
metadata
language:
- zh
- en
tags:
- chatglm-6b
- chatglm2-6b
- pytorch
- peft
- ft
- sft
- PPO
- RLHF
- RM
- Transformer
license: apache-2.0
重要提醒本模型只能运行在之前版本的transformers框架下,如4.30.2
- 模型体验地址:https://huggingface.co/spaces/fb700/chatglm-fitness-RLHF 测试用户过多,服务压力太大,为确保体验现设置密码,未来视情况定期更新密码,现账号密码为:test/qwer4321
- 模型能力测试报告:https://huggingface.co/fb700/Bofan-chatglm-Best-lora/blob/main/modelapplytest.md
重磅消息
- 本项目经过多位网友实测,中文总结能力超越了GPT3.5各版本,健康咨询水平在同参数规模模型也出类拔萃,可能是任何个人和中小企业首选模型。
重大突破
- 虽然新版本的chatglm2-6b支持32k,但是我训练的模型在之前经优化,早就可以支持无限context,远大于4k、8K、16K......
ChatGLM-6B RLHF & LoRA Model
ChatGLM-6B 是开源中英双语对话模型,本次训练基于ChatGLM-6B 的第一代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上开展训练。通过训练我们对模型有了更深刻的认知,LLM在一直在进化,好的方法和数据可以挖掘出模型的更大潜能。
本次训练使用的方法
- 首先,用40万条高质量数据进行强化训练,以提高模型的基础能力;
- 第二,使用30万条人类反馈数据,构建一个表达方式规范优雅的语言模式(RM模型);
- 第三,在保留SFT阶段三分之一训练数据的同时,增加了30万条fitness数据,叠加RM模型,对ChatGLM-6B进行强化训练。
- 成果,训练后在健康咨询,文档总结能力上不但强于chatglm-6b,而且部分能力上更是强于chatglm2-6b,配合“闻达”和“langchain-chatglm”等知识库项目,应用体验上对比chatglm-6b、chatglm2-6b和百川-7b均匀显著提升。
- 性能,fp16运行时速度上比原模型提升20%.可以代替原有官方模型,大家可以fp16、int4、int8使用。
- 兼容性,本项目全模型的运行方式与原模型一致。lora文件运行方式,建议在原模型chatglm-6b上运行,在chatglm2-6b上可以正常加载但不推荐,经(网友:大笨熊)测试有一定效果,但是效果不能完全发挥。
- 特性,基于模型对自然对话的超强理解力和总结能力,连续会话不受tokens限制,支持无限轮次的智能对话。
- 协议
- 本仓库的代码依照 Apache-2.0 协议开源,ChatGLM2-6B 模型的权重的使用则需要遵循 Model License。
- 授权方式,与原项目一致,未经过chatglm-6b原开发方允许,不得用于商业用途。详细见原项目相关规定,模型地址https://huggingface.co/THUDM/chatglm-6b
- 本次训练由智能AI用户[帛凡]于2023年基于ChatGLM-6b进行独立完成。(未经作者同意,严禁售卖或者用于商业项目,任何通过此项目产生的知识仅用于参考,作者不承担任何责任)。
- 百度网盘 https://pan.baidu.com/s/1l9q_7h8nGdelIwYlCbllMg?pwd=klhu (感谢网友 :宋小猫 提供分享)
- 夸克网盘 https://pan.quark.cn/s/d947c6dbf592
- 模型能力测试:https://huggingface.co/fb700/Bofan-chatglm-Best-lora/blob/main/modelapplytest.md
- 原模型量化评测
