standard IEEE 754 half-precision floating-point number. |
| BF16 | Wikipedia | 16-bit shortened version of the 32-bit IEEE 754 single-precision floating-point number. |
| I16 | GH | 16-bit fixed-width integer number. |
| Q8_0 | GH | 8-bit round-to-nearest quantization (q). Each block has 32 weights. Weight formula: w = q * block_scale. Legacy quantization method (not used widely as of today). |
| Q8_1 | GH | 8-bit round-to-nearest quantization (q). Each block has 32 weights. Weight formula: w = q * block_scale + block_minimum. Legacy quantization method (not used widely as of today) |
| Q8_K | GH | 8-bit quantization (q). Each block has 256 weights. Only used for quantizing intermediate results. All 2-6 bit dot products are implemented for this quantization type. Weight formula: w = q * block_scale. |
| I8 | GH | 8-bit fixed-width integer number. |
| Q6_K | GH | 6-bit quantization (q). Super-blocks with 16 blocks, each block has 16 weights. Weight formula: w = q * block_scale(8-bit), resulting in 6.5625 bits-per-weight. |
| Q5_0 | GH | 5-bit round-to-nearest quantization (q). Each block has 32 weights. Weight formula: w = q * block_scale. Legacy quantization method (not used widely as of today). |
| Q5_1 | GH | 5-bit round-to-nearest quantization (q). Each block has 32 weights. Weight formula: w = q * block_scale + block_minimum. Legacy quantization method (not used widely as of today). |
| Q5_K | GH | 5-bit quantization (q). Super-blocks with 8 blocks, each block has 32 weights. Weight formula: w = q * block_scale(6-bit) + block_min(6-bit), resulting in 5.5 bits-per-weight. |
| Q4_0 | GH | 4-bit round-to-nearest quantization (q). Each block has 32 weights. Weight formula: w = q * block_scale. Legacy quantization method (not used widely as of today). |
| Q4_1 | GH | 4-bit round-to-nearest quantization (q). Each block has 32 weights. Weight formula: w = q * block_scale + block_minimum. Legacy quantization method (not used widely as of today). |
| Q4_K | GH | 4-bit quantization (q). Super-blocks with 8 blocks, each block has 32 weights. Weight formula: w = q * block_scale(6-bit) + block_min(6-bit), resulting in 4.5 bits-per-weight. |
| Q3_K | GH | 3-bit quantization (q). Super-blocks with 16 blocks, each block has 16 weights. Weight formula: w = q * block_scale(6-bit), resulting. 3.4375 bits-per-weight. |
| Q2_K | GH | 2-bit quantization (q). Super-blocks with 16 blocks, each block has 16 weight. Weight formula: w = q * block_scale(4-bit) + block_min(4-bit), resulting in 2.625 bits-per-weight. |
| IQ4_NL | GH | 4-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix. |
| IQ4_XS | HF | 4-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 4.25 bits-per-weight. |
| IQ3_S | HF | 3-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 3.44 bits-per-weight. |
| IQ3_XXS | HF | 3-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 3.06 bits-per-weight. |
| IQ2_XXS | HF | 2-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 2.06 bits-per-weight. |
| IQ2_S | HF | 2-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 2.5 bits-per-weight. |
| IQ2_XS | HF | 2-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 2.31 bits-per-weight. |
| IQ1_S | HF | 1-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 1.56 bits-per-weight. |
| IQ1_M | GH | 1-bit quantization (q). Super-blocks with 256 weights. Weight w is obtained using super_block_scale & importance matrix, resulting in 1.75 bits-per-weight. |
if there’s any inaccuracy on the table above, please open a PR on this file.
< > Update on GitHub