
license: cc-by-nc-nd-4.0
language:
- te
datasets:
- MIRACL
tags:
- miniMiracle
- passage-retrieval
- knowledge-distillation
- middle-training
pretty_name: >-
miniMiracle is a family of High-quality, Light Weight and Easy deploy
multilingual embedders / retrievers, primarily focussed on Indo-Aryan and
Indo-Dravidin Languages.
library_name: transformers
pipeline_tag: sentence-similarity

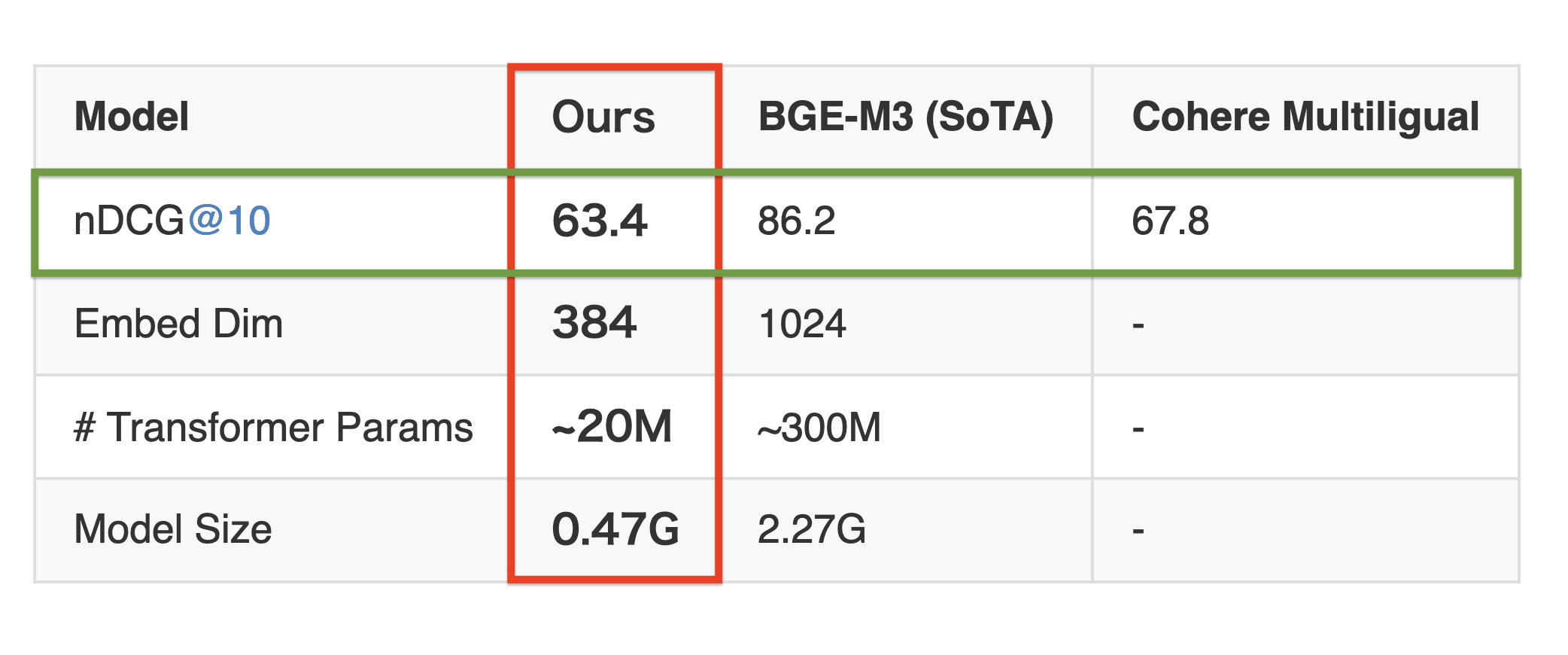
Table 1: Telugu retrieval performance on the MIRACL dev set (measured by nDCG@10)
Table Of Contents
- License and Terms:
- Detailed comparison & Our Contribution:
- ONNX & GGUF Variants:
- Usage:
- Notes on Reproducing:
- Reference:
- Note on model bias
License and Terms:

Detailed comparison & Our Contribution:
English language famously have all-minilm series models which were great for quick experimentations and for certain production workloads. The Idea is to have same for the other popular langauges, starting with Indo-Aryan and Indo-Dravidian languages. Our innovation is in bringing high quality models which easy to serve and embeddings are cheaper to store without ANY pretraining or expensive finetuning. For instance, all-minilm are finetuned on 1-Billion pairs. We offer a very lean model but with a huge vocabulary - around 250K. We will add more details here.
