
Commit
•
ab41624
1
Parent(s):
d8194c8
Upload 14 files
Browse files- 1_Pooling/config.json +10 -0
- README.md +180 -0
- config.json +31 -0
- config_sentence_transformers.json +9 -0
- eval.png +0 -0
- eval/mse_evaluation_talks-en-ru-dev.tsv.gz_results.csv +29 -0
- eval/translation_evaluation_talks-en-ru-dev.tsv.gz_results.csv +29 -0
- model.safetensors +3 -0
- modules.json +14 -0
- sentence_bert_config.json +4 -0
- special_tokens_map.json +7 -0
- tokenizer.json +0 -0
- tokenizer_config.json +55 -0
- vocab.txt +0 -0
1_Pooling/config.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"word_embedding_dimension": 768,
|
| 3 |
+
"pooling_mode_cls_token": false,
|
| 4 |
+
"pooling_mode_mean_tokens": true,
|
| 5 |
+
"pooling_mode_max_tokens": false,
|
| 6 |
+
"pooling_mode_mean_sqrt_len_tokens": false,
|
| 7 |
+
"pooling_mode_weightedmean_tokens": false,
|
| 8 |
+
"pooling_mode_lasttoken": false,
|
| 9 |
+
"include_prompt": true
|
| 10 |
+
}
|
README.md
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: sentence-transformers
|
| 3 |
+
pipeline_tag: sentence-similarity
|
| 4 |
+
tags:
|
| 5 |
+
- sentence-transformers
|
| 6 |
+
- feature-extraction
|
| 7 |
+
- sentence-similarity
|
| 8 |
+
- transformers
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# Enbeddrus v0.1 D+PC - English and Russian embedder
|
| 12 |
+
|
| 13 |
+
> This is the model trained on Domain, then Parallel Corpora
|
| 14 |
+
|
| 15 |
+
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional
|
| 16 |
+
dense vector space and can be used for tasks like clustering or semantic search.
|
| 17 |
+
|
| 18 |
+
- **Parameters**: 168 million
|
| 19 |
+
- **Layers**: 12
|
| 20 |
+
- **Hidden Size**: 768
|
| 21 |
+
- **Attention Heads**: 12
|
| 22 |
+
- **Vocabulary Size**: 119,547
|
| 23 |
+
- **Maximum Sequence Length**: 512 tokens
|
| 24 |
+
|
| 25 |
+
The Enbeddrus model is designed to extract similar embeddings for comparable English and Russian phrases. It is based on
|
| 26 |
+
the [bert-base-multilingual-uncased](https://huggingface.co/google-bert/bert-base-multilingual-cased) model and was
|
| 27 |
+
trained over 20 epochs on the following datasets:
|
| 28 |
+
|
| 29 |
+
- [evilfreelancer/opus-php-en-ru-cleaned](https://huggingface.co/datasets/evilfreelancer/opus-php-en-ru-cleaned) (
|
| 30 |
+
train): 1.6k lines
|
| 31 |
+
- [Helsinki-NLP/opus_books](https://huggingface.co/datasets/Helsinki-NLP/opus_books/viewer/en-ru) (en-ru, train): 17.5k
|
| 32 |
+
lines
|
| 33 |
+
|
| 34 |
+
The goal of this model is to generate identical or very similar embeddings regardless of whether the text is written in
|
| 35 |
+
English or Russian.
|
| 36 |
+
|
| 37 |
+
## Usage (Sentence-Transformers)
|
| 38 |
+
|
| 39 |
+
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
|
| 40 |
+
|
| 41 |
+
```
|
| 42 |
+
pip install -U sentence-transformers
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Then you can use the model like this:
|
| 46 |
+
|
| 47 |
+
```python
|
| 48 |
+
from sentence_transformers import SentenceTransformer
|
| 49 |
+
|
| 50 |
+
sentences = [
|
| 51 |
+
"PHP является скриптовым языком программирования, широко используемым для веб-разработки.",
|
| 52 |
+
"PHP is a scripting language widely used for web development.",
|
| 53 |
+
"PHP поддерживает множество баз данных, таких как MySQL, PostgreSQL и SQLite.",
|
| 54 |
+
"PHP supports many databases like MySQL, PostgreSQL, and SQLite.",
|
| 55 |
+
"Функция echo в PHP используется для вывода текста на экран.",
|
| 56 |
+
"The echo function in PHP is used to output text to the screen.",
|
| 57 |
+
"Машинное обучение помогает создавать интеллектуальные системы.",
|
| 58 |
+
"Machine learning helps to create intelligent systems.",
|
| 59 |
+
]
|
| 60 |
+
|
| 61 |
+
model = SentenceTransformer('evilfreelancer/enbeddrus')
|
| 62 |
+
embeddings = model.encode(sentences)
|
| 63 |
+
print(embeddings)
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
## Usage (HuggingFace Transformers)
|
| 67 |
+
|
| 68 |
+
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input
|
| 69 |
+
through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word
|
| 70 |
+
embeddings.
