
NeMo Curator - Classifier Models
Collection
Classifier models that can be used in NeMo Curator for labelling/filtering datasets.
•
11 items
•
Updated
•
16
This is a multi-headed model which classifies English text prompts across task types and complexity dimensions. Tasks are classified across 11 common categories. Complexity is evaluated across 6 dimensions and ensembled to create an overall complexity score. Further information on the taxonomies can be found below.
This model is ready for commercial use.
Task types:
Complexity dimensions:
This model is released under the NVIDIA Open Model License Agreement.
The model architecture uses a DeBERTa backbone and incorporates multiple classification heads, each dedicated to a task categorization or complexity dimension. This approach enables the training of a unified network, allowing it to predict simultaneously during inference. Deberta-v3-base can theoretically handle up to 12k tokens, but default context length is set at 512 tokens.
NeMo Curator improves generative AI model accuracy by processing text, image, and video data at scale for training and customization. It also provides pre-built pipelines for generating synthetic data to customize and evaluate generative AI systems.
The inference code for this model is available through the NeMo Curator GitHub repository. Check out this example notebook to get started.
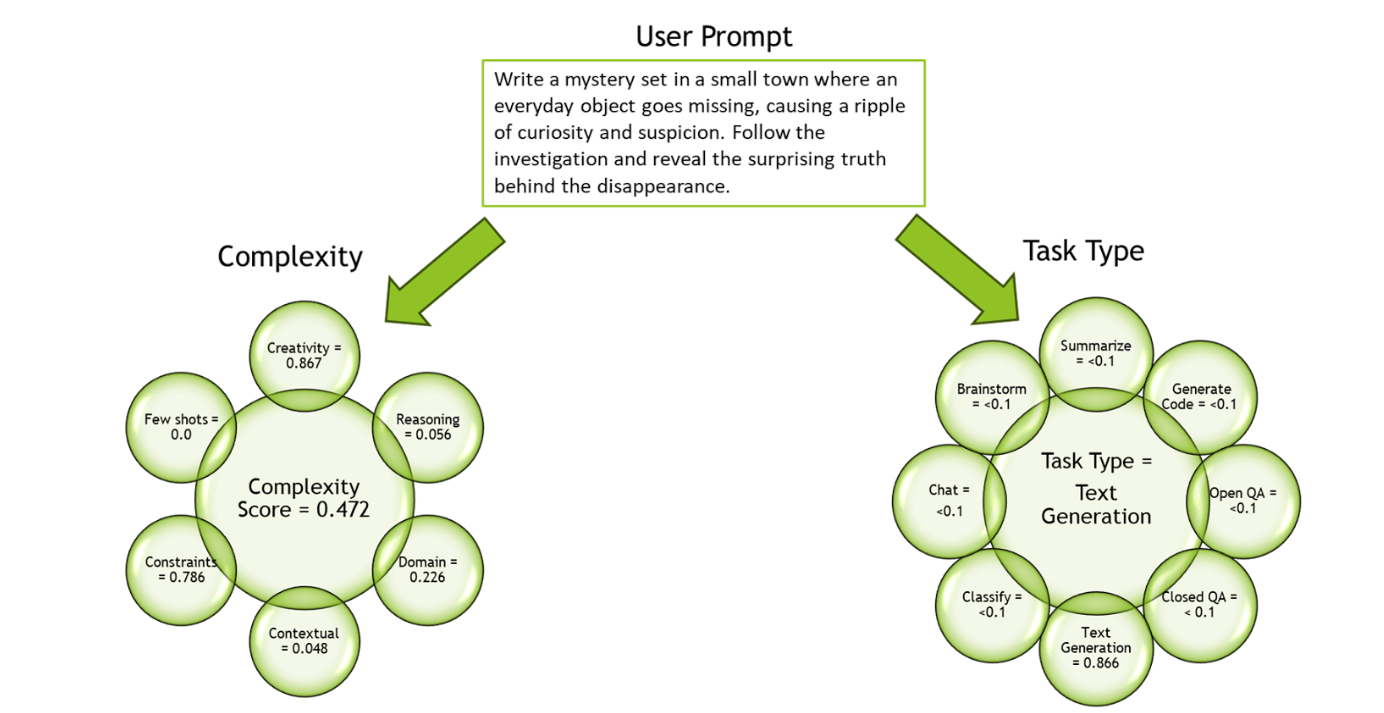
Prompt: Write a mystery set in a small town where an everyday object goes missing, causing a ripple of curiosity and suspicion. Follow the investigation and reveal the surprising truth behind the disappearance.
