

license: mit
tags:
- image-to-text
- image-to-image
- text-to-image
- text-to-text
- image-editing
- image-variation
- generation
- vision
datasets:
- Laion2B-en
widget:
- text: A high tech solarpunk utopia in the Amazon rainforest
example_title: Amazon rainforest
Versatile Diffusion V1.0 Model Card
We built Versatile Diffusion (VD), the first unified multi-flow multimodal diffusion framework, as a step towards Universal Generative AI. Versatile Diffusion can natively support image-to-text, image-variation, text-to-image, and text-variation, and can be further extended to other applications such as semantic-style disentanglement, image-text dual-guided generation, latent image-to-text-to-image editing, and more. Future versions will support more modalities such as speech, music, video and 3D.
Resources for more information: GitHub, arXiv.
Model Details
One single flow of Versatile Diffusion contains a VAE, a diffuser, and a context encoder, and thus handles one task (e.g., text-to-image) under one data type (e.g., image) and one context type (e.g., text). The multi-flow structure of Versatile Diffusion shows in the following diagram:
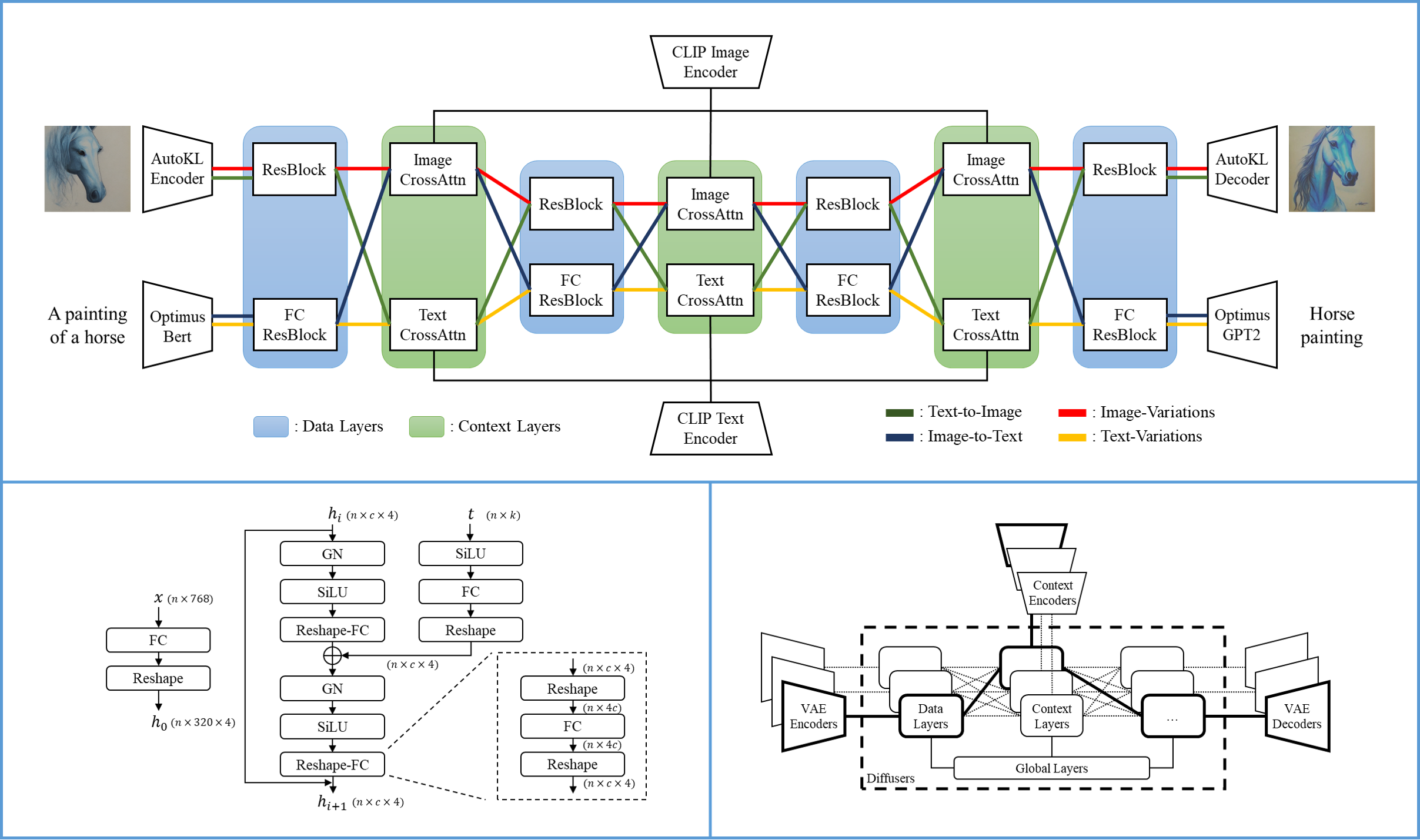
- Developed by: Xingqian Xu, Atlas Wang, Eric Zhang, Kai Wang, and Humphrey Shi
- Model type: Diffusion-based multimodal generation model
- Language(s): English
- License: MIT
- Resources for more information: GitHub Repository, Paper.
- Cite as:
@article{xu2022versatile,
title = {Versatile Diffusion: Text, Images and Variations All in One Diffusion Model},
author = {Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2211.08332},
eprint = {2211.08332},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
Usage
You can use the model both with the 🧨Diffusers library and the SHI-Labs Versatile Diffusion codebase.
🧨 Diffusers
Diffusers let's you both use a unified and more memory-efficient, task-specific pipelines.
Make sure to install transformers from "main" in order to use this model.:
pip install git+https://github.com/huggingface/transformers
VersatileDiffusionPipeline
To use Versatile Diffusion for all tasks, it is recommend to use the VersatileDiffusionPipeline
#! pip install git+https://github.com/huggingface/transformers diffusers torch
from diffusers import VersatileDiffusionPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
pipe = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# prompt
prompt = "a red car"
# initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
# text to image
image = pipe.text_to_image(prompt).images[0]
