
File size: 4,303 Bytes
e41d3a3 bdd0be7 e41d3a3 7860b70 e41d3a3 cd50e5a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
---
license: apache-2.0
pipeline_tag: text-to-video
---
<h1 align="center">
<a href="https://yhzhai.github.io/mcm/"><b>Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation</b></a>
</h1>
[[Project page]](https://yhzhai.github.io/mcm/) [[Code]](https://github.com/yhZhai/mcm) [[arXiv]](https://arxiv.org/abs/2406.06890) [[Demo]](https://huggingface.co/spaces/yhzhai/mcm) [[Colab]](https://colab.research.google.com/drive/1ouGbIZA5092hF9ZMHO-AchCr_L3algTL?usp=sharing)
**TL;DR**: Our motion consistency model not only accelerates text2video diffusion model sampling process, but also can benefit from an additional high-quality image dataset to improve the frame quality of generated videos.
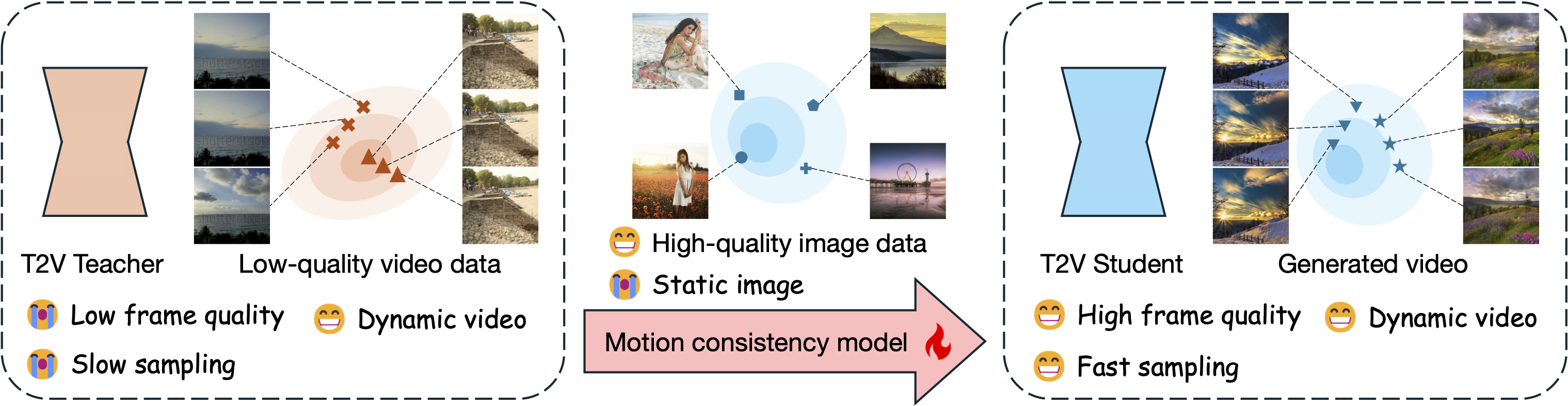
## Usage
```python
from typing import Optional
import torch
from diffusers import (
AnimateDiffPipeline,
DiffusionPipeline,
LCMScheduler,
MotionAdapter,
)
from diffusers.utils import export_to_video
from peft import PeftModel
def main():
# select model_path from ["animatediff-laion", "animatediff-webvid",
# "modelscopet2v-webvid", "modelscopet2v-laion", "modelscopet2v-anime",
# "modelscopet2v-real", "modelscopet2v-3d-cartoon"]
model_path = "modelscopet2v-laion"
prompts = ["A cat walking on a treadmill", "A dog walking on a treadmill"]
num_inference_steps = 4
model_id = "yhzhai/mcm"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if "animatediff" in model_path:
pipeline = get_animatediff_pipeline()
elif "modelscope" in model_path:
pipeline = get_modelscope_pipeline()
else:
raise ValueError(f"Unknown pipeline {model_path}")
lora = PeftModel.from_pretrained(
pipeline.unet,
model_id,
subfolder=model_path,
adapter_name="pretrained_lora",
torch_device="cpu",
)
lora.merge_and_unload()
pipeline.unet = lora
pipeline = pipeline.to(device)
output = pipeline(
prompt=prompts,
num_frames=16,
guidance_scale=1.0,
num_inference_steps=num_inference_steps,
generator=torch.Generator("cpu").manual_seed(42),
).frames
if not isinstance(output, list):
output = [output[i] for i in range(output.shape[0])]
for j in range(len(prompts)):
export_to_video(
output[j],
f"{j}-{model_path}.mp4",
fps=7,
)
def get_animatediff_pipeline(
real_variant: Optional[str] = "realvision",
motion_module_path: str = "guoyww/animatediff-motion-adapter-v1-5-2",
):
if real_variant is None:
model_id = "runwayml/stable-diffusion-v1-5"
elif real_variant == "epicrealism":
model_id = "emilianJR/epiCRealism"
elif real_variant == "realvision":
model_id = "SG161222/Realistic_Vision_V6.0_B1_noVAE"
else:
raise ValueError(f"Unknown real_variant {real_variant}")
adapter = MotionAdapter.from_pretrained(
motion_module_path, torch_dtype=torch.float16
)
pipe = AnimateDiffPipeline.from_pretrained(
model_id,
motion_adapter=adapter,
torch_dtype=torch.float16,
)
scheduler = LCMScheduler.from_pretrained(
model_id,
subfolder="scheduler",
timestep_scaling=4.0,
clip_sample=False,
timestep_spacing="linspace",
beta_schedule="linear",
beta_start=0.00085,
beta_end=0.012,
steps_offset=1,
)
pipe.scheduler = scheduler
pipe.enable_vae_slicing()
return pipe
def get_modelscope_pipeline():
model_id = "ali-vilab/text-to-video-ms-1.7b"
pipe = DiffusionPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, variant="fp16"
)
scheduler = LCMScheduler.from_pretrained(
model_id,
subfolder="scheduler",
timestep_scaling=4.0,
)
pipe.scheduler = scheduler
pipe.enable_vae_slicing()
return pipe
if __name__ == "__main__":
main()
``` |