

pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: stella-base-zh-v3-1792d
results:
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 54.5145388936202
- type: cos_sim_spearman
value: 59.223125058197134
- type: euclidean_pearson
value: 57.819377838734695
- type: euclidean_spearman
value: 59.22310494948463
- type: manhattan_pearson
value: 57.44029759610327
- type: manhattan_spearman
value: 58.88336250854381
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 54.544243591344866
- type: cos_sim_spearman
value: 58.43052988038229
- type: euclidean_pearson
value: 62.1608405146189
- type: euclidean_spearman
value: 58.43052762862396
- type: manhattan_pearson
value: 61.88443779892169
- type: manhattan_spearman
value: 58.26899143609596
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.343999999999994
- type: f1
value: 44.46931958420461
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 68.52081000538426
- type: cos_sim_spearman
value: 70.44089935351529
- type: euclidean_pearson
value: 69.24671010626395
- type: euclidean_spearman
value: 70.44090281761693
- type: manhattan_pearson
value: 69.00737718109357
- type: manhattan_spearman
value: 70.24344902456502
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 42.86119436460332
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 39.97521728440642
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 88.34151862240452
- type: mrr
value: 90.40380952380953
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 89.06288758814637
- type: mrr
value: 90.91285714285713
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.651000000000003
- type: map_at_10
value: 38.576
- type: map_at_100
value: 40.534
- type: map_at_1000
value: 40.64
- type: map_at_3
value: 34.016000000000005
- type: map_at_5
value: 36.675999999999995
- type: mrr_at_1
value: 39.06
- type: mrr_at_10
value: 47.278
- type: mrr_at_100
value: 48.272999999999996
- type: mrr_at_1000
value: 48.314
- type: mrr_at_3
value: 44.461
- type: mrr_at_5
value: 46.107
- type: ndcg_at_1
value: 39.06
- type: ndcg_at_10
value: 45.384
- type: ndcg_at_100
value: 52.796
- type: ndcg_at_1000
value: 54.55
- type: ndcg_at_3
value: 39.497
- type: ndcg_at_5
value: 42.189
- type: precision_at_1
value: 39.06
- type: precision_at_10
value: 10.17
- type: precision_at_100
value: 1.6179999999999999
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 22.247
- type: precision_at_5
value: 16.529
- type: recall_at_1
value: 25.651000000000003
- type: recall_at_10
value: 56.82899999999999
- type: recall_at_100
value: 87.134
- type: recall_at_1000
value: 98.709
- type: recall_at_3
value: 39.461
- type: recall_at_5
value: 47.329
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 83.1870114251353
- type: cos_sim_ap
value: 90.42393852164342
- type: cos_sim_f1
value: 84.10685985963323
- type: cos_sim_precision
value: 81.5229317533465
- type: cos_sim_recall
value: 86.85994856207621
- type: dot_accuracy
value: 83.1870114251353
- type: dot_ap
value: 90.41339758845682
- type: dot_f1
value: 84.10685985963323
- type: dot_precision
value: 81.5229317533465
- type: dot_recall
value: 86.85994856207621
- type: euclidean_accuracy
value: 83.1870114251353
- type: euclidean_ap
value: 90.42393581056393
- type: euclidean_f1
value: 84.10685985963323
- type: euclidean_precision
value: 81.5229317533465
- type: euclidean_recall
value: 86.85994856207621
- type: manhattan_accuracy
value: 82.77811184606134
- type: manhattan_ap
value: 90.18115714681704
- type: manhattan_f1
value: 83.75083130126357
- type: manhattan_precision
value: 79.62065331928345
- type: manhattan_recall
value: 88.33294365209258
- type: max_accuracy
value: 83.1870114251353
- type: max_ap
value: 90.42393852164342
- type: max_f1
value: 84.10685985963323
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 68.388
- type: map_at_10
value: 76.819
- type: map_at_100
value: 77.153
- type: map_at_1000
value: 77.16
- type: map_at_3
value: 74.98700000000001