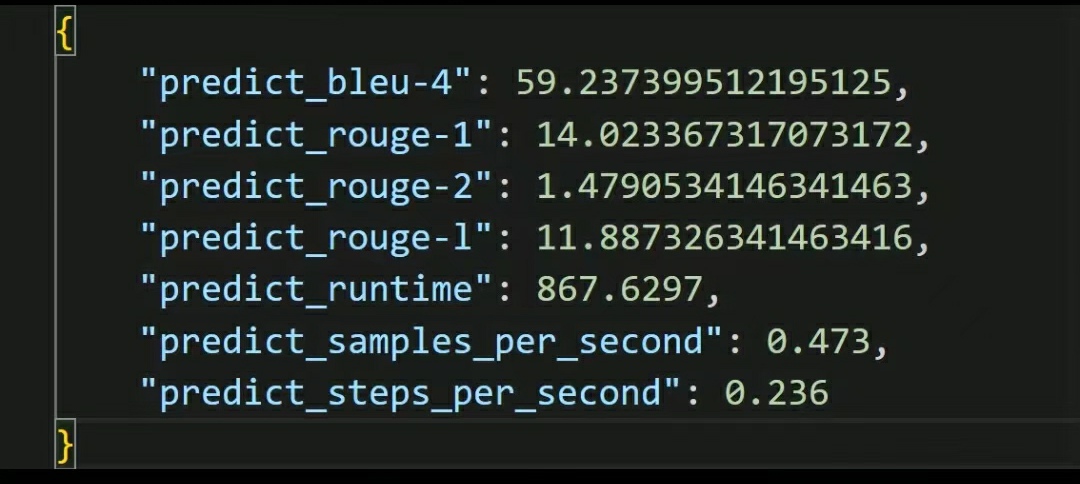
- 训练后量化评测



Usage1 16G及以上显存用下载压缩包即lora文件使用,可支持ChatGLM原生模型和LoRA微调后的模型
16G及以上显存用下载压缩包即lora文件使用,可支持ChatGLM原生模型和LoRA微调后的模型 (HuggingFace Transformers) First, you pass your input through the transformer model, then you get the generated sentence. Install package:
pip install transformers
import sys
from peft import PeftModel
from transformers import AutoModel, AutoTokenizer
sys.path.append('..')
model = AutoModel.from_pretrained("THUDM/chatglm-6b", device_map='auto')
model = PeftModel.from_pretrained(model, "model/chatglm_fitness_lora")#"model/chatglm_fitness_lora"为您下载本项目压缩包后,解压后本地lora目录
model = model.half().cuda() # fp16
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
sents = ['新冠肺炎怎么预防。\n答:']
for s in sents:
response = model.chat(tokenizer, s, max_length=128, eos_token_id=tokenizer.eos_token_id)
print(response)
output:
例一:常识综合问答
问: 新冠肺炎怎么预防
答:新冠肺炎是一种由新型冠状病毒引起的疾病,可以通过飞沫传播和接触传播。以下是一些预防新冠肺炎的建议:
戴口罩:佩戴口罩可以防止呼吸道飞沫传播,减少感染风险。在公共场合、公共交通工具上、与他人交往时,应佩戴医用口罩或N95口罩。
勤洗手:经常用肥皂和温水洗手,尤其在接触公共场所、物品或与他人交往后,或咳嗽、打喷嚏、擤鼻涕后等。
保持社交距离:尽量避免近距离接触他人,保持至少1米的社交距离。
避免聚集:尽量避免参加人员密集的聚会、活动或旅行。
加强室内通风:在室内保持良好的通风可以降低病毒在空气中的浓度。
健康生活方式:保持充足的睡眠、均衡的饮食、适量的运动等健康生活方式可以增强身体免疫力,预防感染。
接种疫苗:疫苗接种是预防新冠肺炎最有效的方法之一。如果有机会,应接种疫苗。
预防新冠肺炎需要个人和社会的共同努力,遵守公共卫生规定,加强个人防护,减少接触风险。
例二:较为专业的医疗和心理学问答
问:系统性红斑狼疮的危害和治疗方法是什么?
答:系统性红斑狼疮(Systemic Lupus Erythematosus,SLE)是一种自身免疫性疾病,可以影响身体的多个器官和组织。SLE的危害包括:
1. 心血管疾病:SLE可以引起高血压、心脏病和中风等心血管疾病。
2. 肾脏疾病:SLE可以引起肾小球肾炎和肾衰竭等肾脏疾病。
3. 口腔溃疡:SLE可以引起口腔和舌头溃疡等口腔疾病。
4. 皮肤疾病:SLE可以引起皮疹、红斑狼疮面容和光敏感等皮肤疾病。
治疗方法包括:
1. 药物治疗:SLE可以使用非甾体抗炎药、激素类药物和免疫抑制剂等药物治疗。
2. 支持性治疗:SLE可以使用营养支持、心理治疗和支持性护理等支持性治疗。
3. 手术治疗:在一些情况下,SLE可能需要手术治疗,如肾脏移植等。
SLE是一种严重的疾病,需要患者及时接受专业治疗。患者需要积极配合医生的治疗,保持良好的生活习惯和饮食习惯,定期进行检查和监测。
例三:无限多轮次的智能对话(第一轮见例二)
问:早期激素和免疫抑制剂用药建议是什么?