|
| 71 |
+
|
| 72 |
+
```python
|
| 73 |
+
from transformers import AutoTokenizer, AutoModel
|
| 74 |
+
import torch
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
# Mean Pooling - Take attention mask into account for correct averaging
|
| 78 |
+
def mean_pooling(model_output, attention_mask):
|
| 79 |
+
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
|
| 80 |
+
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
|
| 81 |
+
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
# Sentences we want sentence embeddings for
|
| 85 |
+
sentences = [
|
| 86 |
+
"PHP является скриптовым языком программирования, широко используемым для веб-разработки.",
|
| 87 |
+
"PHP is a scripting language widely used for web development.",
|
| 88 |
+
"PHP поддерживает множество баз данных, таких как MySQL, PostgreSQL и SQLite.",
|
| 89 |
+
"PHP supports many databases like MySQL, PostgreSQL, and SQLite.",
|
| 90 |
+
"Функция echo в PHP используется для вывода текста на экран.",
|
| 91 |
+
"The echo function in PHP is used to output text to the screen.",
|
| 92 |
+
"Машинное обучение помогает создавать интеллектуальные системы.",
|
| 93 |
+
"Machine learning helps to create intelligent systems.",
|
| 94 |
+
]
|
| 95 |
+
|
| 96 |
+
# Load model from HuggingFace Hub
|
| 97 |
+
tokenizer = AutoTokenizer.from_pretrained('evilfreelancer/enbeddrus')
|
| 98 |
+
model = AutoModel.from_pretrained('evilfreelancer/enbeddrus')
|
| 99 |
+
|
| 100 |
+
# Tokenize sentences
|
| 101 |
+
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
|
| 102 |
+
|
| 103 |
+
# Compute token embeddings
|
| 104 |
+
with torch.no_grad():
|
| 105 |
+
model_output = model(**encoded_input)
|
| 106 |
+
|
| 107 |
+
# Perform pooling. In this case, mean pooling.
|
| 108 |
+
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
|
| 109 |
+
|
| 110 |
+
print("Sentence embeddings:")
|
| 111 |
+
print(sentence_embeddings)
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
## Evaluation Results
|
| 115 |
+
|
| 116 |
+
The model was tested on the `eval` split of the
|
| 117 |
+
dataset [evilfreelancer/opus-php-en-ru-cleaned](https://huggingface.co/datasets/evilfreelancer/opus-php-en-ru-cleaned),
|
| 118 |
+
which contains 100 pairs of sentences in Russian and English on the topic of PHP. The results of the testing are
|
| 119 |
+
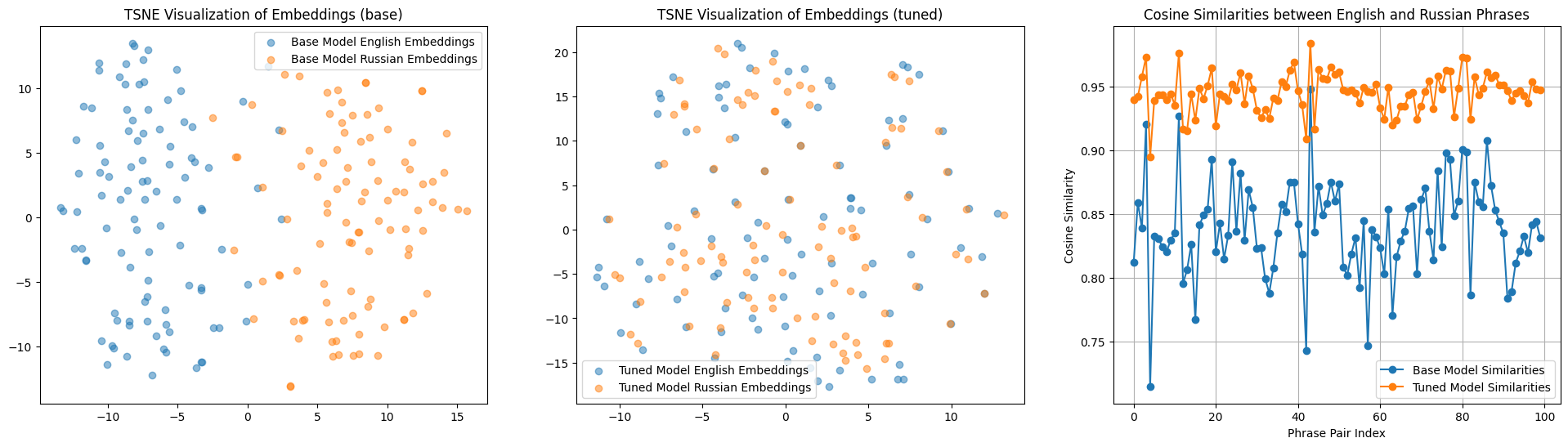
presented in the image below.