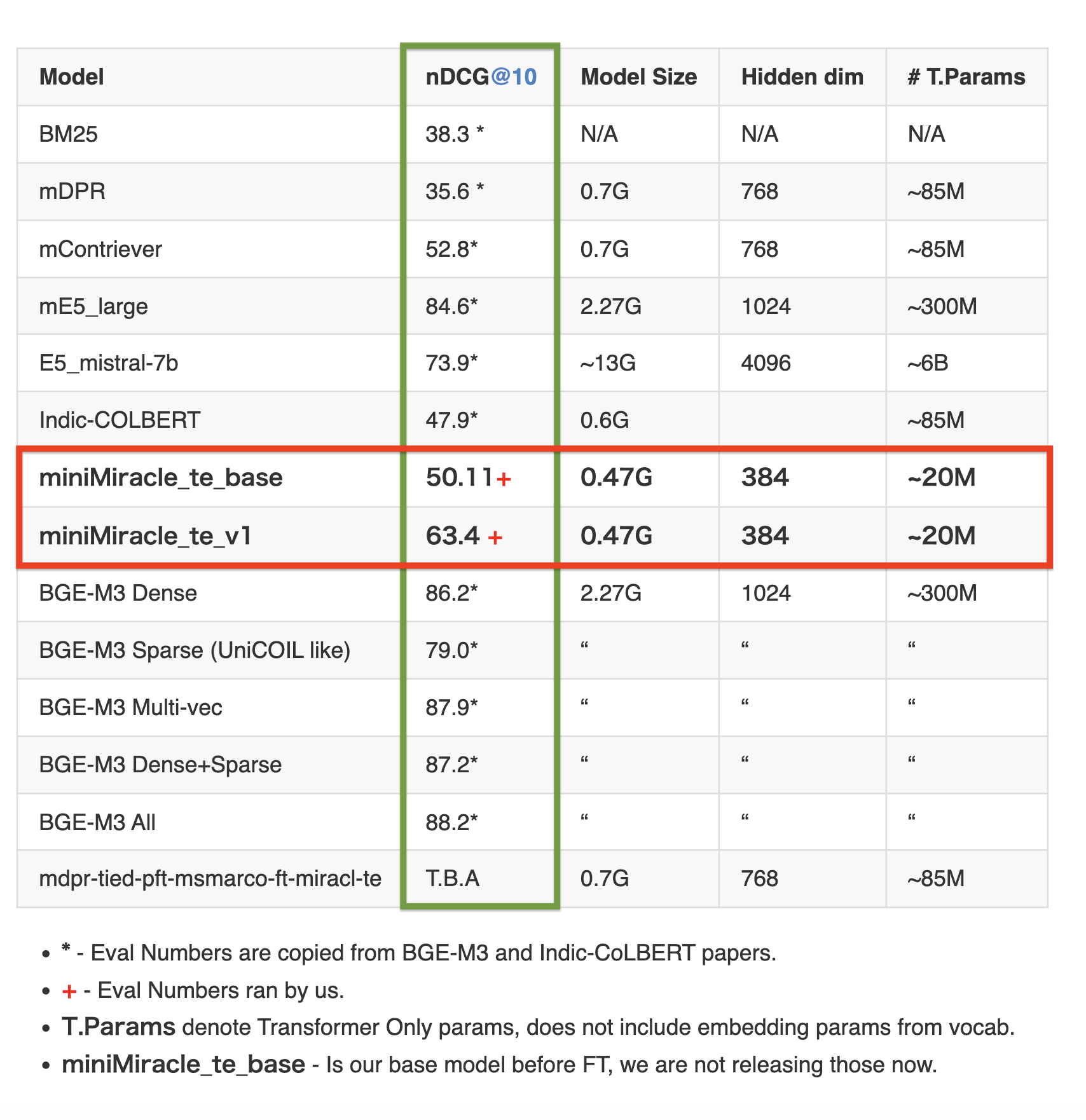
Table 2: Detailed Telugu retrieval performance on the MIRACL dev set (measured by nDCG@10)
Full set of evaluation numbers for our model
{'NDCG@1': 0.45773, 'NDCG@3': 0.58701, 'NDCG@5': 0.60938, 'NDCG@10': 0.63416, 'NDCG@100': 0.66138, 'NDCG@1000': 0.6682}
{'MAP@1': 0.45129, 'MAP@3': 0.55509, 'MAP@5': 0.56774, 'MAP@10': 0.57728, 'MAP@100': 0.58319, 'MAP@1000': 0.58346}
{'Recall@10': 0.79247, 'Recall@50': 0.89936, 'Recall@100': 0.93639, 'Recall@200': 0.96276, 'Recall@500': 0.97967, 'Recall@1000': 0.98933}
{'P@1': 0.45773, 'P@3': 0.22947, 'P@5': 0.14903, 'P@10': 0.08152, 'P@100': 0.00965, 'P@1000': 0.00102}
{'MRR@10': 0.5813, 'MRR@100': 0.58704, 'MRR@1000': 0.58729}
Usage:
With Sentence Transformers:
from sentence_transformers import SentenceTransformer
import scipy.spatial
model = SentenceTransformer('prithivida/miniMiracle_te_v1')
corpus = [
'ఒక వ్యక్తి ఆహారం తింటున్నాడు.',
'ప్రజలు రొట్టె ముక్క తింటారు.',
'అమ్మాయి ఒక బిడ్డను ఎత్తుకుందు.',
'ఒక వ్యక్తి గుర్రం మీద సవారీ చేస్తున్నాడు.',
'ఒక మహిళ వయోలిన్ వాయిస్తోంది.',
'రెండు వ్యక్తులు అడవిలో కారును తోస్తున్నారు.',
'ఒక వ్యక్తి ఒక తెల్ల గుర్రం మీద ఒక మూసిన ప్రదేశంలో సవారీ చేస్తున్నాడు.',
'ఒక కోతి డ్రమ్ వాయిస్తోంది.',
'ఒక చిరుత తన వేట వెనుక పరుగెడుతోంది.',
'ప్రజలు పెద్ద భోజనాన్ని ఆస్వాదించారు.'
