|
--- |
|
datasets: |
|
- tomg-group-umd/cinepile |
|
language: |
|
- en |
|
license: apache-2.0 |
|
library_name: peft |
|
pipeline_tag: video-text-to-text |
|
--- |
|
# Model Card for Video-LLaVA - CinePile fine tune |
|
|
|
 |
|
|
|
Video multimodal research often emphasizes activity recognition and object-centered tasks, such as determining "what is the person wearing a red hat doing?" However, this focus overlooks areas like theme exploration, narrative and plot analysis, and character and relationship dynamics. |
|
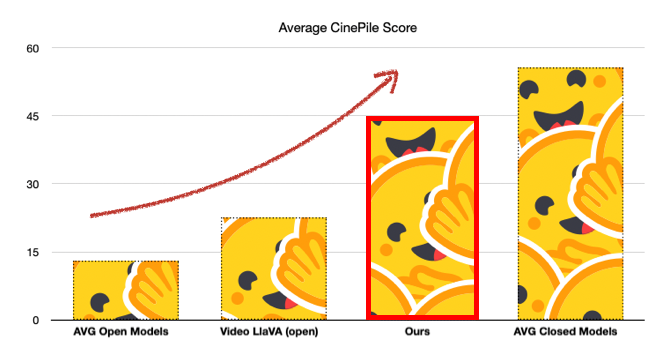
CinePile addresses these areas in their benchmark and they find that Large Language Models significantly lag behind human performance in these tasks. Additionally, there is a notable disparity in performance between open and closed models. |
|
|
|
In our initial fine-tuning, our goal was to assess how well open models can approach the performance of closed models. By fine-tuning Video LlaVa, we achieved performance levels comparable to those of Claude 3 (Opus). |
|
|
|
## Results |
|
|
|
| Model | Average | Character and relationship dynamics | Narrative and Plot Analysis | Setting and Technical Analysis | Temporal | Theme Exploration | |
|
|--------------------------------|---------|-------------------------------------|-----------------------------|--------------------------------|----------|-------------------| |
|
| Human | 73.21 | 82.92 | 75 | 73 | 75.52 | 64.93 | |
|
| Human (authors) | 86 | 92 | 87.5 | 71.2 | 100 | 75 | |
|
| GPT-4o | 59.72 | 64.36 | 74.08 | 54.77 | 44.91 | 67.89 | |
|
| GPT-4 Vision | 58.81 | 63.73 | 73.43 | 52.55 | 46.22 | 65.79 | |
|
| Gemini 1.5 Pro | 61.36 | 65.17 | 71.01 | 59.57 | 46.75 | 63.27 | |
|
| Gemini 1.5 Flash | 57.52 | 61.91 | 69.15 | 54.86 | 41.34 | 61.22 | |
|
| Gemini Pro Vision | 50.64 | 54.16 | 65.5 | 46.97 | 35.8 | 58.82 | |
|
| Claude 3 (Opus) | 45.6 | 48.89 | 57.88 | 40.73 | 37.65 | 47.89 | |
|
| **Video LlaVa - this fine-tune** | **44.16** | **45.26** | **45.14** | **46.93** | **32.55** | **49.47** | |
|
| Video LLaVa | 22.51 | 23.11 | 25.92 | 20.69 | 22.38 | 22.63 | |
|
| mPLUG-Owl | 10.57 | 10.65 | 11.04 | 9.18 | 11.89 | 15.05 | |
|
| Video-ChatGPT | 14.55 | 16.02 | 14.83 | 15.54 | 6.88 | 18.86 | |
|
| MovieChat | 4.61 | 4.95 | 4.29 | 5.23 | 2.48 | 4.21 | |
|
|
|
|
|
|
|
|
|
Fine-tuned model taking as starting point [Video-LlaVA](https://huggingface.co/LanguageBind/Video-LLaVA-7B-hf) to evaluate its performance on CinePile. |
|
|
|
|
|
|
|
## Model Sources |
|
|
|
<!-- Provide the basic links for the model. --> |
|
|
|
- **Repository:** [Github](https://github.com/mfarre/Video-LLaVA-7B-hf-CinePile) with fine-tunning and inference notebook. |
|
## Uses |
|
|
|
|
|
Although the model can answer questions based on the content, it is specifically optimized for addressing CinePile-related queries. |
|
When the questions do not follow a CinePile-specific prompt, the inference section of the notebook is designed to refine and clean up the text produced by the model. |
