Spaces:
Paused


A newer version of the Gradio SDK is available:
5.6.0
Model Overview
Description:
BigVGAN is a generative AI model specialized in synthesizing audio waveforms using Mel spectrogram as inputs.
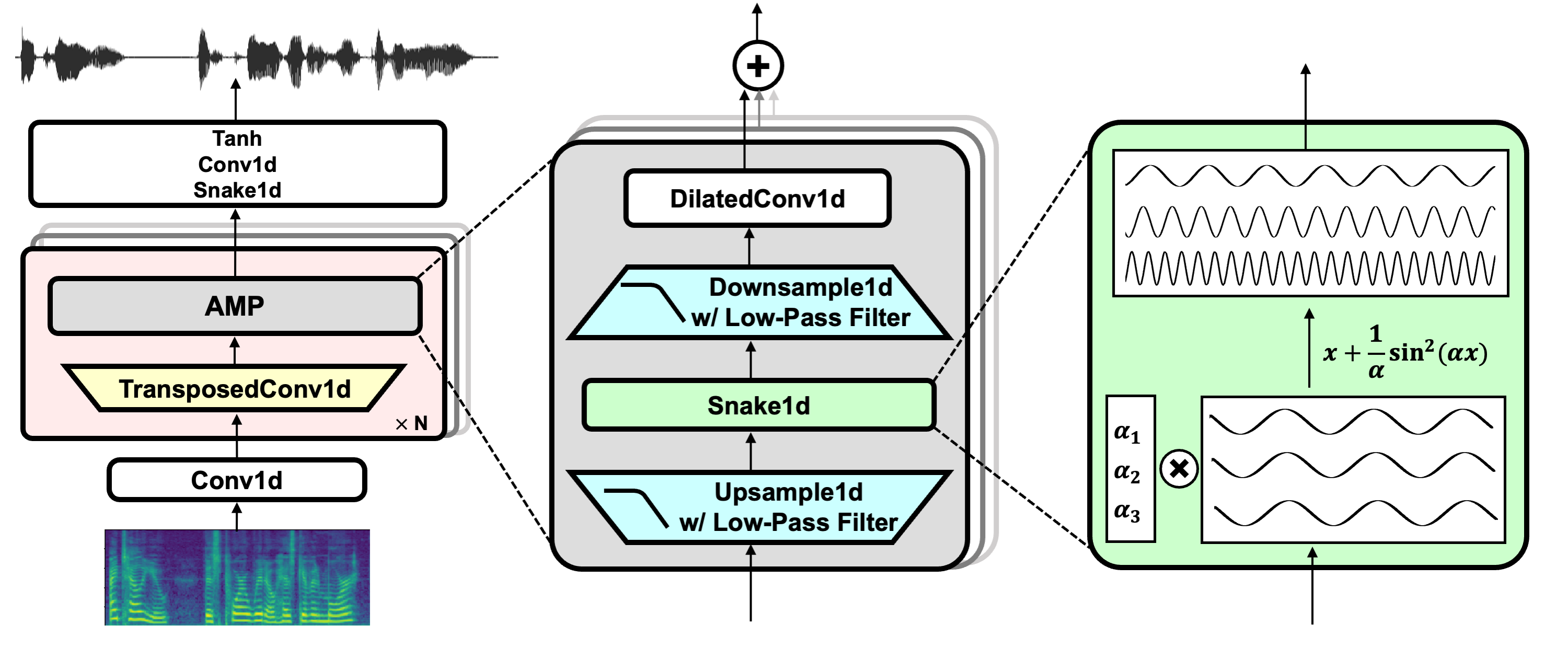
BigVGAN is a fully convolutional architecture with several upsampling blocks using transposed convolution followed by multiple residual dilated convolution layers.
BigVGAN consists of a novel module, called anti-aliased multi-periodicity composition (AMP), which is specifically designed for generating waveforms. AMP is specialized in synthesizing high-frequency and periodic soundwaves drawing inspiration from audio signal processing principles.
It applies a periodic activation function, called Snake, which provides an inductive bias to the architecture in generating periodic soundwaves. It also applies anti-aliasing filters to reduce undesired artifacts in the generated waveforms.
This model is ready for commercial use.
References(s):
Model Architecture:
Architecture Type: Convolution Neural Network (CNN)
Network Architecture: You can see the details of this model on this link: https://github.com/NVIDIA/BigVGAN and the related paper can be found here: https://arxiv.org/abs/2206.04658
Model Version: 2.0
Input:
Input Type: Audio
Input Format: Mel Spectrogram
Input Parameters: None
Other Properties Related to Input: The input mel spectrogram has shape [batch, channels, frames], where channels refers to the number of mel bands defined by the model and frames refers to the temporal length. The model supports arbitrary long frames that fits into the GPU memory.
Output:
Input Type: Audio
Output Format: Audio Waveform
Output Parameters: None
Other Properties Related to Output: The output audio waveform has shape [batch, 1, time], where 1 refers to the mono audio channels and time refers to the temporal length. time is defined as a fixed integer multiple of input frames, which is an upsampling ratio of the model (time = upsampling ratio * frames). The output audio waveform consitutes float values with a range of [-1, 1].
Software Integration:
Runtime Engine(s): PyTorch
Supported Hardware Microarchitecture Compatibility: NVIDIA Ampere, NVIDIA Hopper, NVIDIA Lovelace, NVIDIA Turing, NVIDIA Volta
Preferred/Supported Operating System(s):
Linux
Model Version(s):
v2.0
Training, Testing, and Evaluation Datasets:
Training Dataset:
The dataset contains diverse audio types, including speech in multiple languages, environmental sounds, and instruments.
Links:
- AAM: Artificial Audio Multitracks Dataset
- AudioCaps
- AudioSet
- common-accent
- Crowd Sourced Emotional Multimodal Actors Dataset (CREMA-D)
- DCASE2017 Challenge, Task 4: Large-scale weakly supervised sound event detection for smart cars
- FSDnoisy18k
- Free Universal Sound Separation Dataset
- Greatest Hits dataset
- GTZAN
- JL corpus
- Medley-solos-DB: a cross-collection dataset for musical instrument recognition
- MUSAN: A Music, Speech, and Noise Corpus
- MusicBench
- MusicCaps
- MusicNet
- NSynth
- OnAir-Music-Dataset
- Audio Piano Triads Dataset
- Pitch Audio Dataset (Surge synthesizer)
- SONYC Urban Sound Tagging (SONYC-UST): a multilabel dataset from an urban acoustic sensor network
- VocalSound: A Dataset for Improving Human Vocal Sounds Recognition
- WavText5K
- CSS10: A Collection of Single Speaker Speech Datasets for 10 Languages
- Hi-Fi Multi-Speaker English TTS Dataset (Hi-Fi TTS)
- IIIT-H Indic Speech Databases
- Libri-Light: A Benchmark for ASR with Limited or No Supervision
- LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
- LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
- The SIWIS French Speech Synthesis Database
- Crowdsourced high-quality Colombian Spanish speech data set
- TTS-Portuguese Corpus
- CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit
** Data Collection Method by dataset
- Human
** Labeling Method by dataset (for those with labels)
- Hybrid: Automated, Human, Unknown
Evaluating Dataset:
Properties: The audio generation quality of BigVGAN is evaluated using dev splits of the LibriTTS dataset and Hi-Fi TTS dataset. The datasets include speech in English language with equal balance of genders.
** Data Collection Method by dataset
- Human
** Labeling Method by dataset
- Automated
Inference:
Engine: PyTorch
Test Hardware: NVIDIA A100 GPU
Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI Concerns here.