|
| 120 |
+
|
| 121 |
+

|
| 122 |
+
|
| 123 |
+
* **Left**: Embedding similarity in Russian and English before training
|
| 124 |
+
(the points are spread out into two distinct clusters).
|
| 125 |
+
* **Center**: Embedding similarity after training
|
| 126 |
+
(the points representing similar phrases are very close to each other).
|
| 127 |
+
* **Right**: Cosine distance before and after training.
|
| 128 |
+
|
| 129 |
+
## Training
|
| 130 |
+
|
| 131 |
+
The model was trained with the parameters:
|
| 132 |
+
|
| 133 |
+
**DataLoader**:
|
| 134 |
+
|
| 135 |
+
`torch.utils.data.dataloader.DataLoader` of length 556 with parameters:
|
| 136 |
+
|
| 137 |
+
```python
|
| 138 |
+
{
|
| 139 |
+
'batch_size': 64,
|
| 140 |
+
'sampler': 'torch.utils.data.sampler.RandomSampler',
|
| 141 |
+
'batch_sampler': 'torch.utils.data.sampler.BatchSampler'
|
| 142 |
+
}
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
**Loss**:
|
| 146 |
+
|
| 147 |
+
`sentence_transformers.losses.MSELoss.MSELoss`
|
| 148 |
+
|
| 149 |
+
Parameters of the fit()-Method:
|
| 150 |
+
|
| 151 |
+
```
|
| 152 |
+
{
|
| 153 |
+
"epochs": 20,
|
| 154 |
+
"evaluation_steps": 100,
|
| 155 |
+
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
|
| 156 |
+
"max_grad_norm": 1,
|
| 157 |
+
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
|
| 158 |
+
"optimizer_params": {
|
| 159 |
+
"eps": 1e-06,
|
| 160 |
+
"lr": 2e-05
|
| 161 |
+
},
|
| 162 |
+
"scheduler": "WarmupLinear",
|
| 163 |
+
"steps_per_epoch": null,
|
| 164 |
+
"warmup_steps": 10000,
|
| 165 |
+
"weight_decay": 0.01
|
| 166 |
+
}
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
## Full Model Architecture
|
| 170 |
+
|
| 171 |
+
```
|
| 172 |
+
SentenceTransformer(
|
| 173 |
+
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
|
| 174 |
+
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
|
| 175 |
+
)
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
## Citing & Authors
|
| 179 |
+
|
| 180 |
+
<!--- Describe where people can find more information -->
|
config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "bert-base-multilingual-uncased",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"directionality": "bidi",
|
| 9 |
+
"hidden_act": "gelu",
|
| 10 |
+
"hidden_dropout_prob": 0.1,
|
| 11 |
+
"hidden_size": 768,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 3072,
|
| 14 |
+
"layer_norm_eps": 1e-12,
|
| 15 |
+
"max_position_embeddings": 512,
|
| 16 |
+
"model_type": "bert",
|
| 17 |
+
"num_attention_heads": 12,
|
| 18 |
+
"num_hidden_layers": 12,
|
| 19 |
+
"pad_token_id": 0,
|
| 20 |
+
"pooler_fc_size": 768,
|
| 21 |
+
"pooler_num_attention_heads": 12,
|
| 22 |
+
"pooler_num_fc_layers": 3,
|
| 23 |
+
"pooler_size_per_head": 128,
|
| 24 |
+
"pooler_type": "first_token_transform",
|
| 25 |
+
"position_embedding_type": "absolute",
|
| 26 |
+
"torch_dtype": "float32",
|
| 27 |
+
"transformers_version": "4.40.2",
|
| 28 |
+
"type_vocab_size": 2,
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"vocab_size": 105879
|
| 31 |
+
}
|
config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "2.7.0",
|
| 4 |
+
"transformers": "4.40.2",
|
| 5 |
+
"pytorch": "2.3.0+cu121"
|
| 6 |
+
},
|
| 7 |
+
"prompts": {},
|
| 8 |
+
"default_prompt_name": null
|
| 9 |
+
}
|
eval.png
ADDED
