
Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation
[Project page] [Code] [arXiv] [Demo] [Colab]
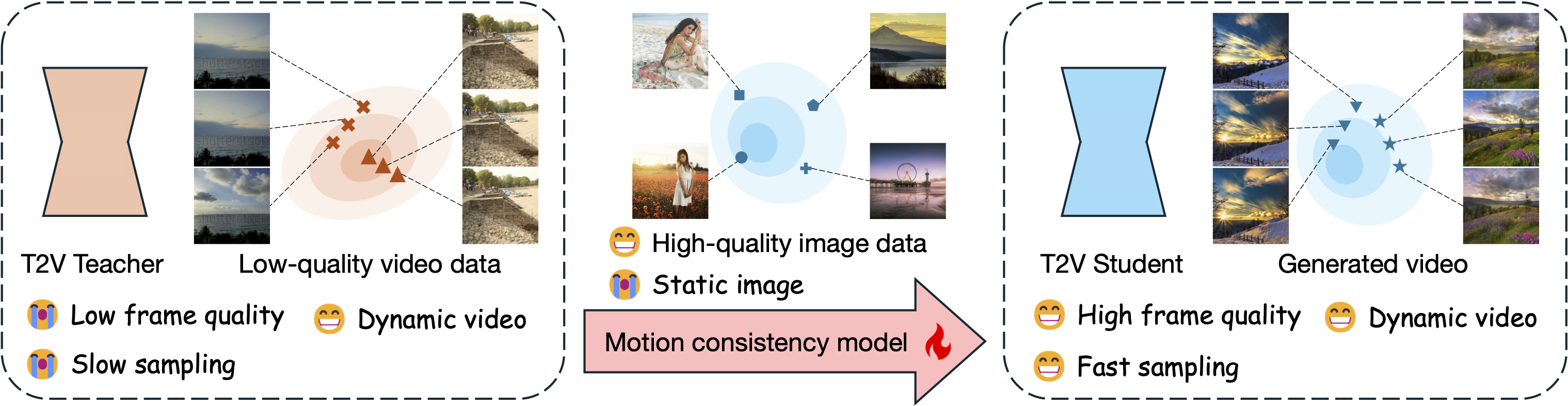
TL;DR: Our motion consistency model not only accelerates text2video diffusion model sampling process, but also can benefit from an additional high-quality image dataset to improve the frame quality of generated videos.
Usage
from typing import Optional
import torch
from diffusers import (
AnimateDiffPipeline,
DiffusionPipeline,
LCMScheduler,
MotionAdapter,
)
from diffusers.utils import export_to_video
from peft import PeftModel
def main():
# select model_path from ["animatediff-laion", "animatediff-webvid",
# "modelscopet2v-webvid", "modelscopet2v-laion", "modelscopet2v-anime",
# "modelscopet2v-real", "modelscopet2v-3d-cartoon"]
model_path = "modelscopet2v-laion"
prompts = ["A cat walking on a treadmill", "A dog walking on a treadmill"]
num_inference_steps = 4
model_id = "yhzhai/mcm"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if "animatediff" in model_path:
pipeline = get_animatediff_pipeline()
elif "modelscope" in model_path:
pipeline = get_modelscope_pipeline()
else:
raise ValueError(f"Unknown pipeline {model_path}")
lora = PeftModel.from_pretrained(
pipeline.unet,
model_id,
subfolder=model_path,
adapter_name="pretrained_lora",
torch_device="cpu",
)
lora.merge_and_unload()
pipeline.unet = lora
pipeline = pipeline.to(device)
output = pipeline(
prompt=prompts,
num_frames=16,
guidance_scale=1.0,
num_inference_steps=num_inference_steps,
generator=torch.Generator("cpu").manual_seed(42),
).frames
if not isinstance(output, list):
output = [output[i] for i in range(output.shape[0])]
for j in range(len(prompts)):
export_to_video(
output[j],
f"{j}-{model_path}.mp4",
fps=7,
)
def get_animatediff_pipeline(
real_variant: Optional[str] = "realvision",
motion_module_path: str = "guoyww/animatediff-motion-adapter-v1-5-2",
):
if real_variant is None:
model_id = "runwayml/stable-diffusion-v1-5"
elif real_variant == "epicrealism":
model_id = "emilianJR/epiCRealism"
elif real_variant == "realvision":
model_id = "SG161222/Realistic_Vision_V6.0_B1_noVAE"
else:
raise ValueError(f"Unknown real_variant {real_variant}")
adapter = MotionAdapter.from_pretrained(
motion_module_path, torch_dtype=torch.float16
)
pipe = AnimateDiffPipeline.from_pretrained(
model_id,
motion_adapter=adapter,
torch_dtype=torch.float16,
)
scheduler = LCMScheduler.from_pretrained(
model_id,
subfolder="scheduler",
timestep_scaling=4.0,
clip_sample=False,
timestep_spacing="linspace",
beta_schedule="linear",
beta_start=0.00085,
beta_end=0.012,
steps_offset=1,
)
pipe.scheduler = scheduler
pipe.enable_vae_slicing()
return pipe
def get_modelscope_pipeline():
model_id = "ali-vilab/text-to-video-ms-1.7b"
pipe = DiffusionPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, variant="fp16"
)
scheduler = LCMScheduler.from_pretrained(
model_id,
subfolder="scheduler",
timestep_scaling=4.0,
)
pipe.scheduler = scheduler
pipe.enable_vae_slicing()
return pipe
if __name__ == "__main__":
main()