Spaces:
Paused


ChatGPT 学术优化
如果喜欢这个项目,请给它一个Star;如果你发明了更好用的学术快捷键,欢迎发issue或者pull requests
If you like this project, please give it a Star. If you've come up with more useful academic shortcuts, feel free to open an issue or pull request.
代码中参考了很多其他优秀项目中的设计,主要包括:
# 借鉴项目1:借鉴了ChuanhuChatGPT中读取OpenAI json的方法、记录历史问询记录的方法以及gradio queue的使用技巧
https://github.com/GaiZhenbiao/ChuanhuChatGPT
# 借鉴项目2:借鉴了mdtex2html中公式处理的方法
https://github.com/polarwinkel/mdtex2html
项目使用OpenAI的gpt-3.5-turbo模型,期待gpt-4早点放宽门槛😂
Note 请注意只有“红颜色”标识的函数插件(按钮)才支持读取文件。目前暂不能完善地支持pdf格式文献的翻译解读,尚不支持word格式文件的读取。
| 功能 | 描述 |
|---|---|
| 一键润色 | 支持一键润色、一键查找论文语法错误 |
| 一键中英互译 | 一键中英互译 |
| 一键代码解释 | 可以正确显示代码、解释代码 |
| 自定义快捷键 | 支持自定义快捷键 |
| 配置代理服务器 | 支持配置代理服务器 |
| 模块化设计 | 支持自定义高阶的实验性功能 |
| 自我程序剖析 | [实验性功能] 一键读懂本项目的源代码 |
| 程序剖析 | [实验性功能] 一键可以剖析其他Python/C++项目 |
| 读论文 | [实验性功能] 一键解读latex论文全文并生成摘要 |
| 批量注释生成 | [实验性功能] 一键批量生成函数注释 |
| chat分析报告生成 | [实验性功能] 运行后自动生成总结汇报 |
| 公式显示 | 可以同时显示公式的tex形式和渲染形式 |
| 图片显示 | 可以在markdown中显示图片 |
| 支持GPT输出的markdown表格 | 可以输出支持GPT的markdown表格 |
新界面