- type: map_at_5
value: 76.101
- type: mrr_at_1
value: 68.599
- type: mrr_at_10
value: 76.844
- type: mrr_at_100
value: 77.168
- type: mrr_at_1000
value: 77.17500000000001
- type: mrr_at_3
value: 75.044
- type: mrr_at_5
value: 76.208
- type: ndcg_at_1
value: 68.599
- type: ndcg_at_10
value: 80.613
- type: ndcg_at_100
value: 82.017
- type: ndcg_at_1000
value: 82.19300000000001
- type: ndcg_at_3
value: 76.956
- type: ndcg_at_5
value: 78.962
- type: precision_at_1
value: 68.599
- type: precision_at_10
value: 9.336
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 27.678000000000004
- type: precision_at_5
value: 17.619
- type: recall_at_1
value: 68.388
- type: recall_at_10
value: 92.36
- type: recall_at_100
value: 98.52499999999999
- type: recall_at_1000
value: 99.895
- type: recall_at_3
value: 82.53399999999999
- type: recall_at_5
value: 87.355
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.1
- type: map_at_10
value: 77.71000000000001
- type: map_at_100
value: 80.638
- type: map_at_1000
value: 80.679
- type: map_at_3
value: 53.187
- type: map_at_5
value: 67.735
- type: mrr_at_1
value: 87.8
- type: mrr_at_10
value: 91.8
- type: mrr_at_100
value: 91.893
- type: mrr_at_1000
value: 91.89500000000001
- type: mrr_at_3
value: 91.51700000000001
- type: mrr_at_5
value: 91.704
- type: ndcg_at_1
value: 87.8
- type: ndcg_at_10
value: 85.55
- type: ndcg_at_100
value: 88.626
- type: ndcg_at_1000
value: 89.021
- type: ndcg_at_3
value: 83.94
- type: ndcg_at_5
value: 83.259
- type: precision_at_1
value: 87.8
- type: precision_at_10
value: 41.295
- type: precision_at_100
value: 4.781
- type: precision_at_1000
value: 0.488
- type: precision_at_3
value: 75.3
- type: precision_at_5
value: 64.13
- type: recall_at_1
value: 25.1
- type: recall_at_10
value: 87.076
- type: recall_at_100
value: 97.095
- type: recall_at_1000
value: 99.129
- type: recall_at_3
value: 56.013999999999996
- type: recall_at_5
value: 73.2
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 53.300000000000004
- type: map_at_10
value: 63.01
- type: map_at_100
value: 63.574
- type: map_at_1000
value: 63.587
- type: map_at_3
value: 60.783
- type: map_at_5
value: 62.098
- type: mrr_at_1
value: 53.300000000000004
- type: mrr_at_10
value: 63.01
- type: mrr_at_100
value: 63.574
- type: mrr_at_1000
value: 63.587
- type: mrr_at_3
value: 60.783
- type: mrr_at_5
value: 62.098
- type: ndcg_at_1
value: 53.300000000000004
- type: ndcg_at_10
value: 67.876
- type: ndcg_at_100
value: 70.434
- type: ndcg_at_1000
value: 70.753
- type: ndcg_at_3
value: 63.275000000000006
- type: ndcg_at_5
value: 65.654
- type: precision_at_1
value: 53.300000000000004
- type: precision_at_10
value: 8.32
- type: precision_at_100
value: 0.9480000000000001
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 23.5
- type: precision_at_5
value: 15.260000000000002
- type: recall_at_1
value: 53.300000000000004
- type: recall_at_10
value: 83.2
- type: recall_at_100
value: 94.8
- type: recall_at_1000
value: 97.3
- type: recall_at_3
value: 70.5
- type: recall_at_5
value: 76.3
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 49.92689495959984
- type: f1
value: 37.784780470986625
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.26641651031895
- type: ap
value: 54.50750244841821
- type: f1
value: 80.94927946681523
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 72.3980811478615
- type: cos_sim_spearman
value: 78.26906056425528
- type: euclidean_pearson
value: 77.87705501225068
- type: euclidean_spearman
value: 78.26905834518651
- type: manhattan_pearson
value: 77.77154630197
- type: manhattan_spearman
value: 78.1940918602169
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 27.48003475319453
- type: mrr
value: 26.400793650793652
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 64.373
- type: map_at_10
value: 73.604
- type: map_at_100
value: 73.953
- type: map_at_1000
value: 73.965
- type: map_at_3
value: 71.70100000000001