| Task | Complexity | Creativity | Reasoning | Contextual Knowledge | Domain Knowledge | Constraints | # of Few Shots |
|---|---|---|---|---|---|---|---|
| Text Generation | 0.472 | 0.867 | 0.056 | 0.048 | 0.226 | 0.785 | 0 |
Prompt: Antibiotics are a type of medication used to treat bacterial infections. They work by either killing the bacteria or preventing them from reproducing, allowing the body’s immune system to fight off the infection. Antibiotics are usually taken orally in the form of pills, capsules, or liquid solutions, or sometimes administered intravenously. They are not effective against viral infections, and using them inappropriately can lead to antibiotic resistance. Explain the above in one sentence.
| Task | Complexity | Creativity | Reasoning | Contextual Knowledge | Domain Knowledge | Constraints | # of Few Shots |
|---|---|---|---|---|---|---|---|
| Summarization | 0.133 | 0.003 | 0.014 | 0.003 | 0.644 | 0.211 | 0 |
NemoCurator Prompt Task and Complexity Classifier v1.1
Task distribution:
| Task | Count |
|---|---|
| Open QA | 1214 |
| Closed QA | 786 |
| Text Generation | 480 |
| Chatbot | 448 |
| Classification | 267 |
| Summarization | 230 |
| Code Generation | 185 |
| Rewrite | 169 |
| Other | 104 |
| Brainstorming | 81 |
| Extraction | 60 |
| Total | 4024 |
For evaluation, Top-1 accuracy metric was used, which involves matching the category with the highest probability to the expected answer. Additionally, n-fold cross-validation was used to produce n different values for this metric to verify the consistency of the results. The table below displays the average of the top-1 accuracy values for the N folds calculated for each complexity dimension separately.
| Task Accuracy | Creative Accuracy | Reasoning Accuracy | Contextual Accuracy | FewShots Accuracy | Domain Accuracy | Constraint Accuracy | |
|---|---|---|---|---|---|---|---|
| Average of 10 Folds | 0.981 | 0.996 | 0.997 | 0.981 | 0.979 | 0.937 | 0.991 |
To use the prompt task and complexity classifier, use the following code:
import numpy as np
import torch
import torch.nn as nn
from huggingface_hub import PyTorchModelHubMixin
from transformers import AutoConfig, AutoModel, AutoTokenizer
class MeanPooling(nn.Module):
def __init__(self):
super(MeanPooling, self).__init__()
def forward(self, last_hidden_state, attention_mask):
input_mask_expanded = (
attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
)
sum_embeddings = torch.sum(last_hidden_state * input_mask_expanded, 1)
sum_mask = input_mask_expanded.sum(1)
sum_mask = torch.clamp(sum_mask, min=1e-9)
mean_embeddings = sum_embeddings / sum_mask
return mean_embeddings
class MulticlassHead(nn.Module):
def __init__(self, input_size, num_classes):
super(MulticlassHead, self).__init__()
self.fc = nn.Linear(input_size, num_classes)
def forward(self, x):
x = self.fc(x)
return x
class CustomModel(nn.Module, PyTorchModelHubMixin):
def __init__(self, target_sizes, task_type_map, weights_map, divisor_map):
super(CustomModel, self).__init__()
self.backbone = AutoModel.from_pretrained("microsoft/DeBERTa-v3-base")
self.target_sizes = target_sizes.values()
self.task_type_map = task_type_map
self.weights_map = weights_map
self.divisor_map = divisor_map
self.heads = [
MulticlassHead(self.backbone.config.hidden_size, sz)
for sz in self.target_sizes
]
for i, head in enumerate(self.heads):
self.add_module(f"head_{i}", head)
self.pool = MeanPooling()
def compute_results(self, preds, target, decimal=4):
if target == "task_type":
task_type = {}
top2_indices = torch.topk(preds, k=2, dim=1).indices
softmax_probs = torch.softmax(preds, dim=1)
top2_probs = softmax_probs.gather(1, top2_indices)
top2 = top2_indices.detach().cpu().tolist()
top2_prob = top2_probs.detach().cpu().tolist()
top2_strings = [
[self.task_type_map[str(idx)] for idx in sample] for sample in top2
]
top2_prob_rounded = [
[round(value, 3) for value in sublist] for sublist in top2_prob
]
counter = 0
for sublist in top2_prob_rounded:
if sublist[1] < 0.1:
top2_strings[counter][1] = "NA"
counter += 1
task_type_1 = [sublist[0] for sublist in top2_strings]
task_type_2 = [sublist[1] for sublist in top2_strings]
task_type_prob = [sublist[0] for sublist in top2_prob_rounded]
return (task_type_1, task_type_2, task_type_prob)
else:
preds = torch.softmax(preds, dim=1)
weights = np.array(self.weights_map[target])
weighted_sum = np.sum(np.array(preds.detach().cpu()) * weights, axis=1)
scores = weighted_sum / self.divisor_map[target]
scores = [round(value, decimal) for value in scores]
if target == "number_of_few_shots":
scores = [x if x >= 0.05 else 0 for x in scores]
return scores
def process_logits(self, logits):
result = {}
# Round 1: "task_type"
task_type_logits = logits[0]
task_type_results = self.compute_results(task_type_logits, target="task_type")
result["task_type_1"] = task_type_results[0]
result["task_type_2"] = task_type_results[1]
result["task_type_prob"] = task_type_results[2]
# Round 2: "creativity_scope"
creativity_scope_logits = logits[1]
target = "creativity_scope"
result[target] = self.compute_results(creativity_scope_logits, target=target)
# Round 3: "reasoning"
reasoning_logits = logits[2]
target = "reasoning"
result[target] = self.compute_results(reasoning_logits, target=target)
# Round 4: "contextual_knowledge"
contextual_knowledge_logits = logits[3]
target = "contextual_knowledge"
result[target] = self.compute_results(
contextual_knowledge_logits, target=target
)
# Round 5: "number_of_few_shots"
number_of_few_shots_logits = logits[4]
target = "number_of_few_shots"
result[target] = self.compute_results(number_of_few_shots_logits, target=target)
# Round 6: "domain_knowledge"
domain_knowledge_logits = logits[5]
target = "domain_knowledge"
result[target] = self.compute_results(domain_knowledge_logits, target=target)
# Round 7: "no_label_reason"
no_label_reason_logits = logits[6]
target = "no_label_reason"
result[target] = self.compute_results(no_label_reason_logits, target=target)
# Round 8: "constraint_ct"
constraint_ct_logits = logits[7]
target = "constraint_ct"
result[target] = self.compute_results(constraint_ct_logits, target=target)
# Round 9: "prompt_complexity_score"
result["prompt_complexity_score"] = [
round(
0.35 * creativity
+ 0.25 * reasoning
+ 0.15 * constraint
+ 0.15 * domain_knowledge
+ 0.05 * contextual_knowledge
+ 0.05 * few_shots,
5,
)
for creativity, reasoning, constraint, domain_knowledge, contextual_knowledge, few_shots in zip(
result["creativity_scope"],
result["reasoning"],
result["constraint_ct"],
result["domain_knowledge"],
result["contextual_knowledge"],
result["number_of_few_shots"],
)
]
return result
def forward(self, batch):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
outputs = self.backbone(input_ids=input_ids, attention_mask=attention_mask)
last_hidden_state = outputs.last_hidden_state
mean_pooled_representation = self.pool(last_hidden_state, attention_mask)
logits = [
self.heads[k](mean_pooled_representation)
for k in range(len(self.target_sizes))
]
return self.process_logits(logits)
config = AutoConfig.from_pretrained("nvidia/prompt-task-and-complexity-classifier")
tokenizer = AutoTokenizer.from_pretrained(
"nvidia/prompt-task-and-complexity-classifier"
)
model = CustomModel(
target_sizes=config.target_sizes,
task_type_map=config.task_type_map,
weights_map=config.weights_map,
divisor_map=config.divisor_map,
).from_pretrained("nvidia/prompt-task-and-complexity-classifier")
model.eval()
prompt = ["Prompt: Write a Python script that uses a for loop."]
encoded_texts = tokenizer(
prompt,
return_tensors="pt",
add_special_tokens=True,
max_length=512,
padding="max_length",
truncation=True,
)
result = model(encoded_texts)
print(result)
# {'task_type_1': ['Code Generation'], 'task_type_2': ['Text Generation'], 'task_type_prob': [0.767], 'creativity_scope': [0.0826], 'reasoning': [0.0632], 'contextual_knowledge': [0.056], 'number_of_few_shots': [0], 'domain_knowledge': [0.9803], 'no_label_reason': [0.0], 'constraint_ct': [0.5578], 'prompt_complexity_score': [0.27822]}
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns here.