
AIDO.DNA
Collection
14 items
•
Updated
AIDO.DNA-7B is DNA foundation model trained on 10.6 billion nucleotides from 796 species, enabling genome mining, in silico mutagenesis studies, gene expression prediction, and directed sequence generation.
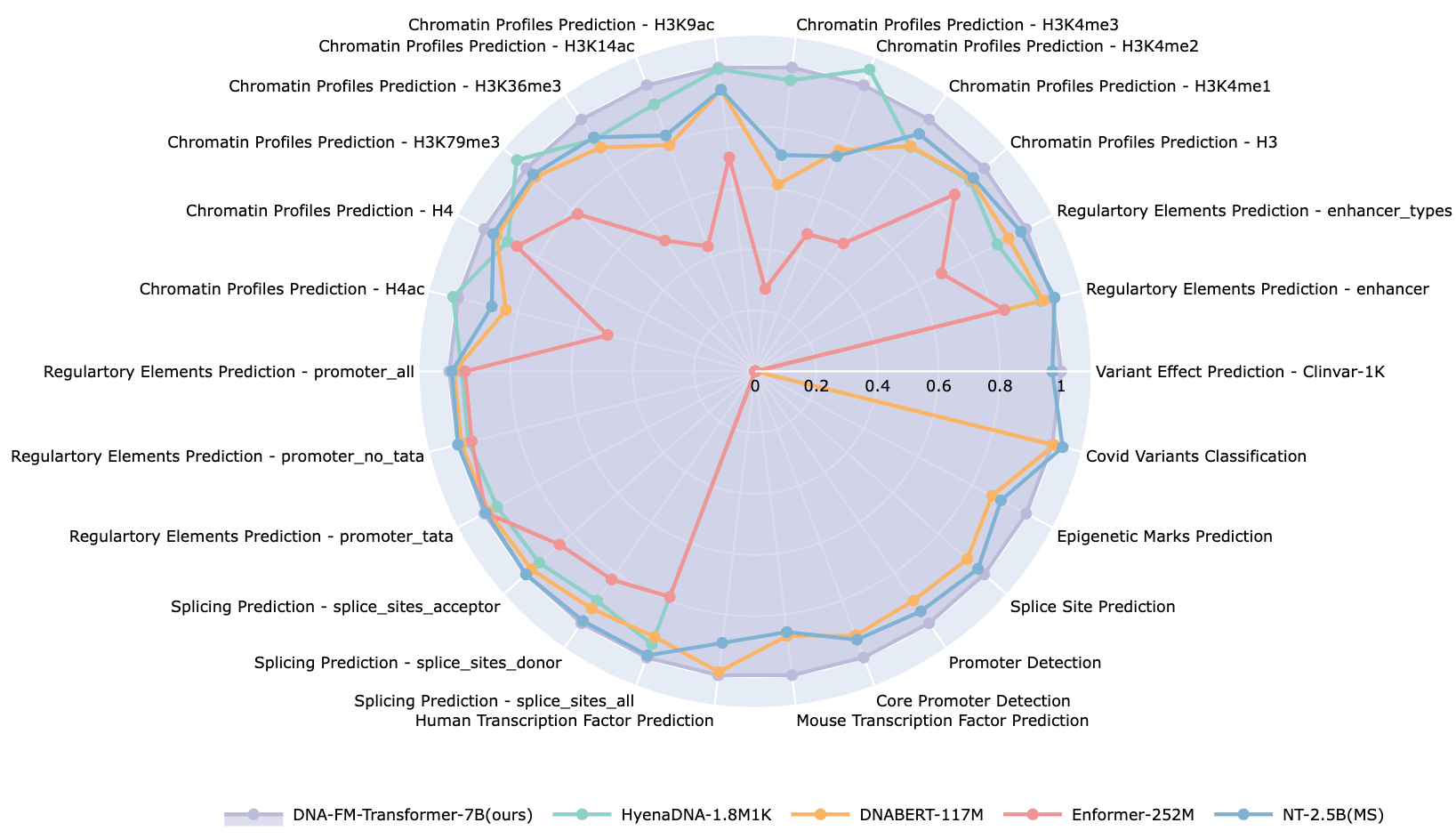
By scaling model depth while maintaining a short context length of 4000 nucleotides, AIDO.DNA shows substantial improvements across a breadth of tasks in functional genomics using transfer learning, sequence generation, and unsupervised annotation of functional elements. Notably, AIDO.DNA outperforms prior encoder-only architectures without new data, suggesting that new scaling laws are needed to achieve compute-optimal DNA language models.