- type: map_at_5
value: 72.859
- type: mrr_at_1
value: 66.676
- type: mrr_at_10
value: 74.248
- type: mrr_at_100
value: 74.56099999999999
- type: mrr_at_1000
value: 74.572
- type: mrr_at_3
value: 72.59100000000001
- type: mrr_at_5
value: 73.592
- type: ndcg_at_1
value: 66.676
- type: ndcg_at_10
value: 77.417
- type: ndcg_at_100
value: 79.006
- type: ndcg_at_1000
value: 79.334
- type: ndcg_at_3
value: 73.787
- type: ndcg_at_5
value: 75.74
- type: precision_at_1
value: 66.676
- type: precision_at_10
value: 9.418
- type: precision_at_100
value: 1.0210000000000001
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 27.832
- type: precision_at_5
value: 17.736
- type: recall_at_1
value: 64.373
- type: recall_at_10
value: 88.565
- type: recall_at_100
value: 95.789
- type: recall_at_1000
value: 98.355
- type: recall_at_3
value: 78.914
- type: recall_at_5
value: 83.56
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.0544720914593
- type: f1
value: 69.61749470345791
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.30262273032953
- type: f1
value: 75.05097671215634
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 55.1
- type: map_at_10
value: 61.284000000000006
- type: map_at_100
value: 61.794000000000004
- type: map_at_1000
value: 61.838
- type: map_at_3
value: 59.75
- type: map_at_5
value: 60.64000000000001
- type: mrr_at_1
value: 55.300000000000004
- type: mrr_at_10
value: 61.38400000000001
- type: mrr_at_100
value: 61.894000000000005
- type: mrr_at_1000
value: 61.938
- type: mrr_at_3
value: 59.85
- type: mrr_at_5
value: 60.74
- type: ndcg_at_1
value: 55.1
- type: ndcg_at_10
value: 64.345
- type: ndcg_at_100
value: 67.148
- type: ndcg_at_1000
value: 68.36
- type: ndcg_at_3
value: 61.182
- type: ndcg_at_5
value: 62.808
- type: precision_at_1
value: 55.1
- type: precision_at_10
value: 7.3999999999999995
- type: precision_at_100
value: 0.8789999999999999
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 21.767
- type: precision_at_5
value: 13.86
- type: recall_at_1
value: 55.1
- type: recall_at_10
value: 74
- type: recall_at_100
value: 87.9
- type: recall_at_1000
value: 97.5
- type: recall_at_3
value: 65.3
- type: recall_at_5
value: 69.3
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 76.21666666666667
- type: f1
value: 76.03732395559548
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 81.8083378451543
- type: cos_sim_ap
value: 85.43050139514027
- type: cos_sim_f1
value: 83.25969563082965
- type: cos_sim_precision
value: 77.79816513761469
- type: cos_sim_recall
value: 89.54593453009504
- type: dot_accuracy
value: 81.8083378451543
- type: dot_ap
value: 85.43050139514027
- type: dot_f1
value: 83.25969563082965
- type: dot_precision
value: 77.79816513761469
- type: dot_recall
value: 89.54593453009504
- type: euclidean_accuracy
value: 81.8083378451543
- type: euclidean_ap
value: 85.43050139514027
- type: euclidean_f1
value: 83.25969563082965
- type: euclidean_precision
value: 77.79816513761469
- type: euclidean_recall
value: 89.54593453009504
- type: manhattan_accuracy
value: 81.53762858689767
- type: manhattan_ap
value: 84.90556637024838
- type: manhattan_f1
value: 82.90258449304174
- type: manhattan_precision
value: 78.30985915492957
- type: manhattan_recall
value: 88.0675818373812
- type: max_accuracy
value: 81.8083378451543
- type: max_ap
value: 85.43050139514027
- type: max_f1
value: 83.25969563082965
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 93.53
- type: ap
value: 91.62070655043128
- type: f1
value: 93.51908163199477
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 38.451787103814375
- type: cos_sim_spearman
value: 43.97299462643919
- type: euclidean_pearson
value: 43.63298716626501
- type: euclidean_spearman
value: 43.973080252178576
- type: manhattan_pearson
value: 43.37465277323481
- type: manhattan_spearman
value: 43.71981281220414
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 37.75882451277358