]
queries = [
'ఒక వ్యక్తి పాస్తా తింటున్నాడు.',
'ఒక గొరిల్లా సూట్ ధరించిన వ్యక్తి డ్రమ్ వాయిస్తోంది.'
]
corpus_embeddings = model.encode(corpus)
query_embeddings = model.encode(queries)
# Find the closest 3 sentences of the corpus for each query sentence based on cosine similarity
closest_n = 3
for query, query_embedding in zip(queries, query_embeddings):
distances = scipy.spatial.distance.cdist([query_embedding], corpus_embeddings, "cosine")[0]
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
print("\n======================\n")
print("Query:", query)
print("\nTop 3 most similar sentences in corpus:\n")
for idx, distance in results[0:closest_n]:
print(corpus[idx].strip(), "(Score: %.4f)" % (1-distance))
# Optional: How to quantize the embeddings
# binary_embeddings = quantize_embeddings(embeddings, precision="ubinary")
With Huggingface Transformers:
- T.B.A
How do I optimise vector index cost ?
Use Binary and Scalar Quantisation
How do I offer hybrid search to address Vocabulary Mismatch Problem?
MIRACL paper shows simply combining BM25 is a good starting point for a Hybrid option: The below numbers are with mDPR model, but miniMiracle_te_v1 should give a even better hybrid performance.| Language | ISO | nDCG@10 BM25 | nDCG@10 mDPR | nDCG@10 Hybrid |
|---|---|---|---|---|
| Telugu | te | 0.383 | 0.356 | 0.602 |
Note: MIRACL paper shows a different (higher) value for BM25 Telugu, So we are taking that value from BGE-M3 paper, rest all are form the MIRACL paper.
Notes on reproducing:
We welcome anyone to reproduce our results. Here are some tips and observations:
- Use CLS Pooling and Inner Product.
- There may be minor differences in the numbers when reproducing, for instance BGE-M3 reports a nDCG@10 of 59.3 for MIRACL hindi and we Observed only 58.9.
Here are our numbers for the full hindi run on BGE-M3
{'NDCG@1': 0.49714, 'NDCG@3': 0.5115, 'NDCG@5': 0.53908, 'NDCG@10': 0.58936, 'NDCG@100': 0.6457, 'NDCG@1000': 0.65336}
{'MAP@1': 0.28845, 'MAP@3': 0.42424, 'MAP@5': 0.46455, 'MAP@10': 0.49955, 'MAP@100': 0.51886, 'MAP@1000': 0.51933}
{'Recall@10': 0.73032, 'Recall@50': 0.8987, 'Recall@100': 0.93974, 'Recall@200': 0.95763, 'Recall@500': 0.97813, 'Recall@1000': 0.9902}
{'P@1': 0.49714, 'P@3': 0.33048, 'P@5': 0.24629, 'P@10': 0.15543, 'P@100': 0.0202, 'P@1000': 0.00212}
{'MRR@10': 0.60893, 'MRR@100': 0.615, 'MRR@1000': 0.6151}
Fair warning BGE-M3 is $ expensive to evaluate, probably that's why it's not part of any of the MTEB benchmarks.
Reference:
- All Cohere numbers are copied form here
- BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
- Making a MIRACL: Multilingual Information Retrieval Across a Continuum of Languages
- IndicIRSuite: Multilingual Dataset and Neural Information Models for Indian Languages
Note on model bias:
- Like any model this model might carry inherent biases from the base models and the datasets it was pretrained and finetuned on. Please use responsibly.