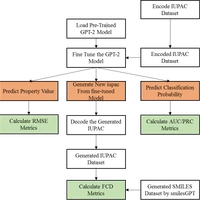
Generative Pre-Training from Molecules
Autoregressive transformer language model for drug discovery. (Pre)trained on a large IUPAC corpus. Evaluated on molecular property prediction and low-data de novo design tasks.
Installation
Set up conda and create a new environment from
environment.yml (if needed, make corresponding edits for GPU-compatibility).
conda env create -f environment.yml
conda activate iupacgpt
git clone https://github.com/sanjaradylov/smiles-gpt.git
cd iupacgpt
Benchmark
Checkpoint
checkpoints/iupac
stores serialized model, tokenizer, and configuration. Do not modify them. Use
from_pretrained method to load HuggingFace objects, e.g.,
from transformers import GPT2Config, GPT2LMHeadModel, PreTrainedTokenizerFast
checkpoint = "checkpoints/iupac"
config = GPT2Config.from_pretrained(checkpoint)
model = GPT2LMHeadModel.from_pretrained(checkpoint)
tokenizer = PreTrainedTokenizerFast.from_pretrained(checkpoint)
Data
data stores Blood-Brain Barrier Penetration classification dataset and 10K subset of ChemBERTa's PubChem-10M. See Examples.
Output
output stores generated SMILES strings.
Examples
Adapter training for molecular property prediction
(replace data/iupacs_logp.csv and LogP arguments with your dataset and taskname(s),
respectively):
python3 scripts/classification.py checkpoints/benchmark-5m data/iupacs_logp.csv LogP
For language model pretraining, see iupac-gpt\notebooks: iupac_language-modeling_train.py