- type: cos_sim_spearman
value: 40.0244327844802
- type: euclidean_pearson
value: 38.11050875514246
- type: euclidean_spearman
value: 40.02440987254504
- type: manhattan_pearson
value: 38.03186803221696
- type: manhattan_spearman
value: 39.757452890246775
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 65.9133992390713
- type: cos_sim_spearman
value: 66.4894937647578
- type: euclidean_pearson
value: 66.19047142189935
- type: euclidean_spearman
value: 66.4894937647578
- type: manhattan_pearson
value: 66.6960935896136
- type: manhattan_spearman
value: 66.88179996508133
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 80.55099417946924
- type: cos_sim_spearman
value: 83.05000687568048
- type: euclidean_pearson
value: 82.62744668792926
- type: euclidean_spearman
value: 83.05000687568048
- type: manhattan_pearson
value: 82.6543207325763
- type: manhattan_spearman
value: 83.06852715971705
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 66.48634798223672
- type: mrr
value: 76.30158461488861
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 27.483999999999998
- type: map_at_10
value: 76.848
- type: map_at_100
value: 80.541
- type: map_at_1000
value: 80.607
- type: map_at_3
value: 54.111
- type: map_at_5
value: 66.46300000000001
- type: mrr_at_1
value: 90.045
- type: mrr_at_10
value: 92.552
- type: mrr_at_100
value: 92.642
- type: mrr_at_1000
value: 92.645
- type: mrr_at_3
value: 92.134
- type: mrr_at_5
value: 92.391
- type: ndcg_at_1
value: 90.045
- type: ndcg_at_10
value: 84.504
- type: ndcg_at_100
value: 88.23100000000001
- type: ndcg_at_1000
value: 88.85300000000001
- type: ndcg_at_3
value: 85.992
- type: ndcg_at_5
value: 84.548
- type: precision_at_1
value: 90.045
- type: precision_at_10
value: 41.91
- type: precision_at_100
value: 5.017
- type: precision_at_1000
value: 0.516
- type: precision_at_3
value: 75.15899999999999
- type: precision_at_5
value: 62.958000000000006
- type: recall_at_1
value: 27.483999999999998
- type: recall_at_10
value: 83.408
- type: recall_at_100
value: 95.514
- type: recall_at_1000
value: 98.65
- type: recall_at_3
value: 55.822
- type: recall_at_5
value: 69.868
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 53.196
- type: f1
value: 51.51679244513836
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 67.87592101539063
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 62.4675464095125
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 57.9
- type: map_at_10
value: 68.099
- type: map_at_100
value: 68.55499999999999
- type: map_at_1000
value: 68.566
- type: map_at_3
value: 66.4
- type: map_at_5
value: 67.46
- type: mrr_at_1
value: 57.9
- type: mrr_at_10
value: 68.099
- type: mrr_at_100
value: 68.55499999999999
- type: mrr_at_1000
value: 68.566
- type: mrr_at_3
value: 66.4
- type: mrr_at_5
value: 67.46
- type: ndcg_at_1
value: 57.9
- type: ndcg_at_10
value: 72.555
- type: ndcg_at_100
value: 74.715
- type: ndcg_at_1000
value: 75.034
- type: ndcg_at_3
value: 69.102
- type: ndcg_at_5
value: 71.004
- type: precision_at_1
value: 57.9
- type: precision_at_10
value: 8.63
- type: precision_at_100
value: 0.963
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 25.633
- type: precision_at_5
value: 16.3
- type: recall_at_1
value: 57.9
- type: recall_at_10
value: 86.3
- type: recall_at_100
value: 96.3
- type: recall_at_1000
value: 98.9
- type: recall_at_3
value: 76.9
- type: recall_at_5
value: 81.5
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 87.27000000000001
- type: ap
value: 71.10883470119464
- type: f1
value: 85.76618863591946
license: mit
新闻 | News
[2024-04-06] 开源puff系列模型,专门针对检索和语义匹配任务,更多的考虑泛化性和私有通用测试集效果,向量维度可变,中英双语。
[2024-02-27] 开源stella-mrl-large-zh-v3.5-1792d模型,支持向量可变维度。
[2024-02-17] 开源stella v3系列、dialogue编码模型和相关训练数据。
[2023-10-19] 开源stella-base-en-v2 使用简单,不需要任何前缀文本。
[2023-10-12] 开源stella-base-zh-v2和stella-large-zh-v2, 效果更好且使用简单,不需要任何前缀文本。
[2023-09-11] 开源stella-base-zh和stella-large-zh
欢迎去本人主页查看最新模型,并提出您的宝贵意见!