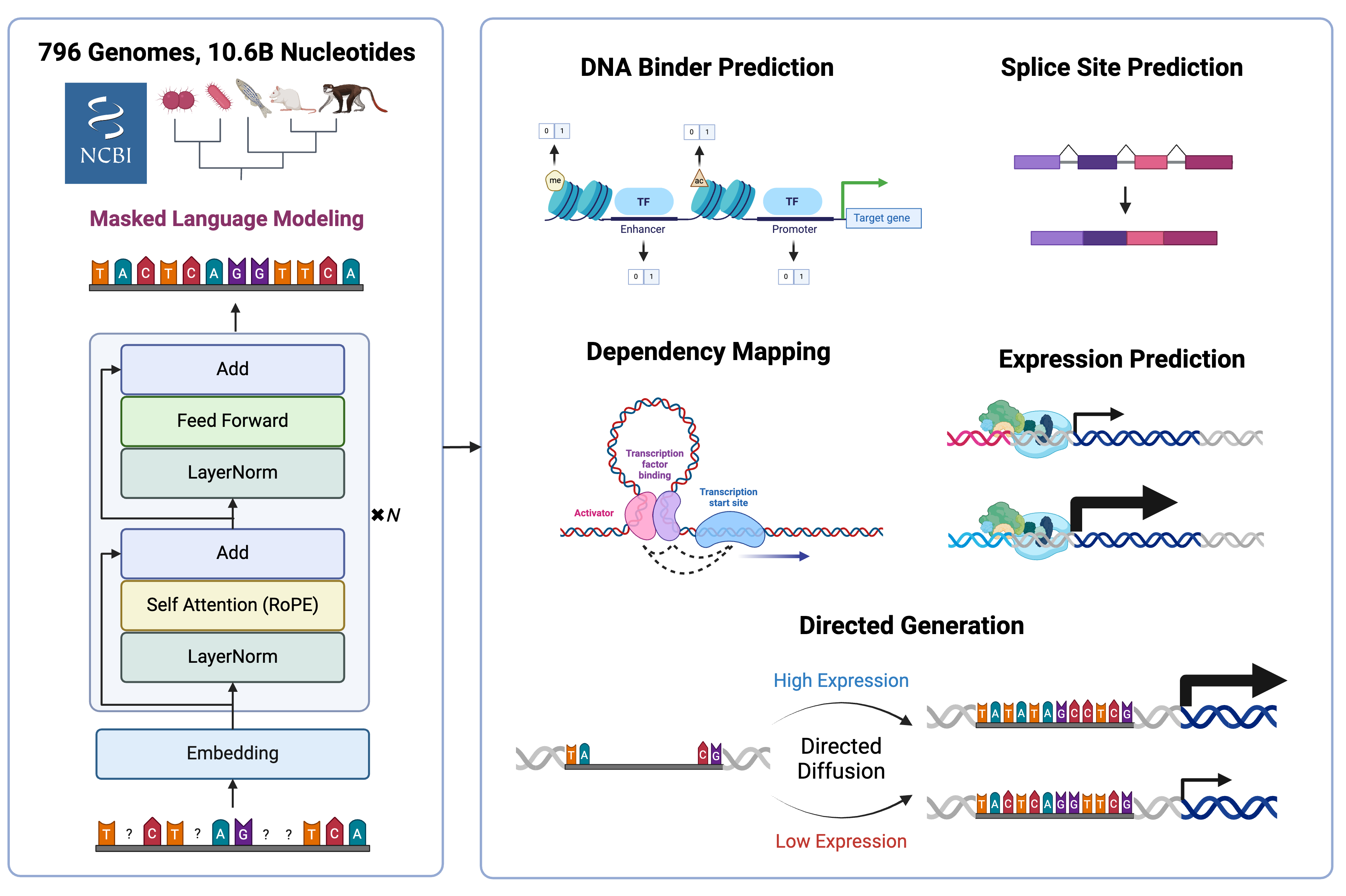
AIDO.DNA-7B is based on the bidirectional transformer encoder (BERT) architecture with single-nucleotide tokenization, and is optimized using a masked language modeling (MLM) training objective.
To learn semantically meaningful representations, we employed an BERT-style encoder-only dense transformer architecture. We make minor updates to this architecture to align with current best practices, including using SwiGLU and LayerNorms. Additionally, we use Rotary Positional Embeddings (RoPE), given that DNA syntax does not function based on absolute nucleotide positions but nucleotides interact in highly local and context-specific ways. Below are more detailes about the model architecture:
| Model Arch Component | Value |
|---|---|
| Num Attention Heads | 32 |
| Num Hidden Layers | 32 |
| Hidden Size | 4352 |
| Intermediate Size | 11584 |
| Vocab Size | 16 |
| Context Length | 4000 |
Here we briefly introduce the details of pre-training of AIDO.DNA-7B. For more detailed information, please refer to our paper.
To test whether representation capacity has limited the development of DNA language models in previous studies, we utilize the data set and splits from the Nucleotide Transformer. Starting from a total of 812 genomes with 712 for training, 50 for validation, and 50 for testing, we removed 17 entries which had been deleted from NCBI since the original dataset’s publication on Hugging Face. One of these was the important model organism Rattus norvegigus, which we replaced with the current reference genome. This resulted in 696 genomes for training, 50 for validation, and 50 for testing. We pre-trained AIDO.DNA-7B With a total of 10.6 billion training tokens.
The weights of our seven billion parameter model occupy over 200GB of memory in 32 bit precision. To train a model of this size, we use model parallelism to split training across 256 H100 GPUs using the Megatron-LM framework. We also employed bfloat16 mixed precision training and FlashAttention-2 to allow for training with large context length at scale. With this configuration, AIDO.DNA-7B took 8 days to train.
| Hyper-params | Value |
|---|---|
| Global Batch Size | 1024 |
| Per Device Micro Batch Size | 2 |
| Precision | Mixed FP32-BF16 |
| Total Iters | 100000 |
To minimize bias and learn high-resolution single-nucleotide dependencies, we opted to align closely with the real data and use character-level tokenization with a 5-letter vocabulary: A, T, C, G, N, where N is commonly used in gene sequencing to denote uncertain elements. Sequences were also prefixed with a [CLS] token and suffixed with a [EOS] token as hooks for downstream tasks. We chose a context length of 4,000 nucleotides as the longest context which would fit within AIDO.DNA-7B during pretraining, and chunked our dataset of 796 genomes into non-overlapping segments.
We evaluate the benefits of pretraining AIDO.DNA-7B by conducting a comprehensive series of experiments related to functional genomics, genome mining, metabolic engineering, synthetic biology, and therapeutics design, covering supervised, unsupervised, and generative objectives. Unless otherwise stated, hyperparameters were determined by optimizing model performance on a 10% validation split of the training data, and models were tested using the checkpoint with the lowest validation loss. For more detailed information, please refer to our paper).
For more information, visit: Model Generator
mgen fit --model SequenceClassification --model.backbone aido_dna_7b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
mgen test --model SequenceClassification --model.backbone aido_dna_7b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
from modelgenerator.tasks import Embed
model = Embed.from_config({"model.backbone": "aido_dna_7b"}).eval()
transformed_batch = model.transform({"sequences": ["ACGT", "AGCT"]})
embedding = model(transformed_batch)
print(embedding.shape)
print(embedding)
import torch
from modelgenerator.tasks import SequenceClassification
model = SequenceClassification.from_config({"model.backbone": "aido_dna_7b", "model.n_classes": 2}).eval()
transformed_batch = model.transform({"sequences": ["ACGT", "AGCT"]})
logits = model(transformed_batch)
print(logits)
print(torch.argmax(logits, dim=-1))
import torch
from modelgenerator.tasks import TokenClassification
model = TokenClassification.from_config({"model.backbone": "aido_dna_7b", "model.n_classes": 3}).eval()
transformed_batch = model.transform({"sequences": ["ACGT", "AGCT"]})
logits = model(transformed_batch)
print(logits)
print(torch.argmax(logits, dim=-1))
from modelgenerator.tasks import SequenceRegression
model = SequenceRegression.from_config({"model.backbone": "aido_dna_7b"}).eval()
transformed_batch = model.transform({"sequences": ["ACGT", "AGCT"]})
logits = model(transformed_batch)
print(logits)
Please cite AIDO.DNA using the following BibTeX code:
@inproceedings{ellington_accurate_2024,
title = {Accurate and General DNA Representations Emerge from Genome Foundation Models at Scale},
url = {https://www.biorxiv.org/content/10.1101/2024.12.01.625444v1},
doi = {10.1101/2024.12.01.625444},
publisher = {bioRxiv},
author = {Ellington, Caleb N. and Sun, Ning and Ho, Nicholas and Tao, Tianhua and Mahbub, Sazan and Li, Dian and Zhuang, Yonghao and Wang, Hongyi and Song, Le and Xing, Eric P.},
year = {2024},
booktitle = {NeurIPS 2024 Workshop on AI for New Drug Modalities},
}