
Introdução


!!! warning
Não nos responsabilizamos por qualquer uso ilegal do código-fonte. Consulte as leis locais sobre DMCA (Digital Millennium Copyright Act) e outras leis relevantes em sua região.
Este repositório de código e os modelos são distribuídos sob a licença CC-BY-NC-SA-4.0.

Requisitos
- Memória da GPU: 4GB (para inferência), 8GB (para ajuste fino)
- Sistema: Linux, Windows
Configuração para Windows
No Windows, usuários avançados podem considerar usar o WSL2 ou Docker para executar o código.
Para Usuários comuns (não-avançados), siga os métodos abaixo para executar o código sem um ambiente Linux (incluindo suporte para torch.compile):
- Extraia o arquivo compactado do projeto.
- Prepare o ambiente conda:
- Abra o
install_env.batpara baixar e iniciar a instalação do miniconda. - Personalize o download (opcional):
- **Site espelho:** Para usar um site espelho para downloads mais rápidos, defina
USE_MIRROR=truenoinstall_env.bat(padrão). Caso contrário, useUSE_MIRROR=false. - **Ambiente compilado:** Para baixar a versão de prévia com o ambiente compilado, defina
INSTALL_TYPE=preview. Para a versão estável sem ambiente compilado, useINSTALL_TYPE=stable.
- **Site espelho:** Para usar um site espelho para downloads mais rápidos, defina
- Abra o
- Se você escolheu a versão de prévia com ambiente compilado (
INSTALL_TYPE=preview), siga para a próxima etapa (opcional):- Baixe o compilador LLVM usando os seguintes links:
- LLVM-17.0.6 (download do site original)
- LLVM-17.0.6 (download do site espelho)
- Após baixar o
LLVM-17.0.6-win64.exe, clique duas vezes para instalá-lo, escolha um local de instalação apropriado. E durante a instalação, marque a opçãoAdd Path to Current Userpara adicionar às variáveis de ambiente. - Confirme se a instalação foi concluída.
- Baixe e instale o pacote Microsoft Visual C++ Redistributable para resolver possíveis problemas de .dll ausentes.
- Baixe e instale o Visual Studio Community Edition para obter as ferramentas de compilação MSVC++, resolvendo as dependências do arquivo de cabeçalho LLVM.
- Download do Visual Studio
- Após instalar o Visual Studio Installer, baixe o Visual Studio Community 2022.
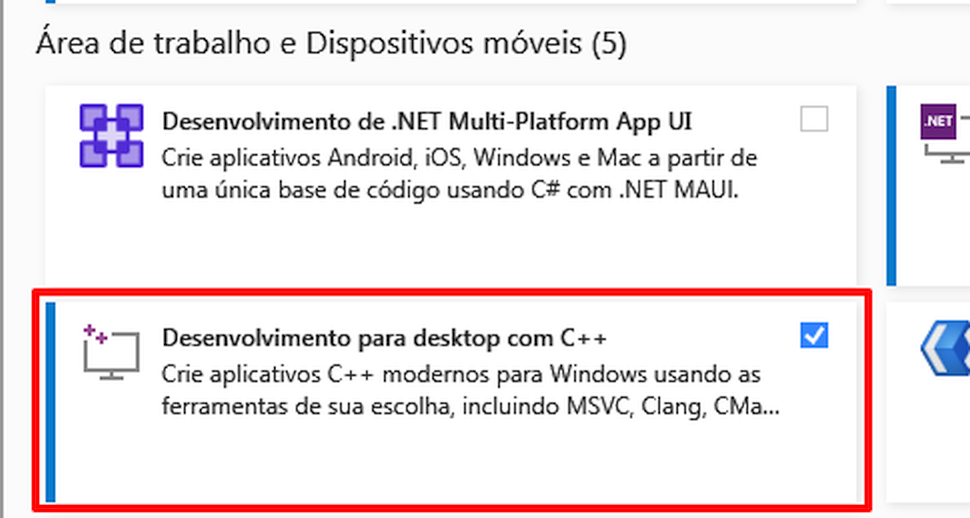
- Clique no botão
Modificar, conforme mostrado abaixo, encontre a opçãoDesenvolvimento para desktop com C++e marque-a para download.
- Instale o CUDA Toolkit 12
- Baixe o compilador LLVM usando os seguintes links:
- Clique duas vezes em
start.batpara entrar na página da WebUI de configuração de inferência de treinamento do Fish-Speech.- (Opcional) Se desejar ir direto para a página de inferência, edite o arquivo
API_FLAGS.txtno diretório raiz do projeto e modifique as três primeiras linhas da seguinte forma:--infer # --api # --listen ... ... - (Opcional) Se preferir iniciar o servidor da API, edite o arquivo
API_FLAGS.txtno diretório raiz do projeto e modifique as três primeiras linhas da seguinte forma:# --infer --api --listen ... ...
- (Opcional) Se desejar ir direto para a página de inferência, edite o arquivo
- (Opcional) Clique duas vezes em
run_cmd.batpara entrar na CLI do conda/python deste projeto.
Configuração para Linux
# Crie um ambiente virtual python 3.10, você também pode usar virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# Instale o pytorch
pip3 install torch torchvision torchaudio
# Instale o fish-speech
pip3 install -e .[stable]
# Para os Usuário do Ubuntu / Debian: Instale o sox
apt install libsox-dev
Histórico de Alterações
- 02/07/2024: Fish-Speech atualizado para a versão 1.2, removido o Decodificador VITS e aprimorado consideravelmente a capacidade de zero-shot.
- 10/05/2024: Fish-Speech atualizado para a versão 1.1, implementado o decodificador VITS para reduzir a WER e melhorar a similaridade de timbre.
- 22/04/2024: Finalizada a versão 1.0 do Fish-Speech, modificados significativamente os modelos VQGAN e LLAMA.
- 28/12/2023: Adicionado suporte para ajuste fino
lora. - 27/12/2023: Adicionado suporte para
gradient checkpointing,causual samplingeflash-attn. - 19/12/2023: Atualizada a interface web e a API HTTP.
- 18/12/2023: Atualizada a documentação de ajuste fino e exemplos relacionados.
- 17/12/2023: Atualizado o modelo
text2semantic, suportando o modo sem fonemas. - 13/12/2023: Versão beta lançada, incluindo o modelo VQGAN e um modelo de linguagem baseado em LLAMA (suporte apenas a fonemas).