Hugging Face
Models
Datasets
Spaces
Posts
Docs
Enterprise
Pricing
Log In
Sign Up
eek
/
segmentation
like
0
Voice Activity Detection
pyannote.audio
PyTorch
pyannote
pyannote-audio-model
audio
voice
speech
speaker
speaker-diarization
speaker-change-detection
speaker-segmentation
overlapped-speech-detection
resegmentation
License:
mit
Model card
Files
Files and versions
Community
Use this model
main
segmentation
2 contributors
History:
2 commits
Radu-Sebastian Amarie
ADD: pyannote speaker segmentation with duration 3
540db3b
8 months ago
.gitattributes
Safe
1.52 kB
initial commit
8 months ago
LICENSE
Safe
1.06 kB
ADD: pyannote speaker segmentation with duration 3
8 months ago
README.md
Safe
4.65 kB
ADD: pyannote speaker segmentation with duration 3
8 months ago
config.yaml
Safe
398 Bytes
ADD: pyannote speaker segmentation with duration 3
8 months ago
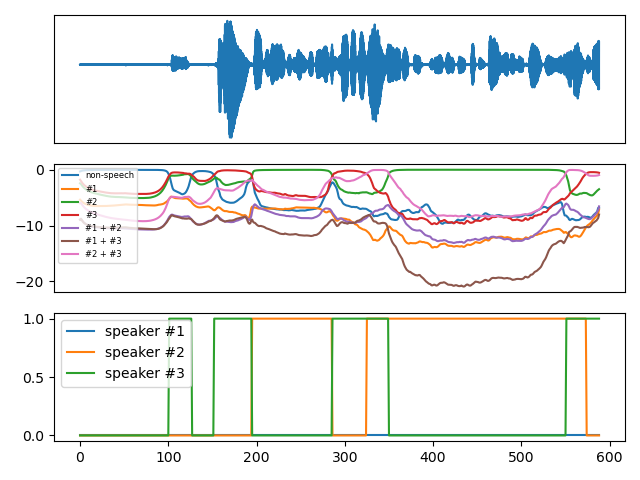
example.png
Safe
69.3 kB
ADD: pyannote speaker segmentation with duration 3
8 months ago
pytorch_model.bin
pickle
Detected Pickle imports (7)
"torch.FloatStorage"
,
"pyannote.audio.core.task.Specifications"
,
"pyannote.audio.core.task.Problem"
,
"collections.OrderedDict"
,
"torch._utils._rebuild_tensor_v2"
,
"torch.torch_version.TorchVersion"
,
"pyannote.audio.core.task.Resolution"
How to fix it?
5.91 MB
LFS
ADD: pyannote speaker segmentation with duration 3
8 months ago

{kind=link}
{kind=link}