Spaces:
Running
on
T4

title: YOLO World
emoji: 🔥
colorFrom: pink
colorTo: blue
pinned: false
license: apache-2.0
app_file: app.py
sdk: gradio
sdk_version: 3.35.2
Tianheng Cheng*2,3, Lin Song*1, Yixiao Ge1,2, Xinggang Wang3, Wenyu Liu3, Ying Shan1,2
1 Tencent AI Lab, 2 ARC Lab, Tencent PCG
3 Huazhong University of Science and Technology
Updates
[2024-1-25]: We are excited to launch YOLO-World, a cutting-edge real-time open-vocabulary object detector.
Highlights
This repo contains the PyTorch implementation, pre-trained weights, and pre-training/fine-tuning code for YOLO-World.
YOLO-World is pre-trained on large-scale datasets, including detection, grounding, and image-text datasets.
YOLO-World is the next-generation YOLO detector, with a strong open-vocabulary detection capability and grounding ability.
YOLO-World presents a prompt-then-detect paradigm for efficient user-vocabulary inference, which re-parameterizes vocabulary embeddings as parameters into the model and achieve superior inference speed. You can try to export your own detection model without extra training or fine-tuning in our online demo!
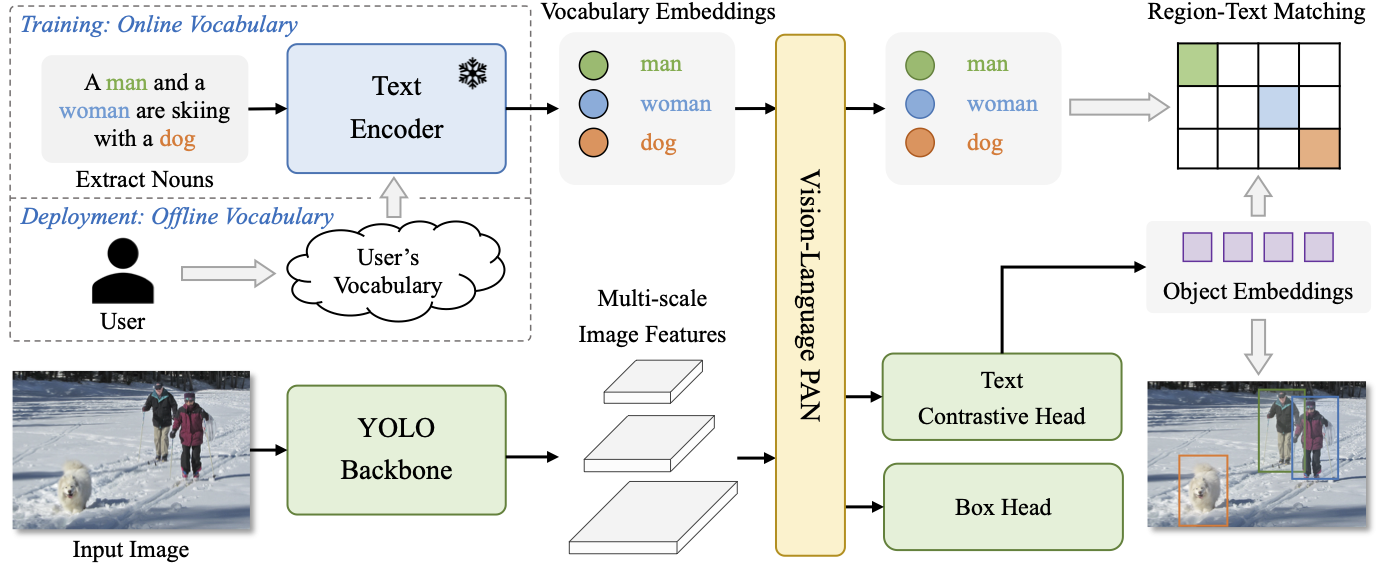
Abstract
The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we introduce YOLO-World, an innovative approach that enhances YOLO with open-vocabulary detection capabilities through vision-language modeling and pre-training on large-scale datasets. Specifically, we propose a new Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to facilitate the interaction between visual and linguistic information. Our method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed. Furthermore, the fine-tuned YOLO-World achieves remarkable performance on several downstream tasks, including object detection and open-vocabulary instance segmentation.
Demo
Main Results
We've pre-trained YOLO-World-S/M/L from scratch and evaluate on the LVIS val-1.0 and LVIS minival. We provide the pre-trained model weights and training logs for applications/research or re-producing the results.
Zero-shot Inference on LVIS dataset
| model | Pre-train Data | AP | APr | APc | APf | FPS(V100) | weights | log |
|---|---|---|---|---|---|---|---|---|
| YOLO-World-S | O365+GoldG | 17.6 | 11.9 | 14.5 | 23.2 | - | wecom | log |
| YOLO-World-M | O365+GoldG | 23.5 | 17.2 | 20.4 | 29.6 | - | wecom | log |
| YOLO-World-L | O365+GoldG | 25.7 | 18.7 | 22.6 | 32.2 | - | wecom | log |
NOTE:
- The evaluation results are tested on LVIS minival in a zero-shot manner.
Getting started
1. Installation
YOLO-World is developed based on torch==1.11.0 mmyolo==0.6.0 and mmdetection==3.0.0.
# install key dependencies
pip install mmdetection==3.0.0 mmengine transformers
# clone the repo
git clone https://xxxx.YOLO-World.git
cd YOLO-World
# install mmyolo
mkdir third_party
git clone https://github.com/open-mmlab/mmyolo.git
cd ..
2. Preparing Data
We provide the details about the pre-training data in docs/data.
Training & Evaluation
We adopt the default training or evaluation scripts of mmyolo.
We provide the configs for pre-training and fine-tuning in configs/pretrain and configs/finetune_coco.
Training YOLO-World is easy:
chmod +x tools/dist_train.sh
# sample command for pre-training, use AMP for mixed-precision training
./tools/dist_train.sh configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py 8 --amp
NOTE: YOLO-World is pre-trained on 4 nodes with 8 GPUs per node (32 GPUs in total). For pre-training, the node_rank and nnodes for multi-node training should be specified.
Evalutating YOLO-World is also easy:
chmod +x tools/dist_test.sh
./tools/dist_test.sh path/to/config path/to/weights 8
NOTE: We mainly evaluate the performance on LVIS-minival for pre-training.
Deployment
We provide the details about deployment for downstream applications in docs/deployment. You can directly download the ONNX model through the online demo in Huggingface Spaces 🤗.
Acknowledgement
We sincerely thank mmyolo, mmdetection, and transformers for providing their wonderful code to the community!
Citations
If you find YOLO-World is useful in your research or applications, please consider giving us a star 🌟 and citing it.
@article{cheng2024yolow,
title={YOLO-World: Real-Time Open-Vocabulary Object Detection},
author={Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying},
journal={arXiv preprint arXiv:},
year={2024}
}
Licence
YOLO-World is under the GPL-v3 Licence and is supported for comercial usage.