|
eval/mse_evaluation_talks-en-ru-dev.tsv.gz_results.csv
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
epoch,steps,MSE
|
| 2 |
+
0,100,2.878684550523758
|
| 3 |
+
0,200,2.5711659342050552
|
| 4 |
+
0,300,2.2758182138204575
|
| 5 |
+
0,400,2.1430378779768944
|
| 6 |
+
0,500,2.025136351585388
|
| 7 |
+
0,-1,1.9794309511780739
|
| 8 |
+
1,100,1.8464291468262672
|
| 9 |
+
1,200,1.7591631039977074
|
| 10 |
+
1,300,1.699366606771946
|
| 11 |
+
1,400,1.635102741420269
|
| 12 |
+
1,500,1.5872221440076828
|
| 13 |
+
1,-1,1.576891914010048
|
| 14 |
+
2,100,1.5398328192532063
|
| 15 |
+
2,200,1.5269143506884575
|
| 16 |
+
2,300,1.4953669160604477
|
| 17 |
+
2,400,1.468233484774828
|
| 18 |
+
2,500,1.4520802535116673
|
| 19 |
+
2,-1,1.4370085671544075
|
| 20 |
+
3,100,1.4182819053530693
|
| 21 |
+
3,200,1.4062595553696156
|
| 22 |
+
3,300,1.4026491902768612
|
| 23 |
+
3,400,1.3922274112701416
|
| 24 |
+
3,500,1.3593204319477081
|
| 25 |
+
3,-1,1.3746432028710842
|
| 26 |
+
4,100,1.3601386919617653
|
| 27 |
+
4,200,1.346716657280922
|
| 28 |
+
4,300,1.3340381905436516
|
| 29 |
+
4,400,1.3312975876033306
|
eval/translation_evaluation_talks-en-ru-dev.tsv.gz_results.csv
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
epoch,steps,src2trg,trg2src
|
| 2 |
+
0,100,0.718,0.681
|
| 3 |
+
0,200,0.727,0.69
|
| 4 |
+
0,300,0.747,0.713
|
| 5 |
+
0,400,0.755,0.729
|
| 6 |
+
0,500,0.759,0.743
|
| 7 |
+
0,-1,0.762,0.745
|
| 8 |
+
1,100,0.769,0.759
|
| 9 |
+
1,200,0.77,0.765
|
| 10 |
+
1,300,0.777,0.771
|
| 11 |
+
1,400,0.784,0.778
|
| 12 |
+
1,500,0.79,0.778
|
| 13 |
+
1,-1,0.792,0.779
|
| 14 |
+
2,100,0.793,0.783
|
| 15 |
+
2,200,0.798,0.782
|
| 16 |
+
2,300,0.797,0.783
|
| 17 |
+
2,400,0.808,0.792
|
| 18 |
+
2,500,0.812,0.791
|
| 19 |
+
2,-1,0.811,0.791
|
| 20 |
+
3,100,0.816,0.795
|
| 21 |
+
3,200,0.816,0.797
|
| 22 |
+
3,300,0.819,0.797
|
| 23 |
+
3,400,0.832,0.799
|
| 24 |
+
3,500,0.835,0.801
|
| 25 |
+
3,-1,0.834,0.797
|
| 26 |
+
4,100,0.839,0.803
|
| 27 |
+
4,200,0.844,0.809
|
| 28 |
+
4,300,0.844,0.809
|
| 29 |
+
4,400,0.845,0.807
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e4e331bc4bcae366b4070862cc6fc98a8b91d2d3b91cdb9efa3d096fb03725a0
|
| 3 |
+
size 669448040
|
modules.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
}
|
| 14 |
+
]
|
sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 512,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "[PAD]",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"100": {
|
| 12 |
+
"content": "[UNK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"101": {
|
| 20 |
+
"content": "[CLS]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"102": {
|
| 28 |
+
"content": "[SEP]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"103": {
|
| 36 |
+
"content": "[MASK]",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"clean_up_tokenization_spaces": true,
|
| 45 |
+
"cls_token": "[CLS]",
|
| 46 |
+
"do_lower_case": true,
|
| 47 |
+
"mask_token": "[MASK]",
|
| 48 |
+
"model_max_length": 512,
|
| 49 |
+
"pad_token": "[PAD]",
|
| 50 |
+
"sep_token": "[SEP]",
|
| 51 |
+
"strip_accents": null,
|
| 52 |
+
"tokenize_chinese_chars": true,
|
| 53 |
+
"tokenizer_class": "BertTokenizer",
|
| 54 |
+
"unk_token": "[UNK]"
|
| 55 |
+
}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|