

license: apache-2.0
language:
- it
- en
metrics:
- wer
pipeline_tag: automatic-speech-recognition
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
library_name: transformers
Descrizione del Modello
Questo modello è una versione di openai/whisper-small ottimizzata per la lingua italiana, addestrata utilizzando una parte dei dati proprietari di Litus AI.
litus-ai/whisper-small-ita rappresenta un ottimo compromesso value/cost ed è ottimale per contesti in cui il budget computazionale è limitato,
ma è comunque necessaria una trascrizione accurata del parlato.
Particolarità del Modello
La peculiarità principale del modello è l'integrazione di token speciali che arricchiscono la trascrizione con meta-informazioni:
- Elementi paralinguistici:
[LAUGH],[MHMH],[SIGH],[UHM] - Qualità audio:
[NOISE],[UNINT](non intelligibile) - Caratteristiche del parlato:
[AUTOCOR](autocorrezioni),[L-EN](code-switching inglese)
Questi token consentono una trascrizione più ricca che cattura non solo il contenuto verbale ma anche elementi contestuali rilevanti.
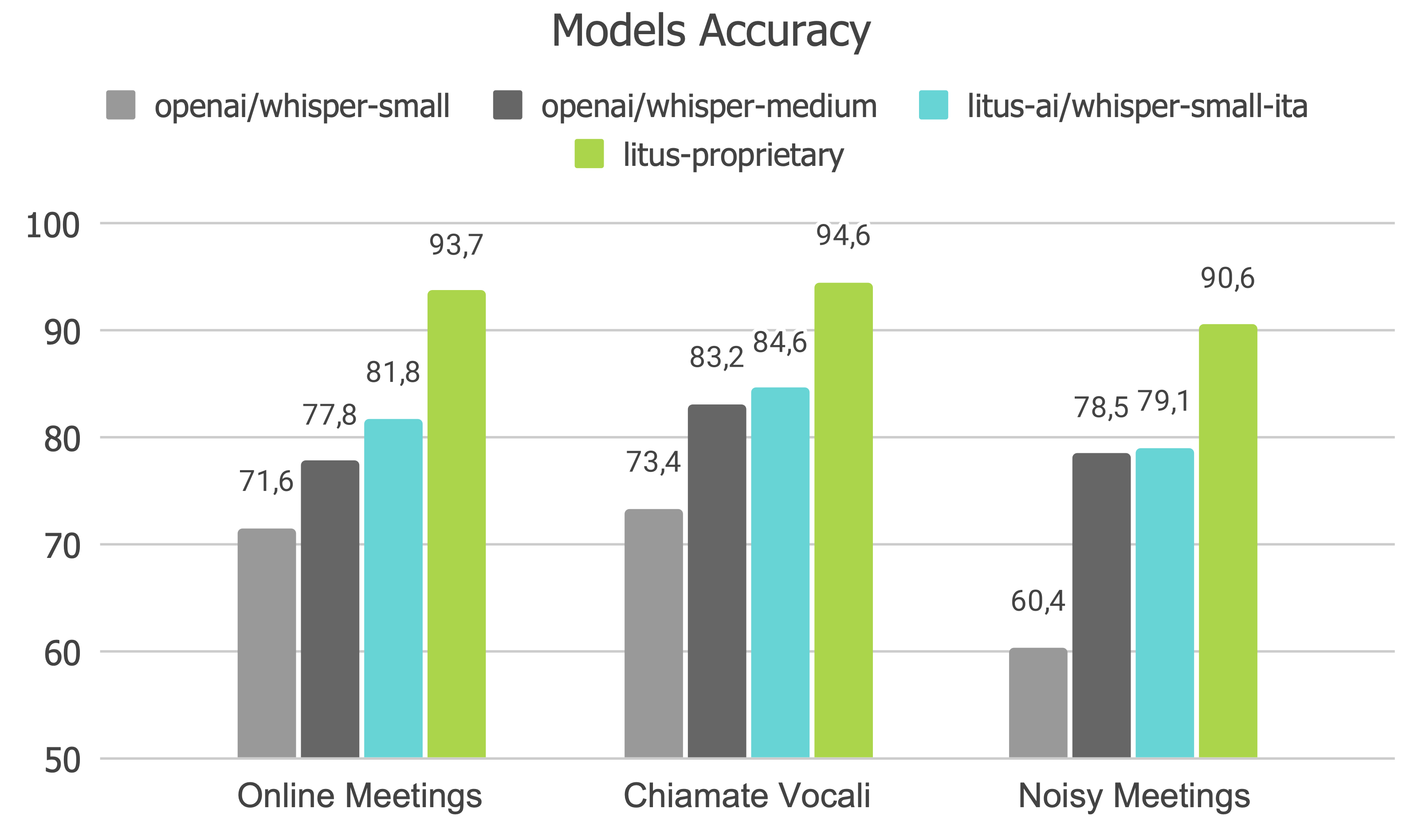
Evaluation
Nel seguente grafico puoi trovare l'Accuracy di openai/whisper-small, openai/whisper-medium, litus-ai/whisper-small-ita e il modello proprietario di Litus AI, litus-proprietary,
su benchmark proprietari per meeting e chiamate vocali in lingua italiana.
Come usare il modello
Puoi utlizzare litus-ai/whisper-small-ita tramite la pipeline di "automatic-speech-recognition" di Hugging Face!
from transformers import WhisperProcessor, WhisperForConditionalGeneration
from datasets import load_dataset
# load model and processor
model_id = "litus-ai/whisper-small-ita"
processor = WhisperProcessor.from_pretrained(model_id)
model = WhisperForConditionalGeneration.from_pretrained(model_id)
# load Meta voxpopuli in italian
ds = load_dataset("facebook/voxpopuli", "it", split="test")
sample = ds[171]["audio"] # sample having an "[UNINT]" token
input_features = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
).input_features
# generate token ids
predicted_ids = model.generate(input_features)
# decode token ids to text
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=False)
# ["<|startoftranscript|><|it|><|transcribe|><|notimestamps|> Siamo all'ultimo miglio, non sprechiamo un'occasione per dimostrare che siamo autonomi [UNINT]<|endoftext|>"]
Conclusions
Per qualsiasi informazione sull'architettura sui dati utilizzati per il pretraining e l'intended use ti preghiamo di rivolgerti al Paper, la Model Card e la Repository originali.