1 开源清单
本次开源2个通用向量编码模型和一个针对dialogue进行编码的向量模型,同时开源全量160万对话重写数据集和20万的难负例的检索数据集。
开源模型:
| ModelName | ModelSize | MaxTokens | EmbeddingDimensions | Language | Scenario | C-MTEB Score |
|---|---|---|---|---|---|---|
| infgrad/stella-base-zh-v3-1792d | 0.4GB | 512 | 1792 | zh-CN | 通用文本 | 67.96 |
| infgrad/stella-large-zh-v3-1792d | 1.3GB | 512 | 1792 | zh-CN | 通用文本 | 68.48 |
| infgrad/stella-dialogue-large-zh-v3-1792d | 1.3GB | 512 | 1792 | zh-CN | 对话文本 | 不适用 |
开源数据:
- 全量对话重写数据集 约160万
- 部分带有难负例的检索数据集 约20万
上述数据集均使用LLM构造,欢迎各位贡献数据集。
2 使用方法
2.1 通用编码模型使用方法
直接SentenceTransformer加载即可:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("infgrad/stella-base-zh-v3-1792d")
# model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
vectors = model.encode(["text1", "text2"])
2.2 dialogue编码模型使用方法
使用场景: 在一段对话中,需要根据用户语句去检索相关文本,但是对话中的用户语句存在大量的指代和省略,导致直接使用通用编码模型效果不好, 可以使用本项目的专门的dialogue编码模型进行编码
使用要点:
- 对dialogue进行编码时,dialogue中的每个utterance需要是如下格式:
"{ROLE}: {TEXT}",然后使用[SEP]join一下 - 整个对话都要送入模型进行编码,如果长度不够就删掉早期的对话,编码后的向量本质是对话中最后一句话的重写版本的向量!!
- 对话用stella-dialogue-large-zh-v3-1792d编码,被检索文本使用stella-large-zh-v3-1792d进行编码,所以本场景是需要2个编码模型的
如果对使用方法还有疑惑,请到下面章节阅读该模型是如何训练的。
使用示例:
from sentence_transformers import SentenceTransformer
dial_model = SentenceTransformer("infgrad/stella-dialogue-large-zh-v3-1792d")
general_model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
# dialogue = ["张三: 吃饭吗", "李四: 等会去"]
dialogue = ["A: 最近去打篮球了吗", "B: 没有"]
corpus = ["B没打篮球是因为受伤了。", "B没有打乒乓球"]
last_utterance_vector = dial_model.encode(["[SEP]".join(dialogue)], normalize_embeddings=True)
corpus_vectors = general_model.encode(corpus, normalize_embeddings=True)
# 计算相似度
sims = (last_utterance_vector * corpus_vectors).sum(axis=1)
print(sims)
3 通用编码模型训练技巧分享
hard negative
难负例挖掘也是个经典的trick了,几乎总能提升效果
dropout-1d
dropout已经是深度学习的标配,我们可以稍微改造下使其更适合句向量的训练。 我们在训练时会尝试让每一个token-embedding都可以表征整个句子,而在推理时使用mean_pooling从而达到类似模型融合的效果。 具体操作是在mean_pooling时加入dropout_1d,torch代码如下:
vector_dropout = nn.Dropout1d(0.3) # 算力有限,试了0.3和0.5 两个参数,其中0.3更优
last_hidden_state = bert_model(...)[0]
last_hidden = last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
last_hidden = vector_dropout(last_hidden)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
4 dialogue编码模型细节
4.1 为什么需要一个dialogue编码模型?