所有按钮都通过读取functional.py动态生成,可随意加自定义功能,解放粘贴板

润色/纠错

支持GPT输出的markdown表格

如果输出包含公式,会同时以tex形式和渲染形式显示,方便复制和阅读

懒得看项目代码?整个工程直接给chatgpt炫嘴里

直接运行 (Windows, Linux or MacOS)
下载项目
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
我们建议将config.py复制为config_private.py并将后者用作个性化配置文件以避免config.py中的变更影响你的使用或不小心将包含你的OpenAI API KEY的config.py提交至本项目。
cp config.py config_private.py
在config_private.py中,配置 海外Proxy 和 OpenAI API KEY
1. 如果你在国内,需要设置海外代理才能够使用 OpenAI API,你可以通过 config.py 文件来进行设置。
2. 配置 OpenAI API KEY。你需要在 OpenAI 官网上注册并获取 API KEY。一旦你拿到了 API KEY,在 config.py 文件里配置好即可。
安装依赖
python -m pip install -r requirements.txt
或者,如果你希望使用conda
conda create -n gptac 'gradio>=3.23' requests
conda activate gptac
python3 -m pip install mdtex2html
运行
python main.py
测试实验性功能
- 测试C++项目头文件分析
input区域 输入 `./crazy_functions/test_project/cpp/libJPG` , 然后点击 "[实验] 解析整个C++项目(input输入项目根路径)"
- 测试给Latex项目写摘要
input区域 输入 `./crazy_functions/test_project/latex/attention` , 然后点击 "[实验] 读tex论文写摘要(input输入项目根路径)"
- 测试Python项目分析
input区域 输入 `./crazy_functions/test_project/python/dqn` , 然后点击 "[实验] 解析整个py项目(input输入项目根路径)"
- 测试自我代码解读
点击 "[实验] 请解析并解构此项目本身"
- 测试实验功能模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
点击 "[实验] 实验功能函数模板"
与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
使用docker (Linux)
# 下载项目
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
# 配置 海外Proxy 和 OpenAI API KEY
config.py
# 安装
docker build -t gpt-academic .
# 运行
docker run --rm -it --net=host gpt-academic
# 测试实验性功能
## 测试自我代码解读
点击 "[实验] 请解析并解构此项目本身"
## 测试实验功能模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
点击 "[实验] 实验功能函数模板"
##(请注意在docker中运行时,需要额外注意程序的文件访问权限问题)
## 测试C++项目头文件分析
input区域 输入 ./crazy_functions/test_project/cpp/libJPG , 然后点击 "[实验] 解析整个C++项目(input输入项目根路径)"
## 测试给Latex项目写摘要
input区域 输入 ./crazy_functions/test_project/latex/attention , 然后点击 "[实验] 读tex论文写摘要(input输入项目根路径)"
## 测试Python项目分析
input区域 输入 ./crazy_functions/test_project/python/dqn , 然后点击 "[实验] 解析整个py项目(input输入项目根路径)"
使用WSL2(Windows Subsystem for Linux 子系统)
选择这种方式默认您已经具备一定基本知识,因此不再赘述多余步骤。如果不是这样,您可以从这里或GPT处获取更多关于子系统的信息。
WSL2可以配置使用Windows侧的代理上网,前置步骤可以参考这里 由于Windows相对WSL2的IP会发生变化,我们需要每次启动前先获取这个IP来保证顺利访问,将config.py中设置proxies的部分更改为如下代码:
import subprocess
cmd_get_ip = 'grep -oP "(\d+\.)+(\d+)" /etc/resolv.conf'
ip_proxy = subprocess.run(
cmd_get_ip, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, shell=True
).stdout.strip() # 获取windows的IP
proxies = { "http": ip_proxy + ":51837", "https": ip_proxy + ":51837", } # 请自行修改
在启动main.py后,可以在windows浏览器中访问服务。至此测试、使用与上面其他方法无异。
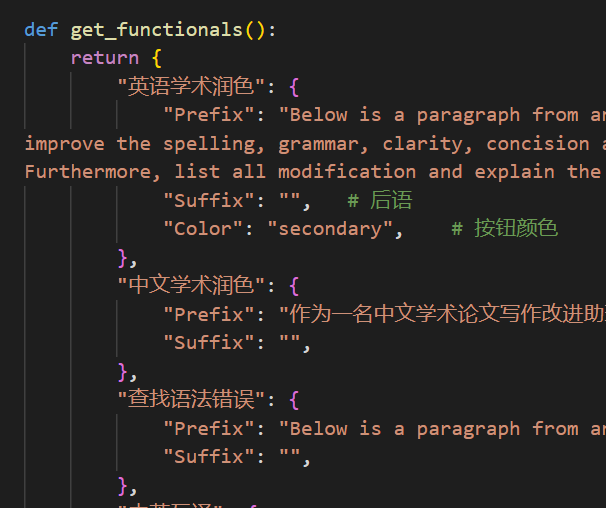
自定义新的便捷按钮(学术快捷键自定义)
打开functional.py,添加条目如下,然后重启程序即可。(如果按钮已经添加成功并可见,那么前缀、后缀都支持热修改,无需重启程序即可生效。) 例如
"超级英译中": {
# 前缀,会被加在你的输入之前。例如,用来描述你的要求,例如翻译、解释代码、润色等等
"Prefix": "请翻译把下面一段内容成中文,然后用一个markdown表格逐一解释文中出现的专有名词:\n\n",
# 后缀,会被加在你的输入之后。例如,配合前缀可以把你的输入内容用引号圈起来。
"Suffix": "",
},

