Spaces:
Running


title: README
emoji: 🐢
colorFrom: purple
colorTo: gray
sdk: static
pinned: false
Intel and Hugging Face are building powerful optimization tools to accelerate training and inference with Transformers.


Intel optimizes the most widely adopted and innovative AI software tools, frameworks, and libraries for Intel® architecture. Whether you are computing locally or deploying AI applications on a massive scale, your organization can achieve peak performance with AI software optimized for Intel® Xeon® Scalable platforms.
Intel’s engineering collaboration with Hugging Face offers state-of-the-art hardware and software acceleration to train, fine-tune and predict with Transformers.
Useful Resources:
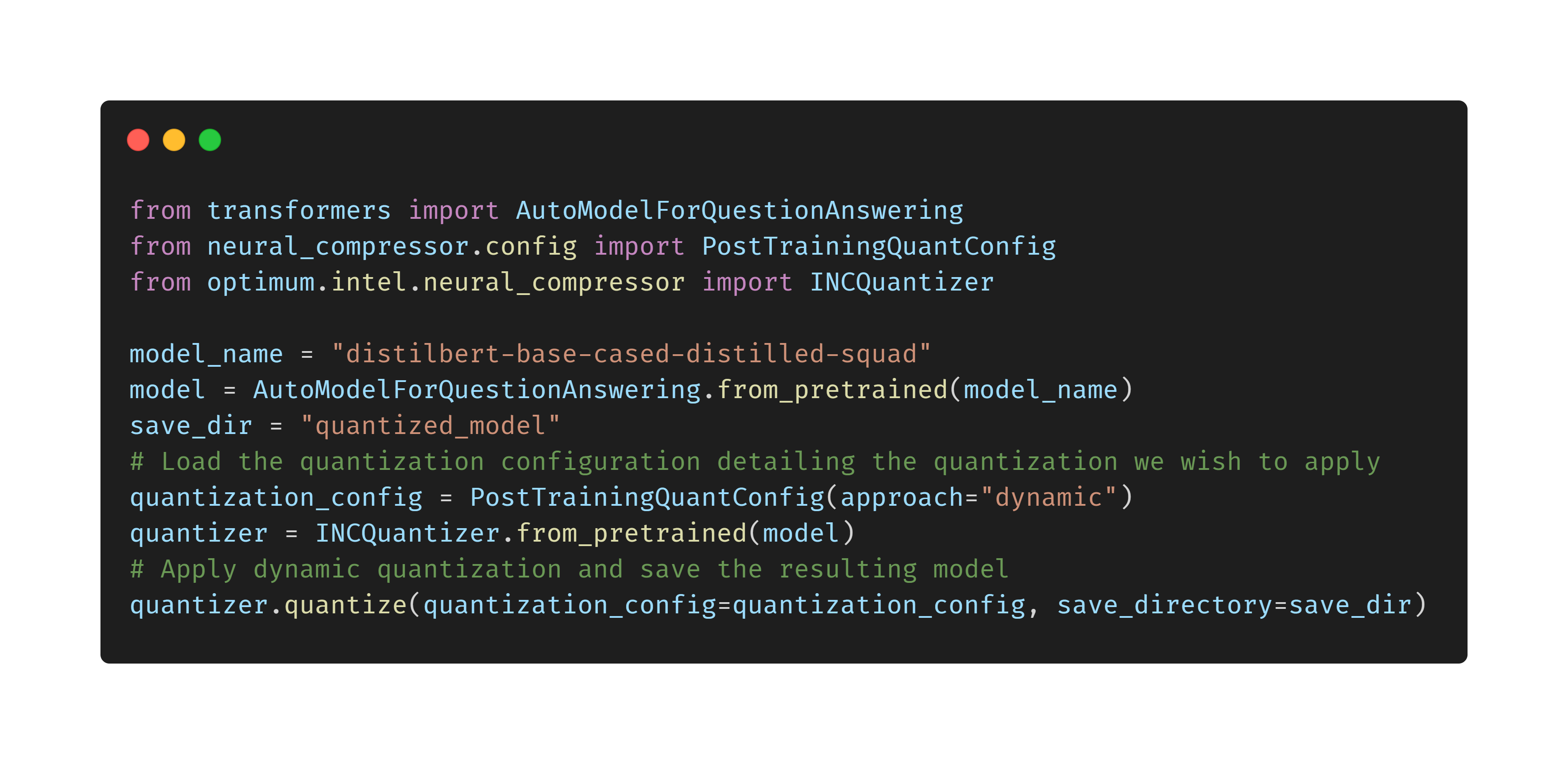
To get started with Intel® hardware and software optimizations, download and install the Optimum-Intel® and Intel® Extension for Transformers libraries with the following commands:
$ python -m pip install "optimum-intel[extras]"@git+https://github.com/huggingface/optimum-intel.git
$ python -m pip install intel-extension-for-transformers
For additional information on these two libraries including installation, features, and usage, see the two links below.
Next, find your desired model (and dataset) by searching in the search box at the top-left of Hugging Face’s website. Add “intel” to your search to narrow your search to Intel®-pretrained models.
On the model’s page (called a “Model Card”) you will find description and usage information, an embedded inferencing demo, and the associated dataset. In the upper-right of your screen, click “Use in Transformers” for helpful code hints on how to import the model to your own workspace with an established Hugging Face pipeline and tokenizer.
Library Source and Documentation: