Spaces:
Runtime error


![]()



 Motivation
Motivation
Spoken Language Understanding (SLU) is one of the core components of a task-oriented dialogue system, which aims to extract the semantic meaning of user queries (e.g., intents and slots).
In this work, we introduce OpenSLU, an open-source toolkit to provide a unified, modularized, and extensible toolkit for spoken language understanding. Specifically, OpenSLU unifies 10 SLU baselines for both single-intent and multi-intent scenarios, which support both non-pretrained and pretrained models simultaneously. Additionally, OpenSLU is highly modularized and extensible by decomposing the model architecture, inference, and learning process into reusable modules, which allows researchers to quickly set up SLU experiments with highly flexible configurations. We hope OpenSLU can help researcher to quickly initiate experiments and spur more breakthroughs in SLU.
 Changelog
Changelog
- 2023-02-09
- We build the first version and release it.
 Installation
Installation
System requirements
OpenSLU requires Python>=3.8, and torch>=1.12.0.
Install from git
git clone https://github.com/LightChen2333/OpenSLU.git && cd OpenSLU/
pip install -r requirements.txt
File Structure
root
├── common
│ ├── config.py # load configuration and auto preprocess ignored config
│ ├── loader.py # load data from hugging face
│ ├── logger.py # log predict result, support [fitlog], [wandb], [local logging]
│ ├── metric.py # evalutation metric, support [intent acc], [slot F1], [EMA]
│ ├── model_manager.py # help to prepare data, prebuild training progress.
│ ├── tokenizer.py # tokenizer also support no-pretrained model for word tokenizer.
│ └── utils.py # canonical model communication data structure and other common tool function
├── config
│ ├── reproduction # configurations for reproducted SLU model.
│ └── **.yaml # configuration for SLU model.
├── logs # local log storage dir path.
├── model
│ ├── encoder
│ │ ├── base_encoder.py # base encoder model. All implemented encoder models need to inherit the BaseEncoder class
│ │ ├── auto_encoder.py # auto-encoder to autoload provided encoder model
│ │ ├── non_pretrained_encoder.py # all common-used no pretrained encoder like lstm, lstm+self-attention
│ │ └── pretrained_encoder.py # all common-used pretrained encoder, implemented by hugging-face [AutoModel].
│ ├── decoder
│ │ ├── interaction
│ │ │ ├── base_interaction.py # base interaction model. All implemented encoder models need to inherit the BaseInteraction class
│ │ │ └── *_interaction.py # some SOTA SLU interaction module. You can easily reuse or rewrite to implement your own idea.
│ │ ├── base_decoder.py # decoder class, [BaseDecoder] support classification after interaction, also you can rewrite for your own interaction order
│ │ └── classifier.py # classifier class, support linear and LSTM classification. Also support token-level intent.
│ └── open_slu_model.py # the general model class, can automatically build the model through configuration.
├── save # model checkpoint storage dir path and dir to automatically save glove embedding.
└── run.py # run script for all function.
 Quick Start
Quick Start
1. Reproducing Existing Models
Example for reproduction of slot-gated model:
python run.py --dataset atis --model slot-gated
2. Customizable Combination Existing Components
- First, you can freely combine and build your own model through config files. For details, see Configuration.
- Then, you can assign the configuration path to train your own model.
Example for stack-propagation fine-tuning:
python run.py -cp config/stack-propagation.yaml
Example for multi-GPU fine-tuning:
accelerate config
accelerate launch run.py -cp config/stack-propagation.yaml
Or you can assign accelerate yaml configuration.
accelerate launch [--config_file ./accelerate/config.yaml] run.py -cp config/stack-propagation.yaml
3. Implementing a New SLU Model
In OpenSLU, you are only needed to rewrite required commponents and assign them in configuration instead of rewriting all commponents.
In most cases, rewriting Interaction module is enough for building a new SLU model.
This module accepts HiddenData as input and return with HiddenData, which contains the hidden_states for intent and slot, and other helpful information. The example is as follows:
class NewInteraction(BaseInteraction):
def __init__(self, **config):
self.config = config
...
def forward(self, hiddens: HiddenData):
...
intent, slot = self.func(hiddens)
hiddens.update_slot_hidden_state(slot)
hiddens.update_intent_hidden_state(intent)
return hiddens
To further meet the
needs of complex exploration, we provide the
BaseDecoder class, and the user can simply override the forward() function in class, which accepts HiddenData as input and OutputData as output. The example is as follows:
class NewDecoder(BaseDecoder):
def __init__(self,
intent_classifier,
slot_classifier,
interaction=None):
...
self.int_cls = intent_classifier
self.slot_cls = slot_classifier
self.interaction = interaction
def forward(self, hiddens: HiddenData):
...
interact = self.interaction(hiddens)
slot = self.slot_cls(interact.slot)
intent = self.int_cls(interact.intent)
return OutputData(intent, slot)
Modules
1. Encoder Modules
- No Pretrained Encoder
- GloVe Embedding
- BiLSTM Encoder
- BiLSTM + Self-Attention Encoder
- Bi-Encoder (support two encoders for intent and slot, respectively)
- Pretrained Encoder
bert-base-uncasedroberta-basemicrosoft/deberta-v3-base- other hugging-face supported encoder model...
2. Decoder Modules
2.1 Interaction Modules
- DCA Net Interaction
- Stack Propagation Interaction
- Bi-Model Interaction(with decoder/without decoder)
- Slot Gated Interaction
2.2 Classification Modules
All classifier support Token-level Intent and Sentence-level intent. What's more, our decode function supports to both Single-Intent and Multi-Intent.
- LinearClassifier
- AutoregressiveLSTMClassifier
- MLPClassifier
3. Supported Models
We implement various 10 common-used SLU baselines:
Single-Intent Model
- Bi-Model [ Wang et al., 2018 ] :
bi-model.yaml
- Slot-Gated [ Goo et al., 2018 ] :
slot-gated.yaml
- Stack-Propagation [ Qin et al., 2019 ] :
stack-propagation.yaml
- Joint Bert [ Chen et al., 2019 ] :
joint-bert.yaml
- RoBERTa [ Liu et al., 2019 ] :
roberta.yaml
- ELECTRA [ Clark et al., 2020 ] :
electra.yaml
- DCA-Net [ Qin et al., 2021 ] :
dca_net.yaml
- DeBERTa [ He et al., 2021 ] :
deberta.yaml
Multi-Intent Model
- AGIF [ Qin et al., 2020 ] :
agif.yaml
- GL-GIN [ Qin et al., 2021 ] :
gl-gin.yaml
Application
1. Visualization Tools
Model metrics tests alone no longer adequately reflect the model's performance. To help researchers further improve their models, we provide a tool for visual error analysis.
We provide an analysis interface with three main parts:
- (a) error distribution analysis;
- (b) label transfer analysis;
- (c) instance analysis.

python tools/visualization.py \
--config_path config/visual.yaml \
--output_path {ckpt_dir}/outputs.jsonl
Visualization configuration can be set as below:
host: 127.0.0.1
port: 7861
is_push_to_public: true # whether to push to gradio platform(public network)
output_path: save/stack/outputs.jsonl # output prediction file path
page-size: 2 # the number of instances of each page in instance anlysis.
2. Deployment
We provide an script to deploy your model automatically. You are only needed to run the command as below to deploy your own model:
python app.py --config_path config/reproduction/atis/bi-model.yaml
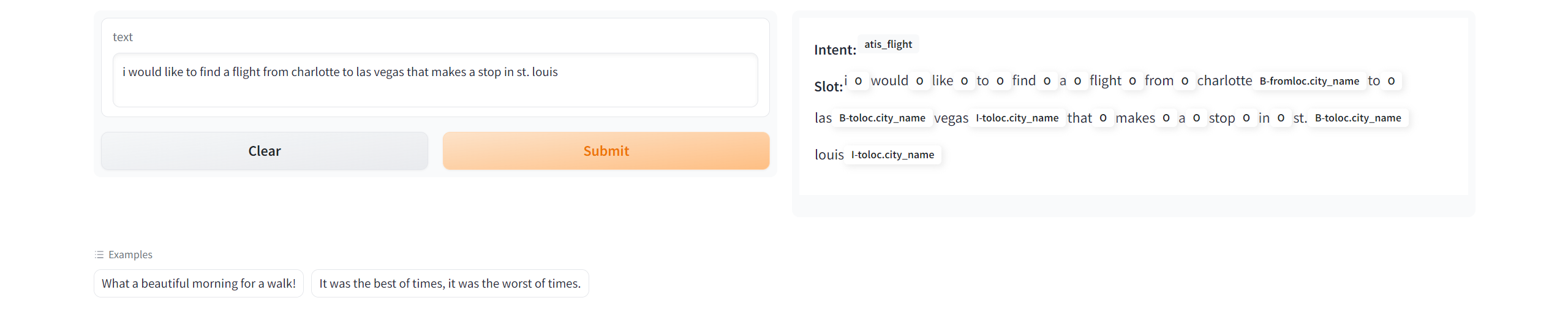
3. Publish your model to hugging face
We also offer an script to transfer models trained by OpenSLU to hugging face format automatically. And you can upload the model to your Model space.
python tools/parse_to_hugging_face.py -cp config/reproduction/atis/bi-model.yaml -op save/temp
It will generate 5 files, and you should only need to upload config.json, pytorch_model.bin and tokenizer.pkl.
After that, others can reproduction your model just by adjust _from_pretrained_ parameters in Configuration.
 Contact
Contact
Please create Github issues here or email Libo Qin or Qiguang Chen if you have any questions or suggestions.