
metadata
license: mit
language:
- es
metrics:
- accuracy
pipeline_tag: fill-mask
widget:
- text: Vamos a comer unos [MASK]
example_title: Vamos a comer unos tacos
tags:
- code
- nlp
- custom
- bilma
tokenizer:
- 'yes'
BILMA (Bert In Latin aMericA)
Bilma is a BERT implementation in tensorflow and trained on the Masked Language Model task under the https://sadit.github.io/regional-spanish-models-talk-2022/ datasets.
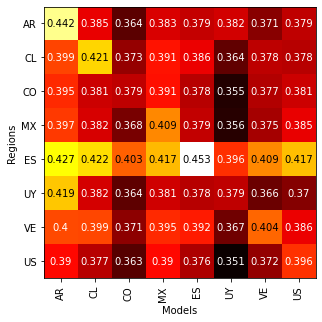
The accuracy of the models trained on the MLM task for different regions are:
Pre-requisites
You will need TensorFlow 2.4 or newer.
Quick guide
Install the following version for the transformers library
!pip install transformers==4.30.2
Instanciate the tokenizer and the trained model
from transformers import AutoTokenizer
tok = AutoTokenizer.from_pretrained("guillermoruiz/bilma_mx")
from transformers import TFAutoModel
model = TFAutoModel.from_pretrained("guillermoruiz/bilma_mx", trust_remote_code=True, include_top=False)
Now,we will need some text and then pass it through the tokenizer:
text = ["Vamos a comer [MASK].",
"Hace mucho que no voy al [MASK]."]
t = tok(text, padding="max_length", return_tensors="tf", max_length=280)
With this, we are ready to use the model
p = model(t)
Now, we get the most likely words with:
import tensorflow as tf
tok.batch_decode(tf.argmax(p["logits"], 2)[:,1:], skip_special_tokens=True)
which produces the output:
['vamos a comer tacos.', 'hace mucho que no voy al gym.']