
DRAGON+ is a BERT-base sized dense retriever initialized from RetroMAE and further trained on the data augmented from MS MARCO corpus, following the approach described in How to Train Your DRAGON: Diverse Augmentation Towards Generalizable Dense Retrieval.
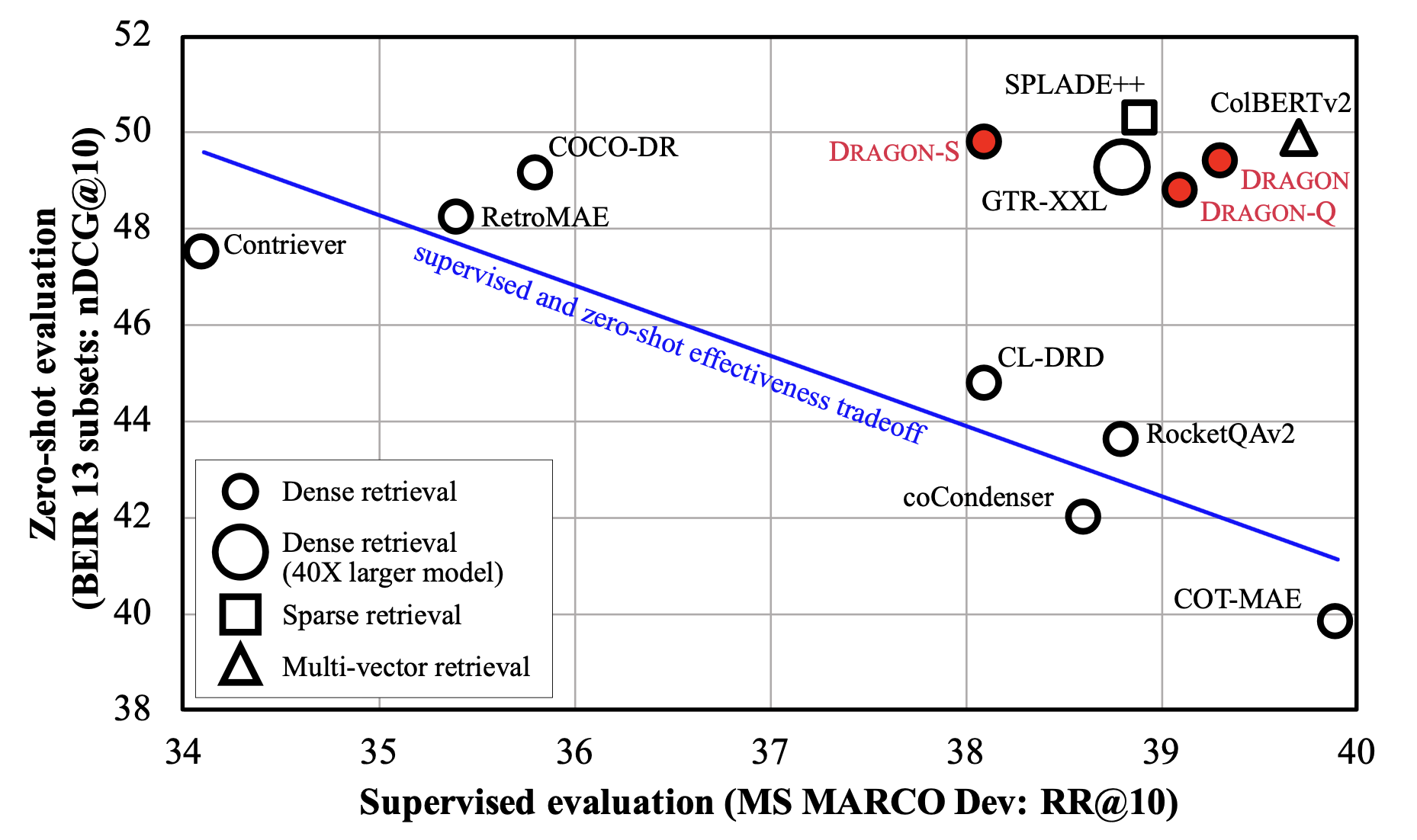
The associated GitHub repository is available here https://github.com/facebookresearch/dpr-scale/tree/main/dragon. We use asymmetric dual encoder, with two distinctly parameterized encoders. The following models are also available:
| Model | Initialization | MARCO Dev | BEIR | Query Encoder Path | Context Encoder Path |
|---|---|---|---|---|---|
| DRAGON+ | Shitao/RetroMAE | 39.0 | 47.4 | facebook/dragon-plus-query-encoder | facebook/dragon-plus-context-encoder |
| DRAGON-RoBERTa | RoBERTa-base | 39.4 | 47.2 | facebook/dragon-roberta-query-encoder | facebook/dragon-roberta-context-encoder |
Usage (HuggingFace Transformers)
Using the model directly available in HuggingFace transformers .
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('facebook/dragon-plus-query-encoder')
query_encoder = AutoModel.from_pretrained('facebook/dragon-plus-query-encoder')
context_encoder = AutoModel.from_pretrained('facebook/dragon-plus-context-encoder')
# We use msmarco query and passages as an example
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Apply tokenizer
query_input = tokenizer(query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
# Compute embeddings: take the last-layer hidden state of the [CLS] token
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :]
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Compute similarity scores using dot product
score1 = query_emb @ ctx_emb[0] # 396.5625
score2 = query_emb @ ctx_emb[1] # 393.8340
- Downloads last month
- 7,406
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.