如果你发明了更好用的学术快捷键,欢迎发issue或者pull requests!
配置代理
在config.py中修改端口与代理软件对应
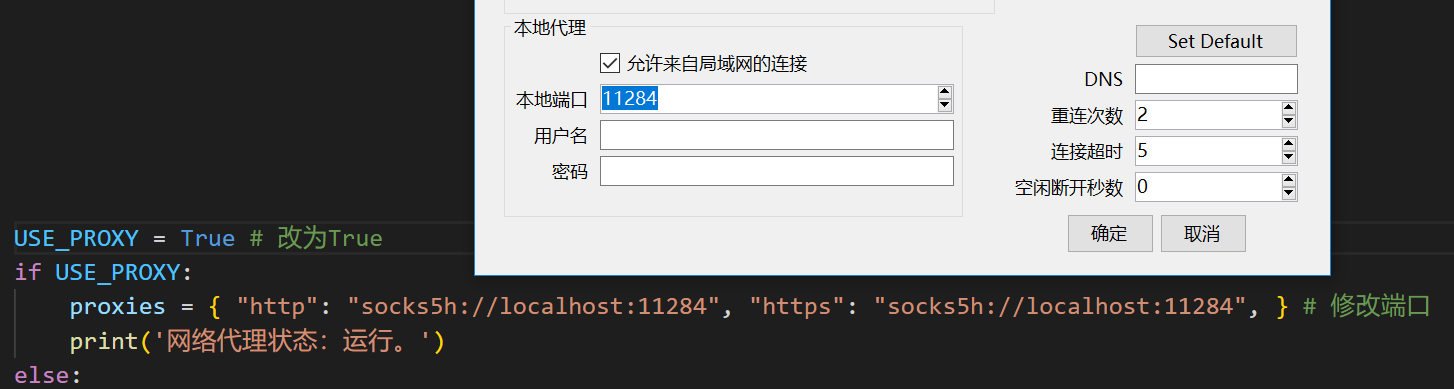
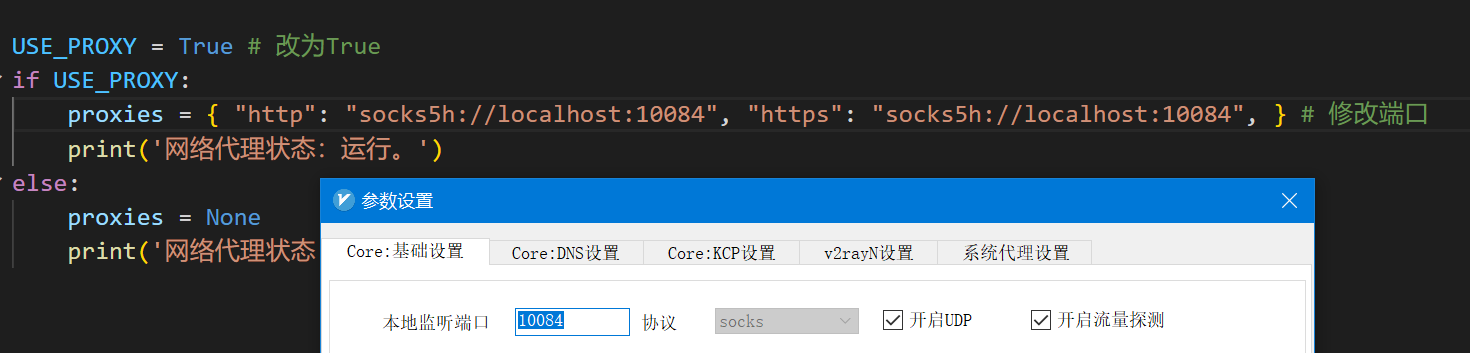
配置完成后,你可以用以下命令测试代理是否工作,如果一切正常,下面的代码将输出你的代理服务器所在地:
python check_proxy.py
兼容性测试
