
google/gemma-2-2b-it
Text Generation
•
Updated
•
409k
•
•
802
Generating text is the task of generating new text given another text. These models can, for example, fill in incomplete text or paraphrase.
Once upon a time,
Once upon a time, we knew that our ancestors were on the verge of extinction. The great explorers and poets of the Old World, from Alexander the Great to Chaucer, are dead and gone. A good many of our ancient explorers and poets have
This task covers guides on both text-generation and text-to-text generation models. Popular large language models that are used for chats or following instructions are also covered in this task. You can find the list of selected open-source large language models here, ranked by their performance scores.
A model trained for text generation can be later adapted to follow instructions. You can try some of the most powerful instruction-tuned open-access models like Mixtral 8x7B, Cohere Command R+, and Meta Llama3 70B at Hugging Chat.
A Text Generation model, also known as a causal language model, can be trained on code from scratch to help the programmers in their repetitive coding tasks. One of the most popular open-source models for code generation is StarCoder, which can generate code in 80+ languages. You can try it here.
A story generation model can receive an input like "Once upon a time" and proceed to create a story-like text based on those first words. You can try this application which contains a model trained on story generation, by MosaicML.
If your generative model training data is different than your use case, you can train a causal language model from scratch. Learn how to do it in the free transformers course!
A popular variant of Text Generation models predicts the next word given a bunch of words. Word by word a longer text is formed that results in for example:
The most popular models for this task are GPT-based models, Mistral or Llama series. These models are trained on data that has no labels, so you just need plain text to train your own model. You can train text generation models to generate a wide variety of documents, from code to stories.
These models are trained to learn the mapping between a pair of texts (e.g. translation from one language to another). The most popular variants of these models are NLLB, FLAN-T5, and BART. Text-to-Text models are trained with multi-tasking capabilities, they can accomplish a wide range of tasks, including summarization, translation, and text classification.
When it comes to text generation, the underlying language model can come in several types:
Base models: refers to plain language models like Mistral 7B and Meta Llama-3-70b. These models are good for fine-tuning and few-shot prompting.
Instruction-trained models: these models are trained in a multi-task manner to follow a broad range of instructions like "Write me a recipe for chocolate cake". Models like Qwen 2 7B, Yi 1.5 34B Chat, and Meta Llama 70B Instruct are examples of instruction-trained models. In general, instruction-trained models will produce better responses to instructions than base models.
Human feedback models: these models extend base and instruction-trained models by incorporating human feedback that rates the quality of the generated text according to criteria like helpfulness, honesty, and harmlessness. The human feedback is then combined with an optimization technique like reinforcement learning to align the original model to be closer with human preferences. The overall methodology is often called Reinforcement Learning from Human Feedback, or RLHF for short. Zephyr ORPO 141B A35B is an open-source model aligned through human feedback.
There are language models that can input both text and image and output text, called vision language models. IDEFICS 2 and MiniCPM Llama3 V are good examples. They accept the same generation parameters as other language models. However, since they also take images as input, you have to use them with the image-to-text pipeline. You can find more information about this in the image-to-text task page.
You can use the 🤗 Transformers library text-generation pipeline to do inference with Text Generation models. It takes an incomplete text and returns multiple outputs with which the text can be completed.
from transformers import pipeline
generator = pipeline('text-generation', model = 'HuggingFaceH4/zephyr-7b-beta')
generator("Hello, I'm a language model", max_length = 30, num_return_sequences=3)
## [{'generated_text': "Hello, I'm a language modeler. So while writing this, when I went out to meet my wife or come home she told me that my"},
## {'generated_text': "Hello, I'm a language modeler. I write and maintain software in Python. I love to code, and that includes coding things that require writing"}, ...
Text-to-Text generation models have a separate pipeline called text2text-generation. This pipeline takes an input containing the sentence including the task and returns the output of the accomplished task.
from transformers import pipeline
text2text_generator = pipeline("text2text-generation")
text2text_generator("question: What is 42 ? context: 42 is the answer to life, the universe and everything")
[{'generated_text': 'the answer to life, the universe and everything'}]
text2text_generator("translate from English to French: I'm very happy")
[{'generated_text': 'Je suis très heureux'}]
You can use huggingface.js to infer text classification models on Hugging Face Hub.
import { HfInference } from "@huggingface/inference";
const inference = new HfInference(HF_TOKEN);
await inference.conversational({
model: "distilbert-base-uncased-finetuned-sst-2-english",
inputs: "I love this movie!",
});
Text Generation Inference (TGI) is an open-source toolkit for serving LLMs tackling challenges such as response time. TGI powers inference solutions like Inference Endpoints and Hugging Chat, as well as multiple community projects. You can use it to deploy any supported open-source large language model of your choice.