答:系统性红斑狼疮的早期治疗非常重要,因为病情的严重程度和进展速度可能会影响患者的生活质量和生命安全。对于系统性红斑狼疮的早期治疗,激素和免疫抑制剂的使用是非常重要的。以下是一些早期激素和免疫抑制剂用药的建议:
1. 激素类药物:激素类药物是系统性红斑狼疮的主要治疗方法之一。在使用激素类药物时,需要遵循医生的建议,根据病情和身体状况进行剂量和用药时间的调整。一般来说,激素类药物需要长期使用,以避免药物副作用和病情的复发。
2. 免疫抑制剂:免疫抑制剂是系统性红斑狼疮另一种重要的治疗方法。在使用免疫抑制剂时,需要遵循医生的建议,根据病情和身体状况进行用药时间和剂量的调整。免疫抑制剂可以用于治疗系统性红斑狼疮的各种症状和并发症,如肾脏疾病、口腔溃疡、皮肤疾病等。
3. 其他治疗:除了激素和免疫抑制剂之外,系统性红斑狼疮的治疗还包括其他治疗方法,如支持性治疗、手术治疗等。在使用这些治疗方法时,需要遵循医生的建议,根据病情和身体状况进行用药和治疗。
早期激素和免疫抑制剂的使用非常重要,需要患者积极配合医生的治疗,遵循医生的建议,定期进行检查和监测,以确保病情得到有效控制和生活质量得到保障。
模型文件组成:
chatglm_fitness_lora ├── adapter_config.json └── adapter_model.bin
Usage2 16G及以下显存用户下载整个模型,可支持fp16、int8、int4
First, you pass your input through the transformer model, then you get the generated sentence.
pip install transformers
import sys
from peft import PeftModel
from transformers import AutoModel, AutoTokenizer
sys.path.append('..')
model = AutoModel.from_pretrained("fb700/chatglm-fitness-RLHF", device_map='auto')#fb700/chatglm-fitness-RLHF为hg自动下载地址,如已经自行下载请替换
#model = PeftModel.from_pretrained(model, "model/chatglm_fitness_lora") # lora文件保存目录
model = model.half().quantize(4).cuda() # int4
#model = model.half().quantize(8).cuda() # int8
#model = model.half().cuda() # fp16
tokenizer = AutoTokenizer.from_pretrained("fb700/chatglm-fitness-RLHF", trust_remote_code=True)
sents = ['新冠肺炎怎么预防。\n答:']
for s in sents:
response = model.chat(tokenizer, s, max_length=128, eos_token_id=tokenizer.eos_token_id)
print(response)
output:
例四:优于chatglm-6b、chatglm2-6b和百川-7b等类似参数量模型的总结归纳能力
问:请用简短的语言总结下面的文字:
大语言模型是指能够生成、理解和处理自然语言的高度智能化的计算机模型。这些模型使用深度学习技术,尤其是循环神经网络(RNN)或变种,如长短期记忆(LSTM)或注意力机制(attention mechanism),从大规模文本语料库中进行训练。
大语言模型的训练过程通常基于预测下一个单词或字符的任务。通过对大量文本数据进行训练,模型能够学习到语言的潜在表达式、结构和语义含义。这使得大语言模型能够产生流畅、连贯的文本,回答问题,完成翻译任务,生成代码等。
答:大语言模型是一种使用深度学习技术训练的计算机模型,能够生成、理解和处理自然语言。通过训练大量文本数据,大语言模型能够产生流畅、连贯的文本,回答问题,完成翻译任务,生成代码等。