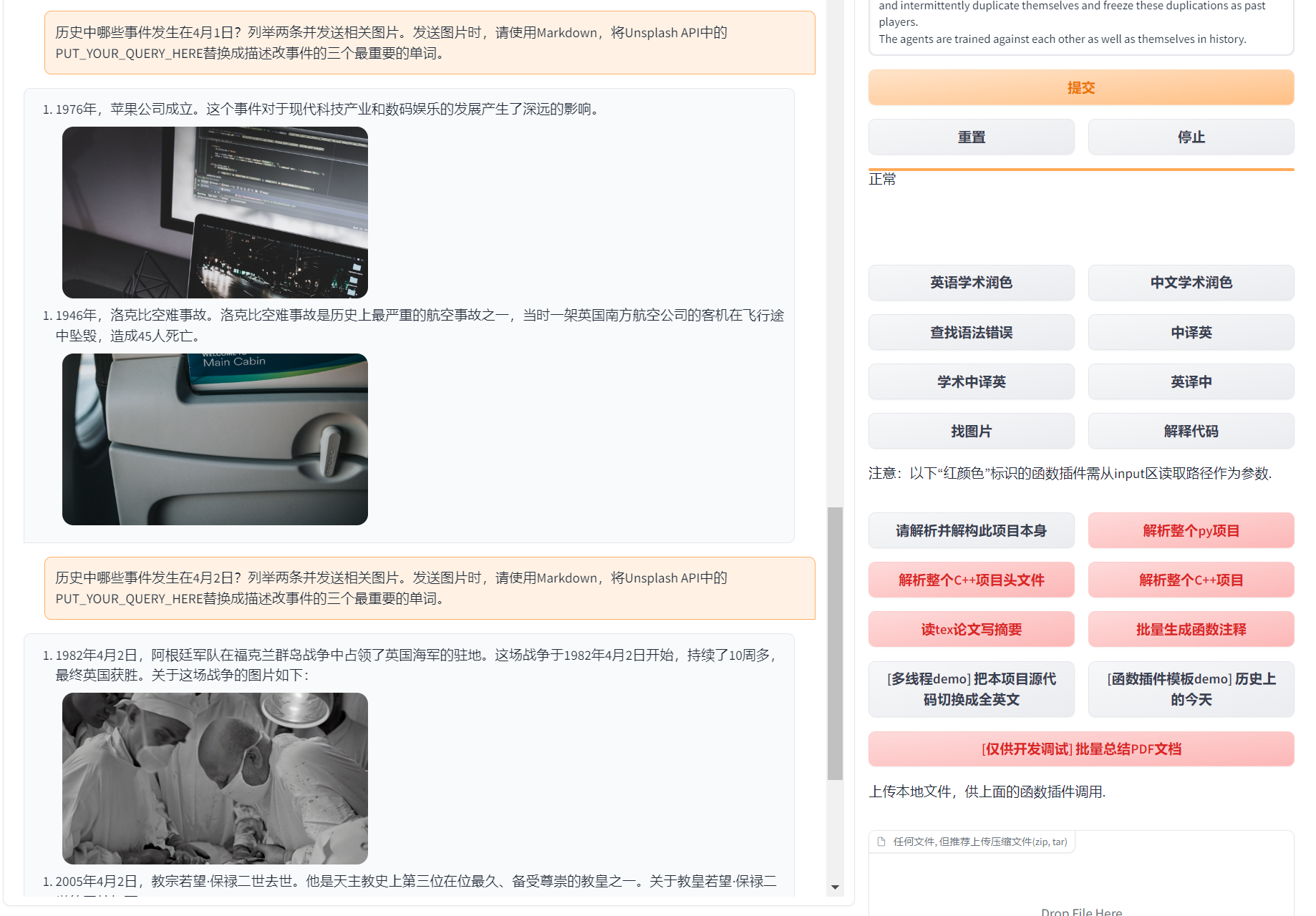
图片显示:
如果一个程序能够读懂并剖析自己:


其他任意Python/Cpp项目剖析:

Latex论文一键阅读理解与摘要生成

自动报告生成



模块化功能设计

Todo:
- (Top Priority) 调用另一个开源项目text-generation-webui的web接口,使用其他llm模型
- 总结大工程源代码时,文本过长、token溢出的问题(目前的方法是直接二分丢弃处理溢出,过于粗暴,有效信息大量丢失)
- UI不够美观