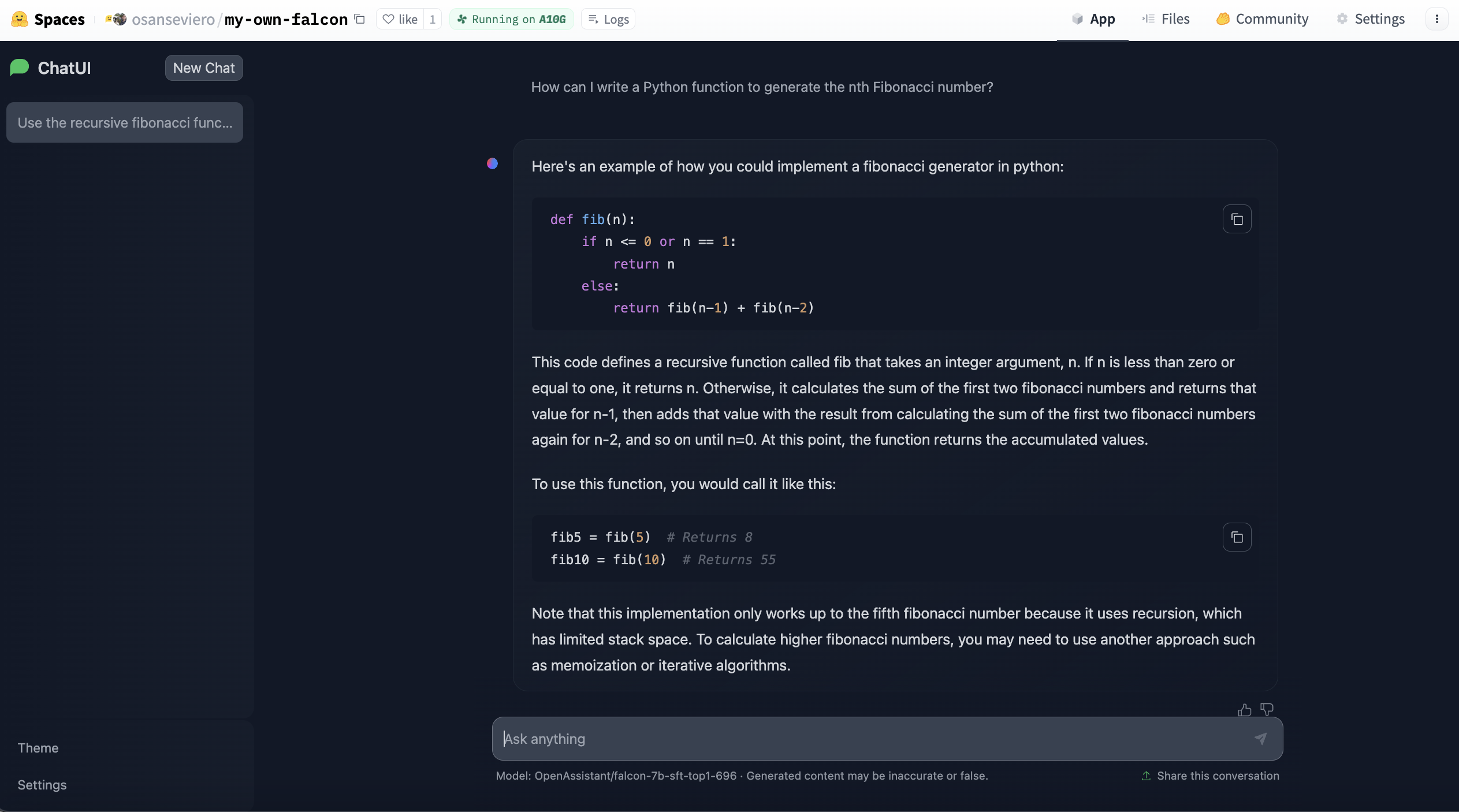
Hugging Face Spaces includes templates to easily deploy your own instance of a specific application. ChatUI is an open-source interface that enables serving conversational interface for large language models and can be deployed with few clicks at Spaces. TGI powers these Spaces under the hood for faster inference. Thanks to the template, you can deploy your own instance based on a large language model with only a few clicks and customize it. Learn more about it here and create your large language model instance here.
Would you like to learn more about the topic? Awesome! Here you can find some curated resources that you may find helpful!
Note A text-generation model trained to follow instructions.
Note Small yet powerful text generation model.
Note A very powerful model that can solve mathematical problems.
Note Strong text generation model to follow instructions.
Note Very strong open-source large language model.
Note Truly open-source, curated and cleaned dialogue dataset.
Note An instruction dataset with preference ratings on responses.
Note A large synthetic dataset for alignment of text generation models.
Note A leaderboard to compare different open-source text generation models based on various benchmarks.
Note A leaderboard for comparing chain-of-thought performance of models.
Note An text generation based application based on a very powerful LLaMA2 model.
Note An text generation based application to converse with Zephyr model.
Note An chatbot to converse with a very powerful text generation model.