参见本人历史文章:https://www.zhihu.com/pin/1674913544847077376
4.2 训练数据
单条数据示例:
{
"dialogue": [
"A: 最近去打篮球了吗",
"B: 没有"
],
"last_utterance_rewrite": "B: 我最近没有去打篮球"
}
4.3 训练Loss
loss = cosine_loss( dial_model.encode(dialogue), existing_model.encode(last_utterance_rewrite) )
dial_model就是要被训练的模型,本人是以stella-large-zh-v3-1792d作为base-model进行继续训练的
existing_model就是现有训练好的通用编码模型,本人使用的是stella-large-zh-v3-1792d
已开源dialogue-embedding的全量训练数据,理论上可以复现本模型效果。
Loss下降情况:
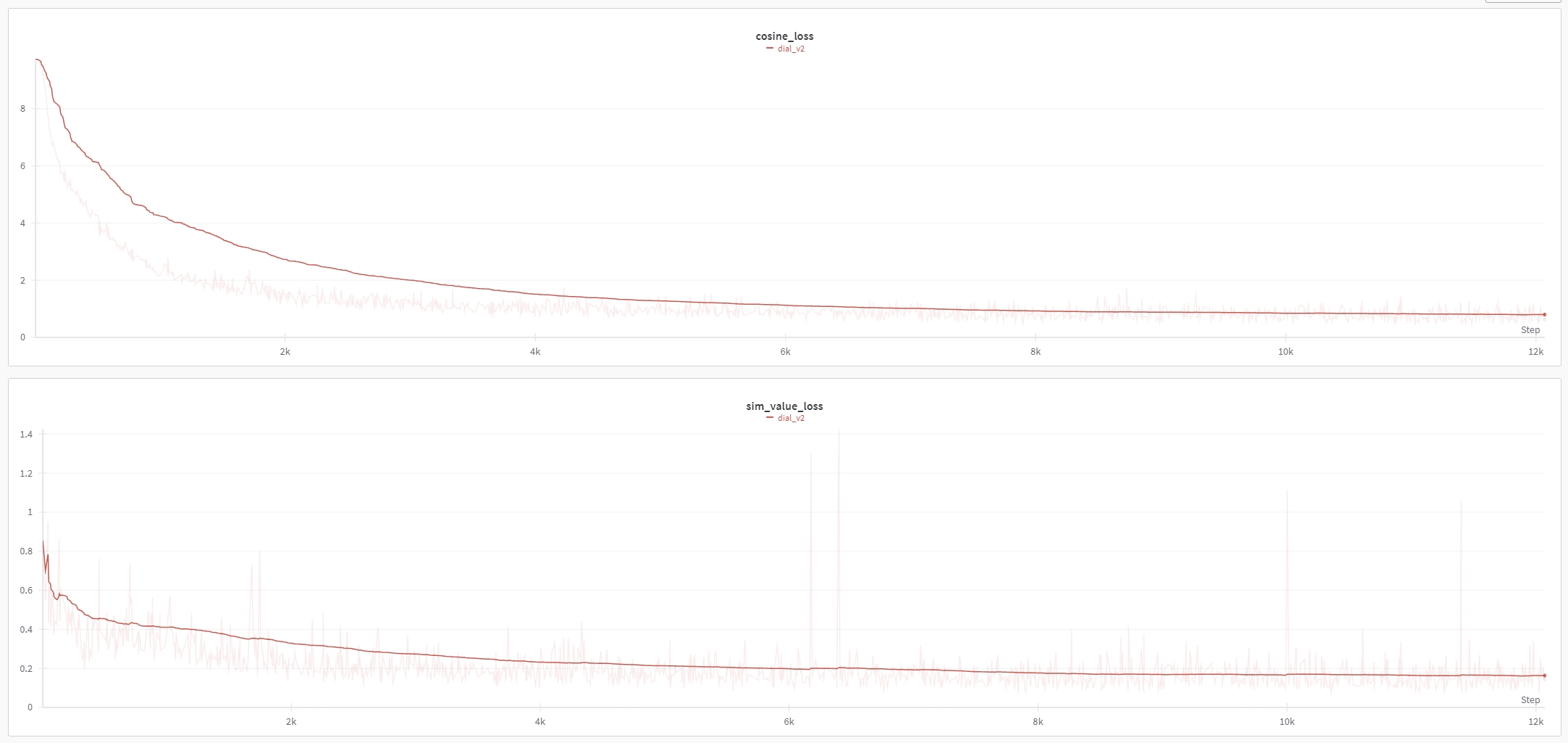
4.4 效果
目前还没有专门测试集,本人简单测试了下是有效果的,部分测试结果见文件dial_retrieval_test.xlsx。
5 后续TODO
- 更多的dial-rewrite数据
- 不同EmbeddingDimensions的编码模型
6 FAQ
Q: 为什么向量维度是1792?
A: 最初考虑发布768、1024,768+768,1024+1024,1024+768维度,但是时间有限,先做了1792就只发布1792维度的模型。理论上维度越高效果越好。
Q: 如何复现CMTEB效果?
A: SentenceTransformer加载后直接用官方评测脚本就行,注意对于Classification任务向量需要先normalize一下
Q: 复现的CMTEB效果和本文不一致?
A: 聚类不一致正常,官方评测代码没有设定seed,其他不一致建议检查代码或联系本人。
Q: 如何选择向量模型?
A: 没有免费的午餐,在自己测试集上试试,本人推荐bge、e5和stella.
Q: 长度为什么只有512,能否更长?
A: 可以但没必要,长了效果普遍不好,这是当前训练方法和数据导致的,几乎无解,建议长文本还是走分块。
Q: 训练资源和算力?
A: 亿级别的数据,单卡A100要一个月起步