# image variation
image = pipe.image_variation(image).images[0]
# image variation
image = pipe.dual_guided(prompt, image).images[0]
Task Specific
The task specific pipelines load only the weights that are needed onto GPU. You can find all task specific pipelines here.
You can use them as follows:
Text to Image
from diffusers import VersatileDiffusionTextToImagePipeline
import torch
pipe = VersatileDiffusionTextToImagePipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
image.save("./astronaut.png")
Image variations
from diffusers import VersatileDiffusionImageVariationPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
pipe = VersatileDiffusionImageVariationPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe(image, generator=generator).images[0]
image.save("./car_variation.png")
Dual-guided generation
from diffusers import VersatileDiffusionDualGuidedPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
text = "a red car in the sun"
pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
text_to_image_strength = 0.75
image = pipe(prompt=text, image=image, text_to_image_strength=text_to_image_strength, generator=generator).images[0]
image.save("./red_car.png")
Original GitHub Repository
Follow the instructions here.
Cautions, Biases, and Content Acknowledgment
We would like the raise the awareness of users of this demo of its potential issues and concerns. Like previous large foundation models, Versatile Diffusion could be problematic in some cases, partially due to the imperfect training data and pretrained network (VAEs / context encoders) with limited scope. In its future research phase, VD may do better on tasks such as text-to-image, image-to-text, etc., with the help of more powerful VAEs, more sophisticated network designs, and more cleaned data. So far, we have kept all features available for research testing both to show the great potential of the VD framework and to collect important feedback to improve the model in the future. We welcome researchers and users to report issues with the HuggingFace community discussion feature or email the authors.
Beware that VD may output content that reinforces or exacerbates societal biases, as well as realistic faces, pornography, and violence. VD was trained on the LAION-2B dataset, which scraped non-curated online images and text, and may contain unintended exceptions as we removed illegal content. VD in this demo is meant only for research purposes.